Область изобретения
Настоящее изобретение, в основном, относится к репликации баз данных и, в частности, к выборочной репликации баз данных, работающих в кластере.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Компьютерные приложения используют базы данных для хранения информации. База данных обычно включает сложный набор функций программного обеспечения, часто называемый системой управления базами данных (DBMS), которая позволяет пользователю определить и создать базу данных, обновить и запросить базу данных и иным образом поддерживать базу данных. Базы данных предлагают безопасность и гарантируют, что обновления являются атомарными, долгосрочными и непротиворечивыми, но часто за счет увеличения сложности. Для бизнеса является обычным делом нанять полностью занятых специалистов по базе данных, чтобы поддержать деловые базы данных. Поставщики приложения могут требовать использовать базу данных для хранения критических данных, таких как данные конфигурации, но не требуют от заказчика дополнительных затрат на поддержание сложного программного обеспечения базы данных или, в некоторых случаях, даже зная, что заказчик использует определенную DBMS. Таким образом, поставщики приложения могут пожелать преимуществ DBMS, но хотят оградить своих клиентов от сложностей, связанных с DBMS.
Некоторые приложения разработаны с расчетом совместной работы в сети распределенным способом. Например, телекоммуникационная система может включить множество серверов данных, объединенных вместе в сеть в виде кластера. Каждый сервер в кластере связывается с другими серверами в кластере. Каждый сервер может иметь соответствующую базу данных, в которой хранится информация, например информация о конфигурации. Информация, сохраняемая в базе данных, может относиться к отдельному серверу, такому как имя узла или адрес по протоколу Интернета (IP), или может быть характерной для каждого сервера в сети, независимо от того, реализуют ли серверы простой протокол управления сетью (SNMP). Для одного сервера в распределенных системах весьма обычно быть идентифицированным как главный или основной сервер и оставшиеся серверы определяются как ведомые или вторичные серверы.
Определенные изменения конфигурации, сделанные в основном сервере, могут быть обязательны для повторения в каждом из вторичных серверов. Идеально, каждый раз, когда такое изменение конфигурации делается в первичном сервере, соответствующее изменение конфигурации будет делаться во вторичных серверах без участия человека. Хотя у современных DBMS сегодня есть определенные возможности распространения данных среди распределенных баз данных, например, через репликацию баз данных, реализация и поддержка тиражированных баз данных может потребовать значительного объема работы по экспертизе. Кроме того, репликация увеличивает сложность восстановления поврежденной базы данных или добавления новой вторичной базы данных к кластеру, не разрешает выборочное обновление вторичных баз данных и требует, чтобы каждая база данных была бы от одного и того же поставщика DBMS. Таким образом, имеется потребность в механизме для тиражирования информации о базе данных среди распределенных баз данных, которая не требует существенной экспертизы базы данных от клиента, обладает надежностью, работает в среде разных производителей и также обеспечивает выборочную репликацию в распределенной сети, в основном, одновременно.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Специалисты в данной области оценят объем настоящего изобретения и смогут реализовать его дополнительные преимущества после чтения последующего подробного описания предпочтительных примеров воплощения со ссылками на сопроводительные чертежи.
Настоящее изобретение относится к выборочному тиражированию (репликации) данных, таких как данные конфигурации, из первичной базы данных в одну или несколько вторичных баз данных. Задача репликации включает обновление первичной базы данных, связанной с первичным сервером, которая должна быть тиражирована в одну или несколько вторичных баз данных, связанных с вторичными серверами. Вторичный сервер определяет, что первичная таблица в первичной базе данных была изменена с первой командой обновления. Первая команда обновления может содержать один или несколько операторов модификации базы данных. Вторичный сервер определяет вторую команду обновления, которая создается на базе первой команды обновления. Вторичный сервер формирует вторичную объединенную таблицу во вторичном сервере, которая связана с первичной таблицей в первичном сервере. Вторичная объединенная таблица обеспечивает доступ к данным из первичной таблицы, используя обычные команды базы данных, таких как операторы языка структурированных запросов (SQL) на вторичном сервере. Вторичный сервер применяет вторую команду обновления к вторичной таблице, используя вторичную объединенную таблицу, таким образом, тиражируя обновление из первичной базы данных во вторичной базе данных.
Согласно одному примеру воплощения изобретения основной сервер формирует вторую команду обновления на основе первой команда обновления и хранит вторую команду обновления в таблице команды обновления в первичной базе данных. Основной сервер уведомляет вторичный сервер, когда первая команда обновления была применена к первичной таблице через триггер или уведомление. После получения уведомления от основного сервера вторичный сервер получает доступ к таблице команды обновления в первичной базе данных и получает вторую команду обновления. Вторичный сервер формирует вторичную объединенную таблицу, которая связана с первичной таблицей, и обновляет вторичную таблицу через вторичную объединенную таблицу. Первичная таблица, вторичная таблица и вторичная объединенная таблица имеют то же самое определение таблицы.
Согласно другому примеру воплощения изобретения каждая задача репликации имеет соответствующий уникальный идентификатор задачи и уникальную подпись. Идентификатор задачи и подпись, связанная с каждой задачей репликации, хранятся в первичной базе данных, когда задача репликации выполняется на первичной базе данных, и тот же самый уникальный идентификатор задачи и уникальная подпись, связанная с задачей репликации, хранятся во вторичной базе данных после того, как задача репликации была выполнена во вторичной базе данных. Когда вторичный сервер уведомлен, что обновление произошло с первичной таблицей в первичной базе данных, вторичный сервер получает идентификаторы задачи и подписи, связанные с задачами репликации от первичной базы данных, и сравнивает подписи с подписями, ранее введенными во вторичную базу данных. Если подпись от первичной базы данных не соответствует подписи от вторичной базы данных, вторичный сервер выполняет задачу репликации на вторичной базе данных и затем хранит подпись от первичной базы данных во вторичной базе данных с тем, чтобы задача репликации не была бы выполнена снова.
Согласно другому примеру воплощения изобретения вторая команда обновления обусловливает обновление вторичной таблицы на основе данных во вторичной базе данных. Например, приложение, установленное на первичном сервере, инициирует задачу репликации, которая устанавливает новую таблицу конфигурации в первичной базе данных, в которой хранятся данные конфигурации, связанные с приложением. Вторичный сервер уведомляется о том, что задача репликации была выполнена на первичной базе данных. Вторичный сервер получает идентификатор задачи и подпись, связанную с задачей репликации, из первичной базы данных и определяет, что задача репликации не была выполнена на вторичной базе данных. Вторичный сервер получает вторую команду обновления на основе первой команды обновления, используемой для составления новой таблицы конфигурации. Однако вторая модификация условий команды обновления вторичной таблицы конфигурации во вторичной базе данных существует во вторичной таблице конфигурации во вторичной базе данных. Поскольку приложение еще не было установлено на вторичном сервере, вторичная таблица конфигурации еще не существует на вторичной базе данных и никакие данные не тиражируются из новой таблицы конфигурации в первичной базе данных к вторичной базе данных. В точке времени в будущем, когда приложение установлено на вторичном сервере и во вторичной таблице конфигурации создается во вторичной базе данных, вторичный сервер может быть направлен на инициирование процесса репликации. Вторичный сервер снова получит идентификатор задачи и подпись, связанную с задачей репликации от первичной базы данных, решит, что подпись от первичной базы данных не соответствует подписи из вторичной базы данных, и выполнит задачу репликации во вторичной базе данных.
Согласно еще одному примеру воплощения изобретения вторая команда обновления обусловливает обновление определенных строк вторичной таблицы на критериях, основанных на данные во вторичной базе данных. Например, приложение на первичном сервере инициирует задачу репликации, которая изменяет определенные ряда в первичной таблице на основе определенного критерия. Вторичный сервер уведомляется о том, что задача репликации была выполнена в первичной базе данных. Вторичный сервер получает идентификатор задачи и подпись, связанную с задачей репликации от первичной базы данных, и определяет, что задача репликации не была выполнена во вторичной базе данных. Вторичный сервер получает вторую команду обновления на основе, первая команда обновления используется для составления новой таблицы конфигурации. Вторичный сервер выполняет задачу репликации, и только определенные ряды во вторичной таблице обновляются на основе определенных критериев.
Согласно еще одному примеру воплощения изобретения новый вторичный сервер добавляется к кластеру существующих вторичных серверов. Новый вторичный сервер инициирует доступ к первичной базе данных, чтобы получить уникальные идентификаторы задачи и подписи, связанные с задачами репликации на первичном сервере. Каждая задача репликации затем выполняется во вторичной базе данных, связанной с новым вторичным сервером. Кроме того, новая вторичная база данных выборочно тиражируется из первичной базы данных без отнимающей много времени ручной конфигурации и без разрушений данных в первичной базе данных или в любых других вторичных базах данных.
КРАТКОЕ ОПИСАНИЕ ФИГУР ЧЕРТЕЖЕЙ
Сопроводительные чертежи являются частью этого описания изобретения, иллюстрирующей несколько примеров воплощения изобретения, и вместе с описанием служат для объяснения принципа действия изобретения.
Фигура 1 - блок-схема системы для выборочной репликации базы данных согласно одному примеру воплощения изобретения.
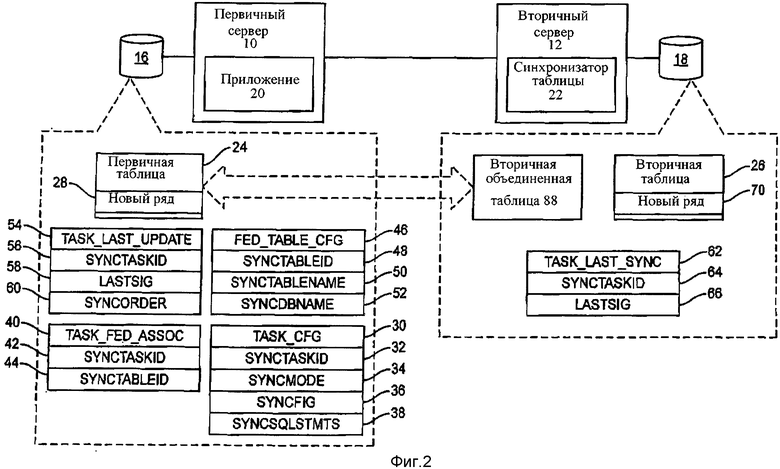
Фигура 2 - подробная блок-схема системы, показанной на фигуре 1.
Фигура 3 - блок-схема, иллюстрирующая процесс обновления первичной таблицы в первичной базе данных согласно одному примеру воплощения изобретения.
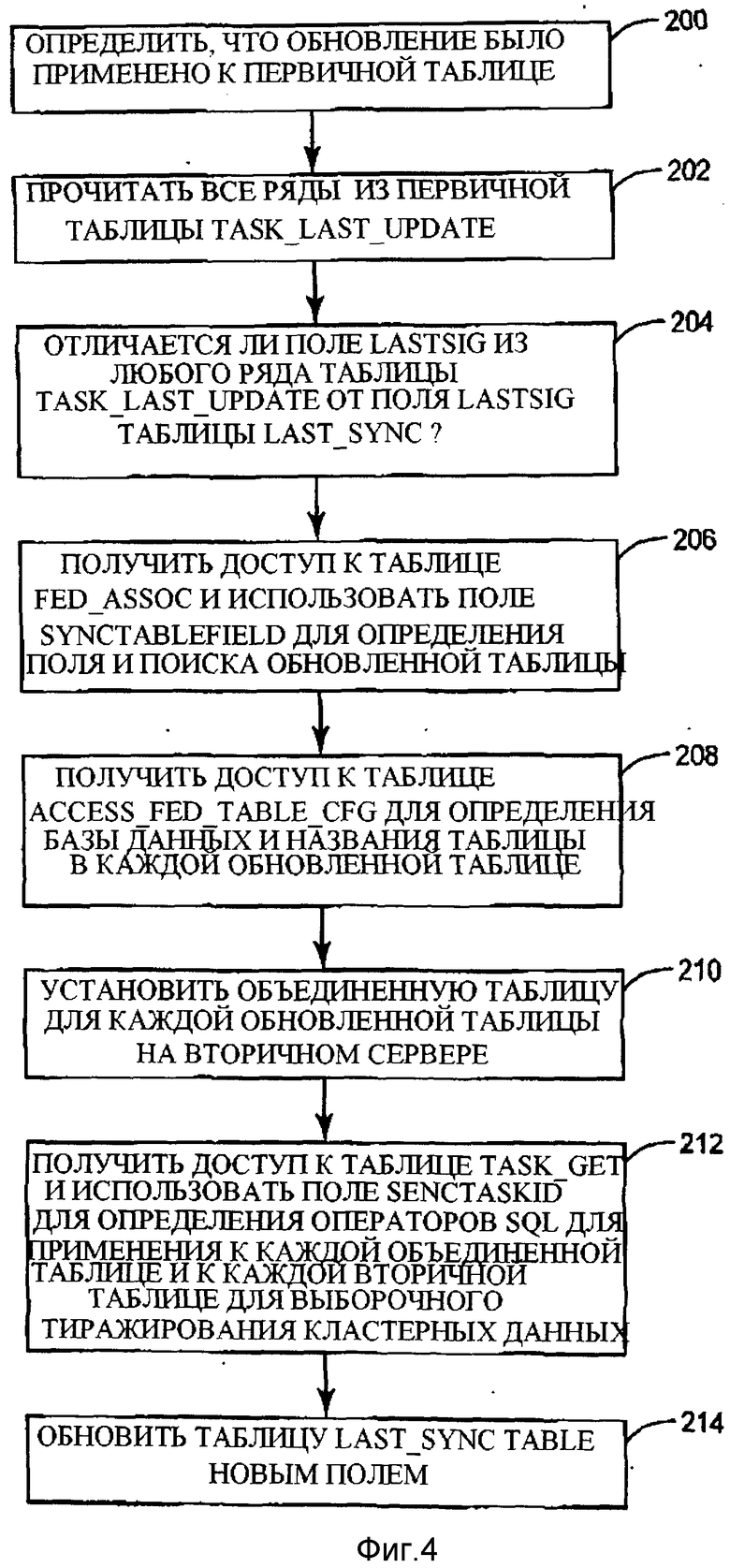
Фигура 4 - блок-схема, иллюстрирующая процесс обновления вторичной таблицы во вторичной базе данных согласно примеру воплощения, представленному на фигуре 3.
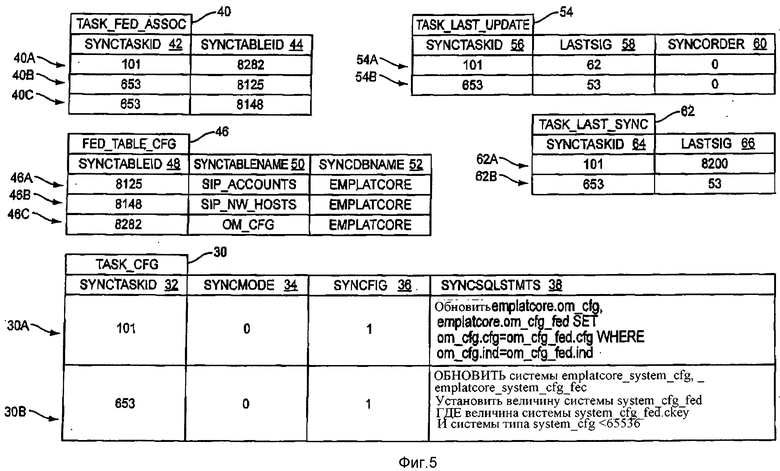
Фигура 5 - блок-схема, иллюстрирующая примерные данные в процессе выборочной репликации согласно другому примеру воплощения изобретения.
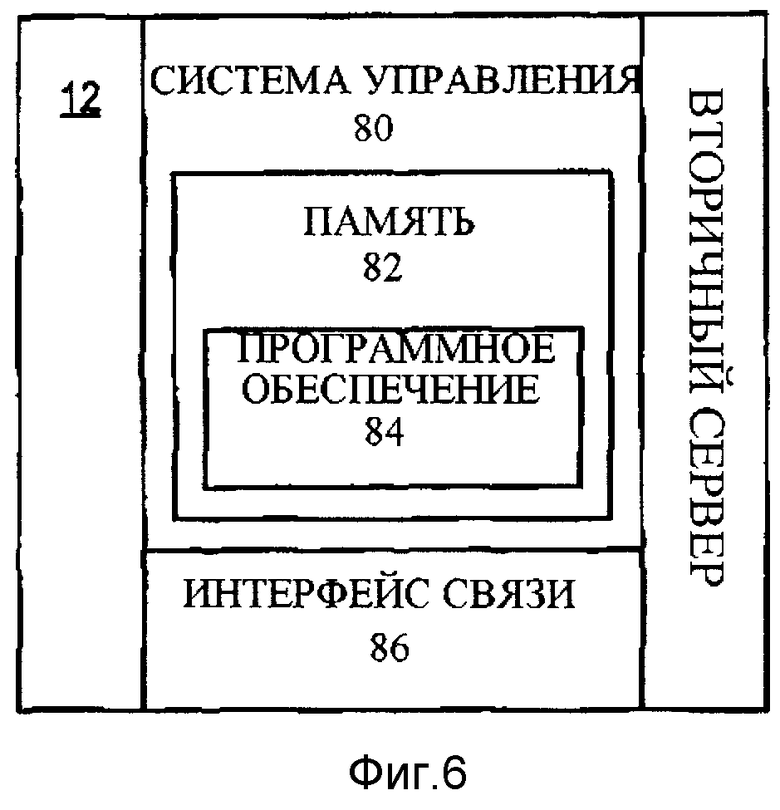
Фигура 6 - блок-схема сервера согласно одному примеру воплощения изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ПРИМЕРОВ ВОПЛОЩЕНИЯ
Описанные ниже примеры воплощения предоставляют необходимую информацию, чтобы специалисты в данной области могли практически осуществить изобретение, и иллюстрируют лучший способ осуществления изобретения. После чтения последующего описания со ссылками на фигуры сопроводительных чертежей специалисты в данной области могут лучше уяснять сущность изобретения и возможности его применения в других, не описанных здесь, областях. Следует понимать, что эти области применения и приложения находятся в пределах объема раскрытия и формулы изобретения. Настоящее изобретение позволяет выборочно тиражировать первичную базу данных, связанную с первичным сервером, во множество вторичных баз данных, связанных с множеством вторичных серверов, которые работают в кластере. Настоящее изобретение использует обычные операторы модификации базы данных, чтобы выполнить репликацию, и устраняет сложности, связанные с обычной репликацией баз данных, одновременно обеспечивая значительно большую гибкость, чем обычная репликация баз данных. Настоящее изобретение позволяет выборочно тиражировать множество кластеризируемых баз данных, в основном, одновременно друг с другом с очень небольшими затратами на обработку или использование сетевых ресурсов. Настоящее изобретение также включает автоматическое восстановление базы данных без вмешательства человека или знания сложных команд базы данных. С помощью обычных операторов базы данных для выполнения задачи репликации настоящее изобретение обеспечивает выборочную репликацию баз данных в среде разных производителей.
Фигура 1 - блок-схема системы для выборочной репликации базы данных согласно одному примеру воплощения изобретения. Первичный сервер 10 связан с множеством вторичных серверов 12 через сеть 14. Первичный сервер 10 и вторичные серверы 12 предпочтительно работают в кластере и обеспечивают одну или несколько услуг через сеть 14 для других устройств (не показаны). Первичный сервер 10 связан с первичной базой данных 16, и каждый вторичный сервер 12 связан с вторичной базой данных 18. Первичный сервер 10 и вторичные серверы 12 могут иногда упоминаться здесь как узлы в кластере. Назначение определенного узла в кластере как первичного или вторичного узла может зависеть от установки. Однако узел, определяемый как первичный сервер, например, первичный сервер 10, является узлом, с которым предпочтительно связаны все другие узлы, такие как вторичные серверы 12, чтобы принять определенную информацию, такую как информация о конфигурации, характерная для каждого узла в кластере. Кроме той роли, которую играют первичные или вторичные серверы, может быть небольшая физическая разница между первичным сервером 10 и вторичными серверами 12. Первичный сервер 10 и вторичные серверы 12 могут быть все вместе упомянуты здесь как серверы 10, 12, когда дальнейшее обсуждение в равной мере относится к первичному серверу 10 и вторичным серверам 12. Серверы 10, 12 могут содержать любое устройство обработки данных, подходящее для выполнения описанных здесь функций. Серверы 10, 12 могут быть серверами универсального компьютера, имеющие обычную или собственную операционную систему, которые реализуют обычные или специализированные операции через одно или несколько приложений, которые выполняются на серверах 10, 12. Альтернативно, серверы 10, 12 могут быть устройствами особого назначения, которые имеют ограниченную функциональность. Согласно одному примеру воплощения изобретения серверы 10, 12 содержат медийные приложения, обеспечивающие множество коммуникационных услуг, таких как передача речи, видео, аудио и других услуг множеству устройств конечного пользователя (не показаны), таких как телефоны, компьютеры, и т.д.
Сеть 14 может быть основана на любых подходящих технологиях связи, с проводными или беспроводными соединениями, способными обеспечить связь между серверами 10, 12 с использованием любых обычных протоколов обмена сообщениями, таких как протокол управления передачей данных (TCP) или протокол Интернета (IP), протокол ускоренной передачи данных (RTP), управляющий протокол носителей ресурса (MRCP) и т.д. Кроме того, могут использоваться собственные протоколы обмена сообщениями. Первичная база данных 16 и вторичные базы данных 18 могут содержать любую подходящую систему управления базами данных (DBMS), такую как обычная реляционная или иерархическая DBMS. В частности, первичная база данных 16 и вторичные базы данных 18 могут быть поставлены одним и тем же поставщиком или различными поставщиками, если базы данных отвечают одному и тому же способу с обычными операторами базы данных, такими как язык структурированных запросов (SQL). Первичная база данных 16 и вторичные базы данных 18 могут быть упомянуты здесь все вместе как базы данных 16, 18, когда дальнейшее обсуждение в равной мере относится к первичной базе данных 16 и вторичным базам данных 18.
Хотя базы данных 16, 18 изображены как связанные с устройствами хранения, которые отделены от серверов 10, 12 соответственно, специалисты в данной области понимают, что DBMS включает не только структуры данных, такие как таблицы, наборы данных и индексы содержания данных, которые могут храниться в устройстве хранения данных, но также и относительно сложные алгоритмы доступа к базе данных, которые выполняются на соответствующих серверах 10, 12 или в специализированных процессорах базы данных, включая прикладные программы для создания, обновления, получения доступа и запроса баз данных 16, 18. Ссылки на основную базу данных 16 как базу «на сервере» или «связанной с» первичным сервером 10 относятся к ассоциации между первичной базой данных 16 и первичным сервером 10, включена ли первичная база данных 16 физически, интегрирована или просто доступна первичному серверу 10 по сети 14 или по другому пути или каналу связи. Точно так же ссылки на вторичную базу данных 18 как «связанную» с соответствующим вторичным сервером 12 относятся к ассоциации между вторичной базой данных 18 и соответствующим вторичным сервером 12, включена ли вторичная база данных 18 физически, интегрирована или просто доступна вторичному серверу 12 по сети 14 или по другому пути или каналу связи. Ссылки на получение информации о базе данных от сервера 10, 12 относятся к получению информации из соответствующей базы данных 16, 18 в зависимости от обстоятельств, связанных с соответствующим сервером 10, 12, включен ли фактически соответствующий сервер 10, 12 при получении данных от соответствующей базы данных 16, 18.
Приложения, которые обеспечивают желательные функции серверов 10, 12, могут использовать базы данных 16, 18 для хранения данных для множества целей, включая информацию, которая относится к действию соответствующих приложений. Например, базы данных 16, 18 могут включать узловые данные, которые относятся исключительно к конкретному серверу 10, 12, с которым связана база данных 16, 18, например, имя узла или протокол Интернета (IP) и адрес соответствующего сервера 10, 12. Базы данных 16, 18 могут также включать кластерные данные, которые относятся ко всем узлам в кластере, в частности, используется ли простой протокол управления сетью (SNMP), чтобы управлять серверами 10, 12. Типы данных, которые могут быть выборочно тиражированы согласно одному примеру воплощения изобретения, могут включать, без ограничения, протокол инициирования сеансов связи (SIP), информацию о конфигурации, включая домены SIP, атрибуты прокси-SIP, SIP доверительных узлов, операционную измерительную информацию о конфигурации, например, заархивирована ли операционная измерительная информация или нет, идентификация информации о кодеке носителей и какие кодеки включены, приоритетное упорядочивание, связанное с кодеками, технические параметры, такие как максимальный предел ожидания центрального процессора, адрес сервера синхронизации времени, лицензионные ключи и т.д. Согласно настоящему изобретению кластерные данные, которые изменены в первичной базе данных 16, могут быть автоматически тиражированы во вторичную базе данных 18, за короткий период времени, например, в течение двух или трех секунд, хотя узловые данные, измененные в первичной базе данных 16, не будут тиражированы во вторичную базу данных 18.
На фигуре 2 представлена более подробная блок-схема первичного сервера 10 и связанной с ним первичной базы данных 16, вторичного сервера 12 и связанной с ним вторичной базы данных 18, показанных на фигуре 1, и включает табличные определения, которые могут использоваться, чтобы выполнить выборочную репликацию согласно одному примеру воплощения изобретения. Первичный сервер 10 включает приложение 20, которое обеспечивает выполнение определенной функции первичного сервера 10. Вторичный сервер 12 включает синхронизатор таблицы 22, который будет использоваться здесь для описания задач настоящего изобретения, выполняемых на одном или нескольких вторичных серверах 12, чтобы выборочно тиражировать данные из первичной базы данных 16 во вторичную базу данных 18. Фигура 2 будет обсуждаться в связи с фигурой 3, которая является блок-схемой, иллюстрирующей процесс обновления первичной таблицы 24 в первичной базе данных 16 согласно одному примеру воплощения изобретения. Фигура 2 также будет обсуждаться в связи с фигурой 4, которая является блок-схемой, иллюстрирующей процесс тиражирования данных из первичной таблицы 24 во вторичную таблицу 26 во вторичной базе данных 18 согласно одному примеру воплощения изобретения. Фигуры 2-4 также будут обсуждаться в связи с фигурой 5, которая является блок-схемой, иллюстрирующей табличные определения конкретных таблиц, которые могут использоваться для выполнения выборочной репликации баз данных согласно одному примеру воплощения настоящего изобретения.
Обратимся теперь к фигурам 2 и 3, предположив, что приложение 20 изменяет первичную таблицу 24, вставляя новый ряд 28 данных, содержащих один или несколько параметров конфигурации в первичную таблицу 24 (стадия 100), и что эта модификация - задача репликации по тиражированию данных во вторичную базу данных 18. Хотя настоящее изобретение описывается в целях иллюстрации, используя DBMS SQL и терминологию реляционной базы данных, таких как таблицы, вставки, соединения и т.д., специалистам в данной области понятно, что описанные здесь концепции применимы к множеству различных типов DBMS, включая иерархические системы DBMS, и изобретение не ограничено использованием реляционных систем DBMS. После вставки нового ряда 28 в первичную таблицу 24, приложение 20 вставляет новый ряд данных, связанных с обновленной первичной таблицей 24, в таблицу TASK_CFG 30. Новый ряд данных может включать поле SYNCTASKID 32, которое содержит уникальный идентификатор задачи, который идентифицирует задачу репликации. Специалисты в данной области знают, что уникальные идентификаторы могут быть получены различными способами, включая вызов предоставленной поставщиком функции операционной системы или функции DBMS, которая обеспечивает уникальные идентификаторы по запросу. Новый ряд в таблице TASK_CFG 30 может также включать поле SYNCMODE 34, которое содержит информацию об операторах базы данных, которые будут использоваться для выполнения репликации во вторичной базе данных 18. Поле SYNCMODE 34 может указать, что задача репликации выполняется с единственным оператором базы данных или с множеством операторов базы данных, которые могут быть получены из поля SYNCSQLSTMTS 38, или на то, что вторичный сервер 12 должен формировать множество операторов базы данных для выполнения задачи репликации на основе схемы определения первичной таблицы 24. Новый ряд может также включать поле SYNCFIG 36, которое содержит индикатор, указывающий, должна ли задача репликации быть применена к вторичной таблице 26. Новый ряд также может включать поле SYNCSQLSTMTS 38, которое может содержать фактические операторы базы данных, которые используются вторичным сервером 12 для выполнения задачи репликации во вторичной таблице 26 (стадия 102) на основе поля SYNCMODE 34. В частности, и как описано ниже более подробно, операторы базы данных, содержащиеся в поле SYNCSQLSTMTS 38, возможно, являются другими операторами базы данных относительно операторов, используемых приложением 20, чтобы вставить новый ряд 28 в первичную таблицу 24, потому что операторы базы данных в поле SYNCSQLSTMTS 38 будут операторами базы данных, которые выполняются на вторичном сервере 12, чтобы тиражировать данные из первичной таблицы 24 во вторичную таблицу 26.
Затем приложение 20 вставляет следующий новый ряд в таблицу TASK_FED_ASSOC 40. Новый ряд в таблице TASK_FED_ASSOC 40 может включать поле SYNCTASKID 42, которое содержит то же самое поле SYNCTASKID, описанное выше (стадия 104). Новый ряд в таблице TASKFEDASSOC 40 может также включать поле SYNCTABLEID 44, которое содержит идентификатор, идентифицирующий первичную таблицу 24. SYNCTABLEID из поля SYNCTABLEID 44 может быть использовано для перекрестной ссылки к таблице FEDTABLECFG 46, которая содержит один ряд для каждой таблицы в первичной базе данных 16. Каждый ряд в таблице FED_TABLE_CFG 46 может включать поле SYNCTABLEID 48, которое является уникальным идентификатором, связанным с определенной таблицей в первичной базе данных 16; поле SYNCTABLENAME 50, которое содержит фактическое имя таблицы в первичной базе данных 16, и поле SYNCDBNAME 52, которое содержит подлинное имя первичной базы данных 16. Таблица FED_TABLE_CFG 46 используется для перекрестной ссылки к конкретному полю SYNCTABLEID с определенной первичной таблицей в первичной базе данных 16.
Затем приложение 20 вставляет новый ряд в таблицу TASKLASTJJPDATE 54. Новый ряд в таблице TASK_LAST_UPDATE 54 может включать поле SYNCTASKID 56, которое содержит описанное выше поле SYNCTASKID, со ссылкой на таблицу TASKFEDASSOC 40 и таблицу TASKCFG 30, и поле LASTSIG 58, которое включает уникальную подпись, которая связана с соответствующим полем SYNCTASKID (стадия 106). Новый ряд также может включать поле SYNCORDER 60, которое содержит данные, которые могут использоваться вторичными серверами 12, чтобы гарантировать, что репликация происходит в определенном порядке с целью эффективности или с целью целостности данных. Хотя таблица TASK_CFG 30, таблица TASKFEDASSOC 40, таблица FEDTABLECFG 46 и таблица TASKJLASTJJPDATE 54 описаны здесь как таблицы в первичной базе данных 16, специалистам в данной области очевидно, что такие таблицы могут быть в базе данных, отделенной из первичной базы данных 16.
Приложение 20 уведомляет синхронизатор таблицы 22, выполняемый на вторичном сервере 12, что задача репликации выполнялась в первичной базе данных 16 (стадия 108). Приложение 20 может уведомить вторичный сервер 12 о задаче репликации, используя любой обычный механизм, который позволяет задаче, выполняющейся на первом сервере, уведомить задачу, выполняющуюся на втором сервера о возникновении события на первом сервере. Согласно одному примеру воплощения настоящего изобретения приложение 20 уведомляет синхронизатор таблицы 22 о том, что задача репликации выполнялась в первичной базе данных 16 через триггер SQL. Триггер может быть запущен при вставке нового ряда в таблицу TASKLASTJJPDATE 54. Триггер может вызвать событие, которое синхронизатор таблицы 22 ожидает, чтобы уведомить синхронизатор таблицы 22 о том, что задача репликации была выполнена в первичной базе данных 16.
Обратимся теперь к фигурам 2 и 4, на которых синхронизатор таблицы 22 определяет, что обновление было применено к первичной таблице 24 (стадия 200). Синхронизатор таблицы 22 получает каждый ряд из таблицы TASK_LAST_UPDATE 54 в первичной базе данных 16 (стадия 202). Синхронизатор таблицы 22 получает доступ к таблице TASK_LAST_SYNC 62 во вторичной базе данных 18, которая включает ряд, связанный с каждой задачей репликации, которая ранее выполнялась во вторичной базе данных 18. Каждый ряд в таблице TASK_LAST_SYNC 62 включает поле SYNCTASKID 64, которое содержит поле SYNCTASKID из первичной базы данных 16, связанной с соответствующей задачей репликации, и поле LASTSIG 66, которое включает поле LASTSIG, связанное с соответствующим полем SYNCTASKID. Синхронизатор таблицы 22 сравнивает поле LASTSIG из каждого ряда таблицы TASK_LAST_UPDATE 54 с полем LASTSIG из каждого ряда таблицы TASK_LAST_SYNC 62, чтобы определить, соответствует ли поле LASTSIG для каждого ряда в таблице TASK_LAST_UPDATE 54 полю LASTSIG ряда таблицы TASKLASTSYNC 62 (стадия 204). Если поле LASTSIG ряда таблицы TASK_LAST_SYNC 62 не соответствует полю LASTSIG какого-либо ряда в таблице TASK_LAST_UPDATE 54, то задача репликации, связанная с этим полем SYNCTASKID, должна быть выполнена во вторичной базе данных 18. Поскольку приложение 20 выполняло новую задачу репликации, которая включила обновление первичной таблицы 24 новым радом 28, поле LASTSIG нового ряда в таблице TASK_LAST_UPDATE 54 не будет соответствовать полю LASTSIG любого ряда в таблице TASK_LAST_SYNC 62.
Затем синхронизатор таблицы 22 получает доступ к таблице TASKJFED_ASSOC 40 в первичной базе данных 16 и использует SYNCTASKID из нового ряда в таблице TASK_LAST_UPDATE 54, чтобы получить доступ к таблице TASK_FED_ASSOC 40 и получить SYNCTABLEID для соответствующей SYNCTASKID (стадия 206). Синхронизатор таблицы 22 затем получает доступ к таблице FEDTABLECFG 46 в первичной базе данных 16, используя SYNCTABLEID из таблицы TASK_FED_ASSOC 40, чтобы получить SYNCTABLENAME таблицы и SYNCDBNAME базы данных, которая использовалась в соответствующей задаче синхронизации (стадия 208). Синхронизатор таблицы 22 затем устанавливает вторичную объединенную таблицу 68, которая относится к или связана с конкретной первичной таблице 24, идентифицированной полем 50 SYNCTABLENAME в таблице FEDTABLECFG 46 (стадия 210). Как очевидно специалистам в данной области, объединенная таблица позволяет таблице базы данных на удаленном сервере появиться как смонтированной таблице базы данных или иным образом существующей на местном сервере. Хотя в некоторых DBMS используется фраза "объединенная таблица", понятно, что возможность и понятие объединенной таблицы существуют во многих различных DBMS, и использование здесь фразы "объединенная таблица" включает представление таблицы в местной базе данных из удаленной базы данных так, что операторы базы данных в приложении к таблице в местной базе данных, получаемой из удаленной базы данных независимо от конкретной терминологии, используются, чтобы описать такой признак в любой конкретной базе DBMS. Вторичная объединенная таблица 68 по настоящему изобретению предпочтительно имеет то же самое определение первичной таблицы 24, с которой связана вторичная объединенная таблица 68, и вторичной таблицы 26.
Синхронизатор таблицы 22 получает доступ к таблице TASK_CFG 30 в первичной базе данных 16, используя соответствующий SYNCTASKID, чтобы получить команду обновления из поля SYNCSQLSTMTS 38 соответствующего ряда таблицы TASK_CFG 30 (стадия 212). Команда обновления базы данных содержит один или несколько операторов базы данных, связанных с соответствующей DBMS. Если команда обновления базы данных содержит единственный оператор базы данных, поле SYNCMODE 34 может иметь значение "0". Если команда обновления базы данных содержит множество операторов базы данных, поле SYNCMODE 34 может иметь значение "1". Синхронизатор таблицы 22 затем применяет операторы базы данных к вторичной таблице 26, используя вторичную объединенную таблицу 68, чтобы создать новый ряд 70, который тиражирует данные из нового ряда 28 в первичную таблицу 24 в первичной базе данных 16. Синхронизатор таблицы 22 затем вставляет новый ряд в таблицу TASK_LAST_SYNC 62, включая SYNCTASKID и LASTSIG, связанные с соответствующей задачей репликации, полученной из таблицы TASK_LAST_UPDATE 54, с тем, чтобы синхронизатор таблицы 22 впоследствии не повторил задачу репликации (стадия 214). После некоторого промежутка времени синхронизатор таблицы 22 может удалить вторичную объединенную таблицу 68. В альтернативном примере воплощения поле SYNCMODE 34 имеет значение "2", которое является указанием синхронизатору таблицы 22 формировать вторую команду на основе схемы первичной таблицы 24. В этом примере воплощения, синхронизатор таблицы 22 просит схему первичной базы данных 16 определить схему таблицы, которая определяет первичную таблицу 24 и вторичную таблицу 26. Синхронизатор таблицы 22 формирует, вставляет, обновляет и удаляет SQL-операторы, которые выполняют соединение на каждом поле с вторичной объединенной таблицей 68. Оператор вставки SQL добавляет новые ряды, которых раньше не было во вторичной таблице 26, из первичной таблицы 24 во вторичную таблицу 26. Оператор обновления SQL обновляет любые ряды во вторичной таблице 26 на основе данных в тех же самых рядах из первичной таблицы 24. Оператор удаления SQL удаляет ряды из вторичной таблицы 26, которые не существуют в первичной таблице 24.
Фигура 5 - блок-схема, иллюстрирующая примерные данные примерной задачи репликации, выполняемой приложением 20 согласно другому примеру воплощения настоящего изобретения. Таблица TASKFEDASSOC 40, таблица TASKCFG 30, таблица FEDTABLECFG 46, таблица TASK_LAST_UPDATE 54 и таблица TASKLASTSYNC 62 содержат поля, идентичные полям, обсужденным со ссылкой на фигуру 2. Однако на фигуре 5 в целях иллюстрации показаны фактические репрезентативные данные. Каждый ряд в соответствующей таблице имеет тот же самый ссылочный номер, как и соответствующая таблица, сопровождаемый алфавитным символом. Например, таблица TASKFEDASSOC 40 содержит три ряда 40А, 40В и 40С. Каждый ряд в таблице TASKFEDASSOC 40 включает поле SYNCTASKID 42, содержащее конкретные значения, и поле SYNCTABLEID 44, содержащее конкретные значения, как обсуждено выше. Данные в поле будут упомянуты здесь по имени соответствующего поле. Предположите, что приложение 20 только что закончило задачу репликации, имеющую SYNCTASKID, равное "101". Приложение 20 сохраняет ряд 30А в таблице TASKCFG 30, в которой SYNCTASKID равно "101", SYNCMODE равно "0", SYNCFIG равно "1" и SYNCSQLSTMTS содержит оператор SQL так, что синхронизатор таблицы 22 должен быть применен к вторичной таблице 26 для выполнения задачи репликации. Приложение 20 также вставило ряд 40А в таблицу TASK_FED_ASSOC 40, содержащую тот же самый SYNCTASKID и относящийся к первичной таблице, имеющей SYNCTABLEID, равное "8282". Приложение 20 вставило ряд 54А в таблицу 54 TASKJLASTJJPDATE, содержащую то же самое поле SYNCTASKID и LASTSIG, равное "62″. Ряд 54А содержит SYNCORDER равное "0", указывающее на то, что порядок этой задачи репликации не связан с порядком других задач репликации. Предположим, что приложение 20 уведомляет синхронизатор таблицы 22 о завершении задачи репликации. Синхронизатор таблицы 22 ряда считывает ряды 54А и 54В из таблицы TASK_U\ST_UPDATE 54 в первичной базе данных 16. Синхронизатор таблицы 22 сравнивает LASTSIG в каждом из рядов 54А и 54В с LASTSIG из рядов 62А и 62 В таблицы TASK_LAST_SYNC 62 во вторичной базе данных 18. Синхронизатор таблицы 22 определяет, что LASTSIG ряда 62А не соответствует LASTSIG ряда 54А. Синхронизатор таблицы 22, используя значение SYNCTASKID "101", считывает таблицу TASK_FED_ASSOC 40 и получает ряд 40А, который содержит SYNCTASKID с идентичным значением "101". Синхронизатор таблицы 22 определяет, что SYNCTABLEID ряда 40А равен "8282 ". Синхронизатор таблицы 22 получает ряд 46С из таблицы FEDTABLECFG 46, используя SYNCTABLEID из ряда 46С. Ряд 46С указывает, что именем таблицы, содержимся в поле SYNCTABLENAME 50, является "OM_CFG, и имя базы данных в поле SYNCDBNAME 52 равно "EMPLATCORE". Синхронизатор таблицы 22 формирует вторичную объединенную таблицу 68 под названием BOM_CFG_FED" во вторичной базе данных 18. Отметим, что синхронизатор таблицы 22 сформировал объединенную таблицу базы данных на основе имени первичной таблицы 24, которая была обновлена в ходе выполнения задачи репликации, снабженной суффиксом "FED". Может использоваться любое подходящее соглашение о присвоении имен, чтобы сформировать вторичную объединенную таблицу 68, если первичный сервер 10 использует то же самое соглашение о присвоении имен для команды обновления, сохраненной в поле SYNCSQLSTMTS 38 таблицы TASK_CFG 30, которая применена к вторичной базе данных 18 для выполнения соответствующей задачи репликации.
Вторичная объединенная таблица 68 связана с первичной таблицей 24 в первичной базе данных 16. Вторичная объединенная таблица 68 по существу обеспечивает виртуальное представление из вторичной базы данных 18 первичной таблицы 24 на первичном сервере 10, в этом операторе SQL, примененном к вторичной базе данных 18, которая относится к вторичной объединенной таблице 68, и получит доступ к первичной таблице 24 на основании общей связи между вторичной объединенной таблицей 68 и первичной таблицы 24, не копируя всю первичную таблицу 24 во вторичную базу данных 18. Синхронизатор таблицы 22 получает доступ к таблице TASKCFG 30 и, используя значение SYNCTASKID, равное "101", получает ряд 30А из таблицы TASK_CFG 30. Значение "О" в поле SYNCMODE 34 указывает, что команда обновления - единственный оператор базы данных. Значение "1" в поле SYNCFIG 36 указывает, что эта задача репликации должна быть перенесена во вторичный сервер 12. Синхронизатор таблицы 22 получает конкретный оператор базы данных из поля SYNCSQLSTMTS 38, которое, как показано на фигуре 5, является оператором SQL "UPDATE", в котором поле "CFG" во вторичной таблице "OM_CFG" 26 будет установлено по значению поля "CFG" из первичной таблицы 24 везде, где поле "IND" вторичной таблицы OMCFG 26 равно полю "IND" первичной таблицы 24. Отметим, что оператор "UPDATE", содержащийся в поле SYNCSQLSTMTS 38, относится к вторичной объединенной таблице 68. Использование вторичной объединенной таблицы 68 позволяет использовать обычные операторы SQL для выполнения задачи репликации на вторичном сервере 12. Отметим также, что каждая из таблиц, показанных на фигуре 5, отражает тот факт, что вторая задача репликации, имеющая величину SYNCTASKID, равную "653", ранее была выполнена в первичной базе данных 16 и во вторичной базе данных 18, и что такая задача репликации включила множество первичных таблиц 24 и множество операторов SQL.
Фигура 6 - блок-схема вторичного сервера 12 согласно одному примеру воплощения настоящего изобретения. Вторичный сервер 12 включает систему управления 80, содержащую память 82, в которой хранится программное обеспечение 84, подходящее для выполнения функций синхронизатора таблицы 22, как описано выше. Вторичный сервер 12 включает интерфейс связи 86 для взаимодействия через этот интерфейс с сетью 14 или с вторичной базой данных 18, если необходимо. Хотя, здесь это не показано, блок-схема первичного сервера 10 может быть подобна блок-схеме вторичного сервера 12, в котором хранящееся в памяти программное обеспечение подходило бы для выполнения функций, описанных относительно приложения 20.
Специалисты в данной области могут внести улучшения и модификации в предпочтительные примеры воплощения настоящего изобретения. Все такие улучшения и модификации рассматриваются входящими в объем раскрытого здесь изобретения и приложенной формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| Система репликации информации в базах данных | 2018 |
|
RU2703961C1 |
| СПОСОБЫ И СИСТЕМЫ ЗАГРУЗКИ ДАННЫХ В ХРАНИЛИЩА ВРЕМЕННЫХ ДАННЫХ | 2012 |
|
RU2599538C2 |
| СИСТЕМА ВЗАИМОДЕЙСТВИЯ БАЗ ДАННЫХ АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ УПРАВЛЕНИЯ | 2006 |
|
RU2324974C1 |
| СИСТЕМА ОБРАБОТКИ СОБЫТИЙ | 2014 |
|
RU2665212C2 |
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
| КЛОНИРОВАНИЕ И УПРАВЛЕНИЕ ФРАГМЕНТАМИ БАЗЫ ДАННЫХ | 2006 |
|
RU2417426C2 |
| Способ репликации информации в базах данных | 2018 |
|
RU2706482C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ ОТКРЫТИЯ ОБЛАСТЕЙ РАБОЧЕЙ КНИГИ В КАЧЕСТВЕ ИСТОЧНИКА ДАННЫХ | 2005 |
|
RU2406147C2 |

Изобретение относится к способу и системе для выборочной репликации данных из первичной базы данных, связанной с первичным сервером, во вторичную базу данных, связанную с вторичным сервером. Технический результат - создание механизма для тиражирования информации о базе данных среди распределенных баз данных, которая не требует существенной экспертизы базы данных от клиента, обладает надежностью, работает в среде разных производителей и также обеспечивает выборочную репликацию в распределенной сети, в основном, одновременно. Для этого вторичный сервер определяет, что задача репликации по первой команде обновления изменила основную базу данных. Вторичный сервер определяет, что первичная таблица в первичной базе данных была обновлена. Вторичный сервер формирует вторичную объединенную таблицу, которая связана с первичной таблицей. Вторичный сервер получает вторую команду обновления на основе первой команды обновления из первичной базы данных и применяет вторую команду обновления к вторичной таблице во вторичной базе данных, используя вторичную объединенную таблицу. 2 н. и 23 з.п. ф-лы, 6 ил.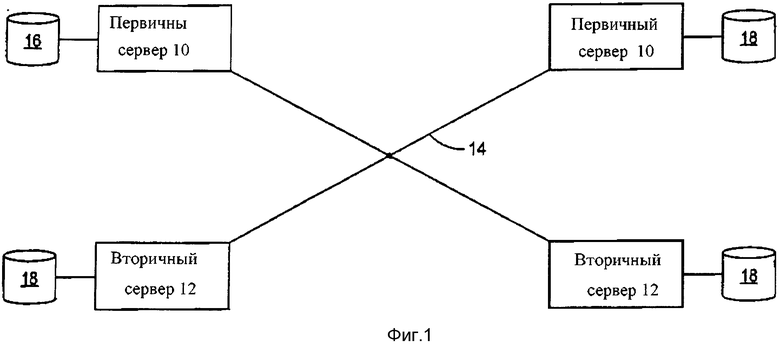
1. Способ репликации баз данных из первой базы данных во вторую базу данных, содержащий:
определение, что первая команда обновления изменила данные в первичной таблице в первичной базе данных, связанной с первичным сервером;
в ответ на определение, что первая команда обновления изменила данные в первичной таблице в первичной базе данных, определение второй команды обновления на основе первой команды обновления; и
применение второй команды обновления для тиражирования данных во вторичную таблицу во вторичной базе данных, связанной с вторичным сервером, используя вторичную объединенную таблицу, связанную с первичной таблицей.
2. Способ по п.1, в котором определение второй команды обновления на основе первой команды обновления содержит получение из первичной базы данных одного или нескольких операторов модификации для приложения к вторичной базе данных.
3. Способ по п.1, в котором определение второй команды обновления на основе первой команды обновления содержит получение схемы таблицы, связанной с первичной таблицей, обновленной первой командой обновления, и формирование второй команды обновления на основе схемы таблицы.
4. Способ по п.2, в котором один или несколько операторов модификации включают ссылку на вторичную объединенную таблицу.
5. Способ по п.1, в котором данные содержат информацию, относящуюся к конфигурации, связанной с вторичным сервером, соединенным с вторичной базой данных.
6. Способ по п.1, в котором первичная база данных хранится в первом устройстве хранения, связанном с первичным сервером, и вторичная база данных хранится во втором устройстве хранения, связанном с вторичным сервером.
7. Способ по п.6, в котором первичный сервер и вторичный сервер содержат серверы с медийными приложениями.
8. Способ по п.1, в котором первичная таблица, вторичная таблица и вторичная объединенная таблица каждая имеет одно и то же определение таблицы.
9. Способ по п.1, в котором определение того, что первая команда обновления изменила первичную таблицу, включает получение уведомления от первичного сервера, о том, что первая команда обновления изменила основную базу данных.
10. Способ по п.1, дополнительно содержащий применение первой команды обновления к первичной таблице в первичном сервере, формируя вторую команду обновления на основе первой команды обновления, и сохранение второй команды обновления в таблице обновления в первичной базе данных.
11. Способ по п.10, в котором вторая команда обновления содержит один или несколько операторов модификации, относящихся к вторичной таблице и к вторичной объединенной таблице.
12. Способ по п.1, в котором применение второй команды обновления для изменения вторичной таблицы дополнительно содержит создание вторичной объединенной таблицы, применяя вторую команду обновления для репликации данных вторичной таблицы, используя вторичную объединенную таблицу и удаляя вторичную объединенную таблицу после применения второй команды обновления.
13. Способ по п.1, в котором вторая команда обновления включает ссылку на вторичную объединенную таблицу и на приложение второй команды обновления, причем данные автоматически передаются из первичной таблицы в первичную базу данных и во вторичную объединенную таблицу со ссылкой на вторичную объединенную таблицу.
14. Способ по п.1, в котором вторичная объединенная таблица содержит виртуальное представление первичной таблицы в первичной базе данных, в котором вторичная объединенная таблица не содержит всех данных, которые содержатся в первичной таблице.
15. Способ по п.1, дополнительно содержащий определение вторичной таблицы, подлежащей обновлению, в котором вторая команда обновления содержит оператор языка структурированных запросов (SQL) для приложения к вторичной таблице.
16. Способ по п.1, дополнительно содержащий множество вторичных серверов, при этом каждое множество вторичных серверов имеет соответствующую вторичную базу данных, причем в ответ на определение, что первая команда обновления изменила данные в первичной таблице в первичной базе данных, каждое множество вторичных серверов определяет вторую команду обновления на основе первой команды обновления и применяет вторую команду обновления для тиражирования данных в соответствующую вторичную таблицу во вторичной базе данных, используя соответствующую вторичную объединенную таблицу, связанную с первичной таблицей, в основном одновременно.
17. Способ по п.16, в котором первичный сервер и множество вторичных серверов каждый имеет узел в кластере серверов.
18. Способ по п.1, в котором вторичная таблица является одной из множества вторичных таблиц во вторичной базе данных.
19. Способ по п.1, в котором применение второй команды обновления для тиражирования данных во вторичную таблицу во вторичной базе данных, используя вторичную объединенную таблицу, связанную с первичной таблицей, обновляет первое множество рядов во вторичной таблице, тогда как второе множество рядов во вторичной таблице не обновляется.
20. Устройство обновления таблицы, содержащее:
интерфейс, выполненный с возможностью для связи с сетью, и
систему управления, связанную с интерфейсом и адаптированную для:
- определения, что первая команда обновления изменила данные в первичной таблице в первичной базе данных, связанной с первичным сервером;
- в ответ на определение, что первая команда обновления изменила данные в первичной таблице в первичной базе данных, определение второй команды обновления на основе первой команды обновления; и
- применение второй команды обновления для тиражирования данных во вторичную таблицу во вторичной базе данных, связанной с вторичным сервером, используя вторичную объединенную таблицу, связанную с первичной таблицей.
21. Устройство по п.20, в котором для определения второй команды обновления система управления выполнена с возможностью дополнительно служить для получения из первичной базы данных одного или нескольких операторов модификации для приложения к вторичной таблице.
22. Устройство по п.21, в котором один или несколько операторов модификации относится к вторичной объединенной таблице.
23. Устройство по п.20, в котором для определения второй команды обновления система управления дополнительно адаптирована для получения схемы таблицы, связанной с первичной таблицей, обновленной первой командой обновления, и формирования второй команды обновления на основе схемы таблицы.
24. Устройство по п.20, в котором вторичная объединенная таблица содержит виртуальное представление первичной таблицы в первичной базе данных и в котором вторичная объединенная таблица не содержит все данные, которые содержатся в первичной таблице.
25. Устройство по п.20, в котором система управления дополнительно адаптирована для определения вторичной таблицы, подлежащей обновлению, и в котором вторая команда обновления содержит оператор языка структурированных запросов (SQL) для приложения к вторичной базе данных.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ РАБОТЫ УЗЛА ИНТЕРФЕЙСА ПОЛЬЗОВАТЕЛЯ В СООТВЕТСТВИИ С РАСПРЕДЕЛЕННОЙ МНОГОВЫХОДОВОЙ СИСТЕМОЙ ПОИСКОВОГО ВЫЗОВА, СПОСОБ РАБОТЫ РАСПРЕДЕЛЕННОЙ МНОГОВЫХОДОВОЙ СИСТЕМЫ ПОИСКОВОГО ВЫЗОВА | 1994 |
|
RU2157596C2 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

