Настоящее изобретение относится к кодеку, поддерживающему режим кодирования с преобразованием с подавлением помех дискретизации во временной области и режим кодирования временной области, равно как и прямое подавление помех дискретизации для переключения между обоими режимами.
Удобно сочетать разные режимы кодирования для того, чтобы кодировать общие аудиосигналы, представляющие сочетание аудиосигналов разных типов, такие как речь, музыка или тому подобное. Отдельные режимы кодирования могут быть адаптированы для конкретных типов аудио, и, таким образом, многорежимный аудиокодер может воспользоваться преимуществом изменения режима кодирования во времени, соответствующего изменению типа аудиоконтента. Другими словами, многорежимный аудиокодер может решить, например, кодировать участки аудиосигнала, имеющего речевой контент, используя режим кодирования, специально выделенный для кодирования речи, и использовать другой режим кодирования для того, чтобы кодировать другие участки аудиоконтента, представляющего неречевой контент, такой как музыка. Режимы кодирования временной области, такие как режимы кодирования с линейным предсказанием возбуждения кодовой книги, имеют склонность быть более подходящими для кодирования речевого контента, тогда как режимы кодирования с преобразованием имеют склонность превосходить режимы кодирования временной области, поскольку имеется отношение к кодированию музыки.
Уже были решения для решения проблемы копирования с сосуществованием разных типов аудио внутри одного аудиосигнала. Появившийся в настоящее время USAC, например, предлагает переключение между режимом кодирования частотной области, главным образом согласовывающимся со стандартом AAC, и двумя дополнительными режимами линейного предсказания, аналогичными режимам подкадров стандарта AMR-WB плюс, а именно основанным на MDCT (Модифицированное дискретное косинусное преобразование) вариантом режима TCX (TCX = кодированное с преобразованием возбуждение) и режима ACELP (линейное предсказание возбуждения адаптивной кодовой книги). Чтобы быть более точным, в стандарте AMR-WB+, TCX основывается на DFT-преобразовании, но в USAC TCX имеет основу MDCT-преобразования. Определенная кадровая структура используется для того, чтобы переключаться между областью FD-кодирования, аналогично AAC, и областью линейного предсказания, аналогично AMR-WB+. Сам стандарт AMR-WB+ использует собственную кадровую структуру, образующую подкадровую структуру, родственную стандарту USAC. Стандарт AMR-WB+ обеспечивает возможность определенной конфигурации подразделения, подразделяющей кадры AMR-WB+ на более мелкие TCX- и/или ACELP-кадры. Аналогично стандарт AAC использует базовую кадровую структуру, но обеспечивает возможность использования разных длин окон для того, чтобы кодировать с преобразованием содержимое кадра. Например, могут быть использованы либо длинное окно и ассоциированная длинная длина преобразования, либо восемь коротких окон с ассоциированными преобразованиями более короткой длины.
MDCT вызывает помехи дискретизации. Это, таким образом, является верным на границах TCX- и FD-кадров. Другими словами, точно так же, как любой кодер частотной области, использующий MDCT, помехи дискретизации возникают в регионах перекрывания окон, которые подавляются при помощи соседних кадров. То есть для переходов между двумя FD-кадрами или между двумя TCX-(MDCT-) кадрами или переходов между либо от FD к TCX, либо от TCX к FD, существует неявное подавление помех дискретизации посредством процедуры перекрывания/добавления в рамках реконструкции на декодирующей стороне. Тогда нет больше помех дискретизации после добавления перекрывания. Однако в случае переходов с ACELP нет собственного подавления помех дискретизации. Тогда должен быть представлен новый инструмент, который может быть назван FAC (прямое подавление помех дискретизации). FAC служит для подавления помех дискретизации, исходящих от соседних кадров, если они отличаются от ACELP.
Другими словами, проблемы подавления помех дискретизации возникают всегда, когда возникают переходы между режимом кодирования с преобразованием и режимом кодирования временной области, как, например, ACELP. Для того чтобы выполнить преобразование от временной области к спектральной области так эффективно, насколько возможно, используется кодирование с преобразованием с подавлением помех дискретизации во временной области, такое как MDCT, т.е. режим кодирования, использующий преобразование с перекрытием, где перекрывающиеся оконные участки сигнала преобразовываются, используя преобразование, согласно которому число коэффициентов преобразования на участок меньше, чем число сэмплов на участок, так что помехи дискретизации возникают, поскольку имеют отношение отдельные участки, при этом помехи дискретизации, являющиеся подавляемыми посредством подавления помех дискретизации во временной области, т.е. посредством добавления перекрывающихся участков с помехами дискретизации соседних участков повторно преобразованного сигнала. MDCT является таким преобразованием с подавлением помех дискретизации во временной области. Неблагоприятно TDAC (подавление помех дискретизации во временной области) недоступно при переходах между режимом TC-кодирования и режимом кодирования временной области.
Для того чтобы решить эту проблему, может быть использовано прямое подавление помех дискретизации (FAC), согласно которому кодер сообщает внутри потока данных дополнительные данные FAC внутри текущего кадра всегда, когда возникает изменение в режиме кодирования с кодирования с преобразованием на кодирование временной области. Это, однако, вынуждает декодер сравнивать режимы кодирования идущих подряд кадров для того, чтобы выявить, содержит ли декодируемый в текущий момент кадр данные FAC внутри своего синтаксиса. Это, в свою очередь, означает, что могут быть кадры, для которых декодер не может быть уверен относительно того, должен ли таковой считать или осуществить синтаксический анализ данных FAC из текущего кадра. Другими словами, в случае когда один или более кадров были потеряны во время передачи, декодер не знает для непосредственно следующих (принятых) кадров относительно того, возникло ли изменение режима кодирования, и относительно того, содержит ли битовый поток кодированных данных текущего кадра данные FAC. Следовательно, декодер должен отбросить текущий кадр и ждать следующий кадр. В качестве альтернативы декодер может осуществить синтаксический анализ текущего кадра посредством выполнения декодирующих испытаний, причем одно, предполагающее, что данные FAC присутствуют, и другое, предполагающее, что данные FAC не присутствуют, с последующим решением относительно того, что одна из двух альтернатив не исполняется. Процесс декодирования наиболее вероятно мог бы привести декодер к аварии при одном из двух условий. То есть в реальности возможность последнего не является допустимым подходом. Декодер должен в любое время знать, как интерпретировать данные и не полагаться на свои собственные предположения о том, как интерпретировать данные.
Следовательно, целью настоящего изобретения является предоставить кодек, который является более устойчивым к ошибкам или устойчивым к потере кадра, с, однако, поддержкой переключения между режимом кодирования с преобразованием с подавлением помех дискретизации во временной области и режимом кодирования временной области.
Эта цель достигается объектом изобретения по любому из независимых пунктов формулы изобретения, прикрепленных посредством этого.
Настоящее изобретение основывается на обнаружении, что более устойчивый к ошибкам и устойчивый к потере кадра кодек, поддерживающий переключение между режимом кодирования с преобразованием с подавлением помех дискретизации во временной области и режимом кодирования временной области, является достижимым, если дополнительный синтаксический участок добавляется к кадрам, в зависимости от которого устройство синтаксического анализа декодера может выбрать между первым действием ожидания, что текущей кадр содержит, и, таким образом, считывая данные прямого подавления помех дискретизации из текущего кадра, и вторым действием неожидания, что текущий кадр содержит, и, таким образом, не считывая данные прямого подавления помех дискретизации из текущего кадра. Другими словами, тогда как небольшая часть эффективности кодирования потеряна из-за обеспечения вторым синтаксическим участком, это всего лишь второй синтаксический участок, который предоставлен для возможности использовать кодек в случае канала связи с потерей кадра. Без второго синтаксического участка декодер был бы не способен декодировать какой-либо участок потока данных после потери и потерпел бы аварию при попытке возобновить синтаксический анализ. Таким образом, в способствующем ошибкам окружении эффективность кодирования предохраняется от стремления к нулю посредством внесения второго синтаксического участка.
Кроме того, предпочтительные варианты осуществления настоящего изобретения являются предметов зависимых пунктов формулы изобретения. Кроме того, предпочтительные варианты осуществления настоящего изобретения подробно описаны ниже относительно чертежей. В частности,
на фиг.1 показана схематичная блок-схема декодера согласно варианту осуществления;
на фиг.2 показана схематичная блок-схема кодера согласно варианту осуществления;
на фиг.3 показана блок-схема возможной реализации реконструктора с фиг.2;
на фиг.4 показана блок-схема возможной реализации модуля FD-декодирования с фиг.3;
на фиг.5 показана блок-схема возможной реализации модуля LPD-декодирования с фиг.3;
на фиг.6 показана схематичная диаграмма, иллюстрирующая процедуру кодирования для того, чтобы сгенерировать данные FAC в соответствии с вариантом осуществления;
на фиг.7 показана схематичная диаграмма возможного повторного преобразования для преобразования TDAC в соответствии с вариантом осуществления;
на фиг.8, 9 показаны блок-схемы для иллюстрации линейной структуры пути данных FAC при кодере дополнительной обработки в кодере, чтобы тестировать изменение режима кодирования в смысле оптимизации;
на фиг.10, 11 показаны блок-схемы обработки декодером для того, чтобы достичь данных FAC, фиг.8 и 9, из потока данных;
на фиг.12 показана схематичная диаграмма реконструкции на основе FAC на декодирующей стороне поперек от границ кадров разных режимов кодирования;
на фиг.13, 14 схематично показана обработка, выполняемая при обработчике переходов с фиг.3 для того, чтобы выполнить реконструкцию с фиг.12;
на фиг.15-19 показаны участки структуры синтаксиса в соответствии с вариантом осуществления; и
на фиг.20-22 показаны участки структуры синтаксиса в соответствии с другим вариантом осуществления.
На фиг.1 показан декодер 10 согласно варианту осуществления настоящего изобретения. Декодер 10 является для декодирования потока данных, содержащего последовательность кадров 14a, 14b и 14c, в которую кодируются временные сегменты 16a-c информационного сигнала 18 соответственно. Как проиллюстрировано на фиг.1, временные сегменты с 16a по 16c являются неперекрывающимися сегментами, которые напрямую примыкают друг к другу во времени и являются последовательно упорядоченными во времени. Как проиллюстрировано на фиг.1, временные сегменты с 16a по 16c могут быть равного размера, но альтернативные варианты осуществления также допустимы. Каждый из временных сегментов с 16a по 16c кодируется в соответствующий один из кадров с 14a по 14c. Другими словами, каждый временной сегмент с 16a по 16c уникально ассоциирован с одним из кадров с 14a по 14c, который, в свою очередь, имеет также порядок, заданный среди них, который следует порядку сегментов с 16a по 16c, которые кодируются в кадры с 14a по 14c соответственно. Хотя фиг.1 предлагает, что каждый кадр с 14a по 14c является равной длины, измеряемой в, например, кодированных битах, это является, конечно, не обязательным. Скорее, длина кадров с 14a по 14c может варьироваться согласно сложности временного сегмента с 16a по 16c, с которым ассоциирован кадр с 14a по 14c.
Для легкости объяснения охарактеризованных ниже вариантов осуществления предполагается, что информационный сигнал 18 является аудиосигналом. Однако следует обратить внимание, что информационный сигнал мог быть также любым другим сигналом, таким как сигнал, выведенный физическим датчиком или тому подобным, таким как оптический датчик или тому подобный. В частности, сигнал 18 может быть дискретизирован с определенной частотой дискретизации, и временные сегменты с 16a по 16c могут покрывать непосредственно идущие подряд участки этого сигнала 18, равные по времени числу сэмплов соответственно. Числом сэмплов на сегмент времени с 16a по 16c может, например, быть 1024 сэмпла.
Декодер 10 содержит устройство 20 синтаксического анализа и реконструктор 22. Устройство 20 синтаксического анализа выполнено с возможностью осуществления синтаксического анализа потока 12 данных и, при синтаксическом анализе потока 12 данных, считывания первого синтаксического участка 24 и второго синтаксического участка 26 из текущего кадра 14b, т.е. кадра, который следует декодировать в текущий момент. На фиг.1 для примера предполагается, что кадр 14b является кадром, который следует декодировать в текущий момент, тогда как кадр 14a является кадром, который был декодирован непосредственно перед этим. Каждый кадр с 14a по 14c имеет первый синтаксический участок и второй синтаксический участок, включенные в него, с их значимостью или значением, описанными ниже. На фиг.1 первый синтаксический участок внутри кадров с 14a по 14c указан с помощью прямоугольника с "1" и второй синтаксический участок указан с помощью прямоугольника с "2".
Естественно, каждый кадр с 14a по 14c также имеет дополнительную информацию, включенную в него, которая необходима для представления ассоциированного временного сегмента с 16a по 16c, как описано более подробно ниже. Эта информация указана на фиг.1 заштрихованным блоком, в котором ссылочное обозначение 28 используется для дополнительной информации текущего кадра 14b. Устройство 20 синтаксического анализа выполнено с возможностью, при синтаксическом анализе потока 12 данных, также считывания информации 28 из текущего кадра 14b.
Реконструктор 22 выполнен с возможностью реконструкции текущего временного сегмента 16b информационного сигнала 18, ассоциированного с текущим кадром 14b, на основе дополнительной информации 28, используя выбранный один из режима декодирования с преобразованием с подавлением помех дискретизации во временной области и режима декодирования временной области. Выбор зависит от первого синтаксического элемента 24. Оба режима декодирования отличаются друг от друга присутствием или отсутствием какого-либо перехода от спектральной области обратно к временной области, используя повторное преобразование. Повторное преобразование (наряду с его соответствующим преобразованием) вносит помехи дискретизации, поскольку рассматриваются отдельные временные сегменты, однако эти помехи дискретизации являются компенсируемыми посредством подавления помех дискретизации во временной области, поскольку рассматриваются переходы на границах между идущими подряд кадрами, кодированными в режиме кодирования с преобразованием с подавлением помех дискретизации во временной области. Режим декодирования временной области не делает необходимым какое-либо повторное преобразование. Скорее, декодирование остается во временной области. Таким образом, в общем говоря, режим декодирования с преобразованием с подавлением помех дискретизации во временной области реконструктора 22 задействует повторное преобразование, которое выполняется реконструктором 22. Это повторное преобразование назначает первое число коэффициентов преобразования, как получено из информации 28 текущего кадра 14b (являясь режимом декодирования с TDAC-преобразованием), на сегмент повторно преобразованного сигнала, имеющий длину сэмпла второго числа сэмплов, которое больше, чем первое число, тем самым вызывая помехи дискретизации. Режим декодирования временной области, в свою очередь, может задействовать режим декодирования с линейным предсказанием, согласно которому коэффициенты возбуждения и линейного предсказания реконструируются из информации 28 текущего кадра, который в этом случае является режимом кодирования временной области.
Таким образом, как стало ясно из рассмотренного выше, в режиме декодирования с преобразованием с подавлением помех дискретизации во временной области, реконструктор 22 получает из информации 28 сегмент сигнала для реконструкции информационного сигнала в соответствующем временном сегменте 16b посредством повторного преобразования. Сегмент повторно преобразованного сигнала длиннее, чем в действительности текущий временной сегмент 16b, и участвует в реконструкции информационного сигнала 18 внутри временного участка, который включает в себя и продолжается за пределы временного сегмента 16b. На фиг.1 проиллюстрировано окно 32 преобразования, используемое при преобразовании первоначального сигнала как при преобразовании, так и при повторном преобразовании. Можно видеть, что окно 32 может содержать нулевой участок 321 в его начале и нулевой участок 322 в его заднем конце и участки 323 и 324 с помехами дискретизации в переднем и заднем крае текущего временного сегмента 16b, в котором участок 325 без помех дискретизации, где окно 32 является одним, может быть расположен между обоими участками 323 и 324 с помехами дискретизации. Нулевые участки 321 и 322 являются необязательными. Также возможно, что присутствует лишь один из нулевых участков 321 и 322. Как показано на фиг.1, оконная функция может быть монотонно увеличивающейся/уменьшающейся внутри участков с помехами дискретизации. Помехи дискретизации возникают внутри участков 321 и 322 с помехами дискретизации, где окно 32 непрерывно ведет от нуля к единице или наоборот. Помехи дискретизации не являются критичными до тех пор, пока предыдущие и следующие временные сегменты тоже кодируются в режиме кодирования с преобразованием с подавлением помех дискретизации во временной области. Эта возможность проиллюстрирована на фиг.1 по отношению к временному сегменту 16c. Пунктирная линия иллюстрирует соответствующее окно 32' преобразования для временного сегмента 16c, участок с помехами дискретизации которого сходится с участком 324 с помехами дискретизации текущего сегмента 16b. Добавление сигналов преобразованных сегментов временных сегментов 16b и 16c реконструктором 22 подавляет помехи дискретизации обоих сегментов повторно преобразованных сигналов между собой.
Однако в случае, где предыдущий или следующий кадр с 14a по 14c кодируется в режиме кодирования временной области, переход между разными режимами кодирования происходит в результате на переднем или заднем крае текущего временного сегмента 16b, и чтобы учитывать соответствующие помехи дискретизации, поток 12 данных содержит данные прямого подавления помех дискретизации внутри соответствующего кадра, непосредственно следующего за переходом, для обеспечения возможности декодеру 10 компенсировать помехи дискретизации, возникающие при этом соответствующем переходе. Например, может случиться, что текущий кадр 14b принадлежит к режиму кодирования с преобразованием с подавлением помех дискретизации во временной области, но декодер 10 не знает, принадлежал ли предыдущий кадр 14a режиму кодирования временной области. Например, кадр 14a может потеряться во время передачи, и декодер 10, соответственно, не будет иметь к нему доступа. Однако в зависимости от режима кодирования кадра 14a текущий кадр 14b содержит данные прямого подавления помех дискретизации для того, чтобы компенсировать помехи дискретизации, возникающие на участке 323 с помехами дискретизации или нет. Аналогично, если текущий кадр 14b принадлежал к режиму кодирования временной области, и предыдущий кадр 14a не был принят декодером 10, тогда текущий кадр 14b имеет данные прямого подавления помех дискретизации, включенные в него, или не зависящие от режима предыдущего кадра 14b. В частности, если предыдущий кадр 14a принадлежал к другому режиму кодирования, т.е. режиму кодирования с преобразованием с подавлением помех дискретизации во временной области, то данные прямого подавления помех дискретизации присутствовали бы в текущем кадре 14b, чтобы подавить помехи дискретизации, иным образом возникающие на границе между временными сегментами 16a и 16b. Однако если предыдущий кадр 14a принадлежал к тому же режиму кодирования, т.е. режиму кодирования временной области, то устройству 20 синтаксического анализа не следовало бы ожидать присутствия данных прямого подавления помех дискретизации в текущем кадре 14b.
Следовательно, устройство 20 синтаксического анализа использует второй синтаксический участок 26, чтобы выявить, присутствуют ли данные 34 прямого подавления помех дискретизации в текущем кадре 14b или нет. При синтаксическом анализе потока 12 данных устройство 20 синтаксического анализа может выбрать одно из первого действия ожидания, что текущий кадр 14b содержит, и, таким образом, считывая данные 34 прямого подавления помех дискретизации из текущего кадра 14b, и второго действия неожидания, что текущий кадр содержит, и, таким образом, не считывая данные 34 прямого подавления помех дискретизации из текущего кадра 14b, причем выбор зависит от второго синтаксического участка 26. Если присутствует, реконструктор 22 выполнен с возможностью выполнения прямого подавления помех дискретизации на границе между текущим временным сегментом 16b и предыдущим временным сегментом 16a предыдущего кадра 14a, используя данные прямого подавления помех дискретизации.
Таким образом, по сравнению с ситуацией, где второй синтаксический участок не присутствует, декодер по фиг.1 не должен отбрасывать или безуспешно прерывать синтаксический анализ, текущий кадр 14b, даже если режим кодирования предыдущего кадра 14a неизвестен декодеру 10, например, из-за потери кадра. Скорее, декодер 10 способен использовать второй синтаксический участок 26, чтобы выявить, имеет ли текущий кадр 14b данные 34 прямого подавления помех дискретизации. Другими словами, второй синтаксический участок предоставляет ясный критерий относительно того, применяет ли и гарантирует ли одна из альтернатив, т.е. данные FAC для границы для предсказываемого кадра, присутствующего или нет, что любой декодер может вести себя также независимо от их реализации, даже в случае потери кадра. Таким образом, вышеописанный вариант осуществления вносит механизмы для преодоления проблемы потери кадра.
Перед подробным описанием вариантов осуществления, представленным ниже, описывается кодер, способный генерировать поток 12 данных по фиг.1, со ссылкой на фиг.2. Кодер по фиг.2 в общем указан ссылочным обозначением 40 и служит для кодирования информационного сигнала в поток 12 данных, так что поток 12 данных содержит последовательность кадров, в которую кодируются временные сегменты с 16a по 16c информационного сигнала соответственно. Кодер 40 содержит конструктор 42 и устройство 44 вставки. Конструктор выполнен с возможностью кодирования текущего временного сегмента 16b информационного сигнала в информацию текущего кадра 14b, используя первый выбранный один из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области. Устройство 44 вставки выполнено с возможностью вставки информации 28 в текущий кадр 14b, наряду с первым синтаксическим участком 24 и вторым синтаксическим участком 26, в котором первый синтаксический участок сообщает первый выбор, т.е. выбор режима кодирования. Конструктор 42, в свою очередь, выполнен с возможностью определения данных прямого подавления помех дискретизации для прямого подавления помех дискретизации на границе между текущим временным сегментом 16b и предыдущим временным сегментом 16a предыдущего кадра 14a, и вставляет данные 34 прямого подавления помех дискретизации в текущий кадр 14b, когда текущий кадр 14b и предыдущий кадр 14a кодированы с использованием разных режимов из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области, и воздерживается от вставки каких-либо данных прямого подавления помех дискретизации в текущий кадр 14b, когда текущий кадр 14b и предыдущий кадр 14a кодированы с использованием одинаковых режимов из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области. То есть всякий раз, когда конструктор 42 кодера 40 решает, что предпочтительно, в некотором смысле оптимизации, переключиться с одного из двух режимов кодирования на другой, конструктор 42 и устройство 44 вставки выполнены с возможностью определения и вставки данных 34 прямого подавления помех дискретизации в текущий кадр 14b, а если сохраняется режим кодирования между кадрами 14a и 14b, данные 34 FAC не вставляются в текущий кадр 14b. Для того чтобы обеспечить возможность декодеру выявлять из текущего кадра 14b, без знания содержимого предыдущего кадра 14a, присутствуют ли данные 34 FAC внутри текущего кадра 14b, определенный синтаксический участок 26 задается в зависимости от того, являются ли текущий кадр 14b и предыдущий кадр 14a кодированными с использованием одинаковых или разных режимов из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области. Конкретные примеры для понимания второго синтаксического участка 26 будут обозначены ниже.
В дальнейшем описан вариант осуществления, согласно которому кодек, к которому принадлежат декодер и кодер вышеописанных вариантов осуществления, поддерживает специальный тип структуры кадра, согласно которой сами кадры с 14a по 14c являются субъектами для образования подкадров, и существуют две версии режима кодирования с преобразованием с подавлением помех дискретизации во временной области. В частности, согласно этим вариантам осуществления, дополнительно описанным ниже, первый синтаксический участок 24 ассоциирует соответствующий кадр, из которого он был считан, с первым типом кадра, называемым в дальнейшем режимом FD-кодирования (частотной области), или со вторым типом кадра, называемым в дальнейшем режимом LPD-кодирования, и, если соответствующий кадр принадлежит ко второму типу кадра, ассоциирует подкадры подразделения соответствующего кадра, составленного из числа подкадров, с соответствующим одним из первого типа подкадра и второго типа подкадра. Как будет подробнее обозначено ниже, первый тип подкадра может задействовать соответствующие подкадры, которые следует кодировать посредством TCX, тогда как второй тип подкадра может задействовать эти соответствующие подкадры, которые следует кодировать с использованием ACELP, т.е. линейного предсказания возбуждения адаптивной кодовой книги. Либо любой другой режим кодирования с линейным предсказанием возбуждения кодовой книги может также быть использован.
Реконструктор 22 по фиг.1 выполнен с возможностью обработки возможностей этих разных режимов кодирования. К этому моменту реконструктор 22 может быть сконструирован так, как изображено на фиг.3. Согласно варианту осуществления по фиг.3, реконструктор 22 содержит два переключателя 50 и 52 и три модуля 54, 56 и 58 декодирования, каждый из которых выполнен с возможностью декодирования кадров и подкадров конкретного типа, как будет подробно описано ниже.
Переключатель 50 имеет вход, на который поступает информация 28 декодируемого в текущий момент кадра 14b, и вход управления, посредством которого переключатель 50 является управляемым в зависимости от первого синтаксического участка 25 текущего кадра. Переключатель 50 имеет два выхода, один из которых присоединен ко входу модуля 54 декодирования, ответственного за FD-декодирование (FD = частотная область), а другой присоединен ко входу подпереключателя 52, который имеет также два выхода, один из которых присоединен ко входу модуля 56 декодирования, ответственного за декодирование с линейным предсказанием кодированного с преобразованием возбуждения, а другой - ко входу модуля 58, ответственного за декодирование с линейным предсказанием возбуждения кодовой книги. Все модули с 54 по 58 декодирования выводят сегменты сигнала, реконструируя соответствующие временные сегменты, ассоциированные с соответствующими кадрами и подкадрами, из которых эти сегменты сигнала были получены посредством соответствующего режима декодирования, и обработчик 60 перехода принимает сегменты сигнала на соответствующие его входы, чтобы выполнить обработку перехода и подавление помех дискретизации, описанные выше и описанные более подробно ниже, чтобы вывести на свой выход реконструированный информационный сигнал. Обработчик 60 перехода использует данные 34 прямого подавления помех дискретизации, как проиллюстрировано на фиг.3.
Согласно варианту осуществления по фиг.3, реконструктор 22 работает следующим образом. Если первый синтаксический участок 24 ассоциирует текущий кадр с первым типом кадра в режиме FD-кодирования, переключатель 50 пересылает информацию 28 на модуль 54 FD-декодирования для использования декодирования частотной области в качестве первой версии режима декодирования с преобразованием с подавлением помех дискретизации во временной области для реконструкции временного сегмента 16b, ассоциированного с текущим кадром 15b. В противном случае, т.е. если первый синтаксический участок 24 ассоциирует текущий кадр 14b со вторым типом кадра в режиме LPD-кодирования, переключатель 50 пересылает информацию 28 на подпереключатель 52, который, в свою очередь, работает над структурой подкадра текущего кадра 14b. Точнее, в соответствии с режимом LPD, кадр разделяется на один или более подкадров, подразделение, соответствующее подразделению соответствующего временного сегмента 16b на неперекрывающиеся подучастки текущего временного сегмента 16b, как будет описано более подробно ниже со ссылкой на следующие фигуры. Синтаксический участок 24 сообщает для каждого из одного или более подучастков, ассоциирован ли таковой с первым или вторым типом подкадра соответственно. Если соответствующий подкадр принадлежит к первому типу подкадра, подпереключатель 52 пересылает соответствующую информацию 28, принадлежащую этому подкадру, на модуль 56 TCX-декодирования, чтобы использовать декодирование с линейным предсказанием кодированного с преобразованием возбуждения в качестве второй версии режима декодирования с преобразованием с подавлением помех дискретизации во временной области для реконструкции соответствующего подучастка текущего временного сегмента 16b. Если, однако, соответствующий подкадр не принадлежит ко второму типу подкадра, подпереключатель 52 пересылает информацию 28 на модуль 58 для того, чтобы выполнить кодирование с линейным предсказанием возбуждения кодовой книги в качестве режима декодирования временной области для реконструкции соответствующего подучастка текущего временного сегмента 16b.
Сегменты реконструированного сигнала, выводимые модулями с 54 по 58, помещаются обработчиком 60 перехода в правильном (презентационном) временном порядке с помощью выполнения соответствующей обработки перехода и добавления перекрытия и обработке по подавлению помех дискретизации во временной области, как описано выше и описано более подробно ниже.
В частности, модуль 54 FD-декодирования может быть сконструирован, как показано на фиг.4, и работает, как описано ниже. Согласно фиг.4, модуль 54 FD-декодирования содержит устройство 70 деквантования и устройство 72 повторного преобразования 72, последовательно присоединенные друг к другу. Как описано выше, если текущий кадр 14b является FD-кадром, таковой пересылается на модуль 54, и устройство 70 деквантования выполняет деквантование с изменяющимся спектром информации 74 коэффициентов преобразования внутри информации 28 текущего кадра 14b, используя информацию 76 масштабного множителя, также содержащуюся в информации 28. Масштабные множители были определены на стороне кодера, используя, например, психоакустические принципы, чтобы удерживать шум квантования ниже порога защиты человека.
Устройство 72 повторного преобразования затем выполняет повторное преобразование информации деквантованных коэффициентов преобразования, чтобы получить сегмент 78 повторно преобразованного сигнала, продолжающийся во времени в пределах и за пределами временного сегмента 16b, ассоциированного с текущим кадром 14b. Как будет обозначено более подробно ниже, повторным преобразованием, выполняемым устройством 72 повторного преобразования, может быть IMDCT (Обратное модифицированное дискретное косинусное преобразование), задействующее DCT IV, за которым следует операция развертки, в которой после того, как выполнена обработка методом окна с использованием окна повторного преобразования, которое могло бы быть равным или отклоняться от окна преобразования, используемого при генерировании информации 74 коэффициентов преобразования посредством использования вышеупомянутых этапов в обратном порядке, а именно обработка методом окна, за которой следует операция свертки, за которой следует DCT IV, за которым следует квантование, которое может управляться психо-акустическими принципами, чтобы удерживать шум квантования ниже порога защиты человека.
Следует отметить, что объем информации 28 коэффициентов преобразования, ввиду природы TDAC повторного преобразования устройства 72 повторного преобразования, меньше, чем число сэмплов, которое соответствует длине сегмента 78 реконструированного сигнала. В случае IMDCT число коэффициентов преобразования внутри информации 47 скорее равно числу сэмплов временного сегмента 16b. То есть лежащее в основе преобразование может быть названо критическим преобразованием дискретизации, делающим необходимым подавление помех дискретизации во временной области, чтобы подавить помехи дискретизации, возникающие из-за преобразования на границах, т.е. передних и задних краях текущего временного сегмента 16b.
В качестве дополнительного примечания следует обратить внимание, что аналогично структуре подкадра LPD-кадров, FD-кадры могли тоже быть субъектом подкадровой структуры. Например, FD-кадры могли принадлежать режиму длинного окна, в котором одиночное окно используется для обработки методом окна участка сигнала, продолжающегося за пределы переднего и заднего края текущего временного сегмента, чтобы кодировать соответствующий временной сегмент, или принадлежать режиму короткого окна, в котором соответствующий участок сигнала, продолжающийся за пределы границ текущего временного сегмента FD-кадра, подразделяется на меньшие подучастки, каждый их которых подвергается соответствующей обработке методом окна и преобразованию по отдельности. В этом случае модуль 54 FD-кодирования вывел бы сегмент повторно преобразованного сигнала для подучастка текущего временного сегмента 16b.
После описания возможной реализации модуля 54 FD-кодирования возможная реализация модуля TCX LP-декодирования и модуля декодирования LP возбуждения кодовой книги 56 и 58, соответственно, описана по отношению к фиг.5. Другими словами, фиг.5 имеет дело со случаем, где текущий кадр является LPD-кадром. В этом случае текущий кадр 14b структурирован на один или более подкадров. В настоящем случае проиллюстрировано структурирование на три подкадра 90a, 90b и 90c. Могло бы быть, что структурирование, по умолчанию, ограничено определенными подструктурирующими способностями. Каждый из подучастков ассоциирован с соответствующим одним из подучастков 92a, 92b и 92c текущего временного сегмента 16b. То есть один или более подучастков c 92a по 92c покрывают без промежутков, без перекрытия, весь временной сегмент 16b. Согласно порядку подучастков c 92a по 92c внутри временного сегмента 16b последовательный порядок задается среди подкадров c 92a по 92c. Как проиллюстрировано на фиг.5, текущий кадр 14b не полностью подразделен на подкадры c 90a по 90c. Другими словами, некоторые участки текущего кадра 14b принадлежат всем подкадрам, как например, первый и второй синтаксические участки 24 и 26, данные 34 FAC и потенциально дополнительные данные, как LPC-информация, как будет описано ниже более подробно, хотя LPC-информация может быть также подразделена на отдельные подкадры.
Для того чтобы иметь дело с TCX-подкадрами, модуль 56 TCX LP-декодирования содержит дифференцирующее устройство 94 спектрального взвешивания, устройство 96 спектрального взвешивания и устройство 98 повторного преобразования. Для целей иллюстрации, показано, что первый подкадр 90a должен быть TCX-подкадром, тогда как предполагается, что второй подкадр 90b должен быть ACELP-подкадром.
Для того чтобы обработать TCX-подкадр 90a, дифференцирующее устройство 94 получает спектральный взвешивающий фильтр из LPC-информации 104 внутри информации 28 текущего кадра 14b, и устройство 96 спектрального взвешивания спектрально взвешивает информацию коэффициентов преобразования в отношении подкадра 90a, используя спектральный взвешивающий фильтр, принятый от дифференцирующего устройства 94, как показано стрелкой 106.
Устройство 98 повторного преобразования, в свою очередь, повторно преобразовывает спектрально взвешенную информацию коэффициентов преобразования, чтобы получить сегмент 108 повторно преобразованного сигнала, продолжающийся, во времени t, в пределах и за пределами подучастка 92a текущего временного сегмента. Повторное преобразование, выполняемое устройством 98 повторного преобразования, может быть таким же, как выполняемое устройством 72 повторного преобразования. В действительности устройство 72 и 98 повторного преобразования может обычно иметь аппаратное обеспечение, стандартное программное обеспечение или программируемый аппаратный участок.
LPC-информация 104, содержащаяся в информации 28 текущего LPD-кадра 16b, может представлять LPC-коэффициенты одного момента времени внутри временного сегмента 16b или для нескольких моментов времени внутри временного сегмента 16b, как, например, один набор LPC-коэффициентов для каждого подучастка с 92a по 92c. Дифференцирующее устройство 94 спектрального взвешивающего фильтра конвертирует LPC-коэффициенты в множители спектрального взвешивания, спектрально взвешивая коэффициенты преобразования внутри информации 90a согласно функции переноса, которая получена из LPC-коэффициентов дифференцирующим устройством 94, так что таковой по существу аппроксимирует синтезирующий LPC-фильтр или некоторую его модифицированную версию. Любое деквантование, выполняемое за пределами спектрального взвешивания посредством устройства 96 спектрального взвешивания, может быть спектрально неизменяемым. Таким образом, отличаясь от режима FD-декодирования, шум квантования, согласно режиму TCX-кодирования, спектрально формируется с использованием LPC-анализа.
Из-за использования повторного преобразования, однако, сегмент 108 повторно преобразованного сигнала страдает от помех дискретизации. С использованием того же повторного преобразования, однако, сегменты 78 и 100 повторно преобразованного сигнала последовательных кадров и подкадров, соответственно, могут иметь свои помехи дискретизации подавленными посредством обработчика 60 перехода просто путем добавления их перекрывающихся участков.
При обработке подкадров 90b ACELP дифференцирующее устройство 100 сигнала возбуждения получает сигнал возбуждения из информации обновления возбуждения внутри соответствующего подкадра 90b, и синтезирующий LPC-фильтр 102 выполняет LPC-фильтрацию синтеза над сигналом возбуждения с использованием LPC-информации, чтобы получить LP-сегмент 110 синтезированного сигнала для подучастка 92b текущего временного сегмента 16b.
Дифференцирующие устройства 94 и 100 могут быть выполнены с возможностью выполнения некоторой интерполяции, чтобы адаптировать LPC-информацию 104 внутри текущего кадра 16b к изменяющемуся положению текущего подкадра, соответствующего текущему подучастку внутри текущего временного сегмента 16b.
Со ссылкой на фиг.3-5 различные сегменты 108, 110 и 78 сигнала входят в обработчик 60 перехода, который, в свою очередь, помещает все сегменты сигнала в правильном временном порядке. В частности, обработчик 60 перехода выполняет подавление помех дискретизации во временной области внутри временно перекрывающихся оконных участков на границах между временными сегментами непосредственно последовательных одних из FD-кадров и FCX-подкадров, чтобы реконструировать информационный сигнал на этих границах. Таким образом, нет необходимости в данных прямого подавления помех дискретизации для границ между последовательными FD-кадрами, границами между FD-кадрами, за которыми следуют TCX-кадры и TCX-подкадры, за которыми следуют FD-кадры соответственно.
Однако ситуация меняется всегда, когда FD-кадр или TCX-подкадр (оба представляющие вариант режима кодирования с преобразованием) переходят к ACELP-подкадру (представляющему вид режима кодирования временной области). В этом случае обработчик 60 перехода получает синтезированный сигнал с прямым подавлением помех дискретизации из данных прямого подавления помех дискретизации из текущего кадра и добавляет первый синтезированный сигнал с прямым подавлением помех дискретизации в сегмент 100 или 78 повторно преобразованного сигнала непосредственно предшествующего временного сегмента, чтобы реконструировать информационный сигнал на соответствующей границе. Если граница попадает во внутреннюю часть текущего временного сегмента 16b, так как TCX-подкадр и ACELP-подкадр внутри текущего кадра задают границу между ассоциированными подучастками временного сегмента, обработчик перехода может выявить возбуждение соответствующих данных прямого подавления помех дискретизации для этих переходов от первого синтаксического участка 24 и подкадровой структуры, описанной там. Синтаксический участок 26 не нужен. Предыдущий кадр 14a может быть потерян или нет.
Однако, в случае границы, совпадающей с границей между последовательными временными сегментами 16a и 16b, устройство 20 синтаксического анализа должно проверить второй синтаксический участок 26 внутри текущего кадра, чтобы определить, имеет ли текущий кадр 14b данные 34 прямого подавления помех дискретизации, данные 34 FAC для подавления помех дискретизации, возникающих на переднем конце текущего временного сегмента 16b, так как либо предшествующий кадр является FD-кадром, либо последний подкадр предшествующего LPD-кадра является TCX-подкадром. По меньшей мере, устройству 20 синтаксического анализа нужно знать синтаксический участок 26 в случае, когда содержимое предыдущего кадра потерялось.
Аналогичные утверждения применяются для переходов в другие направления, т.е. от ACELP-подкадров к FD-кадрам или TCX-кадрам. До тех пор, пока соответствующие границы между соответствующими сегментами и подучастками сегментов попадают во внутреннюю часть текущего временного сегмента, устройство 20 синтаксического анализа не имеет проблем в определении существования данных 34 прямого подавления помех дискретизации для этих переходов от самого текущего кадра 14b, а именно от первого синтаксического участка 24. Второй синтаксический участок не нужен и даже неуместен. Однако если граница возникает или совпадает с границей между предыдущим временным сегментом 16a и текущим временным сегментом 16b, устройству 20 синтаксического анализа нужно проверить второй синтаксический участок 26, чтобы определить, присутствуют ли данные 34 прямого подавления помех дискретизации для перехода на переднем конце текущего временного сегмента 16b - по меньшей мере в случае, когда не имеется доступа к предыдущему кадру.
В случае переходов от ACELP к FD или TCX обработчик 60 перехода получает второй синтезированный сигнал с прямым подавлением помех дискретизации из данных 34 прямого подавления помех дискретизации и добавляет второй синтезированный сигнал с прямым подавлением помех дискретизации к сегменту реконструированного сигнала внутри текущего временного сегмента, чтобы реконструировать информационный сигнал на границе.
После описания вариантов осуществления со ссылкой на фиг.3-5, которые относятся к варианту осуществления, согласно которому существуют кадры и подкадры разных режимов кодирования, конкретная реализация этих вариантов осуществления будет описана более подробно ниже. Описание этих вариантов осуществления одновременно включает в себя возможные меры при генерировании соответствующего потока данных, содержащего такие кадры и подкадры соответственно. В дальнейшем этот конкретный вариант осуществления описывается как единый речевой и аудиокодек (USAC), хотя описанные принципы могут быть перенесены на другие сигналы.
Переключение окон в USAC имеет несколько целей. Оно смешивает FD-кадры, т.е. кадры, кодированные с помощью частотного кодирования, и LPD-кадры, которые, в свою очередь, структурированы на ACELP-(под)кадры и TCX-(под)кадры. ACELP-кадры (кодирование временной области) применяют обработку методом окна с прямоугольными, неперекрывающимися окнами к входным сэмплам, тогда как TCX-кадры (кодирование частотной области) применяют обработку методом окна с непрямоугольными, перекрывающимися окнами к входным сэмплам и затем кодируют сигнал, используя преобразование с подавлением помех дискретизации во временной области (TDAC), а именно MDCT, например. Чтобы согласовать окна в целом, TCX-кадры могут использовать центрированные окна с однородной формой, и чтобы управлять переходами на границах ACELP-кадров, передается явная информация для подавления эффектов помех дискретизации во временной области и обработки методом окна согласованных TCX-окон. Эта дополнительная информация может рассматриваться как подавление помех дискретизации (FAC). Данные FAC квантуются в следующем варианте осуществления во взвешенной с помощью LPC области, так что шум квантования FAC и декодированное MDCT имеют одну природу.
На фиг.6 показана обработка в кодере в кадре 120, кодированном с помощью кодирования с преобразованием (TC), которому предшествует и за которым следует кадр 122, 124, кодированный с помощью ACELP. В соответствии с рассмотрением выше, понятие TC включает в себя MDCT над длинными и короткими блоками, использующими AAC, равно как и TCX на основе MDCT. То есть кадр 120 может быть либо FD-кадром, либо TCX-(под)кадром, как подкадр 90a, 92a на фиг.5, например. На фиг.6 показаны маркеры временной области и границы кадров. Границы кадра или временного сегмента указаны пунктирными линиями, тогда как маркеры временной области являются короткими вертикальными линиями вдоль горизонтальных осей. Следует упомянуть, что в следующем описании термины "временной сегмент" и "кадр" иногда используются как синонимы из-за уникальной связи между ними.
Таким образом, вертикальные пунктирные линии на фиг.6 показывают начало и конец кадра 120, который может быть подкадром/подчастью временного сегмента или кадром/временным сегментом. LPC1 и LPC2 должны указывать центр анализирующего окна, соответствующего коэффициентам LPC-фильтра или LPC-фильтрам, которые используются в дальнейшем для того, чтобы выполнять подавление помех дискретизации.
Эти коэффициенты фильтра получаются в декодере посредством, например, реконструктора 22 или дифференцирующих устройств 90 и 100 посредством использования LPC-информации 104 (см. фиг.5). LPC-фильтры содержат: LPC1, соответствующее его вычислению в начале кадра 120, и LPC2, соответствующее его вычислению в конце кадры 120. Предполагается, что кадр 122 был кодирован с помощью ACELP. То же самое применяется к кадру 124.
Фиг.6 структурирована на 4 линии, пронумерованных в правой части фиг.6. Каждая линия представляет этап в обработке в кодере. Следует понимать, что каждая линия выровнена по времени с линией выше.
Линия 1 на фиг.6 представляет первоначальный аудиосигнал, сегментированный на кадры 122, 120 и 124, как указано выше. Отсюда слева от маркера "LPC1" первоначальный сигнал кодируется с помощью ACELP. Между маркерами "LPC1" и "LPC2" первоначальный сигнал кодируется, используя TC. Как описано выше, при TC ограничение шума применяется прямо в области преобразования, а не во временной области. Справа от маркера LPC2 первоначальный сигнал снова кодируется с помощью ACELP, т.е. режим кодирования временной области. Эта последовательность режимов кодирования (ACELP, затем TC, затем ACELP) выбрана, чтобы проиллюстрировать обработку при FAC, так как FAC имеет отношение к обоим переходам (от ACELP к TC и от TC к ACELP).
Однако следует отметить, что переходы при LPC1 и LPC2 на фиг.6 могут возникать внутри внутренней части текущего временного сегмента или могут совпадать с его передним концом. В первом случае может быть выполнено определение существования ассоциированных данных FAC посредством устройства 20 синтаксического анализа лишь на основе первого синтаксического участка 24, тогда как в случае потери кадра устройству 20 синтаксического анализа может понадобиться синтаксический участок 26, чтобы сделать так в последнем случае.
Линия 2 на фиг.6 соответствует декодированным (синтезированным) сигналам в каждом из кадров 122, 120 и 124. Следовательно, ссылочное обозначение 110 с фиг.5 используется в кадре 122 соответственно возможности, что последний подучасток кадра 122 является подучастком, кодированным с помощью ACELP, как 92b на фиг.5, тогда как комбинация ссылочных обозначений 108/78 используется, чтобы указывать долю сигнала для кадра 120, аналогично фиг.5 и 4. Снова слева от маркера LPC1 предполагается, что синтез этого кадра 122 был кодирован с помощью ACELP. Отсюда синтезированный сигнал 110 слева от маркера LPC1 идентифицируется как синтезированный ACELP-сигнал. Существует, в принципе, высокое сходство между ACELP-синтезом и первоначальным сигналом в этом кадре 122, так как ACELP выполняет кодирование формы волны так точно, насколько возможно. Тогда сегмент между маркерами LPC1 и LPC2 на линии 2 на фиг.2 представляет выход обратного MDCT этого сегмента 120, как видно на декодере. Снова сегмент 120 может быть временным сегментом 16b FD-кадра или подучастком подкадром, кодированным с помощью TCX, как, например, 90b на фиг.5, например. На данной фигуре этот сегмент 108/78 называется "выход кадра TC". На фиг.4 и 5 этот сегмент был назван сегментом повторно преобразованного сигнала. В случае кадра/сегмента 120, являющегося подчастью TCX-сегмента, выход TC-кадра представляет повторно обработанный методом окна синтезированный TLP-сигнал, где TLP значит "кодирование с преобразованием с линейным предсказанием", чтобы указать, что в случае TCX ограничение шума соответствующего сегмента завершено в области преобразования посредством фильтрации MDCT-коэффициентов, используя спектральную информацию из LPC-фильтров LPC1 и LPC2, соответственно, что было также описано выше по отношению к фиг.5 касательно устройства 96 спектрального взвешивания. Также следует отметить, что синтезированный сигнал, т.е. заранее реконструированный сигнал, включающий в себя помехи дискретизации, между маркерами "LPC1" и "LPC2" на линии 2 на фиг.6, т.е. сигнал 108/78, содержит эффекты обработки методом окна и помех дискретизации во временной области в своем начале и конце. В случае MDCT как TDAC-преобразования помехи дискретизации во временной области могут быть изображены символически как развертки 126a и 126b соответственно. Другими словами, верхняя кривая в линии 2 на фиг.6, которая продолжается от начала к концу этого сегмента 120 и указана ссылочными обозначениями 108/78, показывает эффект обработки методом окна из-за преобразующей обработки методом окна, являющейся плоской в середине, чтобы оставить преобразованный сигнал неизмененным, но не в начале и конце. Эффект свертки показан нижними кривыми 126a и 126b в начале и конце сегмента 120 с помощью знака минус в начале сегмента и знака плюс в конце сегмента. Этот эффект обработки методом окна и помех дискретизации во временной области (или свертки) является свойственным для MDCT, которое служит в качестве явного примера для преобразований TDAC. Помехи дискретизации могут быть подавлены, когда два последовательных кадра кодируются с использованием MDCT, как это было описано выше. Однако в случае, где кадру 120, "кодированному с помощью MDCT", не предшествуют и/или не следуют другие MDCT-кадры, его обработка методом окна и помехи дискретизации во временной области не подавляются и остаются в сигнале временной области после обратного MDCT. Подавление помех дискретизации (FAC) может затем быть использовано для корректирования этих эффектов, как описано выше. Наконец, также предполагается, что сегмент 124 после маркера LPC2 на фиг.6 следует кодировать с использованием ACELP. Следует отметить, что для получения синтезированного сигнала в этом кадре, состояния фильтра LPC-фильтра 102 (см. фиг.5), т.е. память устройств долговременного и кратковременного предсказания, в начале кадра 124 должна быть надлежащей, что предполагает, что эффекты временных помех дискретизации и обработки методом окна на конце предыдущего кадра 120 между маркерами LPC1 и LPC2 могут быть подавлены посредством применения FAC конкретным образом, как разъяснено ниже. Чтобы подвести итог, линия 2 на фиг.6 содержит синтез заранее реконструированных сигналов из последовательных кадров 122, 120 и 124, включающих в себя эффект обработки методом окна при помехах дискретизации во временной области на выходе обратного MDCT для кадра между маркерами LPC1 и LPC2.
Чтобы получить линию 3 на фиг.6, вычисляется разница между линией 1 на фиг.6, т.е. в первоначальном аудиосигнале 18, и линией 2 на фиг.6, т.е. синтезированных сигналах 110 и 108/78, соответственно, как описано выше. Это дает первый разностный сигнал 128.
Дополнительная обработка на стороне кодера, касающаяся кадра 120, разъясняется в дальнейшем по отношению к линии 3 на фиг.6. В начале кадра 120, во-первых, две доли, взятые из ACELP-синтеза 110 слева от маркера LPC1 на линии 2 на фиг.6, добавляются друг к другу, как следует ниже:
Первая доля 130 является обработанной методом окна и обращенной во времени (развернутой) версией последних синтезированных ACELP-сэмплов, т.е. последние сэмплы сегмента 110 сигнала, показанного на фиг.5. Длина и форма окна для этого обращенного во времени сигнала являются такими же, как часть с помехами дискретизации окна преобразования слева от кадра 120. Эта доля 130 может быть видна как хорошая аппроксимация помех дискретизации во временной области, присутствующих в кадре 120 MDCT линии 2 на фиг.6.
Вторая доля 132 является обработанным методом окна ответом при отсутствии входного сигнала (ZIR) синтезирующего фильтра LPC1 с исходным состоянием, взятым как итоговые состояния этого фильтра на конце ACELP-синтеза 110, т.е. на конце кадра 122. Длина и форма окна этой второй доли могут быть такими же, как для первой доли 130.
С новой линией 3 на фиг.6, т.е. после добавления двух долей 130 и 132 выше, новая разница берется кодером для получения линии 4 на фиг.6. Следует отметить, что разностный сигнал 134 останавливается на маркере LPC2. Приближенный вид ожидаемой огибающей сигнала ошибки во временной области показан на линии 4 на фиг.6. Ошибка в ACELP-кадре 122 ожидается приблизительно плоской по амплитуде во временной области. Затем ожидается, что ошибка в TC-кадре 120 проявит общую форму, т.е. огибающую временной области, как показано в этом сегменте 120 линии 4 на фиг.6. Эта ожидаемая форма амплитуды ошибки показана здесь только для целей иллюстрации.
Следует отметить, если что декодер использовал только синтезированные сигналы линии 3 на фиг.6, чтобы произвести или реконструировать декодированный аудиосигнал, тогда шум квантования был бы обычно как ожидаемая огибающая сигнала 136 ошибки на линии 4 с фиг.6. Таким образом, следует понимать, что корректировка должна быть отправлена на декодер, чтобы компенсировать эту ошибку в начале и конце TC-кадра 120. Ошибка появляется из-за эффектов обработки методом окна и помех дискретизации во временной области, свойственных паре MDCT/обратное MDCT. Обработка методом окна и помехи дискретизации во временной области были уменьшены в начале TC-кадра 120 посредством добавления долей 132 и 130 цилиндрической области из предыдущего ACELP-кадра 122, как сказано выше, но не могут быть полностью подавлены, как в действительной TDAC-операции последовательных MDCT-кадров. Справа от TC-кадра 120 на линии 4 на фиг.6 сразу перед маркером LPC2 вся обработка методом окна и помехи дискретизации во временной области остаются от пары MDCT/обратное MDCT и должны быть, таким образом, полностью подавлены посредством прямого подавления помех дискретизации.
Перед переходом к описанию процесса кодирования, чтобы получить данные прямого подавления помех дискретизации, сделана ссылка на фиг.7, чтобы кратко разъяснить MDCT как один пример обработки по TDAC-преобразованию. Оба направления преобразования изображены и описаны со ссылкой на фиг.7. Переход от временной области к области преобразования проиллюстрирован в верхней половине фиг.7, тогда как повторное преобразование изображено в нижней части фиг.7.
При переходе от временной области к области преобразования TDAC-преобразование задействует обработку 150 методом окна, применяемую к интервалу 152 сигнала, который следует преобразовать, который продолжается за пределы временного сегмента 154, для которого последние результирующие коэффициенты преобразования в действительности передаются внутри потока данных. Окно, применяемое при обработке 150 методом окна, показано на фиг.7 как содержащее часть Lk с помехами дискретизации, пересекающую передний конец временного сегмента 154, и часть Rk с помехами дискретизации в заднем конце временного сегмента 154 с частью Mk без помех дискретизации, продолжающуюся между ними. MDCT 156 применяется к сигналу, обработанному методом окна. То есть выполняется свертка 158, чтобы свернуть первую четверть интервала 152, продолжающуюся между передним концом интервала 152 и передним концом временного сегмента 154 назад вдоль левой (передней) границы временного сегмента 154. То же самое делается касательно участка Rk с помехами дискретизации. Затем DCT IV 160 выполняется над результирующим обработанным методом окна и свернутым сигналом, имеющим столько сэмплов, сколько и временной сигнал 154, чтобы получить коэффициенты преобразования того же числа. Затем выполняется квантование в 162. Естественно, квантование 162 может рассматриваться как не содержащееся в TDAC-преобразовании.
Повторное преобразование делает обратное. То есть вслед за деквантованием 164 выполняется IMDCT 166, задействуя, во-первых, DCT-1 IV 168, чтобы получить временные сэмплы, число которых равняется числу сэмплов временного сегмента 154, который следует реконструировать. Затем процесс 168 развертки выполняется над участком обратно преобразованного сигнала, принятым из модуля 168, тем самым продлевая временной интервал или число временных сэмплов результата IMDCT посредством удвоения длины участков с помехами дискретизации. Затем обработка методом окна выполняется в 170, используя окно 172 повторного преобразования, которое может быть таким же, как окно, используемое обработкой 150 методом окна, но может также быть другим. Остальные блоки на фиг.7 иллюстрируют TDAC или обработку перекрывания/добавления, выполняемые на перекрывающихся участках идущих подряд сегментов 154, т.е. добавление его развернутых участков с помехами дискретизации, как выполнено обработчиком перехода на фиг.3. Как проиллюстрировано на фиг.7, TDAC посредством блоков 172 и 174 приводит к подавлению помех дискретизации.
Описание фиг.6 теперь продолжается дальше. Чтобы эффективно компенсировать эффекты обработки методом окна и помех дискретизации во временной области в начале и конце TC-кадра 129 на линии 4 на фиг.6, и предполагая, что TC-кадр 120 использует ограничение шума во временной области (FDNS), применяется прямая корректировка помех дискретизации (FAC), следующая обработке, описанной на фиг.8. Сначала следует обратить внимание, что фиг.8 описывает эту обработку для обоих: левой части TC-кадра 120 около маркера LPC1 и для правой части TC-кадра 120 около маркера LPC2. Следует вспомнить, что TC-кадру 120 на фиг.6, как предполагается, предшествует ACELP-кадр 122 на границе маркера LPC1 и следует ACELP-кадр 124 на границе маркера LPC2.
Чтобы компенсировать эффекты обработки методом окна и помех дискретизации во временной области около маркера LPC1, обработка описана на фиг.8. Сначала взвешивающий фильтр W(z) вычисляется из фильтра LPC1. Взвешивающий фильтр W(z) мог бы быть модифицированным анализирующим или отбеливающим фильтром A(z) для LPC1. Например, W(z)=A(z/λ), где λ - предварительно определенный коэффициент взвешивания. Сигнал ошибки в начале TC-кадра указан ссылочным обозначением 138, как на линии 4 на фиг.6. Эта ошибка называется целью FAC на фиг.8. Сигнал 138 ошибки фильтруется фильтром W (z) в 140, с исходным состоянием этого фильтра, т.е. с исходным состоянием, если это память фильтра, являясь ACELP-ошибкой 141 в ACELP-кадре 122 на линии 4 на фиг.6. Выход фильтра W(z) тогда формирует вход преобразования 142 на фиг.6. Данное преобразование для примера показано как MDCT. Коэффициенты преобразования, выведенные посредством MDCT, затем квантуются и кодируются в модуле 143 обработки. Эти кодированные коэффициенты могли бы сформировать по меньшей мере часть вышеупомянутых данных 34 FAC. Эти кодированные коэффициенты могут быть переданы кодирующей стороне. Выход процесса Q, а именно квантованных MDCT-коэффициентов, является входом обратного преобразования, такого как IMDCT 144, для формирования сигнала временной области, который затем фильтруется обратным фильтром 1/W(z) в 145, который имеет нулевую память (нулевое исходное состояние). Фильтрация через 1/W(z) продолжается свыше длины цели FAC, используя нулевой вход для сэмплов, которые продолжаются после цели FAC. Выход фильтра 1/W(z) является синтезированным FAC-сигналом 146, который является корректирующим сигналом, который может быть теперь применен в начале TC-кадра 120, чтобы компенсировать эффект обработки методом окна и помех дискретизации во временной области, возникающий там.
Теперь описывается обработка для корректировки обработки методом окна и помех дискретизации во временной области на конце TC-кадра 120 (до маркера LPC2). Для этого делается ссылка на фиг.9.
Сигнал ошибки в конце TC-кадра 120 на линии 120 на фиг.6 предоставлен ссылочным обозначением 147 и представляет цель FAC на фиг.9. Цель 147 FAC подвергается той же последовательности процессов, что и цель 138 FAC на фиг.8, с помощью обработки, отличающейся лишь исходным состоянием взвешивающего фильтра W(z) 140. Исходным состоянием фильтра 140, чтобы фильтровать цель 147 FAC, является ошибка в TC-кадре 120 на линии 4 на фиг.6, указанная ссылочным обозначением 148 на фиг.6. Дополнительные этапы с 142 по 145 обработки являются такими же, как на фиг.8, которые имеют дело с обработкой цели FAC в начале TC-кадра 120.
Обработка на фиг.8 и 9 выполняется полностью слева направо, когда применяется в кодере для получения локального FAC-синтеза и для вычисления результирующей реконструкции, чтобы выявить, является ли изменение режима кодирования, задействованного посредством выбора режима TC-кодирования кадра 120, оптимальным выбором. В декодере обработка на фиг.8 и 9 применяется только с середины направо. То есть кодированные и квантованные коэффициенты преобразования, переданные процессором Q 143, декодируются для формирования входа IMDCT. См., например, фиг.10 и 11. Фиг.10 равняется правой части фиг.8, тогда как фиг.11 равняется правой части фиг.9. Обработчик 60 перехода с фиг.3 может, в соответствии с конкретным вариантом осуществления, быть реализован в соответствии с фиг.10 и 11. То есть обработчик 60 перехода может подвергать информацию коэффициентов преобразования внутри данных 34 FAC, представленных внутри текущего кадра 14b, повторному преобразованию, чтобы выдать первый синтезированный FAC-сигнал 146 в случае преобразования из ACELP-подчасти временного сегмента во временной FD-сегмент или FCX-подчасть, или второй синтезированный FAC-сигнал 149, при переходе от временного FD-сегмента или TCX-подчасти временного сегмента в ACELP-подчасть временного сегмента.
Следует отметить, что данные 34 FAC могут относиться к такому переходу, возникающему внутри текущего временного сегмента, когда существование данных 34 FAC является получаемым для устройства 20 синтаксического анализа исключительно из синтаксического участка 24, тогда как устройству 20 синтаксического анализа нужно, в случае потери предыдущего кадра, использовать синтаксический участок 26 для того, чтобы определить, существуют ли данные 34 FAC для таких переходов на переднем крае текущего временного сегмента 16b.
На фиг.12 показано, как целый синтезированный сигнал или реконструированный сигнал для текущего кадра 120 может быть получен посредством использования синтезированных FAC-сигналов на фиг.8-11 и применения обратных этапов по фиг.6. Следует опять отметить, что этапы, которые показаны на фиг.12, также выполняются посредством кодера, чтобы выявить, приводит ли режим кодирования для текущего кадра к наилучшей оптимизации, например, в смысле скорость/искажение или тому подобном. На фиг.12 предполагается, что ACELP-кадр 122 слева от маркера LPC1 уже синтезирован или реконструирован, например, модулем 58 по фиг.3, вплоть до маркера LPC1, тем самым приводя к синтезированному ACELP-сигналу на линии 2 с фиг.12 со ссылочным обозначением 110. Так как корректировка FAC также используется в конце TC-кадра, также предполагается, что кадр 124 после маркера LPC2 будет ACELP-кадром. Тогда, чтобы произвести синтезированный сигнал или реконструированный сигнал в TC-кадре 120 между маркерами LPC1 и LPC2 на фиг.12, выполняются следующие этапы. Эти этапы также проиллюстрированы на фиг.13 и 14, причем фиг.13 иллюстрирует этапы, выполняемые обработчиком 60 перехода, для того чтобы справиться с переходами от сегмента, кодированного с помощью TC, или подчасти сегмента к подчасти сегмента, кодированного с помощью ACELP, а на фиг.14 описана работа обработчика перехода для обратных переходов.
1. Одним этапом является декодировать TC-кадр, кодированный с помощью MDCT, и расположить таким образом полученный сигнал временной области между маркерами LPC1 и LPC2, как показано на линии 2 на фиг.12. Декодирование выполняется модулем 54 или модулем 56 и включает в себя обратное MDCT, как пример для повторного TDAC-преобразования, так чтобы декодированный TC-кадр содержал эффекты обработки методом окна и помех дискретизации во временной области. Другими словами, подчасть сегмента или временного сегмента, которую следует декодировать в текущий момент и указанная индексом k на фиг.13 и 14, может быть подчастью 92b временного сегмента, которая кодируется с помощью ACELP, как проиллюстрировано на фиг.13, или временным сегментом 16b, который является подчастью 92a, кодированной с помощью FD или кодированной с помощью TCX, как проиллюстрировано на фиг.14. В случае фиг.13 ранее обработанный кадр является подчастью сегмента, кодированного с помощью TC, или временного сегмента, и в случае фиг.14 ранее обработанный временной сегмент является подчастью, кодированной с помощью ACELP. Реконструированный или синтезированный сигнал, в качестве выведенного модулями с 54 по 58, частично страдает от эффектов помех дискретизации. Это также является верным для сегментов 78/108 сигнала.
2. Другим этапом при обработке обработчика 60 перехода является генерирование синтезированного FAC-сигнала согласно фиг.10 в случае фиг.14 и в соответствии с фиг.11 в случае фиг.13. То есть обработчик 60 перехода может выполнять повторное преобразование 191 над коэффициентами преобразования внутри данных 34 FAC, чтобы получить синтезированные FAC-сигналы 146 и 149 соответственно. Синтезированные FAC-сигналы 146 и 149 располагаются в начале и конце сегмента, кодированного с помощью TC, который, в свою очередь, страдает от эффектов помех дискретизации и зарегистрирован на временной сегмент 78/108. В случае фиг.13, например, обработчик 60 перехода располагает синтезированный FAC-сигнал 149 в конце кадра k-1, кодированного с помощью TC, как также показано на линии 1 с фиг.12. В случае фиг.14, обработчик 60 перехода располагает синтезированным FAC-сигналом 146 в начале кадра k, кодированного с помощью TC, как показано на линии 1 с фиг.12. Следует снова отметить, что кадр k является кадром, который следует декодировать в текущий момент, и что кадр k-1 является ранее декодированным кадром.
3. До тех пор, пока рассматривается ситуация с фиг.14, где возникает изменение режима кодирования в начале текущего TC-кадра k, обработанный методом окна и свернутый (обращенный), синтезированный ACELP-сигнал 130 из ACELP-кадра k-1, предшествующего TC-кадру k, и обработанный методом окна ответ при отсутствии входного сигнала, или ZIR, синтезирующего фильтра LPC1, т.е. сигнал 132, располагаются так, чтобы регистрироваться к сегменту 78/108 повторно преобразованного сигнала, имеющему помехи дискретизации. Эта доля показана на линии 3 с фиг.12. Как показано на фиг.14 и как уже было описано выше, обработчик 60 перехода получает сигнал 132 подавления помех дискретизации посредством продолжения LPC-фильтрации синтеза предшествующего CELP-подкадра за пределами передней границы текущего временного сегмента k и обработки методом окна продолжения сигнала 110 внутри текущего сигнала k с помощью обоих этапов, указанных ссылочными номерами 190 и 192 на фиг.14. Для того чтобы получить сигнал 130 подавления помех дискретизации, обработчик 60 перехода также обрабатывает методом окна на 194 сегмент 110 реконструированного сигнала предшествующего CELP-кадра и использует этот обработанный методом окна и обращенный во времени сигнал как сигнал 130.
4. Доли линий 1, 2 и 3 на фиг.12 и доли 78/108, 132, 130 и 146 на фиг.14 и доли 78/108, 149 и 196 на фиг.13 добавляются обработчиком 60 перехода в зарегистрированных положениях, разъясненных выше, для формирования синтезированного или реконструированного аудиосигнала для текущего кадра k в первоначальной области, как показано на линии 4 с фиг.12. Следует отметить, что обработка с фиг.13 и 14 производит синтезированный или реконструированный сигнал 198 в TC-кадре, где эффекты помех дискретизации во временной области и обработки методом окна подавляются в начале и конце кадра, и где потенциальная неравномерность границы кадра около маркера LPC1 была сглажена и перцепционно замаскирована фильтром 1/W(z) на фиг.12.
Таким образом, фиг.13 относится к текущей обработке кадра k, кодированного с помощью CELP, и приводит к прямому подавлению помех дискретизации в конце предшествующего сегмента, кодированного с помощью TC. Как проиллюстрировано в 196, окончательно реконструированный аудиосигнал является реконструированным без помех дискретизации на границе между сегментами k-1 и k. Обработка по фиг.14 приводит к прямому подавлению помех дискретизации в начале текущего сегмента k, кодированного с помощью TC, как проиллюстрировано в ссылочном обозначении 198, показывающем реконструированный сигнал на границе между сегментами k-1 и k. Оставшиеся помехи дискретизации в заднем конце текущего сегмента k либо подавляются посредством TDAC, если следующий сегмент является сегментом, кодированным с помощью TC, либо посредством FAC согласно фиг.13, если последующий сегмент является сегментом, кодированным с помощью ACELP. На фиг.13 упомянута эта последняя возможность посредством ссылочного обозначения 198, присвоенного сегменту сигнала временного сегмента k-1.
В дальнейшем будут упомянуты конкретные возможности относительно того, как может быть реализован второй синтаксический участок 26.
Например, чтобы обработать возникновение потерянных кадров, синтаксический участок 26 может быть осуществлен как 2-битное поле prev_mode, которое явно сообщает внутри текущего кадра 14b режим кодирования, который был применен в предыдущем кадре 14a согласно следующей таблице:
Другими словами, это 2-битное поле может быть названо prev_mode и может таким образом указывать режим кодирования предыдущего кадра 14a. В случае только что упомянутого примера различаются четыре разных состояния, а именно:
1) Предыдущий кадр 14a является LPD-кадром, последний подкадр которого является ACELP-подкадром;
2) предыдущий кадр 14a является LPD-кадром, последний подкадр которого является подкадром, кодированным с помощью TCX;
3) предыдущий кадр является FD-кадром, использующим длинное окно преобразования и
4) предыдущий кадр является FD-кадром, использующим короткие окна преобразования.
Возможность потенциального использования разных длин окон режима FD-кодирования была уже упомянута выше по отношению к описанию с фиг.3. Естественно, синтаксический участок 26 может иметь всего лишь три разных состояния, и режимом FD-кодирования можно лишь оперировать с помощью постоянной длины окна, тем самым суммируя две последних длины вышеприведенных опций 3 и 4.
В любом случае, на основе вышеуказанного 2-битного поля устройство 20 синтаксического анализа способно решать, присутствуют ли данные FAC для перехода между текущим временным сегментом и предыдущим временным сегментом 16a внутри текущего кадра 14a. Как будет описано более подробно ниже, устройство 20 синтаксического анализа и реконструктор 22 способны определять на основе prev_mode, был ли предыдущий кадр FD-кадром, использующим длинное окно (FD_long), или был ли предыдущий кадр FD-кадром, использующим короткое окно (FD_short), и следует ли текущий кадр 14b (если текущий кадр является LPD-кадром) за FD-кадром или LPD-кадром, дифференцирование которых необходимо согласно следующему варианту осуществления, чтобы корректно осуществить синтаксический анализ потока данных и реконструировать информационный сигнал соответственно.
Таким образом, в соответствии с упомянутой возможностью использования 2-битного идентификатора, в качестве синтаксического участка 26 каждый кадр с 16a по 16c был бы обеспечен дополнительным 2-битным идентификатором в дополнение к синтаксическому участку 24, который задает режим кодирования текущего кадра, который должен быть режимом FD- или LPD-кодирования, и подкадровой структуры в случае режима LPD-кодирования.
Для всех вариантов осуществления выше следует упомянуть, что также следует избегать других внутрикадровых зависимостей. Например, декодер с фиг.1 мог иметь возможность SBR. В этом случае частота разделения могла быть синтаксически проанализирована устройством 20 синтаксического анализа из каждого кадра с 16a по 16c внутри соответствующих данных SBR-расширения вместо осуществления синтаксического анализа такой частоты разделения с помощью SBR-заголовка, который мог быть передан внутри потока данных 12 менее часто. Другие внутрикадровые зависимости могли быть удалены аналогичным образом.
Целесообразно отметить для всех вышеописанных вариантов осуществления, что устройство 20 синтаксического анализа могло быть выполнено с возможностью буферизирования по меньшей мере декодируемого в текущий момент кадра 14b внутри буфера с пропусканием всех кадров с 14a по 14c через этот буфер FIFO-(первый вошел - первый вышел). При буферизации устройство 20 синтаксического анализа могло выполнять очистку кадров из этого буфера в единицах кадров с 14a по 14c. То есть заполнение и очистка буфера устройства 20 синтаксического анализа могли быть выполнены в единицах кадров с 14a по 14c, с тем чтобы удовлетворять ограничениям, наложенным максимально доступным пространством буфера, например, вмещает лишь один или более чем один кадр максимального размера за раз.
Далее будет описана альтернативная возможность сообщения для синтаксического участка 26 с уменьшенной долей битов. Согласно этой альтернативе используется другая структура конструкции синтаксического участка 26. В варианте осуществления, описанном до этого, синтаксический участок 26 был 2-битным полем, которое передается в каждом кадре с 14a по 14c кодированного USAC-потока данных. Так как для FD-части для декодера важно только знать, должен ли он считать данные FAC из битового потока в случае, если предыдущий кадр 14a был потерян, эти 2 бита могут быть разделены на два 1-битных флага, где один из них сообщается в каждом кадре с 14a по 14c как fac_data_present. Этот бит может быть внесен в структуру single_channel_element и channel_pair_element соответственно, как показано в таблицах на фиг.15 и 16. Фиг.15 и 16 могут рассматриваться как определение высокоуровневой структуры синтаксиса кадров 14 в соответствии с настоящим вариантом осуществления, где функции "function_name(...)" вызывают стандартные подпрограммы, и написанные жирным имена синтаксических элементов указывают считывание соответствующего синтаксического элемента из потока данных. Другими словами, помеченные участки или заштрихованные участки на фиг.15 и 16 показывают, что каждый кадр с 14a по 14c, в соответствии с этим вариантом осуществления, обеспечивается флагом fac_data_present. Ссылочные номера 199 показывают эти участки.
Другой 1-битный флаг flag prev_frame_was_lpd затем передается в текущем кадре, только если таковой был кодирован с использованием LPD-части USAC, и сообщает, был ли предыдущий кадр также кодирован с использованием LPD-пути USAC. Это показано в таблице с фиг.17.
Таблица с фиг.17 показывает часть информации 28 на фиг.1 в случае, когда текущий кадр 14b является LPD-кадром. Как показано в 200, каждый LPD-кадр обеспечен флагом prev_frame_was_lpd. Эта информация используется для осуществления синтаксического анализа синтаксиса текущего LPD-кадра. Данное содержимое и положение данных 34 FAC в LPD-кадрах зависит от перехода в переднем конце текущего LPD-кадра, являющегося переходом между режимом TCX-кодирования и режимом CELP-кодирования, или переходом от режима FD-кодирования к режиму CELP-кодирования, получается из фиг.18. В частности, если декодируемый в текущий момент кадр 14b является LPD-кадром, которому только что предшествовал FD-кадр 14a, и fac_data_present сообщает, что данные FAC присутствуют в текущем LPD-кадре (так как передний подкадр является ACELP-подкадром), тогда данные FAC считываются в конце синтаксиса LPD-кадра в 202 с данными 34 FAC, включающими в себя, в этом случае множитель усиления fac_gain, как показано в 204 на фиг.18. С этим множителем усиления доля 149 с фиг.13 является регулируемой с помощью усиления.
Если, однако, текущий кадр является LPD-кадром, причем предшествующий кадр также является LPD-кадром, т.е. если переход между TCX- и CELP-подкадрами возникает между текущим кадром и предыдущим кадром, данные FAC считываются в 206 без опции регулируемости с помощью усиления, т.е. без данных 34 FAC, включающих в себя синтаксический элемент усиления FAC fac_gain. К тому же положение данных FAC, считанных в 206, отличается от положения, при котором данные FAC считаны в 202 в случае, когда текущий кадр является LPD-кадром и предыдущий кадр является FD-кадром. Пока положение считывания 202 возникает в конце текущего LPD-кадра, считывание данных FAC в 206 возникает до считывания характерных подкадру данных, т.е. ACELP- и TCX-данные, т.е. ACELP- и TCX-данные зависят от режимов подкадров структуры подкадров в 208 и 210 соответственно.
В примере фиг.15-18 LPC-информация 104 (фиг.5) считывается после характерных подкадру данных, таких как 90a и 90b (сравни фиг.5) в 212.
Только для полноты структура синтаксиса LPD-кадра согласно фиг.17 дополнительно разъясняется касательно данных FAC, потенциально дополнительно содержащихся внутри LPD-кадра, чтобы предоставить информацию FAC касательно переходов между TCX- и ACELP-подкадрами во внутренней части текущего временного сегмента, кодированного с помощью LPD. В частности, в соответствии с вариантом осуществления по фиг.15-18, структура LPD-подкадра ограничена для подразделения текущего временного сегмента, кодированного с помощью LPD, лишь в единицах четвертей, с назначением этих четвертей либо TCX, либо ACELP. Точная LPD-структура задается синтаксическим элементом lpd_mode, считанным в 214. Первая, вторая, третья и четвертая четверти могут формировать вместе TCX-подкадр, тогда как ACELP-кадры ограничены только длиной четверти. TCX-подкадр может также продолжаться на весь временной сегмент, кодированный с помощью LPD, в случае чего число подкадров лишь один. Цикл с проверкой условия на фиг.17 поэтапно проходит через четверти временного сегмента, кодируемого в текущий момент с помощью LPD, и передает всегда, когда текущая четверть k является началом нового подкадра внутри внутренней части временного сегмента, кодируемого в текущий момент с помощью LPD, данные FAC в 216, предоставленный непосредственно предшествующий подкадр начинающегося/декодируемого в текущий момент LPD-кадра принадлежит к другому режиму, т.е. режиму TCX, если текущий подкадр принадлежит к режиму ACELP и наоборот.
Только ради полноты на фиг.19 показана возможная структура синтаксиса FD-кадра в соответствии с вариантом осуществления по фиг.15-18. Можно видеть, что данные FAC считываются в конце FD-кадра при решении относительно того, присутствуют ли данные 34 FAC, лишь задействуя флаг fac_data_present. В сравнении с этим синтаксический анализ fac_data 34 в случае LPD-кадров, как показано на фиг.17, делает необходимым, для корректного синтаксического анализа, знание флага prev_frame_was_lpd.
Таким образом, 1-битный флаг prev_frame_was_lpd передается, только если текущий кадр кодируется с использованием LPD-части USAC, и сообщается, был ли предыдущий кадр кодирован с использованием LPD-пути кодека USAC (см. Синтаксис lpd_channel_stream() на фиг.17).
Касательно варианта осуществления по фиг.15-19 следует дополнительно отметить, что дополнительный синтаксический элемент мог быть передан в 220, т.е. в случае, когда текущий кадр является LPD-кадром, и предыдущий кадр является FD-кадром (при этом первый кадр текущего LPD-кадра, являющийся ACELP-кадром), так чтобы данные FAC подлежали считыванию в 202 для адресации перехода от FD-кадра к ACELP-подкадру в переднем конце текущего LPD-кадра. Этот дополнительный синтаксический элемент, считанный в 220, мог указывать, принадлежит ли предыдущий FD-кадр 14a FD_long или FD_short. В зависимости от синтаксического элемента на данные FAC в 202 могло быть оказано влияние. Например, на длину синтезированного сигнала 149 могло быть оказано влияние в зависимости от длины окна, использованного для преобразования предыдущего LPD-кадра. Суммируя вариант осуществления по фиг.15-19 и перенося признаки, упомянутые в них, на вариант осуществления, описанный по отношению к фиг.1-4, нижеследующее могло быть применено в последних вариантах осуществления либо по отдельности, либо в комбинации:
1) Данные 34 FAC, упомянутые на предыдущих фигурах, имелись в виду, чтобы в первую очередь отмечать данные FAC, присутствующие в текущем кадре 14b, для того, чтобы обеспечить возможность возникновения прямого подавления помех дискретизации между предыдущим кадром 14a и текущим кадром 14b, т.е. между соответствующими временными сегментами 16a и 16b. Однако могут присутствовать дополнительные данные FAC. Эти дополнительные данные FAC, однако, имеют дело с переходами между подкадрами, кодированными с помощью TCX, и подкадрами, кодированными с помощью CELP, расположенными внутри текущего кадра 14b в случае, когда таковой принадлежит режиму LPD. Присутствие или отсутствие этих дополнительных данных не зависит от синтаксического участка 26. На фиг.17 эти дополнительные данные FAC были считаны в 216. Их присутствие или существование лишь зависит от lpd_mode, считанного в 214. Последний синтаксический элемент, в свою очередь, является частью синтаксического участка 24, раскрывающего режим кодирования текущего кадра, lpd_mode наряду с core_mode, считанные в 230 и 232, показанных на фиг.15 и 16, соответствуют синтаксическому участку 24.
2) К тому же синтаксический участок 26 может быть составлен из более чем одного синтаксического элемента, как описано выше. Флаг FAC_data_present указывает, присутствует ли fac_data для границы между предыдущим кадром и текущим кадром. Этот флаг присутствует в LPD-кадре, а также в FD-кадрах. Дополнительный флаг, в вышеуказанном варианте осуществления, называемый prev_frame_was_lpd, передается в LPD-кадрах только для того, чтобы обозначить, принадлежал ли предыдущий кадр 14a режиму LPD. Другими словами, этот второй флаг, включенный в синтаксический участок 26, указывает, был ли предыдущий кадр 14a FD-кадром. Устройство 20 синтаксического анализа ожидает и считывает этот флаг лишь в случае, когда текущий кадр является LPD-кадром. На фиг.17 этот флаг считывается в 200. В зависимости от этого флага устройство 20 синтаксического анализа может ожидать наличия данных FAC и таким образом считать из текущего кадра значение усиления fac_gain. Значение усиления используется реконструктором для задания усиления синтезированного FAC-сигнала для FAC при переходе между текущим и предыдущим временными сегментами. В варианте осуществления с фиг. 15 по 19 этот синтаксический элемент считывается в 204 при зависимости от второго флага, являясь освобожденным от сравнения условий, приводящих к считыванию 206 и 202 соответственно. В качестве альтернативы или дополнительно prev_frame_was_lpd может управлять положением, где устройство 20 синтаксического анализа ожидает и считывает данные FAC. В варианте осуществления по фиг.15-19 этими положениями были 206 и 202. Кроме того, второй синтаксический участок 26 может дополнительно содержать дополнительный флаг в случае, когда текущий кадр является LPD-кадром, при этом передний подкадр которого является ACELP-кадром и предыдущий кадр является FD-кадром, чтобы указать, кодирован ли предыдущий FD-кадр с использованием длинного окна преобразования или короткого окна преобразования. Последний флаг мог быть считан в 220 в случае предыдущего варианта осуществления по фиг.15-19. Знание об этой длине FD-преобразования может быть использовано, чтобы определить длину синтезированных FAC-сигналов и размер данных 38 FAC соответственно. Посредством этой меры данные FAC могут быть адаптированы в размере, чтобы перекрывать длину окна предыдущего FD-кадра, чтобы достичь лучшего компромисса между качеством кодирования и скоростью кодирования.
3) Посредством разделения второго синтаксического участка 26 на только что упомянутые три флага возможно передать лишь один флаг или бит для сообщения второго синтаксического участка 26 в случае, когда текущий кадр является FD-кадром, лишь двух флагов или бита в случае, когда текущий кадр является LPD-кадром и предыдущий кадр тоже является LPD-кадром. Лишь в случае перехода от FD-кадра к текущему LPD-кадру третий флаг следует передать в текущем кадре. В качестве альтернативы, как сказано выше, второй синтаксический участок 26 может быть 2-битным указателем, передаваемым для каждого кадра и указывающим режим, когда кадр, предшествующий этому кадру, нужный для устройства синтаксического анализа, чтобы решить, должны ли быть считаны данные 38 FAC из текущего кадра, и если так, откуда и насколько длинным является синтезированный FAC-сигнал. То есть конкретный вариант осуществления по фиг.15-19 может быть легко перенесен на вариант осуществления с использованием вышеуказанного 2-битного указателя для реализации второго синтаксического участка 26. Вместо FAC_data_present на фиг.15 и 16 2-битный идентификатор был бы передан. Флаги в 200 и 220 не должны передаваться. Вместо этого содержимое fac_data_present в условном операторе, ведущем к 206 и 218, могло быть получено устройством 20 синтаксического анализа из 2-битного идентификатора. К следующей таблице можно осуществить доступ в декодере, чтобы использовать 2-битный указатель.
Синтаксический участок 26 может также иметь лишь три разных возможных значения, в данном случае FD-кадры будут использовать только одну возможную длину.
Немного отличающаяся, но очень похожая структура синтаксиса той, описанной выше по отношению к фиг.15-19, показана на фиг.20-22, использующих те же самые ссылочные обозначения, что и на фиг.15-19, так что ссылка сделана на этот вариант осуществления для разъяснения варианта осуществления по фиг.20-22.
Касательно вариантов осуществления, описанных по отношению к фиг.3 и следующим, следует отметить, что любая схема кодирования с преобразованием при уместности помех дискретизации может быть использована в связи с TCX-кадрами, в отличие от MDCT. К тому же, схема кодирования с преобразованием, как, например, FFT, могла быть также использована, тогда без помех дискретизации в LPD-режиме, т.е. без FAC для переходов подкадров внутри LPD-кадров и, таким образом, без нужды передачи данных FAC для границ подкадров между LPD-границами. Данные FAC были бы тогда лишь включены в состав для каждого перехода от FD к LPD и наоборот.
Касательно вариантов осуществления, описанных по отношению к фиг.1 и следующим, следует отметить, что таковые были направлены на случай, где дополнительный синтаксический участок 26 был задан совместно, т.е. однозначно в зависимости от сравнения между режимом кодирования текущего кадра и режимом кодирования предыдущего кадра, как задано в первом синтаксическом участке предыдущего кадра, так что во всех вышеуказанных вариантах осуществления декодер или устройство синтаксического анализа было способно однозначно предвидеть содержимое второго синтаксического участка текущего кадра посредством использования или сравнения первого синтаксического участка этих кадров, а именно предыдущего и текущего кадра. То есть в случае без потери кадра было возможно для декодера или устройства синтаксического анализа получить из переходов между кадрами, присутствуют ли данные FAC в текущем кадре, если кадр потерян; второй синтаксический участок, такой как бит fac_data_present, явно дает эту информацию. Однако в соответствии с другим вариантом осуществления кодер мог использовать эту явную возможность сигнализации, предложенную вторым синтаксическим участком 26, с тем чтобы применить обратное кодирование, согласно которому синтаксический участок 26 является адаптивным, при решении после выполнения на покадровой основе, например, задать так, чтобы хотя переход между текущим кадром и предыдущим кадром принадлежит к типу, который обычно идет вместе с данными FAC (как например, FD/TCX, т.е. любой режим TC-кодирования, к ACELP, т.е. любому режиму кодирования временной области или наоборот), синтаксический участок текущего кадра указывает отсутствие FAC. Декодер мог быть тогда реализован, чтобы строго действовать согласно синтаксическому участку 26, тем самым эффективно устраняя возможность, или подавляя, передачи данных FAC в кодере, который сообщает это подавление, лишь задавая, например, fac_data_present=0. Сценарием, где это могло бы быть благоприятной опцией, является, когда кодирование при очень низких битовых скоростях, где дополнительные данные FAC могли стоить слишком много битов, тогда как артефакты результирующих помех дискретизации могли бы быть терпимыми, по сравнению с общим качеством звука.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признака этапа способа. Аналогично аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут быть исполнены посредством (или используя) аппаратного устройства, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления некоторый один или более из наиболее важных этапов способа могут быть исполнены таким устройством.
Патентоспособный кодированный аудиосигнал может быть сохранен в цифровой среде хранения или может быть передан в среде передачи, такой как среда беспроводной передачи или среда проводной передачи, такой как Интернет.
В зависимости от определенных требований реализации варианты осуществления данного изобретения могут быть реализованы в аппаратном обеспечении или программном обеспечении. Данная реализация может быть выполнена, используя цифровую среду хранения, например, floppy-диск, DVD, Blue-Ray, CD, ROM, PROM, EPROM, EEPROM или flash-память, имеющий электронно-считываемые сигналы управления, хранящиеся на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так чтобы выполнялся соответствующий способ. Вследствие этого цифровая среда хранения может быть считываемым компьютером.
Некоторые варианты осуществления согласно данному изобретению содержат носитель данных, имеющий электронно-считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, так чтобы выполнялся один из способов, описанных в настоящем документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код, являющийся действующим для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на считываемом машиной носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем документе, хранящихся на считываемом машиной носителе.
Другими словами, вариант осуществления патентоспособного способа, вследствие этого, является компьютерной программой, имеющей программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления патентоспособных способов, вследствие этого, является носителем данных (или цифровой средой хранения или считываемой компьютером средой), содержащей записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровая среда хранения или записывающая среда обычно материальны и/или постоянны.
Дополнительный вариант осуществления патентоспособного способа, вследствие этого, является потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов могут, например, быть выполненными с возможностью быть перенесенными через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления согласно данному изобретению содержит устройство или систему, выполненные с возможностью переноса (например, электронно или оптически) компьютерной программы для выполнения одного из способов, описанных в настоящем документе, в приемник. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или тому подобным. Устройство или система могут, например, содержать файл-сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для выполнения некоторых или всех функциональных возможностей способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. В общем, способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и вариации данных компоновок и подробности, описанные в настоящем документе, будут очевидны специалистам в данной области техники. Это является замыслом, вследствие этого, который следует ограничить только объемом предстоящих пунктов формулы изобретения, и не конкретными подробностями, представленными с целью описания и разъяснения вариантов осуществления в настоящем документе.
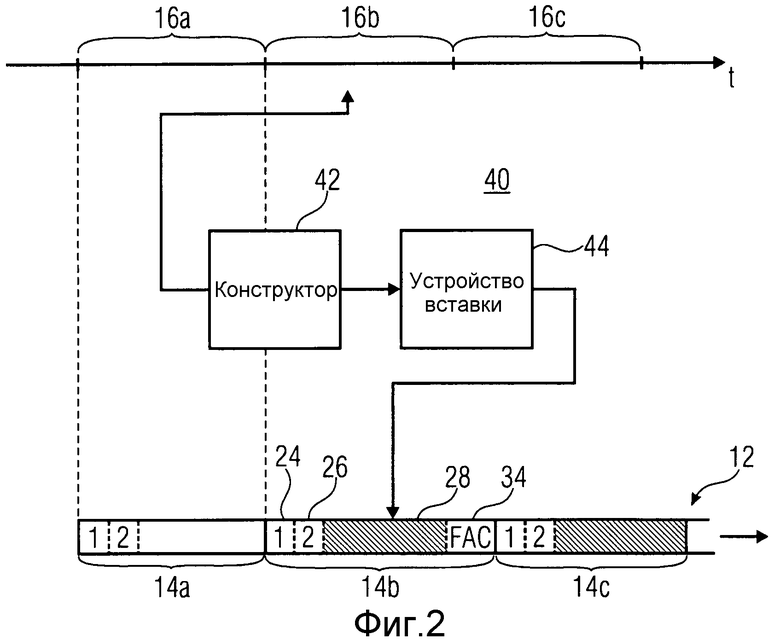
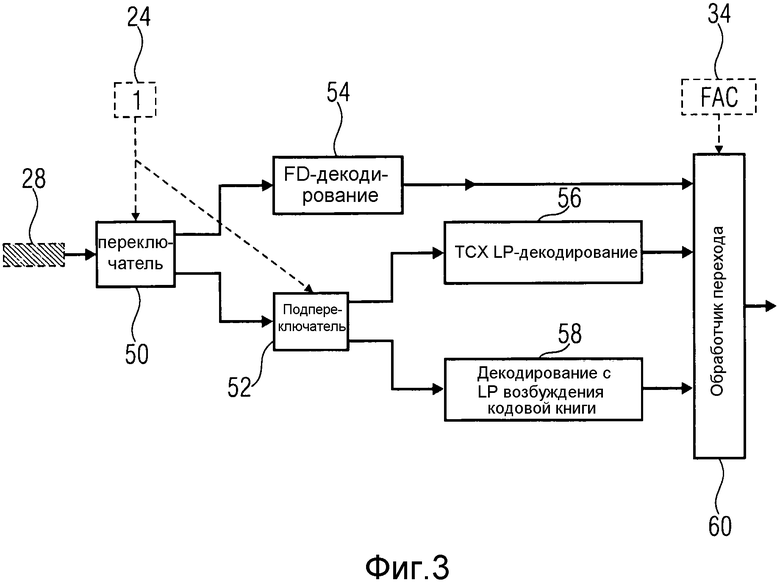
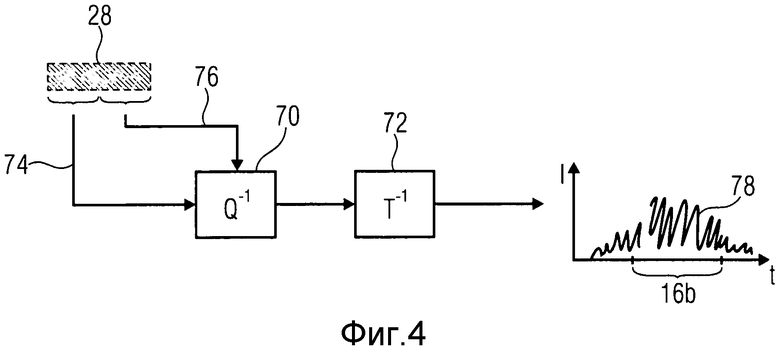
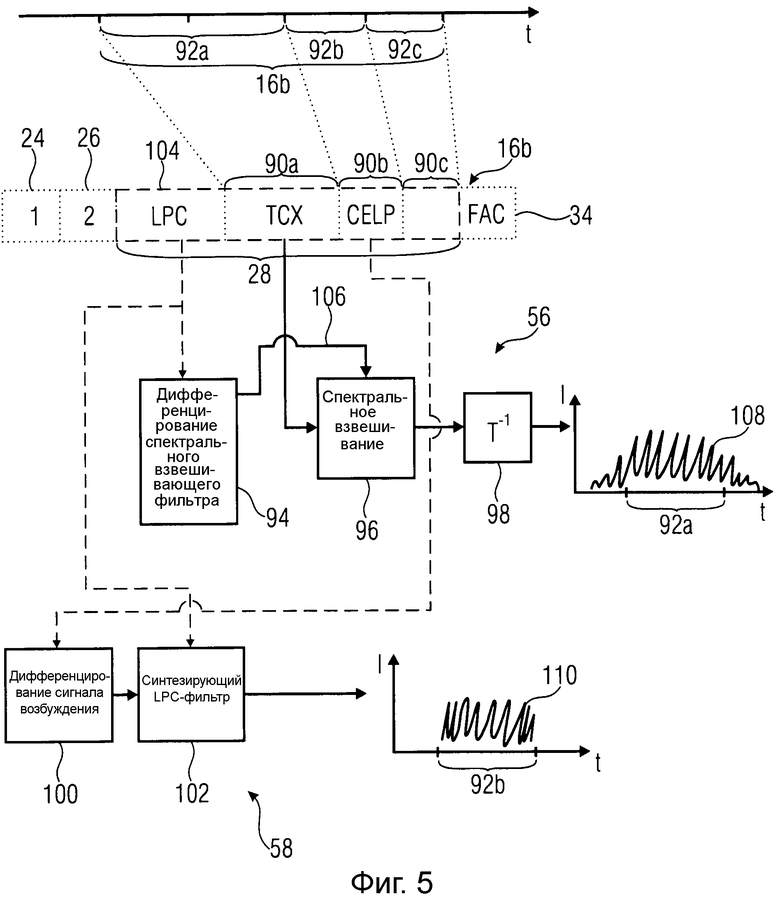
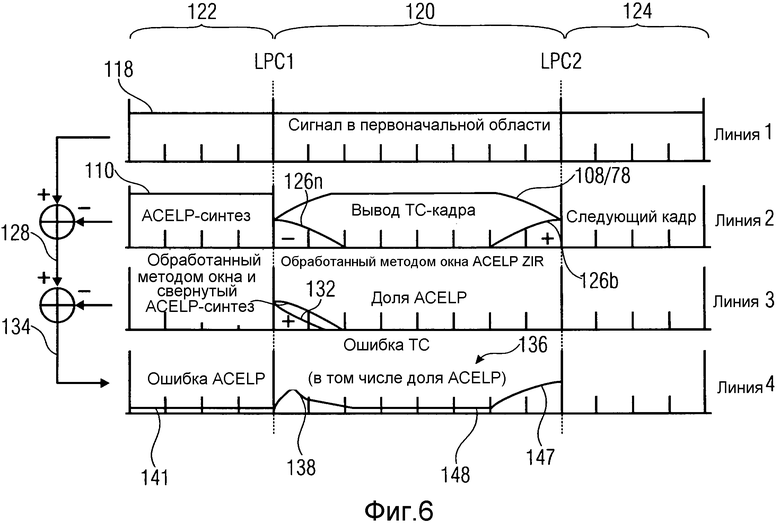
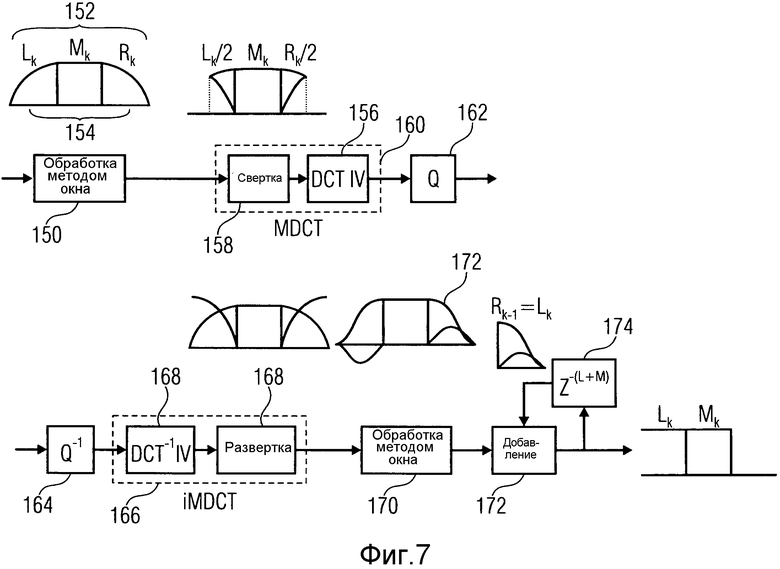
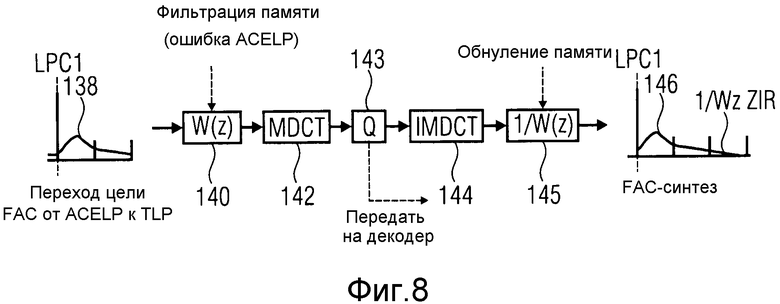
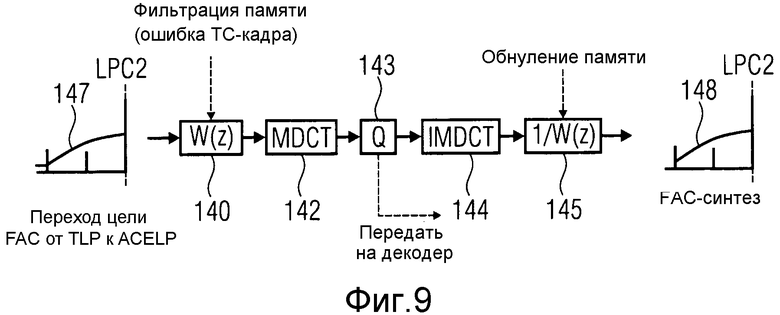
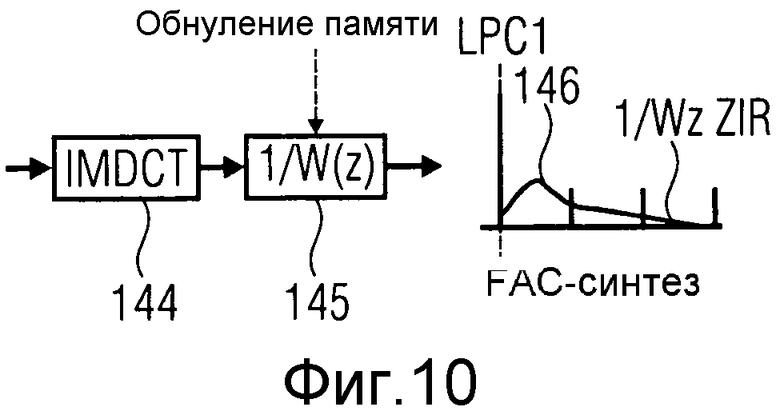
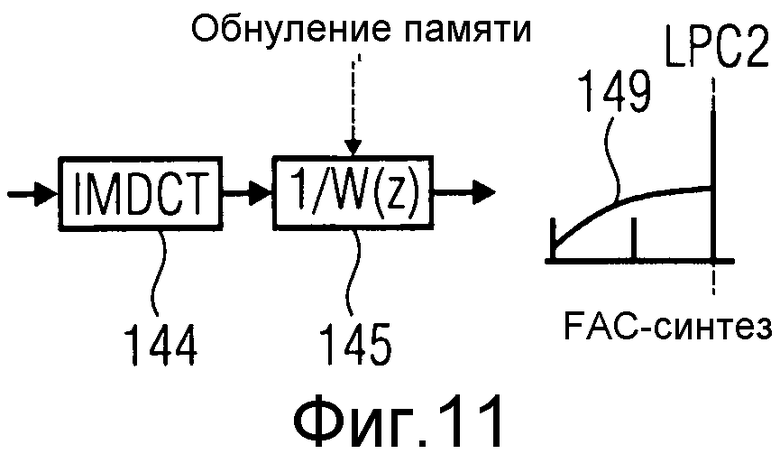
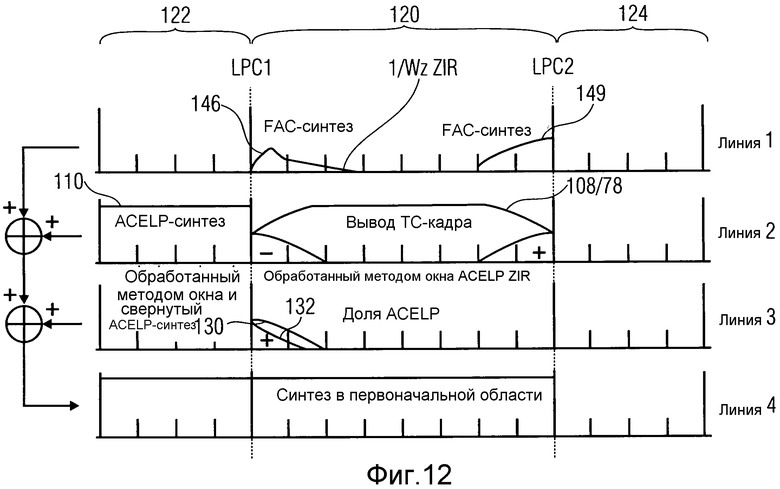
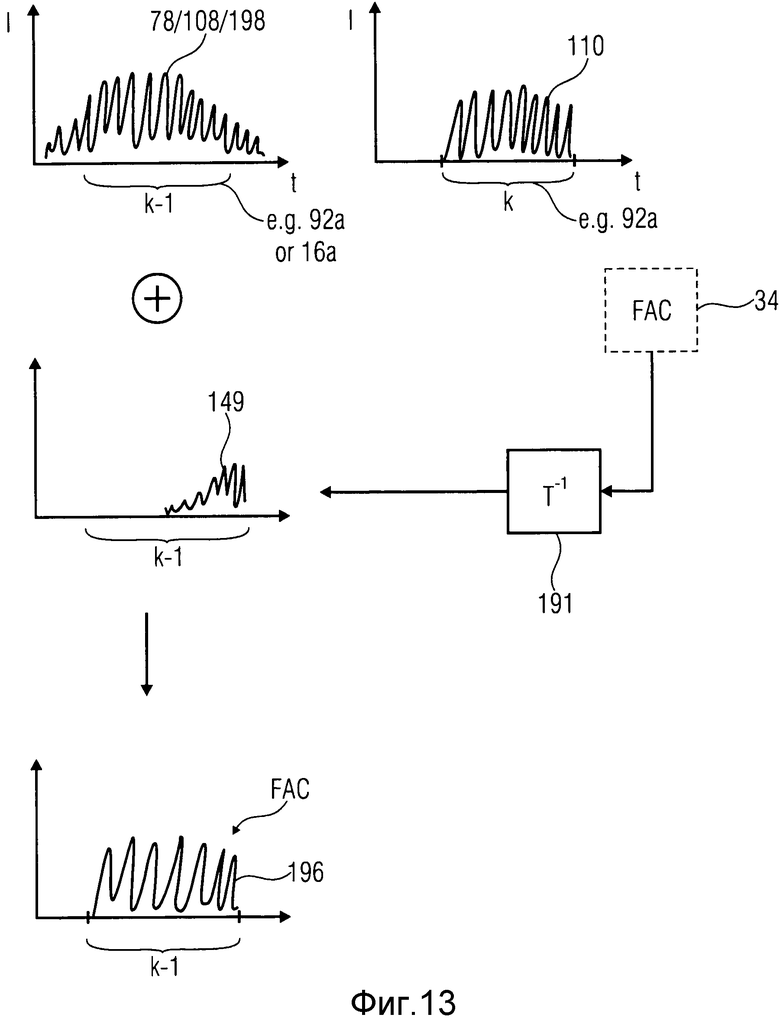
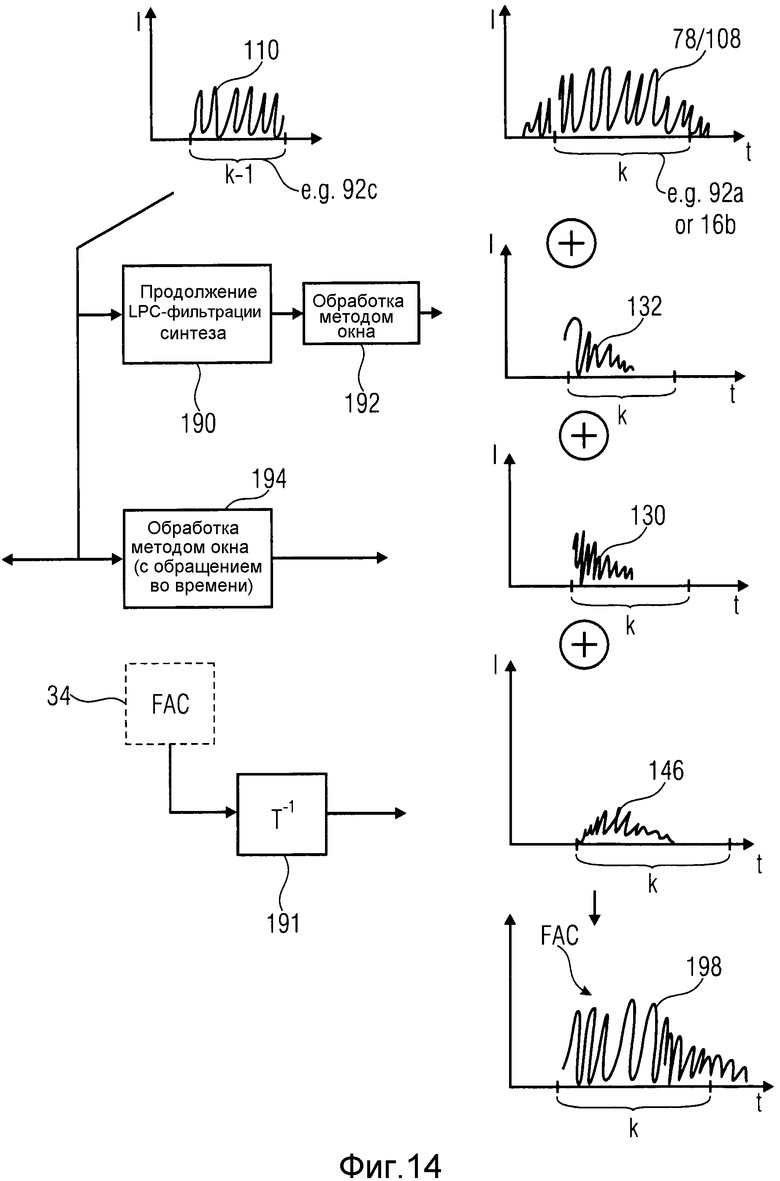
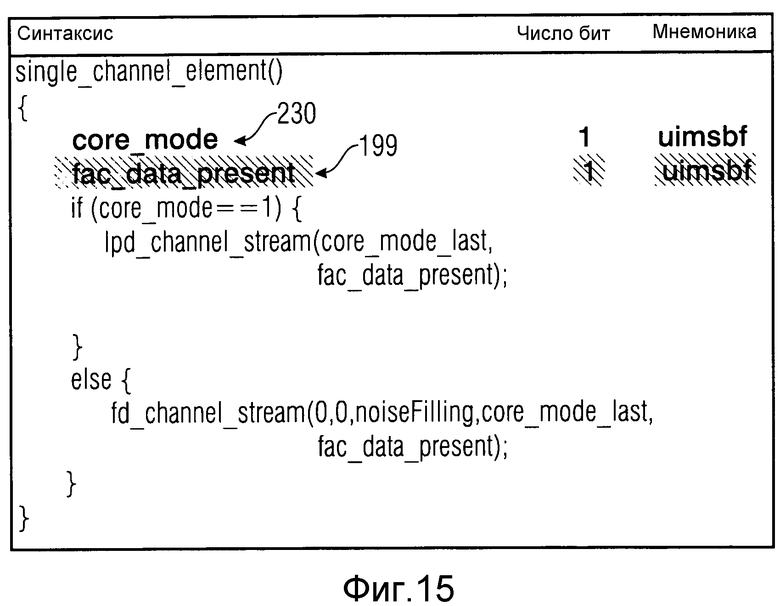
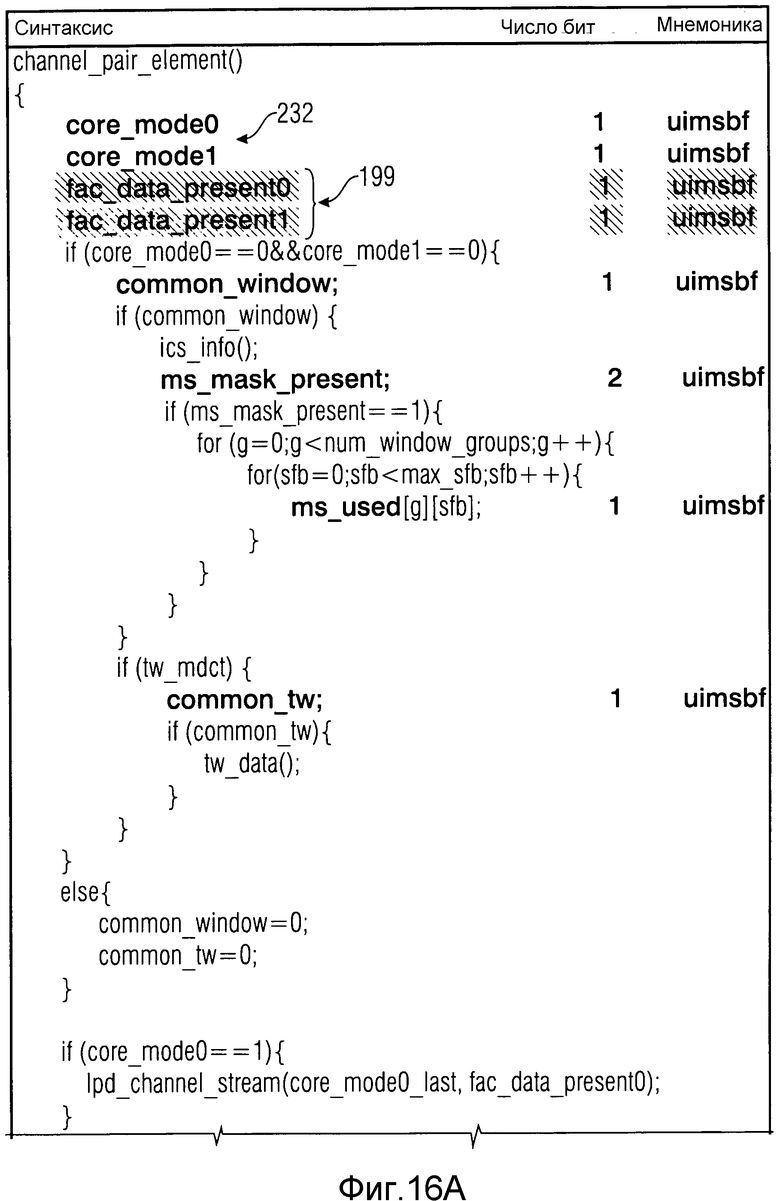
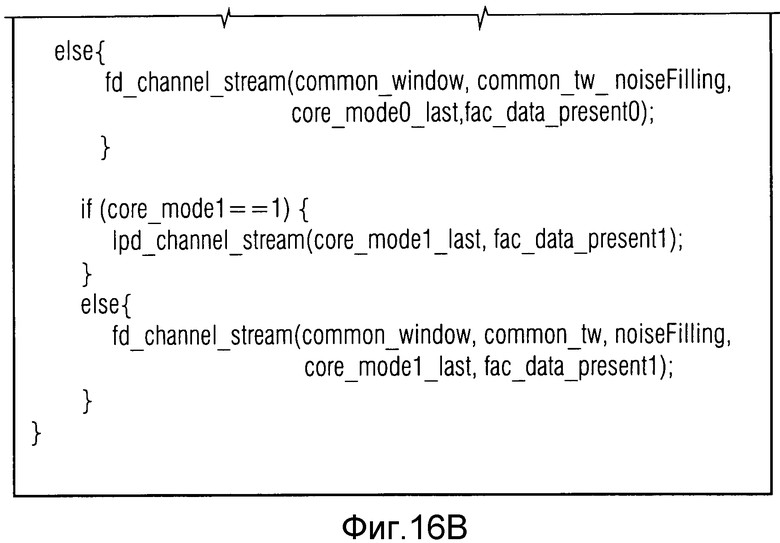

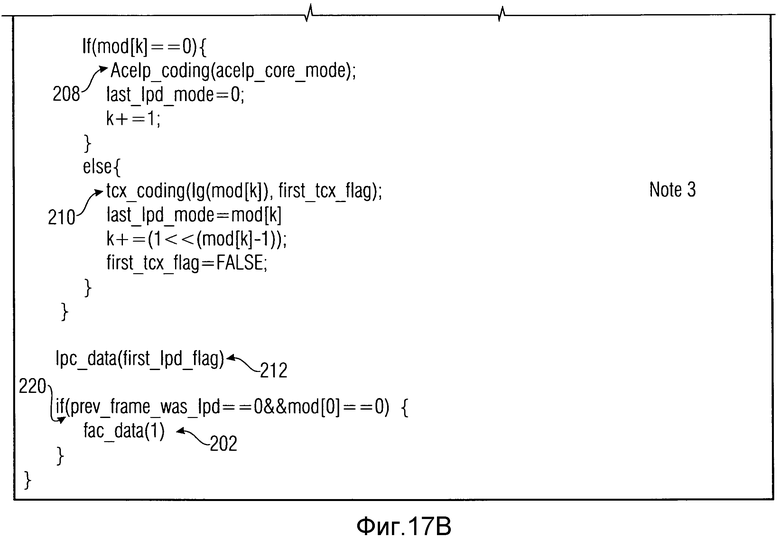


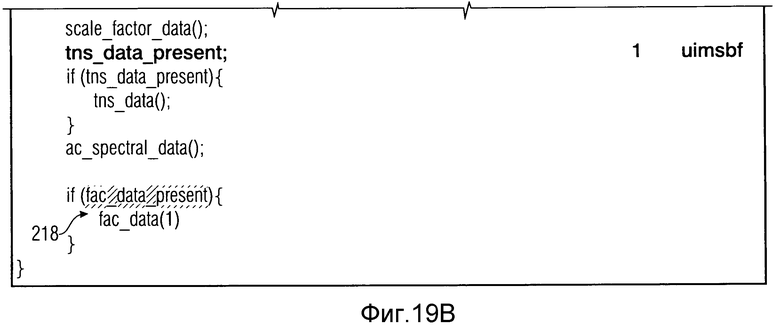



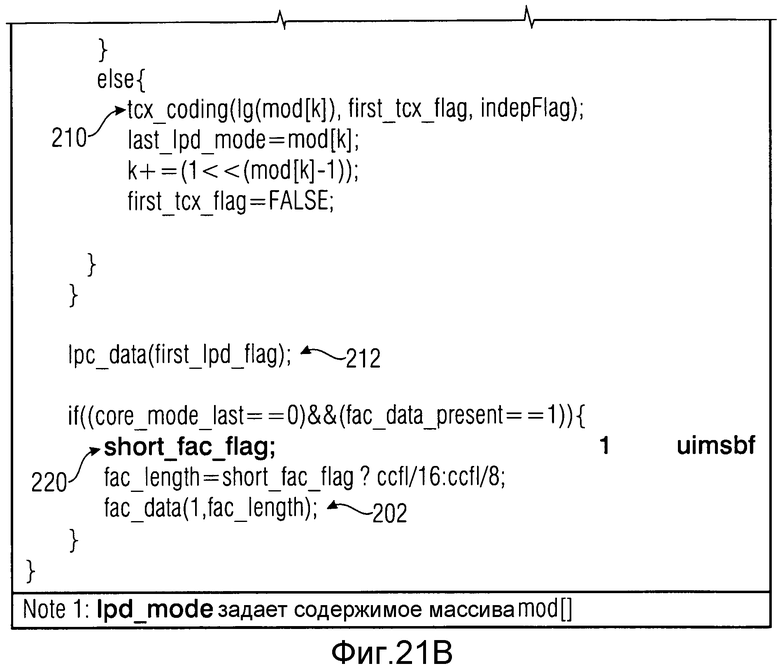
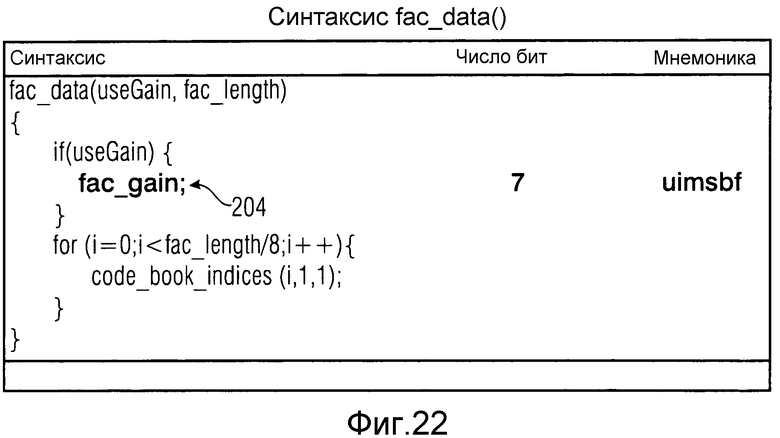
Изобретение относится к кодеку, поддерживающему переключение между режимом кодирования с преобразованием с подавлением помех дискретизации во временной области и режимом кодирования временной области. Технический результат состоит в том, что кодек сделан менее подверженным потере кадра. Это достигается посредством добавления дополнительного синтаксического участка к кадрам, в зависимости от которого устройство синтаксического анализа декодера может выбрать между первым действием ожидания, что текущий кадр содержит, и, таким образом, считывая данные прямого подавления помех дискретизации из текущего кадра, и вторым действием неожидания, что текущий кадр содержит, и, таким образом, не считывая данные прямого подавления помех дискретизации из текущего кадра. 6 н. и 14 з.п. ф-лы, 27 ил.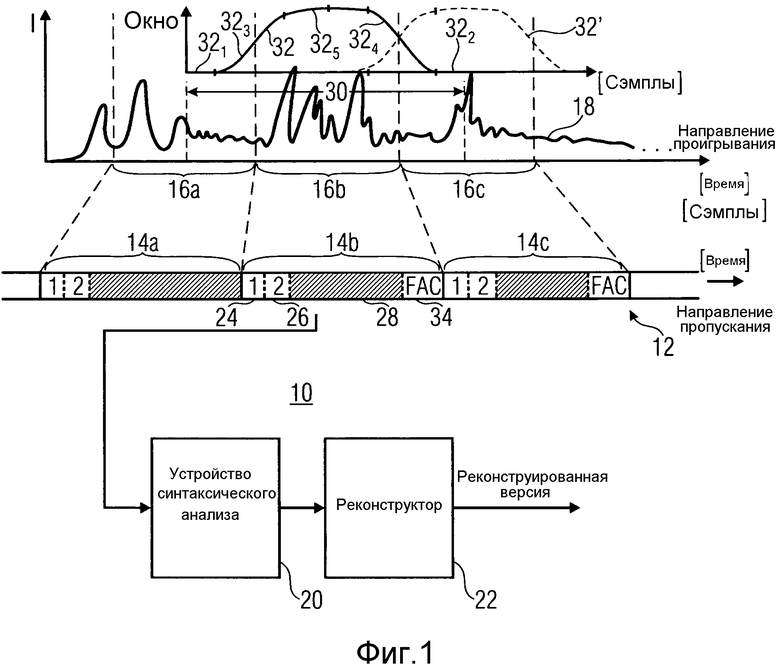
1. Декодер (10) для декодирования потока (12) данных, содержащий последовательность кадров, в которую кодируются временные сегменты информационного сигнала (18), соответственно, содержащий:
устройство (20) синтаксического анализа, выполненное с возможностью осуществления синтаксического анализа потока (12) данных, причем устройство синтаксического анализа выполнено с возможностью, при синтаксическом анализе потока (12) данных, считывать первый синтаксический участок (24) и второй синтаксический участок из текущего кадра (14b); и
реконструктор (22), выполненный с возможностью реконструкции текущего временного сегмента (16b) информационного сигнала (18), ассоциированного с текущим кадром (14b), на основе информации (28), полученной из текущего кадра посредством синтаксического анализа, используя первый выбранный один из режима декодирования с преобразованием с подавлением помех дискретизации во временной области и режима декодирования временной области, причем первый выбор зависит от первого синтаксического участка (24),
причем устройство (20) синтаксического анализа выполнено с возможностью, при синтаксическом анализе потока (12) данных, выполнения первого действия ожидания, что текущий кадр (14b) содержит, и, таким образом, считывая данные (34) прямого подавления помех дискретизации из текущего кадра (14b), или второго действия неожидания, что текущий кадр (14b) содержит, и, таким образом, не считывая данные (34) прямого подавления помех дискретизации из текущего кадра (14b), причем устройство синтаксического анализа выполняет второй выбор, выбирающий, которое из первого действия и второго действия выполняется, и зависящий от второго синтаксического участка,
причем реконструктор (22) выполнен с возможностью выполнения прямого подавления помех дискретизации на границе между текущим временным сегментом (16b) и предыдущим временным сегментом (16а) предыдущего кадра (14а), используя данные (34) прямого подавления помех дискретизации.
2. Декодер (10) по п. 1, в котором первый и второй синтаксические участки содержатся в каждом кадре, в котором первый синтаксический участок (24) ассоциирует соответствующий кадр, из которого таковой был считан, с первым типом кадра или вторым типом кадра, и если соответствующий кадр принадлежит ко второму типу кадра, ассоциирует подкадры подразделения соответствующего кадра, составленного из некоторого числа подкадров, с соответствующим одним из первого типа подкадра и второго типа подкадра, в котором реконструктор (22) выполнен, если первый синтаксический участок (24) ассоциирует соответствующий кадр с первым типом кадра, с возможностью использования декодирования частотной области в качестве первой версии режима декодирования с преобразованием подавления помех дискретизации во временной области для реконструкции временного сегмента, ассоциированного с соответствующим кадром, и, если первый синтаксический участок (24) ассоциирует соответствующий кадр со вторым типом кадра, использования, для каждого подкадра соответствующего кадра, декодирования с линейным предсказанием кодированного с преобразованием возбуждения в качестве второй версии режима декодирования с преобразованием с подавлением помех дискретизации во временной области для реконструкции соответствующего подучастка текущего временного сегмента соответствующего кадра, который ассоциирован с соответствующим подкадром, если первый синтаксический участок (24) ассоциирует соответствующий подкадр соответствующего кадра с первым типом подкадра, и декодирования с линейным предсказанием возбуждения кодовой книги в качестве режима декодирования временной области, чтобы реконструировать подучасток временного сегмента соответствующего кадра, который ассоциирован с соответствующим подкадром, если первый синтаксический участок (24) ассоциирует соответствующий подкадр со вторым типом подкадра.
3. Декодер (10) по п. 1, в котором второй синтаксический участок имеет набор возможных значений, каждое из которых однозначно ассоциировано с одним из набора возможностей, содержащий:
предыдущий кадр (14а), принадлежащий к первому типу кадра, предыдущий кадр (14а), принадлежащий ко второму типу кадра, с последним его подкадром, принадлежащим к первому типу подкадра, и
предыдущий кадр (14а), принадлежащий ко второму типу, с последним его подкадром, принадлежащим ко второму типу подкадра, и
устройство (20) синтаксического анализа выполнено с возможностью выполнения второго выбора на основе сравнения между вторым синтаксическим участком текущего кадра (14b) и первым синтаксическим участком (24) предыдущего кадра (14а).
4. Декодер по п. 3, в котором устройство (20) синтаксического анализа выполнено с возможностью выполнения считывания данных (34) прямого подавления помех дискретизации из текущего кадра (14b), если текущий кадр (14b) принадлежит ко второму типу кадра, зависящему от предыдущего кадра (14а), принадлежащего ко второму типу кадра с его последним подкадром, принадлежащим первому типу подкадра, или предыдущий кадр (14а), принадлежащий первому типу кадра, поскольку усиление прямого подавления помех дискретизации получено посредством синтаксического анализа из данных (34) прямого подавления помех дискретизации в случае, где предыдущий кадр (14а), принадлежащий первому типу кадра, и нет, если предыдущий кадр, принадлежащий ко второму типу кадра с его последним подкадром, принадлежащим первому типу подкадра, причем реконструктор (22) выполнен с возможностью выполнения прямого подавления помех дискретизации с интенсивностью, которая зависит от усиления прямого подавления помех дискретизации в случае, в котором предыдущий кадр (14а) принадлежит первому типу кадра.
5. Декодер (10) по п. 4, в котором устройство (20) синтаксического анализа выполнено с возможностью выполнения считывания, если текущий кадр (14b) принадлежит первому типу кадра, усиления прямого подавления помех дискретизации из данных (34) прямого подавления помех дискретизации, в котором реконструктор выполнен с возможностью выполнения прямого подавления помех дискретизации с интенсивностью, которая зависит от усиления прямого подавления помех дискретизации.
6. Декодер (10) по п. 1, в котором второй синтаксический участок имеет набор возможных значений, каждое из которых однозначно ассоциировано с одним из набора возможностей, содержащий:
предыдущий кадр (14а), принадлежащий к первому типу кадра, с задействованием длинного окна преобразования,
предыдущий кадр (14а), принадлежащий к первому типу кадра, с задействованием коротких окон преобразования,
предыдущий кадр (14а), принадлежащий ко второму типу кадра, с последним его подкадром, принадлежащим к первому типу подкадра, и
предыдущий кадр (14а), принадлежащий ко второму типу кадра, с последним его подкадром, принадлежащим ко второму типу подкадра, и
устройство синтаксического анализа выполнено с возможностью выполнения второго выбора на основе сравнения между вторым синтаксическим участком текущего кадра (14b) и первым синтаксическим участком (24) предыдущего кадра (14а) и выполнения считывания данных (34) прямого подавления помех дискретизации из текущего кадра (14b), если предыдущий кадр (14а) принадлежит к первому типу кадра, в зависимости от предыдущего кадра (14а) задействования длинного окна преобразования или коротких окон преобразования, так что объем данных (34) прямого подавления помех дискретизации больше, если предыдущий кадр (14а) задействует длинное окно преобразования, и меньше, если предыдущий кадр (14а) задействует короткие окна преобразования.
7. Декодер (20) по п. 2, в котором реконструктор выполнен с возможностью, на каждый кадр первого типа кадра, выполнения деквантования (70) с изменяющимся спектром информации коэффициентов преобразования внутри соответствующего кадра первого типа кадра на основе информации масштабного множителя внутри соответствующего кадра первого типа кадра и повторного преобразования информации деквантованных коэффициентов преобразования для получения сегмента (78) повторно преобразованного сигнала, продолжающегося во времени в пределах и за пределами временного сегмента, ассоциированного с соответствующим кадром первого типа кадра, и
на каждый кадр второго типа кадра,
на каждый подкадр первого типа подкадра соответствующего кадра второго типа кадра,
получения (94) фильтра спектрального взвешивания из LPC-информации внутри соответствующего кадра второго типа кадра,
спектрального взвешивания (96) информации коэффициентов преобразования внутри соответствующего подкадра первого типа подкадра, используя фильтр спектрального взвешивания, и
повторного преобразования (98) спектрально взвешенной информации коэффициентов преобразования для получения сегмента повторно преобразованного сигнала, продолжающегося во времени в пределах и за пределами участка временного сегмента, ассоциированного с соответствующим подкадром первого типа подкадра, и
на каждый подкадр второго типа подкадра соответствующего кадра второго типа кадра,
получения (100) сигнала возбуждения из информации обновления возбуждения внутри соответствующего подкадра второго типа подкадра,
выполнения LPC-фильтрации (102) синтеза над сигналом возбуждения, используя LPC-информацию внутри соответствующего кадра второго типа кадра для того, чтобы получить сегмент (110) синтезированного LP-сигнала для подучастка временного сегмента, ассоциированного с соответствующим подкадром второго типа подкадра, и
выполнения подавления помех дискретизации во временной области внутри временно перекрывающихся оконных участков на границах между временными сегментами непосредственно идущих подряд одних из кадров первого типа кадров и подучастков временных сегментов, которые ассоциированы с подкадрами первого типа подкадра, чтобы реконструировать информационный сигнал (18) между ними, и
если предыдущий кадр принадлежит к первому типу кадра или второму типу кадра с его последним подкадром, принадлежащим к первому типу подкадра, и текущий кадр (14b) принадлежит ко второму типу кадра с его первым подкадром, принадлежащим ко второму типу подкадра, получения первого синтезированного сигнала с прямым подавлением помех дискретизации из данных (34) прямого подавления помех дискретизации и добавления первого синтезированного сигнала с прямым подавлением помех дискретизации в сегмент (78) повторно преобразованного сигнала внутри предыдущего временного сегмента для реконструкции информационного сигнала (18) на границе между предыдущим и текущим кадрами (14а, 14b), и
если предыдущий кадр (14а) принадлежит ко второму типу кадра с его первым подкадром, принадлежащим ко второму типу подкадра, и текущий кадр (14b) принадлежит к первому типу кадра или ко второму типу кадра с его последним подкадром, принадлежащим к первому типу подкадра, получения второго синтезированного сигнала с прямым подавлением помех дискретизации из данных (34) прямого подавления помех дискретизации и добавления второго синтезированного сигнала с прямым подавлением помех дискретизации в сегмент повторно преобразованного сигнала внутри текущего временного сегмента (16b) для реконструкции информационного сигнала (18) на границе между предыдущим и текущим временными сегментами (16а, 16b).
8. Декодер (10) по п. 7, в котором реконструктор выполнен с возможностью:
получения первого синтезированного сигнала с прямым подавлением помех дискретизации из данных (34) прямого подавления помех дискретизации посредством выполнения повторного преобразования информации коэффициентов преобразования, содержащейся в данных (34) прямого подавления помех дискретизации, и/или
получения второго синтезированного сигнала с прямым подавлением помех дискретизации из данных (34) прямого подавления помех дискретизации посредством выполнения повторного преобразования информации коэффициентов преобразования, содержащейся в данных (34) прямого подавления помех дискретизации.
9. Декодер по п. 1, в котором второй синтаксический участок содержит первый флаг, сообщающий, присутствуют ли данные (34) прямого подавления помех дискретизации в соответствующем кадре, и устройство синтаксического анализа выполнено с возможностью выполнения второго выбора в зависимости от первого флага, и в котором второй синтаксический участок дополнительно содержит второй флаг лишь внутри кадров второго типа кадров, причем второй флаг сообщает, принадлежит ли предыдущий кадр к первому типу кадра или ко второму типу кадра с его последним подкадром, принадлежащим к первому типу подкадра.
10. Декодер по п. 9, в котором устройство синтаксического анализа выполнено с возможностью выполнения считывания данных (34) прямого подавления помех дискретизации из текущего кадра (14b), если текущий кадр (14b) принадлежит ко второму типу кадра, в зависимости от второго флага, при этом усиление прямого подавления помех дискретизации получается посредством синтаксического анализа из данных (34) прямого подавления помех дискретизации в случае, где предыдущий кадр принадлежит первому типу кадра, и нет, если предыдущий кадр принадлежит ко второму типу кадра с его последним подкадром, принадлежащим первому типу подкадра, в котором реконструктор выполнен с возможностью выполнения прямого подавления помех дискретизации с интенсивностью, которая зависит от усиления прямого подавления помех дискретизации в случае, где предыдущий кадр принадлежит первому типу кадра.
11. Декодер по п. 10, в котором второй синтаксический участок дополнительно содержит третий флаг, сообщающий, задействует ли предыдущий кадр длинное окно преобразования или короткие окна преобразования, лишь внутри кадров второго типа кадра, если второй флаг сообщает, что предыдущий кадр принадлежит первому типу кадра, в котором устройство (20) синтаксического анализа выполнено с возможностью выполнения считывания данных (34) прямого подавления помех дискретизации из текущего кадра (14b), в зависимости от третьего флага, так что объем данных (34) прямого подавления помех дискретизации больше, если предыдущий кадр задействует длинное окно преобразования, и меньше, если предыдущий кадр задействует короткие окна преобразования.
12. Декодер по п. 1, в котором реконструктор выполнен с возможностью, если предыдущий кадр принадлежит ко второму типу кадра с его последним подкадром, принадлежащим ко второму типу подкадра, и текущий кадр (14b) принадлежит к первому типу кадра или второму типу кадра с его последним подкадром, принадлежащим к первому типу подкадра, выполнения обработки методом окна сегмента синтезированного LP-сигнала последнего подкадра предыдущего кадра для получения первого сегмента сигнала подавления помех дискретизации и добавления первого сегмента сигнала подавления помех дискретизации в сегмент повторно преобразованного сигнала внутри текущего временного сегмента.
13. Декодер по п. 7, в котором реконструктор выполнен с возможностью, если предыдущий кадр принадлежит ко второму типу кадра с его последним подкадром, принадлежащим ко второму типу подкадра, и текущий кадр (14b) принадлежит к первому типу кадра или второму типу кадра с его последним подкадром, принадлежащим к первому типу подкадра, продолжения LPC-фильтрации синтеза, выполняемой над сигналом возбуждения из предыдущего кадра в текущий кадр, осуществления обработки методом окна таким образом полученного продолжения сегмента синтезированного LP-сигнала предыдущего кадра (14b) внутри текущего кадра для получения второго сегмента сигнала подавления помех дискретизации и добавления второго сегмента сигнала подавления помех дискретизации в сегмент повторно преобразованного сигнала внутри текущего временного сегмента.
14. Декодер по п. 1, в котором устройство (20) синтаксического анализа выполнено с возможностью, при синтаксическом анализе потока (12) данных, выполнения второго выбора в зависимости от второго синтаксического участка и независимо от того, являются ли текущий кадр (14b) и предыдущий кадр (14а) кодированными, используя одинаковые или разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области.
15. Кодер для кодирования информационного сигнала (18) в поток (12) данных, так чтобы поток (12) данных содержал последовательность кадров, в которую кодируются временные сегменты информационного сигнала (18), соответственно содержащий:
конструктор (42), выполненный с возможностью кодирования текущего временного сегмента (16b) информационного сигнала (18) в информацию текущего кадра (14b), используя первый выбранный один из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области; и
устройство (44) вставки, выполненное с возможностью вставки информации (28) в текущий кадр (14b) наряду с первым синтаксическим участком (24) и вторым синтаксическим участком, в котором первый синтаксический участок (24) сообщает первый выбор,
причем конструктор (42) и устройство (44) вставки выполнены с возможностью:
определения данных (34) прямого подавления помех дискретизации для прямого подавления помех дискретизации на границе между текущим временным сегментом (16b) и предыдущим временным сегментом предыдущего кадра и вставки данных (34) прямого подавления помех дискретизации в текущий кадр (14b) в случае, когда текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области,
и воздержания от вставки каких-либо данных (34) прямого подавления помех дискретизации в текущий кадр (14b) в случае, когда текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя одинаковые режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области,
причем второй синтаксический участок (26) задается в зависимости от того, являются ли текущий кадр (14b) и предыдущий кадр (14а) кодированными, используя одинаковые или разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области.
16. Кодер по п. 15, в котором кодер выполнен,
если текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя одинаковые режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области, с возможностью задания второго синтаксического участка в первое состояние, сообщающее отсутствие данных (34) прямого подавления помех дискретизации в текущем кадре, и
если текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области, с возможностью решения в смысле оптимизации скорости/искажения с тем, чтобы
воздержаться от вставки данных (34) прямого подавления помех дискретизации в текущий кадр (14b), хотя текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области, при этом задавая второй синтаксический участок так, чтобы таковой сообщал отсутствие данных (34) прямого подавления помех дискретизации в текущем кадре (14b), или
вставить данные (34) прямого подавления помех дискретизации в текущий кадр (14b), при этом задавая второй синтаксический участок так, чтобы таковой сообщал вставку данных (34) прямого подавления помех дискретизации в текущем кадре (14b).
17. Способ для декодирования потока (12) данных, содержащий последовательность кадров, в которую кодируются временные сегменты информационного сигнала (18), соответственно содержащий:
синтаксический анализ потока (12) данных, в котором синтаксический анализ потока данных содержит считывание первого синтаксического участка (24) и второго синтаксического участка из текущего кадра (14b); и
реконструкцию текущего временного сегмента информационного сигнала (18), ассоциированного с текущим кадром (14b), на основе дополнительной информации, полученной из текущего кадра (14b) посредством синтаксического анализа, используя первый выбранный один из режима декодирования с преобразованием с подавлением помех дискретизации во временной области и режима декодирования временной области, причем первый выбор зависит от первого синтаксического участка (24),
причем, при синтаксическом анализе потока (12) данных, выполняется первое действие ожидания, что текущий кадр (14b) содержит, и, таким образом, считывая данные (34) прямого подавления помех дискретизации из текущего кадра (14b), или второго действия неожидания, что текущий кадр содержит, и, таким образом, не считывая данные (34) прямого подавления помех дискретизации из текущего кадра (14b), причем второй выбор в отношении того, которое из первого действия и второго действия выполняется, выполняется в зависимости от второго синтаксического участка,
причем реконструкция содержит выполнение прямого подавления помех дискретизации на границе между текущим временным сегментом и предыдущим временным сегментом (16а) предыдущего кадра, используя данные (34) прямого подавления помех дискретизации.
18. Способ для кодирования информационного сигнала (18) в поток (12) данных так, чтобы поток (12) данных содержал последовательность кадров, в которую кодируются временные сегменты информационного сигнала (18), соответственно содержащий
кодирование текущего временного сегмента информационного сигнала (18) в информацию текущего кадра (14b), используя первый выбранный один из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области; и
вставку информации в текущий кадр (14b) наряду с первым синтаксическим участком (24) и вторым синтаксическим участком, в котором первый синтаксический участок (24) сообщает первый выбор,
определение данных (34) прямого подавления помех дискретизации на границе между текущим временным сегментом и предыдущим временным сегментом предыдущего кадра и вставку данных (34) прямого подавления помех дискретизации в текущий кадр (14b) в случае, когда текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области, и воздержание от вставки каких-либо данных (34) прямого подавления помех дискретизации в текущий кадр (14b) в случае, когда текущий кадр (14b) и предыдущий кадр (14а) кодированы, используя одинаковые режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области,
причем второй синтаксический участок задается в зависимости от того, являются ли текущий кадр (14b) и предыдущий кадр кодированными, используя одинаковые или разные режимы из режима кодирования с преобразованием с подавлением помех дискретизации во временной области и режима кодирования временной области.
19. Считываемый машиной носитель, хранящий компьютерную программу, имеющую программный код для выполнения, когда выполняется на компьютере, способа по п. 17.
20. Считываемый машиной носитель, хранящий компьютерную программу, имеющую программный код для выполнения, когда выполняется на компьютере, способа по п. 18.
| СИСТЕМЫ, СПОСОБЫ И УСТРОЙСТВО ШИРОКОПОЛОСНОГО РЕЧЕВОГО КОДИРОВАНИЯ | 2006 |
|
RU2381572C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПОДАВЛЕНИЯ ШУМОВ | 2006 |
|
RU2351024C2 |
| US 6593872 B2, 15.07.2003 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| BERNDT GEISER and PETER VARY: "JOINT PRE-ECHO CONTROL AND FRAME ERASURE CONCEALMENT FOR VOIP AUDIO CODECS", 24-28 августа 2009, найдено в Интернет 14.10.2014 и размещено по адресу: http://www.ind.rwth-aachen.de/fileadmin/publications/geiser09a.pdf. | |||

