Область техники
Настоящее изобретение относится к кодерам для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), а также к соответствующим способам кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2). Также, настоящее изобретение относится к декодерам для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), а также к соответствующим способам декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3). Также, настоящее изобретение относится к компьютерным программным продуктам, включающим энергонезависимый машиночитаемый носитель, на котором хранят машиночитаемые инструкции, при этом машиночитаемые инструкции могут быть исполнены на компьютеризованном устройстве, включающем процессорную аппаратуру в целях выполнения упомянутых выше способов. Настоящее изобретение относится также к кодекам, включающим по меньшей мере один упомянутый кодер и по меньшей мере один упомянутый декодер.
Предпосылки создания изобретения
Кодирование длин серий (Run Length Encoding, RLE) - это метод кодирования, который может применяться для сжатия данных за счет уменьшения соответствующего количества символов при помощи передачи непрерывных серий повторяющихся символов особым образом (см. ссылку [1] в приведенном ниже библиографическом указателе). Также известен метод скользящего RLE-кодирования (Split RLE, SRLE) (см. ссылку [2] в библиографическом указателе), который является вариантом RLE-кодирования и позволяет передавать и сжимать символы и непрерывные серии символов различным образом.
На существующем уровне техники известны множество различных реализаций RLE-кодирования. В качестве одного из примеров, в некоторых существующих реализациях возможна передача непрерывных серий любых из различных символов. В других реализациях непрерывные серии передают, только если в потоке символов имеются по меньшей мере два одинаковых символа. При этом также известен один специализированный вариант RLE-кодирования, ZRLE-кодирование (см. ссылку [3] в библиографическом указателе), в котором по отдельности передают ненулевые значения и серии нулевых значений, предшествующие ненулевым значениям. Метод ZRLE-кодирования эффективен, когда входные данные содержат много нулевых значений. ZRLE-кодирование используют, например, для сжатия коэффициентов дискретного косинусного преобразования (Discrete Cosine Transform, DCT) в технологии сжатия JPEG (Joint Photographic Experts Group, Объединенная группа экспертов по фотографии).
Упомянутые выше методы кодирования, RLE и SRLE, могут применяться для битов, чисел или символов, тогда как ZRLE-кодирование может применяться только для чисел.
RLE-кодирование и SRLE-кодирование эффективны только тогда, когда в данных достаточно последовательностей из одинаковых символов, однако ни один из этих символов не преобладает.ZRLE-кодирование эффективно, только когда преобладающим значением в данных являются нули.
К сожалению, при использовании ZRLE-кодирования в стандарте JPEG нули не всегда являются преобладающими значениями, особенно когда необходимо высокое качество, а степень квантования - низка. В подобных случаях ZRLE-квантование будет крайне неэффективным.
Соответственно, необходимо предложить альтернативные методы кодирования, позволяющие преодолеть недостатки, связанные с существующими, например, описанными выше, методами кодирования данных. Упомянутые недостатки относятся, к примеру, к максимально достижимой степени сжатия данных.
Сущность изобретения
Цель настоящего изобретения - предложить усовершенствованный кодер для кодирования данных (D1) с целью формирования соответствующих кодированных данных (Е2).
Другая цель настоящего изобретения - предложить усовершенствованный декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3).
Еще одна цель настоящего изобретения - по меньшей мере частично преодолеть описанные выше недостатки существующего уровня техники. В первом аспекте вариантов осуществления настоящего изобретения предложен кодер для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), отличающийся тем, что:
кодер (110) выполнен с возможностью:
(a) анализа входных данных (D1) для выявления в них по меньшей мере одного модового символа;
(b) формирования значений данных по меньшей мере первого типа и второго типа из входных данных (D1), при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, где упомянутый по меньшей мере один модовый символ - это символ, который наиболее часто встречается во входных данных (D1), а немодовые символы - это остальные символы, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных (D1);
(c) формирования информации, указывающей на количество немодовых символов во входных данных (D1), и информации, указывающей по меньшей мере на один модовый символ; и
(d) сборки или кодирования информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих последовательности по меньшей мере из одного модового символа, для получения кодированных данных (Е2).
Настоящее изобретение обладает тем преимуществом, что в случаях, когда входные данные (D1) содержат по меньшей мере один преобладающий символ (то есть, модовый символ), описанный выше кодер способен обеспечить большую степень сжатия при сжатии данных без потерь, по сравнению с другими, известными на существующем уровне техники методами сжатия.
При этом формируемые таким образом кодированные данные (Е2) могут быть декодированы быстрее, по сравнению с традиционными методами энтропийного кодирования.
Следует отметить, что описанный выше кодер может применяться для символов различного типа, включая, например, числа, биты, алфавитно-цифровые знаки, слова и т.п. Нужно понимать, что один или более результирующих потоков могут дополнительно подвергаться энтропийному кодированию. При наличии нескольких модовых значений в результате могут формироваться множество потоков, поскольку для каждого модового значения получают два потока при использовании SMRLE-кодирования, и только один поток - при использовании MRLE-кодирования. Таким образом, варианты осуществления настоящего изобретения включают также реализацию, в которой формируют только один поток, например, в случаях, когда используют MRLE-кодирование.
Опционально, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в один или более потоков данных, перед шагом (d). В соответствии с одним из вариантов осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в разные потоки данных. Опционально, в этой связи, значения данных первого типа и значения данных второго типа вставляют в первый поток данных и второй поток данных соответственно. Опционально, в этой связи, кодер выполнен с возможностью рекурсивной обработки первого потока данных, включающего значения данных первого типа, а именно, немодовые символы, согласно шагам (a)-(d).
В соответствии с другим вариантом осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в чередующемся формате (с «интерливингом») или в планарном формате в один поток данных.
Альтернативно, опционально, когда значения данных первого типа и значения данных второго типа вставляют в первый и второй потоки данных, кодер выполнен с возможностью комбинирования первого и второго потока данных, в результате чего формируют один результирующий поток данных, в чередующемся формате или в планарном формате.
Опционально, кодер выполнен с возможностью чередования значений данных первого и второго типов, в результате чего получают один результирующий поток данных. Опционально, кодер выполнен с возможностью чередования значений данных первого и второго типов в виде чередующихся блоков данных, в результате чего получают один результирующий поток данных.
При этом здесь следует отметить, что в планарном формате все значения данных первого типа вставляют в один результирующий поток данных, и за ними следуют все значения данных второго типа, или наоборот.
Также, опционально, кодер выполнен с возможностью использования по меньшей мере одного метода энтропийного кодирования для сжатия упомянутых одного или более потоков данных, совместно или по отдельности. Опционально, в этой связи, упомянутый по меньшей мере один метод энтропийного кодирования включает по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Приведенные примеры по меньшей мере одного метода кодирования более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
Опционально, кодер выполнен с возможностью сборки, или кодирования, дополнительной информации, относящейся к передаче по меньшей мере одного из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных
Опционально, в этой связи, кодер выполнен с возможностью передачи, по меньшей мере в один декодер, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, кодер выполнен с возможностью передачи упомянутой выше дополнительной информации в качестве предваряющей информации, до передачи кодированных данных (Е2). Альтернативно, опционально, кодер выполнен с возможностью передачи дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Опционально, кодер выполнен с возможностью формирования символов во входных данных (D1) перед выполнением шагов (a)-(d) при помощи разбиения или комбинирования исходных символов, содержащихся во входных данных (D1). Опционально, в этой связи, кодер выполнен с возможностью:
(i) разбиения одного или более фрагментов входных данных (D1), в результате чего формируют один или более новых символов для обработки данных согласно шагам (a)-(d); и/или
(i) комбинирования одного или более алфавитно-цифровых знаков из одного или более фрагментов входных данных (D1), в результате чего формируют новые комбинированные символы для обработки данных согласно шагам (a)-(d).
Опционально, кодер выполнен с возможностью использования дополнительных методов кодирования для кодирования одного или более фрагментов входных данных (D1), при этом такие дополнительные методы кодирования включают по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Дополнительные методы более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
Опционально, кодер выполнен с возможностью динамического выбора, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)-(d), в зависимости от одного или более свойств входных данных (D1), за счет чего получают повышенную степень сжатия кодированных данных (Е2).
Во втором аспекте вариантов осуществления настоящего изобретения предложен способ кодирования входных данных (D1) в кодере для формирования соответствующих кодированных данных (Е2), включающий конфигурирование кодера для::
(a) анализа входных данных (D1) для выявления в них по меньшей мере одного модового символа;
(b) формирования значений данных по меньшей мере первого типа и второго типа из входных данных (D1), при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, где упомянутый по меньшей мере один модовый символ - это символ, который наиболее часто встречается во входных данных (D1), а немодовые символы - это остальные символы, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных (D1);
(с) формирования информации, указывающей на количество немодовых символов во входных данных (D1), и информации, указывающей по меньшей мере на один модовый символ; и
сборки или кодирования информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих последовательности по меньшей мере из одного модового символа, для получения кодированных данных (Е2).
Опционально, способ дополнительно включает вставку значений данных первого типа и значений данных второго типа в один или более потоков данных перед шагом (d).
В соответствии с одним из вариантов осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, способ включает вставку значений данных первого типа и значений данных второго типа в разные потоки данных. Опционально, в этой связи, значения данных первого типа и значения данных второго типа вставляют в первый поток данных и второй поток данных соответственно.
Опционально, способ включает рекурсивную обработку первого потока данных, включающего немодовые символы, согласно шагам (a)-(d).
В соответствии с другим вариантом осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, способ включает вставку значений данных первого типа и значений данных второго типа в чередующемся формате или в планарном формате в один поток данных.
Альтернативно, опционально, когда значения данных первого типа и значения данных второго типа вставляют в первый и второй потоки данных, способ включает комбинирование первого и второго потока данных, в результате чего формируют один результирующий поток данных, в чередующемся формате или в планарном формате. Также, опционально, способ включает использование по меньшей мере одного метода энтропийного кодирования для сжатия упомянутых одного или более потоков данных, совместно или по отдельности. Опционально, в этой связи, упомянутый по меньшей мере один метод энтропийного кодирования включает по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Опционально, способ включает сборку, или кодирование, дополнительной информации, относящейся к передаче по меньшей мере одного из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных
Опционально, в этой связи, способ включает передачу, по меньшей мере в один декодер, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, способ включает передачу упомянутой выше дополнительной информации в качестве предваряющей информации, до передачи кодированных данных (Е2). Альтернативно, опционально, способ включает передачу дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2). Опционально, способ включает формирование символов во входных данных (D1) перед выполнением шагов (a)-(d) при помощи разбиения или комбинирования исходных символов, содержащихся во входных данных (D1). Опционально, в этой связи способ включает:
(i) разбиение одного или более фрагментов входных данных (D1), в результате чего формируют один или более новых символов для обработки данных согласно шагам (a)-(d);
и/или
(i) комбинирование одного или более алфавитно-цифровых знаков из одного или более фрагментов входных данных (D1), в результате чего формируют новые комбинированные символы для обработки данных согласно шагам (a)-(d). Опционально, способ включает использование дополнительных методов кодирования для кодирования одного или более фрагментов входных данных (D1), при этом такие дополнительные методы кодирования включают по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy.
Опционально, способ включает динамический выбор, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)-(d), в зависимости от одного или более свойств входных данных (D1), за счет чего получают повышенную степень сжатия кодированных данных (Е2). В третьем аспекте вариантов осуществления настоящего изобретения предложен декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), отличающийся тем, что:
(i) декодер выполнен с возможностью декодирования, из кодированных данных (Е2), информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных (D1); и
(ii) декодер выполнен с возможностью вставки, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа, в результате чего формируют декодированные данные (D3).
Опционально, декодер выполнен с возможностью приема, в кодированных данных (Е2), одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
В соответствии с одним из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в разных потоках данных.
В соответствии с другим из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в чередующемся формате или в планарном формате в одном потоке данных. Опционально, декодер выполнен с возможностью использования по меньшей мере одного метода, обратного методу энтропийного кодирования, который был использован в соответствующем кодере для сжатия упомянутых одного или более потоков данных, совместно или по отдельности.
Опционально, когда в кодированных данных (Е2) использованы более одного модовых символов, декодер выполнен с возможностью рекурсивного выполнения шагов (i)-(ii) для каждого модового символа, в результате чего формируют декодированные данные (D3).
В соответствии с одним из вариантов осуществления настоящего изобретения декодер выполнен с возможностью приема дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных. Опционально, в этой связи, декодер выполнен с возможностью приема, из соответствующего кодера, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет. Опционально, декодер выполнен с возможностью приема упомянутой выше дополнительной информации в качестве предваряющей информации, до приема кодированных данных (Е2). Альтернативно, опционально, декодер выполнен с возможностью приема дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Опционально, когда кодированные данные (Е2) были кодированы с использованием дополнительных методов кодирования, декодер выполнен с возможностью декодирования кодированных данных (Е2) в порядке выполнения шагов обработки, который обратен порядку шагов обработки, выполненных при кодировании исходных входных данных (D1) для формирования кодированных данных (Е2) соответствующим кодером. В этой связи, опционально, декодер выполнен с возможностью использования дополнительных методов декодирования, при этом дополнительные методы декодирования включают по меньшей мере одно из следующего: дельта-декодирование, О-дельта-декодирование, RLE-декодирование, SRLE-декодирование, MRLE-декодирование, SMRLE-декодирование, декодирование Хаффмана, VLC-декодирование, диапазонное декодирование, арифметическое декодирование, декодирование энтропийным модификатором (ЕМ), декодирование «континуумным оператором», декодирование TrueBitsCopy. Дополнительные методы более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
Во втором аспекте вариантов осуществления настоящего изобретения предложен способ декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), включающий: (i) декодирование, из кодированных данных (Е2), информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных (D1); и (ii) вставку, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа, в результате чего формируют декодированные данные (D3).
Опционально, способ включает прием, в кодированных данных (Е2), одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
В соответствии с одним из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в разных потоках данных.
В соответствии с другим из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в чередующемся формате или в планарном формате в одном потоке данных.
Опционально, способ включает использование по меньшей мере одного метода, обратного методу энтропийного кодирования, который был использован в соответствующем кодере для сжатия упомянутых одного или более потоков данных, совместно или по отдельности. Опционально, когда в кодированных данных (Е2) использованы более одного модовых символов, способ включает рекурсивное выполнение шагов (i)-(ii) для каждого модового символа, в результате чего формируют декодированные данные (D3).
В соответствии с одним из вариантов осуществления настоящего изобретения способ включает прием дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных.
Опционально, в этой связи, способ включает прием, из соответствующего кодера, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, способ включает прием упомянутой выше дополнительной информации в качестве предваряющей информации, до приема кодированных данных (Е2). Альтернативно, опционально, способ включает прием дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Опционально, когда кодированные данные (Е2) были кодированы с использованием дополнительных методов кодирования, способ включает декодирование кодированных данных (Е2) в порядке выполнения шагов обработки, который обратен порядку шагов обработки, выполненных при кодировании исходных входных данных (D1) для формирования кодированных данных (Е2) соответствующим кодером. В этой связи, опционально, способ включает использование дополнительных методов декодирования, при этом дополнительные методы декодирования включают по меньшей мере одно из следующего: дельта-декодирование, О-дельта-декодирование, RLE-декодирование, SRLE-декодирование, MRLE-декодирование, SMRLE-декодирование, декодирование Хаффмана, VLC-декодирование, диапазонное декодирование, арифметическое декодирование, декодирование энтропийным модификатором (ЕМ), декодирование «континуумным оператором», декодирование TrueBitsCopy. Дополнительные методы более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
В пятом аспекте вариантов осуществления настоящего изобретения предложен кодек, включающий по меньшей мере кодер для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) в соответствии с описанным выше первым аспектом настоящего изобретения, и по меньшей мере один декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3) в соответствии с описанным выше третьим аспектом настоящего изобретения. В шестом аспекте вариантов осуществления настоящего изобретения предложен компьютерный программный продукт, включающий энергонезависимый машиночитаемый носитель, на котором хранят машиночитаемые инструкции, при этом машиночитаемые инструкции могут быть исполнены на компьютеризованном устройстве, включающем процессорную аппаратуру для исполнения любых из описанных выше способов согласно второму или четвертым аспектам настоящего изобретения. Для уяснения дополнительных аспектов, преимуществ, отличительных признаков и целей настоящего изобретения следует обратиться к чертежам и подробному описанию примеров его осуществления, которые следует рассматривать в сочетании с приложенной формулой изобретения. Нужно понимать, что отличительные признаки настоящего изобретения в пределах объема настоящего изобретения, заданного приложенной формулой изобретения, могут комбинироваться произвольным образом.
Краткое описание чертежей
Краткое описание изобретения, приведенное выше, а также приведенное ниже подробное описание примеров осуществления настоящего изобретения, могут быть поняты более детально при его прочтении в сочетании с приложенными чертежами. В целях иллюстрации настоящего изобретения на чертежах показаны различные его примеры. Однако настоящее изобретение не ограничено конкретными способами и устройствами, описанными в данном документе. При этом специалисты в данной области техники должны понимать, что чертежи выполнены не в масштабе. Там, где это возможно, аналогичные элементы обозначены аналогичными числовыми обозначениями.
Далее, исключительно в качестве примера и со ссылками на приложенные чертежи, будут описаны примеры осуществления настоящего изобретения, где:
фиг. 1 представляет собой эскизную иллюстрацию кодера для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) и декодера для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), при этом кодер и декодер вместе образуют кодек, в соответствии с одним из вариантов осуществления настоящего изобретения, и при этом опциональный энтропийный кодер понижает энтропию кодированных данных (Е2) с результате чего получают энтропийно-сжатиые кодированные данные (Е3), при этом, также, опциональный энтропийный декодер распаковывает энтропийно-сжатые кодированные данные (Е3), приводя их обратно к виду кодированных данных (Е2), после чего они могут быть декодированы с получением декодированных данных (D3); фиг. 2 представляет собой эскизную блок-схему алгоритма, которая иллюстрирует шаги способа кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), в соответствии с одним из вариантов осуществления настоящего изобретения; и
фиг. 3 представляет собой эскизную блок-схему алгоритма, которая иллюстрирует шаги способа декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), в соответствии с одним из вариантов осуществления настоящего изобретения.
На приложенных чертежах числа, выделенные подчеркиванием, используются для обозначения элементов, над которыми находится подчеркнутое число, или рядом с которыми оно расположено. Неподчеркнутые числовые обозначения относятся к объектам, указанным линией, которая соединяет неподчеркнутое число и объект.
Подробное описание вариантов осуществления изобретения
В приведенном ниже подробном описании рассмотрены варианты осуществления настоящего изобретения и способы, которыми они могут быть реализованы. В настоящем документе описаны несколько конкретных вариантов осуществления настоящего изобретения, однако специалисты в данной области техники должны понимать, что возможны также другие варианты осуществления или практического применения настоящего изобретения. В первом аспекте вариантов осуществления настоящего изобретения предложен кодер для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), отличающийся тем, что:
(a) кодер выполнен с возможностью анализа входных данных (D1) с целью выявления в них по меньшей мере одного модового символа;
(b) кодер выполнен с возможностью формирования значений данных по меньшей мере первого типа и второго типа, при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных (D1);
(c) кодер выполнен с возможностью формирования информации, указывающей на количество немодовых символов, и информации, указывающей по меньшей мере на один модовый символ; и (d) кодер выполнен с возможностью сборки, или кодирования, информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих серии по меньшей мере из одного модового символа, в результате чего получают кодированные данные (Е2).
Входные данные (D1) могут быть данными любого рода, допускающими представление при помощи символов. Примеры символов, включают, без ограничения перечисленным, алфавитные знаки, алфавитно-цифровые знаки, числовые знаки и их последовательности. Также, входные данные (D1) могут быть исходными данными, необработанными данными, данными, обработанными с помощью какого-либо другого метода кодирования, или потоком данных. Примеры входных данных (D1) включают, без ограничения перечисленным, двоичные данные, текстовые данные, аудиоданные, данные изображений, видеоданные, данные измерений, данные датчиков, биометрические данные, биологические генетические данные, данные генома, данные коэффициентов преобразований, преобразованные данные, обработанные данные или частичные данные.
Для упомянутых выше данных по коэффициентам преобразования и упомянутых выше преобразованных данных, некоторые примеры соответствующих преобразований входных данных (D1), коэффициенты которых могут быть использованы в упомянутом выше способе или способах согласно настоящему изобретению, могут включать:
дискретное косинусное преобразование (Discrete Cosine Transform, DCT), дискретное или быстрое преобразование Фурье (Discrete/Fast Fourier Transform, DFT/FFT), преобразование Xaapa, вейвлеты, дискретное синусное преобразование (Discrete Sine Transform, DST), преобразование Карунена-Лоэва (Karhunen-Loeve Transform, KLT), линейные преобразования, аффинные преобразования, отражения, параллельные смещения, повороты, масштабирование, наклон, многоуровневое кодирование, О-дельта-кодирование, квантование, преобразование цветового пространства, линейные фильтры (FIR, IIR), нелинейные преобразования (частичные функции) и нелинейные фильтры (медианный, модовый), однако без ограничения перечисленным. Упомянутые преобразования, опционально, используют для обработки входных данных (D1) перед тем, как соответствующие обработанные данных будут использованы в способе или способах, соответствующих настоящему изобретению. Подобные преобразования более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
Описанный выше кодер очень эффективен в случаях, когда во входных данных (D1) имеется по меньшей мере один преобладающий символ. В настоящем документе под выражением «модовый символ» понимают символ, преобладающий во входных данных (D1), тогда как под выражением «немодовый символ» понимают символ, не являющийся преобладающим во входных данных (D1). Другими словами, модовый символ -это символ, встречающийся во входных данных (D1) наиболее часто, а немодовый символ -это любой другой символ, не являющийся модовым символом.
Нужно понимать, что «модовый» не обязательно значит «нулевой», хотя в некоторых случаях его значение может быть нулевым, если во входных данных (D1) преобладают нули.
Здесь следует отметить, что во входных данных (D1) может присутствовать более одного модового символа, и варианты осуществления настоящего изобретения при наличии более одного модового символа могут быть реализованы аналогичным образом. Опционально, в таком случае кодер может быть выполнен с возможностью рекурсивного выполнения шагов (a)-(d) для каждого модового символа.
В соответствии с одним из вариантов осуществления настоящего изобретения, кодер выполнен с возможностью формирования символов во входных данных (D1) перед выполнением шагов (a)-(d) при помощи разбиения или комбинирования исходных символов, содержащихся во входных данных (D1). Опционально, в этой связи, кодер выполнен с возможностью:
(i) разбиения одного или более фрагментов входных данных (D1), в результате чего формируют один или более новых символов для обработки данных согласно шагам (a)-(d); и/или (ii) комбинирования одного или более алфавитно-цифровых знаков из одного или более фрагментов входных данных (D1), в результате чего формируют новые комбинированные символы для обработки данных согласно шагам (a)-(d).
Чтобы проиллюстрировать, каким образом входные данные (D1) могут быть разбиты в пункте (i), рассмотрим пример, в котором входной поток данных (D1) является битовым потом, включающим следующие 24 бита:
1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1
Такой битовый поток может быть разбит на N-битные символы, которые затем могут быть сжаты согласно шагам (a)-(d). В данном примере фрагменты битового потока могут разбиваться с получением новых 4-битных символов следующим образом:
(1, 0, 0, 0), (0, 1, 1, 1), (1, 0, 1, 1), (1, 0, 0, 0), (1, 0, 0, 0), (1, 0, 1, 1)
Показанные выше новые 4-битные символы разделены скобками исключительно для простоты понимания. Далее, чтобы проиллюстрировать, как может выполняться комбинирование алфавитно-цифровых знаков в пункте (ii), рассмотрим пример, в котором входной поток данных (D1) включает 20 следующих алфавитно-цифровых знаков:
А, В, В, А, А, А, В, В, А, В, А, В, А, В, В, А, В, В, А, А
В данном примере неоднократно повторяются некоторые последовательности алфавитно-цифровых знаков, а именно, ‘A, B’, ‘A, A’ и ‘A, B’. Соответственно, эти алфавитно-цифровые знаки могут быть скомбинированы, в результате чего формируют следующие новые комбинированные символы:
ABB, АА, ABB, АВ, АВ, ABB, ABB, АА
Над этими новыми символами затем может быть выполнена обработка согласно шагам (a)-(d). Опционально, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в один или более потоков данных перед шагом (d).
В соответствии с одним из вариантов осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в разные потоки данных. Опционально, в этой связи, значения данных первого типа и значения данных второго типа вставляют в первый поток данных и второй поток данных, соответственно.
Опционально, в этой связи, кодер выполнен с возможностью рекурсивной обработки первого потока данных, включающего значения данных первого типа, а именно, немодовые символы, согласно шагам (a)-(d). В таком случае всякий раз, когда выполняют рекурсию, для заданного модового символа формируются значения данных двух различных типов. В результате количество различных типов значений данных, а значит, и количество различных потоков данных, кодируемых в кодированные данные (Е2), равно количеству выполняемых рекурсий плюс единица. Следует отметить, что количество рекурсий равно количеству модовых символов, отличающихся от исходных символов. Другими словами, количество модовых символов отражает, сколько раз будет выполняться рекурсия при кодировании. Здесь следует отметить, что первый поток данных, а именно, значения данных первого типа, получают после того, как удаляют из входных данных (D1) предыдущий модовый символ. То есть, первый поток данных может быть обработан рекурсивно согласно шагам (a)-(d), если по меньшей мере одно из значений данных, входящих в первый поток данных, явно выделяется как модовый символ.
Также, опционально, кодер выполнен с возможностью рекурсивной обработки второго потока данных, включающего серии по меньшей мере из одного модового символа, согласно шагам (a)-(d). Это особенно эффективно в случаях, когда отдельные серии значений состоят из явных модовых символов.
Ниже будет рассмотрен один из примеров того, как может выполняться подобная рекурсивная обработка. В соответствии с другим вариантом осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, кодер выполнен с возможностью вставки значений данных первого типа и значений данных второго типа в чередующемся формате или в планарном формате в один поток данных. Альтернативно, опционально, когда значения данных первого типа и значения данных второго типа вставляют в первый и второй потоки данных, кодер выполнен с возможностью комбинирования первого и второго потока данных, в результате чего формируют один результирующий поток данных, в чередующемся формате или в планарном формате. В соответствии с одним из вариантов осуществления настоящего изобретения, кодер выполнен с возможностью чередования значений данных первого и второго типов, в результате чего получают один результирующий поток данных. В соответствии с другим вариантом осуществления настоящего изобретения, кодер выполнен с возможностью чередования значений данных первого и второго типов, в виде чередующихся блоков данных, в результате чего получают один результирующий поток данных. Примеры того, каким образом значения данных первого и второго типов могут чередоваться, будут приведены ниже.
Метод кодирования, в котором значения данных первого типа (А) и значения данных второго типа (В) передают в виде чередующихся пар (А, В), будем называть далее модовым кодированием длин серий (Mode Run-Length Encoding, MRLE). При этом здесь следует отметить, что в планарном формате все значения данных первого типа вставляют в один результирующий поток данных, и за ними следуют все значения данных второго типа, или наоборот.
Также, опционально, кодер выполнен с возможностью использования по меньшей мере одного метода энтропийного кодирования для сжатия упомянутых одного или более потоков данных, совместно или по отдельности. Опционально, в этой связи, упомянутый по меньшей мере один метод энтропийного кодирования включает по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Упомянутые методы кодирования более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя). Также, опционально, в упомянутом по меньше мере одном методе энтропийного кодирования для минимизации диапазона значений данных и/или количества альтернатив сигнализируемых символов могут применяться такие решения, как Pedestal, Maxlndex или таблицы поиска (Look-Up Table, LUT). Упомянутые методы более подробно описаны, например, в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу (доступны в базе данных Espacenet Европейского патентного бюро с «Ossi Kalevo» в качестве имени изобретателя).
Опционально, перед упомянутыми одним или более потоками данных в кодированных данных (Е2) передают информацию, указывающую на количество немодовых символов. В соответствии с одним из вариантов осуществления настоящего изобретения кодер выполнен с возможностью передачи кодированных данных (Е2) по меньшей мере в один декодер. В качестве примера, кодированные данные (Е2) записывают, при помощи кодера, в файл, и затем считывают из этого файла при помощи по меньшей мере одного декодера. В качестве другого примера, выполняют потоковую передачу кодированных данных (Е2) из кодера по меньшей мере в один декодер. Опционально, кодер выполнен с возможностью сборки, или кодирования, дополнительной информации, относящейся к передаче по меньшей мере одного из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных.
Опционально, в этой связи, кодер выполнен с возможностью передачи, по меньшей мере в один декодер, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, кодер выполнен с возможностью передачи упомянутой выше дополнительной информации в качестве предваряющей информации, до передачи кодированных данных (Е2). Альтернативно, опционально, кодер выполнен с возможностью передачи дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Также, когда упомянутый указатель, передаваемый по меньшей мере в один декодер, включает информацию о выборе метода кодирования, применяемого в кодере (а именно, например, выбора, сделанного кодером), например, метода модового RLE-кодирования (MRLE-кодирования) или скользящего модового RLE-кодирования (SMRLE-кодирования), этот указатель может быть назван указателем выбора метода. В качестве примера такого указателя выбора метода можно привести ‘SMRLE2_X1_X2’, где цифра ‘2’ в указателе означает, что в кодированных данных (Е2) присутствуют два модовых символа, при этом каждый символ ‘Xn’ в указателе означает, что модовые символы (n=1, 2, …, N) передают в составе кодированных данных (Е2). В качестве другого примера, когда количество модовых символов передают в составе кодированных данных (Е2), может применяться указатель выбора метода ‘SMRLEN’, где символ ‘N’ указывает на то, что количество модовых символов и сами модовые символы передаются в составе кодированных данных (Е2). В еще одном примере, когда модовые символы не передают в составе кодированных данных (Е2), может применяться указатель выбора метода ‘SMRLE2_H_F’, где символы ‘Н’ и ‘F’ представляют используемые модовые символы. В качестве еще одного примера, когда применяют один модовый символ, который передают в составе кодированных данных (Е2), может применяться указатель выбора метода ‘SMRLE1_X1’.
Таким образом, по меньшей мере один модовый символ и количество модовых символов передают по меньшей мере в один декодер при помощи описанного выше указателя. Нужно понимать, что в этом указателе информация о выбранном методе может вставляться как до, так и после по меньшей мере модового символа и количества модовых символов, а также между ними. Также, опционально, описанные выше указатели могут использоваться для указания, являются ли первый символ, последний символ, или одновременно первый и последний символы во входных данных (D1) немодовыми символами или нет. В качестве примера, указатель выбора метода ‘SMRLE1_X1_First’ указывает на то, что первый символ во входных данных (D1) является немодовым символом, а указатель выбора метода ‘SMRLE1_X1_Last’ указывает на то, что последний символ во входных данных (D1) является немодовым символом. Аналогично, указатель выбора метода ‘SMRLE1_X1_FirstAndLast’ указывает на то, что и первый, и последний символы во входных данных (D1) являются немодовыми.
В отношении упомянутой выше дополнительной информации, передача вероятностных таблиц и указателей была описана подробно в выданном патенте Великобритании GB 2523348.
Опционально, в случаях, когда применяют несколько модовых символов, дополнительная информация, относящаяся к передаче модовых символов и количеству различных модовых символов, указывает, сколько рекурсивных модовых символов было использовано. Опционально, в случаях, когда применяют несколько модовых символов, информация, указывающая по меньшей мере на один модовый символ, включает, например, только первый модовый символ, тогда как упомянутая дополнительная информация включает информацию об остальных модовых символах.
Опционально, количество немодовых символов также сообщают при помощи упомянутого указателя.
В соответствии с одним из вариантов осуществления настоящего изобретения, кодер выполнен с возможностью динамического выбора, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)-(d), в зависимости от одного или более свойств входных данных (D1), за счет чего получают повышенную степень сжатия кодированных данных (Е2).
В этой связи, опционально, динамически выбирают наиболее эффективный алгоритм кодирования, поскольку характер содержимого кодируемых входных данных (D1) может меняться; под «характером» в данном случае понимается структура входных данных (D1), например, спектр распределений значений во входных данных (D1), локализованные концентрации конкретных числовых значений во входных данных (D1), паттерны повторения данных во входных данных (D1), однако без ограничения перечисленным. Как отмечалось, примеры входных данных (D1) включают, без ограничения перечисленным, двоичные данные, текстовые данные, аудиоданные, данные изображений, видеоданные, данные измерений, данные датчиков, биометрические данные, биологические генетические данные, данные генома, данные коэффициентов преобразований, преобразованные данные, обработанные данные или частичные данные. Опционально, выбор наиболее эффективного алгоритма кодирования выполняют при помощи следующего:
(i) сжатие входных данных (D1) с использованием различных алгоритмов кодирования;
(ii) вычисление энтропии сжатых данных, полученных с использованием каждого из упомянутых различных алгоритмов кодирования;
(iii) вычисление, или оценка, для каждого из различных алгоритмов кодирования, объема данных, необходимого для передачи упомянутой выше дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных; и
(iv) сравнение различных алгоритмов кодирования в отношении энтропии сжатых данных и/или объема данных, необходимого для передачи дополнительной информации. Шаги (i) и (ii) могут быть заменены также энтропийным кодированием различных типов данных уже до выбора метода. Такой подход требует большего количества вычислительных ресурсов, однако с другой стороны обеспечивает более эффективный выбор, поскольку основан на фактическом объеме данных.
В качестве примере, некоторые фрагменты входных данных (D1) могут сжиматься при помощи непосредственного диапазонного кодирования этих фрагментов входных данных (D1), если передача таблицы диапазонов может быть выполнена эффективно. Соответственно, кодированные данные (Е2) могут быть также сжаты энтропийно при помощи различных методов энтропийного кодирования (а именно, взаимно отличающихся друг от друга методов энтропийного кодирования), поскольку процедура выбора алгоритма кодирования учитывает также дополнительные преимущества, привносимые для различных значений данных за счет энтропийного сжатия на шагах (ii) и (iii). Это применимо как к значениям, кодированным в одном или более потоках, так и к еще не кодированным значениям.
В соответствии с одним из вариантов осуществления настоящего изобретения, кодер выполнен с возможностью использования дополнительных методов кодирования для кодирования одного или более фрагментов входных данных (D1), при этом такие дополнительные методы кодирования включают по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. В настоящем документе под «дельта кодированием» подразумевается метод хранения или передачи данных в форме разностей между последовательными значениями данных, вместо файлов целиком, тогда как под термином «О-дельта-кодирование» понимается разностный тип кодирования, основанный на циклическом обращении в двоичной системе счета, например, соответствующий описанию в патентном документе GB 1412937.3. Может применяться RLE-, SRLE- и ZRLE-кодирование, например, в соответствии с описанием по ссылкам [1], [2] и [3] в библиографическом указателе соответственно. Нужно отметить, что методы MRLE- и SMRLE-кодирования перечислены из-за поддержки рекурсии. Зачастую наиболее эффективно выполнять рекурсию таким образом, чтобы последовательности данных, являющиеся либо первыми значениями, либо вторыми значениями, подавались в качестве входных данных в точности в такую же систему кодирования в составе блока энтропийного кодирования. Блок энтропийного кодирования затем рекурсивно выбирает методы MRLE/SMRLE-кодирования, или в противном случае выбирает, например, диапазонное кодирование. Кодирование при помощи континуумного оператора может выполняться, например, в соответствии с описанием по ссылке [4] в библиографическом указателе. Нужно понимать, что серии по меньшей мере из одного модового символа в некоторых случаях могут быть очень многочисленными, и соответственно, для представления такого большого числа могут применяться управляющие (escape) значения, например, с применением континуумного оператора или другого решения на основе управляющих значений. Применение управляющих значений дает возможность использовать несколько символов для сигнализации одного большого значения данных, без необходимости иметь нерационально широкий диапазон значений для представления значений данных. Может применяться модификация энтропии, например, в соответствии с описанием по ссылке [5] в библиографическом указателе. В настоящем документе под копирующим кодированием (типа Сору) может пониматься либо прямое копирование, либо так называемое ‘true bits’ (истинное побитовое) копирование. Другими словами, например, если данные исходно имеют 8-битные значения, но диапазон значений данных может быть представлен 5 битами, то сигнализацию символов выполняют методом «истинно-битового» копирования в форме 5-битных символов вместо 8-битных символов. Следует понимать, что метод TrueBitsCopy позволяет сигнализировать значения данных с использованием минимально возможного диапазона значения таким образом, что встречающиеся пьедестальные значения могут пропускаться и сигнализироваться, и могут также сигнализироваться значения Maxlndex и необходимая битовая глубина. Может применяться также метод LUTCopy, при котором сначала значения, встречающиеся в данных, сигнализируют в виде таблицы поиска, и затем требуемые данные кодируют с использованием индексов в таблице LUT. ‘TrueBitsCopy’ является зарегистрированной торговой маркой.
В качестве примера, указатель выбора метода, ‘ODeltaSMRLE1_X1Coded’ указывает на то, что входные данные (D1) были сначала О-дельта-кодированы, и затем кодированы с использованием одного или более способов кодирования согласно вариантам осуществления настоящего изобретения; в данном примере SMRLE-кодирование с одним передаваемым модовым символом задействуют для формирования модового символа, а также первого и второго потоков данных, и затем первый и второй потоки данных кодируют с использованием одного или более заранее заданных (или выбранных с передачей информацией о выборе) методов энтропийного кодирования, таких как: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Кодированные данные (Е2), сформированные таким образом, декодируют по меньшей мере в одном декодере, выполняя шаги обработки в порядке, обратном порядку, применяемому при кодировании входных данных (D1) с целью формирования кодированных данных (Е2); при этом обратный порядок применяют, когда в упомянутом по меньшей одном декодере не требуется преобразование из одного кода в другой.
Также, опционально, описанный выше кодер может применяться совместно с другими известными кодерами; например, в связке с блочным кодером, описанным по ссылке [6] в библиографическом указателе.
Далее, исключительно для иллюстрации, будут рассмотрены несколько примеров того, каким образом может быть реализован описанный выше кодер, согласно вариантам осуществления настоящего изобретения. Рассмотрим фрагмент входного потока данных (D1), включающий 38 символов (алфавитно-цифровых знаков), представленных следующим образом:
FHFFFJFFFFHFFFFHFHFFFIFFFFFFHFHIFFFFHF
В данном фрагменте потока входных данных (D1) присутствуют следующее количество различных символов: F (28), Н (7), I (2), 3(1)
Поскольку численность символов ‘F’ превышает численность других символов, символ ‘F’ выбирают в качестве модового символа в потоке входных данных (D1). Нужно понимать, что под «численностью» здесь фактически понимают значения в вероятностной таблице. Поскольку в данном примере имеется лишь несколько различных символов, то в потенциале более эффективной может быть передача индексной таблицы для этих символов и их вероятностей, или, скорее, частот их появления (а именно, «численность»), чем передача всей вероятностной таблицы. В данном примере большинство из других возможных различных символов имеют нулевую частоту появления. Таким образом, индексы символов ‘F’, ‘Н’, ‘I’ и ‘J’ передают, например, друг за другом, а именно в виде индексной таблицы. В качестве примера, символы ‘F’, ‘Н’, ‘I’ и ‘J’ могут при кодировании могут соответствовать индексам ‘0’, ‘1’, ‘2’ и ‘3’ соответственно, вслед за которыми передают их вероятности, ‘28’, ‘7’, ‘2’ и ‘1’, а именно, вероятностную таблицу.
В данном примере, если символы во входных данных (D1) являются алфавитно-цифровыми знаками, а не целыми числами, индекс для ‘F’, опционально вычисляют, например, следующим образом: Индекс (F)=ASCII-код (F) - ASCII-код (А), а именно, 70-65=5. Нужно также понимать, что поскольку входные данные (D1) кодируют с использованием описанного выше метода MRLE/SMRLE-кодирования, возможны варианты, когда выбирают, передаются ли используемые модовые символы в виде отдельных значений, или они получаются непосредственно из переданных вероятностных таблиц и индексных таблиц. Если используемые модовые символы передают в виде отдельных значений, то, опционально, их передают уже не в связи с переданными таблицами. Если используемые модовые символы получают непосредственно из переданных вероятностных таблиц и индексных таблиц, то требований о необходимости отдельной передачи используемых модовых символов не ставится.
В соответствии с одним из вариантов осуществления настоящего изобретения, кодер выполнен с возможностью передачи модового символа, немодового потока, а именно, первого потока, который включает немодовые символы, в том виде, как они встречаются во фрагменте потока входных данных (D1), и потока серий, а именно, второго потока, который включает серии модовых символов, встречающиеся перед каждым из немодовых символов.
Следовательно, немодовый поток (а именно, первый поток) может быть представлен следующим образом:
HJHHHIHHIH,
тогда как поток серий (а именно, второй поток) может быть представлен следующим образом:
1, 3, 4, 4, 1, 3, 6, 1, 0, 4, (1)
В рассмотренном примере имеется одно появление модового символа (далее называемое последней серей модового символа) после последнего немодового символа в этом фрагменте потока входных данных (D1). Опционально, последняя серия модового символа после последнего немодового символа может быть описана при помощи передачи общего числа символов, которое в данном примере равно 38. Альтернативно, опционально, последняя серия модового символа после последнего немодового символа может быть описана добавлением значения ‘1’ в конец потока серий (см. выше в скобках).
Когда значение ‘1’ не добавляют, количество серий модового символа в потоке серий равно количеству немодовых символов в немодовом потоке, которое в рассмотренном примере составляет 10. В этом случае, поскольку общее количество символов передают вместе с кодированными данными (Е2), последняя серия модового символа после последнего немодовых символов может быть определена при последующем декодировании кодированных данных (Е2). С другой стороны, когда значение ‘1’ добавляют, количество серий модового символа в потоке серий на единицу больше количества немодовых символов в немодовом потоке. Это указывает на наличие последней серии модового символа после последнего немодового символа. Опционально, в кодере, соответствующем вариантам осуществления настоящего изобретения, может применяться континуумный оператор, например, описанный по ссылке [4] в библиографическом указателе. Если задействуют континуумный оператор, количество серий модового символа может быть увеличено, тогда как количество немодовых символов в немодовом потоке остается прежним. Исходные серии немодовых символов получают позже, после декодирования континуумным оператором в заданном декодере.
В рассмотренном выше примере передают «информацию, которая указывает на количество немодовых символов», вместо передачи «количества немодовых символов». Однако нужно понимать, что варианты осуществления настоящего изобретения охватывают оба подхода при кодировании с целью формирования кодированных данных (Е2).
В первом примере модовый символ, немодовый поток (а именно, первый поток) и поток серий (а именно, второй поток) могут передаваться как чередующиеся друг за другом блоки данных, следующим образом:
F, 10, H, J, H, H, Н, I, Н, Н, I, Н, 1, 3, 4, 4, 1, 3, 6, 1, 0, 4, 1
В приведенном выше примере первый символ ‘F’ указывает на модовый символ, а второй символ ‘10’ указывает на количество немодовых символов. Передача количества немодовых символов позволяет заданному декодеру корректно декодировать кодированные данные (Е2), используя количество немодовых символов как ограничитель счетчика в цикле декодирования, применяемого в заданном декодере. Как отмечалось, нужно понимать, что вместо передачи количества немодовых символов может применяться передача общего количества символов, и при этом заданный декодер также будет способен корректно функционировать, даже без передачи конкретного значения по количеству немодовых символов, поскольку в декодере будут приняты другие соответствующие значения, из которых может быть при необходимости получена требуемая информация, а именно, количество немодовых символов. Соответственно, информация о «численности», опционально, может быть получена не только при помощи передачи этого конкретного значения, но и другими способами.
Нужно понимать, что варианты осуществления настоящего изобретения позволяют передавать информацию о «численности» таким образом, чтобы любой заданный декодер был способен завершать декодирование в правильном месте. Опционально, не имеет значения, передают ли «численности» или комбинацию «численностей», если обеспечивается возможность корректно вычислить ограничитель счетчика для цикла декодирования, применяемого в декодере.
При этом серии модового символа передают после последнего немодового символа. Соответственно, общее количество символов передавать не нужно. Если необходимо значить общее количество символов, оно может быть вычислено, исходя из количества немодовых символов и серий модового символа, а именно, их суммированием. Нужно понимать, что если известно любое из этих чисел, то есть, общее количество символов или количество немодовых символов, то второе из них всегда может быть вычислено. Альтернативно, опционально, в качестве минимального требования, должна быть известна одна из этих двух величин, при этом для декодирования первой и второй потоки разбивают, например, при помощи чередования, таким образом, чтобы декодирование могло быть выполнено с помощью известного количества.
В первом примере из кодера в заданный декодер передают указатель выбора метода ‘SMRLE1_X1’. Указатель выбора метода ‘SMRLE1_X1’ указывает на то, что присутствует один модовый символ и этот модовый символ содержится в кодированных данных (Е2).
В рассмотренном выше первом примере из кодера в заданный кодер необходимо передать только 23 символа. Во втором примере немодовые символы и серии модового символа, встречающиеся до, после немодовых символов, и между ними, могут передаваться следующим образом:
F, 10, 1, Н, 3, 3, 4, Н, 4, Н, 1, Н, 3, 1, 6, Н, 1, Н, 0, 1, 4, Н, 1
Немодовые символы и серии модового символа чередуют проиллюстрированным выше образом, например, когда сжимать немодовый поток и поток серий по отдельности не удобно.
Кодированные данные (Е2) в том виде, как их передают во втором примере, сравнительно просто воспринять и декодировать. Как и прежде, символ ‘F’ указывает на модовый символ, а второй символ ‘10’ указывает на количество немодовых символов. При декодировании все серии модового символа (а именно, чисел) заменяют на аналогичные числа, означающие количество появлений модового символа. Следовательно, декодированные данные (D3) потом получают в следующем виде:
FHFFFJFFFFHFFFFHFHFFFIFFFFFFHFHIFFFFHF
Также, в рассмотренном выше примере, можно заметить, что немодовый поток содержит множественные повторения символа ‘Н’. В этой связи, опционально, может быть выполнена рекурсивная обработка немодового потока согласно шагам (a)-(d), в результате которой получают другой поток, имеющий следующий вид:
Н, 3, 1, J, 3,1, 2,1, 1
Здесь символ ‘Н’ означает второй модовый символ, а символ ‘3’ указывает на количество оставшихся немодовых символов. Затем, как это проиллюстрировано выше, передают оставшиеся немодовые символы и серии второго модового символа, расположенные до, после остальных немодовых символов, а также между ними.
В третьем примере кодированные данные (Е2) в целом могут быть переданы следующим образом:
Н, F, 3, 10, J, I, I, 1, 3, 2, 1, 1,3, 4, 4, 1, 3, 6, 1, 0, 4, 1
В третьем примере из кодера в заданный декодер передают указатель выбора метода ‘SMRLE1_X1_X2’. Указатель выбора метода ‘SMRLE1_X1_X2’ означает, что имеются два модовых символа (а именно, символы ‘Н’ и ‘F’, и эти символы содержатся в кодированных данных (Е2)).
В четвертом примере передано количество модовых символов может быть передано в составе кодированных данных (Е2), которые могут иметь следующий вид:
2, Н, F, 3, 10, J, I, I, 1, 3, 2, 1, 1, 3, 4, 4, 1, 3, 6, 1, 0, 4, 1
В четвертом примере из кодера в заданный декодер передают указатель выбора метода ‘SMRLEN’. Указатель выбора метода ‘SMRLEN’ указывает на то, что модовые символы и количество модовых символов содержатся в кодированных данных (Е2).
В пятом примере количество модовых символов не передают в составе кодированных данных (Е2), которые могут иметь следующий вид:
3, 10, J, I, I, 1, 3, 2, 1, 1, 3, 4, 4, 1, 3, 6, 1, 0, 4, 1
В пятом примере из кодера в заданный декодер передают указатель выбора метода ‘SMRLE2_H_F’. Указатель выбора метода ‘SMRLE2_H_F’ указывает на то, что имеются два модовых символа, а именно символы ‘Н’ и ‘F’.
Также, опционально, потоки серий для всех модовых символов могут быть скомбинированы и совместно сжаты.
В шестом примере комбинированный поток серий может иметь следующий вид:
1, 3, 2, 1, 1, 3, 4, 4, 1, 3, 6, 1, 0, 4, 1
В комбинированном потоке серий имеются следующие количества различных серийных символов:
0 (1), 1 (6), 2 (1), 3 (3), 4 (3), 6 (1)
В качестве примера, комбинированные потоки серий могут сжиматься при помощи методов диапазонного кодирования или кодирования Хаффмана.
Далее, исключительно для иллюстрации, будет рассмотрен еще один из примеров того, каким образом может быть реализован описанный выше кодер, согласно вариантам осуществления настоящего изобретения. Рассмотрим фрагмент входного потока данных, включающий 12 символов (алфавитно-цифровых знаков), представленных следующим образом:
2, 2, 3, 0, 2, 2, 2, 0, 2, 2, 1, 4
Соответственно, кодированные данные (Е2), передаваемые кодером, соответствующим вариантам осуществления настоящего изобретения, могут иметь следующий вид:
2, 5, 3,0,0, 1, 4, 2, 0, 3, 2, 0
В приведенном выше примере первый символ ‘2’ указывает на модовый символ, а второй символ ‘5 указывает на количество немодовых символов. За вторым символом ‘5’ следует немодовый поток, после которого идет поток серий. В рассмотренном примере исходный немодовый поток не может включать значение ‘2’, то есть, модовый символ ‘2’. Соответственно, опционально, все значения, превосходящие 2, уменьшают на единицу, в результате чего получают модифицированный немодовый поток. Это может выполняться как при кодировании, так и после кодирования, перед сжатием. В результате максимальное значение в немодовом потоке уменьшается от ‘4’ до ‘3’, и модифицированный немодовый поток имеет следующий вид:
2, 0, 0, 1, 3
При последующем декодировании заданный декодер восстанавливает исходный немодовый поток из модифицированного немодового потока, увеличивая все значения, большие или равные модовому значению ‘2’, на единицу. Нужно понимать, что такое восстановление может выполняться перед декодированием или в связи с декодированием. Примеры, для ясности и простоты, были приведены для случая, когда во входных данных (D1) присутствует только один модовый символ. Однако следует отметить, что во входных данных (D1) может присутствовать более одного модового символа, и варианты осуществления настоящего изобретения при наличии более одного модового символа могут быть реализованы аналогичным образом.
Во втором аспекте вариантов осуществления настоящего изобретения предложен способ кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), включающий:
(a) анализ входных данных (D1) для выявления в них по меньшей мере одного модового символа;
(b) формирование значений данных по меньшей мере первого типа и второго типа, при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных (D1);
(c) формирование информации, указывающей на количество немодовых символов, и информации, указывающей по меньшей мере на один модовый символ; и
сборку, или кодирование, информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих последовательности по меньшей мере из одного модового символа, в результате чего получают кодированные данные (Е2).
В соответствии с одним из вариантов осуществления настоящего изобретения, способ включает формирование символов во входных данных (D1) перед выполнением шагов (a)-(d) при помощи разбиения или комбинирования исходных символов, содержащихся во входных данных (D1). Опционально, в этой связи способ включает: (i) разбиение одного или более фрагментов входных данных (D1), в результате чего формируют один или более новых символов для обработки данных согласно шагам (a)-(d); и/или
(ii) комбинирование одного или более алфавитно-цифровых знаков из одного или более фрагментов входных данных (D1), в результате чего формируют новые комбинированные символы для обработки данных согласно шагам (a)-(d). Опционально, способ дополнительно включает вставку значений данных первого типа и значений данных второго типа в один или более потоков данных перед шагом (d). В соответствии с одним из вариантов осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, способ включает вставку значений данных первого типа и значений данных второго типа в разные потоки данных. Опционально, в этой связи, значения данных первого типа и значения данных второго типа вставляют в первый поток данных и второй поток данных соответственно.
В соответствии с одним из вариантов осуществления настоящего изобретения, способ допускает рекурсивное применение. Опционально, в этой связи, способ включает рекурсивную обработку первого потока данных, включающего немодовые символы, согласно шагам (a)-(d). В соответствии с другим вариантом осуществления настоящего изобретения, когда выполняют вставку в один или более потоков данных, способ включает вставку значений данных первого типа и значений данных второго типа в чередующемся формате или в планарном формате в один поток данных.
Альтернативно, опционально, когда значения данных первого типа и значения данных второго типа вставляют в первый и второй потоки данных, способ включает комбинирование первого и второго потока данных, в результате чего формируют один результирующий поток данных, в чередующемся формате или в планарном формате.
В соответствии с одним из вариантов осуществления настоящего изобретения, способ включает чередование значений данных первого и второго типов, в результате чего получают один результирующий поток данных. В соответствии с другим вариантом осуществления настоящего изобретения, способ включает чередование значений данных первого и второго типов, в виде чередующихся блоков данных, в результате чего получают один результирующий поток данных.
Также, опционально, способ включает использование по меньшей мере одного метода энтропийного кодирования для сжатия упомянутых одного или более потоков данных, совместно или по отдельности. Также, может быть выбран вариант без энтропийного кодирования одного из двух потоков, например, один из потоков может подвергаться энтропийному кодированию, а второй - нет. Опционально, в этой связи, упомянутый по меньшей мере один метод энтропийного кодирования включает по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy.
В соответствии с одним из вариантов осуществления настоящего изобретения способ включает передачу кодированных данных (Е2) по меньшей мере в один декодер. В качестве примера, кодированные данные (Е2) записывают, при помощи заданного кодера, в файл, и затем считывают из этого файла при помощи по меньшей мере одного декодера. В качестве другого примера, выполняют потоковую передачу кодированных данных (Е2) из заданного кодера по меньшей мере в один декодер.
В соответствии с одним из вариантов осуществления настоящего изобретения, способ включает сборку, или кодирование, дополнительной информации, относящейся к передаче по меньшей мере одного из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных.
Опционально, в этой связи, способ включает передачу, по меньшей мере в один декодер, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, способ включает передачу упомянутой выше дополнительной информации в качестве предваряющей информации, до передачи кодированных данных (Е2). Альтернативно, опционально, способ включает передачу дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
В соответствии с одним из вариантов осуществления настоящего изобретения, способ включает динамический выбор, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)-(d), в зависимости от одного или более свойств входных данных (D1), за счет чего получают повышенную степень сжатия кодированных данных (Е2).
В соответствии с одним из вариантов осуществления настоящего изобретения, способ включает использование дополнительных методов кодирования для кодирования одного или более фрагментов входных данных (D1), при этом такие дополнительные методы кодирования включают по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, Кодирование энтропийным модификатором (ЕМ), кодирование «континуумным оператором», кодирование TrueBitsCopy. Эти дополнительные методы кодирования более подробно были описаны выше. В третьем аспекте вариантов осуществления настоящего изобретения предложен декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), отличающийся тем, что:
(i) декодер выполнен с возможностью декодирования, из кодированных данных (Е2), информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных (D1); и
(ii) декодер выполнен с возможностью вставки, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа, в результате чего формируют декодированные данные (D3). Опционально, декодер выполнен с возможностью приема, в кодированных данных (Е2), одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
В соответствии с одним из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в разных потоках данных.
В соответствии с другим из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в чередующемся формате или в планарном формате в одном потоке данных. Опционально, декодер выполнен с возможностью использования по меньшей мере одного метода, обратного методу энтропийного кодирования, который был использован в соответствующем кодере для сжатия упомянутых одного или более потоков данных, совместно или по отдельности.
Опционально, когда в кодированных данных (Е2) использованы более одного модовых символов, декодер выполнен с возможностью рекурсивного выполнения шагов (i)-(ii) для каждого модового символа, в результате чего формируют декодированные данные (D3).
В соответствии с одним из вариантов осуществления настоящего изобретения декодер выполнен с возможностью приема дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных. Опционально, в этой связи, декодер выполнен с возможностью использования дополнительной информации для декодирования кодированных данных (Е2).
Опционально, в этой связи, декодер выполнен с возможностью приема, из соответствующего кодера, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, декодер выполнен с возможностью приема упомянутой выше дополнительной информации в качестве предваряющей информации, до приема кодированных данных (Е2). Альтернативно, опционально, декодер выполнен с возможностью приема дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Опционально, когда кодированные данные (Е2) были кодированы с использованием дополнительных методов кодирования, декодер выполнен с возможностью декодирования кодированных данных (Е2) в порядке выполнения шагов обработки, который обратен порядку шагов обработки, выполненных при кодировании исходных входных данных (D1) для формирования кодированных данных (Е2) соответствующим кодером. В этой связи, опционально, декодер выполнен с возможностью использования дополнительных методов декодирования, при этом дополнительные методы декодирования включают по меньшей мере одно из следующего: дельта-декодирование, О-дельта-декодирование, RLE-декодирование, SRLE-декодирование, MRLE-декодирование, SMRLE-декодирование, декодирование Хаффмана, VLC-декодирование, диапазонное декодирование, арифметическое декодирование, декодирование энтропийным модификатором (ЕМ), декодирование «континуумным оператором», декодирование TrueBitsCopy. Следовательно, методы декодирования являются обратными методам кодирования, применяемым в кодере; однако, если в декодере применяют преобразование кодов, то в декодере требуется применение дополнительных или альтернативных методов, то есть, данные D1 и D3 могу отличаться друг от друга, однако при этом зачастую содержать по существу одинаковый контент; например, декодер может быть реализован на мобильном устройстве беспроводной связи, и в нем может применяться перекодирование для изменения формата видеоконтента, содержащегося во входных данных (D1), и кодированного в кодированные данные (Е2), чтобы этот контент мог быть представлен подходящим образом на миниатюрном пиксельном дисплее на мобильном устройстве беспроводной связи. Эти дополнительные, или альтернативные методы, например, были более подробно описаны выше.
Также, опционально, описанный выше декодер может применяться совместно с другими известными декодерами; например, в связке с блочным декодером, описанным по ссылке [7] в библиографическом указателе.
Во четвертом аспекте вариантов осуществления настоящего изобретения предложен способ декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), включающий: (i) декодирование, из кодированных данных (Е2), информации, которая указывает по меньшей мере на один модовый символ, информации, которая указывает на количество немодовых символов, значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных (D1); и (ii) вставку, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа, в результате чего формируют декодированные данные (D3).
Опционально, способ включает прием, в кодированных данных (Е2), одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
В соответствии с одним из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в разных потоках данных. В соответствии с другим из вариантов осуществления настоящего изобретения значения данных первого типа и значения данных второго типа принимают в чередующемся формате или в планарном формате в одном потоке данных.
Опционально, способ включает использование по меньшей мере одного метода, обратного методу энтропийного кодирования, который был использован в соответствующем кодере для сжатия упомянутых одного или более потоков данных, совместно или по отдельности.
Опционально, когда в кодированных данных (Е3) использованы более одного модовых символов, способ включает рекурсивное выполнение шагов (i)-(ii) для каждого модового символа, в результате чего формируют декодированные данные (D3).
В соответствии с одним из вариантов осуществления настоящего изобретения способ включает прием дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели на выбранные методы кодирования, значения данных, максимальные индексы различных данных. Опционально, в этой связи, способ включает использование дополнительной информации для декодирования кодированных данных (Е2). Опционально, в этой связи, способ включает прием, из соответствующего кодера, указателя, который указывает по меньшей мере на одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных (Е2) или нет.
Опционально, способ включает прием упомянутой выше дополнительной информации в качестве предваряющей информации, до приема кодированных данных (Е2). Альтернативно, опционально, способ включает прием дополнительной информации вместе с кодированными данными (Е2), как части кодированных данных (Е2).
Опционально, когда кодированные данные (Е2) были кодированы с использованием дополнительных методов кодирования, способ включает декодирование кодированных данных (Е2) в порядке выполнения шагов обработки, который обратен порядку шагов обработки, выполненных при кодировании исходных входных данных (D1) для формирования кодированных данных (Е2) соответствующим кодером. В этой связи, опционально, способ включает использование дополнительных методов декодирования, при этом дополнительные методы декодирования включают по меньшей мере одно из следующего: дельта-декодирование, О-дельта-декодирование, RLE-декодирование, SRLE-декодирование, MRLE-декодирование, SMRLE-декодирование, декодирование Хаффмана, VLC-декодирование, диапазонное декодирование, арифметическое декодирование, декодирование энтропийным модификатором (ЕМ), декодирование «континуумным оператором», декодирование TrueBitsCopy. Такие дополнительные методы декодирования описаны в упомянутых выше документах, а также в документах из приведенного ниже библиографического указателя, (также, упомянутые методы описаны в таких базах данных, как Википедия (доступна в сети Интернет, действующей на базе протокола TCP/IP), а также в различных опубликованных патентных документах, в качестве заявителя которых выступила компания Gurulogic Microsystems Оу, и которые имеют «Ossi Kalevo» в качестве имени изобретателя).
В пятом аспекте вариантов осуществления настоящего изобретения предложен кодек, включающий по меньшей мере кодер для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) в соответствии с описанным выше первым аспектом настоящего изобретения, и по меньшей мере один декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3) в соответствии с описанным выше третьим аспектом настоящего изобретения. Рассмотрим один из примеров кодека, который показан на фиг.1 и который будет более подробно описан ниже. Кодек включает по меньшей мере один кодер 110 для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) и по меньшей мере один декодер 120 для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3). Кодер 110 включает MRLE/SMRLE-кодер 111, который используют для кодирования входных данных (D1) согласно вариантам осуществления настоящего изобретения. Кодер 110, опционально, включает энтропийный кодер 112, который применяют для энтропийного кодирования кодированных данных (Е2), в результате чего получают энтропийно-сжатые кодированные данные (Е3). Декодер 120 включает MRLE/SMRLE-декодер 121, который применяют для декодирования кодированных данных (Е2). Декодер 120, опционально, включает энтропийный декодер 122 для энтропийной распаковки энтропийно-сжатых кодированных данных (Е3), в результате чего получают кодированные данные (Е2). По меньшей мере один кодер 110 и по меньшей мере один декодер 120 вместе образуют кодек 130.
Входные данные (D1), или их часть, могут быть кодированы при помощи MRLE/SMRLE-кодера 111 или при помощи иного метода кодирования. Кодированные данные (Е2), опционально, могут быть энтропийно сжаты при помощи энтропийного кодера 112 или при помощи другого энтропийного компрессора. Кодированные данные (Е2) могут быть декодированы при помощи MRLE/SMRLE-декодера 121, если они были кодированы при помощи MRLE/SMRLE-кодера 111, или при помощи метода, являющегося обратным использованному методу кодирования. Если кодированные данные (Е2) были, опционально, энтропийно-сжаты, в форме энтропийно-сжатых кодированных данных (Е3), то перед декодированием их энтропийно распаковывают, получая снова кодированные данные (Е2), применяя метод, обратный использованному в энтропийном кодере 112 методу энтропийного кодирования. Когда применяют опциональное энтропийное кодирование для одного или более фрагментов данных или для значений в одном или более фрагментов данных, информация об использованном методе и все данные, необходимые в этом методе для корректного декодирования, должны быть введены в состав кодированных данных.
Опционально, декодированные данные (D3) идентичны входным данным (D1), в случае режима кодирования без потерь. Альтернативно и опционально, декодированные данные (D3) приблизительно аналогичны входным данным (D1), в случае кодирования с потерями. Также, альтернативно и опционально, декодированные данные (D3) могут отличаться от входных данных (D1), например, вследствие преобразования, однако содержат по существу ту же информацию, которая присутствовала во входных данных (D1); например, из практических соображений, декодированные данные (D3) могут отличаться от входных данных (D1), если требуется переформатирование декодированных данных (D3), например, в целях совместимости с различными типами платформ связи, уровнями программного обеспечения, устройствами связи и т.п. Упомянутый по меньшей мере один кодер содержит систему обработки данных для обработки входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) согласно вариантам осуществления настоящего изобретения. Опционально, упомянутую схему обработки данных в кодере реализуют с применением по меньшей мере одного процессора на архитектуре с ограниченным набором команд (Reduced Instruction Set Computing, RISC), который выполнен с возможностью исполнения программных инструкций, в соответствии предшествующим описанием.
Также, опционально, по меньшей мере один кодер 110 выполнен с возможностью передачи кодированных данных (Е2) в сервер и/или хранилище с целью сохранения в базе данных. Сервер и/или хранилище 108 данных, для возможности последующего декодирования кодированных данных (Е2), сконфигурированы так, чтобы быть доступными по меньшей мере для одного декодера 120, либо через сеть связи, или по прямому соединению, которые, предпочтительно, совместимыми по меньшей мере с одним кодером 110.
В некоторых из примеров по меньшей мере один декодер 120, опционально, выполнен с возможностью доступа к кодированным и шифрованным данным (Е2), находящимся на сервере и/или в хранилище. В альтернативных примерах по меньшей мере один кодер 110, опционально, выполнен с возможностью потоковой передачи кодированных данных (Е2) по меньшей мере в один декодер 112, либо при помощи сети связи, либо по прямому соединению. При этом, следует отметить, что устройство, оснащенное аппаратным или программным кодером, может также осуществлять связь напрямую с другим устройством, также оснащенным аппаратным или программным кодером. В еще одном из альтернативных примеров по меньшей мере один кодер 120, опционально, реализуют таким образом, чтобы он извлекал кодированные данные (Е2) с энергонезависимого машиночитаемого носителя, например, с жесткого диска или с твердотельного диска (Solid-State Drive, SSD). Упомянутый по меньшей мере один декодер 120 содержит систему обработки данных для обработки кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3) согласно вариантам осуществления настоящего изобретения. Опционально, упомянутую схему обработки данных в декодере 120 реализуют с применением по меньшей мере одного процессора на архитектуре с ограниченным набором команд (RISC), который выполнен с возможности исполнения программных инструкций, в соответствии с предшествующим описанием; при этом RISC-процессор способен выполнять сравнительно простые операции конкатенации данных с очень высокой скоростью, и хорошо подходит для кодирования и декодирования данных, поступающих в потоковом формате, например, в реальном времени.
Если при реализации вариантов осуществления настоящего изобретения применяют методы многоадресной передачи, могут быть использованы несколько подобных декодеров.
Опционально, кодек 130 реализуют внутри одного устройства. Альтернативно и опционально, кодек 130, из практических соображений, реализуют с распределением по различным устройствам. Опционально, кодек 130 может быть реализован в качестве цифрового аппаратного обеспечения, разработанного по заказу, например, при помощи одной или более заказных интегральных схем (application-specific integrated circuits, ASIC). Альтернативно, или в дополнение, опционально, кодек 130 реализуют при помощи вычислительного оборудования, которое выполнено с возможностью исполнения программных инструкций, например, подаваемых в вычислительное оборудование на энергонезависимом машиночитаемом информационном носителе.
В качестве примера, по меньшей мере кодер 110 и/или по меньшей мере один декодер 120 допускают эффективное применение в потребительской электронной аппаратуре, аппаратуре беспроводной связи и ассоциированных с ней системах, цифровых камерах, смартфонах, планшетных компьютерах, персональных компьютерах, научно-измерительной аппаратуре, оборудовании связи, оборудовании для видеоконференцсвязи, спутниковом оборудовании, без ограничения перечисленным. В шестом аспекте вариантов осуществления настоящего изобретения предложен компьютерный программный продукт, включающий машиночитаемый носитель, на котором хранят машиночитаемые инструкции, при этом машиночитаемые инструкции могут быть исполнены на компьютеризованном устройстве, включающем процессорную аппаратуру для исполнения любых из описанных выше способов согласно второму или четвертым аспектам настоящего изобретения.
Опционально, машиночитаемые инструкции могут быть загружены в компьютеризованное устройство из магазина программных приложений, например, "Арр store". Далее варианты осуществления настоящего изобретения будут описаны со ссылками на чертежи.
В соответствии с иллюстрацией фиг.1, варианты осуществления настоящего изобретения относятся:
(i) к кодеру 110 для кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2) и к соответствующим, описанным выше, способам кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2);
(ii) к декодеру 120 и декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), а также к соответствующим способам декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3); и
(iii) к кодеку 130, включающему комбинацию по меньшей мере из одного кодера и по меньшей мере одного декодера, например, комбинацию из кодера 110 и декодера 120.
Кодер 110 включает MRLE/SMRLE-кодер 111, а декодер 120 включает MRLE/SMRLE-декодер 121. Опционально, кодер 110 включает энтропийный кодер 112 для понижения энтропии кодированных данных (Е2), в результате чего получают энтропийно-сжатые кодированные данные (Е3), а декодер 120 включает энтропийный декодер 122 для распаковки энтропийно-сжатых кодированных данных (Е3) обратно в форму кодированных данных (Е2).
На фиг. 1 показан лишь один из примеров, который никоим образом не ограничивает объем настоящего изобретения, заданный в приложенной формуле изобретения. Нужно понимать, что конкретная структура кодека 130 приведена исключительно в качестве примера и не должна рассматриваться как ограничивающая кодек 130 конкретным количеством, типами или схемой размещения кодеров и декодеров. Специалистам в данной области техники могут быть очевидны множество вариаций, альтернатив и изменений в вариантах осуществления настоящего изобретения. Обратимся к фиг. 2, представляющей собой собой эскизную блок-схему алгоритма, которая иллюстрирует шаги способа кодирования входных данных (D1) с целью формирования соответствующих кодированных данных (Е2), в соответствии с одним из вариантов осуществления настоящего изобретения. Способ проиллюстрирован в виде набора шагов на блок-схеме алгоритма, последовательность шагов которого может быть реализована в виде аппаратного обеспечения, программного обеспечения или их комбинации, например, в соответствии с предшествующим описанием.
На шаге 202 анализируют входные данные (D1) для выявления в них по меньшей мере одного модового символа.
На шаге 204 формируют значения данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа. Серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов, а также между ними, во входных данных (D1).
На шаге 206 формируют информацию, указывающую на количество немодовых символов, и информацию, указывающую по меньшей мере на один модовый символ.
На шаге 208 информацию, которая указывает по меньшей мере на один модовый символ, сформированную на шаге 206, информацию, которая указывает на количество немодовых символов, сформированную на шаге 206, и значения данных первого и второго типов, сформированную на шаге 204, кодируют, в результате чего получают кодированные данные (Е2).
Шаги 202-208 являются исключительно примерами, и соответственно, в пределах объема настоящего изобретения могут быть предложены также различные альтернативы, в которых добавлены один или более шагов, один или более шагов опущены, или один или более шагов выполняют в другой последовательности. Обратимся к фиг. 3, представляющей собой эскизную блок-схему алгоритма, которая иллюстрирует шаги способа декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), в соответствии с одним из вариантов осуществления настоящего изобретения. Способ проиллюстрирован в виде набора шагов на блок-схеме алгоритма, последовательность шагов которого может быть реализована в виде аппаратного обеспечения, программного обеспечения или их комбинации, например, в соответствии с предшествующим описанием.
На шаге 302 из кодированных данных (Е2) декодируют информацию, которая указывает по меньшей мере на один модовый символ, информацию, которая указывает на количество немодовых символов, значения данных первого типа, включающие немодовые символы, а также значения данных второго типа, включающие серии по меньшей мере из одного модового символа.
На шаге 304 соответствующие серии по меньшей мере из одного модового символа вставляют до или после немодовых символов, в результате чего формируют декодированные данные (D3). Шаги 302-304 являются исключительно примерами, и соответственно, в пределах объема настоящего изобретения могут быть предложены также различные альтернативы, в которых добавлены один или более шагов, один или более шагов опущены, или один или более шагов выполняют в другой последовательности.
В пределах сущности и объема, заданных приложенной формулой изобретения, возможны модификации вариантов осуществления настоящего изобретения, приведенных в предшествующем описании. Такие выражения, как «включающий», «содержащий», «охватывающий», «состоящий из», «имеющий», «представляющий собой», которые использованы в описании и в формуле настоящего изобретения, должны пониматься как неисключающие, то есть, как допускающие также присутствие объектов, компонентов или элементов, явно не упомянутых. Использование единственного числа может также пониматься как относящееся ко множественному числу. Числовые обозначения на приложенных чертежах, приведенные в скобках, имеют целью упрощение понимания пунктов формулы изобретения и не должны пониматься как сколь-либо ограничивающие сущность изобретения, заданного этими пунктами формулы изобретения.
Библиографический указатель
[1] Run-length encoding - Википедия, свободная энциклопедия (по состоянию на 25 марта 2015 года); URL: http://en.wikipedia.org/wiki/Run-length encoding
[2] Кодер данных, декодер данных и соответствующий способ (по состоянию на 25 марта 2015 года); URL: http://quruloqic.com/files/US8823560B1.pdf
[3] Предложение по новой стратегии zlib: Z_RLE (по состоянию на 25 марта 2015 года); URL: http://optipnq.sourceforge.net/pngtech/z rle.html
[4] Устройство кодирования, устройство декодирования и соответствующий способ (по состоянию на 25 марта 2015 года); URL: http://quruloqic.com/files/US8933826B2.pdf
[5] Энтропийный модификатор и соответствующий способ (по состоянию на 25 марта 2015 года); URL: http://quruloqic.com/files/US8754791B1.pdf
[6] Кодер и соответствующий способ (по состоянию на 25 марта 2015 года); URL: http://quruloqic.com/files/US8675731B2.pdf
[7] Декодер и соответствующий способ (по состоянию на 25 марта 2015 года); URL: http://quruloqic.com/files/US2014044191A1.pdf
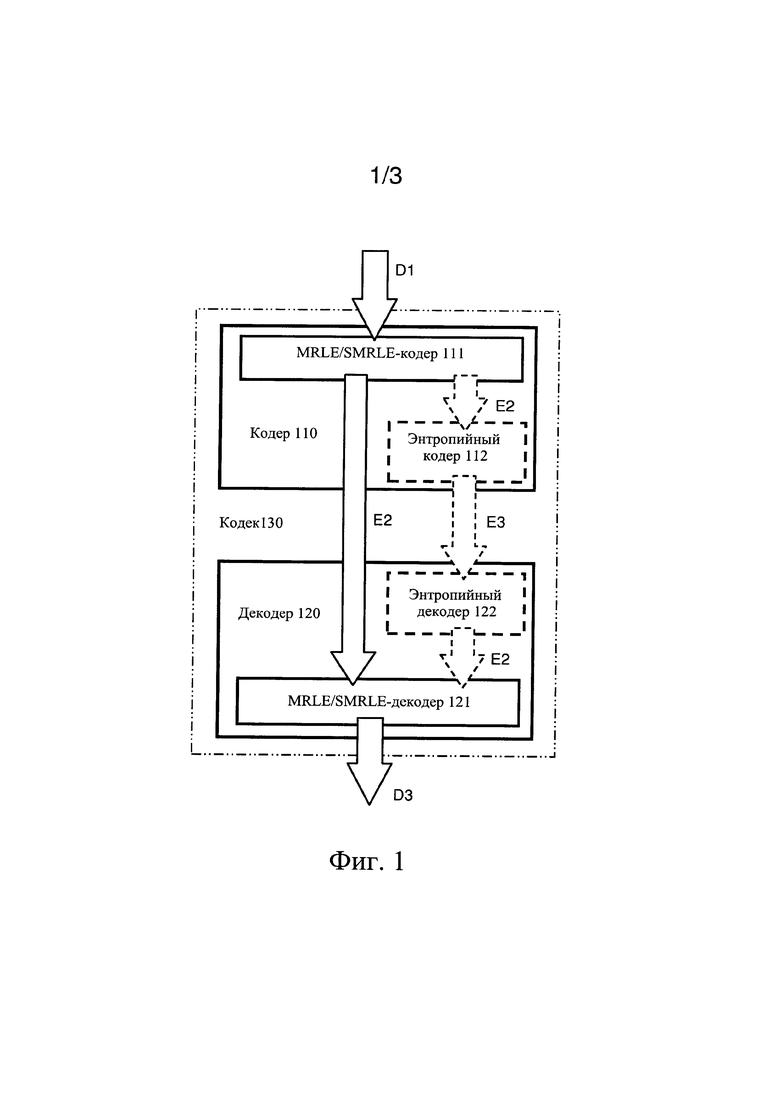
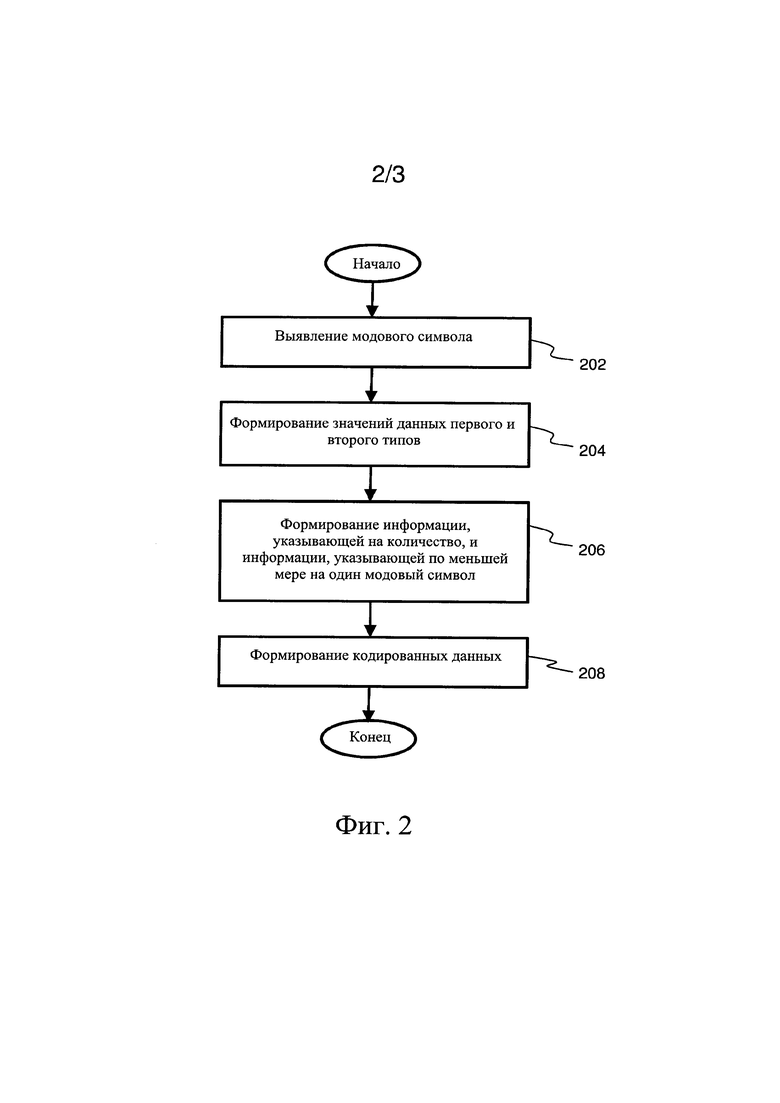
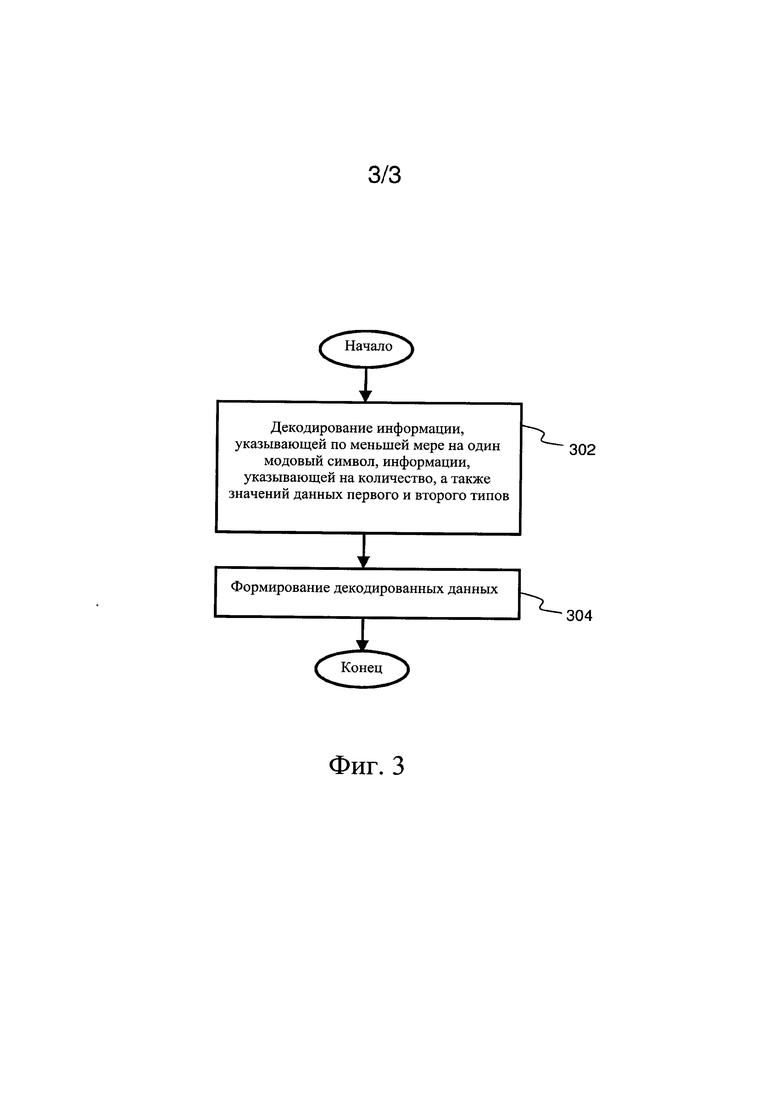
Изобретение относится к кодированию и декодированию данных. Технический результат – повышение эффективности кодирования и декодирования. Кодер выполнен с возможностью анализа входных данных (D1) с целью выявления в них по меньшей мере одного модового символа. Кодер выполнен с возможностью формирования значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающие последовательности по меньшей мере из одного модового символа. Также кодер выполнен с возможностью формирования информации, указывающей на количество немодовых символов, и информации, указывающей по меньшей мере один модовый символ. Также кодер выполнен с возможностью сборки или кодирования информации, которая указывает по меньшей мере на один модовый символ, и информации, которая указывает на количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих последовательности по меньшей мере из одного модового символа, в результате чего получают кодированные данные (Е2). 6 н. и 20 з.п. ф-лы, 3 ил.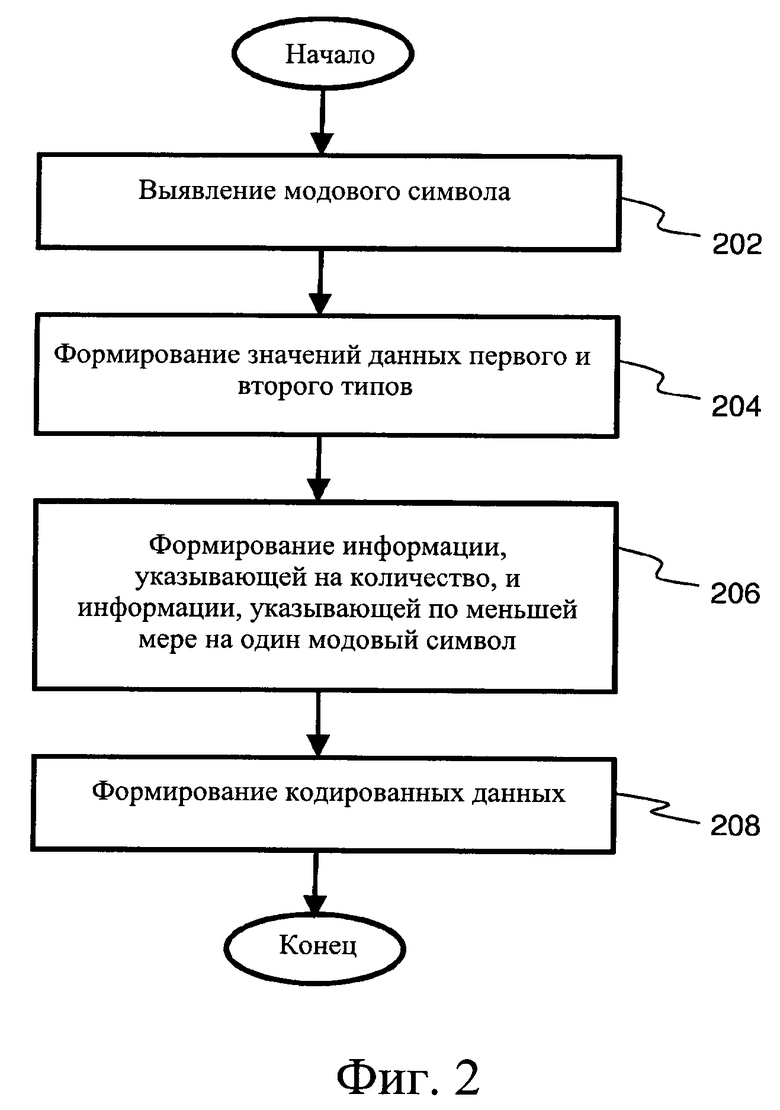
1. Кодер для кодирования входных данных для формирования соответствующих кодированных данных, отличающийся тем, что
кодер конфигурирован для:
(а) анализа входных данных для выявления в них по меньшей мере одного модового символа;
(b) формирования значений данных по меньшей мере первого типа и второго типа из входных данных, при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, где упомянутый по меньшей мере один модовый символ - это символ, который наиболее часто встречается во входных данных, а немодовые символы - это остальные символы, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных;
(с) формирования информации, указывающей количество немодовых символов во входных данных, и информации, указывающей по меньшей мере один модовый символ; и
(d) сборки или кодирования информации, которая указывает по меньшей мере один модовый символ, информации, которая указывает количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих серии по меньшей мере из одного модового символа, для получения кодированных данных.
2. Кодер по п. 1, отличающийся тем, что кодер конфигурирован для вставки значений данных первого типа и значений данных второго типа в один или более потоков данных перед шагом (d).
3. Кодер по п. 2, отличающийся тем, что когда он выполняет вставку в один или более потоков данных, кодер конфигурирован выполнять вставку значений данных первого типа и значений данных второго типа в разные потоки данных.
4. Кодер по п. 2, отличающийся тем, что кодер конфигурирован для рекурсивной обработки заданного потока данных, включающего немодовые символы, согласно шагам (a)−(d).
5. Кодер по п. 2, отличающийся тем, что когда он выполняет вставку в один или более потоков данных, кодер конфигурирован выполнять вставку значений данных первого типа и значений данных второго типа в чередующемся формате или в планарном формате в один поток данных.
6. Кодер по п. 2, отличающийся тем, что кодер конфигурирован для использования по меньшей мере одного метода энтропийного кодирования для сжатия упомянутых одного или более потоков данных, совместно или по отдельности.
7. Кодер по п. 6, отличающийся тем, что упомянутый по меньшей мере один метод энтропийного кодирования включает по меньшей мере одно из следующего: дельта-кодирование, О-дельта-кодирование, RLE-кодирование, SRLE-кодирование, ZRLE-кодирование, MRLE-кодирование, SMRLE-кодирование, кодирование Хаффмана, VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование EM, кодирование континуумным оператором, кодирование TrueBitsCopy.
8. Кодер по п. 1, отличающийся тем, что кодер конфигурирован для сборки или кодирования дополнительной информации, относящейся к передаче по меньшей мере одного из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели выбранных методов кодирования, значения данных, максимальные индексы различных данных.
9. Кодер по п. 8, отличающийся тем, что кодер конфигурирован для передачи по меньшей мере в один декодер указателя, который указывает по меньшей мере одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных или нет.
10. Кодер по п. 8, отличающийся тем, что кодер конфигурирован для передачи упомянутой дополнительной информации в качестве предваряющей информации до передачи кодированных данных.
11. Кодер по п. 8, отличающийся тем, что кодер конфигурирован для передачи дополнительной информации вместе с кодированными данными как части кодированных данных.
12. Кодер по п. 1, отличающийся тем, что кодер конфигурирован для динамического выбора, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)−(d), в зависимости от одного или более свойств входных данных, для получения повышенной степени сжатия кодированных данных.
13. Способ кодирования входных данных в кодере для формирования соответствующих кодированных данных, включающий:
(а) анализ кодером входных данных для выявления в них по меньшей мере одного модового символа;
(b) формирование кодером значений данных по меньшей мере первого типа и второго типа из входных данных, при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, где упомянутый по меньшей мере один модовый символ - это символ, который наиболее часто встречается во входных данных, а немодовые символы - это остальные символы, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных;
(с) формирование кодером информации, указывающей количество немодовых символов во входных данных, и информации, указывающей по меньшей мере один модовый символ; и
(d) сборку или кодирование кодером информации, которая указывает по меньшей мере один модовый символ, информации, которая указывает количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих серии по меньшей мере из одного модового символа, для получения кодированных данных.
14. Способ по п. 13, включающий вставку кодером значений данных первого типа и значений данных второго типа в один или более потоков данных перед шагом (d).
15. Способ по п. 14, включающий рекурсивную обработку кодером заданного потока данных, включающего немодовые символы, согласно шагам (a)−(d).
16. Способ по п. 13, включающий динамический выбор кодером, из множества алгоритмов кодирования, алгоритма кодирования, используемого на шагах (a)−(d), в зависимости от одного или более свойств входных данных, для получения повышенной степени сжатия кодированных данных.
17. Декодер для декодирования кодированных данных для формирования соответствующих декодированных данных, отличающийся тем, что:
(i) декодер конфигурирован для декодирования, из кодированных данных, информации, которая указывает по меньшей мере один модовый символ, информации, которая указывает количество немодовых символов, и значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных; и
(ii) декодер конфигурирован для вставки, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа для формирования декодированных данных.
18. Декодер по п. 17, отличающийся тем, что декодер конфигурирован для приема, в кодированных данных, одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
19. Декодер по п. 17, отличающийся тем, что декодер конфигурирован для рекурсивного выполнения шагов (i)−(ii) для каждого модового символа, для формирования декодированных данных, когда в кодированных данных использованы более одного модовых символов.
20. Декодер по п. 17, отличающийся тем, что декодер конфигурирован для приема дополнительной информации, относящейся по меньшей мере к одному из следующего: вероятностные и индексные таблицы, модовые символы, количество модовых символов, указатели выбранных методов кодирования, значения данных, максимальные индексы различных данных.
21. Декодер по п. 20, отличающийся тем, что декодер конфигурирован для приема, от соответствующего кодера, указателя, который указывает по меньшей мере одно из следующего: выбранный способ кодирования, по меньшей мере один модовый символ, количество модовых символов, содержится ли по меньшей мере один модовый символ в кодированных данных или нет.
22. Способ декодирования кодированных данных для формирования соответствующих декодированных выходных данных, включающий:
(i) декодирование декодером, из кодированных данных, информации, которая указывает по меньшей мере один модовый символ, информации, которая указывает количество немодовых символов, и значений данных по меньшей мере первого типа и второго типа, при этом значения данных первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов в исходных входных данных; и
(ii) вставку декодером, до или после немодовых символов, соответствующих серий по меньшей мере из одного модового символа для формирования декодированных данных.
23. Способ по п. 22, отличающийся тем, что способ включает прием декодером, в кодированных данных, одного или более потоков данных, включающих значения данных первого типа и значения данных второго типа.
24. Способ по п. 22, отличающийся тем, что способ включает рекурсивное выполнение декодером шагов (i)−(ii) для каждого модового символа для формирования декодированных данных, когда в кодированных данных использованы более одного модовых символов.
25. Кодек, включающий по меньшей мере один кодер по п. 1 для кодирования входных данных для формирования соответствующих кодированных данных и по меньшей мере один декодер для декодирования кодированных данных для формирования соответствующих декодированных данных.
26. Машиночитаемый носитель, имеющий хранимые на нем машиночитаемые инструкции, которые могут быть исполнены при помощи компьютеризованного устройства, включающего процессорное аппаратное обеспечение, для выполнения способа, содержащего:
(а) анализ входных данных для выявления в них по меньшей мере одного модового символа;
(b) формирование значений данных по меньшей мере первого типа и второго типа из входных данных, при этом значения первого типа включают немодовые символы, а значения данных второго типа включают серии по меньшей мере из одного модового символа, где упомянутый по меньшей мере один модовый символ - это символ, который наиболее часто встречается во входных данных, а немодовые символы - это остальные символы, при этом серии по меньшей мере из одного модового символа указывают на присутствие упомянутого по меньшей мере одного модового символа до или после немодовых символов во входных данных;
(с) формирование информации, указывающей количество немодовых символов во входных данных, и информации, указывающей по меньшей мере один модовый символ; и
(d) сборку или кодирование информации, которая указывает по меньшей мере один модовый символ, информации, которая указывает количество немодовых символов, значений данных первого типа, включающих немодовые символы, и значений данных второго типа, включающих серии по меньшей мере из одного модового символа, для получения кодированных данных.
| US 8907823 B2, 09.12.2014 | |||
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 1995 |
|
RU2117388C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КОДИРОВАНИЯ ЗНАЧИМЫХ КОЭФФИЦИЕНТОВ ПРИ ВИДЕОСЖАТИИ | 2007 |
|
RU2406256C2 |
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |

