ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к кодерам для кодирования данных (D1), представляющих собой различный контент, например, неподвижные изображения, видеоконтент, графический контент, аудиоконтент, данные измерений и так далее, с формированием соответствующих кодированных данных (D2). Кроме того, настоящее изобретение относится к способам кодирования данных (D1), представляющих собой различный контент, например, неподвижные изображения, видеоконтент, графический контент, аудиоконтент, данные измерений и так далее, с формированием соответствующих кодированных данных (E2). Также настоящее изобретение относится к декодерам для декодирования кодированных данных (E2), сформированных вышеупомянутыми кодерами. Кроме того, настоящее изобретение также относится к способам декодирования данных (E2), сформированных вышеупомянутыми кодерами. Также настоящее изобретение относится к программным продуктам, хранящимся на машиночитаемых носителях, при этом выполнение указанных программных продуктов осуществляют посредством вычислительных аппаратных средств для реализации вышеупомянутых способов.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Существует много известных современных способов кодирования данных (D1) с формированием кодированных данных (E2), а также способов декодирования кодированных данных (E2) с формированием декодированных данных (D3). Однако способ кодирования данных, который подходил бы для кодирования широкого диапазона контента, представленного указанными данными (D1), например, неподвижных изображений, видеоконтента, аудиоконтента или графического контента, отсутствует. Первоочередной задачей такого кодирования является формирование кодированных данных (E2), которые будут более компактными, чем соответствующие данные (D1), которые должны быть кодированы. Кроме того, также отсутствует соответствующий декодер для декодирования таких кодированных данных (E2). Известные способы кодирования изображений, такие как JPEG (Joint Photographic Experts Group, «объединенная группа экспертов в области фотографии», а именно кодирование на основе дискретного косинусного преобразования (Discrete Cosine Transform, DCT) с потерями информации), JPEG2000 (а именно кодирование на основе вейвлет-преобразования) и WebP (кодирование формата изображений, которое использует во время кодирования как сжатие с потерями, так и сжатие без потерь) хорошо приспособлены для сжатия обычного содержимого изображений, но меньше подходят для сжатия текста или изображений, цвета которых описываются только несколькими значениями цвета и содержимое которых имеет относительно высокую пространственную частотную компоненту. Известный альтернативный способ кодирования данных называется GIF (Graphics Interchange Format, формат обмена графическими данными) и использует алгоритм сжатия на основе цветовой палитры, который хорошо приспособлен для кодирования изображений, которые могут быть представлены относительно небольшим количеством значений цвета, необходимых для восстановления изображений, например, 256 значениями цвета; однако, если изображения, которые должны быть кодированы с использованием алгоритмов GIF, включают обычные объекты, имеющие тонкие постепенные пространственные изменения цвета, GIF формирует нежелательные артефакты, заметные в соответствующих декодированных изображениях GIF. Известный современный способ кодирования PNG (Portable Networks Graphics, переносимая сетевая графика, кодирование без потерь) в целом аналогичен кодированию GIF и обеспечивает больше опций для кодирования данных изображений, но тем не менее не подходит для изображений, который содержат небольшой диапазон значений цвета. Другие известные способы кодирования применяют кодирование текста с использованием оптического распознавания символов (Optical Character Recognition, OCR) в комбинации с кодированием символов; OCR иногда является подходящим способом для использования, но оно чувствительно к позиционированию текста в изображении, наклону текста в изображении, шрифту текста, а также объекту, в котором находится текст; кроме того, для осуществления оптического распознавания символов может потенциально требоваться значительная вычислительная мощность. В последнее время научные публикации предлагают альтернативные способы кодирования, подходящие для кодирования данных, которые имеют двухуровневый формат последовательности блоков данных; подробности этих научных публикаций приведены в таблице 1.
Вышеуказанные известные способы кодирования данных и соответствующие известные способы декодирования таких кодированных данных не подходят для широкого диапазона контента, представленного указанными данными, несмотря на то, что упомянутые известные способы используют широкий диапазон взаимно различающихся подходов. Несмотря на многочисленные исследования на протяжении многих лет для развития более эффективных алгоритмов кодирования с обеспечением улучшенного сжатия данных, а именно, обработки потокового видеоконтента, представляющей особую важность для систем связи, оптимальный способ кодирования еще должен быть разработан.
В патенте США №6,151,409 («Способы сжатия и восстановления цветных изображений в вычислительной системе») раскрывается способ сжатия цветного изображения путем применения визуального усеченного блочного кодирования изображения (visual block pattern truncation coding, VBPTC), в котором стандартное усеченное блочное кодирование (block truncation coding, BTC) служит для кодирования исходного изображения. Данный способ задает краевой блок в соответствии со зрительным восприятием человека. В случае если разность между двумя квантованными значениями BTC в блоке больше порогового значения, которое задано зрительными характеристиками, указанный блок будет идентифицирован в качестве краевого блока. В краевом блоке растровое изображение адаптировано для вычисления ориентации градиента блока и согласования с шаблоном блока.
Указанный способ подходит только для изображения, которое содержит только блоки 4×4, которые дополнительно содержат либо уровень DC, или чистый край под углом 90° или 45°. Кроме того, указанный способ может обеспечивать устранение шума или удаление деталей, если маска не попадает в цель точно. Также указанный способ совершенно не подходит для кодирования текста или текстуры, а также не подходит для кодирования шаблонов, которые не могут быть изображены с использованием прямой линии или которые имеют направления, отличные от кратных 45°.
В опубликованном патенте США №5,668,932 («Способ сжатия цифровых видеоданных»), описан альтернативный способ сжатия цифровых видеоданных, который обеспечивает улучшенное сжатие по сравнению со стандартными способами сжатия блоков. В указанном альтернативном способе данные изображения разбивают на ячейки и многократно сжимают. Ячейки сжимают с использованием форматов сжатия, которые наиболее подходят для содержимого ячеек. В первую очередь определяют, является ли ячейка по существу идентичной следующей ячейке в предыдущем кадре. Если ячейка является по существу идентичной ячейке в предыдущем кадре, указанную ячейку кодируют в сжатом виде как копию предыдущей ячейки. Кроме того, в упомянутый способ сжатия могут быть объединены подходы одноцветного сжатия и подходы восьмицветного сжатия.
Таким образом, упомянутый способ использует битовую маску, которая сообщает, относится ли заданный обработанный пиксель к более высокому значению, а именно, к более ярким пикселям, или к более низкому значению, а именно, к более тусклым пикселям, для каждого блока, ячейки или субблока. Кроме того, в упомянутом способе предпринята попытка кодирования полного изображения.
В опубликованной международной заявке WO 00/19374 («Сжатие и распаковка данных изображений с использованием четырехуровневого блочного кодирования») описан способ и устройство для сжатия и распаковки данных изображений. Опционально, указанный способ сжатия цветовой ячейки включает следующие шаги:
I) задание по меньшей мере четырех уровней яркости цветовых ячеек;
II) формирование битовой маски для цветовых ячеек, при этом указанная битовая маска имеет множество элементов, каждый из которых соотносится с соответствующим одним из пикселей, и каждый из элементов для хранения данных идентифицирует один из уровней яркости, связанных с соответствующим одним из указанных пикселей.
III) вычисление первого среднего значения цвета пикселей, связанных с первым уровнем яркости;
IV) вычисление второго среднего значения цвета пикселей, связанных со вторым уровнем яркости; и
V) сохранение указанной битовой маски, связанной с указанным первым средним значением цвета и указанным вторым средним значением цвета.
Опционально, цветовая ячейка включает матрицу 4×4 пикселей, битовая маска включает 32 бита, а каждое из значений цвета включает 16 бит, так что достигается степень сжатия, равная 4 бит на пиксель. Указанный способ применяется для сжатия данных текстур, так что данные текстур могут быть более эффективно кэшированы и перемещены во время отображения текстур; также может быть достигнуто сжатие текстур яркости, интенсивности и альфа-текстур.
Кроме того, вышеупомянутые известные способы кодирования имеют различные недостатки, которые делают их неподходящими для широкого спектра типов данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение обеспечивает улучшенный способ кодирования данных (D1) с формированием соответствующих кодированных данных (E2), например, кодированных данных (E2), сжатых по сравнению с их соответствующими некодированными данными (D1).
Настоящее изобретение обеспечивает улучшенный способ кодирования данных (D1) с формированием соответствующих кодированных данных (E2), например, кодированных данных (E2), сжатых по сравнению с их соответствующими некодированными данными (D1).
Кроме того, настоящее изобретение обеспечивает улучшенный способ декодирования данных (E2), сформированных кодерами согласно настоящему изобретению.
Дополнительно, настоящее изобретение предлагает улучшенный декодер для декодирования данных (E2), сформированных кодерами согласно настоящему изобретению.
Согласно первому аспекту, предложен кодер в соответствии с п.1 приложенной формулы изобретения: предложен кодер для кодирования данных (D1) с формированием соответствующих кодированных данных (E2), характеризующийся тем, что указанный кодер содержит:
блок для анализа одной или более частей данных (D1), которые должны быть кодированы, и направление указанных одной или более частей в соответствующие один или более блоков кодирования, которые выполнены с возможностью кодирования в них указанных одной или более частей с формированием кодированных данных (E2), причем:
указанные один или более блоков кодирования выполнены с возможностью применения взаимно различающихся алгоритмов кодирования при кодировании указанных одной или более частей;
по меньшей мере один блок кодирования из указанных одного или более блоков кодирования выполнен с возможностью вычисления значений данных, имеющихся в каждой части, принятой этим блоком, для разделения указанных значений данных по меньшей мере на два набора, вычисления по меньшей мере одного агрегированного значения для заданного набора, полученного из указанных значений данных, имеющихся в заданном наборе, и сохранение пространственной маски указанной части, при этом указанная пространственная маска (320) и информация, представляющая указанные значения, вычисленные для указанных по меньшей мере двух наборов данных, включены в указанные кодированные данные (E2).
Преимуществом настоящего изобретения является то, что указанный кодер выполнен с возможностью вычисления агрегированных значений наборов и маек, задающих расположение частей данных (D1), которые должны быть кодированы, для включения в кодированные данные (E2) кодера, которые обеспечивают эффективное кодирование конкретных типов содержимого, представленного в указанных данных (D1), которые должны быть кодированы.
Опционально, кодер включает выходной блок кодера для приема кодированных выходных данных из указанного одного или более блоков кодирования и для последующего кодирования указанных кодированных выходных данных с формированием кодированных данных (E2) кодера.
Опционально, кодер дополнительно включает входную ступень для разделения и/или объединения данных (D1), которые должны быть кодированы, с формированием указанной одной или более частей, если указанные данные (D1), которые должны быть кодированы, еще не включены в указанную одну или более частей.
Опционально, в кодере указанный по меньшей мере один блок кодирования из указанных одного или более блоков кодирования выполнен с возможностью разделения значений данных, представленных в каждой части, на от 2 до 8 наборов данных или 2 или более наборов данных. Например, 8 наборов данных опционально используют для 8-битовых двоичных данных.
Опционально, кодер выполнен с возможностью сохранения информации, представляющей одну или более маску указанной одной или более частей, в удаленной базе данных для доступа одним или более декодерами при декодировании указанных кодированных данных (Е2), сформированных указанным кодером.
Опционально, в кодере указанное по меньшей мере одно агрегированное значение представляет собой среднее арифметическое, скошенное среднее значение, логарифмическое среднее, взвешенное среднее, среднее значение, минимальное значение, максимальное значение, значение моды или медианное значение. Также возможны другие типы вычислений, например, вычисленный результат комплексной математической функции, например, полиномиальное вычисление, которое обеспечивает форму агрегированного результата. Один из примеров других типов вычислений включает выбор исходного значения набора данных таким способом, который минимизирует расстояние между исходным значением и средним значением максимального значения и минимального значения. Такой тип агрегированного значения минимизирует максимальную ошибку в наборе данных и также часто формирует маленькую среднеквадратическую ошибку (mean-square error, MSE).
Согласно второму аспекту предложен способ кодирования данных (D1) с формированием соответствующих кодированных данных (E2), характеризующийся тем, что указанный способ включает:
a) использование блока для анализа одной или более частей данных (D1), которые должны быть кодированы, и направление указанных одной или более частей в соответствующие один или более блоков кодирования, которые выполнены с возможностью кодирования в них указанных одной или более частей с формированием кодированных данных (E2), причем указанные один или более блоков кодирования выполнены с возможностью применения взаимно различающихся алгоритмов кодирования при кодировании указанных одной или более частей; и
b) использование по меньшей мере одного блока кодирования из указанных одного или более блоков кодирования для вычисления значений данных, имеющихся в каждой части, принятой в этом блоке, для разделения указанных значений данных по меньшей мере на два набора, вычисления по меньшей мере одного агрегированного значения для заданного набора, полученного из указанных значений данных, имеющихся в заданном наборе, и сохранение пространственной маски указанной части, при этом указанная пространственная маска и информация, представляющая указанные значения, вычисленные для указанных по меньшей мере двух наборов данных, включены в указанные кодированные данные (E2).
Опционально, указанный способ включает использование выходного блока кодера для приема кодированных выходных данных из указанного одного или более блоков кодирования и для последующего кодирования указанных кодированных выходных данных с формированием кодированных данных (E2).
Опционально, указанный способ включает использование по меньшей мере одного блока кодирования из указанных одного или более блоков кодирования для разделения значений данных, представленных в каждой части, на от 2 до 8 наборов данных или 2 или более наборов данных.
Опционально, указанный способ включает сохранение информации, представляющей одну или более маску указанной одной или более частей, в удаленной базе данных для доступа одним или более декодерами при декодировании указанных кодированных данных (E2).
Опционально, в указанном способе кодированные данные (E2) дополнительно кодированы и/или сжаты. Опционально, в указанном способе дополнительное кодирование и/или сжатие включает по меньшей мере одно из следующего: дифференциальную импульсно-кодовую модуляцию (differential pulse-code modulation, DPCM), кодирование длин серий (run-length encoding, RLE), скользящее кодирование длин серий (SRLE, «Split run-length encoding», способ, раскрытый в заявке GB 1303660.3, поданной Gurulogic Microsystems Oy 01.03.2013), модификатор энтропии (ЕМ, «Entropy Modifier», способ, раскрытый в заявке GB 1303658.7, поданной Gurulogic Microsystems Oy 01.03.2013), арифметическое кодирование, дельта-кодирование, кодирование ODelta (способ, раскрытый в заявке GB1303661.1, поданной Gurulogic Microsystems Oy 01.03.2013), кодирование с переменной длиной (Variable-Length Coding, VLC), кодирование на основе преобразования Лемпеля-Зива (Lempel-Ziv coding, ZLIB, LZO, LZSS, LZ77), кодирование на основе преобразования Барроуза-Уиллера (Burrow-Wheeler transform-based coding, RLE, BZIP2), кодирование Хаффмана.
Согласно третьему аспекту, предложен декодер для декодирования кодированных данных (E2) с формированием соответствующих декодированных данных (D3), характеризующийся тем, что указанный декодер включает:
блок для доставки одной или более частей указанных кодированных данных (E2) и направления указанных одной или более частей в соответствующие один или более блоков декодирования, которые выполнены с возможностью декодирования в них указанных одной или более частей с формированием декодированных данных (D3); при этом
по меньшей мере один из указанных одного или более блоков декодирования выполнен с возможностью извлечения пространственной маски и информации, представляющей агрегированные значения по меньшей мере для двух наборов данных, включенных в указанные кодированные данные (E2), и для присвоения значений элементам в блоке данных, в соответствии с тем, к какому из наборов эти элементы принадлежат, как задано указанной маской.
Опционально, декодер включает выходной блок декодера для приема декодированных выходных данных из указанного одного или более блоков декодирования и для последующего объединения указанных декодированных выходных данных с формированием общих декодированных данных (D3) декодера.
Опционально, декодер дополнительно включает входную ступень для извлечения одной или более частей из указанных кодированных данных (E2) для их направления, как задано параметрами кодирования, имеющимися в указанных кодированных данных, в один или более блоков декодирования.
Опционально, в декодере указанный по меньшей мере один из указанных одного или более блоков декодирования выполнен с возможностью присвоения значений элементам маски, соответствующей указанным наборам данных, при этом имеется от 2 до 8 наборов данных или 2 или более наборов данных. Например, 8 наборов данных опционально используют для 8-битовых двоичных данных.
Опционально, декодер выполнен с возможностью извлечения информации, представляющей указанную одну или более маску указанной одной или более частей из удаленной базы данных, при декодировании указанных кодированных данных (E2), сформированных кодером.
Опционально, указанный декодер осуществляют так, чтобы указанное агрегированное значение представляло собой по меньшей мере одно из следующего: среднее арифметическое, скошенное среднее значение, логарифмическое среднее, взвешенное среднее, среднее значение, минимальное значение, максимальное значение, модальное значение моды или медианное значение. Также возможны другие типы вычислений, например, вычисленный результат комплексной математической функции, например, полиномиальное вычисление, которое обеспечивает форму агрегированного результата. Один из примеров других типов вычислений включает выбор исходного значения набора данных таким способом, который минимизирует расстояние между исходным значением и средним значением максимального значения и минимального значения. Такой тип агрегированного значения минимизирует максимальную ошибку в наборе данных и также часто формирует маленькую среднеквадратическую ошибку (MSE).
Согласно четвертому аспекту, предложен способ декодирования кодированных данных (E2) с формированием соответствующих декодированных данных (D3), характеризующийся тем, что указанный способ включает:
a) использование блока для доставки одной или более частей указанных кодированных данных (E2) и направления указанных одной или более частей в соответствующие один или более блоков декодирования, которые выполнены с возможностью декодирования в них указанных одной или более частей с формированием декодированных данных (D3); и
b) использование по меньшей мере одного блока декодирования из указанных одного или более блоков декодирования для извлечения пространственной маски и информации, представляющей агрегированные значения, вычисленные по меньшей мере для двух наборов данных, включенных в указанные кодированные данные (E2), и для присвоения значений элементам в блоке данных, в соответствии с тем, к какому из наборов эти элементы принадлежат, как задано указанной маской.
Опционально, указанный способ включает использование выходного блока декодера для приема декодированных данных из указанного одного или более блоков декодирования и для последующего объединения указанных декодированных выходных данных с формированием общих декодированных данных (D3).
Опционально, указанный способ дополнительно включает использование входной ступени для извлечения одной или более частей из указанных кодированных данных (E2) для их направления, как задано параметрами кодирования, имеющимися в указанных кодированных данных (E2), в один или более блоков декодирования.
Опционально, в указанном способе указанный по меньшей мере один блок декодирования из указанных одного или более блоков декодирования выполнен с возможностью присвоения значений элементам маски, соответствующей указанным наборам данных, при этом имеется от 2 до 8 наборов данных или 2 или более наборов данных. Такой пример предпочтительно используется для 8-битовых двоичных данных, хотя дополнительно опционально используют 16-битовые, 32-битовые и так далее двоичные данные.
Опционально, указанный способ включает извлечение информации, представляющей указанную одну или более маску указанной одной или более частей из удаленной базы данных, при декодировании указанных кодированных данных (E2), сформированных кодером.
Опционально, при использовании указанного способа указанное по меньшей мере одно агрегированное значение представляет собой по меньшей мере одно из следующего: среднее арифметическое, скошенное среднее значение, логарифмическое среднее, взвешенное среднее, среднее значение, минимальное значение, максимальное значение, значение моды или медианнное значение. Также возможны другие типы вычислений, например, вычисленный результат комплексной математической функции, например, полиномиальное вычисление, которое обеспечивает форму агрегированного результата. Один из примеров других типов вычислений включает выбор исходного значения набора данных таким способом, который минимизирует расстояние между исходным значением и средним значением максимального значения и минимального значения. Такой тип агрегированного значения минимизирует максимальную ошибку в наборе данных и также часто формирует маленькую среднеквадратическую ошибку (MSE).
Согласно пятому аспекту, предложена система передачи данных, включающая по меньшей мере один кодер в соответствии с первым аспектом для кодирования данных (D1) и формирования соответствующих кодированных данных (E2), и по меньшей мере один декодер в соответствии с третьим аспектом для декодирования указанных кодированных данных (E2) с формированием декодированных данных (D3).
Согласно шестому аспекту, предложен способ передачи данных в системе передачи данных в соответствии с пятым аспектом, при этом указанный способ передачи данных использует комбинацию способа в соответствии со вторым аспектом и способа в соответствии с четвертым аспектом.
Согласно седьмому аспекту, предложен программный продукт, хранящийся на машиночитаемых носителях, характеризующийся тем, что выполнение указанного программного продукта посредством вычислительных аппаратных средств обеспечивает выполнение способа в соответствии со вторым аспектом.
Согласно восьмому аспекту, предложен программный продукт, хранящийся на машиночитаемых носителях, характеризующийся тем, что выполнение указанного программного продукта посредством вычислительных аппаратных средств обеспечивает выполнение способа в соответствии с четвертым аспектом.
Необходимо понимать, что признаки настоящего изобретения допускают их объединение в различных комбинациях без выхода за рамки объема настоящего изобретения, заданного приложенной формулой изобретения.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Далее только в качестве примера будут описаны варианты осуществления настоящего изобретения со ссылкой на следующие чертежи, на которых:
на фиг.1 проиллюстрированы кодер и декодер;
фиг.2A представляет собой схематическое изображение кодера для осуществления способа кодирования данных;
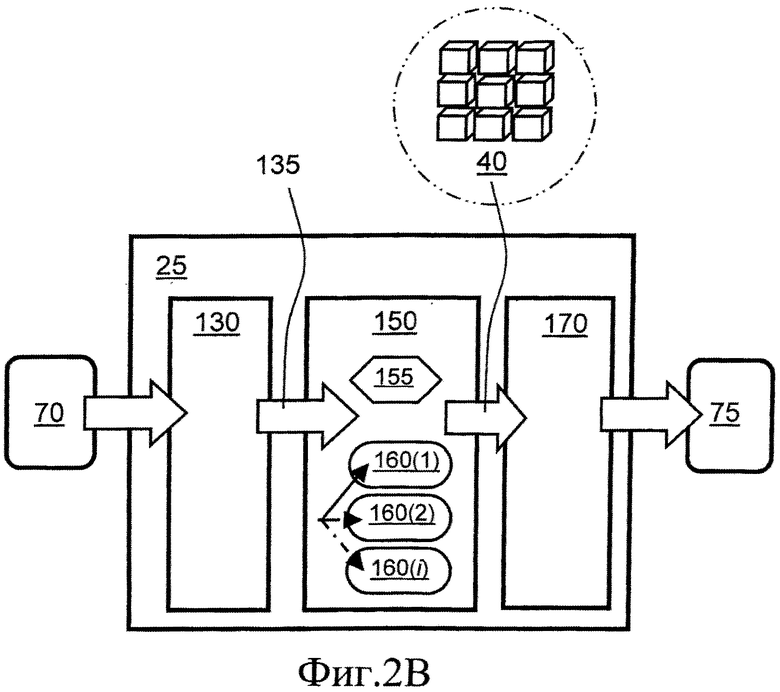
фиг.2B представляет собой схематическое изображение декодера для осуществления способа декодирования данных (E2), которые были кодированы согласно настоящему изобретению;
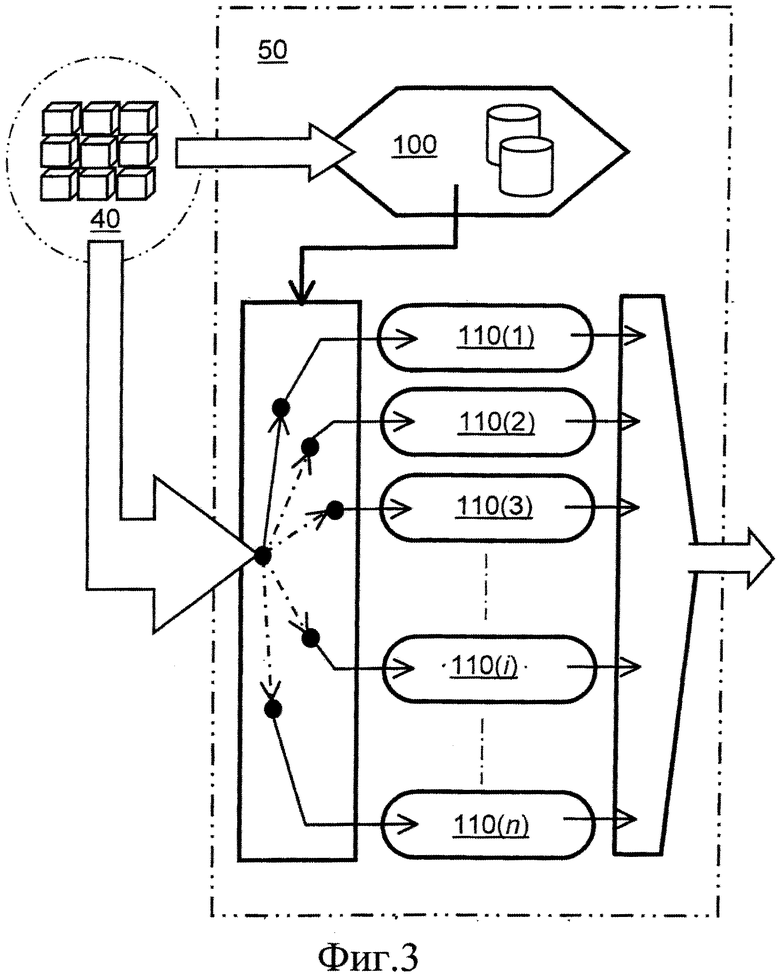
фиг.3 представляет собой схематическое изображение второй ступени кодирования кодера, показанного на фиг.2A;
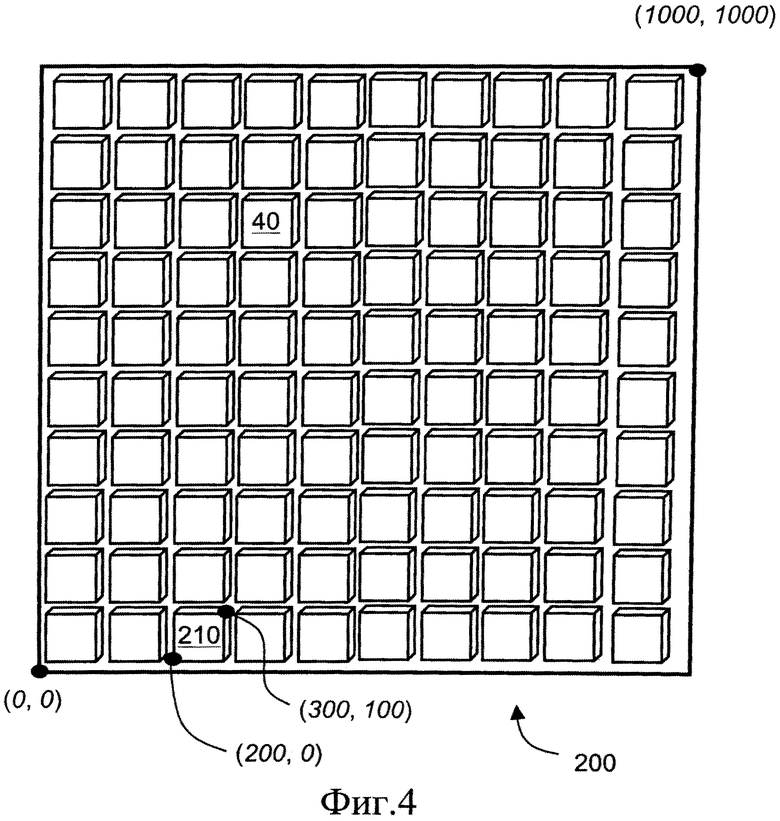
на фиг.4 проиллюстрировано разделение данных изображения на блоки данных, а именно, части, для кодирования в указанной второй ступени кодирования кодера, показанного на фиг.2A;
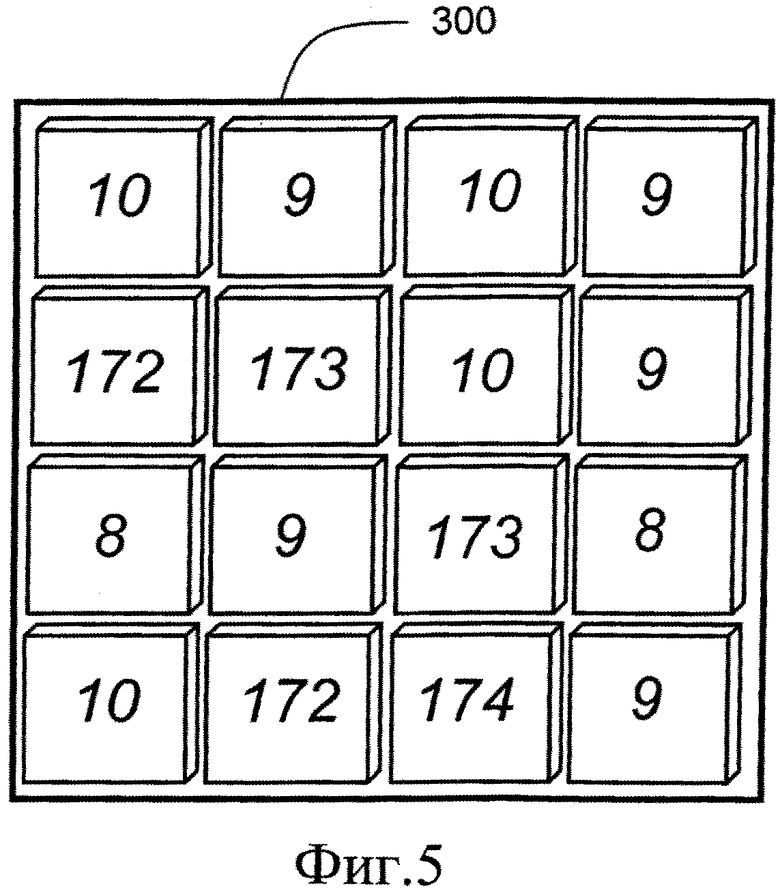
на фиг.5 проиллюстрирован блок данных, который должен быть кодирован с использованием кодера, показанного на фиг.2A;
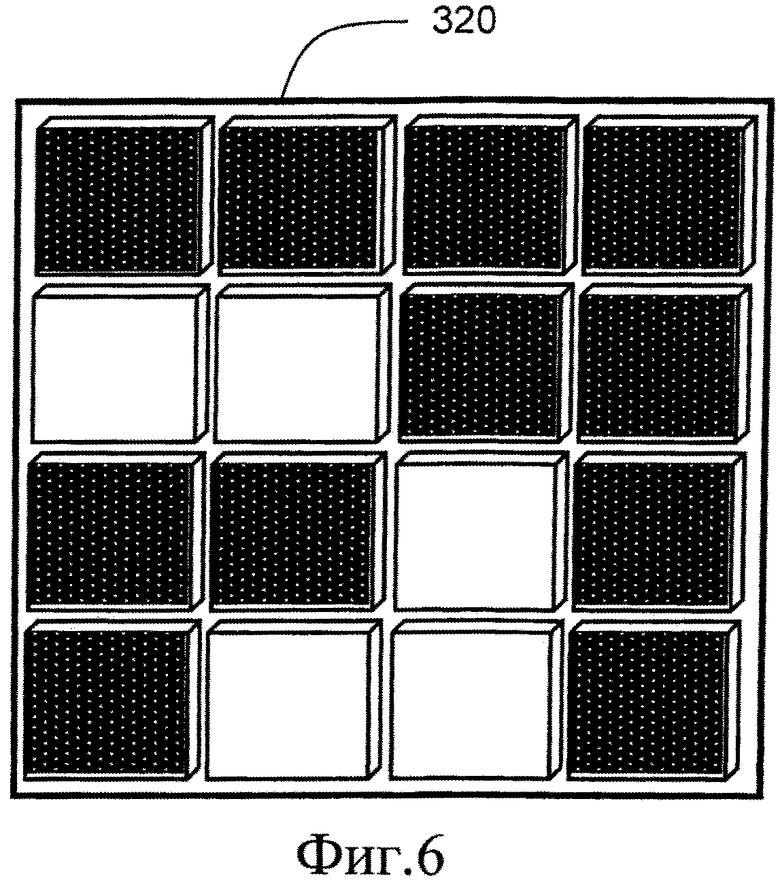
на фиг.6 проиллюстрирована маска для блока данных, показанного на фиг.5, после вычисления агрегированных значений для наборов уровней, примененных к блоку данных, представленному на фиг.5; и
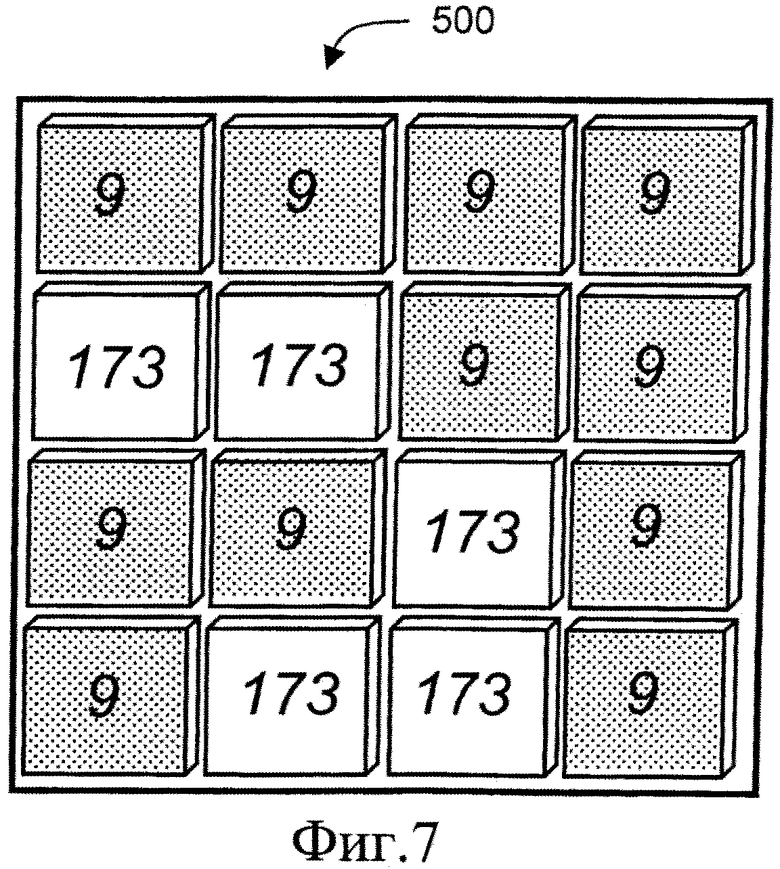
на фиг.7 проиллюстрирован восстановленный декодированный блок данных, извлеченный из кодированных данных, сформированных кодером, показанным на фиг.2A.
На сопровождающих чертежах подчеркнутые номера позиций используются для представления элемента, над которым расположен подчеркнутый номер, или элемента, рядом с которым находится подчеркнутый номер. Неподчеркнутый номер относится к элементу, идентифицируемому линией, связывающей неподчеркнутый номер с указанным элементом. Если номер не подчеркнут и сопровождается соответствующей стрелкой, указанный неподчеркнутый номер используется для идентификации общего элемента, на который указывает стрелка.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
В общем, настоящее изобретение относится к улучшенному способу кодирования данных (D1) с формированием соответствующих кодированных данных (E2), при этом указанный способ может обеспечить повышенную степень эффективности кодирования. Указанный улучшенный способ может обеспечить эффективное кодирование широкого диапазона содержимого, представленного в данных (D1), которые должны быть кодированы, например, неподвижных изображений, видеоконтента, графического контента, аудиоконтента, электрокардиограммы (electrocardiogram, ECG), сейсмических данных и так далее.
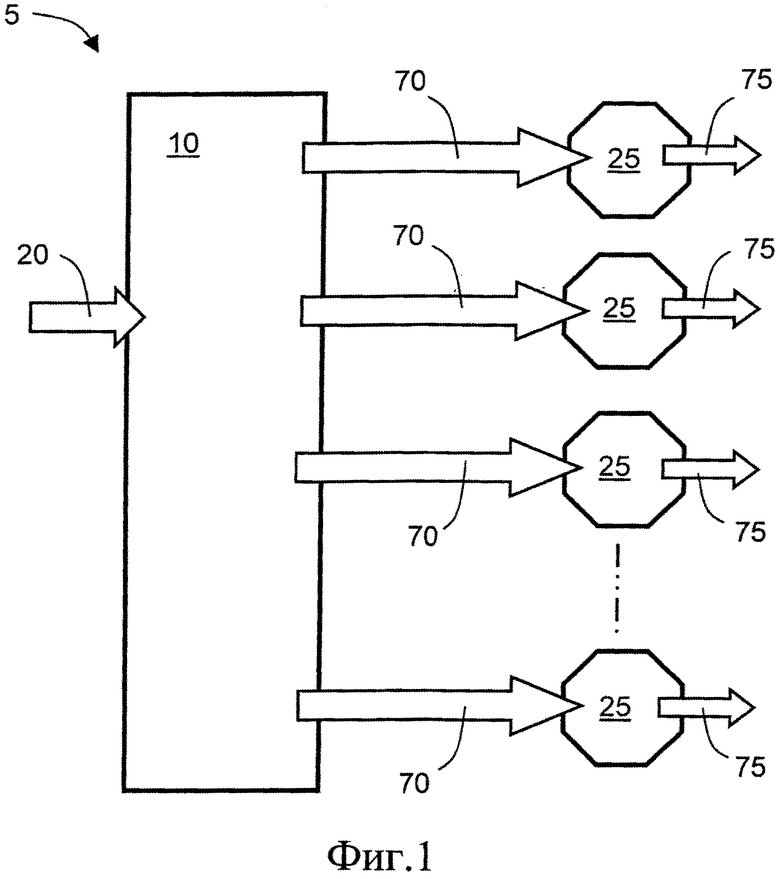
На фиг.1 проиллюстрирован кодер 10, выполненный с возможностью кодирования данных 20 (D1) с использованием способа в соответствии с настоящим изобретением. Кодер 10 формирует кодированные данные 70 (E2), которые могут быть сохранены и/или переданы с использованием потоковой передачи для последующего декодирования в одном или более декодерах 25. Указанные один или более декодеров 25 выполнены с возможностью формирования соответствующих декодированных данных 75 (D3) для использования одним или более пользователями. Декодированные данные 75 (D3) опционально соответствуют по существу некодированным данным 20. Комбинация по меньшей мере одного кодера 10 и по меньшей мере одного соответствующего декодера 25 формирует систему передачи данных, обозначенную в целом позицией 5, а именно кодек.
На фиг.2A проиллюстрирован кодер 10, выполненный с возможностью кодирования данных 20 (D1) с использованием способа в соответствии с настоящим изобретением. Кодер 10 использует первую ступень 30, которая разделяет данные 20 (D1), которые должны быть кодированы, на блоки 40 данных, если указанные данные 20 (D1) еще не в формате блока данных; такое разделение данных 20 (D1), которые должны быть кодированы, опционально приводит к получению блоков 40 данных, имеющих взаимно различающиеся размеры, то есть неоднородных блоков, в зависимости от характера содержимого, включенного в указанные блоки 40 данных; это отличается от многих известных алгоритмов кодирования, которые применяют однородное разделение данных (D1) на соответствующие блоки данных. Во второй ступени 50 кодер 10 включает блок 100 анализа и множество блоков 110(1)-110(n) кодирования, применяющих различные типы алгоритмов кодирования, которые являются взаимно различающимися, а некоторые из алгоритмов кодирования могут быть известными алгоритмами, например, DCT, но не ограничиваются упомянутым, при этом указанные блоки 110(1)-110(n) кодирования выборочно используют для обработки каждого блока 40 данных. Необходимо понимать, что некоторые из алгоритмов, применяемых в блоках 110(1)-110(n) кодирования, являются по существу аналогичными, но выполняются параллельно во времени. По меньшей мере один из блоков 110(1)-110(n) кодирования выполнен с возможностью сортировки данных, имеющихся в блоке 40 данных, по меньшей мере на два уровня, а также формирования маски или маек, описывающих, какие значения данных в указанном блоке 40 данных относятся к соответствующему уровню, а также вычисления агрегированных значений данных, отсортированных для каждого уровня, например, среднего значения или аналогичного. Третья ступень 60 включает сжатие битового отображения, а также агрегированных значений для каждого уровня с формированием кодированных данных 70 (E2) из кодера 10; для третьей ступени 60 могут опционально использоваться различные алгоритмы сжатия, например, кодирование длин серий (RLE), дифференциальная импульсно-кодовая модуляция (DPCM), кодирование с переменной длиной (VLC), скользящее кодирование длин серий (SRLE), модификатор энтропии (EM), кодирование ODelta, диапазонное кодирование, хотя альтернативно или дополнительно используются другие алгоритмы сжатия данных, например, многоступенчатое сжатие данных. Опционально, кодер (10) может использоваться в комбинации с другими кодерами для достижения гибридного кодирования данных 20 (D1) с формированием кодированных данных 70 (E2), например, DCT, цветовая палитра, DPCM. На практике термин «уровень» может соответствовать одному или более из следующего: уровню цветности, уровню яркости, значению цвета, яркости освещенности, амплитуде, частоте, интенсивности, однако, термин «уровень» может также включать другие параметры, описывающие физические переменные, в зависимости от характера данных 20 (D1), которые должны быть кодированы.
На первом шаге 30 блоки 40 данных могут отличаться по размеру в зависимости от характера содержимого, имеющегося в данных 20 (D1), которые должны быть кодированы. Данные 20 (D1) опционально являются одномерными, например, аудиоконтент, данные электрокардиографии, сейсмические данные. Альтернативно, данные 20 (D1) являются многомерными, например, неподвижные изображения, видеоконтент, графический контент, трехмерные (3D) изображения/видео/графика. Кроме того, двумерные входные данные включают, например, квадрат, треугольник, круг и подобные элементы, то есть опционально, любой тип двумерной геометрической формы. Кроме того, трехмерные данные изображений включают, например, элементы, являющиеся кубическими, пирамидальными, цилиндрическими, сферическими и так далее. Если данные 20 (D1), которые должны быть кодированы, включают пространственные высокочастотные компоненты и только несколько уровней для задания пространственных элементов, представленных в указанных данных 20 (D1), известные современные способы кодирования особенно не эффективны, но эффективно обрабатываются в кодере 10. Опционально, кодер 10 может кодировать данные 20 (D1) в виде исходных данных или данных, сформированных путем предварительной обработки перед кодированием, например, с помощью DPCM, оценки движения, пространственного предсказания.
Как было упомянуто выше, во второй ступени 50 кодера 10 используется способ сжатия согласно настоящему изобретению, как показано на фиг.3. Осуществляют анализ блоков 40 данных из первой ступени 30 в блоке 100 анализа для определения наиболее подходящего алгоритма кодирования, чтобы использовать его для кодирования указанных блоков 40 данных; в зависимости от того, выполнен ли анализ только блоком 100 анализа или блоком 100 анализа совместно с одним или более блоками 110(1)-110(n) кодирования, указанные блоки данных направляют в один или более блоков 110(1)-110(n) кодирования, при этом n является целым числом и описывает общее количество различных алгоритмов кодирования, применяемых во второй ступени 50; указанное общее количество различных алгоритмов кодирования опционально включает комбинацию известных алгоритмов кодирования совместно с, например, двухуровневым алгоритмом кодирования согласно настоящему изобретению, при котором вычисленные значения, связанные с двумя уровнями определяют, например, из вычислений среднего значения, значения моды или медианного значения, примененных к значениям данных в заданном кодированном блоке 40 данных; необходимо понимать, что двухуровневый алгоритм кодирования является только примером и что опционально могут применяться различные многоуровневые алгоритмы. Блок 100 анализа анализирует количество различных цветов, представленных в блоках 40 данных, и информацию о пространственной частоте, представленной в блоках 40 данных, для принятия решения о том, какой блок 110 кодирования является оптимальным для использования для кодирования заданного типа блока 40 данных. Блоки 110 кодирования опционально используют один или более из следующих видов кодирования: кодирование постоянной составляющей (Direct Current, DC), кодирование изменения, дискретное косинусное преобразование (DCT), кодирование цветовой палитры, кодирование базы данных, кодирование VQ (vector quantization, векторное квантование), кодирование с масштабированием, линейное кодирование, способы интерполяции и экстраполяции. В кодированные данные из второй ступени 50 включены данные, указывающие, какой из блоков 110 кодера использовался для любого заданного блока 40 данных. По меньшей мере один блок 110(i) кодирования из блоков 110 кодирования, причем целое число i находится в диапазоне от 1 до n, использует алгоритм кодирования согласно настоящему изобретению, который будет описан более подробно далее. Опционально, размеры блоков 40 данных могут различаться в потоке данных, поступившем из первой ступени 30, при этом информация, передаваемая во вторую ступень 50 также включает информацию, которая в пространственном отношении указывает, какие блоки 40 данных включены в какое-либо одно или более заданных изображений; такая информация включена в кодированные данные, поступающие из второй ступени 50; предпочтительно реализуется такое включение данных, указывающих положение блока данных, как описано в заявке на патент Великобритании GB 1214414.3 (кодер), которая также подана как US 13/584005 и EP 13002521.6, и заявке на патент Великобритании GB 1214400.2 (декодер), которая также подана как US 13/584,047 и ЕР 13002520.8, указанные заявки включены в настоящее описание путем ссылки, также в настоящее описание путем ссылки включены соответствующие связанные иностранные заявки. Альтернативно, такое включение предпочтительно осуществляют в третьей ступени 60. Размеры блоков данных могут быть представлены как высота × ширина, выраженные в пикселях. Пространственные положения блоков данных предпочтительно задают как координаты относительно изображения, например, x, y пикселей от угла изображения. Опционально, блок 100 анализа и первая ступень 30 функционируют итеративно для разделения данных 20 (D1), которые должны быть кодированы, на блоки 40 данных так, чтобы обеспечить наиболее эффективное сжатие данных в одном или более выбранных блоков 110(1)-110(n) кодера, например, в данных 20 (D1) выбирают пространственные положения и размеры блоков 40 данных с учетом доступных для кодера 10 различных блоков 110(1)-110(n) кодера. Опционально, блоки 110(1)-110(n) кодера реализуют, по меньшей мере частично, с использованием программного обеспечения и они обновляются на периодической основе для постепенного улучшения характеристик кодирования кодера 10, например, для обеспечения гибкой адаптации кодера 10 к различным типам данных 20 (D1).
На фиг.2B показан декодер 25, соответствующий кодеру 10. Декодер 25 включает первую ступень 130 декодирования, которая выполнена с возможностью приема кодированных данных 70 и выполнения над указанными кодированными данными 70 операции, обратной кодированию, примененному третьей ступенью 60 кодера 10, с формированием промежуточных декодированных данных, обозначенных позицией 135. Промежуточные декодированные данные включают информацию о том, какой тип блока 110 кодирования использовался для кодирования заданного блока 40 данных, маски для блока 40 данных, агрегированного значения, если это необходимо, и так далее; опционально, указанное агрегированное значение является средним значением, значением моды, медианным значением, но не ограничивается перечисленным. Декодер 25 дополнительно включает вторую ступень 150, которая включает блок 155 доставки и один или более блоков 160(1)-160(n) декодирования, соответствующие указанным одному или более блокам 110 кодирования, при этом указанные кодированные блоки данных, имеющиеся в промежуточных декодированных данных 135 направляются блоком 155 доставки в соответствующие блоки 160(1)-160(n) декодирования, включенные во вторую ступень, для восстановления блоков 40 данных в декодере 25. Декодер 25 дополнительно включает третью ступень 170, которая выполнена с возможностью выполнения операций, обратных операциям, выполненным в первой ступени 30 кодера 10, для формирования декодированных данных 75 (D3), соответствующих по существу данным 20 (D1) и/или кодированным данным (E2). Дополнительно или альтернативно, информация о пространственных характеристиках и размере блоков 40 данных опционально формируется в первой ступени 130 декодирования. Указанную информацию о пространственных характеристиках и положении предпочтительно передают далее во вторую ступень 150 для обеспечения надлежащей работы способов, используемых в указанных одном или более блоках 160(1)-160(n) декодирования, с информацией о размере, и далее передают в третью ступень 170 для обеспечения размещения блоков данных в соответствующих пространственных положениях.
Алгоритм кодирования согласно настоящему изобретению допускает применение для кодирования блоков 40 данных любого размера, хотя предпочтительно используется для кодирования блоков 40 данных, включающих от 8 до 256 элементов или значений, например, пикселей. Кроме того, указанный алгоритм кодирования называется способом многоуровневого кодирования. В первой и наиболее полезной реализации указанного алгоритма используют два уровня, например, цветов, хотя не ограничиваются вышеупомянутым вариантом, и оптимизируют его для кодирования таких объектов, как подсказки командного кода, текст и другое содержимое, которое включает только два уровня. Однако опционально допустимо выполнять указанный алгоритм для кодирования более двух уровней, например, трех уровней, четырех уровней или даже большего количества уровней, то есть «множества уровней»; предпочтительно, чтобы количество уровней, на которых кодируют блоки данных, было значительно меньше, чем количество уровней, имеющихся в блоках 40 данных до их кодирования, например, предпочтительно, по меньшей мере в 3 раза меньше, более предпочтительно - по меньшей мере в 5 раз меньше, и еще более предпочтительно - по меньшей мере в 10 раз меньше. Количество уровней, имеющихся в блоках данных до кодирования во второй ступени 50, называется исходным количеством уровней, то есть показателем динамических уровней, имеющихся в блоках 40 данных, представляющих, например, содержимое изображений, видео, аудио или графики. Например, как показано на фиг.4, поле 200 изображения включает 1000×1000 точек-пикселей в двумерной матрице, при этом поле 200 изображения подразделяется в первой ступени 30 кодера 10 на 100 блоков 40 данных, обозначенных позицией 210, причем каждый блок 210 соответствует размеру 100×100 пикселей, то есть всего 10000 пикселей. Каждый пиксель представлен в цвете и/или с некоторой интенсивностью 8-ю битами, задающими 256 уровней динамического диапазона. Указанный динамический диапазон также может быть ограничен, и тогда указанное количество уровней также может быть вычислено с использованием следующего уравнения:
количество уровней = значение амплитуды = максимальный уровень - минимальный уровень + 1
Количество уровней также может быть описано с использованием количества различных уровней, используемых в указанных данных или блоке данных, кроме того, указанное значение может быть равным значению амплитуды или меньшим его. Для исходного количества уровней могут быть использованы все различные уравнения, но выходное количество уровней обычно соответствует количеству различных уровней, используемых в указанном блоке данных. Когда блок 110(i) кодирования кодирует заданный блок 210, количество уровней уменьшается, например, в диапазоне от 2 до 8, совместно с дополнительными данными, как будет описано далее. В случае если блок 110(i) кодирования использует, например, более 8 уровней, указанный блок 110(i) кодирования становится менее эффективным при осуществлении сжатия данных, что требует использования предварительной обработки изображения 200, например, кодирования с предсказанием или дельта-кодирования, перед тем, как данные поступят во вторую ступень 50. Один из вариантов также включает доставку уровней агрегированных значений путем использования битов для описания того, находится ли значение в диапазоне значений, например, диапазоне, заданном минимальным (min) и максимальным (max) параметрами, используемыми для вычисления указанного агрегированного значения для уровня; например, если указанные агрегированные значения равны 10, 12, 13, 15, 17, то доставка значений уровня включает значения 10 (= минимальное агрегированное значение), от 6 до 8 (= количество следующих битов) и (1)011010(1) для описания того, какие агрегированные значения используются для различных уровней. Кроме того, 6 битов в этом примере достаточно, поскольку вследствие известности двух первых доставленных значений 10 и 6, уже известно, что используются первое значение 10 и последнее значение 17. По существу, аналогичный пример с дельта-кодированием формирует такие значения как 10 и 2, 1, 2, 2, которые могут быть разделены, например, на два потока данных для обеспечения более эффективного энтропийного кодирования для минимальных значений и дельта-значений.
Указанный алгоритм кодирования, применяемый в блоке 110(i) кодирования, опционально используют для кодирования изображения в оттенках шкалы серого или другой информации, которая использует только один канал. Кроме того, указанный алгоритм кодирования, применяемый в блоке 110(i) кодирования, опционально используют для цветных изображений или другого многоканального содержимого. Многоканальное содержимое, например, трехмерные (3D) цветные изображения, опционально кодируют так, что все каналы кодированы/сжаты одинаково, или альтернативно и опционально кодированы/сжаты взаимно различающимся образом, например, блоки данных аудиоканалов опционально кодируют различными способами в блоки данных видеоканалов. Множество каналов также могут быть кодированы совместно или по отдельности, например, как 24-битовый RGB-триплет или как 3×8-битовые значения цветов (R, G, B). В случае если каналы кодированы взаимно различающимися способами, могут быть использованы различные алгоритмы кодирования в блоках 110 кодирования и различные размеры блоков 40 данных, выбор размеров блоков 40 данных, как упомянуто выше, опционально осуществляют на основе типа содержимого, имеющегося в данных 20 (D1), которые должны быть кодированы. Размер блоков данных или используемые алгоритмы кодирования также могут отличаться на основе содержимого данных, если каналы кодированы аналогично, но по отдельности, например, отдельные каналы R, G и B.
Значения блоков данных, сформированные путем использования многоуровневого способа согласно настоящему изобретению, опционально также передают в базу данных, так чтобы они могли быть использованы позднее последующими блоками данных. Указанная база данных может быть сформирована отдельно в кодере 10 во время кодирования данных 20 (D1) и опционально в декодере 25 во время декодирования указанных кодированных данных 70 (E2). Альтернативно, как кодер 10, так и декодер 25 могут использовать общую базу данных, которая была сформирована любым из них или которая была сформирована другим устройством или программным приложением и которую они оба могут использовать аналогично. В обоих случаях, базы данных, которые используют кодер 10 и декодер 25, предпочтительно являются идентичными, таким образом, передаваемая ссылка на базу данных всегда представляет аналогичные значения данных во всех ступенях, то есть при вычислении в кодере 10, восстановлении в кодере 10, а также восстановлении в декодере 25. Со значениями блоков данных или вместо значений блоков данных также в базу данных могут быть переданы маски, используемые в многоуровневом способе. И маски, и значения блоков данных могут быть извлечены из базы данных для использования при кодировании содержимого будущих блоков данных или блоков данных, кодированных с использованием многоуровневого способа согласно настоящему изобретению, тем самым уменьшается размер данных, которые необходимо сохранить и/или передать, что также улучшает коэффициент сжатия, достигаемый в кодеке 5.
Многоуровневый способ согласно настоящему изобретению также может быть использован, например, для сжатия баз данных или отдельных элементов в базах данных. Указанный способ очень хорошо подходит как для сжатия без потерь, так и для сжатия с потерями. Для многих типов данных, представленных в данных 20 (D1), которые должны быть кодированы, таких как аудио и изображения или видеоданные, сжатие с потерями не только приемлемо, оно также значительно улучшает достигаемый коэффициент сжатия в отношении кодированных данных 70 (E2). Однако некоторым другим типам данных, таким как базы данных, документы или двоичные данные, часто, если не всегда, необходимо сжатие без потерь, и, следовательно, обычно возникает необходимость использования множества уровней в многоуровневом способе, или альтернативно, в кодеке 5 опционально могут быть использованы блоки данных меньшего размера.
Алгоритм кодирования, используемый в блоке 110(i) кодирования, будет описан более подробно со ссылкой на фиг.5. На фиг.5 пример исходного блока 40 данных обозначен позицией 300. Как показано, блок 300 данных включает 4×4 пикселей, имеющих значения по шкале уровней серого. Предпочтительно, блок 300 данных допускает эффективное кодирование в блоке 110(i) с использованием алгоритма согласно настоящему изобретению с небольшой ошибкой кодирования, возникающей во время кодирования.
При применении указанного алгоритма сначала предпочтительно задают значение, которое разделяет данные на два набора данных, например, среднее значение для всех пикселей или элементов в блоке 300 вычисляют в вычислительных аппаратных средствах или специализированных цифровых аппаратных средствах кодера 10 согласно уравнению 1:
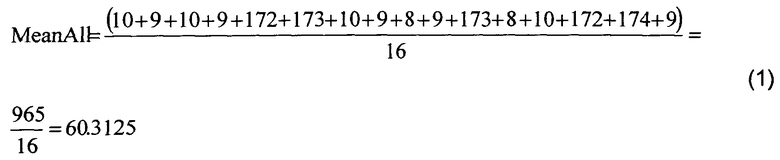
Далее, указанный алгоритм задает два набора уровней, а именно Level_0 (Уровень_0) и Level_1 (Уровень_1), при этом набор Level_0 включает все пиксели, значения которых меньше значения MeanAll (Общее среднее), а набор Level_1 включает все пиксели, значения которых равны значению MeanAll или превышают его. Пиксели блока 300 данных затем отображают на соответствующий блок 320 данных, как показано на фиг.6, при этом пространственные положения пикселей сохраняются, но они теперь представлены только двумя уровнями, соответствующими наборам Level_0 и Level_1. Для каждого набора уровней, а именно Level_0 и Level_1, средние значения, то есть, например, агрегированные значения, вычисляют в вышеупомянутых вычислительных аппаратных средствах или специализированных цифровых аппаратных средствах согласно уравнению 2 или уравнению 3:
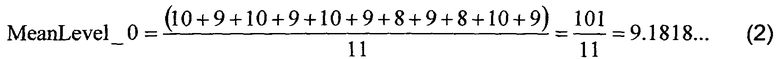
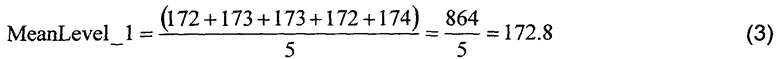
Опционально, каждое из чисел, суммируемых в скобках выше, умножают на соответствующий коэффициент, если необходимо вычислить пространственный взвешенный средний уровень, при этом указанные соответствующие коэффициенты могут взаимно различаться. В случае если кодер 10 и декодер 25 используют эти коэффициенты и их инвертированные значения, если это необходимо, допустимо помечать «водяными знаками» данные при кодировании и сжатии, например, чтобы предотвратить несанкционированное копирование данных, при этом декодеру 25 предоставляют инвертированные коэффициенты, например, из базы данных, в ответ на оплату, например, регулярную оплату подписки. Это позволяет, например, осуществлять потребление содержимого данных заданным конечным пользователем в ухудшенном качестве бесплатно и в высоком качестве при осуществлении оплаты подписки или аналогичного типа платежа.
После этого, согласно уравнениям (2) и (3), приведенным выше, при выполнении алгоритма пространственное представление пикселей в блоке 300 данных сохраняют в виде маски 320 пикселей совместно с агрегированными значениями для каждого из наборов уровней, то есть MeanLevel_0 (Среднее Уровня_0) and MeanLevel_1 (Среднее Уровня_1); альтернативно, вместо сохранения в памяти осуществляют потоковую передачу таких данных из блока 110(i) кодирования. Хотя для упомянутого алгоритма выше описано вычисление среднего арифметического, необходимо понимать, что возможны и другие типы вычислений, например, скошенное среднее, асимметричное среднее, логарифмическое среднее, геометрическое среднее, минимальное значение, максимальное значение, значение моды, медианное значение. Опционально, значения для каждого из набора уровней могут быть вычислены с использованием любых вычислительных средств и путем использования специализированных цифровых аппаратных средств и/или вычислительного устройства, осуществляющего выполнение программных продуктов. Один из примеров вычисления агрегированного значения заключается в выборе значения исходных данных, которое минимизирует расстояние между исходным значением данных и средним значением максимального значения и минимального значения. Такой тип агрегированного значения минимизирует максимальную ошибку в наборе данных и также часто приводит к небольшой среднеквадратической ошибке (MSE). С точки зрения декодера, используемый способ вычисления не имеет принципиального значения. Опциональные примеры вычислительных средств включают способы «грубой силы», методы Монте-Карло и т.д., для нахождения оптимального количества уровней и значений для набора уровней. Пример оптимизации может представлять собой оптимизацию Скорость-Искажения (Rate-Distortion) для определения того, как много битов должно быть использовано при кодировании и как много ошибок допустимо для кодированной информации. Вместо вывода на основе способа двух агрегированных значений опционально выводят одно агрегированное значение на основе ссылки на одно или более других агрегированных значений и разностное значение для указанного одного или более агрегированных значений относительно опорного значения, например, 9.1818 и (172.8-9.1818). Опционально, указанные агрегированные значения, вычисленные так, как указано выше, квантованы, например, до ближайших целых значений, для получения более высокой степени сжатия данных в выходных данных из блока 110(i) кодирования. Опционально, применяемая степень квантования является динамической функцией того, как много наборов необходимо для представления блока 300 данных. Квантование до ближайшего целого значения для вышеупомянутого примера предоставляет агрегированные значения MeanLevel_0=9 и MeanLevel_1=173.
При формировании кодированных данных 70 (E2) из блока 110(i) кодирования пространственное представление пикселей, то есть маску, выводят на основе маски 320 пикселей в множестве возможных порядков сканирования, например, слева направо и сверху вниз, как показано на фиг.6, зигзагообразно, беспорядочно и т.д. В указанном примере маску выводят слева направо и сверху вниз так, чтобы маска была выражена в выходных данных из блока 110(i) кодирования как 0000110000100110.
Если кодер 10 используется для кодирования видеоконтента (D1), последовательность изображений подают в кодер 10, при этом каждое изображение допускает разбиение на блоки 40 данных, которые затем соответствующим образом кодируют с использованием блоков 110 кодирования в зависимости от их содержимого, в соответствии с анализом блоком 100 анализа. Предпочтительно, как было упомянуто выше, кодер 10 динамически переключается между различными блоками 110 кодирования в зависимости от характера блоков данных, поданных во вторую ступень 50 для кодирования. Выбор блоков 110 кодирования, как было упомянуто выше, записывается в кодированных данных из второй ступени 50. Третья ступень 60 опционально применяет дополнительное кодирование и/или сжатие, например, использование одного или более из следующего: дифференциальной импульсно-кодовой модуляции (DPCM), кодирования длин серий (RLE), скользящего кодирования длин серий (SRLE), модификатора энтропии (EM), арифметического кодирования, дельта-кодирования, кодирования ODelta, кодирования с переменной длиной (VLC), способов кодирования на основе преобразования Лемпеля-Зива (ZLIB, LZO, LZSS, LZ77), способов кодирования на основе преобразования Барроуза-Уиллера (RLE, BZIP2) и кодирования Хаффмана. Доставку маски, то есть порядка сканирования для наборов данных, полученных из второй ступени 50, предпочтительно осуществляют с использованием базы данных, например, как описано в заявке на патент США №2010/0322301 («Процессор изображений, генератор изображений и компьютерная программа»), которая включена в настоящее описание путем ссылки. Использование такой базы данных для предоставления пути, по которому указанную маску передают в соответствующий декодер, может предоставить форму ключа доступа, например, для препятствования несанкционированному распространению кодированного содержимого в кодированном виде (то есть несанкционированного обмена файлами).
Восстановленная декодированная версия блока 300 данных, показанного на фиг.5, проиллюстрирована на фиг.7 и обозначена позицией 500. Указанный восстановленный блок 500 данных соответствует части декодированных выходных данных 75 (D3), переданных из декодера 25. Необходимо понимать, что происходит только незначительная потеря информации, имеющейся в блоке 500 данных в сравнении с исходным блоком 40, 300 данных, введенным в кодер.
В другом примере имеется 17 отсчетов данных измерений, которые также могут быть эффективно кодированы с использованием многоуровневого способа согласно настоящему изобретению. Исходные значения отсчетов следующие:
122, 153, 190, 198, 188, 156, 153, 119, 148, 122, 122, 153, 196, 120, 198, 152, 154
Среднее значение (=155.53) может быть использовано для разделения этих значений на две группы, но это не лучшее решение для кодирования данных. Две группы содержат следующие значения:
низкие = 122, 153, 153, 119, 148, 122, 122, 153, 120, 152, 154 (Среднее = 138)
высокие = 190, 198, 188, 156, 196, 198 (Среднее = 187, 66)
Эти два уровня со средними значениями в качестве агрегированных значений (138 и 188) приводят в результате к большой ошибке восстановления (сумма абсолютных разностей (sum of absolute differences) (SAD)=230).
Лучшая точка разделения может быть найдена, например, с использованием следующего уравнения:
(Min+Max)/2=(119+198)/2=158.5,
после чего указанные две группы содержат следующие значения:
низкие = 122, 153, 156, 153, 119, 148, 122, 122, 153, 120, 152, 154
(Среднее = 139,5)
высокие = 190, 198, 188,196, 198
(Среднее = 194)
Эти два уровня со значениями 140 и 194 приводят в результате к меньшей ошибке (SAD=204).
Аналогичное разделение на две группы уровней (низкий и высокий) опционально также вычисляют несколькими другими способами. Одно из предпочтительных решений для разделения на группы уровней представляет собой решение, при котором данные разделяют на новые группы уровней, если изменение данных большое или наибольшее. Такое наибольшее изменение может быть легко обнаружено, если данные сначала упорядочить от соответствующего наименьшего значения до соответствующего наибольшего значения. Упорядоченные значения данных следующие:
119, 120, 122, 122, 122, 148, 152, 153, 153, 153, 154, 156, 188, 190, 196, 198, 198,
и наибольшее изменение данных находится между значениями 188 и 156 (=32).
С двумя уровнями ошибка восстановления все еще довольно высока, и аналогичное правило разделения может быть продолжено для группы, в которой изменения данных самые высокие. В этом случае точка второго разделения может быть найдена между значениями 148 и 122 (=26). Теперь группы уровней следующие:
Теперь, с указанными тремя уровнями и агрегированными значениями 121, 153 и 194 SAD составляет только (6+10+20=) 36.
Также можно использовать значения моды или модели в качестве агрегированных значений для этих трех уровней, тогда агрегированные значения будут следующие: 122, 153 и 198. Теперь SAD составляет (5+10+20=) 35.
Использование медианы в качестве агрегированного значения приводит к формированию значений 122, 153 и 196. Теперь SAD составляет (5+10+18=)33. Указанное агрегированное значение всегда может быть свободно выбрано, и для различных групп могут использоваться различные агрегированные значения для обеспечения лучшего восстановления в зависимости от выбранных критериев ошибки.
Если значение SAD, равное 33, не является достаточно хорошим, можно сформировать еще больше уровней, например, 4-12 уровней, или ошибка восстановления, то есть значения дельта, может быть кодирована с использованием какого-либо способа кодирования, например, VLC.
Если значение SAD, равное 33, является достаточно хорошим, то эти три агрегированные значения (122, 153 и 196) используются в маске, которая описывает, какие данные относятся к какому уровню. Теперь, поскольку уровень 1 имеет наибольшее количество значений, то значения маски устанавливают равными «0», значения уровня 0 устанавливают равными «10», а значения уровня 2 устанавливают равными «11». Таким образом, значения маски могут быть представлены следующим образом:
10, 0, 11, 11, 11, 0, 0, 10, 0, 10, 10, 0, 11, 10, 11, 0, 0
Также опционально можно использовать два набора двоичных маек для описания маски, которая задает данные для различных уровней. Например, первая двоичная маска задает первое разделение для низких значений (≤156) как «0» и высоких значений (≥188) как «1»:
0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0,
Например, первая двоичная маска задает первое разделение для низких значений (≤0) как «0» и высоких значений (≥148) как «1»:
0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1.
Одним из предпочтительных решений для разделения данных на различные наборы всегда является разделение набора, который содержит самую большую амплитуду, то есть (max-min+1). Если множество наборов имеют одинаковую амплитуду, то для разделения предпочтительно выбирают набор, который содержит больше значений данных. Такое разделение на наборы продолжается до тех пор, пока наибольшая амплитуда не станет достаточно маленькой, то есть не будет превышать пороговое значение. После этого агрегированные значения задают для каждого набора с использованием, например, значений моды или медианы.
Опционально, возможно повторение наборов с добавлением одного набора во времени, так что всегда, если новое разделение на наборы выполнено, имеются также новые сформированные агрегированные значения; после этого новые наборы восстанавливают путем помещения всех значений данных в тот набор, агрегированное значение которого наиболее близко к указанному значению данных. Существует много предпочтительных реализации, доступных для формирования наборов и определений агрегированных значений, но конечный результат кодирования всегда должен применять одну или более маску 320 и два или более агрегированных значений, и они выводятся с использованием способа, реализуемого посредством применения блока 110(i) кодирования.
Все примеры масок и агрегированных значений могут быть дополнительно сжаты с использованием множества способов, таких как дельта, RLE, VLC, база данных и т.д.
Кодер 10 и/или декодер 25 предпочтительно реализуют с использованием специализированных электронных аппаратных средств, например, пользовательской цифровой интегральной микросхемы, программируемой вентильной матрицы (field-programmable gate array, FPGA) или тому подобного. Альтернативно или дополнительно, кодер 10 и/или декодер 25 могут быть реализованы путем исполнения одного или более программных продуктов, хранящихся на машиночитаемых носителях, вычислительными аппаратными средствами, связанными посредством передачи данных с памятью данных. Опционально, указанные вычислительные аппаратные средства реализованы в виде высокоскоростного процессора с сокращенным набором команд (reduced-instruction-set (RISC)). Кодированные данные 70 (E2) опционально являются одним из следующего: потоковыми данными, сохраненными на носителе данных, таком как оптический диск, сохраненными в памяти данных и т.д.
Возможны модификации вышеописанных вариантов осуществления настоящего изобретения без выхода за рамки объема настоящего изобретения, заданного приложенной формулой изобретения. Такие выражения как «включающий», «содержащий», «состоящий из», «имеет», «является», используемые для описания настоящего изобретения и в его формуле, должны истолковываться неисключительным образом, а именно должны допускать возможность наличия также объектов, компонентов или элементов, не описанных в явном виде. Следует также понимать, что ссылки на единственное число относятся также ко множественному числу. Числа в круглых скобках в приложенных пунктах формулы изобретения предназначены для обеспечения понимания формулы изобретения и не должны истолковываться любым образом, ограничивающим объект изобретения, заявленный в этих пунктах формулы изобретения.
Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении эффективного кодирования для широкого диапазона содержимого, представленного в кодируемых данных. Кодер для кодирования данных с формированием соответствующих кодированных данных содержит блок для анализа одной или более частей данных, которые должны быть кодированы, для определения наиболее подходящего алгоритма кодирования для применения при кодировании данных, и направления одной или более частей в один или более блоков кодирования, которые выполнены с возможностью кодирования в них одной или более частей с формированием кодированных данных и применения различных типов алгоритмов кодирования при кодировании одной или более частей; по меньшей мере один блок кодирования выполнен с возможностью разделения значений данных, имеющихся в по меньшей мере одной или более частей, принятых этим блоком, по меньшей мере на два набора на основе указанных значений данных, вычисления по меньшей мере одного агрегированного значения для по меньшей мере одного из полученных наборов значений данных на основе значений данных, имеющихся в этом наборе, и сохранения пространственной маски указанной части. 8 н. и 15 з.п. ф-лы, 8 ил., 1 табл.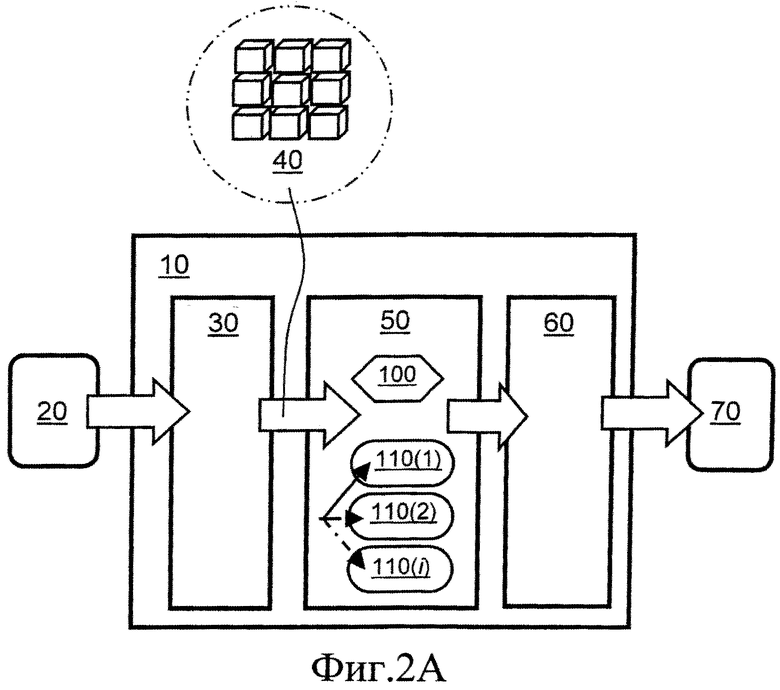
1. Кодер (10) для кодирования данных (20, D1) с формированием соответствующих кодированных данных (70, Е2), характеризующийся тем, что указанный кодер (10) содержит:
блок (100) для анализа одной или более частей (40) данных (20, D1), которые должны быть кодированы, для определения наиболее подходящего алгоритма кодирования для применения при кодировании указанных данных и направления указанных одной или более частей (40) в соответствующие один или более блоков (110) кодирования, которые выполнены с возможностью кодирования в них указанных одной или более частей (40) с формированием кодированных данных (70, Е2), причем:
указанные один или более блоков (110) кодирования выполнены с возможностью применения различных типов алгоритмов кодирования при кодировании указанных одной или более частей (40);
по меньшей мере один блок (110(i)) кодирования из указанных одного или более блоков (110) кодирования выполнен с возможностью разделения значений данных, имеющихся в по меньшей мере одной из указанных одной или более частей (40), принятых этим блоком, по меньшей мере на два набора на основе указанных значений данных, вычисления по меньшей мере одного агрегированного значения для по меньшей мере одного из полученных наборов значений данных на основе значений данных, имеющихся в этом наборе, и сохранения пространственной маски (320) указанной части (40), при этом указанная пространственная маска (320) и информация, представляющая указанные агрегированные значения, вычисленные для указанных по меньшей мере двух наборов данных, включены в указанные кодированные данные (70, Е2).
2. Кодер (10) по п. 1, отличающийся тем, что он включает выходной блок (60) кодера для приема кодированных выходных данных из указанного одного или более блоков (110) кодирования и для последующего кодирования указанных кодированных выходных данных с формированием общих кодированных данных (70, Е2) кодера (10).
3. Кодер (10) по п. 1 или 2, отличающийся тем, что он дополнительно включает входную ступень (30) для разделения и/или объединения данных (20, D1), которые должны быть кодированы, с формированием указанной одной или более частей (40), если указанные данные (20, D1), которые должны быть кодированы, еще не включены в указанную одну или более частей (40).
4. Кодер (10) по п. 1 или 2, отличающийся тем, что он выполнен с возможностью сохранения информации, представляющей одну или более маску (320) указанной одной или более частей, в удаленной базе данных для доступа одним или более декодерами при декодировании указанных кодированных данных (70, Е2), сформированных указанным кодером (10).
5. Кодер (10) по п. 1 или 2, отличающийся тем, что указанное по меньшей мере одно агрегированное значение представляет собой среднее арифметическое, скошенное среднее, логарифмическое среднее, взвешенное среднее, среднее значение, минимальное значение, максимальное значение, значение моды или медианное значение.
6. Способ кодирования данных (20, D1) с формированием соответствующих кодированных данных (70, Е2), характеризующийся тем, что указанный способ включает:
а) использование блока (100) для анализа одной или более частей (40) данных (20, D1), которые должны быть кодированы, для определения наиболее подходящего алгоритма кодирования для применения при кодировании указанных данных и направления указанных одной или более частей (40) в соответствующие один или более блоков (110) кодирования, которые выполнены с возможностью кодирования в них указанных одной или более частей (40) с формированием кодированных данных (70, Е2), причем указанные один или более блоков (110) кодирования выполнены с возможностью применения различных типов алгоритмов кодирования при кодировании указанных одной или более частей (40); и
b) использование по меньшей мере одного блока (110(i)) кодирования из указанных одного или более блоков (110) кодирования для разделения значений данных, имеющихся в по меньшей мере одной из указанных одной или более частей (40), принятых этим блоком, по меньшей мере на два набора на основе указанных значений данных, вычисления по меньшей мере одного агрегированного значения для по меньшей мере одного из полученных наборов значений данных на основе значений данных, имеющихся в этом наборе, и сохранения пространственной маски (320) указанной части (40), при этом указанную пространственную маску (320) и информацию, представляющую указанные агрегированные значения, вычисленные для указанных по меньшей мере двух наборов данных, включают в указанные кодированные данные (70, Е2).
7. Способ по п. 6, отличающийся тем, что он включает использование выходного блока (60) кодера для приема кодированных выходных данных из указанного одного или более блоков (110) кодирования и для последующего кодирования указанных кодированных выходных данных с формированием общих кодированных данных (70, Е2).
8. Способ по п. 6 или 7, отличающийся тем, что он включает сохранение информации, представляющей одну или более маску (320) указанной одной или более частей, в удаленной базе данных для доступа одним или более декодерами при декодировании указанных кодированных данных (70, Е2).
9. Способ по любому из пп. 6 или 7, отличающийся тем, что указанные кодированные данные (70, Е2) дополнительно кодируют и/или сжимают.
10. Способ по п. 9, отличающийся тем, что дополнительное кодирование и/или сжатие включает по меньшей мере одно из следующего: дифференциальную импульсно-кодовую модуляцию (DPCM), кодирование длин серий (RLE), скользящее кодирование длин серий (SRLE), модификатор энтропии (ЕМ), арифметическое кодирование, дельта-кодирование, кодирование ODelta, кодирование с переменной длиной (VLC), кодирование на основе преобразования Лемпеля-Зива (ZLIB, LZO, LZSS, LZ77), кодирование на основе преобразования Барроуза-Уиллера (RLE, BZIP2), кодирование Хаффмана.
11. Декодер (25) для декодирования кодированных данных (70, Е2) с формированием соответствующих декодированных данных (75, D3), характеризующийся тем, что указанный декодер (25) включает блок (155) для доставки одной или более частей (40) указанных кодированных данных (70, Е2) и направления указанных одной или более частей (40) в соответствующие один или более блоков (160) декодирования, которые используют различные типы алгоритмов декодирования и выполнены с возможностью декодирования в них указанных одной или более частей (40) с формированием декодированных данных (70, D3), причем:
по меньшей мере один блок (160(i)) декодирования из указанных одного или более блоков (160) декодирования выполнен с возможностью извлечения пространственной маски (320) и информации, представляющей агрегированные значения по меньшей мере для двух наборов данных, включенных в указанные кодированные данные (70, Е2), и для присвоения значений элементам в блоке (500) данных, в соответствии с тем, к какому из наборов эти элементы принадлежат, как задано указанной маской (320).
12. Декодер (25) по п. 11, отличающийся тем, что он включает выходной блок (170) декодера для приема декодированных выходных данных из указанного одного или более блоков (160) декодирования и для последующего объединения указанных декодированных выходных данных с формированием общих декодированных данных (75, D3) декодера (25).
13. Декодер (25) по п. 11 или 12, отличающийся тем, что он дополнительно включает входную ступень (130) для извлечения одной или более частей из указанных кодированных данных (70, Е2) для их направления, как задано параметрами кодирования, имеющимися в указанных кодированных данных (70, Е2), в блок (155) доставки и в один или более блоков (160) декодирования.
14. Декодер (25) по п. 11 или 12, отличающийся тем, что он выполнен с возможностью извлечения информации, представляющей указанную одну или более маску (320) указанной одной или более частей, из удаленной базы данных при декодировании указанных кодированных данных (70, Е2), сформированных кодером (10).
15. Способ декодирования кодированных данных (70, Е2) с формированием соответствующих декодированных данных (75, D3), характеризующийся тем, что указанный способ включает:
a) использование блока (155) для доставки одной или более частей (40) указанных кодированных данных (70, Е2) и направления указанных одной или более частей (40) в соответствующие один или более блоков (160) декодирования, которые используют различные типы алгоритмов декодирования и выполнены с возможностью декодирования в них указанных одной или более частей (40) с формированием декодированных данных (70, D3); и
b) использование по меньшей мере одного блока (160(i)) декодирования из указанных одного или более блоков (160) декодирования для извлечения пространственной маски (320) и информации, представляющей агрегированные значения, вычисленные по меньшей мере для двух наборов данных, включенных в указанные кодированные данные (70, Е2), и для присвоения значений элементам в блоке (500) данных, в соответствии с тем, к какому из наборов эти элементы принадлежат, как задано указанной маской (320).
16. Способ по п. 15, отличающийся тем, что он включает использование выходного блока (170) декодера для приема декодированных выходных данных из указанного одного или более блоков (160) декодирования и для последующего объединения указанных декодированных выходных данных с формированием общих декодированных данных (75, D3).
17. Способ по п. 15 или 16, отличающийся тем, что он дополнительно включает использование входной ступени (130) для извлечения одной или более частей из указанных кодированных данных (70, Е2) для их направления, как задано параметрами кодирования, имеющимися в указанных кодированных данных (70, Е2), в блок (155) доставки и в один или более блоков (160) декодирования.
18. Способ по п. 15 или 16, отличающийся тем, что указанный по меньшей мере один блок (160(i)) декодирования из указанных одного или более блоков (160) декодирования выполнен с возможностью присвоения значений элементам маски (320), соответствующей наборам данных, при этом имеется от 2 до 8 наборов данных или 2 или более наборов данных.
19. Способ по п. 15 или 16, отличающийся тем, что он включает извлечение информации, представляющей указанную одну или более маску (320) указанной одной или более частей, из удаленной базы данных при декодировании указанных кодированных данных (70, Е2), сформированных кодером (10).
20. Система (5) передачи данных, включающая по меньшей мере один кодер (10) по п. 1 для кодирования данных (20, D1) и формирования соответствующих кодированных данных (70, Е2), и по меньшей мере один декодер (25) по п. 11 для декодирования указанных кодированных данных (70, Е2) с формированием декодированных данных (75, D3).
21. Способ передачи данных в системе (5) передачи данных по п. 20, при этом указанный способ передачи данных использует комбинацию способа кодирования данных по п. 6 и способа декодирования кодированных данных по п. 15.
22. Машиночитаемый носитель, на котором хранится программный продукт, характеризующийся тем, что выполнение указанного программного продукта посредством вычислительных аппаратных средств обеспечивает выполнение способа по любому из пп. 6-10.
23. Машиночитаемый носитель, на котором хранится программный продукт, характеризующийся тем, что выполнение указанного программного продукта посредством вычислительных аппаратных средств обеспечивает выполнение способа по любому из пп. 15-19.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

