I. Область изобретения
Настоящее изобретение относится к структуре узлов, предназначенных для представления трехмерных объектов на основе изображений с глубиной, и, более конкретно, к способу генерирования структуры узлов, предназначенных для представления объектов посредством изображений с использованием информации о глубине.
II. Предшествующий уровень техники
С момента начала исследований в области трехмерной графики основная задача исследователей - синтезировать реалистичную графическую сцену, подобную реальному изображению. Таким образом, были выполнены исследования в области традиционных технологий визуализации (визуализации), использующих полигональные модели, и в результате были разработаны достаточные для обеспечения весьма реалистичных трехмерных сред технологии моделирования и визуализации. Однако процесс формирования сложной модели требует значительных усилий специалистов и занимает много времени. Также для реалистичной и сложной среды требуется колоссальный объем информации, что обуславливает меньшую эффективность при хранении и передаче информации.
На текущий момент для представления трехмерных объектов в области компьютерной графики обычно используются полигональные модели. По существу, объект произвольной формы можно представить посредством наборов цветных полигонов, например, треугольников. Наиболее передовые программные алгоритмы и развитие графических аппаратных средств дают возможность визуализировать сложные объекты и сцены как в значительной степени реалистичные неподвижные и движущиеся полигональные модели изображений.
Тем не менее, в течение последнего десятилетия проводились весьма активные исследования в области альтернативных трехмерных представлений. Основные причины этих исследований включают в себя сложность построения полигональных моделей для объектов реального мира, а также сложность визуализации и неудовлетворительное качество формирования истинно фотореалистичной сцены.
Приложения, требующие значительных ресурсов, запрашивают огромное количество полигонов; например, детализированная модель человеческого тела содержит несколько миллионов треугольников, которые очень не просто обрабатывать. Несмотря на то, что последние достижения в способах определения дальности, например, использование лазерного сканера дальности, позволяет получать плотные данные о дальности с приемлемой ошибкой, до сих пор получение бесстыковой полной полигональной модели всего объекта оказывается весьма дорогостоящим и трудным. С другой стороны, алгоритмы визуализации, предназначенные для получения качества, близкого к фотографии, оказываются сложными с точки зрения вычислений и, таким образом, далеки от визуализации реального времени.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Одним из аспектов настоящего изобретения является создание способа генерирования структуры узлов для компьютерной графики и анимации, предназначенных для представления трехмерных объектов с использованием изображений с глубиной и называемых представлениями на основе изображений с глубиной (ПОИГ), которые были приняты в качестве Расширения Структуры Анимации (РСА) формата MPEG-4.
Согласно одному из аспектов, структура узла, основывающаяся на изображениях с глубиной, включает в себя поле texture (текстура), в которое записано цветное изображение, содержащее цвет для каждого пикселя, и поле depth (глубина), в которое записано значение глубины для каждого пикселя.
Согласно другому аспекту, структура узла, основывающаяся на изображениях с глубиной, включает в себя поле size (размер), в которое записана информация о размере плоскости изображения; поле resolution (разрешение), в которое записано разрешение по глубине для каждого пикселя; поле depth (глубина), в которое записано множество сегментов информации о глубине, относящейся к каждому пикселю, и поле color (цвет), в которое записана информация о цвете, относящаяся к каждому пикселю.
Согласно еще одному аспекту, структура узла, основывающаяся на изображениях с глубиной, включает в себя поле viewpoint (точка наблюдения), в которое записана точка наблюдения плоскости изображения; поле visibility (область наблюдения), в которое записана область наблюдения от точки наблюдения до плоскости изображения; поле projection method (способ проецирования), в которое записан способ проецирования из точки наблюдения на плоскость изображения;
поле distance (расстояние), в которое записано расстояние от ближней плоскости до дальней плоскости, и поле texture (текстура), в которое записано цветное изображение.
Согласно еще одному аспекту, структура узла на основе изображений с глубиной включает в себя поле resolution (разрешение), в которое записано максимальное число листьев октодерева, расположенных вдоль грани заключающего его куба, который содержит объект; поле octree (октодерево), в которое записана структура внутреннего узла октодерева; поле index (индекс), в которое записан индекс эталонного изображения, соответствующего данному внутреннему узлу, и поле image (изображение), в которое записано эталонное изображение.
В соответствии с настоящим изобретением, время визуализации (визуализации) для моделей, основанных на изображениях с глубиной, пропорционально числу пикселей в эталонном и результирующем изображениях, но, в общем случае, не пропорционально геометрической сложности, что имеет место для случая полигональных моделей. Более того, в случае, когда представление на основе изображений с глубиной, применяется к объектам и сценам реального мира, становится возможной визуализация естественной сцены с фотографическим качеством без использования миллионов полигонов и дорогостоящих вычислений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Вышеупомянутые задачи и преимущества настоящего изобретения поясняются в последующем подробном описании предпочтительных вариантов его осуществления, приведенном со ссылками на сопровождающие чертежи, на которых представлено следующее:
фиг.1 - схема примеров представления на основе изображений, интегрированного в имеющееся на данный момент эталонное программное обеспечение;
фиг.2 - схема структуры октодерева и порядок дочерних углов;
фиг.3 - график, иллюстрирующий степень сжатия октодерева;
фиг.4 - схема примеров многослойного изображения с глубиной (МИГ): (а) иллюстрирует проекцию объекта, где темные ячейки (воксели) соответствуют единицам, а белые ячейки - нулям, а (б) иллюстрирует двумерное сечение в координатах (x, глубина);
фиг.5 - схема, иллюстрирующая цветовую компоненту модели "Ангел" после переупорядочивания ее цветовых данных;
фиг.6 - схема, иллюстрирующая ортогональную инвариантность вероятности появления узла: (а) иллюстрирует исходный текущий и порождающий узел, а (б) иллюстрирует текущий и порождающий узел, повернутые вокруг оси у на 90°;
фиг.7, 8 и 9 - данные сжатия геометрии для лучшего способа, основывающегося на предсказании посредством частичного совпадения (ПЧС);
фиг.10 - схема, иллюстрирующая два способа переупорядочивания поля color (цвет) модели "Ангел" формата PointTexture (точечная текстура) в двумерное изображение;
фиг.11 - схема примеров сжатия геометрии без потерь и сжатия цвета с потерями: (а) и (б) - соответственно, исходная и сжатая версии модели "Ангел", а (в) и (г) - соответственно, исходная и сжатая версии модели "Мортон256";
фиг.12 - схема, иллюстрирующая модель "Ангел" в формате бинарного волюметрического октодерева (БВО) и модель "Ангел" в формате текстурированного БВО (ТБВО);
фиг.13 - схема, иллюстрирующая дополнительные изображения, снимаемые дополнительными камерами в случае ТБВО: (а) - изображение индекса камеры, (б) - первое дополнительное изображение и (в) - второе дополнительное изображение;
фиг.14 - схема, иллюстрирующая пример записи потока данных БВО: (а) иллюстрирует структуру дерева ТБВО. Серый цвет соответствует "неопределенному" символу текстуры. Каждый цвет обозначает индекс камеры, (б) иллюстрирует порядок обхода октодерева в узле БВО и индексы камер, (в) иллюстрирует результирующий поток данных ТБВО, в котором заполненные кубы и куб октодерева обозначают байты текстуры и байты БВО, соответственно;
фиг.15, 17, 18 и 19 - схемы, иллюстрирующие сжатие ТБВО для моделей "Ангел", "Мортон", "Пальма512" и "Роботы512", соответственно;
фиг.16 - схема, иллюстрирующая изображения моделей "Ангел" и "Мортон", полученные после избирательного удаления части вокселей;
фиг.20 - схема примера изображения рельефной текстуры и карты глубины;
на фиг.21 приведена схема примера многослойного изображения с глубиной (МИГ): (а) иллюстрирует проецирование объекта, а (б) иллюстрирует многослойные пиксели;
фиг.22 - схема примера блочной текстуры (БТ), в котором для визуализации показанной в центре модели используются шесть объектов SimpleTexture (простой текстуры) (пары изображения и карты глубины);
фиг.23 - схема примера обобщенной блочной текстуры (ОБТ): (а) иллюстрирует положения камеры для модели "Пальма", (б) иллюстрирует плоскости эталонных изображений для той же самой модели (используется 21 объект SimpleTexture);
фиг.24 - схема примера, показывающего двумерное представление октодерева: (а) иллюстрирует "облако точек", (б) иллюстрирует соответствующие усредненные карты;
фиг.25 - псевдокод, предназначенный для записи битового потока ТБВО;
фиг.26 - спецификация узлов ПОИГ;
фиг.27 - схематичное представление объемной модели для DepthImage (изображение с глубиной): (а) в перспективе, (б) в ортогональной проекции;
фиг.28 - псевдокод визуализации SimpleTexture, основывающегося на OpenGL;
фиг.29 - пример, иллюстрирующий сжатие эталонного изображения в формате SimpleTexture: (а) иллюстрирует исходное эталонное изображение, и (б) иллюстрирует модифицированное эталонное изображение в формате JPEG;
фиг.30 - пример, иллюстрирующий результат визуализации модели "Мортон" в соответствии с различными форматами: (а) в исходном полигональном формате, (б) в формате DepthImage (изображение с глубиной) и (в) в формате OctreeImage (изображение октодерева);
фиг.31 - примеры визуализации: (а) иллюстрирует сканированную модель "Башня" в формате DepthImage, (б) иллюстрирует ту же самую модель в формате OctreeImage (данные сканера использовались без удаления шумов, поэтому в верхней части модели видны черные точки);
фиг.32 - примеры визуализации модели "Пальма": (а) иллюстрирует исходный полигональный формат, (б) иллюстрирует ту же самую модель, но в формате DepthImage;
фиг.33 - пример визуализации, иллюстрирующий кадр из анимации "Дракон512" в формате OctreeImage;
фиг.34 - пример визуализации модели "Ангел512" в формате PointTexture;
фиг.35а и 35б - схемы, иллюстрирующие взаимоотношения соответствующих узлов при представлении объекта в формате DepthImage, имеющем узлы SimpIeTexture и узлы PointTexture, соответственно;
фиг.36 - схема, иллюстрирующая структуру соответствующего узла OctreeImage при представлении объекта посредством узлов OctreeImage.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Данная заявка на патент основана на предварительных заявках на патент США, перечисленных ниже и полностью включенных в данный документ посредством ссылок.
Ниже излагается изобретение, описанное в предварительной заявке №60/333167 на патент США, поданной 27 ноября 2001 г. и озаглавленной "Способ и устройство для кодирования данных представления на основе изображений в трехмерной сцене".
I. КОДИРОВАНИЕ ДВИЖУЩИХСЯ ИЗОБРАЖЕНИЙ И АУДИОСИГНАЛОВ В СООТВЕТСТВИИ С ISO/IEC JTC 1/SC 29/WG 11
1. Введение
В этом документе приведены результаты основного эксперимента РСА А8.3 по визуализации на основе изображений. Основной эксперимент касается технологии визуализации на основе изображений, в которой используются текстуры с информацией о глубине. Также представлены некоторые изменения, внесенные в спецификацию узлов на основе экспериментов, выполненных после 57-го заседания Экспертной Группы по вопросам Движущегося Изображения (MPEG) и обсуждений во время заседания Специальной Группы РСА, прошедшего в октябре.
2. Экспериментальные результаты
2.1 Тестовые модели
Для неподвижных объектов
Узел DepthImage (изображение с глубиной) с SimpleTexture (простой текстурой)
Собака
Тиранозавр (DepthImage, с использованием около 20 камер)
Монстр (DepthImage, около 20 камер)
ChumSungDae (DepthImage, сканированные данные)
Пальма (DepthImage, 20 камер)
Узел DepthImage с LayeredTexture (многослойной текстурой)
Ангел
Узел DepthImage с PointTexture (точечной текстурой)
Ангел
Узел OctreeImage (изображение октодерева)
Существо
Для анимированных объектов
Узел DepthImage с SimpleTexture
Дракон
Дракон в окружении сцены
Узел DepthImage с LayeredTexture
Не предоставлен
Узел OctreeImage
Робот
Дракон в окружении сцены
Дополнительные данные (полученные в результате сканирования или моделирования) будут предоставлены в будущем.
2.2 Результаты тестов
Все предложенные в Сиднее узлы интегрированы в эталонное программное обеспечение blaxxun contact 4.3. Тем не менее, исходные коды до сих пор не загружены на сервер Системы Управления Версиями (СУВ).
Для форматов анимации представления на основе изображений (ПОИ) необходима синхронизация между множеством файлов кинофрагмента, выполняемая таким образом, чтобы изображения в одном и том же ключевом кадре из каждого файла кинофрагмента подавались в одно и то же время. Однако, имеющееся на текущий момент эталонное программное обеспечение не поддерживает эту возможность синхронизации, которая возможна в системах MPEG. Таким образом, на текущий момент форматы анимации можно визуализировать в предположении, что все анимационные данные уже находятся в файле. Для каждой анимационной текстуры временно используются файлы кинофрагментов в формате AVI.
После нескольких экспериментов с многослойными текстурами мы убедились в том, что узел LayeredTexture (многослойная текстура) оказывается неэффективным. Этот узел был предложен для многослойного изображения с глубиной. Однако, также есть узел PointTexture (точечная текстура), который поддерживает этот тип изображения. Поэтому мы предлагаем удалить узел LayeredTexture из спецификации узлов. фиг.1 иллюстрирует примеры ПОИ, интегрированного в имеющееся на текущий момент эталонное программное обеспечение.
(Фигура удалена)
3. Обновления спецификации узлов ПОИ
Выводом заседания в Сиднее о предложениях по ПОИ является то, что необходимо иметь поток данных ПОИ, который содержит изображения и информацию о камерах, а узлу ПОИ необходимо лишь содержать ссылку (унифицированный указатель информационного ресурса (url) на этот поток. Однако результатом обсуждения ПОИ во время заседания Специальной Группы в Ренне явилось то, что изображения и информация о камерах должны содержаться и в узлах ПОИ, и в потоке. Таким образом, ниже приведена обновленная спецификация узлов ПОИ. Требования к потоку данных ПОИ приводятся в разделе, который поясняет поле (url).
Декодер (битовые потоки) - спецификация узлов

Узел DepthImage определяет одну текстуру СИИ. Когда несколько узлов DepthImage связаны друг с другом, они обрабатываются как группа, и, таким образом, их следует подчинить одному и тому же узлу Transform (преобразование).
Поле diTexture задает текстуру с глубиной, которая отображается на область, определенную в узле DepthImage. Эта текстура относится к одному из множества типов текстур, основывающихся на изображениях с глубиной (SimpleTexture или PointTexture).
Поля position (положение) и orientation (ориентация) задают относительное положение точки наблюдения текстуры ПОИ в местной системе координат. Положение определяется относительно начала (0, 0, 0) системы координат, в то время как ориентация задает поворот относительно ориентации, принятой по умолчанию. В положении и ориентации, принятым по умолчанию, наблюдатель находится на оси Z и смотрит вниз по оси -Z в направлении начала координат со смещением +Х вправо и +Y вверх. Однако, иерархия преобразований влияет на конечные положение и ориентацию точки наблюдения.
Поле fieldOfView (область наблюдения) задает угол наблюдения от точки наблюдения камеры, определяемой полями position и orientation. Первая величина обозначает угол с горизонтальной стороной, а вторая величина обозначает угол с вертикальной стороной. Значения, принятые по умолчанию, равны 45° в радианах. Однако в случае, если поле orthogonal (ортогональное) задано как TRUE (истинно), поле fieldOfView обозначает ширину и высоту ближней плоскости и дальней плоскости.
Поля nearPlane (ближняя плоскость) и farPlane (дальняя плоскость) задают расстояния от точки наблюдения до ближней плоскости и до дальней плоскости области наблюдения. Данные о текстурах и глубине отображают область, заключенную между ближней плоскостью, дальней плоскостью и fieldOfView. Данные о глубине нормируются расстоянием между nearPlane и farPlane.
Поле orthogonal задает тип вида текстуры ПОИ. В случае, если данное поле установлено равным TRUE, текстура ПОИ основывается на ортогональном виде. В противном случае текстура ПОИ основывается на перспективном виде.
Поле depthImageUrl задает адрес потока данных изображений с глубиной, который опционально может включать в себя:
position
orientation
fieldOfView
nearPlane
farPlane
orthogonal
diTexture
однобайтовый заголовок, предназначенный для флагов наличия/отсутствия вышеперечисленных полей.

Узел SimpleTexture определяет отдельный слой текстуры ПОИ.
Поле texture задает плоское изображение, которое содержит цвет для каждого пикселя. Оно относится к одному из множества типов узлов текстур (ImageTexture (текстура изображения), MovieTexture (текстура кинофрагмента) или PixelTexture (пиксельная текстура).
Поле depth (глубина) задает глубину для каждого пикселя в поле texture. Размер карты глубины должен совпадать с размером изображения или кинофильма в поле texture. Это поле относится к одному из множества типов узлов текстур (ImageTexture, MovieTexture или PixelTexture). В случае, если узел depth равен NULL или поле depth не задано, альфа-канал в поле texture будет использоваться в качестве карты глубины.

Узел PointTexture определяет множество слоев точек ПОИ.
Поля width (ширина) и height (высота) задают ширину и высоту текстуры, соответственно.
Поле depth (глубина) задает множество значений глубины для каждой точки (в нормированных координатах) в плоскости проекции в порядке, при котором обход начинается с точки в левом нижнем углу и продолжается слева направо до завершения горизонтальной строки, после чего выполняется переход на строку, расположенную выше. Для каждой точки сначала запоминается количество значений глубины (пикселей), а затем - сами значения глубины.
Поле color (цвет) задает цвет текущего пикселя. Порядок тот же самый, что и для поля depth за исключением того, что не включается указанное число глубин (пикселей) для каждой точки.
(Фиг.1 и 2 удалены)

Узел OctreeImage (изображение октодерева) определяет структуру октодерева и проецируемые текстуры. Размер куба, заключающего в себе все октодерево, есть 1×1×1, а центром куба октодерева является начало (0, 0, 0) местной системы координат.
Поле octreeresolution (разрешение октодерева) задает максимальное число листьев октодерева, расположенных вдоль грани заключающего его куба. Уровень октодерева можно определить из поля octreeresolution (разрешение октодерева), используя следующее уравнение: octreelevel = int (log2 (octreeresolution -1)) +1).
Поле octree (октодерево) задает набор внутренних узлов октодерева. Каждый внутренний узел представлен байтом. 1 в i-м бите из этого байта означает, что для i-го дочернего узла рассматриваемого внутреннего узла существуют дочерние узлы, в то время как 0 означает, что этих узлов не существует. Порядок внутренних узлов - это порядок обхода октодерева по схеме "сначала в ширину". Порядок для восьми дочерних узлов внутреннего узла приведен на фиг.2.
(Фиг.3 удалена)
Поле octreeimages (изображения октодерева) задает набор узлов DepthImage, где в качестве поля diTexture выступает SimpleTexture. Однако, поля nearPlane и farPlane узла DepthImage и поле depth узла SimpleTexture не используются.
Поле octreeUrl задает адрес потока данных octreeImage, который включает в себя:
заголовок для флагов
octreeresolution
octree
octreeimages (множество узлов DepthImage)
nearPlane не используется
farPlane не используется
diTexture → SimpleTexture без поля depth
Ниже излагается изобретение, описанное в предварительной заявке №60/363545 на патент США, поданной 8 марта 2002 г. и озаглавленной "Способ и устройство для сжатия и формирования потока данных представления на основе изображений с глубиной".
II. КОДИРОВАНИЕ ДВИЖУЩИХСЯ ИЗОБРАЖЕНИЙ И АУДИОСИГНАЛОВ В СООТВЕТСТВИИ С ISO/IEC JTC 1/SC 29/WG 11
1. Введение
В этом документе приведены результаты основного эксперимента РСА А8.3 в области представлений на основе изображений с глубиной (ПОИГ). Данный основной эксперимент касается узлов представлений на основе изображений с глубиной, для которых используются текстуры с информацией о глубине. Эти узлы получили одобрение и были включены в предложение для Редакционной Комиссии во время заседания в Паттайе. Однако работы по преобразованию этой информации в поток данных посредством поля octreeUrl узла OctreeImage и поля depthImageUrl узла DepthImage все еще продолжаются. Настоящий документ описывает формат формирования потока данных, связанных этими полями url. Формат формирования потока данных включает в себя сжатие поля octree узла OctreeImage и полей depth/color узла PointTexture.
2. Формат формирования потока данных для octreeUrl
2.1 Формат потока
Узел OctreeImage включает в себя поле octreeUrl, которое задает адрес потока данных OctreeImage. Этот поток может дополнительно включать в себя:
заголовок для флагов
octreeresolution
octree
octreeImages (множество узлов DepthImage)
nearPlane не используется
nearPlane не используется
diTexture → SimpleTexture без поля depth
Поле octree задает набор внутренних узлов октодерева. Каждый внутренний узел представлен байтом. 1 в i-м бите из этого байта означает, что для i-гo дочернего узла рассматриваемого внутреннего узла существуют дочерние узлы, в то время как 0 означает, что этих узлов не существует. Порядок внутренних узлов - это порядок обхода октодерева по схеме "сначала в ширину". Порядок для восьми дочерних узлов внутреннего узла приведен на фиг.2.
(Фиг.1 удалена)
Поле octree узла OctreeImage представлено в компактном формате. Однако данное поле можно дополнительно сжать с целью обеспечения эффективного преобразования в поток данных. Нижеследующий раздел описывает схему сжатия для поля octree узла OctreeImage.
2.2. Схема сжатия для поля octree
В представлении ПОИГ на основе октодерева данные состоят из поля octree, которое представляет собой геометрическую компоненту. Октодерево - это набор точек в заключающем его кубе, которые полностью представляют поверхность объекта.
Неидентичное воспроизведение геометрии из сжатого представления приводит к хорошо заметным артефактам. Следовательно, геометрия должна быть сжата без потерь информации.
2.2.1. Сжатие octree
Для сжатия поля octree, представленного в форме октодерева с порядком обхода по схеме "сначала в глубину", нами разработан способ сжатия без потерь, в котором используются некоторые идеи подхода, известного как предсказание посредством частичного совпадения (ПЧС) [1, 2]. Основная используемая идея состоит в "предсказании" (то есть, оценке вероятности) следующего символа посредством нескольких предшествующих символов, которые называются "контекст". Для каждого контекста существует таблица вероятности, содержащая оцененную вероятность появления каждого символа в этом контексте. Эта процедура используется в комбинации с арифметическим кодером, называемым кодером дальности [3, 4].
Двумя основными отличительными признаками данного способа являются:
1) использование порождающего узла в качестве контекста для дочернего узла;
2) использование предположения об "ортогональной инвариантности" с целью уменьшения числа контекстов.
Вторая идея основывается на наблюдении, которое заключается в том, что "вероятность перехода" для пар "порождающий узел - дочерний узел" обычно инвариантна при ортогональных преобразованиях (повороте и преобразовании симметрии). Это предположение проиллюстрировано в Приложении 1. Это предположение позволяет нам использовать более сложный контекст, обходясь при этом без излишне большого числа таблиц вероятности. Это, в свою очередь, позволило нам достичь весьма хороших результатов в смысле объема и скорости, так как чем больше контекстов используется, тем точнее оценка вероятности и, таким образом, тем более компактен код.
Кодирование - это процесс построения и обновления таблицы вероятности в соответствии с контекстной моделью. В прелагаемом способе контекст моделируется как иерархия "порождающий узел - дочерний узел" в структуре октодерева. Во-первых, мы определяем символ как узел размером в один байт, биты которого указывают на заполнение подкуба после внутреннего разбиения. Следовательно, каждый узел октодерева может представлять собой символ, а его числовое значение лежит в пределах от 0 до 255. Таблица вероятности (ТВ) содержит 256 целых чисел. Значение i-й переменной (0≤i≤255), деленное на сумму всех переменных, равно частоте (оценке вероятности) появления i-го символа. Таблица вероятности контекстов (ТВК) - это набор таблиц ТВ. Вероятность символа определяется из одной и только одной из таблиц ТВ. Число конкретных таблиц ТВ зависит от контекста. Пример ТВК приведен в таблице 1.
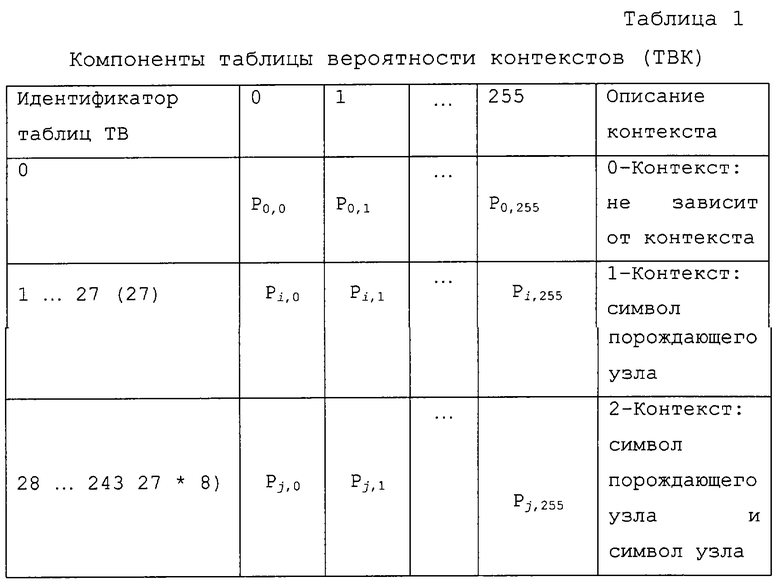
Кодер работает следующим образом. Сначала он использует 0-контекстную модель (то есть, одна и та же ТВ для всех символов, в исходном состоянии характеризуемая равномерным распределением элементов и обновляемая после каждого нового кодового символа). Дерево обходится в порядке обхода по схеме “сначала в глубину”. После того, как собран достаточный объем статистических данных (эмпирически определенное значение соответствует 512 кодовым символам), кодер переключается на 1-контекстную модель. Она содержит 27 контекстов, которые задаются следующим образом.
Рассмотрим набор из 32 фиксированных ортогональных преобразований, которые включают в себя преобразования симметрии и повороты на 90° относительно осей координат (см. Приложение 2). Далее, мы можем категоризировать символы в соответствии с шаблоном заполнения их подкубов. Согласно нашему способу, имеются 27 наборов символов, в данном документе называемых группами, которые характеризуются следующим свойством: 2 символа связаны посредством одного из этих фиксированных преобразований тогда и только тогда, когда они принадлежат одной группе.
В байтовом обозначении группы представлены 27 наборами чисел (см. Приложение 2). Мы полагаем, что таблица вероятности зависит не от самого порождающего узла (в этом случае мы получили бы 256 таблиц), а только от группы (обозначаемой в таблице 1 как ParentSymbol), к которой принадлежит этот порождающий узел (таким образом, 27 таблиц).
В момент переключения таблицы ТВ для всех контекстов задаются равными копиям ТВ, соответствующей 0-контекстной модели. Далее, каждая из 27 таблиц ТВ обновляется, если она используется для кодирования.
После кодирования 2048 (еще одно эвристическое значение) символов в соответствии с 1-контекстной моделью, мы переключаемся на 2-контекстную модель, которая использует пары (ParentSymbol, NodeSymbol) в качестве контекстов. NodeSymbol просто представляет собой положение текущего узла в порождающем узле. Таким образом, у нас есть 27*8 контекстов для 2-контекстной модели. В момент переключения на эту модель таблицы ТВ, полученные для каждого контекста, используются для каждого узла "внутри" этого контекста и с этого момента обновляются независимо.
Более детально, кодирование для 1-контекстной и 2-контекстной моделей осуществляется следующим образом. Для контекста текущего символа (то есть, порождающего узла) определяется его группа. Это делается посредством поиска в таблице (геометрический анализ был выполнен на этапе разработки программы). Далее, мы применяем ортогональное преобразование, которое превращает наш контекст в "стандартный" (выбранный произвольным образом раз и навсегда) элемент группы, к которой он принадлежит. То же самое преобразование применяется к самому символу (эти операции также реализуются с помощью таблицы преобразования, при этом, естественно, все вычисления для всех возможных комбинаций были выполнены заранее). В общих чертах, вышеописанная процедура представляет собой вычисление корректной позиции текущего символа в таблице вероятности для группы, содержащей его контекст. Далее, соответствующая вероятность подается на кодер дальности.
Таким образом, при заданных порождающем узле и позиции субузла определяется ContextID, который задает идентификатор группы и позицию ТВ в ТВК. Распределение вероятности в ТВ и ContextID подаются на кодер дальности. После кодирования ТВК обновляется с целью использования при следующем кодировании. Следует отметить, что кодер дальности представляет собой вариант арифметического кодирования, при котором выполняется повторное нормирование в байтах вместо битов, в результате чего время выполнения снижается вдвое, а сжатие ухудшается на 0,01% по сравнению со стандартной реализацией арифметического кодирования.
Процесс декодирования, по существу, является обратным процессу кодирования. Это абсолютно стандартная процедура, которая не требует описания, так как она использует в точности те же самые способы определения контекстов, обновления вероятностей и т.д.
2.3. Результаты тестов
На фиг.3 представлена это таблица, предназначенная для сравнения нашего подхода как для неподвижных, так и для анимационных моделей (ось ординат обозначает степень сжатия). Степень сжатия октодерева варьируется в районе 1,5-2 раз по сравнению с исходным размером октодерева и не менее чем на 30% превосходит способы сжатия без потерь, предназначенные для общих целей (на основе алгоритма Лемпеля-Зива, например, программа RAR).
(Фиг.3 удалена)
3. Формат преобразования в поток данных для depthImageUrl
3.1. Формат потока
Узел DepthImage включает в себя поле depthImageUrl, которое задает адрес потока данных изображений с глубиной. Этот поток дополнительно может включать в себя:
однобайтовый заголовок для флагов наличия/отсутствия нижеприведенных полей
position
orientation
fieldOfView
nearPlane
farPlane
orthogonal
diTexture (SimpleTexture или PointTexture)
Определение узла PointTexture, который можно использовать в поле diTexture, проводится следующим образом.
PointTexture{

Узел PointTexture определяет множество слоев точек ПОИ. Поля width и height задают ширину и высоту текстуры, соответственно. Поле depth задает множество значений глубины каждой точки (в нормированных координатах) в плоскости проекции в порядке, при котором обход начинается с точки в левом нижнем углу и продолжается слева направо до завершения горизонтальной строки, после чего выполняется переход на строку, расположенную выше. Для каждой точки сначала запоминается количество значений глубины (пикселей), а затем - сами значения глубины. Поле color задает цвет текущего пикселя. Порядок тот же самый, что и для поля depth за исключением того, что не включается указанное число глубин (пикселей) для каждой точки.
Поля depth и color узла PointTexture представлены в формате необработанных данных, и размер этих полей, по всей вероятности, будет очень большим. Следовательно, необходимо сжатие этих полей с целью обеспечения эффективного преобразования в поток данных. Нижеследующий раздел описывает схему сжатия для упомянутых полей узла PointTexture.
3.2. Схема сжатия для PointTexture
3.2.1. Сжатие поля depth
Поле depth узла PointTexture просто является набором точек в "дискретизированном заключающем кубе". Мы предполагаем, что плоскостью проекции является нижняя плоскость. При условии, что для модели заданы сетки размерностью m*n*I, причем точки являются центрами ячеек (в случае октодерева мы называем их вокселями) данной сетки, мы можем рассматривать занятые воксели в качестве единиц, а пустые воксели - в качестве нулей. Далее результирующий набор битов (m*n*I битов) организуется в поток байтов. Это осуществляется посредством просмотра вокселей по направлению в глубину (ортогонально плоскости проекции) по слоям глубиной 8, и в обычном (по столбцам) порядке в плоскости проекции (при необходимости последний слой байтов дополняется нулями в случае, если размерность глубины не делится на 8 нацело). Таким образом, мы можем рассматривать наш набор точек в качестве стека 8-битовых изображений (в качестве варианта - 16-битовых изображений) шкалы уровней серого. Соответствие вокселей и битов проиллюстрировано на фиг.4 (а), приведенной ниже.
(Фиг.4 удалена)
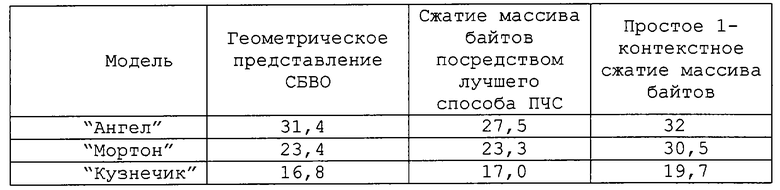
Например, на фиг.4(б) черные квадраты соответствуют точкам на объекте. Плоскостью проекции является горизонтальная плоскость. Рассмотрим "срез" высотой 16 (его верхняя граница обозначена жирной линией). Будем интерпретировать "столбцы" как байты. Иными словами, столбец, находящийся над отмеченной на рассматриваемой фигуре точкой, представляет собой стек из 2 байтов со значениями 18 и 1 (или 16-битовое целое 274). Если мы применим лучшие из имеющихся на настоящий момент способов сжатия, основывающихся на ПЧС, к полученному таким образом объединению байтов, то получим весьма хорошие результаты. Однако, если в рассматриваемом случае напрямую применяется простой 1-контекстный способ (конечно, в рассматриваемом случае не может использоваться ортогональная инвариантность или иерархические контексты), степень сжатия для этих результатов оказывается немного меньше. Ниже приведена таблица объемов, требуемых для различных типов геометрических представлений МИГ: сжатие БВО (СБВО); вышеупомянутый массив байтов, сжатый лучшим уплотнителем информации ПЧС, и тот же самый массив, сжатый используемым в текущий момент нашим уплотнителем информации (цифры в Кбайтах).
3.2.2. Сжатие поля color
Поле color узла PointTexture представляет собой набор цветов, являющихся атрибутом точек объекта. В отличие от случая октодерева, поле color имеет однозначное соответствие с полем depth. Идея состоит в том, чтобы представить информацию о цвете в качестве одного изображения, которое можно сжать посредством одного из известных способов сжатия с потерями. Число элементов этого изображения значительно меньше, чем число элементов эталонных изображений в случае октодерева или DepthImage, что является серьезной мотивацией для такого подхода. Изображение можно получить посредством сканирования точек с глубиной в том или ином естественном порядке.
Рассмотрим сначала порядок сканирования, диктуемый нашим исходным форматом хранения данных для МИГ (PointTexture) - сканирование геометрии по схеме "сначала в глубину". Мультипиксели сканируются в естественном порядке поперек плоскости проекции так, как будто они являются простыми пикселями, а точки внутри того же самого мультипикселя сканируются в направлении глубины. Результатом этого порядка сканирования является одномерный массив цветов (1-й ненулевой мультипиксель, 2-й ненулевой мультипиксель и т.д.). Как только глубина становится известной, цвета точек можно последовательно воссоздать из этого массива. Для того чтобы сделать возможным применение способов сжатия изображений, мы должны однозначно отобразить эту длинную строку в двумерный массив. Это можно сделать разными способами.
Подход, используемый в нижеприведенных тестах, представляет собой так называемое "блочное сканирование", при котором строка цвета упорядочивается в виде блоков 8*8, а эти блоки упорядочиваются по столбцам ("блочное сканирование"). Результирующее изображение приведено на фиг.5.
Сжатие данного изображения выполнялось несколькими способами, включая стандартный способ JPEG. Оказывается, что по крайней мере для этого типа цветного сканирования значительно лучшие результаты получаются при использовании способа сжатия текстур, описанного в [5]. Этот способ основывается на адаптивном локальном пакетировании каждого блока 8*8. У этого способа есть два режима: восьми- и двенадцатикратное сжатие (по сравнению с "необработанным" форматом BMP с реалистичным цветовоспроизведением при 24 битах на пиксель). Успех данного способа для этого типа изображений можно точно объяснить из характера его палитры, которая позволяет нам принимать во внимание резкие (даже не обособленные линейные структуры в контрастных цветах) локальные вариации цвета, возникающие вследствие "смешивания" цветов точек передней и задней поверхностей (которые могут разительно различаться, как в случае модели "Ангел"). Целью поиска оптимального сканирования является уменьшение этих вариаций насколько это возможно.
(Фиг.5 удалена)
3.3. Результаты тестов
В Приложении 3 приводятся примеры моделей в исходном и сжатом форматах. Качество некоторых моделей (например, "Ангел") после сжатия до сих пор остается не достаточно удовлетворительным, в то время как качество остальных моделей очень хорошее ("Кузнечик"). Однако есть ощущение, что эту проблему можно решить посредством надлежащего сканирования. Потенциально можно было бы использовать режим двенадцатикратного сжатия, так чтобы общий уровень сжатия повысился на еще большую величину. В конце концов, сжатие без потерь можно улучшить так, чтобы приблизиться к результатам в сжатии геометрии на основе лучших способов ПЧС.
Здесь мы приводим таблицу степеней сжатия.

4. Заключение
В этом документе приводится отчет о результатах основного эксперимента РСА А8.3 в области представлений, основывающихся на изображениях с глубиной. Вводятся потоки данных ПОИГ, связь с которыми осуществляется через поля url узлов ПОИГ. Эти потоки состоят из всех элементов узла ПОИГ совместно с флагом для каждого элемента, указывающим на необязательность этого элемента. Также исследуется сжатие данных октодерева и PointTexture.
5. Ссылки
[1] Cleary J.G., Witten I.H., Data compression using adaptive coding and partial string matching, IEEE Transactions on Communications, Vol.32(4), pp.396-402, April 1984.
[2] Rissanen J.J., Langdon G.G., Universal modeling and coding // IEEE Transactions on Information Theory, Vol.27(1), pp.12-23, Jan. 1981.
[3] Schindler M., A byte oriented arithmetic coding, Proceedings of Data Compression Conference, 1998.
[4] Martin G.N.N., Range encoding an algorithm for removing redundancy from a digitized message. Video & Data Recording Conference, March 1979.
[5] Levkovich-Maslyuk L., Kalyzhny P., Zhirkov A., Texture compression with adaptive block partitions, Proceedings of 8th ACM International Conference on Multimedia (Multimedia 2000).
Приложение 1. Геометрический смысл ортогональной инвариантности контекстов в алгоритме сжатия БВО.
Предположение об ортогональной инвариантности проиллюстрировано на фиг.6. Рассмотрим поворот относительно вертикальной оси на 90° по часовой стрелке. Рассмотрим произвольные шаблоны заполнения узла и его порождающего до (верхний рисунок) и после поворота (нижний рисунок). Далее два различных шаблона можно рассматривать в качестве одного и того же шаблона.
(Фигура удалена)
Приложение 2. Группы и преобразования.
1. 32 фиксированных ортогональных преобразования.
Каждое преобразование задается 5-битовым словом. Комбинация битов представляет собой композицию следующих базовых преобразований (то есть, если k-й бит равен 1, то выполняется соответствующее преобразование)
1-й бит: перестановка координат x и y;
2-й бит: перестановка координат y и z;
3-й бит: преобразование симметрии в плоскости (y-z);
4-й бит: преобразование симметрии в плоскости (x-z);
5-й бит: преобразование симметрии в плоскости (x-y);
2. 27 групп
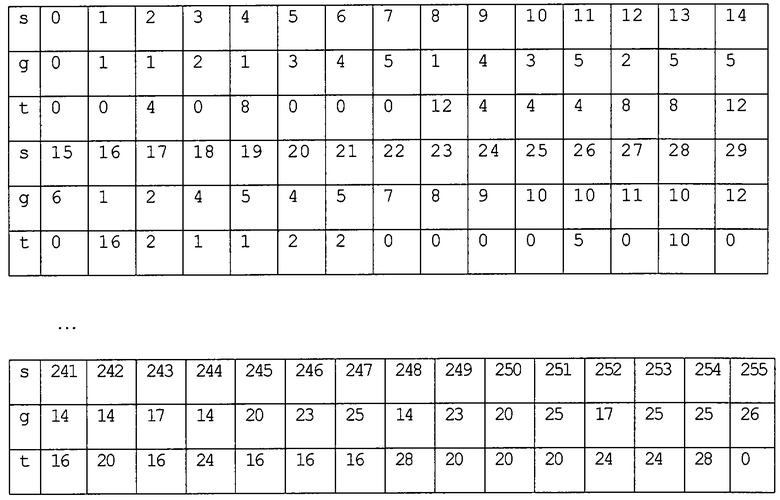
Для каждой группы здесь приводится порядок данной группы и число ненулевых битов в ее элементах: NumberOfGroup, QuantityOfGroup и NumberOfFillBits(SetVoxels).

3. Символы и преобразования
Для каждого символа (s) имеется индекс (g) группы, к которой он принадлежит, и значение (t) преобразования, которое превращает его в “стандартный” элемент данной группы.
Бинарный номер символа отображается в бинарные координаты вокселя следующим образом: координатами i-го бита упомянутого номера являются х=i&1, y=i&(1<<1), z=i&(1<<2).
Приложение 3. Экранные изображения сжатия точечной текстуры.
На фиг.7, 8 и 9 приведены данные, характеризующие сжатие геометрии для лучшего способа, основывающегося на ПЧС.
(Фигуры удалены)
Ниже излагается изобретение, описанное в предварительной заявке №60/376563 на патент США, поданной 1 мая 2002 г. и озаглавленной "Способ и устройство для сжатия и формирования потока данных представления на основе изображений с глубиной".
III. Результаты основного эксперимента для представлений на основе изображений с глубиной (РСА А8.3)
1. Введение
В настоящем документе приведены результаты основного эксперимента РСА А8.3 для представлений на основе изображений с глубиной (ПОИГ). Данный основной эксперимент касается узлов представления на основе изображений с глубиной, использующих текстуры с информацией о глубине. Такие узлы получили одобрение и были включены в предложения для Редакционной Комиссии на заседании в Паттайе. Однако работы по преобразованию этой информации в поток данных посредством узла OctreeImage и узла DepthImage все еще продолжаются. Настоящий документ описывает формат формирования потока данных, связь с которым осуществляется этими узлами. Формат формирования потока данных включает в себя сжатие поля octree узла OctreeImage и полей depth/color узла PointTexture.
2. Сжатие форматов ПОИГ
В настоящем документе приводится описание нового способа эффективного сжатия несвязанной структуры данных октодерева без потерь, который позволяет в наших экспериментах сократить объем этого уже компактного представления примерно в 1,5-2 раза. Мы также предлагаем несколько способов сжатия без потерь и с потерями формата PointTexture с использованием промежуточного воксельного представления в комбинации со статистическим кодированием и специализированным блочным способом сжатия текстур [6].
2.1. Сжатие OctreeImage
Поля octreeimages и octree в OctreeImage сжимаются раздельно. Описываемые далее способы разрабатывались исходя из наблюдения, что поле octree требуется сжимать без потерь, в то время как для поля octreeimages допустима некоторая визуально приемлемая степень искажений. Поле octreeimages сжимают посредством способа сжатия изображений MPEG-4 (в случае статических моделей), либо с помощью средств для сжатия видеоизображений (в случае анимационных моделей).
(Фиг.1 удалена)
2.1.1. Сжатие поля octree.
Сжатие octree является наиболее важной частью сжатия OctreeImage, так как оно относится к сжатию и без того уже очень компактного представления в виде несвязанного бинарного дерева. Однако в наших экспериментах рассматриваемый ниже способ сократил объем этой структуры примерно до половины ее исходного размера. В случае анимационной версии OctreeImage выполняется отдельное сжатие поля octree для каждого трехмерного кадра.
2.1.1.1. Контекстная модель
Сжатие выполняется с применением варианта адаптивного арифметического кодирования (реализованного в виде "кодера дальности", [3], [4]), в котором явно используется геометрическая природа данных. Поле octree представляет собой поток байтов. Каждый байт представляет узел (то есть, подкуб) дерева, в котором его биты определяют занятость данного подкуба после внутреннего разбиения. Эта комбинация битов называется шаблоном заполнения узла. Рассматриваемый алгоритм сжатия обрабатывает байты один за одним следующим образом:
Определяется контекст текущего байта.
Из соответствующей данному контексту "таблицы вероятности" (ТВ) извлекается "вероятность" (нормированная частота) появления текущего байта в данном контексте.
Значение вероятности подается на кодер дальности.
Текущая ТВ обновляется посредством прибавления 1 к значению частоты появления текущего байта в текущем контексте (и, если необходимо, впоследствии нормируется повторно, подробно см. ниже).
Таким образом, кодирование представляет собой процесс построения и обновления таблиц ТВ в соответствии с контекстной моделью. В основывающихся на контекстах схемах адаптивного арифметического кодирования (таких, как "Предсказание посредством частичного совпадения" [1]-[3]), контекст символа обычно представляет собой строку из нескольких предшествующих ему символов. Однако, в нашем случае эффективность сжатия увеличивается посредством использования структуры октодерева и геометрической природы данных. Рассматриваемый подход основывается на двух идеях, которые, очевидно, впервые применяются в задаче сжатия октодерева.
А. Для текущего узла контекст - это либо его порождающий узел, либо пара {порождающий узел, положение текущего узла в порождающем узле}.
Б. Предполагается, что "вероятность" появления данного узла в конкретной геометрической позиции в конкретном порождающем узле является инвариантной по отношению к некоторому набору ортогональных преобразований (таких как повороты или преобразования симметрии).
Предположение “Б” проиллюстрировано на фиг.6 для преобразования R, которое является поворотом на -90° в плоскости x-z. Основная идея предположения "Б" состоит в наблюдении, что вероятность появления некоторого конкретного типа дочернего узла в некотором конкретном типе порождающего узла должна зависеть только от их относительного положения. Данное предположение подтверждается в наших экспериментах путем анализа таблиц вероятности. Оно позволяет нам использовать более сложный контекст без слишком большого числа таблиц вероятности. Это, в свою очередь, помогает достигать весьма хороших результатов в смысле объема данных и скорости. Следует отметить, что чем больше контекстов используется, тем точнее оценка вероятности и, следовательно, тем более компактен код.
Введем набор преобразований, для которых мы предполагаем инвариантность распределений вероятности. Для того чтобы эти преобразования можно было использовать в нашем случае, они должны сохранять заключающий куб без изменений. Рассмотрим набор G ортогональных преобразований в евклидовом пространстве, которые получаются посредством всех всевозможных сочетаний в произвольном количестве и порядке трех следующих базовых преобразований (генераторов) m1, m2 и m3, заданных следующим образом:
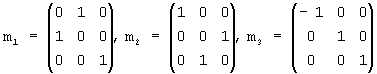
где m1 и m2 - это отражения относительно плоскостей х=z и y=z, соответственно, а m3 - отражение относительно плоскости х=0. Один из классических результатов теории групп, полученных посредством отражений [27], гласит, что G содержит 48 различных ортогональных преобразований и является, по сути, максимальной группой ортогональных преобразований, которые преобразуют куб сам в себя (так называемая группа Когзетера [27]). Например, поворот R по фиг.6 посредством генераторов выражается как
R=m3·m2·m1·m2,
где “·” обозначает операцию умножения матриц.
Будучи примененным к узлу октодерева, преобразование, задаваемое G, формирует узел с отличающимся шаблоном заполнения подкубов. Это позволяет категоризировать узлы в соответствии с шаблонами заполнения их подкубов. Используя терминологию теории групп, можно сказать, что G воздействует на набор всех шаблонов заполнения узлов октодерева. Вычисления показывают, что имеется 22 отличающихся класса (в теории групп они также называются орбитами), для которых по определению два узла принадлежат одному и тому же классу тогда и только тогда, если они связаны преобразованием, задаваемым G. Количество элементов в классе меняется от 1 до 24 и всегда является делителем 48.
Практическим следствием предположения "Б" является тот факт, что таблица вероятности зависит не от самого порождающего узла, а только от класса, к которому принадлежит этот порождающий узел. Следует отметить, что в первом случае для контекста, основывающегося на порождающих узлах, потребовались бы 256 таблиц, и дополнительные 256×8=2048 таблиц для контекста, основывающегося на взаимном расположении порождающих и дочерних узлов, в то время как во втором случае для контекста, основывающегося на классе порождающего узла, требуются только 22 таблицы плюс 22×8=176 таблиц. Следовательно, представляется возможным использовать одинаково сложный контекст с относительно небольшим числом таблиц вероятности. Сформированные ТВ будут иметь форму, приведенную в таблице 2.

2.1.1.2 Процесс кодирования
Чтобы повысить точность статистических данных для таблиц вероятности, эти данные собираются различными способами на трех этапах процесса кодирования.
На первом этапе контекст вообще не используется, принимается "0-контекстная модель", и поддерживается одна таблица вероятности с 256 ячейками, в исходном состоянии характеризуемая равномерным распределением элементов.
Как только выполнено кодирование первых 512 узлов (данное число было получено эмпирически), выполняется переключение на "1-контекстную модель" с порождающим узлом в качестве контекста. В момент данного переключения ТВ, соответствующая 0-контекстной модели, копируется в таблицы ТВ для всех 22 контекстов.
После выполнения кодирования 2048 узлов (также эвристическая величина), выполняется переключение на "2-контекстную модель". В данный момент таблицы ТВ для конфигураций порождающих узлов, соответствующие 1-контекстной модели, копируются в таблицы ТВ для каждого из положений в той же конфигурации порождающего узла.
Ключевым моментом данного алгоритма является определение контекста и вероятности для текущего байта. Он реализуется следующим образом. Для каждого класса фиксируется один элемент, который называется "стандартным элементом". Мы сохраняем таблицу отображения классов (ТОК), указывающую на класс, которому принадлежит каждый из 256 возможных узлов, а также заранее вычисленное преобразование, задаваемое G, которое переводит данный конкретный узел в стандартный элемент его класса. Таким образом, чтобы вычислить вероятность текущего узла N, выполняют следующие этапы:
Получить порождающий узел Р текущего узла.
Извлечь из ТОК класс, которому принадлежит Р, и преобразование Т, которое переводит Р в стандартный узел этого класса. Пусть номер класса равен с.
Применить Т к Р и найти положение р дочернего узла в стандартном узле, на который отображается текущий узел N.
Применить Т к N. В результате только что полученный шаблон заполнения TN находится в положении р в стандартном узле класса с.
Извлечь требующееся значение вероятности из ячейки TN таблицы вероятности, соответствующей комбинации класс-положение (с, р).
Модификация вышеприведенных этапов для 1-контекстной модели очевидна. Нет нужды говорить, что все преобразования вычисляются заранее и реализуются в виде таблицы, по которой осуществляется их поиск.
Следует отметить, что на этапе декодирования узла N его родитель Р уже прошел декодирование и, следовательно, преобразование Т известно. Все этапы на стадии декодирования аналогичны соответствующим этапам кодирования.
Наконец, рассмотрим процесс обновления значения вероятности. Пусть Р - это таблица вероятности для некоторого контекста. Обозначим элемент Р, соответствующий вероятности появления узла N в данном контексте, как Р (N). В нашей реализации Р (N) - это целое число, и после каждого появления N значение P(N) обновляется следующим образом:
P(N)=P(N)+А,
где А - это целый параметр приращения, величина которого для различных контекстных моделей обычно варьируется между 1 и 4. Пусть S (Р) равно сумме значений всех элементов в Р. Тогда "вероятность" того, что N поступит на арифметический кодер (кодер дальности в нашем случае), вычисляется как P(N)/S(P). Как только величина S (Р) достигнет порогового значения 216, выполняется повторное нормирование всех ячеек: чтобы избежать появления в Р нулевых значений, элементы, равные 1, остаются без изменений, а все остальные элементы делятся на 2.
2.2. Сжатие PointTexture.
Узел PointTexture содержит два подлежащих сжатию поля, а именно depth и color. Основные трудности, возникающие при сжатии данных PointTexture, связаны со следующими требованиями:
Сжатие геометрии необходимо выполнять без потерь, так как искажения при данном типе геометрического представления зачастую очень заметны.
Информация о цвете не обладает естественной двумерной структурой, следовательно, способы сжатия изображений нельзя применять непосредственно.
В этом разделе предлагаются три способа сжатия модели PointTexture:
Способ сжатия без потерь для узлов в стандартном представлении.
Способ сжатия без потерь для узлов в представлении с уменьшенным разрешением.
Способ сжатия для узлов в представлении с уменьшенным разрешением, при котором геометрия сжимается без потерь, а цвет сжимается с потерями.
Эти способы соответствуют трем уровням "достоверности" описания объекта. В первом способе предполагается, что необходимо хранить информацию о глубине с точностью вплоть до исходных 32 бит. Однако, на практике информацию о глубине можно без потери качества дискретизировать на гораздо меньшее число бит. В частности, если модель PointTexture получена путем преобразования из полигональной модели, то разрешение дискретизации выбирают согласно фактическому размеру видимых деталей исходной модели, а также требуемому выходному разрешению экрана. В таком случае 8-11 бит могут вполне удовлетворить приведенные требования, и значения глубины изначально сохраняются в данном формате с уменьшенным разрешением. Тогда наш второй способ обеспечивает сжатие без потерь для такого представления с уменьшенным разрешением. Важное наблюдение состоит в том, что для такого относительно небольшого (в сравнении со стандартными 32) числа битов можно использовать промежуточное воксельное представление модели, что позволяет существенно сжимать поле depth без потери информации. В обоих случаях информация о цвете сжимается без потерь и после группирования цветовых данных в виде вспомогательного двумерного изображения сохраняется в формате PNG (Portable Network Graphics, переносимая сетевая графика).
Наконец, третий способ позволяет достичь гораздо большей степени сжатия путем комбинирования сжатия геометрии без потерь и сжатия цветовых данных с потерями. Последнее выполняется посредством специализированного способа блочного сжатия текстур. В нижеследующих трех подразделах эти способы описаны во всех деталях.
2.1.1. Способ сжатия PointTexture без потерь для узлов в стандартном представлении.
Данный способ представляет собой простой способ кодирования без потерь, который работает следующим образом:
Поле depth сжимают с помощью адаптивного кодера дальности, подобного кодеру, который использовался при сжатии поля octree. Для данного формата мы используем вариант, в котором таблица вероятности ведется для каждого из односимвольных контекстов, а контекст - это просто предшествующий байт. Следовательно, используют 256 таблиц ТВ. Поле depth рассматривается как поток байтов, и геометрическая структура явно не используется.
Поле color сжимают после его преобразования в плоское изображение с реалистичным цветовоспроизведением. Цвета точек в модели PointTexture сначала записываются во временный одномерный массив в том же порядке, что и значения глубины в поле depth. Если общее количество точек в рассматриваемой модели равно 1, то вычисляют наименьшее целое число L, такое что 1·1≥L, и "упаковывают" эту длинную "строку" цветовых значений в квадратное изображение со стороной 1 (по необходимости дополняя ее черными пикселями). Затем это изображение сжимают одним из средств MPEG-4 сжатия изображений без потерь. В нашем подходе мы применяли формат переносимой сетевой графики (PNG). На фиг.10(а) приведено полученное описанным способом изображение модели "Ангел".
2.2.2. Способ сжатия PointTexture без потерь для узлов в представлении с уменьшенным разрешением.
Во многих случаях 16-битное разрешение для информации о глубине оказывается излишне точным. Фактически, разрешение по глубине должно соответствовать разрешению экрана, на котором визуализируется модель. В тех ситуациях, когда малые вариации в глубине модели в разных точках приводят к смещениям в экранной плоскости, размер которых намного меньше размера пикселя, представляется разумным использовать меньшее разрешение по глубине, и модели зачастую представляют в формате, в котором значения глубины занимают 8-11 бит. Такие модели обычно получают из других форматов, например полигональных моделей, посредством дискретизации значений глубины и цвета по подходящей пространственной сетке.
Такое представление с уменьшенным разрешением само по себе может рассматриваться как сжатая форма стандартной модели с 32-битной глубиной. Однако, для таких моделей существует более компактное представление с использованием промежуточного воксельного пространства. Действительно, точки модели можно рассматривать как принадлежащие узлам однородной пространственной сетки, размер ячейки которой определяется шагом дискретизации. Всегда можно предположить, что сетка является однородной и ортогональной, так как в случае перспективной модели можно работать в параметрическом пространстве. На основе указанного наблюдения сжатие полей depth и color для PointTexture с уменьшенным разрешением выполняется следующим образом.
Поле color сжимают с помощью способов сжатия изображения без потерь, так же как и в предыдущем способе.
Поле depth сначала преобразуют в воксельное представление и затем сжимают посредством варианта кодера дальности, описанного в предыдущем подразделе.
Промежуточная воксельная модель строится следующим образом. Рассмотрим дискретное воксельное пространство размера width × height ×2s (параметры width и height описаны в спецификации PointTexture), соответствующее разрешению s модели по глубине. Для наших целей нет необходимости работать с потенциально огромным воксельным пространством целиком, а только с его "тонкими" поперечными сечениями. Обозначим координаты по строкам-столбцам в плоскости проекции как (r, с), и пусть d обозначает координату по глубине. Преобразуем "срезы" {с=const}, то есть поперечные сечения модели "вертикальными плоскостями", к воксельному представлению. При сканировании, среза вдоль "столбцов", параллельных плоскости проекции, воксель (r, с, d) устанавливается "черным" тогда и только тогда, если существует такая точка модели со значением глубины d, которая проецируется в (r, с). Данный процесс показан на фиг.4.
(Фиг.2 удалена)
Как только срез сформирован, его сжимают с помощью 1-контекстного кодера дальности, после чего начинается процесс сжатия следующего среза. Таким образом мы избегаем работы с очень большими массивами. Инициализация таблиц вероятности для каждого нового среза не выполняется. Для широкого диапазона моделей только малая доля вокселей оказывается черными, что позволяет достичь весьма высокой степени сжатия. Декомпрессия выполняется путем очевидного обращения описанных операций.
Далее описывается сравнение сжатия поля depth посредством только что описанного способа и посредством представления в виде октодерева. Тем не менее, общая степень сжатия модели определяется полем color, так как подобные нерегулярные изображения нельзя сильно сжать без искажений. В следующем подразделе рассматривается комбинация сжатия геометрии без потерь и сжатия цвета с потерями.
2.2.3. Сжатие PointTexture в представлении с уменьшенным разрешением, при котором геометрия сжимается без потерь, а цвет сжимается с потерями.
Аналогично предшествующему способу, данный способ преобразует поле depth в воксельное представление, которое затем сжимают с помощью 1-контекстного адаптивного кодера дальности. Поле color также отображается на двумерное изображение. Однако делается попытка выполнить это отображение таким образом, чтобы точки, близко расположенные в трехмерном пространстве, отобразились в соседние точки в плоскости двумерного изображения. Затем к результирующему изображению применяют специализированный способ сжатия текстур (адаптивное разбиение на блоки, АРБ). Данный алгоритм включает в себя следующие основные этапы:
1. Преобразовать "срез" из четырех последовательных "вертикальных плоскостей" модели PointTexture к воксельному представлению.
2. Просканировать полученный массив из width × 4 × 2s вокселей посредством:
Обхода вертикальной "плоскости" из 4×4×4 субкубов вокселей вдоль "столбцов", параллельных плоскости проекции: сначала - столбец, ближайший к плоскости проекции, затем следующий ближайший столбец и т.д. (то есть, в обычном порядке обхода двумерного массива).
Обхода вокселей внутри каждого субкуба 4×4×4 в порядке, аналогичном порядку, который используется для обхода субкубов узлов OctreeImage.
3. Записать во вспомогательный одномерный массив цвета точек рассматриваемой модели по мере их появления при таком порядке обхода.
4. Переупорядочить полученный массив цветов в двумерное изображение таким образом, чтобы:
5. Последовательные 64 цветовые выборки упорядочивались по столбцам в блок 8×8 пикселей, а следующие 64 выборки – в соседний -блок 8×8 пикселей и т. д.
6. Сжать полученное изображение посредством способа АРБ.
(Фиг.3 удалена)
Такой способ сканирования трехмерного массива и отображения результата на двумерное изображение был выбран исходя из следующих соображений. Отметим, что субкубы 4×4×4 и блоки 8×8 изображения содержат одинаковое число выборок. Если несколько последовательно просканированных субкубов содержат число цветовых выборок, достаточное для заполнения блока 8×8, то весьма вероятно, что этот блок будет достаточно однородным, и, как следствие, после декомпрессии искажения в трехмерной модели едва ли будут заметны. Алгоритм АРБ выполняет сжатие блоков 8×8 независимо друг от друга с помощью локального пакетирования. В наших тестах искажения, вносимые сжатием АРБ в результирующую трехмерную модель, были значительно меньшими, чем искажения при использовании JPEG. Еще одной причиной выбора этого алгоритма послужила высокая скорость декомпрессии (для которой он изначально и разрабатывался). Степень сжатия может принимать одно из двух значений: 8 или 12. Для алгоритма сжатия PointTexture мы фиксируем степень сжатия равной 8.
К сожалению, этот алгоритм не обладает универсальной применимостью. Хотя показанное на фиг.10(б) изображение, полученное из поля color указанным образом, обладает гораздо больше однородностью, чем изображение, полученное посредством сканирования в "естественном" порядке, иногда двумерные блоки 8×8 могут содержать цветовые выборки, соответствующие удаленным друг от друга точкам в трехмерном пространстве. В этом случае способ сжатия АРБ с потерями может "смешать" цвета от удаленных областей модели, что приводит к локальным, но заметным искажениям после декомпрессии.
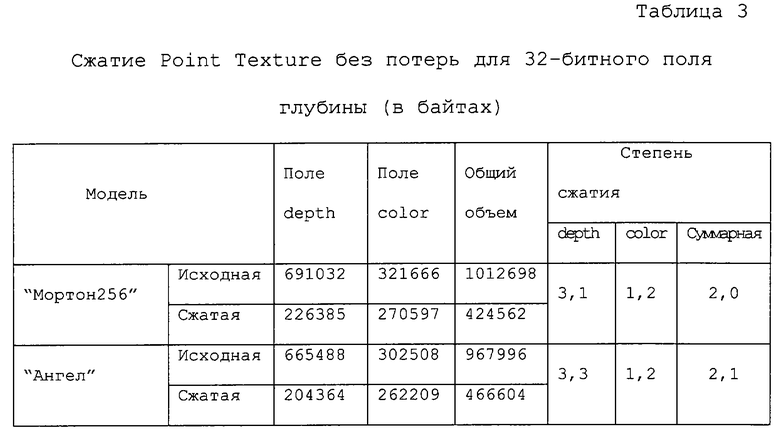
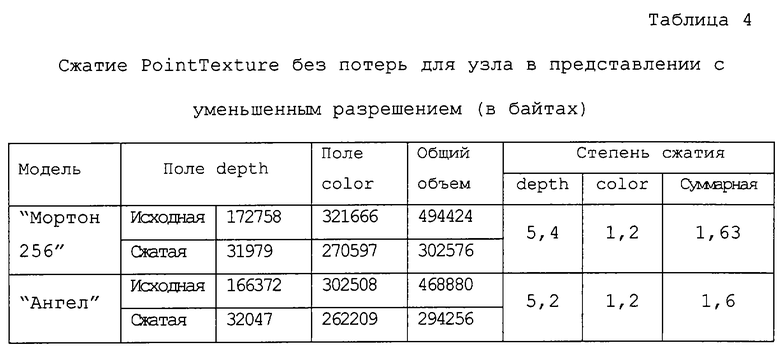
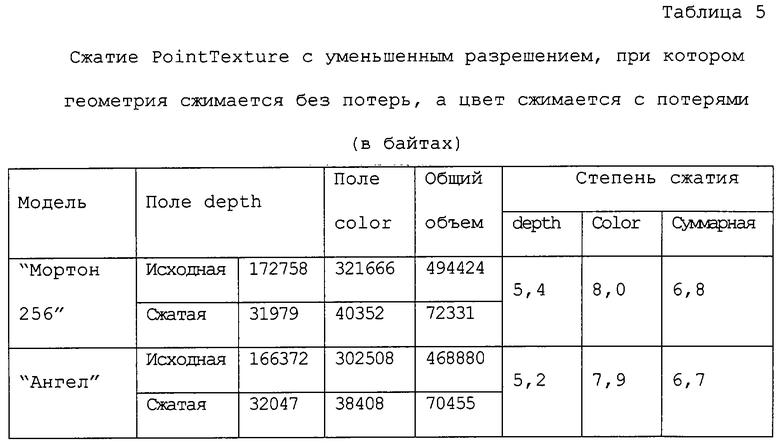
Тем не менее, для многих моделей этот алгоритм работает хорошо. На фиг.11 приведены "плохой" случай (модель "Ангел") и хороший случай (модель "Мортон256"). В обоих случаях объем модели уменьшился примерно в 7 раз.
(Фиг.4 удалена)
3. Результаты тестов
В этом разделе приведено сравнение результатов сжатия двух моделей "Ангел" и "Мортон256"' в двух различных форматах - OctreeImage и PointTexture. Размер эталонных изображений для каждой из моделей составил 256×256 пикселей.
3.1. Сжатие PointTexture.
В таблицах 3-5 приведены результаты использования различных способов сжатия. Модели для этого эксперимента были получены из моделей с 8-битным полем depth. Значения глубины были расширены в диапазоне (1, 230) с использованием шага дискретизации, равного 231+1, чтобы добиться более однородного распределения битов по 32-битным значениям глубины, тем самым в некоторой степени имитируя "истинные" 32-битные значения.
От данного способа сжатия не следует ожидать больших степеней сжатия. Уменьшение объема по порядку величины совпадает с типичными способами сжатия без потерь для изображений с реалистичным цветовоспроизвдением. Так как при данном подходе геометрическая природа данных не используется, то после сжатия поля depth и color сравнимы по размеру.
Теперь исследуем вопрос, насколько одну и ту же модель можно сжать без потерь в случае, когда берется ее "истинное" значение разрешения по глубине. В отличие от предыдущего случая поле depth можно сжать без потерь примерно в 5-6 раз. Это достигается благодаря промежуточному воксельному представлению, которое делает избыточность геометрических данных гораздо более выраженной - действительно, только малая доля вокселей оказывается черной. Однако, так как размер несжатых моделей меньше, чем для случая 32 битов, общая степень сжатия теперь определяется степенью сжатия поля color, которая оказывается даже меньше, чем для случая 32 битов (хотя размер выходных файлов также оказывается меньше). Таким образом, представляется желательным получить возможность сжимать поле color по меньшей мере также хорошо, как и поле depth.
С этой целью в нашем третьем способе используется способ сжатия с потерями, который называется АРБ [6]. Этот способ обеспечивает гораздо большее сжатие. Однако, как и любой другой способ сжатия с потерями, он в некоторых случаях может привести к неприятным артефактам. Примером объекта, для которого это имеет место, является модель "Ангел". В процессе сканирования точек этой модели пространственно удаленные точки иногда действительно попадают в один и тот же блок двумерного изображения. Цвета таких удаленных точек данной модели могут существенно различаться, и если в некотором блоке оказывается слишком много разных цветов, то локальное пакетирование не способно обеспечить точную аппроксимацию. С другой стороны, именно локальное пакетирование позволяет точно сжимать подавляющее большинство блоков, для которых искажения, вносимые, например, стандартным алгоритмом сжатия JPEG, становятся совершенно неприемлемыми после того, как восстановленные цвета помещаются в соответствующие им точки трехмерного пространства. Тем не менее, визуальное качество модели "Мортон256", сжатие которой выполнялось с применением того же самого способа, оказывается превосходным, и это имеет место для большинства моделей в наших экспериментах.
3.2. Сжатие OctreeImage
В таблице 6 представлены размеры сжатых и несжатых компонентов октодерева для двух наших тестовых моделей. Как можно видеть, размер этого поля уменьшается примерно в 1,6-1,9 раза.
Тем не менее, если сравнить эти результаты с несжатыми моделями PointTexture даже с 8-битным полем depth, OctreeImage оказывается гораздо более компактным. В таблице 7 приведены степени сжатия, равные 7,2 и 11,2. Эти степени сжатия превышают те, с которыми можно сжать PointTexture без преобразования к OctreeImage (6,7 и 6,8 раза, соответственно). Однако, как уже упоминалось, OctreeImage может содержать неполную информацию о цвете, что и имеет место в случае модели "Ангел". В таких случаях используется трехмерная интерполяция цветов.
Подводя итог, можно заключить, что представленные выше эксперименты доказывают эффективность разработанных средств сжатия. Выбор наилучшего средства для данной модели зависит от ее геометрической сложности, характера цветового распределения, требуемой скорости визуализации и прочих факторов.


4. Список литературы.
[1] J.Cleary and I.Witten, "Data compression using adaptive coding and partial string matching", IEEE Trans. on Communications, vol.32, no.4, pp.396-402, April 1984.
[2] J.Rissanen and G.Langdon, "Universal modeling and coding", IEEE Trans. on Information Theory, vol.27, no.1, pp.12-23, January 1981.
[3] M.Schindler, "A byte oriented arithmetic coding", Proc. of Data Compression Conference, March 1998.
[4] G.Martin, "Range encoding: an algorithm for removing redundancy from a digitized message". Video & Data Recording Conference, March 1979.
[5] H.Coxeter and W.Moser, Generators and relations for discrete groups, 3rd edition, Springer-Verlag, 1972.
[6] L.Levkovich-Maslyuk, P.Kalyuzhny and A.Zhirkov, "Texture compression with adaptive block partitions", Proc. of 8th ACM International Conference on Multimedia, pp.401-403, October, 2000.
5. Комментарии к Исследованию ISO/IEC 14496-1/PDAM4
После внесения нижеследующих исправлений в Исследование ISO/IEC 14496-1/PDAM4 (N4627) переработанное Исследование ISO/IEC 14496-1/PDAM4 следует включить в ISO/IEC 14496-1/FPDAM4.
Пункт 6.5.3.1.1., технический
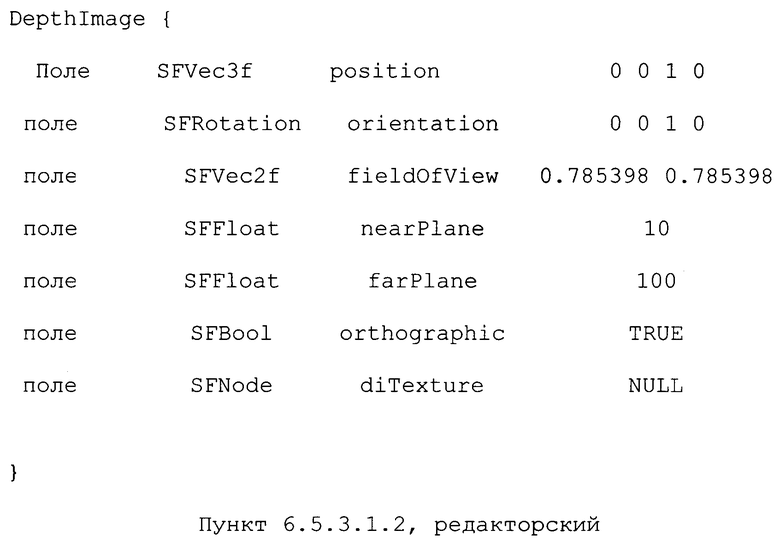
Проблема: Выбираемое по умолчанию значение orthographic должно быть значением, используемым в наиболее общем случае.
Решение: изменить принятое по умолчанию значение orthographic с "FALSE" (ложью) на "TRUE" (истинно) следующим образом.
Предложенное исправление:

Проблема: преобразование ПОИГ в поток данных должно осуществляться способом однородного преобразования данных в поток, предназначенным для РСА.
Решение: удалить поле depthImageUrl из узла DepthImage.
Предложенное исправление:
Проблема: термин "нормируются" может ввести в заблуждение, будучи примененным к полю depth в текущем контексте.
Решение: в 5-м абзаце заменить "нормируются" на "представляются в масштабе".
Предложенное исправление:
Поля nearPlane и farPlane задают расстояния от точки наблюдения до ближней и дальней плоскостей области наблюдения. Данные о текстурах и глубине отображают область, находящуюся между ближней плоскостью, дальней плоскостью и feildOfView. Данные о глубине представляются в масштабе расстояния от nearPlane до farPlane.
Пункт 6.5.3.1.2., технический
Проблема: преобразование ПОИГ в поток данных должно осуществляться способом однородного преобразования данных в поток, предназначенным для РСА.
Решение: удалить пояснение поля depthImageUrl (7-й абзац и ниже).
Пункт 6.5.3.2.2, редакторский
Проблема: семантика поля depth задана не полностью.
Решение: Изменить спецификацию поля depth в 3-м абзаце следующим образом:
Предложенное исправление:
Поле depth задает глубину каждого пикселя в поле texture. Карта глубины должна быть того же размера, что и изображение или кинофрагмент в поле texture. Поле depth должно относиться к одному из различных типов узлов текстур (ImageTexture, MovieTexture или PixelTexture), для которых допускаются только узлы, представляющие изображения в виде шкалы уровней серого. Если поле depth не задано, то в качестве карты глубины будет использоваться альфа-канал в поле texture. Если карта глубины не задана ни посредством поля depth, ни посредством альфа-канала, то результат не определен.
Поле глубины позволяет вычислять фактическое расстояние от трехмерных точек модели до плоскости, проходящей через точку наблюдения параллельно ближней и дальней плоскостям:
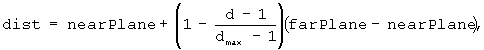
где d - это значение глубины, a dmax – максимальное разрешенное значение глубины. Предполагается, что для точек модели d>0, причем d=1 соответствует дальней плоскости, а d=dmax соответствует ближней плоскости.
Данная формула верна как для случая перспективной, так и для случая ортогональной проекции, так как d - это расстояние между рассматриваемыми точкой и плоскостью, dmax является максимальным значением d, которое может быть представлено числом битов, использующихся для каждого пикселя:
(1) Если глубина задана посредством поля depth, то значение глубины d равно шкале уровней серого.
(2) Если глубина задана посредством альфа-канала в изображении, определенном через поле texture, то значение глубины d равно значению альфа-канала.
Значение глубины также используется для указания на то, какие точки принадлежат модели: только точки с ненулевым d принадлежат данной модели.
Для анимационных моделей, основывающихся на DepthImage, используется DepthImage с SimpleTexture в качестве diTexture.
Каждый из объектов SimpleTexture можно анимировать одним из следующих способов:
(1) Поле depth представляет собой неподвижное изображение, удовлетворяющее вышеприведенному условию, а поле texture - это произвольная MovieTexture.
(2) Поле depth - это произвольная MovieTexture, которая удовлетворяет вышеприведенному условию, накладываемому на поле depth, а поле texture представляет собой неподвижное изображение.
(3) Как поле depth, так и поле texture представляют собой MovieTexture, а поле depth удовлетворяет вышеприведенному условию.
(4) Поле depth не используется, а информация о глубине извлекается из альфа-канала MovieTexture, которая используется для анимации поля texture.
Пункт 6.5.3.3.2, редакторский
Проблема: семантика поля depth задана не полностью.
Решение: Заменить спецификацию поля depth (3-й абзац) на предложенное исправление.
Геометрический смысл значений глубины, а также все соглашения по их интерпретации, принятые для SimpleTexture, остаются в силе и в этом случае.
Поле depth задает множество значений глубины для каждой точки в плоскости проекции, за которую принимается farPlane (см. выше), в порядке, при котором обход начинается с точки в левом нижнем углу и продолжается слева направо до завершения горизонтальной строки, после чего выполняется переход на строку, расположенную выше. Для каждой точки сначала запоминается количество значений глубины (пикселей), а затем - сами значения глубины.
Пункт 6.5.3.4.1, H.1, технический
Проблема: Использование типа SFString поля для поля octree может привести к несогласованным результатам.
Решение: Заменить тип поля octree на MFInt32.
Предложенное исправление:

В Пункте H.1, таблица для Octree, изменить столбец octree следующим образом:

Пункт 6.5.3.4.1, технический
Проблема: преобразование ПОИГ в поток данных должно осуществляться способом однородного преобразования данных в поток, предназначенным для РСА.
Решение: удалить поле octreeUrl из узла OctreeImage.
Предложенное исправление:

Проблема: определение поля octreeresolution (2-й абзац) допускает неверную интерпретацию.
Решение: Исправить описание путем добавления слова "возможное"
Предложенное исправление:
Поле octreeresolution задает максимально возможное число листьев октодерева, расположенных вдоль грани заключающего его куба. Уровень октодерева можно определить из octreeresolution по следующей формуле: octreelevel = int(log2(octreeresolution-1)) +1)
Пункт 6.5.3.4.2, технический
Проблема: преобразование ПОИГ в поток данных должно осуществляться способом однородного преобразования данных в поток, предназначенным для РСА.
Решение: удалить описание поля octreeUrl (5-й абзац и далее).
Пункт 6.5.3.4.2, редакторский
Проблема: описание анимации OctreeImage приведено не полностью.
Решение: добавить абзац в конце пункта 6.5.3.4.2, описывающий порядок анимации OctreeImage
Предложенное исправление:
Анимацию OctreeImage можно выполнить посредством тех же самых подходов, что и в трех описанных выше способах анимации, основывающейся на DepthImage, с единственным различием, состоящим в том, что вместо поля depth используется поле octree.
Пункт H.1, технический
Проблема: диапазон данных о глубине в узле PointTexture может оказаться слишком малым для будущих приложений. Многие графические средства допускают использовать для z-буфера данные о глубине с разрядностью 24 или 36 битов. Однако поле depth в PointTexture имеет диапазон значений [0, 65535], что составляет 16 битов.
Решение: В пункте H.1, таблица для PointTexture, изменить столбец для диапазона значений depth согласно предложению.
Предложенное исправление:

Ниже излагается изобретение, описанное в предварительной заявке №60/395304 на патент США, поданной 12 июля 2002 г. и озаглавленной “Способ и устройство для представления и сжатия данных октодерева в представлении на основе изображений с глубиной”.
IV. КОДИРОВАНИЕ ДВИЖУЩИХСЯ ИЗОБРАЖЕНИЙ И АУДИОСИГНАЛОВ В СООТВЕТСТВИИ С ISO/IEC JTC 1/SC 29/WG 11
1. Введение
В настоящем документе приведено описание улучшенной версии OctreeImage для представлений на основе изображений с глубиной (ПОИГ), РСА А8.3. Узел OctreeImage получил одобрение и был включен в предложения для Редакционной Комиссии во время заседания в Паттайе. Однако, вследствие окклюзии геометрии объекта в некоторых специфических случаях наблюдалось неудовлетворительное качество визуализации. Данный документ описывает улучшенную версию узла OctreeImage, то есть текстурированное бинарное волюметрическое октодерево (ТБВО), а также способ его сжатия для преобразования в поток данных.
2. Текстурированное бинарное волюметрическое октодерево (ТБВО)
2.1. Общее описание ТБВО
Цель ТБВО как улучшенного варианта бинарного волюметрического октодерева (БВО) состоит в том, чтобы предоставить более гибкий формат представления/сжатия с быстрой визуализацией. Это достигается посредством хранения некоторой дополнительной информации на основе БВО. Представление на основе БВО состоит из (структуры октодерева + набора эталонных изображений), в то время как представление, основывающееся на ТБВО, состоит из (структуры БВО + набора эталонных изображений + индексов камер).
Основная проблема визуализации БВО состоит в том, что в процессе визуализации необходимо определить соответствующий каждому векселю индекс камеры. В этой связи требуется не только выполнить проецирование на камеры, но и процедуру обратной трассировки лучей. Необходимо, по меньшей мере, определить наличие камеры, с которой виден данный воксель. Следовательно, требуется найти все воксели, которые проецируются на некоторую конкретную камеру. Но при использовании "лобового" подхода данная процедура оказывается очень медленной. Нами разработан алгоритм, который обеспечивает быстроту и точность для подавляющего большинства форм объектов. Однако, все еще имеются трудности с вокселями, которые не видны ни с одной из камер.
Возможным решением могло бы быть хранение явного цвета для каждого вокселя. Однако в этом случае мы сталкиваемся с некоторой проблемой при сжатии информации о цвете. Иными словами, если мы группируем цвета вокселей в формате изображения и сожмем его, то корреляция цветов соседних вокселей нарушается, так что степень сжатия становится неудовлетворительной.
В случае ТБВО проблема решается посредством хранения индекса камеры (изображения) для каждого вокселя. Данный индекс обычно оказывается одним и тем же для больших групп вокселей, что позволяет использовать структуру октодерева для экономного хранения дополнительной информации. Следует отметить, что в экспериментах с нашими моделями в среднем наблюдалось лишь 15%-ное увеличение объема. Упомянутое моделирование немного более сложное, зато оно предоставляет более гибкие пути представления объектов произвольной геометрии.
(Фиг.1 удалена)
Преимущества ТБВО перед БВО заключаются в том, что визуализация с его помощью выполняется проще и намного быстрее, чем с использованием БВО, а также практически не накладывает никаких ограничений на геометрию объекта.
2.2. Пример ТБВО
В данном разделе приведен типичный пример, который иллюстрирует эффективность и ключевые составляющие элементы представления на основе ТБВО. На фиг.12(а) показана модель "Ангел", основывающаяся на БВО. Так как некоторые части тела и крыла не наблюдаются ни в одной из камер, то при использовании стандартных для БВО 6 текстур полученное посредством визуализации изображение содержит множество видимых "трещин". При представлении той же самой модели на основе ТБВО используются 8 камер (6 граней куба + 2 дополнительные камеры). На фиг.13(а) представлено изображение индекса камеры. Различающиеся индексы камеры обозначены различными цветами. Дополнительные камеры размещены внутри куба и ориентированы на переднюю и заднюю плоскости куба под прямым углом. На фиг.13(б) и (в) представляют дополнительные изображения, полученные посредством дополнительных камер. В результате, как показано на фиг.12(б), достигается гладкая и чистая визуализация рассматриваемой модели.
(Фиг.2 удалена)
2.3. Описание несжатого потока данных ТБВО
Мы полагаем, что 255 камер будет достаточно, и выделяем на индекс вплоть до 1 байта. Поток данных ТБВО - это поток символов. Каждый символ ТБВО - это символ БВО или символ текстуры. Символ-текстуры обозначает индекс камеры, которым может быть конкретное число или код "не определено". Пусть в последующем описании в качестве кода "не определено" фигурирует ‘?’.
Поток данных ТБВО обходится в порядке по схеме "сначала в ширину". Далее приводится описание процедуры записи потока данных ТБВО в случае, если у нас имеется БВО, а для вокселя каждого листа имеется индекс камеры. Это должно быть сделано на этапе моделирования. Все узлы БВО, включая узлы листьев (для которых нет символа БВО), обходятся в порядке по схеме "сначала в ширину". Приведенный ниже псевдокод выполняет запись потока.
Если CurNode не является узлом листа, то
{
Записать текущий символ БВО, соответствующий этому узлу
}
Если для всех потомков один и тот же индекс камеры (текстура-символ), то
{
Если индекс камеры родителя CurNode равен ‘?’, то
Записать индекс камеры, равный индексу камеры для субузлов
}
В противном случае
{
Записать символ ‘?’
}
Фиг.3 Псевдокод для записи потока ТБВО.
В соответствии с данной процедурой для дерева ТБВО по фиг.14(а) можно получить поток символов, изображенный на фиг.14(б). В этом примере для представления символов-текстур используется один байт. Однако в реальном потоке данных для каждого символа-текстуры требуется только 2 бита, так как необходимо представить только три значения (две камеры и код "не определено").
(Фиг.4 удалена)
2.4. Сжатие ТБВО
Сжатие полей octreeimages и octree узла OctreeImage выполняется раздельно. Рассматриваемые ниже способы разрабатывались исходя из соображения, что сжатие поля octree следует выполнять без потерь, в то время как для поля octreemages допустима некоторая визуально приемлемая степень искажений.
2.4.1. Сжатие поля octreeimages
Поле octreeimages сжимают средствами сжатия изображений MPEG-4 (в случае статической модели), либо с помощью допустимых в рамках MPEG-4 средств сжатия видеоизображений (в случае анимационной модели). В нашем подходе для octreeimages применялся формат JPEG (после определенной предварительной обработки, которую мы называем "минимизацией" изображений JPEG, в процессе которой в каждой текстуре сохранялись только те точки, которые необходимы для трехмерной визуализации; другими словами, неиспользуемые на стадии трехмерной визуализации части текстуры можно сжимать настолько грубо, насколько это приемлемо для нас).
(Фиг.5 удалена)
2.4.2. Сжатие поля octree
Сжатие поля octree является наиболее важной частью процесса сжатия OctreeImage, так как оно связано со сжатием уже весьма компактного представления в форме несвязанного бинарного дерева. Однако, в наших экспериментах рассматриваемый ниже способ привел к уменьшению объема этой структуры примерно до половины ее первоначального размера. В случае анимационной версии OctreeImage сжатие поля octree выполняется отдельно для каждого трехмерного кадра.
2.4.2.1. Контекстная модель
Сжатие выполняется с применением варианта адаптивного арифметического кодирования (реализованного в виде "кодера дальности", [3], [4]), в котором явно используется геометрическая природа данных. Поле octree представляет собой поток байтов. Каждый байт представляет узел (то есть, подкуб) дерева, в котором его биты определяют занятость данного подкуба после внутреннего разбиения. Эта комбинация битов называется шаблоном заполнения узла. Рассматриваемый алгоритм сжатия обрабатывает байты один за одним следующим образом:
Определяется контекст текущего байта.
Из соответствующей данному контексту "таблицы вероятности" (ТВ) извлекается "вероятность" (нормированная частота) появления текущего байта в данном контексте.
Значение вероятности подается на кодер дальности.
Текущая ТВ обновляется посредством прибавления 1 к значению частоты появления текущего байта в текущем контексте (и, если необходимо, впоследствии нормируется повторно, подробно см. ниже).
Таким образом, кодирование представляет собой процесс построения и обновления таблиц ТВ в соответствии с контекстной моделью. В основывающихся на контекстах схемах адаптивного арифметического кодирования (таких, как "Предсказание посредством частичного совпадения" [1]-[3]), контекст символа обычно представляет собой строку из нескольких предшествующих ему символов. Однако, в нашем случае эффективность сжатия увеличивается посредством использования структуры октодерева и геометрической природы данных. Рассматриваемый подход основывается на двух идеях, которые, очевидно, впервые применяются в задаче сжатия октодерева.
А. Для текущего узла контекст - это либо его порождающий узел, либо пара {порождающий узел, положение текущего узла в порождающем узле}.
Б. Предполагается, что "вероятность" появления данного узла в конкретной геометрической позиции в конкретном порождающем узле является инвариантной по отношению к некоторому набору ортогональных преобразований (таких как повороты или преобразования симметрии).
Предположение "Б" проиллюстрировано на фиг.6 для преобразования R, которое является поворотом на -90° в плоскости x-z. Основная идея предположения “Б” состоит в наблюдении, что вероятность появления некоторого конкретного типа дочернего узла в некотором конкретном типе порождающего узла должна зависеть только от их относительного положения. Данное предположение подтверждается в наших экспериментах путем анализа таблиц вероятности. Оно позволяет нам использовать более сложный контекст без слишком большого числа таблиц вероятности. Это, в свою очередь, помогает достигать весьма хороших результатов в смысле объема данных и скорости. Следует отметить, что чем больше контекстов используется, тем точнее оценка вероятности, и, следовательно, тем более компактен код.
Введем набор преобразований, для которых мы предполагаем инвариантность распределений вероятности. Для того чтобы эти преобразования можно было использовать в нашем случае, они должны сохранять заключающий куб без изменений. Рассмотрим набор G ортогональных преобразований в евклидовом пространстве, которые получаются посредством всех всевозможных сочетаний в произвольном количестве и порядке трех следующих базовых преобразований (генераторов) m1, m2 и m3, заданных следующим образом:
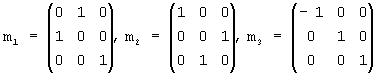
где m1 и m2 - это отражения относительно плоскостей х=z и y=z, соответственно, а m3 - отражение относительно плоскости x=0. Один из классических результатов теории групп, полученных посредством отражений [27], гласит, что G содержит 48 различных ортогональных преобразований и является, по сути, максимальной группой ортогональных преобразований, которые преобразуют куб сам в себя (так называемая группа Когзетера). Например, поворот R по фиг.6 посредством генераторов выражается как
R=m3·m2·m1·m2,
где “·” обозначает операцию умножения матриц.
Будучи примененным к узлу октодерева, преобразование, задаваемое G, формирует узел с отличающейся конфигурацией заполнения субкубов. Это позволяет категоризировать узлы в соответствии с конфигурациями заполнения их субкубов.
Используя терминологию теории групп, можно сказать, что G воздействует на набор всех конфигураций заполнения узлов октодерева. Вычисления показывают, что имеется 22 отличающихся класса (в теории групп они также называются орбитами), для которых по определению два узла принадлежат одному и тому же классу тогда и только тогда, если они связаны преобразованием, задаваемым G. Количество элементов в классе меняется от 1 до 24 и всегда является делителем 48.
Практическим следствием предположения "Б" является тот факт, что таблица вероятности зависит не от самого порождающего узла, а только от класса, к которому принадлежит этот порождающий узел. Следует отметить, что в первом случае для контекста, основывающегося на порождающих узлах, потребовались бы 256 таблиц, и дополнительные 256×8=2048 таблиц для контекста, основывающегося на взаимном расположении порождающих и дочерних узлов, в то время как во втором случае для контекста, основывающегося на классе порождающего узла, требуются только 22 таблицы плюс 22×8=176 таблиц. Следовательно, представляется возможным использовать одинаково сложный контекст с относительно небольшим числом таблиц вероятности. Сформированные ТВ будут иметь форму, приведенную в таблице 8.
2.4.2.2. Процесс кодирования
Чтобы повысить точность статистических данных для таблиц вероятности, эти данные собираются различными способами на трех этапах процесса кодирования.
На первом этапе контекст вообще не используется, принимается "0-контекстная модель", и поддерживается одна таблица вероятности с 256 ячейками, в исходном состоянии характеризуемая равномерным распределением элементов.
Как только выполнено кодирование первых 512 узлов (данное число было получено эмпирически), выполняется переключение на "1-контекстную модель" с порождающим узлом в качестве контекста. В момент данного переключения ТВ, соответствующая 0-контекстной модели, копируется в таблицы ТВ для всех 22 контекстов.
После выполнения кодирования 2048 узлов (также эвристическая величина), выполняется переключение на "2-контекстную модель". В данный момент таблицы ТВ для конфигураций порождающих узлов, соответствующие 1-контекстной модели, копируются в таблицы ТВ для каждого из положений в той же конфигурации порождающего узла.
Ключевым моментом данного алгоритма является определение контекста и вероятности для текущего байта. Он реализуется следующим образом. Для каждого класса фиксируется один элемент, который называется "стандартным элементом". Мы сохраняем таблицу отображений классов (ТОК), указывающую на класс, которому принадлежит каждый из 256 возможных узлов, а также заранее вычисленное преобразование, задаваемое G, которое переводит данный конкретный узел в стандартный элемент его класса. Таким образом, чтобы вычислить вероятность текущего узла N, выполняют следующие этапы:
Получить порождающий узел Р текущего узла.
Извлечь из ТОК класс, которому принадлежит Р, и преобразование Т, которое переводит Р в стандартный узел этого класса. Пусть номер класса равен с.
Применить Т к Р и найти положение р дочернего узла в стандартном узле, на который отображается текущий узел N.
Применить Т к N. В результате только что полученная конфигурация заполнения TN находится в положении р в стандартном узле класса с.
Извлечь требующееся значение вероятности из ячейки TN таблицы вероятности, соответствующей комбинации класс-положение (с, р).
Модификация вышеприведенных этапов для 1-контекстной модели очевидна. Нет нужды говорить, что все преобразования вычисляются заранее и реализуются в виде таблицы, по которой осуществляется их поиск.
Следует отметить, что на этапе декодирования узла N его порождающий узел Р уже прошел декодирование и, следовательно, преобразование Т известно. Все этапы на стадии декодирования аналогичны соответствующим этапам кодирования.
Наконец, рассмотрим процесс обновления значения вероятности. Пусть Р - это таблица вероятности для некоторого контекста. Обозначим элемент Р, соответствующий вероятности появления узла N в данном контексте, как P(N). В нашей реализации P(N) - это целое число, и после каждого появления N значение Р(N) обновляется следующим образом:
P(N)=P(N)+А,
где А - это целый параметр приращения, величина которого для различных контекстных моделей обычно варьируется между 1 и 4. Пусть S (Р) равно сумме значений всех элементов в Р. Тогда "вероятность" того, что N поступит на арифметический кодер (кодер дальности в нашем случае), вычисляется как Р(N)/S(Р). Как только величина S (Р) достигнет порогового значения 216, выполняется повторное нормирование всех ячеек: чтобы избежать появления в Р нулевых значений, элементы, равные 1, остаются без изменений, а все остальные элементы делятся на 2.
2.4.2.3. Кодирование "узлов камер"
Сжатие потока символов, определяющих номера текстур (камер) для каждого вокселя, осуществляется с использованием своей собственной таблицы вероятности. Используя терминологию, введенную выше, данный поток обладает единичным контекстом. Обновление элементов ТВ выполняется со значением приращения, большим чем то, что использовалось для узлов octree; в остальном, данная процедура кодирования не отличается от кодирования символов узлов.
2.5. Результаты сжатия ТБВО и визуализации.
На фиг.15, 17, 18 и 19 приведены результаты сжатия ТБВО. На фиг.16 показаны изображения моделей "Ангел" и "Мортон", полученные после избирательного удаления части вокселей. Объем в сжатом состоянии сравнивается со сжатым БВО: в третьем столбце число в скобках указывает объем сжатой геометрии, а первое число указывает общий объем сжатой модели, основывающейся на ТБВО (то есть, с учетом текстур). В качестве меры визуальных искажений вычислялось отношение сигнал/шум по мощности (ОСШМ), служащее оценкой разницы в цвете после преобразования МИГ→(Т)БВО→МИГ. Объем сжатой модели вычислялся как сумма объемов всех текстур (сохраненных в форме минимизированного JPEG, см. 0) плюс объем сжатой геометрии. В случае ТБВО сжатая геометрия также включает в себя и информацию о камерах. Для ТБВО наблюдается существенное улучшение ОСШМ по сравнению с БВО.
С помощью ТБВО достигается более высокая скорость визуализации, чем с помощью БВО. Для модели "Ангел" частота кадров в случае ТБВО-12 составляет 10,8 кадр/с, в то время как для БВО она составляет 7,5 кадр/с. Для модели "Мортон" частота кадров в случае ТБВО-12 составляет 3,0 кадр/с, а для БВО - 2,1 кадр/с (процессор Celeron 850 МГц). С другой стороны, было обнаружено, что в случае анимационного ТБВО визуализация ускоряется еще сильнее. Для модели "Дракон" частота кадров в случае ТБВО-12 составила 73 кадр/с, в то время как для БВО - 29 кадр/с (процессор Pentium IV 1,8 ГГц).
(Фиг.6 удалена)
Формат ТБВО обеспечивает большую гибкость. Например, на фиг.6 проиллюстрированы два способа использования 12 камер - ТБВО-12 и ТБВО-(6+6). В случае ТБВО-12 используются 6 камер БВО (грани куба) плюс 6 параллельных граням изображений, полученных из центра куба. В конфигурации (6+6) используются 6 камер БВО, после чего все видимые для данных камер воксели удаляются, и с помощью этих же 6 камер "фотографируются" те части, которые становятся видимыми для них после такого удаления. Примеры таких изображений приведены на фиг.16.
(Фиг.7 удалена)
Следует обратить внимание на огромные различия в качестве (как субъективно, так и по величине ОСШМ) между моделью "Ангел" в представлении БВО и ТБВО-6. Несмотря на то, что в обоих случаях используются одни и те же положения камер, ТБВО позволяет присвоить номера камер всем имеющимся вокселям - даже тем, что не видны ни с одной из камер. Эти номера выбираются таким образом, чтобы добиться максимально точного соответствия исходным цветам (то есть, для каждой точки независимо от ее прямой видимости выбирают наилучшее цветовое совпадение среди всех "изображений камер". В случае модели "Ангел" это приводит к великолепным результатам).
Также следует отметить весьма скромную разницу в объеме "геометрии" (то есть, БВО + камеры) между случаями с 6-ю и 12-ю камерами. Фактически, дополнительные камеры обычно покрывают области малого размера, и, как следствие, их идентификаторы встречаются редко, а соответствующие им текстуры разрежены (и хорошо поддаются сжатию). Все вышесказанное относится не только к модели "Ангел", но и к моделям "Мортон", "Пальма512" и "Роботы512".
(Фиг.8-10 удалены)
2.6. Спецификация узла

Узел OctreeImage определяет структуру ТБВО, в которой присутствуют структура бинарного октодерева, соответствующий массив индексов камер и ряд изображений в формате октодерева.
Поле octreeimages задает набор узлов DepthImage с SimpleTexture в качестве поля diTexture; поле depth в этих узлах SimpleTexture не используется. Для узлов DepthImage поле orthographiсs должно иметь значение TRUE. Поле texture каждого из объектов SimpleTexture хранит информацию о цвете объекта или части вида объекта (например, его поперечного сечения плоскостью камеры), получаемой посредством ортогональной камеры, положение и ориентация которой заданы в соответствующих полях DepthImage. Соответствие между различными частями объекта и каждой из камер устанавливается на этапе построения модели. Разбиение объекта с использованием значений полей position, orientation и texture выполняется с целью минимизации числа камер (или, что то же самое, используемых изображений в формате октодерева) и, в то же время, включения всех частей объекта, потенциально видимых из произвольно выбранного положения. Поля orientation должны удовлетворять следующему условию: вектор визирования камеры должен иметь только одну ненулевую компоненту (то есть быть перпендикулярным одной из граней заключающего куба). Кроме того, стороны изображения SimpleTexture должны быть параллельны соответствующим сторонам заключающего куба.
Поле octree полностью описывает геометрию объекта. Геометрия представляется в виде набора вокселей, составляющих данный объект. Октодерево представляет собой древовидную структуру данных, каждый из узлов которой представлен одним байтом. 1 в i-м бите из этого байта означает, что для i-го дочернего узла рассматриваемого внутреннего узла существуют дочерние узлы, в то время как 0 означает, что этих узлов не существует. Порядок внутренних узлов октодерева - это порядок обхода октодерева по схеме "сначала в ширину". Порядок 8 дочерних узлов внутреннего узла показан на фиг.14(б). Размер заключающего куба для всего октодерева составляет 1×1×1, а центр куба октодерева располагается в начале (0, 0, 0) местной системы координат.
Поле cameraID содержит массив индексов камер, присвоенных вокселям. На этапе визуализации цвет, являющийся атрибутом листа октодерева, определяется посредством ортогонального проецирования данного листа на одно из изображений в формате октодерева с конкретным индексом. Индексы хранятся в форме, подобной октодереву: если некоторую камеру можно использовать для всех листьев, содержащихся в конкретном узле, то узел, содержащий индекс этой камеры, выводится в поток; в противном случае, выводится узел, содержащий фиксированный код "дополнительное разбиение", что означает, что индекс камеры определяется отдельно для дочерних субузлов текущего узла (в той же рекурсивной форме). Если поле cameraID пустое, то индексы камер определяются на этапе визуализации (как в случае БВО).
Поле octreeresolution задает максимальное разрешенное число листьев октодерева, расположенных вдоль грани заключающего его куба. Уровень октодерева можно определить из octreeresolution, используя следующее уравнение:
octreelevel = [log2 (octreeresolution)]
2.7. Спецификация битового потока
2.7.1. Сжатие октодерева
2.7.1.1. Обзор
Узел OctreeImage в представлении, основывающемся на изображениях с глубиной, задает структуру октодерева и проецируемые текстуры. Каждая из текстур, сохраненных в массиве octreeimages, определяется через узел DetphImage с SimpleTexture. Сжатие прочих полей узла OctreeImage можно выполнить посредством сжатия октодерева.
2.7.1.2. Octree
2.7.1.2.1. Синтаксис

2.7.1.2.2. Семантика
Сжатый поток данных октодерева содержит заголовок октодерева и один или более кадров октодерева, каждому из которых предшествует octree_frame_start_code. Значение octree_frame_start_code всегда равно 0×000001C8. Данное значение детектируется в процессе упреждающего синтаксического анализа (next) этого потока.
2.7.1.3. OctreeHeader
2.7.1.3.1. Синтаксис

2.7.1.3.2. Семантика
Данный класс считывает заголовочную информацию при сжатии октодерева.
Переменная octreeResotlution, длина которой задается посредством octreeResolutionBits, содержит значение поля octreeResotlution узла OctreeImage. Это значение используется для получения уровня октодерева.
Переменная NumOfTextures, длина которой равна значению textureNumBits, описывает число текстур (или камер), используемых в узле OctreeImage. Это значение используется для арифметического кодирования идентификатора камеры для каждого узла октодерева. Если значение octreeResolutionBits равно 0, то curTexture корневого узла устанавливается равным 255 и символы текстур не кодируются.
2.7.1.4. OctreeFrame
2.7.1.4.1. Синтаксис

2.7.1.4.2 Семантика
Данный класс считывает один кадр октодерева в порядке обхода по схеме "сначала в ширину". После того, как, начиная с 1-го узла на уровне 0, считаны все узлы на текущем уровне, число узлов на следующем уровне определяется посредством подсчета единиц в каждом символе узла. При переходе на следующий уровень из потока считывается полученное число узлов (nNodesInCurLevel).
Для декодирования каждого узла предоставляется соответствующий contextID согласно тому, как это описано в Пункте 2.7.1.6.
Если идентификатор текстуры (или камеры) для текущего узла (curTexture) в порождающем узле не определен, то идентификатор текстуры также считывается из рассматриваемого потока, используя контекст для идентификатора текстуры, задаваемый посредством переменной textureContextID. Если извлечено ненулевое значение (идентификатор текстуры определен), то это же значение будет применяться ко всем дочерним узлам на последующих уровнях. После декодирования каждого узла данное значение идентификатора текстуры присваивается тем узлам листьев октодерева, которым так и не было присвоено значение идентификатора текстуры.
2.7.1.5. Адаптивное арифметическое декодирование
В данном разделе с использованием синтаксического описания в стиле C++ описывается адаптивный арифметический кодер, используемый при сжатии октодерева. aa_decode() - это функция, которая декодирует символ с использованием модели, заданной посредством массива cumul_freq[], а РСТ - это массив таблиц вероятности контекстов, описанный в Пункте 2.7.1.6.

2.7.1.6. Процесс декодирования
Общая структура процесса декодирования описана в Пункте 0 (см. также описание процесса кодирования, приведенное выше). В этом пункте показано, как можно получить узлы ТБВО из потока битов, который составляет модель ТБВО, кодированную (сжатую) посредством арифметического кодирования.
На каждом этапе процесса декодирования необходимо обновлять номер контекста (то есть, индекс используемой таблицы вероятности), а также саму таблицу вероятности. Объединение всех таблиц вероятности (целочисленных массивов) мы называем вероятностной моделью, j-й элемент i-й таблицы вероятности, будучи разделенным на сумму всех ее элементов, дает оценку вероятности появления j-го символа в i-м контексте.
Процесс обновления таблицы вероятности выполняется следующим образом. В самом начале все таблицы вероятности инициализируются таким образом, что все их элементы равны 1. До начала декодирования символа требуется выбрать номер контекста (ContextID). ContextID определяется на основании уже декодированных данных, как указано ниже в Пунктах 0 и 0. После того, как получен ContextID, декодирование символа выполняется посредством бинарного арифметического декодера. Затем посредством прибавления адаптивного приращения к значению частоты декодированного символа обновляют таблицу вероятности. Если полная (кумулятивная) сумма элементов таблицы становится больше кумулятивного порога, то выполняют нормирование (см. 2.7.1.5.1).
2.7.1.6.1. Контекстное моделирование символа текстуры.
При моделировании символа текстуры используют только один контекст. Это означает, что используется только одна таблица вероятности. Размер этой таблицы равен величине numOfTextures плюс один. Вначале все элементы этой таблицы инициализируются единицами. Максимально допустимое значение элемента устанавливается равным 256. Адаптивное приращение устанавливается равным 32. Данная комбинация значений параметров позволяет адаптироваться к сильно меняющемуся потоку чисел текстур.
2.7.1.6.2. Контекстное моделирование символа узла
Имеются 256 различных символов узлов, каждый из которых представляет бинарный массив вокселей размером 2×2×2. К этим массивам можно применить трехмерное ортогональное преобразование, которое преобразует соответствующие символы друг в друга.
Рассмотрим набор из 48 фиксированных ортогональных преобразований, то есть поворотов на 90*n (n=1, 1, 2, 3) градусов относительно осей координат и преобразований симметрии. Матрицы таких преобразований приведены ниже в порядке следования их номеров:
OrthogonalTransoforms[48] =
{

}
Имеются 22 набора символов, называемых классами, таких, что два символа связаны посредством подобного преобразования тогда и только тогда, когда они принадлежат одному и тому же классу. При данном способе кодирования построение ТВК выполняют следующим образом: Context ID некоторого символа равен либо номеру класса, к которому принадлежит его порождающий узел, либо составному числу (класс порождающего узла, положение текущего узла в порождающем узле). Это позволяет значительно уменьшить число контекстов, что сокращает время, необходимое для сбора содержательных статистических данных.
Для каждого класса определяется один базовый символ (см. таблицу 9), а для каждого символа заранее вычисляется ортогональное преобразование, которое переводит этот символ в базовый символ его класса (в реальном процессе кодирования/декодирования используется таблица, по которой осуществляется поиск). После того как для символа определен ContextID, применяется преобразование, обратное (то есть заданное транспонированной матрицей) тому, которое переводит его родителя в базовый элемент. В таблице 10 для каждого символа приведены контексты и соответствующие прямые преобразования.
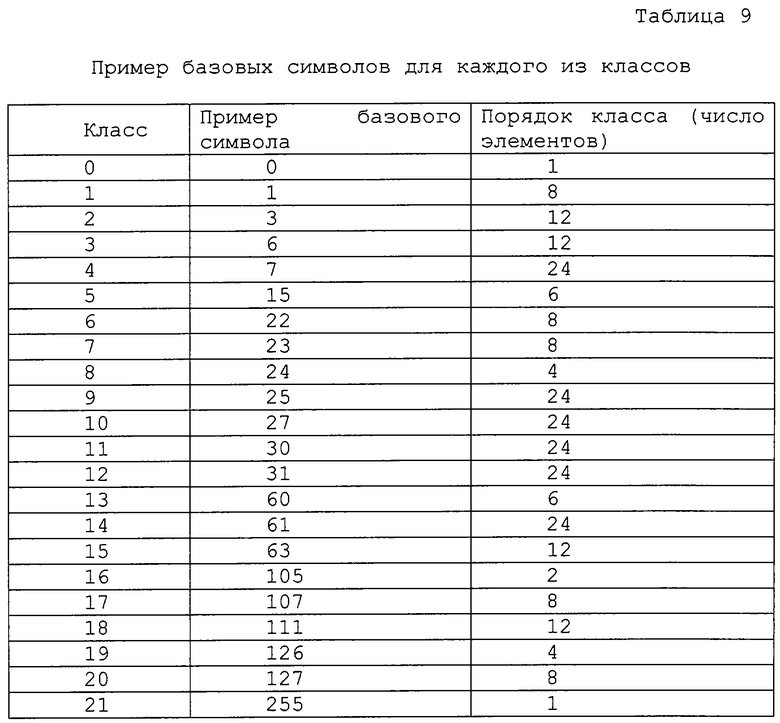
Выбор контекстной модели зависит от числа N уже декодированных символов:
Для N<512 имеется только один контекст. Элементы таблицы вероятности инициализируются единицами. Число символов в таблице вероятности равно 256. Адаптивное приращение равно 2. Максимальная кумулятивная частота равна 8192.
Для 512≤N<2560 (=2048+512) используется 1-контекстная модель (в том смысле, что номер контекста - это одиночный параметр, номер класса). В данной модели используются 22 таблицы ТВК. ContextID - это номер класса, к которому принадлежит родитель декодированного узла. Этот номер всегда можно определить по таблице, по которой осуществляется поиск (см. таблицу 10), так как декодирование родителя выполняется до декодирования потомка. Каждая из 22 таблиц ТВК инициализируется с помощью ТВК с предыдущего этапа. Число символов в каждой таблице вероятности равно 256. Адаптивное приращение равно 3. Максимальная кумулятивная частота также равна 8192. После декодирования символ преобразуют с использованием определенного выше обратного ортогонального преобразования. Номер ортогонального преобразования можно найти в таблице 10 при идентификаторе символа узла, соответствующем порождающему узлу символа текущего узла.
После декодирования 2560 символов декодер переключается на 2-контекстную модель (в том смысле, что теперь номер контекста скомпонован из двух параметров так, как это объясняется далее). В данной модели используются 176 (=22*8, то есть, 22 класса на 8 положений) ТВК. В данном случае ContextID зависит от класса порождающего узла и положения текущего узла в порождающем узле. Начальные значения таблиц вероятности в этой модели зависят исключительно от контекста, но не от положения: для каждого из 8 положений соответствующая ТВК является клоном ТВК, полученной для данного класса на предыдущем этапе. Число символов в каждой таблице вероятности равно 256. Адаптивное приращение равно 4. Максимальная кумулятивная частота также равна 8192.
Как и в случае с предыдущей моделью, после декодирования символ также преобразуют с использованием обратного ортогонального преобразования (к символу, заданному в таблице 10).
С помощью таблицы 10 можно легко получить геометрию базовых элементов для каждого класса. Базовые элементы - это символы, для которых идентификатор преобразования равен 0 (0 присваивается тождественному преобразованию).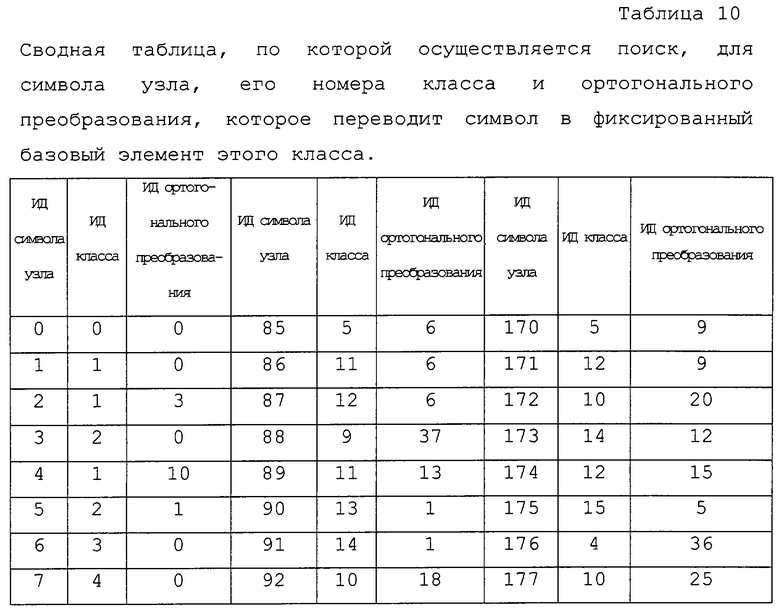
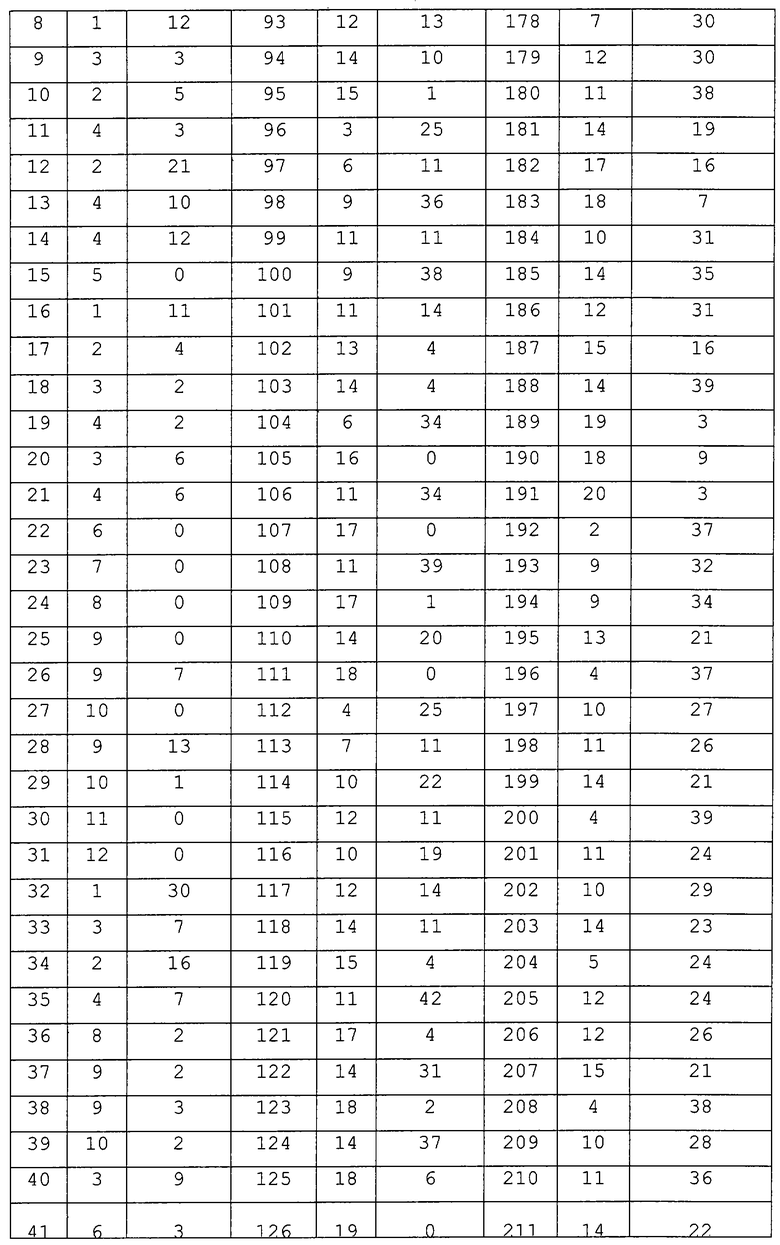
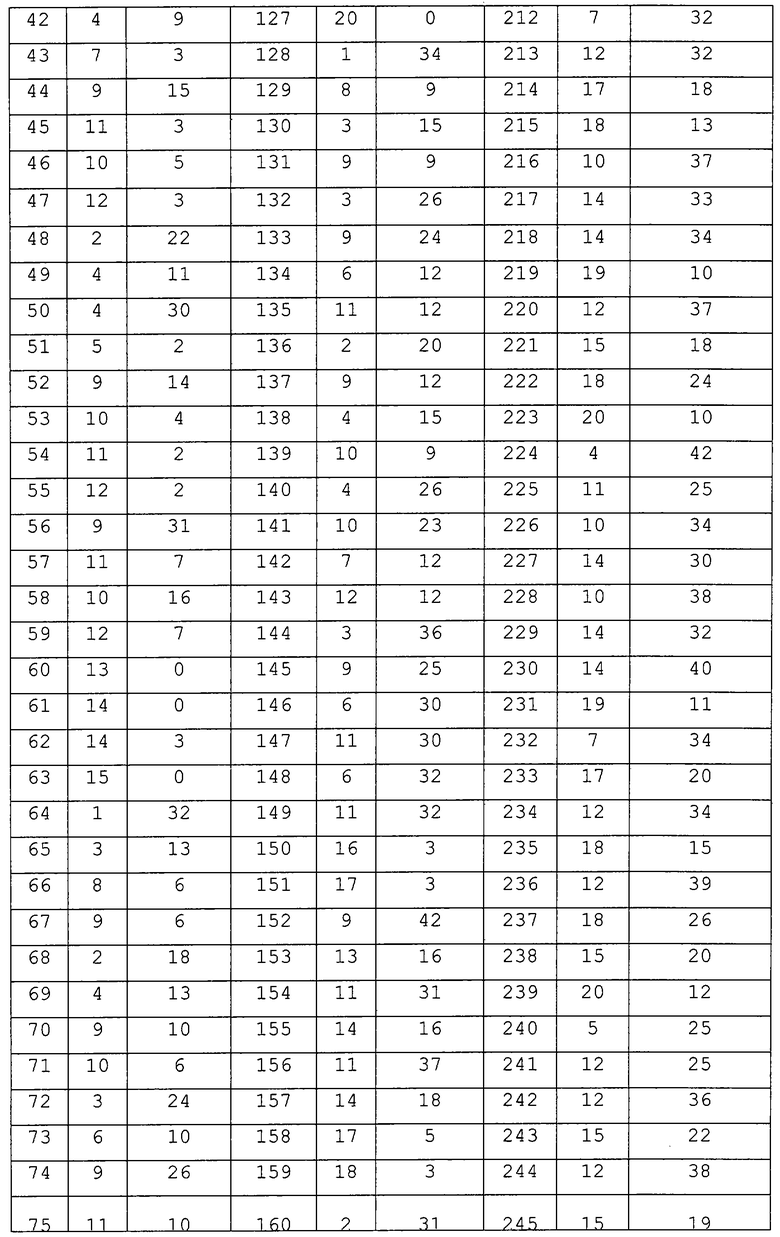
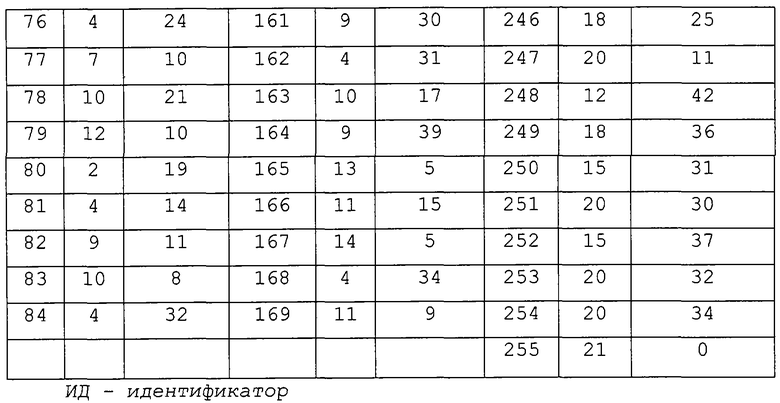
3. Список литературы.
[1] J.Cleary and I.Witten, "Data compression using adaptive coding and partial string matching", IEEE Trans. on Communications, vol.32, no.4, pp.396-402, April 1984.
[2] J.Rissanen and G.Langdon, "Universal modeling and coding", IEEE Trans. on Information Theory, vol.27, no.1, pp.12-23, January 1981.
[3] M.Schindler, "A byte oriented arithmetic coding", Proc. of Data Compression Conference, March 1998.
[4] G.Martin, "Range encoding: an algorithm for removing redundancy from a digitized message". Video & Data Recording Conference, March 1979.
[5] H.Coxeter and W. Moser, Generators and relations for discrete groups, 3rd edition, Springer-Verlag, 1972.
Далее приводится подробное описание спецификации узлов MPEG-4 и способов сжатия форматов изображений на основе октодерева, используемых в соответствующих настоящему изобретению устройстве и способе представления трехмерных объектов на основе изображений с глубиной.
В этом изобретении описывается семейство структур данных - представлений на основе изображений с глубиной (ПОИГ), которые обеспечивают эффективные и рациональные представления, основывающиеся, в основном, на изображениях и картах глубины, полностью используя при этом вышеописанные преимущества. Далее приводится краткая характеристика основных форматов ПОИГ - SimpleTexture, PointTexture и OctreeImage.
На фиг.20 приведена схема примера изображения рельефной текстуры и карты глубины, а на фиг.21 - схема примера многослойного изображения с глубиной (МИГ). (а) иллюстрирует проецирование объекта, а (б) иллюстрирует многослойные пиксели.
SimpleTexture - это структура данных, состоящая из изображения, соответствующей карты глубины и описания камеры (ее положения, ориентации и типа - ортогонального или перспективного). Возможности представления одной SimpleTexture ограничиваются объектами, подобными фасаду здания: фронтальное изображение с картой глубины позволяет воспроизвести виды фасада в значительном диапазоне углов. Однако, коллекция объектов SimpleTexture, выдаваемая позиционированными надлежащим образом камерами, позволяет воспроизводить все здание целиком - в этом случае эталонные изображения покрывают все потенциально видимые части поверхности здания. Естественно, то же самое относится к деревьям, фигурам людей, машинам и т.д. Более того, объединение объектов SimpleTexture предоставляет весьма естественное средство для обработки трехмерных анимационных данных. В этом случае эталонные изображения заменяются эталонными видеопотоками. Карты глубины для каждого трехмерного кадра можно представить либо посредством значений альфа-канала этих видеопотоков, либо отдельными видеопотоками в представлении шкалы уровней серого. При таком типе представления изображения можно хранить в форматах сжатия с потерями, таком как, например, JPEG. Это значительно уменьшает объем информации о цвете, особенно в случае анимации. Однако, информацию о геометрии (карты глубины) следует сжимать без потерь, что оказывает влияние на суммарное уменьшение хранимой информации.
Для объектов сложной формы иногда оказывается крайне сложным покрыть всю видимую поверхность приемлемым числом эталонных изображений. Предпочтительным представлением для таких случаев может быть PointTexutre. В этом формате также хранятся эталонное изображение и карта глубины, но в рассматриваемом случае они оказываются многозначными: для каждого луча зрения, предоставляемого камерой (ортогональной или перспективной), цвет и расстояние хранятся для каждого пересечения рассматриваемого луча с объектом. Число пересечений может меняться от луча к лучу. Объединение нескольких объектов PointTexture предоставляет очень подробное представление даже для сложных объектов. Но данному формату в первую очередь недостает двумерной регулярности SimpleTexture, и, таким образом, для него не существует естественной сжатой формы, основывающейся на изображениях. По той же самой причине он используется только для неподвижных объектов.
Формат OctreeImage занимает промежуточное положение между "преимущественно двумерным" SimpleTexture и "преимущественно трехмерным" PointTexture: в нем хранится геометрия объекта в объемном представлении, структурированном в виде октодерева (иерархически организованных вокселей обычного бинарного разбиения заключающего куба), в то время как цветовая компонента представлена набором изображений. Этот формат также содержит дополнительную структуру, подобную октодереву, в которой для вокселя каждого листа хранится индекс эталонного изображения, содержащего его цвет. На этапе визуализации OctreeImage цвет вокселя листа определяется посредством его ортогонального проецирования на соответствующее эталонное изображение. Нами разработан высокоэффективный способ сжатия для геометрической части OctreeImage. Этот способ является вариантом адаптивного арифметического кодирования, основывающегося на контекстах, где контексты создаются с явным использованием геометрической природы данных. Использование этого способа сжатия совместно с эталонными изображениями, сжатыми с потерями, делает OctreeImage очень экономичным в смысле объема представлением. Подобно SimpleTexture, у OctreeImage есть анимационная версия: эталонные видеопотоки вместо эталонных изображений плюс два дополнительных потока данных октодеревьев, представляющих геометрию и соответствие между вокселями и изображениями для каждого трехмерного кадра. Очень полезным отличительным признаком формата OctreeImage является встроенная в него возможность усредненного отображения.
Семейство ПОИГ разработано для новой версии стандарта MPEG-4 и принято для включения в Расширение Структуры Анимации (РСА) стандарта MPEG. РСА предоставляет более усовершенствованные отличительные признаки для синтетических сред MPEG-4 и включает в себя коллекцию способных к взаимодействию средств, которые обеспечивают многократно используемую архитектуру для интерактивного анимационного содержимого (совместимого с существующим MPEG-4). Каждое средство РСА обладает совместимостью с узлом двоичного формата для сцен (ДФС), потоком синтезированных данных и аудио-визуальным потоком. Текущая версия РСА состоит из высокоуровневых описаний анимации (например, скелетной анимации), усовершенствованной визуализации (например, процедурного текстурирования, технологии наложения цвета на объекты), компактных представлений (например, представления в виде неравномерных рациональных би-сплайнов (НРБС), монолитного представления, поверхностей разбиения), анимации с низкой битовой скоростью (например, сжатия интерполятором) и других описаний, включая и предлагаемое нами ПОИГ.
Форматы ПОИГ были разработаны с целью объединения преимуществ различных идей, предложенных ранее, тем самым обеспечивая пользователя гибкими средствами, которые наилучшим образом приспособлены для конкретной задачи. Например, неанимационные форматы SimpleTexture и PointTexture являются частными случаями известных форматов, в то время как OctreeImage - это, очевидно, новое представление. Но в контексте MPEG-4 все три основных формата ПОИГ можно рассматривать в качестве строительных блоков, а их комбинации посредством структурных компонентов MPEG-4 не только охватывают многие из предложенных в литературе представлений, основывающихся на изображениях, но также предоставляют огромный потенциал для создания новых подобных форматов.
Далее описывается представление на основе изображений с глубиной.
Принимая во внимание идеи, отмеченные в предыдущем разделе, а также некоторые из наших собственных разработок, мы предлагаем следующий набор форматов, основывающихся на изображениях с глубиной и предназначенных для использования в РСА MPEG-4: SimpleTexture, PointTexture, DepthImage и OctreeImage. Следует отметить, что для SimpleTexture и OctreeImage имеются анимационные версии.
SimpleTexture представляет собой отдельное изображение, объединенное с изображением с глубиной. Она эквивалентна рельефной текстуре (РТ), в то время как PointTexture эквивалентна МИГ.
Выбирая SimpleTexture и PointTexture в качестве строительных блоков, мы можем построить множество представлений, используя структурные компоненты MPEG-4. Формальные спецификации приводятся ниже, а здесь полученный результат описывается с геометрической точки зрения.
Структура DepthImage определяет либо SimpleTexture, либо PointTexture совместно с ограничивающим кубом, положением в пространстве и некоторой дополнительной информацией. Набор объектов DepthImage можно объединить в одну структуру, называемую узлом Transform, что позволяет строить множество полезных представлений. Наиболее общее применение имеют два из них, причем для них нет специфических для MPEG-4 имен, однако в нашей практике мы называем их "блочная текстура" (БТ) и "обобщенная блочная текстура" (ОБТ). БТ представляет собой объединение шести объектов SimpleTexture, соответствующих граням куба, ограничивающего объект или сцену, в то время как ОБТ представляет собой объединение произвольного числа объектов SimpleTexture, которые вместе обеспечивают согласованное трехмерное представление. Пример БТ приводится на фиг.22, на которой показаны эталонные изображения, карты глубины и результирующий трехмерный объект. Визуализацию на основе БТ можно выполнять с помощью алгоритма деформации с приращениями [6], но нами используется другой подход, который также применим и к ОКТ. Пример представления на основе ОКТ приведен на фиг.23, где для представления сложного объекта, пальмового дерева, используется 21 объект SimpleTexture.
Следует отметить, что для представления одного и того же объекта или частей одного и того же объекта механизм объединения позволяет, например, использовать несколько изображений МИГ с разными камерами. Следовательно, структуры данных, подобные объектам, основывающимся на изображениях с глубиной, ячейкам дерева МИГ, ячейкам древовидной структуры, основывающейся на элементах поверхности, являются частными случаями данного формата, что, очевидно, обеспечивает значительно большую гибкость при адаптации положения и разрешения объектов SimpleTexture и PointTexture к структуре сцены.
Далее описывается OctreeImage: текстурированное бинарное волюметрическое октодерево (ТБВО).
Для использования геометрии и текстур с переменным разрешением при более гибком представлении и быстрой визуализации нами разрабатывается представление OctreeImage, которое основывается на текстурированном бинарном волюметрическом октодереве (ТБВО). Задачей ТБВО является разработка гибкого формата представления/сжатия с быстрой высококачественной визуализацией. ТБВО состоит из трех основных компонентов: бинарного объемного октодерева (БВО), которое представляет геометрию, набора эталонных изображений и индексов изображений, соответствующих узлам октодерева.
Информация о геометрии в форме БВО представляет собой набор бинарных (занятых или пустых) вокселей, разделенных регулярными интервалами и объединенных в ячейки большего размера обычным для октодерева способом. Это представление можно легко получить из данных DepthImage через промежуточную форму "облака точек", так как каждый пиксель с глубиной определяет уникальную точку в трехмерном пространстве. Преобразование облака точек в БВО проиллюстрировано на фиг.24. Аналогичный процесс допускает преобразование полигональной модели в БВО. Относящуюся к БВО информацию о текстурах можно извлечь из эталонных изображений. Эталонное изображение представляет собой текстуру вокселей при заданном положении и ориентации камеры. Таким образом, БВО совместно с эталонными изображениями обеспечивает представление модели. При этом оказывается, что дополнительная структура, предназначенная для хранения индекса эталонного изображения для каждого листа БВО, позволяет выполнять визуализацию значительно быстрее и с более высоким качеством.
Основной проблемой визуализации БВО является то, что мы должны определить соответствующий индекс камеры для каждого вокселя в процессе визуализации. В связи с этим мы должны, по меньшей мере, определить наличие камеры, с которой виден данный воксель. Эта процедура оказывается крайне медленной, если используется "лобовой" подход к решению описанной проблемы. В дополнение к этой проблеме имеют место некоторые трудности для вокселей, которые невидимы ни с одной из камер, что приводит к нежелательным артефактам в изображении, полученном при визуализации.
Возможным решением могло бы быть хранение явного цвета для каждого вокселя. Однако в этом случае мы сталкиваемся с некоторой проблемой при сжатии информации о цвете. Иными словами, если мы группируем цвета вокселей в формате изображения и сожмем его, то корреляция цветов соседних вокселей нарушается, так что степень сжатия становится неудовлетворительной.
В случае ТБВО проблема решается посредством хранения индекса камеры (изображения) для каждого вокселя. Данный индекс обычно оказывается одним и тем же для больших групп вокселей, что позволяет использовать структуру октодерева для экономного хранения дополнительной информации. Следует отметить, что во время экспериментов с нашими моделями в среднем наблюдалось 15%-ное увеличение объема по сравнению с представлением, для которого используется только БВО и эталонные изображения. Упомянутое моделирование немного более сложное, зато оно предоставляет более гибкие пути представления объектов произвольной геометрии.
Следует отметить, что ТБВО представляет собой очень удобное представление, предназначенное для визуализации с помощью "сплатов", так как размер "сплата" легко вычислить по размеру вокселя. Цвет вокселя можно легко определить, используя эталонные изображения и индекс изображения данного вокселя.
Далее описывается преобразование текстурированного бинарного волюметрического октодерева в поток данных.
Мы полагаем, что 255 камер будет достаточно, и выделяем на индекс вплоть до 1 байта. Поток данных ТБВО - это поток символов. Каждый символ ТБВО - это символ БВО или символ текстуры. Символ текстуры обозначает индекс камеры, которым может быть конкретное число или код "не определено".
Пусть в последующем описании в качестве кода "не определено" фигурирует ‘?’. Поток данных ТБВО обходится в порядке по схеме "сначала в ширину". Далее приводится описание процедуры записи потока данных ТБВО в случае, если у нас имеется БВО, а для вокселя каждого листа имеется индекс изображения. Это должно быть сделано на этапе моделирования. Все узлы БВО, включая узлы листьев (для которых нет БВО-символа) обходятся в порядке по схеме "сначала в ширину". На фиг.25 приведен псевдокод, который завершает запись потока данных.
Пример записи битового потока ТБВО приведен на фиг.14. В соответствии с данной процедурой для дерева ТБВО по фиг.14(а) можно получить поток символов, изображенный на фиг.14(в). В этом примере для представления текстур-символов используется один байт. Однако в реальном потоке данных для каждой текстуры-символа требуется только 2 бита, так как необходимо представить только три значения (две камеры и код "не определено").
Далее описывается анимация ПОИГ.
Анимационные версии были определены для двух форматов ПОИГ: DepthImage, содержащего только объекты SimpleTexutre, и OctreeImage. Объем данных является одной из основных проблем, связанных с трехмерной анимацией. Мы выбрали именно эти форматы, потому что видеопотоки можно естественным образом встроить в их анимационные версии, обеспечивая тем самым значительное уменьшение объема данных.
В случае DepthImage анимация выполняется посредством замещения эталонных изображений объектами MovieTexture стандарта MPEG-4. Высококачественное сжатие видеоданных с потерями не оказывает серьезного влияния на внешний вид результирующих трехмерных объектов. Карты глубины можно хранить (в режиме, для которого почти отсутствуют потери) в альфа-каналах эталонных видеопотоков. На этапе визуализации визуализация кадра выполняется после того, как получены и декомпрессированы все кадры эталонных изображений и глубины.
Анимация OctreeImage аналогична вышеописанной - эталонные изображения замещаются объектами MovieTexture стандарта MPEG-4, в результате чего возникает новый поток данных октодерева.
Далее определяется спецификация узлов MPEG-4.
Форматы ПОИГ подробно описаны в спецификациях узлов РСА MPEG-4 [4]. DepthImage содержит поля, определяющие параметры конуса видимости либо для SimpleTexture, либо для PointTexture. Узел OctreeImage представляет объект в виде геометрических данных, определяемых ТБВО, и набора форматов эталонных изображений. Информация, зависящая от сцены, хранится в специальных полях структур данных ПОИГ, обеспечивающих корректное взаимодействие объектов ПОИГ с оставшейся частью сцены. Определение узлов ПОИГ показано на фиг.26.
Фиг.27 иллюстрирует пространственное представление DepthImage, при этом показано значение каждого поля. Следует отметить, что узел DepthImage определяет отдельный объект ПОИГ. Когда несколько узлов DepthImage взаимосвязаны, они обрабатываются как группа, и, таким образом, их следует подчинить одному узлу Transform. Поле diTexture задает текстуру с глубиной (SimpleTexture или PointTexture), которая отображается на область, определенную в узле DepthImage.
Узел OctreeImage определяет структуру октодерева и проецируемые текстуры. Поле octreeResolution задает максимальное число листьев октодерева, расположенных вдоль грани заключающего его куба. Поле octree задает набор внутренних узлов октодерева. Каждый внутренний узел представлен байтом. 1 в i-м бите этого байта означает, что для i-го дочернего узла рассматриваемого внутреннего узла существуют дочерние узлы, в то время как 0 означает, что таких узлов не существует. Порядком внутренних узлов октодерева является порядок обхода октодерева по схеме "сначала в ширину". Порядок восьми дочерних узлов внутреннего узла приведен на фиг.14(б). Поле voxelImageIndex содержит массив индексов изображений, присвоенных вокселю. На этапе визуализации цвет, являющийся атрибутом листа октодерева, определяется посредством ортогонального проецирования этого листа на одно из изображений с конкретным индексом. Индексы хранятся в форме, подобной октодереву: если отдельное изображение можно использовать для всех листьев, содержащихся в конкретном вокселе, то воксель, содержащий индекс этого изображения, выводится в поток; в противном случае, выводится воксель, содержащий фиксированный код "дополнительное разбиение", что означает, что индекс изображения определяется отдельно для каждого дочернего узла текущего вокселя (в той же рекурсивной форме). В случае, если поле voxelImageIndex пусто, индексы изображений определяются на этапе визуализации. Поле images задает набор узлов Depthlmage с SimpleTexture в качестве поля diTexture. Однако поля nearPlane и farPlane узла DepthImage и поле depth узла SimpleTexture не используются.
Способы визуализации для форматов ПОИГ не являются частью РСА, но тем не менее необходимо пояснить идеи, используемые для достижения простоты, скорости и качества визуализации объектов ПОИГ. Наши способы визуализации основываются на "оплатах" - малых плоских пятнах неправильной формы, используемых в качестве "примитивов визуализации". Два излагаемых ниже подхода ориентированы на два различных представления: DepthImage и OctreeImage. С целью ускорения визуализации в нашей реализации для формирования "сплатов" используются функции OpenGL. Тем не менее, также возможна программная визуализация, которая допускает оптимизированные вычисления с использованием простой структуры DepthImage или OctreeImage.
Способ, используемый нами для визуализации объектов DepthImage, предельно прост. Тем не менее следует отметить, что он зависит от функций OpenGL и работает значительно быстрее при помощи аппаратного ускорителя. Согласно этому способу мы преобразуем все пиксели с глубиной, относящиеся к объектам SimpleTexture и PointTexture, визуализация которых должна быть выполнена, в трехмерные точки, затем позиционируем малые полигоны ("сплаты") на эти точки и применяем функции визуализации из состава OpenGL. Псевдокод данной процедуры для случая SimpleTexture приведен на фиг.28. Случай PointTexture обрабатывается в точности таким же способом.
Размер "сплата" необходимо адаптировать к расстоянию между рассматриваемой точкой и наблюдателем. Мы использовали следующий простой подход. Во-первых, куб, заключающий заданный трехмерный объект, представляется в виде грубой равномерной сетки. Размер "сплата" вычисляется для каждой ячейки рассматриваемой сетки, и это значение используется для точек внутри данной ячейки. Упомянутое вычисление выполняется следующим образом:
- Отобразить ячейку на экран посредством OpenGL.
Вычислить длину L наибольшей диагонали проекции (в пикселях).
- Оценить D (диаметр "сплата") как 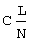 , где N – это среднее число точек, приходящееся на грань ячейки, а С - это эвристическая константа, приблизительно равная 1,3.
, где N – это среднее число точек, приходящееся на грань ячейки, а С - это эвристическая константа, приблизительно равная 1,3.
Нам бы хотелось подчеркнуть, что этот способ, конечно, можно улучшить посредством более точных вычислений радиуса, более сложных "сплатов", сглаживания контурных неровностей (исключение дефектов наложения изображений). Тем не менее, даже этот простой подход обеспечивает хорошее визуальное качество.
Тот же самый подход работает и для случая OctreeImage, в котором узлы октодерева, расположенные на одном из более грубых уровней, используются для вышеописанных вычислений размера "сплата". Однако, в случае OctreeImage информацию о цвете следует сперва отобразить на набор вокселей. Это можно сделать очень просто, так как для каждого вокселя есть соответствующий индекс эталонного изображения. Позиция пикселя в эталонном изображении также становится известна во время синтаксического анализа потока данных октодерева. Как только определяются цвета вокселей OctreeImage, описанным выше способом выполняется оценка размеров "сплатов" и используется визуализация на основе OpenGL.
Форматы ПОИГ были реализованы и протестированы на нескольких трехмерных моделях. Одна из таких моделей ("Башня") была получена посредством сканирования реального физического объекта (использовался цветной трехмерный сканер Cyberware), в то время как остальные были конвертированы из демонстрационного программного пакета 3DS-MAX. Тесты выполнялись на процессоре Intel Pentium-IV 1,8 ГГц с ускорителем OpenGL.
В нижеследующих подразделах поясняются способы преобразования полигональных форматов в форматы ПОИГ и представлены результаты моделирования, представления и сжатия для различных форматов ПОИГ. Большая часть данных относится к моделям DepthImage и OctreeImage; для этих форматов есть анимационные версии и их можно эффективно сжимать. Все представленные модели построены при помощи ортогональной камеры, так как в общем случае это является предпочтительным способом представления "компактных" объектов. Следует отметить, что перспективная камера в основном используется для экономного представления ПОИГ удаленных сред.
Формирование модели ПОИГ начинается с получения достаточного количества объектов SimpleTexture. Для полигонального объекта объекты SimpleTexture вычисляются, в то время как для объекта реального мира эти данные получаются с цифровых камер и сканирующих устройств. Следующий этап зависит от формата ПОИГ, который мы собираемся использовать.
DepthImage - это просто объединение полученных объектов SimpleTexture. Несмотря на то, что карты глубины можно хранить в сжатом виде, в данном случае приемлемо только сжатие без потерь, так как даже малое искажение геометрии зачастую сильно бросается в глаза.
Эталонные изображения можно хранить в сжатом виде с потерями, но в этом случае требуется предварительная обработка. Несмотря на то, что, в общем случае, приемлемо использовать популярные способы сжатия с потерями типа JPEG, на формируемых видах трехмерного объекта граничные артефакты становятся более заметны - особенно благодаря границам между объектом и фоном эталонного изображения, где цвет фона "проникает" в данный объект. Решение, использованное нами для преодоления этой проблемы, состоит в расширении изображения в граничных блоках на фон эталонного изображения, используя осредненный цвет блока и быстрое затухание интенсивности, и в последующем применении сжатия JPEG. Получаемый эффект походит на "выдавливание" искажения в фоновое изображение, где оно безвредно, так как пиксели фонового изображения для визуализации не используются. Внутренние границы эталонных изображений, сжатых с потерями, также могут создавать артефакты, но, в общем случае, они менее заметны.
Для формирования моделей OctreeImage мы используем промежуточное представление на основе точек (ПОТ). Набор точек, составляющих ПОТ, представляет собой объединение цветных точек, получаемых посредством сдвига пикселей в эталонных изображениях на расстояния, задаваемые в соответствующих картах глубины. Исходные объекты SimpleTexture следует создавать таким образом, чтобы результирующее ПОТ обеспечивало достаточно точную аппроксимацию поверхности объекта. После этого ПОТ преобразуется в OctreeImage так, как показано на фиг.24, и используется для формирования нового полного набора эталонных изображений, удовлетворяющих накладываемым данным форматом ограничениям. В то же время формируется структура voxelImageIndex дополнительных данных, представляющая индексы эталонных изображений для вокселей октодерева. В случае, если эталонные изображения следует хранить в форматах сжатия с потерями, эти изображения проходят предварительную обработку так, как это разъяснялось в предыдущем подразделе. Помимо этого, так как структура ТБВО явно задает для каждого вокселя пиксель, содержащий его цвет, то избыточные пиксели отбрасываются, что дополнительно уменьшает объем voxelImageIndex. Примеры исходных и обработанных эталонных изображений в формате JPEG приведены на фиг.29.
Следует отметить, что ухудшение качества вследствие сжатия с потерями пренебрежимо мало для объектов OctreeImage, но все еще иногда заметно для объектов DepthImage.
Модели PointTexture строятся с использованием проекции объекта на опорную плоскость так, как это пояснялось в Разделе 2.1. Если при этом создается недостаточное количество выборок (что может иметь место для частей поверхности, расположенных почти по касательной к вектору проекции), то для формирования большего числа выборок создаются дополнительные объекты SimpleTexture. Полученный набор точек затем реорганизуется в структуру PointTexture.
Далее представляются данные о скорости визуализации. Скорость визуализации модели "Пальма" формата DepthImage составляет около 2 кадр/с (следует отметить, что это 21 простая текстура), в то время как для остальных статических моделей, которые мы тестировали со стороной эталонного изображения равной 512, визуализация выполнялась со скоростью 5-6 кадр/с. Следует отметить, что скорость визуализации в основном зависит от числа и разрешения эталонных изображений, но не от сложности сцены. Это является важным преимуществом над полигональными представлениями, особенно в случае анимации. Анимационная модель "Дракон512" формата OctreeImage визуализируется со скоростью 24 кадра в секунду (кадр/с).
Модель "Ангел256" формата DepthImage показана на фиг.22. На фиг.30-34 приведены некоторые другие модели ПОИГ и полигональные модели. На фиг.30 проводится сравнение внешнего вида модели "Мортон" в полигональном формате и формате DepthImage. Модель DepthImage использует эталонные изображения в формате JPEG, а визуализация выполняется посредством простейшего формирования "сплатов", описанного в Разделе 5, но при этом качество изображения вполне приемлемо. На фиг.31 проводится сравнение двух версий сканированной модели "Башня". Черные точки в верхней части данной модели обусловлены зашумленными входными данными. На фиг.32 демонстрируется более сложная модель "Пальма", скомпонованная из 21 объекта SimpleTexture. Она также хорошего качества, несмотря на то, что в общем случае листья получились шире, чем на оригинале 3DS-MAX, что является следствием упрощенного формирования "сплатов".
На фиг.33 приведен трехмерный кадр из анимации "Дракон512" формата OctreeImage. Фиг.34 демонстрирует способность формата PointTexture обеспечивать модели отличного качества.
Соответствующая настоящему изобретению структура узла, основывающаяся на изображениях с глубиной, включает в себя узел SimpleTexture, узел PointTexture, узел DepthImage и узел OctreeImage. Узел DepthImage скомпонован из информации о глубине и цветного изображения. Цветное изображение выбирается из узла SimpleTexture и узла PointTexture.
В случае, когда объект наблюдается с шести точек наблюдения (спереди, сзади, в плане, с тыла, с левой и правой сторон), данный объект можно представить шестью парами узлов SimpleTexture. Спецификация узла SimpleTexture приведена на фиг.26.
Согласно фиг.26 узел SimpleTexture скомпонован из поля Texture, в которое записано цветное изображение, содержащее цвет каждого пикселя, и поле depth, в которое записана глубина для каждого пикселя. Узел SimpleTexture определяет отдельную текстуру ПОИ. В рассматриваемом случае понятие "текстура" означает цветное плоское изображение.
Плоское изображение, содержащее цвет для каждого из пикселей, формирующих изображение, находится в поле texture. Глубина для каждого из пикселей, формирующих изображение, записана в поле depth. Набор глубин в поле depth формирует изображения с глубиной, соответствующие плоскому изображению в поле texture. Изображения с глубиной - это плоские изображения, представленные шкалой уровней серого в соответствии со значениями глубины. В случае видеоформата, предназначенного для формирования анимационных объектов, информация о глубине и информация о цвете представляют собой множество последовательностей кадров изображений.
Плоское изображение в поле texture (то есть, цветное изображение) и плоское изображение в поле depth (то есть, изображение, представленное шкалой уровней серого) составляют узел SimpleTexture. На фиг.20 приведены объекты "Мортон", представленные узлами SimpleTexture для фронтальных точек наблюдения. В конечном итоге, данные объекты представляются посредством шести узлов SimpleTexture, которые являются парами изображений, сформированными для шести точек наблюдения. На фиг.22 приведены объекты "Ангел", представленные шестью узлами SimpleTexture.
Цветное изображение можно представить посредством узлов PointTexture. На фиг.21 приведены точечные текстуры, сформированные посредством проецирования объекта на опорную плоскость (в этом случае на плоскость, удаленную от объекта на заранее заданное расстояние таким образом, чтобы располагаться лицом к задней поверхности объекта).
На фиг.26 также приведена спецификация узла PointTexture.
Согласно фиг.26 узел PointTexture скомпонован из поля size, поля resolution, поля depth и поля color. Информация о размере плоскости изображения записана в поле size. Поле size скомпоновано из полей width и height, в которые записаны ширина и высота плоскости изображения, соответственно. Размер плоскости изображения устанавливается равным размеру, достаточному для покрытия всего объекта, проецируемого на опорную плоскость.
Информация о разрешении по глубине для каждого пикселя записана в поле resolution. Например, в случае, когда в поле resolution записано число "8", глубина объекта представлена 256 уровнями шкалы на основе на расстоянии от опорной плоскости.
Множество сегментов информации о глубине для каждого пикселя записано в поле depth. Информация о глубине представляет собой последовательность чисел пикселей, проецируемых на плоскость изображения, и глубин для соответствующих пикселей. Информация о цвете представляет собой последовательность цветов, корреспондирующих соответствующим пикселям, проецируемыми на плоскость изображения.
Информация о точке наблюдения, составляющая узел DepthImage, включает в себя несколько полей, таких как viewpoint, visibility, projection method или distance.
В поле viewpoint записаны точки наблюдения, из которых наблюдается плоскость изображения. Поле viewpoint имеет поля position и orientation, в которые записаны положение и ориентация точки наблюдения, соответственно. Положение, записанное в поле position, представляет собой положение точки наблюдения относительно начала (0, 0, 0) системы координат, в то время как ориентация, записанная в поле orientation, представляет собой величину поворота точки наблюдения относительно ориентации, принятой по умолчанию.
В поле visibility записана область наблюдения от точки наблюдения до плоскости изображения. В поле projection method записан способ проецирования из точки наблюдения на плоскость изображения. В настоящем изобретении способ проецирования включает способ ортогонального проецирования, в котором область наблюдения представлена шириной и высотой, и способ перспективного проецирования, в котором область наблюдения представлена горизонтальным углом и вертикальным углом. Если выбирается способ ортогонального проецирования, то есть, если поле projection method установлено равным TRUE, то ширина и высота области наблюдения соответствуют ширине и высоте плоскости изображения, соответственно. Если выбирается способ перспективного проецирования, то горизонтальный и вертикальный углы области наблюдения соответствуют углам, образуемым плоскостями, проходящими через точку наблюдения и вертикальные и горизонтальные стороны плоскости изображения, соответственно.
В поле distance записаны расстояние от точки наблюдения до ближней граничной плоскости и расстояние от точки наблюдения до дальней граничной плоскости. Поле distance скомпоновано из полей nearPlane и farPlane. Поле distance определяет область для информации о глубине.
На фиг.35а и 35б приведены схемы, иллюстрирующие взаимоотношения соответствующих узлов при представлении объекта в формате DepthImage, имеющем узлы SimpleTexture и узлы PointTexture, соответственно.
Согласно фиг.35а, рассматриваемый объект можно представить посредством наборов узлов DepthImage, соответствующих шести точкам наблюдения. Каждый из соответствующих узлов DepthImage состоит из информации о точке наблюдения и SimpleTexutre. SimpleTexutre состоит из пары цветного изображения и изображения с глубиной.
Согласно фиг.35б, рассматриваемый объект можно представить посредством узла DepthImage. Спецификация узла DepthImage описывается также, как это делалось ранее. Узел PointTexutre скомпонован из информации о плоскости, на которую проецируется объект, а также информации о глубине и информации о цвете для различных точек объектов, проецируемых на плоскость изображения.
В случае узла OctreeImage объект представлен структурой внутренних узлов, составляющих воксели, которые содержат объект и эталонные изображения. Спецификация узла OctreeImage приведена на фиг.26.
Согласно фиг.26, узел OctreeImage включает в себя поля octreeResolution, octree, voxelImageIndex и images.
В поле octreeResolution записано максимальное число листьев октодерева, расположенных вдоль грани заключающего его куба, который содержит рассматриваемый объект. В поле octree записана структура внутреннего узла. Внутренний узел - это узел для субкуба, сформированного в результате разбиения заключающего куба, который содержит весь объект целиком. Разбиение каждого субкуба выполняется итерационно для формирования 8 субкубов и продолжается до тех пор, пока не будет достигнуто заранее определенное число субкубов. В случае, когда итерационное разбиение выполняется трижды, узел для субкуба после первой итерации разбиения называется порождающим узлом, и узел для субкуба после третьей итерации разбиения называется дочерним узлом, полагая при этом, что узел для субкуба после второй итерации разбиения называется текущим узлом. Порядок 8 разделенных субкубов - это порядок с приоритетом в ширину. На фиг.14 приведен способ назначения номеров приоритета субкубов. Каждый внутренний узел представлен байтом. Информация узла, записанная в составляющий этот байт битовые потоки, представляет наличие или отсутствие дочерних узлов у дочерних узлов, принадлежащих рассматриваемому внутреннему узлу.
В поле index записаны индексы эталонных изображений, корреспондирующие соответствующим внутренним узлам. В поле image записаны эталонные изображения, соответствующие индексам, записанным в поле index. Эталонные изображения - это узлы DepthImage, структура которых описывается так, как это делалось выше.
На фиг.36 приведена схема, иллюстрирующая структуру соответствующего узла OctreeImage при представлении объекта с использованием узлов OctreeImage.
Согласно фиг.36, узлы OctreeImage инкапсулированы битовыми упаковщиками. Каждый битовый упаковщик включает в себя узел OctreeImage. В случае, когда объект представлен в виде узлов SimpleTexture, узел OctreeImage включает в себя 6 узлов DepthImage, причем каждый узел DepthImage содержит узел SimpleTexture. С другой стороны, в случае, когда объект представлен в виде узлов PointTexture, узел OctreeImage включает в себя один узел DepthImage.
Настоящее изобретение можно реализовать на записывающем машинно-читаемом носителе записи с использованием машинно-читаемых кодов. Машинно-читаемый носитель записи включает в себя все виды устройств записи, с которых можно считать данные, понятные для компьютерной системы, и примерами этих устройств являются постоянное запоминающее устройство (ПЗУ), запоминающее устройство с произвольной выборкой (ЗУПВ), ПЗУ на компакт-диске, магнитные ленты, дискеты, оптические устройства хранения данных и т.п., а также этот носитель может быть реализован в виде несущей волны, распространяющейся, например, из Интернета или другой среды передачи данных. Также машинно-читаемый носитель записи распределяется в компьютерной системе, подключенной к сети, таким образом, что машинно-читаемые коды хранятся и реализуются распределенным способом.
В соответствии с настоящим изобретением, в представлениях на основе изображений, используемый алгоритм прост и может поддерживаться аппаратными средствами во многих аспектах в силу того, что истинная информация о цветном трехмерном объекте кодируется посредством набора двумерных изображений простой и регулярной структуры, которая была незамедлительно принята в широко известные способы обработки и сжатия изображений. Более того, время визуализации для моделей, основывающихся на изображениях, пропорционально числу пикселей в эталонных и результирующих изображениях, но, в общем случае, не пропорционально геометрической сложности, что имеет место в случае полигональных моделей. Более того, в случае, когда представление, на основе изображений, применяется к объектам и сценам реального мира, визуализация натуральной сцены с фотографическим качеством становится возможной без использования миллионов полигонов и дорогостоящих вычислений.
Предшествующее описание варианта реализации настоящего изобретения представлено в иллюстративных и описательных целях. Оно не является исчерпывающим и не ограничивает настоящее изобретение отдельно взятой описанной формой. Модификации и вариации возможны в свете вышеописанных идей или могут быть получены из практической реализации настоящего изобретения. Объем настоящего изобретения определяется пунктами формулы изобретения и их эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНОГО ОБЪЕКТА НА ОСНОВЕ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237283C2 |
| ИЕРАРХИЧЕСКОЕ ОСНОВАННОЕ НА ИЗОБРАЖЕНИЯХ ПРЕДСТАВЛЕНИЕ НЕПОДВИЖНОГО И АНИМИРОВАННОГО ТРЕХМЕРНОГО ОБЪЕКТА, СПОСОБ И УСТРОЙСТВО ДЛЯ ИСПОЛЬЗОВАНИЯ ЭТОГО ПРЕДСТАВЛЕНИЯ ДЛЯ ВИЗУАЛИЗАЦИИ ОБЪЕКТА | 2001 |
|
RU2215326C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ ТРЕХМЕРНЫХ ОБЪЕКТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2003 |
|
RU2267161C2 |
| Способ и устройство для кодирования облака точек | 2020 |
|
RU2778377C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ ОБЛАКА ТОЧЕК | 2020 |
|
RU2799041C1 |
| СИСТЕМА КТ ДЛЯ ДОСМОТРА И СООТВЕТСТВУЮЩИЙ СПОСОБ | 2015 |
|
RU2599277C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ ОБЛАКА ТОЧЕК | 2021 |
|
RU2792020C1 |
| Система для построения модели трехмерного пространства | 2023 |
|
RU2812950C1 |
| СПОСОБ СОЗДАНИЯ ИЗОБРАЖЕНИЙ ТРЕХМЕРНЫХ ОБЪЕКТОВ ДЛЯ СИСТЕМ РЕАЛЬНОГО ВРЕМЕНИ | 2011 |
|
RU2467395C1 |
| ОСНОВАННЫЕ НА ИЗОБРАЖЕНИЯХ СПОСОБ ПРЕДСТАВЛЕНИЯ И ВИЗУАЛИЗАЦИИ ТРЕХМЕРНОГО ОБЪЕКТА И СПОСОБ ПРЕДСТАВЛЕНИЯ И ВИЗУАЛИЗАЦИИ АНИМИРОВАННОГО ОБЪЕКТА | 2001 |
|
RU2216781C2 |
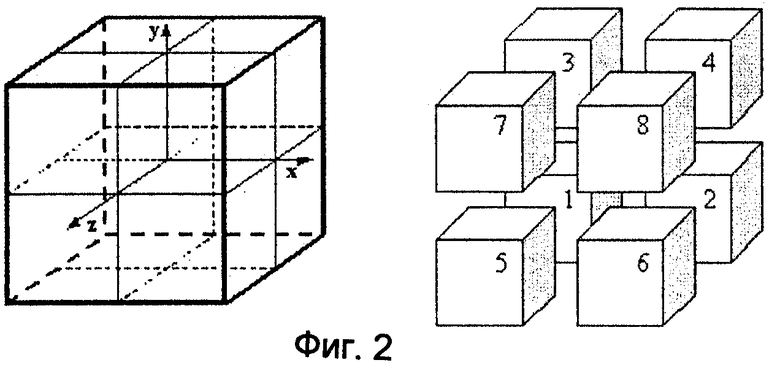


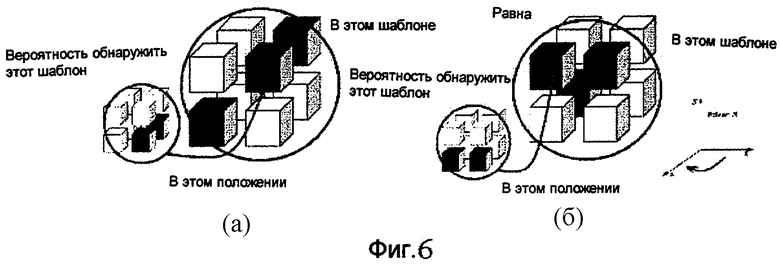
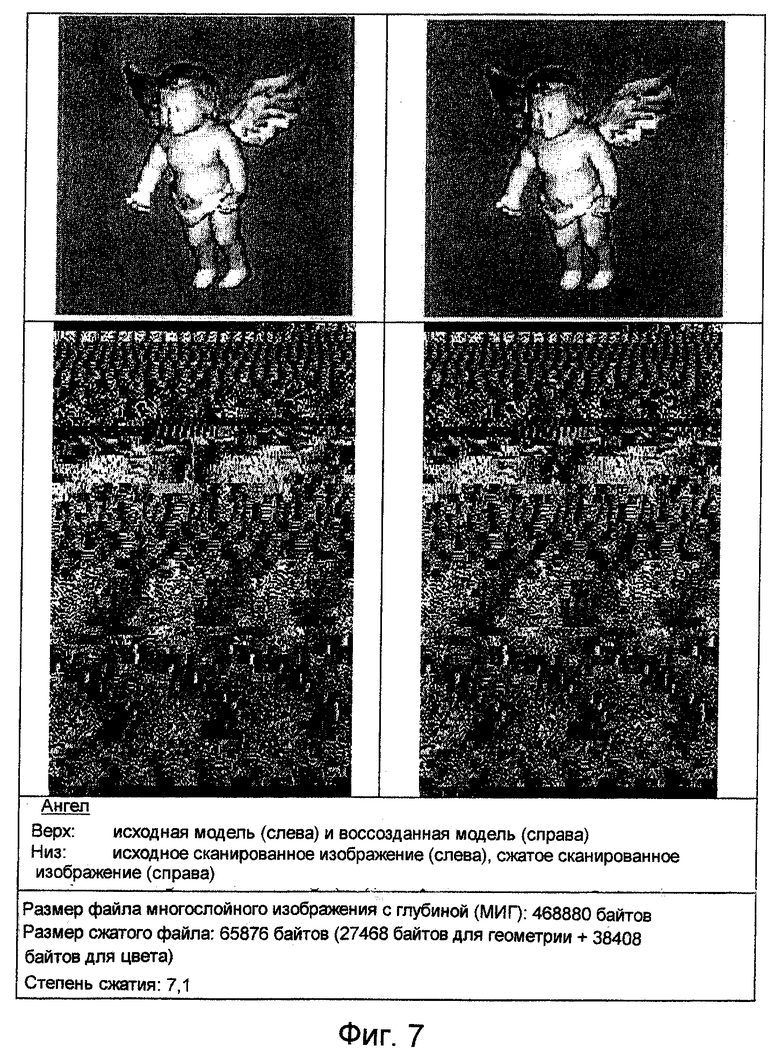

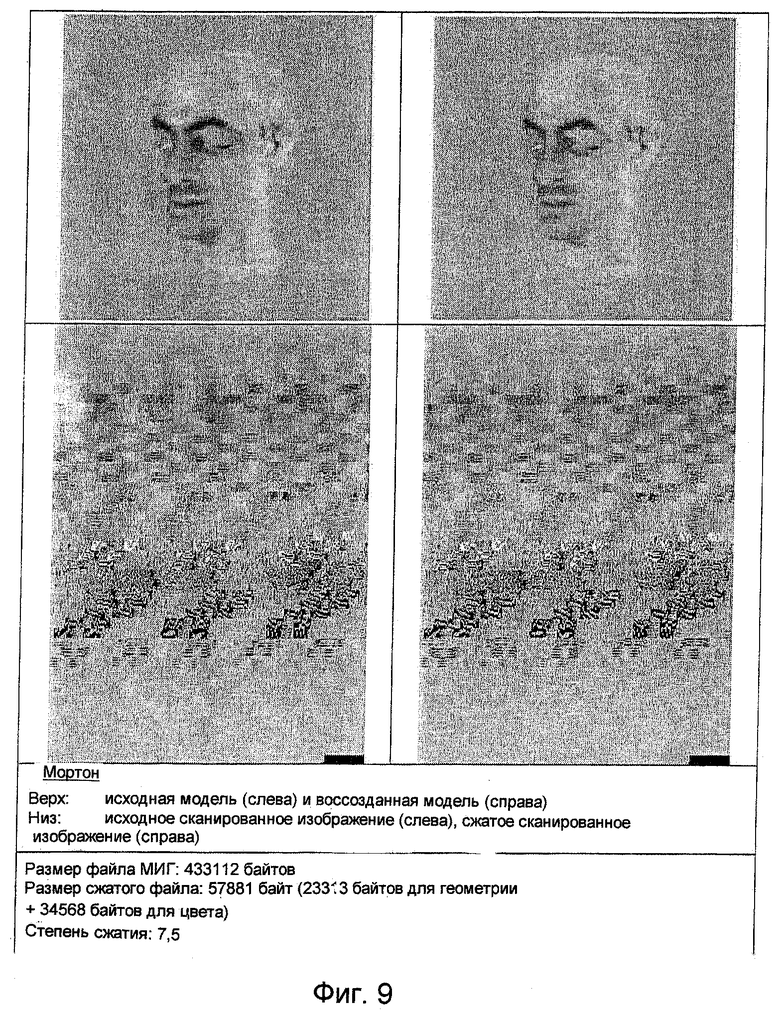

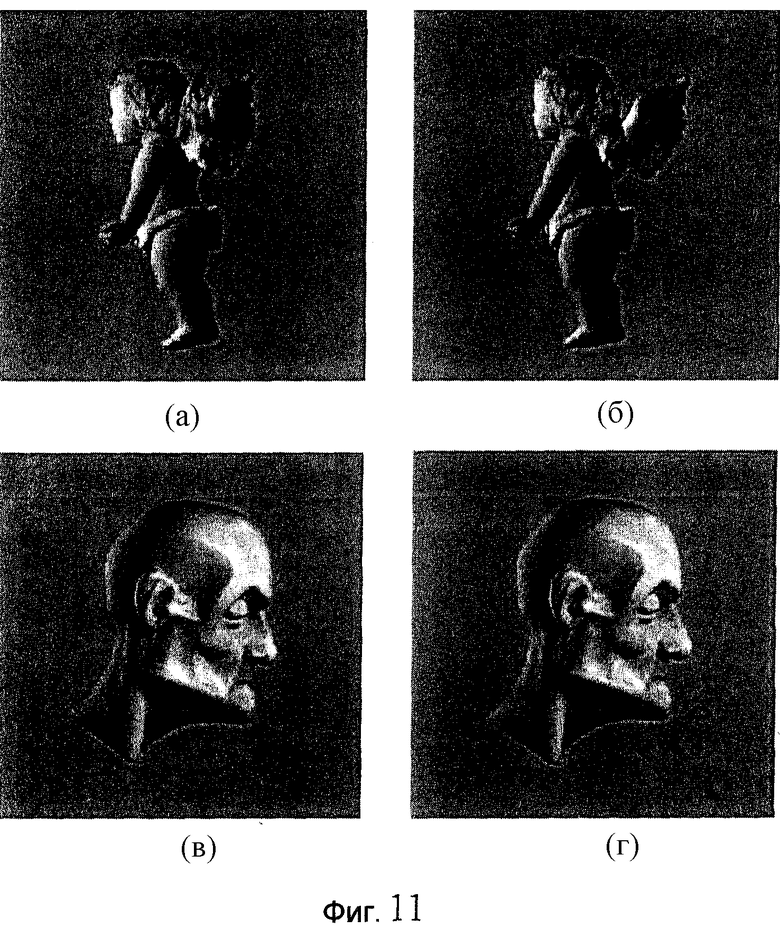
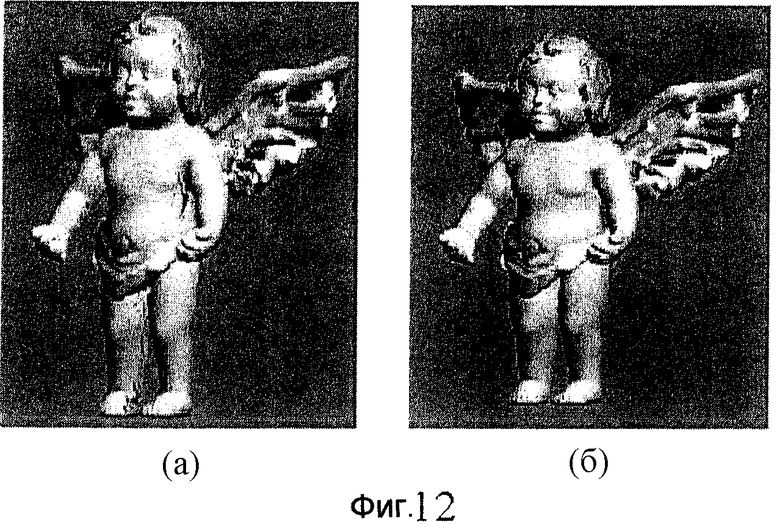
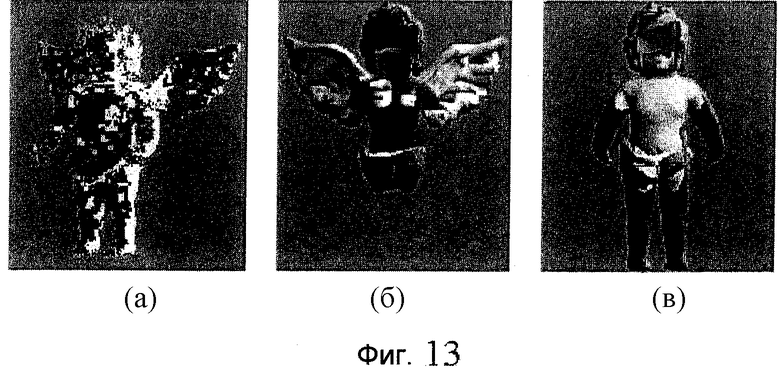
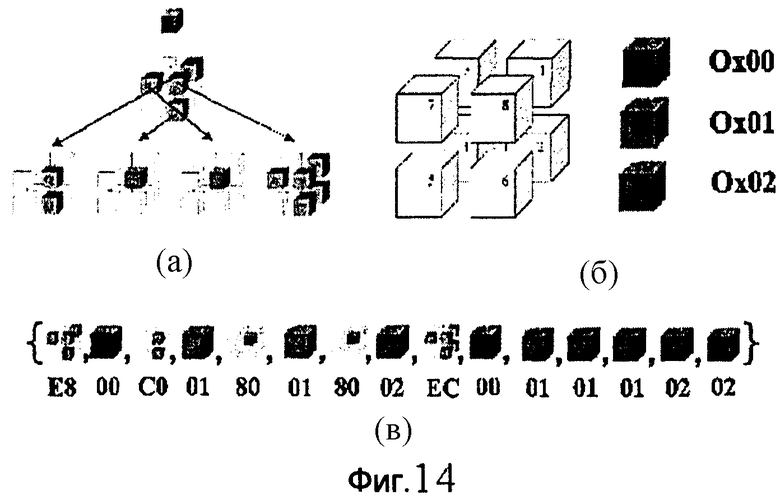
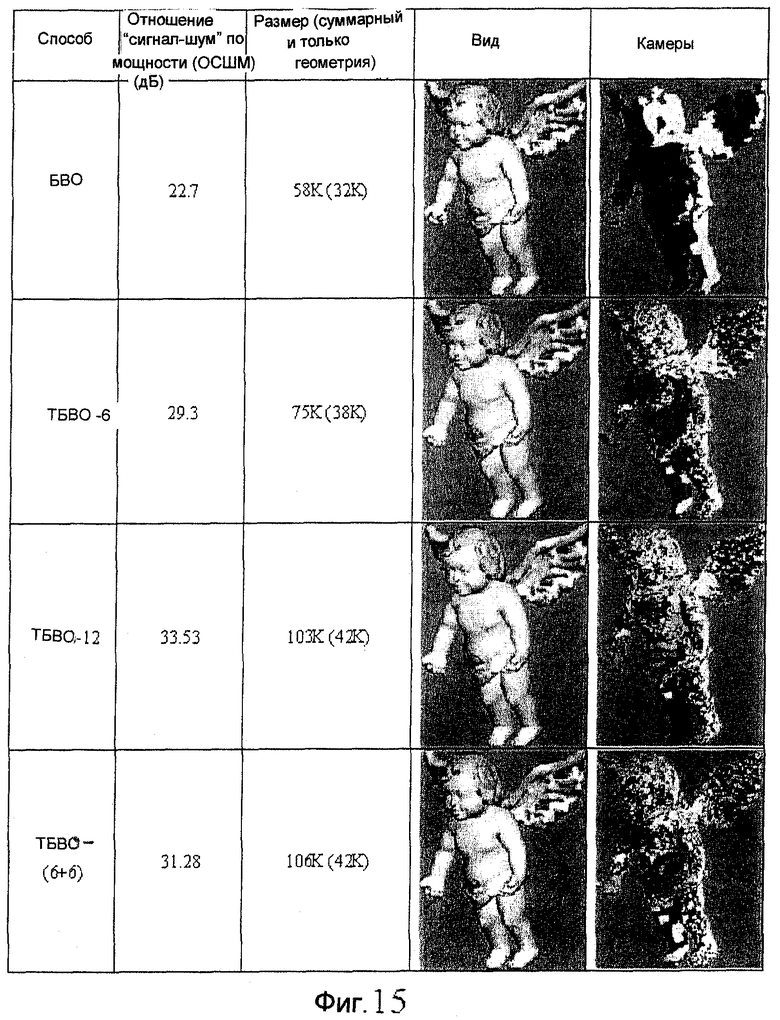
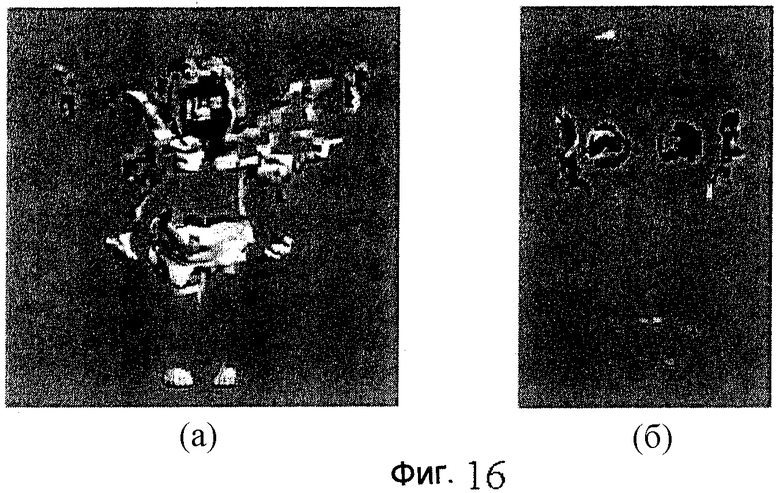
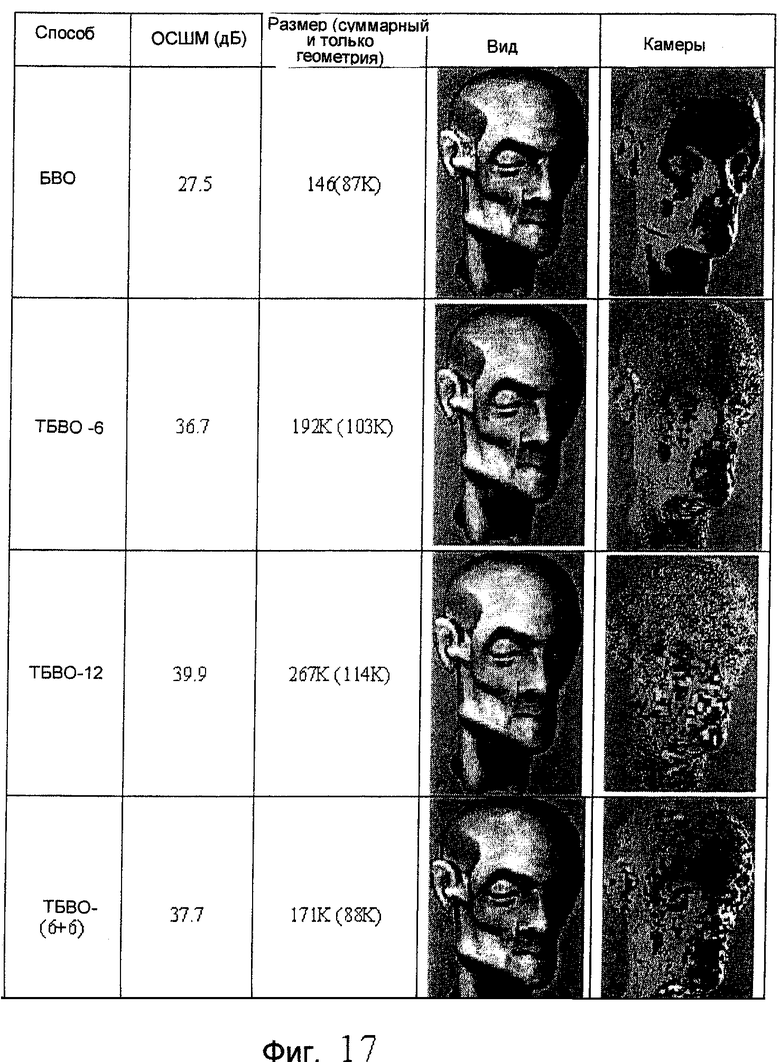

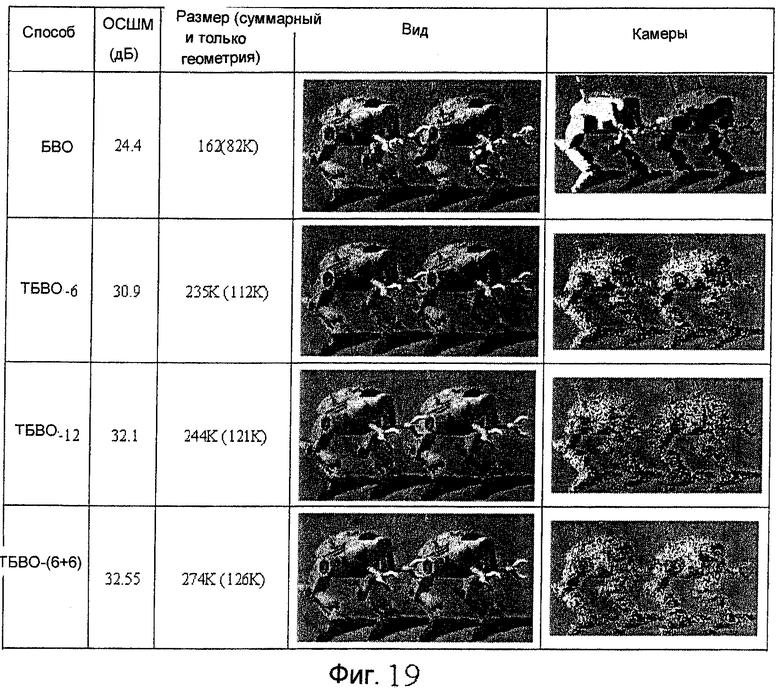

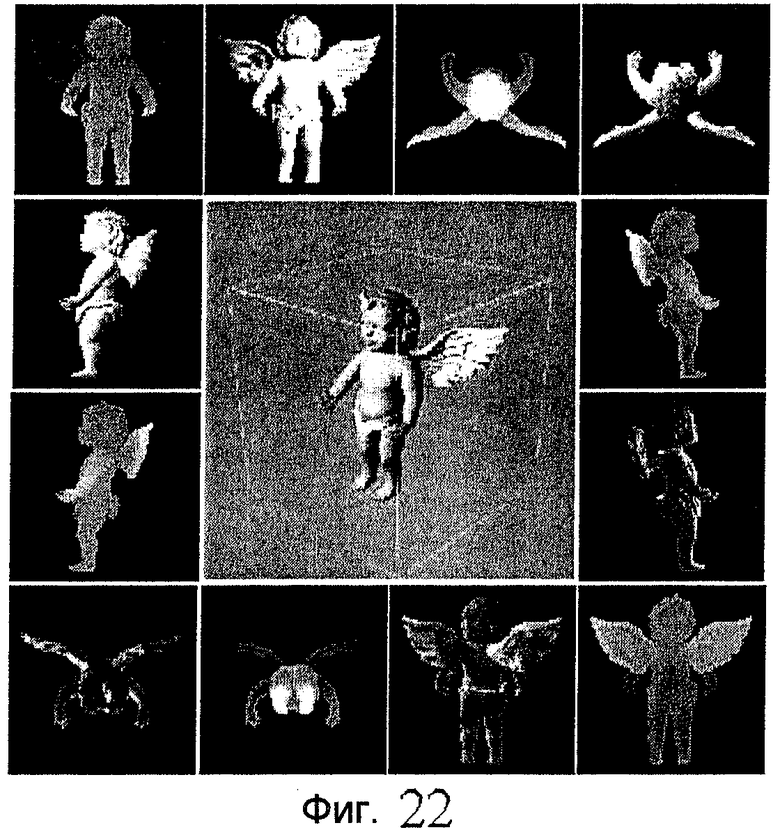
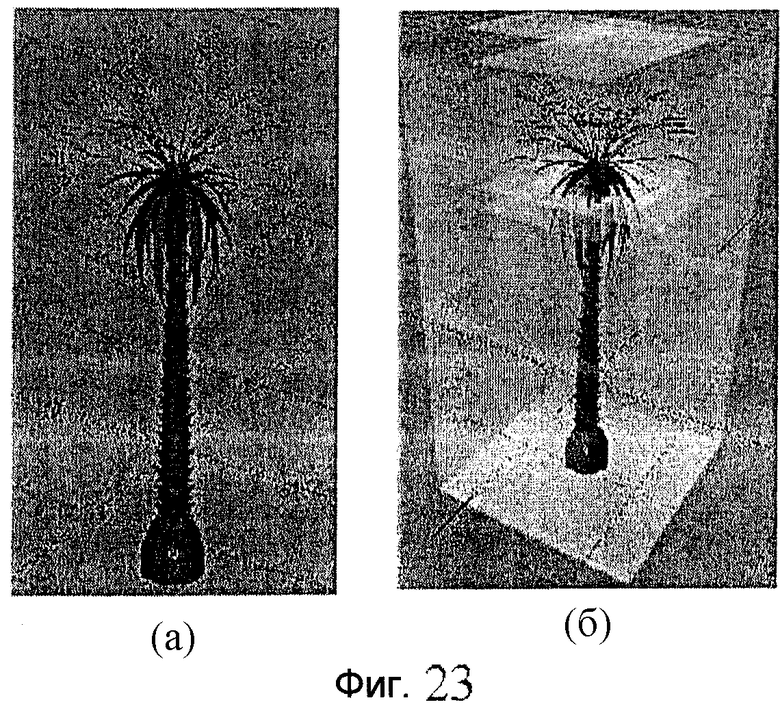
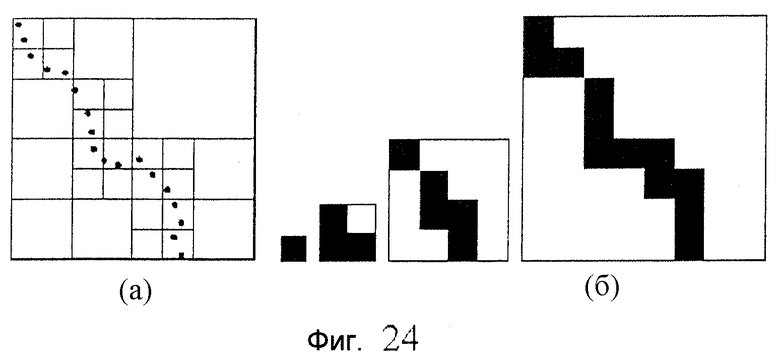


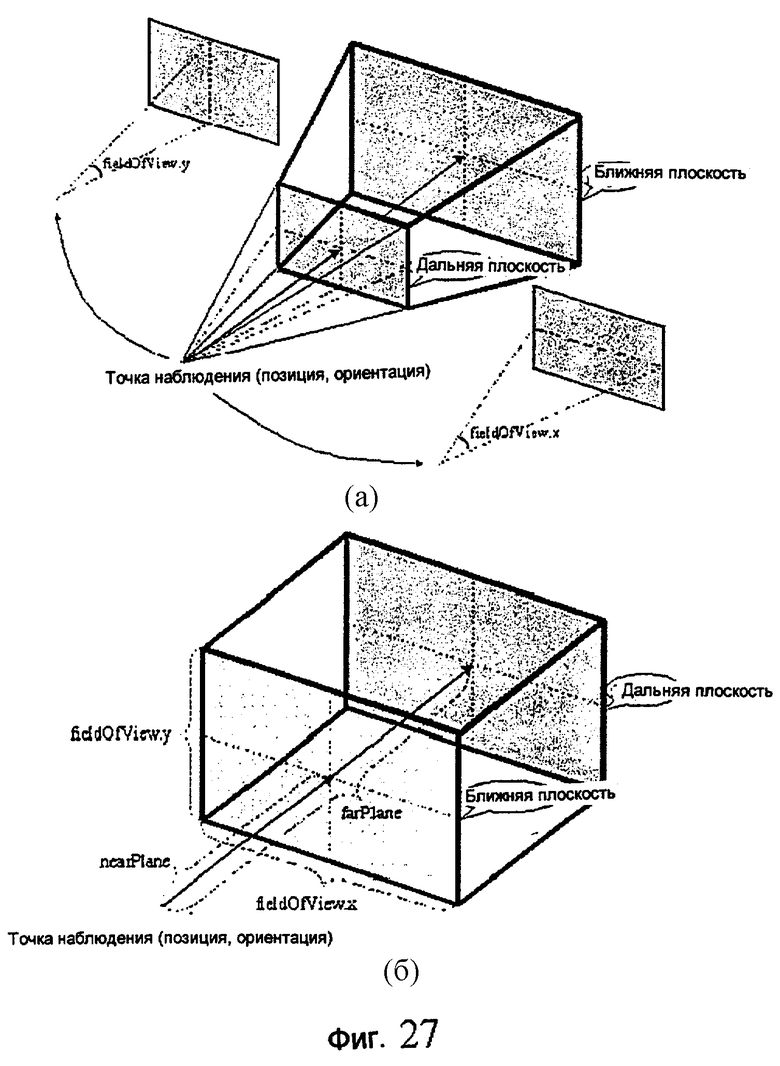

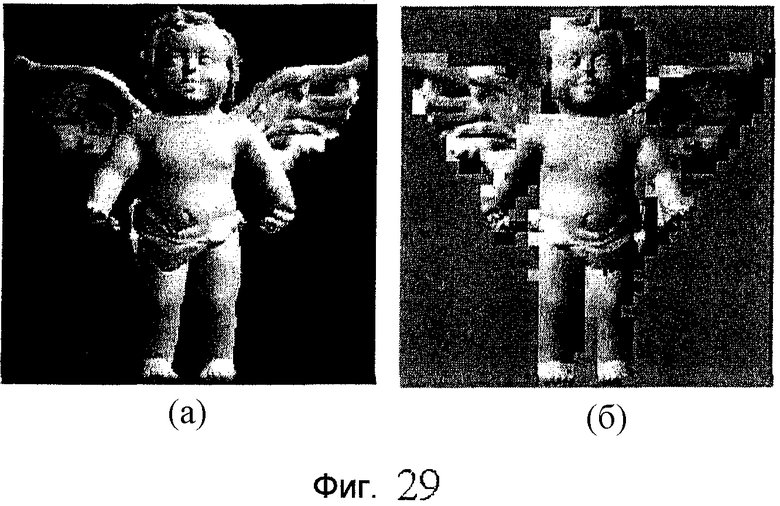
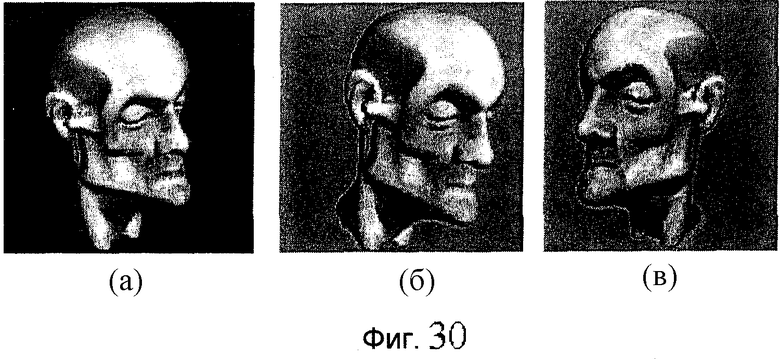




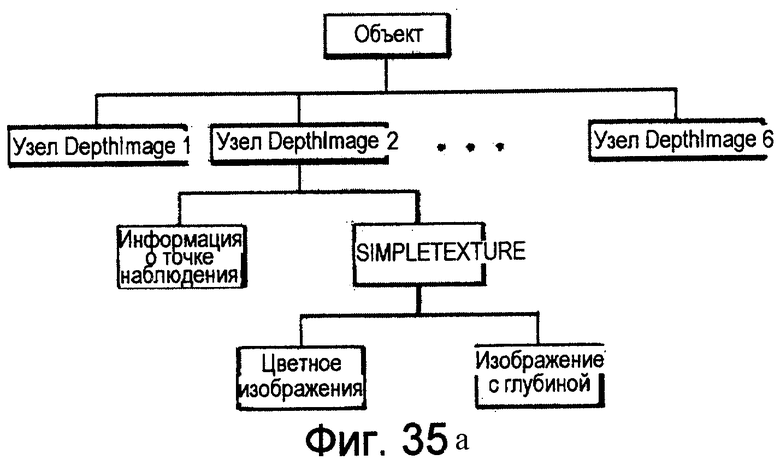
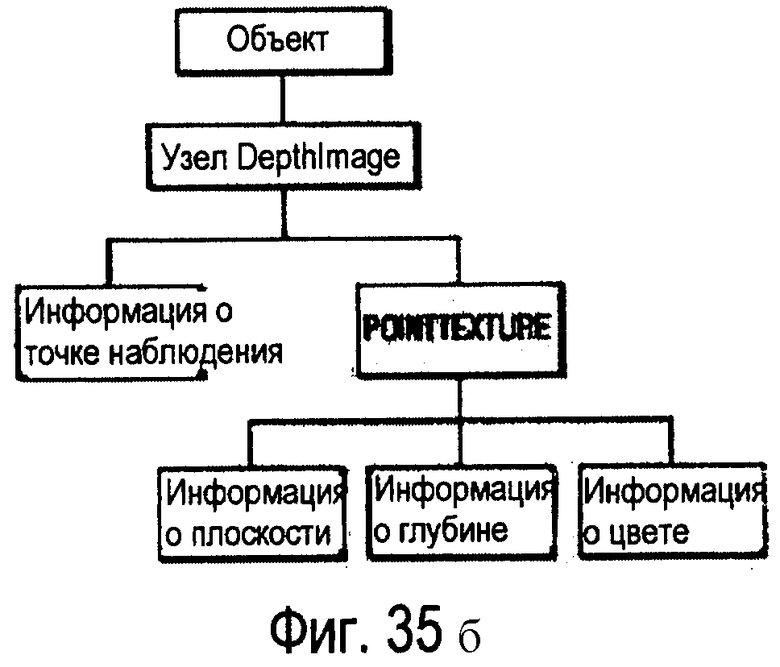
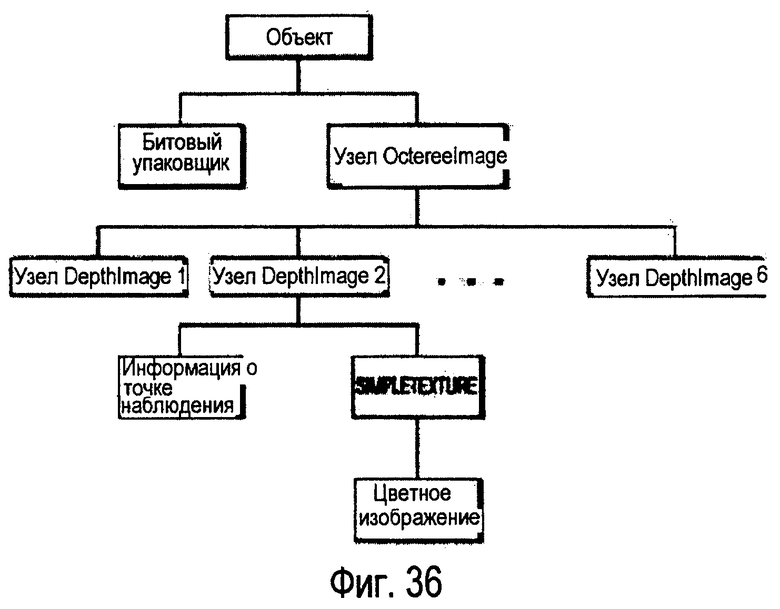
Изобретение относится к представлению трехмерных объектов на основе изображений с глубиной. Его применение, при визуализации трехмерного изображения в компьютерной графике и анимации позволяет получить технический результат в виде обеспечения компактности хранения информации об изображении, быстрой визуализации с высоким качеством выходного изображения. Этот результат достигается благодаря тому, что способ включает в себя этапы, на которых: создают поле текстуры, в которое записывают цветное изображение, содержащее информацию о цвете для каждого пиксела; создают поле глубины, в которое записывают изображение с глубиной, содержащее информацию глубины для каждого пиксела, и генерируют узел простой текстуры путем объединения поля текстуры и поля глубины в заданном порядке. 8 н. и 15 з.п. ф-лы, 36 ил., 10 табл.

| СПОСОБ АВТОМАТИЗИРОВАННОГО ИЗМЕРЕНИЯ С ИСПОЛЬЗОВАНИЕМ МОДЕЛИ ВНЕШНЕЙ СРЕДЫ В СТЕРЕОТЕЛЕВИЗИОННОЙ СИСТЕМЕ ТЕХНИЧЕСКОГО ЗРЕНИЯ | 1997 |
|
RU2148794C1 |
| US 5708764 А, 13.01.1998 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| US 6088035 А, 11.07.2000. | |||

