ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к кодерам для кодирования исходных данных, например, данных захваченных изображений и/или аудиоданных, с формированием соответствующих кодированных данных; кроме того, настоящее изобретение относится к декодерам для декодирования указанных кодированных данных с формированием соответствующих декодированных данных, например, декодированных данных, представляющих указанные исходные данные; при этом указанные кодеры и декодеры выполнены с возможностью, например, использовать одну или более базу данных, которые включают информацию, обрабатываемую совместно с кодированными данными в декодерах, для формирования указанных декодированных данных; причем указанная одна или более база данных находится, например, в одном или более сервере данных. Дополнительно, настоящее изобретение касается способов кодирования исходных данных с формированием соответствующих кодированных данных; кроме того, настоящее изобретение касается способов декодирования указанных кодированных данных с формированием соответствующих декодированных данных, например, декодированных данных, представляющих исходные данные; при этом указанные способы включают, например, использование одной или более базы данных, которые включают информацию, обрабатываемую совместно с указанными кодированными данными, для формирования указанных декодированных данных. Также настоящее изобретение относится к программным продуктам, хранящимся на машиночитаемых носителях, при этом выполнение указанных программных продуктов осуществляют посредством вычислительных аппаратных средств для реализации вышеупомянутых способов.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Традиционно, кодирование исходных данных, например, посредством современного кодирования MPEG (Motion Pictures Experts Group, экспертная группа по вопросам движущегося изображения) данных захваченного изображения, включает обработку указанных исходных данных для преобразования исходных данных в кодированные данные путем применения одного или более преобразования к указанным исходным данным. Кроме того, декодирование кодированных данных включает обработку указанных кодированных данных для их преобразования в соответствующие декодированные данные, например, декодированные данные, представляющие исходные данные, путем применения к указанным кодированным данным одного или более обратного преобразования. Такое кодирование может быть применено для сжатия исходных данных, например, для уменьшения размера данных для их передачи или хранения на носителе данных; альтернативно или дополнительно, такое кодирование может быть использовано для повышения безопасности исходных данных при их передаче через среду передачи, например, через Интернет. Традиционной практикой является реализация таких кодеров и декодеров в виде автономных блоков обработки, например, встроенных в цифровые камеры, DVD-плееры и аналогичные потребительские продукты. Однако в настоящее время с ростом взаимосвязанности устройств обработки данных, более современной практикой стала разработка кодеров и декодеров, реализуемых с использованием программных продуктов, чтобы они могли быть реконфигурированы, например, для адаптации декодеров к возможности работы с кодированными данными, которые были кодированы с использованием недавно разработанных и модернизированных преобразований кодирования.
В опубликованном патенте США №4553171 описан способ цифровой печати цифрового изображения посредством ссылки на последовательность кодовых слов, представляющих блоки пикселей исходного изображения. Исходное изображение кодируют путем разделения его на блоки пикселей одинакового размера. Опционально, для каждого из блоков пикселей задают уникальный идентификатор, если он не идентичен любому из ранее сканированных блоков. Идентичные блоки пикселей заданы одним и тем же идентификатором. При печати исходного изображения, представленного вышеописанными блоками пикселей, которые представлены идентификаторами, выраженными в виде кодовых слов, указанные идентификаторы последовательно сканируют и соответствующие блоки пикселей последовательно сохраняют в буферной памяти для управления принтером, который формирует распечатку исходного изображения. Таким образом, исходное изображение печатают на основе данных, включающих идентификаторы, содержащие порядковые номера блоков, которые ссылаются на некоторую форму базы данных, в которой хранятся представления блоков пикселей.
В опубликованном патенте США №4013828 описан способ обработки изображения, в котором изображение сканируют и обрабатывают с помощью сглаживания с получением групп элементов изображения заранее заданного размера. Каждая группа элементов изображения соответствует соответствующей группе ячеек удаленно расположенного дисплея. Когда каждую группу элементов изображения сканируют, шаблон, представленный путем соотнесения битов сглаженного изображения с указанной группой элементов изображения, сравнивают с каталогом шаблонов, сохраненных в первой памяти. Если указанный шаблон отсутствует среди шаблонов, сохраненных в первой памяти, ему назначают соответствующее кодовое слово и вводят в память. Кроме того, как шаблон, так и его кодовое слово передают в удаленно расположенный дисплей, где их сохраняют во второй памяти; после этого получают доступ к указанной второй памяти и включают отдельные ячейки из группы ячеек, соответствующей сканированному изображению, в соответствии с шаблоном, сохраненным во второй памяти. Если сканированный шаблон является таким же, как уже сохраненный в первой памяти шаблон, в удаленное местоположение передают только кодовое слово, связанное с этим шаблоном, для уменьшения потока данных между первой памятью и второй памятью, то есть путем повторного использования данных, которые уже были переданы во вторую память. Однако указанный способ не осуществляет непосредственное сжатие потока данных в общепринятом смысле.
В опубликованном патенте Великобритании №2362055 описан способ кодирования изображения, который включает:
a) разделение изображения на блоки изображения;
b) кодирование блоков изображения таким образом, чтобы осуществлять сравнение указанных блоков изображения с уже существующими блоками в базе данных, и выбор существующего блока из базы данных, который является достаточно хорошим совпадением с одним из соответствующих блоков изображения; и
с) кодирование блоков изображения со ссылкой на коды, представляющие уже существующие блоки.
Указанный способ использует библиотеку кодов, то есть базу данных. Однако, вследствие того, что данные, связанные с элементами базы данных, не имеют какой-либо связи друг с другом, выполнение поиска соответствий в базе данных является сложным и требует значительных вычислительных ресурсов, поскольку размер базы данных увеличивается. Наоборот, если база данных мала, совпадение блоков изображения с уже существующими блоками в базе данных невелико, вследствие чего изображение с достаточной степенью качества не может быть создано на основе кодированных данных, сформированных с использованием указанного способа. Однако указанный способ включает создание новых элементов, если достаточно хорошие совпадения не найдены, при этом указанный новый элемент передают совместно с опорным значением, которое его идентифицирует.
Использование цифровых данных, например, видео, изображений, графики и аудио, стремительно возрастает с каждым годом. Вследствие этого, количество сохраняемых и передаваемых данных также быстро увеличивается со временем. Кроме того, такое увеличение сохраняемых и передаваемых данных требует значительно большего увеличения ресурсов для аппаратных средств, например, больше электрической мощности, потребляемой для обеспечения большей производительности обработки, и большей полосы пропускания при передаче. Генератор изображений, описанный в опубликованной заявке на патент США №2010/322,301 (заявитель Gurulogic Microsystems Oy), обеспечивает техническое решение, направленное на то, как сохранить байты и генерировать различные изображения посредством использования базы данных. Однако имеется необходимость в кодере и соответствующем декодере, основанном на использовании усовершенствованной базы данных и выполненном с возможностью доставки баз данных различных типов более эффективным способом, для использования со всеми видами цифровых данных, например, изображениями, видео, графикой и аудиоконтентом.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение обеспечивает улучшенный способ кодирования исходных данных, например, данных захваченных изображений, аудиоданных и тому подобного, с формированием соответствующих кодированных выходных данных, а также кодер, выполненный с возможностью осуществления указанного способа кодирования исходных данных.
Кроме того, настоящее изобретение также обеспечивает улучшенный способ декодирования кодированных данных с формированием соответствующих декодированных выходных данных.
Согласно первому аспекту, предложен способ в соответствии с п.1 приложенной формулы изобретения; предложен способ кодирования исходных данных с формированием соответствующих кодированных данных для передачи или хранения, при этом указанные исходные данные включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, характеризующийся тем, что указанный способ включает:
a) установление соответствия одной или более части исходных данных с одним или более элементом (Е) в одной или более базе данных, при этом указанный один или более элемент (Е) представляет соответствующий один или более блок данных, и запись опорных значений (R), которые связывают указанную одну или более часть исходных данных с указанным одним или более соответственным элементом (Е); и
b) включение указанных опорных значений (R) в кодированные данные совместно с указанной одной или более базой данных и/или информацией, идентифицирующей указанную одну или более базу данных,
при этом указанный способ дополнительно включает:
c) разделение исходных данных на области, имеющие уникальный идентификатор (U) области;
d) взятие зависящих от областей выборок из указанных областей и вычисление соответствующих опорных значений (R) на основе указанных выборок; и
e) проверку, были ли уже переданы или сохранены в указанной одной или более базе данных указанные опорные значения (R), полученные в результате вычислений, примененных к исходным данным, и сохранение и/или передачу указанных опорных значений (R) или опорных значений (R) в сжатом состоянии для однозначной идентификации элементов (Е) в указанных кодированных данных или сохранение и/или передачу указанных кодированных и/или исходных данных в указанных кодированных данных и, опционально, сохранение в качестве нового элемента (Е) в указанной одной или более базе данных в случае, если указанные опорные значения (R) не были ранее сохранены в указанной одной или более базе данных.
Преимущество настоящего изобретения состоит в том, что предложенный кодек выполнен с возможностью получения декодированного видео, изображений, графики и аудиоконтента высшего качества при использовании меньшего количества передаваемых битов данных в сравнении с известными современными кодеками.
Упомянутый на шаге с) уникальный идентификатор (U) области однозначно описывает размер, форму и расположение блока данных. Указанный размер опционально является фиксированным размером, например, 32 значения данных, 8x8 значений данных, или размер опционально зависит от типа содержимого данных, например, блока данных за блоком данных. Идентификаторы (U) областей или информация об идентификаторах (U) областей опционально доставляются или опционально заранее заданы.
Относительно взятия выборки, упомянутого на шаге d), необходимо отметить, что опционально возможно использовать все выборки данных при вычислении опорного значения (R) или только часть из них. Кроме того, опционально возможно использовать только часть выборок, что тем самым обеспечивает более высокие производительность (и точность в соответствующей области выбранных выборок. Также опционально возможно использовать взвешивание выборок при вычислении опорного значения (R) для обеспечения одного или более требуемого преимущества по сравнению с одинаковыми весами. Применяемый способ выборки может быть выбран в зависимости от необходимости в отдельном заданном случае, например, для повышения надежности или улучшения характеристик данных.
Опорные значения (R) опционально формируются следующим образом:
I) возможно вычислять несколько значений данных для блока/пакета; одно из них может быть, например, опорным значением, вычисленным на основе значений данных всего блока/пакета, и дополнительно одно или более опорное значение, вычисленное на основе значений данных субблоков/пакетов;
II) опорное значение элемента может состоять из множества частей, таких как амплитуда, стандартное отклонение, среднее значение, минимальное значение, максимальное значение, хэш, индекс и т.д.; и
III) опорные значения могут быть вычислены с различной точностью, например, как функция пространственных деталей, представленных в кодируемых данных.
Опционально указанный способ включает применение одной или более базы данных с нулевым средним для реализации указанной одной или более базы данных. Базы данных с нулевым средним используют одно или более транслированное или преобразованное значение данных, которые задействуют меньший объем памяти данных в сравнении с соответствующими значениями данных до их транслирования или преобразования. Например, базу данных с нулевым средним формируют путем вычисления среднего значения всех значений данных в заданном элементе базы данных и последующего вычитания указанного среднего значения из значений данных, так чтобы транслированные или преобразованные значения данных изменялись относительно нулевого значения. Такие одна или более база данных с нулевым средним потенциально меньше по размеру и более эффективно сжаты при возникновении необходимости их передачи по сети связи. Опционально, элемент базы данных с нулевым средним очень редко является нулевым средним. Однако, имеется еще элемент базы данных, в котором либо путем его увеличения на единицу, либо путем его уменьшения на единицу можно получить новое среднее значение, которое дальше от нуля, чем указанное среднее значение этого элемента базы данных, или по меньшей мере так же далеко от нуля как указанное среднее значение этого элемента базы данных. Основанием для этого является следующее: указанное среднее значение исходного заданного блока данных часто не является целым числом, а вместо этого является действительным числом, то есть числом с плавающей точкой, и, следовательно, если указанную целую часть вычитают из указанного среднего значения, то есть из всех значений данных указанного элемента, то указанная дробная часть будет либо в диапазоне (-0.5…0.5], либо в диапазоне [-0.5…0.5).
Назначением нулевого среднего является сохранение пространства, то есть использования памяти, в одной или более базе данных, но не для передачи данных. На практике, размер данных для отдельного блока увеличивается при использовании среднего нулевого, поскольку вместо исходного динамического диапазона необходим один дополнительный бит для представления средних нулевых значений, так как знаковый разряд в таком случае необходим для каждого значения элемента. Необходимость в использовании фактического знакового разряда может быть устранена в хранилище базы данных путем использования заранее заданного опорного значения с элементом базы данных с нулевым средним. Динамический диапазон значений элементов базы данных также может быть уменьшен путем квантования, при котором будет потеряна часть информации. Кроме того, для динамического сжатия могут быть использованы таблицы поиска, но такой подход также приводит к потере информации. Однако при использовании элементов с нулевым средним отсутствует необходимость во введении новых элементов в базу данных при изменении среднего значения, вместо этого может быть повторно использован тот же самый элемент и, таким образом, один элемент подходит для всех средних значений в рассматриваемом динамическом диапазоне. Если осуществляют передачу самой базы данных, то необходимо передать только один элемент вместо, например, 256 элементов (в 8-битовом динамическом диапазоне); то есть, изменение среднего значения опорного значения не вводит новые элементы в базу данных, но вместо этого указанное среднее значение используется совместно с указанным элементом в базе данных для формирования конечного блока данных.
Опционально, указанные одна или более база данных находится в одном или более сервере, например одном или более сервере, принадлежащем третьей стороне, например, одному или более поставщику услуг. Кроме того, опционально, использование указанной одной или более базы данных должно быть оплачено, например, посредством платы за подписку и/или платы за использование, для получения доступа к указанной одной или более базе данных.
Опционально, при осуществлении указанного способа указанная одна или более база данных включает одну или более статическую базу данных и/или одну или более динамическую базу данных.
Опорное значение (R) состоит из значений, которые были вычислены на основе выборок данных, но оно может содержать также другие части. Кроме того, опорное значение фактически является неточным понятием. Другими словами, опорные значения вычисляют для осуществления быстрого поиска, и, следовательно, может быть большое количество опорных значений и их точность также может быть очень большой или, альтернативно, маленькой.
Однако, что касается передаваемого опорного значения (R), оно относится к значению, которое идентифицирует рассматриваемый блок между кодером и декодером в отдельности, и сохранение элементов в базе данных основывается на этом передаваемом опорном значении (R). Для статической базы данных, передаваемое опорное значение (R) обычно содержит несколько квантованных, или более точных, опорных значений (R), которые были использованы при поиске, и часто также некоторое значение, которое относится к порядковому номеру. Для динамической базы данных, передаваемое опорное значение (R) обычно представляет собой только значение, которое описывает порядок формирования данного элемента и вероятность его наличия.
Статическую базу данных обычно не модифицируют и, таким образом, передаваемое опорное значение (R) всегда является одним и тем же для каждого элемента (Е) как в кодере, так и в декодере. С другой стороны, динамическая база данных может изменяться непрерывно; поскольку некоторый элемент (Е) становится более вероятным, его опорное значение (R) опционально непрерывно уменьшается, так что оно может быть сжато более эффективно. Однако необходимо понимать, что даже динамическое передаваемое опорное значение (R) опционально содержит части, которые связаны с выборками блока, но они не являются обязательными.
Однако, что касается поиска для динамического элемента (Е), опционально это может быть дополнительно ускорено посредством использования соответствующих опорных значений (R), которые были сформированы из выборок блока, сохраненного с хорошей точностью, для каждого элемента (Е). Поиск в динамической базе данных также опционально ускоряют путем сохранения элементов (Е) в порядке их вероятности, и, следовательно, элемент (Е), который встречается часто, находят быстрее. Также необходимо отметить, что, поскольку передаваемое опорное значение (R) статической базы данных содержит вышеупомянутую часть, которая относится к порядковому номеру, эта часть, особенно если ее длина составляет несколько битов, также опционально используется динамически, если это необходимо, также как и вышеупомянутое передаваемое опорное значение (R) динамической базы данных.
Однако этот вид динамики в заданной статической базе данных часто не является желательным, поскольку в таком случае полный поток данных должен будет быть кодирован от его начала до положения используемого бита, пока не будет гарантировано, к какому элементу происходит обращение в каком-либо заданном случае. Следовательно, будет потеряно одно очень важное преимущество статической базы данных, а именно, то, что она является однозначной и явно заданной. Потенциально достигается немного более высокая степень сжатия, но одновременно будет потерян соответствующий свободный «прыжок» при декодировании данных, который достигается посредством динамической части опорного значения (R).
Ввиду этого, опционально использование динамической базы данных предпочтительно ограничено по времени, в таком случае вышеупомянутые «прыжки» в данных могут быть выполнены так, чтобы декодирование возобновлялось в точке возврата в исходное положение динамической базы данных. Вторым важным преимуществом статической базы данных является то, что она всегда известна до инициирования кодирования и, следовательно, ее элементы (Е) часто не нужно передавать ни в декодер, ни в кодер. Другими словами, имеются опорные значения (R), квантованные опорные значения (R), порядковые числа и передаваемые опорные значения (R) (а именно, индексы), которые состоят из комбинации вышеперечисленного и которые ссылаются на один уникальный элемент (Е) в базе данных.
Таким образом, при выполнении поиска в кодере могут использоваться все более и более точные опорные значения (R), чем значения, которые были переданы из кодера в файл или в декодер. Также для кодера предпочтительно для каждой базы данных сохранять набор опорных значений (R), который является настолько большим и настолько точным, насколько это возможно, так чтобы гарантировать, что поиск будет быстрым и точным, то есть будет необходимо только несколько проверок, но, тем не менее, редко будет пропущен лучший элемент (Е).
Опционально, указанный способ использует по меньшей мере одно из следующего:
a) формирование указанной одной или более статической базы данных путем выбора элементов из одной или более динамической базы данных;
b) обработку информации, представленной в указанной одной или более части исходных данных, с формированием одного или более элемента (Е) для включения в указанную одну или более динамическую базу данных; и
c) выбор элементов (Е) из одной или большего количества более ранних баз данных и включение их в указанную одну или более динамическую базу данных для использования с указанными кодированными данными.
Кроме того, настоящее изобретение обеспечивает преимущество, которое заключается в уменьшенном размере данных при хранении данных, например, в памяти данных, на носителе данных или тому подобном, что обеспечивает экономию вычислительных ресурсов, потребления электрической мощности и времени загрузки данных.
Кроме того, опционально, в указанном способе поставщики услуг Интернет (Internet Service Provider, ISP) по всему миру могут предоставить более быстрые серверы статических баз данных в клиентских локальных сетях (Local Area Network, LAN), тем самым обеспечивая достижение более эффективной передачи данных, поскольку при работе передают только относительно небольшое количество новых блоков данных, и в заданной сети LAN принимают опорные блоки данных существующей базы данных от сервера статической базы данных. Опционально, указанный способ реализуют в кодере, который связан посредством сети связи с указанной одной или более базой данных. Кроме того, опционально, по меньшей мере одна из указанной одной или более базы данных находится в локальной сети (LAN) сети связи, аналогичной локальной сети кодера. Опционально, указанные одна или более базы данных размещены в одном или более сервере данных. Например, сервер базы данных опционально реализуют так, чтобы он был расположен пространственно близко к кодеку, осуществляющему выполнение способа, например, в памяти, расположенной пространственно рядом с ним.
Опционально, в указанном способе опорные значения (R) включают множество частей, которые кодируют по отдельности для включения в кодированные данные. Кроме того, опционально, в указанном способе одну или более из указанных множества частей объединяют перед кодированием для включения в кодированные данные. Опционально, указанное множество частей относится к характеристикам дисперсии V, среднего значения М и амплитуды А одного или более блока данных, к которым получен доступ путем использования опорного значения (R).
Опционально, вместо дисперсии V может быть использовано стандартное отклонение, и, кроме того, опционально, в качестве новых опорных значений (R) используются минимальное значение, максимальное значение, мода и медиана. Что касается минимального значения, максимального значения и амплитуды, только два из них являются опционально необходимыми; третье значение может быть предпочтительно вычислено на основе двух остальных значений. Кроме того, различные значения хэш-функции и значения CRC (Cyclic Redundancy Check, циклический контроль по избыточности) также являются допустимыми опорными значениями (R), когда осуществляют поиск подходящего совпадения или когда есть необходимость различить друг от друга блоки, имеющие в противном случае одинаковые опорные значения (R), в комбинации блоков иным образом, чем путем использования порядкового номера. Такой подход является предпочтительным, поскольку значения случайных данных и CRC могут быть вычислены на основе данных заданного блока данных и, следовательно, они не зависят от порядка передачи.
Опционально, все значения могут использоваться при поиске, причем с высокой точностью, но если передают опорные значения (R) или сохраняют элементы (Е) в базе данных, то выбирают конкретные опорные значения (0-n элементов) с конкретной точностью и опционально также выбирают разделы или части, которые связаны с порядковым номером и которые явно и однозначно идентифицируют сохраненные в базе данных элементы и их значения данных.
Точность и количество параметров передаваемого опорного значения (R) также могут зависеть от параметра качества (Q). Например, опорное значение (R), передаваемое из статической базы данных с хорошим качеством, будет содержать 8-битовое среднее значение, 8-битовое значение стандартного отклонения, 6-битовое значение амплитуды, 6-битовое минимальное значение и 8-битовый порядковый номер, тогда как для опорного значения (R), передаваемого из статической базы данных с низким качеством, опционально будет достаточно 7-битового среднего значения, 7-битового значения стандартного отклонения, 5-битового значения амплитуды и 4-битового порядкового номера.
Что касается динамической базы данных, опорное значение (R), передаваемое из динамической базы данных с хорошим качеством, опционально включает порядковое число, выраженное, например, 18 битами, и с низким качеством, например, 10 битов было бы достаточно. Сохраненные опорные значения (R) и опорные значения (R), используемые при поиске, например, опционально выражаются 16 битами для их среднего значения и для стандартного отклонения, и, совместно с информацией, описывающей динамику данных, например, 8 битами для амплитуды, минимального значения, максимального значения, моды и медианы. Кроме того, необходимо понимать, что все опорные значения (R), которые зависят от данных, опционально вычисляют на основе выборок декодированного блока данных, например, как в кодере, так и в декодере, и, следовательно, и кодер, и декодер всегда могут вычислить их с одинаковой точностью и с требуемой для них самих точностью.
В кодере необходима полная точность для выполнения быстрого поиска и, кроме того, в кодере и декодере необходимо даже, чтобы эти значения уже были вычислены, по меньшей мере с точностью, необходимой для передачи, так что элементы (Е) базы данных могут быть сохранены в правильном адресе базы данных для дальнейшего использования, как указано передаваемым опорным значением (R). Необходимо также понимать, что квантование и сжатие опорного значения (R) представляют собой различные понятия, хотя оба будут обеспечивать уменьшение количества кодированных данных. Однако сжатие является обратимым, в то время как квантование приводит к потере информации требуемым образом, чтобы сделать указанное значение более легким для использования, например, явно уменьшает размер базы данных и количества передаваемых данных.
Опционально, в указанном способе указанные опорные значения (R) включают информацию для направления поиска соответствующего одного или более элемента (Е) в указанной одной или более базе данных.
Опционально, в указанном способе указанные элементы (Е) включают один или более параметр, на основе которого посредством интерполяции может быть вычислен один или более соответствующий блок данных. Дополнительно или альтернативно к интерполяции опционально используют другие вычисления, например, децимацию, экстраполяцию и обрезку. Такие вычисления относятся ко всем таким элементам (Е), которые могут быть использованы посредством масштабирования вверх или вниз, или посредством увеличения значений в более крупные блоки, или путем использования только меньших разделов указанного элемента. Для экстраполяции и обрезки дополнительно требуется также бит информации, указывающий, где будет иметь место экстраполяция и в какой части блока должна быть выполнена обрезка, а интерполяция и децимация могут функционировать автоматически в соответствии с соотношением между размером декодируемого блока и размером блока элемента (Е) базы данных. Опционально, указанные способы интерполяции и децимации могут быть сохранены и/или переданы в кодированных данных или могут быть заранее выбраны.
Опционально, в указанном способе указанную одну или более динамическую базу данных формируют на ограниченное время, после чего их удаляют.
Опционально, указанный способ включает реструктурирование одной или более базы данных как функции частоты доступа к элементам (Е) в базах данных для более быстрого представления более часто используемых элементов (Е) для получения доступа с использованием опорных значений (R).
Опционально, в указанном способе элементы (Е) указанной одной или более динамической базы данных формируют, если совпадения указанной одной или более части исходных данных с одним или более элементом (Е) в указанной одной или более статической базе данных не могут быть обнаружены или элементы (Е) используют слишком много битов в их передаваемом опорном значении (значениях) (R).
Опционально, в указанном способе установление соответствия указанной одной или более части исходных данных с одним или более элементом (Е) указанной одной или более базы данных осуществляют в пределах порога качества, который динамически изменяется во время формирования опорных значений (R).
Опционально, в указанном способе указанное одно или более опорное значение (R) используют для восстановления одной или более соответствующей части исходных данных с использованием одного или более элемента (Е), заданного указанным одним или более опорным значением (R), при этом определяют ошибки между указанной восстановленной одной или более частью и соответствующей исходной одной или более частью в исходных данных, а также кодируют указанные ошибки и включают их в кодированные данные.
Опционально, в указанном способе указанный один или более блок данных, соответствующий указанному одному или более элементу (Е), является по меньшей мере одним из следующего: одномерными (1-D), двумерными (2-D), трехмерными(3-D), многоугольными при визуальном отображении, прямоугольными при визуальном отображении, эллиптическими при визуальном отображении, круговыми при визуальном отображении, удлиненными при визуальном отображении, треугольными при визуальном отображении.
Опционально, в указанном способе один или более элемент (Е) первой базы данных ссылается на один или более элемент (Е), представленный в одной или более другой базе данных из указанной одной или более базы данных. Другими словами, элемент (Е) в первой базе данных может ссылаться на элемент (Е) во второй базе данных, из которой извлечен соответствующий блок данных.
Опционально, в указанном способе одно или более опорное значение (R), включенное в кодированные данные, представлено в сжатом виде.
Опционально, в указанном способе указанную одну или более базу данных выбирают и/или изменяют в размере в зависимости от характера содержимого, представленного в исходных данных.
Согласно второму аспекту предложен кодер для кодирования исходных данных с формированием соответствующих кодированных данных (30), характеризующийся тем, что указанный кодер включает:
а) первые аппаратные средства обработки данных для установления соответствия одной или более части исходных данных с одним или более элементом (Е) в одной или более базе данных, при этом указанный один или более элемент (Е) представляет соответствующий один или более блок данных, и для записи опорных значений (R), которые связывают указанную одну или более часть исходных данных с указанным одним или более соответственным элементом (Е); и
b) вторые аппаратные средства обработки данных для включения указанных опорных значений (R) в кодированные данные совместно с указанной одной или более базой данных и/или информацией, идентифицирующей указанную одну или более базу данных;
при этом указанные исходные данные включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений;
при этом кодер выполнен с возможностью:
c) приема исходных данных в виде одного или более блока данных, разделения указанного одного или более блока данных на области, имеющие уникальный идентификатор (U) области;
d) взятия зависящих от областей выборок из указанных областей указанного одного или более блока данных и вычисления соответствующих опорных значений (R) на основе указанных выборок; и
e) проверки, были ли уже переданы или сохранены в указанной одной или более базе данных указанные опорные значения (R), полученные в результате вычислений, примененных к указанному одному или более блоку данных, и сохранения и/или передачи вычисленных опорных значений (R) или сжатых опорных значений для однозначной идентификации элементов (Е) в указанных кодированных данных или сохранения и/или передачи указанных кодированных и/или исходных данных в указанных кодированных данных, и, опционально, сохранения в качестве нового элемента (Е) в указанной одной или более базе данных в случае, если указанные опорные значения (R) не были ранее сохранены в указанной одной или более базе данных.
Опционально, в кодере указанная одна или более база данных включает одну или более статическую базу данных и/или одну или более динамическую базу данных.
Опционально, указанный кодер использует по меньшей мере одно из следующего:
а) формирование указанной одной или более статической базы данных путем выбора элементов из одной или более динамической базы данных;
b) обработку информации, представленной в указанной одной или более части исходных данных, с формированием одного или более элемента (Е) для включения в указанные одну или более динамическую базу данных; и
c) выбор элементов (Е) из одной или большего количества более ранних баз данных и включение их в указанную одну или более динамические базу данных для использования с указанными кодированными данными.
Опционально, кодер связан посредством сети связи с указанной одной или более базой данных, при этом по меньшей мере одна из указанной одной или более базы данных находится в локальной сети (LAN, local area network) сети связи, аналогичной локальной сети кодера. Опционально, указанная одна или более база данных реализована с использованием одного или более сервера данных.
Кроме того, опционально, в указанном кодере указанные первые аппаратные средства обработки данных выполнены с возможностью формирования опорных значений (R) для включения множества частей, которые кодированы по отдельности, в кодированные данные. Кроме того, опционально, указанный кодер выполнен с возможностью объединения одной или более из указанных множества частей перед их кодированием для включения в кодированные данные.
Опционально, в кодере указанные опорные значения (R) включают информацию для направления поиска соответствующего одного или более элемента (Е) в указанной одной или более базе данных.
Опционально, в кодере указанные опорные значения (R) включают параметры, на основе которых посредством интерполяции могут быть вычислен один или более соответствующий блок данных. Опционально или альтернативно, в кодере используют децимацию, экстраполяцию и обрезку. Такие вычисления предпочтительно относятся ко всем таким элементам базы данных, которые могут быть использованы посредством масштабирования вверх или вниз, или посредством увеличения значений в более крупные блоки, или путем использования только меньшей части указанного элемента. Для экстраполяции и обрезки дополнительно требуется информация о том, где будет иметь место экстраполяция и в какой части блока будет выполнена обрезка, а интерполяция и децимация могут функционировать автоматически в соответствии с соотношением между размером декодируемого блока и размером блока элемента базы данных. Опционально, указанные способы интерполяции и децимации могут быть сохранены и/или переданы в кодированных данных или могут быть заранее выбраны.
Опционально, в кодере указанную одну или более динамическую базу данных формируют на ограниченное время, после чего их удаляют.
Опционально, указанный кодер выполнен с возможностью реструктурирования одной или более базы данных в зависимости от частоты доступа к элементам (Е) в базах данных для более быстрого представления более часто используемых элементов (Е) для получения доступа с использованием опорных значений (R).
Опционально, в кодере элементы (Е) указанной одной или более динамической базы данных формируют, если совпадения указанной одной или более части исходных данных с одним или более элементом (Е) в указанной одной или более статической базе данных не могут быть обнаружены или элементы (Е) используют слишком много битов в их передаваемом опорном значении (значениях) (R).
Опционально, в кодере установление соответствия указанной одной или более части исходных данных с одним или более элементом (Е) указанной одной или более базы данных осуществляется первыми аппаратными средствами обработки данных в пределах порога качества, который динамически изменяется во время формирования опорных значений (R).
Опционально, в кодере указанные первые аппаратные средства обработки данных выполнены с возможностью использования указанного одного или более опорного значения (R) для восстановления одной или более соответствующей части исходных данных с использованием одного или более элемента (Е), заданного указанным одним или более опорным значением (R), при этом указанные первые аппаратные средства обработки данных выполнены с возможностью идентификации ошибок между указанной восстановленной одной или более частью и соответствующей исходной одной или более частью в исходных данных, а вторые аппаратные средства обработки данных выполнены с возможностью кодирования указанных ошибок и включения их в кодированные данные.
Опционально, в указанном кодере указанный один или более блок данных, соответствующий указанному одному или более элементу (Е), являются по меньшей мере одним из следующего: одномерными (1-D), двумерными (2-D), трехмерными(3-D), многоугольными при визуальном отображении, прямоугольными при визуальном отображении, эллиптическими при визуальном отображении, круговыми при визуальном отображении, удлиненными при визуальном отображении, треугольными при визуальном отображении.
Опционально, в указанном кодере один или более элемент (Е) первой базы данных ссылается на один или более элемент (Е), представленный в одной или более другой базе данных из указанной одной или более базы данных.
Опционально, в указанном кодере одно или более опорное значение (R), включенное в кодированные данные, представлены в сжатом виде.
Опционально, в указанном кодере первые аппаратные средства обработки данных выполнены с возможностью выбора указанной одной или более базы данных в зависимости от характера содержимого, представленного в исходных данных.
Согласно третьему аспекту предложен способ декодирования кодированных данных с формированием соответствующих декодированных выходных данных, характеризующийся тем, что указанный способ включает:
a) прием кодированных данных, включающих опорные значения (R) и информацию об идентификаторах областей, а также информацию об одной или более базе данных;
b) декодирование указанных опорных значений (R) из указанных кодированных данных;
c) извлечение одного или более элемента (Е) из указанной одной или более базы данных согласно указанным опорным значениям (R), при этом указанный один или более элемент (Е) представляет один или более соответствующий блок данных; и
d) формирование указанного одного или более блока данных для сборки соответствующих общих декодированных выходных данных.
Опционально, указанный способ включает:
e) сохранение данных в базе данных, которые включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, соответствующие опорным значениям (R);
f) формирование идентификаторов (U) областей на основе информации об идентификаторах областей, включенных в кодированных данные;
g) прием или извлечение из кодированных данных опорного значения (R), соответствующего одному или более идентификатору (U) областей;
h) извлечение из базы данных на основе опорного значения (R) для соответствующего одного или более идентификатора (U) области данных, соответствующих указанному опорному значению (R); и
i) формирование, на основе данных, излеченных из указанной базы данных, блока данных, который собран в виде общих декодированных выходных данных на основе идентификатора (U) области.
В отношении шага с) указанного способа, необходимо отметить, что опорными значениями (R) для элементов (Е) в декодере являются такие значения, которые были использованы при передаче, то есть квантованные и состоящие из нескольких разделов значения. Для одного и того же элемента (Е) могут существовать несколько опорных значений (R), поскольку опорное значение (R) может использоваться одновременно в одной или более динамической базе данных и/или в одной или более статической базе данных. Кроме того, ряд блоков данных хорошего качества могут быть использованы также в блоке данных более низкого качества, в таком случае часть опорного значения (R) при различных уровнях квантования будет формировать отличающееся от него опорное значение (R) указанного блока. Другими словами, заданный элемент (Е) опционально может иметь несколько опорных значений (R), но одно и то же опорное значение (R) не может ссылаться на несколько элементов (Е), если они не присутствуют в различных базах данных, или если они не используются для различного качества, или если они не содержат такую характеристику для элемента (Е), которая явно и однозначно может быть выбрана из нескольких вариантов.
Например, если такие элементы (Е) используют, когда среднее значение опущено, то блок с большой амплитудой, который был сформирован путем использования большого среднего значения, может быть использован в качестве отрицания для блока, который имеет малое среднее значение, тогда как он все еще может быть по существу использован для блока с большим средним значением. Если попытаться заменить одно на другое, то были бы получены выходные значения, которые не лежали бы в динамическом диапазоне значений данных, например, 8-битовых данных, для которых используют элементы базы +/-8-битовых данных без среднего значения. Если, например, амплитуда равна 200, а среднее значение1 при сохранении равно 220 и среднее значение 2 при использовании равно 30, то использование отрицания или не использование отрицания очевидно является выводимым. В этом случае значение данных элемента базы данных без среднего значения могло бы быть, например, равным -170 и не могло бы использоваться совместно со средним значением 2, но в качестве отрицания +170 для рассматриваемого значения данных было бы действительным. Таким образом, передаваемое опорное значение может содержать другую информацию кроме разделов опорных значений или порядковых чисел, хотя на практике эту другую информацию часто предпочтительно передают в виде отдельной части информации кодирования. Например, в случае базы данных без среднего значения, уже одно среднее значение является частью информации, которая всегда необходима, и оно может быть частью опорного значения (R) или отдельной вставкой в информацию кодирования.
Соответственно, если необходимо, чтобы один и тот же элемент (Е) содержал повернутые или зеркально отображенные версии, то для различных изменений может существовать отдельный числовой раздел информации в опорном значении (R) или альтернативно выполняется отдельная доставка информации кодирования для обозначения той же самой информации. Общим во всем этом является тот факт, что для одного элемента (Е), сохраненного в базе данных, могут быть сформированы различные блоки декодирования в зависимости от того, какие параметры заданы, например, среднее значение, вращение и зеркальное отображение, аналогично для масштабирования, обрезки, экстраполяции и так далее.
Часть этой информации является такой, что на основе другой уже принятой информации или на основе ранее декодированных блоков может быть выведено корректное изменение, но, соответственно, часть ее должна будет передаваться так, чтобы однозначно выполнить способ декодирования, если в декодере разрешено использование альтернатив. Например, соотношение между амплитудой и средним значением с отрицанием может быть выведено с большими амплитудами и маленькими или большими средними значениями, иначе оно не является выводимым. Соответственно, в случае ранее декодированных блоков, вывод часто может быть сделан на основе связей, при которых вращение или зеркальное отображение были бы корректными. Однако во всех этих случаях, при которых выведение не является однозначно ясным, необходимо передавать дополнительную информацию либо в качестве части опорного значения (R), либо в качестве отдельной части информации.
Опционально, в указанном способе указанная одна или более база данных включает одну или более статическую базу данных и/или одну или более динамическую базу данных.
Опционально, в указанном способе указанная одна или более база данных пространственно расположены в аппаратных средствах обработки данных, выполненных с возможностью выполнения указанного способа. Кроме того, опционально, в указанном способе указанная одна или более база данных размещена в локальной сети (LAN), которая также включает указанные аппаратные средства обработки данных.
Опционально, указанный способ включает формирование одной или более динамической базы данных из одного или более элемента (Е) указанной одной или более статической базы данных и/или из информации, предоставленной в кодированных данных, при этом указанную сформированную одну или более динамическую базу данных используют для декодирования указанных кодированных данных.
Опционально, указанный способ включает формирование из указанного одного или более элемента (Е) соответствующего одного или более блока данных, которые являются по меньшей мере одним из следующего: одномерными (1-D), двумерными (2-D), трехмерными(3-D), многоугольными при визуальном отображении, прямоугольными при визуальном отображении, эллиптическими при визуальном отображении, круговыми при визуальном отображении, удлиненными при визуальном отображении, треугольными при визуальном отображении.
Согласно четвертому аспекту, предложен декодер для декодирования кодированных данных с формированием соответствующих декодированных данных, характеризующийся тем, что указанный декодер включает:
a) первые аппаратные средства обработки данных для приема кодированных данных, включающих опорные значения (R) и информацию об идентификаторах (U) областей, а также информацию об одной или более базе данных;
b) вторые аппаратные средства обработки данных для декодирования указанных опорных значений (R) из указанных кодированных данных;
c) третьи аппаратные средства обработки данных для извлечения одного или более элемента (Е) из указанной одной или более базы данных согласно указанным опорным значениям (R), при этом указанный один или более элемент (Е) представляет один или более соответствующий блок данных; и
d) четвертые аппаратные средства обработки данных для формирования указанного одного или более блока данных для сборки соответствующих общих декодированных выходных данных.
Необходимо понимать, что указанные первые и вторые аппаратные средства обработки данных могут быть одним и тем же блоком обработки или отдельными блоками обработки. Аналогично, может быть множество блоков обработки, выполняющих функции указанных первых и/или вторых аппаратных средств обработки данных.
Имеется множество возможностей осуществления, и они не ограничиваются примерами, рассмотренными в настоящем описании.
Опционально, декодер конфигурирован для:
e) сохранения в базе данных опорных значений (R) и данных, которые включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, соответствующие опорным значениям (R);
f) формирования идентификаторов (U) областей на основе информации об идентификаторах областей, включенных в кодированных данные;
g) приема или извлечения из кодированных данных опорного значения (R), соответствующего одному или более идентификатору (U) областей;
h) извлечения из памяти на основе опорного значения (R) для одного или более идентификатора (U) области данных, соответствующих указанному опорному значению (R); и
i) формирования, на основе данных, излеченных из указанной базы данных, блока данных, который собран в виде общих декодированных выходных данных на основе идентификатора (U) области.
Опционально, в декодере указанная одна или более база данных включают одну или более статическую базу данных и/или одну или более динамическую базу данных.
Опционально, в указанном декодере указанная одна или более база данных пространственно расположена в аппаратных средствах обработки данных декодера. Кроме того, опционально, в указанном декодере указанная одна или более база данных размещена в локальной сети (LAN), которая также включает указанные аппаратные средства обработки данных декодера. Альтернативно, или дополнительно, указанная одна или более база данных расположена в декодере, например, в его памяти данных (RAM, ROM).
Опционально, указанный декодер выполнен с возможностью формирования одной или более динамической базы данных из одного или более элемента (Е), и/или одной или более статической базы данных, и/или из информации, предоставленной в кодированных данных, при этом указанную сформированную одну или более динамическую базу данных используют для декодирования указанных кодированных данных с формированием соответствующих декодированных данных.
Опционально, декодер выполнен с возможностью формирования указанного одного или более блока данных из указанного одного или более элемента (Е), при этом указанный один или более блок данных является по меньшей мере одним из следующего: одномерными (1-D), двумерными (2-D), трехмерными (3-D), многоугольными при визуальном отображении, прямоугольными при визуальном отображении, эллиптическими при визуальном отображении, круговыми при визуальном отображении, удлиненными при визуальном отображении, треугольными при визуальном отображении.
Согласно пятому аспекту, предложен кодек, включающий по меньшей мере один кодер в соответствии со вторым аспектом для кодирования исходных данных с формированием соответствующих кодированных данных, и по меньшей мере один декодер в соответствии с четвертым аспектом для приема указанных кодированных данных и их декодирования с формированием соответствующих декодированных данных.
Опционально, кодек включен в состав одного или более потребительских электронных товаров, например, персональных компьютеров (PC), видеомагнитофонов, видеоплееров, смартфонов, игровых устройств, научного оборудования, медицинского оборудования, устройств наблюдения, охранных устройств, датчиков и других измерительных приборов и цифровых камер.
Опционально, кодек выполнен так, чтобы указанный по меньшей мере один кодер и указанный по меньшей мере один декодер совместно использовали одну или более базу данных, на которые ссылаются опорные значения (R), включенные в указанные кодированные данные.
В соответствии с шестым аспектом, предложен программный продукт, хранящийся на машиночитаемых носителях, отличающийся тем, что выполнение указанного программного продукта осуществляют посредством вычислительных аппаратных средств кодера для реализации способа в соответствии с первым аспектом настоящего изобретения.
В соответствии с седьмым аспектом, предложен программный продукт, хранящийся на машиночитаемых носителях, отличающийся тем, что выполнение указанного программного продукта осуществляют посредством вычислительных аппаратных средств декодера для реализации способа в соответствии с третьим аспектом настоящего изобретения.
Необходимо понимать, что признаки настоящего изобретения допускают их объединение в различных комбинациях без выхода за рамки объема настоящего изобретения, заданного приложенной формулой изобретения.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Далее только в качестве примера будут описаны варианты осуществления настоящего изобретения со ссылкой на следующие чертежи, на которых:
фиг.1 представляет собой схематическую иллюстрацию кодера и декодера, составляющих в комбинации кодек, согласно настоящему изобретению;
фиг.2 представляет собой схематическую иллюстрацию нового элемента, отправляемого в кодек, показанный на фиг.1;
фиг.3 представляет собой схематическую иллюстрацию множества отдельно заданных частей опорного значения, передаваемого в кодеке, показанном на фиг.1.
На сопровождающих чертежах подчеркнутые номера позиций используются для представления элемента, над которым расположен подчеркнутый номер, или элемента, рядом с которым находится подчеркнутый номер. Неподчеркнутый номер относится к элементу, идентифицируемому линией, связывающей неподчеркнутый номер с указанным элементом.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
При описании вариантов осуществления настоящего изобретения далее будут использоваться следующие аббревиатуры, представленные в таблице 1:
В общем виде, как показано на фиг.1, настоящее изобретение относится к кодеру 10 для кодирования исходных данных 20 с формированием соответствующих кодированных данных 30 и декодеру 50 для приема и декодирования кодированных данных 30 с формированием соответствующих декодированных данных 60; в комбинации указанные кодер 10 и декодер 50 образуют кодек 5. Декодированные данные 60 опционально представляют собой исходные данные 20, например, по меньшей мере одно из следующего: аудиоданные, одномерные изображения (1-D), двумерные изображения (2-D), трехмерные изображения (3-D), видеоконтент, графические данные, захваченные аудиоданные, захваченные изображения, захваченные видеоданные, ASCII (American Standard Code for Information Interchange, американский стандартный код для обмена информацией) и двоичные данные, а также данные измерений и сформированные данные. Кодер 10 и декодер 50 выполнены с возможностью использования одной или более базы 100 данных для кодирования исходных данных 20 и для декодирования кодированных данных 30. Кроме того, указанные одна или более база 100 данных включают одну или более статическую базу 110 данных и/или одну или более динамическую базу 120 данных, как будет более подробно описано далее. Опционально, указанную одну или более базу 110, 120 данных предоставляют посредством одного или более сервера данных, например сервера, пространственно удаленного от кодера 10 и декодера 50. Опционально, как для кодера 10, так и для декодера 50 предоставляют по меньшей мере одну и ту же базу 100 данных; такая схема может обеспечить более высокую безопасность данных, поскольку отсутствует необходимость в том, чтобы делать доступными множество копий данных в сети передачи данных, например, во множестве пространственно разнесенных серверов данных, реализованных, например, как одноранговая сеть серверов данных. Альтернативно, указанная одна или более база 100 данных опционально выполнены так, чтобы каждый из указанных кодера 10 и декодера 50 имел свои собственные выделенные базы данных кодера и базы данных декодера, соответственно, например, размещенные в одном или более сервере данных.
Необходимо понимать, что указанная одна или более база 100 данных могут быть реализованы многими различными способами. Например, если одному или более из указанных кодера 10 и декодера 50 необходима информация из указанных одной или более баз 100 данных, например, осуществленных в виде одного или более сервера данных, указанная информация может быть предоставлена непосредственно, альтернативно, информация может быть предоставлена опосредованно. Для непосредственного получения информации кодер 10 и/или декодер 50 отправляют запрос в один или более сервер данных; после чего указанный один или более сервер данных поставляют указанную информацию в кодер 10 и/или декодер 50, например, информацию шифрования, информацию о способе кодирования, информацию о способе декодирования, библиотеку элементов изображения и так далее. При опосредованном получении информации кодер 10 и/или декодер 50 отправляют первый запрос в один или более сервер, которые в ответ предоставляют информацию об одном или более сервере, из которого доступна информация; после этого кодер 10 и/или декодер 50 отправляют второй запрос в указанный один или более другой сервер данных для получения информации в кодере 10 и/или декодере 50. Опционально, применяют более двух уровней запросов в отношении серверов данных. Опционально, по меньшей мере один из указанных первого запроса и второго запроса шифруют для предотвращения несанкционированного кодирования и/или декодирования, например, для предотвращения несанкционированной доставки файлов, что является основной проблемой для современной музыкальной индустрии. Опционально, указанный первый запрос передают в пространственно удаленный сервер данных, а второй запрос передают в пространственно более близко расположенный сервер данных; информационный трафик, связанный с первым запросом опционально является умеренным, тем самым легко предоставляется сетью связи, тогда как информационный трафик, связанный с ответом на второй запрос, может быть значительным и его наиболее удобно предоставлять пространственно близко к кодеру 10 и/или декодеру 50. Опционально, первый запрос включает информацию о положении, указывающую, где в пространственном отношении или в какой сети связи находятся кодер 10 и/или декодер 50, а ответ на первый запрос включает информацию о подходящей базе данных, расположенной наиболее близко в пространственном отношении, или о ближайшей базе данных, подключенной подходящим образом, например, о сервере данных, к кодеру 10 и/или декодеру 50, которая может предоставить существенную информацию о кодировании и/или декодировании в кодер 10 и/или декодер 50. Опционально, ответ на первый запрос предоставляет кодеру 10 и/или декодеру 50 возможность выбора из множества возможных баз данных, которые могут предоставить подходящую информацию; опционально, такой выбор основывается на одном или более технических критериях, например, самом быстром возможном информационном соединении, информационном соединении с наименьшим энергопотреблением, наименее дорогом информационном соединения, но не ограничивается перечисленным. Хотя в настоящем описании рассматривается ситуация, при которой используют первый запрос и второй запрос, необходимо понимать, что опционально может применяться более двух запросов, если это необходимо, например, множество запросов, например, для обнаружения несанкционированного декодирования кодированного контента, даже еще более сложного для доступа неавторизованным сторонам.
Опционально, по этой причине из центрального местоположения распределяют один или более код доступа для предоставления декодеру 50 возможности получать данные для декодирования контента, так чтобы множеству таких декодеров 50 была временно предоставлена такая возможность по существу одновременно, например, в случае выхода нового фильма-блокбастера и его распространения по сети связи, при этом при необходимости осуществляют координирование и управление выходом фильма для просмотра. Такое управление также позволяет обеспечить цензуру видеоконтента после выпуска, например, в случае установления судебного запрета или нарушения авторского права.
Варианты осуществления настоящего изобретения предпочтительно используют способы, описанные для генератора изображений в заявке на патент США №2010/0322301 («Процессор изображений, генератор изображений и компьютерная программа» («Image processor, image generator and computer program»), изобретатель - Tuomas Kärkkäinen; заявитель - Gurulogic Microsystems Oy), содержание которой включено в настоящее описание путем ссылки. Однако в вариантах осуществления настоящего изобретения такие способы, а также другие способы, используются более эффективно и обычным путем.
В вариантах осуществления настоящего изобретения указанную одну или более динамическую базу 120 данных и их соответствующие элементы Е формируют при доставке кодированных данных 30 из кодера 10 в декодер 50. Кроме того, указанную одну или более статическую базу 110 данных предпочтительно формируют из указанной одной или более динамической базы 120 данных или заранее доставляют до того, как кодированные данные 30 будут доставлены в декодер 50, или предварительно устанавливают в декодер 50.
При доставке новых элементов E базы данных в декодер 50 их опционально передают совместно с одним или более опорным значением R, частично с опорным значением R или без опорного значения R в зависимости от используемого алгоритма кодирования. Предпочтительно, кодер 10 и декодер 50 выполнены с возможностью вычисления полного опорного значения R или части опорного значения R заданного элемента Е базы данных непосредственно на основе данных, которые должны быть сохранены в заданном элементе Е базы данных, то есть в виде восстановленного блока данных. Кроме того, в отношении заданного элемента E базы данных реализуют механизм обнаружения ошибки, когда по меньшей мере часть вычисленного опорного значения R заданного элемента Е базы данных доставляют между кодером 10 и декодером 50.
Кодер 10 и декодер 50 предпочтительно выполнены с возможностью кодирования и декодирования, соответственно, данных, которые по меньшей мере частично кодированы согласно известным стандартам кодирования, приведенным в таблице 2.
На фиг.1 данные для элементов E в одной или более базе 100 данных кодируют для передачи из кодера 10 в декодер 50, что обеспечивает доставку элементов E базы данных одновременно при доставке кодированных данных изображения или других типов данных, таких как аудиоданные, видеоданные, графические данные, данные измерений, текстовые данные, двоичные данные. Элементы E часто формируют из кодированных данных, а именно, после декодирования. Кроме того, кодирование элементов E из одной или более базы 100 данных обеспечивает эффективную доставку базы данных между кодером 10 и декодером 50, то есть обеспечивает эффективное сохранение базы 100 данных в используемых устройствах, например, для реализации декодера 50. В случае если используют одну или более статическую базу 110 данных, кодер 10 и декодер 50 уведомляют о доступных базах данных; альтернативно, кодер 10 и декодер 50 взаимно обмениваются информацией для определения того, какие базы данных доступны для использования. Опционально, и кодер, и декодер 50 посредством взаимного диалога друг с другом определяют, какие базы данных необходимо использовать, например, один или более сервер данных, до передачи кодированных данных из кодера 10 в декодер 50, при этом указанные базы данных используют для декодирования кодированных данных 30 в декодере 50 с формированием декодированных данных 60.
Кодер 10 и декодер 50 предпочтительно используют в широком диапазоне практических применений, показанных в таблице 3, например, в различных отраслях промышленности.
Предпочтительно, в таких практических применениях, которые показаны в таблице 3, используют кодер, описанный в заявке на патент Великобритании №1214414.3 и эквивалентной заявке на патент США №13/584,005, а также в соответствующей Европейской заявке на патент №13002521, содержание которых полностью включено в настоящее описание путем ссылки, и декодер, описанный в заявке на патент Великобритании №1214400.2 и эквивалентной заявке на патент США №13/584,047, а также в соответствующей Европейской заявке на патент №13002520, содержание которых полностью включено в настоящее описание путем ссылки. Кроме того, содержание находящихся на рассмотрении заявок на патенты, таких как заявка на патент Великобритании №1218942.9 с соответствующей Европейской заявкой на патент №13003859, заявки на патент Великобритании №1303658.7, №1303661.1, №1303660.3, №1312815.2 и №1312818.6, полностью включено в настоящее описание путем ссылки.
В общем виде, кодек 5, показанный на фиг.1, функционирует так, что цифровые данные, например, видео, изображения, графика и аудиоконтент, которые необходимо передать из кодера 10 в декодер 50, часто большей частью или полностью сформированы из элементов E базы данных, извлеченных из указанной одной или более базы 100 данных. Указанные одна или более используемая база 100 данных может зависеть от одного или более фактора:
I) указанная одна или более используемая база 100 данных может изменяться по размеру, например, на основе типа содержимого, передаваемого из кодера 10 в декодер 50;
II) указанная одна или более используемаях база 100 данных могут зависеть от требуемого качества восстановления данных в декодере 50;
III) указанная одна или более используемая база 100 данных могут зависеть от размера данных, передаваемых из кодера 10 в декодер 50;
IV) указанная одна или более используемая база 100 данных могут зависеть от ширины полосы пропускания, доступной для передачи кодированных данных 30 из кодера 10 в декодер 50;
V) указанная одна или более используемая база 100 данных могут зависеть от ширины доступной полосы пропускания между указанными одной или более базами 100 данных и декодером 50 и/или кодером 10;
VI) указанная одна или более используемая база 100 данных могут зависеть от времени ответа между указанными одной или более базами 100 данных и декодером 50 и/или кодером 10;
VII) указанная одна или более используемая база 100 данных могут зависеть от стоимости доступа к их данным, а именно денежной платы;
VIII) указанная одна или более используемая база 100 данных могут зависеть от функции ошибок данных, которые возникают в данных, поступающих из них;
IX) указанная одна или более используемая база 100 данных также могут зависеть от пространственного (географического) местоположения указанных баз данных и опционально также учитываются;
хотя не ограничиваются вышеприведенным выбором.
Кроме того, в кодированных данных 30 одно или более опорное значение R, обмен которыми осуществляется, сохраняют и передают вместо блоков кодированных данных. Для достижения такого способа передачи данных из кодера 10 в декодер 50 указанные одна или более статических и динамических баз данных 110, 120 должны быть настолько большими, насколько возможно. Несмотря на то, что более крупные базы данных требуют большего объема памяти для их хранения, такие большие базы данных предоставляют кодеку 5 возможность достижения лучшего качества восстановления декодированных данных 60. Предпочтительно, кодек 5 выполнен с возможностью выбора среди баз 100 данных для нахождения их комбинации, которая наиболее подходит для заданного типа данных, которые должны быть переданы в виде кодированных данных 30, например, видео, изображения, графика и аудиоконтент, то есть для достижения эффективного использования баз 100 данных и соответствующего увеличения степени сжатия. Однако необходимо понимать, что для опорных значений R базы данных требуется больше битов данных, если базы 100 данных более крупные и включают больше элементов Е.
Для эффективного использования указанной одной или более базы 100 данных предпочтительно формируют несколько статических баз 110 данных для общих цифровых данных, например, видео, изображений, графики и аудиоконтента. Одна или более статическая база 110 данных могут использоваться в кодере 10 для обеспечения сжатия данных в отношении кодированных данных 30. Например, статическую базу 110 данных выбирают в зависимости от типа кодируемых цифровых данных, причем указанные статические базы 110 данных могут широко отличаться по своему размеру, а также в зависимости от используемого объема памяти и от требуемого качества восстановления, которое должно быть достигнуто в декодере 50; статические базы 110 данных могут отличаться в зависимости от размеров используемых блоков данных, количества используемых элементов E базы данных и так далее.
Как было упомянуто выше, кодер 10 и декодер 50 в комбинации образуют кодек 5, при этом указанные одна или более динамическая база 120 данных предпочтительно используются при передаче данных из кодера 10 в декодер 50. Динамическая база 120 данных часто содержит различные элементы E по сравнению со статической базой 110 данных, поскольку элементы E динамической базы 120 данных обычно формируются кодером 10, когда недостаточно подходящих элементов в статической базе 110 данных при кодировании исходных данных 20. Однако, как было упомянуто выше, и кодер 10, и декодер 50 опционально могут иметь необходимость формирования одной или более динамической базы 120 данных во время кодирования исходных данных 20 и декодирования соответствующих кодированных данных 30, так что совместимость между кодером 10 и декодером 50 может быть гарантирована, и восстановленные декодированные данные 60 по существу будут совпадать, например, с исходными данными 20. Указанную одну или более динамическую базу 120 данных опционально формируют для временного использования, например, в течение заданного интервала видеокадров, если кодированные данные 30 включают видеоконтент; кроме того, указанную одну или более динамическую базу 120 данных опционально формируют повторно, например, каждую секунду, и могут использовать после этого в течение периода времени, равного 30 с, до того, как они будут удалены. Указанный период опционально изменяется в диапазоне от нескольких секунд до полной видеосцены и раздела фильма, например, в течение минут кодированного видеоконтента. Опционально, согласно настоящему изобретению допустимо создавать новую статическую базу 110 данных из элементов E, сформированных для ранее созданных одной или более динамических баз данных; в других вариантах создаваемые динамические базы 120 данных могут быть постоянными в своем содержимом и, соответственно, могут функционировать как статические базы 110 данных.
Кодек 5 согласно настоящему изобретению, содержащий кодер 10 в комбинации с декодером 50, независимо от того, какой тип базы 100 данных используется, статическая или динамическая, при работе может обеспечивать уменьшение времени обработки, то есть требуемых ресурсов обработки и объема памяти данных, при хранении и передаче данных, соответствующих кодированным данным 30, например, видео, изображению, графике и аудиоконтенту. Такое преимущество является очень важным при передаче кодированных данных 30 по сетям связи, например, беспроводным сетям связи и Интернету, поскольку кодированные данные 30 менее требовательны к сетям связи, например, для потоковой передачи в реальном времени.
В сравнении с генератором изображений, описанным в опубликованной заявке на патент США №2010/322,301, кодек 5, показанный на фиг.1, может обеспечивать более высокую степень сжатия данных в кодированных данных 30. Улучшенное сжатие относится к передаче как опорных значений (R), так и информации об идентификаторах (U) областей. Идентификаторы (U) областей в контексте настоящего изобретения используют для передачи пространственной информации о том, откуда извлечен заданный блок в соответствующих данных, например, в исходном изображении, в исходных данных датчика и т.п. Предпочтительно, идентификатор (U) области описывает размер, форму и расположение блока данных в указанных данных. Опционально, идентификатор (U) области передают в соответствующем блоке, но часто это является слишком неэффективным способом. Предпочтительно, при реализации вариантов осуществления настоящего изобретения информацию об идентификаторах (U) областей опционально передают в качестве альтернативы только при передаче самих идентификаторов (U) областей. Например, идентификаторы (U) областей опционально получают во время декодирования из кодированных данных на основе информации, относящейся к указанным идентификаторам (U) областей, например, информации о разделении/объединении. Кроме того, опционально, идентификаторы (U) областей могут быть заранее заданы и тогда необходимость в доставке другой информации отсутствует. Предпочтительно, база данных не редактирует каким-либо образом или не извлекает идентификаторы (U) областей, вместо этого берут элементы (Е), извлеченные из базы данных на основе опорного значения (R) и размещают восстановленные блоки данных в восстановленных результирующих данных в местоположении, указанном идентификатором (U) области.
Иногда заранее задают информацию об идентификаторах (U) областей в данных, например, блоки имеют одинаковый размер, и кодируют их в конкретном порядке; в этом случае отсутствует необходимость в передаче новой фактической информации. Поскольку в указанных данных отсутствует дополнительная информация об идентификаторах (U) областей для изменения заранее заданного способа формирования идентификаторов (U) областей для поступающего кодированного блока данных в соответствии с их порядком, очевидным является тот факт, что используют указанный заранее заданный способ.
Иногда опционально передают информацию, указывающую один или более требуемых размеров блоков и порядок обработки, или передают указанные один или более размеров блоков и порядок обработки, выбранные из нескольких альтернатив. Иногда кодер может передавать в декодер также такую информацию о разбиении/объединении, которая задает размеры, формы и местоположения блоков данных, а также порядок их обработки, так что принятый и декодированный блок данных, например, блок данных, извлеченный из базы данных, всегда может быть однозначно и уникально размещен в правильном местоположении в восстановленных результирующих данных.
Такой вид информации о разбиении/объединении для задания идентификаторов (U) областей может быть передан, например, посредством использования способа кодирования, предложенного в заявках на патент США №13/584,005 и 13/584,047.
Формирование идентификаторов (U) областей опционально осуществляют различными способами в зависимости от используемого способа кодирования. Опционально, в вышеупомянутых кодерах/декодерах блоков, включенных в настоящее описание путем ссылки, информацию об идентификаторе (U) области извлекают из информации о разбиении/объединении при разбиении/объединении блоков, а иногда информация об идентификаторе (U) области уже доступна или известна, в таком случае информация относительно идентификаторов (U) областей представляет собой просто информацию об идентификаторе (U) области, которая уже доступна и/или известна.
Иногда, из-за способа, используемого при передаче и хранении, порядок кодированных данных не может быть гарантирован. По этой причине, опционально используют больше идентификаторов (U) областей в данных, чем необходимо для фактического кодирования и декодирования данных. Кроме того, один идентификатор (U) области опционально вводят, например, в каждую часть данных, чтобы отразить, где расположен первый блок данных, соответствующий этой части данных. Аналогично, иногда к каждой части данных опционально добавляют порядковый номер для обозначения порядка частей данных. Эта информация отменяет необходимость в дополнительных идентификаторах (U) областей. Настоящее изобретение опционально используется совместно с решением, в котором применяются измененные и неизмененные блоки данных, как описано, например, в патенте США №8,169,547. Если имеется решение, в котором доставляют только измененные блоки данных, то идентификаторы (U) областей необходимо использовать для описания положения таких измененных блоков, особенно, если отсутствует другая информация, которая однозначно описывает положение измененных блоков данных.
Такое увеличенное сжатие данных достигается, как показано на фиг.2, посредством передачи нового элемента E 200 динамической базы 120 данных из кодера 10 в декодер 50, без необходимости передачи его соответствующего опорного значения R 210 совместно с указанным новым элементом 200. Такая характеристика выполняется всеми опорными значениями R для элементов E 200 для блоков 220 цифровых данных, которые допускают повторное вычисление с использованием вычислительных аппаратных средств 230, 230R из восстановленного блока 220' данных, как декодере 50, так и в кодере 10. Необходимо понимать, что по существу элемент E 200 является только частью кодированных данных 30, переданных из кодера 10 в декодер 50. Опционально, часть опорного значения R предпочтительно содержит информацию, которая иным образом представлена как в кодере 10, так и в декодере 50, например, извлечена из данных о том, как много элементов E базы данных уже доступно в указанных одной или более базах 100 данных, или иным образом может быть вычислена (повторно рассчитана) на основе блока кодированных данных (после декодирования). Дополнительно к количеству/подсчету, на числовую часть опорного значения R может влиять, например, порядок вероятности элементов E. Кроме того, вышеупомянутое количество/подсчет или порядок вероятности не всегда должно относиться ко всей базе данных, вместо этого, например, оно может относиться к выбранной комбинации передаваемых опорных значений R, для которой, следовательно, может быть задано более одного различного изменения с помощью этого значения.
Кодер 10 и декодер 50 предпочтительно применяют способ вычисления опорных значений R, который до настоящего времени не был известен. Предпочтительно, кодер 10 выполнен с возможностью восстановления, то есть квантования и деквантования, значений блоков данных перед вычислением соответствующих опорных значений R. По этой причине каждый блок 220 данных может быть кодирован в кодере 10 с использованием любых известных алгоритмов сжатия с потерями или без потерь, например, алгоритмов, указанных в таблице 2, или путем комбинации таких алгоритмов сжатия с потерями или без потерь; кодек 5, показанный на фиг.1, может таким образом быть универсальным в отношении алгоритмов сжатия, которые он использует, что обеспечивает основные преимущества сжатия данных. Эти способы включают кодирование постоянной составляющей (Direct Current, DC), кодирование изменения, линейное кодирование, многоуровневое кодирование, дискретное косинусное преобразование (Discrete Cosine Transform, DCT), интерполяцию и экстраполяцию, но не ограничиваются перечисленным. Элементы 200 базы данных также могут быть сформированы, например, для любого размера блока и из любого положения декодированного изображения. Предпочтительно, опорные значения R содержат множество компонентов, которые могут быть вычислены независимо, например, один компонент описывает среднее значение значений блока, другой компонент описывает дисперсию значений блока, еще один компонент описывает амплитуду значений блока, еще один компонент описывает контрольную сумму для значений блока или элементов Е, включенных в данную базу 100 данных. Кроме того, полное опорное значение R или часть опорного значения R также опционально доставляют в декодер 50 совместно с кодированными данными 30; такую информацию предпочтительно применяют для оценки корректности доставки, например, любого ухудшения качества, возникающего при передаче кодированных данных 30 из кодера 10 в декодер 50. Опционально, декодер 50 выполнен с возможностью возвращения полного опорного значения R или его части обратно в кодер 10, например, для проверки достоверности и/или контроля качества.
Для вышеупомянутых опорных значений R базы данных требуется больше битов данных, если заданные базы 100 данных являются более крупными. Количество битов несжатых данных, требуемых для задания одного уникального опорного значения R базы данных, может быть вычислено путем взятия значения логарифма log2 числа элементов E 200 в базе 100 данных. Таким образом, для более высоких опорных значений R базы данных будет требоваться больше битов, а степень сжатия, достигаемая в кодированных данных 30, уменьшается для каждого существующего блока данных базы данных. Обычно в опорном значении R базы данных предпочтительно имеется один или более битов, которые зарезервированы для неиспользуемых элементов E данных. Однако, чтобы избежать наличия избыточных неиспользуемых элементов E в большой статической базе 110 данных или динамической базе 120 данных, элементы E новой меньшей динамической базы 120 данных могут быть сформированы из элементов E используемой статической базы 110 данных или используемой динамической базы 120 данных. Новая меньшая динамическая база 120 данных затем может быть использована в декодере 50 для декодирования, при этом для указанной новой динамической базы данных требуется меньше битов в его опорных значениях R для однозначной идентификации элементов E, представленных в новой небольшой динамической базе данных, по сравнению с более крупной исходной базой данных.
Необходимо отметить, что упомянутое в настоящем описании опорное значение R является точно передаваемым опорным значением (индексом, который однозначно определяет элемент E в базе данных), которое таким образом принимает меньшее число единиц в новой меньшей базе данных, чем исходное передаваемое опорное значение использует в старой большей базе данных. Это конечно не оказывает эффекта на фактическое точное опорное значение R, которое используют при поиске, поскольку оно зависит от фактического значения данных элемента E, которое так или иначе здесь не изменяется.
Опорное значение R для новой динамической базы данных может быть, например, общим числом элементов E, представленных в новой базе данных. Опционально, это опорное значение R, соответствующее элементу E базы данных в новой динамической базе данных, включает фактические данные или оно может быть связано с другой, большей базой данных. Если новая динамическая база данных используется для кодирования опорных значений R, обнаружено, что указанные опорные значения R могут быть эффективно сжаты путем применения известного алгоритма кодирования, например, известного дельта-кодирования. Таким образом, используя новую динамическую базу данных, можно сохранить значительное количество несжатых битов опорного значения R по существу без ухудшения эффективности или качества декодированных данных 60, которые выводятся из декодера 50.
В качестве примера:
a) если заданная статическая база 110 данных содержит 16 миллионов элементов E, выраженных с использованием 24 битов данных для соответствующих значений R данных;
b) динамическая база 120 данных содержит только 1024 элемента E, выраженные с использованием 10 битов данных для соответствующих значений R данных; и
c) блок данных существует в динамической базе 120 данных с конкретным индексом блока данных,
то для опорного значения R будет требоваться только 10 битов для однозначного задания блока данных посредством динамической базы 120 данных по сравнению с 24 битами для однозначного задания блока данных, если он был включен в статическую базу 110 данных. Если в этом примере заданный блок данных передают из статической базы 110 данных в динамическую базу 120 данных, требуется меньшее количество битов для однозначной идентификации блока данных; предпочтительно, кодер 10 информирует декодер 50 относительно перемещения, или копирования, одного или более блоков данных из статической базы 110 данных в динамическую базу 120 данных. Кодек 5, показанный на фиг.1, предпочтительно также опционально выполнен с возможностью работы так, чтобы один или более блоков данных перемещался или копировался из статической базы 110 данных в динамическую базу 120 данных в зависимости от количества использований баз данных, которые происходят для указанных одного или более блоков данных. Другими словами, если кодированные опорные значения R часто относятся к заданному блоку данных, указанный блок данных в декодере 50 предпочтительно получают из заданной динамической базы 120 данных, переданной в декодер 50 или сделанной доступной для декодера 50, а не из статической базы 110 данных, переданной в декодер 50 или сделанной доступной для декодера 50. Как упомянуто выше, базы 110, 120 данных опционально размещают на одном или более серверах данных, например, серверах, принадлежащих одной или более третьим сторонам.
Кодек 5, показанный на фиг.1, обеспечивает экономию битов для опорных значений R базы данных посредством формирования статической или динамической базы данных малого размера из наиболее часто используемых элементов E статической или динамической баз 100 данных большего размера. В кодеке 5, динамические базы 120 данных и/или статические базы 110 данных большего размера содержат счетчик использований для всех существующих блоков данных, и новые базы данных формируют путем выбора элементов E в качестве основы такой информации о счетчике использований. Такую базу данных меньшего размера предпочтительно формируют во время кодирования в кодере 10 и затем передают или иным образом делают доступной декодеру 50 для декодирования кодированных данных 30; такая база данных меньшего размера, доступ к которой обеспечен иным образом, может включать, например, кодированные данные 30, включающие ссылку URL (Uniform Resource Locator, унифицированный указатель ресурса) на базу данных меньшего размера, сделанную доступной для загрузки в декодер 50 из удаленного сервера на основе Интернет и/или из серверов баз данных в клиентской локальной сети LAN, например, размещенных в облачной вычислительной среде и доступных множеству таких декодеров 50, альтернативно размещенных в локальной сети LAN, аналогичной локальной сети декодера 50.
При кодировании исходных данных 20 кодер 10 в любой момент выбирает, как много различных баз 100 данных, какие виды баз 100 данных и какие конкретно базы 100 данных должны использоваться для декодирования соответствующих кодированных данных 30 при их приеме в декодере 50, при этом информацию, описывающую выбор базы 100 данных, сделанный кодером 10, передают в декодер 50. Эта информация может быть предоставлена локально, то есть в виде зависящей от приложения информации о базе данных, или глобально, то есть в виде всегда одной и той же информации о базе данных. В конкретных ситуациях выбранные базы данных уже известны декодеру 50 и в таких случаях не требуется обмениваться конкретной информацией, сохранять и/или передавать ее, то есть информация может также быть уже известной декодеру 50. Указанную информацию, описывающую выбор базы 100 данных, а также выбор используемого способа кодирования, сохраняют в видеозаголовке или контейнере кодированных данных 30. Кроме того, декодер 50 опционально снабжают всеми из указанных одной или более статических баз 110 данных перед выполнением задачи декодирования кодированных данных 30. В случае если декодер 50 обнаруживает, что у него отсутствует база данных, заданная в кодированных данных 30, декодер 50 посылает запрос в кодер 10 для передачи отсутствующей заданной базы данных в декодер 50 или иным образом делает ее доступной, например, из удаленного сетевого сервера данных. Опционально, удаленный сервер расположен относительно близко к декодеру 50, например, в аналогичной локальной сети LAN, тем самым обеспечивается быстрая доставка отсутствующих баз 100 данных в декодер 50. Опционально, отсутствующие базы данных предоставляют в декодер 50 в сжатом формате, так что декодер 50 осуществляет распаковку отсутствующих баз данных для сохранения в памяти данных декодера 50. Предпочтительно, блоки данных, которые наиболее часто используются декодером 50, сохраняются в небольшой статической базе 110 данных.
Чтобы освободить ресурсы RAM, либо в кодере 10, либо в декодере 50, либо в обоих неиспользуемые элементы базы данных предпочтительно удаляют. Использование элементов Е базы данных предпочтительно измеряют путем подсчета количества используемых элементов Е в базе данных или путем сохранения статистики о том, когда в последний раз использовались элементы Е базы данных. В кодеке 5, показанном на фиг.1, все динамические базы 120 данных обрабатывают для их очистки, чтобы удалить неиспользуемые элементы Е. Опционально, статические базы 110 данных также подвергают очистке; альтернативно, указанные одну или более статических баз 110 данных периодически для очистки заменяют на новые статические базы данных. Опционально, старые базы 110 данных также могут быть переданы в резервную память, так чтобы они могли быть доступны позднее, если необходимо, для возврата в кодер 10 и/или декодер 50, но не занимали память в статических базах 110 данных; предпочтительно, резервную память реализуют посредством накопителя на жестких дисках, флеш-памяти, внешней памяти, постоянных запоминающих устройств (ROM) на оптических дисках, облачного хранилища данных и так далее. При работе декодер 50 предпочтительно уведомляют о любых отклоняющихся от нормы изменениях в одной или более базах 100 данных, например, для предоставления декодеру 50 возможности запрашивать обновление его баз 100 данных для обращения к любым таким отклонениям. Предпочтительно, базы 100 данных также идентифицируют посредством уникальных идентификаторов, например, номеров версий. Если одна или более база 100 данных изменяется, например, в кодере 10, желательно, чтобы в декодер 50 были переданы только изменения в базах 100 данных, а не все базы 100 данных полностью. Опционально, указанные одна или более базы 100 данных могут обновляться с кодерами, например, известные типы кодеров; кроме того, кодер 10 опционально снабжается соответствующей заранее загруженной статистической базой 110 данных, например, сохраненной в твердотельном постоянном запоминающем устройстве ROM. Кроме того, если указанные одна или более динамические базы 120 данных обновляются в декодере 50, могут применяться различные режимы обновления, например:
I) в первом режиме обновления старый элемент E перезаписывают новым элементом E; и
II) во втором режиме обновления старый элемент E сохраняют, а новый элемент E добавляют с увеличением размера указанных одной или более динамических баз 120 данных.
Опционально, если небольшая динамическая база 120 данных заполнена, то есть все ее элементы E распределены, осуществляют проверку указанной небольшой динамической базы 120 данных с использованием одного или более автоматических программных инструментов, выполняемых с использованием вычислительных аппаратных средств, для определения того, какие элементы E указанной небольшой динамической базы 120 данных используются наиболее часто, после этого сортируют элементы E в базе 120 данных, так чтобы наиболее часто используемые элементы E были перемещены в начало базы 120 данных, например, для более быстрого представления базы 120 данных с получением доступа к более часто используемым элементам E и/или для представления базы 120 данных более эффективно сжатой, например, для передачи из кодера 10 в один или более декодеров 50 по сети связи, например, Интернет или беспроводной сети связи; предпочтительно, другие менее часто используемые элементы E небольшой динамической базы 120 данных освобождают. Такую проверку и сортировку предпочтительно выполняют как кодер 10, так и декодер 50, если указанные одна или более базы 120 данных заполнены. Опционально, такую проверку и сортировку инициируют посредством инструкции, отправленной из кодера 10.
При инициализации сохранения данных или передачи данных кодер 10 выполняет выбор того, какая из баз 100 данных должна будет впоследствии использоваться декодером 50, например, являются ли базы 100 данных пустыми в начале декодирования кодированных данных 30 или базы 100 данных уже содержат ряд элементов E базы данных в начале декодирования кодированных данных 30. Например, декодер 50 опционально начинает декодирование кодированных данных 30 с использованием небольшой общей статистической базы 110 данных, при этом декодер 50 приступает к заполнению динамической базы 120 данных отсутствующими элементами E, которые декодер 50 определил из блоков данных, включенных в кодированные данные 30; затем динамическую базу 120 данных предпочтительно очищают, если необходимо, с использованием вышеупомянутых правил. Опционально, сформированная динамическая база 120 данных сохраняется декодером 50 в качестве новой статистической базы 110 данных для будущего применения при декодировании будущих кодированных данных 30, принятых в декодере 50.
При кодировании исходных данных 20, например, данных, соответствующих по меньшей мере одному из следующего: видео, изображению, графике и аудиоконтенту, кодер 10 опционально передает опорные значения R базы данных заданного блока данных, даже если база данных, включающая указанный блок данных, еще не существует в декодере 50, например, в случае, когда кодеру 10 известно, что декодер 50 может извлечь подходящую статистическую базу 110 данных, включающую элемент E, описывающий заданный блок данных, из хранилища статистической базы данных, доступного локально от декодера 50, например, расположенного в локальной сети LAN, ISP или другом сервере, аналогичном локальной сети LAN, ISP или серверу декодера 50. Такой подход позволяет одному кодеру 10 осуществить доставку одних и тех же кодированных данных 30 во множество декодеров 50, которые имеют немного различающиеся базы данных, доступные для них. При использовании такого подхода декодерам 50 не нужно размещать большие статистические базы данных или связанные с ними ресурсы. Таким образом, кодер 10 предпочтительно осуществляет согласование с декодером 50, если такой способ может быть применен. Чтобы способ был осуществлен успешно, кодеру 10 должно быть известно об общедоступных и/или частных базах данных, к которым декодер 50 может получить доступ для обеспечения декодера 50 одной или более базами 100 данных, которые ему необходимы для выполнения декодирования кодированных данных 30, переданных из кодера 10. Этот способ хорошо подходит, когда вообще нет необходимости передавать кодированные блоки данных, когда такая передача блоков данных в декодер 50 из другого кодера является возможной, причем указанный другой кодер ранее кодировал указанные кодированные данные. Опционально, передачу блоков данных от других кодеров осуществляют с использованием одноранговой связи. Кроме того, указанный способ подходит для живой потоковой передачи кодированных видеоданных через Интернет, что обеспечивает потоковую передачу кодированных видеоданных из удаленного на большое расстояние местоположения от декодера 50, при этом блоки данных могут быть переданы локально в декодер 50; в таком случае передают по существу только опорные значения R из местоположения, значительно удаленного от декодера 50.
Как было упомянуто выше, указанные одну или более динамические базы 120 данных предпочтительно сравнивают с элементами Е базы данных, которые были сформированы или скопированы из восстановленных блоков данных либо в кодере 10, либо в декодере 50. Блоки данных могут быть одномерными (1-D), двумерными (2-D) или трехмерными (3-D), или их комбинацией. Опционально, блоки данных могут изменяться по размеру и форме, например, при просмотре на дисплее, могут иметь, например, многоугольную, прямоугольную, эллиптическую, круговую, удлиненную, треугольную форму, как было упомянуто в качестве примеров.
Опционально, форма одномерного блока данных может быть набором одномерных элементов данных при представлении их в декодированных данных 60. Кроме того, опционально, форма двумерного блока данных может быть квадратом, прямоугольником, треугольником, параллелограммом или кругом при представлении в декодированных данных 60. Кроме того, форма трехмерного блока данных может быть полиморфной, например, кубом, пирамидой, цилиндром, шаром и так далее; такой трехмерный блок данных, например, является предпочтительным, когда декодированные данные 60 предназначены для трехмерных графических дисплеев, например, для подачи 3-D изображений для просмотра пользователем. Применяемый обычно двумерный блок данных соответствует 8x8 пикселям или аналогичным элементам отображения, которые предпочтительно применяют в вариантах осуществления настоящего изобретения; существует множество различных и очень эффективных известных способов кодирования для размеров блоков 8×8 пикселей, которые могут использоваться кодером 10 при формировании кодированных данных 30.
Для более подробного рассмотрения настоящего изобретения будет описано кодирование блоков данных в кодере 10.
Шаг 1. В идеальной ситуации заданное опорное значение R базы данных вычисляют для соответствующего заданного блока данных, представленного в исходных данных 20, например, для части изображения и/или аудио, представленного в исходных данных 20. Если в одной или более базах 100 данных имеется подходящий существующий элемент E, то есть может быть обнаружено совпадение с существующим элементом E для заданного блока данных в указанных одной или более базах 100 данных, то опорное значение R вычисляют для выбора сущестующего элемента E из указанных одной или более баз 100 данных. Указанное совпадение определяют при условии, что ошибка между заданным блоком данных и существующим блоком данных меньше заданного порогового значения, при этом указанное заданное пороговое значение соответствует индексу качества кодирования.
Шаг 2. Если на шаге 1 обнаружено совпадение, опорное значение R для выбранного существующего блока сохраняют или передают, например, в кодированных данных 30. Выбранный существующий блок данных может быть найден из множества баз 100 данных, при этом сохраненное или переданное опорное значение R также включает идентификатор базы 100 данных, причем выбранный существующий блок данных может быть обнаружен декодером 50. Наоборот, если на шаге 1 подходящее совпадение не обнаружено, то кодируют заданный блок данных, например, с использованием DC-кодирования, кодирования изменения, многоуровневого кодирования, DCT-кодирования или любого другого подходящего алгоритма кодирования, и вычисляют опорное значение (R) базы данных для восстановленного блока данных; указанный блок кодированных данных предпочтительно включают в кодированные данные 30 для приема в декодере 50.
Альтернативно или дополнительно, кодер 10 выполнен с возможностью проверки, имеется ли подходящий элемент E, доступный для восстановленного блока данных, аналогично элементу E для исходного блока; в таком случае может быть использовано отличающееся пороговое значение качества кодирования. Если выбран конкретный элемент E для представления восстановленного блока данных, его опорное значение R может быть сохранено или передано, например, в кодированных данных 30. Альтернативно, если подходящий элемент E базы данных не может быть выбран для представления восстановленного блока данных, то есть восстановленного блока данных, то указанный восстановленный блок данных или заданный блок данных в исходных данных 20 должен быть передан с использованием алгоритма кодирования, который наиболее подходит для восстановленного блока данных, то есть восстановленного блока данных. Предпочтительно, выбирают способ, который формирует меньше битов в кодированных данных 30, создает меньше ошибок или оптимизирует использованные биты для сформированных ошибок, например, путем использования коэффициента лямбда, соответствующего RD-оптимизации. Этот кодированный блок данных может затем быть добавлен к одной или более динамическим базам 120 данных для последующего использования при кодировании данных в кодере 10 и/или в декодере 50.
Опционально, кодер 10 применяет способы кодирования, описанные в Европейском патенте №1787262 и Европейской заявке на патент №12173534.4, содержание которых включено в настоящее описание путем ссылки; при применении этих способов, например, для кодирования видеоконтента, цвет, который представляет неизмененный блок данных, может быть найден в базе 100 данных, или неизмененные блоки могут быть обнаружены и кодированы по-другому. Только для измененных блоков данных требуется применение кодирования, например, известных алгоритмов кодирования, таких как, например, алгоритмы, приведенные в таблице 2; в дополнение к таблице 2 опционально применяют различные виды способов кодирования, поскольку таблица 2 описывает только полные решения для кодирования, а не отдельные способы, такие как интерполяция и экстраполяция, многоуровневое кодирование, дискретное косинусное преобразование (DCT) и так далее. Аналогичные функциональные возможности могут быть предоставлены как для кодера 10, так и для декодера 50 для оптимизации рабочих характеристик в этом примере на основе Европейского патента №1787262 и Европейской заявки на патент №12173534.4, содержание которых, как было упомянуто выше, включены в настоящее описание путем ссылки. Содержание других связанных заявок на патенты также включено в настоящее описание путем ссылки, а именно, Европейская заявка на патент №13172237.3, поданная 17.06.2013 г.
Для дальнейшего разъяснения вариантов осуществления настоящего изобретения далее более подробно будут описаны базы 100 данных и вышеупомянутые опорные значения R; например, будет сделана ссылка на опубликованную заявку на патент США №2010/322,301, содержание которой включено в настоящее описание путем ссылки. Как было упомянуто выше, существует два вида баз данных: статические базы 110 данных и динамические базы 120 данных. Статические базы 110 данных могут храниться в памяти любого типа; для более высокой производительности статические базы 110 данных опционально хранятся в постоянной памяти (ROM), например, ROM может быть записана или запрограммирована на кремниевой интегральной схеме. Альтернативно или дополнительно, статические базы 110 данных жестко программируют в виде компилированных программных продуктов, записанных на машиночитаемых носителях для хранения данных. Например, в вариантах осуществления настоящего изобретения статические базы 110 данных могут быть созданы из динамической базы 120 данных, как было упомянуто выше, и затем сохранены в качестве соответствующей статической базы 110 данных. Предпочтительно, каждую статическую базу 110 данных идентифицируют посредством уникального опорного кода, относящегося к ней. Динамические базы 120 данных опционально записывают в оперативную память (RAM) или любую эквивалентную память для считывания/записи данных, например, магнитный или оптический носитель данных, такой как высокоскоростное магнитное дисковое хранилище данных.
Опционально, варианты осуществления настоящего изобретения используют «перескоки». «Перескок» дает возможность получить отсутствующие в базе 100 данных элементы E где-либо в другом месте. Кроме того, «перескок» может использоваться как для статических, так и для динамических баз 110, 120 данных, соответственно. Кроме того, «перескок» дает возможность динамическим базам 120 данных быстро обновляться в отношении отсутствующих элементов. Предпочтительно, чтобы обеспечить эффективное функционирование для такого «перескока», желательно, чтобы все данные были декодированы одинаковым образом, начиная с создания базы данных до текущего времени использования.
Вышеуказанные опорные значения R уникально идентифицируют соответствующие элементы E в базе 100 данных, при этом элементы E представляют различные типы блоков данных. Однако желательно, чтобы опорные значения R формировались с использованием способа, который подходит для типа контента, представленного в исходных данных 20, которые должны быть кодированы кодером 10. Другими словами, опорное значение R вычисляют в кодере для каждого соответствующего блока данных, представленного в частях исходных данных 20 или соответствующем кодированном блоке данных. В кодере 10 кодированный блок данных, представленный его опорным значением R, восстанавливают, то есть кодируют и затем снова декодируют в кодере 10, чтобы гарантировать, что декодер 50 будет способен сформировать такое же опорное значение R базы данных для кодированного блока данных, которое добавляют к указанным одной или более базам 100 данных; причиной такого порядка работы является то, что если способ кодирования для заданного рассматриваемого блока выбран, то на основе параметров, которые он формирует, блок восстанавливают или декодируют. Этот восстановленный блок представляет собой блок, из которого затем восстанавливают элемент Е базы данных и его опорное значение R. Декодер 50 формирует точно такие же одну или более базы 100 данных, как базы данных, применяемые в кодере 10 при кодировании исходных данных 20. При реализации вариантов осуществления настоящего изобретения могут применяться различные способы для вычисления опорных значений R, но предпочтительно их вычисляют на основе значений амплитуды (или минимума и максимума), дисперсии (или стандартного отклонения), среднего значения (или суммы) и контрольной суммы (хэш или индекс), относящихся к блокам данных, представленных в исходных данных 20, кодируемых в кодере 10. «Амплитуда» относится, например, к разности между наибольшим и наименьшим значениями исходных данных или пикселей в заданном блоке данных. Значение суммы для двумерного блока данных (block(ij)) опционально вычисляют с использованием следующего уравнения (1):

где:
SUM - значение суммы;
m×n - количество пикселей или значений данных, представленных в указанном двумерном блоке данных, например, n=8, m=8 для блока данных 8×8 пикселей; и
i, j - опорные индексы.
Среднее значение вычисляют путем умножения значения суммы на 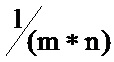
Кроме того, дисперсия для двумерного блока данных может быть вычислена с использованием следующего уравнения (2):
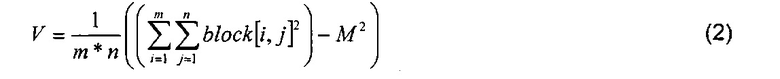
где:
V - дисперсия.
Стандартное отклонение может быть вычислено как квадратный корень из дисперсии V.
Предпочтительно, контрольную сумму для блока данных вычисляют с использованием логической функции «исключающее ИЛИ» для каждого значения, то есть пикселя в области, представляющей интерес (region of interest, ROI). Например, для статических и динамических баз 110, 120 данных, соответственно, амплитуда, дисперсия V, среднее значение М и контрольная сумма представлены в таблице 4.
Для известных элементов Е базы данных вычисление опорного значения R, псевдокода могут быть выполнены, например, следующим образом:
DBREF = (AMPLITUDE SHL (DBREF_BITS - AMPLITUDE_BITS)) + (VARIANCE SHL (DBREF_BITS - (AMPLITUDE_BITS + VARIANCE_BITS))) + (MEAN SHL (DBREF_BITS - (AMPLITUDE_BITS + VARIANCE_BITS + MEAN_BITS))) + CHECKSUM
Необходимо отметить, что опорное значение R, которое необходимо рассчитать, представляет собой передаваемое опорное значение R для статической базы 110 данных и что при фактическом поиске элемента E могут быть использованы более точные и/или более неточные значения. Контрольная сумма не оказывает влияния на ограничение поиска, пока не будет найдено точное соответствие.
Максимальное количество распределенных байтов статической или динамической баз 110, 120 данных, соответственно, задается опорным значением R базы данных. Для вычисления общего количества битов для заданного опорного значения R базы данных все элементы E должны быть добавлены, где вычисляется опорное значение R, при этом указанные элементы E включают амплитуду, дисперсию V, среднее значение М и контрольную сумму, то есть комбинацию MVA. Например, количество битов для опорного значения R базы данных может быть вычислено следующим образом:
DBREF_BITS = AMPLITUDE_BITS + VARIANCE_BITS + MEAN_BITS + CHECKSUM_BITS
База данных не может содержать больше элементов, чем длина зависящей от элементов части передаваемого опорного значения R, то есть среднее значение не оказывает эффект на длину, если база данных не использует среднее значение, например, база данных с нулевым средним, в противном случае среднее значение оказывает эффект.
Например, если биты передают, как показано в примере в таблице 4, то для стандартной базы данных количество элементов E будет соответствовать 20 битам, а для базы данных, которая не использует среднее значение, 12 битам, и, соответственно, количество элементов будет приблизительно равно миллиону элементов в сравнении с 4000 элементов. Кроме того, для каждого элемента E, конечно, требуются байты в соответствии с форматом представления данных. Например, для блока 8×8 с 8-битовыми значениями для стандартного элемента, то есть элемента, который имеет среднее значение, необходимо 64 байта на элемент, тогда как для элемента, который не имеет части со средним значением, требуется 64*9/8=72 байта на элемент, поскольку знаковый разряд должен быть сохранен для каждого значения данных. Это приводит к тому, что максимальный размер для базы данных 8×8, как представлено в примере, для базы данных, которая использует среднее значение, составляет 64 МБ, а для базы данных, которая не использует среднее значение, составляет только 288 кБ. Эти числа, таким образом, представляют максимальное распределение для значений данных элементов базы данных по отдельности, и размер, таким образом, зависит от количества битов для различных частей опорного значения (R), от размера блока и от динамики значений данных. В дополнение к этому, для выполнения быстрого поиска необходимо будет сохранить в кодере 10 более точные и/или более неточные опорные значения (R). Для декодера 50 достаточно иметь такую базу данных, которая организована таким образом, чтобы адреса правильных опорных данных было легко найти.
В еще одном примере, вычисленный общий размер заданной базы 100 данных составляет 1048576 элементов, а именно значение 220, то есть приблизительно 1 миллион элементов. Если каждый элемент E включает 64 пикселя, то есть, реализован в виде блока данных 8×8 пикселей, который имеет динамический диапазон 1 байт на пиксель, то общий размер несжатой заданной базы 100 данных составляет 64 Мб.
Как показано на фиг.3, заданное опорное значение R указано позицией 300 и включает несколько различных частей 310A, 310B и 310С, например, дисперсию V, среднее значение М, амплитуду A, соответственно. Эти части предпочтительно вычисляют по отдельности, и, таким образом, поиск в кодере 10 и/или декодере 50 может быть осуществлен так быстро, как это возможно, что обеспечивает быстрое выполнение операций кодирования и/или декодирования. Различные части 310 предпочтительно функционируют как отдельные субссылки базы данных, то есть индексы, например, с добавлением циклического контроля по избыточности (Cyclic Redundancy Check, CRC), как обозначено позицией 310D. Кроме того, если большая база 100 данных сформирована так, что она основана только на порядке формирования или, альтернативно, на CRC, для кодека предпочтительно также формировать таблицу поиска. Предпочтительно, эту таблицу поиска используют для быстрого просмотра подходящей комбинации среднего значения М, дисперсии V и амплитуды А.
При вычислении опорных значений R 300 могут использоваться различные подходы к взятию выборок, и опорные значения R 300 предпочтительно включают дополнительные весовые коэффициенты, которые обеспечивают поиск среди нескольких альтернатив или предоставляют кодеку возможность найти элемент E, например, для краев изображений, которые менее важны относительно качества декодирования по сравнению с центральной частью изображения; это может быть достигнуто, например, путем применения динамически изменяющегося порогового значения качества в кодере 10 при кодировании исходных данных 20. Таким образом, поиск в кодеке 5 может быть выполнен быстрее, поскольку опорное значение R включает более точные параметры данных, к которым они относятся; кроме того, CRC или подобный индекс делает возможным наличие нескольких элементов E базы данных для одной основной комбинации.
Опционально, поиск в одной или более базах 100 данных на основе заданного опорного значения R выполняют, начиная с большой базы 100 данных, которая содержит ссылку на то, какие элементы E и в каких из меньших баз 100 данных имеют такие же или подобные типы элементов E. Альтернативно, небольшая база 100 данных также содержит такую информацию о комбинациях MVA в отношении данных, которые хранятся в указанной небольшой базе 100 данных; эта информация обеспечивает возможность быстрого игнорирования меньшей базы 100 данных кодером 10 и/или декодером 50, если указанная искомая комбинация в заданном блоке данных отличается существенно.
В отношении вышеуказанного опорного значения R 300, опционально является предпочтительным осуществлять совместное сжатие дисперсии V и амплитуды A, например, для уменьшения общего числа битов, необходимых для задания опорного значения R 300, и, следовательно, уменьшения размера кодированных данных 30, которые необходимо передать из кодера 10 в декодер 50, показанных на фиг.1; такое преимущество следует из того факта, что дисперсия V и амплитуда A строго коррелированы. Наоборот, среднее значение М и части CRC/индекса опорного значения R 300 предпочтительно сжимают по отдельности, поскольку среднее значение М часто совместимо с относительной дельта-характеристикой, a CRC может быть весьма случайным. Для комбинации частей дисперсии V и амплитуды A, которые квантованы с использованием меньшего количества битов, предпочтительно использовать кодирование длин серий (Run-Length Encoding, RLE) для формирования кодированных данных 30; альтернативно, для этих целей может быть использовано дельта-кодирование. Если первая заданная комбинация дисперсии V и амплитуды A квантована с использованием относительно меньшего количества битов, а вторая заданная комбинация дисперсии V и амплитуды A кодирована с использованием большего количества битов в кодированных данных 30, предпочтительно, чтобы указанные комбинации были кодированы по отдельности, например, для первой заданной комбинации может быть использовано кодирование RLE, а для второй заданной комбинации может быть использовано кодирование Хаффмана, без ограничения вышеуказанным. Предпочтительно используют другие типы кодирования, например:
Диапазон, SRLE: «Скользящее кодирование длин серий» ("Split run-length encoding"), способ, раскрытый в заявке на патент Великобритании №1303660.3, поданной 1 марта 2013 заявителем Gurulogic Microsystems Oy;
ЕМ: «Модификатор энтропии» ("Entropy Modifier"), способ, раскрытый в заявке на патент Великобритании №1303658.7, поданной 1 марта 2013 заявителем Gurulogic Microsystems Oy; и
Odelta: способ, раскрытый в заявке на патент Великобритании №1303661.1, поданной 1 марта 2013 заявителем Gurulogic Microsystems Oy,
но не ограничиваясь перечисленным.
Опорные значения R 300, передаваемые посредством кодированных данных 30 из кодера 10 в декодер 50, предпочтительно сжимают с использованием различных способов сжатия, например:
I) способы на основе кодирования с переменной длиной (Variable Length Coding, VLC), такие как кодирование Хаффмана со способами кодирования баз данных, использующими алгоритмы Лемпеля-Зива (Lempel-Ziv), например, ZLIB, LZO, LZSS, LZ77; и
II) кодирование Хаффмана или аналогичное для вышеупомянутых комбинаций значений, например, дисперсии V и амплитуды A.
Опционально, опорные значения R 300 могут быть сжаты как целые значения или части опорных значений R 300, например, как показано на фиг.3, могут быть сжаты по отдельности. Кроме того, опционально возможно использовать комбинацию способов сжатия данных для достижения еще большего сжатия данных в кодированных данных 30; например, части дисперсии V опорных значений R 300 могут быть сначала сжаты с использованием дельта-кодирования с формированием первых сжатых данных, а затем к указанным первым сжатым данным могут быть применены алгоритмы кодирования длин серий (RLE) с формированием вторых сжатых данных, после чего ко вторым сжатым данным может быть применено кодирование Хаффмана с формированием третьих сжатых данных, которые, например, передают в виде кодированных данных 30 из кодера 10 в декодер 50.
Одна или более базы 100 данных могут содержать элементы E, которые состоят из значений данных блоков данных в заранее известном порядке, например, в ступенчатом порядке. Если указанный порядок отличается от порядка по умолчанию, предполагаемого для кодека 5, показанного на фиг.1, такой отличающийся порядок предпочтительно задают в кодированных данных 30 посредством параметра конфигурирования порядка. Например, такой вид элемента E базы данных со значениями данных может быть сформирован из любого блока данных, имеющего корректный размер, например, из восстановленного изображения. Опционально, может осуществляться переключение указанного параметра между состояниями в ходе передачи кодированных данных 30 из кодера 10 в декодер 50.
Опционально, указанные одна или более динамические базы 120 данных, которые обновляются в соответствии с заранее известным порядком, используют изменяющееся количество элементов E на кадр, например, для предоставления кодеку 5, показанному на фиг.1, возможности достичь большей степени сжатия данных для изображений с относительно меньшим объемом информации. Например, если размеры заданной динамической базы 120 данных для различных кадров составляют 126, 193, 252, 303 элементов, то количество битов, необходимых для однозначной адресации каждого элемента для каждого кадра, составляет 7, 8, 8 и 9 битов, соответственно. В большой базе 100 данных элементы E могут быть расположены в виде структуры («установить число», «получить число») с адресацией относительно элемента E; например, в байте содержится 8 битов, один бит байта резервируется для уведомления получателя, было ли передано полное значение, а оставшиеся семь битов используются для задания передаваемого значения, опционально с большим количеством битов после него. Благодаря использованию такого подхода, возможно передавать семиразрядную информацию в одном байте и четырнадцатиразрядную информацию в двух байтах. Отсутствие необходимости включать биты информации в кодированные данные 30 обеспечивает возможность улучшенного сжатия данных в кодеке 5, показанном на фиг.1.
Опционально, элементы Е, включенные в указанные одну или более базы 100 данных, могут быть объединены, например, чтобы занимать меньший объем памяти данных, или они могут содержать сумму или элементы коэффициента, например, для базы 100 данных масштабирования или базы 100 данных с нулевым средним, которые могут быть вычислительно приспособлены с использованием одного или более параметров для соответствующего предоставления элементов Е при кодировании исходных данных 20 и/или при декодировании указанных кодированных данных 30.
Опционально, возможно использовать любые один или более параметров или такие один или более параметров, которые были удалены из самого блока перед их введением в базу 100 данных. Соответственно, при использовании элемента E базы данных указанные данные, формируемые этими параметрами, должны быть добавлены к элементу E при формировании результирующего блока. В первой реализации используется средний цветовой параметр. Также могут быть использованы цветовые параметры изменения и другие параметры. В принципе, с этим элементом E базы данных, который находится в памяти, могут быть использованы предсказание или любые другие способы кодирования. Указанное среднее значение очень полезно, поскольку можно использовать среднее значение в качестве части опорного значения R также и другими способами, и, следовательно, не требуется передача новых данных для его использования, таким образом, можно значительно уменьшить размер фактической базы 100 данных, которая сохранена в памяти. Конечно, путем добавления битов к другим опорным значениям R можно увеличить размер базы 100 данных, сохраненной в памяти, и таким образом также получить множество новых элементов E, что может быть предпочтительно использовано при кодировании. Если среднее значение удаляют из блока, то указанный элемент становится приблизительно равным нулевому среднему значению.
Далее приведен пример, в котором используется опускание среднего значения из значений блока, что обеспечивает более эффективное использование базы данных в связи с различными средними значениями. Вышеупомянутый способ кодирования предпочтительно применяется для скользящих блоков, для предсказаний или для блоков, кодированных каким-либо другим образом. Полученный таким образом результат может быть затем удален из базы данных перед формированием элементов E базы данных и, соответственно, присоединен к элементу Е базы данных, который был извлечен из базы данных в связи с декодированием при восстановлении блока данных.
Следовательно, среднее значение представляет собой простейший способ кодирования, и предпочтительно также в этом отношении, что оно фактически явно устраняет необходимость для одного элемента или части в опорном значении R, если опорное значение R формируется из множества частей, что тем самым уменьшает размер базы данных. Амплитуда также могла бы использоваться для релятивизации значений данных, что тем самым обеспечило бы преимущества для охвата базы данных без уменьшения размера базы данных.
Другие предсказания или способы кодирования фактически только формируют блоки ошибки предсказания и их использование не является таким практичным. Конечно, средние значения в них могут быть также опущены, что предоставит базу данных ошибок предсказания с соответствующими характеристиками в качестве базы данных для исходных блоков. Необходимо понимать, что элементы E базы данных могут использоваться в качестве данных ошибок предсказания для другого блока базы данных, и, таким образом, согласно настоящему изобретению, также поддерживается рекурсия элементов E базы данных.
Однако выполнение большого количества рекурсий не является предпочтительным, если база данных не является очень маленькой или если необходимо действительно точное восстановление, поскольку, в противном случае, размер кодированных данных блока данных быстро будет значительно увеличиваться.
Кроме того, указанные одна или более базы 100 данных могут включать элементы E, которые были вычислены, например, с использованием способов экстраполяции; другими словами, в кодеке 5 имеются сведения о способе вычисления, который был использован для формирования заданного блока данных, и общем размере заданного блока данных, предпочтительно совместно с одним или более значениями для обеспечения основы для вычисления значений данных блока данных. Такое вычисление предпочтительно осуществляют с использованием способа DC (постоянная составляющая) и способа наклона. Способ DC использует одно значение, например, значение сдвига, которое затем применяют ко всем значениям данных в заданном блоке данных. Напротив, способ наклона, например, реализуемый в виде одномерного способа наклона, использует два значения, например, первое значение данных и последнее значение данных в заданном блоке, и затем вычисляет остальные значения для блока данных путем линейной интерполяции на основе первого и последнего значений данных линейным способом, альтернативно, полиномиальным способом. Кроме того, опционально применяют двумерный способ наклона, который использует четыре значения, соответствующие угловым точкам в блоке данных, при этом оставшиеся точки в блоке данных вычисляют с использованием билинейной интерполяции. Кроме того, опционально применяют другие типы вычислительных алгоритмов для вычисления значений для блоков данных на основе нескольких исходных значений в кодеке 5, показанном на фиг.1.
Одна или более баз 100 данных опционально включают элементы E, которые являются ссылками на другие базы данных, например, иерархическими. В таком случае элемент E включает информацию, задающую другую базу 100 данных, и также предпочтительно опорное значение R для элемента E в этой другой базе 100 данных. На основе такой информации могут быть вычислены значения данных для заданного требуемого блока данных. Такой способ получения доступа к одному или более элементам E из второй базы данных, вызываемым из элемента E первой базы данных, предпочтительно использует один или более коэффициентов масштабирования и/или один или более сдвигов значений пикселей, например, если элемент E базы данных, на который осуществляется ссылка во второй базе данных, имеет другой размер, например, размер блока данных, относительно требуемого блока данных, возвращаемого посредством вызова элемента E первой базы данных. Предпочтительно, такой подход использует аффинную модель, как описано в публикации в Wikipedia, доступной в Интернете с 19.10.2012 г. (см. http://en.wikipedia.org/wiki/Affine_transformation). В таблице 5 приведен обзор типов элементов баз данных, применяемых для реализации кодека 5, показанного на фиг.1.
Варианты осуществления настоящего изобретения имеют потенциально широкое применение в электронных продуктах, которые выполнены с возможностью передачи и/или приема данных, представляющих различные типы контента, например, контента потокового видео, онлайн-телевидения, контента, передаваемого с помощью физических носителей данных, например, дисков с оптическим считыванием и так далее. Кроме того, если базы 100 данных доступны только для конкретных сторон, так что, например, по существу большая часть опорных значений R передают в виде кодированных данных 30, настоящее изобретение может обеспечить услуги шифрования данных; цель настоящего изобретения состоит в том, чтобы с помощью ссылок из базы данных можно было передать по меньшей мере большинство кодированных данных, и только для небольшой части будет требоваться кодирование значений блоков с использованием других способов кодирования. Таким образом, варианты осуществления настоящего изобретения применимы во многих различных технических отраслях. Кроме того, варианты осуществления настоящего изобретения могут уменьшить нагрузку на сети связи и требования к ним, снизить требования к емкости устройств для хранения данных, а также обеспечить потенциальное достижение высокого качества кодирования и декодирования данных; это предпочтительные технические преимущества и эффекты, обеспечиваемые настоящим изобретением.
Кодер 10 и декодер 50 предпочтительно осуществляют в виде одного или более процессоров данных. Опционально, процессоры данных осуществляют аппаратно, например, посредством применения специализированных интегральных микросхем (Application-Specific Integrated Circuit, ASIC) или аналогичных цифровых схем. Опционально, процессоры данных осуществляют с использованием вычислительных аппаратных средств, которые реализованы с возможностью выполнения одного или более программных продуктов, хранящихся на машиночитаемых носителях для хранения данных.
Вышеупомянутые одну или более базы 100 данных опционально осуществляют в кодере 10, декодере 50, локальной сети (LAN), предоставленной поставщиком услуг Интернет (ISP), осуществляют в отдельной памяти, например, памяти на основе накопителя на жестких дисках, в картах памяти, дисках BlueRay, в оперативной памяти (RAM), постоянной памяти (ROM), флеш-памяти, на твердотельных дисках (Solid-State Disk, SSD), универсальных цифровых дисках (Digital Versatile Disk, DVD), компакт-дисках (Compact Disk, CD) и любом другом типе носителей данных, предоставляющих доступ к данным. "BlueRay" является зарегистрированным товарным знаком.
Указанные одна или более базы 100 данных, предоставленные одним или более серверами данных, например, реализованные в виде одной или более карт памяти, где бы ни располагались в пространственном отношении указанные один или более серверы данных, могут быть соединены с кодером 10 и/или декодером 50 одним или более из следующих способов: посредством фиксированных соединений, точек контакта, кабелей, беспроводных линий, беспроводных сетей (например, таких как BlueTooth и WLAN (wireless LAN, беспроводная локальная сеть)), сотовых сетей (например, таких как GSM, 3G, 4G, 5G, LTE), спутниковых соединений, но не ограничиваются перечисленным. "BlueTooth" является зарегистрированным товарным знаком.
Опционально, как было описано выше, элементы E могут быть введены в базу 100 данных из декодированных блоков данных поодиночке, совместно или могут использоваться только частично. То есть, в принципе, любой декодированный набор значений данных может сформировать новый элемент E в базе данных в соответствии с заданными или установленными принципами, и любой способ кодирования или решение для кодирования может быть использовано для формирования декодированных данных, элементы из которых вводят в базу данных.
Опционально, кодер 10 и декодер 50 включают в качестве субкомпонентов в многоуровневый кодер и соответствующий многоуровневый декодер согласно способу, раскрытому в заявке на патент Великобритании №1218942.9 и эквивалентной заявке на патент США №13/657,382, а также в соответствующих заявках EP 13003859.9 и US 14/058,793. В многоуровневом кодере исходные данные 20 анализируют и разделяют на множество потоков данных, например, в зависимости от характера содержимого, представленного в исходных данных 20. Один из множества потоков данных подают в кодер 10, который формирует соответствующие кодированные данные; указанные соответствующие кодированные данные объединяют с другими кодированными выходными данными из других кодеров, обрабатывающих другие потоки данных из множества потоков данных, с формированием конечных кодированных данных, подаваемых из многоуровневого кодера. В многоуровневом декодере принимают конечные кодированные данные и разбивают их на множество потоков данных, при этом один из указанных потоков данных подают в декодер 50 с формированием соответствующих декодированных данных; указанные соответствующие декодированные данные объединяют с декодированными данными, предоставленными другими декодерами многоуровневого декодера, с формированием конечных декодированных выходных данных. Хотя такие многоуровневые кодеры и декодеры являются более сложными, чем кодер 10 и декодер 50, такие многоуровневые кодеры и декодеры могут обеспечить исключительные характеристики кодирования, декодирования и сжатия данных при обработке широкого спектра типов данных.
Возможны модификации вышеописанных вариантов осуществления настоящего изобретения без выхода за рамки объема настоящего изобретения, заданного приложенной формулой изобретения. Такие выражения как «включающий», «содержащий», «состоящий из», «имеет», «является», используемые для описания настоящего изобретения и в его формуле, должны истолковываться неисключительным образом,, а именно должны допускать возможность наличия также объектов, компонентов или элементов, не описанных в явном виде. Следует также понимать, что ссылки на единственное число относятся также к множественному числу. Числа в круглых скобках в приложенных пунктах формулы изобретения предназначены для обеспечения понимания формулы изобретения и не должны истолковываться любым образом, ограничивающим объект изобретения, заявленный в этих пунктах формулы изобретения.
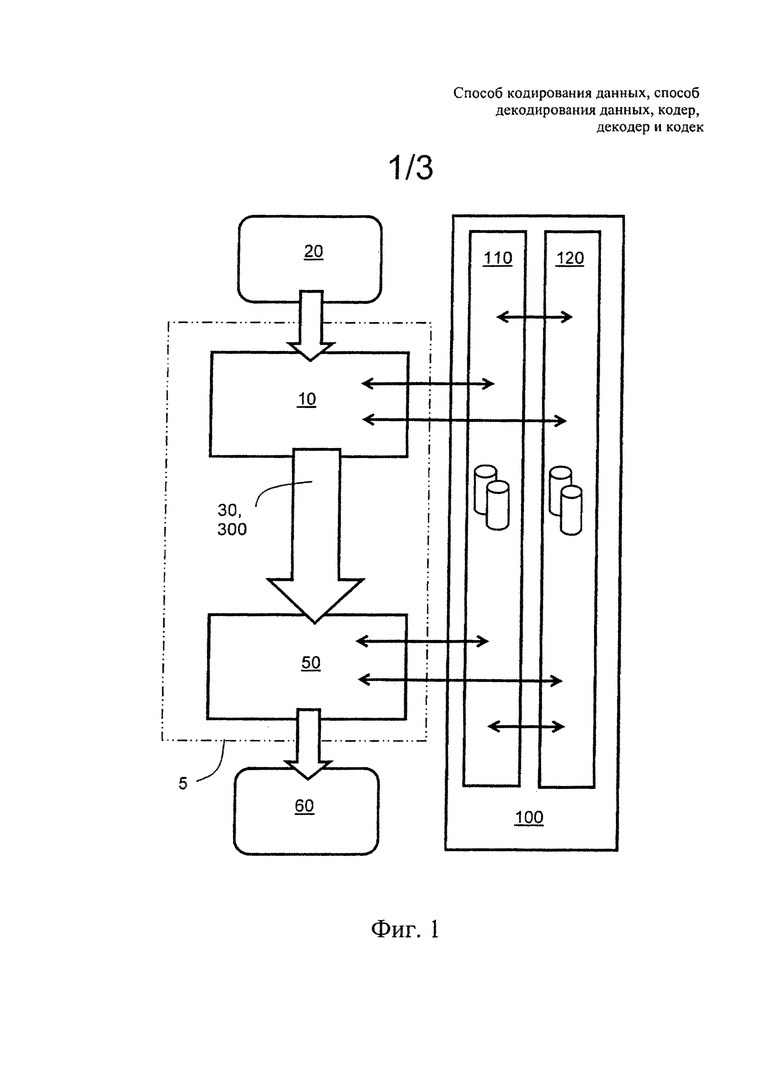
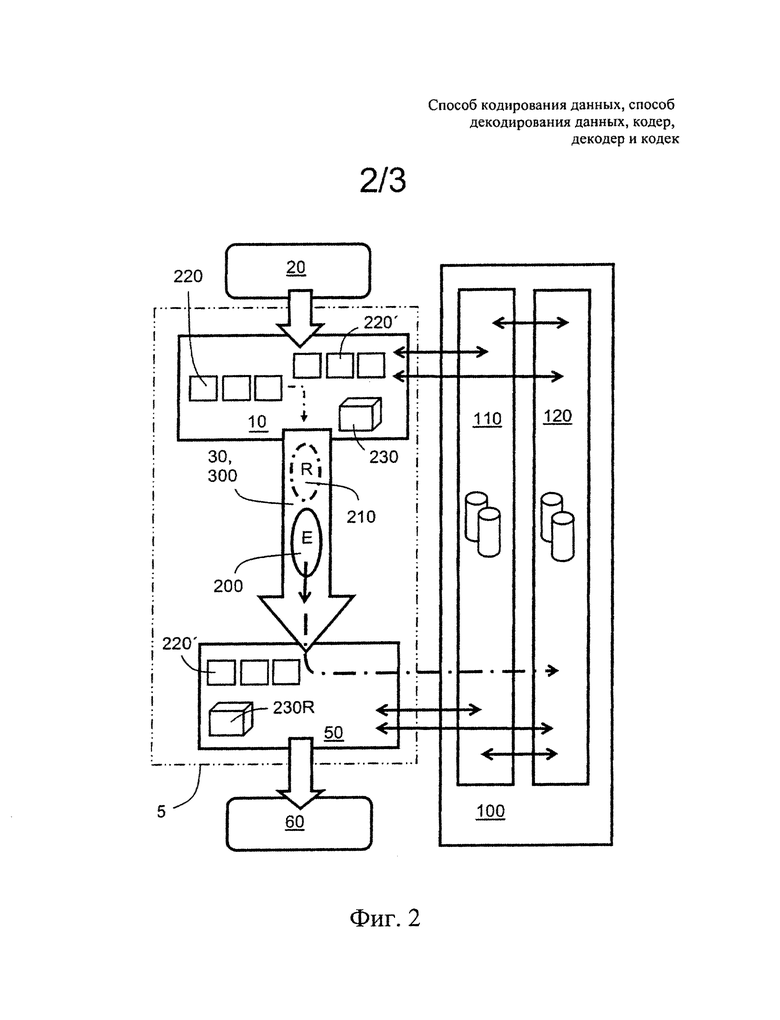
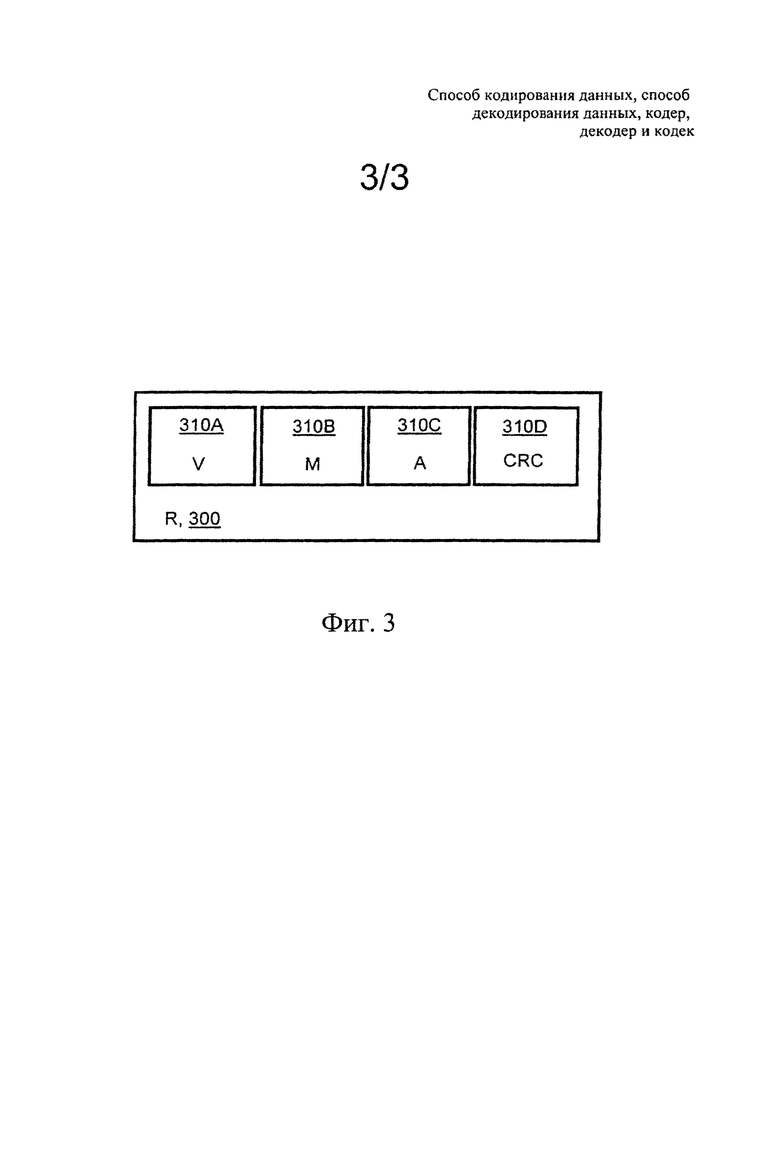
Изобретение относится к средствам кодирования и декодирования. Технический результат заключается в повышении эффективности кодирования/декодирования данных. Устанавливают соответствие одной или более части исходных данных с одним или более элементом в одной или более базе данных, при этом указанный один или более элемент представляет соответствующий один или более блок данных, и записывают опорные значения, которые связывают указанную одну или более часть исходных данных с указанным одним или более соответственным элементом. Включают опорные значения в кодированные данные совместно с указанной одной или более базой данных и/или информацией, идентифицирующей указанную одну или более базу данных. Принимают кодированные данные, включающие опорные значения и информацию об идентификаторах областей, а также информацию об одной или более базе данных. Декодируют опорные значения из кодированных данных. Извлекают один или более элемент из указанной одной или более базы данных согласно указанным опорным значениям, при этом указанный один или более элемент представляет один или более соответствующий блок данных. Формируют указанный один или более блок данных для сборки соответствующих декодированных данных для вывода. 7 н. и 23 з.п. ф-лы, 5 табл., 3 ил.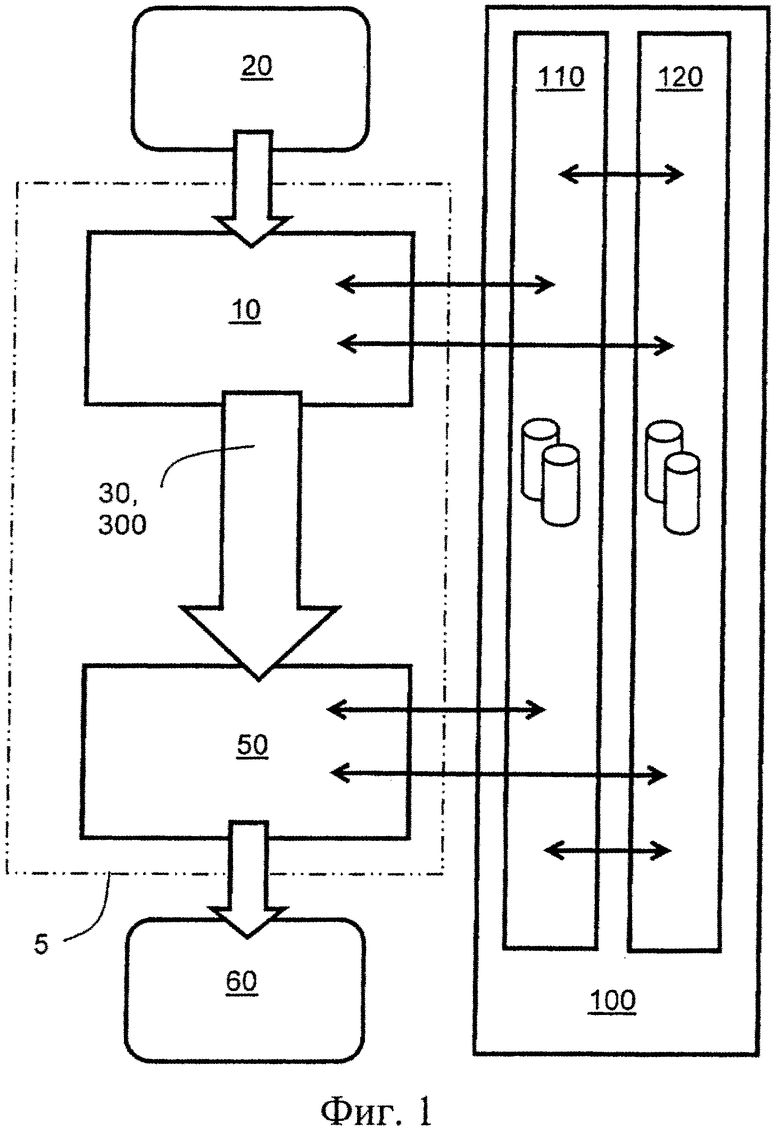
1. Способ кодирования исходных данных (20) с формированием соответствующих кодированных данных (30) для передачи или хранения, при этом указанные исходные данные включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, характеризующийся тем, что указанный способ включает:
a) установление соответствия одной или более части исходных данных (20) с одним или более элементом (Е) в одной или более базе (100) данных, при этом указанный один или более элемент (Е) представляет соответствующий один или более блок данных, и запись опорных значений (R), которые связывают указанную одну или более часть исходных данных (20) с указанным одним или более соответственным элементом (Е); и
b) включение указанных опорных значений (R) в кодированные данные (30) совместно с указанной одной или более базой (100) данных и/или информацией, идентифицирующей указанную одну или более базу (100) данных,
при этом способ дополнительно включает:
c) разделение исходных данных (20) на области, имеющие уникальный идентификатор (U) области;
d) взятие зависящих от областей выборок из указанных областей и вычисление соответствующих опорных значений (R) на основе указанных выборок; и
e) проверку, была ли или нет передана или сохранена в указанной одной или более базе (100) данных одна или более область исходных данных (20), соответствующих указанным опорным значениям (R), полученным в результате вычислений, примененных к исходным данным (20);
f) передачу указанных опорных значений (R) или указанных опорных значений (R) в сжатом состоянии для однозначной идентификации элементов (Е) в указанных кодированных данных (30), когда упомянутая одна или более область исходных данных (20) уже была передана или сохранена в одной или более базе (100) данных; и
g) передачу указанных кодированных и/или некодированных исходных данных (20) в указанных кодированных данных (30), когда упомянутая одна или более область исходных данных (20) не была ранее передана или сохранена в одной или более базе (100) данных, и, опционально, сохранение в качестве нового элемента (Е) в указанной одной или более базе (100) данных в случае, если упомянутая одна или более область исходных данных (20), соответствующих указанным опорным значениям (R), не была ранее сохранена в указанной одной или более базе (100) данных.
2. Способ по п. 1, отличающийся тем, что он включает применение одной или более базы данных с нулевыми средними значениями хранимых данных для реализации указанной одной или более базы данных.
3. Способ по п. 1, отличающийся тем, что он включает по меньшей мере одно из следующего:
I) формирование указанной одной или более статической базы (110) данных путем выбора элементов из одной или более динамической базы (120) данных;
II) обработку информации, представленной в указанной одной или более части исходных данных (20), с формированием одного или более элемента (Е) для включения в указанную одну или более динамическую базу (120) данных; и
III) выбор элементов (Е) из одной или большего количества баз (100) данных и включение их в указанную одну или более динамическую базу (120) данных для использования с кодированными данными (30).
4. Способ по п. 1, отличающийся тем, что указанная одна или более база (100) данных включает одну или более статическую базу (110) данных и/или одну или более динамическую базу (120) данных, при этом указанная одна или более база (100) данных размещается в одном или более сервере данных.
5. Способ по п. 4, отличающийся тем, что он включает удаленное управление указанным одним или более сервером.
6. Способ по п. 4, отличающийся тем, что он включает совместное использование указанной одной или более базы (100) данных по меньшей мере одним кодером (10), выполненным с возможностью формирования кодированных данных (30), и по меньшей мере одним декодером (50), предназначенным для приема кодированных данных (30).
7. Способ по п. 1, отличающийся тем, что его осуществляют в кодере (10), который связан посредством сети связи с указанной одной или более базой (100) данных, при этом по меньшей мере одна из указанной одной или более базы (100) данных находится в той же локальной сети, к которой подключен кодер (10) (кабель, BlueTooth, WLAN, GSM, 3G, 4G, 5G, LTE).
8. Способ по п. 1, отличающийся тем, что опорные значения (R, 300) включают множество частей (310A, 310В, 310С), которые кодированы по отдельности для включения в кодированные данные (30).
9. Способ по п. 1, отличающийся тем, что элементы указанной одной или более динамической базы (120) данных формируют, если совпадения указанной одной или более части исходных данных (20) с одним или более элементом в указанной одной или более статической базе (110) данных не обнаружены.
10. Способ по п. 1, отличающийся тем, что установление соответствия указанной одной или более части исходных данных (20) с одним или более элементом (Е) указанной одной или более базы (100) данных осуществляют в пределах порога качества, который динамически изменяется во время формирования опорных значений (R).
11. Способ по п. 1, отличающийся тем, что указанное одно или более опорное значение (R) используют для восстановления одной или более соответствующей части исходных данных (20) с использованием одного или более элемента (Е), заданного указанным одним или более опорным значением (R), при этом определяют ошибки между указанной восстановленной одной или более частью и соответствующей исходной одной или более частью в исходных данных, а также кодируют указанные ошибки и включают их в кодированные данные (30).
12. Способ по п. 1, отличающийся тем, что один или более элемент (Е) первой базы (100) данных ссылается на один или более элемент (Е), представленный в одной или более другой базе данных из указанной одной или более базы (100) данных.
13. Способ по п. 1, отличающийся тем, что указанную одну или более базу (100) данных выбирают и/или изменяют в размере в зависимости от характера содержимого, представленного в исходных данных (20).
14. Кодер (10) для кодирования исходных данных (20) с формированием соответствующих кодированных данных (30), при этом указанные исходные данные включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, характеризующийся тем, что указанный кодер (10) включает:
a) первые аппаратные средства обработки данных для установления соответствия одной или более части исходных данных (20) с одним или более элементом (Е) в одной или более базе (100) данных, при этом указанный один или более элемент (Е) представляет соответствующий один или более блок данных, и для записи опорных значений (R), которые связывают указанную одну или более часть исходных данных (20) с указанным одним или более соответственным элементом (Е); и
b) вторые аппаратные средства обработки данных для включения указанных опорных значений (R) в кодированные данные (30) совместно с указанной одной или более базой (100) данных и/или информацией, идентифицирующей указанную одну или более базу (100) данных;
при этом кодер (10) выполнен с возможностью:
c) приема исходных данных (20), разделения указанных исходных данных (20) на области, имеющие уникальный идентификатор (U) области;
d) взятия зависящих от областей выборок из указанных областей и вычисления соответствующих опорных значений (R) на основе указанных выборок; и
e) проверки, была ли или нет уже передана или сохранена в указанной одной или более базе (100) данных одна или более область исходных данных (20), соответствующих указанным опорным значениям (R), полученным в результате вычислений, примененных к исходным данным (20); и
передачи указанных опорных значений (R) или указанных опорных значений (R) в сжатом состоянии для однозначной идентификации элементов (Е) в указанных кодированных данных (30), когда упомянутая одна или более область исходных данных (20) уже была передана или сохранена в одной или более базе (100) данных; и
передачи указанных кодированных и/или некодированных исходных данных (20) в указанных кодированных данных (30), когда упомянутая одна или более область исходных данных (20) не была ранее передана или сохранена в одной или более базе (100) данных, и, опционально, сохранения в качестве нового элемента (Е) в указанной одной или более базе (100) данных в случае, если упомянутая одна или более область исходных данных (20), соответствующих указанным опорным значениям (R), не была ранее сохранена в указанной одной или более базе (100) данных.
15. Кодер по п. 14, отличающийся тем, что он выполнен с возможностью выполнения способа кодирования по любому из пп. 1-13.
16. Способ декодирования кодированных данных (30), полученных с использованием способа по п. 1, с формированием соответствующих декодированных данных (60), характеризующийся тем, что указанный способ декодирования включает:
a) прием кодированных данных (30), включающих опорные значения (R, 300) и информацию об идентификаторах (U) областей, а также информацию об одной или более базе (100) данных;
b) декодирование указанных опорных значений (R, 300) из указанных кодированных данных (30);
c) извлечение одного или более элемента (Е) из указанной одной или более базы (100) данных согласно указанным опорным значениям (R, 300), при этом указанный один или более элемент (Е) представляет один или более соответствующий блок данных; и
d) формирование указанных одного или более блока данных для сборки соответствующих общих декодированных выходных данных (60).
17. Способ по п. 16, отличающийся тем, что он включает:
e) сохранение данных в базе данных, которые включают по меньшей мере одно из следующего: аудиоданные, данные изображений, видеоданные, графические данные, многомерные данные, данные измерений, соответствующие опорным значениям (R);
f) формирование идентификаторов (U) областей на основе информации об идентификаторах областей, включенных в кодированные данные (30);
g) прием или извлечение из кодированных данных опорного значения (R), соответствующего одному или более идентификатору (U) областей;
h) извлечение из базы данных, на основе опорного значения (R) для соответствующего идентификатора (U) области, данных, соответствующих указанному опорному значению (R); и
i) формирование, на основе данных, излеченных из указанной базы данных, блока данных, который собран в виде общих декодированных выходных данных (60) на основе идентификатора (U) области.
18. Способ по п. 16, отличающийся тем, что указанная одна или более база (100) данных включает одну или более статическую базу (110) данных и/или одну или более динамическую базу (120) данных.
19. Способ по п. 16, отличающийся тем, что его выполняют в декодере (50), связанном посредством сети связи с одной или более базой (100) данных.
20. Способ по п. 16, отличающийся тем, что указанная одна или более база (100) данных пространственно расположена в локальной близости от аппаратных средств (50) обработки данных, выполненных с возможностью выполнения способа декодирования.
21. Способ по п. 20, отличающийся тем, что указанная одна или более база (100) данных находится в локальной сети (LAN, BlueTooth, WLAN, GSM, 3G, 4G, 5G, LTE), которая также включает аппаратные средства (50) обработки данных, связанные с одной или более базой (100) данных в той же локальной сети, к которой подключен кодер (10) (кабель, BlueTooth, WLAN, GSM, 3G, 4G, 5G, LTE).
22. Способ по п. 16, отличающийся тем, что указанная одна или более база (100) данных предоставлена одним или более сервером данных.
23. Способ по п. 22, отличающийся тем, что управление указанным одним или более сервером осуществляют удаленно.
24. Способ по п. 22, отличающийся тем, что указанная одна или более база (100) данных используется совместно по меньшей мере одним кодером (10), выполненным с возможностью формирования кодированных данных (30), и по меньшей мере одним декодером, включающим аппаратные средства (50) обработки данных, предназначенные для приема указанных кодированных данных (30).
25. Способ по п. 16, отличающийся тем, что он включает формирование одной или более динамической базы (120) данных из одного или более элемента (Е) указанной одной или более статической базы (110) данных и/или из информации, предоставленной в кодированных данных (30), при этом указанную сформированную одну или более динамическую базу (120) данных используют для декодирования указанных кодированных данных (30).
26. Декодер (50) для декодирования кодированных данных (30) с формированием соответствующих декодированных данных (60), при этом указанный декодер (50) включает:
a) первые аппаратные средства обработки данных для приема кодированных данных (30), включающих опорные значения (R, 300) и информацию об идентификаторах (U) областей, а также информацию об одной или более базе (100) данных;
b) вторые аппаратные средства обработки данных для декодирования указанных опорных значений (R, 300) из указанных кодированных данных (30);
c) третьи аппаратные средства обработки данных для извлечения одного или более элемента (Е) из указанной одной или более базы (100) данных согласно указанным опорным значениям (R, 300), при этом указанный один или более элемент (Е) представляет один или более соответствующий блок данных; и
d) четвертые аппаратные средства обработки данных для формирования указанного одного или более блока данных для сборки соответствующих общих декодированных выходных данных (60).
27. Декодер (50) по п. 26, отличающийся тем, что он выполнен с возможностью выполнения способа по любому из пп. 17-25.
28. Кодек (5), включающий по меньшей мере один кодер (10) по п. 14 для кодирования исходных данных (20) с формированием соответствующих кодированных данных (30) и по меньшей мере один декодер (50) по п. 26 для приема кодированных данных (30) и декодирования указанных кодированных данных (30) с формированием соответствующих декодированных данных (60).
29. Машиночитаемый носитель данных, содержащий программный продукт, при этом выполнение указанного программного продукта осуществляют посредством вычислительных аппаратных средств кодера (10) для осуществления способа по любому из пп. 1-13.
30. Машиночитаемый носитель данных, содержащий программный продукт, при этом выполнение указанного программного продукта осуществляют посредством вычислительных аппаратных средств декодера (50) для осуществления способа по любому из пп. 16-25.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ПЛОСКИЙ ГИДРОРАСПРЕДЕЛИТЕЛЬ | 2008 |
|
RU2362055C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 4553171 A, 12.11.1985 | |||
| US 4013828 A, 22.03.1977 | |||
| ФОРМИРОВАНИЕ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ ЭФФЕКТА БЛИЗОСТИ | 2005 |
|
RU2388172C2 |

