Область техники, к которой относится изобретение
Настоящее изобретение относится к области безопасного кодирования изделий, чтобы обеспечить их идентификацию, аутентификацию, а также отслеживание и контроль, в частности к способу сериализации изделий и соответствующей системе для их сериализации.
Предпосылки изобретения
С годами подделка потребительских товаров, в частности фармацевтической продукции, превратилась в огромную проблему, в результате чего на мировых рынках появляется большое количество некачественной опасной продукции, что приводит к значительным потерям доходов для производителей.
Текущие решения проблемы подделки включают сериализацию изделий и/или сериализацию этикеток, которая заключается в печати уникальных кодов на последовательности продуктов, упаковок, марок и т. д., чтобы можно было однозначно идентифицировать каждый отдельный продукт. Как правило, код представляет собой последовательность символов, таких как, например, глифы, знаки, цифры, полученные в результате шифрования уникального (серийного) номера, связанного с изделием. Этот уникальный серийный номер фактически определяет ранг изделия в данной серии изделий (например, ранг изделия в производственной линии), в этой перспективе серийный номер соответствует порядковому номеру. Основная цель шифрования таких уникальных серийных номеров заключается в сокрытии фактического порядка изделий, чтобы фальшивомонетчик не мог легко угадать правдоподобную последовательность серийных номеров (соответствующих последовательным изделиям).
Например, в документе WO2018204319A1 описано отслеживание и аутентификация продуктов, таких как фармацевтические таблетки и другие элементы, хранящиеся в блистерах или аналогичной упаковке, для верификации их аутентичности. Последовательность продуктов, определяемая физическими атрибутами и расположением фармацевтических продуктов в упаковке, шифруется и используется для маркирования упаковки кодом.
Обычно при сериализации не возникает проблем с синхронизацией, каждый продукт/изделие/этикетка получает один уникальный код с использованием надлежащего пускового устройства или кодирующего устройства. Обычно продукты с опечатками могут автоматически сбрасываться с линии. Такая классическая сериализация работает нормально только тогда, когда каждое изделие строго маркировано своим уникальным кодом без ошибок.
Однако в некоторых случаях может произойти линейная десинхронизация, т. е. неправильная регистрация кодов (неправильная синхронизация) среди изделий, что приводит к разделению кодов между последовательными изделиями, так что в одном изделии конец предыдущего кода может быть сцеплен с началом следующего кода. В этом случае классическая сериализация не может дешифровать код, чтобы найти правильный серийный номер. Линейная неправильная регистрация может происходить по разным техническим причинам, например, при нанесении предварительной маркировки на фольгу, которая затем вырезается без строгого контроля положения разрезов при нанесении на изделия. Например, сериализованные номера партии изделий могут быть последовательно напечатаны на непрерывной полосе (как правило, на бумаге) и впоследствии разрезаны на фрагменты с длиной, соответствующей длине кода, наносимого на изделия: из-за возможного смещения на этапе резки фрагмент, наносимый на заданное изделие, может содержать только часть соответствующего кода и часть соседнего кода. В частности, это касается банкнот, имеющих сериализованную защитную нить: кодированные серийные номера печатаются последовательно на непрерывной нити, и эта нить разрезается на фрагменты с длиной, обычно соответствующей ширине банкноты, и каждый фрагмент наносится на (или вставляется в) соответствующую банкноту, с возможной проблемой смещения. Даже боковое расположение нити на банкнотах может различаться. В некоторых случаях регистрация может быть затруднена из-за высокой скорости движения изделий, отсутствия сложных механизмов регистрации или механической невозможности регистрации. В любом случае линейная неправильная регистрация делает классическую сериализацию невозможной, ставя под угрозу последующую идентификацию и/или аутентификацию закодированных изделий (такие несовмещенные разрезы могут возникать также на этапах получения и считывания).
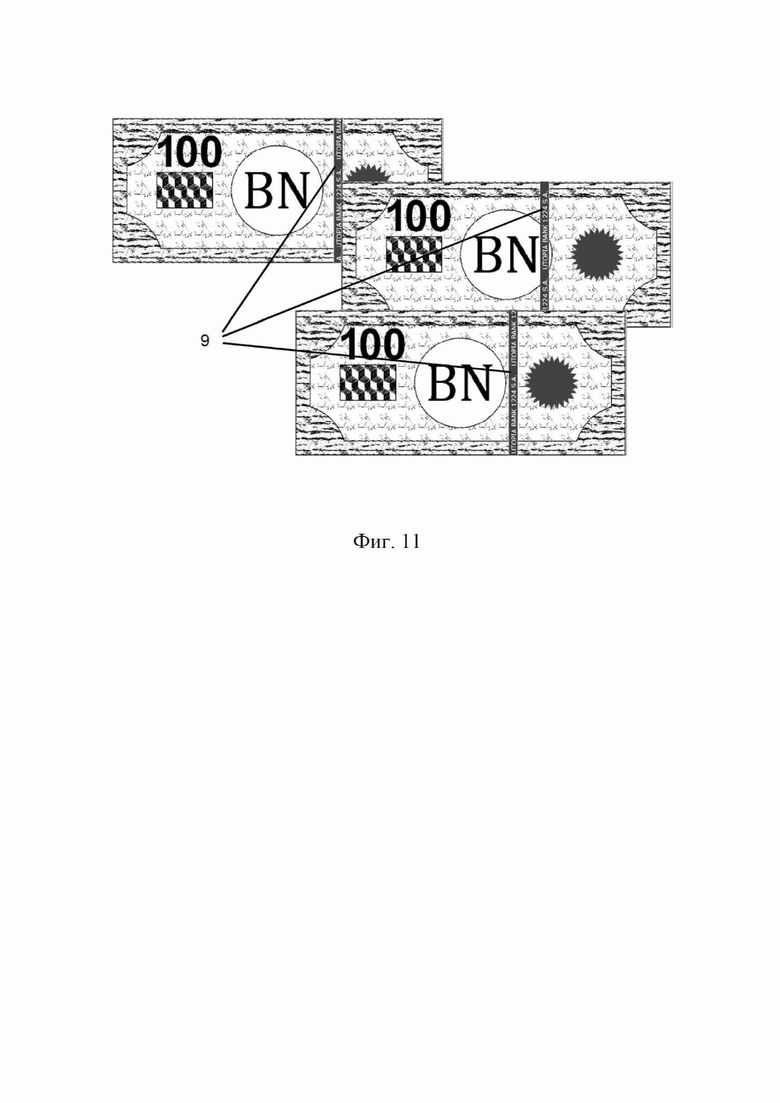
Один из примеров относится к защитным нитям, вставляемым в банкноты многих центральных банков в качестве признака аутентификации, как показано на фиг. 11. Такие нити выполнены из крупногабаритной полимерной или металлической фольги и маркируются неизменяющейся печатью. Фольга нарезается непрерывно на большие рулоны и делится на нити, которые включаются в защитную бумагу в процессе ее изготовления. Нити в конечном итоге обрезаются только на конце внутри банкнот, после печати. Классическая сериализация невозможна из-за отсутствия линейной регистрации. Следовательно, защитные нити в настоящее время таким образом не используются.
Следовательно, задачей настоящего изобретения является создание способа и соответствующей системы для сериализации изделий, что позволяет использовать линейное кодирование, устойчивое к десинхронизации, и позволят применять надлежащую сериализацию в любых ситуациях, включая те, когда регистрация кодов затруднена или невозможна.
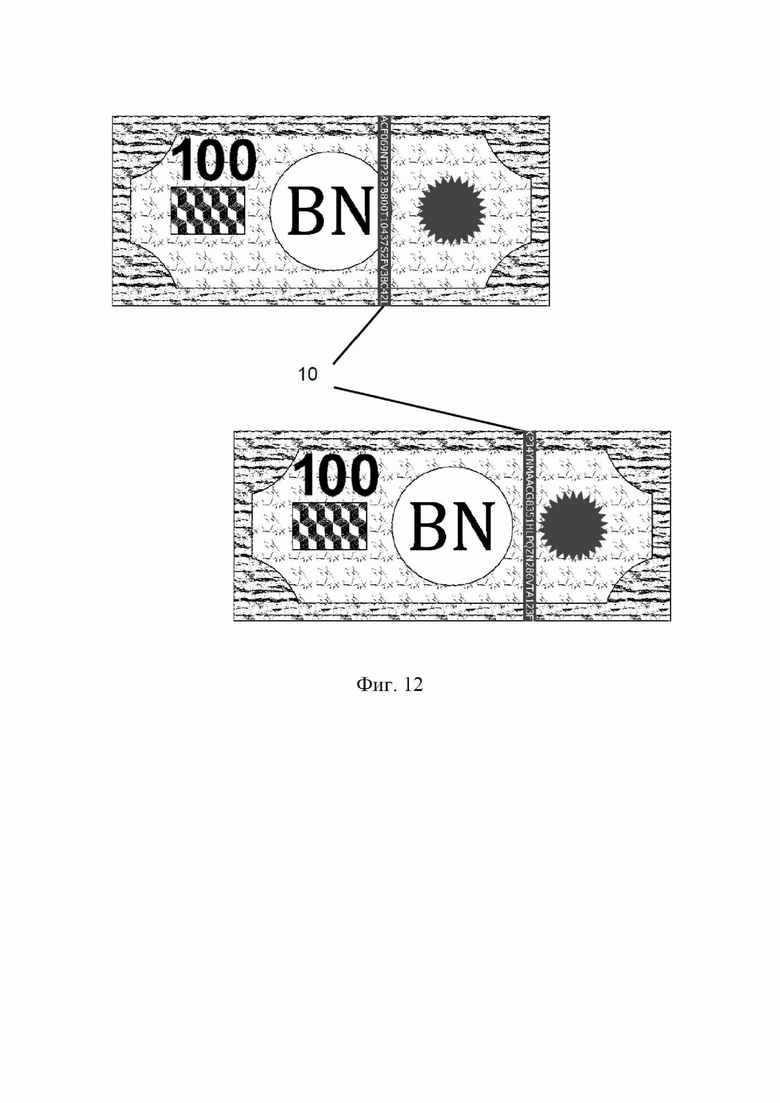
Благодаря настоящему изобретению фармацевтические блистеры, упомянутые выше, теперь могут быть сериализованы перед их разрезанием и использованием для упаковки лекарственных пилюль. Защитные нити банкнот могут извлечь выгоду из настоящего изобретения и могут быть сериализованы, как показано на фиг. 12. В частности, непрерывный поток кодов, печатаемых на защитных нитях, теперь может создавать две разные банкноты, никогда не содержащие одну и ту же надпись, и, таким образом, эти банкноты могут быть однозначно аутентифицированы. Более того, устойчивость к десинхронизации сделает их читаемыми при любых обстоятельствах. Такой дополнительный защитный признак может быть как человекочитаемым, так и машиночитаемым.
Краткое описание изобретения
Согласно одному аспекту настоящее изобретение относится к способу сериализации изделий, включающему:
- шифрование уникального серийного номера каждого изделия с использованием ключа шифрования k для получения соответствующего уникального кода, и
- маркирование каждого изделия его соответствующим уникальным кодом,
при этом каждый уникальный код имеет длину L и включен в строку символов с длиной L’, которой маркируется соответствующее изделие, и при этом L’ больше L.
Символы строки символов могут включать графические символы, выбранные из человекочитаемых знаков и машиночитаемых символов. Эти символы строки символов могут быть выбраны из набора глифов, предпочтительно из буквенных, буквенно-цифровых или цифровых символов.
Согласно варианту вышеупомянутого способа уникальный код присутствует в строке символов при смещении, при этом L’ больше или равна (2L-1). В другом варианте уникальный код присутствует в строке символов при смещении, при этом L’ меньше (2L-1).
В вышеупомянутом способе смещение уникального кода в строке символов предпочтительно осуществляют путем нанесения разных алфавитов для разных положений символов в уникальном коде, или путем нанесения маркировки между последовательными уникальными кодами, при этом маркировка выбрана из пробела, конкретного знака или блока. Также возможно использование без индикатора смещений, т. е. без маркировки и с одним алфавитом для всех символов.
Вышеупомянутое маркирование изделий строками символов может включать непосредственное маркирование или печать, нанесение напечатанных этикеток или лазерную гравировку. Шифрование серийного номера изделия для получения уникального кода можно осуществлять путем применения блочного шифрования или блочного шифрования в сочетании с шифрованием с сохранением формата (FPE).
В качестве альтернативы, шифрование серийного номера изделия для получения уникального кода можно осуществлять с помощью самосинхронизирующегося поточного шифрования на основе обратной связи по шифротексту, при этом символы серийных номеров шифруются один за одним в конструкции поточного шифра с помощью шифрования с сохранением формата (FPE). Обратная связь по шифротексту («CFB») означает, что шифрование одного символа зависит от одного или нескольких предыдущих зашифрованных символов. Более того, минимальная длина L’ строки символов, которой маркируется изделие, может быть равна (L+K), причем K > 0 является длиной обратной связи, состоящей из нескольких знаков или по меньшей мере одного символа в дополнение к указанной длине L уникального кода. В этом варианте смещение предпочтительно указывается с использованием разных алфавитов для разных положений символов в уникальном коде или конкретного символа в начале кода.
Согласно другому аспекту настоящее изобретение относится к способу дешифрования для восстановления уникального кода и соответствующего серийного номера из строки символов, которой маркируется изделие согласно способу сериализации, описанному выше, включающему:
- считывание строки символов с длиной L’, которой маркируется изделие;
- дешифрование на основе ключа дешифрования k’ блоков символов с длиной L со смещениями от 0 до L-1 в строке символов с длиной L’, считываемых на изделии, при этом L’ больше L;
- для каждого варианта серийного номера n для соответствия его блоку с длиной L, вычисление предыдущего серийного номера n-1 и следующего серийного номера n+1;
- шифрование с помощью ключа шифрования k серийных номеров n-1 и n+1, соответственно, с получением, соответственно, предыдущего и следующего вариантов серийных номеров, представленных в виде строк символов;
- посимвольное сравнение предыдущего варианта серийного номера с соответствующей левой частью строки символов с длиной L’ и следующего варианта серийного номера с соответствующей правой частью строки символов с длиной L’,
при этом
• в случае совпадения всех сравненных символов, восстанавливают правильный уникальный код и соответствующий правильный серийный номер n из считанной строки символов; и
• в случае неудачи по меньшей мере одного сравнения символов для смещения, серийный номер не соответствует указанному смещению.
Согласно дополнительному аспекту настоящее изобретение также относится к системе для сериализации изделий, содержащей:
- память и процессор, причем память вместе с процессором выполнены с возможностью запуска системы для шифрования серийного номера каждого изделия с использованием ключа шифрования k, сохраненного в памяти, для получения соответствующих уникальных кодов, и
- устройство для маркирования, подключенное к процессору и выполненное с возможностью маркирования изделий уникальными кодами, принятыми от процессора,
при этом система выполнена с возможностью включения каждого уникального кода с длиной L в строку символов с длиной L’, при этом L’ больше L, и маркирования соответствующего изделия строкой символов.
Память вместе с процессором могут быть выполнены с возможностью запуска системы для применения блочного шифрования или самосинхронизирующегося поточного шифрования на основе обратной связи в сочетании с шифрованием с сохранением формата (FPE).
В качестве альтернативы, память вместе с процессором могут быть выполнены с возможностью запуска системы для применения шифрования с сохранением формата (FPE), при этом шифры серийных номеров шифруются один за одним в конструкции поточного шифра.
Согласно другому аспекту настоящее изобретение дополнительно относится к системе для восстановления уникального кода и соответствующего серийного номера из строки символов, которой маркируется изделие с помощью системы для сериализации изделий, как описано выше, причем система содержит блок обработки, оснащенный блоком памяти и считывающее устройство, при этом считывающее устройство выполнено с возможностью считывания строки символов, которой маркируется изделие, и сохранения считанной строки символов в блоке памяти, и блок обработки выполнен с возможностью запуска системы для осуществления операций:
- дешифрования на основе ключа дешифрования k’, сохраненного в блоке памяти, блоков символов с длиной L со смещениями от 0 до L-1 в строке символов с длиной L’, сохраненных в блоке памяти, причем L’ больше L;
- вычисления для каждого варианта серийного номера n для соответствия его блоку с длиной L, предыдущего серийного номера n-1 и следующего серийного номера n+1;
- шифрования с помощью ключа шифрования k серийных номеров n-1 и n+1, соответственно, и получения, соответственно, предыдущего и следующего вариантов серийных номеров;
- посимвольного сравнения предыдущего варианта серийного номера с соответствующей левой частью строки символов с длиной L’ и следующего варианта серийного номера с соответствующей правой частью строки символов с длиной L’,
при этом
• в случае совпадения всех сравненных символов, система выполнена с возможностью доставки сигнала о восстановлении правильного уникального кода и соответствующего правильного серийного номера n из считанной строки символов; и
• в случае неудачи по меньшей мере одного сравнения символов для смещения, серийный номер не соответствует указанному смещению.
Далее настоящее изобретение будет описано более полно со ссылкой на прилагаемые чертежи, на которых одинаковые цифры представляют одинаковые элементы на разных фигурах и на которых проиллюстрированы основные аспекты и признаки настоящего изобретения.
Краткое описание чертежей
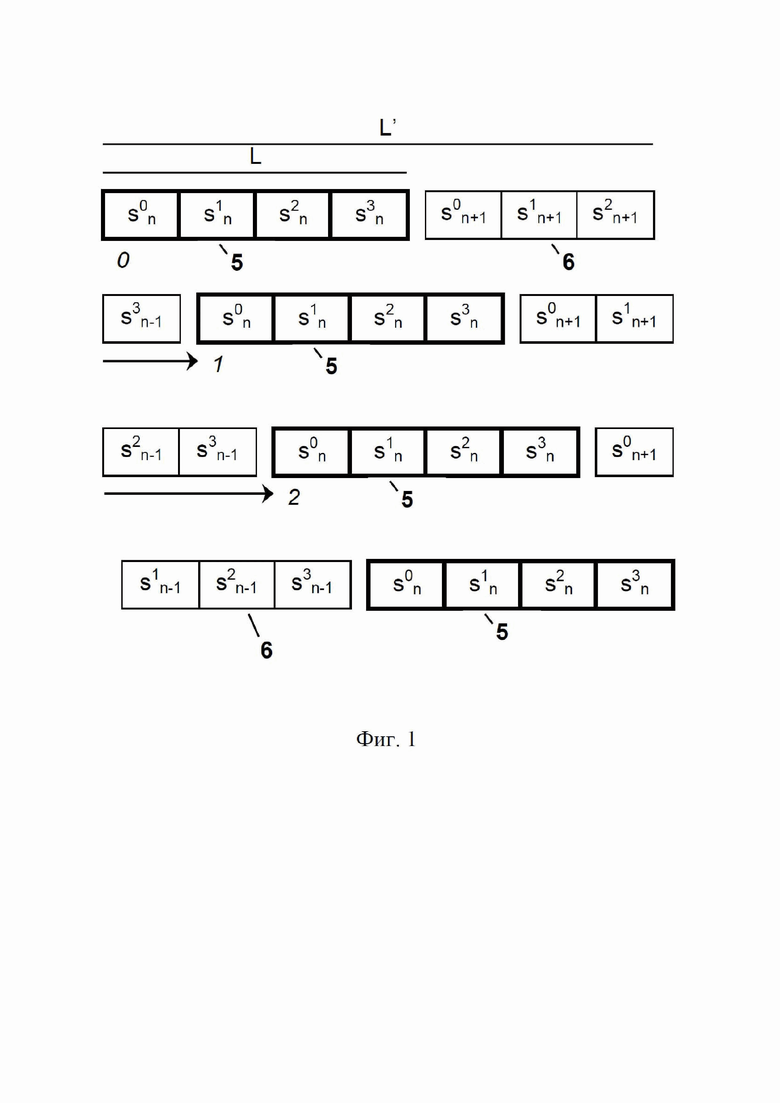
На фиг. 1 проиллюстрирован пример с семью напечатанными знаками (символы строки конкатенации с длиной L’ = 7) для кодов с длиной в 4 знака (символы кодов с длиной L = 4).
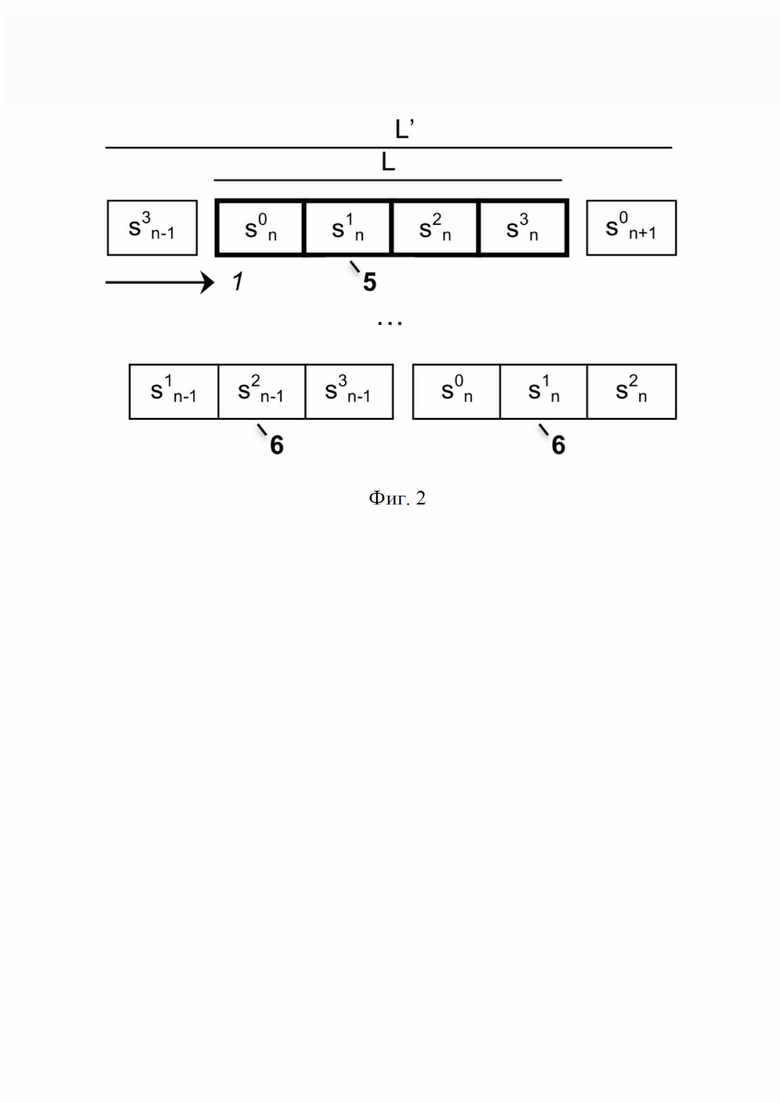
На фиг. 2 проиллюстрирован пример с шестью напечатанными знаками (L’ = 6) для кодов с длиной в 4 знака (L = 4).
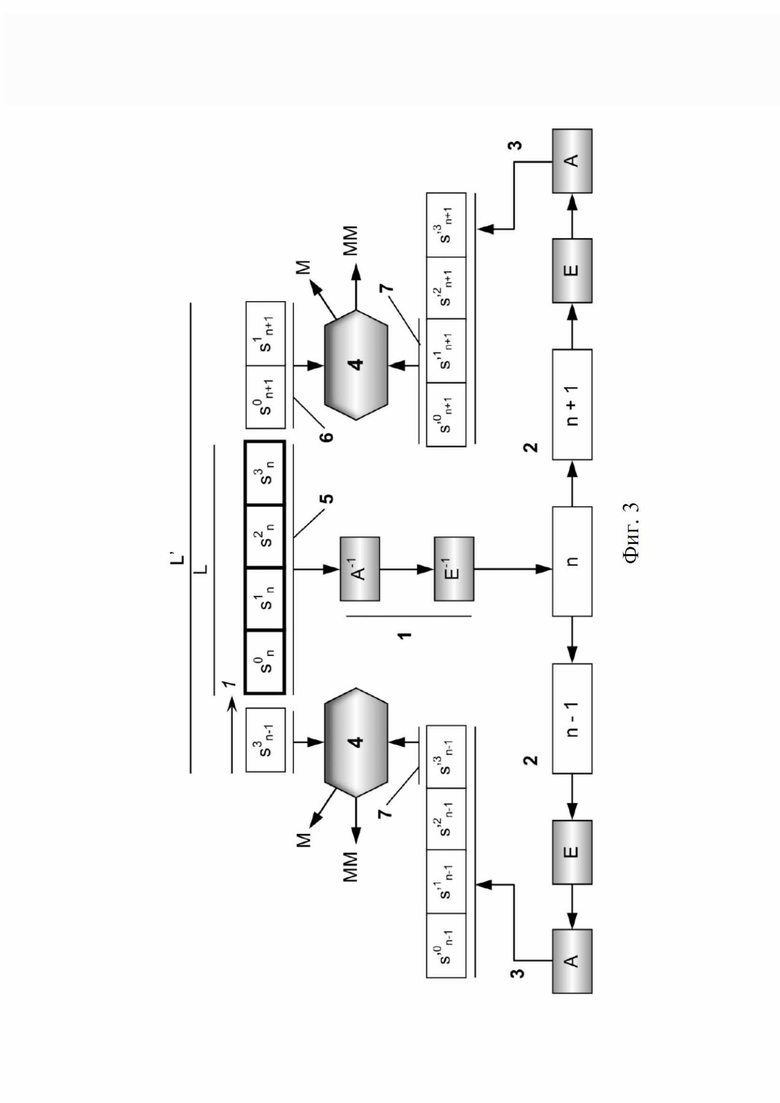
На фиг. 3 представлена схематическая иллюстрация способа дешифрования серийных номеров с более длинными напечатанными кодами, чем фактическая серийная длина.
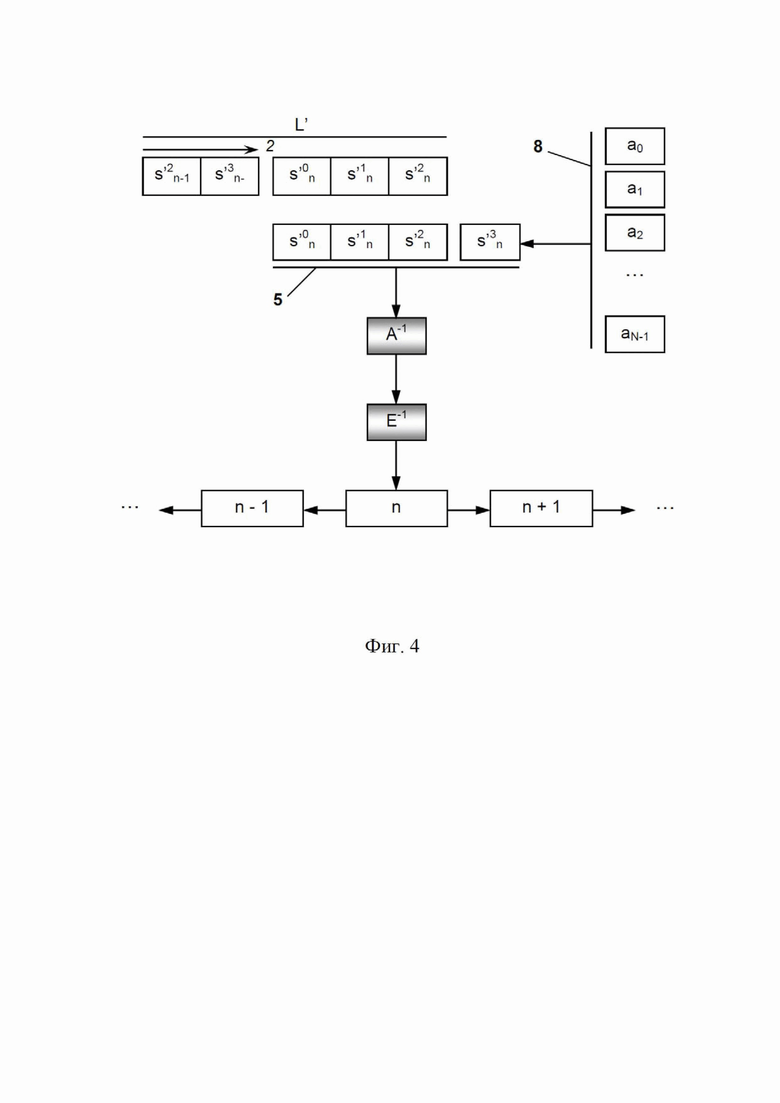
На фиг. 4 представлена схематическая иллюстрация способа дешифрования серийных номеров, когда код с длиной L отсутствует в знаках L’, что может произойти, когда L’ меньше 2L - 1.
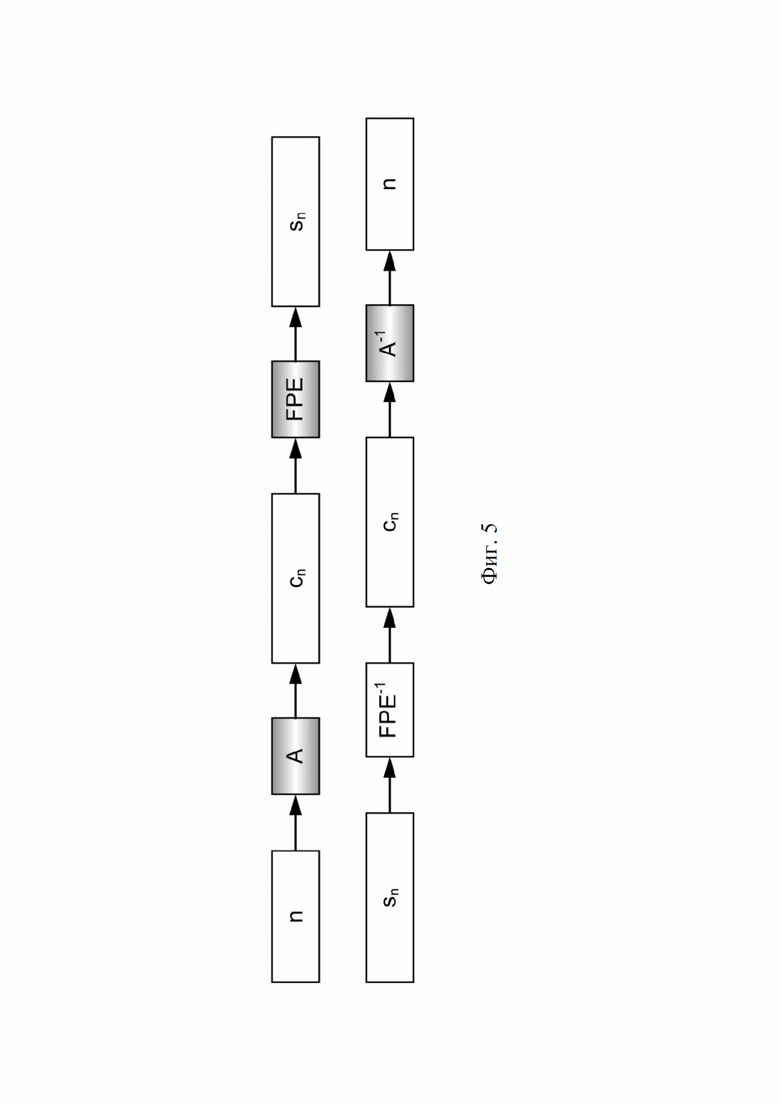
На фиг. 5 проиллюстрировано использование шифрования с сохранением формата для сериализации.
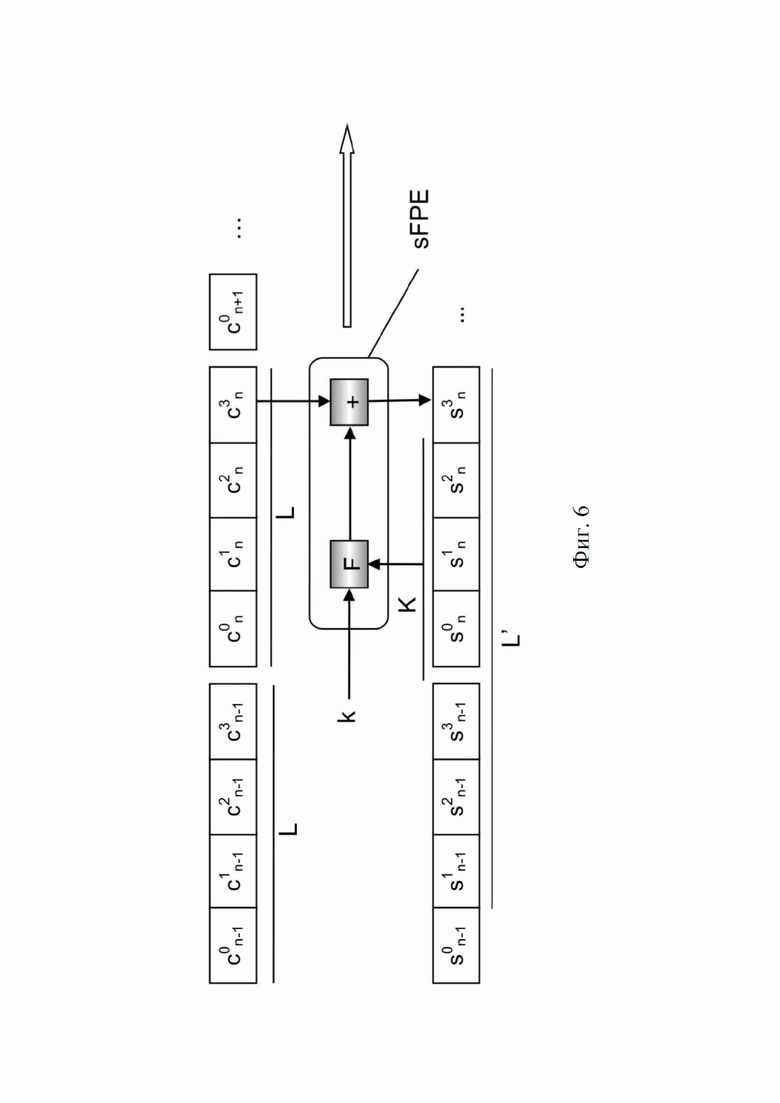
На фиг. 6 проиллюстрировано использование поточного шифрования по шифротексту с сохранением формата для сериализации, для кодов с длиной в 4 знака (L = 4) и обратной связи по шифротексту с длиной в 3 знака (K = 3).
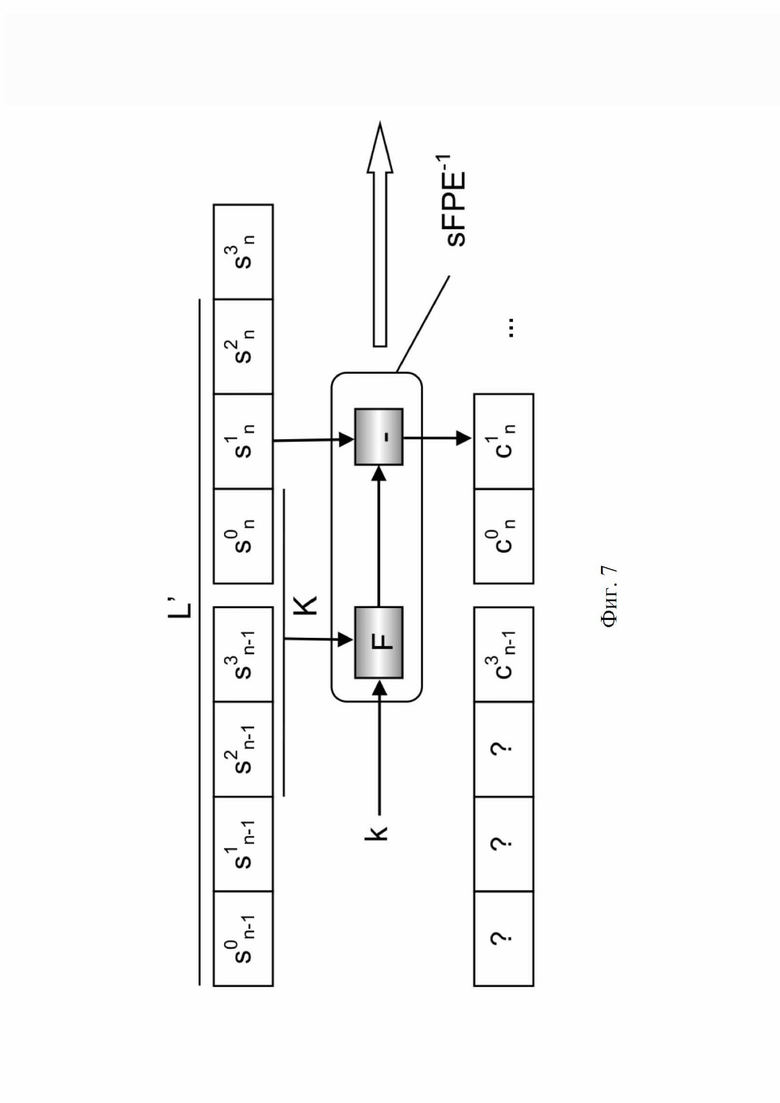
На фиг. 7 проиллюстрирована схема дешифрования сериализации, которая требует по меньшей мере L’ = L + K напечатанных знаков для правильного дешифрования L знаков.
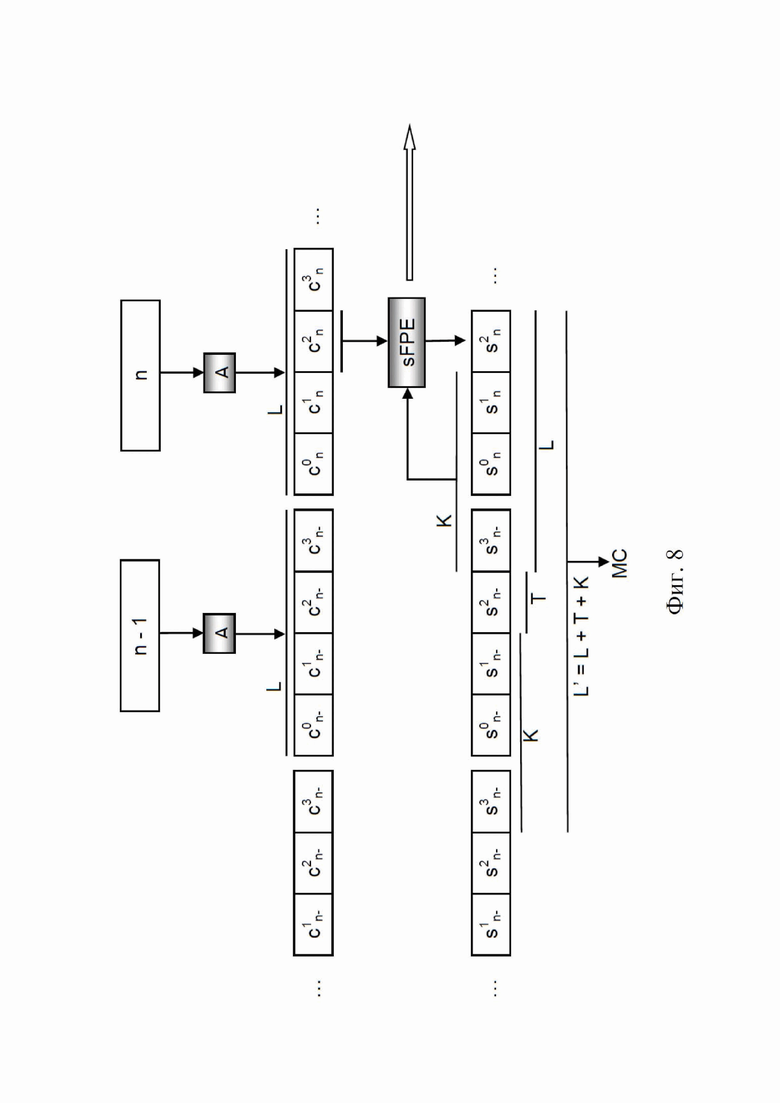
На фиг. 8 представлена схематическая иллюстрация поточного шифрования по шифротексту для сериализации, где L’ = L + K + T, T является необязательной дополнительной длиной, т. е. T ≥ 0 (в данном случае: T = 1 и L’ = 8).
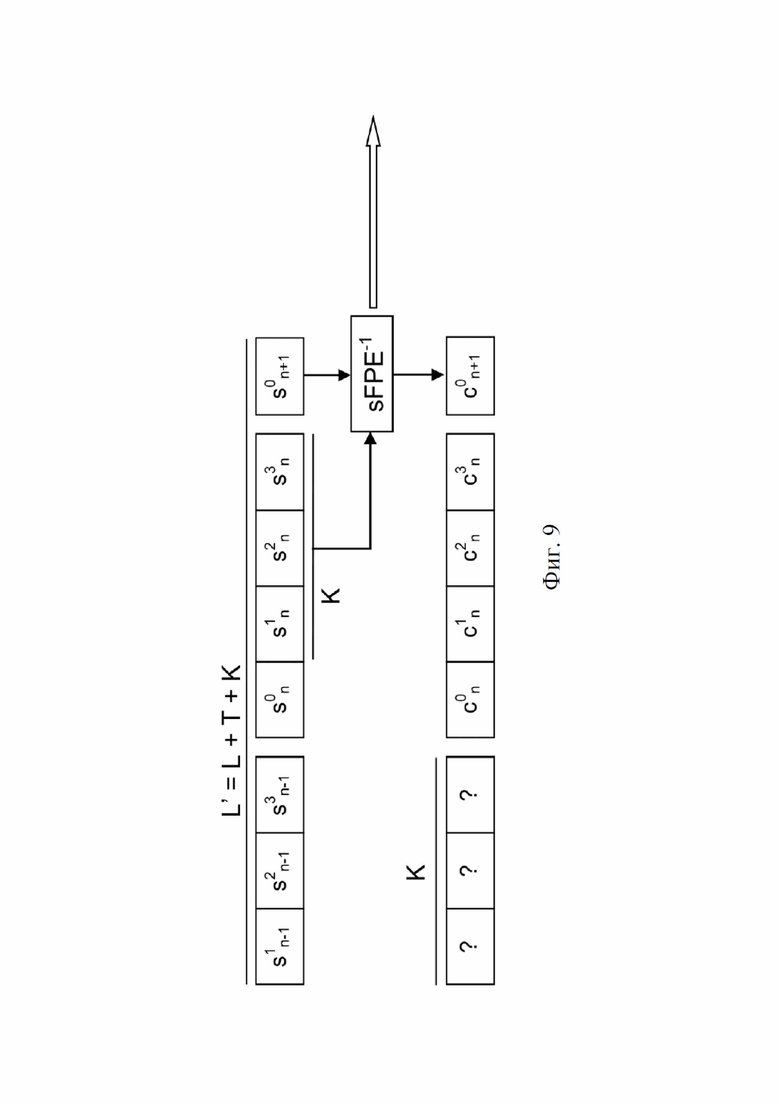
На фиг. 9 проиллюстрирован пример поточного дешифрования по шифротексту для сериализации знаков.
На фиг. 10 показан пример запатентованного штрих-кода/символики, состоящего из одномерных/двумерных мини-рисунков, напечатанных линейно, причем каждый рисунок представляет собой символ алфавита.
На фиг. 11 проиллюстрированы обычные защитные нити, встроенные в банкноты многих стран, демонстрирующие десинхронизацию их надписи по длине и различное латеральное расположение.
На фиг. 12 проиллюстрирована защитная нить, маркированная с помощью линейной устойчивой к десинхронизации сериализации, которую можно использовать в качестве дополнительного признака аутентификации банкнот.
Подробное описание
Серийный номер - это уникальный номер, связанный с одним изделием. Серийный номер соответствует порядковому номеру, принадлежащему набору серийных номеров, логически упорядоченных в известной последовательности, такой как 0, 1, 2, 3, 4, …, n-1, n, n+1, …, M-1: эта коллекция содержит в общей сложности M разных серийных номеров, причем M больше или равно общему количеству изделий, которые должны быть промаркированы (например, общее количество изделий в производственной партии). Следовательно, каждое изделие однозначно связано с серийным номером, как, например, серийный номер n связан с n-м изделием, n+1 — (n+1)-м изделием и так далее. Серийные номера могут быть представлены в любой системе счисления, такой как десятичная или двоичная: минимальная длина в битах Lbin, необходимая для кодирования этих M разных серийных номеров, равна Lbin = ceil(log2(M)), или минимальная длина до десятичного знака Ldec равна Ldec = ceil(log10(M)) (где log2(.) и log10(.) представляют собой логарифмы в двоичной системе и десятичной системе, соответственно, и ceil(.) представляет собой наименьшее значение, большее или равное целому числу).
Затем эти серийные номера засекречиваются (например, шифруются), чтобы скрыть их фактический порядок, чтобы потенциальный фальшивомонетчик не смог легко угадать последовательность серийных номеров по нескольким известным серийным номерам. Для этой цели серийные номера шифруются с помощью алгоритма шифрования с использованием ключа шифрования k, который должен храниться в секрете, в результате чего получаются засекреченные серийные номера, которые будут преобразованы/отформатированы в закодированные числа или коды для маркирования изделий ими. Поскольку шифрование является обратимым один к одному, между серийными номерами и засекреченными серийными номерами (т. е. кодами) есть биективное отношение: последнее также является уникальным, и каждый исходный серийный номер можно восстановить путем дешифрования засекреченного серийного номера с помощью ключа дешифрования k’, соответствующего ключу k, используемому для шифрования. Порядок засекреченных серийных номеров не может быть предсказан фальшивомонетчиком, не зная ключа дешифрования k’. Засекреченные отформатированные серийные номера могут быть представлены в другой системе счисления, чем не засекреченные отформатированные серийные номера, хотя обычно для обоих используется одна и та же система счисления.
Альтернативой шифрованию может быть простое создание последовательности истинных случайных кодов и сохранение их в базе данных, связанных с их последовательными индексами 0, 1, …, n, n+1, …. Однако это не гарантирует их уникальности в очень длинной последовательности кодов. Более того, проверка каждого нового кода, которого еще нет в базе данных, была бы нецелесообразна с вычислительной точки зрения.
Напротив, первое преимущество шифрования серийных номеров заключается в том, что это очень простой и часто используемый метод генерирования кодов в случайном порядке из-за биективной природы шифрования. Эти коды также можно сохранять в базе данных (со связанными с ними серийными номерами в качестве индексов), как если бы они были действительно случайными, но без необходимости проверки уникальности.
Второе преимущество шифрования серийных номеров заключается в том, что оно позволяет нам избежать использования базы данных кодов: для поиска серийного номера по коду требуется только ключ.
Обычно шифрование для сериализации использует симметричное шифрование, т. е. k = k’, которое следует держать в секрете. Это обозначается блоком Е на фиг. 3, причем обратное дешифрование обозначается E-1. Обобщение до асимметричного шифра является теоретически возможным (где есть разные k и k’, k сохраняется в тайне), но ценой значительно более длинных засекреченных серийных номеров для обеспечения достаточной криптографической защиты: например, для RSA рекомендуется минимум 2048 бит, или 256 или 384 для эллиптической криптографии и т. д. Необходимость в таких длинных серийных номерах (и засекреченных серийных номерах) обычно является проблемой для сериализации изделий серийными номерами, где требуется самая короткая возможная длина L’ маркируемых строк.
Напротив, симметричное шифрование предлагает возможность уменьшить длину серийного номера в битах до кратчайшего значения, обеспечивающего достаточное общее количество серийных номеров M. Обычно используется симметричное блочное шифрование, такое как AES, Twofish, IDEA, DES, Triple-DES и т. д., для шифрования серийных номеров один за одним. Однако в них используются фиксированные длины блоков: 64 бита, 128 бит и т. д., поэтому необходимо предпринять шаг, чтобы размер блока лучше соответствовал M необходимым серийным номерам (обычно короче 64 бит). Это можно сделать, применяя хорошо известные и проверенные методы составления поверх этих схем, такие как конструкция Фейстеля. Также можно получить специальные шифры с ключом длины блока из алгоритмов безопасного хеширования без ключа (таких как семейство SHA-2, Whirlpool и т. д.) с конструкциями Луби-Ракоффа.
В случае симметричного шифрования другое обобщение состоит в использовании неблочного шифрования, такого как поточное шифрование или поточный шифр: биты или группы битов входных данных последовательно и непрерывно шифруются путем объединения этих групп битов с псевдослучайной последовательностью групп битов, причем эта псевдослучайная последовательность криптографически генерируется в зависимости от ключа k (обычно биты объединяются по схеме XOR с битами исходных данных). Однако для обеспечения этапа декодирования следует использовать механизмы повторной синхронизации. Поточное шифрование не подходит и не рекомендуется для первого метода сериализации через симметричное блочное шифрование (т. е. «Метод 1»). Напротив, второй метод сериализации (т. е. «Метод 2») полностью использует преимущества поточного шифрования на основе обратной связи по шифротексту и описан в следующем абзаце.
Перед маркировкой изделий засекреченные серийные номера должны быть отформатированы в строки из L символов (т. е. строки с длиной L или код с длиной L), в результате чего получаются коды, которые, следовательно, также засекречиваются (поскольку их порядок в последовательности кодов является непредсказуемым). Форматирование представлено как операция «А» на фиг. 3, а обратная ей операция, т. е. разформатирование, как операция «A-1». Каждый символ берется из конечного набора из N возможных символов, называемого алфавитом с мощностью N. Такое форматирование обычно представляет собой переход от одного основания, где основание равно мощности N алфавита, при необходимости с разбиением кода на небольшие группы символов, чтобы сделать этот переход более эффективным. В общем случае, символы в разных положениях от начала кода с длиной L можно закодировать разными символами из одного алфавита или из разных алфавитов в зависимости от этого положения в коде и, возможно, с разной мощностью. Однако обычно для всех L символов используется один и тот же алфавит и одинаковая мощность. Код с длиной L уникальным образом представляет собой серийный номер, но обычно в системе счисления, отличной от двоичной системы счисления, и, как правило, в формате, более подходящем для маркирования изделий и чтения человеком.
Следовательно, длина L кода должна быть достаточно большой, чтобы можно было маркировать все изделия: L = ceil(logN(M)), где N — мощность алфавита (для простоты рассматривают один и тот же алфавит для всех символов), logN(.) — логарифм по основанию N, ceil(.) — наименьшее значение, большее или равное целочисленному значению, а M - общее количество различных серийных номеров, кодов или изделий для маркирования.
Обычной практикой в области сериализации является выбор M во много раз большим, чем общее количество ожидаемых изделий, чтобы сделать коды менее приемлемыми для угадывания злоумышленником. Это снижает вероятность того, что случайный (угадываемый) код случайно соответствует существующему серийному номеру/существующему изделию.
Наконец, для маркирования физического изделия, каждому символу кода должно быть дано графическое представление. Они могут быть (и не ограничиваться ими) любым человекочитаемым знаком, графическим символом, идеограммой, глифом, рисунком и т. д. или даже машиночитаемым символом, таким как одномерные или двумерные штрих-коды, в монохромном или цветном исполнении. В качестве альтернативы, он может быть незаметен для человеческого глаза (например, напечатан ИК- или УФ-краской) и обнаруживаться исключительно машинами и алгоритмами. Такое представление кода, готового к маркировке, называют маркируемым кодом.
Выше было описано, как серийные номера могут быть засекречены (т. е. зашифрованы) перед форматированием в коды с длиной L, но это не является обязательным: возможно также форматирование серийных номеров перед их засекречиванием. В этом случае получают отформатированные серийные номера (но еще не засекреченные, и поэтому они не являются «кодами»), состоящие из символов с длиной L из введенного выше алфавита(-ов). Их порядок генерации по-прежнему предсказуем, и тогда их нужно засекретить. Чтобы сохранить форматирование при шифровании, следует использовать шифрование с сохранением формата (FPE), т. е. шифр, который принимает строку символов с длиной L в качестве входных данных и приводит к зашифрованной строке символов с длиной L, обычно берущейся из того же алфавита(-ов) с той же мощностью(-ями). В современных технологиях FPE используется, например: для шифрования номеров кредитных карт; шифрования текстов, таких как слова на одном языке, зашифрованные в другие слова того же языка; и т. д. Существует несколько алгоритмов, но FPE также может быть построен из блочных шифров (таких как AES, DES, представленных выше), например, с использованием конструкций Фейстеля. Такой шифр работает на уровне символов, а не на уровне битов. В конце концов, наконец, получают коды, которые необходимо преобразовать в строки глифов с длиной L, что приведет к маркируемым кодам. Все предыдущие размышления, приведенные для симметричного блочного шифрования, остаются теми же, серийные номера шифруются последовательно в маркируемые коды.
Такая сериализация легко читается и декодируется, когда коды синхронизированы с изделиями: просто нужно считывать и дешифровывать коды один за другим. Однако этот подход уже не работает, когда происходит десинхронизация: отсутствие триггера, отсутствие видимой метки, пробела и т. д. не позволяют найти начало и конец каждого кода. В худшем случае одна часть предыдущего кода может быть конкатенирована с одной частью следующего кода в одном маркированном изделии.
Поэтому для восстановления таких кодов используются дополнительные методы, а также маркирование одного изделия большим количеством кодовых символов/глифов, т. е. L’ больше фактической длины L кода, чтобы облегчить эту повторную синхронизацию. Для этого последовательно генерируются маркируемые коды с длиной L, причем код соответствует серийному номеру n (и соответствующему изделию), следующий код – следующему серийному номеру (его обозначение – n+1), следующий-следующий код – серийному номеру n+2 и так далее. Все маркируемые коды образуют длинную (непрерывную) строку, состоящую из последовательных строк символов с длиной L, конкатенированных вместе в описанном порядке. Как правило, чтобы маркировать изделие кодом, эта длинная строка обрезается в (более или менее) неконтролируемом положении/длине, что приводит к короткой «строке конкатенации», т. е. строке символов, содержащей символы только части (с длиной короче чем L) кода с длиной L. Эта короткая строка конкатенации представляет собой строку символов, которой эффективно маркируется изделие. Следовательно, короткие строки конкатенации не синхронизированы, т. е. неизвестно, какой(-ие) символ(-ы)/глиф(-ы) является (являются) первым(-и) из маркируемого кода в таких коротких строках конкатенации. Описан тот случай, когда нельзя использовать никакой другой метод синхронизации, например, нет ни видимой метки, ни триггерных сигналов, помогающих повторной синхронизации при считывании кодов. Согласно настоящему изобретению, чтобы избежать такого возможного эффекта рассинхронизации (или эффекта десинхронизации), длина L’ строки конкатенации должна быть строго больше, чем L (L’ > L), следовательно, эта строка конкатенации теперь содержит по меньшей мере две части двух последовательных кодов.
В общем, это также включает случаи, когда такая десинхронизация происходит на этапе считывания, а не на этапе маркирования, например, когда присутствует длинный непрерывный маркированный поток символов без видимой метки синхронизации.
Вышеупомянутый метод 1 согласно настоящему изобретению представляет собой способ восстановления надлежащего кода и соответствующего серийного номера из одного маркированного изделия, полученного с помощью описанного выше способа генерирования кода и маркирования. Таким образом, есть строка конкатенации с длиной L’, где L’ > L (где L — длина кода) и неизвестная синхронизация внутри изделий. Можно выделить два случая: случай с L’ ≥ (2L – 1) и случай с L’ < (2L – 1)
1) Случай L’ ≥ (2L – 1):
Этот случай изображен на фиг. 1 с кодом с длиной L = 4 и маркированной строкой символов (т. е. строкой конкатенации) с длиной L’ = 7, поэтому в данном случае L’ = (2L – 1). Синхронизация не является известной, т. е. неизвестно каково положение первого символа кода с длиной L в строке конкатенации с длиной L’. Это положение называется положением смещения или просто смещением кода с длиной L от начала кода конкатенации с длиной L’. Но известно, что полный код с длиной L (см. блок (5) на фиг. 1) с четырьмя символами S0n, S1n, S2n, S3n, всегда присутствует хотя бы один раз в строке конкатенации с длиной L’, т. е. блоках конкатенации (5)+(6), окруженных слева и/или справа неполными частями кода, т. е. частью (6) (соответствующей трем символам S0n+1, S1n+1, S2n+1 следующего изделия n+1). Следует попробовать разные положения смещения L; этого достаточно, поскольку возможное количество десинхронизаций, очевидно, равно длине полного кода, а любое дополнительное смещение повторяет ранее проверенное смещение.
Метод, проиллюстрированный на фиг. 3, включает следующие этапы, на которых:
- для каждого положения смещения, текущее положение 1, указанное стрелкой на фиг. 3, от 0 до L-1 от начала строки конкатенации с длиной L, вырезают вариант кода с длиной L Sn (5), состоящий из символов Sin, i = 0, 1, 2, 3;
- этот вариант кода дешифровывают с помощью ключа дешифрования k’, в результате чего получают вариант серийного номера n. Дешифрование применяется обратным способом применения шифрования, и в зависимости от этого осуществляют:
• либо: (1) инвертирование форматирования (т. е. применение A-1), т. е. разформатирование этого варианта кода символа с длиной L для получения соответствующего засекреченного серийного номера, затем дешифрование результата для получение соответствующего варианта серийного номера n (т. е. применение E-1) с использованием ключа дешифрования k’;
• либо: дешифрование кода из символов с длиной L с помощью шифрования с сохранением формата (применение FPE-1, не представлено в данном случае) для получения отформатированного варианта серийного номера с использованием ключа дешифрования k’, затем инвертирование форматирования (т. е. применение A-1) последнего, чтобы найти соответствующий вариант серийного номера n;
• для этого варианта серийного номера n вычисляют его предыдущий вариант n-1 и его следующий вариант n+1 (2);
- из этого предыдущего варианта n-1 и этого следующего варианта n+1 получают соответствующие засекреченные и отформатированные предыдущий и следующий варианты, соответственно (3), путем:
• либо: шифрования вариантов предыдущего n-1 и следующего n+1 серийных номеров с использованием ключа шифрования k, и форматирования (с помощью операции A) полученных вариантов предыдущего и следующего засекреченных серийных номеров для формирования вариантов предыдущего и следующего кодов S’n-1, S’n+1, соответственно;
• либо: форматирования (A) вариантов предыдущего и следующего серийных номеров n-1 и n+1, соответственно, для получения отформатированных вариантов серийных номеров, шифрования их с помощью FPE с использованием ключа шифрования k для получения вариантов предыдущего и следующего кодов S’n-1, S’n+1, соответственно. Кодирование с использованием FPE изображено на фиг. 5: шифрование применяется после форматирования, а не до него;
- символы предыдущего варианта S’n-1 (7) сравнивают (4) (см. на фиг. 3) с соответствующими символами считанной строки конкатенации (6) слева перед рассматриваемым в настоящее время положением смещения (если таковое имеется); символы следующего варианта S’n+1 (7) сравнивают (4) с соответствующими символами считанной строки конкатенации (6) справа, начиная с рассматриваемого в настоящее время смещения + L (если таковое имеется):
• в случае совпадения всех символов (результат M из 4, слева и справа), то правильное смещение, правильный код и правильный серийный номер n были найдены: можно сохранить этот серийный номер n как правильно декодированный вариант;
• в случае неудачи по меньшей мере одного сравнения символов (т. е. несовпадения, результат MM слева или справа), никакой серийный номер не соответствует этому смещению;
• если были перепробованы все смещения от 0 до L-1 и во всех случаях хотя бы одна из сравниваемых пар символов не совпадает (MM), то код не может быть декодирован: возможно, в считанном коде есть ошибки.
Обычно ожидается, что только одно пробное смещение в строке конкатенации приведет к действительному декодированному серийному номеру n. Однако возможно, что иногда более чем один серийный номер n’ и n’’ успешно декодируется из одной и той же строки конкатенации с длиной L’: это неоднозначность, которой, вероятно, нельзя избежать: для любого действительного кода может существовать другой код в полной последовательности М кодов, совпадающий при десинхронизации. Однако в таком случае только одно из n’, n’’ является правильным, т. е. было использовано для кодирования. Чтобы уменьшить такие неоднозначности, можно применить следующие методы:
- следует убедиться, что L достаточно велика, чтобы используемый(-е) алфавит(-ы) имел(-и) достаточную(-ые) мощность(-и) N; на практике тестирование показало, что для кодов с длиной L = 6, использующих кодировку Крокфорда с основанием 32 (т. е. мощность алфавита N = 32), неоднозначности возникают с вероятностью 1,7x10-7 для L’ = 2L - 1 = 11, и 6,2x10-9 для L’ = 2L = 12;
- следует использовать априорно известную информацию, не закодированную в самом коде, но обычно относящуюся к соответствующей партии изделий, из которой можно узнать ожидаемые свойства последовательности серийных номеров. Примером может служить ожидаемый номер партии, т. е. начальный n1 и конечный n2 серийные номера, поэтому любое декодированное n, которое не соответствует условию n1 ≤ n ≤ n2, может быть отклонено.
В принципе, L’ не имеет верхнего предела, и увеличение L’ уменьшает возникновение вышеперечисленных неоднозначностей. Но, конечно, L’ выбирается настолько малым, насколько это практически приемлемо в целевом контексте.
2) Случай L’ < 2L – 1:
Этот случай изображен на фиг. 2 с L = 4 и L’ = 6, таким образом, L’ < 2L – 1. В этом случае для некоторых положений смещения присутствует полный код с длиной L (5), но для некоторых других смещений в строке конкатенации с длиной L’ нет полного кода: для последних строка конкатенации состоит из конкатенации частей (6) из двух последовательных кодов, но ни один из них не является полным. Тем не менее, полный вариант кода может быть обрезан для некоторых смещений, поскольку L’ > L.
Процесс декодирования работает так же, как и для случая L’ ≥ 2L – 1, описанного выше, без каких-либо изменений, когда из строки конкатенации вырезается вариант полного кода с длиной L. Но в случае варианта кода с длиной < L, как показано на фиг. 4, необходим специальный метод. В этой ситуации начальное положение смещения P определяется как отрицательное, когда L’ < (2L – 2), как поясняется ниже. Дополнительные методы используются для смещений, в которых присутствуют только две неполные части вариантов кодов. Это тот случай, когда P является отрицательным (P < 0: символ(-ы) пропущен(-ы) слева) или когда положение последнего символа варианта кода превышает длину строки конкатенации (т. е. P + L > L’: символ(-ы) пропущен(-ы) справа).
Случаи варианта неполного кода решаются путем исчерпывающего поиска этого (этих) пропущенного(-ых) символа(-ов). Решение случая варианта неполного кода работает следующим образом:
• первое (самое левое) положение смещения, которое нужно попробовать, может быть задано следующим образом: P = floor((L’ – (2L – 1)) / 2), по отношению к началу строки конкатенации с длиной L’, где floor(.) – наибольшее значение, меньшее или равное целочисленному значению, и «/» – разделение; |P| – на самом деле половина потенциально максимальных пропущенных символов по отношению к длине (2L – 1). Цель состоит в том, чтобы свести к минимуму пропущенные слева или справа символы варианта кода, поэтому P может быть отрицательным;
• последнее положение смещения представлено как P’ = P + L – 1; также можно определить положение последнего символа для данного последнего смещения как Q = P’ + L – 1 = (P + L – 1) + L – 1 = P + 2(L – 1), где Q представляет собой самое правое положение последнего символа варианта кода в строке конкатенации с длиной L’;
• для каждого положения смещения p от P до P’ (включая P’) обрезают вариант кода с длиной L. Ниже представлены следующие подслучаи:
• если p ≥ 0 и p + L – 1 < L’, то ни слева, ни справа от варианта кода с длиной L не пропущено ни одного символа: он завершен и больше ничего не нужно делать;
• если p < 0 (возможно, если P < 0), то получают |p| пропущенных символов слева; следовательно, R = |P| представляет собой максимальное количество пропущенных символов слева варианта кода с длиной L. С другой стороны, если p + L > L’, то символы пропущены справа; следовательно, не более R = Q – (L’ – 1) = P + 2(L – 1) – (L’ – 1) = P + 2L – L’ – 1 представляет собой максимальное количество пропущенных символов справа варианта с длиной L. В обоих случаях пропущенные символы слева или справа заполняются всеми комбинациями (8) (см. фиг. 4) пропущенных символов из их алфавита(-ов) (ai, i = 0,…, N-1), что приводит к как можно большему числу вариантов кодов (5) с длиной L. Следует отметить, что символы могут быть пропущены с левой стороны или с правой стороны, но никогда с обеих сторон, в результате условия L’ > L;
• для каждого такого вероятного кода с длиной L последующие этапы точно такие же, как для случая L’ ≥ 2L – 1 выше. Единственная разница состоит в том, что для каждого случая пропущенного(-ых) символа(-ов) один вариант становится в данном случае многими вариантами в соответствии с исчерпывающим поиском пропущенного(-ых) символа(-ов);
• чтобы уменьшить неоднозначность, можно использовать априорно известную информацию, относящуюся к партии, как для случая L’ >= 2L – 1: например, ожидаемый диапазон партии, т. е. начальный n1 и конечный n2 серийные номера и т. д.
В вышеупомянутом методе 1:
- исчерпывающий поиск пропущенного(-ых) символа(-ов) может потребовать значительных вычислительных ресурсов, ограничивая на практике максимальное количество пропущенных символов, которое метод может получить в реальных сценариях. Следовательно, L’ должна оставаться достаточно близкой к 2L – 1: максимальное количество исчерпывающих поисков, необходимых для заданного положения смещения, равно NR, где R – максимальное количество пропущенных символов в алфавите с мощностью N, и это количество быстро увеличивается. Например, можно считать максимум R = 2 или 3 пропущенных символов приемлемым максимумом для 32-кратного алфавита (т. е. для N = 32 R = 2 приводит к 1024 итерациям, а R = 3 приводит к 32 768 итерациям!);
- как уже упоминалось, начальное положение смещения P является отрицательным, чтобы ограничить максимальное количество пропущенных символов R, иначе это количество было бы в два раза больше, если положения смещения просто начинались с 0;
- наконец, угадывание пропущенных символов увеличивает количество случаев неоднозначностей, которые могут возникнуть на этапе декодирования, поскольку меньше информации доступно в строке конкатенации с длиной L’ при уменьшении L’. В крайнем случае L’ = L, положение всех опробованных смещений будет неоднозначным, поэтому ограничение L’ > L зафиксировано. Опять же, L’ должна оставаться достаточно близкой к 2L – 1, чтобы добиться низкой вероятности неоднозначностей.
Вышеупомянутый метод 1 согласно настоящему изобретению основан на подходе блочного шифрования, в отличие от метода 2, в котором серийные номера шифруются и дешифруются один за другим. Однако существуют шифры с возможностями самосинхронизации, которые можно использовать для решения проблем десинхронизации. Они называются самосинхронизирующимися поточными шифрами, и это свойство делает их естественным образом подходящими для десинхронизированной сериализации.
Поточный шифр - это схема шифрования, в которой цифры открытого текста (или знаки, символы и т. д.) объединяются с псевдослучайным потоком, зависящим от ключа. Каждая цифра открытого текста шифруется одна за другой соответствующей цифрой псевдослучайного потока, в результате чего получается зашифрованная цифра. Поскольку шифрование каждой цифры зависит от текущего состояния шифра, оно также известно как шифр состояния. Обычно цифра — это бит, а операция объединения по схеме XOR. Для достижения посимвольного (не побитового) шифрования используется шифрование с сохранением формата (FPE), сохраняющее алфавит каждого символа. Поскольку это также поточное шифрование, его называют поточным FPE или sFPE.
Самосинхронизирующийся поточный шифр — это поточный шифр, в котором текущее состояние зависит от K предыдущих цифр, символов и т. д. шифротекста. Такие схемы также известны как асинхронные поточные шифры. Преимущество идеи самосинхронизации заключается в том, что приемник автоматически синхронизируется с генератором потока ключей после получения K цифр шифротекста: в случае ошибки (ошибок) схема автоматически повторно синхронизируется после дешифрования K цифр. Примером самосинхронизирующегося поточного шифра является блочный шифр, используемый в режиме обратной связи по шифру (CFB).
Поточные шифры часто используются из-за их скорости и простоты, особенно в приложениях, где открытый текст имеет неизвестную длину. Это также позволяет избежать проблемы необходимости заполнения для блочного шифра (и, как следствие, потери производительности или пространства), когда данные должны передаваться непрерывно цифра за цифрой (часто: знаки, байты).
Примерами распространенных поточных шифров являются ChaCha, RC4, A5/1, A5/2, Chameleon, FISH, Helix, ISAAC, MUGI, Panama, Phelix, Pike, SEAL, SOBER, SOBER-128 и WAKE. Защищенные поточные шифры также могут быть созданы из блочного шифра или криптографически безопасных хэш-кодов с определенными конструкциями.
Для ключа шифрования k и ключа дешифрования k’ применимы те же соображения, что и для метода 1: теоретически поточное шифрование может быть либо симметричным, либо асимметричным шифрованием.
Однако существующий поток и FPE на самом деле являются симметричными шифрами. Это связано с их посимвольной природой, где символ представляет собой элемент с короткой битовой длиной, в то время как асимметричное шифрование, такое как RSA, требует больших (или очень больших) слов, что не является целесообразным. Наиболее важным является то, что псевдослучайная последовательность, используемая для шифрования, требует одинакового повторного создания одного и того же начального числа, что подразумевает симметричный ключ, где k’ = k.
Хотя поточное шифрование/дешифрование повторно синхронизируется автоматически, оно не дает информации о фактическом начале кода с длиной L. Следовательно, требуются дополнительные методы для идентификации синхронизации кода в строках конкатенации, которые описаны ниже.
Для генерирования серийных номеров и маркировки в настоящем изобретении используется самосинхронизирующийся поточный шифр, применяемый к отформатированным серийным номерам, как проиллюстрировано на фиг. 6. Как и в случае метода 1, серийные номера однозначно связаны с изделиями, обозначенными 0, 1, 2, 3, 4, …, n-1, n, n+1, …, M-1 в последовательном порядке. Однако, в отличие от метода 1, они предпочтительно сначала форматируются, объединяются в непрерывный поток, а затем шифруются. Следовательно, требуется sFPE («поточное FPE»).
Метод проиллюстрирован фиг. 6 для шифрования и фиг. 7 для дешифрования, применительно к сериализации, где длина кода составляет L = 4, количество полученных зашифрованных символов – L’ = 7 и, таким образом, K = L’ – L = 3. Односторонняя криптографическая функция F непрерывно генерирует псевдослучайные значения из K ранее зашифрованных символов Sin (i = 0,1,2…) и ключа k, прогрессируя в направлении стрелки. Для общности комбинация псевдослучайных значений потока с символами данных открытого текста Cin представлена как добавление «+» для шифрования (например, на фиг. 6, добавлено к C3n), и как вычитание «-» для дешифрования (например, на фиг. 7, вычтено из S1n). При дешифровании K первых символов не могут быть дешифрованы, поскольку в них отсутствуют K предыдущих символов в строке конкатенации с длиной L, и они помечаются как «?» на фиг. 7.
Определение L’ = L + K (где K > 0) как минимальная длина (строки символов), позволяющая дешифровать по меньшей мере L символов. Но в общем случае L’ ≥ L + K или L’ = L + T + K, где T ≥ 0. Общий метод изображен на фиг. 8 для шифрования и на фиг. 9 для дешифрования, где L = 4, T = 1, K = 3 и, следовательно, L’ = 8.
Генерирование кодов, соответствующих методу 2, работает следующим образом:
- серийные номера форматируют с использованием символов кода из алфавита(-ов), как определено в методе 1, в результате чего получают отформатированные серийные номера Cin согласно фиг. 8. Они еще не засекречены;
- последовательность отформатированных серийных номеров можно рассматривать как конкатенированную, расположенную в том же порядке, что и входные серийные номера, чтобы сформировать более длинную и еще не зашифрованную непрерывную строку. Длина строки конкатенации равна L’ = L + T + K, где K > 0 — длина обратной связи, а T ≥ 0 — количество дополнительных символов, полезных для повторной синхронизации, когда необходимо декодировать серийные номера;
- затем к этой незашифрованной строке применяют самосинхронизирующийся поточный шифр с использованием ключа шифрования k, принимая в качестве входных данных символы строки Cin один за другим последовательно, и последовательность, сформированную K (где K > 0) предыдущих зашифрованных символов в качестве обратной связи для достижения самосинхронизации при дешифровании. Обратная связь распространяется на последовательные коды, а это означает, что один или более первых символов каждого кода зависят от обратной связи от зашифрованных символов предыдущего кода;
- для работы с символами этот шифр представляет собой поточное шифрование с сохранением формата (sFPE), поэтому он шифрует отформатированные серийные номеров посимвольно из одного алфавита(-ов) в один алфавит(-ы) – обычно один и тот же алфавит, в результате получая зашифрованные символы Sin. Это приводит к «бесконечной» строке кодов с длиной L, зашифрованных и конкатенированных в последовательном порядке. Шифрование одного символа может работать, например, путем арифметического сложения вывода функции шифрования с входным символом по модулю N мощности соответствующего алфавита;
- как и в методе 1, эту строку разрезают на подстроки с длиной L’, где L’ > L, (более или менее) неконтролируемым образом, образуя строки конкатенации. Следует гарантировать, что L’ = L + T + K, где K > 0 и T ≥ 0, чтобы обеспечить декодируемость в будущем, являющуюся результатом механизма обратной связи по шифротексту;
- символы этих строк конкатенации с длиной L’, преобразованные в глифы или графические элементы, как в методе 1, для формирования маркируемых кодов MC, затем наносят на последовательные изделия.
Строки конкатенации должны иметь по меньшей мере длину L’ = L + K (где T = 0), чтобы обеспечить правильное декодирование как минимум L символов. Эти символы могут быть непоследовательными с одной частью предыдущего кода, конкатенированного с текущим кодом после дешифрования. Затем будут использовать методы повторной синхронизации, описанные далее, зная, что предыдущий код равен n-1 по отношению к текущему коду n, как в методе 1. Кроме того, использование дополнительных символов (где T > 0) предоставляет дополнительную информацию, способствующую повторной синхронизации, зная, что поточный шифр гарантирует, что (L + T) символы будут правильно дешифрованы (но без указания фактического смещения кода), как описано ниже.
В предположении непрерывной и уникальной последовательности кодов, соответствующих серийным номерам от 0 до М-1, каждый код зависит от своего предыдущего кода. В случае кодов, сгенерированных из разных партий изделий: первая строка конкатенации с длиной L’ каждой партии должна включать конечную часть с длиной K последнего кода предыдущей партии; все партии должны были бы генерироваться последовательно, чтобы знать последний код каждой партии; и для самой первой строки конкатенации (соответствующей серийному номеру 0) потребуется исходная строка обратной связи с длиной K, определенная либо как случайная, либо установленная на фиксированную константу, например, как «все нули» для простоты.
Тогда вся последовательность кодов, соответствующих серийным номерам от 0 до М – 1, полностью зависела бы от этой исходной строки обратной связи в дополнение к ключу шифрования k. Это значение требуется для будущего дешифрования, но оно по определению включено в строки конкатенации. Такое значение инициализации, влияющее на последующий поток шифрования, в криптографическом сообществе часто называют одноразовым номером или вектором инициализации («IV»).
Однако принудительное обеспечение уникальности всей последовательности кодов, как только что объяснено, не требуется для сериализации. На практике коды могут генерироваться разными партиями, которые не обязательно должны быть последовательными или непротиворечивыми друг другу с точки зрения обратной связи шифрования. Единственным обязательным ограничением для разных партий является соответствие непересекающимся диапазонам серийных номеров относительно друг друга. Произвольное значение IV (или фиксированная константа, или значение «все нули») может быть определено в начале каждой партии. В крайнем случае, хотя это и нецелесообразно, для каждого нового кода может быть сгенерирован случайный IV. Самый первый код (или несколько первых кодов) можно просто пропустить, чтобы сгенерировать первую строку конкатенации партии. Это возможно, потому что символы IV/обратной связи включены в строку конкатенации и, таким образом, их не нужно сохранять для дешифрования: это дешифрование из строк конкатенации всегда приводит к правильному серийному номеру n.
Но IV, используемые для партий, должны храниться (с партиями, имеющими начало и конец) только в том случае, если одни и те же партии должны быть повторно сгенерированы несколько раз, идентично, если только не используются постоянные (например, «все нули») IV. Более того, такие IV, присоединенные к партии, можно использовать в качестве дополнительной информации (или «вторичной информации») для проверки того, что декодированная строка конкатенации была действительно правильно дешифрована.
На этапе декодирования самосинхронизирующийся поточный шифр обеспечивает всегда правильно дешифрованные символы из любых входных данных после K первых символов, но сам по себе не дает информацию о синхронизации: нужно еще найти начало (и конец) хотя бы одного кода. Таким образом, необходимы дополнительные методы для нахождения положения смещения кода в строке конкатенации.
Первый подход заключается в предоставлении дополнительных символов (где T > 0), чтобы обеспечить проверку опробованных положений смещения путем посимвольного сравнения. Это соответствует этапу декодирования случая 1 «Декодирование серийного номера», описанного ниже, для которого никакая информация о синхронизации не включается в зашифрованное кодированное сообщение с длиной L. Тогда T > 0 просто добавляет более правильно декодированные символы, помогая уменьшить неоднозначность декодирования.
Второй подход заключается во включении дополнительной информации о синхронизации (добавленной перед шифрованием), именованной тегами синхронизации, как части кода с длиной L (добавленная информация теперь зашифрована) при форматировании серийных номеров. Это случай 2 из описания «Дешифрование серийного номера» ниже. Это может быть сделано, но не ограничивается:
- тегами типа 1: добавляют символ синхронизации, например, в начале каждого отформатированного серийного номера в дополнение к оставшимся символам с (L–1) отформатированного серийного номера;
- тегами типа 2: используют символы из одного подмножества алфавита для первого символа каждого отформатированного серийного номера (обычно половина алфавита) и символы из другого подмножества алфавита для оставшихся символов с (L–1) (обычно дополнительная половина подмножества).
Важно, что такое тегирование синхронизации осуществляют в незашифрованном домене, что делает его скрытым в результирующих зашифрованных кодах и строках конкатенации: злоумышленнику не предоставляется никакой информации о синхронизации, зная, что он имеет доступ только к засекреченным кодам. Чтобы достичь этого, символы шифруются по всей мощности(-ях) N алфавита, независимо от различных подмножеств алфавита, используемых для входных символов, или от того, используется ли символ-разделитель. Следовательно, такое тегирование не эквивалентно введению видимых меток, разделяющих коды.
Это тегирование должно быть обратимым на этапе декодирования, чтобы можно было восстановить исходные серийные номера n из дешифрованных отформатированных серийных номеров. Тегирование можно рассматривать как дополнительный этап в форматировании серийных номеров в дополнение к переходу от одного основания.
Тегирование может увеличить требуемую длину L кода, чтобы охватить все M изделий с заданным алфавитом по отношению к нетегированной версии, поскольку теги добавляют информацию для синхронизации, которая не является частью исходной информации о серийном номере. Согласно двум приведенным выше примерам тегов, для общего количества M серийных номеров и алфавита с мощностью N можно получить следующие значения длины L кода:
• теги типа 1: вставка символа-разделителя:
L = ceil(logN(M)) + 1,
• теги типа 2: использование двух различных подмножеств алфавита с мощностью N/2 каждое (пусть N будет четным), одно для первого символа, а другое для остальных символов:
L = ceil(logN/2(M)).
На практике это увеличение L часто составляет 1 или 2: например, для алфавита из 32 различных символов (значение, называемое мощностью):
• для M = 106 изделий: L = 4 без тегов, L = 6 для тегов типа 1 и L = 5 для тегов типа 2, можно было бы выбрать последнее, чтобы минимизировать L для маркирования изделия.
• для M = 1011: L = 8 без тегов, 9 с тегами типа 1, 10 с тегами типа 2, тогда тип 1 предпочтительнее.
Для алфавита с мощностью 40:
• для M = 1011: L = 7 без тегов, 8 с тегами типа 1 и 9 с тегами типа 2, таким образом, теги типа 1 являются лучшими.
Как и в методе 1, каждому символу кода должно быть дано графическое представление перед маркированием физического изделия, такое как любой человекочитаемый символ, графический символ или машиночитаемый символ, подобный штрих-коду, в монохромном или цветном исполнении.
Что касается аспекта декодирования серийного номера, декодирование серийного номера в соответствии со методом 2 изображено на фиг. 9. Что касается метода 1, фактический серийный номер может быть декодирован из строки конкатенации с длиной L’, считанной из изделий. Но в отличие от метода 1, дешифрование всегда выводит правильно декодированные символы, но только после K первых символов в обработанных строках конкатенации с длиной L’.
Следовательно, только символы от положения K до последнего положения (L’-1) строки конкатенации могут быть точно дешифрованы. Игнорируя K первых недешифрованных символов (обозначенных на фигуре как «?») после дешифрования, получают строку с длиной (L’ – K) правильно дешифрованных символов. Таким образом, в общем случае получается строка с длиной (L’ – K) = (L + T) правильно дешифрованных символов, где T ≥ 0 – количество дополнительных символов. Однако эти символы все еще могут быть десинхронизированы. Пока еще неизвестна правильная синхронизация, т. е. фактическое положение смещения кода с длиной L в этой дешифрованной строке конкатенации. Следовательно, после дешифрования необходимы дополнительные методы синхронизации.
Дешифрование строки конкатенации осуществляют следующим образом:
- дешифруют строку конкатенации с длиной L с использованием ключа дешифрования sFPE k’, в результате чего получают дешифрованную строку конкатенации с длиной (L’ – K) или (L + T). Соответственно, что касается описанного этапа шифрования, символ может быть дешифрован путем вычитания выходных данных функции шифрования из входного символа по модулю мощности N соответствующего алфавита. Способ работает следующим образом:
• последовательное дешифрование каждого символа строки конкатенации, начиная с положения смещения K и предпочтительно к смещению (L’ – 1), чтобы использовать T дополнительных символов, если таковые имеются, или по меньшей мере к смещению (L + K – 1). Для дешифрования каждого символа используют для обратной связи K первых символов зашифрованной строки конкатенации;
• символы при смещениях от 0 до (K – 1) (обозначенные знаком «?») не могут быть дешифрованы, поскольку для них недоступны зашифрованные символы с обратной связью: поэтому они игнорируются в результирующей дешифрованной строке конкатенации с длиной (L’ – K).
Результирующая строка с длиной (L’ – K) представляет собой строку точно декодированных символов с длиной (L + T), где T ≥ 0. Она содержит либо полный отформатированный серийный номер с длиной L, либо две возможно неполные части последовательных отформатированных серийных номеров.
Синхронизация должна быть определена для того, чтобы реконструировать исходный серийный номер, т. е. найти границу между двумя частями кода в дешифрованной строке конкатенации. Можно выделить следующие два случая: случай 1, в котором отсутствуют дополнительные теги синхронизации; случай 2, в котором присутствуют теги синхронизации. И для этих двух случаев либо T = 0, либо T > 0, напоминая, что:
- строки конкатенации имеют длину: L’ = (L + T + K), где T ≥ 0 и K > 0;
- дешированные строки конкатенации имеют длину: (L’ – K) = (L + T), и могут быть десинхронизированы.
Соответственно, этапы синхронизации включают:
Случай 1. Отсутствуют теги синхронизации:
- подслучай 1.a: для дешифрованной строки синхронизации с длиной L (т. е. T = 0 или сохранены только первые правильно декодированные символы с L): извлечение отформатированных вариантов серийных номеров с длиной L, начиная с положений смещения от 0 до (L – 1), к сожалению, приводит к множеству неоднозначностей! Это связано с тем, что любой вариант отформатированного серийного номера n со сдвигом смещения равен некоторому действительному отформатированному серийному номеру n со сдвигом смещения 0 где-то еще в пространстве, образованном M возможными серийными номерами. И отсутствие тегов означает, что информация о синхронизации недоступна для указания фактического смещения кода. Следовательно, этот подслучай 1.а неприменим в данном случае 1 и должен быть отброшен;
- подслучай 1.b: доступна дешифрованная строка синхронизации с длиной от (L + 1) до (2L – 1) (т. е. 0 < T < L), содержащая строго более правильных символов с L. Чтобы проверить это, можно проверить каждый вариант отформатированного серийного номера с длиной L со сдвигом смещения с оставшимися символами. Это делается аналогично методу 1 путем сопоставления n-1 и n+1, вычисленных из n, посимвольно в отформатированном виде, но с той разницей, что нет необходимости в дешифровании/шифровании (символы уже дешифрованы). Это похоже на случай L < L’ ≤ (2L – 1) метода 1. Неоднозначности могут по-прежнему появляться для некоторых положений смещения, но их появление уменьшается по мере увеличения T: тогда строки конкатенации с длиной L’ должны быть достаточно близки к (2L + K) (или T достаточно близко к L), чтобы достичь практически низкой вероятности неоднозначностей;
- подслучай 1.c: доступна строка конкатенации с длиной (2L + K) или дешифрованная строка конкатенации с длиной 2L или длиннее, что подразумевает T ≥ L: можно проверить каждый отформатированный серийный номер с длиной L со сдвигом смещения, как указано выше. Это похоже на случай L’ > 2L – 1 метода 1. Однако в этом подслучае неоднозначности могут быть устранены, поскольку один и только один действительный вариант n совместим с парой (n-1, n) или парой (n, n+1): это можно проверить, поскольку у одного есть действительные символы с 2L. Более того, с более чем правильно дешифрованными символами с 2L можно даже определить, были ли ошибки во входной строке конкатенации, проверив декодированные символы с большим количеством вхождений серийных номеров, таких как (n-2), (n+2) и т. д.
Случай 2. Присутствуют теги синхронизации:
После дешифрования каждая правильно дешифрованная строка конкатенации с длиной (L’ – K) или (L + T) содержит теги, используемые для шифрования. Из неполных примеров тегов типа 1 и типа 2, приведенных при описании кодирования, дешифрованные теги включают:
• теги типа 1: символ-разделитель, вставляемый в начале каждого отформатированного серийного номера;
• теги типа 2: символ из одного из подмножеств алфавита, указывающий, что это первый символ отформатированного серийного номера, остальные символы происходят из дополнительного подмножества алфавита.
Затем правильное положение смещения может быть определено с помощью тегов. Кроме того, возможно:
- сначала проверить согласованность тегов для обнаружения ошибочных входных данных и отклонить декодирование в случае ошибки. Например, проверив, что:
• символы-разделители разделены ровно L положениями;
• первые символы разделены ровно L положениями;
- затем повторно синхронизировать дешифрованную строку конкатенации, удалить теги и восстановить правильный серийный номер n.
С учетом подслучаев, как в случае 1 выше, представлено следующее:
- подслучай 2.a: доступна дешифрованная строка конкатенации с длиной L (или T = 0): она повторно синхронизируется, теги удаляются, а серийный номер n преобразуется, зная, что ожидаемая последовательность серийных номеров (n-1), n, (n+1).
- подслучай 2.b: L’ = (L + T + K), где T > 0: она повторно синхронизируется благодаря тегам, и дополнительные символы можно использовать для сопоставления результирующих символов, чтобы гарантировать, что серийный номер n может быть правильно декодирован, зная, что ожидаемая последовательность (n-1), n, (n+1). С большим количеством дополнительных символов T становится даже возможным проверить больше символов, чтобы, возможно, включить (n-2), (n+2) или более в проверку. Таким образом, становится проще определить, была ли входная строка конкатенации неправильной, и отклонить декодирование, как в случае 1, подслучай 1.c выше.
Для подслучая 2.b, поскольку сравнения дешифрованных строк конкатенации проще выполнять в отформатированном домене, а не напрямую с двоичными серийными номерами n (хотя это не исключено), это можно сделать следующим образом:
• выполняя вычисления в отформатированном домене с использованием соответствующего основания (символы Ci), а не в домене серийного номера (n), но с удалением тегов синхронизации, если они есть;
• предыдущая часть и следующая часть дешифрованной строки конкатенации должны быть повторно конкатенированы в правильном порядке путем добавления 1 к предыдущей части, поскольку предыдущая часть соответствует серийному номеру n-1, а текущая часть соответствует n, или вычитания 1 из следующего серийного номера, поскольку он равен n+1, для восстановления надлежащего незашифрованного кода с длиной L; этот реконструированный отформатированный серийный номер известен как правильный благодаря способности sFPE выводить правильно дешифрованные значения;
• наконец, этот реконструированный отформатированный серийный номер можно разформатировать, чтобы получить фактический серийный номер n.
Для обоих приведенных выше подслучаев можно уменьшить неоднозначность, используя дополнительную информацию, например:
• ожидаемый диапазон партии для проверки декодированного n: начальный n1 и конечный n2 серийных номеров, проверка того, что n является таковым, что n1 ≤ n ≤ n2.
• сохраненные векторы инициализации (IV) и результирующие промежуточные значения кода сохраняются для каждой партии, как объяснено в приведенном выше обсуждении векторов инициализации.
Относительно длины обратной связи K:
Длина обратной связи K может быть небольшой, так что K ≤ L. Однако она должна быть достаточно большой, т. е. близкой к L, особенно если L является малой. Длина обратной связи K определяет при мощности N алфавита изменчивость V шифрования (т. е. количество возможных различных шифрований) для данного ключа шифрования k: V = NK.
Злоумышленник не должен легко угадать допустимую строку обратной связи. С другой стороны, нет верхней границы для K, но, вероятно, значение K, значительно превышающее L, не принесет такой дополнительной защиты. Предполагается, что изменчивость V должна быть по меньшей мере несколько миллионов для достижения хорошей защиты, что ограничивает эффективность подходов грубой силы для атаки на сериализацию.
Например, для мощности алфавита 32 можно предложить K = L или (L - 1) для малых значений L, таких как 6, и фиксированное значение K на 6 для больших значений L. Для мощности алфавита N = 32, K = 4 обеспечивает изменчивость шифрования V = 1 миллион, а K = 6 достигает V = 1 миллиард.
Настоящее изобретение направлено главным образом на человекочитаемую сериализацию, когда пользователь может вводить и запрашивать код вручную. Однако, методы, описанные в данном документе, не ограничиваются только человекочитаемым кодированием, но также могут использоваться для машиночитаемого кодирования. Кодирование может включать:
- человекочитаемое кодирование с использованием латиницы, кириллицы, азиатского алфавита или любого другого алфавита;
- человекочитаемое кодирование, но оптимизированное для машинного чтения с использованием специальных политик и шрифтов, таких как (но не ограничиваясь ими) OCRA для оптического распознавания элементов;
- только машиночитаемый код, который может быть напечатан линейно, например (но не ограничиваясь):
последовательность очень маленьких одномерных/двумерных штрих-кодов;
штрих-код Intelligent Mail barcode (IM), используемый для почтовых приложений или аналогичные;
запатентованное кодирование, состоящее из небольших графических элементов, каждый из которых представляет символ алфавита и печатается линейно.
На фиг. 10 показан пример запатентованного штрих-кода/символики, состоящего из одномерных/двумерных мини-рисунков, напечатанных линейно, причем каждый рисунок представляет собой символ алфавита.
Маркирование можно осуществлять следующим образом:
- прямое кодирование с использованием непрерывной струйной печати, лазерной гравировки или любых других методов, обеспечивающих прямое кодирование;
- предварительное кодирование на ленте, которую потом можно резать и клеить на изделия, без гарантии регистрации.
Сериализацию согласно настоящему изобретению можно применять в любой ситуации, когда регистрация затруднена по разным причинам, таким как высокая скорость движущихся изделий, отсутствие сложных механизмов регистрации или механическая невозможность регистрации. Защитные нити 9, встроенные в банкноты, как проиллюстрировано на фиг. 11, являются хорошим примером, где можно использовать такую сериализацию. Способ сериализации, раскрытый в настоящем изобретении, будет надежно маркировать такие нити 10 независимо от их неправильной регистрации, как показано на фиг. 12, и может даже использоваться для машинного считывания. Способ позволяет снизить (до нуля) вероятность ошибок дешифрования, добиться надлежащей аутентификации/идентификации. Он подходит для любого кодировки или маркировки, которые могут быть расположены линейно в виде непрерывной строки.
Вышеуказанный предмет изобретения следует считать иллюстративным, а не ограничивающим, и он служит для лучшего понимания настоящего изобретения, определяемого независимыми пунктами формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ БЛОЧНОГО ШИФРОВАНИЯ ИНФОРМАЦИИ | 2004 |
|
RU2266622C1 |
| СПОСОБ ШИФРУЮЩЕГО ПРЕОБРАЗОВАНИЯ ИНФОРМАЦИИ | 2003 |
|
RU2254685C2 |
| ЗАЩИТА ДАННЫХ С ПЕРЕВОДОМ | 2013 |
|
RU2631983C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ) | 2013 |
|
RU2656734C2 |
| СПОСОБ ЗАЩИТЫ ИНФОРМАЦИИ В РАДИО И ЛОКАЛЬНОЙ ВЫЧИСЛИТЕЛЬНОЙ СЕТИ | 2004 |
|
RU2266621C1 |
| СПОСОБЫ И УСТРОЙСТВА ВЫБОРОЧНОГО ШИФРОВАНИЯ ДАННЫХ | 2009 |
|
RU2505931C2 |
| СПОСОБ ШИФРОВАНИЯ БЛОКОВ ЦИФРОВЫХ ДАННЫХ | 1997 |
|
RU2124814C1 |
| Повышение неоднозначности | 2016 |
|
RU2737917C1 |
| СПОСОБ КРИПТОЗАЩИТЫ СИСТЕМЫ ТЕЛЕКОММУНИКАЦИОННЫХ ТЕХНОЛОГИЙ | 1995 |
|
RU2077113C1 |
| Способ криптографической защиты данных, передаваемых по открытому каналу связи | 2024 |
|
RU2837327C1 |

Изобретение относится к области безопасного кодирования изделий для их идентификации, аутентификации, отслеживания и контроля, а именно к сериализации изделий. Техническим результатом является обеспечение возможности использования линейного кодирования, устойчивого к десинхронизации, и применения надлежащей сериализации в ситуациях, когда регистрация кодов затруднена или невозможна. Для этого осуществляют шифрование уникального серийного номера каждого изделия с использованием ключа шифрования k для получения соответствующего уникального кода и маркирование каждого изделия его соответствующим уникальным кодом. При этом каждый уникальный код имеет длину L и включен в строку символов с длиной L’, которой маркируется соответствующее изделие, при этом L’ больше L, а строка символов дополнительно включает по меньшей мере часть уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или по меньшей мере часть уникального кода, полученного из шифрования следующего уникального серийного номера. Кроме того, в строке символов уникальный код, соответствующий изделию, конкатенируют впереди с концом уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или конкатенируют после с началом уникального кода, полученного из шифрования следующего уникального серийного номера. 4 н. и 11 з.п. ф-лы, 12 ил.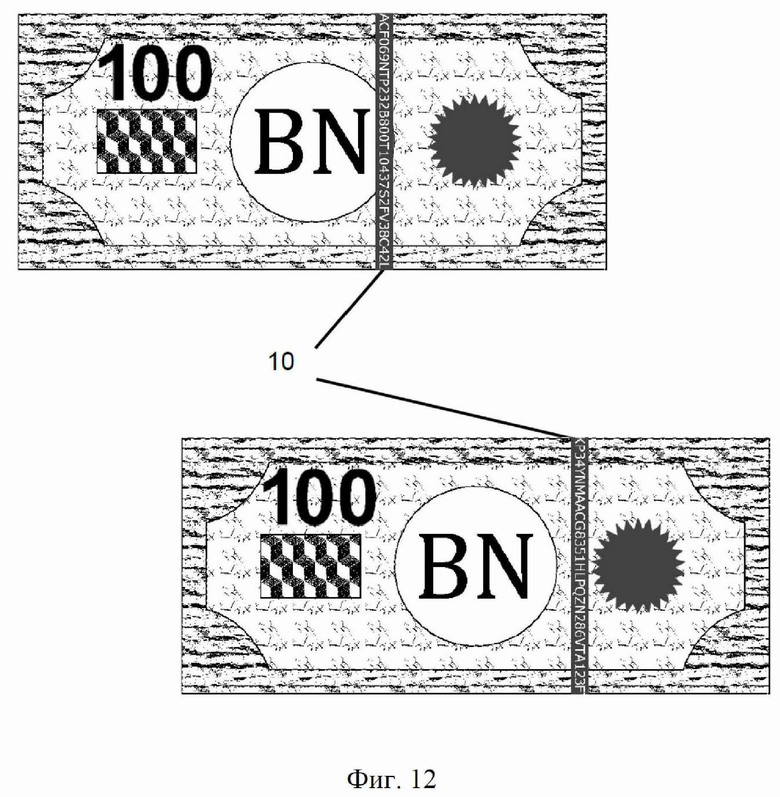
1. Способ сериализации изделий, включающий:
шифрование уникального серийного номера каждого изделия с использованием ключа шифрования k для получения соответствующего уникального кода, и
маркирование каждого изделия его соответствующим уникальным кодом,
отличающийся тем, что каждый уникальный код имеет длину L и включен в строку символов с длиной L’, которой маркируется соответствующее изделие, при этом L’ больше L, и при этом строка символов дополнительно включает по меньшей мере часть уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или по меньшей мере часть уникального кода, полученного из шифрования следующего уникального серийного номера, при этом в строке символов уникальный код, соответствующий изделию, конкатенируют впереди с концом уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или конкатенируют после с началом уникального кода, полученного из шифрования следующего уникального серийного номера.
2. Способ по п. 1, отличающийся тем, что символы строки символов включают графические символы, выбранные из человекочитаемых знаков и машиночитаемых символов.
3. Способ по п. 2, отличающийся тем, что символы строки символов выбраны из набора глифов, предпочтительно из буквенных, буквенно-цифровых или цифровых символов.
4. Способ по любому из пп. 1-3, отличающийся тем, что уникальный код присутствует в строке символов при смещении, при этом L’ больше или равна (2L-1).
5. Способ по любому из пп. 1-3, отличающийся тем, что уникальный код присутствует в строке символов при смещении, при этом L’ меньше (2L-1).
6. Способ по любому из пп. 4 или 5, отличающийся тем, что смещение уникального кода в строке символов обозначают путем нанесения разных алфавитов для разных положений символов в уникальном коде или путем нанесения маркировки между последовательными уникальными кодами, при этом маркировка выбрана из пробела, конкретного знака или блока.
7. Способ по любому из предыдущих пунктов, отличающийся тем, что маркирование изделий строками символов включает непосредственное маркирование или печать, нанесение напечатанных этикеток или лазерную гравировку.
8. Способ по любому из предыдущих пунктов, отличающийся тем, что шифрование серийного номера изделия для получения уникального кода осуществляют путем применения блочного шифрования или блочного шифрования в сочетании с шифрованием с сохранением формата (FPE).
9. Способ по п. 2, отличающийся тем, что шифрование серийного номера изделия для получения уникального кода осуществляют с помощью самосинхронизирующегося поточного шифрования на основе обратной связи, при этом символы серийных номеров шифруются один за одним в конструкции поточного шифра с помощью шифрования с сохранением формата (FPE).
10. Способ по п. 9, отличающийся тем, что минимальная длина L’ строки символов, которой маркируется изделие, равна (L+K), причем K является длиной обратной связи, состоящей из нескольких знаков или по меньшей мере одного символа в дополнение к указанной длине L уникального кода.
11. Способ дешифрования для восстановления уникального кода и соответствующего серийного номера из строки символов, которой маркируется изделие согласно способу сериализации по любому из предыдущих пунктов, включающий:
считывание строки символов с длиной L’, которой маркируется изделие;
дешифрование на основе ключа дешифрования k’ блоков символов с длиной L со смещениями от 0 до L-1 в строке символов с длиной L’, считываемых на изделии, причем L’ больше L;
для каждого варианта серийного номера n для соответствия его блоку с длиной L, вычисление предыдущего серийного номера n-1 и следующего серийного номера n+1;
шифрование с помощью ключа шифрования k серийных номеров n-1 и n+1, соответственно, получение, соответственно, предыдущего и следующего вариантов серийных номеров;
посимвольное сравнение символов предыдущего варианта серийного номера с соответствующими символами строки символов с длиной L’ слева перед рассматриваемым в настоящее время положением смещения, если таковое имеется, и символов следующего варианта серийного номера с соответствующими символами строки символов с длиной L’ справа, начиная с рассматриваемого в настоящее время смещения +L, если таковое имеется,
при этом
в случае совпадения всех сравненных символов, восстанавливают правильный уникальный код и соответствующий правильный серийный номер n из считанной строки символов; и
в случае неудачи по меньшей мере одного сравнения символов для смещения, серийный номер не соответствует указанному смещению.
12. Система для сериализации изделий, содержащая:
память и процессор, причем память вместе с процессором выполнены с возможностью запуска системы для шифрования серийного номера каждого изделия с использованием ключа шифрования k, сохраненного в памяти, для получения соответствующих уникальных кодов, и
устройство для маркирования, подключенное к процессору и выполненное с возможностью маркирования изделий уникальными кодами, принятыми от процессора,
отличающаяся тем, что система выполнена с возможностью включения каждого уникального кода с длиной L в строку символов с длиной L’, при этом L’ больше L, и при этом строка символов дополнительно включает по меньшей мере часть уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или по меньшей мере часть уникального кода, полученного из шифрования следующего уникального серийного номера, и маркирования соответствующего изделия строкой символов, при этом в строке символов уникальный код, соответствующий изделию, конкатенируют впереди с концом уникального кода, полученного из шифрования предыдущего уникального серийного номера, и/или конкатенируют после с началом уникального кода, полученного из шифрования следующего уникального серийного номера.
13. Система по п. 12, отличающаяся тем, что память вместе с процессором выполнена с возможностью запуска системы для применения блочного шифрования или самосинхронизирующегося поточного шифрования на основе обратной связи в сочетании с шифрованием с сохранением формата (FPE).
14. Система по п. 12, отличающаяся тем, что память вместе с процессором выполнены с возможностью запуска системы для применения шифрования с сохранением формата (FPE), при этом шифры серийных номеров шифруются один за одним в конструкции поточного шифра.
15. Система для восстановления уникального кода и соответствующего серийного номера из строки символов, которой маркируется изделие с помощью системы для сериализации изделий по любому из пп. 12-14, причем система содержит блок обработки, оснащенный блоком памяти, и считывающее устройство, при этом считывающее устройство выполнено с возможностью считывания строки символов, которой маркируется изделие, и сохранения считанной строки символов в блоке памяти, и блок обработки выполнен с возможностью запуска системы для осуществления операций:
дешифрования на основе ключа дешифрования k’, сохраненного в блоке памяти, блоков символов с длиной L со смещениями от 0 до L-1 в строке символов с длиной L’, сохраненных в блоке памяти, причем L’ больше L;
вычисления для каждого варианта серийного номера n для соответствия его блоку с длиной L, предыдущего серийного номера n-1 и следующего серийного номера n+1;
шифрования с помощью ключа шифрования k серийных номеров n-1 и n+1, соответственно, и получения, соответственно, предыдущего и следующего вариантов серийных номеров;
посимвольного сравнения символов предыдущего вероятного серийного номера с соответствующими символами строки символов с длиной L’ слева перед рассматриваемым в настоящее время положением смещения, если таковое имеется, и символов следующего варианта серийного номера с соответствующими символами строки символов с длиной L’ справа, начиная с рассматриваемого в настоящее время смещения +L, если таковое имеется,
при этом
в случае совпадения всех сравненных символов, система выполнена с возможностью доставки сигнала о восстановлении правильного уникального кода и соответствующего правильного серийного номера n из считанной строки символов; и
в случае неудачи по меньшей мере одного сравнения символов для смещения, серийный номер не соответствует указанному смещению.
| СПОСОБ СЕРТИФИКАЦИИ И АУТЕНТИФИКАЦИИ ЗАЩИЩЕННЫХ ДОКУМЕНТОВ НА ОСНОВАНИИ РЕЗУЛЬТАТА ИЗМЕРЕНИЯ ОТКЛОНЕНИЙ ОТНОСИТЕЛЬНОГО ПОЛОЖЕНИЯ В РАЗЛИЧНЫХ ПРОЦЕССАХ, ВОВЛЕЧЕННЫХ В ИЗГОТОВЛЕНИЕ ТАКИХ ЗАЩИЩЕННЫХ ДОКУМЕНТОВ | 2014 |
|
RU2684498C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ) | 2013 |
|
RU2656734C2 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

