Настоящее изобретение относится к кодированию, обработке и декодированию аудиосигналов, и, в частности, к кодеру, декодеру и способам для адаптивного к сигналу переключения отношения перекрытия при кодировании аудио с преобразованием.
В течение последних 20 лет, конкретно после разработки кодеров MPEG-1 Layer 3 (MP3) и AC-2 (Dolby Digital), перцепционное кодирование аудио полагается исключительно на модифицированное дискретное косинусное преобразование (MDCT), введенное Принсеном и др. (см. [1], [2]) и дополнительно исследованное, под названием модулированное перекрывающееся преобразование (MLT), Малваром (см. [3]), для волновой формы, сохраняющей спектральное квантование. Обратное для этого преобразования, при заданном спектре длины M 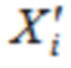 для индекса кадра i, может быть записано как
для индекса кадра i, может быть записано как
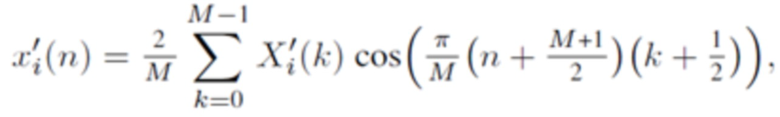 (1)
(1)
где 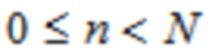 и N является длиной окна. Так как
и N является длиной окна. Так как 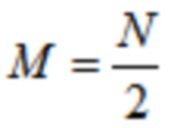 , отношение перекрытия равняется 50%. В недавних стандартах на основе спецификации усовершенствованного кодирования аудио (AAC) MPEG-2 (см. [4], [5]), эта концепция была расширена, чтобы также делать возможными параметрические инструменты, такие как заполнение шумом в области MDCT. Инфраструктура MPEG-H 3D аудио (см. [6], [7]), например, предлагает для полупараметрического кодирования области преобразования, например, функциональные возможности заполнения шумом нулевых спектральных линий выше некоторой частоты; заполнение стерео для полупараметрического кодирования объединенного стерео (см. [8], [9]); и интеллектуальное заполнение промежутков (IGF) для расширения полосы пропускания (см. [10]).
, отношение перекрытия равняется 50%. В недавних стандартах на основе спецификации усовершенствованного кодирования аудио (AAC) MPEG-2 (см. [4], [5]), эта концепция была расширена, чтобы также делать возможными параметрические инструменты, такие как заполнение шумом в области MDCT. Инфраструктура MPEG-H 3D аудио (см. [6], [7]), например, предлагает для полупараметрического кодирования области преобразования, например, функциональные возможности заполнения шумом нулевых спектральных линий выше некоторой частоты; заполнение стерео для полупараметрического кодирования объединенного стерео (см. [8], [9]); и интеллектуальное заполнение промежутков (IGF) для расширения полосы пропускания (см. [10]).
В [9], для комбинации IGF и заполнения стерео, озаглавленная подстановка спектральных диапазонов (SBS) в [8], с помощью переключения ядер преобразования для ввода с нетривиальными разностями фаз между каналами, было показано, что она доставляет хорошее качество аудио для большинства сигналов. На квазистационарных гармонических сегментах, однако, субъективная производительность была ниже, чем субъективная производительность альтернативной конфигурации 3D аудио с высокой задержкой/сложностью с использованием репликации спектральных диапазонов (SBR) и MPEG Surround "объединенного стерео" в области псевдо-QMF. Объяснением для этого поведения является более высокое частотное разрешение преобразований MDCT, используемых в последней конфигурации: при заданной выходной частоте дискретизации, равной 48 кГц, преобразования ядра размера M работают на 24 кГц дискретизированных с понижением микшированных с понижением и остаточных сигналах, удваивая длину кадра.
Основанное на SBS кодирование 3D аудио, вследствие его задержки, сложности, и преимуществ временного разрешения [8], представляет вариант выбора, по меньшей мере, для моно- и стереофонических сигналов, и является желательным улучшить его дизайн - при поддержании длины кадра - так что его производительность может соответствовать производительности основанной на QMF конфигурации даже на одиночном инструменте и других тональных записях. Жизнеспособным решением для увеличенной спектральной эффективности на квазистационарных сегментах является расширенное перекрывающееся преобразование (ELT), предложенное Малваром (см. [11], [12]), чья обратная (соответствующая синтезу) версия является идентичной (1), за исключением того, что 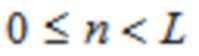 , где
, где 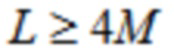 .
.
Таким образом, формула (1) указывает обратное MLT также как обратное ELT. Единственное отличие состоит в том, что в случае обратного MLT n определяется для , например, где 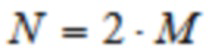 , и в случае обратного ELT, n определяется для , например, где .
, и в случае обратного ELT, n определяется для , например, где .
К сожалению, как будет показано ниже, отношение перекрытия для ELT является, по меньшей мере, 75% вместо 50% для MDCT, что часто ведет к слышимым артефактам для переходных частей волновых форм, таких как удары барабана или тональные начала. Более того, практические решения для переключения длины блоков между преобразованиями ELT разных длин - или между ELT и MLT - аналогично способу, применяемому в кодеках MDCT для в точности таких переходных кадров, не были представлены и была опубликована только теоретическая работа (см. например, [13], [14], [15], [16], [17]).
Цель настоящего изобретения состоит в том, чтобы обеспечить улучшенные концепции для кодирования, обработки и декодирования аудиосигналов. Цель настоящего изобретения решается посредством декодера по п. 1 формулы, посредством кодера по п. 26 формулы, посредством системы по п. 52 формулы, посредством способа по п. 55 формулы, посредством способа по п. 56 формулы и посредством компьютерной программы по п. 57 формулы.
Обеспечивается декодер для декодирования множества аудиовыборок спектральной области. Декодер содержит первый модуль декодирования для генерирования первой группы и второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области. Более того, декодер содержит модуль сложения с перекрытием для осуществления сложения с перекрытием первой группы промежуточных аудиовыборок временной области с перекрытием более чем 5% и самое большее 50% со второй группой промежуточных аудиовыборок временной области. Дополнительно, декодер содержит второй модуль декодирования для генерирования третьей группы и четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области. Более того, декодер содержит интерфейс вывода. Модуль сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области. Более того, модуль сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, второй группы и третьей группы промежуточных аудиовыборок временной области, или осуществлять сложение с перекрытием, по меньшей мере, четвертой группы и первой группы промежуточных аудиовыборок временной области.
В частности, обеспечивается декодер для декодирования множества аудиовыборок спектральной области. Декодер содержит первый модуль декодирования для декодирования первой группы аудиовыборок спектральной области посредством генерирования первой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области первой группы аудиовыборок спектральной области, и для декодирования второй группы аудиовыборок спектральной области посредством генерирования второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области второй группы аудиовыборок спектральной области.
Более того, декодер содержит модуль сложения с перекрытием, при этом модуль сложения с перекрытием сконфигурирован с возможностью выполнять сложение с перекрытием в точности двух групп промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы являются первой группой и второй группой промежуточных аудиовыборок временной области, при этом модуль сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием упомянутых в точности двух групп с перекрытием более чем 5% и самое большее 50%, при этом упомянутое сложение с перекрытием упомянутых в точности двух групп дает результатом генерирование первого множества выходных аудиовыборок временной области аудиосигнала.
Дополнительно, декодер содержит второй модуль декодирования для декодирования третьей группы аудиовыборок спектральной области посредством генерирования третьей группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области третьей группы аудиовыборок спектральной области, и для декодирования четвертой группы аудиовыборок спектральной области посредством генерирования четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области четвертой группы аудиовыборок спектральной области.
Более того, декодер содержит интерфейс вывода для вывода первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала,
модуль сложения с перекрытием сконфигурирован с возможностью получать второе множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области.
Более того, модуль сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или при этом модуль сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области.
Более того, обеспечивается кодер для кодирования множества аудиовыборок временной области аудиосигнала посредством генерирования множества групп аудиовыборок спектральной области из множества групп аудиовыборок временной области.
Кодер содержит первый модуль кодирования для генерирования первой группы из групп аудиовыборок спектральной области из первой группы из групп аудиовыборок временной области, и для генерирования второй группы из групп аудиовыборок спектральной области из второй группы из групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области и вторая группа аудиовыборок временной области являются соседними во времени внутри групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок первой группы аудиовыборок временной области.
Дополнительно, кодер содержит второй модуль кодирования для генерирования третьей группы из групп аудиовыборок спектральной области из третьей группы из групп аудиовыборок временной области, и для генерирования четвертой группы из групп аудиовыборок спектральной области из четвертой группы из групп аудиовыборок временной области, при этом третья группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области.
Более того, кодер содержит модуль вывода для вывода первой группы аудиовыборок спектральной области, второй группы аудиовыборок спектральной области, третьей группы аудиовыборок спектральной области и четвертой группы аудиовыборок спектральной области.
Третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
Дополнительно, обеспечивается система. Система содержит кодер согласно одному из вышеописанных вариантов осуществления, и декодер согласно одному из вышеописанных вариантов осуществления. Кодер сконфигурирован с возможностью кодировать множество аудиовыборок временной области аудиосигнала посредством генерирования множества аудиовыборок спектральной области. Более того, декодер сконфигурирован с возможностью принимать множество аудиовыборок спектральной области от кодера. Дополнительно, декодер сконфигурирован с возможностью декодировать множество аудиовыборок спектральной области.
Более того, обеспечивается способ для декодирования множества аудиовыборок спектральной области. Способ содержит:
- Декодирование первой группы аудиовыборок спектральной области посредством генерирования первой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области первой группы аудиовыборок спектральной области, и декодирование второй группы аудиовыборок спектральной области посредством генерирования второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области второй группы аудиовыборок спектральной области.
- Сложение с перекрытием в точности двух групп промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы являются первой группой и второй группой промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы складываются с перекрытием с перекрытием более чем 5% и самое большее 50%, при этом упомянутое сложение с перекрытием упомянутых в точности двух групп дает результатом генерирование первого множества выходных аудиовыборок временной области аудиосигнала.
- Декодирование третьей группы аудиовыборок спектральной области посредством генерирования третьей группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области третьей группы аудиовыборок спектральной области, и декодирование четвертой группы аудиовыборок спектральной области посредством генерирования четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области четвертой группы аудиовыборок спектральной области.
- Вывод первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала.
- Получение второго множества выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области. И:
- Получение третьего множества выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или получение третьего множества выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области.
Дополнительно, обеспечивается способ для кодирования множества аудиовыборок временной области аудиосигнала посредством генерирования множества групп аудиовыборок спектральной области из множества групп аудиовыборок временной области. Кодер содержит:
- Генерирование первой группы из групп аудиовыборок спектральной области из первой группы из групп аудиовыборок временной области, и генерирование второй группы из групп аудиовыборок спектральной области из второй группы из групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области и вторая группа аудиовыборок временной области являются соседними во времени внутри групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок первой группы аудиовыборок временной области.
- Генерирование третьей группы из групп аудиовыборок спектральной области из третьей группы из групп аудиовыборок временной области, и генерирование четвертой группы из групп аудиовыборок спектральной области из четвертой группы из групп аудиовыборок временной области, при этом третья группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области.
- Вывод первой группы аудиовыборок спектральной области, второй группы аудиовыборок спектральной области, третьей группы аудиовыборок спектральной области и четвертой группы аудиовыборок спектральной области.
Третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
Более того, обеспечиваются компьютерные программы, при этом каждая из компьютерных программ сконфигурирована с возможностью осуществлять один из вышеописанных способов, когда исполняется на компьютере или сигнальном процессоре, так что каждый из вышеописанных способов осуществляется посредством одной из компьютерных программ.
Современные перцепционные кодеры аудио, все из которых применяют модифицированное дискретное косинусное преобразование (MDCT), с отношением перекрытия, равным 50%, для квантования частотной области, обеспечивают хорошее качество кодирования даже при низких битрейтах.
Однако варианты осуществления основываются на обнаружении, что относительно длинные кадры требуются для приемлемой низкочастотной производительности также для квазистационарного гармонического ввода, что ведет к увеличенной алгоритмической задержке и уменьшенному временному разрешению кодирования.
Некоторые варианты осуществления расширяют отношение перекрытия в кодировании на основе перекрывающегося преобразования до более чем стандартные 50%, используемые в современных аудиокодеках.
Согласно некоторым вариантам осуществления расширенное перекрывающееся преобразование (ELT) с отношением перекрытия 75% используется для такого ввода. Чтобы поддерживать высокое временное разрешение для кодирования переходных сегментов, определение ELT модифицируется таким образом, что становится возможным покадровое переключение между кодированием ELT (для квазистационарных) и MDCT (для нестационарных или нетональных областей), с полным устранением алиасинга временной области (TDAC) и без увеличения в длине кадра.
Некоторые варианты осуществления обеспечивают новые модификации концепций ELT и новые модификации формул ELT, обеспечивая возможность переходов идеального восстановления между преобразованиями с отношением перекрытия 50% и 75%. В вариантах осуществления, достигается должное TDAC, между кодированием MDCT с отношением перекрытия, равным 50, и кодированием ELT с отношением, равным 75%.
В некоторых вариантах осуществления, обеспечивается новое, изобретательское окно ELT. Например, в некоторых вариантах осуществления, обеспечивается новая, изобретательская оконная функция ELT с улучшенным подавлением боковых лепестков/низкими уровнями боковых лепестков для избегания кадровых артефактов.
Согласно некоторым вариантам осуществления, новые модификации концепций ELT и новые модификации формул ELT могут, например, использоваться в комбинации с новым, изобретательским окном ELT.
Некоторые варианты осуществления обеспечивают адаптивную к сигналу схему кодирования, применяющую принцип переключения отношения. Обеспечивается полная схема кодирования на основе спецификации MPEG-H 3D Audio (для подробностей в отношении спецификации MPEG-H 3D Audio, см. [7]).
Варианты осуществления обеспечивают кодер, декодер, систему и способы для переключения адаптивным к сигналу образом между MDCT, MDST, и косинус- или синус-модулированным кодированием ELT. Варианты осуществления реализуют кодирование переходного ввода с высоким временным разрешением.
Предпочтительные варианты осуществления обеспечиваются в зависимых пунктах формулы изобретения.
В последующем, варианты осуществления настоящего изобретения описываются более подробно со ссылкой на фигуры, на которых:
Фиг. 1a иллюстрирует декодер согласно одному варианту осуществления,
Фиг. 1b иллюстрирует кодер согласно одному варианту осуществления,
Фиг. 1c иллюстрирует систему согласно одному варианту осуществления,
Фиг. 2a иллюстрирует перекрытие четырех групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от коротких групп к длинным группам,
Фиг. 2b иллюстрирует перекрытие шести групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от коротких групп к длинным группам,
Фиг. 3a иллюстрирует перекрытие четырех групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от длинных групп к коротким группам,
Фиг. 3b иллюстрирует перекрытие шести групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от длинных групп к коротким группам,
Фиг. 4 иллюстрирует TDAC во время сложения с перекрытием (OLA) в перекрывающемся преобразовании, на фиг. 4(a) для MLT, на фиг. 4(b) для ELT, и на фиг. 4(c) для MLT посредством ELT,
Фиг. 5 иллюстрирует переключение от MLT к ELT с преобразованиями перехода согласно вариантам осуществления, при этом фиг. 5(a) показывает некорректное неидеальное восстановление, при этом фиг. 5(b) изображает требуемое идеальное восстановление, и при этом фиг. 5(c) иллюстрирует MLT посредством требуемого (модифицированного) ELT,
Фиг. 6 иллюстрирует переключение от ELT к MLT с преобразованиями перехода согласно вариантам осуществления.
Фиг. 7 иллюстрирует дизайны окна идеального восстановления, на фиг. 7(a) для MLT, на фиг. 7(b) для ELT, и на фиг. 7(c) для переходов согласно вариантам осуществления,
Фиг. 8 иллюстрирует результирующий покадровый выбор ELT и MDCT для четырех входных сигналов согласно вариантам осуществления,
Фиг. 9 иллюстрирует вид с увеличенным масштабом результатов теста прослушивания с интервалами доверия 95% согласно вариантам осуществления,
Фиг. 10 иллюстрирует множество окон анализа согласно одному варианту осуществления,
Фиг. 11 иллюстрирует множество окон синтеза согласно одному варианту осуществления,
Фиг. 12 иллюстрирует базовые блоки фильтров с перекрывающимися преобразованиями согласно некоторым конкретным вариантам осуществления, при этом фиг. 12(a) иллюстрирует MDCT/MDST, и при этом фиг. 12(b) иллюстрирует ELT,
Фиг. 13 иллюстрирует TDAC в четным образом уложенных блоках фильтров согласно некоторым конкретным вариантам осуществления, при этом фиг. 13(a) иллюстрирует Принсена-Брэдли, и при этом фиг. 13(b) иллюстрирует MELT-II,
Фиг. 14 иллюстрирует конкретное согласующееся с TDAC переключение ядер для MELT-IV блоков фильтров согласно конкретным вариантам осуществления, при этом фиг. 14(a) иллюстрирует переходы от косинусной к синусной модуляции, и при этом фиг. 14(b) иллюстрирует переходы от синусной к косинусной модуляции, и
Фиг. 15 иллюстрирует улучшенную, корректную оконную обработку согласно конкретным вариантам осуществления со специальной формой "остановка-начало", указанной посредством тире, во время временных переходов, при этом фиг. 15(a) иллюстрирует временные переходы отношения перекрытия от 75 к 50%, и при этом фиг. 15(b) иллюстрирует временные переходы отношения перекрытия от 50 к 75%.
Перед тем, как подробно описывать конкретные варианты осуществления, описываются принципы кодирования на основе перекрывающегося преобразования.
ELT, MLT, и MDCT, как упомянуто выше, могут рассматриваться как конкретные реализации общей формулировки перекрывающегося преобразования, с формулой (1) для определения обратного и где 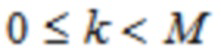 и
и
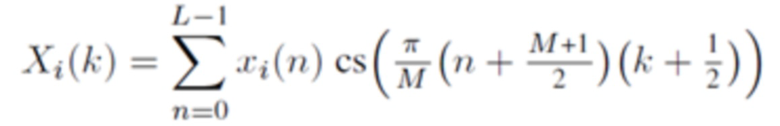 (2)
(2)
для прямого (соответствующего анализу) случая.
В формуле (2), функция cos( ) заменена на заполнитель cs( ), чтобы подчеркнуть, что также можно использовать функцию sin( ) в (1, 2), чтобы получать синус-модулированные формы как модифицированное дискретное синусное преобразование (MDST), применяемое в MCLT (модулированном комплексном перекрывающемся преобразовании) (см. [18]) и в [8], [9].
Таким образом, cs( ) является заполнителем, чтобы указывать, что может использоваться sin( ) или cos( ).
Вместо формулы (1) для обратного MLT (осуществляющего синтез для MLT) или формулы (2) для (прямого) ELT (осуществляющего анализ для ELT), множество других формул используются в качестве уравнений перекрывающегося преобразования, когда выполняется MLT (например, MDCT или MDST) или ELT. Примеры таких уравнений теперь представляются как формулы (2a)-(2j).
Во всех формулах (2a)-(2j) и в формулах (4a)-(4h) ниже, применяется и 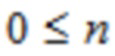 , где
, где 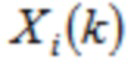 является частотной выборкой в k и
является частотной выборкой в k и 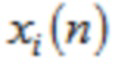 является временной выборкой в n.
является временной выборкой в n.
Обобщенная формулировка перекрывающегося преобразования может, например, формулироваться как в формулах (2a) и (2b):
Прямое (соответствующее анализу) определение обобщенного перекрывающегося преобразования:
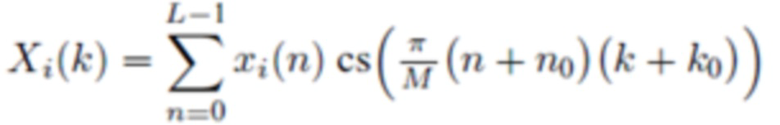 (2a)
(2a)
Обратное (соответствующее синтезу) определение обобщенного перекрывающегося преобразования:
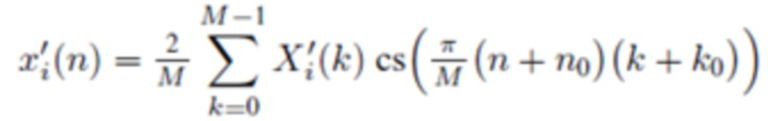 (2b)
(2b)
Перекрывающиеся преобразования с отношением перекрытия 50% могут, например, формулироваться как в формулах (2c)-(2j):
Прямое (соответствующего анализу) MDCT, типа 4, называемое MDCT-IV, 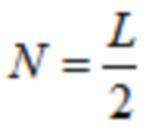 :
:
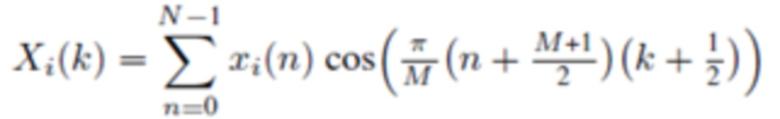 (2c)
(2c)
Обратное (соответствующее синтезу) MDCT, типа 4, называемое IMDCT-IV, 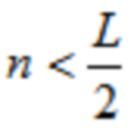 :
:
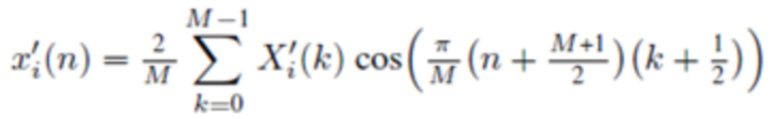 (2d)
(2d)
Прямое (соответствующее анализу) MDCT, типа 2, называемое MDCT-II, :
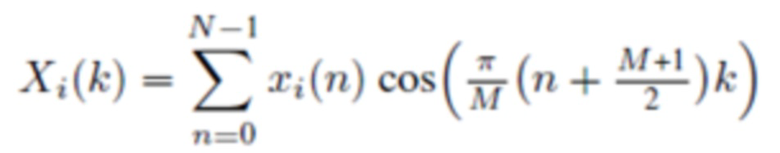 (2e)
(2e)
Обратное (соответствующее синтезу) MDCT, типа 2, называемое IMDCT-II, :
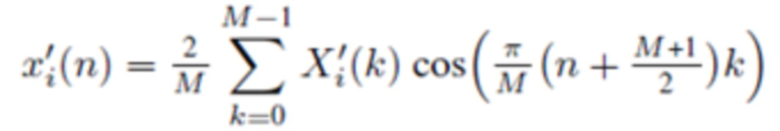 (2f)
(2f)
Прямое (соответствующее анализу) MDST, типа 4, называемое MDST-IV, :
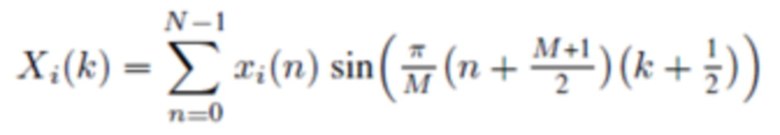 (2g)
(2g)
Обратное (соответствующее синтезу) MDST, типа 4, называемое IMDST-IV, :
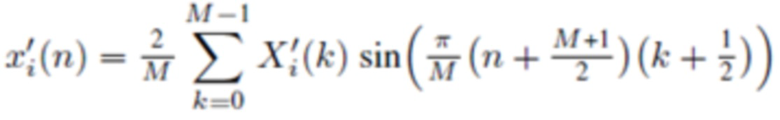 (2h)
(2h)
Прямое (соответствующее анализу) MDST, типа 2, называемое MDST-II, :
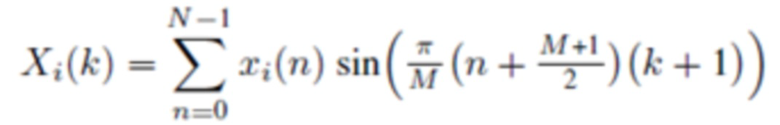 (2i)
(2i)
Обратное (соответствующее синтезу) MDST, типа 2, называемое IMDST-II, :
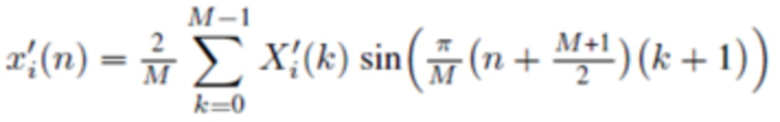 (2j)
(2j)
Перекрывающиеся преобразования с отношением перекрытия 75%, например, прямое или обратное расширенное перекрывающееся преобразование (ELT) Малвара, могут, например, формулироваться таким же образом, что и формулы (2c) и (2d), но где N=L и n<L.
Чтобы достигать идеального восстановления (PR) входного сигнала si(n) после подвергания преобразованиям анализа и синтеза в формулах (1) и (2), соответственно, по меньшей мере, в отсутствии спектрального искажения, например, посредством квантования (указанного посредством ' в формуле (1)), окна 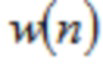 используются, чтобы взвешивать ввод анализа размера L
используются, чтобы взвешивать ввод анализа размера L 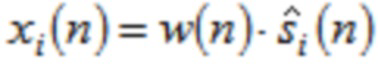 также как вывод синтеза
также как вывод синтеза 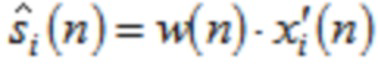 . Так как
. Так как 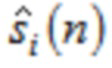 демонстрирует алиасинг временной области (TDA) вследствие свойства критической дискретизации перекрывающегося преобразования, должно удовлетворять конкретным ограничениям дизайна (см. [1], [2], [12]). Для преобразований ELT с четным
демонстрирует алиасинг временной области (TDA) вследствие свойства критической дискретизации перекрывающегося преобразования, должно удовлетворять конкретным ограничениям дизайна (см. [1], [2], [12]). Для преобразований ELT с четным 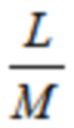 , при предположении равного, симметричного для анализа и синтеза, они даются посредством
, при предположении равного, симметричного для анализа и синтеза, они даются посредством
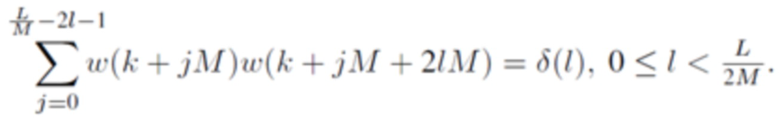 (3)
(3)
Для MLT, MDCT, или MDST (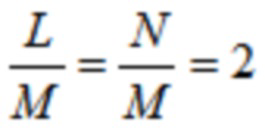 , упомянутые три члена будут применяться взаимозаменяемо ниже), TDA устраняется посредством комбинирования первой временной половины
, упомянутые три члена будут применяться взаимозаменяемо ниже), TDA устраняется посредством комбинирования первой временной половины  со второй половиной
со второй половиной 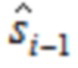 предыдущего кадра посредством процедуры перекрытия и сложения (OLA). Результирующее отношение перекрытия между преобразованиями равняется
предыдущего кадра посредством процедуры перекрытия и сложения (OLA). Результирующее отношение перекрытия между преобразованиями равняется 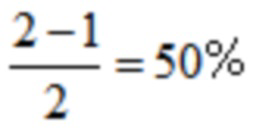 . В случае ELT, где
. В случае ELT, где 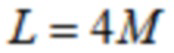 , этап OLA должен комбинировать первую четверть со второй четвертью , третьей четвертью
, этап OLA должен комбинировать первую четверть со второй четвертью , третьей четвертью 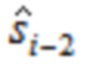 , и четвертой четвертью
, и четвертой четвертью 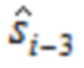 , так что отношение растет к
, так что отношение растет к 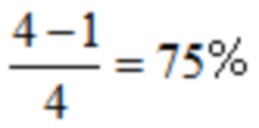 .
.
Фиг. 4 иллюстрирует это различие и предварительное эхо наихудшего случая (временной разброс ошибок кодирования). Более подробное описание TDA и идеального восстановления может быть найдено в [15], [16], [17], [18], [19] и [20].
В частности, фиг. 4 иллюстрирует TDAC во время OLA в перекрывающемся преобразовании, на фиг. 4(a) для MLT, на фиг. 4(b) для ELT, и на фиг. 4(c) для MLT посредством ELT. Длина линии ниже окон указывает максимальное предварительное эхо. Можно видеть, что максимальное предварительное эхо в случае ELT является более длинным, чем в случае MLT.
Также следует отметить, что четным образом уложенные преобразования ELT линейной фазы на основе DCT-II, или преобразования ELT нечетной длины, где, например, L=3M, также являются возможными (см. [21], [22]), и что варианты осуществления, описанные ниже, также применяются к таким преобразованиям ELT.
Фокусируясь на ELT длины 4M (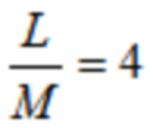 ), можно наблюдать, что, как показано на фиг. 5(a), идеальное восстановление не достигается во время переключений на и от кодирования MLT, так как симметрии TDA являются несовместимыми. Другими словами, необходимость смежных четных-нечетных комбинаций (см. [9], [19]) нарушается между кадрами i-4 и i-3.
), можно наблюдать, что, как показано на фиг. 5(a), идеальное восстановление не достигается во время переключений на и от кодирования MLT, так как симметрии TDA являются несовместимыми. Другими словами, необходимость смежных четных-нечетных комбинаций (см. [9], [19]) нарушается между кадрами i-4 и i-3.
Теперь подробно описываются варианты осуществления.
Фиг. 1b иллюстрирует кодер для кодирования множества аудиовыборок временной области аудиосигнала посредством генерирования множества групп аудиовыборок спектральной области из множества групп аудиовыборок временной области согласно одному варианту осуществления.
Кодер содержит первый модуль 210 кодирования для генерирования первой группы из групп аудиовыборок спектральной области из первой группы из групп аудиовыборок временной области, и для генерирования второй группы из групп аудиовыборок спектральной области из второй группы из групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области и вторая группа аудиовыборок временной области являются соседними во времени внутри групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок первой группы аудиовыборок временной области.
Дополнительно, кодер содержит второй модуль 220 кодирования для генерирования третьей группы из групп аудиовыборок спектральной области из третьей группы из групп аудиовыборок временной области, и для генерирования четвертой группы из групп аудиовыборок спектральной области из четвертой группы из групп аудиовыборок временной области, при этом третья группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области.
Более того, кодер содержит модуль 230 вывода для вывода первой группы аудиовыборок спектральной области, второй группы аудиовыборок спектральной области, третьей группы аудиовыборок спектральной области и четвертой группы аудиовыборок спектральной области.
Третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
Варианты осуществления среди прочего основываются на обнаружении, что, для некоторых частей аудиосигнала временной области, более длинные окна преобразования, имеющие более высокое перекрытие, являются более подходящими, в то время как для других групп сигналов частей аудиосигнала временной области, более короткие окна преобразования с более низким перекрытием являются более подходящими. Переключение между разными окнами преобразования поэтому реализуется во время исполнения. Чтобы реализовать кодирование аудио без слышимых артефактов, соседние окна преобразования перекрываются, даже когда их длина окна изменяется.
На фиг. 1b, первый модуль 210 кодирования предназначен для кодирования более малых групп аудиовыборок временной области, которые имеют более малое перекрытие с другими группами аудиовыборок временной области. Однако, так как даже для первого модуля 210 кодирования, по меньшей мере, некоторое перекрытие должно существовать, требуется перекрытие более чем 5%.
Второй модуль 220 кодирования предназначен для кодирования более больших групп аудиовыборок временной области, которые имеют более большое перекрытие по сравнению с теми группами, которые обрабатываются посредством первого модуля 210 кодирования. Требуется минимальное перекрытие более чем 60%.
Фиг. 2a иллюстрирует перекрытие четырех групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от коротких групп к длинным группам.
В частности, каждая из первой группы 410 аудиовыборок временной области, второй группы 420 аудиовыборок временной области, третьей группы 430 аудиовыборок временной области и четвертой группы 440 аудиовыборок временной области схематически изображена посредством соответствующего блока. Пунктирные линии помогают идентифицировать область перекрытия.
Как можно видеть, первая группа 410 аудиовыборок временной области и вторая группа 420 аудиовыборок временной области имеют перекрытие 50%. Таким образом, первая группа 410 аудиовыборок временной области содержит в точности 50% аудиовыборок временной области второй группы 420 аудиовыборок временной области, и наоборот.
Более того, как можно видеть, третья группа 430 аудиовыборок временной области и четвертая группа 440 аудиовыборок временной области имеют перекрытие 75%. Таким образом, третья группа 430 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области четвертой группы 440 аудиовыборок временной области, и наоборот.
Дополнительно, как можно видеть, третья группа 430 аудиовыборок временной области содержит аудиовыборки второй группы 420 аудиовыборок временной области, так как обе группы имеют перекрывающийся диапазон.
Резюмируя вариант осуществления из фиг. 2a, первая группа 410 аудиовыборок временной области предшествует второй группе 420 аудиовыборок временной области во времени, вторая группа 420 аудиовыборок временной области предшествует третьей группе 430 аудиовыборок временной области во времени, третья группа 430 аудиовыборок временной области предшествует четвертой группе 440 аудиовыборок временной области во времени, и третья группа 430 аудиовыборок временной области содержит аудиовыборки второй группы 420 аудиовыборок временной области. То же имеет место для варианта осуществления из фиг. 2b.
Пример для переключения от длинных групп к коротким группам обеспечивается посредством фиг. 3a.
Фиг. 3a иллюстрирует перекрытие четырех групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от длинных групп к коротким группам.
В частности, снова, каждая из первой группы 411 аудиовыборок временной области, второй группы 421 аудиовыборок временной области, третьей группы 431 аудиовыборок временной области и четвертой группы 441 аудиовыборок временной области схематически изображена посредством соответствующего блока. Пунктирные линии снова помогают идентифицировать область перекрытия.
Как можно видеть, первая группа 411 аудиовыборок временной области и вторая группа 421 аудиовыборок временной области имеют перекрытие 50%. Таким образом, первая группа 411 аудиовыборок временной области содержит в точности 50% аудиовыборок временной области второй группы 421 аудиовыборок временной области, и наоборот.
Более того, как можно видеть, третья группа 431 аудиовыборок временной области и четвертая группа 441 аудиовыборок временной области имеют перекрытие 75%. Таким образом, третья группа 431 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области четвертой группы 441 аудиовыборок временной области, и наоборот.
Дополнительно, как можно видеть, четвертая группа 441 аудиовыборок временной области содержит аудиовыборки первой группы 411 аудиовыборок временной области, так как обе группы имеют перекрывающийся диапазон.
Резюмируя вариант осуществления из фиг. 3a, третья группа 431 аудиовыборок временной области предшествует четвертой группе 441 аудиовыборок временной области во времени, четвертая группа 441 аудиовыборок временной области предшествует первой группе 411 аудиовыборок временной области во времени, первая группа 411 аудиовыборок временной области предшествует второй группе 421 аудиовыборок временной области во времени, и четвертая группа 441 аудиовыборок временной области содержит аудиовыборки первой группы 411 аудиовыборок временной области. То же имеет место для варианта осуществления из фиг. 3b.
Согласно одному варианту осуществления, первая группа 410, 411 аудиовыборок временной области может, например, содержать в точности 50% аудиовыборок второй группы 420, 421 аудиовыборок временной области, и вторая группа аудиовыборок временной области может, например, содержать в точности 50% аудиовыборок первой группы аудиовыборок временной области. Фиг. 2a, фиг. 3a, фиг. 2b и фиг. 3b реализуют такой вариант осуществления.
Третья группа 430, 431 аудиовыборок временной области может, например, содержать, по меньшей мере, 75% и менее чем 100% аудиовыборок четвертой группы 440, 441 аудиовыборок временной области, и четвертая группа 440, 441 аудиовыборок временной области может, например, содержать, по меньшей мере, 75% и менее, чем 100% аудиовыборок третьей группы 430, 431 аудиовыборок временной области. Фиг. 2a, фиг. 3a, фиг. 2b и фиг. 3b также реализуют такой вариант осуществления.
В одном варианте осуществления, первый модуль 210 кодирования может, например, быть сконфигурирован с возможностью выполнять модифицированное дискретное косинусное преобразование или модифицированное дискретное синусное преобразование, и второй модуль 220 кодирования может, например, быть сконфигурирован с возможностью выполнять расширенное перекрывающееся преобразование или модифицированное расширенное перекрывающееся преобразование.
Согласно одному варианту осуществления, третья группа 430, 431 аудиовыборок временной области может, например, содержать в точности 75% аудиовыборок четвертой группы 440, 441 аудиовыборок временной области, и четвертая группа 440, 441 аудиовыборок временной области может, например, содержать в точности 75% аудиовыборок третьей группы 430, 431 аудиовыборок временной области.
В одном варианте осуществления, первое количество аудиовыборок временной области первой группы аудиовыборок временной области может, например, равняться второму количеству аудиовыборок временной области второй группы аудиовыборок временной области. Третье количество аудиовыборок временной области третьей группы аудиовыборок временной области может, например, равняться четвертому количеству аудиовыборок временной области четвертой группы аудиовыборок временной области. Второе количество может, например, равняться третьему количеству, разделенному на 2, и при этом первое количество может, например, равняться четвертому количеству, разделенному на 2.
Например, конкретный пример такого варианта осуществления состоит в том, что все группы, кодированные посредством второго модуля 220 кодирования, имеют в точности вдвое больше выборок из всех групп, кодированных посредством первого модуля 210 кодирования.
Согласно одному варианту осуществления кодера из фиг. 1b, второй модуль 220 кодирования сконфигурирован с возможностью генерировать пятую группу аудиовыборок спектральной области из пятой группы аудиовыборок временной области, и при этом второй модуль 220 кодирования сконфигурирован с возможностью генерировать шестую группу аудиовыборок спектральной области из шестой группы аудиовыборок временной области. Третья или четвертая группа аудиовыборок временной области содержит, по меньшей мере, 75% и менее чем 100% аудиовыборок пятой группы аудиовыборок временной области, при этом пятая группа аудиовыборок временной области содержит, по меньшей мере, 75% и менее чем 100% аудиовыборок третьей или четвертой группы аудиовыборок временной области, при этом пятая группа аудиовыборок временной области содержит, по меньшей мере, 75% и менее чем 100% аудиовыборок шестой группы аудиовыборок временной области, при этом шестая группа аудиовыборок временной области содержит, по меньшей мере, 75% и менее чем 100% аудиовыборок пятой группы аудиовыборок временной области. Модуль 230 вывода сконфигурирован с возможностью дополнительно выводить пятую группу аудиовыборок спектральной области, и шестую группу аудиовыборок спектральной области.
Фиг. 2b иллюстрирует перекрытие шести групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от коротких групп к длинным группам.
Как можно видеть, четвертая группа 440 аудиовыборок временной области и пятая группа 450 аудиовыборок временной области имеют перекрытие 75%. Таким образом, пятая группа 450 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области четвертой группы 440 аудиовыборок временной области, и наоборот.
Более того, как можно видеть, пятая группа 450 аудиовыборок временной области и пятая группа 460 аудиовыборок временной области имеют перекрытие 75%. Таким образом, шестая группа 460 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области пятой группы 450 аудиовыборок временной области, и наоборот.
Согласно варианту осуществления, первая группа 410, 411 аудиовыборок временной области и вторая группа аудиовыборок 420, 421 временной области являются соседними во времени. Например, на фиг. 2b проиллюстрированы шесть групп аудиовыборок временной области, именно 410, 420, 430, 440, 450, 460. Последовательность во времени может определяться для этих шести групп.
Например, первая выборка первой группы 410 аудиовыборок временной области относится к точке во времени, более ранней (более в прошлом), чем первая выборка второй группы 420 аудиовыборок временной области.
Первая выборка второй группы 420 аудиовыборок временной области относится к той же точке во времени, что и первая выборка третьей группы 430 аудиовыборок временной области. Однако последняя выборка второй группы 420 аудиовыборок временной области относится к точке во времени, более ранней, чем последняя выборка третьей группы 430 аудиовыборок временной области.
Первая выборка третьей группы 430 аудиовыборок временной области относится к точке во времени, более ранней, чем первая выборка четвертой группы 440 аудиовыборок временной области.
Первая выборка четвертой группы 440 аудиовыборок временной области относится к точке во времени, более ранней, чем первая выборка пятой группы 450 аудиовыборок временной области.
Первая выборка пятой группы 450 аудиовыборок временной области относится к точке во времени, более ранней, чем первая выборка шестой группы 460 аудиовыборок временной области.
Результирующая последовательность во времени для фиг. 2b является 410, 420, 430, 440, 450, 460.
Применение такого же рассуждения для фиг. 3b относится к последовательности во времени для фиг. 3b: 461, 451, 431, 441, 411, 421.
Рассуждение для определения последовательности во времени является:
Если первая выборка группы A аудиовыборок временной области относится к точке во времени, более ранней, чем первая выборка группы B аудиовыборок временной области, то группа A появляется ранее в последовательности времени, затем группа B.
Если первая выборка группы A аудиовыборок временной области относится к той же точке на временной шкале, что и первая выборка группы B, то группа A появляется ранее в последовательности времени, затем группа B, если последняя выборка группы A аудиовыборок временной области относится к точке во времени, более ранней, чем последняя выборка группы B.
Две группы аудиовыборок временной области являются соседними во времени, если они являются (непосредственными) соседями в последовательности во времени групп аудиовыборок временной области.
Например, рассмотрим последовательность во времени для фиг. 2b: 410, 420, 430, 440, 450, 460. Там, группы 410 и 420 являются соседними во времени, группы 420 и 430 являются соседними во времени, группы 430 и 440 являются соседними во времени, группы 440 и 450 являются соседними во времени и группы 450 и 460 являются соседними во времени, но никакие другие пары двух групп не являются соседними во времени.
Например, рассмотрим последовательность во времени для фиг. 3b: 461, 451, 431, 441, 411, 421. Там, группы 461 и 451 являются соседними во времени, группы 451 и 431 являются соседними во времени, группы 431 и 441 являются соседними во времени, группы 441 и 411 являются соседними во времени и группы 411 и 421 являются соседними во времени, но никакие другие пары двух групп не являются соседними во времени.
Что касается фиг. 3b, она иллюстрирует перекрытие шести групп аудиовыборок временной области согласно одному варианту осуществления, когда выполняется переключение от длинных групп к коротким группам.
Как можно видеть, третья группа 431 аудиовыборок временной области и пятая группа 451 аудиовыборок временной области имеют перекрытие 75%. Таким образом, пятая группа 451 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области третьей группы 431 аудиовыборок временной области, и наоборот.
Более того, как можно видеть, пятая группа 451 аудиовыборок временной области и пятая группа 461 аудиовыборок временной области имеют перекрытие 75%. Таким образом, шестая группа 461 аудиовыборок временной области содержит в точности 75% аудиовыборок временной области пятой группы 451 аудиовыборок временной области, и наоборот.
В вариантах осуществления, оконная функция может применяться к аудиовыборкам временной области первым модулем 210 кодирования или вторым модулем 220 кодирования, чтобы получать взвешенные выборки временной области, и после этого, первый модуль 210 кодирования или второй модуль 220 кодирования может генерировать аудиовыборки спектральной области из взвешенных выборок временной области.
В одном варианте осуществления, кодер сконфигурирован с возможностью либо использует первый модуль 210 кодирования или второй модуль 220 кодирования для генерирования текущей группы аудиовыборок спектральной области в зависимости от свойства сигнала части аудиосигнала временной области.
Согласно одному варианту осуществления, кодер сконфигурирован с возможностью определять в качестве свойства сигнала, содержит ли текущая группа множества аудиовыборок временной области, по меньшей мере, одну из нестационарных областей и нетональных областей. Кодер сконфигурирован с возможностью использовать первый модуль 210 кодирования, чтобы генерировать текущую группу аудиовыборок спектральной области в зависимости от текущей группы множества аудиовыборок временной области, если текущая группа множества аудиовыборок временной области содержит упомянутую, по меньшей мере, одну из нестационарных областей и нетональных областей. Более того, кодер сконфигурирован с возможностью использовать второй модуль 220 кодирования, чтобы генерировать текущую группу аудиовыборок спектральной области в зависимости от текущей группы множества аудиовыборок временной области, если текущая группа множества аудиовыборок временной области не содержит упомянутую, по меньшей мере, одну из нестационарных областей и нетональных областей.
В одном варианте осуществления, модуль 230 вывода сконфигурирован с возможностью выводить бит, имеющий либо первое битовое значение, либо второе битовое значение в зависимости от свойства сигнала. Таким образом, бит может использоваться на стороне декодера, чтобы определять, использовал ли кодер первый модуль 210 кодирования или второй модуль 220 кодирования для кодирования.
Фиг. 1a иллюстрирует декодер для декодирования множества аудиовыборок спектральной области согласно одному варианту осуществления.
Декодер содержит первый модуль 110 декодирования для декодирования первой группы аудиовыборок спектральной области посредством генерирования первой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области первой группы аудиовыборок спектральной области, и для декодирования второй группы аудиовыборок спектральной области посредством генерирования второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области второй группы аудиовыборок спектральной области.
Более того, декодер содержит модуль 130 сложения с перекрытием, при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью выполнять сложение с перекрытием в точности двух групп промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы являются первой группой и второй группой промежуточных аудиовыборок временной области, при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием упомянутых в точности двух групп с перекрытием более чем 5% и самое большее 50%, при этом упомянутое сложение с перекрытием упомянутых в точности двух групп дает результатом генерирование первого множества выходных аудиовыборок временной области аудиосигнала.
Дополнительно, декодер содержит второй модуль 120 декодирования для декодирования третьей группы аудиовыборок спектральной области посредством генерирования третьей группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области третьей группы аудиовыборок спектральной области, и для декодирования четвертой группы аудиовыборок спектральной области посредством генерирования четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области четвертой группы аудиовыборок спектральной области.
Более того, декодер содержит интерфейс 140 вывода для вывода первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала,
модуль 130 сложения с перекрытием сконфигурирован с возможностью получать второе множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области.
Более того, модуль 130 сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области.
Описания, которые были обеспечены со ссылкой на фиг. 2a, фиг. 2b, фиг. 2c и фиг. 2d для перекрытия групп аудиовыборок 410, 411, 420, 421, 430, 431, 440, 441, 450, 451, 460 и 461 временной области, равным образом применимы для групп промежуточных аудиовыборок временной области.
В вариантах осуществления, первые выходные аудиовыборки генерируются на основе сложения с перекрытием первых и вторых выходных аудиовыборок временной области, вторые выходные аудиовыборки генерируются на основе сложения с перекрытием третьих и четвертых выходных аудиовыборок временной области,
В вариантах осуществления декодера, соответствующих ситуации на фиг. 2a и 2b, первое множество выходных аудиовыборок временной области аудиосигнала предшествует третьему множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом третье множество выходных аудиовыборок временной области аудиосигнала предшествует второму множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или
в вариантах осуществления декодера, соответствующих ситуации на фиг. 3a и 3b, второе множество выходных аудиовыборок временной области аудиосигнала предшествует третьему множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом третье множество выходных аудиовыборок временной области аудиосигнала предшествует первому множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области.
Более того, было очерчено, что первая группа и вторая группа промежуточных аудиовыборок временной области перекрываются более чем 5% и самое большее 50%. В большинстве вариантов осуществления, первый модуль 110 декодирования генерирует группы промежуточных аудиовыборок временной области, которые имеют одно и то же количество выборок, другими словами, окно, используемое первым модулем 110 декодирования, имеет в общем всегда один и тот же размер. Затем, чтобы определять перекрытие первой и второй группы промежуточных аудиовыборок временной области, количество промежуточных аудиовыборок временной области первой группы, которые перекрываются с выборками второй группы промежуточных аудиовыборок временной области в сложении с перекрытием, (например, 1024 выборок) разделяется на полное количество выборок первой группы промежуточных аудиовыборок временной области (например, 2048 выборок), чтобы определять перекрытие сложения с перекрытием (1024/2048=50%). Однако в исключительном варианте осуществления, когда первый модуль 110 декодирования генерирует группы промежуточных аудиовыборок временной области, которые имеют разное количество выборок, то рассматривается более большая одна из групп промежуточных аудиовыборок временной области и перекрытие определяется как количество промежуточных аудиовыборок временной области более большой группы, которые перекрываются с выборками более малой группы, (например, 768 выборок) разделенное на полное количество выборок более большей группы (например, 2048 выборок) (перекрытие: 768/2048=37.5%).
Дополнительно, было очерчено, что третья группа и четвертая группа промежуточных аудиовыборок временной области перекрываются с более чем 60% и менее чем 100%. В большинстве вариантов осуществления, второй модуль 120 декодирования генерирует группы промежуточных аудиовыборок временной области, которые имеют одно и то же количество выборок, другими словами, окно, используемое вторым модулем 120 декодирования, имеет в общем всегда один и тот же размер (но размер групп/окон часто отличается от размера групп/окон, которые генерируются/используются первым модулем 110 декодирования). Затем, чтобы определять перекрытие третьей и четвертой группы промежуточных аудиовыборок временной области, количество промежуточных аудиовыборок временной области третьей группы, которые перекрываются с выборками четвертой группы промежуточных аудиовыборок временной области в сложении с перекрытием, (например, 3584 выборок) разделяется на полное количество выборок первой группы промежуточных аудиовыборок временной области (например, 4096 выборок), чтобы определять перекрытие сложения с перекрытием (3584/4096=87,5%). Однако в исключительном варианте осуществления, когда второй модуль 120 декодирования генерирует группы промежуточных аудиовыборок временной области, которые имеют разное количество выборок, то рассматривается более большая одна из групп промежуточных аудиовыборок временной области и перекрытие определяется как количество промежуточных аудиовыборок временной области более большой группы, которые перекрываются с выборками более малой группы, (например, 3072 выборок) разделенное на полное количество выборок более большей группы (например, 4096 выборок) (перекрытие: 3072/4096=75%).
Сложение с перекрытием является хорошо известным специалисту в данной области техники. Сложение с перекрытием двух групп аудиовыборок временной области является особенно хорошо известным специалисту в данной области техники.
Один способ осуществления сложения с перекрытием трех или более групп может, например, состоять в том, чтобы осуществлять сложение с перекрытием двух из упомянутых трех или более групп, чтобы получать промежуточный результат сложения с перекрытием, и затем осуществлять сложение с перекрытием третьей группы из упомянутых трех или более групп с промежуточным результатом сложения с перекрытием, и продолжать осуществление подобным образом, до тех пор когда все группы будут подвергнуты сложению с перекрытием с (обновленным) промежуточным результатом.
Другой подход состоит в том, чтобы сначала перекрывать все из упомянутых трех или более групп подходящим образом и затем складывать соответствующие выборки групп в перекрытии, чтобы получать результат сложения с перекрытием.
Согласно одному варианту осуществления, модуль 130 сложения с перекрытием может, например, быть сконфигурирован с возможностью осуществлять сложение с перекрытием первой группы промежуточных аудиовыборок временной области с перекрытием в точности 50% со второй группой промежуточных аудиовыборок временной области. Модуль 130 сложения с перекрытием может, например, быть сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием, по меньшей мере, 75% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области.
В одном варианте осуществления, первый модуль 110 декодирования может, например, быть сконфигурирован с возможностью выполнять обратное модифицированное дискретное косинусное преобразование или обратное модифицированное дискретное синусное преобразование. Второй модуль 120 декодирования сконфигурирован с возможностью выполнять обратное расширенное перекрывающееся преобразование или обратное модифицированное расширенное перекрывающееся преобразование.
Согласно одному варианту осуществления, модуль 130 сложения с перекрытием может, например, быть сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, третьей группы промежуточных аудиовыборок временной области с перекрытием в точности 75% с четвертой группой промежуточных аудиовыборок временной области.
В одном варианте осуществления, первое количество промежуточных аудиовыборок временной области первой группы промежуточных аудиовыборок временной области может, например, равняться второму количеству промежуточных аудиовыборок временной области второй группы промежуточных аудиовыборок временной области. Третье количество промежуточных аудиовыборок временной области третьей группы промежуточных аудиовыборок временной области может, например, равняться четвертому количеству промежуточных аудиовыборок временной области четвертой группы промежуточных аудиовыборок временной области. Второе количество может, например, равняться третьему количеству, разделенному на 2, и при этом первое количество равняется четвертому количеству, разделенному на 2.
Согласно одному варианту осуществления декодера из фиг. 1a, второго модуля 120 декодирования может, например, быть сконфигурирован с возможностью декодировать пятую группу аудиовыборок спектральной области посредством генерирования пятой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области пятой группы аудиовыборок спектральной области, и для декодирования шестой группы аудиовыборок спектральной области посредством генерирования шестой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области шестой группы аудиовыборок спектральной области. Модуль 130 сложения с перекрытием сконфигурирован с возможностью получать второе множество выходных аудиовыборок временной области посредством осуществления сложения с перекрытием третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области и пятой группы промежуточных аудиовыборок временной области и шестой группы промежуточных аудиовыборок временной области, так что третья или четвертая группа промежуточных аудиовыборок временной области перекрывается с, по меньшей мере, 75% и менее чем 100% с пятой группой промежуточных аудиовыборок временной области, и так что пятая группа промежуточных аудиовыборок временной области перекрывается с, по меньшей мере, 75% и менее чем 100% с шестой группой промежуточных аудиовыборок временной области.
Ссылка делается на описания, обеспеченные выше по отношению к группам аудиовыборок 410, 411, 420, 421, 430, 431, 440, 441, 450, 451, 460 и 461 временной области на фиг. 2b и фиг. 3b, при этом эти описания равным образом применимы к группам промежуточных аудиовыборок временной области.
В одном варианте осуществления, модуль 130 сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, так что все промежуточные аудиовыборки временной области второй группы промежуточных аудиовыборок временной области перекрываются с промежуточными аудиовыборками временной области третьей группы промежуточных аудиовыборок временной области. Или, модуль 130 сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, так что все промежуточные аудиовыборки временной области первой группы промежуточных аудиовыборок временной области перекрываются с четвертой группой промежуточных аудиовыборок временной области.
Фиг. 1c иллюстрирует систему согласно одному варианту осуществления. Система содержит кодер 310 согласно одному из вышеописанных вариантов осуществления, и декодер 320 согласно одному из вышеописанных вариантов осуществления. Кодер 310 сконфигурирован с возможностью кодировать множество аудиовыборок временной области аудиосигнала посредством генерирования множества аудиовыборок спектральной области. Более того, декодер 320 сконфигурирован с возможностью принимать множество аудиовыборок спектральной области от кодера. Дополнительно, декодер сконфигурирован с возможностью декодировать множество аудиовыборок спектральной области.
Чтобы уменьшать или избегать алиасинга временной области, в отношении одного варианта осуществления кодера из фиг. 1b, второй модуль 220 кодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из третьей группы и четвертой группы аудиовыборок спектральной области в зависимости от
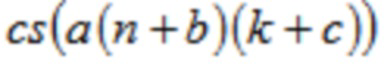 ,
,
где cs( ) является cos( ) или sin( ),
где n указывает временной индекс одной из аудиовыборок временной области третьей или четвертой группы аудиовыборок временной области,
где k указывает спектральный индекс одной из аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где -0,1≤c≤0,1, или 0,4≤c≤0,6, или 0,9≤c≤1,1,
где 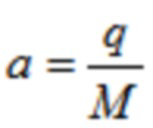 ,
,
где 0,9⋅π≤q≤1,1⋅π.
M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где 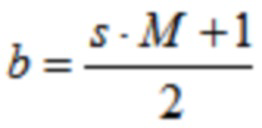 , и
, и
где 1,5≤s≤4,5.
В одном варианте осуществления, первый модуль 210 кодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из первой группы и второй группы аудиовыборок спектральной области в зависимости от
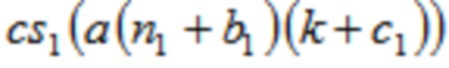 ,
,
где 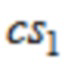 ( ) является cos( ) или sin( ),
( ) является cos( ) или sin( ),
где n1 указывает временной индекс одной из аудиовыборок временной области первой или второй группы аудиовыборок временной области,
где -0,1≤c1≤0,1, или 0,4≤c1≤0,6, или 0,9≤c1≤1,1,
где 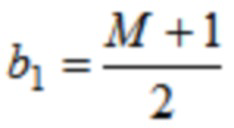 .
.
Согласно одному варианту осуществления c=0, или c=0,5, или c=1, q=π, и s=3.
Установка s=3 достигает оптимального уменьшения алиасинга временной области, в то время как установка 1,5≤s≤4,5, где s≠3 достигает некоторой степени уменьшения алиасинга временной области, но, в общем, не настолько большого уменьшения как для s=3.
Конкретные варианты осуществления работают особенно хорошо. См. таблицу 1 и таблицу 2:
Таблица 1:


Таблица 1 показывает переключение от MLT к ELT. В каждой строке, проиллюстрированы функции для четырех последующих окон/соответствующих групп аудиовыборок временной области. Первые два столбца относятся к последним двум окнам MLT (предпоследнему и последнему окну MLT), столбец 3 и 4 относится к первому и второму окну ELT, соответственно. Каждая строка представляет особенно хорошую комбинацию функций для последующих окон. Формулы для MDCT-II, MDST-II, MDCT-IV и MDST-IV и для MECT-II, MEST-II, MECT-IV и MEST-IV и соответствующие обратные формулы представлены по отношению к формулам (2a)-(2j) и (4a)-(4h). Проиллюстрированные комбинации работают равным образом хорошо для обратных преобразований с обратными функциями.
Таким образом, например, в одном варианте осуществления, q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и  =0,5.
=0,5.
В другом варианте осуществления q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и c1=0.
В другом варианте осуществления q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и c1=1.
В другом варианте осуществления q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и c1=1.
В другом варианте осуществления q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и c1=0.5.
В другом варианте осуществления q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и c1=0.5.
В другом варианте осуществления q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и c1=0.
В другом варианте осуществления q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и c1=0.
Таблица 2:


Таблица 2 показывает переключение от ELT к MLT. В каждой строке, проиллюстрированы функции для четырех последующих окон (соответствующих группам аудиовыборок временной области). Первые два столбца относятся к последним двум окнам ELT (предпоследнему и последнему окну ELT), столбец 3 и 4 относится к первому и второму окну MLT, соответственно. Каждая строка представляет особенно хорошую комбинацию функций для последующих окон. Формулы для MDCT-II, MDST-II, MDCT-IV и MDST-IV и для MECT-II, MEST-II, MECT-IV и MEST-IV и соответствующие обратные формулы представлены по отношению к формулам (2a)-(2j) и (4a)-(4h). Проиллюстрированные комбинации работают равным образом хорошо для обратных преобразований с обратными функциями.
В одном варианте осуществления, второй модуль 220 кодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из третьей группы и четвертой группы аудиовыборок спектральной области в зависимости от
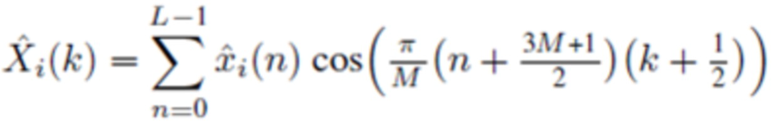 , или
, или
в зависимости от
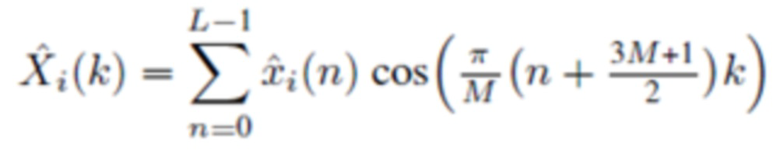 , или
, или
в зависимости от
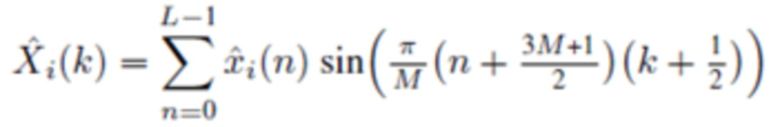 , или
, или
в зависимости от
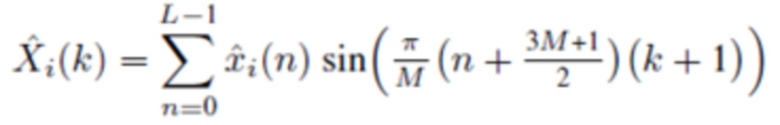 ,
,
где 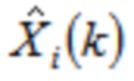 указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и где
указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и где 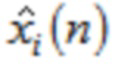 указывает значение временной области.
указывает значение временной области.
Согласно одному варианту осуществления, второй модуль 220 кодирования сконфигурирован с возможностью применять вес к аудиовыборке временной области 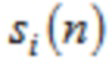 третьей группы или четвертой группы аудиовыборок временной области согласно
третьей группы или четвертой группы аудиовыборок временной области согласно
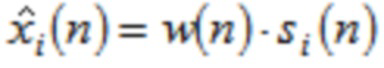
чтобы генерировать значение временной области .
В одном варианте осуществления, все аудиовыборки временной области второй группы аудиовыборок временной области перекрываются с аудиовыборками временной области третьей группы аудиовыборок временной области, или при этом все аудиовыборки временной области первой группы аудиовыборок временной области перекрываются с четвертой группой аудиовыборок временной области.
Аналогично, в отношении декодера из фиг. 1a, в одном варианте осуществления, второй модуль 120 декодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области в зависимости от
,
где cs( ) является cos( ) или sin( ), где n указывает временной индекс одной из промежуточных аудиовыборок временной области третьей или четвертой группы промежуточных аудиовыборок временной области, где k указывает спектральный индекс одной из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области,
где -0,1≤c≤0,1, или 0,4≤c≤0,6, или 0,9≤c≤1,1,
где ,
где 0,9⋅π≤q≤1,1⋅π,
где M указывает количество аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области,
где , и
где 1,5≤s≤4,5.
В одном варианте осуществления, первый модуль 110 декодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из первой группы промежуточных аудиовыборок временной области и второй группы промежуточных аудиовыборок временной области в зависимости от
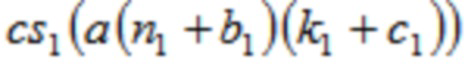 ,
,
где cs( ) является cos( ) или sin( ),
где n указывает временной индекс одной из промежуточных аудиовыборок временной области третьей или четвертой группы промежуточных аудиовыборок временной области,
где k указывает спектральный индекс одной из аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где -0,1≤c≤0,1, или 0,4≤c≤0,6, или 0,9≤c≤1,1,
где ,
где 0,9⋅π≤q≤1,1⋅π,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где , и
где 1,5≤s≤4,5.
В одном варианте осуществления, первый модуль 110 декодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из первой группы промежуточных аудиовыборок временной области и второй группы промежуточных аудиовыборок временной области в зависимости от
,
где ( ) является cos( ) или sin( ),
где 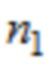 указывает временной индекс одной из промежуточных аудиовыборок временной области первой или второй группы промежуточных аудиовыборок временной области,
указывает временной индекс одной из промежуточных аудиовыборок временной области первой или второй группы промежуточных аудиовыборок временной области,
где -0,1≤c1≤0,1, или 0,4≤c1≤0,6, или 0,9≤c1≤1,1,
где .
Согласно одному варианту осуществления c=0, или c=0,5, или c=1, q=π, и s=3.
Установка s=3 достигает оптимального уменьшения алиасинга временной области, в то время как установка 1,5≤s≤4,5, где s≠3 достигает некоторой степени уменьшения алиасинга временной области, но, в общем, не настолько большого уменьшения, как для s=3.
В одном варианте осуществления, второй модуль 120 декодирования сконфигурирован с возможностью генерировать, по меньшей мере, одну из третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области в зависимости от
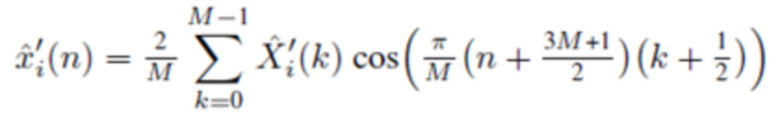 , или
, или
в зависимости от
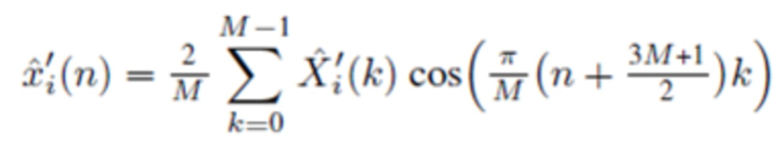 , или
, или
в зависимости от
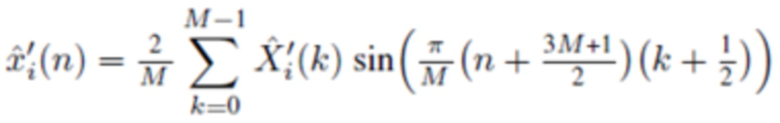 , или
, или
в зависимости от
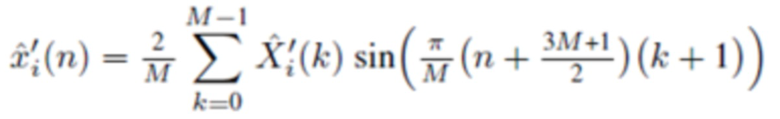 ,
,
где 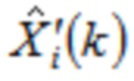 указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и где
указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и где 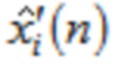 указывает значение временной области.
указывает значение временной области.
Согласно одному варианту осуществления, второй модуль 120 декодирования сконфигурирован с возможностью применять вес к значению временной области согласно
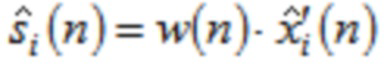
чтобы генерировать промежуточную аудиовыборку временной области 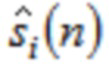 третьей или четвертой группы промежуточных аудиовыборок временной области.
третьей или четвертой группы промежуточных аудиовыборок временной области.
Относительно кодера из фиг. 1b, согласно одному варианту осуществления, welt является первой оконной функцией, при этом wtr является второй оконной функцией, при этом часть второй оконной функции wtr определяется согласно
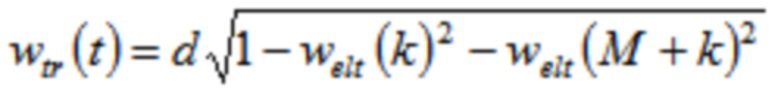 ,
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где 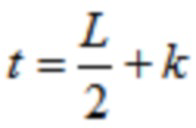 , или где
, или где 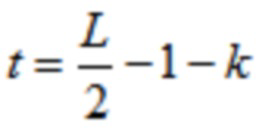 .
.
L указывает количество выборок третьей группы или четвертой группы аудиовыборок временной области.
Третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, и где второй модуль 220 кодирования сконфигурирован с возможностью применять первую оконную функцию welt к четвертой группе аудиовыборок временной области, и при этом второй модуль 220 кодирования сконфигурирован с возможностью применять вторую оконную функцию wtr к третьей группе аудиовыборок временной области. Или, четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области, и при этом второй модуль 220 кодирования сконфигурирован с возможностью применять первую оконную функцию welt к третьей группе аудиовыборок временной области, и при этом второй модуль 220 кодирования сконфигурирован с возможностью применять вторую оконную функцию wtr к четвертой группе аудиовыборок временной области.
Согласно одному варианту осуществления, wtr1 является третьей оконной функцией, при этом часть третьей оконной функции определяется согласно
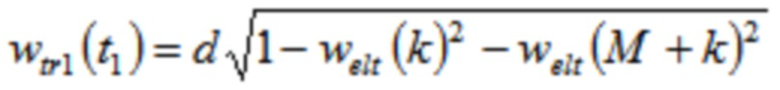 ,
,
где 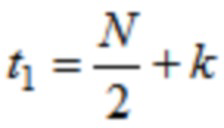 , или где
, или где 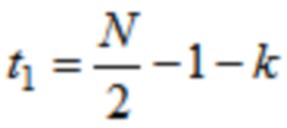 ,
,
где N указывает количество аудиовыборок временной области первой группы или второй группы аудиовыборок временной области.
Третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, и где второй модуль (220) кодирования сконфигурирован с возможностью применять третью оконную функцию wtr1 к второй группе аудиовыборок временной области. Или, четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью применять третью оконную функцию wtr1 к первой группе аудиовыборок временной области.
В одном варианте осуществления, первая оконная функция welt определяется согласно
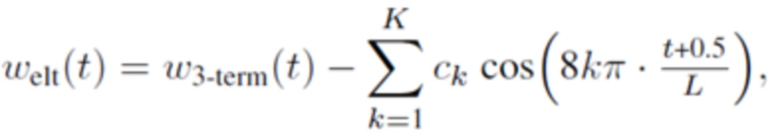
где
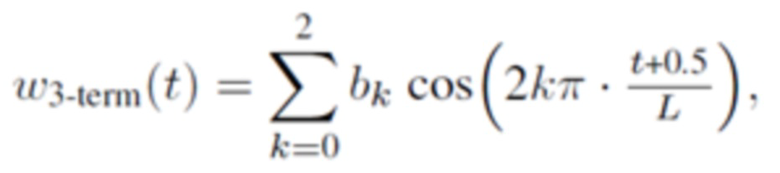
где b0, b1 и b2 являются вещественными числами.
где 0≤t<L, и где K является положительным целым числом, и где ck указывает вещественное число.
Согласно одному варианту осуществления, K=3;
0,3≤b0≤0,4; -0,6≤b1≤-0,4; 0,01≤b2≤0,2;
0,001≤c1≤0,03; 0,000001≤c2≤0,0005; 0,000001≤c3≤0,00002.
Согласно одному варианту осуществления,
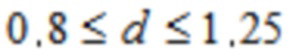 .
.
В одном конкретном варианте осуществления, 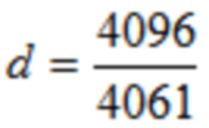 .
.
Согласно альтернативному варианту осуществления, d=1.
Аналогично, в отношении декодера из фиг. 1a, согласно одному варианту осуществления, welt является первой оконной функцией, при этом wtr является второй оконной функцией, при этом часть второй оконной функции определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области, где k является числом, где , где d является вещественным числом,
где , или где .
L указывает количество выборок третьей группы или четвертой группы промежуточных аудиовыборок временной области.
Модуль 130 сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, при этом второй модуль 120 декодирования сконфигурирован с возможностью генерировать четвертую группу промежуточных аудиовыборок временной области в зависимости от первой оконной функции welt, и при этом второй модуль 120 декодирования сконфигурирован с возможностью генерировать третью группу промежуточных аудиовыборок временной области в зависимости от второй оконной функции wtr. Или, модуль 130 сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, при этом второй модуль 120 декодирования сконфигурирован с возможностью генерировать третью группу промежуточных аудиовыборок временной области в зависимости от первой оконной функции welt, и при этом второй модуль 120 декодирования сконфигурирован с возможностью генерировать четвертую группу промежуточных аудиовыборок временной области в зависимости от второй оконной функции wtr.
Согласно одному варианту осуществления, wtr1 является третьей оконной функцией, при этом часть третьей оконной функции определяется согласно
,
где , или где ,
где N указывает количество промежуточных аудиовыборок временной области первой группы или второй группы промежуточных аудиовыборок временной области.
Модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, и при этом первый модуль (110) декодирования сконфигурирован с возможностью генерировать вторую группу промежуточных аудиовыборок временной области в зависимости от третьей оконной функции wtr1. Модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием, по меньшей мере, четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, и при этом первый модуль (110) декодирования сконфигурирован с возможностью генерировать первую группу промежуточных аудиовыборок временной области в зависимости от третьей оконной функции wtr1.
В одном варианте осуществления, первая оконная функция welt определяется согласно
где
где b0, b1 и b2 являются вещественными числами, где 0≤t<L, и где K является положительным целым числом, и где ck указывает вещественное число.
Согласно одному варианту осуществления, K=3;
0,3≤b0≤0,4; -0,6≤b1≤-0,4; 0,01≤b2≤0,2;
0,001≤c1≤0,03; 0,000001≤c2≤0,0005; 0,000001≤c3≤0,00002.
В одном варианте осуществления,
.
Согласно одному варианту осуществления, 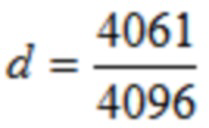 .
.
В одном альтернативном варианте осуществления, d=1.
Относительно системы из фиг. 1c, согласно одному варианту осуществления, декодер 320 системы использует оконную функцию перехода
, где 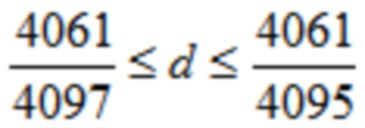 , и
, и
кодер 310 системы использует оконную функцию перехода
, где 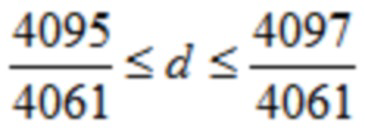 .
.
Согласно конкретному варианту осуществления, декодер 320 системы использует оконную функцию перехода
, где , и
кодер 310 системы использует оконную функцию перехода
, где .
Согласно одному варианту осуществления, декодер из фиг. 1a сконфигурирован с возможностью принимать информацию декодирования, указывающую, должна ли часть множества аудиовыборок спектральной области декодироваться посредством первого модуля 110 декодирования или посредством второго модуля 120 декодирования. Декодер сконфигурирован с возможностью декодировать упомянутую часть множества аудиовыборок спектральной области посредством использования либо первого модуля 110 декодирования или второго модуля 120 декодирования в зависимости от информации декодирования, чтобы получать первую или вторую или третью или четвертую группу промежуточных аудиовыборок временной области.
В одном варианте осуществления, декодер сконфигурирован с возможностью принимать первый бит и второй бит, при этом первый бит и второй бит вместе имеют первую комбинацию битовых значений, или вторую комбинацию битовых значений, которая отличается от первой комбинации битовых значений, или третью комбинацию битовых значений, которая отличается от первой и второй комбинации битовых значений, или четвертую комбинацию битовых значений, которая отличается от первой и второй и третьей комбинации битовых значений. Более того, декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области в зависимости от функции Кайзера-Бесселя посредством использования первого модуля 110 декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют первую комбинацию битовых значений. Дополнительно, декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области в зависимости от функции синуса или функции косинуса посредством использования первого модуля 110 декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют вторую комбинацию битовых значений. Декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области посредством использования первого модуля 110 декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют третью комбинацию битовых значений. Более того, декодер сконфигурирован с возможностью декодировать упомянутую часть множества аудиовыборок спектральной области посредством использования второго модуля 120 декодирования, чтобы получать третью или четвертую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют четвертую комбинацию битовых значений.
Конкретные варианты осуществления теперь описываются более подробно.
Варианты осуществления обеспечивают модифицированное расширенное перекрывающееся преобразование, которое описывается в последующем.
Чтобы корректировать проблему идеального восстановления на фиг. 5 (a) посредством достижения полного устранения TDA (TDAC) также в переходных 3-частных областях OLA, один класс преобразования должен переопределяться, так чтобы его симметрии TDA образовывали дополнение симметрий других, например, как на фиг. 5 (b), и фиг. 5 (c).
В частности, фиг. 5 иллюстрирует переключение от MLT к ELT с преобразованиями перехода, при этом фиг. 5 (a) показывает некорректное неидеальное восстановление, при этом фиг. 5 (b) изображает требуемое идеальное восстановление, и при этом фиг. 5 (c) иллюстрирует MLT посредством требуемого ELT.
Более того, аналогично, фиг. 6 иллюстрирует переключение от ELT к MLT с преобразованиями перехода согласно вариантам осуществления.
Так как является желательным избегать изменений для существующих реализаций MDCT и MDST, фокус помещается на ELT. Более того, чтобы легко получать переход идеального восстановления и окна устойчивого состояния для всех преобразований, соответствующие аналитические выражения являются желательными.
Сначала, описываются модификации для адаптации отношения перекрытия согласно вариантам осуществления.
Чтобы дать ELT требуемую совместимость TDA с MLT, временной фазовый сдвиг изменяется в его базовых функциях:
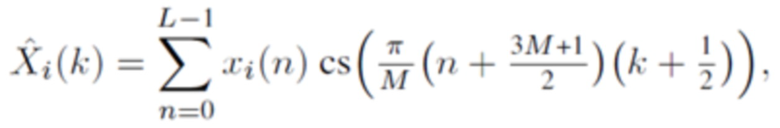 (4)
(4)
где k, cs определены как для формулы (2) и обратного ELT (1), с использованием 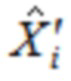 , адаптированным соответствующим образом. (как выше cs( ) может быть cos( ) или sin( )).
, адаптированным соответствующим образом. (как выше cs( ) может быть cos( ) или sin( )).
Как описано выше, например, посредством модификации формул (2c)-(2j) посредством установки N=L (например, для формул (2c), (2e), (2g) и (2i) анализа) и посредством установки (например, для формул (2d), (2f), (2h) и (2j) синтеза), получаются формулы ELT и формулы обратного ELT.
Применение концепции формулы (4) к этим формулам ELT и обратного ELT дает результатом формулы (4a)-(4h), которые представляют новые, изобретательские осуществления модифицированного расширенного перекрывающегося преобразования (MELT). Конкретные варианты осуществления формул (4a)-(4h) реализуют перекрывающиеся преобразования с отношением перекрытия 75%:
Прямое косинус-модулированное MELT, типа 4, теперь упоминаемое как MECT-IV:
(4a)
Обратное косинус-модулированное MELT, типа 4, теперь упоминаемое как IMECT-IV, n<L:
(4b)
Прямое косинус-модулированное MELT, типа 2, теперь упоминаемое как MECT-II:
(4c)
Обратное косинус-модулированное MELT, типа 2, теперь упоминаемое как IMECT-II, n<L:
(4d)
Прямое синус-модулированное MELT, типа 4, теперь упоминаемое как MEST-IV:
(4e)
Обратное синус-модулированное MELT, типа 4, теперь упоминаемое как IMEST-IV, n<L:
(4f)
Прямое синус-модулированное MELT, типа 2, теперь упоминаемое как MEST-II:
(4g)
Обратное синус-модулированное MELT, типа 2, теперь упоминаемое как IMEST-II, n<L:
(4h)
Некоторые варианты осуществления обеспечивают особенно подходящий дизайн окна для переходов от MLT к ELT и от ELT к MLT, которые описываются в последующем.
Можно показать, что, как фиг. 5 указывает, 4 четверти переходных окон MLT и ELT основываются на соответствующих взвешиваниях устойчивого состояния, где первая и/или четвертая четверть установлены на ноль и критические четверти описываются посредством
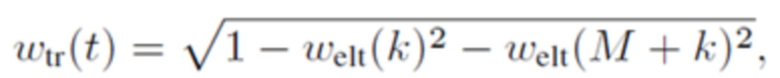 (5)
(5)
где для переключения как на фиг. 5 или для обратных переходов ELT к MLT. Использование формулы (5) для получения критических четвертей 511, 512, 521, 522 (показанных на фиг. 5) и критических четвертей 631, 632 (показанных на фиг. 6) для обоих взвешиваний переходов ELT и MLT завершает определение переходных окон, оставляя только выбор функций устойчивого состояния.
Полное определение окна перехода для расширенных перекрывающихся преобразований формул (5) будет, например, определяться как окно (M)ELT в уравнении (5a) для переходов отношения перекрытия от 50 к 75%:
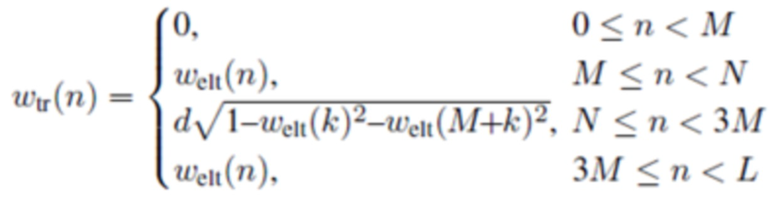 (5a)
(5a)
Для окна (M)ELT для переходов отношения перекрытия от 75 к 50% определение будет определением уравнения (5a), но wtr будет обращенным по времени.
В уравнении (5a), d может, например, быть постоянной, например, вещественным числом.
В уравнениях (5) и (5a) welt(n) может, например, указывать окно для расширенного перекрывающегося преобразования, например, окно расширенного перекрывающегося преобразования состояния данной области техники (см. семейство окон, определенных посредством формул (16)-(19) в источнике [11]: S. Malvar, "Modulated QMF Filter Banks with Perfect Reconstruction", Electronics Letters, vol. 26, no. 13, pp. 906-907, June 1990).
Или, в уравнениях (5) и (5a) welt(n) может, например, быть новым, изобретательским, окном расширенного перекрывающегося преобразования, как определено в формуле (8) ниже.
В уравнениях (5) и (5a), L является числом, например, указывающим размер окна ELT. N является числом, указывающим размер окна MLT. M является числом, при этом, например, .
В формуле (5a) n является числом, например, в диапазоне . k является числом.
В формулах (5) и (5a), k определяется в диапазоне .
В последующем, окна перекрывающегося преобразования идеального восстановления устойчивого состояния согласно вариантам осуществления описываются со ссылкой на фиг. 7.
Фиг. 7 иллюстрирует дизайны окна идеального восстановления, на фиг. 7 (a) для MLT, на фиг. 7 (b) для ELT, и на фиг. 7 (c) для переходов согласно вариантам осуществления.
Были задокументированы несколько дополняющих по мощности (PC) окон MLT, усиливающих так называемое условие Принсена-Брэдли для идеального восстановления (см. [2]). Фиг. 7 (a) изображает формы и соответствующие избыточно дискретизированные передаточные функции окон, используемых в аудиокодеках MPEG (см. [5], [7]), синусные MLT (см. [3], [11]) и выведенные Кайзером-Бесселем (KBD) окна (см. [23]). Также показана дополняющая по мощности функция в [24], чья форма является аналогичной форме окна KBD, но которая, как можно отметить, демонстрирует более низкие первые (ближнего поля) уровни боковых лепестков. В заключение, синусное окно для удвоенной длины кадра, как используется в случае SBR двойной частоты, служит в качестве эталона и иллюстрирует, что более длинные окна могут заметно уменьшать как ширину полосы пропускания, так и уровень полосы задерживания.
Идеально, окно ELT, в зависимости от ограничений идеального восстановления формулы (3), должно демонстрировать частотную характеристику, соизмеримую с частотной характеристикой синусного окна двойной длины, но можно наблюдать, что, вследствие ограничений идеального восстановления, ширина основного лепестка может минимизироваться только посредством обеспечения меньшего ослабления бокового лепестка. Было обнаружено, что окно Малвара [11] с p=1, например, имеет наименьшую возможную ширину основного лепестка из всех дизайнов ELT, но также нежелательно высокие уровни полосы задерживания, как показано на фиг. 7 (b). Его временные границы являются заметно прерывающимися (так как выборки за расширением окна предполагаются равными нулю), что дает результатом затухание боковых лепестков, равное только -6 дБ/октаве (см. [24]) и кадровые артефакты в наших экспериментах. Темеринак и Эдлер (см. [16]) представили подход рекурсивного дизайна, который они использовали, чтобы получить окно ELT, также показанное на фиг. 7 (следует отметить, что значение -0,038411 пропущено в столбце "L=4N" их таблицы 1). Это окно, которое может близко приближаться посредством уравнений Малвара с p=0,14, обеспечивает большее, но все еще достаточно слабое ослабление полосы задерживания.
Следует отметить, что, для p=1, формулировка Малвара может модифицироваться на обозначение, аналогичное обозначению для окна Хэнна:
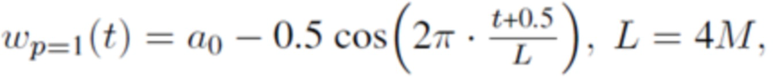 (6)
(6)
где 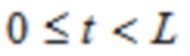 обозначает временные выборки окна и
обозначает временные выборки окна и 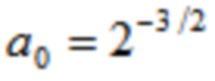 выбрано, чтобы усиливать ограничения идеального восстановления (см. [11], [12], [13], [14]). Интуитивно, функция с большим ослаблением бокового лепестка, такая как
выбрано, чтобы усиливать ограничения идеального восстановления (см. [11], [12], [13], [14]). Интуитивно, функция с большим ослаблением бокового лепестка, такая как
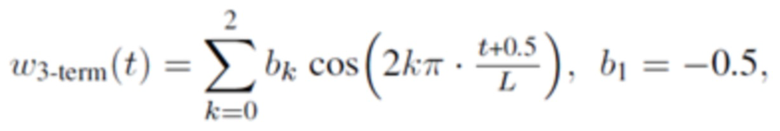 (7)
(7)
где 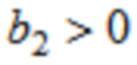 , которая может использоваться, чтобы выводить окно Блэкмэна (см. [24]), кажется применимой также. К сожалению, можно показать, что идеальное восстановление не может достигаться с таким классом окна независимо от значения b0.
, которая может использоваться, чтобы выводить окно Блэкмэна (см. [24]), кажется применимой также. К сожалению, можно показать, что идеальное восстановление не может достигаться с таким классом окна независимо от значения b0.
Однако согласно вариантам осуществления, добавляется больше членов.
Согласно вариантам осуществления, обеспечивается welt(t):
(8)
где bk как выше, результирующая форма для любого выбора 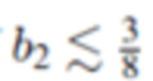 может корректироваться, так что идеальное восстановление приближается произвольно близко. Нацеливаясь, в частности, на низкий уровень полосы задерживания и наложение, в дополнение к условиям идеального восстановления, ограничению левой половины изотона и, следовательно, наклона окна правой половины антитона, идеальное восстановление может приближаться с ошибкой ниже
может корректироваться, так что идеальное восстановление приближается произвольно близко. Нацеливаясь, в частности, на низкий уровень полосы задерживания и наложение, в дополнение к условиям идеального восстановления, ограничению левой половины изотона и, следовательно, наклона окна правой половины антитона, идеальное восстановление может приближаться с ошибкой ниже  посредством использования K=3, b2=0,176758, и, в зависимости от этих значений, b0=0,3303 и
посредством использования K=3, b2=0,176758, и, в зависимости от этих значений, b0=0,3303 и
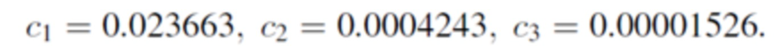 (9)
(9)
Эта оконная функция ELT, изображенная на фиг. 7 (b), является менее прерывистой на ее границах, чем предложения из [11] и [16] и, как результат, обеспечивает возможность такого же уровня подавления боковых лепестков, что и синусное окно двойной длины из фиг. 7 (a). Одновременно, ее основной лепесток остается более узким, чем основной лепесток синусного окна MLT. Интересным образом, она также имеет сходство с последним окном по форме.
Фиг. 7 (c) иллюстрирует спектральные и временные формы окон перехода MDCT/MDST и ELT, на основе дополняющего по мощности дизайна из [24] и welt с использованием формул (8) и (9), и, для сравнения, начальное окно двойной длины для AAC.
Варианты осуществления используют обобщенную биортогональную ELT организацию окон перехода.
Уравнение (5) определило то, как может определяться критическая четверть окна расширенного перекрывающегося преобразования (ELT) длины 4M для переходов от либо кодирования MLT к ELT или кодирования ELT к MLT.
В вариантах осуществления, уравнение (5) регулируется посредством умножения на постоянную d (см. в качестве примера, формулу (5a)) следующим образом:
, (10)
где k=0, 1,..., M-1 и t, как определено ранее с использованием обоих k и L. Это обеспечивает возможность так называемого биортогонального подхода по отношению к организации окон перехода переключения отношения, где разные критические четверти окна могут использоваться для преобразований анализа и синтеза. Более конкретно, чтобы достигать TDAC и, таким образом, идеального восстановления, wtr(t) может использовать d=d' на стороне анализа (кодера), и на стороне синтеза (декодера), wtr(t) может применять обратное, то есть d=1/d'. При заданном конкретном окне ELT устойчивого состояния welt, предпочтительно окне, выведенном посредством уравнений (8) и (9) здесь, d' предпочтительно определяется на основе обоих из следующих двух рассмотрений.
Предпочтительно, для определения d', уравнение (10) выбирается, чтобы формировать, во время всех переходов переключения отношения, как оптимальные спектральные атрибуты окон анализа, так и максимальное выходное ослабление при декодировании.
Для достижения оптимальных спектральных свойств оконной обработки анализа, некоторые варианты осуществления достигают наименьшей возможной величины ширины основного лепестка и самой сильной возможной величины ослабления бокового лепестка в окнах анализа, чтобы максимизировать спектральное уплотнение особенно стационарных, гармонических аудиосигналов. При условии, что окно welt устойчивого состояния уже было оптимизировано для этой цели, можно показать, что это может достигаться в wtr посредством избегания прерывностей на границах между четырьмя четвертями окна. Более точно, посредством выбора d' таким образом, чтобы максимальное значение wtr(t) в (10) равнялось максимальному значению welt(n), где n=0, 1,..., L-1, перескоки в форме переходного окна полностью избегаются.
Следовательно, в одном варианте осуществления, d' должно отражать отношение между упомянутыми двумя максимумами, которое в случае формул (8) и (9) может приближаться посредством
d'=4096/4061 → 1/d'=4061/4096.
Согласно одному варианту осуществления, достигается максимальное выходное ослабление при оконной обработке синтеза. Чтобы подавлять искажение спектральной области в кодировании аудио, введенное квантованием элементов дискретизации преобразования, настолько, насколько возможно, может быть полезным ослаблять выходную волновую форму во время обработки оконной обработки синтеза до обработки OLA настолько, насколько возможно. Однако вследствие требований идеального восстановления/TDAC, сильное ослабление посредством окна не является реализуемым, так как этот подход будет воспроизводить дополняющее окно анализа, вредное в терминах эффективности. Можно показать, что хорошее компромиссное соотношение между хорошими свойствами окна и приемлемым выходным ослаблением стороны декодера может получаться посредством снова выбора
1/d'=4061/4096 → d'=4096/4061.
Другими словами, обе подхода оптимизация для wtr предпочтительно ведут к одному и тому же значению d'.
Примеры для преобразований уже были обеспечены, например, преобразования состояния данной области техники из формул (2a)-(2j) или новые, изобретательские преобразования из формул (4a)-(4h).
Пример для окна перехода из уравнения (10) согласно одному варианту осуществления, например, обеспечен выше посредством уравнения (5a).
Фиг. 10 иллюстрирует соответствующие окна анализа согласно вариантам осуществления, как описано выше.
Подобным образом, фиг. 11 иллюстрирует соответствующие окна синтеза согласно вариантам осуществления, как описано выше.
В последующем, описывается адаптивный к входу выбор отношения перекрытия.
Подход переключающего кодирования, обеспеченный выше, например, с использованием окон, обеспеченных выше, может интегрироваться в кодек преобразования. Это среди прочего верифицирует его ожидаемое субъективное преимущество на тональном вводе. По причинам краткости, будут описываться только высокоуровневые аспекты.
Рассматриваются спецификация и преобразования синтеза декодера.
Дополнительный бит, применение сигнализации для ELT, принимается в расчете на канал и/или кадр, в котором длинное преобразование (без переключения блоков) используется кодером. В случае кодирования MPEG для этой цели может повторно использоваться бит формы окна (например, "0" означает: используется MLT с использованием окна из источника [23] или из источника [24], например, "1" означает: используются концепции ELT вариантов осуществления).
На основе этого бита и оконной последовательности (длины преобразования и типа), как для текущего, так и последнего кадра, декодер может затем выводить и применять обратное перекрывающееся преобразование с использованием корректного отношения перекрытия и окна, как описано выше.
Например, дополнительный бит может указывать, может ли или нет кодер переключаться между MLT и ELT. Если дополнительный бит указывает, что кодер может переключаться между MLT и ELT, бит формы окна повторно используется для указания, используется ли MLT или ELT, например, для текущего кадра.
Теперь, рассматриваются детектор ELT и преобразования анализа кодера.
Кодер, применяющий и передающий выбор MLT/ELT в расчете на канал/кадр, так что кодер и декодер синхронизируются, может обнаруживать стационарные, гармонические кадры посредством вычисления кодирования с линейным предсказанием (LPC, например, порядка 16) остатка ввода, как делается в речевых кодерах (см. [25]).
Кодер, например, выводит оттуда временную плоскостность  как отношение между энергией остатка следующего и текущего кадра, со стационарностью, определенной как
как отношение между энергией остатка следующего и текущего кадра, со стационарностью, определенной как 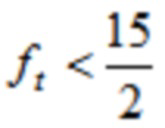 . Более того, кодер, например, выводит оттуда спектральную плоскостность
. Более того, кодер, например, выводит оттуда спектральную плоскостность  , также известную как энтропия Винера, полученную из спектра мощности DFT конкатенированного остатка текущего и следующего кадра, с высокой тональностью, указанной посредством
, также известную как энтропия Винера, полученную из спектра мощности DFT конкатенированного остатка текущего и следующего кадра, с высокой тональностью, указанной посредством 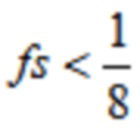 .
.
В последующем, обеспечиваются дополнительные аспекты модифицированного расширенного перекрывающегося преобразования (MELT) согласно некоторым вариантам осуществления.
В частности, обеспечивается подробное описание внедренческих аспектов предпочтительных вариантов осуществления интегрирования переключаемого MELT в систему базового кодирования MPEG-H 3D аудио.
Сначала, описывается декодер, его спецификация и преобразование синтеза согласно некоторым вариантам осуществления.
Глобальный однобитный синтаксический элемент, например, называемый use_melt_extension, вводится в конфигурацию потока спецификаций синтаксиса одноканального элемента (SCE), элемента канальной пары (CPE) и, необязательно, элемента усиления низкой частоты (LFE). Это может достигаться посредством помещения use_melt_extension в таблицу mpegh3DACoreConfig() стандартного текста. Когда заданный битовый поток содержит в себе свойство use_melt_extension=0, базовый декодер работает стандартным способом MPEG-H, как определено в состоянии данной области техники. Это означает, что позволяются только преобразования MDCT (или преобразования MDST, в случае активированного переключения ядер в кадре/канале, см. [28], в частности, см. конец раздела 4, Discrete Multi-Channel Coding Tool, из [28]) с 50% отношением перекрытия преобразования, и что не имеется никаких новых ограничений относительно window_sequence (только длинная, длинное начало, восемь коротких, длинная остановка, остановка-начало) и window_shape (синус или KBD). (В [28], адаптивный спектрально-временной преобразователь переключается между ядрами преобразования первой группы ядер преобразования с одним или более ядрами преобразования, имеющими разные симметрии на сторонах ядра, и второй группой ядер преобразования, содержащих одно или более ядер преобразования, имеющих одинаковые симметрии на сторонах ядра преобразования).
Однако, когда use_melt_extension=1 в битовом потоке, смысл покадрового однобитного элемента window_shape для кадров/каналов с "только длинной" window_sequence предпочтительно модифицируется, как описано ранее (0: MDCT/MDST с использованием существующей оконной функции KBD, где α=4 (см. [23]), 1: MELT с оконной функцией welt, предложенной здесь).
Показана схематическая блок-схема декодера 2 для декодирования кодированного аудиосигнала 4. Декодер содержит адаптивный спектрально-временной преобразователь 6 и процессор 8 сложения с перекрытием. Адаптивный спектрально-временной преобразователь преобразует последовательные блоки спектральных значений 4' в последовательные блоки временных значений 10, например, посредством частотно-временного преобразования. Дополнительно, адаптивный спектрально-временной преобразователь 6 принимает информацию 12 управления и переключается, в ответ на информацию 12 управления, между ядрами преобразования первой группы ядер преобразования, содержащих одно или более ядер преобразования, имеющих разные симметрии на сторонах ядра, и второй группы ядер преобразования, содержащих одно или более ядер преобразования, имеющих одинаковые симметрии на сторонах ядра преобразования. Более того, процессор 8 сложения с перекрытием осуществляет перекрытие и сложение последовательных блоков временных значений 10, чтобы получать значения 14 декодированного аудио, которые могут быть декодированным аудиосигналом.
Имеется три причины для этого дизайна. Во-первых, так как имеется только одна требуемая оконная функция для MELT устойчивого состояния, и никакое окно ELT, выведенное из функции Кайзера-Бесселя, не существует в предшествующем уровне техники, бит window_shape для "только длинных" кадров/каналов и активированного MELT может рассматриваться устаревшим и, таким образом, излишним, так как его значение (когда интерпретируется, как определено в состоянии данной области техники) должно будет игнорироваться.
Во-вторых, использование кодирования MELT в кадре/канале, которое не является "только длинным", не поддерживается - последовательность из восьми коротких преобразований MELT вместо преобразований MDCT/MDST, например, является реализуемой, но сильно усложняет способ переключения блоков и является контрпродуктивной с перцепционной точки зрения, так как целью последовательностей "восемь коротких" является максимизированное временное разрешение кодирования).
В-третьих, изобретателями было обнаружено, что "только длинный" кадр/канал, для которого синусное окно дает более хорошее качество кодирования, чем окно KBD, на заданной части входного сигнала, получает выгоду даже более из предложенного дизайна ELT, когда активируется на той же части сигнала. Другими словами, предложение ELT соответствует или даже субъективно превосходит преобразования MDCT/MDST с "синусной" window_shape на сегментах волновой формы, где они, в свою очередь, заметно превосходят кодирование MDCT/MDST с "KBD" window_shape. Таким образом, посредством повторного использования и повторного специфицирования существующего бита window_shape, когда window_sequence является "только длинной" и use_melt_extension=1, избыточность избегается полностью, и никакие дополнительные в расчете на кадр биты не требуются для сигнализации в отношении того, используется ли предложенное переключение на или от MELT в заданном кадре/канале.
Для битовых потоков с use_melt_extension=1, базовое декодирование MPEG-H частотной области (FD) выполняется как обычно, за исключением обработок обратного преобразования и перекрытия и сложения (OLA), которые выполняются следующим образом.
Для кадров/каналов с window_sequence="только длинная" и window_shape=0 (KBD), или с window_sequence≠"только длинная" и любым window_shape, покадровое обратное преобразование, оконная обработка синтеза, и OLA выполняются, как определено в стандарте MPEG-H 3D аудио, то есть, ISO/IEC 23008-3:2015, подпункт 5.5.3.5.1, и ISO/IEC 23003-3:2012, подпункт 7.9.
Однако, чтобы учитывать увеличенную задержку организации окон переключаемого MELT, вывод сегмента волновой формы в расчете на кадр, результирующий из этапа OLA, задерживается на один кадр. Это означает, например, что, когда заданный кадр является первым кадром в потоке, выводится нулевая волновая форма.
Для кадров/каналов с window_sequence="только длинная" и window_shape=1 (ранее: синус), обратное преобразование выполняется с использованием формулы для MELT, предложенной здесь, что эквивалентно уравнению, заданному в ISO/IEC 23003-3:2012, подпункт 7.9.3.1 за исключением того, что 0≤n<2N и n0=(3N/2+1)/2. Отметим, что модификации для переключения ядер, именно использование функции sin( ) вместо cos( ) и k0=0 (для модуляции косинуса типа II) или k0=1 (для модуляции синуса типа II) также являются возможными с MELT (предполагается совместимая с TDA последовательность). Оконная обработка синтеза затем применяется, как описано в разделах 2 и 3 ранее, с окнами перехода, детектированными, как табулировано в Таблице 3, с использованием значений window_shape и window_sequence, как для текущего, так и предыдущего кадра, для заданного канала. Таблица 3 также указывает набор всех разрешаемых переходов последовательности/формы.
Следует отметить, что обратное MELT (или исходное ELT, для этого рассмотрения) может осуществляться с использованием существующих реализаций MDCT и MDST, которые, в свою очередь, применяют осуществления быстрого DCT/DST на основе быстрого преобразования Фурье (FFT). Более конкретно, синус-модулированное обратное MELT может реализовываться посредством инвертирования каждой спектральной выборки с нечетным индексом (где индексация начинается с нуля), за которым следует применение обратного MDCT-IV, и завершается посредством временного повторения результирующих 2N выходных выборок с инвертированными знаками.
Подобным образом, косинус-модулированное обратное MELT может получаться посредством инвертирования каждой спектральной выборки с четным индексом, за которым следует исполнение обратного MDST-IV, и, в заключение, такое же временное повторение с инвертированными знаками. Аналогичные реализации могут достигаться для косинус-модулированных типа II или синус-модулированных обратных преобразований MELT как используется в случае переключения ядер, также как для прямого (соответствующего анализу) преобразования для всех из вышеописанных конфигураций MELT. Поэтому увеличение сложности, вызванное обработкой MELT, в сравнении с традиционными алгоритмами MDCT/MDST происходит только вследствие необходимости инвертированного временного повторения (расширения в обратном случае или сжатия в прямом случае), что представляет простую операцию копирования/умножения-сложения с масштабированием посредством -1) 2N входных или выходных выборок, оконную обработку анализа или синтеза в два раза большего числа выборок по сравнению с MDCT/MDST (4N вместо 2N), и больше сложений во время OLA в декодере. Другими словами, при заданной алгоритмической сложности O(n(logn+c)) преобразования, только постоянная c увеличивается в случае MELT (или ELT), и так как n=1024 или 768 в настоящем варианте осуществления, любое увеличение c с коэффициентом, равным приблизительно от двух до трех, может рассматриваться незначительным (то есть, оно сводится только к менее чем четверти сложности полного преобразования, организации окон, и OLA/обработки кадров, что, в свою очередь, является только долей от всей сложности декодера 3D аудио).
Таблица 3 иллюстрирует поддерживаемые оконные последовательности в случае схемы переключения MELT. Долгая последовательность означает MDCT/MDST, где допускается только форма окна "KBD", так как LONG с "синусной" оконной конфигурацией повторно используется для сигнализации последовательности ELT-LONG.
Таблица 3:
Из ↓
√=допускается; x=не допускается
tr←tr=переход от ELT; tr→tr=переход к ELT;
KBD=выведенное Кайзером-Бесселем.
В последующем, описывается оценка интеграции кодека, которая была выполнена. Слепая субъективная оценка предложения переключения отношения подтвердила преимущество адаптивного к сигналу дизайна. Ссылка делается на фиг. 8 и фиг. 9.
Фиг. 8 иллюстрирует основанный на спектральной и временной плоскостности выбор для ELT. В частности, фиг. 8 иллюстрирует результирующий покадровый выбор ELT и MDCT для четырех входных сигналов (преобразования MDST не используются на этом материале). Стационарные, тональные отрывки обнаруживаются надежным образом. Внизу (розовая) линия "выбора" имеет значение "0" для MELT и значение "-1" для MLT.
Фиг. 9 иллюстрирует масштабированный вид результатов теста прослушивания с интервалами доверия 95%. Анкерные количественные оценки 3.5 кГц пропущены для ясности.
Дизайны и результаты субъективных тестов этой схемы, интегрированные в кодек 3D аудио, описываются в последующем:
Два слепых эксперимента прослушивания согласно принципу MUSHRA (множество стимулов со скрытым эталоном и анкером) (см. [26]) выполнялись, чтобы оценивать субъективную производительность системы кодирования с переключением MDCT-ELT в сравнении со стандартной схемой, использующей только преобразования MDCT (или преобразования MDST, как в случае предложения переключения ядер, см. [9]). С этой целью, архитектура переключения отношения была интегрирована в реализацию кодера и декодера MPEG-H 3D аудио кодека, с использованием IGF для расширения полосы пропускания и заполнения стерео (SF) для полупараметрического кодирования канальной пары при 48 килобит/с стерео, как описано в [8], [9]. Тестирование выполнялось с помощью 12 опытных слушателей (возраста 39 и младше, включая сюда 1 женщину) в тихом помещении с использованием безвентиляторного компьютера и современных наушников STAX.
Первый выполненный эксперимент, тест 48 килобит/с с использованием тональных инструментальных сигналов, предназначался, чтобы получить количественную оценку преимущества ELT над традиционным кодированием MDCT на тональном, гармоническом аудио материале, также как преимущество переключения от кодирования ELT к MDCT на переходных состояниях и тональных началах, как описано в последнем разделе. Для каждого из четырех тональных тестовых сигналов, уже использованных в прошлых оценках кодека MPEG [25], [27] - аккордеон, волынка/камертон-дудка, и клавесин - кодированные стимулы 3D аудио с и без переключаемым ELT были представлены рядом с эталонным условием 3D аудио, использующим SBR объединенного стерео и MPEG Surround 2-1-2 (и, таким образом, удвоенную длину кадра).
Результаты этого теста, вместе с интервалами доверия в расчете на стимул 95-%, проиллюстрированы как общие средние количественные оценки на фиг. 9(a) и как дифференциальные средние количественные оценки, по отношению к условию ELT, на фиг. 9(b). Они демонстрируют, что для трех из четырех элементов качество основанного на SBS 3D аудио кодека может быть улучшено значительно посредством переключения на ELT во время отрывков стационарных сигналов. Более того, посредством обращения к кодированию MDCT во время нестационарных тональных начал и переходных состояний, перцепционные деградации вследствие более сильных артефактов предварительного эха избегаются. В заключение, субъективная производительность конфигурации 3D аудио с IGF и SF может быть приведена более близко к субъективной производительности эталона объединенного стерео более длинного размера кадра для таких элементов. Все стимулы за исключением sm01 (волынок) теперь демонстрируют хорошее качество.
Был сконструирован второй "виртуальный" тест прослушивания, виртуальный тест 48 килобит/с с использованием различных типов сигнала, в котором результаты субъективной оценки в [9] были комбинированы с присутствующими данными для элемента phi7 (камертона-дудки, единственного сигнала в [9], для которого преобразования ELT применяются в более, чем нескольких кадрах).
Эта установка должна выявлять, может ли кодирование 3D аудио на основе SBS, усовершенствованное посредством схемы переключаемого ELT, превосходить основанную на QMF конфигурацию 3D аудио на разнообразном наборе тестов.
Фиг. 9(c) изображает в расчете на стимул и общие абсолютные средние количественные оценки, снова с интервалами доверия, для этого теста. В самом деле, благодаря вызванным ELT усилениям качества на сигналах, таких как phi7, средняя перцепционная производительность конфигурации SBS+ELT воспроизводится значительно лучше, чем средняя перцепционная производительность эталона объединенного стерео. При условии, что последнее демонстрирует более высокую алгоритмическую задержку и сложность вследствие требуемых дополнительных псевдо-QMF блоков, этот исход является в высокой степени удовлетворительным.
Перцепционное преимущество подхода переключения ELT было подтверждено посредством формальной субъективной оценки, которая не выявила никаких деградаций качества по сравнению с инфраструктурой 3D аудио и которая дополнительно указывает, что долгосрочная цель изобретателей в отношении хорошего качества кодирования на каждом типе входного сигнала при 48 килобит/с стерео может фактически достигаться только с немного большей настройкой кодера.
Некоторые варианты осуществления обеспечивают улучшения для отрывков квазистационарных гармонических сигналов посредством адаптивного применения модифицированного расширенного перекрывающегося преобразования (MELT).
В этом контексте, фиг. 12 иллюстрирует базовые блоки фильтров с перекрывающимися преобразованиями согласно некоторым конкретным вариантам осуществления, при этом фиг. 12(a) иллюстрирует MDCT/MDST, и при этом фиг. 12(b) иллюстрирует ELT.
Основываясь на ELT, в некоторых вариантах осуществления, MELT конструирует нечетным образом уложенный блок фильтров с 75% перекрытием между преобразованиями, как изображено на фиг. 12(b), давая более большую частотную избирательность, чем блок фильтров MDCT или MDST с 50% перекрытием, как показано на фиг. 12(a), при такой же длине кадра M. Однако в отличие от ELT, MELT обеспечивает возможность непосредственных переходов, например, с использованием в некоторых вариантах осуществления только специальных переходных окон, на и от преобразований MDCT. В частности, некоторые варианты осуществления могут, например, обеспечивать соответствующую покадровую адаптивную к сигналу схему переключения отношения перекрытия.
Теперь описываются конкретные варианты осуществления, которые реализуют косинус- и синус-модулированное кодирование MELT.
Как уже описано выше, прямое (соответствующее анализу) MDCT для кадра на индексе i, при заданном временном сигнале x и возврате спектра X, может, например, быть записано как
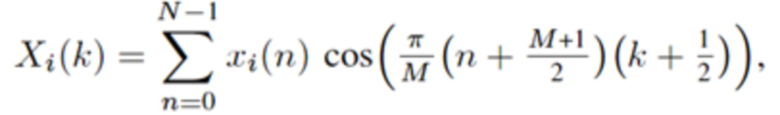 (11a)
(11a)
где длина окна N=2M и 0≤k<M. Подобным образом, прямое MDST определяется с использованием члена синуса вместо косинуса:
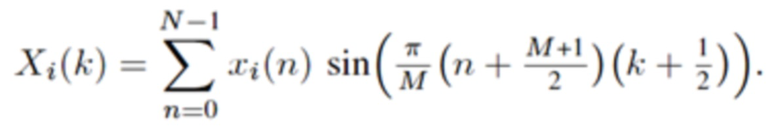 (11b)
(11b)
В вариантах осуществления, посредством изменения временной длины и смещения фазы это дает MELT,
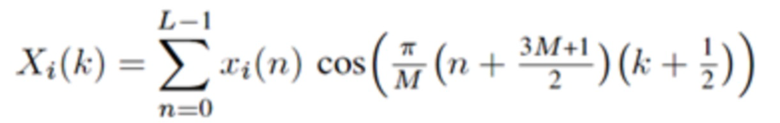 (11c)
(11c)
с увеличенной длиной окна L=4M и косинусной модуляцией. Естественно, синус-модулированная ответная часть также может определяться,
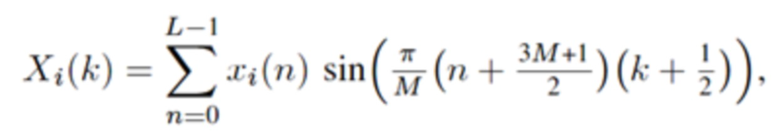 (11d)
(11d)
Обратные (соответствующие синтезу) варианты MELT являются, например,
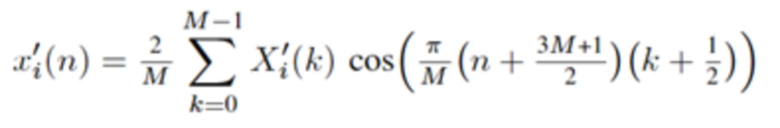 (11e)
(11e)
для косинусных блоков, применяющих формулу (11c), и, соответственно, для синусных блоков,
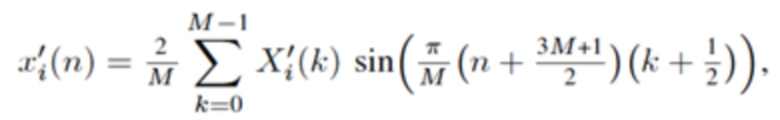 (11f)
(11f)
где ′ обозначает спектральную обработку, и 0≤n<L.
Следует отметить, что, хотя используемая длина окна может, например, изменяться между формулами (11a), (11b) и формулами (11c), (11d), (11e) и (11f), длина преобразования M, и, тем самым, размер шага между преобразованиями, проиллюстрированный на фиг. 12, остается одинаковой, что объясняет различие в отношении перекрытия. Определения косинус- и синус-модулированного MELT из формул (11c), (11d), (11e) и (11f) могут, в некоторых вариантах осуществления, дополнительно улучшаться для реализации переключения ядер, и, поэтому, эффективное кодирование сигналов с ±90 градусов параметра IPD, даже в случае 75% перекрытия между преобразованиями. Преобразования перехода типа II, принятые из четным образом уложенного блока фильтров Принсена-Брэдли, могут, например, использоваться для устранения алиасинга временной области (TDAC), при переключении между преобразованиями MDCT и преобразованиями MDST типа IV, см. формулы (11a) и (11b). Конкретно, MDST-II требуется во время изменений от кодирования MDCT-IV к MDST-IV в канале, и MDCT-II требуется при возврате к кодированию MDCT-IV.
Помимо вышеупомянутых определений типа IV (см. формулы (11c), (11d), (11e) и (11f)), основанный на ELT блок фильтров, обеспечивающий возможность быстрых осуществлений с использованием DCT-II, также может конструироваться, что доказывает, что блоки фильтров типа II с более чем 50% перекрытием между преобразованиями являются фактически реализуемыми. Альтернативный, но эквивалентный подход, следующий дизайну блока фильтров TDAC, состоит в том, чтобы разработать четным образом уложенную систему посредством изменяющегося использования версии косинус-модулированного MELT типа II,
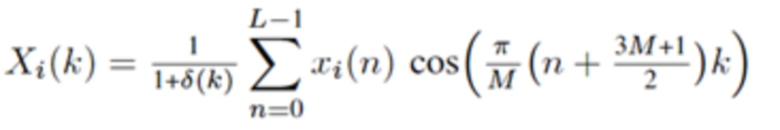 (11g)
(11g)
где дельта Кронекера δ(0)=1, и основанное на синусе MELT типа II,
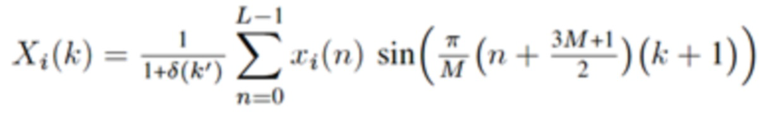 (11h)
(11h)
где k′=M-1-k для масштабирования коэффициента Найквиста.
Формулы (11g) и (11h) на стороне анализа и, соответственно,
 (11i)
(11i)
и
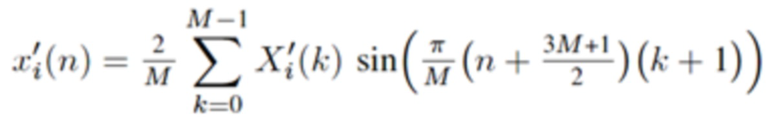 (11j)
(11j)
на стороне синтеза ведут к TDAC, как изображено на фиг. 13.
В частности, фиг. 13 иллюстрирует TDAC в четным образом уложенных блоках фильтров согласно некоторым конкретным вариантам осуществления, при этом фиг. 13(a) иллюстрирует Принсена-Брэдли, и при этом фиг. 13(b) иллюстрирует MELT-II. TDAC является возможным в случае четной-нечетной или нечетной-четной комбинации алиасинга временной области между смежными преобразованиями.
Относительно комбинации кодирования MELT и переключения ядер, можно показать, что TDAC является невозможным, когда, аналогично обработке для 50% перекрытия, переходный экземпляр типа II формул (11g) и (11i) или формул (11h) и (11j) используется, при переключении между косинус- и синус-модулированными преобразованиями MELT типа IV, см. формулы (11c), (11d), (11e) и (11f). Так как является желательным удерживать архитектурную сложность кодека низкой, когда допускается переключение ядер независимо от мгновенного отношения перекрытия, предлагается следующий обходной путь. Чтобы переключаться от косинус-модулированного MELT-IV (см. формулы (11c) и (11e)) на синус-модулированное MELT-IV (см. формулы (11d) и (11f)), может, например, использоваться переходный кадр MDST-II, комбинированный с временным уменьшением отношения перекрытия до 50% на обеих стороне анализа и синтеза. Подобным образом, промежуточное MDCT-II может использоваться при возврате назад от синус- на косинус-основанное кодирование MELT. Фиг. 14 иллюстрирует конкретное согласующееся с TDAC переключение ядер для MELT-IV блоков фильтров согласно конкретным вариантам осуществления, при этом фиг. 14(a) иллюстрирует переходы от косинусной к синусной модуляции, и при этом фиг. 14(b) иллюстрирует переходы от синусной к косинусной модуляции.
Полное TDAC получается в обоих случаях, так как, как визуализировано на фиг. 14, длина перекрытия между каждым переходом типа II и его соседями MELT типа IV ограничено . Следовательно, не имеется никакого связанного с временным алиасингом перекрытия между косинус- и синус-модулированным MELT-IV, которое требует TDAC. Чтобы реализовать должную организацию окон, в вариантах осуществления, специальное окно "остановка-начало" должно применяться к преобразованиям типа II, как показано на фиг. 15(a). Такое, например, симметричное, окно, которое основывается на асимметричных переходных взвешиваниях, согласно некоторым вариантам осуществления, описывается более подробно ниже.
В частности, фиг. 15 иллюстрирует улучшенную организацию окон согласно конкретным вариантам осуществления со специальной формой "остановка-начало", указанной посредством тире, во время временных переходов, при этом фиг. 15(a) иллюстрирует временные переходы отношения перекрытия от 75 к 50%, и при этом фиг. 15(b) иллюстрирует временные переходы отношения перекрытия от 50 к 75%.
В последующем, описываются переходы от и к кадрам MELT согласно некоторым вариантам осуществления.
Согласно некоторым вариантам осуществления, переключения кадр-кадр могут, например, реализовываться от MDCT-подобного преобразования с 50% к MELT с 75% отношением перекрытия, и наоборот. Чтобы поддерживать полное TDAC во время переключений, могут, например, использоваться назначенные асимметричные окна перехода, выведенные из взвешиваний устойчивого состояния, примененных во время отрывков квазистационарных сигналов. Эти окна могут, например, определяться как
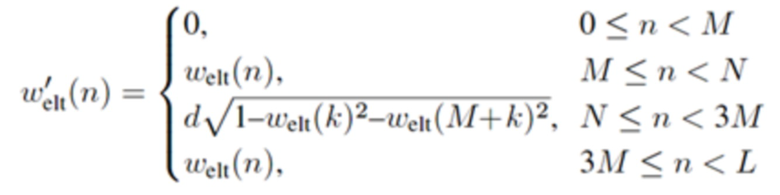 (12)
(12)
для первого окна MELT при увеличении перекрытия от 50 к 75% (форма, изображенная полужирной линией, изображенная на фиг. 15 (a) для кадра i) и
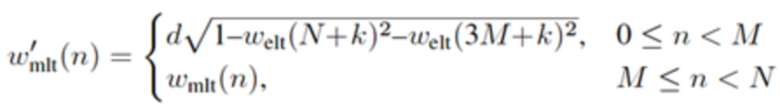 (13)
(13)
для первого окна MDCT/MDST при уменьшении перекрытия до 50% (форма, изображенная полужирной линией на фиг. 15(b) для того же кадра). Комплементарными для 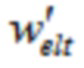 и
и 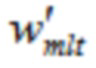 , последнее окно MELT при переключении на 50% перекрытие, и последнее окно MDCT/MDST во время переключения назад на 75% перекрытие (кадр i-2 на фиг. 15), являются временные обращения формул (12) и (13), соответственно. k, используется в критических оконных частях (см. также фиг. 14), определенных как выше, в то время как
, последнее окно MELT при переключении на 50% перекрытие, и последнее окно MDCT/MDST во время переключения назад на 75% перекрытие (кадр i-2 на фиг. 15), являются временные обращения формул (12) и (13), соответственно. k, используется в критических оконных частях (см. также фиг. 14), определенных как выше, в то время как 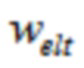 соответственно
соответственно 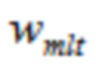 указывают лежащие в основе оконные функции для MELT устойчивого состояния и MDCT/MDST. Для первого, которое также применимо к ELT (см. [12]), улучшенный дизайн, предотвращающий артефакты блочности, был обеспечен выше.
указывают лежащие в основе оконные функции для MELT устойчивого состояния и MDCT/MDST. Для первого, которое также применимо к ELT (см. [12]), улучшенный дизайн, предотвращающий артефакты блочности, был обеспечен выше.
Пусть wtr(t), где t охватывает число M выборок временной области, например, представляет критическую четверть окна, например, сегмент длины M, характеризующийся членом квадратного корня, масштабированным посредством действительного значения d, либо или , когда применяется либо к стороне анализа (кодера) или синтеза (декодера). Использование d обеспечивает возможность так называемого биортогонального подхода по отношению к организации окон перехода переключения отношения, где разные критические оконные части могут использоваться для преобразований анализа и синтеза. Более конкретно, чтобы достигать TDAC и, таким образом, PR, 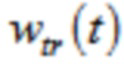 может использовать d=d′ на стороне анализа (кодера), и на стороне синтеза (декодера), может применять обратное, например,
может использовать d=d′ на стороне анализа (кодера), и на стороне синтеза (декодера), может применять обратное, например, 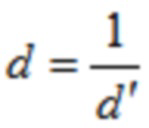 . При заданном конкретном окне ELT устойчивого состояния , d′ предпочтительно определяется таким образом, что, во время всех переходов переключения отношения, оно ведет как к оптимальным спектральным атрибутам окон анализа во время кодирования, так и максимальному выходному ослаблению посредством окон синтеза во время декодирования.
. При заданном конкретном окне ELT устойчивого состояния , d′ предпочтительно определяется таким образом, что, во время всех переходов переключения отношения, оно ведет как к оптимальным спектральным атрибутам окон анализа во время кодирования, так и максимальному выходному ослаблению посредством окон синтеза во время декодирования.
Согласно одному варианту осуществления декодера, welt является первой оконной функцией, wmlt является второй оконной функцией, и является третьей оконной функцией, при этом третья оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области, где k является числом, где , где d является вещественным числом, где n является целым числом, и при этом модуль 130 сложения с перекрытием сконфигурирован с возможностью генерировать, по меньшей мере, одну из первой и второй и третьей и четвертой группы промежуточных аудиовыборок временной области в зависимости от третьей оконной функции .
Аналогично, согласно одному варианту осуществления кодера, welt является первой оконной функцией, wmlt является второй оконной функцией, и является третьей оконной функцией, при этом третья оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области, где k является числом, где , где d является вещественным числом, где n является целым числом, и где, по меньшей мере, один из первого модуля 210 кодирования и второй модуль 220 кодирования сконфигурирован с возможностью применять третью оконную функцию к, по меньшей мере, одной из первой и второй и третьей и четвертой группы аудиовыборок временной области.
В последующем, описываются улучшенные, предпочтительно оптимальные, спектральные свойства оконной обработки анализа согласно некоторым вариантам осуществления. Некоторые варианты осуществления пытаются достичь малой, предпочтительно наименьшей возможной, величины ширины главного лепестка и сильной, предпочтительно самой сильной возможной, величины ослабления бокового лепестка в окнах анализа, чтобы увеличивать спектральное уплотнение особенно стационарных, гармонических аудиосигналов.
Так как, для некоторых из вариантов осуществления, окно устойчивого состояния уже было сконструировано для этой цели, можно показать, что это может достигаться в и (и, конечно, их временных обращениях) посредством избегания прерывностей на границах между оконными частями. Более точно, посредством выбора d′ таким образом, что максимальное значение 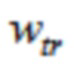 равняется максимальному значению (или, например, значению, которое находится близко к этому максимуму), перескоки в форме переходного окна полностью избегаются. Следовательно, d′ должно отражать отношение между упомянутыми двумя максимумами, которое в текущем случае может приближаться посредством
равняется максимальному значению (или, например, значению, которое находится близко к этому максимуму), перескоки в форме переходного окна полностью избегаются. Следовательно, d′ должно отражать отношение между упомянутыми двумя максимумами, которое в текущем случае может приближаться посредством 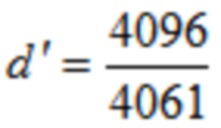 .
.
В последующем, описывается увеличенное, предпочтительно максимальное, выходное ослабление при оконной обработке синтеза. Чтобы более хорошо (предпочтительно настолько, насколько возможно) подавлять искажение спектральной области в кодировании аудио, вызванное квантованием элементов дискретизации преобразования, может быть полезным ослаблять выходную волновую форму во время обработки оконной обработки синтеза до обработки OLA, предпочтительно настолько, насколько возможно. Однако вследствие требований PR/TDAC, сильное ослабление посредством окна является трудным, так как этот подход будет воспроизводить дополняющее окно анализа, вредное в терминах эффективности. Согласно некоторым вариантам осуществления, хорошее компромиссное соотношение между хорошими свойствами окна и приемлемым выходным ослаблением стороны декодера может получаться посредством выбора 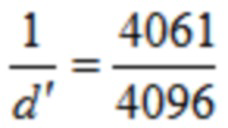 .
.
Другими словами, обе подхода оптимизация для предпочтительно ведут к одному и тому же значению для d′. При использовании , прерывности в и являются очень незначительными (см. фиг. 9), и не ожидается, что их избегание, по меньшей мере, на стороне синтеза дает слышимое улучшение. Специальное переходное окно "остановка-начало" для основанного на MELT переключения ядер, описанного выше, изображенное для конкретного варианта осуществления посредством пунктирной линии на фиг. 15(a) и обозначаемое посредством wss ниже, может выводиться из критической оконной части из формул (12) или (13):
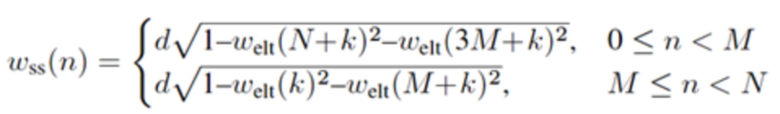 (14)
(14)
Другими словами, wss является симметричным окном с критическими частями в обеих половинах, таким образом, обеспечивая возможность переходов отношения перекрытия на обеих сторонах. Следует отметить, что wss может применяться к MDCT и MDST также как разным вариантам MELT (при предположении, что внешние четверти взвешивания длины L установлены на ноль). Фактически, его использование для организации окон стороны анализа воспроизводит идентичные коэффициенты MDCT и косинус-модулированного MELT-IV, за исключением различий знака, как указано посредством фиг. 5(c). Помимо обеспечения переключения ядер, wss также может использоваться, чтобы делать схему переключения отношения перекрытия более гибкой. Например, с ней может достигаться конфигурация временного переключения (от 50 к 75% перекрытия), показанная на фиг. 15(b).
Согласно одному варианту осуществления декодера, welt является первой оконной функцией, wss является второй оконной функцией, при этом вторая оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области, где k является числом, где , где d является вещественным числом, где n является целым числом, и где модуль 130 сложения с перекрытием сконфигурирован с возможностью генерировать, по меньшей мере, одну из первой и второй и третьей и четвертой группы промежуточных аудиовыборок временной области в зависимости от второй оконной функции wss.
Аналогично, согласно одному варианту осуществления кодера, welt является первой оконной функцией, wss является второй оконной функцией, при этом вторая оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области, где k является числом, где , где d является вещественным числом, где n является целым числом, и где, по меньшей мере, один из первого модуля 210 кодирования и второй модуль 220 кодирования сконфигурирован с возможностью применять вторую оконную функцию wss к, по меньшей мере, одной из первой и второй и третьей и четвертой группы аудиовыборок временной области.
Хотя некоторые аспекты были описаны в контексте устройства, должно быть ясным, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторое или все из этапов способа могут исполняться посредством (или с использованием) устройства аппаратного обеспечения, такого как, например, микропроцессора, программируемого компьютера или электронной схемы. В некоторых вариантах осуществления, один или более из наиболее важных этапов способа могут исполняться посредством такого устройства.
В зависимости от некоторых требований осуществления, варианты осуществления изобретения могут осуществляться в аппаратном обеспечении или в программном обеспечении или, по меньшей мере, частично в аппаратном обеспечении или, по меньшей мере, частично в программном обеспечении. Осуществление может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронным образом считываемые сигналы управления, сохраненные на нем, которые работают вместе (или способны работать вместе) с программируемой компьютерной системой, так что соответствующий способ выполняется. Поэтому, цифровой запоминающий носитель может быть считываемым компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронным образом считываемые сигналы управления, которые являются способными работать вместе с программируемой компьютерной системой, так что один из способов, здесь описанных, выполняется.
В общем, варианты осуществления настоящего изобретения могут осуществляться как компьютерный программный продукт с программным кодом, при этом программный код является работоспособным для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, здесь описанных, сохраненную на машиночитаемом носителе.
Другими словами, один вариант осуществления нового способа является, поэтому, компьютерной программой, имеющей программный код для выполнения одного из способов, здесь описанных, когда компьютерная программа исполняется на компьютере.
Один дополнительный вариант осуществления новых способов является, поэтому, носителем данных (или цифровым запоминающим носителем, или считываемым компьютером носителем), содержащим, записанную на нем, компьютерную программу для выполнения одного из способов, здесь описанных. Носитель данных, цифровой запоминающий носитель или записывающий носитель являются обычно материальными и/или нетранзиторными.
Один дополнительный вариант осуществления нового способа является, поэтому, потоком данных или последовательностью сигналов, представляющей компьютерную программу для выполнения одного из способов, здесь описанных. Поток данных или последовательность сигналов может, например, быть сконфигурирована с возможностью передаваться посредством соединения передачи данных, например, посредством сети Интернет.
Один дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное с возможностью или выполненное с возможностью выполнять один из способов, здесь описанных.
Один дополнительный вариант осуществления содержит компьютер, имеющий, установленную на нем компьютерную программу для выполнения одного из способов, здесь описанных.
Один дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную с возможностью передавать (например, электронным образом или оптическим образом) компьютерную программу для выполнения одного из способов, здесь описанных, в приемник. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или подобным. Устройство или система может, например, содержать файловый сервер для передачи компьютерной программы в приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться, чтобы выполнять некоторые или все из функциональных возможностей способов, здесь описанных. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может работать вместе с микропроцессором, чтобы выполнять один из способов, здесь описанных. В общем, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Устройство, здесь описанное, может осуществляться с использованием устройства аппаратного обеспечения, или с использованием компьютера, или с использованием комбинации устройства аппаратного обеспечения и компьютера.
Способы, здесь описанные, могут выполняться с использованием устройства аппаратного обеспечения, или с использованием компьютера, или с использованием комбинации устройства аппаратного обеспечения и компьютера.
Вышеописанные варианты осуществления являются всего лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, здесь описанных, должны быть ясны другим специалистам в данной области техники. Предполагается, поэтому, что ограничения накладываются только посредством объема прилагаемой патентной формулы изобретения и не посредством конкретных подробностей, представленных посредством описания и объяснения вариантов осуществления отсюда.
ИСТОЧНИКИ
[1] J. P. Princen and A. B. Bradley, "Analysis/Synthesis Filter Bank Design Based on Time Domain Aliasing Cancellation", IEEE Trans. Acoustics, Speech, and Signal Processing, vol. 34, no. 5, pp. 1153-1161, Oct. 1986.
[2] J. P. Princen, A. W. Johnson, and A. B. Bradley, "Subband/transform coding using filter bank design based on time domain aliasing cancellation", in Proc. of IEEE ICASSP '87, Apr. 1987, vol. 12, pp. 2161-2164.
[3] H. S. Malvar, "Lapped Transforms for Efficient Transform/Subband Coding", IEEE Trans. Acoustics, Speech, and Signal Proc., vol. 38, no. 6, pp. 969-978, June 1990.
[4] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, M. Dietz, J. Herre, G. Davidson, and Y. Oikawa, "ISO/IEC MPEG-2 Advanced Audio Coding", J. Audio Eng. Soc., vol. 45, no. 10, Oct. 1997.
[5] ISO/IEC MPEG-2 13818-3, "Information technology - Generic coding of moving pictures and associated audio information - Part 3: Audio", Apr. 1998.
[6] J. Herre, J. Hilpert, A. Kuntz, and J. Plogsties, "MPEG-H Audio - The New Standard for Universal Spatial/3D Audio Coding", J. Audio Eng. Soc., vol. 62, no. 12, pp. 821-830, Dec. 2014.
[7] ISO/IEC MPEG-H 23008-3, "Information technology - High efficiency coding and media delivery in heterogeneous environments - Part 3: 3D audio", Mar. 2015.
[8] C. R. Helmrich, A. Niedermeier, S. Bayer, and B. Edler, "Low-complexity semi-parametric joint-stereo audio transform coding", in Proc. of EUSIPCO '15, Sep. 2015.
[9] C. R. Helmrich and B. Edler, "Signal-adaptive transform kernel switching for stereo audio coding", in Proc. of IEEE WASPAA '15, New Paltz, Oct. 2015, pp. 1-5.
[10] C. R. Helmrich, A. Niedermeier, S. Disch, and F. Ghido, "Spectral envelope reconstruction via IGF for audio transform coding", in Proc. of IEEE ICASSP '15, Apr. 2015, pp. 389-393.
[11] H. S. Malvar, "Modulated QMF Filter Banks with Perfect Reconstruction", Electronics Letters, vol. 26, no. 13, pp. 906-907, June 1990.
[12] H. S. Malvar, "Extended Lapped Transforms: Properties, Applications, and Fast Algorithms", IEEE Trans. Signal Proc., vol. 40, no. 11, pp. 2703-2714, Nov. 1992.
[13] R. L. de Queiroz and K. R. Rao, "Adaptive extended lapped transforms", in Proc. of IEEE ICASSP '93, Apr. 1993, vol. 3, pp. 217-220.
[14] R. L. de Queiroz and K. R. Rao, "Time-Varying Lapped Transforms and Wavelet Packets", IEEE Trans. Signal Proc., vol. 41, no. 12, pp. 3293-3305, Dec. 1993.
[15] M. Temerinac and B. Edler, "LINC: A Common Theory of Transform and Subband Coding", IEEE Trans. Communications, vol. 41, no. 2, pp. 266-274, Feb. 1993.
[16] M. Temerinac and B. Edler, "Overlapping Block Transform: Window Design, Fast Algorithm, and an Image Coding Experiment", IEEE Trans. Communic., vol. 43, no. 9, pp. 2417-2425, Sep. 1995.
[17] G. D. T. Schuller and T. Karp, "Modulated Filter Banks with Arbitrary System Delay: Efficient Implementations and the Time-Varying Case", IEEE Trans. Signal Proc., vol. 48, no. 3, pp. 737-748, Mar. 2000.
[18] H. S. Malvar, "A modulated complex lapped transform and its applications to audio processing", in Proc. of IEEE ICASSP '99, Mar. 1999, vol. 3, pp. 1421-1424.
[19] B. Edler, Äquivalenz von Transformation und Teilbandzerlegung (Subband Decomposition) in der Quellencodierung, Ph.D. thesis, Univ. Hannover, Germany, 1995.
[20] S. Shlien, "The Modulated Lapped Transform, Its Time-Varying Forms, and Its Applications to Audio Coding Standards", IEEE Trans. Speech and Audio Proc., vol. 5, no. 4, pp. 359-366, July 1997.
[21] M. Padmanabhan and K. Martin, "Some further results on modulated/extended lapped transforms", in Proc. of IEEE ICASSP '92, Mar. 1992, vol. 4, pp. 265-268.
[22] K. M. A. Hameed and E. Elias, "Extended lapped transforms with linear phase basis functions and perfect reconstruction", in Proc. of IEEE ICECS '05, Dec. 2005.
[23] L. D. Fielder, M. Bosi, G. Davidson, M. Davis, C. Todd, and S. Vernon, "AC-2 and AC-3: Low-Complexity Transform-Based Audio Coding", AES collected papers on Digital Audio Bit-Rate Reduction, pp. 54-72, 1996.
[24] C. R. Helmrich, "On the Use of Sums of Sines in the Design of Signal Windows", in Proc. of DAFx-10, Graz, Sep. 2010, online at http://dafx10.iem.at/proceedings/.
[25] M. Neuendorf, M. Multrus, N. Rettelbach, G. Fuchs, J. Robilliard, J. Lecomte, S. Wilde, S. Bayer, S. Disch, C. R. Helmrich, R. Lefebvre, P. Gournay, B. Bessette, J. Lapierre, K. Kjörling, H. Purnhagen, L. Villemoes, W. Oomen, E. Schuijers, K. Kikuiri, T. Chinen, T. Norimatsu, K. S. Chong, E. Oh, M. Kim, S. Quackenbush, and B. Grill, "The ISO/MPEG Unified Speech and Audio Coding Standard - Consistent High Quality for all Content Types and at all Bit Rates", J. Audio Eng. Soc., vol. 61, no. 12, pp. 956-977, Dec. 2013.
[26] ITU, Radiocommunication Sector, "Recommendation BS.1534-2: Method for the subjective assessment of intermediate quality level of audio systems", June 2014.
[27] K. Brandenburg and M. Bosi, "Overview of MPEG-Audio: Current and Future Standards for Low Bit-Rate Audio Coding", in Proc. of AES 99th Convention, New York, Oct. 1995, no. 4130.
[28] ISO/IEC SC29/WG11, N15399, "Text of ISO/IEC 23008-3:201x/PDAM 3, MPEG-H 3D Audio phase 2", July 2015.
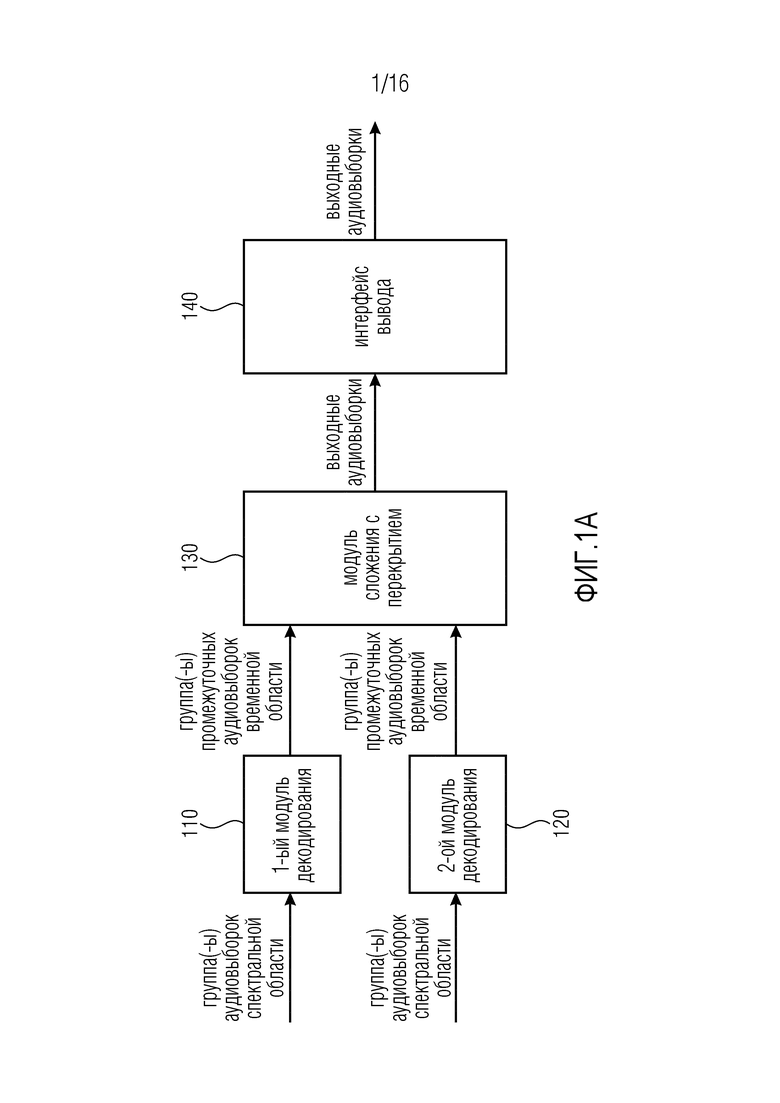
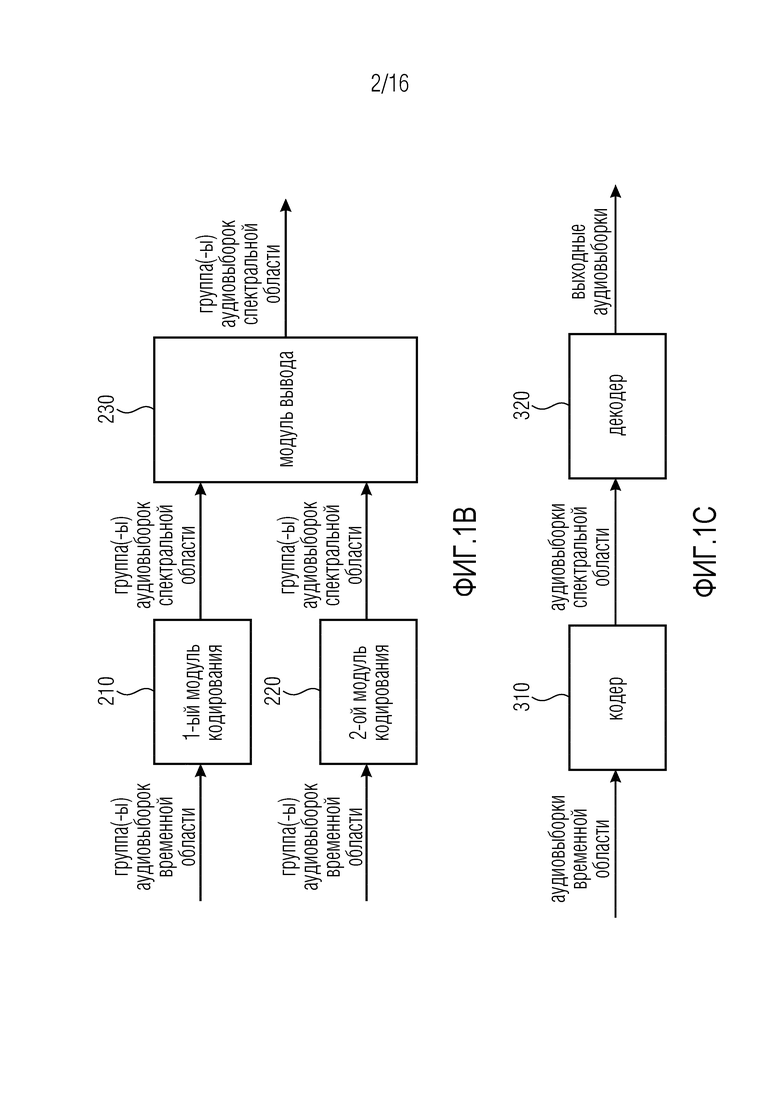
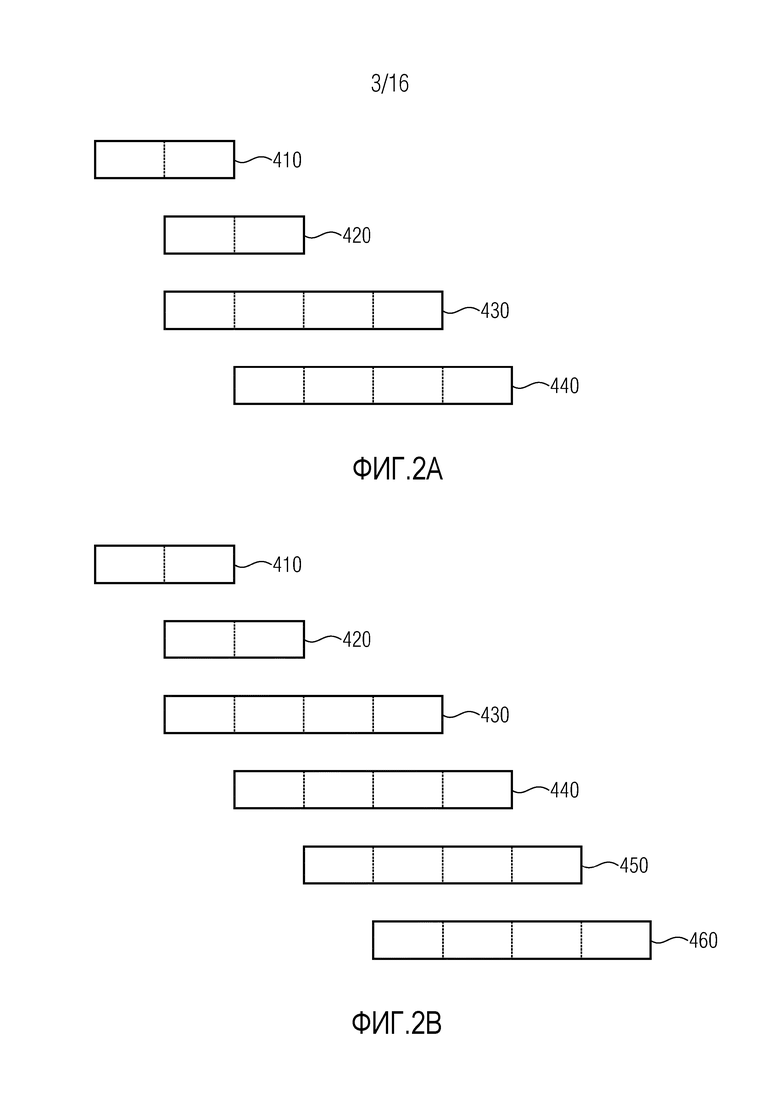
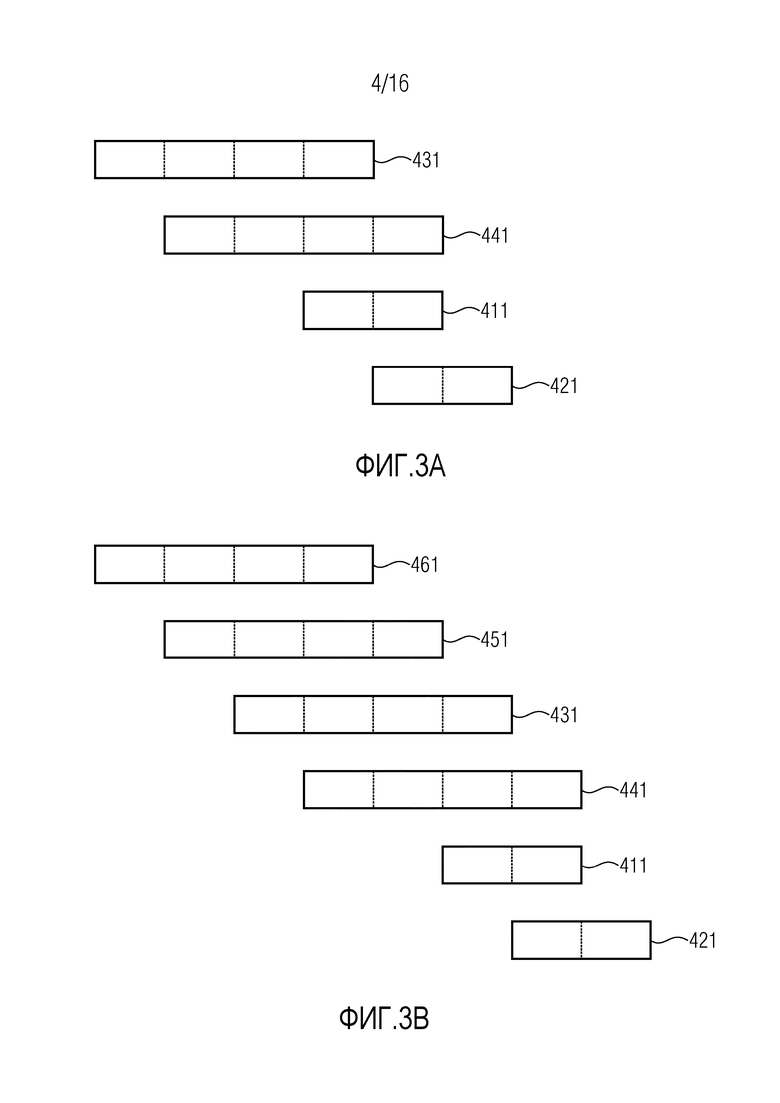
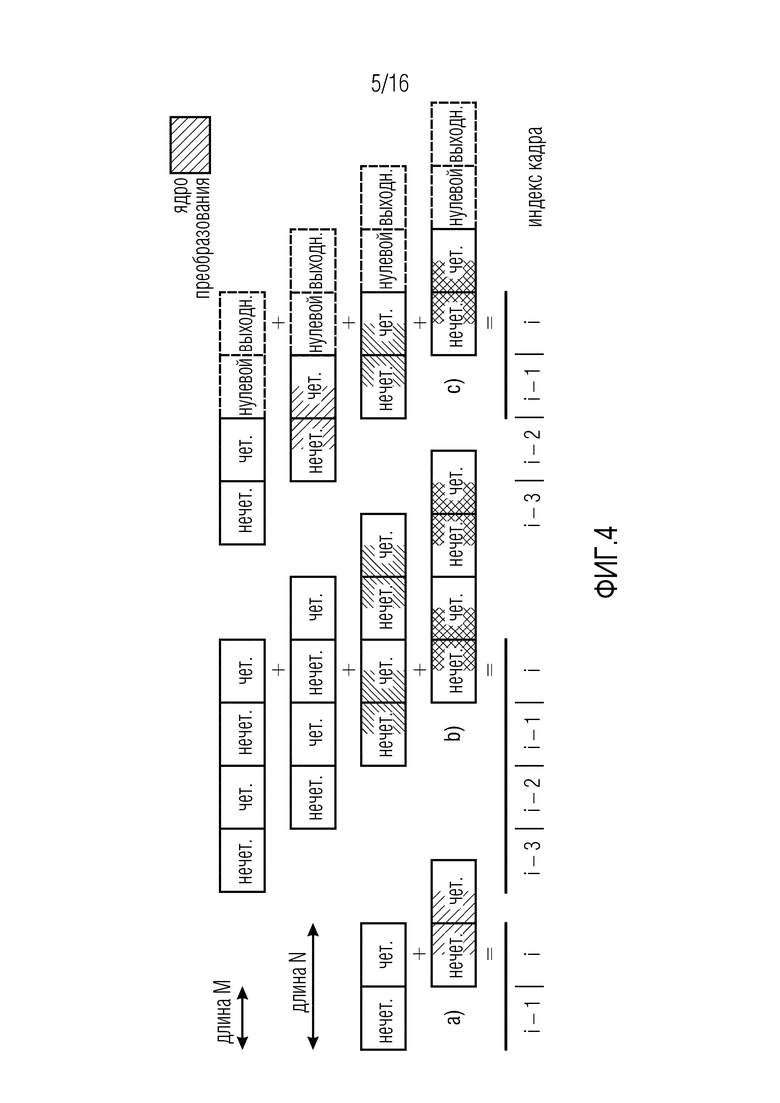
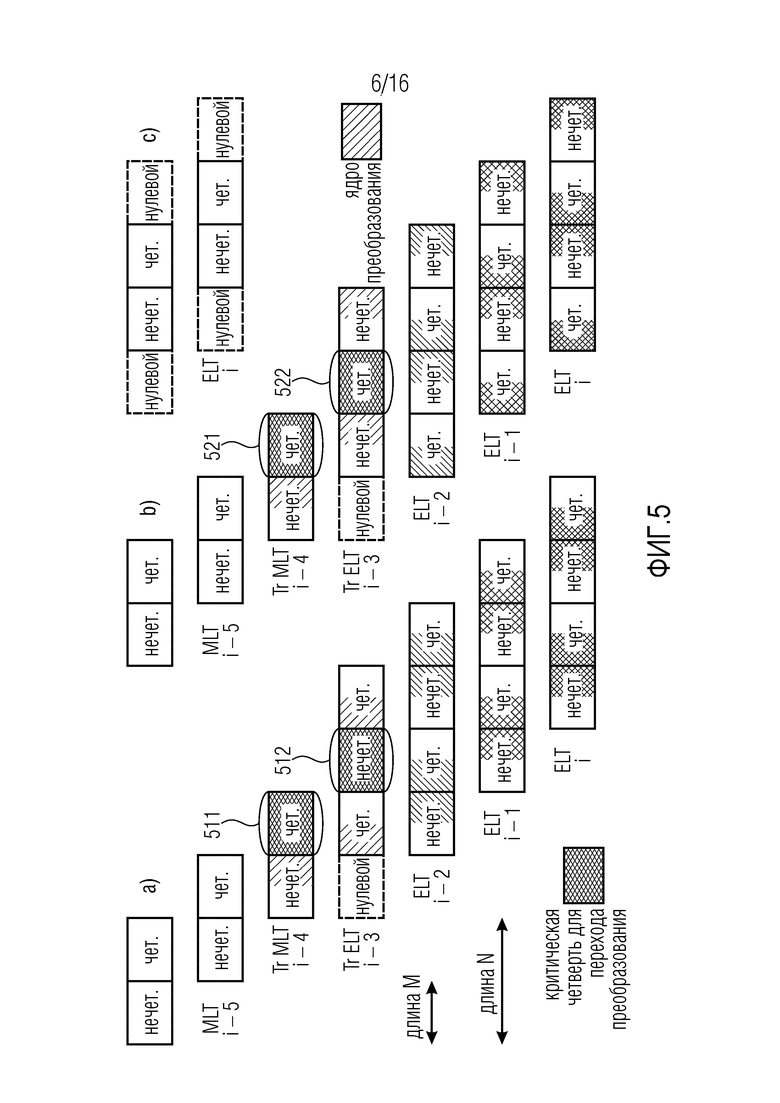
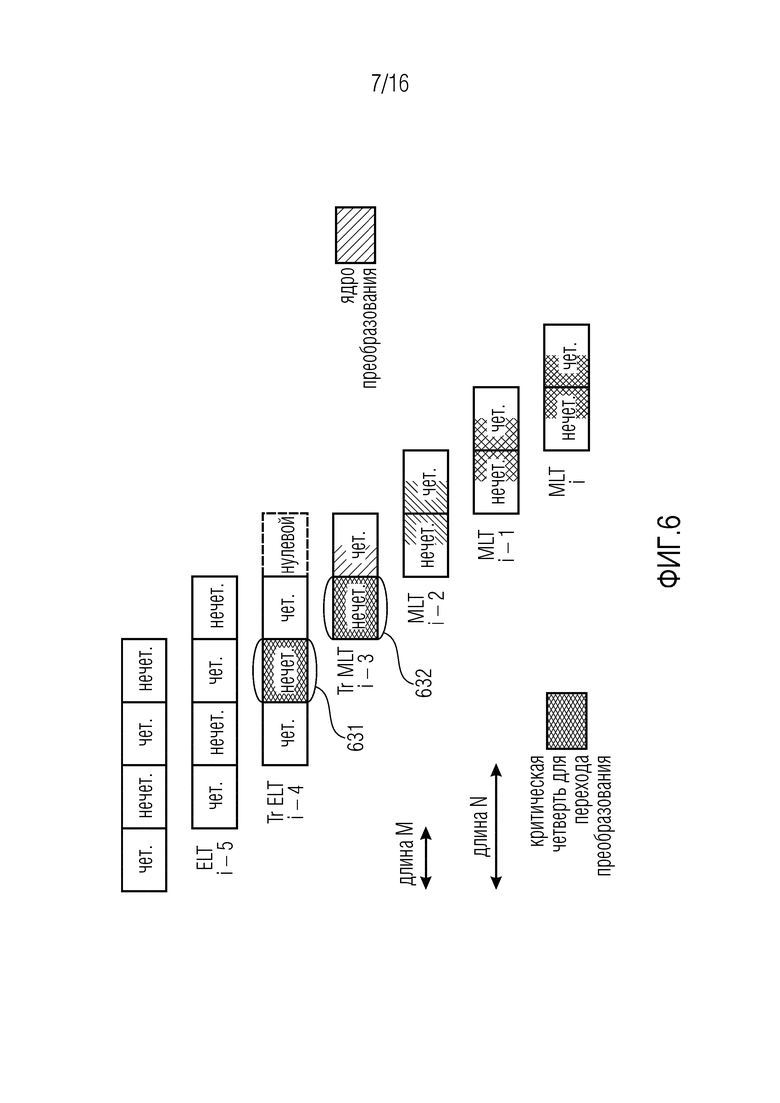
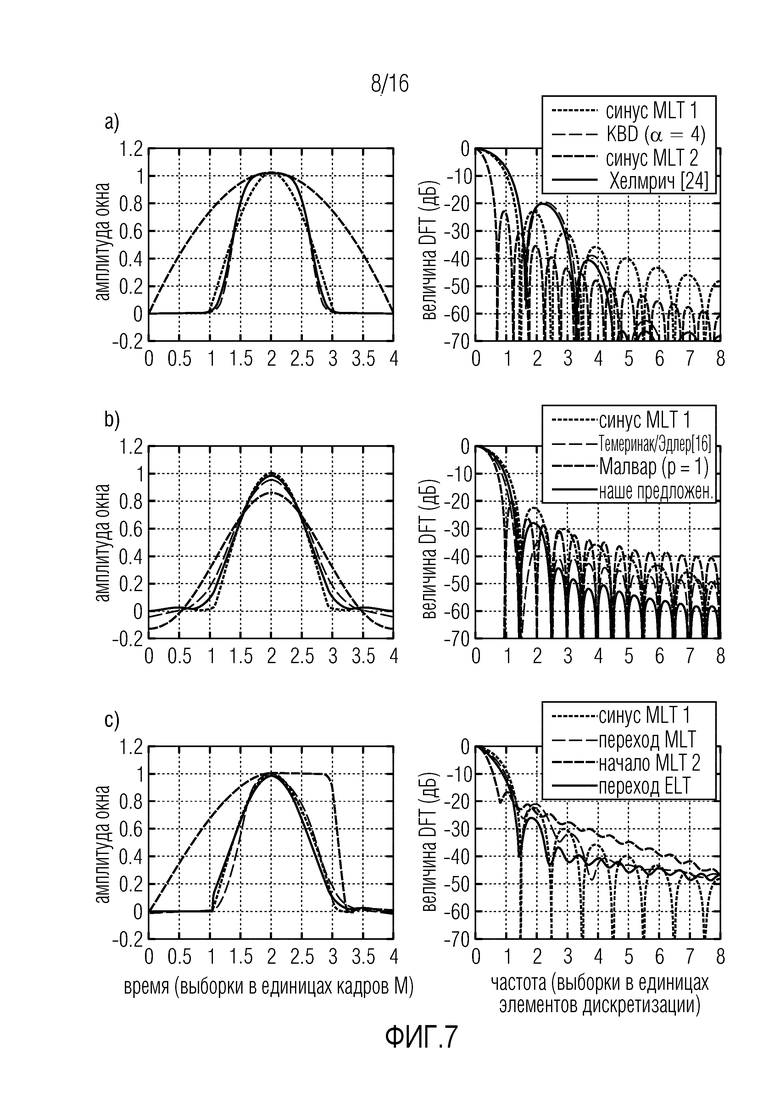
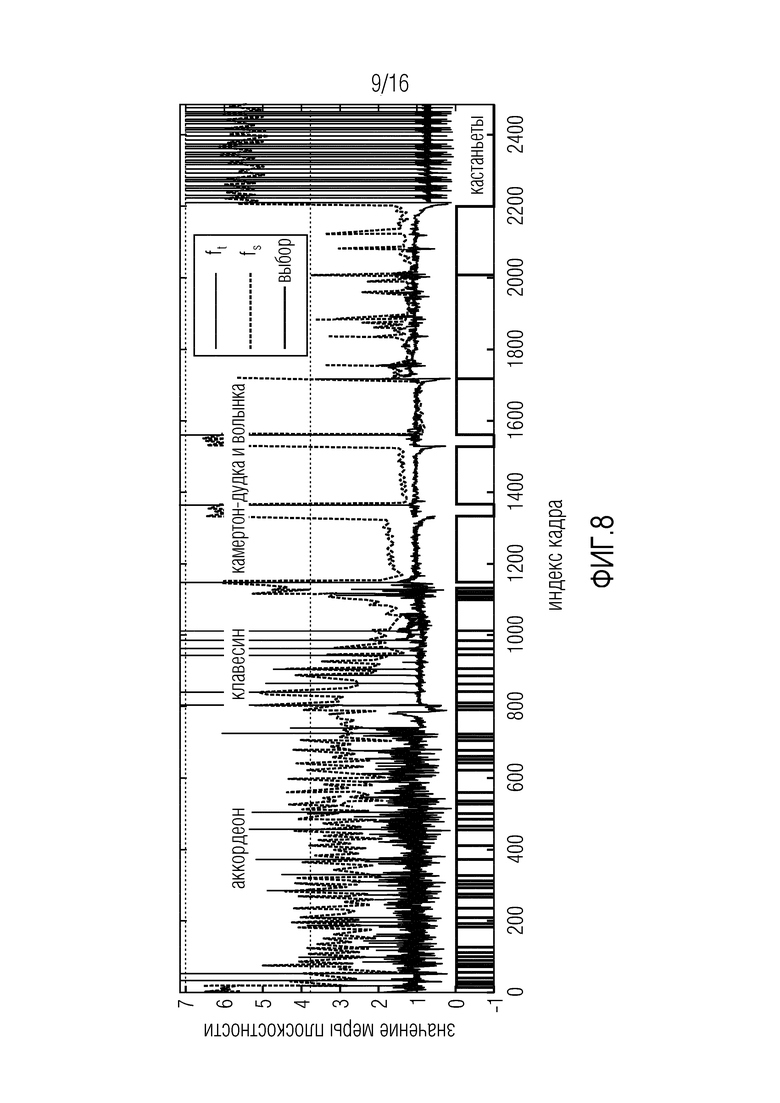
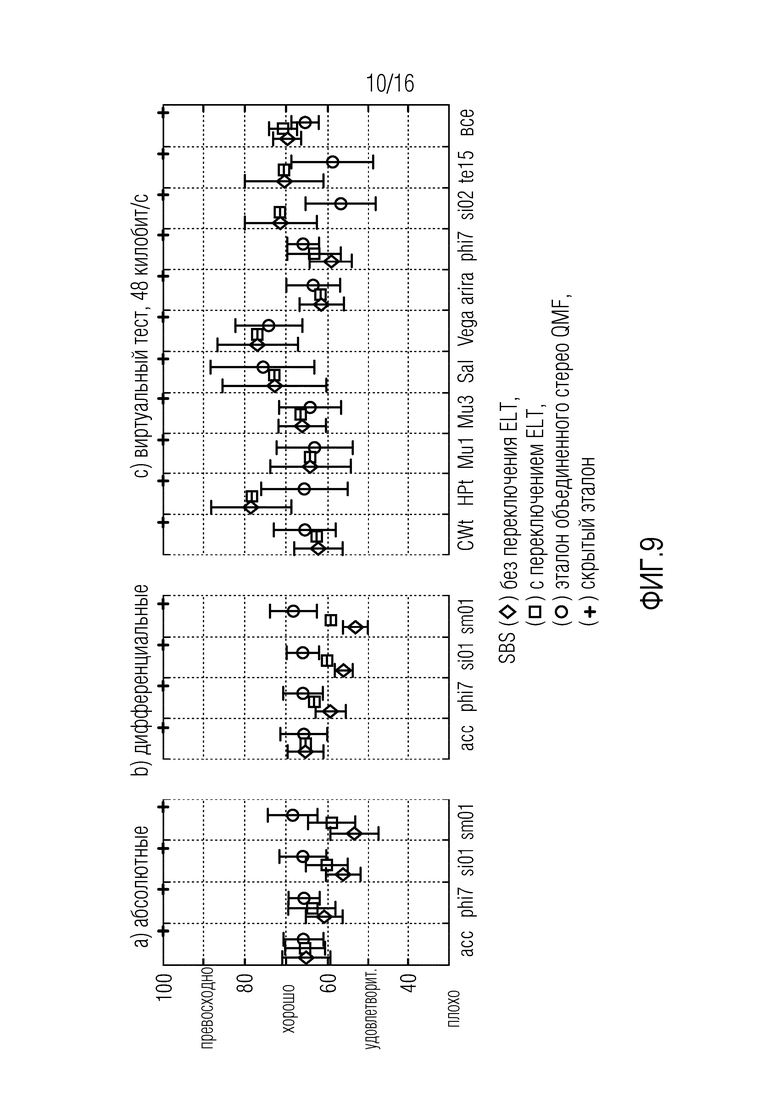
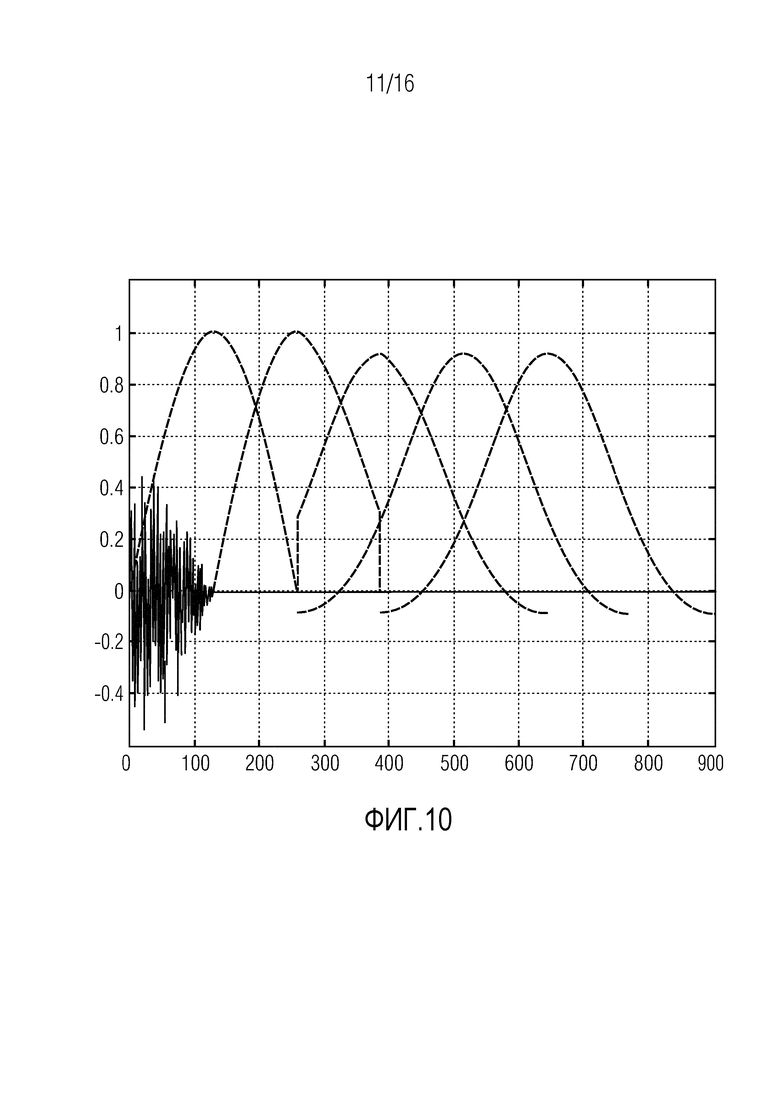
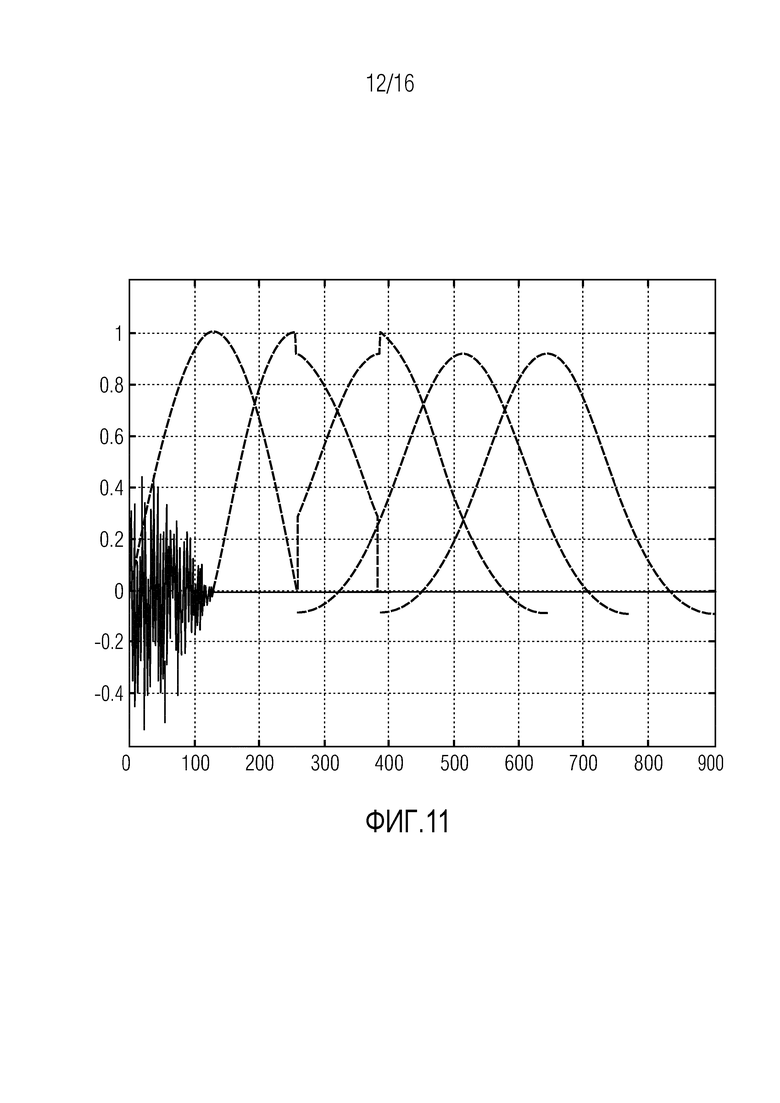
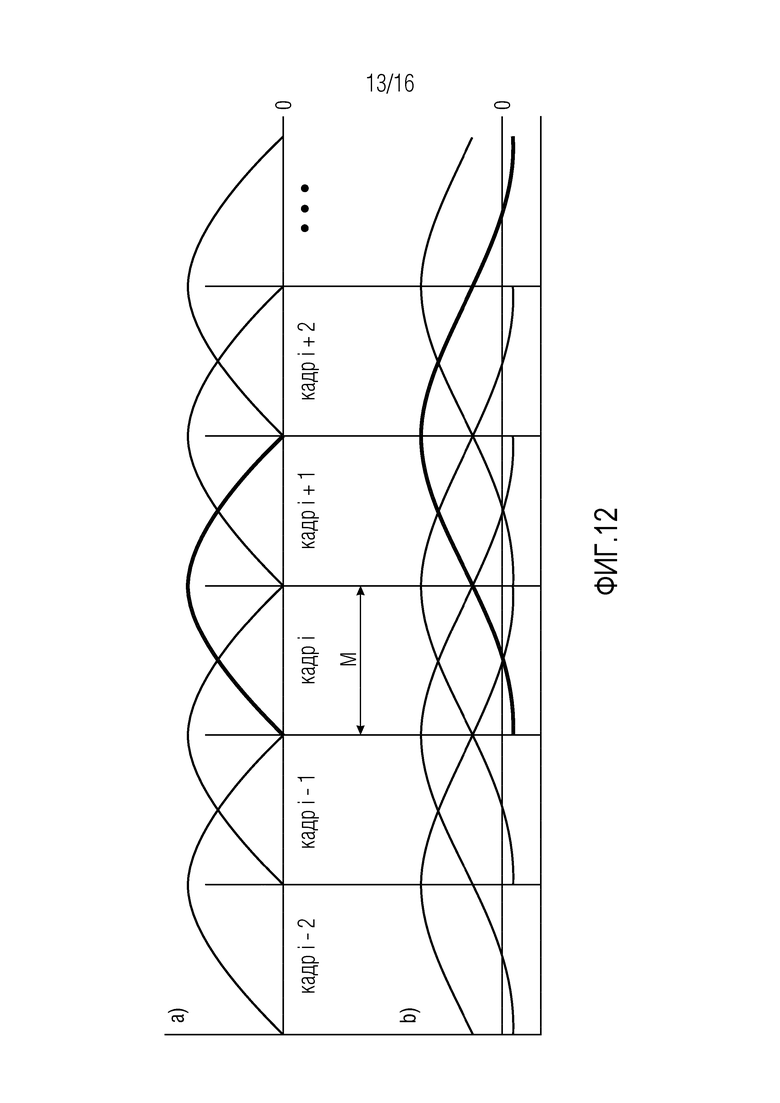
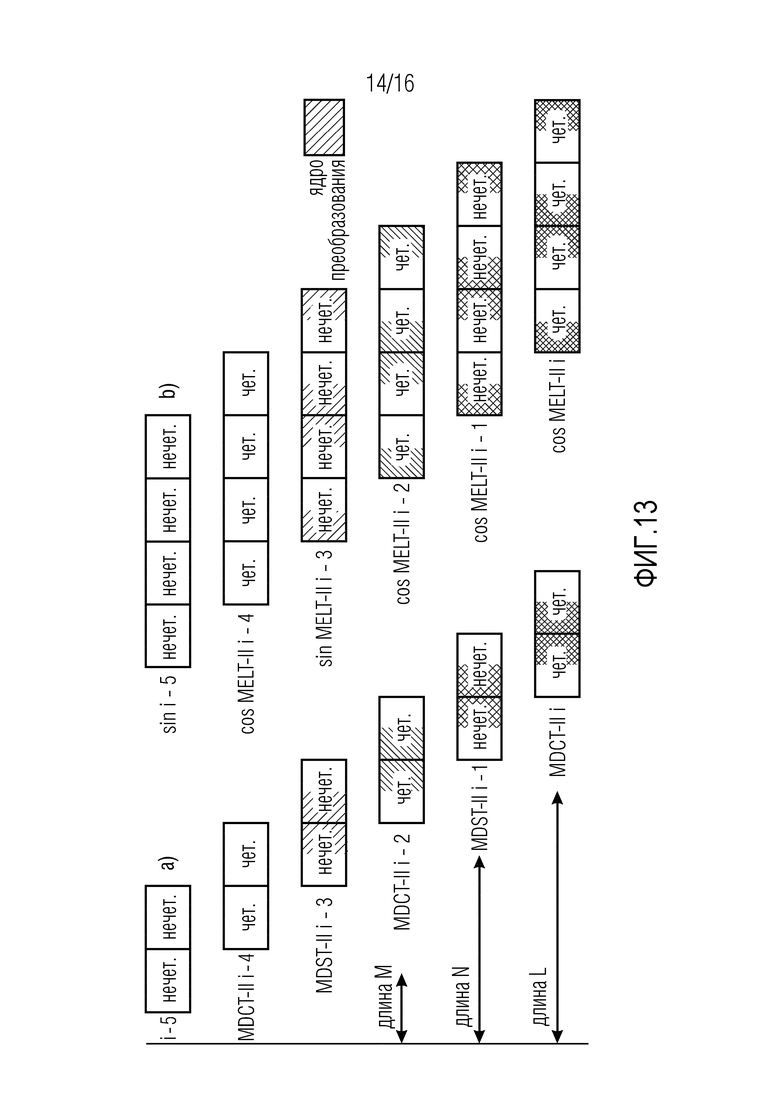
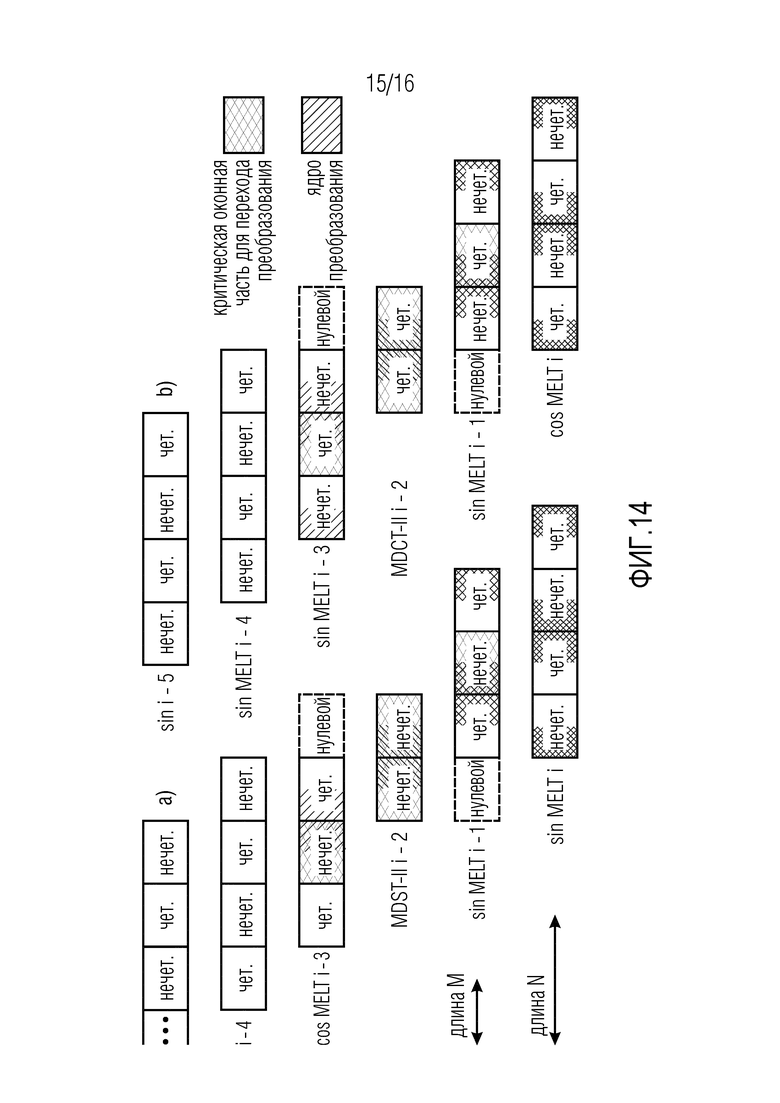
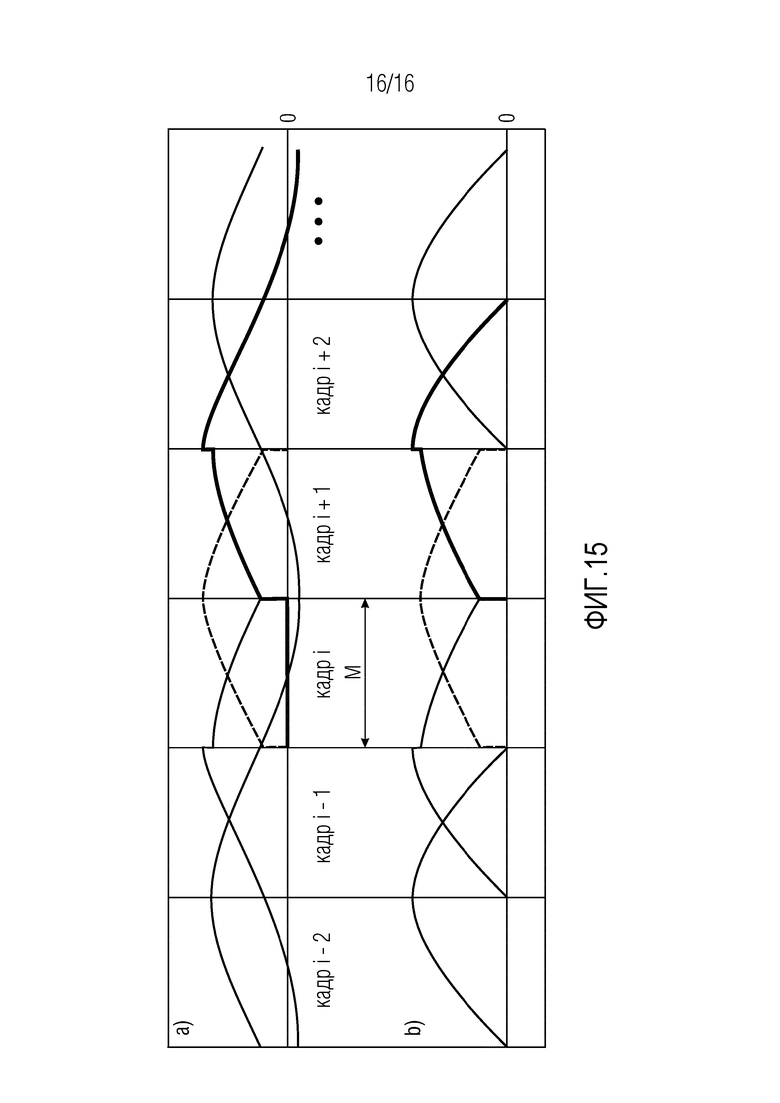
Изобретение относится к области обработки аудиоданных. Технический результат заключается в повышении точности обработки аудио данных. Технический результат достигается за счет вывода первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала, получения второго множества выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области. 7 н. и 51 з.п. ф-лы, 3 табл., 19 ил.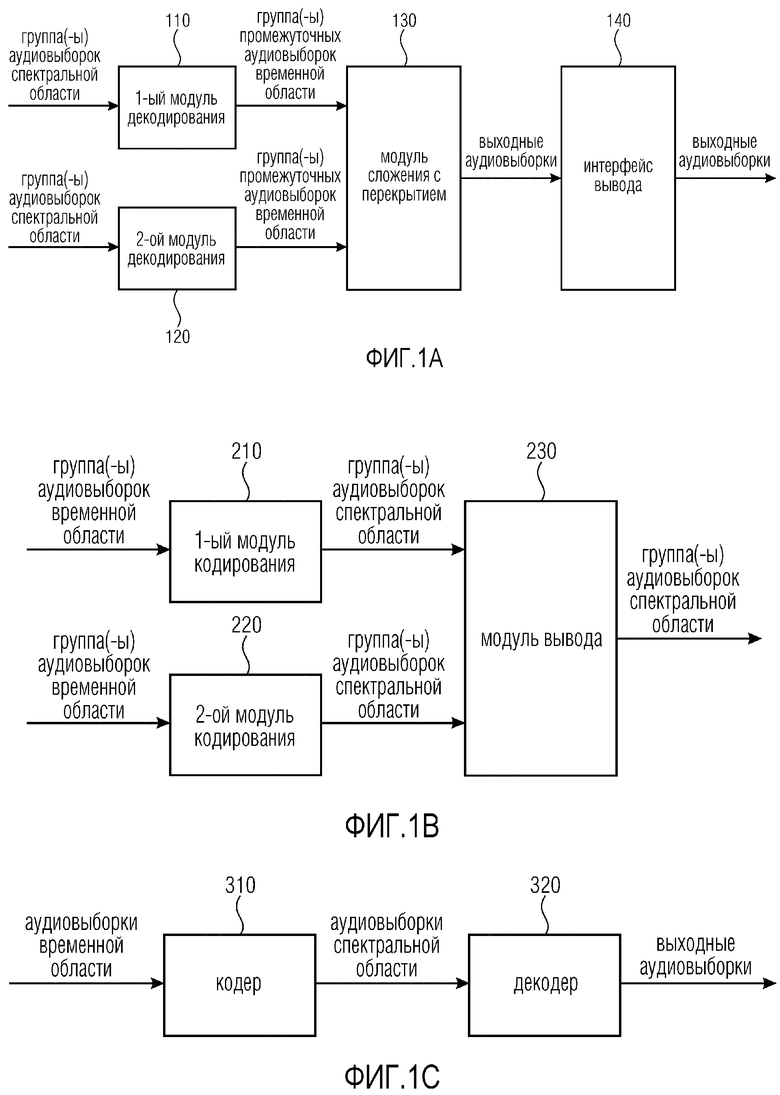
1. Декодер для декодирования множества аудиовыборок спектральной области, при этом декодер содержит:
первый модуль (110) декодирования для декодирования первой группы аудиовыборок спектральной области посредством генерирования первой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области первой группы аудиовыборок спектральной области, и для декодирования второй группы аудиовыборок спектральной области посредством генерирования второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области второй группы аудиовыборок спектральной области,
модуль (130) сложения с перекрытием, при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью выполнять сложение с перекрытием в точности двух групп промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы являются первой группой и второй группой промежуточных аудиовыборок временной области, при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием упомянутых в точности двух групп с перекрытием более чем 5% и самое большее 50%, при этом упомянутое сложение с перекрытием упомянутых в точности двух групп дает результатом генерирование первого множества выходных аудиовыборок временной области аудиосигнала,
второй модуль (120) декодирования для декодирования третьей группы аудиовыборок спектральной области посредством генерирования третьей группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области третьей группы аудиовыборок спектральной области, и для декодирования четвертой группы аудиовыборок спектральной области посредством генерирования четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области четвертой группы аудиовыборок спектральной области, и
интерфейс (140) вывода для вывода первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала,
при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью получать второе множество выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области, и
при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области.
2. Декодер по п. 1,
в котором первое множество выходных аудиовыборок временной области аудиосигнала предшествует третьему множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом третье множество выходных аудиовыборок временной области аудиосигнала предшествует второму множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или
в котором второе множество выходных аудиовыборок временной области аудиосигнала предшествует третьему множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом третье множество выходных аудиовыборок временной области аудиосигнала предшествует первому множеству выходных аудиовыборок временной области аудиосигнала во времени, и при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью получать третье множество выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области.
3. Декодер по п. 1,
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием первой группы промежуточных аудиовыборок временной области с перекрытием в точности 50% со второй группой промежуточных аудиовыборок временной области, и
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере третьей группы промежуточных аудиовыборок временной области с перекрытием по меньшей мере 75% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области.
4. Декодер по п. 3,
в котором первый модуль (110) декодирования сконфигурирован с возможностью выполнять обратное модифицированное дискретное косинусное преобразование или обратное модифицированное дискретное синусное преобразование, и
в котором второй модуль (120) декодирования сконфигурирован с возможностью выполнять обратное расширенное перекрывающееся преобразование или обратное модифицированное расширенное перекрывающееся преобразование.
5. Декодер по п. 3, в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере третьей группы промежуточных аудиовыборок временной области с перекрытием в точности 75% с четвертой группой промежуточных аудиовыборок временной области.
6. Декодер по п. 1,
в котором первое количество промежуточных аудиовыборок временной области первой группы промежуточных аудиовыборок временной области равняется второму количеству промежуточных аудиовыборок временной области второй группы промежуточных аудиовыборок временной области,
в котором третье количество промежуточных аудиовыборок временной области третьей группы промежуточных аудиовыборок временной области равняется четвертому количеству промежуточных аудиовыборок временной области четвертой группы промежуточных аудиовыборок временной области,
в котором второе количество равняется третьему количеству, разделенному на 2, и при этом первое количество равняется четвертому количеству, разделенному на 2.
7. Декодер по п. 1,
в котором второй модуль (120) декодирования сконфигурирован с возможностью декодировать пятую группу аудиовыборок спектральной области посредством генерирования пятой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области пятой группы аудиовыборок спектральной области, и для декодирования шестой группы аудиовыборок спектральной области посредством генерирования шестой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области шестой группы аудиовыборок спектральной области, и
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью получать второе множество выходных аудиовыборок временной области посредством осуществления сложения с перекрытием третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области и пятой группы промежуточных аудиовыборок временной области и шестой группы промежуточных аудиовыборок временной области, так что третья или четвертая группа промежуточных аудиовыборок временной области перекрывается с по меньшей мере 75% и менее чем 100% с пятой группой промежуточных аудиовыборок временной области, и так что пятая группа промежуточных аудиовыборок временной области перекрывается с по меньшей мере 75% и менее чем 100% с шестой группой промежуточных аудиовыборок временной области.
8. Декодер по п. 1,
в котором второй модуль (120) декодирования сконфигурирован с возможностью генерировать по меньшей мере одну из третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области в зависимости от
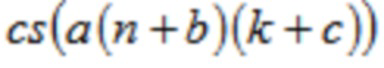 ,
,
где cs( ) является cos( ) или sin( ),
где n указывает временной индекс одной из промежуточных аудиовыборок временной области третьей или четвертой группы промежуточных аудиовыборок временной области,
где k указывает спектральный индекс одной из аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где -0,1≤c≤0,1, или 0,4≤c≤0,6, или 0,9≤c≤1,1,
где 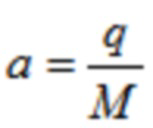 ,
,
где 0,9⋅π≤q≤1,1⋅π,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где 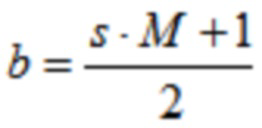 , и
, и
где 1,5≤s≤4,5.
9. Декодер по п. 1,
в котором первый модуль (110) декодирования сконфигурирован с возможностью генерировать по меньшей мере одну из первой группы промежуточных аудиовыборок временной области и второй группы промежуточных аудиовыборок временной области в зависимости от
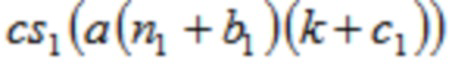 ,
,
где  ( ) является cos( ) или sin( ),
( ) является cos( ) или sin( ),
где 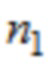 указывает временной индекс одной из промежуточных аудиовыборок временной области первой или второй группы промежуточных аудиовыборок временной области,
указывает временной индекс одной из промежуточных аудиовыборок временной области первой или второй группы промежуточных аудиовыборок временной области,
где -0,1≤с1≤0,1, или 0,4≤с1≤0,6, или 0,9≤с1≤1,1,
где 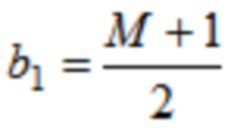 .
.
10. Декодер по п. 8,
где c=0, или c=0,5, или c=1,
где q=π, и
где s=3.
11. Декодер по п. 9,
где q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и с1=0,5, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и с1=0, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и с1=1, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и с1=1, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и с1=0,5, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и с1=0,5, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и с1=0, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и с1=0.
12. Декодер по п. 10,
в котором второй модуль (120) декодирования сконфигурирован с возможностью генерировать по меньшей мере одну из третьей группы промежуточных аудиовыборок временной области и четвертой группы промежуточных аудиовыборок временной области
в зависимости от
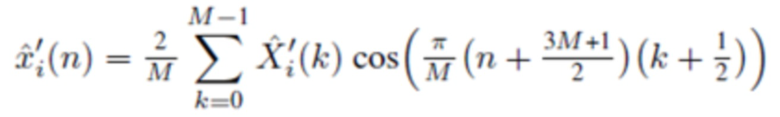 , или
, или
в зависимости от
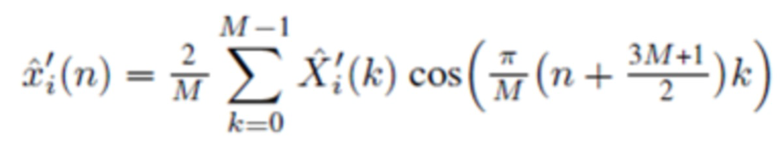 , или
, или
в зависимости от
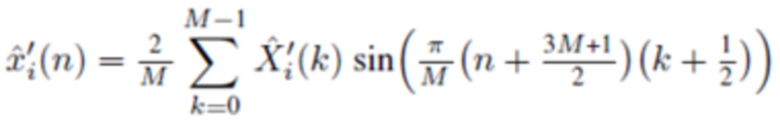 , или
, или
в зависимости от
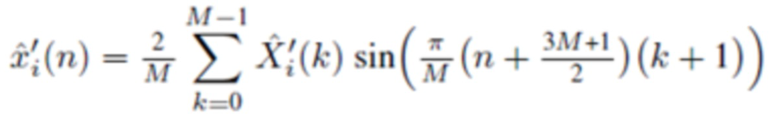 ,
,
где 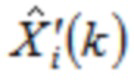 указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и
указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и
где 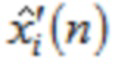 указывает значение временной области.
указывает значение временной области.
13. Декодер по п. 8, в котором второй модуль (120) декодирования сконфигурирован с возможностью применять вес 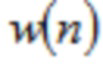 к значению временной области согласно
к значению временной области согласно
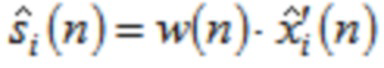
чтобы генерировать промежуточную аудиовыборку 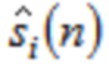 временной области третьей или четвертой группы промежуточных аудиовыборок временной области.
временной области третьей или четвертой группы промежуточных аудиовыборок временной области.
14. Декодер по п. 1,
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, так что все промежуточные аудиовыборки временной области второй группы промежуточных аудиовыборок временной области перекрываются с промежуточными аудиовыборками временной области третьей группы промежуточных аудиовыборок временной области, или
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, так что все промежуточные аудиовыборки временной области первой группы промежуточных аудиовыборок временной области перекрываются с четвертой группой промежуточных аудиовыборок временной области.
15. Декодер по п. 1,
в котором welt является первой оконной функцией,
при этом wtr является второй оконной функцией, при этом часть второй оконной функции определяется согласно
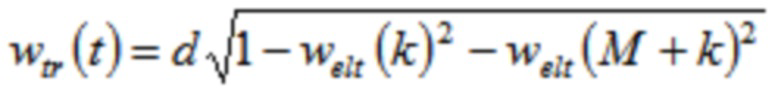 ,
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где 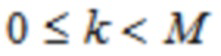 ,
,
где d является вещественным числом,
где 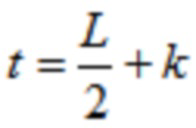 , или где
, или где 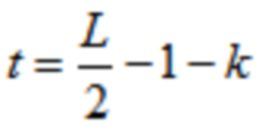 ,
,
где L указывает количество промежуточных аудиовыборок временной области третьей группы или четвертой группы промежуточных аудиовыборок временной области,
при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, при этом второй модуль (120) декодирования сконфигурирован с возможностью генерировать четвертую группу промежуточных аудиовыборок временной области в зависимости от первой оконной функции welt, и при этом второй модуль (120) декодирования сконфигурирован с возможностью генерировать третью группу промежуточных аудиовыборок временной области в зависимости от второй оконной функции wtr, или
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, при этом второй модуль (120) декодирования сконфигурирован с возможностью генерировать третью группу промежуточных аудиовыборок временной области в зависимости от первой оконной функции welt, и при этом второй модуль (120) декодирования сконфигурирован с возможностью генерировать четвертую группу промежуточных аудиовыборок временной области в зависимости от второй оконной функции wtr.
16. Декодер по п. 15,
в котором wtr1 является третьей оконной функцией, при этом часть третьей оконной функции определяется согласно
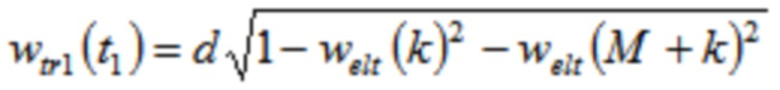 ,
,
где 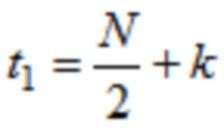 , или где
, или где 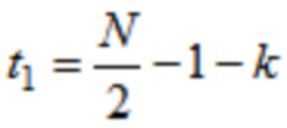 ,
,
где N указывает количество промежуточных аудиовыборок временной области первой группы или второй группы промежуточных аудиовыборок временной области,
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, и при этом первый модуль (110) декодирования сконфигурирован с возможностью генерировать вторую группу промежуточных аудиовыборок временной области в зависимости от третьей оконной функции wtr1, или
в котором модуль (130) сложения с перекрытием сконфигурирован с возможностью осуществлять сложение с перекрытием по меньшей мере четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области, и при этом первый модуль (110) декодирования сконфигурирован с возможностью генерировать первую группу промежуточных аудиовыборок временной области в зависимости от третьей оконной функции wtr1.
17. Декодер по п. 15,
в котором первая оконная функция welt определяется согласно
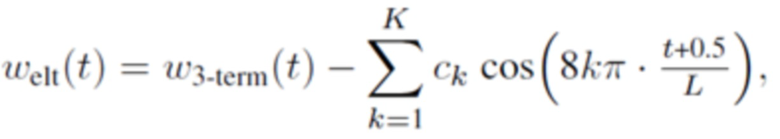
при этом
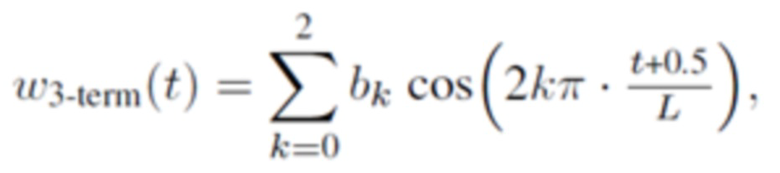
где b0, b1 и b2 являются вещественными числами,
где 0≤t<L, и
где K является положительным целым числом и
где ck указывает вещественное число.
18. Декодер по п. 17,
в котором K=3;
где 0,3≤b0≤0,4,
где -0,6≤b1≤-0,4,
где 0,01≤b2≤0,2,
где 0,001≤c1≤0,03,
где 0,000001≤c2≤0,0005,
где 0,000001≤c3≤0,00002.
19. Декодер по п. 1,
в котором welt является первой оконной функцией,
при этом wmlt является второй оконной функцией, и
при этом 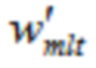 является третьей оконной функцией, при этом третья оконная функция определяется согласно
является третьей оконной функцией, при этом третья оконная функция определяется согласно
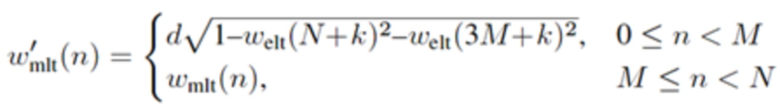 ,
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где n является целым числом, и
при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью генерировать по меньшей мере одну из первой и второй и третьей и четвертой группы промежуточных аудиовыборок временной области в зависимости от третьей оконной функции .
20. Декодер по п. 1,
в котором welt является первой оконной функцией,
при этом wss является второй оконной функцией, при этом вторая оконная функция определяется согласно
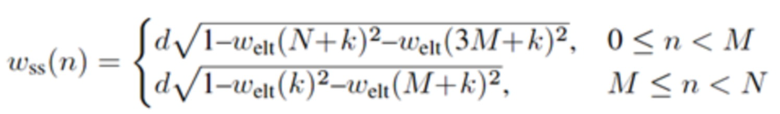 ,
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где n является целым числом, и
при этом модуль (130) сложения с перекрытием сконфигурирован с возможностью генерировать по меньшей мере одну из первой и второй и третьей и четвертой группы промежуточных аудиовыборок временной области в зависимости от второй оконной функции wss.
21. Декодер по п. 15, в котором
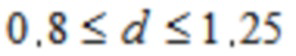 .
.
22. Декодер по п. 21, в котором
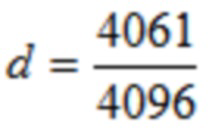 .
.
23. Декодер по п. 15, в котором d=1.
24. Декодер по п. 1,
при этом декодер сконфигурирован с возможностью принимать информацию декодирования, указывающую, должна ли часть множества аудиовыборок спектральной области декодироваться посредством первого модуля (110) декодирования или посредством второго модуля (120) декодирования, и
при этом декодер сконфигурирован с возможностью декодировать упомянутую часть множества аудиовыборок спектральной области посредством использования либо первого модуля (110) декодирования, либо второго модуля (120) декодирования в зависимости от информации декодирования, чтобы получать первую или вторую или третью или четвертую группу промежуточных аудиовыборок временной области.
25. Декодер по п. 1,
при этом декодер сконфигурирован с возможностью принимать первый бит и второй бит, при этом первый бит и второй бит вместе имеют первую комбинацию битовых значений, или вторую комбинацию битовых значений, которая отличается от первой комбинации битовых значений, или третью комбинацию битовых значений, которая отличается от первой и второй комбинации битовых значений, или четвертую комбинацию битовых значений, которая отличается от первой и второй и третьей комбинации битовых значений,
при этом декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области в зависимости от функции Кайзера-Бесселя посредством использования первого модуля (110) декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют первую комбинацию битовых значений,
при этом декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области в зависимости от функции синуса или функции косинуса посредством использования первого модуля (110) декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют вторую комбинацию битовых значений,
при этом декодер сконфигурирован с возможностью декодировать часть множества аудиовыборок спектральной области посредством использования первого модуля (110) декодирования, чтобы получать первую или вторую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют третью комбинацию битовых значений, и
при этом декодер сконфигурирован с возможностью декодировать упомянутую часть множества аудиовыборок спектральной области посредством использования второго модуля (120) декодирования, чтобы получать третью или четвертую группу промежуточных аудиовыборок временной области, если первый бит и второй бит вместе имеют четвертую комбинацию битовых значений.
26. Кодер для кодирования множества аудиовыборок временной области аудиосигнала посредством генерирования множества групп аудиовыборок спектральной области из множества групп аудиовыборок временной области, при этом кодер содержит:
первый модуль (210) кодирования для генерирования первой группы из групп аудиовыборок спектральной области из первой группы из групп аудиовыборок временной области, и для генерирования второй группы из групп аудиовыборок спектральной области из второй группы из групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области и вторая группа аудиовыборок временной области являются соседними во времени внутри групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок первой группы аудиовыборок временной области, и
второй модуль (220) кодирования для генерирования третьей группы из групп аудиовыборок спектральной области из третьей группы из групп аудиовыборок временной области, и для генерирования четвертой группы из групп аудиовыборок спектральной области из четвертой группы из групп аудиовыборок временной области, при этом третья группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области, и
модуль (230) вывода для вывода первой группы аудиовыборок спектральной области, второй группы аудиовыборок спектральной области, третьей группы аудиовыборок спектральной области и четвертой группы аудиовыборок спектральной области,
при этом третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
27. Кодер по п. 26,
в котором первая группа аудиовыборок временной области предшествует второй группе аудиовыборок временной области во времени, и при этом вторая группа аудиовыборок временной области предшествует третьей группе аудиовыборок временной области во времени, и при этом третья группа аудиовыборок временной области предшествует четвертой группе аудиовыборок временной области во времени, и при этом третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или
при этом третья группа аудиовыборок временной области предшествует четвертой группе аудиовыборок временной области во времени, и при этом четвертая группа аудиовыборок временной области предшествует первой группе аудиовыборок временной области во времени, и при этом первая группа аудиовыборок временной области предшествует второй группе аудиовыборок временной области во времени, и при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
28. Кодер по п. 26,
в котором первая группа аудиовыборок временной области содержит в точности 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит в точности 50% аудиовыборок первой группы аудиовыборок временной области, и
при этом третья группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области.
29. Кодер по п. 28,
в котором первый модуль (210) кодирования сконфигурирован с возможностью выполнять модифицированное дискретное косинусное преобразование или модифицированное дискретное синусное преобразование, и
при этом второй модуль (220) кодирования сконфигурирован с возможностью выполнять расширенное перекрывающееся преобразование или модифицированное расширенное перекрывающееся преобразование.
30. Кодер по п. 28, в котором третья группа аудиовыборок временной области содержит в точности 75% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит в точности 75% аудиовыборок третьей группы аудиовыборок временной области.
31. Кодер по п. 26,
в котором первое количество аудиовыборок временной области первой группы аудиовыборок временной области равняется второму количеству аудиовыборок временной области второй группы аудиовыборок временной области,
в котором третье количество аудиовыборок временной области третьей группы аудиовыборок временной области равняется четвертому количеству аудиовыборок временной области четвертой группы аудиовыборок временной области,
при этом второе количество равняется третьему количеству, разделенному на 2, и при этом первое количество равняется четвертому количеству, разделенному на 2.
32. Кодер по п. 26,
в котором второй модуль (220) кодирования сконфигурирован с возможностью генерировать пятую группу из групп аудиовыборок спектральной области из пятой группы из групп аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью генерировать шестую группу из групп аудиовыборок спектральной области из шестой группы из групп аудиовыборок временной области,
при этом третья или четвертая группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок пятой группы аудиовыборок временной области, при этом пятая группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок третьей или четвертой группы аудиовыборок временной области, при этом пятая группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок шестой группы аудиовыборок временной области, при этом шестая группа аудиовыборок временной области содержит по меньшей мере 75% и менее чем 100% аудиовыборок пятой группы аудиовыборок временной области, и
при этом модуль (230) вывода сконфигурирован с возможностью дополнительно выводить пятую группу аудиовыборок спектральной области, и шестую группу аудиовыборок спектральной области.
33. Кодер по п. 26, при этом кодер сконфигурирован с возможностью либо использовать первый модуль (210) кодирования, либо второй модуль (220) кодирования для генерирования текущей группы аудиовыборок спектральной области в зависимости от свойства сигнала части аудиосигнала временной области.
34. Кодер по п. 33,
при этом кодер сконфигурирован с возможностью определять в качестве свойства сигнала, содержит ли текущая группа множества аудиовыборок временной области по меньшей мере одну из нестационарных областей и нетональных областей,
при этом кодер сконфигурирован с возможностью использовать первый модуль (210) кодирования, чтобы генерировать текущую группу аудиовыборок спектральной области в зависимости от текущей группы множества аудиовыборок временной области, если текущая группа множества аудиовыборок временной области содержит упомянутую по меньшей мере одну из нестационарных областей и нетональных областей, и
при этом кодер сконфигурирован с возможностью использовать второй модуль (220) кодирования, чтобы генерировать текущую группу аудиовыборок спектральной области в зависимости от текущей группы множества аудиовыборок временной области, если текущая группа множества аудиовыборок временной области не содержит упомянутую по меньшей мере одну из нестационарных областей и нетональных областей.
35. Кодер по п. 33, в котором модуль (230) вывода сконфигурирован с возможностью выводить бит, имеющий либо первое битовое значение, либо второе битовое значение в зависимости от свойства сигнала.
36. Кодер по п. 26,
в котором второй модуль (220) кодирования сконфигурирован с возможностью генерировать по меньшей мере одну из третьей группы и четвертой группы аудиовыборок спектральной области в зависимости от
,
где cs( ) является cos( ) или sin( ),
где n указывает временной индекс одной из аудиовыборок временной области третьей или четвертой группы аудиовыборок временной области,
где k указывает спектральный индекс одной из аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где -0,1≤c≤0,1, или 0,4≤c≤0,6, или 0,9≤c≤1,1,
где ,
где 0,9⋅π≤q≤1,1⋅π,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где , и
где 1,5≤s≤4,5.
37. Кодер по п. 26,
в котором первый модуль (210) кодирования сконфигурирован с возможностью генерировать по меньшей мере одну из первой группы и второй группы аудиовыборок спектральной области в зависимости от
,
где ( ) является cos( ) или sin( ),
где указывает временной индекс одной из аудиовыборок временной области первой или второй группы аудиовыборок временной области,
где -0,1≤с1≤0,1, или 0,4≤с1≤0,6, или 0,9≤с1≤1,1,
где .
38. Кодер по п. 36,
где c=0, или c=0,5, или c=1,
где q=π, и
где s=3.
39. Кодер по п. 37,
где q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и с1=0,5, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и с1=0, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и с1=1, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и с1=1, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является sin( ), и где c=0,5, и с1=0,5, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является sin( ), и где c=0, и с1=0,5, или
где q=π, где s=3, где cs( ) является cos( ), и ( ) является cos( ), и где c=0,5, и с1=0, или
где q=π, где s=3, где cs( ) является sin( ), и ( ) является cos( ), и где c=1, и с1=0.
40. Кодер по п. 38,
в котором второй модуль (220) кодирования сконфигурирован с возможностью генерировать по меньшей мере одну из третьей группы и четвертой группы аудиовыборок спектральной области
в зависимости от
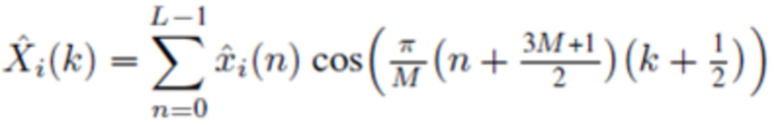 , или
, или
в зависимости от
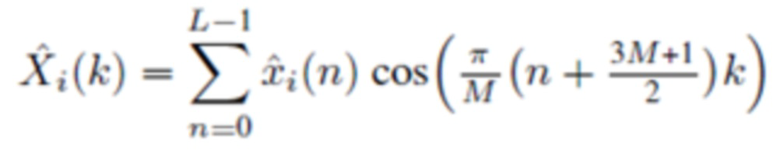 , или
, или
в зависимости от
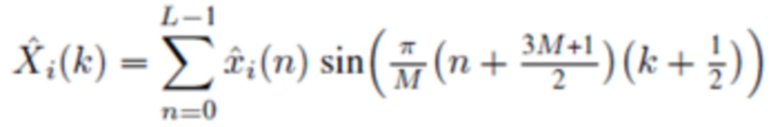 , или
, или
в зависимости от
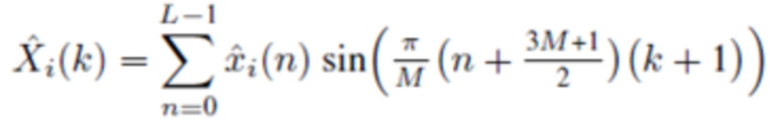 ,
,
где 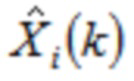 указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и
указывает одну из аудиовыборок спектральной области третьей или четвертой группы аудиовыборок спектральной области, и
при этом 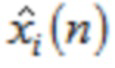 указывает значение временной области.
указывает значение временной области.
41. Кодер по п. 36, в котором второй модуль (220) кодирования сконфигурирован с возможностью применять вес к аудиовыборке 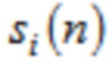 временной области третьей группы или четвертой группы аудиовыборок временной области согласно
временной области третьей группы или четвертой группы аудиовыборок временной области согласно
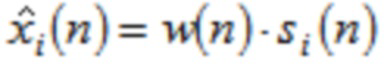
чтобы генерировать значение временной области.
42. Кодер по п. 26,
в котором все аудиовыборки временной области второй группы аудиовыборок временной области перекрываются с аудиовыборками временной области третьей группы аудиовыборок временной области, или
в котором все аудиовыборки временной области первой группы аудиовыборок временной области перекрываются с четвертой группой аудиовыборок временной области.
43. Кодер по п. 26,
в котором welt является первой оконной функцией,
при этом wtr является второй оконной функцией, при этом часть второй оконной функции определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где , или где ,
где L указывает количество аудиовыборок временной области третьей группы или четвертой группы аудиовыборок временной области,
при этом третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, и где второй модуль (220) кодирования сконфигурирован с возможностью применять первую оконную функцию welt к четвертой группе аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью применять вторую оконную функцию wtr к третьей группе аудиовыборок временной области, или
при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью применять первую оконную функцию welt к третьей группе аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью применять вторую оконную функцию wtr к четвертой группе аудиовыборок временной области.
44. Кодер по п. 43,
в котором wtr1 является третьей оконной функцией, при этом часть третьей оконной функции определяется согласно
,
где , или где ,
где N указывает количество аудиовыборок временной области первой группы или второй группы аудиовыборок временной области,
при этом третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, и где второй модуль (220) кодирования сконфигурирован с возможностью применять третью оконную функцию wtr1 к второй группе аудиовыборок временной области, или
при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области, и при этом второй модуль (220) кодирования сконфигурирован с возможностью применять третью оконную функцию wtr1 к первой группе аудиовыборок временной области.
45. Кодер по п. 43,
в котором первая оконная функция welt определяется согласно
при этом
где b0, b1 и b2 являются вещественными числами,
где 0≤t<L, и
где K является положительным целым числом и
где ck указывает вещественное число.
46. Кодер по п. 45,
в котором K=3;
где 0,3≤b0≤0,4,
где -0,6≤b1≤-0,4,
где 0,01≤b2≤0,2,
где 0,001≤c1≤0,03,
где 0,000001≤c2≤0,0005,
где 0,000001≤c3≤0,00002.
47. Кодер по п. 26,
в котором welt является первой оконной функцией,
при этом wmlt является второй оконной функцией, и
при этом является третьей оконной функцией, при этом третья оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где n является целым числом, и
при этом по меньшей мере один из первого модуля (210) кодирования и второго модуля (220) кодирования сконфигурирован с возможностью применять третью оконную функцию к по меньшей мере одной из первой и второй и третьей и четвертой группы аудиовыборок временной области.
48. Кодер по п. 26,
в котором welt является первой оконной функцией,
при этом wss является второй оконной функцией, при этом вторая оконная функция определяется согласно
,
где M указывает количество аудиовыборок спектральной области первой или второй или третьей или четвертой группы аудиовыборок спектральной области,
где k является числом, где ,
где d является вещественным числом,
где n является целым числом, и
при этом по меньшей мере один из первого модуля (210) кодирования и второго модуля (220) кодирования сконфигурирован с возможностью применять вторую оконную функцию wss к по меньшей мере одной из первой и второй и третьей и четвертой группы аудиовыборок временной области.
49. Кодер по п. 43, в котором
.
50. Кодер по п. 49, в котором
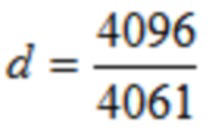 .
.
51. Кодер по п. 43, в котором d=1.
52. Система для кодирования и декодирования аудиовыборок, при этом система содержит:
кодер (310) по п. 26, и
декодер (320) по п. 1,
при этом кодер (310) по п. 26 сконфигурирован с возможностью кодировать упомянутые аудиовыборки, являющиеся множеством аудиовыборок временной области аудиосигнала, посредством генерирования множества аудиовыборок спектральной области,
при этом декодер (320) по п. 1 сконфигурирован с возможностью принимать множество аудиовыборок спектральной области от кодера,
при этом декодер (320) по п. 1 сконфигурирован с возможностью декодировать множество аудиовыборок спектральной области.
53. Система по п. 52,
в которой кодер (310) является кодером по п. 49, и
в которой декодер (320) является декодером по п. 21.
54. Система по п. 53,
в которой кодер (310) является кодером по п. 50, и
в которой декодер (320) является декодером по п. 22.
55. Способ для декодирования множества аудиовыборок спектральной области, в котором способ содержит:
декодирование первой группы аудиовыборок спектральной области посредством генерирования первой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области первой группы аудиовыборок спектральной области, и декодирование второй группы аудиовыборок спектральной области посредством генерирования второй группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области второй группы аудиовыборок спектральной области,
сложение с перекрытием в точности двух групп промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы являются первой группой и второй группой промежуточных аудиовыборок временной области, при этом упомянутые в точности две группы складываются с перекрытием с перекрытием более чем 5% и самое большее 50%, при этом упомянутое сложение с перекрытием упомянутых в точности двух групп дает результатом генерирование первого множества выходных аудиовыборок временной области аудиосигнала,
декодирование третьей группы аудиовыборок спектральной области посредством генерирования третьей группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области третьей группы аудиовыборок спектральной области, и декодирование четвертой группы аудиовыборок спектральной области посредством генерирования четвертой группы промежуточных аудиовыборок временной области из аудиовыборок спектральной области четвертой группы аудиовыборок спектральной области,
вывод первого множества выходных аудиовыборок временной области аудиосигнала, второго множества выходных аудиовыборок временной области аудиосигнала и третьего множества выходных аудиовыборок временной области аудиосигнала,
получение второго множества выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере третьей группы промежуточных аудиовыборок временной области с перекрытием более чем 60% и менее чем 100% с четвертой группой промежуточных аудиовыборок временной области, и
получение третьего множества выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере второй группы промежуточных аудиовыборок временной области с третьей группой промежуточных аудиовыборок временной области, или получение третьего множества выходных аудиовыборок временной области с использованием сложения с перекрытием по меньшей мере четвертой группы промежуточных аудиовыборок временной области с первой группой промежуточных аудиовыборок временной области.
56. Способ для кодирования множества аудиовыборок временной области аудиосигнала посредством генерирования множества групп аудиовыборок спектральной области из множества групп аудиовыборок временной области, при этом кодер содержит:
генерирование первой группы из групп аудиовыборок спектральной области из первой группы из групп аудиовыборок временной области, и генерирование второй группы из групп аудиовыборок спектральной области из второй группы из групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области и вторая группа аудиовыборок временной области являются соседними во времени внутри групп аудиовыборок временной области, при этом первая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок второй группы аудиовыборок временной области, и при этом вторая группа аудиовыборок временной области содержит более чем 5% и самое большее 50% аудиовыборок первой группы аудиовыборок временной области,
генерирование третьей группы из групп аудиовыборок спектральной области из третьей группы из групп аудиовыборок временной области, и генерирование четвертой группы из групп аудиовыборок спектральной области из четвертой группы из групп аудиовыборок временной области, при этом третья группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок четвертой группы аудиовыборок временной области, и при этом четвертая группа аудиовыборок временной области содержит более чем 60% и менее чем 100% аудиовыборок третьей группы аудиовыборок временной области, и
вывод первой группы аудиовыборок спектральной области, второй группы аудиовыборок спектральной области, третьей группы аудиовыборок спектральной области и четвертой группы аудиовыборок спектральной области,
при этом третья группа аудиовыборок временной области содержит аудиовыборки второй группы аудиовыборок временной области, или при этом четвертая группа аудиовыборок временной области содержит аудиовыборки первой группы аудиовыборок временной области.
57. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 55, когда исполняется на компьютере или сигнальном процессоре.
58. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 56, когда исполняется на компьютере или сигнальном процессоре.
| КОДИРОВАНИЕ ИНФОРМАЦИОННОГО СИГНАЛА | 2007 |
|
RU2413312C2 |
| ПОДДИАПАЗОННЫЙ РЕЧЕВОЙ КОДЕКС С МНОГОКАСКАДНЫМИ ТАБЛИЦАМИ КОДИРОВАНИЯ И ИЗБЫТОЧНЫМ КОДИРОВАНИЕМ | 2006 |
|
RU2418324C2 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

