Область техники
Настоящее изобретение относится к способам кодирования данных (D1) с целью формирования соответствующих кодированных данных (Е2), при этом в упомянутых способах, с целью обеспечения более эффективного сжатия данных и/или повышенной точности кодирования, применяют интерполяцию значений данных. Также настоящее изобретение относится к способам декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), причем в способах декодирования декодированные данные (D3) формируют на основе параметров интерполяции, закодированных внутри кодированных данных (Е2). Также настоящее изобретение относится к кодерам, декодерам и кодекам, выполненным с возможностью применения упомянутых выше способов. Также, дополнительно, настоящее изобретение относится к программным продуктам, записанным на машиночитаемом носителе для хранения данных, при этом упомянутые программные продукты могут исполняться на вычислительной аппаратуре с целью реализации упомянутых выше способов.
Предпосылки создания изобретения
С течением времени объемы данных, передаваемых по современным сетям обмена данными, таким как Интернет и беспроводные телефонные сети, неуклонно растут. В качестве примеров можно упомянуть технологии трехмерного видео и HD-видео, которые в последнее время получают все большее распространение. Существующие способы кодирования изображений и видеокодирования, например, такие как JPEG, JPEG2000, WebP, Н.264, WebM и VC-1, перечисленные в таблице 1, эффективны при сжатии контента естественных изображений, но не столь хорошо подходят для сжатия информационного контента других типов, например, для сжатия изображений рабочего стола, анимации, графической информации а также контента естественных изображений, содержащего локальные или глобальные вариации в значениях данных.


Способы кодирования GIF и PNG, дополнительная информация по которым может быть найдена в приведенной выше таблице 1, также способны обеспечить эффективное кодирование некоторых типов данных, но не столь применимы, если заданное кодируемое изображение содержит множество различных типов контента или в значительный степени однообразный контент; при этом данные способы кодирования слабоэффективны или дают большое количество ошибок при восстановлении данных в ходе последующего декодирования в декодере. В особенности, если заданное изображение содержит в том числе какие-либо естественные объекты, формат обмена графической информацией (GIF), из-за несовершенства метода кодирования, порождает заметные артефакты, а в способе, применяемом для кодирования данных портативной сетевой графики (PNG), задействуется огромное количество битов для кодирования «шума», например, частей заданного изображения со случайной пространственной текстурой. Способы, основанные на одиночных преобразованиях, таких как дискретное косинусное преобразование или вейвлет-преобразование, недостаточно хорошо подходят для структурированного контента.
Кодирование длин серий (Run Length Encoding, RLE) позволяет эффективно кодировать множество сходных значений данных, являющихся смежными друг с другом, однако метод RLE также обладает собственными ограничениями и/или недостатками, в частности, связанными с оптимизацией в отношении периодических значений данных. В сочетании с дельта-кодированием (Delta encoding, DE) способ RLE-кодирования может эффективно применяться для простых линейных блоков данных, но не для сложных одномерных блоков, и совсем неудовлетворительно работает для сложных двумерных или трехмерных блоков данных. Во многих существующих современных способах применяют понижающее масштабирование всего изображения, или одного из каналов изображения, и затем интерполируют восстановленное изображение, или один из его каналов, до исходного разрешения, например, подобная схема применена в современном формате YUV4207YUV422, который используется для кодирования изображений и для видеокодирования. Подобные современные существующие способы, тем не менее, не подходят для множества современных сценариев применения, поскольку они не позволяют выполнять поблочную обработку заданного объема данных. При этом в существующих способах интерполяцию применяют всегда одинаковым образом, что серьезно сказывается на детализации изображения и не позволяет обеспечить эффективное сжатие в однородных областях изображения. Также в них не хватает дополнительных способов кодирования, которые бы обеспечивали дополнительное сжатие значений данный после понижающего масштабирования.
В статье «Кодирование сканированных составных документов с использованием многомасштабных рекуррентных паттернов» («Encoding Using Multiscale Recurrent Patterns», Francisco, N.C.; Rodrigues, N.M.M.; da Silva, E.A.B.; de Carvalho, M.B.; De Faria, S.M.M.; da Silva, E.A.B), опубликованной в октябре 2010 ("Image Processing",» IEEE Transactions on», том. 19, №. 10, стр. 2712-2466) (по состоянию на 26 апреля 2013 года), URL:http://ieeexplore.ieee.org/xpl/login.jsp?reload=true&tp=&arnumber=5454328&url=http%3A%2F%2Fieeexplore.ieee.org%2Fiel5%2F83%2F5577553%2F05454328.pdf%3Farnumber%3D5454328, описан способ кодирования данных, предназначенный для кодирования сканированных составных документов и обеспечивающий возможность использования ранее закодированных паттернов, сохраненных в многомасштабных словарях для будущего использования.
Упомянутые выше существующие способы не вполне подходят для поблочного кодирования данных, и следовательно, необходимо предложить усовершенствованные способы кодирования подобных блочных данных. На существующем уровне техники имеются множество доступных способов кодирования, но ни один из этих доступных способов в достаточной степени не подходит для кодирования данных множества различных изображений, видеоданных, аудиоданных, графических данных, данных в формате Unicode или двоичных данных, или аналогичных распространенных форматов и типов данных. По этой причине необходим новый метод, дополняющий собой доступный выбор способов кодирования с целью обеспечения эффективного сжатия любых видов данных. К примеру, не существует быстрого и эффективного метода, позволяющего закодировать блок данных из пятнадцати следующих значений:
(7, 8, 10, 14, 22, 38, 70, 134, 70, 38, 22, 14, 10, 8, и 7),
в котором последовательность значений данных является возрастающей заранее заданным образом, к примеру, возрастает в сторону срединной области последовательности значений данных, и при этом убывает одинаковым образом в сторону начала и в сторону конца последовательности, или же убывание в сторону конца последовательности значений данных может иметь отличающийся характер.

Сущность изобретения
Цель настоящего изобретения - предложить усовершенствованный способ кодирования данных (D1), предназначенный для формирования соответствующих кодированных данных (Е2).
Еще одна цель настоящего изобретения - предложить усовершенствованный кодер, выполненный с возможностью применения упомянутого выше усовершенствованного способа кодирования данных (D1).
Цель настоящего изобретения - предложить усовершенствованный способ декодирования кодированных данных (Е2), сформированных при помощи упомянутого выше усовершенствованного способа кодирования данных. Цель настоящего изобретения - предложить усовершенствованный декодер, в котором может быть применен упомянутый выше усовершенствованный способ декодирования кодированных данных (Е2).
В соответствии с первым аспектом настоящего изобретения предложен способ кодирования данных по п. 1 приложенной формулы изобретения: предложен способ кодирования данных (D1) в кодере с целью формирования соответствующих кодированных данных (Е2), включающий:
(a) прием кодируемых данных (D1) и анализ субфрагментов кодируемых данных (D1) для определения одного или более способов кодирования, которые будут применены для кодирования этих субфрагментов, при этом один или более способов кодирования включают по меньшей мере один алгоритм, использующий интерполяцию, причем информацию об этом по меньшей мере одном алгоритме включают в кодированные данные (Е2);
(b) вычисление одного или более параметров интерполяции для упомянутых одного или более способов кодирования, использующих по меньшей мере один алгоритм, использующий интерполяцию, при этом параметры интерполяции представляют значения данных из субфрагмента данных (D1), кодируемого при помощи по меньшей мере одного алгоритма, использующего интерполяцию, причем упомянутые один или более параметров интерполяции содержат меньшее количество значений данных, чем количество значений данных в субфрагменте входных данных (D1), который они представляют;
(c) кодирование остальных субфрагментов кодируемых данных (D1) с использованием одного или более других способов кодирования; и
(d) комбинирование данных, сформированных на шагах (а), (b) и (с), в результате чего получают кодированные данные (Е2).
Настоящее изобретение обеспечивает полезный результат, заключающийся в том, что упомянутый по меньшей мере один алгоритм интерполяции позволяет кодировать блоки и/или пакеты данных, кодирование которых является сложным, с использованием более совершенных алгоритмов интерполяции. Также полезным результатом настоящего изобретения является создание высокоэффективного способа кодирования определенных типов данных изображений, видеоданных, аудиоданных, графических данных, текстовых данных, данных ASCII, а также данных символов Unicode, двоичных блочных данных или пакетов данных. При этом предложенный высокоэффективный способ кодирования позволяет обеспечить, при своем функционировании, очень высокую степень сжатия данных, имеющих высокий разброс значений, частотный состав которых, однако, не является самым высоким из возможных. Такие данные, подлежащие кодированию с использованием предложенного высокоэффективного способа, легко описываются с помощью небольшого набора значений и/или параметров вместе с выбранным способом интерполяции, ассоциированным с ними. В дополнение, предложенный высокоэффективный способ позволяет выполнять восстановление кодированных данных (Е2), как с потерями, так и без потерь, например, в декодере. При этом его применяют, предпочтительно, в сочетании с другими способами с целью оптимизации, например, показателя «битовая скорость - искажения», для данных, закодированных с потерями, или использованных битов для восстановленных данных при кодировании без потерь. Предложенный способ упрощает масштабирование качества, в частности, применяемое в целях понижения битрейта (битовой скорости передачи), при помощи квантования значений, и при этом не вносит значительных объективных или субъективных ошибок в восстановленные данные, например, в декодере. Если для интерполяции данных заданного блока или пакета не используют предсказание на основе окружающих значений пакета или блока данных, то заданный блок или пакет данных является полностью независимым от остальных блоков или пакетов данных, что, соответственно, дает возможность более просто реализовать параллельную обработку и дает дополнительный полезный результат, заключающийся в снижении распространения ошибок в ходе декодирования кодированных данных (Е2).
Опционально, в способе кодирования данных (D1) упомянутый по меньшей мере один способ кодирования, использующий по меньшей мере один алгоритм, использующий интерполяцию, включает по меньшей мере одно из следующего: способ скольжения, способ масштабирования, пирамидный способ, полиномиальный способ, кусочно-постоянный способ, четырехточечный способ масштабирования, пятиточечный пирамидный способ, способ Хилла и 9-точечный способ масштабирования.
Опционально, в способе кодирования данных (D1) упомянутый по меньшей мере один алгоритм, использующий интерполяцию, или параметр интерполяции для использования с упомянутым по меньшей мере одним алгоритмом, использующим интерполяцию, включает по меньшей мере одну из:(i) кусочно-постоянной;
(ii) линейной;
(iii) полиномиальной; и
(iv) сплайновой интерполяций.
Опционально, способ включает выполнение над данными, скомбинированными на шаге (d), одной или более процедур сжатия с целью формирования кодированных данных (Е2), при этом одна или более процедур сжатия данных включают по меньшей мере одно из следующего: SRLE-кодирование, RLE-кодирование, РСМ-модуляция, DPCM-модуляция, О-дельта-кодирование, модификатор энтропии (Entropy modifier, ЕМ), VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование Хаффмана, DCT-преобразование, вэйвлет-преобразование, кодирование с палитрой, векторное квантование (VQ), кодирование с использованием базы данных, DC-преобразование, скользящее кодирование, многоуровневое кодирование, масштабируемое кодирование, линейное кодирование, экстраполяция и интерполяция.
Опционально, способ включает применение на шаге (с) по меньшей мере одного из следующего: DCT-кодирование, вейвлет-кодирование, кодирование с палитрой, кодирование с векторным квантованием (VQ), кодирование с использованием базы данных, кодирование с РСМ-модуляцией, кодирование с DPCM-модуляцией, кодирование с DC-преобразованием, диапазонное кодирование, RLE-кодирование, скользящее кодирование, многоуровневое кодирование, масштабируемое кодирование, линейное кодирование и кодирование с экстраполяцией.
Опционально, способ включает вычисление ошибки, например, ошибки дельта, между данными, входящими в состав кодируемых данных (D1) и восстановленными данными, сформированными на основе кодированных данных (Е2), на шаге (d), при этом способ включает добавление и/или предоставление данных ошибки, с кодированием или без кодирования, в кодированные данных (Е2). Также, опционально, способ включает помещение ошибки в кодированные данные (Е2), индивидуально для каждого заданного блока данных или заданного пакета данных, в зависимости от характера контента, содержащегося в заданном блоке данных или заданном пакете данных. Также, опционально, способ включает выбор одного или более алгоритмов для кодирования кодируемых данных (D1), при этом кодируемые данные (D1) включают по меньшей мере одно из следующего: одномерные данные (1D), данные ЭКГ, сейсмологические данные, двумерные данные (2D), данные изображений, двумерные видеоданные, двумерные графические данные, трехмерные данные изображений, трехмерные видеоданные трехмерные данные изображений. Опционально, способ подразумевает, на шаге (d), включение в кодированные данные (Е2) информации, относящейся по меньшей мере к одному из следующего: значения данных, значения градиентов, способы интерполяции, биты подтверждения предсказания, позиции значений данных, значения ошибки, порядки сканирования, способы кодирования. Также, опционально, способ включает передачу одного или более параметров в кодированных данных (Е2) в виде их собственных потоков сжатых данных. Также, опционально, способ включает квантование упомянутых одного или более параметров с целью обеспечения повышенной степени сжатия данных в кодированных данных (Е2).
В соответствии со вторым аспектом настоящего изобретения предложен способ декодирования кодированных данных (Е2) в декодере с целью формирования соответствующих декодированных выходных данных (D3), включающий:
(а) прием кодированных данных (Е2) с целью определения одного или более параметров кодирования, включенных в кодированные данные (Е2), и одного или более способов кодирования, к которым они относятся, при этом упомянутый по меньшей мере один способ кодирования включает по меньшей мере один способ кодирования, использующий один или более алгоритм, использующий интерполяцию;
(b) извлечение значений данных для субфрагментов кодированных данных (Е2) при помощи применения обратных алгоритмов к одному или более параметрам и связанным с ними данным, присутствующим в кодированных данных (Е2) и восстановление значений данных субфрагментов данных, причем количество восстановленных значений данных превышает количество значений кодированных данных; и
(c) комбинирование восстановленных значений данных субфрагментов, в результате чего формируют декодированные данные (D3).
Опционально, способ, использующий один или более один алгоритм, использующий интерполяцию, включает применение способов, обратных по меньшей мере одному из следующего: способ скольжения, способ масштабирования, пирамидный способ, полиномиальный способ, кусочно-постоянный способ, четырехточечный способ масштабирования, пятиточечный пирамидный способ, способ Хилла и 9-точечный способ масштабирования.
Опционально, в способе декодирования кодированных данных (Е2) упомянутый по меньшей мере один алгоритм, использующий интерполяцию, или по меньшей мере один параметр интерполяции для использования с упомянутым по меньшей мере одним алгоритмом, использующим интерполяцию, включают по меньшей мере одну из:
(i) кусочно-постоянной;
(ii) линейной;
(iii) полиномиальной; и
(iv) сплайновой интерполяций.
Опционально, способ, перед шагом (а), включает декомпрессию кодированных данных (Е2) с использованием процедур, обратных по меньшей мере одному из следующего: SRLE-кодирование, RLE-кодирование, РСМ-модуляция, DPCM-модуляция, О-дельта-кодирование, модификатор энтропии (Entropy modifier, ЕМ), VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование Хаффмана, DCT-преобразование, вэйвлет-преобразование, кодирование с палитрой, векторное квантование (VQ), кодирование с использованием базы данных, DC-преобразование, скользящее кодирование, многоуровневое кодирование, масштабируемое кодирование, линейное кодирование, экстраполяция и интерполяция.
В соответствии с третьим аспектом настоящего изобретения предложен кодер для кодирования данных (D1) с целью формирования соответствующих кодированных данных (Е2), выполненный с возможностью применения способа согласно первому аспекту настоящего изобретения с целью кодирования кодированных данных (D1), в результате чего формируют кодированные данные (Е2).
В соответствии с четвертым аспектом настоящего изобретения предложен декодер для декодирования кодированных данных (Е2) с целью формирования соответствующих декодированных данных (D3), выполненный с возможностью применения способа согласно второму аспекту настоящего изобретения с целью декодирования кодированных данных (Е2), в результате чего формируют соответствующие декодированные данные (D3).
В соответствии с пятым аспектом настоящего изобретения предложен кодек, включающий по меньшей мере один кодер согласно третьему аспекту настоящего изобретения, для формирования кодированных данных (Е2), и по меньшей мере один декодер согласно четвертому аспекту настоящего изобретения, для декодирования кодированных данных (Е2).
В соответствии с шестым аспектом настоящего изобретения предложен программный продукт, записанный на постоянном машиночитаемом носителе для хранения данных и допускающий исполнение на вычислительном оборудовании с целью реализации способа согласно первому аспекту настоящего изобретения и/или второму аспекту настоящего изобретения.
Нужно понимать, что отличительные признаки настоящего изобретения в пределах объема настоящего изобретения, заданного приложенной формулой изобретения, могут комбинироваться произвольным образом.
Описание чертежей
Далее, исключительно в качестве примера и со ссылками на приложенные чертежи, будут описаны примеры осуществления настоящего изобретения, где:
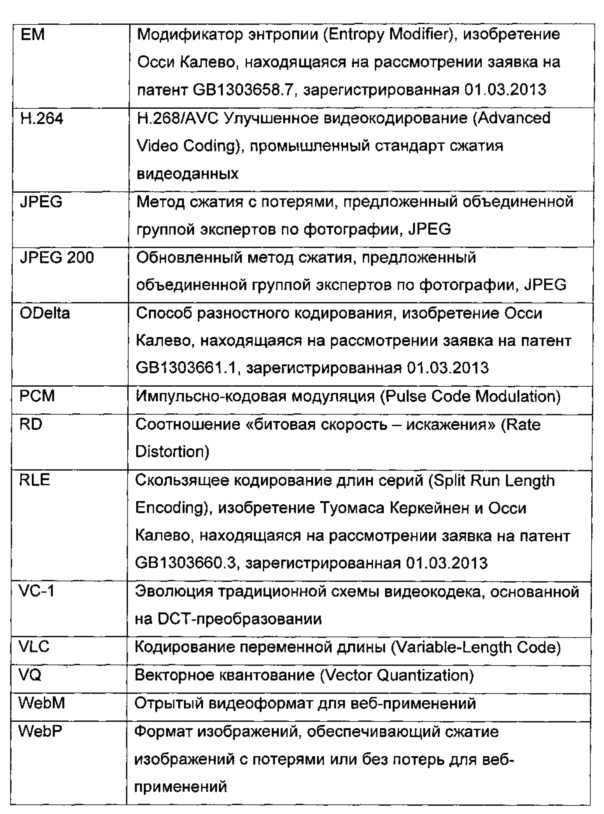
Фиг. 1 представляет собой иллюстрацию кодера и соответствующего декодера, которые вместе образуют кодек, при этом кодер и декодер выполнены с возможностью, для исполнения способов в соответствии с настоящим изобретением при обработке пропускаемых через них данных.
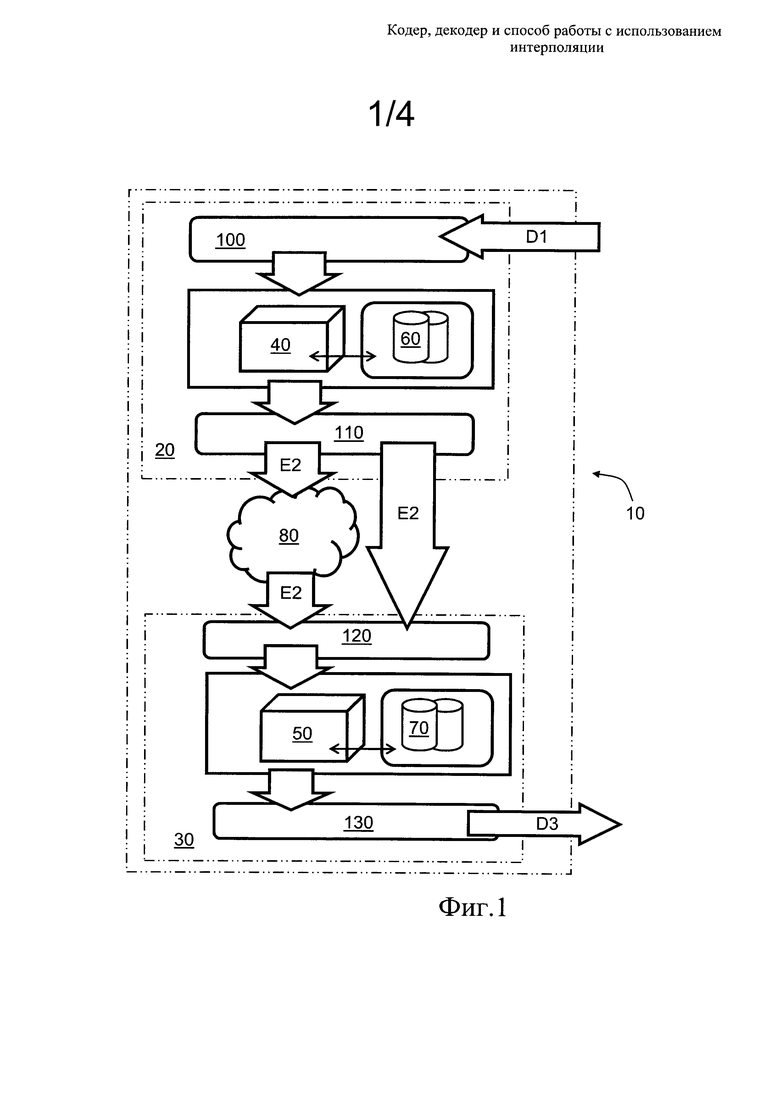
Фиг. 2 представляет собой иллюстрацию примеров различных методов интерполяции, в которых применяются различные алгоритмы интерполяции.
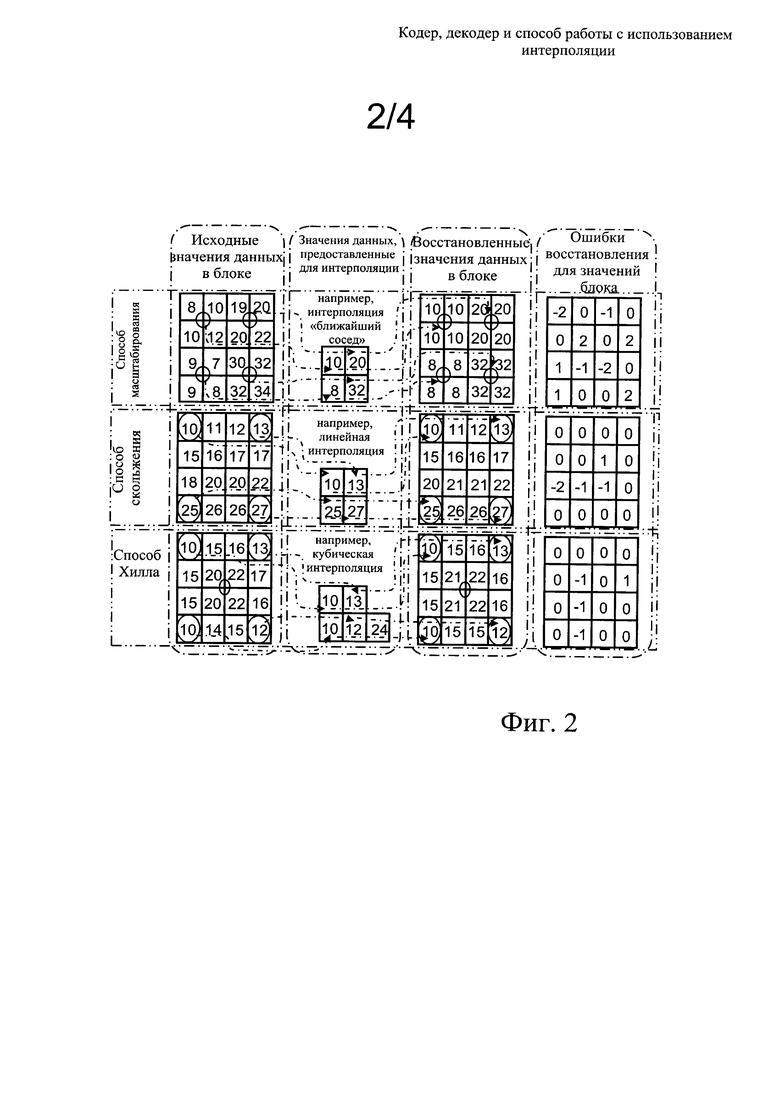
Фиг. 3 представляет собой иллюстрацию значений предсказания, вычисленных с использованием способа скольжения в соответствии с настоящим изобретением; и
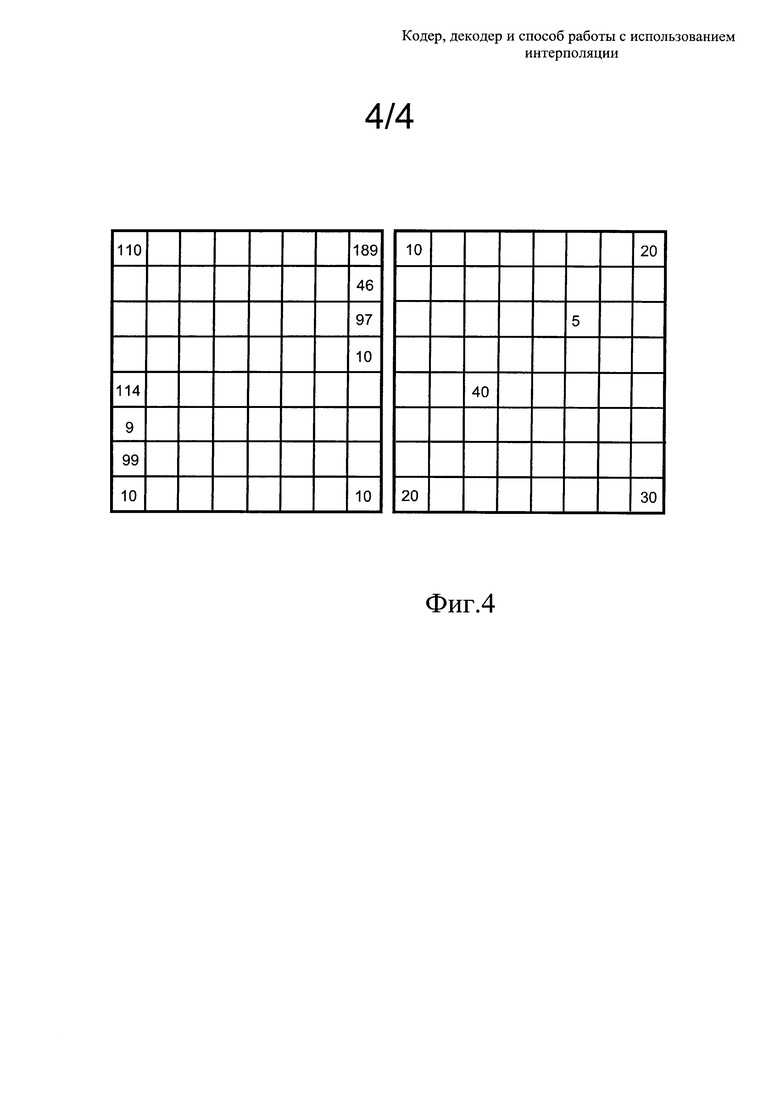
Фиг. 4 представляет собой иллюстрацию интерполяции значений данных в условиях нехватки отсчетов, используемых для интерполяции.
На приложенных чертежах числа, выделенные подчеркиванием, используются для обозначения элементов, над которыми находится подчеркнутое число, или рядом с которыми оно расположено. Неподчеркнутые числовые обозначения относятся к объектам, указанным линией, которая соединяет неподчеркнутое число и объект. Если число не выделено подчеркиванием и сопровождается связанной с ним стрелкой, это неподчеркнутое число используется для обозначения общего элемента, на который указывает стрелка.
Описание вариантов осуществления изобретения
В общем, цель настоящего изобретения - предложить быстродействующий и эффективный способ интерполяции для целей кодирования и декодирования. Способ назван «способом интерполяции», поскольку в нем с целью восстановления промежуточных значений, лежащих между данными, которые заданы упомянутыми сравнительно малочисленными параметрами, применяется сравнительно малое количество параметров, участвующих в интерполяционных вычислениях. Для конкретных вариантов этого способа могут также использоваться и другие наименования, например, «способ скольжения», «способ масштабирования», «пирамидный способ» и т.п. Примеры предложенного способа будут рассмотрены ниже. При этом предложенный способ оптимально подходит для блоков данных определенного типа, в которых набор значений элементов данных интерполируют в целях получения необходимых значений одномерных, двумерных или трехмерных данных; данный способ позволяет также работать и с более высокими размерностями. При этом, опционально, способ, предложенный в настоящем изобретении, может применяться, в частности, для данных изображений, видеоданных, графических данных и аудиоданных, и может замещать предшествующие способы кодирования, такие, например, как DCT-преобразование, вейвлет-преобразование, DPCM-модуляцию и другие способы, известные на существующем уровне техники.
В настоящем изобретении предложен способ кодирования данных (D1), а также соответствующий способ декодирования кодированных данных (Е2), например, для использования в кодере и декодере, соответственно, которые позволяют повысить достижимую эффективность кодирования при сжатии данных изображений, видеоданных, графических данных, аудиоданных, текстовых данных, данных ЭКГ-измерений, сейсмологических данных, ASCII-данных, данных символов Unicode, данных двоичных файлов и потоков данных, и т.п. Способ включает преобразование содержимого или блока данных в форму, допускающую более простое сжатие. Дополнительно, для других блоков данных или пакетов данных, могут применяться другие способы кодирования, в комбинации со способами, предложенными в настоящем изобретении, или параллельно с ними, например, в случае кодирования данных изображений или аудиоданных. Способ, предложенный в настоящем изобретении, подразумевает оценку значений данных в блоке одномерных, двумерных или трехмерных данных на основе набора значений элементов данных с использованием интерполяционных вычислений.
Опционально, метод интерполяционных вычислений, например, одно или более из следующего: интерполяция типа «ближайший сосед», линейная, полиномиальная, сплайновая интерполяция, может выбираться в зависимости от характера контента в заданном блоке данных, при этом соответствующее решение о выборе может быть предоставлено из кодера в соответствующий декодер, которые, например, совместно сконфигурированы в виде кодека. Опционально, в целях выполнения интерполяции в декодер могут предоставляться позиции использованных данных, например, из способа масштабирования, способа скольжения, заранее заданные 5 точек и 6 точек с дополнительной информацией. Опционально, в декодер могут предоставляться биты подтверждения, указывающие на успешное предсказание, по меньшей мере для части значений элементов данных, а также опциональное значение дельта предсказания. Когда предсказание не является успешным, предпочтительно, в декодер предоставляют также исходные значения соответствующих элементов данных, с дельта-кодированием или без него.
Для сжатия необходимой информации могут применяться различные способы сжатия, к примеру, одно или боле из следующего: SRLE-кодирование, RLE-кодирование, РСМ-модуляция, DPCM-модуляция, О-дельта-кодирование, модификатор энтропии (ЕМ), VLC-кодирование, диапазонное кодирование, арифметическое кодирование, кодирование Хаффмана. Сжимаемая информация может представлять собой: выбранные способы, значения данных, значения градиентов, способы интерполяции, биты подтверждения предсказания, позиции значений данных, значения ошибки, порядки сканирования и способы кодирования. Предоставление кодированных данных (Е2) из кодера в декодер включает любые механизмы предоставления, к примеру, без ограничения перечисленным: сохранение в файле или потоковую передачу данных в декодер.
Способ кодирования, соответствующий одному из вариантов осуществления настоящего изобретения, может применяться совместно с другими методами кодирования, например, DCT-преобразованием, вейвлет-преобразованием, кодированием с палитрой, векторным квантованием, кодированием с использованием базы данных, DPCM-модуляцией, DC-кодированием, многоуровневым кодированием, линейным кодированием и экстраполяцией. При использовании способа кодирования, соответствующего настоящему изобретению, каждую последовательность или блок данных заданного изображения, видеофрагмента, аудиофрагмента и/или графической иллюстрации кодируют с помощью способа кодирования, который выбирают как наиболее подходящий для кодирования последовательности или блока данных этого конкретного типа. Размеры заданного блока данных в изображении, видеофрагменте, аудиофрагменте в соответствии с одним из вариантов осуществления настоящего изобретения могут изменяться в зависимости от их содержимого. Как было показано в рассмотренном выше примере, последовательность данных в блоке данных может, опционально, быть одномерной (1D), например, это могут быть аудиоданные, данные ЭКГ или сейсмологические данные, или может быть многомерной, к примеру, это могут быть двумерные изображение (2D), двумерные видеоданные, двумерные графические данные, трехмерные изображения (3D), трехмерные видеоданные или трехмерные графические данные, хотя последовательность данных, или блок данных, при реализации вариантов осуществления настоящего изобретения могут иметь и более высокую размерность.
Изображения рабочего стола компьютера, анимация, графические данные и естественные данные, имеющие локальные или глобальные вариации внутри блока данных, или пакета данных, особенно плохо поддаются сжатию известными на сегодняшний день способами кодирования, и поэтому в вариантах осуществления настоящего изобретения предложен способ кодирования, оптимизированный для сжатия подобного контента, плохо поддающегося сжатию. Очевидно, данные, подлежащие кодированию и сжатию, могут быть исходными данными, или они могут представлять собой данные ошибки предсказания, сформированными с использованием одного из способов предсказания, например, DPCM-модуляции, дельта-кодирования, оценки движения или других типов временного предсказания, или пространственного предсказания.
Обратимся к фиг. 1, где показана иллюстрация кодека, обозначенного в целом как 10. Кодек 10 включает кодер 20, который выполнен с возможностью приема кодируемых данных D1 и кодирования данных D1, в результате чего формируют соответствующие кодированные данные Е2. При этом кодек 10 дополнительно включает один или более декодеров 30, которые выполнены с возможностью приема кодированных данных Е2 и декодирования кодированных данных Е2, в результате чего формируют соответствующие декодированные данные D3. Опционально, декодированные данные D3 представляют собой воспроизведение кодируемых данных D1, по существу не имеющее потерь. Кодер 20 и один или более декодеров 30 включают, соответственно, процессоры 40, 50 данных, которые, опционально, имеют соединение с одним или более блоками 60, 70 данных, соответственно. Процессоры 40, 50 данных, предпочтительно, реализованы в виде жестко запрограммированного цифрового оборудования и/или вычислительного оборудования, выполненного с возможностью исполнения одного или более программных продуктов, записанных на машиночитаемом носителе для хранения данных, то есть информационном носителе. Опционально кодированные данные Е2 передают из кодера 20 в один или более декодеров 30 по сети 80 обмена данными; альтернативно, кодированные данные Е2 передают из кодера в один или более декодеров 30 при помощи разделяемой памяти данных, например, разделяемой базы данных или физического носителя для хранения данных, к примеру, оптического диска для хранения данных.
Опционально, кодируемые данные перед их передачей в процессор 40 данных предварительно обрабатывают в препроцессоре 100. Опционально, над кодированными данными, сформированными процессором 40 данных, выполняют постобработку в постпроцессоре 110, в результате чего формируют кодированные данные Е2, которые затем, например, подвергают обработке дополнительными способами сжатия, такими как RLE-кодирование, модификатор энтропии, кодирование Хаффмана и т.п.
Опционально, кодируемые данные Е2 перед их передачей в процессор 50 данных предварительно обрабатывают в препроцессоре 120. Опционально, над декодированными данными, сформированными процессором 50 данных, выполняют постобработку в постпроцессоре 130, в результате чего формируют декодированные данные D3.
В ходе работы устройства кодируемые данные D1 разбивают на один или более блоков данных, к примеру, различным образом. Эти один или более блоков данных впоследствии независимо анализируют и находят наиболее подходящий способ кодирования каждого отдельного блока из одного или более блоков данных. Наиболее подходящий способ может зависеть от информационного контента, содержащегося в одном или более блоках данных. Одним из таких подходящих способов может быть способ интерполяции согласно настоящему изобретению, который будет описан ниже более подробно. Другие подходящие способы могут включать традиционные способы, известные на существующем уровне техники, при этом информационный контент каждого отдельного блока данных кодируют одним из известных способов, наиболее подходящим для этой цели. Кодированные данные Е2 включают информацию, указывающую на один или более блоков данных и соответствующие один или более способов, которые были выбраны в процессоре 40 данных для кодирования этих одного или более блоков данных. В декодере 30 кодированные данные Е2 могут быть проанализированы в соответствии с одним или более блоками данных и способами, использованными в процессоре данных для кодирования этих одного или более блоков данных; при этом процессор 50 данных выполнен с возможностью применения к одному или более блоков данных способов, обратных выбранным подходящим способам, в результате чего формируют декодированные данные, которые могут быть использованы для формирования декодированных данных D3. Таким образом, способ интерполяции, соответствующий настоящему изобретению, в процессоре 40 данных используют совместно с множеством других способов, а также совместно с множеством обратных им способов в процессоре данных 50, и по этой причине выбранный способ кодирования должен быть также сохранен в файле с кодированными данными или в потоке данных, например, в кодированных данных Е2, которые подают в декодер 30, для каждого кодированного блока данных. Если размеры блоков данных допускают изменение, то аналогичным образом в декодер 30 должна быть предоставлена информация, указывающая на размер данных и каким образом блоки, находящиеся в составе данных D1, должны быть кодированы. Это может быть реализовано, например, при помощи способа, описанного в заявке на патент Великобритании №1214414.3 и эквивалентной заявке на патент США №13/584005 («Кодер»), а также заявке на патент Великобритании №1214400.2 и эквивалентной заявке на патент США №13/584,047 («Декодер»), содержимое которых полностью включено в настоящий документ путем ссылки: содержимое соответствующих заявок на европейский патент №13002521.6 («Кодер») и №13002520.8 («Декодер») также включено в настоящий документ путем ссылки.
Размер блоков данных или пакетов данных, которые кодируют при помощи способа кодирования в соответствии с настоящим изобретением, может быть любым, однако предпочтительно, размер лежит в диапазоне от 5 до 100000 значений данных. Количество значений данных, используемых для интерполяции, может быть произвольным, однако предпочтительно, количество значений данных, используемых для интерполяции, лежит в диапазоне от 1 до 1000 значений. Если необходимо большее количество значений, то, как правило, более рационально разбить заданный блок данных или пакет данных и применить к результирующим блокам или пакетам различные способы или различные параметры.
Значения данных, используемых для интерполяции, могут быть кодированы с использованием различных способов сжатия, например, РСМ-модуляция, DPCM-модуляция, VLC-кодирование, RLE-кодирование, DCT-преобразование и способы, основанные на базах данных, которые, например, могут быть реализованы в постпроцессоре 110. Если доступны несколько вариантов выбора, то информацию о сделанном выборе предоставляют в декодер 30. Может также меняться порядок сканирования значений данных, например, слева направо, сверху вниз, сверху вниз слева направо, зигзагообразный, U-образный, С-образный или Z-образный. Если могут применяться несколько различных порядков сканирования, то информацию о выбранном порядке предоставляют в декодер 30.
Способ, предложенный в настоящем изобретении, а именно, способ, основанный на алгоритмах интерполяции, позволяет сэкономить большее количество байт при кодировании, обеспечивая более эффективное сжатие данных, благодаря чему обеспечивается также экономия электроэнергии и процессорного времени, по сравнению с общераспространенными сложными и энергозатратными способами, известными на существующем уровне техники, поскольку при использовании способов, соответствующих настоящему изобретению, кодируют только один набор значений элементов данных в заданном блоке данных, в отличие от кодирования всех значений данных в случае применения существующих способов. Как правило, при кодировании набора элементов данных, значения выбирают из блока данных, затем, опционально, их сжимают и передают в декодер 30, где элементы данных принимают и, опционально, распаковывают, после чего их используют для интерполяции с целью восстановления значений в заданном блоке данных. Для интерполяции могут использоваться переданные значения данных, а также, опционально, переданные значения градиентов. Возможные способы интерполяции, в соответствии с настоящим изобретением, могут быть основаны на предположении, что значения данных являются непрерывными, гладкими, периодическими и т.п. В ходе интерполяции может также выполняться оценка изменения градиента на основе известных значений. Различные способы интерполяции, которые могут применяться, включают, например:
(a) кусочно-постоянная (=«ближайший сосед»);
(b) линейная;
(c) полиномиальная; и
(d) сплайновая интерполяция.
Применяться могут также различные варианты этих способов интерполяции, к примеру, с различным количеством значений данных, различными позициями значений данных, например, способ с четырехточечной шкалой, или способ скольжения, пятиточечный пирамидальный способ, или способ Хилла, или способ с девятиточечной шкалой.
Способ интерполяции в соответствии с настоящим изобретением может быть выбран заранее, или выбор может выполняться, например, на основе информационного контента или на основе оптимизации «битовая скорость - искажения» для заданного кодируемого блока данных или пакета данных. Как отмечалось выше, если способ интерполяции выбирают из нескольких альтернативных способов, то чтобы данные могли быть декодированы, информация о выбранном способе также должна быть предоставлена в декодер 30. Выбор используемого способа, например, выбор способа интерполяции вместо других способов для блоков данных или пакетов данных, как правило, выполняют на основе значений «битовая скорость - искажения», которые могут вычисляться различными способами. Чтобы данные могли быть декодированы, информацию о выбранном способе часто также требуется предоставлять в декодер 30. Выбор этого способа и выбора способа интерполяции зачастую могут быть скомбинированы совместно, например, в целях получения большей степени сжатия кодированных данных Е2. В упомянутом способе, как правило, используют значения, которые предоставляют в декодер и которые основаны на значениях данных внутри заданного блока данных, но также в нем могут дополнительно применяться значения предсказания, лежащие вне этого блока данных, а именно, если эти значения доступны, вместе с дополнительной информацией или без нее. Могут присутствовать отдельные биты подтверждения для каждого значения, переданного в составе кодированных данных Е2 из кодера 20 в декодер 30. Опционально, для подтверждения всех значений предсказания сразу может использоваться один бит, вместо передачи нескольких бит в составе кодированных данных Е2. Если упомянутый один бит, применяемый опционально, не подтверждает все предсказанные значения данных, то, опционально, могут требоваться отдельные биты для каждого значения. Это позволяет получить решение, в котором используют только часть предсказанных значений или используют отличающиеся значения, когда на границе блока данных происходит какое-либо изменение. Эти предсказанные и, опционально, подтвержденные граничные значения блока, в целях интерполяции, могут применяться совместно с одним или более другими значений элементов данных. Способ, в котором применяют интерполяцию, предпочтительно, применяют для кодирования отдельных блоков данных или пакетов данных. Помимо прочего, это означает, что остальные части данных могут быть закодированы при помощи одного и того же способа или различных способов. Способ интерполяции допускает применение для данных любого размера и любой формы, то есть, блока данных или пакета данных любой размерности. Существуют множество методов, которыми может быть реализован упомянутый способ интерполяции, например, методы, более подробно описанные ниже. При этом могут присутствовать несколько критериев выбора и/или формул вычисления значений элементов данных, которые применяют для формирования значений, предоставляемых в декодер и используемых при восстановлении данных, а именно, при восстановительной интерполяции, например, в декодере 30 при декодировании кодированных данных Е2. Существуют различные типы алгоритмов интерполяции, которые могут быть использованы при реализации способа интерполяции, к примеру, кусочно-постоянная, линейная, кубическая и сплайновая интерполяция. При этом могут также варьироваться позиции значений данных, в соответствии с последующим более подробным описанием.
На фиг. 2 проиллюстрирован пример, в котором 2×2 и 2×2+1 значений данных используют для реализации способа интерполяции с масштабированием, способа скользящей интерполяции или способа Хилла для блоков данных размером 4×4, при помощи изменения позиций значений данных. Данный пример, проиллюстрированный на фиг. 2, показывает также, каким образом могут варьироваться алгоритмы интерполяции для различных выбранных способов интерполяции, однако их варьирование является опциональным, то есть, данные способы, при реализации вариантов осуществления настоящего изобретения, могут применяться со всеми различными алгоритмами интерполяции. Окружностями на фиг. 2 показаны опциональные позиции, которые, предпочтительно, используют в качестве позиций данных для 4 или 5 значений данных, предоставляемых в декодер, в различных способах интерполяции. Настоящее изобретение не ограничено проиллюстрированным примером, при этом, как правило, коэффициент масштабирования на практике также имеет более высокое значение; это означает, например, что для кодирования более крупных блоков данных, к примеру, имеющих размер больший 4×4, могут применяться значения данных размером 2×2.
В декодере 30, если к восстановлению кодированных данных Е2 в форме декодированных данных D3 предъявляются очень высокие требования качества, предпочтительно, данные ошибки восстановления, показанные, к примеру, в правой части фиг. 2, также кодируют с использованием различных способов кодирования и включают в состав кодированных данных Е2, применяя их затем в декодере 30 с целью уточнения декодированных данных D3. В большинстве практических применений это, как правило, не требуется, это необходимо, пожалуй, только для сверхвысококачественных статических изображений, к примеру, для изображений воздушной разведки, изображений со спутника и т.п. Если способ интерполяции, в его различных реализациях, в соответствии с предшествующим описанием, не является достаточно эффективным, то для кодирования блоков данных или пакетов данных в кодере 20 выбирают другой способ, или применяют аналогичный способ, но с меньшим размером блока, что дает повышенную точность значений данных, включаемых в кодированные данные Е2, однако за счет несколько меньшей степени сжатия кодированных данных Е2 по сравнению с данными D1.
Обратимся далее к фиг. 3: если доступны значения данных из окрестности кодируемого блока, которые уже закодированы в кодере 20 и при этом также декодированы в декодере 30, то эти значения могут дополнительно применяться для предсказания значений данных, которые в обратном случае не требовалось бы передавать из кодера 20 в декодер 30. При этом, если предсказанное значение удовлетворительно, оно может быть использовано в том же виде, как оно было предсказано. При этом также, опционально, из кодера 20 в декодер 30 предоставляют информацию подтверждения, обеспечивающую возможность предсказания некоторых из значений, однако остальные значения передают в виде соответствующих значений данных или значений разности между соответствующими значениями данных и предсказанными значениями. На фиг. 3 проиллюстрирован пример, в котором имеются доступные окружающие значения данных, и при этом часть окружающих значений дает удовлетворительные предсказанные значения, тогда как остальные окружающие значения не дают удовлетворительных предсказанных значений. В такой ситуации в кодере 20, при кодировании блоков данных или пакетов данных могут предприниматься попытки применения нескольких различных, отличающихся друг от друга алгоритмов интерполяции до тех пор, пока не будет найден алгоритм интерполяции в соответствии с настоящим изобретением, который обеспечит предсказание удовлетворительной точности. В случае, когда ни один из алгоритмов интерполяции в кодере 20 не позволяет кодировать заданный блок данных или пакет данных с достаточной точностью, кодер 20 переходит к поиску альтернативных способов и/или разбивает заданный блок данных для повышения точности кодирования, и/или комбинирует заданный блок данных с одним или более смежными блоками данных, с получением составного блока данных, который затем кодируют, например, с использованием алгоритма полиномиальной интерполяции более высокого порядка. Пример, проиллюстрированный на фиг. 3, не ограничивает настоящее изобретение. При реализации вариантов осуществления настоящего изобретения, предпочтительно, имеются несколько различных методов предсказания, допускающих применение в кодере 20 при кодировании кодируемых данных D1 с целью формирования соответствующих кодированных данных Е2, а также соответствующие способы декодирования в декодере 30 для декодирования кодированных данных Е2 с целью формирования декодированных данных D3, при этом упомянутые способы предсказания могут применяться для предсказания значений, например, в заданном блоке данных на основе нескольких параметров управления предсказанием, к примеру, с использованием интерполяции или аналогичного метода. Однако существуют несколько простых способов, описанных ниже, которые удобны для пояснения процедуры предоставления значений данных из кодера 20 в декодер 30. При подобном предсказании, опционально, может также применяться большее количество доступных значений данных, а не только значения данных из ближайшего окружения.
На фиг. 3 верхнее левое значение способа скольжения может предсказываться, например, с использованием трех окружающих значений данных, а именно, значения сверху, значение слева и значения сверху-слева. Относительно хороший результат предсказания может быть получен при помощи способа, в котором значения предсказывают на основе уравнения 1 (Ур. 1):
Значение предсказания = (значение сверху) + (значение слева) - (значение сверху-слева) = 12 + 11 - 11 = 12 (Ур. 1),
то есть, значение предсказано с достаточной точностью.
Верхнее правое значение может предсказываться (например), на основе трех окружающих значений данных, однако в данном случае предсказание может вычисляться на основе значения сверху, следовательно, предсказанное значение, будет равно 30, что является неточным предсказанием («неудовлетворительное значение»). При этом нижнее левое значение может предсказываться, например, на основе значения слева, следовательно, значение предсказания будет равно 11, то есть это значение будет «удовлетворительным значением» или «неудовлетворительным значением» в зависимости от требований, предъявляемых к точности. В примере фиг. 3 это предсказанное значение считается «удовлетворительным значением», то есть, более точным.
Для верхнего правого значения не имеется доступных окружающих пикселей. Возможна ситуация, в которой значение не предсказывают совсем, или предсказывают с использованием трех предсказанных значений или трех значений, применяемых для интерполяции, и при этом используют управление, аналогичное применяемому для предсказания верхнего левого значения, то есть, значение предсказания = 30+11-12=29, то есть, сравнительно неточное, «неудовлетворительное значение», или значение предсказания =15+11-12=14, которое может быть точным «удовлетворительным значением» или неточным «неудовлетворительным значением» в зависимости от требований к качеству, предъявляемых кодеком 10. В примере фиг. 3, в данном случае, вычисленное значение считают точным «удовлетворительным значением». Также, данный пример показывает, что в случае применения предсказания, как правило, лучше выбирать значения, которые будут использоваться при интерполяции, отдавая им предпочтение перед значениями, которые просто предсказывают, не корректируя их, как это было в случае предсказания нижнего правого пикселя.
Ниже будут описаны два способа, используемые для предоставления значений данных в декодера, а именно, первый способ и второй способ. Первый способ вообще не подразумевает предсказания нижнего правого значения, а во втором способе предсказание выполняют с использованием трех значений, применяемых для интерполяции. В первом способе в декодер предоставляют биты подтверждения, равные 1, 0 и 1, а недостающие значения данных передают как 15 и 15. Опционально, при предоставлении значений данных может использоваться разностное кодирование. Во втором способе в декодер предоставляют биты подтверждения, равные 1, 0, 1, 1, а недостающее значение данных передают как равное 15.
В предыдущем примере описаны значения данных для способа, не требующего большего количества значений. Если необходимо больше значений, то эти дополнительные значения могут предоставляться после того, как в ходе работы появятся неточные «неудовлетворительные» предсказания значений данных, или, опционально, значений данных, для которых совсем не выполнено предсказания, например, в целях обеспечения максимальной точности. При этом, опционально, при предоставлении кодированных данных Е2 из кодера 20 в декодер 30, например, в виде одного или более потоков данных, может применяться разностное кодирование или другие способы сжатия. Ниже будет рассмотрен пример, в котором проиллюстрирован метод, позволяющий эффективно кодировать одномерные данные. Данный пример является очень простым и требует передачи только трех значений, а именно, значений 7, 134 и 7, а также, дополнительно, информации о том, что интерполяцию выполняют с использованием значений степени двойки. Однако, если значения меняются более сложным образом, например, несколько значений в конце убывают (7, 8, 10, 14, 22, 38, 70, 134, 70, 38, 22, 14, 10), то для удовлетворительной интерполяции из кодера 20 в декодер 30 должен быть предоставлен больший объем информации; из кодера 20 в декодер 30 должен быть предоставлен слегка увеличенный объем информации.
В данном случае тремя предоставляемыми значениями являются 7, 134 и 10. Также предоставляют информацию о том, что в качестве центрального значения используется позиция 7, если нумерация начинается с 0. При этом интерполяцию выполняют с применением значений степени двойки. Как в кодер 20, так и в декодер 30, предоставляют информацию, указывающую на длину данных, если принята эта информация, когда, например, кодер 20 и декодер 30 реализованы в виде блочного кодера и блочного декодера соответственно; при выбранном способе подобную информацию не требуется предоставлять снова. Данный пример не ограничивает настоящее изобретение, которое определено приложенной формулой изобретения.
Опционально, для использования в кодере 20 могут быть доступными другие способы, при этом подобные другие способы отличаются в отношении методов выбора отсчетов и их предоставления в декодер 30, а также в отношении методов интерполяции для восстановления значений блоков данных в декодере 30. При этом формирование отсчетов может быть основано, например, на регулярных структурах, низких или высоких значения данных, а также на граничных значениях. Следующий пример, показанный на фиг. 4, представляет собой иллюстрацию метода, при помощи которого могут выбираться значения данных, в случае, когда применяется нерегулярное формирование отсчетов. Когда формирование отсчетов не является регулярным, или когда принцип формирования отсчетов неизвестен, опционально, желательным является предоставление из кодера 20 в декодер 30 информации о схеме расположения значений отсчетов.
Блок данных, расположенный слева на фиг. 4, получен на основе изображения, которое, к примеру, включает наклонные детали неба, несколько линий, имеющих диагональное направление с углом 22°, и траву в нижней части. При наличии десяти значений данных, показанных на иллюстрации, информационный контент, то есть, значения всего блока данных размером 8×8, может быть интерполирован с удовлетворительным результатом. Блок, расположенный в правой части фиг. 4, содержит, например, область варьирующегося цвета, включающую один максимум и один минимум, причем с помощью этих 6 значений контент в декодере могут быть удовлетворительно интерполирован контент (значения данных) всего блока данных размером 8×8. В вариантах осуществления настоящего изобретения для предоставления значений данных из кодера 20 в декодер 30 применяют, опционально, несколько различных методов. Один из таких способов включает предоставление угловых значений данных, относящихся к блокам данных, с использованием упомянутого выше способа скольжения, совместно со вспомогательной информацией, включающей дополнительные значения, их количество и указаниями на порядок сканирования; упомянутые угловые значения данных и/или вспомогательную информацию, опционально, передают с использованием разностных значений, или без этого. К примеру, на фиг. 4 дополнительными значениями для блока, расположенного справа, являются:
2 (= количество дополнительных значений данных); и
21, 34 (->порядковые номера дополнительных значений данных),
причем порядковый номер верхнего левого угла равен 0, а сканирование выполняют построчно слева направо, начиная с верхнего левого угла. Предоставляемыми значениями данных в случае примере фиг. 4, таким образом, будут 10, 20, 20, 30, 5, и 40. С учетом реально применяемого порядка сканирования значения данных могут быть упорядочены как 10, 20, 5, 40, 20, 30, и тогда все углы скользящего окна, опционально, не передают в качестве первых значений.
Опционально, могут применяться и другие способы доставки и/или упорядочивания значений. Значения блока данных, расположенного в правой части фиг. 4, опционально, передают в следующем виде: 110, 1 4, 9, 99, 10, 10, 10, 97, 46 и 189. В дополнение, передача информации из кодера 20 в декодер 30 должна выполняться таким образом, чтобы предоставлялись только граничные значения блока данных, начиная с левого верхнего угла и в направлении «вниз». Значения данных, которые предоставляют из кодера 20 в декодер 30, могут быть описаны следующим потоком данных или информационным словом:
1000111100000010001111000000
Опционально, эта же самая информация может, дополнительно или альтернативно, предоставляться из кодера 20 в декодер 30 в виде длин серий, к примеру, 1, 3, 4, 6,1, 3, 4 и 6, где первое значение определено как указание на серию доступных значений. В рассмотренных выше примерах осуществления настоящего изобретения представлены различные способы применения алгоритмов интерполяции, а также альтернативные метода предоставления значений данных из кодера 20 в декодер 30. При практической реализации кодека 10, информационный контент, содержащийся в кодируемых данных D1, а также его свойства, определяют, сколько в кодере 20 будет выбрано альтернативных способов формирования кодированных данных Е2, при этом альтернативные способы выбирают, предпочтительно, индивидуально для каждого блока и/или пакета данных; опционально, в кодере 20 блоки данных и/или пакеты данных разбивают, на основе кодируемых данных D1, методом, который позволяет получить наиболее эффективное кодирование, к примеру, в отношении достижимой точности кодирования и/или степени сжатия данных. Как отмечалось выше, в декодер 30 предоставляют информацию, указывающую на способы, которые были применены в кодере 20, а также данные, указывающие на форму блоков данных и/или пакетов данных, которые были закодированы в кодированные данные Е2. Все выбранные альтернативные способы применяют совместно с другими возможными способами кодирования, а в случае выбора способа интерполяции в соответствии с настоящим изобретением, все необходимые параметры кодируют с помощью множества различных способов энтропийного кодирования, например, SRLE-кодирование, RLE-кодирование, РСМ-модуляция, DPCM-модуляция, О-дельта-кодирование, энтропийный модификатор, VLC-кодирование, диапазонное кодирование, кодирование Хаффмана или арифметическое кодирование, но, опционально, без ограничения перечисленным. Таким образом, все значения различных параметров, к примеру, выбранные способы, значения данных, значения градиентов. Способы интерполяции, биты подтверждения предсказания, позиции значений данных, значения ошибки, порядки сканирования и способы кодирования передают в виде собственных потоков сжатых данных внутри кодированного битового потока кодированных данных Е2, что позволяет достичь максимально возможной степени сжатия данных. При необходимости может также выполняться квантование данных, что позволяет повысить степень сжатия кодированных данных Е2. При практическом применении схемы кодирования данных, предложенной в настоящем изобретении, способ интерполяции применяют для интерполяции основной части данных, то есть, как правило, значительно превышающей половину значений данных в блоках данных и/или пакетах данных, которые передают при помощи кодека 10. Предложенные в настоящем изобретении способы, описанные выше, применяют, предпочтительно, с использованием параллельной обработки данных, например, с применением массива процессоров, выполненных с возможностью одновременной обработки блоков данных и/или пакетов данных. В случае, когда предсказание значений данных не выполняют, все блоки данных могут быть обработаны независимо и параллельно. Только когда для сжатия потока данных в кодере 20 необходимо, чтобы все кодированные данные были расположены в правильном порядке, применение параллельной обработки в кодере является менее предпочтительным. Аналогично, декодер 30, опционально, также выполнен с возможностью параллельной обработки принятых кодированных данных Е2 при помощи множества процессоров, к примеру, по меньшей мере в случае применения двух различных способов. В случае, когда в кодированных данных Е2, используются одно или более предсказанных значений, и необходимо их последующее декодирование, в кодированных данных Е2 могут быть выделены, например, «исходные» блоки или «исходные» пакеты, которые являются независимыми и могут быть обработаны отдельно друг от друга. В этом случае данные из различных исходных блоков или исходных пакетов также могут быть кодированы независимо, что дополнительно упрощает обмен данными в кодеке 10, а также упрощает реализацию декодера 30.
Кодер 20 и декодер 30, предпочтительно, могут быть реализованы на практике в одном или более из перечисленного: смартфон, персональный компьютер, телефон-планшет, планшетный компьютер, видеоаппаратура, аппаратура видеонаблюдения, научный прибор, высокоточная аудиоаппаратура, телевизионное оборудование, - без ограничения перечисленным. Способы, предложенные в настоящем изобретении, могут быть реализованы, предпочтительном, с использованием вычислительной аппаратуры, при этом такая вычислительная аппаратура должна быть выполнена с возможностью исполнения одного или более программных продуктов, записанных на постоянном машиночитаемом носителе для хранения данных. Альтернативно или дополнительно, варианты осуществления настоящего изобретения могут быть реализованы, по меньшей мере частично, с использованием цифровой аппаратуры специального назначения, к примеру, заказных электронных интегральных схем, электрически программируемых матриц логических вентилей (field-programmable logic gate array, PLGA) или аналогичной аппаратуры. В дополнение, кодированные данные Е2 допускают могут передаваться при помощи физических информационных носителей, например, компакт-дисков, оптических дисков, магнитных дисков, полупроводников запоминающих устройств, или могут передаваться в виде потоков по сетям обмена данными, например, сети Интернет, сетям беспроводной телефонии и т.п.
В пределах сущности и объема, заданных приложенной формулой изобретения, возможны модификации вариантов осуществления настоящего изобретения, приведенных в предшествующем описании. Такие выражения, как «включающий», «содержащий», «охватывающий», «состоящий из», «имеющий», «представляющий собой», которые использованы в описании и в формуле настоящего изобретения, должны пониматься как неисключающие, то есть допускающие также присутствие объектов, компонентов или элементов, явно не упомянутых. Использование единственного числа может также пониматься как относящееся к множественному числу. Числовые обозначения, приведенные в скобках, имеют целью упрощение понимания пунктов формулы изобретения и не должны пониматься как ограничивающие сущность изобретения, заданного этими пунктами формулы изобретения.

Изобретение относится к области кодирования данных. Технический результат – обеспечение эффективного сжатия данных. Способ кодирования входных данных в кодере для формирования соответствующих кодированных данных включает: прием входных кодируемых данных (D1) и анализ субфрагментов D1 для определения способов кодирования, которые будут применены для кодирования этих субфрагментов, при этом по меньшей мере один из этих способов кодирования включает алгоритм, использующий интерполяцию; вычисление параметров интерполяции для упомянутого способа кодирования, причем параметры интерполяции содержат меньшее или равное количество значений данных по сравнению с половиной количества значений данных в субфрагментах D1; кодирование субфрагментов с использованием способа кодирования, включающего алгоритм, использующий интерполяцию; кодирование остальных субфрагментов D1 с использованием других способов кодирования и включение в кодированные данные (Е2) информации, идентифицирующей субфрагменты и соответствующие способы кодирования, которые используют для кодирования, и параметров интерполяции вычисленных для одного или более субфрагментов. 7 н. и 15 з.п. ф-лы, 4 ил., 2 табл.
1. Способ кодирования входных данных (D1) в кодере (20) для формирования соответствующих кодированных данных (Е2), включающий:
(a) прием входных кодируемых данных (D1) и анализ субфрагментов входных кодируемых данных (D1) для определения двух или более способов кодирования, которые будут применены для кодирования этих субфрагментов, при этом по меньшей мере один из этих способов кодирования включает алгоритм, использующий интерполяцию;
(b) вычисление одного или более параметров интерполяции для упомянутого по меньшей мере одного способа кодирования, включающего упомянутый алгоритм, использующий интерполяцию, при этом один или более параметров интерполяции представляют значения данных из субфрагментов данных (D1), кодируемых при помощи по меньшей мере одного способа кодирования, включающего алгоритм, использующий интерполяцию, и упомянутые один или более параметров интерполяции содержат меньшее или равное количество значений данных по сравнению с половиной количества значений данных в субфрагментах входных данных (D1), которые они представляют;
(c) кодирование одного или более субфрагментов с использованием по меньшей мере одного способа кодирования, включающего алгоритм, использующий интерполяцию;
(d) кодирование остальных субфрагментов входных данных (D1) с использованием одного или более других способов кодирования и
(e) включение в кодированные данные (Е2):
(i) информации, идентифицирующей субфрагменты и соответствующие способы кодирования, которые используют для кодирования на шагах (с) и (d); и
(ii) упомянутых одного или более параметров интерполяции, вычисленных для одного или более субфрагментов на шаге (с).
2. Способ по п. 1, отличающийся тем, что упомянутый по меньшей мере один способ кодирования, включающий алгоритм, использующий интерполяцию, включает по меньшей мере одно из следующего: способ скольжения, способ масштабирования, пирамидный способ, полиномиальный способ, кусочно-постоянный способ, четырехточечный способ масштабирования, пятиточечный пирамидный способ, способ Хилла и 9-точечный способ масштабирования.
3. Способ по п. 1, отличающийся тем, что упомянутый алгоритм, использующий интерполяцию, включает по меньшей мере одну из:
(i) кусочно-постоянной интерполяции;
(ii) линейной интерполяции;
(iii) полиномиальной интерполяции и
(iv) сплайновой интерполяции.
4. Способ по п. 1, включающий выполнение над данными, скомбинированными на шаге (d), одной или более процедур сжатия данных для формирования кодированных данных (Е2), при этом одна или более процедур сжатия данных включают по меньшей мере одно из следующего: скользящее кодирование длин серий (SRLE), кодирование длин серий (RLE), импульсно-кодовую модуляцию (РСМ), дифференциальную импульсно-кодовую модуляцию (DPCM), О-дельта-кодирование, кодирование с использованием модификатора энтропии (ЕМ), кодирование переменной длины (VLC), диапазонное кодирование, арифметическое кодирование, кодирование Хаффмана, дискретное косинусное преобразование (DCT), вейвлет-преобразование, кодирование с палитрой, векторное квантование (VQ), кодирование с использованием базы данных, скользящее преобразование, многоуровневое преобразование, масштабирование, линейное преобразование, экстраполяцию и интерполяцию.
5. Способ по п. 1, отличающийся тем, что на шаге (с) способ включает использование по меньшей мере одного из следующего: DCT-кодирование, вейвлет-кодирование, кодирование с палитрой, кодирование с векторным квантованием (VQ), кодирование с использованием базы данных, кодирование с РСМ-модуляцией, кодирование с DPCM-модуляцией, кодирование с DC-преобразованием, диапазонное кодирование, RLE-кодирование, скользящее кодирование, многоуровневое кодирование, масштабируемое кодирование, линейное кодирование и кодирование с экстраполяцией.
6. Способ по п. 1, отличающийся тем, что алгоритм, использующий интерполяцию, применяемый для кодирования, включает выполнение интерполяции на основе информации, предоставляемой из базы данных.
7. Способ по п. 1, включающий вычисление ошибки между данными, входящими в состав кодируемых данных (1) и восстановленными данными, сформированными на основе кодированных данных (Е1) на шаге (d), при этом способ включает добавление и/или предоставление данных ошибки, с кодированием или без кодирования, в кодированные данные (Е2).
8. Способ по п. 7, включающий встраивание ошибки в кодированные данные (Е2) на основе заданного блока данных или заданного пакета данных, в зависимости от контента, содержащегося в заданном блоке данных или заданном пакете данных.
9. Способ по п. 8, включающий выбор одного или более алгоритмов для кодирования данных (D1), при этом кодируемые данные (D1) включают по меньшей мере одно из следующего: одномерные данные (1D), звуковые данные, данные ЭКГ, сейсмологические данные, двумерные данные (2D), данные изображений, двумерные видеоданные, двумерные графические данные, трехмерные данные изображений, трехмерные видеоданные, трехмерные графические данные.
10. Способ по п. 1, отличающийся тем, что упомянутые один или более параметров интерполяции включают по меньшей мере одно из следующего: значения данных, значения градиентов, способы интерполяции, биты подтверждения предсказания, позиции значений данных, значения дельта, порядки сканирования, способы кодирования.
11. Способ по п. 10, включающий передачу одного или более параметров в кодированных данных (Е2) в виде их собственных сжатых потоков данных.
12. Способ по п. 10, включающий квантование по меньшей мере одного из одного или более параметров для обеспечения улучшенного сжатия кодированных данных (Е2).
13. Способ декодирования кодированных данных (Е2) в декодере (30) для формирования соответствующих декодированных выходных данных (D3), включающий:
(a) прием кодированных данных (Е2) с целью определения одного или более параметров интерполяции, включенных в кодированные данные (Е2), и по меньшей мере одного способа кодирования, к которому упомянутые один или более параметров интерполяции относятся, причем один или более параметров интерполяции представляют значения данных из субфрагментов декодированных данных (D3), при этом два или более способов кодирования включают по меньшей мере один способ кодирования, использующий один или более алгоритм, использующий интерполяцию;
(b) применение обратных алгоритмов к одному или более параметрам интерполяции и связанным с ними данным, присутствующим в кодированных данных (Е2), для восстановления значений данных субфрагментов декодированных данных (D3), причем количество восстановленных значений данных превышает количество значений данных одного или более параметров интерполяции; и
(c) комбинирование восстановленных значений данных субфрагментов для формирования декодированных данных (D3).
14. Способ по п. 13, отличающийся тем, что способ кодирования, использующий один или более один алгоритм, использующий интерполяцию, включает применение способов, обратных по меньшей мере одному из следующего: способ скольжения, способ масштабирования, пирамидный способ, полиномиальный способ, кусочно-постоянный способ, четырехточечный способ масштабирования, пятиточечный пирамидный способ, способ Хилла и 9-точечный способ масштабирования.
15. Способ по п. 13, отличающийся тем, что упомянутый по меньшей мере один алгоритм, использующий интерполяцию, включает по меньшей мере одну из:
(i) кусочно-постоянной интерполяции;
(ii) линейной интерполяции;
(iii) полиномиальной интерполяции и
(iv) сплайновой интерполяции.
16. Способ по п. 13, включающий, перед шагом (а), декомпрессию кодированных данных (Е2) с использованием процедуры, обратной по меньшей мере одному из следующего: SRLE, RLE, PCM, DPCM, О-дельта, модификатор энтропии (ЕМ), VLC, диапазонное кодирование, арифметическое кодирование, кодирование Хаффмана, DCT, вейвлет-преобразование, палитра, векторное квантование (VQ), база данных, DC, скользящее преобразование, многоуровневое преобразование, масштабирование, линейное преобразование, экстраполяция и интерполяция.
17. Способ по п. 13, отличающийся тем, что один или более алгоритмов, использующих интерполяцию, включают выполнение интерполяции на основе информации, предоставляемой из базы данных.
18. Кодер (20) для кодирования данных (D1) для формирования соответствующих кодированных данных (Е2), выполненный с возможностью применения способа по п. 1 для кодирования данных (D1) для формирования кодированных данных (Е2).
19. Декодер (30) для декодирования кодированных данных (Е2) для формирования соответствующих декодированных данных (D3), выполненный с возможностью применения способа по п. 13 для декодирования кодированных данных (Е2) для формирования соответствующих декодированных данных (D3).
20. Кодек (10), включающий по меньшей мере один кодер (20) по п. 18 для формирования кодированных данных (Е2) и по меньшей мере один декодер (30) по п. 19 для декодирования кодированных данных (Е2).
21. Машиночитаемый носитель (60), содержащий программный продукт для исполнения способа по п. 1 посредством вычислительного оборудования (40).
22. Машиночитаемый носитель (70), содержащий программный продукт для исполнения способа по п. 13 посредством вычислительного оборудования (50).
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| ТЕХНОЛОГИИ ПРОГНОЗИРОВАНИЯ ДЛЯ ИНТЕРПОЛЯЦИИ ПРИ КОДИРОВАНИИ ВИДЕО | 2009 |
|
RU2479941C2 |

