ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к коммуникационным технологиям и, в частности, к способу и устройству обработки ввода.
УРОВЕНЬ ТЕХНИКИ
В настоящее время интеллектуальные устройства, такие как смартфоны и планшетные компьютеры, становятся все более популярными. Большинство этих устройств использует сенсорный экран, который требует выполнения операций ввода с использованием виртуальной клавиатуры. Ограниченный областью экрана, пользователь не может выполнять операцию ввода с использованием десяти пальцев одновременно. Поэтому эффективность ввода с использованием виртуальной клавиатуры намного ниже, чем эффективность ввода с использованием физической клавиатуры. Особенно в определенных ситуациях (например, во время езды или сидя в вибрирующем автобусе) для гибридного ввода прописных и строчных букв, цифр и символов, например, когда пользователь должен ввести адрес электронной почты (например, Jacky12345@huawei.com), пользователь должен часто переключаться между режимами ввода цифр, букв и символов пунктуации, чтобы выполнить ввод. Эффективность ввода не только низка, но также по ошибке легко может быть нажата неправильная клавиша, что мешает обеспечить точность ввода.
Для решения вышеупомянутой проблемы устройства, такие как смартфоны и планшетные компьютеры в предшествующем уровне техники, главным образом используют голосовой ввод и/или способы рукописного ввода для улучшения эффективности ввода пользователя. Однако голосовой ввод не может быть реализован без сетевой поддержки, он может распознавать только стандартное произношение конкретного языка, и имеет низкий коэффициент распознавания для различных акцентов; а для рукописного ввода почерк должен соответствовать некоторым спецификациям, и для символов, имеющих много элементов, требуется вторичный выбор. Поэтому, вышеупомянутые способы все еще имеют проблему низкой эффективности ввода.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Варианты воплощения настоящего изобретения обеспечивают способ и устройство обработки ввода с тем, чтобы реализовать быстрый и точный ввод сложных слов, таким образом, эффективно улучшая эффективность ввода.
В соответствии с первым аспектом настоящее изобретение обеспечивает способ обработки ввода, включающий в себя:
получение терминальным устройством в соответствии с режимом ввода, выбранным пользователем, первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
кодирование терминальным устройством первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
запрос терминальным устройством предварительно установленного словаря для получения подходящего слова, соответствующего коду.
В первом возможном способе осуществления первого аспекта получение первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, включает в себя:
когда режим ввода является режимом жестикуляционного ввода, получение первой траектории прикосновения, которая вводится на виртуальной клавиатуре терминального устройства пользователем; или, когда режим ввода является режимом голосового ввода, сбор первой звуковой информации с использованием звукового датчика терминального устройства.
Кодирование первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, включает в себя:
когда полученная первая вводимая информация является первой траекторией прикосновения пользователя на виртуальной клавиатуре терминального устройства, объединение символов, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации; и
когда полученная первая вводимая информация является первой звуковой информацией, кодирование первой звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
Со ссылкой на первый аспект или первый возможный способ осуществления первого аспекта, во втором возможном способе осуществления первого аспекта способ дополнительно включает в себя:
прием терминальным устройством запроса на обработку слова, где запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова;
прием терминальным устройством в соответствии с запросом на обработку слова второй вводимой информации, которая вводится пользователем и соответствует режиму обработки слова; и кодирование второй вводимой информации в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации; и
установление терминальным устройством отображающей зависимости между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранение отображающей зависимости в словарь;
Со ссылкой на второй возможный способ осуществления первого аспекта, в третьем возможном способе осуществления первого аспекта прием второй вводимой информации, которая вводится пользователем и соответствует режиму обработки слова, включает в себя:
когда режим обработки слова является режимом жестикуляционной обработки слова, получение второй траектории прикосновения, которая вводится на виртуальной клавиатуре терминального устройства пользователем; или
когда режим обработки слова является режимом голосовой обработки слова, сбор второй звуковой информации с использованием звукового датчика терминального устройства.
Соответственно, когда полученная вторая вводимая информация является второй траекторией прикосновения пользователя на виртуальной клавиатуре терминального устройства, символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, объединяются для получения кода, соответствующего второй вводимой информации; и
когда полученная вторая вводимая информация является второй звуковой информацией, выполняется обработка с помощью кодирования второй звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации.
Со ссылкой на первый аспект, в возможных способах осуществления с первого по третий первого аспекта после запроса предварительно установленного словаря для получения подходящего слова, соответствующего коду, способ дополнительно включает в себя:
когда получено множество подходящих слов, соответствующих коду, расположение множества подходящих слов в соответствии с порядком убывания по частоте и отображение на экране терминального устройства отсортированного множества подходящих слов для выбора пользователем; и отображение в определенной области на экране терминального устройства слова, выбранного пользователем из отсортированного множества подходящих слов.
В соответствии со вторым аспектом настоящее изобретение обеспечивает устройство обработки ввода, включающее в себя:
модуль получения информации, сконфигурированный получать в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
модуль обработки с помощью кодирования, сконфигурированный кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
модуль запроса и сбора, сконфигурированный запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду.
В первом возможном способе осуществления второго аспекта модуль получения информации специально сконфигурирован: когда режим ввода является режимом жестикуляционного ввода, получать первую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или
модуль получения информации специально сконфигурирован: когда режим ввода является режимом голосового ввода, собирать первую звуковую информацию с использованием звукового датчика устройства обработки ввода; и
модуль обработки с помощью кодирования специально сконфигурирован: когда первая вводимая информация, полученная модулем получения информации, является первой траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации; или
модуль обработки с помощью кодирования специально сконфигурирован: когда первая вводимая информация, полученная модулем получения информации, является первой звуковой информацией, кодировать первую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
Со ссылкой на второй аспект или первый возможный способ осуществления второго аспекта, во втором возможном способе осуществления второго аспекта устройство обработки ввода дополнительно включает в себя: приемный модуль и модуль сохранения слова, где
приемный модуль сконфигурирован принимать запрос на обработку слова, где запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова;
модуль получения информации дополнительно сконфигурирован принимать, в соответствии с запросом на обработку слова, вторую вводимую информацию, которая вводится пользователем и соответствует режиму обработки слова;
модуль обработки с помощью кодирования дополнительно сконфигурирован кодировать вторую вводимую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации; и
модуль сохранения слова сконфигурирован устанавливать отображающую зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранять отображающую зависимость в словарь.
Со ссылкой на второй возможный способ осуществления второго аспекта, в третьем возможном способе осуществления второго аспекта модуль получения информации специально сконфигурирован: когда режим обработки слова является режимом жестикуляционной обработки слова, получать вторую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или
модуль получения информации специально сконфигурирован: когда режим обработки слова является режимом голосовой обработки слова, собирать вторую звуковую информацию с использованием звукового датчика устройства обработки ввода.
Со ссылкой на третий возможный способ осуществления второго аспекта, в четвертом возможном способе осуществления второго аспекта модуль обработки с помощью кодирования специально сконфигурирован: когда вторая вводимая информация, полученная модулем получения информации, является второй траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего второй вводимой информации; или
модуль обработки с помощью кодирования специально сконфигурирован: когда вторая вводимая информация, полученная модулем получения информации, является второй звуковой информацией, кодировать вторую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации.
Со ссылкой на второй аспект, в возможных способах осуществления с первого по четвертый второго аспекта, в пятом возможном способе осуществления второго аспекта устройство обработки ввода дополнительно включает в себя:
модуль обработки с помощью сортировки, сконфигурированный: когда получено множество подходящих слов, соответствующих коду, сортировать множество подходящих слов в соответствии с порядком убывания по частоте, и отображать на экране устройства обработки ввода отсортированное множество подходящих слов для выбора пользователем; и
модуль дисплея, сконфигурированный отображать, в определенной области на экране устройства обработки ввода, слово, выбранное пользователем из отсортированного множества подходящих слов.
В вариантах воплощения настоящего изобретения в соответствии с режимом ввода, выбранным пользователем, получается первая вводимая информация, которая вводится пользователем и соответствует режиму ввода; выполняется обработка с помощью кодирования первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и, наконец, запрашивается предварительно установленный словарь для получения подходящего слова, соответствующего коду. Путем получения первой вводимой информации в соответствии с различными режимами ввода, получения соответствующего кода в соответствии с первой вводимой информацией, и затем получения, с помощью кодирования, слова, которое нужно ввести пользователю, реализован быстрый и точный ввод составных слов, таким образом, эффективно улучшая эффективность ввода и улучшая опыт пользователя.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для более ясного описания технических решений в вариантах воплощения настоящего изобретения нижеследующее кратко представляет прилагаемые чертежи, необходимые для описания вариантов воплощения. Очевидно, прилагаемые чертежи в нижеследующем описании показывают просто некоторые варианты воплощения настоящего изобретения, и средние специалисты в области техники могут получить другие чертежи из этих прилагаемых чертежей без каких-либо творческих усилий.
Фиг. 1 является блок-схемой последовательности операций варианта воплощения способа обработки ввода настоящего изобретения;
фиг. 2 является блок-схемой последовательности операций другого варианта воплощения способа обработки ввода настоящего изобретения;
фиг. 3 является блок-схемой последовательности операций еще одного варианта воплощения способа обработки ввода настоящего изобретения;
фиг. 4 является принципиальной схемой интерфейса ввода терминального устройства;
фиг. 5 является другой принципиальной схемой интерфейса ввода терминального устройства;
фиг. 6 является блок-схемой последовательности операций еще одного варианта воплощения способа обработки ввода настоящего изобретения;
фиг. 7 является еще одной принципиальной схемой интерфейса ввода терминального устройства;
фиг. 8 является схематической структурной диаграммой варианта воплощения устройства обработки ввода настоящего изобретения;
фиг. 9 является схематической структурной диаграммой другого варианта воплощения устройства обработки ввода настоящего изобретения; и
фиг. 10 является схематической структурной диаграммой еще одного варианта воплощения устройства обработки ввода настоящего изобретения.
ОПИСАНИЕ ВАРИАНТОВ ВОПЛОЩЕНИЯ
Чтобы сделать цели, технические решения и преимущества вариантов воплощения настоящего изобретения более понятными, нижеследующее ясно описывает технические решения в вариантах воплощения настоящего изобретения со ссылкой на прилагаемые чертежи в вариантах воплощения настоящего изобретения. Очевидно, описанные варианты воплощения являются лишь частью, а не всеми вариантами воплощения настоящего изобретения. Все другие варианты воплощения, полученные средними специалистами в области техники, основанные на вариантах воплощения настоящего изобретения без каких-либо творческих усилий, должны находиться в пределах объема защиты настоящего изобретения.
Фиг. 1 является блок-схемой последовательности операций варианта воплощения способа обработки ввода настоящего изобретения. Как показано на фиг. 1, способ обработки ввода, обеспеченный в этом варианте воплощения, выполняется терминальным устройством, и способ обработки ввода, в частности, включает в себя следующие этапы:
Этап 101: терминальное устройство получает, в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода.
В этом варианте воплощения терминальное устройство может быть мобильным телефоном, планшетным компьютером и т.п. В частности, пользователь выбирает режим ввода, активируя соответствующую кнопку на интерфейсе ввода терминального устройства. Предпочтительно, режим ввода является режимом голосового ввода или режимом жестикуляционного ввода. Затем получается первая вводимая информация, которая вводится пользователем и соответствует режиму ввода. Различные режимы ввода соответствуют различной вводимой информации, таким образом, первая вводимая информация меняется в зависимости от различных режимов ввода. Например, в режиме голосового ввода первая вводимая информация является фрагментом звуковой информации, а в режиме жестикуляционного ввода первая вводимая информация является фрагментом информации о траектории прикосновения, где информация о траектории прикосновения может быть, например, текстовой или графической информацией.
Этап 102: терминальное устройство кодирует первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации.
В этом варианте воплощения после того, как получена первая вводимая информация, которая вводится пользователем и соответствует режиму ввода, выполняется обработка с помощью кодирования первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации. Для различных режимов ввода заданы, соответственно, различные правила кодирования, и генерируется соответствующий код. В частности, есть предварительная установка правила кодирования для режима жестикуляционного ввода, и есть также предварительная установка правила кодирования для режима голосового ввода.
Этап 103: терминальное устройство запрашивает предварительно установленный словарь для получения подходящего слова, соответствующего коду.
В этом варианте воплощения после того, как получен код, соответствующий первой вводимой информации, запрашивается предварительно установленный словарь для получения подходящего слова, соответствующего коду. В частности, предварительно установленный словарь может быть словарем на сервере, соединенным с терминальным устройством, или локальным словарем, установленным самим терминальным устройством, или локальным словарем, загруженным терминальным устройством с сервера и сохраненным в память терминального устройства. Словарь может включать в себя "горячие" слова, специальные слова, определяемые пользователем слова и т.п., и устанавливается отображающая зависимость между кодом и словами, так что соответствующее подходящее слово может быть быстро проиндексировано из локального словаря в соответствии с кодом. Кроме того, подходящее слово может специально быть в виде одного или комбинации нескольких из следующих элементов: одного слова, фразы, предложения, длинной строки символов, таких как цифры и буквы, например, учетной записью QQ 1234657 или адресом электронной почты yagneos235@hotmail.com.cn.
Предпочтительно, когда получено одно подходящее слово, соответствующее коду, это одно подходящее слово является словом, которое нужно ввести пользователю. Когда получено множество подходящих слов, соответствующих коду, множество подходящих слов может быть отсортировано в порядке убывания по частоте. Затем отсортированное множество подходящих слов отображается на экране терминального устройства для выбора пользователем, и слово, выбранное пользователем из отсортированного множества подходящих слов, отображается в определенной области на экране терминального устройства.
В этом варианте воплощения в соответствии с режимом ввода, выбранным пользователем, получается первая вводимая информация, которая вводится пользователем и соответствует режиму ввода; выполняется обработка с помощью кодирования первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и, наконец, предварительно установленный словарь запрашивается для получения подходящего слова, соответствующего коду. Путем получения первой вводимой информации в соответствии с различными режимами ввода, получения соответствующего кода в соответствии с первой вводимой информацией, и затем получения, с помощью кодирования, слова, которое нужно ввести пользователю, реализован быстрый и точный ввод сложных слов, таким образом, эффективно улучшая эффективность ввода и улучшая опыт пользователя.
Кроме того, в другом варианте воплощения настоящего изобретения, основанном на вышеупомянутом варианте воплощения, показанном на фиг. 1, получение первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, на этапе 101 может, в частности, быть реализовано следующими способами:
способ 1: когда режим ввода является режимом жестикуляционного ввода, получить первую траекторию прикосновения, которая вводится на виртуальной клавиатуре терминального устройства пользователем; и
способ 2: когда режим ввода является режимом голосового ввода, собрать первую звуковую информацию путем использования звукового датчика терминального устройства.
В этом варианте воплощения словарь должен быть предварительно установлен на сервере, где словарь включает в себя "горячие" слова, специальные слова, определяемые пользователем слова и т.п. Здесь определяемое пользователем слово является словом, заранее заданным пользователем и зарезервированным в словаре с помощью терминального устройства, и определяемое пользователем слово должно быть связано с личной учетной записью пользователя, например, словарь хранит идентификатор пользователя и определяемое пользователем слово, соответствующее идентификатору пользователя. Сервер индексирует и сортирует собранные слова, например, индексирует на основании системы транслитерации китайских иероглифов, фонетических алфавитов, элементов иероглифов, повторяемости и т.п. Чтобы словарь предоставлял более часто встречающиеся слова, специальный технический персонал может быть обязан своевременно собирать широко используемые фразы и часто встречающиеся слова из Интернета и своевременно добавлять их в словарь. Кроме того, для удобства использования пользователем, пользователь может загрузить с помощью терминального устройства словарь в локальный словарь терминального устройства, такого как мобильный телефон или планшетный компьютер. Следует отметить, что определяемое пользователем слово в локальном словаре соответствует идентификатору пользователя. Между тем, для удовлетворения требований различных пользователей локальный словарь может дополнительно иметь мощную функцию настройки. Пользователь может добавить некоторые из его или ее часто используемых слов в независимый файл в локальном словаре и загрузить файл на сервер, а сервер записывает слова в файле в определяемые пользователем слова для выполнения резервирования.
Следует дополнительно отметить, что сервер может также получить определяемые пользователем слова, соответствующие множеству идентификаторов пользователей, и установить индексы в соответствии с порядком убывания по частоте, чтобы генерировать и добавить "горячие" слова в словарь.
Во время использования пользователем терминальное устройство может предпочтительно загружать слова, связанные с учетной записью пользователя, то есть определяемые пользователем слова, в локальный словарь. Для профессиональных слов, "горячих" слов и т.п. сервер сообщает пользователю, что доступно обновление, и пользователь выбирает обновление и загружает профессиональные слова и "горячие" слова в локальный словарь.
В этом варианте воплощения локальный словарь имеет мощную функцию настройки, и пользователь может добавить его или ее часто используемые слова в библиотеку с помощью функции настройки для облегчения последующего использования пользователем. Ниже подробно описано, как пользователь определяет слово.
В другом варианте воплощения настоящего изобретения, как показано на фиг. 2, которая является блок-схемой последовательности операций другого варианта воплощения способа обработки ввода настоящего изобретения, основанного на вышеупомянутом варианте воплощения, показанном на фиг. 1, перед этапом 101 способ этого варианта воплощения может дополнительно включать в себя следующие этапы:
Этап 201: терминальное устройство принимает запрос на обработку слова, где запрос на обработку слова используется для запроса на добавление слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова.
В этом варианте воплощения режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова, а запрос на обработку слова используется для запроса добавления слова в словарь. Пользователь может выбрать режим обработки слова путем активации соответствующей кнопки на интерфейсе ввода, и ввести в режиме обработки слова слово, которое нужно добавить. Слово, которое нужно добавить, является словом, которое отсутствует в локальном словаре и определяется пользователем. Слово, которое нужно добавить, может быть часто используемой учетной записью QQ, адресом электронной почты, паролем, телефонным номером и т.п. пользователя. Часто используемое слово пользователя добавляется в словарь путем использования запроса на обработку слова.
Этап 202: терминальное устройство принимает, в соответствии с запросом на обработку слова, вторую вводимую информацию, которая вводится пользователем и соответствует режиму обработки слова; и кодирует вторую вводимую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации.
В этом варианте воплощения вторая вводимая информация, которая вводится пользователем и соответствует режиму обработки слова, принимается в соответствии с запросом на обработку слова, и вторая вводимая информация меняется в зависимости от различных режимов обработки слова. В режиме жестикуляционной обработки слова вторая вводимая информация является траекторией прикосновения пользователя на виртуальной клавиатуре терминального устройства, а в режиме голосового ввода вторая вводимая информация является звуковой информацией, собранной с помощью звукового датчика терминального устройства. Кроме того, выполняется обработка с помощью кодирования принятой второй вводимой информации в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации, где код однозначно определяет вторую вводимую информацию. Для различных режимов ввода используются различные способы кодирования. Предварительная установка правила кодирования для режима жестикуляционной обработки слова объединяет символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения пользователя на виртуальной клавиатуре терминального устройства; и предварительно заданное правило кодирования для режима голосовой обработки текста является хеш- (Hash) алгоритмом, алгоритмом скрытой марковской модели (Hidden Markov model, HMM для краткости) или алгоритмом динамической трансформации шкалы времени при распознавании речи (Dynamic Time Warping, DTW для краткости).
Этап 203: терминальное устройство устанавливает отображающую зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохраняет отображающую зависимость в словарь.
В этом варианте воплощения отображающая зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, устанавливается в соответствии с кодом, соответствующим второй вводимой информации и слову, и отображающая зависимость сохраняется в словарь. Таким образом, устанавливается соответствие между вводимой информацией пользователя и словом.
В этом варианте воплощения слово, добавленное пользователем, сохраняется в словарь, и между вводимой информацией пользователя и словом устанавливается отображающая зависимость, так что когда пользователь вводит новую информацию, вводимая информация пользователя может быть распознана, может быть получен код, соответствующий вводимой информации, и подходящее слово, необходимое пользователю, может быть быстро проиндексировано в соответствии с отображающей зависимостью между кодом и словом, которое сохранено в локальном словаре.
Фиг. 3 является блок-схемой последовательности операций еще одного варианта воплощения способа обработки ввода настоящего изобретения. В этом варианте воплощения в подробностях представлено техническое решение этого варианта воплощения путем использования примера, где способ выполняется терминальным устройством, таким как мобильный телефон, режим ввода является режимом обработки жестикуляционного ввода, а первая вводимая информация является траекторией прикосновения, введенной пользователем. Как показано на фиг. 3, способ включает в себя:
Этап 301: Принять запрос на обработку слова, где запрос на обработку слова включает в себя режим жестикуляционной обработки слова и слово, которое должно быть добавлено, а запрос на обработку слова используется для добавления слова в словарь.
В этом варианте воплощения запрос на обработку слова вводится пользователем с использованием интерфейса ввода терминального устройства. Фиг. 4 является принципиальной схемой интерфейса ввода терминального устройства. Фиг. 5 является еще одной принципиальной схемой интерфейса ввода терминального устройства. Во-первых, пользователь открывает страницу на интерфейсе ввода для того, чтобы добавить определяемое пользователем слово, и на странице имеются соответствующие кнопки, которые соответственно представляют различные режимы обработки слова. Как показано на фиг. 4, имеется режим жестикуляционной обработки слова и режим голосовой обработки слова. Когда пользователь выбирает режим жестикуляционной обработки слова, появляется страница, показанная на фиг. 5, и в режиме жестикуляционной обработки слова пользователь вводит слово 12345678, которое должно быть добавлено, и задает информацию примечания для слова, где примечание указывает, что это учетная запись QQ.
Этап 302: Принять, в соответствии с запросом на обработку слова, вторую траекторию прикосновения, которая вводится пользователем и соответствует режиму жестикуляционной обработки слова; и закодировать вторую траекторию прикосновения в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй траектории прикосновения.
В этом варианте воплощения в режиме жестикуляционной обработки слова пользователь производит кратковременное нажатие на виртуальной клавиатуре терминального устройства, чтобы генерировать вторую траекторию прикосновения, и когда вторая траектория прикосновения пользователя на виртуальной клавиатуре терминального устройства получена, выполняется обработка с помощью кодирования второй траектории прикосновения в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй траектории прикосновения. Правило кодирования является предварительно заданным, и в этом варианте воплощения символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, объединяются в код для получения кода, соответствующего второй траектории прикосновения. Символы являются цифрами или буквами, таким образом, в качестве кода могут использоваться цифры, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения, или в качестве кода могут использоваться буквы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения.
Как показано на фиг. 5, вторая информация о траектории прикосновения является L-образным графическим символом, нарисованным пользователем, и графический символ рисуется пользователем за один прием. Траектория прикосновения L-образного графического символа последовательно проходит через цифровые кнопки 1478 на клавиатуре, начальной точкой траектории является 1, и конечной точкой траектории является 8, где конечная точка траектории прикосновения указывает конец второй траектории прикосновения. В этом варианте воплощения правило кодирования объединяет символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре. На фиг. 5 виртуальная клавиатура на интерфейсе ввода является обычной числовой клавиатурой, числовая клавиатура имеет десять цифр 0-9, каждая цифра соответствует одной кнопке, пользователь может нарисовать любой графический символ на числовой клавиатуре, и цифры, соответствующие кнопкам, через которые последовательно проходит траектория прикосновения пользователя при рисовании графического символа, используются для кодирования. Поэтому для этого варианта воплощения код, соответствующий второй траектории прикосновения, имеет вид 1478. Когда интерфейс ввода является виртуальной клавиатурой PC, кодирование может выполняться в соответствии с буквами, соответствующими кнопкам, через которые проходит траектория прикосновения.
Этап 303: Установить отображающую зависимость между кодом, соответствующим второй траектории прикосновения и словом, которое нужно добавить, и сохранить отображающую зависимость в предварительно установленный словарь.
В частности, на этапе 302 генерируется код 1478, соответствующий второй траектории прикосновения; установлена отображающая зависимость между кодом 1478 и словом, которое нужно добавить, которое введено на этапе 301, где слово, которое нужно добавить, является учетной записью QQ 12345678, то есть код 1478 однозначно определяет слово 12345678; и отображающая зависимость сохраняется в словарь. В этом варианте воплощения одна траектория прикосновения пользователя соответствует единственному коду. Однако следует отметить, что один код может также соответствовать множеству слов, например, код 1478 может также соответствовать другим словам. Например, когда пользователь имеет множество учетных записей QQ, код 1478 может соответствовать множеству учетных записей QQ, при условии, что отображающая зависимость между кодом 1478 и словами добавлена.
Кроме того, например, словарь может также хранить отображающую зависимость между кодом и словами в следующем виде, как показано в Таблице 1:
Этап 304: В соответствии с режимом жестикуляционного ввода, выбранным пользователем, получить первую траекторию прикосновения, соответствующую режиму жестикуляционного ввода.
Этап 305: Закодировать первую траекторию прикосновения в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой траектории прикосновения.
На этом этапе заданное правило кодирования является тем же самым, что и правило кодирования, используемое для кодирования второй траектории прикосновения на этапе 302, а именно: объединение символов, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой траектории прикосновения.
Этап 306: Запросить предварительно установленный словарь для получения подходящего слова, соответствующего коду.
На этом этапе, так как предварительно установленный словарь уже хранит отображающую зависимость между кодом и словами, подходящее слово, соответствующее коду, может быть получено путем поиска в словаре в соответствии с полученным кодом.
В этом варианте воплощения, когда пользователю нужно ввести учетную запись QQ пользователя, пользователь может переключить интерфейс ввода на терминальном устройстве в режим жестикуляционного ввода. В режиме жестикуляционного ввода пользователь рисует графический символ за один прием на интерфейсе ввода, чтобы инициировать получение терминальным устройством информации о траектории прикосновения в соответствии с режимом жестикуляционного ввода и распознание информации о траектории прикосновения для получения соответствующего кода. Например, определено, что областью, через которую проходит траектория прикосновения пользователя, является 1478, и, соответственно, код равен 1478. В этом случае запрашивается локальный словарь для получения подходящего слова, то есть учетной записи QQ 12345678, соответствующей коду 1478.
Кроме того, следует также отметить, что если есть одно подходящее слово, то подходящее слово (то есть учетная запись QQ 12345678) является словом, которое нужно ввести пользователю; а если есть множество подходящих слов, то множество подходящих слов сортируется в соответствии с порядком убывания по частоте множества подходящих слов, и отсортированное множество подходящих слов отображается на экране терминального устройства так, чтобы пользователь выбрал из них одно подходящее слово в качестве слова, которое нужно ввести пользователю; и, наконец, терминальное устройство отображает слово, выбранное пользователем из отсортированного множества подходящих слов в определенной области на экране терминального устройства. Здесь определенная область является областью ввода, задаваемой прикладной программой, используемой в настоящий момент пользователем, или прикладной программой, ожидающей текстового ввода.
В способе обработки ввода, представленном в этом варианте воплощения, траектория прикосновения простого графического символа, рисуемого пользователем, код, соответствующий траектории прикосновения, и отображающая зависимость между кодом и словом заранее сохранены в локальном словаре, так что установлена отображающая зависимость между сложными словами и простыми графическими символами, где слова являются некоторыми сложными словами, часто используемыми пользователем, например, учетной записью QQ, адресом электронной почты, паролем и т.п. пользователя. При использовании пользователю нужно только переключить режим ввода в режим жестикуляционного ввода и нарисовать графический символ за один прием на интерфейсе ввода, а устройство распознает информацию о траектории прикосновения графического символа, получает код, соответствующий информации о траектории прикосновения, ищет в словаре соответствующее подходящее слово в соответствии с отображающей зависимостью между кодом и словом, и использует подходящее слово в качестве слова, которое нужно ввести пользователю. Таким образом, пользователь может выполнить ввод длинного и сложного слова с помощью одной операции ввода, тем самым улучшая эффективность и точность ввода.
Способ обработки ввода, обеспеченный в этом варианте воплощения, применим к вводу сложных слов. По сравнению с обычным рукописным вводом, в способе обработки ввода, обеспеченном в этом варианте воплощения, не выполняется распознавание нарисованного графического символа и текста, а вместо этого кодируется траектория прикосновения нарисованного графического символа и устанавливается отображающая зависимость между кодом и словом. Например, когда нарисован L-образный графический символ, нет необходимости распознавать, является ли графический символ буквой L, а вместо этого получается соответствующий код в соответствии с траекторией прикосновения графического символа, и соответствующее слово находится в соответствии с кодом. Таким образом, улучшается не только эффективность ввода, но также улучшается и точность ввода.
Фиг. 6 является блок-схемой последовательности операций еще одного варианта воплощения способа обработки ввода настоящего изобретения. В этом варианте воплощения в подробностях представлено техническое решение этого варианта воплощения путем использования примера, где способ выполняется терминальным устройством, таким как мобильный телефон, режим ввода является режимом обработки голосового ввода, а первая вводимая информация является звуковой информацией, вводимой пользователем. Как показано на фиг. 6, способ включает в себя:
Этап 601: Принять запрос на обработку слова, где запрос на обработку слова включает в себя режим голосовой обработки слова и слово, которое нужно добавить, и запрос на обработку слова используется для добавления слова в словарь.
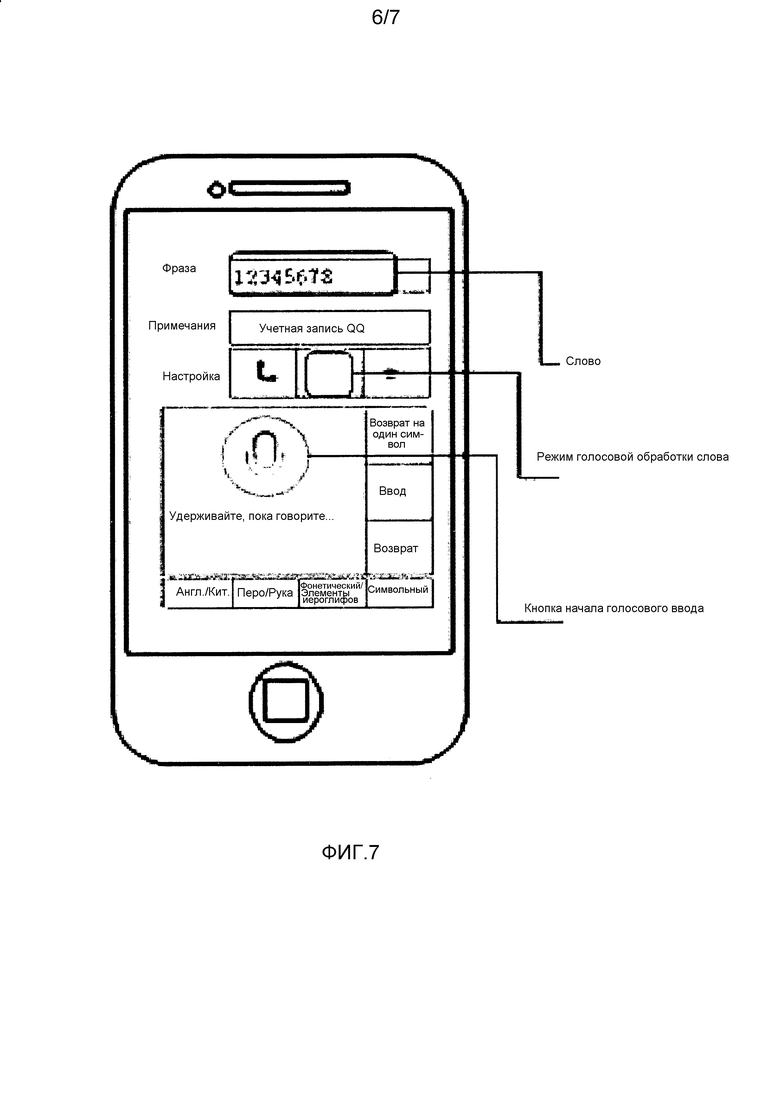
В этом варианте воплощения запрос на обработку слова вводится пользователем с помощью интерфейса ввода терминального устройства. Фиг. 7 является еще одной принципиальной схемой интерфейса ввода терминального устройства. Во-первых, пользователь открывает страницу для добавления определяемого пользователем слова на интерфейсе ввода, и на странице заданы соответствующие кнопки, которые соответственно представляют различные режимы обработки слова. Как показано на фиг. 4, есть режим жестикуляционной обработки слова и режим голосовой обработки слова. Когда пользователь выбирает режим голосовой обработки слова, появляется страница, показанная на фиг. 7, и в режиме голосовой обработки слова пользователь вводит слово, которое нужно добавить, и задает для слова информацию примечания, где примечание указывает, что это почта 163.
Этап 602: Принять, в соответствии с запросом на обработку слова, вторую звуковую информацию, которая вводится пользователем и соответствует режиму голосовой обработки слова; и закодировать вторую звуковую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй звуковой информации.
В этом варианте воплощения в соответствии с запросом на обработку слова принимается вторая звуковая информация, которая вводится пользователем и соответствует режиму голосовой обработки слова, где вторая звуковая информация собирается терминальным устройством с помощью звукового датчика терминального устройства. После приема второй звуковой информации выполняется обработка с помощью кодирования второй звуковой информации в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй звуковой информации. В частности, обработка с помощью кодирования второй звуковой информации может быть выполнена с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации.
Ниже приведено описание с использованием конкретного примера. Как показано на фиг. 7, в режиме голосовой обработки слова кнопка начала голосового ввода (также служащая кнопкой завершения голосового ввода) может быть задана на интерфейсе ввода терминального устройства. Путем нажатия или удержания кнопки начала голосового ввода включается микрофон или другое устройство голосового ввода на терминальном устройстве; пользователь издает звук, например, пользователь издает звуковую информацию адреса электронной почты; терминальное устройство начинает собирать звуковую информацию пользователя; пользователь отпускает кнопку начала голосового ввода. Таким образом, завершен один процесс сбора звуковой информации, и собранная звуковая информация является второй звуковой информацией.
После сбора второй звуковой информации вторая звуковая информация кодируется для генерации кода, соответствующего звуковой информации. Здесь правило кодирования является предварительно заданным, и правило кодирования может преобразовывать собранную звуковую информацию в строку символов или текст с использованием алгоритма распознавания речи, обычно используемого в предшествующем уровне техники, например, хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW). Правило кодирования не имеет особых ограничений в варианте воплощения настоящего изобретения. Путем кодирования второй звуковой информации, введенной пользователем, получается код, соответствующий второй звуковой информации. Например, в этом варианте воплощения код, соответствующий второй звуковой информации, имеет вид Sjdegsogea4512.
Этап 603: Установить отображающую зависимость между кодом, соответствующим второй звуковой информации, и словом, которое нужно добавить, и сохранить отображающую зависимость в словарь.
В частности, на этапе 602 генерируется код Sjdegsogea4512, соответствующий второй звуковой информации; установлена отображающая зависимость между кодом Sjdegsogea4512 и словом, которое нужно добавить, Jacky.Chen@163.com, которое введено на этапе 601, где код Sjdegsogea4512 однозначно определяет слово Jacky.Chen@163.com; и отображающая зависимость сохраняется в словарь. В этом варианте воплощения один кусок звуковой информации пользователя соответствует единственному коду. Следует отметить, что один код может соответствовать множеству слов. Например, у пользователя есть множество адресов электронной почты, и для простоты запоминания пользователь устанавливает отображающую зависимость между кодом, соответствующим звуковой информации электронной почты, и множеством адресов электронной почты, при условии, что отображающая зависимость между кодом и соответствующими словами добавлена в локальный словарь.
Например, локальный словарь может также хранить отображающую зависимость между кодом и словами в следующем виде, как показано в Таблице 2:
Здесь аудио 1, аудио 2 и аудио 3 записывают звуковую информацию, введенную пользователем.
Этап 604: В соответствии с режимом голосового ввода, выбранным пользователем, получить первую звуковую информацию, соответствующую режиму голосового ввода.
В режиме голосового ввода первая звуковая информация собирается терминальным устройством с использованием датчика.
Этап 605: Кодирует первую звуковую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой звуковой информации.
Правило кодирования, используемое на этом этапе, является тем же правилом кодирования, которое использовалось на этапе 602, и оно может, в частности, быть: кодированием первой звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
Этап 606: Запросить предварительно установленный словарь для получения подходящего слова, соответствующего коду.
На этом этапе, так как предварительно установленный словарь уже хранит отображающую зависимость между кодом и словами, подходящее слово, соответствующее коду, может быть получено с помощью поиска в словаре в соответствии с полученным кодом.
В этом варианте воплощения, когда пользователю необходимо ввести адрес электронной почты пользователя, пользователь вначале переключает интерфейс ввода терминального устройства в режим голосового ввода. В режиме голосового ввода пользователь издает звуковую информацию, нажимая и удерживая кнопку начала голосового ввода на интерфейсе ввода, чтобы инициировать получение терминальным устройством звуковой информации в соответствии с режимом голосового ввода и распознание звуковой информации для получения кода, соответствующего звуковой информации. Например, распознано, что кодом, соответствующим звуковой информации, введенной пользователем, является Sjdegsogea4512. В этом случае запрашивается локальный словарь для получения подходящего слова, то есть Jacky.Chen@163.com, соответствующего коду Sjdegsogea4512.
Кроме того, следует также отметить, что если есть одно подходящее слово, подходящее слово (то есть Jacky.Chen@163.com) является словом, которое нужно ввести пользователю; а если есть множество подходящих слов, множество подходящих слов сортируется в соответствии с порядком убывания по частоте множества подходящих слов, и отсортированное множество подходящих слов отображается пользователю так, чтобы пользователь выбрал из них одно подходящее слово в качестве слова, которое нужно ввести пользователю; и пользователь выбирает слово, которое нужно ввести, из отсортированного множества подходящих слов, соответствующих коду, и вводит слово.
В способе обработки ввода, обеспеченном в этом варианте воплощения, краткая звуковая информация пользователя, код, соответствующий звуковой информации, и отображающая зависимость между кодом и словом заранее сохраняются в локальном словаре, так что установлена отображающая зависимость между сложными словами и звуковой информацией, при этом слова являются некоторыми сложными словами, часто используемыми пользователем, например, адресом электронной почты, паролем, номером мобильного телефона и т.п. пользователя. При использовании пользователь должен лишь переключить режим ввода в режим голосового ввода и выполнить соответствующую операцию для ввода звуковой информации пользователя, и устройство распознает звуковую информацию, получит код, соответствующий звуковой информации, и произведет поиск в локальном словаре соответствующего подходящего слова в соответствии с отображающей зависимостью между кодом и словом. Таким образом, может быть реализован ввод длинного и сложного слова путем ввода краткой звуковой информацию, тем самым улучшая эффективность ввода.
Способ обработки ввода, обеспеченный в этом варианте воплощения, применим к сценарию работы, в котором имеются вибрации и который сложен для рукописного ввода, например, когда пользователю нужно что-то ввести во время вождения. Путем переключения режима ввода в режим голосового ввода пользователь может выполнить ввод сложного слова, просто вводя краткую звуковую информацию, что удобно и улучшает эффективность ввода. В отличие от обычного голосового ввода, в способе обработки ввода, обеспеченном в этом варианте воплощения, распознавание звука и текста не выполняется, а вместо этого просто устанавливается соответствие между введенным звуком и словом, что улучшает точность ввода. Например, когда звуковая информация, введенная пользователем, это "Моя электронная почта", программа не распознает звуковую информацию и текст "Моя электронная почта", и не должна возвращать текст "Моя электронная почта" пользователю, а вместо этого возвращается адрес электронной почты пользователя в соответствии с отображающей зависимостью между кодом, соответствующим звуковому сигналу, и словом.
Кроме того, следует также отметить, что в настоящем изобретении для получения слова, которое нужно ввести пользователю, может также использоваться режим ввода символов. В частности, пользователь может переключить интерфейс ввода в режим ввода символов, и в этом режиме терминальное устройство получает символьную информацию, введенную пользователем, индексирует и получает подходящее слово, соответствующее символьной информации, из локального словаря, сортирует множество найденных подходящих слов, соответствующих символьной информации, в соответствии с порядком убывания по частоте, и отображает отсортированное множество подходящих слов пользователю с помощью интерфейса терминального устройства. Пользователь выбирает слово, которое нужно ввести, из возвращенного множества подходящих слов. После получения терминальным устройством слова, которое нужно ввести, которое выбрано пользователем, может быть дополнительно выполнена вторичная индексация локального словаря в соответствии с контекстом слова, чтобы предсказать слово, которое пользователь может впоследствии ввести. После вторичной индексации пользователь может непосредственно выбрать слово, которое нужно ввести, из подходящих слов, полученных после вторичной индексации, без дальнейшего ввода каких-либо символов.
Например, пользователь вводит "ao" с использованием Системы транслитерации китайских иероглифов, и множество соответствующих подходящих слов (слова), таких как  и
и  найдены в локальном словаре в соответствии с "ao". Подходящие слова могут быть выведены, после сортировки, в соответствии с порядком убывания по частоте. Когда пользователь выбирает подходящее слово
найдены в локальном словаре в соответствии с "ao". Подходящие слова могут быть выведены, после сортировки, в соответствии с порядком убывания по частоте. Когда пользователь выбирает подходящее слово  в качестве слова, которое нужно ввести пользователю, может быть дополнительно выполнена вторичная индексация локального словаря в соответствии с
в качестве слова, которое нужно ввести пользователю, может быть дополнительно выполнена вторичная индексация локального словаря в соответствии с  для получения из локального словаря множества подходящих слов, связанных с
для получения из локального словаря множества подходящих слов, связанных с  таких как
таких как  и
и  для выбора пользователем. Когда второе слово, выбранное пользователем, это
для выбора пользователем. Когда второе слово, выбранное пользователем, это 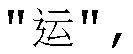 и контекстом является
и контекстом является  то в этом случае множество соответствующих подходящих слов, таких как
то в этом случае множество соответствующих подходящих слов, таких как  и
и  может быть дополнительно получено в соответствии с
может быть дополнительно получено в соответствии с 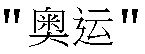 . Наконец,
. Наконец,  выбранное пользователем, получается в качестве слова, которое нужно ввести пользователю.
выбранное пользователем, получается в качестве слова, которое нужно ввести пользователю.
Фиг. 8 является схематической структурной диаграммой варианта воплощения устройства обработки ввода настоящего изобретения. Как показано на фиг. 8, устройство 800 обработки ввода, обеспеченное в этом варианте воплощения, включает в себя модуль 801 получения информации, модуль 802 обработки с помощью кодирования и модуль 803 запроса и сбора. Модуль 801 получения информации сконфигурирован получать, в соответствии с режимом ввода, выбранным пользователем, первую вводимую информация, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода. Модуль 802 обработки с помощью кодирования сконфигурирован кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации. Модуль 803 запроса и сбора сконфигурирован запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду.
Устройство 800 обработки ввода этого варианта воплощения может выполнять техническое решение варианта воплощения способа на фиг. 1, и принципы варианта осуществления аналогичны принципам варианта воплощения способа, поэтому подробности будут опущены.
В этом варианте воплощения в соответствии с режимом ввода, выбранным пользователем, получается первая вводимая информация, которая соответствует режиму ввода; выполняется обработка с помощью кодирования первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и, наконец, запрашивается предварительно установленный словарь для получения подходящего слова, соответствующего коду. Путем получения первой вводимой информации в соответствии с различными режимами ввода, получения соответствующего кода в соответствии с первой вводимой информацией, и затем получения, с помощью кодирования, слова, которое нужно ввести пользователю, реализован быстрый и точный ввод сложных слов, тем самым эффективно улучшая эффективность ввода.
Дополнительно, в другом варианте воплощения настоящего изобретения, основанного на вышеупомянутом варианте воплощения, показанном на фиг. 8, устройство обработки ввода дополнительно включает в себя сенсорный экран и звуковой датчик, и виртуальная клавиатура отображается на сенсорном экране для выполнения пользователем сенсорных операций. Звуковой датчик сконфигурирован для сбора звука. Соответственно, модуль 801 получения информации специально сконфигурирован: когда режим ввода является режимом жестикуляционного ввода, получать первую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; и модуль 802 обработки с помощью кодирования специально сконфигурирован: когда первая вводимая информация, полученная модулем 801 получения информации, является первой траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации.
Модуль 801 получения информации дополнительно специально сконфигурирован: когда режим ввода является режимом голосового ввода, собирать первую звуковую информацию с использованием звукового датчика устройства обработки ввода. Модуль 802 обработки с помощью кодирования специально сконфигурирован: когда первая вводимая информация, полученная модулем 801 получения информации, является первой звуковой информацией, кодировать первую звуковую информацию в соответствии с предварительно заданным правилом кодирования, например, с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
После запроса предварительно установленного словаря для получения подходящего слова, соответствующего коду, модуль 803 запроса и сбора дополнительно сконфигурирован: когда получено множество подходящих слов, соответствующих коду, сортировать множество подходящих слов в соответствии с порядком убывания по частоте, и показывать отсортированное множество подходящих слов пользователю; и принимать слово, соответствующее коду и введенное пользователем, где слово, соответствующее коду, является словом, выбранным пользователем из отсортированного множества подходящих слов.
Фиг. 9 является схематической структурной диаграммой другого варианта воплощения устройства обработки ввода настоящего изобретения. Как показано на фиг. 9, устройство 900 обработки ввода, обеспеченное в этом варианте воплощения, включает в себя: приемный модуль 901, модуль 902 получения информации, модуль 903 обработки с помощью кодирования, модуль 904 сохранения слова, модуль 905 запроса и сбора, модуль 906 обработки с помощью сортировки и модуль 907 дисплея. Приемный 901 модуль сконфигурирован принимать запрос на обработку слова, где запрос на обработку слова используется для запроса добавления слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова. Модуль 902 получения информации сконфигурирован принимать, в соответствии с запросом на обработку слова, вторую вводимую информацию, которая вводится пользователем и соответствует режиму обработки слова. Модуль 903 обработки с помощью кодирования сконфигурирован кодировать вторую вводимую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации. Модуль 904 сохранения слова сконфигурирован устанавливать отображающую зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранять отображающую зависимость в словарь. Модуль 902 получения информации дополнительно сконфигурирован получать в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода. Модуль 903 обработки с помощью кодирования дополнительно сконфигурирован кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации. Модуль 905 запроса и сбора сконфигурирован запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду.
В этом варианте воплощения запрос на обработку слова, принятый приемным модулем 901, вводится пользователем с использованием интерфейса ввода терминального устройства, запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом голосовой обработки слова или режимом жестикуляционной обработки слова. Слово, которое нужно добавить, является словом, которое отсутствует в словаре, и слово может быть одним словом, фразой, предложением или длинной строкой символов, таких как цифры и буквы, например, учетной записью QQ 8945145182 или адресом электронной почты yagneos235@hotmail.com.cn.
Модуль 902 получения информации специально сконфигурирован: когда режим обработки слова является режимом жестикуляционной обработки слова, получать вторую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; и когда режим обработки слова является режимом голосовой обработки слова, собирать вторую звуковую информацию с использованием звукового датчика устройства обработки ввода.
Модуль 903 обработки с помощью кодирования специально сконфигурирован: когда вторая вводимая информация, полученная модулем 902 получения информации, является второй траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего второй вводимой информации; и, когда вторая вводимая информация, полученная модулем 902 получения информации, является второй звуковой информацией, кодировать вторую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации. Код, соответствующий второй вводимой информации, однозначно определяет вторую вводимую информацию.
В этом варианте воплощения модуль 904 сохранения слова устанавливает отображающую зависимость между кодом, соответствующим второй вводимой информации, генерируемой модулем 903 обработки с помощью кодирования, и словом, которое нужно добавить и которое принято приемным модулем 901, и сохраняет отображающую зависимость в предварительно установленный словарь. Таким образом, устанавливается отображающая зависимость между вводимой информацией пользователя и словом, и отображающая зависимость сохраняется в локальном словаре. Когда пользователь снова вводит вводимую информацию, вводимая информация пользователя может быть распознана, и может быть получен код, соответствующий вводимой информации.
В этом варианте воплощения модуль 902 получения информации специально сконфигурирован: когда режим ввода является режимом жестикуляционного ввода, получать первую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или, когда режим ввода является режимом голосового ввода, собирать первую звуковую информацию с использованием звукового датчика устройства обработки ввода.
После получения модулем 902 получения информации первой вводимой информации, введенной пользователем, модуль 903 обработки с помощью кодирования кодирует первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации. Модуль 903 обработки с помощью кодирования специально сконфигурирован: когда полученная первая вводимая информация является первой траекторией прикосновения на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре для получения кода, соответствующего первой вводимой информации. Символы могут быть цифрами или буквами, то есть код может быть получен путем объединения цифр, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения, или код может быть получен путем объединения букв, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения.
Модуль 903 обработки с помощью кодирования дополнительно сконфигурирован: когда полученная первая вводимая информация является первой звуковой информацией, кодировать первую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
В частности, модуль 905 запроса и сбора производит поиск в предварительно установленном словаре в соответствии с кодом, соответствующим первой вводимой информации и полученной модулем 903 обработки с помощью кодирования, при этом словарь хранит отображающую зависимость между кодом и соответствующим словом, и получает подходящее слово, соответствующее коду в соответствии с отображающей зависимостью между кодом и словом. Кроме того, следует также отметить, что если модуль 905 запроса и сбора получает одно подходящее слово, то подходящее слово является словом, которое нужно ввести пользователю; и если модуль 905 запроса и сбора получает множество подходящих слов, модуль 906 обработки с помощью сортировки сортирует множество подходящих слов в соответствии с порядком убывания по частоте, и отображает на экране устройства обработки ввода отсортированное множество подходящих слов для выбора пользователем. Модуль 907 дисплея сконфигурирован отображать, в определенной области на экране устройства обработки ввода, слово, выбранное пользователем из отсортированного множества подходящих слов.
Устройство обработки ввода, обеспеченное в этом варианте воплощения, может быть сконфигурировано выполнять техническое решение любого варианта воплощения способа настоящего изобретения, а принципы варианта осуществления аналогичны принципам варианта воплощения способа, поэтому подробности будут опущены.
Фиг. 10 является схематической структурной диаграммой еще одного варианта воплощения устройства обработки ввода настоящего изобретения. Как показано на фиг. 10, устройство 700 обработки ввода этого варианта воплощения включает в себя: по меньшей мере один процессор 701, память 702 и шину. Процессор 701 и память 702 соединены и осуществляют связь друг с другом с использованием шины. Шина может быть шиной архитектуры промышленного стандарта (Архитектура промышленного стандарта, ISA для краткости), шиной взаимодействия периферийных компонентов (Взаимодействие периферийных компонентов, PCI для краткости) или шиной расширенной архитектуры промышленного стандарта (Расширенная архитектура промышленного стандарта, EISA для краткости) и так далее. Шина может быть разделена на адресную шину, шину данных, шину управления и так далее. Для простоты иллюстрации шина обозначена на фиг. 10 лишь одной сплошной линией, но это не значит, что существует только одна шина или один тип шины.
Память 702 сконфигурирована хранить код исполняемой программы. Код программы включает в себя инструкции машинных операций. Память 702 может включать в себя высокоскоростную память с произвольным доступом (RAM, память с произвольным доступом), и может также включать в себя энергонезависимую память (энергонезависимая память), например, по меньшей мере одну память на дисках.
В варианте воплощения процессор 701 выполняет программу, соответствующую коду исполняемой программы, путем чтения кода исполняемой программы, сохраненного в памяти 702, для того, чтобы:
получить, в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, где режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
запросить предварительно установленный словарь для получения подходящего слова, соответствующего коду.
В частности, в варианте воплощения устройство обработки ввода дополнительно включает в себя сенсорный экран и звуковой датчик, а виртуальная клавиатура отображается на сенсорном экране для выполнения пользователем сенсорных операций. Звуковой датчик сконфигурирован для сбора звука. Соответственно, кодирование первой вводимой информации в соответствии с предварительно установленным правилом кодирования для получения кода, соответствующего первой вводимой информации, в частности, включает в себя: когда полученная первая вводимая информация является первой траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединение символов, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации; и, когда полученная первая вводимая информация является первой звуковой информацией, кодирование первой звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (HMM) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
Дополнительно, в варианте воплощения процессор 701 выполняет программу, соответствующую коду исполняемой программы, путем чтения кода исполняемой программы, сохраненный в памяти 702, дополнительно чтобы:
принять запрос на обработку слова, где запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова включает в себя режим обработки слова и слово, которое нужно добавить, и режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова;
принять, в соответствии с запросом на обработку слова, вторую вводимую информацию, которая вводится пользователем и соответствует режиму обработки слова; и закодировать вторую вводимую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации; и
установить отображающую зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранить отображающую зависимость в словарь.
Средние специалисты в области техники могут понять, что все или часть этапов вышеуказанных вариантов воплощения способа могут быть реализованы с помощью программы, инструктирующей соответствующие аппаратные средства. Вышеуказанная программа может быть сохранена на машиночитаемом носителе данных. Когда выполняется программа, выполняются этапы предшествующих вариантов воплощения способа. Вышеуказанные носители данных включают в себя различные носители, способные хранить код программы, такие как ROM, RAM, магнитный диск или оптический диск.
Наконец, следует отметить, что предшествующие варианты воплощения предназначены просто для описания технических решений настоящего изобретения, а не для ограничения настоящего изобретения. Хотя настоящее изобретение подробно описано со ссылкой на вышеуказанные варианты воплощения, средние специалисты в области техники должны понимать, что они могут модифицировать технические решения, описанные в вышеуказанных вариантах воплощения, или сделать эквивалентные замены некоторых или всех их технических характеристик, не отступая от сущности и объема технических решений вариантов воплощения настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕДСТАВЛЕНИЕ ДАННЫХ НА ОСНОВЕ ВВЕДЕННЫХ ПОЛЬЗОВАТЕЛЕМ ДАННЫХ | 2004 |
|
RU2360281C2 |
| УЧЕБНО-ДЕМОНСТРАЦИОННЫЙ МОДУЛЬ И СИСТЕМА ОБУЧЕНИЯ ГЛУХИХ, НЕМЫХ И ГЛУХОНЕМЫХ ЛЮДЕЙ РАЗГОВОРНОЙ РЕЧИ | 2019 |
|
RU2715792C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ВВОДА | 2015 |
|
RU2632422C2 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
| УЛУЧШЕННЫЙ ТЕРМИНАЛ МОБИЛЬНОЙ СВЯЗИ И СООТВЕТСТВУЮЩИЙ СПОСОБ | 2006 |
|
RU2413986C2 |
| УСТРАНЕНИЕ НЕОДНОЗНАЧНОСТИ КЛАВИАТУРНОГО ВВОДА | 2015 |
|
RU2707148C2 |
| МОДЕМ С АКУСТИЧЕСКИМ СОЕДИНЕНИЕМ | 2005 |
|
RU2388166C2 |
| Устройство и способ для голосового взаимодействия с сохранением конфиденциальности | 2018 |
|
RU2768506C2 |
| НАВИГАЦИОННОЕ УСТРОЙСТВО И СПОСОБ ДЛЯ ПРИЕМА И ВОСПРОИЗВЕДЕНИЯ ЗВУКОВЫХ ОБРАЗЦОВ | 2007 |
|
RU2425329C2 |
| ДИНАМИЧЕСКАЯ ПРОГРАММНАЯ КЛАВИАТУРА | 2009 |
|
RU2504820C2 |





Изобретение относится к устройствам обработки данных ввода. Технический результат заключается в повышении скорости ввода данных. Такой результат достигается тем, что получают терминальным устройством в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода; кодируют первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, и запрашивают предварительно установленный словарь для получения подходящего слова, соответствующего коду. 4 н. и 12 з.п. ф-лы, 10 ил.
1. Способ обработки ввода, содержащий:
получение терминальным устройством в соответствии с режимом ввода, выбранным пользователем, первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, при этом режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
кодирование терминальным устройством первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
запрос терминальным устройством предварительно установленного словаря для получения подходящего слова, соответствующего коду,
при этом получение первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, содержит:
когда режим ввода является режимом жестикуляционного ввода, получение первой траектории прикосновения пользователя на виртуальной клавиатуре терминального устройства; или, когда режим ввода является режимом голосового ввода, сбор первой звуковой информации с использованием звукового датчика терминального устройства,
при этом кодирование первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, содержит:
когда полученная первая вводимая информация является первой траекторией прикосновения пользователя на виртуальной клавиатуре терминального устройства, объединение символов, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации.
2. Способ обработки ввода по п. 1, в котором кодирование первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, также содержит:
когда полученная первая вводимая информация является первой звуковой информацией, кодирование первой звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
3. Способ обработки ввода по п. 1 или 2, содержащий также:
прием терминальным устройством запроса на обработку слова, при этом запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова содержит режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова;
прием терминальным устройством в соответствии с запросом на обработку слова второй вводимой информации, которая вводится пользователем и соответствует режиму обработки слова; и кодирование второй вводимой информации в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации; и
установление терминальным устройством отображающей зависимости между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранение отображающей зависимости в словарь.
4. Способ обработки ввода по п. 3, в котором прием второй вводимой информации, которая вводится пользователем и соответствует режиму обработки слова, содержит:
когда режим обработки слова является режимом жестикуляционной обработки слова, получение второй траектории прикосновения пользователя на виртуальной клавиатуре терминального устройства; или
когда режим обработки слова является режимом голосовой обработки слова, сбор второй звуковой информации с использованием звукового датчика терминального устройства.
5. Способ обработки ввода по п. 4, в котором кодирование второй вводимой информации в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации, содержит:
когда полученная вторая вводимая информация является второй траекторией прикосновения пользователя на виртуальной клавиатуре терминального устройства, объединение символов, соответствующих кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего второй вводимой информации; и
когда полученная вторая вводимая информация является второй звуковой информацией, кодирование второй звуковой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации.
6. Способ обработки ввода по п. 1, в котором после запроса предварительно установленного словаря для получения подходящего слова, соответствующего коду, способ дополнительно содержит:
когда получено множество подходящих слов, соответствующих коду, расположение множества подходящих слов в соответствии с порядком убывания по частоте и отображение на экране терминального устройства отсортированного множества подходящих слов для выбора пользователем; и
отображение в определенной области на экране терминального устройства слова, выбранного пользователем из отсортированного множества подходящих слов.
7. Устройство обработки ввода, содержащее:
модуль получения информации, сконфигурированный получать, в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, при этом режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
модуль обработки с помощью кодирования, сконфигурированный кодировать первую вводимую информацию в соответствии с предварительно установленным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
модуль запроса и сбора, сконфигурированный запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду,
при этом модуль получения информации специально сконфигурирован:
когда режим ввода является режимом жестикуляционного ввода, получать первую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или
когда режим ввода является режимом голосового ввода, собирать первую звуковую информацию с использованием звукового датчика устройства обработки ввода, и
при этом модуль обработки с помощью кодирования специально сконфигурирован:
когда первая вводимая информация, полученная модулем получения информации, является первой траекторией прикосновения на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации.
8. Устройство обработки ввода по п. 7, в котором модуль обработки с помощью кодирования также сконфигурирован:
когда первая вводимая информация, полученная модулем получения информации, является первой звуковой информацией, кодировать первую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
9. Устройство обработки ввода по п. 7, в котором устройство обработки ввода дополнительно содержит: приемный модуль и модуль сохранения слова, в котором
приемный модуль сконфигурирован принимать запрос на обработку слова, при этом запрос на обработку слова используется для того, чтобы запросить добавление слова в словарь, запрос на обработку слова содержит режим обработки слова и слово, которое нужно добавить, а режим обработки слова является режимом жестикуляционной обработки слова или режимом голосовой обработки слова;
модуль получения информации дополнительно сконфигурирован принимать, в соответствии с запросом на обработку слова, вторую вводимую информацию, которая вводится пользователем и соответствует режиму обработки слова;
модуль обработки с помощью кодирования дополнительно сконфигурирован кодировать вторую вводимую информацию в соответствии с предварительно заданным правилом кодирования для генерации кода, соответствующего второй вводимой информации; и
модуль сохранения слова сконфигурирован устанавливать отображающую зависимость между кодом, соответствующим второй вводимой информации, и словом, которое нужно добавить, и сохранять отображающую зависимость в словарь.
10. Устройство обработки ввода по п. 9, в котором модуль получения информации специально сконфигурирован: когда режим обработки слова является режимом жестикуляционной обработки слова, получать вторую траекторию прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или
модуль получения информации специально сконфигурирован: когда режим обработки слова является режимом голосовой обработки слова, собирать вторую звуковую информацию с использованием звукового датчика устройства обработки ввода.
11. Устройство обработки ввода по п. 10, в котором модуль обработки с помощью кодирования специально сконфигурирован:
когда вторая вводимая информация, полученная модулем получения информации, является второй траекторией прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода, объединять символы, соответствующие кнопкам, через которые последовательно проходит вторая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего второй вводимой информации; или
модуль обработки с помощью кодирования специально сконфигурирован:
когда вторая вводимая информация, полученная модулем получения информации, является второй звуковой информацией, кодировать вторую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего второй вводимой информации.
12. Устройство обработки ввода по п. 7, дополнительно содержащее:
модуль обработки с помощью сортировки, сконфигурированный:
когда получено множество подходящих слов, соответствующих коду, сортировать множество подходящих слов в соответствии с порядком убывания по частоте и отображать на экране устройства обработки ввода отсортированное множество подходящих слов для выбора пользователем; и
модуль дисплея, сконфигурированный отображать, в определенной области на экране устройства обработки ввода, слово, выбранное пользователем из отсортированного множества подходящих слов.
13. Устройство обработки ввода, содержащее: процессор, память и шину, процессор и память соединены и осуществляют связь друг с другом с использованием шины, процессор выполняет программу, соответствующую коду исполняемой программы, путем чтения кода исполняемой программы, сохраненного в памяти, чтобы:
получать в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, при этом режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду,
при этом устройство обработки ввода дополнительно содержит:
сенсорный экран, при этом на сенсорном экране отображается виртуальная клавиатура, чтобы пользователь мог выполнять сенсорные операции, а первая вводимая информация является первой траекторией прикосновения на виртуальной клавиатуре;
процессор выполняет программу, соответствующую коду исполняемой программы, путем чтения кода исполняемой программы, сохраненного в памяти, чтобы:
объединять символы, соответствующие кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации.
14. Устройство обработки ввода по п. 13, в котором устройство обработки ввода дополнительно содержит: звуковой датчик, при этом звуковой датчик сконфигурирован собирать звук, а первая вводимая информация является первой звуковой информацией, собранной звуковым датчиком;
процессор выполняет программу, соответствующую коду исполняемой программы, путем чтения кода исполняемой программы, сохраненного в памяти, чтобы:
кодировать первую звуковую информацию с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
15. Энергонезависимый машиночитаемый носитель, содержащий операции, сохраненные на нем, которые при обработке по меньшей мере одним процессорным блоком заставляют систему совершать следующие действия:
получать, в соответствии с режимом ввода, выбранным пользователем, первую вводимую информацию, которая вводится пользователем и соответствует режиму ввода, при этом режим ввода является режимом жестикуляционного ввода или режимом голосового ввода;
кодировать первую вводимую информацию в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации; и
запрашивать предварительно установленный словарь для получения подходящего слова, соответствующего коду,
при этом получение первой вводимой информации, которая вводится пользователем и соответствует режиму ввода, содержит:
когда режим ввода является режимом жестикуляционного ввода, получение первой траектории прикосновения пользователя на виртуальной клавиатуре устройства обработки ввода; или когда режим ввода является режимом голосового ввода, сбор первой звуковой информации с использованием звукового датчика устройства обработки ввода, и
при этом кодирование первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, содержит:
когда полученная первая вводимая информация является первой траекторией прикосновения на виртуальной клавиатуре устройства обработки ввода, объединение символов, соответствующих кнопкам, через которые последовательно проходит первая траектория прикосновения на виртуальной клавиатуре, для получения кода, соответствующего первой вводимой информации.
16. Энергонезависимый машиночитаемый носитель, содержащий операции, сохраненные на нем, которые при обработке по меньшей мере одним процессорным блоком заставляют систему совершать действия по п. 15, при этом кодирование первой вводимой информации в соответствии с предварительно заданным правилом кодирования для получения кода, соответствующего первой вводимой информации, также содержит:
когда полученная первая вводимая информация является первой голосовой информацией, кодирование первой голосовой информации с использованием хеш-алгоритма, алгоритма скрытой марковской модели (НММ) или алгоритма динамической трансформации шкалы времени при распознавании речи (DTW) для получения кода, соответствующего первой вводимой информации.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| ПРЕДСКАЗАНИЕ СЛОВА | 2007 |
|
RU2424547C2 |
| АВТОМАТИЧЕСКОЕ РАСПОЗНАВАНИЕ РЕЧИ | 1999 |
|
RU2216052C2 |

