Область техники, к которой относится изобретение
Настоящее изобретение относится к обработке данных и, в частности, к устройству и управляемому компьютером способу обнаружения структур данных в потоке данных с детерминированным конечным автоматом.
Уровень техники
Количество данных, передаваемых по телекоммуникационной сети, резко возрастает. Сеть с коммутацией пакетов с высокой скоростью и высокой производительностью и серверы используются для передачи этих данных. Среди другой информации для целей проверки и отслеживания, чтобы гарантировать желаемое или согласованное качество обслуживания QoS, например, информации о заголовке пакета, например, источник и целевой адрес не является достаточной для получения требуемой информации. В некоторых случаях пакеты данных полезной нагрузки должны быть проверены, например, на наличие конкретных структур данных. Извлечение информации, обнаружение вирусов данных и других вредоносных данных являются дополнительными примерами, которые могут потребовать проверку пакетов данных.
В способе проверки пакетов используется конечный автомат, такой как описанный в US 2008/270764 A1 и EP 1986390 A2. Конечный автомат или просто машина состояний является управляемым компьютером способом, который используется в качестве абстрактной конечной машины, работающей на состояниях в соответствии с таблицей перехода состояний или регистром перехода состояний. Такая таблица перехода состояний содержит для множества состояний конечного автомата - переход из настоящего, начального состояния в следующее целевое состояние после ввода определенного символа данных в текущем состоянии, в конечном итоге приводящее к согласованной структуре данных, в частности, строке символов входных данных. Такие символы данных являются, например, символами данных, которые содержаться в алфавите, таком как известный американский стандартный код компьютерного алфавита для обмена информацией, или сокращенно ASCII. Таким образом, переход состояния в последующее целевое состояние может также вызывать переход к тому же состоянию автомата, именуемый непереадресуемым переходом. В таком случае, переход состояния является переходом, в котором начальное состояние идентично целевому состоянию, например, непереадресуемому циклу в одном и том же состоянии.
В общем, могут быть рассмотрены два типа конечных автоматов. Детерминированный конечный автомат DFA, и недетерминированный конечный автомат NFA. DFA является предпочтительным в скорости обработки, так как он требует только постоянное количество обращений к памяти при анализе через полезную нагрузку пакета. Издержкой такой эффективности вычислений является хранение верхней памяти, поскольку количество состояний и переходов состояний экспоненциально увеличивает объем памяти. NFA имеет более низкие требования к памяти для хранения, но после каждого состояния следующее состояние может быть несколько другим параллельным, это требует много вычислительных ресурсов для проверки всех возможных случаев.
И DFA и NFA имеют свои сильные и слабые стороны и могут быть использованы в программных средствах для систем контроля пакета данных.
Так как количество данных, передаваемых по телекоммуникационной сети, быстро возрастает, сетевые серверы, использующие конечный автомат могут потребовать слишком большое количество ресурсов, то есть запоминающее устройство и контроллеры доступа к памяти, обычно определяемых как объем памяти. Соответственно, существует потребность в усовершенствованном способе обнаружения структур данных посредством реализации конечного автомата.
Раскрытие изобретения
Задача настоящего изобретения состоит в создании усовершенствованного устройства и способа обнаружения структур данных в потоке данных.
Также, в частности, задача настоящего изобретения состоит в создании устройства и управляемого компьютером способа обнаружения структур данных, выполненных с возможностью реализации детерминированного конечного автомата с высокой скоростью потока данных.
В первом аспекте предложено устройство для обнаружения структур данных в потоке данных, содержащем множество символов данных, представляющих знаки алфавита. Устройство реализует детерминированный конечный автомат и содержит следующее. Регистр перехода состояний содержит множество состояний, включающее в себя начальное состояние и по меньшей мере одно поглощающее состояние и переходы состояний из начального состояния в целевое состояние, инициируемые посредством символа данных потока данных. Кроме того, оно содержит средство определения положения знака для определения для каждого символа данных каждого состояния регистра перехода состояний, соответствующего положения знака в алфавите, средство обновления для обновления регистра перехода состояний таким образом, чтобы он содержал диапазоны символов данных для символов данных с соответствующими последовательными положениями знаков в переходах, инициируемых посредством алфавита в одно и то же целевое состояние. Кроме того, оно содержит средство определения диапазона для определения, содержится ли символ данных потока данных в диапазоне символов данных обновленного регистра перехода состояний, и для определения соответствующего ему целевого состояния, и средство инициирования для инициирования перехода состояний из начального состояния в определенное целевое состояние для обнаружения структуры данных.
Для обработки потока данных посредством устройства для обнаружения структур данных устройство выполнено с возможностью сравнения символов данных, содержащихся в потоке данных с символами данных, хранящихся в таблице перехода состояний. Вначале конечный автомат находится в его первом состоянии, т.е. начальном состоянии. Для начального состояния и каждого последующего состояния конечного автомата, таблица перехода состояний содержит информацию о переходах состояний. Это означает, что для каждого состояния сочетание целевых состояний и соответствующих символов данных содержатся в регистре. Символ данных обрабатывается в потоке данных, например, анализируется, и в этот момент сравнивается с символами данных, которые хранятся в регистре перехода состояний. Соответствующий символ данных регистра содержит соответствующее целевое состояние, и, таким образом переход инициируется в это целевое состояние. Затем процесс повторяется, и обрабатывается следующий символ данных потока данных, например сравнивается с регистром перехода состояний.
Если символы данных потока данных содержатся в машинном алфавите, например, алфавите в расширенном формате ASCII, каждый символ данных может быть одним из 256 различных возможных знаков. Таким образом, таблица перехода состояний, хранящаяся в памяти, содержит целевые состояния для всех этих 256 знаков для каждого состояния конечного автомата. Регистр перехода состояний для обнаружения, например, относительно коротких простых 5 строк знаков ASCII содержит информацию о 5 × 256 = 1280 переходах состояний. Можно предположить, что для обнаружения расширенных строк и большого количества строк, требования к памяти быстро увеличатся.
В соответствии с аспектом настоящего изобретения был найден альтернативный способ хранения информации в регистре перехода состояний с более низкими требованиями к ресурсам памяти. Переходы состояний, хранящиеся в регистре перехода состояний, часто содержат множество переходов к одному целевому состоянию. По существу, по меньшей мере часть информации, хранящейся в регистре, восприимчива к сжатию.
Символы данных потока данных, и также символы данных, хранящиеся в таблице перехода состояний, представлены в виде знаков, например алфавита (расширенного формата) ASCII. В алфавите каждый знак имеет последующее число, например, символ данных "А" является представлением 65 кода знака ASCII, и символ данных "B" является представлением 66 кода знака ACSII. Авторы изобретения использовали идею, что хранилище символов данных в таблице перехода состояний, может быть сжато, если использование производится из диапазона символов данных как представление множества одиночных символов данных, так как существует чаще всего меньше целевых состояний, чем возможных знаков. Таким образом, эти символы данных с последующими положениями знаков в алфавите, которые имеют одинаковое соответствующее целевое состояние, могут быть сгруппированы в единое представление.
Так как знаки имеют фиксированные последующие положения в диапазонах алфавита, знаки могут быть сгруппированы, чтобы инициировать такое же целевое состояние.
Устройство в соответствии с первым аспектом настоящего изобретения содержит средство определения положения знака всех символов данных, содержащихся в регистре перехода состояний. По состоянию регистра перехода состояний все записи проверяются для определения того, какая последовательность символов данных относится к последующим положениям знаков, которые имеют такое же соответствующее целевое состояние. Если, например, символы данных "A", "B", "C", "D" и "Е", например, состояния 1 инициировали переход к целевому состоянию 2, то эти символы могут быть сгруппированы и представлены с меньшим объемом потребляемой памяти. Символы данных представляют положения знаков 65-69, и, например, одиночный диапазон символов данных может быть показывающим для всех символов, содержащихся в нем. Регистр перехода состояний может быть обновлен с этими менее интенсивно использующими память направлениями и, таким образом посредством устройства достигается сокращение ресурсов памяти.
После выполнения сжатия, например обновления таблицы перехода состояний, устройство содержит средство для определения, содержится ли символ данных потока данных в диапазоне символов данных обновленного регистра перехода состояний, и впоследствии определяет его соответствующее целевое состояние. Со средством инициирования устройство реализует конечный автомат в соответствии с целевым состоянием и инициирует переход к нему. Таким образом, реализуется конечный автомат для обнаружения структур данных в соответствии с регистром перехода состояний в потоке данных.
В дополнительном примере, средство для определения выполнено с возможностью сортировки для каждого состояния регистра перехода состояний, всех символов данных в соответствии с соответствующим положением знака в алфавите.
Поскольку символы данных могут быть представлены в виде знаков алфавита, они имеют определенные положения знаков в алфавите. Для обновления регистра перехода состояний так, чтобы он содержал диапазоны символов данных как представление для символов данных с последующими положениями знаков, выгодно сначала сортировать символы данных в соответствии с их относительным положением в алфавите. Это увеличивает обработку, поскольку устройство может легко определять, какие переходы состояний могут быть сгруппированы, если переходы состояний, т.е. наборы символов данных с соответствующими целевыми состояниями, сортируются в соответствии с их положением знака или представлением кода знака в соответствии с алфавитом.
В другом примере алфавит содержит машинный алфавит и, в частности, алфавит в формате ASCII или расширенном формате ASCII.
Алфавит может быть любым алфавитом, который обрабатывается устройством, то есть компьютером, осуществляющим управляемый компьютером способ обнаружения структур данных. Помимо этого, алфавит может быть любым удобочитаемым человеком алфавитом, например латинским или греческим алфавитами. В удобочитаемых человеком алфавитах символы данных, например знаки, часто связаны в соответствии с обычным порядком символов, также известным как алфавитный порядок как способ сортировки.
Алфавит может быть машинным или математическим алфавитом, то есть знаки упорядочиваются в соответствии с кодировкой знаков, т.е. в соответствии с порядком алфавита ASCII или лексикографическим порядком. Например, ASCII кодировка знака и расширенный ASCII часто используются в коммуникационной сети. Более современные типы кодировок также могут быть использованы, например кодировка в соответствии с универсальным набором символов ISO/IEC 10646 и Unicode или, более конкретно, с ISO/IEC 8859-1 через 16 или UTF-8 или UTF-16.
В дополнительном примере символы данных представляют знаки алфавита ASCII, и, в частности алфавита в расширенном формате ASCII, и в котором положение знака представляют двоичный, восьмеричный, десятичный или шестнадцатеричный коды символов ASCII. Согласно кодировке алфавита, например в соответствии с алфавитным порядком, может быть осуществлено использование их соответствующих представлений двоичного, восьмеричного, десятичного или шестнадцатеричного кодов.
В другом примере устройство выполнено с возможностью выполнения определения положений знака и обновления таблицы перехода состояний, независимой от определения символа данных в диапазоне символов данных и инициирования перехода состояний.
В первом примере устройство выполнено с возможностью чтения регистра перехода состояний, содержащего переход состояний в соответствии с которым реализуется конечный автомат. Таблица перехода состояний обновляется так, чтобы она содержала символ данных в диапазоне для снижения потребления памяти. Кроме того, устройство реализует конечный автомат в соответствии с обновленным/сжатым регистром перехода состояний. Результатом конечного автомата, например, является ли структура данных соответствующей или нет, является тем же, если выполняется в соответствии с регистром перехода в качестве начального состояния, когда выполняется в соответствии с обновленной таблицей перехода состояний.
После обновления таблица перехода состояний может быть повторно использована в дополнительных реализациях конечного автомата. Соответственно, это или любое устройство может быть выполнено с возможностью обновления регистра перехода состояний для того, чтобы содержать диапазоны символов данных, и в другой момент или с другим устройством обновленный регистр перехода состояний может использоваться для обнаружения структур данных. Также, если выполнено в одном устройстве, то устройство выполнено с возможностью осуществления как конечного автомата со сжатым регистром таблицы перехода состояний, содержащим удаленные символы данных, так и обновления регистра перехода состояний для того, чтобы содержать эти удаленные символы данных. Если устройство реализует дополнительный конечный автомат, содержащий посредством регистра перехода состояний, то можно повторно использовать обновленный регистр перехода состояний, вместо осуществления этапа обновления.
В еще одном дополнительном примере устройство выполнено с возможностью завершения обнаружения структуры данных при инициировании перехода состояний в поглощающее состояние детерминированного конечного автомата.
Обычная теория автоматов предписывает, чтобы были обработаны все символы данных, прежде чем будет выдан результат в виде соответствия или несоответствия для обнаруженной структуры. Это означает, что, несмотря на то, что автомат достигает состояния, из которого он никогда не может перейти в поглощающее состояние, все символы входных данных потока данных должны быть обработаны. Это оказывает основное влияние на анализирующую скорость автомата.
Согласно некоторым применениям устройство выполнено с возможностью работы в соответствии с обычной теорией автоматов. Однако, если некоторые формальные требования ослаблены, то может быть достигнута более высокая степень сжатия регистра перехода состояний. Например, в области анализа пакетов часто нет необходимости сообщать обо всех экземплярах соответствия структуры в потоке символов входных данных. Первое соответствие, т.е. первое состояние, которое будет достигнуто конечным автоматом, которое является поглощающим состоянием, может быть достаточным для завершения конечного автомата и сообщения его результата.
Следовательно, посредством реализации функции возврата, в которой обнаружение завершается, т.е. конечный автомат возвращается в исходное состояние, дополнительные переходы состояний могут быть удалены из регистра перехода состояний. Преимущественно, это приводит к дополнительному сжатию и также к дополнительному снижению объема требуемой памяти.
В другом примере поток данных обрабатывается посредством компьютера в соответствии с обнаруженной структурой данных. Реализуемый компьютером способ может быть использован для множества сервисов. Например, для фильтрации трафика в настройке шлюза. Таким образом, компьютер может обнаруживать нежелательный трафик в потоке данных. Поток данных принимается компьютером и сопоставляется в соответствии со структурами данных. Если структура сопоставляется, и, таким образом, обнаружен нежелательный трафик, компьютер может выполнить дополнительные действия по потоку данных. Надлежащее действие может быть выполнено в зависимости от структур. Например, данные, соответствующие нежелательным протоколам или вирусам, могут быть удалены или перенаправлены.
Во втором примере представлен управляемый компьютером способ обнаружения структур данных в потоке данных, принятом посредством компьютера, причем поток данных содержит множество символов данных, представляющих знаки алфавита, причем компьютер реализует детерминированный конечный автомат, содержащий сжатый регистр перехода состояний, содержащий множество состояний, включающее в себя начальное состояние и по меньшей мере одно поглощающее состояние, и переходы состояний из начального состояния в целевое состояние, инициируемые посредством символа данных потока данных, причем сжатый регистр перехода состояний содержит по меньшей мере один диапазон символов данных, причем способ содержит этапы, на которых:
- определяют посредством компьютера из сжатого регистра перехода состояний, содержится ли символ данных потока данных в диапазоне символов данных сжатого регистра перехода состояний, и определяют соответствующее ему целевое состояние, и
- инициируют посредством компьютера переход состояний из начального состояния в определенное целевое состояние для обнаружения структуры данных.
В соответствии со способом с описанными выше этапами структуры данных могут быть обнаружены в потоке данных, принятом посредством компьютера, осуществляющий способ. В соответствии с теорией автоматов регистр перехода состояний присутствует в компьютере, однако, в соответствии с аспектом настоящего изобретения регистр представляет собой сжатый регистр перехода состояний, в котором по меньшей мере один набор символов данных представлен в диапазоне символов данных. Способ содержит этап, на котором выполняют процесс поиска для определения следующего целевого состояния автомата в соответствии с символом данных потока данных, обрабатываемого в данный момент. В соответствии с теорией автоматов, символ данных сравнивается с соответствующим символом данных в регистре перехода состояний. Соответствующее целевое состояние представляет собой состояние, к которому будет инициирован конечный автомат.
Однако в соответствии со вторым примером теория автоматов реализуется в соответствии с этапом определения, в котором для символа данных потока входных данных определяется, к какой группе он принадлежит. Это означает, что если он представлен в диапазоне символов данных, то определяют его соответствующее целевое состояние. Если он не представлен в диапазоне символов данных, то определяют целевое состояние, в соответствии с обычной теорией автоматов. Тогда на дополнительном этапе, соответственно, инициируется переход к целевому состоянию.
В третьем примере представлен управляемый компьютером способ формирования сжатого регистра перехода состояний в соответствии с вышеупомянутым описанием, содержащий этапы, на которых:
- определяют посредством компьютера для каждого символа данных каждого состояния регистра перехода состояний соответствующее положение знака в алфавите; и
- обновляют посредством компьютера регистр перехода состояний так, что он содержал диапазоны символов данных для символов данных с соответствующими последовательными положениями знаков в переходах, инициируемых посредством алфавита в одно и то же целевое состояние.
Как только регистр перехода состояний обновлен, он может быть использован в качестве замены для регистра перехода исходного состояния для реализации конечного автомата для обнаружения структур данных с его помощью. Таким образом, этапы обновления способа могут быть выполнены одним и тем же компьютером, что и этапы реализации конечного автомата способа с обновленным регистром. Тем не менее они также могут быть выполнены отдельно посредством других компьютеров. Первый компьютер, например, может быть выполнен с возможностью сжатия регистров перехода состояний, т.е. анализа одного или множества регистров перехода состояний библиотеки, и второй компьютер для реализации конечного автомата по одному или множеству обновленного/сжатого регистра или регистров библиотеки.
Также, выполнение управляемого компьютером способа определения положения знака символа данных в алфавите, например определение осуществляется в алфавитном порядке, и обновление регистра перехода состояний так, чтобы он содержал диапазоны символов для символов данных с соответствующими последовательными положениями знаков в переходах, инициируемых посредством алфавита, в одно и то же целевое состояние, имеет то преимущество, что оно может быть выполнено независимо от исполнения конечного автомата.
В дополнительном примере способ дополнительно содержит этап, на котором сортируют посредством компьютера, для каждого состояния каждого регистра перехода состояний, все символы данных в соответствии с соответствующим положением знака в алфавите.
Символы данных потока данных могут быть представлены в виде знаков алфавита. Также, они имеют определенные положения в алфавите. Обновление регистра перехода состояний так, чтобы он содержал диапазоны, может быть выполнено в соответствии с этими положениями. Сортировка символов данных в соответствии с их положением в алфавите, например упорядочивание по алфавиту или размещение в алфавитном порядке, имеет то преимущество, что скорость анализа регистра увеличивается, поскольку могут быть сформированы группы перехода состояний, например, диапазоны символов данных для неизменных целевых состояний последующих символов данных регистра.
В еще одном примере способ дополнительно содержит этап, на котором удаляют из таблицы перехода состояний каждый переход состояний для состояния, в котором для всех соответствующих переходов состояний начальное состояние является идентичным целевому состоянию.
Как описано выше, несжатые регистры перехода состояний содержат символы данных и соответствующие целевые состояния для каждого состояния конечного автомата. Сжатые регистры перехода состояний в соответствии с примером изобретения также содержат по меньшей мере один диапазон символов данных. Для некоторых состояний соответствующие переходы состояний не содержат какой-либо переход к дополнительному состоянию. Это означает, что конечный автомат перешел на заблокированную дорожку, и также будет продолжать оставаться в этом состоянии, или инициировать на каждый символ данных переход в состояние, также известное как непереадресуемый переход. Так как эта информация, содержащаяся в регистре перехода состояний, не будет способствовать обнаружению структуры данных, выгодно удалять такую информацию. Также, все дополнительные переходы состояний могут быть удалены из регистра, из которого конечный автомат не может инициировать переход в другое состояние, и также в котором целевое состояние представляет собой начальное состояние.
В другом примере способ дополнительно содержит этап, на котором удаляют из таблицы перехода состояний каждый переход состояний для состояния, в котором никакой соответствующий переход состояний не может привести к поглощающему состоянию.
В дополнение к удалению переходов состояний для непереадресуемых состояний, последующие состояния за этими состояниями также могут быть удалены из таблицы перехода состояний. Кроме того, эти переходы состояний могут быть удалены, в которых никакие последующие состояния этой дорожки конечного автомата не содержат поглощающее состояние. Это означает, что на примере обнаружения структуры данных конечный автомат может перейти в определенное состояние, из которого все непосредственные целевые состояния, для которых текущее состояние представляет собой исходное состояние, и для всех дополнительных целевых состояний ни одно из них не является поглощающим состоянием. Соответственно, нет шансов на соответствие структуре данных, и вследствие этого целесообразно удалить соответствующую информацию, то есть символы данных и целевые состояния этих состояний из регистра перехода состояний для достижения его дополнительного сжатия.
В дополнительном примере способ дополнительно содержит этап, на котором удаляют из таблицы перехода состояний, каждый переход состояний, в котором начальное состояние представляет собой конечное состояние. Для некоторых применений достаточно первого совпадения конечного автомата, например соответствие для структуры данных представляется, при входе в первое поглощающее состояние. Для таких применений регистр перехода состояний может быть еще больше сжат посредством удаления всех последующих его переходов состояний, поскольку для таких применений это не добавляет требуемой информации об обнаруженных структурах.
В четвертом примере представлен компьютерный программный продукт, содержащий устройство хранения данных, на котором сохранены данные компьютерного программного кода, выполненные с возможностью осуществления способа в соответствии с любыми вышеописанными признаками, когда данные программного кода загружены в память электронного блока обработки и исполняются электронным блоком обработки.
В пятом примере представлена телекоммуникационная сеть, содержащая сетевой сервер в соответствии с вышеприведенным описанием.
Краткое описание чертежей
Настоящее изобретение будет далее рассмотрено более подробно ниже с использованием ряда примерных вариантов выполнения, со ссылкой на прилагаемые чертежи, на которых
Фиг. 1 иллюстрирует упрощенный конечный автомат, содержащий пять состояний, и переходы состояний между состояниями;
Фиг. 2 иллюстрирует упрощенный конечный автомат, дополнительно содержащий регистр перехода состояний;
Фиг. 3 иллюстрирует упрощенный конечный автомат, дополнительно содержащий удаленный/сжатый регистр перехода состояний;
Фиг.4 иллюстрирует блок-схему в соответствии с одним аспектом настоящего изобретения;
Фиг. 5 иллюстрирует сетевой сервер в соответствии с еще одним аспектом настоящего изобретения;
Фиг.6 иллюстрирует телекоммуникационную сеть в соответствии с другим аспектом настоящего изобретения.
Осуществление изобретения
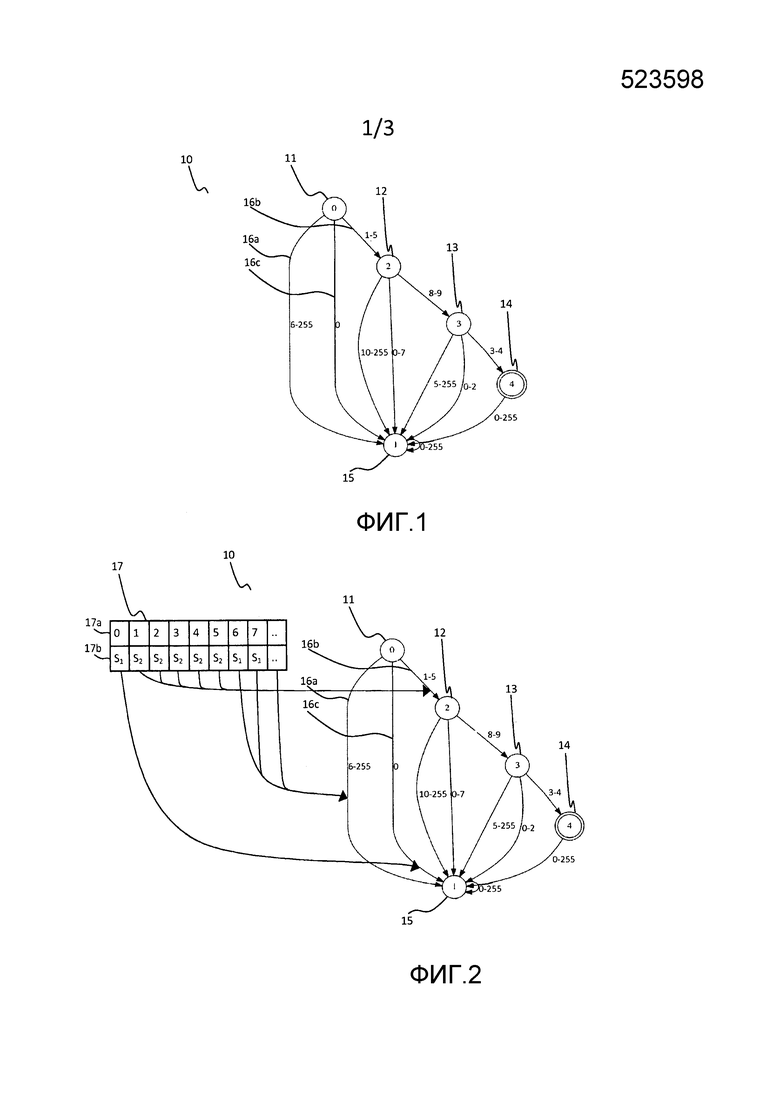
На Фиг. 1 раскрыт пример представления конечного автомата 10. Конечный автомат может быть использован для идентификации структур данных в потоках данных, то есть информационная нагрузка в телекоммуникационных сетях. Такая идентификация может, например, применяться к обнаружению вирусов и шпионских программ, системам обнаружения проникновения, фильтрации контента, сопоставления протоколов и т.д.
Конечный автомат 10, показанный на Фиг. 1, содержит множество состояний 11, 12, 13, 14, 15. Эти состояния также могут называться узлами. Процесс сопоставления структуры данных начинается с начального состояния 11 конечного автомата 10. Начальное состояние может быть определено как состояние, для которого никакое входное действие не присутствует, то есть для которого не существует никакого перехода, приводящего к этому состоянию. На Фиг. 1 такое состояние 11 является начальным состоянием.
Поток данных, обрабатываемый компьютером, содержит последовательность символов данных. Эти символы данных, или знаки, которые принимаются посредством компьютера и используются по одному в качестве ввода в текущем состоянии конечного автомата 10 для инициирования перехода 16a, 16b, 16c состояний. После начала процесса сопоставления структур начальное состояние 11 представляет собой текущее состояние или исходное состояние. Первый символ данных потока данных определяет переход 16 состояний. Если, например, первый символ данных относится к знаку 0 таблицы ASCII, то есть код знака 0, тогда инициируется переход 16c состояний от начального состояния 11, нулевого состояния, к первому состоянию 15. Однако, если первый символ данных относится к знаку (коду) 1, тогда инициируется переход 16b состояний во второе состояние 12. После первого перехода 16b состояний состояние, к которому инициируется переход, например, состояние 12 или 15 в то время представляет собой текущее состояние.
С другой стороны, для текущего состояния, т.е. состояния 12, следующий символ данных потока данных используется для определения следующего перехода состояний. Если следующий символ данных является кодом 5 знака, то инициируется переход состояний в первое состояние 15, те же самые значения для всех кодов в диапазоне 0-7 и все знаки в диапазоне 10-255. Тем не менее, если следующий символ данных в потоке данных является знак 8 или 9, то инициируется переход состояний в третье состояние 13. Тогда, для третьего символа данных инициируется переход состояний в первое состояние для всех знаков 0-2 и 5-255. Тем не менее, если третий символ данных является знаком 3 или 4, то наступает четвертое состояние 14. Это поглощающее состояние или конечное состояние и представлено двойным кружком.
Когда поглощающее состояние достигнуто, конечный автомат выдает соответствующую структуру данных в соответствии с конечным автоматом. В этом примере, это соответствие для регулярного выражения {[1-5], [8-9], [3-4]}, представляющее собой один из знаков 1-5 для первого символа данных, либо знак 8 или 9 для второго символа данных и, наконец, знак 3 или 4 для третьего символа данных.
Может существовать множество конечных автоматов, что приводит к множеству структур данных для определения множества протоколов, строк данных, вирусов и т.д. Конечный автомат, раскрытый на Фиг. 1, представляет собой упрощенный вариант конечного автомата, поскольку есть только определенное количество переходов и показанных состояний. В действительности, полный конечный автомат отображает переход состояний для каждого возможного символа входных данных. Поэтому, для 256 возможных символов данных в знаковом алфавите ASCII, каждое состояние конечного автомата имеет 256 переходов состояний. Тем не менее большинство переходов состояний инициируют переход к тому же последующему состоянию и, может, поэтому визуально быть представлено в виде одного диапазона. В примере Фиг. 1 переход состояний для нулевого состояния 11 в первое состояние 15 состоит из 2 переходов состояний, одного одиночного перехода состояний для знака 0 и удаленного перехода состояний для всех знаков в диапазоне от 6 до 255.
Отображенный граф на Фиг. 1 представляет собой конечный автомат в виде диаграммы состояний, но он представляет собой только пример представления. Существуют и другие типы представлений. Известные из уровня техники конечные автоматы хранятся в компьютере в более формальном виде. Отображенная диаграмма состояний на Фиг. 1 показывает только ограниченное количество перехода состояний для каждого состояния. Прототип таблицы перехода состояний, будучи исполненной сохраненным конечным автоматом в компьютере, содержит записи для всех возможных переходов состояний для каждого состояния. Поскольку отображение такого регистра с диаграммой состояний было бы неясным, диаграммы состояний могут быть упрощенными представлениями регистра перехода состояний. Регистры перехода состояний, однако, имеют формальный и функциональный способ содержания того же регулярного выражения посредством визуализации, отображенной на Фиг. 1. Регистры переходов состояний аналогичны таблицам истинности, определяющим выходные данные для состояния после определенного ввода.
Символы данных потока данных, который обрабатывается посредством компьютера, реализующий конечный автомат, представлены в виде знаков. Эти знаки могут быть хорошо известными знаками, такими как "1", "a" и "β", однако они также могут быть компьютерными знаками, такими как ">", "-" или "¬". Эти знаки являются частью алфавита, который содержит в себе стандартный, фиксированный набор символов данных. Существуют множество алфавитов, известные удобочитаемые для человека, естественные алфавиты, такие как арабский, сирийское письмо, кириллица, греческий, иврит и латинский алфавит. Тем не менее также компьютерные алфавиты можно считать алфавитами, и они могут содержать не только буквы, включая в себя цифры, знаки препинания и управляющие знаки, которые не соответствуют символам в определенном естественном языке.
Таким образом, в соответствии с изобретением алфавит следует считать набором символов в самом широком контексте. В компьютерных системах алфавиты кодируются посредством представления текстовых элементов на основе последовательностей знаков и/или блоков текстовой информации. Знаки в свою очередь представлены в компьютере в двоичных числах. Система преобразования знаков в двоичные данные представляет собой кодирование набора знаков, кодирование знаков или схему кодирования.
Американский стандартный код для обмена информацией, ASCII, является примером стандарта кодирования знаков, в котором представлены буквы, цифры, знаки препинания и т.д. Каждый знак, т.е. каждый символ данных, имеет свой собственный уникальный номер, по которому он может быть указан. Таким образом, каждый символ данных имеет заранее определенное, установленное положение в этой схеме кода. ASCII является лишь примером схемы кодирования знаков, другие схемы кодирования, такие как расширенный ASCII, формат преобразования Unicode, UTF, также могут быть использованы для индикации символов данных в соответствии с установленным уникальным представлением числа, пока известны положения для символов данных в алфавите, например схема кода.
В соответствии с Фиг. 1, существуют 256 различных представлений кода символов данных, например 0-255. В зависимости от схемы кода они могут представлять различные знаки. Если, например, используется схема кода ASCII, тогда десятичный код 97 представляет знак "а". Таким образом, если компьютер, осуществляющий конечный автомат, обрабатывает поток данных, считывает знак "а" как текущий символ данных в потоке входных данных, причем десятичное представление его является 97, например 97-е положение в алфавите, в соответствии со схемой кода ASCII. Все возможные символы данных представляют собой уникальные положения в схеме кода, и также в алфавите, и могут быть отсортированы в соответствии с ним.
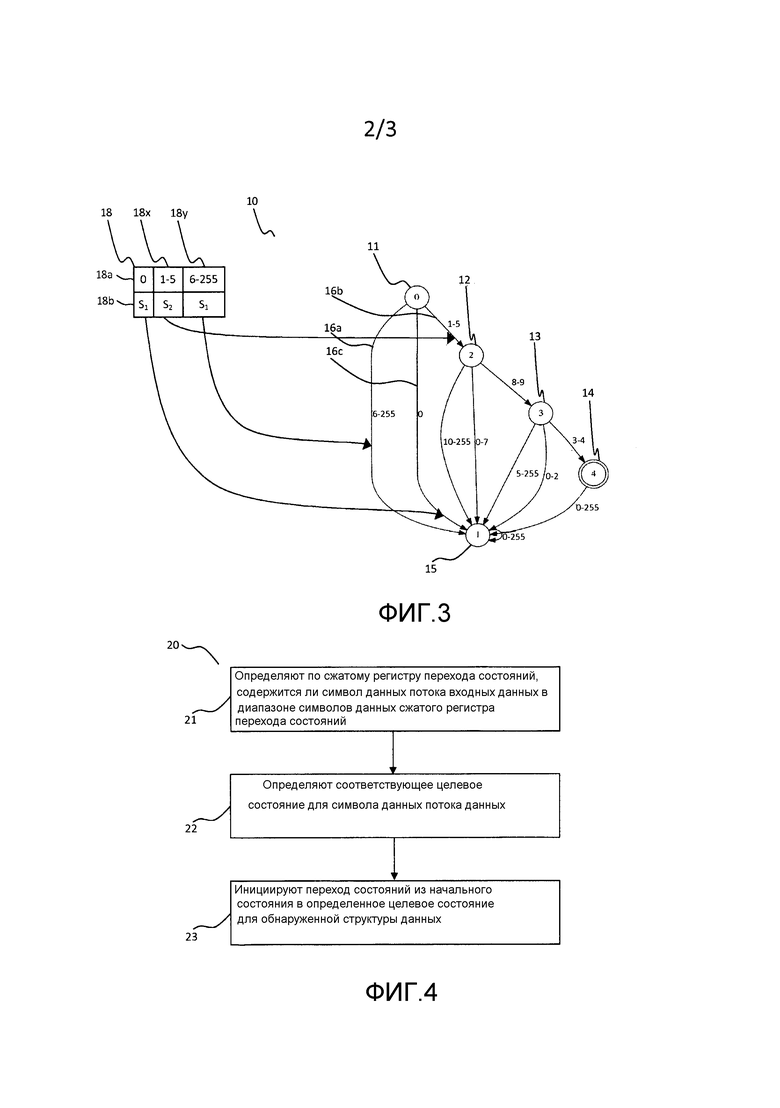
На Фиг. 2 раскрыта диаграмма 10 состояний Фиг.1, однако с соответствующей таблицей 17 перехода состояний. Таблицу перехода состояний можно считать таблицей истинности, аналогичной способу сохранения информации о том, какие переходы состояний должны инициироваться после ввода определенных символов данных в текущем, начальном состоянии. Упрощенная таблица 17 перехода состояний, показанная на этом чертеже, содержит две строки 17а, 17b. Первая строка 17а содержит все символы данных алфавита, например конечный набор 256 символов данных, содержащихся в таблице расширенного ASCII, представленных посредством их представления десятичного числа. Тогда для каждого символа данных во второй строке 17b представлено соответствующее состояние. Это состояние, к которому инициируется переход состояний, если соответствующий символ данных является символом данных потока данных. Таким образом, для каждого состояния такая информация содержится в таблице перехода состояний.
Существуют множество таблиц переходов состояний, например одно- и двумерные таблицы состояний. Таблица(ы) перехода состояний содержатся в памяти компьютера, реализующего конечный автомат в форме регистра перехода состояний. Также, регистр перехода состояний в соответствии с изобретением может, например, быть определен как таблица 17 перехода состояний, раскрытая на Фиг. 2.
Даже простое регулярное выражение требует относительно большого объема памяти, так как регистр перехода состояний содержит переходы состояний для каждого возможного состояния и символ данных обрабатываемого потока данных. Для определенного применения должно быть обработано большое количество регулярных выражений и, таким образом, объем требуемой памяти для конечного автомата (регистров перехода состояний) является большим. Для того чтобы снизить объем требуемой памяти и иметь возможность обрабатывать конечный автомат с не ограниченным количеством памяти, выгодно сжимать регистр перехода состояний.
Визуальное изобретение, используемое для представления конечного автомата Фиг. 1 и 2, может также быть выполнено с возможностью сжатия реальных регистров перехода состояний. Различие может быть сделано между переходами состояний, которые представлены как переходы состояний для одиночного кода знака и переходы состояний для диапазона кодов знака. Например, переход состояний 16c на Фиг. 1 и 2 является одиночным переходом состояний. Переходы состояний 16a и 16b Фиг. 1 и 2, представляют собой удаленные переходы состояний, которые представляют 250 (16a) и, соответственно, 5 (16b) различных знаков.
В первом аспекте настоящего изобретения такое различие реализуется между одиночным и сгруппированными или удаленными переходами. Для каждого представления удаленного перехода состояний достигается снижение хранилища данных и, также, снижение объема требуемой памяти. Реализация удаленных переходов состояний для детерминированного конечного автомата несколько отличается от обычной теории автоматов, так как обычная теория автоматов предписывает хранение всех одиночных переходов.
Дистанционные переходы состояний представляют переходы состояний, идущие к тому же целевому состоянию в качестве уникального удаленного перехода. Для преобразования переходов состояний в удаленные переходы состояний в регистре перехода состояний может использоваться уже вычисленный детерминированный конечный автомат. Здесь все состояния детерминированного конечного автомата получены в результате итерации. Для каждого состояния массив обеспечивается уникальным положением для всех символов данных, присутствующих во входном алфавите. Для каждого символа данных в алфавите создается удаленный переход, если последующий символ данных алфавита, то есть следующий знак в соответствии с таблицей кодов знаков, идет в то же целевое состояние детерминированного конечного автомата. Тогда только диапазоны состояний вместо отдельных состояний сохраняются в регистре и тем самым получают уменьшение размера, что приводит к снижению объема требуемой памяти.
Использование сжатого регистра перехода состояний, в сравнении с регистром перехода состояний в соответствии с формальной реализацией теории автоматов, является несколько иным. В соответствии с использованием сжатого регистра перехода состояний первый этап, здесь, определяет, содержится ли символ данных потока входных данных в удаленном переходе или в одиночном переходе в регистре. В сжатом регистре перехода состояний компьютер определяет, относится ли символ данных, то есть код знака к диапазону, или к одиночному переходу знаков.
Диапазоны могут определяться множеством способов. Например, каждый диапазон может содержать начальное представление кода знака, то есть код 41, и конечное представление кода знака, то есть код 48, описывая диапазон кодов знаков, представленных таким образом. Компьютер может определять, содержится ли символ входных данных в диапазоне посредством последовательного анализа символов 17а данных в регистре 17 перехода состояний. Если текущий и прошедший код знака неуспешно обрабатываются и символ входных данных содержится здесь, то происходит обращение, и соответствующее состояние 17b может быть считано для того, чтобы инициализировать, например, инициировать переход к нему. Кроме того, диапазоны также можно определять посредством определения только представления кода начального знака. Из последующего кода знака можно определить, сохраняются ли одиночные символы данных в таблице перехода состояний или диапазон.
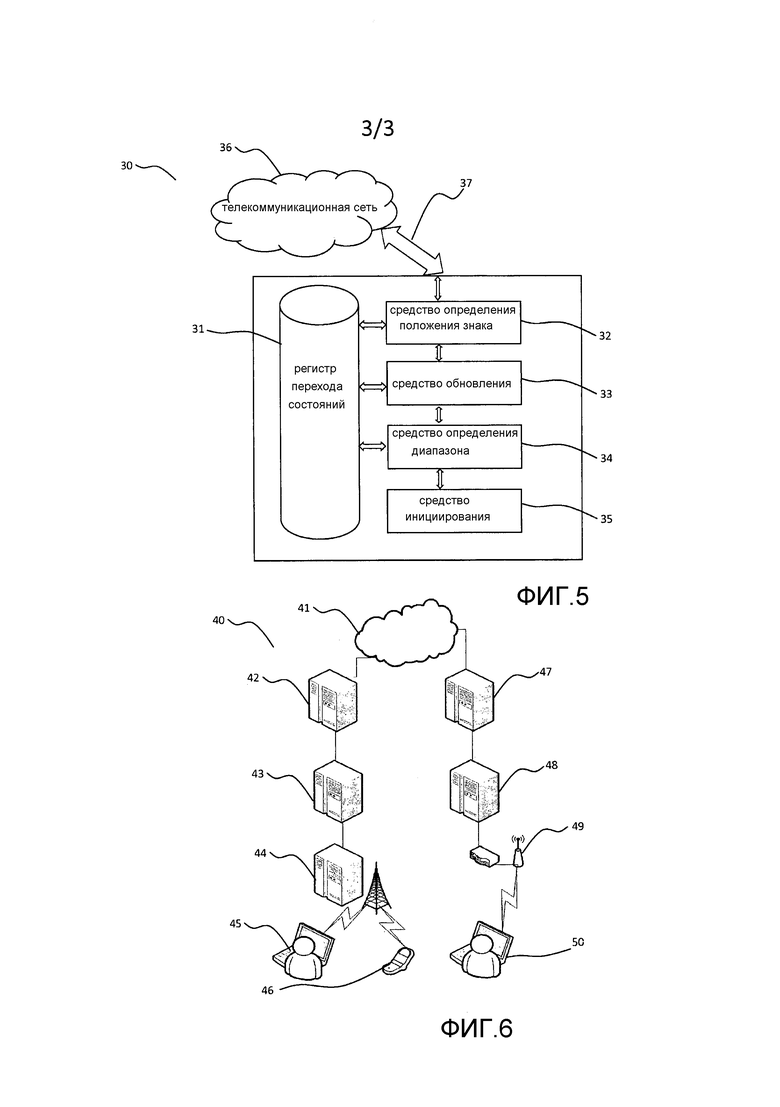
Фиг. 3 показывает такую сжатую, например, удаленную таблицу перехода состояний, в которой для соответствующих переходов состояний диаграммы 10 состояний из определенного состояния к одному и тому же целевому состоянию, инициированному посредством последующих положений кодов знаков в алфавите, представлены в виде диапазонов 18X, 18Y.
Для начального нулевого состояния 11 возможны 256 переходов состояний в соответствии с 256 возможными символами данных, то есть десятичное представление кодов знаков ASCII. Из диаграммы видно, что эти 256 переходов приводят лишь к переходу в одно 12 или второе 15 целевое состояние. Также, все символы данных могут быть сгруппированы в соответствии с этими состояниями. Тем не менее, чтобы определить, какой символ данных принадлежит к какой группе, весь регистр должен быть проанализирован многократно. Посредством сортировки символов данных в регистре в соответствии с относительным положением в алфавите, такой многократный анализ может быть пропущен. Символы 18а данных регистра 18 могут быть последовательно проанализированы давая прямую адресацию состояния, в которое должен быть инициирован переход.
На Фиг. 4 описаны этапы способа, на которых используют сжатый регистр перехода состояний, т.е. регистр перехода состояний, который обновляется для того, чтобы содержать удаленные переходы состояний для последующих символов данных, инициирующих переход в целевое состояние. На этом первом этапе 21 определяют, по обновленному или сжатому регистру перехода состояний, содержится ли символ данных потока входных данных в диапазоне символов данных регистра.
На втором этапе 22 компьютер определяет соответствующее целевое состояние, к которому конечный автомат инициирует переход. Это целевое состояние соответствует символу данных или диапазону символов данных, определенному на предыдущем этапе 21.
На конечном этапе 23 конечный автомат инициирует переход в целевое состояние, определенное на этапе 22. Также, компьютер обработал символ данных потока данных и продолжает обработку следующего символа данных потока, начиная этапы 21-23 способа заново.
Фиг.5 представляет собой упрощенное представление компьютера 30 для реализации управляемого компьютером способа в соответствии с настоящим изобретением. Компьютер для нормальной работы может содержать дополнительные блоки, такие как центральный процессор, не раскрытый на Фиг. 5, но существующий в компьютере, или более конкретный сетевой сервер или узел в телекоммуникационной сети.
Компьютер 30 содержит регистр 31 перехода состояний, в котором сохранены переходы состояний для всех состояний конечного автомата. Компьютер соединен с телекоммуникационной сетью 36 посредством соединения 37. Телекоммуникационная сеть 36 может быть любой сетью, в которой данные передаются между сторонами, узлами или их комбинации. В сети 36 и, в частности, по сетевому соединению 37 передаются потоки данных. Эти потоки данных обрабатываются компьютером 30, реализующим конечный автомат. Компьютер, кроме того, содержит средство 32 определения положения знака. При этом символы данных потока 37 данных обрабатываются и анализируются. Каждый символ данных представлен посредством знака, причем знак представляет собой код знака в алфавите, в соответствии со схемой кодирования знаков. Символ данных, обработанный в определенный момент в потоке данных, может, например, знаком “a”. Компьютер 30 и, в частности, средство 32 определения положения знака содержат, какая схема кода знака используется, например какой применяется алфавит. Если, например, используется схема кода знака ASCII, то средство 32 определения положения знака может сравнивать символ данных потока 37 данных с таблицей кода ASCII и определять его положение, т.е. десятичное положение 97 для знака “a”.
Средство 33 обновления компьютера 30 выполнено с возможностью считывания таблицы перехода состояний, в соответствии со схемой кодирования средства 32 определения положения знака, и определения положения символов данных, содержащихся в регистре. Для символов данных, которые имеют последующие положения в соответствии со схемой кодирования, то есть "а"-"е", так как их коды ASCII являются 97-101, и для которых соответствующее целевое состояние является тем же, средство 33 обновления выполнено с возможностью обновления регистра 31 перехода состояний для того, чтобы содержать диапазоны кодов на смену отдельных символов данных. Исходные символы данных могут быть удалены из регистра, таким образом, уменьшая количество информации, хранящейся в нем, и также снижая объем требуемой памяти.
Средство 34 определения диапазона выполнено с возможностью определения, после реализации конечного автомата, содержится ли символ данных потока 37 данных в регистре перехода состояний в диапазоне или нет. Если регистр перехода состояний содержит только отдельные символы данных, то компьютер может просто проанализировать символы данных последовательно, чтобы сравнивать тогда с потоком входных данных. Средство 34 определения диапазона информирует средство 35 инициирования, в которое соответствующее целевое состояние должно инициироваться переход. Средство инициирования тогда выполняет этот переход. Тогда компьютер 30 может продолжать обрабатывать следующий символ данных потока данных.
Компьютер 30, показанный на Фиг. 5, содержит несколько блоков. Каждый из этих блоков имеет свою собственную уникальную задачу. Тем не менее в соответствии с одним из аспектов компьютер 30 может также содержать только несколько из этих блоков 32, 33, 34, 35. Например, только блоки 32 и 33 для обновления регистра 31 перехода состояний к обновленному регистру перехода состояний, содержащему удаленные переходы. Компьютер 30 может также содержать блоки 34 и 35 для исполнения конечного автомата с сжатым регистром перехода состояний, не обновляя обычный регистр перехода состояний до сжатого регистра.
На фиг.6 показано множество сетевых серверов или узлов 42, 43, 44, 47, 48 в телекоммуникационной сети 40. Каждый сетевой сервер выполнен с возможностью и, в частности, способен к выполнению определенной задачи в сети. Примером этого являются шлюз пакетной радиосвязи общего назначения (GPRS), узел поддержки GGSN, обозначенный ссылочным номером 42. GGSN является шлюзом, ответственным за соединение и маршрутизацию потоков данных по сети GPRS с внешней сетью, такой как Интернет 41. GGSN, в его функции в качестве шлюза, пропускает через себя поток данных. Для пакетов данных, содержащихся в потоке данных GGSN, по меньшей мере знает о пункте назначения, однако чаще всего не знает о фактической полезной нагрузке, содержащейся в пакетах.
Для выполнения полезной нагрузки, обусловленной обработкой, сетевой сервер, такой как GGSN, может быть снабжен блоками в соответствии с компьютером 30, проиллюстрированным на Фиг. 5. Также сетевой сервер выполнен с возможностью, если выполнен с возможностью содержания регистра перехода состояний, реализации конечного автомата с уменьшенным объемом памяти.
Фиг.6 дополнительно показывает несколько другие сетевые серверы, такие как сервер узла 43 поддержки GPRS (SGSN), выполненный с возможностью доставки пакетов данных из и в мобильные станции в пределах определенной области, и мультиплексор 48 доступа по цифровой абонентской линии (DSLAM), который группирует данные определенного количества цифровой абонентской линии, DSL-модемы для того, чтобы дополнительно транспортировать их по одной линии сети, базовая радиостанция 43 (RBS) или широкополосный сервер 47 удаленного доступа (BRAS). Каждый из этих серверов дает возможность связываться между терминалами 45, 46, 50, которые могут быть выполнены с возможностью осуществления способа в соответствии с одним из аспектов настоящего изобретения, содержащего по меньшей мере блоки, проиллюстрированные на Фиг.5. Сетевые серверы показаны на Фиг. 6, однако показаны только в качестве иллюстрации. Способ в соответствии с аспектом настоящего изобретения не ограничивается этими сетевыми серверами, показанными на этом чертеже, но может быть выполнен со множеством сетевых серверов.
Изобретение относится к устройству, способу, устройству хранения данных и телекоммуникационной сети для обнаружения структур данных в потоке данных. Технический результат заключается в возможности обнаружения структур данных в потоке данных. Устройство реализует детерминированный конечный автомат и содержит регистр перехода состояний, средство определения положения знака для определения для каждого символа данных каждого состояния регистра перехода состояний соответствующего кода знака в алфавите в соответствии со схемой кодирования знаков, средство обновления для обновления регистра перехода состояний таким образом, чтобы он содержал диапазоны кодов знаков в алфавите в соответствии со схемой кодирования знаков для символов данных с соответствующими последовательными положениями знаков в переходах, инициируемых посредством символа данных в одно и тоже целевое состояние, средство определения диапазона для определения, содержится ли символ данных потока данных в диапазоне кодов знаков в алфавите в соответствии со схемой кодирования знаков обновленного регистра перехода состояний и для определения соответствующего ему целевого состояния, и средство инициирования для инициирования перехода состояний из начального состояния в определенное целевое состояние для обнаружения упомянутой структуры данных. 4 н. и 10 з.п. ф-лы, 6 ил.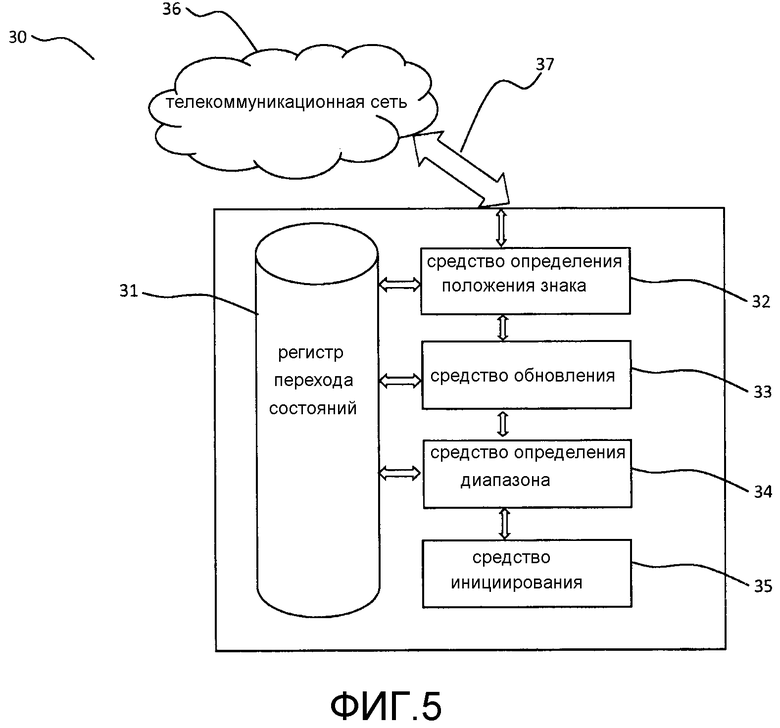
1. Устройство (30) для обнаружения структур данных в потоке (37) данных, содержащем множество символов данных, представляющих знаки алфавита, причем упомянутое устройство (30) реализует детерминированный конечный автомат, причем упомянутое устройство содержит:
- регистр (31) перехода состояний, содержащий множество состояний (11, 12, 13, 14, 15), включающее в себя начальное состояние (11) и по меньшей мере одно поглощающее состояние (14), и переходы (16а, 16b, 16с) состояний из начального состояния в целевое состояние, инициируемые символом данных упомянутого потока (37) данных;
- средство (32) определения положения знака для определения для каждого символа данных каждого состояния упомянутого регистра (31) перехода состояний соответствующего кода знака в упомянутом алфавите в соответствии со схемой кодирования знаков;
- средство (33) обновления для обновления упомянутого регистра (31) перехода состояний таким образом, чтобы он содержал диапазоны кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков для символов данных с соответствующими последовательными положениями (18b) знаков в упомянутых переходах, инициируемых посредством символа данных в одно и то же целевое состояние;
- средство (34) определения диапазона для определения, содержится ли символ данных упомянутого потока (37) данных в диапазоне кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков упомянутого обновленного регистра (31) перехода состояний, и для определения упомянутого соответствующего ему целевого состояния (18b), и
- средство (35) инициирования для инициирования перехода (16а, 16b, 16с) состояний из упомянутого начального состояния в упомянутое определенное целевое состояние для обнаружения упомянутой структуры данных.
2. Устройство (30) по п. 1, в котором упомянутое средство (32) определения положения знака выполнено с возможностью сортировки для каждого состояния упомянутого регистра (31) перехода состояний всех символов (17а) данных в соответствии с упомянутым соответствующим кодом знака в упомянутом алфавите в соответствии со схемой кодирования знаков.
3. Устройство (30) по п. 1 или 2, в котором упомянутый алфавит содержит машинный алфавит и, в частности, алфавит в формате ASCII или расширенном формате ASCII.
4. Устройство (30) по п. 1, при этом упомянутое устройство (30) выполнено с возможностью осуществления упомянутого определения упомянутых положений (32) знаков и обновления упомянутой таблицы (33) перехода состояний независимо от упомянутого определения упомянутого символа данных в диапазоне кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков и упомянутого инициирования упомянутого перехода (35) состояний.
5. Устройство (30) по п. 1, при этом упомянутое устройство (30) выполнено с возможностью завершения упомянутого обнаружения упомянутой структуры данных при инициировании перехода (16а, 16b, 16с) состояний в поглощающее состояние (14) упомянутого детерминированного конечного автомата (10).
6. Устройство (30) по п. 1, при этом упомянутое устройство (30) выполнено с возможностью обработки потока (37) данных в соответствии с упомянутой обнаруженной структурой данных.
7. Устройство (30) по п. 1, при этом упомянутое устройство (30) представляет собой сетевой сервер (42, 43, 44, 47, 48), работающий в телекоммуникационной сети (40) для обнаружения структуры данных в потоке (37) данных упомянутой телекоммуникационной сети (40).
8. Управляемый компьютером (30) способ (20) обнаружения структур данных в потоке (37) данных, принимаемом посредством упомянутого компьютера (30), причем упомянутый поток (37) данных содержит множество символов данных, представляющих знаки алфавита, причем упомянутый компьютер (30) реализует детерминированный конечный автомат, содержащий сжатый регистр (31) перехода состояний, содержащий множество состояний (11, 12, 13, 14, 15), включающее в себя начальное состояние (11) и по меньшей мере одно поглощающее состояние (14), и переходы (16а, 16b, 16с) состояний из начального состояния в целевое состояние, инициируемые символом данных из упомянутого потока (37) данных, причем сжатый регистр (31) перехода состояний содержит по меньшей мере один диапазон кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков, причем упомянутый способ содержит этапы, на которых:
- определяют посредством упомянутого компьютера (30) для каждого символа данных каждого состояния регистра (31) перехода состояний соответствующий код знака в упомянутом алфавите в соответствии со схемой кодирования знаков;
- обновляют посредством упомянутого компьютера (30) упомянутый регистр (31) перехода состояний таким образом, чтобы он содержал диапазоны кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков для символов данных с соответствующими последовательными положениями знаков в упомянутых переходах (16b), инициируемых посредством символа данных в одно и то же целевое состояние (12);
- определяют (21) посредством упомянутого компьютера (30) из упомянутого сжатого регистра (31) перехода состояний, содержится ли символ данных упомянутого потока данных в диапазоне кодов знаков в упомянутом алфавите в соответствии со схемой кодирования знаков упомянутого сжатого регистра (31) перехода состояний, и определяют (22) упомянутое соответствующее ему целевое состояние (18b); и
- инициируют (22) посредством упомянутого компьютера (30) переход (16а, 16b, 16с) состояний из упомянутого начального состояния в упомянутое определенное целевое состояние для обнаружения упомянутой структуры данных.
9. Способ (20) по п. 8, при этом упомянутый способ (20) дополнительно содержит этап, на котором сортируют посредством упомянутого компьютера (30) для каждого состояния упомянутого регистра (31) перехода состояний все символы данных в соответствии с упомянутым соответствующим кодом знака в упомянутом алфавите в соответствии со схемой кодирования знаков.
10. Способ (20) по п. 8 или 9, при этом упомянутый способ (20) дополнительно содержит этап, на котором удаляют из упомянутой таблицы (31) перехода состояний каждый переход состояний для состояния (15), в котором для всех соответствующих переходов состояний упомянутое начальное состояние является равным упомянутому целевому состоянию.
11. Способ (20) по п. 8 или 9, при этом упомянутый способ (20) дополнительно содержит этап, на котором удаляют из упомянутой таблицы (31) перехода состояний каждый переход состояний для состояния (15), в котором никакой соответствующий переход состояний не может привести к поглощающему состоянию (14).
12. Способ (20) по п. 8 или 9, при этом упомянутый способ (20) дополнительно содержит этап, на котором удаляют из упомянутой таблицы (37) перехода состояний каждый переход состояния, в котором упомянутое начальное состояние (14) представляет собой конечное состояние (14).
13. Устройство хранения данных, хранящее данные компьютерного программного кода, предназначенные для осуществления способа по любому из пп. 8-12, когда упомянутые данные программного кода загружены в память электронного блока обработки и исполняются упомянутым электронным блоком обработки.
14. Телекоммуникационная сеть (40), содержащая устройство (30) для обнаружения структур данных в потоке (37) данных по любому из пп. 1-7, при этом устройство (30) представляет собой сетевой сервер (42, 43, 44, 47, 48).
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| EP 1983717 A1, 22.10.2008 | |||
| EP 1986390 A2, 29.10.2008 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 1995 |
|
RU2117388C1 |

