Область применения изобретения
Настоящее изобретение, в общем, имеет отношение к способу и системе шифрования данных, а более конкретно, к способу и системе для сокрытия существования шифрования данных в канале связи, при эффективном распределении ширины полосы пропускания.
Предпосылки к созданию изобретения
Трафики потоков в современной крупной сети часто могут быть подвергнуты воздействию механизмов, основанных на необдуманной политике, для "формирования" такого трафика. Часто такое движимое политикой формирование является вредным для шифрованных потоков, даже когда такие потоки обычно не "формированы", если это не нужно для шифрования.
Кроме того, в некоторых глобальных регионах трафик, который шифрован, часто подвергают дополнительному изучению при помощи инвазивных технологий наблюдения, по сравнению с незашифрованным трафиком. В самом деле, шифрованный трафик, даже если он является "безвредным," может привлекать чрезмерное внимание просто по причине наличия шифрования. Во многих местах в современном Internet, в особенности поблизости от границы сети, используют технологию формирования трафика, позволяющую автоматически обнаруживать шифрованные потоки и производить их обработку иным образом, в соответствии с местной политикой. Такая обработка может фактически предусматривать отбрасывание трафика или помещение этого трафика в Quality of Service ("QoS") очередь, которая имеет очень низкий приоритет.
Шифрованный трафик, за исключением фиксированных заголовков, имеет специфическое статистическое свойство, заключающееся в том, что он является неразличимым от устойчивой псевдослучайной последовательности такой же длины. Однако, если шифрованный трафик наблюдать в течение достаточно длительного временного интервала, то получают весьма однородное распределение битов, или октетов, которое обычно делает этот трафик различимым от незашифрованного трафика. Именно это свойство позволяет формирующей трафик аппаратуре распознавать шифрованные потоки и применять соответствующую "политику" к этим потокам. Потоки, которые являются незашифрованными, имеют совсем другое статистическое распределение битов (октетов), чем шифрованные потоки.
Несколько тестов могут быть осуществлены на трафике, чтобы определить, что трафик имеет статистические свойства шифрованного трафика. Весь шифрованный трафик должен проходить эти тесты, однако прохождение этих тестов не обязательно говорит о наличии шифрования. Например, трафики потоков, которые были сжаты, имеют долговременные статистические свойства, которые почти неразличимы от свойств случайных или шифрованных потоков.
Обычный тестовый комплект проверки на случайность позволяет обычно показывать наличие или отсутствие шифрования трафика. Тестовый комплект, который описан в федеральном стандарте по обработке информации ("FIPS") 140-2, позволяет легко различать похожие на случайные потоки от не похожих на случайные потоков, обычно при наличии всего 4 килобайт трафика потока.
Аналогично, в течение более длительного срока попытка сжатия содержимого потока с использованием любой одной из ряда функций сжатия может быть использована для различения потоков случайного типа от потоков, которые не являются случайными. Например, попытка сжатия чисто случайного потока не приводит к сжатию или даже приводит к увеличению размера, в зависимости от использованного алгоритма сжатия. Потоки, которые не являются случайными, могут быть умеренно или сильно сжаты,
Существует историческая поддержка использования стенографии для сокрытия секретных сообщений, так что только отправитель и назначенный получатель могут понять, что имеется скрытое сообщение. Таким образом, представляется естественным и заманчивым использование стенографической техники для сокрытия кажущихся случайными бит шифрованного потока внутри некоторого потока, который кажется статистически незашифрованным.
Уже известно, что некоторые группы позволяют укрывать шифрованные сообщения внутри таких безопасных объектов как файлы цифрового изображения в Internet, и известно их использование в узкополосной технике связи. Уже существуют различные инструменты, помогающие созданию стенографических материалов, с использованием аудио- и видеофайлов и файлов изображения как "носителей" для стенографически скрытой информации.
Однако эффективность использования полосы частот "традиционной" стенографической техники типично является очень низкой, причем "носитель" информации доминирует в ширине спектра, использованного для передачи стенографических объектов. Отношение информации носителя к скрытой информации, которое составляет около 100:1 или хуже, является обычным при использовании этой техники. Тем не менее, преимуществом стенографической техники является то, что результирующие потоки данных имеют четко неравномерные статистические распределения октетов, а это означает, что их трудно идентифицировать как шифрованный трафик при помощи автоматического оборудования в сети Internet.
Можно также кодировать шифрованные битовые потоки, так чтобы они были похожи, например, на обычный английский текст. Такие технологии, как использование словаря обычных английских слов для отображения группировок битов шифрованного текста, исторически уже использовали для сокрытия наличия лежащего в основе шифрованного сообщения. Например, если группы из четырех бит рассматривать одновременно, то они могут быть использованы как "указатель" в короткой матрице английских (или немецких, испанских, французских и т.п.) слов. Эти слова заменены в битовой последовательности, и получатель просто отыскивает соответствующую битовую последовательность, когда он встречает один из словарных элементов. Эта технология является достаточно эффективной для обмана автоматических проверок на случайность, в особенности тех проверок, которым неизвестно существование карты замены битов на слова, и если такая карта является достаточно обширной.
Проблемы возникают в том случае, когда эффективность использования полосы рабочих частот канала связи имеет особую важность при разработке системы кодирования для сокрытия шифрованных потоков. Описанная выше система, например, требует существенных расходов для отображения 4 битов "реальной" информации. Типично, от 40 до 50 битов передают для того, чтобы отобразить эти 4 бита реальной информации.
Существует множество технологий кодирования, которые используют для преобразования двоичных данных в системы кодирования, которые подходят для сильно ограниченных каналов, таких как e-mail ASCII передача, и т.п. Эти системы кодирования являются относительно эффективными по ширине спектра и позволяют получить 30% увеличение занятой ширины полосы пропускания. Во многих протоколах, которые используют в настоящее время в Internet, применяют некоторый вариант Base64 кодирования, который преобразует 24 бита входных данных в 32 бита выходных данных, при сильном ограничении выходного алфавита. Однако кодирование, которое основано на Base64, легко может быть идентифицировано автоматическим образом, а это означает, что это кодирование может быть удалено, а результирующий битовый поток дополнительно проанализирован на случайность.
Ключевая концепция снижения способности обнаружения шифрованных потоков заключается в снижении плотности информации шифрованного потока. Поток шифрованных данных кажется строгой псевдослучайной последовательностью, а это означает, что он имеет максимальную плотность информации, или минимальную избыточность. Любая технология, которая снижает количество информации, переносимой переданным битом, снижает вероятность идентификации результирующего потока как строго псевдослучайного и, таким образом, снижает вероятность идентификации шифрованного потока.
Стандартное кодирование, такое как Base64, снижает информацию, переносимую переданным битом. Однако, так как Base64 легко распознать, поток может быть декодирован и результирующая битовая последовательность проанализирована на случайность. Таким образом, имеется необходимость в создании системы и способа кодирования, которые одновременно снижают плотность информации потока трафика и снижают вероятность обнаружения схемы кодирования, так что не обнаруживают, что трафик является шифрованным, и поэтому трафик не анализируют на основании обнаружения схемы кодирования.
Сущность изобретения
В соответствии с настоящим изобретением предлагаются способ и система для сокрытия существования шифрованного трафика данных в сети связи, так что трафик не идентифицируют как шифрованный и поэтому трафик не анализируют на основании обнаружения схемы кодирования. Как правило, шифрованные данные дополнительно кодируют в соответствии с Base64 схемой кодирования, с использованием псевдослучайно генерированного алфавитного набора, на основании набора ключей шифрования. Элементы алфавитного кодирования преимущественно являются фактически неизвестными.
В соответствии с первым аспектом настоящего изобретения предлагается способ для сокрытия существования шифрования данных в сети связи. Набор знаков генерируют за счет использования набора ключей шифрования для ввода псевдослучайной функции. Каждый знак соответствует значению указателя. Шифрованные детали разделяют на множество частей. Каждую часть секционируют на множество групп и кодируют за счет отображения каждой группы знаком в наборе знаков, в соответствии с его значением указателя. Отображенные знаки передают через сеть связи. В соответствии с другим аспектом настоящего изобретения предлагается сетевой интерфейс для сокрытия существования шифрования данных, который содержит контроллер и интерфейс связи. Интерфейс связи имеет связь с контроллером. Контроллер генерирует набор знаков за счет использования набора ключей шифрования в качестве ввода в псевдослучайную функцию, причем каждый знак соответствует значению указателя.
Контроллер дополнительно подразделяет шифрованные данные на множество частей, секционирует каждую часть множества частей на множество групп и кодирует каждую часть за счет отображения каждой группы множества групп знаком в наборе знаков в соответствии с его значением указателя. Интерфейс связи передает отображенные знаки через сеть связи.
В соответствии с еще одним аспектом настоящего изобретения предлагается система для сокрытия существования шифрования данных в сети связи, которая содержит первый сетевой интерфейс и второй сетевой интерфейс. Первый сетевой интерфейс генерирует набор алфавитных знаков (букв) за счет использования набора ключей шифрования в качестве ввода в псевдослучайную функцию, причем каждый алфавитный знак соответствует значению указателя. Первый сетевой интерфейс дополнительно подразделяет шифрованные данные на множество частей, секционирует каждую часть на множество групп и кодирует каждую часть за счет отображения каждой группы множества групп знаком в наборе знаков в соответствии с его значением указателя. Первый сетевой интерфейс передает отображенные знаки через сеть связи. Второй сетевой интерфейс получает кодированный блок данных. Кодированный блок данных содержит отображенные знаки. Второй сетевой интерфейс подразделяет кодированный блок данных на множество групп знаков, отображает каждый знак его значением указателя, для восстановления множества частей и дешифрует каждую часть множества частей.
Указанные ранее и другие характеристики и преимущества изобретения будут более ясны из последующего детального описания, приведенного со ссылкой на сопроводительные чертежи, которые являются схематичными и приведены не в реальном масштабе, если специально не указано иное.
Краткое описание чертежей
На фиг.1 показана блок-схема примерной системы сокрытия шифрования данных, сконструированной в соответствии с принципами настоящего изобретения.
На фиг.2 показана блок-схема примерного шифратора данных, сконструированного в соответствии с принципами настоящего изобретения.
На фиг.3 показана схема последовательности операций примерного способа сокрытия шифрования данных в соответствии с принципами настоящего изобретения.
На фиг.4 показана схема последовательности операций примерного способа декодирования при наличии сокрытия шифрования данных в соответствии с принципами настоящего изобретения.
Подробное описание изобретения
Ранее подробного описания примерных вариантов осуществления настоящего изобретения, следует отметить, что эти варианты в первую очередь представляют собой комбинации компонентов устройств и операций обработки, связанные с внедрением системы, и способа для сокрытия существования шифрования данных в канале связи, при эффективном использовании ширины полосы пропускания канала. Таким образом, компоненты системы и способа, обозначенные соответственно стандартными символами на чертежах, представляют собой только те специфические детали, которые необходимы для понимания вариантов осуществления настоящего изобретения, в то время как не показаны другие детали, доступные пониманию специалистов в данной области после ознакомления с описанием настоящего изобретения, чтобы не усложнять описание настоящего изобретения.
Использованные здесь относительные термины, такие как "первый" и "второй," "верхний" и "нижний," и т.п., могут быть использованы только для того, чтобы различать один объект или элемент от другого объекта или элемента, без необходимости любой физической или логической связи между такими объектами или элементами. Кроме того, использованный в описании и формуле изобретения термин "Zigbee" относится к последовательности протоколов беспроводной связи высокого уровня, определенной в IEEE стандарте 802.15.4. Дополнительно, "Wi-Fi" относится к стандарту связи в соответствии с IEEE 802.11. Термин "WiMAX" относится к протоколам связи в соответствии с IEEE 802.16. Термин "BLUETOOTH" относится к техническим требованиям для беспроводной персональной сети связи ("PAN"), разработанной фирмой Bluetooth Special Interest Group.
В соответствии с первым вариантом осуществления настоящего изобретения предлагаются способ и система для кодирования шифрованных потоков так, чтобы избежать автоматического обнаружения (обнаружения наличия шифрования) при помощи различных типов критериев проверки случайности, в том числе критерия проверки случайности FIPS 140-2. Вариант защищен от некоторых известных атак с использованием схемы, которая содержит различные неоднозначные механизмы кодирования.
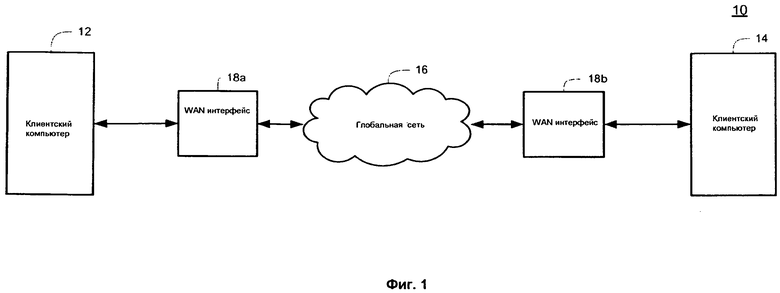
Обратимся теперь к рассмотрению чертежей, на которых аналогичные детали имеют одинаковые позиционные обозначения. На фиг.1 показана примерная система 10 для сокрытия данных шифрования. Система 10 содержит первый клиентский компьютер 12, имеющий связь со вторым клиентским компьютером 14 по глобальной сети ("WAN") 16. Глобальной сетью 16 может быть Internet, intranet или другая сеть связи. Клиентскими компьютерами 12, 14 могут быть персональные компьютеры, портативные компьютеры, «карманные» компьютеры ("PDAs"), серверы, мобильные телефоны и т.п. Каждый клиентский компьютер 12, 14 передает данные через WAN 16, через WAN интерфейс 18а. 18b, коллективно названный как WAN интерфейс 18. Несмотря на то что сеть связи показана на фиг.1 как сеть WAN, принципы настоящего изобретения также могут быть применены к другим видам сетей связи, таким как персональные сети ("PANs"), локальные сети ("LANs"), университетские сети ("CANs"), городские сети ("MANs"), и т.п. Кроме того, несмотря на то что на фиг.1 показаны два клиентских компьютера, следует иметь в виду, что эта конфигурация приведена только для примера. Например, система 10 может иметь множество WAN интерфейсов 18. WAN интерфейс 18 может иметь связь с различными типами клиентских устройств, такими как маршрутизаторы, переключатели, и т.п. Кроме того, WAN интерфейсом 18 может быть автономное устройство, или же это может быть часть другого ресурса, такого как клиентский компьютер 12, 14.
Каждый WAN интерфейс 18 шифрует данные от клиентского компьютера 12, 14 в соответствии с одной или несколькими известными схемами шифрования. WAN интерфейс 18 содержит укрыватель шифрования, описанный далее более подробно, применяемый для сокрытия того факта, что данные были зашифрованы с использованием Base64 схемы кодирования со случайно (случайным образом) генерированным алфавитом, в отличие от стандартного Base64 кодирования, которое типично предусматривает использование единственного, известного алфавита. Каждый WAN интерфейс 18 также осуществляет обратные функции, когда WAN интерфейс 18 получает Base64 кодированные и шифрованные блоки данных по сети WAN 16, которые затем декодируют и дешифруют, с использованием случайно генерированного алфавита, для получения данных, исходно переданных от клиентского компьютера 12, 14. Несмотря на то что каждый WAN интерфейс 18 на фиг.1 показан как подключенный к одному клиентскому компьютеру 12. 14, примерный WAN интерфейс 18, сконструированный в соответствии с принципами настоящего изобретения, может быть подключен к множеству компьютеров 12, 14, что не выходит за рамки настоящего изобретения.
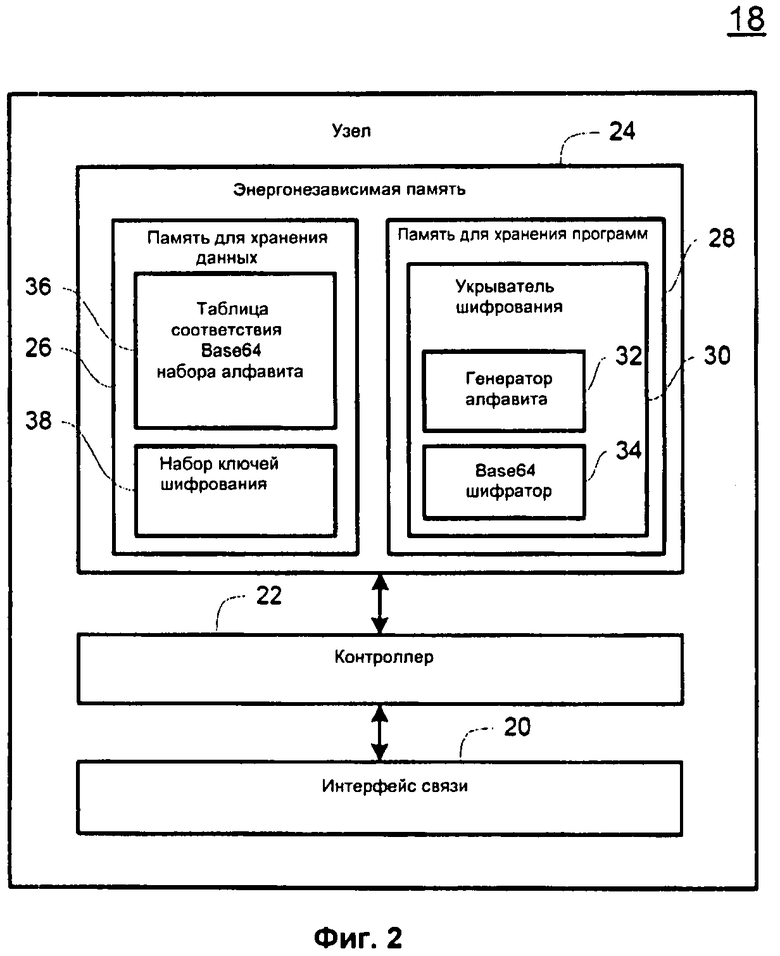
Обратимся теперь к рассмотрению фиг.2, на которой показан примерный WAN интерфейс 18, который содержит интерфейс 20 связи, соединенный с контроллером 22. Интерфейс 20 связи может быть проводным, беспроводным или любой их комбинацией. Интерфейс 20 связи передает пакеты данных между WAN интерфейсом 18 и другими ресурсами глобальной сети 16 с использованием известных протоколов связи, например Ethernet, Wi-Fi, WiMAX, BLUETOOTH и т.п. Интерфейс связи может иметь любое число портов связи.
Контроллер 22 управляет обработкой информации и работой WAN интерфейса 18, чтобы реализовать описанные здесь функции. Контроллер 22 также имеет связь с энергонезависимой памятью 24. Энергонезависимая память 24 содержит память 26 для хранения данных и память 28 для хранения программ. Память 28 для хранения программ содержит укрыватель 30 шифрования, который обеспечивает сокрытие того факта, что данные были зашифрованы, от автоматического обнаружения при помощи других объектов, подключенных к WAN 16, работа которых описана далее более подробно. Укрыватель 30 шифрования содержит генератор 32 алфавита для случайного генерирования содержащего шестьдесят четыре (64) знака Base64 набора алфавита из стандартных двухсот пятидесяти шести (256) возможных ASCII символов и Base64 шифратор 34, который кодирует шифрованные данные в соответствии с Base64 схемой кодирования, с использованием Base64 алфавита. Память 26 данных хранит файлы данных, такие как таблица 36 соответствия, обеспечивающая корреляцию Base64 набора алфавита с соответствующими ASCII символами и набором 38 ключей шифрования, которые пропускают между WAN интерфейсом 18 и ресурсом пункта назначения, таким как клиентский компьютер 14, ранее передачи каких-либо данных пользователя.
В дополнение к описанным здесь выше структурам, каждый WAN интерфейс 18 может иметь дополнительные, факультативные структуры (не показаны), которые могут быть необходимы для осуществления других функций интерфейса 18.
Когда используют Base64 схему кодирования, тогда обычно используют единственный, стандартизованный алфавит для преобразования входных триплетов (троек) октетов в выходные четверки октетов, за счет чего эффективно снижается плотность информации, например за счет исключения случайных побочных эффектов. Такое кодирование предназначено для пропускания произвольных двоичных данных через "каналы", которые могут быть непрозрачными для таких данных. RFC-822 email представляет собой один из примеров такого канала.
В Base64 схеме набор 64 печатных знаков выбирают из всех возможных ASCII символов и используют его как "алфавит кодирования". Существует немного вариантов этого алфавита, но обычно используют только один или два варианта. Важно учитывать комбинаторику, связанную с выбором подходящего алфавита для кодирования двоичных (и шифрованных или случайных) данных. Уравнение (1) дает полное число возможных алфавитов, когда 64 знака выбраны из поля 256 знаков (8-ми битовый ASCII или UTF-8):
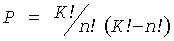
где К - полное число октетов, например 256, a n - размер подмножества, например 64.
С учетом приведенных выше параметров получаем ориентировочно 1061 алфавитов, содержащих 64 знака, выбранных из поля 256 возможных значений октета. Если рассматривать информационно-теоретические аспекты схемы кодирования, то следует иметь в виду, что способность результирующего кодирования производить чисто печатные ASCII символы является совершенно неважной. Что важно, так это то, что результирующее кодирование снижает плотность информации результирующего потока. Любое кодирование, которое расширяет 24-битовый триплет в 32-битовую четверку, достаточно для снижения плотности информации результирующего потока.
При внедрении настоящего изобретения представляется заманчивым создание небольшого числа алфавитов (или может быть только одного алфавита), которые не являются Base64 алфавитами, и использование этих алфавитов для кодирования шифрованных потоков. Однако немедленно становится ясной проблема, возникающая при любой такой схеме кодирования: единственный, фиксированный, алфавит подвержен декодированию "противниками" в той же степени, что и Base64 схема. Можно предположить, что "противникам" станет известен алфавит (алфавиты), использованный в такой схеме, и они смогут произвести обработку аналогично описанной здесь выше обработке Base64.
Таким образом, варианты настоящего изобретения, в которых алфавит 34 выбран динамически, например, во время создания долговременного шифрованного потока, имеют лучшую защиту от обнаружения, чем потоки с использованием статических алфавитов.
Кроме того, в большинстве шифрованных сеансов связи создают ключевой материал, например ключи 38 шифрования, на ранней стадии создания сеанса, чтобы создать объединенные ключи шифрования и целостности для лежащей в основе криптографической "упаковки." Часть этого ключевого материала может быть использована для помощи при выборе динамических алфавитов 34 шифрования, так как такие ключи 38 совместно используют на обеих сторонах системы связи в результате создания шифрованного канала.
Обратимся теперь к рассмотрению фиг.3, на которой показана примерная последовательность операций, осуществляемых укрывателем 30 шифрования для сокрытия существования шифрования данных. Процесс начинается тогда, когда WAN интерфейс 18 определяет, что имеются шифрованные данные для передачи (операция S102). Шифрованные данные могут быть получены от клиентского компьютера 12 в шифрованном виде или без шифрования. В последнем случае, WAN интерфейс 18 может шифровать данные в соответствии с известными способами шифрования.
WAN интерфейс 18 начинает безопасный сеанс связи с устройством адресата через интерфейс 20 связи (операция S104). Как часть инициализации безопасного сеанса связи, WAN интерфейс 18 и устройство адресата обмениваются ключевым материалом (операция S106), например ключами 38 шифрования. Ключи 38 шифрования используют для генерирования единственного псевдослучайно выбранного алфавита из 64 элементов, выбранных из более широкого поля 256 элементов, например из полного набора ASCII символов (операция S 108).
Любой генератор случайных чисел может быть использован для генерирования объединенного алфавита кодирования, однако для улучшения возможности взаимодействия используют стандартизованную криптографически стойкую псевдослучайную функцию, так что на обеих сторонах системы связи получают одинаковый алфавит кодирования. Подходящий алгоритм описан в публикации Internet Request For Comments ("RFC") 4615, причем выход псевдослучайной функции ("PRF") является переменной сцепления для следующего вызова PRF, а требуемый ключ, К, берут из объединенного ключевого материала из инициализации сеанса. Примеры символического кода приведены в таблице 1.
Таблица 1
Для начала шифрования в соответствии с настоящим изобретением шифрованные данные секционируют на части, такие как триплеты октетов, то есть 3 части из 8 битов (операция S110). Входной триплет октетов части данных подразделяют на группы из 6 битов (операция S112), и эти 6 битов используют как указатель в таблице 36 шестидесяти четырех выбранных элементов алфавита (операция S114). Данные кодируют путем отображения каждой группы из 6 битов соответствующим знаком алфавита с использованием 6 битов как указателя в таблице 36 соответствия (операция S116). Кодированные данные, то есть 4 знака алфавита для исходной части триплета октетов, передают через WAN 16 на устройство адресата (операция S 118).
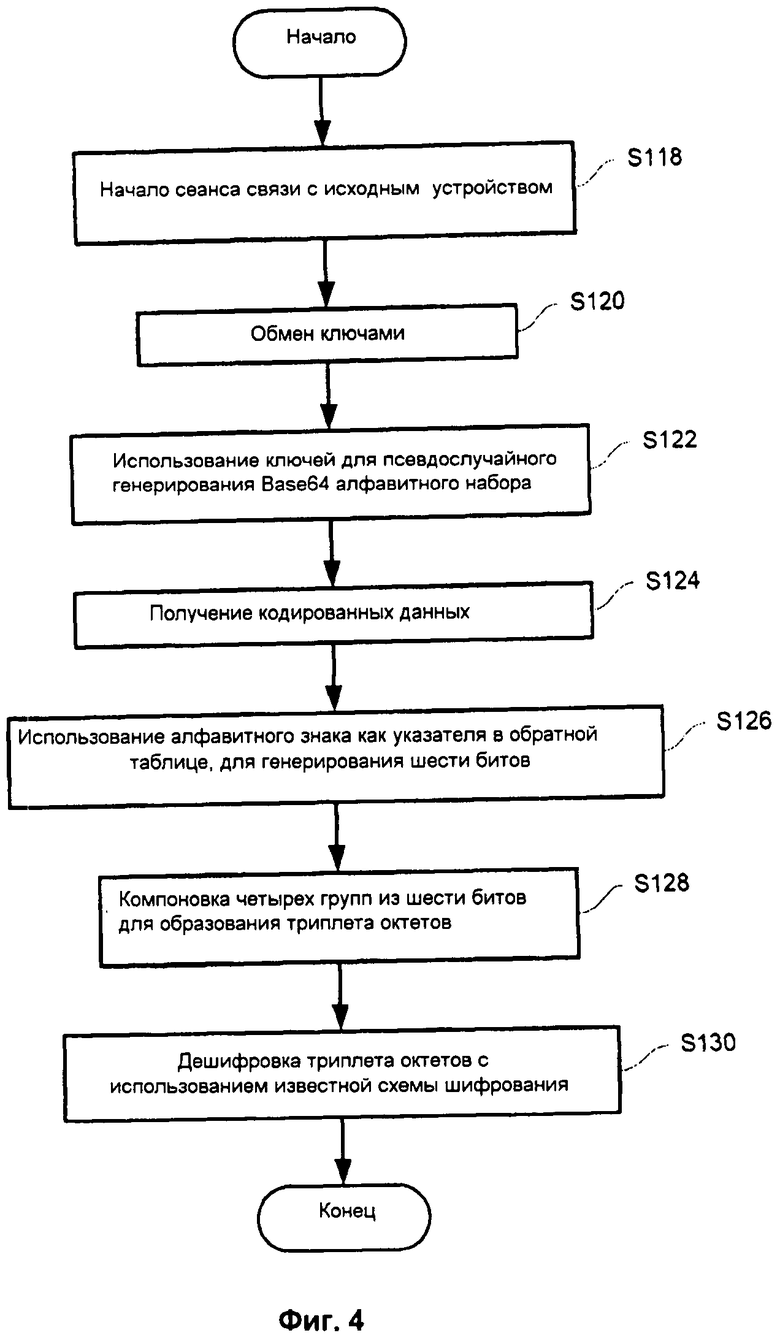
На фиг.4 показана примерная схема последовательности операций, выполняемых устройством адресата, таким как приемный WAN интерфейс 18 или клиентский компьютер 14, после получения блока данных, имеющих шифрование, сокрытое в соответствии с принципами настоящего изобретения. Способ, описанный со ссылкой на фиг.4, в основном представляет собой способ, описанный со ссылкой на фиг.3, выполняемый в обратном порядке. Как и раньше, устройство адресата образует безопасный сеанс связи с исходным устройством (операция S118) и производит обмен ключей 38 шифрования (операция S120). Ключи 38 шифрования используют для псевдослучайного генерирования того же самого Base64 алфавитного набора, который был использован для кодирования шифрованных данных (операция S122). Так называемая "обратная" таблица может быть рассчитана с использованием, например, символического кода, приведенного в таблице 2.
Таблица 2
Устройство адресата получает кодированные данные, которые содержат группы алфавитных знаков, содержащихся в псевдослучайно генерированном Base64 алфавитном наборе (операция S124). При декодировании алфавитный знак используют как указатель в обратной таблице, что дает 6-битовые данные (операция S126). Серии (группы) 6 битовых данных компонуют в группы по 4 для восстановления первоначально шифрованного триплета октетов (операция S128). Исходные данные получают за счет дешифровки триплета октетов с использованием известной схемы шифрования (операция S130).
Результат применения описанной технологии состоит в том, что входные данные будут эффективно зашифрованы при моноалфавитной замене символа из (секретного) алфавита с образованием дополнительного слоя шифрования. Эта технология позволяет надежно получать схемы кодирования, вырабатывающие данные, соответствующие FIPS 140-2 критерию проверки случайности.
Избыточность может быть дополнительно повышена за счет введения тонкого смещения в генерированный алфавит. Например, генерированный алфавит может быть устроен так, что существует меньшая вероятность выбора ASCII управляющих символов в качестве элементов алфавита, и так, что существует немного большая вероятность выбора ASCII групп "ETAOIN S" и "еtаоins" в качестве элементов алфавита. Это немного снижает число возможных алфавитов, но одновременно снижает плотность информации.
Дополнительное усовершенствование схемы кодирования против комбинаторно-сложных "атак" может быть реализовано за счет встраивания множества выбранных случайным образом алфавитов в выходную четверку октетов. Генерирование трех различных алфавитов и использование различных алфавитов для выходной четверки октетов позволяет обмануть любые механизмы, которые могут быть использованы для надежной идентификации трафика, закодированного по этой схеме. Присвоение (назначение) алфавитов выходным четверкам может быть фиксированным, таким как 1-2-3-1, или может быть выбрано псевдослучайно, с использованием той же самой PRF, которая была использована для генерирования алфавитов. Несмотря на то что это не улучшает информационно-теоретические аспекты этой системы, это позволяет повысить комбинаторную сложность любых "атак" против системы.
Атаку против этой схемы можно считать успешной, если третья сторона может надежно идентифицировать шифрованный трафик, кодированный по этой схеме. Полезно рассматривать только те атаки, которые могут быть эффективно автоматизированы, так как именно эти "атаки" представляют собой атаки, от которых схема должна быть защищена. Если рассматривать пример Base64 схемы кодирования, то "атакующий" должен произвести проверку трафиков потока на достаточную глубину, чтобы гарантировать, что только знаки от Base64 шифрования используются в потоке, и затем должен декодировать результирующий поток и проверить результирующий битовый поток на случайность. Следует иметь в виду, что так как Base64 используют для защиты многих различных типов данных, а не только шифрованных данных, то многие попытки декодирования Base64 дадут "не случайный" вердикт при автоматической атаке.
Гипотетическим сценарием опасной "атаки" является тот сценарий, в котором противник обладает некоторым значительным числом всех возможных алфавитов кодирования, вырабатываемых при помощи этой схемы. "Атакующий" должен произвести проверку на значительную глубину потока трафика с учетом всех возможных алфавитов, чтобы прийти к заключению о том, что трафик действительно кодирован с использованием одного из этих алфавитов. Так как атакующий не может заранее определить, какой алфавит (алфавиты) будет использован для кодирования любого данного потока, то возникает задача большой сложности, чтобы надежно различить трафик, который кодирован по данной схеме, от любого другого, незашифрованного, трафика в типичном Internet сценарии.
Полное число возможных алфавитов ориентировочно составляет, как уже было указано здесь выше, 10. Примерная PRF образует ориентировочно 10" состояний до повторения. Таким образом, верхний предел числа возможных алфавитов, вырабатываемых при помощи этой схемы, ориентировочно составляет 10. Так как каждый алфавит имеет длину 64 байта, то для хранения всех 10 алфавитов требуется слишком большой объем памяти.
Наиболее опасной атакой является атака, которая позволяет надежно обнаружить трафик, который кодирован по этой схеме, однако она не может надежно сделать заключение о наличии шифрованных данных. Если атакующий начинает с гипотезы, что исследуемые данные были кодированы по этой схеме, то тогда он должен поддерживать частотные таблицы для каждого октета в выходной четверке и после анализа достаточного количества данных просматривать частотные таблицы, в которых только 64 ввода имеют не равное нулю число, для всех 4 выходных октетов. Поддержание частотных таблиц обязательно должно осуществляться на базе потока, так как алфавиты созданы в начале потока. Проблема, в перспективе "атаки", состоит в том, что Base64 и другие 24 бита в 32 бита схемы кодирования также дают ошибочный результат. Так как атакующий имеет для работы только частотные таблицы и не знает обратного отображения в 6 битов, то он не может однозначно идентифицировать такой трафик, как шифрованный, так как трафик не может быть декодирован. Атакующий всего только знает, что каждый октет ограничен 64 значениями - что не является явной уликой, а всего лишь скромным намеком на то, что лежащие в основе данные, которые были кодированы по этой схеме, могут быть шифрованными данными.
Обсуждавшаяся здесь выше "атака", в которой похожая на Base64 схема кодирования может быть надежно обнаружена, даже при наличии выбора случайного алфавита, может быть отбита за счет использования неоднозначной (неопределенной) схемы кодирования, в которой некоторые из входных 6-битовых последовательностей могут быть представлены несколькими выходными октетами. В одной такой схеме, степень "неопределенности" кодирования может быть выбрана случайно в начале сеанса связи, точно так же, как отображения алфавита выбирают случайно в начале сеанса связи. Для каждого из 3 алфавитов и соответствующих обратных отображений некоторое число избыточных кодовых точек, например до 23 кодовых точек, генерируют в алфавитной таблице, соответствующих в пределе 23 вводам в алфавит. Таким образом, алфавит может иметь любую длину от 64 до 87 элементов. При шифровании, принимают случайное решение, когда кодируют 6 бит, какую из двух возможных схем шифрования использовать. Вероятность такого решения может быть любой, но во внедренном примере использована вероятность 50%.
Решение относительно того, какие вводы будут иметь "неопределенное" кодирование в алфавите, также может быть задано динамически, с использованием генератора случайных чисел для выбора сдвига в первичном алфавите. Использование неопределенной схемы кодирования, в которой почти 30% 6-битовых последовательностей имеют неопределенное кодирование, позволяет повысить защиту результирующего шифрованного потока от обнаружения при помощи описанного здесь выше анализа с использованием частотной таблицы,
Настоящее изобретение может быть реализовано с использованием аппаратных средств, программных средств или комбинации аппаратных средств и программных средств. Любые виды систем вычисления или других устройств, приспособленных для реализации описанных здесь способов, подходят для выполнения описанных здесь функций.
Типичная комбинация аппаратных средств и программных средств может быть специализирована, или же может быть использована вычислительная система общего назначения, имеющая один или несколько процессорных элементов и компьютерную программу, которая хранится в запоминающей среде и которая, после загрузки и осуществления, управляет вычислительной системой так, что она осуществляет описанные здесь способы. Настоящее изобретение также может быть реализовано в виде компьютерного программного продукта, который содержит все характеристики, позволяющие внедрить все описанные здесь способы, и который, после загрузки в вычислительную систему, позволяет осуществлять эти способы. Запоминающей средой может быть любое энергозависимое или энергонезависимое запоминающее устройство.
Компьютерной программой или приложением в настоящем контексте считают любое выражение, на любом языке, с использованием любого кода или системы счисления, набора команд, предназначенных для того, чтобы побуждать систему, имеющую ресурсы для обработки информации, осуществлять специфическую функцию, непосредственно или после любой одной из или обеих следующих операций: а) преобразование на другой язык, в другой код или систему счисления; и b) воспроизведение в другой материальной форме.
Несмотря на то что был описан предпочтительный вариант осуществления изобретения, совершенно ясно, что в него специалистами в данной области могут быть внесены изменения и дополнения, которые не выходят однако за рамки приведенной далее формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и комплекс изделий для скрытной передачи команд | 2021 |
|
RU2782337C1 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ) | 2013 |
|
RU2656734C2 |
| СПОСОБ ПОТОЧНОГО КОДИРОВАНИЯ ДИСКРЕТНОЙ ИНФОРМАЦИИ | 2002 |
|
RU2205516C1 |
| СПОСОБ ЗАЩИТЫ ИНФОРМАЦИИ | 2017 |
|
RU2648598C1 |
| Способ шифрования двоичной информации | 2018 |
|
RU2701128C1 |
| СПОСОБ И СИСТЕМА ДЛЯ СЕРИАЛИЗАЦИИ ИЗДЕЛИЙ И ВОССТАНОВЛЕНИЯ ДАННЫХ ИЗ СЕРИАЛИЗОВАННЫХ ИЗДЕЛИЙ | 2021 |
|
RU2829899C1 |
| УСТРОЙСТВО, СПОСОБ И СЕТЕВОЙ СЕРВЕР ДЛЯ ОБНАРУЖЕНИЯ СТРУКТУР ДАННЫХ В ПОТОКЕ ДАННЫХ | 2012 |
|
RU2608464C2 |
| СПОСОБ ПОТОЧНОГО КОДИРОВАНИЯ ДИСКРЕТНОЙ ИНФОРМАЦИИ | 2003 |
|
RU2251816C2 |
| Кодер, декодер и способ кодирования и шифрования входных данных | 2015 |
|
RU2638639C1 |
| СПОСОБ СКРЫТОЙ ПЕРЕДАЧИ ЗАШИФРОВАННОЙ ИНФОРМАЦИИ ПО МНОЖЕСТВУ КАНАЛОВ СВЯЗИ | 2011 |
|
RU2462825C1 |
Предлагаются система, способ и сетевой интерфейс для сокрытия существования шифрованного трафика данных в сети связи. Набор знаков генерируют за счет использования набора ключей шифрования для ввода псевдослучайной функции. Каждый знак соответствует значению указателя. Шифрованные детали разделяют на множество частей. Каждую часть секционируют на множество групп и кодируют за счет отображения каждой группы знаком в наборе знаков в соответствии с его значением указателя. Отображенные знаки передают через сеть связи. 3 н. и 17 з.п.ф-лы, 4 ил.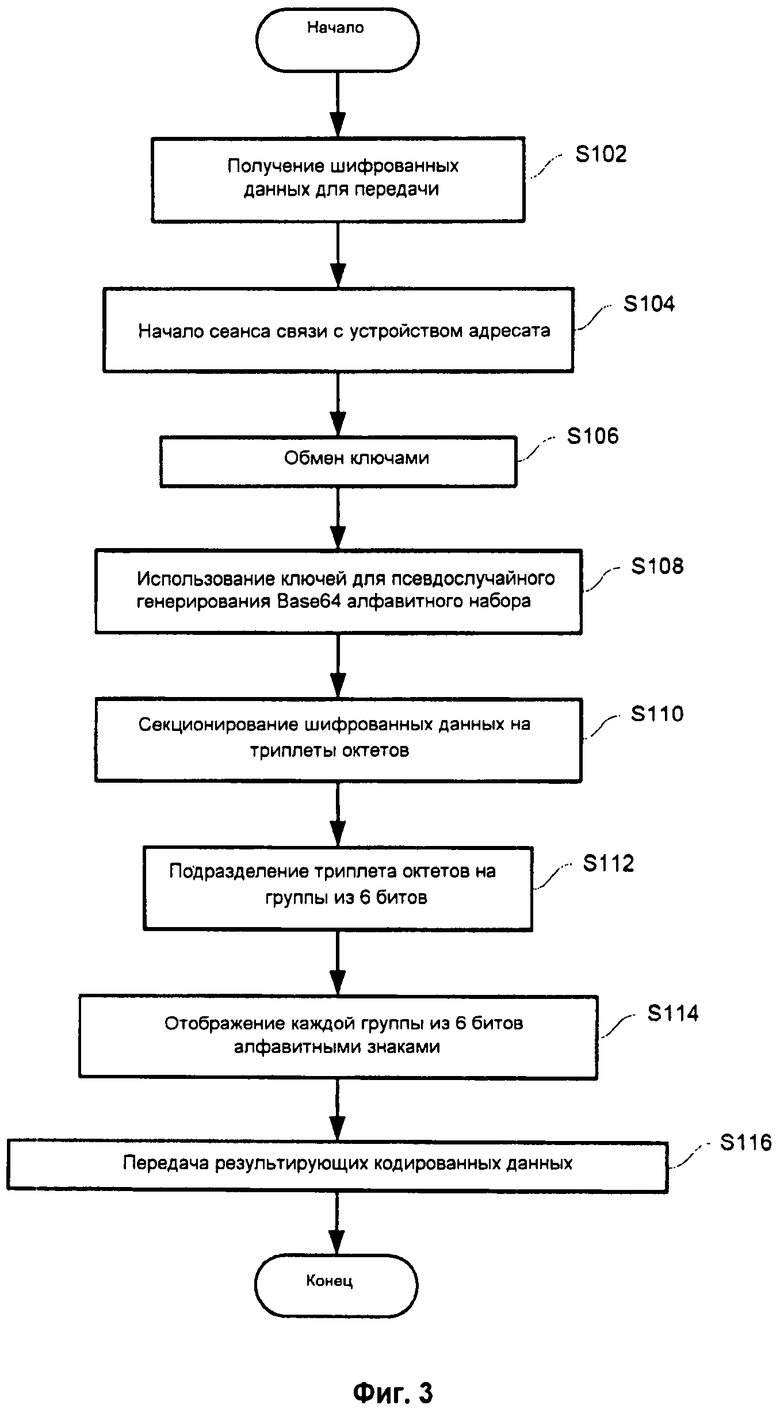
1. Способ сокрытия существования шифрования данных в сети связи, включающий в себя следующие операции:
генерирование набора знаков путем использования набора ключей шифрования в качестве ввода в псевдослучайную функцию, причем каждый знак соответствует значению указателя;
подразделение шифрованных данных на множество частей;
секционирование каждой части на множество групп;
кодирование каждой части за счет отображения каждой группы знаком в наборе знаков в соответствии с его значением указателя; и
передача отображенных знаков через сеть связи.
2. Способ по п.1, в котором набор знаков содержит шестьдесят четыре знака.
3. Способ по п.2, в котором шестьдесят четыре знака псевдослучайно выбраны из полного набора 256 ASCII символов.
4. Способ по п.1, который дополнительно предусматривает смещение генерирования набора знаков, так что вероятность выбора ASCII управляющих символов в качестве элементов набора снижается.
5. Способ по п.1, который дополнительно предусматривает смещение генерирования набора знаков, так что вероятность выбора группы знаков в качестве элементов набора увеличивается.
6. Способ по п.1, в котором часть использованных данных представляет собой триплет октетов, а каждая группа имеет шесть битов.
7. Способ по п.1, который дополнительно включает в себя следующие операции:
генерирование множества наборов знаков; и
использование различных наборов знаков для кодирования соседних частей.
8. Способ по п.7, в котором присвоение наборов знаков частям производят псевдослучайным образом.
9. Способ по п.8, в котором присвоение наборов знаков частям производят с использованием псевдослучайной функции, использованной для генерирования наборов знаков.
10. Способ по п.1, который дополнительно включает в себя следующие операции:
прием кодированного блока данных, причем кодированный блок данных содержит знаки в наборе знаков;
подразделение кодированного блока данных на группы знаков;
отображение каждого знака его соответствующим значением указателя, чтобы восстановить множество частей; и
дешифровка каждой части из множества частей.
11. Сетевой интерфейс для сокрытия существования шифрования данных, содержащий:
контроллер, который:
генерирует набор знаков за счет использования набора ключей шифрования в качестве ввода в псевдослучайную функцию, причем каждый знак соответствует значению указателя;
подразделяет шифрованные данные на множество частей;
секционирует каждую часть множества частей на множество групп;
кодирует каждую часть за счет отображения каждый группы множества групп знаком в наборе знаков в соответствии с его значением указателя;
и
интерфейс связи, имеющий связь с контроллером, причем интерфейс связи передает отображенные знаки через сеть связи.
12. Сетевой интерфейс по п.11, в котором часть шифрованных данных представляет собой триплет октетов, а каждая группа имеет шесть битов.
13. Сетевой интерфейс по п.12, в котором шестьдесят четыре знака псевдослучайно выбраны из полного набора 256 ASCII символов.
14. Сетевой интерфейс по п.11, в котором контроллер дополнительно смещает генерирование набора знаков, так что вероятность выбора ASCII управляющих символов в качестве элементов набора знаков снижается.
15. Сетевой интерфейс по п.11, в котором контроллер дополнительно смещает генерирование набора знаков, так что вероятность выбора группы знаков в качестве элементов набора знаков увеличивается.
16. Сетевой интерфейс по п.11, в котором контроллер дополнительно:
генерирует множество наборов знаков; и
использует различные наборы знаков для кодирования соседних частей.
17. Сетевой интерфейс по п.16, в котором присвоение наборов знаков частям является фиксированным.
18. Сетевой интерфейс по п.16, в котором присвоение наборов знаков частям производят псевдослучайным образом.
19. Сетевой интерфейс по п.11, в котором интерфейс связи дополнительно получает кодированный блок данных, причем кодированный блок данных содержит знаки в наборе знаков; при этом контроллер дополнительно:
подразделяет кодированный блок данных на множество групп знаков;
отображает каждый знак его соответствующим значением указателя, чтобы восстановить множество частей; и
дешифрует каждую часть множества частей.
20. Система для сокрытия существования шифрования данных в сети связи, содержащая:
первый сетевой интерфейс, который:
генерирует набор алфавитных знаков путем использования набора ключей шифрования в качестве ввода в псевдослучайную функцию, причем каждый алфавитный знак соответствует значению указателя;
подразделяет шифрованные данные на множество частей;
секционирует каждую часть на множество групп;
кодирует каждую часть за счет отображения каждой из множества групп знаком в наборе знаков в соответствии с его значением указателя; и
передает отображенные знаки через сеть связи;
второй сетевой интерфейс, который:
получает кодированный блок данных, причем кодированный блок данных содержит отображенные знаки;
подразделяет кодированный блок данных на множество групп знаков;
отображает каждый знак его соответствующим значением указателя, чтобы восстановить множество частей; и
дешифрует каждую часть множества частей.
| RU 2006103630 A, 27.07.2006 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6192129 B1, 20.02.2001 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6445797 B1, 03.09.2002 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

