Уровень техники
Установление связей между приложениями и базами данных является давней проблемой. В 1996 г. Кери и ДеВит обрисовали, почему многочисленные технологии, включающие объектно-ориентированные базы данных и постоянные языки программирования, не получили широкого признания из-за ограничений в обработке запросов и обновления, производительности транзакций и масштабируемости. Они допускали, что объектно-реляционные (O/R) базы данных будут преобладать в 2006 г. Несомненно, системы базы данных DB2® и Oracle® включают в себя встроенный объектный уровень, который использует жестко закодированное O/R-отображение поверх традиционной реляционной подсистемы. Однако свойства O/R, предлагаемые этими системами, кажется, редко используются для хранения данных предприятия, с исключением мультимедийных и пространственных типов данных. Среди причин находятся независимость данных и производителей, затраты на перемещение устаревших баз данных, сложности с масштабируемостью, когда бизнес-логика выполняется внутри базы данных вместо среднего яруса, и недостаточная интеграция с языками программирования.
С середины 1990-х уровни отображения данных на стороне клиента достигли популярности с помощью роста Интернет-приложений. Основной функцией подобного уровня является предоставление обновляемого представления, которое раскрывает модель данных, тесно связанную с моделью данных приложения, управляемой явным отображением. Многие коммерческие продукты и проекты открытых ресурсов выступили с предложением этих возможностей. Практически каждая структура предприятия предоставляет уровень постоянного хранения на стороне клиента (например, EJB в J2EE). Большинство пакетов бизнес-приложений, например ERP- и CRM-приложения, включает внутренние интерфейсы доступа к данным (например, BAPI в SAP R/3).
Одним широко используемым открытым источником структуры объектно-реляционной проекции (ORM) для Java® является Hibernate®. Он поддерживает множество сценариев отображения наследования, оптимистическое управление параллельными процессами и обширные объектные службы. Самый последний вариант Hibernate соответствует стандарту EJB 3.0, который включает в себя язык Java запросов постоянного хранения. С коммерческой стороны популярные ORM включают в себя Oracle TopLink® и LLBLGen®. Последнее запускается на платформе .NET. Эти и другие ORM тесно связаны с объектными моделями своих целевых языков программирования.
ВЕА® недавно представила новый продукт межплатформенного программного обеспечения, называемого платформой® службы данных AquaLogic (ALDSP). Он использует схему XML для моделирования прикладных данных. Данные XML собираются, используя XQuery из баз данных и веб-служб. Рабочий цикл ALDSP поддерживает запросы по многочисленным источникам данных и осуществляет оптимизацию запросов на стороне клиента. Обновления выполняются как обновления представлений для представления XQuery. Если обновление не имеет однозначной трансляции, разработчику необходимо заменить логику обновления, используя императивный код. Плоскость программирования ALDSP основана на объектах служебных данных (SDO).
Современные уровни отображения со стороны клиента предлагают широко варьирующиеся степени возможностей, надежности и общей стоимости владения. Типично отображение между компонентами приложения и объектами базы данных, используемое ORM, имеет нечеткую семантику и приводит к обоснованию для каждого случая. Реализация, управляемая сценарием, ограничивает интервал поддерживаемых отображений и часто выдает хрупкий рабочий цикл, который сложно расширить. Немногие решения доступа к данным усиливают методики трансформации данных, разрабатываемые сообществом баз данных, и часто полагаются на специальные решения для трансляции запроса и обновления.
Исследование баз данных содействовало многочисленным мощным методикам, которые могут быть усилены для создания уровней постоянного хранения. И все же существуют значительные пробелы. Среди наиболее критичных находится поддержка обновлений через отображения. В сравнении с запросами с обновлениями намного более сложно иметь дело, так как им необходимо сохранить целостность данных сквозь отображения, инициировать бизнес-правила и так далее. Как следствие, коммерческие системы баз данных и продукты доступа к данным предлагают очень ограниченную поддержку для обновляемых представлений. В последнее время исследователи обращаются к альтернативным подходам, например двусторонние трансформации.
Традиционно концептуальное моделирование было ограничено базой данных и прикладным проектом, обратным проектированием и трансляцией схемы. Многие средства проектирования используют UML. Только самое последнее концептуальное моделирование начало проникать в решения отображения данных. Например, концепция сущностей и отношений обнаруживается как в ALDSP, так и в EJB 3.0. ALDSP накладывает отношения E-R-типа поверх XML-данных составного типа, тогда как EJB 3.0 допускает уточнение отношений между объектами, используя комментарии к классу.
Методики отображения схемы используются в многочисленных продуктах интеграции данных, например Microsoft® BizTalk Server®, IBM® Rational Data Architect®, и средствах ETL®. Эти продукты разрешают разработчикам проектировать трансформации данных или компилировать их из отображений для трансляции сообщений электронной коммерции или загружать хранилища данных.
Сущность изобретения
Системы, способы и машиночитаемые носители предоставлены для осуществления и использования архитектуры доступа к данным, которая включает в себя архитектуру отображения для отображения данных, как может использоваться приложением, в данные так, как хранится в базе данных. В одном варианте осуществления архитектура отображения использует два типа представлений отображения - представление запроса, которое помогает в трансляции запросов, и представления обновления, которое помогает в трансляции обновлений. Поддержание инкрементного представления может использоваться для трансляции данных между приложением и базой данных. Дополнительные аспекты и варианты осуществления описаны ниже.
Краткое описание чертежей
Системы и способы для архитектуры отображения с поддержанием инкрементного представления согласно настоящему изобретению дополнительно описываются со ссылкой на сопроводительные чертежи, в которых:
Фиг.1 иллюстрирует архитектуру примерной архитектуры сущностей, как рассмотрено в данном документе.
Фиг.2 иллюстрирует примерную реляционную схему.
Фиг.3 иллюстрирует примерную схему модели сущность-данные (EDM).
Фиг.4 иллюстрирует отображение между схемой сущностей (слева) и схемой баз данных (справа).
Фиг.5 иллюстрирует отображение, представленное в терминах запросов по схеме сущностей и реляционной схеме.
Фиг.6 иллюстрирует двунаправленные представления - представления запроса и обновления, сформированные с помощью компилятора отображения для отображения на фиг.5.
Фиг.7 иллюстрирует процесс для усиления осуществленных алгоритмов поддержания представления для распространения обновлений через двунаправленные представления.
Фиг.8 иллюстрирует пользовательский интерфейс разработчика отображения.
Фиг.9 иллюстрирует компиляцию отображения, заданного в языке спецификаций отображений (MSL) для формирования представлений запроса и обновления.
Фиг.10 иллюстрирует обработку обновления.
Фиг.11 иллюстрирует примерные логические части средства OR-отображения (объектно-реляционного).
Фиг.12 иллюстрирует формирование представления запроса и обновления посредством платформы данных сущностей (EDP) во время обработки отображения, заданного в спецификации MSL.
Фиг.13 иллюстрирует использование QMView в трансляции запроса.
Фиг.14 иллюстрирует использование UMView в трансляции обновления.
Фиг.15 иллюстрирует цикл компиляции и рабочий цикл обработки представлений отображения.
Фиг.16 иллюстрирует взаимодействие различных компонентов в процессе компиляции представления.
Фиг.17 иллюстрирует архитектуру EQT (транслятор запроса EDP). EQT использует отображение метаданных для трансляции запросов от пространства объект/EDM в пространство баз данных.
Фиг.18 иллюстрирует построение множества выражений с дельтой для получения выражения с дельтой для таблиц в терминах выражений с дельтой для объекта.
Подробное описание
Новая архитектура доступа к данным
В одном варианте осуществления новшество может быть реализовано в пределах и включать аспекты новой архитектуры доступа к данным - “архитектура сущностей”, как описано в этом разделе. Примером такой архитектуры сущностей является архитектура доступа к данным ADO.NET vNEXT®, разработанная корпорацией MICROSOFT®. Последующее является общим описанием архитектуры доступа к данным ADO.NET vNEXT вместе с многочисленными подробностями конкретного варианта осуществления, которые не должны рассматриваться необходимыми для осуществления изобретения.
Обзор
Традиционные клиент-серверные приложения передают операции запроса и постоянного хранения по своим данным в системы баз данных. Система базы данных оперирует данными в форме строк и таблиц, тогда как приложение оперирует данными в терминах конструкций языка программирования высокого уровня (классы, структуры и т.д.). Потеря соответствия в службах управления данными между приложением и уровнем базы данных была проблемой даже в традиционных системах. С приходом службо-ориентированных архитектур (SOA), серверов приложений и многоуровневых приложений необходимость в доступе к данным и услугам по управлению, которые хорошо интегрированы со средами программирования и могут оперировать на любом уровне, очень возросла.
Архитектура сущностей ADO.NET Microsoft является платформой для программирования в отношении данных, которые поднимают уровень абстракции от реляционного уровня к концептуальному (сущностному) уровню, и таким образом значительно снижает потерю соответствия для приложений и служб, ориентированных на данные. Аспекты архитектуры сущностей, общая системная архитектура и базовые методики описаны ниже.
Введение
Современные приложения требуют услуг управления данными на всех уровнях. Им необходимо обрабатывать в большей степени наполненные формы данных, которые включают в себя не только структурированные бизнес-данные (например, Клиенты и Заказы), но также полуструктурированный и неструктурированный контент, например электронную почту, календари, файлы и документы. Этим приложениям необходимо интегрировать данные из многочисленных источников данных, а также собрать, очистить, трансформировать и сохранить эти данные, чтобы обеспечить более быстрый процесс принятия решения. Разработчикам этих приложений необходимы средства доступа к данным, средства программирования и разработки для увеличения своей производительности. Тогда как реляционные базы данных стали де-факто хранилищем наиболее структурированных данных, появляется несоответствие - хорошо известная проблема потери соответствия - между моделью данных (и возможностями), раскрываемой посредством таких баз данных, и возможностями моделирования, необходимыми приложениям.
Два других фактора также играют важную роль в проектировании систем предприятия. Во-первых, представление данных для приложений развивается иначе от основных баз данных. Во-вторых, многие системы сформированы из несопоставимых прикладных частей базы данных с различными степенями возможностей. Прикладная логика на среднем ярусе отвечает за трансформацию данных, которые согласуют эти отличия и представляют более однородное представление данных. Эти трансформации данных быстро становятся сложными. Их реализация, особенно когда основные данные необходимо сделать обновляемыми, является трудной проблемой и добавляет сложности приложению. Значительная часть разработки приложения - в некоторых случаях до 40% - посвящена написанию заказной логики доступа к данным, чтобы обойти эти проблемы.
Те же самые проблемы существуют, и они не менее тяжелы у служб, ориентированных на данные. Традиционные службы, например запрос, обновления и транзакции, реализованы на (реляционном) уровне логической схемы. Однако подавляющее большинство более новых служб, например репликация и анализ, лучше оперируют с объектами, типично ассоциируемыми с высокоуровневой, концептуальной моделью данных. Например, репликация SQL SERVER® изобрела структуру, называемую “логическая запись”, чтобы представлять ограниченную форму сущности. Аналогично, служба отчетов SQL Server создает отчеты поверх модели данных, аналогичной сущностям, называемой семантическим языком модели данных (SDML). Каждая из этих служб имеет собственные средства для определения концептуальных сущностей и отображает их вниз на реляционные таблицы - сущность Клиент, следовательно, необходимо определить и отобразить одним способом для репликации, другим способом для создания отчетов, еще одним способом для других служб анализа и так далее. Что касается приложений, каждая служба типично оканчивается созданием конкретного решения для этой проблемы, и, следовательно, существует удвоение кода и ограниченное взаимодействие между этими службами.
Методики объектно-реляционного отображения (ORM), например HIBERNATE® и ORACLE TOPLINK®, являются популярной альтернативой для заказной логики доступа к данным. Отображения между базой данных и приложениями выражены в заказной структуре или посредством аннотации к схеме. Эти заказные структуры могут казаться аналогичными в концептуальной модели; однако приложения не могут программировать непосредственно в отношении этой концептуальной модели. Тогда как отображения предоставляют степень независимости между базой данных и приложением, проблема обработки многочисленных приложений с незначительно отличающимися представлениями тех же самых данных (например, представим два приложения, которые желают взглянуть на различные проекции сущности Клиент), или потребностей служб, которые оказываются более динамичными (априори методики формирования классов не работают хорошо для служб данных, так как основная база данных может развиваться быстрее), и недостаточно обращены к этим решениям.
Архитектура сущностей ADO.NET является платформой для программирования в отношении данных, которые значительно снижают потерю соответствия для приложений и служб, ориентированных на данные. Она отличается от других систем и решений в, по меньшей мере, следующих отношениях.
1. Архитектура сущностей определяет расширенную концептуальную модель данных (модель сущность-данные, или EDM) и новый язык управления данными (Entity SQL), который работает с экземплярами этой модели. Как и SQL, EDM является основанной на значениях, т.е. EDM определяет структурные аспекты сущностей, а не поведение (или методы).
2. Эта модель выполнена “крепкой” с помощью рабочего цикла, который включает в себя подсистему отображения межплатформенного программного обеспечения, поддерживающего мощные двунаправленные (EDM - реляционные) отображения для запросов и обновлений.
3. Приложения и услуги могут программировать непосредственно в отношении концептуального уровня, основанного на значении, или в отношении абстракций объектов с конкретным языком программирования, которые могут быть наслоены на концептуальную (сущностную) абстракцию, предоставляя функциональность, аналогичную ORM. Мы полагаем, что концептуальная EDM-абстракция, основанная на значении, является более гибкой основой для совместного использования данных среди приложений и служб, ориентированных на данные, нежели объекты.
4. В конечном итоге архитектура сущностей усиливает методики нового интегрированного в язык запроса (LINQ) от Microsoft, которые, собственно, расширяют языки программирования с помощью выражений запроса до дополнительного снижения и, для некоторых сценариев, исключения потери соответствия для приложений.
Архитектура сущностей ADO.NET может быть встроена в большую структуру, например архитектуру Microsoft.NET.
Оставшееся описание архитектуры доступа к данным в контексте варианта осуществления архитектуры сущностей ADO.NET организовано следующим образом. Раздел "мотивация" предоставляет дополнительную мотивацию для архитектуры сущностей. Раздел "архитектура сущностей" представляет архитектуру сущностей и модель сущность-данные. Раздел "образцы программирования" описывает образцы программирования для архитектуры сущностей. Раздел "объектные службы" выделяет модуль объектных служб. Раздел "отображение" фокусируется на компоненте отображения архитектуры сущностей, тогда как "обработка запроса" и раздел "обработка обновления" поясняет, как обрабатываются запросы и обновления. "Метаданные" и "средства" описывают компоненты подсистемы метаданных и средств архитектуры сущностей.
Мотивация
Этот раздел рассматривает, почему уровень моделирования данных более высокого уровня стал необходимым для приложений и служб, ориентированных на данные.
Информационные уровни в приложениях данных
Современные преобладающие методологии информационного моделирования для формирования проектов баз данных разбивают информационную модель на четыре основных уровня: физический, логический (реляционный), концептуальный и программирования/представления.
Физическая модель описывает, как представлены данные в физических ресурсах, таких как память, сеть или диск. Словарь терминов, рассматриваемых на этом уровне, включает в себя форматы записи, файловые разделы и группы, динамически распределяемые области памяти ("кучи") и индексы. Физическая модель является типично невидимой для приложения - изменения физической модели не должны влиять на логику приложения, но могут влиять на производительность приложения.
Логическая модель данных является полной и точной информационной моделью целевой области. Реляционная модель является представлением выбора для большинства логических моделей данных. Термины, рассматриваемые на логическом уровне, включают в себя таблицы, строки, ограничения первичного ключа/внешнего ключа и нормализацию. Тогда как нормализация помогает достичь непротиворечивости данных, улучшенного параллелизма и лучшей OLTP-производительности, она также внедряет значительные проблемы для приложений. Нормализованные данные на логическом уровне являются часто слишком фрагментированными, и логике приложения необходимо компоновать строки из множества таблиц в сущности более высокого уровня, которые более близко походят на компоненты прикладной области.
Концептуальная модель захватывает основные информационные сущности из области задач и их отношения. Хорошо известной концептуальной моделью является модель сущность-отношение, представленная Питером Ченом в 1976 г. UML является самым последним примером концептуальной модели. Большинство приложений включают в себя концептуальную проектную фазу в самом начале жизненного цикла разработки приложения. Однако, к сожалению, диаграммы концептуальных моделей данных остаются "прикрепленными к стене", со все более возрастающей несовместимостью с реальностью реализации приложения во времени. Важной целью архитектуры сущностей является выполнение концептуальной модели данных (осуществленной с помощью модели сущность-данные, описанной в следующем разделе) крепкой, программируемой абстракцией платформы данных.
Модель программирования/представления описывает, как сущности и отношения концептуальной модели необходимо показать (представить) в различных формах на основе решаемой задачи. Некоторые сущности необходимо трансформировать в объекты языка программирования для осуществления прикладной бизнес-логики; другие необходимо трансформировать в XML-потоки для применения в веб-службах; еще одни необходимо трансформировать в структуры внутренней памяти, например, списки или словари для целей привязки данных пользовательского интерфейса. Естественно, не существует универсальной модели программирования или формы представления; таким образом, приложениям необходимы гибкие механизмы для трансформации сущностей в различные формы представления.
Большинство приложений и служб, ориентированных на данные, предпочтительно рассуждают в терминах концепций высокого уровня, таких как заказ, не в нескольких таблицах, по которым заказ может быть нормализован в реляционной схеме базы данных. Сам заказ может показываться на уровне представления/программирования как экземпляр класса в Visual Basic или С#, инкапсулирующий состояние и логику, ассоциируемую с заказом, или как XML-поток для взаимодействия с веб-службой. Нет подходящей модели представления, однако существует ценность в предоставлении крепкой концептуальной модели и затем возможности использовать эту модель как основу для гибких отображений в и из различных моделей представления и других высокоуровневых служб данных.
Эволюция приложений и служб
Приложения на основе данных 10-20 лет назад были типично структурированы как монолиты данных; закрытые системы с логикой, разбиваемой с помощью функций команда-объект (например, создать-заказ, обновить-заказчик), которые взаимодействовали с системой базы данных на уровне логической схемы. Несколько значительных тенденций сформировали способ, которым современные приложения на основе данных сегодня разбиваются и внедряются. Основными среди них являются объектно-ориентированное разбиение, формирование использования служебного уровня и службы высокого уровня, ориентированные на данные. Концептуальные сущности являются важной частью современных приложений. Эти сущности должны быть отображены во множество представлений и привязаны к множеству служб. Не существует одного корректного представления или привязки к службе: XML, реляционные или объектные представления - все являются важными, но никакой взятой в отдельности недостаточно для всех приложений. Следовательно, существует потребность в структуре, которая поддерживает уровень высокоуровневого моделирования данных и также позволяет многочисленным уровням представления быть подключенными - архитектура сущностей направлена на выполнение этих требований.
Службы, ориентированные на данные, также развивались аналогичным образом. Службы, предоставлявшиеся “платформой данных” 20 лет назад, были минимальными и фокусировались вокруг логической схемы в RDBMS. Эти службы включали в себя запрос и обновление, целостные транзакции и массовые операции, например резервное копирование и загрузка/извлечение.
SQL Server сам по себе развивается из традиционной RDBMS до полной платформы данных, которая предоставляет множество высокоуровневых служб, ориентированных на данные, с помощью сущностей, реализованных на уровне концептуальной схемы. Несколько высокоуровневых служб, ориентированных на данные, в продукте SQL Server - репликация, конструктор отчетов, чтобы только назвать пару, - все в большей степени привносят свои услуги на уровень концептуальной схемы. В настоящее время каждая из этих служб имеет отдельное средство для описания концептуальных сущностей и отображения их в уровень основной логической схемы. Целью архитектуры сущностей является предоставление общей концептуальной абстракции высокого уровня, которую все из этих служб могут совместно использовать.
Архитектура сущностей
Структура ADO.NET Microsoft, которая существовала до архитектуры сущностей, описанной в данном документе, была технологией доступа к данным, которая позволяла приложениям соединяться с хранилищами данных и управлять данными, содержащимися в них различными способами. Это было частью структуры .NET Microsoft и она была высоко интегрирована с остальной библиотекой классов структуры .NET. Предшествующая структура ADO.NET имела две основные части: поставщики и службы. Поставщики ADO.NET являются компонентами, которые знают, как взаимодействовать с конкретными хранилищами данных. Поставщики сформированы из трех основных частей функциональных возможностей: доступ к управлению соединениями к основному источнику данных; команды, представляющие команду (запрос, вызов процедуры и т.д.), которую необходимо выполнить в отношении источника данных; и средства считывания данных, представляющие результат выполнения команды. Службы ADO.NET включают в себя компоненты, нейтральные для поставщика, например DataSet, чтобы разрешить автономные сценарии программирования данных. (DataSet является представлением данных, постоянно находящихся в памяти, которое предоставляет целостную реляционную модель программирования безотносительно источника данных).
Архитектура сущностей - обзор
Структура объектов ADO.NET строится на предварительном существовании существующей модели поставщика ADO.NET и дополняется следующими функциональными возможностями.
1. Новая концептуальная модель данных, сущностная модель данных (EDM), чтобы содействовать моделированию концептуальных схем.
2. Новый язык управления данными (DML), Entity SQL, чтобы управлять экземплярами EDM, и программное представление запроса (канонические деревья команд) для связи с различными поставщиками.
3. Возможность определять отображения между концептуальной схемой и логическими схемами.
4. Модель программирования поставщика ADO.NET в отношении концептуальной схемы.
5. Уровень объектных служб для предоставления функциональных возможностей, аналогичных ORM.
6. Интеграция с технологией LINQ, чтобы облегчить программирование в отношении данных как объектов из языков .NET.
Модель сущность-данные
Модель сущность-данные (EDM) разрешает разработку расширенных приложений, ориентированных на данные. Она расширяет классическую реляционную модель понятиями из E-R-области. В примерном варианте осуществления, предоставленном в данном документе, организационные концепции в EDM включают в себя сущности и отношения. Сущности представляют элементы верхнего уровня с идентификаторами, тогда как отношения используются для установления отношения (или описания связи между ними) между двумя или более сущностями.
В одном варианте осуществления EDM скорее основана на значениях подобно реляционной модели (и SQL), чем на объекте/ссылке подобно С# (CLR). Несколько объектных моделей программирования могут быть легко наслоены поверх EDM. Аналогично, EDM может отображать в одну или более реализации DBMS для постоянного хранения.
EDM и Entity SQL представляют собой более расширенную модель данных и язык управления данными для платформы данных и предназначены, чтобы позволить приложениям, таким как CRM и ERP, службам, работающим с большими объемами данных, таким как составление отчетов, бизнес-аналитика, репликация и синхронизация, и приложениям, работающим с большими объемами данных, моделировать и управлять данными на уровне структуры и семантики, которые ближе к их потребностям. Теперь рассмотрим различные понятия, относящиеся к EDM.
Типы EDM
EntityType описывает структуру сущности. Сущность может иметь ноль или более свойств (атрибутов, полей), которые описывают структуру сущности. Кроме того, тип сущности должен определять ключ - набор свойств, значения которых уникально идентифицируют экземпляр сущности в совокупности сущностей. EntityType может быть производным от (или подтипом) другого типа сущности - EDM поддерживает модель простого наследования. Свойства сущности могут быть простым или составным типом. SimpleType представляет собой скалярные (или элементарные) типы (например, целое число, строка), тогда как ComplexType представляет собой структурированные свойства (например, Адрес). ComplexType формируется из нуля или более свойств, которые могут сами собой являться свойствами скалярного или составного типа. RelationshipType описывает связи между двумя (или более) типами сущностей. Схемы EDM предоставляют механизм группировки для типов - типы должны быть определены в схеме. Пространство имен схемы, вместе с названием типа, однозначно идентифицирует конкретный тип.
Модель экземпляров EDM
Экземпляры сущностей (или просто сущности) логически содержатся в EntitySet. EntitySet является гомогенной совокупностью сущностей, т.е. все объекты в EntitySet должны быть одного (или производного) EntityType. EntitySet является концептуально аналогичным таблице базы данных, тогда как сущность аналогична строке таблицы. Экземпляр сущности должен принадлежать точно одному набору сущностей. Аналогичным образом экземпляры отношений логически содержатся в RelationshipSet. Определение RelationshipSet охватывает связь. То есть оно идентифицирует EntitySet, которые содержат экземпляры типов сущностей, которые участвуют в отношении. RelationshipSet является концептуально аналогичным таблице связей в базе данных. SimpleType и ComplexType могут быть воплощены только как свойства EntityType. EntityContainer является логической группировкой множеств EntitySet и RelationshipSet, похожей на то, как схема является механизмом группировки для типов EDM.
Пример схемы EDM



Архитектура высокого уровня
Этот раздел обрисовывает архитектуру сущностей ADO.NET. Ее основные функциональные компоненты проиллюстрированы на фиг.1 и содержат следующее.
Поставщики данных, зависимые от источника. Архитектура 100 сущностей создается на модели поставщиков данных ADO.NET. Существуют определенные поставщики 122-125 для нескольких источников, например SQL Server 151, 152, реляционные источники 153, нереляционные 154 и источники веб-служб 155. Поставщики 122-125 могут быть вызваны API 121 источника ADO.NET, зависимого от хранилища.
Поставщик EntityClient. Поставщик 110 EntityClient представляет конкретный концептуальный уровень программирования. Это новый поставщик данных на основе значений, где доступ к данным осуществляется в терминах сущностей EDM и отношений, и запрос/обновление выполнятся, используя язык SQL, основанный на сущностях (Entity SQL). Поставщик 111 EntityClient создает часть пакета служб 110 объектных данных, которая может также включать в себя службы 112 метаданных, конвейер 113 запросов и обновлений, поддержку 115 транзакций, рабочий цикл 116 менеджера представлений и подсистему 114 отображения представлений, которая поддерживает обновляемые преставления EDM по простым реляционным таблицам. Отображение между таблицами и сущностями задается декларативно через язык определения отображений.
Объектные службы и другие уровни программирования. Компонент 131 объектных служб архитектуры 100 сущностей предоставляет расширенную объектную абстракцию над сущностями, расширенный набор служб над этими сущностями и разрешает приложениям программировать во взаимодействии 161 с императивным кодированием, используя знакомые конструкции языка программирования. Этот компонент предоставляет службы управления состоянием для объектов (включая отслеживание изменений, анализ идентичности), поддерживает службы для навигации и загрузки объектов и отношений, поддерживает запросы посредством LINQ и Entity SQL, используя компоненты, такие как Xlinq 132, и разрешает объектам обновляться и постоянно храниться.
Архитектура сущностей разрешает подключать многочисленные уровни программирования, похожие на 130, к уровню 110 служб данных сущностей на основе значений, который раскрывается поставщиком 111 EntityClient. Компонент объектных служб 131 является одним таким уровнем программирования, который обнаруживает объекты CLR и предоставляет функциональные возможности, аналогичные ORM.
Компонент служб 112 метаданных управляет метаданными для потребностей цикла проектирования и рабочего цикла архитектуры 100 сущностей и приложений поверх архитектуры сущностей. Все метаданные, ассоциируемые с концепциями EDM (объекты, отношения, EntitySet, RelationshipSet), концепциями хранения (таблицы, столбцы, противоречия) и концепциями отображения, раскрываются посредством интерфейсов метаданных. Компонент 112 метаданных также служит как связь между средствами моделирования области, которые поддерживают проект приложения, управляемый моделью.
Проект и средства метаданных. Архитектура 100 сущностей интегрируется с проектировщиками 170 области, чтобы позволить разработку приложения, управляемого моделью. Средства включают в себя средства проектирования EDM, средства 171 моделирования, средства 172 проектирования отображений, средства 173 проектирования просмотра, средства 174 проектирования привязки, средства 175 формирования кода и разработчики модели запросов.
Службы. Расширенные службы, ориентированные на данные, например отчеты 141, синхронизация 142, веб-службы 143 и бизнес-анализ, могут быть построены, используя архитектуру 100 сущностей.
Образцы программирования
Архитектура сущностей ADO.NET вместе с LINQ увеличивает продуктивность разработчика приложений посредством значительного снижения потери соответствия между кодом приложения и данными. В этом разделе мы опишем эволюцию в образцах программирования доступа к данным на логическом, концептуальном уровнях и уровне объектной абстракции.
Рассмотрим следующий фрагмент реляционной схемы на основе образца базы данных AdventureWorks. Эта база данных состоит из таблиц SContacts 201, SEmployees 202, SSalesPersons 203 и SSalesOrders 204, которые могут придерживаться реляционной схемы, например, проиллюстрированной на фиг.2.
SContacts (ContactId, Name, Email, Phone)
SEmployees (EmployeeId, Title, HireDate)
SSalesPersons (SalesPersonId, Bonus)
SSalesOrders (SalesOrderId, SalesPersonId)
Рассмотрим фрагмент кода приложения для получения названия и даты найма продавцов, которые были наняты до некоторой даты (показано ниже). Существуют четыре основных недостатка в этом фрагменте кода, которые не имеют возможности бизнес-вопроса, на который необходимо получить ответ. Во-первых, хотя запрос может быть начат на английском языке очень кратко, выражение SQL является достаточно подробным и требует у разработчика быть осведомленным о нормализованной реляционной схеме для формулирования операции присоединения к многочисленным таблицам, чтобы получить соответствующие столбцы от таблиц SContacts, Semployees и SsalesPerson. Кроме того, любое изменение низлежащих схем баз данных требует соответствующих изменений во фрагменте кода ниже. Во-вторых, пользователь должен определить явную связь с источником данных. В-третьих, так как возвращаемые результаты строго не типизированы, любая ссылка на несуществующие имена столбцов обнаруживается только после выполнения запроса. В-четвертых, выражение SQL является текстовым свойством для командного API, и любые ошибки в его формулировании обнаруживаются только во время выполнения. Тогда как этот код написан, используя ADO.NET 2.0, образец кода и его недостатки применяются к любому другому API доступа к реляционным данным, такому как ODBC, JDBC или OLE-DB.

Примерная реляционная схема может быть получена на концептуальном уровне посредством схемы EDM, как проиллюстрировано на фиг.3. Она задает тип ESalesPerson 302 сущности, который абстрагируется от фрагментации таблиц Contacts 201, SEmployees 202 и SSalesPersons 203. Она также фиксирует отношение наследования между типами сущностей EStoreOrder 301 и ESalesOrder 303.
Эквивалентная программа на концептуальном уровне записывается следующим образом:

Выражение SQL значительно упрощено - пользователю больше не нужно знать о точной компоновке базы данных. Кроме того, логика приложения может быть изолирована от изменений низлежащей схемы базы данных. Однако этот фрагмент все еще основан на текстовой строке, все еще не получает выгод от проверки типов языка программирования и возвращает слабо типизированные результаты.
Добавляя тонкий упаковщик объектов вокруг сущностей и используя расширения интегрированного в язык запроса (LINQ) в С#, можно переписать эквивалентную функцию без потери соответствия следующим образом:

Запрос является простым; приложение (в основном) изолировано от изменений низлежащей схемы базы данных; и запрос полностью проверяется на соответствие типов компилятором С#. В дополнение к запросам можно взаимодействовать с объектами и осуществлять обычные операции Создать, Прочесть, Обновить и Удалить (CRUD) над объектами. Эти примеры описаны в разделе обработки обновления.
Объектные службы
Компонент объектных служб является уровнем программирования/представления по концептуальному (сущностному) уровню. Он содержит несколько компонентов, которые облегчают взаимодействие между языком программирования и сущностями концептуального уровня на основе значений. Ожидается, что одна объектная служба существует на каждый рабочий цикл языка программирования (например, .NET, Java). Если спроектирована поддержка .NET CLR, программы в любом языке .NET могут взаимодействовать с помощью архитектуры сущностей. Объектные службы собираются из следующих основных компонентов.
Класс ObjectContext содержит связь с базой данных, рабочую область метаданных, менеджер состояний объекта и материализатор объектов. Этот класс включает в себя интерфейс запроса объектов ObjectQuery<T>, чтобы разрешить формулировку запросов либо через объектный SQL, либо через синтаксис LINQ, и возвращает результаты по объектам со строгим типом как ObjectReader<T>. ObjectContext также раскрывает интерфейсы объектного уровня запросов и обновлений (т.е. SaveChanges) между уровнем языка программирования и концептуальным уровнем. Менеджер состояний объектов имеет три основных функции: (а) кэширование результатов запроса, предоставление анализа идентичности и управление политиками для слияния объектов из перекрывающихся результатов запроса, (b) отслеживать изменения во внутренней памяти и (с) создавать ввод списка изменений для инфраструктуры обработки обновления. Менеджер состояний объектов поддерживает состояние каждой сущности в кэше - обособленным (от кэша), добавленным, неизмененным, модифицированным и удаленным - и отслеживает переходы их состояний. Материализатор объектов осуществляет трансформации в течение запроса и обновления между значениями сущности с концептуального уровня и соответствующими объектами CLR.
Отображение
В одном варианте осуществления основой уровня доступа к данным общего назначения, такого как архитектура сущностей ADO.NET, может быть отображение, которое устанавливает отношение между данными приложения и данными, хранящимися в базе данных. Приложение запрашивает и обновляет данные в объекте или концептуальном уровне, и эти операции транслируются в хранилище посредством отображения. Существует множество технических проблем, которые должны быть адресованы любым решением отображения. Построение ORM, которая использует отображение один-к-одному, чтобы раскрыть каждую строку в реляционной таблице как объект, является относительно простым, особенно если не требуется декларативное управление данными. Однако по мере рассмотрения более сложных отображений, операций на основе множеств, производительности, поддержки производителем многочисленных DBMS и других требований специальные решения сразу быстро увеличиваются.
Проблема: Обновления посредством отображений
Проблема доступа к данным посредством отображений может моделироваться в терминах “представлений”, т.е. объекты/сущности на клиентском уровне могут рассматриваться как расширенные представления над строками таблиц. Однако хорошо известно, что только ограниченный класс представлений является обновляемым, т.к. системы коммерческих баз данных не допускают обновлений множества таблиц в представлениях, содержащих слияния или объединения. Поиск однозначной трансляции обновления даже по совсем простым представлениям редко является возможным из-за свойственной недостаточной спецификации поведения при обновлении представления. Исследование показало, что выделение семантики обновления из представлений является сложным и может требовать значимой оценки пользователем. Однако для доступа к данным, управляемым отображением, выгодно, чтобы существовала хорошо определенная трансляция каждого обновления в представление.
Кроме того, в сценариях, управляемых отображениями, требование обновляемости превышает простое представление. Например, бизнес-приложение, которое управляет сущностями Клиент или Заказ, эффективно осуществляет операции в отношении двух представлений. Иногда согласующееся состояние может быть достигнуто лишь с помощью одновременного обновления нескольких представлений. Трансляция для каждого отдельного случая таких обновлений может привести к комбинаторному взрыву логики обновления. Делегирование ее реализации разработчикам приложения является неудовлетворительным, так как требует у них вручную браться за наиболее сложную часть доступа к данным.
Подход ADO.NET к отображению
Архитектура сущностей ADO.NET поддерживает передовую архитектуру отображений, которая направлена к исследованию вышеуказанных проблем. Она использует следующие идеи.
1. Спецификация: отображения задаются, используя декларативный язык, который имеет строго очерченную семантику и делает доступным широкий диапазон сценариев отображений для пользователей, не являющихся экспертами.
2. Компиляция: отображения компилируются в двусторонние представления, называемые представлениями запроса и обновления, которые управляют обработкой запроса и обновления в подсистеме рабочего цикла.
3. Выполнение: трансляция обновления выполняется, используя общий механизм, который усиливает поддержание материализованного представления, надежную технологию баз данных. Трансляция запроса использует разворачивание представления.
Новая архитектура отображений позволяет построить мощный стек технологий, управляемых отображениями, принципиально перспективным образом. Более того, она открывает интересные направления исследования немедленной практической значимости. Следующие подразделы иллюстрируют спецификацию и компиляцию отображений. Выполнение рассматривается в разделах обработки запросов и обработки обновления ниже. Дополнительные аспекты и варианты осуществления примерной архитектуры отображений, предоставленной в данном документе, также изложены в разделе ниже, озаглавленные "дополнительные аспекты и варианты осуществления".
Спецификация отображений
Отображение задается, используя набор фрагментов отображений. Каждый фрагмент отображения является ограничением формы QEntities=QTables, где CEntities является запросом по схеме сущностей (на стороне приложения) и QTables является запросом по схеме базы данных (на стороне хранилища). Фрагмент отображения описывает, как часть данных сущности соответствует части реляционных данных. То есть фрагмент отображения является элементарным блоком спецификации, который может быть понят независимо от других фрагментов.
Для иллюстрации рассмотрим примерный сценарий отображения на фиг.4. Фиг.4 иллюстрирует отображение между схемой сущностей (слева) и схемой базы данных (справа). Отображение может быть определено, используя XML-файл или графическое средство. Схема сущностей соответствует схеме в разделе модели сущность-данные в данном документе. На стороне хранилища существуют четыре таблицы, SSalesOrders, SSalesPersons, Semployees и SContacts. На стороне схемы сущностей существуют два множества сущностей, ESalesOrder и ESalesPersons, и одно множество ассоциаций ESalesPersonOrders.
Отображение представлено в терминах запросов по схеме сущностей и реляционной схеме, как показано на фиг.5.
На фиг.5 фрагмент 1 сообщает, что множество (Id, AccountNum) значений для всех сущностей точного типа ESalesOrder в ESalesOrders идентично множеству (SalesOrderld, AccountNum) значений, получаемых из таблицы SsalesOrders, для которой IsOnline является истиной. Фрагмент 2 является аналогичным. Фрагмент 3 отображает множество ассоциаций ESalesPersonOrders в таблицу SSalesOrders и сообщает, что каждая запись ассоциации соответствует паре первичный ключ, внешний ключ для каждой строки в этой таблице. Фрагменты 4, 5 и 6 сообщают, что сущности в множестве сущностей ESalesPersons разделены по трем таблицам SSalesPersons, SContacts, SEmployees.
Двунаправленные представления
Отображения компилируются в двунаправленные представления Entity SQL, которые управляют рабочим циклом. Представления запросов выражают сущности в терминах таблиц, тогда как представления обновления выражают таблицы в терминах сущностей.
Представления обновлений могут быть несколько трудными для понимания, так как они задают постоянные данные в терминах виртуальных конструкций, но как покажем позже, они могут быть усилены для поддержки обновлений изящным способом. Сформированные представления 'имеют отношение' к отображению в строго очерченном значении и имеют следующие признаки (заметьте, что представление немного упрощено, особенно постоянное состояние не полностью определяется виртуальным состоянием):
Entities = Query Views(Tables)
Tables = UpdateViews(Entities)
Entities = QueryViews(UpdateViews(Entities))
Последнее условие является критерием полного обхода, который гарантирует, что все данные сущностей могут храниться в базе данных и повторно собираться из базы данных без потерь. Компилятор отображений, включенный в архитектуру сущностей, гарантирует, что сформированные представления удовлетворяют критерию полного обхода. Он выдает ошибку, если подобные представления не могут быть сформированы из введенного отображения.
Фиг.6 показывает двунаправленные представления - представления запроса и обновления - сформированные с помощью компилятора отображений для отображения на фиг.5. В общем представления могут быть значительно более сложными, чем введенное отображение, так как они явно задают требуемые трансформации данных. Например, в QV1 множество сущностей ESalesOrders конструируется из таблицы SSalesOrders так, чтобы либо ESalesOrder, либо EStoreSalesOrder были воплощены в зависимости от того, является ли истиной флаг IsOnline. Для того чтобы пересобрать множество сущностей ESalesPersons из реляционных таблиц, необходимо осуществить объединение между таблицами SsalesPersons, SEmployees и Scontacts (QV3).
Написание представлений запросов и обновлений вручную, удовлетворяющих критерию полного обхода, является сложным и требует значительного опыта в базах данных; следовательно, настоящие варианты осуществления архитектуры сущностей только приемлют представления, сформированные встроенным компилятором отображений, хотя прием представлений, сформированных другими компиляторами или вручную, определенно допустим в альтернативных вариантах осуществления.
Компилятор отображений
Архитектура сущностей содержит компилятор отображений, который формирует представления запроса и обновления из схемы EDM, схемы хранилища и отображения (компоненты метаданных обсуждаются в разделе метаданных в данном документе). Эти представления используются конвейерами запроса и обновления. Компилятор может привлекаться либо в цикле проектирования, либо в рабочем цикле, когда первый запрос выполняется в отношении схемы EDM. Алгоритмы формирования представления, используемые в компиляторе, основаны на методиках ответа на запрос с использованием представлений для точных перезаписей.
ОБРАБОТКА ЗАПРОСА
Языки запроса
В одном варианте осуществления архитектура сущностей может быть спроектирована, чтобы работать с многочисленными языками запросов. Мы описываем варианты осуществления с Entity SQL и LINQ более подробно в данном документе, понимая, что те же самые или аналогичные принципы могут быть расширены в других вариантах осуществления.
Entity SQL
Entity SQL является производным от SQL, спроектированный для запроса и управления экземплярами EDM. Entity SQL расширяет стандартный SQL следующими способами.
1. Собственная поддержка конструкций EDM (отношения, составные типы и т.д.): конструкторов, средств доступа к членам, запроса типа, перемещения отношений, вкладывания и т.д.
2. Пространство имен. Entity SQL использует пространства имен как группирующую конструкцию для типов и функций (аналогичных XQuery и другим языкам программирования).
3. Расширяемые функции. Entity SQL не поддерживает встроенные функции. Все функции (min, max, substring) задаются внешним образом в пространстве имен и импортируются в запрос, обычно из низлежащего хранилища.
4. Более ортогональная обработка подзапросов и других конструкций по сравнению с SQL.
Архитектура сущностей может, например, поддерживать Entity SQL как язык запросов на уровне поставщика EntityClient и в компоненте объектных служб. Примерный запрос Entity SQL показан в разделе шаблонов программирования в данном документе.
Интегрированный в язык запрос (LINQ)
Интегрированный в язык запрос, или LINQ, является новшеством в языках программирования .NET, который представляет конструкции, относящиеся к запросу, в основные языки программирования, такие как С# и Visual Basic. Выражения запросов не обрабатываются внешним средством или языковым препроцессором, но вместо этого являются сами по себе первоклассными выражениями языков. LINQ допускает извлечение выгоды из расширенных метаданных проверки синтаксиса компиляции во времени, статическое задание типа данных и IntelliSense выражениями запросов, что было доступно только для императивного кода. LINQ определяет набор стандартных операторов запроса общего назначения, которые допускают выражение прямым декларативным образом в любом языке программирования на основе .NET операций прослеживания, фильтрации, присоединения, проекции, сортировки и группировки. Языки .NET, такие как Visual Basic и С#, также поддерживают полноту запросов - расширения языкового синтаксиса, которые усиливают стандартные операторы запросов. Примерный запрос, использующий LINQ в С#, показан в разделе шаблонов программирования в данном документе.
Канонические деревья команд
В одном варианте осуществления канонические деревья команд - проще, деревья команд - могут быть программным (древовидным) представлением всех запросов в архитектуре сущностей. Запросы, выраженные посредством Entity SQL или LINQ, могут быть сначала проанализированы и преобразованы в деревья команд; вся последующая обработка может осуществляться по деревьям команд. Архитектура сущностей может также допускать запросы для динамического создания (или редактирования) посредством API создания дерева команд/редактирования. Деревья команд могут представлять запросы, вставки, обновления, удаления и вызовы процедур. Дерево команд составлено из одного или более выражений. Выражение просто представляет собой некоторое вычисление - архитектура сущностей может предоставлять множество выражений, которые включают в себя константы, параметры, арифметические операции, реляционные операции (проекция, фильтр, объединения и т.д.), вызовы функций и так далее. В конечном счете деревья команд могут использоваться как средства связи для запросов между поставщиком EntityClient и низлежащим поставщиком, зависящим от хранилища.
Конвейер запросов
Выполнение запроса в одном варианте осуществления архитектуры сущностей может быть делегировано хранилищу данных. Инфраструктура обработки запроса архитектуры сущностей отвечает за разбиение запроса Entity SQL или LINQ на один или более элементарных, только реляционных запросов, которые могут быть оценены низлежащим хранилищем, вместе с дополнительной информацией о сборке, которая используется для переформирования одноуровневых результатов более простых запросов в более расширенные структуры EDM.
Архитектура сущностей может предполагать, например, что хранилища должны поддерживать возможности, аналогичные SQL Server 2000. Запросы могут быть разбиты на более простые запросы одноуровневых отношений, которые соответствуют этому профилю. Другие варианты осуществления архитектуры сущностей могут разрешать хранилищам брать на себя большие части обработки запросов.
Типичный запрос может быть обработан следующим образом.
Анализ синтаксиса и семантики. Запрос Entity SQL сначала разбирается и семантически анализируется, используя информацию от компонента служб метаданных. Запросы LINQ разбираются и анализируются как часть соответствующего языкового компилятора.
Преобразование в каноническое дерево команд. Теперь запрос преобразуется в дерево команд, независимо от того, как он исходным образом был выражен, и подтверждается.
Разворачивание представления отображения. Запросы в архитектуре сущностей нацелены на концептуальные (EDM) схемы. Эти запросы должны транслироваться, чтобы ссылаться на низлежащие таблицы базы данных и представления. Этот процесс - упоминаемый как разворачивание представления отображения - аналогичен механизму разворачивания представления в системах баз данных. Отображения между схемой EDM и схемой базы данных компилируются в представления запроса и обновления. Представление запроса затем разворачивается в пользовательском запросе - теперь запрос нацелен на таблицы базы данных и представления.
Исключение структурированных типов. Все ссылки на структурированные типы теперь исключаются из запроса и добавляются к информации о пересборке (чтобы направлять результирующую сборку). Это включает в себя ссылки на конструкторы типов, средства доступа к членам, выражения запроса типов.
Отсечение проекций. Запрос анализируется, и несвязанные выражения в запросе исключаются.
Поднятие вложений. Любые операции вложения (создающие вложенные совокупности) в запросе выталкиваются до основания дерева запроса по поддереву, содержащему только простые реляционные операторы. Типично операция вложения трансформируется в левостороннее внешнее объединение (или внешнее наложение), и простые результаты из последующего запроса пересобираются (смотри Сборку Результатов ниже) в подходящие результаты.
Трансформации. Множество эвристических трансформаций применяется для упрощения запроса. Они включают в себя фильтрацию сверху вниз, преобразование наложений в объединения, сворачивания условных выражений и т.д. Излишние объединения (самообъединения, объединения с первичным ключом, с внешним ключом) исключаются на этом этапе. Заметьте, что инфраструктура обработки запроса здесь не осуществляет какую-либо оптимизацию на основе стоимости.
Трансляция в команды, специфичные для поставщика. Запрос (т.е. дерево команд) теперь передается поставщикам для формирования команды, специфичной для поставщика, возможно, на собственном SQL-диалекте поставщика. Мы ссылаемся на этот этап как SQLGen.
Выполнение. Команды поставщика выполняются.
Сборка результатов. Результаты (DataReaders) от поставщиков затем переформируются в подходящую форму, используя информацию компоновки, собранную ранее, и единственный DataReader возвращается вызывающему.
Материализация. Для запросов, выпущенных посредством компонента объектных служб, результаты затем материализуются в подходящие объекты языка программирования.
SQLGen
Как упомянуто в предыдущем разделе, выполнение запроса может быть делегировано низлежащему хранилищу. В таких вариантах осуществления запрос должен сначала транслироваться в форму, которая является подходящей для хранилища. Однако различные хранилища поддерживают различные диалекты SQL, и непрактично для архитектуры сущностей собственно поддерживать все из них. Вместо этого конвейер запросов может передавать запрос в форме дерева команд поставщику хранилища. Поставщик хранилища может затем транслировать дерево команд в собственную команду. Это может быть выполнено с помощью трансляции дерева команд в собственный SQL-диалект поставщика - отсюда термин SQLGen для этой фазы. Результирующая команда может затем выполняться для формирования значимых результатов.
Обработка обновления
Этот раздел описывает, как обработка обновления может осуществляться в примерной архитектуре сущностей ADO.NET. В одном варианте осуществления существуют две фазы для обработки обновления, цикла компиляции и рабочего цикла. В разделе двунаправленных представлений, предоставленном в данном документе, мы описываем процесс компиляции спецификации отображения в совокупность выражений представлений. Этот раздел описывает, как эти выражения представлений используются в рабочем цикле для трансляции модификаций объекта, осуществляемых на объектном уровне (или Entity SQL DML обновляет уровень EDM) в эквивалентные SQL-обновления на реляционном уровне.
Обновления через поддержание представления
Одна из идей, используемых в примерной архитектуре отображений ADO.NET, в том, что алгоритмы поддержания материализованных представлений могут быть усилены для распространения обновлений через двунаправленные представления. Этот процесс иллюстрируется на фиг.7.
Таблицы внутри базы данных, как проиллюстрировано с правой стороны фиг.7, содержат постоянные данные. EntityContainer, как проиллюстрировано на левой стороне фиг.7, представляет собой виртуальное состояние этих постоянных данных, так как типично только малая часть объектов в EntitySets материализована у клиента. Целью является трансляция обновления ΔEntities на состояние Entities в обновление ΔTables на постоянное состояние Tables. Этот процесс упоминается как поддержание инкрементного представления, так как обновление осуществляется на основе обновления ΔEntities, представляющих собой измененные аспекты сущности.
Это может быть сделано, используя следующие два этапа.
1. Поддержание представления:
ΔTables=ΔUpdateViews(Entities, ΔEntities)
2. Разворачивание представления:
ΔTables=ΔUpdateViews (QueryViews(Tables), ΔEntities)
На этапе 1 алгоритмы поддержания представления используются для обновления представлений. Это формирует набор выражений с дельтой, ΔUpdateViews, которые сообщают нам, как получить ΔTables из ΔEntities и снимок Entities. Так как последнее не полностью материализовано у клиента, на этапе 2 разворачивание представления используется для комбинирования выражений с дельтой с представлениями запросов. Совместно, эти этапы формируют выражение, которое принимает как ввод первоначальное состояние базы данных и обновление для сущностей и вычисляет обновление для базы данных.
Этот подход приводит к чистому, единообразному алгоритму, который работает как для обновления объекта-за-раз, так и для обновлений на основе множества (т.е. те, которые выражены, используя утверждения управления данными) и усиливает надежную технологию баз данных. На практике этап 1 часто является достаточным для трансляции обновления, так как многие обновления не зависят напрямую от текущего состояния базы данных; в таких ситуациях мы имеем ΔTables=ΔUpdateViews(ΔEntities). Если ΔEntities заданы как набор модификаций объект-за-раз по помещенным в кэш сущностям, затем этап 1 может быть дополнительно оптимизирован выполнением алгоритмов поддержания представлений скорее непосредственно над модифицируемыми сущностями, чем вычислением выражения ΔUpdateViews.
Трансляция обновлений на объекты
Для того чтобы проиллюстрировать подход, очерченный выше, рассмотрим следующий пример, который дает премию и повышение подходящим продавцам, которые проработали в компании, по меньшей мере, 5 лет.

AdventureWorksDB является классом, сформированным средством и производным от класса служб общих объектов, называемого ObjectContext, который содержит соединение с базой данных, рабочее пространство метаданных и структуру данных кэша объектов и показывает способ SaveChanges. Как мы пояснили в разделе объектных служб, кэш объекта поддерживает перечень сущностей, каждая из которых является одним из следующих состояний: обособленное (от кэша), добавленное, неизменное, модифицированное и удаленное. Вышеуказанный кодовый фрагмент описывает обновление, которое модифицирует свойства наименования и премии объектов ESalesPerson, которые хранятся в таблицах SEmployees и, соответственно, SSalesPersons. Процесс трансформирования обновлений объектов в соответствующие обновления таблиц, инициированный вызовом метода SaveChanges, может содержать следующие четыре этапа.
Формирование списка изменений. Создается список изменений для каждого набора сущностей из кэша объектов. Обновления представляются как списки удаленных и вставленных элементов. Добавленные объекты становятся вставками. Удаленные объекты становятся удалениями.
Распространение выражения значений. Этот этап принимает список изменений и представлений обновления (сохраняемый в рабочем пространстве метаданных) и, используя выражения поддержания инкрементного материализованного представления ΔUpdateViews, трансформирует список изменений объектов в последовательность выражений табличной вставки и удаления на алгебраической основе в отношении низлежащих изменяемых таблиц. Для этого примера значимыми представлениями обновления являются UV2 и UV3, показанные на фиг.6. Эти представления являются простыми запросами выбора проекций, поэтому применение правил поддержки представлений является прямым. Мы получаем следующие выражения ΔUpdateViews, которые являются теми же самыми для вставок (Δ+) и удалений (Δ-):
ΔSSalesPersons=SELECT p.Id, p.Bonus
FROM ΔESalesPersons AS p
ΔSEmployees=SELECT p.Id, p.Title
FROM ΔESalesPersons AS p
ΔSContacts=SELECT p.Id, p.Name, p.Contact.Email,
p.Contact.Phone FROM ΔESalesPersons AS p
Предположим, что цикл, показанный выше, обновил объект Eold=ESalesPersons(1, 20, “”, “Alice”, Contact(“a@sales”, NULL)) на Enew=ESalesPersons(1, 30, “Senior …”, “Alice”, Contact(“a@sales”, NULL)). Тогда первоначальная дельта равна Δ+ESalesOrders={Enew} для вставок и Δ-ESalesOrders={Eold} для удаления. Мы получаем Δ+SSalesPersons={(1, 30)}, Δ-SSalesPersons={(1, 20)}. Вычисленные вставки и удаление по таблице SSalesPersons затем комбинируются в единое обновление, которое устанавливает премиальное значение на 30. Дельты по SEmployees вычисляются аналогично. Для Scontacts мы получаем Δ+SContacts=Δ-Scontacts, не требуется никакого обновления.
В дополнение к вычислению дельт по изменяемым основным таблицам, эта фаза отвечает за (а) правильный порядок, в котором должны осуществляться обновления таблиц, принимая во внимание ограничения ссылочной целостности, (b) получение ключей, сформированных хранилищем, необходимых до представления конечных обновлений базе данных, и (c) получение информации для оптимистичного контроля параллелизма.
SQL DML или формирование вызовов хранимых процедур. Этот этап трансформирует список вставленных и удаленных дельт, включая дополнительные аннотации, относящиеся к обработке параллелизма, в утверждения SQL DML или вызовы хранимых процедур. В этом примере утверждениями обновлений, сформированными для изменяемых продавцов, являются:
BEGIN TRANSACTION
UPDATE [dbo].[SSalesPersons] SET [Bonus]=30
WHERE [SalesPersonID]=1
UPDATE [dbo].[SEmployees]
SET [Title]=N' Senior Sales Representative'
WHERE [EmployeeID]=1
END TRANSACTION
Синхронизация кэша. Если обновления осуществлены, состояние кэша синхронизируется с новым состоянием базы данных. Таким образом, если необходимо, этап обработки мини-запроса осуществляется для преобразования нового модифицированного реляционного состояния в его соответствующую сущность и состояние объекта.
МЕТАДАННЫЕ
Подсистема метаданных аналогична каталогу базы данных и спроектирована, чтобы удовлетворять нуждам метаданных в цикле проектирования и рабочем цикле архитектуры сущностей.
Компоненты метаданных
Компоненты метаданных могут включать в себя, например, следующее.
Концептуальная схема (CSDL-файлы). Концептуальная схема может быть определена в CSDL-файле (язык определения концептуальной схемы) и содержит EDM-типы (типы сущностей, отношения) и множества сущностей, которые описывают концептуальное представление данных приложения.
Схема хранилища (SSDL-файлы). Информация о схеме хранилища (таблицы, столбцы, ключи и т.д.) может быть выражена, используя термины словаря CSDL. Например, EntitySets обозначают таблицы, и свойства обозначают столбцы. Они могут быть заданы в SSDL-файле (язык определения схемы хранения).
Спецификация C-S-отображения (MSL-файл). Отображение между концептуальной схемой и схемой хранилища фиксируется в спецификации отображения, типично в MSL-файле (язык спецификации отображения). Эта спецификация используется компилятором отображения для создания представлений запроса и обновления.
Указание поставщика. Указание поставщика может предоставлять описание функциональных возможностей, поддерживаемых каждым поставщиком, и может включать в себя следующую примерную информацию.
1. Примитивные типы (varchar, int и т.д.), поддерживаемые поставщиком, и EDM-типы (string, int32 и т.д.), которым они соответствуют.
2. Встроенные функции (и их сигнатуры) для поставщика.
Эта информация может использоваться синтаксическим анализатором Entity SQL как часть анализа запроса. В дополнение к этим компонентам подсистема метаданных может также продолжать отслеживать классы сформированных объектов и преобразования между ними и соответствующими типами концептуальных сущностей.
Архитектура служб метаданных
Метаданные, используемые архитектурой сущностей, могут происходить из различных источников в различных форматах. Подсистема метаданных может быть построена на наборе однообразных интерфейсов метаданных низкого уровня, которые разрешают рабочему циклу метаданных работать независимо от подробностей различных постоянных форматов/источников метаданных.
Примерные службы метаданных могут включать в себя:
Перечисление различных типов метаданных.
Поиск метаданных по ключу.
Просмотр/передвижение в метаданных.
Создание переходных метаданных (например, для обработки запроса).
Кэширование независимых метаданных в сеансе и повторное использование.
Подсистема метаданных включает в себя следующие компоненты. Кэш метаданных кэширует метаданные, получаемые от различных источников, и предоставляет клиентам общий API, чтобы получать и управлять метаданными. Так как метаданные могут быть представлены в различных формах и хранятся в различных местах, подсистема метаданных может преимущественно поддерживать интерфейс загрузчика. Загрузчики метаданных реализуют интерфейс загрузчика и отвечают за загрузку метаданных из соответствующего источника (CSDL/SSDL-файлы и т.д.). Рабочее пространство метаданных группирует несколько частей метаданных для предоставления полного набора метаданных приложению. Рабочее пространство метаданных обычно содержит информацию о концептуальной модели, схеме хранилища, объектных классах и отображениях между этими конструкциями.
СРЕДСТВА
В одном варианте осуществления архитектура сущностей может также включать в себя набор средств цикла проектирования для увеличения производительности разработки. Примерными средствами являются.
Проектировщик моделей. Одним из начальных этапов в разработке приложения является определение концептуальной модели. Архитектура сущностей разрешает проектировщикам приложения и аналитикам описывать основные идеи своего приложения в терминах сущностей и отношений. Проектировщик моделей является средством, которое разрешает интерактивно осуществлять эту задачу концептуального моделирования. Компоненты проекта фиксируются непосредственно в компоненте метаданных, которые могут постоянно хранить свое состояние в базе данных. Проектировщик моделей может также формировать и использовать описания данных (заданных через CSDL) и может синтезировать EDM-модели из реляционных метаданных.
Проектировщик отображений. Если EDM-модель спроектирована, разработчик может задавать, как концептуальная модель отображается в реляционную базу данных. Эта задача облегчается проектировщиком отображений, который может представлять пользовательский интерфейс, как проиллюстрировано на фиг.8. Проектировщик отображений помогает разработчикам описать, как сущности и отношения в сущностной схеме, представленной с левой стороны пользовательского интерфейса, отображаются в таблицы и столбцы в базе данных, как отражено в схеме базы данных, представленной на правой стороне пользовательского интерфейса на фиг.8. Связи на диаграмме, представленные в средней части фиг.8, визуализируют выражения отображений, заданные декларативно как равенства запросов Entity SQL. Эти выражения становятся вводом в компонент компиляции двунаправленного отображения, который формирует представления запроса и обновления.
Формирование кода. Концептуальная модель EDM достаточна для многих приложений, так как она предоставляет знакомую модель взаимодействия на основе шаблонов кода ADO.NET (команды, связи, считыватели данных). Однако многие приложения предпочитают взаимодействовать с данными как с объектами со строгим контролем типов. Архитектура сущностей включает в себя набор средств формирования кода, который воспринимает EDM-модели как ввод и создает CLR-классы со строгим контролем типов для типов сущностей. Средства формирования кода могут также формировать контекст объектов со строгим контролем типов (например, AdventureWorksDB), который раскрывает совокупности со строгим контролем типов для всех множеств сущностей и отношений, определенных моделью (например, ObjectQuery<SalesPerson>).
Дополнительные аспекты и варианты осуществления
Службы отображения
В одном варианте осуществления компонент отображения, например 114 на фиг.1, управляет всеми аспектами отображений и используется внутренне клиентским поставщиком 111 сущностей. Отображение логически задает трансформацию между конструкциями в двух потенциально различных пространствах типов. Например, сущность - в концептуальном пространстве, поскольку этот термин использован выше, - может быть задана в терминах таблиц базы данных в пространстве хранения, как графически проиллюстрировано на фиг.8.
Установленные отображения являются теми, где система автоматически определяет подходящие отображения для конструкций. Неустановленные отображения позволяют проектировщикам приложения управлять различными аспектами отображения. Отображение может иметь несколько аспектов. Конечные точки отображения (сущности, таблицы и т.д.), набор отображенных свойств, поведение обновления, эффекты рабочего цикла, например задержка загрузки, поведение при разрешении конфликтов при обновлениях и т.д. являются только частичным списком подобных аспектов.
В одном варианте осуществления компонент 114 отображения может создавать представления отображения. Рассмотрим отображения между пространством хранения и пространством схемы. Сущность сформирована из строк из одной или более таблиц. Представления запросов выражают сущность в пространстве схемы как запрос в терминах таблиц в пространстве хранения. Сущности могут быть материализованы с помощью оценки представлений запросов.
Когда необходимо отразить изменения множества сущностей обратно в соответствующие таблицы хранилища, изменения могут быть распространены обратным образом через представления запросов. Это аналогично задаче обновления представлений в базах данных - процесс распространения обновлений логически осуществляет обновления через инверсное(ые) представление(я) запросов. Для этой цели предлагается концепция представлений обновления - эти представления описывают таблицы хранилища в терминах объектов и могут быть рассмотрены как инверсные представления запросов.
Однако во многих случаях, в чем мы действительно заинтересованы, так это в инкрементных изменениях. Представления обновлений с дельтой являются представлениями (запросами), которые описывают изменения в таблицах в терминах изменений в соответствующих совокупностях сущностей. Обработка обновлений для совокупностей сущностей (или прикладных объектов), следовательно, содержит вычисления соответствующих изменений таблиц с помощью оценки представлений обновления с дельтой и затем применение этих изменений к таблицам.
Аналогичным образом представления запросов с дельтой описывают изменения для совокупностей сущностей в терминах изменений низлежащих таблиц. Недостоверность и более широко уведомления являются сценариями, которые могут требовать использование представлений запросов с дельтой.
Как и с представлениями в базах данных, представления отображений, выраженные как запросы, могут быть затем сформированы с помощью пользовательских запросов, что приводит к более общей обработке отображений. Аналогично, представления отображений с дельтой, выраженные как запросы, допускают более широкий и лучший подход к обновлениям обработки.
В одном варианте осуществления возможности представлений отображений могут быть ограничены. Конструкции запросов, используемые в представлении отображений, могут быть только подмножеством всех конструкций запросов, которые поддерживаются архитектурой сущностей. Это разрешает более простые и более эффективные выражения отображений - особенно в случае выражений с дельтой.
Представления с дельтой могут быть вычислены в компоненте 114 отображений по схеме вычисления алгебраического изменения для создания представлений обновления (и запроса) с дельтой из представлений обновления (и запроса). Дополнительные аспекты схемы вычисления алгебраического изменения рассмотрены позже.
Представления обновления с дельтой разрешают архитектуре сущностей поддерживать обновления с помощью автоматической трансляции изменений сущностей, выполняемых вычислительными приложениями в обновлениях на уровне хранилища в базе данных. Во многих случаях отображение должно быть расширено дополнительной информацией для производительности и/или целостности данных.
В некоторых случаях прямое отображение обновлений сущностей в некоторые или все из низлежащих таблиц хранилища может быть нежелательно. В таких случаях обновления должны быть внесены с помощью хранимых процедур, чтобы допустить проверку достоверности данных для поддержания доверительных границ. Отображение допускает спецификации хранимых процедур для обработки обновлений и запросов по сущностям.
Отображение может также предоставлять поддержку для оптимистичного контроля параллелизма в объектных службах 131. Конкретно, свойства сущности могут быть помечены как поля контроля параллелизма, например временные отметки или поля версий, и изменения этих объектов последуют только, если значения полей контроля параллелизма в хранилище такие же, как в сущности. Следует заметить, что поля оптимистичного контроля параллелизма не являются единственно значимыми ни на уровне прикладного объекта, ни на уровне 120, зависящем от хранилища.
В одном варианте осуществления проектировщики приложений могут использовать язык спецификации отображений (MSL) для описания различных аспектов отображений. Типичная спецификация отображения содержит один или более из следующих разделов.
1. Область данных может содержать описания классов, таблиц и/или EDM-типов. Эти описания могут описывать существующие классы/таблицы/типы или могут использоваться для формирования таких экземпляров. Значения, сформированные сервером, ограничения, первичные ключи и т.д. задаются как часть этого раздела.
2. Раздел отображения описывает фактические отображения между пространствами типов. Например, каждое свойство сущности EDM задается посредством одного или более столбцов из таблицы (или множества таблиц).
3. Область рабочего цикла может задавать различные куски, которые управляют исполнением, например параметры оптимистичного контроля параллелизма и стратегию выборки.
Компилятор отображения
В одном варианте осуществления компонент 172 отображения средств моделирования области может содержать компилятор отображений, который компилирует спецификации отображений в представление запроса, представление обновления и соответствующие представления с дельтой. Фиг.9 иллюстрирует компиляцию MSL для формирования представлений запроса и обновления.
Конвейер компиляции осуществляет следующие этапы.
1. Генератор 902 представления, вызываемый из API 900, транслирует информацию 901 отображения объект ↔ сущность (заданную посредством MSL) и производит представление запроса, представление обновления и соответствующие (запроса и обновления) выражения 904 с дельтой в пространстве О↔Е (объект в сущность). Эта информация может быть размещена в хранилище 908 метаданных.
2. Генератор 906 представления транслирует информацию 903 отображения сущность ↔ хранилище (заданную посредством MSL) и производит представление запроса, представление обновления и соответствующие (запроса и обновления) выражения 907 с дельтой в пространстве Е↔S (сущность в хранилище). Эта информация может быть размещена в хранилище 908 метаданных.
3. Компонент 909 анализа зависимостей проверяет представления, созданные генератором 906 представления и определяет порядок 910 согласующихся зависимостей для обновлений, который не нарушает ссылочной целостности и другие подобные ограничения. Эта информация может быть размещена в хранилище 908 метаданных.
4. Представления, выражения с дельтой и порядок 908 зависимостей затем проходят через компонент служб метаданных (112 на фиг.1).
Обработка обновления
Этот раздел описывает конвейер обработки обновления. В одном варианте осуществления архитектура сущностей может поддерживать два вида обновлений. Однократные изменения объектов являются изменениями, сделанными для индивидуальных объектов во время перемещения по графу объекта. Для однократных изменений объекта система отслеживает объекты, которые были созданы, обновлены и удалены в текущей транзакции. Это доступно только на уровне(ях) объектов. Изменения на основе запросов являются изменениями, осуществляемыми выпуском утверждения обновления/удаления на основе объектного запроса, например, как сделано в реляционных базах данных для таблиц обновления. Поставщики объектов, например 131 на фиг.1, могут быть сконфигурированы для поддержки однократных изменений объекта, но не изменений на основе запросов. Клиентский поставщик 111 сущностей, с другой стороны, может поддерживать изменения на основе запросов, но не однократные изменения объекта.
Фиг.10 предоставляет иллюстрацию обработки обновления в одном примерном варианте осуществления. На фиг.10 пользователь 1001 приложения на прикладном уровне 1000 может сохранить изменения 1002 для данных, управляемых таким приложением. На уровне 1010 поставщика объектов перечень изменений компилируется 1011. Группировки 1012 изменений осуществляется по перечню изменений. Обработка 1013 ограничений может производить информацию ограничений и модель 1022 зависимостей, которая сохраняется в хранилище 1017 метаданных. Расширенные операции выполняются 1014. Выражение контроля параллелизма формируется 1015, и модель 1023 параллелизма может быть сохранена в хранилище 1017 метаданных. Преобразователь 1016 объект-сущность может сохранять выражения 1024 объект-сущность с дельтой в хранилище 1017 метаданных.
Дерево 1018 выражений сущностей передается вниз на уровень 1030 поставщика EDM. Выборочный разветвитель 1031 обновлений может выбрать конкретные обновления и разделить их, как необходимо. Преобразователь 1032 хранилища EDM может сохранять выражения 1033 объект-хранилище с дельтой в хранилище 1036 метаданных. Компонент 1035 разворачивания представления запроса может сохранять представления 1035 отображений запроса в хранилище 1036 метаданных. Осуществляется компенсация 1037 объект-хранилище, и дерево 1038 выражений хранилища передается на уровень 1040 поставщика хранилища.
На уровне 1040 поставщика хранилища сначала может работать компонент 1041 упрощения, за которым следует компонент 1042 формирования SQL, который формирует SQL-обновления 1043, которые должны выполняться в базе 1044 данных. Любые результаты обновления могут быть переданы в компонент 1039 в уровень 1030 поставщика EDM для обработки значений, сформированных сервером. Компонент 1039 может передавать результаты в аналогичный компонент на уровне 1021 поставщика объектов. В конечном итоге любое подтверждение 1003 результатов или обновления возвращается на прикладной уровень 1000.
Как описано выше, представления обновлений с дельтой сформированы как часть компиляции отображения. Эти представления используются в процессах обновления для идентификации изменений в таблицах в хранилище.
Для набора связанных таблиц в хранилище архитектура сущностей может выгодно использовать обновления в конкретном порядке. Например, существование ограничений внешнего ключа может требовать изменений, которые необходимо применять в конкретной последовательности. Фаза анализа зависимостей (часть компиляции отображения) идентифицирует любые требования по упорядочению зависимостей, которые могут быть вычислены в цикле компиляции.
В некоторых случаях методика статического анализа зависимостей может быть недостаточной, например при ограничениях циклической ссылочной целостности (или ограничений самоссылочной целостности). Архитектура сущностей принимает оптимистический подход и допускает прохождение таких обновлений. В рабочем цикле, если обнаружен цикл, поднимается исключение.
Как проиллюстрировано на фиг.10, конвейер обработки обновлений для обновлений на основе экземпляров на прикладном уровне 1000 имеет следующие этапы.
Группировка 1012 изменений. Сгруппировать изменения согласно различным совокупностям объектов из средства слежения за изменениями, например, все изменения для совокупности Персона группируются в множество вставок, удалений и обновлений для этой совокупности.
Обработка 1013 ограничений. Этот этап осуществляет любые операции, которые корректируют то обстоятельство, что никакая бизнес-логика не выполняется на уровне значений, по существу, он позволяет объектному уровню расширять набор изменений. Компенсация удаления каскадов и упорядочение зависимостей (для соответствия ограничений EDM) выполняются на этом этапе.
Выполнение 1014 расширенных операций. Дополнительные (например, удаление) операции выполняются так, чтобы могла выполняться соответствующая бизнес-логика.
Генератор 1015 выражений контроля параллелизма. Для того чтобы обнаружить, устарели ли модифицированные объекты, мы можем сформировать выражения, которые проверяют столбец временной метки или множество столбцов, как задано в метаданных отображения.
Преобразование 1016 объект - EDM. Списки изменений, заданные посредством множества вставок, удалений и обновлений объекта, теперь преобразуются, используя выражения отображения с дельтой, хранимые в хранилище 1017 метаданных, которые хранятся после компиляции отображения, описанной со ссылкой на фиг.9. После этого этапа изменения доступны как деревья 1018 выражений, выраженные только с помощью сущностей EDM.
Дерево выражений с этапа 1018 далее передается поставщику EDM на уровень 1030 поставщика EDM. У поставщика EDM дерево выражений обрабатывается, и изменения предоставляются в хранилище. Следует заметить, что это дерево 1018 выражений может также создаваться другим способом - когда приложение непосредственно программирует в отношении поставщика EDM, оно может выполнять утверждения DML в отношении него. Подобный оператор DML сначала преобразуется поставщиком EDM в дерево 1018 выражений EDM. Дерево выражений, полученное из утверждения DML или от прикладного уровня 1000, обрабатывается следующим образом.
Выборочный разветвитель 1031 обновлений. На этом этапе некоторые из обновлений разделяются на вставки и удаления. В общем, мы распространяем обновления, как они есть, на нижние уровни. Однако в определенных случаях может быть невозможно осуществлять подобные обновления либо потому, что правила выражений с дельтой не разработаны для тех условий, либо потому, что правильная трансляция фактически приводит к вставкам и/или удалениям в основные таблицы.
Отображение 1032 EDM - хранилище. Дерево 1018 выражений EDM-уровня транслируется в пространство хранения, используя выражения с дельтой из подходящего отображения.
Разворачивание 1034 представления отображения запроса. Дерево 1018 выражений может содержать некоторые концепции EDM-уровня. Для того чтобы их исключить, мы разворачиваем дерево выражений, используя представления 1035 отображения запроса для получения дерева только в терминах концепций уровня хранилища. Дерево 1038 дополнительно обрабатывается компонентом 1037 компенсации E-S.
Дерево 1038 выражений, которое теперь в терминах пространства хранения теперь отдается поставщику хранилища на уровне 1040 поставщика хранилища, которое выполняет следующие этапы.
Упрощение 1041. Дерево выражений упрощается с помощью использования логических правил трансляции выражений.
Формирование 1042 SQL. Если дерево выражений задано, поставщик хранилища формирует фактический SQL 1043 из дерева 1038 выражений.
Выполнение 1044 SQL. Фактические изменения осуществляются на базе данных.
Значения, сформированные сервером. Значения, сформированные сервером, возвращаются на уровень 1030 EDP. Поставщик 1044 передает значения, сформированные сервером, в компонент 1039 на уровне 1030, который транслирует их в концепции EDM, используя отображение. Прикладной уровень 1000 подбирает эти изменения 1003 и распространяет их на концепции объектного уровня, для установки в различные приложения и объекты, используемые на этом уровне.
Во многих случаях таблицы хранилища не могут быть непосредственно обновляемы из-за, например, политик администратора базы данных (DBA). Обновления в таблицах могут быть лишь возможны посредством хранимых процедур, чтобы могли быть выполнены определенные проверки достоверности. В таких ситуациях компонент отображения должен транслировать изменения объектов в вызовы этих хранимых процедур, а не выполнять “непосредственно” вставку, удаление и обновление утверждений SQL. В других случаях “хранимые” процедуры могут быть заданы в EDP 1010 или на прикладном уровне 1000 - в таких случаях компонент отображения должен транслировать модифицированные объекты в пространство EDM и затем вызвать подходящую процедуру.
Для того чтобы разрешить эти сценарии, MSL допускает задавать хранимые процедуры как часть отображения; кроме того, MSL также поддерживает механизмы для определения отображения различных столбцов базы данных в параметры хранимых процедур.
Уровень 1010 EDP поддерживает оптимистичный контроль параллелизма. Когда CDP отсылает множество изменений в хранилище, измененные строки могут быть уже модифицированы другой транзакцией. CDP должен поддерживать способ, чтобы пользователи могли обнаружить подобные конфликты и затем разрешать такие конфликты.
MSL поддерживает простые механизмы - временная отметка, номер версии, столбцы измененных столбцов - для обнаружения конфликтов. Когда конфликты обнаружены, поднимается исключение и конфликтующие объекты (или сущности EDM) доступны приложению для разрешения конфликта.
Примерные требования к отображению
Инфраструктура отображений может преимущественно предоставлять возможность транслировать различные операции из прикладного пространства в реляционное пространство, например объектные запросы, написанные разработчиком, транслируемые в реляционное пространство (хранения). Эти трансляции должны быть эффективными без чрезмерного копирования данных. Средство отображения может предоставлять трансляции для следующих примерных операций.
1. Запросы. Объектные запросы необходимо преобразовать в конечную реляционную область и записи, получаемые из базы данных, необходимо преобразовать в прикладные объекты. Следует заметить, что эти запросы могут быть запросами на основе множеств (например, CSQL или последовательности С#) или на основе перемещения (например, простое следование ссылкам).
2. Обновления. Изменения, сделанные приложением в его объектах, необходимо распространить обратно на базу данных. Кроме того, изменения, сделанные с объектами, могут быть объектами на основе множеств или отдельными объектами. Другим аспектом, который необходимо рассмотреть, это полностью ли загружаются модифицируемые объекты в память или частично (например, совокупность, ожидающая объект, может быть не представлена в памяти). Для обновлений в частично загружаемых объектах схемы, в которых нет необходимости полностью загружать эти объекты в память, могут быть предпочтительны.
3. Недостоверность и извещения. Приложения, выполняющиеся на среднем ярусе или клиентском ярусе, могут требовать уведомления, когда какие-либо объекты изменяются в конечных точках. Таким образом, компонент OR-отображения должен транслировать регистрацию на объектном уровне в реляционное пространство; аналогично, когда сообщения принимаются клиентом о модифицируемых записях, средство OR-отображения должно транслировать эти извещения в изменения объектов. Следует заметить, что WinFS поддерживает такие “извещения” посредством механизма слежения, однако в этом случае отображение установленное, тогда как архитектура сущностей должна поддерживать средства отслеживания по неустановленному отображению.
4. Механизм, аналогичный извещениям, также необходим для признания недействительными устаревших объектов из обработки архитектуры сущностей, выполняющейся на среднем или клиентском ярусе - если архитектура сущностей предоставляет поддержку для оптимистичного контроля параллелизма для обработки конфликтующих считываний/записей, приложения могут гарантировать, что данные, кэшированные в архитектуре сущностей, обоснованно новые (так, чтобы транзакции не прерывались из-за считываний/записей объектов); иначе они могут принять решения на старых данных и/или прервать свои транзакции позже. Таким образом, подобно извещениям, средство OR-отображения должно транслировать сообщения “недостоверности” от серверов базы данных в недостоверности объектов.
5. Резервное копирование/Восстановление/Синхронизация. Резервное копирование и зеркалирование множества Entities являются двумя признаками, которые могут быть включены в некоторые варианты осуществления. Требования для этих признаков могут просто транслироваться в специализированный запрос по Entities с позиции средства OR-отображения; иначе, может быть предоставлена специальная поддержка для таких операций. Аналогично, синхронизации может быть необходима поддержка от подсистемы OR-отображения для трансляции изменений объектов, конфликтов и т.д. в хранилище и наоборот.
6. Участие в контроле параллелизма. Средство OR-отображения может преимущественно поддерживать различные способы, с помощью которых может использоваться оптимистичный контроль параллелизма приложением, например, используя значение временной метки, некоторое конкретное множество полей и т.д. Средство OR-отображения должно транслировать информацию контроля параллелизма, например свойства временной метки в/из пространства объектов и из/в реляционное пространство. Средство OR-отображения может даже предоставлять поддержку для пессимистичного контроля параллелизма (например, как Hibernate).
7. Сообщение об ошибке рабочего цикла. В примерном варианте осуществления, проиллюстрированном в данном документе, ошибки рабочего цикла обычно происходят на уровне хранилища. Эти ошибки могут транслироваться в прикладной уровень. Средство OR-отображения может использоваться для облегчения трансляций этих ошибок.
Сценарии отображений
До того как мы рассмотрим примерные сценарии разработчика, которые может поддерживать архитектура сущностей, мы проиллюстрируем различные логические части средства OR-отображения. В одном варианте реализации существует пять частей в средстве OR-отображения, как проиллюстрировано на фиг.11.
1. Объекты/Классы/XML (также известное как прикладное пространство) 1101. Разработчик определяет классы и объекты на языке по выбору - в конечном счете, эти классы компилируются в сборки CLR и доступны через отражение API. Эти классы включают в себя постоянные и также непостоянные члены; кроме того, конкретные языковые подробности могут быть включены в эту часть.
2. Сущностная схема модели данных (известная как концептуальное пространство) 1102. Пространство EDM используется разработчиком для моделирования данных. Как рассмотрено выше, спецификация модели данных выполняется посредством типов EDM, связи сущностей через ассоциации, наследования и так далее.
3. Схема базы данных (известная как пространство хранения) 1103. В этом пространстве разработчик определяет, как размечены таблицы; ограничения, например ограничения внешнего ключа и первичного ключа, также определяются здесь. Спецификация в этом пространстве может использовать преимущество признаков, зависящих от изготовителей, например вложенные таблицы, UDT и т.д.
4. Отображение 1104 объект-EDM. Отображение определяет, как различные объекты и сущности EDM относятся друг к другу, например, массив может быть отображен в ассоциацию один-ко-многим. Следует заметить, что нет необходимости, чтобы это отображение было тривиальным/идентичным, например, множество классов может отображаться в данный тип EDM или наоборот. Следует заметить, что может возникнуть или не возникнуть избыточность/денормализация в этих отображениях (естественно, с денормализацией возможно столкнуться с проблемами сохранения согласованности объектов/сущностей).
5. Отображение 1105 EDM-хранилище. Это отображение определяет, как сущности EDM и типы относятся к различным таблицам в базе данных, например, различные стратегии отображения наследования могут быть использованы здесь.
Разработчик может определять одно или более пространств 1101, 1102 или 1103 и соответствующие отображения между одним или более отображениями между ними. Если какое-либо пространство отсутствует, разработчик может задать подсказки, как сформировать это пространство или ожидать от EDP формирования этих пространств автоматически, с соответствующими установленными отображениями. Например, если разработчик определяет существующие классы, таблицы и отображение между ними, EDP формирует внутреннюю схему EDM и соответствующие отображения объект-EDM и EDM-хранилище. Естественно, в самом общем случае разработчик может иметь полный контроль и определять модели данных в этих трех пространствах вместе с двумя отображениями. Таблица ниже показывает различные сценарии, поддерживаемые в EDP. Это исчерпывающий перечень случаев, где разработчик может определять или не определять объекты, сущности EDM, таблицы.
В зависимости от вышеуказанных сценариев, которые EDP требует поддерживать, мы должны предоставлять средства для создания незаданных пространств данных и отображений (установленным образом или на основе подсказок, если они предоставлены). Внутренняя подсистема OR-отображений предполагает, что все 5 частей отображения (объекты, спецификации EDM, таблицы, ОЕ-отображение, ES-отображение) являются доступными. Таким образом, проект отображения должен поддерживать наиболее общий случай, т.е. (G) в вышеуказанной таблице.
Язык спецификаций отображений
Одной из “видимых” частей средства OR-отображения с точки зрения разработчика является язык спецификаций отображений или MSL - разработчик определяет, как различные части отображения связаны друг с другом, используя этот язык. Контроль рабочего цикла (например, вставка задержки, элементы оптимистичного контроля параллелизма) также определяются, используя MSL.
Мы разбиваем отображение на три различных концепции - каждая идея затрагивает отдельное значение процесса отображения. Следует заметить, что мы не утверждаем, сохраняются ли эти спецификации в единственном файле, множестве файлов или определяются с помощью внешнего репозитория (например, для спецификации данных).
1. Спецификация данных. В этой области разработчик может определять описания классов, описания таблиц и описания EDM. Эти описания могут быть предоставлены как описания для целей формирования, или они могут быть спецификациями для таблиц/объектов, которые уже существуют.
Спецификации объектов и таблиц могут быть описаны в нашем формате, или они могут быть импортированы из внешнего репозитория метаданных, используя какое-либо средство импорта.
Следует заметить, что спецификация значений, сформированных сервером, ограничений, первичных ключей и т.д. выполняется в этом разделе (например, в спецификации EDM ограничения определяются как часть спецификации типов).
2. Спецификация отображения. Разработчик определяет отображения для различных объектов, типов EDM и таблиц. Мы разрешаем разработчикам определять отображения объект-EDM, EDM-хранилище и объект-хранилище. Этот раздел пытается иметь минимальную избыточность со спецификацией данных.
Во всех трех случаях отображения (OS, ES и OE), мы определяем отображения для каждого класса либо “непосредственно” на верхнем уровне, либо “косвенно” внутри другого класса. В каждом отображении поле/свойство отображается в другое поле, скалярную функцию полей, компонент или множество. Для того чтобы допустить обновления, эти отображения необходимо сделать двунаправленными, т.е. переход от объекта в пространство хранения и обратно не должен потерять какую-либо информацию; мы можем также разрешить недвунаправленные отображения из условия, что объекты были бы только считываемы.
Отображения объект-EDM. В одном варианте реализации мы определяем отображение для каждого объекта посредством типов EDM.
Отображения EDM-хранилище. В одном варианте осуществления мы определяем отображение для каждого объекта посредством таблиц.
Преобразования объект-хранилище. В одном варианте осуществления мы определяем отображение для каждого объекта посредством таблиц.
3. Спецификация рабочего цикла. В одном варианте осуществления мы разрешаем разработчикам задавать различные куски, которые управляют исполнением, например параметры оптимистичного контроля параллелизма и стратегию выборки.
Здесь есть пример файла отображения для случая, где объект OPerson содержит множество адресов. Этот объект отображается в тип сущности EDM, и множество отображается в тип линейного множества. Данные сохраняются в двух таблицах - одна для лиц и другая для адресов. Как утверждалось ранее, нет необходимости для разработчика определять все объекты, типы EDM и таблицы - мы просто показываем случай (G) из вышеуказанной таблицы. Не предполагается, что спецификации описывают какой-либо определенный синтаксис; подразумевается, что они иллюстрируют и допускают проектирование системы по концепциям, раскрытым в данном документе.
Спецификации EDM
Мы определяем один тип CPerson сущности и линейный тип CAddress из условия, что каждый CPerson имеет совокупность элементов CAddress.
Спецификации хранилища
Мы определяем два типа SPerson и SAddress таблиц вместе с их ключами (tpid и taid).
Отображения объект-CDM
Следующее отображение для OPerson сообщает, что тип OPerson (объекта) отображается в сущность Cperson. Список после этого определяет, как отображается каждое поле OPerson - название отображается в название и совокупность addrs отображается в совокупность адресов.
Преобразования EDM-хранилище
Тип CPerson сущности EDM отображается в тип SPerson таблицы со своим ключом и атрибутами названия cname. InlineType CAddress отображается в SAddress простым образом. Следует заметить, что таблица SAddress может хранить внешний ключ в SPerson; это ограничение может быть определено в спецификации модели данных таблицы, не в отображении.
Спецификации рабочего цикла
Разработчик может потребовать определить, что оптимистичный контроль параллелизма по OPerson должен быть сделан по полям pid и наименований. Для OAddress он/она могут определять контроль параллелизма по полю состояний.
Обзор проекта отображения
Большинство технологий OR-отображения, например Hibernate и ObjectSpaces, имеют важный недостаток - они обрабатывают обновления относительно специальным образом. Когда изменения объектов необходимо поместить обратно в сервер, механизмы, используемые этими системами, обрабатывают обновления на основе каждого случая, таким образом ограничивая расширяемость системы. Так как поддерживаются больше случаев отображения, конвейер обновлений становится более сложным, и сложно сформировать отображения для обновлений. Так как система развивается, эта часть системы становится совершенно громоздкой для изменения, когда гарантируется, что оно корректно.
Для того чтобы избежать таких проблем, мы используем новый подход, где мы осуществляем процесс отображения, используя два типа “представлений отображения” - одно, которое поможет нам в трансляции запросов, и другое, которое помогает в трансляции обновлений. Как показано на фиг.12, когда спецификация 1201 MSL обрабатывается с помощью EDP, она формирует два представления 1202 и 1203 внутренним образом для выполнения основной подсистемы отображений. Как мы увидим позже, с помощью моделирования отображений посредством этих представлений мы можем усилить существующее знание технологии материализованного представления в реляционных базах данных, особенно мы используем преимущество методик поддержания инкрементного представления для моделирования обновлений правильным, изящным и расширяемым образом. Теперь рассмотрим эти два типа представлений отображения.
Мы используем понятие представлений отображения запросов или QMViews для отображения табличных данных в объекты и представления отображения обновлений или UMViews для отображения объектных изменений в обновлениях таблиц. Эти представления названы из-за (основной) причины, почему они созданы. Представление запроса транслирует объектные запросы в реляционные запросы и преобразует входящие реляционные записи в объекты. Таким образом, для отображения EDM-хранилище каждое QView показывает, как сконструирован тип EDM из различных таблиц. Например, если сущность Person создана из объединения двух таблиц Т_Р и Т_А, мы определяем Person посредством объединения этих двух таблиц. Когда запрос делается по совокупности Person, QMView для Person заменяет Person выражением в терминах Т_Р и Т_А; это выражение затем формирует соответствующий SQL. Затем запрос выполняется в базе данных; когда ответ принят от сервера, QMView материализует объекты из возвращенных записей.
Для того чтобы обработать обновления объектов, можно допустить пропускание изменений через QMViews и усиления технологии “обновления представления”, разработанной для реляционных баз данных. Однако обновляемые представления имеют множество ограничений на них, например, SQL Server не разрешает модифицировать множество основных таблиц с помощью обновления представления. Таким образом, вместо ограничения типов отображений, допускаемых в EDP, варианты осуществления изобретения усиливают другой аспект технологии материализованного представления, который имеет много меньше ограничений - поддержание представления.
Мы определяем представления отображения обновлений или UMViews для выражения каждой таблицы в системе посредством типов EDM, т.е. в некотором смысле UMViews являются инверсными от QMViews. UMView для табличного типа по границе EDM-хранилище представляет собой способ, с помощью которого различные типы EDM используются для создания столбцов с этим табличным типом. Таким образом, если мы определили, что тип объекта Person отображается в табличные типы Т_Р и Т_А, мы не только формируем QMView для типа Person в терминах Т_Р и Т_А, мы также формируем UMView, который задает, как может быть сконструирована строка Т_Р при заданном типе объекта Person (аналогично для Т_А). Если транзакция создает, удаляет или обновляет какие-либо объекты Person, мы можем использовать представления обновлений для трансляции подобных изменений из объектов во вставку SQL, утверждения обновления и удаления по Т_Р и Т_А - UMViews помогает нам в осуществлении этих обновлений, так как они сообщают нам, как реляционные записи получены из объектов (через CDM-типы). Фиг.13 и 14 показывают, на высоком уровне, как QMViews и UMViews используются в трансляции запроса и обновления.
При условии, что этот подход задан для моделирования таблиц как представлений на объектах, процесс распространения обновления объектов обратно в таблицы аналогичен для задачи поддержания представления, где объекты являются “основными отношениями” и таблицы являются “представлениями”. Существует большое количество литературы, которая обращается к задаче поддержания представления, и мы можем усилить ее для наших целей. Например, существует значительное количество работ, которые показывают, как инкрементные изменения основных отношений могут транслироваться в инкрементные изменения по представлениям. Мы используем алгебраический подход для определения выражений, необходимых для осуществления инкрементных обновлений по представлениям - мы ссылаемся на эти выражения как выражения с дельтой. Использование алгебраического подхода, что противопоставляется процедурному, для инкрементной поддержки представления является подходящим, так как он является более поддающимся оптимизации и упрощениям с обновлениями.
В общем, преимущества использования представлений отображения в основной подсистеме EDP включают в себя следующее.
1. Представления предоставляют значительные возможности и гибкость для выражения отображения между объектами и отношениями. Мы можем начать выражение с языка с ограниченным выражением представления в основной части подсистемы OR-отображения. Так как время и ресурсы позволяют, возможности представлений могут использоваться для изящного развития системы.
2. Известно, что представления формируются совершенно изящно с запросами, обновлениями и самими представлениями. Способность к формированию, особенно в отношении обновлений, была проблематичным элементом, с некоторыми из подходов OR-отображения, которые пробовались ранее. Принимая технологию на основе представлений, мы можем избежать подобных опасений.
Использование идеи представлений позволяет нам усиливать значительный массив работы, содержащийся в литературе по базам данных.
Архитектурное разделение на уровни для обновлений
Важный элемент для рассмотрения в осуществлении аспектов изобретения в том, что является возможностями языка отображения представления (или MVL), в которых выражены запрос и представления отображения обновлений. Почти с достаточной производительностью является захват всех неустанавливаемых отображений между объектами и EDM вместе с отображениями между EDM и хранилищем. Однако для MVL, который собственно поддерживает все нереляционные концепции CLR и EDM, необходимо спроектировать выражения с дельтой или правила обновления инкрементного представления для всех подобных конструкций. В частности, один примерный вариант осуществления может потребовать правил обновления для последующих нереляционных алгебраических операторов/концепций.
Составные типы - доступ к частям объектов, конструкторам записей, выравнивание, составные константы и т.д.
Совокупности - вложение и разложение, построение множества/выравнивание, перекрестное наложение и т.д.
Массивы/списки - упорядочение элементов не является реляционной конструкцией; очевидно, алгебра для упорядоченных списков является достаточно сложной.
Другие конструкции EDM и конструкции объектов в CLR/C#, которые необходимо смоделировать.
Возможно проектировать выражения с дельтой для инкрементных обновлений для этих конструкций. Основной проблемой с поддержкой большого набора конструкций собственно в MVL является то, что он может значительно усложнить основную подсистему. В одном варианте осуществления более желательным подходом может быть разделение системы на уровни из условия, что “основная подсистема отображения” обрабатывает простой MVL и затем накладывает нереляционные конструкции поверх этого ядра. Теперь мы рассмотрим подобный проект.
Наш подход для OR-отображения адресует вышеуказанную проблему к “разделению на уровни” - во время компиляции, мы сначала транслируем каждую нереляционную конструкцию в объекте, EDM и пространствах баз данных (WinFS поддерживает вложение, UDT и т.д.) в соответствующую реляционную конструкцию заданным образом и затем осуществляем запрашиваемые незаданные трансляции между реляционными конструкциями. Мы ссылаемся на этот подход как подход отображения представлений с разделением на уровни. Например, если класс CPerson содержит совокупность адресов, мы сначала транслируем эту совокупность в реляционную конструкцию как ассоциацию один-ко-многим и затем осуществляем запрашиваемую незаданную трансляцию в таблицах в реляционном пространстве.
Схема MVL
MVL разбивается на два уровня - первый, который имеет дело с фактическим неустановленным отображением в реляционных терминах и устанавливающей трансляцией нереляционных конструкций в реляционные термины. Предыдущий язык упоминается как R-MVL (для реляционного MVL), и соответствующие отображения называются R-MVL-отображениями; аналогично, последний (более производительный) язык упоминается как N-MVL (нереляционный MVL), и отображения называются N-MVL-отображениями.
В одном варианте осуществления отображение предусматривается с помощью структурирования проекта из условия, чтобы все нереляционные конструкции проталкивались в окончания конвейеров запросов и обновлений. Например, материализация объектов может включать в себя конструирование объектов, массивов, указателей и т.д. - подобные “операторы” выталкиваются наверх конвейера запросов. Аналогично, когда происходят обновления объектов, мы транслируем изменения нереляционных объектов (например, вложенные совокупности, массивы) в начале конвейера и затем распространяем эти изменения с помощью конвейера обновлений. В системах, подобных WinFS, нам необходимо транслировать в конце конвейера обновлений в UDT.
Ограничивая неустановленные отображения в R-MVL, теперь у нас появляется небольшой набор реляционных конструкций, для которого нам необходимы правила поддержки инкрементного представления - подобные правила уже разработаны для реляционных баз данных. Мы ссылаемся на упрощенные конструкции/схемы, которые допустимы в R-MVL как реляционно-выраженная схема или RES. Таким образом, когда некоторые нереляционные конструкции необходимо поддержать (скажем) в объектной области, мы предлагаем соответствующую конструкцию RES и заданную трансляцию между объектом и конструкцией RES, например, мы транслируем совокупность объектов в ассоциацию один-ко-многим в пространстве RES. Кроме того, для того чтобы распространить обновления на нереляционные конструкции N, мы предлагаем выражения с дельтой, которые транслируют вставки, удаления и обновления от N до N-соответствующей конструкции RES. Следует заметить, что эти выражения с дельтой заданы и сформированы нами во время проектирования, например, мы знаем, как протолкнуть изменения в совокупность по ассоциации один-ко-многим. Выражения с дельтой для фактических неустановленных отображений формируются автоматически, используя правила поддержания инкрементного представления для реляционных баз данных. Эта разделенная на уровни методология не только удаляет требование предложения обобщенных правил поддержания инкрементного представления для избытка нереляционных конструкций, но также упрощает внутренний конвейер обновлений.
Следует заметить, что наш подход отображения с разделением на уровни имеет также аналогичную выгоду по конвейеру уведомлений - когда изменения записей принимаются от сервера, нам необходимо транслировать их в инкрементные изменения объектов. Это то же самое требование, как и конвейер обновлений, исключая то, что нам необходимо использовать представления отображения запросов для распространения этих изменений, т.е. мы формируем выражения с дельтой для QMViews.
Кроме упрощения конвейера обновлений и уведомлений, разделение MVL на уровни имеет важное преимущество - оно допускает “языкам верхнего уровня” (объекты, EDM, база данных) развиваться без значительного воздействия на основную подсистему отображений. Например, если новая концепция добавляется к EDM, все, что нам необходимо сделать, это предложить заданный способ отображения его в соответствующую RES для этой конструкции. Аналогично, если нереляционная концепция присутствует в SQL Server (например, UDT, вложение), мы можем транслировать эти конструкции в MVL заданным образом и получить минимальное воздействие на MVL и основную подсистему. Следует заметить, что трансляция между RES-хранилице и таблицами хранилища не обязательно является идентичной трансляцией. Например, в системах вычислительных машин баз данных (например, вычислительная машина WinFS базы данных), которые поддерживают UDT, вложения и т.д., трансляция аналогична заданным отношениям объектов.
Фиг.15 иллюстрирует цикл компиляции и рабочий цикл обработки представлений отображений. При заданной модели данных и спецификациях отображений в MSL, как проиллюстрировано 1501, 1502 и 1503, мы сначала формируем соответствующие RES 1521, 1522 и 1523 для нереляционных конструкций 1511, 1512, 1513 и установленные трансляции между этими конструкциями и RES, т.е. отображения N-MVL. Затем мы формируем представления отображения запросов и обновлений, объект-EDM в R-MVL и EDM-хранилище в R-MVL для неустановленных отображений, запрашиваемых разработчиком, следует заметить, что эти представления отображений действуют по RES, используя язык R-MVL. С этой точки зрения, мы формируем выражения с дельтой (выражения поддержания представления) для представлений отображений запросов и обновлений - такие правила разработаны для реляционных конструкций. Следует заметить, что выражения с дельтой для QMViews необходимы с целью уведомлений. Для преобразований N-MVL выражения с дельтой определяются нами в цикле проектирования, так как эти отображения устанавливаются, например, когда мы отображаем совокупность Address в ассоциацию один-ко-многим, мы также проектируем соответствующие выражения поддержания представления.
При указанных выше представлениях и трансляциях (N-MVL и R-MVL) мы можем сформировать их, чтобы получить представления отображений запросов, которые могут выражать объекты 1531 посредством таблиц в хранилище 1533, и представления отображений обновлений, которые могут выражать таблицы 1533 посредством объектов 1531. Как показывает фиг.15, мы можем выбрать поддержание представлений отображения из условия, что объекты EDM в 1532 не полностью исключены из отображения для рабочего цикла - возможной причиной для сохранения этих представлений является допущение определенных видов оптимизации запросов, которые пользуются преимуществом ограничений EDM. Естественно, это не означает, что мы действительно сохраняем объекты EDM в рабочем цикле.
Фиг.16 показывает, как различные компоненты достигают процесса компиляции представления, описанного выше. Приложения вызывают API 1600. Генераторы 1601, 1603 представлений отвечают за три функции: трансляция нереляционных конструкций в конструкции RES, формирование представлений запросов/обновлений и формирование выражений с дельтой для распространения обновлений и уведомлений. Они могут использовать метаданные 1602 в выполнении этих функций. Компоновщик 1605 представлений ОЕ принимает информацию от объектов и EDM и компонует ее из условия, чтобы мы имели алгебраические выражения объектов посредством типов EDM; аналогично, компоновщик 1606 представлений ES создает алгебраические выражения типов EDM посредством таблиц. Мы компонуем эти представления дополнительно в компоновщике 1607 представлений OS и получаем единый набор представлений в хранилище 1608 метаданных. Как рассмотрено выше, мы может сохранять два набора представлений для возможностей вероятной оптимизации запросов. В конечном счете компонент 1604 анализа зависимостей может также действовать на выводе генератора представлений ES для предоставления порядка зависимости хранилищу 1608 метаданных.
Сущность компиляции отображения
Для того чтобы подвести итог для каждой спецификации М класса, типа EDM или таблицы, мы формируем соответствующие RES и установленные трансляции между М и соответствующей RES. Таким образом, мы формируем следующее, как проиллюстрировано на фиг.15.
1. RES, соответствующая М - обозначена как RES-CDM(M), RES-объект(М) или RES-хранилище(М).
2. Установленная трансляция для выражения каждой спецификации М посредством отношений RES.
3. Установленная трансляция для выражения такого отношения RES посредством М.
4. Представления отображения запросов. Существуют два таких представления - OE QMViews выражают объекты посредством типов EDM и ES QMViews, которые выражают типы EDM посредством хранилища (таблиц).
5. Представления отображения обновлений. Существуют два таких представления - OE UMViews выражают типы EDM посредством объектов и ES UMViews, которые выражают таблицы хранилища посредством типов EDM.
6. Для инкрементного поддержания обновлений мы также формируем выражения с дельтой по UMViews.
После компоновки этих представлений мы заканчиваем четырьмя отображениями. Эти отображения сохраняются в хранилище 1608 метаданных и вместе упоминаются как скомпилированные представления отображений.
Отображения запросов. Выражают объекты/CDM посредством CDM/таблиц.
Отображения обновлений. Выражают таблицы/CDM посредством CDM/объектов.
Выражения с дельтой для обновлений. Выражают дельты по таблицам/CDM посредством дельт по CDM/объектам.
Выражениям с дельтой для уведомлений. Выражают дельты по объектам/CDM посредством дельт по CDM/таблицам.
Порядок зависимости. Порядок, в котором различные операции вставки, удаления, обновления должны осуществляться по различным отношениям - этот порядок гарантирует, что ограничения базы данных не нарушены во время процесса обновления.
Пример совокупности
Сейчас мы кратко показываем установленные трансляции и неустановленные отображения для примера Person, который мы рассматривали. Мы представляем как представления отображения запросов, так и обновлений - соответствующие выражения поддержания представления рассмотрены дополнительно ниже.
RESs
Мы транслируем OPerson в конструкцию RES R_OPerson, которая просто отражает название и pid; аналогично, мы транслируем OAddress в R_OAddress. Для того чтобы транслировать совокупность адресов, мы используем ассоциацию R_OPerson_Address один-ко-многим. Аналогично, то же самое для конструкций EDM. RES для таблиц (R_SPerson, R_SAddress) являются идентичными отображениями для SPerson и SAddress. Эти RES являются:
Представления преобразования запросов
Мы покажем отображение объект-хранилище (скомпонованное с помощью отображений объект-EDM и EDM-хранилище).
Неустановленные представления в пространстве RES
Отображения между объектом и пространством EDM являются по сути идентичными.
Все три представления R_CPerson, R_CAddress и R_CPerson_Address являются простыми проекциями по R_SPerson и R_Saddress.
Установленная трансляция (объекты посредством RES-объектов)
Объект Operson выражен, используя R_OPerson, R_OAddress и R_OPerson_Address, выполняя объединение R_OPerson_Address с R_OAddress и вложение результата.
SELECT pid name NEST (SELECT Address (a aid a state)
FROM R OAddress a R_OPerson_Address pa
Скомпонованное представление CPerson
Скомпонованное выражение после упрощения может быть (напоминаем, что у нас есть идентичная трансляция между таблицами и их RES-конструкциями для этого примера):
Конечное представление формулирует, что можно было получить, используя подход “непосредственного” отображения. Одно преимущество подхода RES проявляется, когда мы смотрим на выражения с дельтой для конвейера обновлений, и также в конвейере уведомлений, где нам необходимы выражения с дельтой для представлений отображений запросов.
Представления преобразования обновлений
Неустановленные представления в пространстве RES
UMView для R_SPerson является просто проекцией на R_CPerson, тогда как R_SAddress создается с помощью объединения R_CAddress с таблицей ассоциаций один-ко-многим - R_CPerson_Address. Отображение между CDM и пространством объектов является идентичным.
Установленная трансляция (RES-объекты посредством объектов)
Нам необходимо транслировать объекты в RESs так, чтобы обновления могли проталкиваться из пространства объектов в пространство RES. Установленная трансляция для R_OPerson является простой проекцией, тогда как трансляции для R_OAddress и R_OPerson_Address получены объединением между лицом и его адресами. Это “объединение указателей” или “объединение перемещения”.
Скомпонованные представления отображений обновлений
Мы компонуем вышеуказанные представления (и с некоторым упрощением), чтобы получить следующие скомпонованные представления отображения:
Таким образом, таблица SPerson может быть выражена как простая проекция на OPerson, тогда как SAddress получен с помощью объединения OPerson с его адресами.
Проверка достоверности представления
Важным свойством, которому должны удовлетворять сформированные представления - это то, что они должны "перемещаться в оба конца", т.е. чтобы предотвратить любую потерю информации, мы должны гарантировать, что, когда сущность/объект сохранен и затем извлечен, нет потери информации. Другими словами, мы хотим гарантировать для всех логических объектов/объектов D:
D=QMView(UMView(D))
Наш алгоритм формирования представления гарантирует это свойство. Если это свойство является истинным, мы также говорим, что “представления обновлений и запросов двусторонне перемещаются” или являются двусторонними. Теперь мы покажем это свойство для примера лицо-адрес. Для простоты мы сфокусируемся на двустороннем перемещении в пространстве RES.
Проверка достоверности для R_OPerson
Заменяя SPerson в представлении запроса для OPerson, мы получаем:
Мы упрощаем, чтобы получить
Это эквивалентно SELECT * FROM Person.
Проверка достоверности для OPerson__Address
Для R_OPerson_Address это немного более сложно. Мы имеем: R_OPerson_Address (pid, aid)=SELECT pid, aid FROM R_SAddress
Заменяя на R_SAddress, мы получаем:
Это упрощается как:
Для того чтобы показать, что вышеуказанное является действительно SELECT * FROM R_OPerson_Address, нам необходимо иметь зависимость внешнего ключа R_OPerson_Address. aid → R_OAddress.aid. Если эта зависимость не сохраняется, мы не можем перемещаться в оба конца. Она сохраняется, хотя так как интервалом свойства addrs с набором значений является R_OAddress. Это ограничение внешнего ключа может быть сформулировано двумя способами:
Замена этого ограничения в вышеуказанном выражении дает нам:
Проверка достоверности для адреса
R_OAddress указан как:
Заменяя на R_SAddress, мы получаем:
Это может быть переформулировано как:
Здесь объединение с R_OPerson_Address является избыточным, если зависимость R_OAddress.aid → R_OPerson_Address.aid внешнего ключа сохраняется. Эта зависимость сохраняется, только если R_OAddress является относящейся к действительности зависимости по R_OPerson (т.е. addrs является композицией). Если это не истина, тогда наши представления не переместятся в оба конца. Таким образом, мы имеем ограничение:
Таким образом, мы получаем следующее выражение:
Трансляция запроса
Транслятор запросов
Транслятор запросов EDP (EQT) отвечает за трансляцию запросов от объектного/EDM пространства в пространство поставщика с помощью использования метаданных отображения. Запросы пользователя могут быть выражены множеством синтаксисов, например eSQL, последовательности С#, VB SQL и т.д. Архитектура EQT показана на фиг.17. Теперь рассмотрим различные компоненты EQT.
Синтаксический анализатор 1711 осуществляет синтаксический анализ с помощью синтаксического анализа пользовательского запроса, выраженного в одной из нескольких форм, включая eSQL, интегрированный в язык запроса (LINQ), последовательности С# и VB Sql. Любые синтаксические ошибки обнаруживаются и отмечаются в этот момент.
Для LINQ синтаксический анализ (и семантический анализ) интегрирован с фазами синтаксического анализа самого языка (С#, VB и т.д.). Для eSQL фаза синтаксического анализа является частью процессора запросов. Типично существует один анализатор синтаксиса на каждый язык.
Результатом фазы синтаксического анализа является дерево синтаксического анализа. Это дерево затем передается на фазу 1712 семантического анализа.
Компоновщик параметров и компонент 1712 семантического анализатора управляет параметрами в пользовательских запросах. Этот модуль отслеживает типы данных и значения параметров в запросе.
Фаза семантического анализа проверяет семантически достоверность дерева синтаксического анализа, произведенное на фазе 1711 синтаксического анализа. Любые параметры в запросе должны быть закреплены в этот момент, т.е. их типы данных должны быть известны. Любые семантические ошибки обнаруживаются и отмечаются здесь; если успешно, результатом этой фазы является семантическое дерево.
Следует заметить, что для LINQ, как упомянуто раньше, фаза семантического анализа интегрирована с фазами семантического анализа самого языка. Существует типично один семантический анализатор на каждый язык, так как существует одно синтаксическое дерево на каждый язык.
Фаза семантического анализа логически содержит следующее.
1. Разрешение имен. Все имена в запросе разрешаются в этот момент. Это включает в себя ссылки на размеры, типы, свойства типов, методы типов и т.д. Как побочный эффект, типы данных таких выражений также выводятся. Эта подфаза взаимодействует с компонентом метаданных.
2. Проверка типов и вывод. Выражения в запросе проверяются на типы, и результирующие типы выводятся.
3. Проверка достоверности. Другие виды проверки достоверности происходят здесь. Например, в процессоре SQL, если блок запросов содержит групповой условный оператор, эта фаза может использоваться для принудительного применения ограничения, что выборочный список может ссылаться только на групповые ключи или совокупные функции.
Результатом фазы семантического анализа является семантическое дерево. В этот момент запрос рассматривается как достоверный - никаких дополнительных семантических ошибок не должно происходить позже в любой момент времени во время компиляции запросов.
Фаза 1713 алгебраизации принимает результат фазы 1712 семантического анализа и преобразует его в вид, более подходящий для алгебраических трансформаций. Результатом этой фазы является дерево логических расширяемых операторов, известных как алгебраическое дерево.
Алгебраическое дерево основано на основных реляционных алгебраических операторах - выбор, проекция, объединение, соединения, и расширяет его с помощью дополнительных операций подобно вложению/обратному вложению и ключевой элемент/отмена ключевого элемента.
Фаза 1714 разворачивания представления транслятора запросов заменяет, возможно, рекурсивно выражения QMView для любых объектов, упоминаемых в пользовательском запросе. По окончании процесса трансляции представления мы получаем дерево, которое описывает запрос в терминах хранилища.
В случае объектного уровня разворачивание представления может быть выполнено в любом случае для пространства хранилища (в случае, когда мы имеем оптимизированное OS-отображение, сохраненное в хранилище метаданных) или дерево запросов может быть трансформировано на уровне EDM. В последнем случае нам необходимо принять это дерево и перенаправить его в компонент разворачивания представления с требованием, чтобы концепции EDM теперь транслировались в концепции хранилища.
Компонент 1715 трансформации/упрощения может зависеть от поставщика 1730, или альтернативным вариантом осуществления может быть исходный EDP-компонент, который может усиливаться различными поставщиками. Существует несколько причин для выполнения трансформаций на дереве запросов.
1. Оператор, проталкиваемый в хранилище. EQT проталкивает составные операторы (например, объединение, фильтрация, агрегирование) в хранилище. Иначе подобные операции должны быть реализованы в EDP. Уровень материализации значений EDP только осуществляет операции “нереляционной корректировки”, например вложение. Если мы не можем протолкнуть оператор X ниже узлов материализации значений в дереве запросов и уровень материализации значений не может осуществлять операцию X, мы объявляем запрос нелегальным. Например, если запрос имеет операцию агрегирования, которую нельзя протолкнуть поставщику, мы объявляем запрос нелегальным, так как уровень материализации значений не осуществляет какое-либо агрегирование.
Улучшенная производительность. Пониженная сложность запроса является важной, и мы хотели бы избежать отправки гигантских запросов в хранилище вычислительной машины базы данных. Например, некоторые из текущих запросов в WinFS являются очень сложными и занимают большой объем времени для выполнения (соответствующие запросы, написанные от руки, больше, чем порядок более быстрой величины).
Улучшенная возможность отладки. Более простые запросы также бы облегчили для разработчика отладку системы и понимание происходящего.
Модуль 1715 трансформации/упрощения может трансформировать часть или все алгебраическое дерево, представляющее запрос, в эквивалентные поддеревья. Следует заметить, что эти эвристические трансформации являются логическими, т.е. не выполнены, используя затратную модель. Вид логических трансформаций может включать в себя следующие примерные службы конкретного поставщика.
Выравнивание подзапроса (подзапросы представлений и вложенные подзапросы)
Исключение соединения.
Исключение и консолидация предикатов.
Перенос предикатов.
Общее исключение подчиненного выражения.
Отсечение проекций.
Трансформации вида: внешнее объединение -> внутреннее объединение.
Левая корреляция исключения.
Этот модуль 1731 формирования SQL является частью компонента 1730 поставщика, так как сформированный SQL является зависящим от поставщика. После упрощения алгебраическое дерево передается поставщику, который может дополнительно осуществлять трансформации, конкретные для поставщика, или упрощения до формирования подходящего SQL.
После того как запрос выполняется на сервере, результаты передаются EDP-клиенту. Поставщик 1730 раскрывает DataReaders, которые могут использоваться приложением для получения результатов как EDM-сущностей. Служба 1741 материализации значений может принять эти считыватели и преобразовать их в соответствующие сущности EDM (как новые DataReaders). Эти объекты могут быть получены приложением или новые DataReaders могут быть переданы в службу материализации объектов верхнего уровня.
EQT 1700 представляет собой материализацию как оператор в дереве запросов. Это допускает конвейер постоянной трансляции запросов для создания объектов в пространстве EDM, который может быть затем непосредственно передан пользователям, вместо требования специальных операций “вне полосы” для осуществления действительной материализации. Это также допускает осуществлять различную оптимизацию подобно частичному извлечению объектов, более легкую загрузку и т.д. по пользовательским запросам.
Пример запроса
Рассмотрим пример лицо-адрес, который мы разрабатываем. Предположим, что пользователь желает осуществлять следующий запрос - найти всех лиц в WA. Мы можем записать этот запрос в псевдо-CSQL как:
Если мы осуществляем разворачивание представления, используя представление запросов для лица в этой точке, мы получаем:
Этот запрос может быть упрощен до отправки в сервер управления базой данных:
Метаданные
EQT требует различные части метаданных во время компиляции и выполнения запроса. Эти метаданные включают в себя
Метаданные прикладного пространства. Информация о расширениях/совокупностях, типах, свойствах типов, методах типов, необходимых во время семантического анализа для подтверждения достоверности пользовательских запросов.
Метаданные пространства схемы. Информация о совокупностях объектов, типов CDM и свойствах, необходимых во время компиляции представлений. Информация об отношениях между сущностями и ограничения сущностей для трансформаций.
Метаданные пространства хранилища. Как описано выше.
Отображения приложение -> схема. Дерево логических операторов, представляющее определение представления, необходимого для расширения представления.
Отображения схема -> хранилища. Как описано выше.
Конвейер сообщений об ошибках
Ошибки на различных уровнях обработки запросов должны сообщаться в понимаемых пользователями терминах. Различные ошибки цикла компиляции и цикла выполнения могут происходить во время обработки запроса. Ошибки во время синтаксического и семантического анализа в большинстве находятся на прикладном уровне и требуют очень мало специальной обработки. Ошибки во время отображений в большинстве являются ошибками ресурсов (вне памяти и т.д.) и нуждаются в некоторой специальной обработке. Ошибки во время формирования кода и последовательного выполнения запроса могут быть соответствующим образом обработаны. Ключевой проблемой в сообщении ошибок является отображение ошибок рабочего цикла, которые происходят на нижних уровнях, в ошибки, которые значимы на прикладном уровне. Это означает, что нам необходимо обработать ошибки нижнего уровня с помощью отображений хранения, концептуального и прикладных отображений.
Пример запроса
Наш пример запроса OO извлекает имена всех лиц, кто имеет адрес в Вашингтоне:
Этап 1. Преобразование в реляционные термины
Этот запрос может быть преобразован в последующий чисто реляционный запрос, выраженный в терминах или R_OPerson, R_OPerson_Address и R_OAddress. По существу, мы расширяем различные навигационные свойства (выражения с точкой “.”) в соединенные выражения, если необходимо.
Следует заметить, что запрос находится все еще в области объектов и в терминах расширения объектов.
Этап 2. Разворачивание представления. Преобразование в пространство хранилища
Теперь мы выполняем разворачивание представления для преобразования запроса в SQL:
Этап 3. Упрощение запроса
Теперь мы можем использовать серии логических трансформаций для упрощения этого запроса.
Теперь мы можем исключить избыточное самообъединение по первичному ключу SAddress (aid) и получить:
Все из вышеуказанного является в достаточной степени понятным. Теперь у нас есть запрос, который может отсылаться через SQL Server.
Обработка обновлений в цикле компиляции
EDP разрешает приложениям создавать новые объекты, обновлять их, удалять их и затем хранить эти изменения постоянно. Компоненту OR-отображения необходимо гарантировать, что эти изменения транслируются корректно в изменения хранилища вычислительной машины базы данных. Как рассмотрено раньше, мы используем представления отображений обновлений, которые объявляют таблицу в терминах объектов. Используя подобные представления, мы по существу снижаем проблему распространения обновлений в задаче поддержания материализованного представления, где изменения с основными отношениями необходимо распространять на представления; в случае UMViews "основными отношениями" являются объекты и "представления" являются таблицами. С помощью моделирования задачи таким образом мы можем усилить знание о технологии поддержания представления, которая разработана в области реляционных баз данных.
Формирование представления отображений обновлений
Как в случае запроса, много работы по отображениям обновлений выполняется в цикле компиляции. Вместе с реляционно выраженными схемами для классов, типов EDM и таблиц мы формируем установленные трансляции между этими типами и соответствующими конструкциями RES. Мы также формируем представления отображения обновлений между конструкциями RES классов и типами EDM между конструкциями RES типов EDM и таблицами хранилища.
Попробуем понять эти UMViews с помощью примера лицо-адрес, который мы разрабатываем. Повторение вызова конструкций RES для объектов R_OPerson, R_OAddress, R_OPerson_Address), которые были созданы.
Представления отображений обновления (RES таблиц посредством RES объектов)
UMView для R_OPerson является просто проекцией на R_SPerson, тогда как R_SAddress создается с помощью соединения R_OAddress с таблицей ассоциаций один-ко-многим - R_OPerson_Address.
Установленные трансляции (RES в терминах объектов)
Нам необходимо транслировать объекты в RES так, чтобы обновления могли проталкиваться из пространства объектов в пространство RES. Мы используем функцию “o2r” для трансляции адреса виртуальной памяти объекта в ключи pid и aid - в реализации мы можем просто получить ключи от теневого состояния объекта. Установленная трансляция для R_OPerson является простой проекцией, тогда как трансляции для R_OAddress и R_OPerson_Address получены, осуществляя объединение между лицом и его адресами.
Скомпонованные представления отображений обновлений
Мы компонуем вышеуказанные представления (и с некоторым упрощением), чтобы получить следующие скомпонованные представления отображений обновлений:
Таким образом, таблица SPerson может быть выражена как простая проекция по OPerson, тогда как SAddress получен с помощью соединения OPerson с его адресами.
Формирование выражения с дельтой
Когда приложение запрашивает, чтобы изменения его объекта были сохранены на вычислительную машину базы данных, варианты осуществления могут транслировать эти изменения в хранилище вычислительной машины базы данных, т.е. могут формировать выражения с дельтой для таблиц (представлений) в терминах выражений с дельтой объектов (основных отношений). Это область, где схема процесса формирования/компиляции представления в конструкциях RES действительно помогает. Выражения с дельтой для неустановленных отображений могут быть сформированы относительно легко, так как эти отображения находятся в реляционном пространстве (RES являются только реляционными), и много работы в реляционных базах данных выполнено для достижения этой цели. Например, в литературе по базам данных правила выражений с дельтой разработаны для представлений, которые выражены в терминах реляционных операторов, например выбора, проекций, внутренних или внешних полусоединений, объединений, пересечений и разностей. Для нереляционных конструкций все, что нам необходимо выполнить - это спроектировать заданные выражения с дельтой, которые преобразуют нереляционные конструкции в/из пространства RES.
Попробуем понять выражения с дельтой с нашим примером Person. Рассмотрим случай, где конструкция RES (например, R_SAddress) выражена как соединение двух совокупностей объектов (R_OAddress и R_OPerson_Address). Выражение с дельтой для такого представления может быть получено, используя следующие правила (предположим, что представление соединения равно V=R JOIN S):
В этом выражении i(X) и d(X) обозначают вставленные и удаленные записи для отношения или представления X, и Rnew обозначает новое значение основных отношений R после применения всех его обновлений.
Таким образом, чтобы облегчить обновления в рабочем цикле, один примерный вариант осуществления может сначала сформировать следующие выражения с дельтой во время компиляции.
1. Заданные выражения 1803 изменений с дельтой для отношений 1811 RES в терминах выражений изменений с дельтой для групп обновляемых совокупностей 1801 объектов, например i(R_OPerson) в терминах i(OPerson).
2. Заданные выражения 1804 изменений с дельтой для таблиц 1802 в терминах выражений изменений с дельтой для отношений 1812 RES, например i(SPerson) в терминах i(R_SPerson).
3. Выражения 1813 с дельтой для отношений RES таблиц, выраженных в терминах выражений с дельтой отношений RES объектов, например i(R_SPerson) в терминах i(R_O Person).
Мы можем сформировать (1), (2) и (3) для получения выражения 1820 с дельтой для таблиц 1822 (например, SPerson) в терминах выражений с дельтой для объектов 1821 (например, OPerson). Этот процесс иллюстрируется на фиг.18. Таким образом, как и в случае запросов, во время компиляции теперь мы имеем прямую трансляцию от объектов к таблицам. В случае обновлений мы действительно усилили схему RES для формирования выражений с дельтой (для QMViews это преимущество является применимым для уведомлений).
Следует заметить, что не нужно выражений с дельтой для обновлений - как мы увидим позже, обновления модели могут быть смоделированы с помощью их размещения в наборе вставок и удаления; этап последующей обработки позже повторно преобразует их обратно в обновления до того, как изменения действительно применяются к базе данных. Одной причиной для этого подхода является то, что существующие работы по поддержанию инкрементного представления типично не имеют выражений с дельтой для обновлений. Альтернативно более сложные варианты осуществления, в которых такие выражения разработаны, являются осуществимыми.
После того как формирование представления осуществлено, выражения с дельтой для таблиц могут быть только в терминах совокупностей объектов и наборов вставок и удаления объектов, например i(SPerson) в терминах OPerson, i(OPerson) и d(OPerson). Некоторым из этих выражений с дельтой может быть необходимо вычислить совокупности объектов, например i(OPerson) необходим EPerson для его вычисления. Однако общая совокупность не может быть помещена в кэш в клиенте EDP (или мы можем потребовать запустить операцию по наиболее непротиворечивому и последнему значению совокупности). Для того чтобы указать на эту проблему, мы развернем совокупности объектов, используя соответствующие представления отображений запросов, например, мы используем QMView для OPerson и выражаем его в терминах SPerson и других отношений, если необходимо. Таким образом, в одном варианте осуществления в конце процесса компиляции все выражения с дельтой для SPerson выражены в терминах i(OPerson), d(OPerson) и отношения самого SPerson - в рабочем цикле, при заданных наборах OPerson вставки и удаления, теперь мы можем сформировать релевантные операторы SQL, которые могут выполняться на сервере.
В резюме, при заданных QMViews и UMViews между конструкциями RES таблиц и объектов и заданных трансляций между этими конструкциями и таблицами/объектами следующие примерные этапы могут быть осуществлены.
1. Сформировать выражения с дельтой, упомянутые на этапах 1, 2 и 3 выше.
2. Скомпоновать эти выражения из условия, что мы имеем выражения с дельтой для таблиц (SPerson) в терминах выражений объектов (OPerson) с дельтой и самими совокупностями объектов.
3. Развернуть совокупности объектов, используя их QMViews для получения выражений с дельтой для таблиц (SPerson) в терминах выражений объектов с дельтой и самих таблиц, т.е. совокупности объектов исключены. Специальные случаи могут существовать, которые допускают варианты осуществления, чтобы избежать разворачивания, или знают о том, что общая совокупность помещается в кэш у клиента.
4. Упростить/оптимизировать выражение так, чтобы оно уменьшало время рабочего цикла.
В дополнение к конкретным вариантам осуществления, явно изложенным в данном документе, другие аспекты и варианты осуществления будут очевидны специалистам в данной области техники из рассмотрения спецификации, раскрытой в данном документе. Подразумевается, что спецификация и проиллюстрированные варианты осуществления рассматриваются только как примеры, с подлинным объемом и духом последующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСШИРЯЕМЫЙ ЯЗЫК ЗАПРОСОВ С ПОДДЕРЖКОЙ ДЛЯ РАСШИРЕНИЯ ТИПОВ ДАННЫХ | 2007 |
|
RU2434276C2 |
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| АНТИВИРУС ДЛЯ ХРАНИЛИЩА ЭЛЕМЕНТОВ | 2005 |
|
RU2393531C2 |
| Способ обработки поисковых запросов для нескольких реляционных баз данных произвольной структуры | 2019 |
|
RU2730241C1 |
| ОБЪЕДИНЕНИЕ МНОГОМЕРНЫХ ВЫРАЖЕНИЙ И РАСШИРЕНИЙ ГЛУБИННОГО АНАЛИЗА ДАННЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ КУБОВ OLAP | 2005 |
|
RU2398273C2 |
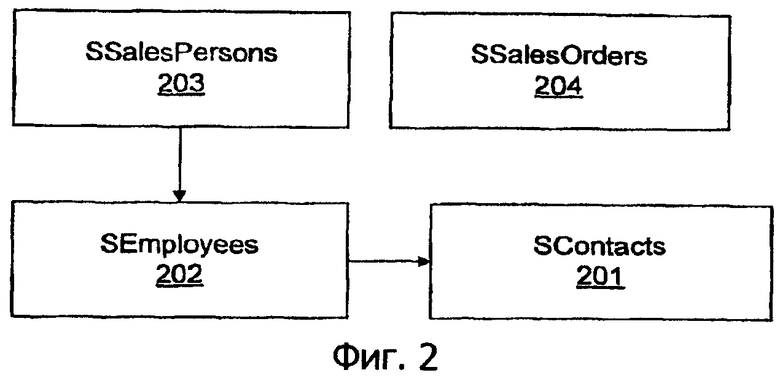
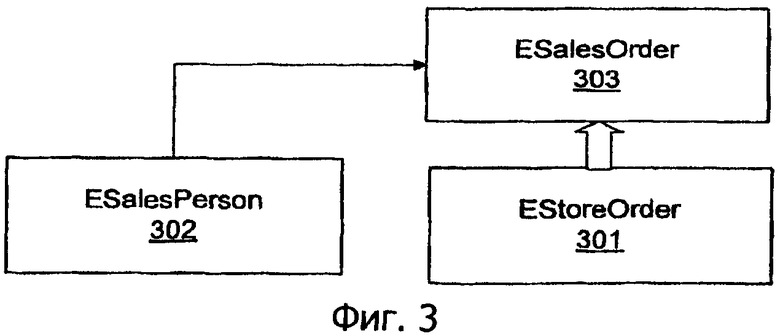
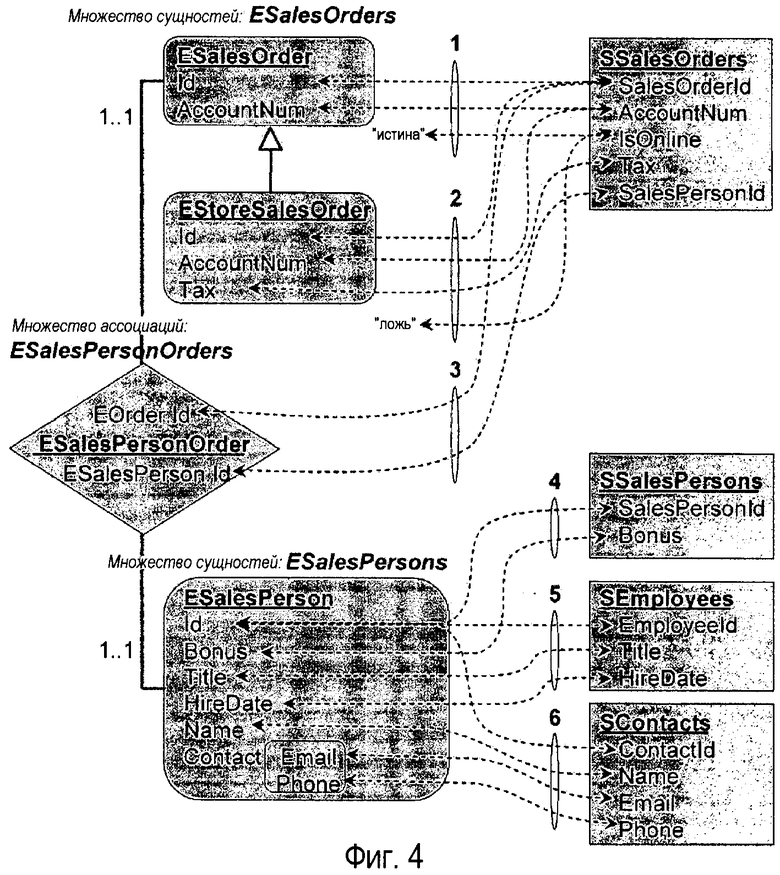

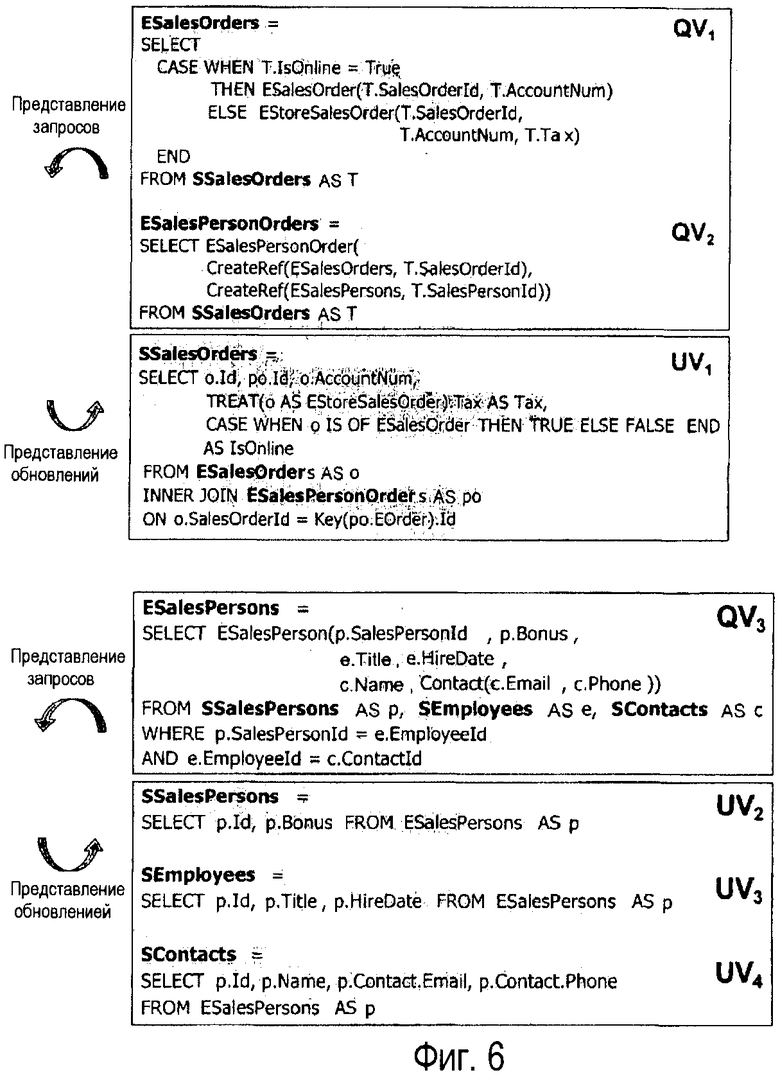
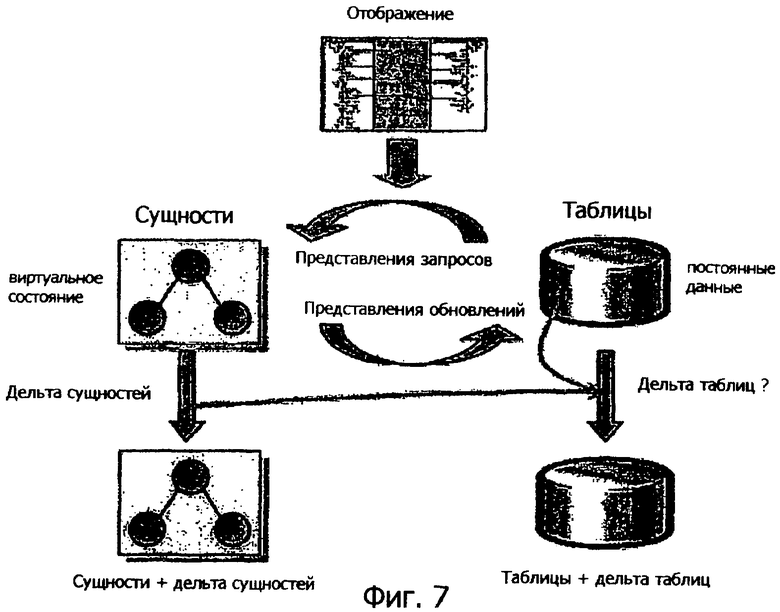
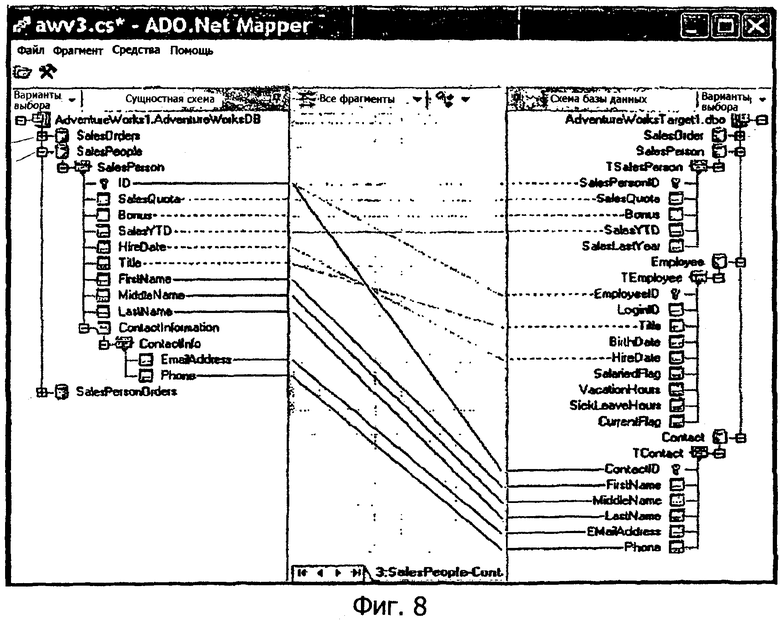
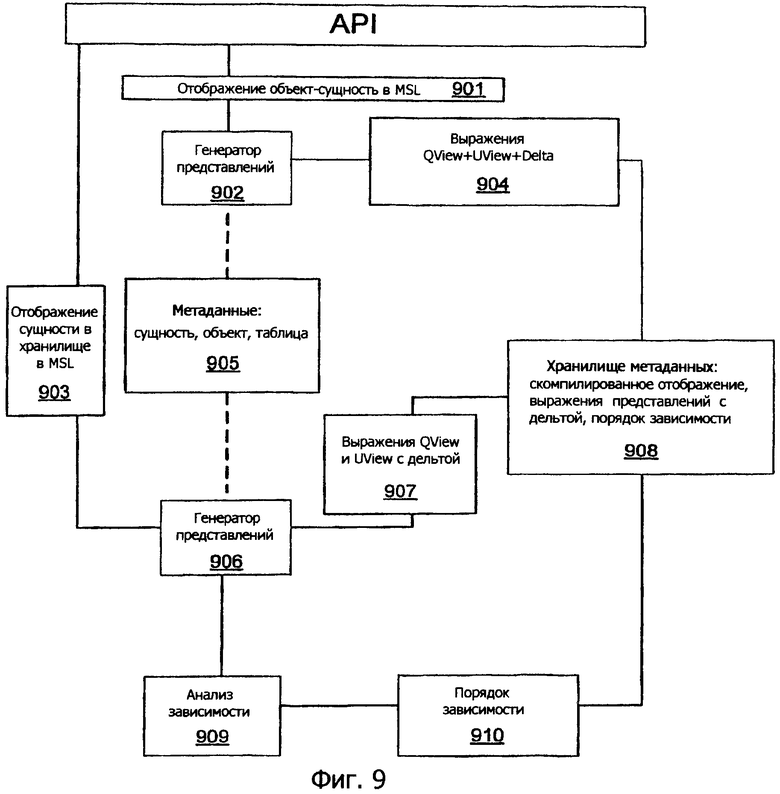
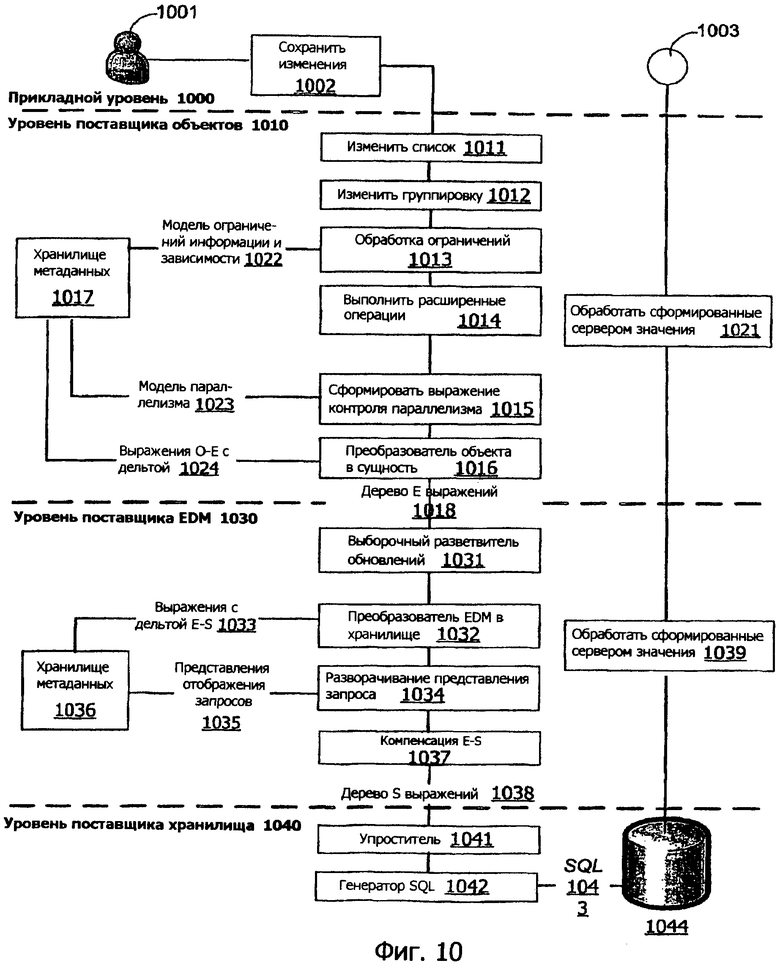
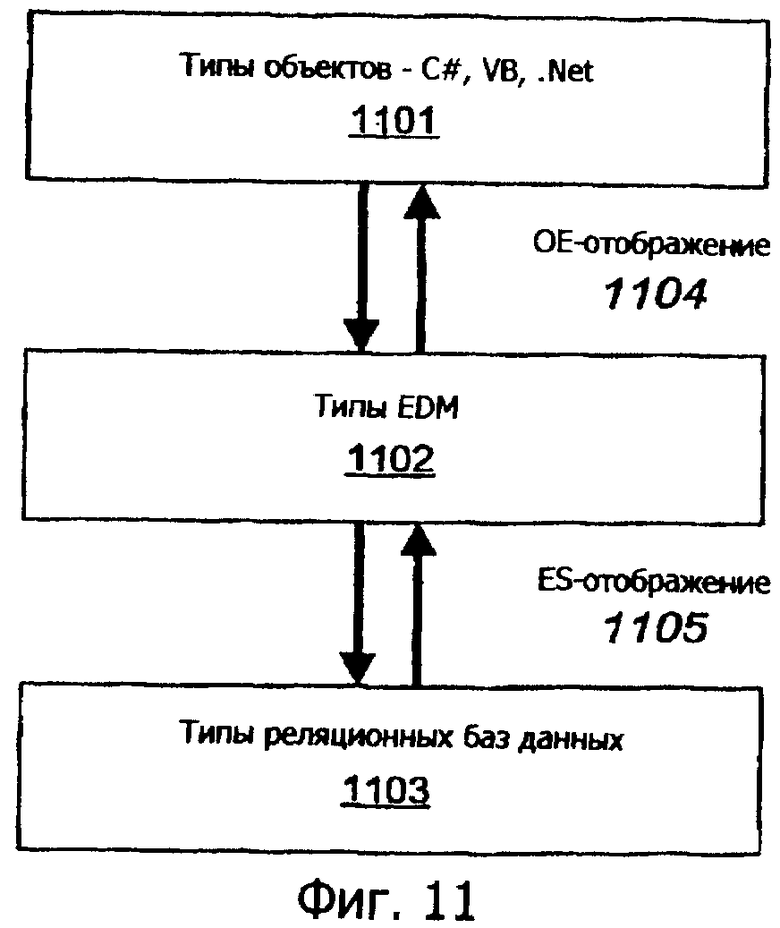
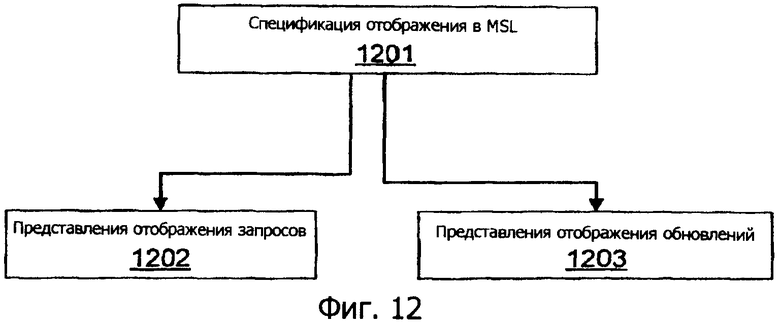
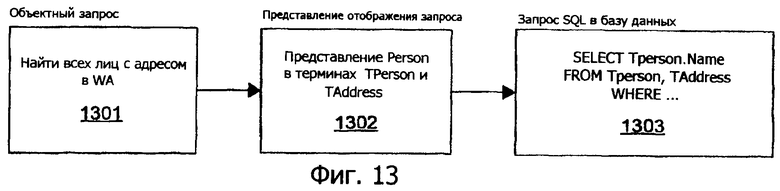
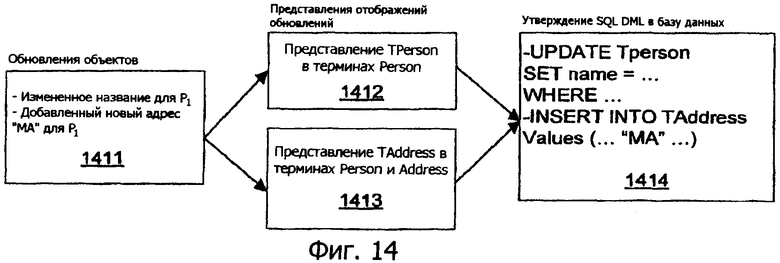
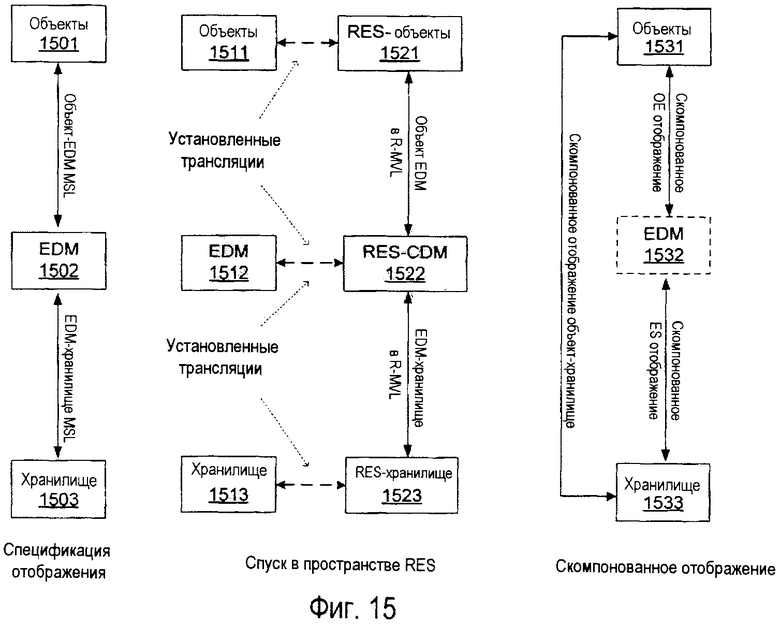
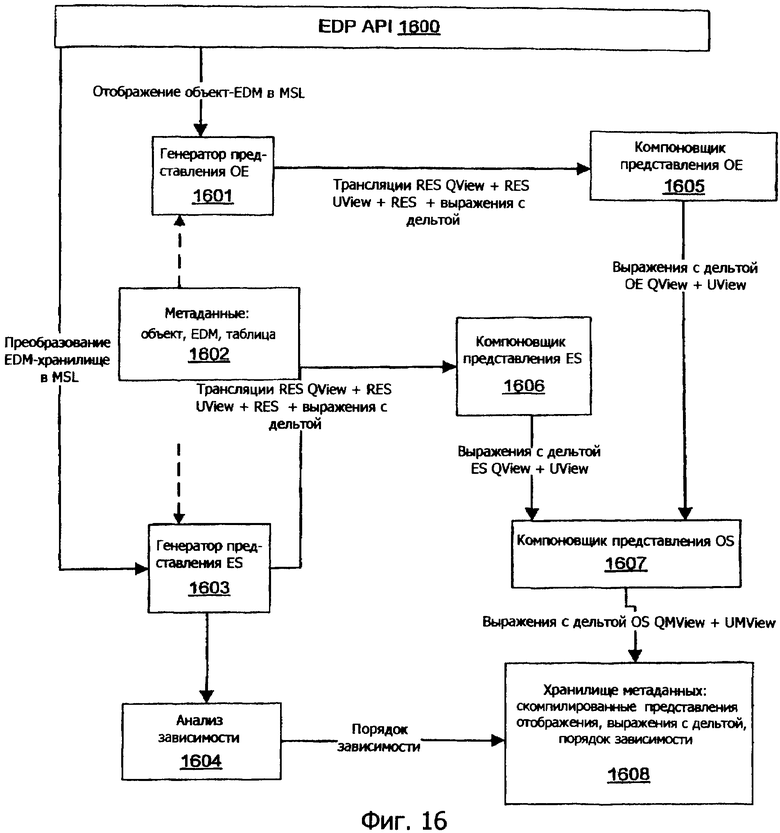
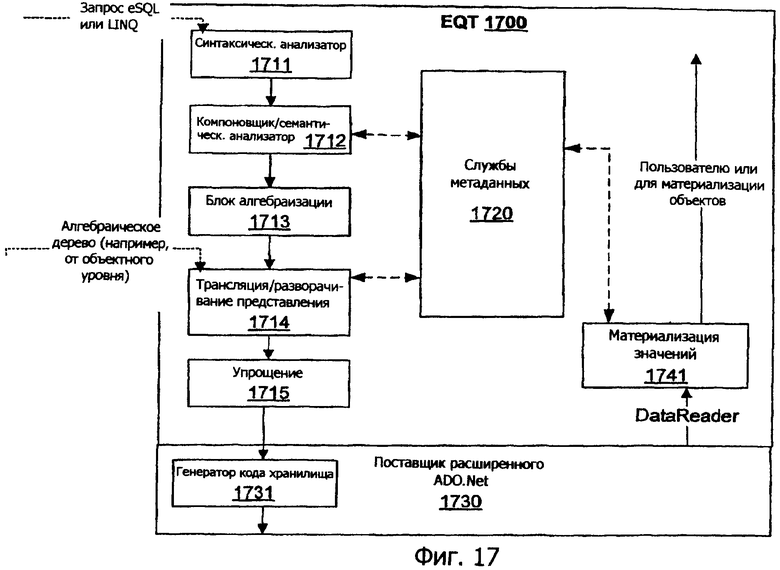
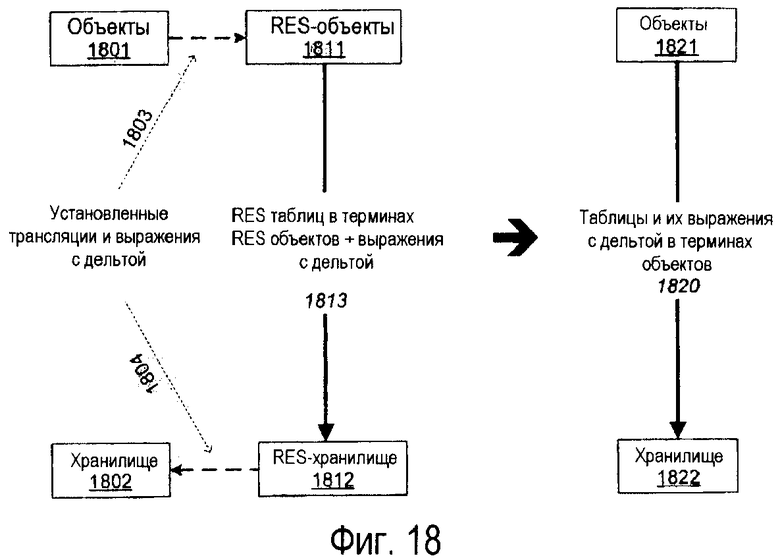
Изобретение относится к области доступа к данным. Техническим результатом является упрощение доступа к данным. Предоставлена архитектура доступа к данным, которая включает в себя архитектуру отображений для отображения данных, как может быть использовано приложением для данных, хранимых в базе данных. Архитектура отображений использует два типа представлений отображения - представление запроса, которое помогает в трансляции запросов, и представление обновлений, которое помогает в трансляции обновлений. Поддержание инкрементного представления может использоваться для трансляции данных между приложением и базой данных. 2 н. и 8 з.п. ф-лы, 18 ил., 1 табл.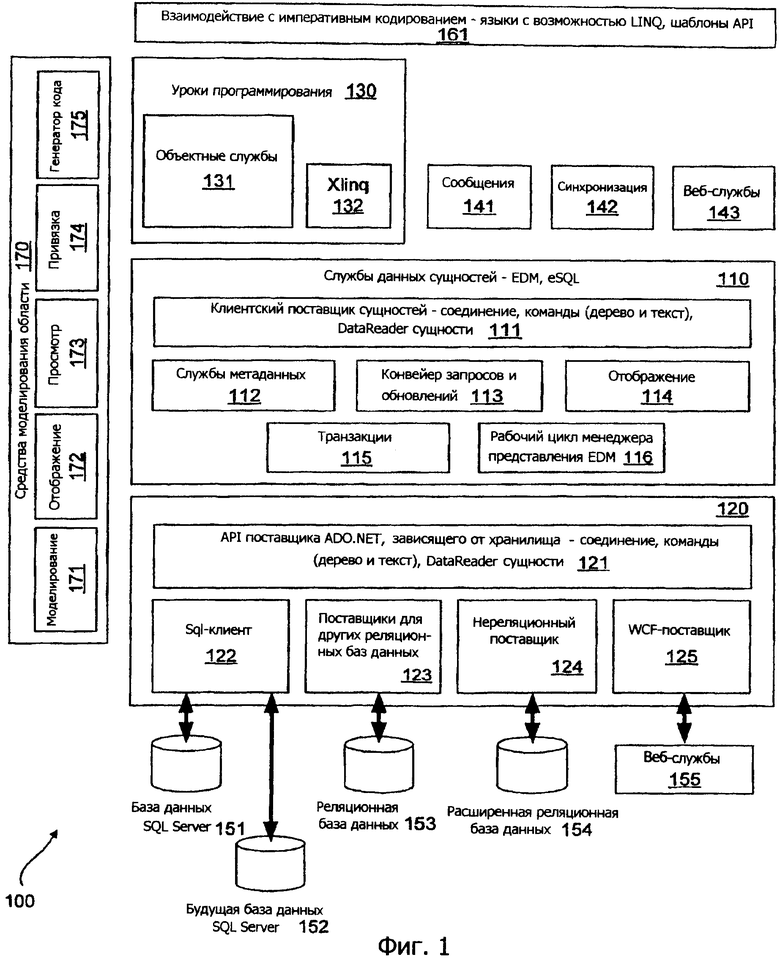
1. Способ предоставления служб данных приложению, содержащий этапы, на которых:
обеспечивают модель сущность-данные (EDM), которая расширяет классическую реляционную модель понятиями из области Сущность-Отношение, включающей в себя сущности, с которыми ассоциирована схема сущностей;
обеспечивают двунаправленное отображение на декларативном языке, который имеет строго определенную семантику, между схемой сущностей и реляционной схемой баз данных, ассоциированной с базой данных, причем это отображение представляется в терминах запросов по схеме сущностей и реляционной схеме баз данных;
компилируют, посредством компилятора отображений, схему сущностей, реляционную схему баз данных и упомянутое отображение для формирования представлений запроса и обновления, причем представление запроса выражает сущность как запрос в терминах таблиц базы данных, а представление обновления выражает таблицу базы данных в терминах сущностей, при этом компилятор отображений гарантирует, что все данные сущностей могут сохраняться и повторно собираться из базы данных без потерь;
транслируют пользовательский запрос, нацеленный на схему сущностей, посредством разворачивания представлений запроса в пользовательском запросе, чтобы запрашивать базу данных от имени запрашивающего приложения;
применяют алгоритм поддержания материализованного представления к представлению обновления для обновления базы данных от имени запрашивающего приложения.
2. Способ по п.1, дополнительно содержащий этап, на котором принимают от запрашивающего приложения одно или более из следующего:
объект на языке программирования, причем этот объект на языке программирования содержит данные для использования в обновлении базы данных,
инструкцию создания, вставки, обновления или удаления, причем эта инструкция создания, вставки, обновления или удаления содержит данные для использования в обновлении базы данных,
выражение на языке управления данными (DML), причем это выражение содержит данные для использования в обновлении базы данных.
3. Способ по п.2, в котором принимаются инструкции создания, вставки, обновления или удаления, при этом при применении алгоритма поддержания материализованного представления к представлению обновления создают выражение с дельтой для представления обновления, причем выражение с дельтой представляет собой выражение, требующееся для выполнения инкрементных изменений по данному представлению, при этом способ дополнительно содержит этап, на котором используют разворачивание представления для комбинирования упомянутого выражения с дельтой с представлением запроса.
4. Способ по любому одному из пп.1-3, в котором схема сущностей поддерживает сущности, отношения, наследование и составные типы.
5. Система доступа к данным для предоставления служб данных приложению, содержащая:
компонент для обеспечения модели сущность-данные (EDM), которая расширяет классическую реляционную модель понятиями из области Сущность-Отношение, включающей в себя сущности, с которыми ассоциирована схема сущностей;
компонент для обеспечения двунаправленного отображения на декларативном языке, который имеет строго определенную семантику, между схемой сущностей и реляционной схемой баз данных, ассоциированной с базой данных, причем это отображение представляется в терминах запросов по схеме сущностей и реляционной схеме баз данных;
компилятор отображений для компиляции схемы сущностей, реляционной схемы баз данных и упомянутого отображения для формирования представлений запроса и обновления, причем представление запроса выражает сущность как запрос в терминах таблиц базы данных, а представление обновления выражает таблицу базы данных в терминах сущностей, при этом компилятор отображений гарантирует, что все данные сущностей могут сохраняться и повторно собираться из базы данных без потерь;
компонент для трансляции пользовательского запроса, нацеленного на схему сущностей, посредством разворачивания представлений запроса в пользовательском запросе, чтобы запрашивать базу данных от имени запрашивающего приложения;
компонент для применения алгоритма поддержания материализованного представления к представлению обновления для обновления базы данных от имени запрашивающего приложения.
6. Система доступа к данным по п.5, дополнительно содержащая компонент для приема от запрашивающего приложения объекта на языке программирования, причем этот объект на языке программирования содержит данные для использования в обновлении базы данных.
7. Система доступа к данным по п.5, дополнительно содержащая компонент для приема от запрашивающего приложения инструкции создания, вставки, обновления или удаления, причем эта инструкция создания, вставки, обновления или удаления содержит данные для использования в обновлении базы данных.
8. Система доступа к данным по п.5, дополнительно содержащая компонент для приема от запрашивающего приложения выражения на языке управления данными (DML), причем это выражение содержит данные для использования в обновлении базы данных.
9. Система доступа к данным по п.8, в которой применением алгоритма поддержания материализованного представления к представлению обновления создается выражение с дельтой для представления обновления, причем выражение с дельтой представляет собой выражение, требующееся для выполнения инкрементных изменений по данному представлению, при этом система дополнительно содержит компонент для использования разворачивания представления для комбинирования упомянутого выражения с дельтой с представлением запроса.
10. Система доступа к данным по любому одному из пп.5-9, в которой схема сущностей поддерживает сущности, отношения, наследование и составные типы.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6058391 A, 02.05.2000 | |||
| US 6175837 B1, 16.01.2001 | |||
| RU 2004131666 A, 10.02.2006. | |||

