Настоящая заявка описывает способ построения и использования индекса поисковых машин и относится к области компьютерной техники и способам обработки информации.
Настоящее изобретение позволяет реализовать функциональность «вытягивания текста» из индекса поисковой машины с произвольного места в тексте, а также существенно снизить трудоемкость анализа совместной встречаемости слов в тексте, что, в свою очередь, позволяет делать предположения о неявных (причинно-следственных, ассоциативных и прочих) связях между объектами в их последовательностях. Изобретение расширяет возможность применения поисковых машин в области индексирования и поиска информации, представленной последовательностью объектов, отличных от объектов текстовой информации. Промышленная применимость изобретения показана на примерах создания и использования информации закодированной Хитами Индекса поисковой машины.
Краткое описание чертежей
Настоящее изобретение лишь проиллюстрировано как примерами, а не как ограничениями применения, сопутствующими чертежами в которых нумерация относится к сходным элементам, среди которых:
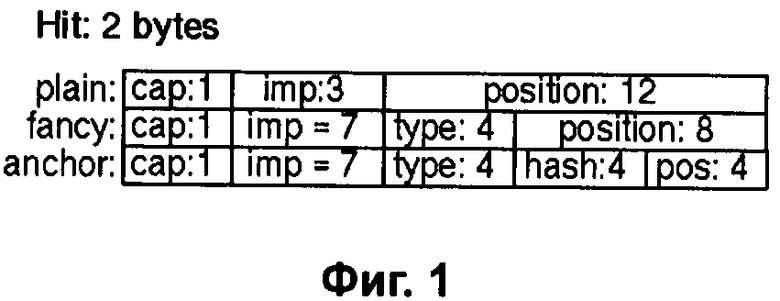
Фиг.1 - Кодирование Хитов поисковой машины Google, как это описано в работе «The Anatomy of a Large-Scale Hypertextual Web Search Engine» (1), Sergey Brin and Lawrence Page.
Фиг.2 - Базовый хит.
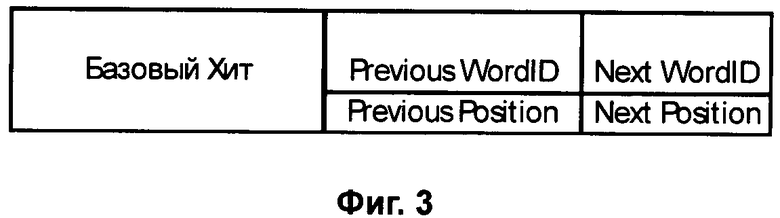
Фиг.3 - Расширение Базового Хита Google путем добавления полей «предыдущего» (Previous) и «последующего» (Next) слов и получение Расширенного Хита в соответствии с настоящим изобретением. Порядковые номера Предыдущего и Следующего слов указаны.
Фиг.4 - Расширенный Хит, в котором порядковые номера Предыдущего и Следующего слов не указаны. Их рассчитывают, зная значение position Базового Хита.
Фиг.5 - Пример текста для индексации.
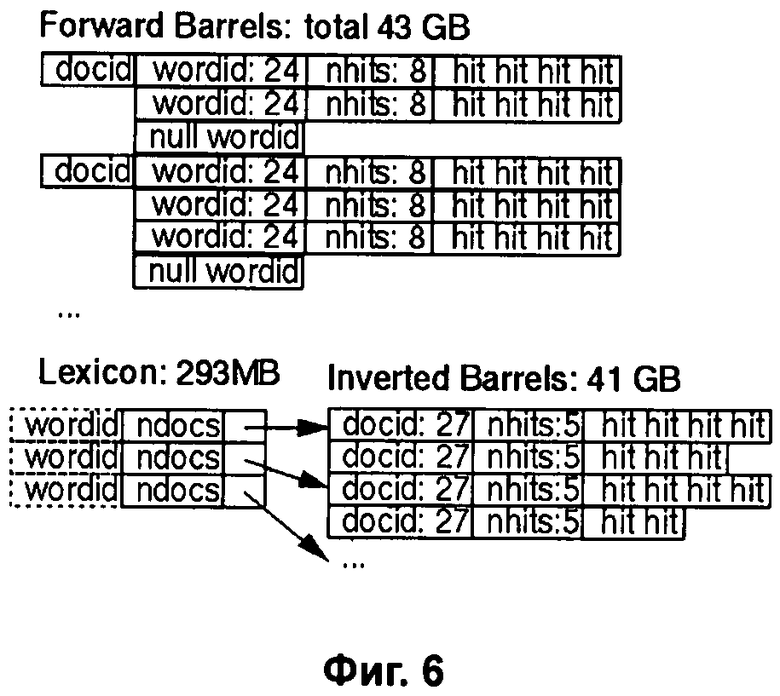
Фиг.6 - Пример содержания Хитов рекурсивного Индекса проиндексированного текста, показанного на Фиг.5.
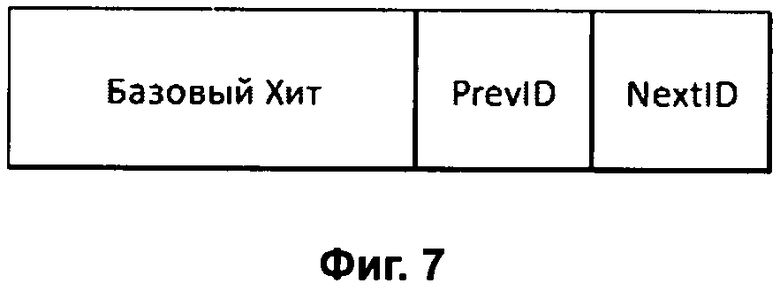
Фиг.7 - Расширенный Хит, в основе которого лежит структура данных Базового Хита Google.
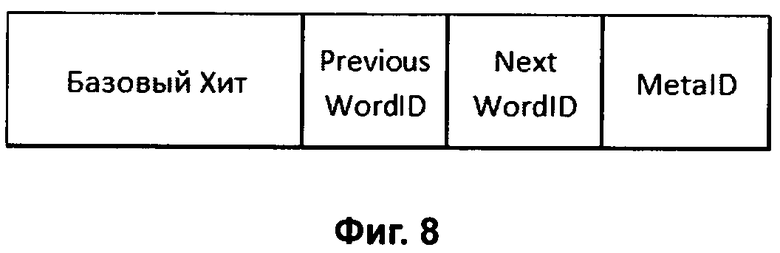
Фиг.8 - Прямой (Forward) и обратный (Inverted) индексы Google из работы (1).
Фиг.9 - Расширенный Хит в соответствии с настоящим изобретением может описывать появление объекта любой природы в соответствующем массиве данных.
Фиг.10 - Добавление указателя «MetaID» доступа к метаданным, например указатель может указывать на местоположение маркировочной информации (tagging) формата ID3v2.
Фиг.11 - Пример таблицы совместной встречаемости нескольких слов языка.
Фиг.12 - Пример «вытягивания» из Рекурсивного Индекса предложений, проходящих через слово «TIGER».
Фиг.13 - Расширенная таблица Базового Хита, добавлен тип данных phrase.
Фиг.14 - Исходный вид сниппета, слово «удобный» выбрано курсором мыши.
Фиг.15 - Вид сниппета после того, как мышью «потянули» за слово «удобный». Это эффект «зуммирования» или «вытягивания» из индекса текста, центром которого является выбранное ранее слово «удобный».
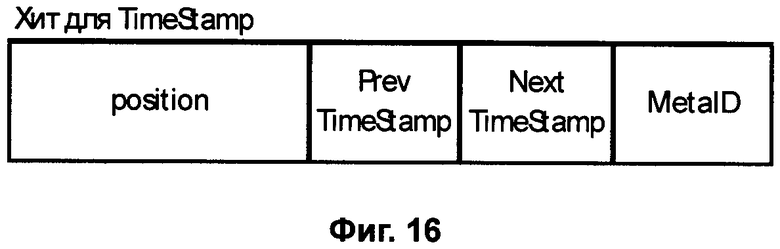
Фиг.16 - Размещение в Расширенном Хите меток времени (TimeStamp) и меток местоположения (Location).
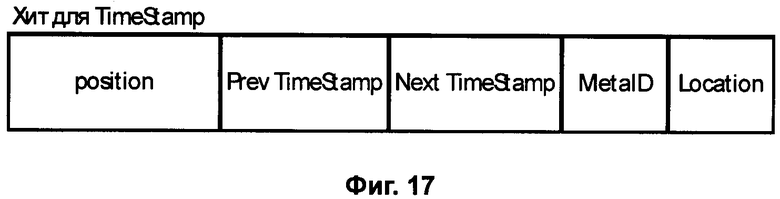
Фиг.17 - Расширенный Хит индекса с меткой времени TimeStamp.
Фиг.18 - Временной Рекурсивный Индекс.
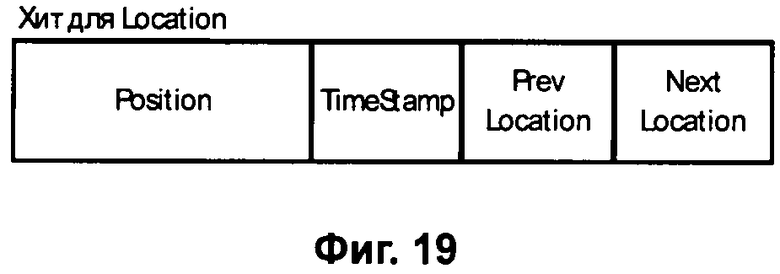
Фиг.19 - Временной Рекурсивный Индекс с меткой местоположения Location.
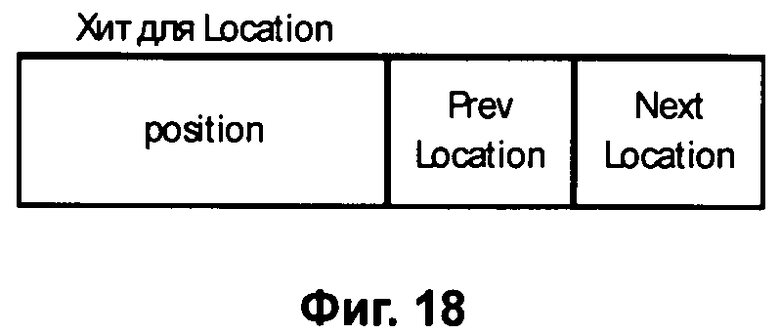
Фиг.20 - Расширенный Хит Рекурсивного Путевого Индекса (местоположения Location).
Фиг.21 - Расширенный Хит Рекурсивного Путевого Индекса (метки времени TimeStamp).
Описание
Известны индексы поисковой машины Google и других поисковых машин, используемые для поиска информации в неструктурированных текстовых данных, размещенных в файловой системе, локальной сети или интернет, текстовых данных, содержащих разметку текста и включенные в текст объекты - графику, музыку, видео и прочее.
Прототипом Индекса поисковых машин является индекс слов бумажных книг, который известен издревле. Такой индекс слов располагается, как правило, в конце или начале бумажной книги и содержит список ключевых слов, которые содержатся в книге. Для каждого слова приводится перечень страниц книги, на которых это слово встречается. Аналогичным образом организован и индекс современных поисковых машин Интернет. В индексе содержится список (lexicon) всех известных слов языка, каждому из которых присвоен идентификатор wordID, список проиндексированных документов, каждому из которых присвоен идентификатор документа dociID, а каждое из появлений слова wordID в конкретном документе представлено Появлением или Хитом (hit). Хит является записью (Фиг.1), содержащей порядковый номер (position) искомого слова (wordID) в документе (docID).
Известен патент США №5265244, G06F 17/30 (20060101); G06F 012/00, описывающий способы построения индекса, но не описывающий содержание статистической информации, размещаемой в Хите индекса. Известен патент США №6490579 (G06F 17/30 (20060101); G06F 017/30) поиска информации с учетом контекстной информации, размещаемой в поисковом запросе. Известен патент США №7,925,641 (G06F 17/30 (20060101); G06F 7/00 (20060101)), описывающий способ индексирования web страниц и размещения в индексе поисковой машины атрибута URI и структуры контента сайта в дизайне, существующем на момент индексирования сайта.
Известна статья в работе «The Anatomy of a Large-Scale Hypertextual Web Search Engine», авторов Sergey Brin и Lawrence Page (далее именуется «работа (1)» http://infolab.stanford.edu/~backrub/gooqle.html), описывающая кодирование статистической информации Хитами индекса поисковой машины Google. Для обеспечения большей релевантности поиска в Интернете поисковые машины Интернет размещают в Индексе признаки, связанные с разметкой языка HTML и использованием гипертекстовых ссылок. Рисунок (Фиг.1), приведенный в работе (1), показывает, что Хит машины Google содержит порядковый номер position слова в нумерованном списке слов текста документа.
Кодирование хитов поясняется в разделе «4.2.5 Hit Lists» работы (1) так: «Существуют два типа хитов: сложные хиты (fancy) и простые хиты (plain). Сложные хиты относятся к URL, наименованиям, видимому тексту гиперссылки или к метаданным вэб страницы. Простые хиты относятся ко всему остальному. Простой хит состоит из бита заглавной буквы (сар:1), размера фонта (imp:3) и 12 битов позиции слова в документе (все позиции выше 4095 обозначены 4096). Размер фонта представлен относительно остальной части документа и использует три бита (на самом деле используются только 7 значений, поскольку значение 111 является флагом сложного хита). Сложный хит содержит бит заглавной буквы (сар:1), размер фонта равен 7 (imp:7), сигнализируя, что это сложный хит, 4 бита кодируют тип (type) сложного хита и 8 битов используются для позиции (position). Для якорного хита (anchor) 8 битов позиции разбиты на 4 бита для позиции в якорном тексте и 4 бита для хеша (hash) значения docID, в котором якорный хит был обнаружен. Это предоставляет ограниченную поисковую функциональность, ограниченную некоторым числом появлений конкретного слова в якорных текстах. Мы собираемся обновить способ размещения якорных хитов с тем, чтобы предоставить большее разрешение для полей позиции и хеша docID. Мы используем размер фонта относительно оставшейся части документа, так как, когда ищем, мы не хотим ранжировать во всем остальном одинаковые документы как разные только потому, что один документ использует больший размер фонта».
Как видно из приведенного описания работы (1), Хит поисковой машины Google кодирует информацию только об одном конкретном слове (wordID), расположенном в конкретной позиции (position) конкретного документа (docID), и далее мы станем называть такой хит «Базовым» (Фиг.2). Главной информацией, которую записывают в Базовый хит, является порядковый номер слова в индексируемом тексте (position), и мы продолжим называть ее номером слова (Position).
В общем, как было сказано выше, появление в тексте некоторого слова представлено в индексе Базовым Хитом, который зависит от набора переменных (cap, type, size, docID, wordID, position), таким образом Базовый Хит пожно условно представить функцией указанного набора переменных:
Базовый Хит = функция (cap, type, size, docID, wordID, position).
Настоящее изобретение предлагает Расширенных Хит, в котором в дополнение к информации Базового Хита размещается (Фиг.3), по меньшей мере, значение идентификатора (wordID) двух слов: «предыдущего слова», позиция которого в документе на единицу меньше и равна (position-1), и «следующего слова», позиция которого в документе на единицу больше и равна (position+1).
Несмотря на то, что в таблице Расширенного Хита (Фиг.3) мы указали позицию предыдущего<Previous Position>=<position-1>и последующего <Next Position>=<position+1> слов в записи Расширенного Хита, как было показано выше эти позиции можно вычислить, что позволяет позиции слов next и previous в записи Расширенного Хита не указывать и тем самым уменьшить объем данных Расширенного Хита индекса (Фиг.4).
Очевидно, что указатель документа DocID для всех трех слов остается по умолчанию одинаковым, так как все три слова являются последовательными словами текста одного и того же документа, имеющего идентификатор DocID.
Таким образом, в соответствии с настоящим изобретением появление некоторого слова в тексте было бы описано Расширенным Хитом как функцией набора переменных так:
Расширенный Хит = функция (cap, type, size, docID, wordID, position, Previous WordID, Next WordID)
или
Расширенный Хит = функция (Базовый Хит, Previous WordID, Next WordID).
Переход от Базового Хита индекса современных поисковых машин к Расширенному Хиту индексу в соответствии с настоящим изобретением позволяет сохранять исходных текст в индексе и восстанавливать исходных текст из индекса, а также повысить эффективность проведения анализа совместной встречаемости слов текста с использованием индекса, по сравнению с тем, как это было возможно, используя Базовый Хит индекса ранее.
В качестве иллюстрации для текста, показанного на Фиг.5, содержание Расширенных хитов Рекурсивного индекса с использованием Расширенных Хитов показано на Фиг.6.
Рекурсивное вытягивание текста из Индекса
Для примера рассмотрим случай Расширенного Хита, в основе которого лежит Базовый Хит поисковой машины Google, а индекс построен для текстовой информации (Фиг.7).
Настоящее изобретение впервые позволяет реализовать рекурсивное «вытягивание» текста из индекса, начиная с любого стартового хита StartHit. Для краткости станем обозначать Previous WordID (предыдущее слово) как <WordID-1> и Next WordID (последующее слово) как <WordID+1>, имея в виду, что номер Предыдущего слова в тексте равен <position-1> и номер Следующего слова в тексте равен <position+1>. Тогда StartHit (Хит текущего слова, находящегося между предыдущим <WordID-1> и следующим <WordID+1> словами) будет представлен следующей зависимостью:
StartHit = Расширенный Хит (WordID, docID, position, WordID-1, WordID+1).
Далее опишем операцию «Восстановления» исходного текста из индекса, представленного Расширенными Хитами. «Восстановление» исходного текста представлено следующими шагами:
Шаг 1:
Извлекаем из StartHit указатели <WordID-1> и/или <WordID+1>.
Шаг 2:
В списке Lexicon (Фиг.8) ищем входы <WordID+1> и/или <WordID-1> и переходя в Обратный Индекс (Inverted Barrels) находим Расширенные Хиты: следующий (NextHit) и предыдущий (PrevHit) соответственно для <WordID+1> и <WordID-1> с номерами слов текста (position+1) и (position-1) для того же документа docID, которые можно записать так:
NextHit = Расширенный Хит (<WordID+1>, docID, position+1, WordID, <WordID+2>)
или
PrevHit = Расширенный Хит (<WordID-1>, docID, position-1, <WordID-2>, <WordID>))
Шаг 3:
Повторяем Шаг 1 и Шаг 2 для записей PrevHit и/или NextHit, извлекая <WordID-3> и <WordID-+3>, переходим к записям Расширенных Хитов для <WordID-3> и <WordID-+3> и так далее до некоторого номера N и соответственно <WordID-N> и <WordID-+N> или до некоторого стоп слова StopWordID.
В результате N повторений Шагов 1 и 2 «Восстановления» получим цепочку слов <WordID-N>→…→<WordID--3>→<WordID--2>→<WordID--1>→<WordID>→<WordID-+1>→<WordID-+2>→<WordID-+3>→…→<WordID-+N>. Текст можно восстанавливать или до начала, или до конца текста, а можно выбрать некоторое условие останова «вытягивания» исходного текста, обозначенное некоторым «стоп словом» (StopWord). В случае использования стоп слова получим цепочку <StorWord>→…→<WordlD--3>→<WordID--2>→<WordID--1>→<WordID>→<WordID-+1>→<WordID-+2>→<WordID-+3>→…→<StorWord>. Стоп словом может служить, например, знак «точка», разделяющая предложения, или номер N в выражении <position+-N>, или другое условие останова «вытягивания» исходного текста из индекса. В случае, например, когда условием останова является конец предложения, «Восстановление» будет происходить, пока не будут достигнуты начало и/или конец предложения. Стоп словом также может служить, например, слово, начинающееся с заглавной буквы (флаг Заглавной буквы <cap>), расположенное в якорном тексте, или слово, имеющее другой признак останова. Точно также можно восстанавливать не одно предложение, а произвольное число предложений текста. Условием остановки «Восстановления» может служить любое условие, которое можно сформулировать для поисковой машины.
Наличие в Индексе признаков «заглавной буквы» (cap) и других атрибутов форматирования текста позволяет восстанавливать текст с той или иной степенью соответствия оригиналу. Расширение числа признаков до числа признаков форматирования, используемых в текстовых редакторах, позволило бы восстанавливать тексты без отличий от исходного оригинала, который был проиндексирован.
Важной особенностью изобретения является то, что оно позволяет индексировать не только текст, но также массивы информации любой природы, представленные нумерованной значением <position> последовательностью объектов.
Для объектов отличной от текста природы цепочка восстановленных объектов будет выглядеть соответственно так:
<Предыдущий Объект N> →…→ <Предыдущий Объект 2> → <Предыдущий Объект 1> → <Предыдущий Объект> → <Объект> → <Следующий Объект 1> → <Следующий Объект 2> →…→ <Следующий Объект N>
или со стоп объектом так:
<Стоп Объект> →…→ <Предыдущий Объект 2> → <Предыдущий Объект 1> → <Предыдущий Объект> → <Объект> → <Следующий Объект 1> → <Следующий Объект 2> →…→ <Стоп Объект>.
Наличие в Расширенных Хитах индекса Предыдущего и Следующего Объектов, позволяет индексу обращаться к самому себе, для извлечения очередного i-го PreviousObject или i-го NextObject, имеющих соответственно номера <position-i> и <position+i> в нумерованной последовательности Объектов исходного массива информации.
Имея в виду свойство рекурсивного «восстановления» последовательности объектов из изобретенного индекса, далее мы станем называть изобретенный индекс Рекурсивным Индексом.
Возможность частичного или полного восстановления текста исходного документа или массива данных другой природы путем его «вытягивания» из Рекурсивного Индекса делает возможным множество полезных применений настоящего изобретения в быту и технике. Ниже приведены некоторые из таких применений.
Индексирование объектов разной природы
Поскольку в современном Интернете помимо текстов присутствует геодезическая информация, медиа информация и множество других типов данных, число которых постоянно увеличивается, то настоящее изобретение предлагает использовать не идентификаторы слов (wordID), а идентификатор объекта любой природы, а библиотеки могут состоять не только из текстовых документов, но также из видеоматериалов, картинок, звуковых файлов, файлов координатной информации и любых других файлов. В этой связи в число идентификаторов, от которых зависит Хит, помимо docID и WordID может быть например тип библиотеки libraryID, вместо docID можно использовать идентификатор источника sourceID, а вместо идентификатора слов WordID можно использовать идентификатор объекта object ID и так далее. Рисунок (Фиг.9) показывает кодирования Расширенного Хита объектов любой природы (включая текст), где Базовый Хит кодирует текущий объект, NextID является идентификатором объекта, следующего в цепочке за текущим, и PrevID является идентификатором объекта, предшествующего текущему объекту в цепочке (Фиг.9).
Метаданные Рекурсивного Индекса
В настоящее время известно много форматов, в том числе медиа форматов, требующих размещения богатой мета информации. В частности это относится к ID3 tag для файлов МР3 и к Metadata файлов MPEG4 (http://atomicparsley.sourceforqe.net/mpeq-4files.html). к данным бегущей текстовой строки для караоке, формату TimedText для фильмов с субтитрами и так далее.
Для расширения функциональности Рекурсивного индекса с целью поддержки индексирования медиа данных и других видов данных, настоящее изобретение предлагает размещение указателя «MetaID» в информации Расширенного Хита (Фиг.10). Метаданные, которые описывает MetaID, расширяют формат Базового Хита, дополняя описание объекта, позицию которого содержит Базовый Хит. Поскольку файлы метаданных MPEG, MP3, MPEG4, караоке и биометрических данных и так далее могут отличаться друг от друга, то MetaID, например, может содержать указатели места размещения метаданных.
Расширенный Хит поисковой машины может иметь множество применений, примерами которых могут служить: размещение списка запросов к поисковой машине, ранжированных по рейтингу в качестве метаданных Рекурсивного Временного Индекса рейтинга поисковых запросов; размещение в Рекурсивном Временном Индексе рецепта приготовления пищи, в котором метаданными могут служить описания ингредиентов, их весовые или объемные доли, температурный режим, описание используемой посуды и другие особенности процесса приготовления; размещение в Индексе последовательности шагов проведения химической реакции или размещение последовательности картографических точек дорог или маршрутов движения и так далее…
Анализ совместной встречаемости объектов
Путем анализа совместной встречаемости слов языка можно установить, какие из словосочетаний являются устойчивыми, а какие нет. Некоторые из устойчивых словосочетаний могут оказаться понятиями, для которых нет одного слова. Таким понятием, например, может служить словосочетание «Нейро-лингвистическое программирование». Очевидно, что встречаемость слов в последовательности <нейро → лингвистическое → программирование> будет существенно выше, чем слов обратной последовательности <программирование → лингвистическое → нейро>. В приведенном примере словосочетание <нейро → лингвистическое → программирование> образует понятие «НЛП». Выявление различного веса прямой и обратной сочетаемости («анизотропия» сочетаемости) слов позволяет делать предположения об устойчивом сочетании слов или позволяет сделать предположение о существовании неявных связей между словами и понятиями, включая причинно-следственные или ассоциативные связи. Так Таблица совместной встречаемости (Фиг.11) содержит условный вес совместной встречаемости слов рассмотренного словосочетания «нейро-лингвистическое программирование» (Фиг.11).
Предположим (Фиг.11), словосочетания «нейро-лингвистическое» и «лингвистическое программирование» встречаются с одинаковой частотой 0,7. Вместе с тем двумерная таблица не позволяет установить вес совместной встречаемости словосочетания трех слов «нейро-лингвистическое программирование», для решения последней задачи пришлось бы строить трехмерную матрицу 3*3*3 слов.
Таким образом, решение задачи совместной встречаемости каждых двух слов из N слов языка, потребует создания двумерной таблицы N*N слов языка и занесения в нее рейтингов совместной встречаемости каждых двух слов, на пересечении которых находится ячейка рейтинга совместной встречаемости. А для изучения совместной встречаемости трех слов понадобилось бы построить уже куб размером N*N*N и так далее, что усложняет задачу экспоненциально.
Поскольку современные поисковые машины используют Базовый Хит, содержащий позицию одного слова, то поиск сочетаний слов, а также анализ частоты взаимной встречаемости двух и более слов языка можно решать только путем построения таблицы NG, где G представляет собой число слов в одном сочетании. Как было показано выше, решение задачи таким способом связано с высокой трудоемкостью и экспоненциальным ростом трудоемкости при увеличении числа слов в словосочетании. Этим объясняется то, что Google и другие поисковые машины не позволяют эффективно искать фразы, содержащие более трех слов.
Использование Рекурсивного Индекса позволяет существенно снизить трудоемкость решения задачи анализа совместной встречаемости сочетаний G слов из N слов языка, перейдя от анализа многомерной области NG слов языка к анализу ограниченной области с радиусом R слов языка, где R>=G, как это показано ниже.
Решение задачи совместной встречаемости с использованием рекурсивного индекса
Для изучения совместной встречаемости, например, слова «лингвистическое» мы «вытягиваем» из Рекурсивного Индекса все цепочки слов, в которых встречается слово «лингвистическое», ограничиваясь некоторым числом R слов до и после слова «лингвистическое». Здесь число R служит условием останова «вытягивания» исходного текста из рекурсивного индекса. Таким образом, если через слово «лингвистическое» проходит множество предложений одного документа или множество предложений разных документов, то в качестве результата «вытягивания» мы получаем сферу из слов с радиусом R слов, в центре которой находится слово «лингвистическое». Если условием останова «вытягивания» будет знак «точка», то мы сможем вытягивать слова до и после слова «лингвистическое» до знака «точка», означающего конец и начало предложения, в котором встретилось слово «лингвистическое». Пример такой сферы, ограниченной началом и концом предложения, центром которой является слово Tiger, показан на Фиг.12. В случае использования конца или начала предложения в качестве условия останова, радиусом Сферы будет не R слов, а одно или R предложений, центральное предложение сферы, при этом будет содержать слово, за которое мы «тянули».
Далее мы можем проводить анализ совместной встречаемости слова «лингвистическое» с другими словами в объеме «вытянутых» цепочек текста. Понятно, что все словосочетания «нейро-лингвистическое программирование» попадут в поле нашего зрения, так как все они попадают в Сферу радиуса R=одно слово или R=одно предложение. Понятно также, что анализ всех предложений, включающих такое словосочетания в указанном радиусе, не представляют большой трудоемкости даже для настольного компьютера. Таким образом, Рекурсивный Индекс и его архитектура, построенная на использовании Расширенного Хита, позволяют решить задачу поиска и анализа совместной встречаемости слов с существенно большей эффективностью, чем это позволяет делать индекс современных поисковых машин, включая Google и другие поисковые машины.
Проиллюстрируем вышесказанное еще на одном примере.
Фиг.12 показывает цепочки слов, проходящие через слово «TIGER» «вытянутые» из Рекурсивного Индекса с R=одно предложение. Все приведенные предложения являются частью одного документа, но относятся к разным Хитам слова Tiger в этом документе, однако Рекурсивный Индекс, содержащий Хиты из разных документов, позволяет проводить анализ с такой же эффективностью по всему множеству доступных документов. Как видно, в цепочках повторно встречаются различные формы слова «large», а также слова «big», «cat», из чего можно сделать вывод о возможной связи слова «tiger» со словами «big», «cat» и «large». Причем слова «big» и «cat» встречаются два раза вместе, что может указывать на существование устойчивого словосочетания «big→cat». Устойчивость произвольного словосочетания Word1→Word2 можно проверить, «вытянув» из Рекурсивного Индекса все цепочки слов, центром которых в одном из случаев будет, например, слово Word1 (слово за которое «тянули», в приведенной на Фиг.12 примере было слово «Tiger»). Для того чтобы проверить тоже самое словосочетание Word1→Word2 на совместную встречаемость в обратном направлении Word1→Word2, следует «потянуть» за слово Word2 из индекса цепочки слов и анализировать в вытянутых цепочках слов, случаи, когда NextWord для Word2 является Word1. Если, например, частота встречаемости сочетания Word1→Word2 окажется существенно больше частоты встречаемости сочетания Word2→Word1, то это будет указывать на то, что сочетание Word1→Word2 является устойчивым, а сочетание Word2→Word1 случайным. Так, например, вытягивая цепочки слова «big» или Хит-слова «cat» и проводя анализ совместной встречаемости слов «big» и «cat», в вытянутых цепочках можно установить, является ли словосочетание «big cat» устойчивым или случайным. На примере Фиг.12 видно, что сочетание «big cat» встречается чаще, чем «cat big», из чего можно сделать вывод о возможной устойчивости словосочетания «big cat» и вероятном отсутствии словосочетания «cat big».
Совместную встречаемость слов (или других объектов) можно понимать и шире, чем образование словосочетаний (сочетаний объектов).
Такие слова, как «огонь» и «дым», могут не образовывать словосочетания, но имеют причинно-следственную связь, из-за которой их появление в одном тексте имеет более высокую вероятность, чем слов, не имеющих причинно-следственной связи. Это обстоятельство позволяет ожидать, что на большой статистике текстов такая вероятность даст всплеск совместной встречаемости слов, не образующих устойчивые словосочетания, но связанных причинно-следственными связями. Можно также ожидать, что встречаемость слов может иметь преимущественное направление, например встречаемость «огонь→дым» может оказаться выше, чем обратная встречаемость «дым→огонь», что может указывать на причинно-следственную связь между словами или понятиями. Можно также ожидать, что, исследуя словосочетания, состоящие из трех слов и более, анализ совместной встречаемости позволит выявлять устойчивые словосочетания PreviousWord(i)→NextWord(j), что позволит делать заключения о наличии связи между словами PreviousWord(i)→NextWord(j). Можно предполагать, что если помимо сочетаемости Предыдущего слова с Текущим (PreviousWord(i)→CurrentWord) и Текущего слова со Следующим (CurrentWord→NextWord(j)) существует прямая сочетаемость слов Предыдущее слово→Следующее слово (PreviousWord(i)→NextWord(j)), то такая связь является ассоциативной, поскольку такая связь обусловлена Текущим словом, но напрямую с ним не связана, а значит Текущее слово играет роль ассоциативной связи между Предыдущим словом и Следующим словом. Различие частоты прямой PreviousWord(i)→NextWord(j) и обратной сочетаемости NextWord(j)→PreviousWord(i) позволит сделать предположение о причинно-следственной связи в ассоциативной цепочке слов или других объектов.
Индексирование выявленных понятий
Поскольку Базовый Хит современных поисковых машин описывает позицию одного слова, а не понятия, то в случаях, когда такое слово является частью устойчивого словосочетания, Базовый Хит не обеспечивает релевантности индексации и поиска информации, так как отдельные слова устойчивого словосочетания не имеют отдельного смысла и являются носителем смысла только когда используются совместно! Часто понятия обозначаются аббревиатурами, таким образом, для них появляется отдельное «слово» языка.
Аналогичная ситуация сложилась со словосочетаниями, составляющими название торговой марки или рекламного слогана, названия песни или фильма, на которые распространяются авторские права их обладателей. Такие словосочетания также становятся устойчивыми для идентификации продукции, фильма, песни или другого предмета авторских прав. Автоматическое выявление таких устойчивых словосочетаний также является трудоемким при использовании индекса Google и других поисковых машин.
Как было показано выше, Рекурсивный Индекс позволяет эффективно проводить анализ совместной встречаемости слов и выявлять устойчивые словосочетания, представляющие понятие, слоган или наименование. Для выявленных устойчивых наименований Рекурсивный Индекс содержит, как было сказано выше, Google использует значение imp=7 в качестве флага для индикации сложного хита. Фиг.13 показывает один из возможных способов расширения функциональности Базового Хита путем кодирования устойчивых словосочетаний, обозначенных «phrase», флагом для обозначения хита устойчивого словосочетания в качестве примера принято нулевое значение размера фонта imp=0, type:2 кодирует число слов в словосочетании (до 4 слов) и 8 битов значения position относится к первому слову словосочетания.
Вместе с тем понятно, что кодирование Базового Хита (Фиг.2, 13) не отражает сегодняшних реалий Интернета как с точки зрения объема информации (даже 12 битов значения position может оказаться недостаточно для кодирования позиции объекта), так и с точки зрения типов данных (plain, phrase, fancy, anchor), поэтому приведенное кодирование расширенной таблицы Базового Хита является лишь иллюстрацией описанного настоящим изобретением способа расширения функциональности индекса поисковых машин.
Индексирование выявленных неявных связей
Для индексирования объектов, имеющих неявную связь с Базовым Хитом, настоящее изобретение предлагает использовать поле метаданных MetaID, куда заносится указатель на файл объектов, ассоциативно/причинно-следственно связанный с Хитом в контексте конкретного документа. Таким образом, для каждого отдельного Хита одного и того же WordID найденного в разных документах docID содержание MetaID будет уникальным и отвечающим контексту использования WordID конкретного Базового Хита.
Некоторые практические применения Рекурсивного Индекса
Рекурсивный Индекс текстов
Рекурсивный индекс, в частности, позволяет упростить Интерфейс пользователя (User Interface или UI) поисковой машины и улучшить «usability» поиска, позволив пользователю «вытягивать» курсором цепочки слов из Сниппета (snippet) в списке результатов поиска, потянув за любое слово, расположенное в тексте сниппета. «Вытянутый» таким образом текст позволяет пользователю с минимальными усилиями понять, насколько результат поиска, представленный таким сниппетом, релевантен поисковому запросу пользователя, не прибегая с загрузке web страницы, сниппет которой был показан в результатах поиска. «Зуммирование» текста сниппетов в результатах поискового запроса к поисковой машине показано на рисунках ниже (Фиг.14, 15). Под «Зуммированием» в данном случае мы имеем в виду «вытягивание» курсором выбранного в тексте сниппета слово (в данном случае слово «удобный»). «Зуммирование» приводит к «вытягиванию» из Рекурсивного Индекса слов текста слева и справа от выбранного слова и вывод «зуммированного» текста в окно просмотра.
Рекурсивный Индекс времени и местоположения
Базовый Хит не является чувствительным к местоположению и времени, так как учитывает лишь положение слова в тексте (Фиг.2). В то же время для видео и аудио хроники (живого общения, речи и событий записанных на видео) время и место может иметь существенное значение. Для индексации объектов, чувствительных ко времени и местоположению, наряду с номером появления <position> следует использовать метки времени <TimeStamp> и координаты <Location>, например геодезические (Фиг.16).
В такой индекс можно записывать, например, распознанные объекты, появляющиеся в кадре при съемке видеокамерой, закрепленной, например, на движущемся автомобиле.
Размещение метки времени TimeStamp или метки сдвига по времени TimeOffset относительно некоторого известного времени TimeStamp (например, относительно времени начала записи звука или видео) в Хитах слов для результатов распознавания речи, при «вытягивании» текста из Рекурсивного Индекса позволяет передать темп произнесения слов во времени. В такой реализации значениями WordID, NextID и PrevID могут являться слова говорящего, коды распознанных видео образов или цифровые объекты другого происхождения, появление которых связано хронологически.
Рекурсивный Индекс для индексации картины мира
Известно, что картина мира для человека складывается из информации, попадающей в мозг через каналы чувств (зрение, осязание, слух, обоняние, вкус, термоцепция и другие). Фиксация поступающей в каждый канал чувств человека информации имеет хронометрический характер и потому может быть представлена Рекурсивным Индексом ощущений. Для зрения - это объекты, которые попадают в поле зрения, а для уха - это ряд звуков, которые улавливаются ухом, и так далее. Таким образом, текст, являющийся результатом распознавания речи, может использовать Расширенные Хиты временного рекурсивного индекса слов (Фиг.17), содержащий также ссылки на предыдущее и следующее слово <Next WordID> и <Prev WordID>.
Если учесть, что события реальной жизни связаны также с местоположением, то наличие в Расширенном Хите не только метки времени TimeStamp, но и метки местоположения Location (Фиг.16) может оказаться важным. Метка местоположения может носить более общий характер и содержать геодезические или некие относительные координаты, например смещение местоположения LocationOffset относительно некоторого известного местоположения Location (например от местоположения начала маршрута), а также идентификатор источника данных, как, например, наименование телеканала. Расширенный Хит (Фиг.16) показан не для Слова, а для любого другого Объекта, видеообраза, химического вещества, местоположения и так далее.
В настоящее время в различных лабораториях проводятся работы по идентификации и синтезу запахов, а также по идентификации и воспроизведению других ощущений человека, и можно представить, что через некоторое время медиа файлы будут содержать не только изображение, звук и строку субтитров, но также информацию о запахе, вкусе, тактильных ощущениях и прочее. Размещение таких данных в соответствующих Рекурсивных Индексах позволит осуществлять по ним поиск, «вытягивать» временные цепочки таких данных для использования, а также проводить анализ их взаимной встречаемости. Метки времени, размещенные в Рекурсивном Индексе, позволят синхронизировать воспроизведение данных из разных Рекурсивных индексов, содержащих информацию разных каналов чувственного восприятия, а метки местоположения позволят делать геодезическую или другую привязку местоположения.
Временной Рекурсивный Индекс
Временной Рекурсивный Индекс содержит вместо WordID метки времени TimeStamp (Фиг.18). Идентификатор MetaID указывает на место размещения метаданных, относящихся к описываемому моменту времени TimeStamp, а метки времени Prev TimeStamp и Next TimeStamp указывают соответственно на Предыдущую метку времени и на Следующую метку времени. В Хите метки времени возможно размещение метки местоположения Location (Фиг.19) или другой необходимой информации.
Рекурсивный Путевой Индекс
Поскольку свойством Рекурсивного Индекса является запоминание последовательности следования объектов индексации, то становится возможным рекурсивное индексирование последовательностей геодезических координат и адресов, представляющих, например, маршруты движения или картографическую информацию дорожной сети. При этом адреса или геодезические координаты точек маршрута вносятся в индекс вместо WordID (Фиг.20 и 21).
Аппаратная реализация работы с Рекурсивным Индексом
Создание поисковой системы, в которой файл Рекурсивного Индекса отделен от Программы анализа и поиска Рекурсивного Индекса (ПАПРИ), позволяет реализовать ПАПРИ в аппаратном виде и ускорить работу ПАПРИ, а также сделать чип, предназначенный для встраивания в различные устройства, связанные с обработкой информации. Последнее обстоятельство позволяет создать устройства, способные «на лету» индексировать распознанные видеообразы, речь, поток данных, поступающих через каналы связи, и любые данные, мгновенно предоставляя возможность поиска в таких данных.
Распределенный Рекурсивный Индекс
Рекурсивная Индексация web сайта или данных персонального или сетевого компьютера/сайта/файла с последующим размещением полученного файла Рекурсивного Индекса на проиндексированном сайте/компьютере/файле позволяет создать модель распределенного Рекурсивного Индекса файловой системы/компьютера/локальной сети или Интернет, при котором Рекурсивные Индексы каждого компьютера или сайта находятся на самом компьютере/сайте, что позволяет предоставить пользователям локальный Рекурсивный поиск по компьютеру/сайту/файлу, без необходимости обращаться к поисковой машине сети или Интернет. Аппаратная реализация ПАПРИ позволяет организовать работу с локальными файлами Рекурсивного Индекса, не обращаясь к центральной поисковой машине. Ниже приведены некоторые примеры автономного размещения рекурсивного индекса. Возможность построения распределенного Рекурсивного Индекса позволяет создать поисковую машину Интернет с распределенным Рекурсивным Индексом.
Повышение релевантности работы поисковой машины
Использование анализа совместной встречаемости в рекурсивном индексе позволяет повысить релевантность поиска поисковых машин, в том числе поисковых машин Интернет.
Для этого дополнительно к поисковому запросу, содержащему одно или несколько слов, в поисковую машину может быть введен образцовый текст с использования слов запроса. Такой текст далее индексируется, и из него создается рекурсивный индекс.
Устанавливается некоторая теоретическая или эмпирическая Избранная Мера Совпадения результатов анализа совместной встречаемости появления одного и того же слова в разных массивах данных.
Для слов поискового запроса производится анализ совместной встречаемости слов запроса со словами образцового текста. Далее производится поиск в индексе поисковой машины Хитов появления слов поискового запроса, а для найденных Хитов производится анализ совместной встречаемости слов поискового запроса с другими словами массивов данных, проиндексированных поисковой машиной, а также анализа совместной встречаемости с другими словами поискового запроса.
Полученные результаты анализа совместной встречаемости слов поискового запроса в образцовом тексте (Образцовые результаты) сравниваются с результатами анализа совместной встречаемости слов поискового запроса в массивах данных, проиндексированных поисковой машиной (Результаты машины), и если мера совпадения Образцовых результатов с Результатами машины соответствует Избранной Мере Совпадения, то найденный Хит считается релевантным результатом поиска.
Некоторые примеры применений Рекурсивного Индекса
Одним из важных применений может служить индексирование видеоинформации - фильмов, видеорепортажей, результатов видеонаблюдения, фотографий и так далее. Индексировать видеоматериалы можно как с помощью Рекурсивного Текстового Индекса, так и с помощью Рекурсивного Временного Индекса. Так, создавая Рекурсивный Индекс текстовой информации субтитров, распознанной речи или текста (Speech or text recognition) с метаданными, служат распознанные видеообразы - лица людей или объекты (face/object recognition). Наоборот, для Рекурсивного Временного Индекса видеоматериала метаданными может служить видеокадр, распознанное изображение и текст. Создание Рекурсивного Индекса видеоматериалов позволит создать механизм поиска распознанных изображений и текста сопровождающего видео, а также позволит создать машину индексирования видеорепортажей и видеоматериалов в реальном времени, что, в свою очередь, позволит встретить такую технологию индексации и поиска видеоданных в фотоаппараты, видеокамеры, телефоны и другие носимые устройства, способные создавать видео, а также компьютеры и другие устройства, способные проигрывать ранее созданное видео.
Пример 1. Размещение рекурсивного индекса данных в медиа файлах
Технология размещения бегущей строки текста песни в «Караоке» или текста субтитров в видеофильмах реализуется с помощью технологии Timed Text или аналогичной технологии, описанной соответственными индустриальными или корпоративными стандартами производителей оборудования и носителей медиа данных.
Применение технологий распознавания лиц и объектов (face и object recognition), распознавание текста (text recognition), а также распознавание речи (speech recognition) позволяет преобразовывать видеоданные и звуковые данные видеозаписей (включая фильмы) и потокового видео в уникальные цифровые коды лиц, объектов и текст оптически распознанного текста и речи. Поскольку распознанные лица, объекты и текст, а также текст распознанной речи представляют собой временную последовательность объектов, представленных в видеоматериалах в машиночитаемом цифровом виде, то после распознавания речи и видеообразов становится возможной их индексация рекурсивным индексом и позволяет предложить хронометрический поиск по распознанным объектам для видеоматериалов, а также хронометрический поиск и позиционирование по тексту речи и поиск появившихся в видеоматериале объектов и лиц.
Индексирование в соответствии с настоящим изобретением распознанных объектов видеосъемки впервые предоставляет возможность поиска распознанных объектов и «вытягивание» событий, предшествующих появлению распознанного объекта или последующих за появлением распознанного объекта. В свою очередь, это позволяет многократно снизить трудоемкость поиска объектом поиска в материалах видеонаблюдения.
Телефон в настоящее время позволяет просто разговаривать, а также осуществлять видеозвонки. Индексирование в соответствии с настоящим изобретением распознанной речи и лиц позволяет создать технологию автоматического стенографирования телефонных переговоров, с возможностью поиска распознанного текста и видеообъектов в их хронологической последовательности.
Для медиа файлов форматов MP3, а также MPEG4 отраслевыми стандартами предусмотрено размещение маркировочной информации в маркировочной системе ID3 (tagging system) и других маркировочных системах (http://atomicparsley.sourceforqe.net/mpeq-4files.html). В частности, система ID3v2 http://www.id3.org/ID3v2Easv способна содержать до 256 мегабайт информации любого содержания, содержащей метаданные медиа файла MP3 или MPEG4. Это позволяет размещать в метаданных ID3v2 полные Рекурсивные Индексы текста субтитров фильма на всех языках, рекурсивные индексы песен, книг, а также рекурсивный индекс распознанных видео образов, распознанный текст и текст распознанной речи.
Индексирование текста электронной книги в соответствии с настоящим изобретением позволяет «вытягивать» текст книги из рекурсивного индекса, начиная с любого слова текста, что позволяет использовать рекурсивный индекс в качестве источника текста электронной книги.
Размещенный в маркировочной системе (ID3 или другой) Рекурсивный Индекс предоставляет возможность поиска текстовой и видеоинформации в метаданных для медиа файлов, включая, но не ограничиваясь аудио форматами CD, MP3, WMA, AAC, AIFF, M4A и видео форматами DVD, Blu-Ray, HD, MP4, AVI, MOV, RAM, SWF, WMV и другими известными медиа форматами, а также возможность «вытягивания» части или полного текста, и/или образов видеоряда произведения в их хронометрическом порядке, осуществления в нем поиска, проведение анализа данных, взаимной встречаемости данных с помощью техники, описанной в настоящей заявке. Размещение Рекурсивного Индекса в метаданных ID3 медиа файлов и в метаданных любого другого формата позволяет реализовать функции «вытягивания» данных, поиска в них, анализа данных на предмет совместной встречаемости и выявление возможных ассоциативных и причинно-следственных связей, независимо от используемого формата, создает основу для индексации и поиска данных любого происхождения и содержания.
Пример 2. Тексты электронных книг
Известно множество открытых и корпоративных форматов электронных книг e-books http://en.wikipedia.org/wiki/Comparison_of_e-book_formats. Вместе с тем использование Рекурсивного Индекса для публикации электронных книг позволяет «вытягивать» текст книги непосредственно из Рекурсивного индекса и одновременно предоставить пользователю функцию поиска в тексте и анализа текста с помощью Рекурсивного Индекса.
Пример 3. Рекурсивный индекс картографической информации.
Размещая в файле Рекурсивного индекса геодезические координаты точки, можно индексировать маршруты движения или схему дорог с учетом разрешенного направления движения.
Пример 4. Рекурсивный Индекс новостей и RSS лент
Новости поступают в разное время, маркеры которого могут использоваться вместо слов для индексирования в Рекурсивном Временном Индексе, Рекурсивный Текстовый Индекс.
Бизнес модели
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в электронных книгах.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в аудиокнигах.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в электронных источниках картографической информации, в том числе геодезической.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в устройствах навигации.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в устройствах связи.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в компьютерах, в том числе мобильных.
Взимание оплаты за создание и/или размещение, и/или использование Рекурсивного Индекса в телефонах, смартфонах, навифонах и медиа устройствах таких как iPod и другие.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса с носителей видео информации, таких как CD, DVD, Blu-Ray и любых других форматов, уже известных, и тех, которые будут использоваться в будущем, включая, но не ограничиваясь аудио форматами MP3, WMA, AAC, AIFF, M4A и видео форматами MP4, AVI, MOV, RAM, SWF, WMV.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса web сайта или ссылки на такой Рекурсивный Индекс web сайта в метаданных web сайта или в структуре данных Semantic Web названного сайта.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса в структуре данных Semantic Web.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса поисковой машины в локальной сети.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса поисковой машины в сети Интернет.
Взимание оплаты за создание и/или запись, и/или считывание Рекурсивного Индекса поисковой машины в произвольной сети коммуникаций.
Взимание оплаты за создание и/или размещение, и/или показ рекламы контекстно или по другому связанной с данными, извлеченными из Рекурсивного Индекса.
Взимание оплаты за проектирование и/или создание, и/или распространение, и/или использование программного обеспечения, способного создавать Расширенные Хиты рекурсивного Индекса, содержащие информацию о Следующем Объекте или Предыдущем Объекте.
Взимание оплаты за проектирование и/или создание, и/или распространение, и/или использование программного обеспечения, способного извлекать из Расширенных Хитов Рекурсивного Индекса информацию о Следующем Объекте или Предыдущем Объекте.
Взимание оплаты за проектирование и/или создание, и/или распространение, и/или использование программного обеспечения, способного создавать Расширенные Хиты Рекурсивного Индекса, содержащие Предыдущий или Следующий Объекты распознавания, распознанные программой распознавания речи (speech recognition), распознавания текста (optical character recognition или text recognition), распознавания лица (face recognition) или распознавания любого другого зрительного объекта или объекта другой природы (химического, геодезического и так далее).
Взимание оплаты за проектирование и/или создание, и/или распространение, и/или использование аппаратного обеспечения (чипа, контроллера, процессора и так далее), способного создавать Расширенные Хиты рекурсивного Индекса, содержащие информацию о Следующем Объекте или Предыдущем Объекте, извлекать из Расширенных Хитов Рекурсивного Индекса информацию о Следующем Объекте или Предыдущем Объекте, проводить анализ совместной встречаемости Объектов.









Изобретение относится к способу построения и использования индекса поисковых машин и относится к области компьютерной техники и способам обработки информации. Техническим результатом является расширение функциональных возможностей поиска информации. Настоящее изобретение позволяет реализовать функциональность «вытягивания текста» из индекса поисковой машины с произвольного места в тексте, а также существенно снизить трудоемкость анализа совместной встречаемости слов в тексте, что, в свою очередь, позволяет делать предположения о неявных (причинно-следственных, ассоциативных и прочих) связях между объектами в их последовательностях. Изобретение расширяет возможность применения поисковых машин в области индексирования и поиска информации, представленной последовательностью объектов, отличных от объектов текстовой информации. Настоящее изобретение предлагает в дополнение информации Базового Хита размещать в Расширенном Хите по меньшей мере wordID для двух слов: «предыдущего слова», позиция которого в документе на единицу меньше и равна (position-1), и «следующего слова», позиция которого в документе на единицу больше и равна (position+1). 2 н. и 33 з.п. ф-лы, 19 ил.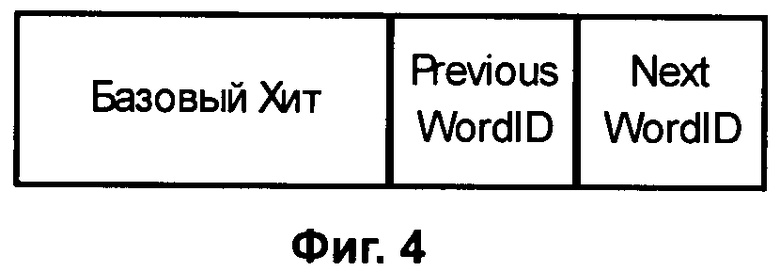
1. Способ индексирования, поиска и извлечения из индекса цифровой информации, при котором цифровая информация представлена множеством машиночитаемых массивов данных, каждый из которых является нумерованной последовательностью Объектов, а каждый из Объектов представлен уникальным машиночитаемым значением Объекта, причем при индексировании массивов данных в индекс для каждого появления уникального Объекта в индексируемом уникальном массиве данных записывают группу данных (Хит) и Хит содержит, по меньшей мере, порядковый номер появления Объекта в нумерованной последовательности Объектов уникального массива данных, имеющий значение <position>, а при поиске появлений уникального Объекта в проиндексированных массивах данных с использованием устройств ввода вводят значение Объекта поиска, извлекают Хиты появления Объекта поиска в массивах данных, содержащие, по меньшей мере, значение <position> номера появления Объекта поиска в нумерованной последовательности Объектов соответствующего массива данных, а извлеченные Хиты появления Объекта поиска в массиве данных используются в качестве результата поиска, отличающийся тем, что при индексировании массивов данных дополнительно в группу данных названного Хита записывают, по меньшей мере, значение Предыдущего Объекта, номер появления которого в нумерованной последовательности Объектов названного уникального массива данных имеет значение на единицу меньше значения <position> Объекта поиска и/или в группу данных Хита записывают значение Следующего Объекта, номер которого в нумерованной последовательности Объектов названного уникального массива данных имеет значение на единицу больше значения <position> Объекта поиска, а дополнительно к операции поиска появления Объекта поиска в массивах данных делают доступной операцию извлечения значения Предыдущего Объекта и/или извлечение значения Следующего Объекта из группы данных Хита Объекта поиска, а также делают доступной операцию вычисления значений <previous position>=<position-1> и/или <next position>=<position+1> соответственно номера Предыдущего Объекта и/или Следующего Объекта в нумерованной последовательности Объектов названного массива данных.
2. Способ по п.1, при котором в группу данных Хита Объекта поиска дополнительно записывают значения <previous position>=<position-1> и <next position>=<position+1> в качестве значений соответственно номера Предыдущего Объекта и/или Следующего Объекта, а вместо операции вычисления значений <previous position>=<position-1> и/или <next position>=<position+1> соответственно номера Предыдущего Объекта и/или Следующего Объекта в нумерованной последовательности Объектов названного массива данных, делают доступной операцию извлечения названных значений <previous position> и/или <next position> из группы данных Хита.
3. Способ по п.1, дополнительно включающий следующие шаги Восстановления Будущего:
присваивают переменной N значение 1, а переменной Start присваивают значение <position> Хита Объекта поиска и выполняют Цикл:
- из Хита Объекта поиска извлекают значение Следующего Объекта и значение его номера <next position> в нумерованной последовательности Объектов названного массива данных и используют извлеченные значения в качестве N-го Результата Восстановления Будущего нумерованной последовательности Объектов названного массива данных;
- в индексе осуществляют поиск Хита Объекта поиска названного массива данных, значение которого совпадает со значением Следующего Объекта из N-го Результата Восстановления Будущего, а значение <position> номера появления которого в нумерованной последовательности Объектов названного массива данных равно значению <Start+N>;
- из группы данных найденного Хита Объекта поиска названного массива данных извлекают значение Следующего Объекта, а также рассчитывают или извлекают значение номера <next position>=<Start+N+1> названного Следующего Объекта в упорядоченной последовательности объектов названного массива данных;
- присваивают переменной N значение (N+1) и выполняют Цикл, пока не будет выполнено некоторое условие останова выполнения Цикла;
- извлекают из каждого N-го Результата Восстановления Будущего значение Следующего Объекта и значение <position> номера появления Следующего Объекта в названном массиве данных, располагают извлеченные Следующие Объекты в порядке следования их номеров <position>, а полученную нумерованную последовательность Объектов используют в качестве результата Будущее операции Восстановления Будущего.
4. Способ по п.1, дополнительно включающий следующие шаги Восстановления Прошлого:
присваивают переменной N значение 1, а переменной Start присваивают значение <position> Хита Объекта поиска и выполняют Цикл:
- из Хита Объекта поиска извлекают значение Предыдущего Объекта и значение его номера <previous position> в нумерованной последовательности Объектов названного массива данных и используют извлеченные значения в качестве N-го Результата Восстановления Прошлого нумерованной последовательности Объектов названного массива данных;
- в индексе осуществляют поиск Хита Объекта поиска названного массива данных, значение которого совпадает со значением Предыдущего Объекта из N-го Результата Восстановления Прошлого, а значение <position> номера появления которого в нумерованной последовательности Объектов названного массива данных равно значению <Start - N>;
- из группы данных найденного Хита названного массива данных извлекают значение Предыдущего Объекта, а также рассчитывают или извлекают значение номера <previous position>=<Start-N-1> названного Предыдущего Объекта в упорядоченной последовательности объектов названного массива данных;
- присваивают переменной N значение (N-1) и выполняют Цикл, пока не будет выполнено некоторое условие останова выполнения Цикла;
- извлекают из каждого N-го Результата Восстановления Прошлого значение Предыдущего Объекта и значение <position> номера появления Предыдущего Объекта в названном массиве данных, располагают извлеченные Предыдущие Объекты в порядке следования их номеров <position>, а полученную нумерованную последовательность Объектов используют в качестве результата Прошлое операции Восстановления Прошлого.
5. Способ по п.3, включающий следующие шаги:
осуществляют операцию поиска Объекта поиска в одном или нескольких машиночитаемых массивах данных, представляющих собой нумерованную последовательность Объектов, в качестве результата поиска получают ограниченное множество Хитов, появления Объекта поиска в названных массивах данных;
создают некоторое условие останова выполнения Цикла операции Восстановления Будущего и осуществляют операцию Восстановления Будущего для каждого Хита названного ограниченного множества Хитов с учетом названного условия останова выполнения Цикла и получают ограниченное множество Объектов Будущего.
6. Способ по п.4, включающий следующие шаги:
осуществляют операцию поиска Объекта поиска в одном или нескольких машиночитаемых массивах данных, представляющих собой нумерованную последовательность Объектов, в качестве результата поиска получают ограниченное множество Хитов, появления Объекта поиска в названных массивах данных;
создают некоторое условие останова выполнения Цикла операции Восстановления Прошлого и осуществляют операцию Восстановления Прошлого для каждого Хита названного ограниченного множества Хитов с учетом названного условия останова выполнения Цикла и получают ограниченное множество Объектов Прошлого.
7. Способ по п.5, при котором с использованием известных методов осуществляют анализ совместной встречаемости Объектов в ограниченном множестве Объектов Будущего.
8. Способ по п.6, при котором с использованием известных методов осуществляют анализ совместной встречаемости Объектов в ограниченном множестве Объектов Прошлого.
9. Способ по п.5, или 6, или 7, или 8, при котором дополнительно вводят Образцовый Массив Данных (ОМД) или указывают адрес доступа к ОМД и вводят, по меньшей мере, один Ключевой Объект ОМД, причем Образцовому Массиву Данных или Ключевому Объекту сопоставляют Адрес Перехода, индексируют ОМД, а при проведении поиска Хитов для каждого Объекта поиска проводят анализ совместной встречаемости Объекта поиска с другими Объектами, по меньшей мере, одного из проиндексированных массивов данных, а при использовании результатов поиска Объекты поиска сравнивают с Ключевыми Объектами ОМД, и при совпадении Объекта поиска с Ключевым Объектом ОМД проводят для Ключевого Объекта ОМД анализ совместной встречаемости с другими Объектами ОМД, причем устанавливают Меру Совпадения результатов анализа совместной встречаемости для сравниваемых Хита Объекта поиска и Хита Ключевого Объекта ОМД, дополнительно сравнивают результаты анализа совместной встречаемости Объекта поиска с результатами анализа совместной встречаемости Ключевого Объекта ОМД, проводят оценку меры совпадения результатов анализа совместной встречаемости Объекта поиска с результатами анализа совместной встречаемости Ключевого Объекта ОМД и, если названная оценка соответствует установленной Мере Совпадения, то в качестве результатов поиска используют Хиты Объекта поиска, и/или Хиты Ключевого Объекта, и/или, по меньшей мере, один Ключевой Объект ОМД, и/или ОМД, и/или Адрес Перехода.
10. Способ по п.1, при котором в Хите дополнительно записывают, по меньшей мере, значение времени TimeStamp и/или значение смещения во времени TimeOffset, а при поиске и восстановлении дополнительно извлекают значение времени TimeStamp и/или смещения во времени TimeOffset и учитывают хронологию появления Объектов поиска.
11. Способ по п.1, при котором в Хите дополнительно записывают, по меньшей мере, значение местоположения Location и/или значение смещения местоположения LocationOffset, а при поиске и извлечении дополнительно извлекают значение местоположения Location и/или значение смещения местоположения LocationOffset для учета местоположения появления Объектов поиска.
12. Способ по п.1, при котором в Хите дополнительно записывают, по меньшей мере, указатель MetalD хранения метаданных Объекта поиска, а при поиске и извлечении дополнительно извлекают значение указателя MetalD для осуществления доступа к метаданным Объектов поиска.
13. Способ по п.1, при котором значением Объекта является значение времени TimeStamp или значение смещения во времени TimeOffset, a нумерованная последовательность Объектов представлена нумерованной последовательностью значений меток времени TimeStamp или значений смещения во времени TimeOffset.
14. Способ по п.1, при котором значением Объекта является значение местоположения Location или значение смещения местоположения LocationOffset, а нумерованная последовательность Объектов представлена нумерованной последовательностью значений меток местоположения Location или значений смещения местоположения LocationOffset.
15. Способ по п.1, при котором машиночитаемые массивы данных представлены файлами и/или потоками данных, содержащими последовательность Объектов распознавания, а перед индексированием массивов данных выполняют следующие шаги:
осуществляют распознавание Объектов распознавания с использованием соответствующей известной технологии распознавания;
каждому из полученных в процессе распознавания Объектов распознавания присваивают номер;
используя присвоенные Объектам распознавания номера, множество Объектов распознавания упорядочивают в виде нумерованной последовательности Объектов;
нумерованную последовательность Объектов используют для индексирования, поиска и извлечения цифровой информации.
16. Способ по п.15, при котором названные файлы и/или потоки данных представляют собой видеофайлы, или аудиофайлы, или потоки аудиоданных, или потоки видеоданных, Объектами распознавания являются слова речи, и/или звуки, и/или совокупность звуков, и/или лица, и/или объекты, и/или совокупность объектов ,и/или множество точек, и/или символы, и/или буквы, и/или цифры, и/или слова текста, а известной технологией распознавания является speech recognition, и/или sound recognition, и/или face recognition, и/или object recognition, и/или optical character recognition, и/или text recognition, или другие известные технологии распознавания.
17. Способ по п.16, при котором машиночитаемые массивы данных представлены в аудиоформате CD, или МР3, или WMA, или ААС, или AIFF, или М4А, или в другом известном аудиоформате или в видеоформате MPEG4, или AVI, или MOV, или RAM, или SWF, или WMV, или DVD, или Blu-Ray, или в другом известном видеоформате.
18. Способ по п.17, при котором индексирование, поиск и извлечение информации из индекса осуществляют одновременно с воспроизведением или одновременно с записью машиночитаемых массивов данных.
19. Способ по п.17, при котором индекс записывают в маркировочный файл IDЗ или маркировочный файл другого известного формата.
20. Способ по п.17, при котором индекс записывают на носитель информации, или в носимое устройство памяти, или в память устройства записи и/или воспроизведения машиночитаемых массивов данных, или в память устройства связи.
21. Способ по п.20, при котором индекс записывают вместе с машиночитаемыми массивами данных.
22. Способ по п.20, при котором носителем информации является CD диск, или DVD диск, или Blu-Ray диск, или диск другого известного аудио- и/или видеоформата, или другой известный съемный носитель информации.
23. Способ по п.15, при котором Объектами распознавания являются геодезические и/или относительные координаты местоположения, а значением Объекта является значение местоположения Location и/или смещения местоположения LocationOffset.
24. Способ по п.15, при котором использование известной технологии распознавания позволяет вычислить значение геодезических координат местоположения Location и/или относительных координат местоположения LocationOffset, а способ далее включает шаги:
в Хите дополнительно размещают, по меньшей мере, значение местоположения Location и/или значение смещения местоположения LocationOffset, а при операциях поиска и восстановления извлекают значение местоположения Location и/или значение смещения местоположения LocationOffset для учета местоположения появления Объектов поиска;
вычисляют значения названных координат местоположения с использованием известной технологии распознавания;
выявляют Объекты распознавания, появление которых в массиве данных связано с вычисленным значением названных координат местоположения;
присваивают вычисленное значение названных координат местоположения полю Location в Хитах выявленных Объектов распознавания.
25. Способ по п.15, при котором использование известной технологии позволяет извлечь или вычислить значение меток времени TimeStamp и/или меток смещения времени TimeOffset, а способ далее включает шаги:
в Хите дополнительно размещают, по меньшей мере, значение времени TimeStamp и/или значение смещения во времени TimeOffset, а при операциях поиска и восстановления извлекают значение времени TimeStamp и/или смещения во времени TimeOffset для учета хронологии появления Объектов поиска;
вычисляют или извлекают значения названных меток с использованием известной технологии;
выявляют Объекты распознавания, появление которых в массиве данных связано с вычисленным или полученным значением названных меток;
присваивают вычисленное значение названных меток времени полю TimeStamp или значение названных меток смещения времени полю TimeOffset в Хитах выявленных Объектов распознавания.
26. Способ по п.1, при котором индекс записывают на CD диск, или на DVD диск, или на Blu-Ray диск, или на другой съемный носитель информации, или индекс записывают в память устройства.
27. Процессор, способный индексировать, искать и извлекать из индекса цифровую информацию, как это указано в пп.1-26.
28. Способ по п.1, при котором массив данных представлен нумерованной последовательностью Объектов текста электронной книги.
29. Способ по п.1, при котором массив данных представлен файлом или потоком данных аудиокниги, а нумерованной последовательностью распознанных Объектов являются Объекты распознавания речи, или звуков, или комбинации звуков.
30. Способ по п.1, при котором массив данных представлен нумерованной последовательностью геодезических координат маршрута движения или карты, причем последовательности геодезических координат индексируют, а индекс размещают на носителе информации, или в носимом устройстве памяти, или в памяти устройства визуализации, анализа совместной встречаемости или другого использования названных геодезических координат, а оплату взимают, по меньшей мере, за названное размещение индекса, или за поиск, или извлечение, или анализ совместной встречаемости названных геодезических координат.
31. Способ по п.1, при котором массив данных представлен нумерованной последовательностью адресов маршрутов движения или карты, причем адреса индексируют, а индекс размещают на носителе информации, или в носимом устройстве памяти, или в памяти устройства визуализации, поиска, извлечения, анализа совместной встречаемости или другого использования названных адресов, а оплату взимают, по меньшей мере, за названное размещение индекса, или за поиск, или извлечение, или анализ совместной встречаемости названных адресов.
32. Способ по п.1, при котором массив данных представлен нумерованной последовательностью Объектов страниц web сайта, а индекс записывают способом, позволяющим осуществлять поиск и извлечение информации из индекса, как при просмотре web сайта, так и без просмотра web сайта, а оплату взимают, по меньшей мере, за одну из названных операций размещения индекса, поиска, извлечения или анализа совместной встречаемости названных Объектов страниц web сайта.
33. Способ по п.32, при котором индекс записан в структуре данных Semantic Web.
34. Способ по п.1, при котором массивы данных представлены массивами данных локальной сети или сети Интернет, а индекс записывают или в памяти компьютеров поисковой машины названной сети, или на устройстве пользователя, или на устройстве, где размещен проиндексированный массив данных.
35. Способ по п.9, при котором ОМД является web сайтом или web страницей, а Адрес Перехода является адресом Интернет.
| ХРАНИЛИЩЕ ДАННЫХ ДЛЯ ОСНОВАННОЙ НА ЗНАНИЯХ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ДАННЫХ | 2003 |
|
RU2297665C2 |
| Химический огнетушитель | 1927 |
|
SU8675A1 |
| МЕХАНИЗМ ОТЛОЖЕННОГО ПОИСКА | 2005 |
|
RU2412477C2 |
| Устройство для замены гирлянд изоляторов воздушной линии электропередачи,находящейся под напряжением | 1986 |
|
SU1365212A2 |
| Способ изготовления гнутых профилей | 1988 |
|
SU1622055A1 |
| US 6490579 B1, 03.12.2002. | |||

