Изобретение относится к области вычислительной техники и предназначено для обработки информации, составленной по правилам контекстно-зависимой грамматики, в целях ее стандартизации и унификации с последующим сравнением и автоматизированным анализом на основе преобразования текстового входного потока в объектную форму (автоматизированный объектный анализ неструктурированных текстовых данных). Изобретение может быть использовано в системах, основанных на знаниях, хранилищах информации, банках данных, системах автоматизированной обработки и анализа неструктурированных текстовых файлов.
Существующие системы автоматизированного анализа неформализованных текстов основываются на:
- способах поиска данных по заданным пользователем поисковым контекстам с использованием логических связок между контекстами,
- методах частотного анализа повторяемости слов,
- методах грамматического анализа текстов, основанных на синтаксическом и семантическом разборе предложений.
Однако грамматический анализ текстов эффективен тогда, когда исходный текст составлен по правилам контекстно-свободных грамматик (КС-грамматик) или грамматик определенных правил (ОК-грамматик). В текстах, основанных на правилах контекстно-зависимых грамматик, каковыми являются подавляющее большинство реально используемых человеком документов, эти методы оказываются неэффективными. Методы частотного анализа дают возможность сделать интегральную оценку текста (дать представление, о чем идет речь), но не позволяют дать детальной картины структуры и взаимосвязей объектов. Большей универсальностью обладают методы контекстного поиска, однако они, как правило, узко специализированы и каждый раз требуют настройки на конкретный поисковый образ (либо необходимо обеспечить хранение группы настроек).
Наиболее близким к заявленному изобретению является метод (Патент РФ 2096825) [6], ориентированный на анализ исходных текстов, который не решает задачу преобразования содержащейся в них информации в единый унифицированный формат таким образом, чтобы в дальнейшем ее можно было подвергнуть автоматизированному анализу, независимо от первоначальных форм представления, с помощью ограниченного набора стандартных процедур.
Указанный метод обработки текстов не предусматривает возможности одновременного перевода поступающих данных с иностранных языков на родной язык пользователя, что становится особенно актуальным в условиях расширения доступа к ресурсам сети Internet.
Для устранения указанных недостатков предлагается способ упорядочения данных, представленных в текстовых информационных блоках данных, составленных по правилам контекстно-зависимой грамматики, отличающийся тем, что формируют языковые словари перевода единиц речи естественных языков в единицы первого внутреннего формата вычислительной системы, формируют настроечные блоки данных, задающие совокупность выбранных пользователем целевых структур, определяющих набор атрибутов, для каждого из которых заданы правила распознавания атрибута в тексте и преобразования распознанного атрибута во второй внутренний формат вычислительной системы, для каждой целевой структуры задают правила определения границ целевой структуры по результатам определения границ атрибутов и правила определения наличия и свойств отношений и связей целевой структуры с другими выбранными пользователем целевыми структурами; считывают текстовые информационные блоки данных, представленные в виде текстовых блоков данных произвольного формата, выявляют признаки, указывающие на принадлежность текстовых информационных блоков данных заранее заданному формату, на основании выявленных признаков определяют формат каждого из текстовых информационных блоков и для каждого из текстовых информационных блоков данных, для которого определен формат, формируют первый промежуточный блок данных путем преобразования формата считанного текстового информационного блока данных во внутренний текстовый формат вычислительной системы, для каждого из первых промежуточных блоков данных определяют принадлежность фрагментов текста первого промежуточного блока данных к одному из естественных языков, и, с учетом определенной принадлежности, выбирают соответствующие языку семантические правила и группу правил распознавания атрибутов, структур и их взаимосвязей, на основании выбранных правил, для каждого из первых промежуточных блоков данных выявляют наличие атрибута, его границ и значений в первом промежуточном блоке данных, после чего производят перекодировку фрагментов первого промежуточного блока данных во второй промежуточный блок данных объектно-ориентированного внутреннего формата вычислительной системы, причем во втором промежуточном блоке данных формируют объект, в который переносят выявленные атрибуты и связи объекта с другими объектами, после чего дополняют объектно-ориентированную базу данных сформированными объектами путем записи второго промежуточного блока данных в область памяти вычислительной системы, занимаемой объектно-ориентированной базой данных.
Для распознавания собственных имен и категорийных понятий во втором промежуточном блоке данных дополнительно используют хранилище информации, в котором в объектном виде хранятся введенные ранее данные. Правила сравнения данных из исходного блока данных с объектами хранилища информации могут выбираться из настроечного блока данных.
В частных случаях реализации способа для каждого из возможных языков, на которых может быть представлен исходный текст, задаются самостоятельные целевые структуры.
Предлагаемый способ автоматизированной обработки информации, представленной в виде исходных неформатированных текстов, и преобразования ее в единый унифицированный формат обеспечивает последующий анализ с помощью типового набора процедур, выбор которых определяется задачами исследований. Предлагаемый способ включает в себя элементы контекстного поиска и грамматического анализа текстов. Контекстный поиск используется для идентификации объектов и их свойств в исходном тексте, а грамматический анализ позволяет найти в тексте границы свойств и их значения, в том числе с учетом контекстной зависимости. При этом также обеспечивается избирательный автоматический перевод актуальной для пользователя информации.
Автоматизированный качественный и количественный анализ информации, поступающей на вход системы, становится возможным, когда эта информация представляется в едином формате, позволяющем подвергнуть ее в дальнейшем обработке с помощью стандартных процедур. Предлагаемое изобретение направлено на решение задачи преобразования поступающей из различных источников разнородной и разноформатной информации, описывающей сложную динамическую систему, состоящую из множества взаимосвязанных разнообразных элементов, или ее отдельные фрагменты в исторически фиксированные промежутки времени, в единый унифицированный формат, определяемый пользователем. Предполагается, что исходные данные могут представляться в различных кодировках по правилам контекстно-зависимой грамматики на различных естественных языках и содержать не только актуальную для пользователя информацию, но и несущественные данные. Структурирование и стандартизация исходной текстовой информации осуществляется путем ее преобразования в объектную форму на основе списка настроек, описывающих состав и структуру значимых для пользователя типов данных, с перечнями параметров этих типов (фиг.1, блок 6). Незначимые данные, не нашедшие своего отражения в списке настроек, при обработке игнорируются. Список настроек для каждого типа данных и каждого параметра, описанного в типе, содержит для каждого поддерживаемого естественного языка одну или несколько процедур уровня типа данных ([1], с.2-15) и соответственно процедур уровня параметра. Процедуры определяют правила выделения места расположения типа данных или его параметра в исходном тексте, поиска и выделения его значения или значений.
Технический результат, получаемый при осуществлении изобретения, заключается в:
- повышении уровня и глубины обработки информации, содержащейся в неструктурированных и слабоструктурированных исходных текстах;
- сокращении времени, затрачиваемого оператором на преобразование разнородной неструктурированной текстовой информации во взаимоувязанные формализованные структуры;
- автоматической или полуавтоматической отбраковке информации, не представляющей интереса для пользователя, из контура дальнейшей обработки;
- возможности в дальнейшем подвергнуть преобразованные данные процедурам автоматического сравнения и анализа за счет приведения их к единому формату в стандарте, определяемом пользователем;
- обеспечение возможности автоматизированного или автоматического перевода информации с любых поддерживаемых системой иностранных языков на родной язык пользователя в процессе преобразования данных в объектную форму с идентификацией непереведенных значений, описывающих те или иные свойства объекта.
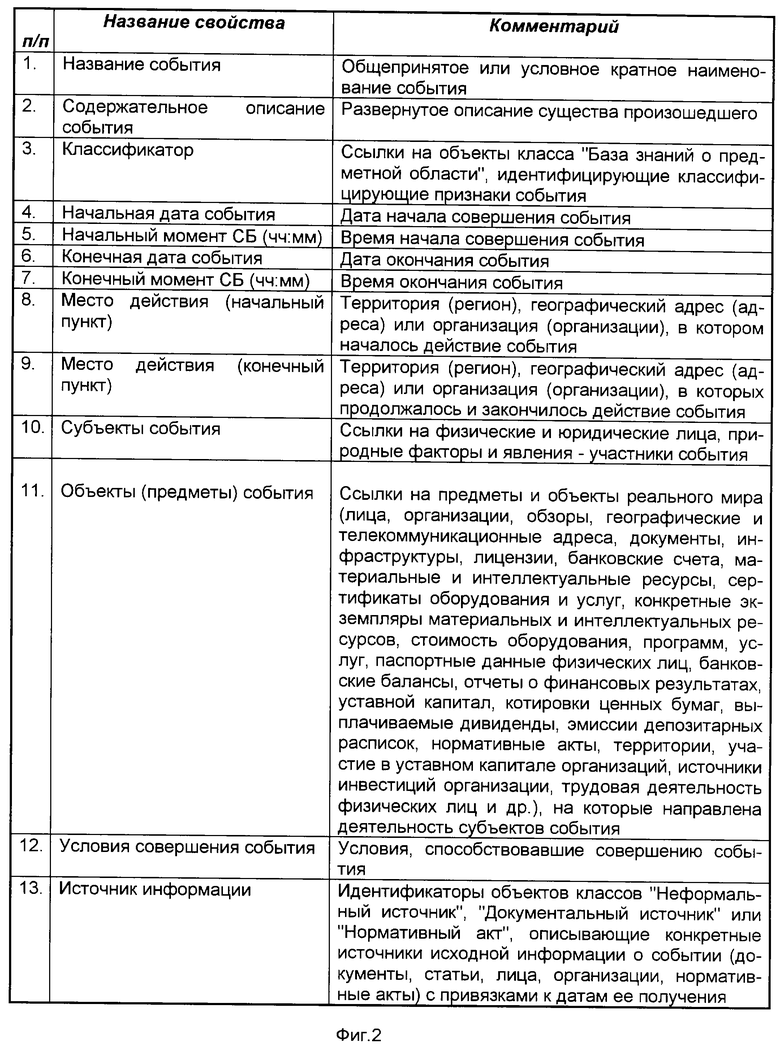
Последовательность действий по преобразованию исходного текста в объектную форму приведена на фиг.1. На фиг.2 представлен один из вариантов описания структуры типа "Событие" (декларативная часть).
Способ реализуется следующим образом.
1. Перед началом обработки исходных неформализованных текстов формируются:
- таблица дешифровки исходных текстов;
- лингвистические словари языков, понимаемых системой;
- список настроек;
- хранилище информации, содержащее объекты с уникальными общепринятыми текстовыми идентификаторами на одном или нескольких естественных языках.
Таблица дешифровки представляет собой совокупность строк, в каждой из которых задан идентификатор кодировки, признаки его распознавания и правила декодирования.
Лингвистические словари представляют собой единый банк данных, организованный в виде языковых миров. Мир языка в рамках банка данных представляет собой список относящихся к этому языку слов, основ слов, словоформ и выражений, связанных ассоциативными связями с соответствующими конструкциями других естественных языков, поддерживаемых системой. Каждая запись банка данных, описывающая одну языковую конструкцию, содержит идентификатор языкового мира, к которому она относится. При необходимости с ней связывается процедура, описывающая правила использования конструкции в тексте и ее взаимоотношения с другими конструкциями языка.
Список настроек содержит в формализованном виде:
- перечень типов (классов) данных, образующих предмет изучения со стороны пользователя;
- перечень параметров каждого типа данных, а также их взаимосвязей и отношений;
- совокупность соотносимых с каждым типом данных и параметром алгоритмических процедур, отвечающих за:
- распознавание в исходном тексте соответствующего параметра и его границ, а по совокупности границ всех параметров и с учетом дополнительных знаний - границ объекта в исходном тексте;
- выбор значений параметров из исходного текста и перенесение их в формализованный объект хранилища информации.
Хранилище информации представляет собой накопленный ранее по интересующей пользователя тематике структурированный информационный массив и используется для идентификации в исходном тексте собственных имен, а также для перевода на родной язык пользователя значений тех параметров объекта, которые используют многоязычное соответствие. Многоязычное соответствие может быть реализовано с помощью:
- атрибута многозначности параметра (в этом случае указывается значение параметра на языке оригинала и всех его переводов на языки, поддерживаемые системой);
- взаимосвязанного объекта точно такой же структуры, но содержащего сведения на другом языке, с выделением отдельного параметра "используемый язык" для каждого объекта;
- с помощью специальных разделителей в поле значения параметра, совместно используемом различными языками.
2. Исходный файл или совокупность файлов поступают на обработку в кодировке и на языках народов мира, на которые произведена настройка системы и которым она обучена. Блок распознавания кодировки (фиг.1, блок 1) осуществляет:
- распознавание собственно кодировки текста, поступающего на вход вычислительной системы;
- распознавание языка, на котором составлен текст (включая возможные варианты: блоки текста составлены на различных языках, или тексты включают в себя фрагменты фраз или понятий на других языках, а также математические формулы).
Для распознавания используются:
- таблица дешифровки (фиг.1, блок 2);
- лингвистические словари языков, понимаемых системой, со списками правил употребления в тексте соответствующих языковых конструкций (фиг.1, блок 3).
Таблица дешифровки автоматически определяет тип кодировки. Для этого используются описанные в строках таблицы правила распознавания кодировки.
Если в какой-либо строке таблицы правило распознавания явно не выражено или не может быть однозначно определено, но при этом правила дешифровки определены (они должны быть известны для конкретной кодировки всегда, иначе наличие строки в таблице дешифровки теряет смысл), то осуществляется пробная дешифровка в промежуточный файл, который затем подвергается статистической обработке на предмет выявления специальных символов (пробелов, точек, запятых и т.д.), их подсчета и соотнесения с объемом текста. Производится сопоставление полученных значений со статистическими значениями, на основании чего делается предварительный вывод о корректности дешифровки. Окончательный вывод делается после выделения из текста, записанного в промежуточный файл, грамматических основ и сопоставления их с объектами лингвистических словарей.
Для этого промежуточный файл пословно сравнивается с содержимым словарей (начиная со словаря родного языка пользователя) с использованием соответствующих данному языку правил семантического анализа (фиг.1, блок 3). Вывод о принадлежности текста языку делается на основании соотношения количества идентифицированных слов и общего количества слов в тексте. Неидентифицированные слова и фрагменты распознанного текста отбираются и последовательно проверяются по другим словарям, начиная со словаря английских слов. Вывод о принадлежности слов нераспознанных фрагментов тому или иному языку делается по относительному соотношению идентифицированных слов к общему количеству слов во фрагменте текста.
3. В результате раскодировки и распознавания языка текста формируется внутренний промежуточный файл с маркерами, определяющими однозначное соответствие фрагментов текста языкам. Перевод текста или его фрагментов при этом не выполняется. Сформированный таким образом файл поступает на вход блока информационно-логической обработки и преобразования исходного текста в объектную форму (фиг.1, блок 4), который осуществляет формализацию содержащейся в нем информации путем создания совокупности взаимосвязанных объектов (в частном случае это может быть всего один объект, а при отсутствии в тексте значимых для пользователя данных объекты вообще не генерируются). При этом в уместных случаях (для текстовых данных) выполняется перевод значений свойств с языка оригинала на родной язык пользователя.
Контролирует процесс преобразования управляющая программа, которая осуществляет:
- распознавание типов форм представления информации в исходном файле (текст, таблица, интервью, справочник и т.д.) и маркировку фрагментов текста, соответствующих той или иной его форме;
- настройку процедур уровня типа данных на соответствующую структуру исходного текста путем передачи этим процедурам необходимой информации;
- поочередный вызов процедур уровня типа данных для формирования объектов соответствующих типов.
4. Распознавание форм представления информации в исходном тексте выполняется с помощью атрибутов, присущих этим формам (например, для табличных форм характерно регулярное чередование определенных символов, это же справедливо для текста в форме интервью; текст в форме справочников имеет свои закономерности - использование имен собственных, чередований последовательностей цифр, обозначающих номера телефонов и др.), с привлечением к анализу содержимого хранилища информации (что особенно может быть полезным при анализе справочников). Границы, соответствующие различным формам текста, помечаются, что дает возможность в дальнейшем вызывать для их обработки адекватные процедуры анализа.
5. Преобразование информации в объектную форму осуществляется с помощью списка настроек (фиг.1, блок 6). Управляющая программа инициализирует список, поочередно просматривая описания типов данных. При этом для каждого типа активизируется процедура уровня типа данных, в задачи которой входит:
- формирование прообраза формализованного объекта, структура которого описывается данным типом (классом) данных;
- определение порядка вызова и активизация тех процедур уровня параметра, обеспечивающих распознавание параметров в исходном файле, которые соответствуют использованным в тексте языкам и структуре информации в файле (неструктурированный текстовый файл, табличный файл и т.д.);
- определение границ объекта в тексте на основании результатов работы методов уровня параметра, а при необходимости и с помощью дополнительных процедур;
- идентификация формируемого объекта с данными, накопленными в хранилище информации (хранилище информации (фиг.1, блок 5) позволяет идентифицировать объекты, имеющие собственные имена, а также понятийный аппарат изучаемой предметной области).
Методы уровня класса, формирующие объекты, функционируют таким образом, что учитывают возможность описания в исходном неформализованном тексте нескольких объектов одного класса с различными возможностями пересечения и вложенности описаний.
6. Активизированный метод уровня класса в определенном порядке просматривает перечень параметров своего класса и для каждого параметра активизирует соответствующий метод распознавания параметра в исходном тексте. Выбор метода зависит от используемых в тексте языков и его структуры (неформализованный текст, таблица, интервью и т.д.).
Вызванный метод уровня параметра по идентифицирующим признакам определяет наличие и местонахождение описания параметра в исходном тексте, границы его описания с учетом контекстной зависимости, а также возможности описания параметра в исходном тексте с помощью нескольких разнесенных фрагментов. Идентифицированные значения параметра переносятся в формируемый объект с приведением их к внутреннему формату системы. Для параметров, значения которых заданы на языках, являющихся для пользователя иностранными, метод уровня параметра активизирует процедуру перевода значения на родной язык путем обращения к соответствующему лингвистическому словарю, а также к хранилищу информации для анализа имеющихся значений одноименных параметров накопленных объектов данного класса на языке оригинала и их сопоставления с анализируемым значением. При обнаружении требуемого значения выбирается его перевод и переносится в качестве значения для рассматриваемого параметра (свойства) формируемого объекта.
В процессе перевода учитывается возможность сохранения в формируемом объекте значения свойства на языке оригинала (как правило, это относится к технологическим терминам и их аббревиатурам).
Описанное относится к содержательным свойствам объекта, т.е. к свойствам, имеющим числовое или текстовое значение, либо графическое или мультимедийное отображение. Свойства, описывающие структурные взаимоотношения и взаимосвязи, идентифицируют взаимосвязанный объект, передают управление соответствующему методу его формирования, а после возврата управления обеспечивают установление между объектами соответствующих ссылок.
7. В результате выполнения процедуры, описанной в пп.5 - 6, для всех классов, описанных в списке настроек, на выходе блока преобразования исходной информации в объектную форму (фиг.1, блок 4) формируется совокупность взаимосвязанных объектов со структурой, стандартизированной в рамках хранилища информации, к которым могут быть применены типовые методы обработки и анализа с использованием средств вычислительной техники.
8. Пользователь системы имеет возможность контролировать результаты работы после каждого этапа и корректировать выполненные преобразования.
Перечень фигур чертежей и иных материалов
Фиг. 1 отражает в общем виде последовательность действий по преобразованию информации из неформализованных текстов в совокупность взаимосвязанных объектов, а также используемые для этого информационные структуры.
Фиг.2 представляет декларативную часть описания класса "Событие". Данное описание является примером и используется при подтверждении возможности осуществления изобретения.
Сведения, подтверждающие возможность осуществления изобретения
Предлагаемый способ автоматизированного объектного анализа неструктурированных текстов базируется на технологии объектно-ориентированных банков данных, получающей в настоящее время распространение и описанной в литературе ([2] , [3], [4]). Существуют реально функционирующие объектно-ориентированные СУБД, в описание классов которых могут быть инкапсулированы методы уровня класса (например, СУБД Jasmine [1]) или методы уровня свойства (СУБД Cronos [5] ). Правда, в отличие от предлагаемого способа, указанные методы позволяют манипулировать уже формализованной информацией в объектной форме на этапе хранения и анализа информации.
Методики выделения классов объектов при разработке объектно-ориентированных программ по техническим заданиям, выполненным на вербальном уровне, описаны, в частности, в [3] и [4], что свидетельствует о возможности их формализации и переносе на произвольные тексты не только в сфере объектно-ориентированного программирования, но и в области объектно-ориентированных банков данных и хранилищ информации.
В качестве примера работы алгоритма преобразования информации в объектную форму рассмотрим следующий текст из газеты "Сегодня", 146 от 17.10.99 г.
Крупнейший немецкий оператор Deutsche Telekom (DT) объявил о покупке у фирмы MediaOne Group (бывшее дочернее предприятие компании US West) за 2 млрд. долл. ее активов в сотовых операторах Польши, Венгрии и России. По данным агентства Bloomberg, MediaOne продает свои владения в Восточной Европе в связи с тем, что их деятельность пересекается с активностью корпорации AT& T на этом рынке (последняя недавно приобрела MediaOne примерно за 58 млрд. долл.).
За свои деньги DT получит 22,5% акций крупнейшего в Восточной Европе сотового оператора Polska Telefonia Cyfrowa (в дополнение к уже имеющемуся такому же пакету), по 49% в венгерских Westel 450 и Westel 900, а также контрольный пакет акций компании Russian Telecommunications Development Corp. (RTDC), имеющей доли в восьми российских сотовых компаниях (Байкалвестком, МСС, Дельта Телеком, Уралвестком, Донтелеком, Нижегородская Сотовая Связь, Акос и Енисей), а также в московской фирме Вестелком.
Общее число клиентов восточноевропейских операторов, подконтрольных MediaОne, - 2,5 млн., но потенциальный рынок значительно шире. Так, по данным московского отделения Deutsche Bank, в России при населении 147 млн. человек насчитывается около 1 млн. пользователей мобильных телефонов, а к концу 2005 г. их численность может вырасти до 7 млн. По оценке IDC, к 2003 г. мобильной телефонной связью будет пользоваться 37% населения Восточной Европы, против 9% в прошлом году.
При поступлении текста на вход системы прежде всего осуществляется его раскодировка. Механизм раскодировки здесь подробно не описывается ввиду того, что он в этой части аналогичен соответствующим методам распознавания формата, используемым в известных программных средствах (таких, как текстовый редактор Word 97, автоматический переводчик Lingvo и т.д.).
После сопоставления раскодированного текста словам и грамматическим основам языковых словарей в промежуточном файле маркируются фрагменты, идентифицирующие однозначное соответствие текста языковым словарям, как это показано в нижеследующем примере. Там, где язык не может быть распознан (например, в случае имен собственных), но может быть идентифицирована знаковая система языка (латинский алфавит, кириллица и т.д.), это находит свое отражение в идентификаторах маркеров 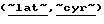 .
.
Далее управляющая программа проверяет текст на наличие в нем различных форм представления данных, осуществляет его дополнительную разметку (в данном случае маркер 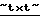 ) и включает в работу механизм преобразования текста во взаимоувязанную совокупность объектов:
) и включает в работу механизм преобразования текста во взаимоувязанную совокупность объектов: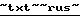 Крупнейший немецкий оператор
Крупнейший немецкий оператор 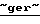 Deutsche Telekom (DT)
Deutsche Telekom (DT)  объявил о покупке у фирмы
объявил о покупке у фирмы 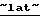 MediaOne
MediaOne 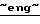 Group
Group  (бывшее дочернее предприятие компании
(бывшее дочернее предприятие компании 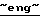 US West
US West  ) за 2 млрд. долл. ее активов в сотовых операторах Польши, Венгрии и России. По данным агентства
) за 2 млрд. долл. ее активов в сотовых операторах Польши, Венгрии и России. По данным агентства 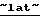 Bloomberg, MediaOne
Bloomberg, MediaOne  продает свои владения в Восточной Европе в связи с тем, что их деятельность пересекается с активностью корпорации
продает свои владения в Восточной Европе в связи с тем, что их деятельность пересекается с активностью корпорации  AT&T
AT&T  на этом рынке (последняя недавно приобрела
на этом рынке (последняя недавно приобрела  MediаОnе примерно за 58 млрд. долл.).
MediаОnе примерно за 58 млрд. долл.).
За свои деньги  DT получит 22,5% акций крупнейшего в Восточной Европе сотового оператора
DT получит 22,5% акций крупнейшего в Восточной Европе сотового оператора  Polska Telefonia Cyfrowa
Polska Telefonia Cyfrowa  (в дополнение к уже имеющемуся такому же пакету), по 49% в венгерских
(в дополнение к уже имеющемуся такому же пакету), по 49% в венгерских  Westel 450
Westel 450  и
и 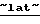 Westel 900,
Westel 900,  , a также контрольный пакет акций компании
, a также контрольный пакет акций компании 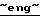 Russian Telecommunications Development Corp. (RТDС
Russian Telecommunications Development Corp. (RТDС  ), имеющей доли в восьми российских сотовых компаниях (
), имеющей доли в восьми российских сотовых компаниях (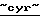 Байкалвестком, МСС, Дельта Телеком, Уралвестком, Донтелеком,
Байкалвестком, МСС, Дельта Телеком, Уралвестком, Донтелеком,  Нижегородская Сотовая Связь,
Нижегородская Сотовая Связь, 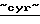 Акос
Акос  и Енисей), а также в московской фирме
и Енисей), а также в московской фирме 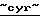 Веcтелком.
Веcтелком.
 Общее число клиентов восточноевропейских операторов, подконтрольных
Общее число клиентов восточноевропейских операторов, подконтрольных  MediaOne, - 2,5
MediaOne, - 2,5  млн., но потенциальный рынок значительно шире. Так, по данным московского отделения
млн., но потенциальный рынок значительно шире. Так, по данным московского отделения 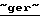 Deutsche Bank,
Deutsche Bank,  в России при населении 147 млн. человек насчитывается около 1 млн. пользователей мобильных телефонов, а к концу 2005 г. их численность может вырасти до 7 млн. По оценке
в России при населении 147 млн. человек насчитывается около 1 млн. пользователей мобильных телефонов, а к концу 2005 г. их численность может вырасти до 7 млн. По оценке 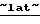 IDC,
IDC,  к 2003 г. мобильной телефонной связью будет пользоваться 37% населения Восточной Европы, против 9% в прошлом году.
к 2003 г. мобильной телефонной связью будет пользоваться 37% населения Восточной Европы, против 9% в прошлом году.
Источник информации: газета "Сегодня", 146 от 17.10.99 г. "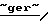 Deutsche Telekom (DT)
Deutsche Telekom (DT)  покупает сотовых операторов Польши, Венгрии и России".
покупает сотовых операторов Польши, Венгрии и России".
Идентификация объектов и их границ в данном списке выполняется соответствующими методами, описанными в таблице настроек.
В рассматриваемом примере содержатся два больших фрагмента, один из которых описывает событие (приобретение компанией Deutsche Telekom у фирмы MediaOne Group ее долей в ряде компаний), а второй дает анализ и прогноз развития рынка сотовой связи в Восточной Европе. Кроме того, в тексте содержатся объекты класса "Организация", а также информация о взаимосвязях и отношениях организаций.
Просматривая поочередно описания классов в списке настроек, управляющая программа доходит до описания класса "Событие" и активизирует соответствующий метод формирования объекта этого класса на основании данных, содержащихся в исходном тексте в соответствии со структурой объекта (фиг.2). Признаком события в данном случае является свершившийся факт, выраженный грамматической конструкцией "объявил о покупке", а также субъекты события, один из которых выражен конструкцией "немецкий оператор Deutsche Telekom", a второй - "у фирмы MediaOne Group". Поэтому первое предложение, выражающее действие, включается в область действия свойства "Предикат события" формируемого объекта класса "Событие". Предикат события в данном описании рассматривается как логически завершенный фрагмент текста, причем левая граница свойства совпадает с началом обрабатываемого текста, а правая граница определяется самим методом обработки свойства "Предикат события" с учетом контекстной зависимости. В простейшем случае это определяется следующим образом: выбираются предложения, в которых упоминаются наименования субъектов события, а также расположенные справа от них предложения, если в качестве подлежащих в них используются грамматические конструкции, указывающие на идентификаторы субъектов события ("эта фирма", "указанная компания" и т.д.). В результате в принятой модели описания события для рассматриваемого примера свойство "Предикат события" будет иметь следующее значение:
"Крупнейший немецкий оператор Deutsche Telekom (DT) объявил о покупке у фирмы MediaOne Group (бывшее дочернее предприятие компании US West) за 2 млрд. долл. ее активов в сотовых операторах Польши, Венгрии и России. По данным агентства Bloomberg, MediaOne продает свои владения в Восточной Европе в связи с тем, что их деятельность пересекается с активностью корпорации AT& T на этом рынке (последняя недавно приобрела MediaOne примерно за 58 млрд. долл.).
За свои деньги DT получит 22,5% акций крупнейшего в Восточной Европе сотового оператора Polska Telefonia Cyfrowa (в дополнение к уже имеющемуся такому же пакету), по 49% в венгерских Westel 450 и Westel 900, а также контрольный пакет акций компании Russian Telecommunications Development Corp. (RTDC), имеющей доли в восьми российских сотовых компаниях (Байкалвестком, МСС, Дельта Телеком, Уралвестком, Донтелеком, Нижегородская Сотовая Связь, Акос и Енисей), а также в московской фирме Вестелком.
Общее число клиентов восточноевропейских операторов, подконтрольных MediaOne, - 2,5 млн., но потенциальный рынок значительно шире".
После выделения предиката события формируется идентификатор объекта и осуществляется его классификация. В качестве идентификатора события выбирается первое предложение описания предиката события (может быть выбран заголовок газетной статьи - источника информации о событии). Для повышения информационной емкости заголовка из него могут быть исключены малозначимые для заголовка грамматические конструкции (например, все слова, заключенные в круглые скобки, которые трактуются как фразы, поясняющие текст). В результате заголовок события имеет вид:
"Deutsche Telekom объявил о покупке у фирмы MediaOne Group за 2 млрд. долл. ее активов в сотовых операторах Польши, Венгрии и России".
Для классификации события используются объекты класса "База знаний о предметной области", хранилища информации, которые выбираются по признаку наличия в них корней слов, содержащихся в предикате события.
Далее производится упорядочение классификаторов следующим образом.
1. Классификаторы объединяются в группы, основными признаками которых является один и тот же поисковый контекст.
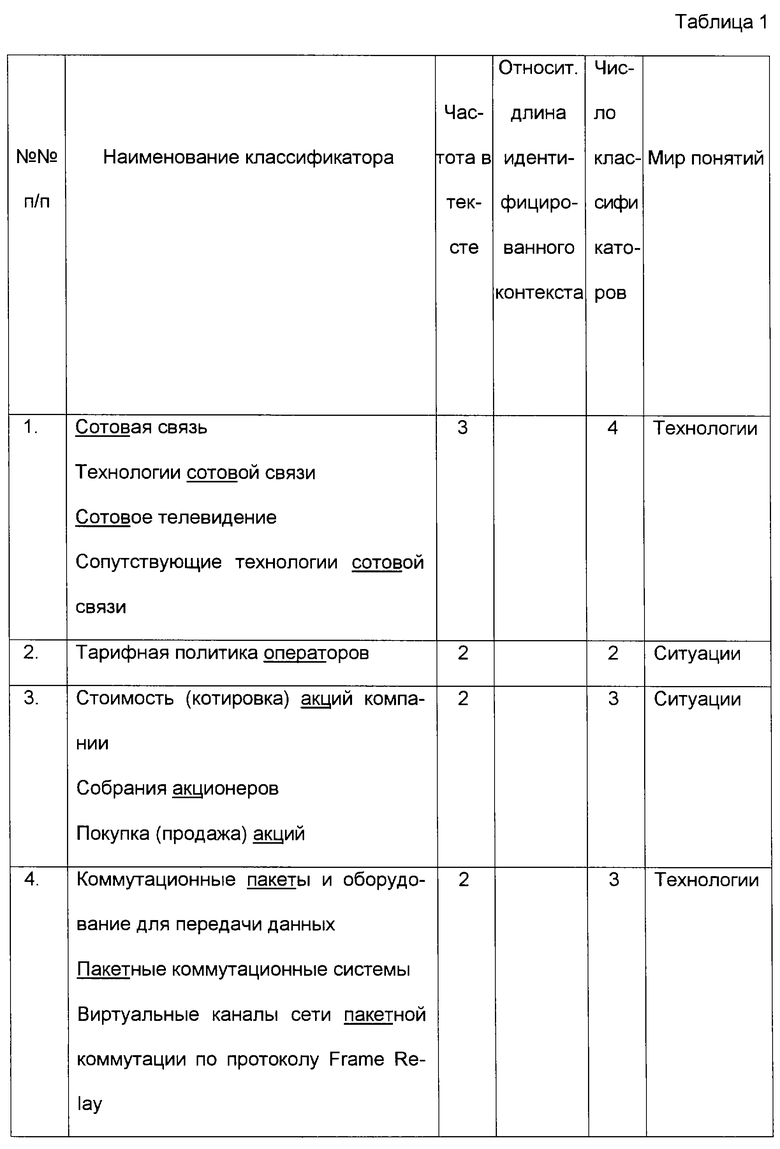
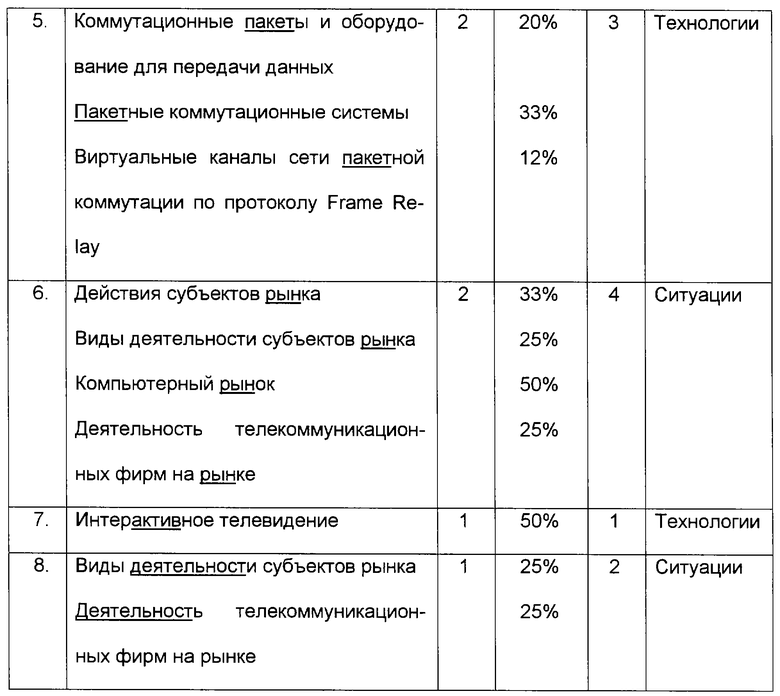
2. Группы классификаторов ранжируются по частоте искомого контекста в обрабатываемом тексте (как отмечено в предыдущем пункте, имеется взаимно однозначное соответствие между группой классификаторов и контекстом). При равных частотах более высокий ранг имеют группы с меньшим числом классификаторов, что отражено в табл. 1.
3. В группах отыскиваются классификаторы с одинаковыми наименованиями, которые попали в разные группы по различным контекстам. Для каждого такого классификатора формируется собственная отдельная группа, состоящая из одного классификатора. При изъятии такого классификатора из других групп соответственно уменьшается на единицу значение числа классификаторов в этих группах, но каждый раз в формируемой новой группе, состоящей из одного этого классификатора, увеличивается на единицу значение частоты повторяющегося наименования. В связи с появлением новых групп производятся изменения в рангах классификаторов по критерию "частота в тексте".
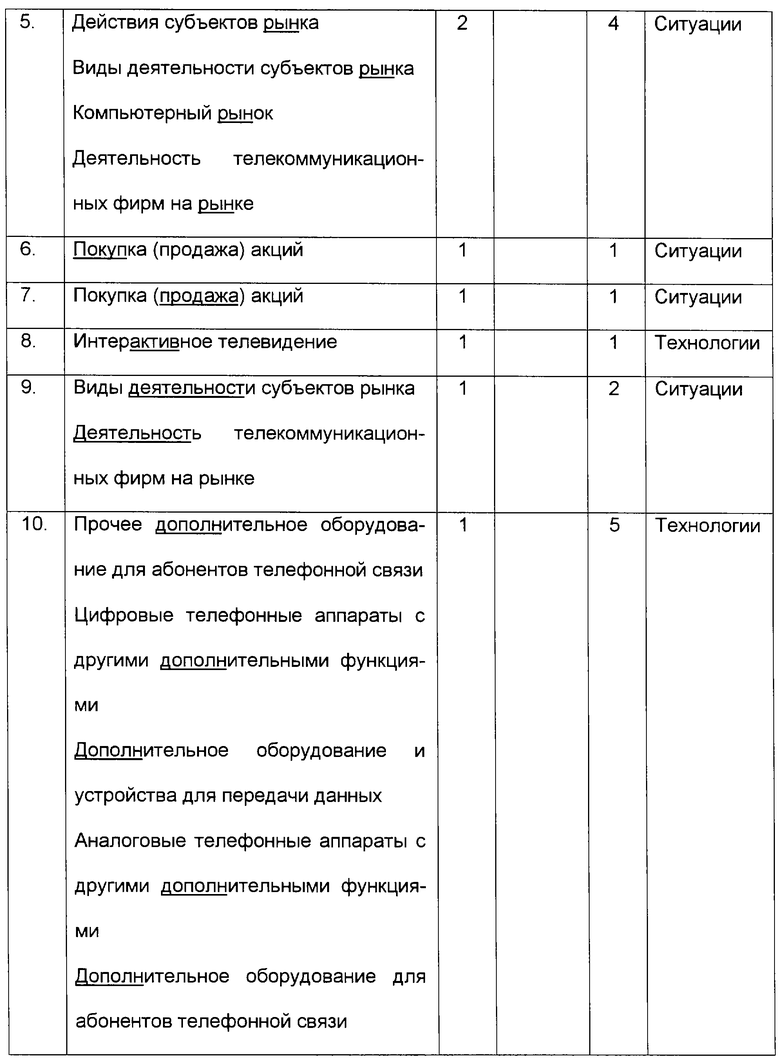
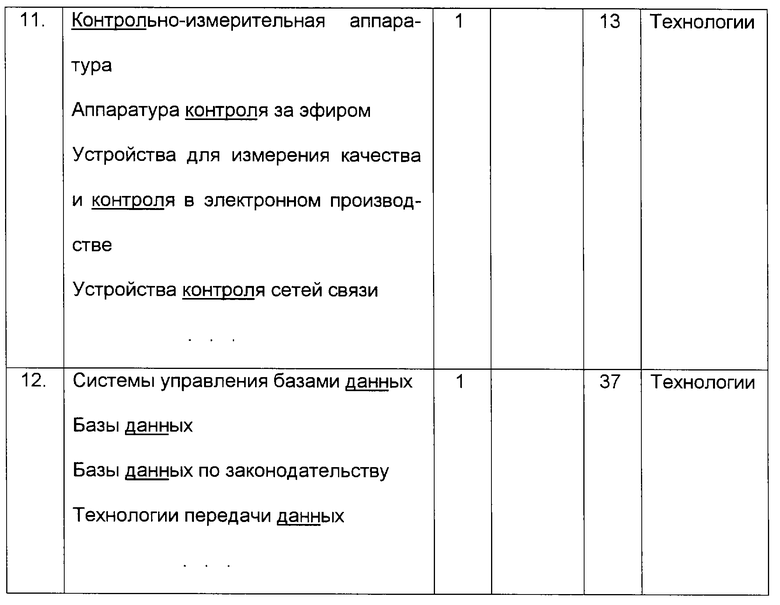
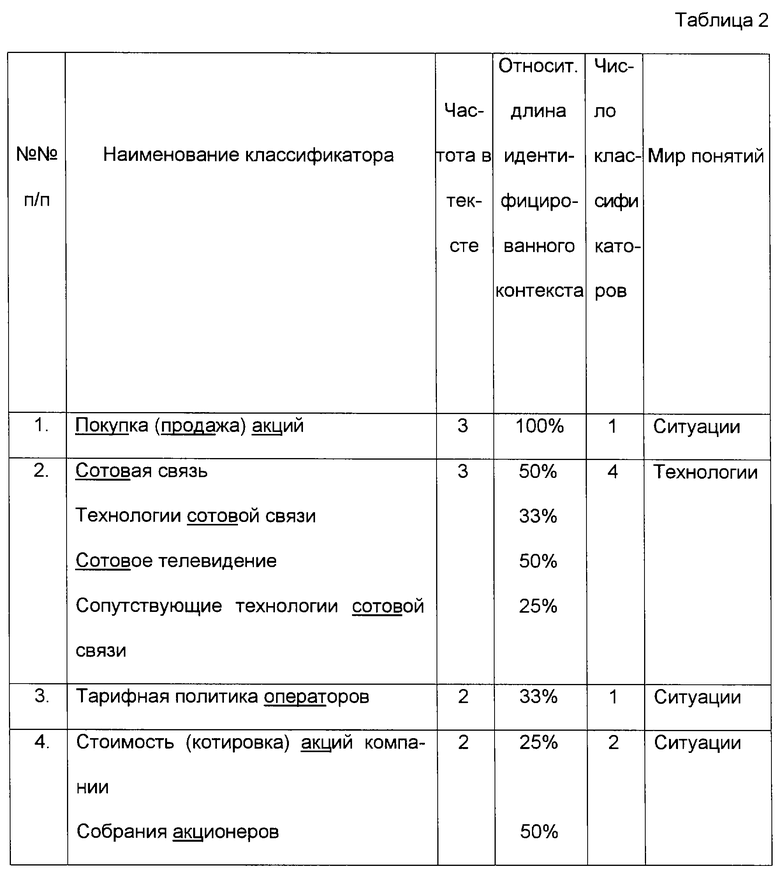
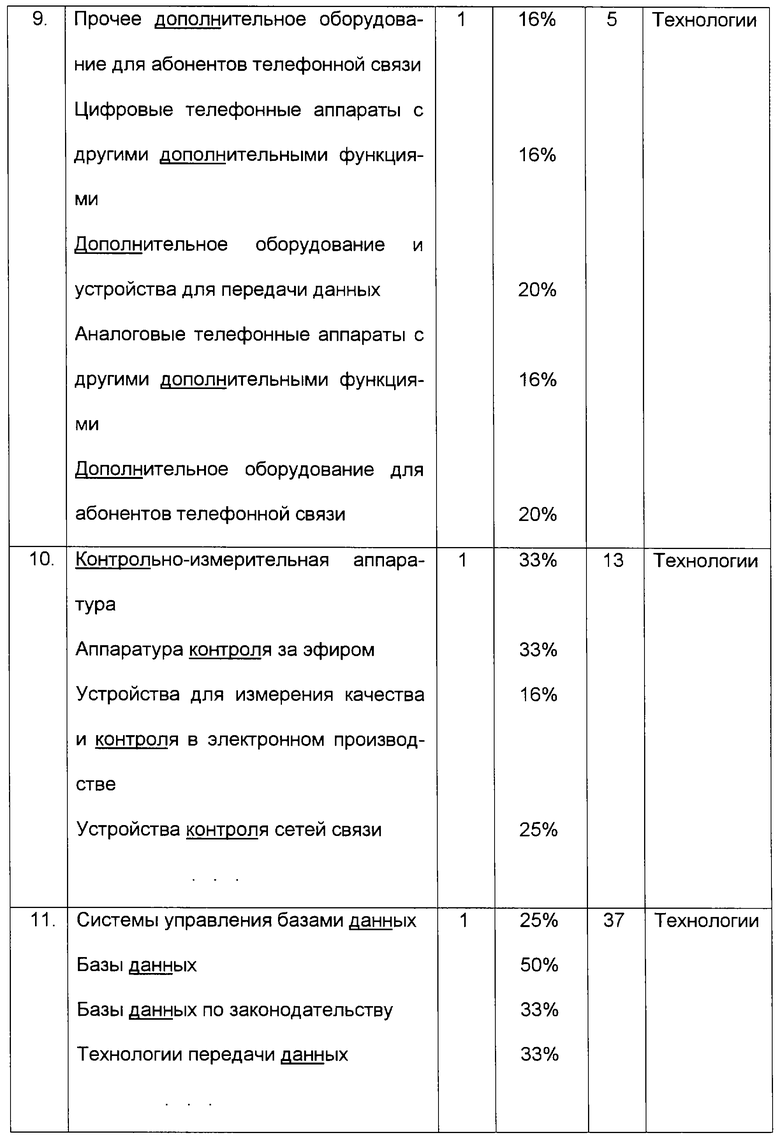
4. Производится подсчет относительной длины идентифицированного в классификаторе контекста путем определения доли слов, составляющих наименование классификатора (без учета предлогов и союзов) и присутствующих в обрабатываемом тексте. Результаты обработки данных показаны в табл. 2.
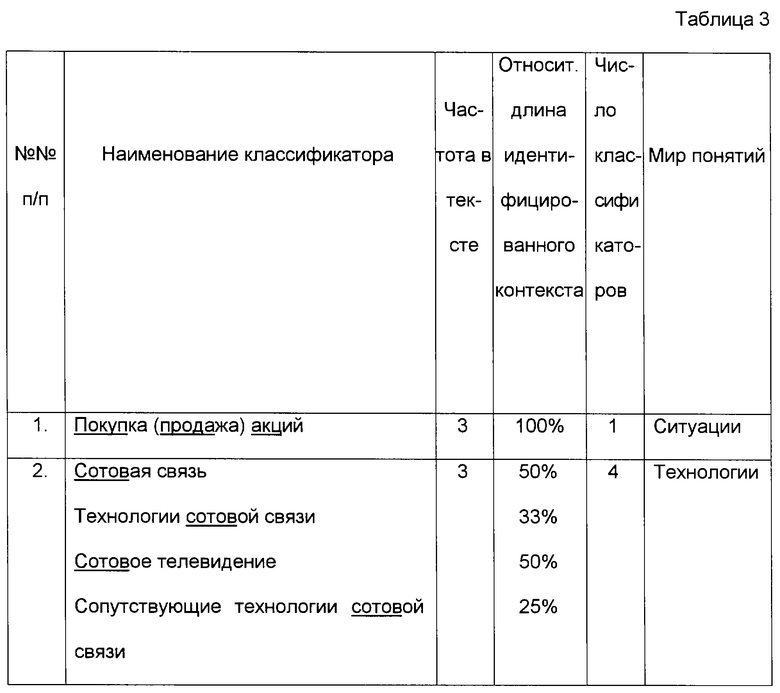
4. Выбирается по одной группе классификаторов, принадлежащих к различным мирам понятий и имеющих максимальную частоту в тексте, остальные группы из дальнейшего рассмотрения исключаются. Сведения, оставшиеся после обработки информации указанным образом, представлены в табл. 3.
5. Для групп, включающих несколько понятий, алгоритм выбора классификатора осуществляется следующим образом:
- выбираются все понятия со 100%-ным набором слов в тексте (по совокупности), остальные понятия отбраковываются;
- если такие понятия не обнаружены, то, в соответствии с иерархической структурой мира понятий базы знаний о предметной области, проверяется возможная вложенность понятий группы. Понятия, находящиеся на нижних уровнях иерархических ветвей, из дальнейшего рассмотрения исключаются как частные категории (в анализе вложенности не участвует понятие самого верхнего уровня, идентифицирующее сам мир понятий);
- если в группе осталось более одного понятия, то производится грамматический анализ оставшихся понятий. Анализ направлен на выявление наиболее общего понятия из всех присутствующих в группе понятий, которые оказались размещенными пользователем в различных иерархических ветвях мира понятий. Понятия ранжируются по числу составляющих их слов (без учета предлогов и союзов) и, начиная с понятий, содержащих наименьшее число слов, осуществляется поиск вхождений этих понятий в качестве контекстов в остальные понятия. В рассматриваемом примере понятие "Сотовая связь" имеет 3 вхождения в классификаторы группы, а понятие "Технологии сотовой связи" - 2 вхождения. Понятие "Сотовая связь" выбирается для классификации формируемого объекта класса "Событие";
- в случае необходимости гарантированная сходимость рассмотренного алгоритма обеспечивается подсказками со стороны пользователя.
Описанный алгоритм классификации, вероятно, является не самым лучшим и надежным. Основная его задача - показать возможность практической реализации механизма автоматической или автоматизированной классификации событий. В качестве другого или дополнительного варианта выбора классификатора из группы может быть использовано сравнение анализируемых понятий с классификаторами хранящихся в банке данных предыдущих событий, в которых участвовали субъекты рассматриваемого события, а также с классификаторами выданных им лицензий и продуктов (услуг).
По завершении процедуры классификации события определяются его временные и географические рамки, В связи с тем, что в тексте нет явного указания на время совершения события (нет контекстов в формате даты, например, "08.12.99", "12/05/98" и т.д., названий месяцев, контекстов "с.r.", "этого года" и др.), событие считается свершившимся накануне появления сообщения о нем, для этого идентифицируется источник сообщения о событии, из него выбирается дата сообщения, из этой даты выбираются месяц и год, которые ставятся в соответствие значению свойства "Дата начала события". При отсутствии даты в источнике информации дата события формируется на основе показаний системных часов (только в случае, если информация обрабатывается в режиме реального времени).
Упоминаний о дате завершения события и месте его совершения в предикате события не имеется, поэтому соответствующие свойства в объекте не заполняются.
Субъектами события являются компании Deutsche Telekom и MediaOne Group. Распознавание субъектов и объектов ведется следующим образом: выделяются все встречающиеся в тексте имена собственные (по признакам слов, начинающихся с заглавных букв в середине предложения, слов в кавычках и т.д.). В состав имени включаются числа, если они следуют сразу же за именем собственным (при наличии дефиса или его отсутствии). Для большей надежности идентификации выбранные имена могут сравниваться с идентификаторами объектов соответствующих классов (организации, лица, инфраструктуры и т.д.) хранилища информации. Для корректного выбора из хранилища информации объекта, идентифицированного на том или ином языке народов мира, используется соответствующая языковая разметка текста, выполненная ранее. Отсутствие объекта с каким-либо именем в хранилище не означает автоматической отбраковки объекта, а свидетельствует о том, что объект является новым.
В рассматриваемом случае будут выделены следующие имена собственные:
Deutsche Telekom,
MediaOne Group,
US West,
Bloomberg,
AT&T,
Polska Telefonia Cyfrowa,
Westel 450,
Westel 900,
Russian Telecommunications Development Corp.,
Байкалвестком,
MCC,
Дельта Телеком,
Уралвестком.
Донтелеком,
Нижегородская Сотовая Связь,
Акос,
Енисей,
Вестелком.
В качестве признаков субъектов события выступают контексты: "Deutsche Telekom объявил о покупке у фирмы MediaOne Group", "MediaOne продает", "DT получит".
Субъекты события в ходе совершения некоторых операций между собой оказывают воздействие на определенные предметы и отношения окружающего мира, которые выступают в качестве объектов события. Это могут быть другие организации и физические лица, документы, системы передачи данных, трудовые отношения организации с лицом и т.д. В общем случае в рамках изучаемой системы этот перечень конечен и может быть перечислен в рамках объектной модели исследуемой реальной системы. В данном случае в качестве объекта события выступают отношения владения долями акций компаний Polska Telefonia Cyfrowa, Westel 450, Westel 900, Russian Telecommunications Development Corp., которые переходят от компании MediaOne Group к компании Deutsche Telekom. Распознавание необходимого объекта события осуществляется методами формализации соответствующих классов. Эти методы поочередно вызываются рассматриваемым методом формализации класса "Событие". Каждый метод проверяет, имеются ли в тексте признаки объектов, соответствующих активизированному классу, и при этом учитывают, что таких объектов в тексте может быть несколько.
Например, когда для распознавания объекта события метод класса "Событие" активизирует соответствующий метод класса "Владение долями уставного капитала", этот метод отыскивает в переданном ему тексте, описывающем предикат события, признаки данных, соответствующих отношению владения долями уставного капитала между юридическими лицами или между компаниями и физическими лицами.
Подобными признаками выступают фразы "компания приобрела активы", "фирма купила доли" и т.д. В общем случае перечень действий, связанных с приобретением доли уставного капитала, конечен и в терминах русского языка описывается глаголами "получить", "купить", "приобрести", "обменять", "продать" и рядом других, которые могут распознаваться системой в дальнейшем помере ее обучения. Эти глаголы в тексте должны быть согласованы с соответствующим дополнением из ограниченного набора слов типа "акции", "активы", "доля уставного капитала" В рассматриваемом тексте общая область действия (граница) объектов класса "Владение долями уставного капитала" (а это будет несколько объектов, так как Deutsche Telekom приобрел доли в нескольких компаниях) будет иметь вид:
"За свои деньги DT получит 22,5% акций крупнейшего в Восточной Европе сотового оператора Polska Telefonia Cyfrowa (в дополнение к уже имеющемуся такому же пакету), по 49% - в венгерских Westel 450 и Westel 900, а также контрольный пакет акций компании Russian Telecommunications Development Corp. (RTDC)".
Распознавание числа формируемых объектов в данном случае осуществляется по числу наименований компаний, в которых DT приобретает доли (4 объекта). Это означает, что метод формализации "Владение долями уставного капитала" должен будет создать 4 объекта одноименного класса, в каждом из которых будет содержаться отсылка на соответствующий объект класса "Организация".
Сформировав прообраз объекта класса "Владение долями уставного капитала", метод формализации этого класса, получивший управление от метода формализации класса "Событие", активизирует соответствующий метод класса "Организация", который, прежде всего, проверяет, не сформированы ли уже объекты, соответствующие этим организациям. Если они ранее уже были сформированы в текущем сеансе работы с системой, то на них устанавливается ссылка. В противном случае запускается процедура формирования объектов, описывающих организации, долю уставного капитала, которую приобрела компания Deutsche Telekom. По завершении формирования этих объектов управление возвращается методу класса "Владение долями уставного капитала" для продолжения формирования этого объекта. Предварительно устанавливается взаимно однозначная отсылка между объектом, описывающим владение долей уставного капитала, и соответствующим объектом класса "Организация". Как отмечалось выше, указанная процедура повторяется 4 раза. Кроме того, в каждом цикле активизируется метод формализации класса "Доля уставного капитала", который определяет в тексте числовые показатели, описывающие процентное или абсолютное значение доли нового участника организации в ее уставном капитале. Метод учитывает (как в данном примере) возможность определения из текстового описания суммарной доли участника, получающейся в результате сложения приобретенной доли с имевшейся ранее долей, или в результате сложения долей организации, приобретаемых у различных участников.
Принципиально процедура формирования объекта "Доля уставного капитала", как и других не рассмотренных в данном примере объектов, соответствует общему механизму предлагаемой схемы формирования объектов.
В завершении процедуры формализации текста выполняется формирование объекта, идентифицирующего источник информации, и привязка его ко всем объектам, сформированным ранее на основе исходного текста.
Формируемый источник информации определяется по строке (или группе строк), содержащей собственное имя источника (юридическое или физическое лицо) или наименование и номер издания (для статей и нормативных документов), а также, возможно, признак источника (газета, журнал, Web-сайт и т.д.), дату издания или получения информации.
Использованные источники информации:
1. Jasmine. Версия 1.1. Концепции. Computer Associates, Fujitsu. 1997.
2. К. Дейт. "Введение в системы баз данных", Киев - Москва, "Диалектика", 1998, глава 22, 23, 24.
3. Эдвард Йордан, Карл Аргила. "Структурные модели в объектно-ориентированном анализе и проектировании", М., "Лори", 1999.
4. Гради Буч. "Объектно-ориентированный анализ и проектирование с примерами приложений на C++. Второе издание", М., "Бином", 1999.
5. Инструментальная система управления базами данных Cronos, М., ЗАО "Кронос-Информ".
6. Патент РФ 2096825.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АНАЛИЗА И ПРОГНОЗИРОВАНИЯ РАЗВИТИЯ ДИНАМИЧЕСКОЙ СИСТЕМЫ И ЕЕ ОТДЕЛЬНЫХ ЭЛЕМЕНТОВ | 2000 |
|
RU2236700C2 |
| СПОСОБ ФОРМИРОВАНИЯ ИНФОРМАЦИОННОЙ МОДЕЛИ ДИНАМИЧЕСКОЙ СИСТЕМЫ И ВИЗУАЛИЗАЦИИ ПОЛУЧЕННЫХ РЕЗУЛЬТАТОВ | 2000 |
|
RU2225033C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПРИНЯТИЯ ПРАВОВОГО РЕШЕНИЯ | 2019 |
|
RU2732071C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ДИНАМИЧЕСКИХ СТРУКТУР С ИЗМЕНЯЕМЫМИ ПАРАМЕТРАМИ | 2001 |
|
RU2217792C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| ИСПОЛЬЗОВАНИЕ ВЕРИФИЦИРОВАННЫХ ПОЛЬЗОВАТЕЛЕМ ДАННЫХ ДЛЯ ОБУЧЕНИЯ МОДЕЛЕЙ УВЕРЕННОСТИ | 2016 |
|
RU2646380C1 |
| СИСТЕМА И СПОСОБ АВТОМАТИЗИРОВАННОЙ ОЦЕНКИ НАМЕРЕНИЙ И ЭМОЦИЙ ПОЛЬЗОВАТЕЛЕЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2020 |
|
RU2762702C2 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
Изобретение относится к средствам для стандартизации и унификации информации в целях последующего сравнения и автоматизированного анализа на основе преобразования текстового входного потока в объектную форму и может быть использовано в системах, основанных на знаниях, хранилищах информации, банках данных, системах обработки и анализа неструктурированных текстовых файлов. Технический результат заключается в расширении функциональных возможностей за счет одновременного перевода поступающих данных с иностранных языков на родной язык пользователя. Суть способа заключается в автоматическом (или автоматизированном) преобразовании исходного текста в совокупность взаимосвязанных объектов на основе таблицы настроек, содержащей знания о структуре исследуемой системы в виде совокупности образующих ее классов, включающих определенный набор атрибутов (в том числе взаимосвязи и отношения между объектами заданных классов) и установленные для каждого атрибута правила распознавания атрибута в тексте. Предусматривается возможность определения формата исходного текста и автоматического перевода его фрагментов в ходе формирования объектов. 5 з.п. ф-лы, 3 табл., 2 ил.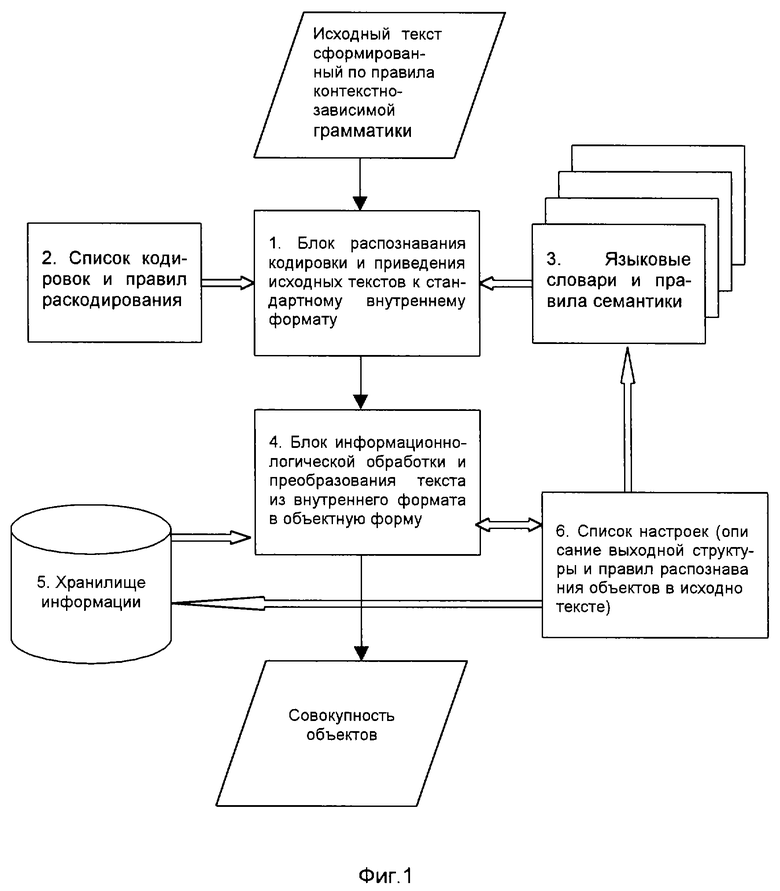
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| US 4821230 С1, 11.04.1989. | |||

