Настоящее изобретение относится к аудиокодеру для кодирования многоканального аудиосигнала и аудиодекодеру для декодирования кодированного аудиосигнала. Варианты осуществления изобретения относятся к переключаемым перцептуальным аудиокодекам, обеспечивающим сохранение формы сигнала и параметрическое стереокодирование.
В настоящее время на практике широко используют перцептуальное кодирование аудиосигналов с целью сокращения объема данных для эффективного запоминания или передачи этих сигналов. В частности, когда должна быть обеспечена максимальная эффективность, используют кодеки, которые хорошо адаптированы к входным характеристикам сигнала. Одним из примеров является базовый кодек MPEG-D USAC, который может быть выполнен с возможностью преимущественного использования кодирования с ACELP (линейное предсказание с алгебраическим кодовым возбуждением) для речевых сигналов, кодирование с TCX (преобразование возбуждающего сигнала) для фонового шума и микшированных сигналов, и AAC (усовершенствованное аудиокодирование) для музыкального контента. Все три внутренние конфигурации кодека могут мгновенно переключаться адаптивным в отношении сигнала образом в зависимости от контента сигнала.
Кроме того, используют способы объединенного многоканального кодирования (кодирование по схеме центральный/боковой и т.д.) или способы параметрического кодирования для обеспечения максимальной эффективности. Способы параметрического кодирования в своей основе нацелены на воссоздание перцептуально эквивалентного аудиосигнала, а не высококачественное восстановление заданной формы сигнала. Соответствующие примеры включают заполнение шума, расширение ширины полосы частот и пространственное аудиокодирование.
При объединении базового кодера, адаптивного к сигналу, и способов либо многоканального, либо параметрического кодирования в известных кодеках, базовый кодек переключают для согласования с характеристиками сигнала, но выбор способов многоканального кодирования, такого как M/S-Stereo, пространственного аудиокодирования или параметрического стерео, остается фиксированным и не зависит от характеристик сигнала. Эти способы обычно используют в базовом кодеке в качестве предпроцессора для базового кодера и постпроцессора для базового декодера, причем и тот, и другой никак не учитывают действительный выбор, реализованный базовым кодеком.
С другой стороны, выбор способов параметрического кодирования для расширения ширины полосы иногда выполняется в зависимости от сигнала. Например, способы, применяемые во временной области, являются более эффективными для речевых сигналов, в то время как обработка в частотной области больше подходит для других сигналов. В указанном случае принятые способы многоканального кодирования должны быть совместимы со способами расширения ширины полосы обоих типов.
Соответствующие материалы, отражающие известный уровень техники, содержат:
PS и MPS в качестве пред/постпроцессора для базового кодека MPEG-D USAC
Стандарт MPEG-D USAC
Стандарт аудио MPEG-H 3D
В MPEG-D USAC описан переключаемый базовый кодер. Однако в USAC способы многоканального кодирования определены в качестве фиксированного выбора, являющегося общим для всего базового кодера независимо от его внутреннего переключателя принципов кодирования, будь то ACELP, TCX («LPD») или AAC («FD»). Таким образом, если необходимо иметь конфигурацию переключаемого базового кодека, этот кодек ограничен использованием параметрического многоканального кодирования (PS) для всего сигнала. Однако, для кодирования, например, музыкальных сигналов больше подходит использование объединенного стереокодирования, которое позволяет обеспечить динамическое переключение между схемой L/R (левый/правый) и схемой M/S (центральный/боковой) для каждого частотного диапазона и каждого кадра.
Таким образом, имеется потребность в усовершенствовании существующего подхода.
Задачей настоящего изобретения является обеспечение усовершенствованной концепции для обработки аудиосигнала. Эта задача решается содержанием независимых пунктов формулы изобретения.
Настоящее изобретение основано на определении того, что параметрический кодер (временной области), использующий многоканальный кодер, является предпочтительным для параметрического многоканального аудиокодирования. Многоканальный кодер может представлять собой многоканальный остаточный кодер, который может уменьшить ширину полосы частот для передачи параметров кодирования по сравнению с отдельным кодированием для каждого канала. Это с успехом можно использовать, например, в комбинации с объединенным многоканальным аудиокодером частотной области. Способы объединенного многоканального кодирования во временной области и частотной области могут быть объединены так, что, например, техническое решение на основе кадров позволит адресовать текущий кадр в период кодирования на временной основе или частотной основе. Другими словами, в вариантах осуществления показана усовершенствованная концепция для объединения переключаемого базового кодека с использованием объединенного многоканального кодирования и параметрического пространственного аудиокодирования в полностью переключаемый перцептуальный кодек, который позволяет использовать другие способы многоканального кодирования в зависимости от выбора базового кодека. Это является преимуществом, поскольку, в отличие от уже существующих методов, варианты осуществления изобретения демонстрируют способ многоканального кодирования, который может мгновенно переключаться наравне с базовым кодером, и, следовательно, окажется хорошо согласованным и адаптированным к выбранному базовому кодеру. Таким образом, можно избежать изложенных проблем, возникающих из-за фиксированного выбора способов многоканального кодирования. Более того, появляется возможность полностью переключаемого объединения заданного базового кодера и соответствующего адаптированного способа многоканального кодирования. Указанный кодер, например, реализующий AAC (усовершенствованное аудиокодирование) с использованием стереокодирования по схеме L/R или M/S позволяет выполнять кодирование музыкального сигнала в базовом кодере в частотной области (FD) с использованием специального объединенного стерео или многоканального кодирования, например, M/S стерео. Это решение можно применить в отдельности для каждой полосы частот в каждом аудиокадре. В случае, например, речевого сигнала базовый кодер может мгновенно переключиться на декодирование с линейным предсказанием (LPD), и на соответствующие другие, например, параметрические способы стереокодирования.
В вариантах осуществления показаны стереообработка, являющаяся уникальной для моно LPD тракта, и схема бесперебойного переключения на основе стереосигнала, которая объединяет выход стерео FD тракта с выходом базового LPD кодера и использует специальное стереокодирование. Это является преимуществом, поскольку позволяет обеспечить бесперебойное переключение кодека, причем свободное от артефактов.
Варианты осуществления относятся к кодеру для кодирования многоканального сигнала. Кодер содержит кодер области линейного предсказания и кодер частотной области. Кроме того, кодер содержит контроллер для переключения с кодера области линейного предсказания на кодер частотной области. Более того, кодер области линейного предсказания может содержать понижающий микшер для понижающего микширования многоканального сигнала с целью получения сигнала понижающего микширования, базовый кодер области линейного предсказания для кодирования сигнала понижающего микширования и первый многоканальный кодер для создания первой многоканальной информации из указанного многоканального сигнала. Кодер частотной области содержит второй объединенный многоканальный кодер для создания второй многоканальной информации из указанного многоканального сигнала, где второй многоканальный кодер отличается от первого многоканального кодера. Контроллер сконфигурирован так, что часть многоканального сигнала представляют либо кодированным кадром кодера области линейного предсказания, либо кодированным кадром кодера частотной области. Кодер области линейного предсказания может содержать ACELP базовый кодер и, например, использовать алгоритм параметрического стереокодирования в виде первого объединенного многоканального кодера. Кодер частотной области может, например, содержать AAC базовый кодер, в котором используют, например, L/R или M/S обработку, в качестве второго объединенного многоканального кодера. Контроллер способен анализировать многоканальный сигнал, например, в отношении характеристик кадра, типа, например, речи или музыки, и принять решение по каждому кадру, последовательности кадров или части многоканального аудиосигнала, какой кодер (кодер области линейного предсказания или кодер частотной области) следует использовать для кодирования данной части многоканального аудиосигнала.
В вариантах осуществления кроме того показан аудиодекодер для декодирования кодированного аудиосигнала. Аудиодекодер содержит декодер области линейного предсказания и декодер частотной области. Кроме того, аудиодекодер содержит первый объединенный многоканальный декодер для создания первого многоканального представления с использованием выхода декодера области линейного предсказания и с использованием многоканальной информации и второй многоканальный декодер для создания второго многоканального представления с использованием выхода декодера частотной области и второй многоканальной информации. Кроме того, аудиодекодер содержит первый объединитель для объединения первого многоканального представления и второго многоканального представления с целью получения декодированного аудиосигнала. Этот объединитель может выполнять бесперебойное переключение при отсутствии артефактов с первого многоканального представления, являющегося, например, многоканальным аудиосигналом линейного предсказания на второе многоканальное представление, являющееся, например, декодированным многоканальным аудиосигналом частотной области.
В вариантах осуществления показано представление ACELP/TCX кодирования в LPD тракте со специальным стереокодированием и независимого AAC стереокодирования в тракте частотной области в переключаемом аудиокодере. Кроме того, в вариантах осуществления показано бесперебойное мгновенное переключение с LPD стерео на FD стерео, где дополнительные варианты осуществления относятся к независимому выбору объединенного многоканального кодирования для сигнального контента разных типов. Например, для речи, которую предпочтительно кодируют, используя LPD тракт, используют параметрическое стерео, в то время как для музыки, которую кодируют в FD тракте, используют более адаптивное стереокодирование, которое позволяет динамически переключаться с L/R схемы на M/S схему для каждой полосы частот и каждого кадра.
Согласно вариантам осуществления речь, которую предпочтительно кодируют, используя LPD тракт, и которая обычно локализована в центре стереоизображения, хорошо подходит простое параметрическое стерео, в то время как музыка, которую кодируют в FD тракте, обычно имеет более сложное пространственное распределение, и можно получить выгоду, применив более адаптивное стереокодирование, которое может обеспечить динамическое переключение между L/R схемой и M/S схемой для каждой полосы частот и каждого кадра.
Кроме того, в вариантах осуществления показан аудиокодер, содержащий понижающий микшер (12) для понижающего микширования многоканального сигнала с целью получения сигнала понижающего микширования, базовый кодер области линейного предсказания для кодирования сигнала понижающего микширования, банк фильтров для создания спектрального представления многоканального сигнала и объединенный многоканальный кодер для создания многоканальной информации из многоканального сигнала. Сигнал понижающего микширования имеет нижний диапазон и верхний диапазон, причем базовый кодер области линейного предсказания выполнен с возможностью обработки, расширяющей полосу частот, для параметрического кодирования верхнего диапазона.
Кроме того, многоканальный кодер выполнен с возможностью обработки спектрального представления, содержащего нижний и верхний диапазон многоканального сигнала. Это является преимуществом, поскольку при каждом параметрическом кодировании можно использовать оптимальную время-частотную декомпозицию для получения его параметров. Это можно реализовать, используя, например, комбинацию ACELP (линейное предсказание с возбуждением по алгебраической кодовой книге) и TDBWE (расширение ширины полосы во временной области), где ACELP можно использовать для кодирования нижнего диапазона аудиосигнала, а TDBWE можно использовать для кодирования верхнего диапазона аудиосигнала, а также параметрическое многоканальное кодирование с внешним банком фильтров (например, DFT). Это комбинация особенно эффективна, поскольку известно, что наилучшее расширение ширины полосы для речи должно иметь место во временной области, и многоканальная обработка в частотной области. Поскольку ACELP+TDBWE не имеют временно-частотный преобразователь, использование внешнего банка фильтров или преобразования типа DFT имеет преимущество. Более того, кадрирование многоканального процессора может совпадать с кадрированием, используемым в ACELP. Даже в том случае, если многоканальная обработка выполняется в частотной области, временное разрешение для вычисления параметров или понижающего микширования в идеале должно приближаться или даже совпадать с кадрированием в ACELP.
Описанные варианты осуществления являются перспективными, поскольку можно использовать независимый выбор объединенного многоканального кодирования для сигнального контента разных типов.
Далее со ссылками на прилагаемые чертежи обсуждаются варианты осуществления настоящего изобретения, где:
Фиг. 1 - блок-схема кодера для кодирования многоканального аудиосигнала;
фиг. 2 - блок-схема кодера области линейного предсказания согласно варианту осуществления;
фиг. 3 - блок-схема кодера частотной области согласно варианту осуществления;
фиг. 4 - блок-схема аудиокодера согласно варианту осуществления;
Фиг. 5а - блок-схема активного понижающего микшера согласно варианту осуществления;
Фиг. 5b - блок-схема пассивного понижающего микшера согласно варианту осуществления;
фиг. 6 - блок-схема декодера для декодирования кодированного аудиосигнала;
фиг. 7 - блок-схема декодера согласно варианту осуществления;
фиг. 8 - блок-схема способа кодирования многоканального сигнала;
фиг. 9 - блок-схема способа декодирования кодированного аудиосигнала;
фиг. 10 - блок-схема кодера для кодирования многоканального сигнала согласно дополнительному аспекту;
фиг. 11 - блок-схема декодера для декодирования кодированного аудиосигнала согласно дополнительному аспекту;
фиг. 12 - блок-схема способа аудиокодирования для кодирования многоканального сигнала согласно дополнительному аспекту;
фиг. 13 - блок-схема способа декодирования кодированного аудиосигнала согласно дополнительному аспекту;
фиг. 14 - временная диаграмма бесперебойного переключения с кодирования в частотной области на LPD кодирование;
фиг. 15 - временная диаграмма бесперебойного переключения с декодирования в частотной области на декодирование LPD области;
фиг. 16 - временная диаграмма бесперебойного переключения с LPD кодирования на кодирование в частотной области;
фиг. 17 - временная диаграмма бесперебойного переключения с LPD декодирования на декодирование в частотной области;
фиг. 18 - блок-схема кодера для кодирования многоканального сигнала согласно дополнительному аспекту;
фиг. 19 - блок-схема декодера для декодирования кодированного аудиосигнала согласно дополнительному аспекту;
фиг. 20 - блок-схема способа аудиокодирования для кодирования многоканального сигнала согласно дополнительному аспекту;
фиг. 21 - блок-схема способа декодирования кодированного аудиосигнала согласно дополнительному аспекту.
Далее подробно раскрываются варианты осуществления изобретения. Элементы, показанные на соответствующих фигурах, имеющие одинаковые или подобные функциональные возможности, имеют привязанные к ним одинаковые ссылочные позиции.
На фиг. 1 схематически представлена блок-схема аудиокодера 2 для кодирования многоканального аудиосигнала 4. Аудиокодер содержит кодер 6 области линейного предсказания, кодер 8 частотной области и контроллер 10 для переключения с кодера 6 области линейного предсказания на кодер 8 частотной области. Контроллер способен анализировать многоканальный сигнал и принять решение по частям многоканального сигнала, какое кодирование (области линейного предсказания или частотной области) является предпочтительным. Другими словами, контроллер сконфигурирован так, что часть многоканального сигнала представляют либо кодированным кадром кодера области линейного предсказания, либо кодированным кадром кодера частотной области. Кодер области линейного предсказания содержит понижающий микшер 12 для понижающего микширования многоканального сигнала 4 с целью получения сигнала 14 многоканального микширования. Кодер области линейного предсказания кроме того содержит базовый кодер 16 области линейного предсказания для кодирования сигнала понижающего микширования и кроме того кодер области линейного предсказания содержит первый объединенный многоканальный кодер 18 для создания первой многоканальной информации 20, содержащей, например, параметры ILD (разница в уровне звукового сигнала, поступающего в оба уха) и/или IPD (интерауральный интервал), из многоканального сигнала 4. Многоканальный сигнал может, например, представлять собой стереосигнал, где понижающий микшер преобразует указанный стереосигнал в моносигнал. Базовый кодер области линейного предсказания может кодировать моносигнал, причем первый объединенный многоканальный кодер может создавать стереоинформацию для кодированного моносигнала в качестве первой многоканальной информации. Кодер частотой области и контроллер не являются обязательными по сравнению с дополнительным аспектом, описанным со ссылками на фиг. 10 и фиг. 11. Однако для адаптивного переключения с кодирования во временной области на кодирование частотой области с использованием кодера частотной области и контроллера является перспективным.
Кроме того, кодер 8 частотной области содержит второй объединенный многоканальный кодер 22 для создания второй многоканальной информации 24 из многоканального сигнала 4, где второй объединенный многоканальный кодер 22 отличается от первого многоканального кодера 18. Однако второй объединенный многоканальный процессор 22 получает вторую многоканальную информацию, позволяющую обеспечить второе качество воспроизведения, превышающее первое качество воспроизведения первой многоканальной информации, полученной первым многоканальным кодером для сигналов, которые лучше кодируются вторым кодером.
Другими словами, согласно вариантам осуществления, первый многоканальный кодер 18 выполнен с возможностью создания первой многоканальной информации 20, позволяющей обеспечить первое качество воспроизведения, где второй объединенный многоканальный кодер 22 выполнен с возможностью создания второй многоканальной информации 24, позволяющей обеспечить второе качество воспроизведения, где второе качество воспроизведения превышает первое качество воспроизведения. Это по меньшей мере соответствует сигналам, таким, например, как речевые сигналы, которые лучше кодируются вторым многоканальным кодером.
Таким образом, первый многоканальный кодер может представлять собой параметрический объединенный многоканальный кодер, содержащий, например, кодер предсказания стерео, параметрический стереокодер или параметрический стереокодер на основе чередования. Более того, второй объединенный многоканальный кодер может обеспечивать сохранение формы сигнала, например, на основе избирательного (в зависимости от диапазона) перехода на стереокодер типа (центральный/боковой) или типа (левый/правый). Как показано на фиг. 1, кодированный сигнал 26 понижающего микширования может передаваться на аудиодекодер и, но не обязательно, выполнять функцию первого объединенного многоканального процессора, где, например, кодированный сигнал понижающего микширования может быть декодирован, и можно вычислить остаточный сигнал из указанного многоканального сигнала до кодирования и после декодирования кодированного сигнала для повышения качества декодирования кодированного аудиосигнала на стороне декодера. Кроме того, контроллер 10 может использовать управляющие сигналы 28а, 28b для управления кодером области линейного предсказания и кодером частотой области соответственно после определения подходящей схемы кодирования для текущей части многоканального сигнала.
На фиг.2 представлена блок-схема кодера 6 области линейного предсказания согласно варианту осуществления. Входом в кодер 6 области линейного предсказания является сигнал 14 понижающего микширования, сформированный понижающим микшером 12. Кроме того, кодер области линейного предсказания содержит ACELP процессор 30 и TCX процессор 32. ACELP процессор 30 выполнен с возможностью работы с сигналом 34 понижающего микширования с понижающей дискретизацией, которая может быть выполнена блоком 35 понижающей дискретизации. Кроме того, процессор 36 расширения ширины полосы во временной области может выполнить параметрическое кодирование диапазона части сигнала 14 понижающего микширования, которая удалена из сигнала 34 понижающего микширования с понижающей дискретизацией, где сигнал 34 является входным сигналом ACELP процессора 30. Процессор 36 расширения ширины полосы во временной области может выдать параметрически кодированный диапазон 38 части сигнала 14 понижающего микширования. Другими словами, процессор 36 расширения ширины полосы во временной области может вычислить параметрическое представление частотных диапазонов сигнала 14 понижающего микширования, которые могут содержать боле высокие частоты по сравнению с частотой среза блока 35 понижающей дискретизации. Таким образом, блок 35 понижающей дискретизации может иметь дополнительное свойство, состоящее в подаче указанных частотных диапазонов, превышающих частоту среза блока понижающей дискретизации, в процессор 36 расширения ширины полосы во временной области, или для подачи частоты среза в процессор расширения ширины полосы во временной области временной области (TD-BWE), чтобы предоставить возможность TD-BWE процессору вычислить параметры 38 для корректной части сигнала 14 понижающего микширования.
Кроме того, TCX процессор выполнен с возможностью работы с сигналом понижающего микширования, который, например, не подвергался понижающей дискретизации, или степень этой понижающей дискретизации меньше понижающей дискретизации для ACELP процессора. Понижающая дискретизация в степени, меньшей понижающей дискретизации ACELP процессора, может представлять собой понижающую дискретизацию, при которой используют более высокую частоту среза, где в TCX процессор подается большее количество диапазонов сигнала понижающего микширования по сравнению с сигналом 35 понижающего микширования с понижающей дискретизацией, являющимся входным сигналом для ACELP процессора 30. TCX процессор может дополнительно содержать первый временно-частотный преобразователь 40, выполняющий, например, преобразования MOCT, DFT или DCT. TCX процессор 32 может дополнительно содержать первый параметрический генератор 42 и первый квантователь-кодер 44. Первый параметрический генератор 42, например, реализующий алгоритм интеллектуального заполнения пропусков (IDF) может вычислить первое параметрическое представление первого набора диапазонов 46, где первый квантователь-кодер 44, использует, например, TCX алгоритм для вычисления первого набора квантованных кодированных спектральных линий 48 для второго набора диапазонов. Другими словами, первый квантователь-кодер может выполнить параметрическое кодирование соответствующих диапазонов, например, тональных диапазонов входящего сигнала, где первый параметрический генератор использует, например, алгоритм IGF для остальных диапазонов входящего сигнала для дополнительного сокращения ширины полосы кодированного аудиосигнала.
Кодер 6 области линейного предсказания кроме того может содержать декодер 50 области линейного предсказания для декодирования сигнала 14 понижающего микширования, представленного, например, сигналом 52 понижающего микширования с понижающей дискретизацией после ACELP обработки и/или первым параметрическим представлением первого набора полос 46 и/или первым набором квантованных кодированных спектральных линий 48 для второго набора полос. Выход декодера 50 области линейного предсказания может представлять собой кодированный и декодированный сигнал 54 понижающего микширования. Этот сигнал 54 может быть введен в многоканальный остаточный кодер 56, который может вычислить и выполнить кодирование многоканального остаточного сигнала 58, используя кодированный и декодированный сигнал 54 понижающего микширования, где кодированный многоканальный остаточный сигнал представляет ошибку между декодированным многоканальным представлением, в котором используют первую многоканальную информацию, и многоканальным сигналом перед понижающим микшированием. Таким образом, многоканальный остаточный кодер 56 может содержать объединенный многоканальный декодер 60 на стороне кодера и разностный процессор 62. Объединенный многоканальный декодер 60 на стороне кодера может создавать декодированный многоканальный сигнал, используя первую многоканальную информацию 20, и кодированный и декодированный сигнал 54 понижающего микширования, где разностный процессор может сформировать разность между декодированным многоканальным сигналом 64 и многоканальным сигналом 4 до понижающего микширования, чтобы получить многоканальный остаточный сигнал 58. Другими словами, объединенный многоканальный декодер на стороне кодера в аудиокодере может выполнять операцию декодирования, что является преимуществом по сравнению с выполнением той же операции декодирования на стороне декодера. Таким образом, первая объединенная многоканальная информация, которую может получить аудиодекодер после передачи, используется в объединенном многоканальном декодере на стороне кодера для декодирования кодированного сигнала понижающего микширования. Разностный процессор 62 может вычислить разность между декодированным объединенным многоканальным сигналом и исходным многоканальным сигналом 4. Кодированный многоканальный остаточный сигнал 58 может повысить качество декодирования, выполняемого аудиодекодером, поскольку разность между декодированным сигналом и исходным сигналом, например, из-за параметрического кодирования, можно уменьшить, если знать, какова разность между этими двумя сигналами. Это позволяет первому объединенному многоканальному кодеру действовать так, чтобы можно было получить многоканальную информацию для всей полосы частот многоканального аудиосигнала.
Более того, сигнал 14 понижающего микширования может содержать нижний диапазон и верхний диапазон, где кодер 6 области линейного предсказания выполнен с возможностью применения обработки, связанной с расширением полосы частот, с использованием, например, процессора 36 расширения ширины полосы во временной области для параметрического кодирования верхнего диапазона, где декодер 6 области линейного предсказания выполнен с возможностью получения в качестве кодированного и декодированного сигнала 54 понижающего микширования только сигнала нижнего диапазона, представляющего нижний диапазон сигнала 14 понижающего микширования, и где кодированный многоканальный остаточный сигнал имеет только частоты в нижнем диапазоне многоканального сигнала перед понижающим микшированием. Другими словами, процессор расширения ширины полосы во временной области может вычислить параметры расширения ширины полосы для частотных диапазонов выше частоты среза, где ACELP процессор выполняет кодирование частот ниже частоты среза. Таким образом, декодер выполнен с возможностью восстановления более высоких частот на основе кодированного сигнала нижнего диапазона и параметров 38 полосы частот.
Согласно дополнительным вариантам осуществления многоканальный остаточный кодер 56 может вычислить боковой сигнал, причем сигнал понижающего микширования представляет собой соответствующий центральный сигнал M/S многоканального аудиосигнала. Таким образом, многоканальный остаточный кодер может вычислить и выполнить кодирование разности вычисленного бокового сигнала, который можно вычислить из полнодиапазонного спектрального представления многоканального аудиосигнала, полученного набором 82 фильтров, и предсказанного бокового сигнала, кратного кодированному и декодированному сигналу 54 понижающего микширования, где указанное кратное, которое может быть представлено предсказанной информацией, оказывается частью многоканальной информации. Однако, сигнал понижающего микширования содержит только сигнал нижнего диапазона. Таким образом, остаточный кодер может дополнительно вычислить остаточный (или боковой) сигнал для верхнего диапазона. Это можно выполнить, например, путем имитации расширения ширины полосы во временной области, как это делается в базовом кодере области линейного предсказания, или путем предсказания бокового сигнала в виде разности между вычисленным (полнодиапазонным) боковым сигналом и вычисленным полнодиапазонным центральным сигналом, где коэффициент предсказания выполнен с возможностью минимизации разности между обоими сигналами.
На фиг. 3 представлена блок-схема кодера 8 частотной области согласно варианту осуществления. Кодер частотной области содержит второй время-частотный преобразователь 66, второй параметрический генератор 68 и второй квантователь-кодер 70. Второй время-частотный преобразователь 66 может преобразовать первый канал 4а многоканального сигнала и второй канал 4b многоканального сигнала в спектральное представление 72а, 72b. Спектральное представление первого канала и второго канала 72а, 72b можно проанализировать и разделить каждое на первый набор диапазонов 74 и второй набор диапазонов 76. Таким образом, второй параметрический генератор 68 может создать второе параметрическое представление 78 второго набора диапазонов 76, где второй квантователь-кодер может создать квантованное и кодированное представление 80 первого набора диапазонов 74. Кодер частотной области, а точнее, второй время-частотный преобразователь 66 может выполнить, например, операцию MDCT для первого канала 4а и второго канала 4b, где второй параметрический генератор 68 может выполнить алгоритм интеллектуального заполнения пропусков, а второй квантователь-кодер 70 может выполнить, например, AAC операцию. Таким образом, как обсуждалось выше со ссылками на кодеры области линейного предсказания, кодер частотной области также способен действовать так, чтобы получить многоканальную информацию для всей полосы частот многоканального аудиосигнала.
На фиг. 4 представлена блок-схема аудиокодера 2 согласно предпочтительному варианту осуществления. LPD тракт 16 выполняет объединенное стерео или многоканальное кодирование, включающее в себя вычисление 12 активного или пассивного DMX понижающего микширования, указывающее, что LPD понижающее микширование может быть активным («частотно избирательным») или пассивным («с постоянными коэффициентами микширования»), как показано на фигурах 5. Понижающее микширование дополнительно кодируется переключаемым ACELP/TCX ядром (моно), поддерживаемым TD-BWE или IGF модулями. Заметим, что ACELP работает с входными аудиоданными 34 после понижающего микширования. Любая инициализация ACELP из-за переключения может быть выполнена на TCX/IG выходе после понижающего микширования.
Поскольку ACELP не содержит какой-либо внутренней время-частотной декомпозиции, для LPD стереокодирования добавляется дополнительный банк фильтров с комплексной модуляцией посредством банка 82 фильтров анализа перед LP кодированием и банка фильтров синтеза после LPD декодирования. В предпочтительном варианте осуществления используется избыточно дискретизированное DFT в области, перекрывающей нижний диапазон. Однако в других вариантах осуществления может использоваться любая избыточно дискретизированная время-частотная декомпозиция с аналогичным временным разрешением. Затем можно вычислить параметры стерео в частотной области.
Параметрическое стереокодирование выполняют посредством блока 18 «LPD параметрического стереокодирования», который выводит LPD стереопараметры 20 в битовый поток. В качестве опции, следующий блок «LPD остаточного кодирования стерео» добавляет в битовый поток остаток 58 низкочастотного понижающего микширования, после векторного квантования.
FD тракт 8 выполнен с возможностью того, чтобы обеспечить собственное внутреннее объединенное стереокодирование или многоканальное кодирование. Для объединенного стереокодирования многократно используется собственный банк 66 действительнозначных фильтров с критической дискретизацией, реализующих, например, преобразование MDCT.
Сигналы, подаваемые на декодер, например, могут быть, мультиплексированы в единый битовый поток. Этот битовый поток может содержать кодированный сигнал 26 понижающего микширования, который может дополнительно содержать по меньшей мере один из диапазонов 38 после расширения ширины полосы во временной области (после параметрического кодирования), сигнал 52 понижающего микширования после понижающей дискретизации и ACELP обработки, первую многоканальную информацию 20, кодированный многоканальный остаточный сигнал 58, первое параметрическое представление первого набора диапазонов 46, первый набор квантованных кодированных спектральных линий для второго набора диапазонов 48 и вторую многоканальную информацию 24, содержащую квантованное и кодированное представление первого набора диапазонов 80 и второе параметрическое представление первого набора диапазонов 78.
В вариантах осуществления показан усовершенствованный способ для объединения переключаемого базового кодека, объединенного многоканального кодирования и параметрического пространственного аудиокодирования в полностью переключаемый перцептуальный кодек, который позволяет использовать разные способы многоканального кодирования в зависимости от выбора базового кодера. В частности, в переключаемом аудиокодере «родное» стереокодирование в частотной области объединяют с ACELP/TCX на основе кодирования с линейным предсказанием, имеющим свое собственное специализированное независимое параметрическое стереокодирование.
На фигурах 5а и 5и соответственно представлены активный и пассивный понижающие микшеры согласно вариантам осуществления. Активный понижающий микшер работает в частотной области, используя, например, время-частотный преобразователь 82 для преобразования сигнала 4 временной области в сигнал частотной области. После понижающего микширования частотно-временное преобразование, например, IDFT, может обеспечить преобразование сигнала понижающего микширования из частотной области в сигнал 14 понижающего микширования временной области.
На фиг. 5b показан пассивный понижающий микшер 12 согласно варианту осуществления. Пассивный понижающий микшер 12 содержит сумматор, где первый канал 4а и первый канал 4b объединяют после взвешивания с использованием веса 84а и веса 84b соответственно. Более того, первый канал 4а и второй канал 4b можно ввести в время-частотный преобразователь 82 перед передачей на LPD параметрическое кодирование стерео.
Другими словами, понижающий микшер выполнен с возможностью преобразования многоканального сигнала в спектральное представление, причем это понижающее микширование выполняют с использованием спектрального представления или использованием время-частотного представления, при этом первый многоканальный кодер выполнен с возможностью использования спектрального представления для создания отдельно первой многоканальной информации для отдельных диапазонов указанного спектрального представления.
На фиг. 6 представлена блок-схема аудиодекодера 102 для декодирования кодированного аудиосигнала 103 согласно варианту осуществления. Аудиодекодер 102 содержит декодер 104 области линейного предсказания, декодер 106 частотной области, первый объединенный многоканальный декодер 108, второй многоканальный декодер 110 и первый объединитель 112. Кодированный аудиосигнал 103, который может представлять собой мультиплексированный битовый поток из ранее описанных кодированных частей, таких как, например, кадры аудиосигнала, может быть декодирован объединенным многоканальным декодером 108 с использованием первой многоканальной информации 20 или декодером 106 частотной области, и декодирован вторым объединенным многоканальным декодером 110 с использованием второй многоканальной информации 24. Первый объединенный многоканальный декодер может выдать первое многоканальное представление 114, а выход второго объединенного многоканального декодера 110 может представлять собой второе многоканальное представление 116.
Другими словами, первый объединенный многоканальный декодер 108 создает первое многоканальное представление 114, используя выход кодера области линейного предсказания и используя первую многоканальную информацию 20. Второй многоканальный декодер 110 создает второе многоканальное представление 116, используя выход декодера частотной области и вторую многоканальную информацию 24. Далее первый объединитель объединяет первое многоканальное представление 114 и второе многоканальное представление 116, например, для получения декодированного аудиосигнала 118. Кроме того, первый объединенный многоканальный декодер 108 может представлять собой параметрический объединенный многоканальный декодер, например, использующий комплексное предсказание, режим параметрического стерео или режим чередования. Второй объединенный многоканальный декодер 110 может представлять собой объединенный многоканальный декодер, сохраняющий форму сигнала, используя, например, избирательный (на основе диапазона) переход на алгоритм декодирования по схеме центральный/боковой или левый/правый.
На фиг. 7 схематически представлен декодер 102 согласно дополнительному варианту осуществления. Здесь декодер 102 области линейного предсказания содержит ACELP декодер 120, синтезатор 122 нижнего диапазона, блок 124 повышающей дискретизации, процессор 126 расширения ширины полосы во временной области, или второй объединитель 126 для объединения сигнала повышающей дискретизации и сигнала расширенной полосы частот. Кроме того, декодер области линейного предсказания может содержать TCX декодер 132 и процессор 132 интеллектуального заполнения пропусков, которые на фиг. 7 изображены как один блок. Кроме того, декодер 2 области линейного предсказания может содержать процессор 134 полнодиапазонного синтеза для объединения выхода второго объединителя 128 и TCX декодера 130 и IGF процессора 132. Как уже было показано в отношении кодера, процессор 126 расширения ширины полосы во временной области, ACELP декодер 120 и TCX декодер 130 работают параллельно для декодирования соответствующей переданной аудиоинформации.
Может быть обеспечен перекрестный кросс-тракт 136 для инициализации синтезатора нижнего диапазона с использованием информации, полученной из спектрально-временного преобразования нижнего диапазона с использованием, например, частотно-временного преобразователя 138 из TCX декодера 130 и IGF процессора 132. Обратимся к модели вокального тракта, где ACELP данные могут моделировать форму вокального тракта, и где TCX данные могут моделировать возбуждение вокального тракта. Может быть обеспечен кросс-тракт 136, представленный частотно-временным преобразователем нижнего диапазона, например, IMDCT декодером дает возможность синтезатору 122 нижнего диапазона использовать форму вокального тракта и подать возбуждение для пересчета или декодирования кодированного сигнала нижнего диапазона. Кроме того, блок 124 повышающей дискретизации выполняет повышающую дискретизацию синтезированного нижнего диапазона, который объединяется с использованием, например, второго объединителя 128 с верхними диапазонами 140 после расширения ширины полосы во временной области, например, для переформирования частот после повышающей дискретизации, например, для восстановления энергии для каждого диапазона повышающей дискретизации.
Полнодиапазонный синтезатор 134 может использовать полно-диапазонный сигнал второго объединителя 128 и расширения от TCX процессора 130 для формирования декодированного сигнала 142 понижающего микширования. Первый объединенный многоканальный декодер 108 может содержать время-частотный преобразователь 144 для преобразования выхода декодера области линейного предсказания, например, декодированного сигнала 142 понижающего микширования в спектральное представление 145. Кроме того, повышающий микшер, реализованный, например, в стереодекодере 146 может управляться первой многоканальной информацией 20 для повышающего микширования спектрального представления в многоканальный сигнал. Более того, частотно-временной преобразователь 148 может преобразовать результат повышающего микширования во временное представление 114. Время-частотный и/или частотно-временной преобразователь может реализовать комплексный режим или режим избыточной дискретизации, например, DFT или IDFT.
Более того, первый объединенный многоканальный декодер, или, в частности, стереодекодер 146 использует только многоканальный остаточный сигнал 58, обеспечиваемый, например, многоканальным кодированным аудиосигналом 103 для создания первого многоканального представления. Кроме того, многоканальный остаточный сигнал может содержать полосу частот ниже первого многоканального представления, где первый объединенный многоканальный декодер выполнен с возможностью восстановления промежуточного первого многоканального представления с использованием первой многоканальной информации, и для добавления многоканального остаточного сигнала к промежуточному первому многоканальному представлению. Другими словами, стереодекодер 146 может содержать многоканальное декодирование с использованием первой многоканальной информации 20 и, но не обязательно, улучшение восстановленного многоканального сигнала путем добавления многоканального остаточного сигнала к восстановленному многоканальному сигналу после того, как было выполнено повышающее микширование спектрального представления декодированного сигнала понижающего микширования в многоканальный сигнал. Таким образом, первая многоканальная информация и остаточный сигнал уже будут готовы работать с многоканальным сигналом.
Второй объединенный многоканальный декодер 110 может использовать в качестве входа спектральное представление, полученное декодером частотной области. Это спектральное представление содержит по меньшей мере для множества диапазонов первый канальный сигнал 150а и второй канальный сигнал 150b. Кроме того, второй объединенный многоканальный процессор 110 можно применить для множества диапазонов первого канального сигнала 150а и второго канального сигнала 150b. Объединенный многоканальный режим, например, маскирование, указывающее для отдельных диапазонов объединенное кодирование «левый/правый» или «центральный/боковой», и где объединенный многоканальный режим представляет собой режим преобразования «центральный/боковой» или «левый/правый» для преобразования диапазонов, указанных упомянутой маской, из представления «центральный/боковой» в представление «левый/правый», которое представляет собой преобразование результата объединенного многоканального режима во временное представление, для получения второго многоканального представления. Кроме того, декодер частотной области может содержать частотно-временной преобразователь 152, например, реализовать режим IMDCT или режим особой дискретизации. Другими словами, маска может содержать флаги, указывающие, например, на L/R или M/S стереокодирование, где второй объединенный многоканальный кодер применяет соответствующий алгоритм стереокодирования к соответствующим аудиокадрам. В качестве опции возможно применение интеллектуального заполнения пропусков к кодированным аудиосигналам для дополнительного уменьшения ширины полосы частот кодированного аудиосигнала. Таким образом, например, тональные частотные диапазоны можно кодировать с высоким разрешением, используя вышеупомянутые алгоритмы стереокодирования, где другие частотные диапазоны могут подвергаться параметрическому кодированию с использованием, например, IGF алгоритма.
Другими словами, в LPD тракте 104 переданный моносигнал восстанавливается переключаемым ACELP/TCX 120/130 декодером, поддерживаемым, например, TD-BWE 126 или IGF модулями 132. Любая ACELP инициализация из-за переключения выполняется на выходе TCX/GF после понижающей дискретизации. Выход ACELP подвергается повышающей дискретизации с использованием, например, блока 124 повышающей дискретизации до полной частоты дискретизации. Все сигналы микшируют, например, с использованием микшера 128 во временной области при высокой частоте дискретизации и дополнительно обрабатываются LPD стереодекодером 146 для обеспечения LPD стерео.
LPD «Стереодекодирование» состоит из повышающего микширования переданного понижающего микширования, управляемого использованием переданных стереопараметров 20. В качестве опции в этом случае в битовом потоке также содержится остаток 58 понижающего микширования, который декодируют и используют при вычислении повышающего микширования, выполняемом блоком 146 «стереодекодирования».
FD тракт 106 сконфигурирован таким образом, что он имеет возможность создания собственного независимого внутреннего объединенного стерео или многоканального декодирования. Для объединенного стереодекодирования многократно используется собственный банк 152 действительно численных фильтров, например, использующих IMDCT.
LPD стереовыход и FD стереовыход микшируют во временной области, используя, например, первый объединитель 112 для обеспечения окончательного выходного сигнала 118 полностью переключаемого кодера.
Хотя многоканальная конфигурация описана применительно к стереодекодированию на соответствующих фигурах, тот же принцип можно также применить в общем случае для многоканальной обработки в случае двух или более каналов.
На фиг. 8 представлена блок-схема способа 800 для кодирования многоканального сигнала. Способ 800 содержит: этап 805 выполнения кодирования в области линейного предсказания; этап 810 выполнения кодирования в частотной области; этап 815 переключения между кодированием в области линейного предсказания и кодированием в частотной области, где кодирование в области линейного предсказания содержит понижающее микширование многоканального сигнала для получения сигнала понижающего микширования, базовое кодирование в области линейного предсказания сигнала понижающего микширования и первое объединенное многоканальное кодирование, создающее первую многоканальную информацию из многоканального сигнала, где кодирование в частотной области содержит второе объединенное многоканальное кодирование, создающее вторую многоканальную информацию из многоканального сигнала, где второе объединенное многоканальное кодирование отличается от первого многоканального кодирования, и где переключение выполняют так, что часть многоканального сигнала представляют либо кодированным кадром кодирования в области линейного предсказания, либо кодированным кадром кодирования в частотной области.
На фиг. 9 представлена блок-схема способа 900 декодирования кодированного аудиосигнала. Способ 900 содержит этап 905 декодирования в области линейного предсказания, этап 910 декодирования в частотной области, этап 915 первого объединенного многоканального декодирования, создающий первое многоканальное представление с использованием выхода декодирования в области линейного предсказания и использованием первой многоканальной информации, этап 920 второго многоканального декодирования, создающий второе многоканальное представление с использованием выхода декодирования в частотной области и второй многоканальной информации, и этап 925 объединения первого многоканального представления и второго многоканального представления для получения декодированного аудиосигнала, где второе декодирование первой многоканальной информации отличается от первого многоканального декодирования.
На фиг. 10 представлена блок-схема аудиокодера для кодирования многоканального сигнала согласно дополнительному аспекту. Аудиокодер 2 содержит кодер 6 области линейного предсказания и многоканальный остаточный кодер 56. Кодер области линейного предсказания содержит понижающий микшер 12 для понижающего микширования многоканального сигнала 4 с целью получения сигнала 14 понижающего микширования, базовый кодер 16 области линейного предсказания для кодирования сигнала 14 понижающего микширования. Кодер 6 области линейного предсказания кроме того содержит объединенный многоканальный кодер 18 для создания многоканальной информации 20 из многоканального сигнала 4. Более того, кодер области линейного предсказания содержит декодер 50 области линейного предсказания для декодирования кодированного сигнала 26 понижающего микширования для получения кодированного и декодированного сигнала 54 понижающего микширования. Многоканальный остаточный кодер 56 может вычислить и кодировать многоканальный остаточный сигнал, используя кодированный и декодированный сигнал 54 понижающего микширования. Многоканальный остаточный сигнал может представлять ошибку между декодированным многоканальным представлением 54 с использованием многоканальной информации 20 и многоканального сигнала 4 до понижающего микширования.
Согласно варианту осуществления сигнал 14 понижающего микширования содержит нижний диапазон и верхний диапазон, причем кодер области линейного предсказания может использовать процессор расширения ширины полосы для применения обработки, касающейся расширения ширины полосы для параметрического кодирования верхнего диапазона, при этом декодер области линейного предсказания выполнен с возможностью получения в качестве кодированного и декодированного сигнала 54 понижающего микширования только сигнала нижнего диапазона, представляющего нижний диапазон сигнала понижающего микширования, и где кодированный многоканальный остаточный сигнал имеет только диапазон, соответствующий нижнему диапазону многоканального сигнала перед понижающим микшированием. Более того, аналогичное описание, относящееся к аудиокодеру 2, можно применить к аудиокодеру 2'. Однако дополнительное частотное кодирование, выполняемое кодером 2, опускают. Это упрощает конфигурацию кодера и, следовательно, является преимуществом, если указанный кодер используют просто для аудиосигналов, содержащий сигналы, которые можно параметрически кодировать во временной области без заметной потери качества, или, когда качество декодированного аудиосигнала находится еще в пределах нормы. Однако, специальное остаточное стереокодирование имеет преимущество, состоящее в повышении качества воспроизведения декодированного аудиосигнала. Если более конкретно, то разность между аудиосигналом перед кодированием и кодированным и декодированным аудиосигналом получают и передают в декодер для повышения качества воспроизведения декодированного аудиосигнала, после чего разность между декодированным аудиосигналом и кодированным аудиосигналом становится известной декодеру.
На фиг. 11 показан аудиодекодер 102 для декодирования кодированного аудиосигнала 103 согласно дополнительному аспекту. Аудиодекодер 102 содержит декодер 104 области линейного предсказания и объединенный многоканальный декодер 108 для создания многоканального представления 114 с использованием выхода декодера 104 области линейного предсказания и объединенной многоканальной информации 20. Кроме того, кодированный аудиосигнал 103 может содержать многоканальный остаточный сигнал 58, который может использовать многоканальный декодер для создания многоканального представления 114. Более того, аналогичные объяснения, относящиеся к аудиодекодеру 102, можно применить к аудиодекодеру 102'. Здесь остаточный сигнал из исходного аудиосигнала для декодированного аудиосигнала используют для декодированного аудиосигнала применяют для достижения, как можно более близкого, качества декодированного аудиосигнала по сравнению с исходным аудиосигналом, даже при использовании параметрического кодирования (а, значит, кодирования с потерями). Однако, частотное декодирование части, показанной применительно к аудиодекодеру 102, в аудиодекодере 102 опущено.
На фиг. 12 представлена блок-схема способа аудиокодирования 1200 для кодирования многоканального сигнала. Способ 1200 содержит этап 1205 кодирования в области линейного предсказания, содержащего понижающее микширование многоканального сигнала для получения многоканального сигнала понижающего микширования, и многоканальной информации, созданной базовым кодером области линейного предсказания из многоканального сигнала, где способ кроме того содержит декодирование сигнала понижающего микширования области линейного предсказания для получения кодированного и декодированного сигнала понижающего микширования, и этап 1210 многоканального остаточного кодирования, на котором вычисляют кодированный многоканальный остаточный сигнал с использованием указанного кодированного и декодированного сигнала понижающего микширования, где многоканальный остаточный сигнал представляет ошибку между декодированным многоканальным представлением с использованием первой многоканальной информации и многоканальным сигналом до понижающего микширования.
На фиг. 13 представлена блок-схема способа 1300 декодирования кодированного аудиосигнала. Способ 1300 содержит этап 1305 декодирования в области линейного предсказания и этап 1310 объединенного многоканального декодирования, создающий многоканальное представление с использованием выхода декодирования в области линейного предсказания и объединенной многоканальной информации, где кодированный многоканальный аудиосигнал содержит канальный остаточный сигнал, и где при объединенном многоканальном декодировании используют многоканальный остаточный сигнал для создания многоканального представления.
Описанные варианты осуществления могут использоваться при распространении вещания всех типов стерео или многоканального аудиоконтента (как речи, так и музыки с постоянным перцептуальным качеством при заданном низком битрейте), например, при использовании цифрового радиовещания, потокового Интернета и приложений аудиосвязи.
На фигурах 14-17 описаны варианты осуществления того, каким образом следует применять предложенное бесперебойное переключение с LPD кодирования на кодирование в частотной области и обратно. В общем случае прошедшее создание окон или обработка показаны с использованием тонких линий; жирные линии показывают текущее создание окон и текущую обработку, где применяется переключение, а пунктирные линии показывают текущую обработку, которая выполняется исключительно для перехода или переключения. Переключение или переход от LPD кодирования к частотному кодированию
На фиг. 14 представлена временная диаграмма, демонстрирующая вариант осуществления бесперебойного переключения между кодированием частотной области и кодированием во временной области. Это может соответствовать действительности, если, например, контроллер 10 указывает, что текущий кадр лучше кодировать с использованием LPD кодирования вместо FD кодирования, использованного для предыдущего кадра. Во время кодирования в частотной области для каждого стереосигнала (который может, но не обязательно, распространяться более, чем по двум каналам) может быть использовано стоповое окно 200a и 200b. Стоповое окно отличается от стандартного MDCT перекрытия с суммированием, затухающего в начале 202 первого кадра 204. Левая часть стопового окна может представлять собой классическое перекрытие с суммированием для кодирования предыдущего кадра с использованием, например, MDCT время-частотного преобразования. Таким образом, кадр перед переключением все еще правильно кодирован. Для текущего кадра 204, где применяется переключение, вычисляют дополнительные стереопараметры, притом, что первое параметрическое представление центрального сигнала для кодирования во временной области вычисляют для следующего кадра 206. Эти два дополнительных анализа стерео выполняют для того, чтобы иметь возможность создания центрального сигнала 208 для предварительного просмотра LPD. Хотя стерео параметры передаются (дополнительно) для двух первых LPD стерео окон. В нормальном случае стереопараметры посылают с задержкой на два LPD стереокадра. Для обновления блоков памяти ACELP, например, таких как блоки памяти для LPC анализа или прямого подавления помех дискретизации (FAC), также предоставляют прошлые данные о центральном сигнале. Поэтому, LPD стерео окна 210a-d для первого стереосигнала и 212a-d для второго стереосигнала можно применить при анализе банка 82 фильтров, например, перед применением время-частотного преобразования с использованием DFT. Центральный сигнал может содержать типовой участок линейного затухания при использовании TCX кодирования, обеспечивая в результате окно 214 LPD анализа. Если для кодирования аудиосигнала, такого как моносигнал нижнего диапазона, используют ACELP, не составит труда выбрать количество частотных диапазонов, на которых применяется LPC анализ, как показано в прямоугольном окне 216 LPD анализа.
Более того, момент времени, показанный вертикальной линией 218, указывает, что текущий кадр, в котором применяется переход, содержит информацию из окон 200a, 200b и вычисленного центрального сигнала 208 и соответствующую стереоинформацию. В течение горизонтальной части окна частотного анализа между линиями 202 и 218 выполняется точное кодирование кадра 204 с использованием кодирования в частотной области. От линии 218 до конца окна частотного анализа на линии 220 кадр 204 содержит информацию об кодировании частотной области и LPD кодировании, а от линии 220 до конца кадра 204 на вертикальной линии 222 в кодировании кадра используют только LPD кодирование. Дополнительное внимание уделено средней части кодирования, поскольку первую и последнюю (третью) часть просто получают из одного способа кодирования без помех дискретизации. Однако, для средней части необходимо различать ACELP и TCX кодирование моносигнала. Поскольку при TCX кодировании используют плавное затухание, как это уже было при кодировании в частотной области, простое плавное уменьшение кодированного сигнала частотной области и плавное увеличение TCX кодированного центрального сигнала обеспечивает полную информацию для кодирования текущего кадра 204. При использовании ACELP для кодирования моносигнала возможно применение более сложной обработки, поскольку зона 224 может не содержать полную информацию для кодирования аудиосигнала. Предложенный способ представляет собой прямую коррекцию помех дискретизации (FAC), описанную, например, в спецификациях USAC в разделе 7.16.
Согласно варианту осуществления, контроллер 10 выполнен с возможностью переключения в текущем кадре 204 многоканального аудиосигнала с использования кодера 8 частотной области для кодирования предыдущего кадра, на кодер области линейного предсказания для декодирования последующего кадра. Первый объединенный многоканальный кодер 18 может вычислить синтезированные многоканальные параметры 210а, 210b, 212a, 22b из многоканального аудиосигнала для текущего кадра, где второй объединенный многоканальный кодер 22 выполнен с возможностью взвешивания второго многоканального сигнала с использованием стопового окна.
На фиг. 15 представлена временная диаграмма декодера, соответствующая операциям кодера по фиг. 14. Здесь восстановление текущего кадра 204 описано согласно варианту осуществления. Как уже было видно из временной диаграммы кодера по фиг. 14, стереоканалы частотной области обеспечиваются из предыдущего кадра с применением стоповых окон 200a и 200b. Переходы с режима FD на LPD сначала выполняются на декодированном центральном сигнале, как и в случае с моносигналом. Это достигается путем искусственного создания центрального сигнала 226 из сигнала 116 временной области, декодированного в FD режиме, где ccfl - длина кадра базового кода, а L_fac обозначает длину окна, кадра, или блока преобразования для подавления помех дискретизации

Затем этот сигнал пересылают в LPD декодер 120 для обновления блоков памяти и применения FAC декодирования, как это делается в случае моносигнала, для переходов из FD режима в ACELP. Указанная обработка описана в спецификациях USAC [ISO/IEC DIS 23003-3, Usac] в разделе 7.16. В случае FD режима для TCX выполняется стандартное перекрытие с суммированием. LPD стереодекодер 146 получает в качестве входного сигнала декодированный (в частотной области после время-частотного преобразования, выполненного время-частотным преобразователем 144) центральный сигнал, например, путем использования переданных стереопараметров 210 и 212 для обработки стерео, где переход уже выполнен. Затем стереодекодер выдает сигналы 228, 230 левого и правого канала, которые перекрывают предыдущий кадр, декодированный в FD режиме. Затем эти сигналы, а именно, FD декодированный сигнал временной области и LPD декодированный сигнал временной области для данного кадра, где используется переход, плавно ослабляют (в объединителе 112) по каждому каналу для сглаживания перехода в левом и правом каналах.


На фиг. 15 схематически показан переход с использованием M=ccfl/2. Более того, указанный объединитель может выполнить плавное ослабление на последовательных кадрах, декодируемых с использованием только FD или LPD декодирования без перехода с одного из этих режимов на другой.
Другими словами, процесс перекрытия с суммированием FD декодирования, особенно при использовании MDCT/IMDCT для время-частотного/частотно-временного преобразования, заменяется плавным ослаблением FD декодированного аудиосигнала и LPD декодированного аудиосигнала. Таким образом декодер должен вычислить LPD сигнал для плавно уменьшающейся части FD декодированного аудиосигнала с целью плавного увеличения LPD декодированного аудиосигнала. Согласно варианту осуществления аудиодекодер 102 выполнен с возможностью переключения в текущем кадре 204 многоканального аудиосигнала с использования декодера 106 частотной области для декодирования предыдущего кадра на использование декодера 104 области линейного предсказания для декодирования последующего кадра. Объединитель 112 может вычислить синтезированный центральный сигнал 226 из второго многоканального представления 116 текущего кадра. Первый объединенный многоканальный декодер 108 может создать первое многоканальное представление 114, используя синтезированный центральный сигнал 226 и первую многоканальную информацию 20. Кроме того, объединитель 112 выполнен с возможностью объединения первого многоканального представления и второго многоканального представления для получения декодированного текущего кадра многоканального аудиосигнала.
На фиг. 16 показана временная диаграмма в кодере для выполнения перехода с использования LPD кодирования на использование FD декодирования в текущем кадре 232. Для переключения с LPD на FD кодирование можно применить стартовое окно 300a, 300b при FD многоканальном кодировании. Это стартовое окно имеет аналогичные функциональные возможности по сравнению со стоповым окном 200a, 200b. Во время плавного уменьшения TCX кодированного моносигнала LPD кодера между вертикальными линиями 234 и 236 стартовое окно 300a, 300b выполняет увеличение сигнала. При использовании ACELP вместо TCX плавное уменьшение уровня моносигнала не выполняется. Тем не менее, в декодере возможно восстановление правильного аудиосигнала с использованием, например, FAC. Окна 238 и 240 LPD стерео вычисляют по общему правилу с обращением к ACELP или TCX кодированному моносигналу, указанному в окнах 241 LPD анализа.
На фиг. 17 показана временная диаграмма в декодере, соответствующая временной диаграмме кодера, описанной со ссылками на фиг. 16.
Для перехода из LPD режима в FD режим стереодекодер 146 декодирует дополнительный кадр. Центральный сигнал, поступающий из декодера в LPD режиме, увеличивают от нуля для кадрового индекса i=ccfl/M

Вышеописанное стереодекодирование можно выполнить путем сохранения последних параметров стерео и отключения обратного квантования бокового сигнала, то есть, cod_mode устанавливают в 0. Более того, правостороннее создание окон после обратного преобразования DFT не применяется, что приводит к резкому спаду 242a, 242b дополнительного окна 244a, 244b LPD стерео. Здесь хорошо видно, что спад находится у плоского участка 246a, 246b, где из FD кодированного аудиосигнала можно получить всю информацию из соответствующей части кадра. Таким образом, правостороннее создание окон (без резкого спада) может привести к нежелательному воздействию LPD информации на FD информацию, и, поэтому оно не применяется.
Затем результирующие левый и правый (LPD декодированные) каналы 250a, 250b (использующие LPD декодированный центральный сигнал, показанный в LPD синтезированных окнах 248 и параметры стерео) объединяют в декодированные в FD режиме каналы следующего кадра путем использования обработки «перекрытие с суммированием» в случае перехода из TCX в FD режим, или путем использования FAC для каждого канала в случае перехода из режима ACELP в режим FD. Указанные переходы схематически проиллюстрированы на фиг. 17, где M=ccfl/2.
Согласно варианту осуществления аудиодекодер 102 может выполнять переключение в текущем кадре 232 многоканального аудиосигнала с использования декодера 104 области линейного предсказания для декодирования предыдущего кадра на использование декодера 106 частотой области для декодирования последующего кадра. Стереодекодер 146 может вычислить синтезированный многоканальный аудиосигнал из декодированного моносигнала из декодера области линейного предсказания для текущего кадра с использованием многоканальной информации предыдущего кадра, где второй объединенный многоканальный декодер может вычислить второе многоканальное представление для текущего кадра и выполнить взвешивание второго многоканального представления, используя стартовое окно. Объединитель 112 может объединить синтезированный многоканальный аудиосигнал и взвешенное второе многоканальное представление для получения декодированного текущего кадра многоканального аудиосигнала.
На фиг. 18 представлена блок-схема кодера 2ʺ для кодирования многоканального сигнала 4. Аудиокодер 2ʺ содержит понижающий микшер 12, базовый кодер 16 области линейного предсказания, банк 82 фильтров и объединенный многоканальный кодер 18. Понижающий микшер 12 выполнен с возможностью понижающего микширования многоканального сигнала 4 для получения сигнала 14 понижающего микширования. Сигнал понижающего микширования может быть моносигналом, таким как, например, центральный сигнал M/S многоканального аудиосигнала. Базовый кодер 16 области линейного предсказания может кодировать сигнал 14 понижающего микширования, где сигнал 14 понижающего микширования имеет нижний диапазон и верхний диапазон, где базовый кодер 16 области линейного предсказания выполнен с возможностью применения обработки, касающейся расширения ширины полосы для параметрического кодирования верхнего диапазона. Кроме того, банк 82 фильтров может создавать спектральное представление многоканального сигнала 4, а объединенный многоканальный кодер 18 может быть выполнен с возможностью обработки спектрального представления, содержащего нижний диапазон и верхний диапазон многоканального сигнала для создания многоканальной информации 20. Многоканальная информация 20 может содержать параметры ILD, IPD и/или IID (разница интенсивности звукового сигнала, поступающего в оба уха), позволяющие декодеру пересчитать многоканальный аудиосигнал исходя из моносигнала. Более подробное графическое представление дополнительных аспектов вариантов осуществления согласно этому аспекту можно найти на предыдущих фигурах, в первую очередь, на фиг. 4.
Согласно вариантам осуществления базовый кодер 16 области линейного предсказания может дополнительно содержать декодер области линейного предсказания для декодирования кодированного сигнала 26 понижающего микширования для получения кодированного и декодированного сигнала 54 понижающего микширования. Здесь базовый кодер области линейного предсказания может сформировать центральный сигнал M/S аудиосигнала, который кодируют для передачи на декодер. Кроме того, аудиокодер дополнительно содержит многоканальный остаточный кодер 56 для вычисления кодированного многоканального остаточного сигнала 58 с использованием кодированного и декодированного сигнала 54 понижающего микширования. Многоканальный остаточный сигнал представляет ошибку между декодированным многоканальным представлением с использованием многоканальной информации 20 и многоканального сигнала 4 перед понижающим микшированием. Другими словами, многоканальный остаточный сигнал 58 может быть боковым сигналом M/S аудиосигнала, соответствующим центральному сигналу, вычисленному с использованием базового кодера области линейного предсказания.
Согласно дополнительным вариантам осуществления базовый кодер 16 области линейного предсказания выполнен с возможностью использования обработки, касающейся расширения ширины полосы, для параметрического кодирования верхнего диапазона и для получения в качестве кодированного и декодированного сигнала понижающего микширования только сигнала нижнего диапазона, представляющего нижний диапазон сигнала понижающего микширования, и где кодированный многоканальный остаточный сигнал 58 имеет только диапазон, соответствующий нижнему диапазону многоканального сигнала перед понижающим микшированием. Вдобавок или в качестве альтернативы, многоканальный остаточный кодер может имитировать расширение ширины полосы во временной области, которое используют для верхнего диапазона многоканального сигнала в базовом кодере области линейного предсказания и для вычисления остаточного или бокового сигнала для верхнего диапазона, чтобы иметь возможность более точного декодирования моносигнала или центрального сигнала для получения декодированного многоканального аудиосигнала. Указанная имитация может содержать одинаковое или подобное вычисление, выполняемое в декодере для декодирования верхнего диапазона расширенной полосы частот. В качестве альтернативного или дополнительного подхода к имитации расширения ширины полосы может быть использовано предсказание бокового сигнала. Таким образом, многоканальный остаточный кодер может вычислить полнодиапазонный остаточный сигнал из параметрического представления 83 многоканального аудиосигнала 4 после время-частотного преобразования в банке 82 фильтров. Этот полнодиапазонный боковой сигнал можно сравнить с частотным представлением полнодиапазонного центрального сигнала, полученного аналогичным образом из параметрического представления 83. Полнодиапазонный центральный сигнал можно вычислить, например, как сумму левого и правого каналов параметрического представления 83, а полнодиапазонный боковой сигнал в виде их разности. Более того, таким образом при предсказании можно вычислить коэффициент предсказания для полнодиапазонного центрального сигнала, минимизирующий абсолютную разность полнодиапазонного бокового сигнала и произведение коэффициента предсказания и полнодиапазонного центрального сигнала.
Другими словами, кодер области линейного предсказания может быть выполнен с возможностью вычисления сигнала 14 понижающего микширования в качестве параметрического представления центрального сигнала M/S многоканального аудиосигнала, где многоканальный остаточный кодер может быть выполнен с возможностью вычисления бокового сигнала, соответствующего центральному сигналу M/S многоканального аудиосигнала, где остаточный кодер может вычислить верхний диапазон центрального сигнала, используя имитацию расширения ширины полосы во временной области, или где остаточный кодер может предсказать верхний диапазон центрального сигнала, используя поиск информации о предсказании, которая минимизирует разность между вычисленным боковым сигналом и вычисленным полнодиапазонным центральным сигналом из предыдущего кадра.
В дополнительных вариантах осуществления показан базовый кодер 16 области линейного предсказания, содержащий ACELP процессор 30. ACELP процессор может работать с сигналом 34 понижающего микширования с понижающей дискретизацией. Кроме того, процессор 38 расширения ширины полосы во временной области выполнен с возможностью параметрического кодирования диапазона части сигнала понижающего микширования, удаленной из входного сигнала ACELP при третьей понижающей дискретизации. Вдобавок или в качестве альтернативы базовый кодер 16 области линейного предсказания может содержать TCX процессор 32. TCX процессор 32 может работать с сигналом 14 понижающего микширования, не подвергавшимся понижающей дискретизации или подвергавшимся понижающей дискретизации в степени, меньшей, чем понижающая дискретизация для ACELP процессора. Кроме того, TCX процессор может содержать первый время-частотный преобразователь 40, первый параметрический генератор 42 для создания параметрического представления 46 первого набора диапазонов и первый квантователь-кодер 44 для создания набора квантованных кодированных спектральных линий 48 для второго набора диапазонов. ACELP процессор и TCX процессор могут работать по отдельности: например, первое количество кадров можно кодировать с использованием ACELP, а второе количество кадров кодировать, используя TCX, или в объединенном варианте, когда и ACELP, и TCX вносят свой вклад в информацию для декодирования одного кадра.
В дополнительных вариантах осуществления показан время-частотный преобразователь 40, отличающийся от банка 82 фильтров. Банк 82 фильтров может содержать параметры фильтров, оптимизированные для создания спектрального представления 83 многоканального сигнала 4, где время-частотный преобразователь 40 может содержать параметры фильтров, оптимизированные для создания параметрического представления 46 первого набора диапазонов. На дополнительном этапе, следует заметить, что кодер области линейного предсказания использует другой банк фильтров или даже вообще его не использует в случае расширения ширины полосы и/или использования ACELP. Кроме того, банк 82 фильтров может вычислить параметры фильтров отдельно для создания спектрального представления 83 независимо от предыдущего выбора параметров кодера и области линейного предсказания. Другими словами, при многоканальном кодировании в LPD режиме можно использовать банк фильтров для многоканальной обработки (DFT), которая отлична от обработки, используемой при расширении ширины полосы во временной области для ACELP и MDCT для TCX. Преимущество такого подхода состоит в том, что при каждом параметрическом кодировании можно использовать оптимальную время-частотную декомпозицию для получения ее параметров. Например, предпочтительным является объединение ACELP+TDBWE и параметрического многоканального кодирования с внешним банком фильтров (например, DFT). Такое объединение особенно эффективно поскольку известно, что наилучшее расширение полосы частот для речи следует реализовать во временной области, а многоканальную обработку в частотной области. Поскольку ACELP+TDBWE не содержит время-частотный преобразователь, предпочтительно или может быть даже необходимо использовать внешний банк фильтров или преобразование типа DFT. Согласно другим концепциям всегда используют один и тот же банк фильтров и, следовательно, не используют другие банки фильтров, такие как, например:
IGF и объединенное стереокодирование для AAC в MDCT
SBR+PS для HeAACv2 в QMF
SBR+MPS212 для USAC в QMF
Согласно дополнительным вариантам осуществления многоканальный кодер содержит первый генератор кадров, а базовый кодер области линейного предсказания содержит второй генератор кадров, где первый и второй генератор кадров выполнены с возможностью формирования кадра из многоканального сигнала 4, причем первый и второй генератор кадров выполнены с возможностью формирования кадра подобной длины. Другими словами, кадрирование, выполняемое многоканальным процессором, может совпадать с кадрированием, используемым в ACELP. Даже если многоканальная обработка выполняется в частотной области, временное разрешение для вычисления ее параметров или понижающего микширования должно быть, как можно более близким или даже полностью совпадать с кадрированием ACELP. Подобная длина в этом случае может относиться к кадрированию ACELP, которое может совпадать или быть близким к временному разрешению для вычисления параметров для многоканальной обработки или понижающего микширования.
Согласно дополнительному варианту осуществления аудиокодер кроме того содержит кодер 6 области линейного предсказания, содержащий базовый кодер 16 области линейного предсказания, и многоканальный кодер 18, кодер 8 частотной области и контроллер 10 для переключения между кодером 6 области линейного предсказания и кодером 8 частотной области. Кодер 8 частотной области может содержать второй объединенный многоканальный кодер 22 для кодирования второй многоканальной информации 24 из многоканального сигнал, где второй объединенный многоканальный кодер 22 отличается от первого объединенного многоканального кодера 18. Кроме того, контроллер 10 сконфигурирован так, что часть многоканального сигнала представляют либо кодированным кадром кодера области линейного предсказания, либо кодированным кадром кодера частотой области.
На фиг. 19 показана блок-схема декодера 102 для декодирования кодированного аудиосигнала 103, содержащего сигнал, кодированный базовым кодером, параметры расширения ширины полосы и многоканальную информацию согласно дополнительному аспекту. Аудиодекодер содержит базовый декодер 104 области линейного предсказания, банк 144 фильтров для анализа, многоканальный декодер 146 и процессор 148 банка фильтров для синтеза. Базовый декодер 104 области линейного предсказания может декодировать сигнал, кодированный базовым кодером, для создания моносигнала. Это может быть (полнодиапазонный) центральный сигнал M/S кодированного аудиосигнала. Банк 144 фильтров для анализа может преобразовать указанный моносигнал в спектральное представление 145, причем многоканальный декодер 146 может создать первый канальный спектр и второй канальный спектр из спектрального представления моносигнала и многоканальной информации 20. Таким образом, многоканальный декодер может использовать многоканальную информацию 20. Следовательно, многоканальный декодер может использовать многоканальную информацию, содержащую, например, боковой сигнал, соответствующий декодированному центральному сигналу. Процессор 148 банка фильтров для синтеза, выполненный с возможностью синтезирующей фильтрации с использованием фильтрации первого канального спектра для получения первого канального сигнала и для синтезирующей фильтрации второго канального спектра для получения второго канального сигнала. Таким образом, предпочтительно иметь возможность использования обратной операции по отношению к банку 144 фильтров для анализа применительно к первому и второму канальному сигналу, причем такой операцией может быть IDFT, если в банке фильтров для анализа используется DFT. Однако, процессор банка фильтров может обрабатывать, например, два канальных спектра одновременно или в последовательном порядке, используя, например, один и тот же банк фильтров. Дополнительные подробные графические иллюстрации, относящиеся к этому дополнительному аспекту, можно видеть на предыдущих чертежах, особенно на фиг. 7.
Согласно дополнительным вариантам осуществления базовый декодер области линейного предсказания содержит: процессор 126 расширения ширины полосы для создания части 140 верхнего диапазона из параметров расширения ширины полосы и моно сигнала нижней полосы или сигнала, кодированного базовым кодером, для получения декодированного верхнего диапазона 140 аудиосигнала; процессор сигнала нижнего диапазона, выполненный с возможностью декодирования моно сигнала нижнего диапазона; и объединитель 128, выполненный с возможностью вычисления полнодиапазонного моносигнала с использованием декодированного моносигнала нижнего диапазона и декодированного верхнего диапазона аудиосигнала. Моносигнал нижнего диапазона может быть, например, представлением в основной полосе частот центрального сигнала M/S многоканального аудиосигнала, где параметры расширения ширины полосы могут применяться для вычисления (в объединителе 128) полнодиапазонного моносигнала из моносигнала нижнего диапазона.
Согласно дополнительному варианту осуществления декодер области линейного предсказания содержит ACELP декодер 120, синтезатор 122 нижнего диапазона, блок 124 повышающей дискретизации, процессор 126 расширения ширины полосы во временной области или второй объединитель 128, где второй объединитель 128 выполнен с возможностью объединения сигнала нижнего диапазона после повышающей дискретизации и сигнала 140 верхнего диапазона с расширенной полосой частот для получения полнодиапазонного ACELP декодированного моносигнала. Декодер области линейного предсказания кроме того может содержать TCX декодер 130 и процессор 132 интеллектуального заполнения пропусков для получения полнодиапазонного TCX декодированного моносигнала. Таким образом, полнодиапазонный синтезирующий процессор 134 может объединить полнодиапазонный ACELP декодированный моносигнал и полнодиапазонный TCX декодированный моносигнал. Вдобавок, может быть обеспечен кросс-тракт 136 для инициализации синтезатора нижнего диапазона с использованием информации, полученной в результате полнодиапазонного преобразования «спектр-время» из TCX декодера и IGF процессора.
Согласно дополнительным вариантам осуществления аудиодекодер содержит декодер 106 частотной области, второй объединенный многоканальный декодер 110 для создания второго многоканального представления 116 с использованием выхода декодера 106 частотной области и второй многоканальной информации 22, 24, и первый объединитель 112 для объединения первого канального сигнала и второго канального сигнала со вторым многоканальным представлением 116 для получения декодированного аудиосигнала 118, где второй объединенный многоканальный декодер отличается от первого объединенного многоканально декодера. Таким образом, аудиодекодер может переключаться между параметрическим многоканальным декодированием с использованием LPD и декодированием частотой области. Этот подход уже был подробно описан со ссылками на предыдущие чертежи.
Согласно дополнительным вариантам осуществления банк 144 фильтров для анализа содержит DFT для преобразования моносигнала в спектральное представление 145, причем полнодиапазонный синтезирующий процессор 148 содержит IDFT для преобразования спектрального представления 145 в первый и второй канальный сигнал. Более того, банк фильтров для анализа может использовать окно в DFT-преобразованном спектральном представлении 145, так чтобы правая часть спектрального представления предыдущего кадра и левая часть спектрального представления текущего кадра перекрывались, где предыдущий кадр и текущий кадр следуют друг за другом. Другими словами, можно применить плавное ослабление для обеспечения плавного перехода между последовательными DFT блоками и/или уменьшить блочные артефакты.
Согласно дополнительным вариантам осуществления многоканальный декодер 146 выполнен с возможностью получения первого и второго канального сигнала из моносигнала, где моносигналом является центральный сигнал многоканального сигнала, и где многоканальный декодер 146 выполнен с возможностью получения M/S многоканального декодированного аудиосигнала, где многоканальный декодер выполнен с возможностью вычисления бокового сигнала из многоканальной информации. Кроме того, многоканальный декодер 146 можно выполнить с возможностью вычисления L/R многоканального декодированного аудиосигнала из M/S многоканального декодированного аудиосигнала, где многоканальный декодер 146 может вычислить L/R многоканальный декодированный аудиосигнал для нижнего диапазона с использованием многоканальной информации и бокового сигнала. Вдобавок или в качестве альтернативы, многоканальный декодер 146 может вычислить предсказанный боковой сигнал из центрального сигнала, причем многоканальный декодер может кроме того быть выполнен с возможностью вычисления L/R многоканального декодированного аудиосигнала для верхнего диапазона с использованием предсказанного бокового сигнала и значения ILD для многоканальной информации.
Более того, многоканальный декодер 146 может быть дополнительно выполнен с возможностью реализации комплексного режима с L/R декодированным многоканальным аудиосигналом, где многоканальный декодер может вычислить амплитуду комплексного режима, используя энергию кодированного центрального сигнала и энергию декодированного L/R многоканального аудиосигнала для получения компенсации энергии. Кроме того, многоканальный декодер выполнен с возможностью вычисления фазы комплексного режима с использованием IPD значения многоканальной информации. После декодирования энергия, уровень или фаза декодированного многоканального сигнала могут отличаться от декодированного моносигнала. Поэтому, указанный комплексный режим может быть определен так, чтобы энергия, уровень или фаза многоканального сигнала была отрегулирована до значений декодированного моносигнала. Более того, фазу можно отрегулировать до значения фазы многоканального сигнала до кодирования, используя, например, вычисленные IPD параметры из многоканальной информации, вычисленной на стороне кодера. Кроме того, можно адаптировать восприятие человеком декодированного многоканального сигнала к восприятию человеком исходного многоканального сигнала до его кодирования.
На фиг. 20 представлена блок-схема способа 2000 для кодирования многоканального сигнала. Способ содержит этап 2050 понижающего микширования многоканального сигнала для получения сигнала понижающего микширования, этап 2100 кодирования сигнала понижающего микширования, где сигнал понижающего микширования имеет нижний диапазон и верхний диапазон, где базовый кодер области линейного предсказания выполнен с возможностью применения обработки расширения полосы для параметрического кодирования верхнего диапазона, этап 2150 создания спектрального представления многоканального сигнала и этап 2200 обработки спектрального представления, содержащего нижний диапазон и верхний диапазон многоканального сигнала, для создания многоканальной информации.
На фиг. 21 схематически представлена блок-схема способа 2100 декодирования кодированного аудиосигнала, содержащего сигнал, кодированный базовым кодером, параметры расширения полосы и многоканальную информацию. Способ содержит этап 2105 декодирования сигнала, кодированного базовым кодером, для создания моносигнала, этап 2110 преобразования моносигнала в спектральное представление, этап 2115 создания первого канального спектра и второго канального спектра из спектрального представления моносигнала и многоканальной информации, и этап 2120 синтеза, фильтрующего первый канальный спектр для получения первого канального сигнала и синтеза, фильтрующего второй канальный спектр для получения второго канального сигнала.
Далее описываются дополнительные варианты осуществления.
Изменения синтаксиса потока бит
Таблицу 23 USAC спецификаций [1] в разделе 5.3.2 Subsidiary payload следует модифицировать следующим образом:
Таблица 1 - Синтаксис UsaccorecoderData

Следует добавить следующую таблицу
Таблица 1 - Синтаксис lpd_stereo_stream()


В раздел 6.2. USAC payload следует добавить следующее описание полезной нагрузки
6.2.x lpd_stereo_stream()
Подробная процедура декодирования описана в разделе 7.x. LPD stereo decoding
Термины и определения
lpd_stereo_stream() - Элемент данных для декодирования стереоданных для режима LPD
res_mode - Флаг, который указывает частотное разрешение диапазонов параметров
q_mode - Флаг, который указывает временное разрешение диапазонов параметров
ipd_mode - Битовое поле, которое определяет максимум диапазонов параметра для параметра IPD
pred_mode - Флаг, который указывает, используется ли предсказание
cod_mode - Битовое поле, которое определяет максимум диапазонов параметров, для которых квантуется боковой сигнал.
Ild_idx[k][b] - Индекс параметра ILD для кадра k и диапазона b
Ipd_idx[k][b] - Индекс параметра IPD для кадра k и диапазона b
pred_gain_idx[k][b] - Индекс коэффициента предсказания для кадра k и диапазона b
cod_gain_idx - Глобальный индекс коэффициента усиления для квантованного бокового сигнала
Вспомогательные элементы
ccfl - Длина кадра базового кода
M - Длина LPD стереокадра, определенная в Таблице 7.x.1
band_config()-Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
band_limits() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
ipd_max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция
cod_max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция
cod_L - Количество линий DFT для декодированного бокового сигнала
Процесс декодирования
LPD стереокодирование
Описание инструментов
LPD стерео - это дискретное M/S стереокодирование, где центральный канал кодируется базовым LPD моно кодером, а боковой сигнал закодирован в DFT области. декодированный центральный сигнал является выходом LPD моно декодера, который затем обрабатывается LPD стерео модулем. Стереодекодирование выполняют в DFT области, где декодируют L и R каналы. Эти два декодированных канала возвращают обратно во временную область, а затем они могут быть объединены в этой области с декодированными каналами, полученными в FD режиме. Режим FD кодирования использует собственные инструменты стерео, то есть, дискретное стерео с или без комплексного предсказания.
Элементы данных
res_mode - Флаг, который указывает частотное разрешение диапазонов параметров
q_mode - Флаг, который указывает временное разрешение диапазонов параметров
ipd_mode - Битовое поле, которое определяет максимум диапазонов для параметра IPD
pred_mode - Флаг, который указывает, используется ли предсказание
cod_mode - Битовое поле, которое определяет максимум диапазонов параметров, для которых квантуется боковой сигнал.
Ild_idx[k][b] - Индекс параметра ILD для кадра k и диапазона b
Ipd_idx[k][b] - Индекс параметра IPD для кадра k и диапазона b
pred_gain_idx[k][b] - Индекс коэффициента предсказания для кадра k и диапазона b
cod_gain_idx - Глобальный индекс коэффициента усиления для квантованного бокового сигнала
Справочные элементы
ccfl - Длина кадра базового кода
M - Длина LPD стереокадра, определенная в Таблице 7.x.1
band_config()-Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
band_limits() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция определена в 7.x
ipd_max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция
cod_max_band() - Функция, которая возвращает количество диапазонов кодированных параметров. Эта функция
cod_L - Количество линий DFT для декодированного бокового сигнала
Процесс декодирования
Стереодекодирование выполняют в частотной области. Оно действует как постобработка, выполняемая LPD декодером. От LPD декодера получают синтезированный центральный моносигнал. Затем декодируют боковой сигнал или выполняют его предсказание в частотной области. Затем восстанавливают канальные спектры в частотной области перед их повторным синтезом во временной области. Стерео LPD работает с фиксированным размером кадра, равным размеру ACELP кадра независимо от режима кодирования, использованного в LPD режиме.
Частотный анализ
DFT спектр с индексом i вычисляют из декодированного кадра x длиной M

где N - объем анализа сигнала, w - окно анализа и x - декодированный временной сигнал из LPD декодера с индексом i кадра, задержанный на величину L перекрытия DFT. M равно размеру ACELP кадра с частотой дискретизации, использованной в FD режиме. N равно размеру стерео LPD кадра плюс размер перекрытия DFT. Эти размеры зависят от используемой версии LPD, как показано в Таблице 7.x.1.
Таблица 7.х.1 - размеры для DFT и кадров стерео LPD
Окно w является синусным окном, определенным в виде:

Конфигурация диапазонов параметров
Спектр DFT разделен на не перекрывающиеся частотные диапазоны, называемые диапазонами параметров. Разбиение спектра является неравномерным и копирует разложение на слуховые частотные составляющие. Возможны два разных варианта разделения спектра с полосами частот, примерно соответствующими либо удвоенной, либо учетверенной эквивалентной прямоугольной полосе (ERB). Вариант разбиения спектра выбирается с использованием элемента res_mode данных и определяется следующим псевдокодом
funtion nbands=band_config(N,res_mod)
band_limits[0]=1;
nbands=0;
while(band_limits[nbands++]<(N/2)){
if(stereo_lpd_res==0)
band_limits[nbands]=band_limits_erb2[nbands];
else
band_limits[nbands]=band_limits_erb4[nbands];
}
nbands--;
band_limits[nbands]=N/2;
return nbands
где nbands - общее количество диапазонов параметров, а N - размер окна DFT анализа. Таблицы band_limits_erb2 и band_limits_erb4 определены в Таблице 7.x.2. Декодер может адаптивно изменять разрешения диапазонов параметров спектра каждые два стерео LPD кадра.
Таблица 7.х.2 - Ограничения диапазонов параметров с учетом индекса k DFT
Максимальное количество диапазонов параметров для IPD посылают в элементе данных ipd_mod 2-битового поля.
Максимальное количество диапазонов параметров для кодирования бокового сигнала посылают в элементе данных cod_mod 2-битового поля
Таблица max_band[][] определена в Таблице 7.х.3
Затем вычисляют количество ожидаемых декодированных линий для бокового сигнала в виде:

Таблица 7.х.3 - Максимальное количество диапазонов для разных кодовых режимов
Обратное квантование стереопараметров
Стереопараметры «межканальные разности уровней» (ILD), «межканальные разности фаз» (IPD) и коэффициенты предсказания посылают в каждом кадре или каждые два кадра в зависимости от флага q_mode. Если q_mode равно 0, то указанные параметры обновляют в каждом кадре. В противном случае, значения параметров обновляют только для нечетных индексов i стерео LPD кадра в USAC кадре. Индекс i стерео LPD кадра в USAC кадре может принимать значение от 0 до 3 в LPD версии 0 и 0 и 1 в LPD версии 1. ILD декодируют следующим образом:

IPD декодируют для первых диапазонов ipd_max_band

Коэффициенты предсказания декодируют только тогда, когда флаг pred_mode установлен в единицу. Тогда декодированные коэффициенты:

если pred_mode равен нулю, все коэффициенты установлены в нуль.
Независимо от значения q_mode декодирование бокового сигнала выполняют в каждом кадре, если code_mode имеет ненулевое значение. Сначала декодируют глобальный коэффициент:

Декодированная форма бокового сигнала является выходом AVQ, описанного в USAC спецификации [1] в разделе

Таблица 7.х.4 - Таблица обратного квантования ild_q[]
Таблица 7.x.5 - Таблица обратного квантования res_pres_gain_q[]
Обратное канальное отображение
Центральный сигнал X и боковой сигнал S сначала преобразуют в левый и правый каналы L и R следующим образом:


где коэффициент g на каждый диапазон параметров получают из параметра ILD:

где 
Для диапазонов параметров ниже cod_max_band два канала обновляют, используя декодированный боковой сигнал:


Для вышележащих диапазонов параметров выполняют предсказание бокового сигнала, и каналы обновляют следующим образом:


Наконец, каналы умножают на комплексное число с целью восстановления исходной энергии и межканальной фазы сигналов:


где

где с ограничено значениями от -12 до 12 дБ,
и где
 ,
,
где atan2(x,y)- четырехквадрантный арктангенс x/y.
Синтез временной области
Из двух декодированных спектров L и R синтезируют два сигнала l и r посредством обратного DFT:

Наконец, операция перекрытия с суммированием позволяет восстановить кадр из M отсчетов:


Постобработка
Басовая постобработка применяется отдельно по двум каналам. Эта обработка предназначена для обоих каналов, как это описано в разделе 7.17 документа [1].
Следует понимать, что в этой спецификации сигналы на линиях иногда обозначены ссылочными позициями для этих линий или иногда указываются самими ссылочными позициями, которые были атрибутированы для этих линий. Таким образом, обозначение таково, что линия, имеющая конкретный сигнал, указывает сам сигнал. Линия может быть физической линией в аппаратной реализации. Однако в компьютеризованной реализации физическая линия не существует, но сигнал, представленный этой линией, передается от одного вычислительно модуля на другой вычислительный модуль.
Хотя настоящее изобретение было описано в контексте блок-схем, где блоки представляют действительные или логические аппаратные компоненты, настоящее изобретение также можно осуществить реализованным на компьютере способом. В последнем случае блоки представляют соответствующие этапы способа, где эти этапы представляют функциональные возможности, выполняемые соответствующими логическими или физическими аппаратными блоками.
Хотя некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или отличительному признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока, элемента или отличительного признака соответствующего устройства. Некоторые или все этапы способа могут выполняться физическим устройством (или с использованием физического устройства), например, типа микропроцессора, программируемого компьютером, или электронной схемой. В некоторых вариантах осуществления указанным устройством может выполняться какой-то один или более из самых важных этапов способа.
Переданный или кодированный согласно изобретению сигнал может храниться на цифровом запоминающем носителе или может передаваться в среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от конкретных требований к реализации варианты осуществления изобретения могут быть реализованы аппаратными средствами или программными средствами. Реализацию можно выполнить, используя цифровой запоминающий носитель, например, гибкий диск, DVD, Blu-Ray, CD, ROM, PROM и EPROM, EEPROM или флэш-память, имеющий хранящиеся на нем электронно-читаемые управляющие сигналы, которые действуют вместе (или способны действовать вместе) с программируемой компьютерной системой, так чтобы выполнялся соответствующий способ. Таким образом, цифровой запоминающий носитель может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению могут содержать носитель данных, имеющий электронно считываемые управляющие сигналы, которые способны совместно действовать с программируемой компьютерной системой, с тем, чтобы выполнялся один из описанных здесь способов.
В общем случае варианты осуществления настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, где программный код действует, выполняя один из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для выполнения одного из описанных здесь способов при исполнении этой компьютерной программы на компьютере.
Таким образом, дополнительный вариант осуществления способа согласно изобретению представляет собой носитель данных (или запоминающий носитель длительного хранения, такой как цифровой запоминающий носитель или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из описанных здесь способов. Носитель данных, цифровой запоминающий носитель или носитель с записанной программой, как правило, являются материальным носителем и/или носителем длительного хранения.
Таким образом, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих упомянутую компьютерную программу для выполнения одного из описанных здесь способов. Этот поток данных или последовательность сигналов может быть сконфигурирована, например, для пересылки через соединение для передачи данных, например, Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью (или адаптированное к) выполнения одного из описанных здесь способов. Дополнительный вариант осуществления содержит компьютер с установленной на нем компьютерной программой для выполнения одного из описанных здесь способов.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью пересылки на приемник (например, электронным или оптическим путем) компьютерной программы для выполнения одного из описанных здесь способов. Приемник может представлять собой, например, компьютер, мобильное устройство, запоминающее устройство или т.п. Указанное устройство или система может, например, содержать файловый сервер для пересылки компьютерной программы на указанный приемник.
В некоторых вариантах для выполнения некоторых или всех функциональных возможностей описанных здесь способов может быть использовано программируемое логическое устройство (например, вентильная матрица, программируемая пользователем). В некоторых вариантах осуществления вентильная матрица, программируемая пользователем, может совместно работать с микропроцессором для выполнения одного из описанных здесь способов. В общем случае предпочтительно, чтобы указанные способы выполнялись каким-либо аппаратным средством.
Вышеописанные варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Понятно, что специалистам в данной области техники очевидны модификации и другие версии указанных конфигураций и описанных здесь деталей. Таким образом, изобретение ограничено только объемом прилагаемой формулы изобретения, а не конкретными деталями, представленными в описании и объяснении описанных здесь вариантов осуществления.
Ссылки
[1] ISO/IEC DIS 23003-3, Usac
[2] ISO/IEC DIS 23008-3, 3D Audio
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА И АУДИОДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2680195C1 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| КОДЕР АУДИОСИГНАЛА, ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С УДАЛЕНИЕМ АЛИАСИНГА (НАЛОЖЕНИЯ СПЕКТРОВ) | 2010 |
|
RU2591011C2 |
| АДАПТИВНОЕ ОСТАТОЧНОЕ АУДИОКОДИРОВАНИЕ | 2006 |
|
RU2380766C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ ОБРАБОТКИ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ С ИСПОЛЬЗОВАНИЕМ КОМПЛЕКСНОГО ПРЕДСКАЗАНИЯ | 2011 |
|
RU2577195C2 |
| СХЕМА АУДИОКОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ С ПЕРЕКЛЮЧЕНИЕМ БАЙПАС | 2009 |
|
RU2483364C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОБРАБОТКИ ДЕКОДИРОВАННОГО АУДИОСИГНАЛА В СПЕКТРАЛЬНОЙ ОБЛАСТИ | 2012 |
|
RU2560788C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ АУДИОСИГНАЛА | 2009 |
|
RU2455709C2 |
| КОДЕР АУДИОСИГНАЛА, ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ КОДИРОВАННОГО ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА, СПОСОБ ДЕКОДИРОВАННОГО ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ПРИЛОЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2010 |
|
RU2596594C2 |









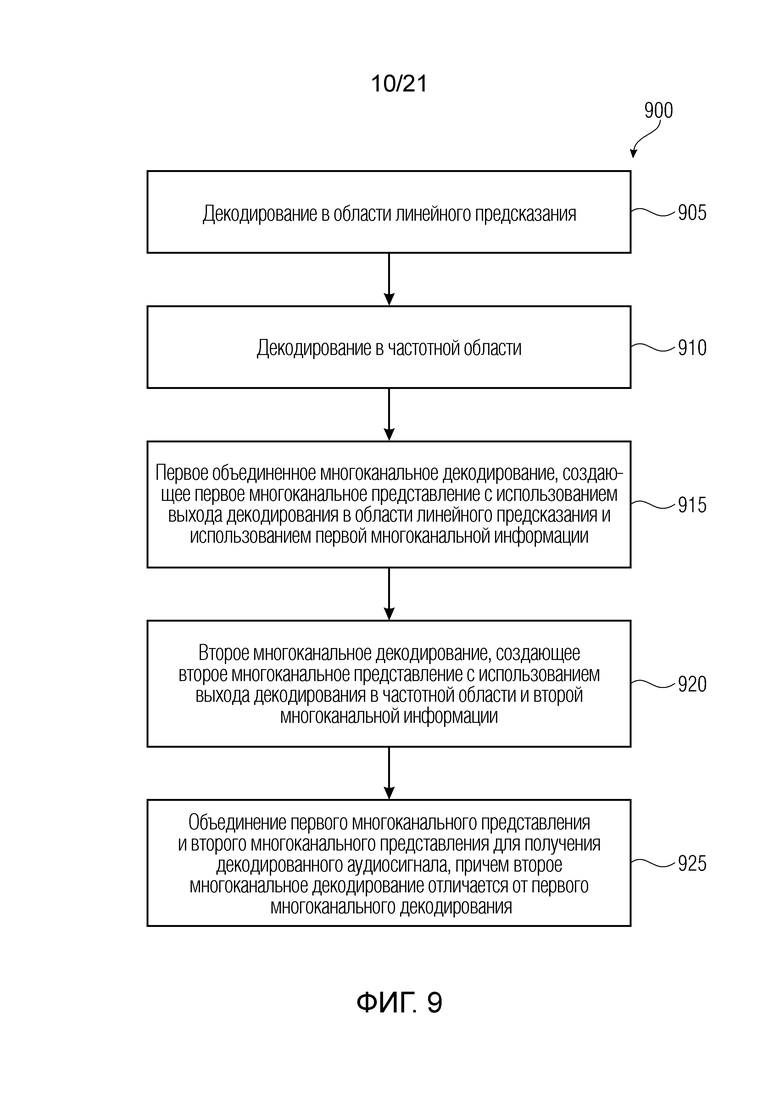



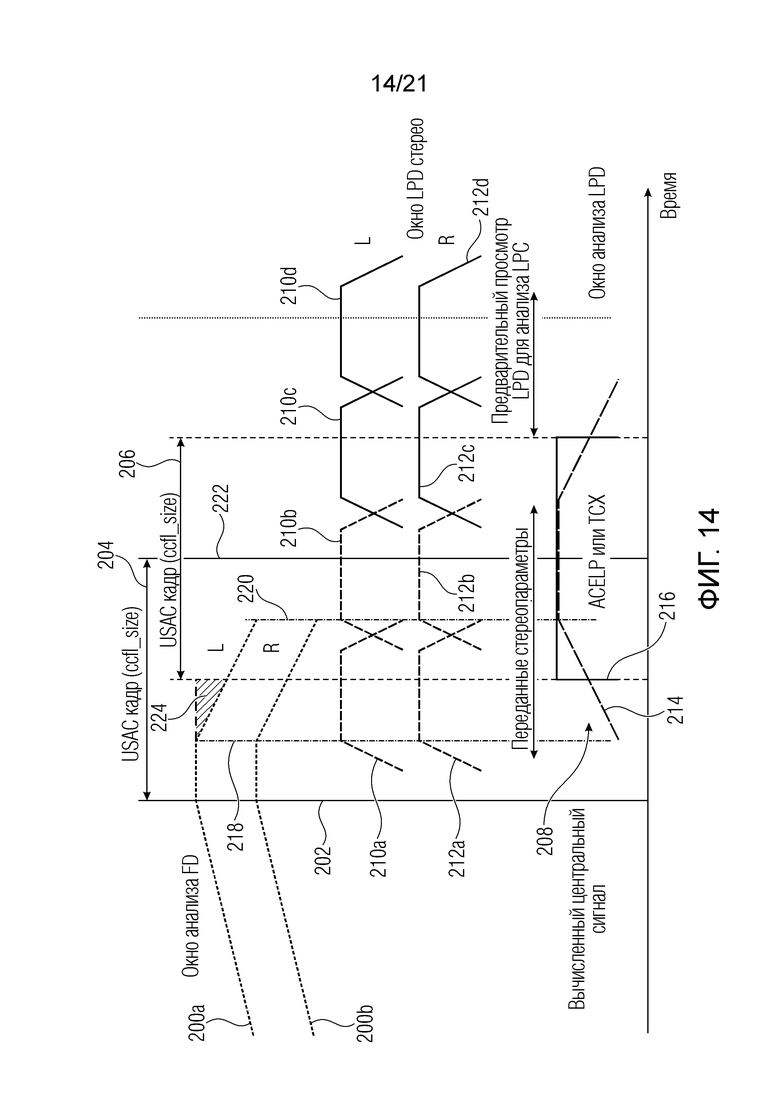
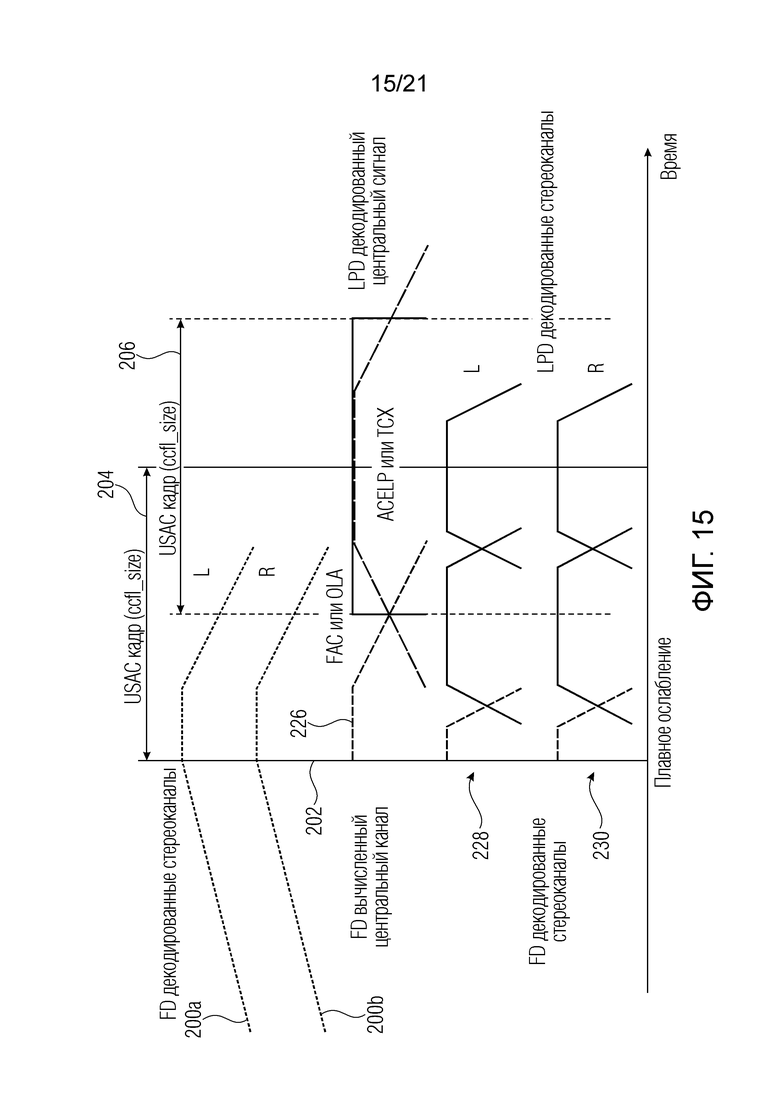






Изобретение относится к средствам для кодирования и декодирования многоканального аудиосигнала. Технический результат заключается в повышении эффективности обработки аудиосигнала. Выполняют кодирование многоканального сигнала в области линейного предсказания. Выполняют кодирование многоканального сигнала в частотной области. Выполняют переключение между кодированием в области линейного предсказания и кодированием в частотной области. Причем кодирование в области линейного предсказания содержит понижающее микширование многоканального сигнала для получения сигнала понижающего микширования, кодирование сигнала понижающего микширования базовым кодером области линейного предсказания, и первое объединенное многоканальное кодирование, создающее первую многоканальную информацию из многоканального сигнала. Причем кодирование в частотной области содержит второе объединенное многоканальное кодирование, создающее вторую многоканальную информацию из многоканального сигнала, причем второе объединенное многоканальное кодирование отличается от первого многоканального кодирования. 6 н. и 15 з.п. ф-лы, 7 табл., 22 ил.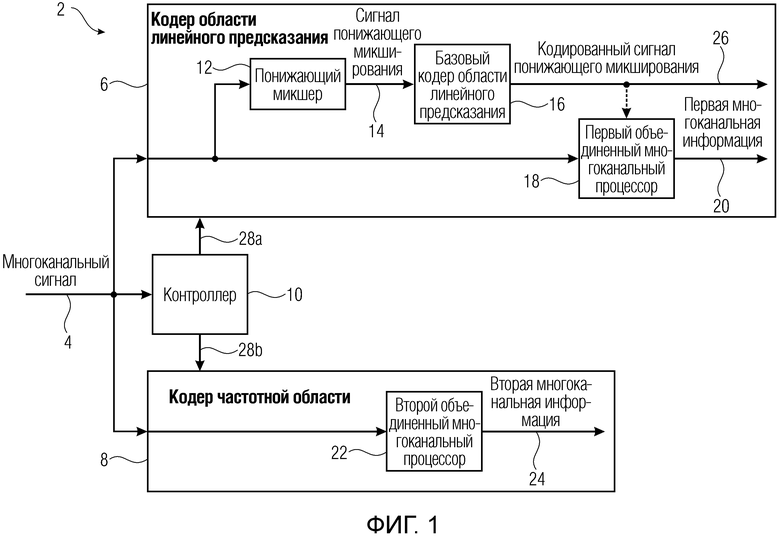
1. Аудиокодер (2) для кодирования многоканального сигнала, содержащий:
кодер (6) области линейного предсказания;
кодер (8) частотной области;
контроллер (10) для переключения между кодером (6) области линейного предсказания и кодером (8) частотной области,
причем кодер (6) области линейного предсказания содержит понижающий микшер (12) для понижающего микширования многоканального сигнала (4) для получения сигнала (14) понижающего микширования, базовый кодер (16) области линейного предсказания для кодирования сигнала (14) понижающего микширования и первый объединенный многоканальный кодер (18) для создания первой многоканальной информации (20) из указанного многоканального сигнала,
причем кодер (8) частотной области содержит второй объединенный многоканальный кодер (22) для кодирования второй многоканальной информации (24) из многоканального сигнала, причем второй объединенный многоканальный кодер (22) отличается от первого объединенного многоканального кодера (18), и
при этом контроллер (10) сконфигурирован так, что часть многоканального сигнала представляют либо кодированным кадром кодера области линейного предсказания, либо кодированным кадром кодера частотной области,
причем кодер (6) области линейного предсказания содержит ACELP процессор (30), TCX процессор (32) и процессор (36) расширения ширины полосы во временной области, причем ACELP процессор (30) выполнен с возможностью работы с сигналом (34) понижающего микширования с понижающей дискретизацией, и при этом процессор (36) расширения ширины полосы во временной области выполнен с возможностью параметрического кодирования диапазона части сигнала понижающего микширования, удаленной из входного сигнала ACELP путем третьего выполнения понижающей дискретизации, и причем TCX процессор (32) выполнен с возможностью работы с сигналом (14) понижающего микширования, не подвергнутого понижающей дискретизации или подвергнутого понижающей дискретизации в степени, меньшей понижающей дискретизации для ACELP процессора (30), и причем TCX процессор содержит первый время-частотный преобразователь (40), первый параметрический генератор (42) для создания параметрического представления (46) первого набора диапазонов и первый квантователь-кодер (44) для создания набора квантованных спектральных линий (48) кодера для второго набора диапазонов,
или
причем аудиокодер дополнительно содержит декодер (50) области линейного предсказания для декодирования сигнала (14) понижающего микширования для получения кодированного и декодированного сигнала (54) понижающего микширования, и многоканальный остаточный кодер (56) для вычисления и кодирования многоканального остаточного сигнала (58) с использованием кодированного и декодированного сигнала (54) понижающего микширования, представляющего ошибку между декодированным многоканальным представлением с использованием первой многоканальной информации (20) и многоканальным сигналом (4) перед понижающим микшированием,
или
причем контроллер (10) выполнен с возможностью переключения в текущем кадре (204) многоканального аудиосигнала с использования кодера (8) частотной области для кодирования предыдущего кадра на использование кодера (6) области линейного предсказания для кодирования последующего кадра, причем первый объединенный многоканальный кодер (18) выполнен с возможностью вычисления синтезированных многоканальных параметров (210a, 210b, 212a, 212b) из многоканального аудиосигнала для текущего кадра, и причем второй объединенный многоканальный кодер (22) выполнен с возможностью взвешивания второго многоканального сигнала с использованием стопового окна.
2. Аудиокодер (2) по п. 1, в котором первый объединенный многоканальный кодер (18) содержит первый время-частотный преобразователь (82), причем второй объединенный многоканальный кодер (22) содержит второй время-частотный преобразователь (66), и при этом первый и второй время-частотные преобразователи отличаются друг от друга.
3. Аудиокодер (2) по п. 1, в котором первый объединенный многоканальный кодер (18) является параметрическим объединенным многоканальным кодером, или
в котором второй объединенный многоканальный кодер (22) является объединенным многоканальным кодером, сохраняющим форму сигнала.
4. Аудиокодер по п. 3,
в котором параметрический объединенный многоканальный кодер содержит кодер создания стерео, параметрический стереокодер или параметрический стереокодер на основе чередования, или
в котором объединенный многоканальный кодер, сохраняющий форму сигнала, содержит стереокодер типа центральный/боковой или типа левый/правый с переключением, избирательным на основе диапазона.
5. Аудиокодер (2) по п. 1, в котором кодер (8) частотной области содержит второй время-частотный преобразователь (66) для преобразования первого канала (4а) многоканального сигнала (4) и второго канала (4b) многоканального сигнала (4) в спектральное представление (72а,b), второй параметрический генератор (68) для создания параметрического представления второго набора диапазонов и второй квантователь-кодер (70) для создания квантованного и кодированного представления первого набора диапазонов (80).
6. Аудиокодер (2) по п. 1,
в котором кодер области линейного предсказания содержит ACELP процессор с расширением полосы во временной области и TCX процессор с MDCT операцией и функциональными возможностями интеллектуального заполнения пропусков, или
в котором кодер частотной области содержит MDCT операцию для первого канала и второго канала, и AAC операцию и функциональные возможности интеллектуального заполнения пропусков, или
в котором первый объединенный многоканальный кодер выполнен с возможностью работы таким образом, чтобы получать многоканальную информацию для полной полосы частот многоканального аудиосигнала.
7. Аудиокодер (2) по п. 1, в котором
сигнал понижающего микширования имеет нижний диапазон и верхний диапазон, причем кодер области линейного предсказания выполнен с возможностью применения обработки для расширения ширины полосы для параметрического кодирования верхнего диапазона, причем декодер области линейного предсказания выполнен с возможностью получения в качестве кодированного и декодированного сигнала (54) понижающего микширования только сигнала нижнего диапазона, представляющего нижний диапазон сигнала понижающего микширования, и при этом кодированный многоканальный остаточный сигнал (58) имеет только частоту в нижнем диапазоне многоканального сигнала перед понижающим микшированием.
8. Аудиокодер (2) по п. 1,
в котором многоканальный остаточный кодер (56) содержит:
объединенный многоканальный декодер (60) для создания декодированного многоканального сигнала (64) с использованием первой многоканальной информации (20) и кодированного и декодированного сигнала (54) понижающего микширования; и
разностный процессор (62) для формирования разности между декодированным многоканальным сигналом и многоканальным сигналом до понижающего микширования для получения многоканального остаточного сигнала.
9. Аудиокодер (2) по п.1,
в котором понижающий микшер (12) выполнен с возможностью преобразования многоканального сигнала в спектральное представление и при этом понижающее микширование выполняют с использованием спектрального представления или с использованием представления временной области, и
в котором первый многоканальный кодер выполнен с возможностью использования спектрального представления для создания по отдельности первой многоканальной информации для отдельных диапазонов спектрального представления.
10. Аудиодекодер (102) для декодирования кодированного аудиосигнала (103), содержащий:
декодер (104) области линейного предсказания;
декодер (106) частотной области;
первый объединенный многоканальный декодер (108) для создания первого многоканального представления (114) с использованием выхода декодера (104) области линейного предсказания и с использованием первой многоканальной информации (20);
второй объединенный многоканальный декодер (110) для создания второго многоканального представления (116) с использованием выхода декодера (106) частотной области и второй многоканальной информации (22, 24); и
первый объединитель (112) для объединения первого многоканального представления (114) и второго многоканального представления (116) для получения декодированного аудиосигнала (118),
причем второй объединенный многоканальный декодер отличается от первого объединенного многоканального декодера,
причем первый объединенный многоканальный декодер (108) является параметрическим объединенным многоканальным декодером, и причем второй объединенным многоканальный декодер является объединенным многоканальным декодером, сохраняющим форму сигнала, причем первый объединенный многоканальный декодер выполнен с возможностью работы на основе комплексного предсказания, режима параметрического стерео или режима чередования, и причем второй объединенный многоканальный декодер выполнен с возможностью применения переключения, избирательного на основе диапазона, для алгоритма стереодекодирования типа центральный/боковой или левый/правый,
или
причем многоканальный кодированный аудиосигнал содержит остаточный сигнал для выхода декодера области линейного предсказания, и причем первый объединенный многоканальный декодер выполнен с возможностью использования многоканального остаточного сигнала для создания первого многоканального представления,
или
причем аудиодекодер (102) выполнен с возможностью переключения в текущем кадре (204) многоканального аудиосигнала с использования декодера (106) частотной области для декодирования предыдущего кадра на декодер (104) области линейного предсказания для декодирования последующего кадра, причем объединитель (112) выполнен с возможностью вычисления синтезируемого центрального сигнала (226) из второго многоканального представления (116) текущего кадра, причем первый объединенный многоканальный декодер (108) выполнен с возможностью создания первого многоканального представления (114) с использованием синтезированного центрального сигнала (226) и первой многоканальной информации (20), и причем объединитель (112) выполнен с возможностью объединения первого многоканального представления и второго многоканального представления для получения декодированного текущего кадра многоканального аудиосигнала,
или
причем аудиодекодер (102) выполнен с возможностью переключения в текущем кадре (232) многоканального аудиосигнала с использования декодера (104) области линейного предсказания для декодирования предыдущего кадра на декодер (106) частотной области для декодирования последующего кадра, причем первый объединенный многоканальный декодер (108) содержит стереодекодер (146), причем стереодекодер (146) выполнен с возможностью вычисления синтезируемого многоканального аудиосигнала из декодированного моносигнала декодера области линейного предсказания для текущего кадра с использованием многоканальной информации предыдущего кадра, причем второй объединенный многоканальный декодер (110) выполнен с возможностью вычисления второго многоканального представления для текущего кадра и взвешивания второго многоканального представления с использованием стартового окна, и причем объединитель (112) выполнен с возможностью объединения синтезируемого многоканального аудиосигнала и взвешенного второго многоканального представления для получения декодированного текущего кадра многоканального аудиосигнала.
11. Аудиодекодер (102) по п. 10, в котором декодер области линейного предсказания содержит:
ACELP декодер (120), синтезатор (122) нижнего диапазона, блок (124) повышающей дискретизации, процессор (126) расширения ширины полосы во временной области или второй объединитель (128) для объединения сигнала после повышающей дискретизации и сигнала после расширения ширины полосы,
TCX декодер (130) и процессор (132) интеллектуального заполнения пропусков,
полнодиапазонный синтезирующий процессор (134) для объединения выхода второго объединителя (128) и TCX декодера (130) и IGF процессора (132) или
в котором кросс-тракт (136) обеспечен для инициализации синтезатора нижнего диапазона с использованием информации, полученной в результате спектр-временного преобразования нижнего диапазона из TCX декодера и IGF процессора.
12. Аудиодекодер (102) по п. 10,
в котором первый объединенный многоканальный декодер содержит время-частотный преобразователь (138) для преобразования выхода декодера (104) области линейного предсказания в спектральное представление (145);
повышающий микшер, управляемый первой многоканальной информацией, оперирующей со спектральным представлением (145); и
частотно-временной преобразователь (148) для преобразования результата повышающего микширования в период временного представления.
13. Аудиодекодер (102) по п. 10,
в котором второй объединенный многоканальный декодер (110) выполнен с возможностью использования в качестве входа спектрального представления, полученного декодером частотной области, причем спектральное представление содержит, по меньшей мере для множества диапазонов, первый канальный сигнал и второй канальный сигнал, и
применения объединенного многоканального режима к множеству диапазонов первого канального сигнала и второго канального сигнала, и преобразования результата объединенного многоканального режима, реализованного объединенным многоканальным декодером, во временное представление для получения второго многоканального представления.
14. Аудиодекодер (102) по п. 13, в котором вторая многоканальная информация (22) является маской, указывающей для отдельных диапазонов, объединенное многоканальное кодирование типа левый/правый или центральный/боковой, и в котором объединенный многоканальный режим представляет собой режим преобразования из типа центральный/боковой в тип левый/правый для преобразования диапазонов, указанных маской из представления центральный/боковой в представление левый/правый.
15. Аудиодекодер (102) по п. 10, в котором многоканальный остаточный сигнал имеет полосу частот ниже первого многоканального представления, и в котором первый объединенный многоканальный декодер выполнен с возможностью восстановления промежуточного первого многоканального представления с использованием первой объединенной многоканальной информации и добавления многоканального остаточного сигнала к промежуточному первому многоканальному представлению.
16. Аудиодекодер (102) по п.12,
в котором время-частотный преобразователь реализует комплексный режим или режим избыточной дискретизации, и
в котором декодер частотной области реализует IMDCT режим или режим критической дискретизации.
17. Аудиодекодер по п. 13, причем многоканальный означает два или более каналов.
18. Способ (800) кодирования многоканального сигнала, содержащий этапы, на которых:
выполняют кодирование в области линейного предсказания;
выполняют кодирование в частотной области;
выполняют переключение между кодированием в области линейного предсказания и кодированием в частотной области,
причем кодирование в области линейного предсказания содержит понижающее микширование многоканального сигнала для получения сигнала понижающего микширования, кодирование сигнала понижающего микширования базовым кодером области линейного предсказания, и первое объединенное многоканальное кодирование, создающее первую многоканальную информацию из многоканального сигнала,
причем кодирование в частотной области содержит второе объединенное многоканальное кодирование, создающее вторую многоканальную информацию из многоканального сигнала, причем второе объединенное многоканальное кодирование отличается от первого многоканального кодирования, и
причем указанное переключение выполняют так, что часть многоканального сигнала представляют либо кодированным кадром кодирования в области линейного предсказания, либо кодированным кадром кодирования в частотной области,
причем кодирование в области линейного предсказания содержит ACELP обработку, TCX обработку и обработку расширения ширины полосы во временной области, причем ACELP обработка выполнена с возможностью работы с сигналом (34) понижающего микширования с понижающей дискретизацией, и при этом обработка расширения ширины полосы во временной области выполнена с возможностью параметрического кодирования диапазона части сигнала понижающего микширования, удаленной из входного сигнала ACELP путем третьего выполнения понижающей дискретизации, и причем TCX обработка выполнена с возможностью работы с сигналом (14) понижающего микширования, не подвергнутого понижающей дискретизации или подвергнутого понижающей дискретизации в степени, меньшей понижающей дискретизации для ACELP обработки, и причем TCX обработка содержит первое время-частотное преобразование, создание параметрического представления (46) первого набора диапазонов и создание набора квантованных спектральных линий (48) кодера для второго набора диапазонов,
или
причем способ аудиокодирования дополнительно содержит декодирование в области линейного предсказания, содержащее декодирование сигнала (14) понижающего микширования для получения кодированного и декодированного сигнала (54) понижающего микширования, и многоканальное остаточное кодирование содержит вычисление и кодирование многоканального остаточного сигнала (58) с использованием кодированного и декодированного сигнала (54) понижающего микширования, представляющего ошибку между декодированным многоканальным представлением с использованием первой многоканальной информации (20) и многоканальным сигналом (4) перед понижающим микшированием,
или
причем переключение содержит переключение в текущем кадре (204) многоканального аудиосигнала с использования кодирования в частотной области для кодирования предыдущего кадра на использование кодирования в области линейного предсказания для кодирования последующего кадра, причем первое объединенное многоканальное кодирование содержит вычисление синтезированных многоканальных параметров (210a, 210b, 212a, 212b) из многоканального аудиосигнала для текущего кадра, и причем второе объединенное многоканальное кодирование содержит взвешивание второго многоканального сигнала с использованием стопового окна.
19. Способ (900) декодирования кодированного аудиосигнала, содержащий этапы, на которых:
выполняют декодирование в области линейного предсказания;
выполняют декодирование в частотной области;
выполняют первое объединенное многоканальное декодирование, создающее первое многоканальное представление с использованием выхода декодирования в области линейного предсказания и с использованием первой многоканальной информации;
выполняют второе многоканальное декодирование, создающее второе многоканальное представление с использованием выхода декодирования в частотной области и второй многоканальной информации; и
выполняют объединение первого многоканального представления и второго многоканального представления для получения декодированного аудиосигнала,
причем второе многоканальное декодирование отличается от первого многоканального декодирования,
причем первое объединенное многоканальное декодирование содержит параметрическое объединенное многоканальное декодирование, и причем второе объединенное многоканальное декодирование содержит объединенное многоканальное декодирование, сохраняющее форму сигнала, причем первое объединенное многоканальное декодирование работает на основе комплексного предсказания, режима параметрического стерео или режима чередования, и причем второе объединенное многоканальное декодирование применяет переключение, избирательное на основе диапазона, для алгоритма стереодекодирования типа центральный/боковой или левый/правый,
или
причем многоканальный кодированный аудиосигнал содержит остаточный сигнал для выхода декодирования в области линейного предсказания, и причем первое объединенное многоканальное декодирование выполнено с возможностью использования многоканального остаточного сигнала для создания первого многоканального представления,
или
причем способ декодирования содержит переключение в текущем кадре (204) многоканального аудиосигнала с использования декодирования в частотной области для декодирования предыдущего кадра на декодирование в области линейного предсказания для декодирования последующего кадра, причем объединение содержит вычисление синтезируемого центрального сигнала (226) из второго многоканального представления (116) текущего кадра, причем первое объединенное многоканальное декодирование содержит создание первого многоканального представления (114) с использованием синтезированного центрального сигнала (226) и первой многоканальной информации (20), и причем объединение содержит объединение первого многоканального представления и второго многоканального представления для получения декодированного текущего кадра многоканального аудиосигнала,
или
причем способ декодирования содержит переключение в текущем кадре (232) многоканального аудиосигнала с использования декодирования в области линейного предсказания для декодирования предыдущего кадра на декодирование в частотной области для декодирования последующего кадра, причем первое объединенное многоканальное декодирование содержит стереодекодирование, причем стереодекодирование содержит вычисление синтезируемого многоканального аудиосигнала из декодированного моносигнала декодирования в области линейного предсказания для текущего кадра с использованием многоканальной информации предыдущего кадра, причем второе объединенное многоканальное декодирование содержит вычисление второго многоканального представления для текущего кадра и взвешивание второго многоканального представления с использованием стартового окна, и причем объединение содержит объединение синтезируемого многоканального аудиосигнала и взвешенного второго многоканального представления для получения декодированного текущего кадра многоканального аудиосигнала.
20. Носитель данных, содержащий сохраненную на нем компьютерную программу для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 18.
21. Носитель данных, содержащий сохраненную на нем компьютерную программу для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 19.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| УСТРОЙСТВО КОДИРОВАНИЯ ЗВУКА, УСТРОЙСТВО ДЕКОДИРОВАНИЯ ЗВУКА, УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЗВУКА И СИСТЕМА ПРОВЕДЕНИЯ ТЕЛЕКОНФЕРЕНЦИЙ | 2009 |
|
RU2495503C2 |

