Изобретение относится к области защиты информации, хранимой в информационных системах персональных данных (ИСПДн), от несанкционированного доступа, обезличиванием персональных данных, которые представлены в виде исходной таблицы.
В настоящем описании термины будут использоваться в следующем толковании.
Под структурированными персональными данными понимаются данные, содержащие информацию различного типа о субъекте, которая представлена в виде отдельных структурных единиц.
Под структурной единицей персональных данных понимается информация о субъекте определенного типа (возраст, номер паспорта, адреса и т.д.).
Под исходной таблицей персональных данных понимается таблица, каждая строка которой содержит персональные данные одного субъекта, соответствующие структурным единицам персональных данных, представленные в виде записей определенной формы.
Под атрибутом персональных данных понимается именованная структурная единица в исходной таблице персональных данных. Атрибут содержит множество однотипных структурных единиц персональных данных разных субъектов, представленных в виде столбца исходной таблицы персональных данных, имеющего название атрибута.
Под таблицей обезличенных персональных данных понимается таблица, размерность которой, состав атрибутов и семантика данных совпадают с размерностью и семантикой исходной таблицы персональных данных, но изменен состав строк таблицы, разрушены связи между типами персональных данных субъектов.
Известна Система и метод маскировки данных [US2004181670], которые предусматривают преобразование (маскировку) идентифицирующих персональных данных и представление их в таблице, структурно совпадающей с исходной таблицей персональных данных. Доступ к персональным данным предоставляется пользователям с установленными ролями (полномочиям) для обратного преобразования обезличенных данных. Недостатками данного способа являются:
- возможность косвенной идентификации субъекта персональных данных по не преобразованным данным, поскольку не все персональные данные преобразуются;
- отсутствие возможности обрабатывать персональные данные без предварительного обратного преобразования обезличенных данных (деобезличивания);
- необходимость непосредственного воздействия на персональные данные в исходной таблице для их преобразования, что может вызвать ошибки при прямом и обратном преобразованиях и нарушить целостность данных;
- необходимость разделять пользователей данных по предоставляемым им ролям (полномочиям), что усложняет работу с большим числом пользователей.
Известна Система и методы деидентификации записей в источнике данных [US7269578], которые предусматривают преобразование персональных данных в зависимости от требований к анонимности (безопасности) данных.
Недостатками способа являются:
- непосредственное воздействие на исходные персональные данные, что может привести к искажению информации на этапах прямого или обратного преобразований или отсутствию возможности обратного преобразования;
- сложности с установлением и изменением требований к анонимности данных, для различных пользователей;
- отсутствие возможностей обработки персональных данных с использованием обезличенных (искаженных) данных без предварительного деобезличивания.
Известна Система защищенной базы данных [EP0884670], основанная на разделении идентификационных и персональных данных субъектов и хранении их в различных таблицах и на различных носителях. Идентификационные данные вместе с ключами, связывающими различные таблицы, шифруются клиентами.
Недостатками способа являются:
- разделение данных по различным таблицам, снижающее надежность всей системы хранения и доступа, а также увеличивающее время обработки запросов к персональным данным;
- использование шифрования клиентами, что приводит к необходимости управления процессом управления ключами (создания и распределения, смена ключей);
- работа с зашифрованными данными усложняет процесс сопоставления данных в различных таблицах;
- невозможность поиска данных, связанных с различными субъектами, без предварительного дешифрования всех данных.
Наиболее близким к предложенному изобретению является способ деперсонализации персональных данных [RU2538913], заключающийся в том, что отдельные атрибуты персональных данных, размещенные в исходной таблице, разбиваются на подмножества (блоки), затем производится циклический сдвиг подмножеств, после чего в каждом подмножестве производится циклический сдвиг находящихся в нем элементов. В результате получается таблица деперсонализированных данных. Параметры циклических сдвигов являются случайными числами для каждого атрибута и составляют ключ преобразования таблицы.
Недостатками способа являются:
- слабое рассеивание элементов атрибута по всему множеству элементов атрибута, поскольку после преобразования все элементы остаются внутри своих подмножеств, что увеличивает вероятность обратного преобразования без знания ключа, при известных данных по множеству физических лиц, чьи персональные данные находятся в исходной таблице;
- ограниченное число возможных вариантов преобразования, связанное с использованием только циклических сдвигов;
- однократное проведение преобразований, не обеспечивающее высокий уровень защищенности обезличенных данных из-за относительно небольшого количества вариантов преобразований;
- ограничение на число записей в таблице, число записей должно быть очень большим для достижения хорошей стойкости к обратным преобразованиям;
- сложности при добавлении новых записей, связанные с необходимостью проводить деперсонализацию данных всей таблицы.
Основными отличиями заявляемого способа от наиболее близкого являются:
- возможность формирования структуры исходной таблицы персональных данных путем определения множества и состава атрибутов;
- отсутствие изменений внутри формируемых при разбиениях блоков персональных данных;
- возможность многоэтапного разбиения с перестановкой формируемых при разбиениях блоков персональных данных, когда количество этапов определяется применяемыми показателями качества преобразования и защищенности персональных данных;
- возможность применения перестановок, отличных от циклических сдвигов;
- возможность формирования ключей преобразований для каждого этапа.
Заявленный способ совпадает с наиболее близким по следующим показателям:
- проведение разбиения исходного множества персональных данных на непересекающиеся блоки;
- возможность, в виде частного случая, проведения циклических перестановок множества блоков атрибутов персональных данных.
Технической задачей, на решение которой направлено заявляемое техническое решение, является обеспечение хранения и обработки персональных данных в обезличенной форме при сохранении семантики данных исходной таблицы, возможность обработки запросов к обезличенным персональным данным в виде их номеров в составе атрибутов.
Техническим результатом, достижение которого обеспечивается реализацией способа, является повышение защищенности персональных данных, повышение безопасности хранимых в обезличенной форме структурированных персональных данных, обеспечение скорости и удобства их обработки без обратного преобразования в режиме реального времени.
Указанный технический результат достигается тем, что способ обезличивания структурированных персональных данных заключается в представлении данных в виде предварительно сформированной исходной таблицы, каждая строка которой содержит персональные данные одного субъекта, разделенные на множество атрибутов, соответствующих заданным единицам структуры персональных данных, и многоэтапном преобразовании каждого атрибута исходной таблицы, включающем разбиения множества элементов атрибута на блоки и перестановки блоков на каждом этапе, при этом состав и порядок внутриблоковых данных при преобразованиях не меняются, на сервере формируется и хранится множество ключей преобразования для всех этапов преобразования каждого атрибута, где каждый ключ содержит число блоков на каждом этапе, вектор элементов в каждом блоке и матрицу перестановки на каждом этапе, при этом преобразование атрибутов исходной таблицы выполняется с применением заданных ключей преобразований для каждого атрибута таким образом, что количество блоков для каждого атрибута и количество элементов в каждом блоке является уникальными для каждого атрибута и каждого этапа.
Кроме того, число этапов преобразования каждого атрибута исходной таблицы является неограниченным.
Кроме того, на сервере обезличивания формируется и хранится множество ключей преобразования для всех этапов преобразования каждого атрибута, где каждый ключ является уникальным и содержит информацию для преобразования на этапе.
Кроме того, исходная таблица персональных данных может быть получена из любой структурированной формы представления персональных данных, получаемой от удаленных источников, и иметь варьируемое количество атрибутов, не совпадающее с количеством структурных единиц в персональных данных, получаемых от удаленных источников, и обеспечивающее повышение защищенности таблицы обезличенных персональных данных, сохраняя семантику элементов атрибутов.
Кроме того, для увеличения защищенности данных исходная таблица персональных данных может создаваться на отдельном сервере и, по запросу, передаваться на сервер обезличивания, входящий в состав информационной системы персональных данных (ИСПДн), где формируются и хранятся ключи преобразований, после проведения обезличивания исходная таблица персональных данных уничтожается, так как возможно ее восстановление по таблице обезличенных персональных данных.
Кроме того, при преобразованиях элементы каждого атрибута перемещаются на всем множестве элементов атрибута, что обеспечивает более эффективную защиту от деобезличивания при прямом переборе вариантов и использовании множества известных персональных данных за счет увеличения количества возможных вариантов обезличивания.
Кроме того, возможно использование различных вариантов хранения таблицы обезличенных персональных данных.
Кроме того, обеспечивается возможность обработки персональных данных с использованием таблицы обезличенных данных без предварительного деобезличивания всей таблицы за счет возможности деобезличивания только запрашиваемых данных.
Исходная таблица персональных данных (ПД) – T0(N, M) – содержит N записей (строк) и M атрибутов (столбцов). Все строки и атрибуты имеют уникальные номера от 1 до N и от 1 до M соответственно.
Далее для удобства будем рассматривать атрибут номер j исходной таблицы, который содержит упорядоченное занумерованное множество из N элементов (данных о субъектах) – Cj0 = {cj0(m)}. Здесь cj0(m) – уникальный номер элемента, имеющего порядковый номер m (стоящего на месте m) во множестве Cj0. В исходной таблице T0(N, M) порядковый номер элемента равен номеру строки, в которой этот элемент находится, и всегда уникальный номер элемента равен его порядковому номеру в исходной таблице: cj0(m) = m, (1 < cj0(m) ≤ N; 1 ≤ m ≤ N). Проводимые преобразования приводят к несовпадению уникальных и порядковых номеров элементов.
Допускается отсутствие данных о субъектах в отдельных элементах атрибутов, в этом случае элементом атрибута является специальный набор символов.
Преобразование множества данных атрибута номер j (j = 1, 2, …, M) происходит в несколько этапов, число которых – Rj (1 ≤ Rj < ∞).
Каждый этап номер r (r = 1, 2, …, Rj) содержит два шага.
На первом шаге происходит разбиение множества данных атрибута на непересекающиеся блоки данных. Число блоков равно Zjr, где 1 < Zjr ≤ N. Все блоки имеют порядковые номера. Каждый блок номер i содержит 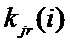
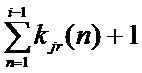



Число блоков Zjr атрибута j на этапе r и вектор количества элементов в каждом блоке kjr = (
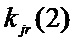
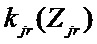 ) являются в общем случае уникальными для каждого атрибута и каждого этапа.
) являются в общем случае уникальными для каждого атрибута и каждого этапа.
На втором шаге этапа r проводится перестановка блоков атрибута, задаваемая матрицей перестановки 

Исходным множеством для преобразования на первом этапе является множество данных атрибута j исходной таблицы – Cj0, исходными множествами для преобразований разбиений на этапах 2, 3, …, Rj являются множества 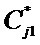
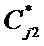


Преобразование исходной таблицы ПД на каждом этапе изменяет порядковые номера элементов всех атрибутов, разрушая связи между элементами строки исходной таблицы.
Пусть требуется вычислить новый порядковый номер n элемента атрибута j после выполнения этапа r, который по окончании этапа (r – 1) имеет порядковый номер m и уникальный номер – cj(r–1)(m). Разбиение и перестановка задаются вектором kjr = (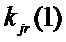
Номер блока h, куда после разбиения входит элемент номер m, вычисляется из условия:

Номер элемента внутри блока h равен:

После перестановки блок номер h будет иметь порядковый номер z, который вычисляется из условия: x2z = h.
Номер элемента после перестановки равен:
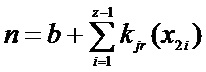
Таким образом, определяется новый порядковый номер элемента после проведения этапа. Этот номер становится номером элемента перед следующим этапом преобразования. Уникальный номер элемента не меняется и всегда остается равным порядковому номеру этого элемента в исходной таблице T0.
Параметры преобразования атрибута задает множество: Kjr = {Zjr, kjr, Xjr}, которое является ключом преобразования атрибута j на этапе r. Вектор Kj = (Kj1, Kj2, …, KjRj) задает множество ключей всех этапов преобразования атрибута j (j = 1, 2, …, M).
Множество ключей для всех атрибутов и всех этапов преобразования исходной таблицы: K(T0(N, M)) = {Kj}, (j = 1, 2, …, M) – это ключ преобразования исходной таблицы.
Оценка защищенности преобразования.
Защищенность таблицы T*(N, M) от атак, направленных на деобезличивание, при отсутствии данных о ключе преобразования можно оценить количеством возможных вариантов преобразования.
Число разбиений N элементов атрибута на k блоков равно числу возможных сочетаний из (N – 1) по (k – 1) и равно:
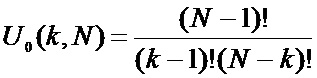
Число возможных разбиений N элементов атрибута равно:
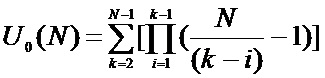
Возможное число перестановок k блоков на этапе равно k!. Следовательно, общее число возможных вариантов преобразования атрибута, содержащего N элементов на одном этапе, равно:
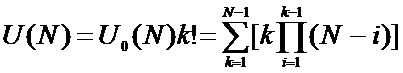
Если полное преобразование одного атрибута номер j проводится за Rj этапов, то число вариантов полного преобразования этого атрибута равно:

Для исходной таблицы T0(N, M), содержащей M атрибутов, число вариантов преобразований равно:
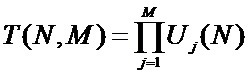
Таким образом, число возможных вариантов преобразования таблицы T0(N, M) очень велико (реальные значения N лежат в диапазоне от 103 до 108). Например, при N = 100, M = 10, Rj = 1, Zj1 = 10 (j = 1, 2, …, 10) получим U0(10, 100) ≈ 105×17310308 ≥ 1012. При фиксированном k = 10U(100) ≥ 1013. Откуда T(100, 10) ≥ 10130.
Для более значительного увеличения числа вариантов при небольших значениях N можно увеличить число M за счет разбиения элементов одного атрибута на несколько новых структурных частей, каждая из которых будет входить в состав своего атрибута (создание новых атрибутов). Например, можно телефон субъекта разделить на 5 частей.
Заявляемый способ реализуется следующим образом.
Для проведения обезличивания из структурированных персональных данных, хранимых в различных удаленных хранилищах, создается исходная таблица, каждая строка которой содержит данные об одном субъекте персональных данных. Для создания таблицы проводится сбор данных с удаленных хранилищ (источников) персональных данных путем передачи персональных данных по открытым или защищенным каналам связи на сервер формирования исходной таблицы. От каждого источника также передается информация о структуре персональных данных этого источника. Все данные поступают на сервер формирования исходной таблицы персональных данных, реализованный либо аппаратно, либо программно, который обеспечивает связь, защиту информации и формирование таблицы исходных данных заданной структуры путем интеграции и необходимых преобразований данных, поступающих от удаленных источников. Для приема и преобразования данных от удаленных источников должно использоваться специализированное программное обеспечение, основу которого составляют программы конвертации данных (PDF to Word, XML конвертеры, табличные процессоры MicrosoftExcel); языки программирования для создания приложений: C++, C#, PHP, Java, Python.
Сформированная исходная таблица персональных данных по запросу передается на сервер обезличивания, который формирует таблицу обезличенных персональных данных. После чего исходная таблица уничтожается.
На сервере обезличивания создаются и хранятся ключи преобразования атрибутов. Для создания, хранения и защиты ключей используется программное обеспечение, которое по заданным алгоритмам формирует ключи преобразования, создает отдельный файл ключей и обеспечивает защиту этого файла от несанкционированного доступа такими способами, как шифрование, перемещение в другое хранилище и т.д. Программное обеспечение может использовать возможности DriveCrypt, PGP Personal Desktop для хранения и защиты файлов ключей, а также языки программирования для создания приложений создающих ключи: C++, C#, PHP, Java, Python.
Исходная таблица персональных данных с применением ключей преобразования атрибутов преобразуется в таблицу обезличенных персональных данных, содержащую те же атрибуты, что и исходная таблица, и сохраняющую семантику записей для каждого атрибута. Для формирования таблицы обезличенных персональных данных используется программное обеспечение, которое реализует заявляемый способ обезличивания, осуществляет многоэтапное преобразование атрибутов исходной таблицы с применением заданных ключей преобразований для каждого атрибута, замену исходной таблицы на получаемую таблицу обезличенных персональных данных. Базой для такого программного обеспечения являются: СУБД – MySQL, Postgre SQL, Microsoft Access; языки программирования для создания приложений – C++, C#, PHP, Java, Python.
Сервер обезличивания может передавать таблицу обезличенных данных на сервер обработки персональных данных для обслуживания запросов на обработку персональных данных от зарегистрированных пользователей.
Разделение функций формирования исходной таблицы, обезличивания и обработки персональных данных позволяет повысить производительность и безопасность системы обработки персональных данных.
Пример заполнения исходных таблиц персональных данных T0(10, 3)
Исходная таблица состоит из 10 строк (N = 10), включает три атрибута A, B, C (M = 3) и имеет вид:
Исходная таблица персональных данных T0(10, 3)
Заданы ключи преобразований для атрибутов:
Атрибут 1: R 1 = 2, Z11 = 3, Z12 = 3. Ключ атрибута: (2, 3, (4, 2, 4), X11, 3, (3, 5, 2), X12),
где X11 = 
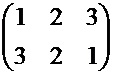
Атрибут 2: R 2 = 1, Z21 = 4. Ключ атрибута: (1, 4, (2, 3, 1, 4), X21),
где X21 = 
Атрибут 3: R 3 = 2, Z31 = 5, Z32 = 3. Ключ атрибута: (2, 5, (2, 1, 2, 2, 3), X31, 3, (5, 2, 3), X32,),
где X31 = 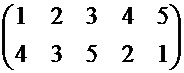
 .
.
После преобразования исходной таблицы получается таблица обезличенных персональных данных:
Таблица обезличенных данных T*(10, 3)
Как видно, каждая строка содержит значения атрибутов, не все из которых соответствуют значениям в исходной таблице, т.е. в каждой строке уже не персональные данные какого-либо субъекта.
Преимуществами заявляемого способа являются:
- обеспечение большей защищенности данных от деобезличивания по косвенным признакам, поскольку исходные номера элементов каждого атрибута после преобразования могут принимать любые значения от 1 до N, а число возможных вариантов преобразования очень велико;
- применение для обезличивания ограниченного числа однотипных преобразований (разбиения и перестановки), что упрощает разработку и эксплуатацию программного обеспечения;
- возможность динамического управления ключами преобразования на каждом этапе и для каждого атрибута;
- возможность обработки персональных данных без предварительного деобезличивания всей таблицы;
- возможность хранения атрибутов таблицы обезличенных данных в различных базах данных и на различных серверах;
- возможность добавления новых атрибутов и их преобразования без деобезличивания созданной таблицы обезличенных персональных данных;
- возможность оперативного управления процессами обезличивания/деобезличивания;
- возможность формирования унифицированной структуры исходной таблицы персональных данных, сочетающей структуры персональных данных, поступающих от различных внешних источников;
- возможность разбиения исходной таблицы на части и формирования нескольких таблиц обезличенных персональных для повышения скорости выполнения процессов доступа и обработки запросов;
- возможность ликвидации исходной таблицы персональных данных после формирования таблицы обезличенных персональных данных;
- возможность хранения таблицы обезличенных персональных данных в виде распределенного реестра с применением технологии блокчейн.
Использование заявленного изобретения обеспечивает:
- существенное повышение защищенности обезличенных данных от деобезличивания;
- повышение качества обработки персональных данных за счет сохранения семантики и отсутствия возможностей для искажения и потерь информации при обезличивании;
- повышение скорости обработки запросов к персональным данным без деобезличивания.
Структурированные персональные данные могут поступать от удаленных источников в виде файлов, таблиц баз данных. Для проведения обезличивания требуется на основе имеющихся форм представления персональных данных составить исходную таблицу персональных данных, каждая строка которой представляет персональные данные одного субъекта, а каждый столбец (атрибут) содержит множество однотипных данных, соответствующих элементам заданной структуры, по всем субъектам, занесенным в таблицу.
Атрибуты исходной таблицы могут быть элементами структурных единиц начальной структуры персональных данных (фамилия субъекта, город, телефон и т.д.), а также могут быть частями или объединениями элементов начальной структуры, что увеличивает сложность задачи несанкционированного деобезличиания и позволяет снизить требования к числу субъектов персональных данных в исходной таблице при заданном числе вариантов деобезличивания.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ деперсонализации персональных данных | 2016 |
|
RU2636106C1 |
| СПОСОБ ДЕПЕРСОНАЛИЗАЦИИ ПЕРСОНАЛЬНЫХ ДАННЫХ | 2012 |
|
RU2538913C2 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ДАННЫХ, ПОДВЕРЖЕННЫХ ДЕАНОНИМИЗАЦИИ, В ОБЕЗЛИЧЕННОМ НАБОРЕ ДАННЫХ | 2024 |
|
RU2837785C1 |
| Быстродействующее устройство формирования уникальной последовательности, используемой при обезличивании персональных данных | 2016 |
|
RU2665899C1 |
| СОПОСТАВЛЕНИЕ БОЛЬНИЦ ИЗ ОБЕЗЛИЧЕННЫХ БАЗ ДАННЫХ ЗДРАВООХРАНЕНИЯ БЕЗ ОЧЕВИДНЫХ КВАЗИИДЕНТИФИКАТОРОВ | 2016 |
|
RU2729458C2 |
| Система защиты персональных данных пользователей в информационной системе на основании деперсонализации и миграции в безопасное окружение | 2017 |
|
RU2698412C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ГЕНЕРАЦИИ СИНТЕТИЧЕСКИХ ДАННЫХ | 2023 |
|
RU2824524C1 |
| Система деперсонализации и миграции персональных данных пользователей на веб-сайтах на основе технологии резервного копирования | 2018 |
|
RU2731110C2 |
Изобретение относится к способу обезличивания структурированных персональных данных. Технический результат заключается в повышении защищенности персональных данных. Способ включает в себя представление данных в виде предварительно сформированной исходной таблицы, каждая строка которой содержит персональные данные одного субъекта, разделенные на множество атрибутов, соответствующих единицам структуры персональных данных, и многоэтапное преобразование каждого атрибута исходной таблицы, включающее разбиения множества элементов атрибута на блоки и перестановки блоков на каждом этапе, при этом состав и порядок внутриблоковых данных при преобразованиях не меняются, на сервере формируется и хранится множество ключей преобразования для всех этапов преобразования каждого атрибута, где каждый ключ содержит число блоков на каждом этапе, вектор элементов в каждом блоке и матрицу перестановки на каждом этапе, при этом преобразование атрибутов исходной таблицы выполняется с применением заданных ключей преобразований для каждого атрибута таким образом, что количество блоков для каждого атрибута и количество элементов в каждом блоке является уникальным для каждого атрибута и каждого этапа. 7 з.п. ф-лы, 2 табл.
1. Способ обезличивания структурированных персональных данных, заключающийся в представлении данных в виде предварительно сформированной исходной таблицы, каждая строка которой содержит персональные данные одного субъекта, разделенные на множество атрибутов, соответствующих единицам структуры персональных данных, и многоэтапном преобразовании каждого атрибута исходной таблицы, включающем разбиения множества элементов атрибута на блоки и перестановки блоков на каждом этапе, отличающийся тем, что состав и порядок внутриблоковых данных при преобразованиях не меняются, на сервере формируется и хранится множество ключей преобразования для всех этапов преобразования каждого атрибута, где каждый ключ содержит число блоков на каждом этапе, вектор элементов в каждом блоке и матрицу перестановки на каждом этапе, при этом преобразование атрибутов исходной таблицы выполняется с применением заданных ключей преобразований для каждого атрибута таким образом, что количество блоков для каждого атрибута и количество элементов в каждом блоке являются уникальными для каждого атрибута и каждого этапа.
2. Способ по п. 1, отличающийся тем, что число этапов преобразования каждого атрибута исходной таблицы является неограниченным.
3. Способ по п. 1, отличающийся тем, что на сервере обезличивания формируется и хранится множество ключей преобразования для всех этапов преобразования каждого атрибута, где каждый ключ является уникальным и содержит информацию для преобразования на этапе.
4. Способ по п. 1, отличающийся тем, что исходная таблица персональных данных может быть получена из любой структурированной формы представления персональных данных, получаемой от удаленных источников, и иметь варьируемое количество атрибутов, не совпадающее с количеством структурных единиц в персональных данных, получаемых от удаленных источников, и обеспечивающее повышение защищенности таблицы обезличенных персональных данных, сохраняя семантику элементов атрибутов.
5. Способ по п. 1, отличающийся тем, что для увеличения защищенности данных исходная таблица персональных данных может создаваться на отдельном сервере и по запросу передаваться на сервер обезличивания, входящий в состав информационной системы персональных данных (ИСПДн), где формируются и хранятся ключи преобразований, после проведения обезличивания исходная таблица персональных данных уничтожается, так как возможно ее восстановление по таблице обезличенных персональных данных.
6. Способ по п. 1, отличающийся тем, что при преобразованиях элементы каждого атрибута перемещаются на всем множестве его элементов, что обеспечивает более эффективную защиту от деобезличивания при прямом переборе вариантов и использовании множества известных персональных данных за счет увеличения количества возможных вариантов обезличивания.
7. Способ по п. 1, отличающийся тем, что возможно использование различных вариантов хранения таблицы обезличенных персональных данных.
8. Способ по п. 1, отличающийся тем, что обеспечивается возможность обработки персональных данных с использованием таблицы обезличенных данных без предварительного деобезличивания всей таблицы за счет возможности деобезличивания только запрашиваемых данных.
| СПОСОБ ДЕПЕРСОНАЛИЗАЦИИ ПЕРСОНАЛЬНЫХ ДАННЫХ | 2012 |
|
RU2538913C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 7269578 B2, 11.09.2007 | |||
| Устройство для фальцевания деталей швейных изделий | 1979 |
|
SU884670A1 |
| US 8355923 B2, 15.01.2013 | |||
| US 9230132 B2, 05.01.2016 | |||
| US 10528761 B2, 07.01.2020 | |||
| ЦЕМЕНТНО-ПОЛИМЕРНАЯ СМЕСЬ ДЛЯ АНТИКОРРОЗИОННОЙ И АБРАЗИВНОЙ ЗАЩИТЫ ВНУТРЕННИХ ПОВЕРХНОСТЕЙ СТАЛЬНЫХ ТРУБОПРОВОДОВ СИСТЕМ ТЕПЛОВОДОСНАБЖЕНИЯ | 2012 |
|
RU2506489C2 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

