Настоящее изобретение относится к обработке аудиоданных и, в частности, к обработке кодированной аудиосцены для целей формирования обработанной аудиосцены для рендеринга, передачи или хранения.
Обычно аудиоприложения, которые обеспечивают средства для пользовательской связи, такие как телефония или видеоконференцсвязь, ограничены главным образом монозаписью и воспроизведением. Тем не менее в последние годы появление новой иммерсивной технологии VR/AR также приводит к возрастающему интересу к пространственному рендерингу сценариев связи. Для удовлетворения этого интереса в данный момент в разработке находится новый аудиоcтандарт 3GPP, называемый «иммерсивными услугами передачи голоса и аудио (IVAS)». На основе недавно выпущенного стандарта улучшенных голосовых услуг (EVS) IVAS обеспечивает многоканальные расширения и расширения VR, допускающие рендеринг иммерсивных аудиосцен, например, для пространственной видеоконференцсвязи при одновременном удовлетворении требований по низкой задержке для сглаженной аудиосвязи. Эта постоянная потребность в сохранении минимальной общей задержки кодека без ухудшения качества воспроизведения обеспечивает мотивацию для работы, описанной ниже.
Кодирование сцено-ориентированного аудиоматериала (SBA) (такого как амбиофоническое содержимое третьего порядка) с помощью системы, которая использует параметрическое кодирование аудио (такое как направленное кодирование аудио (DirAC) [1][2]) на низких скоростях передачи битов (например, в 32 Кбит/с и ниже) обеспечивает возможность непосредственного кодирования только одного (транспортного) канала при восстановлении пространственной информации через боковые параметры в декодере в области гребенки фильтров. В случаях, если компоновка динамиков в декодере допускает только стереовоспроизведение, полное восстановление трехмерной аудиосцены не требуется. Для более высоких скоростей передачи битов, кодирование 2 транспортных каналов или более является возможным, так что в этих случаях стереофоническое воспроизведение сцены может непосредственно извлекаться и воспроизводиться вообще без параметрического пространственного повышающего микширования (при полном пропуске модуля пространственного рендеринга) и дополнительной задержки, которая его сопровождает (например, вследствие дополнительного анализа/синтеза на основе гребенки фильтров, такой как гребенка комплекснозначных фильтров с низкой задержкой (CLDFB)). Тем не менее, в низкоскоростных случаях только с одним транспортным каналом это является невозможным. Таким образом, в случае DirAC, к настоящему моменту для стереовывода требуется повышающее микширование на основе FOA (амбиофонии первого порядка) со следующим преобразованием L/R. Это проблематично, поскольку этот случай теперь имеет более высокую полную задержку, чем другие возможные выходные стереоконфигурации в системе, и должно быть желательным совмещение всей выходной стереоконфигурации.
Пример стереорендеринга DirAC с высокой задержкой
Фиг. 12 показывает пример блок-схемы традиционной обработки с помощью декодера для повышающего стереомикширования DirAC с высокой задержкой.
Например, в кодере, который не иллюстрируется, один канал понижающего микширования извлекается через пространственное понижающее микширование в обработке с помощью кодера DirAC и затем кодируется с помощью базового кодера, к примеру, по стандарту улучшенных голосовых услуг (EVS) [3].
В декодере, например, с использованием традиционного процесса повышающего микширования DirAC, изображенного на фиг. 12, один доступный транспортный канал сначала декодируется посредством использования монодекодера или монодекодера 1210 IVAS из потока 1212 битов, приводя к сигналу временной области, который может рассматриваться качестве декодированного понижающего мономикширования 1214 исходной аудиосцены.
Декодированный моносигнал 1214 вводится в CLDFB 1220 для анализа сигнала 1214 (преобразования сигнала в частотную область), который вызывает задержку. Существенно задержанный выходной сигнал 1222 вводится в модуль 1230 рендеринга DirAC. Модуль 1230 рендеринга DirAC обрабатывает задержанный выходной сигнал 1222, и передаваемая вспомогательная информация, а именно, боковые параметры 1213 DirAC, используется для преобразования сигнала 1222 в представление FOA, а именно в повышающее микширование 1232 FOA исходной сцены с восстановленной пространственной информацией из боковых параметров 1213 DirAC.
Передаваемые параметры 1213 могут содержать направляющие углы, например, одно значение азимута для горизонтальной плоскости и один угол места для вертикальной плоскости и одно значение рассеянности в расчете на полосу частот, чтобы перцепционно описывать полную трехмерную аудиосцену. Вследствие обработки для каждой полосы частот повышающего стереомикширования DirAC, параметры 1213 отправляются многократно в расчете на кадр, а именно, по одному набору для каждой полосы частот. Кроме того, каждый набор содержит несколько параметров направления для отдельных субкадров в полном кадре (например, с длиной на 20 мс), с тем чтобы увеличивать временное разрешение.
Результат модуля 1230 рендеринга DirAC, например, может представлять собой полную трехмерную сцену в формате FOA, а именно повышающее микширование 1232 FOA, которое может теперь превращаться, с использованием матричных преобразований 1240, в сигнал 1242 L/R, подходящий для воспроизведения в компоновке стереодинамиков. Другими словами, сигнал 1242 L/R может вводиться в стереодинамик или может вводиться в синтез 1250 CLDFB, который использует заданные канальные весовые коэффициенты. синтез 1250 CLDFB преобразует вводимые два выходных канала (сигнал 1242 L/R) в частотной области во временную область, приводя к выходному сигналу 1252, готовому к стереовоспроизведению.
В качестве альтернативы, можно использовать одинаковое повышающее стереомикширование DirAC для непосредственного формирования рендеринга для выходной стереоконфигурации, что исключает промежуточный этап формирования сигнала FOA. Это должно уменьшать алгоритмическую сложность для потенциальной комплексификации инфраструктуры. Тем не менее, оба подхода требуют использования дополнительной гребенки фильтров после базового кодирования, что приводит к дополнительной задержке в 5 мс. Дополнительный пример рендеринга DirAC содержится в [2].
Подход на основе повышающего стереомикширования DirAC является довольно субоптимальным с точки зрения как задержки, так и сложности. Вследствие использования гребенки фильтров CLDFB, вывод существенно задерживается (в примере DirAC на дополнительные 5 мс) и в силу этого имеет одинаковую полную задержку с полным повышающим микшированием SBA (по сравнению с задержкой выходной стереоконфигурации, в которой дополнительный этап рендеринга не требуется). Обоснованное предположение также заключается в том, что проведение полного повышающего микширования SBA для формирования стереосигнала, не является идеальным относительно сложности системы.
Задача настоящего изобретения состоит в создании усовершенствованной концепции для обработки кодированной аудиосцены.
Данная задача решается устройством для обработки кодированной аудиосцены по пункту 1 формулы, способом обработки кодированной аудиосцены по пункту 32 формулы или компьютерной программой по пункту 33 формулы.
Настоящее изобретение основано на понимании того, что, в соответствии с первым аспектом, связанным с преобразованием параметров, усовершенствованная концепция для обработки кодированной аудиосцены получается посредством преобразования данных параметров в кодированной аудиосцене, связанной с виртуальным положением слушателя, в преобразованные параметры, связанные с канальным представлением данного выходного формата. Эта процедура обеспечивает высокую гибкость при обработке и конечном рендеринге обработанной аудиосцены в канально-ориентированном окружении.
Вариант осуществления согласно первому аспекту настоящего изобретения содержит устройство для обработки кодированной аудиосцены, представляющей звуковое поле, связанное с виртуальным положением слушателя, причем кодированная аудиосцена содержит информацию в отношении транспортного сигнала, например, базового кодированного аудиосигнала и первого набора параметров, связанных с виртуальным положением слушателя. Устройство содержит преобразователь параметров для преобразования первого набора параметров, например, боковых параметров направленного кодирования аудио (DirAC) в B-формате или формате амбиофонии первого порядка (FOA), во второй набор параметров, например, в стереопараметры, связанные с канальным представлением, содержащим два или более каналов для воспроизведения в заданных пространственных положениях для двух или более каналов, и выходной интерфейс для формирования обработанной аудиосцены с использованием второго набора параметров и информации относительно транспортного сигнала.
В варианте осуществления, гребенка фильтров на основе кратковременного преобразования Фурье (STFT) используется для повышающего микширования, вместо модуля рендеринга на основе направленного кодирования аудио (DirAC). Таким образом, появляется возможность микширования с повышением одного канала понижающего микширования (включенного в поток битов) в стереовывод вообще без дополнительной полной задержки. За счет использования окон с очень короткими перекрытиями для анализа в декодере, повышающее микширование позволяет оставаться в пределах полной задержки, необходимой для кодеков связи или последующих иммерсивных услуг передачи голоса и аудио (IVAS). Это значение, например, может составлять 32 миллисекунды. В таких вариантах осуществления, постобработка для целей расширения полосы пропускания может вообще исключаться, поскольку такая обработка может выполняться параллельно с преобразованием параметров или преобразованием параметров.
Посредством преобразования конкретных для слушателя параметров для сигналов полосы низких частот (LB) в набор конкретных для канала стереопараметров для полосы низких частот, может достигаться повышающее микширование с низкой задержкой для полосы низких частот в области DFT. Для полосы высоких частот, один набор стереопараметров обеспечивает возможность выполнять повышающее микширование в полосе высоких частот во временной области, предпочтительно параллельно со спектральным анализом, спектральным повышающим микшированием и спектральным синтезом для полосы низких частот.
В качестве примера, преобразователь параметров выполнен с возможностью использования одного параметра бокового усиления для панорамирования и параметра остаточного прогнозирования, который тесно связан со стереошириной, а также тесно связан с параметром рассеянности, используемым в направленном кодировании аудио (DirAC).
Этот подход на основе «стереорежима DFT» в варианте осуществления обеспечивает возможность того, что кодек IVAS остается в пределах той же полной задержки, что и в EVS, в частности, в 32 миллисекунды, в случае обработки кодированной аудиосцены (сцено-ориентированного аудио) таким образом, чтобы получить стереовывод. За счет реализации простой обработки через стереорежим DFT вместо пространственного рендеринга DirAC, достигается более низкая сложность параметрического повышающего стереомикширования.
Настоящее изобретение основано на понимании того, что, в соответствии со вторым аспектом, связанным с расширением полосы пропускания, получается усовершенствованная концепция для обработки кодированной аудиосцены.
Вариант осуществления согласно второму аспекту настоящего изобретения содержит устройство для обработки аудиосцены, представляющей звуковое поле, причем аудиосцена содержит информацию в отношении транспортного сигнала и набора параметров. Устройство дополнительно содержит выходной интерфейс для формирования обработанной аудиосцены с использованием набора параметров и информации относительно транспортного сигнала, при этом выходной интерфейс выполнен с возможностью формирования необработанного представления двух или более каналов с использованием набора параметров и транспортного сигнала, модуль многоканального улучшения для формирования улучшающего представления двух или более каналов с использованием транспортного сигнала и модуль комбинирования сигналов для комбинирования необработанного представления двух или более каналов и улучшающего представления двух или более каналов для получения обработанной аудиосцены.
Формирование необработанного представления двух или более каналов, с одной стороны, и отдельное формирование улучшающего представления двух или более каналов, с другой стороны, обеспечивают значительную гибкость в выборе алгоритмов для необработанного представления и улучшающего представления. Конечное комбинирование уже осуществляется для каждого из одного или более выходных каналов, т.е. в многоканальной выходной области, а не в более низкой области канального ввода или кодированной сцены. Следовательно, после комбинирования, два или более каналов синтезируются и могут использоваться для дополнительных процедур, таких как рендеринг, передача или хранение.
В варианте осуществления, часть базовой обработки, такая как расширение полосы пропускания (BWE) речевого кодера на основе линейного прогнозирования с возбуждением по алгебраическому коду (ACELP) для улучшающего представления может выполняться параллельно стереообработке DFT для необработанного представления. Таким образом, любые задержки, понесенные посредством обоих алгоритмов, не накапливаются, но только данная задержка, понесенная посредством одного алгоритма, должна представлять собой конечную задержку. В варианте осуществления, только транспортный сигнал, например, сигнал (канал) полосы низких частот (LB), вводится в выходной интерфейс, например, стереообработку DFT, тогда как полоса высоких частот (HB) микшируется с повышением отдельно во временной области, например, посредством использования модуля многоканального улучшения таким образом, что стереодекодирование может обрабатываться в целевом временном окне в 32 миллисекунды. Посредством использования широкополосного панорамирования, например, на основе преобразованных боковых усилений, например, из преобразователя параметров, прямое повышающее микширование во временной области для целой полосы высоких частот получается вообще без существенной задержки.
В варианте осуществления, уменьшенная задержка в стереорежиме DFT может не получаться полностью в результате разностей в перекрытии двух преобразований, например, задержки на преобразование в 5 мс, вызываемой посредством CLDFB, и задержки на преобразование в 3,125 мс, вызываемой посредством STFT. Вместо этого, стереорежим DFT использует преимущество того факта, что последние 3,25 мс из целевой задержки кодера EVS в 32 мс по существу исходят из ACELP BWE. Все остальное (оставшиеся миллисекунды до тех пор, пока не будет достигнута целевая задержка кодера EVS) просто искусственно задерживается для обеспечения совмещения двух преобразованных сигналов (сигнала HB повышающего стереомикширования и заполняющего сигнала HB с базовым стереосигналом LB) снова в конце. Следовательно, чтобы исключать дополнительную задержку в стереорежиме DFT, только все остальные компоненты кодера преобразуются, например, в пределах очень короткого перекрытия окон DFT, тогда как ACELP BWE, например, с использованием модуля многоканального улучшения, микшируется с повышением почти без задержек во временной области.
Настоящее изобретение основано на понимании того, что, в соответствии с третьим аспектом, связанным со сглаживанием параметров, усовершенствованная концепция для обработки кодированной аудиосцены получается посредством выполнения сглаживания параметров относительно времени в соответствии с правилом сглаживания. Таким образом, обработанная аудиосцена, полученная посредством применения сглаженных параметров, а не необработанных параметров, к транспортному каналу(ам), должна иметь повышенное качество звука. Это является, в частности, истинным, когда сглаженные параметры представляют собой параметры повышающего микширования, но для любых других параметров, таких как параметры огибающей или LPC-параметры, или параметры шума, или параметры в виде коэффициентов масштабирования, использование или сглаженные параметры, полученные посредством правила сглаживания, должны приводить к повышенному субъективному качеству звучания полученной обработанной аудиосцены.
Вариант осуществления согласно третьему аспекту настоящего изобретения содержит устройство для обработки аудиосцены, представляющей звуковое поле, причем аудиосцена содержит информацию в отношении транспортного сигнала и первого набора параметров. Устройство дополнительно содержит процессор параметров для обработки первого набора параметров для получения второго набора параметров, при этом процессор параметров выполнен с возможностью вычисления по меньшей мере одного необработанного параметра для каждого выходного временного кадра с использованием по меньшей мере одного параметра из первого набора параметров для входного временного кадра, вычислять информацию сглаживания, такую как коэффициент для каждого необработанного параметра, в соответствии с правилом сглаживания и применять соответствующую информацию сглаживания к соответствующему необработанному параметру для извлечения параметра из второго набора параметров для выходного временного кадра, и выходной интерфейс для формирования обработанной аудиосцены с использованием второго набора параметров и информации относительно транспортного сигнала.
За счет сглаживания необработанных параметров во времени, сильные флуктуации в усилениях или параметрах между кадрами исключаются. Коэффициент сглаживания определяет силу сглаживания, которая вычисляется адаптивно в предпочтительных вариантах осуществления, посредством процессора параметров, который также имеет, в вариантах осуществления, функциональность преобразователя параметров для преобразования связанных с положением слушателя параметров в связанные с каналом параметры. Адаптивное вычисление обеспечивает возможность получать более быстрый отклик каждый раз, когда аудиосцена внезапно изменяется. Адаптивный коэффициент сглаживания вычисляется для каждой полосы частот из изменения энергий в текущей полосе частот. Энергии для каждой полосы частот вычисляются во всех субкадрах, включенных в кадр. Помимо этого, изменение энергий во времени характеризуется посредством двух средних, кратковременного среднего и долговременного среднего, таким образом, что крайние случаи не оказывают влияние на сглаживание, тогда как менее быстрое увеличение энергии не снижает сглаживание настолько сильно. Таким образом, коэффициент сглаживания вычисляется для каждого стереосубкадра DTF в текущем кадре из частного средних.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше и поясненные ниже, могут использоваться отдельно, т.е. без любого аспекта. Тем не менее, в других вариантах осуществления, два или более из аспектов комбинируются друг с другом, и в других вариантах осуществления, все аспекты комбинируются между собой для получения большего компромисса между полной задержкой, достижимым качеством звучания и требуемыми усилиями по реализации.
Ниже предпочтительные варианты осуществления настоящего изобретения поясняются с обращением к сопровождающим чертежам, на которых:
Фиг. 1 является блок-схемой устройства для обработки кодированной аудиосцены с использованием преобразователя параметров согласно варианту осуществления;
Фиг. 2a иллюстрирует принципиальную схему для первого набора параметров и для второго набора параметров согласно варианту осуществления;
Фиг. 2b является вариантом осуществления преобразователя параметров или процессора параметров для вычисления необработанного параметра;
Фиг. 2c является вариантом осуществления преобразователя параметров или процессора параметров для комбинирования необработанных параметров;
Фиг. 3 является вариантом осуществления преобразователя параметров или процессора параметров для выполнения комбинирования со взвешиванием необработанных параметров;
Фиг. 4 является вариантом осуществления преобразователя параметров для формирования параметров бокового усиления и параметров остаточного прогнозирования;
Фиг. 5a является вариантом осуществления преобразователя параметров или процессора параметров для вычисления коэффициента сглаживания для необработанного параметра;
Фиг. 5b является вариантом осуществления преобразователя параметров или процессора параметров для вычисления коэффициента сглаживания для полосы частот;
Фиг. 6 иллюстрирует принципиальную схему усреднения транспортного сигнала для коэффициента сглаживания согласно варианту осуществления;
Фиг. 7 является вариантом осуществления преобразователя параметров или процессора параметров для вычисления рекурсивного сглаживания;
Фиг. 8 является вариантом осуществления устройства для декодирования транспортного сигнала;
Фиг. 9 является вариантом осуществления устройства для обработки кодированной аудиосцены с использованием расширения полосы пропускания;
Фиг. 10 является вариантом осуществления устройства для получения обработанной аудиосцены;
Фиг. 11 является блок-схемой варианта осуществления модуля многоканального улучшения;
Фиг. 12 является блок-схемой традиционного процесса повышающего стереомикширования DirAC;
Фиг. 13 является вариантом осуществления устройства для получения обработанной аудиосцены с использованием преобразования параметров; и
Фиг. 14 является вариантом осуществления устройства для получения обработанной аудиосцены с использованием расширения полосы пропускания.
Фиг. 1 иллюстрирует устройство для обработки кодированной аудиосцены 130, например, представляющей звуковое поле, связанное с виртуальным положением слушателя. Кодированная аудиосцена 130 содержит информацию в отношении транспортного сигнала 122, например, потока битов и первого набора 112 параметров, например, множества параметров DirAC, также включенных в потоке битов, которые связаны с виртуальным положением слушателя. Первый набор 112 параметров вводится в преобразователь 110 параметров или процессор параметров, который преобразует первый набор 112 параметров во второй набор 114 параметров, которые связаны с канальным представлением, содержащим по меньшей мере два или более каналов. Устройство допускает поддержку различных аудиоформатов. Аудиосигналы могут быть акустическими по своему характеру, сниматься посредством микрофонов либо электрическими по своему характеру, причем они предположительно должны передаваться в громкоговорители. Поддерживаемые аудиоформаты могут представлять собой моносигнал, сигнал полосы низких частот, сигнал полосы высоких частот, многоканальный сигнал, компоненты амбиофонии первого порядка и высшего порядка и аудиообъекты. Аудиосцена также может описываться посредством комбинирования различных входных форматов.
Преобразователь 110 параметров выполнен с возможностью вычисления второго набора 114 параметров в качестве параметрических стерео- или многоканальных параметров, например, двух или более каналов, которые вводятся в выходной интерфейс 120. Выходной интерфейс 120 выполнен с возможностью формирования обработанной аудиосцены 124 посредством комбинирования транспортного сигнала 122 или информации относительно транспортного сигнала и второго набора 114 параметров для получения транскодированной аудиосцены в качестве обработанной аудиосцены 124. Другой вариант осуществления содержит повышающее микширование транспортного сигнала 122 с использованием второго набора 114 параметров в сигнал повышающего микширования, содержащий два или более каналов. Другими словами, преобразователь параметров 120 преобразует первый набор 112 параметров, например, используемых для рендеринга DirAC, во второй набор 114 параметров. Второй набор параметров может содержать параметр бокового усиления, используемый для панорамирования, и параметр остаточного прогнозирования, который, при применении в повышающем микшировании, приводит к улучшенному пространственному изображению аудиосцены. Например, параметры первого набора 112 параметров могут содержать по меньшей мере один из параметра направления поступления, параметра рассеянности, параметра информации направления, связанного со сферой с виртуальным положением прослушивания в качестве начала координат сферы, и параметра расстояния. Например, параметры из второго набора 114 параметров могут содержать по меньшей мере один из параметра бокового усиления, параметра усиления для остаточного прогнозирования, параметра межканальной разности уровней, параметра межканальной разности времен, параметра межканальной разности фаз и параметра межканальной когерентности.
Фиг. 2a иллюстрирует принципиальную схему для первого набора 112 параметров и для второго набора 114 параметров согласно варианту осуществления. В частности, изображается разрешение параметров для обоих параметров (первого и второго). Каждая абсцисса на фиг. 2a представляет время, и каждая ордината на фиг. 2a представляет частоту. Как показано на фиг. 2a, входной временной кадр 210, с которым связан первый набор 112 параметров, содержит два или более входных временных субкадров 212 и 213. Непосредственно ниже, выходной временной кадр 220, с которым связан второй набор 114 параметров, показывается на соответствующей схеме, связанной с верхней схемой. Это указывает, что выходной временной кадр 220 меньше по сравнению с входным временным кадром 210, и что выходной временной кадр 220 больше по сравнению с входным временным субкадром 212 или 213. Следует отметить, что входной временной субкадр 212 или 213 и выходной временной кадр 220 могут содержать множество частот в качестве полосы частот. Полоса 230 входных частот может содержать одинаковые частоты с полосами 240 выходных частот. Согласно вариантам осуществления, полосы частот для полосы 230 входных частот и полос 240 выходных частот могут не соединяться или не коррелироваться между собой.
Следует отметить, что боковое усиление и остаточное усиление, которые описываются на фиг. 4, типично вычисляются для кадров таким образом, что для каждого входного кадра 210, одно боковое усиление и одно остаточное усиление вычисляются. Тем не менее, в других вариантах осуществления, не только одно боковое усиление и одно остаточное усиление вычисляются для каждого кадра, но группа боковых усилений и группа остаточных усилений вычисляются для входного временного кадра 210, причем каждое боковое усиление и каждое остаточное усиление связаны с определенным входным временным субкадром 212 или 213, например, полосы частот. Таким образом, в вариантах осуществления, преобразователь 110 параметров вычисляет, для каждого кадра первого набора 112 параметров и второго набора 114 параметров, группу боковых усилений и группу остаточных усилений, причем число боковых и остаточных усилений для входного временного кадра 210 типично равно числу полос 230 входных частот.
Фиг. 2b показывает вариант осуществления преобразователя 110 параметров для вычисления 250 необработанного параметра 252 из второго набора 114 параметров. Преобразователь 110 параметров вычисляет необработанный параметр 252 для каждого из двух или более входных временных субкадров 212 и 213 последовательно во времени. Например, вычисление 250 извлекает, для каждой полосы 230 входных частот и момента времени (входного временного субкадра 212, 213), преобладающее направление поступления (DOA) азимута θ и преобладающее направление поступления угла места φ, и параметр ψ рассеянности.
Для направленных компонентов, таких как X, Y и Z, обеспечивается возможность того, что сферические гармоники первого порядка в центральном положении могут извлекаться посредством всенаправленного компонента w(b,n) и параметров DirAC с использованием следующих уравнений:
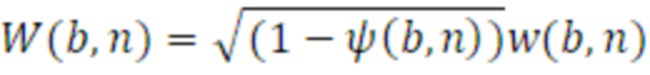
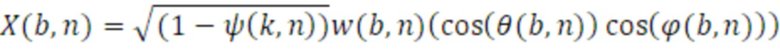
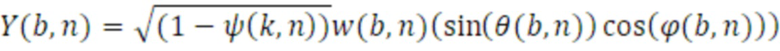

W-канал представляет ненаправленный монокомпонент сигнала, соответствующий выводу всенаправленного микрофона. X-, Y- и Z-каналы представляют собой направленные компоненты в трех измерениях. Из этих четырех каналов FOA, есть возможность получать стереосигнал (стереоверсию, стереовывод) посредством декодирования, заключающего в себе W-канал и Y-канал, с использованием преобразователя 110 параметров, что приводит к двум кардиоидам, указывающим на углы азимута в +90 градусов и -90 градусов. Вследствие этого факта, следующее уравнение показывает взаимосвязь стереосигнала, левого и правого, в котором, посредством суммирования Y-канала с W-каналом, представляется левый канал L, и в котором, посредством вычитания Y-канала из W-канала, представляется правый канал R.
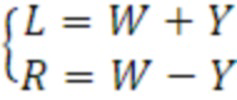
Другими словами, это декодирование соответствует формированию диаграммы направленности первого порядка, указывающей в двух направлениях, которое может выражаться с использованием следующего уравнения:
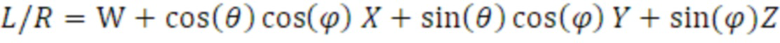
Следовательно, предусмотрена непосредственная взаимосвязь между стереовыводом (левым каналом и правым каналом) и первым набором 112 параметров, а именно параметрами DirAC.
Но, с другой стороны, второй набор 114 параметров, а именно, параметры DFT базируются на модели левого L канала и правого R канала на основе среднего сигнала M и бокового сигнала S, которая может выражаться с использованием следующего уравнения:
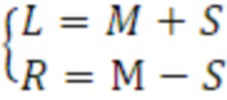
Здесь, M передается в качестве моносигнала (канала), который соответствует всенаправленному каналу W в случае сцено-ориентированного аудиорежима (SBA). Кроме того, в стереорежиме DFT S прогнозируется из M с использованием параметра бокового усиления, который поясняется ниже.
Фиг. 4 показывает вариант осуществления преобразователя 110 параметров для формирования параметров 455 бокового усиления и параметров 456 остаточного прогнозирования, например, с использованием процесса 450 вычисления. Преобразователь 110 параметров предпочтительно обрабатывает вычисление 250 и 450 для вычисления необработанного параметра 252, например, бокового параметра 455 для полосы 241 выходных частот с использованием следующего уравнения:
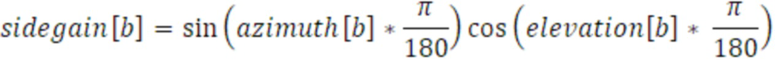
Согласно уравнению, b является полосой выходных частот, sidegain является параметром 455 бокового усиления, azimuth является азимутальным компонентом параметра направления поступления, и elevation является компонентом угла места параметра направления поступления. Как показано на фиг. 4, первый набор 112 параметров содержит параметры 456 направления поступления (DOA) для полосы 231 входных частот, как описано выше, и второй набор 114 параметров содержит параметр 455 бокового усиления в расчете на полосу 230 входных частот. Тем не менее, если первый набор 112 параметров дополнительно содержит параметр ψ 453 рассеянности для полосы 231 входных частот, преобразователь 110 параметров выполнен с возможностью вычисления 250 параметра 455 бокового усиления для полосы 241 выходных частот с использованием следующего уравнения:
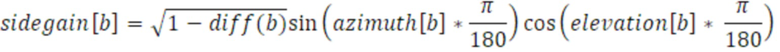
Согласно уравнению, diff(b) является параметром ψ 453 рассеянности для полосы b 230 входных частот. Следует отметить, что параметры 456 направления из первого набора 112 параметров могут содержать различные диапазоны значений, например, параметр 451 азимута составляет [0;360], параметр 452 угла места составляет [0;180], и результирующий параметр 455 бокового усиления составляет [-1;1]. Как показано на фиг. 2c, преобразователь 110 параметров комбинирует, с использованием модуля 260 комбинирования по меньшей мере два необработанных параметра 252 таким образом, что параметр из второго набора 114 параметров, связанного с выходным временным кадром 220, извлекается.
Согласно варианту осуществления, второй набор 114 параметров дополнительно содержит параметр 456 остаточного прогнозирования для полосы 241 выходных частот из полос 240 выходных частот, которая показывается на фиг. 4. Преобразователь 110 параметров может использовать, в качестве параметра 456 остаточного прогнозирования для полосы 241 выходных частот, параметр ψ 453 рассеянности из полосы 231 входных частот, как проиллюстрировано посредством модуля 410 остаточного выбора. Если полоса 231 входных частот и полоса 241 выходных частот равны друг другу, то преобразователь 110 параметров использует параметр ψ 453 рассеянности из полосы 231 входных частот. Из параметра ψ 453 рассеянности для полосы 231 входных частот извлекается параметр ψ 453 рассеянности для полосы 241 выходных частот, и параметр ψ 453 рассеянности используется для полосы 241 выходных частот в качестве параметра 456 остаточного прогнозирования для полосы 241 выходных частот. Затем преобразователь 110 параметров может использовать параметр ψ 453 рассеянности из полосы 231 входных частот.
В стереообработке DFT остаток прогнозирования, с использованием модуля 410 остаточного выбора, предполагается и ожидается некогерентным и моделируется посредством своей энергии и декорреляции остаточных сигналов, идущих в левый L и в правый R. Остаток прогнозирования бокового сигнала S со средним сигналом M в качестве моносигнала (канала) может выражаться следующим образом:
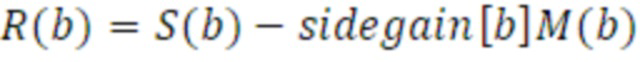
Его энергия моделируется в стереообработке DFT с использованием усиления для остаточного прогнозирования с использованием следующего уравнения:
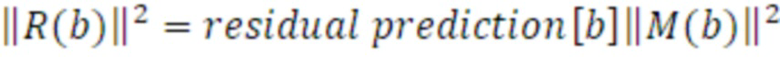
Поскольку остаточное усиление представляет компонент межканальной некогерентности стереосигнала и пространственной ширины, оно непосредственно взаимосвязано с рассеянной частью, моделируемой посредством DirAC. Следовательно, остаточная энергия может перезаписываться в качестве функции параметра рассеянности DirAC:
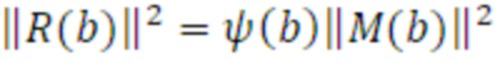
Фиг. 3 показывает преобразователь 110 параметров для выполнения комбинирования 310 со взвешиванием необработанных параметров 252 согласно варианту осуществления. По меньшей мере два необработанных параметра 252 вводятся в комбинирование 310 со взвешиванием, при этом весовые коэффициенты 324 для комбинирования 310 со взвешиванием извлекаются на основе связанного с амплитудой показателя 320 транспортного сигнала 122 в соответствующем входном временном субкадре 212. Кроме того, преобразователь 110 параметров выполнен с возможностью использования в качестве связанного с амплитудой показателя 320 значения энергии или мощности транспортного сигнала 112 в соответствующем входном временном субкадре 212 или 213. Связанный с амплитудой показатель 320 измеряет энергию или мощность транспортного сигнала 122 в соответствующем входном временном субкадре 212, например, таким образом, что весовой коэффициент 324 для этого входного субкадра 212 больше в случае более высокой энергии или мощности транспортного сигнала 122 в соответствующем входном временном субкадре 212 по сравнению с весовым коэффициентом 324 для входного субкадра 212, имеющего более низкую энергию или мощность транспортного сигнала 122 в соответствующем входном временном субкадре 212.
Как описано выше, параметры направления, параметры азимута и параметры угла места имеют соответствующие диапазоны значений. Тем не менее, параметры направления из первого набора 112 параметров обычно имеют более высокое временное разрешение, чем из второго набора 114 параметров, что означает, что два или более значений азимута и угла места должны использоваться для вычисления одного значения бокового усиления. Согласно варианту осуществления, вычисление основано на энергозависимых весовых коэффициентах, которые могут получаться в качестве вывода связанного с амплитудой показателя 320. Например, для всех K входных временных субкадров 212 и 213 энергия nrg субкадра вычисляется с использованием следующего уравнения:
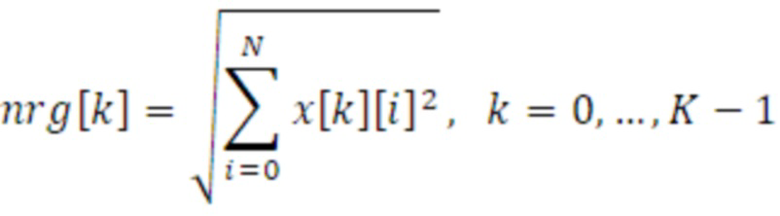 ,
,
где x является входным сигналом временной области, N является числом выборок в каждом субкадре, и i является индексом выборки. Кроме того, для каждого выходного временного кадра l, 230 весовых коэффициентов 324 затем могут вычисляться для доли каждого входного временного субкадра k 212, 213 в каждом выходном временном кадре l следующим образом:
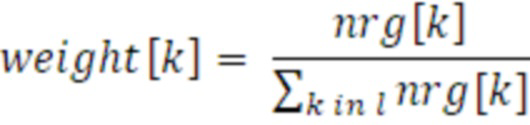
Параметры 455 бокового усиления затем в конечном счете вычисляются с использованием следующего уравнения:
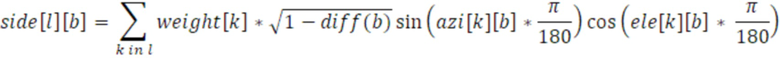
Вследствие подобия между параметрами, параметр 453 рассеянности в расчете на полосу частот непосредственно преобразуется в параметр 456 остаточного прогнозирования всех субкадров в той же полосе частот. Подобие может выражаться с помощью следующего уравнения:
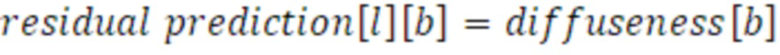
Фиг. 5a показывает вариант осуществления преобразователя 110 параметров или процессора параметров для вычисления коэффициента 512 сглаживания для каждого необработанного параметра 252 в соответствии с правилом 514 сглаживания. Кроме того, преобразователь 110 параметров выполнен с возможностью применения коэффициента 512 сглаживания (соответствующего коэффициента сглаживания для одного необработанного параметра) к необработанному параметру 252 (к одному необработанному параметру, соответствующему коэффициенту сглаживания) для извлечения параметра из второго набора 114 параметров для выходного временного кадра 220, а именно параметра выходного временного кадра.
Фиг. 5b показывает вариант осуществления преобразователя 110 параметров или процессора параметров для вычисления коэффициента 522 сглаживания для полосы частот с использованием функции 540 сжатия. Функция 540 сжатия может отличаться для различных полос частот, так что сила сжатия функции 540 сжатия является большей для полосы нижних частот, чем для полосы верхних частот. Преобразователь 110 параметров дополнительно выполнен с возможностью вычисления коэффициента 512, 522 сглаживания с использованием выбора 550 максимального предела. Другими словами, преобразователь 110 параметров может получать коэффициент 512, 522 сглаживания посредством использования различных максимальных пределов для различных полос частот, так что максимальный предел для полосы нижних частот выше максимального предела для полосы верхних частот.
Как функция 540 сжатия, так и выбор 550 максимального предела вводятся в вычисление 520, получающее коэффициент 522 сглаживания для полосы 522 частот. Например, преобразователь 110 параметров не ограничен использованием двух вычислений 510 и 520 для вычисления коэффициентов 512 и 522 сглаживания таким образом, что преобразователь 110 параметров выполнен с возможностью вычисления коэффициентов 512, 522 сглаживания с использованием только одного блока вычисления, который может выводить коэффициенты 512 и 522 сглаживания. Другими словами, коэффициент сглаживания вычисляется для каждой полосы частот (для каждого необработанного параметра 252) из изменения энергий в текущей полосе частот. Например, посредством использования процесса сглаживания параметров, параметр 455 бокового усиления и параметр 456 остаточного прогнозирования сглаживаются во времени, с тем чтобы исключать сильные флуктуации в усилениях. Поскольку это требует относительно сильного сглаживания большую часть времени, но требует более быстрого отклика каждый раз, когда аудиосцена 130 внезапно изменяется, коэффициент 512, 522 сглаживания, определяющий силу сглаживания, вычисляется адаптивно.
Следовательно, энергии nrg для каждой полосы частот вычисляются во всех субкадрах k с использованием следующего уравнения:
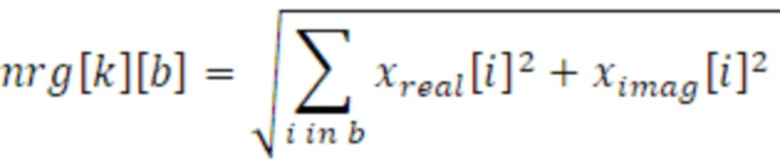 ,
,
где x являются частотными элементами разрешения преобразованного DFT сигнала (действительного и мнимого), и i является индексом элемента выборки по всем элементам разрешения в текущей полосе b частот.
Чтобы захватывать изменение энергий во времени, два средних, одно кратковременное среднее 331 и одно долговременное среднее 332, вычисляются с использованием связанного с амплитудой показателя 320 транспортного сигнала 122, как показано на фиг. 3.
Фиг. 6 иллюстрирует принципиальную схему связанного с амплитудой показателя 320, усредняющего транспортный сигнал 122 для коэффициента 512 сглаживания согласно варианту осуществления. Ось X представляет время, и ось Y представляет энергию (транспортного сигнала 122). Транспортный сигнал 122 иллюстрирует схематичную часть синусоидальной функции 122. Как представлено на фиг. 6, вторая временная часть 631 меньше первой временной части 632. Изменение энергий по средним 331 и 332 вычисляется для каждой полосы b частот согласно следующему уравнению:
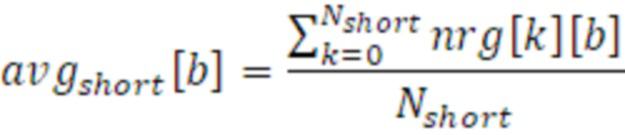
и:
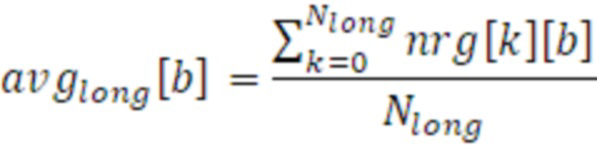 ,
,
где Nshort и Nlong являются числом предыдущих временных субкадров k, для которых вычисляются отдельные средние. Например, в этом конкретном варианте осуществления, Nshort задано равным значению 3, и Nlong задано равным значению 10.
Кроме того, преобразователь параметров или процессор 110 параметров выполнен с возможностью вычисления коэффициента 512, 522 сглаживания с использованием вычисления 510 на основе соотношения между долговременным средним 332 и кратковременным средним 331. Другими словами, частное двух средних 331 и 332 вычисляется таким образом, что более высокое кратковременное среднее, указывающее недавнее увеличение энергии, приводит к уменьшению сглаживания. Следующее уравнение показывает корреляцию коэффициента 512 сглаживания и двух средних 331 и 312.
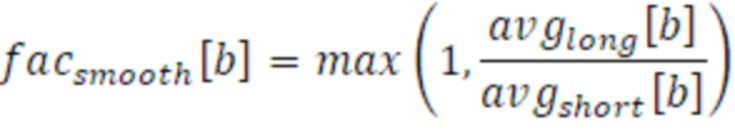
Вследствие того, что более высокие долговременные средние 332, указывающие снижающуюся энергию, не приводят к уменьшенному сглаживанию, коэффициент 512 сглаживания задан равным максимуму в 1 (на данный момент). Как результат, вышеприведенная формула ограничивает минимум  до Nshort/Nlong (в этом варианте осуществления как 0,3). Тем не менее, коэффициент должен составлять близко к 0 в крайних случаях, вследствие чего значение преобразуется из диапазона [Nshort/Nlong; 1] в диапазон [0;1] с использованием следующего уравнения:
до Nshort/Nlong (в этом варианте осуществления как 0,3). Тем не менее, коэффициент должен составлять близко к 0 в крайних случаях, вследствие чего значение преобразуется из диапазона [Nshort/Nlong; 1] в диапазон [0;1] с использованием следующего уравнения:
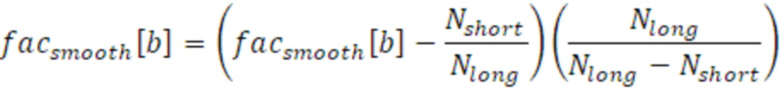
В варианте осуществления, сглаживание уменьшается чрезмерно, по сравнению со сглаживанием, проиллюстрированным выше, так что коэффициент сжимается с помощью функции вычисления корня к значению 1. Поскольку стабильность является особенно важной в наименьших полосах частот, корень четвертой степени используется в полосах частот в b=0 и b=1. Уравнение для наименьших полос частот является следующим:
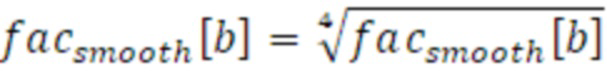
Уравнение для всех других полос частот в b>1 выполняет сжатие посредством функции вычисления квадратного корня, с использованием следующего уравнения.
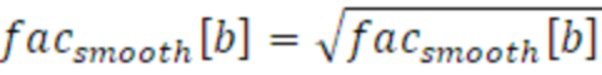
Посредством применения функции вычисления квадратного корня для всех других полос частот в b>1, крайние случаи, в которых энергия может увеличиваться экспоненциально, становятся меньшими, тогда как менее быстрое увеличение энергии не снижает сглаживание настолько сильно.
Кроме того, максимальное сглаживание устанавливается в зависимости от полосы частот для следующего уравнения. Следует отметить, что коэффициент в 1 должен просто повторять предыдущее значение без доли текущего усиления.
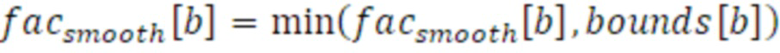
Здесь, bounds[b] представляет данную реализацию с 5 полосами частот, которые задаются согласно следующей таблице:
Коэффициент сглаживания вычисляется для каждого стереосубкадра k DFT в текущем кадре.
Фиг. 7 показывает преобразователь 110 параметров согласно варианту осуществления с использованием рекурсивного сглаживания 710, в котором как параметр gside[k][b] 455 бокового усиления, так и параметр gpred[k][b] 456 усиления для остаточного прогнозирования рекурсивно сглаживаются согласно следующим уравнениям:
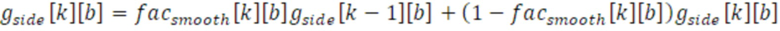
и:
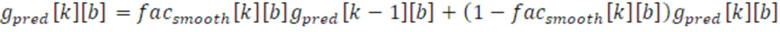
Посредством комбинирования параметра для предшествующего выходного временного кадра 532, взвешенного посредством первого весового значения, и необработанного параметра 252 для текущего выходного временного кадра 220, взвешенного посредством второго весового значения, вычисляется рекурсивное сглаживание 710 для последовательных во времени выходных временных кадров для текущего выходного временного кадра. Другими словами, сглаженный параметр для текущего выходного временного кадра вычисляется таким образом, что первое весовое значение и второе весовое значение извлекаются из коэффициента сглаживания для текущего временного кадра.
Эти преобразованные и сглаженные параметры (gside, gpred) вводятся в стереообработку DFT, а именно в выходной интерфейс 120, в котором стереосигнал L/R формируется из понижающего микширования DMX, сигнала PRED остаточного прогнозирования и преобразованных параметров gside и gpred. Например, понижающее микширование DMX получается из понижающего микширования или посредством усовершенствованного стереозаполнения, с использованием всечастотных фильтров или посредством стереозаполнения, с использованием задержки.
Повышающее микширование описано следующими уравнениями:
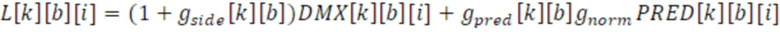
и:
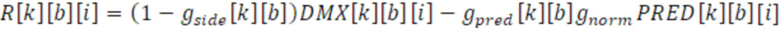
Повышающее микширование обрабатывается для каждого субкадра k во всех элементах i разрешения в полосах b частот, что описано в ранее показанной таблице. Кроме того, каждое боковое усиление gside взвешивается посредством коэффициента gnorm нормализации энергии, вычисленного из энергий понижающего микширования DMX и параметра PRED усиления для остаточного прогнозирования или gpred[k][b], как указано выше.
Преобразованное и сглаженное боковое усиление 755 и преобразованное и сглаженное остаточное усиление 756 вводятся в выходной интерфейс 120 для получения сглаженной аудиосцены. Следовательно, обработка кодированной аудиосцены с использованием параметра сглаживания, на основе вышеприведенного описания, приводит к большему компромиссу между достижимым качеством звучания и усилиями по реализации.
Фиг. 8 показывает устройство для декодирования транспортного сигнала 122 согласно варианту осуществления. (Кодированный) аудиосигнал 816 вводится в базовый декодер 810 транспортных сигналов для базового декодирования (базового кодированного) аудиосигнала 816, чтобы получать (декодированный необработанный) транспортный сигнал 812, который вводится в выходной интерфейс 120. Например, транспортный сигнал 122 может представлять собой кодированный транспортный сигнал 812, который выводится из базового кодера 810 транспортных сигналов. (Декодированный) транспортный сигнал 812 вводится в выходной интерфейс 120, который выполнен с возможностью формирования необработанного представления 818 двух или более каналов, например, левого канала и правого канала, с использованием набора 814 параметров, содержащего второй набор 114 параметров. Например, базовый декодер 810 транспортных сигналов для декодирования базового кодированного аудиосигнала для получения транспортного сигнала 122, представляет собой декодер ACELP. Кроме того, базовый декодер 810 выполнен с возможностью подачи декодированного необработанного транспортного сигнала 812 в двух параллельных ветвях, причем первая ветвь из двух параллельных ветвей содержит выходной интерфейс 120, и вторая ветвь из двух параллельных ветвей содержит модуль 820 улучшения транспортных сигналов или модуль 990 многоканального улучшения либо и то, и другое. Модуль 940 комбинирования сигналов выполнен с возможностью приёма первого ввода, который должен комбинироваться из первой ветви, и второго ввода, который должен комбинироваться из второй ветви.
Как показано на фиг. 9 устройство для обработки кодированной аудиосцены 130 может использовать процессор 910 расширения полосы пропускания. Транспортный сигнал 901 полосы низких частот вводится в выходной интерфейс 120 для получения двухканального представления 972 в полосе низких частот транспортного сигнала. Следует отметить, что выходной интерфейс 120 обрабатывает транспортный сигнал 901 в частотной области 955, например, во время процесса 960 повышающего микширования и преобразует двухканальный транспортный сигнал 901 во временной области 966. Это осуществляется посредством преобразователя 970, который преобразует микшированное с повышением спектральное представление 962, которое представляет частотную область 955, во временную область для получения двухканального представления 972 в полосе низких частот транспортного сигнала.
Как показано на фиг. 8, одноканальный транспортный сигнал 901 полосы низких частот вводится в преобразователь 950, выполняющий, например, преобразование временной части транспортного сигнала 901, соответствующей выходному временному кадру 220, в спектральное представление 952 транспортного сигнала 901, т.е. из временной области 966 в частотную область 955. Например, как описано на фиг. 2, часть (выходного временного кадра) меньше входного временного кадра 210, в котором организуются параметры 252 первого набора 112 параметров.
Спектральное представление 952 вводится в повышающий микшер 960 для повышающего микширования спектрального представления 952, с использованием, например, второго набора 114 параметров таким образом, чтобы получить микшированное с повышением спектральное представление 962, которое (по-прежнему) обрабатывается в частотной области 955. Как указано выше, микшированное с повышением спектральное представление 962 вводится в преобразователь 970 для преобразования микшированного с повышением спектрального представления 962, а именно каждого канала из двух или более каналов, из частотной области 955 во временную область 966 (временное представление), чтобы получать представление 972 в полосе низких частот. Таким образом вычисляются два или более каналов в микшированном с повышением спектральном представлении 962. Предпочтительно, выходной интерфейс 120 выполнен с возможностью работы в области комплексного дискретного преобразования Фурье, при этом операция повышающего микширования выполняется в области комплексного дискретного преобразования Фурье. Преобразование из области комплексного дискретного преобразования Фурье обратно в действительнозначное представление во временной области проводится с использованием преобразователя 970. Другими словами, выходной интерфейс 120 выполнен с возможностью формирования необработанного представления двух или более каналов с использованием повышающего микшера 960 во второй области, а именно в частотной области 955, при этом первая область представляет временную область 966.
В варианте осуществления, операция повышающего микширования повышающего микшера 960 основана на следующем уравнении:
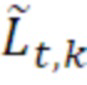 =
= 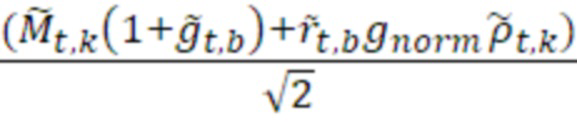
и:
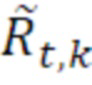 =
= 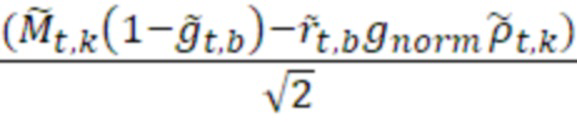 ,
,
- при этом 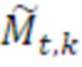 является транспортным сигналом 901 для кадра t и частотного элемента k разрешения, при этом
является транспортным сигналом 901 для кадра t и частотного элемента k разрешения, при этом 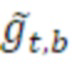 является параметром 455 бокового усиления для кадра t и подполосы b частот, при этом
является параметром 455 бокового усиления для кадра t и подполосы b частот, при этом 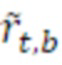 является параметром 456 усиления для остаточного прогнозирования для кадра t и подполосы b частот, при этом gnorm является энергетическим регулирующим коэффициентом, который может использоваться или не использоваться, и при этом
является параметром 456 усиления для остаточного прогнозирования для кадра t и подполосы b частот, при этом gnorm является энергетическим регулирующим коэффициентом, который может использоваться или не использоваться, и при этом 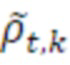 является необработанным остаточным сигналом для кадра t и частотного элемента k разрешения.
является необработанным остаточным сигналом для кадра t и частотного элемента k разрешения.
Транспортный сигнал 902, 122 обрабатывается во временной области 966, в отличие от транспортного сигнала 901 полосы низких частот. Транспортный сигнал 902 вводится в процессор 910 расширения полосы пропускания (процессор BWE) для формирования сигнала 912 полосы высоких частот и вводится в многоканальный фильтр 930 для применения операции многоканального заполнения. Сигнал 912 полосы высоких частот вводится в повышающий микшер 920 для повышающего микширования сигнала 912 полосы высоких частот в микшированный с повышением сигнал 922 полосы высоких частот с использованием второго набора 144 параметров, а именно, параметра выходного временного кадра 262, 532. Например, повышающий микшер 920 может применять процесс широкополосного панорамирования во временной области 966 к сигналу 912 полосы высоких частот с использованием по меньшей мере одного параметра из второго набора 114 параметров.
Представление 972 в полосе низких частот, микшированный с повышением сигнал 922 полосы высоких частот и многоканальный заполненный транспортный сигнал 932 вводятся в модуль 940 комбинирования сигналов для комбинирования, во временной области 966, результата широкополосного панорамирования 922, результата стереозаполнения 932 и представления 972 в полосе низких частот двух или более каналов. Это комбинирование приводит в результате к многоканальному сигналу 942 полной полосы частот во временной области 966 в качестве канального представления. Как указано ранее, преобразователь 970 преобразует каждый канал из двух или более каналов в спектральном представлении 962 во временное представление, чтобы получать необработанное временное представление 972 двух или более каналов. Следовательно, модуль 940 комбинирования сигналов комбинирует необработанное временное представление двух или более каналов и улучшающее временное представление двух или более каналов.
В варианте осуществления, только транспортный сигнал 901 полосы низких частот (LB) вводится в обработке (в стереорежиме DFT) в выходном интерфейсе 120, тогда как транспортный сигнал 912 полосы высоких частот (HB) микшируется с повышением (с использованием повышающего микшера 920) отдельно во временной области. Такой процесс реализуется через операцию панорамирования с использованием процессора 910 BWE плюс стереозаполнение во временной области, с использованием модуля 930 многоканального заполнения для формирования доли объемного окружения. Процесс панорамирования содержит широкополосное панорамирование, которое основано на преобразованных боковых усилениях, например, на преобразованном и сглаженном боковом усилении 755 в расчете на кадр. Здесь, предусмотрено только одно усиление в расчете на кадр, покрывающее полную частотную область полосы высоких частот, что упрощает вычисление левого и правого каналов полосы высоких частот из канала понижающего микширования, который основан на следующих уравнениях:
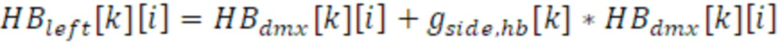
и:
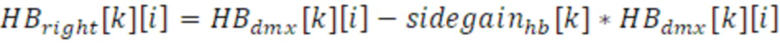
для каждой выборки i в каждом субкадре k.
Сигнал PREDhb стереозаполнения полосы высоких частот, а именно, многоканальный заполненный транспортный сигнал 932 получается посредством задержки HBdmx и его взвешивания посредством gside,hb и дополнительно с использованием коэффициента gnorm нормализации энергии, как описано в следующих уравнениях:
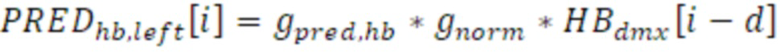
и:
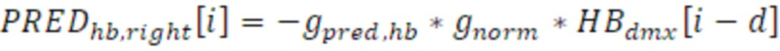
для каждой выборки i в текущем временном кадре (проводится для полного временного кадра 210, а не для временных субкадров 213 и 213); d является числом выборок, на которое понижающее микширование полосы высоких частот задерживается для формирования заполняющего сигнала 932, полученного посредством модуля 930 многоканального заполнения. Другие способы для формирования заполняющего сигнала, за исключением задержки, могут приспосабливаться, такие как усовершенствованная обработка декорреляции либо использование шумового сигнала или любого другого сигнала, извлекаемого из транспортного сигнала другим способом по сравнению с задержкой.
Как панорамированный стереосигнал 972 и 922, так и сформированный сигнал 932 стереозаполнения комбинируются (микшируются обратно) в базовый сигнал после синтеза DFT с использованием модуля 940 комбинирования сигналов.
Этот описанный процесс для полосы высоких частот ACELP также отличается от обработки DirAC с более высокой задержкой, в которой базовые кадры ACELP и кадры ACELP TCX искусственно задерживаются таким образом, что они совмещаются с полосой высоких частот ACELP. Таким образом, CLDFB (анализ) выполняется для полного сигнала, что означает то, повышающее микширование полосы ACELP высоких частот также проводится в области CLDFB (в частотной области).
Фиг. 10 показывает вариант осуществления устройства для получения обработанной аудиосцены 124. Транспортный сигнал 122 вводится в выходной интерфейс 120 для формирования необработанного представления 972 двух или более каналов, с использованием второго набора 114 параметров и в модуль 990 многоканального улучшения для формирования улучшающего представления 992 двух или более каналов. Например, модуль 990 многоканального улучшения выполнен с возможностью выполнения по меньшей мере одной операции из группы операций, содержащих операцию расширения полосы пропускания, операцию заполнения интервалов отсутствия сигнала, операцию повышения качества или операцию интерполяции. Как необработанное представление 972 двух или более каналов, так и улучшающее представление 992 двух или более каналов вводятся в модуль 940 комбинирования сигналов для получения обработанной аудиосцены 124.
Фиг. 11 показывает блок-схему варианта осуществления модуля 990 многоканального улучшения для формирования улучшающего представления 992 двух или более каналов, содержащего модуль 820 улучшения транспортных сигналов, повышающий микшер 830 и модуль 930 многоканального заполнения. Транспортный сигнал 122 и/или декодированный необработанный транспортный сигнал 812 вводятся в модуль 820 улучшения транспортных сигналов, формирующий улучшающий транспортный сигнал 822, который вводится в повышающий микшер 830 и модуль 930 многоканального заполнения. Например, модуль 820 улучшения транспортных сигналов выполнен с возможностью выполнения по меньшей мере одной операции из группы операций, содержащих операцию расширения полосы пропускания, операцию заполнения интервалов отсутствия сигнала, операцию повышения качества или операцию интерполяции.
Как видно на фиг. 9 модуль 930 многоканального заполнения формирует многоканальный заполненный транспортный сигнал 932 с использованием транспортного сигнала 902 и по меньшей мере одного параметра 532. Другими словами, модуль 990 многоканального улучшения выполнен с возможностью формирования улучшающего представления двух или более каналов 992 с использованием улучшающего транспортного сигнала 822 и второго набора 114 параметров либо с использованием улучшающего транспортного сигнала 822 и микшированного с повышением улучшающего транспортного сигнала 832. Например, модуль 990 многоканального улучшения содержит или повышающий микшер 830, или модуль 930 многоканального заполнения либо как повышающий микшер 830, так и модуль 930 многоканального заполнения для формирования улучшающего представления 992 двух или более каналов с использованием транспортного сигнала 122 или улучшающего транспортного сигнала 933 и по меньшей мере одного параметра из второго набора 532 параметров. В варианте осуществления, модуль 820 улучшения транспортных сигналов или модуль 990 многоканального улучшения выполнен с возможностью работы параллельно с выходным интерфейсом 120 при формировании необработанного представления 972, или преобразователь 110 параметров выполнен с возможностью работы параллельно с модулем 820 улучшения транспортных сигналов.
На фиг. 13, поток 1312 битов, который передается из кодера в декодер, может быть одинаковым со схемой повышающего микширования на основе DirAC, показанной на фиг. 12. Один транспортный канал 1312, извлекаемый из процесса пространственного понижающего микширования на основе DirAC, вводится в базовый декодер 1310 и декодируется с помощью базового декодера, например, монодекодера EVS или IVAS, и передается наряду с соответствующими боковыми параметрами 1313 DirAC.
В этом стереоподходе DFT для обработки аудиосцены без дополнительной задержки, начальное декодирование в базовом монодекодере (монодекодере IVAS) транспортного канала также остается неизменным. Вместо прохождения через гребенку 1220 фильтров CLDFB из фиг. 12, декодированный сигнал 1314 понижающего микширования вводится в анализ 1320 DFT, для преобразования декодированного моносигнала 1314 в область STFT (частотную область), к примеру, посредством использования окон с очень коротким перекрытием. Таким образом, анализ 1320 DFT вообще не вызывает дополнительную задержку относительно целевой задержки в системе в 32 мс только с использованием оставшегося запаса мощности между полной задержкой и того, что уже вызывается посредством анализа/синтеза MDCT базового декодера.
Боковые параметры 1313 DirAC или первый набор 112 параметров вводятся в преобразование 1360 параметров, которое, например, может содержать преобразователь 110 параметров или процессор параметров для получения боковых стереопараметров DFT, а именно второго набора 114 параметров. Сигнал 1322 частотной области и боковые параметры 1362 DFT вводятся в стереодекодер 1330 DFT для формирования сигнала 1332 повышающего стереомикширования, например, посредством использования повышающего микшера 960, описанного на фиг. 9. Два канала повышающего стереомикширования 1332 вводятся в синтез DFT, для преобразования повышающего стереомикширования 1332 из частотной области во временную область, например, с использованием преобразователя 970, описанного на фиг. 9, приводя к выходному сигналу 1342, который может представлять обработанную аудиосцену 124.
Фиг. 14 показывает вариант осуществления для обработки кодированной аудиосцены с использованием расширения 1470 полосы пропускания. Поток 1412 битов вводится в базовый (или в полосе низких частот) декодер 1410 ACELP вместо монодекодера IVAS, как описано на фиг. 13, для формирования декодированного сигнала 1414 полосы низких частот. Декодированный сигнал 1414 полосы низких частот вводится в анализ 1420 DFT для преобразования сигнала 1414 в сигнал 1422 частотной области, например, в спектральное представление 952 транспортного сигнала 901 из фиг. 9. Стереодекодер 1430 DFT может представлять повышающий микшер 960, который формирует повышающее стереомикширование 1432 LB с использованием декодированного сигнала 1442 полосы низких частот в частотной области и боковых стереопараметров 1462 DFT из преобразования 1460 параметров. Сформированное повышающее стереомикширование 1432 LB вводится в блок 1440 синтеза DFT для выполнения преобразования во временную область, с использованием, например, преобразователя 970 фиг. 9. Представление 972 в полосе низких частот транспортного сигнала 122, а именно, выходной сигнал 1442 каскада 1440 синтеза DFT вводится в модуль 940 комбинирования сигналов, комбинирующий микшированный с повышением стереосигнал 922 полосы высоких частот и многоканальный заполненный транспортный сигнал 932 полосы высоких частот и представление 972 в полосе низких частот транспортного сигнала, приводящее к многоканальному сигналу 942 полной полосы частот.
Декодированный сигнал 1414 LB и параметры 1415 для BWE 1470 вводятся в декодер 910 ACELP BWE для формирования декодированного сигнала 912 полосы высоких частот. Преобразованные боковые усиления 1462, например, преобразованные и сглаженные боковые усиления 755 для спектральной области полосы низких частот вводятся в стереоблок 1430 DFT, и преобразованное и сглаженное одно боковое усиление для целой полосы высоких частот перенаправляется в блок 920 повышающего микширования в полосе высоких частот и блок 930 стереозаполнения. Блок 920 повышающего микширования HB для повышающего микширования декодированного сигнала 912 HB с использованием бокового усиления 1472 в полосе высоких частот, к примеру, параметров 532 выходного временного кадра 262 из второго набора 114 параметров, формирует микшированный с повышением сигнал 922 полосы высоких частот. Блок 930 стереозаполнения для заполнения декодированного транспортного сигнала 912, 902 полосы высоких частот использует параметры 532, 456 выходного временного кадра 262 из второго набора 114 параметров и формирует заполненный транспортный сигнал 932 полосы высоких частот.
В качестве вывода, варианты осуществления согласно изобретению создают концепцию для обработки кодированной аудиосцены с использованием преобразования параметров и/или с использованием расширения полосы пропускания, и/или с использованием сглаживания параметров, которая приводит к большему компромиссу между полной задержкой, достижимым качеством звучания и усилиями по реализации.
Ниже проиллюстрированы дополнительные варианты осуществления аспектов изобретения и, в частности, сочетание аспектов изобретения. Предлагаемое решение для обеспечения повышающего микширования с низкой задержкой заключается в использовании параметрического стереоподхода, например, подхода, описанного в [4], с использованием гребенок фильтров на основе кратковременного преобразования Фурье (STFT), а не модуля рендеринга DirAC. В этом подходе на основе «стереорежима DFT» описано повышающее микширование одного канала понижающего микширования в стереовывод. Преимущество этого способа состоит в том, что окна с очень короткими перекрытиями используются для анализа DFT в декодере, что обеспечивает возможность оставаться в пределах гораздо более низкой полной задержки, необходимой для кодеков связи, таких как EVS [3] или последующий кодек IVAS (32 мс). Кроме того, в отличие от DirAC CLDFB, стереообработка DFT не представляет собой этап постобработки в базовый кодер, а выполняется параллельно с частью базовой обработки, а именно, с расширением полосы пропускания (BWE) речевого кодера на основе линейного прогнозирования с возбуждением по алгебраическому коду (ACELP), без превышения этой уже заданной задержки. Относительно задержки в 32 мс для EVS, стереообработка DFT может в силу этого называться «свободной от задержки», поскольку она работает при равной полной задержке кодера. С другой стороны, DirAC может рассматриваться в качестве постпроцессора, который вызывает дополнительную задержку в 5 мс вследствие CLDFB, расширяющую полную задержку до 37 мс.
В общем, усиление в задержке достигается. Низкая задержка исходит из этапа обработки, который происходит параллельно с базовой обработкой, тогда как примерная версия CLDFB представляет собой этап постобработки для выполнения необходимого рендеринга, который происходит после базового кодирования.
В отличие от DirAC, стереорежим DFT использует искусственную задержку в 3,25 мс для всех компонентов, за исключением ACELP BWE, посредством преобразования только этих компонентов в область DFT с использованием окон с очень коротким перекрытием в 3,125 мс, которые вписываются в доступный запас мощности, без вызывания большей задержки. Таким образом, только TCX и ACELP без BWE микшируются с повышением в частотной области, тогда как ACELP BWE микшируется с повышением во временной области посредством отдельного свободного от задержки этапа обработки, называемого «межканальным расширением полосы пропускания (ICBWE)» [5]. В специальном случае стереовывода данного варианта осуществления, эта обработка BWE во временной области немного изменяется, что описано в конце варианта осуществления.
Передаваемые параметры DirAC не могут использоваться непосредственно для повышающего стереомикширования DFT. Преобразование данных параметров DirAC в соответствующие стереопараметры DFT становится в силу этого необходимым. Хотя DirAC использует углы азимута и углы места для пространственного размещения наряду с параметром рассеянности, стереорежим DFT имеет один параметр бокового усиления, используемый для панорамирования, и параметр остаточного прогнозирования, который тесно связан со стереошириной и в силу этого с параметром рассеянности DirAC. С точки зрения разрешения параметров, каждый кадр разделяется на два субкадра и несколько полос частот в расчете на субкадр. Боковое и остаточное усиление, используемые в стереорежиме DFT, описаны в [6].
Параметры DirAC извлекаются из анализа для каждой полосы частот аудиосцены первоначально в B-формате или FOA. Он затем извлекает для каждой полосы k частот и момента n времени преобладающее направление поступления азимута θ(b,n) и угла места φ(b,n) и коэффициента ψ(b,n) рассеянности. Для направленных компонентов, обеспечивается возможность того, что сферические гармоники первого порядка в центральном положении могут извлекаться посредством всенаправленного компонента w(b,n) и параметров DirAC:
Кроме того, из каналов FOA можно получать стереоверсию посредством декодирования, заключающего в себе W и Y, что приводит к двум кардиоидам, указывающим на углы азимута в +90 и -90 градусов.
Это декодирование соответствует формированию диаграммы направленности первого порядка, указывающей в двух направлениях.
Следовательно, предусмотрена непосредственная взаимосвязь между стереовыводом и параметрами DirAC. С другой стороны, параметры DFT базируются на модели L- и R-каналов на основе среднего сигнала M и бокового сигнала S.
M передается в качестве моноканала и соответствует всенаправленному каналу W в случае режима SBA. В стереорежиме DFT S прогнозируется из M с использованием бокового усиления, которое затем может выражаться с использованием параметров DirAC следующим образом:
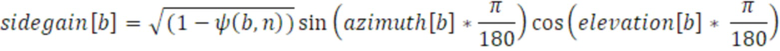
В стереорежиме DFT остаток прогнозирования предполагается и ожидается некогерентным и моделируется посредством своей энергии и декорреляции остаточных сигналов, идущих в левый и в правый. Остаток прогнозирования S с M может выражаться следующим образом:
Кроме того, его энергия моделируется в стереорежиме DFT с использованием усилений для прогнозирования следующим образом:
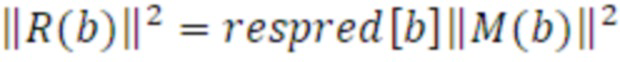
Поскольку остаточное усиление представляет компонент межканальной некогерентности стереосигнала и пространственной ширины, оно непосредственно взаимосвязано с рассеянной частью, моделируемой посредством DirAC. Следовательно, остаточная энергия может перезаписываться в качестве функции параметра рассеянности DirAC:
Поскольку конфигурация полосы частот, нормально используемая в стереорежиме DFT, не является одинаковой с DirAC, она должно быть выполнена с возможностью покрытия одинаковых частотных диапазонов с полосами частот DirAC. Для этих полос частот направляющие углы DirAC затем могут преобразовываться в параметр бокового усиления стереорежима DFT через следующее:
,
где b является текущей полосой частот, и диапазоны параметров составляют [0;360] для азимута, [0; 180] для угла места и [-1; 1] для результирующего значения бокового усиления. Тем не менее, параметры направления DirAC обычно имеют более высокое временное разрешение, чем стереорежим DFT, что означает, что для вычисления одного значения бокового усиления должны использоваться 2 или более значений азимута и угла места. Один способ заключается в выполнении усреднения между субкадрами, но в этой реализации вычисление основано на энергозависимых весовых коэффициентах. Для всех K субкадров DirAC, энергия субкадра вычисляется следующим образом:
,
где x является входным сигналом временной области, N является числом выборок в каждом субкадре, и i является индексом выборки. Для каждого стереосубкадра l DFT, весовые коэффициенты затем могут вычисляться для доли каждого субкадра DirAC k внутри l следующим образом:
Боковые усиления затем в конечном счете вычисляются в следующим образом:
Вследствие подобия между параметрами, одно значение рассеянности в расчете на полосу частот непосредственно преобразуется в параметр остаточного прогнозирования всех субкадров в той же полосе частот:
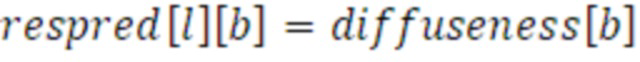
Кроме того, параметры сглаживаются во времени, с тем чтобы исключать сильные флуктуации в усилениях. Поскольку это требует относительно сильного сглаживания большую часть времени, но требует более быстрого отклика каждый раз, когда сцена внезапно изменяется, коэффициент сглаживания, определяющий силу сглаживания, вычисляется адаптивно. Этот адаптивный коэффициент сглаживания вычисляется для каждой полосы частот из изменения энергий в текущей полосе частот. Следовательно, энергии для каждой полосы частот должны вычисляться во всех субкадрах k сначала:
,
где x являются частотными элементами разрешения преобразованного DFT сигнала (действительного и мнимого), и i является индексом элемента выборки по всем элементам разрешения в текущей полосе b частот.
Чтобы захватывать изменение энергий во времени, 2 средних, одно кратковременное и одно долговременное, затем вычисляются для каждой полосы b частот согласно:
и:
,
где Nshort и Nlong являются числом предыдущих субкадров k, для которых вычисляются отдельные средние. В этой конкретной реализации Nshort задано равным 3, и Nlong задано равным 10. Коэффициент сглаживания затем вычисляется из частного средних таким образом, что более высокое кратковременное среднее, указывающее недавнее увеличение энергии, приводит к уменьшению сглаживания:
Более высокие долговременные средние, указывающие снижающуюся энергию, не приводят к уменьшенному сглаживанию, так что коэффициент сглаживания на данный момент установлен равным максимуму в 1.
Вышеприведенная формула ограничивает минимум до Nshort/Nlong (в этой реализации как 0,3). Тем не менее, коэффициент должен составлять близко к 0 в крайних случаях, вследствие чего значение преобразуется из диапазона [Nshort/Nlong; 1] в диапазон [0;1] через следующее:
Для менее крайних случаев, сглаживание теперь уменьшается чрезмерно, так что коэффициент сжимается с помощью функции вычисления корня к значению 1. Поскольку стабильность является особенно важной в наименьших полосах частот, корень четвертой степени используется в полосах частот в b=0 и b=1:
,
тогда как все другие полосы частот в b>1 сжимаются посредством квадратного корня:
Таким образом, крайние случаи остаются близкими к 0, тогда как менее быстрое увеличение энергии не снижает сглаживание настолько сильно.
В завершение, максимальное сглаживание устанавливается в зависимости от полосы частот (коэффициент в 1 должен просто повторять предыдущее значение без доли текущего усиления):
,
где bounds[b] в данной реализации с 5 полосами частот установлены согласно следующей таблице:
Коэффициент сглаживания вычисляется для каждого стереосубкадра k DFT в текущем кадре.
На последнем этапе, как боковое усиление, так и усиление для остаточного прогнозирования рекурсивно сглаживаются согласно:
и:
Эти преобразованные и сглаженные параметры теперь подаются в стереообработку DFT, в которой стереосигнал L/R формируется из понижающего микширования DMX, сигнала PRED остаточного прогнозирования (полученного из понижающего микширования или посредством «усовершенствованного стереозаполнения» с использованием всечастотных фильтров [7], или посредством регулярного стереозаполнения с использованием задержки) и преобразованных параметров gside и gpred. Повышающее микширование описано в общем посредством следующих формул [6]:
и:
,
для каждого субкадра k все элементы i разрешения в полосах b частот. Кроме того, каждое боковое усиление gside взвешивается посредством коэффициента gnorm нормализации энергии, вычисленного из энергий DMX и PRED.
В завершение, микшированный с повышением сигнал преобразуется обратно во временную область через IDFT для воспроизведения в данной стереокомпоновке.
Поскольку «расширение полосы пропускания во временной области (TBE)» [8], которое используется в ACELP, формирует собственную задержку (в реализации, этот вариант осуществления основан точно на 2,3125 мс), она не может преобразовываться в область DFT при пребывании в пределах полной задержки в 32 мс (при этом 3,25 мс оставляются для стереодекодера, из которых STFT уже использует 3,125 мс). Таким образом, только полоса низких частот (LB) помещается в стереообработку DFT, указываемую посредством 1450 на фиг. 14, тогда как полоса высоких частот (HB) должна микшироваться с повышением отдельно во временной области, как показано в блоке 920 на фиг. 14. В обычном -стереорежиме DFT это выполняется через межканальное расширение полосы пропускания (ICBWE) [5] для панорамирования плюс стереозаполнение во временной области для объемного окружения. В данном случае, стереозаполнение в блоке 930 вычисляется аналогично регулярному стереорежиму DFT. Тем не менее обработка ICBWE полностью пропускается вследствие отсутствующих параметров и заменяется посредством незначительных ресурсов, требующих широкополосного панорамирования в блоке 920 на основе преобразованных боковых усилений 1472. В данном варианте осуществления, предусмотрено только одно усиление, покрывающее полную область HB, что упрощает вычисление левого и правого каналов HB в блоке 920 из канала понижающего микширования как:
и:
,
для каждой выборки i в каждом субкадре k.
Сигнал HB PREDhb стереозаполнения получается в блоке 930 посредством задержки HBdmx и взвешивания посредством gside,hb и коэффициента gnorm нормализации энергии следующим образом:
и:
,
для каждой выборки i в текущем кадре (проводится для полного кадра, а не для субкадров), и где d является числом выборок, на которое понижающее микширование HB задерживается для заполняющего сигнала.
Как панорамированный стереосигнал, так и сформированный сигнал стереозаполнения в конечном счете микшируются обратно в базовый сигнал после синтеза DFT в модуле 940 комбинирования.
Эта специальная обработка ACELP HB также отличается от обработки DirAC с более высокой задержкой, в которой базовые кадры ACELP и кадры ACELP TCX искусственно задерживаются таким образом, что они совмещаются с ACELP HB. Таким образом, CLDFB выполняется для полного сигнала, т.е. повышающее микширование ACELP HB также проводится в области CLDFB.
Преимущества предложенного способа
Отсутствие дополнительной задержки позволяет кодеку IVAS оставаться в пределах той же полной задержки, что и в EVS (32 мс), для этого конкретного случая из ввода SBA в стереовывод.
Гораздо более низкая сложность параметрического повышающего стереомикширования через DFT, чем при пространственном рендеринге DirAC, обусловлена в целом более простой и более прямолинейной обработкой.
Дополнительные предпочтительные варианты осуществления
1. Устройство, способ или компьютерная программа для кодирования или декодирования, как описано выше.
2. Устройство или способ для кодирования или декодирования или связанная компьютерная программа, содержащая:
- систему, в которой ввод кодируется с помощью модели на основе пространственного аудиопредставления звуковой сцены с первым набором параметров и декодируется в выводе с помощью стереомодели для 2 выходных каналов или с помощью многоканальной модели более чем для 2 выходных каналов со вторым набором параметров; и/или
- преобразование пространственных параметров в стереопараметры; и/или
- преобразование из входного представления/параметров на основе одной частотной области в выходное представление/параметры на основе другой частотной области; и/или
- преобразование параметров с более высоким временным разрешением в более низкое временное разрешение; и/или
- более низкую выходную задержку вследствие более короткого перекрытия окон второго преобразования частоты; и/или
- преобразование параметров DirAC (направляющих углов, рассеянности) в стереопараметры DFT (боковое усиление, усиление для остаточного прогнозирования) для вывода кодированного DirAC содержимого SBA в качестве стерео; и/или
- преобразование из входного представления/параметров на основе CLDFB в выходное представление/параметры на основе DFT; и/или
- преобразование параметров с разрешением в 5 мс в параметры с 10 мс; и/или
- Преимущество: более низкая выходная задержка вследствие более короткого перекрытия окон DFT по сравнению с CLDFB.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше, и все аспекты, определяемые независимыми пунктами нижеприведенной формулы изобретения, могут использоваться по отдельности, т.е. без альтернатив или целей, отличных от предполагаемой альтернативы, цели или независимого пункта формулы изобретения. Тем не менее, в других вариантах осуществления могут быть объединены друг с другом две или более из альтернатив или аспектов или независимых пунктов формулы изобретения, и в других вариантах осуществления могут быть объединены друг с другом все аспекты или альтернативы и все независимые пункты формулы изобретения.
Следует отметить, что различные аспекты изобретения связаны с аспектом преобразования параметров, аспектом сглаживания и аспектом расширения полосы пропускания. Эти аспекты могут быть реализованы отдельно или независимо друг от друга, или могут быть объединены любые два аспекта по меньшей мере из трех аспектов, или могут быть объединены все три аспекта в одном варианте осуществления, как описано выше.
Кодированный сигнал согласно изобретению может сохраняться на цифровом носителе хранения данных или на постоянном носителе хранения данных либо может передаваться в среде передачи, такой как беспроводная среда передачи или проводная среда передачи, например Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе хранения данных.
Другими словами, таким образом вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с обеспечением возможности передачи через соединение для передачи данных, например через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются лишь иллюстрацией в отношении принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидны модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, но не конкретными подробностями, представленными в порядке описания и пояснения вариантов осуществления в данном документе.
Список использованной литературы
[1] V. Pulkki, M.-V. V. J. Laitinen, J. Ahonen, T. Lokki и T. Pihlajamäki "Directional audio coding-perception-based reproduction of spatial sound", in INTERNATIONAL WORKSHOP ON THE PRINCIPLES AND APPLICATION ON SPATIAL HEARING, 2009 г.
[2] G. Fuchs, O. Thiergart, S. Korse, S. Döhla, M. Multrus, F. Küch, Bouthéon, A. Eichenseer и S. Bayer "Apparatus, method and computer program for encoding, decoding, scene processing and other procedures related to dirac based spatial audio coding using low-order, mid-order and high-order components generators". WO 2020115311A1, 11.06.2020.
[3] 3GPP TS 26.445 "Codec for Enhanced Voice Services (EVS); Detailed algorithmic description".
[4] S. Bayer, M. Dietz, S. Döhla, E. Fotopoulou, G. Fuchs, W. Jaegers, G. Markovic, M. Multrus, E. Ravelli и M. Schnell "APPARATUS AND METHOD FOR ESTIMATING AN INTER-CHANNEL TIME DIFFERENCE". WO 17125563, 27.07.2017.
[5] V. S. C. S. Chebiyyam и V. Atti "Inter-channel bandwidth extension". WO 2018187082A1, 11.10.2018.
[6] J. Büthe, G. Fuchs, W. Jägers, F. Reutelhuber, J. Herre, E. Fotopoulou, M. Multrus и S. Korse "Apparatus and method for encoding or decoding the multichannel signal using the side gain and the residual gain". WO 2018086947A1, 17.05.2018.
[7] J. Büthe, F. Reutelhuber, S. Disch, G. Fuchs, M. Multrus и R. Geiger "Apparatus for Encoding or Decoding the Encoded Multichannel Signal Using the Filling signal Generated by the Broad Band Filter". WO 2019020757A2, 31.01.2019.
[8] V. A. et al. "Super-wideband bandwidth extension for speech in the 3GPP EVS codec", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, 2015 г.
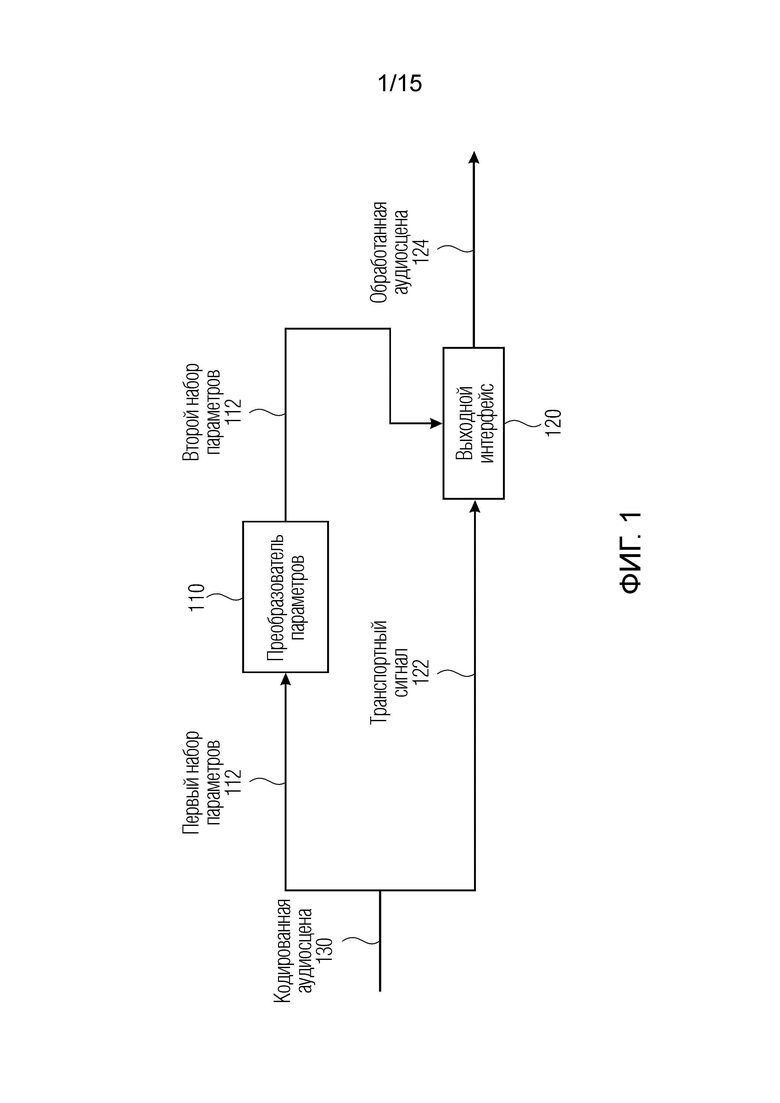
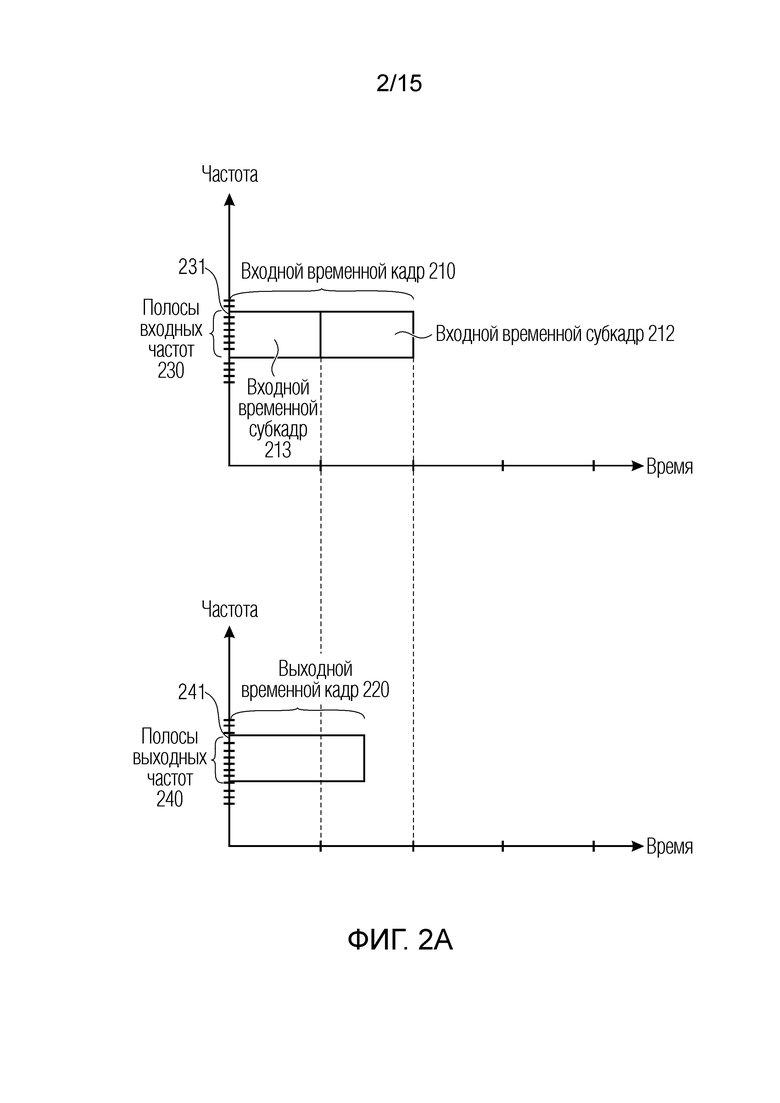
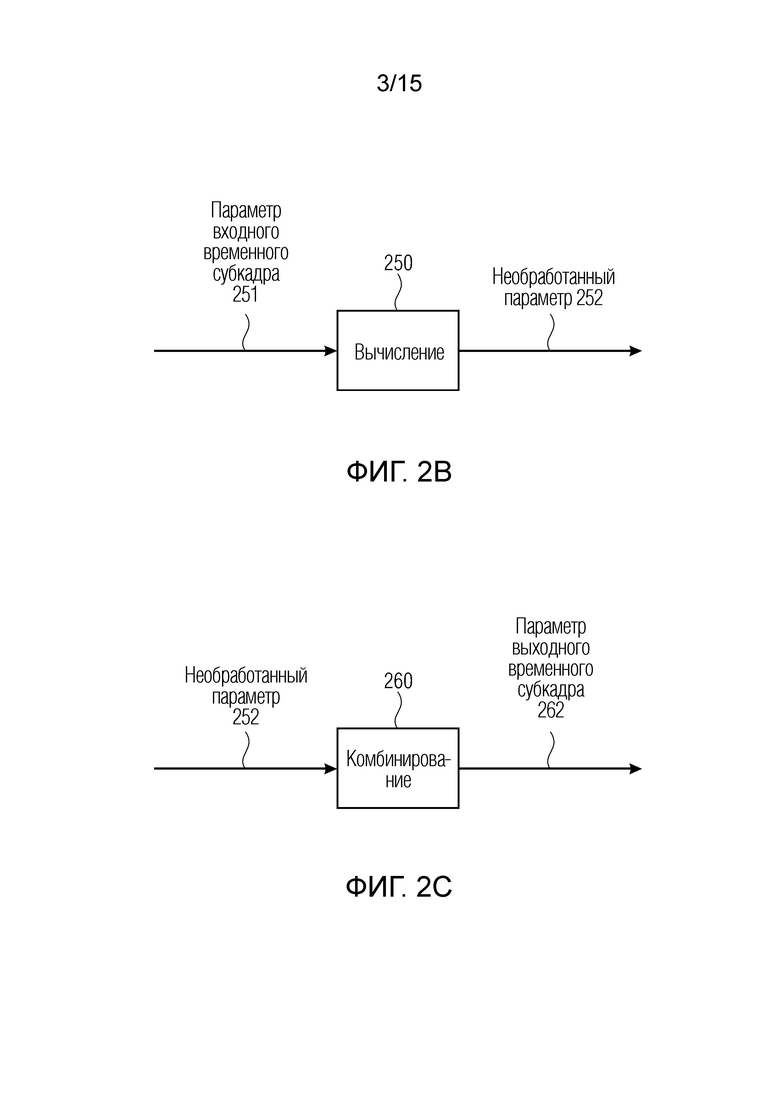
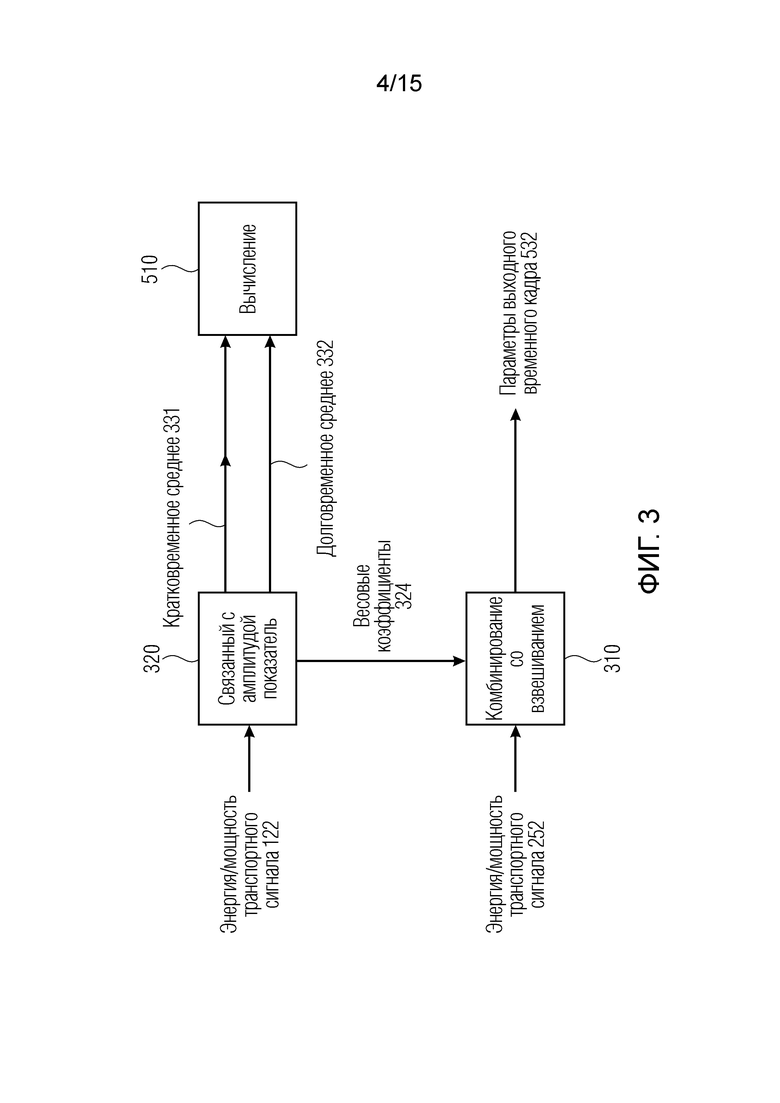
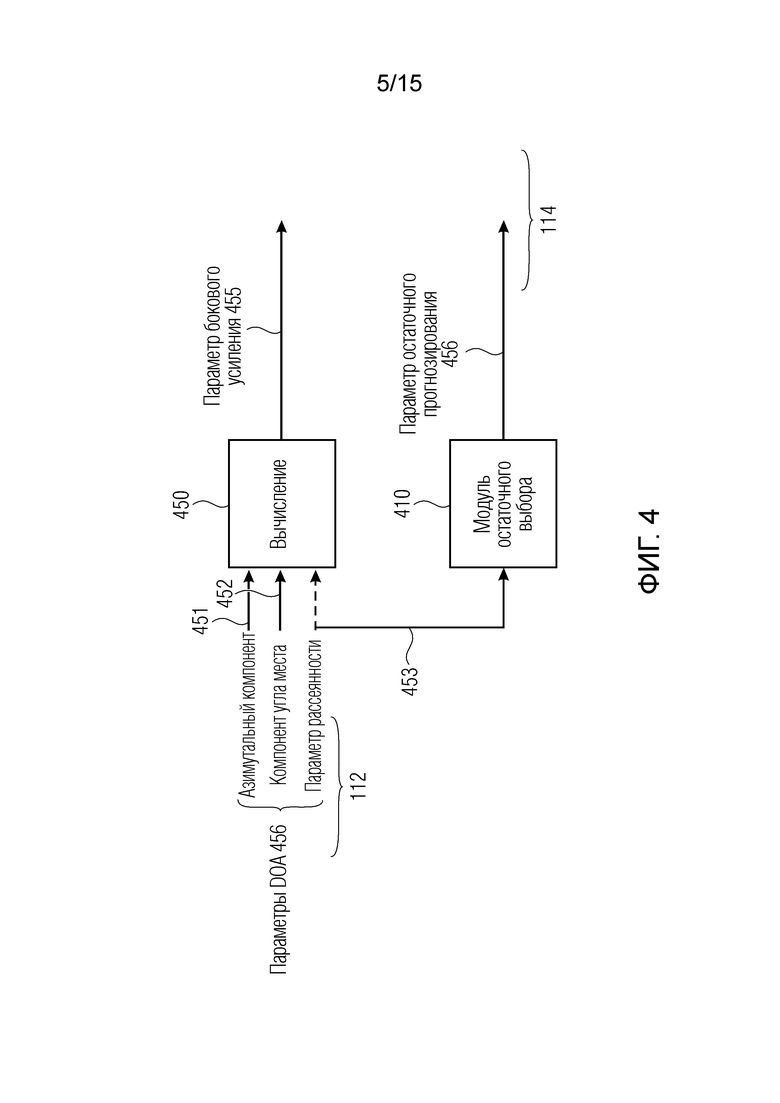
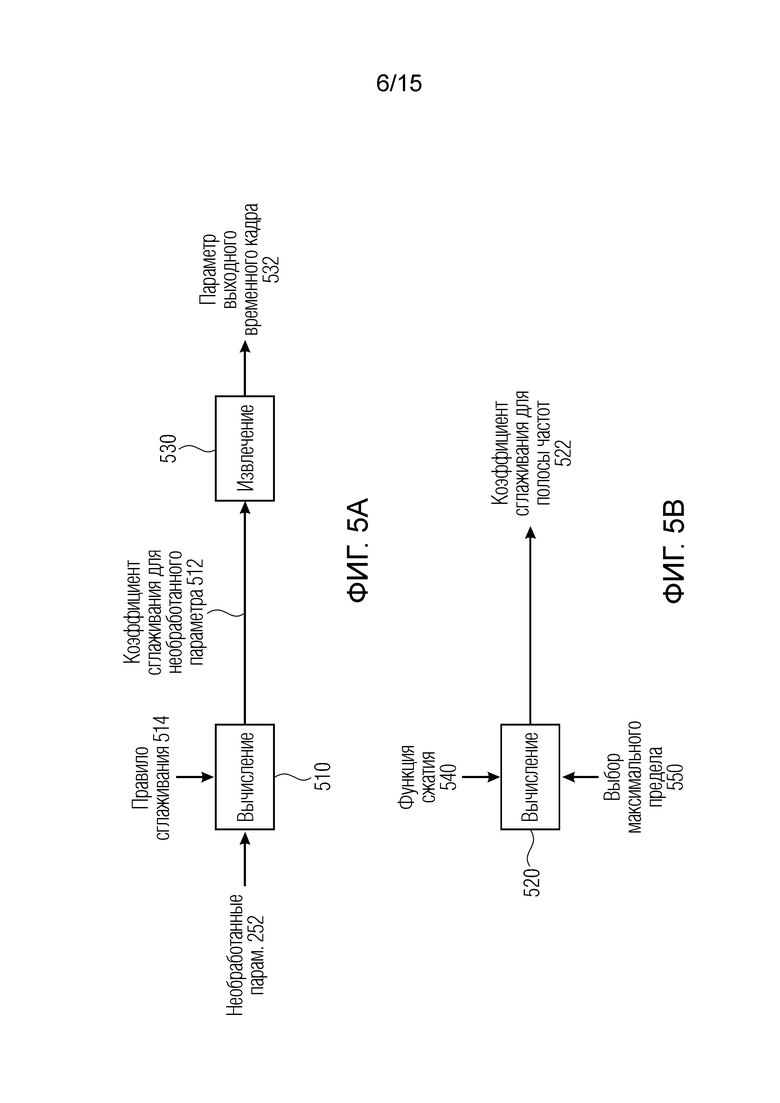
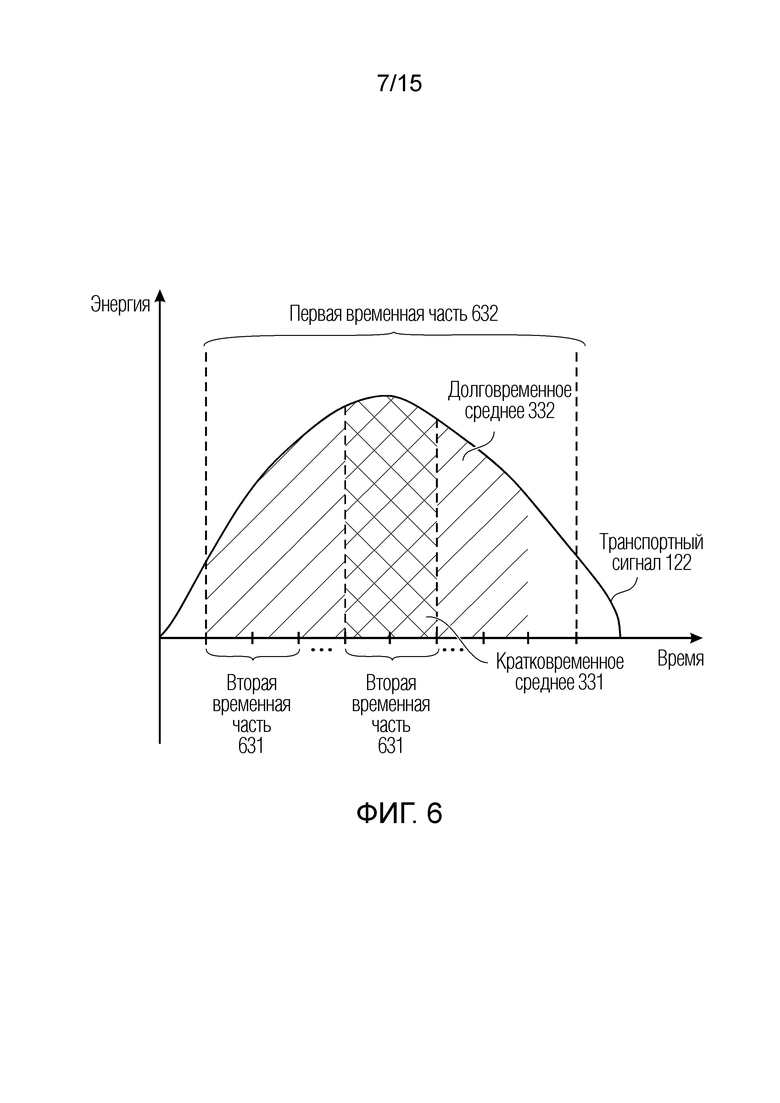
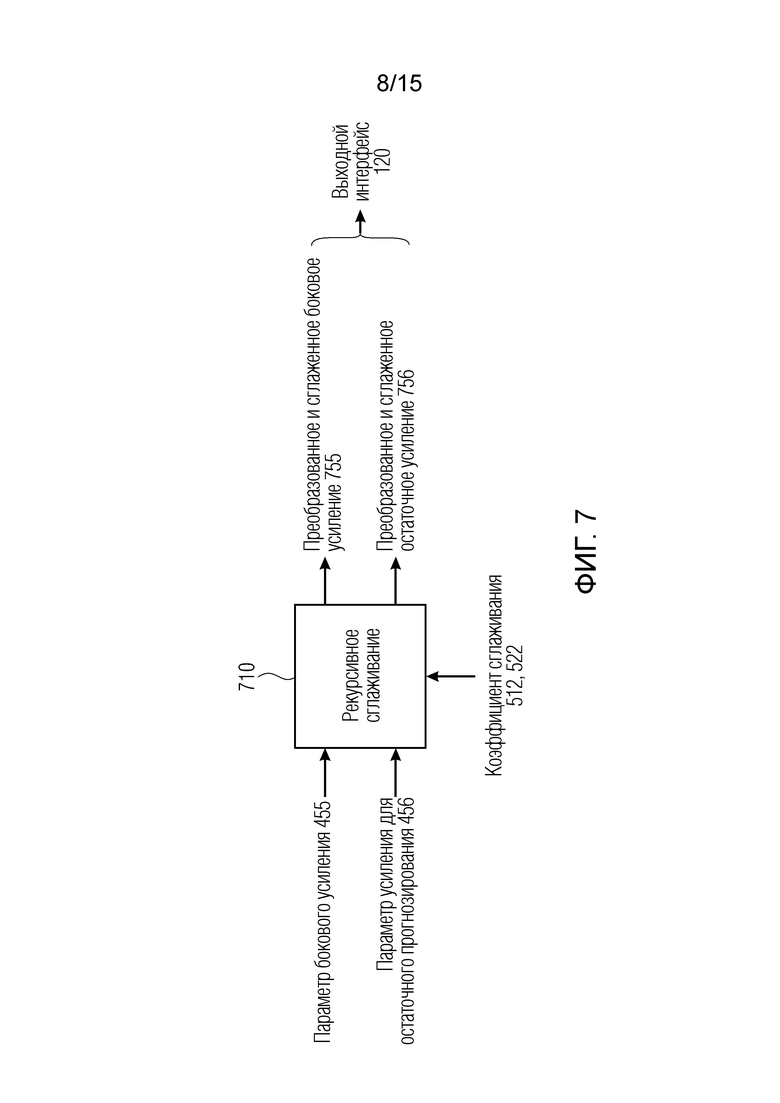
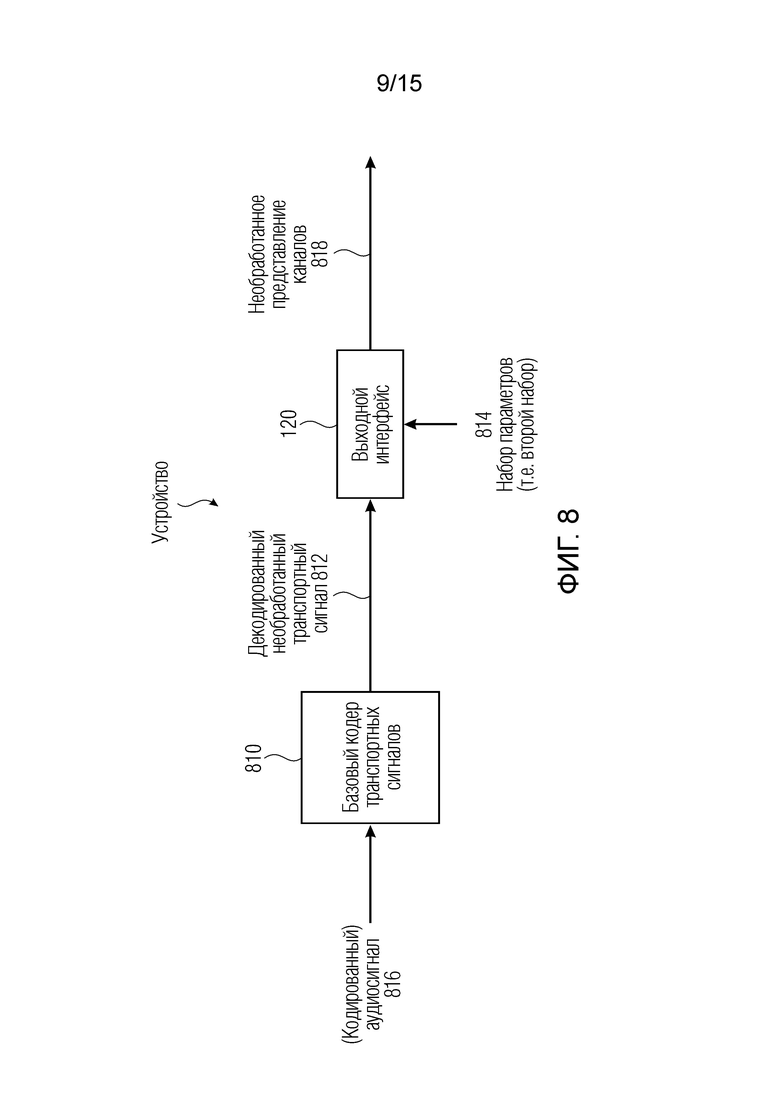
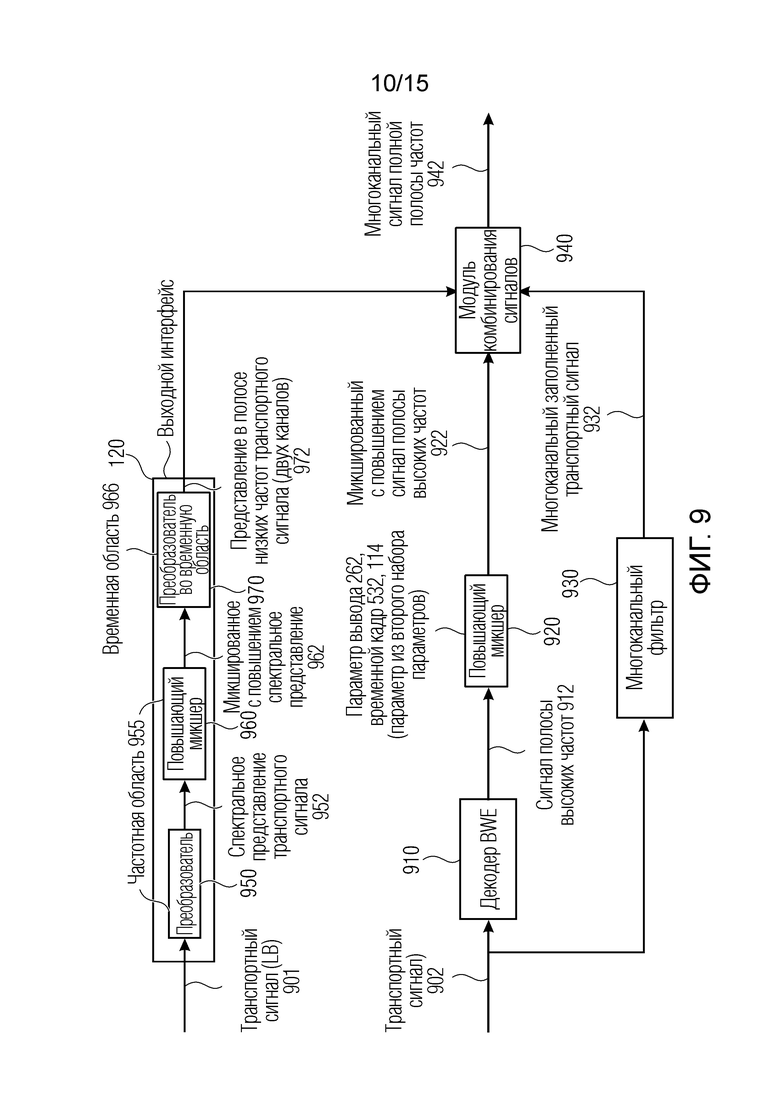
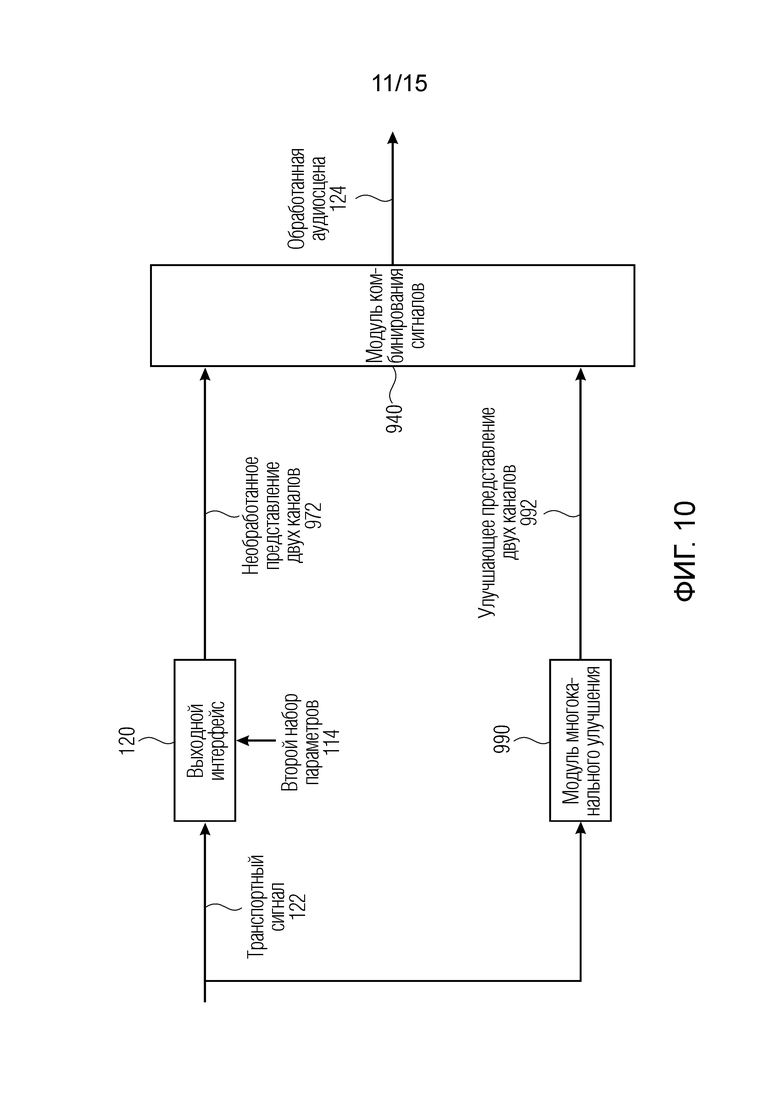
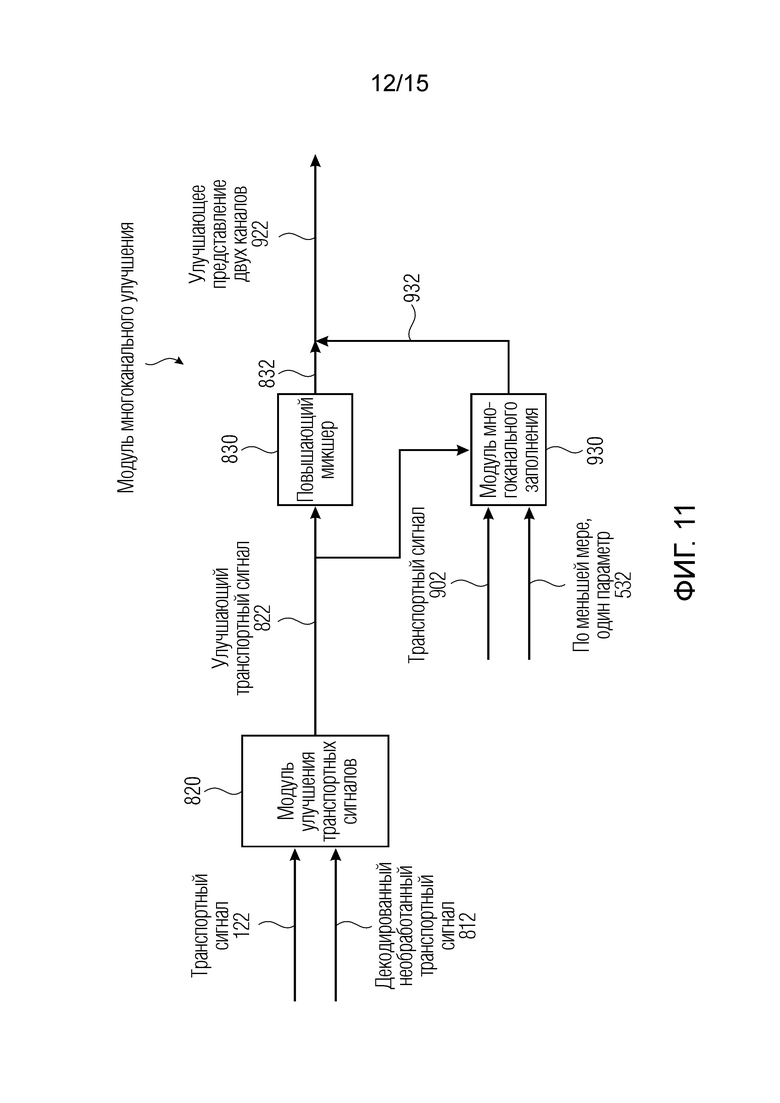
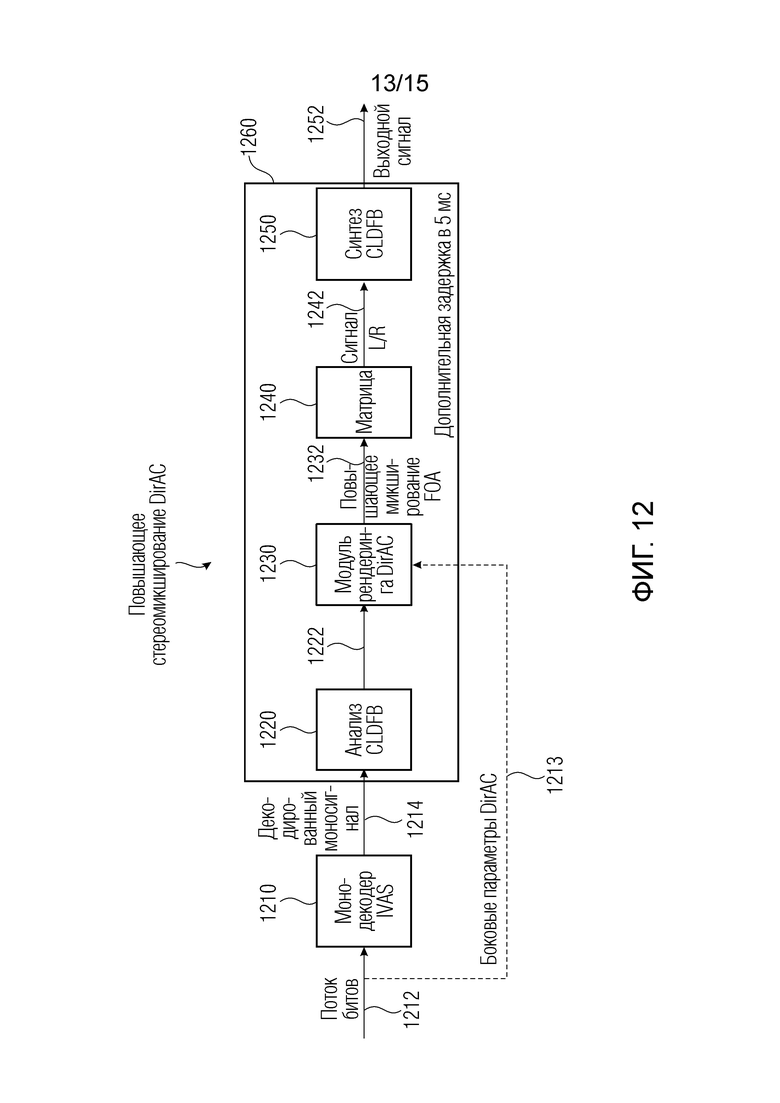
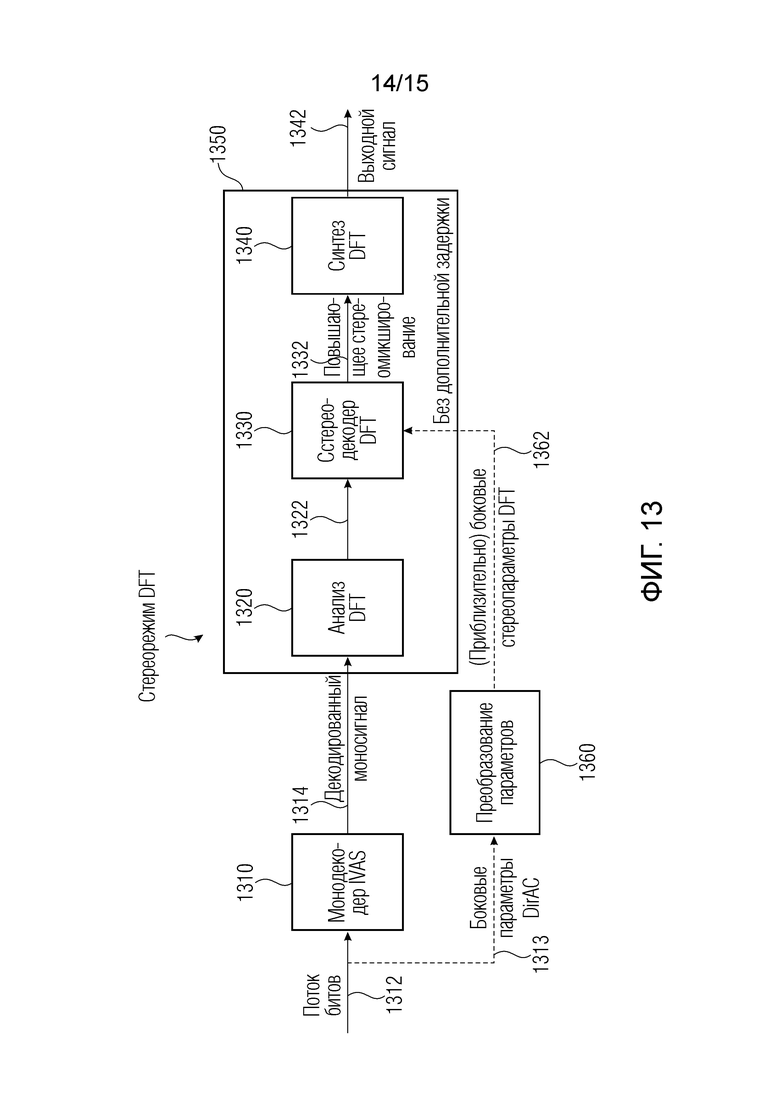
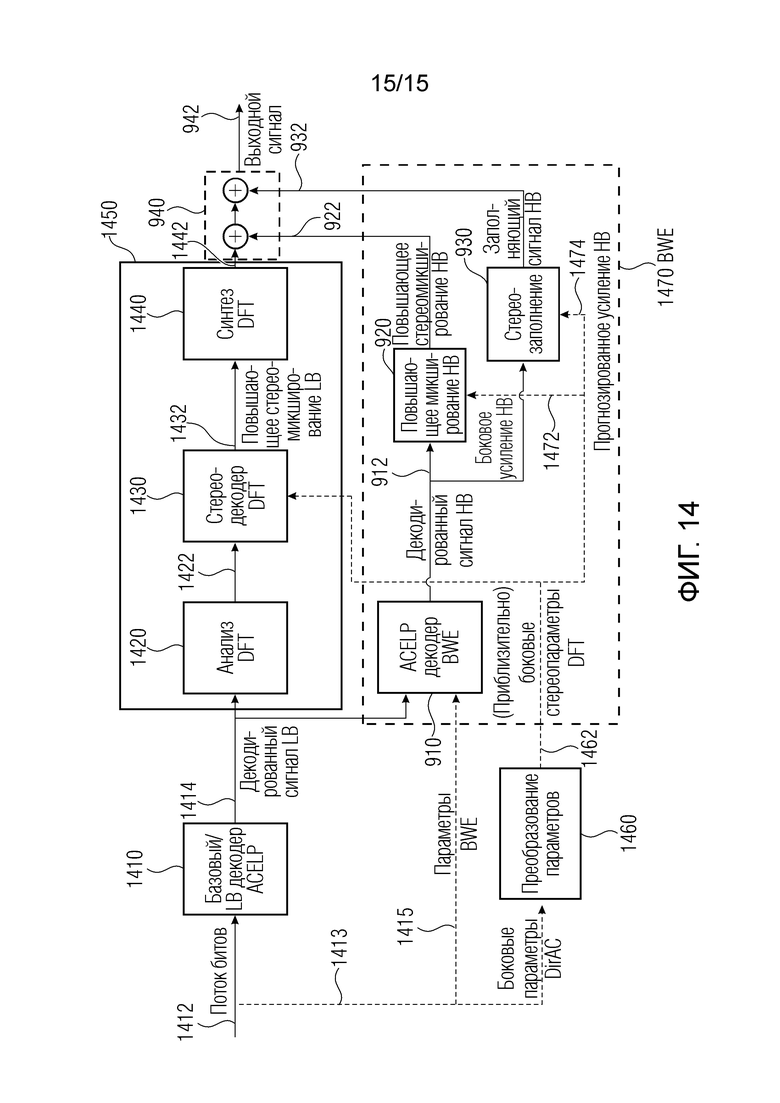
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности обработки кодированной аудиосцены. Технический результат достигается за счет того, что формируют обработанную аудиосцену с использованием набора параметров и информации относительно транспортного сигнала, при этом формирование содержит этап, на котором формируют необработанное представление двух или более каналов с использованием набора параметров и транспортного сигнала, многоканально формируют улучшающее представление двух или более каналов с использованием транспортного сигнала, при этом многоканальное формирование содержит этап, на котором формируют улучшающий транспортный сигнал, выполняют микширование с повышением и многоканальное заполнение для формирования улучшающего представления двух или более каналов с использованием улучшающего транспортного сигнала и по меньшей мере одного параметра из набора параметров, и комбинируют необработанное представление двух или более каналов и улучшающее представление двух или более каналов для получения обработанной аудиосцены. 3 н. и 29 з.п. ф-лы, 1 табл., 17 ил.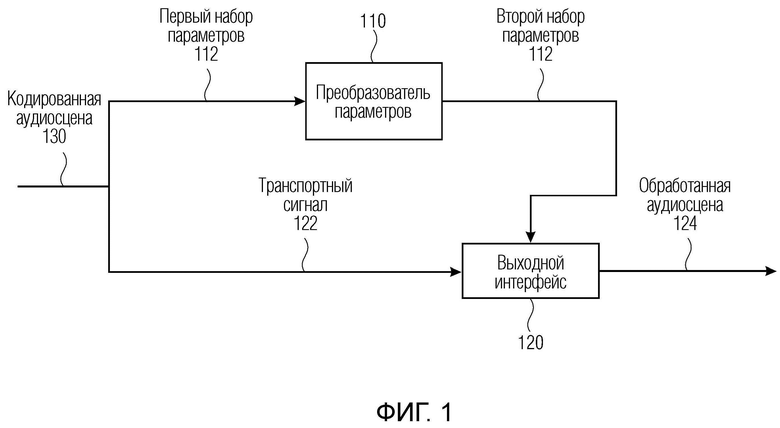
1. Устройство для обработки аудиосцены (130), представляющей звуковое поле, причем аудиосцена (130) содержит информацию в отношении транспортного сигнала (122) и набора (112; 114) параметров, причем устройство содержит:
- выходной интерфейс (120) для формирования обработанной аудиосцены (124) с использованием набора (112; 114) параметров и информации относительно транспортного сигнала (122), при этом выходной интерфейс (120) выполнен с возможностью формирования необработанного представления двух или более каналов с использованием набора (112; 114) параметров и транспортного сигнала (112; 144);
- модуль (990) многоканального улучшения для формирования улучшающего представления двух или более каналов с использованием транспортного сигнала (122), при этом модуль (990) многоканального улучшения содержит:
модуль (820) улучшения транспортных сигналов для формирования улучшающего транспортного сигнала (822); и
повышающий микшер (920); и модуль (930) многоканального заполнения для формирования улучшающего представления двух или более каналов с использованием улучшающего транспортного сигнала (822) и по меньшей мере одного параметра из набора (114) параметров; и
- модуль (940) комбинирования сигналов для комбинирования необработанного представления двух или более каналов и улучшающего представления двух или более каналов для получения обработанной аудиосцены (124).
2. Устройство по п. 1, в котором транспортный сигнал (122) представляет собой кодированный транспортный сигнал, и при этом устройство дополнительно содержит:
- базовый декодер (810) транспортных сигналов для формирования декодированного необработанного транспортного сигнала,
- при этом модуль (820) улучшения транспортных сигналов выполнен с возможностью формирования улучшающего транспортного сигнала с использованием декодированного необработанного транспортного сигнала, и
- при этом выходной интерфейс (120) выполнен с возможностью формирования необработанного представления двух или более каналов с использованием набора (112; 114) параметров и декодированного необработанного транспортного сигнала.
3. Устройство по п. 1, в котором модуль (820) улучшения транспортных сигналов и повышающий микшер (920) выполнены с возможностью работы параллельно с выходным интерфейсом (120) при формировании необработанного представления двух или более каналов.
4. Устройство по одному из пп. 1-3, в котором выходной интерфейс (120) выполнен с возможностью формирования необработанного представления двух или более каналов с использованием повышающего микширования во второй области,
- при этом модуль (820) улучшения транспортных сигналов выполнен с возможностью формирования улучшающего транспортного сигнала (822) в первой области, отличающейся от второй области, и при этом модуль (990) многоканального улучшения выполнен с возможностью формирования улучшающего представления двух или более каналов с использованием улучшающего транспортного сигнала (822) в первой области, и
- при этом модуль (940) комбинирования сигналов выполнен с возможностью комбинирования необработанного представления двух или более каналов и улучшающего представления двух или более каналов в первой области.
5. Устройство по п. 4, в котором первая область представляет собой временную область, и вторая область представляет собой спектральную область.
6. Устройство по одному из пп. 1-5, в котором модуль (820) улучшения транспортных сигналов выполнен с возможностью выполнения по меньшей мере одной операции из группы операций, содержащих операцию расширения полосы пропускания, операцию заполнения интервалов отсутствия сигнала, операцию повышения качества или операцию интерполяции.
7. Устройство по одному из пп. 1-6,
- в котором преобразователь (110) параметров для преобразования принимаемого набора (112) параметров в набор (114) параметров, при этом набор (114) параметров связан с канальным представлением, содержащим два или более каналов для воспроизведения в заданных пространственных положениях для двух или более каналов, причем канальное представление соответствует обработанной аудиосцене (124), выполнен с возможностью работы параллельно с модулем (820) улучшения транспортных сигналов.
8. Устройство по одному из пп. 2-7, в котором базовый декодер (810) транспортных сигналов выполнен с возможностью подачи декодированного необработанного транспортного сигнала в двух параллельных ветвях, причем первая ветвь из двух параллельных ветвей содержит выходной интерфейс (120), и вторая ветвь из двух параллельных ветвей содержит модуль (820) улучшения транспортных сигналов и повышающий микшер (920), и при этом модуль (940) комбинирования сигналов выполнен с возможностью приема первого ввода, который должен комбинироваться из первой ветви, и второго ввода, который должен комбинироваться из второй ветви.
9. Устройство по одному из пп. 1-8, в котором выходной интерфейс (120) выполнен с возможностью:
- выполнения преобразования временной части транспортного сигнала (122), соответствующего выходному временному кадру (220), в спектральное представление,
- выполнения операции повышающего микширования спектрального представления с использованием набора (114) параметров для получения двух или более каналов в спектральном представлении; и
- преобразования каждого канала из двух или более каналов в спектральном представлении во временное представление для получения необработанного временного представления двух или более каналов, и
- при этом модуль (940) комбинирования сигналов выполнен с возможностью комбинирования необработанного временного представления двух или более каналов и улучшающего временного представления двух или более каналов.
10. Устройство по одному из предшествующих пунктов, при этом устройство выполнено с возможностью приема набора параметров, и
- при этом устройство дополнительно содержит преобразователь (110) параметров для преобразования принимаемого набора (112) параметров в набор (114) параметров, при этом набор (114) параметров связан с канальным представлением, содержащим два или более каналов для воспроизведения в заданных пространственных положениях для двух или более каналов, причем канальное представление соответствует обработанной аудиосцене (124); и
- при этом выходной интерфейс (120) выполнен с возможностью формирования обработанной аудиосцены (124) с использованием набора (114) параметров и информации относительно транспортного сигнала (122).
11. Устройство по одному из предшествующих пунктов,
- в котором выходной интерфейс (120) выполнен с возможностью повышающего микширования транспортного сигнала (122) с использованием набора (114) параметров в сигнал повышающего микширования, содержащий два или более каналов.
12. Устройство по одному из предшествующих пунктов, в котором выходной интерфейс (120) выполнен с возможностью формирования обработанной аудиосцены (124) посредством комбинирования транспортного сигнала (122) или информации относительно транспортного сигнала (122) и набора (114) параметров для получения транскодированной аудиосцены в качестве обработанной аудиосцены (124).
13. Устройство по одному из пп. 10-12, в котором принимаемый набор (112) параметров содержит, для каждого входного временного кадра (210) из множества входных временных кадров и для каждой полосы (231) входных частот из множества полос (230) входных частот по меньшей мере один параметр DirAC,
- при этом преобразователь (110) параметров выполнен с возможностью вычисления набора (114) параметров в качестве параметрических стерео- или многоканальных параметров.
14. Устройство по п. 13, в котором по меньшей мере один параметр содержит по меньшей мере один из параметра направления поступления, параметра рассеянности, параметра информации направления, связанного со сферой с виртуальным положением прослушивания в качестве начала координат сферы, и параметра расстояния, и
- при этом параметрические стерео- или многоканальные параметры содержат по меньшей мере один из параметра (455) бокового усиления, параметра (456) усиления для остаточного прогнозирования, параметра межканальной разности уровней, параметра межканальной разности времен, параметра межканальной разности фаз и параметра межканальной когерентности.
15. Устройство по одному из пп. 10-14, в котором входной временной кадр (120), с которым связан принимаемый набор (112) параметров, содержит два или более входных временных субкадров, и при этом выходной временной кадр (220), с которым связан набор (114) параметров, меньше входного временного кадра (210) и больше входного временного субкадра из двух или более входных временных субкадров, и
- при этом преобразователь (110) параметров выполнен с возможностью вычисления необработанного параметра (252) из набора (114) параметров для каждого из двух или более входных временных субкадров, которые являются последовательными во времени, и комбинировать по меньшей мере два необработанных параметра для извлечения параметра из набора (114) параметров, связанного с выходным субкадром.
16. Устройство по п. 15, в котором преобразователь (110) параметров выполнен с возможностью выполнения при комбинировании по меньшей мере двух необработанных параметров комбинирования со взвешиванием по меньшей мере двух необработанных параметров, при этом весовые коэффициенты для комбинирования со взвешиванием извлекаются на основе связанного с амплитудой показателя (320) транспортного сигнала (122) в соответствующем входном временном субкадре.
17. Устройство по п. 16, в котором преобразователь (110) параметров выполнен с возможностью использования энергии или мощности в качестве связанного с амплитудой показателя (320), и при этом весовой коэффициент для входного субкадра больше в случае более высокой энергии или мощности транспортного сигнала (122) в соответствующем входном временном субкадре по сравнению с весовым коэффициентом для входного субкадра, имеющего более низкую энергию или мощность транспортного сигнала (122) в соответствующем входном временном субкадре.
18. Устройство по одному из пп. 13-17, в котором преобразователь (110) параметров выполнен с возможностью вычисления по меньшей мере один необработанный параметр (252) для каждого выходного временного кадра (220) с использованием по меньшей мере одного параметра из принимаемого набора (112) параметров для входного временного кадра (210),
- при этом преобразователь (120) параметров выполнен с возможностью вычисления коэффициента (512; 522) сглаживания для каждого необработанного параметра (252) в соответствии с правилом сглаживания, и
- при этом преобразователь (110) параметров выполнен с возможностью применения соответствующего коэффициента (512; 522) сглаживания к соответствующему необработанному параметру (252) для извлечения параметра из набора (114) параметров для выходного временного кадра (220).
19. Устройство по п. 18, в котором преобразователь (110) параметров выполнен с возможностью:
- вычисления долговременного среднего (332) для связанного с амплитудой показателя (320) первой временной части транспортного сигнала (122), и
- вычисления кратковременного среднего (331) для связанного с амплитудой показателя (320) второй временной части транспортного сигнала (120), при этом вторая временная часть меньше первой временной части, и
- вычисления коэффициента (512; 522) сглаживания на основе соотношения между долговременным средним (332) и кратковременным средним (331).
20. Устройство по п. 18 или 19, в котором преобразователь (110) параметров выполнен с возможностью вычисления коэффициента (512; 522) сглаживания для полосы частот с использованием функции (540) сжатия, причем функция сжатия отличается для различных полос частот, и при этом сила сжатия функции сжатия является большей для полосы нижних частот, чем для полосы верхних частот.
21. Устройство по одному из пп. 18-20, в котором преобразователь (110) параметров выполнен с возможностью вычисления коэффициента (512; 522) сглаживания с использованием различных максимальных пределов для различных полос частот, при этом максимальный предел для полосы нижних частот выше максимального предела для полосы верхних частот.
22. Устройство по одному из пп. 18-21, в котором преобразователь (110) параметров выполнен с возможностью применения в качестве правила сглаживания правила (710) рекурсивного сглаживания для последовательных во времени выходных временных кадров таким образом, что сглаженный параметр для текущего выходного временного кадра (220) вычисляется посредством комбинирования параметра для предшествующего выходного временного кадра (220), взвешенного посредством первого весового значения, и необработанного параметра (252) для текущего выходного временного кадра (220), взвешенного посредством второго весового значения, при этом первое весовое значение и второе весовое значение извлекаются из коэффициента (512; 522) сглаживания для текущего временного кадра.
23. Устройство по одному из предшествующих пунктов, в котором выходной интерфейс (120) выполнен с возможностью:
- выполнения преобразования временной части транспортного сигнала (122), соответствующего выходному временному кадру (220), в спектральное представление, при этом часть меньше входного временного кадра (210), в котором организуются параметры из принимаемого набора (112) параметров,
- выполнения операции повышающего микширования спектрального представления с использованием набора (114) параметров для получения двух или более каналов в спектральном представлении; и
- преобразования каждого канала из двух или более каналов в спектральном представлении во временное представление.
24. Устройство по п. 23, в котором выходной интерфейс (120) выполнен с возможностью:
- преобразования в область комплексного дискретного преобразования Фурье,
- выполнения операции повышающего микширования в области комплексного дискретного преобразования Фурье, и
- выполнения преобразования из области комплексного дискретного преобразования Фурье в действительнозначное представление во временной области.
25. Устройство по п. 23 или 24, в котором выходной интерфейс (120) выполнен с возможностью выполнения операции повышающего микширования на основе следующего уравнения:
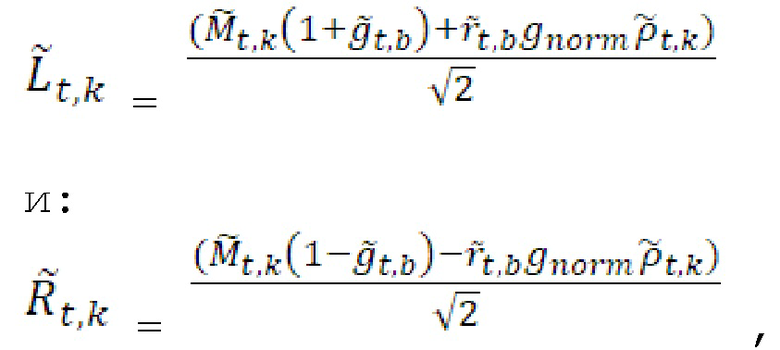
- при этом 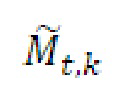 является транспортным сигналом (122) для кадра t и частотного элемента k разрешения, при этом
является транспортным сигналом (122) для кадра t и частотного элемента k разрешения, при этом 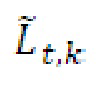 является первым каналом из двух или более каналов в спектральном представлении для кадра t и частотного элемента k разрешения, при этом
является первым каналом из двух или более каналов в спектральном представлении для кадра t и частотного элемента k разрешения, при этом 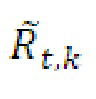 является вторым каналом из двух или более каналов в спектральном представлении для кадра t и частотного элемента k разрешения, при этом
является вторым каналом из двух или более каналов в спектральном представлении для кадра t и частотного элемента k разрешения, при этом 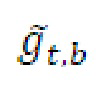 является параметром (455) бокового усиления для кадра t и подполосы b частот, при этом
является параметром (455) бокового усиления для кадра t и подполосы b частот, при этом 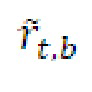 является параметром (456) усиления для остаточного прогнозирования для кадра t и подполосы b частот, при этом gnorm является энергетическим регулирующим коэффициентом, который может использоваться или не использоваться, и при этом
является параметром (456) усиления для остаточного прогнозирования для кадра t и подполосы b частот, при этом gnorm является энергетическим регулирующим коэффициентом, который может использоваться или не использоваться, и при этом 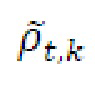 является необработанным остаточным сигналом для кадра t и частотного элемента к разрешения.
является необработанным остаточным сигналом для кадра t и частотного элемента к разрешения.
26. Устройство по одному из пп. 10-25,
- в котором принимаемый набор (112) параметров представляет собой параметр направления поступления для полосы (231) входных частот, и при этом набор (114) параметров содержит параметр (455) бокового усиления в расчете на полосу (231) входных частот, и
- при этом преобразователь (110) параметров выполнен с возможностью вычисления параметра (455) бокового усиления для полосы (241) выходных частот с использованием следующего уравнения:
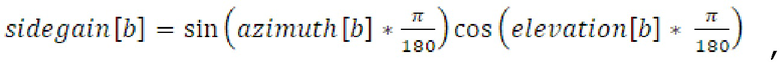
- при этом b является полосой (241) выходных частот, при этом sidegain является параметром (455) бокового усиления, при этом azimuth является азимутальным компонентом параметра направления поступления, и при этом elevation является компонентом угла места параметра направления поступления.
27. Устройство по п. 26,
- в котором принимаемый набор (112) параметров дополнительно содержит параметр рассеянности для полосы (231) входных частот, и при этом преобразователь (110) параметров выполнен с возможностью вычисления параметра (455) бокового усиления для полосы (241) выходных частот с использованием следующего уравнения:
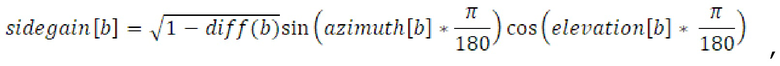
- при этом diff(b) является параметром рассеянности для полосы (231) b входных частот.
28. Устройство по одному из пп. 10-27,
- в котором принимаемый набор (112) параметров содержит параметр рассеянности в расчете на полосу (231) входных частот, и
- при этом набор (114) параметров содержит параметр (456) остаточного прогнозирования для полосы (241) выходных частот, и
- при этом преобразователь (110) параметров должен использовать, в качестве параметра (456) усиления для остаточного прогнозирования для полосы частот выходных параметров, параметр рассеянности из полосы частот входных параметров, когда полоса частот входных параметров и полоса частот выходных параметров равны друг другу, или извлекать, из параметра рассеянности для полосы частот входных параметров, параметр рассеянности для полосы частот выходных параметров и затем использовать параметр рассеянности для полосы частот выходных параметров в качестве параметра (456) усиления для остаточного прогнозирования для полосы частот выходных параметров.
29. Устройство по одному из пп. 1-28,
- в котором информация относительно транспортного сигнала (122) содержит базовый кодированный аудиосигнал, и при этом устройство дополнительно содержит:
- базовый декодер (810) транспортных сигналов для базового декодирования базового кодированного аудиосигнала для получения транспортного сигнала (122).
30. Устройство по одному из пп. 2 или 29, в котором базовый декодер (810) транспортных сигналов находится в декодере ACELP, или
- при этом выходной интерфейс (120) выполнен с возможностью преобразования (1420) транспортного сигнала (122), представляющего собой сигнал полосы низких частот, в спектральное представление, повышающего микширования (1430) спектрального представления и преобразования (1440) микшированного с повышением спектрального представления во временной области для получения представления (1442) в полосе низких частот двух или более каналов,
- при этом модуль (820) улучшения транспортных сигналов содержит процессор (910) расширения полосы пропускания для формирования сигнала (912) полосы высоких частот из транспортного сигнала (122) во временной области, причем модуль (930) многоканального заполнения выполнен с возможностью применения операции стереозаполнения к сигналу (912) полосы высоких частот из транспортного сигнала (122) во временной области,
- при этом повышающий микшер (920) выполнен с возможностью применения широкополосного панорамирования во временной области к сигналу (912) полосы высоких частот из транспортного сигнала (122) с использованием по меньшей мере одного параметра (1472) из набора (114) параметров, при этом результат (922) широкополосного панорамирования и результат (932) операции стереозаполнения представляют улучшающее представление двух или более каналов, и
- при этом модуль (940) комбинирования сигналов выполнен с возможностью комбинирования во временной области результата (922) широкополосного панорамирования, результата (932) стереозаполнения и, в качестве необработанного представления двух или более каналов, представления (1442) в полосе низких частот двух или более каналов для получения многоканального сигнала (942) полной полосы частот во временной области в качестве обработанной аудиосцены (124).
31. Способ обработки аудиосцены (130), представляющей звуковое поле, связанное с виртуальным положением слушателя, причем аудиосцена (130) содержит информацию в отношении транспортного сигнала и набора параметров, при этом способ содержит этапы, на которых:
- формируют обработанную аудиосцену (124) с использованием набора параметров и информации относительно транспортного сигнала, при этом формирование содержит этап, на котором формируют необработанное представление двух или более каналов с использованием набора параметров и транспортного сигнала,
- многоканально формируют улучшающее представление двух или более каналов с использованием транспортного сигнала, при этом многоканальное формирование содержит этап, на котором формируют улучшающий транспортный сигнал (822), выполняют микширование (920) с повышением и многоканальное заполнение (930) для формирования улучшающего представления двух или более каналов с использованием улучшающего транспортного сигнала (822) и по меньшей мере одного параметра из набора (114) параметров, и
- комбинируют необработанное представление двух или более каналов и улучшающее представление двух или более каналов для получения обработанной аудиосцены (124).
32. Физический носитель, на котором сохранена компьютерная программа для осуществления при выполнении на компьютере или процессоре способа по п. 31.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| АУДИОКОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2008 |
|
RU2452043C2 |

