Область техники, к которой относится изобретение
Изобретение относится к системе и способу для обработки звука и, в частности, но не исключительно, к повышающему микшированию стереосигнала в трехканальный сигнал.
Уровень техники
Традиционно, большой объем аудиоконтента обеспечивается в виде стереоконтента. Такой стереоконтент может содержать различные источники сигнала, имеющие очень разные пространственные характеристики. Например, для стереомузыкального контента, желаемое пространственное воспроизведение вокала и инструментов аранжировки может быть очень разным. Обычно вокалист должен восприниматься хорошо пространственно локализованным, тогда как инструменты аранжировки могут предпочтительно восприниматься более рассеянно для обеспечения широкой звуковой картины.
В последние годы, воспроизведение многоканального звука с более чем двумя каналами приобретает все большую популярность и все более широкое распространение. Соответственно, стереоконтент может все шире воспроизводиться с использованием систем многоканального воспроизведения, например, с использованием систем окружающего звука.
Соответственно, были предложены способы и процессы для апмиксинга стереосигнала в многоканальный сигнал с более чем двумя каналами. Пример такой системы раскрыт в патентной публикации США US20090198356A1. Системы наподобие раскрытой в US20090198356A1, осуществляют разделение сигнала на первичный сигнал и сигнал внешнего звука путем выделения главных компонентов сигнала из принятого сигнала. Таким образом, подобные системы пригодны для идентификации преобладающих сигналов где-либо в звуковой картине с последующим их выделением. Этот подход не позволяет обеспечить оптимальное слушательское восприятие во всех сценариях. Например, для некоторого контента он позволяет выделять преобладающие сигналы, которые, однако, не идеально воспринимаются как четко пространственно определенные звуковые объекты, но, вместо этого, принимают участие в обеспечении восприятия широкой стереозвуковой картины. Кроме того, подход может приводить к тому, что компоненты сигнала, которые лучше всего подходят для восприятия как четко пространственно определенные, могут не быть таковыми. Например, для стереосигнала, содержащего источник голоса, который не является преобладающим источником звука, голосовой сигнал может воспроизводиться как более рассеянный звук, тогда как источник преобладающего сигнала, который, например, является частью внешнего звукового окружения, может воспроизводиться более четко пространственно определенное.
Кроме того, такие подходы часто могут приводить к некоторым пространственным искажениям, вносимым обработкой, в результате чего источники звука пространственно смещаются или размываются. В действительности, систему воспроизведения можно адаптировать для воспроизведения преобладающих или главных компонентов сигнала в идентифицированных положениях в звуковой картине. Однако система воспроизведения может не быть идеальной для воспроизведения таких положений и, таким образом, может демонстрировать частично оптимальные показатели.
Таким образом, повышающее микширование на основе такого анализа преобладающего или главного сигнала часто может приводить к внесению пространственных искажений или нарушений. В результате, пространственная звуковая картина, представляемая системой многоканального воспроизведения, может отличаться от той, которая была первоначально задумана автором оригинального стереосигнала.
Следовательно, имела бы преимущество усовершенствованная система обработки и, в частности, имела бы преимущество система, обеспечивающая повышенную гибкость, сниженную сложность, улучшенное пространственное восприятие, усовершенствованный пространственное повышающее микширование и/или более высокие показатели. В частности, имела бы преимущество система обработки, обеспечивающая повышающее микширование стереосигнала с улучшенным поддержанием пространственных характеристик стереосигнала.
Сущность изобретения
Соответственно, задачей изобретения является, предпочтительно, нивелировать, ослаблять или устранять один или более из вышеупомянутых недостатков по отдельности или в любой комбинации.
Согласно аспекту изобретения, предусмотрена система обработки звука, содержащая: приемник для приема стереосигнала; блок сегментации для разделения стереосигнала на частотно-временные сегменты стереосигнала; блок разложения, выполненный с возможностью разложения частотно-временных сегментов стереосигнала, для каждой пары частотно-временных сегментов стереосигнала, посредством: определения меры подобия, указывающей степень подобия пары частотно-временных сегментов стереосигнала; генерации частотно-временного сегмента суммарного сигнала как суммы пары частотно-временных сегментов стереосигнала; генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала в соответствии с мерой подобия; генерации пары боковых частотно-временных сегментов стереосигнала из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия; и генератор сигнала для генерации многоканального сигнала, содержащего центральный сигнал, генерируемый из центральных частотно-временных сегментов сигнала, и боковые сигналы, генерируемые из боковых частотно-временных сегментов стереосигнала.
Изобретение может обеспечивать улучшенное повышающее микширование стереосигнала и, в частности, может обеспечивать улучшенную пространственную характеристику сигнала, микшированного с повышением. Во многих сценариях изобретение может обеспечивать генерацию сигнала, микшированного с повышением, пространственные характеристики которого более точно соответствуют пространственным характеристикам стереосигнала. В частности, положения источников звука могут быть ближе к положениям источников звука в стереосигнале, предусмотренным автором стереосигнала.
Изобретение может обеспечивать эффективную реализацию и допускает автоматическую адаптацию к характеристикам сигнала. В частности, изобретение может обеспечивать гибкое разложение стереосигнала на три канала, включая центральный сигнал.
Подход, в частности, предусматривает выделение источников звука, расположенных в центре, вместо выделения преобладающих источников звука, которые могут находиться в разных позициях в звуковой картине. Благодаря тому, что повышающее микширование базируется на фиксированном пространственном рассмотрении, а не на оценивании преобладающих или главных компонентов сигнала, достигается улучшенное пространственное согласование. В частности, изобретение позволяет гарантировать, что центральный канал, микшированный с повышением, содержит только компоненты сигнала, которые также располагаются в центре в оригинальной стереозвуковой картине.
Каждый частотно-временной сегмент сигнала может содержать одну (обычно комплексную) выборку. Каждый частотно-временной сегмент сигнала может соответствовать выборке частотной области во временном сегменте. Стереоканал может составлять часть многоканального сигнала, например, левого и правого фронтального канала сигнала окружающего звука. Устройство обработки звука может быть выполнено с возможностью генерации повышающего микширования, содержащего дополнительные сигналы помимо центрального сигнала и боковых сигналов. Например, устройство обработки звука может быть выполнено с возможностью повышающего микширования стереосигнала в сигнал окружающего звука, содержащий, например, несколько тыловых или боковых каналов окружающего звука помимо центрального и боковых каналов. Дополнительные каналы могут генерироваться в соответствии с мерой подобия или вне зависимости от нее.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью генерации центрального частотно-временного сегмента сигнала посредством масштабирования частотно-временного сегмента суммарного сигнала, причем масштабирование зависит от меры подобия.
Это может обеспечивать улучшенное повышающее микширование во многих сценариях. В частности, это может обеспечивать улучшенное разложение. Подход может обеспечивать низкую сложность при высоком качестве разложения и повышающего микширования.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью генерации пары боковых частотно-временных сегментов стереосигнала посредством масштабирования пары частотно-временных сегментов стереосигнала, причем масштабирование зависит от меры подобия.
Это может обеспечивать улучшенное повышающее микширование во многих сценариях. В частности, это может обеспечивать улучшенное разложение.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью определения меры подобия в соответствии со значением корреляции для пары частотно-временных сегментов стереосигнала.
Это может обеспечивать особенно пригодную меру подобия и может приводить к повышенным показателям и качеству звучания сигнала, микшированного с повышением. Значение корреляции может быть усредненным значением корреляции, причем усреднение производится по времени и/или частоте.
Значение корреляции может представлять собой значение, зависящее от разности амплитуд и разности фаз в паре частотно-временных сегментов стереосигнала.
В частности, значение корреляции может определяться как действительная или мнимая часть комплексного значения корреляции, которое, например, может определяться путем умножения одного сегмента пары частотно-временных сегментов стереосигнала на комплексно сопряженное значение другого сегмента пары частотно-временных сегментов стереосигнала.
Такой подход, во многих сценариях, может обеспечивать улучшенную меру подобия, приводящую к улучшенному повышающему микшированию и качеству звучания.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью определения меры подобия в соответствии со значением корреляции для пары частотно-временных сегментов стереосигнала относительно меры мощности, по меньшей мере, одного из пары частотно-временных сегментов стереосигнала.
Это может обеспечивать улучшенное повышающее микширование во многих сценариях. В частности, это может обеспечивать улучшенное разложение и/или качество звучания. Подход может, например, обеспечивать повышенную независимость абсолютных уровней.
В некоторых вариантах осуществления можно добиться конкретных преимущественных показателей путем определения меры подобия в соответствии со значением корреляции для пары частотно-временных сегментов стереосигнала относительно мер мощности обоих из пары частотно-временных сегментов стереосигнала. Меры мощности могут представлять собой усредненные меры мощности, например, во временной или частотной области (или обеих).
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью определения меры подобия в соответствии с мерой мощности для одного из пары частотно-временных сегментов стереосигнала относительно меры мощности для другого из пары частотно-временных сегментов стереосигнала.
Это может обеспечивать улучшенное повышающее микширование во многих сценариях. В частности, это может обеспечивать улучшенное разложение и/или качество звучания.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью определения меры подобия в соответствии с разностью уровней в паре частотно-временных сегментов стереосигнала.
Это может обеспечивать улучшенное повышающее микширование во многих сценариях. В частности, это может обеспечивать улучшенное разложение и/или качество звучания.
В соответствии с необязательным признаком изобретения, блок разложения выполнен с возможностью генерации центрального частотно-временного сегмента сигнала и пары боковых частотно-временных сегментов стереосигнала в качестве результирующего вектора матричного умножения вектора, содержащего пару частотно-временных сегментов стереосигнала, причем, по меньшей мере, некоторые коэффициенты матричного умножения зависят от меры подобия.
Это может обеспечивать высокие показатели при поддержании низкой сложности.
В соответствии с необязательным признаком изобретения, система обработки звука дополнительно содержит блок воспроизведения для воспроизведения многоканального сигнала, в котором воспроизведение центрального сигнала отличается от воспроизведения боковых сигналов.
Изобретение может обеспечивать улучшенное воспроизведение, адаптированное к конкретным характеристикам разных частей звуковой картины.
Блок воспроизведения выполнен с возможностью применения стереорасширения к многоканальному сигналу, причем степень стереорасширения, применяемого к центральному сигналу, меньше, чем степень стереорасширения, применяемого к боковым сигналам.
Это может обеспечивать улучшенное воспроизведение и может, во многих вариантах осуществления, обеспечивать улучшенное пространственное восприятие.
В соответствии с необязательным признаком изобретения, приемник выполнен с возможностью генерации центральных частотно-временных сегментов сигнала только для частотного интервала стереосигнала, причем частотный интервал является только частью полосы стереосигнала.
Это может снижать сложность, одновременно поддерживая качество звучания. Частотный интервал может соответствовать, например, типичной полосе частот аудио- или голосового сигнала. Например, во многих вариантах осуществления, частота нижних 3 дБ интервала может находиться в интервале [100 Гц; 400 Гц] и частота более высоких 3 дБ интервала может находиться в интервале [2 кГц; 6 кГц].
В соответствии с необязательным признаком изобретения, система обработки звука дополнительно содержит детектор голоса, выполненный с возможностью генерации оценки присутствия голоса для центрального сигнала; причем блок разложения дополнительно выполнен с возможностью генерации центрального сигнала в соответствии с оценкой присутствия голоса.
Это может обеспечивать повышенные показатели и улучшенное восприятие звука во многих вариантах осуществления.
Согласно аспекту изобретения предусмотрен способ системы обработки звука, содержащий этапы, на которых: принимают стереосигнал; делят стереосигнал на частотно-временные сегменты стереосигнала; разлагают частотно-временные сегменты стереосигнала, для каждой пары частотно-временных сегментов стереосигнала, посредством: определения меры подобия, указывающей степень подобия пары частотно-временных сегментов стереосигнала; генерации частотно-временного сегмента суммарного сигнала, как суммы пары частотно-временных сегментов стереосигнала; генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала в соответствии с мерой подобия; генерации пары боковых частотно-временных сегментов стереосигнала из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия; и генерации многоканального сигнала, содержащего центральный сигнал, генерируемый из центральных частотно-временных сегментов сигнала, и боковые сигналы, генерируемые из боковых частотно-временных сегментов стереосигнала.
Эти и другие аспекты, признаки и преимущества изобретения явствуют из и поясняются со ссылкой на описанные ниже вариант(ы) осуществления.
Краткое описание чертежей
Варианты осуществления изобретения будут описаны исключительно в порядке примера, со ссылкой на чертежи, в которых
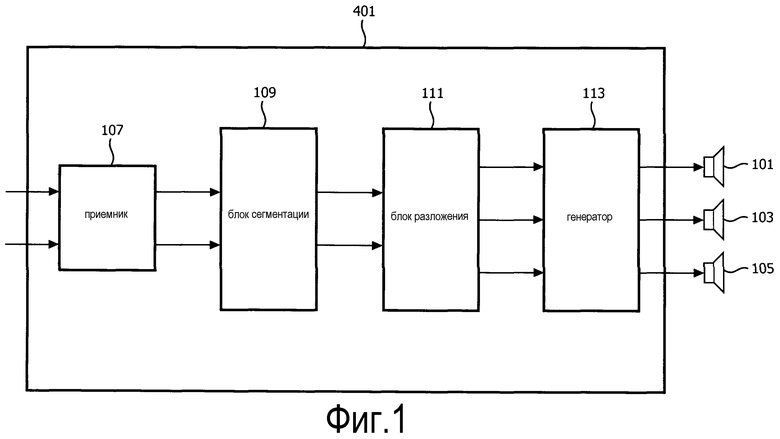
фиг. 1 иллюстрирует пример системы воспроизведения звука в соответствии с некоторыми вариантами осуществления изобретения;
фиг. 2 иллюстрирует пример гистограммы позиций источников звука для выборки музыкальных файлов;
фиг. 3 иллюстрирует пример блока разложения сигнала для системы воспроизведения звука в соответствии с некоторыми вариантами осуществления изобретения; и
фиг. 4 иллюстрирует пример системы воспроизведения звука в соответствии с некоторыми вариантами осуществления изобретения.
Подробное описание некоторых вариантов осуществления изобретения
Фиг. 1 иллюстрирует пример системы воспроизведения звука в соответствии с некоторыми вариантами осуществления изобретения. Система воспроизведения звука принимает стереосигнал и осуществляет его повышающее микширование в трехканальный сигнал, который затем воспроизводится из трех разных громкоговорителей 101, 103, 105.
Подход повышающего микширования, во многих сценариях, может обеспечивать повышенное качество, поскольку он позволяет обеспечивать адаптацию воспроизведения компонентов сигнала к их конкретным характеристикам. Например, центральный громкоговоритель может выделяться и воспроизводиться из центрально расположенного громкоговорителя 103, тогда как компоненты сигнала внешнего звука воспроизводятся из громкоговорителей 101, 105, расположенных перед позицией прослушивания.
В примере, показанном на фиг. 1, повышающее микширование осуществляется путем разложения стереосигнала на центральный сигнал и стереосигнал. Разложение основано на частотно-временных сегментах сигнала и для каждой пары сегментов стереосигнала мера подобия используется для оценивания, насколько центрально располагается соответствующий компонент сигнала в стереозвуковой картине. Частотно-временной сегмент сигнала соответствует представлению сигнала в данных интервале времени и частотном интервале. Обычно частотно-временной сегмент сигнала соответствует (комплексной) частотной выборке, генерируемой для данного временного сегмента. Таким образом, каждый частотно-временной сегмент сигнала может быть значением бита FFT, генерируемого путем применения FFT к соответствующему сегменту. В дальнейшем, термин «частотно-временной элемент» будет использоваться в отношении комбинация интервала времени и частотного интервала, т.е. позиция в частотно-временной области. Таким образом, термин «элемент» означает позицию, тогда как термин «сегмент сигнал» означает значение(я) сигнала.
Затем генерируемая пара сегментов стереосигнала распределяется на центральный канал и боковые каналы в зависимости от меры подобия. Подход не предполагает оценивания позиций преобладающих компонентов сигнала или осуществления разделения на первичные и остаточные (или внешние) сигналы, но предусматривает выделение центрально расположенного источника звука в зависимости от преобладания центрально расположенного источника звука для конкретного частотно-временного элемента сегмента.
Таким образом, система, показанная на фиг. 1, использует способ обработки сигнала, где стереоконтент разлагается на три новых сигнала, причем один сигнал, в основном, содержит преобладающий центральный источник, например, обычно, певца в музыке, и два других сигнала соответствуют (возможно, улучшенному) стереосигналу, который не содержит преобладающий центральный источник, или где уровень этого источника значительно ослаблен. Затем сигнал центрального источника можно воспроизводить с использованием подходящего способа, который может обеспечивать чистую хорошо позиционированную центральную картину, тогда как более рассеянное и менее центральное воспроизведение используется для других сигналов. В частности, алгоритм пространственного расширения можно применять к результирующему стереосигналу.
Система призвана разделять источник звука, расположенный в центре или очень близко от центра сигнала как целого. Кроме того, разделение является динамическим адаптивным разделением, которое автоматически регулируется, чтобы отражать характеристики сигнала и, в частности, чтобы отражать, на самом деле ли такой преобладающий сигнал присутствует в центральной пространственной позиции.
Одно из преимуществ использования центрального выделения вместо разделения на первичные/преобладающие и остаточные сигналы состоит в том, что оно позволяет системе поддерживать пространственную организацию и конфигурацию оригинального стереосигнала.
Кроме того, для многих практических применений, разумно предположить, что преобладающие источники располагаются в центре. На самом деле, для подавляющего большинства музыкальных записей существует преобладающий источник, панорамированный в точности в центральную позицию. Например, фиг. 2 иллюстрирует пример гистограммы направлений панорамирования для центральной области спектра вокала приблизительно в 1400 песнях разных музыкальных жанров. Как показано, преобладающий контент обычно панорамируется в центр пространственной картины.
Система воспроизведения звука, показанная на фиг. 1, содержит приемник 107, который принимает стереосигнал. Стереосигнал может приниматься от любого подходящего внутреннего или внешнего источника и может составлять часть многоканального сигнала, например, сигнала окружающего звука. Например, стереосигнал может быть образован фронтальными боковыми каналами сигнала окружающего звука.
Приемник 107 подключен к блоку 109 сегментации, который делит стереосигнал на частотно-временные сегменты стереосигнала. В частности, каждый из двух стереосигналов делится на выборки сигнала, соответствующие конкретному частотному интервалу в конкретном интервале времени.
В частности, входные стереосигналы делятся на временные сегменты, и сигнал в каждом временном сегменте преобразуется в частотную область для генерации частотно-временных сегментов сигнала.
В частности, два стереосигнала сегментируются на временные сегменты путем применения вырезающей функции в перекрывающихся коротких временных сегментах, например, с использованием вырезающей функции Хенинга. Затем, в каждом временном сегменте, быстрое преобразование Фурье (FFT) применяется для генерации представления сегмента в частотной области. Таким образом, получаются частотно-временные сегменты сигнала и, в частности, каждый частотно-временной сегмент сигнала содержит одну выборку (для каждого канала, т.е. частотно-временной сегмент стереосигнала будет содержать одну выборку для каждого канала). Генерируемые частотно-временные сегменты сигнала можно представить спектральными векторами 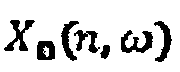 и
и 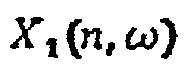 , соответствующими двум входным сигналам вырезанного сегмента
, соответствующими двум входным сигналам вырезанного сегмента 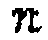 и частотной переменной
и частотной переменной  . Для удобства обозначения перейдем к матричному представлению, где
. Для удобства обозначения перейдем к матричному представлению, где
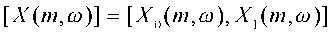 .
.
Таким образом, блок 109 сегментации делит входной стереосигнал на частотно-временные сегменты стереосигнала. Затем эти частотно-временные сегменты стереосигнала поступают на блок 111 разложения, подключенный к блоку 109 сегментации.
Блок 111 разложения выполнен с возможностью разложения входного частотно-временного сегмента стереосигнала на центральный частотно-временной сегмент сигнала и два боковых частотно-временных сегмента стереосигнала. В частности, для каждой пары выборок стереосигнала (соответствующих частотно-временному сегменту стереосигнала), блок 111 разложения генерирует одну выборку, которая соответствует центрально расположенному источнику звука, а также пару выборок, соответствующих результирующему стереосигналу после компенсации выделения центрального источника.
Центральный частотно-временной сегмент сигнала, в частности, генерируется из суммы частотно-временных сегментов сигнала для двух каналов стереосигнала и, таким образом, представляет компонент сигнала, который является общим в двух каналах, соответствующих центральной пространственной позиции. Таким образом, блок 111 разложения не разлагает стереосигнал на первичный или преобладающий сигнал и сигнал внешнего звука, но вместо этого разлагает стереосигнал на центральный компонент и боковой компонент сигнала.
Блок 111 разложения подключен к генератору 113 сигнала, который принимает частотно-временные сегменты суммарного сигнала и объединяет их в центральный сигнал. Кроме того, генератор 113 сигнала принимает боковые частотно-временные сегменты стереосигнала и объединяет их в два боковых сигнала. Затем центральный сигнал и два боковых сигнала могут поступать на центральный громкоговоритель 103, и два боковых громкоговорителя 101, 105 соответственно. Генератор 113 сигнала может, в частности, сопоставлять надлежащие частотно-временные сегменты сигнала в каждом временном сегменте и осуществлять обратное FFT, известное в технике.
Подход, таким образом, предусматривает разложение входного стереосигнала на сигнал, соответствующий центральной позиции в звуковой картине входного сигнала, и два боковых сигнала, соответствующие боковым позициям. Разложение осуществляется в частотно-временных элементах, где распределение входного стереосигнала по разным каналам, для каждого частотно-временного элемента, зависит от меры подобия для входных стереоканалов в частотно-временном элементе.
Фиг. 3 более подробно иллюстрирует блок 111 разложения, показанный на фиг. 1. Пары и частотно-временных сегментов стереосигнала поступают на процессор 301 подобия, который выполнен с возможностью генерации меры подобия для каждой пары частотно-временных сегментов сигнала. Мера подобия указывает степень подобия между частотно-временными элементами пары частотно-временных сегментов сигнала, т.е. насколько близки сигналы в этом временном и частотном интервале. Мера подобия может быть усредненной мерой подобия, например, за счет того, что сама мера усредняется по времени и/или частоте или за счет того, что одно или более значений, используемых при вычислении меры, усредняются по времени и/или частоте. Таким образом, подобие для одного частотно-временного элемента можно определять из усреднения по множеству частотно-временных элементов во временной и/или частотной области.
Кроме того, пары и частотно-временных сегментов стереосигнала поступают на процессор 303 суммирования, который выполнен с возможностью генерации частотно-временного сегмента суммарного сигнала, как суммы частотно-временных сегментов стереосигнала. Таким образом, для каждого частотно-временного элемента, частотно-временной сегмент суммарного сигнала генерируется суммированием двух сегментов пары частотно-временных сегментов стереосигнала этого частотно-временного элемента. Поскольку суммарный сегмент генерируется путем фиксированного невзвешенного суммирования, он представляет центральную позицию в пространственном сегменте и, таким образом, суммарный сигнал можно рассматривать как вклад частотно-временного элемента в источник звука в центре картины.
Кроме того, пары и частотно-временных сегментов стереосигнала поступают на процессор 305 повышающего микширования, который, помимо прочего, подключен к процессору 303 суммирования и процессору 301 подобия. Процессор 305 повышающего микширования выполнен с возможностью генерации трех выходных частотно-временных сегментов сигнала из двух входных частотно-временных сегментов и сигнала и частотно-временного сегмента суммарного сигнала. В частности, центральный частотно-временной сегмент сигнала генерируется из частотно-временного сегмента суммарного сигнала в соответствии с мерой подобия. В частности, чем выше мера подобия, тем больший вес присваивается суммарному сигналу, и, таким образом, тем выше амплитуда результирующего центрального частотно-временного сегмента сигнала. Аналогично, пара боковых частотно-временных сегментов стереосигнала генерируется из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия. В частности, чем ниже мера подобия, тем больший вес присваивается частотно-временному сегменту стереосигнала, и, таким образом, тем выше амплитуда результирующего бокового частотно-временного сегмента сигнала. Таким образом, блок 205 повышающего микширования выполнен с возможностью генерации первого бокового частотно-временного сегмента сигнала из первого из частотно-временных сегментов стереосигнала путем его взвешивания в зависимости от меры подобия, генерации второго бокового частотно-временного сегмента сигнала из второго из частотно-временных сегментов стереосигнала путем его взвешивания в зависимости от меры подобия, и генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала путем его взвешивания в зависимости от меры подобия.
В примере, взвешивание сегментов сигнала осуществляется путем их масштабирования низкой сложности, где значение масштабирования зависит от меры подобия. В примере, блок 111 разложения выполнен, в частности, с возможностью генерации центрального частотно-временного сегмента сигнала и пары боковых частотно-временных сегментов стереосигнала в качестве результирующего вектора матричного умножения вектора, содержащего пару частотно-временных сегментов стереосигнала с коэффициентами матричного умножения, зависящими от меры подобия. Кроме того, генерация суммарного сигнала реализуется как часть этой матричной операции (например, процессор 303 суммирования и процессор 305 повышающего микширования, показанные на фиг. 2, можно рассматривать как единое устройство).
Таким образом, блок 111 разложения может реализовать отображение двух входных частотно-временных сегментов сигнала
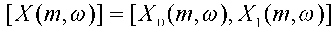
В выходной вектор Y(n,ω), содержащий три частотно-временных сегментов сигнала, а именно, центральный частотно-временной сегмент сигнала и два боковых частотно-временных сегмента сигнала согласно матричной операции:

где матрица 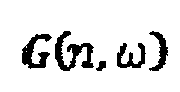 повышающего микширования задана в виде
повышающего микширования задана в виде

где g(n,ω) представляет меру подобия с диапазоном [0,1], где 1 указывает, что два входных частотно-временных сегмента стереосигнала равны между собой, и 0 указывает, что два входных частотно-временных сегмента стереосигнала существенно отличаются, независимы или не коррелируют между собой.
Таким образом, когда значение меры подобия близко к единице, сигнал, представленный с частотным индексом 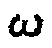 , т.е. пара входных частотно-временных сегментов стереосигнала маршрутизируется в центральный сигнал в качестве суммарного сигнала, и если оно близко к нулю, два стереосигнала маршрутизируются непосредственно в два боковых выходных сигнала.
, т.е. пара входных частотно-временных сегментов стереосигнала маршрутизируется в центральный сигнал в качестве суммарного сигнала, и если оно близко к нулю, два стереосигнала маршрутизируются непосредственно в два боковых выходных сигнала.
Таким образом, система, показанная на фиг. 1, выделяет из звуковой картины компонент сигнала в центральном пространственном положении и генерирует его как отдельный канал, который затем может воспроизводиться независимо. Кроме того, боковые каналы генерируются, когда этот сигнал источника в центральной позиции удален (или, по меньшей мере, ослаблен). Кроме того, разложение адаптировано так, что оно, в каждом частотно-временном элементе, зависит от преобладания центральной пространственной позиции относительно других позиций. В результате, выделенный центральный сигнал не является просто звуковым сигналом, который располагается в центре, но, напротив, является конкретным значимым источником звука, находящимся в центральной позиции. Таким образом, подход может приводить к выделению единичного центрального источника звука, в то время как фоновые источники звука более низкого уровня, расположенные в центре, могут оставаться в боковых каналах. Например, система может позволять выделять центральный голос, одновременно позволяя, например, высоко- или низкочастотному фоновому шуму оставаться в боковых каналах для обработки совместно с нецентральным фоновым шумом.
Подход выделения центральных источников звука вместо просто преобладающих или главных источников звука гарантирует, что пространственные характеристики генерируемого центрального сигнала точно известны и, таким образом, могут точно воспроизводиться. В частности, центральный сигнал можно воспроизводить непосредственно в центре, например, с помощью отдельного громкоговорителя. Таким образом, система не вносит пространственных изменений и может более точно воспроизводить задуманную авторами звуковую картину с помощью системы многоканального (более 2) воспроизведения.
Подход обеспечивает высоко преимущественные результаты для стереоконтента, где важные источники звука расположены в центре. В частности, для стереоконтента, в котором перцептивно преобладающий звук (например, голос солиста в музыке) панорамируется в точности в центр пространственной картины, достигается особо преимущественное воспроизведение звука. Однако, как указано на фиг. 2, такие ситуации часто возникают на практике.
В разных вариантах осуществления можно использовать разные меры подобия. Например, в некоторых вариантах осуществления, мера подобия может генерироваться как указание или содержать вклад из меры мощности для одного из пары частотно-временных сегментов стереосигнала относительно меры мощности для другого из пары частотно-временных сегментов стереосигнала и/или значения разности уровней для пары частотно-временных сегментов стереосигнала.
Например, можно использовать отношение энергий:
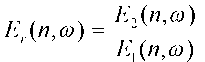
где En обозначает энергии или мощность канала n входного стереосигнала.
В качестве более практического примера, значение подобия может генерироваться из:
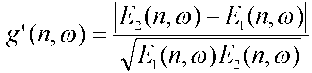
Обычно значение подобия определяется с учетом множества частотно-временных элементов. Таким образом, значение подобия может быть усредненным значением, полученным либо прямым усреднением значения подобия, либо усреднением одного или более значений, используемых для вычисления значения подобия. Усреднение можно проводить по последовательности значений 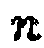 времени, частотных индексов или любым из них.
времени, частотных индексов или любым из них.
В дальнейшем будет описано особенно преимущественное значение подобия, которое основано на значении корреляции для пары частотно-временных сегментов стереосигнала. В конкретном примере, генерируется мера, которая связывает значение корреляции с мерой мощности, по меньшей мере, одного сегмента из пары частотно-временных сегментов стереосигнала. На самом деле, генерируется мера подобия, содержащая вклад из отношения между значением корреляции и мерой мощности одного сегмента из пары частотно-временных сегментов стереосигнала, а также вклад из отношения между значением корреляции и мерой мощности для обоих сегментов пары частотно-временных сегментов стереосигнала. Два вклада могут обеспечивать разные соотношения между разностями уровней и значением подобия, и относительное взвешивание каждого из них может зависеть от конкретных характеристик отдельного варианта осуществления.
В частности, кросс-корреляция между двумя стереосигналами с частотным индексом задается в виде
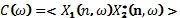
где <.> - математическое ожидание, и звездочка * обозначает комплексное сопряжение.
В конкретных вариантах осуществления, значение математического ожидания генерируется путем усреднения значения корреляции по интервалу времени с использованием интегратора со скользящим интервалом. В частности, можно использовать интегратор первого порядка:
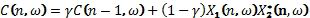
где параметром 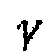 интегрирования является значение, которое обычно выбирается близким к единице (например, 0,8).
интегрирования является значение, которое обычно выбирается близким к единице (например, 0,8).
Кроме того, математическое ожидание мощности/энергии сигнала на частоте 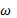 канала M входного стереосигнала задается в виде
канала M входного стереосигнала задается в виде
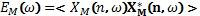
Его также можно вычислять с использованием интегратора со скользящим интервалом, что дает
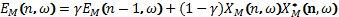 .
.
Значение подобия может генерироваться путем определения значения, необходимого для масштабирования одного сигнала, чтобы он был идентичен другому сигналу. В этом случае, коэффициент усиления можно получить минимизацией следующей функции стоимости
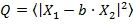
Минимизация Q дает:
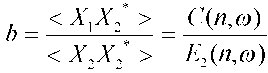
Разность b уровней пригодна для выражения в логарифмической форме. Таким образом, комплекснозначный корреляционный член можно заменить, что обычно делается его абсолютным значением или абсолютным значением действительной части члена.
В результате, значение подобия выражается в виде:
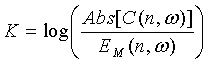
где M представляет один из входных стереоканалов (т.е. M=1 или 2). В некоторых вариантах осуществления, это значение можно определять для обоих каналов, т.е. для M=1 и M=2.
С использованием действительного значения корреляции вместо самой корреляции или абсолютного значения корреляции гарантирует, что значение корреляции также отражает разность фаз между частотно-временными сегментами сигнала.
В ряде случаев, может генерироваться значение подобия, которое связывает значение корреляции с энергией обоих стереосигналов. Например, значение подобия может генерироваться в виде:
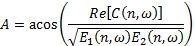
Мера подобия может генерироваться из одного или более этих значений подобия.
В частности, можно вычислить следующее значение подобия:
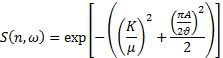
где параметры 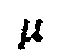 и
и  можно использовать для управления характеристикой разложения взвешиванием разных вкладов значения подобия в обеспечение желаемой характеристики. Обычно подходящие значения для типичного стереофонического аудиоматериала могут составлять около ==0,4. Заметим, что использование гауссовой функции двух переменных является здесь примером функции, которая дает максимальное значение (единица) с определенной(ыми) комбинацией или комбинациями двух мер и меньшее значение (≥0) для всех остальных комбинаций значений. Очевидно, что существуют многие альтернативные функции, обладающие такими же свойствами, и что можно, например, использовать любую такую функцию.
можно использовать для управления характеристикой разложения взвешиванием разных вкладов значения подобия в обеспечение желаемой характеристики. Обычно подходящие значения для типичного стереофонического аудиоматериала могут составлять около ==0,4. Заметим, что использование гауссовой функции двух переменных является здесь примером функции, которая дает максимальное значение (единица) с определенной(ыми) комбинацией или комбинациями двух мер и меньшее значение (≥0) для всех остальных комбинаций значений. Очевидно, что существуют многие альтернативные функции, обладающие такими же свойствами, и что можно, например, использовать любую такую функцию.
Вычисленное значение подобия S(n,ω) близко к единице, когда сигналы схожи, и близко к нулю, когда они отличаются. Таким образом, в некоторых вариантах осуществления, это значение можно непосредственно использовать в качестве меры подобия:
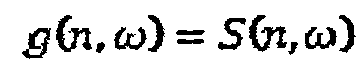 .
.
В некоторых вариантах осуществления, можно предусмотреть дополнительное временное сглаживание значения параметра с использованием, например, интегратор с расползанием, аналогичный тому, который использовался выше для EM(ω).
Подход, таким образом, предусматривает генерацию трех сигналов, микшированных с повышением, из входного стереосигнала. Затем три выходных сигнала можно воспроизводить и, в частности, к центральному сигналу можно применять другое воспроизведение, чем к боковым сигналам.
Например, центральный сигнал может воспроизводиться разными громкоговорителями, как, например, в примере, показанном на фиг. 1. Альтернативно или дополнительно, к центральному сигналу можно применять другую обработку сигнала, чем к боковым сигналам. В частности, стереорасширение можно применять к боковым сигналам, но не к центральному сигналу. Это может приводить к воспроизведению звуковой картины как улучшенной расширенной звуковой картины с одновременным поддержанием восприятия четко пространственно определенного источника звука в центре.
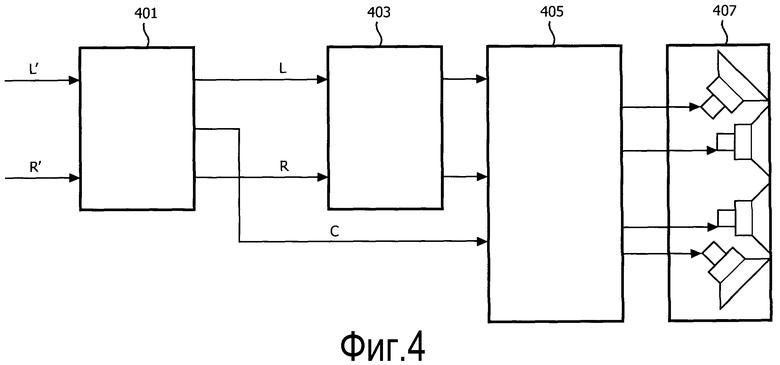
Фиг. 4 иллюстрирует пример системы обработки или воспроизведения звука, в которой для центрального сигнала используется другой поднабор имеющихся громкоговорителей, чем для любых боковых сигналов. Кроме того, система стерео применяет расширение к боковым сигналам, микшированным с повышением, но не к центральному сигналу.
Фиг. 4 иллюстрирует блок 401 повышающего микширования, который реализует обработку сигнала, описанную со ссылкой на фиг. 1, и, таким образом, генерирует центральный сигнал C и два боковых сигнала L, R. Боковые сигналы L, R поступают на блок 403 стереорасширения, который осуществляет стереорасширение. Очевидно, что можно применять любое подходящее стереорасширение, и в технике известны различные алгоритмы для выполнения этой функции. Стереорасширенный сигнал поступает на микшер 405 воспроизведения, который также принимает центральный сигнал. Микшер 405 воспроизведения подключен к набору громкоговорителей 407, который, в данном примере, включает в себя четыре громкоговорителя. Микшер 405 воспроизведения воспроизводит входной сигнал с использованием отдельного поднабора громкоговорителей для каждого сигнала. В частности, левый боковой сигнал и правые боковые сигналы воспроизводятся только с помощью левого и правого громкоговорителя соответственно, тогда как центральный канал воспроизводится всеми громкоговорителями.
Очевидно, что в некоторых вариантах осуществления, центральный сигнал также может претерпевать некоторое пространственное расширение (например, с одним из боковых сигналов). Однако степень расширения в таких сценариях может быть меньше в случае участия центрального сигнала, чем в случае участия только боковых сигналов.
В некоторых вариантах осуществления, описанное повышающее микширование можно применять только к частотному интервалу входного стереосигнала. Например, генерацию центрального сигнала можно осуществлять только в частотном интервале, например, только для полосы аудиосигнала, например, от 200 Гц до 5 кГц. Таким образом, в таких вариантах осуществления, центральные частотно-временные сегменты стереосигнала можно генерировать только посредством описанного процесса в ограниченном частотном интервале, и, соответственно, результирующий центральный сигнал может ограничиваться ограниченным частотным интервалом. Однако во многих вариантах осуществления центральный источник звука можно ограничивать в частотной области, и, таким образом, этот подход может вносить только ограниченное ухудшение, в то же время, достигая существенного снижения необходимого вычислительного ресурса.
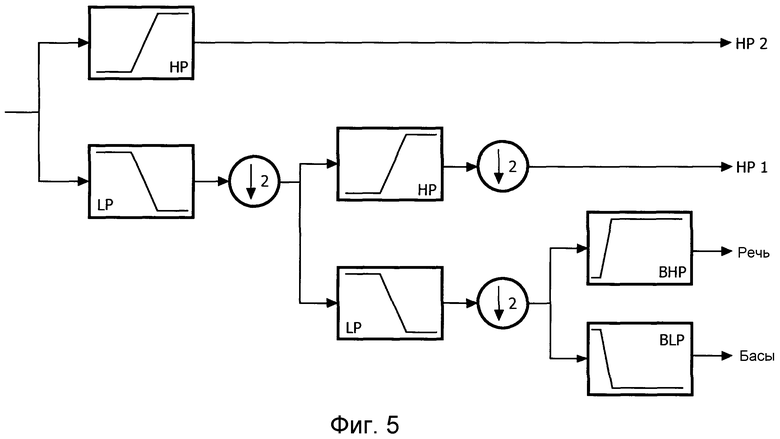
Например, для системы обработки голоса, вычислительную сложность обработки голоса можно значительно сократить, если применять ее только к полосе частот, где в основном сконцентрирована спектральная энергия человеческого голоса. Эта область простирается приблизительно от 150 Гц до 5 кГц. В некоторых вариантах осуществления, частотнозависимая обработка осуществляется путем разложения входного сигнала на три или более поддиапазонов, которые затем подвергаются понижающей дискретизации до номинальной частоты, соответствующей ширине полосы.
Такое разложение на поддиапазоны можно осуществлять, например, на основе архитектуры квадратурного зеркального фильтра, например, проиллюстрированного на фиг. 5. Набор фильтров анализа делит сигнал на три поддиапазона. Соответственно, после обработки, для реконструкции сигнала можно использовать банк фильтров синтеза.
В некоторых вариантах осуществления обработки голоса, система может дополнительно содержать детектор голоса, который генерирует оценку присутствия голоса для центрального сигнала. Эта оценка присутствия голоса может указывать вероятность того, что генерируемый центральный сигнал соответствует голосовому сигналу. Очевидно, что любой подходящий алгоритм для генерации оценки присутствия голоса (или речевой активности) можно использовать без отхода от сущности изобретения, и что специалисту в данной области известны многие подходящие алгоритмы.
В таких вариантах осуществления, система может быть выполнена с возможностью генерации центрального сигнала в соответствии с оценкой присутствия голоса. Это можно делать, например, осуществляя генерацию частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала в зависимости от оценки присутствия голоса. Например, если оценка присутствия голоса указывает, что выделенный в данный момент центральный сигнал не содержит голоса (или маловероятно, что содержит) значение g(n,ω) можно уменьшить, в связи с чем, больше сигнала остается в боковых сигналах, соответствующих оригинальному стереосигналу.
В порядке примера, в некоторых вариантах осуществления алгоритм обнаружения голоса можно использовать для анализа контента в отдельном голосовом центральном канале, и коэффициенты усиления можно регулировать так, чтобы центральный канал отделялся только если выделенный сигнал содержит человеческий голос.
Очевидно, что в вышеприведенном описании для наглядности варианты осуществления изобретения описаны со ссылкой на различные функциональные схемы, блоки и процессоры. Однако очевидно, что любое подходящее распределение функциональных возможностей между разными функциональными схемами, блоками или процессорами можно использовать без отхода от сущности изобретения. Например, функциональные возможности, проиллюстрированные как осуществляемые отдельными процессорами или контроллерами, могут осуществляться одним и тем же процессором или контроллером. Следовательно, ссылки на конкретные функциональные блоки или схемы следует рассматривать только как ссылки на подходящие средства для обеспечения описанных функциональных возможностей, а не указание конкретной логической или физической структуры или организации.
Изобретение можно реализовать в любой подходящей форме, включая аппаратную, программную, программно-аппаратную или любую их комбинацию. Изобретение можно, в необязательном порядке, реализовать, по меньшей мере, частично в виде компьютерного программного обеспечения, выполняющегося на одном или более процессорах данных и/или цифровых сигнальных процессорах. Элементы и компоненты варианта осуществления изобретения можно физически, функционально и логически реализовать любым подходящим способом. На самом деле, функциональные возможности можно реализовать в едином блоке, во множестве блоков или как часть других функциональных блоков. Таким образом, изобретение может быть реализовано в едином блоке или может быть физически и функционально распределено между разными блоками, схемами и процессорами.
Хотя настоящее изобретение описано в связи с некоторыми вариантами осуществления, оно не призвано ограничиваться конкретной представленной здесь формой. Напротив, объем настоящего изобретения ограничен только нижеследующей формулой изобретения. Дополнительно, хотя тот или иной признак может быть описанный в связи с конкретными вариантам осуществления, специалисту в данной области техники очевидно, что различные признаки описанных вариантов осуществления можно комбинировать в соответствии с изобретением. В формуле изобретения, термин «содержащий» не исключает наличия других элементов или этапов.
Кроме того, хотя они перечислены по отдельности, множество средств, элементов, схем или этапов способ можно реализовать, например, с помощью единичной схемы, блока или процессора. Дополнительно, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, их можно преимущественно комбинировать, и включение в разные пункты формулы изобретения не означает, что комбинация признаков не является пригодной и/или преимущественной. Кроме того, включение признака в одну категорию пунктов формулы изобретения не налагает ограничения на эту категорию, но, напротив, указывает, что признак в равной степени применим к другим категориям пунктов формулы изобретения, если таковые присутствуют. Кроме того, порядок признаков в формуле изобретения не предусматривает никакого конкретного порядка, в котором нужно работать с признаками, и, в частности, порядок указания отдельных этапов в пункте способа не подразумевает, что этапы должны осуществляться в этом порядке. Напротив, этапы могут осуществляться в любом подходящем порядке. Кроме того, ссылки в единственном числе не исключают множественности. Таким образом, ссылки на элемент в единственном числе, "первый элемент", "второй элемент" и т.д. не исключают наличия множества таких элементов. Ссылочные позиции в формуле изобретения приведены исключительно в качестве пояснительного примера и не подлежат рассмотрению в порядке какого-либо ограничения объема формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОСТРАНСТВЕННОЕ ВОСПРОИЗВЕДЕНИЕ ЗВУКА | 2011 |
|
RU2559713C2 |
| ФОРМИРОВАНИЕ БИНАУРАЛЬНЫХ СИГНАЛОВ | 2009 |
|
RU2505941C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ РАЗЛОЖЕНИЯ ВХОДНОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ЗАРАНЕЕ ВЫЧИСЛЕННОЙ ЭТАЛОННОЙ КРИВОЙ | 2011 |
|
RU2554552C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ РАЗЛОЖЕНИЯ ВХОДНОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕГО МИКШЕРА | 2011 |
|
RU2555237C2 |
| МАНИПУЛИРОВАНИЕ ЗОНОЙ НАИЛУЧШЕГО ВОСПРИЯТИЯ ДЛЯ МНОГОКАНАЛЬНОГО СИГНАЛА | 2007 |
|
RU2454825C2 |
| СПОСОБ, УСТРОЙСТВО, КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И АУДИОСИСТЕМА | 2005 |
|
RU2396608C2 |
| АУДИОКОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2008 |
|
RU2452043C2 |
| БИНАУРАЛЬНАЯ ВИЗУАЛИЗАЦИЯ МУЛЬТИКАНАЛЬНОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2512124C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ ПОЗИЦИИ МИКРОФОНА | 2014 |
|
RU2635286C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ГЕНЕРАЦИИ БИНАУРАЛЬНОГО АУДИОСИГНАЛА | 2008 |
|
RU2443075C2 |

Изобретение относится к средствам обработки звука. Технический результат заключается в улучшении пространственного восприятия звукового сигнала. Система обработки звука принимает стереосигнал, который с помощью блока сегментации делится на частотно-временные сегменты стереосигнала, каждый из которых может соответствовать выборке частотной области в данном временном сегменте. Блок разложения разлагает частотно-временные сегменты сигнала, для каждой пары частотно-временных сегментов стереосигнала, путем осуществления этапов: определения меры подобия, указывающей степень подобия частотно-временных сегментов стереосигнала; генерации частотно-временного сегмента суммарного сигнала, как суммы частотно-временных сегментов стереосигнала; и генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала и пары боковых частотно-временных сегментов стереосигнала из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия. Затем генератор сигнала генерирует многоканальный сигнал, содержащий центральный сигнал, генерируемый из частотно-временных сегментов суммарного сигнала, и боковые сигналы, генерируемые из боковых частотно-временных сегментов стереосигнала. 2 н. и 12 з.п. ф-лы, 5 ил.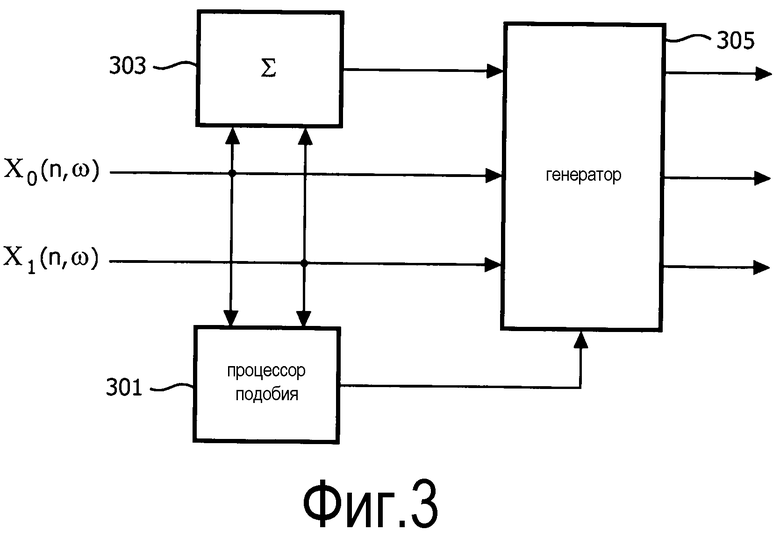
1. Система обработки звука, содержащая
приемник (107) для приема двухканального стереосигнала,
блок (109) сегментации для разделения двухканального стереосигнала на пары частотно-временных сегментов стереосигнала,
блок (111) разложения, выполненный с возможностью разложения частотно-временных сегментов стереосигнала, для каждой пары частотно-временных сегментов стереосигнала, посредством
- определения меры подобия, указывающей степень подобия пары частотно-временных сегментов стереосигнала,
- генерации частотно-временного сегмента суммарного сигнала как суммы пары частотно-временных сегментов стереосигнала, и
- генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала в соответствии с мерой подобия,
- генерации пары боковых частотно-временных сегментов стереосигнала из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия, и
генератор (113) сигнала для генерации многоканального сигнала, содержащего центральный сигнал, генерируемый из центральных частотно-временных сегментов сигнала, и боковые сигналы, генерируемые из боковых частотно-временных сегментов стереосигнала,
блок стереорасширения для применения стереорасширения к многоканальному сигналу, причем степень стереорасширения, применяемого к центральному сигналу, меньше степени стереорасширения, применяемого к боковым сигналам.
2. Система обработки звука по п. 1, в которой блок (111) разложения выполнен с возможностью генерации центрального частотно-временного сегмента сигнала посредством масштабирования частотно-временного сегмента суммарного сигнала, причем масштабирование зависит от меры подобия.
3. Система обработки звука по п. 1, в которой блок (111) разложения выполнен с возможностью генерации пары боковых частотно-временных сегментов стереосигнала посредством масштабирования пары частотно-временных сегментов стереосигнала, причем масштабирование зависит от меры подобия.
4. Система обработки звука по п. 1, в которой блок (111) разложения выполнен с возможностью определения меры подобия в соответствии со значением корреляции для пары частотно-временных сегментов стереосигнала.
5. Система обработки звука по п. 4, в которой значение корреляции представляет собой значение, зависящее от разности амплитуд и разности фаз пары частотно-временных сегментов стереосигнала.
6. Система обработки звука по п. 4, в которой блок (111) разложения выполнен с возможностью определения меры подобия в соответствии со значением корреляции для пары частотно-временных сегментов стереосигнала относительно меры мощности, по меньшей мере, одного из пары частотно-временных сегментов стереосигнала.
7. Система обработки звука по п. 4, в которой блок (111) разложения выполнен с возможностью определения меры подобия в соответствии с мерой мощности для одного из пары частотно-временных сегментов стереосигнала относительно меры мощности для другого из пары частотно-временных сегментов стереосигнала.
8. Система обработки звука по п. 1, в которой блок (111) разложения выполнен с возможностью определения меры подобия в соответствии с разностью уровней в паре частотно-временных сегментов стереосигнала.
9. Система обработки звука по п. 1, в которой блок (111) разложения выполнен с возможностью генерации центрального частотно-временного сегмента сигнала и пары боковых частотно-временных сегментов стереосигнала в качестве результирующего вектора матричного умножения вектора, содержащего пару частотно-временных сегментов стереосигнала, причем, по меньшей мере, некоторые коэффициенты матричного умножения зависят от меры подобия.
10. Система обработки звука по п. 1, дополнительно содержащая блок (403, 405, 407) воспроизведения для воспроизведения многоканального сигнала, в котором воспроизведение центрального сигнала отличается от воспроизведения боковых сигналов.
11. Система обработки звука по п. 10, в которой блок (403, 405, 407) воспроизведения выполнен с возможностью для воспроизведения многоканального сигнала с использованием набора громкоговорителей (407), и поднабор набора громкоговорителей (407), используемых для воспроизведения центрального сигнала, отличается от поднабора набора громкоговорителей (407), используемых для воспроизведения боковых сигналов.
12. Система обработки звука по п. 1, в которой приемник (107) выполнен с возможностью генерации центральных частотно-временных сегментов сигнала только для частотного интервала двухканального стереосигнала, причем частотный интервал является только частью полосы двухканального стереосигнала.
13. Система обработки звука по п. 1, дополнительно содержащая детектор голоса, выполненный с возможностью генерации оценки присутствия голоса для центрального сигнала, причем блок (111) разложения дополнительно выполнен с возможностью генерации центрального сигнала в соответствии с оценкой присутствия голоса.
14. Способ системы обработки звука, содержащий этапы, на которых
принимают двухканальный стереосигнал,
делят двухканальный стереосигнал на пары частотно-временных сегментов стереосигнала,
разлагают частотно-временные сегменты стереосигнала, для каждой пары частотно-временных сегментов стереосигнала, посредством
- определения меры подобия, указывающей степень подобия пары частотно-временных сегментов стереосигнала,
- генерации частотно-временного сегмента суммарного сигнала как суммы пары частотно-временных сегментов стереосигнала,
- генерации центрального частотно-временного сегмента сигнала из частотно-временного сегмента суммарного сигнала в соответствии с мерой подобия, и
- генерации пары боковых частотно-временных сегментов стереосигнала из пары частотно-временных сегментов стереосигнала в соответствии с мерой подобия;
- генерируют многоканальный сигнал, содержащий центральный сигнал, генерируемый из центральных частотно-временных сегментов сигнала, и боковые сигналы, генерируемые из боковых частотно-временных сегментов стереосигнала; и
- применяют стереорасширение к многоканальному сигналу, причем степень стереорасширения, применяемого к центральному сигналу, меньше степени стереорасширения, применяемого к боковым сигналам.
| US 2007041592 A1, 22.02.2007 |

