В заявке описаны способы и нуклеиновые кислоты для получения иммуноглобулинов в клетках млекопитающих.
Предпосылки создания изобретения
Системы экспрессии для получения рекомбинантных полипептидов известны в данной области и опубликованы. Для получения полипептидов применяют фармацевтически приемлемые клетки млекопитающих, например, клетки СНО, клетки ВНК, клетки NSO, клетки Sp2/0, клетки COS, клетки НЕК, клетки PER.C6® и другие. Нуклеиновые кислоты, кодирующие полипептид, внедряют в клетки, например, с помощью плазмиды, например, экспрессирующей плазмиды. Важными элементами экспрессирующей плазмиды являются прокариотическая единица размножения плазмид, например, плазмид Escherichia coli, включающая начало репликации (репликатор) и селективный маркер, эукариотический селективный маркер и одну или несколько экспрессирующих кассет для экспрессии целевой нуклеиновой кислоты (кислот), каждая из которых включает промотор, структурный ген и терминатор транскрипции, включая сигнал полиаденилирования. Для временной экспрессии в клетки млекопитающих может быть включен репликатор млекопитающих, например, SV40 Ori или OriP. В качестве промотора может быть выбран конститутивный или индуцибельный промотор. Для оптимизации транскрипции последовательность Kozak может быть включена в 5'-нетранслируемую область. Для процессинга иРНК также может быть включен сигнал полиаденилирования.
Белки, особенно иммуноглобулины, занимают важное место в арсенале современной медицины. Для назначения людям каждое фармацевтическое вещество должно соответствовать определенным критериям. Чтобы убедиться в безопасности биофармацевтических агентов для людей, вещества, которые могут вызвать серьезные повреждения, должны быть особенно тщательно удалены.
Сплайсинг иРНК регулируется наличием сайта донора сплайсинга в комбинации с сайтом акцептора сплайсинга, которые расположены по 5'-концу и 3'-концу интрона, соответственно. По кн.: «Recombinant DNA: A Short course», 1983, под ред. Watson и др., изд-во Scientific American Books, распространение книг осуществляет фирма W.H.Freeman and Company, Нью-Йорк, Нью-Йорк, США, описывают консенсусную последовательность ag|gtragt 5'-сайта донора сплайсинга (экзон|интрон) и (y)nNcag|g 3'-сайта акцептора сплайсинга (экзон|интрон) (r=пуриновое основание; y=пиримидиновое основание; n=целое число; N=какое-либо природное основание).
В 1980 годы были опубликованы первые статьи, рассматривающие репликатор секретируемых и связанных с мембраной форм иммуноглобулинов. Формирование секретированной (sIg) и связанной с мембраной (mIg) изоформ происходит в результате иного сплайсинга иРНК-предшественника тяжелой цепи. В изоформе mIg сайт сплайсинга донора в экзоне, кодирующем С-концевой домен секретированной формы (т.е. домен CH3 или CH4, соответственно), и сайт акцептора сплайсинга, расположенный от него на расстоянии вниз по цепи, используют для связи константной области с расположенными ниже по цепи экзонами, кодирующими трансмембранный домен.
Способ получения молекул синтетической нуклеиновой кислоты с пониженными несоответствующими или непредусмотренными показателями транскрипции при экспрессии в отдельных клетках-хозяевах описан в WO 2002/016944. В WO 2006/042158 описаны молекулы нуклеиновой кислоты, модифицированные для повышенной экспрессии рекомбинантного белка и/или понижения или элиминации ошибочно сплайсированных и/или интронных побочных продуктов, сформировавшихся в результате сплошного считывания.
Таким образом, существует потребность в способе получения рекомбинантных продуктов применительно к иммуноглобулинам с пониженным содержанием побочных продуктов.
Краткое описание изобретения
Первый объект настоящего изобретения предусматривает нуклеиновую кислоту, кодирующую аминокислотную последовательность С-концевой части CH3-домена иммуноглобулинов класса IgE или IgM, в которой дипептид глицин-лизин, включенный в первичную аминокислотную последовательность С-концевой части CH3- или CH4-домена, кодируется нуклеиновой кислотой ggaaaa, или нуклеиновой кислотой ggcaaa, или нуклеиновой кислотой gggaaa, или нуклеиновой кислотой gggaag, или нуклеиновой кислотой ggcaag, или нуклеиновой кислотой ggaaag.
В одном из вариантов осуществления настоящее изобретение нуклеиновая кислота кодирует аминокислотную последовательность, выбранную из аминокислотных последовательностей SEQ ID NO:1, 3, 4, 5, 6, 7 или 8. В другом варианте осуществления настоящее изобретение представляет нуклеиновую кислоту, кодирующую дипептид глицин-лизин, предворяемый нуклеотидом g или а. В другов варианте осуществления настоящего изобретения нуклеиновой кислотой, кодирующей дипептид глицин-лизин, является нуклеиновая кислота ggaaaa, или нуклеиновая кислота ggcaaa, или нуклеиновая кислота gggaaa.
Второй объект настоящего изобретения представляет собой плазмиду, включающую нуклеиновую кислоту по настоящему изобретению, а третьим объектом настоящего изобретения являются клетки, включающие нуклеиновую кислоту по настоящему изобретению.
Другим объектом настоящего изобретения является нуклеотидная последовательность SEQ ID NO:17, 18, 19, 20, 21, 22, 23, 30 или 31.
Пятым объектом настоящего изобретения является способ получения иммуноглобулина в клетках млекопитающего, включающий следующие стадии:
а) трансфекции клеток млекопитающего нуклеиновой кислотой, кодирующей тяжелую цепь иммуноглобулина, представляющей нуклеиновую кислоту SEQ ID NO:17, 18, 19, 20, 21, 22, 23, 30 или 31, которая кодирует С-концевую часть тяжелой цепи иммуноглобулина,
б) культивирования трансфецированных клеток млекопитающего в условиях, пригодных для экспрессии иммуноглобулина,
в) выделения иммуноглобулина из культуры или из клеток.
В одном из вариантов осуществления настоящего изобретения клетками млекопитающих являются клетки СНО, клетки ВНК, клетки NSO, клетки Sp2/0, клетки COS, клетки НЕК или клетки PER.C6®. Предпочтительно клетками млекопитающих являются клетки СНО, или клетки ВНК, или клетки PER.C6®. В другом варианте осуществления настоящего изобретения клетки млекопитающих трансфецированы двумя нуклеиновыми кислотами, причем первая нуклеиновая кислота включает экспрессирующую кассету, кодирующую легкую цепь иммуноглобулина, а вторая нуклеиновая кислота включает экспрессирующую кассету, кодирующую тяжелую цепь иммуноглобулина, включающую нуклеиновую кислоту SEQ ID NO:17, 18, 19, 20, 21, 22, 23, 30 или 31, кодирующую С-концевую часть тяжелой цепи иммуноглобулина.
Заключительным объектом настоящего изобретения является способ улучшения экспрессии иммуноглобулина в клетках млекопитающих, в котором нуклеиновая кислота, кодирующая тяжелую цепь иммуноглобулина, включает нуклеиновую кислоту ggaaaa, или нуклеиновую кислоту ggcaaa, или нуклеиновую кислоту gggaaa, или нуклеиновую кислоту ggaaag, или нуклеиновую кислоту ggcaag, или нуклеиновую кислоту gggaag, кодирующую дипептид глицин-лизин, содержащийся в CH3- или CH4-домене.
Подробное описание изобретения
Настоящее изобретение включает нуклеиновую кислоту, кодирующую аминокислотную последовательность С-концевой части CH3-домена иммуноглобулина класса IgA или IgG, или С-концевой части CH4-домена иммуноглобулина класса IgE или IgM, в котором дипептид глицин-лизин, включенный в аминокислотную последовательность С-концевой части CH3- или CH4-домена, кодируется нуклеиновой кислотой ggaaaa, или нуклеиновой кислотой ggcaaa, или нуклеиновой кислотой gggaaa, или нуклеиновой кислотой ggaaag, или нуклеиновой кислотой ggcaag, или нуклеиновой кислотой gggaag, причем нуклеиновой кислоте, кодирующей дипептид глицин-лизин, необязательно предшествует или нуклеотид g, или нуклеотид а.
Способы и методики, которые могут использоваться в настоящем изобретении, известны специалистам в данной области и описаны, например, в кн.: «Current Protocols in Molecular Biology», 1997, под ред. Ausubel F.M., т.I-III, и в кн. Sambrook и др.: «Molecular Cloning: A Laboratory Manual», 1989, 2-е изд., изд. Cold Spring Harbor Laboratory Press, Cold Spring Harbor Нью-Йорк. Специалистам в данной области известно, что применение методов рекомбинации ДНК позволяет получать многочисленные производные нуклеиновой кислоты и/или полипептида. Такие производные могут, например, модифицироваться в одном определенном или в нескольких положениях путем замещения, изменения, обмена или инсерции. Модификация или дериватизация может, например, выполняться методами сайт-направленного мутагенеза. Такие модификации могут быть легко выполнены специалистами в данной области (см., например, Sambrook J. и др. в кн.: «Molecular Cloning: A laboratory manual», 1999, изд. Cold Spring Harbor Laboratory Press, Нью-Йорк, США). Применение рекомбинантной методики помогает специалистам в данной области трансформировать разные клетки-хозяева гетерологичными нуклеиновыми кислотами. Хотя в механизмах транскрипции и трансляции, т.е. экспрессии, в разных клетках использованы одни и те же элементы, клетки, принадлежащие к разным видам, могут иметь помимо других отличий разные используемые кодоны. Таким образом, идентичные полипептиды (по аминокислотной последовательности) могут кодироваться разными нуклеиновыми кислотами. Кроме того, из-за вырожденности генетического кода разные нуклеиновые кислоты могут кодировать один и тот же полипептид.
В контексте настоящего изобретения понятие «нуклеиновая кислота» относится к полимерной молекуле, состоящей из отдельных нуклеотидов (также называемых основаниями) а, с, g и t (или и в РНК), например, для ДНК, РНК или их модификаций. Полинуклеотидная молекула может быть молекулой природного полинуклеотида, или молекулой синтетического полинуклеотида, или комбинацией одной или нескольких природных молекул полинуклеотида с одной или несколькими синтетическими молекулами полинуклеотида. Это понятие также относится к природным полинуклеотидным молекулам, в которых один или несколько нуклеотидов заменены (например, с помощью мутагенеза), делегированы или добавлены. Нуклеиновая кислота также может быть выделенной или интегрированной в другую нуклеиновую кислоту, например, в экспрессирующую кассету, плазмиду или хромосому клетки-хозяина. Нуклеиновая кислота также отличается последовательностью нуклеиновой кислоты, состоящей из отдельных нуклеотидов.
Специалистам в данной области хорошо известны методы преобразования аминокислотной последовательности, например, полипептида, в соответствующую последовательность нуклеиновой кислоты, кодирующую аминокислотную последовательность. Следовательно, нуклеиновая кислота отличается последовательностью нуклеиновой кислоты, состоящей из отдельных нуклеотидов, а также последовательностью аминокислот полипептида, кодируемого этой нуклеиновой кислотой.
К понятию «плазмида» относятся, например, векторные и экспрессирующие плазмиды, а также плазмиды трансфекции. Понятие «вектор» в настоящем изобретении используют в качестве синонима понятия «плазмида». Обычно «плазмида» также включает начало репликации (репликатор), например, репликатор ColE1 или oriP, и селективный маркер (например, маркер ампицилина, канамицина, тетрациклина или хлорамфеникола) для репликации и селекции, соответственно, плазмиды в бактериях.
Понятие «экспрессирующая кассета» относится к конструкции, которая содержит требуемые регуляторные элементы, например, промотор и сайт полиаденилирования, для экспрессии по меньшей мере содержащейся в клетке нуклеиновой кислоты.
Понятие «селективный маркер» означает нуклеиновую кислоту, которая позволяет клеткам, несущим селективный маркер, быть специфически отобранными по этому признаку по типу «за» или «против» в присутствии соответствующего селективного агента. Обычно селективный маркер может подтвердить устойчивость к лекарственному средству или компенсировать метаболический или катаболический дефект в клетке-хозяине. Маркер может быть положительным, отрицательным или бифункциональным. Удобным положительным селективным маркером является ген устойчивости к антибиотику. Такой селективный маркер позволяет клеткам-хозяевам, трансфецированным этим маркером, быть положительно отобранными в присутствии соответствующего селективного агента, т.е. антибиотика. Нетрансформированные клетки-хозяева не могут расти или выживать в условиях селективной культуры, т.е. в присутствии селективного агента, в культуре. Положительные селективные маркеры позволяют проводить отбор клеток, несущих маркер, а маркеры отрицательной селекции позволяют селективно элиминировать клетки, несущие маркер. К селективным маркерам, применяемым в эукариотических клетках, относятся, например, гены аминогликозидфосфотрансферазы (aminoglycoside phosphotransferase - АРН), например, селективные маркеры гигромицин (hyg), неомицин (neo) и G418, дигидрофолатредуктаза (DHFR), тимидинкиназа (tk), глутаминсинтетаза (GS), аспарагинсинтетаза, триптофансинтетаза (селективным агентом является индол), гистидинолдегидрогеназа (селективный агент гистидинола D) и нуклеиновые кислоты, обусловливающие устойчивость к пуромицину, блеомицину, флеомицину, хлорамфениколу, зеоцину и морфофеноловой кислоте. Другие маркеры описаны в WO 92/08796 и WO 94/28143.
В контексте настоящего изобретения понятие «экспрессия» относится к процессам транскрипции и/или трансляции в клетке. Уровень транскрипции исследуемой последовательности нуклеиновой кислоты может быть установлен на основе количества соответствующей иРНК, которая имеется в клетке. Например, транскрибированная с исследуемой последовательности иРНК может быть оценена количественно методом РВ-ПЦР или норзен-гибридизацией (см. выше Sambrook и др., 1989). Полипептиды, кодированные исследуемой нуклеиновой кислотой, могут быть оценены количественно разными методами, например, ELISA, по оценке биологической активности полипептида или анализом, зависящим от такой активности, например, вестерн-блоттингом или радиоиммуноанализом, используя иммуноглобулины, которые распознают и связывают полипептид (см. выше Sambrook и др.).
Понятие «клетка» или «клетка-хозяин» в контексте настоящего изобретения означает клетку, в которой нуклеиновая кислота, например, кодирующая гетерологичный полипептид, может быть, или уже является, интродуцированной/трансфецированной. Понятие «клетка» включает и прокариотические клетки, которые используют для размножения плазмид, и эукариотические клетки, которые используют для экспрессии нуклеиновой кислоты. Предпочтительно эукариотические клетки являются клетками млекопитающих. Предпочтительно клетки млекопитающих выбраны из группы клеток млекопитающих, включающей клетки СНО (например, СНО K1, CHO DG44), клетки ВНК, клетки NSO, клетки SP2/0, клетки НЕК 293, клетки НЕК 293 EBNA, клетки PER.C6® и клетки COS. Понятие экспрессирующей «клетки» в контексте настоящего изобретения означает клетку субъекта и ее потомство. Таким образом, понятие «трансформант» и «трансформированная клетка» включает первичную клетку субъекта и клетки в культурах, полученные из нее независимо от числа переносов. Также очевидно, что потомство может в точности быть не идентично по содержанию ДНК из-за продуманных или непредвиденных мутаций. К этому варианту также относится вариант потомства с той же функцией или с тем же биологическим действием, которые выявлены в первоначально трансформированной клетке.
Понятие «полипептид» означает полимер, включающий аминокислоты, соединенные пептидными связями, независимо то того, являются ли они природными или синтетическими. Полипептиды, длиной примерно не более 20 аминокислотных остатков, могут быть обозначены «пептидами», причем молекулы, включающие два или несколько полипептидов, или включающие один полипептид более чем из 100 аминокислотных остатков, могут быть названы «белками». Полипептид может также включать компоненты, не являющиеся аминокислотами, например, углеводные группы, ионы металлов или эфиры карбоновых кислот. Компоненты, не являющиеся аминокислотами, могут быть присоединены клеткой, в которой экспрессирован полипептид, и могут меняться в зависимости от типа клеток. Полипептиды в настоящем изобретении выражены с точки зрения их аминокислотной структуры или нуклеиновой кислоты, их кодирующей. Добавления, например углеводные группы, обычно точно не установлены, но тем не менее они могут присутствовать.
Понятие «аминокислота» в контексте настоящего изобретения означает группу карбокси α-аминокислот, которая непосредственно или в форме предшественника может быть кодирована нуклеиновой кислотой. Отдельные аминокислоты кодируются нуклеиновыми кислотами, каждая из которых состоит из трех нуклеотидов и называется кодоном или триплетом. Каждая аминокислота кодируется по меньшей мере одним кодоном. Например, аминокислота глицин может кодироваться каждым из четырех нуклеиновых кислот (кодонов) gga, ggc, ggg и ggt, а аминокислота лизин кодируется двумя нуклеиновыми кислотами - ааа и aag. Этот феномен называется «вырожденностью генетического кода». Группа аминокислот включает аланин (трехбуквенный код: ala, обозначение одной буквой: А), аргинин (arg, R), аспарагин (asn, N), аспарагиновая кислота (asp, D), цистеин (cys, С), глутамин (gin, Q), глутаминовая кислота (glu, Е), глицин (gly, G), гистидин (his, Н), изолейцин (ile, I), лейцин (leu, L), лизин (lys, К), метионин (met, М), фенилаланин (phe, F), пролин (pro, Р), серии (ser, S), треонин (thr, Т), триптофан (trp, W), тирозин (tyr, Y) и валин (val, V).
Понятие «иммуноглобулин» в контексте настоящего изобретения означает белок, состоящий из одного или нескольких полипептидов, главным образом кодированных генами иммуноглобулина. Это определение включает варианты, например, мутантные формы, т.е. формы с замещениями, делениями и инсерциями одной или нескольких аминокислот, усеченные с N-конца формы, гибридные формы, химерные формы, а также гуманизированные формы. Установленные гены иммуноглобулина включают гены разных константных областей, а также гены неисчислимого количества вариабельной области иммуноглобулина, например, у приматов или грызунов. Предпочтительными являются моноклональные иммуноглобулины. Каждая из тяжелой и легкой полипептидных цепей иммуноглобулина может включать константную область (обычно карбоксильную концевую часть).
Понятие «моноклональный иммуноглобулин» в контексте настоящего изобретения означает иммуноглобулин, полученный из популяции в значительной степени гомогенных иммуноглобулинов, т.е. отдельные иммуноглобулины, составляющие популяцию, идентичны за исключением возможных естественных мутаций, которые могут присутствовать в минорных количествах. Моноклональные иммуноглобулины высокоспецифичны, направлены против определенных антигенных сайтов. Кроме того, в отличие от препаратов поликлонального иммуноглобулина, которые включают разные иммуноглобулины, направленные против разных антигенных сайтов (детерминантов или эпитопов), каждый моноклональный иммуноглобулин направлен против единственного антигенного сайта на антигене. Преимущество моноклональных иммуноглобулинов, помимо их специфичности, заключается в том, что они могут быть синтезированы без примесей в виде других иммуноглобулинов. Определение «моноклональный» характеризует иммуноглобулин в качестве полученного из популяции иммуноглобулинов, являющейся в значительной степени гомогенной, и не означает, что требуется получение иммуноглобулина каким-либо определенным способом.
«Гуманизированные» формы иммуноглобулинов, не являющихся иммуноглобулинами человека (например, иммуноглобулины грызуна), представляют химерные иммуноглобулины, которые содержат неполные последовательности, производные от иммуноглобулина, не являющегося иммуноглобулином человека, и от иммуноглобулина человека. В основном гуманизированные иммуноглобулины производны от иммуноглобулина человека (реципиента иммуноглобулина), в котором остатки из гипервариабельной области заменены остатками гипервариабельной области иммуноглобулинов других видов, не человека, являющихся донорами иммуноглобулина, например, мыши, крысы, кролика или обезьяны, обладающих желаемой специфичностью или сродством (см., например, Morrison S.L. и др., Proc. Natal. Acad. Sci. USA 81, 1984, сс.6851-6855, US 5202238, US 5204244). В некоторых случаях остатки каркасного участка (framework region - FR) иммуноглобулина человека замещены на соответствующие остатки не от человека. Кроме того, гуманизированные иммуноглобулины могут включать дополнительные модификации, например, аминокислотные остатки, которые не обнаружены у иммуноглобулина реципиента или у иммуноглобулина донора. Эти модификации приводят к вариантам таких иммуноглобулинов реципиента или донора, которые являются гомологичными, но не идентичными соответствующей исходной последовательности. Такие модификации получают для проведения дополнительной очистки. В общем гуманизированный иммуноглобулин может включать практически все из по меньшей мере одного, обычно двух вариабельных доменов, в которых все или практически все из гипервариабельных петель соответствуют петлям иммуноглобулина донора, коим не является человек, и все или практически все из участков FR являются участками FR реципиентного иммуноглобулина человека. Гуманизированный иммуноглобулин необязательно также может включать по меньшей мере часть константной области иммуноглобулина, обычно иммуноглобулина человека. Способы гуманизирования иммуноглобулина, не являющегося иммуноглобулином человека, известны в данной области. Предпочтительно гуманизированный иммуноглобулин содержит один или несколько аминокислотных остатков, внедренных в него из источника, которым не является человек. Такие аминокислотные остатки, не связанные с человеком, часто обозначаются «импортными» остатками, которые обычно берут из «импортного» вариабельного домена. Гуманизирование может быть по существу выполнено по методу Winter с соавторами путем замещения последовательностей гипервариабельной области для соответствующих последовательностей иммуноглобулина, не являющегося иммуноглобулином человека. Следовательно, такие «гуманизированные» иммуноглобулины являются химерными иммуноглобулинами, причем существенно в меньшей степени по сравнению с интактным вариабельным доменом человека замещены соответствующей последовательностью от представителя вида, но не человека. На практике гуманизированные иммуноглобулины обычно являются иммуноглобулинами человека, в которых некоторые остатки гипервариабельной области и возможно некоторые остатки каркасного участка замещены остатками от аналогичных сайтов у иммуноглобулинов грызунов или обезьян.
В зависимости от аминокислотной последовательности константной области тяжелых цепей, иммуноглобулины поделены на классы: IgA, IgD, IgE, IgG и IgM. Некоторые из них могут быть дополнительно поделены на подклассы (изотипы), например, IgG1, IgG2, IgG3 и IgG4, IgA1 и IgA2. По константным областям тяжелой цепи разные классы тяжелых цепей иммуноглобулинов обозначаются α-, δ-, ε-, γ- и µ-цепь, соответственно. Константная область тяжелой цепи иммуноглобулина человека полной длины класса IgA, IgD и IgG составлена из константного домена 1 (обозначаемого в настоящем изобретении «CH1»), шарнирной области, константного домена 2 (CH2) и константного домена 3 (CH3). Иммуноглобулины человека класса IgE и IgM включают дополнительный четвертый константный домен (CH4). Кроме того, иммуноглобулины класса IgM представляют полимеры, включающие разнообразные иммуноглобулины, например, пять или шесть, ковалентно связанные дисульфидными связями. Аминокислотные последовательности С-концевого константного домена таких разных классов иммуноглобулина человека перечислены в табл.1. Первая аминокислота последовательности SEQ ID NO:01-08 может присутствовать или отсутствовать, поскольку эта аминокислота кодируется двумя экзонами: экзоном, кодирующим С-концевой константный домен, и экзоном, кодирующим предшествующий домен.
Понятие «С-концевая часть CH3-домена иммуноглобулина класса IgA или IgG, или С-концевая часть CH4-домена иммуноглобулина класса IgE или IgM» означает аминокислотные последовательности тяжелой цепи иммуноглобулина, которые локализованы с С-конца полной длины или природной тяжелой цепи иммуноглобулина, причем С-конец указанной С-части идентичен С-концу первичной аминокислотной последовательности тяжелой цепи иммуноглобулина. Понятие «первичная аминокислотная последовательность» означает аминокислотную последовательность тяжелой цепи иммуноглобулина после трансляции соответствующей иРНК. Такая первичная аминокислотная последовательность может также быть модифицирована в экспрессирующих клетках после трансляции иРНК, например, пептидазами, отщепляющими одну или несколько С-концевых аминокислот из первичной аминокислотной последовательности. Следовательно, первичная аминокислотная последовательность и секретированная аминокислотная последовательность могут быть неидентичны, но могут отличаться некоторыми аминокислотами по С-концу. В одном из вариантов осуществления настоящего изобретения С-концевая часть включает по меньшей мере 100 С-концевых аминокислот первичной аминокислотной последовательности тяжелой цепи иммуноглобулина или предпочтительно по меньшей мере 50 С-концевых аминокислот первичных аминокислотных последовательностей тяжелой цепи иммуноглобулина, или предпочтительно по меньшей мере 20 С-концевых аминокислот первичной аминокислотной последовательности тяжелой цепи иммуноглобулина. В одном из вариантов осуществления настоящего изобретения нуклеиновая кислота по настоящему изобретению кодирует аминокислотную последовательность С-концевой части CH3-домена иммуноглобулина класса IgG, или С-концевой части CH4-домена иммуноглобулина класса IgE. В другом варианте осуществления настоящего изобретения нуклеиновая кислота по настоящему изобретению кодирует аминокислотную последовательность С-концевой части домена CH3 иммуноглобулина класса IgG.
Аминокислотные последовательности С-концевого константного домена разных иммуноглобулинов человека кодируются соответствующими последовательностями ДНК. В геноме такие последовательности ДНК содержат кодирующие (экзонные) и некодирующие (интронные) последовательности. После транскрипции ДНК в иРНК-предшественника, указанная иРНК-предшественник также содержит такие интронные и экзонные последовательности. Перед трансляцией некодирующие интронные последовательности удаляются в ходе процессинга иРНК за счет их сплайсинга из первичного транскрипта иРНК для получения зрелой иРНК. Сплайсинг первичной иРНК контролируется сайтом сплайсирования донора в комбинации с должным образом расположенным на расстоянии сайтом сплайсирования акцептора. Сайт сплайсирования донора локализован на 5'-конце, а сайт сплайсирования акцептора локализован на 3'-конце интронной последовательности, и оба частично удаляются во время процесса сплайсинга иРНК-предшественника.
Понятие «должным образом расположенные на расстоянии» в контексте настоящего изобретения означает, что сайт сплайсинга донора и сайт сплайсинга акцептора в нуклеиновой кислоте собраны таким образом, что все требуемые элементы для сплайсинга имеются и находятся в соответствующем положении, что позволяет осуществляться процессу сплайсинга.
Настоящее изобретение включает нуклеиновую кислоту, кодирующую аминокислотную последовательность С-концевой части CH3-домена иммуноглобулина класса IgA или IgG или С-концевой части CH4-домена иммуноглобулина класса IgE или IgM, в которой дипептид глицин-лизин, включенный в указанную аминокислотную последовательность С-концевой части CH3- или CH4-домена, кодируется нуклеиновой кислотой ggaaaa, или нуклеиновой кислотой ggcaaa, или нуклеиновой кислотой gggaaa.
Неожиданно было установлено, что с нуклеиновой кислотой по настоящему изобретению формирование нежелательных побочных продуктов в результате эпизодов нежелательного сплайсинга может быть понижено.
Понятие «дипептид глицин-лизин» в контексте настоящего изобретения означает пептид, включающий в направлении от N-конца к С-концу две аминокислоты, глицин и лизин, связанные пептидной связью. Понятие «дипептид глицин-лизин» в контексте настоящего изобретения означает фракцию дипептида более крупного полипептида или белка, которая может быть обнаружена в начале, внутри или с конца более крупного полипептида. Аминокислота лизин может кодироваться нуклеиновой кислотой ааа или aag. Таким образом, в другом варианте осуществления настоящего изобретения дипептид глицин-лизин, включенный в аминокислотную последовательность С-концевой части CH3- или CH4-домена тяжелой цепи иммуноглобулина, кодируется нуклеиновой кислотой ggaaag, или нуклеиновой кислотой ggcaag, или нуклеиновой кислотой gggaag. В другом варианте осуществления настоящего изобретения нуклеиновой кислоте, кодирующей дипептид глицин-лизин, предшествует нуклеотид а или g.
Последовательности нуклеиновых кислот, кодирующие С-концевой константный домен разных классов и подклассов иммуноглобулина человека, перечислены в табл.2. Для домена CH3 IgG1 и IgG2 человека известны два варианта формы. В одном из вариантов осуществления настоящего изобретения нуклеиновая кислота кодирует часть С-концевого константного домена тяжелой цепи иммуноглобулина.
В одном из вариантов осуществления настоящего изобретения нуклеиновая кислота по настоящему изобретению кодирует аминокислотную последовательность, выбранную из аминокислотных последовательностей SEQ ID NO:1,3, 4, 5, 6, 7 или 8.
В одном из вариантов осуществления настоящего изобретения нуклеиновая кислота кодирует часть С-концевого константного домена тяжелой цепи иммуноглобулина класса IgA, IgE, IgM или IgG и выбрана из нуклеиновых кислот SEQ ID NO:17, 18, 19, 20, 21, 22, или 23, или 30, или 31. В другом варианте осуществления настоящего изобретения нуклеиновая кислота кодирует часть С-концевого константного домена тяжелой цепи иммуноглобулина класса IgA, IgE, IgM или IgG и выбрана из нуклеиновых кислот SEQ ID NO:17, 18, 19, 22, 23, 30 или 31. В другом варианте осуществления настоящего изобретения нуклеиновая кислота кодирует часть С-концевого константного домена тяжелой цепи иммуноглобулина класса IgA, IgE, IgM или IgG и выбрана из нуклеиновых кислот SEQ ID NO:17, 18. 19, 22 или 23.
Нуклеиновые кислоты с нуклеотидной последовательностью SEQ ID NO:17-23 и 30-31 также являются объектом настоящего изобретения. В одном из вариантов осуществления настоящего изобретения нуклеотидные последовательности SEQ ID NO:17, 18, 19, 22, 23, 30 или 31 являются объектом настоящего изобретения. В другом варианте осуществления настоящего изобретения нуклеотидные последовательности SEQ ID NO:17, 18, 19, 22 или 23 являются объектом настоящего изобретения.
В одном из вариантов осуществления настоящего изобретения нуклеиновая кислота кодирует С-концевой константный домен иммуноглобулина класса IgA, IgE, IgM или IgG и включает нуклеиновую кислоту, выбранную из нуклеиновых кислот SEQ ID NO:17, 18, 19, 20, 21, 22 или 23, или 30, или 31, которая кодирует часть С-концевого домена тяжелой цепи иммуноглобулина. В другом варианте осуществления настоящего изобретения нуклеиновая кислота кодирует С-концевой константный домена иммуноглобулина класса IgA, IgE, IgM или IgG и включает нуклеиновую кислоту, выбранную из нуклеиновых кислот SEQ ID N0: 17, 18, 19, 22, 23, 30 или 31, которая кодирует часть С-концевого домена тяжелой цепи иммуноглобулина. В другом варианте осуществления настоящего изобретения нуклеиновая кислота кодирует С-концевой константный домен иммуноглобулинов класса IgA, IgE, IgM или IgG и включает нуклеиновую кислоту, выбранную из нуклеиновых кислот SEQ ID NO:17, 18, 19, 22 или 23, которая кодирует часть С-концевого домена тяжелой цепи иммуноглобулина.
Нуклеиновая кислота по настоящему изобретению кодирует по меньшей мере часть С-концевого константного домена иммуноглобулина класса IgA, IgE, IgM или IgG. Понятие «С-концевой константный домен» означает либо CH3-домен тяжелой цепи иммуноглобулина класса IgA или IgG, либо CH4-домен тяжелой цепи иммуноглобулина класса IgE или IgM. Экспрессия «части» означает С-концевую фракцию С-концевого константного домена тяжелой цепи иммуноглобулина класса IgA, IgE, IgM или IgG, по меньшей мере из 20 последовательно расположенных аминокислот, или по меньшей мере из 50 последовательно расположенных аминокислот, по меньшей мере из 100 последовательно расположенных аминокислот первичной аминокислотной последовательности, отсчитанные с С-конца в направлении к N-концу тяжелой цепи иммуноглобулина.
Рекомбинантное получение иммуноглобулинов известно в данной области и описано, например, в обзорах Makrides S.C., Protein Expr. Purif. 17, 1999, сс.183-202, Geisse S. и др., Protein Expr. Purif. 8, 1996, сс.271-282, Kaufman R.J., Mol. Biotechnol. 16, 2000, сс.151-160, Werner R.G., Arzneimittelforschung - Drug Research, 48, 1998, сс.870-880.
Для получения иммуноглобулина, включающего аминокислотную последовательность, кодируемую нуклеиновой кислотой по настоящему изобретению, также предусмотрен способ получения иммуноглобулина в клетках млекопитающих, включающий следующие стадии:
а) трансфекции указанных клеток млекопитающего нуклеиновой кислотой, кодирующей тяжелую цепь иммуноглобулина, причем нуклеиновая кислота выбрана из последовательностей нуклеиновых кислот SEQ ID NO:17, 18, 19, 20, 21, 22, или 23, или 30, или 31 кодирует домен С-концевого домена тяжелой цепи иммуноглобулина,
б) культивирования трансфецированных клеток млекопитающего в условиях, пригодных для экспрессии иммуноглобулина,
в) выделения иммуноглобулина из культуры или из клеток. Понятие «в условиях, допускающих экспрессию иммуноглобулина» в контексте настоящего изобретения означает условия, применимые для культивирования клеток млекопитающих, экспрессирующих иммуноглобулин, которые известны и могут быть легко определены специалистами в данной области. Специалистам в данной области также известно, что эти условия могут варьировать в зависимости от типа культивируемых клеток млекопитающих и типа экспрессируемого иммуноглобулина. В целом клетки млекопитающих культивируют при температуре, например, от 20°С до 40°С, в течение времени, достаточного для эффективного образования белка, а именно иммуноглобулина, например, в течение 4-28 суток.
В одном из вариантов осуществления настоящего изобретения клетки млекопитающих трансфецируют нуклеиновой кислотой, кодирующей тяжелую цепь иммуноглобулина, причем нуклеиновая кислота выбрана из нуклеиновых кислот SEQ ID NO:17, 18, 19, 22, 23, 30 или 31, которые кодируют часть С-концевого домена тяжелой цепи иммуноглобулина. В еще одном из вариантов осуществления настоящего изобретения клетки млекопитающих трансфецируют нуклеиновой кислотой, кодирующей тяжелую цепь иммуноглобулина, причем нуклеиновая кислота, выбранная из нуклеиновых кислот SEQ ID NO:17, 18, 19, 22 или 23, кодирует часть С-концевого домена тяжелой цепи иммуноглобулина. В одном из вариантов осуществления настоящего изобретения клетки млекопитающих трансфецируют одной нуклеиновой кислотой, включающей экспрессирующую кассету, которая кодирует тяжелую цепь иммуноглобулина, и экспрессирующую кассету, которая кодирует легкую цепь иммуноглобулина. В другом варианте осуществления настоящего изобретения предусмотрены клетки млекопитающих, трансфецированные двумя нуклеиновыми кислотами, из которых одна включает экспрессирующую кассету, кодирующую легкую цепь иммуноглобулина, и другая включает экспрессирующую кассету, кодирующую тяжелую цепь иммуноглобулина.
Иммуноглобулин, получаемый по способу настоящего изобретения, предпочтительно является гетерологичным иммуноглобулином. Понятие «гетерологичный иммуноглобулин» означает иммуноглобулин, который в норме образуется указанными клетками млекопитающего. Иммуноглобулин, получаемый способом настоящего изобретения, получают методами рекомбинации. Такие методы широко известны в данной области и включают экспрессию белка в клетках прокариот и эукариот с последующим выделением и очисткой гетерологичного иммуноглобулина, причем обычно очищают до фармацевтически приемлемой чистоты. Для получения, т.е. экспрессии, нуклеиновой кислоты, кодирующей легкую цепь иммуноглобулина, и нуклеиновой кислоты, кодирующей тяжелую цепь, которая включает нуклеиновую кислоту по настоящему изобретению, указанные нуклеиновые кислоты инсертируют в экспрессирующую кассету стандартными методами. Нуклеиновые кислоты, кодирующие иммуноглобулины, легко выделяются и секвенируются по стандартным процедурам. Гибридомные клетки могут быть источником таких нуклеиновых кислот. Экспрессирующие кассеты могут быть инсертированы в экспрессирующие плазмиды (плазмиду), которые затем трансфецируют в клетки-хозяева, которые без этого не могут вырабатывать иммуноглобулины. Экспрессию проводят в соответствующих прокариотических или эукариотических клетках-хозяевах и иммуноглобулин выделяют из клеток после лизиса или из супернатанта культуры.
Известные и широко распространенные методы используют для выделения белка и очистки, например, аффинную хроматографию с микробными белками (например, аффинную хроматографию с применением белка А или белка G), ион-обменную хроматографию (например, катионобменную (карбоксиметильные смолы), анионообменную (аминоэтильные смолы) и смешанного типа обменную хроматографию), тиофильную адсорбцию (например, с бета-меркаптоэтанолом и другими SH лигандами), хроматографию гидрофобного взаимодействия или ароматической адсорбции (например, с фенил-сефарозой, аза-аренофильными смолами или m-аминофенилборной кислотой), аффинную хроматографию с хелатированием металла (например, с Ni(II)- и Cu(II)-аффинным материалом), эксклюзионную хроматографию и методы электрофореза (например, методы гель-электрофореза, капиллярного электрофореза) (Vijayalakshmi M.A., Appl. Biochem. Biotech. 75, 1998, сс.93-102).
Настоящее изобретение также включает нуклеиновую кислоту, кодирующую тяжелую цепь иммуноглобулина, представляющую нуклеиновую кислоту по настоящему изобретению. Кроме того, настоящее изобретение предусматривает плазмиду, включающую нуклеиновую кислоту по настоящему изобретению, и клетки, включающие эту плазмиду.
Другой объект настоящего изобретения представляет способ улучшения экспрессии иммуноглобулина в клетках млекопитающих, в котором нуклеиновая кислота, кодирующая тяжелую цепь иммуноглобулина, включает нуклеиновую кислоту ggaaaa, или нуклеиновую кислоту ggcaaa, или нуклеиновую кислоту gggaaa, или нуклеиновую кислоту ggaaag, или нуклеиновую кислоту ggcaag, или нуклеиновую кислоту gggaag, которые кодируют дипептид глицин-лизин, содержащийся в CH3- или CH4-домене. С такой нуклеиновой кислотой нежелательный сплайсинг может быть уменьшен или подавлен.
В одном из вариантов осуществления настоящего изобретения тяжелая цепь иммуноглобулина является либо тяжелой цепью иммуноглобулина человека подкласса IgG4, либо тяжелой цепью иммуноглобулина антитела человека подкласса IgG1, IgG2 или IgG3. В одном из вариантов осуществления настоящего изобретения тяжелая цепь иммуноглобулина является тяжелой цепью иммуноглобулина человека и предпочтительно либо из подкласса IgG4 человека, либо мутантной тяжелой цепью иммуноглобулина из подкласса IgG1 человека. В другом варианте осуществления настоящего изобретения тяжелая цепь иммуноглобулина происходит из подкласса IgG1 человека с мутациями L234A и L235A. В еще одном из вариантов осуществления настоящего изобретения тяжелая цепь иммуноглобулина является тяжелой цепью иммуноглобулина IgG4 человека с мутацией S228P. В одном из вариантов осуществления настоящего изобретения тяжелая цепь иммуноглобулина подкласса IgG4, или подкласса IgG1 или IgG2, с мутацией L234, L235, и/или D265, и/или содержит мутацию PVA236. В других вариантах осуществления настоящего изобретения мутациями являются S228P, L234A, L235A, L235E и/или PVA236 (PVA236 означает, что аминокислотная последовательность ELLG (по однобуквенному коду аминокислот) из аминокислот в положении с 233 по 236 в IgG1 или EFLG иммуноглобулина IgG4 замещена на PVA). Предпочтительными являются мутации S228P в IgG4, и L234A и L235A в IgG1 (нумерация по EU индексу по Kabat).
Понятие «регуляторные элементы» в контексте настоящего изобретения означает нуклеотидные последовательности в положении cis, необходимые для транскрипции и/или трансляции последовательности нуклеиновой кислоты, кодирующей исследуемый полипептид. В норме элементы регуляции транскрипции включают промотор, расположенный выше по экспрессируемой цепи нуклеотидной последовательности, кодирующей целевой полипептид. В норме элементы регуляции транскрипции включают промотор, расположенный выше экспрессируемой последовательности нуклеиновой кислоты, сайты инициации и терминации транскрипции и сигнальную последовательность полиаденилирования. Понятие «сайт инициации транскрипции» относится к основанию нуклеиновой кислоты в составе нуклеиновой кислоты, соответствующей первой нуклеиновой кислоте, включенной в первичный транскрипт, т.е. иРНК-предшественник; сайт инициации транскрипции может перекрываться с последовательностью промотора. Понятие «сайт терминации транскрипции» относится к нуклеотидной последовательности, в норме находящейся с 3'-конца целевого гена, подвергаемого транскрипции, которая приводит к терминации транскрипции РНК-полимеразой. Сигнальная последовательность полиаденилирования или дополнительный сигнал поли-А представляет сигнал для расщепления по определенному сайту с 3'-конца эукариотической иРНК и пост-транскрипционное добавление в ядро последовательности примерно из 100-200 адениновых нуклеотидов (хвост поли-А) к отщепленному 3'-концу. Сигнальная последовательность полиаденилирования может включать консенсусную последовательность ААТААА, расположенную примерно на 10-30 нуклеотидов выше по цепи от сайта расщепления.
Для получения секретированного полипептида целевая нуклеиновая кислота включает сегмент ДНК, который кодирует сигнальную последовательность/лидерный пептид. Сигнальная последовательность направляет вновь синтезированный полипептид к мембране эндоплазматической сети и через нее к месту, к которому полипептид может быть направлен для секреции. Сигнальную последовательность отщепляют сигнальными пептидазами во время пересечения белком мембраны эндоплазматической сети. Для функционирования сигнальной последовательности важно распознавание механизмом секреции клетки-хозяина. Следовательно, используемая сигнальная последовательность должна распознаваться белками и ферментами механизма секреции клетки-хозяина.
К элементам регуляции трансляции относятся кодон инициации трансляции (AUG) и стоп-кодон (ТАА, TAG или TGA). Внутренняя сторона входа рибосомы (internal ribosome entry site - IRES может быть включена в некоторые конструкции.
Понятие «промотор» в контексте настоящего изобретения означает полинуклеотидную последовательность, контролирующую транскрипцию гена/структурного гена или последовательность нуклеиновой кислоты, с которой она функционально связана. Промотор включает сигналы для связывания РНК-полимеразы и инициации транскрипции. Используемые промоторы могут быть функциональными в клетках-хозяевах такого типа, в котором происходит экспрессия выбранной последовательности. Большое количество промоторов, включая конститутивные, индуцибельные и репрессируемые промоторы из различных источников, известно в данной области (они идентифицированы, например, в базе данных GenBank) и доступны сами по себе или в составе клонированных полинуклеотидов (например, депонированных в коллекции АТСС, а также их других коммерческих или индивидуальных источников). Понятие «промотор» включает нуклеотидную последовательность, которая направляет транскрипцию структурного гена. Обычно промотор расположен на 5'-конце некодируемой или нетранслируемой области гена, проксимальной по отношению к сайту начала транскрипции структурного гена. Элементы последовательностей в составе промоторов, функция которых заключается в инициации транскрипции, часто отличаются консенсусными нуклеотидными последовательностями. К таким элементам промотора относятся сайты связывания РНК-полимеразы, последовательности ТАТА, последовательности СААТ, специфичные по дифференциации элементы (differentiation-specific elements - DSE; McGehee R.E. и др., Mol. Endocrinol. 7, 1993, сс.551-560), элементы ответа цАМФ (cyclic AMP response elements - CRE), элементы сывороточного ответа (serum response elements - SRE; Treisman R. Seminars in Cancer Biol. 1, 1990, сс.47-58), элементы глюкокортикоидного ответа (glucocorticoid response elements - GRE), и сайты связывания для других факторов транскрипции, например, CRE/ATF (Treisman R., Seminars in Cancer Biol. 1, 1990, сс.47-58; O'Reilly M.A. и др., J. Biol. Chem. 267, 1992, с.19938), АР2 (Ye J. и др., J. Biol. Chem. 269, 1994, с.25728), SP1, белки, связывающие элементы ответа цАМФ (cAMP response element binding protein - CREB; Loeken M.R., Gene Expr. 3, 1993, с.253) и октамерные факторы (см. в общем кн.: «Molecular Biology of the Gene», 1987, под ред. Watson и др., 4-е изд., изд. The Benjamin/Cummings Publishing Company, Inc., и Lemaigre F.P., Rousseau G.G., Biochem. J. 303, 1994, сс.1-14). Если промотор является индуцибельным промотором, скорость транскрипции возрастает в ответ на индицирующий агент. Напротив, скорость транскрипции не регулируется индуцирующим агентом, если промотор является конститутивным промотором. Также известны репрессирующие промоторы. Например, промотор c-fos специфически активируется при связывании гормона роста с его рецептором на поверхности клетки. Экспрессия, регулируемая тетрациклином (tet), может быть достигнута искусственными гибридными промоторами, которые состоят, например, из промотора CMV с последующими двумя сайтами Tet-оператора. Tet-репрессор связывается с двумя сайтами Tet-оператора и блокирует транскрипцию. При добавлении индукторного тетрациклина Tet-репрессор высвобождается с сайтов Tet-оператора и происходит транскрипция (Gossen M. и Bujard H. PNAS 89, 1992, сс.5547-5551). О других индуцируемых промоторах, включая металлотионеин и промоторы теплового шока, см., например, Sambrook и др. (выше) и Gossen M., Curr. Opin. Biotech. 5, 1994, сс.516-520. Среди эукариотических промоторов, идентифицированных в качестве сильных промоторов для высокого уровня экспрессии, находятся ранний промотор SV40, главный поздний промотор аденовируса, промотор металлотионеина-1 мыши, длинный концевой повтор вируса саркомы Рауша, фактор элонгации 1 альфа китайского хомячка (Chinese hamster elongation factor - CHEF-1; см., например, US 5888809), EF-1 альфа человека, убиквитин и очень ранний промотор цитомегаловируса человека (CMV IE).
Понятие «промотор» в контексте настоящего изобретения означает конститутивный или индуцибельный промотор. Энхансер (т.е. элемент cis-действующей ДНК, который воздействует на промотор для повышения транскрипции) может быть необходим для функционирования совместно с промотором для повышения уровня экспрессии, получаемой только с промотора, и может быть включен в качестве элемента регуляции транскрипции. Часто полинуклеотидный сегмент, содержащий промотор, может также включать последовательности энхансера (например, CMV или SV40).
Понятие «энхансер» в контексте настоящего изобретения означает полинуклеотидную последовательность, которая повышает транскрипцию гена или кодирующей последовательности, с которыми он функционально связан. В отличие от промоторов, энхансеры не зависят от ориентации и положения и были установлены с 5'-конца или 3'-конца (Lusky М. и др., Mol. Cell Bio., 3, 1983, сс.1108-1122) по отношению к единице транскрипции, в составе интрона (Banerji J. и др., Cell, 33, 1983, сс.729-740), а также в самой кодирующей последовательности (Osborne T.F. и др., Mol. Cell Bio., 4, 1984, сс.1293-1305). Таким образом, энхансеры могут быть помещены выше или ниже по цепи от сайта инициации транскрипции или на значительных расстояниях от промотора, хотя на практике энхансеры могут перекрываться физически и функционально с промоторами. Большое количество энхансеров из разных источников известно в данной области (и идентифицировано в базах данных, например, в GenBank) и доступно в качестве клонированных полинуклеотидных последовательностей или включенных в них последовательностей (например, депонированных в коллекции АТСС, а также в других коммерческих или индивидуальных источниках). Ряд полинуклеотидов, представляющих промоторные последовательности (например, обычно используемый промотор CMV), также включают последовательности энхансера. Например, все сильные промоторы, перечисленные выше, могут также включать сильные энхансеры (см., например, кн.: Bendig M.M. «Genetic Engineering», 1988, изд. Academic Press, т.7, сс.91-127).
Понятие «внутренняя сторона входа рибосомы (internal ribosome entry site - IRES)» означает последовательность, которая функционально индуцирует инициацию трансляции независимо от генного 5'-конца последовательности IRES и позволяет двум цистронам (открытым рамкам считывания) транслироваться с одного транскрипта в клетке животного. IRES предусматривает независимую сторону входа рибосомы для трансляции открытой рамки считывания непосредственно вниз по цепи (в настоящем изобретении понятие «вниз по цепи» используют взаимозаменяемо с 3') от нее. В отличие от бактериальной иРНК, которая может быть полицистронной, т.е. может кодировать несколько разных полипептидов, которые последовательно транслируются с молекул иРНК, большинство молекул иРНК животных клеток моноцистронны и кодируют синтез только одного белка. В случае моноцистронного транскрипта в эукариотических клетках, трансляция может инициироваться с 5'-конца сайта инициации трансляции, терминироваться по первому стоп-кодону, и транскрипт может быть высвобожден с рибосомы, приводя к трансляции только первого кодируемого полипептида в иРНК. В эукариотических клетках полицистронный транскрипт, у которого IRES функционально связана со второй или последующей открытой рамкой считывания в транскрипте, допускает последовательную трансляцию транскрипта, расположенного ниже по цепи открытой рамки считывания для получения двух или нескольких полипептидов, кодируемых тем же транскриптом. Применение элементов IRES в конструкции вектора было описано ранее, см., например, Pelletier J. и др., Nature 334, 1988, сс.320-325, Jang S.K. и др., J. Virol. 63, 1989, сс.1651-1660, Davies M.V. и др., J. Virol. 66, 1992, сс.1924-1932, Adam М.А. и др., J. Virol. 65, 1991, сс.4985-4990, Morgan, R.A. и др., Nucl. Acids Res. 20, 1992, сс.1293-1299; Sugimoto Y. и др., Biotechnology 12, 1994, сс.694-698, Ramesh N. и др., Nucl. Acids Res. 24, 1996, сс.2697-2700, Mosser D.D. и др., BioTechniques 22, 1997, сс.150-161).
Понятие «функционально связанный» означает непосредственное соседство двух или нескольких компонентов, причем такие компоненты находятся во взаимодействии, позволяя им функционировать предназначенным образом. Например, промотор и/или энхансер функционально связан с кодирующей последовательностью, если он действует в cis-положении для контроля или модулирования транскрипции связанной последовательности. Обычно, но не непременно, последовательности ДНК, являющиеся «функционально связанными», расположены рядом и, если необходимо, объединяют две области, кодирующие белки, например, секреторный лидерный и полипептид, прилегающий и в рамке (считывания). Однако, хотя функционально связанный промотор обычно расположен перед кодирующей последовательностью, он не обязательно расположен рядом с ней. Энхансер функционально связан с кодирующей последовательностью, если энхансер повышает транскрипцию кодирующей последовательности. Функционально связанные энхансеры могут быть расположены выше по цепи, внутри или ниже кодирующих последовательностей и на существенном расстоянии от промотора. Сайт полиаденилирования функционально связан с кодирующей последовательностью, если он расположен ниже по цепи к концу кодирующей последовательности таким образом, что транскрипция продолжается через кодирующую последовательность на последовательность полиаденилирования. Стоп-кодон трансляции функционально связан с последовательностью экзонной нуклеиновой кислоты, если он расположен по расположенному ниже по цепи концу (3'-концу) кодирующей последовательности таким образом, что трансляция происходит с кодирующей последовательности до стоп-кодона и на нем заканчивается. Связывание выполняют методами рекомбинации, известными в данной области, например, с помощью ПЦР и/или лигированием по соответствующим сайтам рестрикции. Если соответствующих сайтов рестрикции нет, тогда используют синтетические олигонуклеотидные адаптеры или линкеры в соответствии с обычной практикой.
Понятия «гетерологичная ДНК» или «гетерологичный полипептид» относятся к молекуле ДНК или к полипептиду, или к популяции молекул ДНК, или популяции полипептидов, которые в естественных условиях в данной клетке-хозяине отсутствуют. Молекулы ДНК, гетерологичные для определенных клеток-хозяев, могут содержать ДНК, полученную от видов клеток-хозяев (т.е. эндогенную ДНК), длина которой такова, что ДНК хозяина комбинирована с ДНК, не принадлежащей хозяину (т.е. экзогенной ДНК). Например, молекулу ДНК, содержащую сегмент ДНК не от хозяина, кодирующий полипептид, функционально связанный с сегментом ДНК хозяина, включающего промотор, оценивают в качестве молекулы гетерологичный ДНК. И наоборот, молекула гетерологичной ДНК может включать эндогенный структурный ген, функционально связанный с экзогенным промотором.
Пептид или полипептид, кодированный молекулой ДНК, не являющейся ДНК хозяина, является «гетерологичным пептидом или полипептидом.
Понятие «экспрессирующая плазмида» в контексте настоящего изобретения означает молекулу нуклеиновой кислоты, кодирующую белок, экспрессируемый в клетке-хозяине. Обычно экспрессирующая плазмида включает прокариотическую плазмидную единицу размножения, например, для Е. coli, включающую репликон, и селективный маркер, эукариотический селективный маркер и одну или несколько экспрессирующих кассет для экспрессии исследуемого структурного гена (генов), каждая из которых включает промотор, структурный ген и терминатор транскрипции, включая сигнал полиаденилирования. Экспрессию гена обычно помещают под контроль промотора, и такой структурный ген называют «функционально связанным» с промотором. Сходным образом регуляторный элемент и коровый промотор функционально связаны, если регуляторный элемент модулирует действие корового промотора.
Понятие «выделенный полипептид» означает полипептид, который в существенной степени свободен от загрязняющих клеточных компонентов, например, углеводов, липидов белковых и других, связанных с полипептидами в природе. Обычно препарат выделенного полипептида содержит полипептид в высокоочищенной форме, т.е. по меньшей мере примерно 80% чистоты, по меньшей мере примерно 90% чистоты, по меньшей мере примерно 95% чистоты, более 95% чистоты или более 99% чистоты. Одним из способов показать, что препарат определенного белка содержит выделенный полипептид, является формирование одной полосы после натрий додецилсульфат-полиактирамидного гель-электрофореза белкового препарата и окраски геля красителем кумаси синим. Однако понятие «выделенный» не исключает того же полипептида в других физических формах, например, димерах или в другом случае гликозилированных или производных форм.
Понятие «терминатор транскрипции» в контексте настоящего изобретения означает последовательность ДНК из 50-750 пар оснований в длину, которая подает РНК-полимеразе сигнал прекращения синтеза иРНК. Высокоэффективные (сильнодействующие) терминаторы с 3'-конца экспрессирующей кассеты могут быть применены для предупреждения считывания РНК-полимеразой, особенно при использовании сильных промоторов. Неэффективные терминаторы транскрипции могут привести к формированию оперон-подобной иРНК, которая может стать причиной нежелательной, например, кодируемой плазмидой, генной экспрессии.
Приводимые ниже примеры, перечень последовательностей и фигуры предусмотрены для лучшего объяснения настоящего изобретения, истинная область охвата которого приведена ниже в прилагаемой формуле изобретения. Очевидно, что модификации могут быть получены в действиях, указанных ниже без отклонения от духа настоящего изобретения.
Описание последовательностей
SEQ ID NO:01. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgA человека.
SEQ ID NO:02. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgD человека.
SEQ ID NO:03. С-концевая часть аминокислотной последовательности константного домена (CH4) тяжелой цепи иммуноглобулина класса IgE человека.
SEQ ID NO:04. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgM человека.
SEQ ID NO:05. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG1 человека.
SEQ ID NO:06. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG2 человека.
SEQ ID NO:07. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG3 человека.
SEQ ID NO:08. С-концевая часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG4 человека.
SEQ ID NO:09. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgA человека.
SEQ ID NO:10. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgD человека.
SEQ ID NO:11. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH4) тяжелой цепи иммуноглобулина класса IgE человека.
SEQ ID NO:12. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH4) тяжелой цепи иммуноглобулина класса IgM человека.
SEQ ID NO:13, 28. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG1 человека (варианты 1 и 2).
SEQ ID NO:14, 29. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG2 человека (варианты 1 и 2).
SEQ ID NO:15. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG3 человека.
SEQ ID NO:16. Нуклеиновая кислота, кодирующая С-концевую часть аминокислотной последовательности константного домена (CH3) тяжелой цепи иммуноглобулина класса IgG4 человека.
SEQ ID NO:17. Нуклеиновая кислота по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH3) иммуноглобулина класса IgA человека.
SEQ ID NO:18. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH4) иммуноглобулина класса IgE.
SEQ ID NO:19. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH4) иммуноглобулина класса IgM.
SEQ ID NO:20, 30. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH3) иммуноглобулина класса IgG1 (варианты 1 и 2).
SEQ ID NO:21,31. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH3) иммуноглобулина класса IgG2 (варианты 1 и 2).
SEQ ID NO:22. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH3) иммуноглобулина класса IgG3.
SEQ ID NO:23. Последовательность нуклеиновой кислоты по настоящему изобретению, кодирующая часть аминокислотных последовательностей С-концевого константного домена (CH3) иммуноглобулина класса IgG4.
SEQ ID NO:24-27. Праймеры нуклеиновых кислот, используемых в примерах.
Описание фигур
Фиг.1. Аннотированная карта плазмиды р4831.
Фиг.2. SDS-PAGE and Western blot analysis антител, секретируемых клоном №23; а) окрашивание красителем кумаси синим, б) анализ методом вестерн-блоттинга с применением пероксидазы, соединенной с антителом против цепи иммуноглобулина гамма человека, в) анализ методом вестерн-блоттинга с применением пероксидазы, соединенной с антителом против легкой цепи иммуноглобулина каппа человека. Полоса 1: анти-IGF-1R-контрольное антитело человека; полоса 2: культура супернатанта клеток CHO-DG44 клона №23, включающая антитело клона №23.
Фиг.3. Аннотированная карта плазмиды р4817.
Фиг.4. Анализ методом вестерн-блоттинг иммуноглобулинов, секретированных клетками CHO-DXB11, трансфецированными р4831 или 4855. Полоса 1: клетки СНО, трансфецированные р4831, полоса 2: клетки СНО, трансфецированные р4855.
Фиг.5. Аннотированная карта плазмиды р5031.
Фиг.6. SDS-PAGE анализ антител, секретированных клетками НЕК-293-EBNA после трансфекции плазмидой р5031 или р5032; полоса 1+2: р5031, полосы 3+4: р5032, полосы 5-8: антитело человека против IGF-1R выступает в качестве контрольного антитела; 5: 0,2 мкг, 6: 0,7 мкг, 7: 2 мкг, 8: 6 мкг.
Фиг.7. Клетки CHO-DG44, трансфецированные плазмидой р5032 и отобранные по стабильной интеграции плазмиды с метотрексатом. Антитела от шести клонов очищают и анализируют методом SDS-PAGE и окрашиванием кумаси.
Материалы и методы
Методы рекомбинантной ДНК
Для работы с ДНК используют стандартные методы, описанные Sambrook и др., 1989 (см. выше). Все реагенты из области молекулярной биологии коммерчески доступны (если не указано иначе) и применяются согласно инструкциям производителя.
Определение последовательности нуклеиновой кислоты
Последовательности ДНК определяют двухцепочечным секвенированием, выполняемым MediGenomix GmbH (Martinsried, Германия).
Анализ последовательностей ДНК и белков и работа с получаемыми результатами
Программное обеспечение GCG's (Genetics Computer Group, Мэдисон, Висконсин, США) версии 10.2 и Infbmax's Vector NTI Advance suite версии 8.0 используют для создания последовательности, картирования, аннотирования и иллюстрирования.
Методы работы с культурами клеток
Клетки CHO-DXB11 выращивают в среде MEM альфа (фирма Invitrogen Corp., Gibco®, номер в каталоге: 22571) с 10% ФСТ (фетальной сывороткой теленка, полученной от фирмы Hyclone, Thermo Fisher Scientific Inc., номер в каталоге: SH3007.03).
Клетки HEK-293-EBNA (коллекция АТСС, №CRL-10852) культивируют в среде DMEM (модифицированной по способу Дульбекко среде Игла) с добавлением 2 мМ глутамина (фирма Gibco®, номер в каталоге: 25030), 1 об.% MEM (минимальной поддерживающей среды) аминокислот, не являющихся незаменимыми (продукт Gibco®, номер в каталоге: 11140), 10 об.% ФСТ с ультранизким содержанием IgG (продукт Gibco®, номер в каталоге: 16250) и 250 мкг/мл G418 (фирма Roche Applied Sciences, Roche Diagnostics GmbH, Германия, номер в каталоге: 1464981).
Средой для культивирования клеток CHO-DG44 является среда MEM альфа (продукт Gibco®, Cat. No.: 22561) с добавлением 10 об.% диализированной ФСТ (продукт Gibco®, номер в каталоге: 26400) и 2 об.% НТ (продукт Gibco®, номер в каталоге: 41065). Для отбора стабильно трансфецированных клеточных линий СНО DG44 добавку НТ не вносят, а добавляют от 20 до 500 нМ метотрексата либо отдельно, либо в комбинации с 400 мкг/мл гигромицина В (фирма Roche Diagnostics GmbH, Roche Applied Sciences, Германия, номер в каталоге: 10843555001).
Все клеточные линии поддерживают во влажных инкубаторах при 37°С в атмосфере 5% СО2. Трансфекцию клеток проводят либо путем нуклеофекции (фирма Amaxa GmbH, Германия), либо путем липофекции, используя FuGENE 6 (фирма Roche Diagnostics GmbH, Roche Applied Sciences, Германия, номер в каталоге: 1815075).
Кроме того, стандартные методики культивирования клеток используют согласно описанию, например, в кн.: «Current Protocols in Cell Biology», 2000, под ред. Bonifacino J.S. и др., изд. John Wiley and Sons, Inc.
Осаждение белком A, SDS-PAGE и вестерн-блоттинг
Иммуноглобулины из супернатантов культур клеток осаждают на гранулах белка А-сефарозы и затем анализируют методом SDS/полиакриламидного гель-электрофореза (натрий додецилсульфат, SDS-PAGE) и вестерн-блоттингом.
Для осаждения иммуноглобулинов супернатанты культур клеток, содержащие до 7 мкг иммуноглобулина, разводят буфером TBS (50 мМ TRIS/HCl, рН 7,5, обогащенным 150 мМ Nad), 1 об.% Nonidet-P40 (фирма Roche Diagnostics GmbH, Roche Applied Sciences, номер в каталоге 1754599) до конечного объема 1 мл и затем инкубируют в течение 1 ч с 15 мкл влажного объема белка А-гранулами сефарозы. Гранулы восстанавливают центрифугированием и промывают TBS с 1 об.% Nonidet P-40, затем двойной концентрации ФСБ (фосфатно солевым буфером) и в заключение - 10 мМ буфером цитрата натрия, рН 5. После последнего промывания супернатант полностью удаляют от гранул. Связанные иммуноглобулины элюируют 20 мкл образца буфера с двойной концентрацией додецилсульфата лития (фирма Invitrogen Corp.), содержащего 50 мМ дитиотреитола. Через 5 мин инкубирования при 95°С суспензию центрифугируют и супернатант собирают для дальнейшего анализа.
SDS-PAGE: SDS-PAGE проводят, используя систему геля NuPAGE® (фирма Invitrogen Corp.) по рекомендациям производителя. Образцы загружают в гели 10% NuPAGE® Novex Bis/TRIS (фирма Invitrogen Corp., номер в каталоге: NP0301) и разделяют белки в проточном буфере с понижением NuPAGE® MES SDS (4-морфолиноэтансульфоновая кислота/натрий додецилсульфат). Обычно загружают 2-3 мкг иммуноглобулина на полосу для окрашивания кумаси с помощью препарата красителя Simply Blue Safe Stain® (фирма Invitrogen Corp.) и 0,4-0,6 мкг для вестерн-блоттинга.
Вестерн-блоттинг: для электропереноса белков из SDS/полиакриламидных гелей используют стандартные поливинилиден дифторидные (polyvinylidene difluoride - PVDF) или нитроцеллюлозные мембраны. После электропереноса мембраны промывают в TBS (физиологический раствор, забуференный трисом, 50 мМ TRIS/HCl, рН 7,5, 150 мМ NaCl). Сайты неспецифического связывания блокируют инкубированием в TBS с 1 мас.% реагентом для вестерн-блоттинга (фирма Roche Diagnostics GmbH, Roche Applied Sciences, номер в каталоге: 11921673001). Цепи тяжелой цепи и цепи легкой цепи иммуноглобулина гамма выявляют с помощью поликлональных антител для обнаружения, соединенных с пероксидазой (подробнее см. следующий параграф), разведенных в TBS с 0,5 мас.% реагентом для вестерн-блоттинга. После трех стадий промывки в TBS с 0,05 об.% Tween® 20 и одной стадии промывки в TBS связанные с пероксидазой антитела для выявления обнаруживают с помощью хемолюминесценции, используя раствор субстрата LumiLightPlus (фирма Roche Diagnostics GmbH, Roche Applied Sciences, номер в каталоге: 12015196001) и анализатор LUMI-Imager F1 (фирма Roche Diagnostics GmbH, Roche Applied Sciences).
Тяжелые цепи (Н) иммуноглобулина гамма человека и легкие цепи (L) иммуноглобулина каппа человека обнаруживают одновременно или раздельно. Для одновременного обнаружения используют пероксидазу, соединенную с антителом козы против IgG (H+L) человека (фирма Jackson ImmunoResearch Laboratories Inc., номер в каталоге: 109-035-088) в разведении 1:2500 (по объему). Для последующего выявления мембраны сначала зондируют пероксидазой, соединенной с антителом кролика против Ig человека (фирма DAKO GmbH, Германия, номер в каталоге: Р0214), в разведении 1:1000 (по объему), или с пероксидазой, соединенной с фрагментом F(ab')2 козы против Fc гамма человека (фирма Jackson ImmunoResearch Laboratories, номер в каталоге: 109-036-008), в разведении 1:7500 (по объему). После обнаружения тяжелой цепи иммуноглобулина гамма мембраны зачищают в течение 30 мин в 62,5 мМ TRIS/HCl, рН 6,7, с добавлением 2 мас.% SDS и 100 мМ β-меркаптоэтанола при 50°С. Для второго обнаружения мембраны заново зондируют пероксидазой, соединенной с антителом кролика против Ig каппа человека (фирма DAKO GmbH, номер в каталоге: Р0129), в разведении 1:1000 (об./об.).
Пример 1. Получение экспрессирующей плазмиды для иммуноглобулина класса IgG1
Плазмида 4831 (называемая в дальнейшем «р4831») является экспрессирующей плазмидой для экспрессии анти-IGF-1R-антитела (геномно организованная экспрессирующая кассета с сохраненной организацией экзон-интрон) в эукариотических клетках (последовательности см., например, в US 2005/0008642 или ЕР 1 646 720). Она включает следующие функциональные элементы:
- репликон, производный от вектора pUC18 (репликон pUC),
- ген β(бета)-лактамазы, определяющий устойчивость к ампициллину у Е. coli (Amp),
- экспрессирующую кассету для экспрессии гамма 1-тяжелой цепи, включающую следующие элементы:
- главный очень ранний промотор и энхансер из цитомегаловируса человека (промотор hCMV IE1),
- синтетический 5'UTR, включающий последовательность Kozak,
- сигнальную последовательность тяжелой цепи иммуноглобулина мыши, включающую интрон сигнальной последовательности (L1_интрон_L2),
- кДНК для вариабельной области тяжелой цепи (VH), соединенную с сайтом сплайсирования донора с 3'-конца,
- область энхансера иммуноглобулина µ мыши,
- ген тяжелой цепи гамма 1 иммуноглобулина человека (human immunoglobulin heavy chain gamma 1-gene - IGHG1), включая экзоны CH1, шарнирную область, СН2 и СН3, инвертированные интроны и 3'UTR, несущий сигнальную последовательность полиаденилирования и необязательно содержащий мутации,
- экспрессирующую кассету для экспрессии каппа-легкой цепи, включающую следующие элементы:
- главный очень ранний промотор и энхансер от цитомегаловируса человека (промотор hCMV IE1), включающий последовательность Kozak,
- сигнальную последовательность тяжелой цепи иммуноглобулина мыши, включающую интрон (L1_интрон_L2),
- кДНК для вариабельной области легкой цепи (VL),соединенную с сайтом сплайсирования донора с 3'-конца,
- энхансерная область интрона Ig-каппа мыши,
- ген иммуноглобулина каппа человека (human immunoglobulin kappa gene - IGK), включающий экзон IGKC и IGK 3'UTR, несущий сигнальную последовательность полиаденилирования,
- единицу транскрипции гигромицин В-фосфотрансферазы, применимую для отбора в эукариотических клетках, включающую
- ранний промотор и репликатор вируса SV40,
- последовательность, кодирующую гигромицин В фосфотрансферазу (HygB),
- ранний сигнал полиаденилирования SV40,
- экспрессирующую кассету дигидрофолатредуктазы (dihydrofolate reductase - DHFR), применимую для отбора ауксотрофов в эукариотических клетках, включающую
- укороченную версию раннего промотора и репликатора SV40,
- кодирующую последовательность DHFR мыши,
- ранний сигнал полиаденилирования SV40.
Аннотированная карта плазмиды р4831 представлена на фиг.1.
Р4831 трансфецируют в клетки CHO-DG44 и выделяют стабильные клеточные линии после отбора на фоне гигромицина В и метотрексата. Антитела, секретируемые клоном №23, осаждают с помощью белок А-сефарозных гранул и анализируют методом SDS-PAGE с окрашиванием кумаси (фиг.2а)). Помимо ожидаемой тяжелой цепи иммуноглобулина гамма-1 массой 50 кДа и легкой цепи иммуноглобулина каппа массой 25 кДа обнаруживают существенные количества побочного продукта белка массой 80 кДа. Этот белок распознают с помощью антител против цепи иммуноглобулина гамма человека (фиг.2б)), а также антител против цепи иммуноглобулина каппа человека (фиг.2в)).
Пример 2. Получение экспрессирующей плазмиды для иммуноглобулина класса IgG1 с модифицированным СН3-доменом
Для предупреждения образования побочных продуктов, возникающих в результате неправильно сплайсированного гамма 1 иРНК-предшественницы, внутренний сайт сплайсирования экзона СН3 exon плазмиды р4831 разрушают путем мутирования Т в положении 4573 на С. В то же время Т4567 замещают на С для удаления сайта рестрикции BsmA I.
Р4855 конструируют следующим образом. Плазмида р4817, исходная плазмида для плазмиды р4831 с той же единицей транскрипции тяжелой цепи гамма 1, состоит из следующих элементов:
- репликатора от вектора pUC18, который допускает репликацию этой плазмиды в Е. coli (pUC Ori)
- гена бета-лактамазы, который обусловливает устойчивость к ампициллину у Е. coli (Amp)
- экспрессирующей кассеты для экспрессии тяжелой цепи гамма, включающей следующие элементы:
- главный очень ранний промотор и энхансер из цитомегаловируса человека (промотор hCMV IE1),
- синтетический 5'UTR, включающий последовательность Kozak,
- сигнальную последовательность тяжелой цепи иммуноглобулина мыши, включающую интрон сигнальной последовательности (L1_интрон_L2),
- кДНК для вариабельной области тяжелой цепи (VH), соединенную с сайтом сплайсирования донора с 3'-конца,
- область энхансера иммуноглобулина µ мыши,
- ген тяжелой цепи гамма 1 иммуноглобулина человека (human immunoglobulin heavy chain gamma 1-gene - IGHG1), включающий экзоны СН1, шарнирную область, СН2 и СН3, внедряющий интроны и 3'UTR, несущий сигнальную последовательность полиаденилирования и необязательно содержащий мутации.
Карта плазмиды р4817 показана на фиг.3.
Плазмиду Р4817 изменяют сайт-направленным мутагенезом, используя набор для сайт-направленного мутагенеза QuickChange Site-Directed Mutagenesis Kit (фирма Stratagene, номер в каталоге: 200518) и олигонуклеотиды специфической последовательности 1 agcctctccc tgtccccggg caaatgagtg cgacggccg (SEQ ID NO:24) и 2 cggccgtcgc actcatttgc ccggggacag ggagaggct (SEQ ID NO:25).
Фрагмент SfiI/SgrAI размером 839 п.о. мутантной плазмиды р4817 вырезают и лигируют с фрагментом SgrAI/SfiI размером 13133 п.о. плазмиды р4831 для формирования плазмиды р4855.
Пример 3. Экспрессия нуклеиновых кислот согласно примерам 1 и 2, выделение выработанного иммуноглобулина и анализ выработанного иммуноглобулина
Плазмиды р4831 и р4855 временно трансфецируют в клетки CHO-DXB11. Клетки культивируют в неселективных условиях. Через трое суток культивирования супернатанты культур клеток собирают и секретированные иммуноглобулины очищают белок А-сефарозными гранулами. Анализ методом вестерн-блоттинга иммуноглобулинов антителами против IgG человека (H+L) показывает, что побочный продукт массой 80 кДа экспрессируется клетками, трансфецированными плазмидой р4831, но не клетками, трансфецированными плазмидой р4855 (фиг.4).
Пример 4. Получение экспрессирующей плазмиды для иммуноглобулина класса IgG4
Плазмиду 5031 создают для кратковременной и стабильной экспрессии антитела против Р-селектина человека в культуре ткани эукариотических клеток. Примеры антител против Р-селектина см., например, в ЕР 1737891 или US 2005/0226876. Плазмида Р5031 состоит из следующих элементов:
- репликатора от вектора pUC18, который допускает репликацию указанной плазмиды в Е. coli (репликатор pUC),
- гена В-лактамазы, который определяет устойчивость к ампициллину у Е. coli (Amp),
- экспрессирующей кассеты для экспрессии гамма 4-тяжелой цепи человека, включающей следующие элементы:
- главный очень ранний промотор и энхансер от цитомегаловируса человека (промотора hCMV IE1),
- синтетический 5'UTR, включающий последовательность Kozak,
- сигнальную последовательность тяжелой цепи иммуноглобулина мыши, включающую интрон сигнальной последовательности (L1_интрон_L2),
- кДНК для вариабельной области тяжелой цепи (VH), соединенную с сайтом сплайсинга донора с 3'-конца,
- область энхансера Ig µ мыши,
- ген тяжелой цепи гамма 4 иммуноглобулина человека (human immunoglobulin heavy chain gamma 4-gene - IGHG4), включающий экзоны СН1, шарнирную область, СН2 и СН3, промежуточные интроны и 3'UTR, несущий сигнальную последовательность полиаденилирования и необязательно содержащий мутации,
- экспрессирующей кассеты для экспрессии легкой цепи каппа человека, включающей следующие элементы:
- главный очень ранний промотор и энхансер из цитомегаловируса человека (промотор hCMV IE1),
- синтетический 5'UTR, включающий последовательность Kozak,
- сигнальную последовательность тяжелой цепи иммуноглобулина мыши, включающую интрон сигнальной последовательности (L1_интрон_L2),
- кДНК для вариабельной области легкой цепи (VL), соединенную с сайтом сплайсирования донора с 3'-конца,
- энхансерная область интрона Ig-каппа мыши,
- ген иммуноглобулина каппа человека (human immunoglobulin kappa gene - IGK), включающий экзон IGKC и IGK 3'UTR, несущий сигнальную последовательность полиаденилирования,
- единицы транскрипции гигромицин В-фосфотрансферазы, применимой для отбора в эукариотических клетках, включающей
- ранний промотор и репликатор SV40,
- последовательность, кодирующая гигромицин В фосфотрансферазу (HygB),
- ранний сигнал полиаденилирования SV40,
- экспрессирующей кассеты для экспрессии дигидрофолатредуктазы (dihydrofolate reductase - DHFR) мыши, применимой для ауксотрофного отбора в эукариотических клетках, включающей
- укороченную версию раннего промотора и репликатора SV40,
- кодирующую последовательность DHFR грызуна,
- ранний сигнал полиаденилирования SV40.
Плазмидная карта плазмиды р5031 представлена на фиг.5.
Если клетки HEK-293-EBNA трансфецированы плазмидой р5031, они вырабатывают иммуноглобулины, включая побочный продукт массой 80 кДа (фиг.6, полоса 1 и 2). По данным анализа методом вестерн-блоттинга этот белок связывается антителом против Ig гамма человека, а также антителом против Ig каппа человека.
Пример 5. Получение экспрессирующей плазмиды для иммуноглобулина класса IgG4 с модифицированным СН3-доменом
Модификацию внедряют согласно примеру 3. Вкратце, Т4565 мутируют на С вместе со вторым нуклеотидом, Т4559, который также заменяют на С для удаления сайта рестрикции BsmAI. Олигонуклеотид 3 gcctctccct gtccctgggc aaatgagtgc cagg (SEQ ID NO:26) и олигонуклеотид 4 cctggcactc atttgcccag ggacagggag aggc (SEQ ID NO:27) используют для сайт-направленного мутагенеза. Полученную плазмиду обозначают р5032.
Пример 6. Экспрессия нуклеиновых кислот по примеру 5, выделение полученного иммуноглобулина и анализ полученного иммуноглобулина
Плазмиды р5031 и р5032 временно трансфецируют в клетки НЕК-293-EBNA. Клетки выращивают в неселективных условиях. После трех суток культивирования супернатанты культур клеток собирают, и сформировавшиеся иммуноглобулины очищают с помощью белок А-сефарозных гранул. Анализ иммуноглобулинов методом вестерн-блоттинга с помощью антител против IgG человека (H+L) показывает, что клетки, трансфецированные плазмидой р5031, экспрессируют побочный продукт массой 80 кДа (фиг.6, полосы 1+2), но побочные продукты не экспрессируют клетки, трансфецированные плазмидой р5032 (фиг.6, полосы 3+4).
В клетках HEK-293-EBNA, трансфецированных плазмидой р5032, белок массой 80 кДа не экспрессируется (фиг.6, полосы 3 и 4). Этот результат четко указывает на то обстоятельство, что гибридный белок массой 80 кДа возникает вследствие нарушенного сплайсинга иРНК-предшественницы, поэтому выработка такого нежелательного белка во время временной экспрессии может быть эффективно подавлена мутацией внутреннего сайта сплайсинга СНЗ гена тяжелой цепи иммуноглобулина гамма 4 (immunoglobulin heavy chain gamma 4 gene - IGHG4).
Мутация внутреннего сайта сплайсинга CH3 в IGHG4 предупреждает экспрессию соединения массой 80 кДа также в стабильных линиях клеток. Клетки CHO-DG44 были трансфецированы плазмидой р5032 и отобраны по стабильной интеграции плазмиды с метотрексатом. Антитела 6 клонов очищают и анализируют с помощью SDS-PAGE и окрашивания красителя кумаси (фиг.7). Ни одно из антител не содержит субъединицы массой 80 кДа.
| название | год | авторы | номер документа |
|---|---|---|---|
| ГЛИКОЗИЛИРОВАННЫЕ КОНЪЮГАТЫ МОЛЕКУЛ С ПОВТОРЯЮЩИМСЯ МОТИВОМ | 2010 |
|
RU2574201C2 |
| СПОСОБ ПОЛУЧЕНИЯ ПОЛИПЕПТИДОВ | 2015 |
|
RU2699715C2 |
| ПРОМОТОР | 2008 |
|
RU2491344C2 |
| БЫСТРЫЙ СПОСОБ КЛОНИРОВАНИЯ И ЭКСПРЕССИИ СЕГМЕНТОВ ГЕНА РОДСТВЕННОЙ ВАРИАБЕЛЬНОЙ ОБЛАСТИ АНТИТЕЛА | 2012 |
|
RU2612910C2 |
| СПОСОБЫ ПОЛУЧЕНИЯ ДВУЦЕПОЧЕЧНЫХ БЕЛКОВ В БАКТЕРИЯХ | 2015 |
|
RU2705274C2 |
| ВЫДЕЛЕННЫЙ РАСТВОРИМЫЙ IL-20 РЕЦЕПТОР (ВАРИАНТЫ) | 2000 |
|
RU2279441C2 |
| ИНТРАТЕКАЛЬНОЕ ВВЕДЕНИЕ ВЕКТОРОВ НА ОСНОВЕ АДЕНОАССОЦИИРОВАННЫХ ВИРУСОВ ДЛЯ ГЕННОЙ ТЕРАПИИ | 2016 |
|
RU2775138C2 |
| СЛИТНЫЕ БЕЛКИ ИММУНОГЛОБУЛИНОВ | 2008 |
|
RU2530168C2 |
| МЕЧЕНЫЕ АЛЬДЕГИДОМ ПОЛИПЕПТИДЫ ИММУНОГЛОБУЛИНА И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2012 |
|
RU2606016C2 |
| ВАРИАНТЫ КОШАЧЬИХ АНТИТЕЛ | 2021 |
|
RU2840969C1 |













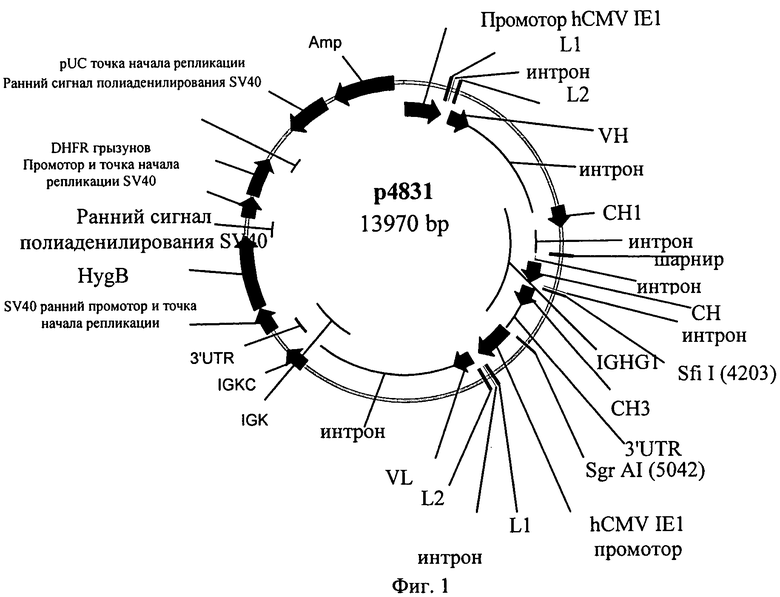
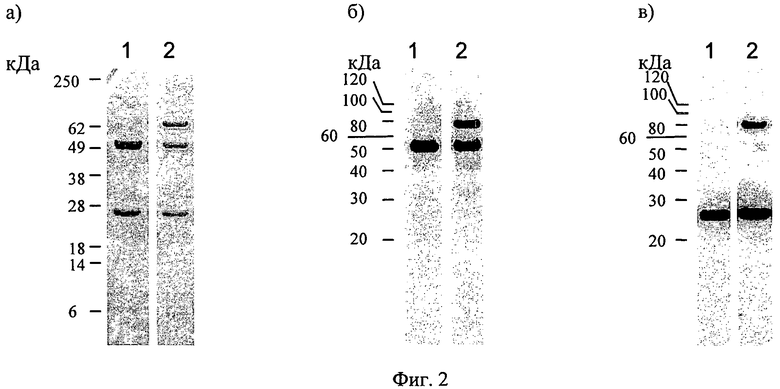
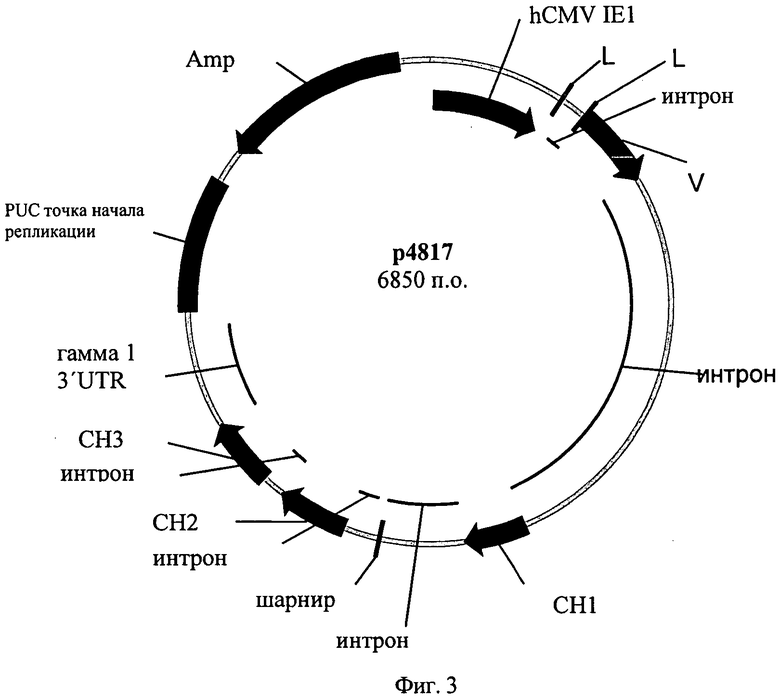
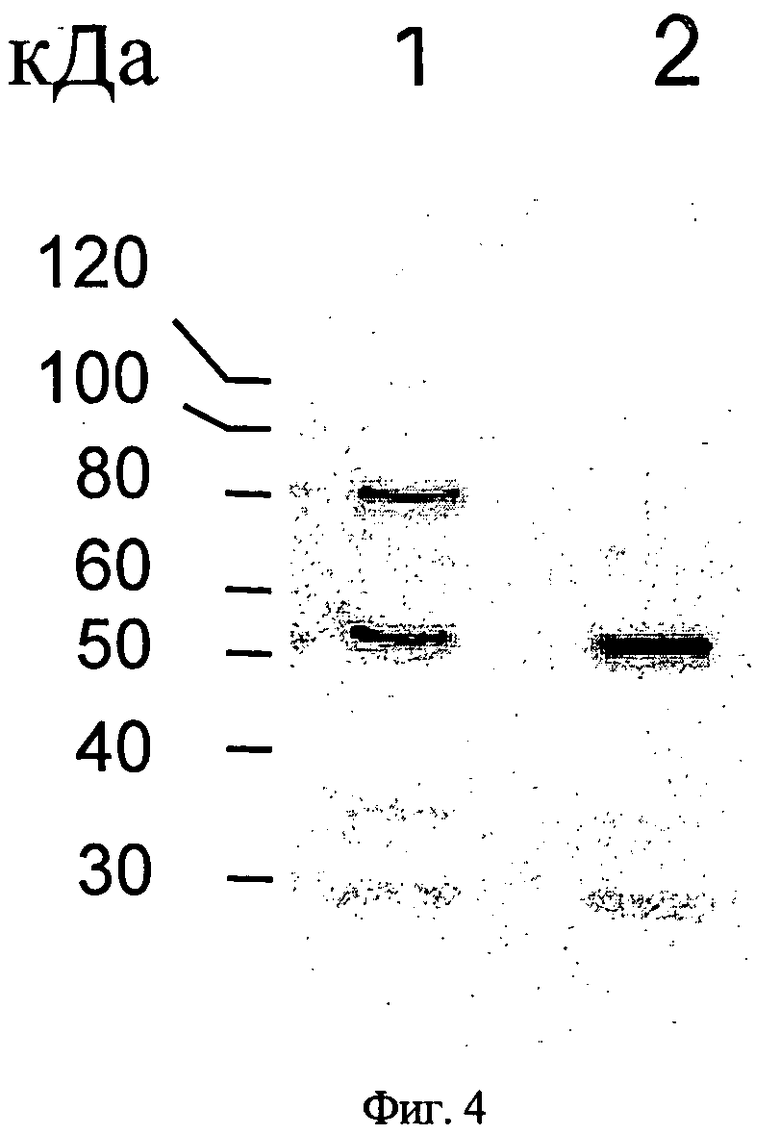
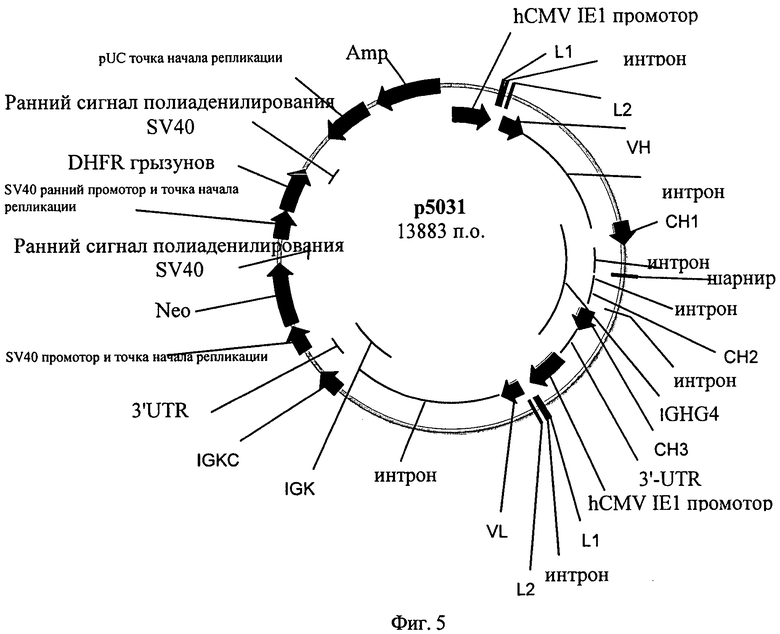
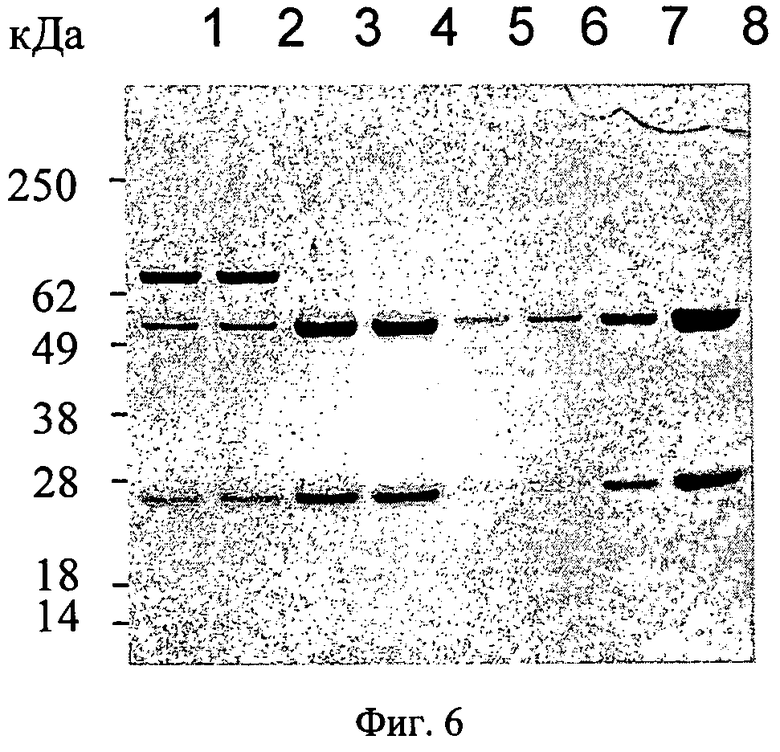
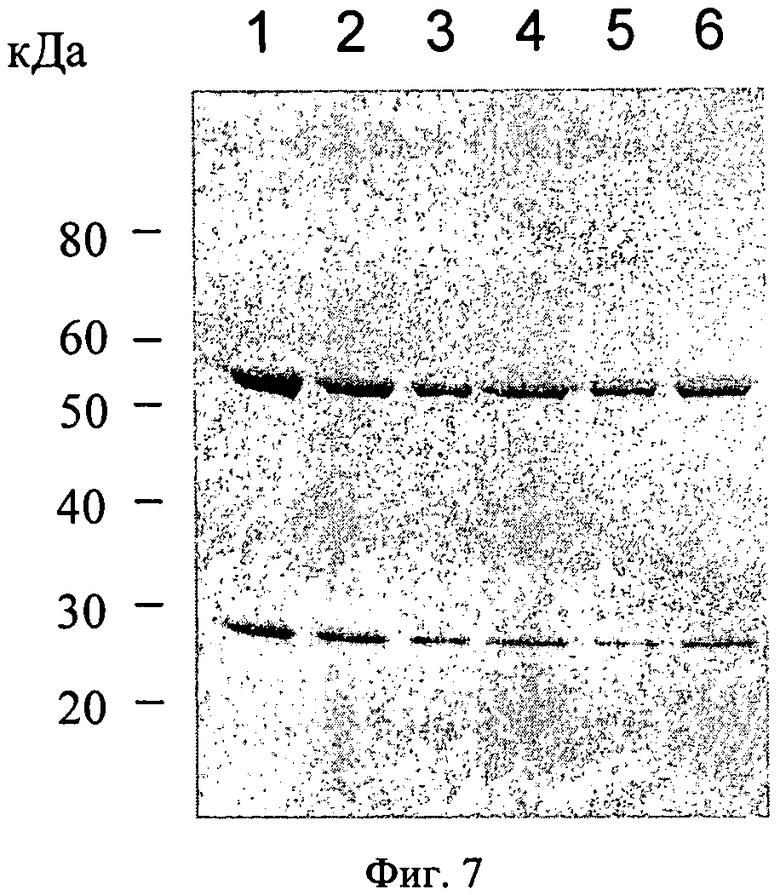
Настоящее изобретение относится к иммунологии и биотехнологии. Предложены варианты нуклеиновых кислот, каждый из которых кодирует аминокислотную последовательность тяжелой цепи иммуноглобулина IgG1. Указанная цепь содержит на С-конце СН3-домена глицин-лизиновый дипептид, кодируемый кодоном ggaaaa, ggcaaa или gggaaa. Описаны: плазмида, кодирующая тяжелую цепь иммуноглобулина; клетки-варианты, обеспечивающие экспрессию иммуноглобулина IgG1; способ получения иммуноглобулина в клетках млекопитающего; способ улучшения экспрессии иммуноглобулина в клетках млекопитающего; - использующие варианты нуклеиновой кислоты. Использование изобретения обеспечивает предупреждение экспрессии побочного продукта массой 80 кДа, что может найти применение при производстве иммуноглобулинов. 7 н. и 11 з.п. ф-лы, 7 ил., 3 табл., 6 пр.
1. Нуклеиновая кислота, кодирующая аминокислотную последовательность тяжелой цепи иммуноглобулина подкласса IgG1, отличающаяся тем, что глицин-лизиновый дипептид, расположенный в области С-концевой части CH3-домена, кодируется нуклеиновой кислотой ggaaaa, или нуклеиновой кислотой ggcaaa, или нуклеиновой кислотой gggaaa.
2. Нуклеиновая кислота по п.1, отличающаяся тем, что указанная С-концевая часть включает по меньшей мере 20 С-концевых аминокислот первичной аминокислотной последовательности тяжелой цепи иммуноглобулина.
3. Нуклеиновая кислота по п.1, отличающаяся тем, что указанная часть С-концевого константного домена тяжелой цепи выбрана из нуклеиновых кислот SEQ ID NO: 20 или 30.
4. Нуклеиновая кислота по п.3, отличающаяся тем, что она содержит нуклеотидную последовательность SEQ ID NO: 20.
5. Нуклеиновая кислота по п.3, отличающаяся тем, что она содержит нуклеотидную последовательность SEQ ID NO: 30.
6. Плазмида, кодирующая тяжелую цепь иммуноглобулина подкласса IgG1 и включающая нуклеиновую кислоту по п.1.
7. Клетки, обеспечивающие экспрессию тяжелой цепи иммуноглобулина подкласса IgGl и включающие нуклеиновую кислоту по п.1.
8. Клетки, обеспечивающие экспрессию иммуноглобулина подкласса IgG1 и включающие нуклеиновую кислоту по п.1.
9. Клетки по п.7 или по п.8, отличающиеся тем, что указанные клетки являются клетками млекопитающего.
10. Клетки по п.9, отличающиеся тем, что указанные клетки являются клетками млекопитающего, выбранными из клеток СНО, клеток НЕК или клеток ВНК.
11. Нуклеиновая кислота, кодирующая аминокислотную последовательность тяжелой цепи иммуноглобулина подкласса IgG1, отличающаяся тем, что она содержит нуклеотидную последовательность SEQ ID NO:20 или 30, где глицин-лизиновый дипептид, расположенный в области С-концевой части CH3-домена, кодируется нуклеиновой кислотой ggcaaa или нуклеиновой кислотой gggaaa.
12. Нуклеиновая кислота по п.11, содержащая нуклеотидную последовательность SEQ ID NO:20.
13. Нуклеиновая кислота по п.11, содержащая нуклеотидную последовательность SEQ ID NO:30.
14. Способ получения иммуноглобулина в клетках млекопитающих, включающий следующие стадии:
а) трансфекции указанных клеток млекопитающего двумя нуклеиновыми кислотами, при которой первая нуклеиновая кислота кодирует легкую цепь иммуноглобулина, а вторая нуклеиновая кислота кодирует тяжелую цепь иммуноглобулина и является нуклеиновой кислотой по п.1 или п.11,
б) культивирования трансфецированных клеток млекопитающего в условиях, пригодных для экспрессии иммуноглобулина,
в) выделения иммуноглобулина из культуры или из клеток.
15. Способ по п.14, отличающийся тем, что указанные клетки млекопитающих трансфецированы одной конструкцией, включающей экспрессирующую кассету, кодирующую тяжелую цепь иммуноглобулина, и экспрессирующую кассету, кодирующую легкую цепь иммуноглобулина.
16. Способ по п.14, отличающийся тем, что указанные клетки млекопитающих трансфецированы двумя конструкциями, причем первая включает экспрессирующую кассету, кодирующую легкую цепь иммуноглобулина, а вторая включает экспрессирующую кассету, кодирующую тяжелую цепь иммуноглобулина.
17. Способ по одному из пп.14-16, отличающийся тем, что указанные трансфецированные клетки млекопитающих содержат нуклеиновую кислоту, кодирующую тяжелую цепь иммуноглобулина, причем нуклеиновая кислота SEQ ID NO: 20 или 30 кодирует С-концевую часть тяжелой цепи иммуноглобулина.
18. Способ улучшения экспрессии иммуноглобулина в клетках млекопитающего, в котором применяется нуклеиновая кислота, кодирующая тяжелую цепь иммуноглобулина, являющаяся нуклеиновой кислотой по п.1 или п.11.
| WO2006122822 A2, 23.11.2006 | |||
| EP1508576 A1, 23.02.2005 | |||
| MEISSNER P | |||
| et al., "Transient gene expression:recombinant protein production with suspension-adapted HEK293-EBNA cells," Biotechnol | |||
| and Bioeng | |||
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| СИНГЕР и др., "Гены и геномы" в 2-х т., т.1 | |||
| Пер | |||
| с анг | |||
| М.: Мир, 1998, стр.135 | |||
| При публикации сведений о выдаче | |||

