Область техники, к которой относится изобретение
Настоящее изобретение касается системы обработки событий и способа обработки событий. Изобретение дополнительно касается масштабируемой обработки потока, объединенной с аналитической обработкой в режиме реального времени для систем (DBMS) управления базами данных, в частности DBMS, использующих SQL (язык структурированных запросов).
Уровень техники
При обработке больших объемов данных для большого количества приложений критичны три важных момента: крупномасштабная обработка событий с хранением состояний, аналитическая обработка в режиме реального времени со сложными описательными запросами (например, SQL запросами) и масштабируемость по нагрузке, то есть количеству запросов и событий, и по размеру базы данных. В качестве примера телекоммуникационному оператору может потребоваться собирать и обрабатывать до миллионов записей о звонках в секунду и обеспечивать поддержку с целью анализа поведения своих клиентов с помощью сложных незапланированных запросов. Технология работы с базами данных, соответствующая уровню техники, в самом лучшем случае может принимать меры по двум из этих трех моментов. Более конкретно, существует два класса систем: (а) Системы (DSMS) управления потоками данных и (б) Системы (DBMS) управления базами данных. DSMS хорошо подходят для обработки сложных событий, но не поддерживают аналитическую обработку в режиме реального времени. Наиболее совершенные DBMS поддерживают (в лучшем случае) аналитическую обработку в режиме реального времени, но плохо подходят для обработки сложных событий. Системы обоих типов часто обладают ограниченной масштабируемостью.
Задача системы (DSMS) управления потоками данных заключается в отслеживании в режиме реального времени широкополосного потока дискретных событий. Системы, соответствующие существующему уровню техники, обеспечивают описательный интерфейс с использованием расширения SQL языка запросов, такого как StreamSQL. Используя StreamSQL, разработчики приложений определяют правила (также называемые непрерывными запросами), которые определяют возможно сложные шаблоны для входного потока событий. Когда во входном потоке событий появится такой шаблон, правило срабатывает и выдает результат, который потребляется приложением как поток событий.
Для выполнения своей функции DSMS должна поддерживать потенциально очень большое количество отражающих состояние переменных, которые нужны для оценки правил. В принципе при появлении каждого события DSMS должна обновлять соответствующие отражающие состояние переменные и проверять, требует ли новое глобальное состояние запуска заранее заданного правила. Соответствующие вычисления заключаются в вычислении новых значений и обновления этих отражающих состояние переменных; при этом соответствующее хранения заключается в поддержании отражающих состояние переменных, так что частое вычисление новых значений может быть выполнено в режиме реального времени.
Современные DSMS могут обрабатывать до сотен тысяч событий в секунду и сотен правил на стандартной одиночной машине. Они делают указанное, благодаря применению некоторого количества оптимизаций. Более конкретно, они внутренне оптимизируют управление отражающих состояние переменных, в частности, для заданного набора правил. Для масштабирования при увеличении количества машин, эти системы дублируют поток событий и обрабатывают разные правила на разных машинах. То есть, они дублируют данные и разделяют нагрузку. Структура этих систем основана на исследовании, выполненном в контексте проекта Поток (Stream) в соответствии с «Брайан Бэбкок (Brian Babcock), Шивнатх Бабу (Shivnath Babu), Мейур Датар (Mayur Datar), Раджив Мотвани (Rajeev Motwani), Дженнифер Видом (Jennifer Widom): Модели и вопросы в Системах потоков данных. PODS 2002: 1-16», проекта Телеграф (Telegraph) в соответствии с «Сайлеш Кришнамурти (Sailesh Krishnamurthy), Сириш Чандрасекаран (Sirish Chandrasekaran), Оуэн Купер (Owen Cooper), Амол Дешпанд (Amol Deshpande), Майкл Дж. Франклин (Michael J. Franklin), Джозеф М. Хеллерсейн (Joseph М. Hellerstein), Вей Хонг (Wei Hong), Самуэль Медден (Samuel Madden), Фредерик Рейсе (Frederick Reiss), Мехул А. Шах (Mehul A. Shah): TelegraphCQ: Отчет о состоянии архитектуры. IEEE Data Eng. Bull. 26(1): 11-18 (2003)» и проектов Аврора / Бореалис (Aurora / Borealis) в соответствии с «Хари Балакришнан (Hari Balakrishnan), Магдалена Балазинска (Magdalena Balazinska), Дональд Карни (Donald Carney), Угур Четинтемел (Ugur 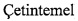 ), Митч Черняк (Mitch Cherniack), Кристиан Конвей (Christian Convey), Эдуардо Ф. Галвез (Eduardo F. Galvez), Джон Салц (Jon Salz), Майкл Стоунбрейкер (Michael Stonebraker), Несим Тетбал (Nesime Tatbul), Ричард Тиббеттс (Richard Tibbetts), Стенли Б. Здоник (Stanley В. Zdonik): Итоги по Авроре. VLDB J. 13(4): 370-383 (2004)» и «Даниэль Дж. Абади (Daniel J. Abadi), Яниф Ахмад (Yanif Ahmad), Магдален Балазинска (Magdalena Balazinska), Угур Четинтемел (Ugur ), Митч Черняк (Mitch Cherniack), Йонг-хейон Хванг (Jeong-Hyon Hwang), Вольфганг Линдер (Wolfgang Lindner), Анараг Маски (Anurag Maskey), Алекс Расин (Alex Rasin), Эстер Ривкина (Esther Ryvkina), Несим Тетбал (Nesime Tatbul), Йинг Ксинг (Ying Xing), Стенли В. Здоник (Stanley В. Zdonik): Структура устройства обработки потока для Бореалис (Borealis). CIDR 2005: 277-289».
), Митч Черняк (Mitch Cherniack), Кристиан Конвей (Christian Convey), Эдуардо Ф. Галвез (Eduardo F. Galvez), Джон Салц (Jon Salz), Майкл Стоунбрейкер (Michael Stonebraker), Несим Тетбал (Nesime Tatbul), Ричард Тиббеттс (Richard Tibbetts), Стенли Б. Здоник (Stanley В. Zdonik): Итоги по Авроре. VLDB J. 13(4): 370-383 (2004)» и «Даниэль Дж. Абади (Daniel J. Abadi), Яниф Ахмад (Yanif Ahmad), Магдален Балазинска (Magdalena Balazinska), Угур Четинтемел (Ugur ), Митч Черняк (Mitch Cherniack), Йонг-хейон Хванг (Jeong-Hyon Hwang), Вольфганг Линдер (Wolfgang Lindner), Анараг Маски (Anurag Maskey), Алекс Расин (Alex Rasin), Эстер Ривкина (Esther Ryvkina), Несим Тетбал (Nesime Tatbul), Йинг Ксинг (Ying Xing), Стенли В. Здоник (Stanley В. Zdonik): Структура устройства обработки потока для Бореалис (Borealis). CIDR 2005: 277-289».
Структура современных DSMS позволяет им хорошо работать для конкретных приложений, для которых эти системы были предназначены, но делает их неподходящими для поддержки аналитической обработки в режиме реального времени. Из-за инкапсуляции всех отражающих состояние переменных и настройке хранилища отражающих состояние переменных под конкретные правила, становится практически невозможным обработать любые незапланированные запросы для данных. В результате никакая из современных DSMS не обладает существенными возможностями по аналитической обработке в режиме реального времени. Принцип «дублирование данных - разделение нагрузки» ограничивает масштабируемость этих систем. Если скорость передачи данных вырастает за пределы возможностей одной машины, эти системы больше не могут поддерживать нагрузку.
Для преодоления проблем масштабируемости современных DSMS, в соответствии с «Даниел Пенг (Daniel Peng), Фрэнк Дабек (Frank Dabek): Широкомасштабная обработка с приращением с использованием распределенных транзакций и уведомлений. OSDI 2010: 251-264» была разработана система Percolator, являющаяся закрытой системой компании «Google». Система Percolator представляет собой гибкую программируемую платформу для распределенной и масштабируемой обработки сложных событий и потоков. С помощью Percolator, разработчик приложений может выбрать модель «разделить данные - разделить нагрузку» для достижения лучшей масштабируемости по данным. Тем не менее, система Percolator не обеспечивает какого-либо описательного механизма для поддержки правил и непрерывных запросов. Более того, система Percolator не обеспечивает никакой поддержки для аналитической обработки в режиме реального времени. Компания «Twitter» разработала систему Шторм (Storm), которая является системой с открытым кодом и для которой справедливы большинство принципов структуры системы Percolator.
В качестве альтернативы DSMS, теоретически возможно использовать современные DBMS для обработки потоков событий и выполнения незапланированных запросов аналитической обработки в режиме реального времени. В этом подходе каждое событие рассматривается как транзакция в DBMS. Тогда незапланированные запросы могут быть выполнены той же DBMS. Современные системы для баз данных в оперативной памяти, такие как Хекатон «Hekaton» в соответствии с «Пер-Эйк Ларсон (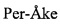 Larson), Майк Звиллинг (Mike Zwilling), Кевин Фарли (Kevin Farlee): Hekaton устройство OLTP с оптимизацией памяти. IEEE Data Eng. Bull. 36(2): 34-40 (2013)» могут обрабатывать сотни тысяч простых транзакций (таких как вставка события) в секунду на одной машине. Более того, они могут масштабироваться путем разделения данных по нескольким узлам. Тем не менее, их поддержка незапланированных запросов ограничена, так как, снова, внутренние структуры данных таких высококачественных систем обработки транзакций специально настроены на обработку большого количества малых транзакций для входных данных. Более того, эти системы обычно не поддерживают запросы, которые включают в себя данные, хранящиеся на нескольких машинах. Даже хуже, эти системы абсолютно не поддерживают обработку правил и непрерывных запросов. Снова, этот недостаток является врожденным для этой архитектуры, и он изначально явился ключевой причиной для разработки DSMS, как описано в «Майкл Стоунбрейкер (Michael Stonebraker): Техническая перспектива - Один размер подходит для всех: идея, чье время пришло и ушло. Commun. ACM 51(12): 76 (2008)». В лучшем случае, эти системы поддерживают, так называемые триггеры, которые запускаются при возникновении определенного события (смотри Дженнифер Видом (Jennifer Widom), Стефано Сери (Stefano Ceri): Введение в активные системы баз данных. Активные системы баз данных: Триггеры и правила для усовершенствованной обработки баз данных 1996: 1-41»), но такие триггер не способны обнаруживать сложные шаблоны, которые обычно встречаются в правилах приложений обработки сложных событий.
Larson), Майк Звиллинг (Mike Zwilling), Кевин Фарли (Kevin Farlee): Hekaton устройство OLTP с оптимизацией памяти. IEEE Data Eng. Bull. 36(2): 34-40 (2013)» могут обрабатывать сотни тысяч простых транзакций (таких как вставка события) в секунду на одной машине. Более того, они могут масштабироваться путем разделения данных по нескольким узлам. Тем не менее, их поддержка незапланированных запросов ограничена, так как, снова, внутренние структуры данных таких высококачественных систем обработки транзакций специально настроены на обработку большого количества малых транзакций для входных данных. Более того, эти системы обычно не поддерживают запросы, которые включают в себя данные, хранящиеся на нескольких машинах. Даже хуже, эти системы абсолютно не поддерживают обработку правил и непрерывных запросов. Снова, этот недостаток является врожденным для этой архитектуры, и он изначально явился ключевой причиной для разработки DSMS, как описано в «Майкл Стоунбрейкер (Michael Stonebraker): Техническая перспектива - Один размер подходит для всех: идея, чье время пришло и ушло. Commun. ACM 51(12): 76 (2008)». В лучшем случае, эти системы поддерживают, так называемые триггеры, которые запускаются при возникновении определенного события (смотри Дженнифер Видом (Jennifer Widom), Стефано Сери (Stefano Ceri): Введение в активные системы баз данных. Активные системы баз данных: Триггеры и правила для усовершенствованной обработки баз данных 1996: 1-41»), но такие триггер не способны обнаруживать сложные шаблоны, которые обычно встречаются в правилах приложений обработки сложных событий.
Краткое изложение
Задача настоящего изобретения заключается в том, чтобы предложить технологию улучшенной обработки событий, обеспечивающую крупномасштабную обработку событий с хранением состояний, аналитическую обработку в режиме реального времени со сложными описательными запросами и масштабируемость по нагрузке и размеру базы данных.
Эта задача решается с помощью признаков из независимых пунктов формулы изобретения. Другие формы реализации ясны из зависимых пунктов формулы изобретения, описания и фиг.
Описанное далее изобретение основано на фундаментальном наблюдении, которое заключается в том, что существуют два ключевых момента с точки зрения предложения улучшенной системы обработки событий, которые состоят в разделении логики и состояния обработки событий и структурировании состояния как матрицы (AM) аналитической обработки и возможности добавить способности по обработке запросов для отдельного состояния для целей аналитической обработки в режиме реального времени.
Так как состояние и логика системы обработки потока могут быть не связаны, может быть возможно масштабировать систему систематическим, горизонтально масштабируемым образом. Горизонтальное масштабирование является простым и хорошо организуемым, так как обновление AM может осуществляться по ключу и AM может быть разделена по ключу. Кроме того, логика без хранения состояний и индекс правил могут быть дублированы для целей масштабирования. Никакие DSMS, соответствующие уровню техники, не могут продемонстрировать получающуюся в результате масштабируемость. Аналогично, слой хранения может быть масштабирован отдельно с учетом размеров данных и/или требований по нагрузке.
Если состояние подсистемы обработки потока поддерживают в системе баз данных в оперативной памяти (в отличие от распределенного хранилища ключ-значение), это может быть использовано для обработки запросов на свежих данных, удовлетворяющих требованиям для аналитической обработки в режиме реального времени. В любом случае, слой аналитической обработки в режиме реального времени можно масштабировать с учетом нагрузки аналогично слою обработки потока; при увеличении или уменьшении нагрузки в любой момент узлы могут быть добавлены и удалены.
Далее описан механизм, называемый матрицей (AM) аналитической обработки, используемый для поддержки состояния обработки событий в специальном выделенном хранилище. Более конкретно, отражающие состояние переменные могут храниться в хранилище ключ-значение на основе распределенной оперативной памяти. Более того, описан отдельный слой для узлов обработки, используемый для обращения с правилами и непрерывными запросами для обработки сложных событий. Описан дополнительный отдельный слой для узлов обработки, используемый для обращения с незапланированными запросами для аналитической обработки в режиме реального времени.
Для подробного описания изобретения будут использованы следующие термины, аббревиатуры и обозначения:
Системы (DMBS) управления базами данных являются специально спроектированными приложениями, которые взаимодействуют с пользователем, другими приложениями и самой базой данных с целью сбора и анализа данных. Система (DMBS) управления базами данных общего назначения является программной системой, спроектированной для определения, создания, выполнения запросов, обновления и администрирования баз данных. Различные DMBS могут взаимодействовать с использованием таких стандартов, как SQL и ODBC или JDBC, чтобы одно приложение могло работать с более чем одной базой данных.
Система (DSMS) управления потоками данных является компьютерной программой для управления непрерывными потоками данных. Она похожа на систему (DMBS) управления базами данных, которая, тем не менее, предназначена для статичных данных в обычных базах данных. DSMS также предлагает гибкую обработку запросов, так что нужная информация может быть выражена с использованием запросов. Тем не менее, в отличие от DBMS, DSMS выполняет непрерывный запрос, который выполняется не один раз, а установлен на постоянной основе. Следовательно, запрос выполняется непрерывно до тех пор, пока он не будет удален. Так как большинство DSMS управляются данными, непрерывный запрос вырабатывает новые результаты до тех пор, пока в систему поступают новые данные. Эта основная идея аналогична обработке сложных событий, так что обе технологии частично срастаются.
Обработка событий, вычисление для событий.
Обработка событий является способом отслеживания и анализа (обработки) потоков информации (данных) о вещах, которые случаются (события) и получения из них заключения. Обработка сложных событий, или СЕР, является обработкой событий, которые объединяют данные из нескольких источников для получения событий или шаблонов, которые предполагают более сложные обстоятельства. Цель обработки сложных событий заключается в идентификации значимых событий (таких как возможности или угрозы) и насколько возможно быстрый ответ на них.
SQL (язык структурированных запросов) представляет собой специализированный язык программирования, предназначенный для управления данными, содержащимися в системе (RDBMS) управления реляционными базами данных.
Изначально основанный на алгебре отношений и исчислении отношений кортежей, SQL состоит из языка определения данных и языка манипулирования данными. Объем SQL включает в себя вставку данных, осуществление запроса, обновление и удаление данных, создание и модификацию схем и управление доступом к данным.
InfiniBand является коммутируемой линией связи компьютерной сети, используемой в высокоскоростных вычислительных и корпоративных центрах обработки данных. Ее свойствами являются высокая пропускная способность, малая задержка, качество работы и восстановление при отказе, и она спроектирована так, чтобы быть масштабируемой. Спецификации архитектуры InfiniBand определяют соединение между ядрами процессора и высокопроизводительными узлами ввода/вывода, такими как запоминающие устройства.
В соответствии с первым аспектом, изобретение касается системы обработки событий, выполненной для обработки потока событий, действующих в системе баз данных, система обработки событий содержит блок балансирования нагрузки для событий, несколько узлов вычислений для событий и несколько хранилищ состояний событий, которые отделены от узлов вычислений для событий, при этом блок балансирования нагрузки для событий выполнен с возможностью направления потока событий на несколько узлов вычислений для событий, в соответствии с критерием балансирования нагрузки для событий; при этом несколько хранилищ состояний событий выполнены с возможностью хранения состояний нескольких узлов вычислений для событий с целью поддержки состояния обработки событий; и при этом несколько узлов вычислений для событий выполнены с возможностью обработки событий, принятых от блока балансирования нагрузки для событий, изменения их состояний в соответствии с обработкой событий и обновления нескольких хранилищ состояний событий на основе их измененных состояний.
Отделение хранилищ состояний событий от узлов вычислений для событий обеспечивает масштабируемую обработку потока. Обработка потока с хранением состояний, то есть обработка потока с учетом внутренних состояний, может быть реализована масштабируемым образом.
Масштабирование обработки потока с хранением состояний позволяет системе обработки событий выдерживать очень высокие интенсивности событий. Объединение возможностей аналитической обработки в режиме реального времени, например, с помощью SQL, с обработкой потока с хранением состояний в одной системе позволяет уменьшить общие затраты и сложность системы.
узел вычислений для событий не связан с соответствующим узлом состояний. Отделение/разъединение состояния и вычисления позволяет любому узлу вычислений обрабатывать любое входящее событие. При входящем событии узел вычислений может прозрачным образом получить доступ к любому хранилищу состояний, чтобы извлечь текущее состояние. Благодаря этому система обработки событий является масштабируемой и сбалансированной, так как любой узел вычислений может обрабатывать любое входящее событие и может получать доступ к любому состоянию в одном из хранилищ состояний.
Таким образом, система обработки событий обеспечивает хранилище состояний, которое достаточно быстро для обработки массовых потоков событий с достаточной производительностью с точки зрения пропускной способности и времени ответа.
Введение этого разделения облегчает различным клиентам в области запросов в режиме реального времени выполнение любого рода сложных аналитических запросов для этого объединенного хранилища состояний.
В первой возможной форме реализации системы обработки событий, соответствующей первому аспекту, система обработки событий дополнительно содержит блок балансирования нагрузки для запросов и несколько узлов обработки запросов, при этом блок балансирования нагрузки для запросов выполнен с возможностью направления потока запросов на несколько узлов обработки запросов в соответствии с критерием балансирования нагрузки для запросов; при этом несколько узлов обработки запросов выполнены с возможностью обработки запросов, принятых от блока балансирования нагрузки для запросов.
Отделение хранилищ состояний событий от узлов вычислений для событий обеспечивает масштабируемую обработку потока с аналитической обработкой в режиме реального времени.
Во второй возможной форме реализации системы обработки событий, соответствующей первой форме реализации первого аспекта, блок балансирования нагрузки для запросов выполнен с возможностью направления каждого запроса точно на один узел обработки запросов.
При направлении каждого запроса точно на один узел обработки запросов, занят только этот узел обработки, так что улучшается эффективность системы.
В третьей возможной форме реализации системы обработки событий, соответствующей первой или второй формам реализации первого аспекта, узел обработки запросов из нескольких узлов обработки запросов выполнен с возможностью получения доступа, по меньшей мере, к одному хранилищу состояний событий из нескольких хранилищ состояний событий с целью обработки запроса, принятого от блока балансирования нагрузки для запросов.
Когда узел обработки запросов получает доступ по меньшей мере к одному хранилищу состояний событий, он может увеличить свое время ответа для обработки запроса.
В четвертой возможной форме реализации системы обработки событий, соответствующей третьей форме реализации первого аспекта, узел обработки запросов выполнен с возможностью получения доступа к дополнительным данным, в частности, основным данным клиента системы баз данных, с целью обработки запроса.
При получении дополнительных данных, таких как основные данные клиента системы баз данных, улучшается точность обработки запроса.
В пятой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из предыдущих форм реализации первого аспекта, несколько узлов обработки запросов выполнены с возможностью обработки незапланированных запросов для аналитической обработки в режиме реального времени.
При обработке незапланированных запросов, система обработки событий способна выполнять аналитическую обработку в режиме реального времени.
В шестой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из предыдущих форм реализации первого аспекта, несколько хранилищ состояний событий содержат хранилище ключ-значение на основе распределенной оперативной памяти.
Распределенная оперативная память позволяет быстрее получать доступ к данным и, таким образом, ускорить систему обработки событий.
В седьмой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из предыдущих форм реализации первого аспекта, несколько узлов вычислений для событий выполнены с возможностью обработки правил и непрерывных запросов с целью обработки сложных событий и одновременной обработки событий в режиме реального времени.
Следовательно, система обработки событий предоставляет возможность аналитической обработки запросов в режиме реального времени с масштабируемой обработкой событий в одной системе в одно и то же время.
В восьмой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из предыдущих форм реализации первого аспекта, блок балансирования нагрузки для событий выполнен с возможностью направления событий на основе определяемого приложением разделения, в частности, на основе ключа клиента, и дублирования правил.
Направление событий на основе определяемого приложением разделения позволяет быстро направлять события и, таким образом, позволяет системе быть высокоэффективной.
В девятой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей восьмой форме реализации первого аспекта, блок балансирования нагрузки для событий выполнен с возможностью такого направления событий, что некоторый узел вычислений для событий из нескольких узлов вычислений для событий обрабатывает конкретное подмножество событий и обрабатывает все правила для конкретного подмножества событий.
Когда узел вычислений для событий обрабатывает конкретное подмножество событий, сложность отдельных узлов вычислений может быть уменьшена, таким образом, уменьшая общую сложность системы обработки событий.
В десятой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из первой - седьмой форм реализации первого аспекта, блок балансирования нагрузки для событий выполнен с возможностью направления событий на основе дублирования событий и разделения правил, так что каждый узел вычислений для событий обрабатывает все события и некоторое подмножество правил.
Когда каждый узел вычислений для событий обрабатывает все события и некоторое подмножество правил, программное обеспечение для каждого узла вычислений для событий может быть одинаковым, тем самым предоставляется возможность уменьшить сложность разработки.
В одиннадцатой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из первой - седьмой форм реализации первого аспекта, блок балансирования нагрузки для событий выполнен с возможностью направления событий на основе кругового разделения событий и дублирования правил, так что некоторый узел вычислений для событий их нескольких узлов вычислений для событий обрабатывает некоторое событие, когда он обладает свободной пропускной способностью.
При направлении событий на основе кругового разделения, все события могут быть обработаны примерно с одинаковой временной задержкой.
В двенадцатой возможной форме реализации системы обработки событий, соответствующей самому первому аспекту или соответствующей любой из первой - седьмой форм реализации первого аспекта, блок балансирования нагрузки для событий выполнен с возможностью направления событий на основе разделения и дублирования событий и правил на несколько узлов вычислений для событий.
Направление событий на основе разделения и дублирования событий и правил позволяет описывать систему с помощью простых правил.
В соответствии со вторым аспектом, изобретение касается способа обработки событий, этот способ включает в себя следующее: направляют поток событий на несколько узлов вычислений для событий, в соответствии с критерием балансирования нагрузки для событий; сохраняют состояния нескольких узлов вычислений для событий в нескольких хранилищах состояний событий, которые отделены от узлов вычислений для событий, с целью поддержания состояния обработки событий; и обрабатывают принятые события в нескольких узлах вычислений для событий, изменяют состояния нескольких узлов вычислений для событий в соответствии с обработкой событий и обновляют состояния нескольких узлов вычислений для событий в нескольких хранилищах состояний событий.
Благодаря разделению хранилищ состояний событий от узлов вычислений для событий, способ способен обрабатывать события потоков с большей скоростью, то есть увеличивается пропускная способность.
В соответствии с третьим аспектом, изобретение касается компьютерного программного продукта, содержащего считываемый носитель информации, хранящий программный код и используемый компьютером, программный код содержит: команды для направления потока событий на несколько узлов вычислений для событий, в соответствии с критерием балансирования нагрузки для событий; команды для сохранения состояний нескольких узлов вычислений для событий в нескольких хранилищах состояний событий, которые отделены от узлов вычислений для событий; и команды для обработки принятых событий в нескольких узлах вычислений для событий, для изменения состояний нескольких узлов вычислений для событий в соответствии с обработкой событий и для обновления состояний нескольких узлов вычислений для событий в нескольких хранилищах состояний событий.
Отделение хранилищ состояний событий от узлов вычислений для событий обеспечивает масштабируемую обработку потока. Масштабирование обработки потока с хранением состояний позволяет системе обработки событий выдерживать очень высокие интенсивности событий. Объединение возможностей аналитической обработки в режиме реального времени с обработкой потока с хранением состояний в одной системе позволяет уменьшить общие затраты и сложность системы. Компьютерная программа может быть спроектирована гибко, так что легко достичь обновления требований. Компьютерный программный продукт может работать в системе обработки событий, что описано ниже.
Таким образом, в аспектах настоящего изобретения предложена технология улучшенной обработки событий, обеспечивающая крупномасштабную обработку событий с хранением состояний, аналитическую обработку в режиме реального времени со сложными описательными запросами и масштабируемость по нагрузке и размеру базы данных.
Краткое описание чертежей
Со ссылками на приложенные чертежи будут описаны дополнительные варианты осуществления настоящего изобретения, на которых:
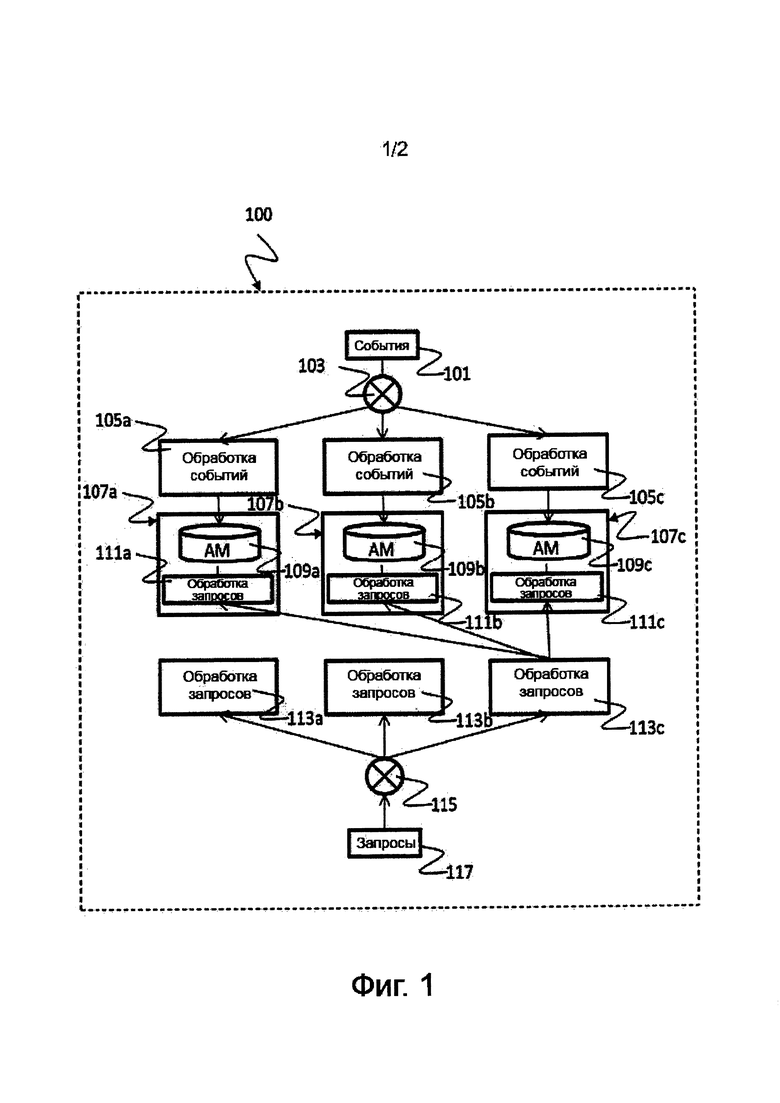
фиг. 1 - вид, показывающий структурную схему, иллюстрирующую систему 100 обработки событий, соответствующую одному варианту реализации; и
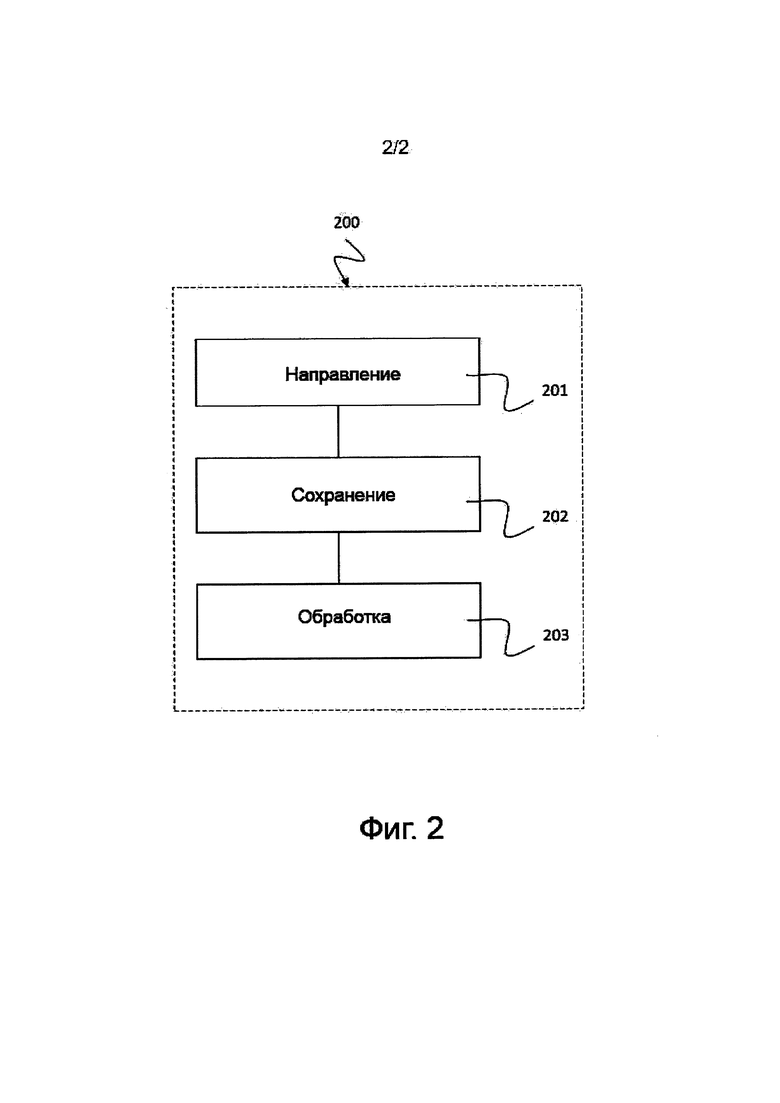
фиг. 2 - вид, показывающий блок-схему, иллюстрирующую способ 200 обработки событий, соответствующий одному варианту реализации.
Подробное описание вариантов осуществления изобретения
В последующем подробном описании содержатся ссылки на приложенные чертежи, которые образуют часть описания и на которых проиллюстрированы конкретные аспекты, в которых может быть реализовано изобретение. Ясно, что могут быть использованы другие аспекты и могут быть выполнены структурные или логические изменения, не выходящие за пределы объема настоящего изобретения. Следовательно, приведенное ниже подробное описание не рассматривается в ограничительном смысле, и объем настоящего изобретения определен в приложенной формуле изобретения.
Устройства и способы, описанные в настоящем документе, могут быть основаны на узлах вычислений для событий и хранилищах состояний событий. Ясно, что комментарии, сделанные в связи с описанным способом, также справедливы для соответствующего устройства или системы, выполненных для осуществления способа, и наоборот. Например, если описан конкретный этап способа, то соответствующее устройство может содержать блок для выполнения описанного этапа способа, даже если такой блок не описан явно или не показан на фиг. Далее, ясно, что признаки для различных описанных в настоящем документе примеров аспектов могут быть объединены друг с другом, если ясно не оговорено обратное.
Описанные в настоящем документе способы и устройства могут быть реализованы в системах управления базами данных, в частности DBMS, использующих SQL. Описанные устройства и системы могут содержать интегральные схемы и/или пассивные элементы и могут быть изготовлены в соответствии с различными технологиями. Например, схемы могут быть спроектированы как логические интегральные схемы, аналоговые интегральные схемы, комбинированные интегральные схемы, оптические схемы, схемы памяти и/или интегральные пассивные элементы.
На фиг. 1 показана структурная схема, иллюстрирующая систему 100 обработки событий, соответствующую одному варианту реализации. Система 100 обработки событий может обрабатывать поток событий 101, действующих в системе баз данных. Система 100 обработки событий может содержать блок 103 балансирования нагрузки для событий, несколько узлов 105а, 105b, 105с вычислений для событий и несколько хранилищ 109а, 109b, 109с состояний событий, которые отделены от узлов 105а, 105b, 105с вычислений для событий. Блок 103 балансирования нагрузки для событий может направлять поток событий 101 на несколько узлов 105а, 105b, 105с вычислений для событий, в соответствии с критерием балансирования нагрузки для событий. Несколько хранилищ 109а, 109b, 109с состояний событий могут хранить состояния нескольких узлов 105а, 105b, 105с вычислений для событий с целью поддержания состояния обработки событий. Несколько узлов 105а, 105b, 105с вычислений для событий могут обрабатывать события 101, принятые от блока 103 балансирования нагрузки для событий, с целью изменения их состояний в соответствии с обработкой событий и с целью обновления нескольких хранилищ 109а, 109b, 109с состояний событий на основе их измененных состояний.
Система 100 обработки событий может дополнительно содержать блок 115 балансирования нагрузки для запросов и несколько узлов 113а, 113b, 113с обработки запросов. Блок 115 балансирования нагрузки для запросов может направлять поток запросов 117 на несколько узлов 113а, 113b, 113с обработки запросов, в соответствии с критерием балансирования нагрузки для запросов. Несколько узлов 113а, 113b, 113с обработки запросов могут обрабатывать запросы 117, принятые от блока 115 балансирования нагрузки для запросов.
В одном примере блок 115 балансирования нагрузки для запросов может направлять каждый запрос 117 точно на один узел 113а, 113b, 113с обработки запросов. В одном примере узел 113а, 113b, 113с обработки запросов может получить доступ, по меньшей мере, к одному хранилищу состояний событий из нескольких хранилищ 109а, 109b, 109с состояний событий с целью обработки запроса 117, принятого из блока 115 балансирования нагрузки для запросов. В одном примере узел 113а, 113b, 113с обработки запросов может получить доступ к дополнительным данным, в частности, основным данным клиента системы баз данных, с целью обработки запроса 117. В одном примере несколько узлов 113а, 113b, 113с обработки запросов могут обрабатывать незапланированные запросы с целью аналитической обработки в режиме реального времени. В одном примере несколько хранилищ 109а, 109b, 109с состояний событий могут содержать хранилище ключ-значение на основе распределенной оперативной памяти. В одном примере несколько узлов 105а, 105b, 105с вычислений для событий могут обрабатывать правила и непрерывные запросы с целью обработки сложных событий вместе с одновременной обработкой событий в режиме реального времени. В одном примере блок 103 балансирования нагрузки для событий может направлять события 101 на основе определяемого приложением разделения, в частности, на основе ключа клиента, и дублирования правил. В одном примере блок 103 балансирования нагрузки для событий может так направлять события 101, что некоторый узел вычислений для событий из нескольких узлов 105а, 105b, 105с вычислений для событий обрабатывает конкретное подмножество событий 101 и обрабатывает все правила для конкретного подмножества событий 101. В одном примере блок 103 балансирования нагрузки для событий может направлять события 101 на основе дублирования событий и разделения правил, так что каждый узел 105а, 105b, 105с вычислений для событий обрабатывает все события 101 и некоторое подмножество правил. В одном примере блок 103 балансирования нагрузки для событий может направлять события 101 на основе кругового разделения событий 101 и дублирования правил, так что некоторый узел вычислений для событий из нескольких узлов 105а, 105b, 105с вычислений для событий обрабатывает некоторое событие 101, когда он обладает свободной пропускной способностью. В одном примере блок 103 балансирования нагрузки для событий может направлять события 101 на основе разделения и дублирования событий 101 и правил на несколько узлов 105а, 105b, 105с вычислений для событий.
На фиг. 1 показана общая архитектура. Верхний слой, содержащий узлы 105а, 105b, 105с вычислений для событий, может быть предназначен для обработки сложных событий. Устройство балансирования нагрузки, здесь и далее называемое блоком 103 балансирования нагрузки для событий, может взять поток событий 101 как вход и может направить события 101 на узлы обработки, здесь и далее называемые узлами 105а, 105b, 105с вычислений для событий. Узлы 105а, 105b, 105с обработки на этом слое могут обрабатывать правила с целью обработки сложных событий и могут вычислять новое состояние отражающих состояние переменных. Они могут обновлять AM (матрицу аналитической обработки), хранящуюся в блоках 107а, 107b, 107b среднего слоя. Блоки нижнего слоя, здесь и далее называемые узлами 113а, 113b, 113с обработки запросов, могут быть предназначены для обработки незапланированных запросов для аналитической обработки в режиме реального времени. Снова, присутствует устройство балансирования нагрузки, здесь и далее называемое блоком 115 балансирования нагрузки для запросов, которое может взять поток незапланированных запросов 117 в качестве входа и может направить незапланированный запрос 117 точно на один узел 113а, 113b, 113с обработки запросов на этом слое. Далее этот узел 113а, 113b, 113 обработки может обработать этот запрос 117, тем самым получив доступ к AM 109а, 109b, 109с и возможно другим данным, например, основным данным клиента. В одной форме реализации для высокой производительности, для выполнения незапланированных запросов на AM 109а, 109b, 109с могут быть использованы технологии специальной, распределенной обработки запросов.
Могут быть реализованы четыре различных варианта для балансирования нагрузки при обработке потока. В первом варианте может быть применено определяемое приложением разделение для событий (например, по ключу клиента) и разделение правил. То есть, узел обработки слоя обработки потока может обрабатывать конкретное подмножество всех событий и может обрабатывать все правила этого множества событий. Во втором варианте может быть применено дублирование событий и разделение правил. То есть, каждый узел обработки слоя обработки потока может обрабатывать все события, но только некоторое подмножество правил. В третьем варианте может быть применено круговое разделение для событий и дублирование правил. То есть, некоторый узел обработки слоя обработки потока может обрабатывать некоторое событие, если он обладает свободной пропускной способностью. В четвертом варианте, может быть применено гибридное решение, то есть разделение и дублирование событий и правил в слое обработки.
Какой вариант является наилучшим, зависит от характеристик нагрузки приложения. В первом и втором вариантах и определенных примерах четвертого варианта отражающие состояние переменные могут быть помещены узлами обработки в кэш-память для более высокой производительности. В третьем варианте для каждого события узел обработки может считывать нужные отражающие состояние переменные из слоя хранения.
Эксперименты показали, что на современном аппаратном обеспечении, то есть сетях InfiniBand, даже третий вариант может работать чрезвычайно хорошо. Точное расположение хранения для AM может зависеть от выбранного варианта балансирования нагрузки при обработке потока. В первом варианте отражающие состояние переменные могут быть разделены по ключу клиента и могут быть сохранены в соответствующем узле, а во втором и третьем вариантах они могут быть сохранены в одном и том же узле, что и правила, которые могут их использовать.
Для достижения высокой производительности считывания и обновления отражающих состояние переменных могут быть использованы технологии хэширования распределенной оперативной памяти; например, такие протоколы, как протоколы, предложенные в системах Струна (Chord) и Выпечка (Pastry), описанных в «Ион Стойка (Ion Stoica), Роберт Моррис (Robert Morris), Дэвид Либен-Новелл (David Liben-Nowell), Дэвид Р. Каргер (David R. Karger), М. Франс Кашоэк (М. Frans Kaashoek), Фрэнк Дабек (Frank Dabek), Хари Балакришнан (Hari Balakrishnan): Струна: масштабируемый одноранговый протокол поиска для интернет-приложений. IEEE/ACM Trans. Netw. 11(1): 17-32 (2003)» и «Энтони И.Т. Роустрон (Antony I. Т. Rowstron), Питер Друсчел (Peter Druschel): Выпечка: Масштабируемое, децентрализованное расположение объектов и направление для крупномасштабных одноранговых систем. Middleware 2001: 329-350». В качестве альтернативы, может быть использована любая другая система баз данных в оперативной памяти (например, продукт Hekaton компании Microsoft, продукт Times Ten компании Oracle или продукт Наnа компании SAP). Более того, могут быть использованы современные сетевые технологии с малой задержкой, такие как InfiniBand.
Для обработки незапланированных запросов аналитической обработки в режиме реального времени, помимо таких систем хранения в распределенной оперативной памяти, могут быть применены новые технологии обработки запросов. Для эффективной обработки событий в узлах обработки слоя обработки потока, могут быть применены специальные технологии сведения правил. Эти технологии могут принимать во внимание специальные семантические элементы каждой отражающей состояние переменной. Например, некоторые отражающие состояние переменные могут быть обработаны полностью с приращениями; для других может понадобиться отслеживать некоторую историю изменений. Компилятор может использовать любые отражающие состояние переменные, тем самым минимизируя как память, так и время.
Система 100 обработки событий может являться частью подсистемы принятия решений в режиме реального времени из системы принятия решений, которая может быть частью CRM системы телекоммуникационного оператора. Эта подсистема может поддерживать смешанную нагрузку одновременной подачи из системы формирования счетов и нескольких различных запросов, поданных пользователями CRM системы. Подсистема может быть разделена на две части. Первой является система (SEP) управления событиями и потоками, которая может обрабатывать и сохранять события и которая специально приспособлена для быстрой оценки бизнес правил. Второй является система (RTA) аналитической обработки в режиме реального времени, которая может выполнять более сложные аналитические запросы.
Новый подход, представленный в этом изобретение, который также называется «Аналитическая обработка (AIM) в движении», не придерживается обычных технологий хранилищ данных, где на RTA подают информацию из SEP с помощью непрерывных ETL (извлечение, преобразование, загрузка) операций, а могут позволять RTA непосредственно получать доступ к хранилищу SEP и, таким образом, могут позволить отвечать на аналитические запросы в режиме реального времени.
Правила, обрабатываемые SEP, могут поддерживать решения о том, какого рода информация о продуктах может передаваться клиенту в соответствии с конкретными предположениями. Условие такого рода запроса может заключаться в высокой избирательности, и группировка может быть частой. Далее опишем RTA запросы. Например, подсистема может поддерживать запрос о сегментации клиентов на группы, чтобы помочь специалистам по маркетингу задумывать и измерять компании. Полное сканирование, агрегирование таблиц и объединение нескольких таблиц может быть частым.
На фиг. 2 показана блок-схема, иллюстрирующая способ 200 обработки событий, соответствующий одному варианту реализации. Способ 200 может включать в себя направление 201 потока событий 101 на несколько узлов 105а, 105b, 105с вычислений для событий, в соответствии с критерием балансирования нагрузки для событий (смотри фиг. 1). Способ 200 может включать в себя сохранение 202 состояний нескольких узлов 105а, 105b, 105с вычислений для событий в нескольких хранилищах 109а, 109b, 109с состояний событий, которые отделены от узлов 105а, 105b, 105с вычислений для событий, что делают для поддержания состояния обработки событий. Способ 200 может включать в себя обработку 203 принятых событий 101 в нескольких узлах 105а, 105b, 105с вычислений для событий, изменение состояний нескольких узлов 105а, 105b, 105с вычислений для событий в соответствии с обработкой событий 101 и обновление состояний нескольких узлов 105а, 105b, 105с вычислений для событий в нескольких хранилищах 109а, 109b, 109с состояний событий.
Описанные в настоящем документе способы, системы и устройства могут быть реализованы в виде программного обеспечения в цифровом сигнальном процессоре (DSP), в микроконтроллере или любом другом неосновном процессоре или в виде аппаратной схемы в специализированной интегральной схеме (ASIC).
Изобретение может быть реализовано в виде цифровой электронной схемы или компьютерного аппаратного обеспечения, аппаратнореализованного программного обеспечения, программного обеспечения или их комбинации, например, в виде доступного аппаратного обеспечения для обычных мобильных устройств, или в виде нового аппаратного обеспечения, приспособленного для осуществления описанных в настоящем документе способов.
Настоящее изобретение также поддерживает компьютерный программный продукт, содержащий исполнимый компьютером код или исполнимые компьютером команды, при выполнении которых, по меньшей мере, одним компьютером, он выполняет и вычисляет описанные в настоящем документе этапы, в частности, способ 200, описанный выше при рассмотрении фиг. 2, и технологии, описанные выше при рассмотрении фиг. 1. Такой компьютерный программный продукт может содержать считываемый носитель информации, хранящий программный код для использования компьютером, программный код содержит: команды для направления потока событий на несколько узлов вычислений для событий, в соответствии с критерием балансирования нагрузки для событий; команды для сохранения состояний нескольких узлов вычислений для событий в нескольких хранилищах состояний событий, которые отделены от узлов вычислений для событий; и команды для обработки принятых событий в нескольких узлах вычислений для событий, для изменения состояний нескольких узлов вычислений для событий в соответствии с обработкой событий и для обновления состояний нескольких узлов вычислений для событий в нескольких хранилищах состояний событий.
Хотя конкретный признак или аспект изобретения может быть описан только для одной из нескольких реализаций, такой признак или аспект может быть объединен с одним или несколькими другими признаками или аспектами других реализаций, что может быть полезно и целесообразно для любого конкретного рассматриваемого приложения. Более того, при использовании или в подробном описании или формуле изобретения терминов «обладает», «имеет», «с» или других подобных вариантов, такие термины предназначены для обозначения аналогичного термина «содержит». Также термины «пример» и «например» используются только в качестве примера, а не для обозначения наилучшего или оптимального элемента.
Хотя в настоящем документе проиллюстрированы и описаны конкретные аспекты, специалисту в рассматриваемой области ясно, что разные альтернативные и/или эквивалентные реализации могут заменить конкретные показанные и описанные аспекты без выхода за границы объема настоящего изобретения. Предусмотрено, что эта заявка покрывает любые адаптации или изменения рассмотренных в настоящем описании конкретных аспектов.
Хотя элементы в приведенной ниже формуле изобретения описаны в конкретной последовательности с соответствующими обозначениями, если в формуле изобретения прямо не оговорено для некоторых или всех этих элементов некоторой конкретной последовательности реализации, то эти элементы не обязательно ограничены реализацией в этой конкретной последовательности.
В свете приведенного выше описания специалист в рассматриваемой области может предложить много альтернатив, модификаций и изменений. Конечно, специалисту в рассматриваемой области ясно, что помимо описанных в настоящем документе существует большое количество приложений изобретения. Хотя настоящее изобретение описано со ссылками на один или несколько конкретных вариантов осуществления изобретения, специалисту в рассматриваемой области ясно, что может быть предложено много изменений, не выходящих за пределы объема настоящего изобретения. Следовательно, ясно, что в рамках объема изобретения, определяемого приложенной формулой изобретения и ее эквивалентами, изобретение может быть реализовано иначе, чем конкретно описано в настоящем документе.
Изобретение относится к средствам обработки событий. Технический результат заключается в увеличении скорости обработки событий. Направляют поток событий на несколько узлов вычислений для событий в соответствии с критерием балансирования нагрузки для событий. Сохраняют состояния нескольких узлов вычислений для событий в нескольких хранилищах состояний событий, которые отделены от узлов вычислений для событий с целью поддержания состояния обработки событий. Обрабатывают принятые события в нескольких узлах вычислений для событий, изменяют состояния нескольких узлов вычислений для событий в соответствии с обработкой событий и обновляют состояния нескольких узлов вычислений для событий в нескольких хранилищах состояний событий. 3 н. и 12 з.п. ф-лы, 2 ил.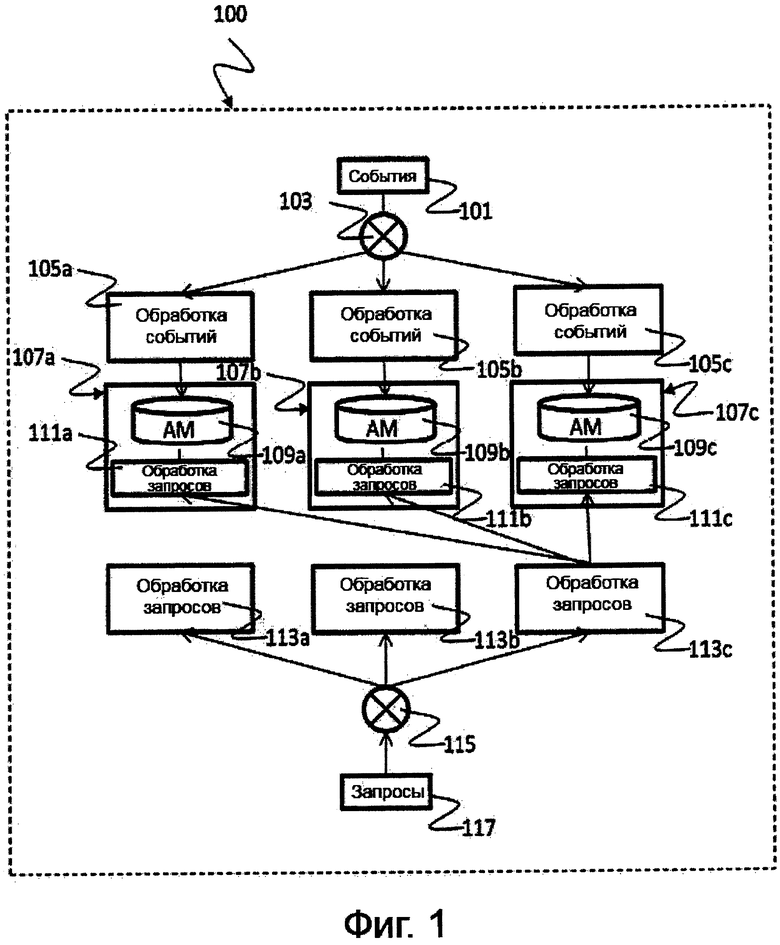
1. Система (100) обработки событий, предназначенная для обработки потока событий (101), действующих в системе баз данных, система (100) обработки событий содержит блок (103) балансирования нагрузки для событий, несколько узлов (105a, 105b, 105c) вычислений для событий и несколько хранилищ (109a, 109b, 109c) состояний событий, которые отделены от узлов (105a, 105b, 105c) вычислений для событий,
при этом блок (103) балансирования нагрузки для событий выполнен с возможностью направления потока событий (101) на несколько узлов (105a, 105b, 105c) вычислений для событий в соответствии с критерием балансирования нагрузки для событий;
при этом несколько хранилищ (109a, 109b, 109c) состояний событий выполнены с возможностью хранения состояний нескольких узлов (105a, 105b, 105c) вычислений для событий с целью поддержания состояния обработки событий; и
при этом несколько узлов (105a, 105b, 105c) вычислений для событий выполнены с возможностью обработки событий (101), принятых от блока (103) балансирования нагрузки для событий, для изменения их состояний в соответствии с обработкой событий и для обновления нескольких хранилищ (109a, 109b, 109c) состояний событий на основе их измененных состояний.
2. Система (100) обработки событий по п. 1, дополнительно содержащая блок (115) балансирования нагрузки для запросов и несколько узлов (113a, 113b, 113c) обработки запросов,
при этом блок (115) балансирования нагрузки для запросов выполнен с возможностью направления потока запросов (117) на несколько узлов (113a, 113b, 113c) обработки запросов в соответствии с критерием балансирования нагрузки для запросов;
при этом несколько узлов (113a, 113b, 113c) обработки запросов выполнены с возможностью обработки запросов (117), принятых от блока (115) балансирования нагрузки для запросов.
3. Система (100) обработки событий по п. 2, в которой блок (115) балансирования нагрузки для запросов выполнен с возможностью направления каждого запроса (117) точно на один узел (113a, 113b, 113c) обработки запросов.
4. Система (100) обработки событий по п. 2, в которой некоторый узел обработки запросов из нескольких узлов (113a, 113b, 113c) обработки запросов выполнен с возможностью получения доступа по меньшей мере к одному хранилищу состояний событий из нескольких хранилищ (109a, 109b, 109c) состояний событий с целью обработки запроса (117), принятого из блока (115) балансирования нагрузки для запросов.
5. Система (100) обработки событий по п. 4, в которой узел (113a, 113b, 113c) обработки запросов выполнен с возможностью получения доступа к дополнительным данным, в частности основным данным клиента системы баз данных, с целью обработки запроса (117).
6. Система (100) обработки событий по п. 1, в которой несколько узлов (113a, 113b, 113c) обработки запросов выполнены с возможностью обработки незапланированных запросов с целью аналитической обработки в режиме реального времени.
7. Система (100) обработки событий по п. 1, в которой несколько хранилищ (109a, 109b, 109c) состояний событий содержат хранилище ключ-значение на основе распределенной оперативной памяти.
8. Система (100) обработки событий по п. 1, в которой несколько узлов (105a, 105b, 105c) вычислений для событий выполнены с возможностью обработки правил и непрерывных запросов с целью обработки сложных событий вместе с одновременной обработкой событий в режиме реального времени.
9. Система (100) обработки событий по п. 1, в которой блок (103) балансирования нагрузки для событий выполнен с возможностью направления событий (101) на основе определяемого приложением разделения, в частности на основе ключа клиента, и дублирования правил.
10. Система (100) обработки событий по п. 9, в которой блок (103) балансирования нагрузки для событий выполнен с возможностью такого направления событий (101), что узел вычислений для событий из нескольких узлов (105a, 105b, 105c) вычислений для событий обрабатывает конкретное подмножество событий (101) и обрабатывает все правила для конкретного подмножества событий (101).
11. Система (100) обработки событий по п. 1, в которой блок (103) балансирования нагрузки для событий выполнен с возможностью направления событий (101) на основе дублирования событий и разделения правил, так что каждый узел (105a, 105b, 105c) вычислений для событий обрабатывает все события (101) и подмножество правил.
12. Система (100) обработки событий по п. 1, в которой блок (103) балансирования нагрузки для событий выполнен с возможностью направления событий (101) на основе кругового разделения событий (101) и дублирования правил, так что некоторый узел вычислений для событий из нескольких узлов (105a, 105b, 105c) вычислений для событий обрабатывает некоторое событие (101), когда он обладает свободной пропускной способностью.
13. Система (100) обработки событий по п. 1, в которой блок (103) балансирования нагрузки для событий выполнен с возможностью направления событий (101) на основе разделения и дублирования событий (101) и правил на несколько узлов (105a, 105b, 105c) вычислений для событий.
14. Способ (200) для обработки событий, при этом способ включает в себя следующее:
направляют (201) поток событий (101) на несколько узлов (105a, 105b, 105c) вычислений для событий в соответствии с критерием балансирования нагрузки для событий;
сохраняют (202) состояния нескольких узлов (105a, 105b, 105c) вычислений для событий в нескольких хранилищах (109a, 109b, 109c) состояний событий, которые отделены от узлов (105a, 105b, 105c) вычислений для событий с целью поддержания состояния обработки событий; и
обрабатывают (203) принятые события (101) в нескольких узлах (105a, 105b, 105c) вычислений для событий, изменяют состояния нескольких узлов (105a, 105b, 105c) вычислений для событий в соответствии с обработкой событий (101) и обновляют состояния нескольких узлов (105a, 105b, 105c) вычислений для событий в нескольких хранилищах (109a, 109b, 109c) состояний событий.
15. Считываемый носитель информации, хранящий программный код для использования компьютером, при этом программный код содержит:
команды для направления потока событий (101) на несколько узлов (105a, 105b, 105c) вычислений для событий в соответствии с критерием балансирования нагрузки для событий;
команды для сохранения состояний нескольких узлов (105a, 105b, 105c) вычислений для событий в нескольких хранилищах (109a, 109b, 109c) состояний событий, которые отделены от узлов (105a, 105b, 105c) вычислений для событий; и
команды для обработки принятых событий (101) в нескольких узлах (105a, 105b, 105c) вычислений для событий, для изменения состояний нескольких узлов (105a, 105b, 105c) вычислений для событий в соответствии с обработкой событий (101) и для обновления состояний нескольких узлов (105a, 105b, 105c) вычислений для событий в нескольких хранилищах (109a, 109b, 109c) состояний событий.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ И СИСТЕМА (ВАРИАНТЫ) ДЛЯ ОБРАБОТКИ ЗАПРОСА | 2010 |
|
RU2534953C2 |

