Область техники
Настоящее изобретение относится к устройству и способу для представления трехмерных (3D) объектов на основе изображений с глубиной, более конкретно, к устройству и способу для представления трехмерных объектов с использованием изображения с глубиной для компьютерной графики и анимации, определяемого как основанные на изображениях с глубиной представления (DIBR), что было принято в стандарте AFX (расширение структуры анимации) MPEG-4.
Описание предшествующего уровня техники
С самого начала исследований в области трехмерной графики конечной целью исследователей является синтезирование реалистичной графической сцены (визуализируемого трехмерного пространства), подобной реальному изображению. С этой целью выполнялись исследования по традиционньм технологиям рендеринга (визуализации) с использованием полигональных моделей, результатом которых стали разработки технологий моделирования и рендеринга, обеспечивающие получение весьма реалистических трехмерных представлений среды. Однако процедура генерирования усложненной модели требует огромных усилий экспертов и больших затрат времени. Кроме того, реалистическое и усложненное представление среды требует очень больших объемов информации и обуславливает снижение эффективности в хранении и передаче.
В настоящее время полигональные модели в типовом случае используются для представления трехмерных объектов в компьютерной графике. Произвольная форма может быть по существу представлена множеством цветных многоугольников, т.е. треугольников. Значительно усовершенствованные алгоритмы программного обеспечения и разработка аппаратных средств графики позволяют визуализировать комплексные объекты и сцены как в значительной мере реалистические полигональные модели неподвижных и движущихся изображений.
Однако в последнее десятилетие весьма активно проводились поиски альтернативных трехмерных представлений. Основные причины этого включают трудность конструирования полигональных моделей для объектов реального мира, а также сложность рендеринга и неудовлетворительное качество формирования сцен истинно фотографического качества.
Необходимые приложения требуют чрезвычайно большого количества многоугольников; например, детальная модель человеческого тела содержит несколько миллионов треугольников, что вызывает трудности в обработке. Хотя последние достижения в методах определения расстояний, например с использованием лазерного сканера расстояний, позволяют получать данные расстояний высокой плотности с допустимыми ошибками, по-прежнему является дорогостоящим и очень трудным получение плавной (без швов) полной полигональной модели объекта в целом. С другой стороны, алгоритмы рендеринга для получения приближенного к фотографии качества требуют сложных вычислений сложными и не обеспечивают рендеринга в реальном времени.
Сущность изобретения
Одним из аспектов настоящего изобретения является создание устройства и способа представления трехмерных объектов на основе изображений с глубиной, для компьютерной графики и анимации, называемого DIBR, принятого в стандарте AFX (расширение структуры анимации) MPEG-4.
Другим аспектом настоящего изобретения является создание компьютерно-читаемого носителя записи, имеющего программу для реализации способа представления трехмерных объектов на основе изображений с глубиной, для компьютерной графики и анимации, DIBR, принятого в стандарте AFX (расширение структуры анимации) MPEG-4.
В одном из аспектов настоящее изобретение предусматривает устройство для представления трехмерных объектов, основанного на изображениях по глубине содержащее генератор информации о точке наблюдения для генерирования по меньшей мере одного фрагмента информации о точке наблюдения, первый генератор изображений для генерирования цветных изображений на основе цветовой информации, соответствующей информации о точке наблюдения, на соответствующих точках пикселов, образующих объект, второй генератор изображений для генерирования изображений с глубиной на основе информации о глубине, соответствующей информации о точке наблюдения, по соответствующим точкам пикселов, образующих объект, генератор узлов для генерирования узлов изображений, состоящих из информации о точке наблюдения, цветного изображения и изображения с глубиной, соответствующего информации о точке наблюдения, и кодер для кодирования сформированных узлов изображения.
В другом аспекте настоящее изобретение предусматривает устройство для представления трехмерных объектов, основанного на изображениях с глубиной, содержащее генератор информации о точке наблюдения для генерирования по меньшей мере одного фрагмента информации о точке наблюдения, из которой наблюдается объект, генератор информации о плоскости для генерирования информации о плоскости, определяющей ширину, высоту и глубину плоскости изображения, соответствующей информации о точке наблюдения, генератор информации о глубине для генерирования последовательности данных о глубине для глубин всех проецируемых точек объекта, которые проецируются на плоскость изображения, генератор информации о цвете для генерирования последовательности данных о цвете по соответствующим проецируемым точкам, и генератор узлов для генерирования узла, составленного на основе информации о плоскости, соответствующей плоскости изображения, последовательности данных о глубине и последовательности данных о цвете.
Еще в одном аспекте настоящее изобретение предусматривает устройство для представления трехмерного объекта на основе изображений с глубиной, содержащее генератор информации о форме для генерирования информации о форме для объекта путем деления октодерева, содержащего объект, на 8 субкубов и определения разделенных субкубов как дочерние узлы, блок определения эталонного изображения для определения эталонного изображения, содержащего цветное изображение для каждого куба, разделенного генератором информацией о форме, генератор индексов для генерирования индексной информации эталонного изображения в соответствии с информацией о форме, генератор узлов для генерирования узлов октодерева, включающих информацию о форме, индексную информацию и эталонное изображение, и кодер для кодирования узлов октодерева в выходные потоки битов, причем генератор информации о форме итеративно выполняет подразделение до тех пор, пока субкуб не станет меньше, чем предварительно определенный размер.
Еще в одном аспекте настоящее изобретение предусматривает устройство для представления трехмерных объектов на основе изображений с глубиной, содержащее блок ввода для ввода битовых потоков, первый блок выделения для выделения узлов октодерева из входных битовых потоков, декодер для декодирования узлов октодерева, второй блок выделения для выделения информации о форме и эталонных изображений для множества кубов, образующих октодеревья, из декодированных узлов октодерева, и блок представления объекта для представления объекта путем комбинации выделенных эталонных изображений соответственно информации о форме.
Альтернативно, настоящее изобретение предусматривает способ представления трехмерного объекта на основе изображений с глубиной, включающий генерирование по меньшей мере одного фрагмента информации о точке наблюдения, генерирование цветных изображений на основе цветовой информации, соответствующей информации о точке наблюдения, по соответствующим точкам пикселов, образующих объект, генерирование изображений с глубиной на основе информации о глубине, соответствующей информации о точке наблюдения, по соответствующим точкам пикселов, образующих объект, генерирование узлов изображений, состоящих из информации о точке наблюдения, цветного изображения и изображения с глубиной, соответствующего информации о точке наблюдения, и кодирование сформированных узлов изображения.
В другом аспекте настоящее изобретение предусматривает способ представления трехмерных объектов на основе изображений с глубиной, включающий генерирование информации о точке наблюдения, из которой наблюдается объект, генерирование информации о плоскости, определяющей ширину, высоту и глубину плоскости изображения, соответствующей информации о точке наблюдения, генерирование последовательности данных о глубине для глубин всех проецируемых точек объекта, которые проецируются на плоскость изображения, генерирование последовательности данных о цвете по соответствующим проецируемым точкам и генерирование узла, состоящего из информации о плоскости, соответствующей плоскости изображения, последовательности данных о глубине и последовательности данных о цвете.
Еще в одном аспекте настоящее изобретение предусматривает способ представления трехмерного объекта на основе изображений с глубиной, включающий генерирование информации о форме для объекта путем деления октодерева, содержащего объект, на 8 субкубов и определения разделенных субкубов как дочерних узлов, определение эталонного изображения, содержащего цветное изображение, для каждого куба, разделенного генератором информации о форме, генерирование индексной информации эталонного изображения, соответствующей информации о форме, генерирование узлов октодерева, включающих информацию о форме, индексную информацию и эталонное изображение, и кодирование узлов октодерева в выходные битовые потоки, причем на этапе генерирования информации о форме подразделение выполняется итеративньм образом до тех пор, пока субкуб не станет меньше, чем предварительно определенный размер.
Еще в одном аспекте настоящее изобретение предусматривает способ представления трехмерных объектов на основе изображений с глубиной, включающий ввод битовых потоков, выделение узлов октодерева из входных битовых потоков, декодирование узлов октодерева, выделение информации о форме и эталонных изображений для множества кубов, образующих октодеревья, из декодированных узлов октодерева, и представление объекта путем комбинации выделенных эталонных изображений соответственно информации о форме.
Согласно настоящему изобретению время визуализации для моделей, основанных на изображениях, пропорционально количеству пикселов в эталонном и выходном изображениях, но, принципиально, не геометрической сложности, как в случае многоугольной модели. Кроме того, когда основанное на изображениях представление применяется к объектам и сценам реального мира, становится возможной визуализация с фотографическим качеством естественной сцены без использования миллионов многоугольников и дорогостоящих вычислений.
Краткое описание чертежей
Вышеописанные задачи и преимущества настоящего изобретения поясняются путем детального описания предпочтительных вариантов осуществления изобретения со ссылками на чертежи, на которых представлено следующее:
фиг.1 - примеры основанного на изображениях представления, интегрированного в современном программном обеспечении;
фиг.2 - диаграмма структуры октодерева и порядок дочерних элементов;
фиг.3 - график, представляющий коэффициенты сжатия октодерева;
фиг.4 - диаграмма примеров многослойного изображения с глубиной (МИГ): а - проекция объекта, где темные ячейки (вокселы) соответствуют единицам ("1") и белые ячейки соответствуют нулям ("0"); b - двумерное сечение в координатах (x, глубина);
фиг.5 - диаграмма, показывающая инвариантность вероятности возникновения узла: а - исходный текущий и порождающий узел; b - текущий и порождающий узел, повернутые вокруг оси на 90 градусов;
фиг.7, 8, 9 - коэффициенты геометрического сжатия для наилучшего способа, основанного на РРМ;
фиг.6 - предположение об ортогональной инвариантности;
фиг.10 - диаграмма, показывающая два пути переупорядочения цветового поля модели точечной текстуры "Ангел" в двумерное изображение;
фиг.11 -диаграмма примеров геометрического сжатия без потерь и цветового сжатия с потерями: а и b - исходная и сжатая модель "Ангел" соответственно; с и d - исходная и сжатая версия модели "Мортон 256" соответственно;
фиг.12 - диаграмма модели бинарного волюметрического дерева (БВО) и модели текстурированного бинарного волюметрического октодерева (ТБВО) "Ангел";
фиг.13 - диаграмма, показывающая дополнительные изображения, снятые дополнительными камерами в ТБВО: а - изображение индекса камеры; b - первое дополнительное изображение; с - второе дополнительное изображение;
фиг.14 - диаграмма, показывающая пример записи потока ТБВО: а - структура дерева ТБВО (серый цвет является "неопределенным" символом текстуры; каждый цвет обозначает индекс камеры; b - порядок прохождения октодерева в узле БВО и индексах камеры; с - результирующий поток ТБВО, в котором заполненные кубы и кубы октодерева обозначают байты текстуры и байты БВО соответственно;
фиг.15, 17, 18 и 19 - диаграммы, показывающие результаты сжатия ТБВО моделей "Ангел", "Мортон", "Пальма 512" и "Роботы 512" соответственно;
фиг.16 - диаграмма, показывающая лишенные оболочки модели "Ангел" и "Мортон";
фиг.20 - диаграмма примера изображения текстуры и карты глубины;
фиг.21 - диаграмма примера многослойного изображения с глубиной (МИГ): а - проекция объекта; b - пикселы многослойного изображения;
фиг.22 - диаграмма примера текстуры блока (БТ), в котором шесть простых текстур (пары изображений и карта глубины) используются для визуализации модели, показанной в центре;
фиг.23 - диаграмма примера обобщенной текстуры блока (ОТБ): а - местоположения камеры для модели "Пальма"; b - плоскости опорного изображения для той же самой модели (использована 21 простая текстура);
фиг.24 - диаграмма примера, показывающего двумерное представление октодерева: а - "совокупность точек"; b - соответствующие средние карты отображения;
фиг.25 - псевдокод для записи потока битов ТБВО;
фиг.26 - диаграмма, показывающая спецификацию узлов представлений на основе изображений с глубиной (ПОИГ);
фиг.27 - диаграмма модели объема наблюдения для изображения с глубиной: а - пространственное представление, b - ортогональное представление;
фиг.28 - псевдокод основанной на OpenGL визуализации простой текстуры;
фиг.29 - диаграмма примера, показывающего сжатие опорного изображения в простой текстуре: а - исходное опорное изображение; b - модифицированное опорное изображение в формате JPEG;
фиг.30 - диаграмма примера, показывающего результат визуализации модели "Мортон" в различных форматах: а - в исходном полигональном формате, b - в формате изображений с глубиной; с - в формате изображения октодерева;
фиг.31 - диаграмма примеров визуализации: а - просканированная модель "Башня" в формате изображения с глубиной; b - та же самая модель в формате изображения октодерева (данные сканера были использованы без устранения шума, отсюда черные точки в верхней части модели);
фиг.32 - диаграмма примеров визуализации модели "Пальма": а - исходный полигональный формат, b - та же самая модель, но в формате изображения с глубиной;
фиг.33 - диаграмма примера визуализации, показывающая кадр анимации "Дракон 512" в формате изображения с глубиной;
фиг.34 - диаграмма примера визуализации модели "Ангел 512" в формате точечной текстуры;
фиг.35 - блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной в соответствии с возможным вариантом осуществления настоящего изобретения;
фиг.36 - детальная блок-схема препроцессора 1820;
фиг.37 - блок-схема, иллюстрирующая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием простой текстуры согласно варианту осуществления настоящего изобретения;
фиг.38 - блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной согласно настоящему изобретению;
фиг.39 - блок-схема, показывающая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием точечной текстуры согласно изобретению;
фиг.40 - блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием октодерева в соответствии с настоящим изобретением;
фиг.41 - детальная блок-схема препроцессора 2310;
фиг.42 - детальная блок-схема генератора 2340 индексов;
фиг.43 - детальная блок-схема кодера 2360;
фиг.44 - детальная блок-схема второй секции 2630 кодирования;
фиг.45 - детальная блок-схема третьей секции 2640 кодирования;
фиг.46 - блок-схема, показывающая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием октодеревьев согласно варианту осуществления настоящего изобретения;
фиг.47 - блок-схема, иллюстрирующая процесс реализации предварительной обработки опорного изображения;
фиг.48 - блок-схема, показывающая процесс реализации генерирования индекса;
фиг.49 - блок-схема, показывающая процесс реализации кодирования;
фиг.50 - блок-схема, показывающая процесс реализации второго этапа кодирования;
фиг.51 - блок-схема, показывающая процесс реализации третьего этапа кодирования;
фиг.52 - блок-схема, показывающая процесс генерирования потоков битов на этапах кодирования;
фиг.53 - блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием октодерева в соответствии с другим вариантом осуществления настоящего изобретения;
фиг.54 - блок-схема, показывающая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием октодеревьев согласно другому варианту осуществления настоящего изобретения.
Описание предпочтительных вариантов осуществления настоящего изобретения
Данная заявка испрашивает приоритет предварительных заявок США, приведенных ниже, которые включены в настоящее описание посредством ссылки во всей своей полноте.
I. Кодирование согласно стандарту ISO/IEC JTC 1/SC 29/WG 11 движущихся изображений и аудиосигналов
1. Введение
В настоящем документе изложены результаты основного эксперимента по визуализации на основе изображений AFX A8.3. Этот основной эксперимент относится к технологии визуализации на основе изображений, использующей текстуры с информацией о глубине. Также представлены изменения, основанные на экспериментах, проведенных после 57-го симпозиума MPEG, и обсуждений в рамках встречи Специальной Группы AFX в октябре, внесенные в спецификации узлов.
2.Экспериментальные результаты
2.1. Модели испытаний
 Для неподвижных объектов
Для неподвижных объектов
 Узел изображения с глубиной с простой текстурой
Узел изображения с глубиной с простой текстурой
 Собака
Собака
 Король Тираннозавр (изображение с глубиной с использованием около 20 камер)
Король Тираннозавр (изображение с глубиной с использованием около 20 камер)
 Терраск (монстр) (изображение с глубиной с использованием около 20 камер)
Терраск (монстр) (изображение с глубиной с использованием около 20 камер)
 ЧунСунгДае (изображение с глубиной, сканированные данные)
ЧунСунгДае (изображение с глубиной, сканированные данные)
 Пальма (изображение с глубиной, 20 камер)
Пальма (изображение с глубиной, 20 камер)
 Изображение с глубиной с многослойной текстурой
Изображение с глубиной с многослойной текстурой
 Ангел
Ангел
 Изображение с глубиной с точечной текстурой
Изображение с глубиной с точечной текстурой
 Ангел
Ангел
 Узел изображения октодерева
Узел изображения октодерева
 Создание
Создание
 Для анимационных объектов
Для анимационных объектов
 Узел изображения с глубиной с простой текстурой
Узел изображения с глубиной с простой текстурой
 Дракон
Дракон  Дракон в окружающей среде
Дракон в окружающей среде
 Изображение с глубиной с многослойной текстурой
Изображение с глубиной с многослойной текстурой
 Не предусмотрено
Не предусмотрено
 Узел изображения октодерева
Узел изображения октодерева
 Робот
Робот
 Дракон в окружающей среде
Дракон в окружающей среде
 В будущем будет обеспечено больше данных (сканированных или моделированных).
В будущем будет обеспечено больше данных (сканированных или моделированных).
2.2. Результаты испытаний
 Все узлы, предложенные в Сиднее, интегрированы в эталонное программное обеспечение blaxxun contact 4.3. Однако источники еще не загружены на сервер cvs.
Все узлы, предложенные в Сиднее, интегрированы в эталонное программное обеспечение blaxxun contact 4.3. Однако источники еще не загружены на сервер cvs.
 Анимационные форматы представлений, основанных на изображениях (ПОИ) должны иметь синхронизацию между множеством файлов кинофрагментов таким путем, что изображения в одном и том же ключевом кадре из каждого файла кинофрагмента должны выдаваться в одно и то же время. Однако современное эталонное программное обеспечение не поддерживает данное свойство синхронизации, что возможно в системах стандартов MPEG. Поэтому в настоящее время анимационные форматы могут быть визуализированы в предположении, что все анимационные данные уже находятся в файле. Временно для каждой анимационной текстуры используются файлы кинофрагментов в формате AVI.
Анимационные форматы представлений, основанных на изображениях (ПОИ) должны иметь синхронизацию между множеством файлов кинофрагментов таким путем, что изображения в одном и том же ключевом кадре из каждого файла кинофрагмента должны выдаваться в одно и то же время. Однако современное эталонное программное обеспечение не поддерживает данное свойство синхронизации, что возможно в системах стандартов MPEG. Поэтому в настоящее время анимационные форматы могут быть визуализированы в предположении, что все анимационные данные уже находятся в файле. Временно для каждой анимационной текстуры используются файлы кинофрагментов в формате AVI.
 После проведения ряда экспериментов с многослойными текстурами было установлено, что узел многослойной текстуры является неэффективным. Такой узел был предложен для многослойного изображения с глубиной. Однако имеется также узел точечной текстуры, который может его поддерживать. Поэтому было предложено удалить узел многослойной текстуры из спецификации узлов. На фиг.1 представлены примеры представлений на основе изображений (ПОИ), интегрированные в современное эталонное программное обеспечение.
После проведения ряда экспериментов с многослойными текстурами было установлено, что узел многослойной текстуры является неэффективным. Такой узел был предложен для многослойного изображения с глубиной. Однако имеется также узел точечной текстуры, который может его поддерживать. Поэтому было предложено удалить узел многослойной текстуры из спецификации узлов. На фиг.1 представлены примеры представлений на основе изображений (ПОИ), интегрированные в современное эталонное программное обеспечение.
3. Обновление данных спецификации узлов ПОИ
Выводы, полученные на встрече в Сиднее в отношении предложения ПОИ, состояли в том, чтобы получить поток ПОИ, который содержит изображения и информацию камер, а узел ПОИ должен только иметь связь (Url - универсальный указатель ресурсов) с ним. Однако на встрече AhG в Ренне в результате обсуждений ПОИ было решено использовать изображения и информацию камер как в узлах ПОИ, так и в потоке. Таким образом, ниже приведена спецификация обновленных узлов для узлов ПОИ. Требования для потока ПОИ приведены в разделе, который поясняет поле Url.

Узел изображения с глубиной определяет отдельную текстуру ПОИ. Когда множество узлов изображения с глубиной связаны друг с другом, они обрабатываются как группа, и поэтому должны быть помещены под одним и тем же узлом преобразования.
Поле "diТекстура" определяет текстуру с глубиной, которая должна быть отображена в область, определяемую в узле изображения с глубиной. Она должна быть одной из текстур различных типов текстуры изображения с глубиной (простая текстура или точечная текстура).
Поля "положение" и "ориентация" определяют относительное местоположение точки наблюдения текстуры ПОИ в локальной системе координат. Положение определяется относительно начала координат (0, 0, 0) системы координат, а ориентация определяет поворот относительно установленной по умолчанию ориентации. В установленных по умолчанию положении и ориентации наблюдатель находится на оси Z и смотрит вдоль Z-оси в направлении начала координат, причем ось +Х находится справа, а ось +Y - впереди в направлении вверх. Однако иерархия преобразования оказывает влияние на окончательное положение и ориентацию.
Поле "поле зрения" определяет угол наблюдения из точки наблюдения камеры, определяемой полями положения и ориентации. Первое значение обозначает угол к горизонтальной стороне, а второе значение обозначает угол к вертикальной стороне. Значения, установленные по умолчанию, равны 45° в радианах. Однако когда ортогональное поле установлено на ИСТИННО, поле "поле зрения" обозначает ширину и высоту ближней и дальней плоскости.
Поля ближней и дальней плоскости определяют расстояния от точки наблюдения до ближней и дальней плоскости зоны наблюдения. Текстура и данные глубины показывают область, ограниченную ближней плоскостью, дальней плоскостью и точкой наблюдения. Данные глубины нормированы к расстоянию от ближней плоскости до дальней плоскости.
Поле "ортогональное" определяет тип наблюдения текстуры ПОИ. Когда оно установлено на ИСТИННО, то текстура ПОИ основана на ортогональном наблюдении. В ином случае текстура ПОИ основана на наблюдении в перспективе.
Поле "изображение с глубиной Url" определяет адрес потока изображения с глубиной, которое может дополнительно включать в себя следующее содержание:
 Положение
Положение
 Ориентация
Ориентация
 Точка наблюдения
Точка наблюдения
 Ближняя плоскость
Ближняя плоскость
 Дальняя плоскость
Дальняя плоскость
 Ортогональное
Ортогональное
 diТекстура (простая текстура или точечная текстура)
diТекстура (простая текстура или точечная текстура)
 Заголовок в 1 байт для флага включения/исключения для приведенных выше полей
Заголовок в 1 байт для флага включения/исключения для приведенных выше полей

Узел простой текстуры определяет отдельный слой текстуры ПОИ.
Поле "текстура" определяет плоское изображение, которое содержит цвет для каждого пиксела. Оно должно быть одним из различных типов узлов текстуры (текстура изображения, текстура кинофрагмента или пиксельная текстура).
Поле "глубина" определяет глубину для каждого пиксела в поле "текстура". Карта глубины должна иметь тот же размер, что и изображение или кинофрагмент в поле "текстура". Оно должно быть одним из различных типов узлов текстур (текстура изображения, текстура кинофрагмента или пиксельная текстура). Если узел глубины установлен на НУЛЬ или поле "глубина" неопределенно, то альфа-канал в поле "текстура" должен использоваться в качестве карты глубины.

Узел "точечная структура" определяет множество слоев точек ПОИ. Поля "ширина" и "высота" определяют ширину и высоту текстуры.
Поле "глубина" определяет множество глубин каждой точки (в нормированных координатах) в плоскости проекции в порядке пересечения, которое начинается из точки в нижнем левом углу и пересекает вправо для завершения на горизонтальной линии перед перемещением на более высокую линию. Для каждой точки число глубин (пиксели) сначала запоминаются, и это число значений глубины затем следует.
Поле "цвет" определяет цвет текущего пикселя. Порядок должен быть тем же самым, что и для поля "глубина", за исключением того, что число глубин (пикселей) для каждой точки не включается.

Узел "изображение октодерева" определяет структуру октодерева и его проецируемые текстуры. Размер описанного куба полного октодерева 1×1×1, и центр куба октодерева должен быть в начале координат (0, 0, 0) локальной системы координат.
Поле "разрешение октодерева" определяет максимальное число листьев октодерева вдоль стороны описанного куба. Уровень октодерева может быть определен из разрешения октодерева с использованием следующего уравнения: уровень октодерева=int(iog2(разрешение октодерева-1))+1).
Поле "октодерево" определяет множество внутренних узлов октодерева. Каждый внутренний узел представлен байтом. "1" в i-м бите этого байта означает, что дочерние узлы существуют для i-го дочернего элемента этого внутреннего узла, а "0" означает, что этого нет. Порядок внутренних узлов октодерева должен быть порядком прохождения сигнала по ширине октодерева. Порядок восьми дочерних элементов внутреннего узла показан на фиг.2.
Поле "изображения октодерева" определяет множество узлов "изображение с глубиной" с простой текстурой для поля "diТекстура". Однако поле "ближний план" и "дальний план" узла "изображение с глубиной" и поле глубины в узле "простая текстура" не используются.
Поле "октодеревоUrl" определяет адрес потока изображения октодерева со следующим содержанием:
 заголовок для флагов
заголовок для флагов
 разрешение октодерева
разрешение октодерева
 октодерево
октодерево
 изображения октодерева (узлы множественного изображения с глубиной)
изображения октодерева (узлы множественного изображения с глубиной)
 ближний план не используется
ближний план не используется
 дальний план не используется
дальний план не используется
 diТекстура → простая текстура без глубины
diТекстура → простая текстура без глубины
II. Кодирование согласно стандарту ISO/IEC JTC 1/SC 29/WG 11 движущихся изображений и аудиосигналов
1. Введение
В настоящем документе изложены результаты основного эксперимента по визуализации на основе изображений с глубиной (DIBR), AFX A8.3. Этот основной эксперимент относится к узлам представления на основе изображений с глубиной с использованием текстур с информацией о глубине. Эти узлы были приняты и включены в предложение для Проекта Комитета на встрече в Паттайя. Однако формирование потока этой информации посредством поля "октодеревоUrl" узла "изображение октодерева" и поля "изображение с глубинойUrl" узла "изображение с глубиной" продолжает еще оставаться предметом исследований. В данном документе описан формат формирования потока, который должен связываться посредством этих полей Url. Формат формирования потока включает компрессию (сжатие) поля "октодерево" узла "изображение октодерева" и полей "глубина/цвет" узла "точечная текстура".
2. Формат формирования потока для "октодереваUrl"
2.1. Формат потока
Узел "избражение октодерева" включает в себя поле "октодеревоUrl", которое определяет адрес потока изображения октодерева. Этот поток может дополнительно включать в себя следующее содержание:
 заголовок для флагов
заголовок для флагов
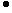 разрешение октодерева
разрешение октодерева
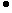 октодерево
октодерево
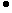 изображения октодерева (узлы множественного изображения с глубиной)
изображения октодерева (узлы множественного изображения с глубиной)
 ближний план не используется
ближний план не используется
 дальний план не используется
дальний план не используется
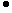 diТекстура → простая текстура без глубины
diТекстура → простая текстура без глубины
Поле "октодерево" определяет множество внутренних узлов октодерева. Каждый внутренний узел представлен байтом. "1" в i-м бите этого байта означает, что дочерние узлы существуют для i-го дочернего элемента этого внутреннего узла, а "0" означает, что этого нет. Порядок внутренних узлов октодерева должен быть порядком прохождения сигнала по ширине октодерева. Порядок восьми дочерних элементов внутреннего узла показан на фиг.2.
Поле "октодерево" узла "изображение октодерева" сформировано в компактном формате. Однако это поле может быть дополнительно сжато, чтобы иметь эффективное формирование потока. В следующем разделе описана схема сжатия октодерева для поля "октодерево" узла "изображение октодерева".
2.2. Схема сжатия для поля "октодерево"
В представлении октодерева, соответствующем DIBR, данные содержатся в поле "октодерево", которое представляет геометрический компонент. Октодерево представляет собой множество точек в описанном кубе, полностью, представляющем поверхность объекта.
Неидеальная реконструкция геометрии из сжатого представления приводит к весьма заметным артефактам. Следовательно, геометрия должна быть сжата без потери информации.
2.2.1. Сжатие октодерева
Для сжатия поля "октодерево", представленного в форме октодерева первого прохода глубины, был разработан способ сжатия без потерь, использующий некоторые идеи метода предсказания посредством частичного согласования (ПЧС). Основная идея, которая была использована, заключается в "предсказании" (т.е. оценке вероятности) следующего символа по нескольким предшествующим символам, которые называются контекстом. Для каждого контекста имеется таблица вероятности, которая содержит оценки вероятностей появления каждого символа в данном контексте. Это используется в комбинации с арифметическим кодером, называемым кодером расстояния.
Двумя главными особенностями способа являются следующие:
1) использование порождающего узла в качестве контекста для дочернего узла;
2) использование предположения "ортогональной инвариантности" для сокращения числа контекстов.
Вторая идея основана на наблюдении того, что "вероятность перехода" для пар узлов "порождающий-дочерний" в типовом случае инварианта для ортогональных преобразований (поворот и симметрия). Это предположение иллюстрируется в Приложении 1. Это предположение позволяет использовать более сложный контекст без необходимости использования слишком большого количества таблиц вероятности. Это, в свою очередь, позволило достичь довольно хороших результатов в смысле объема и скорости, так как чем больше контекстов используется, тем более точной является оценка вероятности и, следовательно, тем более компактньм является код.
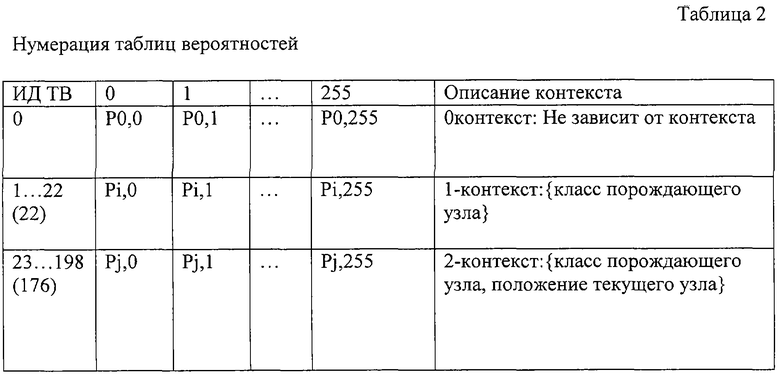
Кодирование является процессом конструирования и обновления таблицы вероятностей в соответствии с контекстной моделью. В предложенном способе контекст моделируется как иерархия типа "порождающий-дочерний" в структуре октодерева. Сначала определяется символ как байтовый узел, биты которого указывают на заполнение субкуба после внутреннего подразделения. Поэтому каждый узел в октодереве может быть символом, и его числовое значение равно от 0 до 255. Таблица вероятностей (ТВ) содержит 256 целочисленных значений. Значение i-й переменной (0≤i≤255), разделенное на сумму всех переменных, равно частоте (оценке вероятности) появления i-го символа. Таблица вероятностного контекста (ТВК) представляет собой набор таблиц вероятностей (ТВ). Вероятность символа определяется из одной и только одной ТВ. Число конкретных ТВ зависит от контекста. Пример ТВК показан в таблице 1.

Кодер работает следующим образом. Он сначала использует 0-контекстную модель (т.е. единственную ТВ для всех символов, начиная с равномерного распределения, и обновляя ТВ после каждого нового кодированного символа. Дерево проходится в первом порядке глубины. Если собрано достаточное количество статистики (эмпирически найденное значение составляет 512 кодированных символов), кодер переключается на 1-контекстную модель. Он имеет 27 контекстов, которые определены следующим образом.
Рассмотрим набор из 32 фиксированных ортогональных преобразований, которые включают в себя симметрию и повороты на 90° относительно осей координат (см. Приложение 2). Затем можно разделить символы по категориям в соответствии с конфигурацией заполнения их субкубов. В использованном заявителем методе будет иметься 27 наборов символов, называемых здесь группами и имеющих следующие свойства: 2 символа связаны одним из этих фиксированных преобразований, если и только если они принадлежат к одной и той же группе.
В байтовой записи группы представлены 27 наборами чисел (см. Приложение 2). Предполагается, что таблица вероятностей зависит не от самого порождающего узла (в этом случае было бы 256 таблиц), а только от группы (обозначено Порождающий символ на фиг.2), к которой принадлежит порождающий узел (отсюда 27 таблиц).
В момент переключения ТВ для всех контекстов устанавливаются на копирование 0-контекстной ТВ. Затем каждая из 27 ТВ обновляется, когда она используется для кодирования.
После того как закодированы 2048 (еще одно эвристическое значение) символов в 1-контекстной модели, производится переключение на 2-контекстную модель, которая использует пары (Порождающий символ, Символ узла) в качестве контекстов. Символ узла представляет собой просто положение текущего узла в порождающем узле. Итак, имеется 27·8 контекстов для 2-контекстной модели. В момент переключения на эту модель ТВ, полученные для каждого контекста, используются для каждого узла "внутри" этого контекста и с этого момента обновляются независимо.
С учетом более детального технического описания, кодирование для 1-контекстной и 20-контектной моделей происходит следующим образом. Для контекста текущего символа (т.е. для порождающего узла) определяется его группа. Это делается путем табличного поиска (перекодировки) (геометрический анализ выполнялся на этапе разработки программы). Затем применяется ортогональное преобразование, которое приводит наш контекст в "стандартный" (произвольно выбранный раз и навсегда) элемент группы, к которой он принадлежит. То же самое преобразование применяется к самому символу (эти операции также выполняются как табличный поиск (перекодировка); разумеется, все вычисления для всех возможных комбинаций сделаны заранее). Эффективным образом это означает вычисление корректного положения текущего символа в таблице вероятностей для группы, содержащей его контекст. Затем соответствующая вероятность вводится в кодер расстояний.
Короче говоря, если заданы порождающий символ и положение субузла, то определяется идентификатор (ИД) контекста, который идентифицирует ИД группы и положение ТВ в ТВК. Распределение вероятностей в ТВ и ИД контекста вводятся в кодер расстояний. После кодирования ТВК обновляется для использования в следующем кодировании. Заметим, что кодер расстояний является вариантом арифметического кодирования, которое осуществляет ренормализацию в байтах вместо битов, в два раза ускоряя выполнение, и характеризуется на 0,01% более худшим сжатием, чем стандартная реализация арифметического кодирования.
Процесс декодирования по существу является инверсным по отношению к процессу кодирования. Он представляет собой абсолютно стандартную процедуру, которую нет необходимости описывать, поскольку она использует точно те же методы определения контекстов, обновления вероятностей и т.д.
2.3. Результаты испытаний
На фиг.3 представлена таблица для сравнения предложенного заявителем подхода как для неподвижных, так и для анимационных моделей (ординаты обозначают коэффициент сжатия). Коэффициент сжатия октодерева варьируется около значений 1,5-2 раза в сравнении с исходным размером октодерева и обеспечивает выполнение универсальных методов сжатия без потерь (на основе метода Лемпеля-Зива, подобных программе RAR) примерно на 30%.
3. Формат формирования потока для поля "изображение с глубиной Url"
3.1. Формат потока
Узел "изображние с глубиной" включает в себя поле "изображение с глубиной Url", которое определяет адрес потока изображения с глубиной. Этот поток может дополнительно включать в себя следующее содержание:
Заголовок в 1 байт для флага включения/исключения для приведенных выше полей
 Положение
Положение
 Ориентация
Ориентация
 Точка наблюдения
Точка наблюдения
 Ближняя плоскость
Ближняя плоскость
 Дальняя плоскость
Дальняя плоскость
 Ортогональное
Ортогональное
 diТекстура (простая текстура или точечная текстура)
diТекстура (простая текстура или точечная текстура)
Определение узла "точечная текстура", которое может быть использовано в поле "diТекстура" узла "изображение с глубиной", имеет следующий вид:

Узел "точечная структура" определяет множество слоев точек IBR. Поля "ширина" и "высота" определяют ширину и высоту текстуры. Поле "глубина" определяет множество глубин каждой точки (в нормированных координатах) в плоскости проекции в порядке пересечения, которое начинается из точки в нижнем левом углу и пересекает вправо для завершения на горизонтальной линии перед перемещением на более высокую линию. Для каждой точки число глубин (пиксели) сначала запоминаются, и это число значений глубины затем следует. Поле "цвет" определяет цвет текущего пикселя. Порядок должен быть тем же самым, что и для поля "глубина", за исключением того, что число глубин (пикселей) для каждой точки не включается.
Поля "глубина" и "цвет" точечной текстуры заданы в исходном (необработанном) формате, и размер этих полей, весьма вероятно, будет очень большим. Поэтому эти поля необходимо сжимать, чтобы иметь эффективное формирование потока. В следующем разделе описана схема сжатия для полей узла "точечная текстура".
3.2. Схема сжатия для точечной текстуры
3.2.1. Сжатие поля "глубина"
Поле "глубина" узла "точечная текстура" представляет собой просто множество точек в "дискретизированном описывающем кубе". Подразумевается, что нижняя плоскость является плоскостью проекции. При условии m·n·1-мерных решеток для модели точки являются центрами ячеек (в случае октодерева принято называть их вокселами) решетки, можно рассматривать заполненные вокселы как "1", а пустые вокселы как "0". Результирующее множество битов (m·n·1-биты) затем организуются в поток байтов. Это делается путем прохождения вокселов в направлении по глубине (ортогонально плоскости проекции) по восьми слоям глубины ("по столбцам") в плоскости проекции (при заполнении, в случае необходимости, последнего слоя байтов нулями, если размер по глубине не является целым кратным 8). Таким образом, можно представить множество точек как наборы ("стеки") изображений 8-битовой шкалы серого (вариант - 16-битовые изображения). Соответствие между вокселами и битами иллюстрируется на фиг.4а.
Например, как показано на фиг.4b, черные квадраты соответствуют точкам объекта. Горизонтальная плоскость является плоскостью проекции. Рассмотрим срез высоты 16 (его верхняя граница показана жирной линией). Будет интерпретировать "столбцы" как байты. Т.е. столбец над точкой, обозначенной на чертеже, представляет стек из 2 байтов со значениями 18 и 1 (или 16-битовое целое число 274 без знака). Если применить наилучшие известные способы сжатия на основе метода ПЧС к совокупности байтов, полученных таким путем, то могут быть получены довольно хорошие результаты. Однако если в данном случае непосредственно применить простой 1-контекстный метод (разумеется, здесь не могут быть использованы ортогональная инвариантность или иерархические контексты), это приведет к несколько лучшей степени сжатия. Ниже приведена таблица столбцов, требуемых для различных типов представлений геометрии на основе многослойных изображений с глубиной (МИГ): по методу сжатия бинарного волюметрического октодерева (СБВО), сжатия вышеупомянутого байтового массива с использованием наилучшего компрессора (системы сжатия данных) метода ПЧС и сжатия того же массива с помощью компрессора. используемого в настоящее время заявителем (цифры приведены в килобайтах).

3.2.2 Сжатие поля "цвет"
Поле "цвет" узла "точечная текстура" представляет собой множество цветов, присвоенных точкам объекта. В отличие от случая октодерева, поле "цвет" характеризуется точным соответствием (один к одному) с полем "глубина". Идея состоит в том, чтобы представить информацию цвета как одиночное изображение, которое может быть сжато одним из известных методов с потерями. Количество элементов этого изображения много меньше, чем у опорных изображений в октодереве или в случае изображения с глубиной, и это является существенной мотивацией для данного метода. Изображение может быть получено путем сканирования точек глубины в том или ином естественном порядке.
Рассмотрим сначала порядок сканирования, диктуемый исходным форматом запоминания для МИГ (точечная текстура) - сканирование "сначала по глубине" геометрии. Мультипикселы сканируются в естественном порядке поперек плоскости проекции, как если бы они были простыми пикселями, и точки внутри одно и того же мультипиксела сканируются в направлении глубины. Этот порядок сканирования формирует одномерный массив цветов (1-й ненулевой мультипиксел, 2-й ненулевой мультипиксел и т.д.). После того как глубина определена, из этого массива может быть успешно восстановлены цвета точек. Для обеспечения применимости методов сжатия изображений, необходимо отобразить эту длинную строку один к одному в двумерную решетку. Это может быть сделано различными путями.
Метод, использованный в испытаниях, представляет собой так называемый метод "блочного сканирования", когда цветовая строка упорядочивается в блоки 8·8, и эти блоки упорядочиваются по столбцам ("блочное сканирование"). Результирующее изображение представлено на фиг.5.
Сжатие этого изображения было выполнено различными методами, включая стандарты JPEG. Оказалось, что по меньшей мере для данного типа цветового сканирования могут быть получены намного лучшие результаты, если использовать метод сжатия текстуры. Этот метод основывается на адаптивной локальной "палетизации" (уменьшении числа битов на точку представлением меньшего числа цветов палитры) каждого блока 8·8. Он имеет два режима: 8- и 12-кратное сжатие (в сравнении с BMP-форматом 24-бита "необработанного" истинного цвета на пиксел). Успешность этого метода при применении к данному типу изображений может быть точно объяснена его "палитровым" характером (созданием на основе палитры), что позволяет учесть резкие (даже отличные от краевых) локальные вариации цветов, обусловленные "смешиванием" точек передней и задней поверхностей (которые могут различаться в очень значительной степени, как в случае модели "Ангел"). Целью поиска оптимального сканирования является сокращение таких вариаций в максимально возможной степени.
3.3. Результаты испытаний
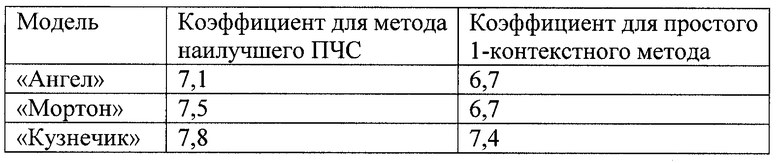
Примеры моделей в исходном и сжатом форматах показаны в Приложении 3. Качество некоторых моделей (например, "Ангел") после сжатия все еще не удовлетворительно, в то время как качество других очень хорошее ("Кузнечик"). Однако ожидается, что эта проблема может быть решена с помощью надлежащего сканирования. Потенциально может использоваться даже режим 12-кратного сжатия, так что общее сжатие увеличится еще более значительно. Наконец, сжатие без потерь будет усовершенствовано, чтобы приблизиться при сжатии геометрии к результатам сжатия на основе наилучшего метода ПЧС.
Ниже представлена таблица коэффициентов сжатия.
4. Выводы
В данном документе представлены результаты основного эксперимента по представлению AFX A8.3 на основе изображений с глубиной. Введен поток представлений на основе изображений с глубиной (DIBR), которые связаны посредством полей Url (универсального указателя ресурсов) узлов DIBR. Эти потоки состоят из всех элементов в узле DIBR вместе с флагом для каждого элемента, чтобы обеспечить возможность необязательного его использования. Также исследовалось сжатие октодерева и данные точечной текстуры.
Приложение 1. Геометрический смысл ортогональной инвариантности контекста в алгоритме сжатия БВО
Предположение об ортогональной инвариантности иллюстрируется на фиг.6. Рассмотрим поворот относительно вертикальной оси на 90° по часовой стрелке. Рассмотрим произвольные конфигурации заполнения узла и его предшественника до (верхний рисунок) и после (нижний рисунок) поворота. Затем две различные конфигурации могут обрабатываться как одна и та же конфигурация.
Приложение 2. Группы и преобразования
1. 32 фиксированных ортогональных преобразования.
Каждое преобразование определено 5-битовым словом. Комбинация битов является композицией следующих базовых преобразований (т.е. если k-й бит есть "1", то выполняется следующее преобразование):
 1-й бит - перестановка x и y координат;
1-й бит - перестановка x и y координат;
 2-й бит - перестановка y и x координат;
2-й бит - перестановка y и x координат;
 3-й бит - симметрия в плоскости (y-z);
3-й бит - симметрия в плоскости (y-z);
 4-й бит - симметрия в плоскости (x-z);
4-й бит - симметрия в плоскости (x-z);
 5-й бит - симметрия в плоскости (x-y).
5-й бит - симметрия в плоскости (x-y).
2. 27 групп
Для каждой группы здесь имеется порядок группы и число ненулевых битов в ее элементах: номер группы, количество групп и число битов заполнения (множество вокселов).
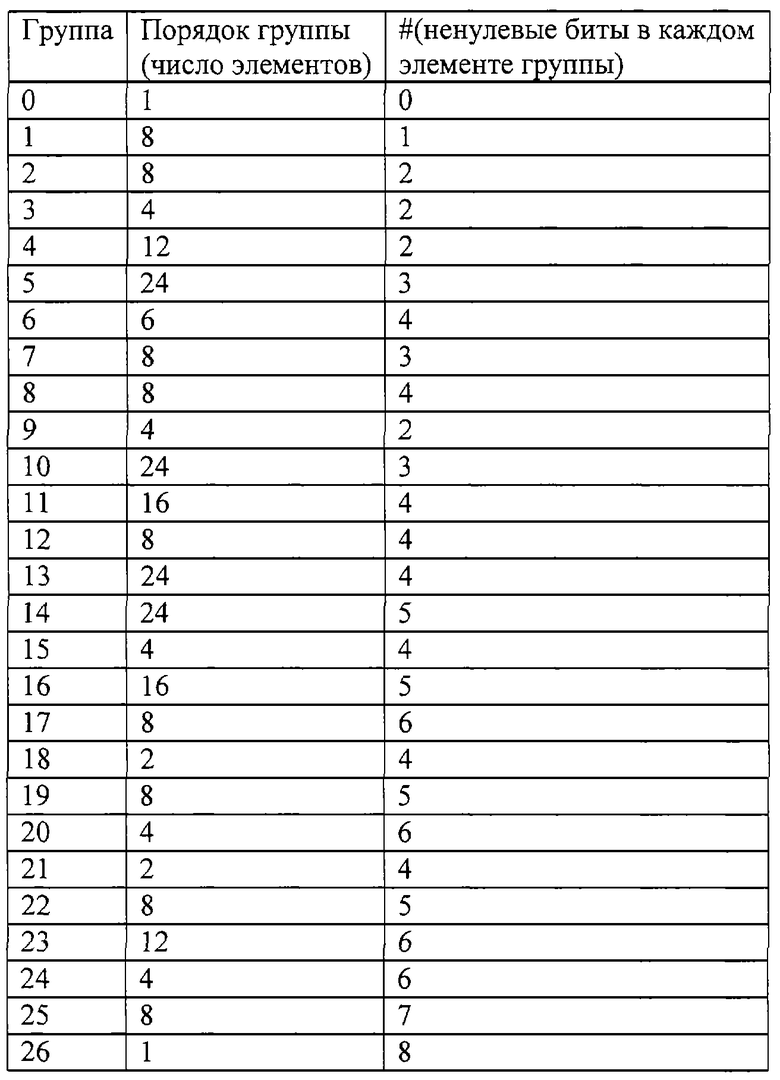
3. Символы и преобразования
Для каждого символа (s) имеется индекс группы (g), к которой он принадлежит, и значение преобразования (t), приводящего его в "стандартный" элемент группы.
Двоичное число символа отображается в бинарные координаты воксела следующим образом: i-й бит числа имеет бинарные координаты x=i&1, v=i&(1<<1), z=i&(1<<2).

Приложение 3. Снимки экранов сжатия точечной текстуры
На фиг.7, 8 и 9 представлены данные сжатия геометрии для метода, основанного на наилучшем ПЧС.
III. Результаты основного эксперимента по представлению на основе изображений с глубиной (AFX A8.3)
1. Введение
В настоящем документе изложены результаты основного эксперимента по визуализации на основе изображений с глубиной (DIBR), AFX A8.3. Этот основной эксперимент относится к узлам представления на основе изображений с глубиной с использованием текстур с информацией о глубине. Эти узлы были приняты и включены в предложение для Проекта Комитета на встрече в Паттайя. Однако формирование потока этой информации посредством узла "изображение октодерева" и узла "изображение с глубиной" продолжает еще оставаться предметом исследований. В данном документе описан формат формирования потока, который должен связываться посредством этих узлов. Формат формирования потока включает сжатие поля "октодерево" узла "изображение октодерева" и полей "глубина/цвет" узла "точечная текстура".
2. Сжатие форматов DIBR
Ниже описан новый способ эффективного сжатия без потерь несвязанной структуры данных октодерева, обеспечивающего возможность уменьшения объема этого компактного представления примерно в 1,5-2 раза, как показали проведенные эксперименты. Также предлагаются различные способы сжатия без потерь и с потерями формата точечной текстуры с использованием промежуточного вокселного представления в комбинации с энтропийным кодированием и специализированным способом блочного сжатия текстуры.
2.1. Сжатие октодерева
Поля "изображение октодерева" и "октодерево" в изображении октодерева сжимаются отдельно. Описанные ниже способы были разработаны на основе положения, что поле "октодерево" должно быть сжато без потерь при некоторой степени визуально приемлемого искажения, допустимого для изображений октодерева. Поле "октодерево" сжимается с использованием метода сжатия изображений стандарта MPEG-4 (для статической модели) или инструментов видеосжатия (для анимационной модели).
2.1.1. Сжатие поля "октодерево"
Сжатие октодерева является наиболее важной частью сжатия изображения октодерева, поскольку его предметом является сжатие уже и так очень компактного представления бинарного дерева без связей. Однако в экспериментах заявителя метод, поясненный ниже, обеспечил уменьшение объема этой структуры примерно до половины ее исходного объема. В анимационной версии изображения октодерева поле "октодерево" сжимается отдельно для каждого трехмерного кадра.
2.1.1.1. Контекстная модель
Сжатие выполняется посредством варианта адаптивного арифметического кодирования (реализованного как "кодер расстояния"), которое осуществляет использование в явном виде геометрического характера данных. Октодерево представляет собой поток байтов. Каждый байт представляет узел (т.е. субкуб) дерева, в котором его биты указывают заполнение субкуба после внутреннего подразделения. Битовая конфигурация называется конфигурацией заполнения узла. Описанный алгоритм сжатия обрабатывает байты с соотношением "один к одному" следующим образом.
- Определяется контекст для текущего байта.
- "Вероятность" (нормированная частота) появления текущего байта в этом контексте извлекается из "таблицы вероятностей" (ТВ) соответственно контексту.
- Значение вероятности вводится в кодер дальности.
- Текущая ТВ обновляется путем добавления 1 к частоте появления текущего байта в текущем контексте (и, при необходимости, с последующей ренормализацией, как более подробно описано ниже).
Таким образом, кодирование является процессом конструирования и обновления ТВ соответственно контекстной модели. В схемах адаптивного арифметического кодирования на основе контекста (таких как "предсказание с частичным согласованием") контекст символа обычно представляет собой строку из некоторого количества предшествующих символов. Однако в нашем случае эффективность сжатия увеличивается путем использования структуры октодерева и геометрических свойств данных. Описанный подход основан на двух идеях, которые являются очевидным образом новыми в проблеме сжатия октодерева.
А. Для текущего узла контекст является или его порождающим узлом или парой {порождающий узел, положение текущего узла в порождающем узле}.
В. Предполагается, что "вероятность" появления заданного узла в конкретном геометрическом положении в конкретном порождающем узле инвариантна по отношению к определенному набору ортогональных (таких как повороты или симметричные преобразования) преобразований.
Предположение "В" иллюстрируется чертежом для преобразования R, которое представляет собой поворот на -90° в плоскости x-z. Основное положение по пункту "В" состоит в том, что вероятность появления конкретного типа дочернего узла в конкретном типе порождающего узла должно зависеть только от их относительного положения. Это допущение подтверждено в экспериментах заявителя путем анализа таблиц вероятностей. Это позволяет использовать более сложный контекст без необходимости иметь слишком много таблиц вероятностей. Это, в свою очередь, способствует достижению достаточно хороших результатов в аспектах размера данных и быстродействия. Заметим, что чем более сложные контексты используются, тем точнее оценка вероятности и тем более компактным является код.
Введем множество преобразований, для которых предполагаем инвариантность распределений вероятности. Для обеспечения возможности их применения в рассматриваемой ситуации, такие преобразования должны сохранять описанный куб. Рассмотрим множество G ортогональных преобразований в евклидовом пространстве, которые получают путем всех композиций в любом числе и порядке трех базовых преобразований (генераторов) m1, m2 и m3, определяемых следующим образом:
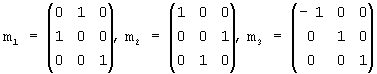
где m1 и m2 - отображения на плоскости x=y и y=z соответственно, и m3 - отображение на плоскость x=0. Один из классических результатов теории групп, генерируемых отображениями, утверждает, что G содержит 48 отдельных ортогональных преобразований, и является, по смыслу, максимальной группой ортогональных преобразований, которая принимает упомянутый куб сама в себя (так называемая группа Coxeter). Например, поворот R на фиг.6 выражается через генераторы следующим образом:
R=m3·m2·m1m2,
где "·" обозначает матричное перемножение.
Преобразование из G, применимое к узлу октодерева, формирует узел с отличающейся конфигурацией заполнения субкубов. Это позволяет подразделять узлы на категории в соответствии с конфигурацией заполнения из субкубов. Используя терминологию теории групп, можно сказать, что G действует на множество всех конфигураций заполнения узлов октодерева. Вычисления показывают, что имеется 22 различных класса (также называемых орбитами в теории групп), в которых, по определению, два узла принадлежат к одному и тому же классу, если и только если они связаны преобразованием из G. Количество элементов в классе варьируется от 1 до 24 и всегда является делителем 48.
Практическим следствием "В" является то, что таблица вероятностей зависит не от самого порождающего узла, а только от класса, к которому принадлежит порождающий узел. Заметим, что будет иметься 256 таблиц для контекста, основанного на порождающем элементе, и дополнительно 256×8=2048 таблиц для контекста, основанного на положении порождающего и дочернего элементов в первом случае, хотя нам требуется только 22 таблицы для контекста, основанного на классе порождающего элемента, плюс 22×8=176 таблиц в последнем случае. Поэтому можно использовать контекст эквивалентной сложности с относительно малым количеством таблиц вероятностей. Сформированная ТВ будет иметь форму, как показано в таблице 2.
2.1.1.2. Процесс кодирования
Чтобы статистика таблиц вероятностей была более точной, ее собирают различными путями на трех этапах процесса кодирования.
- На первом этапе контекст не используется совсем, принимается "модель 0-контекста", и поддерживается одна таблица вероятностей с 256 записями, начиная с равномерного распределения.
- Как только первые 512 узлов (это эмпирически найденное число) закодированы, переключаемся на "1-контекстную модель" с использованием порождающего узла в качестве контекста. В момент переключения ТВ 0-контекста копируется в ТВ для всех 22 контекстов;
- После того как 2048 узлов (еще одно эвристическое значение) закодированы, переключаемся на "2-контекстную модель". В этот момент 1-контекстные ТВ порождающих узлов копируются во все ТВ для каждого положения в той же самой конфигурации порождающего узла.
Ключевым моментом данного алгоритма является определение контекста и вероятности для текущего байта. Это реализуется следующим образом. В каждом случае фиксируем один элемент, который называется "стандартным элементом". Сохраняем таблицу отображения класса (ТОК), которая показывает класс, к которому принадлежит каждый из возможных 256 узлов, и предварительно вычисленное преобразование из G, которое переводит данный конкретный узел в стандартный элемент его класса. Таким образом, чтобы определить вероятность текущего узла N, выполняем следующие этапы.
- Определить порождающий узел Р текущего узла.
- Извлечь класс из ТОК, к которому принадлежит Р, и преобразование Т, которое переводит Р в стандартный узел класса. Пусть номер класса будет с.
- Применить Т к Р и найти положение р дочернего узла в стандартном узле, на который отображается текущий узел N.
- Применить Т к N. Затем вновь полученная конфигурация TN заполнения находится в положении р в стандартном узле класса с.
- Извлечь требуемую вероятность из записи TN таблицы вероятностей, соответствующей комбинации "класс-положение" (с, р).
Для 1-контекстной модели вышеописанные этапы модифицируются очевидным образом. Само собой разумеется, все преобразования предварительно вычислены и реализованы в виде таблиц перекодировки.
Заметим, что на этапе декодирования узла N его порождающий узел Р уже декодирован, и, следовательно, преобразование Т известно. Все шаги, выполняемые на этапе декодирования, абсолютно идентичны соответствующим шагам процедуры кодирования.
Наконец, опишем процедуру обновления вероятности. Пусть Р таблица вероятностей для некоторого контекста. Обозначим P(N) запись Р, соответствующую вероятности появления узла N в этом контексте. В описываемой реализации P(N) - целое число, и после каждого появления N, P(N) обновляется как
P(N)=P(N)+A,
где А - целочисленный параметр приращения, изменяющийся в типовом случае от 1 до 4 для различных контекстных моделей.
Пусть S(P) - сумма всех записей в РП. Тогда вероятность того, что N вводится в арифметический кодер (в данном случае кодер расстояний), вычисляется как P(N)/S(P). Как только S(P) достигает порогового значения 21, все записи ренормируются: чтобы избежать появления нулевых значений в Р, записи, равные 1 остаются, как они есть, а другие делятся на 2.
2.2. Сжатие точечной текстуры
Узел "точечная текстура" содержит два поля, которые подвергаются сжатию, т.е. "глубина" и "цвет". Основные трудности со сжатием данных точечной текстуры обусловлены следующими требованиями.
- Геометрия должна быть сжата способом без потерь, поскольку искажения в геометрическом представлении этого типа часто весьма заметны.
- Информация цвета не имеет естественной двумерной структуры, и поэтому методы сжатия изображения непосредственно не применимы.
В этом разделе предложено три метода для сжатия модели точечной текстуры.
- Метод стандартного представления узла без потерь.
- Метод представления узла с низким разрешением без потерь.
- Метод сжатия геометрии без потерь и сжатия цвета с потерями для представления узла с низким разрешением.
Эти методы соответствуют трем уровням "достоверности" описания объектов. Первый метод предполагает, что необходимо сохранять информацию о глубине с точностью до исходных 32 битов. Однако на практике информация о глубине может зачастую квантоваться с намного меньшим числом битов без потери качества. В частности, когда модель "точечная структура" преобразована из полигональной модели, то разрешение квантования выбирается в соответствии с действительным размером видимых деталей, которыми обладает исходная модель, а также желательным выходным разрешением экранного изображения. В этом случае 8-11 битов могут вполне удовлетворить указанным требованиям, и значения глубины первоначально сохраняются в этом формате более низкого разрешения. Вышеупомянутый второй метод использует сжатие без потерь представления "низкого разрешения". Ключевым моментом в данном случае является то, что для такого относительно малого числа битов может быть использовано промежуточное представление посредством вокселов модели, и это позволяет сжимать поле "глубина" по существу без потери информации. Информация цвета в обоих случаях сжимается без потерь и сохраняется в формате PNG после переупорядочения данных цвета в виде вспомогательного двумерного изображения. Наконец, третий метод позволяет достичь намного более высокого сжатия, комбинируя сжатие без потерь геометрии со сжатием без потерь данных цвета. Последнее выполняется с помощью специализированного метода блочного сжатия текстуры. В следующих трех подразделах эти методы описаны более детально.
2.1.1. Сжатие точечной текстуры без потерь для стандартного представления узла
Это простой метод кодирования без потерь, который работает следующим образом.
- Поле "глубина" сжимается адаптивным кодером расстояния, подобным используемому при сжатии поля "октодерево". Для данного формата использована версия, в которой таблица вероятностей поддерживается для каждого из 1-символьных контекстов, и контекстом является просто предыдущий байт. Поэтому используются 256 ТВ. Поле "глубина" рассматривается как поток байтов, и геометрическая структура в явном виде не используется.
- Поле "цвет" сжимается после преобразования в плоское изображение истинного цвета. Цвета точек в модели точечной текстуры сначала записываются во временный одномерный массив в том же самом порядке, что и значения глубины в поле "глубина". Если общее число точек в модели равно L, то вычисляется наименьшее целое 1 такое, что 1-1≤L, и эта "длинная строка" значений цвета "сворачивается" в квадратное изображение со стороной 1 (при необходимости, с заполнением черными пикселами). Это изображение затем сжимается с использованием одного из инструментов MPEG-4 сжатия изображений без потерь. В этом подходе использовался формат PNG. Полученное изображение для модели "Ангел" показано на фиг.10а.
2.2.2. Сжатие точечной текстуры без потерь для представления узла с более низким разрешением
Во многих случаях 16-битовое разрешение для информации о глубине является очень хорошим. В действительности, разрешение по глубине должно соответствовать разрешению экрана, на котором должна визуализироваться модель. В ситуациях, когда малые вариации по глубине модели в различных точках приводят к смещению в плоскости экрана много меньше, чем размер пиксела, целесообразно использовать более низкое разрешение по глубине, и модели часто представляются в формате, где значения глубины занимают 8-11 битов. Такие модели обычно получают из других форматов, например, полигональной модели, путем дискретизации значений глубины и цвета по надлежащей пространственной сетке.
Такое представление с пониженным разрешением может быть рассмотрено как сжатая форма стандартной модели с 32-битовой глубиной. Однако для таких моделей существует более компактное представление, использующее промежуточное пространство вокселов. На самом деле, точки модели можно представить принадлежащими к узлам равномерной пространственной сетки с ячейками, определяемыми шагом дискретизации. Можно предположить, что сетка равномерна и ортогональна, поскольку в случае модели в перспективном представлении можно работать в параметрическом пространстве. Используя эти допущения, поля "глубина" и "цвет" точечной текстуры с пониженным разрешением сжимаются следующим образом.
- Поле "цвет" сжимается методом сжатия изображений без потерь, как в предыдущем методе.
- Поле "глубина" сначала преобразуется в представление на основе вокселов и затем сжимается с использованием версии кодера расстояния, описанного в предыдущем разделе.
Промежуточная модель с использованием вокселов создается следующим образом. В соответствии с разрешением s по глубине модели, рассмотрим пространство из дискретных вокселов размера ширина×высота×2s (параметры "ширина" и "высота" пояснены в спецификации точечной текстуры). Для наших целей требуется работать не с пространством потенциально огромного количества вокселов, как целым, а только с его "тонкими" сечениями. Обозначим (r, с) координаты строка-столбец в плоскости проекции, и примем d в качестве координаты глубины. Преобразуем "срезы" {c=const}, т.е. сечения модели "вертикальными плоскостями", в представление на основе вокселов. Сканируя срез по "столбцам" параллельно плоскости проекции, установим воксел (r, c, d) как "черный", если только существует точка модели со значением d глубины, которая проецируется на (r, с). Данный процесс иллюстрируется на фиг.4.
Как только срез построен, он сжимается 1-контекстным кодером расстояния, и начинается сжатие следующего среза. Таким путем можно избежать работы с очень большими массивами данных. Таблицы вероятностей не инициализируются для каждого нового среза. Для широкого диапазона моделей только незначительная доля вокселов определяется как "черные", что позволяет достичь высоких коэффициентов сжатия. Декомпрессия выполняется очевидной инверсией описанных операций.
Будет приведено сравнение сжатия поля "глубина" данным методом и с использованием представления октодерева. Общий коэффициент сжатия модели определяется, однако, полем "цвет", поскольку такое нерегулярное изображение не может быть строгим образом сжато без искажений. В следующем подразделе рассмотрена комбинация метода сжатия без потерь геометрии и сжатия с потерями цвета.
2.2.3. Сжатие без потерь геометрии и сжатие с потерями цвета для представления точечной текстуры с пониженным разрешением
Подобно описанному выше, данный метод обеспечивает преобразование поля "глубина" в представление на основе вокселов, которое затем сжимается адаптивным 1-контексным кодером расстояния. Поле "цвет" также отображается в двумерное изображение. Нами сделана попытка организовать отображение таким образом, чтобы точки, близкие в трехмерном пространстве, отображались в близкие точки в плоскости двумерного изображения. К полученному изображению применяется специальный метод сжатия текстуры (ABR - адаптивное подразделение на блоки). Основные шаги алгоритма состоят в следующем.
1. Преобразовать "срез" четырех последовательных "вертикальных плоскостей" модели точечной текстуры в представление на основе вокселов.
2. Просканировать полученный массив вокселов ширина ×4×2s путем:
- прохождения вертикальной "плоскости" субкубов из 4×4×4 вокселов вдоль "столбцов" параллельно плоскости проекции: сначала столбец, ближайший к плоскости проекции, затем следующий ближайший столбец и т.д. (т.е. в обычном порядке прохождения двумерного массива);
- прохождения вокселов внутри каждого субкуба 4×4×4 в порядке, аналогичном порядку, используемому при прохождении субкубов узлов октодерева.
3. Записать цвета точек модели, обнаруженных при этом порядке прохождения, во вспомогательный одномерный массив.
4. Переупорядочить полученный массив цветов в двумерное изображение.
5. Последовательные 64 выборки цвета упорядочиваются по столбцам в блок из 8×8 пикселов, следующие 64 выборки переупорядочиваются в соседний блок из 8×8 пикселов и т.д.
6. Сжать полученное изображение методом ABR.
Этот метод сканирования трехмерного массива и отображения результата в двумерное изображение был выбран из следующих соображений. Заметим, что субкубы 4×4×4 и блоки 8×8 изображения содержат одно и то же число выборок. Если несколько последовательно просканированных субкубов содержат достаточно выборок цвета для заполнения блока 8×8, то весьма вероятно, что этот блок будет достаточно равномерным и поэтому искажение будет весьма заметным на трехмерной модели после декомпрессии. Алгоритм ABR сжимает блоки 8×8 независимо друг от друга с помощью локальной палетизации (уменьшением числа битов на точку представлением меньшего числа цветов палитры). В проведенных испытаниях искажение, обусловленное сжатием по алгоритму ABR, введенное в конечную трехмерную модель, было значительно меньше, чем искажение для алгоритма JPEG. Другая причина выбора данного алгоритма состоит в высокой скорости декомпрессии (для чего он и был первоначально создан). Коэффициент сжатия может иметь два значения - 8 и 12. В алгоритме сжатия точечной текстуры заявителем было выбрано значение 8 коэффициента сжатия.
К сожалению, данный алгоритм не является универсально применимым. Хотя изображение, полученное этим методом из цветового поля, показанное на фиг.10b, намного более равномерное, чем для "естественного" порядка сканирования, некоторые двумерные блоки 8×8 могут содержать выборки цвета, соответствующие удаленным точкам в трехмерном пространстве. В этом случае метод ABR с потерями может обеспечить "смешивание" цветов из удаленных частей модели, что приведет к локальному, но заметному искажению после декомпрессии.
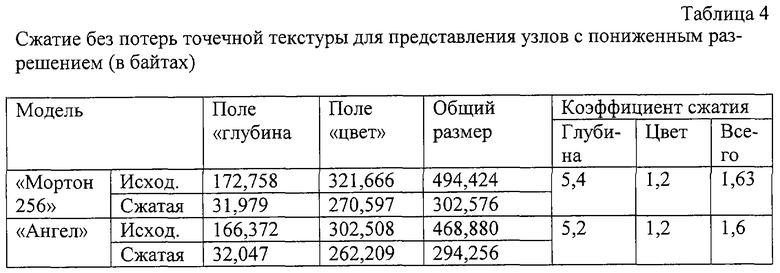
Однако для многих моделей этот алгоритм работает хорошо. На фиг.11 показан "плохой" случай (модель "Ангел") и "хороший" случай (модель "Мортон 256"). Сокращение объема модели в обоих случаях составляет около 7 раз.
3. Результаты испытаний
В этом разделе приведено сравнение результатов сжатия двух моделей, "Ангел" и "Мортон 256", в двух разных форматах - изображение октодерева и точечная текстура. Размеры эталонных изображений для каждой модели составляли 256×256 пикселов.
3.1.Сжатие точечной текстуры
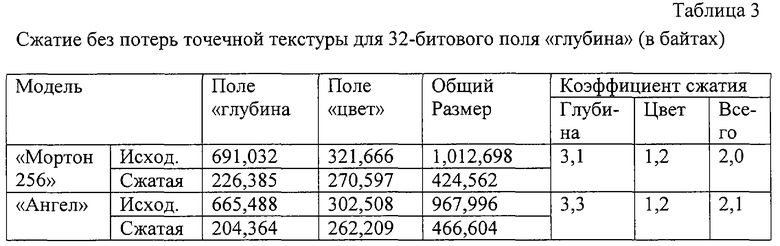
В таблицах 3-5 приведены результаты различных методов сжатия. Модели для данного эксперимента были получены из моделей с 8-битовым полем "глубина". Значения глубины распределены по диапазону (1, 230) с использованием шага квантования 221+1, чтобы сделать распределение битов в 32-битовых значениях глубины более равномерным, имитируя до некоторой степени "истинные" 32-битовые значения.
Высокие коэффициенты сжатия не ожидаются от использования данной модели. Сокращение объема того же порядка, что и для типового сжатия без потерь истинных цветных изображений. Сжатые поля глубины и цвета имеют сопоставимые размеры, поскольку геометрические свойства данных не затрагиваются данным методом.
Теперь посмотрим, сколько раз одни и те же модели могут быть сжаты без потерь, если их использовать при их "истинном" разрешении по глубине. В отличие от предыдущего случая, поле "глубина" сжимается без потерь примерно 5-6 раз. Это является следствием промежуточного вокселного представления, которое делает избыточность геометрических данных намного более явно выраженной - на самом деле, только малая доля вокселов относится к черным. Однако поскольку несжатый размер моделей меньше, чем для 32-битового случая, коэффициент сжатия поля "цвет" теперь определяет общий коэффициент сжатия, который меньше, чем для 32-битового случая (хотя выходные файлы тоже меньше). Таким образом, желательно иметь возможность сжимать поле "цвет" по меньшей мере так же хорошо, что и поле "глубина".
Наш третий метод использует для этой цели метод сжатия с потерями, называемый АВР 6. Данный метод дает намного более высокое сжатие. Однако, подобно всем методам сжатия с потерями, в некоторых случаях он может привести к неприятньм артефактам. Примером объекта, для которого это имеет место, является модель "Ангел". В процессе сканирования точек модели пространственно удаленные точки иногда попадают в один и тот же блок двумерного изображения. Цвета в удаленных точках этой модели могут различаться очень значительно, и локальная палетизация не может обеспечить точной аппроксимации, если в блоке имеется слишком много различающихся цветов. С другой стороны, именно локальная палетизация позволяет точно сжать огромное количество блоков, для которых искажение, введенное, например, стандартом JPEG, становится абсолютно недопустимым, после того как реконструированные цвета становятся черными в их трехмерных местоположениях. Однако визуальное качество модели "Мортон 256", сжатой тем же самым методом, является превосходным, и это имело место для большинства моделей в проведенных нами экспериментах.

3.2. Сжатие октодерева
В таблице 6 приведены размеры сжатых и несжатых компонентов октодерева в двух моделях испытаний. Наблюдалось уменьшение этого поля примерно в 1,6-1,9 раза.
Однако по сравнению с несжатыми моделями точечной текстуры, даже при 8-битовом поле "глубина", изображение октодерева намного более компактное. Таблица 7 показывает коэффициенты сжатия 7.2 и 11.2. Это больше, чем могло бы быть обеспечено при сжатии точечной текстуры без преобразования в изображение октодерева (соответственно в 6.7 и 6.8 раза). Однако, как упоминалось выше, изображение октодерева может содержать неполную информацию о цвете, что имеет место для модели "Ангел". В таких случаях используется трехмерная интерполяция цветов.
В результате можно заключить, что представленные эксперименты доказывают эффективность разработанных методов сжатия. Выбор наилучшего инструмента для заданной модели зависит от геометрической сложности, характера распределения цветов, требуемой скорости визуализации и других факторов.
4.1.2, для моделей изображения октодерева и их компонентов (размеры файлов округлены до килобайтов).


5. Комментарии к исследованию ISO/IEC 14496-1/PDAM4
После применения следующих пересмотренных разделов к исследованию ISO/IEC 14496-1/PDAM4 (N4627) пересмотренное исследование ISO/IEC 14496-1/PDAM4 должно быть включено в ISO/IEC 14496-1/FPDAM4.
Раздел 6.5.3.1.1, техническое изменение
Проблема: Устанавливаемое по умолчанию значение поля "ортогональный" должно быть наиболее общим используемым значением.
Решение: Заменить значение по умолчанию поля "ортогональный" с ЛОЖНО на ИСТИННО как показано ниже.
Предложенное изменение:

Раздел 6.5.3.1.1, техническое изменение
Проблема: Формирование потока DIBR должно быть осуществлено методом равномерного формирования потока для AFX.
Решение: Удалить поле "изображение с глубиной Url" из узла изображения с глубиной. Предложенное изменение:

Раздел 6.5.3.1.2, редакционное изменение
Проблема: Термин "нормированы" вводит в заблуждение в применении к полю "глубина" в нынешнем его контексте.
Решение: В 5-м абзаце заменить "нормированы" на "масштабированы".
Предложенное изменение:
Поля ближней и дальней плоскости определяют расстояния от точки наблюдения до ближней плоскости и дальней плоскости зоны наблюдения. Текстура и данные глубины показывают область, окруженную ближней плоскостью, дальней плоскостью и точкой наблюдения. Данные глубины масштабированы к расстоянию от ближней плоскости до дальней плоскости.
Раздел 6.5.3.1.2, техническое изменение
Проблема: Формирование потока DIBR должно быть осуществлено методом равномерного формирования потока для AFX.
Решение: Удалить определение поля "изображение с глубиной Url" (7-й абзац и ниже).
Предложенное изменение:
Раздел 6.5.3.2.2, редакционное изменение
Проблема: Семантика поля "глубина" определена неполно.
Решение: Изменить спецификацию поля "глубина" в 3-м абзаце следующим образом.
Поле "глубина" определяет глубину для каждого пиксела в поле "текстура". Карта глубины должна иметь тот же размер, что и изображение или кинофрагмент в поле "текстура". Поле "глубина" должно быть одним из различных типов узлов текстур (текстура изображения, текстура кинофрагмента или пикселная текстура), где допустимы только узлы, представляющие изображения по шкале серого. Если поле "глубина" не определено, то альфа-канал в поле "текстура" должен использоваться в качестве карты глубины. Если карта глубины не определена посредством поля "глубина" или альфа-канала, то результат не определен.
Поле "глубина" позволяет вычислять текущее расстояние точек трехмерного представления модели до плоскости, которая проходит через точку наблюдения и параллельна ближней плоскости и дальней плоскости:
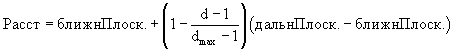
где d - значение глубины и dmax - максимальное допустимое значение глубины. Предполагается, что для точек модели d>0, где d=1 соответствует дальней плоскости a d=dmax соответствует ближней плоскости.
Эта формула справедлива как для случая перспективного представления, так и для ортогонального случая, поскольку d представляет собой расстояние между точкой и плоскостью, dmax является максимальным значением d, которое может быть представлено битами, используемыми для каждого пиксела.
(1) Если глубина определена через поле глубины, то значение глубины d эквивалентно шкале серого.
(2) Если глубина определена через альфа-канал в изображении, определенном через поле текстуры, то значение глубины d эквивалентно значению альфа-канала.
Значение глубины также используется для указания точек, принадлежащих модели: только точка, для которой d ненулевое, принадлежит модели.
Для анимационной модели на основе изображения с глубиной используется только изображение с глубиной с простыми текстурами как diTeкстуры.
Каждая из простых текстур может быть сделана анимационной одним из следующих способов:
(1) поле "глубина" является неподвижным изображением, удовлетворяющим вышеуказанному условию, поле "текстура" является произвольной текстурой кинофрагмента;
(2) поле "глубина" является произвольной текстурой кинофрагмента, удовлетворяющей вышеуказанному условию для поля "глубина", поле "текстура" является неподвижным изображением;
(3) как глубина, так и текстура являются текстурами кинофрагмента, и поле "глубина" удовлетворяет вышеуказанному условию;
(4) поле "глубина" не используется, и информация о глубине извлекается из альфа-канала текстуры кинофрагмента, который "оживляет" поле "текстура".
Раздел 6.5.3.3., редакционное изменение
Проблема: Семантика поля "глубина" определена не полно.
Решение: Заменить спецификацию поля "глубина" (3-й абзац) предложенной измененной редакцией.
Предложенная измененная редакция:
Геометрический смысл значений глубины, и все соглашения по их интерпретации, принятые для простой текстуры, здесь также применимы.
Поле "глубина" определяет множество глубин каждой точки в плоскости проекции, которая предполагается дальней плоскостью (см. выше) в порядке прохождения, которое начинается из точки в нижнем левом углу и переходит вправо, заканчиваясь на горизонтальной линии перед перемещением на более высокую линию. Для каждой точки число глубин (пикселы) сначала запоминаются, и это число значений глубины затем следует.
Раздел 6.5.3.4.1, Н.1, техническое изменение
Проблема: Поле типа SFString, используемое для поля "октодерево", может привести к несовместимым значениям.
Решение: Изменить тип поля для поля "октодерево" на MFInt32.
Предложенное изменение:
В разделе 6.5.3.4.1

В разделе H.1, таблица для октодерева, изменить столбец октодерево следующим образом:

Раздел 6.5.3.4.1, техническое изменение
Проблема: формирование потока DIBR должно делаться с равномерным методом формирования потока для AFX.
Решение: Удалить поле "октодерево Url" из узла "изображение октодерева).
Предложенное изменение:

Раздел 6.5.3.4.2, редакционное изменение
Проблема: Определение поля "разрешение октодерева" (2-й абзац) допускает неверную интерпретацию.
Решение: Изменить описание путем добавления слова "допустимое".
Поле "разрешение октодерева" определяет максимальное допустимое число листьев октодерева вдоль стороны описанного куба. Уровень октодерева может быть определен из разрешения октодерева с использованием следующего уравнения: уровень октодерева=int (log2(разрешение октодерева-1))+1)
Раздел 6.5.3.4.2, техническое изменение
Проблема: формирование потока DIBR должно осуществляться методом равномерного формирования потока для AFX.
Решение: Исключить объяснение поля "октодерево Url" (5-й абзац и ниже).
Предложенное изменение:
Раздел 6.5.3.4.2, редакционное изменение
Проблема: Анимация изображения октодерева описана не полно.
Решение: Добавить абзац в конце Раздела 6.5.3.4.2, описывающего анимацию изображения октодерева.
Предложенное изменение:
Анимация изображения октодерева может быть выполнена тем же методом, как первые три способа анимации, основанным на изображении с глубиной, с единственным отличием, что используется поле "октодерево" вместо поля "глубина".
Раздел Н. 1. Техническое изменение
Проблема: Диапазон данных глубины в узле точечной текстуры может быть слишком малым для будущих приложений. Многие графические программные инструментальные средства позволяют использовать 24-битовые или 36-битовые данные глубины для их z-буфера. Однако поле "глубина" в точечной текстуре имеет диапазон [0,65535], что соответствует 16 битам.
Решение: В разделе H.1, в таблице для точечной текстуры, изменить диапазон столбца "глубина", как предложено.

IV. Кодирование согласно стандарту ISO/IEC JTC 1/SC 29/WG11 движущихся изображений и аудиосигналов
1. Введение
В настоящем документе описано изображение октодерева в представлении на основе изображений с глубиной (DIBR), AFX A8.3. Узел "изображение октодерева" был принят и включен в предложение для Проекта Комитета на встрече в Паттайя. Однако было установлено, что качество визуализации в некоторых специальных случаях неудовлетворительно, ввиду перекрытия геометрии объекта. В данном документе описана усовершенствованная версия узла "изображение октодерева", т.е. текстурированного бинарного волюметрического октодерева (ТБВО), а также способ его сжатия для формирования потока.
2. Текстурированное бинарное волюметрическое октодерево (ТБВО)
2.1.Основные свойства ТБВО
Целью ТБВО является создание более гибкого формата представления/сжатия с быстрой визуализацией, в качестве усовершенствования бинарного волюметрического октодерева (БВО). Это достигается путем сохранения некоторой дополнительной информации на основе БВО. Представление на основе БВО состоит из (структуры октодерева+набора эталонных изображений), в то время как представление, основанное на ТБВО, состоит из (структуры октодерева БВО+набор эталонных изображений+индексы камер).
Основная проблема визуализации БВО состоит в том, что мы должны определить индекс камеры для каждого воксела при визуализации. С этой целью необходимо не только проецировать на камеры, но и осуществить обратную процедуру приведения лучей. Мы должны по меньшей мере определить существование камеры, из которой воксел наблюдается. Поэтому мы должны найти все вокселы, которые проецируются на конкретную камеру. Но эта процедура очень низкоскоростная, если использовать метод "грубой силы". Мы разработали алгоритм, который выполняет ее быстро и точно для большинства форм объектов. Однако еще имеются затруднения для вокселов, которые не наблюдаются ни с одной из камер.
Возможным решением могло бы быть сохранение явно выраженного цвета для каждого воксела. Однако в этом случае имели место проблемы в сжатии информации цвета. Т.е. если сгруппировать цвета вокселов как формат изображения и сжать его, то корреляция цветов соседних вокселов разрушается, так что коэффициент сжатия будет неудовлетворительным.
В ТБВО проблема решается путем сохранения индекса камеры (изображения) для каждого воксела. Индекс обычно один и тот же для большой группы вокселов. И это позволяет использовать структуру октодерева для экономного хранения дополнительной информации. Заметим, что, в среднем, только 15% увеличения объема наблюдалось в экспериментах с нашими моделями. Такое моделирование несколько более сложно, но обеспечивает более гибкий способ представления объектов и любой геометрии.
Преимущества ТБВО по сравнению с БВО состоят в том, что его визуализация проще и является более быстродействующей и, очевидно, не накладывает ограничений на геометрию объекта.
2.2. Пример ТБВО
В данном разделе показан типовой пример, который иллюстрирует эффективность и ключевые компоненты представления ТБВО. На фиг.12а показана модель БВО "Ангел". С использованием обычных шести текстур БВО некоторые части тела и крыло не наблюдаются никакой камерой, что приводит к визуализации изображения с большим количеством наблюдаемых "трещин". В представлении ТБВО той же самой модели используется всего 8 камер (6 граней куба+2 дополнительные камеры). На фиг.13а представлено изображение индекса камеры. Различный цвет обозначает отличающийся индекс камеры. Дополнительные камеры помещаются внутри куба, наблюдая переднюю и заднюю грани ортогональным образом. На фиг.13b и с - дополнительные изображения, снятые дополнительными камерами. В результате получен плавный и четко визуализируемый результат модели, как показано на фиг.12b.
2.3. Описание несжатого потока ТБВО
Мы предполагаем, что достаточно 255 камер, и присваиваем 1 байт для индекса. Поток ТБВО является потоком символов. Каждый ТБВО-символ является БВО-символом или символом текстуры.
Символ текстуры обозначает индекс камеры, что может представлять собой конкретный номер или код "неопределенный". Примем код "неопределенный" в последующем описании как "?".
Поток ТБВО проходится в порядке по ширине. Опишем, как записать поток ТБВО, если мы имеем БВО, и воксел каждого листа имеет номер камеры. Это должно быть сделано на этапе моделирования. Он будет пересекать все узлы БВО включая узлы листьев (которые не имеют БВО-символа) в порядке по ширине. Следующий псевдокод реализует запись потока.
Если ТекущийУзел не является узлом листа
{
Записать текущий БВО-символ соответственно этому узлу
}
если все дочерние элементы имеют идентичный индекс камеры
(символ текстуры)
{
если Текущий Узел имеет "?" индекс камеры
Записать индекс камеры эквивалентно субузлам
}
еще
{
Записать "?" символ
}
Соответственно этой процедуре, для дерева ТБВО, показанного на фиг.14а, может быть получен поток символов, как показано на фиг.14b. В этом примере символы текстуры представлены в байте. Однако в реальном потоке каждый символ текстуры потребует только 2 бита, поскольку нам необходимо представлять три значения (две камеры и неопределенный код).
2.4. Сжатие ТБВО
Поля "изображения октодерева" и "октодерево" в узле "изображение октодерева" сжимаются отдельно. Описанные методы были разработаны на основе того факта, что поле "октодерева" должно сжиматься без потерь, в то время как для изображений октодерева допустима некоторая степень визуально воспринимаемого искажения.
2.4.1. Сжатие поля "изображения октодерева"
Поле "изображения октодерева" сжимается посредством алгоритма сжатия изображений MPEG-4 (для статической модели), или инструментов сжатия видеосигналов (для анимационной модели), которые обеспечиваются в MPEG-4. В нашем походе мы использовали формат JPEG для изображений октодерева (после некоторой предварительной обработки, которую мы называем "минимизацией" изображений JPEG, сохраняя для каждой текстуры только точки, необходимые для трехмерной визуализации; иными словами, части данной текстуры, которые не используются на этапе трехмерной визуализации, могут быть сжаты так грубо, как это желательно).
2.4.2. Сжатие поля "октодерево"
Сжатие октодерева является наиболее важной частью сжатия изображения октодерева, поскольку его предметом является сжатие уже и так очень компактного представления бинарного дерева без связей. Однако в наших экспериментах метод, поясненный ниже, обеспечил уменьшение объема этой структуры примерно до половины ее исходного объема. В анимационной версии изображения октодерева поле "октодерево" сжимается отдельно для каждого трехмерного кадра.
2.4.2.1. Контекстная модель
Сжатие выполняется посредством варианта адаптивного арифметического кодирования (реализованного как "кодер расстояния"), которое использует в явном виде геометрический характер данных. Октодерево представляет собой поток байтов. Каждый байт представляет узел (т.е. субкуб) дерева, в котором его биты указывают заполнение субкуба после внутреннего подразделения. Битовая конфигурация называется конфигурацией заполнения узла. Описанный алгоритм сжатия обрабатывает байты с соотношением "один к одному" следующим образом.
- Определяется контекст для текущего байта.
- "Вероятность" (нормированная частота) появления текущего байта в этом контексте извлекается из "таблицы вероятностей" (ТВ) соответственно контексту.
- Значение вероятности вводится в кодер дальности.
- Текущая ТВ обновляется путем добавления 1 к частоте появления текущего байта в текущем контексте (при необходимости, с последующей ренормализацией, как более подробно описано ниже).
Таким образом, кодирование является процессом создания и обновления ТВ соответственно контекстной модели. В схемах адаптивного арифметического кодирования на основе контекста (таких как "предсказание с частичным согласованием") контекст символа обычно представляет собой строку из некоторого количества предшествующих символов. Однако в нашем случае эффективность сжатия увеличивается путем использования структуры октодерева и геометрических свойств данных. Описанный подход основан на двух идеях, которые являются очевидным образом новыми в проблеме сжатия октодерева.
А. Для текущего узла контекст является или его порождающим узлом или парой {порождающий узел, положение текущего узла в порождающем узле}.
В. Предполагается, что "вероятность" появления заданного узла в конкретном геометрическом положении в конкретном порождающем узле инвариантна по отношению к определенному набору ортогональных (таких как повороты или симметричные преобразования) преобразований.
Предположение "В" иллюстрируется чертеже для преобразования R, которое представляет собой поворот на -90° в плоскости x-z. Основная идея пункта "В" состоит в том, что вероятность появления конкретного типа дочернего узла в конкретном типе порождающего узла должна зависеть только от их относительного положения. Это допущение подтверждено в наших экспериментах путем анализа таблиц вероятностей. Это позволяет использовать более сложный контекст, не требуя слишком много таблиц вероятностей. Это, в свою очередь, способствует достижению достаточно хороших результатов в аспектах размера данных и быстродействия. Заметим, что чем более сложные контексты используются, тем точнее оценка вероятности и тем более компактным является код.
Введем множество преобразований, для которых предполагаем инвариантность распределений вероятности. Для обеспечения возможности их применения в рассматриваемой ситуации, такие преобразования должны сохранять охватывающий куб. Рассмотрим множество G ортогональных преобразований в евклидовом пространстве, которые получают путем всех композиций в любом числе и порядке трех базовых преобразований (генераторов) m1, m2 и m3, определяемых следующим образом:
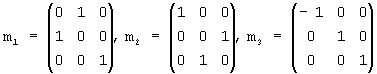
где m1 и m2 - отображения на плоскости x=y и y=z соответственно, и m3 - отображение на плоскость x=0.
Один из классических результатов теории групп, генерируемых отображениями, утверждает, что G содержит 48 отдельных ортогональных преобразований, и является, по смыслу, максимальной группой ортогональных преобразований, которая принимает упомянутый куб сама в себя (так называемая группа Coxeter). Например, поворот R на фиг.6 выражается через генераторы следующим образом:
R=m3·m2·m1·m2,
где "·" обозначает матричное перемножение.
Преобразование из G, применимое к узлу октодерева, формирует узел с отличающейся конфигурацией заполнения субкубов. Это позволяет подразделять узлы на категории в соответствии с конфигурацией заполнения из субкубов. Используя терминологию теории групп, можно сказать, что G действует на множество всех конфигураций заполнения узлов октодерева. Вычисления показывают, что имеется 22 различных класса (также называемых орбитами в теории групп), в которых, по определению, два узла принадлежат к одному и тому же классу, только если они связаны преобразованием из G. Число элементов в классе составляет от 1 до 24 и всегда является делителем 48.
Практическим следствием "В" является то, что таблица вероятностей зависит не от самого порождающего узла, а только от класса, к которому принадлежит порождающий узел. Заметим, что будет иметься 256 таблиц для контекста, основанного на порождающем элементе, и дополнительно 256x8=2048 таблиц для контекста, основанного на положении порождающего и дочернего элементов в первом случае, хотя требуется только 22 таблицы для контекста, основанного на классе порождающего элемента, плюс 22x8=176 таблиц в последнем случае. Поэтому можно использовать контекст эквивалентной сложности с относительно малым количеством таблиц вероятностей. Сформированная ТВ будет иметь форму, как показано в таблице 8.

2.4.2.2. Процесс кодирования
Чтобы статистика таблиц вероятностей была более точной, ее собирают различными путями на трех этапах процесса кодирования.
- На первом этапе контекст не используется совсем, принимается "0-контекстная модель", и поддерживается одна таблица вероятностей с 256 записями, начиная с равномерного распределения.
- Как только первые 512 узлов (это эмпирически найденное число) закодированы, переключаемся на "1-контекстную модель" с использованием порождающего узла в качестве контекста. В момент переключения ТВ 0-контекста копируется в ТВ для всех 22 контекстов.
- После того как 2048 (еще одно эвристическое значение) закодированы, переключаемся на "2-контекстную модель". В этот момент 1-контекстные ТВ порождающих узлов копируются во все ТВ для каждого положения в той же самой конфигурации порождающего узла.
Ключевым моментом данного алгоритма является определение контекста и вероятности для текущего байта. Это реализуется следующим образом. В каждом случае фиксируем один элемент, который называется "стандартным элементом". Сохраняем таблицу отображения класса (ТОК), которая показывает класс, к которому принадлежит каждый из возможных 256 узлов, и предварительно вычисленное преобразование из G, которое переводит данный конкретный узел в стандартный элемент его класса. Таким образом, чтобы определить вероятность текущего узла N, выполняем следующие этапы:
- Определить порождающий узел Р текущего узла.
- Извлечь класс из ТОК, к которому принадлежит Р, и преобразование Т, которое переводит Р в стандартный узел класса. Пусть номер класса будет с.
- Применить Т к Р и найти положение р дочернего узла в стандартном узле, на который отображается текущий узел N.
- Применить Т к N. Тогда вновь полученная конфигурация TN заполнения находится в положении р в стандартном узле класса с.
- Извлечь требуемую вероятность из записи TN таблицы вероятностей, соответствующей комбинации "класс-положение" (с, р).
Для 1-контекстной модели вышеописанные этапы модифицируются очевидным образом. Само собой разумеется, все преобразования предварительно вычислены и реализованы в виде таблиц перекодировки.
Заметим, что на этапе декодирования узла N его порождающий узел Р уже декодирован, и, следовательно, преобразование Т известно. Все шаги, выполняемые на этапе декодирования, абсолютно идентичны соответствующим шагам процедуры кодирования.
Наконец, опишем процедуру обновления вероятности. Пусть Р таблица вероятностей для некоторого контекста. Обозначим P(N) запись Р, соответствующую вероятности появления узла N в этом контексте. В описываемой реализации P(N) - целое число, и после каждого появления N, P(N) обновляется как
P(N)=P(N)+A,
где А - целочисленный параметр приращения, изменяющийся в типовом случае от 1 до 4 для различных контекстных моделей.
Пусть S(P) - сумма всех записей в Р. Тогда вероятность того, что N вводится в арифметический кодер (в данном случае кодер расстояний), вычисляется как P(N)/S(P). Как только S(P) достигает порогового значения 216, все записи ренормируются: чтобы избежать появления нулевых значений в Р, записи, равные 1, остаются, как они есть, а другие делятся на 2.
2.4.2.3. Кодирование "узлов камеры"
Поток символов, определяющий числа текстуры (камеры) для каждого воксела, сжимается с использованием своей собственной таблицы вероятностей. В терминах, использованных выше, он имеет один контекст. Записи таблицы вероятностей обновляются с большим приращением, чем записи узлов октодерева; в остальном нет отличий от кодирования символов узла.
2.5. Результаты сжатия и визуализации ТБВО
На фиг.15, 17, 18 и 19 приведены результаты сжатия ТБВО. На фиг.16 приведены "очищенные" (со снятой оболочкой) изображения моделей "Ангел" и "Мортон". Сжатые размеры сравнимы со сжатым БВО: в третьем столбце число в скобках представляет сжатый объем геометрии, а первое число - полный объем модели, сжатой на основе ТБВО (т.е. текстуры принимаются во внимание). В качестве меры визуального искажения, было вычислено отношение сигнал/шум (PSNR) для оценки различия в цвете после преобразования МИГ→(Т)БВО→МИГ. Сжатый размер модели есть размер всех текстур (сохраненных как минимизированных JPEG, см.0) плюс размер сжатой геометрии. В случае ТБВО сжатая геометрия включает также информацию о камере. Отношение с/ш PSNR для ТБВО улучшается существенно по сравнению с БВО.
ТБВО обеспечивает более быструю визуализацию, чем БВО. Для модели "Ангел" частота кадров ТБВО-12 есть 10,8 к/с, в то время как для БВО она равна 7,5 к/с. Для модели "Мортон" соответствующий параметр для ТБВО-12 равен 3,0 к/с, а для БВО 2,1 (на Селерон 850 МГц). С другой стороны, наблюдалось, что визуализация ускорялась намного больше в анимационных ТБВО. Для модели "Дракон" частота кадров для ТБВО-12 была равна 73 к/с, в то время как для БВО она равна 29 к/с (на Пентиум IV 1.8 ГГц).
Формат ТБВО обеспечивает значительную гибкость. Например, 2 способа использования 12 камер показаны на фиг.6: ТБВО-12 и ТБВО-6+6). ТБВО-12 использует 6 камер БВО (грани куба) плюс 6 изображений, взятых из центра куба и параллельных граням. Конфигурация (6+6) использует 6 камер БВО и затем удаляет ("очищает") все вокселы, наблюдаемые этими камерами, и "фотографирует" часть, которая стала видимой этими же 6 камерами. Примеры таких изображений показаны на фиг.16.
Отметим существенное различие по качеству (субъективное и значение PSNR) между БВО и ТБВО-6 для моделей "Ангел". Хотя использованы те же самые местоположения камер, ТБВО позволяет распределять камеры по всем вокселам, даже тем, которые не наблюдаются камерами. Их количество выбираются так, чтобы наилучшим образом согласовать исходные цвета (т.е. для каждой точки выбирается наилучшее совпадение во всех "изображениях камер", независимо от непосредственной наблюдаемости). В случае модели "Ангел" это дает заметный результат).
Отметим также очень умеренную разницу в объеме "геометрии" (т.е. БВО-камер) между случаями 6 и 12 камер. Реально, дополнительные камеры покрывают в типовом случае малые области, их идентификаторы редки, и их текстуры разреженные (и хорошо сжимаются). Все это применимо не только к модели "Ангел", но и к моделям "Мортон", "Пальма 512" и "Роботы 512".
2.6. Спецификация узлов

Узел октодерева определяет структуру ТБВО, в которой существует структура октодерева, соответствующая массиву индексов камер, и набор изображений октодерева.
Поле "изображение октодерева" определяет набор узлов "изображение с глубиной" с простой текстурой для поля "diТекстура"; поле "глубина" в этих узлах простой текстуры не используется. Поле "ортогональный" должно быть ИСТИННЫМ для узлов "изображение с глубиной". Для каждой простой текстуры поле "текстура" сохраняет информацию цвета объекта или часть вида объекта (например, его сечение плоскостью камеры), полученного ортогональной камерой, положение и ориентация которой определены в соответствующих полях изображения с глубиной. Части объекта, соответствующие каждой камере, распределяются на этапе конструирования модели. Подразделение объекта с использованием значений полей положения, ориентации и текстуры выполняется так, чтобы минимизировать число камер (или, эквивалентно, используемых изображений октодерева), и в то же время включить все части объекта, потенциально наблюдаемые из произвольно выбранного положения. Поля ориентации должны удовлетворять условиям: вектор наблюдения камеры имеет только одну ненулевую составляющую (т.е. перпендикулярен одной из граней охватывающего куба). Также стороны изображения простой текстуры должны быть параллельны соответствующим сторонам охватывающего куба.
Поле "октодерево" полностью описывает геометрию объекта. Геометрия представлена как набор вокселов, которые составляют данный объект. Октодерево представляет собой древовидную структуру данных, в которой каждый узел представлен байтом. "1" в i-м бите данного байта означает, что дочерние узлы существуют для i-го дочернего узла этого внутреннего узла; а "0" означает, что этого нет. Порядок внутренних узлов октодерева должен быть порядком прохождения по ширине октодерева. Порядок для восьми дочерних узлов внутреннего узла показан на 14b. Размер охватывающего куба полного октодерева равен 1×1×1, и центр куба октодерева должен соответствовать началу координат (0,0,0) локальной системы координат.
Поле "ИД камеры" содержит массив индексов камеры, присвоенных вокселам. На этапе визуализации цвет, присвоенный листьям октодерева, определяется путем ортогонального проецирования листьев на одно из изображений октодерева с конкретным индексом. Индексы сохраняются способом, подобным октодереву: если конкретная камера может быть использована для всех листьев, содержащихся в конкретном узле, то узел, содержащий индекс камеры, выдается в поток, а противном случае выдается узел, содержащий фиксированный код "дальнейшего подразделения", означая, что индекс камеры будет определен отдельно для дочерних субузлов текущего узла (тем же рекурсивным способом). Если поле "ИД камеры" пусто, то индексы камеры определяются на этапе визуализации (как в случае БВО).
Поле "разрешение октодерева" определяет максимальное допустимое число листьев октодерева вдоль стороны охватывающего куба. Уровень октодерева может быть определен из разрешения октодерева с использованием соотношения:
Уровень октодерева = log2(разрешение октодерева)
log2(разрешение октодерева)
2.7. Спецификация потока битов
2.7.1. Сжатие октодерева
2.7.1.1. Общие сведения
Узел "изображение октодерева" в представлении, основанном на изображениях с глубиной, определяет структуру октодерева и его проецируемые текстуры. Каждая текстура, сохраненная в массиве изображений октодерева, определяется через узел "изображение с глубиной" с простой текстурой. Другие поля узла "изображение октодерева" могут быть сжаты путем сжатия октодерева.
2.7.1.2 Октодерево
2.7.1.2.1 Синтаксис
class Octree ()
{
OctreeHeader ();
aligned bit (32)* next;
while(next= =0×000001 C8)
{
aligned bit (32) octree_frame_start_code;
OctreeFrame(octreeLevel);
aligned bit (32)* next;
}
)
2.7.1.2.2. Семантика
Сжатый поток октодерева содержит заголовок октодерева и один или более кадров октодерева, каждому из которых предшествует octree_frame_start_code (код начала кадра октодерева). Значение octree_frame_start_code всегда равно 0×000001С8. Это значение обнаруживается упреждающим синтаксическим анализом потока.
2.7.1.3. Заголовок октодерева
2.7.1.3.1 Синтаксис
class OctreeHeader ()
{
unsigned int (5) octreeResolutionBits;
unsigned int (octreeResolutionBits) octreeResolution;
int octreeLevel=ceil(log(octreeResolution)/log(2));
unsigned int (3) textureNumBits;
unsigned int (textureNumBits) numOfTextures;
}
2.7.1.3.2. Семантика
Данный класс считывает информацию заголовка для сжатия октодерева.
Поле octreeResolution (разрешение октодерева), длина которого описывается посредством octreeResolutionBits (биты разрешения октодерева), содержит значение поля "разрешение октодерева" узла "изображение октодерева". Это значение используется для получения уровня октодерева.
Поле numOfTexture (число текстур), которое имеет длину textureNumBits (биты числа текстур), описывает число текстур (или камер), использованных в узле "изображение октодерева". Это значение используется для арифметического кодирования ИД камеры для каждого узла октодерева. Если значение textureNumBits равно 0, то символы текстуры не кодируются путем установки "текущей текстуры" корневого узла в 255.
2.7.1.4. Кадр октодерева
2.7.1.4.1.Синтаксис
class OctreeFrame (int octreeLevel)
{
for (int curl_evel=0; curLevel<octreeLevel; curLevel++0
{
for (int nodelndex=0; nodelndex<nNodeslnCurLevel; nodelndex++)
{
int nodeSym=ArithmeticDecodeSymbol (contextID);
if(curTexture==0)
{
curTexture=ArithmeticDecodeSymbol(textureContextID);
}
}
}
for (int nodelndex=0; nodelndex<nNodeslnCurLevel; nodelndex++)
if(curTexture==0)
curTexture=ArithmeticDecodeSymbol(textureContextID);
}
2.7.1.4.2. Семантика
Этот класс считывает один кадр октодерева в порядке похождения по ширине. Начиная с 1-го узла на уровне 0, после считывания каждого узла на текущем уровне, число узлов на следующем уровне известно путем подсчета всех "1" в каждом символе узла. На следующем уровне это число узлов (nNodeslnCurLevel - n узлов на текущем уровне) будет считано из потока.
Для декодирования каждого узла задается соответствующий contextID (контекст ИД), как описано в разделе 2.7.1.6.
Если ИД текстуры (или камеры) для текущего узла (curTexture - текущая текстура) не определен порождающим узлом, то ИД текстуры также считывается из потока, с использованием контекста для ИД текстуры, определяемого полем textureContextID. Если извлекается ненулевое значение (ИД текстуры определен), то это значение также будет применяться ко всем дочерним узлам на следующих уровнях. После декодирования каждого узла, textureID будет присвоено узлам листьев октодерева, которым еще не было присвоено значение textureID.
2.7.1.5. Адаптивное арифметическое декодирование
В этом разделе описан адаптивный арифметический кодер, использованный при сжатии октодерева, с применением описания синтаксиса в C++ стиле.
aa_decode() - функция, которая декодирует символ, используя модель, определенную массивом cumul_freq[]; PCT - таблица контекстов вероятности, как описано в разделе 2.7.1.6.
int ArithmeticDecodeSymbol (int contextID)
{
unsigned int MAXCUM=1"13;
unsigned int TextureMAXCUM=256;
int*p, allsym, maxcum;
if (contextID !=textureContextID)
{
p=PCT[contextID];
allsym=256;
maxcum = MAXCUM;
}
else
{
p=TexturePCT;
allsym=numOfTextures;
maxcum=TextureMAXCUM;
}
int cumul_freq[allsym];
int cum=0;
for (int i=allsym-l; i>=0; i-)
{
cum+=p[i];
cumul_freq[i]=cum;
}
if (cum>maxcum)
{
cum=0;
for (int i=allsym-l; i>=0; i--)
{
PCT[contextID][i]=(PCT[contextID][i]+l)/2;
cum+=PCT[contextID] [i];
cumul_freq [i] =cum;
}
}
return aa_decode(cumul_freq);
}
2.7.1.6. Процесс декодирования
Общая структура процесса декодирования описана в разделе 0 (см. также процесс кодирования, описанный выше). Он показывает, как получают узлы ТБВО из потока битов, который образует арифметически кодированную (сжатую) модель ТБВО.
На каждом этапе процесса декодирования необходимо обновлять номер контекста (т.е. индекс используемой таблицы вероятностей) и таблицу вероятностей. Назовем Вероятностной моделью совокупность всех таблиц вероятностей (массивы целых чисел), j-й элемент i-й таблицы вероятностей, деленный на сумму ее элементов, оценивает вероятность появления j-го символа в i-м контексте.
Процедура обновления таблицы вероятностей состоит в следующем. Сначала таблицы вероятностей инициализируются так, чтобы все записи были равны 1. Перед декодированием символа должен быть выбран номер контекста (ContextID). ContextID определяется из ранее декодированных данных, как показано ниже. Когда ContextID получен, символ декодируется с использованием бинарного арифметического декодера. После этого таблица вероятностей обновляется путем добавления адаптивного шага к частоте декодированного символа. Если общая (кумулятивная) сумма элементов таблицы превысит кумулятивный порог, то выполняется нормализация (см. 2.7.1.5.1).
2.7.1.6.1 Контекстное моделирование символа текстуры
Символ текстуры моделируется только с одним контекстом. Это означает, что используется только одна таблица вероятностей. Размер этой таблицы равен числу numOfTextures (число текстур)+1. Сначала эта таблица инициализируется со всеми "1". Максимальное допустимое значение записи установлено на 256. Адаптивный шаг установлен на 32. Эта комбинация значений параметров позволяет осуществить адаптацию к переменному в значительной степени потоку чисел текстуры.
2.7.1.6.2. Контекстное моделирование символа узла
Имеется 256 различных символов узлов, каждый символ представляет 2×2×2 бинарную матрицу вокселов. К этим матрицам может быть применено трехмерное ортогональное преобразование, обеспечивающее преобразование соответствующих символов друг в друга.
Рассмотрим набор из 48 фиксированных ортогональных преобразований, т.е. повороты на 90·n (n=0, 1, 2, 3) градусов относительно осей координат и симметричные преобразования. Их матрицы приведены ниже в порядке их номеров:
Ортогональные преобразования [48]=

}
Имеется 22 набора символов, называемых классами, так что 2 символа соединены таким преобразованием, только если они принадлежат одному и тому же классу. Метод кодирования формирует РСТ следующим образом: ContextID символа равен номеру класса, к которому принадлежит его порождающий элемент, либо комбинированному номеру (класс порождающего элемента, положение текущего узла в порождающем узле). Это позволяет значительно сократить число контекстов, снижая время, требуемое для получения значимой статистики.
Для каждого класса определен один базовый символ (см. таблицу 9), и для каждого символа предварительно вычислено ортогональное преобразование, которое приводит его в базовый символ своего класса (в реальном процессе кодирования/ декодирования используется таблица перекодировки). После того как ContextID для символа определен, применяется преобразование, инверсное (т.е. транспонированная матрица) тому, которое приводит его порождающий элемент в базовый элемент. В таблице 10 приведены контексты и соответствующие прямые преобразования для каждого символа.
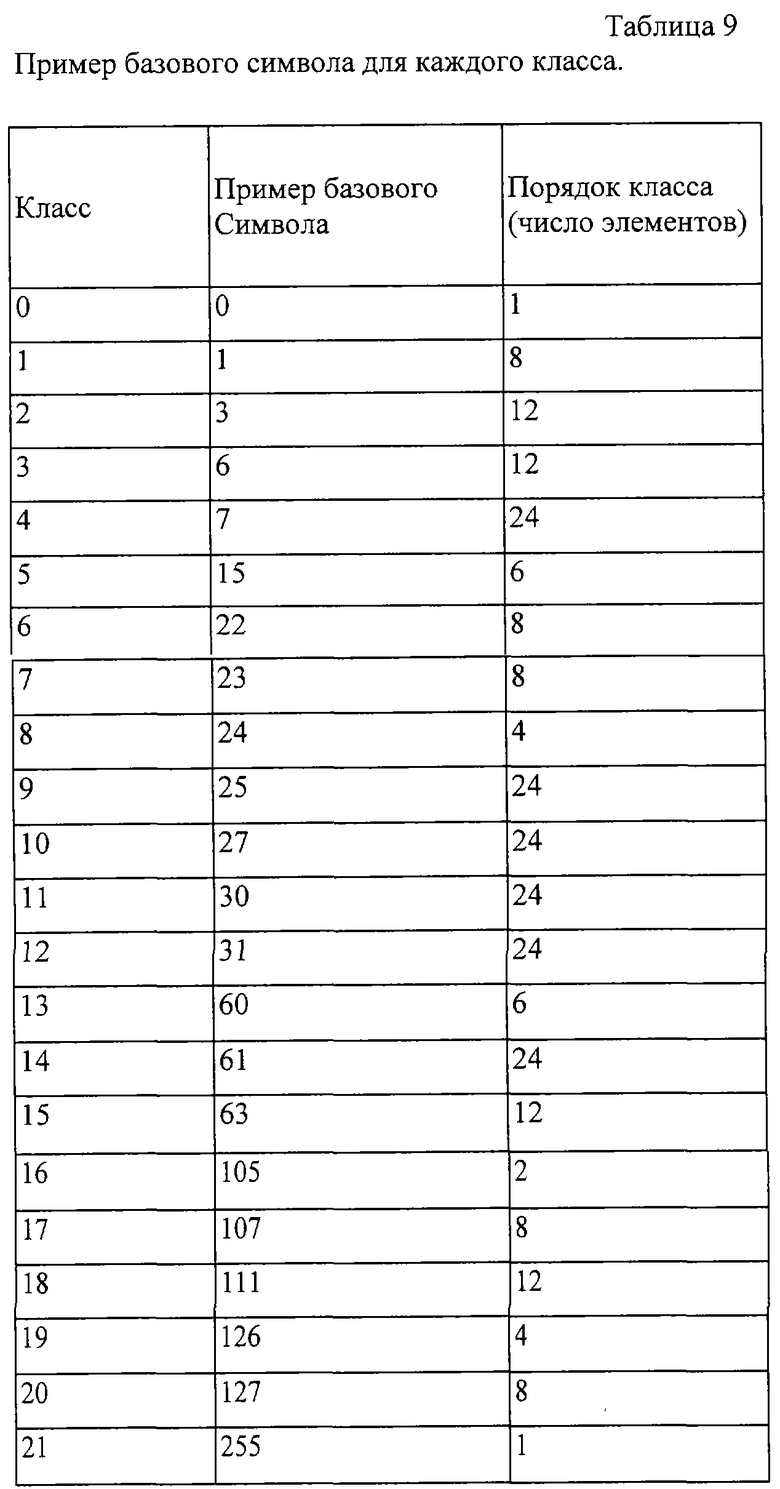
Контекстная модель зависит от числа N уже декодированных символов:
Для N<512 имеется только один контекст. Таблица вероятностей инициализируется со всеми "1". Число символов в таблице вероятностей равно 256. Шаг адаптации равен 2. Максимальная кумулятивная частота равна 8192.
Для 512≤N<2560 (=2048+512), используется 1-контекстная (в том смысле, что число контекстов является одним параметром, номером класса) модель. Эта модель использует 22 РСТ. СоntextID - номер класса, к которому принадлежит порождающий узел декодируемого узла. Этот номер можно определить из таблицы перекодировки (см. таблицу 10), поскольку порождающий узел декодируется раньше, чем дочерний. Каждая из 22 РСТ инициализируется посредством РСТ предыдущего этапа. Число символов в каждой таблице вероятностей равно 256. Шаг адаптации равен 3. Максимальная кумулятивная частота также равна 8192. После декодирования символа, он преобразуется с использованием инверсного ортогонального преобразования, определенного выше. Номер ортогонального преобразования может быть найден в таблице 10 для ИД символа узла, равного порождающему узлу для символа текущего узла.
Когда 2560 символов декодированы, декодер переключается на 2-контекстую модель (в том смысле, что число контекстов теперь состоит из двух параметров, как поясняется ниже). Эта модель использует 176 (=22·8, т.е. 2 класса по 8 позиций) РСТ. ContextID здесь зависит от класса порождающего элемента и положения текущего узла в порождающем узле. Исходные таблицы вероятностей для данной модели зависят только от контекста, но не от положения: для всех 8 позиций РСТ является клоном РСТ, полученной для данного класса на предыдущем этапе. Число символов в каждой таблице вероятностей равно 256. Шаг адаптации равен 4. Максимальная кумулятивная частота равна также 8192.
После того как символ декодирован, он также преобразуется с использованием инверсного ортогонального преобразования (в приведенное в таблице 10), как и предшествующей модели.
Можно легко получить геометрию базовых элементов для каждого класса, используя таблицу 10. Базовые элементы являются символами, для которых ИД ортогонального преобразования равен 0 (число 0 присвоено идеальному преобразованию).
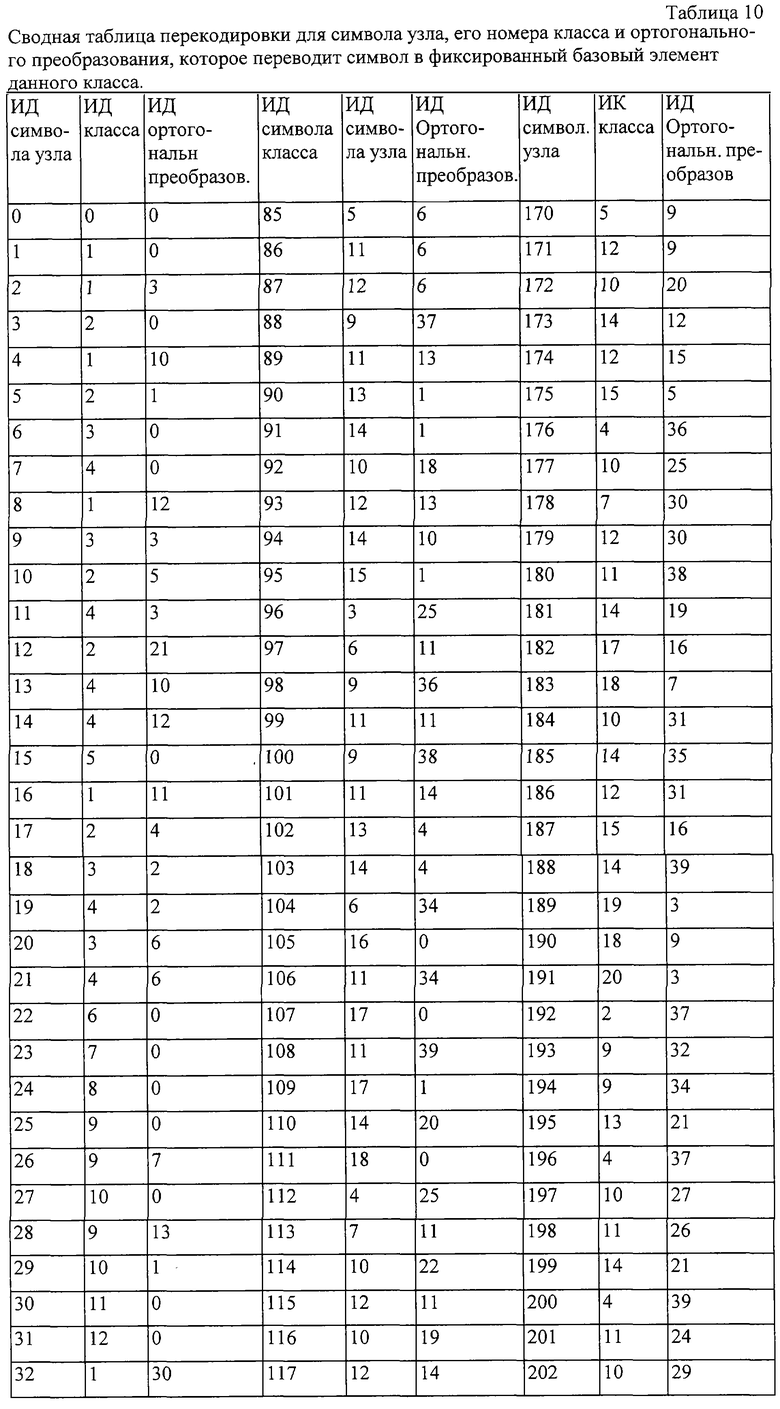
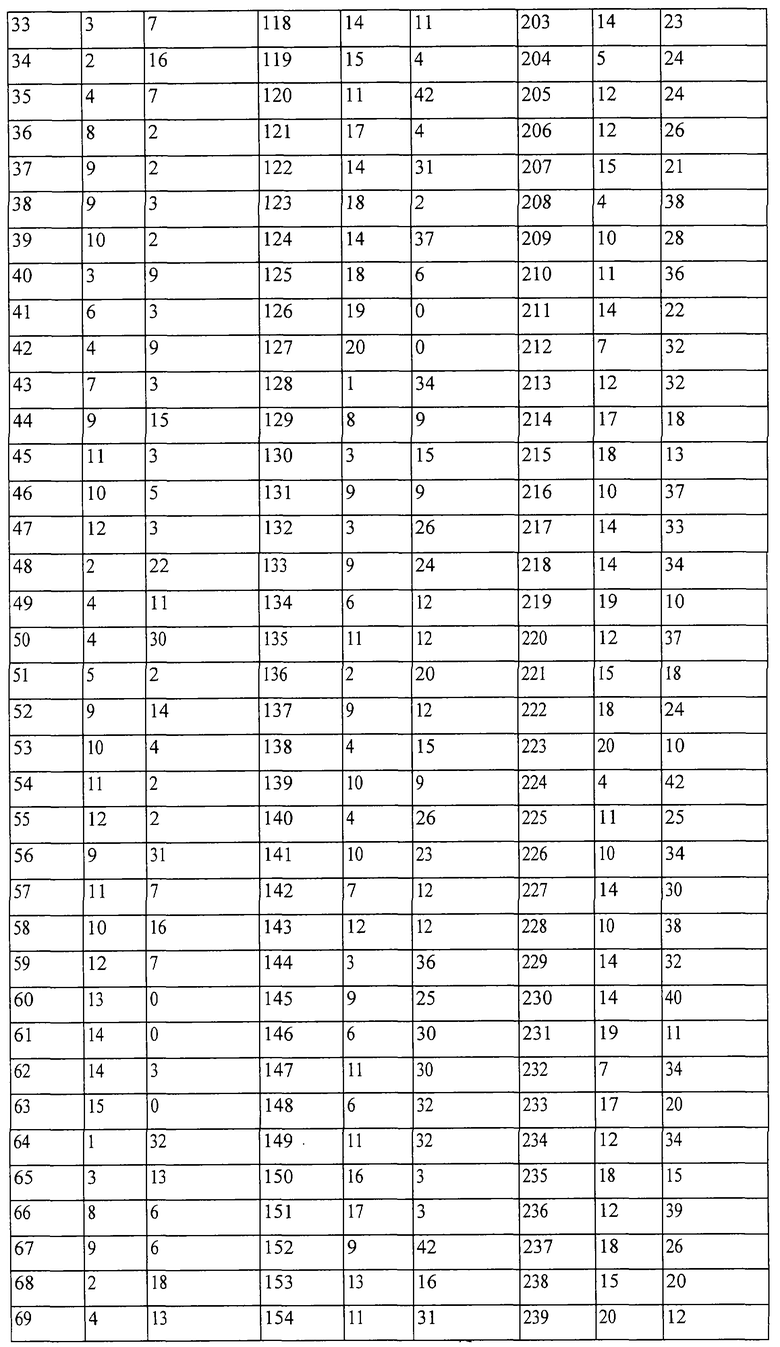
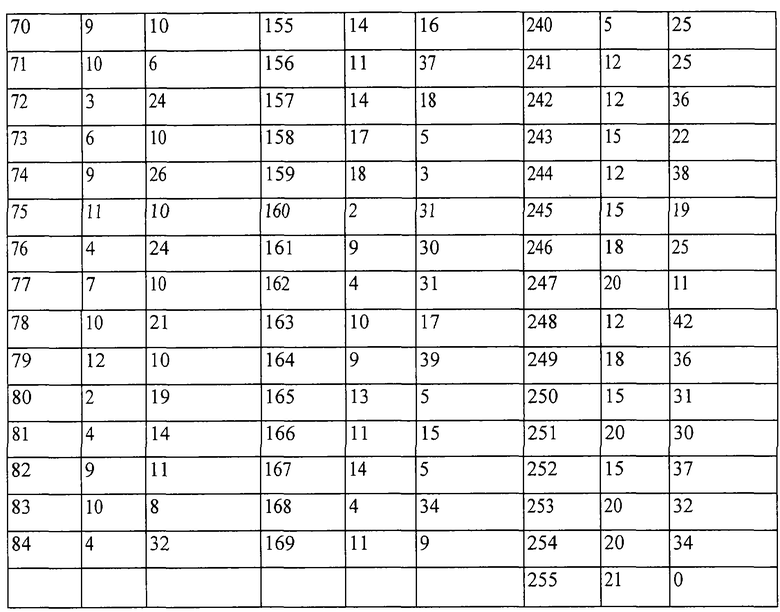
Ниже более детально описаны MPEG-4 спецификация узлов и методы сжатия форматов изображения октодерева, используемые в устройстве и способе трехмерного представления на основе изображений с глубиной, согласно настоящему изобретению.
Настоящее изобретение описывает семейство структур данных, представления на основе изображений с глубиной (DIBR), которые обеспечивают эффективные и действенные представления, основанные главным образом на изображениях и картах глубины, полностью использующие преимущества, описанные выше. Охарактеризуем кратко основные форматы DIBR - SimpleTexture (простая текстура), PointTexture (точечная текстура) и Octreelmage (изображение октодерева).
На фиг.20 представлена диаграмма примера изображения текстуры и карты глубины, на фиг.21 - диаграмма примера многослойного изображения с глубиной: а - проекция объекта; b - слои пикселов.
Простая структура представляет собой структуру данных, которая состоит из изображения, соответствующей карты глубины и описания камеры (ее позиция, ориентация и тип, ортогональный или перспективный). Возможности представления одиночной простой текстуры ограничены объектами, подобными фасадам зданий: фронтальное изображение с картой глубины позволяет осуществить реконструкцию видов фасада в существенном диапазоне углов. Однако набор простых текстур, сформированный надлежащим образом позиционированными камерами, позволяет получить представления всего здания - в случае, когда эталонные изображения покрывают все потенциально видимые части поверхности здания. Разумеется, то же самое применимо к деревьям, человеческим фигурам, автомобилям и т.п. Более того, совокупность простых текстур обеспечивает практически естественное средство для обработки трехмерных анимационных данных. В этом случае эталонные изображения заменяются эталонными потоками видеоданных. Карты глубины для каждого трехмерного кадра могут быть представлены либо значениями альфа-канала этих потоков видеоданных, либо отдельными потоками видеоданных шкалы серого. В этом типе представления изображения могут быть сохранены в форматах сжатия с потерями, подобными JPEG. Это существенно сокращает объем цветовой информации, особенно в анимационном случае. Однако данные геометрии (карты глубины) должны сжиматься без потерь, что оказывает влияние на сокращение в целом объема памяти.
Для объектов сложной формы иногда трудно покрыть всю видимую поверхность приемлемым количеством эталонных изображений. Предпочтительным представлением для таких случаев может быть точечная текстура. Этот формат также предусматривает сохранение эталонного изображения и карты глубины, но в этом случае они являются многозначными: для каждой линии визирования камеры (ортогональной или перспективной) цвет и расстояние сохраняются для каждого пересечения линии с объектом. Число пересечений может варьироваться от линии к линии. Совокупность нескольких точечных текстур обеспечивает очень детальное представление даже сложных объектов. Но данному формату не хватает двумерной регулярности простой текстуры, и поэтому он не обеспечивает естественной основанной на изображении сжатой формы. По той же причине он используется только для неподвижных объектов.
Формат изображения октодерева занимает промежуточное положение между "большей частью двумерной" простой текстурой и "большей частью трехмерной точечной текстурой": он сохраняет геометрию объекта в структурированном в октодереве волюметрическом представлении (иерархически организованные вокселы в обычном бинарном подразделении охватывающего куба), причем компонент цвета представлен набором изображений. Этот формат также содержит структуру данных, подобную октодереву, которая сохраняет, для каждого воксела листа, индекс эталонного изображения, содержащего его цвет. На этапе визуализации изображения октодерева цвет воксела листа определяется путем ортогонального проецирования его на соответствующее эталонное изображение. Нами разработан высокоэффективный метод сжатия для геометрической части изображения октодерева. Он представляет собой вариант адаптивного основанного на контексте арифметического кодирования, где контексты конструируются с использованием в явном виде геометрического свойства данных. Использование сжатия вместе со сжатыми с потерями эталонными изображениями делает изображение октодерева весьма эффективным по пространству представлением. Подобно простой текстуре, изображение октодерева имеет анимационную версию: эталонные потоки видеоданных вместо эталонных изображений, плюс два дополнительных потока октодеревьев, представляющих геометрию и соответствие воксел-изображения для каждого трехмерного кадра. Весьма полезным свойством формата изображения октодерева является присущее ему свойство усреднения отображения.
Семейство DIBR было разработано для новой версии стандарта MPEG-4 и принято для включения в стандарт AFX MPEG. AFX обеспечивает более усовершенствованные характеристики для синтезированных сред MPEG-4, и включает набор взаимодействующих инструментальных средств, обеспечивающих повторно используемые архитектуры для интерактивных анимационных содержаний (совместимых с существующим стандартом MPEG-4). Каждое инструментальное средство AFX проявляет совместимость с узлом BIFS, синтезированным потоком и аудиовизуальным потоком. Текущая версия AFX состоит из описаний высокого уровня анимации (например, анимация, основанная на построении скелета и формировании на его основе внешней оболочки), усовершенствованного рендеринга (например, процедурное текстурирование, отображение световых полей), компактных представлений (например, NURBS, сплошное представление, поверхности подразделения), анимации низких скоростей передачи битов (например, интерполяционное сжатие) и других, а также предложенного нами метода DIBR.
Форматы DIBR были разработаны так, чтобы объединить преимущества различных предложенных ранее идей, предоставляя пользователю гибкие инструментальные средства, наилучшим образом подходящие для конкретной задачи. Например, неанимационная простая текстура и точечная текстура являются частными случаями известных форматов, в то время как изображения октодерева характеризуют собой новое представление. Но в контексте MPEG-4 все три фазовых формата DIBR могут рассматриваться как составные элементы, и их комбинации на основе MPEG-4 не только охватывают многие из представлений на основе изображений, предложенных в литературе, но и обеспечивают значительный потенциал для создания новых форматов.
Ниже описано представление на основе изображений с глубиной.
Принимая во внимание идеи, охарактеризованные выше, а также некоторые из наших собственных разработок, мы предложили следующий набор форматов на основе изображений для использования в MPEG-4 AFX: SimpleTexture (простая текстура), PointTexture (точечная текстура), Depthlmage (изображение с глубиной) и Octreelmage (изображение октодерева). Простая текстура и изображение октодерева имеют анимационные версии.
Простая текстура представляет собой одиночное изображение, объединенное с изображением с глубиной. Оно эквивалентно RT, в то время как точечная текстура эквивалента МИГ.
Основываясь на простой текстуре и точечной текстуре в качестве составных элементов, можно создать множество представлений, используя конструкции MPEG-4. Формальная спецификация приведена ниже, а здесь представлено геометрическое описание результата.
Структура изображения с глубиной определяет либо простую текстуру, либо точечную структуру вместе со связывающим блоком, положением в пространстве и некоторой другой информацией.
Набор изображений с глубиной может быть объединен под единой структурой, называемой узлом преобразования, что позволяет построить множество полезных представлений. Наиболее часто используемыми являются два из них, которые не имеют специального определения в рамках MPEG-4, но в нашей практике мы называем их блочной текстурой (БТ) и обобщенной блочной текстурой (ОБТ). БТ представляет собой совокупность шести простых текстур, соответствующих связывающему кубу объекта или сцены, в то время как ОБТ представляет собой произвольную совокупность любого числа простых текстур, которые совместно обеспечивают согласованное трехмерное представление. Пример БТ приведен на фиг.22, где показаны эталонные изображения, карты глубины и результирующий трехмерный объект. БТ может быть визуализирована с помощью алгоритма деформации с приращениями, но мы использовали иной подход, применимый также к ОБТ. Пример представления ОБТ показан на фиг.23, где для представления сложного объекта (пальмы) использована 21 простая текстура.
Следует отметить, что механизм объединения позволяет, например, использовать несколько МИГ с различными камерами для представления того же самого объекта или частей того же самого объекта. Поэтому структуры данных, подобные основанным на изображениях объектам, элементам дерева МИГ, элементам древовидных структур на основе поверхностных элементов, являются частными случаями данного формата, что обеспечивает намного большую гибкость в адаптации положения и разрешения простых текстур и точечных текстур к структуре сцены.
Ниже описано изображение октодерева: текстурированное бинарное волюметрическое октодерево (ТБВО).
Чтобы использовать геометрию мультиразрешения и текстуру с более гибким представлением и быстрой визуализацией, мы разработали представление изображения октодерева, которое основано на текстурированном бинарном волюметрическом октодереве (ТБВО). Целью ТБВО является создание гибкого формата представления/сжатия с быстрой высококачественной визуализацией. ТБВО состоит из трех главных компонентов: бинарного волюметрического дерева (БВО), которое представляет геометрию, набора эталонных изображений и индексов изображений, соответствующих узлам октодерева.
Геометрическая информация в форме БВО представляет собой множество бинарных (заполненных или пустых) регулярно разнесенных вокселов, объединенных в более крупные элементы обычным способом октодерева. Это представление может быть легко получено из данных изображения октодерева посредством промежуточной формы "скоплений точек", поскольку каждый пиксел с глубиной определяет уникальную точку в трехмерном пространстве. Преобразование скопления точек в БВО иллюстрируется на фиг.24. Аналогичный процесс позволяет осуществить преобразование полигональной модели в БВО. Информация текстуры БВО может быть получена из эталонных изображений. Эталонное изображение представляет собой текстуру вокселов при заданном положении и ориентации камеры. Следовательно, само БВО, вместе с эталонными изображениями, уже обеспечивает представление модели. Однако оказалось, что дополнительная структура, сохраняющая индекс эталонного изображения для каждого листа БВО, обеспечивает намного более быструю визуализацию с лучшим качеством.
Основная проблема визуализации БВО состоит в том, что мы должны определить соответствующий индекс камеры каждого воксела при визуализации. С этой целью мы должны сначала определить существование камеры, с которой наблюдается данный воксел. Эта процедура весьма длительна, если использовать метод решения "в лоб". Помимо этой проблемы, имеются еще некоторые трудности для вокселов, не видимых ни с одной из камер, что приводит к нежелательным артефактам в визуализированном изображении.
Возможным решением могло бы быть сохранение в явном виде цвета для каждого воксела. Однако в этом случае мы столкнулись бы с проблемами при сжатии информации цвета. Т.е. если сгруппировать цвета вокселов как формат изображения и сжать его, то корреляция цвета соседних вокселов разрушается, так что коэффициент сжатия будет неудовлетворительным.
В случае ТБВО эта проблема решается путем сохранения индекса камеры (изображения) для каждого воксела. Индекс обычно является тем же самым для большой группы вокселов, что позволяет использовать структуру октодерева для экономного хранения дополнительной информации. Заметим, что в экспериментах с нашими моделями в среднем наблюдалось всего лишь 15%-ное увеличение объема по сравнению с представлениями с использованием только БВО и эталонных изображений. Их моделирование является немного более сложным, но обеспечивает более гибкий способ представления объектов любой геометрии.
Заметим, что ТБВО является весьма удобным представлением для визуализации с помощью сплатов, поскольку размер сплата легко вычисляется из размера воксела. Цвет воксела легко определяется с использованием эталонных изображений и индекса изображения для воксела.
Ниже описано формирование потока текстурированного бинарного волюметрического дерева.
Предполагаем, что достаточно 255 камер и присваиваем до 1 байта для индекса. Поток ТБВО является потоком символов. Каждый символ ТБВО является символом БВО или символом текстуры. Символ текстуры обозначает индекс камеры, который может быть конкретным числом или кодом "не определено".
Обозначим в последующем описании код "не определено" в виде "?". Поток ТБВО проходится в порядке по ширине. Опишем, каким образом записать поток ТБВО, если мы имеем БВО, и каждый воксел листа имеет индекс изображения. Это может быть сделано на этапе моделирования. Он будет проходить все узлы БВО, включая узлы листьев (которые не имеют символа БВО) в порядке по ширине. На фиг.25 показан псевдокод, который соответствует записи потока.
Пример записи потока битов ТБВО показан на фиг.14. Для ТБВО, показанного на фиг.14а, поток символов может быть получен, как показано на фиг.14с, согласно процедуре. В данном примере символы текстуры представлены в байте. Однако в реальном потоке каждый символ текстуры потребует только 2 бита, поскольку нам только необходимо представить три значения (две камеры и код "не определено").
Ниже описана анимация на основе DIBR.
Анимационные версии были определены для двух их форматов DIBR: изображения с глубиной, содержащего только простые текстуры, и изображения октодерева. Объем данных является одним из принципиально важных вопросов при трехмерной анимации. Эти конкретные форматы были выбраны потому, что потоки видеоданных можно естественным образом встроить в анимационные версии, обеспечивая существенное сокращение объема данных.
Для изображения с глубиной анимация выполнялась путем замены эталонных изображений текстурами кинофрагментов стандарта MPEG-4. Высококачественное сжатие видеоданных с потерями не влияет заметным образом на результирующие трехмерные объекты. Карты глубины могут быть сохранены (в режиме практически без потерь) в альфа-каналах эталонных потоков видеоданных. На этапе визуализации трехмерный кадр визуализируется после того, как все эталонное изображение и кадры глубины приняты и подвергнуты декомпрессии.
Анимация изображения октодерева аналогична - изображения октодерева заменяются текстурами кинофрагментов стандарта MPEG-4, и возникает новый поток октодерева.
Ниже описана спецификация узла MPEG-4.
Форматы DIBR детально описаны в спецификациях узлов MPEG-4 AFX. Изображение с глубиной содержит поля, определяющие параметры вида, усеченного для простой текстуры или для точечной текстуры. Узел изображения октодерева представляет объект в форме геометрии, определенной ТБВО, и набора форматов эталонных изображений. Информация, зависящая от сцены, сохраняется в специальных полях структур данных DIBR, обеспечивая возможность корректного взаимодействия объектов DIBR с остальной частью сцены. Определение узлов DIBR показано на фиг.26.
На фиг.27 показано пространственное представление изображения с глубиной, в котором показано значение каждого поля. Заметим, что узел изображения с глубиной определяет один объект DIBR. Если множество узлов изображения с глубиной связаны друг с другом, они обрабатываются как группа, и поэтому должны быть помещены под одними тем же узлом преобразования. Поле "diTeкстура" определяет текстуру с глубиной (простую текстуру или точечную текстуру), которая должна быть отображена в область, определенную в узле изображения с глубиной.
Узел изображения октодерева определяет структуру октодерева и его проецируемые текстуры. Поле "разрешение октодерева" определяет максимальное число листьев октодерева вдоль стороны охватывающего куба. Поле "октодерево" определяет набор внутренних узлов октодерева. Каждый внутренний узел представлен байтом. "1" в i-м бите этого байта означает, что дочерние узлы существуют для i-гo дочернего элемента этого внутреннего узла, в то время как "0" означает, что этого нет. Порядок внутренних узлов октодерева должен быть порядком прохождения по ширине этого октодерева. Порядок восьми дочерних элементов внутреннего узла показан на фиг.14b. Поле "индекс изображения воксела" содержит массив индексов изображения, присвоенных вокселу. На этапе визуализации цвет, присвоенный листу октодерева, определяется ортогональным проецированием листа на одно из изображений с конкретным индексом. Индексы сохраняются в древовидной конфигурации: если конкретное изображение может быть использовано для всех листьев, содержащихся в конкретном векселе, воксел, содержащий индекс изображения выдается в поток; в противном случае выдается воксел, содержащий фиксированный код "дальнейшего подразделения", означая, что индекс изображения должен быть определен отдельно для каждого дочернего элемента текущего воксела (тем же рекурсивным способом). Если поле "индекс изображения воксела" пустое, то индексы изображения определяются на этапе визуализации. Поле "изображение" определяет набор узлов "изображение с глубиной" с простой текстурой для поля "diТекстура". Однако поле "ближняя плоскость" и "дальняя плоскость" узла "изображение с глубиной" и поле "глубина" узла "простая текстура" не используются.
Ниже описано сжатие формата изображения октодерева.
В данном разделе рассматривается метод сжатия для изображения октодерева. Типовые результаты тестирования представлены и прокомментированы далее. Следует отметить, что сжатие точечной текстуры в настоящее время еще не поддерживается и будет реализовано в следующей версии AFX.
Поля "изображение октодерева" и "октодерево" в изображении октодерева сжимаются отдельно. Предложенные методы были разработаны на основе положения, что поле "октодерево" должно быть сжато без потерь при некоторой степени визуально приемлемого искажения, допустимого для изображений октодерева.
Поле "октодерево" сжимается с использованием метода сжатия изображений (для статической модели) или инструментов сжатия видеоданных (для анимационной модели), поддерживаемых стандартом MPEG-4. В нашем подходе мы использовали формат JPEG для изображений октодерева. Дополнительная предварительная обработка изображений путем отбрасывания нерелевантных пикселов и подавления артефактов сжатия на границе объект/фон одновременно увеличивает скорость сжатия и качество визуализации.
Сжатие октодерева является наиболее важной частью сжатия изображения октодерева, поскольку его предметом является сжатие уже и так очень компактного представления бинарного дерева без связей. Однако в наших экспериментах метод, поясненный ниже, обеспечил уменьшение объема этой структуры примерно до половины ее исходного объема. В анимационной версии изображения октодерева поле "октодерево" сжимается отдельно для каждого трехмерного кадра.
Сжатие выполняется посредством варианта основанного на контексте адаптивного арифметического кодирования, которое осуществляет использование в явном виде геометрического характера данных. Октодерево представляет собой поток байтов. Каждый байт представляет узел (т.е. субкуб) дерева, в котором его биты указывают заполнение субкуба после внутреннего подразделения. Битовая конфигурация называется конфигурацией заполнения узла. Описанный алгоритм сжатия обрабатывает байты с соотношением "один к одному" следующим образом.
- Определяется контекст для текущего байта.
- "Вероятность" (нормированная частота) появления текущего байта в этом контексте извлекается из "таблицы вероятностей" (ТВ) соответственно контексту.
- Значение вероятности вводится в арифметический кодер.
- Текущая ТВ обновляется путем добавления определенного шага к частоте появления текущего байта в текущем контексте (и, при необходимости, с последующей ренормализацией, как более подробно описано ниже).
Таким образом, кодирование является процессом создания и обновления ТВ соответственно контекстной модели. В схемах адаптивного арифметического кодирования на основе контекста (таких как "предсказание с частичным согласованием") контекст символа обычно представляет собой строку из некоторого количества предшествующих символов. Однако в нашем случае эффективность сжатия увеличивается путем использования структуры октодерева и геометрических свойств данных. Предложенный подход основан на двух новых идеях в проблеме сжатия октодерева.
А1: Для текущего узла контекст является его порождающим узлом или парой {порождающий узел, положение текущего узла в порождающем узле};
А2: Предполагается, что "вероятность" появления заданного узла в конкретном геометрическом положении в конкретном порождающем узле инвариантна по отношению к определенному набору ортогональных (таких как повороты или симметричные преобразования) преобразований.
Предположение "А1" иллюстрируется на фиг.6 для преобразования R, которое представляет собой поворот на -90° в плоскости x-z. Основное положение по пункту "А2" состоит в том, что вероятность появления конкретного типа дочернего узла в конкретном типе порождающего узла должно зависеть только от их относительного положения. Это допущение подтверждено в наших экспериментах путем анализа таблиц вероятностей. Это позволяет использовать более сложный контекст, не требуя слишком много таблиц вероятностей. Это, в свою очередь, способствует достижению достаточно хороших результатов в аспектах размера данных и быстродействия. Заметим, что чем более сложные контексты используются, тем точнее оценка вероятности и тем более компактным является код.
Введем множество преобразований, для которых предполагаем инвариантность распределений вероятности. Для обеспечения возможности их применения в рассматриваемой ситуации, такие преобразования должны сохранять охватывающий куб. Рассмотрим множество G ортогональных преобразований в евклидовом пространстве, которые получают путем всех композиций в любом числе и порядке трех базовых преобразований (генераторов) m1, m2 и m3, определяемых следующим образом:

где m1 и m2 - отображения на плоскости х=y и y=z соответственно, и m3 - отображение на плоскость х=0.
Один из классических результатов теории групп, генерируемых отображениями, утверждает, что G содержит 48 отдельных ортогональных преобразований, и является, по смыслу, максимальной группой ортогональных преобразований, которая принимает упомянутый куб сама в себя (так называемая группа Coxeter). Например, поворот R на фиг.6 выражается через генераторы следующим образом:
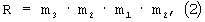
где "·" обозначает матричное перемножение.
Преобразование из G, применимое к узлу октодерева, формирует узел с отличающейся конфигурацией заполнения субкубов. Это позволяет подразделять узлы на категории в соответствии с конфигурацией заполнения из субкубов. Используя терминологию теории групп, можно сказать, что G действует на множество всех конфигураций заполнения узлов октодерева. Вычисления показывают, что имеется 22 различных класса (также называемых орбитами в теории групп), в которых, по определению, два узла принадлежат к одному и тому же классу, только если они связаны преобразованием из G. Количество элементов в классе варьируется от 1 до 24 и всегда является делителем 48.
Практическим следствием "В" является то, что таблица вероятностей зависит не от самого порождающего узла, а только от класса, к которому принадлежит порождающий узел. Заметим, что будет иметься 256 таблиц для контекста, основанного на порождающем элементе, и дополнительно 256×8=2048 таблиц для контекста, основанного на положении порождающего и дочернего элементов в первом случае, хотя потребуется только 22 таблицы для контекста, основанного на классе порождающего элемента, плюс 22×8=176 таблиц в последнем случае. Поэтому можно использовать контекст эквивалентной сложности с относительно малым количеством таблиц вероятностей. Сформированная ТВ будет иметь форму, как показано в таблице 11.

Чтобы статистика таблиц вероятностей была более точной, ее собирают различными путями на трех этапах процесса кодирования.
На первом этапе контекст не используется совсем, принимается "0-контекстная модель", и поддерживается одна таблица вероятностей с 256 записями, начиная с равномерного распределения.
Как только первые 512 узлов (это эмпирически найденное число) закодированы, переключаемся на "1-контекстную модель" с использованием порождающего узла в качестве контекста. В момент переключения ТВ 0-контекста копируется в ТВ для всех 22 контекстов.
После того как 2048 узлов (еще одно эвристическое значение) закодированы, переключаемся на "2-контекстную модель". В этот момент 1-контекстные ТВ порождающих узлов копируются во все ТВ для каждого положения в той же самой конфигурации порождающего узла.
Ключевым моментом данного алгоритма является определение контекста и вероятности для текущего байта. Это реализуется следующим образом. В каждом случае фиксируем один элемент, который называется "стандартным элементом". Сохраняем таблицу отображения класса (ТОК), которая показывает класс, к которому принадлежит каждый из возможных 256 узлов, и предварительно вычисленное преобразование из G, которое переводит данный конкретный узел в стандартный элемент его класса. Таким образом, чтобы определить вероятность текущего узла N, выполняем следующие этапы.
- Определить порождающий узел Р текущего узла.
- Извлечь класс из ТОК, к которому принадлежит Р, и преобразование Т, которое переводит Р в стандартный узел класса. Пусть номер класса будет с.
- Применить Т к Р и найти положение р дочернего узла в стандартном узле, на который отображается текущий узел N.
- Применить Т к N. Тогда вновь полученная конфигурация TN заполнения есть положение р в стандартном узле класса с.
- Извлечь требуемую вероятность из записи TN таблицы вероятностей, соответствующей комбинации класс-положение (с, р).
- Для 1-контекстной модели вышеописанные этапы модифицируются очевидным образом. Само собой разумеется, все преобразования предварительно вычислены и реализованы в виде таблиц перекодировки.
Заметим, что на этапе декодирования узла N его порождающий узел Р уже декодирован, и, следовательно, преобразование Т известно. Все шаги, выполняемые на этапе декодирования, абсолютно идентичны соответствующим шагам процедуры кодирования.
Наконец, опишем процедуру обновления вероятности. Пусть Р таблица вероятностей для некоторого контекста. Обозначим P(N) запись Р, соответствующую вероятности появления узла N в этом контексте. В описываемой реализации P(N) - целое число, и после каждого появления N, P(N) обновляется как
P(N)=P(N)+A,
где А - целочисленный параметр приращения, изменяющийся в типовом случае от 1 до 4 для различных контекстных моделей.
Пусть S(P) - сумма всех записей в РП. Тогда вероятность того, что N вводится в арифметический кодер (в данном случае кодер расстояний), вычисляется как P(N)/S(P). Как только S(P) достигает порогового значения 216, все записи ренормализуются: чтобы избежать появления нулевых значений в Р, записи, равные 1, остаются, как они есть, а другие делятся на 2.
Поток символов, определяющих индекс изображения для каждого воксела, сжимается с использованием его собственной таблицы вероятностей. В терминах, использованных выше, он имеет один контекст. Записи ТВ обновляются с приращением большей величины, чем записи для узлов октодерева: это позволяет адаптировать вероятности к высокой варьируемости использованных частот символов; в остальном нет отличий от кодирования символов узла.
Методы визуализации форматов DIBR не являются частью AFX, но необходимо пояснить идеи, использованные для достижения простоты, скорости и качества визуализации объектов DIBR. Наши методы визуализации основаны на сплатах, маленьких плоских цветных "заплатках", используемых в качестве "примитивов визуализации". Два подхода, охарактеризованных ниже, ориентированы на два различных представления: изображение с глубиной и изображение октодерева. В нашей реализации для ускорения визуализации с использованием сплатов используются функции OpenGL. Тем не менее, также возможна программно реализуемая визуализация, позволяющая оптимизировать вычисления с использованием простой структуры изображения с глубиной или изображения октодерева.
Метод, использованный нами для визуализации изображения с глубиной, чрезвычайно прост. Следует отметить, однако, что он зависит от функций OpenGL и работает намного быстрее с помощью аппаратного ускорителя. В этом методе мы преобразуем все пикселы с глубиной из простых текстур и точечных текстур, которые должны быть визуализированы, в трехмерные точки, затем помещаем маленькие многоугольники (сплаты) в эти точки и применяем функции визуализации OpenGL. Псевдокод этой процедуры для случая простой текстуры приведен на фиг.28. Случай точечной текстуры реализуется тем же путем.
Размер сплата должен быть адаптирован к расстоянию между точкой и наблюдателем. Мы использовали следующий простой подход. Сначала охватывающий куб данного трехмерного объекта подразделяется на грубую равномерную сетку. Размер сплата вычисляется для каждой ячейки сетки, и это значение используется для точек внутри ячейки. Вычисление выполняется следующим образом.
- Отобразить ячейку на экране посредством функции OpenGL.
- Вычислить длину L максимальной диагонали или проекции (в пикселах).
- Оценить D (диаметр оплата) как  , где N - усредненное число точек на сторону ячейки и С - эвристическая константа, приближенно равная 1,3.
, где N - усредненное число точек на сторону ячейки и С - эвристическая константа, приближенно равная 1,3.
Следует подчеркнуть, что этот метод может быть усовершенствован за счет более точных вычислений радиуса, более сложных сплатов, фильтрации-сглаживания. Однако даже этот простой метод обеспечивает хорошее визуальное качество.
Тот же метод пригоден для изображения октодерева, где узлы октодерева на одном из более грубых уровней используются в вышеуказанных вычислениях размера сплата. Однако для изображения октодерева информация цвета должна быть сначала отображена на набор вокселов. Это может быть сделано весьма просто, потому что каждый воксел имеет свой индекс соответствующего эталонного изображения. Положение пиксела на эталонном изображении также известно в процессе синтаксического анализа потока октодерева. Как только цвета вокселов изображения октодерева определены, размеры сплатов оцениваются и используется визуализация на основе функций OpenGL, как описано выше.
Форматы DIBR были реализованы и протестированы на нескольких трехмерных моделях. Одна из моделей ("Башня") была получена сканированием реального физического объекта (был использован цветной трехмерный сканер Cyberware), другие были преобразованы из демонстрационного пакета программ 3DS-MAX. Тестирование было выполнено на Pentium-IV с частотой 1,8 ГГц с использованием ускорителя OpenGL.
Ниже поясняются методы преобразования из полигонального формата в формат DIBR, и затем представлены результаты моделирования, представления и сжатия различных форматов DIBR. Большая часть данных относятся к моделям, соответствующим изображению с глубиной и изображению октодерева; эти форматы имеют анимационные версии и могут быть эффективным образом сжаты. Все представленные модели были созданы с помощью ортогональной камеры, поскольку это предпочтительный способ представления "компактных" объектов. Заметим, что камера перспективы используется главным образом для экономичного представления DIBR удаленных сцен окружающей среды.
Генерация модели DIBR начинается с получения достаточного числа простых текстур. Для полигонального объекта простые текстуры вычисляются, в то время как для объекта реального мира данные получают с цифровых камер и устройств сканирования. Следующий этап зависит от формата DIBR, который желательно использовать.
Изображение с глубиной представляет собой просто совокупность полученных простых текстур. Хотя карта глубин может быть сохранена в сжатой форме, приемлемо только сжатие без потерь, поскольку даже малое искажение в геометрии часто весьма заметно.
Эталонные изображения могут быть сохранены в сжатой форме с потерями, но в этом случае необходима предварительная обработка. Хотя в общем случае допустимо использовать популярные методы, подобные сжатию с потерями по стандарту JPEG, пограничные артефакты становятся более заметными на генерируемых видах трехмерного объекта, особенно вследствие наличия границ между объектом и фоном эталонного изображения, где цвет фона представляется "переливающимся" в объект. Решение, которое было использовано, чтобы справиться с этой проблемой, состояло в том, чтобы расширить изображение в пограничных блоках на фон с использованием усредненного цвета блока и быстрого спадания интенсивности, и затем применения сжатия по стандарту JPEG. Эффект напоминает "сдавливание" искажения к фону, где оно безвредно, поскольку пикселы фона не используются для визуализации. Внутренние границы в эталонном изображении, сжатом с потерями, могут также генерировать артефакты, но они в общем случае менее заметны.
Для генерации моделей изображений октодерева мы используем промежуточное основанное на точках представление (ОТП). Множество точек, которые образуют ОТП, представляет собой совокупность цветных точек, полученных путем сдвига пикселов в эталонном изображении, на расстояния, определенные в соответствующих картах глубин. Исходные простые текстуры должны строиться так, чтобы результирующие ОТП обеспечивали достаточно хорошую аппроксимацию поверхности объекта. После этого ОТП преобразуется в изображение октодерева, как представлено на фиг.24, и используется для генерации нового полного множества эталонных изображений, которые удовлетворяют ограничениям, накладываемым этим форматом. В то же время генерируется дополнительная структура данных - индекс изображения воксела, представляющая индексы эталонного изображения для вокселов октодерева. В случае, когда эталонные изображения должны сохраняться в форматах с потерями, они сначала подвергаются предварительной обработке, как объяснено в предыдущем подразделе. Кроме того, поскольку структура ТБВО определяет в явном виде пиксел, содержащий цвет каждого воксела, избыточные пикселы отбрасываются, что дополнительно сокращает объем данных индекса изображения воксела. Примеры исходного и обработанного эталонных изображений в формате JPEG показаны на фиг.29.
Заметим, что ухудшение качества вследствие сжатия с потерями пренебрежимо мало для изображений октодерева, но иногда является заметным для объектов изображения с глубиной.
Модели точечной текстуры создаются с использованием проецирования объекта на эталонную плоскость. Если это не обеспечивает достаточно выборок (что может иметь место для частей поверхности, близких к касательньм к вектору проекции), для получения большего количества выборок формируются дополнительные простые текстуры. Полученная совокупность точек затем переупорядочивается в структуру точечной текстуры.
В таблице 12 приведено сравнение размеров данных различных полигональных моделей и их версий DIBR. Числа в именах моделей обозначают разрешение (в пикселах) их эталонных изображений.
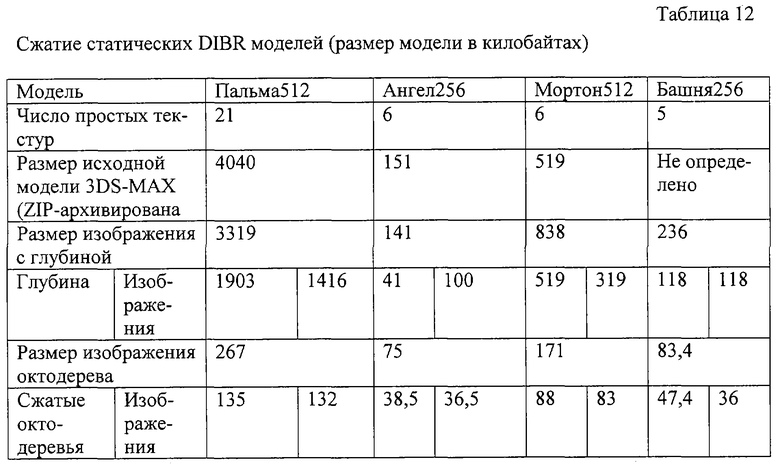
Карты глубины в изображения октодерева были сохранены в формате PNG, а эталонные изображения в высококачественном формате JPEG. Данные в таблице 12 показывают, что размер модели изображения с глубиной не всегда меньше, чем размер архивированной полигональной модели. Однако сжатие, обеспечиваемое изображением октодерева, обычно намного выше. Это является следствием унификации карт глубины в единую эффективно сжимаемую структуру данных октодерева, а также сложной предварительной обработки, которая устраняет избыточные пикселы из эталонных изображений. С другой стороны, структура изображений с глубиной обеспечивает простое и универсальное средство для представления сложных объектов, подобных модели "Пальма" без затруднительной предварительной обработки.
Таблица 13 представляет данные специфические для изображения октодерева, иллюстрируя идею эффективности сжатия, разработанного для этого формата. Записи в таблице являются размерами данных сжатой и несжатой части моделей, содержащих компоненты октодерева и индекса изображения воксела. Показано, что сокращение этой части варьируется в пределах от 2 до 2,5 раз. Заметим, что модель "Пальма" в таблице 13 не та же самая, что модель "Пальма" в таблице 12
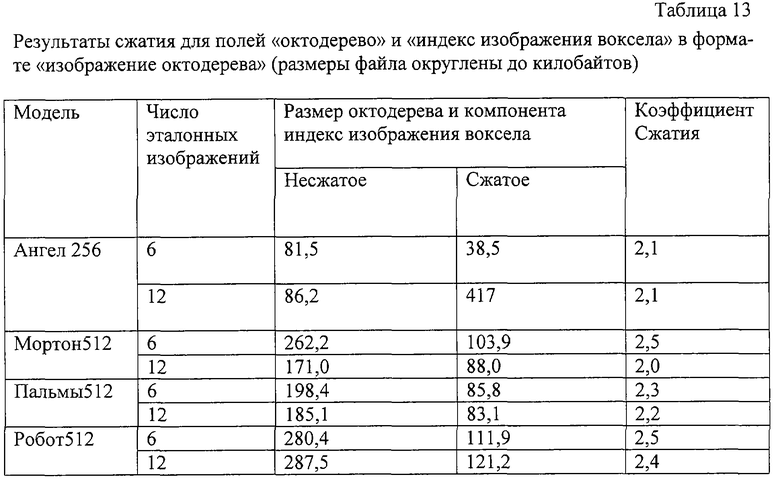
Ниже представлены данные по скорости визуализации.
Скорость визуализации изображения с глубиной модели "Пальмы 512" примерно 2 кадров/с (к/с) (заметим, что это 21 простая текстура, в то время как другие протестированные статические модели, со стороной эталонного изображения 512, визуализируются при скорости 5-6 к/с. Заметим, что скорость визуализации зависит главным образом от количества и разрешения эталонных изображений, но не от сложности сцены. Это важное преимущество перед полигональными представлениями, особенно в анимационном случае. Анимационное изображение октодерева модели "Дракон 512" визуализируется со скоростью 24 к/с. Результаты сжатия следующие:
- сжатый размер октодерева плюс компонент индекса изображения воксела: 910 КБ (696 КБ и 214 КБ соответственно);
- шесть эталонных потоков видеоданных в сжатом формате AVI: 1370 КБ.
Полный объем данных: 2280 КБ.
Модель изображения с глубиной "Ангел 256" показана на фиг.22. фиг.30-34 показывают несколько других DIBR и полигональных моделей. На фиг.30 приведено сравнение вида модели "Мортон" для полигонального случая и для случая изображения с глубиной. Модель изображения с глубиной использует эталонные изображения в формате JPEG, и визуализация выполняется простейшим формированием сплатов, как описано в разделе 5, но качество изображения вполне приемлемо. На фиг.31 приведено сравнение двух версий сканированной модели "Башня". Черные точки в верхней части модели обусловлены зашумлением входных данных. На фиг.32 представлена более сложная модель "Пальма", состоящая из 21 простой текстуры. Она также демонстрирует хорошее качество, хотя листья, в общем случае, шире, чем в оригинале 3DS-MAX, что является следствием упрощенного формирования сплатов.
На фиг.33 представлен трехмерный кадр из анимации изображения октодерева модели "Дракон 512". На фиг.34 представлены возможности формата точечной текстуры для получения моделей превосходного качества.
Устройство и способ для представления трехмерных объектов на основе изображений с глубиной в соответствии с настоящим изобретением описаны ниже со ссылками на фиг.35-54.
На фиг.35 представлена блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием простой текстуры в соответствии с возможным вариантом осуществления настоящего изобретения.
Согласно фиг.35, устройство 1800 для представления трехмерных объектов на основе изображений с глубиной содержит генератор 1810 информации о точке наблюдения, препроцессор 1820, первый генератор 1830 изображений, второй генератор 1840 изображений, генератор 1850 узлов и кодер 1860.
Генератор 1810 информации о точке наблюдения генерирует по меньшей мере один фрагмент информации о точке наблюдения. Информация о точке наблюдения включает в себя множество полей, определяющих плоскость изображения для объекта. Поля, составляющие информацию о точке наблюдения, включают в себя поле положения, поле ориентации, поле наблюдения, поле метода проецирования и поле расстояния.
В полях положения и ориентации записаны положение и ориентация, в которых наблюдается плоскость изображения. Положение в поле положения представляет собой относительное местоположение точки наблюдения по отношению к началу координат системы координат, в то время как ориентация в поле ориентации представляет величину поворота точки наблюдения относительно установленной по умолчанию ориентации.
В поле наблюдения записана область наблюдения из точки наблюдения к плоскости изображения.
В поле метода проецирования записан метод проецирования из точки наблюдения на плоскость изображения. В настоящем изобретении метод проецирования включает метод ортогональной проекции, в котором область наблюдения представлена шириной и высотой, и метод проецирования в перспективе, в котором область наблюдения представлена горизонтальным углом и вертикальным углом. Когда выбирается метод ортогональной проекции, ширина и высота области наблюдения соответствуют ширине и высоте плоскости изображения соответственно. При выборе метода проецирования в перспективе, горизонтальный и вертикальный углы области наблюдения соответствуют углам, образованным с горизонтальной и вертикальной сторонами видов в диапазоне от точки наблюдения до плоскости изображения.
В поле расстояния записано расстояние от точки наблюдения до ближней граничной плоскости и расстояние от точки наблюдения до дальней граничной плоскости. Поле расстояния составлено из поля ближней плоскости и поля дальней плоскости. Поле расстояния определяет область для информации о глубине.
Первый генератор 1830 изображений генерирует цветные изображения на основе информации о цвете, соответствующей информации о точке наблюдения, на соответствующих точках пикселов, образующих объект. В случае формата видеоданных для формирования анимационного объекта информация о глубине и информация о цвете представляют собой множество последовательностей кадров изображений. Второй генератор 1840 изображений генерирует изображения с глубиной, соответствующие информации о точке наблюдения на основе информации о глубине по соответствующим точкам пикселов, образующим объект. Генератор 1850 узлов генерирует узлы изображения, состоящие из информации о точке наблюдения, цветного изображения и изображения с глубиной, соответствующих информации о точке наблюдения.
Препроцессор 1820 осуществляет предварительную обработку пикселов на границе между объектом и фоном цветного изображения. На фиг.36 предпроцессор показан более детально. Согласно фиг.36, препроцессор 1820 содержит секцию 1910 расширения и секцию 1920 сжатия. Секция 1910 расширения распространяет цвета пограничных пикселов на фон с использованием усредненного цвета блоков и быстрого спада интенсивности. Секция 1920 сжатия выполняет поблочное сжатие, чтобы затем сместить искажение в область фона. Кодер 1920 кодирует генерированные узлы изображения для выдачи битовых потоков.
На фиг.37 показана блок-схема, иллюстрирующая процедуру реализации способа для представления трехмерных объектов на основе изображений с глубиной с использованием простой текстуры согласно одному из вариантов осуществления изобретения.
Согласно фиг.37, на этапе S2000 генератор 1810 информации о точке наблюдения генерирует информацию о точке наблюдения, из которой наблюдается объект. На этапе S2010 первый генератор 1830 изображений генерирует цветные изображения на основе информации о цвете, соответствующей информации о точке наблюдения, на соответствующих точках пикселов, образующих объект. На этапе S2020 второй генератор 1840 изображений генерирует изображения с глубиной, соответствующие информации о точке наблюдения, на основе информации о глубине для соответствующих точек пикселов, образующих объект. На этапе S2030 генератор 1850 узлов генерирует узлы изображения, состоящие из информации о точке наблюдения, информации о цвете и изображения с глубиной, соответствующего информации о точке наблюдения.
На этапе S2040 секция 1910 расширения распространяет цвета пикселов на границе между блоками на фон с использованием усредненного цвета блоков и быстрого спада интенсивности. На этапе секция 1920 сжатия выполняет блочное сжатие, чтобы затем сместить искажение в область фона. На этапе S2060 кодер 1920 кодирует генерированные узлы изображения для выдачи битовых потоков.
Те же самые устройство и способ для представления трехмерных объектов на основе изображений с глубиной, соответствующие настоящему изобретению, описанные выше со ссылками на фиг.35-37, также применимы для представления объектов на основе простой текстуры, причем простая текстура иллюстрируется на фиг.26.
На фиг.38 представлена блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием точечной текстуры в соответствии с настоящим изобретением.
Согласно фиг.38, устройство 2100 для представления трехмерных объектов на основе изображений с глубиной содержит блок 2110 формирования выборок, генератор 2120 информации о точке наблюдения, генератор 2130 информации о плоскости, генератор 2140 информации о глубине, генератор 2150 информации о цвете и генератор 2160 узлов.
Блок 2110 формирования выборок генерирует выборки для плоскости изображения путем проецирования объекта на эталонную плоскость. Выборки для плоскости изображения состоят из пар изображений - цветного изображения и изображения с глубиной.
Генератор 2120 информации о точке наблюдения генерирует информацию о точке наблюдения, из которой наблюдается объект. Информация о точке наблюдения включает в себя множество полей, определяющих плоскость изображения для объекта. Поля, составляющие информацию о точке наблюдения, включают в себя поле положения, поле ориентации, поле наблюдения, поле метода проецирования и поле расстояния.
В полях положения и ориентации записаны положение и ориентация, в которых наблюдается плоскость изображения. Точка наблюдения определяется положением и ориентацией. В поле наблюдения записана ширина и высота области наблюдения из точки наблюдения к плоскости изображения. В поле метода проецирования записан метод проецирования, выбранный из метода ортогональной проекции, в котором область наблюдения представлена шириной и высотой, и метода проецирования в перспективе, в котором область наблюдения представлена горизонтальным углом и вертикальным углом. В поле расстояния записано расстояние от точки наблюдения до ближней граничной плоскости и расстояние от точки наблюдения до дальней граничной плоскости. Поле расстояния составлено из поля ближней плоскости и поля дальней плоскости. Поле расстояния определяет область для информации о глубине.
Генератор 2130 информации о плоскости генерирует информацию о плоскости, определяющую ширину, высоту и глубину плоскости изображения, состоящей из набора точек, полученных из выборок для плоскости изображения, соответствующей информации о точке наблюдения. Информация о плоскости состоит из множества полей. Поля, образующие информацию о плоскости, включают первое поле, в котором записана ширина плоскости изображения, второе поле, в котором записана высота плоскости изображения, и поле разрешения по глубине, в котором записано разрешение информации по глубине.
Генератор 2140 информации о глубине генерирует последовательность информации о глубинах всех проецируемых точек объекта, спроецированного на плоскость изображения. Генератор 2150 информации о цвете генерирует последовательность информации о цвете на соответствующих спроецированных точках. В последовательности информации о глубине последовательно записаны число спроецированных точек и значения глубины соответствующих спроецированных точек. В последовательности информации о цвете последовательно записаны значения цвета, соответствующие значениям глубины соответствующих спроецированных точек.
Генератор 2160 узлов генерирует узлы изображения, состоящие из информации о плоскости, соответствующей плоскости изображения, последовательности информации о глубине и последовательности информации о цвете.
На фиг.39 показана блок-схема, иллюстрирующая процедуру реализации способа для представления трехмерных объектов на основе изображений с глубиной с использованием точечной текстуры согласно настоящему изобретению.
Согласно фиг.39 на этапе S2200 генератор 2120 информации о точке наблюдения генерирует информацию о точке наблюдения, из которой наблюдается объект. На этапе S2210 генератор 2130 информации о плоскости генерирует информацию о плоскости, определяющую ширину, высоту и глубину плоскости изображения, соответствующей информации о точке наблюдения. На этапе S2220 блок 2110 формирования выборок генерирует выборки для плоскости изображения путем проецирования объекта на эталонную плоскость. Этап S2220 выполняется для того, чтобы обеспечить максимально возможное количество выборок для плоскости изображения. Если имеется достаточное количество выборок для плоскости изображения, то этап S220 не выполняется.
На этапе S2230 генератор 2140 информации о глубине генерирует последовательность информации о глубинах всех проецируемых точек объекта, спроецированного на плоскость изображения.
На этапе S2240 генератор 2150 информации о цвете генерирует последовательность информации о цвете на соответствующих спроецированных точках. На этапе генератор 2160 узлов генерирует узлы изображения, состоящие из информации о плоскости, соответствующей плоскости изображения, последовательности информации о глубине и последовательности информации о цвете.
Те же самые устройство и способ для представления трехмерных объектов на основе изображений с глубиной, соответствующие настоящему изобретению, описанные выше со ссылками на фиг.35-37, также применимы для представления объектов на основе точечной текстуры, причем простая текстура иллюстрируется на фиг.26.
На фиг.40 представлена блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием октодерева согласно настоящему изобретению.
Согласно фиг.40 устройство 2300 для представления трехмерных объектов на основе изображений с глубиной содержит препроцессор 2310, блок 2320 определения эталонного изображения, генератор 2330 информации о форме, генератор 2340 индексов, генератор 2350 узлов и кодер 2360.
Препроцессор 2310 осуществляет предварительную обработку эталонного изображения. Детальная структура препроцессора 2310 показана на фиг.41. Согласно фиг.41 препроцессор 2310 содержит секцию 2410 расширения и секцию 2420 сжатия. Секция 2410 расширения распространяет цвета пикселов на границе между блоками в эталонном изображении на фон с использованием усредненного цвета блоков и быстрого спада интенсивности. Секция 2420 сжатия выполняет поблочное сжатие на эталонном изображении, чтобы затем сместить искажение в область фона.
Блок 2320 определения эталонного изображения определяет опорное изображение, содержащее цветное изображение для каждого куба, разделенного генератором 2330 информации о форме. Эталонное изображение представляет собой узел изображения с глубиной, состоящий из информации о точке наблюдения и цветного изображения, соответствующего информации о точке наблюдения. Здесь информация о точке наблюдения включает в себя множество полей, определяющих плоскость изображения для объекта. Соответствующие поля, образующие информацию о точке наблюдения, описаны выше, и детальная информация о них не приводится. Цветное изображение, содержащееся в узле изображения с глубиной, может представлять собой либо простую текстуру, либо точечную текстуру.
Генератор 2330 информации о форме генерирует информацию о форме для объекта путем деления октодерева, содержащего объект, на 8 субкубов и определения разделенных субкубов как дочерних узлов. Генератор 2330 информации о форме итеративным образом выполняет подразделение до тех пор, пока каждый субкуб не станет меньше, чем предварительно определенный размер. Информация о форме включает поле "разрешение", в котором записано максимальное количество листов октодерева вдоль стороны куба, содержащего объект, и поле "октодерево", в котором записана последовательность структур внутренних узлов, и поле "индекс", в котором записаны индексы эталонных изображений, соответствующих каждому внутреннему узлу. Генератор 2340 индексов генерирует информацию индексов эталонного изображения, соответствующего информации о форме. На фиг.42 представлена детальная структура генератора 2340 индексов. Согласно фиг.42, генератор 2340 включает в себя генератор 2510 цветных точек, генератор 2520 основанного на точках представления (ОТП), преобразователь 2530 изображения и генератор 2540 индексной информации.
Генератор 2510 цветных точек получает цветные точки путем сдвига пикселов, имеющихся в эталонном изображении, на расстояние, определенное в карте глубины, соответствующей ему. Генератор 2520 ОТП генерирует промежуточное изображение ОТП посредством набора цветных точек. Преобразователь 2530 изображения преобразует изображение ОТП в изображение октодерева, представленное кубом, соответствующим каждой точке. Генератор 2540 индексной информации генерирует индексную информацию эталонного изображения, соответствующего каждому кубу.
Генератор 2350 узлов генерирует узлы октодерева, включающие в себя информацию формы, индексную информацию и эталонное изображение.
Кодер 2360 кодирует узлы октодерева в выходные битовые потоки. Детальная структура кодера 2360 показана на фиг.43. Согласно фиг.43 кодер 2360 включает в себя секцию 2610 определения контекста, первую секцию 2620 кодирования, вторую секцию 2630 кодирования, третью секцию 2640 кодирования, секцию 2650 записи байтов символов и секцию 2660 записи индекса изображения.
Секция 2610 определения контекста определяет контекст текущего узла октодерева на основе количества циклов кодирования для узла октодерева. Первая секция 2620 кодирования кодирует первые 512 узлов 0-контекстной моделью и арифметическим кодированием при поддержании одиночной таблицы вероятностей с 22 записями. Первая секция 2620 кодирования начинает кодирование с равномерного распределения.
Вторая секция 2630 кодирования кодирует узлы с 513-го по 2048-й после того, как 512-й узел кодирован 1-контекстной моделью с использованием порождающего узла в качестве контекста. В момент переключения с 0-контекстной на 1-контекстную модель вторая секция 2630 кодирования копирует таблицу вероятностей 0-контекстной модели во все таблицы вероятностей 1-контекстной модели.
На фиг.44 представлена блок-схема второй секции 2630 кодирования. Согласно фиг.44 вторая секция 2360 кодирования содержит секцию 2710 извлечения вероятности, арифметический кодер 2720 и секцию 2730 обновления таблиц. Секция 2710 извлечения вероятности извлекает вероятность генерирования текущего узла в контексте из таблицы вероятностей, соответствующей контексту. Арифметический кодер 2720 сжимает октодеревья последовательностью вероятностей, содержащей извлеченную вероятность. Секция 2730 обновления таблиц обновляет таблицы вероятностей с предварительно определенным приращением, например 1, для генерирования частот текущего узла в текущем контексте.
Третья секция 2640 кодирования кодирует узлы, следующие после 2048-х узлов, посредством 2-контекстной модели и арифметического кодирования с использованием порождающего и дочерних узлов в качестве контекстов. В момент переключения с 1-контекстной на 2-контекстную модель третья секция 2640 кодирования копирует таблицы вероятностей 1-контекстной модели для конфигурации порождающего узла в 2-контекстные таблицы вероятностей, соответствующие соответствующим положениям в той же самой конфигурации порождающего узла.
На фиг.45 представлена блок-схема третьей секции 2640 кодирования. Согласно фиг.45 третья секция 2640 кодирования содержит первую секцию 2810 извлечения, первую секцию 2820 определения, вторую секцию 2830 извлечения, секцию 2840 получения конфигурации, вторую секцию 2850 определения, арифметический кодер 2860 и секцию 2870 обновления таблиц.
Первая секция 2810 извлечения извлекает порождающий узел текущего узла. Первая секция 2820 определения определяет класс, к которому принадлежит извлеченный порождающий узел, и определяет преобразование, посредством которого порождающий узел преобразуется в стандартный узел определенного класса. Вторая секция 2830 извлечения применяет полученное преобразование к порождающему узлу и извлекает положение текущего узла в преобразованном порождающем узле. Секция 2840 получения конфигурации применяет преобразование к текущему узлу и получает конфигурацию как комбинацию определенного класса и индекса положения текущего узла. Вторая секция 2850 определения определяет необходимые вероятности из записей таблицы вероятностей, соответствующей полученной конфигурации. Арифметический кодер 2860 сжимает октодеревья посредством последовательности вероятностей, содержащей извлеченную вероятность. Секция 2870 обновления таблиц обновляет таблицы вероятностей с предварительно определенным приращением, например 1, для генерации частот текущего узла в текущем контексте.
Если текущий узел не является узлом листа, то секция 2650 записи байтов символов записывает байты символов, соответствующие текущему узлу в битовые потоки. Если все дочерние узлы текущего узла имеют тот же самый индекс эталонного изображения и порождающий узел текущего узла имеет "неопределенный" индекс эталонного изображения, то секция 2660 записи индекса изображения записывает тот же самый индекс эталонного изображения в битовые потоки для субузлов текущего узла. Если дочерние узлы имеют отличающиеся индексы эталонного изображения, то секция 2660 записи индекса изображения записывает "неопределенный" индекс эталонного изображения в битовые потоки для субузлов текущего узла.
На фиг.46 представлена блок-схема, иллюстрирующая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием октодерева, согласно возможному варианту осуществления настоящего изобретения. Согласно фиг.46 на этапе S2900 генератор 2330 информации о форме генерирует информацию о форме для объекта путем деления октодерева, содержащего объект, на субкубы и определения разделенных субкубов как дочерних узлов. Информация о форме включает поле "разрешение", в котором записано максимальное количество листов октодерева вдоль стороны куба, содержащего объект, и поле "октодерево", в котором записана последовательность структур внутренних узлов, и поле "индекс", в котором записаны индексы эталонных изображений, соответствующих каждому внутреннему узлу. Каждый внутренний узел представлен байтом. Информация узла записана в битовой последовательности, составляющей байт, представляющий присутствие или отсутствие дочернего узла из дочерних узлов, принадлежащих внутреннему узлу. На этапе S2910 подразделение выполняется итеративным образом для формирования 8 субкубов, если каждый субкуб больше, чем предварительно определенный размер (это значение может быть найдено эмпирически.).
На этапе S2920 блок 2320 определения эталонного изображения определяет эталонное изображение, содержащее цветное изображение для каждого куба, разделенное генератором 2330 информации о форме. Эталонное изображение представляет собой узел изображения с глубиной, состоящий из информации о точке наблюдения и цветного изображения, соответствующего информации о точке наблюдения. Состав информации о точке наблюдения описан выше. Для эталонного изображения может быть выполнен этап предварительного изображения.
На фиг.47 представлена блок-схема, иллюстрирующая процедуру реализации предварительной обработки эталонного изображения. Согласно фиг.47 на этапе S3000 секция 1910 расширения распространяет цвета пикселов на границе между блоками на фон с использованием усредненного цвета блоков и быстрого спада интенсивности. На этапе S3010 выполняется блочное сжатие, чтобы затем сместить искажение в область фона.
На этапе S2930 генератор 2340 индексов генерирует индексную информацию эталонного изображения соответственно информации о форме.
На фиг.48 представлена блок-схема, иллюстрирующая процедуру реализации генерации индексов. Согласно фиг.48 на этапе S3100 генератор 2510 цветных точек получает цветные точки путем сдвига пикселов, имеющихся в эталонном изображении, на расстояние, определенное в карте глубины, соответствующей ему. На этапе генератор 2520 ОТП генерирует промежуточное изображение ОТП посредством набора цветных точек. На этапе S3120 преобразователь 2530 изображения преобразует изображение ОТП в изображение октодерева, представленное кубом, соответствующим каждой точке. На этапе S313 0 генератор 2540 индексной информации генерирует индексную информацию эталонного изображения, соответствующего каждому кубу.
На этапе S2940 генератор 2350 узлов генерирует узлы октодерева, включающие в себя информацию формы, индексную информацию и эталонное изображение.
На этапе S2950 кодер 2360 кодирует узлы октодерева в выходные битовые потоки.
На фиг.49 представлена блок-схема, иллюстрирующая процесс реализации кодирования. Согласно фиг.49 на этапе S3200 секция 2610 определения контекста определяет контекст текущего узла октодерева на основе количества циклов кодирования для узла октодерева. На этапе S3210 определяется, является ли положение текущего узла меньшим или равным 512. Если да, то на этапе S3220 выполняется первый этап кодирования посредством 0-контекстной модели и арифметического кодирования. Если на этапе S3210 определено, что текущее положение узла больше чем 512, то определяется контекст текущего узла (этап S3430) и выполняется второй этап кодирования посредством 1-контекстной модели с использованием порождающего узла в качестве контекста (этап S3240). Если на этапе S3250 определено, что положение текущего узла больше чем 2048, то определяется контекст текущего узла (этап S3260) и выполняется третий этап кодирования посредством 2-контекстной модели с использованием порождающего узла в качестве контекста (этап S3270).
Здесь 0-контекст означает независимость от контекста, 1-контекст - это класс порождающего узла. Общее число классов равно 22. Если классы связаны ортогональными преобразованиями G, генерируемыми базовыми преобразованиями, то два узла принадлежат одному и тому же классу. Базовые преобразования m1, m2 и m3 определяются следующим образом:
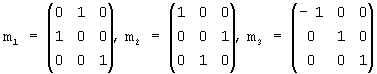
где m1 и m2 - отображения на плоскости х=y и y=z соответственно, m3 - отображение на плоскость х=0. 2-контекст включает в себя класс порождающего узла и положение текущего узла в порождающем узле.
На фиг.50 представлена блок-схема, иллюстрирующая процедуру реализации второго этапа кодирования. Согласно фиг.50 на этапе S3300 секция 2710 извлечения вероятности извлекает вероятность генерирования текущего узла в контексте из таблицы вероятностей, соответствующей контексту. На этапе S3310 арифметический кодер 2720 сжимает октодеревья последовательностью вероятностей, содержащей извлеченную вероятность. На этапе S3320 секция 2730 обновления таблиц обновляет таблицы вероятностей с предварительно определенным приращением, например 1, для генерирования частот текущего узла в текущем контексте.
На фиг.51 представлена блок-схема, иллюстрирующая процедуру реализации третьего этапа кодирования. Согласно фиг.51 на этапе S3400 первая секция 2810 извлечения извлекает порождающий узел текущего узла. На этапе S3410 первая секция 2820 определения определяет класс, к которому принадлежит извлеченный порождающий узел, и определяет преобразование, посредством которого порождающий узел преобразуется в стандартный узел определенного класса. На этапе S3420 вторая секция 2830 извлечения применяет полученное преобразование к порождающему узлу и извлекает положение текущего узла в преобразованном порождающем узле. На этапе S3430 секция 2840 получения конфигурации применяет определенное преобразование к текущему узлу и получает конфигурацию как комбинацию определенного класса и индекса положения текущего узла. На этапе S3440 вторая секция 2850 определения определяет необходимые вероятности из записей таблицы вероятностей, соответствующей полученной конфигурации. На этапе S3450 арифметический кодер 2860 сжимает октодеревья посредством последовательности вероятностей, содержащей извлеченную вероятность. На этапе S3460 секция 2870 обновления таблиц обновляет таблицы вероятностей с предварительно определенным приращением, например 1, для генерации частот текущего узла в текущем контексте.
На фиг.52 представлена блок-схема процедуры генерирования битовых потоков в процессе кодирования. Согласно фиг.52, если на этапе S3500 определено, что текущий узел не является узлом листа, то секция 2650 записи байтов символов на этапе S3510 записывает байты символов, соответствующие текущему узлу, в битовые потоки и переходит к этапу S3520. Если текущий узел является узлом листа, то процедура переходит непосредственно к этапу S3520 без выполнения этапа S3510.
Если на этапе S3520 определено, что все дочерние узлы текущего узла имеют тот же самый индекс эталонного изображения и порождающий узел текущего узла имеет "неопределенный" индекс эталонного изображения, то секция 2660 записи индекса изображения на этапе S3530 записывает тот же самый индекс эталонного изображения в битовые потоки для субузлов текущего узла. Если на этапе S3520 определено, что дочерние узлы имеют отличающиеся индексы эталонного изображения, то секция 2660 записи индекса изображения на этапе S3540 записывает "неопределенный" индекс эталонного изображения в битовые потоки для субузлов текущего узла.
На фиг.53 представлена блок-схема устройства для представления трехмерных объектов на основе изображений с глубиной с использованием октодерева согласно другому варианту осуществления настоящего изобретения. На фиг.54 представлена блок-схема, иллюстрирующая процедуру реализации способа представления трехмерных объектов на основе изображений с глубиной с использованием октодерева, согласно другому варианту осуществления настоящего изобретения.
Согласно фиг.53 и 54 устройство 3600 для представления трехмерных объектов на основе изображений с глубиной, соответствующее настоящему изобретению, содержит блок 3610 ввода, первый блок 3620 выделения, декодер 3630, второй блок 3640 выделения и блок 3650 представления объекта.
На этапе S3700 первый блок 3610 ввода вводит битовые потоки из внешнего устройства. На этапе S3710 первый блок 3620 выделяет узлы октодерева из входных битовых потоков.
На этапе S3720 декодер декодирует выделенные узлы октодерева. Декодер 3630 включает в себя секцию определения контекста, первую секцию декодирования, вторую секцию декодирования и третью секцию декодирования. Операции, осуществляемые соответствующими компонентами, образующими декодер 3630, аналогичны соответствующим операциям аналогичных компонентов кодеров, описанных со ссылками на фиг.43-45 и на фиг.49-52, и поэтому их детальное описание здесь не приводится. На этапе S3730 второй блок 3540 выделяет информацию о форме и эталонные изображения для множества кубов, образующих октодеревья, из декодированных узлов октодеревьев. На этапе S3740 блок 3650 представления объекта представляет объект путем комбинирования выделенных эталонных изображений в соответствии с информацией о форме.
Настоящее изобретение может быть реализовано на компьютерно-читаемом носителе записи компьютерно-читаемыми кодами. Компьютерно-читаемый носитель записи включает в себя все типы устройств записи, с которых могут считываться данные, читаемые компьютерной системой, и примерами которых могут служить ПЗУ, ОЗУ, ПЗУ на компакт-дисках, магнитные ленты, гибкие диски, оптические устройства хранения данных и т.п., а также реализованные на несущей волне, например, из Интернет или иной среды передачи. Также компьютерно-читаемый носитель записи распространяется в компьютерной системе, связанной с сетью, так что компьютерно-читаемые коды сохраняются и реализуются способом распространения.
В соответствии с настоящим изобретением в представлениях, основанных на изображениях, поскольку высококачественная информация о цветном трехмерном объекте кодируется посредством набора простых и регулярных структур двумерных изображений, в настоящее время применяющихся в хорошо известных способах обработки и сжатия изображений, алгоритм прост и может поддерживаться аппаратными средствами во многих аспектах. Кроме того, время визуализации для моделей, основанных на изображениях, пропорционально числу пикселов в эталонном и выходном изображениях, но, в общем случае, не геометрической сложности, как в полигональном случае. Кроме того, поскольку представление на основе изображений применимо к объектам и сценам реального мира, то близкая к фотографической визуализация реальной сцены становится возможной без использования миллионов многоугольников и дорогостоящих вычислений.
Изложенное выше описание реализации изобретения представлено в целях иллюстрации и пояснения. Оно не является исчерпывающим и не ограничивает изобретение до точно раскрытой формы. Возможны модификации и вариации в свете вышеизложенных принципов или с учетом практической реализации изобретения. Объем изобретения определяется пунктами формулы изобретения и их эквивалентами.
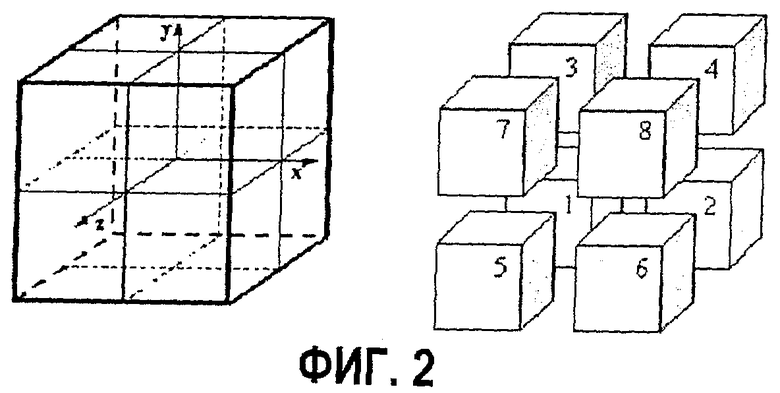
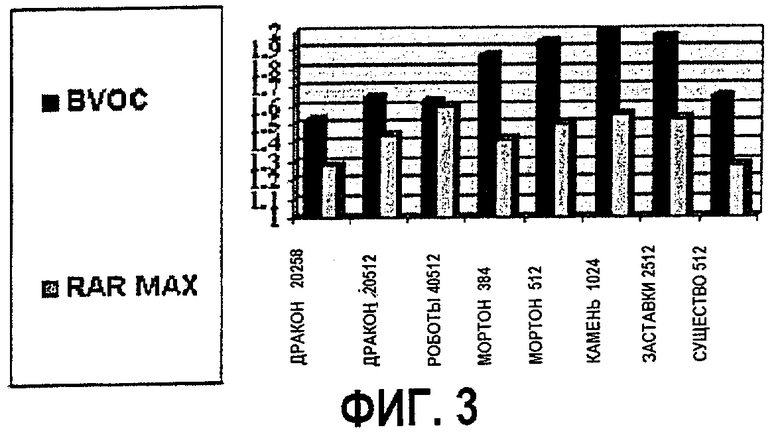

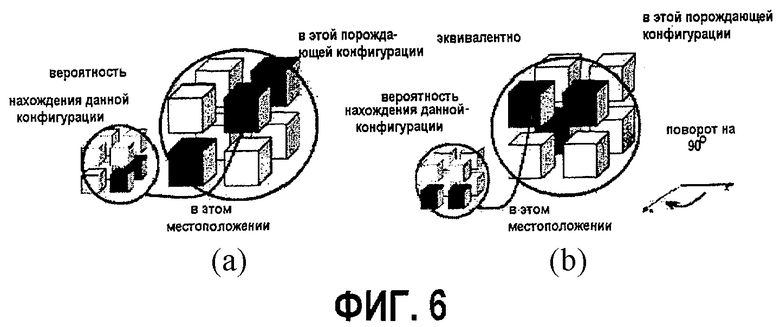
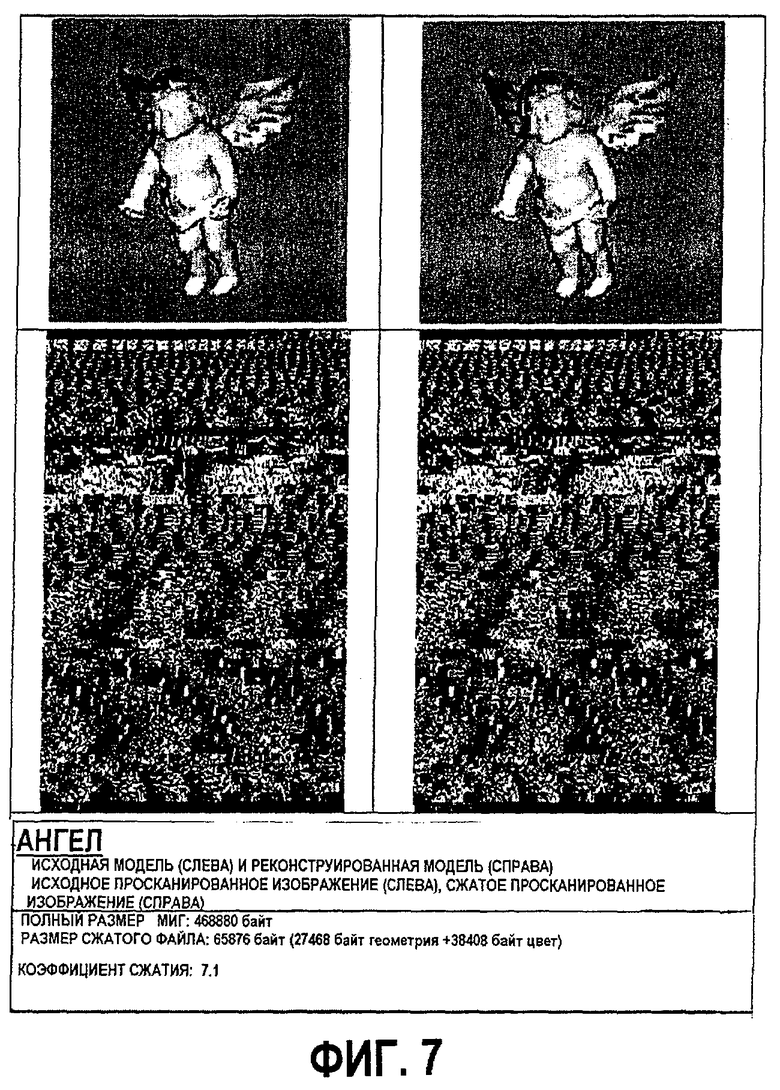



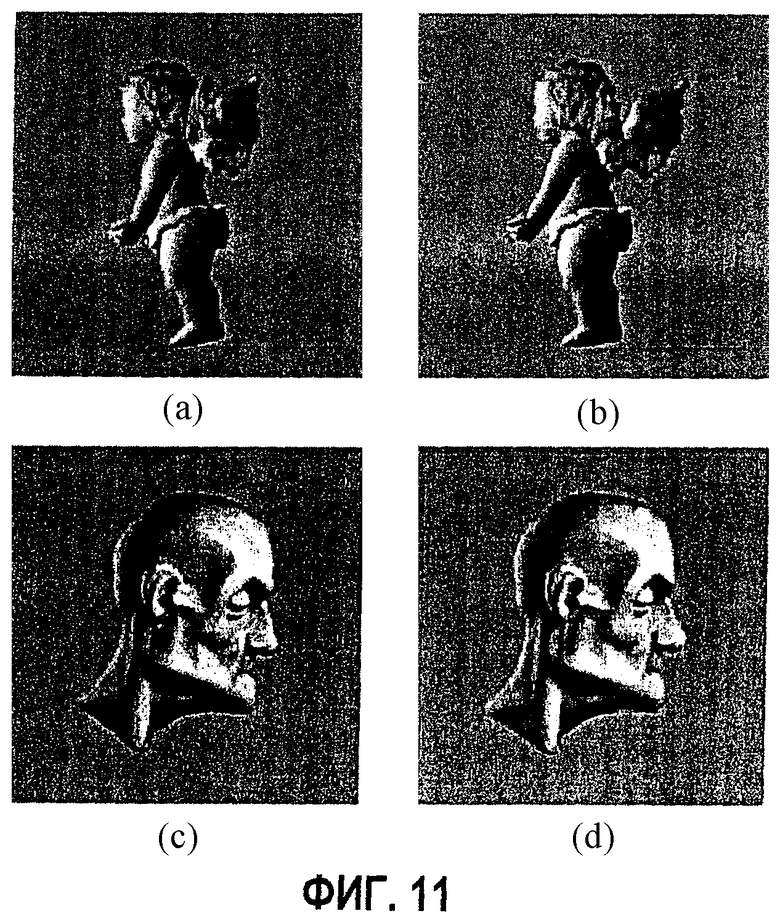


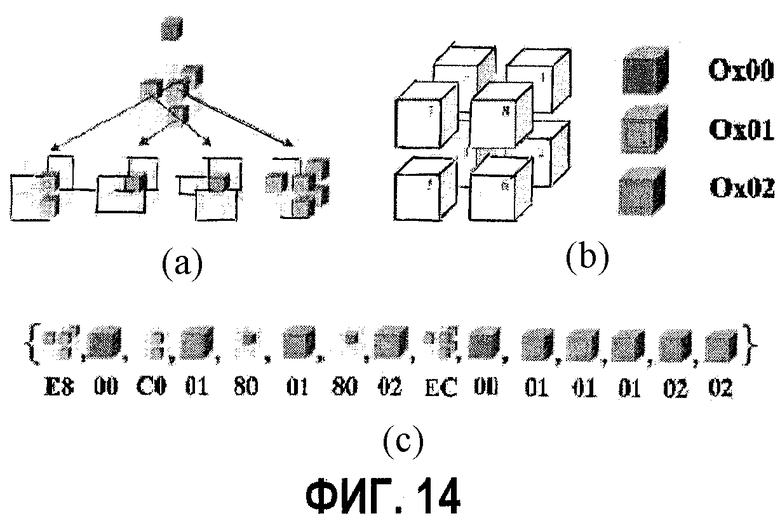
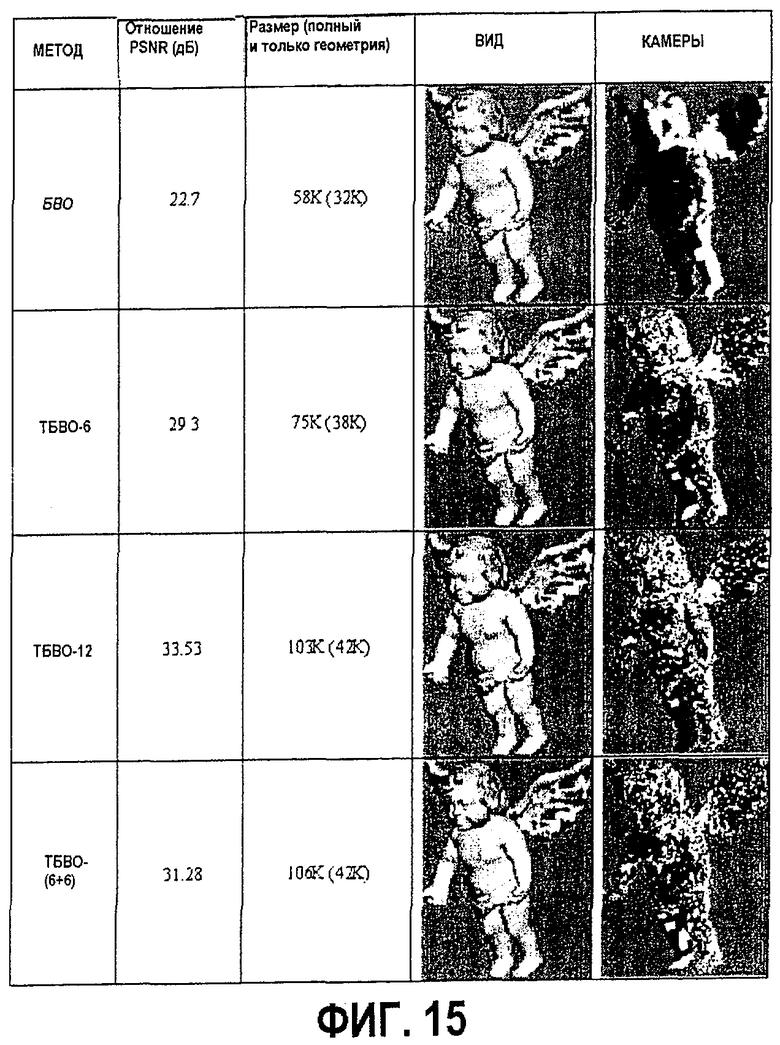

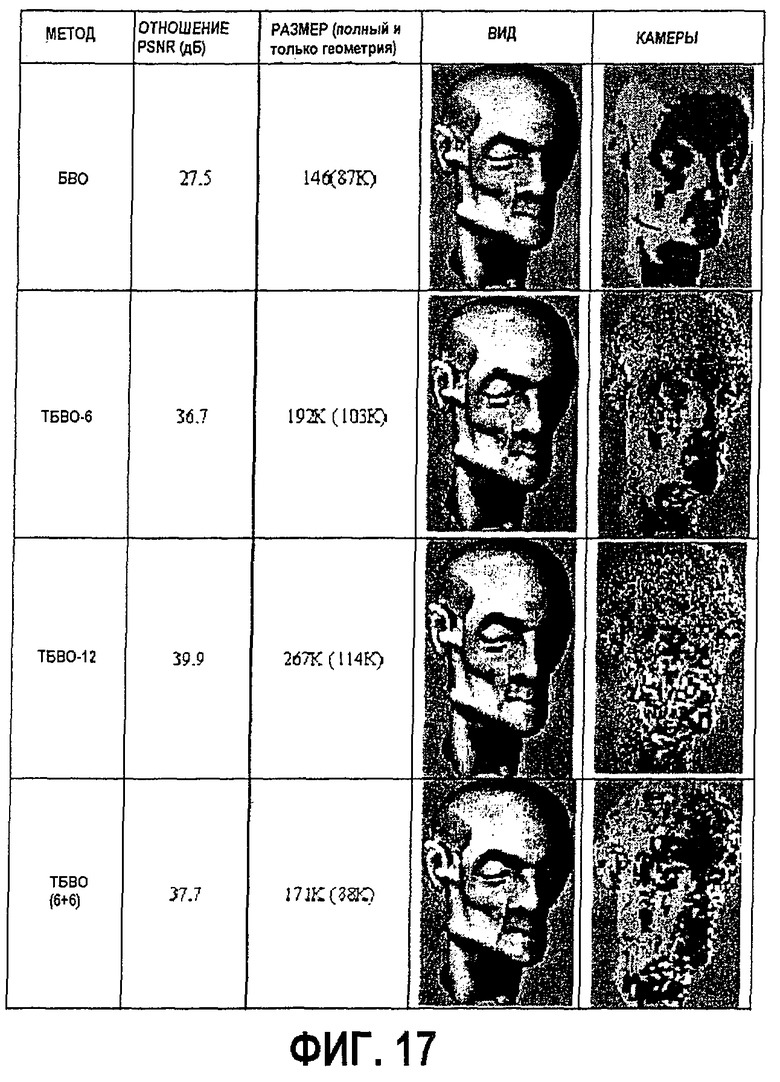

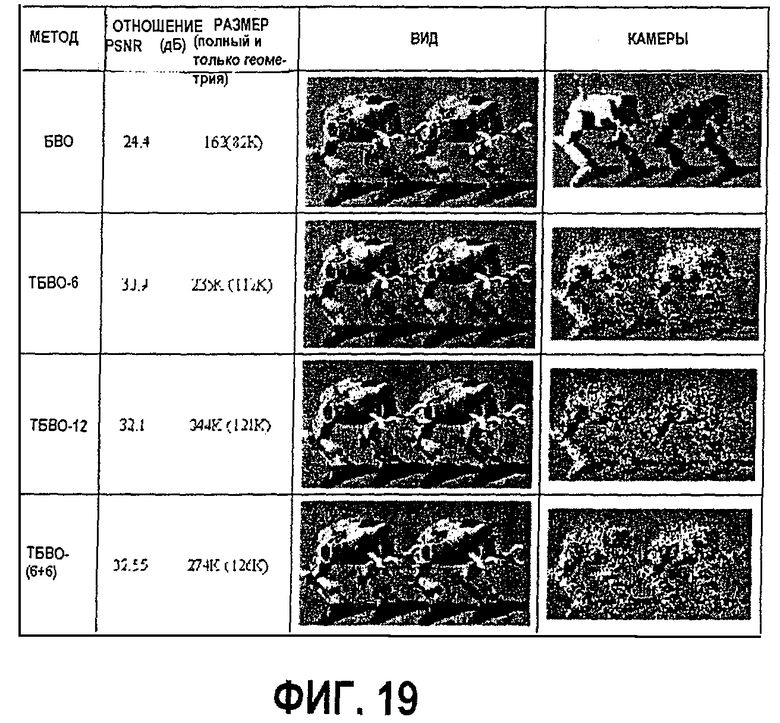


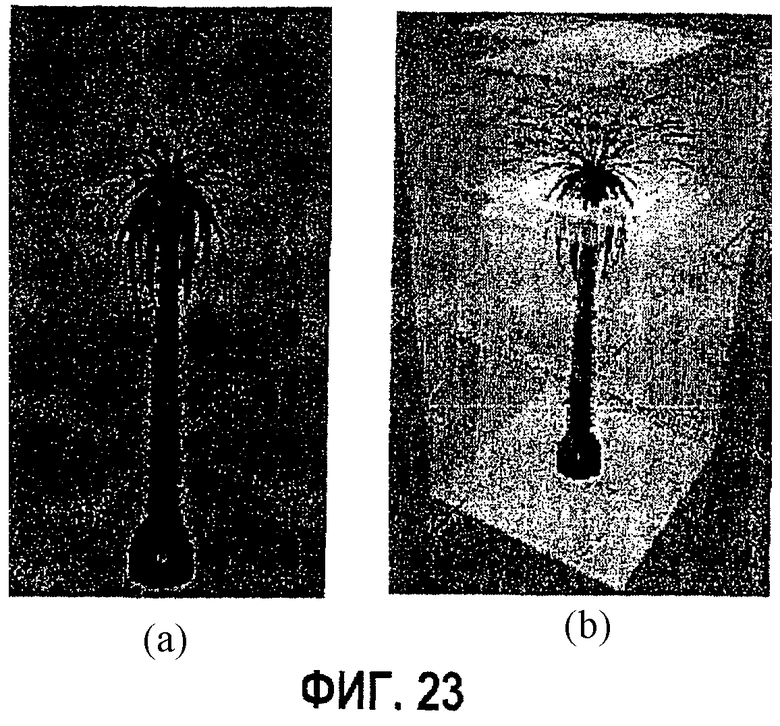
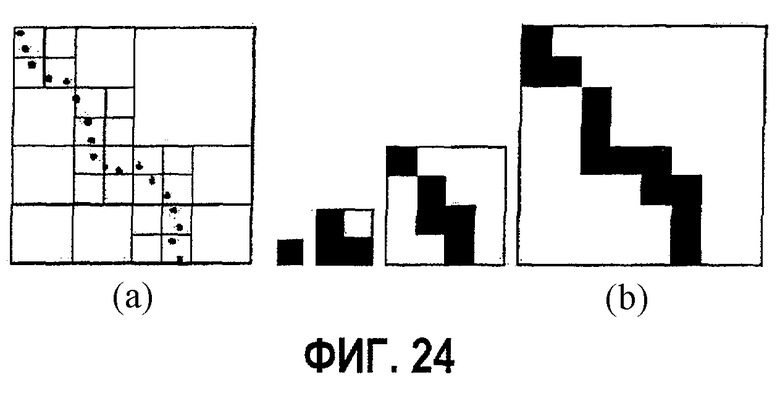


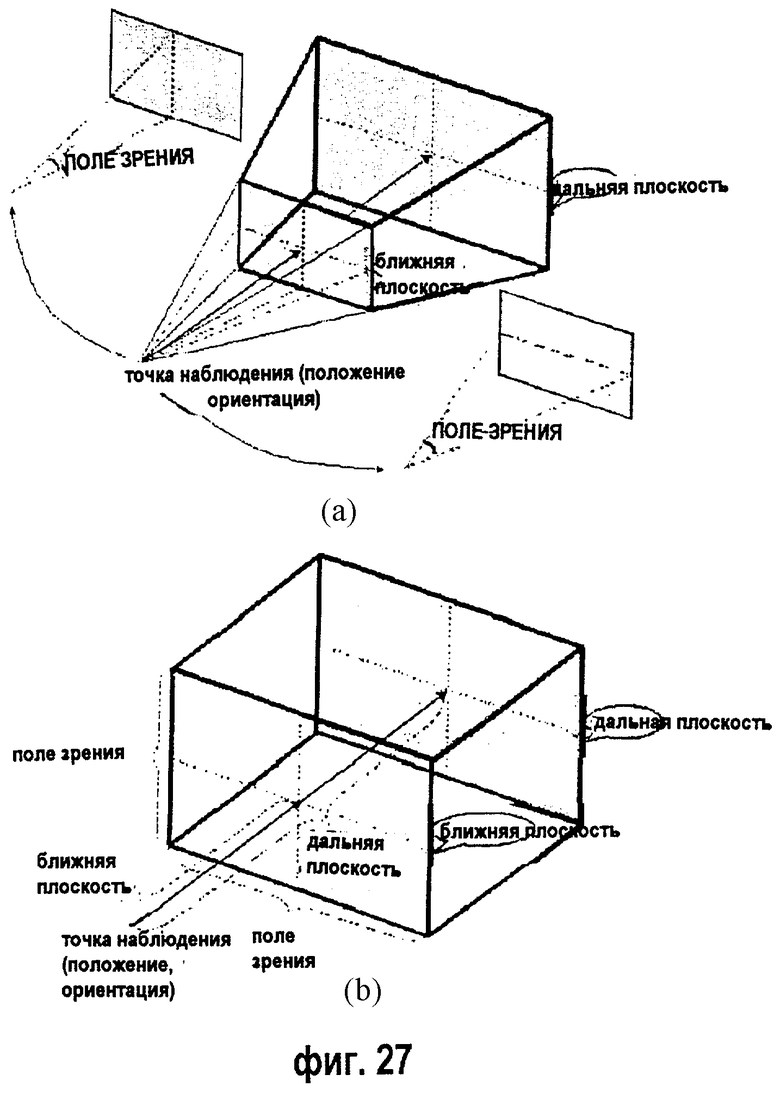


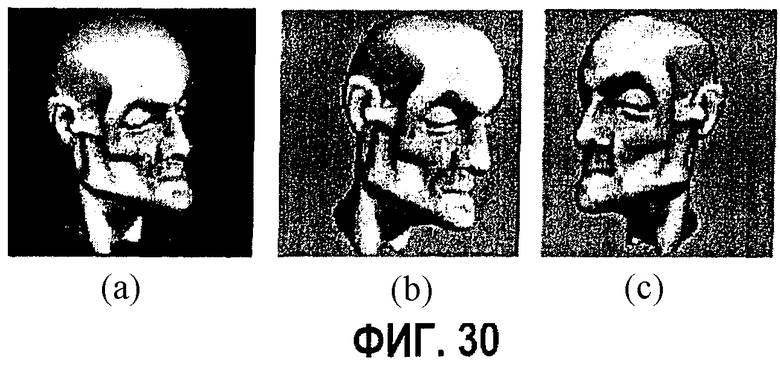
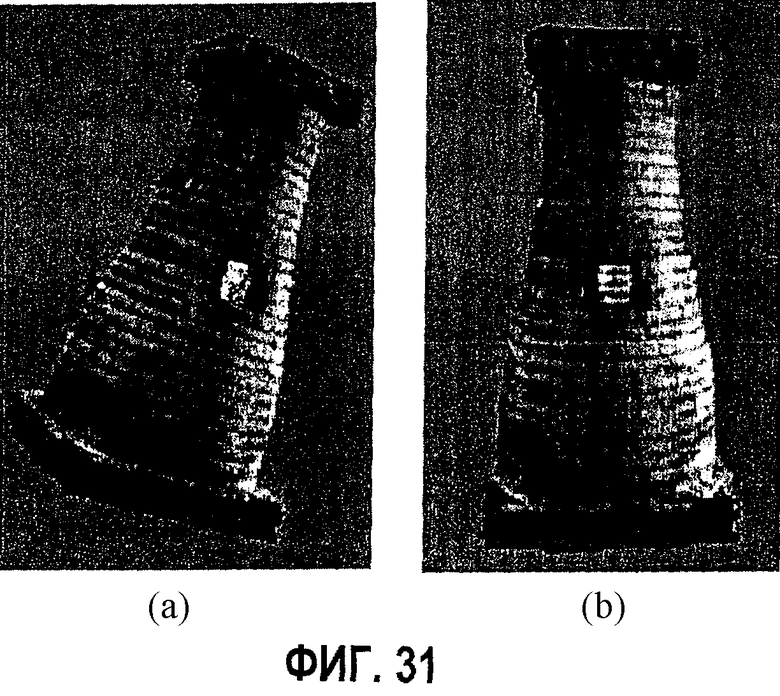
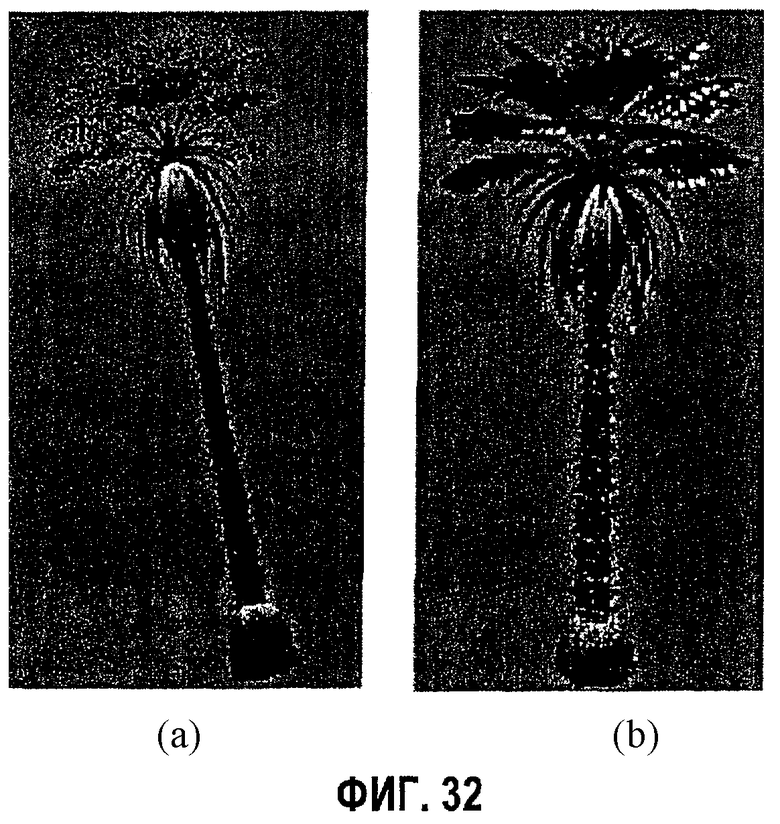
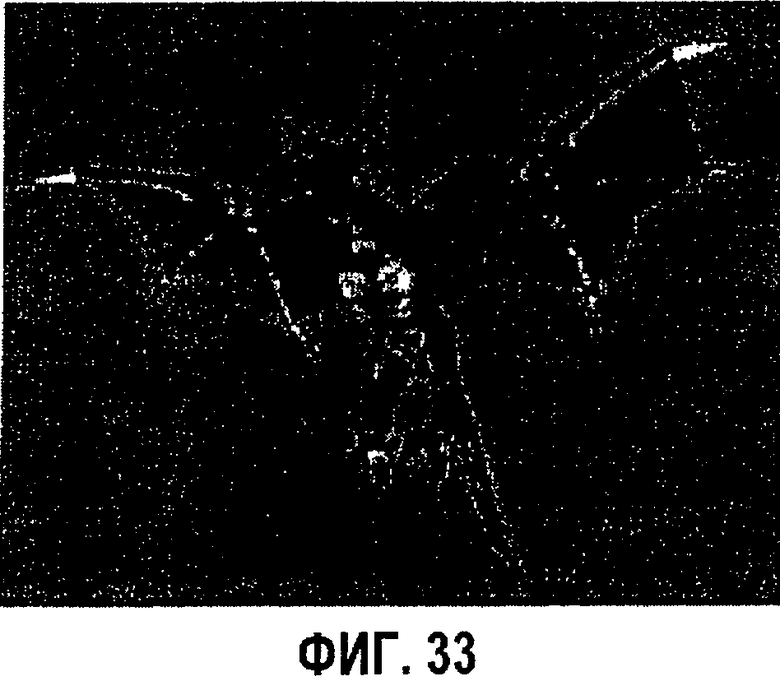

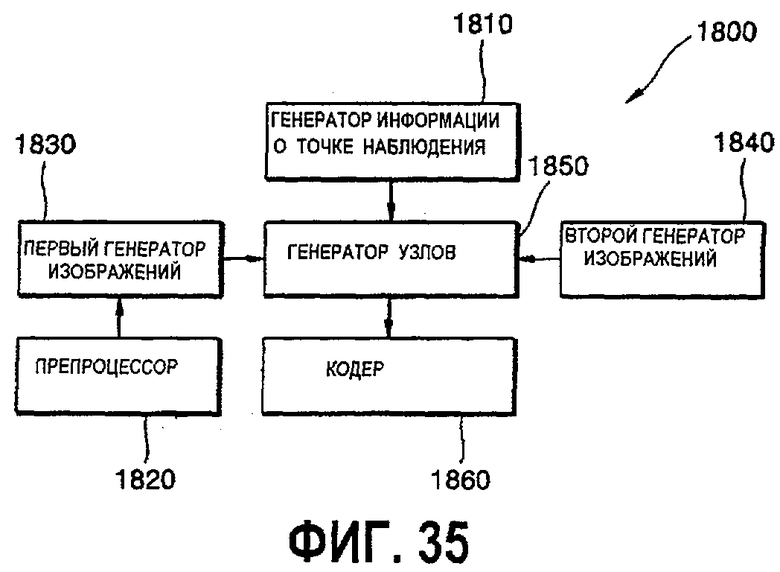

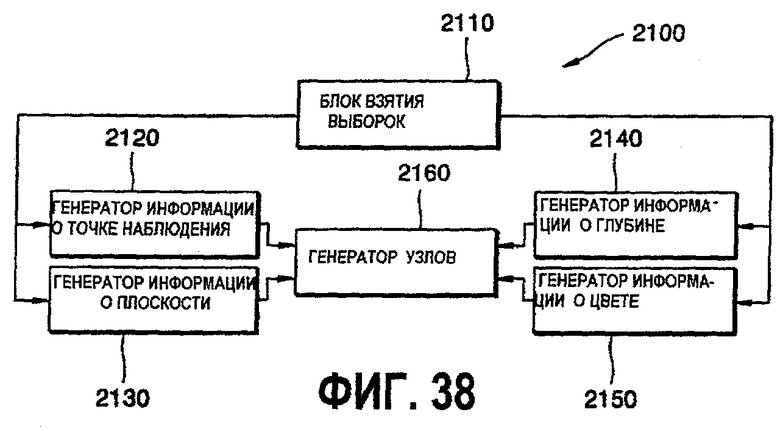
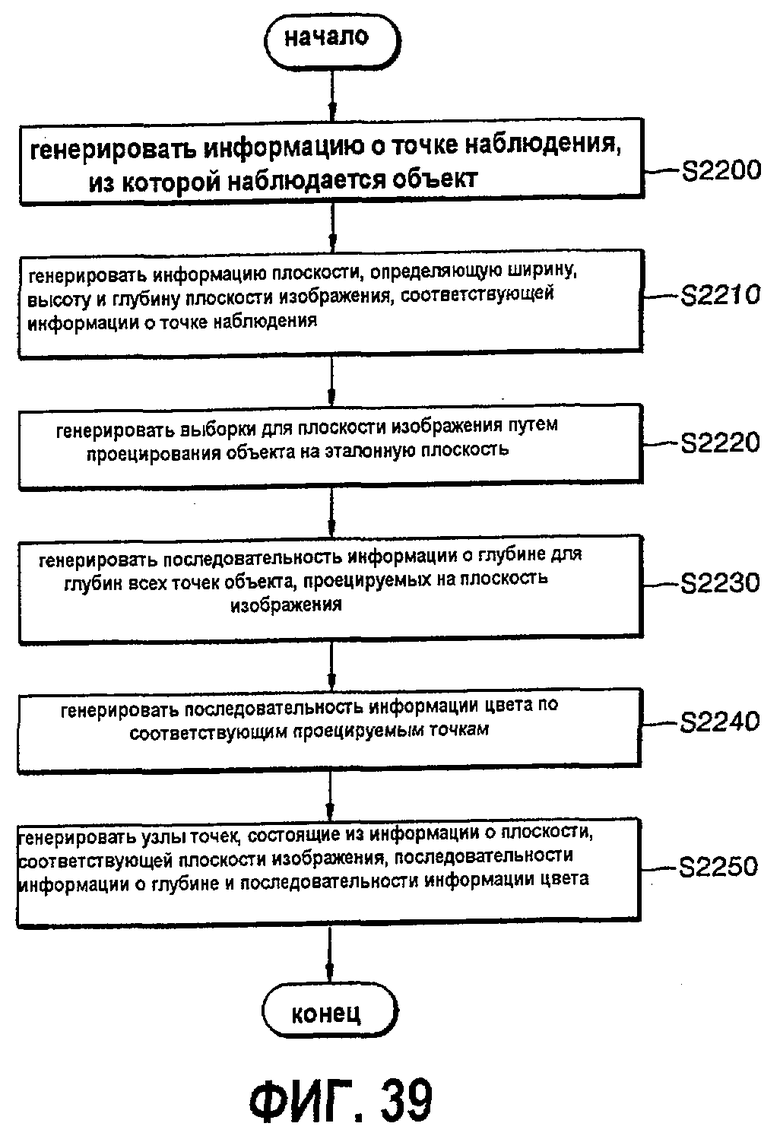
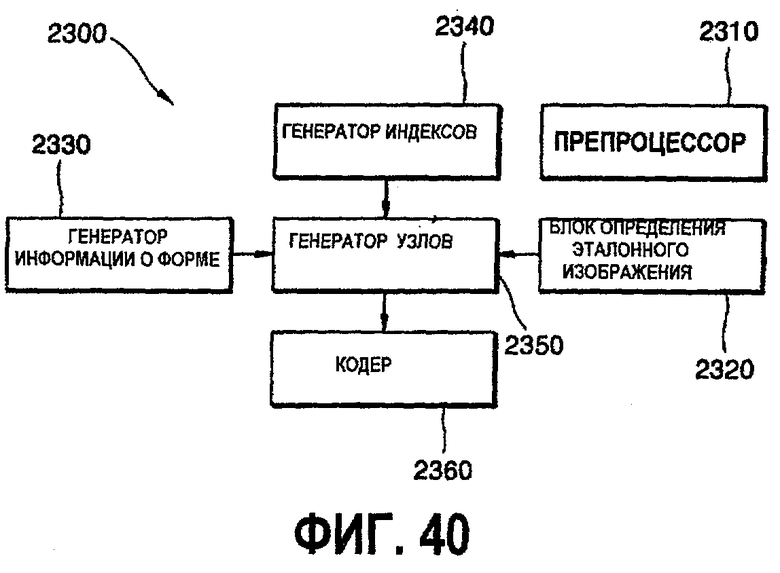
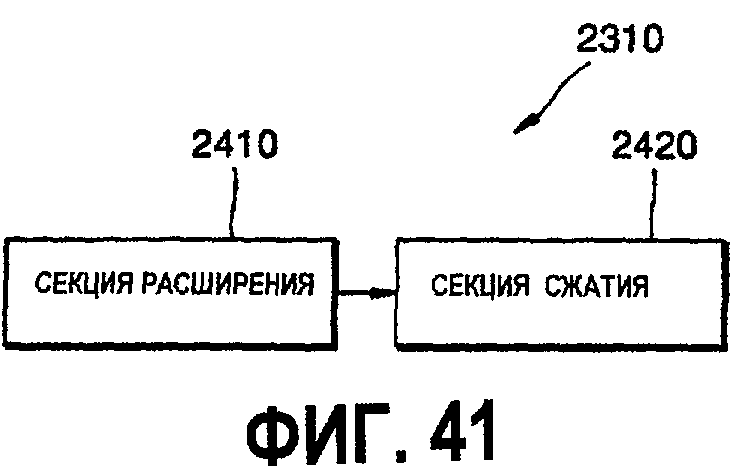
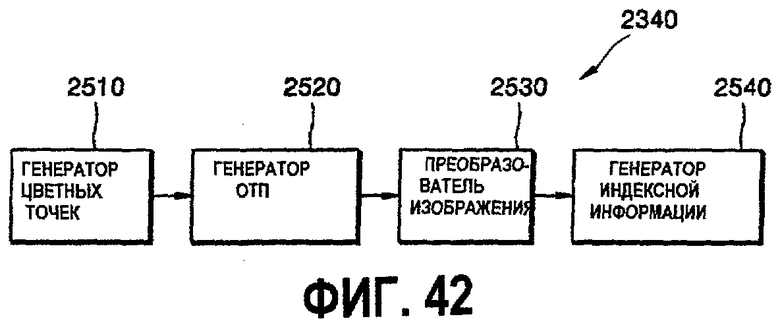
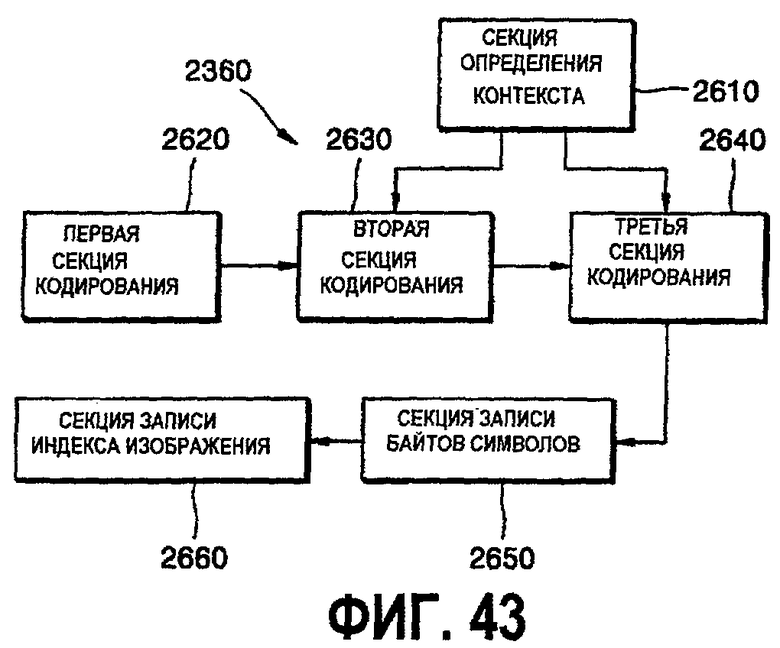
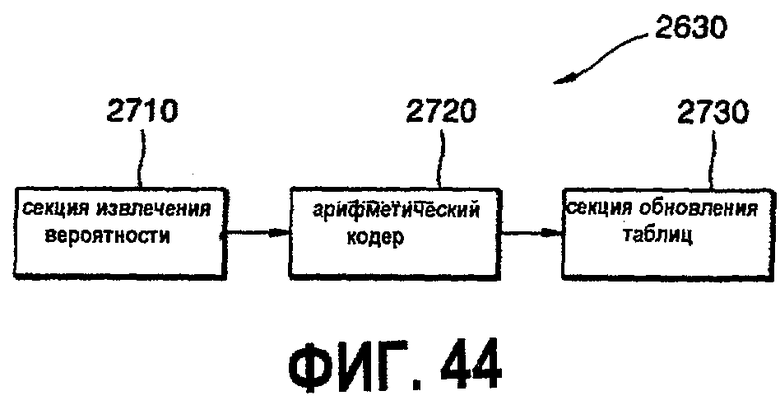

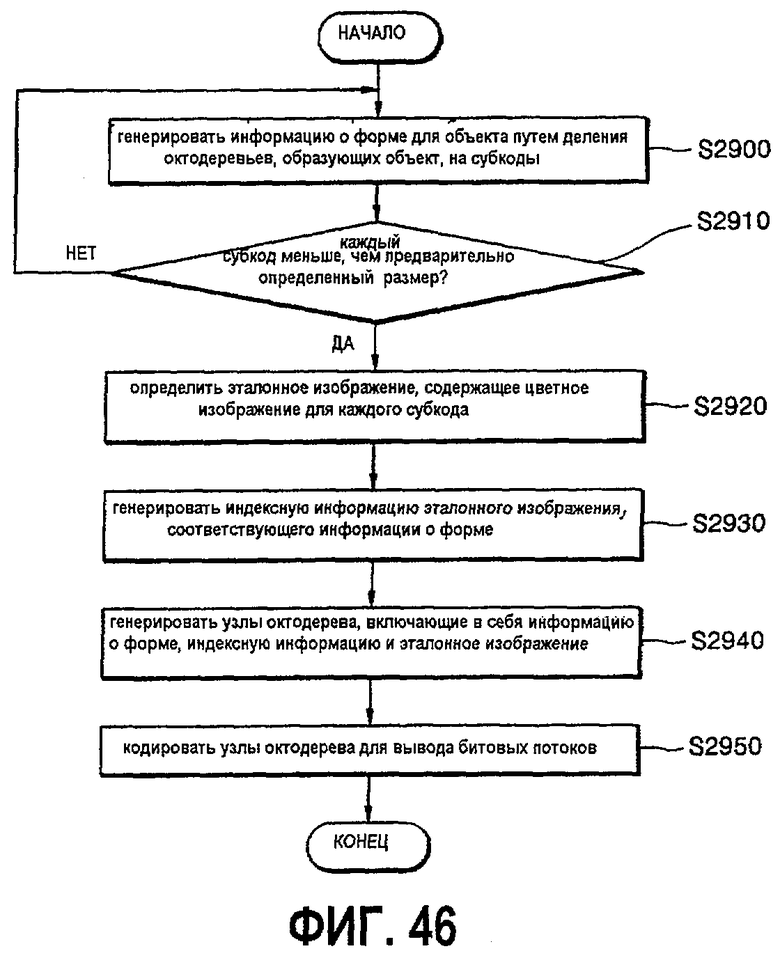

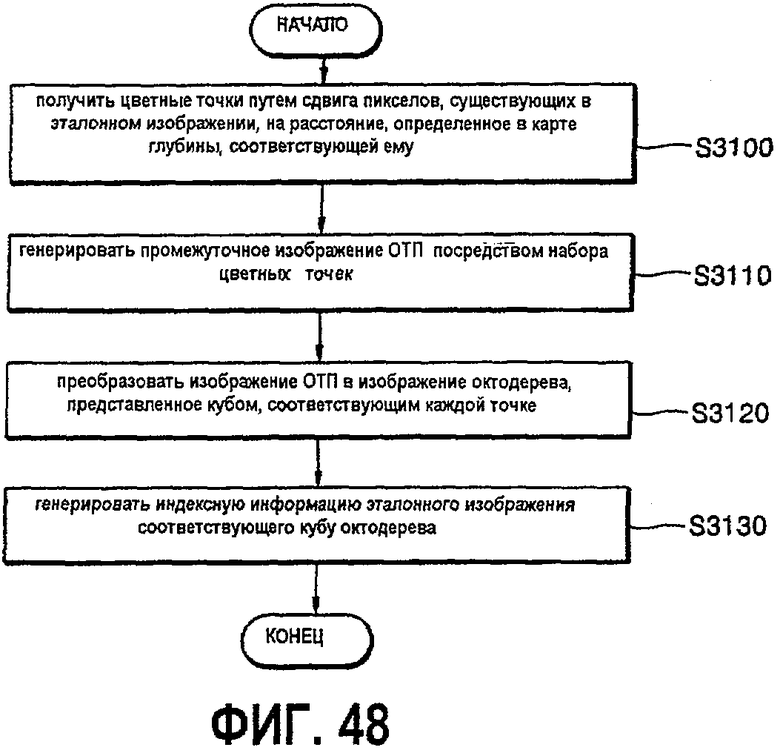
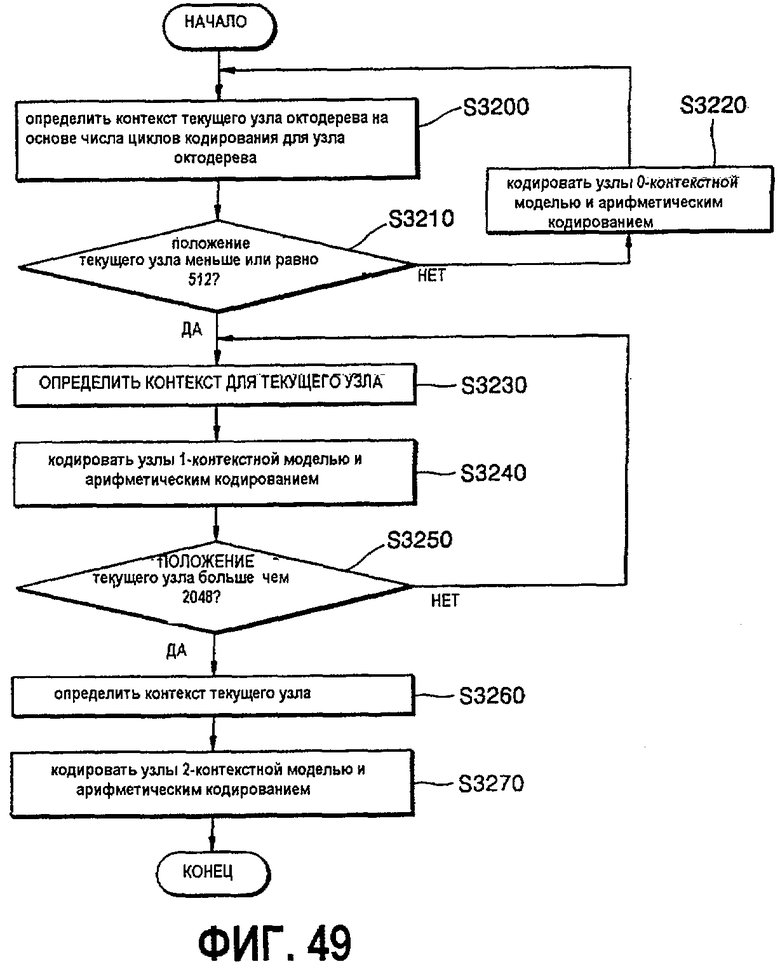
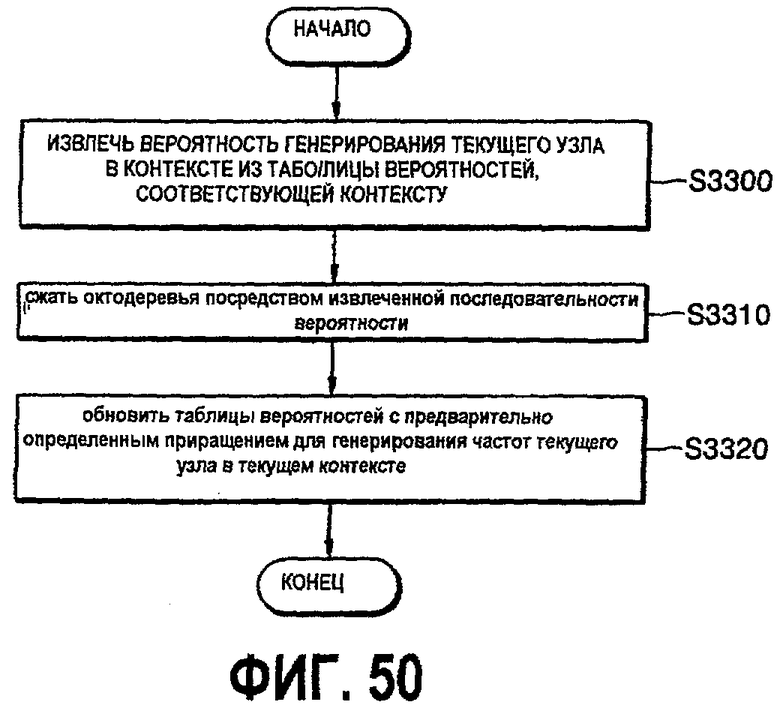
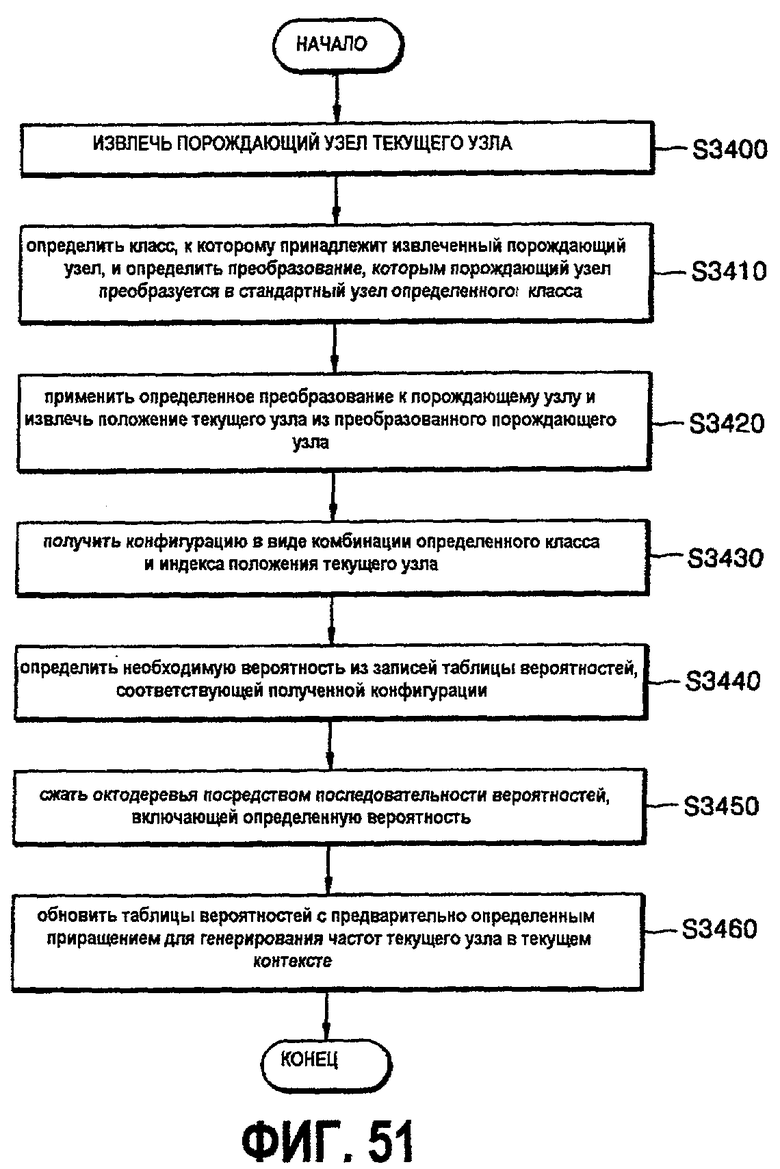

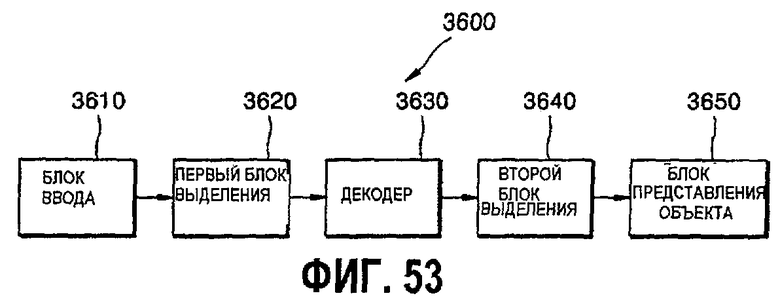
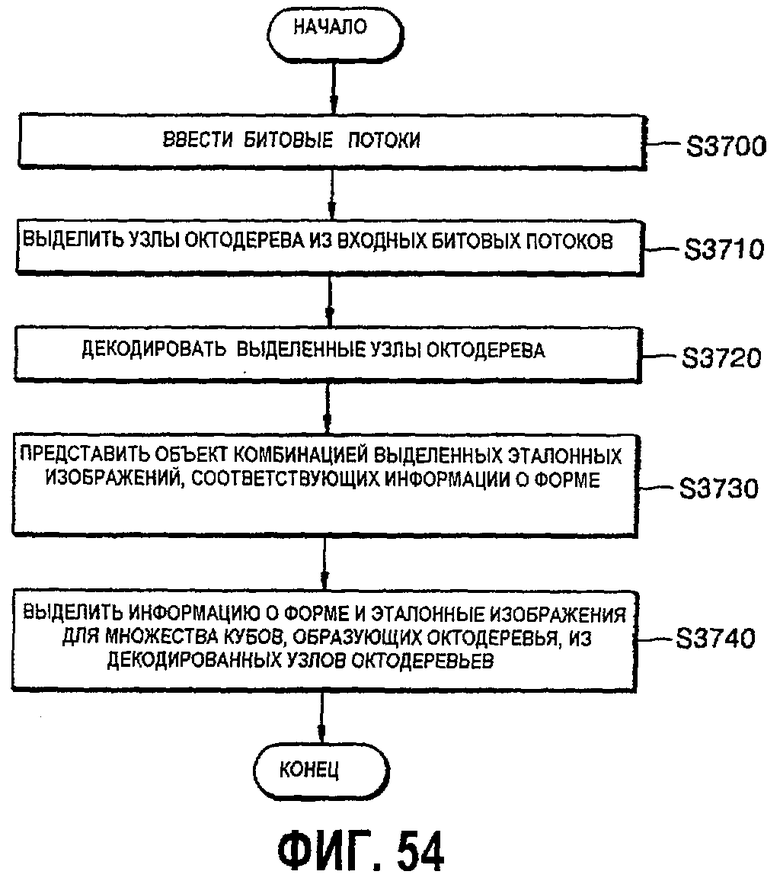
Изобретение относится к представлению трехмерных объектов на основе изображений с глубиной. Его применение при визуализации трехмерного изображения в компьютерной графике и анимации позволяет получить технический результат в виде обеспечения компактности хранения информации об изображении, быстрой визуализации с высоким качеством выходного изображения. Этот результат достигается благодаря тому, что способ включает в себя генерирование: фрагмента информации о точке наблюдения, цветных изображений на основе информации о цвете, соответствующих точек пикселов, составляющих объект, изображений с глубиной, узлов изображений, состоящих из информации о точке наблюдения, цветного изображения и изображения с глубиной, соответствующих информации о точке наблюдения; и кодирование генерированных узлов изображений. 10 с. и 56 з.п.ф-лы, 54 ил., 13 табл.

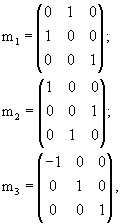
где m1 и m2 - отображения на плоскости x=y и y=z соответственно;
m3 - отображение на плоскость x=0.
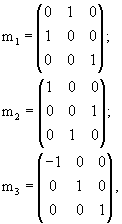
где m1 и m2 - отображения на плоскости x=y и y=z соответственно;
m3 - отображение на плоскость x=0.
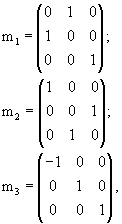
где m1 и m2 - отображения на плоскости x=y и y=z соответственно;
m3 - отображение на плоскость x=0.
| СПОСОБ АВТОМАТИЗИРОВАННОГО ИЗМЕРЕНИЯ С ИСПОЛЬЗОВАНИЕМ МОДЕЛИ ВНЕШНЕЙ СРЕДЫ В СТЕРЕОТЕЛЕВИЗИОННОЙ СИСТЕМЕ ТЕХНИЧЕСКОГО ЗРЕНИЯ | 1997 |
|
RU2148794C1 |
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| US 6088035 А, 11.07.2000 | |||
| US 5600763 A, 04.02.1997 | |||
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |

