Изобретение относится к способу компьютерной генерации управляемой данными модели технической системы, в частности газовой турбины или ветрогенератора, а также к соответствующему компьютерному программному продукту.
Для автоматической эксплуатации технической системы могут использоваться управляемые данными модели, обучаемые на основе соответствующих тренировочных данных, которые представляют собой эксплуатационные параметры технической системы. При этом такая обученная, управляемая данными модель должна отражать поведение технической системы и может использоваться затем для разработки моделей контроля и/или регулирования соответствующей технической системы. Эти модели контроля и регулирования могут использоваться затем в реальной работе технической системы для настройки ее соответствующих управляющих переменных на основе текущих эксплуатационных параметров или для эксплуатационных параметров автоматического определения ее ложных эксплуатационных состояний.
Как правило, тренировочные данные, с помощью которых обучается управляемая данными модель, распределены в пространстве состояний эксплуатационных параметров технической системы неравномерно. Обычно в эксплуатационных диапазонах технической системы, представляющих нормальный режим, имеется существенно больше данных, чем в граничных диапазонах эксплуатации или для ложных эксплуатационных состояний технической системы. Эта проблема возникает, в частности, при управлении газовыми турбинами и ветрогенераторами, которые во избежание повреждений не эксплуатируются, как правило, в граничных диапазонах. Таким образом, в часто используемых эксплуатационных диапазонах газовой турбины или ветрогенератора существует большое число полезных наборов тренировочных данных, однако их информационное содержание является большей частью избыточным. Для редко используемых эксплуатационных режимов, напротив, имеется мало данных.
Таким образом, для тренировочных данных, используемых для обучения управляемой данными модели, существуют диапазоны разной плотности данных. Обычно эта плотность данных не учитывается при отборе соответствующих тренировочных данных и основанной на них генерации модели соответствующей технической системы.
Вследствие этого соответствующие модели регулирования и контроля, рассчитываемые на основе управляемых данными моделей, могут при работе технической системы выдавать неправильные или субоптимальные регулирующие действия или неправильные предупреждения. Так, например, возможно, что понижения температуры, возникающие при работе газовой турбины или ветрогенератора и отсутствующие на тренировочном этапе управляемой данными модели, приведут к срабатыванию ложной тревоги. Точно так же управляемая данными модель, обучаемая только с помощью тренировочных данных для типичных эксплуатационных состояний, может привести к увеличению сбоев, так что основанная на этом модель регулирования или управления в реальной работе технической системы неоптимально настраивает соответствующие управляющие переменные, например количество подаваемого газа или положение входных направляющих лопаток в газовой турбине. Это может привести к снижению мощности или к.п.д. или срока службы технической системы.
Традиционным образом при генерации управляемой данными модели технической системы после устранения резко выпадающих значений и ошибок используются либо все наборы тренировочных данных, либо случайный отбор этих наборов данных. Принятие во внимание всех тренировочных данных создает их очень большое и все более возрастающее количество, которое может замедлить генерацию соответствующей управляемой данными модели и привести к ресурсным проблемам компьютера или компьютеров (например, нехватке размера основной памяти). Простое ограничение случайным отбором наборов тренировочных данных ускоряет, правда, расчет управляемой данными модели, однако повышает риск потери релевантной информации через техническую систему. Эта проблема у управляемых данными моделей, представляющих динамическое поведение технической системы, усиливается за счет того, что при обучении модели приходится сообща учитывать определенное количество взаимосвязанных по времени наборов данных.
Задачей изобретения является создание способа компьютерной генерации управляемой данными модели, которая с помощью меньшего объема вычислительного ресурса позволила бы обучить хорошую управляемую данными модель технической системы.
Эта задача решается посредством независимых пунктов формулы изобретения. Варианты его осуществления приведены в зависимых пунктах.
Предложенный способ служит для компьютерной генерации управляемой данными модели технической системы, в частности газовой турбины или ветрогенератора. Управляемая данными модель служит преимущественно для использования в целях решения автоматизированных задач контроля, и/или прогнозирования, и/или регулирования в технической системе и создается на основе тренировочных данных, включающих в себя большое число наборов данных, представляющих соответственно несколько эксплуатационных параметров технической системы. Под несколькими эксплуатационными параметрами следует понимать измеряемые величины и при необходимости управляющие переменные технической системы. При этом измеряемыми величинами являются величины, которые определяются на или в окружении технической системы подходящими датчиками или выводятся из значений датчиков. Управляющими переменными являются такие эксплуатационные параметры технической системы, которые можно настраивать или изменять, чтобы за счет этого влиять на ее работу.
Предложенный способ протекает итеративно, причем для некоторого числа этапов итерации посредством наборов тренировочных данных обучаются соответственно управляемая данными модель и оценщик плотности. Обученная по завершении итерации управляемая данными модель является тогда генерированной предложенным способом управляемой данными моделью. (Обученный) оценщик плотности выдает для наборов тренировочных данных соответственно доверительный уровень, который тем выше, чем выше схожесть соответствующего набора данных с другими наборами тренировочных данных. Схожесть наборов данных описывается в предпочтительном варианте соответствующим расстоянием в пространстве между представляющими наборы данных точками данных. При этом оценщик плотности за счет своего доверительного уровня указывает, имеют ли место для соответствующего набора данных высокая плотность в пространстве данных и, тем самым, много схожих наборов тренировочных данных. Методы, с помощью которых можно реализовать описанный оценщик плотности, достаточно известны из уровня техники и поэтому подробно не поясняются. В одном предпочтительном варианте в качестве оценщика плотности применяется метод, основанный на нейронных облаках. При этом применяется преимущественно метод, описанный в источнике информации [1]. Все раскрытое содержание этого источника информации путем ссылки включено в содержание данной заявки.
Обученная в предложенном способе на одном этапе итерации управляемая данными модель служит для воспроизведения наборов тренировочных данных. При этом возникает модельная ошибка, представляющая собой различие между воспроизведенными наборами данных и фактическими наборами тренировочных данных. Эта ошибка качественно хорошей, управляемой данными модели должна быть минимальной. При этом управляемая данными модель выполнена, в частности, таким образом, что первая часть эксплуатационных параметров соответствующих наборов тренировочных данных представляет собой ввод управляемой данными модели, а ее выводом является вторая часть содержащихся в соответствующих наборах данных эксплуатационных параметров. В этом случае модельная ошибка возникает за счет различия между второй частью эксплуатационных параметров, выдаваемых управляемой данными моделью, и соответствующей второй частью эксплуатационных параметров соответствующих наборов тренировочных данных.
В рамках предложенного способа посредством оценщика данных и управляемой данными модели, которые были обучены на соответствующем этапе итерации, отбираются или взвешиваются наборы тренировочных данных для обучения на следующем этапе итерации, причем подборки тренировочных данных с низким доверительным уровнем и большими модельными ошибками отбираются скорее или взвешиваются выше. Это значит, что набор тренировочных данных, который при равной модельной ошибке имеет более низкий доверительный уровень, чем другой набор данных, отбирается скорее или взвешивается выше, чем другой набор данных. Точно так же набор данных, который при равном доверительном уровне имеет большую модельную ошибку, чем другой набор данных, отбирается предпочтительно или взвешивается выше, чем другой набор данных.
Изобретение основано на том факте, что особенно эффективное обучение управляемой данными модели технической системы достигается тогда, когда используются тренировочные данные, имеющие высокую степень «новизны», т.е. доверительный уровень которых низок и для которых вследствие этого существует мало схожих наборов данных. Точно так же интерес для методов обучения представляют те диапазоны тренировочных данных, для которых модель еще ошибочна, т.е. для которых возникают еще большие модельные ошибки. За счет моделирования подходящей взаимосвязи, при которой наборы данных с низким доверительным уровнем или большими модельными ошибками на новом этапе итерации учитываются сильнее, достигается, тем самым, обучение, обеспечивающее эффективную генерацию хорошей управляемой данными модели технической системы.
Предложенным способом можно подходящим образом экстрагировать имеющиеся в больших количествах тренировочных данных взаимосвязи и использовать их для моделирования поведения технической системы и, в частности, газовой турбины или ветрогенератора. Хорошее моделирование соответствующей технической системы обеспечивается при этом даже тогда, когда наборы тренировочных данных содержат мало эксплуатационных параметров или количество тренировочных данных распределено по немногим наборам. В предложенном способе используются лишь важные информационно-релевантные наборы данных или диапазоны тренировочных данных, так что соответствующую модель можно создать быстро и с малыми вычислительными ресурсами. Кроме того, за счет предложенного способа оптимизируется процентильное представление генерированной управляемой данными модели. Это предпочтительно особенно тогда, когда управляемая данными модель используется в рамках компьютерного управления технической системой или ее контроля.
Предложенный способ имеет далее то преимущество, что он создает обученный оценщик плотности, который может быть затем интегрирован при расчете модели управления и/или регулирования или модели контроля технической системы. При этом оценщик плотности дает информацию о достоверности текущих эксплуатационных параметров технической системы. В частности, могут быть динамически согласованы соответствующие информационные пороги или максимальные значения изменений управляющих переменных. Таким образом, можно избежать ложных тревог при контроле технических систем в реальном времени и, в частности, газовых турбин или ветрогенераторов. Далее авторизацию генерированной управляемой данными модели можно сделать зависимой от доверительного уровня и, тем самым, от плотности соответствующего набора данных текущих эксплуатационных параметров технической системы, т.е. только при достаточной плотности данных начинается работа управляемой данными модели или продолжается работа технической системы. Таким образом, можно избежать настроек управляющих переменных на технической системе, которые, например, за счет слишком большой динамики сгорания в газовой турбине приводят к повреждению технической системы.
С помощью генерированной предложенным способом управляемой данными модели можно моделировать, в частности, также динамическое (т.е. зависимое от времени) поведение технической системы. В этом случае набор данных включает в себя не только эксплуатационные параметры в один и тот же момент времени, но и последовательность эксплуатационных параметров связанных друг с другом моментов времени в соответствии с архитектурой управляемой данными модели.
Предложенным способом в качестве управляемой данными модели обучается преимущественно нейронная сеть и, в частности, рекуррентная нейронная сеть. Такая рекуррентная нейронная сеть позволяет очень хорошо воспроизводить поведение технической системы на основе соответствующих тренировочных данных. Обучение нейронной сети происходит преимущественно известным методом обратного распространения ошибки. В одном особенно предпочтительном варианте в качестве нейронной сети используется описанная в DE 102010011221 А1 сеть, которая называется также марковской сетью (марковский процесс принятия решений).
Предложенный способ особенно хорошо подходит для моделирования газовой турбины. Ее подходящие измеряемые параметры, учитываемые в качестве эксплуатационных параметров технической системы в наборах данных, включают в себя один или несколько следующих параметров:
- температуру окружающего пространства, в котором эксплуатируется газовая турбина;
- влажность воздуха окружающего пространства, в котором эксплуатируется газовая турбина;
- давление воздуха в окружающем пространстве, в котором эксплуатируется газовая турбина;
- мощность газовой турбины, в частности процентное значение мощности;
- качество топлива газовой турбины;
- выброс газовой турбиной токсичных веществ, в частности выброс оксидов азота и/или моноксида углерода;
- температуру отходящих газов газовой турбины;
- динамику сгорания в газовой турбине.
Термин «динамика сгорания» касается зарегистрированных подходящими датчиками амплитудных значений колебаний давления в газовой турбине.
В противоположность этому для газовой турбины особенно подходящими оказались следующие управляющие переменные в качестве эксплуатационных параметров в наборах данных:
- положение одной или нескольких направляющих лопаток газовой турбины;
- количество подаваемого в газовую турбину газа;
- заданное значение температуры отходящих газов газовой турбины.
При этом следует обратить внимание на то, что в газовых турбинах нужное значение температуры отходящих газов можно устанавливать с помощью подходящего регулятора. Это значение соответствует упомянутому заданному значению.
Другой предпочтительной областью применения предложенного способа является создание управляемой данными модели ветрогенератора. При этом в качестве измеряемых эксплуатационных параметров в наборах данных используются преимущественно один или несколько следующих параметров:
- выработанная ветрогенератором электрическая мощность;
- скорость ветра в окружающем пространстве, в котором эксплуатируется ветрогенератор;
- частота вращения ветрогенератора;
- изгибающие усилия и/или отклонения и/или знакопеременные нагрузки на лопастях ветрогенератора;
- вращение башни ветрогенератора.
В качестве управляющих переменных эксплуатационных параметров ветрогенератора в наборах данных используются преимущественно одна или несколько следующих переменных:
- угол установки лопастей ветрогенератора;
- параметрическое поле ветрогенератора, которое представляет взаимосвязь между частотой вращения и выработанной ветрогенератором мощностью.
В другом особенно предпочтительном варианте с помощью генерированной предложенным способом управляемой данными модели рассчитывается модель управления и/или регулирования эксплуатации технической системы на основе одного или нескольких критериев оптимизации. Эта рассчитанная модель управления и/или регулирования указывает изменения одной или нескольких управляющих переменных эксплуатационных параметров технической системы в зависимости от одной или нескольких измеряемых величин эксплуатационных параметров технической системы и обеспечивает за счет этого в ее реальной работе подходящую настройку управляющих переменных.
Если рассчитывается модель управления и/или регулирования газовой турбины, то критерий/критерии оптимизации включает/включают в себя преимущественно минимальный выброс и/или минимальную динамику сгорания или же максимально высокий к.п.д. или максимально высокую мощность. Таким образом, гарантируется экологичная работа газовой турбины или длительный срок ее службы.
Если рассчитывается модель управления и/или регулирования ветрогенератора, то критерий/критерии оптимизации включает/включают в себя, в частности, его максимально высокий к.п.д. и/или минимальные изгибающие усилия на его лопастях. Это гарантирует оптимальную работу или также длительный срок службы ветрогенератора.
В другом особенно предпочтительном варианте модель управления и/или регулирования выполняется таким образом, что с помощью обученного оценщика плотности соответствующие доверительные уровни наборов данных возникающих при работе технической системы эксплуатационных параметров определяются, причем ограничивается изменение одной или нескольких управляющих переменных эксплуатационных параметров и/или работа связанной с управляемой данными моделью функции и/или технической системы прерывается или вообще не начинается, если соответствующий доверительный уровень ниже заданного порога. Таким образом, обученный в рамках предложенного способа оценщик плотности может использоваться также для авторизации работы технической системы только тогда, когда эксплуатационные параметры технической системы лежат в диапазоне достаточно высокой плотности данных.
В другом варианте предложенного способа с помощью обученной, управляемой данными модели рассчитывается модель контроля, которая в случае, если один или несколько возникающих при работе технической системы эксплуатационных параметров более чем на заданную меру отличаются от соответствующего или соответствующих, воспроизведенных генерированной управляемой данными моделью эксплуатационных параметров, выдает предупредительный и/или тревожный сигнал и/или вызывает автоматическое срабатывание меры безопасности технической системы. Преимущественно в такой модели контроля можно подходящим образом учесть также обученный оценщик плотности. В этом случае модель контроля выполнена таким образом, что соответствующие доверительные уровни для наборов данных из возникающих при работе технической системы эксплуатационных параметров определяются с помощью обученного оценщика плотности, причем заданный уровень, на основе которого вырабатывается предупредительный сигнал, настраивается тем выше, чем ниже соответствующий доверительный уровень входных параметров модели. Следовательно, подходящим образом повышается сигнальный порог для наборов данных меньшей плотности. При необходимости в случае, если соответствующий доверительный уровень ниже заданного порогового значения, выдается также сигнал о том, что из-за слишком малой плотности данных не могут выдаваться никакие предупредительные сигналы и, тем самым, невозможен никакой контроль.
В одном особенно предпочтительном варианте модель управления и/или регулирования и/или модель контроля рассчитывается на основе метода обучения с подкреплением и/или метода модельно-предикативного регулирования, и/или метода оптимизации. Методы обучения с подкреплением и модельно-предикативного регулирования достаточно известны из уровня техники. Точно так же известны соответствующие методы оптимизации. Например, метод оптимизации может быть осуществлен основанным на градиенте или стохастическим методом поиска соответственно определенного оптимального значения согласно модели управления или регулирования или модели контроля. В другом, особенно предпочтительном варианте модель управления и/или регулирования и/или модель контроля обучается на основе нейронной сети, в частности рекуррентной нейронной сети.
В качестве техники расчета соответствующей модели управления и/или регулирования и/или модели контроля подходят, в частности, методы, описанные в публикациях DE 102007001025 Al (Reccurent-Control-Neural-Network), DE 102007017259 Al (Neural-Rewards-Regression) и DE 102007042440 B3 (Policy-Gradient-Neural-Rewards-Regression). Точно так же для расчета соответствующих моделей управления и/или регулирования и/или моделей контроля может применяться известный метод Neural-Fitted-Q-Iteration [2].
При необходимости при обучении модели управления и/или регулирования и/или модели контроля с помощью нейронной сети могут применяться методы регуляризации. Например, помимо ошибки для соответствующего набора данных может быть добавлен так называемый штрафной терм для весов в нейронной сети (англ.: weight penalty term), так что в областях с низкой плотностью данных создаются скорее линейные и, тем самым, лучше экстраполирующие модели. Точно так же могут быть отрезаны веса нейронной сети, отбираемые с помощью известной функции оценки Inverse Kurtosis, благодаря чему стабилизируется поведение в областях с низкой плотностью данных. Это предпочтительно, в частности, при расчете модели управления и/или регулирования и/или модели контроля для газовой турбины или ветрогенератора.
В одном предпочтительном варианте взаимосвязь между доверительными уровнями или модельными ошибками и отбором или взвешиванием наборов данных моделируется при генерации управляемой данными модели посредством функции. При этом определяется функция, зависимая от доверительного уровня и модельной ошибки, причем функция на основе доверительного уровня и модельной ошибки устанавливает, отбирается ли набор данных или насколько высоко его взвешивание. В зависимости от случая применения функция может быть разной. Конкретное установление такой функции лежит в рамках действий специалиста. Например, функция может моделировать соответствующие взаимосвязи дискретно посредством лестниц или подходящим образом непрерывно.
В другом предпочтительном варианте предложенного способа наборы данных при генерации управляемой данными модели отбираются для следующего этапа итерации на основе соответствующих наборам данных вероятностей посредством взятия выборок. Это значит, что наборам данных на основе соответствующих доверительных уровней или модельных ошибок подходящим образом присваиваются вероятности, которые затем учитываются в рамках выборки. Присвоение вероятностей может осуществляться, например, посредством описанной функции.
В другом варианте предложенного способа наборам тренировочных данных присваиваются веса, которые учитываются при обучении оценщика плотности и управляемой данными модели, причем веса посредством оценщика плотности и управляемой данными модели, обученных на соответствующем этапе итерации, актуализируются таким образом, что наборы тренировочных данных с более низкими доверительными уровнями и большими модельными ошибками приобретают более высокие веса. Веса могут учитываться оценщиком плотности и управляемой данными моделью по-разному. В одном варианте осуществления изобретения веса представляют вероятности, обрабатываемые оценщиком плотности и управляемой данными моделью. Например, посредством оценщика плотности и/или управляемой данными модели можно отбирать для обучения наборы тренировочных данных на основе вероятностей. Вероятности можно учитывать подходящим образом также в рамках обучения, например методом стохастического градиентного подъема, который применятся оценщиком плотности и управляемой данными моделью.
Предложенный способ можно инициализировать по-разному. В одном варианте способ инициализируется частичным количеством наборов тренировочных данных, установленным, например, случайно. Точно так же способ может инициализироваться со всеми наборами тренировочных данных с подходящим образом установленными начальными весами.
Выявленные в рамках предложенного способа модельные ошибки могут быть представлены, например, абсолютной величиной отклонения воспроизведенного посредством управляемой данными модели набора данных или воспроизведенных эксплуатационных параметров набора данных от соответствующего набора тренировочных данных и соответствующих эксплуатационных параметров этого набора данных. Точно так же модельные ошибки могут представлять собой относительные отклонения, в случае которых определяется абсолютная величина отклонения по отношению к стандартному отклонению всех модельных ошибок наборов данных, воспроизводимых на соответствующем этапе итерации.
Выдаваемый в предложенном способе доверительный уровень может быть также подходящим образом нормирован, например, по интервалу между нулем и единицей, причем значение «нуль» не представляет никакого доверия (т.е. низкую плотность данных), а значение «единица» - высокое доверие (т.е. высокую плотность данных).
Осуществляемая в рамках предложенного способа итерация может быть завершена на основе различных критериев. В одном предпочтительном варианте итерация завершается тогда, когда, по меньшей мере, одна заданная доля модельных ошибок наборов данных, отобранных или взвешенных для следующего этапа итерации, лежит ниже заданного порога, и/или когда, по меньшей мере, одна заданная доля доверительных уровней наборов данных, отобранных или взвешенных для следующего этапа итерации, лежит выше заданного порога. Таким образом, гарантируется окончание способа по достижению определенного минимального качества обученной, управляемой данными модели. При этом заданная доля может составлять, например, 95 или 99% или более всех модельных ошибок или доверительных уровней.
В другом варианте предложенного способа итерация завершается тогда, когда средняя модельная ошибка наборов данных, отобранных или взвешенных для следующего этапа итерации, больше не уменьшается по сравнению с предшествующим этапом итерации и/или когда все доверительные уровни наборов данных, отобранных или взвешенных для следующего этапа итерации, лежат выше заданного порога.
Помимо описанного выше способа генерации управляемой данными модели изобретение относится далее к способу эксплуатации технической системы, при котором управляемая данными модель генерируется предложенным способом или генерирована его одним или несколькими предпочтительными вариантами, а затем используется для анализа эксплуатации технической системы и/или для воздействия (в частности, прямого воздействия) на нее.
В этом способе используется, тем самым, генерированная, согласно изобретению, управляемая данными модель в рамках реальной работы технической системы. При этом для генерации управляемой данными модели используется преимущественно вариант, в котором рассчитывается модель управления и/или регулирования или модель контроля. В этом случае техническая система регулируется и/или управляется с помощью модели управления и/или регулирования и/или контролируется с помощью модели контроля.
Помимо описанных способов изобретение относится далее к компьютерному программному продукту с хранящимся на машиночитаемом носителе программным кодом для осуществления предложенного способа или его одного или нескольких вариантов, если программный код выполняется на компьютере.
Примеры осуществления изобретения подробно описаны ниже со ссылкой на прилагаемые чертежи.
На фиг.1 изображена блок-схема первого варианта предложенного способа;
на фиг.2 - блок-схема второго варианта предложенного способа.
Описанные ниже варианты служат для генерации управляемой данными модели технической системы с использованием тренировочных данных, включающих в себя большое число наборов данных. Генерированные с помощью этих вариантов управляемые данными модели могут использоваться затем подходящим образом для расчета соответствующих моделей управления и/или регулирования или моделей контроля для технической системы, как это описано выше. Эти модели управления и/или регулирования или модели контроля могут затем использоваться в реальной работе технической системы, как это также описано выше. Особенно предпочтительным применением описанных ниже вариантов является при этом генерация управляемой данными модели газовой турбины или ветрогенератора.
В описанном здесь варианте отдельные наборы данных представляют собой векторы, включающие в себя большое число эксплуатационных параметров технической системы. Примеры таких эксплуатационных параметров были приведены выше для газовых турбин и ветрогенераторов. Эксплуатационные параметры векторов представляют собой в одном варианте следующие друг за другом по времени измеряемые величины и управляющие переменные технической системы, так что с помощью управляемой данными модели обучается динамическое поведение технической системы. Эксплуатационные параметры в тренировочных данных регистрировались в ее реальной работе и сохранялись в базе данных.
Целью предложенного способа является извлечение релевантной информации из тренировочных данных и устранение избыточной информации для повышения качества управляемой данными модели, обучаемой с помощью тренировочных данных. В частности, при этом должно быть улучшено так называемое процентильное представление обученной модели. Это значит, что качество управляемой данными модели в рабочих диапазонах технической системы должно быть повышено с небольшим числом наборов данных.
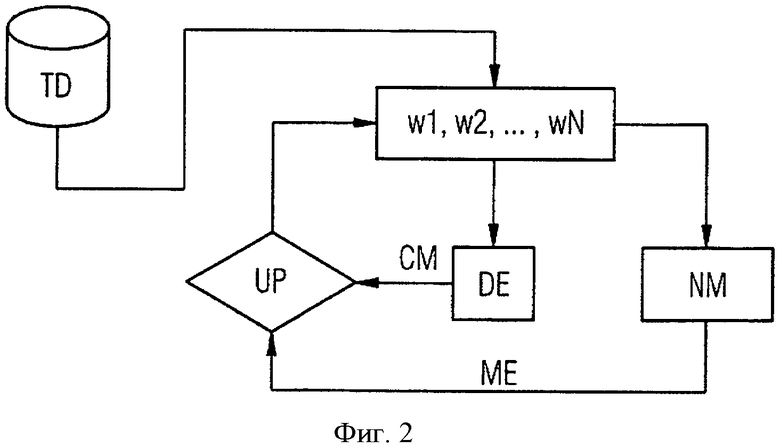
На фиг.1 изображен вариант предложенного способа, при котором обрабатываются тренировочные данные TD, хранящиеся в соответствующей базе данных. Как уже сказано, эти тренировочные данные относятся к наборам данных в виде эксплуатационных параметров технической системы, причем при необходимости было предпринято предварительное фильтрование, так что обрабатываются только определенные, релевантные для управляемой данными модели эксплуатационные параметры наборов данных или только определенные наборы данных. Вариант на фиг.1 основан на той идее, что для обучения управляемой данными модели подходящим образом посредством выборки (т.е. взятия выборок) из тренировочных данных TD отбираются их частичные количества. При инициализации способа сначала происходит случайный отбор частичного количества тренировочных данных на этапе RS (Random Sampling - случайная выборка). Это частичное количество обозначено на фиг.1 RD (Reduced Dataset - уменьшенный набор данных). С помощью этого уменьшенного частичного количества обучается управляемая данными модель в виде нейронной сети или нейронной модели NM, причем для этого применяются известные методы обучения, например метод обучения с подкреплением.
Параллельно с помощью частичного количества обучается оценщик плотности или инкапсюлятор данных DE. В описанном здесь варианте в качестве инкапсюлятора данных используется известный из [1] оценщик плотности на основе нейронных облаков. Оценка плотности на основе этого метода известна и потому подробно не описана. Целью оценки плотности является определение для соответствующего набора или точки данных его/ее «новизны» в том отношении, насколько другие наборы тренировочных данных схожи с рассматриваемым набором данных, причем схожесть описывается расстоянием между наборами данных. Это расстояние определяется евклидовым расстоянием между точками данных в пространстве данных. С помощью оценщика плотности из [1] сначала осуществляется нормализация отдельных наборов или точек данных на основе метода нормализации по минимуму и максимуму. Затем происходит кластеризация точек данных на основе видоизменения известного из уровня техники алгоритма k-means (алгоритм k-средних), называемого также «продвинутый алгоритм k-means». Этот алгоритм создает центры кластеров в пространстве точек данных. На следующем этапе через центры прокладываются гауссовы колокола, после чего происходит их нормализация. В качестве конечного результата алгоритма получают обученный инкапсюлятор данных, определяющий доверие для соответствующего набора данных, которое представляет его схожесть с наборами тренировочных данных и оценивается в [1] как вероятность выхода из строя рассматриваемой технической системы.
По окончании обучения нейронной сети NM наборы тренировочных данных воспроизводятся до модельной ошибки. При этом определенная доля эксплуатационных параметров набора данных обрабатывается в виде вектора ввода нейронной сети. Последняя выдает тогда иные эксплуатационные параметры соответствующего набора данных в виде вектора вывода. В результате различия между фактическим вектором вывода в соответствии с тренировочными данными и рассчитанным посредством нейронной сети вектором вывода возникает соответствующая модельная ошибка.
В варианте на фиг.1 соответствующие доверительные уровни СМ инкапсюлятора данных DE и соответствующие модельные ошибки ME нейронной сети NM используются для осуществления взвешенной выборки WS. Для взвешенной выборки для всех наборов тренировочных данных TD определяются возникающая с обученной нейронной сетью модельная ошибка и возникающий за счет инкапсюлятора данных доверительный уровень. Для каждой комбинации этих значений для соответствующего набора данных устанавливается вероятность, причем вероятности для всех наборов данных нормированы на 1. При этом вероятности определяются подходящим образом так, что набор данных с низким доверительным уровнем имеет более высокую вероятность, чем набор данных с более высоким доверительным уровнем при одинаковой модельной ошибке. Кроме того, вероятности установлены таким образом, что набор данных с большой модельной ошибкой имеет большую вероятность, чем набор данных с меньшей модельной ошибкой при одинаковом доверительном уровне. Затем с этими вероятностями осуществляется выборка WS. При этом в результате выборки из тренировочных данных отбираются, скорее, такие наборы данных, которые имеют высокую степень новизны за счет низкого доверительного уровня или которые плохо воспроизводятся управляемой данными моделью.
По окончании взвешенной выборки WS получают новое частичное количество наборов данных RD, которые на следующем этапе итерации используются для дальнейшего обучения инкапсюлятора данных DE и нейронной сети NM. После этого опять осуществляется новая взвешенная выборка WS, однако для этого соответствующие вероятности для нее устанавливаются заново посредством еще раз обученного инкапсюлятора данных и еще раз обученной нейронной сети. Наконец способ продолжается с заново генерированным частичным количеством наборов данных на следующем этапе итерации.
Итеративное обучение инкапсюлятора данных и нейронной сети завершается на основе подходящего критерия прекращения. Этот критерий установлен таким образом, что способ завершается тогда, когда для всех наборов данных заново генерированного частичного количества соответствующие модельные ошибки меньше заданного порогового значения, а соответствующие доверительные уровни выше заданного порогового значения. В качестве конечного результата способа получают обученную нейронную сеть, которая затем может быть использована для расчета модели управления и/или регулирования или модели контроля технической системы.
На фиг.2 изображен второй вариант предложенного способа. В отличие от варианта на фиг.1 при обучении инкапсюлятора данных DE и нейронной сети NM всегда используются все наборы тренировочных данных TD (при необходимости подходящим образом предварительно отфильтрованных). Однако наборы данных подходящим образом взвешиваются с использованием обученных инкапсюлятора данных и нейронной сети. На фиг.2 способ вначале подходящим образом инициализируется, причем в рамках инициализации определяются соответствующие веса w1, w2, …, wN для N рассматриваемых наборов данных. Веса могут инициализироваться, например, случайно или со значением 1/N. Веса представляют собой в описанном варианте вероятности, которые учитываются инкапсюлятором данных DE и нейронной сетью NM.
В отличие от варианта на фиг.1 все тренировочные данные учитываются без предварительного отбора. Посредством представленных весами вероятностей инкапсюлятор данных, соответствующий оценщику данных в [1], отбирает соответствующие наборы данных. Вероятности могут использоваться в инкапсюляторе данных при описанной выше нормализации, причем в соответствии с вероятностями отбираются наборы данных, учитываемые при нормализации. Точно так же вероятности могут использоваться при описанной выше кластеризации. При этом посредством вероятностей отбирается, какие наборы данных используются при нахождении центров кластеров. Точно так же вероятности могут использоваться при используемом в инкапсюляторе данных расчете расстояний между центрами кластеров. Также в этом случае посредством вероятностей устанавливается, какие наборы данных учитываются при расчете расстояний. В рамках нормализации, кластеризации и расчета расстояний соответственно используемые наборы данных могут определяться одноразово или заново отдельно для каждого из этих этапов.
Кроме того, посредством весов отбираются наборы данных, учитываемые в рамках обучения нейронной сети. Например, при обучении на основе отбора наборов данных градиент может определяться известным методом стохастического градиентного подъема.
После обучения инкапсюлятора данных и нейронной сети осуществляется этап актуализации UP, на котором на основе обученных инкапсюлятора данных и нейронной сети заново рассчитываются первоначальные инициализированные веса. Это происходит по аналогии с фиг.1 за счет того, что для всех наборов тренировочных данных определяются соответствующие доверительные уровни инкапсюлятора данных и соответствующие модельные ошибки нейронной сети, за счет чего веса и вероятности выводятся таким образом, что вероятность тем выше, чем ниже доверительный уровень и чем больше модельная ошибка рассматриваемого набора данных. Установление соответствующей взаимосвязи, например, на основе функции, лежит в рамках действий специалиста. Например, посредством соответствующей функции можно моделировать линейную взаимосвязь.
Вариант на фиг.2 продолжается с актуализированными на этапе UP весами на следующем этапе итерации. На нем инкапсюлятор данных и нейронная сеть еще раз обучаются с учетом новых весов, а затем с обученными инкапсюлятором данных и нейронной сетью происходит новая актуализация весов. Этот итеративный способ завершается с помощью подходящего критерия прекращения, причем он по аналогии с фиг.1 установлен таким образом, что способ завершается тогда, когда возникающие для соответствующих наборов данных доверительные уровни инкапсюлятора данных лежат выше заданного порогового значения или возникающие для соответствующих наборов данных модельные ошибки нейронной сети лежат ниже заданного порогового значения. Обученная таким образом нейронная сеть может затем использоваться также для расчета модели управления или контроля соответствующей технической системы.
Описанные выше варианты предложенного способа обладают рядом преимуществ. В частности, из большого количества тренировочных данных можно выделить такие наборы данных, которые позволяют хорошо описать лежащую в основе наборов данных техническую систему. При этом за счет подходящего отбора частичных количеств наборов данных или взвешивания наборов данных можно обучить управляемую данными модель, которая лучше учитывает области с малым количеством наборов данных. Таким образом, лучше учитываются такие эксплуатационные состояния технической системы, которые отличаются от нормального эксплуатационного режима.
С помощью предложенного способа можно за счет отбора релевантных наборов данных достичь на основе тренировочных данных более быстрого обучения соответствующей управляемой данными модели. Кроме того, обученная, управляемая данными модель имеет лучшее процентильное представление, поскольку обучение происходит предпочтительно в областях с малым объемом данных. Хорошее процентильное представление имеет значение при корректном прогнозе ошибок во время работы технической системы.
Список литературы
[1] В. Lang et al., Neural Clouds for Monitoring of Complex Systems, Optical Memory and Neural Networks (Information Optics), 2008, Vol.17, No.3, S.183-192.
[2] M. Riedmiller, Neural Fitted Q Iteration - First Experiences with a Data Efficient Neural Reinforcement Learning Method, Proc. of the Eurorean Conf. on Machine Learning, 2005, S.317-328.
Изобретение относится к способу компьютерной генерации управляемой данными модели технической системы, в частности газовой турбины или ветрогенератора. Управляемая данными модель обучается предпочтительно в областях тренировочных данных с низкой плотностью. Оценщик плотности выдает для наборов данных из тренировочных данных соответственно доверительный уровень, который тем выше, чем больше схожесть соответствующего набора данных с другими наборами данных из тренировочных данных, причем посредством управляемой данными модели воспроизводят наборы тренировочных данных соответственно с модельной ошибкой. Посредством оценщика плотности и управляемой данными модели, обученными на соответствующем этапе итерации, отбирают или взвешивают наборы данных из тренировочных данных для обучения на следующем этапе итерации, причем наборы данных из тренировочных данных с низкими доверительными уровнями и большими модельными ошибками отбирают скорее или взвешивают выше. Генерированная модель данных обучается быстрее и с малыми вычислительными ресурсами. За счет установления критериев оптимизации, например низких токсичных выбросов или малой динамики сгорания в газовой турбине, можно увеличить срок службы технической системы при ее эксплуатации. 2 н. и 22 з.п. ф-лы, 2 ил.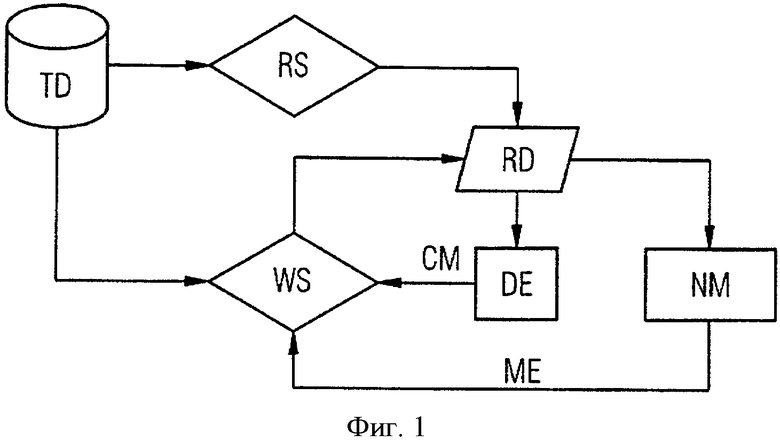
1. Способ компьютерной генерации управляемой данными модели (NM) технической системы, в частности газовой турбины или ветрогенератора, для решения задач автоматизированного контроля, и/или прогнозирования, и/или регулирования, причем управляемую данными модель генерируют на основе тренировочных данных, включающих в себя большое число наборов данных, которые представляют соответственно несколько эксплуатационных параметров технической системы, при котором:
- для определенного числа этапов итерации посредством наборов данных из тренировочных данных (TD) обучают соответственно управляемую данными модель (NM) и оценщик плотности (DE), причем оценщик плотности (DE) выдает для наборов данных из тренировочных данных соответственно доверительный уровень (СМ), который тем выше, чем больше схожесть соответствующего набора данных с другими наборами данных из тренировочных данных (TD), и причем посредством управляемой данными модели (NM) воспроизводят наборы тренировочных данных соответственно с модельной ошибкой (ME),
- посредством оценщика плотности (DE) и управляемой данными модели (NM), обученными на соответствующем этапе итерации, отбирают или взвешивают наборы данных из тренировочных данных (TD) для обучения на следующем этапе итерации, причем наборы данных из тренировочных данных (TD) с низкими доверительными уровнями (СМ) и большими модельными ошибками (ME) отбирают скорее или взвешивают выше.
2. Способ по п.1, при котором в качестве управляемой данными модели (NM) обучают нейронную сеть, в частности рекуррентную нейронную сеть.
3. Способ по п.1 или 2, при котором эксплуатационные параметры технической системы включают в себя одну или несколько следующих измеряемых величин газовой турбины:
- температуру окружающего пространства, в котором эксплуатируют газовую турбину,
- влажность воздуха окружающего пространства, в котором эксплуатируют газовую турбину;
- давление воздуха в окружающем пространстве, в котором эксплуатируют газовую турбину;
- мощность газовой турбины, в частности процентное значение мощности;
- качество топлива газовой турбины;
- выброс газовой турбиной токсичных веществ, в частности выброс оксидов азота и/или моноксида углерода;
- температуру отходящих газов газовой турбины;
- динамику сгорания в газовой турбине.
4. Способ по п.1 или 2, при котором эксплуатационные параметры технической системы включают в себя один или несколько следующих управляющих переменных газовой турбины:
- положение одной или нескольких направляющих лопаток газовой турбины;
- количество подаваемого в газовую турбину газа;
- заданное значение температуры отходящих газов газовой турбины.
5. Способ по п.1 или 2, при котором эксплуатационные параметры технической системы включают в себя одну или несколько следующих измеряемых величин ветрогенератора:
- выработанную ветрогенератором электрическую мощность;
- скорость ветра в окружающем пространстве, в котором эксплуатируют ветрогенератор;
- частоту вращения ветрогенератора;
- изгибающие усилия, и/или отклонения, и/или знакопеременные нагрузки на лопастях ветрогенератора;
- вращение башни ветрогенератора.
6. Способ по п.1 или 2, при котором эксплуатационные параметры технической системы включают в себя один или несколько следующих управляющих переменных ветрогенератора:
- угол установки лопастей ветрогенератора;
- параметрическое поле ветрогенератора, которое представляет взаимосвязь между частотой вращения и выработанной ветрогенератором электрической мощностью.
7. Способ по п.1 или 2, при котором с помощью генерированной, управляемой данными модели (NM) рассчитывают модель управления и/или регулирования работы технической системы на основе одного или нескольких критериев оптимизации, причем модель управления и/или регулирования указывает изменения одной или нескольких управляющих переменных эксплуатационных параметров технической системы в зависимости от одной или нескольких измеряемых величин эксплуатационных параметров технической системы.
8. Способ по п.7, при котором рассчитывают модель управления и/или регулирования газовой турбины, причем критерий/критерии оптимизации включает/включают в себя минимальный выброс и/или минимальную динамику сгорания и/или максимально высокий к.п.д. и/или максимально высокую мощность.
9. Способ по п.7, при котором создают модель управления и/или регулирования ветрогенератора, причем критерий/критерии оптимизации включает/включают в себя максимально высокий к.п.д. и/или минимальные изгибающие усилия и/или отклонения и/или знакопеременные нагрузки на лопастях ветрогенератора.
10. Способ по п.7, при котором модель управления и/или регулирования выполнена таким образом, что с помощью обученного оценщика плотности (DE) определяют соответствующие доверительные уровни (СМ) наборов данных возникающих при работе технической системы эксплуатационных параметров, причем ограничивают изменение одной или нескольких управляющих переменных эксплуатационных параметров и/или прерывают или не начинают работу связанной с управляемой данными моделью функции и/или технической системы, если соответствующий доверительный уровень ниже заданного порога.
11. Способ по п.1 или 2, при котором с помощью обученной, управляемой данными модели рассчитывают модель контроля, которая в случае, если один или несколько возникающих при работе технической системы эксплуатационных параметров более чем на заданную меру отличаются от соответствующего или соответствующих, воспроизведенных генерированной, управляемой данными моделью эксплуатационных параметров, выдает предупредительный и/или тревожный сигнал и/или вызывает автоматическое срабатывание меры безопасности технической системы.
12. Способ по п.11, при котором модель контроля выполнена таким образом, что с помощью обученного оценщика плотности определяют соответствующие доверительные уровни (СМ) наборов данных возникающих при работе технической системы эксплуатационных параметров, причем заданный уровень, на основе которого вырабатывают предупредительный сигнал, настраивают тем выше, чем ниже соответствующий доверительный уровень (СМ).
13. Способ по п.7, при котором модель управления и/или регулирования и/или модель контроля рассчитывают на основе метода обучения с подкреплением и/или метода модельно-предикативного регулирования и/или метода оптимизации.
14. Способ по п.7, при котором модель управления и/или регулирования и/или модель контроля обучают на основе нейронной сети, в частности рекуррентной нейронной сети.
15. Способ по п.1 или 2, при котором посредством зависимой от доверительного уровня (СМ) и от модельной ошибки (ME) функции осуществляют отбор или взвешивание наборов данных из тренировочных данных (TD).
16. Способ по п.1 или 2, при котором наборы данных отбирают из тренировочных данных посредством взятия выборок для следующего этапа итерации на основе присвоенных наборам данных вероятностей.
17. Способ по п.1 или 2, при котором наборам данных из тренировочных данных (TD) присваивают веса (w1, w2, …, wN), которые учитывают при обучении оценщика плотности (DE) и управляемой данными модели (NM), причем веса (w1, w2, …, wN) посредством обученных на соответствующем этапе итерации оценщика плотности (DE) и управляемой данными модели (NM) актуализируют таким образом, что наборы данных из тренировочных данных (TD) с низкими доверительными уровнями (СМ) и большими модельными ошибками (ME) приобретают более высокие веса.
18. Способ по п.17, при котором веса (w) представляют вероятности, обрабатываемые оценщиком плотности (DE) и управляемой данными моделью (NM).
19. Способ по п.18, при котором посредством оценщика плотности (DE) и/или управляемой данными модели (NM) наборы данных отбирают из тренировочных данных (TD) для обучения или в рамках обучения на основе вероятностей.
20. Способ по п.1 или 2, при котором его инициализируют с частичным количеством (RD) наборов данных из тренировочных данных (TD), установленным, в частности, случайно, или со всеми наборами данных из тренировочных данных (TD) с начальными весами (w).
21. Способ по п.1 или 2, при котором оценщик плотности (DE) основан на алгоритме «нейронные облака».
22. Способ по п.1 или 2, при котором итерацию завершают тогда, когда, по меньшей мере, одна заданная доля модельных ошибок (ME) наборов данных, отобранных или взвешенных для следующего этапа итерации, лежит ниже заданного порога, и/или когда, по меньшей мере, одна заданная доля доверительных уровней (СМ) наборов данных, отобранных или взвешенных для следующего этапа итерации, лежит выше заданного порога.
23. Способ эксплуатации технической системы, при котором управляемую данными модель генерируют способом по одному из предыдущих пунктов, а затем используют для анализа эксплуатации технической системы и/или для воздействия на нее.
24. Способ по п.23, при котором техническую систему регулируют и/или управляют ею и/или контролируют с помощью модели управления и/или регулирования и/или контроля.
| RU 2008152896 A, 10.07.2010 | |||
| US 5335291 A, 02.08.1994 | |||
| СN 101819411 A, 01.09.2010. |

