Настоящее изобретение относится к системам связи с расширенным спектром и, в частности, относится к способу обнаружения сигнала с расширенным спектром, в соответствии с родовым понятием первого пункта формулы изобретения. Настоящее изобретение относится также к системе обнаружения сигнала с расширенным спектром.
Среди различных так называемых систем с расширенным спектром в настоящее время наиболее популярны системы расширенного спектра с применением кода прямой последовательности (DSSS).
Например, использование техники расширенного спектра с применением кода прямой последовательности DSSS предоставляет широкую полосу пропускания канала, используемого совместно посредством метода множественного доступа с кодовым разделением (CDMA).
Метод доступа CDMA позволяет распознать, что множество передатчиков совместно использует тот же самый канал и что каждый из них использует отличающийся псевдослучайный код при равной нулю взаимной корреляции этих различающихся кодов. Затем приемник должен выбрать подходящий псевдослучайный код и осуществить способ обнаружения, который позволяет приемнику определить частоту и задержку кода принятого сигнала. В некоторых приложениях, например в приложениях GNSS (Глобальная Навигационная Спутниковая Система), приемник заранее не знает, был ли принятый сигнал передан от определенного передатчика, чтобы применять способ обнаружения с использованием возможных копий различных псевдослучайных кодов, доступных для приемника.
В частности, для приемника GNSS первая задача заключается в поиске сигналов, передаваемых спутниками. Этот процесс называется способом обнаружения. Когда сигнал обнаружен, то этот сигнал отслеживается, чтобы получить информацию, требуемую для определения местоположения приемника. Если сигнал по каким-то причинам потерян, то способ обнаружения выполняется снова для его поиска на том же самом или на другом спутнике. Способ обнаружения сигнала отображает поиск в двумерном временном пространстве (для определения фазы или задержки кода) и по частоте (для определения доплеровского сдвига несущей, то есть сдвига частоты относительно номинальной несущей частоты вследствие того, что спутники движутся по орбитальным траекториям со скоростями в несколько км в секунду, создавая существенный доплеровский сдвиг, который также вызван рассогласованием частоты синхросигналов передатчика и приемника). Более конкретно, поиск в двумерном пространстве определяется в области неопределенности такого пространства. Пространство поиска квантовано в обоих измерениях, и время и частота разделены на конечное число блоков или "ячеек".
В данной области техники известно несколько способов обнаружения сигнала GNSS или, в общем смысле, известны различные способы обнаружения сигнала с расширенным спектром для определения в приемнике задержки кода и доплеровского сдвига для принятого сигнала.
Известны, например, способы обнаружения, которые называют способами "согласованной фильтрации" (или способ последовательного поиска). В способах этого типа последовательно сканируются возможные "ячейки" доплеровского сдвига и задержки кода. Способы этого типа, описанные, например, в US 2003/0161543, имеют недостаток из-за необходимости в длительных периодах времени для сканирования двумерного пространства поиска.
Также известны способы обнаружения с так называемым "параллельным поиском", которые содержат параллельный анализ размера двумерной сетки поиска. Поскольку эта сетка двумерная, то существуют два способа параллельного поиска различного типа:
- параллельный поиск кода (PCS), причем все ячейки задержки кода тестируются одновременно;
- параллельный частотный поиск (PFS), причем все ячейки сдвига частоты тестируются одновременно.
Способы PCS и PFS гарантируют хорошие результаты в отношении времени сканирования сетки поиска. Однако способы PCS требуют память большой емкости, тогда как способы PFS имеют большие вычислительные затраты.
Задача настоящего изобретения заключается в том, чтобы предоставить способ обнаружения, имеющий рабочие параметры, которые представляют собой компромисс между временем сканирования сетки поиска, вычислительными затратами и требованиями к устройству памяти.
Этих недостатков удается избежать в способе обнаружения в соответствии с пунктом 1 приложенной формулы изобретения.
Другие варианты осуществления изобретения описаны в последующих пунктах формулы.
Другая задача настоящего изобретения заключается в системе обнаружения по пункту 13 формулы.
Дальнейшие характеристики и преимущества настоящего изобретения станут очевидными из следующего описания предпочтительных и не ограничивающих примеров настоящего изобретения, причем:
Фиг. 1 изображает функциональную блок-схему способа обнаружения сигнала с расширенным спектром;
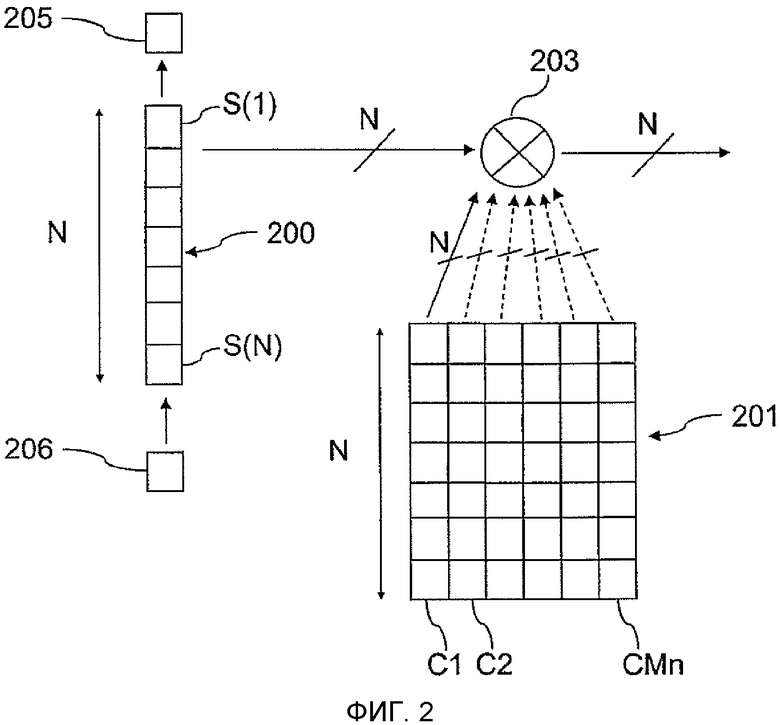
Фиг. 2 - схема одного из этапов способа обнаружения на Фиг. 1;
Фиг. 3a-3c, 4a-4c и 5a-5c - диаграммы сигналов, относящиеся к способу обнаружения на Фиг. 1; и
Фиг. 6 - иллюстративная функциональная блок-схема системы обнаружения сигнала с расширенным спектром.
На чертежах для одних и тех же элементов используются одинаковые цифровые обозначения.
На Фиг. 1 ссылочная позиция 100 указывает в целом способ обнаружения сигнала s(t) с расширенным спектром с применением кода прямой последовательности или DSSS способ обнаружения сигнала. Например, сигнал s(t) представляет собой сигнал, предоставленный спутником системы GNSS, и предпочтительно представляет собой сигнал CDMA (множественного доступа с кодовым разделением). В соответствии с дополнительным вариантом осуществления, сигнал s(t) представляет собой сигнал CDMA такой, как предоставляется в системе UMTS.
Сигнал s(t) представляет собой сигнал, модулированный псевдослучайным кодовым сигналом, или кодом PRN, с длиной Nc, и который передается на несущей частоте. Например, сигнал кода состоит из Nc=4092 микрокадров, которые периодически передаются каждые Tc=4мс (Tc отображает так называемый сверхкадр кода), как имеет место, например, в случае Е1-B и Е1-C сигналов, предоставляемых спутниками группировки GALILEO.
Способ 100 обнаружения содержит этап 101 приема сигнала s(t). Предпочтительно, этап 101 приема содержит этап соответствующей обработки сигнала s(t), чтобы демодулировать и преобразовать упомянутый сигнал в исходный сигнал (или почти в исходный сигнал), этап выделения синфазной и квадратурной компонент исходного сигнала и этап дискретизации на частоте fs для преобразования принятого сигнала в поток комплексных цифровых выборок. Вышеупомянутые этапы известны специалистам в данной области техники и поэтому подробно не описываются.
В соответствии с вариантом осуществления этап 101 приема содержит этап прореживания потока комплексных цифровых выборок, чтобы уменьшить частоту этого потока от значения fs до пониженного значения fk, которое отображает рабочую частоту или тактовую частоту способа 100 обнаружения. Например, можно задать fk=fs/2. В этом случае, как будет уточнено ниже, для сжатия принятого сигнала используется локальная копия дискретизированного PRN кода с частотой fk, которая состоит из М=tc*fk выборок. Предпочтительно, на этапе 101 приема перед прореживанием предоставляется фильтрация потока цифровых выборок посредством фильтра нижних частот, например посредством FIR фильтра, чтобы избежать или уменьшить эффект наложения спектров, возникающий в прореженном потоке.
В преимущественном варианте осуществления этап 101 приема содержит этап сохранения цифровых выборок принятого сигнала, который в этом примере фильтруется и прореживается на линии задержки, предоставленной с N отводами. Предпочтительно, число отводов N представляет собой число, содержащееся целое число раз в числе выборок М локальной копии PRN кода, то есть существует целое число Mn, для которого справедливо следующее Mn=M/N.
Следует отметить, что сохранение цифровых выборок принятого сигнала в линии задержки, предоставленной с N отводами, обеспечивает, в любой тактовый момент, ряд N последовательных выборок принятого сигнала, то есть сегменты с длиной N, имеющие различные тактовые времена и задержку кода, увеличивающуюся между 0 и N-1 относительно локально имеющейся опорной кодовой последовательности.
Как известно, принятый сигнал s(t) показывает относительно выходящего от спутника сигнала задержку кода, или фазовую задержку, и доплеровский сдвиг относительно передаваемой несущей частоты. Поэтому способ 100 обнаружения предоставляется для определения задержки кода, или фазовой задержки, принятого сигнала с расширенным спектром и доплеровского сдвига относительно несущей частоты передаваемого сигнала (в этом примере - спутником), причем упомянутое определение легко выполняется в двумерном дискретном пространстве М возможных задержек кода и F возможных частотных сдвигов, причем М - длина локальной копии PRN кода, дискретизированного с частотой fk, и F - положительное целое число.
На Фиг. 1 способ 100 обнаружения содержит этап 102 предоставления сигнала локальной копии псевдослучайного кодового сигнала, или PRN кода. Такой сигнал отображает опорную кодовую последовательность.
В особенно предпочтительных вариантах осуществления М выборок PRN кода, дискретизированного с операционной частотой fk, сохраняются в таблице соответствия, то есть в структуре матрицы данных, содержащей векторы с длиной N, каждый снабженный для сохранения сегментом с длиной N PRN кода, и причем последовательные сегменты PRN кода являются последовательно сохраняемыми в последовательных векторах упомянутой структуры матрицы данных. Далее предполагается, без каких-либо ограничений, что структура данных сформирована матрицей с N строками и Mn столбцами и что первые N выборок PRN кода сохраняются в первом столбце C1 структуры матрицы данных, следующие N выборок PRN сохраняются во втором столбце C2 структуры матрицы данных, и так далее. В соответствии с этим вариантом осуществления этап 102 предоставления локальной копии PRN кода содержит этап считывания из таблицы соответствия сохраняемых в ней выборок PRN, чтобы предоставить векторы выборок, имеющие длину N.
Кроме того, способ обнаружения 100 содержит этап 103 выполнения сжатия дискретизированного сигнала с расширенным спектром, в этом примере - на операционной частоте fk, посредством сигнала локальной копии PRN кода, при выполнении упомянутого сжатия для множества возможных задержек кода между дискретизированным сигналом и сигналом копии PRN кода.
В соответствии с вариантом осуществления этап 103 сжатия содержит этапы сжатия посредством Mn=M/N последовательных сегментов длиной N сигнала локальной копии, Mn=M/N сегментов длиной N дискретизированного сигнала, посредством выполнения для каждого из упомянутых Mn сегментов сигнала локальной копии сжатия для N возможных последовательных задержек между упомянутым сигналом локальной копии и упомянутым дискретизированным сигналом. Этап сжатия 103 такой, чтобы обеспечить на выходе множество векторов, которые будут называться "сжатыми векторами", содержащими Mn сжатых векторов для каждой задержки кода.
Предпочтительно, операция сжатия представляет собой побитное умножение двух векторов с длиной N. Далее почти исключительно будет рассматриваться этап 103 сжатия, на котором выполняется сжатие посредством выполнения побитного векторного умножения, без введения каких-либо ограничений.
На Фиг. 2 ссылочной позицией 200 обозначена линия задержки, содержащая в любой момент N выборок принятого сигнала, а 201 указывает таблицу соответствия, содержащую выборки локальной копии PRN кода. В данный момент N сохраненных выборок в линии 200 задержки умножаются на N сохраненных выборок кода в столбце Cl таблицы 201 соответствия. На следующем этапе содержание линии 200 задержки обновляется сдвигом на одно положение выборок, сохраненных на предыдущем этапе, причем старая выборка 205 выводится из линии 200 задержки, и новая выборка 206 вводится в линию задержки. Обновленное содержание линии 200 задержки умножается, используя векторное умножение 203 на N выборок столбца Cl таблицы 201 соответствия. Это эквивалентно сжатию сегментов с длиной N принятого сигнала посредством сегмента с длиной N PRN кода с дополнительной задержкой кода, равной задержке между принятым сигналом и кодом PRN, относительно предыдущего этапа. Эта операция выполняется для N последовательных моментов, то есть для N задержек кода, обновляющих на каждом этапе содержание линии 200 задержки, но без изменения столбца Cl. Затем выполняется умножение содержания линии 200 задержки на столбец C2 для дополнительных N задержек кода, то есть обновляя N раз содержание линии 200 задержки, и так далее, до достижения умножения на столбец CMn. Как только N умножение содержания линии 200 задержки и содержания столбца CMn также выполнено, то есть после полного сканирования столбца за столбцом таблицы 201 соответствия, для каждой задержки кода между 0 и N-1, Mn сжатых векторов с длиной N становятся доступными.
В связи с Фиг. 1, результат этапа 103 сжатия подвергается следующему этапу 104 вычисления Фурье преобразования для выполнения параллельного частотного поиска по результатам, предоставленным на выходе этапа 103 сжатия. Если сжатие 103 выполняется при использовании векторного побитного умножения, то можно заметить, что такое умножение, объединенное с Фурье преобразованием, отображает этап корреляции, причем дополнительно вследствие умножения на комплексную экспоненту, включенную в Фурье преобразование, выполняется параллельное удаление множественных доплеровских частот.
Предпочтительно применяемое Фурье преобразование представляет собой дробное Фурье преобразование. Этот этап преобразования позволяет вычислить дискретное Фурье преобразование (DFT), которое применяется только на участке спектра с большим разрешением, в противоположность его применению для диапазона всех возможных частот [-fk/2, fk/2]. Предпочтительно дробное Фурье преобразование вычисляется для F выборок, которые однородно распределены в интервале [-Δfw/F, +Δfw/F], и более предпочтительно, для F=N, причем N - размерность векторов, выводимых этапом 103 сжатия. Интервал [-Δfw/F, +Δfw/F] может поэтому быть выбран как интервал, подходящий для покрытия самых обычных доплеровских частот, которые принятый сигнал может иметь.
Таким образом, выход преобразования представляет собой отображение векторного входа в пространстве N частотных выборок, которые разделены интервалом Δfd=Δfw/F=Δfw/N.
В соответствии с вариантом осуществления дробное Фурье преобразование выполняется посредством выполнения двух быстрых преобразований Фурье (FFT) на 2*Nopt выборках; причем Nopt, например, выбрано как наименьшая степень, вдвое большая, чем N. Следует отметить, что относительно традиционного FFT преобразования, экономия вычислительных затрат очень велика, так как для достижения того же самого разрешения с алгоритмом FFT может потребоваться множество выборок, равных fs/Δfd=(fsN)/(Δfw)>>Nopt.
В особенно предпочтительном варианте осуществления вычисление Фурье преобразования 104 содержит вычисление Фурье преобразования каждого из сжатых векторов, выводимых этапом 103, чтобы получить множество соответствующих векторов, преобразованных в дискретной частотной области.
В связи с Фиг. 1, способ 100 содержит, кроме того, этап 105, 106, накопления когерентным образом сжатых векторов, выводимых этапом 103 и связанных с той же самой задержкой кода так, чтобы было получено множество совокупных векторов, каждый из которых связан с соответствующей задержкой кода.
В соответствии с особенно предпочтительным вариантом осуществления этап 105, 106 накопления выполняется после Фурье преобразования 104 посредством когерентного накопления в N совокупных векторов сжатых векторов, связанных с той же самой задержкой между 0 и N-1 и преобразованных в частотной области этапом 104 Фурье преобразования. Следует отметить, что в соответствии с вариантом осуществления, отвечающим схемам на Фиг. 1 и 2, во время этапа 105 накопления два сжатых вектора, связанных с той же самой задержкой, будут доступны для накопления в том же самом совокупном векторе относительно упомянутой задержки каждые N входных выборок линии 200 задержки. Фактически, после введения N новых выборок в линию 200 задержки принятый и дискретизированный сигнал сдвигается на N выборок, но также и локальная копия PRN кода сдвигается на ту же самую величину из-за сдвига столбца в таблице 201 соответствия. Можно отметить, что в настоящем примере частотно преобразованный сжатый вектор отображает вклад корреляции, связанный с данной задержкой кода, который добавляется (то есть накапливается) к другим корреляционным вкладам, связанным с той же самой задержкой.
В особенно предпочтительном варианте осуществления этап 105 накопления содержит этап 106 синтезирования сигнала фазовой коррекции, коррекции посредством упомянутого сигнала фазовой коррекции результата накопления 105 на предшествующем этапе, связанном с данной задержкой между 0 и N-1, и добавления накопленного и скорректированного результата к новому сжатому вектору, связанному с упомянутой задержкой между 0 и N-1. Практически фазовая коррекция применяется к содержанию каждого совокупного вектора перед добавлением нового сжатого вектора или, более определенно, его Фурье преобразования к содержанию упомянутого совокупного вектора.
Предпочтительно коррекция фазы выполняется умножением каждого элемента v(i), где i находится между 0 и N-1, совокупного вектора v, на соответствующий коэффициент коррекции фазы pi=ej2πf D,i, с 0≤i≤N, где fD,i - дискретная доплеровская частота (элемент разрешения по частоте), связанная с i-м элементом преобразованного совокупного вектора.
В показанном примере, начиная с N умножений содержания линии 200 задержки на содержание столбца C1, посредством сканирования целой матрицы 201 PRN кода, столбец за столбцом, когда N умножений содержания линии 200 задержки и содержания столбца CMn закончены, для каждой задержки между 0 и N-1, Mn сжатых векторов с длиной N будут накапливаться, которые преобразуются в пространственную область дискретных доплеровских частот. Иначе говоря, в конце этапа 105 накопления будет получена матрица комплексных чисел или матрица поиска, которая в этом примере является матрицей N×N, которая идентифицирует пространство поиска N задержек и N дискретных частот.
В отношении Фиг. 1 способ обнаружения 100 содержит:
последовательный этап 107 вычисления модуля, простого или квадратичного, элементов упомянутой матрицы поиска;
последовательный этап 108 поиска максимума, или пика, модулей элементов матрицы поиска;
последовательный этап 109 сравнения максимума с порогом для определения того, произошел ли захват сигнала.
Как показано на Фиг. 1, от этапа 110 выбора, если установлено обнаружение спутника, способ 100, кроме того, содержит этап 111 выбора другой таблицы соответствия, содержащей выборки PRN кода относительно другого спутника и новой итерации способа 100 для обнаружения упомянутого спутника, и так далее, для возможных дополнительных спутников группировки GNSS, которые должны обнаруживаться.
Как обозначено этапом 110 выбора, если сравнение с порогом не предоставило обнаружения сигнала, вышеупомянутые этапы способа 100 повторяются от начала:
- сбросом совокупных векторов, записанных на этапе 105; и
- выполнением этапа 103 сжатия, в этом случае начиная со второго столбца C2 таблицы 201 соответствия.
Если после этой итерации, на этапе 110 выбора, обнаружение сигнала не установлено, этапы способа 100 повторяются, начиная с третьего столбца таблицы соответствия, и так далее, пока не будет достигнут последний столбец CMn. Как можно легко заметить из вышеупомянутого описания, таким образом, поиск М возможных задержек кода выполняется посредством рассмотрения отдельных последовательных сегментов N задержек.
В соответствии с модификацией, вместо того, чтобы искать каждый раз максимум, после сканирования сегмента N возможных задержек кода, можно неоднократно выполнять поиск, всегда посредством деления на под-поиски сегментов N возможных задержек, полностью сканируя весь PRN код много раз и накапливая некогерентным образом (то есть после выполнения этапа 107 вычисления модуля) величину Nacc (произвольное целое число) NxN-размерных сеток поиска, полученных повторением сканирования матрицы, содержащей выборки PRN кодов, начиная с того же самого столбца. Если пик не найден, выполняется поиск на последовательных N PRN задержках кода для нового PRN кода. Если после сканирования для М возможных задержек пик не найден, поиск нового PRN кода начинается снова (в этом практическом примере поиск нового спутника). Следует отметить, что эта стратегия обнаружения такова, что увеличивается время поиска, хотя при этом увеличивается чувствительность способа обнаружения. Поэтому удобно установить Nacc=1 с относительно высокими отношениями мощности несущей к мощности шума (это эквивалентно тому, что выполняется нормальный способ, описанный в связи с Фиг. 1), и вместо установки Nacc>1 для относительно низких отношений несущей к шумовой мощностей.
В соответствии с дополнительным вариантом осуществления возможно предвидеть этап оценки в реальном времени мощности шума, адаптивно варьируя исходя из оценки порог, используемый для этапа сравнения, на этапе 109. В особенно предпочтительном варианте осуществления оценка мощности шума выполняется исходя из преобразованных сжатых векторов, выводимых этапом 104 преобразования. Например, вычисляется квадратичный модуль (или модуль) комплексных векторов, выводимых этапом 104 преобразования, и формируется среднее значение на всех преобразованных выводах (мощность шума является инвариантом относительно частоты) и затем фильтруется по времени, предпочтительно с использованием фильтра с бесконечным импульсным откликом (IIR) первого порядка. Такая фильтрация позволяет сократить оценку шума.
В соответствии с особенно предпочтительным вариантом осуществления порог устанавливается как реальное кратное число оцененной мощности шума, причем упомянутое кратное число определяется исходя из определенных требований вероятности ложных тревог и обновляется в реальном времени или в почти реальном времени.
Вышеупомянутый способ может быть осуществлен посредством программного обеспечения или комбинацией аппаратных средств и программного обеспечения, например в FPGA.
В дополнительно модифицированном варианте осуществления, который удобно осуществить, когда в принятом сигнале вторичный PRN код, или последовательность символов, или информационных битов, накладывается на первичный PRN код (характеристики последовательности данных или вторичного кода относительно первичного кода хорошо известны специалистам в данной области техники; иначе говоря, элементарная посылка вторичного кода такой же длины, что и целый первичный код, и символ или информационный бит такой же длины, что и целое число раз первичного кода), поскольку этот вторичный код или последовательность данных может искажать результат когерентного накопления, можно предвидеть, что этап 103 сжатия выполняется, сохраняя тот же самый начальный столбец матрицы 201 для двух или более полных сканирований всех столбцов C1-CMn упомянутой матрицы.
Ниже вышеупомянутая проблема и ее решение описываются более ясно.
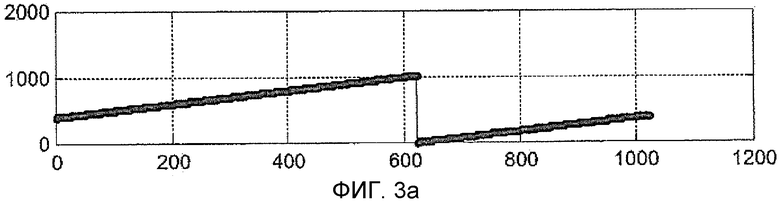
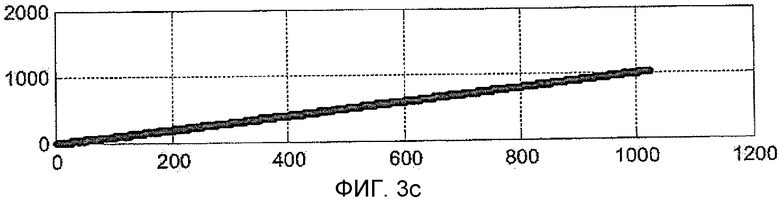
На Фиг. 3a, 3b и 3c показано изменение во времени фазы кода принятого сигнала (то есть входного сигнала линии задержки), сигнал локальной копии PRN кода (то есть тот, что извлечен из таблицы соответствия) и содержание когерентного накопителя (этап 105 способа на Фиг. 1), соответственно. Для ясности представления на Фиг. 3a и 3b последовательность первичного PRN кода отображена возрастающим пилообразным сигналом, хотя в действительности это прямоугольная последовательность положительных и отрицательных символов; на Фиг. 3c показана амплитуда модуля содержания когерентного накопителя. Диаграммы на Фиг. 3a, 3b, 3c были получены при условии, что вторичный код не присутствует. Фаза кода представлена графически условно, как возрастающее целое число от 0 до максимального числа элементарных посылок в коде минус 1. В этом случае рассматривается длина кода 1023. Как можно видеть из Фиг. 3a, 3b, 3c, принятый сигнал (Фиг. 3a) и сигнал PRN кода (Фиг. 3b) идеально выровнены, то есть они имеют одну и ту же фазу кода в каждый момент времени, и когерентное накопление (Фиг. 3c) всегда увеличивается, достигая максимального значения, равного длине кода.
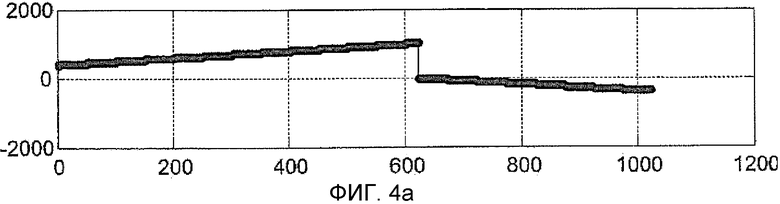
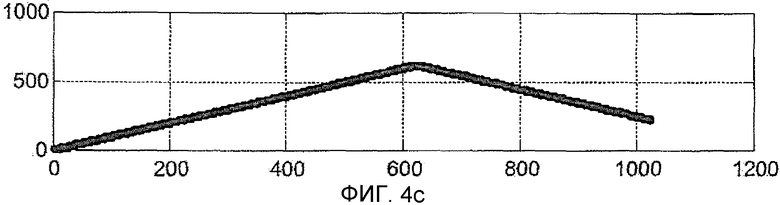
На Фиг. 4a, 4b, 4c показаны диаграммы, которые соответствуют представленным на Фиг. 4a, 4b, 4c, для случая, когда присутствует вторичный PRN код, то есть код, элементарная посылка которого такой же длины, что и целый первичный PRN код (1023 в этом примере), и в предположении перехода знака между элементарной посылкой вторичного кода и следующей элементарной посылкой. Графически эта инверсия знака представлена как изменение знака в фазе кода принятого сигнала (Фиг. 4a). Очевидно, такая инверсия может произойти только, когда фаза кода составляет 0, то есть в начале каждого первичного кода. Как и в ситуации на Фиг. 3a и 3b, принятый сигнал и сигнал кода идеально выровнены, но когерентное накопление на Фиг. 4c не может достигнуть предыдущего максимального значения (Фиг. 3c), поскольку при переходе знака элементарной посылки вторичного кода оно начинает падать и конечное значение составляет почти нуль. Конечное значение зависит от начальной фазы кода принятого сигнала.
Для устранения этой проблемы найденное решение предполагает сохранение того же самого начального столбца матрицы, содержащей код для двух периодов кода, вместо только одного. Период кода - это временная длина кода. Поэтому это должно соответствовать увеличению когерентного времени интегрирования до 2 периодов кода.
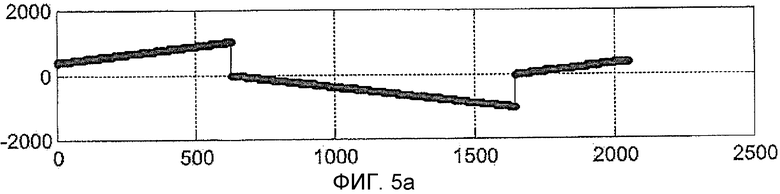
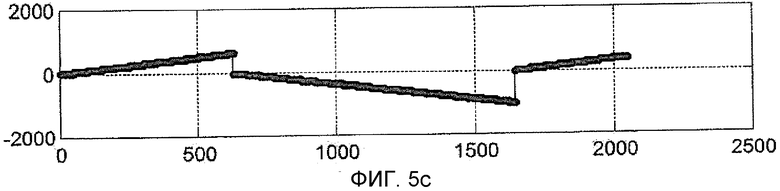
На Фиг. 5a, 5b, 5c, Фиг. 5a и 5b относятся к тому же случаю, что и Фиг. 4a и 4b (будучи им идентичными), тогда как Фиг. 5c показывает результат накопления в случае вышеупомянутого решения. Практически когерентный накопитель восстанавливается в начале нового периода кода, то есть когда фаза сигнала PRN кода начинается снова от 0 так, чтобы снова был получен максимум (модуль) значения, равный 1023 (знак "-" на диаграмме возникает только из-за перехода знака).
Однако результат вышеупомянутой операции заключается в увеличении вдвое полного времени обнаружения и, в общем случае, большем одного накопления, это влечет за собой потерю времени только одного периода кода.
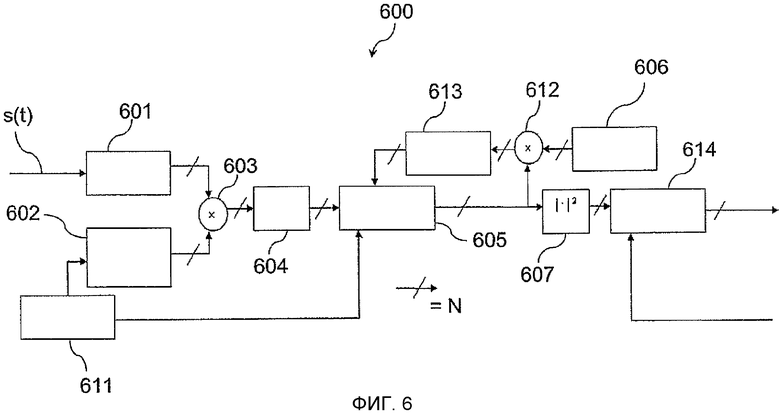
На Фиг. 6 очень схематично в целях иллюстрации показана блок-схема системы 600 обнаружения для выполнения вышеупомянутого способа обнаружения. Эта система, например, представляет собой компоненту GNSS приемника как спутникового навигатора.
Система 600 содержит линию задержки с N отводами 601 для сохранения выборок комплексного принятого сигнала базовой полосы или почти базовой полосы, который при необходимости предварительно фильтруется и прореживается.
Система 600, кроме того, содержит, по меньшей мере, одно устройство памяти 602, например таблицу соответствия для сохранения локальной копии PRN кода, в соответствии с уже описанной процедурой в связи со способом 100. Предпочтительно система 600 содержит память 602 для сохранения больше чем одной таблицы соответствия, каждая из которых относится к PRN коду соответствующего спутника.
Система 600, кроме того, содержит векторный умножитель 603 для выполнения этапа 103 сжатия способа.
Система 600, кроме того, содержит модуль 604 для выполнения Фурье преобразования комплексных векторов, произведенных и выводимых умножителем 603, в соответствии с описанием способа 100. Кроме того, система снабжена когерентным сбрасываемым накопителем 605 для вывода совокупных векторов, каждый из которых связан с соответствующей задержкой кода между kN и kN-1 (где k - целое число), модуль 607 для вычисления модуля или квадратичного модуля, и который предпочтительно снабжен сбрасываемым некогерентным накопителем 614 для интегрирования при Nacc>1 последовательных периодов кода, в соответствии с описанием способа 100. Обнуление этого накопителя 614 выполняется перед началом поиска нового кодового сигнала от спутника.
Кроме того, система 600 обнаружения содержит синтезатор 606 фазы для коррекции фазы посредством умножителя 612 совокупных векторов, чтобы позволить когерентное накопление с векторами, которые последовательно предоставляются на выходе блока 604 преобразования. Кроме того, система 600 обнаружения содержит линию 613 задержки для задержки выходного сигнала умножителя 613 на N тактовых циклов, причем упомянутая задержка учитывает тот факт, что обновление каждого из совокупных векторов вкладом выхода блока 602 происходит каждые N тактовых циклов, как уже описано для способа 100 обнаружения.
Система 600 также содержит управляющий логический блок 611 для корректного обращения к столбцам таблицы соответствия, сохраняемой в памяти 602, и для посылки с корректной синхронизацией, требуемой вышеупомянутым способом 100, сигнала сброса на когерентный накопитель 604.
На Фиг. 6 для большей ясности не показаны участки системы 100, относящиеся к оценке мощности шума, к установке и обновлению порога, к вычислению максимумов и сравнению порога.
Система 100 может быть осуществлена посредством подходящей комбинации аппаратных средств и программного обеспечения, например c FPGA или ASIC.
Экспериментальные результаты, полученные моделированием с использованием пакетов MATLAB™ или GRANADA™, подтвердили, что способ обнаружения вышеупомянутого типа имеет преимущество в том, что он быстрый, точный, легко приспосабливаемый, позволяющий обнаруживать сигналы более чем одного типа и может применяться для других сигналов с расширенным спектром, отличных от CDMA сигналов в GNSS.
Как пример было промоделировано обнаружение сигнала E1c системы GNSS GALILEO с размером кода М=Tc×Fk, равным 19 000 (то есть число выборок в периоде кода с Tc=4 мс и Fk=4,75 МГц с четырьмя выборками для каждой элементарной посылки), причем окно доплеровского поиска было выбрано как 20 кГц с 120 возможными отыскиваемыми смещениями частоты (элемент разрешения по частоте). В нижеследующей таблице сравниваются характеристики вышеупомянутого способа ("ACSE", как указано в таблице, для алгоритма механизма ускорения обнаружения) со способами, известными в данной области техники. Указанные в таблице вычислительные затраты представляют собой числа комплексных умножений, требуемых для сканирования всей сетки поиска.
Как можно видеть из предоставленных в этой таблице данных, способ ACSE имеет вычислительные затраты, которые ниже, чем для других алгоритмов, за исключением параллельного поиска фазы, который, с другой стороны, требует более длительного FFT, что является проблематичным, когда способ осуществляется на FPGA.
Поэтому очевидно, что способ вышеупомянутого типа предоставляет преимущества в том, что он требует относительно низких вычислительных затрат (сопоставимых с таковыми для обнаружения с параллельным поиском фазы, и намного ниже, чем таковые для способов другого типа), относительно короткие времена поиска и имеет относительно сниженные требования к объему и конфигурации памяти.
Специалисты в данной области техники для удовлетворения конкретных потребностей могут привнести некоторые модификации и вариации для вышеупомянутого способа и системы обнаружения, которые тем не менее находятся в пределах объема защиты, как определено в соответствии с приложенными пунктами формулы изобретения.



Изобретение относится к системе связи с расширенным спектром и предназначено для сокращения времени сканирования сетки поиска и сокращения вычислительных затрат. Изобретение раскрывает, в частности, способ (100) для обнаружения сигнала (s(t)) расширенного спектра с прямой кодовой последовательностью, который передается на несущей частоте и модулирован сигналом кода длиной, равной Nc элементарных посылок, для определения задержки кода упомянутого сигнала с расширенным спектром и доплеровского сдвига относительно упомянутой несущей частоты, причем упомянутое определение выполняется в дискретном двумерном пространстве М возможных задержек кода и F возможных частотных сдвигов, причем способ (100) содержит следующие этапы: прием и дискретизация (102) упомянутого сигнала с расширенным спектром, чтобы получить дискретизированный сигнал с расширенным спектром; выполнение операции (103) сжатия упомянутого дискретизированного сигнала с расширенным спектром с сигналом локальной копии упомянутого сигнала кода посредством выполнения упомянутого сжатия для множества возможных задержек кода между упомянутым дискретизированным сигналом и упомянутым сигналом копии; выполнение параллельного частотного поиска (104, 105, 107, 108, 109) по результатам упомянутого этапа сжатия посредством выполнения этапа (104) вычисления Фурье преобразования упомянутых результатов. Причем, Фурье преобразование представляет собой дробное Фурье преобразование. 3 н. п. и 12 з.п. ф-лы, 12 ил. 
1. Способ (100) для обнаружения сигнала (s(t)) расширенного спектра с прямой кодовой последовательностью, который передается на несущей частоте и который модулирован сигналом кода с длиной, равной Nc элементарных посылок, для определения задержки кода сигнала с расширенным спектром и доплеровского сдвига относительно упомянутой несущей частоты, причем упомянутое определение выполняется в дискретном двумерном пространстве М возможных задержек кода и F возможных частотных сдвигов, причем способ (100) содержит следующие этапы:
прием и дискретизацию (102) упомянутого сигнала с расширенным спектром, чтобы получить дискретизированный сигнал с расширенным спектром;
выполнение операции (103) сжатия упомянутого дискретизированного сигнала с расширенным спектром с сигналом локальной копии упомянутого сигнала кода, выполняя упомянутое сжатие для множества возможных задержек кода между упомянутым дискретизированным сигналом и упомянутым сигналом копии;
выполнение частотного поиска (104, 105, 107, 108, 109) посредством выполнения этапа (104) вычисления Фурье преобразования;
отличающийся тем, что
упомянутый частотный поиск (104, 105, 107, 108, 109) представляет собой параллельный частотный поиск, выполняемый по результатам упомянутого этапа сжатия,
упомянутое Фурье преобразование представляет собой дробное Фурье преобразование, выполняемое по упомянутым результатам.
2. Способ (100) по п.1, в котором этап (103) сжатия содержит этапы сжатия посредством Mn=M/N последовательных сегментов длиной N дискретизированного сигнала, выполняя, посредством каждого из упомянутых сегментов Mn сигнала локальной копии, сжатие для N возможных последовательных задержек между упомянутым сигналом локальной копии и упомянутым дискретизированным сигналом.
3. Способ (100) по п.2, в котором этап (103) сжатия таков, чтобы предоставить на выходе множество сжатых векторов, причем упомянутое множество содержит Mn сжатых векторов для каждой задержки кода.
4. Способ (100) по п.3, причем упомянутый этап вычисления Фурье преобразования содержит этап вычисления Фурье преобразования для каждого из упомянутых сжатых векторов упомянутого множества, чтобы получить множество соответствующих преобразованных векторов в дискретной частотной области.
5. Способ (100) по п.2, причем
этап (103) сжатия содержит этап умножения, по выборкам, сегментов сигнала на соответствующие сегменты копии, предоставляя соответствующее произведение векторов, и причем упомянутый этап вычисления Фурье преобразования выполняется на каждом из упомянутых произведений векторов.
6. Способ (100) по п.2, дополнительно содержащий этап когерентного накопления, в совокупные векторы, сжатых векторов, связанных с той же самой задержкой кода, обеспечивая N совокупных векторов, каждый из которых связан с соответствующей задержкой.
7. Способ (100) по п.6, в котором этап (105) накопления выполняется после упомянутого этапа вычисления Фурье преобразования (104) и, таким образом, упомянутые преобразованные векторы когерентно накапливаются в частотной области.
8. Способ (100) по п.7, в котором упомянутый этап (105) накопления содержит этап (106) аннулирования фазового сдвига частичного результата упомянутого накопления, перед добавлением нового вклада в упомянутый частичный результат.
9. Способ (100) по любому из п.п.1-8, в котором упомянутый этап приема и дискретизации (102) содержит этап сохранения упомянутого дискретизированного сигнала в линии задержки (200).
10. Способ (100) по п.9, в котором линия задержки (200) представляет собой линию задержки с N отводами.
11. Способ (100) по п.10, в котором упомянутый сигнал локальной копии сохраняется в матричной структуре (201) данных, содержащей Mn векторов с длиной N, каждый для сохранения сегмента N выборок упомянутого кода, и причем последовательные сегменты выборки упомянутого кода последовательно сохраняются в последовательных векторах упомянутой матрицы, при этом этап (103) сжатия содержит этап умножения N раз одного вектора упомянутой матрицы (201) на содержание упомянутой линии задержки (200), причем упомянутая линия задержки соответственно обновляется выборками упомянутого принятого сигнала.
12. Способ (100) по п.11, дополнительно содержащий этап поиска максимума (108), после выполнения, по меньшей мере, одного сканирования, посредством упомянутого умножения по всем векторам упомянутой матрицы (201), и, кроме того, содержащий этап установления обнаружения посредством сравнения (109) упомянутого максимума с порогом.
13. Способ (100) по п.12, дополнительно содержащий этапы:
оценки, начиная с результата упомянутого этапа вычисления Фурье преобразования, мощности шума;
адаптивного варьирования упомянутого порога исходя из упомянутой оцененной мощности шума.
14. Система обнаружения (600), содержащая блок обработки для осуществления способа по любому п.п.1-13.
15. Приемник GNSS сигнала, содержащий систему обнаружения по п.14.
| US 2003161543 A1, 28.08.2003 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 0007224721 B2, 29.05.2007 | |||
| US 7436878 B1, 14.10.2008 | |||
| CN 1889546 A, 03.01.2007 | |||
| RU 2004134568 A, 20.08.2005. | |||

