ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к кодированию видео и, более конкретно, статистическому кодированию для кодирования видео.
УРОВЕНЬ ТЕХНИКИ
[0002] Цифровые возможности видео могут быть встроены в широкий диапазон устройств, включая цифровые телевизоры, цифровые системы прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), ноутбуки или настольные компьютеры, цифровые камеры, цифровые устройства записи, цифровые медиа проигрыватели, видеоигровые устройства, видеоигровые консоли, сотовые или спутниковые радиотелефоны, устройства организации видео телеконференций, и т.п. Цифровые видео устройства реализуют способы сжатия видео, такие как описаны в стандартах, определенных MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное кодирование видео (AVC), или находящий в стадии становления стандарт кодирования видео высокой эффективности (HEVC), и расширения таких стандартов.
[0003] Способы сжатия видео выполняют пространственное предсказание и/или временное предсказание, чтобы уменьшить или удалить избыточность, присущую последовательностям видео. Для основанного на блоках кодирования видео, кадр видео или вырезка могут быть разделены в блоки видео или блоки кодирования (CU). CU может быть далее разделены в один или более блоков предсказания (PU), чтобы определить прогнозирующие данные видео для CU. Способы сжатия видео могут также разделить CU в один или более блоков преобразования (TU) блоков остаточных данных видео, которые представляют разность между блоком видео, который должен быть закодирован, и прогнозирующими данными видео. Линейные преобразования, такие как двумерное дискретное косинусное преобразование (DCT), могут быть применены к TU, чтобы преобразовать блоки остаточных данных видео из пиксельной области в частотную область, чтобы достигнуть дальнейшего сжатия.
[0004] После преобразования коэффициенты преобразования в TU могут быть далее сжаты посредством квантования. После квантования модуль статистического кодирования может применять зигзагообразный просмотр или другой порядок просмотра, ассоциированный с размером TU, чтобы просмотреть двумерное множество коэффициентов в TU, чтобы сформировать преобразованный в последовательную форму вектор, который может быть статистически кодирован. Модуль статистического кодирования затем статистически кодирует преобразованный в последовательную форму вектор коэффициентов. Например, модуль статистического кодирования может выполнить контекстно-адаптивное кодирование с переменной длиной кода (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), или другой способ статистического кодирования. В случае контекстно-адаптивного статистического кодирования модуль статистического кодирования может выбрать контексты для каждого из коэффициентов в TU согласно контекстной модели, ассоциированной с размером TU. Коэффициенты могут затем быть статистически закодированы на основании выбранных контекстов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] В целом настоящее изобретение описывает способы для выполнения статистического кодирования и декодирования коэффициентов преобразования, ассоциированных с блоком остаточных данных видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. Например, объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. В некоторых случаях больше чем два размера блоков преобразования могут совместно использовать одну и ту же объединенную контекстную модель. В качестве одного примера, объединенная контекстная модель может быть объединенной контекстной моделью карты значимости для блока преобразования. В других примерах объединенная контекстная модель может быть ассоциирована с другой информацией кодирования или элементами синтаксиса.
[0006] В находящемся в стадии становления стандарте кодирования видео с высокой эффективностью (HEVC), блок кодирования (CU) может включать в себя один или более блоков преобразования (TU), которые включают в себя остаточные данные видео для преобразования. Дополнительные размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео, но также и привели к увеличенной памяти и вычислительным требованиям для поддержания контекстной модели для каждого из дополнительных размеров блока преобразования. Выполнение статистического кодирования, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, может уменьшить объем памяти, необходимой, чтобы сохранить контексты и вероятности на устройствах кодирования и декодирования видео, и уменьшить вычислительные затраты поддержания контекстных моделей на устройствах кодирования и декодирования видео.
[0007] В некоторых примерах способы могут также уменьшить требования промежуточной буферизации для больших размеров блока преобразования при выполнении двумерных преобразований. В этом случае способы включают в себя обнуление, то есть, установление значений в ноль, поднабора более высокочастотных коэффициентов преобразования, включенных в блок преобразования первого размера после применения каждого направления двумерного преобразования, чтобы сгенерировать блок оставшихся коэффициентов. В этом примере объединенная контекстная модель для статистического кодирования может быть совместно использована между блоком преобразования, имеющим первый размер, с коэффициентами, обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоком преобразования, первоначально имеющим второй размер. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. В других примерах объединенная контекстная модель для статистического кодирования может быть совместно использована между блоком преобразования, имеющим первый размер, и блоком преобразования, имеющим второй размер.
[0008] В одном примере изобретение описывает способ декодирования данных видео, содержащий поддержание объединенной контекстной модели, совместно используемой блоком преобразования, имеющим первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоком преобразования, имеющим второй размер, в котором первый размер и второй размер различны. Способ также включает в себя выбор контекстов для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера с блоком оставшихся коэффициентов и второго размера согласно объединенной контекстной модели, и статистическое кодирование коэффициентов, ассоциированных с блоком преобразования согласно процессу кодирования на основании выбранных контекстов.
[0009] В другом примере изобретение описывает устройство кодирования видео, содержащее память, которая хранит объединенную контекстную модель, совместно используемую блоком преобразования, имеющим первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоком преобразования, имеющим второй размер, при этом первый размер и второй размер различны. Устройство кодирования видео далее включает в себя процессор, конфигурируемый, чтобы поддерживать объединенную контекстную модель, выбирать контексты для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера с блоком оставшихся коэффициентов и второго размера, согласно объединенной контекстной модели, и статистически кодировать коэффициенты, ассоциированные с блоком преобразования, согласно процессу кодирования, на основании выбранных контекстов.
[0010] В другом примере изобретение описывает устройство кодирования видео, содержащее средство для поддержания объединенной контекстной модели, совместно используемой блоком преобразования, имеющим первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоком преобразования, имеющим второй размер, в котором первый размер и второй размер различны. Устройство кодирования видео также содержит средство для выбора контекстов для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера с блоком оставшихся коэффициентов и второго размера согласно объединенной контекстной модели, и средство для статистического кодирования коэффициентов, ассоциированных с этим блоком преобразования, согласно процессу кодирования на основании выбранных контекстов.
[0011] В другом примере изобретение описывает считываемый компьютером носитель, содержащий инструкции для кодирования данных видео, которые, когда выполняются, заставляют процессор поддерживать объединенную контекстную модель, совместно используемую блоком преобразования, имеющим первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоком преобразования, имеющим второй размер, в котором первый размер и второй размер различны. Инструкции также заставляют процессор выбирать контексты для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера с блоком оставшихся коэффициентов и второго размера согласно объединенной контекстной модели, и статистически кодировать коэффициенты, ассоциированные с этим блоком преобразования, согласно процессу кодирования на основании выбранных контекстов.
[0012] В другом примере изобретение описывает способ кодирования данных видео, содержащий поддержание объединенной контекстной модели, совместно используемой блоком преобразования, имеющим первый размер, и блоком преобразования, имеющим второй размер, при этом первый размер и второй размер различны. Способ также включает в себя выбор контекстов для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера и второго размера, согласно объединенной контекстной модели, и статистическое кодирование коэффициентов блока преобразования согласно процессу кодирования на основании выбранных контекстов.
[0013] В дополнительном примере изобретение описывает устройство кодирования видео, содержащее память, которая хранит объединенную контекстную модель, совместно используемую блоком преобразования, имеющим первый размер, и блоком преобразования, имеющим второй размер, в котором первый размер и второй размер различны, и процессор, конфигурируемый, чтобы поддерживать объединенную контекстную модель, выбирать контексты для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера и второго размера согласно объединенной контекстной модели, и статистически кодировать коэффициенты блока преобразования согласно процессу кодирования на основании выбранных контекстов.
[0014] В дальнейшем примере изобретение описывает устройство кодирования видео, содержащее средство для поддержания объединенной контекстной модели, совместно используемой блоком преобразования, имеющим первый размер, и блоком преобразования, имеющим второй размер, при этом первый размер и второй размер различны. Устройство кодирования видео также включает в себя средство для выбора контекстов для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера и второго размера согласно объединенной контекстной модели, и средство для статистического кодирования коэффициентов блока преобразования согласно процессу кодирования на основании выбранных контекстов.
[0015] В другом примере изобретение описывает считываемый компьютером носитель, содержащий инструкции для кодирования данных видео, которые, когда выполняются, заставляют процессор поддерживать объединенную контекстную модель, совместно используемую блоком преобразования, имеющим первый размер, и блоком преобразования, имеющим второй размер, при этом первый размер и второй размер являются различными, выбирать контексты для коэффициентов, ассоциированных с блоком преобразования, имеющим один из первого размера и второго размера согласно объединенной контекстной модели, и статистически кодировать коэффициенты блока преобразования согласно процессу кодирования на основании выбранных контекстов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0016] Фиг. 1 является блок-схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может использовать способы для выполнения статистического кодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры.
[0017] Фиг. 2 является блок-схемой, иллюстрирующей примерный кодер видео, который может реализовать способы для статистического кодирования коэффициентов видео, используя объединенную контекстную модель.
[0018] Фиг. 3A и 3B - концептуальные диаграммы, соответственно иллюстрирующие квадратные и прямоугольные области блоков оставшихся коэффициентов, имеющих второй размер, из блока преобразования, имеющего первый размер.
[0019] Фиг. 4 является блок-схемой, иллюстрирующей примерный декодер видео, который может реализовать способы для статистического декодирования коэффициентов видео, используя объединенную контекстную модель.
[0020] Фиг. 5 является блок-схемой, иллюстрирующей примерный модуль статистического кодирования, конфигурируемый, чтобы выбрать контексты для коэффициентов видео согласно объединенной контекстной модели.
[0021] Фиг. 6 является блок-схемой, иллюстрирующей примерный модуль статистического декодирования, конфигурируемый, чтобы выбрать контексты для коэффициентов видео согласно объединенной контекстной модели.
[0022] Фиг. 7 является последовательностью операций, иллюстрирующей примерную операцию статистического кодирования и статистического декодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между первым блоком преобразования, имеющим первый размер, и вторым блоком преобразования, имеющим второй размер.
[0023] Фиг. 8 является последовательностью операций, иллюстрирующей примерную операцию статистического кодирования и декодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между первым блоком преобразования, имеющим первый размер, с коэффициентами, обнуленными, чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и вторым блоком преобразования, имеющим второй размер.
ПОДРОБНОЕ ОПИСАНИЕ
[0024] В целом это изобретение описывает способы для выполнения статистического кодирования и декодирования коэффициентов преобразования, ассоциированных с блоком остаточных данных видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. Например, объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. В находящемся в стадии становления стандарте кодирования видео с высокой эффективностью (HEVC) блок кодирования (CU) может включать в себя один или более блоков преобразования (TU), которые включают в себя остаточные данные видео. До преобразования остаточные данные видео включают в себя остаточные пиксельные значения в пространственной области. После преобразования остаточные данные видео включают в себя остаточные коэффициенты преобразования в области преобразования. Дополнительные размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео, но также привело к увеличению памяти и вычислительным требованиям, чтобы поддерживать контекстные модели для каждого из дополнительных размеров блока преобразования. Выполнение статистического кодирования, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, может уменьшить объем памяти, необходимой, чтобы сохранить контексты и вероятности на устройствах кодирования и декодирования видео, и уменьшить вычислительные затраты поддержания контекстных моделей на устройствах кодирования и декодирования видео.
[0025] В некоторых примерах способы могут также уменьшить требования промежуточной буферизации для более крупных размеров блоков преобразования при выполнении двумерных преобразований. Способы включают в себя обнуление, то есть, установку значений в ноль, поднабора более высокочастотных коэффициентов преобразования, включенных в блок преобразования первого размера, после того как каждое направление двумерного преобразования было применено, чтобы генерировать блок оставшихся коэффициентов. Устройства кодирования и декодирования видео могут затем буферизовать сокращенное количество коэффициентов между применением каждого направления, то есть, строки и столбцы, двумерного преобразования. Когда более высокочастотные коэффициенты обнулены из блока преобразования, имеющего первый размер, коэффициенты, включенные в блок оставшихся коэффициентов, имеют аналогичную вероятностную статистику, что и коэффициенты, включенные в блок преобразования первоначально второго размера. В этом случае объединенная контекстная модель для статистического кодирования может быть совместно использована между блоками преобразования, имеющими первый размер, с коэффициентами, обнуленными для генерирования блока оставшихся коэффициентов, и блоками преобразования, первоначально имеющими второй размер. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. В других случаях блок оставшихся коэффициентов может иметь размер, равный третьему размеру, отличному и от первого размера и от второго размера.
[0026] В других примерах коэффициенты, включенные в первый блок преобразования, имеющий первый размер, могут иметь подобную статистику вероятности, как и коэффициенты, включенные во второй блок преобразования второго размера даже без обнуления более высокочастотных коэффициентов в пределах первого блока преобразования. Это возможно потому, что более высокочастотные коэффициенты могут представлять такие маленькие остаточные данные видео, что влияние на вероятностную статистику соседних коэффициентов для статистического кодирования незначительно. В этом случае объединенная контекстная модель для статистического кодирования может быть совместно использована между блоками преобразования, имеющими первый размер, и блоками преобразования, имеющими второй размер.
[0027] Фиг. 1 является блок-схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может использовать способы для выполнения статистического кодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. Как показано на Фиг. 1, система 10 включает в себя исходное устройство 12, которое может хранить кодированное видео и/или передавать кодированное видео на устройство-адресат 14 через коммуникационный канал 16. Исходное устройство 12 и устройство-адресат 14 могут не обязательно участвовать в активной связи в реальном времени друг с другом. В некоторых случаях исходное устройство 12 может сохранять кодированные данные видео на носитель данных, к которому устройство-адресат 14 может получить доступ при необходимости с помощью обращения к диску, или может сохранить кодированные данные видео на файл-сервер, к которому устройство-адресат 14 может получить доступ при необходимости с помощью потоковой передачи. Исходное устройство 12 и устройство-адресат 14 могут содержать любое из широкого диапазона устройств. В некоторых случаях исходное устройство 12 и устройство-адресат 14 могут содержать устройства беспроводной связи, которые могут обмениваться информацией видео по коммуникационному каналу 16, когда коммуникационный канал 16 является беспроводным.
[0028] Однако, способы согласно настоящему изобретению, которые касаются статистического кодирования коэффициентов видео, используя объединенную контекстную модель, не обязательно ограничены беспроводными приложениями или параметрами настройки. Например, эти способы могут относиться к эфирному телевизионному вещанию, передачам кабельного телевидения, передачам спутникового телевидения, передачам видео по Интернет, кодированному цифровому видео, которое закодировано на носитель данных, или другим сценариям. Соответственно, коммуникационный канал 16 может содержать любую комбинацию беспроводных или проводных носителей, подходящих для передачи кодированных данных видео, и устройства 12, 14 могут содержать любое из множества устройств с проводными или беспроводными носителями, такими как мобильные телефоны, смартфоны, цифровые медиа-проигрыватели, телевизионные приставки, телевизоры, дисплеи, настольные компьютеры, портативные компьютеры, планшетные компьютеры, игровые консоли, портативные игровые устройства или подобное.
[0029] В примере согласно Фиг. 1 исходное устройство 12 включает в себя источник 18 видео, кодер 20 видео, модулятор/демодулятор (модем) 22 и передатчик 24. Устройство-адресат 14 включает в себя приемник 26, модем 28, декодер 30 видео и устройство 32 отображения. В других примерах исходное устройство и устройство-адресат могут включать в себя другие компоненты или компоновки. Например, исходное устройство 12 может принимать данные видео от внешнего источника 18 видео, такого как внешняя камера, запоминающее устройство видео, источник компьютерной графики или подобное. Аналогично, устройство-адресат 14 может сопрягаться с внешним устройством отображения, вместо включения интегрированного устройства отображения.
[0030] Иллюстрированная система 10 согласно фиг. 1 является просто одним примером. В других примерах любое цифровое устройство кодирования и/или декодирования видео может выполнять раскрытые способы для статистического кодирования коэффициентов видео, используя объединенную контекстную модель. Способы могут быть также выполнены кодером/декодером видео, обычно называемым "кодеком". Кроме того, способы согласно настоящему изобретению могут быть также выполнены препроцессором видео. Исходное устройство 12 и устройство-адресат 14 являются просто примерами таких устройств кодирования, в которых исходное устройство 12 генерирует кодированные данные видео для передачи на устройство-адресат 14. В некоторых примерах устройства 12, 14 могут работать по существу симметричным образом таким образом, что каждое из устройств 12, 14 включают в себя компоненты кодирования и декодирования видео. Следовательно, система 10 может поддерживать однонаправленную или двунаправленную передачу видео между видео устройствами 12, 14, например, для потоковой передачи видео, воспроизведения видео, беспроводного вещания видео или видео телефонии.
[0031] Источник 18 видео из исходного устройства 12 может включать в себя устройство захвата видео, такое как видео камера, видео архив, содержащий ранее захваченное видео, и/или подачу видео от поставщика видео контента. В качестве другой альтернативы, источник 18 видео может генерировать основанные на компьютерной графике данные в качестве исходного видео, или комбинации видео в реальном времени, архивированного видео и генерируемого компьютером видео. В некоторых случаях, если источник 18 видео является видео камерой, исходное устройство 12 и устройство-адресат 14 могут формировать так называемые камерофоны или видео телефоны. Как упомянуто выше, однако, способы, описанные в настоящем изобретении, могут быть применимыми к кодированию видео вообще, и могут быть применены к беспроводным и/или проводным приложениям. В каждом случае захваченное, предварительно захваченное или генерируемое компьютером видео может быть закодировано кодером 20 видео. Закодированная информация видео может затем модулироваться модемом 22 согласно стандарту связи, и передана на устройство-адресат 14 через передатчик 24. Модем 22 может включать в себя различные смесители, фильтры, усилители или другие компоненты, разработанные для модуляции сигнала. Передатчик 24 может включать в себя схемы, разработанные для передачи данных, включая усилители, фильтры и одну или более антенн.
[0032] В соответствии с настоящим изобретением кодер 20 видео из исходного устройства 12 может быть сконфигурирован, чтобы применять способы для статистического кодирования коэффициентов видео, используя объединенную контекстную модель. Блок кодирования (CU) кадра видео, который должен быть закодирован, может включать в себя один или более блоков преобразования (TU), которые включают в себя остаточные данные видео. До преобразования остаточные данные видео включают в себя остаточные пиксельные значения в пространственной области. После преобразования остаточные данные видео включают в себя остаточные коэффициенты преобразования в преобразованной области. Кодер 20 видео может поддерживать объединенную контекстную модель, совместно используемую между блоками преобразования, имеющие различные размеры, и выбирать контексты для коэффициентов, ассоциированных с одним из преобразованных блоков согласно объединенной контекстной модели. Кодер 20 видео может затем статистически кодировать коэффициенты на основании выбранных контекстов.
[0033] В качестве примера объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. В других примерах более чем два размера блоков преобразования могут совместно использовать одну и ту же объединенную контекстную модель. Кроме того, два или более размеров блоков преобразования могут совместно использовать некоторые или все из контекстных моделей для блоков TU. В одном случае объединенная контекстная модель может быть объединенной контекстной моделью карты значимости для TU. В других случаях объединенная контекстная модель может быть ассоциирована с другой информацией кодирования или элементами синтаксиса. Эти способы поэтому могут уменьшить объем памяти, необходимой, чтобы хранить контексты и вероятности на кодере 20 видео и уменьшить вычислительные затраты поддержания контекстных моделей на кодере 20 видео.
[0034] В одном примере кодер 20 видео может обнулять, то есть, устанавливать значения равными нулю, более высокочастотный поднабор коэффициентов преобразования, включенных в блок преобразования первого размера, после того как каждое направление двумерного преобразования применено, чтобы генерировать блок оставшихся коэффициентов. В этом случае способы могут уменьшить количество коэффициентов, которые должны быть буферизованы между применением каждого направления, то есть, строки и столбцы, двумерного преобразования. Когда высокочастотные коэффициенты обнуляются из блока преобразования, коэффициенты, включенные в блок оставшихся коэффициентов, имеют аналогичную вероятностную статистику, что и коэффициенты, включенные в блок преобразования первоначально второго размера. В этом примере кодер 20 видео может поддерживать объединенную контекстную модель, совместно используемую блоками преобразования, имеющими первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоками преобразования, имеющими второй размер, и выбирать контексты для коэффициентов блока преобразования одного из первого размера с блоком оставшихся коэффициентов и второго размера, согласно объединенной контекстной модели. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. В других случаях блок оставшихся коэффициентов может иметь размер, равный третьему размеру, отличному и от первого размера и от второго размера.
[0035] В другом примере коэффициенты, включенные в первый блок преобразования, имеющий первый размер, может иметь подобную статистику вероятности, что и коэффициенты, включенные во второй блок преобразования, имеющий второй размер, даже без обнуления высокочастотных коэффициенты в пределах первого блока преобразования. Это возможно, так как высокочастотные коэффициенты могут представлять такие маленькие остаточные данные видео, что влияние на вероятностную статистику соседних коэффициентов для статистического кодирования незначительно. В этом примере кодер 20 видео может поддерживать объединенную контекстную модель, совместно используемую блоками преобразования, имеющими первый размер и второй размер, и выбирать контексты для коэффициентов в блоке преобразования одного из первого и второго размера согласно объединенной контекстной модели. В некоторых случаях только высокочастотные коэффициенты в пределах преобразованных блоков первого размера и второго размера могут совместно использовать объединенную контекстную модель. Низкочастотные коэффициенты, например, компоненты DC и соседние коэффициенты, в преобразовании первого размера могут использовать отличную контекстную модель, чем низкочастотные коэффициенты в преобразовании второго размера.
[0036] Приемник 26 из устройства-адресата 14 принимает информацию по каналу 16, и модем 28 демодулирует эту информацию. Информация, переданная по каналу 16, может включать в себя информацию синтаксиса, определенную кодером 20 видео, которая также используется декодером 30 видео, которая включает в себя элементы синтаксиса, которые описывают характеристики и/или обработку блоков кодирования (CU), блоков предсказания (PU), блоков преобразования (TU) или другие единицы кодированного видео, например, вырезок видео, кадров видео, и последовательностей видео или групп картинок (GOP). Устройство 32 отображения отображает декодированные данные видео пользователю, и может содержать любое множество устройств отображения, таких как электронно-лучевая трубка (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светоизлучающих диодах (OLED), или другой тип устройства отображения.
[0037] В соответствии с настоящим изобретением декодер 30 видео из устройства-адресата 14 может быть сконфигурирован, чтобы применять способы статистического декодирования коэффициентов видео, используя объединенную контекстную модель. Блок CU кадра видео, который должен быть декодирован, может включать в себя один или более блоков TU, которые включают в себя остаточные данные видео до и после преобразования. Декодер 30 видео может поддерживать объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, и выбирать контексты для коэффициентов, ассоциированных с одним из преобразованных блоков, согласно объединенной контекстной модели. Декодер 30 видео может затем статистически декодировать коэффициенты на основании выбранных контекстов.
[0038] В качестве примера объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. Как описано выше, в других примерах больше чем два размера блоков преобразования могут совместно использовать одну и ту же объединенную контекстную модель. Кроме того, два или более размеров блоков преобразования могут совместно использовать некоторые или все контекстные модели для блоков TU. В одном случае объединенная контекстная модель может быть объединенной контекстной моделью карты значимости для TU. В других случаях объединенная контекстная модель может быть ассоциирована с другой информацией кодирования или элементами синтаксиса. Эти способы поэтому могут уменьшать объем памяти, необходимой, чтобы сохранить контексты и вероятности на декодере 30 видео, и уменьшить вычислительные затраты на поддержание контекстных моделей на декодере 30 видео.
[0039] В одном примере декодер 30 видео может принять поток битов, который представляет кодированные коэффициенты, ассоциированные с блоком оставшихся коэффициентов, и обнуленные коэффициенты от блока преобразования, имеющего первый размер. Когда высокочастотные коэффициенты являются обнуленными из блока преобразования, коэффициенты, включенные в блок оставшихся коэффициентов, имеют аналогичную вероятностную статистику, что и коэффициенты, включенные в блок преобразования первоначально второго размера. В этом примере декодер 30 видео может поддерживать объединенную контекстную модель, совместно используемую блоками преобразования, имеющими первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и блоками преобразования, имеющими второй размер, и выбирать контексты для кодированных коэффициентов, ассоциированных с блоком преобразования одного из первого размера с блоком оставшихся коэффициентов и второго размера, согласно объединенной контекстной модели. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. В других случаях блок оставшихся коэффициентов может иметь размер, равный третьему размеру, отличному и от первого размера и от второго размера.
[0040] В другом примере декодер 30 видео может принять поток битов, который представляет кодированные коэффициенты, ассоциированные с блоком преобразования, имеющим один из первого размера и второго размера. Коэффициенты, включенные в первый блок преобразования, имеющий первый размер, могут иметь подобную статистику вероятности, что и коэффициенты, включенные во второй блок преобразования второго размера, даже без обнуления высокочастотных коэффициентов в пределах первого блока преобразования. В этом примере декодер 30 видео может поддерживать объединенную контекстную модель, совместно используемую блоками преобразования, имеющими первый размер и второй размер, и выбирать контексты для кодированных коэффициентов, ассоциированных с блоком преобразования одного из первого и второго размера, согласно объединенной контекстной модели. В некоторых случаях только высокочастотные коэффициенты в пределах преобразованных блоков первого размера и второго размера могут совместно использовать объединенную контекстную модель. Низкочастотные коэффициенты, например, компоненты DC и соседние коэффициенты, в преобразовании первого размера могут использовать отличную контекстную модель, чем низкочастотные коэффициенты в преобразовании второго размера.
[0041] В примере на Фиг. 1 коммуникационный канал 16 может содержать любой из беспроводного или проводного носителя связи, такого как радиочастотный (RF, РЧ) спектр или одна или более физических линий передачи, или любую комбинацию беспроводного и проводного носителя. Коммуникационный канал 16 может формировать часть основанной на пакетной передаче сети, такой как локальная сеть, широко-масштабная сеть, или глобальная сеть, такая как Интернет. Коммуникационный канал 16 обычно представляет собой любой подходящий коммуникационный носитель, или коллекцию различных коммуникационных носителей, для того, чтобы передать данные видео от исходного устройства 12 на устройство-адресат 14, включая любую подходящую комбинацию проводного или беспроводного носителя. Коммуникационный канал 16 может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть использовано, чтобы облегчить передачу от исходного устройства 12 на устройство-адресат 14. Как описано выше, в некоторых случаях исходное устройство 12 и устройство-адресат 14 могут не участвовать в активной связи в реальном времени через коммуникационный канал 16. Например, исходное устройство 12 может вместо этого сохранить кодированные данные видео на носитель данных, к которому устройство-адресат 14 может получить доступ при необходимости с помощью доступа к диску, или сохранить кодированные данные видео в файл-сервер, к которому устройство-адресат 14 может получить доступ при необходимости с помощью потоковой передачи.
[0042] Кодер 20 видео и декодер 30 видео могут работать согласно стандарту сжатия видео, такому как находящийся в стадии становления стандарт кодирования видео с высокой эффективностью (HEVC) или стандарт ITU-T H.264, альтернативно называемый MPEG-4, Часть 10, Усовершенствованное кодирование видео (AVC). Способы из настоящего изобретения, однако, не ограничены никаким конкретным стандартом кодирования. Другие примеры включают в себя MPEG-2 и ITU-T H.263. Хотя не показано на Фиг. 1, в некоторых аспектах кодер 20 видео и декодер 30 видео могут быть каждый интегрированы с кодером и декодером аудио, и могут включать в себя соответствующие блоки MUX-DEMUX (мультиплексирования-демультиплексирования), или другое аппаратное обеспечение и программное обеспечение, чтобы обрабатывать кодирование и аудио и видео в общем потоке данных или отдельных потоках данных. Если применимо, блоки MUX-DEMUX могут соответствовать протоколу ITU H.223 мультиплексора или другим протоколам, таким как протокол дейтаграмм пользователя (UDP).
[0043] Усилия по стандартизации HEVC основаны на модели устройства кодирования видео, называемого Тестовая Модель HEVC (HM). HM предполагает несколько дополнительных возможностей устройства кодирования видео относительно существующих устройств, согласно, например, ITU-T H.264/AVC. HM ссылается на блок данных видео как блок кодирования (CU). Данные синтаксиса в пределах потока битов могут определять наибольший блок кодирования (LCU), который является наибольшим блоком кодирования в терминах количества пикселей. В целом, CU имеет аналогичное назначение к макроблоку стандарта H.264, за исключением того, что CU не имеет разности в размерах. Таким образом, CU может быть разделен в под-CU. В целом, ссылки в настоящем изобретении на CU могут относиться к наибольшему блоку кодирования картинки или под-CU в LCU. LCU может быть разделен на под-CU, и каждый под-CU может быть далее разделен в под-CU. Данные синтаксиса для потока битов могут определить максимальное количество раз, сколько LCU может быть разделен, называемое глубиной CU. Соответственно, поток битов может также определить наименьший блок кодирования (SCU).
[0044] CU, которая далее не разделен (то есть, листовой узел LCU) может включать в себя один или более блоков предсказания (PU). В целом, PU представляет весь или часть соответствующего CU, и включает в себя данные для извлечения опорной выборки для PU. Например, когда PU является закодированным во внутреннем режиме, PU может включать в себя данные, описывающие режим внутреннего предсказания для PU. В качестве другого примера, когда PU является закодированным во внешнем режиме, PU может включать в себя данные, определяющие вектор движения для PU. Данные, определяющие вектор движения, могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешение для вектора движения (например, точность в полпикселя, точность в четверть пикселя, или точность в одну восьмую пикселя), опорный кадр, на который вектор движения указывает, и/или список опорных кадров (например, Список 0 или Список 1) для вектора движения. Данные для CU, определяющие PU(s), могут также описывать, например, фрагментирование CU в один или более блоков PU. Режимы фрагментирования могут отличаться между тем, является ли CU пропущенным или кодированным в прямом режиме, кодированным в режиме внутреннего предсказания, или кодированным в режиме внешнего предсказания.
[0045] CU, имеющий один или более PU, может также включать в себя один или более блоков преобразования (TU). Следуя предсказанию, используя PU, кодер видео может вычислить остаточные значения для части CU, соответствующей PU. Остаточные значения, включенные в блоки TU, соответствуют значениям пиксельной разности, которые могут быть преобразованы в коэффициенты преобразования, затем квантованы и сканированы, чтобы сформировать преобразованные в последовательную форму коэффициенты преобразования для статистического кодирования. TU не обязательно ограничен размером PU. Таким образом, блоки TU могут быть большими или меньшими, чем соответствующий PU для одного и того же CU. В некоторых примерах максимальный размер TU может быть размером соответствующего CU. Настоящее изобретение использует термин "блок видео", чтобы обращаться к любому из CU, PU или TU.
[0046] Кодер 20 видео и декодер 30 видео каждый может быть реализован как любое из множества подходящих схем кодера, таких как один или более микропроцессоров, цифровых сигнальных процессоров (DSP), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), дискретной логики, программного обеспечения, аппаратного обеспечения, программно-аппаратных средств или любых их комбинаций. Каждый кодер 20 видео и декодер 30 видео может быть включен в один или более кодеры или декодеры, любой из которых может быть интегрирован как часть объединенного кодера/декодера (кодека) в соответствующую камеру, компьютер, мобильное устройство, устройство абонента, устройство вещания, телевизионную приставку, сервер или подобное.
[0047] Последовательность видео или группа картинок (GOP, ГК) обычно включают в себя ряд кадров видео. GOP может включать данные синтаксиса в заголовок GOP, заголовок одного или более кадров в GOP, или в другое место, которые описывают количество кадров, включенных в GOP. Каждый кадр может включать в себя данные синтаксиса кадра, которые описывают режим кодирования для соответствующего кадра. Кодер 20 видео обычно оперирует над блоками видео в пределах индивидуальных кадров видео, чтобы закодировать данные видео. Блок видео может соответствовать CU или PU в CU. Блок видео может иметь фиксированный или переменный размеры, и может отличаться по размеру согласно указанному стандарту кодирования. Каждый кадр видео может включать в себя множество вырезок. Каждая вырезка может включать в себя множество CU, которые могут включать в себя один или более PU.
[0048] В качестве примера Тестовая Модель HEVC (HM) поддерживает предсказание в CU различных размеров. Размер LCU может быть определен с помощью информации синтаксиса. Предполагая, что размер конкретного CU равен 2Nx2N, HM поддерживает внутреннее предсказание в размерах 2Nx2N или NxN, и внешнее предсказание в симметричных размерах 2Nx2N, 2NxN, Nx2N или NxN. HM также поддерживает асимметричное разделение для внешнего предсказания для 2NxnU, 2NxnD, nLx2N и nRx2N. В асимметричном разделении одно направление CU не разделяется, в то время как другое направление разделяется на 25% и 75%. Часть CU, соответствующая 25%-ому разделению, обозначается "n" с сопровождающей индикацией "Верхний", "Нижний", "Левый" или "Правый". Таким образом, например, "2NxnU" относится к 2Nx2N CU, который разделен горизонтально с 2Nx0.5N PU сверху и 2Nx1.5N PU внизу.
[0049] В настоящем изобретении "NxN" и "N на N" может использоваться взаимозаменяемо, чтобы относиться к пиксельным измерениям блока видео (например, CU, PU или TU) в терминах вертикальных и горизонтальных измерений, например, 16x16 пиксели или 16 на 16 пикселей. Блок 16x16 будет иметь 16 пикселей в вертикальном направлении (y=16) и 16 пикселей в горизонтальном направлении (x=16). Аналогично, блок NxN имеет N пикселей в вертикальном направлении и N пикселей в горизонтальном направлении, где N представляет неотрицательное целочисленное значение. Пиксели в блоке могут быть размещены в строках и столбцах. Кроме того, блоки не обязательно должны иметь то же количество пикселей в горизонтальном направлении, как в вертикальном направлении. Например, блоки могут содержать прямоугольные области с пикселями NxM, где М не обязательно равно N.
[0050] После кодирования с внутренним предсказанием или внешним предсказанием, чтобы сформировать PU для CU, кодер 20 видео может вычислить остаточные данные, чтобы сформировать один или более блоков TU для CU. Остаточные данные могут соответствовать пиксельным разностям между пикселями незакодированной картинки и значениями предсказания PU в CU. Кодер 20 видео может сформировать один или более блоков TU, включающих в себя остаточные данные для CU. Кодер 20 видео может затем преобразовать блоки TU. До применения преобразования, такого как дискретное косинусное преобразование (DCT), целочисленное преобразование, вейвлет преобразование, или концептуально подобное преобразование, блоки TU в CU могут содержать остаточные данные видео, содержащие значения пиксельной разности в пиксельной области. После применения преобразования блоки TU могут содержать коэффициенты преобразования, которые представляют остаточные данные видео в частотной области.
[0051] После любых преобразований для формирования коэффициентов преобразования может быть выполнено квантование коэффициентов преобразования. Квантование в целом относится к процессу, в котором коэффициенты преобразования квантуются, чтобы возможно уменьшить количество данных, используемых для представления коэффициентов. Процесс квантования может уменьшить глубину в битах, ассоциированную с некоторыми или всеми коэффициентами. Например, значение n-битов может быть округлено в меньшую сторону до битового значения m-битов во время квантования, где n больше чем m.
[0052] Кодер 20 видео может применить зигзагообразный просмотр, горизонтальный просмотр, вертикальный просмотр или другой порядок просмотра, ассоциированный с размером TU, чтобы сканировать (просмотреть) квантованные коэффициенты преобразования, чтобы сформировать преобразованный в последовательную форму вектор, который может быть статистически кодирован. В некоторых примерах кодер 20 видео может использовать заранее заданный порядок просмотра, чтобы просмотреть квантованные коэффициенты преобразования. В других примерах кодер 20 видео может выполнить адаптивный просмотр (сканирование). После просмотра квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, кодер 20 видео может статистически кодировать одномерный вектор, например, согласно контекстно-адаптивному кодированию с переменной длиной кода (CAVLC), контекстно-адаптивному двоичному арифметическому кодированию (CABAC), или другому методу статистического кодирования.
[0053] Чтобы выполнить контекстно-адаптивное статистическое кодирование, кодер 20 видео должен назначить контекст на каждый коэффициент согласно контекстной модели, которая может относиться к, например, тому, являются ли значения соседних коэффициентов отличными от нуля. Кодер 20 видео затем определяет процесс кодирования для этого коэффициента, ассоциированного с назначенным контекстом в контекстной модели. Обычно, кодер 20 видео должен поддерживать отдельные контекстные модели для каждого из различных размеров блоков TU, поддерживаемых реализованным стандартом сжатия видео. Для стандарта HEVC дополнительные размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео, но дополнительные размеры TU также приводят к увеличенной памяти и вычислительным требованиям, чтобы поддерживать контекстную модели для каждого из дополнительных размеров блока преобразования.
[0054] В соответствии с способами настоящего изобретения, чтобы выполнить контекстно-адаптивное статистическое кодирование, кодер 20 видео может выбрать контексты для коэффициентов согласно объединенной контекстной модели, совместно используемой между блоками TU различных размеров. Более конкретно, кодер 20 видео может назначить контекст в объединенной контекстной модели заданному коэффициенту блока TU на основании значений ранее кодированных соседних коэффициентов этого TU. Назначенный контекст выбирают на основании критериев, определенных объединенной контекстной моделью, совместно используемой посредством TU. Кодер 20 видео может определить процесс кодирования для коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели. Кодер 20 видео затем статистически кодирует этот коэффициент на основании определенной оценки вероятности. Например, в случае CABAC кодер 20 видео может определить оценку вероятности для значения (например, 0 или 1) коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели. Кодер 20 видео затем обновляет оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели, на основании фактически кодированного значения коэффициента.
[0055] В качестве примера кодер 20 видео может выбрать контексты, используя одну и ту же объединенную контекстную модель для коэффициентов, ассоциированных или с блоком оставшихся коэффициентов в пределах первого блока преобразования, первоначально имеющего первый размер, или со вторым блоком преобразования, первоначально имеющим второй размер. Кроме того, кодер 20 видео может обновить оценки вероятности, ассоциированные с выбранными контекстами в объединенной контекстной модели, на основании фактических кодированных значений коэффициентов или блока оставшихся коэффициентов в пределах первого блока преобразования первоначально первого размера, или второго блока преобразования первоначально второго размера. В качестве другого примера, кодер 20 видео может выбрать контексты, используя одну и ту же объединенную контекстную модель для коэффициентов, ассоциированных или с первым блоком преобразования, имеющим первый размер, или со вторым блоком преобразования, имеющим второй размер. В этом случае кодер 20 видео может затем обновить оценки вероятности, ассоциированные с выбранными контекстами в объединенной контекстной модели, на основании фактических кодированных значений коэффициентов или первого блока преобразования первого размера или второго блока преобразования второго размера.
[0056] В любом случае совместно используя объединенную контекстную модель между двумя или более размерами блоки преобразования, можно уменьшить объем памяти, необходимой, чтобы сохранить контексты и вероятности в кодере 20 видео. Кроме того, совместное использование объединенной контекстной модели может также уменьшить вычислительные затраты поддержания контекстных моделей на кодере 20 видео, включая переустановку всей контекстной модели в начале вырезки видео.
[0057] Кодер 20 видео может также статистически кодировать элементы синтаксиса, указывающие информацию предсказания. Например, кодер 20 видео может статистически кодировать элементы синтаксиса, указывающие информацию блока видео, включающую размеры блоков CU, PU и TU, информацию вектора движения для предсказания во внутреннем режиме, и информацию карты значимых коэффициентов, то есть, карты единиц и нулей, указывающих позицию значимых коэффициентов, для CABAC. Декодер 30 видео может работать способом, по существу симметричным таковому кодера 20 видео.
[0058] Фиг. 2 является блок-схемой, иллюстрирующей примерный кодер видео, который может реализовать способы для статистического кодирования коэффициентов видео, используя объединенную контекстную модель. Кодер 20 видео может выполнять внутреннее и внешнее кодирование блоков кодирования в пределах кадров видео. Внутреннее кодирование полагается на пространственное предсказание, чтобы уменьшить или удалить пространственную избыточность в видео в пределах заданного кадра видео. Внешнее кодирование полагается на временное предсказание, чтобы уменьшить или удалить временную избыточность в видео в пределах смежных кадров последовательности видео. Внутренний режим (I режим) может относиться к любому из нескольких пространственно-основанных режимов сжатия. Внешние режимы, такие как однонаправленное предсказание (P-режим), двунаправленное предсказание (B-режим), или обобщенное предсказание P/B (режим GPB) могут относиться к любому из нескольких время-основанных режимов сжатия.
[0059] В примере на Фиг. 2 кодер 20 видео включает в себя модуль 38 выбора режима, модуль 40 предсказания, модуль 50 суммирования, модуль 52 преобразования, модуль 54 квантования, модуль 56 статистического кодирования и память 64 опорных кадров. Модуль 40 предсказания включает в себя модуль 42 оценки движения, модуль 44 компенсации движения и модуль 46 внутреннего предсказания. Для реконструкции блока видео кодер 20 видео также включает в себя модуль 58 обратного квантования, модуль 60 обратного преобразования и модуль 62 суммирования. Фильтр удаления блочности или другие контурные фильтры, такой адаптивный контурный фильтр (ALF) и адаптивное смещение вырезки (SAO) (не показан на Фиг. 2) могут быть также включены, чтобы фильтровать границы блока, чтобы удалить артефакты блочности изображения из реконструированного видео. Если желательно, фильтр удаления блочности обычно может фильтровать выходной сигнал модуля 62 суммирования.
[0060] Как показано на Фиг. 2, кодер 20 видео принимает блок видео в пределах кадра видео или вырезки, которые должны быть кодированы. Кадр или вырезка могут быть разделены на множественные блоки видео или CU. Модуль 38 выбора режима может выбрать один из режимов кодирования, внутренний или внешний, для блока видео на основании результатов ошибки. Модуль 40 предсказания затем выдает получающееся внутренне или внешне кодированный блок прогнозирования к модулю 50 суммирования, чтобы сгенерировать остаточные данные блока, и к модулю 62 суммирования, чтобы восстановить (реконструировать) кодированный блок для использования в качестве как опорного блока в опорном кадре.
[0061] Модуль 46 внутреннего предсказания в модуле 40 предсказания выполняет кодирование с внутренним прогнозированием блока видео относительно одного или более соседних блоков в том же самом кадре, что и блок видео, который должен быть кодирован. Модуль 42 оценки движения и модуль 44 компенсации движения в модуле 40 предсказания выполняют кодирование с внешним прогнозированием блока видео относительно одного или более опорных блоков в одном или более опорных кадрах, сохраненных в памяти 64 опорных кадров. Модуль 42 оценки движения и модуль 44 компенсации движения могут быть высоко интегрированы, но иллюстрированы по отдельности в концептуальных целях. Оценка движения, выполненная модулем 42 оценки движения, является процессом генерирования векторов движения, которые оценивают движение для блоков видео. Вектор движения, например, может указать смещение блока видео или PU в пределах текущего кадра видео относительно опорного блока или PU в пределах опорного кадра. Опорный блок является блоком, который обнаружен как близко соответствующий блоку видео или PU, который должен быть закодирован, в терминах пиксельной разности, которая может быть определена посредством суммы абсолютной разности (SAD), суммы разности квадратов (SSD), или другими метриками разности.
[0062] Модуль 42 оценки движения посылает вычисленный вектор движения в модуль 44 компенсации движения. Компенсация движения, выполненная модулем 44 компенсации движения, может вовлечь выборку или генерирование блока прогнозирования на основании вектора движения, определенного посредством оценки движения. Кодер 20 видео формирует остаточный блок видео, вычитая блок прогнозирования из кодируемого блока видео. Модуль 50 суммирования представляет компонент или компоненты, которые выполняют эту операцию вычитания.
[0063] Модуль 44 компенсации движения может генерировать элементы синтаксиса, определенные для представления информации предсказания на одном или более из уровня последовательности видео, уровня кадра видео, уровня вырезки видео, уровня CU видео, или уровня PU видео. Например, модуль 44 компенсации движения может генерировать элементы синтаксиса, указывающие информацию блока видео, включая размеры CU, PU и TU, и информацию вектора движения для предсказания во внутреннем режиме.
[0064] После того, как кодер 20 видео сформировал остаточный блок видео посредством вычитания блока прогнозирования из текущего блока видео, модуль 52 преобразования может сформировать один или более блоков TU из остаточного блока. Модуль 52 преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT), целочисленное преобразование, вейвлет преобразование или концептуально подобное преобразование, к TU, чтобы сформировать блок видео, содержащий остаточные коэффициенты преобразования. Преобразование может преобразовывать остаточный блок из пиксельной области в область преобразования, такую как частотная область. Более конкретно, до применения преобразования TU может содержать остаточные данные видео в пиксельной области, и после применения преобразования TU может содержать коэффициенты преобразования, которые представляют остаточные данные видео в частотной области.
[0065] В некоторых примерах модуль 52 преобразования может содержать двумерное разделимое преобразование. Модуль 52 преобразования может применять двумерное преобразование к TU посредством сначала применения одномерного преобразования к строкам остаточных данных видео в блоке TU, то есть, в первом направлении, и затем применения одномерного преобразования к столбцам остаточных данных видео в блоке TU, то есть, во втором направлении, или наоборот. В качестве одного примера, TU может содержать 32x32 TU. Модуль 52 преобразования может сначала применить одномерное 32-точечное преобразование к каждой строке пиксельных данных в TU, чтобы сгенерировать 32x32 TU промежуточных коэффициентов преобразования, и во-вторых применить 32-точечное одномерное преобразование к каждому столбцу промежуточных коэффициентов преобразования в TU, чтобы генерировать 32x32 TU коэффициентов преобразования.
[0066] После применения одномерного преобразования в первом направлении к остаточным видео данным в TU, кодер 20 видео буферизует промежуточные коэффициенты преобразования для применения одномерного преобразования во втором направлении. Как описано выше, в стандарте HEVC большие размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео. Большие размеры TU, однако, также приведут к увеличенным требованиям промежуточной буферизации для двумерного преобразования. Например, в случае 32x32 TU, кодер 20 видео должен буферизовать 1024 промежуточных коэффициентов преобразования после одномерного преобразования в первом направлении.
[0067] Чтобы уменьшить требования промежуточной буферизации для больших размеров TU, способы, описанные в настоящем изобретении, включают в себя обнуление высокочастотного поднабора коэффициентов преобразования, включенных в TU первого размера, после того как каждое направление двумерного преобразования было применено. Таким образом, модуль 52 преобразования может генерировать блок оставшихся коэффициентов в блоке TU, который имеет второй размер, меньший чем первый размер TU.
[0068] Процесс обнуления содержит установление значений поднабора коэффициентов преобразования в блоке TU, равными нулю. Коэффициенты преобразования, которые являются обнуленными, не вычисляются или отклоняются; вместо этого, обнуленные коэффициенты преобразования просто устанавливаются равными нулю и не имеют никакого значения для сохранения или кодирования. Согласно настоящему изобретению обнуленные коэффициенты преобразования обычно являются более высокочастотными коэффициентами преобразования относительно оставшихся более низкочастотных коэффициентов преобразования в TU. Высокочастотные коэффициенты преобразования представляют остаточные данные видео, которые обычно соответствуют очень маленьким пиксельным разностям между блоком видео, который должен быть закодирован, и блоком прогнозирования. Высокочастотные коэффициенты преобразования поэтому могут содержать такие маленькие остаточные данные видео, что установка этих значений равными нулю, имеет незначительное влияние на качество декодированного видео.
[0069] В качестве примера модуль 52 преобразования может применять одномерное преобразование в первом направлении, например, построчно, к остаточным видео данным в 32x32 TU и обнулять половину промежуточных коэффициентов преобразования, полученных из преобразования. Кодеру 20 видео затем только требуется буферизовать оставшуюся половину промежуточных коэффициентов преобразования. Модуль 52 преобразования может затем применить одномерное преобразование во втором направлении, например, по столбцам, к оставшимся промежуточным коэффициентам преобразования в 32x32 TU и снова обнулить оставшуюся половину коэффициентов преобразования, полученных из преобразования. Таким образом, модуль 52 преобразования может генерировать блок оставшихся коэффициентов значимых коэффициентов, имеющих размер 16x16 в блоке TU первоначально размера 32x32.
[0070] В примере, описанном выше, модуль 52 преобразования был сконфигурирован, чтобы сгенерировать 16x16 блок оставшихся коэффициентов, то есть, одну четверть первоначального размера TU. В других случаях модуль 52 преобразования может быть сконфигурирован, чтобы генерировать блок оставшихся коэффициентов, имеющий отличный размер, посредством обнуления большего или меньшего процента коэффициентов в зависимости от требований сложности кодирования для процесса кодирования. Кроме того, в некоторых случаях модуль 52 преобразования может быть сконфигурирован, чтобы генерировать блок оставшихся коэффициентов, имеющий прямоугольную область. В этом случае способы обеспечивают дальнейшее сокращение требований промежуточной буферизации посредством сначала применения одномерного преобразования в направлении более короткой стороны (то есть, меньше оставшихся коэффициентов преобразования) прямоугольной области. Таким образом, кодер 20 видео может буферизовать меньше, чем половину промежуточных коэффициентов преобразования до применения одномерного преобразования в направлении более длинной стороны прямоугольной области. Процессы обнуления блоков оставшихся коэффициентов и для квадратной и для прямоугольной области описаны более подробно со ссылками на фиг. 3A и 3B.
[0071] Модуль 52 преобразования может послать получающиеся коэффициенты преобразования к модулю 54 квантования. Модуль 54 квантования квантует коэффициенты преобразования, чтобы далее уменьшить скорость передачи (частоту следования) битов. Процесс квантования может уменьшить глубину в битах, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть изменена посредством регулировки параметра квантования. Модуль 56 статистического кодирования или модуль 54 квантования может затем выполнять просмотр TU, включающего в себя квантованные коэффициенты преобразования. Модуль 56 статистического кодирования может применить зигзагообразный просмотр, или другой порядок просмотра, ассоциированный с размером TU, чтобы просмотреть квантованные коэффициенты преобразования, чтобы сформировать преобразованный в последовательную форму вектор, который может быть статистически кодирован.
[0072] В одном примере, в котором коэффициенты TU первоначально первого размера были обнулены, чтобы сгенерировать блок оставшихся коэффициентов, имеющий второй размер, модуль 56 статистического кодирования может просмотреть оставшиеся коэффициенты, используя порядок просмотра относительно TU второго размера. В этом случае модуль 56 статистического кодирования может применить порядок просмотра 16x16 к блоку оставшихся коэффициентов, имеющему размер 16x16 в блоке TU первоначально размера 32x32. В другом примере, в котором коэффициенты TU первоначально первого размера были обнулены, чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, модуль 56 статистического кодирования может просмотреть оставшиеся коэффициенты, используя порядок просмотра относительно TU первого размера, который был изменен, чтобы пропустить коэффициенты TU, не включенные в блок оставшихся коэффициентов. В этом случае блок статистического кодирования может применить порядок просмотра 32x32 к блоку оставшихся коэффициентов, имеющему размер 16x16, пропуская все обнуленные коэффициенты в блоке TU первоначально размера 32x32.
[0073] После просмотра квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, модуль 56 статистического кодирования статистически кодирует вектор квантованных коэффициентов преобразования. Например, модуль 56 статистического кодирования может выполнить контекстно-адаптивное статистическое кодирование, такое как CABAC, CAVLC, или другой способ статистического кодирования. После статистического кодирования посредством модуля 56 статистического кодирования кодированный поток битов может быть передан к видео декодеру, такому как декодер 30 видео, или заархивирован для более поздней передачи или извлечения.
[0074] Чтобы выполнить контекстно-адаптивное статистическое кодирование, модуль 56 статистического кодирования назначает контекст на каждый коэффициент согласно контекстной модели, которая может относиться, например, к тому, являются ли значения соседних коэффициентов отличными от нуля. Модуль 56 статистического кодирования также определяет процесс кодирования для коэффициента, ассоциированного с назначенным контекстом в контекстной модели. Модуль 56 статистического кодирования затем статистически кодирует коэффициенты на основании назначенных контекстов. Например, в случае CABAC модуль 56 статистического кодирования может определить оценку вероятности для значения (например, 0 или 1) коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели. Модуль 56 статистического кодирования затем обновляет оценку вероятности, ассоциированную с назначенным контекстом в контекстной модели, на основании фактически кодированного значения этого коэффициента.
[0075] Обычно кодер 20 видео поддерживает отдельные контекстные модели для каждого из различных размеров блоков TU, поддерживаемых реализованным стандартом сжатия видео. Для стандарта HEVC дополнительные размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео, но эти дополнительные размеры TU также приводят к увеличенной памяти и вычислительным требованиям, чтобы поддерживать контекстную модель для каждого из дополнительных размеров блока преобразования. В некоторых случаях большие размеры TU могут использовать больше контекстов, которые могут привести к увеличенной памяти и вычислительному требованию, чтобы поддерживать увеличенное число контекстов для больших размеров TU.
[0076] Согласно способам настоящего изобретения модуль 56 статистического кодирования может быть сконфигурирован, чтобы выполнять статистическое кодирование коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. Эти способы главным образом описываются относительно способа статистического кодирования CABAC. В некоторых случаях, однако, эти способы могут быть также применены к другим контекстно-адаптивным способам статистического кодирования. Совместное использование объединенной контекстной модели между двумя или более размерами блоков преобразования может уменьшить объем памяти, необходимой, чтобы сохранить контексты и вероятности на кодере 20 видео. Кроме того, совместное использование объединенной контекстной модели может также уменьшить вычислительные затраты поддержания контекстных моделей на кодере 20 видео, включая сброс всех контекстных моделей в начале вырезки видео. В случае CABAC эти способы могут также уменьшить затраты вычисления непрерывного обновления оценок вероятности моделей контекста на основании фактических кодированных значений коэффициентов.
[0077] В соответствии с настоящим изобретением модуль 56 статистического кодирования может поддерживать объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, и выбирать контексты для коэффициентов, ассоциированных с одним из преобразованных блоков согласно объединенной контекстной модели. Модуль 56 статистического кодирования может затем статистически кодировать значимые коэффициенты в пределах преобразованных блоков на основании выбранных контекстов. В качестве примера объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. В некоторых случаях больше чем два размера блоков преобразования могут совместно использовать одну и ту же объединенную контекстную модель. В одном примере объединенная контекстная модель может быть объединенной контекстной моделью карт значимости для блоков преобразования. В других примерах объединенная контекстная модель может быть ассоциирована с другой информацией кодирования или элементами синтаксиса. Процесс кодирования CABAC, использующий объединенные контекстные модели, описан более подробно со ссылками на фиг. 5.
[0078] В одном примере модуль 56 статистического кодирования может поддерживать объединенную контекстную модель, совместно используемую посредством блока TU, имеющего первый размер, с коэффициентами, которые являются обнуленными, чтобы генерировать блок оставшихся коэффициентов, и TU, первоначально имеющим второй размер. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. Например, когда высокочастотные коэффициенты являются обнуленными из TU первого размера, коэффициенты, включенные в блок оставшихся коэффициентов второго размера, имеют аналогичную статистику вероятности, что и коэффициенты, включенные в TU первоначально второго размера. В этом случае, когда блок оставшихся коэффициентов второго размера сгенерирован посредством обнуления коэффициентов TU первоначально первого размера, модуль 56 статистического кодирования может выбрать контексты для коэффициентов блока оставшихся коэффициентов согласно объединенной контекстной модели. Модуль 56 статистического кодирования затем статистически кодирует значимые коэффициенты в блоке оставшихся коэффициентов на основании выбранных контекстов. В случае CABAC модуль 56 статистического кодирования также обновляет оценки вероятности, ассоциированные с выбранными контекстами в объединенной контекстной модели, на основании фактических кодированных значений коэффициентов.
[0079] В другом примере модуль 56 статистического кодирования может поддерживать объединенную контекстную модель, совместно используемую первым TU, имеющим первый размер, и вторым TU, имеющим второй размер. В некоторых случаях коэффициенты, включенные в первый TU, имеющий первый размер, могут иметь аналогичную статистику вероятности, что и коэффициенты, включенные во второй TU, имеющий второй размер, даже без обнуления высокочастотных коэффициентов в первом TU. Это возможно, так как высокочастотные коэффициенты могут представлять такие маленькие остаточные данные видео, что влияние на вероятностную статистику соседних коэффициентов для статистического кодирования является незначительным. В этом примере модуль 56 статистического кодирования может выбрать контексты для коэффициентов в блоке TU из одного из первого и второго размера согласно объединенной контекстной модели. Модуль 56 статистического кодирования затем статистически кодирует значимые коэффициенты в блоке TU на основании выбранных контекстов. В случае CABAC модуль 56 статистического кодирования может затем обновить оценки вероятности, ассоциированные с выбранными контекстами в объединенной контекстной модели, на основании фактических кодированных значений коэффициентов.
[0080] Модуль 56 статистического кодирования может также статистически кодировать элементы синтаксиса, указывающие векторы движения и другую информацию предсказания для кодируемого видео блока. Например, модуль 56 статистического кодирования может статистически кодировать элементы синтаксиса, указывающие карту значимости, то есть, карту единиц и нулей, указывающих позицию значимых коэффициентов в TU, используя способы, описанные в настоящем изобретении. Модуль 56 статистического кодирования может также конструировать информацию заголовка, которая включает в себя соответствующие элементы синтаксиса, генерируемые модулем 44 компенсации движения, для передачи в закодированном потоке битов. Кодер 20 видео может статистически кодировать элементы синтаксиса, указывающие информацию блока видео, включая размеры блоков CU, PU и TU, и информацию вектора движения для предсказания во внутреннем режиме. Для статистического кодирования элементов синтаксиса модуль 56 статистического кодирования может выполнить CABAC посредством бинаризации элементов синтаксиса в один или более двоичных битов и выбора контекстов для каждого бита согласно контекстной модели.
[0081] Модуль 58 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы реконструировать остаточный блок в пиксельной области для более позднего использования в качестве опорного блока опорного кадра. Модуль 62 суммирования суммирует реконструированный остаточный блок в прогнозирующий блок, генерируемый модулем 44 компенсации движения, чтобы сформировать опорный блок для хранения в памяти 64 опорных кадров. Опорный блок может использоваться модулем 42 оценки движения и модулем 44 компенсации движения в качестве опорного блока, чтобы внутренне предсказать блок в последующем кадре видео.
[0082] Фиг. 3A и 3B являются концептуальными диаграммами, соответственно иллюстрирующими квадратные и прямоугольные области блоков оставшихся коэффициентов, имеющих второй размер в блоке преобразования, имеющего первый размер. На концептуальных иллюстрациях на Фиг. 3A и 3B различные прямоугольники представляют коэффициенты преобразования в блоке TU после применения преобразования. Коэффициенты в пределах отмеченных штриховкой областей содержат оставшиеся коэффициенты преобразования, а коэффициенты, не включенные в отмеченные штриховкой области (то есть, белый или затемненные прямоугольники), содержат коэффициенты, которые были обнулены во время двумерного преобразования.
[0083] Как описано выше, способы согласно настоящему изобретению уменьшают требования промежуточной буферизации для больших размеров TU, например, 32x32 вплоть до 128x128, посредством обнуления высокочастотного поднабора коэффициентов преобразования, включенных в TU первого размера, после каждого направления двумерного преобразования. Таким образом, модуль 52 преобразования согласно Фиг. 2 может генерировать блок оставшихся коэффициентов в блоке TU, который имеет второй размер, меньший чем первый размер TU.
[0084] Процесс обнуления содержит установление значений поднабора коэффициентов преобразования в блоке TU равными нулю. Коэффициенты преобразования, которые являются обнуленными, не вычисляются или отклоняются; вместо этого обнуленные коэффициенты преобразования просто устанавливаются равными нулю и не имеют никакого значения для сохранения или кодирования. Согласно настоящему изобретению обнуленные коэффициенты преобразования являются высокочастотными коэффициентами преобразования относительно оставшихся коэффициентов преобразования в TU. Высокочастотные коэффициенты преобразования представляют остаточные данные видео, которые соответствуют очень маленьким пиксельным разностям между блоком видео, который должен быть закодирован, и блоком прогнозирования. Высокочастотные коэффициенты преобразования поэтому может содержать такие маленькие остаточные данные видео, что установка этих значений равными нулю имеет незначительное влияние на качество декодированного видео.
[0085] Фиг. 3A иллюстрируют TU 70, имеющий первый размер 16x16, и блок 74 оставшихся коэффициентов, имеющий окончательную квадратную область второго размера 8x8 в блоке TU 70. Размер и форма блока 74 оставшихся коэффициентов может быть выбрана на основании требований сложности кодирования для процесса кодирования. В этом примере модуль 52 преобразования согласно фиг. 2 может быть сконфигурирован, чтобы генерировать блок 74 оставшихся коэффициентов с квадратной областью размером 8x8 в блоке TU 70 первоначально размера 16x16. Чтобы сгенерировать блок 74 оставшихся коэффициентов, модуль 52 преобразования может обнулить половину более высокочастотных коэффициентов после применения каждого направления, то есть, строк и столбцов, двумерного преобразования. В других случаях модуль 52 преобразования может быть сконфигурирован обнулять больший или меньший поднабор коэффициентов в зависимости от требований сложности кодирования для процесса кодирования.
[0086] Сначала модуль 52 преобразования может применять одномерное преобразование к строкам остаточных данных видео в TU 70, и обнулять поднабор (в этом случае половину) промежуточных коэффициентов преобразования, полученных из преобразования. В иллюстрированном примере на Фиг. 3A оставшиеся промежуточные коэффициенты преобразования включены в блок 73 оставшихся промежуточных коэффициентов (то есть, затемненные блоки в TU 70), которые имеют прямоугольную область 16x8, равную половине исходного размера 16x16 в TU 70. Обнуленный поднабор (то есть, белые блоки в TU 70) могут включать в себя коэффициенты со значениями частоты, которые выше, чем коэффициенты в пределах блока 73 оставшихся промежуточных коэффициентов из TU 70. В иллюстрированном примере, модуль 52 преобразования обнуляет половину коэффициентов с 8 самыми высокими значениями частоты в каждой строке TU 70. Этот процесс обнуления приводит к блоку 73 оставшихся промежуточных коэффициентов с прямоугольной областью 16x8 в блоке TU 70. В других примерах область блока 73 оставшихся промежуточных коэффициентов может иметь другой размер или форму. Модуль 52 преобразования может обнулять половину коэффициентов с самыми высокими значениями частоты среди всех коэффициентов в TU 70 16x16. Этот процесс обнуления может привести к сохраненному промежуточному блоку коэффициентов с треугольной областью в верхнем левом углу в TU 70.
[0087] Посредством обнуления половины промежуточных коэффициентов преобразования, полученных из преобразования в первом направлении, кодеру 20 видео только требуется буферизовать коэффициенты в пределах блока 73 оставшихся промежуточных коэффициентов прежде, чем применить преобразование во втором направлении. Коэффициенты в пределах обнуленного поднабора (то есть, белые блоки в TU 70) не имеют никакого значения для сохранения, преобразования или кодирования. Таким образом, эти способы могут уменьшить требования промежуточной буферизации при выполнении двумерных преобразований. Это может быть особенно полезно для больших размеров блока преобразования, например, 32x32 вплоть до 128x128, которые были предложены для стандарта HEVC.
[0088] После буферизации модуль 52 преобразования может затем применить одномерное преобразование к столбцам оставшихся промежуточных коэффициентов преобразования в блоке 73 оставшихся промежуточных коэффициентов и обнулить поднабор (в этом случае половину), коэффициентов преобразования, полученных из преобразования. В иллюстрированном примере на Фиг. 3A оставшиеся коэффициенты преобразования включены в блок 74 оставшихся коэффициентов (то есть, отмеченные штриховкой блоки в TU 70), которые имеют квадратную область размером 8x8, равную одной четвертой исходного размера 16x16 в TU 70. Обнуленный поднабор (то есть, не отмеченные штриховкой квадраты в блоке 73 оставшихся промежуточных коэффициентов) может включать в себя коэффициенты со значениями частоты, которые выше, чем коэффициенты в блоке 74 оставшихся коэффициентов из TU 70. В иллюстрированном примере модуль 52 преобразования обнуляет половину коэффициентов с 8 самыми высокими значениями частоты в каждом столбце блока 73 оставшихся промежуточных коэффициентов. В других примерах модуль 52 преобразования может обнулять половину коэффициентов с самыми высокими значениями частоты среди всех коэффициентов в блоке 73 оставшихся промежуточных коэффициентов 16x8. В любом случае процесс обнуления приводит к блоку 74 оставшихся коэффициентов с квадратной областью 8x8 в блоке TU 70.
[0089] Фиг. 3B иллюстрирует TU 76, имеющий первый размер 16x16 и блок 78 оставшихся коэффициентов, имеющий окончательную прямоугольную область второго размера 4x16 в блоке TU 76. Размер и форма блока 78 оставшихся коэффициентов может быть выбрана на основании требования сложности кодирования для процесса кодирования. Более конкретно, окончательная прямоугольная область блока 78 оставшихся коэффициентов может быть выбрана на основании по меньшей мере одного из режима внутреннего кодирования, шаблона просмотра и позиции последнего значимого коэффициента для блока 78 оставшихся коэффициентов.
[0090] В иллюстрированном примере на Фиг. 3B модуль 52 преобразования может быть сконфигурирован, чтобы генерировать блок 78 оставшихся коэффициентов с прямоугольной областью размером 4x16 в блоке TU 76 первоначально размера 16x16. Модуль 52 преобразования может сначала быть применен к TU 76 в направлении самой короткой стороны (например, столбцам) окончательной прямоугольной области блока 78 оставшихся коэффициентов. Чтобы генерировать блок 78 оставшихся коэффициентов, блок 52 преобразования может обнулить три четверти коэффициентов после применения двумерного преобразования в первом направлении (например, столбцам). В других случаях модуль 52 преобразования может быть сконфигурирован для обнуления большего или меньшего поднабора коэффициентов в зависимости от требований сложности кодирования для процесса кодирования.
[0091] Когда прямоугольная область выбрана для блока оставшихся коэффициентов, способы могут обеспечить дальнейшее сокращение требований промежуточной буферизации посредством сначала применения одномерного преобразования в направлении более короткой стороны (то есть, меньше оставшихся коэффициентов преобразования) прямоугольной области. Таким образом, кодер 20 видео может буферизовать меньше чем половину промежуточных коэффициентов преобразования до применения одномерного преобразования в направлении более длинной стороны прямоугольной области. В иллюстрированном примере на Фиг. 3B, высота (H) окончательной прямоугольной области блока 78 оставшихся коэффициентов меньше, чем ширина (W) прямоугольной области, таким образом меньше промежуточных коэффициентов преобразования будет сохранено в вертикальном направлении. Модуль 52 преобразования может поэтому сначала применить преобразование к столбцам TU 76 таким образом, что кодер 20 видео может буферизовать меньше, чем половину (в этом случае одну четверть) промежуточных коэффициентов преобразования перед применением преобразования к строкам TU 76.
[0092] Более конкретно, модуль 52 преобразования может применить одномерное преобразование к столбцам остаточных данных видео в TU 76, и обнулить поднабор (в этом случае три четверти) промежуточных коэффициентов преобразования, полученных из преобразования. В иллюстрированном примере на Фиг. 3B, оставшиеся промежуточные коэффициенты преобразования включены в блок 77 оставшихся промежуточных коэффициентов (то есть, затемненные блоки в TU 76), которые имеют прямоугольную область 4x16, равную одной четверти исходного размера 16x16 в TU 76. Обнуленный поднабор (то есть, белые блоки в TU 76) может включать в себя коэффициенты со значениями частоты, которые выше, чем коэффициенты в блоке 77 оставшихся промежуточных коэффициентов из TU 76. В иллюстрированном примере модуль 52 преобразования обнуляет три четверти коэффициентов с 12 самыми высокими значениями частоты в каждом столбце в TU 76. Эти процесс обнуления приводит к блоку 77 оставшихся промежуточных коэффициентов с прямоугольной областью 4x16 в блоке TU 76.
[0093] Посредством обнуления трех четвертей промежуточных коэффициентов преобразования, полученных из преобразования в первом направлении, кодеру 20 видео только требуется буферизовать коэффициенты в блоке 77 оставшихся промежуточных коэффициентов, прежде чем применить преобразование во втором направлении. Коэффициенты в пределах обнуленного поднабора (то есть, белые блоки в TU 76) не имеют никакого значения для сохранения, преобразования или кодирования. Таким образом, эти способы могут уменьшить требования промежуточной буферизации при выполнении двумерных преобразований. Это может быть особенно полезно для больших размеров блока преобразования, например, 32x32 вплоть до 128x128, которые были предложены для стандарта HEVC.
[0094] После буферизации модуль 52 преобразования может затем применить одномерное преобразование к строкам коэффициентов в блоке 77 оставшихся промежуточных коэффициентов. В этом примере модуль 52 преобразования может не обнулять любой из коэффициентов преобразования, полученных из преобразования, так как TU 76 уже был обнулен до одной четверти первоначального размера 16x16. В иллюстрированном примере на Фиг. 3В оставшиеся коэффициенты преобразования включены в блок 78 оставшихся коэффициентов (то есть, отмеченные штриховкой блоки в TU 76), которые имеют ту же самую прямоугольную область 4x16, что и блок 77 оставшихся промежуточных коэффициентов. Процесс обнуления приводит к блоку 78 оставшихся коэффициентов с прямоугольной областью 4x16 в блоке TU 70.
[0095] Фиг. 4 является блок-схемой, иллюстрирующей примерный декодер видео, который может реализовать способы для статистического декодирования коэффициентов видео, используя объединенную контекстную модель. В примере на Фиг. 4 декодер 30 видео включает в себя модуль 80 статистического декодирования, модуль 81 предсказания, модуль 86 обратного квантования, модуль 88 обратного преобразования, модуль 90 суммирования и память 92 опорных кадров. Модуль 81 предсказания включает в себя модуль 82 компенсации движения и модуль 84 внутреннего предсказания. Декодер 30 видео, в некоторых примерах, может выполнить проход декодирования, в целом обратный к проходу кодирования, описанному относительно кодера 20 видео (Фиг. 2).
[0096] Во время процесса декодирования декодер 30 видео принимает кодированный поток битов видео, который представляет кодированные кадры видео или вырезки и элементы синтаксиса, которые представляют информацию кодирования из кодера 20 видео. Модуль 80 статистического декодирования статистически декодирует поток двоичных сигналов, чтобы генерировать квантованные коэффициенты преобразования в пределах TU. Например, модуль 80 статистического декодирования может выполнить контекстно-адаптивное статистическое декодирование, такое как CABAC, CAVLC или другой способ статистического кодирования. Модуль 80 статистического декодирования также статистически декодирует элементы синтаксиса, включая карту значимости, то есть, карту единиц и нулей, указывающих позицию значимых коэффициентов в TU, используя способы, описанные в настоящем изобретении. Модуль 80 статистического декодирования может также статистически декодировать векторы движения и другие элементы синтаксиса предсказания.
[0097] Чтобы выполнить контекстно-адаптивное статистическое декодирование, модуль 80 статистического декодирования назначает контекст на каждый кодированный коэффициент, представленный в потоке битов, согласно контекстной модели, которая может относится к тому, например, являются ли значения ранее декодированных соседних коэффициентов отличными от нуля. Модуль 80 статистического декодирования также определяет процесс кодирования для кодированного коэффициента, ассоциированного с назначенным контекстом в контекстной модели. Модуль 80 статистического декодирования затем статистически декодирует коэффициенты на основании назначенных контекстов. В случае CABAC модуль 80 статистического декодирования определяет оценку вероятности для значения (например, 0 или 1) кодированного коэффициента, ассоциированного с назначенным контекстом в контекстной модели. Модуль 80 статистического декодирования затем обновляет оценку вероятности, ассоциированную с назначенным контекстом в контекстной модели, на основании фактического декодированного значения этого коэффициента.
[0098] Обычно декодер 30 видео должен поддерживать отдельные контекстные модели для каждого из различных размеров блоков TU, поддерживаемых посредством реализованного стандарта сжатия видео. Для стандарта HEVC дополнительные размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео, но дополнительные размеры TU также приводят к увеличенной памяти и вычислительным требованиям, чтобы поддерживать контекстную модель для каждого из дополнительных размеров блока преобразования.
[0099] Согласно способам настоящего изобретения модуль 80 статистического декодирования может быть сконфигурирован, чтобы выполнять статистическое декодирование коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. Способы главным образом описаны относительно статистического декодирования способа CABAC. В некоторых случаях, однако, способы могут быть также применены к другим контекстно-адаптивным способам статистического кодирования. Совместное использование объединенной контекстной модели между двумя или более размерами блоков преобразования может уменьшить объем памяти, необходимой, чтобы сохранить контексты и вероятности на декодере 30 видео. Кроме того, совместное использование объединенной контекстной модели может также уменьшить вычислительные затраты поддержания контекстных моделей на декодере 30 видео, включая установку в исходное состояние всех контекстных моделей в начале вырезки видео. В случае CABAC эти способы могут также уменьшить затраты вычислений непрерывно обновляемых оценок вероятности моделей контекста на основании фактических кодированных значений коэффициентов.
[0100] В соответствии с настоящим изобретением модуль 80 статистического декодирования может поддерживать объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, и выбирать контексты для коэффициентов, ассоциированных с одним из блоков преобразования, согласно объединенной контекстной модели. Модуль 80 статистического декодирования может затем статистически декодировать значимые коэффициенты, ассоциированные с блоками преобразования, на основании выбранных контекстов. В качестве примера объединенная контекстная модель может быть совместно использована между блоками преобразования, имеющими первый размер 32x32, и блоками преобразования, имеющими второй размер 16x16. В некоторых случаях больше чем два размера блоков преобразования могут совместно использовать одну и ту же объединенную контекстную модель. В одном примере объединенная контекстная модель может быть объединенной контекстной моделью карт значимости для блоков преобразования. В других примерах объединенная контекстная модель может быть ассоциирована с другой информацией кодирования или элементами синтаксиса. Процесс декодирования CABAC, использующий объединенную контекстную модель, описан более подробно со ссылками на фиг. 6.
[0101] В одном примере модуль 80 статистического декодирования может поддерживать объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, и TU, первоначально имеющим второй размер. В некоторых случаях блок оставшихся коэффициентов может иметь размер, равный второму размеру. Например, в этом случае модуль 80 статистического декодирования может выбрать контексты для коэффициентов блока оставшихся коэффициентов, имеющего второй размер, в блоке TU, первоначально имеющем первый размер, согласно объединенной контекстной модели. Модуль 80 статистического декодирования затем арифметически декодирует кодированные значимые коэффициенты в блок оставшихся коэффициентов в блоке TU, имеющего первый размер, на основании выбранных контекстов. В случае CABAC модуль 80 статистического декодирования также обновляет оценки вероятности, ассоциированные с выбранными контекстами, в объединенной контекстной модели, на основании фактических декодированных значений коэффициентов.
[0102] В другом примере модуль 80 статистического декодирования может поддерживать объединенную контекстную модель, совместно используемую первым TU, имеющим первый размер, и вторым TU, имеющим второй размер. В этом примере модуль 80 статистического декодирования может выбрать контексты для кодированных коэффициентов, ассоциированных с TU одного из первого и второго размера согласно объединенной контекстной модели. Модуль 80 статистического декодирования затем статистически декодирует кодированные значимые коэффициенты в TU на основании выбранных контекстов. В случае CABAC модуль 80 статистического декодирования может затем обновить оценки вероятности, ассоциированные с выбранными контекстами, в объединенной контекстной модели на основании фактических декодированных значений коэффициентов. В любом случае модуль 80 статистического декодирования направляет квантованные декодированные коэффициенты преобразования в блоках TU или первого размера или второго размера к модулю 86 обратного квантования.
[0103] Модуль 86 обратного квантования обратно квантует, то есть, деквантует, квантованные коэффициенты преобразования, декодированные в блоки TU, с помощью модуля 80 статистического декодирования, как описано выше. Обратный процесс квантования может включать в себя использование параметра квантования QP, вычисленного кодером 20 видео для каждого блока видео или CU, чтобы определить степень квантования и, аналогично, степень обратного квантования, которая должна быть применена. Модуль 88 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, обратное вейвлет преобразование, или концептуально подобный процесс обратного преобразования к коэффициентам преобразования в пределах блоков TU, чтобы сформировать остаточные данные видео в пиксельной области.
[0104] В некоторых примерах модуль 88 обратного преобразования может содержать двумерное разделимое преобразование. Модуль 88 обратного преобразования может применить двумерное преобразование к TU с помощью сначала применения одномерного обратного преобразования к строкам коэффициентов преобразования в блоке TU, и затем применить одномерное обратное преобразование к столбцам коэффициентов преобразования в блоке TU, или наоборот. После применения одномерного обратного преобразования в первом направлении к коэффициентам преобразования в TU декодер 30 видео буферизует промежуточные остаточные данные для применения одномерного обратного преобразования во втором направлении. Как описано выше, в стандарте HEVC большие размеры блока преобразования, например, 32x32 вплоть до 128x128, были предложены, чтобы улучшить эффективность кодирования видео. Большие размеры TU, однако, также приведут к увеличенным требованиям промежуточной буферизации для двумерных преобразований.
[0105] Чтобы уменьшить требования промежуточной буферизации для больших размеров TU, способы, описанные в настоящем изобретении, могут включать в себя обнуление высокочастотного поднабора коэффициентов преобразования, включенных в TU, кодером 20 видео согласно фиг. 2. Обнуленные коэффициенты преобразования в блоке TU просто устанавливаются равными нулю и не имеют никакого значения для сохранения, преобразования или кодирования. Модуль 80 статистического декодирования поэтому принимает кодированный поток битов, который представляет кодированные коэффициенты, ассоциированные с блоком оставшихся коэффициентов, имеющим второй размер в блоке TU, первоначально имеющего первый размер. Модуль 80 статистического декодирования декодирует коэффициенты в блок оставшихся коэффициентов в блоке TU, имеющего первый размер. TU тогда включает в себя коэффициенты в блоке оставшихся коэффициентов второго размера, и нули, которые представляют оставшиеся коэффициенты в пределах этого TU.
[0106] Таким образом, процесс обнуления коэффициентов преобразования в кодере 20 видео может также уменьшить требования к промежуточной буферизации для больших размеров TU при выполнении обратного преобразования в декодере 30 видео. В качестве примера модуль 88 обратного преобразования может применить одномерное обратное преобразование в первом направлении, например, построчно, к коэффициентам преобразования блоке оставшихся коэффициентов, имеющем размер 16x16 в блоке TU, имеющего размер 32x32. После обратного преобразования строки декодеру 30 видео может только потребоваться буферизовать промежуточные остаточные данные, преобразованные из коэффициентов в блоке оставшихся коэффициентов, который содержит только половину TU, то есть коэффициенты 32x16. Модуль 88 обратного преобразования может затем применить одномерное обратное преобразование во втором направлении, например, по столбцам, к промежуточным остаточным данным в TU. Таким образом, модуль 88 обратного преобразования может генерировать TU первоначального размера 32x32 посредством включения остаточных данных в блок оставшихся коэффициентов, имеющий размер 16x16, и добавления нулей для представления оставшихся остаточных данных в TU.
[0107] Модуль 80 статистического декодирования также передает декодированные векторы движения и другие элементы синтаксиса предсказания к модулю 81 предсказания. Декодер 30 видео может принять элементы синтаксиса на уровне блока предсказания видео, уровне блока кодирования видео, уровне вырезки видео, уровне кадра видео и/или уровне последовательности видео. Когда кадр видео кодируется как внутренне кодированный кадр, модуль 84 внутреннего предсказания из модуля 81 предсказания генерируют данные предсказания для блоков видео текущего кадра видео на основании данных от ранее декодированных блоков текущего кадра. Когда кадр видео кодируется как внешне кодированный кадр, модуль 82 компенсации движения из модуля 81 предсказания формирует блоки прогнозирования для блоков видео текущего кадра видео на основании декодированных векторов движения, принятых от модуля 80 статистического декодирования. Блоки прогнозирования могут генерироваться относительно одного или более опорных блоков опорного кадра, сохраненных в памяти 92 опорных кадров.
[0108] Модуль 82 компенсации движения определяет информацию предсказания для блока видео, который должен быть декодирован, посредством синтаксического анализа векторов движения и другого синтаксиса предсказания, и использует информацию предсказания, чтобы генерировать блоки прогнозирования для текущего декодируемого блока видео. Например, модуль 82 компенсации движения использует некоторые из принятых элементов синтаксиса, чтобы определить размеры блоков CU, используемых для кодирования текущего кадра, разделения информации, которая описывает, как каждый CU кадра разделен, режимы, указывающие, как каждое разделение кодируется (например, с помощью внутреннего или внешнего предсказания), тип вырезки внешнего предсказания (например, B вырезка, P вырезка, или вырезка GPB), команды построения списка опорных кадров, интерполяционные фильтры, относящиеся опорным кадрам, векторы движения для каждого блока кадра видео, значения параметров видео, ассоциированных с векторами движения, и другую информацию, чтобы декодировать текущий кадр видео.
[0109] Декодер 30 видео формирует декодированный блок видео посредством суммирования остаточных блоков от модуля 88 обратного преобразования с соответствующими блоками предсказания, генерируемыми модулем 82 компенсации движения. Модуль 90 суммирования представляет компонент или компоненты, которые выполняют эту операцию суммирования. Если желательно, фильтр удаления блочности также может быть применен, чтобы фильтровать декодированные блоки, чтобы удалить артефакты блочности на квадраты. Декодированные блоки видео затем сохраняются в опорных кадрах в памяти 92 опорных кадров, которая обеспечивает опорные блоки опорных кадров для последующей компенсации движения. Память 92 опорных кадров также формирует декодированное видео для представления на устройстве отображения, таком как устройство 32 отображения согласно фиг. 1.
[0110] Фиг. 5 является блок-схемой, иллюстрирующей пример модуля 56 статистического кодирования согласно фиг. 2, сконфигурированного, чтобы выбрать контексты для коэффициентов видео согласно объединенной контекстной модели. Модуль 56 статистического кодирования включает в себя модуль 94 контекстного моделирования, модуль 99 арифметического кодирования и хранилище 98 объединенной контекстной модели. Как описано выше, способы согласно настоящему изобретению направлены на выполнение статистического кодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. В частности, способы описаны здесь относительно процесса кодирования CABAC.
[0111] Модуль 56 статистического кодирования поддерживает объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, в хранилище 98 объединенной контекстной модели. В качестве одного примера, хранилище 98 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, с коэффициентами, обнуленными, чтобы сгенерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, первоначально имеющим второй размер. В качестве другого примера, хранилище 98 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, и TU, имеющим второй размер. В некоторых случаях первый размер может содержать 32x32, и второй размер может содержать 16x16.
[0112] Модуль 94 контекстного моделирования принимает коэффициенты преобразования, ассоциированные с TU или первого размера или второго размера, которые были сканированы, в вектор для статистического кодирования. Модуль 94 контекстного моделирования затем назначает контекст на каждый из коэффициентов TU на основании значений ранее кодированных соседних коэффициентов в TU согласно объединенной контекстной модели. Более конкретно, модуль 94 контекстного моделирования может назначить контексты согласно тому, являются ли значения ранее кодированных соседних коэффициентов отличными от нуля. Назначенный контекст может ссылаться на индекс контекста, например, контекст (i), где i=0, 1, 2..., N, в объединенной контекстной модели.
[0113] После того, как контекст назначен коэффициенту, модуль 94 контекстного моделирования может определить оценку вероятности для значения (например, 0 или 1) коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели. Каждый различный индекс контекста ассоциирован с оценкой вероятности для значения коэффициента с этим индексом контекста. Оценка вероятности, выполненная для CABAC посредством модуля 94 контекстного моделирования, может быть основана на управляемом таблицей модуле оценки, использующем конечный автомат (FSM). Для каждого контекста FSM поддерживает ассоциированную оценку вероятности, отслеживая прошлые значения контекста и обеспечивая текущее состояние как наилучшую оценку вероятности того, что заданный коэффициент имеет значение 0 или 1. Например, если состояния вероятности изменяются от 0 до 127, состояние 0 может означать, что вероятность коэффициента, имеющего значение 0, равна 0,9999, и состояние 127 может означать, что вероятность коэффициента, имеющего значение 0, равна 0,0001.
[0114] Модуль 99 арифметического кодирования арифметически кодирует коэффициент на основании определенной оценки вероятности коэффициента, ассоциированного с назначенным контекстом. Таким образом, модуль 99 арифметического кодирования генерирует кодированный поток битов, который представляет арифметически кодированные коэффициенты, ассоциированные с TU или первого размера или второго размера, согласно объединенной контекстной модели.
[0115] После кодирования модуль 99 арифметического кодирования подает фактическое кодированное значение коэффициента назад к модулю 94 контекстного моделирования, чтобы обновить оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели, в хранилище 98 объединенной контекстной модели. Модуль 94 контекстного моделирования выполняет обновление вероятности для назначенного контекста в объединенной контекстной модели, переходя между состояниями вероятности. Например, если фактическое кодированное значение коэффициента равно 0, то вероятность, что значение коэффициента равно 0, может быть увеличена, переходя к более низкому состоянию. Посредством непрерывного обновления оценок вероятности объединенной контекстной модели, чтобы отразить фактические кодированные значения коэффициентов, оценки вероятности для будущих коэффициентов, назначенных на те же самые контексты в объединенной контекстной модели, могут быть более точными и привести к дальнейшему уменьшенному кодированию битов модулем 99 арифметического кодирования.
[0116] В первом примере хранилище 98 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, первоначально имеющим второй размер. Например, хранилище 98 объединенной контекстной модели может сохранить объединенную контекстную модель, совместно используемую блоками оставшихся коэффициентов, имеющими размер 16x16 в блоках TU, первоначально имеющих размер 32x32, и TU, первоначально имеющих размер 16x16.
[0117] Первый коэффициент в блоке оставшихся коэффициентов размера 16x16 в первом TU размером 32x32 может быть назначенным контекстом (5) в объединенной контекстной модели, совместно используемой блоком TU размером 32x32 с коэффициентами, обнуленными, чтобы генерировать блок оставшихся коэффициентов размера 16x16, и TU размером 16x16. Модуль 94 контекстного моделирования затем определяет оценку вероятности для значения первого коэффициента, ассоциированного с назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с назначенным контекстом (5) в объединенной контекстной модели, на основании фактического закодированного значения первого коэффициента. Второму коэффициенту во втором TU размером 16x16 можно также назначить тот же самый контекст (5) в объединенной контекстной модели, что и коэффициент блоке оставшихся коэффициентов в первом TU. Модуль 94 контекстного моделирования затем определяет оценку вероятности для значения второго коэффициента, ассоциированного с тем же назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с тем же назначенным контекстом (5) в объединенной контекстной модели, на основании фактического закодированного значения второго коэффициента.
[0118] Во втором примере хранилище 98 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, и блоком TU, имеющим второй размер. Например, хранилище 98 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоками TU, имеющими размеры 32x32 и 16x16. Первый коэффициент в первом TU размером 32x32 может быть назначенным контекстом (5) в объединенной контекстной модели, совместно используемой блоками TU размером 32x32 и 16x16. Модуль 94 контекстного моделирования затем определяет оценку вероятности для значения первого коэффициента, ассоциированного с назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с назначенным контекстом (5) в объединенной контекстной модели, на основании фактического закодированного значения первого коэффициента. Второму коэффициенту во втором TU размером 16x16 можно также назначить тот же самый контекст (5) в объединенной контекстной модели, что и коэффициенту в первом TU. Модуль 94 контекстного моделирования затем определяет оценку вероятности для значения второго коэффициента, ассоциированного с тем же самым назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с тем же самым назначенным контекстом (5) в объединенной контекстной модели, на основании фактического закодированного значения второго коэффициента.
[0119] Фиг. 6 является блок-схемой, иллюстрирующей пример модуля 80 статистического декодирования, сконфигурированного, чтобы выбрать контексты для коэффициентов видео согласно объединенной контекстной модели. Модуль 80 статистического декодирования включает в себя модуль 102 арифметического кодирования, модуль 104 контекстного моделирования и хранилище 106 объединенной контекстной модели. Как описано выше, способы согласно настоящему изобретению направлены на выполнение статистического декодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры. В частности, способы описаны здесь относительно процесса декодирования CABAC. Модуль 80 статистического декодирования может работать способом, по существу обратным таковому для модуля 56 статистического кодирования согласно фиг. 5.
[0120] Модуль 80 статистического декодирования поддерживает объединенную контекстную модель, совместно используемую между блоками преобразования, имеющими различные размеры, в хранилище 106 объединенной контекстной модели. Объединенная контекстная модель, сохраненная в хранилище 106 объединенной контекстной модели, по существу подобна объединенной контекстной модели, сохраненной в хранилище 98 объединенной контекстной модели в модуле 56 статистического кодирования согласно фиг. 5. В качестве одного примера, хранилище 106 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, первоначально имеющим второй размер. В качестве другого примера, хранилище 106 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, и TU, имеющим второй размер. В некоторых случаях первый размер может содержать 32x32, и второй размер может содержать 16x16.
[0121] Модуль 102 арифметического декодирования принимает закодированный поток битов, который представляет закодированные коэффициенты преобразования, ассоциированные с блоком TU или первого размера или второго размера. Модуль 102 арифметического декодирования декодирует первый коэффициент, включенный в битовый поток. Модуль 104 контекстного моделирования затем назначает контекст на последующий кодированный коэффициент, включенный в битовый поток, на основании значения первого декодированного коэффициента. Аналогичным образом модуль 104 контекстного моделирования назначает контекст на каждый из кодированных коэффициентов, включенных в битовый поток, на основании значений ранее декодированных соседних коэффициентов TU согласно объединенной контекстной модели. Более конкретно, модуль 104 контекстного моделирования может назначить контексты согласно тому, являются ли значения ранее декодированных соседних коэффициентов отличными от нуля. Назначенный контекст может относиться к индексу контекста в объединенной контекстной модели.
[0122] После того, как контекст назначен кодированному коэффициенту, модуль 104 контекстного моделирования может определить оценку вероятности для значения (например, 0 или 1) кодированного коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели. Каждый различный индекс контекста ассоциирован с оценкой вероятности. Модуль 104 контекстного моделирования подает определенную оценку вероятности кодированного коэффициента назад к модулю 102 арифметического декодирования. Модуль 102 арифметического декодирования затем арифметически декодирует кодированный коэффициент на основании определенной оценки вероятности коэффициента, ассоциированного с назначенным контекстом. Таким образом, модуль 102 арифметического декодирования генерирует декодированные коэффициенты преобразования в TU или первого размера или второго размера согласно объединенной контекстной модели.
[0123] После декодирования модуль 102 арифметического декодирования подает фактическое декодированное значение коэффициента к модулю 104 контекстного моделирования, чтобы обновить оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели в хранилище 106 объединенной контекстной модели. Посредством непрерывного обновления оценок вероятности объединенной контекстной модели, чтобы отразить фактические декодированные значения коэффициентов, оценки вероятности для будущих коэффициентов, назначенные на одни и те же контексты в объединенной контекстной модели, могут быть более точными и привести к дальнейшему уменьшенному декодированию битов посредством модуля 102 арифметического декодирования.
[0124] В первом примере хранилище 106 объединенной контекстной модели может сохранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, первоначально имеющим второй размер. Например, хранилище 106 объединенной контекстной модели может сохранить объединенную контекстную модель, совместно используемую блоком оставшихся коэффициентов, имеющим размер 16x16 в блоке TU, первоначально имеющем размер 32x32, и TU, первоначально имеющем размер 16x16.
[0125] Первый кодированный коэффициент, ассоциированный с блоком оставшихся коэффициентов размером 16x16 в первом TU размером 32x32, может быть назначенным контекстом (5) в объединенной контекстной модели, совместно используемой блоком TU размером 32x32 с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, имеющий размер 16x16, и TU размером 16x16. Модуль 104 контекстного моделирования затем определяет оценку вероятности для значения первого кодированного коэффициента, ассоциированного с назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с назначенным контекстом (5) в объединенной контекстной модели, на основании фактического декодированного значения первого коэффициента. Второму закодированному коэффициенту, ассоциированному со второй блоком TU размером 16x16, может быть назначен тот же самый контекст (5) в объединенной контекстной модели, что и первый кодированный коэффициент, ассоциированный с блоком оставшихся коэффициентов в первом TU. Модуль 104 контекстного моделирования затем определяет оценку вероятности для значения второго кодированного коэффициента, ассоциированного с одним и тем же назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с одним и тем же назначенным контекстом (5) в объединенной контекстной модели, на основании фактического декодированного значения второго коэффициента.
[0126] Во втором примере хранилище 106 объединенной контекстной модели может сохранить объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, и блоком TU, имеющим второй размер. Например, хранилище 106 объединенной контекстной модели может хранить объединенную контекстную модель, совместно используемую блоками TU, имеющими размеры 32x32 и 16x16. Первый кодированный коэффициент, ассоциированный с первой блоком TU размером 32x32, может иметь назначенный контекст (5) в объединенной контекстной модели, совместно используемой блоком TU размером 32x32, и блоком TU размером 16x16. Модуль 104 контекстного моделирования затем определяет оценку вероятности для значения первого кодированного коэффициента, ассоциированного с назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с назначенным контекстом (5) в объединенной контекстной модели, на основании фактического декодированного значения первого коэффициента. Второму кодированному коэффициенту, ассоциированному со вторым блоком TU размером 16x16, может быть назначен тот же самый контекст (5) в объединенной контекстной модели, что и первый кодированный коэффициент, ассоциированный с первой блоком TU. Модуль 104 контекстного моделирования затем определяет оценку вероятности для значения второго кодированного коэффициента, ассоциированного с одним и тем же назначенным контекстом (5) в объединенной контекстной модели, и обновляет оценку вероятности, ассоциированную с одним и тем же назначенным контекстом (5) в объединенной контекстной модели, на основании фактического декодированного значения второго коэффициента.
[0127] Фиг. 7 является последовательностью операций, иллюстрирующей примерную операцию статистического кодирования и декодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между первым блоком преобразования, имеющим первый размер, и вторым блоком преобразования, имеющим второй размер. Иллюстрированная операция описана в отношении модуля 56 статистического кодирования согласно фиг. 5 в кодере 20 видео согласно фиг. 2 и модуля 80 статистического декодирования согласно фиг. 6 в декодере 30 видео согласно фиг. 3, хотя другие устройства могут реализовать подобные способы.
[0128] В иллюстрированной операции модуль 56 статистического кодирования в кодере 20 видео и модуль 80 статистического кодирования в декодере 30 видео могут поддерживать объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер, и блоком TU, имеющим второй размер. В этом случае коэффициенты, включенные в первый TU, имеющий первый размер, например, 32x32, могут иметь аналогичную статистику вероятности, что и коэффициенты, включенные во второй TU второго размера, например, 16x16, даже без обнуления высокочастотных коэффициентов в первом TU. Это может быть возможно, когда высокочастотные коэффициенты представляют такие маленькие остаточные данные видео, что влияние на вероятностную статистику соседних коэффициентов для статистического кодирования незначительно.
[0129] В одном случае кодер 20 видео может использовать модуль 52 преобразования, чтобы преобразовать остаточные данные видео в коэффициенты преобразования в блоке TU, имеющем первый размер (120). В другом случае кодер 20 видео может использовать модуль 52 преобразования, чтобы преобразовать остаточные данные видео в коэффициенты преобразования в блоке TU, имеющем второй размер (121). Независимо от того, имеет ли TU первый размер или второй размер, способы согласно настоящему изобретению позволяют модулю 56 статистического кодирования статистически кодировать коэффициенты в блоке TU согласно одной и той же объединенной контекстной модели. Эти способы поэтому уменьшают объем памяти, необходимой, чтобы хранить контексты и вероятности на кодере 20 видео, и уменьшить вычислительные затраты поддержания контекстных моделей на кодере 20 видео.
[0130] Модуль 94 контекстного моделирования в модуле 56 статистического кодирования выбирает контекст для каждого коэффициента в блоке TU согласно объединенной контекстной модели, совместно используемой блоками TU, имеющими и первый размер и второй размер (122). Более конкретно, модуль 94 контекстного моделирования назначает контекст на заданный коэффициент блока TU на основании значений ранее кодированных соседних коэффициентов этого блока TU согласно объединенной контекстной модели. Модуль 94 контекстного моделирования затем может определить оценку вероятности для значения (например, 0 или 1) коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели в хранилище 98 объединенной контекстной модели. Модуль 99 арифметического кодирования затем арифметически кодирует этот коэффициент на основании выбранного контекста для этого коэффициента (124).
[0131] После кодирования модуль 99 арифметического кодирования подает фактические кодированные значения коэффициентов назад к модулю 94 контекстного моделирования. Модуль 94 контекстного моделирования может затем обновить оценку вероятности объединенной контекстной модели на основании фактических кодированных значений коэффициентов в блоке TU или первого размера или второго размера (126). Кодер 20 видео передает поток битов, представляющий кодированные коэффициенты, ассоциированные с блоком TU или первого размера или второго размера, к декодеру 30 видео (128).
[0132] Декодер 30 видео может принять поток битов, который представляет кодированные коэффициенты, ассоциированные с блоком TU, имеющим или первый размер или второй размер (130). Независимо от того, имеет ли TU первый размер или второй размер, способы согласно настоящему изобретению позволяют модулю 80 статистического декодирования статистически декодировать коэффициенты, ассоциированные с блоком TU, на основании одной и той же объединенной контекстной модели. Эти способы поэтому могут уменьшить объем памяти, необходимой, чтобы хранить контексты и вероятности на декодере 30 видео, и уменьшить вычислительные затраты поддержания контекстных моделей на декодере 30 видео.
[0133] Модуль 104 контекстного моделирования в модуле 80 статистического декодирования выбирает контекст для каждого кодированного коэффициента, ассоциированного с блоком TU, согласно объединенной контекстной модели, совместно используемой блоками TU, имеющими и первый размер и второй размер (132). Более конкретно, модуль 104 контекстного моделирования может назначить контекст на последующий кодированный коэффициент, ассоциированный с блоком TU, на основании значений ранее декодированных соседних коэффициентов TU согласно объединенной контекстной модели. Модуль 104 контекстного моделирования затем может определить оценку вероятности для значения (например, 0 или 1) кодированного коэффициента, ассоциированного с назначенным контекстом, в объединенной контекстной модели в хранилище 106 объединенной контекстной модели. Модуль 104 контекстного моделирования подает определенную оценку вероятности, ассоциированную с выбранным контекстом для кодированного коэффициента, назад к модулю 102 арифметического декодирования. Модуль 102 арифметического декодирования затем арифметически декодирует кодированный коэффициент в блок TU или первого размера или второго размера на основании выбранного контекста (134).
[0134] После декодирования, модуль 102 арифметического декодирования подает фактические декодированные значения коэффициентов к модулю 104 контекстного моделирования. Модуль 104 контекстного моделирования может затем обновить оценку вероятности объединенной контекстной модели на основании фактических декодированных значений коэффициентов в блоке TU или первого размера или второго размера (136). В одном случае декодер 30 видео может использовать модуль 88 обратного преобразования для обратного преобразования коэффициентов в блоке TU, имеющем первый размер, в остаточные данные видео (138). В другом случае декодер 30 видео может использовать модуль 88 обратного преобразования для обратного преобразования коэффициентов в блоке TU, имеющем второй размер, в остаточные данные видео (139).
[0135] Фиг. 8 является последовательностью операций, иллюстрирующей примерную операцию статистического кодирования и декодирования коэффициентов видео, используя объединенную контекстную модель, совместно используемую между первым блоком преобразования, имеющим первый размер, с коэффициентами, обнуленными, чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и вторым блоком преобразования, имеющим второй размер. Иллюстрированная операция описана в отношении модуля 56 статистического кодирования согласно фиг. 4 в кодере 20 видео согласно фиг. 2 и модуля 80 статистического декодирования согласно фиг. 5 в декодере 30 видео согласно фиг. 3, хотя другие устройства могут реализовать подобные способы.
[0136] В иллюстрированной операции модуль 56 статистического кодирования в кодере 20 видео и модуль 80 статистического кодирования в декодере 30 видео могут поддерживать объединенную контекстную модель, совместно используемую блоком TU, имеющим первый размер с коэффициентом, обнуленным, чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, имеющим второй размер. В этом случае коэффициенты, включенные в блок оставшихся коэффициентов, имеющий второй размер, например, 16x16, в первом блоке TU, имеющем первый размер, например, 32x32, может иметь аналогичную статистику вероятности, что и коэффициенты, включенные во второй TU второго размера, например, 16x16.
[0137] В одном случае кодер 20 видео может использовать модуль 52 преобразования, чтобы преобразовать остаточные данные видео в коэффициенты преобразования в блоке TU, имеющем первый размер (140). Кодер 20 видео обнуляет поднабор коэффициентов, включенных в первый TU после преобразования, для генерирования блока оставшихся коэффициентов, имеющего второй размер в первом TU (141). Поднабор обнуленных коэффициентов преобразования обычно включает в себя высокочастотные коэффициенты преобразования относительно коэффициентов в блоке оставшихся коэффициентов. Высокочастотные коэффициенты преобразования могут содержать такие маленькие остаточные данные видео, что установка этих значений равными нулю имеет незначительное влияние на качество декодированного видео. В другом случае кодер 20 видео может использовать модуль 52 преобразования, чтобы преобразовать остаточные данные видео в коэффициенты преобразования в блоке TU, имеющем второй размер (142).
[0138] Независимо от того, имеет ли TU первоначально первый размер или второй размер, способы согласно настоящему изобретению позволяют модулю 56 статистического кодирования статистически кодировать оставшиеся коэффициенты в блоке TU согласно одной и той же объединенной контекстной модели. Эти способы поэтому уменьшают объем памяти, необходимой, чтобы хранить контексты и вероятности на кодере 20 видео и уменьшить вычислительные затраты поддержания контекстных моделей на кодере 20 видео.
[0139] Модуль 94 контекстного моделирования в модуле 56 статистического кодирования выбирает контекст для каждого оставшегося коэффициента в блоке TU согласно объединенной контекстной модели, совместно используемой блоком TU, имеющим первый размер, с коэффициентами, обнуленными до второго размера, и блоком TU, имеющим второй размер (144). Более конкретно, модуль 94 контекстного моделирования назначает контекст на заданный коэффициент в блоке оставшихся коэффициентов первого блока TU на основании значений ранее кодированных соседних коэффициентов блока оставшихся коэффициентов согласно объединенной контекстной модели. Модуль 94 контекстного моделирования затем может определить оценку вероятности для значения (например, 0 или 1) коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели, в хранилище 98 объединенной контекстной модели. Модуль 99 арифметического кодирования затем арифметически кодирует этот коэффициент на основании выбранного контекста для коэффициента (146).
[0140] После кодирования модуль 99 арифметического кодирования подает фактические кодированные значения коэффициентов назад к модулю 94 контекстного моделирования. Модуль 94 контекстного моделирования может затем обновить оценку вероятности объединенной контекстной модели на основании фактических кодированных значений коэффициентов в блоке оставшихся коэффициентов второго размера в блоке TU первого размера, или TU первоначально второго размера (148). Кодер 20 видео передает поток битов, представляющий кодированные коэффициенты, ассоциированные с блоком оставшихся коэффициентов в блоке TU первого размера, или блоком TU второго размера, к декодеру 30 видео (150).
[0141] Декодер 30 видео может принять поток битов, который представляет кодированные коэффициенты, ассоциированные с блоком оставшихся коэффициентов второго размера в блоке TU первого размера, или блоком TU первоначально второго размера (152). Независимо от того, имеет ли TU первый размер или второй размер, способы согласно настоящему изобретению позволяют модулю 80 статистического декодирования статистически декодировать коэффициенты, ассоциированные с блоком TU на основании одной и той же объединенной контекстной модели. Эти способы поэтому уменьшают объем памяти, необходимой, чтобы хранить контексты и вероятности на декодере 30 видео, и уменьшить вычислительные затраты поддержания контекстных моделей на декодере 30 видео.
[0142] Модуль 104 контекстного моделирования в модуле 80 статистического декодирования выбирает контекст для каждого коэффициента, ассоциированного с блоком TU согласно объединенной контекстной модели, совместно используемой блоком TU, имеющим первый размер, с коэффициентами, обнуленными чтобы генерировать блок оставшихся коэффициентов, имеющий второй размер, и блоком TU, имеющим второй размер (154). Более конкретно, модуль 104 контекстного моделирования может назначить контекст на последующий кодированный коэффициент, ассоциированный с блоком оставшихся коэффициентов первого TU на основании значений ранее декодированных соседних коэффициентов блока оставшихся коэффициентов согласно объединенной контекстной модели. Модуль 104 контекстного моделирования затем может определить оценку вероятности для значения (например, 0 или 1) кодированного коэффициента, ассоциированного с назначенным контекстом в объединенной контекстной модели, в хранилище 106 объединенной контекстной модели. Модуль 104 контекстного моделирования подает определенную вероятность, ассоциированную с выбранным контекстом для кодированного коэффициента, назад к модулю 102 арифметического декодирования. Модуль 102 арифметического декодирования затем арифметически декодирует кодированный коэффициент в блок оставшихся коэффициентов в блоке TU первого размера, или TU второго размера на основании выбранного контекста (156).
[0143] После декодирования модуль 102 арифметического декодирования подает фактические декодированные значения коэффициентов к модулю 104 контекстного моделирования. Модуль 104 контекстного моделирования может затем обновить оценку вероятности объединенной контекстной модели на основании фактических декодированных значений коэффициентов в блоке оставшихся коэффициентов второго размера в блоке TU первого размера, или блоке TU первоначально второго размера (158). В одном случае декодер 30 видео может использовать модуль 88 обратного преобразования для обратного преобразования коэффициентов блока оставшихся коэффициентов, имеющего второй размер в блоке TU, имеющем первый размер, в остаточные данные видео (160). Таким образом, модуль 88 обратного преобразования может генерировать TU, имеющий первый размер, посредством включения остаточных данных блока оставшихся коэффициентов, имеющего второй размер, и добавления нулей, представляющих оставшиеся остаточные данные в TU. В другом случае декодер 30 видео может использовать модуль 88 обратного преобразования для обратного преобразования коэффициентов в блоке TU, имеющем второй размер, в остаточные данные видео (162).
[0144] В одном или более примерах описанные функции могут быть реализованы в аппаратном обеспечении, программном обеспечении, программно-аппаратных средствах, или любой их комбинации. Если реализовано в программном обеспечении, эти функции могут быть сохранены на или переданы, как одна или более инструкций или код, посредством считываемого компьютером носителя и выполнены основанным на аппаратном обеспечении блоком обработки. Считываемый компьютером носитель может включать в себя считываемый компьютером носитель данных, который соответствует материальному носителю, такому как запоминающий носитель данных, или коммуникационный носитель, включающий в себя любой носитель, который облегчает передачу компьютерной программы от одного места к другому, например, согласно протоколу связи. В этом способе считываемый компьютером носитель в целом может соответствовать (1) материальному считываемому компьютером носитель данных, который является невременным, или (2) коммуникационному носителю, такому как сигнал или несущая. Запоминающим носителем данных может быть любой доступный носитель, к которой могут получить доступ один или более компьютеров или один или более процессоров, чтобы извлечь инструкции, код и/или структуры данных для реализации способов, описанных в настоящем изобретении. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
[0145] Посредством примера, а не ограничения, такие считываемые компьютером носители данных могут содержать RAM, ROM, EEPROM, CD-ROM или другое запоминающее устройство на оптические дисках, запоминающее устройство на магнитных дисках, или другие магнитные устройства хранения, флэш-память, или любой другой носитель, который может использоваться, чтобы хранить желательный код программы в форме инструкций или структур данных, и к которому может получить доступ компьютер. Кроме того, любое соединение должным образом называют считываемым компьютером носителем. Например, если инструкции переданы от вебсайта, сервера, или другого удаленного источника, использующего коаксиальный кабель, волоконно-оптический кабель, витую пару, цифровую абонентскую линию (DSL), или беспроводные технологии, такие как инфракрасное, радио и микроволновое излучения, то эти коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL, или беспроводные технологии, такие как инфракрасное, радио и микроволновое излучения включаются в определение носителя. Нужно подразумевать, однако, что считываемые компьютером носители данных и запоминающие устройства данных не включают в себя соединения, несущие, сигналы, или другие временные носители, но вместо этого направлены на невременные, материальные носители данных. Диск и диск, как используется здесь, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), дискета и диск Blu-ray, где диски (disks) обычно воспроизводят данные магнитным образом, в то время как диски (dicks) обычно воспроизводят данные оптически с помощью лазеров. Комбинации вышеупомянутого должны также быть включены в рамки считываемого компьютером носителя.
[0146] Инструкции могут быть выполнены один или более процессорами, такими как один или более цифровых сигнальных процессоров (DSP), микропроцессоры общего назначения, специализированные интегральные схемы (ASIC), программируемые пользователем логические матрицы (FPGA), или другие эквивалентные интегральные или дискретные логические схемы. Соответственно, термин "процессор", как используется здесь, может относиться к любой предшествующей структуре или любой другой структуре, подходящей для реализации способов, описанных здесь. Кроме того, в некоторых аспектах функциональные возможности, описанные здесь, могут быть обеспечены в специализированном аппаратном обеспечении и/или программных модулях, сконфигурированных для кодирования и декодирования, или встроенные в объединенный кодек. Кроме того, способы могут быть полностью реализованы в одной или более схемах или логических элементах.
[0147] Способы согласно настоящему изобретению могут быть реализованы в широком разнообразии устройств или устройств, включая беспроводную телефонную трубку, интегральную схему (IC) или набор IC (например, микропроцессорный набор). Различные компоненты, модули, или блоки описаны в настоящем изобретении, чтобы подчеркнуть функциональные аспекты устройств, конфигурируемых, чтобы выполнять раскрытые способы, но не обязательно требовать реализации различными блоками аппаратного обеспечения. Вместо этого, как описано выше, различные блоки могут быть объединены в блок аппаратного обеспечения кодека или снабжены коллекцией взаимодействующих блоков аппаратного обеспечения, включая один или более процессоров, как описано выше, в соединении с подходящим программным обеспечением и/или программно-аппаратными средствами.
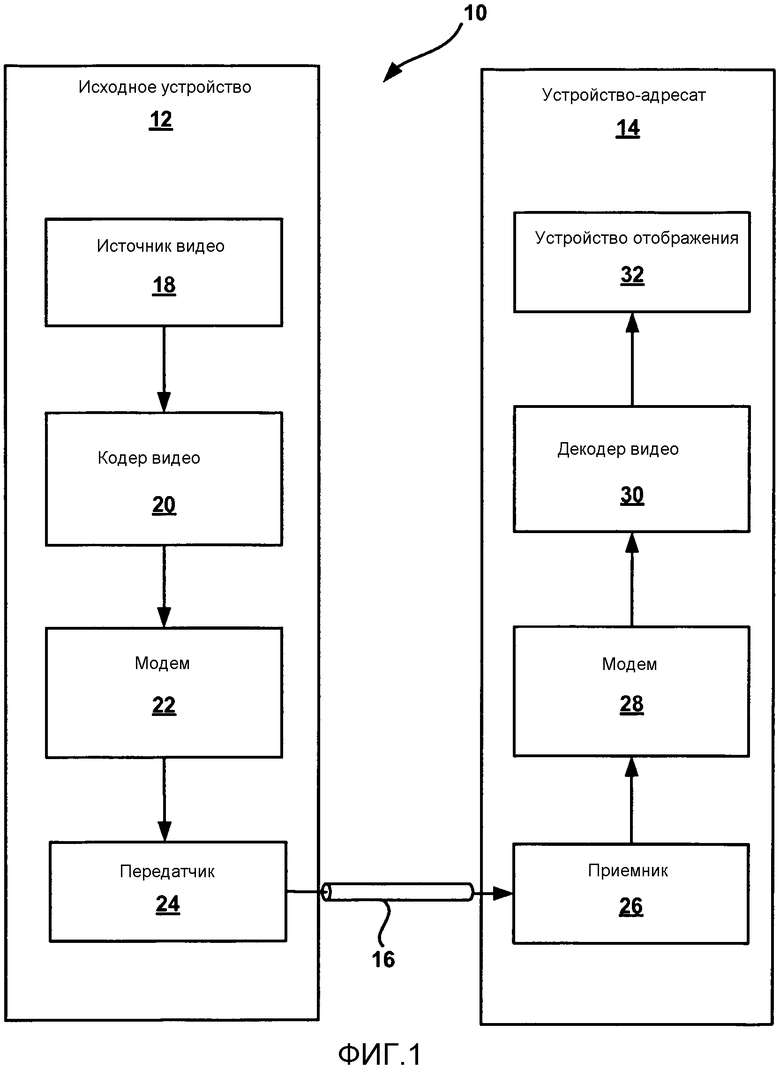
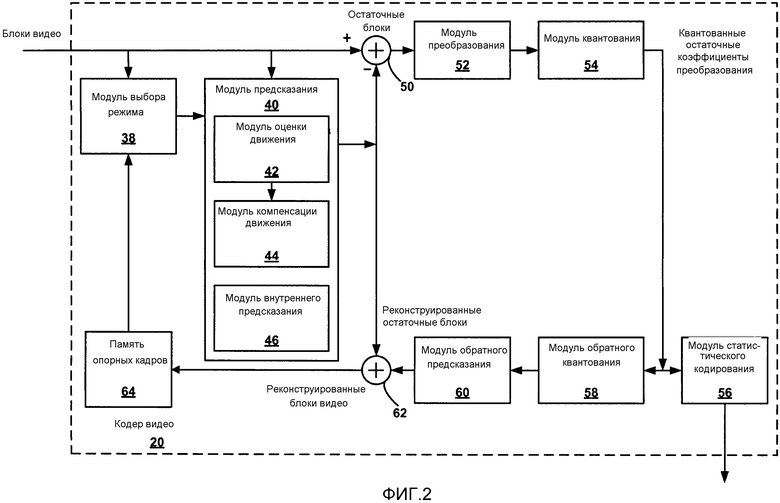
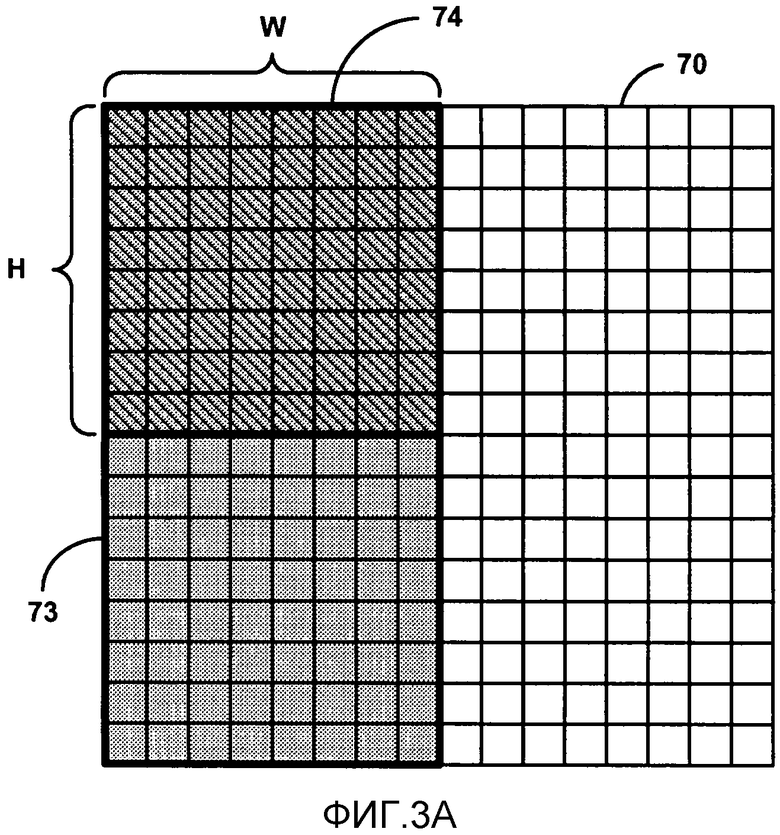
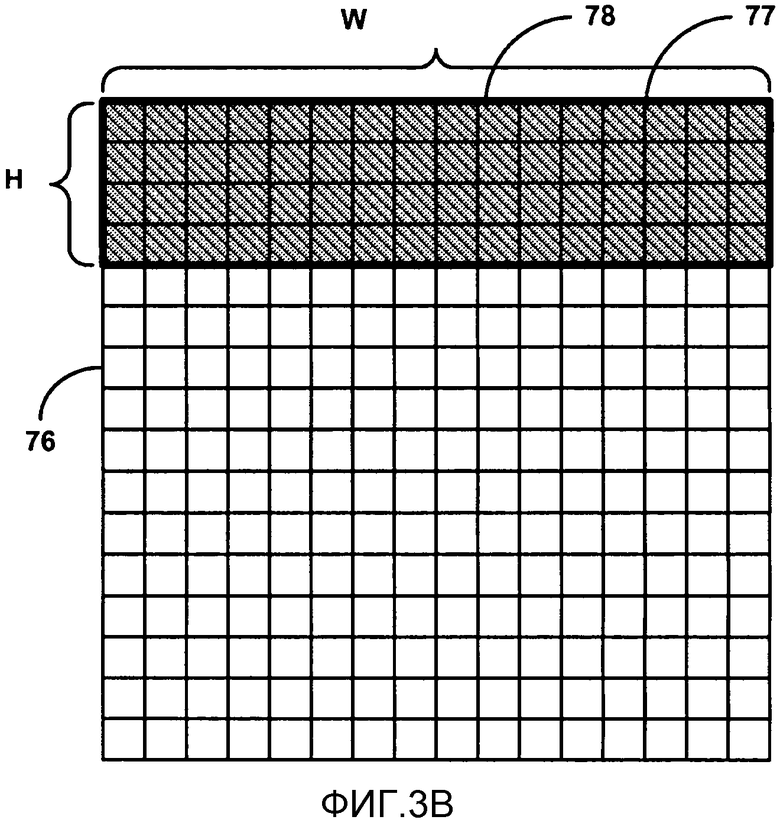
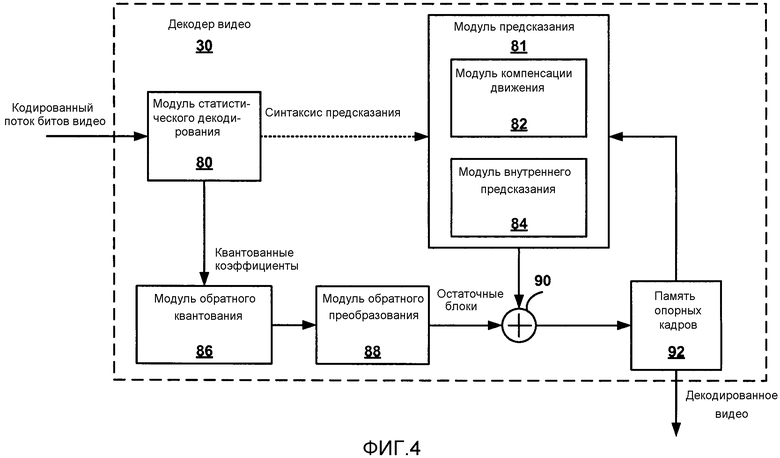
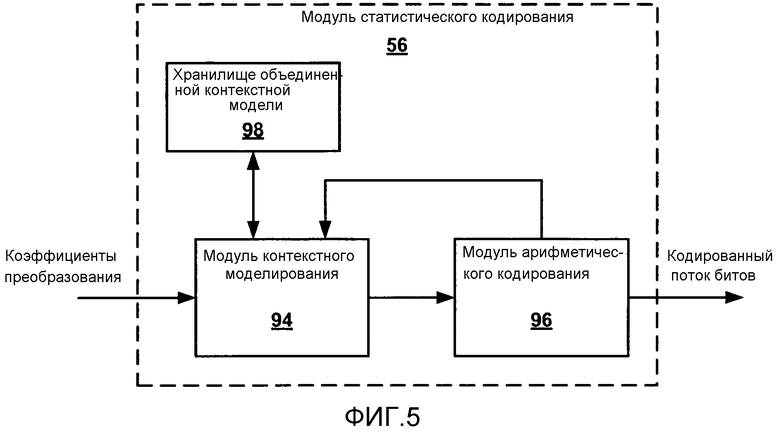
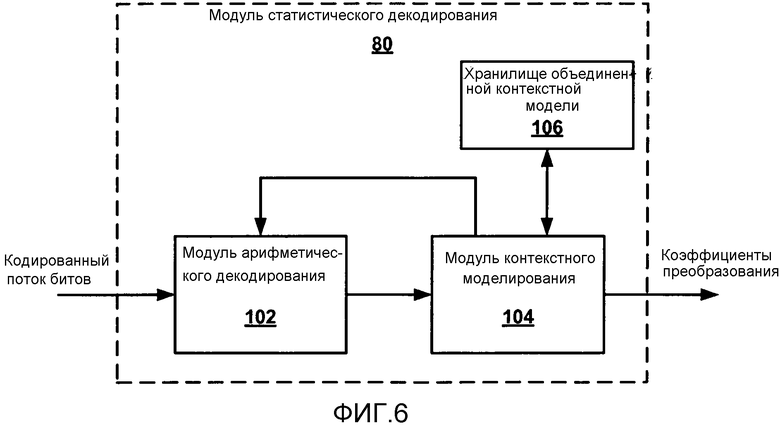
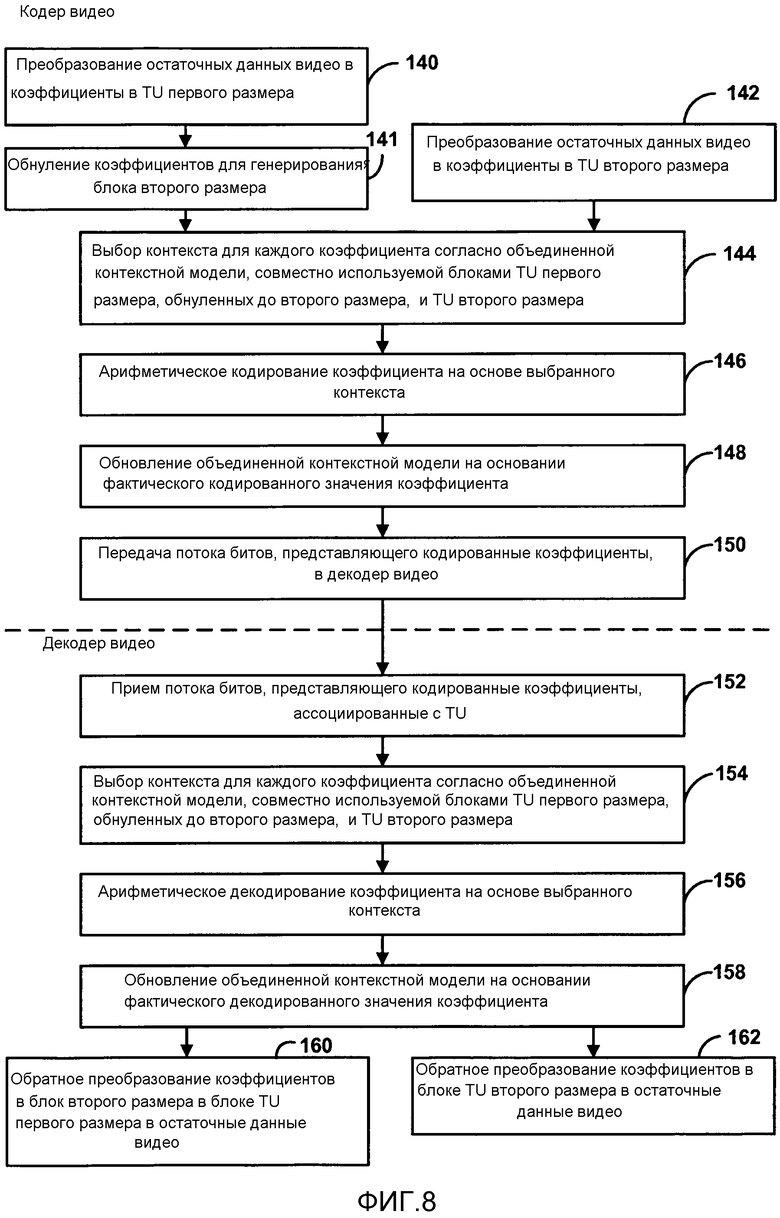
Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении объема памяти, необходимой для сохранения контекстов и вероятностей на устройствах кодирования и декодирования видео. Способ кодировки видео данных содержит поддержание множества контекстных моделей для энтропийного кодирования коэффициентов преобразования видео данных, при этом множество контекстных моделей включает в себя одну или более контекстных моделей, причем каждая используется для различного размера единицы преобразования, и по меньшей мере одну объединенную контекстную модель, используемую для двух или более размеров единицы преобразования; выбор объединенной контекстной модели, совместно используемой первой единицей преобразования и второй единицей преобразования; выбор контекстов для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели; и энтропийное кодирование коэффициентов преобразования упомянутой одной из единиц преобразования, используя контекстно-адаптивное двоичное арифметическое кодирование (САВАС) на основании выбранных контекстов. 4 н. и 30 з.п. ф-лы, 9 ил.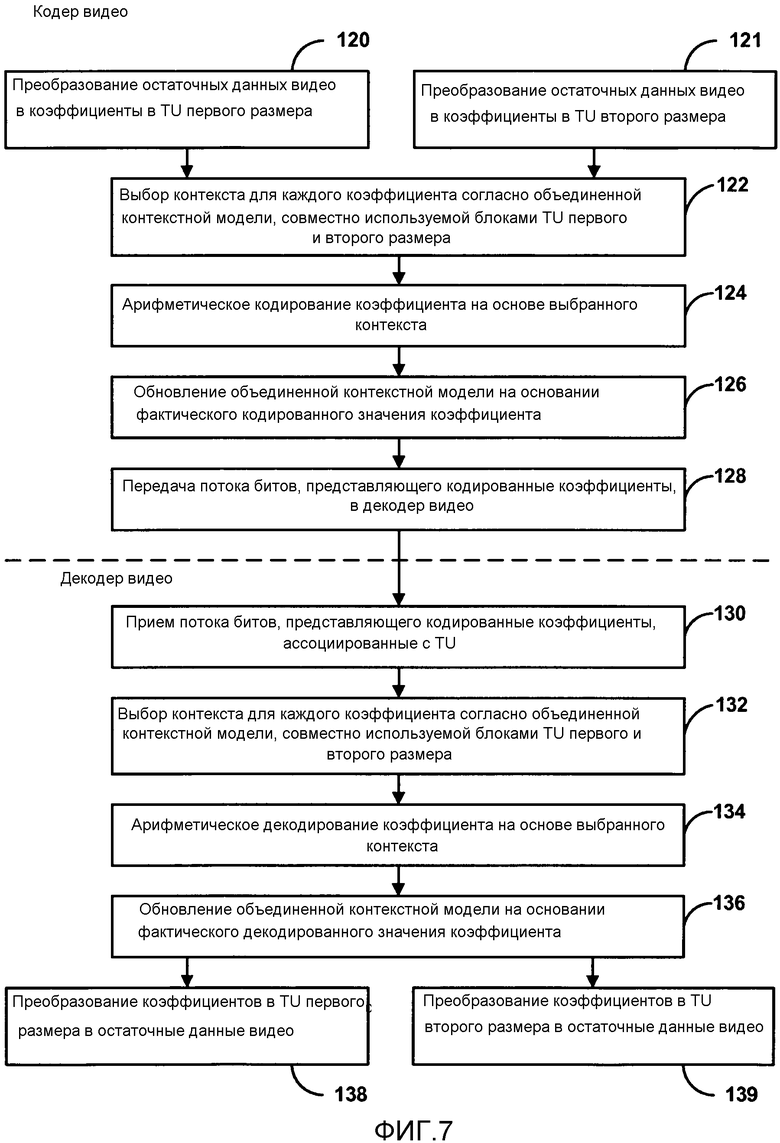
1. Способ кодировки видео данных, содержащий:
поддержание множества контекстных моделей для энтропийного кодирования коэффициентов преобразования видео данных, при этом множество контекстных моделей включает в себя одну или более контекстных моделей, причем каждая используется для различного размера единицы преобразования, и по меньшей мере одну объединенную контекстную модель, используемую для двух или более размеров единицы преобразования;
выбор объединенной контекстной модели, совместно используемой первой единицей преобразования, имеющей первый размер, и второй единицей преобразования, имеющей второй размер, для энтропийного кодирования коэффициентов преобразования в одной из первой единицы преобразования или второй единицы преобразования, при этом первый размер и второй размер различны, и при этом каждая из единиц преобразования содержит остаточную единицу данных видео, включающую в себя множество блоков коэффициентов преобразования;
выбор контекстов для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели, при этом выбор контекстов для коэффициентов преобразования содержит назначение контекста в объединенной контекстной модели заданному одному из коэффициентов преобразования на основании значений ранее закодированных соседних коэффициентов преобразования упомянутой одной из единиц преобразования и определение оценки вероятности для значения заданного одного из коэффициентов преобразования, ассоциированных с назначенным контекстом в объединенной контекстной модели; и
энтропийное кодирование коэффициентов преобразования упомянутой одной из единиц преобразования, используя контекстно-адаптивное двоичное арифметическое кодирование (САВАС) на основании выбранных контекстов.
2. Способ по п. 1, при этом объединенная контекстная модель содержит объединенную контекстную модель карты значимости, дополнительно содержащий:
выбор контекстов для компонентов карты значимости для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели; и
энтропийное кодирование компонентов карты значимости, ассоциированных с упомянутой одной из единиц преобразования на основании выбранных контекстов.
3. Способ по п. 1, дополнительно содержащий обновление оценки вероятности, ассоциированной с назначенным контекстом, в объединенной контекстной модели на основании фактических закодированных значений коэффициентов преобразования первой единицы преобразования, имеющей первый размер, и второй единицы преобразования, имеющей второй размер.
4. Способ по п. 1, в котором способ содержит способ декодирования видео данных, причем способ дополнительно содержит:
прием потока битов, который представляет закодированные коэффициенты преобразования, ассоциированные с одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбор контекстов для закодированных коэффициентов преобразования согласно объединенной контекстной модели; и
энтропийное декодирование закодированных коэффициентов преобразования в одну из единиц преобразования на основании выбранных контекстов.
5. Способ по п. 4, дополнительно содержащий обратное преобразование коэффициентов преобразования упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер, в остаточные пиксельные значения.
6. Способ по п. 1, в котором способ содержит способ кодирования видео данных, причем способ дополнительно содержит:
преобразование остаточных пиксельных значений в коэффициенты преобразования в пределах упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбор контекстов для коэффициентов преобразования упомянутой одной из единиц преобразования согласно объединенной контекстной модели; и
энтропийное кодирование коэффициентов преобразования упомянутой одной из единиц преобразования на основании выбранных контекстов.
7. Способ по п. 1, в котором первая единица преобразования первого размера содержит единицу преобразования 32×32, и в котором вторая единица преобразования второго размера содержит единицу преобразования 16×16.
8. Способ по п. 1, в котором выбор контекстов согласно объединенной контекстной модели содержит:
назначение контекста в объединенной контекстной модели первому коэффициенту преобразования первой единицы преобразования, имеющей первый размер, на основании значений ранее закодированных соседних коэффициентов преобразования первой единицы преобразования;
определение оценки вероятности для значения первого коэффициента преобразования, ассоциированного с назначенным контекстом в объединенной контекстной модели;
обновление оценки вероятности, ассоциированной с назначенным контекстом в объединенной контекстной модели на основании фактического закодированного значения первого коэффициента преобразования;
назначение того же самого контекста в объединенной контекстной модели второму коэффициенту преобразования второй единицы преобразования, имеющей второй размер, на основании значений ранее закодированных соседних коэффициентов преобразования второй единицы преобразования;
определение оценки вероятности для значения второго коэффициента преобразования, ассоциированного с тем же самым назначенным контекстом в объединенной контекстной модели; и
обновление оценки вероятности, ассоциированной с тем же самым назначенным контекстом в объединенной контекстной модели на основании фактического закодированного значения второго коэффициента преобразования.
9. Способ по п. 1, дополнительно содержащий выбор одной из упомянутых одной или более контекстных моделей для энтропийного кодирования коэффициентов преобразования в единице преобразования, имеющей третий размер, при этом третий размер отличается от первого размера и второго размера.
10. Способ по п. 1, в котором энтропийное кодирование коэффициентов преобразования упомянутой одной из единиц преобразования, используя САВАС, содержит арифметическое кодирование заданного одного из коэффициентов преобразования на основании определенной оценки вероятности для значения заданного одного из коэффициентов преобразования, ассоциированных с назначенным контекстом.
11. Устройство кодировки видео, содержащее:
память, сконфигурированную для хранения множества контекстных моделей для энтропийного кодирования коэффициентов преобразования видео данных, при этом множество контекстных моделей включает в себя одну или более контекстных моделей, которые каждая используются для различного размера единицы преобразования, и по меньшей мере одну объединенную контекстную модель, используемую для двух или более размеров единицы преобразования; и
процессор, сконфигурированный для:
выбора объединенной контекстной модели, совместно используемой первой единицей преобразования, имеющей первый размер, и второй единицей преобразования, имеющей второй размер, для энтропийного кодирования коэффициентов преобразования в одной из первой единицы преобразования или второй единицы преобразования, при этом первый размер и второй размер различны, и при этом каждая из единиц преобразования содержит остаточную единицу данных видео, включающую в себя множество блоков коэффициентов преобразования,
выбора контекстов для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели, при этом процессор сконфигурирован, чтобы назначать контекст в объединенной контекстной модели заданному одному из коэффициентов преобразования на основании значений ранее закодированных соседних коэффициентов преобразования упомянутой одной из единиц преобразования и определять оценку вероятности для значения заданного одного из коэффициентов преобразования, ассоциированных с назначенным контекстом в объединенной контекстной модели, и
энтропийно кодировать коэффициенты преобразования упомянутой одной из единиц преобразования, используя контекстно-адаптивное двоичное арифметическое кодирование (САВАС) на основании выбранных контекстов.
12. Устройство кодировки видео по п. 11, в котором объединенная контекстная модель содержит объединенную контекстную модель карты значимости, при этом процессор сконфигурирован, чтобы:
выбирать контексты для компонентов карты значимости для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели; и
энтропийно кодировать компоненты карты значимости, ассоциированные с упомянутой одной из единиц преобразования на основании выбранных контекстов.
13. Устройство кодировки видео по п. 11, в котором процессор сконфигурирован, чтобы обновлять оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели на основании фактических закодированных значений коэффициентов преобразования первой единицы преобразования, имеющей первый размер, и второй единицы преобразования, имеющей второй размер.
14. Устройство кодировки видео по п. 11, в котором устройство кодировки видео содержит устройство декодирования видео, в котором процессор сконфигурирован, чтобы:
принимать поток битов, который представляет закодированные коэффициенты преобразования, ассоциированные с одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбирать контексты для закодированных коэффициентов преобразования согласно объединенной контекстной модели; и
энтропийно декодировать закодированные коэффициенты преобразования в одну из единиц преобразования на основании выбранных контекстов.
15. Устройство кодировки видео по п. 14, в котором процессор сконфигурирован для обратного преобразования коэффициентов преобразования упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер, в остаточные пиксельные значения.
16. Устройство кодировки видео по п. 11, в котором устройство кодировки видео содержит устройство кодирования видео, в котором процессор сконфигурирован, чтобы:
преобразовывать остаточные пиксельные значения в коэффициенты преобразования в пределах упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбирать контексты для коэффициентов преобразования упомянутой одной из единиц преобразования согласно объединенной контекстной модели; и
энтропийно кодировать коэффициенты преобразования упомянутой одной из единиц преобразования на основании выбранных контекстов.
17. Устройство кодировки видео по п. 11, в котором первая единица преобразования первого размера содержит единицу преобразования 32×32, и в котором вторая единица преобразования второго размера содержит единицу преобразования 16×16.
18. Устройство кодировки видео по п. 11, в котором процессор сконфигурирован, чтобы:
назначать контекст в объединенной контекстной модели первому коэффициенту преобразования первой единицы преобразования, имеющей первый размер, на основании значений ранее закодированных соседних коэффициентов преобразования первой единицы преобразования;
определять оценку вероятности для значения первого коэффициента преобразования, ассоциированного с назначенным контекстом в объединенной контекстной модели;
обновлять оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели, на основании фактического закодированного значения первого коэффициента преобразования;
назначать тот же самый контекст в объединенной контекстной модели второму коэффициенту преобразования второй единицы преобразования, имеющей второй размер, на основании значений ранее закодированных соседних коэффициентов преобразования второй единицы преобразования;
определять оценку вероятности для значения второго коэффициента преобразования, ассоциированного с тем же самым назначенным контекстом, в объединенной контекстной модели; и
обновлять оценку вероятности, ассоциированную с тем же самым назначенным контекстом в объединенной контекстной модели, на основании фактического закодированного значения второго коэффициента преобразования.
19. Устройство кодировки видео по п. 11, в котором процессор сконфигурирован, чтобы выбирать одну из упомянутых одной или более контекстных моделей для энтропийного кодирования коэффициентов преобразования в единице преобразования, имеющей третий размер, при этом третий размер отличается от первого размера и второго размера.
20. Устройство кодировки видео по п. 11, в котором процессор сконфигурирован для арифметической кодировки заданного одного из коэффициентов преобразования на основании определенной оценки вероятности для упомянутого значения одного из коэффициентов преобразования, ассоциированных с назначенным контекстом.
21. Устройство кодировки видео, содержащее:
средство для поддержания множества контекстных моделей для энтропийного кодирования коэффициентов преобразования видео данных, при этом множество контекстных моделей включает в себя одну или более контекстных моделей, причем каждая используется для различного размера единицы преобразования, и по меньшей мере одну объединенную контекстную модель, используемую для двух или более размеров единицы преобразования;
средство для выбора объединенной контекстной модели, совместно используемой первой единицей преобразования, имеющей первый размер, и второй единицей преобразования, имеющей второй размер, для энтропийного кодирования коэффициентов преобразования в одной из первой единицы преобразования или второй единицы преобразования, при этом первый размер и второй размер различны, и при этом каждая из единиц преобразования содержит остаточную единицу данных видео, включающую в себя множество блоков коэффициентов преобразования;
средство для выбора контекстов для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели, при этом средство для выбора контекстов для коэффициентов преобразования содержит средство для назначения контекста в объединенной контекстной модели заданному одному из коэффициентов преобразования на основании значений ранее закодированных соседних коэффициентов преобразования упомянутой одной из единиц преобразования и средство для определения оценки вероятности для значения заданного одного из коэффициентов преобразования, ассоциированных с назначенным контекстом в объединенной контекстной модели; и
средство для энтропийного кодирования коэффициентов преобразования упомянутой одной из единиц преобразования, используя контекстно-адаптивное двоичное арифметическое кодирование (САВАС), на основании выбранных контекстов.
22. Устройство кодировки видео по п. 21, причем объединенная контекстная модель содержит объединенную контекстную модель карты значимости, дополнительно содержащее:
средство для выбора контекстов для компонентов карты значимости для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели; и
средство для энтропийного кодирования компонентов карты значимости, ассоциированных с упомянутой одной из единиц преобразования, на основании выбранных контекстов.
23. Устройство кодировки видео по п. 21, дополнительно содержащее средство обновления оценки вероятности, ассоциированной с назначенным контекстом в объединенной контекстной модели, на основании фактических закодированных значений коэффициентов преобразования первой единицы преобразования, имеющей первый размер, и второй единицы преобразования, имеющей второй размер.
24. Устройство кодировки видео по п. 21, в котором устройство кодировки видео содержит устройство декодирования видео, дополнительно содержащее:
средство для приема потока битов, который представляет закодированные коэффициенты преобразования, ассоциированные с одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
средство для выбора контекстов для закодированных коэффициентов преобразования согласно объединенной контекстной модели; и
средство для энтропийного декодирования закодированных коэффициентов преобразования в одну из единиц преобразования на основании выбранных контекстов.
25. Устройство кодировки видео по п. 24, дополнительно содержащее средство для обратного преобразования коэффициентов преобразования упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер, в остаточные пиксельные значения.
26. Устройство кодировки видео по п. 21, в котором устройство кодировки видео содержит устройство кодирования видео, дополнительно содержащее:
средство для преобразования остаточных пиксельных значений в коэффициенты преобразования в пределах упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
средство для выбора контекстов для коэффициентов преобразования упомянутой одной из единиц преобразования согласно объединенной контекстной модели; и
средство для энтропийного кодирования коэффициентов преобразования упомянутой одной из единиц преобразования на основании выбранных контекстов.
27. Устройство кодировки видео по п. 21, в котором первая единица преобразования первого размера содержит единицу преобразования 32×32, и в котором вторая единица преобразования второго размера содержит единицу преобразования 16×16.
28. Считываемый компьютером носитель, имеющий сохраненные на нем инструкции для кодировки видео данных, которые, когда выполняются, вынуждают процессор:
поддерживать множество контекстных моделей для энтропийного кодирования коэффициентов преобразования видео данных, при этом множество контекстных моделей включает в себя одну или более контекстных моделей, причем каждая используется для различного размера единицы преобразования, и по меньшей мере одну объединенную контекстную модель, используемую для двух или более размеров единицы преобразования;
выбирать объединенную контекстную модель, совместно используемую первой единицей преобразования, имеющей первый размер, и второй единицей преобразования, имеющей второй размер, для энтропийного кодирования коэффициентов преобразования в одной из первой единицы преобразования или второй единицы преобразования, при этом первый размер и второй размер различны, и при этом каждая из единиц преобразования содержит остаточную единицу данных видео, включающую в себя множество блоков коэффициентов преобразования;
выбирать контексты для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели, при этом инструкции дополнительно вынуждают процессор назначать контекст в объединенной контекстной модели заданному одному из коэффициентов преобразования на основании значений ранее закодированных соседних коэффициентов преобразования упомянутой одной из единиц преобразования и определять оценку вероятности для значения заданного одного из коэффициентов преобразования, ассоциированных с назначенным контекстом в объединенной контекстной модели; и
энтропийно кодировать коэффициенты преобразования упомянутой одной из единиц преобразования, используя контекстно-адаптивное двоичное арифметическое кодирование (САВАС), на основании выбранных контекстов.
29. Считываемый компьютером носитель по п. 28, причем объединенная контекстная модель содержит объединенную контекстную модель карты значимости, дополнительно содержащий инструкции, которые вынуждают процессор:
выбирать контексты для компонентов карты значимости для коэффициентов преобразования, ассоциированных с одной из первой единицы преобразования или второй единицы преобразования согласно объединенной контекстной модели; и
энтропийно кодировать компоненты карты значимости, ассоциированные с упомянутой одной из единиц преобразования, на основании выбранных контекстов.
30. Считываемый компьютером носитель по п. 28, в котором инструкции вынуждают процессор:
обновлять оценку вероятности, ассоциированную с назначенным контекстом в объединенной контекстной модели, на основании фактических закодированных значений коэффициентов преобразования первой единицы преобразования, имеющей первый размер, и второй единицы преобразования, имеющей второй размер.
31. Считываемый компьютером носитель по п. 28, в котором инструкции содержат инструкции для декодирования видео данных, дополнительно содержащие инструкции, которые вынуждают процессор:
принимать поток битов, который представляет закодированные коэффициенты преобразования, ассоциированные с одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбирать контексты для закодированных коэффициентов преобразования согласно объединенной контекстной модели; и
энтропийно декодировать закодированные коэффициенты преобразования в одну из единиц преобразования на основании выбранных контекстов.
32. Считываемый компьютером носитель по п. 31, дополнительно содержащий инструкции, которые вынуждают процессор обратно преобразовывать коэффициенты преобразования упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер, в остаточные пиксельные значения.
33. Считываемый компьютером носитель по п. 28, в котором инструкции содержат инструкции для кодирования видео данных, дополнительно содержат инструкции, которые вынуждают процессор:
преобразовывать остаточные пиксельные значения в коэффициенты преобразования в пределах упомянутой одной из первой единицы преобразования, имеющей первый размер, или второй единицы преобразования, имеющей второй размер;
выбирать контексты для коэффициентов преобразования упомянутой одной из единиц преобразования согласно объединенной контекстной модели; и
энтропийно кодировать коэффициенты преобразования упомянутой одной из единиц преобразования на основании выбранных контекстов.
34. Считываемый компьютером носитель по п. 28, в котором первая единица преобразования первого размера содержит единицу преобразования 32×32, и в котором вторая единица преобразования второго размера содержит единицу преобразования 16×16.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 7535387 B1, 19.05.2009 | |||
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 1995 |
|
RU2117388C1 |

