Область техники, к которой относится изобретение
В целом, данное изобретение относится к процессу кодирования при звукозаписи и воспроизведении звука, а конкретно - к способу и к устройству формирования выровненного многоканального аудиосигнала.
Уровень техники
Современные аудиовизуальные стандарты кодирования, такие как стандарт MPEG-1 и стандарт MPEG-2, обеспечивают средства для транспортировки многокомпонентной аудио- и видеоинформации в едином транспортном информационном потоке. Индивидуальные и отдельные аудиокомпоненты могут быть выровнены с выбранными видеокомпонентами. Синхронизированный многоканальный аудиосигнал, такой как объемный звук, обеспечивается только в виде единственного, предварительно микшированного компонента объемного звука, например одиночного аудиокомпонента Dolby 5.1. Однако в настоящее время нет никаких средств, предназначенных для транспортировки в синхронизированной форме индивидуализированных многоканальных аудиокомпонентов.
В частности, в технических требованиях стандартов MPEG-1 и MPEG-2 (ISO/IEC 11172-3 и ISO/IEC 13818-3 соответственно) описываются средства кодирования и пакетирования цифровых аудиосигналов. Они содержат схемы, предназначенные для поддержки различных форм многоканального звука, которые используют единственный компонент транспортного потока стандарта MPEG-2. Данные средства являются обратно совместимыми с предшествующей аудиосистемой стандарта MPEG-1. На предшествующем уровне развития техники обеспечение необходимой синхронизации каналов было возможно только путем объединения нескольких аудиоканалов в такой единственный транспортный компонент. Для каждой из этих схем требуется:
[a] использование способов сжатия объемного звука (например, Dolby 5.1) или
[b] использование способов компрессии собственной разработки, или
[c] использование аудиосигнала без компрессии.
Использование способов сжатия в системе объемного звучания позволяет уменьшить потребную пропускную способность множественных каналов за счет использования избыточности, существующей между несколькими каналами, а также особенностей человеческого слуха, которые приводят к тому, что определенные пространственные характеристики звука не могут быть обнаружены и поэтому могут быть маскированы в процессе обработки. Эти сложные схемы обеспечивают достаточные средства в случае однократного кодирования, при котором осуществляется только одна операция кодирования и декодирования, однако они не являются идеальными в случае сигналов, для которых по практическим и эксплуатационным причинам (например, данные поступают из удаленного местоположения в центр обработки) может потребоваться неоднократная перекодировка в сетях передачи данных. Вследствие конкатенации из-за многократных операций кодирования происходит поэтапное ухудшение качества звука. Это особенно явно проявляется в случае ограниченных ресурсов, что приводит к существенному уменьшению скорости передачи информации, оставляя небольшую величину разности между номинальным уровнем сигнала и его максимальным значением без искажения, что приводит к ухудшению качества аудиосигнала при кодировании и при передаче с конкатенацией.
Использование способов компрессии собственной разработки обычно требует использования дополнительного внешнего специального оборудования, что приводит к возрастанию расходов и усложнению эксплуатации. Данный способ также может привнести такое же ухудшение качества, как и конкатенация более одного результата разных стадий кодирования/декодирования.
Поскольку, если отправка аудиоданных осуществляется в несжатом формате (например, несжатые отсчеты линейной ИКМ), то необходимая скорость передачи данных имеет очень большую величину (например, примерно 3 Мбит/с на каждую двухканальную пару).
В общем случае вышеизложенное не является проблемой при доставке аудиовизуального содержания потребителям, однако это представляет проблему для производителей мультимедиа-продукции, поскольку в промышленности все шире используются повсеместно распространенные современные высокоскоростные сети передачи данных для передачи «необработанной» аудиовизуальной информации (то есть исходных материалов для телевидения, производства кинофильмов и иных средств массовой информации), практически мгновенно, в сжатой форме между объектами производственного оборудования, либо от производственного оборудования к точкам распределения сетей теле- и радиовещания, например, к наземным передатчикам, спутниковым каналам восходящей связи или кабельным коробкам оконечного пользователя.
Например, съемочные группы обычно передают аудиовизуальный материал на центральные телевизионные студии для редактирования и передачи его на ретрансляционные станции для вещания телезрителям. Вышеупомянутые аудиовизуальные стандарты кодирования не позволяют осуществлять пересылку синхронизированных многоканальных аудиоданных без предварительного смешения, тем самым усложняя аппаратуру, либо препятствуя обеспечению многоканального аудио.
Имеется специфическая потребность в возможности передачи многоканальных аудиоданных, для которой актуальным является требование по точному многоканальному выравниванию таким образом, чтобы аудиосигналы можно было затем закодировать как объемный звук, для которого критически важным является временное выравнивание множественных каналов, используя вышеупомянутые стандарты MPEG, поскольку большая часть промышленного оборудования уже настроена на использование данных стандартов.
Соответственно, в настоящем изобретении предложены способы и устройство, обеспечивающие реализацию рентабельного и удобного механизма транспортировки многоканальных аудиоданных при обеспечении качества звука и точного выравнивания каналов относительно друг друга по времени.
Раскрытие изобретения
Осуществления настоящего изобретения обеспечивают способ кодирования аудиоданных и включения их в цифровой транспортный поток данных, содержащий прием на входе кодера множества совмещенных по времени аудиосигналов, назначение идентичных временных меток в единицу времени всему множеству совмещенных аудиосигналов и включение помеченных таким образом аудиосигналов в цифровой транспортный поток данных.
Опционально этап приема дополнительно содержит дискретизацию аудиосигналов, совмещенных по времени для того, чтобы сформировать кадры аудиоданных предопределенного размера и осуществить выравнивание этих аудиокадров, с целью временного совмещения аудиосигналов, причем этап назначения идентичных временных меток выполняется на выровненных кадрах аудиоданных.
Опционально способ далее содержит сжатие выровненных кадров аудиоданных с идентичными установками параметров конфигурации кодера аудиосигналов перед назначением временных меток и назначения сжатых и идентично помеченных аудиоданных множеству моноканалов транспортного потока.
Опционально множество моноканалов содержит один или несколько обычных двойных моно аудиокомпонентов.
Опционально предопределенный размер представляет собой размер модуля доступа в стандарте MPEG, а транспортный поток видеоинформации представляет собой транспортный поток MPEG-1 или MPEG-2.
Опционально временные метки являются временными метками представления.
Опционально способ любого предшествующего пункта, в котором этап включения аудиоданных в цифровой видеопоток содержит операцию мультиплексирования сжатых и помеченных временными метками аудиоданных в транспортный поток.
Осуществления настоящего изобретения также обеспечивают способ декодирования цифрового транспортного потока, содержащего аудиосигнал, закодированный согласно любому из вышеупомянутых способов кодирования, который включает в себя: прием множества помеченных временными метками аудиосигналов, представляющих множество совмещенных во времени индивидуальных аудиоканалов, путем обнаружения временных меток для того, чтобы определить совместно используемые временные метки и осуществить вывод множества совмещенных во времени индивидуальных аудиоканалов, согласно продетектированным временным меткам, в виде множественных каналов.
Опционально множество помеченных временными метками аудиосигналов, дискретизованных и выровненных для того, чтобы сформировать выровненные кадры аудиоданных, причем возможно применение идентичных временных меток к выровненным кадрам аудиоданных.
Опционально выровненные кадры аудиоданных были подвергнуты сжатию перед назначением им временных меток, и способ далее содержит восстановление сжатых кадров аудиоданных для того, чтобы осуществить вывод индивидуальных аудиосигналов.
Опционально этап вывода множества совмещенных во времени индивидуальных аудиоканалов содержит представление аудиоданных с использованием временной метки только одного из совмещенных во времени аудиосигналов.
Опционально цифровой транспортный поток представляет собой цифровой транспортный поток видеоинформации, а выровненные кадры аудиоданных содержат пакеты пакетированного элементарного потока (PES).
Осуществления настоящего изобретения также содержат аппаратуру кодирования, адаптированную для выполнения любого из вышеуказанных способов кодирования.
Осуществления настоящего изобретения также содержат аппаратуру декодирования, адаптированную для выполнения любого из вышеуказанных способов декодирования.
Осуществления настоящего изобретения также содержат цифровую транспортную систему, состоящую из, по меньшей мере, одного описанного устройства кодирования, из, по меньшей мере, одного описанного устройства декодирования, и канала связи между ними.
Осуществления настоящего изобретения также содержат машиночитаемый носитель, содержащий инструкции, которые при их выполнении побуждают компьютерную логику выполнять любое описанное здесь кодирование, декодирование или оба способа.
Осуществления настоящего изобретения далее содержат устройство кодирования для кодирования аудиосигналов и формирования транспортного потока из множества совмещенных по времени аудиоканалов, включающее в себя, по меньшей мере, один кодер для кодирования аудиосигнала, согласно предопределенному способу сжатия, функцию кодирования для каждого кодера для пакетирования кодированного аудиосигнала в предопределенные порции аудиоданных, функцию сборки, выполненную с возможностью предоставления идентичной временной маркировки в функцию пакетирования для включения ее в состав множества предварительно определенных порций аудиоданных таким образом, чтобы закодированный аудиосигнал представлял собой совмещенные по времени аудиоканалы, и мультиплексор для мультиплексирования выхода, по меньшей мере, одной пары, состоящей из кодера и функции пакетирования.
Краткое описание чертежей
Способ и устройство для реализации выровненного многоканального аудиосигнала далее описываются только в качестве примера, со ссылкой на сопроводительные чертежи, где:
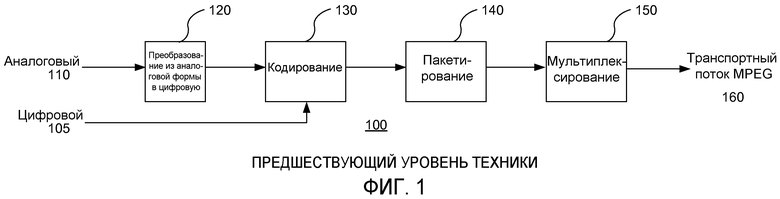
на фиг.1 показана функциональная схема части аналогового или цифрового одноканального устройства кодирования, соответствующего предшествующему уровню техники.
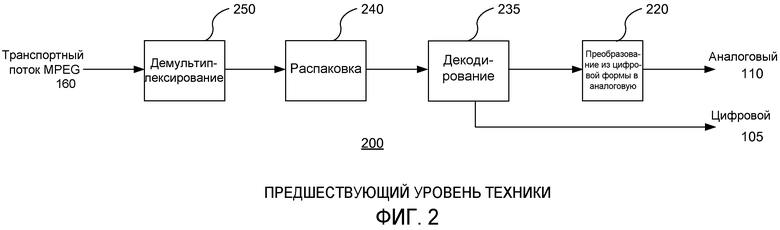
На фиг.2 показана функциональная схема части аналогового или цифрового одноканального устройства декодирования, соответствующего предшествующему уровню техники.
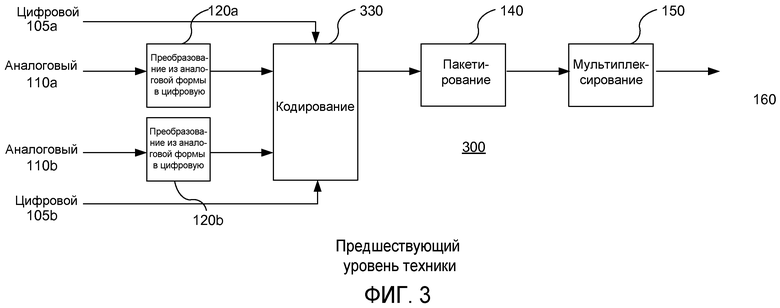
На фиг.3 показана функциональная схема части аналогового или цифрового стерео- или двойного одноканального устройства кодирования, соответствующего предшествующему уровню техники.
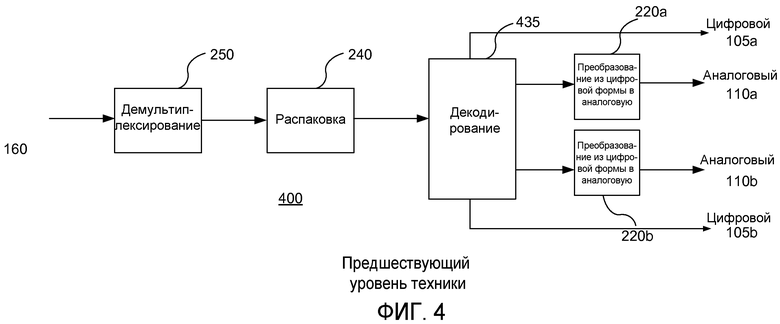
На фиг.4 показана функциональная схема части аналогового или цифрового стерео- или двойного одноканального устройства декодирования, соответствующего предшествующему уровню техники.
На фиг.5 показана блок-схема последовательности операций части кодирования в способе формирования выровненного многоканального аудиосигнала, согласно осуществлению данного изобретения.
На фиг.6 показана блок-схема последовательности операций части декодирования в способе формирования выровненного многоканального аудиосигнала, согласно осуществлению данного изобретения.
На фиг.7 показана функциональная схема части многоканального аналогового или цифрового устройства кодирования, согласно осуществлению данного изобретения.
На фиг.8 показана функциональная схема части многоканального аналогового или цифрового устройства декодирования, согласно осуществлению данного изобретения.
Осуществление изобретения
Осуществление изобретения далее описывается со ссылками на чертежи, на которых одинаковые элементы или этапы обозначаются одними и теми же ссылочными номерами.
Нижеизложенное основано на стандарте MPEG-2. Однако является очевидным, что суть изобретения в равной степени применима к другим стандартам сжатия аудиосигнала, поддерживающим двойное/монокодирование, такое как формат усовершенствованного кодирования аудиосигнала (AAC) или цифровой формат Dolby Digital.
Стандарты MPEG-1 и MPEG-2 описывают средства кодирования и пакетирования цифровых аудиосигналов. Обработанные аудиоданные передаются на системный уровень (ISO/IEC 13818-1) стандарта MPEG для дальнейшего включения их в транспортный поток (TS) перед передачей их по сетям связи, таким как системы связи или трансляционные системы. Данные правила пакетирования стандарта MPEG определяют структуру предоставления синтаксиса потокам двоичных сигналов. В частности, потоки двоичных сигналов содержат временные метки, которые используются декодером для управления синхронизацией декодированного и восстановленного выходного аудиосигнала. Данные временные метки используются для точной синхронизации как аудио, так и видеокомпонентов.
В стандартах MPEG определены два типа временных меток - временная метка декодера (DTS), определяющая, когда полученные кодированные данные должны быть представлены декодеру, и временные метки представления (PTS), определяющие, когда декодированные аудио- или видеосигналы должны быть выданы системой для прослушивания или просмотра соответственно. Указанный последний тип временной метки используется наиболее часто.
Благодаря управлению этими временными метками, как это описано ниже более подробно, аудиовизуальная система передачи, соответствующая осуществлению настоящего изобретения, обеспечивает представление нескольких отдельных аудиосигналов многоканального множества для кодирования или декодирования в одно и то же время, обеспечивая, таким образом, необходимую синхронизацию между каналами многоканального множества.
На фиг.1 показана функциональная схема части аналогового или цифрового одноканального устройства кодирования, соответствующая предшествующему уровню развития техники, иллюстрирующая процесс кодирования систематизированного потока аудиоданных, например, стандарта MPEG-2. Процесс декодирования является обратным по отношению к процессу кодирования и показан на фиг.2.
Во всех примерах обозначены двойные аналоговые 110 и цифровые 105 входы, при этом аналоговые входные сигналы проходят через аналогово-цифровой (A/D) преобразователь 120 для преобразования в цифровую форму перед подачей их на кодер 130. Цифровой аудиосигнал 105 вводится в кодер 130 непосредственно. Отдельные каналы обозначены метками a-d. Однако представляется очевидным, что настоящее изобретение не ограничено мощностью множества каналов и является полностью масштабируемым, а входной аудиосигнал может быть только аналоговым, только цифровым, либо представлен в двойном формате, как это показано.
Если входной сигнал представлен в аналоговой форме, то производится дискретизация аналогового звука, например, по алгоритму линейной импульсно-кодовой модуляции ИКМ (PCM), до подачи его на кодер 130, где он преобразуется к представлению в битовой форме.
Кодер 130 выдает множественные закодированные цифровые потоки двоичных сигналов, по одному для каждого отдельного аудиоканала, в функцию 140 пакетирования, которая осуществляет упаковку аудиоданных в аудиовыборки. Определенные группы аудиовыборок собираются и связываются в кодированной области в блоки битов, называемые «модулями доступа». Каждый модуль доступа представляет собой упакованную часть аудиоданных, например кадр из 1152 аудиовыборок.
Затем отдельные упакованные каналы мультиплексируются вместе мультиплексором 150 для того, чтобы сформировать транспортный поток 160.
Устройство декодирования, показанное на фиг.2, является, по существу, обратным по отношению к устройству, реализующему процесс кодирования. Транспортный поток 160 демультиплексируется демультиплексором 250, который формирует отдельные упакованные аудиоканалы, для распаковки функцией 240 распаковки, перед этапом декодирования их декодером 235, и осуществляется вывод либо в виде прямого цифрового потока 105, либо путем преобразования посредством цифроаналогового преобразователя 220 в аналоговую форму 110.
На фиг.3 и 4 показано устройство кодирования и декодирования для вариантов двойного моно- или синхронизированного стерео. Множественные стерео или двойные монопары могут быть добавлены в систему, но эти пары не будут сопряжены вместе, поскольку в технических требованиях стандарта MPEG это не предусмотрено в явном виде (за исключением вариантов объемного звука, для которых характерны проблемы, описанные в разделе «предшествующий уровень техники»), и, таким образом, они остаются отдельными объектами с отдельными временными метками, при этом восстановление каждого из них на выходе декодера производится независимо.
Несколько независимых аудиоканалов, например дорожки звукового сопровождения на различных языках, могут быть включены в любой данный транспортный поток, при этом каждый из них будет закодирован отдельно.
Существует ряд различных сочетаний между входными аудиогруппами и их закодированными копиями, в зависимости от требуемого количества каналов, критериев качества и выбора системным оператором распределения скорости передачи информации по каждому каналу. Нормальный режим работы заключается в том, что эти аудиоканалы закодированы независимо, и нет никаких специальных требований для связи их между собой.
Некоторые из этих каналов могут быть связаны с сопровождающим их видеосигналом (то есть представлять собой аудиосопровождение видео- или телевизионного изображения), и система должна выровнять эти аудиосигналы относительно соответствующих видеосигналов, используя временные метки, которые являются общими для видео и аудиопотоков. Выравнивание аудиосигнала в данном случае не очень точно, оно только должно быть достаточным для синхронизации с артикуляцией губ. Данный уровень выравнивания не настолько точен, как это требуется для многоканального объемного звука.
Поэтому считается нормальным, что каждый независимый монофонический, двойной монофонический аудиосигнал или стереопара (см. фиг.3) имеет отдельный ресурс (т.е. элементарный поток) в рамках мультиплексированного выходного потока, и, таким образом, каждый из них имеет свою собственную временную метку, независимо сформированную устройством кодирования на этапе пакетирования, и используемую независимо в декодере.
Другими словами, предлагаемое решение по устранению недостатков предшествующего уровня развития техники, описанных выше, состоит в адаптации нормальных форматов передачи стандарта MPEG-2, используемых для стандартного монофонического канала или двух стереоканалов, путем использования средств управления синхронизацией, предусмотренных для этих случаев, и распространения их на данный многоканальный вариант. Таким образом, декодеры, согласно осуществлениям данного изобретения, могут обеспечить точное выравнивание множественных аудиоканалов, что решает проблему синхронизации и позволяет избежать конкатенации в системе кодирования и сопутствующего ухудшения качества.
Решение является полностью совместимым с существующим синтаксисом стандарта MPEG-2, и поэтому соответствующие нормальные декодеры смогут обеспечить многоканальное аудио с временными соотношениями предшествующего уровня техники, а способ обеспечивает повторяемость в системах с конкатенацией без ухудшения качества, хотя и уступает степени точности выравнивания декодера, соответствующего осуществлению данного изобретения.
Более подробно, в предлагаемом многоканальном способе синхронизации несколько входных аудиосигналов, подлежащих обработке отдельным и синхронным способом, обрабатываются при помощи тех же самых средств управления синхронизацией таким образом, чтобы те же самые временные метки назначались в синтаксической структуре передачи таким образом, чтобы декодер также поддерживал процесс выравнивания.
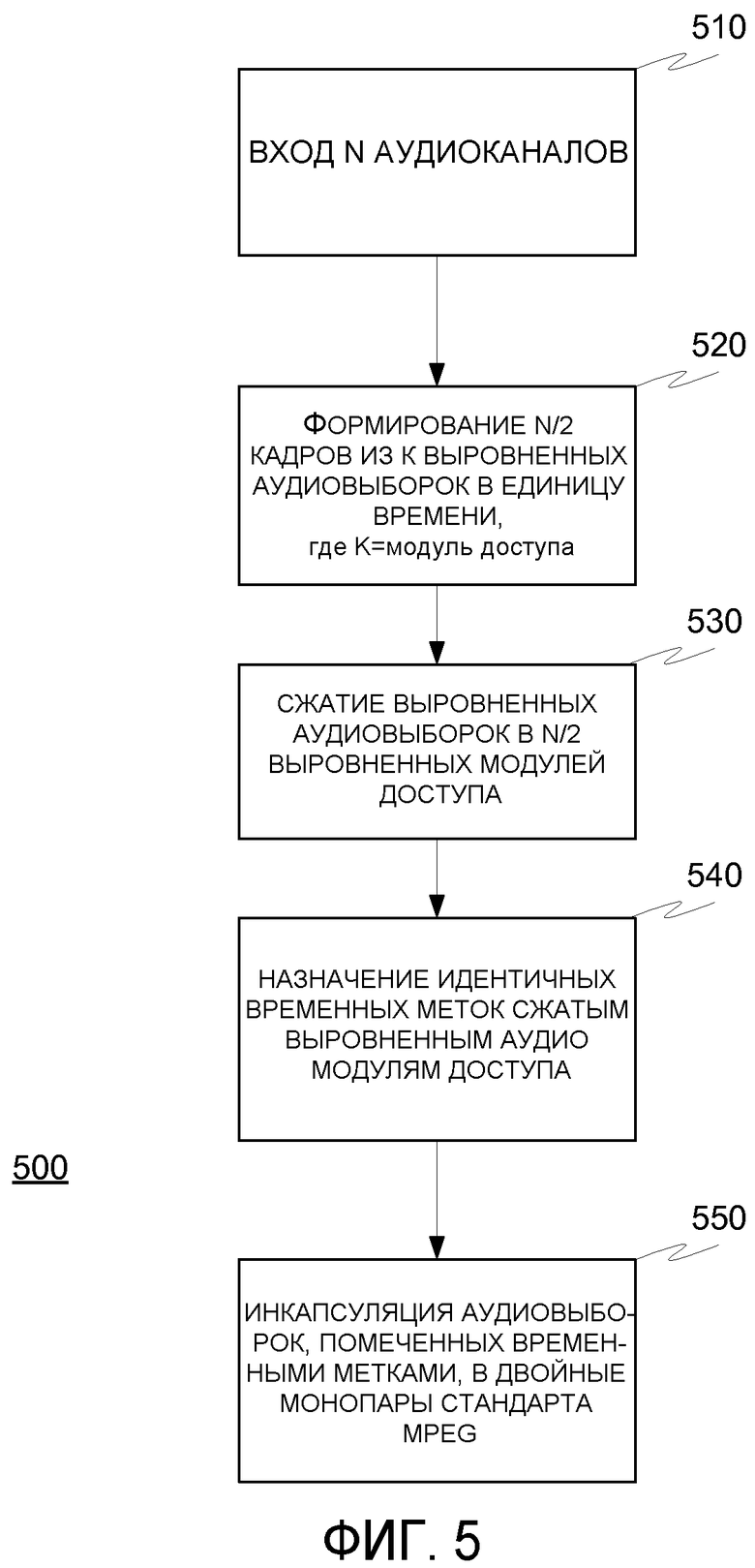
На фиг.5 показана часть способа 500 кодирования, согласно осуществлению настоящего изобретения.
На этапе 510 предопределенное число (N) независимых аудиоканалов, которые должны быть синхронизированы и транспортированы по единственному транспортному потоку, без преобразования в единый компонент, вводятся в устройство кодирования. Устройство кодирования формирует К выровненных аудиовыборок в единицу времени, беря по одной выборке от каждого входного аудиоканала, где выборки соответствуют одному и тому же моменту времени.
Устройство кодирования формирует N/2 кадров из К выровненных аудиовыборок в единицу времени (этап 520), где каждый кадр соответствует тому же самому исходному моменту времени, однако для индивидуальных аудиоканалов, подготовленных к сжатию с использованием выбранного метода сжатия на этапе 530, для того чтобы сформировать модули доступа, обычно используется двойное-моно аудиосжатие для каждой пары аудиоканалов.
Сжатым кадрам (т.е. модулям доступа) аудиовыборок затем назначают идентичные временные метки, обычно в форме поля заголовка, на этапе 540.
Сжатые кадры с временными метками аудиовыборок инкапсулируются (т.е. упаковываются) в пакеты элементарного потока (PES), содержащие двойные монопары соответствующего используемого стандарта, например стандарта MPEG-2, на этапе 550. Остальная часть процесса кодирования такая же, как в обычном случае, то есть пакетированный аудиосигнал упаковывается для передачи и мультиплексируется с любым видеосигналом (если применимо) и другими каналами в выходной транспортный поток 160.
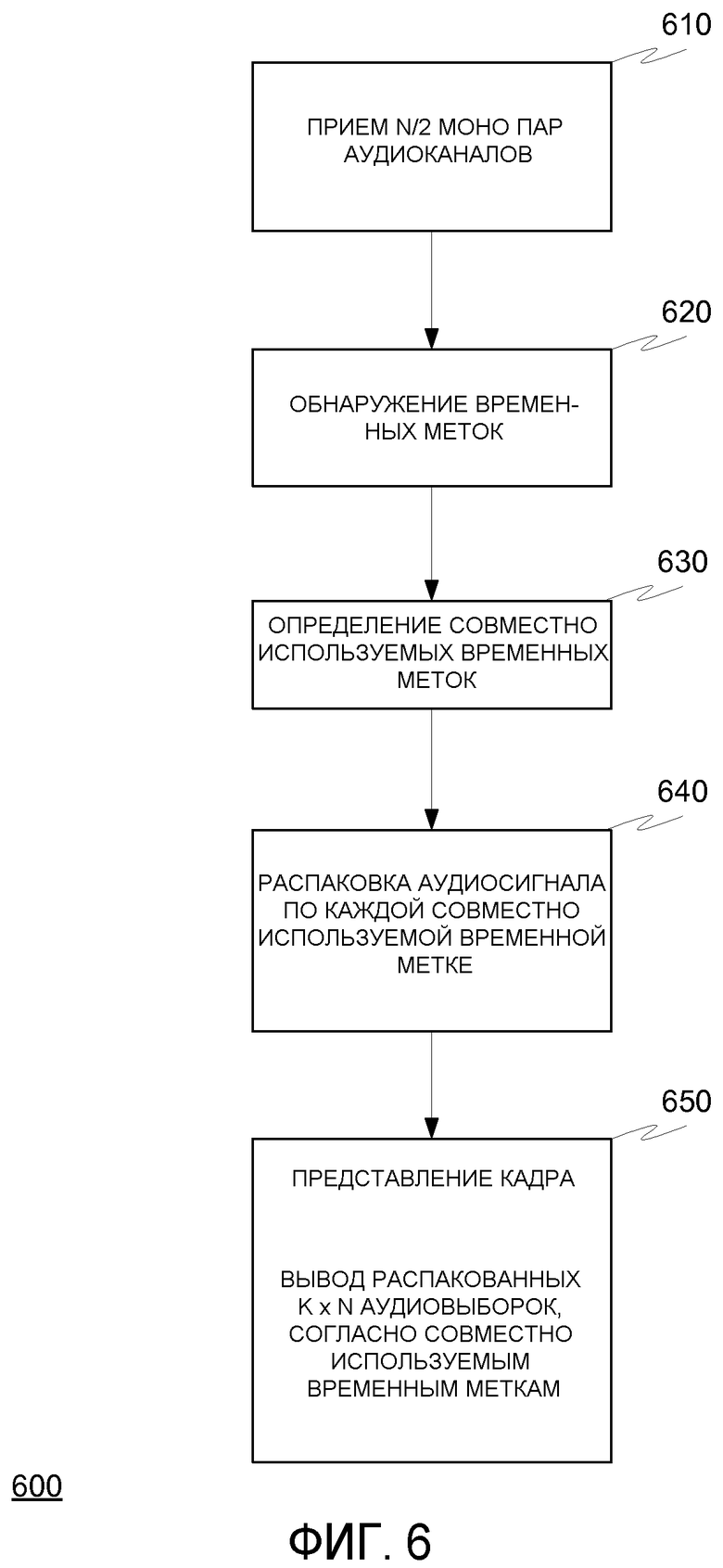
На фиг.6 показан обратный процесс декодирования, согласно осуществлению настоящего изобретения.
В частности, способ декодирования содержит прием N/2 пар моно аудиоканалов 610, обнаружение временных меток 620, определение, какие пары совместно используют временные метки 630, распаковку их в N модулях доступа моно аудиовыборок, относящихся к тому же самому моменту времени 640 представления, и затем вывод распакованного аудиосигнала для того, чтобы представить N выборок точно в то же самое время, согласно единой общей временной метке 650.
Представляется очевидным, что выравнивание, сжатие и постановка временной метки могут быть выполнены одним аппаратным компонентом устройства кодирования, а обратных им процессов - одним аппаратным компонентом устройства декодирования.
Устройство кодирования для реализации вышеописанного способа кодирования согласно осуществлению настоящего изобретения показано на фиг.7, где можно заметить, что имеется дополнительный этап (т.е. ступень 770 многоканальной синхронизации кадров), заключающийся в выравнивании нескольких аудиосигналов и упорядочении использования общей временной метки между отдельными, но синхронизированными аудиоканалами, на этапе 140 пакетирования.
Способ и устройство предпочтительно функционируют с использованием двойных моноканалов, чтобы осуществить обработку отдельных, но синхронизированных аудиоканалов. Следовательно, представленное на фиг.7 устройство 700 кодирования (и соответствующее ему, представленное на фиг.8, устройство 800 кодирования), показано с отдельным кодером/декодером и устройством пакетирования/распаковки для каждой пары аудиоканалов.
На фиг.7 показан пример синхронизации четырех отдельных аудиоканалов, которые должны быть синхронизированы, при двух типах входных сигналов (аналоговый/цифровой). Аналоговые сигналы проходят через аналого-цифровые преобразователи A/D 120 (a-d) для преобразования их в цифровую форму перед ступенью 770 синхронизации кадров. Цифровые входные сигналы непосредственно поступают на ступень 770 синхронизации кадров.
В ступени 770 синхронизации кадров создаются блоки совмещенных по времени аудиовыборок из всех аудиоканалов и осуществляется их маркировка для того, чтобы обработать вместе с идентичными временными метками для всех других аудиовыборок, совмещенных по времени. Обычно формируется сигнал синхронизации временной метки 780, который передается на ступень 140 пакетирования для дальнейшей обработки.
Тем временем, аудиовыборки поступают в ступень 730 стандартного кодирования в качестве позиционированных кадров двойных дискретизированных монопар, сформированных в ступени 770 синхронизации кадров, который, в свою очередь, обеспечивает доставку закодированных аудиовыборок в ступени 140 пакетирования, где они упаковываются в соответствии с сигналом синхронизации временной метки 780, поступающим из ступени 770 синхронизации кадров.
В предпочтительном варианте осуществления изобретения используются отсортированные по размеру блоки выборок модулей доступа, и связанные временные метки представления (PTS) с модулями доступа, принадлежащими парам множественных каналов, сжимаемые с использованием единственного цифрового сигнального процессора, что приводит к формированию множества пакетов PES с идентичными значениями PTS, содержащих сжатый аудиосигнал, точно соответствующий исходным выборкам аудиоданных.
Если количество входных каналов нечетное, а в качестве транспортного механизма используются двойные моноканалы, то один из двойных моноканалов может быть просто заполнен тишиной (нулевым сигналом).
Выходные сигналы каждой из двойных моноцепочек (пары из кодера и функции пакетирования) затем мультиплексируются вместе обычным способом при помощи мультиплексора 150 для того, чтобы сформировать выходной транспортный поток 160.
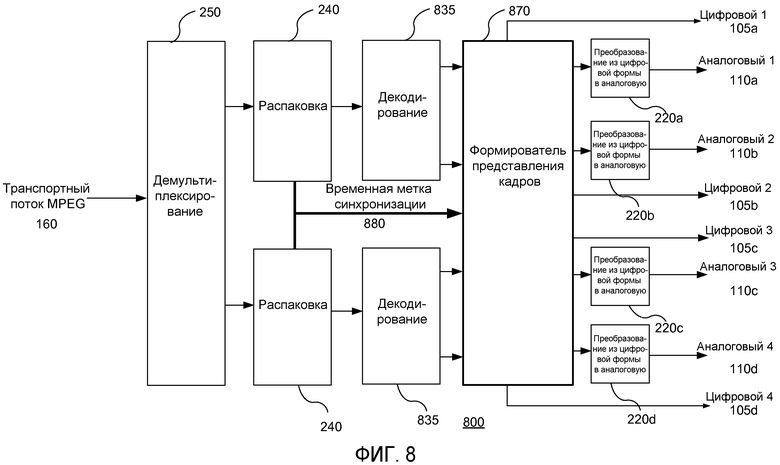
Устройство 800 кодирования, согласно осуществлению данного изобретения, представлено на фиг.8.
При операции декодирования осуществляется восстановление сжатых дискретных модулей доступа аудиоданных, относящихся к множественным двойным моно аудиокомпонентам, путем использования их временных меток представления 835. Кадры декодированных выборок затем представляются в блок 870 представления кадров в идентичные моменты времени, согласно общей временной метке, используемой ими совместно. Таким образом, множественные пары выборок, относящиеся к моментам времени выборок, представляются вместе, следовательно, достигается цель поддержания точного поканального аудиовыравнивания по множественным канальным парам по всей цепочке процессов кодирования/декодирования.
Таким образом, в полной схеме синхронизации нескольких аудиоканалов используются следующие особенности в устройстве кодирования:
- выборки, которые совмещены по времени на входах множественных аудиоканалов, формируются в выровненные кадры аудиовыборок, чтобы соответствовать сжатым размерам модулей доступа.
- Выровненные аудиокадры сжимаются при идентичных конфигурациях аудиокодера, предпочтительно назначая два монофонических канала (в качестве пары) каждому сжатому аудиокомпоненту. Однако стереоканалы или индивидуальные моноканалы могут использоваться как совместно с двойной монопарой, так и вместо нее.
- Сжатым модулям доступа предпочтительно назначаются идентичные значения временных меток представления или временных меток декодера (DTS) с предопределенным временным запаздыванием.
- Сжатые компоненты аудиосигнала передаются как множественные обычные двухканальные сжатые монокомпоненты аудиосигнала в транспортном потоке MPEG-2.
В устройстве декодирования (т.е. в месте приема):
- Множественные сжатые компоненты аудиосигнала декодируются, в результате чего формируются множества (т.е. декодированные каналы) распакованных кадров аудиовыборок, имеющих идентичные временные метки по каналам для любого данного момента времени в соответствующих потоках.
- Распакованные аудиокадры для множественных каналов представляются на выходе с использованием временной метки представления только одного компонента таким образом, что выходные аудиовыборки были совмещены по времени (или в предопределенном периоде времени после меток декодера DTS).
Вышеописанный способ и устройство обеспечивают средства, посредством которых несколько аудиосигналов могут быть переданы по системе связи таким образом, что они остаются синхронизированными, при этом обеспечивается точность синхронизации выборок друг относительно друга. Предшествующие средства обеспечения синхронизации были ограничены стереопарами и кодированием объемного звука, что приводило к ухудшению качества звука при множественной конкатенации результатов стадий кодирования. Настоящий способ и устройство предотвращают ухудшение качества, характерное для систем предшествующего уровня развития техники, и устраняют необходимость дальнейшего усложнения, а иногда и разработки специальных технических решений из области объемного звука.
Поэтому варианты осуществления настоящего изобретения обеспечивают средства для «необработанного» многоканального аудиосигнала (т.е. еще не микшированного в форму объемного звука), чтобы передать его посредством того же самого транспортного потока, как и видеосигнал, к которому он относится, при этом степень ухудшения качества аудиосигнала, обусловленного конкатенациями и иными факторами, характерными для известных ранее способов передачи, уменьшается. Благодаря данному изобретению также отпадает необходимость обработки объемного звука с потерей информации до его передачи, либо использования очень широкой полосы пропускания при алгоритме линейной ИКМ (PCM) без сжатия.
Настоящее изобретение особенно хорошо подходит для передачи видеосигнала студийного качества, при которой используется многоканальный аудиосигнал без преобразования его в единственный компонент (например, версия 5.1 системы объемного звука). Однако представляется очевидным, что осуществления настоящего изобретения могут быть в равной степени применены только к транспортным потокам аудиосигналов, таким как многоканальные аудиосигналы, передаваемые по радио, или им подобным.
Настоящее изобретение особенно выгодно в тех системах, где сжатый аудиосигнал передается в другое местоположение, с целью преобразования его в объемный звук. Это объясняется тем, что при использовании таких сжатых источников при объемном микшировании несовмещение сжатых аудиовыборок может вызвать погрешности сжатия, которые, в свою очередь, могут привести к нежелательным ухудшениям качества при заключительном объемном аудиомикшировании.
Согласно варианту осуществления настоящего изобретения, его примерная реализация должна включать в себя устройство кодирования на одном конце линии связи и устройство декодирования - на другом. Реализации таких системных пар могут быть повторены на многих каналах связи, если это потребуется.
Вышеописанный способ может быть выполнен любыми адаптированными или специально разработанными аппаратными средствами. Части данного способа могут также быть осуществлены во множестве команд, хранящемся в машиночитаемом носителе, которые при загрузке и выполнении в компьютере, цифровом сигнальном процессоре (DSP) или в аналогичном им устройстве побуждают компьютер выполнять вышеописанный способ.
В равной мере данный способ может быть реализован как посредством специального программного обеспечения, так и при помощи разработанного аппаратного обеспечения, интегральной микросхемы, реализующей этот способ для аудиоданных, загружаемых в данную интегральную микросхему. Интегральная микросхема может представлять собой часть универсальной ЭВМ, такой как персональный компьютер и т.п., либо она может быть сформирована как часть гораздо более специализированного устройства, такого как игровая консоль, мобильный телефон, переносной компьютер или аппаратный аудио/видеокодер/декодер.
Один из примерных аппаратных вариантов осуществления изобретения представляет собой программируемую вентильную матрицу (FPGA), запрограммированную для выполнения описанного способа и/или реализации описанного устройства, причем матрица FPGA размещается на дочерней плате в составе устанавливаемого в приборную стойку видеосервера, находящегося в информационном центре, для использования, например, в телевизионной системе IPTV, и/или в Телевизионной студии, или в автофургоне новостной съемочной бригады.
Другой примерный аппаратный вариант осуществления настоящего изобретения представляет аудио- и видеопередатчик, содержащий пару передатчика и приемника, где передатчик содержит устройство кодирования, а приемник содержит устройство декодирования, где каждое кодирующее устройство реализовано в виде специализированной интегральной микросхемы (ASIC).
Специалисту в данной области техники будет ясно, что точный порядок следования и алгоритм этапов, выполняемых при описанном здесь способе, могут быть изменены, согласно требованиям определенного набора выполняемых параметров, таких как скорость кодирования и т.п. Кроме того, является очевидным, что различные варианты осуществления раскрытого здесь устройства могут выборочно осуществлять определенные функции настоящего изобретения в различных комбинациях, согласно требованиям специфической реализации данного изобретения в целом. Соответственно с этим нумерация, используемая в формуле изобретения, не должна рассматриваться как строго заданная, она позволяет перемещать функции по пунктам формулы изобретения, и такие части зависимых пунктов формулы изобретения могут быть использованы произвольным образом.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| ПРЕОБРАЗОВАНИЕ ФОРМАТА АУДИОФАЙЛА | 2004 |
|
RU2335022C2 |
| ДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ МУЛЬТИМЕДИЙНОГО СИГНАЛА И КОДЕР ДЛЯ КОДИРОВАНИЯ ВТОРИЧНЫХ МУЛЬТИМЕДИЙНЫХ ДАННЫХ, СОДЕРЖАЩИХ МЕТАДАННЫЕ ИЛИ УПРАВЛЯЮЩИЕ ДАННЫЕ ДЛЯ ПЕРВИЧНЫХ МУЛЬТИМЕДИЙНЫХ ДАННЫХ | 2015 |
|
RU2679379C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ SAOC ОБЪЕМНОГО (3D) АУДИОКОНТЕНТА | 2014 |
|
RU2666239C2 |
| СПОСОБ И КОДЕР И ДЕКОДЕР ДЛЯ ВОСПРОИЗВЕДЕНИЯ БЕЗ ПРОМЕЖУТКА АУДИО СИГНАЛА | 2011 |
|
RU2546602C2 |
| МНОГОКАНАЛЬНЫЙ АУДИОКОДЕК БЕЗ ПОТЕРЬ, КОТОРЫЙ ИСПОЛЬЗУЕТ АДАПТИВНУЮ СЕГМЕНТАЦИЮ С ВОЗМОЖНОСТЯМИ ТОЧЕК ПРОИЗВОЛЬНОГО ДОСТУПА (RAP) И МНОЖЕСТВА НАБОРОВ ПАРАМЕТРОВ ПРЕДСКАЗАНИЯ (MPPS) | 2009 |
|
RU2495502C2 |
| МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР БЕЗ ПОТЕРЬ | 2005 |
|
RU2387023C2 |
| КОДЕР, ДЕКОДЕР И СПОСОБЫ ДЛЯ ОБРАТНО СОВМЕСТИМОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ С ПЕРЕМЕННЫМ РАЗРЕШЕНИЕМ | 2013 |
|
RU2669079C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИООБЪЕКТОВ | 2012 |
|
RU2618383C2 |
Изобретение относится к средствам кодирования и декодирования аудиоданных и включения их в цифровой транспортный поток данных. Технический результат заключается в повышении качества звука за счет точного выравнивания каналов аудиоданных относительно друг друга по времени. Принимают на входе кодера множества совмещенных по времени аудиосигналов. Дискретизируют сигналы, совмещенные по времени, чтобы сформировать выровненные кадры аудиоданных предопределенного размера. Назначают идентичные временные метки в единицу времени всем из множества совмещенных аудиосигналов. Включают помеченные таким образом аудиосигналы в цифровой транспортный поток данных. 7 н.з. и 8 з.п. ф-лы, 8 ил.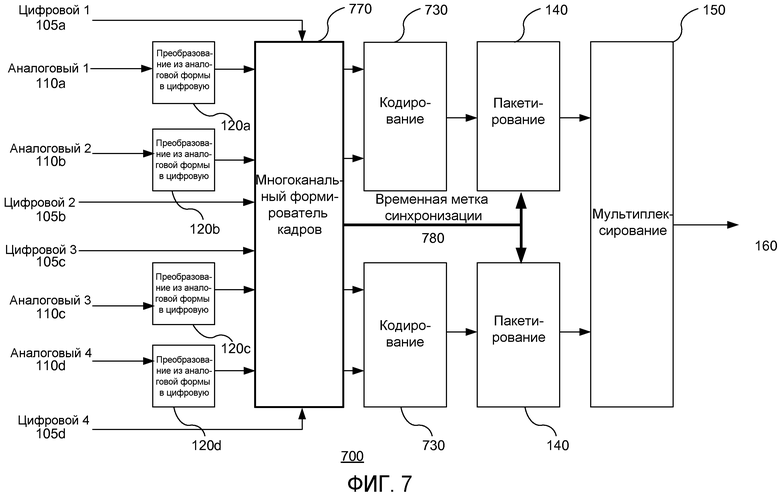
1. Способ кодирования аудио и включения упомянутого кодированного аудио в цифровой транспортный поток, включающий в себя:
прием на входе кодера множества аудиосигналов, совмещенных по времени;
дискретизацию аудиосигналов, совмещенных по времени, чтобы сформировать выровненные кадры аудиоданных предопределенного размера;
назначение идентичных временных меток в каждой единице времени выровненным кадрам аудиоданных; и
включение аудиосигналов, идентично помеченных временными метками, в цифровой транспортный поток.
2. Способ по п.1, дополнительно включающий в себя:
сжатие выровненных кадров аудиоданных с идентичными настройками конфигурации аудиокодера перед назначением временных меток; и
распределение сжатых и идентично помеченных временными метками аудиоданных множеству моноканалов транспортного потока.
3. Способ по п.2, в котором множество моноканалов содержит один или несколько обычных двойных моно аудиокомпонентов.
4. Способ по любому из пп.1-3, в котором предопределенный размер представляет собой размер модуля доступа в стандарте MPEG, а транспортный поток видеоинформации представляет собой транспортный поток MPEG-1 или MPEG-2.
5. Способ по п.1, в котором временные метки являются временными метками представления.
6. Способ по п.1, в котором этап включения аудиоданных в цифровой видеопоток содержит:
мультиплексирование сжатых и идентично помеченных временными метками аудиоданных в цифровой транспортный поток.
7. Способ декодирования цифрового транспортного потока, включающий в себя:
прием цифрового транспортного потока, включающего в себя кодированное аудио;
получение, из транспортного потока, кадров аудиовыборок, представляющих множество индивидуальных аудиоканалов,
совмещенных по времени;
обнаружение временных меток для каждого кадра, чтобы определить кадры, помеченные идентичными временными метками, и
представление кадров, помеченных идентичными временными метками, в идентичные моменты времени, посредством использования временной метки только одного из совмещенных по времени аудиосигналов.
8. Способ по п.7, в котором кодированное аудио было дискретизовано и выровнено, чтобы сформировать выровненные кадры аудиоданных, причем идентичные временные метки были применены к выровненным кадрам аудиоданных.
9. Способ по п.8, в котором выровненные кадры аудиоданных были сжаты перед назначением временных меток, и способ дополнительно содержит:
восстановление сжатых кадров аудиоданных, чтобы сформировать
индивидуальные аудиосигналы для представления.
10. Способ по любому из пп.7-9, в котором цифровой транспортный поток представляет собой цифровой видео транспортный поток, а выровненные кадры аудиоданных содержат пакеты пакетированного элементарного потока (PES).
11. Кодер для кодирования аудио и включения упомянутого кодированного аудио в цифровой транспортный поток, причем кодер выполнен с возможностью:
приема на входе кодера множества аудиосигналов, совмещенных по времени;
дискретизации аудиосигналов, совмещенных по времени, чтобы сформировать выровненные кадры аудиоданных предопределенного размера;
назначения идентичных временных меток в каждой единице времени выровненным кадрам аудиоданных и
включения аудиосигналов, идентично помеченных временными метками, в цифровой транспортный поток.
12. Декодер для декодирования цифрового транспортного потока, выполненный с возможностью:
приема цифрового транспортного потока, включающего в себя кодированное аудио;
получение, из транспортного потока, кадров аудиовыборок, представляющих множество индивидуальных аудиоканалов,
совмещенных по времени;
обнаружение временных меток для каждого кадра, чтобы определить кадры, помеченные идентичными временными метками, и
представление кадров, помеченных идентичными временными метками, в идентичные моменты времени, посредством использования временной метки только одного из совмещенных по времени аудиосигналов.
13. Цифровая транспортная система, содержащая по меньшей мере один кодер и по меньшей мере одни декодер, причем кодер выполнен с возможностью:
приема на входе кодера множества аудиосигналов, совмещенных по времени;
дискретизации аудиосигналов, совмещенных по времени, чтобы сформировать выровненные кадры аудиоданных предопределенного размера;
назначения идентичных временных меток в каждой единице времени выровненным кадрам аудиоданных и
включения аудиосигналов, идентично помеченных временными метками, в цифровой транспортный поток;
при этом декодер выполнен с возможностью:
приема цифрового транспортного потока, включающего в себя кодированное аудио;
получение, из транспортного потока, кадров аудиовыборок, представляющих множество индивидуальных аудиоканалов,
совмещенных по времени;
обнаружение временных меток для каждого кадра, чтобы определить кадры, помеченные идентичными временными метками, и
представление кадров, помеченных идентичными временными метками, в идентичные моменты времени, посредством использования временной метки только одного из совмещенных по времени аудиосигналов.
14. Машиночитаемый носитель, содержащий инструкции, которые при их выполнении побуждают компьютерную логику выполнять способ кодирования аудио и включения упомянутого кодированного аудио в цифровой транспортный поток по любому из пп.1-6.
15. Машиночитаемый носитель, содержащий инструкции, которые при их выполнении побуждают компьютерную логику выполнять способ декодирования цифрового транспортного потока по любому из пп.7-10.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| EP 1403854 A1, 31.03.2004 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СИНХРОНИЗИРУЮЩЕЕ УСТРОЙСТВО ДЛЯ ПРИЕМНИКА СЖАТОГО СИГНАЛА ЗВУКА И ИЗОБРАЖЕНИЯ | 2000 |
|
RU2262211C2 |

