Изобретение относится к области защиты информации, хранимой в информационных системах персональных данных (ИСПДн), от несанкционированного доступа (НСД) и может быть использовано на стадиях разработки и оптимизации ИСПДн в защищенном исполнении.
Известен способ защиты от несанкционированного доступа к информации пользователя в системе обработки информации (патент RU №2309450, МПК G06F 12/14, дата приоритета 26.04.2006, дата публикации 27.10.2007) [1], основанный на том, что формирование сервисных служб системы обработки информации производится из доступного пользователю набора функциональных блоков, расположенных на различных серверах системы. Рабочая информация пользователя подвергается преобразованию, уникальному для каждого обращения пользователя к системе обработки информации, сведения о хранении учетной записи пользователя также подвергаются уникальному для данного случая преобразованию и сохраняются в других местах системы обработки информации. Недостатком известного технического решения является то, что выполнение указанных в способе требований влечет за собой значительные материальные затраты на внедрение дополнительных функциональных блоков.
Наиболее близким к предлагаемому изобретению по совокупности существенных признаков и принятым в качестве прототипа является способ защиты текстовой информации от несанкционированного доступа (патент RU №2439693, МПК G06F 21/24, дата приоритета 04.06.2010, дата публикации 10.01.2012) [2], использующий искажение в системах передачи данных без использования секретных ключей и пин-кодов. Способ включает: шифрование текстового сообщения А, его передачу, дешифрование принятого текстового сообщения А, предоставление восстановленного сообщения пользователю, при этом перед шифрованием на передающей стороне искажают исходное текстовое сообщение А с помощью известного пин-кода Р путем отображения -ого слова, где 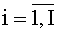
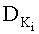

К недостаткам данного способа можно отнести то, что при большой размерности задачи приходится хранить большую таблицу возможных значений для кодирования, что понижает защищенность информации. При небольшом количестве слов в текстовой информации высока вероятность успешного применения метода полного перебора и получения исходного сообщения.
Задача, на решение которой направлено предлагаемое изобретение, заключается в разработке надежного способа деперсонализации персональных данных, позволяющего повысить уровень безопасности ИСПДн на стадиях разработки и оптимизации путем перемешивания персональных данных, относящихся к различным субъектам и снизить требования к уровню защищенности данных, сократив, тем самым, соответствующие расходы.
Сущность изобретения заключается в перемешивании персональных данных, хранящихся в ИСПДн, относящихся к различным субъектам. Данный способ обладает следующими преимуществами: персональные данные хранятся в одной информационной системе и значительно снижается вероятность успеха контекстного анализа.
В качестве исходных данных рассматривается таблица персональных данных D(d1, d2, …, dN), где N - число атрибутов, а M - число строк таблицы, множество данных Ai, относящееся к одному атрибуту - di(i=1, 2, …, N). Все элементы каждого множества пронумерованы.
Способ обеспечивает перемешивание данных каждого множества атрибутов исходной таблицы пошагово. На каждом шаге используется принцип циклических перестановок.
На первом шаге множество данных Ai, относящееся к одному атрибуту, разбивается на Ki (М>Ki>1) непересекающихся подмножеств, где число элементов подмножества Aij равно Mij(M>Mij>1), j=1, 2, …, Ki. Разбиение каждого множества должно обладать следующими свойствами:
1) подмножества разбиения включают все элементы множества данных одного атрибута;
2) каждое подмножество не пусто, а пересечение любых двух подмножеств пусто;
3) все элементы в подмножествах упорядочены как по внутренним номерам (номера элементов внутри подмножества), там и по внешней нумерации самих подмножеств в разбиении;
4) суммарное число элементов всех подмножеств множества данных одного атрибута равно общему числу элементов этого множества.
Для каждого подмножества из разбиения определяется циклическая перестановка (подстановка) pij(rij), в которой производится циклический сдвиг всех элементов подмножества на некоторое число, называемое параметром перестановки. Таким образом, перестановки для всех подмножеств множества данных одного атрибута можно задать набором (вектором) параметров этих перестановок. Данный вектор задает первый уровень способа перемешивания, т.е. перестановки первого уровня.
На втором шаге способа рассматривается циклическая перестановка второго уровня p0i(r0i), элементами которой выступают подмножества, состоящие из Ki элементов, из описанного ранее разбиения. В результате применения данной перестановки производится циклический сдвиг элементов на некоторую величину - параметр перестановки второго уровня.
В результате последовательного проведения перестановок первого и второго уровней (или одной результирующей перестановки pi(r0i, ri,)) получается перемешивание элементов множества данных одного атрибута так, что меняется нумерация этих элементов по отношению к исходной нумерации.
Доступность персональных данных (получение достоверных персональных сведений при легитимном обращении к ним) обеспечивается посредством решения обратного способа деперсонализации. Решением обратного способа деперсонализации является формирование исходной таблицы.
Для оценки защищенности предложенного способа деперсонализации используют такую характеристику, как число вариантов деперсонализации, получаемых при применении данного способа. При большом количестве записей число вариантов получается очень большим, что обеспечивает очень малую вероятность подбора параметров и соответственно хорошую защиту обезличенных данных.
В совокупности признаков заявленного способа используются следующие терминология и обозначения:
- запись в таблице - совокупность элементов множеств разных атрибутов с одинаковыми номерами, при этом в исходной таблице каждая запись имеет определенный смысл, связанный с конкретным субъектом (физическим лицом), т.е. содержит персональные данные конкретного лица, определенного в этой же записи;
- внешний номер mijk - номер элемента в подмножестве Aij, имеющего внутренний номер k, 1≤mijk≤M, т.е. mijk - это порядковый номер элемента во множестве Ai, соответствующий элементу с внутренним номером k;
- циклическая перестановка первого уровня - перестановка, в которой элементы первой строки матрицы, стоящей в правой части равенства, соответствуют внутренним номерам элементов подмножества Aij до перестановки (в исходной таблице), а элементы, стоящие во второй строке, соответствуют внутренним номерами элементов подмножества Aij, стоящим на местах, с номерами, определенными в верхней строке, после перестановки:

- параметр перестановки первого уровня rij - некоторое случайное число, задаваемое генератором случайных чисел (ГСЧ) в интервале [1; Mij-1];
- циклическая перестановка второго уровня - перестановка, в которой элементы верхней строки матрицы перестановки соответствуют исходным номерам подмножеств Aij, а элементы нижней строки матрицы соответствуют номерам подмножеств Aij, стоящим на местах с номерами, определенными в верхней строке, после перестановки:
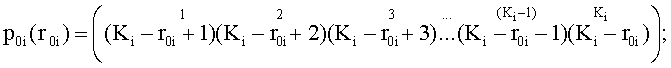
- параметр перестановки второго уровня r0i - некоторое случайное число, задаваемое генератором случайных чисел (ГСЧ) в интервале [1; Ki-1],
- результирующая перестановка - полученная с учетом правил перемножения перестановок первого и второго уровней перестановка, в которой верхняя строка матрицы содержит порядковые номера элементов множества атрибута i, в соответствии с их размещением в столбце после перестановок, а нижняя строка содержит внешние номера элементов множества этого атрибута, соответствующие их размещению в исходной таблице:

Применение данного способа позволяет обеспечить защиту персональных сведений от несанкционированного доступа, в том числе от компрометации информации при ее утечке по техническим каналам, а также обеспечить гарантированный доступ к персональным данным при легитимном обращении. При этом все персональные сведения хранятся в одной таблице, а их получение посредством контекстного анализа или путем перебора весьма трудоемко, а зачастую практически невозможно. Практическое применение данного способа является аналогом абонентского шифрования. Его реализация подразумевает, что персональные данные хранятся на постоянном запоминающем устройстве (ПЗУ) в деперсонализированном виде. При необходимости работы с персональными данными оператор применяет обратный алгоритм деперсонализации (запускает программу работы с персональными данными, реализующую прямой и обратный алгоритм). Следует отметить, что открытая (персонализированная) информация, с которой работает оператор, как правило, хранится в ОЗУ и только по завершении работы (или команде сохранения/синхронизации) записывается в файл в ПЗУ, где она хранится только в закрытом виде.
Эти отличительные признаки по сравнению с прототипом позволяют сделать вывод о соответствии заявляемого технического решения критерию «новизна».
Новое свойство совокупности существенных признаков, приводящих к существенному затруднению НСД к персональной информации, хранящейся и обрабатываемой в ИСПДн, путем перемешивания данных, относящихся к различным субъектам, позволяет сделать вывод о соответствии предлагаемого технического решения критерию «изобретательский уровень».
Предлагаемый способ защиты ПДн от НСД опробован в лабораторных условиях. Способ деперсонализации может быть реализован в виде программного обеспечения на языке программирования С#. Исходные данные могут подаваться на вход в виде текстового файла. Также возможна реализация, в которой данные на вход программы поступают непосредственно из информационной системы. Параметры разбиений исходных множеств данных могут задаваться как пользователем, так и программой, используя генератор случайных чисел (ГСЧ).
В результате работы программы пользователь получает деперсонализированные данные в той же форме, в которой они подавались на вход. Кроме того, создается файл, хранящий параметры перестановок и разбиений, который будут необходимы для решения обратного способа деперсонализации.
Для простоты описания работы устройства представим, что алгоритм перестановки, определенный для множества, соответствующего одному атрибуту, применяется ко всем множествам атрибутов исходной таблицы. В этом случае полный алгоритм перестановки задается следующим набором параметров:
1. (K1, K2, …, KN) - множество, определяющее количество подмножеств для множества каждого атрибута, которое определяет подмножества элементов 
2. 
3. ((r01, r1),(r02, r2), …, (r0N, rN)) - множество параметров перестановок для множества каждого атрибута. Этот набор задает параметры алгоритма деперсонализации для исходной таблицы D(d2, d2, …, dN).
В результате применения процедуры вместо исходной таблицы D(d2, d2, …, dN) получается таблица обезличенных данных 
Набор параметров:
C(D(d1, d2, …, dN))={(K1, K2, …, KN),
((r01, r1), (r02, r2), …, (r0N, rN))}
полностью и однозначно задает алгоритм деперсонализации для исходной таблицы D(d1, d2, …, dN).
Пусть исходная таблица D(d1, d2, …, dN) имеет вид (таблица 1):
Для этой таблицы заданы следующие параметры алгоритма деперсонализации:
C(D(d1, d2, d3, d4, d5, d6))
={(3,2,4,3,3,2), ((3,3,4), (6,4), (2,3,2,3), (3,4,3), (5,2,3), (3,7)),
((2, (1,2,3)), (1, (3,1)), (3, (1,2,1/1)), (2, (2,1,2)), (2, (4,1,1)), (1, (1/4)))}.
После выполнения алгоритма деперсонализации получаем таблицу 2 -
Как видно из примера, в результате применения алгоритма деперсонализации получена преобразованная таблица, в которой записи не соответствуют записям в исходной таблице, что обеспечивает достаточно высокую сложность восстановления исходной таблицы при отсутствии сведений о параметрах алгоритма деперсонализации.
Реализация предлагаемого способа не вызывает затруднений, так как блоки и узлы общеизвестны и широко описаны в технической литературе.
Таким образом, заявляемый способ деперсонализации персональных данных позволяет повысить уровень безопасности ИСПДн на стадиях разработки и оптимизации путем перемешивания персональных данных, относящихся к различным субъектам и снизить требования к обеспечению надлежащего уровня защищенности данных, сократив, тем самым, соответствующие расходы.
Источники информации
1. Патент RU №2309450 «Способ защиты от несанкционированного доступа к информации пользователя в системе обработки информации». G06F 12/14, дата приоритета 26.04.2006, дата публикации 27.10.2007.
2. Патент RU №2439693 «Способ защиты текстовой информации от несанкционированного доступа» МПК G06F 21/24, дата приоритета 04.06.2010, дата публикации 10.01.2012.
3. Куракин А.С. Алгоритм деперсонализации персональных данных // Научно-технический вестник информационных технологий, механики и оптики. СПб НИУ ИТМО, 2012. Выпуск №6.
4. Стенли Р. Перечислительная комбинаторика. М.: Мир, 1990. 440 с.
Изобретение относится к области защиты информации, хранимой в информационных системах персональных данных (ИСПДн), от несанкционированного доступа (НСД) и может быть использовано на стадиях разработки и оптимизации ИСПДн в защищенном исполнении. Техническим результатом является повышение уровня безопасности ИСПДн. Способ деперсонализации персональных данных обеспечивает защиту ИСПДн от НСД на стадиях разработки и оптимизации, оперирует персональными данными субъектов, хранящимися и обрабатываемыми в ИСПДН, и осуществляет двухэтапное перемешивание данных, относящихся к разным субъектам, используя перестановки первого и второго уровней, при этом на первом этапе исходное множество данных D(d1, d2, …, dN), где N - число атрибутов, разбивается на непересекающиеся подмножества данных Ai, относящихся к одному атрибуту di, а на втором этапе происходит непосредственно перестановка данных сначала внутри подмножеств Ai и затем элементами перестановки являются сами подмножества. При росте количества субъектов ПДн уменьшается вероятность подбора параметров деперсонализации, соответственно повышается защищенность ИСПДн. Разбиение исходного множества данных на подмножества позволяет сократить размерность задачи и упростить ее практическую реализацию. 1 з.п. ф-лы, 2 табл.
1. Способ деперсонализации персональных данных, заключающийся в производимом при передаче в оперативное запоминающее устройство преобразовании информации, составляющей по совокупности персональные данные, из постоянного запоминающего устройства путем выполнения двухэтапного перемешивания данных, относящихся к разным субъектам, используя перестановки первого и второго уровней, при этом на первом этапе исходное множество данных D(d1,d2,…,dN), где N - число атрибутов, разбивается на непересекающиеся подмножества данных Ai, относящихся к одному атрибуту di, и на втором этапе происходит непосредственно перестановка данных сначала внутри подмножеств Ai, а затем элементами перестановки являются сами подмножества; для представления ее пользователю и обратном преобразовании информации при ее записи - передаче из оперативного запоминающего устройства в постоянное запоминающее устройство.
2. Способ по п.1, отличающийся тем, что параметры разбиений исходных множеств данных задаются при помощи генератора случайных чисел.
| СПОСОБ ЗАЩИТЫ ТЕКСТОВОЙ ИНФОРМАЦИИ ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА | 2010 |
|
RU2439693C1 |
| СПОСОБ ЗАЩИТЫ ЧАСТНОЙ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМЕ ОБРАБОТКИ ИНФОРМАЦИИ | 2006 |
|
RU2309450C1 |
| УСТРОЙСТВО ЗАЩИТЫ ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА К ИНФОРМАЦИИ, ХРАНИМОЙ В ПЕРСОНАЛЬНОЙ ЭВМ | 2003 |
|
RU2263950C2 |
| US 7975149 B2, 05.07.2011 | |||
| US 8074283 B2, 06.12.2011 | |||

