ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Варианты осуществления изобретения относятся к области кодирования источника аудиосигнала. Более конкретно, варианты осуществления изобретения относятся к способу для кодирования информации относительно оригинальных достоверных аудиоданных и ассоциированному декодеру. Более конкретно, варианты осуществления изобретения предоставляют восстановление аудиоданных с их оригинальной продолжительностью.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Аудиокодеры обычно используются для сжатия аудиосигнала для передачи или хранения. В зависимости от используемого кодера сигнал может кодироваться без потерь (разрешая идеальное восстановление) или с потерями (для не идеального, но достаточного восстановления). Ассоциированный декодер инвертирует операцию кодирования и создает идеальный или неидеальный аудиосигнал. Когда литература упоминает артефакты, то обычно подразумевается потеря информации, которая является обычной для кодирования с потерями. Они включают в себя ограниченную аудиополосу пропускания, эхо и звенящие артефакты и другую информацию, которая может быть слышимой или маскируемой из-за особенностей человеческого слуха.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Проблема, которой занимается настоящее изобретение, относится к другому набору артефактов, которые обычно не охвачены в литературе кодирования аудио: дополнительные периоды тишины в начале и в конце кодирования. Существуют решения для этих артефактов, которые часто называются способами воспроизведения без промежутка. Источниками для этих артефактов является в первую очередь «крупнозернистость» закодированных аудиоданных, где, например, один блок закодированных аудиоданных всегда содержит информацию для 1024 оригинальных незакодированных аудиовыборок. Во-вторых, обработка цифрового сигнала часто возможна только с алгоритмическими задержками из-за используемых цифровых фильтров и банков фильтров.
Множество приложений не требуют восстановления оригинально достоверных выборок. Радиопередачи, например, обычно не испытывают проблем, так как закодированный аудиопоток является непрерывным и конкатенация не имеет место между отдельными устройствами кодирования. Телевизионные программы также часто статически сконфигурированы, и единственный кодер используется перед передачей. Однако дополнительные периоды тишины становятся проблемой, когда несколько предварительно закодированных потоков «склеиваются вместе (как использовано для добавления-вставки), когда синхронизация аудио, видео становится проблемой для хранения сжатых данных, где декодирование не должно проявлять дополнительных аудиовыборок в начале и в конце (особенно для кодирования без потерь, требующего точного восстановления битов оригинальных несжатых аудиоданных) и для редактирования в сжатой области.
В то время как множество пользователей уже приспособились к этим дополнительным периодам тишины, другие пользователи жалуются на дополнительную тишину, что особенно проблематично, когда конкатенируются несколько кодирований и ранее несжатые аудиоданные без промежутка становятся прерванными при кодировании и декодировании.
Задачей настоящего изобретения является предоставление улучшенного подхода, разрешающего удаление не желаемой тишины вначале и в конце кодирований.
Кодирование видео, использующее различные механизмы кодирования, используя I-кадры, P-кадры и B-кадры, не вводит каких-либо дополнительных кадров в начале или в конце. Напротив, аудиокодер обычно имеет дополнительные предварительно обусловленные выборки. В зависимости от их количества они могут привести к заметной потере синхронизации аудио, видео. Это часто называется проблемой синхронизации артикуляции, несоответствием между осуществлением движения рта говорящего и слышимым звуком. Множество приложений занимаются этой проблемой посредством наличия выравнивания для синхронизации артикуляции, которая должна быть сделана пользователем, так как она является очень переменной в зависимости от используемого кодера-декодера и его настроек. Задачей настоящего изобретения является предоставление улучшенного подхода, разрешающего синхронизацию воспроизведения аудио и видео.
Цифровые вещания стали более гетерогенными в прошлом с региональными различиями и персонифицированными программами и объявлениями. Главный поток вещания, следовательно, заменяется и соединяется с локальным или специфичным для пользователя контентом, который может быть потоком в реальном времени или предварительно закодированными данными. Соединение этих потоков главным образом зависит от системы передачи; однако аудио может не всегда быть отлично соединено, как хотелось бы, из-за неизвестных периодов тишины. Текущий способ должен часто убирать периоды тишины в сигнале, хотя эти промежутки в аудиосигнале могут быть восприняты. Задачей настоящего изобретения является предоставление улучшенного подхода, разрешающего соединение двух сжатых аудиопотоков.
Редактирование обычно выполняют в несжатой области, где операции редактирования хорошо известны. Однако если исходный материал является уже закодированным аудиосигналом с потерями, тогда даже простые операции вырезания требуют нового полного кодирования, приводя к каскаду артефактов кодирования. Следовательно, нужно избегать каскадных операций декодирования и кодирования. Задачей настоящего изобретения является предоставление улучшенного подхода вырезания сжатого аудиопотока.
Другим аспектом является стирание недостоверных аудиовыборок в системах, которые требуют защищенного тракта данных. Защищенный тракт медиа используется для введения в действие управления цифровыми правами и для гарантии целостности данных при использовании зашифрованной связи между компонентами системы. В этих системах это требование может быть выполнено, если непостоянные продолжительности блока аудиоданных становятся возможными, так как только в доверенных элементах операции редактирования аудио защищенного тракта медиа могут быть применены. Этими доверенными элементами обычно являются только декодеры и элементы воспроизведения.
Варианты осуществления изобретения предоставляют способ для выдачи информации относительно достоверности закодированных аудиоданных, причем закодированные аудиоданные являются последовательностью блоков закодированных аудиоданных, при этом каждый блок закодированных аудиоданных может содержать информацию относительно достоверности аудиоданных, причем способ содержит:
выдачу или информации относительно уровня закодированных аудиоданных, которая описывает количество данных в начале блока аудиоданных, являющихся недостоверными,
или выдачу информации относительно уровня закодированных аудиоданных, которая описывает количество данных в конце блока аудиоданных, являющихся недостоверными,
или выдачу информации относительно уровня закодированных аудиоданных, которая описывает количество данных в начале и в конце блока аудиоданных, являющихся недостоверными.
Дополнительные варианты осуществления изобретения предоставляют кодер для выдачи информации относительно достоверности данных: причем кодер сконфигурирован для применения способа для выдачи информации относительно достоверности данных.
Дополнительные варианты осуществления изобретения предоставляют способ для приема закодированных данных, включающих в себя информацию относительно достоверности данных, и выдачи декодированных выходных данных, причем способ содержит:
прием закодированных данных или с информацией относительно уровня закодированных аудиоданных, которая описывает количество данных в начале блока аудиоданных, являющихся недостоверными,
или информацией относительно уровня закодированных аудиоданных, которая описывает количество данных в конце блока аудиоданных, являющихся недостоверными,
или информацией относительно уровня закодированных аудиоданных, которая описывает количество данных в начале и в конце блока аудиоданных, являющихся недостоверными;
и выдачу декодированных выходных данных, которые содержат только выборки, не маркированные как недостоверные,
или содержащих все аудиовыборки блока закодированных аудиоданных и выдачу информации в приложение, какая часть данных является достоверной.
Дополнительные варианты осуществления изобретения предоставляют декодер для приема закодированных данных и выдачи декодированных выходных данных, причем декодер содержит:
вход для приема последовательностей блоков закодированных аудиоданных с множеством закодированных аудиовыборок в них, где некоторые блоки аудиоданных содержат информацию относительно достоверности данных, причем информация форматирована, как описано в способе для приема закодированных аудиоданных, включающих в себя информацию относительно достоверности данных,
часть декодирования, подсоединенную к входу и сконфигурированную для применения информации относительно достоверности данных,
выход для выдачи декодированных аудиовыборок, где выдаются только достоверные аудиовыборки
или где выдается информация относительно достоверности декодированных аудиовыборок.
Варианты осуществления изобретения предоставляют считываемый компьютером носитель для хранения команд для выполнения по меньшей мере одного из способов в соответствии с вариантами осуществления изобретения.
Изобретение предоставляет новый подход для обеспечения информации относительно достоверности данных, отличающийся от существующих подходов, которые находятся вне подсистемы аудио, и/или подходы, которые выдают только значение задержки и продолжительность оригинальных данных.
Варианты осуществления изобретения выгодны, так как они применимы в аудиокодере и аудиодекодере, которые уже имеют дело со сжатыми и несжатыми аудиоданными. Это позволяет системам сжимать и выполнять декомпрессию только достоверных данных, как упомянуто выше, которые не нуждаются в дополнительной обработке аудиосигнала, вне кодера и декодера аудио. Варианты осуществления изобретения разрешают сигнализацию достоверных данных не только для основанных на файле приложений, но также и для основанных на потоке приложений и приложений, работающих в реальном времени, где продолжительность достоверных аудиоданных не известна в начале кодирования.
В соответствии с вариантами осуществления изобретения закодированный поток содержит информацию достоверности относительно уровня блока аудиоданных, которая может быть блоком аудиодоступа AAC MPEG-4. Для сохранения совместимости с существующими декодерами эта информация помещается в часть блока доступа, которая является дополнительной и может быть проигнорирована декодерами, не поддерживающими информацию достоверности. Такая часть является расширенной полезной информацией блока аудиодоступа AAC MPEG-4. Изобретение применимо к большинству существующих схем кодирования аудио, включающих в себя аудио уровня 3 MPEG-1 (MP3) и дополнительные схемы кодирования аудио, которые работают на основании блоков и/или страдают от алгоритмической задержки.
В соответствии с вариантами осуществления изобретения предоставлен новый подход для удаления недостоверных данных. Новый подход основан на уже существующей информации, доступной для кодера, декодера и уровней системы, включающих в себя кодер или декодер.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления, соответствующие настоящему изобретению, будут впоследствии описаны со ссылками на приложенные чертежи, на которых:
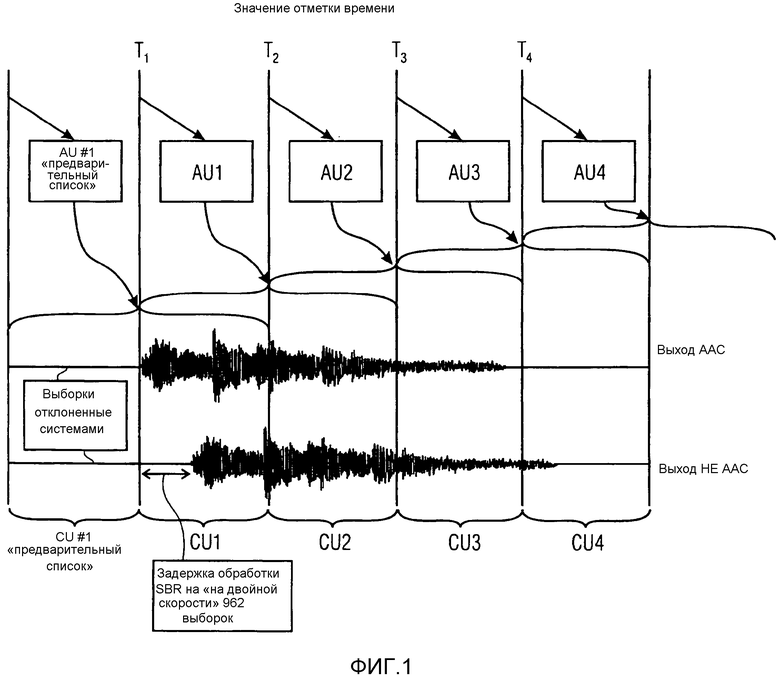
Фиг. 1 иллюстрирует поведение декодера AAC НЕ: режим двойной скорости;
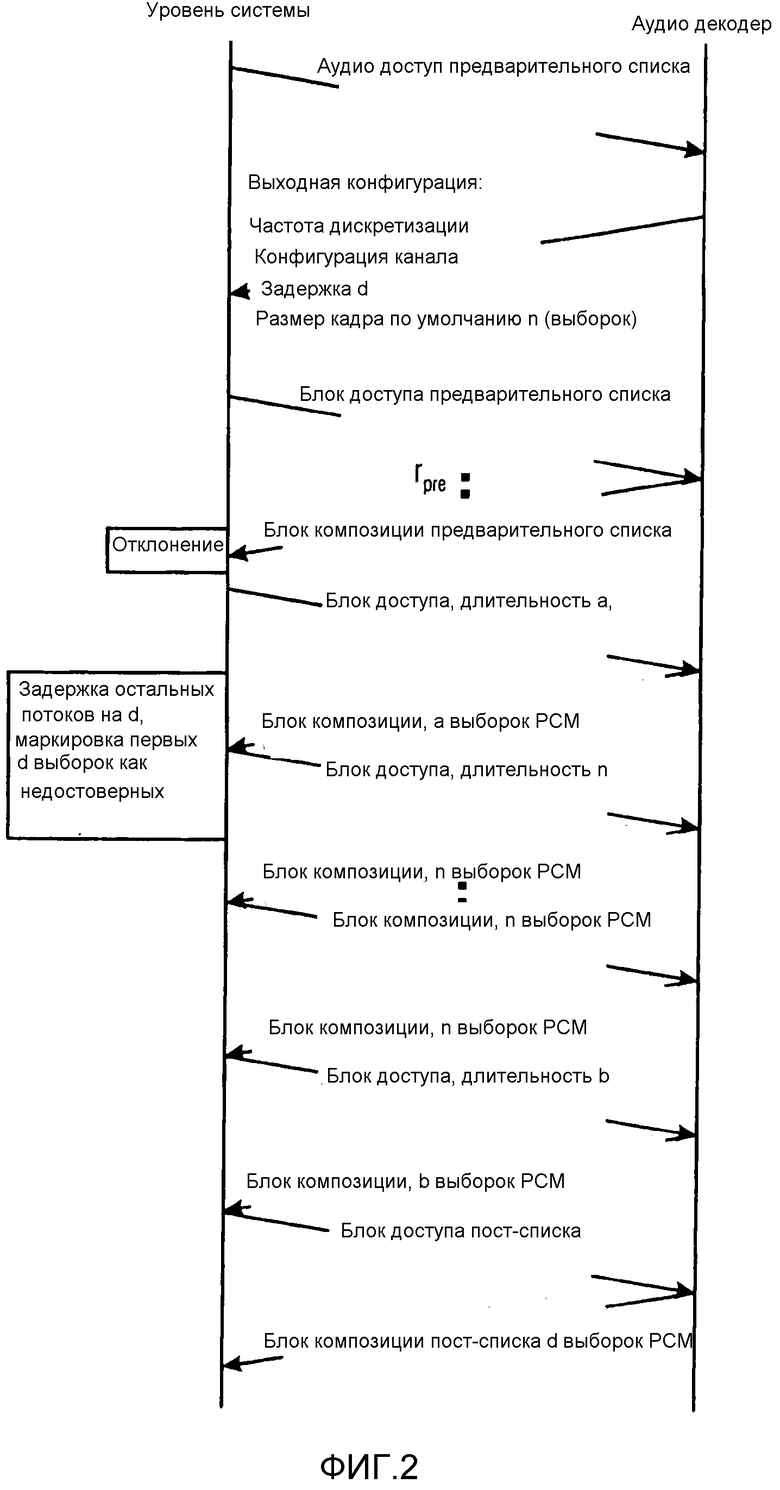
Фиг. 2 иллюстрирует обмен информацией между объектом уровня систем и аудиодекодером;
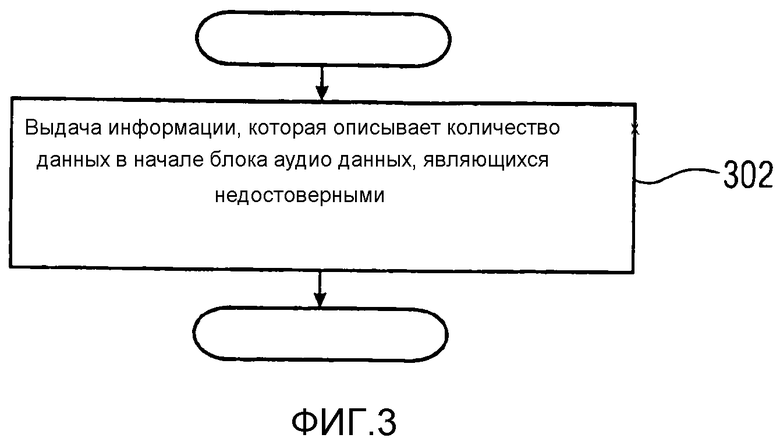
Фиг. 3 показывает схематичную блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии с первым возможным вариантом осуществления;
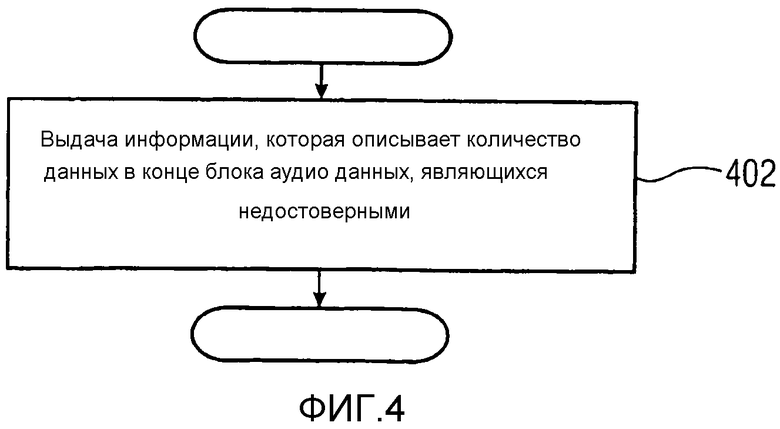
Фиг. 4 показывает схематическую блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии со вторым возможным вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 5 показывает схематическую блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии с третьим возможным вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 6 показывает схематическую блок-схему способа для приема закодированных данных, включающих в себя информацию относительно достоверности данных в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 7 показывает схематическую блок-схему способа для приема закодированных данных в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 8 показывает диаграмму ввода/вывода кодера в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 9 показывает схематическую диаграмму ввода/вывода кодера в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании;
Фиг. 10 показывает схематическую блок-схему декодера в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании; и
Фиг. 11 показывает схематическую блок-схему декодера в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании.
ПОДРОБНОЕ ОПИСАНИЕ ИЛЛЮСТРАТИВНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Фиг. 1 показывает поведение декодера относительно блоков доступа (AU) и ассоциированных блоков (CU) композиции. Декодер подсоединяется к объекту, именованному "Системы", который принимает выходной сигнал, генерируемый посредством декодера. В качестве примера предполагается, что декодер должен выполнять функцию в соответствии со стандартом HE-AAC (усовершенствованное кодирование аудио с высокой эффективностью). Декодер HE-AAC является, по существу, декодером AAC, сопровождаемым каскадом последующей обработки SBR (уменьшения спектрального диапазона). Дополнительная задержка, наложенная инструментальным средством SBR, имеет место из-за банка QMF и буферов данных в инструментальном средстве SBR. Она может быть получена посредством следующей формулы:
DelaySBR-TOOL=LAnalysisFilter-NAnalysisChannels+1+Delaybuffer
где
NAnalysisChannels=32, LAnalysisFilter=320 и Delaybuffer=6×32.
Это означает, что задержка, внесенная инструментальным средством SBR (при входной частоте дискретизации, то есть выходной частоте дискретизации AAC), равна
DelaySBR-TOOL=320-32+1+6×32=481 выборок.
Как правило, инструмент SBR работает в режиме "повышения дискретизации" (или "двойной частоты"), в этом случае задержка 481 выборок при частоте дискретизации AAC преобразуется в задержку 962 выборки при частоте вывода SBR. Он может также работать при той же частоте дискретизации, как вывод AAC (обозначенный как "режим пониженной дискретизации SBR"), в этом случае дополнительной задержкой является только 481 выборка при частоте вывода SBR. Имеется режим "обратной совместимости", в котором пренебрегается инструмент SBR, и вывод AAC является выводом декодера. В этом случае дополнительной задержки нет.
Фиг. 1 показывает поведение декодера для большинства обычных случаев, в которых инструмент SBR работает в режиме повышения дискретизации и дополнительная задержка равна 962 выходных выборок. Эта задержка соответствует приблизительно 47% длины кадра AAC повышенной дискретизации (после обработки SBR). Должно быть отмечено, что T1 является отметкой времени, ассоциированной с CU 1 после задержки в 962 выборок, то есть отметкой времени для первой достоверной выборки вывода НЕ-AAC. Дополнительно должно быть отмечено, что если НЕ-AAC запущен в "режиме пониженной дискретизации SBR" или режиме "единственной частоты", задержка будет составлять 481 выборок, но отметка времени будет идентичной, так как в режиме единственной частоты CU составляют половину количества выборок таким образом, чтобы задержка оставалась по прежнему 47% от продолжительности CU.
Для всех доступных механизмов сигнализации (то есть неявной сигнализации, обратно совместимой явной сигнализации или иерархической явной сигнализации), если декодер является НЕ-AAC, то он должен передавать на Системы любую дополнительную задержку, подвергнутую обработке SBR, иначе отсутствие индикации от декодера указывает, что декодером является AAC. Следовательно, Системы могут регулировать отметку времени так, чтобы компенсировать дополнительную задержку SBR.
Следующая секция описывает, как кодер и декодер для основанного на преобразовании аудиокодека относятся к Системам MPEG, и предлагает дополнительный механизм для гарантий идентичности сигнала после передачи «туда и обратно» сигнала кодека, кроме "кодирования артефактов", особенно при наличии расширений кодека. Использование описанных способов гарантирует предсказуемую операцию с точки зрения Систем и также удаляет потребность в дополнительной составляющей собственность сигнализации "без промежутка", обычно необходимой для описания поведения кодера.
В этой секции ссылка сделана на следующие стандарты:
[1] ISO/IEC TR 14496-24:2007: Information Technology - Coding of audio-visual objects - Part 24: Audio and systems interaction
[2] ISO/IEC 14496-3:2009 Information Technology - Coding of audio-visual objects - Part 3: Audio
[3] ISO/IEC 14496-12:2008 Information Technology - Coding of audio-visual objects - Part 12: ISO base media file format
Кратко [1] описан в этой секции. В основном AAC (усовершенствованное кодирование аудио) и его преемники НЕ-AAC, НЕ-AAC v2 являются кодеками, которые не имеют соответствия 1:1 между сжатыми и несжатыми данными. Кодер добавляет дополнительные аудиовыборки в начало и в конец несжатых данных и также формирует блоки доступа со сжатыми данными для них в дополнение к блокам доступа, охватывающим несжатые оригинальные данные. Декодер, совместимый со стандартами, затем генерирует несжатый поток данных, содержащий дополнительные выборки, добавляемые посредством кодера.
[1] описывает, как существующие инструменты основанного на ISO формата [3] медиа файла могут быть повторно использованы для маркировки достоверного диапазона развернутых данных таким образом, чтобы (помимо артефактов кодека) мог быть восстановлен оригинальный несжатый поток. Маркировка достигается посредством использования списка редактирования с входом, содержащим достоверный диапазон после операции декодирования.
Так как это решение не было готово вовремя, составляющие собственность решения для маркировки достоверного периода теперь широко распространены в использовании (только два названия: Apple iTunes и Ahead Nero). Можно было утверждать, что предложенный способ в [1] является не очень практичным и страдает от проблемы, что списки редактирования были изначально предназначены для другой, потенциально сложной, цели, для которой доступны только несколько реализаций.
Дополнительно [1] показывает, как предварительный список данных может быть обработан посредством использования групп [3] выборки FF ISO (формат файла ISO). Предварительный список не маркирует, какие данные являются достоверными, но сколько блоков доступа (или выборок в номенклатуре FF ISO) должны быть декодированы до вывода декодера в произвольной точке во времени. Для AAC это всегда одна более ранняя выборка (то есть один блок доступа) из-за накладывающихся окон в области MDCT, следовательно, значением для предварительного запуска является 1 для всех блоков доступа.
Другой аспект относится к дополнительному предварительному просмотру множества кодеров. Дополнительные предварительные просмотры зависят, например, от внутренней обработки сигнала в кодере, который пытается создать вывод в реальном времени. Одна опция для принятия во внимание дополнительного предварительного просмотра может состоять в использовании списка редактирования также для задержки предварительного просмотра кодера.
Как упомянуто выше, вызывает сомнение, было ли оригинальной целью инструмента списка редактирования маркировать оригинальные достоверные диапазоны в медиа. [1] не содержит ничего относительно реализаций дополнительного редактирования файла со списками редактирования, следовательно, можно предположить, что использование списка редактирования для цели [1] добавляет некоторую слабость.
В качестве стороннего замечания, все составляющие собственность решения и решения для аудио MP3 определяли дополнительную задержку от начала до конца и длину оригинальных несжатых аудиоданных, очень похоже на решения Nero и iTunes, упомянутые выше, и для чего используют список редактирования в [1].
В общем, [1] не содержит ничего о корректном поведении поточных приложений в реальном времени, которые не используют формат файла MP4, но требуют отметок времени для корректной аудио-видеосинхронизации и часто работают в очень беззвучном режиме. Эти отметки времени часто устанавливаются некорректно, и, следовательно, в устройстве декодирования требуется кнопка для приведения всего назад в синхронизм.
Интерфейс между Аудио MPEG-4 и Системами MPEG-4 описан более подробно в следующих абзацах.
Каждый блок доступа, доставленный аудиодекодеру от интерфейса Систем, должен приводить к соответствующему блоку композиции, доставленному от аудиодекодера к интерфейсу систем, то есть компоновщику. Это должно включать в себя условия запуска и завершения, то есть когда блок доступа является первым или последним в конечной последовательности блоков доступа.
Для блока композиции аудиоотметка времени композиции (CTS) ISO/IEC 14496-1 подпункта 7.1.3.5 задает, что время композиции относится к n-й аудиовыборке в блоке композиции. Значение n равно 1, если не определено иначе в остальной части этого подпункта.
Для сжатых данных, таких как кодированное аудио НЕ-AAC, которое может быть декодировано различными конфигурациями декодера, необходима особая осторожность. В этом случае декодирование может быть сделано в форме обратной совместимости (только AAC), а также в расширенной форме (AAC+SBR). Для гарантии того, что отметки времени композиции обрабатываются корректно (таким образом, чтобы аудио оставался синхронизированным с другой медиа информацией), применяется следующее:
- Если сжатые данные разрешают как обратно совместимое, так и расширенное декодирование, и если декодер работает в форме обратной совместимости, то декодер не должен предпринимать специальных действий. В этом случае значение n равно 1.
- Если сжатые данные разрешают как обратную совместимость, так и расширенное декодирование, и если декодер работает в расширенной форме таким образом, что он использует пост-процессор, который вставляет некоторую дополнительную задержку (например, пост-процессор SBR в НЕ-AAC), то он должен гарантировать, что эта дополнительная задержка времени, внесенная относительно режима обратной совместимости, как описано соответствующим значением n, принята во внимание при представлении блока композиции. Значение n определено в следующей таблице.
Описание интерфейса между Аудио и Системами доказало, что он работает надежно, охватывая большинство используемых в настоящее время случаев. Однако если посмотреть внимательно, не упоминаются две проблемы:
- Во многих системах началом отметки времени является значение ноль. Блоки AU предварительного списка не предполагаются как существующие, хотя например, AAC имеет неотъемлемую минимальную задержку кодера одного блока доступа, который требует один блок доступа перед блоком доступа в нулевой отметке времени. Решение для формата файла MP4 для этой проблемы описано в [1];
- нецелочисленные продолжительности размера кадра не охватываются. Структура AudioSpecificConfig () разрешает сигнализацию малого набора размеров кадров, которые описывают длины банка фильтров, например 960 и 1024 для AAC. Однако данные в реальном времени обычно не выравниваются по сетке фиксированных размеров кадров, и, следовательно, кодер должен дополнять последний кадр.
Эти два неучтенных результата недавно стали проблемой с появлением передовых мультимедийных приложений, которые требуют соединения двух потоков AAC или восстановления диапазона достоверных выборок после передачи «туда и обратно» сигнала кодека, особенно в отсутствии формата файла MP4 и способов, описанных в [1].
Для преодоления проблемы, упомянутой выше, предварительный список, пост-список и все другие источники должны быть описаны должным образом. Дополнительно, механизм для нецелочисленные множителей размеров кадров является необходимым, чтобы иметь аудио представления с точной выборкой.
Предварительный список требуется изначально для декодера таким образом, чтобы он был в состоянии полностью декодировать данные. Например, AAC требует предварительный список из 1024 выборок (один блок доступа) перед декодированием блока доступа таким образом, чтобы выходные выборки в операции наложения - добавления представляли желаемый оригинальный сигнал, как иллюстрировано в [1]. Другие аудиокодеки могут иметь другие требования предварительного списка.
Пост-список эквивалентен предварительному списку с тем лишь отличием, что больше данных после декодирования блока доступа должно быть загружено в декодер. Причиной для пост-списка является расширения кодека, которые повышают эффективность кодека в обмен на алгоритмическую задержку, такую как перечислена в таблице выше. Так как операция двойного режима часто желательна, предварительный список остается постоянным таким образом, чтобы декодер без реализованных расширений мог полностью использовать закодированные данные. Следовательно, предварительный список и отметки времени относятся к способностям унаследованного декодера. Затем требуется пост-список в дополнение к декодеру, поддерживающему эти расширения, так как существующая внутренняя линия задержки должна закончиться, чтобы извлечь полное представление оригинального сигнала. К сожалению, пост-список является зависимым от декодера. Однако возможно обрабатывать предварительный список и пост-список независимо от декодера, если значения предварительного списка и пост-списка известны уровню систем, и может быть просмотрен вывод предварительного списка и пост-списка из декодера.
Относительно переменного размера аудиокадра, так как аудиокодеки всегда кодируют блоки данных с фиксированным количеством выборок, представление с точностью до выборки становится возможным только посредством дополнительной сигнализации на уровне Систем. Так как для декодера проще всего работать с обрезанием с точностью до выборки, кажется желательным иметь декодер, вырезающий сигнал. Следовательно, предлагается дополнительный механизм расширения, который разрешает обрезку выходных выборок посредством декодера.
Относительно задержки специфичного для вендора кодера, MPEG задает только операцию декодера, тогда как кодеры предоставляются только произвольно. Это одно из преимуществ технологий MPEG, где кодеры могут улучшаться со временем, чтобы полностью использовать способности кодека. Гибкость в проектировании кодера, однако, приводит к проблемам взаимодействия задержек. Так как кодеры обычно нуждаются в предварительном просмотре аудиосигнала для принятия более "разумных" решений кодирования, это является преимущественно специфичным для вендора. Причинами для этой задержки кодера являются, например, решения с коммутацией блоков, которые требуют задержки возможных наложений окна и других оптимизаций, которые главным образом относятся к кодерам в реальном времени.
Основанное на файле кодирование, доступное для офлайн контента, не требует этой задержки, которая является уместной, только когда кодируются данные в реальном времени, тем не менее большинство кодеров достоверно добавляет паузу также к началу офлайн кодирований.
Одной частью решения для этой проблемы является корректная установка отметок времени на уровне систем таким образом, чтобы эти задержки были неуместными и имели, например, отрицательные значения отметки времени. Это может также быть достигнуто со списком редактирования, как предложено в [1].
Другой частью решения является выравнивание задержки кодера по границам кадра, таким образом, чтобы целое число блоков доступа, например, с отрицательными отметками времени могло быть пропущено изначально (помимо блоков доступа предварительного списка).
Способы, описанные в настоящем описании, также относятся к промышленному стандарту ISO/IEC 14496-3:2009, подраздел 4, секция 4.1.1.2. В соответствии с описаниями, раскрытыми в настоящем описании, предложено следующее:
при наличии, пост-декодерный инструмент обрезания выбирает часть восстановленного аудиосигнала таким образом, чтобы два потока могли быть соединены вместе в закодированной области, и восстановление точной выборки становится возможным на уровне аудио.
Вводом в пост-декодерный инструмент обрезания является:
- восстановленный аудиосигнала во временной области
- информация управления пост-обрезанием.
Выводом пост-декодерного инструмента обрезания является:
- восстановленный аудиосигнал во временной области.
Если пост-декодерный инструмент обрезания не является активным, восстановленный аудиосигнал во временной области непосредственно переходит на выход декодера. Этот инструмент применяется после любого предыдущего инструмента кодирования аудио.
Следующая таблица иллюстрирует предложенный синтаксис структуры данных extension_payload(), который может быть использован для реализации способов, описанных в настоящем описании.


Нижеследующая таблица иллюстрирует предложенный синтаксис структуры данных trim_info (), который может быть использован для реализации способа, описанного в настоящем описании.

со следующими определениями, относящимися к пост-декодерному обрезанию:
custom_resolution_present - флаг, который указывает, присутствует ли custom_resolution.
custom_resolution - настраиваемое разрешение в Гц, которое используется для операции обрезания. Рекомендуется установить настраиваемое разрешение, когда возможна мульти-частотная обработка аудиосигнала, и операция обрезания должна быть выполнена с самым высоким подходящим разрешением.
trim_resoIution - значение по умолчанию является номинальной частотой дискретизации, как указано в Таблице 1.16 ISO/IEC 14496-3:2009 посредством samplingFrequency или samplingFrequencyldx. Если установлен флаг custom_resolution_present, то разрешение для пост-декодерного инструмента обрезания является значением custom_resolution.
trim_from_beginning (NB) - количество выборок PCM, которые должны быть удалены из начала блока композиции. Значение является достоверным для аудиосигнала только со скоростью trim_resolution. Если trim_resolution не равно частоте дискретизации входного сигнала во временной области, значение должно быть соответственно измерено в соответствии со следующим уравнением:
NB=floor (NB sampling_frequency/trim_resolution)
trim_from_end (NE) - количество выборок PCM, которые должны быть удалены из конца блока композиции. Если trim_resolution не равно частоте дискретизации входного сигнала во временной области, значение должно быть соответственно измерено в соответствии со следующим уравнением:
NE=floor (NE sampling_frequency/trim_resolution)
Другой возможный алгоритм смешивания потоков может принимать во внимание неразрывное соединение (без возможности прерываний сигнала). Эта проблема также достоверна для несжатых данных PCM и является ортогональной способам, описанным в настоящем описании.
Вместо настраиваемого разрешения процентное содержание может также быть подходящим. Альтернативно может быть использована самая высокая частота выборок, но она может конфликтовать с обработкой на двойной частоте и декодерами, которые поддерживают обрезание, но не обработку на двойной частоте, следовательно, предпочитается реализация решения с независимым декодером, и персональное разрешение обрезания кажется разумным.
Относительно процесса декодирования применяется пост-декодерное обрезание после обработки всех данных блока доступа (то есть после того как будут применены расширения, такие как DRC, SBR, PS и т.д.). Обрезание не выполняется на уровне Систем MPEG-4; однако отметки времени и значения длительности блока доступа должны соответствовать предположению, что применяется обрезание.
Обрезание выполняется для блока доступа, который переносит информацию, только если никакая дополнительная задержка не была введена из-за дополнительных расширений (например, SBR). Если эти расширения находятся в месте и используются в декодере, то применение операции обрезания задерживается посредством задержки опциональных расширений. Следовательно, информация об обрезании должна храниться в декодере и дополнительные блоки доступа должны быть предоставлены уровнем Систем.
Если декодер может работать с более чем одной частотой, рекомендуется использовать настраиваемое разрешение для операции обрезания с самой высокой частотой.
Обрезание может приводить к прерываниям сигнала, что может вызвать искажение сигнала. Следовательно, информация обрезания должна быть вставлена в поток битов только в начале или в конце всего кодирования. Если два потока соединяются вместе, этих прерываний нельзя избежать, кроме кодера, который тщательно устанавливает значения trim_from_end и trim_from_beginning таким образом, чтобы два выходных сигнала временной области подходили друг другу без прерываний.
Обрезанные блоки доступа могут привести к неожиданным вычислительным требованиям. Множество реализаций принимают постоянное время обработки для блоков доступа с постоянной длительностью, которая больше не является достоверной, если длительность изменяется из-за обрезания, но вычислительные требования для блока доступа остаются. Следовательно, должны быть приняты декодеры с ограниченными вычислительными ресурсами, и, следовательно, обрезание должно быть использовано редко предпочтительно посредством кодирования данных способом, который по границам блока доступа, и обрезание используется только в конце кодирования, как описано в [ISO/IEC 14496-24:2007 Приложение B.2].
Описания, раскрытые в настоящем описании, также относятся к промышленному стандарту ISO/IEC 14496-24:2007. В соответствии с описаниями, раскрытыми в настоящем описании, нижеследующее предлагается относительно интерфейса аудиодекодера для доступа с точностью до выборки: аудиодекодер будет всегда создавать один блок композиции (CU) из одного блока доступа (AU). Необходимое количество блоков AU предварительного списка и пост-списков является постоянным для последовательного набора блоков AU посредством одного кодера.
Когда начинается операция декодирования, декодер инициализируется посредством AudioSpecificConfig (ASC). После того как декодер обработал эту структуру, наиболее релевантные параметры могут быть запрошены у декодера. Дополнительно, уровень Систем передает параметры, которые в общем являются независимыми от типа потока, будь это аудио-, или видео-, или другие данные. Они включают в себя информацию тактирования, данные предварительного списка и пост-списка. В общем, декодер нуждается в 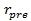 блоках AU предварительного списка перед AU, который содержит требуемую выборку. Дополнительно, необходим предварительный список rpost, это зависит, однако, от режима декодирования (декодирование расширения может требовать блоки AU пост-списка, тогда как основная операция декодирования определяется как не требующая AU пост-списка).
блоках AU предварительного списка перед AU, который содержит требуемую выборку. Дополнительно, необходим предварительный список rpost, это зависит, однако, от режима декодирования (декодирование расширения может требовать блоки AU пост-списка, тогда как основная операция декодирования определяется как не требующая AU пост-списка).
Каждый AU должен быть маркирован для декодера, является ли он AU предварительного списка или пост-списка, чтобы разрешить декодеру создавать необходимую внутреннюю информацию состояния для пост-декодирования или сбрасывать остающиеся данные в декодере соответственно.
Связь между уровнем систем и аудиодекодером иллюстрируется на Фиг. 2.
Аудиодекодер инициализируется уровнем Систем с помощью структуры audioSpecificConfig(), которая приводит к конфигурации вывода декодера для уровня Систем, содержащего информацию относительно частоты дискретизации, конфигурации канала (например, 2 для стерео), размера кадра n (например, 1024 в случае LC AAC) и дополнительной задержки d для явным образом сигнализированных расширений кодека, таких как SBR. В частности, Фиг. 2 показывает следующие действия:
1. Первые блоков доступа предварительного списка выдаются в декодер и «тихо» отклоняются после декодирования посредством уровня Систем.
2. Первый блок доступа не из предварительного списка может содержать информацию trim_from_beginning в полезных данных расширения типа EXT_TRIM таким образом, чтобы декодер выводил только α выборок PCM. Дополнительно, должны быть стерты d дополнительных выборок PCM, генерируемых дополнительным расширением кодека.
В зависимости от реализации это может иметь место посредством задержки всех других параллельных потоков на d или посредством маркировки первых d выборок как недостоверных и принятия соответствующего действия, такого как стирание недостоверных выборок во время предоставления или предпочтительно в декодере.
Если стирание d
выборок имеет место в декодере, как рекомендуется, то уровень систем должен быть уведомлен о том, что первый блок композиции, содержащий α выборок, может выдан только декодером после использования 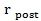 блоков доступа, как обозначено на 6-м этапе.
блоков доступа, как обозначено на 6-м этапе.
3. Затем декодируются все блоки доступа с постоянной длительностью n и блоки композиции предоставляются уровню Систем.
4. Блок доступа перед блоками доступа пост-списка могут содержать опциональную информацию trim_from_end таким образом, чтобы декодер только генерировал b выборок PCM.
5. Последние 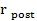 блоков доступа пост-списка выдаются в аудиодекодер таким образом, чтобы могли генерироваться пропущенные b выборок PCM. В зависимости от значения d
(которое может быть нулем) это может привести к блокам композиции без каких-либо выборок. Рекомендуется предоставить все блоки доступа пост-списка декодеру таким образом, чтобы он мог быть полностью деинициализирован независимо от значения дополнительной задержки d.
блоков доступа пост-списка выдаются в аудиодекодер таким образом, чтобы могли генерироваться пропущенные b выборок PCM. В зависимости от значения d
(которое может быть нулем) это может привести к блокам композиции без каких-либо выборок. Рекомендуется предоставить все блоки доступа пост-списка декодеру таким образом, чтобы он мог быть полностью деинициализирован независимо от значения дополнительной задержки d.
Кодеры должны иметь поведение с согласованным тактированием. Кодер должен выравнивать входной сигнал таким образом, чтобы после декодирования 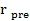 блоков AU предварительного списка оригинальный входной сигнал заканчивался без первоначальной потери и без заглавных выборок. Специально для основанных на файле операций кодера это потребует, чтобы дополнительные опережающие выборки кодера и дополнительно вставленные выборки тишины были целым кратным размера аудиокадра и, таким образом, могли быть отвергнуты в выходном сигнале кодера.
блоков AU предварительного списка оригинальный входной сигнал заканчивался без первоначальной потери и без заглавных выборок. Специально для основанных на файле операций кодера это потребует, чтобы дополнительные опережающие выборки кодера и дополнительно вставленные выборки тишины были целым кратным размера аудиокадра и, таким образом, могли быть отвергнуты в выходном сигнале кодера.
В сценариях, где такое выравнивание невозможно, например кодирование аудио в реальном времени, кодер должен вставить информацию обрезания таким образом, чтобы декодеру было разрешено стирать случайно вставленные опережающие выборки пост-декодерным инструментом обрезания. Точно так же кодеры должны вставить информацию пост-декодерного обрезания для окончания выборки. Это должно быть сигнализировано в блок доступа, который предшествует последним блокам AU пост-списка.
Информация тактирования, установленная в кодере, должна быть установлена, предполагая, что пост-декодерный инструмент обрезания является доступным.
Фиг. 3 показывает схематическую блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии с первым возможным вариантом осуществления. Способ содержит этап 302, в соответствии с которым выдается информация, которая описывает количество данных в начале блока аудиоданных, являющихся недостоверными. Эта выданная информация может затем быть вставлена в или объединена с блоком закодированных аудиоданных, который является рассматриваемым. Количество данных может быть выражено как количество выборок (например, выборок PCM), микросекунд, миллисекунд или процент от длины секции аудиосигнала, предоставленной блоком закодированных аудиоданных.
Фиг. 4 показывает схематическую блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии со вторым возможным вариантом осуществления описаний, раскрытых в настоящем описании. Способ содержит этап 402, в соответствии с которым выдается информация, которая описывает количество данных в конце блока аудиоданных, являющих недостоверными.
Фиг. 5 показывает схематическую блок-схему способа для выдачи информации относительно достоверности закодированных аудиоданных в соответствии с третьим возможным вариантом осуществления описаний, раскрытых в настоящем описании. Способ содержит этап 502, в соответствии с которым выдается информация, которая описывает количество данных в начале и в конце блока аудиоданных, являющихся недостоверными.
В вариантах осуществления, иллюстрированных на Фиг. 3-5, информация, описывающая количество данных в блоке аудиоданных, являющихся недостоверными, может быть получена из процесса кодирования, который генерирует закодированные аудиоданные. Во время кодирования аудиоданных алгоритм кодирования может рассматривать входной диапазон аудиовыборок, который простирается по границе (начала или конца) аудиосигнала, который должен быть закодирован. Типовые процессы кодирования собирают множество аудиовыборок в "блоках" или "кадрах" таким образом, чтобы блок или кадр, который не полностью заполнен фактическими аудиовыборками, мог быть заполнен "ложными" аудиовыборками, которые обычно имеют нулевую амплитуду. Для алгоритма кодирования это предлагает преимущества, что входные данные всегда группируются одним и тем же способом таким образом, чтобы обработка данных в алгоритме не была изменена в зависимости от обработанных аудиоданных, содержащих границу (начало или конец). Другими словами, входные данные приводятся, относительно организации и измерения данных, к требованиям алгоритма кодирования. Как правило, создание требуемых условий входных данных неотъемлемо приводит к соответствующей структуре выходных данных, то есть выходные данные отражают приведение к требуемым условиям входных данных. Следовательно, выведенные данные отличаются от оригинальных входных данных (перед приведением к требуемым условиям). Это отличие обычно является неслышимым, так как только выборки, имеющие нулевую амплитуду, добавляются к оригинальным аудиоданным. Однако приведение к требуемым условиям может изменить длительность первоначальных аудиоданных, обычно удлиняя первоначальные аудиоданные «тихими» сегментами.
Фиг. 6 показывает схематическую блок-схему способа для приема закодированных данных, включающих в себя информацию относительно достоверности данных, в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании. Способ содержит этап 602 приема закодированных данных. Закодированные данные содержат информацию, которая описывает количество данных, являющихся недостоверными. Можно различить по меньшей мере три случая: информация может описывать количество данных в начале блока аудиоданных, являющихся недостоверными, количество данных в конце блока аудиоданных, являющихся недостоверными, и количество данных в начале и в конце блока аудиоданных, являющихся недостоверными.
На этапе 604 способа для приема закодированных данных выдаются декодированные выходные данные, которые содержат только выборки, не маркированные как недостоверные. Потребитель декодированных выходных данных, находящийся далее в тракте обработки сигнала, относительно элемента, выполняющего способ для приема закодированных данных, может использовать выданные декодированные выходные данные, не сталкиваясь с проблемой достоверности частей выходных данных, таких как единичные выборки.
Фиг. 7 показывает схематическую блок-схему способа для приема закодированных данных в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании. Закодированные данные принимаются на этапе 702. На этапе 704 выдаются декодированные выходные данные, содержащие все аудиовыборки блока закодированных аудиоданных, например, в приложение, находящееся далее в тракте обработки сигнала, потребляющее декодированные выходные данные. Кроме того, выдается на этапе 706 информация, какая часть декодированных выходных данных является достоверной. Приложение, потребляющее декодированные выходные данные, может затем отделить недостоверные данные и конкатенировать последовательные сегменты достоверных данных, например. В этом способе декодированные выходные данные могут быть обработаны приложением, чтобы не содержать искусственной «тишины».
Фиг. 8 показывает диаграмму ввода/вывода кодера 800 в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании. Кодер 800 принимает аудиоданные, например поток выборок PCM. Аудиоданные затем кодируются, используя алгоритм кодирования без потерь или алгоритм кодирования с потерями. Во время выполнения алгоритм кодирования может быть вынужден изменить аудиоданные, поданные на вход кодера 800. Причина для такой модификации может состоять в том, чтобы сделать первоначальные аудиоданные соответствующими требованиям алгоритма кодирования. Как упомянуто выше, обычной модификацией оригинальных аудиоданных является вставка дополнительных аудиовыборок таким образом, чтобы оригинальные аудиоданные вписывались в целое число кадров или блоков, и/или таким образом, чтобы алгоритм кодирования инициализировался должным образом до того, как обработается первая истинная аудиовыборка. Информация о выполненной модификации может быть получена из алгоритма кодирования или объекта кодера 800, выполняющего приведение к требуемым условиям входных аудиоданных. Из этой информации модификации может быть получена информация, которая описывает количество информации в начале и/или в конце блока аудиоданных, которое является не достоверным. Кодер 800 может, например, содержать счетчик для счета выборок, маркированных как недостоверные алгоритмом кодирования или объектом, приводящим к требуемым условиям входные аудиоданные. Выдается информация, описывающая количество информации в начале и/или в конце блока аудиоданных, являющееся недостоверным, на выход кодера 800 вместе с закодированными аудиоданными.
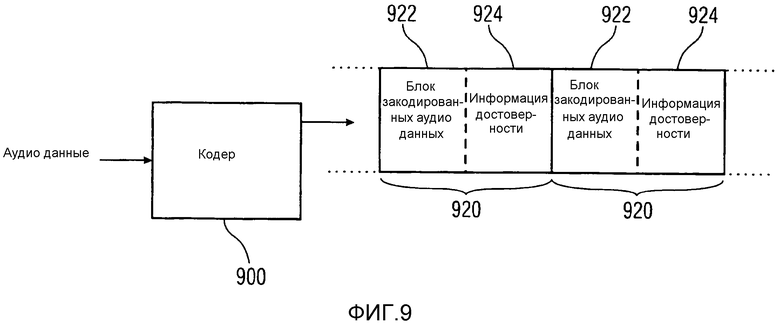
Фиг. 9 показывает схематическую диаграмму ввода/вывода кодера 900 в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании. По сравнению с кодером 800, показанным на Фиг. 8, выходной сигнал кодера 900, показанный на Фиг. 9, следует другому формату. Закодированные аудиоданные, выведенные кодером 900, форматируются в качестве потока или последовательностей блоков 922 кодированных аудиоданных. Наряду с каждым блоком 922 закодированных аудиоданных информация 924 достоверности содержится в этом потоке. Блок 922 закодированных аудиоданных и его соответствующая информация 924 достоверности могут расцениваться как расширенный блок 920 закодированных аудиоданных. Используя информацию 924 достоверности, приемник потока расширенных блоков 920 аудиоданных может декодировать блоки 922 закодированных аудиоданных и использовать только те части, которые маркированы как достоверные данные. Должно быть отмечено, что термин "расширенный блок закодированных аудиоданных" не обязательно подразумевает, что его формат отличается от нерасширенных блоков закодированных аудиоданных. Например, информация достоверности может храниться в неиспользуемом в настоящее время поле данных блока закодированных аудиоданных.
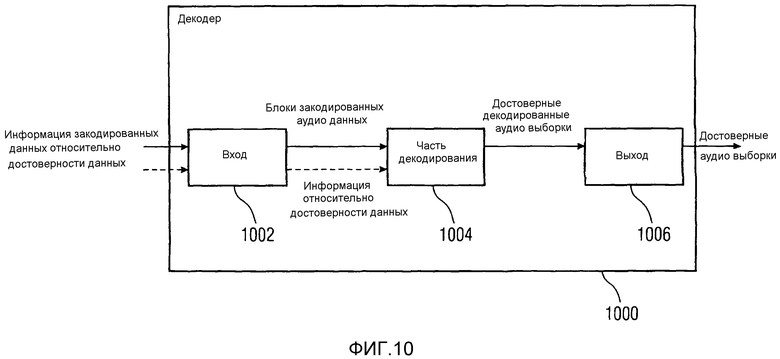
Фиг. 10 показывает схематическую блок-схему декодера 1000 в соответствии с вариантом осуществления описаний, раскрытых в настоящем описании. Декодер 1000 принимает закодированные данные на входе (входном блоке) 1002, который направляет блоки закодированных аудиоданных на часть 1004 декодирования. Закодированные данные содержат информацию относительно достоверности данных, как описано выше относительно описания способа для выдачи информации относительно достоверности закодированных аудиоданных или соответствующего кодера. Вход 1002 декодера 1000 может быть сконфигурирован для приема информации относительно достоверности данных. Этот признак является необязательным, как указано пунктирной стрелкой, ведущей к входу 1002. Дополнительно, вход 1002 может быть сконфигурирован для обеспечения информации относительно достоверности данных части 1004 декодирования. Снова, этот признак является необязательным. Вход 1002 может просто направлять информацию относительно достоверности данных к части 1004 декодирования, или вход 1002 может извлекать информацию относительно достоверности данных из закодированных данных, в которых содержится информация относительно достоверности данных. В качестве альтернативы входу 1002 обработки информации относительно достоверности данных часть 1004 декодирования может извлекать эту информацию и использовать ее для фильтрования недостоверных данных. Часть 1004 декодирования подсоединяется к выводу (выходному блоку) 1006 декодера 1000. Выборки достоверного декодированного аудио передаются или посылаются посредством части 1004 декодирования на выход 1006, который выдает достоверные аудиовыборки в объект потребления, находящийся далее по тракту сигнала достоверных аудиовыборок, такой как блок воспроизведения аудио. Обработка информации относительно достоверности данных является прозрачной объекту потребления, находящемуся далее в тракте обработки сигнала. По меньшей мере одно из: части 1004 декодирования и выхода 1006 может быть сконфигурировано для компоновки достоверных декодированных аудиовыборок таким образом, чтобы не было промежутка, даже если недостоверные аудиовыборки были удалены из потока аудиовыборок, которые должны быть представлены объекту потребления, находящемуся далее в тракте обработки сигнала.
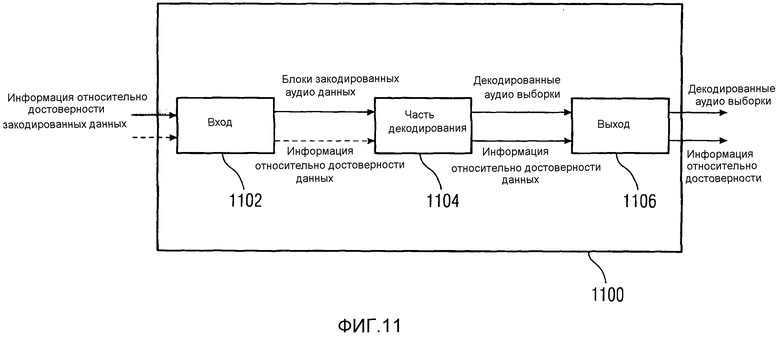
Фиг. 11 показывает схематическую блок-схему декодера 1100 в соответствии с другим вариантом осуществления описаний, раскрытых в настоящем описании. Декодер 1100 содержит вход (входной блок) 1102, часть 1104 декодирования и выход (выходной блок) 1106. Вход 1102 принимает закодированные данные и выдает блоки закодированных аудиоданных в часть 1104 декодирования. Как объяснено выше в связи с декодером 1000, показанным на Фиг. 10, вход 1102 в качестве опции может принимать отдельную информацию достоверности, которая может затем быть направлена на часть 1104 декодирования. Часть 1104 декодирования преобразовывает блоки закодированных аудиоданных в декодированные аудиовыборки и направляет их на выход 1106. Кроме того, часть декодирования также направляет информацию относительно достоверности данных на выход 1106. В случае если информация, относящаяся к достоверности данных, не была выдана посредством входа 1102 в часть1104 декодирования, часть 1104 декодирования может определять информацию относительно достоверности данных непосредственно. Выход 1106 выдает декодированные аудиовыборки и информацию относительно достоверности данных в объект потребления, находящийся далее в тракте обработки сигнала.
Объект потребления, находящийся далее в тракте обработки сигнала, может затем использовать информацию относительно достоверности данных непосредственно. Декодированные аудиовыборки, генерируемые частью 1104 декодирования и выданные выходом 1106, содержат обычно все декодированные аудиовыборки, то есть достоверные аудиовыборки и недостоверные аудиовыборки.
Способ для выдачи информации относительно достоверности закодированных аудиоданных может использовать информацию различных частей для определения количества данных блока аудиоданных, которое является недостоверной. Также кодер может использовать эту информацию. Следующие секции описывают множество частей информации, которые могут быть использованы для этой задачи: количество данных предварительного списка, количество дополнительных искусственных данных, добавленных кодером, длину первоначальных несжатых входных данных и величину пост-списка.
Одной важной частью информации является количество данных предварительного списка, которое является количеством сжатых данных, которые должны быть декодированы перед блоком сжатых данных, соответствующим началу оригинальных несжатых данных. В качестве примера объясняется кодирование и декодирование набора блоков несжатых данных. Учитывая размер кадра 1024 выборок и величину предварительного списка также 1024 выборок, первоначальный набор несжатых аудиоданных PCM, состоящий из 2000 выборок, будет закодирован в качестве трех блоков закодированных данных. Первый блок закодированных данных будет блоком данных предварительного списка с длительностью 1024 выборок. Второй блок закодированных данных приведет к первоначальным 1024 выборкам сигнала источника (не задаются никакие другие артефакты кодирования). Третий блок закодированных данных приводит к 1024 выборкам, состоящим из оставшихся 976 выборок исходного сигнала и 48 хвостовых выборок, введенных степенью детализации кадра. Из-за вовлеченных свойств способов кодирования, таких как MDCT (модифицированное дискретное косинусное преобразование) или QMF (квадратурный зеркальный фильтр), предварительный список не может быть пропущен и является существенным для декодера для восстановления всего оригинального сигнала. Следовательно, для вышеуказанного примера всегда требуется один блок сжатых данных, больший, чем ожидается неспециалистом. Количество данных предварительного списка является зависимым от кодирования и фиксированным для режима кодирования, и постоянным во времени. Поэтому это также требуется для получения случайного доступа к блокам сжатых данных. Предварительный список также должен получать декодированные несжатые выходные данные, соответствующие несжатым входным данным.
Другой частью информации является количество дополнительных искусственных данных, добавленных кодером. Эти дополнительные данные обычно получают из предварительного просмотра будущих выборок в кодере таким образом, чтобы более "разумные" решения относительно кодирования могли быть приняты, подобно переключению от коротких банков фильтров к длинным банкам фильтров. Только кодер знает это значение предварительного просмотра, и оно отлично между реализациями кодера конкретного вендора для одного и того же самого кодирования, хотя постоянно во времени. Длину этих дополнительных данных трудно обнаружить декодером, и часто применяется эвристика, например, количество «тишины» в начале, как предполагается, является дополнительной задержкой кодера или «магическим» значением, если некоторый кодер обнаруживается посредством некоторой другой эвристики.
Следующая часть информации, доступная только для кодера, является длиной оригинальных несжатых входных данных. В примере, описанном выше, 48 хвостовых выборок создаются декодером, которые не присутствовали в оригинальном входе несжатых данных. Причиной является степень детализации кадра, которая фиксирована для зависимого от кодека значения. Обычно это значение равно 1024 или 960 для MPEG-4 AAC, следовательно, кодер всегда дополняет оригинальные данные для выравнивания размера кадра по сетке. Существующие решения обычно добавляют метаданные на уровне системы, который содержит сумму всех дополнительных выборок заголовка, полученных из предварительного списка и дополнительных искусственных данных, и длины исходных аудиоданных. Этот способ, однако, работает только для операции на основании файла, где длительность известна перед кодированием. Он также имеет некоторую недолговечность при применении редактирования к файлу; затем также должны быть обновлены метаданные. Альтернативным подходом является использование отметок времени или длительностей на уровне системы. Использование этого, к сожалению, ясно не определяет, какая половина данных является достоверной. Кроме того, обрезание обычно не может быть сделано на уровне системы.
Наконец, другая часть информации становится все более важной, которая является количеством информации пост-списка. Пост-список определяет, сколько данных должно быть задано для декодера после блока закодированных данных таким образом, чтобы декодер мог выдавать несжатые данные, соответствующие несжатым оригинальным данным. В общем, пост-список может быть обменен с предварительным списком и наоборот. Однако сумма пост-списка и предварительного списка не является постоянной для всех режимов декодера. Современные спецификации, такие как [ISO/IEC 14496-24:2007], предполагают фиксированный предварительный список для всех режимов декодера и игнорируют упомянутый пост-список в пользу определения дополнительной задержки, которая имеет эквивалентное значение для пост-списка. Хотя иллюстрированное на фиг. 4 [ISO/IEC 14496-24:2007] не упоминает, что последний блок закодированных данных (Блок Доступа, AU, в терминологии MPEG) является необязательным и фактически является AU пост-списка, который необходим только для обработки на двойной частоте на декодере с низкой частотой и расширения с удвоенной частотой. Это является вариантом осуществления изобретения, чтобы также определить способ для удаления недостоверных данных при наличии пост-списка.
Информация, описанная выше, является, например, частично используемой в [ISO/IEC 14496-24:2007] для MPEG-4 AAC в формате файла MP4 [ISO/IEC 14496-14]. Здесь используется так называемый список редактирования для отметки достоверной части закодированных данных посредством определения смещения и периода достоверности для закодированных данных в так называемом редактировании. Также величина предварительного списка может быть определена относительно степени детализации кадра. Неудобством этого решения является использование списка редактирования для преодоления проблем, специфичных для кодирования аудио. Это конфликтует с предыдущим использованием списков редактирования для определения универсального нелинейного редактирования без модификации данных. Следовательно, становится трудно или даже невозможно найти различия между редактированиями, специфичными для аудио, и универсальными редактированиями.
Другим потенциальным решением является способ для восстановления оригинальной длины файла в mp3 и mp3Pro. Здесь задержка кодека и полная длительность файла предоставляются в первом блоке закодированных аудиоданных. Это, к сожалению, имеет ту проблему, что он работает только для основанных на файле операций или потоков со всей длиной, уже известной, когда кодер создает первый блок закодированных аудиоданных, так как информация содержится в нем.
Для преодоления неудобства существующих решений варианты осуществления изобретения выдают информацию относительно достоверности данных на выходе кодера в закодированных аудиоданных. Части информации присоединяются к блокам закодированных аудиоданных, которые затронуты. Следовательно, искусственные дополнительные данные вначале маркируются как недостоверные данные, и хвостовые данные, используемые для заполнения кадра, также маркируются как недостоверные данные, которые должны быть обрезаны. Маркировка в соответствии с вариантами осуществления изобретения разрешает различие достоверных от недостоверных данных в закодированном блоке данных таким образом, чтобы декодер мог стереть недостоверные данные до того, как он выдаст данные на выход или мог, альтернативно, маркировать данные, например, способом, подобным представлению в блоке закодированных данных, таким образом, надлежащие действия могут иметь место в других обрабатывающих элементах. Другие релевантные данные, которые являются предварительным списком и последующим списком, определяются в системе и понимаются как кодером, так и декодером таким образом, чтобы для заданного режима декодера эти значения были известны.
Следовательно, аспект раскрытых описаний предлагает разделение переменных во времени данных и не переменных во времени данных. Переменные во времени данные состоят из информации относительно искусственных дополнительных данных, которые присутствуют только в начале, и хвостовых данных, используемых для заполнения кадра. Переменные во времени данные состоят из данных предварительного списка и пост-списка и, таким образом, не должны быть переданы в блоках закодированных аудиоданных, но должны быть переданы вместо этого вне полосы или известны заранее посредством режима декодирования, который может быть получен из записи конфигурации декодера для заданной схемы кодирования аудио.
Дополнительно, рекомендуется устанавливать отметки времени закодированных аудиоданных в соответствии с информацией, которую представляет блок закодированных аудиоданных. Следовательно, оригинальная несжатая аудиовыборка с отметкой времени t, как предполагается, должна быть восстановлена операцией декодирования блока закодированных аудиоданных с отметкой времени t. Это не включает в себя блоки данных предварительного списка или пост-списка, которые необходимы помимо всего. Например, заданный оригинальный аудиосигнал с 1500 выборками и первоначальной отметкой времени со значением 1 будут закодированы в качестве трех блоков закодированных аудиоданных с размером кадра 1024, предварительного списка 1024 и дополнительной искусственной задержки в 200 выборок. Первый блок закодированных аудиоданных имеет отметку времени 1-1024=-1023 и исключительно используется для предварительного списка. Второй блок закодированных аудиоданных имеет отметку времени 1 и включает в себя информацию в блоке закодированных аудиоданных для обрезки первых 200 выборок. Хотя результат декодирования обычно состоит из 1024 выборок, первые 200 выборок удаляются из выходного сигнала и остаются только 824 выборки. Третий блок закодированных аудиоданных имеет отметку времени 825 и также содержит информацию в блоке закодированных аудиоданных для обрезки получившихся выборок выходного аудио длины 1024 до остающихся 676 выборок. Следовательно, информация, что последние 1024-676=348 выборок являются недостоверными, сохраняется в блоках закодированных аудиоданных.
При наличии, например, пост-списка из 1000 выборок из-за различного режима декодера выходной сигнал кодера изменится до четырех блоков закодированных аудиоданных. Три первых блока закодированных аудиоданных остаются постоянными, но прилагаются другие закодированные аудиоданные. При декодировании операция для первого блока доступа предварительного списка остается, как в примере, описанном выше. Декодирование для второго блока доступа, однако, должно принимать во внимание дополнительную задержку альтернативного режима декодера. Три основных решения представлены в этом документе для корректного регулирования дополнительной задержки декодера:
1. Задержка декодера передается от декодера в систему, которая затем задерживает все другие параллельные потоки для сохранения аудио-видеосинхронизации.
2. Задержка декодера передается от декодера в систему, которая может затем удалять недостоверные выборки в обрабатывающем элементе аудио, например, воспроизводящем элементе.
3. Задержка декодера удаляется в декодере. Это приводит к декомпрессированному блоку данных или с меньшим размером изначально из-за удаления дополнительной задержки, или с задержкой выходных данных до тех пор, пока сигнализированное количество блоков закодированных данных пост-списка не будет предоставлено декодеру. Последний способ рекомендуется и предполагается для оставшейся части документа.
Или декодер, или системный уровень вставки будут отвергать весь выходной сигнал, выданный декодером для любых блоков закодированных данных предварительного списка и/или пост-списка. Для блоков закодированных аудиоданных с включенной дополнительной информацией обрезания или декодер или и уровень вставки, управляемые аудиодекодером с дополнительной информацией, могут удалять выборки. Три основных решения существуют для корректного регулирования обрезания:
1. Информация обрезания передается от декодера в систему, которая для первоначальной обрезки задерживает все другие параллельные потоки для сохранения аудио-видеосинхронизации. Обрезание в конце не применяется.
2. Информация обрезания передается от декодера в систему наряду с декомпрессированными блоками данных, которые затем могут быть применены для удаления недостоверных выборок в обрабатывающем элементе аудио, например воспроизводящем элементе.
3. Информация обрезания применяется в декодере, и недостоверные выборки удаляются с начала или с конца декомпрессированного блока данных до того, как он будет выдан в систему. Это приводит к декомпрессированным блокам данных с более короткой длительностью, чем общая длительность кадра. Рекомендуется для системы принимать декодер, который применяет обрезание и отметки времени, и поэтому длительность в системе должна отражать обрезание, которое должно быть применено.
Для операций мульти-частотного декодера разрешение операций обрезания должно быть отнесено к оригинальной частоте дискретизации, которая обычно кодируется в качестве компонента более высокой частоты. Несколько разрешений для операции обрезания являются воображаемыми, например фиксированное разрешение в микросекундах, самая низкая частота дискретизации или самая высокая частота дискретизации. Для соответствия оригинальной частоте дискретизации вариант осуществления изобретения предоставляет разрешение операции обрезания вместе со значениями обрезания в качестве настраиваемого разрешения. Следовательно, формат информации обрезания может быть выдан в качестве синтаксиса, например, как:

Должно быть отмечено, что представленный синтаксис является только примером того, как информация обрезания может содержаться в блоке закодированных аудиоданных. Другие модифицированные варианты охватываются изобретением, предполагая, что они разрешают осуществить различия между достоверными и недостоверными выборками.
Хотя некоторые аспекты изобретения были описаны в контексте устройства, должно быть отмечено, что эти аспекты также представляют описание соответствующего способа, то есть блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока, или элемента, или признака соответствующего устройства.
Закодированные данные в соответствии с изобретением могут храниться на цифровом носителе данных или могут быть переданы на носителе передачи, таком как беспроводный носитель передачи или проводной носитель передачи, такой как Интернет.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может быть выполнена используя цифровой носитель данных, например дискету, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-память, имеющий электронно считываемые сигналы управления, сохраненные на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой таким образом, чтобы выполнялся соответствующий способ. Другие варианты осуществления изобретения содержат носитель информации, имеющий электронно считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой таким образом, чтобы выполнялся один из способов, описанных в настоящем описании.
Дополнительно, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с программным кодом, причем программный код работает для выполнения одного из способов, когда компьютерный программный продукт запущен на компьютере. Программный код, например, может быть сохранен на считываемом машиной носителе. Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем описании, сохраненную на считываемом машиной носителе.
Дополнительным вариантом осуществления изобретения является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем описании. Поток данных или последовательность сигналов, например, могут быть сконфигурированы для передачи с помощью соединения связи и передачи данных, например, с помощью Интернета.
Еще один дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или приспособленное для выполнения одного из способов, описанных в настоящем описании.
Заявленное изобретение относится к средствам для выдачи информации относительно достоверности закодированных аудиоданных. Технический результат заключается в обеспечении возможности обрезания недостоверных данных. Каждый блок закодированных аудиоданных может содержать информацию относительно достоверных аудиоданных. Способ содержит: выдачу информации относительно уровня закодированных аудиоданных, которая описывает количество данных в начале блока аудиоданных, являющихся недостоверными, или выдачу информации относительно уровня закодированных аудиоданных, которая описывает количество данных в конце блока аудиоданных, являющихся недостоверными, или выдачу информации относительно уровня закодированных аудиоданных, которая описывает количество данных вначале и в конце блока аудиоданных, являющихся недостоверными. Также описан способ для приема закодированных данных, включающих в себя информацию относительно достоверности данных, и выдачи декодированных выходных данных. 6 н. и 12 з.п. ф-лы, 3 табл., 11 ил.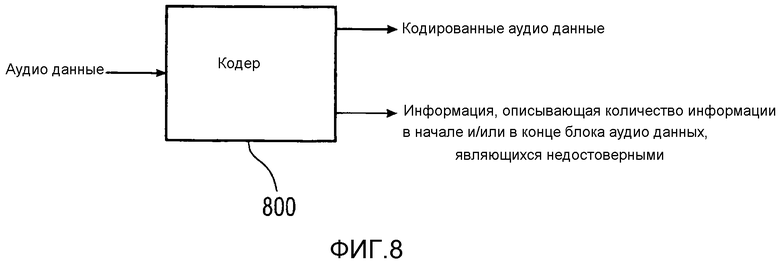
1. Способ для выдачи информации относительно достоверности закодированных аудиоданных так, что недостоверные данные, полученные в результате задержки кодера или полученные в результате заполнения кадра данными, могут быть обрезаны, причем закодированные аудиоданные являются последовательностью кадров (920), при этом каждый кадр может содержать информацию (924) относительно достоверных аудиоданных, причем способ содержит:
или выдачу (302) информации относительно уровня кадра, которая описывает количество данных в начале кадра (920), являющихся недостоверными,
или выдачу (402) информации относительно уровня кадра, которая описывает количество данных в конце кадра (920), являющихся недостоверными, или
выдачу (502) информации относительно уровня кадра, которая описывает количество данных в начале и в конце кадра (920), являющихся недостоверными.
2. Способ по п. 1, в котором информация (924) относительно достоверности закодированных аудиоданных помещается в часть кадра (920), которая является опциональной и может быть проигнорирована.
3. Способ по п. 1, в котором информация (924) относительно достоверности закодированных аудиоданных присоединяется к кадрам (920), на которые оказывается влияние.
4. Способ по п. 1, в котором достоверные аудиоданные происходят из основанного на потоке приложения или приложения в реальном времени.
5. Способ по п. 1, дополнительно содержащий: определение по меньшей мере одного из количества данных предварительного списка и количества данных пост-списка.
6. Способ по п. 1, в котором информация (924) относительно достоверности закодированных аудиоданных содержит различные изменяющиеся во времени данные и не изменяющиеся во времени данные.
7. Кодер (800, 900) для выдачи информации относительно достоверности данных, при этом кодер сконфигурирован для применения способа для выдачи информации относительно достоверности данных по п. 1.
8. Способ для приема закодированных данных, включающих в себя информацию относительно достоверности данных, так что недостоверные данные, полученные в результате задержки кодера или полученные в результате заполнения данными кадра, могут быть обрезаны, и выдачи декодированных выходных данных, причем способ содержит:
прием (602, 702) закодированных данных
или с информацией (924) относительно уровня кадра, которая описывает количество данных в начале кадра (920), являющихся недостоверными,
или с информацией (924) относительно уровня кадра, которая описывает количество данных в конце кадра (920), являющихся недостоверными,
или с информацией (924) относительно уровня кадра, которая описывает количество данных как в начале, так и в конце кадра (920), являющихся недостоверными, и
выдачу (604, 704) декодированных выходных данных, которые содержат только выборки, не маркированные как недостоверные, или содержащих все аудиовыборки кадра и выдачу (706) информации в приложение, какая часть данных является достоверной.
9. Способ по п. 8, дополнительно содержащий: определение по меньшей мере одного из величины предварительного списка и величины пост-списка и использование по меньшей мере одного из кадров (920), принадлежащих пост-списку, и кадров, принадлежащих последующему списку, для восстановления оригинального сигнала.
10. Способ по п. 8, дополнительно содержащий передачу задержки декодера из декодера (1000, 1100) в систему, используя декодированные выходные данные; и выполнение задержки посредством упомянутой системы, других параллельных потоков для сохранения аудио-видеосинхронизации.
11. Способ по п. 8, дополнительно содержащий передачу задержки декодера из декодера (1000, 1100) в систему, используя декодированные входные данные; и
удаление посредством упомянутой системы недостоверных аудиовыборок в элементе, обрабатывающем аудио.
12. Способ по п. 8, дополнительно содержащий удаление задержки декодера в декодере.
13. Способ по п. 8, в котором кадры (920) содержат дополнительную информацию обрезания, и способ дополнительно содержит передачу информации обрезания от декодера в систему, используя декодированные выходные данные; задержку посредством упомянутой системы других параллельных потоков.
14. Способ по п. 8, в котором кадры (920) содержат дополнительную информацию обрезания, и способ дополнительно содержит:
передачу информации обрезания наряду с декодированными кадрами (920) из декодера (1000, 1100) в систему, используя декодированные выходные аудиоданные;
применение информации обрезания для удаления недостоверных выборок в элементе, обрабатывающем аудио.
15. Способ по п. 8, в котором кадры (920) содержат дополнительную информацию обрезания, и способ дополнительно содержит:
применение информации обрезания в декодере (1000, 1100) и удаление недостоверных выборок с начала или с конца декодированного кадра (920) данных для получения обрезанного декодированного кадра; и
выдачу обрезанного декодированного кадра в систему, используя декодированные выходные аудиоданные;
16. Декодер (1000, 1100) для приема закодированных данных и выдачи декодированных выходных данных, причем декодер содержит:
вход (1002, 1102) для приема последовательности закодированных кадров (920) с множеством закодированных аудиовыборок (922) в них, причем некоторые кадры содержат информацию (924) относительно достоверности данных, так что недостоверные данные, полученные в результате задержки кодера или полученные в результате заполнения данными кадра, могут быть обрезаны, причем эта информация форматирована так, что закодированные аудиоданные включают в себя на уровне кадра информацию (924) относительно уровня кадра, которая описывает количество данных в начале кадра (920), являющихся недостоверными, или информацию (924) относительно уровня кадра, которая описывает количество данных в конце кадра (920), являющихся недостоверными, или информацию (924) относительно уровня кадра, которая описывает количество данных в начале и в конце кадра (920), являющихся недостоверными, как описано в способе для приема закодированных аудиоданных, включающих в себя информацию относительно достоверности данных по п. 8,
средство (1004, 1104) обработки декодирования, подсоединенное к входу (1002, 1102) и сконфигурированное для применения информации (924) относительно достоверности данных,
выход (1006, 1106) для выдачи декодированных аудиовыборок, где выдаются или только достоверные аудиовыборки, или где выдается информация относительно достоверности декодированных аудиовыборок.
17. Считываемый компьютером носитель, содержащий набор инструкций для выполнения при работе на компьютере способа для выдачи информации относительно достоверности закодированных аудиоданных, так что недостоверные данные, полученные в результате задержки кодера или полученные в результате заполнения данными кадра, могут быть обрезаны, причем закодированные аудиоданные являются последовательностью блоков закодированных кадров (920), при этом каждый закодированный кадр может содержать информацию относительно достоверных аудиоданных, причем способ содержит:
или выдачу (302) информации относительно уровня кадра, которая описывает количество данных в начале кадра (920), являющихся недостоверными,
или выдачу информации (402) относительно уровня кадра, которая описывает количество данных в конце кадра (920), являющихся недостоверными,
или выдачу информации (502) относительно уровня кадра, которая описывает количество данных в начале и в конце кадра (920), являющихся недостоверными.
18. Считываемый компьютером носитель, содержащий набор инструкций для выполнения при работе на компьютере способа для приема закодированных данных, включающих в себя информацию относительно достоверности данных, и выдачи декодированных выходных данных, так что недостоверные данные, полученные в результате задержки кодера или полученные в результате заполнения данными кадра, могут быть обрезаны, причем способ содержит:
прием (602, 702) закодированных данных
или с информацией (924) относительно уровня кадра, которая описывает количество данных в начале кадра (920), являющихся недостоверными,
или с информацией (924) относительно уровня кадра, которая описывает количество данных в конце кадра (920), являющихся недостоверными,
или с информацией (924) относительно уровня кадра, которая описывает количество данных в начале и в конце кадра (920), являющихся недостоверными,
и выдачу (604, 704) декодированных выходных данных, которые содержат только выборки, не маркированные как недостоверные, или содержащих все аудиовыборки кадра и выдачу (706) информации в приложение, какая часть данных является достоверной.
| US 2008065393 A1 , 13.03.2008 |

