Область техники, к которой относится изобретение
Изобретение относится к обработке цифровых данных с помощью компьютерных систем, а именно к методам обработки данных, специально предназначенных для специфических функций, мобильных приложений.
Предшествующий уровень техники
В настоящее время в мире широко известны и массово используются поисковые машины, которые обеспечивают пользователям возможность осуществлять в Интернете поиск Web-страниц, содержащих нужную для них информацию, по вводимым ими поисковым запросам. Популярными поисковыми машинами являются, в частности, Yahoo!, Google, Yandex, Rambler.
Общий принцип работы известных поисковых машин основан на сборе информации по Web-страницам в Интернете, ее обработке и индексировании для дальнейшего предоставления пользователю возможности поиска необходимой информации в том объеме, который был обработан машиной. В состав каждой поисковой машины входят поисковые роботы, целью которых является сканирование Web-страниц Интернета и их загрузка. После обращения поискового робота по указанному адресу Web-страницы он просматривает, например, http-заголовки, проверяя, когда в последний раз была модифицирована эта страница. Если поисковый робот уже просматривал данную Web-страницу, а дата последней модификации страницы изменилась, тогда он загрузит ее для обработки вновь, если же просматриваемая им Web-страница вообще не просматривалась, тогда она сразу будет загружена для обработки.
Web-страницы, загруженные поисковым роботом, обрабатываются соответствующими программно-аппаратными компонентами поисковой машины. Целью такой обработки является анализ страницы: как правило, вначале из Web-страницы извлекается заголовок (Title), поскольку он несет в себе общую информацию о Web-странице. Далее извлекается и обрабатывается весь текст, который так или иначе выделен, например, курсивом, подчеркиванием или размером (в частности, размер его шрифта больше размера шрифта основного текста), поскольку поисковая машина предполагает, что это ключевые места в тексте и на них сделан акцент.
Некоторые поисковые машины просматривают метатеги Web-страниц, предполагая, что в них имеются ключевые слова или словосочетания страницы. В то же время, поскольку в содержимом метатегов зачастую дается недостоверная информация, некоторые поисковые машины не используют их для определения ключевых слов страницы.
Также весь текст Web-страницы подвергается полной обработке. Например, те поисковые машины, которые не используют метатеги для определения ключевых слов Web-страницы, ищут ключевые слова путем выполнения проверки на предмет того, как часто встречается то или иное слово в тексте, и для этого из текста удаляются все стоп-слова, такие как <а>, <он>, <ты>, <в>, а также все символы и цифры, поскольку они создают шум при поиске ключевых слов.
Наконец, обработанный текст Web-страницы индексируется поисковой системой надлежащим образом так, чтобы предоставить пользователю посредством Web-интерфейса (например, браузера) возможность удобного поиска по базе данных поисковой машины на основе ввода поисковых запросов.
Структура и базовые принципы функционирования машин, представлены, в частности, в The anatomy of a large-scale hypertextual Web search engine, Brin, S., Page, L., Computer Networks and ISDN Systems, 30(1-7):107-117, 1998; Effective Web Crawling, Castillo, C., PhD thesis, University of Chile, 2004; Crawling the Web. Web Dynamics: Adapting to Change in Content, Size, Topology and Use, ed. by M. Levene, A. Poulovassilis, 153-178, Pant, G., Srinivasan, P., Menczer, F., 2004.
Однако построенные таким образом поисковые машины перестают отвечать требованиям сегодняшнего дня в силу все увеличивающегося объема и разнообразия информации, представляемой в Интернете. В частности, при проведении такого основывающегося на тексте поиска Web-страниц, где содержались бы интересующие пользователя картинки или видео, выдается обширный результирующий список Web-страниц, в котором доля страниц, действительно отвечающих требованиям и запросам пользователя, оказывается невелика, поскольку в данный список, в силу специфики описываемых поисковых машин, также попадут те Web-страницы, которые содержат упоминания, обсуждения, рекламу, отзывы и т.п., касающиеся требующихся картинок или видео, но непосредственно не содержат самих требующихся картинок или видео. По мере же роста совокупного объема и разнообразия Web-контента в Интернете доля релевантных Web-страниц при такого рода специфических поисках будет лишь снижаться, и, как следствие, пользователи вынуждены строить хитроумные, скорее всего неоднократные поисковые запросы и тратить время на просеивание больших массивов результатов поиска.
Этой проблемой обуславливается актуальность создания специализированных так называемых вертикальных поисковых систем, строго ориентированных на поиск по тематическим ресурсам Интернета.
Одним из примеров такой специализированной вертикальной поисковой системы является поиск приложений для мобильных телефонов. Здесь мы сталкиваемся с дополнительными ограничениями возможностей индексирования. Приложения для мобильных телефонов можно условно разделить на три группы. Первая - «Функциональные» приложения, характеризуются тем, что исполняемую ими функцию или содержащийся в них контент легко отразить в описании приложения. Вторая - приложение «клиентская часть большого сервиса (on-line кинотеатр) характеризуется тем, что основной контент подтягивается из сети, а в приложении содержатся меню и в лучшем случае описания. Третья - приложения, содержащие контент и ориентированные на автономную работу, это - «Справочник кулинарных рецептов», «Электронная библиотека», «Телефонный справочник», характеризуются тем, что лучшим их описанием является содержащийся в них контент, но реальное описание никогда его не содержит потому, что не позволяет размер.
Таким образом, на сегодняшний день существует большое и при этом быстро растущее количество контента, который не имеет адекватно отображающего его текста на Web-страницах, а основной подлежащий индексированию контент содержится внутри приложений и становится доступным только после скачивания и распаковки установочного файла.
Применяемым на сегодняшний день, способом извлечения контента, является прямой анализ установочного файла приложения, всегда некий архив. Установочный файл разархивируется, и полученный каталог просматривается вручную человеком. На основе априорных знаний человека о том, как формируется контент и как он отображается на экране, человек классифицирует содержимое файлов с данными, определяет смысл содержания файлов, после чего он пишет программный код. Данный код призван решить следующие задачи: извлечь содержательную часть информации из установочных файлов мобильных приложений, объединить разрозненные элементы контента в единый документ и преобразовать контент приложения к форме, пригодной для дальнейшей обработки.
Недостатком является то, что доля ручного труда очень высокая - стоимость поискового индекса или какого-либо другого результата машинной обработки данных чрезмерно дорогая.
Способов автоматического извлечения контента из приложений и последовательности действий, которые можно было бы перепоручить серверам, на сегодняшний момент не известно.
Из так называемых «вертикальных» поисковых систем известен патент РФ на изобретение №2399090, МПК G06F 17/30 от 10.06.2010 г. «СИСТЕМА И СПОСОБ ДЛЯ ИНТЕРНЕТ-ПОИСКА МУЛЬТИМЕДИЙНОГО КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ». Изобретение относится к средствам поиска мультимедийного (AV) контента реального времени. Техническим результатом является расширение области применения поиска мультимедиа контента в реальном времени. Поисковая система включает в себя: модуль поиска признаков, выполняющий анализ текущей загруженной Web-страницы на предмет присутствия признаков, свидетельствующих о наличии на ней вещания AV контента реального времени, из заранее заданного набора признаков; базу данных, в которой сохраняются адреса Web-страниц, где установлено наличие вещания AV контента реального времени; пользовательский интерфейс для обеспечения пользователю возможности поиска по базе данных; при этом при анализе модуль поиска признаков выполняет разбор текстового содержимого файлов Web-страницы сначала на предмет обнаружения в нем признаков, указывающих на средство воспроизведения AV контента, и затем, при успешном обнаружении, на предмет присутствия в нем признаков, указывающих на то, что воспроизводимый AV контент является именно AV контентом реального времени.
Это изобретение частично решает проблему низкой доли страниц, действительно отвечающих требованиям и запросам пользователя, за счет того, что создает вертикальную поисковую систему и способ, конкретно ориентированные на поиск в Интернете Web-страниц, на которых имеет место вещание AV контента в масштабе реального времени или, иными словами, так называемое живое вещание. Типичными примерами живого AV контента в Интернете являются телевизионное (ТВ) и радиовещание эфирных студий, специальное Интернет-вещание профессиональных и любительских студий, потоковое вещание с Web-камер. Характерной чертой такого контента является невозможность выполнения в отношении него перемотки вперед с помощью средств клиентского воспроизводящего приложения.
Недостатком вышеупомянутого изобретения является то, что такая система и способ реализуют поиск только по Web-страницам в Интернете и никак не позволяет извлечь полезный контент из установочных файлов мобильных приложений для дальнейшей машинной обработки данных, в частности поиска.
Раскрытие изобретения
Задачей заявляемого изобретения является создание способа, основанного на вертикальной поисковой системе, позволяющего автоматически извлекать полезный контент из установочных файлов мобильных приложений для дальнейшего индексирования, машинной обработки данных и хранения полезного контента мобильных приложений в базе данных на сервере для дальнейшего обеспечения поиска.
Техническая задача решается за счет того, что способ извлечения полезного контента из установочных файлов мобильных приложений для дальнейшей машинной обработки данных, в частности поиска, содержит этапы, на которых:
- загружают из Интернета на сервер установочный файл приложения неизвестного формата;
- подбирают к нему разархиватор;
- разархивируют загруженный установочный файл в каталог с файлами;
- анализируют полученный каталог, составляют список файлов, содержащихся в нем;
- выбирают из списка файл для дальнейшего анализа;
- подбирают программное обеспечение для чтения файла;
- анализируют выбранный файл на предмет поиска первичного контента;
- формируют список адресов внутреннего размещения первичного контента в виде набора строк;
- переходят к анализу следующего файла, до тех пор пока в каталоге есть файлы;
- проводят анализ текстового содержимого списка адресов внутреннего размещения первичного контента и разделяют текст каждой строки на набор символов, идентифицирующих способ хранения соответствующей единицы контента, набор символов, идентифицирующий документ, к которому относится данная единица контента, и набор символов, идентифицирующий тип этой единицы контента;
- разделяют строки адресов внутреннего размещения единицы контента по способу хранения на служебный контент и полезный контент;
- служебный контент удаляют;
- выделяют в оставшемся списке группы строк с адресами внутреннего размещения единиц контента, имеющие полностью совпадающие по месторасположению и тексту группы символов, отражающие способ хранения контента;
- проводят статистическую фильтрацию выделенных групп;
- проводят анализ текстового содержимого строк списка адресов по набору символов, идентифицирующих документ, и формируют документы путем реферирования;
- выкачивают из приложения полезный контент;
- формируют описания приложений;
- сохраняют в базе данных название приложения, ссылку на приложение и описание приложения;
- загружают установочный файл нового приложения и повторяют все описанные последовательности;
- производят машинную обработку полученной базы данных;
- хранят созданный индексируемый массив базы данных на сервере;
- используют для поисковых запросов пользователей, поступающих через Интернет.
При этом разархиватор подбирают из заранее созданного расширяемого и модифицируемого набора всех известных архиваторов, а программное обеспечение для чтения файла подбирают из заранее созданного расширяемого и модифицируемого набора программного обеспечения. Причем статистическую фильтрацию проводят с помощью заранее созданных пороговых значений фильтров, а список адресов внутреннего размещения первичного контента формируют путем следующих действий: проводят поиск внутрифайловых адресов всех единиц контента самого нижнего уровня, затем проверяют эти единицы контента на соответствие первичному контенту, при этом, если контент является не первичным, повторно подбирают программное обеспечение и находят внутрифайловые адреса контента нижнего уровня. Каждая строка из набора строк списка адресов содержит информацию о местонахождении файла в каталоге, полный внутрифайловый адрес каждой единицы первичного контента с указанием полного перечня программного обеспечения, с помощью которого открывают эту единицу, а анализ списка адресов внутреннего размещения первичного контента проводят, используя свойства его текстового содержимого, при этом текст каждой строки разделяют на набор символов, идентифицирующих способ хранения соответствующей единицы контента, набор символов, идентифицирующих документ, к которому относится данная единица контента, и набор символов, идентифицирующих тип этой единицы контента, причем строки адресов внутреннего размещения единицы контента разделяют на адреса со способом хранения, характерным для хранения служебного контента, и адреса со способом хранения, характерным для хранения полезного контента с помощью заранее созданного расширяемого и модифицируемого набора правил. Анализ же единиц контента в строках адресов проводят на предмет совпадения типа контента и способа хранения контента, при этом в строках адресов единиц контента, хранящихся одинаковым способом, эти строки выделяют, а при несовпадении условий строки удаляют. Анализ текстового содержимого строк списка адресов проводят по набору символов, идентифицирующих документ, и формируют документы путем реферирования, при этом выявляют строки с различным набором символов, идентифицирующих способ хранения соответствующей единицы контента, и совпадающим набором символов, идентифицирующих документ, к которому эта единица контента относится, после чего разделяют на документ при несовпадении набора символов и на часть документа, если совпадают наборы символов, после чего последние объединяют в единый документ путем реферирования. Полезный контент из приложения выкачивают в виде набора документов, пригодных для дальнейшей машинной обработки, а описания приложений формируют путем объединения текстового содержимого документов в единый текст, отражающий набор документов, содержащихся в приложении. Установочный файл нового приложения загружают и повторяют все описанные последовательности до тех пор, пока в глобальных компьютерных сетях и маркетах имеются новые не обработанные приложения.
Особенностью контента мобильных приложений является то, что мобильные приложения разрабатываются большим сообществом программистов. При разработке используются различные языки программирования. Мобильные приложения очень разнообразны как по способу представления данных пользователю, так и по способу хранения данных в пакете приложения. Для мобильных приложений не существует никакого жесткого стандарта представления данных и хранения данных. Контент, содержащийся в этих приложениях, никак не приспособлен для чтения и осуществления доступа к данным из вне. По этим причинам индексация контента приложений отличается от индексации Web-страниц, которые представлены в одном единственном формате html, доступ к которым организован по одному единственному протоколу http и разработчики которых всячески стараются оптимизировать свои страницы для удобства их индексирования.
Актуальность технического решения по предлагаемому изобретению обуславливается также все возрастающим количеством смартфонов, а также тем, что количество выходов в интернет с мобильных устройств в 2013 году превысило количество выходов в интернет со стационарных компьютеров, а также тем, что использование смартфона в первую очередь связано с использованием адаптированных под него приложений, и классическое использование Web затруднительно, так как у пользователя имеется маленький экран, нет клавиатуры, нет мыши и т.д.
Перечень фигур
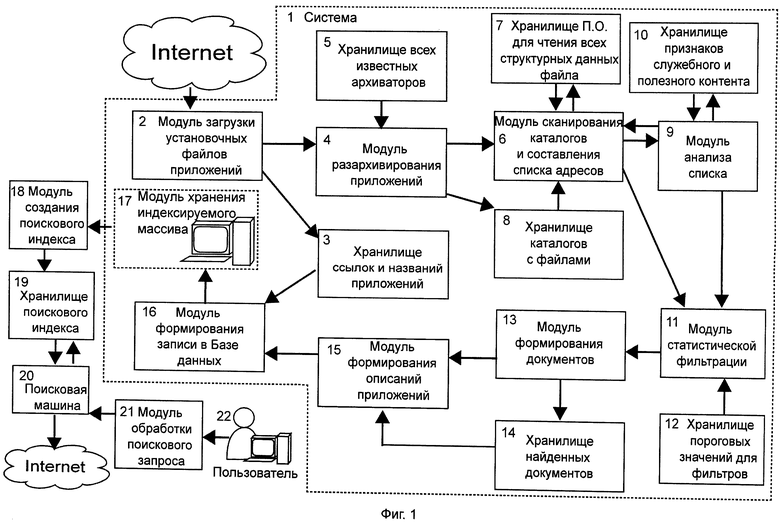
На фиг.1 изображена блок-схема последовательности операций, позволяющая реализовать способ извлечения полезного контента из установочных файлов мобильных приложений.
На фиг.2 изображена схематическая иллюстрация структуры и работы системы по заявленному изобретению.
Блок-схема последовательности операций (см. фиг.1) содержит систему как таковую 1, модуль загрузки установочных файлов приложений 2, хранилище ссылок и названий приложений 3, модуль разархивирования приложений 4, хранилище всех известных архиваторов 5, модуль сканирования каталогов и составления списка адресов 6, хранилище программного обеспечения для чтения всех структурных данных файла 7, хранилище каталогов с файлами 8, модуль анализа списка 9, хранилище признаков служебного и полезного контента 10, модуль статистической фильтрации 11, хранилище пороговых значений для фильтра 12, модуль формирования документов 13, хранилище найденных документов 14, модуль формирования описаний приложений 15, модуль формирования записи в базе данных 16, модуль хранения индексируемого массива 17. Для обеспечения работы поисковой системы введены модуль создания поискового индекса 18, хранилище поискового индекса 19. Поиск осуществляется через поисковую машину 20. Через модуль обработки поискового запроса 21 и интернет пользователь производит поиск.
Последовательности действий для реализации заявленного способа извлечения полезного контента из установочных файлов мобильных приложений для дальнейшей машинной обработки данных, в частности поиска, содержат этапы, на которых:
1. Загружают из Интернета на сервер установочный файл приложения неизвестного формата (модуль загрузки установочных файлов приложений 2). При этом известно только то, что это некий заархивированный файл.
2. Подбирают к нему разархиватор из заранее созданного расширяемого и модифицируемого набора всех известных архиваторов (хранилище всех известных архиваторов 5).
3. Разархивируют загруженный установочный файл (модуль разархивирования приложений 4). Получают каталог с файлами (хранилище каталога с файлами 8).
4. Анализируют полученный каталог, составляют список файлов, содержащихся в каталоге (модуль сканирования каталогов с файлами 6).
5. Выбирают из списка файл для дальнейшего анализа (модуль анализа списка 9).
6. Подбирают из заранее созданного расширяемого и модифицируемого набора программное обеспечение для чтения файла (хранилище программного обеспечения для чтения всех структурных данных файла 7).
7. Находят в выбранном файле (допустим это база данных Sql) внутрифайловые адреса всех единиц контента самого нижнего уровня (для Sql это будет название таблицы, название столбца и номер строки в столбце).
8. Проверяют, являются ли единицы контента, найденные во внутрифайловых адресах контента самого нижнего уровня файла, первичным контентом - текст, картинка, видео.
9. Если во внутрифайловых адресах контента нижнего уровня лежит не первичный контент, то п.6 и п.7 повторяют для содержимого этих адресов.
10. Формируют список адресов внутреннего размещения найденного первичного контента, который представляет из себя набор строк, каждая из которых содержит информацию о местонахождении файла в каталоге, полный внутрифайловый адрес каждой единицы первичного контента с указанием полного списка программного обеспечения, с помощью которого открывают эту единицу контента на каждом этапе.
11. Выбирают следующий файл из списка файлов, содержащихся в каталоге.
12. Формировать список адресов внутреннего размещения найденного первичного контента прекращают после того, когда все строки списка файлов, содержащихся в каталоге, проанализированы до нахождения первичного контента (текст, картинка, видео).
13. Проводят анализ списка адресов внутреннего размещения найденного первичного контента, используя свойства его текстового содержимого, разделяют текст каждой строки на набор символов, идентифицирующий способ хранения соответствующей единицы контента, набор символов, идентифицирующий документ. к которому относится данная единица контента, и набор символов, идентифицирующий тип этой единицы контента.
14. Разделяют строки адресов внутреннего размещения единиц контента на адреса со способом хранения, характерным для хранения служебного контента, и адреса со способом хранения, характерным для хранения полезного контента, на основе заранее созданного расширяемого и модифицируемого набора правил (хранилище признаков служебного и полезного контента 10).
15. Строки с адресами со способом хранения, характерным для хранения служебного контента, удаляют из списка и исключают из дальнейшего рассмотрения.
16. Проводят статистический анализ на предмет совпадения типа контента в строках адресов единиц контента, хранящихся одинаковым способом (модуль статистической фильтрации 11, хранилище пороговых значений для фильтра 12).
17. Если процентное соотношение количества строк адресов единиц контента, хранящихся одинаковым способом и имеющих одинаковый тип контента, и строк адресов, где это условие не выполняется, ниже определенного порога, то строки с адресами, содержащими этот способ хранения, удаляют из списка и исключают из дальнейшего рассмотрения как адреса предположительно служебного контента. Если указанное соотношение выше порога, то во все строки адресов единиц контента, хранящихся этим способом, вносятся данные об этом типе контента.
18. Проводят анализ текстового содержимого оставшихся строк списка адресов внутреннего размещения по набору символов, идентифицирующих документ, к которому относится соответствующая единица контента, на предмет поиска строк с различным набором символов, идентифицирующих способ хранения соответствующей единицы контента, и совпадающим набором символов, идентифицирующих документ, к которому эта единица контента относится.
19. Если в списке адресов внутреннего размещения строк с совпадающими наборами символов, идентифицирующими документ, нет, то каждая единица контента определяется как документ, если есть, то производится реферирование - объединение частей в единый документ (модуль формирования документов 13).
20. Выкачивают из приложения полезный контент в виде набора документов, пригодных для дальнейшей машинной обработки.
21. Создают описание приложения, объединяя текстовое содержимое документов в единый текст, отражающий набор документов, содержащихся в приложении (модуль формирования описаний приложений 15).
22. Сохраняют в базе данных название приложения, ссылку на приложение и описание приложения (модуль формирования записи в базе данных 16, хранилище ссылок и названий приложений 3, модуль хранения индексируемого массива).
23. Загружают установочный файл нового приложения и повторяют все описанные последовательности (модуль загрузки установочных файлов приложений 2).
24. Процесс продолжается до тех пор, пока в глобальных компьютерных сетях в маркетах есть новые (не обработанные) приложения.
25. Производят машинную обработку полученной базы данных, в частности для обеспечения поиска двухуровневое индексирование инвертированным индексом «Поисковое слово - Документ, содержащий поисковое слово» и инвертированным индексом «Документ - Приложение, содержащее документ» (модуль создания поискового индекса 18, хранилище поискового индекса 19, поисковая машина 20).
26. Поиск осуществляет пользователь 22 через Интернет и модуль обработки поискового запроса 21.
Схематическая иллюстрация структуры и работы системы по заявленному изобретению изображена на фиг.2.
Описание структуры работы системы
Способ содержит этапы, на которых: А) Заранее задают расширяемый и модифицируемый набор всех известных архиваторов, набор всех известных структур данных (базы данных, форматы сжатия данных, форматы записи данных и т.д.), набор метрик распознавания данных. В) Осуществляют анализ каталога с файлами, полученного в результате загрузки и распаковки установочного файла приложения. Распакованный каталог представляет из себя случайный набор файлов различных типов. Это могут быть архивированные файлы, базы данных, специальные форматы представления данных и непосредственно сами данные, которые в целях решения задачи делятся на две категории: Непосредственно данные и Структуры данных (все, что данными не является, но может их содержать). Целью является: раскрыть все структуры данных, дойти до данных самого нижнего уровня (когда данные - это непосредственно данные, а не какая-либо структура) и каждой найденной единице контента поставить в соответствие некий адрес этой единицы в пакете приложения. С) Если выявлены признаки, что все данные - это непосредственно данные, то приступают к процессу создания описания путем разделения найденного контента на две категории: Первая - контент, ради хранения которого создавалось приложение («истинные» результаты поиска), и Вторая - служебные данные, или контент, используемый самим приложением («ложные» результаты поиска). D) Если на этапе С) выявлены признаки того, что «истинные» результаты поиска представляют из себя документы, состоящие из нескольких найденных единиц контента, то производится реферирование - формирование единых документов из их частей. Если таких признаков нет, то переходят сразу к пункту Е). Е) Сохраняют в базе данных название приложения, ссылку на приложение и описание приложения, состоящее из набора документов, находящихся в приложении.
Предлагаемый способ характеризуется тем, что анализ по этапу В) осуществляют посредством разархивирования имеющегося установочного файла множеством декодирующих программ (плагинов), настроенных на использование различных архиваторов. Если в результате работы какой-либо из декодирующих программ в нужном месте появляется приемлемый каталог с файлами, то архиватор, который использовала эта декодирующая программа, и является нужным. Название архиватора записывается в адрес. Затем в распакованном каталоге открывают все папки и составляют список всех файлов, находящихся в каталоге. Каждая строка этого списка представляет из себя: Название архиватора; Последовательно прописанный путь с названиями всех папок от корневого каталога до папки, содержащей файл; название самого файла. Затем каждый из файлов читается множеством декодирующих программ (плагинов), настроенных на чтение различных структур данных. Если в результате работы какой-либо из декодирующих программ, появляется возможность прочитать внутреннее содержимое файла, то структура данных, на которую настроена эта декодирующая программа, и является нужной. Каждая строка списка дополняется данными о структуре (с помощью чего этот файл читать). Затем, зная с помощью какого инструментария мы можем читать внутреннее содержимое, приступаем к чтению самой структуры. Дойдя до самого нижнего уровня, применяем программы распознавания контента (плагинов), настроенные на метрики различных видов контента.
Примеры осуществления изобретения
Пример 1
После разархивирования в папке каталога bd находится файл example.sql, представляющий из себя SQL-базу данных, состоящую из трех таблиц: table_1, table_2 и table_3, состоящих из двух столбцов: name и data, по четыре строки в каждом, в полях которых хранятся текстовые данные, то по шагам тексты исходного списка будут меняться следующим образом:
После поиска файлов имеем список:
1. «$file://bd/exempl.sql»
Все найденные файлы мы пытаемся открыть множеством декодирующих программ (плагинов), настроенных на чтение различных структур данных.
Декодирующая программа, ориентированная на чтение SQL-базы данных, дает нам название трех таблиц:
1. «$file://bd/exempl.sql//table_1»
2. «$file://bd/exempl.sql//table_2»
3. «$file://bd/exempl.sql//table_3»
Каждую из таблиц мы опять пытаемся открыть множеством декодирующих программ (плагинов), настроенных на чтение различных структур данных.
Декодирующая программа, ориентированная на чтение SQL-базы данных, дает нам название шести столбцов:
1. «$file://bd/exempl.sql//table_1/name»
2. «$file://bd/exempl.sql//table_1/data»
3. «$file://bd/exempl.sql//table_2/name»
4. «$file://bd/exempl.sql//table_2/data»
5. «$file://bd/exempl.sql//table_3/name»
6. «$file://bd/exempl.sql//table_3/data»
Каждый из столбцов мы пытаемся открыть множеством декодирующих программ (плагинов), настроенных на чтение различных структур данных.
Декодирующая программа, ориентированная на чтение SQL-базы данных, дает нам адреса двадцати четырех непустых полей:
1. «$file://bd/exempl.sql//table_1/name/id=1»
2. «$file://bd/exempl.sql//table_1/name/id=2»
3. «$file://bd/exempl.sql//table_1/name/id=3»
4. «$file://bd/exempl.sql//table_1/name/id=4»
5. «$file://bd/exempl.sql//table_1/data/id=1»
6. «$file://bd/exempl.sql//table_1/data/id=2»
7. «$file://bd/exempl.sql//table_1/data/id=3»
8. «$file://bd/exempl.sql//table_1/data/id=4»
9. «$file://bd/exempl.sql//table_2/name/id=1»
10. «$file://bd/exempl.sql//table_2/name/id=2»
11. «$file://bd/exempl.sql//table_2/name/id=3»
12. «$file://bd/exempl.sql//table_2/name/id=4»
13. «$file://bd/exempl.sql//table_2/data/id=1»
14. «$file://bd/exempl.sql//table_2/data/id=2»
15. «$file://bd/exempl.sql//table_2/data/id=3»
16. «$file://bd/exempl.sql//table_2/data/id=4»
17. «$file://bd/exempl.sql//table_3/name/id=1»
18. «$file://bd/exempl.sql//table_3/name/id=2»
19. «$file://bd/exempl.sql//table_3/name/id=3»
20. «$file://bd/exempl.sql//table_3/nanne/id=4»
21. «$file://bd/exempl.sql//table_3/data/id=1»
22. «$file://bd/exempl.sql//table_3/data/id=2»
23. «$file://bd/exempl.sql//table_3/data/id=3»
24. «$file://bd/exempl.sql//table_3/data/id=4»
Содержание каждого поля мы пытаемся открыть множеством декодирующих программ (плагинов), настроенных на чтение различных структур данных.
Ни одна из декодирующих программ не видит в содержании поля какой-либо структуры данных. Это первый признак того, что мы дошли до данных самого нижнего уровня - предположительно контента.
После этого применяем программы распознавания контента (плагинов), настроенных на метрики различных видов контента.
Программа, ориентированная на распознавание текста, дает нам данные, что это текст. И соответственно конечный список внутренних адресов размещения предполагаемого контента будет выглядеть так:
1. «$file://bd/exempl.sql//table_1/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//table_1/name/id=2//text»=«text»
3. «$file.//bd/exempl.sql//table_1/name/id=3//text»=«text»
4. «$file://bd/exempl.sql//table_1/name/id=4//text»=«text»
5. «$file://bd/exempl.sql//table_1/data/id=1//text»=«text»
6. «$file://bd/exempl.sql//table_1/data/id=2//text»=«text»
7. «$file://bd/exempl.sql//table_1/data/id=3//text»=«text»
8. «$file://bd/exempl.sql//table_1/data/id=4//text»=«text»
9. «$file://bd/exempl.sql//table_2/name/id=1//text»=«text»
10. «$file://bd/exempl.sql//table_2/name/id=2//text»=«text»
11. «$file://bd/exempl.sql//table_2/name/id=3//text»=«text»
12. «$file://bd/exempl.sql//table_2/name/id=4//text»=«text»
13. «$file://bd/exempl.sql//table_2/data/id=1//text»=«text»
14. «$file://bd/exempl.sql//table_2/data/id=2//text»=«text»
15. «$file://bd/exempl.sql//table_2/data/id=3//text»=«text»
16. «$file://bd/exempl.sql//table_2/data/id=4//text»=«text»
17. «$file://bd/exempl.sql//table_3/name/id=1//text»=«text»
18. «$file://bd/exempl.sql//table_3/name/id=2//text»=«text»
19. «$file://bd/exempl.sql//table_3/name/id=3//text»=«text»
20. «$file://bd/exempl.sql//table_3/name/id=4//text»=«text»
21. «$file://bd/exempl.sql//table_3/data/id=1//text»=«text»
22. «$file://bd/exempl.sql//table_3/data/id=2//text»=«text»
23. «$file://bd/exempl.sql//table_3/data/id=3//text»=«text»
24. «$file://bd/exempl.sql//table_3/data/id=4//text»=«text»
Анализ по этапу С) осуществляют посредством разбора текстового содержимого, полученного на этапе В) конечного списка внутренних адресов размещения предполагаемого контента. Этот список обладает следующими свойствами:
1. Первым свойством идентификатора контента является то, что текст каждой его строки позволяет однозначно извлечь из приложения именно тот контент, который он идентифицирует.
2. Текст каждой его строки содержит в себе текст, указывающий на способ хранения некоторого количества единиц контента (идентификатор способа хранения), текст, идентифицирующий конкретную единицу контента из этого количества (идентификатор документа), и текст, идентифицирующий тип контента (идентификатор типа контента), - это исчерпывающий список, более этот текст не содержит ничего.
3. Единицы контента, хранящиеся одним и тем же способом (имеющие один и тот же идентификатор способа хранения), относятся к одной группе контента.
4. Наборы символов, отражающие тексты идентификаторов способов хранения и идентификаторов документов, могут быть выделены из текстов идентификаторов контента на основе их повторяемости в списке (список придает текстам идентификаторов контента дополнительное свойство, позволяющее их расшифровать).
Разделение текстов каждой строки на идентификаторы способов хранения, идентификаторы типов контента и идентификаторы документов на основе повторяемости в списке делается на основе свойств этих наборов символов:
1. Набор символов, совпадающий в разных строках (выбираются строки, в которых совпадают одинаковое количество символов), - идентификатор способа хранения.
2. Набор символов, отражающий идентификатор типа контента (этот набор символов мы сами назначили в прошлой процедуре), - идентификатор типа контента.
3. Набор символов, который не входит в предыдущие две группы (это то, чем строки отличаются друг от друга), - идентификатор документа.
Эти свойства позволяют разделить строку на группы методом замещения набора символов, отражающих предположительное положение идентификатора документа, на набор одинаковых символов во всех строках списка. После чего сравниваем, после какого замещения у нас получилось наибольшее количество строк, имеющих абсолютно одинаковый текст.
Пример 2
При обработке строки могут быть выбраны абсолютно разные алгоритмы выбора замещаемых символов. Для конечного списка внутренних адресов размещения предполагаемого контента из Примера 1 будем замещать по очереди весь текст, находящийся между символами «l». Итак, исходный список:
1. «$file://bd/exempl.sql//table_1/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//table_1/name/id=2//text»=«text»
3. «$file://bd/exempl.sql//table_1/name/id=3//text»=«text»
4. «$file://bd/exempl.sql//table_1/name/id=4//text»=«text»
5. «$file://bd/exempl.sql//table_1/data/id=1//text»=«text»
6. «$file://bd/exempl.sql//table_1/data/id=2//text»=«text»
7. «$file://bd/exempl.sql//table_1/data/id=3//text»=«text»
8. «$file://bd/exempl.sql//table_1/data/id=4//text»=«text»
9. «$file://bd/exempl.sql//table_2/name/id=1//text»=«text»
10. «$file://bd/exempl.sql//table_2/name/id=2//text»=«text»
11. «$file.//bd/exempl.sql//table_2/name/id=3//text»=«text»
12. «$file://bd/exempl.sql//table_2/name/id=4//text»=«text»
13. «$file://bd/exempl.sql//table_2/data/id=1//text»=«text»
14. «$file://bd/exempl.sql//table_2/data/id=2//text»=«text»
15. «$file://bd/exempl.sql//table_2/data/id=3//text»=«text»
16. «$file://bd/exempl.sql//table_2/data/id=4//text»=«text»
17. «$file://bd/exempl.sql//table_3/name/id=1//text»=«text»
18. «$file.//bd/exempl.sql//table_3/name/id=2//text»=«text»
19. «$file://bd/exempl.sql//table_3/name/id=3//text»=«text»
20. «$file://bd/exempl.sql//table_3/name/id=4//text»=«text»
21. «$file://bd/exempl.sql//table_3/data/id=1//text»=«text»
22. «$file://bd/exempl.sql//table_3/data/id=2//text»=«text»
23. «$file://bd/exempl.sql//table_3/data/id=3//text»=«text»
24. «$file://bd/exempl.sql//table_3/data/id=4//text»=«text»
Тексты всех строк отличаются друг от друга. Заменяем группу символов «$file:» на «******» и получаем:
1. «******//bd/exempl.sql//table_1/name/id=1//text»=«text»
2. «******//bd/exempl.sql//table_1/name/id=2//text»=«text»
3. «******//bd/exempl.sql//table_1/name/id=3//text»=«text»
4. «******//bd/exempl.sql//table_1/name/id=4//text»=«text»
5. «******//bd/exempl.sql//table_1/data/id=1//text»=«text»
6. «******//bd/exempl.sql//table_1/data/id=2//text»=«text»
7. «******//bd/exempl.sql//table_1/data/id=3//text»=«text»
8. «******//bd/exempl.sql//table_1/data/id=4//text»=«text»
9. «******//bd/exempl.sql//table_2/name/id=1//text»=«text»
10. «******//bd/exempl.sql//table_2/name/id=2//text»=«text»
11. «******//bd/exempl.sql//table_2/name/id=3//text»=«text»
12. «******//bd/exempl.sql//table_2/name/id=4//text»=«text»
13. «******//bd/exempl.sql//table_2/data/id=1//text»=«text»
14. «******//bd/exempl.sql//table_2/data/id=2//text»=«text»
15. «******//bd/exempl.sql//table_2/data/id=3//text»=«text»
16. «******//bd/exempl.sql//table_2/data/id=4//text»=«text»
17. «******//bd/exempl.sql//table_3/name/id=1//text»=«text»
18. «******//bd/exempl.sql//table_3/name/id=2//text»=«text»
19. «******//bd/exempl.sql//table_3/name/id=3//text»=«text»
20. «******//bd/exempl.sq!//table_3/name/id=4//text»=«text»
21. «******//bd/exempl.sql//table_3/data/id=1//text»=«text»
22. «******//bd/exempl.sql//table_3/data/id=2//text»=«text»
23. «******//bd/exempl.sql//table_3/data/id=3//text»=«text»
24. «******//bd/exempl.sql//table_3/data/id=4//text»=«text»
Тексты всех строк по-прежнему разные - во временный файл ничего не пишем. То же самое будет при попытке заменить на звездочки группы символов «bd» и «exempl.sql» - эти участки текста одинаковы во всех строках и, как следствие, должны относиться к тексту идентификатора способа хранения. Если же заменить звездочками группу символов, отражающую название таблицы, то у нас появятся три строки с абсолютно одинаковым текстом, отражающим первую строку в столбце «name», в трех таблицах: «table_1»,» table_2» и «table_3», и во временный файл пишется:
1. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
3. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
Если заменить на звездочки название столбца, то во временный файл будут дописаны две строки, отражающие первую строку в обоих столбцах «table_1», и он будет иметь вид:
Группа символов = "table_1"
1. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
3. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
Группа символов = "name"
1. «$file://bd/exempl.sql//table_1/****/id=1//text»=«text»
2. «$file://bd/exempl.sql//table_1/****/id=1//text»=«text»
Если заменить на звездочки номер строки в столбце «name», то во временный файл будут дописаны четыре строки, отражающие все строки в столбце «name» таблицы «table_1», и он будет иметь вид:
Группа символов = "table_1"
1. «$file.//bd/exempl.sql//*******/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
3. «$file://bd/exempl.sql//*******/name/id=1//text»=«text»
Группа символов = "name"
1. «$file://bd/exempl.sql//table_1/****/id=1//text»=«text»
2. «$file://bd/exempl.sql//table_1/****/id=1//text»=«text»
Группа символов = "id=1"
1. «$file://bd/exempl.sql//table_1/name/****//text»=«text»
2. «$file://bd/exempl.sql//table_1/name/****//text»=«text»
3. «$file://bd/exempl.sql//table_1/name/****//text»=«text»
4. «$file://bd/exempl.sql//table_1/name/****//text»=«text»
Наибольшее количество строк с полным совпадением текста имеем при замене на звездочки группы символов, отражающих номер строки. Значит для первой строки исходного списка у нас назначается:
Идентификатор способа хранения:
«$file://bd/exempl.sql//table_1/name/»;
Идентификатор единицы контента: «id=1»;
Идентификатор типа контента: «text»
Т.е. компьютерно-реализуемым способом, без использования априорных знаний человека об организации файловых структур, получены данные, что в корневом каталоге«$file:» в папке «bd» в SQL-файле «exempl.sql» в таблице «table_1» и столбце «name» хранится контент, имеющий одинаковое для этого способа хранения значение (в нашем случае Имя), и текстовый формат.
Дальнейшая обработка списка заключается в том, что, обработав первую строку, формируют строку в списке идентификаторов способа хранения. Для этого из текста строки «вырезают» текст идентификатора документа и добавляют в конец строки список всех идентификаторов документов, имеющих этот идентификатор способа хранения. В случае из Примера 2 это будет: строка
«$file://bd/exempl.sql//table_1/name/id=1//text»=«text»
преобразуется в строку списка идентификаторов способа хранения:
«$file://bd/exempl.sql//table_1/name//text»=«text» (id=1,2,3,4).
После чего из исходного списка удаляются все строки, имеющие вышеназванный идентификатор способа хранения, и вся процедура начинается сначала до тех пор, пока в исходном списке есть строки. Т.е. обработка конечного списка внутренних адресов размещения предполагаемого контента из Примера 2 закончится формированием списка идентификаторов способов хранения в виде:
Исходный список:
1. «$file://bd/exempl.sql//table_1/name/id=1//text»=«text»
2. «$file://bd/exempl.sql//table_1/name/id=2//text»=«text»
3. «$file://bd/exempl.sql//table_1/name/id=3//text»=«text»
4. «$file://bd/exempl.sql//table_1/name/id=4//text»=«text»
5. «$file://bd/exempl.sql//table_1/data/id=1//text»=«text»
6. «$file://bd/exempl.sql//table_1/data/id=2//text»=«text»
7. «$file://bd/exempl.sql//table_1/data/id=3//text»=«text»
8. «$file://bd/exempl.sql//table_1/data/id=4//text»=«text»
9. «$file://bd/exempl.sql//table_2/name/id=1//text»=«text»
10. «$file://bd/exempl.sql//table_2/name/id=2//text»=«text»
11. «$file://bd/exempl.sql//table_2/name/id=3//text»=«text»
12. «$file://bd/exempl.sql//table_2/name/id=4//text»=«text»
13. «$file://bd/exempl.sql//table_2/data/id=1//text»=«text»
14. «$file.//bd/exempl.sql//table_2/data/id=2//text»=«text»
15. «$file://bd/exempl.sql//table_2/data/id=3//text»=«text»
16. «$file://bd/exempl.sql//table_2/data/id=4//text»=«text»
17. «$file://bd/exempl.sql//table_3/name/id=1//text»=«text»
18. «$file://bd/exempl.sql//table_3/name/id=2//text»=«text»
19. «$file://bd/exempl.sql//table_3/name/id=3//text»=«text»
20. «$file://bd/exempl.sql//table_3/name/id=4//text»=«text»
21. «$file://bd/exempl.sql//table_3/data/id=1//text»=«text»
22. «$file://bd/exempl.sql//table_3/data/id=2//text»=«text»
23. «$file://bd/exempl.sql//table_3/data/id=3//text»=«text»
24. «$file://bd/exempl.sql//table_3/data/id=4//text»=«text»
Результирующий список:
1. «$file://bd/exempl.sql//table_1/name//text»=«text»(id=1,2,3,4)
2. «$file://bd/exempl.sql//table_1/data//text»=«text»(id=1,2,3,4)
3. «$file://bd/exempl.sql//table_2/name//text»=«text»(id=1,2,3,4)
4. «$file://bd/exempl.sql//table_2/data//text»=«text»(id=1,2,3,4)
5. «$file://bd/exempl.sql//table_3/name//text»=«text»(id=1,2,3,4)
6. «$file://bd/exempl.sql//table_3/data//text»=«text»(id=1,2,3,4)
Полный алгоритм обработки исходного списка и формирования списка идентификаторов контента указан на блок-схеме Фиг.2.
Пройдя эту фазу обработки, «исходный» список внутренних адресов размещения предполагаемого контента преобразуется в новый список идентификаторов способа хранения, который имеет следующие свойства:
1. Пройдя по всему списку идентификаторов документов, относящихся к одному способу хранения, можно уточнить тип контента (хранимый этим способом) на основе статистических методов (у одной единицы контента тип данных может быть определен с ошибкой, у 100 единиц контента вероятность ошибки в определении типа данных резко уменьшается).
2. Если список идентификаторов документов состоит из двух элементов и менее, то эти данные внимания не заслуживают.
3. Если на основе статистического анализа тип контента определить не удается, то данные, хранящиеся этим способом хранения, внимания не заслуживают.
4. Если списки идентификаторов документов у разных способов хранения совпадают, то этими способами хранения хранятся разные куски одних и тех же документов.
На основании этих свойств, посредством разбора текстового содержимого строк этого списка производится разделение найденного контента на две категории: Первая - контент, ради хранения которого создавалось приложение («истинные» результаты поиска), и Вторая - служебные данные, или контент, используемый самим приложением («ложные» результаты поиска). «Истинные» результаты поиска включаются в список контента для формирования описания приложения, чем и заканчивается анализ по этапу С).
Если в некоторых строках списка идентификаторов способа хранения встречается одинаковый список идентификаторов документов, то это является признаком, по которому делается переход на:
анализ по этапу D) осуществляют путем разбора текстового содержимого строк, списка идентификаторов способа хранения. Выделяется список идентификаторов документов, повторяющийся в нескольких строках списка идентификаторов способа хранения. Берется первый элемент из этого списка и ему ставятся в соответствие все внутренние адреса размещения контента, имеющие различные способы хранения и содержащие данный идентификатор документа.
Пример 3
Найден файл, который является базой данных SQLite, - начинается проход по таблицам этой БД, в каком-то поле таблицы найдена строка в формате JSON - начинается проход по полям этого пакета JSON, в каком-то поле этого пакета найдена просто текстовая строка - она сохраняется в памяти как "предположительно текстовый контент" и сканирование продолжается.
Допустим, база данных найдена в файле 123.sql, находящейся в папке db в пакете приложения. В этой базе есть таблица «example_table», у нее есть primary key «id», а в колонке «data» находится пакет JSON, который в свою очередь в поле «text» содержит некий текст, который мы запомнили как «предположительно текстовый контент».
Тогда путь к первой единице данного контента может выглядеть, например, так:
$file://db/123.sql$sqlite://example_table,id=1/data$json.7/text,
а список внутренних адресов размещения предполагаемого контента будет выглядеть так:
…
«$file.//db/123.sql$sqlite://example_table,id=1/data$json.7/text»=«text»
«$file://db/123.sql$sqlite.//example_table,id=2/data$json://text»=«text»
«$file://db/123.sql$sqlite.7/example_table,id=3/data$json://text»=«text»
«$file://db/123.sql$sqlite://example_table,id=1/img»=«image»
«$file://db/123.sql$sqlite://example_table,id=2/img»=«image»
«$file://db/123.sql$sqlite://example_table,id=3/img»=«image»
«$file://db/123.sql$sqlite://example_table,id=1/data$json://header»=«text»
«$file://db/123.sql$sqlite://example_table,id=2/data$json://header»=«text»
«$file://db/123.sql$sqlite://example_table,id=3/data$json://header»=«text»
…
Список идентификаторов способа хранения будет выглядеть так:
«$file://db/123.sql$sqlite://example_table,id=%id-1%/data$json://text»=«text»(id1=1,2,3)
«$file://db/123.sql$sqlite://example_table,id=%id-1%/img»=«image»(id1=1,2,3)
«$file://db/123.sql$sqlite://example_table,id=%id-1%/data$json.//header»=«text»(id1=1,2,3)
Список сформированных документов по итогам Этапа D) будет выглядеть так:
id=1:(«$file://db/123.sql$sqlite://example_table,id=1/data$json://text»=«text»,
«$file://db/123.sql$sqlite://example_table,id=1/img»=«image»,
«$file://db/123.sql$sqlite://example_table,id=1/data$json://header»=«text»);
id=2:(«$file://db/123.sql$sqlite://example_table,id=2/data$json://text»=«text»,
«$file://db/123.sql$sqlite://example_table,id=2/img»=«image»,
«$file://db/123.sql$sqlite://example_table,id=2/data$json://header»=«text»);
id=3:(«$file://db/123.sql$sqlite://example_table,id=3/data$json://text»=«text»,
«$file://db/123.sql$sqlite://example_table,id=3/img»=«image»,
«$file://db/123.sql$sqlite://example_table,id=3/data$json://header»=«text»).
Т.е. каждой единице контента принадлежит три поля: это картинка и еще два текстовых поля.
В примере 1 и примере 2 представлена структура и работы системы по заявленному изобретению.
Именно разработанная структура позволяет извлекать контент из установочных файлов мобильных приложений с помощью процесса, который можно перепоручить серверу. Представленный способ является перспективным для исключения ручного труда при извлечении контента из мобильных приложений.
Способ реализуется благодаря системе (см. фиг.1) в виде программно-аппаратного комплекса. Программно-аппаратный комплекс может располагаться отдельно или совместно с другими программно-аппаратными комплексами на любом компьютере с операционной системой Windows, Linux и т.д. с объемом дискового пространства достаточным, чтобы сохранить скачанный установочный файл приложения (от 100 Мбайт до 1 Гбайта свыше требований операционной системы).
Вышеприведенные примеры доказывают решение поставленной технической задачи, а именно создание способа, основанного на вертикальной поисковой системе, позволяющего автоматически извлекать полезный контент из установочных файлов мобильных приложений для дальнейшего индексирования, машинной обработки данных и хранения полезного контента мобильных приложений в базе данных на сервере для дальнейшего обеспечения поиска.
Примеры также подтверждают промышленную применимость данного способа.
Перечень позиций:
1. Система
2. Модуль загрузки установочных файлов приложений
3. Хранилище ссылок и названий приложений
4. Модуль разархивирования приложений
5. Хранилище всех известных архиваторов
6. Модуль сканирования каталогов и составления списка адресов
7. Хранилище ПО для чтения всех структурных данных файла
8. Хранилище каталогов с файлами
9. Модуль анализа списка
10. Хранилище признаков служебного и полезного контента
11. Модуль статистической фильтрации
12. Хранилище пороговых значений для фильтра
13. Модуль формирования документов
14. Хранилище найденных документов
15. Модуль формирования описаний приложений
16. Модуль формирования записи в базе данных
17. Модуль хранения индексируемого массива
18. Модуль создания поискового индекса
19. Хранилище поискового индекса
20. Поисковая машина
21. Модуль обработки поискового запроса
22. Пользователь
Изобретение относится к обработке цифровых данных с помощью компьютерных систем, а именно к методам обработки данных, специально предназначенных для специфических функций, мобильных приложений. Техническим результатом является автоматическое извлечение полезного контента из установочных файлов мобильных приложений для дальнейшего индексирования, машинной обработки данных и хранения полезного контента мобильных приложений в базе данных на сервере для дальнейшего обеспечения поиска. Способ извлечения полезного контента из установочных файлов мобильных приложений для дальнейшей машинной обработки данных содержит этапы, на которых загружают из Интернета на сервер установочный файл приложения, представляющий всегда некий архив; подбирают к нему разархиватор; в случае успешного подбора разархиватора разархивируют загруженный установочный файл в каталог с файлами; анализируют полученный каталог, составляют список файлов, содержащихся в нем; выбирают из списка файл для дальнейшего анализа; подбирают программное обеспечение для чтения файла путем перебора всех известных форматов; в случае успешного подбора программного обеспечения для чтения файла анализируют выбранный файл на предмет поиска первичного контента; формируют список адресов внутреннего размещения первичного контента в виде набора строк; переходят к анализу следующего файла до тех пор, пока в каталоге есть файлы; проводят анализ текстового содержимого списка адресов внутреннего размещения первичного контента и разделяют текст каждой строки на набор символов, идентифицирующих способ хранения соответствующей единицы контента, набор символов, идентифицирующий документ, к которому относится данная единица контента, и набор символов, идентифицирующий тип этой единицы контента; разделяют строки адресов внутреннего размещения единицы контента по способу хранения на служебный контент и полезный контент; служебный контент удаляют; выделяют в оставшемся списке группы строк с адресами внутреннего размещения единиц контента, имеющие полностью совпадающие по месторасположению и тексту группы символов, отражающие способ хранения контента; проводят статистическую фильтрацию выделенных групп; проводят анализ текстового содержимого строк списка адресов по набору символов, идентифицирующих документ, и выделяют группы адресов единиц контента, относящихся к каждому документу полезного контента приложения; выкачивают из приложения полезный контент, относящийся к каждому документу, в отдельный файл, тем самым формируя документы приложения; индексируют полученные файлы документов приложения на предмет принадлежности к нему, тем самым формируют описание его контента; сохраняют в базе данных название приложения, ссылку на приложение и описание приложения; загружают установочный файл нового приложения и повторяют все описанные последовательности; производят машинную обработку полученной базы данных; хранят созданный индексируемый массив базы данных на сервере; используют для поисковых запросов пользователей, поступающих через Интернет. 12 з.п. ф-лы, 2 ил.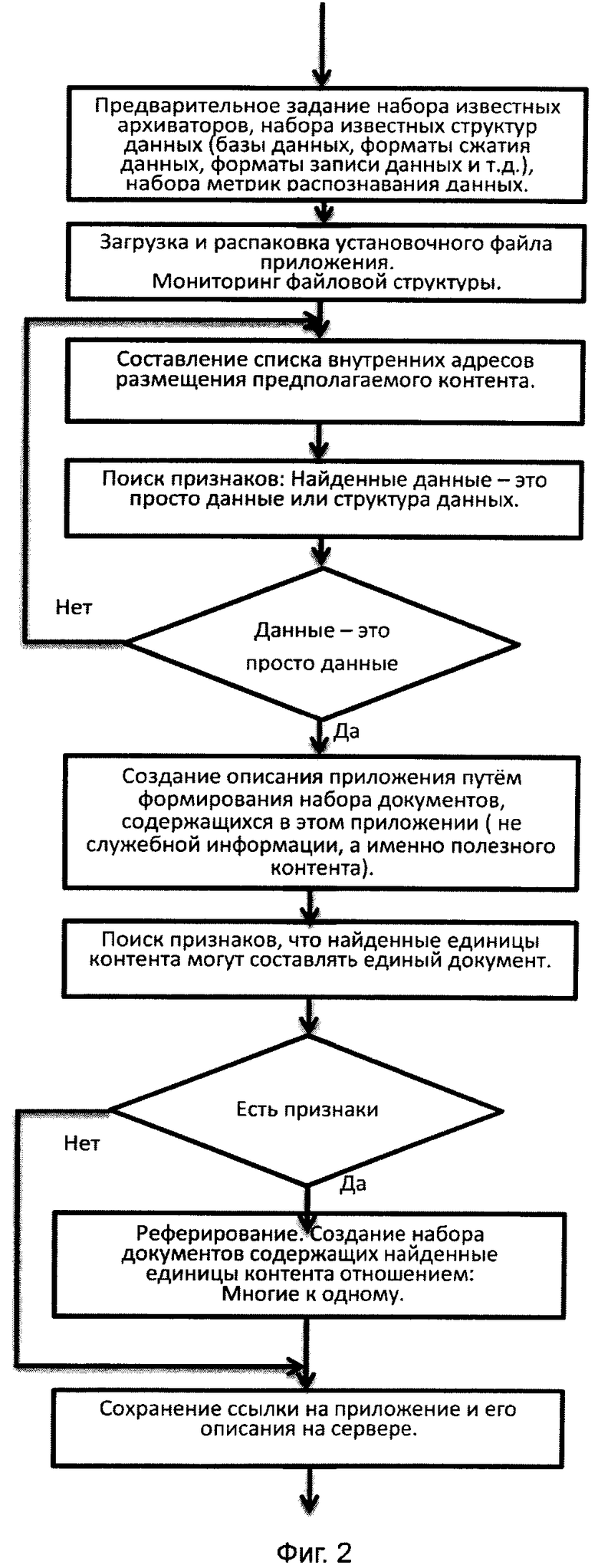
1. Способ извлечения полезного контента из установочных файлов мобильных приложений для дальнейшей машинной обработки данных, содержащий этапы, на которых:
- загружают из Интернета на сервер установочный файл приложения, представляющий всегда некий архив;
- подбирают к нему разархиватор;
- в случае успешного подбора разархиватора разархивируют загруженный установочный файл в каталог с файлами;
- анализируют полученный каталог, составляют список файлов, содержащихся в нем;
- выбирают из списка файл для дальнейшего анализа;
- подбирают программное обеспечение для чтения файла путем перебора всех известных форматов;
- в случае успешного подбора программного обеспечения для чтения файла анализируют выбранный файл на предмет поиска первичного контента;
- формируют список адресов внутреннего размещения первичного контента в виде набора строк;
- переходят к анализу следующего файла до тех пор, пока в каталоге есть файлы;
- проводят анализ текстового содержимого списка адресов внутреннего размещения первичного контента и разделяют текст каждой строки на набор символов, идентифицирующих способ хранения соответствующей единицы контента, набор символов, идентифицирующий документ, к которому относится данная единица контента, и набор символов, идентифицирующий тип этой единицы контента;
- разделяют строки адресов внутреннего размещения единицы контента по способу хранения на служебный контент и полезный контент;
- служебный контент удаляют;
- выделяют в оставшемся списке группы строк с адресами внутреннего размещения единиц контента, имеющие полностью совпадающие по месторасположению и тексту группы символов, отражающие способ хранения контента;
- проводят статистическую фильтрацию выделенных групп;
- проводят анализ текстового содержимого строк списка адресов по набору символов, идентифицирующих документ, и выделяют группы адресов единиц контента, относящихся к каждому документу полезного контента приложения;
- выкачивают из приложения полезный контент, относящийся к каждому документу, в отдельный файл, тем самым формируя документы приложения;
- индексируют полученные файлы документов приложения на предмет принадлежности к нему, тем самым формируют описание его контента;
- сохраняют в базе данных название приложения, ссылку на приложение и описание приложения;
- загружают установочный файл нового приложения и повторяют все описанные последовательности;
- производят машинную обработку полученной базы данных;
- хранят созданный индексируемый массив базы данных на сервере;
- используют для поисковых запросов пользователей, поступающих через Интернет.
2. Способ по п. 1, в котором разархиватор подбирают из заранее созданного расширяемого и модифицируемого набора всех известных архиваторов.
3. Способ по п. 1, в котором список файлов составляется путем формирования строк, содержащих полный путь к файлу в каталоге и название файла.
4. Способ по п. 1, в котором программное обеспечение для чтения файла подбирают из заранее созданного расширяемого и модифицируемого набора программного обеспечения.
5. Способ по п. 1, в котором анализ выбранного файла на предмет поиска первичного контента производят путем следующих действий: проводят поиск внутрифайловых адресов всех единиц контента самого нижнего уровня, затем проверяют эти единицы контента на соответствие первичному контенту, при этом, если контент является не первичным, повторно подбирают программное обеспечение, раскрывают вложенную структуру данных, проверяют все внутриструктурные адреса контента нижнего уровня и так до тех пор, пока во внутрифайловых адресах самого нижнего уровня не будет найден первичный контент.
6. Способ по п. 1, в котором каждая строка из набора строк списка адресов содержит информацию о местонахождении файла в каталоге, полный внутрифайловый адрес каждой единицы первичного контента с указанием всех этапов по извлечению этой единицы первичного контента и полного перечня программного обеспечения, с помощью которого открывают эту единицу на каждом этапе.
7. Способ по п. 1, в котором анализ текстового содержимого списка адресов внутреннего размещения первичного контента производят путем выделения перебором комбинаций или на основе эмпирических правил наборов символов, а затем присвоения этому набору символов смыслового значения на основе данных о его месторасположении и повторяемости в списке.
8. Способ по п. 1, в котором строки адресов внутреннего размещения единицы контента разделяют на адреса со способом хранения, характерным для хранения служебного контента, и адреса со способом хранения, характерным для хранения полезного контента, с помощью заранее созданного расширяемого и модифицируемого набора правил.
9. Способ по п. 1, в котором статистическая фильтрация производится на основании условия: если файлы, входящие в группы, являются однотипными, то это полезный контент, а если файлы, входящие в группу, имеют различные типы, то этот контент является служебным, при этом используют правило превышения порогового значения на процентное содержание неоднотипных файлов, причем тип контента - база данных, текст, звук, картинка, видео - могут иметь различные форматы, но при этом остаются типом.
10. Способ по п. 1, в котором проводят анализ текстового содержимого строк списка адресов по набору символов, идентифицирующих документ, и формируют документы путем следующих действий: производят анализ текстового содержимого оставшихся строк списка на предмет поиска строк с различными наборами символов, идентифицирующих способ хранения, и совпадающими наборами символов, идентифицирующих документ, к которому относится контент, адресом которого является эта строка, при этом если в списке адресов внутреннего размещения таких строк нет, то каждая единица контента определяется как отдельный документ, если есть, то выделяют группы строк, в которых совпадают идентификаторы документа и различаются идентификаторы способа хранения, затем контент, хранящийся по адресам, выделенным в эти группы, объединяют в документы путем объединения частей.
11. Способ по п. 1, в котором полезный контент из приложения выкачивают в виде набора документов, пригодных для дальнейшей машинной обработки.
12. Способ по п. 1, в котором описания приложений формируют путем объединения текстового содержимого документов в единый текст, отражающий набор документов, содержащихся в приложении.
13. Способ по п. 1, в котором установочный файл нового приложения загружают и повторяют все описанные последовательности до тех пор, пока в глобальных компьютерных сетях и маркетах имеются новые не обработанные приложения.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 7401064 B1, 15.07.2008 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ИНТЕРНЕТ-ПОИСКА МУЛЬТИМЕДИЙНОГО КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ | 2008 |
|
RU2399090C2 |

