ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к кодированию звука, и в частности, к расширению полосы пропускания звукового сигнала нижней полосы.
УРОВЕНЬ ТЕХНИКИ
Настоящее изобретение относится к расширению полосы пропускания (BWE) звуковых сигналов. Схемы BWE все больше используют в кодировании/декодировании речи и аудиосигналов для улучшения воспринимаемого качества при заданной скорости передачи битов. Главной идеей в основе BWE является то, что часть звукового сигнала не передают, а восстанавливают (оценивают) в декодере из компонентов принятого сигнала.
Таким образом, в схеме BWE часть спектра сигнала восстанавливают в декодере. Восстановление выполняют, используя некоторые особенности спектра сигнала, который был фактически передан, используя традиционные методы кодирования. Обычно верхнюю полосу (HB) сигнала восстанавливают из некоторых особенностей звукового сигнала нижней полосы (LB).
Зависимости между особенностями LB и характеристиками сигнала HB часто моделируют с помощью модели гауссовых смесей (GMM) или скрытых марковских моделей (ХМ), например, [1-2]. Чаще всего предсказанные характеристики HB относятся к спектральным и/или временным огибающим.
Существуют два основных подхода BWE:
• В первом подходе характеристики сигнала HB полностью предсказывают из некоторых особенностей LB. Эти решения BWE вносят артефакты в восстановленный сигнал HB, что в некоторых случаях приводит к ухудшению качества по сравнению с сигналом с ограниченной полосой. Сложные сопоставления (например, основанные на GMM или ХМ) вполне вероятно приводят к ухудшению качества при неизвестных данных. Практика обычно такова, что чем сложнее сопоставление (большое количество обучающих параметров), тем более вероятно возникновение артефактов при данных того типа, который не присутствует в обучающем наборе данных. Не является тривиальной задачей найти сопоставление с такой сложностью, которая обеспечивает оптимальный баланс между общей точностью предсказания и низким количеством выбросов (данных, которые заметно отклоняются от данных в обучающем наборе, т.е. компонентов, которые не могут быть очень хорошо смоделированы).
• Вторым подходом (пример описан в [3]) является восстановление сигнала HB из комбинации особенностей LB и небольшого количества переданной информации HB. Схемы BWE с помощью переданной информации HB приводят к улучшению эффективности (за счет увеличения битового бюджета), но не предлагают обобщенную схему объединения переданных и предсказанных параметров. Обычно один набор параметров HB передают, а другой набор параметров HB предсказывают, что означает, что переданная информация не может компенсировать неудачи в предсказанных параметрах.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задачей настоящего изобретения является достижение улучшенной схемы BWE.
Эта задача достигается с помощью прилагаемой формулы изобретения.
Согласно первому аспекту настоящее изобретение содержит способ оценки расширения верхней полосы звукового сигнала нижней полосы. Этот способ включает в себя следующие этапы. Извлекают набор особенностей звукового сигнала нижней полосы. Извлеченные особенности сопоставляют по меньшей мере с одним параметром верхней полосы с помощью обобщенного аддитивного моделирования. Копию звукового сигнала нижней полосы сдвигают по частоте в верхнюю полосу. Огибающей сдвинутой по частоте копии звукового сигнала нижней полосы управляют по меньшей мере с помощью одного параметра верхней полосы.
Согласно второму аспекту настоящее изобретение содержит устройство для оценки расширения верхней полосы звукового сигнала нижней полосы. Блок извлечения особенностей конфигурируют для извлечения набора особенностей звукового сигнала нижней полосы. Блок сопоставления включает в себя следующие элементы: модуль сопоставления с помощью обобщенного аддитивного моделирования, сконфигурированный для сопоставления извлеченных особенностей по меньшей мере с одним параметром верхней полосы с помощью обобщенного аддитивного моделирования; модуль сдвига частоты, сконфигурированный для сдвига по частоте копии звукового сигнала нижней полосы в верхнюю полосу; модуль управления огибающей, сконфигурированный для управления огибающей сдвинутой по частоте копии с помощью упомянутого по меньшей мере одного параметра верхней полосы.
Согласно третьему аспекту настоящее изобретение содержит речевой декодер, включающий в себя устройство согласно второму аспекту.
Согласно четвертому аспекту настоящее изобретение содержит сетевой узел, включающий в себя речевой декодер согласно третьему аспекту.
Преимущество предложенной схемы BWE состоит в том, что она предлагает хороший баланс между сложными схемами сопоставления (хорошая средняя эффективность, но сильные выбросы) и более ограниченной схемой сопоставления (ниже средняя эффективность, но более устойчивая).
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Данное изобретение, вместе с дополнительными задачами и преимуществами, можно лучше всего понять, обращаясь к последующему описанию, рассмотренному вместе с сопроводительными чертежами, на которых:
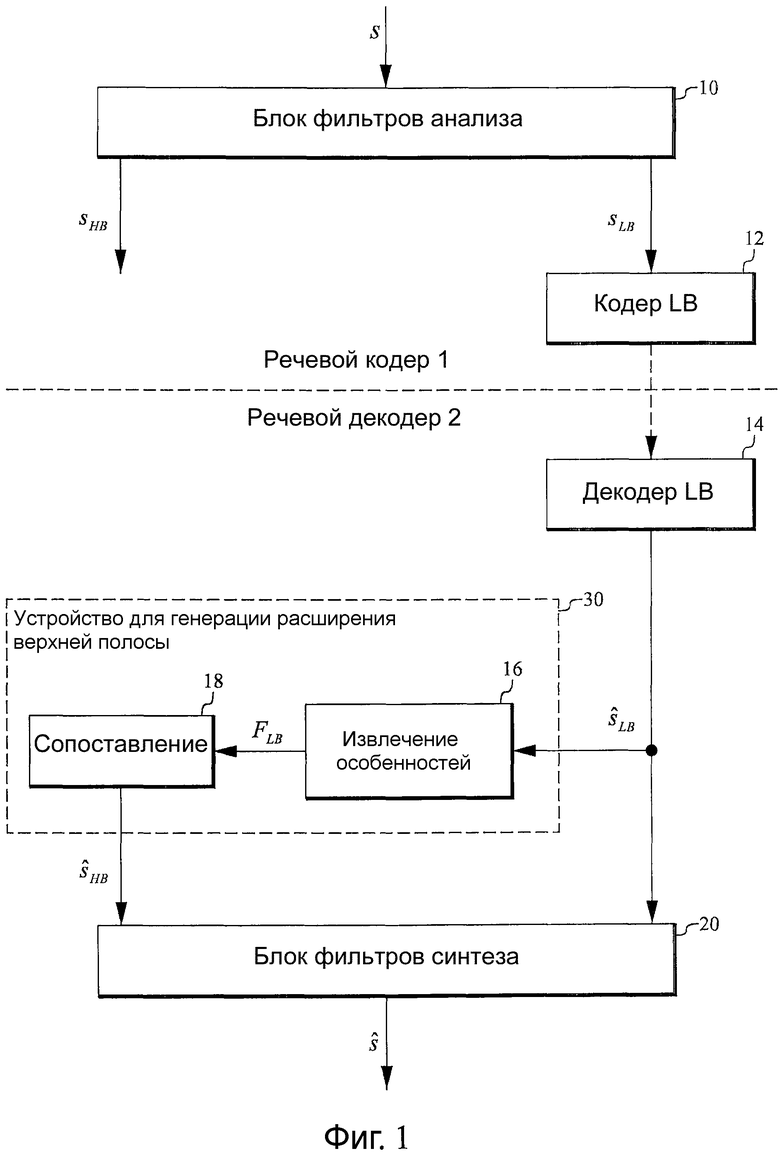
Фиг.1 - структурная схема, иллюстрирующая вариант осуществления структуры кодирования/декодирования, которая включает в себя речевой декодер согласно одному из вариантов осуществления настоящего изобретения;
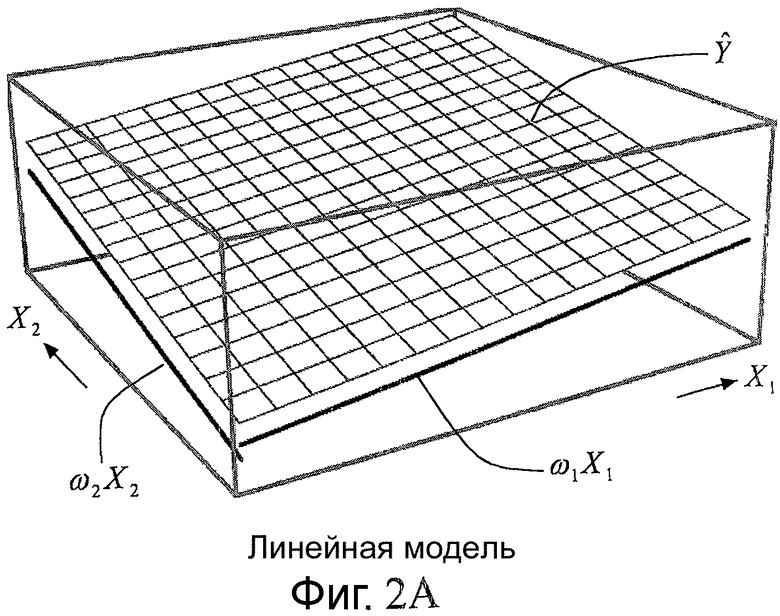
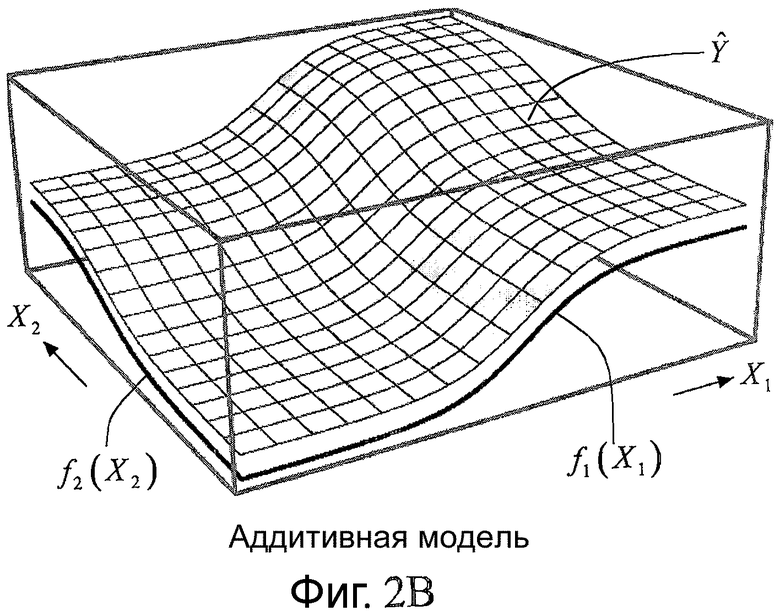
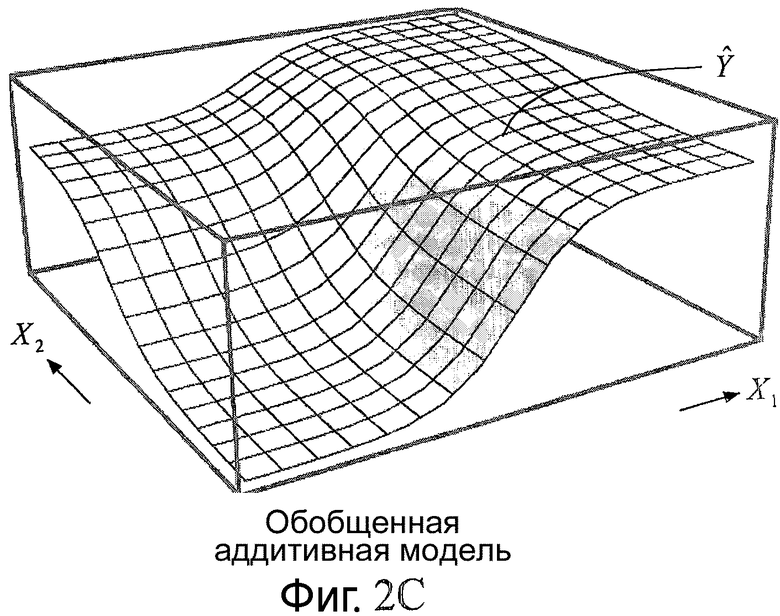
Фиг.2A-C являются схемами, иллюстрирующими принципы обобщенных аддитивных моделей;
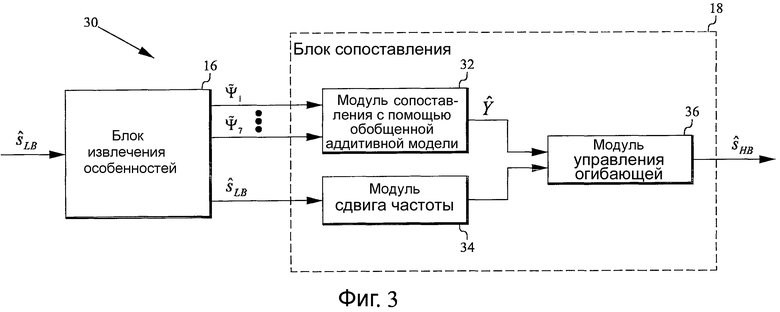
Фиг.3 - структурная схема, иллюстрирующая вариант осуществления устройства согласно настоящему изобретению для генерации расширения HB;
Фиг.4 - схема, иллюстрирующая пример параметра верхней полосы, полученного с помощью обобщенного аддитивного моделирования согласно одному из вариантов осуществления настоящего изобретения;
Фиг.5 - схема, иллюстрирующая определение подходящих для извлечения особенностей в другом варианте осуществления настоящего изобретения;
Фиг.6 - структурная схема, иллюстрирующая вариант осуществления устройства согласно настоящему изобретению, подходящий для генерации расширения HB, основываясь на особенностях, проиллюстрированных на фиг.5;
Фиг.7 - схема, иллюстрирующая пример параметров верхней полосы, полученных с помощью обобщенного аддитивного моделирования согласно одному из вариантов осуществления настоящего изобретения, основываясь на особенностях, проиллюстрированных на фиг.5;
Фиг.8 - структурная схема, иллюстрирующая другой вариант осуществления структуры кодирования/декодирование, которая включает в себя речевой декодер согласно другому варианту осуществления настоящего изобретения;
Фиг.9 - структурная схема, иллюстрирующая дополнительный вариант осуществления структуры кодирования/декодирования, которая включает в себя речевой декодер согласно дополнительному варианту осуществления настоящего изобретения;
Фиг.10 - структурная схема, иллюстрирующая другой вариант осуществления устройства согласно настоящему изобретению для генерации расширения HB;
Фиг.11 - структурная схема, иллюстрирующая дополнительный вариант осуществления устройства согласно настоящему изобретению для генерации расширения HB;
Фиг.12 - структурная схема, иллюстрирующая вариант осуществления сетевого узла, включающего в себя вариант осуществления речевого декодера согласно настоящему изобретению;
Фиг.13 - структурная схема, иллюстрирующая вариант осуществления речевого декодера согласно настоящему изобретению; и
Фиг.14 - последовательность операций, которая иллюстрирует вариант осуществления способа согласно настоящему изобретению.
ПОДРОБНОЕ ОПИСАНИЕ
Элементы, имеющие одинаковые или подобные функции, будут обеспечены теми же самыми условными обозначениями на чертежах.
Далее объясняют набор особенностей LB и их использование для оценки части HB сигнала посредством сопоставления. Дополнительно, также объясняют, как переданная информация HB может использоваться для управления сопоставлением.
Фиг.1 - структурная схема, иллюстрирующая вариант осуществления структуры кодирования/декодирования, которая включает в себя речевой декодер согласно одному из вариантов осуществления настоящего изобретения. Речевой кодер 1 принимает (обычно кадр) исходный звуковой сигнал s, который направляют к блоку 10 фильтров анализа, который разделяет звуковой сигнал на часть SLB нижней полосы и часть SHB верхней полосы. В данном варианте осуществления часть HB не используют (что подразумевает, что блок фильтров анализа может просто содержать низкочастотный фильтр). Часть LB SLB звукового сигнала кодируют в кодере 12 LB (обычно в кодере линейного предсказания с кодовым возбуждением (CELP), например, в кодере с линейным предсказанием с алгебраическим кодовым возбуждением (ACELP)), и код посылают в речевой декодер 2. Пример кодирования/декодирования ACELP можно найти в [4]. Код, принимаемый речевым декодером 2, декодируют в декодере 14 LB (обычно в декодере CELP, например, в декодере ACELP), который выдает звуковой сигнал ŝLB нижней полосы, соответствующий SLB. Этот звуковой сигнал ŝLB нижней полосы направляют к блоку 16 извлечения особенностей, который извлекает набор особенностей FLB (описан ниже) сигнала ŝLB. Извлеченные особенности FLB направляют к блоку 18 сопоставления, который сопоставляет их по меньшей мере с одним параметром верхней полосы (описан ниже) с помощью обобщенного аддитивного моделирования (описано ниже). Параметр(ы) HB используется(ются) для управления огибающей копии звукового сигнала LB ŝLB, которая была сдвинута по частоте в верхнюю полосу, который дает предсказание или оценку ŝHB части HB, которую не используют, SHB. Сигналы SLB и SHB направляют к блоку 20 фильтров синтеза, который восстанавливает оценку ŝ оригинального исходного звукового сигнала. Блок 16 извлечения особенностей и блок 18 сопоставления вместе формируют устройство 30 (дополнительно описано ниже) для генерации расширения HB.
Представленные ниже в качестве примера особенности звукового сигнала LB, называемые локальными особенностями, используют для предсказания некоторых характеристик сигнала HB. Можно использовать все особенности или подмножество представленных в качестве примера особенностей. Все эти локальные особенности вычисляют на покадровой основе, и динамика локальных особенностей также включает в себя информацию из предыдущего кадра. В последующем n является индексом кадра, l является индексом выборки и s(n,l) является речевой выборкой.
Первые две примерные особенности относятся к наклону спектра и к динамике наклона. Они измеряют частотное распределение энергии:
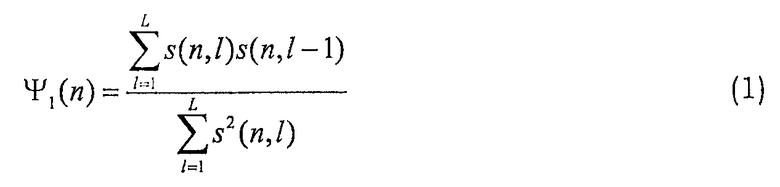
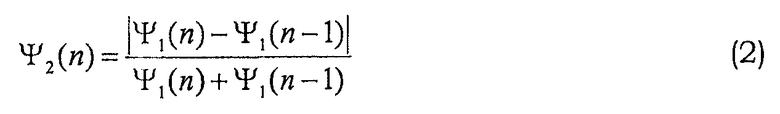
Следующие две примерные особенности измеряют частоту основного тона (основную частоту речи) и динамику частоты основного тона. Поиск оптимальной задержки ограничен имеющим смысл диапазоном частоты основного тона, τMIN и τMAX, например, 50-400 Гц:

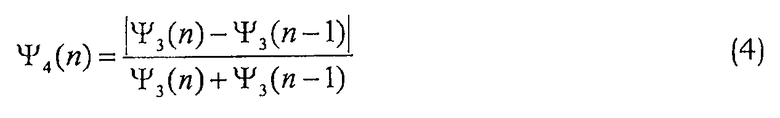
Пятая и шестая примерные особенности отражают баланс между тоновым и шумоподобным компонентами в сигнале. В данном случае σ2 ACB и σ2 FCB являются энергией адаптивной и фиксированной кодовой книги в кодеках CELP, например, в кодеках ACELP, и является энергией сигнала возбуждения:
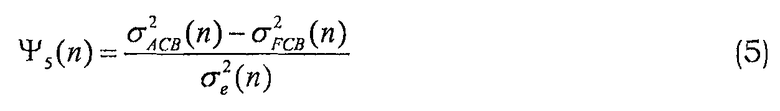
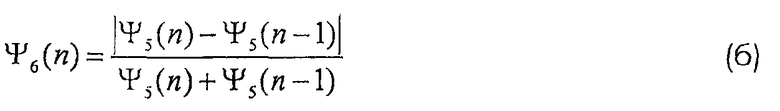
Последняя локальная особенность в данном примерном наборе фиксирует динамику энергии на покадровой основе. В данном случае σ2 S является энергией речевого кадра:
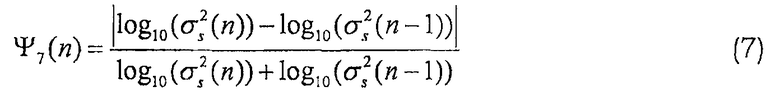
Все эти локальные особенности, которые используются при сопоставлении, масштабируются перед сопоставлением следующим образом:

где ΨΜΙΝ и ΨΜАX являются предварительно определенными константами, которые соответствуют минимальному и максимальному значению для заданной особенности. Это дает набор извлеченных особенностей Ψ=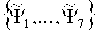
Согласно настоящему изобретению оценка расширения HB из локальных особенностей основана на обобщенном аддитивном моделировании. По этой причине данная концепция будет кратко описана в отношении фиг.2A-C. Дополнительные подробности относительно обобщенных аддитивных моделей могут быть найдены, например, в [5].
В статистике регрессионные модели часто используют для оценки поведения параметров. Простой моделью является линейная модель:
 ,
,
где Ŷ - оценка переменной Y, которая зависит от (случайных) переменных X1,..., XM. Это показано для М=2 на фиг.2A. В этом случае Ŷ будет плоской поверхностью.
Характерной особенностью линейной модели является то, что каждый элемент суммирования линейно зависит только от одной переменной. Обобщением этой особенности является изменение (по меньшей мере одной из) этих линейных функций на нелинейные функции (каждая из которых все еще зависит только от одной переменной). Это приводит к аддитивной модели:

Эта аддитивная модель проиллюстрирована на фиг.2B для М = 2. В этом случае поверхность, представляющая Ŷ, является изогнутой. Функции fm(Xm) обычно являются сигмоидальными функциями (в общем случае функциями, имеющими форму «S»), как проиллюстрировано на фиг.2B. Примерами сигмоидальных функций являются логистическая функция, кривая Гомперца, S-образная кривая и функция гиперболического тангенса. Изменяя параметры, которые определяют сигмоидальную функцию, сигмоидальная форма может изменяться непрерывно от приблизительно линейной формы между минимумом и максимумом до приблизительно ступенчатой функции между теми же самыми минимумом и максимумом.
Дополнительное обобщение получают с помощью обобщенной аддитивной модели

где g(⋅) называют связывающей функцией. Это проиллюстрировано на фиг.2C, где поверхность Ŷ дополнительно изменяют (Ŷ получают, беря инверсию g-1(⋅), обычно также сигмоидальную, обеих сторон в уравнении (11)). В особом случае, когда связывающая функция g(⋅) является функцией тождественности, уравнение (11) уменьшают до уравнения (10). Так как оба случая представляют интерес, в целях настоящего изобретения «обобщенная аддитивная модель» будет также включать в себя случай связывающей функции тождественности. Однако, как отмечено выше, по меньшей мере одна из функций fm(Xm) нелинейна, что делает модель нелинейной (поверхность Ŷ изогнута).
В одном из вариантов осуществления настоящего изобретения 7 (нормализованных) особенностей Ψ=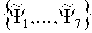

где β можно выбирать как, например, β = 0,2. Другой пример:

В уравнениях (12) и (13) параметр β и функцию log10 используют для преобразования соотношения энергии в сжатую «обусловленную восприятием» область. Это преобразование выполняют для учета приблизительно логарифмических характеристик чувствительности человеческого уха.
Так как энергия EHB(n) не доступна в декодере, соотношение Y(n) предсказывают или оценивают. Это делают с помощью моделирования оценки Ŷ(n) соотношения Y(n), основываясь на извлеченных особенностях LB и обобщенной аддитивной модели. Пример задан с помощью:
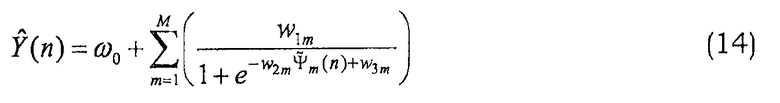
где М = 7 при заданных извлеченных локальных особенностях (меньшее количество особенностей также допустимо). Если сравнивать с уравнением (11), то очевидно, что 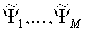
Фиг.3 - структурная схема, иллюстрирующая вариант осуществления устройства 30 согласно настоящему изобретению для генерации расширения HB. Устройство 30 включает в себя блок 16 извлечения особенностей, сконфигурированный для извлечения набора особенностей 
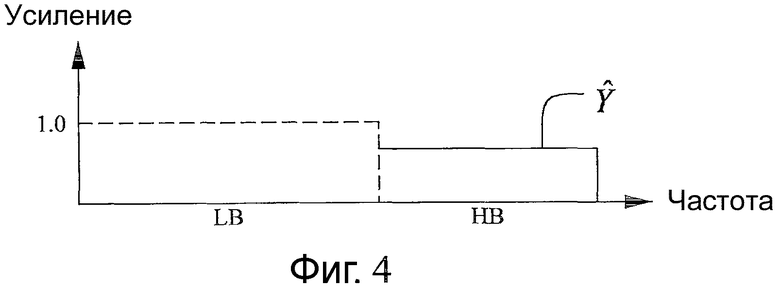
Фиг.4 - схема, иллюстрирующая пример параметра верхней полосы, полученного с помощью обобщенного аддитивного моделирования согласно одному из вариантов осуществления настоящего изобретения. Она иллюстрирует, как предполагаемое соотношение (усиление) Ŷ используется для управления огибающей сдвинутой по частоте копии сигнала LB (в этом случае в частотной области). Пунктирная линия представляет постоянное усиление (1,0) сигнала LB. Таким образом, в данном варианте осуществления расширение HB получают с помощью применения одного предполагаемого усиления Ŷ к сдвинутой по частоте копии сигнала LB.
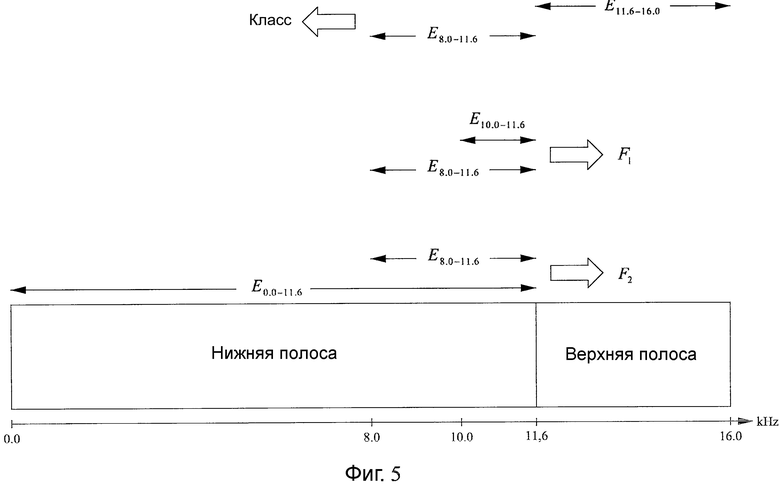
Фиг.5 - схема, иллюстрирующая определение подходящих для извлечения особенностей в другом варианте осуществления настоящего изобретения. В данном варианте осуществления извлекают только 2 особенности F1, F2 сигнала LB.
В показанном на фиг.5 варианте осуществления особенность F1 определяют с помощью:

где
E10,0-11,6 - оценка энергии звукового сигнала нижней полосы в частотной полосе 10,0-11,6 кГц,
E8,0-11,6 - оценка энергии звукового сигнала нижней полосы в частотной полосе 8,0-11,6 кГц.
Кроме того, в проиллюстрированном на фиг.5 варианте осуществления особенность F2 определяют с помощью:

где
E8,0-11,6 - оценка энергии звукового сигнала нижней полосы в частотной полосе 8,0-11,6 кГц,
E0,0-11,6 - оценка энергии звукового сигнала нижней полосы в частотной полосе 0,0-11,6 кГц.
Особенности F1, F2 представляют наклон спектра и аналогичны описанной выше особенности Ψ1, но их определяют в частотной области вместо временной области. Кроме того, может применяться определение особенностей F1, F2 по другим частотным интервалам сигнала LB. Однако в данном варианте осуществления настоящего изобретения важно, что F1, F2 описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
Используя извлеченные особенности F1, F2, теперь возможно, чтобы модуль 32 сопоставления сопоставлял их с параметрами HB 
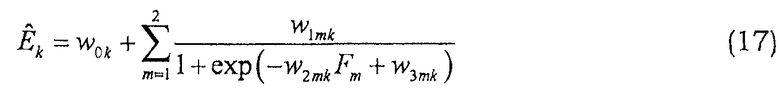
где
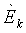
{w0k, w1mk, w2mk, w3mk} являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра 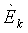
Fm, m=1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
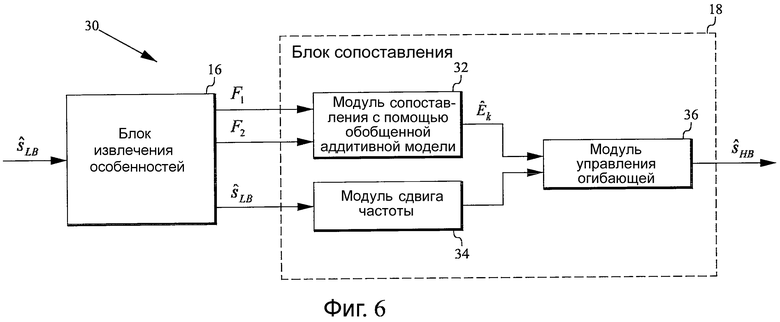
Фиг.6 - структурная схема, иллюстрирующая вариант осуществления устройства согласно настоящему изобретению, подходящий для генерации расширения HB, основываясь на особенностях, проиллюстрированных на фиг.5. Данный вариант осуществления включает в себя аналогичные элементы, как вариант осуществления на фиг.3, но в этом случае они сконфигурированы для сопоставления особенностей F1, F2 с K усилениями 
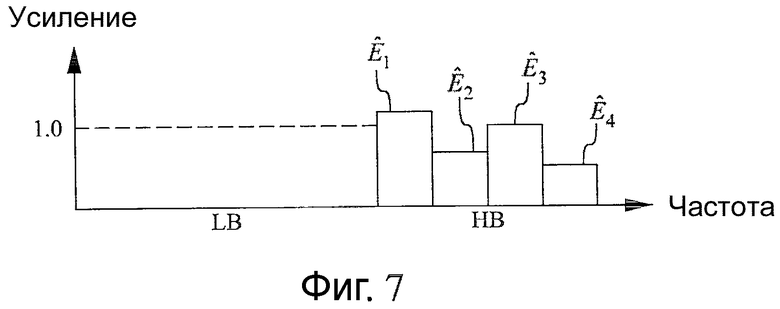
Фиг.7 - схема, иллюстрирующая пример параметров верхней полосы, полученных с помощью обобщенного аддитивного моделирования согласно одному из вариантов осуществления настоящего изобретения, основываясь на особенностях, проиллюстрированных на фиг.5. В данном примере существует K=4 усилений 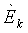

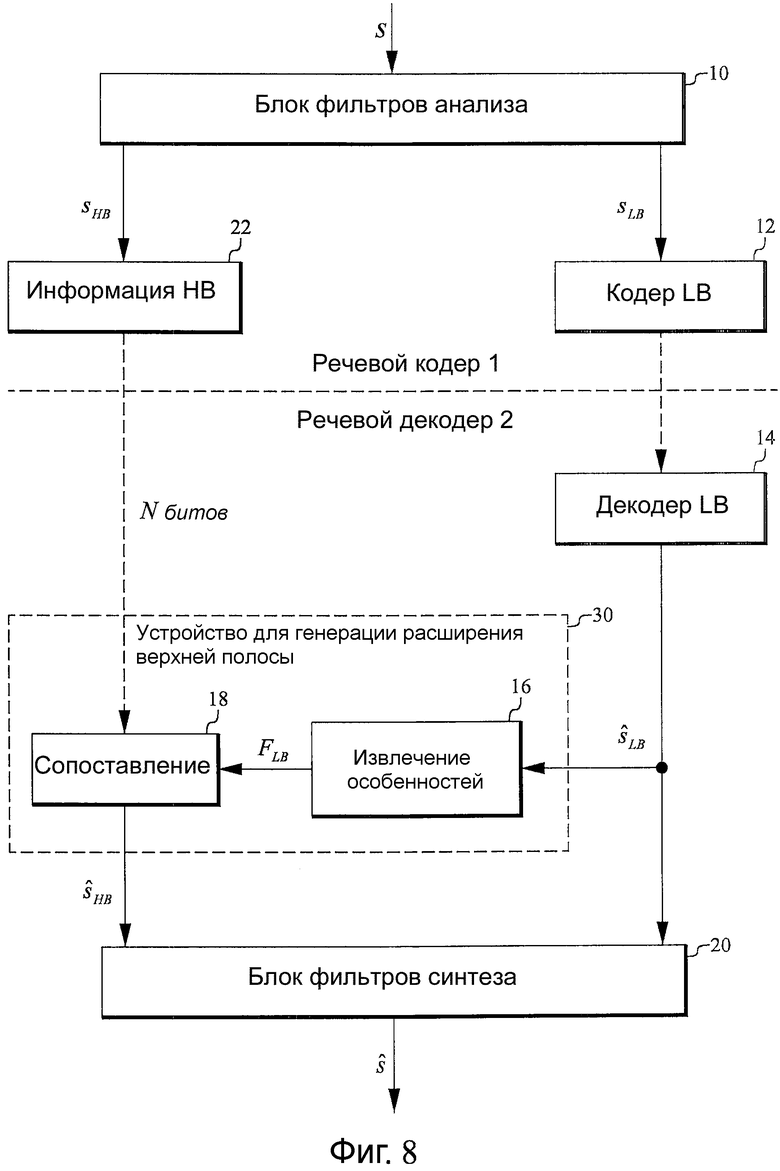
Фиг.8 - структурная схема, иллюстрирующая другой вариант осуществления структуры кодирования/декодирования, которая включает в себя декодер согласно другому варианту осуществления настоящего изобретения. Данный вариант осуществления отличается от варианта осуществления на фиг.1 тем, что в нем используют сигнал HB SHB. Вместо этого сигнал HB направляют к блоку 22 информации HB, который классифицирует сигнал HB и посылает N-битовый индекс класса в речевой декодер 2. Если передача информации HB разрешена, как проиллюстрировано на фиг.8, то сопоставление выполняют по частям с совокупностями, которые обеспечивают с помощью данной передачи, причем количество классов зависит от количества доступных битов. Индекс класса используют с помощью блока 18 сопоставления, как будет описано ниже.
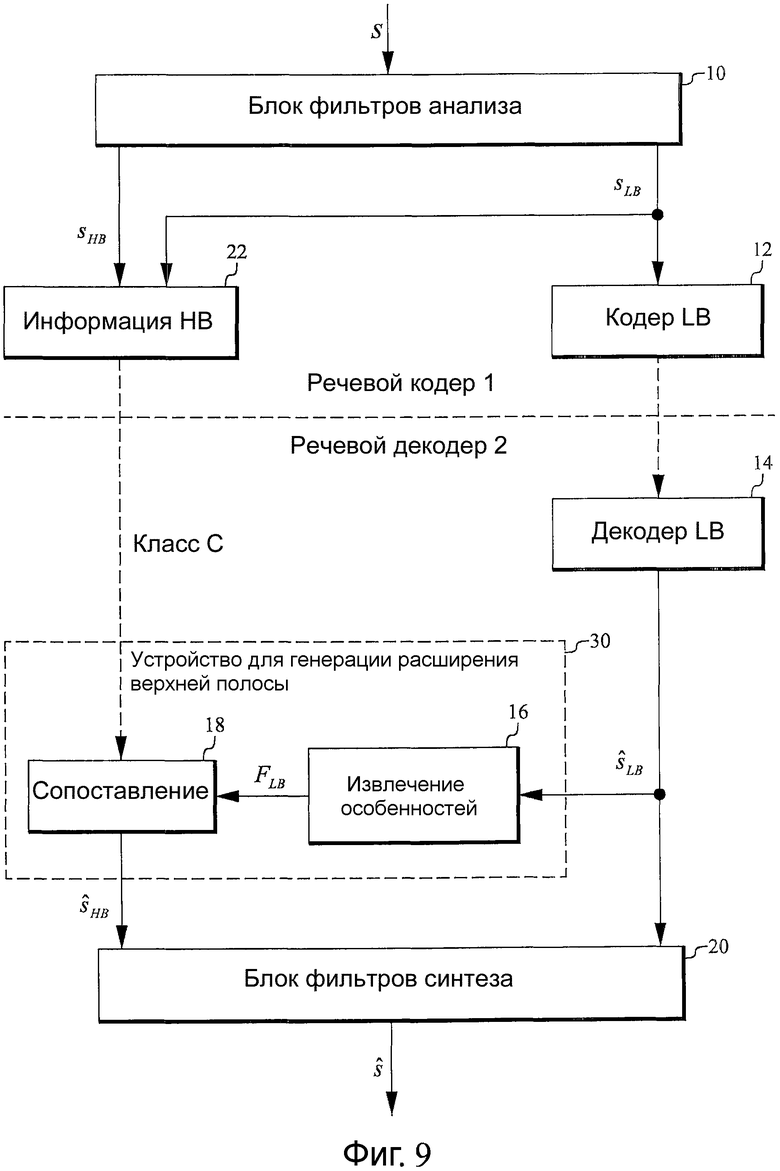
Фиг.9 - структурная схема, иллюстрирующая дополнительный вариант осуществления структуры кодирования/декодирования, которая включает в себя декодер согласно дополнительному варианту осуществления настоящего изобретения. Этот вариант осуществления аналогичен варианту осуществления на фиг.8, но формирует индекс класса, используя и сигнал HB sHB, и сигнал LB sLB. В данном примере N=1 бит, но также возможно иметь больше 2 классов, если индекс будет включать в себя большее количество битов.
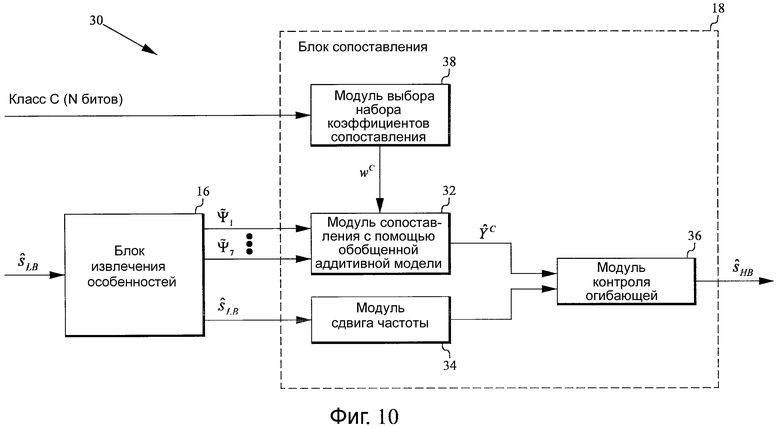
Фиг.10 - структурная схема, иллюстрирующая другой вариант осуществления устройства согласно настоящему изобретению для генерации расширения HB. Данный вариант осуществления отличается от варианта осуществления на фиг.3 тем, что он включает в себя модуль 38 выбора набора коэффициентов сопоставления, который сконфигурирован для выбора набора коэффициентов сопоставления ωC = 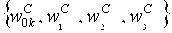
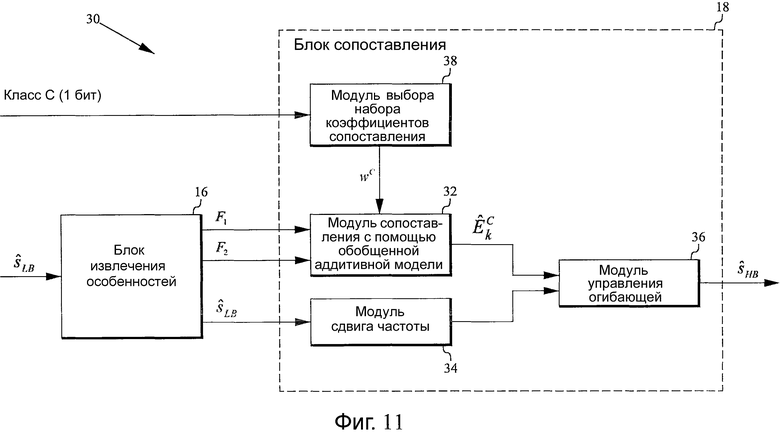
Фиг.11 - структурная схема, иллюстрирующая дополнительный вариант осуществления устройства согласно настоящему изобретению для генерации расширения HB. Данный вариант осуществления аналогичен варианту осуществления на фиг.10, но основан на особенностях F1, F2, описанных в отношении фиг.5. Кроме того, в данном варианте осуществления класс C сигнала задают с помощью (также относится к верхней части фиг.5):

где
ES 8,0-11,6 - оценка энергии исходного звукового сигнала в частотной полосе 8,0-11,6 кГц, и
ES 11,6-16,0 - оценка энергии исходного звукового сигнала в частотной полосе 11,6-16,0 кГц.
В данном примере C классифицирует (грубо говоря, чтобы дать мысленное представление того, что означает данная примерная классификация) звуки на «вокализованные» (класс 1) и «невокализованные» (класс 2).
Основываясь на этой классификации, блок 18 сопоставления можно конфигурировать для выполнения сопоставления согласно (обобщенной аддитивной модели 32):
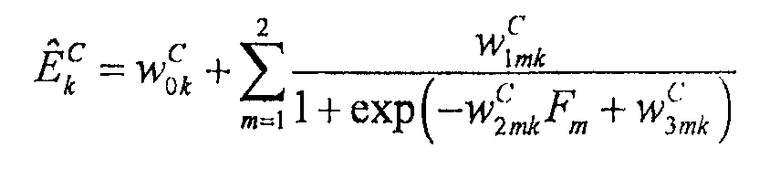
где
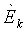
Fm, m = 1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
В качестве примера K = 4, и F1, F2 можно определять с помощью (15) и (16).
Преимущество вариантов осуществления на фиг.8-11 состоит в том, что они обеспечивают «точную настройку» сопоставления извлеченных особенностей с типом кодируемого звука.
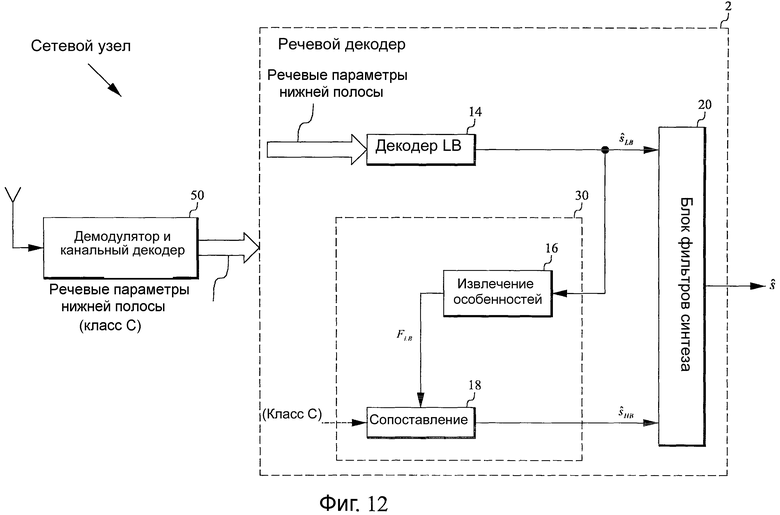
Фиг.12 - структурная схема, иллюстрирующая вариант осуществления сетевого узла, включающего в себя вариант осуществления речевого декодера 2 согласно настоящему изобретению. Этот вариант осуществления иллюстрирует радио-терминал, но другие сетевые узлы можно также применять. Например, если передача голоса по IP (Интернет протоколу) используется в сети, то узлы могут содержать компьютеры.
В сетевом узле на фиг.12 антенна принимает закодированный речевой сигнал. Демодулятор и канальный декодер 50 преобразовывает этот сигнал в речевые параметры нижней полосы (и дополнительно - в класс C сигнала, как обозначено «(класс C)» и штриховой линией сигнала) и направляет их к речевому декодеру 2 для генерации речевого сигнала s, как описано выше в отношении различных вариантов осуществления.
Описанные в данном документе этапы, функции, процедуры и/или блоки можно воплощать в аппаратном обеспечении, используя любую обычную технологию, такую как технология дискретных схем или интегральных схем, которые включают в себя и универсальную электронную схему, и специальную схему.
Альтернативно, по меньшей мере некоторые из описанных этапов, функций, процедур и/или блоков можно воплощать в программном обеспечении для выполнения с помощью подходящего устройства обработки, такого как микропроцессор, цифровой сигнальный процессор (DSP) и/или любое подходящее программируемое логическое устройство, например, устройство на основе программируемой пользователем вентильной матрицы (FPGA).
Нужно также подразумевать, что можно многократно использовать обычные возможности обработки сетевых узлов. Это можно сделать, например, с помощью перепрограммирования существующего программного обеспечения или добавления новых компонентов программного обеспечения.
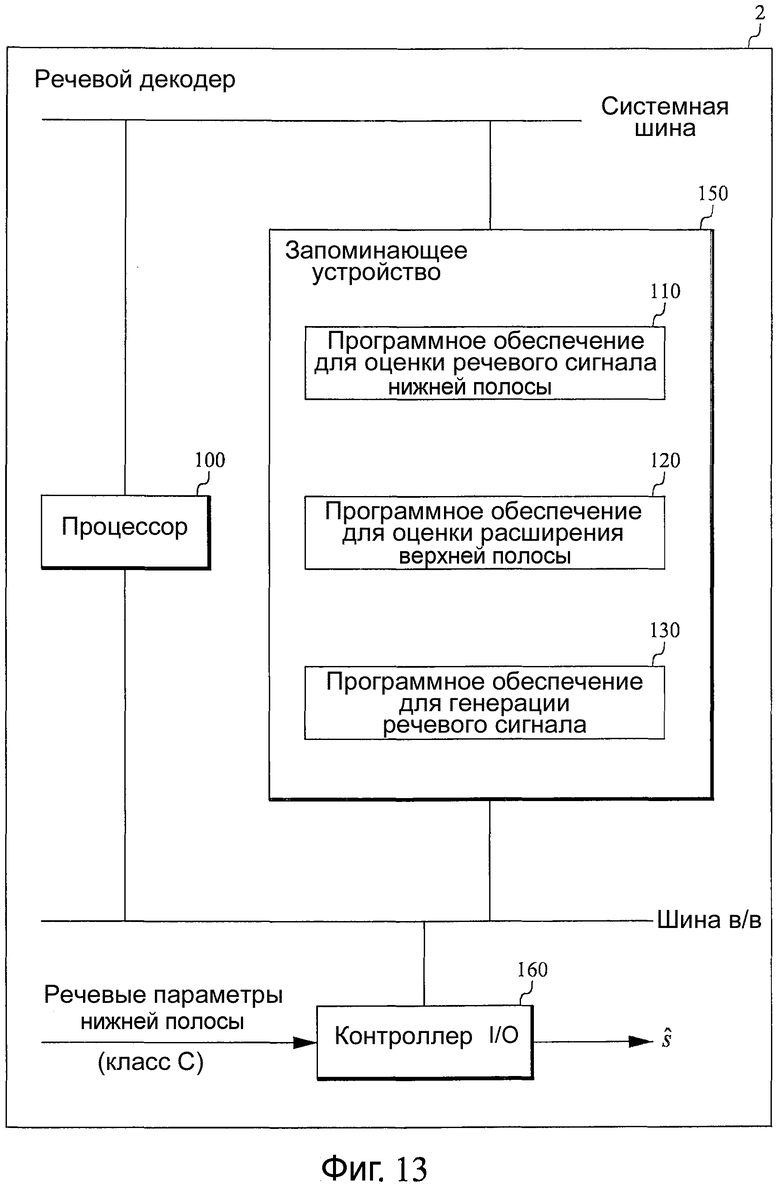
В качестве примера реализации, фиг.13 является структурной схемой, иллюстрирующей вариант осуществления примера речевого декодера 2 согласно настоящему изобретению. Данный вариант осуществления основан на процессоре 100, например, микропроцессоре, который выполняет компонент 110 программного обеспечения для оценки речевого сигнала нижней полосы ŝLB, компонент 120 программного обеспечения для оценки речевого сигнала верхней полосы ŝHB, и компонент 130 программного обеспечения для генерации речевого сигнала ŝ из ŝLB и ŝHB. Данное программное обеспечение хранится в памяти 150. Процессор 100 осуществляет связь с памятью по системной шине. Параметры речи нижней полосы (и дополнительно класс C сигнала) принимаются с помощью контроллера 160 ввода/вывода (I/O), который управляет шиной I/O, с которой соединены процессор 100 и память 150. В данном варианте осуществления параметры, принимаемые контроллером 150 I/O, сохраняются в памяти 150, где они обрабатываются с помощью компонентов программного обеспечения. Компонент 110 программного обеспечения может воплощать функциональные возможности блока 14 в описанных выше вариантах осуществления. Компонент 120 программного обеспечения может воплощать функциональные возможности блока 30 в описанных выше вариантах осуществления. Компонент 130 программного обеспечения может воплощать функциональные возможности блока 20 в описанных выше вариантах осуществления. Речевой сигнал, полученный из компонента 130 программного обеспечения, выводится из памяти 150 с помощью контроллера 160 I/O по шине I/O.
В варианте осуществления на фиг.13 речевые параметры принимаются с помощью контроллера 160 I/O, а другие задачи, такие как демодуляция и канальное декодирование в радио-терминале, как предполагается, обрабатываются в другом месте в принимающем сетевом узле. Однако, в качестве альтернативы можно предоставлять возможность дополнительным компонентам программного обеспечения в памяти 150 также выполнять всю или часть цифровой обработки сигналов для извлечения речевых параметров из принимаемого сигнала. В таком варианте осуществления речевые параметры можно получать непосредственно из памяти 150.
В случае, если принимающий сетевой узел является компьютером, принимающим пакеты передачи голоса по IP-протоколу, то IP-пакеты обычно направляются к контроллеру 160 I/O, а речевые параметры извлекаются с помощью дополнительных компонентов программного обеспечения в памяти 150.
Некоторые или все описанные выше компоненты программного обеспечения можно переносить на компьютерно-читаемом носителе, например, на CD (компакт-диске), на DVD (цифровом универсальном диске) или на жестком диске, и загружать в память для выполнения с помощью процессора.
Фиг.14 - последовательность операций, которая иллюстрирует один из вариантов осуществления способа согласно настоящему изобретению. На этапе S1 извлекают набор особенностей 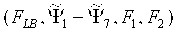
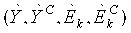
Специалистам будет понятно, что различные модификации и изменения могут быть сделаны в настоящем изобретении без отступления от его объема, который определен с помощью прилагаемой формулы изобретения.
СОКРАЩЕНИЯ
ACELP - линейное предсказание с алгебраическим кодовым возбуждением
BWE - расширение полосы пропускания
CELP - линейное предсказание с кодовым возбуждением
DSP - цифровой сигнальный процессор
FPGA - программируемая пользователем вентильная матрица
GMM - модель гауссовых смесей
HB - верхняя полоса
HMM - скрытые марковские модели
IP - Интернет-протокол
LB - нижняя полоса
ССЫЛКИ
[1] M. Nilsson and W. B. Kleijn, «Avoiding over-estimation in bandwidth extension of telephony speech», Proc. IEEE Int. Conf. Acoust. Speech Sign. Process., 2001.
[2] P. Jax and P. Vary, «Wideband extension of telephone speech using a hidden Markov model», IEEE Workshop on Speech Coding, 2000.
[3] ITU-T Rec. G.729.1, «G.729-based embedded variable bit-rate coder: An 8-32 kbit/s scalable wideband coder bitstream interoperable with G.729», 2006.
[4] 3GPP TS 26. 190, «Adaptive Multi-Rate - Wideband (AMR-WB) speech codec; Transcoding functions», 2008.
[5] «New Approaches to Regression by Generalized Additive Models and Continuous Optimization for Modern Applications in Finance, Science and Technology», Pakize Taylan, Gerhard- Wilhelm Weber, Amir Beck, http://www3.iam.metu.edu.tr/iam/images/1/10/Preprint56.pdf
[6] Numerical Recipes in C++: The Art of Scientific Computing, 2nd edition, reprinted 2003, W. Press, S. Teukolsky, W. Vetterling, B. Flannery.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ ВЫХОДНЫХ ДАННЫХ РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ | 2009 |
|
RU2494477C2 |
| АДАПТИВНОЕ РАСШИРЕНИЕ ПОЛОСЫ ПРОПУСКАНИЯ И УСТРОЙСТВО ДЛЯ ЭТОГО | 2014 |
|
RU2641224C2 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ОБРАБОТКИ КОДИРОВАННОЙ АУДИОСЦЕНЫ С ИСПОЛЬЗОВАНИЕМ РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ | 2021 |
|
RU2820946C1 |
| СИСТЕМЫ И СПОСОБЫ ПЕРЕДАЧИ ИЗБЫТОЧНОЙ ИНФОРМАЦИИ КАДРА | 2014 |
|
RU2673847C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РАСШИРЕНИЯ ШИРИНЫ ПОЛОСЫ АУДИОСИГНАЛА | 2008 |
|
RU2447415C2 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ОБРАБОТКИ КОДИРОВАННОЙ АУДИОСЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СГЛАЖИВАНИЯ ПАРАМЕТРОВ | 2021 |
|
RU2818033C1 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ОБРАБОТКИ КОДИРОВАННОЙ АУДИОСЦЕНЫ С ИСПОЛЬЗОВАНИЕМ ПРЕОБРАЗОВАНИЯ ПАРАМЕТРОВ | 2021 |
|
RU2822446C1 |
| УСТРОЙСТВО И СПОСОБ РАСЧЕТА ПАРАМЕТРОВ РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ ПОСРЕДСТВОМ УПРАВЛЕНИЯ ФРЕЙМАМИ НАКЛОНА СПЕКТРА | 2009 |
|
RU2443028C2 |
| ГЕНЕРАЦИЯ СИГНАЛА ВЕРХНЕЙ ПОЛОСЫ | 2016 |
|
RU2667460C1 |
| ГЕНЕРАЦИЯ СИГНАЛА ВЕРХНЕЙ ПОЛОСЫ | 2016 |
|
RU2742296C2 |
Изобретение относится к средствам расширения верхней полосы звукового сигнала по нижней полосе звукового сигнала. Технический результат заключается в повышении эффективности расширения полосы звукового сигнала. Расширение полосы звукового сигнала включает в себя следующие этапы: извлекают (S1) набор особенностей звукового сигнала нижней полосы; сопоставляют (S2) извлеченные особенности по меньшей мере с одним параметром верхней полосы с помощью обобщенного аддитивного моделирования; сдвигают (S3) по частоте копию звукового сигнала нижней полосы в верхнюю полосу; управляют (S4) огибающей сдвинутой по частоте копии звукового сигнала нижней полосы с помощью упомянутого по меньшей мере одного параметра верхней полосы. 4 н. и 9 з.п. ф-лы, 14 ил.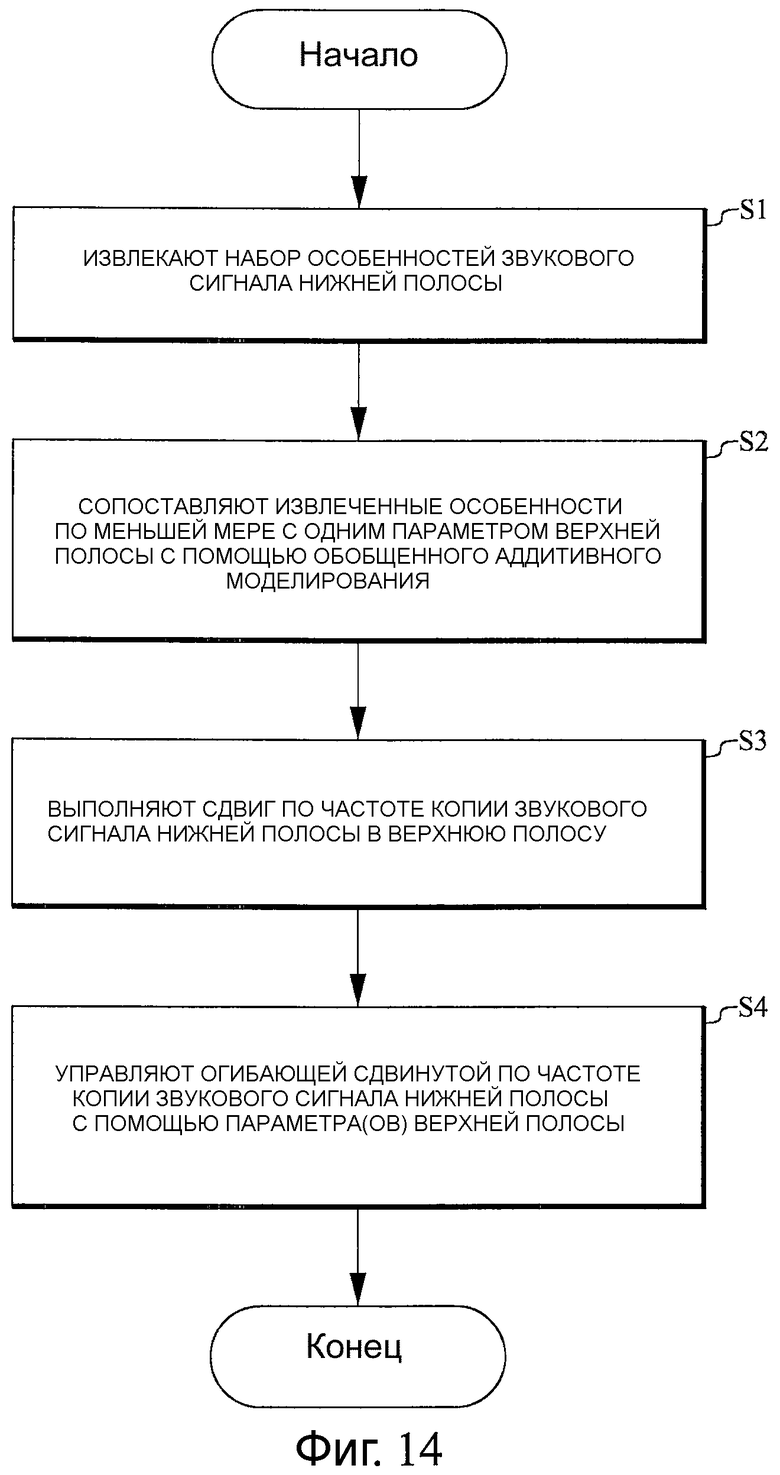
1. Способ расширения верхней полосы звукового сигнала по нижней полосе звукового сигнала, который включает в себя этап извлечения (S1) набора особенностей 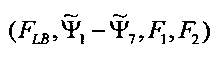 звукового сигнала нижней полосы, причем упомянутый способ отличается тем, что содержит этапы, на которых:
звукового сигнала нижней полосы, причем упомянутый способ отличается тем, что содержит этапы, на которых:
сопоставляют (S2) извлеченные особенности по меньшей мере с одним параметром верхней полосы 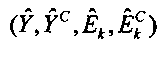 с помощью обобщенного аддитивного моделирования;
с помощью обобщенного аддитивного моделирования;
сдвигают (S3) по частоте копию звукового сигнала нижней полосы 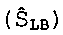 в верхнюю полосу;
в верхнюю полосу;
управляют (S4) огибающей сдвинутой по частоте копии звукового сигнала нижней полосы с помощью упомянутого по меньшей мере одного параметра верхней полосы.
2. Способ по п. 1, в котором сопоставление основано на сумме сигмоидальных функций извлеченных особенностей 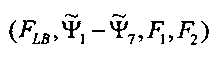 .
.
3. Способ по п. 2, в котором сопоставление задают с помощью:
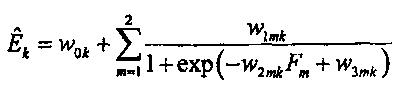
где
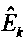 , k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, управляющее огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
, k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, управляющее огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
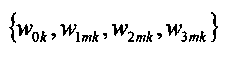 являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра
являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра 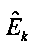 верхней полосы,
верхней полосы,
Fm, m=1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
4. Способ по п. 2, в котором сопоставление задают с помощью:
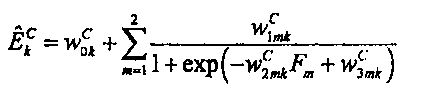
где
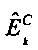 , k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, связанное с классом С сигнала, который классифицирует исходный звуковой сигнал, представленный звуковым сигналом нижней полосы , и управляют огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
, k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, связанное с классом С сигнала, который классифицирует исходный звуковой сигнал, представленный звуковым сигналом нижней полосы , и управляют огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
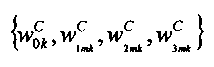 являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра
являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра 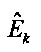 верхней полосы в классе С сигнала,
верхней полосы в классе С сигнала,
Fm, m=1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
5. Способ по п. 3 или 4, в котором К=4.
6. Устройство (30) расширения верхней полосы звукового сигнала по нижней полосе звукового сигнала, которое включает в себя блок (16) извлечения особенностей, сконфигурированный для
извлечения набора особенностей 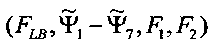 звукового сигнала нижней полосы, причем упомянутое устройство отличается тем, что содержит блок (18) сопоставления, который включает в себя:
звукового сигнала нижней полосы, причем упомянутое устройство отличается тем, что содержит блок (18) сопоставления, который включает в себя:
модуль (32) сопоставления с помощью обобщенного аддитивного моделирования, сконфигурированный для сопоставления извлеченных особенностей по меньшей мере с одним параметром верхней полосы 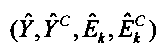 с помощью обобщенного аддитивного моделирования;
с помощью обобщенного аддитивного моделирования;
модуль (34) сдвига частоты, сконфигурированный для сдвига по частоте копии звукового сигнала нижней полосы 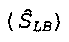 в верхнюю полосу;
в верхнюю полосу;
модуль (36) управления огибающей, сконфигурированный для управления огибающей сдвинутой по частоте копии с помощью упомянутого по меньшей мере одного параметра верхней полосы.
7. Устройство по п. 6, в котором модуль (32) сопоставления с помощью обобщенного аддитивного моделирования сконфигурирован для сопоставления, основанного на сумме сигмоидальных функций извлеченных особенностей 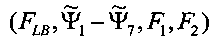 .
.
8. Устройство по п. 7, в котором модуль (32) сопоставления с помощью обобщенного аддитивного моделирования сконфигурирован для выполнения сопоставления согласно:
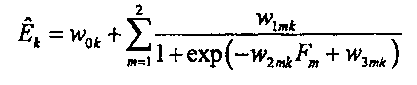
где
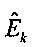 , k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, управляющее огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
, k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, управляющее огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
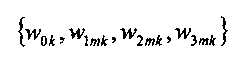 являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра
являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра 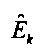 верхней полосы,
верхней полосы,
Fm, m=1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
9. Устройство по п. 7, в котором модуль (32) сопоставления с помощью обобщенного аддитивного моделирования сконфигурирован для выполнения сопоставления согласно:
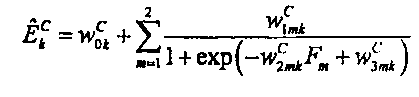
где
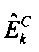 , k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, связанное с классом С сигнала, который классифицирует исходный звуковой сигнал, представленный звуковым сигналом нижней полосы , и управляют огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
, k=1,…, К, являются параметрами верхней полосы, которые определяют усиление, связанное с классом С сигнала, который классифицирует исходный звуковой сигнал, представленный звуковым сигналом нижней полосы , и управляют огибающей К предварительно определенных частотных полос сдвинутой по частоте копии звукового сигнала нижней полосы,
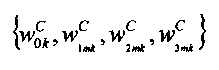 являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра
являются наборами коэффициентов сопоставления, которые определяют сигмоидальные функции для каждого параметра 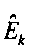 верхней полосы в классе С сигнала,
верхней полосы в классе С сигнала,
Fm, m=1, 2, являются особенностями звукового сигнала нижней полосы, которые описывают соотношения энергии между различными частями спектра звукового сигнала нижней полосы.
10. Устройство по п. 8 или 9, в котором модуль (32) сопоставления с помощью обобщенного аддитивного моделирования сконфигурирован для сопоставления извлеченных особенностей с К=4 параметрами верхней полосы 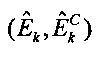 .
.
11. Речевой декодер, включающий в себя устройство (30) по любому из предыдущих пп. 6-9.
12. Сетевой узел, включающий в себя речевой декодер по п. 11.
13. Сетевой узел по п. 12, в котором сетевой узел является радио-терминалом.
| US 2009144062 A1, 04.06.2009 | |||
| Винтовой питатель | 1988 |
|
SU1638083A1 |
| Устройство для определения динамических характеристик термодатчиков | 1978 |
|
SU732687A1 |
| US 2007067163 A1, 22.03.2007 | |||
| US 2006277039 A1, 07.12.2006 | |||
| EP 1300833 A2, 09.04.2003 | |||
| US 2004078194 A1, 22.04.2004 | |||
| US 2004002856 A1, 01.01.2004 | |||
| СПОСОБ ПОСЛЕДУЮЩЕЙ ОБРАБОТКИ С ВЫСОКОЙ РАЗРЕШАЮЩЕЙ СПОСОБНОСТЬЮ ДЛЯ РЕЧЕВОГО ДЕКОДЕРА | 1998 |
|
RU2199157C2 |

