Предшествующий уровень техники
Системы баз данных обычно используются для эффективного управления информацией, которая организована для обеспечения возможности доступа. Для обеспечения доступности система может включать в себя резервные копии базы данных на случай, когда основная копия повреждена или потеряна. Одним обычным способом для резервирования базы данных является периодическое копирование всей базы данных на машиночитаемые носители. Например, администратор информационной системы может копировать базу данных на диски или магнитные ленты в конце каждой недели. Хотя копия базы данных может сохраняться этим способом, копирование всей базы данных требует временных затрат, и действия между интервалами резервирования теряются, если только не отслеживаются другими средствами.
Другой метод резервирования базы данных связан с поддержанием копий той же самой базы данных на различных вычислительных машинах. В случае, когда одна из баз данных становится недоступной для использования, другая копия базы данных на другой вычислительной машине может по-прежнему быть доступной. Этот тип резервирования для обхода отказа может обеспечить доступность базы данных. Однако синхронизация множества копий всей базы данных на различных машинах в реальном времени является сложным и дорогостоящим процессом.
Эффективный путь обеспечения доступности базы данных без излишней сложности или ненужных потерь данных по-прежнему остается задачей, требующей решения специалистами в данной области техники.
Сущность изобретения
Далее представлено упрощенное краткое раскрытие в целях обеспечения базового понимания читающего. Это краткое описание не является исчерпывающим обзором раскрытия и не выявляет ключевых/критических элементов изобретения и не очерчивает объема изобретения. Его единственной целью является представить некоторые принципы, раскрытые здесь, в упрощенной форме в качестве вступления к более детальному описанию, которое представлено далее.
Представленный пример обеспечивает механизмы и методы для клонирования и управления фрагментами базы данных. Объект базы данных, такой как таблица, набор строк, индекс или раздел таблицы или индекса, разделен на фрагменты. Отметим, что “набор строк” рассматривается как набор строк в таблице или элементов в индексе. Термины “строка” и “запись” рассматриваются как, по существу, идентичные. Таким образом, набор строк также эквивалентен набору записей. Каждый фрагмент клонируется для создания клонированных фрагментов, которые операционно, по существу, идентичны друг другу. Один из клонированных фрагментов может быть обозначен как первичный клонированный фрагмент для выполнения операций базы данных, а один или более клонированных фрагментов могут быть обозначены как вторичные клонированные фрагменты, служащие в качестве резерва для клона первичного фрагмента. Обновления для каждого фрагмента реализуются над первичным клонированным фрагментом и затем распространяются от первичного клонированного фрагмента к соответствующим вторичным клонированным фрагментам.
Клонированный фрагмент может становиться автономным (офлайновым), становясь недоступным для обновлений. Такой автономный, недоступный клонированный фрагмент определен как устаревший клонированный фрагмент, так как данные в таком клонированном фрагменте больше не могут быть транзакционно современными с соответствующим первичным клонированным фрагментом. Когда устаревший клонированный фрагмент возвращается в оперативное (онлайновое) состояние, клонированный фрагмент регенерируется с данными, включенными в первичный клонированный фрагмент. После регенерации клонированный фрагмент может продолжать обновляться. Клонированный фрагмент становится немедленно пригодным для выбора в качестве кандидата на назначение в качестве первичного клонированного фрагмента, когда процесс регенерации завершается.
Многие из сопутствующих признаков будут лучше поняты при обращении к последующему детальному описанию со ссылками на иллюстрирующие чертежи.
Описание чертежей
Представленное раскрытие можно лучше понять из следующего детального описания, при его прочтении в свете иллюстрирующих чертежей, на которых представлено следующее:
Фиг.1 - пример структуры клонирования данных объекта базы данных, управляемого системой базы данных.
Фиг.2 - пример клонированных фрагментов объекта базы данных.
Фиг.3 - пример операций для обновления клонированных фрагментов объекта базы данных.
Фиг.4 - пример операций для регенерации устаревшего клонированного фрагмента, ассоциированного с объектом базы данных.
Фиг.5 - пример структур данных для идентификации клонированного фрагмента.
Фиг.6 - пример структур данных для идентификации элемента в клонированном фрагменте объекта базы данных.
Фиг.7 - пример процессов для обновления вторичных клонированных фрагментов индекса и вторичных клонированных фрагментов данных.
Фиг.8 - развитие состояний при регенерации устаревшего клонированного фрагмента.
Фиг.9 - пример системы базы данных с клонированными фрагментами базы данных.
Фиг.10 - пример процесса для обновления объекта базы данных.
Фиг.11 - пример процесса регенерации, который регенерирует устаревший клонированный фрагмент объекта базы данных.
Фиг.12 - пример процесса для модифицирования идентификаторов обновления клона (CUID).
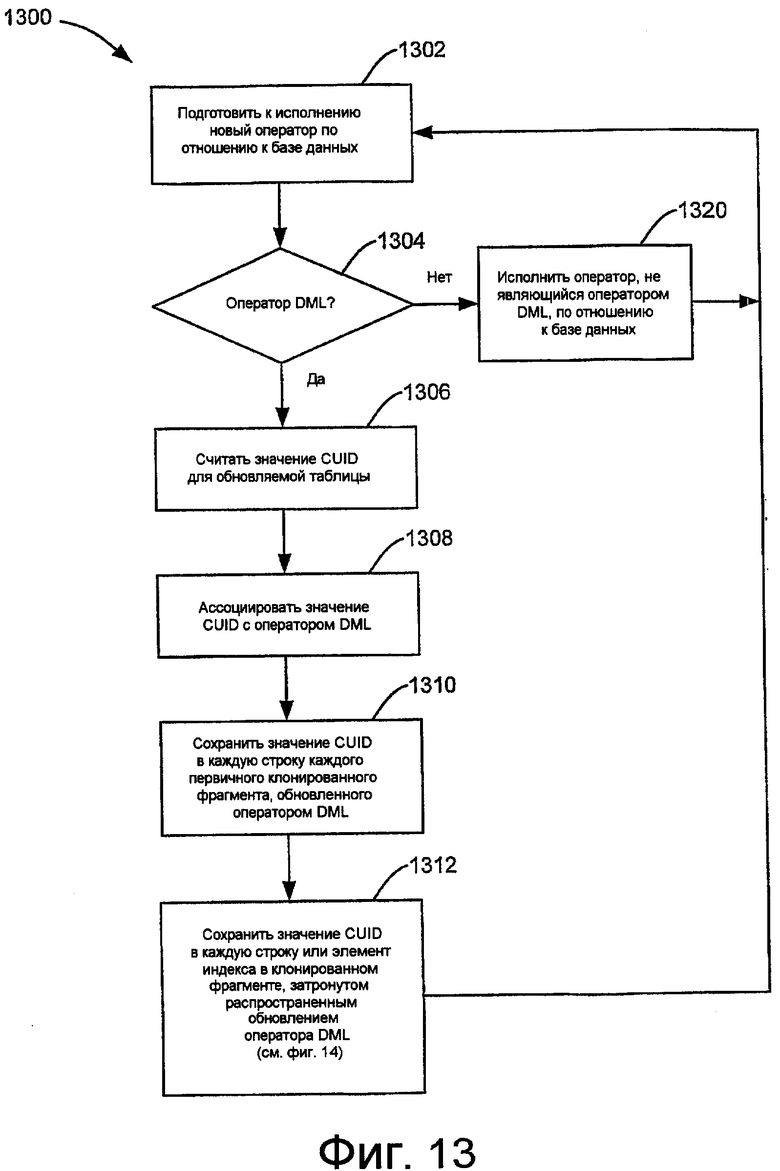
Фиг.13 - пример процесса для присвоения значения CUID, назначенного в соответствии с процессом, показанным на фиг.12.
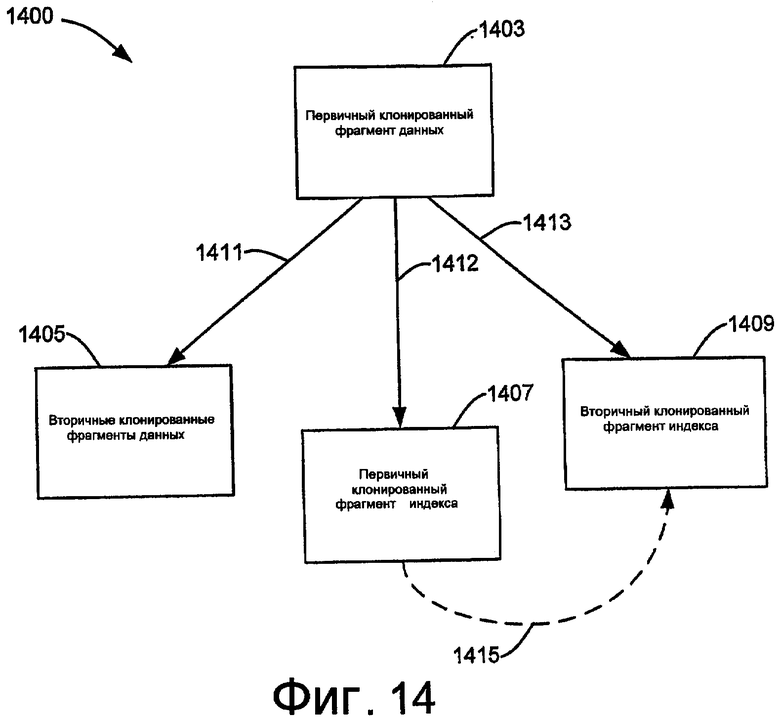
Фиг.14 - пример путей распространения для значений CUID.
Фиг.15 - пример вычислительного устройства для реализации описанных систем и способов.
Фиг.16 - пример процесса для распространения и применения обновлений для записи и распространения старого значения CUID из первичного клонированного фрагмента ко всем вторичным клонированным фрагментам данных, а также ко всем клонированным фрагментам индекса, которые содержат копию записи.
Фиг.17 - пример процесса для приведения устаревшего клона в текущее состояние как часть процесса регенерации, показанного на фиг.11.
Одинаковые ссылочные позиции используются для обозначения подобных элементов на приложенных чертежах.
Детальное описание
Детальное описание, представленное ниже, в связи с приложенными чертежами, является описанием представленного примера и не претендует на представление форм, в которых только может быть создан или использован представленный пример. Описание устанавливает функции этого примера и последовательность шагов для создания и функционирования этого примера. Однако те же или эквивалентные функции и последовательности могут быть реализованы отличающимися примерами.
Хотя представленные примеры описаны и проиллюстрированы здесь как реализованные в системе клонирования и управления фрагментами базы данных, описанная система предложена в качестве примера, но не ограничения, поскольку специалистам в данной области техники должно быть понятно, что представленные примеры подходят для применения во множестве различных типов систем клонирования и управления фрагментами базы данных.
На фиг.1 представлен пример структуры 100 клонирования данных объекта 105 базы данных, управляемого системой базы данных. База данных является коллекцией информации, организованной таким способом, который позволяет быстро выбирать и/или обновлять желательные части данных в базе данных. Объект базы данных может быть всей базой данных или некоторой частью базы данных. Например, объект 105 базы данных может быть всей таблицей, индексом, набором строк или т.п.
Объект 105 базы данных может быть разделен на разделы 111-113. В типовом случае объект 105 базы данных разделяется для удобства или по причинам, связанным с рабочими характеристиками. Например, объект 105 базы данных может включать в себя данные, ассоциированные с многими годами. Объект 105 базы данных может быть разделен на разделы 111-113, где каждое разделение ассоциировано с конкретным годом. Разделение объекта 105 базы данных является факультативным этапом, который может быть реализован или не реализован в действительной реализации.
Каждый раздел 111-113 объекта 105 базы данных (или весь, не разделенный объект 105) в типовом случае делится на фрагменты, такие как фрагменты 121-124. Фрагменты 121-124 являются частями объекта 105 базы данных, разделенными системой базы данных на операционной основе. Например, фрагменты 121-124 могут быть назначены различным вычислительным устройствам, так что запрос, ассоциированный с объектом 105 базы данных, может выполняться с фрагментами 121-124 вычислительными устройствами, работающими параллельно.
Фрагменты в объекте 105 базы данных далее клонируются для создания клонированных фрагментов. Как показано на фиг.1, каждый из логически разделенных фрагментов 121-124 клонируется для формирования примерных клонированных фрагментов 131, 140-146. В типовом случае, фрагменты объекта базы данных (или раздел объекта базы данных) создаются путем разбиения такого объекта на дискретные наборы строк (для таблиц) или элементы индекса (для индексов). Хеширование по ключу таблицы или индекса является одним основанием для выполнения такого разбиения. Наборы строк иногда упоминаются как “наборы строк” или “наборы записей”. Клонированные фрагменты будут обсуждены более детально в связи с фиг.2. Формулируя кратко, при надлежащем обновлении клонированные фрагменты, ассоциированные с конкретным фрагментом объекта 105 базы данных, операционно идентичны, так что клонированные фрагменты могут быть легко использованы системой базы данных. Использование клонированных фрагментов позволяет двум или более копиям конкретного фрагмента быть доступными для использования так, чтобы поддерживать высокий уровень доступности данных, ускорять запросы и другие операции базы данных, выполнять выравнивание нагрузки и т.п. Например, для поддержания высокого уровня доступности данных, по меньшей мере, один клонированный фрагмент может служить как резервная копия другого клонированного фрагмента, который используется для операций базы данных. Для ускорения поисков множество операционно идентичных клонированных фрагментов могут быть использованы одновременно для запросов базы данных. Для выполнения выравнивания нагрузки различные, но операционно идентичные копии клонированных фрагментов могут быть активированы, базируясь на условиях рабочей нагрузки.
На фиг.2 показаны приведенные для примера клонированные фрагменты 131-139 объекта базы данных. Как показано на этом чертеже, клонированные фрагменты 131-139 могут быть представлены как три группы 151-153. Каждая группа клонированных фрагментов относится к конкретному фрагменту объекта базы данных. Клонированные фрагменты внутри каждой группы создаются как операционно идентичные друг другу. Таким образом, при надлежащем обновлении каждый из клонированных фрагментов 131-139 может быть использован для операций базы данных, которые применимы для соответствующих фрагментов 151-153.
В одном варианте осуществления клонированные фрагменты 131-139 могут быть конфигурированы для обеспечения высокого уровня доступности данных. В этом варианте осуществления клонированный фрагмент из каждой из групп 151-153 может быть обозначен как первичный клонированный фрагмент для операций базы данных. Другие клонированные фрагменты в группе являются вторичными клонированными фрагментами, которые служат в качестве легко доступных резервных копий. На фиг.2 клонированные фрагменты 131, 135 и 139 показаны как первичные клонированные фрагменты, в то время как остальные клонированные фрагменты обозначены как вторичные клонированные фрагменты.
Для обеспечения высокого уровня доступности данных каждый из клонированных фрагментов в группе может быть включен в различные устройства, так что если одно устройство выходит из строя, вторичный клонированный фрагмент в другом устройстве может быстро заменить клонированный фрагмент в отказавшем устройстве в качестве первичного клонированного фрагмента. Например, каждый из клонированных фрагментов 131-133 может быть включен в отдельные устройства, так что любой из вторичных клонированных фрагментов 132-133 может быть указан как первичный, если устройство, в которое включен первичный клонированный фрагмент 131, вышло из строя.
Система базы данных, которая управляет клонированными фрагментами, может выполнять различные операции с клонированными фрагментами. Эти операции в типовом случае выполняются с использованием стандартных операций базы данных, таких как операторы языка управления (манипулирования) данными (DML) или операторы другого языка структурированных запросов (SQL). Примеры операций для обновления и регенерации клонированных фрагментов будут обсуждены более подробно ниже в связи с фиг.3 и 4. В одной примерной реализации операции могут включать следующее:
1. Создание клонированного фрагмента
Клонированный фрагмент может быть создан как неразличимый от нормальной таблицы или набора строк индекса в базе данных.
2. Удаление клонированного фрагмента
Клоны могут быть удалены подобно наборам строк в базе данных.
3. Полная инициализация данных клонированных фрагментов
Клонированный фрагмент может быть полностью инициализирован, из рабочей области, чтобы содержать новый набор строк, который загружен в клонированный фрагмент.
4. Распространение изменений данных в клонированный фрагмент
Изменения для первичного клонированного фрагмента распространяются в один или более вторичных клонированных фрагментов. Распространение возникает внутри того же самого транзакционного контекста как обновления для первичного клонированного фрагмента.
5. Регенерация устаревшего клонированного фрагмента
Когда клонированный фрагмент был автономным или иным образом не принимал транзакционное распространение обновлений из первичного клонированного фрагмента, он определяется как устаревший клонированный фрагмент. Устаревшие клонированные фрагменты также могут быть определены как не обновленные (устарелые, несовременные) клоны фрагментов. Процесс возвращения устаревшего клона в транзакционное соответствие с клоном первичного фрагмента называется регенерацией (восстановлением).
6. Считывание клонированного фрагмента
Клонированный фрагмент может быть считан для целей извлечения данных (табличный доступ) или для установления соответствия (индексного доступа) подобно тому, как осуществляется доступ и считывание в случае обычных таблиц или индексов. В этой реализации пользовательские рабочие нагрузки только считывают из первичных клонированных фрагментов. Это ограничение может быть использовано для целей упрощения механизма для устранения излишних взаимоблокировок в системе. Однако это ограничение может быть ослаблено, если взаимоблокировки либо не являются проблемой, либо их можно избежать с помощью других средств в данной системе.
7. Обновление клонированного фрагмента
Пользовательские нагрузки обновляют первичный клонированный фрагмент, и система базы данных распространяет и применяет эти изменения к вторичным клонам, соответствующим этому первичному фрагменту в пределах той же самой транзакции. Распространение изменения означает применение по существу идентичной операции DML к вторичному клону, которая была применена к первичному клону.
Фиг.3 показывает примерные операции 300 для обновления клонированных фрагментов 131-139 объекта базы данных. Обновления базы данных могут включать в себя любые типы модификаций, такие как добавление, удаление и изменение данных. Если определены изменения, ассоциированные с объектом базы данных, то выявляются фрагменты в объекте базы данных, которые требуют обновления. Первичные клонированные фрагменты, соответствующие идентифицированным фрагментам, обновляются. Как показано на чертеже, операции 301-303 являются операциями для обновления первичных клонированных фрагментов 131, 135, 139, соответственно. После того как первичные клонированные фрагменты 131, 135 и 139 обновлены, обновления затем распространяются в соответствующие вторичные клонированные фрагменты. На фиг.3 операции 311-313 являются операциями для обновления вторичных клонированных фрагментов, соответствующих обновленным первичным клонированным фрагментам.
В типовом случае операции 301-303 и 311-313 реализуются посредством стандартных операций базы данных, таких как вставка, обновление и удаление, которые реализует семантика операторов DML. Чтобы достичь соответствия, операции по обновлению первичного клонированного фрагмента и операции по обновлению вторичных фрагментов, соответствующих первичному клонированному фрагменту, могут быть конфигурированы как элементарный набор операций.
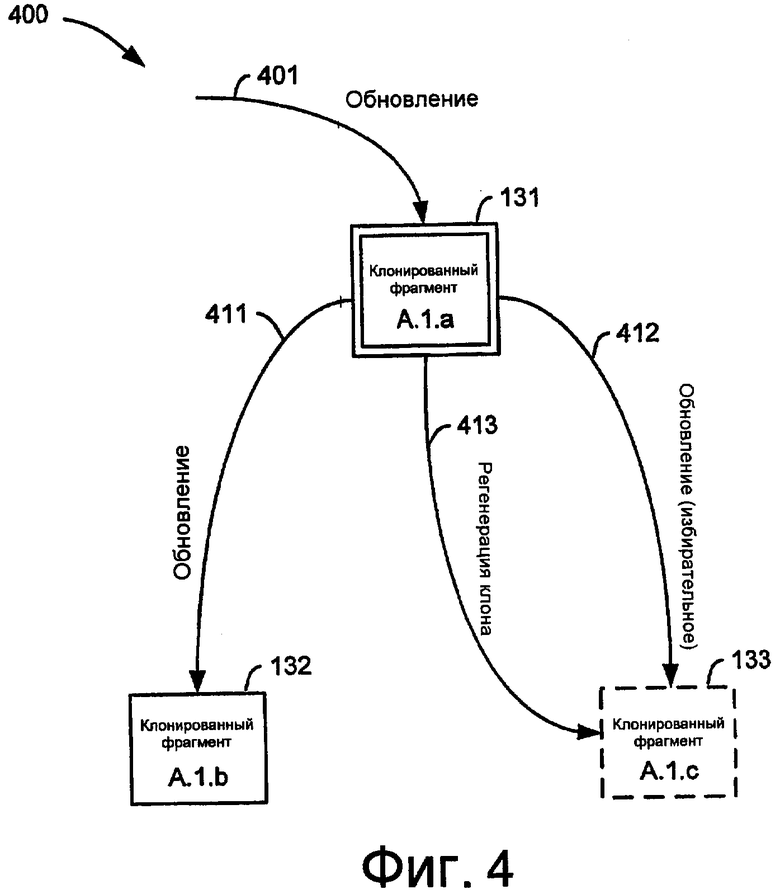
Фиг.4 показывает примерные операции 400 для регенерации устаревшего клонированного фрагмента 133, ассоциированного с объектом базы данных. Клонированный фрагмент является устаревшим, если фрагмент был недоступен для исполнения операций распространенных обновлений, ассоциированных с объектом базы данных, соответствующим устаревшему фрагменту. Например, клонированный фрагмент 133 может быть недоступным для обновления ввиду различных причин, таких как отказ устройства, потеря связности, системное обновление и т.п. Для того чтобы быть полезным, вторичный клонированный фрагмент 133 должен быть возвращен в транзакционное соответствие с первичным клонированным фрагментом 131 с помощью процесса регенерации.
Когда клонированный фрагмент 133 возвращается в онлайновое состояние и становится доступным для исполнения операций обновления, клонированный фрагмент 133 регенерируется на основе данных, включенных в текущий первичный клонированный фрагмент, который содержит все текущие и прошлые обновления. Например, на фиг.4 операция 413 регенерации клона выполняется для регенерации клонированного фрагмента 133 данными, включенными в первичный клонированный фрагмент 131. Таким способом клонированный фрагмент 133 регенерируется с обновлениями, которые возникли в то время, когда клонированный фрагмент 133 был недоступным. Для эффективности, операция 413 регенерации клона может быть реализована посредством операций удаления SQL, которые удаляют устаревшие строки, и операций вставки SQL, которые добавляют новые строки, скопированные из первичного клона. Такая реализация обеспечивает возможность управления операцией регенерации по маршрутам исполнения, подобным тем, которые используются в обычных исполнениях операторов SQL в системе базы данных без добавления дополнительных процессов.
Операция 401 обновления для первичного клонированного фрагмента 131 возникает, когда обновление для объекта базы данных воздействует на часть объекта, соответствующую первичному клонированному фрагменту 131. Обновление затем распространяется к вторичным клонированным фрагментам, ассоциированным с первичным клонированным фрагментом 131. Как показано на фиг.4, вторичный клонированный фрагмент 132 обновляется операцией 411, ассоциированной с первичным клонированным фрагментом 131. Необходимость в обновлении клонированного фрагмента может возникнуть, когда клонированный фрагмент регенерируется. Например, обновление для клонированного фрагмента 133 может возникнуть, когда выполняется операция 413 регенерации клона. Операция 412 обновления может выполняться над клонированным фрагментом 133, в то время как выполняется операция 413 регенерации клона. В типовом случае, пользовательская операция 412 обновления является более высокоприоритетной операцией базы данных, чем операция 413 регенерации клона. Операция 412 обновления и операция 413 регенерации клона могут быть реализованы различными путями и с различным хронированием по отношению друг к другу. Например, если необходимо обновление, то операция 412 обновления над клонированным фрагментом 133 может быть завершена, прежде чем продолжится операция 413 регенерации клона. Кроме того, операция 413 регенерации клона проектируется для минимизации как частоты, так и продолжительности любой задержки, обусловленной вследствие блокирования по отношению к любой данной операции 412 обновления. Регенерация клона выполняется как последовательность малых транзакционных групп, которые требуют и удерживают блокировку только в течение коротких интервалов времени. Операция 412 обновляет только строки или элементы в устаревшем клоне, которые уже были регенерированы операцией 413 или которые остались неизменными в первичном клоне, пока устаревший клон был офлайновым. То есть, в операции 412 не допускается обновление строки, которая является несовременной в устаревшем клоне. Распространенной операции обновления не разрешается создавать несогласованную строку в устаревшем клоне, которая представляется требующей обновления. Это ограничение может быть смягчено в реализации, где вся строка распространяется с обновлением 412. Однако причины эффективности заставили бы отказаться от такой операции 412, которая распространяла бы целые строки для всех операций DML, независимо от того, что изменились только несколько значений столбцов. Введение новых, обновленных строк в устаревший клон является обязанностью операции 413 регенерации клона.
Операции 400 для регенерации устаревшего клонированного фрагмента, показанные на фиг.4, позволяют системе базы данных регенерировать устаревший клонированный фрагмент для обеспечения его транзакционной непротиворечивости с соответствующим первичным фрагментом, при поддержании онлайнового статуса того первичного фрагмента, с использованием стандартных операций базы данных. Использование стандартных операций базы данных, таких как представляющие операторы DML, позволяет управлять регенерацией клонов как дополнительной, но стандартной нагрузкой операторов SQL, не требуя специальных процессов. Операции 400 также обеспечивают регенерацию устаревшего клонированного фрагмента, не вызывая избыточного блокирования всего фрагмента и не требуя продления процесса регенерации, чтобы учесть обновления, которые могли возникнуть в течение процесса регенерации, поскольку эти обновления продолжают применяться в течение выполнения операции 413 регенерации. Важно, что операции 400 также позволяют эффективно обновлять вторичный клонированный фрагмент, чтобы быстро становиться готовым к выбору в качестве первичного клонированного фрагмента.
В одной примерной реализации операция 413 регенерации клона включает в себя множество малых серий (групп) операций регенерации. Использование множества малых групп операций регенерации позволяет предотвратить блокирование одновременных пользовательских рабочих нагрузок в течение длительных периодов времени. Таким образом, процесс регенерации выполняется инкрементным способом, позволяя процессу сосуществовать в онлайновом режиме с пользовательскими рабочими нагрузками.
Множество экземпляров операции 413 регенерации клона, показанной на фиг.4, может исполняться одновременно по отношению к различным устаревшим клонированным фрагментам внутри тех же самых или различных фрагментов любого объекта базы данных. Таким образом, операции регенерации являются независимыми друг от друга.
На фиг.5 показана примерная структура 511-514 данных для идентификации клонированного фрагмента 500. Структура 500 данных используется для идентификации клонированного фрагмента, соответствующего объекту базы данных. В этом примере структура данных идентифицирует клонированный фрагмент 500, который соответствует таблице, ассоциированной с базой данных. Как показано на фиг.5, идентификатор для клонированного фрагмента 500 может включать в себя идентификатор 511 таблицы, идентификатор 512 раздела, идентификатор 513 фрагмента и идентификатор 514 клона. Идентификатор 511 таблицы идентифицирует объект базы данных (таблицу в данном случае), которой соответствует клонированный фрагмент 500. Объект базы данных может быть разделен на разделы для разделения данных для удобства или по соображениям эффективности работы. Идентификатор 512 раздела идентифицирует разделы, которым соответствует клонированный фрагмент 500.
Система базы данных, которая управляет объектом базы данных, конфигурирована для автоматического разделения объекта базы данных на фрагменты и клонирования фрагментов. Идентификатор 513 фрагмента идентифицирует конкретный фрагмент объекта базы данных, которому соответствует клонированный фрагмент 500. Идентификатор 514 клона идентифицирует клонированный фрагмент 500 среди множества клонированных фрагментов, ассоциированных с конкретным фрагментом объекта базы данных.
На фиг.6 показана примерная структура 611-612 данных для идентификации записи 600 в клонированном фрагменте объекта базы данных. Клонированный фрагмент может включать в себя записи (или элементы индекса) базы данных. Например, клонированный фрагмент может включать в себя записи, воплощенные как строки в части таблицы, ассоциированной с базой данных. Структуры 611-612 данных в записи 600 обеспечивают возможность идентификации записи 600 в клонированном фрагменте и статуса обновления записи.
Как показано на фиг.6, запись 600 может включать в себя идентификатор 611 клонированной записи и идентификатор 612 обновления клона. Идентификатор 611 клонированной записи уникальным образом идентифицирует запись 600 в соответствующей таблице или индексе. Идентификаторы клонированных записей в записях индексов распространяются с обновлениями от соответствующих клонированных фрагментов данных. Определенный пользователем уникальный ключ может быть использован как идентификатор клонированной записи, или определенный системой уникальный ключ может быть добавлен (или усилен по отношению к определенному пользователем ключу), так что составной ключ является достаточно уникальным, чтобы служить в качестве идентификатора клонированной записи. Например, идентификатор фрагмента может быть добавлен к ключу в целях обеспечения дополнительной уникальности. Идентификатор обновления клона идентифицирует статус обновления записи 600. В этой примерной реализации идентификатор 611 клонированной записи должен быть уникальным в контексте данной таблицы. Идентификатор 612 обновления клона должен только уникальным образом идентифицировать статус обновления записи относительно статуса обновления других записей с тем же самым идентификатором 611 клонированной записи для данного объекта базы данных уникально во времени.
В одном варианте осуществления система базы данных включает в себя первичные клонированные фрагменты и вторичные клонированные фрагменты, а клонированные фрагменты включают в себя строки. Как идентификатор 611 клонированной записи, так и идентификатор 612 обновления клона могут быть включены как столбцы в строки клонированных фрагментов. Столбцы идентификатора 611 клонированной записи и идентификатора 612 обновления клона могут быть включены во вторичные клонированные фрагменты и могут содержать идентичные значения, как в первичном клонированном фрагменте, когда вторичный клонированный фрагмент транзакционно согласован. Таким образом, идентификатор 611 клонированной записи позволяет отображать строки между первичным и вторичным клонированными фрагментами, а идентификатор 612 обновления клона позволяет проверять, являются ли строки согласованными.
Процесс регенерации для устаревшего клонированного фрагмента использует идентификатор клонированной записи (CRID) и идентификатор обновления клона (CUID) для определения того, должна ли конкретная запись в клонированном фрагменте быть регенерирована. Например, запись в устаревшем клонированном фрагменте может включать в себя следующее:
CRID = x и CUID = y.
Соответствующая запись в первичном клонированном фрагменте, ассоциированном с устаревшим клонированным фрагментом, может включать в себя следующее:
CRID = x и CUID = z.
Процесс регенерации использует CRID для идентификации каждой записи в устаревшем клонированном фрагменте и для локализации соответствующей записи в первичном клонированном фрагменте, если он существует. Процесс регенерации затем сравнивает каждую такую запись в устаревшем клонированном фрагменте с соответствующей записью в первичном клонированном фрагменте, если она существует, для определения того, должна ли запись в устаревшем клонированном фрагменте быть обновлена.
Фрагменты объекта базы данных могут быть фрагментами любого типа, такими как фрагмент данных, фрагмент индекса и т.п. Для фрагмента индекса каждая строка в индексе определяет, откуда получена строка, путем сохранения ее идентификатора фрагмента данных как части ключа индекса. Самому индексу не требуется знать, какой из клонов фрагмента базовой таблицы является в текущий момент первичным. Так как имеется один первичный клонированный фрагмент для данного фрагмента, запись индекса может быть отображена на конкретный фрагмент в целях доступа, в любой данный момент времени. Таким образом, фрагменты индекса могут включать в себя сосуществующую коллекцию разобщенных вторичных наборов строк (или элементов индекса), которые ссылаются на различные фрагменты таблицы. Поскольку каждый такой вторичный набор строк обрабатывается отдельно от других в том же самом фрагменте индекса, то применимы предположения и методы, охарактеризованные выше. В целях реализации блокирование строк во фрагменте индекса, соответствующем любому конкретному фрагменту базовой таблицы, не должно вызывать какого-либо блокирования других строк во фрагменте индекса (которые не соответствуют данному фрагменту базовой таблицы).
Фрагменты индекса могут быть клонированы подобно фрагментам данных. Для целей распространения обновлений клонированные фрагменты индекса обрабатываются как дополнительные индексы на том же наборе фрагментов базовой таблицы. То есть, обновления ко всем клонированным фрагментам индекса распространяются прямо из первичных клонированных фрагментов данных базовой таблицы, на которой построены клонированные фрагменты индекса. Хотя можно распространять обновления от одного фрагмента индекса к другому, этот процесс может ввести дополнительный этап задержки. Если набор элементов индекса в данном фрагменте индекса, соответствующем записям в конкретном фрагменте данных, обрабатывается как вторичный набор строк, то соответствующий первичный набор строк, по существу, идентичен фрагменту базовой таблицы. Каждый вторичный набор строк в клоне фрагмента индекса является, таким образом, независимым от всех других вторичных наборов строк в том же самом клоне для целей распространения обновлений.
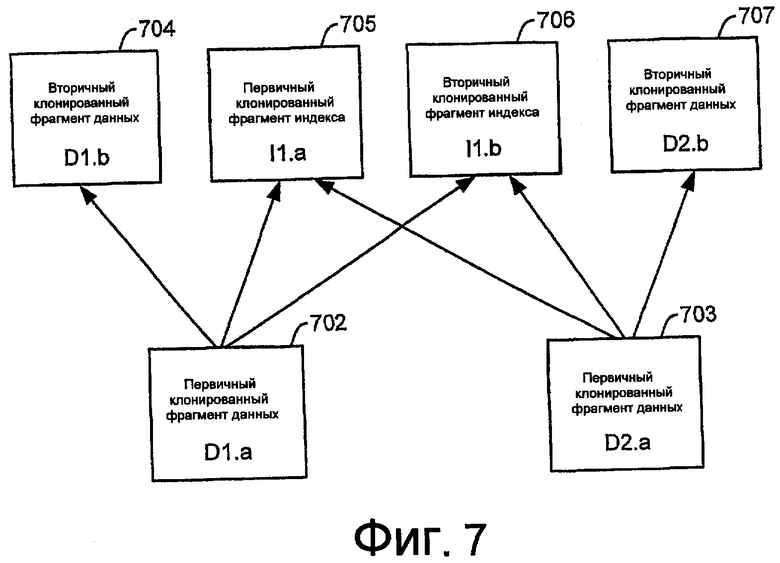
На фиг.7 показаны примеры процессов для обновления клонированных фрагментов индекса и клонированных фрагментов данных. Как описано выше, обновленный (или текущий) вторичный клонированный фрагмент фрагмента данных, по существу, идентичен первичному клонированному фрагменту для конкретного фрагмента данных. Аналогичным образом, обновленный вторичный клонированный фрагмент фрагмента индекса, по существу, идентичен первичному клонированному фрагменту для данного фрагмента индекса. Клонированные фрагменты индекса могут содержать элементы индекса, которые ссылаются на записи в более чем одном фрагменте данных. Следовательно, клонированные фрагменты индекса могут получать распространенные обновления более чем от одного клонированного фрагмента данных.
Пример на фиг.7 показывает фрагмент l1 индекса, содержащий элементы индекса, которые ссылаются на записи в двух отдельных фрагментах данных D1 и D2. В этом примере как первичный клонированный фрагмент l1.a 705 индекса, так и вторичный клонированный фрагмент l1.b 706 индекса получают распространенные обновления непосредственно как от первичного клонированного фрагмента D1.a 702 данных, так и от первичного клонированного фрагмента D2.a 703 данных.
Отображение между фрагментами данных и фрагментами индекса представляют результат стандартной операции базы данных, называемой физической структурой базы данных. Для любого данного индексированного столбца таблицы значения столбца могут быть дискретно отображены на один или более фрагментов индекса, основываясь на определениях разделения и фрагментации индекса. Определения разделения для таблиц и индексов могут определять любой из традиционных методов базы данных по разделению записей на наборы, например, посредством диапазона значений, хеширования значений или циклических назначений. Определяемое системой определение фрагментации реализуется посредством хеширования ключа таблицы или индекса. Однако если основанная на хешировании фрагментация заполняет фрагменты строками (или элементами индекса) с существенной диспропорцией и асимметрией в данных, то может быть использовано циклическое назначение строк фрагментам.
Когда клонированный фрагмент индекса становится устаревшим и требует регенерации, имеется два возможных пути для выполнения регенерации. Если существует первичный клонированный фрагмент индекса, то устаревший вторичный клонированный фрагмент индекса может быть регенерирован прямо из первичного клонированного фрагмента индекса. Альтернативно, устаревший вторичный клонированный фрагмент индекса может быть регенерирован прямо из набора первичных клонированных фрагментов данных индексированной таблицы. В последнем случае в регенерации используются только те записи в первичных клонированных фрагментах данных, значения ключей которых отображаются на фрагмент индекса, который регенерируется.
В примерной реализации значения идентификатора обновления клона (CUID) могут поддерживаться на основе по каждой таблице. То есть, для оператора DML, который обновляет данный первичный клонированный фрагмент, значение CUID считывается из метаданных, специфических для соответствующей таблицы фрагмента. Записям, которые обновляются посредством того оператора, присваивается это значение CUID. Если обновления этих записей распространяются к вторичному клонированному фрагменту, то новые присвоенные значения CUID также распространяются.
В этой примерной реализации значения CUID являются уникальными для данной таблицы во времени. Текущее значение CUID сохраняется транзакционно в метаданных, которые описывают данную таблицу.
В момент, когда значения CUID достигают точки возвращения от максимального значения к минимальному значению, различные методы могут быть использованы для переустановки CUID в непротиворечивое минимальное значение. При условии заданного байтового диапазона значений для CUID (например, всего 6 байтов) этот случай может возникнуть на исторической шкале времени. Один простой метод для переустановки значений CUID использовал бы привилегированное блокирование таблицы и переустановку значений CUID во всех записях в первичных клонированных фрагментах этой таблицы на минимальное значение CUID. Затем нормальный механизм распространения обновлений эффективным образом переустановил бы CUID во вторичных клонированных фрагментах.
Значения CUID для таблицы получают приращения каждый раз, когда фрагмент таблицы становится офлайновым. Эта реализация обсуждена ниже со ссылкой на фиг.12.
Также возможны другие стратегии назначения CUID, но каждая имеет возможность влияния на базовый метод для регенерации клона. Например, идентификаторы транзакции могут быть использованы в качестве базы для значений CUID, но требуют несколько менее предпочтительного метода регенерации клонов, чтобы гарантировать корректное взаимодействие распространения обновлений и регенерации клонов. Более конкретно, на этапе “ожидания распространения” (описан ниже), базовый метод “регенерации клона” должен ожидать завершения всех текущих активных транзакций вместо того, чтобы ожидать завершения выполнения всех текущих операторов DML.
В принципе, метод управления значениями CUID может быть реализован, если метод может удовлетворять следующим требованиям:
а) для данного значения CRID, используемого во фрагменте, все записи, идентифицированные этим значением CRID в транзакционно согласованных вторичных клонированных фрагментах, должны иметь значения CUID, которые идентичны значению CUID в записи, идентифицированной этим значением CRID в первичном клонированном фрагменте;
b) для данного фрагмента, если CRID найдено в устаревшем вторичном клонированном фрагменте (до регенерации), а также в первичном клонированном фрагменте, то значения CUID могут быть теми же самыми, только если строки не были обновлены в первичном клонированном фрагменте с тех пор, когда вторичный клонированный фрагмент стал устаревшим.
Пример оператора DML для обновления клонированного фрагмента показан ниже. Пример оператора DML включает: две записи в Sales.2004.1.a (клонированные идентификаторы записи (CRID): 5&3), которые обновляются с использованием значения CUID, равного 3.
Пример первичного клонированного фрагмента Sales.2004.1.a показан в Таблице 1.
Первичный клонированный фрагмент Sales.2004.1.a
После того как первичный клонированный фрагмент Sales.2004.1.a обновлен, эти обновления распространяются и применяются к вторичному клонированному фрагменту Sales.2004.1.b, как показано в таблице 2.
Вторичный клонированный фрагмент Sales.2004.1.b
В данный момент времени доступный фрагмент имеет один первичный клонированный фрагмент (потенциальный источник для регенерации клона) и N вторичных клонов (потенциальных объектов регенерации). Вторичный клонированный фрагмент, у которого строки не являются транзакционно согласованными с соответствующими строками в первичном клонированном фрагменте, является устаревшим клонированным фрагментом. Строки (записи или элементы индекса) в устаревшем клонированном фрагменте могут быть в одном из следующих приведенных для примера состояний. Термин “первичная строка” ссылается на строку в первичном клонированном фрагменте. Строки в устаревшем клонированном фрагменте могут быть:
1. Согласованными
Первичная строка не изменилась за время, пока устаревший вторичный клонированный фрагмент был в офлайновом состоянии. Или иначе, процесс регенерации уже обновил строку в устаревшем вторичном клонированном фрагменте, чтобы она была согласована с соответствующей первичной строкой. Согласованная строка во вторичном клонированном фрагменте имеет те же самые значения CRID и CUID.
2. Несогласованными
Первичная строка была изменена за время, пока устаревший вторичный клонированный фрагмент был в офлайновом состоянии. Несогласованная строка в устаревшем вторичном клонированном фрагменте соответствует строке в первичном клонированном фрагменте с тем же самым значением CRID, но с другим значением CUID.
3. Пропущенными
Новая первичная строка была создана за время, пока устаревший вторичный клонированный фрагмент был в офлайновом состоянии. Пропущенная строка в устаревшем вторичном клонированном фрагменте описывает случай, когда существует первичная строка со значением CRID, для которого нет соответствующей строки в устаревшем вторичном клонированном фрагменте с тем же самым значением CRID.
4. Излишними
Первичная строка была удалена за время, пока устаревший вторичный клонированный фрагмент был в офлайновом состоянии. Излишняя строка в устаревшем вторичном клонированном фрагменте описывает случай, когда существует строка в устаревшем вторичном клонированном фрагменте со значением CRID, для которого нет соответствующей строки в первичном клонированном фрагменте с тем же самым значением CRID.
CRID строк устаревших клонов, которые являются не согласованными, помещаются во временный файл (StaleCloneCRIDs - “CRID устаревших клонов”) на раннем этапе метода регенерации. Этот временный файл имеет столбец Stale_CRID со значением, которое идентифицирует записи, которые необходимо регенерировать, например, которые не согласованы, пропущены или являются лишними. В одной реализации временного файла (StaleCloneCRIDs) может быть добавлен дополнительный столбец Batch_ID (“ИД группы”), который инициализируется со значениями, которые упрощают процесс доступа к дискретным наборам строк в StaleCloneCRIDs в некотором количестве малых инкрементных операций группового процесса.
На фиг.8 показано развитие состояний при регенерации устаревшего вторичного клонированного фрагмента. Как показано на фиг.8, вторичный клонированный фрагмент 805 развивается из состояния “офлайн” в состояние “предрегенерация”. В то время как устаревший клон остается в состоянии “предрегенерация”, к устаревшему клону могут быть применены операции в целях оптимизации операции регенерации. Затем вторичный клонированный фрагмент 805 рассматривается как онлайновый и помещается в состояние “в регенерации”. Устаревший клонированный фрагмент остается в состоянии “в регенерации”, находясь в процессе регенерации. В этом состоянии вторичный клонированный фрагмент 805 может быть обновлен посредством изменений, распространяемых из первичного клонированного фрагмента 803.
После того как процесс регенерации выполнен, вторичный клонированный фрагмент 805 переходит в состояние “текущий”. Как только вторичный клонированный фрагмент 805 переходит в состояние “текущий”, он может быть выбран для того, чтобы стать первичным фрагментом.
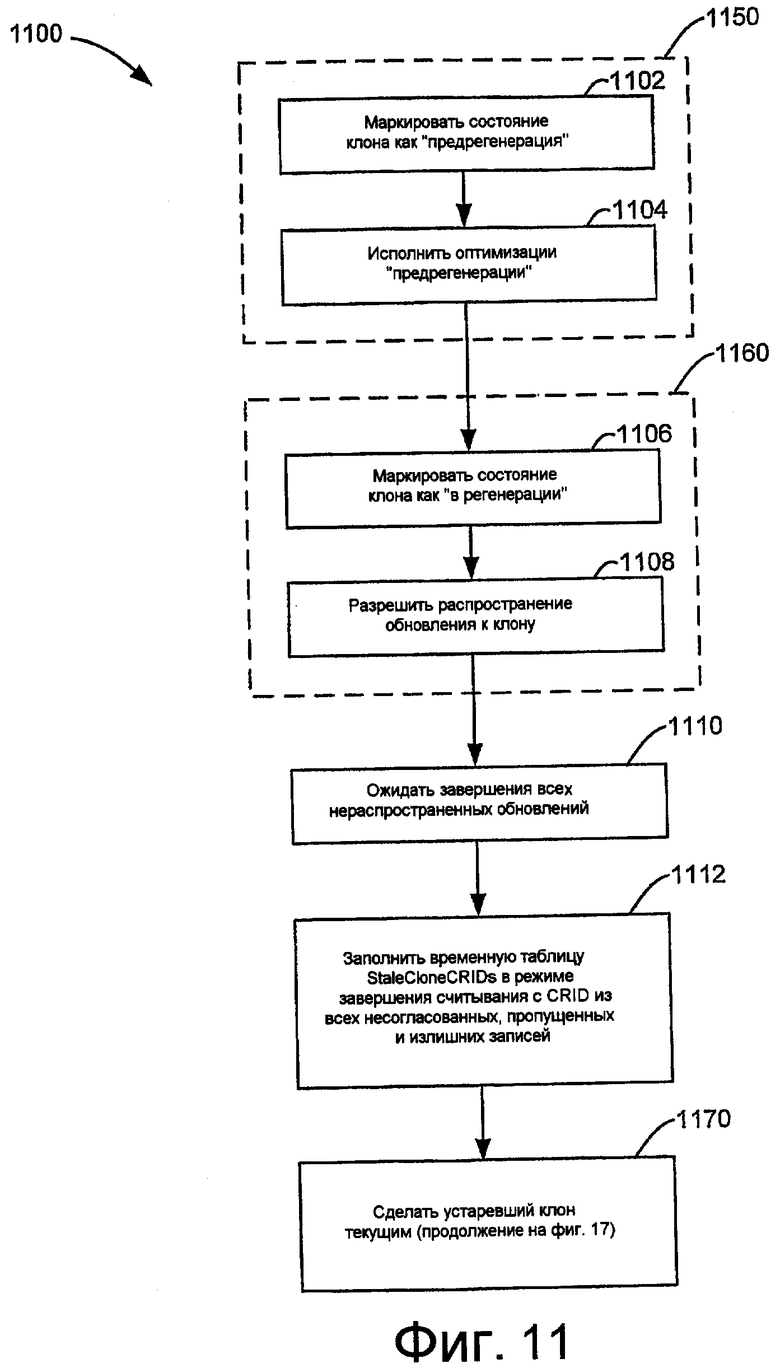
Фиг.11 показывает приведенный для примера процесс 1100 регенерации, который регенерирует устаревший клонированный фрагмент объекта базы данных.
0. StaleCloneOnline (“устаревший клон в онлайновом состоянии”) 1150:
В блоке 1102, когда устаревший клон становится объектом регенерации клона (например, когда он становится доступным для системы после нахождения в состоянии “офлайн”), он помещается в состояние “предрегенерация”. Затем в блоке 1104 может быть исполнена оптимизация перед прогоном, в то время как клонированный фрагмент находится в состоянии “предрегенерация”. Такая оптимизация предназначена для оптимизации последующих рабочих характеристик остального процесса 1100 регенерации.
1. EnableUpdatePropagation (“разрешить распространение обновления”) 1160:
Устаревший клонированный фрагмент маркируется как находящийся в состоянии “в регенерации” в блоке 1106. Затем в блоке 1108 разрешается распространение обновлений из первичного клонированного фрагмента в устаревший клонированный фрагмент. Применение распространяемых обновлений к устаревшему клонированному фрагменту может быть избирательным. Например, применение распространяемых обновлений выполняется только по тем записям, которые уже были регенерированы или которые могут быть определены как не требующие регенерации. То есть, распространяемые обновления применяются только к записям, у которых значения CUID для данного значения CRID согласуются с такими значениями соответствующей записи в первичном клонированном фрагменте. В другой примерной реализации, если все значения строк распространяются путем обновлений, то обновления могут распространяться и применяться к любой записи устаревшего клонированного фрагмента, когда клонированный фрагмент регенерируется.
2. WaitForPropagation (“ожидать распространения”) 1110:
В следующем блоке 1110 процесс 1100 регенерации ожидает, пока все активные операторы DML над первичным клонированным фрагментом не запустят распространение обновлений к устаревшему клонированному фрагменту. (Или используется эквивалентный механизм, который гарантирует, что все последующие DML к первичному фрагменту согласованным образом распространяются к устаревшему клонированному фрагменту.). Блок 1110 может быть достигнут путем ожидания завершения всех текущих исполняемых операторов DML, когда любой вновь активированный оператор DML гарантированным образом распространяет обновления ко всем онлайновым клонированным фрагментам, включая устаревшие клонированные фрагменты в состоянии “в регенерации”.
3. BuildStaleCloneCRIDs (“создать CRID устаревших клонов”) 1112:
В блоке 1112, в режиме ReadCommitted (“считывание завершено”) временная таблица StaleCloneCRIDs создается и инициализируется. Гарантировано, что StaleCloneCRIDs покрывает все несовременные строки (несогласованные, пропущенные и излишние строки) в устаревшем клонированном фрагменте, но ввиду исполняющегося режима изоляции ReadCommitted, StaleCloneCRIDs может случайным образом включать в себя строки CRID, которые действительно согласованы. В одной реализации заполнения временной таблицы StaleCloneCRIDs операция внешнего соединения SQL может быть использована над соответствующими столбцами клонированных идентификаторов записи (crid) первичных и устаревших клонированных фрагментов, где соответствующие значения столбцов идентификаторов обновления клонов (cuid) не согласованы или равны нулю. Следующий псевдокод обеспечивает пример одного такого внешнего соединения. Заметим, что в этом примере дополнительный столбец Batch_Id добавлен к таблице StaleCloneCRIDs для обеспечения примерной базы, которая может быть использована для создания групп регенерации заданного размера.


4. MakeCurrent (“сделать текущим”) 1170:
На фиг.17 показан примерный процесс 1170, чтобы сделать устаревший клон текущим. Процесс 1170 является частью примерного процесса 1100 регенерации, показанного на фиг.11.
Первая малая группа (BatchOfStaleCRIDs) Stale_CRIDs из временной таблицы StaleCloneCRIDs инициализируется в блоке 1114. В одном примере блока 1114 BatchOfStaleCRID определены как CRID строк во временной таблице StaleCloneCRIDs, в которой значения столбцов Batch_Id находятся между параметризованными значениями @start_Id и @end_Id. Начальное действительное значение @start_Id устанавливается на наименьшее значение столбца Batch_Id (например, Batch_Id инициализируется с начальным значением 1 посредством функции IDENTITY (“идентификационные данные”)) во временной таблице StaleCloneCRIDs. Начальное действительное значение @end_Id затем устанавливается на значение желательного BatchSize (“размер группы”). Значение BatchSize может изменяться для достижения различных целей регенерации. Меньшее значение BatchSize может обеспечивать большую одновременность с исполняемыми в текущий момент пользовательскими рабочими нагрузками. Большее значение для BatchSize может потенциально дать лучшее выполнение регенерации. В решающем блоке 1116 проводится проверка, не является ли BatchOfStaleCRIDs пустым. Если BatchOfStaleCRIDs является пустым, то процесс 1100 регенерации переходит к блоку 1118 и маркирует регенерируемый клонированный фрагмент как находящийся в текущем состоянии. Вторичный клонированный фрагмент в текущем состоянии может быть выбран, чтобы стать первичным клонированным фрагментом. Затем процесс 1100 выполняет выход в блоке 1120.
Если в решающем блоке 1116 найдено, что BatchOfStaleCRIDs не является пустым, то:
а. В блоке 1122 новая транзакция запускается в режиме повторного считывания.
b. В блоке 1124 блокирования считывания устанавливаются на строки в первичном клонированном фрагменте, идентифицированные посредством BatchOfStaleCRIDs. Этот этап не требуется функционально, но важен для того, чтобы избежать потенциальных взаимоблокировок с распространяемыми обновлениями.
с. В блоке 1126 удаляются строки в устаревшем клонированном фрагменте, которые идентифицированы посредством CRID в BatchOfStaleCRIDs. Следующий псевдокод описывает одну примерную реализацию удаления устаревших строк из устаревшего клонированного фрагмента. Действительные значения @start_Id и @end_Id являются теми, которые установлены ранее в процессе MakeCurrent 1170 (в блоке 1114 или блоке 1132).

d. В блоке 1128 вводятся строки из первичного клона, которые идентифицированы посредством BatchOfStaleCRIDs, в устаревший клонированный фрагмент. Пример описания псевдокода одной примерной реализации вставки новых строк из первичного фрагмента в устаревший клонированный фрагмент приведен ниже. Действительные значения @start_Id и @end_Id являются теми, которые установлены ранее в процессе MakeCurrent 1170 (в блоке 1114 или блоке 1132).

е. В блоке 1130 завершается транзакция.
f. В блоке 1132 следующая группа CRID из временной таблицы StaleCloneCRIDs идентифицируется как следующая BatchOfStaleCRIDs. Действительные значения, используемые для @start_Id и @end_Id, получаются приращением на значение желательного BatchSize.
g. Процесс 1100 регенерации затем переходит назад к блоку 1116.
Если возникают ошибки во время обработки BatchOfStaleCRIDs, то транзакция прерывается, и процесс 1100 регенерации выполняет выход.
Если процесс 1100 регенерации не завершается успешно, то устаревший клонированный фрагмент перемещается в состояние “предрегенерация” (или в состояние “офлайн”, если был полностью потерян доступ к устаревшему клонированному фрагменту).
Примерный метод регенерации клонированных фрагментов осуществляет непрерывное прямое развитие при минимизации конфликтов с существующими рабочими нагрузками посредством малых, коротких транзакций. Метод регенерации клона, описанный выше, может также быть применен к клонированным фрагментам индекса, точно так, как он применен к клонированным фрагментам данных. В одной примерной реализации устаревшие вторичные клонированные фрагменты индекса могут быть регенерированы из соответствующих первичных клонированных фрагментов индекса.
Если все из клонированных фрагментов данных для фрагмента базовой таблицы переходит в офлайновое состояние, то строки, соответствующие этому фрагменту в каждом фрагменте индекса, также являются эффективно офлайновыми. Когда первичный клонированный фрагмент базовой таблицы вновь становится офлайновым, то метод регенерации работает над любыми устаревшими клонированными фрагментами данных таблицы, а также над любыми устаревшими клонированными фрагментами индекса. В данный момент, операции обновления распространяются к устаревшим вторичным клонированным фрагментам индекса и данных, которые регенерируются. Аналогичным образом, если все клонированные фрагменты для фрагмента индекса становятся офлайновыми, маршрут доступа к индексу, использующий этот фрагмент индекса, будет офлайновым. Устаревший клонированный фрагмент индекса восстанавливается посредством регенерации клона, когда он снова становится доступным. В одной примерной реализации устаревшие клонированные фрагменты индекса регенерируются непосредственно с использованием строк фрагментов базовой таблицы. Однако устаревший вторичный клонированный фрагмент может также быть регенерирован из соответствующего первичного клонированного фрагмента индекса.
Эффективность механизма клонирования и управления фрагментами базы данных, описанного выше, может быть повышена посредством примерных оптимизаций, описанных ниже:
а) Этап предрегенерации регенерации клона
Перед выполнением метода регенерации клона тот же самый метод регенерации (описанный для процесса 1100 на фиг.11) может быть запущен, но полностью в режиме завершения считывания. (Например, при исполнении в течение этапа предрегенерации, блок 1122 процесса 1100 запускает транзакцию в режиме завершения считывания.). В отсутствие множества параллельных обновлений этот предварительный прогон позволит привести в порядок подавляющее большинство строк в клонированном фрагменте, оставляя лишь небольшое количество несогласованностей и, возможно, вводя еще немного. Идея состоит в том, что после выполнения предварительного прогона строгая операция регенерации (процесс 1170 на фиг.17) в повторяемом режиме считывания будет работать намного быстрее. Меньше строк будет блокировано (ввиду меньшего количества групп) в течение всего, более короткого периода времени, тем самым увеличивая одновременность в системе.
Если первичный клонированный фрагмент имеет множество вторичных клонированных фрагментов, которые требуют регенерации, прогоны регенерации по всем вторичным клонированным фрагментам могут исполняться независимо один от другого. Степень параллелизма может управляться на основе того, как быстро клонированные фрагменты должны приводиться вновь в онлайновое состояние, с учетом того, какая степень одновременности должна быть достигнута в системе.
b) Гибкость транзакции к сбою вторичного клонированного фрагмента
Когда распространяемое обновление к вторичному клонированному фрагменту безуспешно ввиду системных причин, клонированный фрагмент может быть маркирован как офлайновый. Результаты происходящих транзакций сохраняются непосредственно в строках первичного клонированного фрагмента. Никакая дополнительная очередь ожидающей выполнения работы не требуется для целей сохранения результатов предыдущих транзакций. Для удобства обработки ошибок, для оператора, обновления которого распространялись, может быть выполнен откат назад. Но это не является обязательным, если сбой распространения обновления к допустившему ошибку вторичному клонированному фрагменту не имеет других побочных влияний на исполнение оператора. Обновления для этого оператора уже должны быть применены и сохранены в первичном клонированном фрагменте.
с) Гибкость транзакции к сбою первичного клонированного фрагмента
Если в первичном клонированном фрагменте происходит сбой, то пользовательскую транзакцию, обращающуюся к этому клонированному фрагменту, не требуется прерывать, если имеется онлайновый согласованный вторичный клонированный фрагмент, который немедленно может быть назначен в качестве нового первичного. Однако для любого оператора, обращающегося в данный момент к допустившему ошибку первичному клонированному фрагменту, будет выполнен откат назад.
d) Гибкость регенерации клона
Если обновление регенерации клона для записи во вторичном клонированном фрагменте безуспешно по системным причинам, то прогон регенерации клона может быть перезапущен с начала, может повторно выполнить текущую активную группу MakeCurrent или повторную итерацию всей обработки MakeCurrent для StaleCloneCRIDs.
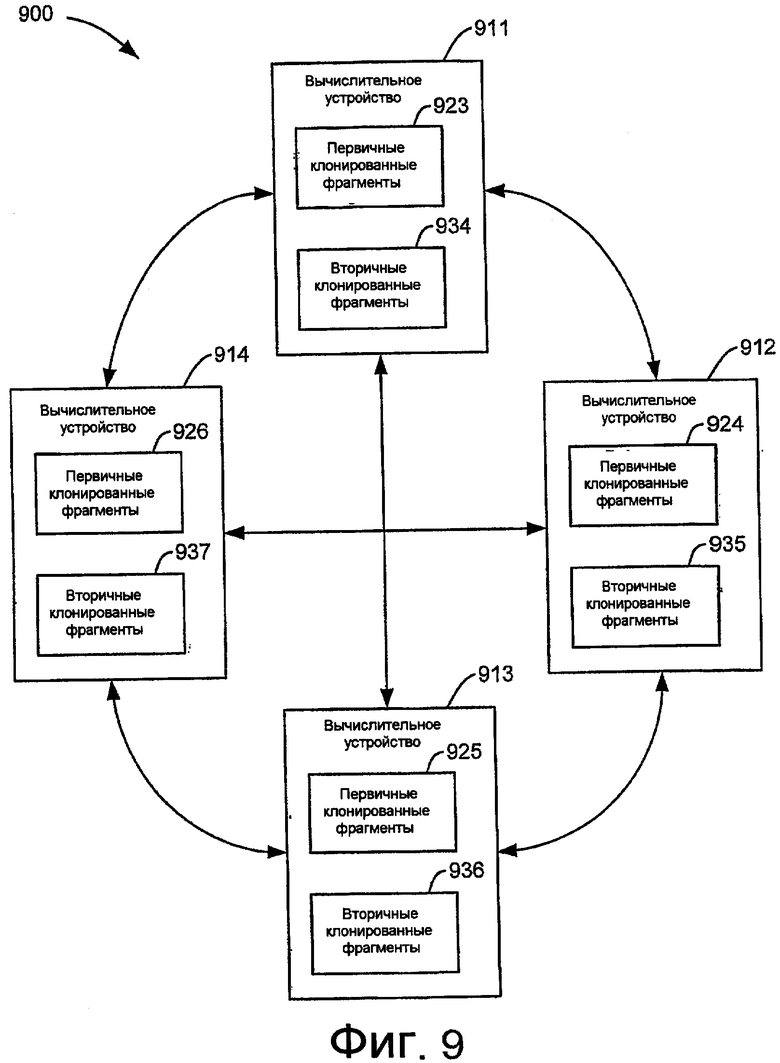
На фиг.9 показан пример системы 900 базы данных с клонированными фрагментами базы данных. Система 900 базы данных в типовом случае включает в себя множество вычислительных устройств 911-914 для распределения рабочей нагрузки и обеспечения надежной доступности для обращения к объекту базы данных, а также выравнивания нагрузки. Объект в примерной базе данных разделен на клонированные фрагменты, которые разделены по вычислительным устройствам 911-914. Этим способом вычислительные устройства 911-914 могут одновременно выполнять операции над различными частями объекта в примерной базе данных. Вычислительные устройства 911-914 могут быть конфигурированы с любым типом системы базы данных, таким как сервер SQL.
Как показано на чертеже, вычислительные устройства 911-914 могут включать в себя первичные клонированные фрагменты 923-926 и вторичные клонированные фрагменты 934-937. В одном варианте осуществления первичные клонированные фрагменты 923-926 используются вычислительными устройствами 911-914 для выполнения задач, связанных с производительностью, таких как добавление, удаление или модифицирование объекта базы данных, запросы, отчеты и т.д. Вторичные клонированные фрагменты 934-937 служат в качестве резервной копии первичных клонированных фрагментов 923-926.
В типичном случае первичные клонированные фрагменты в каждом вычислительном устройстве не соответствуют вторичным клонированным фрагментам в устройстве. Если одно из вычислительных устройств 911-914 неисправно, то другое вычислительное устройство может взять на себя операции с использованием вторичных клонированных фрагментов, которые соответствуют первичным клонированным фрагментам, управляемым отказавшим устройством. Таким способом система 900 базы данных может гарантировать, что фрагмент объекта базы данных остается доступным, пока, по меньшей мере, один клон этого фрагмента остается доступным.
В другом варианте осуществления вычислительные устройства 911-914 могут включать в себя перекрывающиеся первичные клонированные фрагменты. Таким способом множество вычислительных устройств могут выполнять операции, такие как запросы, над той же самой частью объекта базы данных.
Фиг.10 показывает примерный процесс 1000 для обновления объекта базы данных. Объект базы данных может включать в себя данные всей базы данных или часть базы данных, такую как таблица, индекс и т.п. Обновление может быть связано с модифицированием одного или более фрагментов. В блоке 1001 идентифицируются фрагменты объекта базы данных, на которые воздействует обновление, и которые образуют набор, называемый SetOfFragments (“набор фрагментов”), который является локальной структурой данных для процесса 1000. Каждый элемент в этом наборе первоначально маркируется как необработанный (это не изменяет действительный фрагмент, а только элемент в локальной структуре данных). Процесс 1000 продолжается до решающего блока 1002, где определяется, имеются ли еще необработанные элементы в наборе SetOfFragments. Если нет, то процесс 1000 продолжается до блока 1012 завершения, где процесс завершается.
Возвращаясь к решающему блоку 1002, если еще остаются необработанные элементы в наборе SetOfFragments, процесс 1000 переходит к блоку 1003, где необработанный элемент получается из набора SetOfFragments; это представляет фрагмент, который должен быть обновлен следующим. В блоке 1004 определяется соответствующий первичный клонированный фрагмент, и набор записей в первичном клонированном фрагменте, которые требуют обновления, идентифицируется, формируя набор, называемый SetOfRecords (“набор записей”), то есть локальную структуру данных для процесса 1000. Каждый элемент в этом наборе первоначально маркируется как необработанный (это не изменяет действительную запись, а только элемент в локальной структуре данных). В решающем блоке 1005 определяется, имеются ли еще необработанные элементы в наборе SetOfRecords. Если нет, то процесс 1000 переходит к блоку 1006 завершения, где текущий элемент в наборе SetOfFragments маркируется как обработанный (это не изменяет действительный фрагмент, а только элемент в локальной структуре данных). Процесс 1000 затем возвращается к решающему блоку 1002.
Возвращаясь к решающему блоку 1005, если еще остаются необработанные элементы в наборе SetOfRecords, процесс 1000 переходит к блоку 1007, где необработанный элемент получается из набора SetOfRecords. Этот элемент представляет запись, которая должна быть обновлена следующей. В блоке 1008 для записи получается СUID. (Сохранение и назначение значения СUID описано в других местах в настоящем документе со ссылками на фиг.12 и 13.)
Процесс 1000 переходит к блоку 1009, где запись обновляется новыми значениями, а также новым СUID. В блоке 1010 старое значение СUID, а также обновленная запись (содержащая новый СUID) распространяется ко всем вторичным клонированным фрагментам данных, а также ко всем клонированным фрагментам индексов, которые содержат копию этой записи, как первичным, так и вторичным. На фиг.16 этот блок показан более детально.
После того как обновление распространено и применено, процесс 1000 продолжается к блоку 1011, где текущий элемент в наборе SetOfRecords маркируется как обработанный (это не изменяет действительную запись, а только элемент в локальной структуре данных). Процесс 1000 затем возвращается к решающему блоку 1005.
Фиг.12 показывает примерный процесс 1200 для модифицирования идентификаторов обновления клонов (CUID). Процесс 1200 может быть реализован для каждого объекта базы данных, такого как таблица базы данных. В блоке 1203 процесс 1200 ожидает обновлений в конфигурации клонированных фрагментов, связанных с таблицей. В решающем блоке 1205 принимается решение, стал ли клонированный фрагмент недоступным. Если все клонированные фрагменты доступны, то процесс 1200 возвращается в состояние ожидания в блоке 1203.
Возвращаясь к решающему блоку 1205, если клонированный фрагмент стал недоступным, процесс 1200 перемещается к блоку 1207, значение CUID таблицы получает приращение. В блоке 1209 новое значение CUID таблицы транзакционно поддерживается.
Фиг.13 показывает примерный процесс 1300 для присвоения значения CUID, распределенного в соответствии с процессом 1200, показным на фиг.12. Система базы данных может быть конфигурирована для исполнения процесса 1300 для операторов, которые воздействуют на базу данных. В блоке 1302 процесс подготавливает для исполнения новый оператор по отношению к базе данных. В решающем блоке 1304 определяется, является ли новый оператор оператором DML, который в типовом случае включает в себя такие операции, как вставка, удаление и модифицирование элементов в базе данных. Если оператор не является оператором DML, то процесс 1300 переходит к блоку 1320, где оператор, не являющийся оператором DML, исполняется в отношении базы данных. Затем процесс возвращается к блоку 1302.
Возвращаясь к решающему блоку 1304, если оператор является оператором DML, то процесс 1300 продолжается к блоку 1306, где считывается значение CUID для таблицы базы данных, которое подлежит обновлению. В блоке 1308 значение CUID ассоциируется с оператором DML. В блоке 1310 значение CUID сохраняется в каждую строку каждого первичного клонированного фрагмента, обновляемого оператором DML. В блоке 1312 значение CUID сохраняется в каждую строку или индекс записи в клонированном фрагменте, на который воздействует посредством распространяемого обновления оператор DML. Значение CUID может быть распространено с обновлением как для клонированных фрагментов данных, так и для клонированных фрагментов индексов. Примерные маршруты распространения для значений CUID обсуждены со ссылками на фиг.14. Если значение CUID распространено, то процесс 1300 возвращается к блоку 1302.
На фиг.14 показаны примерные маршруты распространения для значений CUID. На фиг.14 первичный клонированный фрагмент 1403 данных реализовал обновление, включенное в оператор DML. Как обсуждено выше, значение CUID, ассоциированное с оператором DML, сохраняется в каждую строку, обновленную оператором DML, в первичном клонированном фрагменте 1403 данных. Первичный клонированный фрагмент 1403 данных может распространять значение CUID вместе с обновлением к вторичным клонированным фрагментам 1405 данных по маршруту 1411. В частности, значение CUID, ассоциированное с оператором DML, присваивается каждой строке, на которую воздействует распространение обновления. В одной реализации значение CUID распространяется к первичному клонированному фрагменту 1407 индекса и вторичному клонированному фрагменту 1409 индекса из первичного клонированного фрагмента данных по маршрутам 1412 и 1413, соответственно. В другой реализации вместо распространения значения CUID по маршруту 1413, значение CUID распространяется от первичного клонированного фрагмента 1407 индекса к вторичному клонированному фрагменту 1409 индекса по маршруту 1415.
Фиг.16 показывает примерный процесс 1600 распространения и применения обновленной записи и старого значения CUID из первичного клонированного фрагмента ко всем вторичным клонированным фрагментам данных, а также ко всем клонированным фрагментам индекса, которые содержат копию этой записи. Эти клонированные фрагменты, получающие распространяемые обновления, могут быть в состоянии Current (“текущее”), или они могут быть в состоянии InRefresh (“в регенерации”). Процесс 1600 в типовом случае образует один этап в более крупном процессе обновления, описанном в другой части этого документа. В блоке 1601 все вторичные клонированные фрагменты данных, а также все клонированные фрагменты индекса (как первичные, так и вторичные), которые содержат копию этой записи, идентифицируются. Эти клонированные фрагменты формируют набор, называемый SetOfSecondaries (“набор вторичных”), который является локальной структурой данных для процесса 1600. Каждый элемент в этом наборе первоначально маркируется как необработанный (это не изменяет действительный клонированный фрагмент, а только элемент в локальной структуре данных). Процесс 1600 продолжается до решающего блока 1602, где определяется, имеются ли еще необработанные элементы в наборе SetOfSecondaries. Если нет, то процесс 1600 продолжается до блока 1603 завершения, где процесс завершается, и любой более укрупненный процесс, который содержит процесс 1600 в качестве этапа, затем продолжается на следующем этапе этого укрупненного процесса.
Возвращаясь к решающему блоку 1602, если еще остаются необработанные элементы в наборе SetOfSecondaries, процесс 1600 переходит к блоку 1604, где необработанный элемент получается из набора SetOfSecondaries. Этот элемент представляет вторичный клонированный фрагмент, который должен быть обновлен следующим. Этот вторичный клонированный фрагмент может быть вторичным клонированным фрагментом данных, первичным клонированным фрагментом индекса или вторичным клонированным фрагментом индекса. В решающем блоке 1605 определяется, существует ли запись во вторичном клонированном фрагменте с тем же самым CRID, как у записи из первичного клонированного фрагмента, и у которой CUID согласуется со старым значением CUID записи из первичного клонированного фрагмента. Если да, то процесс 1600 переходит к блоку 1606, где запись обновляется новыми значениями и новым CUID. Затем процесс 1600 переходит к блоку 1609.
Возвращаясь к блоку 1605, если согласующаяся запись не найдена, процесс 1600 продолжается к решающему блоку 1607, где определяется, находится ли вторичный клонированный фрагмент в состоянии InRefresh. Если нет, то в блоке 1608 вторичный клонированный фрагмент маркируется как офлайновый, поскольку он больше не согласуется с первичным клонированным фрагментом. Затем процесс 1600 переходит к блоку 1609.
Возвращаясь к блоку 1607, если вторичный клонированный фрагмент находится в состоянии InRefresh, процесс 1600 переходит к блоку 1609, где текущий элемент в наборе SetOfSecondaries маркируется как обработанный (это не изменяет действительный клонированный фрагмент, а только элемент в локальной структуре данных). Процесс 1600 затем возвращается к решающему блоку 1602.
Фиг.15 показывает примерное компьютерное устройство 1500 для реализации описанных систем и способов. В своей наиболее базовой конфигурации вычислительное устройство 1500 в типовом случае включает в себя, по меньшей мере, один центральный процессор (CPU) 1505 и память 1510.
В зависимости от точной конфигурации и типа вычислительного устройства, память 1510 может быть энергозависимой (такой как ОЗУ), энергонезависимой (такой как ПЗУ, флэш-память и т.д.), или комбинацией обоих типов. Дополнительно вычислительное устройство 1500 может также иметь дополнительные признаки/функциональность. Например, вычислительное устройство 1500 может содержать множество центральных процессоров. Описанные способы могут исполняться любым образом любым блоком обработки в вычислительном устройстве 1500. Например, описанный процесс может исполняться множеством CPU параллельно.
Вычислительное устройство 1500 может также содержать дополнительное ЗУ (съемное и/или несъемное), включая, без ограничения указанным, магнитные или оптические диски или магнитную ленту. Такие дополнительные ЗУ показаны на фиг.15 посредством ЗУ 1515. Компьютерные носители для хранения данных включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Память 1510 и ЗУ 1515 являются примерами компьютерных носителей для хранения данных. Компьютерные носители для хранения данных включают в себя, без ограничения указанным, ОЗУ, ПЗУ, электронно-стираемые программируемые ПЗУ, флэш-память или другие технологии памяти, ПЗУ на компакт-дисках (CD-ROM), цифровые многофункциональные диски (DVD) или другие оптические ЗУ, магнитные кассеты, магнитные ленты, ЗУ на магнитных дисках или другие магнитные ЗУ, или любые другие носители, которые могут использоваться для хранения полезной информации, и к которым может осуществляться доступ вычислительным устройством 1500. Любой такой носитель для хранения данных может быть частью вычислительного устройства 1500.
Вычислительное устройство 1500 может также содержать коммуникационные устройства 1540, которые позволяют устройству осуществлять связь с другими устройствами. Коммуникационные устройства 1540 являются примером коммуникационной среды. Коммуникационные среды в типовом случае воплощают считываемые компьютером команды, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущее колебание или другой транспортный механизм, и включают в себя любую среду доставки информации. Термин “модулированный сигнал данных” означает сигнал, у которого одна или более из его характеристик установлена или изменяется таким способом, чтобы кодировать информацию в сигнале. В качестве примера, но не ограничения, коммуникационные среды включают в себя проводные среды, такие как проводные сети или прямые проводные соединения, и беспроводные среды, такие как акустические, радиочастотные и инфракрасные и другие беспроводные среды. Термин “машиночитаемые носители” или “считываемые устройством носители”, как использовано в настоящем документе, включает в себя как компьютерные носители для хранения данных, так и коммуникационные среды. Описанные способы могут кодироваться на любых машиночитаемых носителях в любой форме, такой как данные, исполняемые компьютером команды и т.д.
Вычислительное устройство 1500 может также иметь устройства 1535 ввода, такие как клавиатура, мышь, перо, устройство речевого ввода, устройство сенсорного ввода. Также могут быть включены устройства 1530 вывода, такие как дисплей, динамики, принтер и т.п. Все эти устройства хорошо известны в технике и не требуют детального обсуждения.
Специалистам в данной области техники должно быть очевидно, что ЗУ, используемые для хранения программных команд, могут распространяться по сети. Например, удаленный компьютер может сохранять пример процесса, описанного в виде программного обеспечения. Локальный компьютер или компьютер-терминал может получать доступ к удаленному компьютеру и загружать часть программного обеспечения или все программное обеспечение для исполнения программы. Альтернативно, локальный компьютер может загружать части программного обеспечения по мере необходимости, или исполнять некоторые программные команды на локальном компьютере, а некоторые - на удаленном компьютере (или компьютерной сети). Специалистам в данной области техники также должно быть понятно, что с использованием обычных методов, известных в технике специалистам, все или часть программных команд можно выполнить посредством специализированной схемы, такой как цифровой процессор сигналов (DSP), программируемая логическая матрица и т.п.










Изобретение относится к методам для клонирования и управления фрагментами базы данных. Технический результат заключается в обеспечении резервирования базы данных. Объект базы данных, такой как таблица, набор строк или индекс, разделен на фрагменты. Каждый фрагмент клонируется для создания клонированных фрагментов, которые операционно идентичны друг другу. Один из клонированных фрагментов может быть обозначен как первичный клонированный фрагмент для выполнения операций базы данных или как вторичный клонированный фрагмент, служащие в качестве резерва. Обновления каждого фрагмента реализуются над первичным клонированным фрагментом и затем распространяются от первичного клонированного фрагмента к соответствующим вторичным клонированным фрагментам. 3 н. 17 з.п. ф-лы, 17 ил., 2 табл.
1. Считываемый устройством носитель с командами, исполняемыми устройством, для выполнения этапов, содержащих создание первичного клонированного фрагмента, ассоциированного с разделом записей в таблице базы данных, причем первичный клонированный фрагмент имеет первое множество записей;
добавление первого множества идентификаторов обновления в первичный клонированный фрагмент, при этом каждый из первого множества идентификаторов обновления является элементом первого множества записей;
в ответ на офлайновое состояние вторичного клонированного фрагмента в течение обновления, сохранение обновления в первичном клонированном фрагменте;
идентификацию вторичного клонированного фрагмента, соответствующего первичному клонированному фрагменту, причем вторичный клонированный фрагмент является устаревшим относительно первичного клонированного фрагмента, и вторичный клонированный фрагмент имеет второе множество записей и второе множество идентификаторов обновления, при этом каждый из второго множества идентификаторов обновления является элементом второго множества записей и
регенерацию устаревшего вторичного клонированного фрагмента с сохраненным обновлением, когда устаревший вторичный клонированный фрагмент возвращается в онлайновое состояние путем выполнения операции базы данных, при этом этап регенерации дополнительно включает в себя:
идентификацию первого идентификатора обновления первой записи в первом множестве записей, включенных в первичный клонированный фрагмент;
идентификацию второго идентификатора обновления второй записи во втором множестве записей, в устаревшем вторичном клонированном фрагменте, вторая запись соответствует первой записи; и
определение, являются ли первая запись и вторая запись с идентичными идентификаторами клонированных записей согласованными, основываясь, по меньшей мере, частично на сравнении первого идентификатора обновления и второго идентификатора обновления; и
при регенерации устаревшего вторичного клонированного фрагмента:
выполняют обновление первичного клонированного фрагмента; и
обновляют устаревший вторичный клонированный фрагмент в ответ на выполнение обновления первично клонированного фрагмента.
2. Считываемый устройством носитель по п.1, в котором этап обновления дополнительно содержит обновление современных строк устаревшего вторичного клонированного фрагмента, но не обновление несовременных строк устаревшего вторичного клонированного фрагмента.
3. Считываемый устройством носитель по п.1, в котором этап регенерации дополнительно содержит, если первая и вторая записи определены как согласованные,
регенерацию второй записи с данными в первой записи и
присвоение значения первого идентификатора обновления второму идентификатору обновления.
4. Считываемый устройством носитель по п.3, дополнительно содержащий выполнение этапов определения, регенерации и присвоения для каждой из записей, включенных во вторичный клонированный фрагмент.
5. Считываемый устройством носитель по п.1, в котором этап регенерации дополнительно содержит выполнение операции предрегенерации над вторичным клонированным фрагментом в режиме завершения считывания.
6. Считываемый устройством носитель по п.5, в котором операция предрегенерации выполняется параллельно над другими вторичными клонированными фрагментами, соответствующими первичному клонированному фрагменту.
7. Считываемый устройством носитель по п.1, в котором операция базы данных для регенерации вторичного клонированного фрагмента включает операции на языке манипулирования данными (DML) вставки, удаления и обновления записей во вторичном клоне.
8. Считываемый устройством носитель с командами, исполняемыми устройством, для выполнения этапов, содержащих идентификацию первичного клонированного фрагмента, ассоциированного с объектом базы данных;
идентификацию вторичного клонированного фрагмента, соответствующего первичному клонированному фрагменту, причем вторичный клонированный фрагмент является устаревшим относительно первичного клонированного фрагмента; и
регенерацию устаревшего вторичного клонированного фрагмента данными в первичном клонированном фрагменте путем выполнения операции базы данных, при этом операция базы данных для регенерации устаревшего вторичного клонированного фрагмента включает в себя группы операций, которые инкрементно регенерируют устаревший вторичный клонированный фрагмент посредством:
идентификации коллекции записей в устаревшем вторичном клонированном фрагменте, которые являются согласованными с соответствующей коллекцией записей в первичном клонированном фрагменте;
создание и инициализация временной таблицы и создание множества записей во временной таблице, ассоциированных с идентифицированной коллекцией записей, которые являются согласованными;
определение размера группы, который указывает количество записей в устаревшем вторичном клонированном фрагменте, который является обновленным при каждом обновлении группы,
инкрементную регенерирацию устаревшего вторичного клонированного фрагмента при завершении множества транзакций, при этом каждая транзакция воздействует на количество записей во временной таблице, указанной посредством размера группы; и
разрешение нового обновления устаревшего вторичного клонированного фрагмента при инкрементной регенерирации устаревшего вторичного клонированного фрагмента.
9. Считываемый устройством носитель по п.8, в котором группы операций для регенерации устаревшего вторичного клонированного фрагмента являются операциями на структурированном языке запроса (SQL).
10. Считываемый устройством носитель с командами, исполняемыми устройством, для выполнения этапов, содержащих разделение таблицы базы данных посредством автоматической генерации, по меньшей мере, двух фрагментов таблицы базы данных;
генерацию первого клонированного фрагмента и второго клонированного фрагмента для каждого из, по меньшей мере, двух фрагментов;
распределение первого клонированного фрагмента на первый компьютер и второго клонированного фрагмента на второй компьютер, который отличается от первого компьютера выполнением оператора языка структурированных запросов;
назначение, по меньшей мере, одного из клонированных фрагментов для каждого из, по меньшей мере, двух фрагментов как первично клонированного фрагмента, сконфигурированного для использования в операциях, ассоциированных с таблицей базы данных; и
назначение других клонированных фрагментов для каждого из, по меньшей мере, двух фрагментов как вторично клонированного фрагмента, соответствующего первично клонированному фрагменту; и
для каждого из, по меньшей мере, двух фрагментов, инициализирующих идентификатор клонированных записей и идентификатор клонированных обновлений в каждом из ассоциированных первично клонированных фрагментов и вторично клонированных фрагментов.
11. Считываемый устройством носитель по п.10, дополнительно содержащий
определение обновления для одного из, по меньшей мере, двух фрагментов таблицы базы данных;
выполнение обновления для первично клонированного фрагмента; и
распространение и применение обновления к другим соответствующим вторичным клонированным фрагментам, ассоциированным с первичным клонированным фрагментом.
12. Считываемый устройством носитель по п.11, при этом этап распространения дополнительно содержит
идентификацию одного из вторичных клонированных фрагментов как устаревшего вторичного клонированного фрагмента, который не включает в себя обновление; и
регенерацию идентифицированного устаревшего вторичного клонированного фрагмента с данными в ассоциированном первичном клонированном фрагменте.
13. Считываемый устройством носитель по п.12, в котором этап регенерации выполняется с использованием стандартных SQL операций базы данных.
14. Считываемый устройством носитель по п.12, дополнительно содержащий
определение другого обновления для идентифицированного фрагмента;
выполнение другого обновления над первичным клонированным фрагментом; и
избирательное выполнение другого обновления над устаревшим вторичным клонированным фрагментом, только если записи в устаревшем вторичном клонированном фрагменте были современными с соответствующими записями в первичном клонированном фрагменте перед упомянутым другим обновлением.
15. Считываемый устройством носитель по п.14, в котором этап избирательного выполнения включает в себя выполнение другого обновления над частью устаревшего клонированного фрагмента, который был регенерирован.
16. Считываемый устройством носитель по п.15, дополнительно содержащий
в ответ на определение, что устаревший клонированный фрагмент был регенерирован, немедленное обозначение регенерированного
клонированного фрагмента, как имеющего возможность выбора в качестве первичного клонированного фрагмента.
17. Считываемый устройством носитель по п.12, в котором этап регенерации реализуется как рабочая нагрузка, которая блокирует малое количество записей устаревшего клонированного фрагмента на короткий интервал времени и которая исполняется одновременно с другими пользовательскими рабочими нагрузками.
18. Считываемый устройством носитель по п.12, в котором этап регенерации выполняется параллельно над множеством устаревших вторичных клонированных фрагментов.
19. Считываемый устройством носитель по п.12, в котором множество устаревших вторичных клонированных фрагментов соответствуют, по меньшей мере, одному из общего первичного клонированного фрагмента, отличающегося первичного клонированного фрагмента или отличающихся объектов базы данных.
20. Считываемый устройством носитель по п.10, в котором генерация первого клонированного фрагмента и второго клонированного фрагмента включает генерацию клонированных фрагментов как, по существу, идентичных для операций базы данных.
| US 6694337 B1, 17.02.2004 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6820180 B2, 16.11.2004 | |||
| US 5555404 А, 10.09.1996 | |||
| СПОСОБ ПОИСКА В БАЗАХ ДАННЫХ С РАЗМЕТКОЙ ДАННЫХ | 2000 |
|
RU2177174C1 |

