Область техники, к которой относится изобретение
Данное изобретение относится, в основном, к системам управления базами данных. Более конкретно, данное изобретение относится к способу и устройству для реализации многопользовательской, эластичной системы управления распределенными реляционными базами данных по запросу, характеризуемой атомарностью, производительностью и масштабируемостью.
Предшествующий уровень техники
В течение последних лет использование баз данных для хранения и извлечения сообщений явилось в качестве важного инструментального средства в многочисленных коммерческих приложениях. Первоначально многие системы баз данных работали на единственной инсталляции сервера с многочисленными пользователями. Однако в течение последних лет обнаружились многочисленные факторы, которые потребовали изменения основного характера архитектуры баз данных. В качестве первого фактора резко повысились требования к объему хранения баз данных. Во-вторых, также стало очень большим количество пользователей, пытающихся обратиться к таким базам данных. В-третьих, использование баз данных для извлечения относительно стабильных данных с минимальными обновлениями было заменено обработкой транзакций.
Транзакция представляет собой единицу работы, которая должна быть завершена полностью. Единственная транзакция может включать в себя многочисленные манипуляции с данными. В качестве примера единственная транзакция может включать в себя операцию чтения, за которой следует операция записи. В последние годы значительные усилия были направлены на то, чтобы реляционным базам данных дать возможностью поддерживать все возрастающие скорости обработки транзакций.
Базы данных теперь оцениваются по стандарту, который определяет свойства ACID, а именно: атомарность, непротиворечивость, изоляция и устойчивость. Атомарность гарантирует, что все задачи транзакции будут завершены полностью. Непротиворечивость гарантирует, что только действительные данные записываются в базу данных. Изоляция гарантирует, что другие операции не могут осуществлять доступ к или «видеть» данные в промежуточном состоянии во время транзакции. Устойчивость гарантирует, что если транзакция была обработана успешно, она не может быть отменена.
Непротиворечивость особенно важна в многопользовательских системах, где для двух или более пользователей возможен запрос одновременного доступа к совместно используемым временным данным. Ранние многопользовательские системы использовали операции блокировки, чтобы гарантировать непротиворечивость. Блокировки могли быть исключающими блокировками или блокировками записи или неисключающими блокировками или блокировками чтения и могли применяться к индивидуальным записям или страницам. Однако так как базы данных увеличились в размере и повысились скорости транзакций, служебные данные для управления блокировками стали существенными и, в некоторых случаях, непомерно высокими.
Многоверсионный контроль параллелизма (MVCC) представляет собой альтернативный процесс для обеспечения параллелизма. MVCC может быть более эффективным, чем блокировки со сложными базами данных. MVCC использует временные метки или возрастающие идентификаторы (ID) транзакции для сериализации разных версий записи. Каждая версия разрешает транзакции чтение самой последней версии объекта, которая предшествует временной метке или ID. С этим способом контроля любое изменение в записи, например, не будет видно другими пользователями, пока изменение не будет зафиксировано. MVCC также устраняет блокировки с другими сопутствующими служебными данными и устанавливает систему, в которой операции чтения не могут блокировать операции записи.
В дополнение к соответствию тестам ACID теперь существует требование к непрерывной доступности для пользователей. Некоторые системы баз данных специализируют одну компьютерную систему на обработку транзакций и другую - на поддержку принятия решений и другие процессы предоставления отчетов. Они связаны между собой, так что одновременно могут поддерживаться другие функции. Так как базы данных растут в размере и сложности, существующие системы обработки данных заменяются более мощной системой обработки данных. Другой подход для обеспечения роста включает в себя реплицируемые системы, где одна машина объявляется «головной» машиной, которая поддерживает все реплицируемые машины в синхронизме. Если головная машина вышла из строя, процесс назначит эту функцию другой реплицируемой машине. Разные реплицируемые машины доступны некоторым пользователям. Этот подход не является масштабируемым, так как все машины должны иметь одни и те же возможности.
В качестве другого подхода, многочисленные автономные системы баз данных могут быть интегрированы в единственную «объединенную» базу данных с компьютерной сетью, соединяющей между собой различные индивидуальные базы данных. Объединенные базы данных требуют «связующего программного обеспечения» для поддержания составляющих баз данных в синхронизме. Это «связующее программное обеспечение» может стать очень сложным. Так как размер баз данных растет, ресурсы, требуемые для работы связующего программного обеспечения, могут налагать такие достаточно большие служебные данные, что ухудшается общая производительность системы.
«Разделение» представляет собой другой подход для реализации баз данных, в которых логическая база данных или ее составляющие элементы разделены на отдельные независимые части. В системе управления распределенной базой данных каждый раздел может распространяться по многочисленным узлам. Пользователи на данном узле могут выполнять локальные транзакции на разделе. Разделение также может выполняться посредством образования меньших баз данных или посредством разделения выбранных элементов только на одну таблицу.
Существует два общих подхода к разделению. При горизонтальном разделении, также называемом «шардинг», разные строки размещаются в разных таблицах и на разных серверах. Как правило, они имеют некоторую общность, такую как диапазон почтовых индексов или фамилий, которые разделены на разные таблицы по диапазонам. Например, первая база данных может содержать все записи для фамилий в диапазоне от А до М; вторая база данных - в диапазоне от N до Z. Шардинг, который представляет собой форму горизонтального разделения, включает в себя расположение строк базы данных на отдельных серверах. Шардинг действительно уменьшает количество строк в каждой таблице и увеличивает эффективность поиска. Однако шардинг использует хэш-код на прикладном уровне, что делает значительно более трудным его реализацию. Он также включает в себя двухфазную фиксацию. Сложности шардинга делают его подходящим для конкретных применений, так как основа для определения шардов довольно хорошо определена.
Вертикальное разделение включает в себя создание таблиц с меньшим количеством столбцов и разделением столбцов по таблицам. Подобно объединенной базе данных вертикальное разделение требует связующего программного обеспечения для определения, как маршрутизировать любой запрос для конкретного поля на соответствующий раздел. Кроме того, эти системы работают с использованием последовательности двухфазной фиксации, которую трудно реализовать.
В еще другом подходе, известном как архитектура «без совместного использования ресурсов», каждый узел является независимым и самодостаточным. Архитектура без совместного использования ресурсов известна для разработки веб-сайтов, так как она может масштабироваться вверх просто посредством добавления узлов в виде недорогих компьютеров. Этот подход является популярным в приложениях по созданию хранилищ данных, где существует тенденция, что обновления являются менее частыми, чем имело бы место с обработкой транзакций. Однако обработка операций объединения является очень сложной над большими наборами данных из разных разделов или машин.
Некоторые системы баз данных упоминаются как «распределенные» системы. Одна реализация распределенной системы включает в себя «кластеры» и два канала связи. Высокоскоростной канал Интернета переносит данные между кластерами. Высокоскоростные выделенные каналы связи требуются для различных функций управления, таких как управление блокировками. Хотя этот подход разрешает вопросы избыточности и доступности для баз данных, управление блокировками, как ранее описано, может ограничить производительность системы.
В системе «с совместным использованием всех ресурсов» очень высокоскоростная связь поддерживает систему в синхронизме. Однако управление блокировками может потребовать существенных ресурсов полосы частот. Чтобы избежать этого, такие системы включают в себя каналы прямой связи и очень сложный контроллер диска.
Совместно эти системы известного уровня техники удовлетворяют некоторым, но не всем известным требованиям к системе базы данных. Тем, что требуется, является архитектура базы данных, которая является масштабируемой, которая удовлетворяет свойствам ACID атомарности, непротиворечивости, изоляции и устойчивости. Тем, что также требуется, является система базы данных, которая работает по Интернету без необходимости в выделенных высокоскоростных каналах связи, которая обеспечивает обработку транзакций и которая может работать по большой географической зоне.
Раскрытие изобретения
Поэтому задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу.
Другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая является отказоустойчивой.
Еще другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая имеет высокую степень доступности.
Еще другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая является платформно-независимой.
Еще другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая является атомарной, непротиворечивой, изолированной и устойчивой.
Еще другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая работает по Интернету без необходимости в выделенных высокоскоростных каналах связи.
Еще другой задачей данного изобретения является обеспечение эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая обеспечивает обработку транзакций и которая адаптирована для реализации по большой географической зоне.
Согласно одному аспекту данного изобретения система управления базой данных, которая позволяет пользователям взаимодействовать с базой данных, состоящей из данных и метаданных, содержит множество узлов и долговременное хранилище с каналами связи между ними. Каждый узел включает в себя интерфейс между командами высокоуровневого ввода и вывода на пользовательском уровне и командами ввода и вывода на системном уровне, которые управляют последовательностью операций для взаимодействия с базой данных, при этом в ответ на некоторые команды системного уровня объекты-атомы генерируют атомы, причем каждый атом содержит заданный фрагмент данных или метаданных, посредством чего набор всех экземпляров атомов совместно определяет все метаданные и данные в базе данных. Каждый узел дополнительно включает в себя управление связью для установления канала связи с каждым другим узлом в системе, метод, реагирующий на системную команду от интерфейса для запрашивания от выбранного узла копии атома, который релевантен запросу, но не присутствует на этом узле, метод, реагирующий на запрос в отношении атома от другого узла для репликации запрашиваемого атома для пересылки на запрашивающий узел, посредством чего только атомы, требуемые для завершения запроса, требуют расположения на любом узле транзакции в любой данный момент времени, и метод, реагирующий на изменение в атоме на этом узле для репликации этого атома для пересылки на каждый другой узел в системе, в котором этот атом является постоянно хранимым. Долговременное хранилище содержит коллекцию атомов, которые совместно содержат все данные и метаданные в базе данных.
Согласно другому аспекту данного изобретения система управления базой данными, которая позволяет пользователям взаимодействовать с базой данных, состоящей из данных и метаданных, упомянутая система включает в себя по меньшей мере один узел транзакции, который обеспечивает пользователей доступом к базе данных, и по меньшей мере один узел архивации, который поддерживает архив всей базы данных. Каждый узел транзакции включает в себя подсистему запросов к базе данных, который обеспечивает интерфейс между командами запросов высокоуровневого ввода и вывода на пользовательском уровне и командами ввода и вывода на системном уровне, которые управляют последовательностью операций для взаимодействия с базой данных. В ответ на некоторые команды системного уровня объекты-атомы генерируют атомы. Каждый атом содержит заданный фрагмент данных или метаданных, посредством чего набор всех экземпляров атомов совместно определяет все метаданные и данные в базе данных. Сеть системы базы данных соединяет между собой все узлы. Управление связью в каждом из узлов устанавливает канал связи с каждым другим узлом в системе. Метод в каждом узле транзакции отвечает на системную команду от подсистемы запросов к базе данных для запрашивания копии атома, который релевантен команде запроса, но не присутствует в этом узле. Другой метод в каждом узле отвечает на запрос атома от другого узла для репликации запрашиваемого атома для пересылки на запрашивающий узел, посредством чего только атомы, требуемые для завершения команды запроса, должны располагаться в любом узле транзакции в любой данный момент времени. Другой метод в каждом узле транзакции отвечает на изменение в атоме на этом узле для репликации этого изменения на каждый другой узел в системе, который содержит копию этого атома.
Согласно еще другому аспекту данного изобретения система управления базой данных для логической базы данных, состоящей из записей данных, организованных в таблицы, к которым необходимо осуществлять доступ с многочисленных узлов транзакции, которые обрабатывают транзакции, связанные с логической базой данных, при этом в отношении базы данных выполняется синтаксический разбор на фрагменты, причем каждый фрагмент хранит часть метаданных и/или данных, относящихся к логической базе данных, для пересылки в системе управления базой данных в качестве сериализованных сообщений и для сохранения в качестве десериализованного сообщения. Система включает в себя по меньшей мере один узел архивации, который хранит все фрагменты в десериализованном виде в долговременном хранилище, таким образом составляя единственное хранилище для всей базы данных. Каждый узел транзакции отвечает на запросы от пользователей посредством установления последовательности низкоуровневых команд для идентификации фрагментов, которые релевантны запросу, и отвечает на низкоуровневые команды посредством получения только тех копий существующих фрагментов, которые релевантны запросу, обрабатываемому на нем, при том что данный фрагмент может существовать на некотором другом узле или только на узле архивации. Каждый узел транзакции реплицирует любой измененный фрагмент на по меньшей мере один узел архивации и каждый узел транзакции, в котором постоянно находится копия этого фрагмента, посредством чего изменения выполняются в фрагментах в других узлах на равноправной основе и посредством чего любой узел транзакции содержит только те фрагменты, которые относятся к запросам, выполняемым пользователями, осуществляющим доступ к базе данных через этот узел транзакции.
Краткое описание чертежей
Прилагаемая формула изобретения конкретно указывает и ясно заявляет предмет данного изобретения. Различные объекты, преимущества и новые признаки данного изобретения более очевидны из чтения последующего подробного описания вместе с прилагаемыми чертежами, на которых подобные ссылочные позиции относятся к подобным деталям и на которых:
фиг.1 представляет собой чертеж в схематическом виде одного варианта осуществления эластичной, масштабируемой, распределенной системы обработки данных по запросу, которая включает в себя данное изобретение с соединенными между собой узлами транзакции и архивации;
фиг.2 описывает организацию узла транзакции;
фиг.3 описывает организацию узла архивации;
фиг.4А и 4В описывают логическую организацию объектов-«атомов», генерируемых классами атома, показанными на фиг.2 и 3, которые являются полезными при реализации данного изобретения, и они могут появиться в любой данный момент времени в узле транзакции;
фиг.5 описывает информацию в атоме «Главный каталог»;
фиг.6 описывает информацию в атоме «Диспетчер транзакций»;
фиг.7 описывает информацию в атоме «База данных»;
фиг.8 описывает информацию в атоме «Схема»;
фиг.9 описывает информацию в атоме «Таблица»;
фиг.10 описывает информацию в атоме «Каталог таблицы»;
фиг.11 описывает информацию в атоме «Индекс»;
фиг.12 описывает информацию в атоме «Состояния записи»;
фиг.13 описывает информацию в атоме «Данные»;
фиг.14 описывает информацию в атоме «Состояния блоба»;
фиг.15 описывает информацию атома «Блоб»;
фиг.16 описывает синтаксис примерного асинхронного сообщения, которое переносится между узлами транзакции и архивации системы базы данных по фиг.1;
фиг.17 описывает различные типы сообщений, посредством которых переносится информация между узлами транзакции и архивации системы базы данных по фиг.1;
фиг.18 представляет собой блок-схему последовательности операций, полезную для понимания способа, посредством которого узел присоединяется к системе базы данных по фиг.1;
фиг.19 описывает информацию в объекте-узле;
фиг.20 представляет собой блок-схему последовательности операций, полезную для понимания способа, посредством которого узел создает атом согласно данному изобретению;
фиг.21 представляет собой блок-схему последовательности операций, полезную для понимания способа, посредством которого уникальные идентификаторы атома назначаются во время способа по фиг.20;
фиг.22 представляет собой блок-схему последовательности операций, полезную для понимания способа, посредством которого один узел получает копию атома от другого узла; и
фиг.23 представляет собой блок-схему последовательности операций, полезную для понимания способа, посредством которого данное изобретение фиксирует транзакцию.
Наилучший вариант осуществления изобретения
Фиг.1 описывает один вариант осуществления эластичной, масштабируемой, распределенной системы 30 базы данных по запросу с множеством узлов обработки данных, которая включает в себя данное изобретение. Узлы N1-N6 представляют собой «узлы транзакции», которые обеспечивают доступ приложениям пользователя к базе данных; узлы A1-A2, «узлы архивации», которые функционируют для поддержания дискового архива всей базы данных на каждом узле архивации. Хотя узел архивации обычно хранит всю базу данных, единственный узел транзакции содержит только ту часть базы данных, которую он определяет, что она необходима для поддержки транзакций, выполняемых на этом узле в этот момент времени.
Каждый узел на фиг.1 может выполнять связь непосредственно с каждым другим узлом в системе 30 посредством сети 31 системы базы данных. Например, узел N1 может устанавливать канал связи с каждым из узлов N2-N6, A1 и A2. Связь между любыми двумя узлами выполняется посредством сериализованных сообщений. В предпочтительном варианте осуществления обмен сообщениями выполняется асинхронным образом, чтобы максимизировать полосу частот, используемую системой, таким образом, выполняя различные операции своевременным и быстрым образом. Обычно сеть 31 системы базы данных работает с объединением каналов с большой полосой пропускания и малой задержкой (например, сеть Эзернета) и каналов с большой полосой пропускания и высокой задержкой (например, сеть WAN (глобальная сеть)). Каждый узел имеет возможность ограничивать использование канала с низкой задержкой для ограниченной во времени связи (например, выборки атома). Канал с высокой задержкой может использоваться для некритической связи (например, запрос на обновление информации для таблицы). Также предпочтительно, сеть обработки данных данного изобретения включает в себя протокол обмена сообщениями, такой как протокол управления передачей (TCP), и гарантирует, что каждый узел обрабатывает сообщения в той же последовательности, в которой они были посланы на него другими узлами.
Фиг.2 описывает представительный узел 32 транзакции, который связывает сеть 31 системы базы данных и различных конечных пользователей 33. Узел 32 транзакции включает в себя центральную систему 34 обработки (CP), которая выполняет связь с сетью 31 системы базы данных посредством сетевого интерфейса 35 и с различными пользователями посредством сетевого интерфейса 37 пользователя. Центральная система 34 обработки также взаимодействует с памятью 38 RAM (оперативная память), которая содержит копию программы управления базой данных, которая реализует предпочтительный вариант осуществления данного изобретения. Эта программа функционирует для обеспечения удаленного интерфейса 40, подсистемы 41 запросов к базе данных и набора 42 классов или объектов.
Подсистема 41 запросов к базе данных существует только на узлах транзакции и представляет собой интерфейс между высокоуровневыми командами ввода и вывода на пользовательском уровне и командами ввода и вывода системного уровня на системном уровне. В общих терминах ее подсистема запросов к базе данных выполняет синтаксический разбор, компиляцию и оптимизацию пользовательских запросов, таких как запросы SQL (языка структурированных запросов), в команды, которые интерпретируются различными классами или объектами в наборе 42.
Для целей объяснения данного изобретения установленный набор 42 классов/объектов разделяется на поднабор 43 «классов атомов», поднабор 44 «классов сообщений» и поднабор 45 «вспомогательных классов». Дополнительные подробности этих классов описаны ниже.
Как станет очевидно и согласно данному изобретению, в любой данный момент времени узел транзакции содержит только те части полной базы данных, которые тогда имеют отношение к активным пользовательским приложениям. Кроме того, различные признаки данного изобретения позволяют всем частям базы данных в использовании быть постоянно хранимыми в памяти 38 произвольного доступа. Нет необходимости обеспечивать вспомогательное хранилище, такое как дисковое хранилище, на узле транзакции во время работы данной системы.
Как показано на фиг.3, каждый узел 50 архивации, такой как узел А1 или А2 архивации на фиг.1, также соединяется с сетью 31 системы базы данных. Однако вместо конечных пользователей 33, связанных с узлом 32 транзакции на фиг.2, узел архивации соединяется только с долговременным хранилищем 51, обычно системой хранения на основе дисков или хранилищем ключевых значений. Узел 50 архивации включает в себя центральную систему 54 обработки, которая выполняет связь с долговременным хранилищем 51 посредством канала 52 ввода/вывода (I/O), и с сетью 31 системы базы данных посредством сетевого интерфейса 55. Центральная система 54 обработки также взаимодействует с памятью 57 RAM, которая содержит набор 62 классов или объектов. Аналогично узлу 32 транзакции на фиг.2, набор 62 классов/объектов на фиг.3 включает в себя набор 63 «классов атомов», набор 64 «классов сообщений» и набор 65 «вспомогательных классов».
Предпочтительный вариант осуществления данного изобретения использует объектно-ориентированное программирование (OOP), в котором, как известно в технике, классы и подклассы, такие как показанные на фиг.2 и 3, определяют методы, структуры данных и процессы, посредством которых может генерироваться «экземпляр», или объект, этого класса или подкласса. «Экземпляр» может генерироваться с использованием «наследования» и/или «полиморфизма». Для специалиста в данной области техники очевидно, что возможны реализации, которые не используют объектно-ориентированное программирование или варианты конкретно описанного варианта осуществления.
Данное изобретение ниже описывается в нескольких фазах. Раздел «Атомы» определяет иерархию и функцию объектов, создаваемых классами 43 и 63 атомов на фиг.2 и 3 соответственно. Раздел «Сообщения» описывает набор сообщений, которые обеспечивают связь между узлами транзакции и архивации, которые могут быть созданы классами 44 и 64 сообщений на фиг.2 и 3 соответственно. Раздел «Методы» описывает основные операции в отношении управления базой данных. Раздел «Пример» описывает взаимодействие атома, сообщения и методов, посредством которых достигаются задачи данного изобретения, в ответ на конкретный запрос к базе данных подсистемы 41 запросов к базе данных.
Атомы
Как ранее указано, каждый из классов 43 на фиг.2 и 63 на фиг.3 атомов создает «атомы». Более конкретно, классы атомов определяют один или несколько «типов атомов» или «объектов-атомов». Каждый «тип атома» или «объекта-атома» создает «экземпляр» самого себя, т.е. «атом». Как становится очевидным при более подробном понимании цели каждого конкретного объекта-атома, каждый «атом» содержит конкретный фрагмент информации базы данных. Некоторые атомы содержат часть метаданных базы данных; другие содержат записи данных; еще другие служат в качестве каталогов, которые создают и отслеживают другие типы атомов. Некоторые «типы атомов» могут только создавать экземпляр одного атома, который реплицирует на все узлы. Другие «типы атомов» могут создавать экземпляр многочисленных атомов, которые реплицируются на другие узлы по мере необходимости.
Атомы имеют некоторые характеристики. В узле транзакции атом существует только в недолговременной памяти и в виде десериализованного сообщения, которое заполнило конкретный тип атома для обеспечения эффективного, постоянно хранимого в памяти формата для атома. Каждый атом имеет средства для кодирования своего содержимого в сериализованное сообщение и средства для декодирования сериализованного сообщения для извлечения содержимого атома. Такие сериализованные сообщения используются в связи с количеством операций, как описано ниже.
Каждое сериализованное сообщение, передаваемое с узла для репликации атома, включает в себя содержимое этого атома с присоединенным идентификатором узла и самым последним номером последовательности фиксации транзакции для этого узла. Когда узел архивации принимает это сериализованное сообщение, он десериализует сообщение, удаляет список узлов и фиксирует номер последовательности перед размещением оставшегося содержимого сообщения (т.е. атома) в долговременном хранилище.
Несколько правил применяется к атомам согласно данному изобретению. Причины и значения этих правил станут более очевидными. Во-первых, каждый атом должен иметь уникальный идентификатор для обеспечения надежной идентификации этого атома где-либо в сети 30 обработки базы данных по фиг.1. Во-вторых, любой атом должен существовать в двух узлах одновременно, чтобы поддерживать избыточность, за исключением того, что единственный атом может существовать после того, как он будет создан, и перед тем, как узел архивации запросит копию. В-третьих, узел транзакции будет загружать атом только по запросу. В-четвертых, каждый раз, когда выполняется изменение в атоме в одном узле, этот узел должен реплицировать этот измененный атом на «равноправной» основе, т.е. всем узлам архивации и только тем узлам транзакции, которые содержат этот самый атом.
Процесс «сборки мусора», описанный более подробно ниже, может происходить на узлах архивации и транзакции. Процесс удаляет неактивные атомы из узлов транзакции и архивации. В результате узел транзакции может хранить те атомы, которые, в этом случае имеют отношение в данный момент к пользовательским приложениям в памяти произвольного доступа на этом узле. Таким образом, подсистема 41 запросов к базе данных «видит» всю базу данных в виде локальной и не знает, что она работает в многоузловой среде и без завершенной копии базы данных на его узле. Узлы архивации имеют возможность сбрасывать содержимое атома после того, как он будет сериализован, на диск, таким образом уменьшая размер памяти, требуемый для хранения. Если узел архивации принимает сообщение репликации для такого атома, узел архивации должен выбрать содержимое из дискового хранилища перед применением информации от реплицируемого атома.
С такими общими основными принципами ниже каждый тип атома описывается на «логическом» или функциональном уровне. Эта информация вместе с дополнительным обсуждением работы данного изобретения предоставит возможность специалисту в данной области техники выполнить и использовать данное изобретение в любой из многочисленных реализаций, включая реализации, основанные на объектно-ориентированном программировании.
Фиг.4А и 4В описывают подсистему 41 базы данных и типовой набор атомов, которые могут постоянно находиться на узле 32 транзакции в любой данный момент времени. В данном примере узел транзакции размещает атом 70 «Главный каталог», атом 71 «Диспетчер транзакций», атом 72 «База данных», атом 73 «Схема», атом 74 «Таблица» и атом 75 «Каталог таблицы». Имеется только один атом 70 «Главный каталог», один атом 71 «Диспетчер транзакций» и один атом 72 «База данных» на одну базу данных. Атом 71 «Диспетчер транзакций», атом 72 «База данных» и атом 73 «Схема» создаются тогда, когда подсистема 41 запросов к базе данных создает новую базу данных.
Как показано на фиг.4А, атом 70 «Главный каталог» отслеживает статус узлов транзакции и архивации в системе 30 базы данных по фиг.1. Он также может рассматриваться как активный индекс, который создает и контролирует атом 71 «Диспетчер транзакций», атом 72 «База данных», каждый атом 73 «Схема», каждый соответствующий набор из атомов 74 «Таблица» и атомов 75 «Каталог таблицы», и «Диспетчер 82 ID последовательности».
Атом 75 «Каталог таблицы» действует в качестве активного индекса и создает и контролирует атомы 76 «Индекс», атомы 77 «Состояние записи», атомы 78 «Данные», атомы 80 «Состояния блоба» и атомы 81 «Блоб», связанные с единственной таблицей. Т.е. имеется один атом 75 «Каталог таблицы» для каждой таблицы.
Фиг.4В полезна для понимания взаимодействия и управления разными типами атомов. В данном контексте ни атом 70 «Главный каталог», ни атом 75 «Каталог таблицы» не выполняют никаких функций управления. Что касается остальных атомов, атом 70 «База данных» управляет каждым атомом 73 «Схема». Каждый атом 73 «Схема» управляет каждым относящимся атомом 74 «Таблица» и атомами 82 «Диспетчер ID последовательности». Каждый атом 74 «Таблица» управляет своим соответствующим атомом 75 «Каталог таблицы», атомами 76 «Индекс», атомами 77 «Состояния записи», атомами 78 «Данные», атомом 80 «Состояния блоба» и атомами 87 «Блоб».
Как также показано на фиг.4В, подсистема 41 запросов к базе данных выполняет связь с атомом 70 «Главный каталог», атомом 71 «Диспетчер транзакций», атомом 72 «База данных», каждым атомом 73 «Схема», каждым атомом 74 «Таблица» и «Диспетчерами 82 ID последовательности». Подсистема 41 запросов к базе данных служит в качестве компилятора для высокоуровневого языка, такого как SQL. В качестве компилятора он выполняет синтаксический разбор, компиляцию и оптимизацию запросов и получает метаданные и данные от атомов для формирования различных фрагментов информации базы данных.
Каждый атом имеет некоторые общие элементы и другие элементы, которые являются характерными для его типа. Как показано на фиг.5, атом 70 «Главный каталог» включает в себя общие элементы 70А-70I. Элемент 70A представляет собой уникальный идентификатор для атома. Так как имеется только один экземпляр атома «Главный каталог», который реплицируется на все узлы, ID 70A атома «Главный каталог» присваивается фиксированное число, обычно «1». В качестве общего правила, указатели 70В и 70С идентифицируют атом «Главный каталог» и атом создающего каталога соответственно. Для атома «Главный каталог» оба указателя идентифицируют сам атом «Главный каталог».
Каждый атом должен имеет председателя. Председатель выполняет функции, как описано ниже. Элемент 70D представляет собой указатель на тот узел, где постоянно находится председатель для этого атома.
Каждый раз когда меняется копия атома на любом узле транзакции, он принимает новый номер изменения. Элемент 70Е записывает этот номер изменения.
Всякий раз когда узел запрашивает атом с другого узла, существует интервал, во время которого запрашивающий узел не будет известен другим узлам транзакции. Элемент 70F представляет собой список всех узлов, для которых подающий узел должен ретранслировать сообщения на запрашивающий узел от всех других узлов, которые содержат этот атом до тех пор, пока не будет завершен запрос.
Операции системы базы данных также делятся на периоды. Элемент 70G ссылки на период обеспечивает номер периода последнего доступа к атому. Элемент 70H представляет собой список всех активных узлов, которые содержат атом. Элемент 70I включает в себя несколько индикаторов статуса.
Как также показано на фиг.5, элемент 70J глобального ID узла содержит диспетчер ID для назначения уникального идентификатора для каждого активного узла в системе. Как известно, такие идентификаторы представляют собой длинные строки знаков. Элемент 70K локального ID узла включает в себя диапазон номеров до общего количества узлов, которые могут быть присоединены к системе. Вместе эти элементы обеспечивают соответствие между двумя типами идентификаторов. Использование локального ID узла повышает эффективность.
Когда узел транзакции присоединяется к системе 30 базы данных по фиг.1, диспетчер 70L соединений осуществляет этот процесс. Конкретная реализация, позволяющая узлу транзакции присоединиться к системе базы данных, описана ниже. Присоединяющийся узел использует элемент 70M статуса ожидающего узла для индикации, что он не будет иметь глобальный адрес для отвечающего узла до тех пор, пока он не примет дополнительную связь от этого отвечающего узла. Элемент 70N UUI базы данных содержит универсальный уникальный идентификатор для базы данных.
Элементы в позиции 70P являются важными, так как они связывают все атомы, для которых атом 70 «Главный каталог» служит в качестве активного индекса. Как ранее указано, они включают в себя атом 72 «База данных» и каждый из атомов 73 «Схема», атомов 74 «Таблица» и атомов 75 «Каталог таблицы».
Элемент 70Q пароля представляет средство для аутентификации соединения в базу данных. Элементы 70R и 70S фактической версии и версии программного обеспечения позволяют системе работать с обратной совместимостью, когда устанавливается более новая версия программного обеспечения. Элемент 70R фактического программного обеспечения идентифицирует версию программного обеспечения в это время в использовании; элемент 70S версии программного обеспечения - номер, соответствующий самой последней установленной версии. Это позволяет индивидуальным узлам обновляться до более новых версий без запрашивания обновления других узлов и без закрытия базы данных для доступа со стороны всех узлов.
Как также показано на фиг.5, атом 70 «Главный каталог» также включает в себя указатель 70T на атом 71 «Диспетчер транзакций», указатель 70U - на конфигурационный объект, указатель 70V - на поток сборки мусора, и указатель 70W - на поток тестового опроса. Поток тестового опроса работает периодически и независимо от других операций на узле. Он «выполняет тестовый опрос» («ping») с каждым другим узлом для предоставления информации, которая может использоваться при определении эффективности связи соответствующего канала. Например, если узел N1 на фиг.1 имеет выбор выполнения связи с любым узлом N2 или N5, узел N1 может использовать информацию тестового опроса при выборе наиболее эффективного из каналов связи к узлам N2 и N5 для этой связи. Также могут быть подставлены или добавлены другие процессы выбора.
Как показано на фиг.6, имеется один атом 71 «Диспетчер транзакций» для каждой базы данных, и он создается во время того же процесса, который создает атом 70 «Главный каталог». Атом 71 «Диспетчер транзакций» создает, отслеживает и завершает транзакции базы данных в ответ на команды базы данных от подсистемы 41 запросов к базе данных. Атом 71 «Диспетчер транзакций» включает в себя элементы 71A-71I, которые соответствуют подобным элементам в атоме «Главный каталог». Однако элемент 71A представляет собой идентификацию атома 71 «Диспетчер транзакций». Элементы 71B и 71C - оба указывают на атом 70 «Главный каталог».
Диспетчер 71J ID обеспечивает уникальную идентификацию последовательности транзакций и поддерживает список 71K активных транзакций, список 71L фиксированных транзакций и список 71M неудачно завершившихся транзакций. Элемент 71N хранит информацию о последовательности фиксации. Диспетчер 71J ID назначает ID транзакции при запуске каждой транзакции. Каждый ID транзакции является уникальным, но необязательно последовательным. Локальный атом «Диспетчер транзакций» назначает номер последовательности фиксации элементу 71N, когда выполняется фиксация транзакции. Номера последовательности являются последовательными, и каждый является характерным для узла, который запросил транзакцию. Счетчик 71P событий перехода транзакции идентифицирует дискретные события, которые происходят во время каждой транзакции, такие как запуск транзакции и успешная фиксация транзакции. Такие счетчики полезны, когда перекрываются многочисленные транзакции, включающие в себя одинаковую информацию.
Как показано на фиг.7, атом 72 «База данных» создается в то же время, когда создается атом 70 «Главный каталог» и атом 71 «Диспетчер транзакций». Атом 72 «База данных» идентифицирует каждый из атомов 73 «Схема». Атом 72 «База данных» может быть включен в процесс аутентификации, когда новый пользователь пытается присоединиться к базе данных. Он также может включать в себя другие данные, касающиеся уровней авторизации.
В основном, атом 72 «База данных» включает в себя элементы 72A-72I, соответствующие подобным элементам на фиг.5. Элемент 72A представляет собой идентификацию атома «База данных». Каждый из указателей 72B и 72C идентифицирует атом 70 «Главный каталог». Реестр 72J имя схемы - ID схемы связывает имена схемы с идентификацией атома «Схема».
Как показано на фиг.8, атом 73 «Схема» создает и отслеживает атомы «Таблица» для этой схемы. Атом 72 «База данных» может управлять многочисленными атомами «Схема», и каждый атом «Схема» может взаимодействовать с многочисленными атомами «Таблица». Атом 73 «Схема» включает в себя элементы 73A-73I, соответствующие элементам 70A-70I на фиг.5. Элемент 73A представляет собой уникальную идентификацию 73A атома «Схема», и элементы 73B и 73C являются указателями на атом 70 «Главный каталог». Таблица имеет уникальное имя в схеме. Реестр 73J имя таблицы - ID атома таблицы обеспечивает соответствие между каждым именем таблицы и соответствующим атомом таблицы. Каждая последовательность схемы имеет имя. Реестр 73K имени последовательности - диспетчера ID последовательности обеспечивает зависимость между этими именами и соответствующими диспетчерами ID последовательности, связанными с каждым атомом «Схема», такими как диспетчеры 82 ID последовательности на фиг.4А и 4В.
Фиг.9 обеспечивает логический вид атома 74 «Таблица», который включает в себя метаданные, относящиеся к полям, форматам, индексам и типам, и который управляет каждым из атомов 76 «Индекс», атомов 77 «Состояния записи» и атомов 80 «Состояния блоба» для этой таблицы. Он также создает и отслеживает данные в таблице. Атом 74 «Таблица» включает в себя элементы 74A-74I, которые соответствуют элементам 70A-70I на фиг.5. Элемент 74A включает в себя уникальный идентификатор атома «Таблица», элементы 74B и 74C - оба указывают на атом «Главный каталог». Указатель 74J идентифицирует соответствующий атом «Каталог таблицы». Элемент 74K содержит список всех полей для таблицы.
Каждый атом «Таблица» имеет несколько диспетчеров ID. Указатель 74L указывает на диспетчер ID, который обеспечивает каждое поле уникальным идентификатором. Указатели 74M, 74N, 74P и 74Q идентифицируют отдельные диспетчеры ID для назначения идентификаторов атомам «Индекс», атомам «Данные», атомам «Блоб» и подтипам соответственно. Элемент 74R представляет собой список существующих подтипов. Массивы 74S и 74T обеспечивают местоположения атомов «Состояния записи» и атомов «Состояния блоба» соответственно.
Как показано на фиг.10, имеется один атом «Каталог таблицы» для каждого атома «Таблица». Каждый атом 75 «Каталог таблицы» создается тогда, когда создается атом «Таблица». В свою очередь, атом «Каталог таблицы» создает и отслеживает атомы, характерные для одной таблицы, включая атомы «Индекс», «Состояния записей», «Данные», «Состояния блоба» и «Блоб». Каждый атом 75 «Каталог таблицы» включает в себя элементы 75A-75I, которые соответствуют элементам 70A-70I на фиг.5. Элемент 75A является уникальным идентификатором атома «Каталог таблицы», назначенным атомом «Главный каталог». Оба элемента 75B и 75C указывают на атом 70 «Главный каталог». Диспетчер 75J ID обеспечивает уникальные идентификаторы атомов для каждого из атомов «Индекс», «Состояния записи», «Данные», «Состояния блоба» и «Блоб». Список 75K идентифицирует все атомы, связанные с соответствующим атомом «Таблица». Указатели в элементе 75L идентифицируют местоположение каждого атома на локальном узле, связанным с соответствующим атомом «Таблица». Последовательность списков 75M идентифицирует для каждого атома список узлов с репликациями этого атома. Битовый массив 75N обеспечивает удобное средство для идентификации других объектов и директорий, когда атом находится в узле архивации.
Как показано на фиг.11, имеется один атом 76 «Индекс» для каждого индекса в таблице, и могут быть многочисленные атомы «Индекс» на таблицу. Каждый атом «Индекс» включает в себя элементы 76A-76I, которые соответствуют элементам 70A-70I на фиг.5 соответственно. Элемент 76A является уникальным идентификатором атома «Индекс», назначенным соответствующим атомом «Каталог таблицы». Указатели 76B и 76C идентифицируют атом «Главный каталог» и атом «Каталог таблицы» соответственно. Элемент 76J содержит двоичное дерево индексных узлов для обеспечения обычной функции индексации. Элемент 76K содержит уровень индекса. Такие структуры индекса и операции известны для специалиста в данной области техники.
Как показано на фиг.12, атом 77 «Состояния записи» управляет версиями записи и состоянием для фиксированного диапазона номеров записи в единственной таблице. Таким образом, данный атом «Таблица» может управлять многочисленными атомами «Состояния записи». Каждый атом «Состояния записи» включает в себя элементы 77A-77I, которые соответствуют элементам 70A-77I на фиг.5. Элемент 77A включает в себя ID атома «Состояния записи», который назначает создающий атом «Каталог таблицы». Указатели 77B и 77С идентифицируют атомы «Главный каталог» и «Каталог таблицы» соответственно. Элемент 77J представляет собой массив для расположения всех атомов «Данные», управляемых атомом 77 «Состояния записи». Элемент 77K содержит номер записи для «базовой записи». Т.е. каждый атом «Данные» хранит многочисленные записи. Элемент 77 представляет собой указатель на соответствующий атом «Таблица».
В приложениях базы данных, к которым относится данное изобретение, многочисленные пользователи могут создавать многочисленные версии одной и той же записи. Предпочтительный вариант осуществления данного изобретения использует многоверсионный контроль параллелизма (MVCC), чтобы гарантировать, что транзакция никогда не должна ожидать базу данных посредством предоставления возможности одновременного существования нескольких версий записи или другого объекта в базе данных. Следовательно, каждый атом 77 «Состояния записи» включает в себя метаданные о каждой версии записи. Элемент 77M представляет собой битовый массив для идентификации местоположения каждой версии записи, что является полезным при сборке мусора.
Атом 77 «Состояния записи» включает в себя, для каждой версии 77N записи, ID 77P транзакции для идентификации транзакции, которая генерировала версию. Элемент 77Q версии формата идентифицирует номер версии для подтипа таблицы, который существовал, когда запись была вставлена. Этот формат идентифицирует физический порядок записи и идентифицирует подтип, к которому принадлежит запись, программы базы данных, который был в использовании в момент времени, когда была создана версия записи. Элемент 77R включает в себя номер последовательности версии записи; элемент 77S, местоположение следующей более старой, или предыдущей, версии записи. Индекс 77T на массив 77J атомов данных и идентификатор 77K базовой записи - вместе обеспечивают адрес для фактического слота 77U в атоме «Данные» с версией записи.
Фиг.13 описывает атом 78 «Данные» с элементами 78A-78I, которые соответствуют элементам 70A-70I на фиг.5. В атоме 78 «Данные» элемент 78A представляет собой идентификатор 78A атома «Данные», назначенный атомом «Каталог таблицы». Элементы 78B и 78C представляют собой указатели на атом «Главный каталог» и соответствующий атом «Каталог таблицы» соответственно. Диспетчер 78J ID назначает идентификатор слота записи для каждой записи в атоме 78 «Данные». Элемент 78K идентифицирует, для каждой записи в атоме 78 «Данные», адрес и длину этой записи. Элемент 78C представляет записи данных и их версии.
Как показано на фиг.14, базы данных также хранят «записи блоба». «Запись блоба» обычно представляет собой коллекцию двоичных данных, хранимых в виде единственной сущности в базе данных. Записи блоба не существуют в версиях. Атом «Состояние блоба» включает в себя элементы 80A-80I, которые соответствуют элементам 70A-70I на фиг.5. Элемент 80A имеет уникальный идентификатор атома у атома «Состояния блоба». Элементы 80B и 80C являются указателями на атомы «Главный каталог» и «Каталог таблицы» соответственно. Список 80J идентифицирует все атомы «Блоб», управляемые единственным атомом 80 «Состояния блоба». Элемент 80K обеспечивает идентификацию базовой записи «Блоб». Элемент 80L указывает на соответствующий атом «Таблица». Для каждой записи блоба атом «Состояния блоба» включает в себя индекс 80M на атом «Блоб». Элемент 80N идентифицирует слот в атоме «Блоб» для записи блоба.
Фиг.15 описывает атом 81 «Блоб» с элементами 81A-81I, которые соответствуют элементам 70A-70I на фиг.5 соответственно. Элемент 81A представляет собой идентификатор атома, назначенный атомом «Каталог таблицы». Элементы 81B и 81C являются указателями на атом «Главный каталог» и на соответствующий атом «Каталог таблицы» соответственно. Диспетчер 81J ID назначает идентификатор слота блоба каждому блобу в атоме 81 «Блоб». Элемент 81K идентифицирует, для каждого блоба в атоме 78 «Блоб», его адрес и длину. Элемент 81L представляет все записи блоба, назначенные атому «Блоб».
Итак, каждый атом имеет отношение только с фрагментом базы данных. Например, атом 72 «База данных» содержит метаданные, которые идентифицируют схему для базы данных. Каждый атом 73 «Схема» содержит метаданные, которые идентифицируют все таблицы, связанные с этой схемой. Для каждой таблицы атом 74 «Таблица» и соответствующий атом 75 «Каталог таблицы» обеспечивают метаданные о таблице, включающей в себя такую информацию в качестве идентификатора полей и их свойств. Атомы «Состояния записи» включают в себя метаданные о группе записей. Атомы «Данные» включают в себя информацию о каждой записи данных с указателями на слоты, которые содержат эти записи и различные версии. Атомы «Состояния блоба» и «Блоб» содержат подобную информацию о записях блоба.
Сообщения
Как ранее указано, связь между любыми двумя узлами выполняется посредством сериализованных сообщений, которые передаются асинхронно с использованием TCP или другого протокола с элементами управления для поддержания последовательностей обмена сообщениями. Фиг.16 описывает основной синтаксис типового сообщения 90, которое включает в себя заголовок 91 переменной длины и тело 92 переменной длины. Заголовок 91 включает в себя код 93 идентификатора сообщения, который задает сообщение и его функцию. Так как данное изобретение предполагает сценарий, согласно которому разные узлы могут работать с разными версиями программного обеспечения, заголовок 91 также включает в себя идентификатор 94 версии программного обеспечения, которая создала сообщение. Оставшиеся элементы в заголовке включают в себя локальный идентификатор 95 отправителя (т.е. от атома «Главный каталог» на фиг.5) и информацию 96 для пункта назначения сообщения, а именно атом каталога (например, ID 75A «Каталог таблицы» на фиг.10) и идентификатор 97 атома (например, ID 77A «Состояния записи» на фиг.12). Из этой информации узел получателя может десериализовать, декодировать и обработать сообщение.
Фиг.17 описывает набор сообщений, имеющих синтаксис по фиг.16, для конкретного варианта осуществления данного изобретения. Каждый выполняет конкретную функцию, как описано ниже.
Как кратко описано ранее, когда сообщение должно быть послано, имеются разные каналы связи к разным узлам. Например, если одному узлу в качестве запрашивающего узла необходимо получить атом, репликации этого атома могут располагаться в многочисленных других узлах. В данном варианте осуществления «тестовый опрос» обеспечивает информацию выбора, полезную для выбора наилучшего канала, соответствующего узлу. Тестовый опрос, как известно, включает в себя определение времени для достижения командой «тестового опроса» своего пункта назначения и приема сообщения подтверждения приема. В данном варианте осуществления изобретения каждый узел периодически использует вспомогательный класс для посылки сообщения 110 «Тестовый опрос» на каждый из других узлов, с которыми он соединяется. Каждый принимающий узел использует вспомогательный класс для возврата сообщения 111 подтверждения приема тестового опроса, которое содержит время тестового опроса. Каждый узел накапливает эту информацию о времени для посылки и приема этих сообщений в объекте-узле, описанном ниже в отношении фиг.8. Когда один узел готовится послать сообщение одному из многочисленных узлов, передающий узел анализирует факторы, включающие в себя, но не ограниченные ими, накопленные данные о тестовом опросе для выбора одного из узлов в качестве принимающего узла для этого сообщения.
Следующий набор сообщений касается подсоединения нового узла к или ранее неактивного узла обратно к системе 30 базы данных по фиг.1. Когда такой узел, например узел N2 транзакции, желает подключиться к системе 30 базы данных, он инициирует процесс подсоединения, подробно описанный ниже в отношении фиг.19. Как показано на фиг.17, если этот процесс идентифицирует активный узел для приема сообщений, присоединяющийся узел посылает сообщение 112 «Соединить» на выбранный узел. Выбранный узел возвращает сообщение 113 «Добро пожаловать» и сообщение 114 «Новый узел» всем другим подсоединенным узлам в системе 30 базы данных. Каждый из других подсоединенных узлов передает свое собственное сообщение 113 «Добро пожаловать» присоединяющемуся узлу. Когда завершается эта последовательность сообщений, присоединяющийся узел может тогда предпринять дополнительные шаги для получения различных атомов.
Узлы архивации могут работать или в активном режиме, или в синхронизирующем режиме, когда они синхронизируются с другим узлом. Вспомогательный класс в узле архивации передает сообщение 115 «Состояние узла» для предупреждения всех других узлов о любом изменении статуса в этом узле архивации.
Следующий набор сообщений привлекается к использованию, когда узел в качестве запрашивающего узла извлекает копию атома из другого узла. Например, после того как узел присоединится к системе 30 базы данных на фиг.1, он, как правило, запрашивает копию атома «Главный каталог». Процесс описан более подробно в связи с объяснением фиг.20 и 21.
Продолжая ссылаться на фиг.17, запрашивающий узел выдает сообщение 116 «Запрос объекта» на выбранный узел, который, как правило, возвращает сообщение 117 «Объект» с запрашиваемым атомом. Выбранный узел также посылает сообщение 118 «Объект доступен» всем другим узлам с этим атомом. Каждый узел, который принимает сообщение 118 «Объект доступен» от выбранного узла, возвращает сообщение 119 «Прием объекта подтвержден» на выбранный узел. Выбранный узел посылает сообщение 120 «Объект завершен» запрашивающему узлу, после того как выбранный узел примет все сообщения 119 «Прием объекта подтвержден».
В некоторых ситуациях выбранный узел посылает сообщение 121 «Объект недоступен» для объявления, что выбранный узел сбросил запрашиваемый атом. Сообщение «Возвращенный объект» от выбранного узла указывает, что запрашиваемый атом не найден в атоме «Главный каталог» или в одном из атомов «Каталог таблицы». Это может произойти, когда транзакция обновления находится в процессе выполнения и выбранный узел не отвечает на сообщение 116 «Запрос объекта», потому что процесс сборки мусора собрал этот атом перед приемом сообщения «Запрос объекта». В качестве ответа запрашивающий узел транзакции может выбрать другой узел в системе базы данных с атомом.
Подсистема 41 запросов к базе данных на фиг.1 и фиг.4А и 4В может периодически генерировать сообщение 123 «Регистрировать объект» или сообщение 124 «Лишить регистрации объект». Эти сообщения относятся к атомам, которые включают в себя реестр, такие как атомы «База данных» и «Схема». Сообщение 125 «Удаление объекта» посылается с узла, когда пользователь на этом узле выдает команду на удаление некоторого предмета, такого как таблица.
Всякий раз когда локальный узел обновляется или модифицируется, его номер изменения увеличивается. Каждое сообщение репликации содержит этот номер локального изменения атома. Каждый атом отслеживает самый последний номер изменения для каждого узла. Когда узел архивации принимает копию модифицированного атома, он копирует номера изменения для атомов, очищает номера изменения и затем сериализует атом на диск. Если было сделано изменение, номер изменения не будет равным нулю. Узел архивации посылает сообщение 126 «Объект записан» с номером изменения, записанным в каждый узел. Каждый принимающий узел сравнивает свой собственный номер изменения с номером в сообщении. Затем узел может обновить статус для атома, чтобы отметить, что атом был архивирован и является потенциальным кандидатом для сборки мусора.
Как ранее указано, каждый атом должен иметь уникальный идентификатор. Когда создается первый атом определенного типа атомов (например, новый атом «Таблица»), создающий узел транзакции объявляется Председателем для этого атома «Таблица». Правила для руководства «председательством» описаны ниже. Всякий раз когда узлу транзакции необходимо создать новый тип атома, он посылает сообщение 127 «Запрос ID» Председателю, если он не имеет доступного идентификатора. Председатель, как правило, возвращает сообщение 128 «Делегирование ID», которое включает в себя блок из по меньшей мере одного уникального идентификатора из его распределения свободных идентификационных значений. Этот процесс описывается более подробно в отношении процесса по фиг.20.
Ссылаясь на фиг.4А и 4В, атом 74 «Таблица» может послать любое количество сообщений. Если подсистема 41 запросов к базе данных инициирует процесс для добавления нового поля, атом «Таблица» на этом соответствующем узле транзакции генерирует новую структуру и посылает сообщение 129 «Поле таблицы добавлено», которое реплицирует изменение на все другие узлы, которые включают в себя этот атом «Таблица». Если узел транзакции обновляет поле, подтип или характеристику поля, которая изменяет формат таблицы, этот узел выдает сообщение 130 «Формат таблицы». Сообщение 131 «Записи запроса таблицы» генерируется всякий раз, когда узлу необходимо создать новый атом «Состояния записи» или «Состояния блоба». Только председатель может создать этот атом; и председатель передает широковещательно сообщение 132 «Объект записей таблицы», когда это происходит.
Каждый раз когда узел транзакции вставляет новую запись в таблицу, он создает сообщение 133 «Запись таблицы». Всякий раз когда становится необходимым создать новый индекс, например, когда к таблице добавляется индексированное поле, создающий атом «Таблица» реплицирует новый атом «Таблица». В этот момент индекс устанавливается на индекс только записи. После того как будут завершены все относящиеся участвующие процессы, узел посылает сообщение 134 «Индекс таблицы добавлен».
В любой момент времени когда атом «Таблица» создает атом «Состояния блоба», атом «Таблица» генерирует сообщение 135 «Объект блобов таблицы». Сообщение 136 «Блоб таблицы» указывает, что был создан новый блоб.
В базе данных, которая использует типы и подтипы, подсистема 41 запросов к базе данных на фиг.1 генерирует команды, вызывающие назначение атомом «Таблица» нового идентификатора типа таблицы. Когда это происходит, сообщение 137 «Тип таблицы» реплицируется на все узлы с подобными атомами «Таблица».
Сообщение 138 «Исключить запись таблицы» обеспечивает номер записи на конкретном атоме «Состояния записи». Сообщение 139 «Собрать мусор таблицы» генерируется Председателем для атома «Таблица», когда определяется, что запись в этой таблице содержит необычно длинную цепочку старых версий или другие критерии. Результатом является то, что «неиспользуемые» атомы «освобождаются» от данных.
Атом 77 «Состояния записи» на фиг.4А и 4В также создает несколько специальных сообщений. Если становится необходимым обновить конкретную запись, система управления базой данных данного изобретения создает новую версию этой записи. Возвращаясь обратно к фиг.17, соответствующий атом «Состояния записи» генерирует сообщение 140 «Запрос обновления записи», которое направляется Председателю, чтобы этот атом получил разрешение на обновление этой конкретной записи. Председатель отвечает генерированием сообщения 141 «Ответ на обновление записей», которое предоставляет или запрещает разрешение на обновление этой записи. Если Председатель предоставляет разрешение, запрашивающий атом «Состояния записи» выполняет обновление и посылает сообщение 142 «Обновление записей» с новой версией атома на каждый узел с копией этого атома.
Атом «Данные» сохраняет до его некоторого максимального количества записей и версий. Соответствующий атом «Состояния записи» контролирует размер атомов «Данные», которыми он управляет. Если атом «Состояния записи» определяет, что управляемый атом «Данные» превысил этот размер, он генерирует новый атом «Данные» и реплицирует этот новый атом «Данные» посредством сообщения 143 «Объект данных записей».
Атом «Состояния записи» генерирует сообщение 144 «Записать записи» для репликации любой новой версии записи. Периодически Председатель атома «Таблица» инициирует процесс, посредством которого атом «Состояния записи» идентифицирует версии записи, которые являются более старыми, чем самая старая активная транзакция. Когда это происходит, атом «Состояние записи» Председателя передает сообщение 145 «Отсечение записей», которое позволяет удалить эти более старые версии записи во время последующего процесса сборки мусора. Если возникает ситуация, при которой становится необходимым откат транзакции, атом «Состояния записи» генерирует сообщение 146 «Отмененная запись», которое обновляет отмененную запись.
Также имеется набор характерных для индекса сообщений. Как известно, индекс имеет оптимальный максимальный размер; и если индекс превышает этот размер, индекс должен быть разделен. Согласно данному изобретению только Председатель может разделить атом «Индекс». Председатель может сделать это односторонне или в ответ на сообщение 147 «Запрос разделения индекса» от другой копии этого атома. Когда Председатель вызывает разделение, Председатель генерирует сообщение 148 «Разделение индекса», которое содержит разделенный индекс. После разделения Председатель посылает сообщение 149 «Отсечение индекса» для усечения первоначального атома «Индекс» после разделения. Каждый раз когда узел индекса добавляется к индексу, он генерирует сообщение «Узел индекса добавлен», которое содержит индексный ключ, идентификатор записи и другую информацию для нового индекса. Когда индекс будет полностью заполнен и поэтому готов для использования во время операций извлечения, генерируется сообщение 151 «Индекс таблицы готов». Как указано ранее, добавление индекса таблицы генерирует атом «Индекс», который представляет собой индекс только для записи и который не является читаемым. Сообщение 151 «Индекс таблицы готов» делает такой индекс только для записи читаемым.
Атом «Состояния блоба» идентифицирует слот в атоме «Блоб» посредством генерирования сообщения 152 «Блоб блобов».
Сообщение 153 «Запись данных» содержит номер слота и длину записи. Оно также включает в себя запись данных.
Когда меняется состояние транзакции, атом 71 «Диспетчер транзакций» для данного узла транзакции генерирует сообщения 154 «Состояние транзакции». Они указывают, находится ли текущий статус транзакции в активном состоянии, состоянии перед фиксацией, состоянии фиксации или состоянии отката. При некоторых обстоятельствах возможно, что запрос, относящийся к одной транзакции, будет блокирован другой транзакцией на другом узле. При этом событии атом «Диспетчер транзакций» принимает сообщение 155 «Блокировка транзакции». Если транзакция находится в тупиковой ситуации и должен быть выполнен откат, атом «Диспетчер транзакций», связанный с узлом, вызывающим тупиковую ситуацию, генерирует сообщение 156 «Тупиковая ситуация транзакции», вызывающее откат транзакции.
Атом «Главный каталог» или любой атом «Каталог таблицы» на узле архивации может запросить момент времени, когда атом был записан в последний раз. Это происходит тогда, когда запрашивающий узел посылает сообщение 158 «Запросить моменты времени записи». Получатель этого сообщения затем возвращает эти запрашиваемые моменты времени в сообщении 159 «Моменты времени записи».
Вышеизложенные сообщения составляют набор, посредством которого различные процедуры, необходимые для поддержания системы управления базой данных, содержащей в себе данное изобретение, могут обрабатываться надлежащим образом. Как очевидно, каждое сообщение имеет минимум служебных данных в заголовке. Каждое сообщение может быть достаточно коротким. При использовании с TCP или другим протоколом обмена сообщениями сообщения должны посылаться последовательно и на любом данном узле при приеме они должны обрабатываться в этой же последовательности, в которой они были посланы даже разными узлами.
Методы
Для дальнейшего понимания данного изобретения является полезным описание некоторых базовых методов, которые относятся к различным аспектам работы данного изобретения. Варианты для каждого очевидны для специалиста в данной области техники.
Фиг.18 представляет собой блок-схему последовательности операций, которые происходят в разных узлах в системе 30 базы данных по фиг.1, когда узел присоединяется к сети. Для целей данного описания предполагается, что узел 5 на фиг.1 должен присоединиться к системе базы данных; он объявляется присоединяющимся к узлу 170 транзакции. В качестве первого процесса присоединяющийся узел 170 транзакции использует этап 171 для установления TCP-соединения с выбранным узлом. В основном присоединяющийся узел 170 транзакции посылает сообщение на фиксированное местоположение, которое идентифицирует базу данных. Посредник соединения, не показанный, но, как известно, в действии отвечает на этот запрос посредством запрещения или предоставления доступа к системе базы данных. Если посредник соединения предоставляет доступ, он выбирает узел, такой как узел N1 транзакции, в качестве выбранного узла 172. Затем посредник соединения посылает сообщение на присоединяющийся узел 170 транзакции с указанием, например, номером порта, выбранного узла 172. Фиг.18 также представляет в качестве группы 173 все другие активные узлы транзакции и архивации в системе базы данных.
Если соединение установлено на этапе 171, присоединяющийся узел 170 транзакции использует этап 174 для посылки сообщения «Соединить» на выбранный узел 172. Выбранный узел 172 отвечает на сообщение «Соединить» на этапе 175 обновлением своего атома «Главный каталог» при помощи своего диспетчера соединений, назначая локальный ID узла присоединяющемуся узлу 170 транзакции и добавляя этот узел в массив локальных узлов в его объекте-узле, пример показан на фиг.19.
Фиг.19 описывает объект-узел такой, как описанный в связи с этапом 175 фиг.18. Он содержит указатель 400А на сокет для узла, указатель 400B на атом «Главный каталог» на узле и указатель 400C на диспетчер соединений в атоме «Главный каталог». Указатель 400D идентифицирует поток, используемый для прослушивания поступающих сообщений, и указатель 400E идентифицирует буфер сокета для приема сообщений. Прослушиватель сообщений ожидает сообщение, определяет тип сообщения и затем обрабатывает сообщения для завершения.
Объект-узел 400 подобно всем атомам включает в себя глобальный ID 400F узла и локальный ID 400G узла для узла, который этот узел прослушивает. Элемент 400H представляет собой указатель на очередь сообщений, которые ожидают посылки с узла. Элементы 400I и 400J содержат идентификаторы для локального порта и удаленных портов. Элемент 400K содержит номер версии для программного обеспечения, работающего на удаленном узле. Элемент 400L типа узла указывает, является ли удаленный узел узлом транзакции, узлом архивации, подвергающимся процессу синхронизации, или онлайновым узлом архивации.
Элемент 400M содержит имя для локального узла; элемент 400N - имя для удаленного узла. Элемент 400P представляет собой указатель на обрабатываемое текущее сообщение. Элементы 400Q и 400R идентифицируют время последней операции тестового опроса и время тестового опроса. Как ранее указано, каждый узел генерирует последовательный номер последовательности фиксации в ответ на каждую операцию фиксации для транзакции, инициированной на этом узле. Элемент 400S содержит этот номер. Элемент 400T указывает, является ли этот объект-узел объектом-узлом для этого узла.
Возвращаясь обратно к фиг.18, на этапе 176 выбранный узел 172 посылает сообщение «Добро пожаловать» на присоединяющийся узел 170 транзакции, который содержит глобальный ID узла. Затем выбранный узел широковещательно передает сообщение «Новый узел» на этапе 177 группе 173 всех других узлов транзакции и архивации.
Каждый узел в группе 173 отвечает на сообщение «Новый узел» посредством записи глобального ID и назначения локального ID присоединяющегося узла транзакции и обновления локального списка всех подсоединенных узлов в их соответствующих атомах «Главный каталог» на этапе 180. Затем каждый использует этап 181 для посылки сообщения «Добро пожаловать» присоединяющему узлу 170 транзакции. При завершении этого процесса присоединяющийся узел 170 транзакции имеет полный список всех активных узлов, включая выбранный узел 172 и все узлы в группе 173.
Когда присоединяющийся узел 170 транзакции принимает сообщение «Добро пожаловать» от выбранного узла на этапе 182, он посылает сообщение «Запрос объекта» (этап 183) на выбранный узел 172, запрашивающий копию атома «Главный каталог». После того как выбранный узел 172 обновит различные элементы информации в его атоме «Главный каталог», выбранный узел выполняет этап 184 для сериализации своего атома «Главный каталог» в сообщении «Объект», которое посылается на присоединяющийся узел 170 транзакции, и широковещательно передает сообщение «Объект доступен» всем другим узлам в системе. Таким образом, атомы «Главный каталог» в каждом узле обновляются и синхронизируются.
Без ожидания приема сообщения «Объект» присоединяющийся узел транзакции также может начать процесс этапа 185 для извлечения копии атома «База данных» и атома «Диспетчер транзакций» с выбранного узла 172.
Каждый другой узел, который принимает сообщение «Объект доступен», отвечает на этапе 186 посылкой сообщения «Прием объекта подтвержден» обратно на выбранный узел.
Подсистема запросов к базе данных в присоединяющемся узле инициирует эту последовательность. Таким образом, когда метод по фиг.18 будет завершен, присоединяющийся узел 170 транзакции присоединяется к системе базы данных и, как показано на фиг.4А и 4В, включает в себя копию атома 70 «Главный каталог», атома 71 «Диспетчер транзакций» и атома 72 «База данных». Присоединяющийся узел 170 транзакции после этого или создает, или получает копии других атомов по мере необходимости.
Во время некоторых операций узел транзакции может создавать новую таблицу, делая необходимым создание нового атома «Таблица». Фиг.20 описывает этот процесс 190, когда узлом А является запрашивающий узел, узлом X является атом, который запрашивает и будет управлять новым атомом Y. Для создания нового атома Y «Таблица», атомом X будет атом «Схема», и локальным каталогом Z будет атом «Главный каталог». Этап 191 представляет подготовительные функции для запроса на получение экземпляра атома Y. Каждый раз когда атом меняется, ему назначается номер изменения; первоначальным значением обычно является «0».
На этапе 192 локальный каталог Z создает этот экземпляр атома Y без содержимого и объявляет локальный узел в качестве председателя для атома Y. Затем процесс 193 позволяет локальному каталогу Z назначить ID объекта новому атому Y. Подробности такого процесса показаны и описаны в отношении фиг.21.
Затем локальный каталог Z устанавливает исключающую блокировку, позволяющую изменениям в нем происходить без какого-либо влияния от внешней автоматической обработки. Пока блокировка в действии, локальный каталог Z устанавливает статус нового атома Y в статус «измененный» и в статус «неоткрытый». Статус «измененный» указывает, что новый атом Y не был реплицирован в архив. Статус «не открытый» указывает, что новый атом Y еще не является доступным для других узлов. На этапе 195 локальный каталог Z обновляет самого себя и затем снимает исключающую блокировку. На этапе 196 каталог Z широковещательно передает сообщение «Объект доступен», идентифицирующее атом Y всем другим экземплярам каталога Z в узлах транзакции и архивации.
На этапе 197 атом X, в качестве управляющего атома для нового атома Y, заполняет экземпляр атома Y и устанавливает статус для атома Y на «открытый», указывающий, что новый атом может реплицироваться. Через некоторое время после этого узел архивации сохранит копию нового атома в долговременном хранилище. Т.е. узел архивации отвечает на прием сообщения «Объект доступен» запрашиванием копии атома Y, чтобы таким образом обеспечить избыточность. Когда это будет завершено, прием сообщения «Приема объекта подтвержден» от узла архивации вызывает изменение статуса «измененный», и это изменение затем будет отражено для всех других узлов, которые имеют копию атома Y.
Процесс 193 назначения по фиг.20 и подобные процессы назначения используются на различных этапах работы данного изобретения для назначения ID объекта. Фиг.21 подробно описывает этот процесс назначения. Конкретно, когда атом каталога собирается назначить ID объекта, он определяет на этапе 200, имеет ли он локальный ID, доступный для него. Если он имеет, управление переходит на этап 201, который назначает доступный ID в ответ на запрос. Если локальный ID не является доступным, управление переходит на этап 202 для определения, имеет ли атом каталога на этом узле статус «председателя». Если он имеет, председатель имеет полномочия идентифицировать доступные ID непосредственно, и управление переходит на этап 201.
Как известно, когда по меньшей мере один другой узел существует для конкретного атома, каждый атом содержит список узлов, которые включают в себя копии запрашиваемого атома. Если это был первый запрос для атома после того, как этот атом был создан в соответствии с процессом по фиг.20, соответствующий каталог в первом узле в списке является председателем. Этап 203 представляет процесс выбора узла и идентификации председателя. Для процесса выбора предпочтительно сначала установить связь с узлом транзакции. Этап 204 представляет передачу сообщения «Запрос ID» председателю.
Когда председатель принимает сообщение запроса ID на этапе 205, он получает блок доступных номеров ID (этап 206). Председатель идентифицирует узел транзакции, выполняющий запрос, в качестве местонахождения этого блока доступных номеров ID (этап 207). Затем председатель посылает сообщение делегирования ID на этапе 210 запрашивающему узлу. Когда запрашивающий узел принимает сообщение «Делегирование ID» от председателя на этапе 211, он сохраняет блок номеров ID на этапе 212 и затем выбирает первый доступный ID для назначения на этапе 201. Ссылаясь снова на фиг.20, в этой ситуации процесс 193 переходит с этапа 200 на этап 202 непосредственно на этап 201, так как председатель объявлен на этапе 192 на фиг.20.
Всякий раз когда подсистема 41 базы данных на фиг.4А и 4В выполняет запрос в отношении атома, обрабатывается ответ 220 на фиг.22. Например, предполагается, что подсистема 41 запросов к базе данных в запрашивающем узле 221 запрашивает копию атома Y (например, атома «Таблица») с выбранного узла 222 в базе данных с другими узлами 223. Когда подсистема 41 запросов к базе данных выполняет требование, этап 224 определяет, присутствует ли атом Y в запрашивающем узле 221. Если присутствует, этап 225 завершает процесс, так как запрашиваемый атом присутствует. Если не присутствует, управление переходит на этап 226, посредством чего локальный каталог Z создает пустой экземпляр атома Y и объявляет атом Y «незаполненным». Если подсистема 41 базы данных запрашивала атом 74 «Таблица», атом 70 «Главный каталог» будет выполнять этот этап. Этап 230 затем использует ранее описанный процесс выбора для идентификации выбранного узла 222. Предпочтением является выбор любого из узлов транзакции перед выбором наиболее быстрореагирующего узла архивации в качестве выбранного узла 222.
На этапе 231 запрашивающий узел 221 посылает сообщение «Запрос объекта» для атома Y на выбранный узел 222. В ответ выбранный узел 222 использует этап 232 для посылки сообщения «Объект» с запрашиваемым атомом Y в его сериализованной форме с узлом и номерами последовательности.
Одновременно выбранный узел 222 широковещательно передает сообщение «Объект доступен» на все другие узлы 223. Он также создает список ретрансляции для всех других узлов с копией атома Y. В этот момент в процессе другие узлы не выполняют связь непосредственно с атомом Y в запрашивающем узле, так как они не знают о том, что они должны посылать сообщения репликации для этого атома на запрашивающий узел. Поэтому, когда любой из других узлов реплицирует свой атом Y, выбранный узел 222 ретранслирует сообщение запрашивающему узлу 221.
Когда запрашивающий узел 221 принимает сообщение «Объект» от выбранного узла 222, он проводит анализ доступности сообщения на этапе 233. Если сообщение содержит текущий атом, атом Y обрабатывает сообщение на этапе 236 и посылает сообщение «Прием объекта подтвержден» на выбранный узел на этапе 237.
Все другие узлы 223 используют этап 240 для ответа на сообщения «Объект доступен» посредством посылки сообщения «Прием объекта подтвержден» на выбранный узел 222. Выбранный узел 222 использует этап 241 для контролирования сообщений «Прием объекта подтвержден». Конкретно, он удаляет каждый из других узлов из его списка ретрансляции в ответ на каждое сообщение «Прием объекта подтвержден» и прекращает ретрансляцию на этот узел. Когда все другие узлы 223 будут удалены из списка, выбранный узел прекращает всю ретрансляцию и широковещательно передает сообщение «Объект завершен».
Другому узлу можно послать сообщение репликации, которое достигает запрашивающего узла 221 в течение времени между этапами 226 и 236 на фиг.22. Оно может прервать обработку сообщения. Следовательно, когда сообщение репликации для атома Y в вышеупомянутом примере принимается на запрашивающем узле, когда атом Y не заполнен, оно помещается в список ожидающих сообщений, который представляет собой часть каждого атома, хотя не показан на любой из фиг.5-13.
Как ранее указано, данное изобретение особенно адаптировано к базе данных, которая взаимодействует с методами обработки транзакций. По существу, должен быть привлечен к участию соответствующий подход для «фиксации» сообщений. Фиг.23 описывает один подход, который гарантирует непротиворечивость данных в такой среде. Конкретно, фиг.23 описывает четыре узла, а именно: узел А 250 транзакции, узел B 251 транзакции, узел C 252 транзакции и узел 253 архивации. Предполагается, что узел B 251 транзакции посылает сообщение «Предварительная фиксация» с ID транзакции, предоставленным атомом «Диспетчер транзакций» на этом узле на этапе 254. Сообщение маршрутизируется на узел архивации на этапе 255. Когда будут завершены все условия для фиксации этой транзакции, узел 255 архивации выдает сообщение фиксации транзакции на этапе 256 и на этапе 257 широковещательно передает это сообщение фиксации. Каждый из узлов транзакции в ответ обновляет свой соответствующий номер транзакции на этапе 258.
Как ранее описано в отношении процесса для запроса копии атома на фиг.21, запрашивающий узел выполняет анализ доступности при любом принятом сообщении на этапе 233. Этот тест обеспечивает гарантию, что любой узел транзакции всегда работает с достоверной информацией и включает в себя анализ номеров ID транзакции и номеров последовательности фиксации. Пониманию этого анализа и других признаков данного изобретения способствует дальнейшее понимание ID транзакции и номеров последовательности фиксации, анализ относительного порядка транзакций и понимание «расфазировки атомов».
Что касается ID транзакций и номеров последовательности фиксации и, как указано ранее, каждый идентификатор транзакции является уникальным по всей системе базы данных по фиг.1. Целью ID транзакции является уникальная постоянная в масштабе системы метка, указывающая, какая транзакция создала конкретную версию записи. Каждый ID транзакции назначается локальной копией атома 71 «Диспетчер транзакций», и одним таким атомом «Диспетчер транзакций» будет председатель, который назначает блоки номеров идентификаторов атомам «Диспетчер транзакций» на каждом узле транзакции в системе базы данных. Атом «Диспетчер транзакций» на данном узле транзакции назначает неиспользуемый номер в назначенном блоке по порядку каждой транзакции, которую запускает узел. В результате ID транзакции более новых транзакций, запущенных на данном узле, могут быть большими, чем ID транзакций, назначенные более старым транзакциям, запущенным на этом же узле. Однако в масштабе системы ID транзакций не подразумевают ничего об относительных моментах запуска разных транзакций.
Следовательно, должны обеспечиваться некоторые способы, чтобы гарантировать, что транзакция может считать версию записи, только если транзакция, которая создала версию записи, была фиксирована перед тем, как была запущена транзакция чтения. В данном изобретении такой способ определения, какая версия записи должна считываться, представляет собой момент времени фиксации транзакции для транзакции, которая создала версию записи, а не момент времени запуска. ID транзакции не содержит ее момента времени фиксации, поэтому атом «Диспетчер транзакций» на каждом узле назначает номер последовательности фиксации каждой транзакции, основываясь на фактической операции фиксации. Каждый узел транзакции генерирует свои номера последовательности фиксации в возрастающем порядке. Если транзакция от данного узла имеет номер последовательности фиксации 467, все транзакции от этого узла с меньшими номерами последовательности фиксации точно должны быть фиксированы. Все узлы генерируют одинаковые номера последовательности фиксации, поэтому интерпретирование номеров требует как номер, так и идентификацию соответствующего узла.
Когда транзакция фиксируется, ее атом «Диспетчер транзакций» посылает сообщение «Фиксация» на все узлы, которые включают в себя соответствующий ID транзакции и номер последовательности фиксации. Когда атом сериализует самого себя, он включает в себя наибольший номер последовательности фиксации, который он обнаружил от каждого узла, который содержит копию этого атома. Например, предполагается, что узлы A, B и C содержат копии атома Z и что узел A генерирует сообщение «Объект» для атома Z. Сериализованная форма этого сообщения будет включать в себя наибольший номер последовательности фиксации, который узел A обнаружил у себя, и наибольшие номера последовательности фиксации, которые он обнаружил у узлов B и C. Сериализованное сообщение от узла A описывает состояние транзакций на всех узлах, которые совместно используют копию атома Y, когда узел A обнаруживает ее. Возможно, что узел B или узел C могут иметь фактически выданные более высокие номера последовательности фиксации для транзакций, которые узел A еще не принял или обработал.
Диспетчер транзакций на каждом узле поддерживает объект транзакции для каждого узла в системе базы данных. Каждый объект транзакции отражает состояние транзакций на всех узлах и назначает каждому объекту еще два номера, которые являются локальными и непрерывно увеличивающимися. Когда атом «Диспетчер транзакций» запускает транзакцию или принимает сообщение перехода транзакции, которое указывает, что другой узел запустил транзакцию, атом «Диспетчер транзакций» создает локальный объект транзакции с новым ID транзакции и назначает ему номер запуска. Когда фиксируется локальная транзакция или когда атом «Диспетчер транзакций» принимает сообщение перехода транзакции, который указывает, что фиксирована транзакция на другом узле, номер окончания транзакции назначается объекту транзакции вместе с номером последовательности фиксации. Номера запуска и окончания поступают из одной и той же последовательности. В качестве примера, если транзакция 123 имеет номер запуска, который больше номера окончания транзакции 453, транзакция 123 может считывать версии записи, созданные транзакцией 453, с любого узла, который исполнил транзакцию 453.
Номера запуска и окончания транзакции являются локальными; т.е. они отражают состояние транзакций, обнаруживаемое на локальном узле. Разные узлы назначают разные значения и обнаруживают разное упорядочение транзакций на других узлах. Как очевидно, могут существовать задержки при приеме и при обработке сообщений «Состояние транзакции». Каждая транзакция выполняется только на ее локальном узле транзакции. Эта систем базы данных предотвращает «обнаружения» одним узлом транзакции транзакции в виде фиксированной перед тем, как транзакция будет фиксирована на ее локальном узле транзакции. Например, если узел A запускает транзакцию 123 после приема и обработки сообщения фиксации от узла B транзакции для транзакции 453, транзакция 123 может считывать изменения из транзакции 453, даже если узел C транзакции, который принял сообщения фиксации и запуска транзакции в другом порядке, считает две транзакции одновременными.
Когда ни одна из транзакций не выполняется на узле C транзакции, информация не релевантна узлу С транзакции. Однако разность в представлении системы базы данных каждым индивидуальным узлом транзакции может вызвать проблемы при некоторых обстоятельствах.
Что касается «расфазировки атомов» согласно одному аспекту данного изобретения, каждый узел должен обрабатывать сообщения от другого узла в порядке, в котором другой узел послал сообщения. Однако все узлы работают независимо. Таким образом, в любой данный момент времени некоторые узлы примут и обработают сообщения, которые другие узлы еще не обработали. Некоторые копии атомов будут включать изменения, которые другие копии не включают. Эти различия не имеют значения для любого узла, который имеет копию, так как каждая копия атома находится в совместимом состоянии для этого узла. Как ранее описано, всякий раз когда узел транзакции изменяет атом, узел реплицирует измененный атом на другие узлы, которые содержат копию этого атома. Если узлы B и C транзакции - каждый содержит копию этого атома, и узел B транзакции изменяет этот атом, узел B транзакции посылает сообщения репликаций на узел C транзакции. Когда узел B транзакции обрабатывает транзакцию, он посылает сообщение «Состояние транзакции» узлу C транзакции и реплицирует любые атомы, которые изменяют узел B транзакции. Когда узел B транзакции фиксирует транзакцию посредством процесса, показанного на фиг.23, узел C транзакции должен принять сообщение «Состояние транзакции», указывающее, что транзакция была фиксирована. Узел C транзакции будет обрабатывать все сообщения, относящиеся к транзакции, перед тем как он примет сообщение «Фиксация» вследствие того факта, что все сообщения будут обработаны в порядке, в котором они были посланы. Копии атомов на разных узлах транзакции могут различаться, но все изменения, сделанные транзакцией на любом узле транзакции, будут на каждом другом узле перед тем, как другой узел обнаружит транзакцию фиксированной.
При просмотре транзакций с системного уровня разные узлы транзакции не действуют синхронно. Моменты времени для единственного сообщения, обрабатываемого разными узлами, может изменяться вследствие различия в эффективности канала связи и в количестве сообщений, которое каждый узел транзакции должен обработать. Должны приниматься во внимание различия в моментах времени обработки на разных узлах. Рассматривается три узла транзакции: узел А, узел B и узел С. Предполагается, что узел B исполняет транзакцию 768, которая изменяет атом X, и что узел C имеет копию атома X. Предполагается, что атом X на узле B посылает сообщение изменения на узел С и что имеется некоторый промежуток времени перед тем, как узел C обработает эти изменения. Предполагается также, что узел B назначил номер последовательности фиксации 47 транзакции 768. Атом «Диспетчер транзакций» на узле B посылает сообщение «Состояние транзакции» на все узлы в системе базы данных. Также предполагается, что узел A запрашивает копию атома X от узла C после приема сообщения фиксации от узла B, но перед тем, как узел C завершит обработку транзакции. Узел A принимает и обрабатывает сообщение «Состояние транзакции» от узла B. С точки зрения узла A транзакция 768 фиксируется и самый большой номер последовательности фиксации для узла B равен 47. Однако с таким моментом времени атом, возвращенный от узла C, не отражает изменения, сделанные транзакцией на узле B.
Согласно данному изобретению, когда атом X на узле C сериализует самого себя для передачи на узел A, он включает в себя наибольший номер последовательности фиксации от каждого узла, который имеет копию атома X. В данном случае предполагается, что сообщение будет включать в себя номер 97 последовательности фиксации для узла C и 46 для узла B.
Возвращаясь к фиг.22, узел А в качестве запрашивающего узла создает пустой экземпляр атома X перед запросом узла C в отношении его содержимого. Анализ доступности на фиг.22 получает текущий наибольший номер последовательности фиксации для каждого узла, обнаруживаемый узлом A. Он также расширяет сериализованное сообщение с атомом X для получения текущих наибольших номеров последовательности фиксации для каждого узла, обнаруживаемых узлом B. При данном сравнении анализ доступности определит, что сериализованный номер последовательности фиксации в сообщении равен 46, тогда как его локальный наибольший номер последовательности фиксации для B равен 47. Таким образом, узел A не может использовать сериализованную версию атома X в его текущем состоянии и должен ожидать атом X на узле C для посылки ему сообщения «Объект завершен». Если номер последовательности фиксации является таким же или больше, узел A может продолжить обработку атома.
Как ранее изложено, когда узел С послал сериализованную копию атома X на узел A, он послал сообщение «Объект доступен» другим копиям атома X, в этом случае копии на узле B. Атом X на узле B посылает сообщение «Прием объекта подтвержден» атому X на узле C и добавляет копию на узле A в его список копий самого себя. После этого атом X на узле B посылает сообщения изменений на его копии на обоих узлах A и C. Между тем, атом X на узле C обрабатывает сообщения от узла B, ретранслируя их на атом A. Атом X на узле A обрабатывает сообщения, приводя себя все ближе к самому последнему обновленному состоянию. Когда атом X на узле C обработает сообщение «Прием объекта подтвержден» от атома X на узле B и все другие копии атома X на других узлах, он посылает сообщение «Объект завершен» на атом X на узле A.
Согласно данному изобретению каждый узел транзакции должен работать без необходимости пересылки каких-либо атомов на диск или другое долговременное хранилище. Это требует удаления неактивных атомов с каждого узла транзакции быстрым образом. Для достижения этой цели вспомогательный класс в каждом узле обеспечивает функцию сборки мусора, вызываемую периодически диспетчером периодов для инициирования нового периода сборки мусора независимо от других операций. Более конкретно, диспетчер периодов выполняет период старения, посредством чего любой атом, упоминаемый в предыдущем периоде, перемещается вперед в списке самого давнего времени использования (LRU) в атоме «Главный каталог» для узла. Диспетчер периодов получает исключающую блокировку, чтобы гарантировать, что другие потоки не являются активными относительно предыдущего периода.
Диспетчер периодов затем запускает поток сборки мусора записей для атома таблицы, который отмечен для сборки мусора записей. Если текущее количество памяти на узле превышает заданную величину, определенную конфигурационным объектом, идентифицированным указателем 70U на фиг.5, поток сборки мусора обрабатывает циклы посредством LRU «Главный каталог» с атомов самого давнего времени использования до последних по времени использования атомов. Он классифицирует атом в качестве кандидата для кандидата сборки мусора, если атом: (1) не является активным, (2) на него не была сделана ссылка в текущем периоде старения, (3) не является атомом «объект не завершен», (4) был изменен локально и не был еще записан в узел архивации и (5) представляет собой каталог, который не имеет постоянно хранимых в памяти атомов. Атом в узле архивации дополнительно не должен быть сериализован на диск.
Если процесс сборки мусора определяет, что все вышеупомянутые условия были выполнены, то существует два варианта. Если узел является узлом архивации и имеются другие экземпляры атома на других узлах, содержимое атома «очищается». Иначе, атом запрашивается на удаление самого себя, что он и делает, проверив сначала свой создающий каталог атом для окончательного теста. Если этот тест проходит, атом каталога сбрасывает свой указатель на атом кандидата, который широковещательно передает сообщение «Объект недоступен» на другие узлы, которые содержат экземпляры атома кандидата, и затем удаляет себя. Этот цикл продолжается с каждым атомом до тех пор, пока оперативная память не будет в допустимых пределах.
В этот процесс включены два механизма. Когда атом «Каталог» запрашивается на поиск атома для классификации, атом «Каталог» устанавливает свой элемент ссылки на период на текущий номер периода. Кроме того, атомы «Диспетчер транзакций», «База данных», «Схема» и «Таблица» получают совместно используемую блокировку на текущий период, так что методы в этих атомах могут удерживать указатели атомов без необходимости приращения числа использований атома для предотвращения сборки мусора объекта или атома.
Фиг.19 и 20 описывают «председательство». Как указано на фиг.20, когда создается атом, создающий узел объявляется в качестве председателя атома и устанавливает упорядоченный список узлов для атома. Когда узел создает атом, он является единственным элементом в упорядоченном списке. Первым узлом в списке является председатель.
Когда другой узел позже запрашивает копию этого атома, выбранный узел размещает идентификатор запрашивающего узла в упорядоченном списке сразу после себя, является ли он председателем или нет. В результате, если узел, объявленный в качестве председателя для любого атома, становится неактивным по любой причине, каждая другая копия этого атома имеет упорядоченный список узлов. Обходя упорядоченный список, следующим председателем является первый оставшийся узел транзакции в списке. Если в списке нет узлов транзакции, объявляется первый несинхронизирующий узел архивации.
Теперь может быть полезным в качестве средства для понимания взаимодействия между разными узлами и атомами в узле описать простой запрос к базе данных. Предполагается, что подсистема запросов к базе данных на узле транзакции принимает запрос к базе данных на выбор всех записей в таблице «член» с почтовым индексом «01944». Предполагается, что атом «Диспетчер транзакций» и атом «Таблица» расположены на локальном узле, что вся обработка запроса была завершена и что индексный атом существует для поля «почтовый индекс» в таблице «член».
Первоначально подсистема 41 запросов к базе данных на фиг.2 выдает команду атому «Диспетчер транзакций» начать новую транзакцию, после чего атом «Диспетчер транзакций» назначает ID транзакции. Затем подсистема запросов к базе данных использует атом «Таблица» для таблицы «член» для определения, существует ли атом «Индекс» для поля «почтовый индекс». Если эти два атома находятся на локальном узле, они обрабатываются. Если нет, получают копии этих атомов от других узлов перед продолжением обработки.
Атом «Таблица» для таблицы «член» использует информацию от соответствующего атома «Каталог таблицы» для сканирования индекса. Это создает битовый массив, который идентифицирует каждую «запись» в таблице «член» с заданным почтовым индексом. Как очевидно, этот битовый массив может ограничиваться конкретным полем или может быть результатом логического объединения индексов из многочисленных полей.
Затем цикл устанавливается на основе результирующего битового массива. Для каждой итерации цикла подсистема запросов к базе данных выдает вызов к атому «Таблица» на обработку метода выборки записи, заданного с ID транзакции в записи. Атом «Таблица» выбирает соответствующий атом «Состояния записи», который связан с атомом «Запись», посредством деления номера записи на фиксированное число, которое соответствует максимальному количеству ID записей, которым управляет атом «Состояния записи». Затем атом «Таблица» использует метод выборки в выбранном атоме «Состояния записи», используя ID транзакции, и идентифицированный номер записи. Для многоверсионных записей атом «Состояния записи» циклически проходит по любым версиям записи для нахождения правильной версии и подходящего указателя на соответствующий атом «Данные». Атом «Состояния записи» вызывает этот атом «Данные» с номером атома данных, который указывает на запись и разрешает ее извлечение. Когда этот процесс будет завершен, подсистема запросов к базе данных предоставляет пользователю набор записей, который перечисляет все записи с заданным почтовым индексом.
Вкратце, для специалиста в данной области техники очевидно, что система управления базой данных, выполненная согласно данному изобретению, обеспечивает эластичную, масштабируемую, распределенную систему обработки данных по запросу. Система является отказоустойчивой и имеет высокую степень доступности. Она является платформно-независимой и работает для обеспечения атомарной, непротиворечивой, изолированной и устойчивой базы данных. Кроме того, она может работать по Интернету без потребности в высокоскоростных каналах связи и адаптирована для обработки транзакций, которая может осуществляться по большой географической зоне.
Данное изобретение достигает решения всех этих задач посредством реализации одного или нескольких следующих признаков. Данное изобретение фрагментирует базу данных на распределенные объекты, которые реплицируются на равноправной основе. Каждый узел транзакции и архивации определяет, какие атомы должны быть постоянно хранимыми в памяти на локальной основе. Атомы каталога отслеживают местоположение для локальных и удаленных копий различных атомов и идентифицируют каталоги, членами которых они являются. Кроме того, каждый узел может определить наилучшие из многочисленных узлов, с которых запросить копию атома, позволяя получить географически рассредоточенные системы.
Данное изобретение было описано в виде некоторых вариантов осуществления. Очевидно, что могут быть сделаны многочисленные модификации описанного устройства без отступления от изобретения. Поэтому целью прилагаемой формулы изобретения является охватывание всех таких вариантов и модификаций, которые подпадают под истинную сущность и объем данного изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2740865C1 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2785613C2 |
| ЗАПИСИ ВАРИАНТОВ В СЕТЕВЫХ РЕПОЗИТОРИЯХ ДАННЫХ | 2008 |
|
RU2477573C2 |
| Способ репликации информации в базах данных | 2018 |
|
RU2706482C1 |
| СЕТЕВОЙ МОСТ ДЛЯ ЛОКАЛЬНОЙ АВТОРИЗАЦИИ ТРАНЗАКЦИЙ | 2016 |
|
RU2715801C2 |
| РАСЩЕПЛЕННАЯ ЗАГРУЗКА ДЛЯ ЭЛЕКТРОННЫХ ЗАГРУЗОК ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2006 |
|
RU2424552C2 |
| ВЫРАВНИВАНИЕ СЕТЕВОЙ НАГРУЗКИ С ПОМОЩЬЮ УПРАВЛЕНИЯ СОЕДИНЕНИЕМ | 2004 |
|
RU2387002C2 |
| ПЛАТФОРМА СОСТАВНЫХ ПРИЛОЖЕНИЙ НА БАЗЕ МОДЕЛИ | 2008 |
|
RU2502127C2 |
| КОНТРОЛЬНЫЕ ТОЧКИ ДЛЯ ФАЙЛОВОЙ СИСТЕМЫ | 2011 |
|
RU2554847C2 |
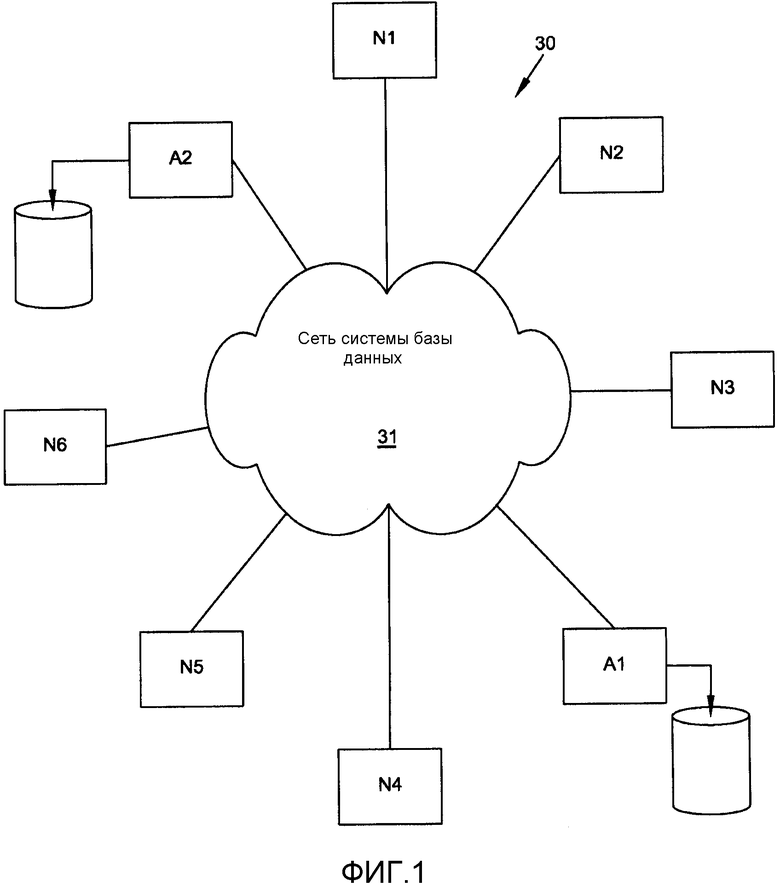
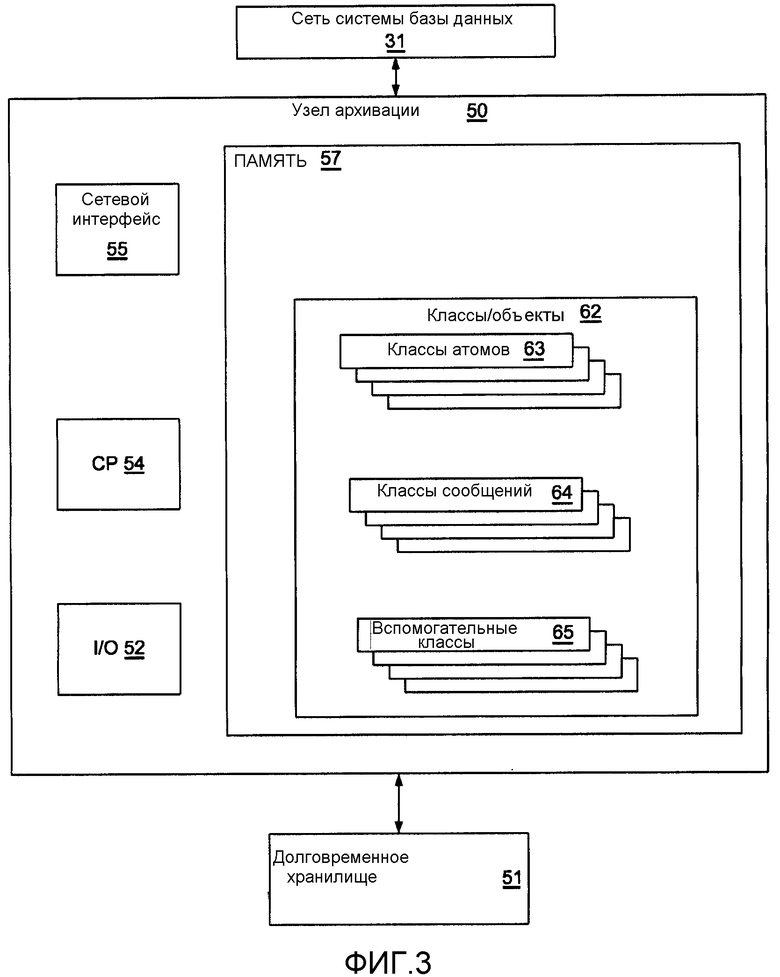
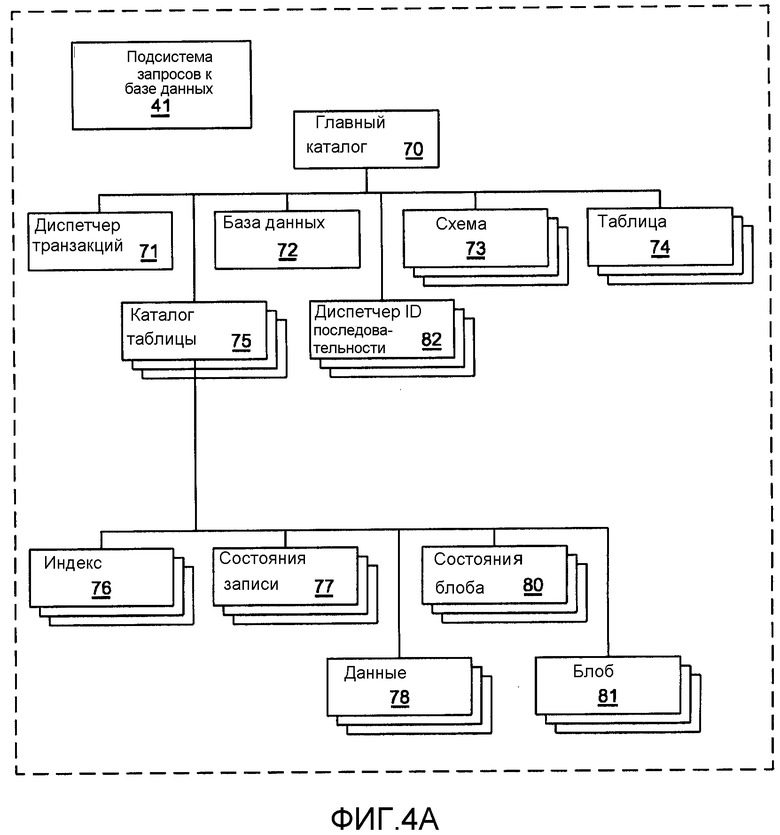
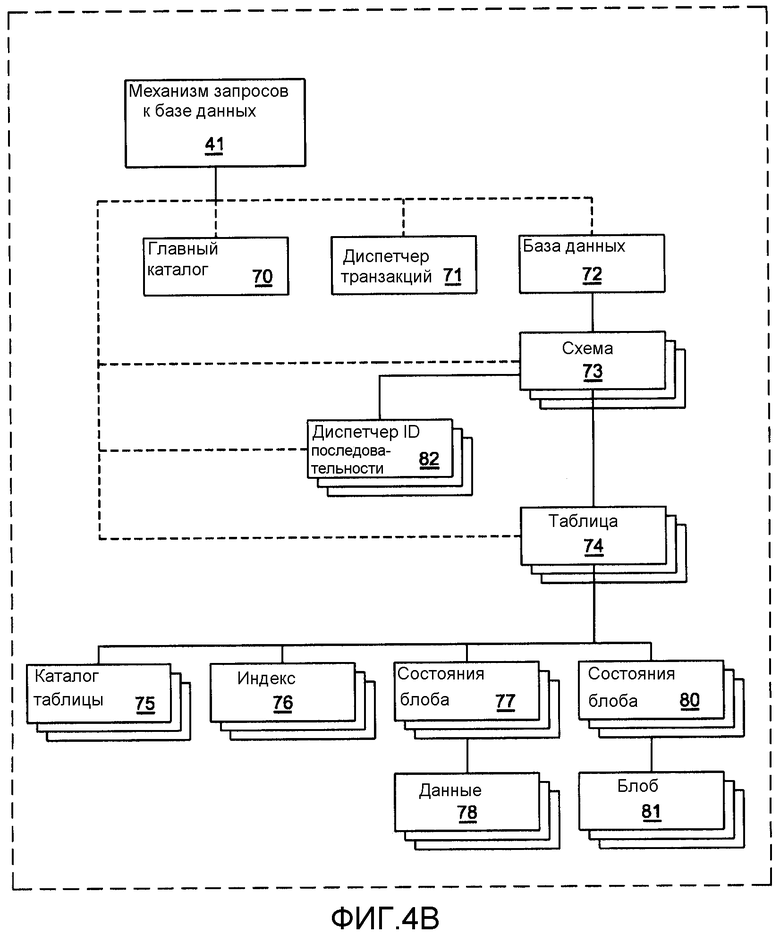




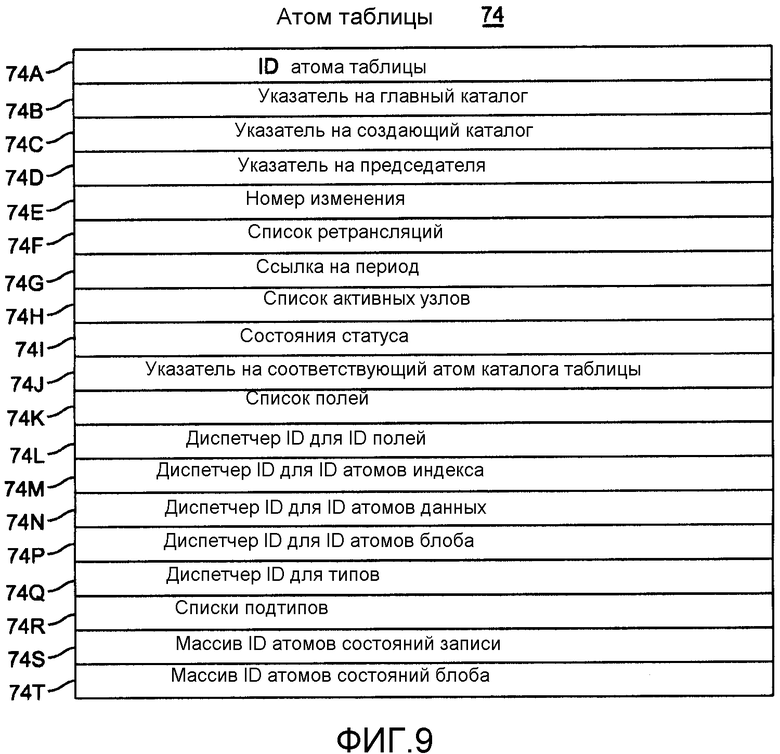
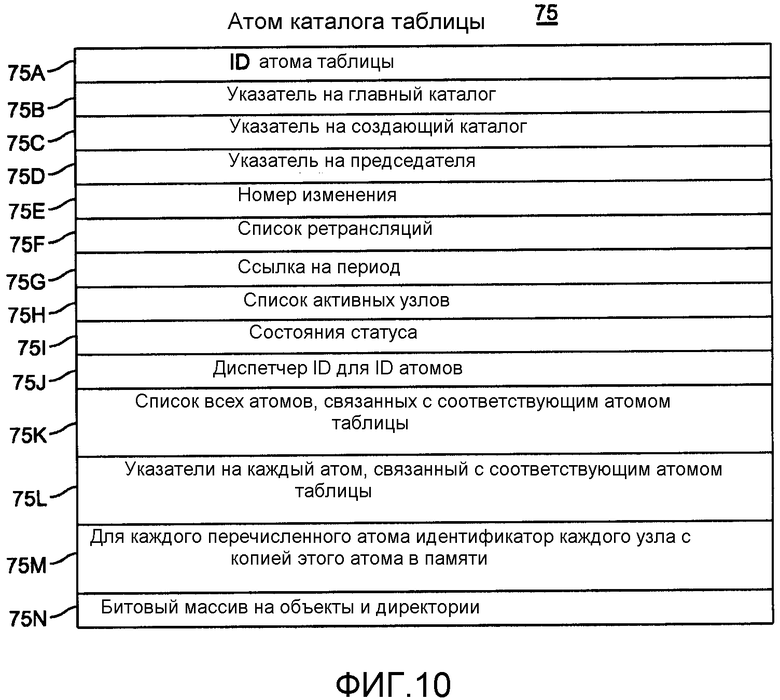

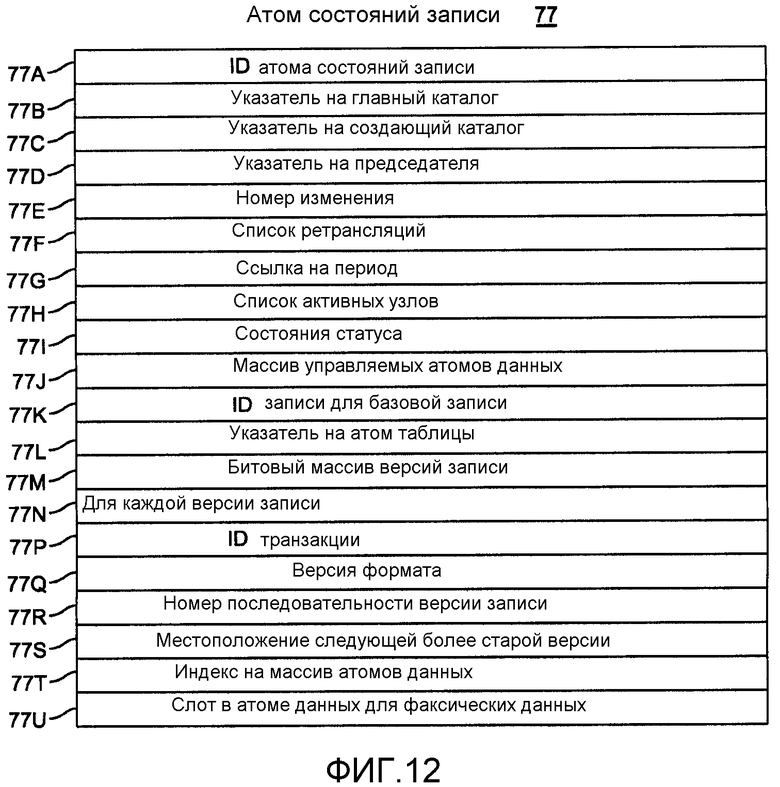



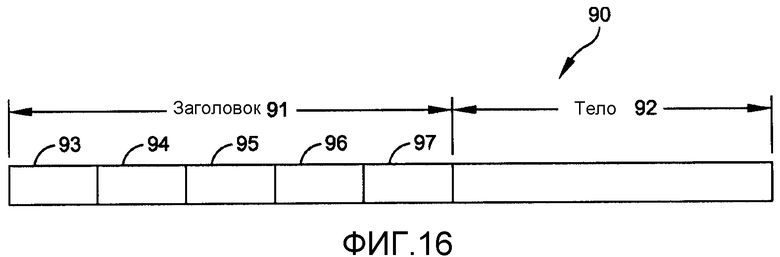

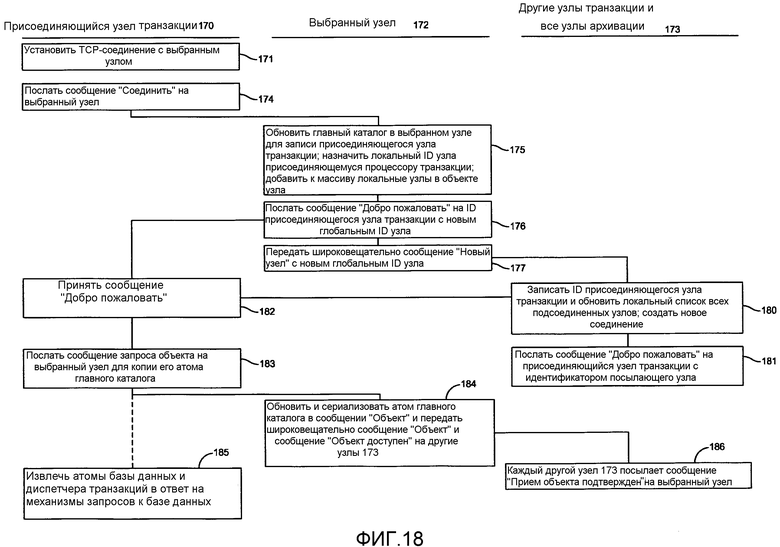
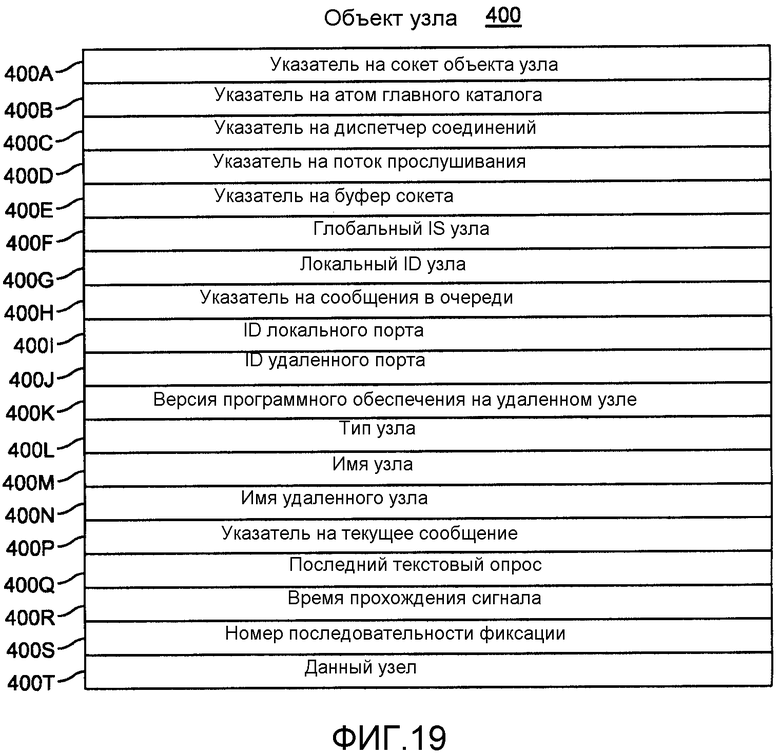
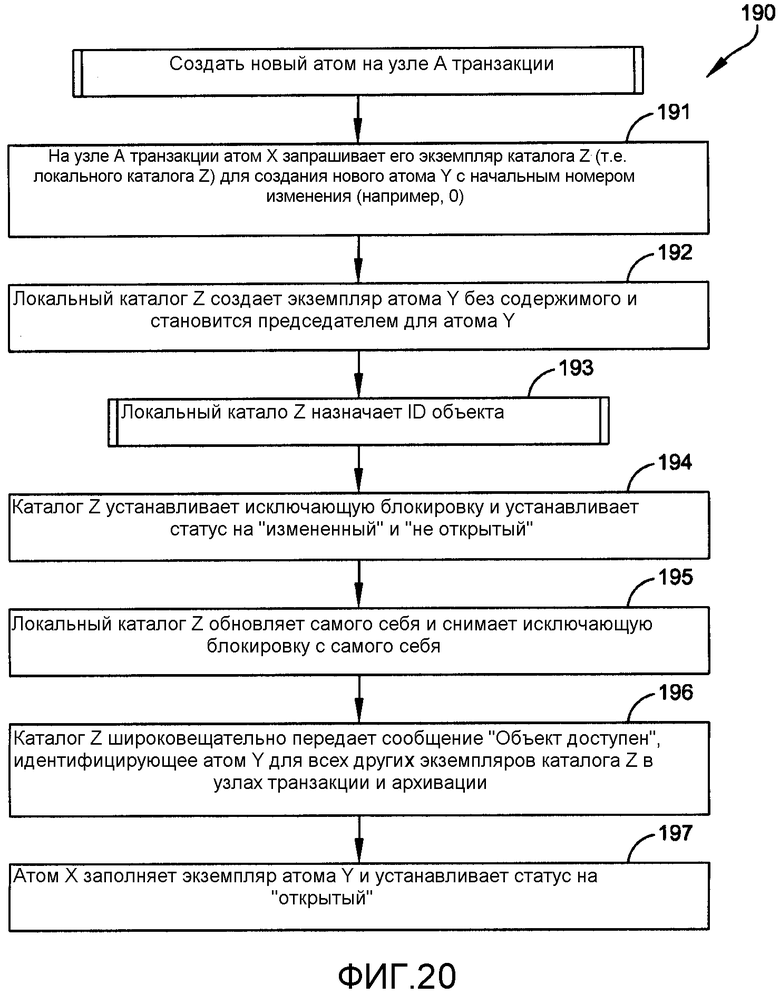
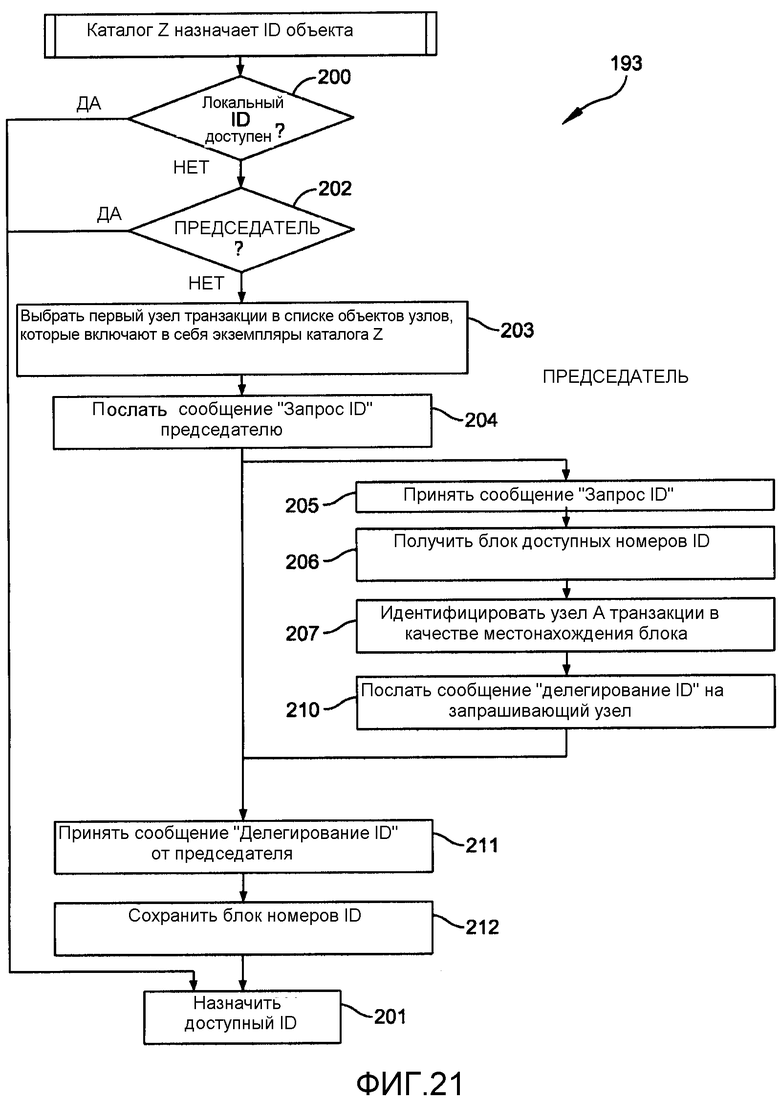
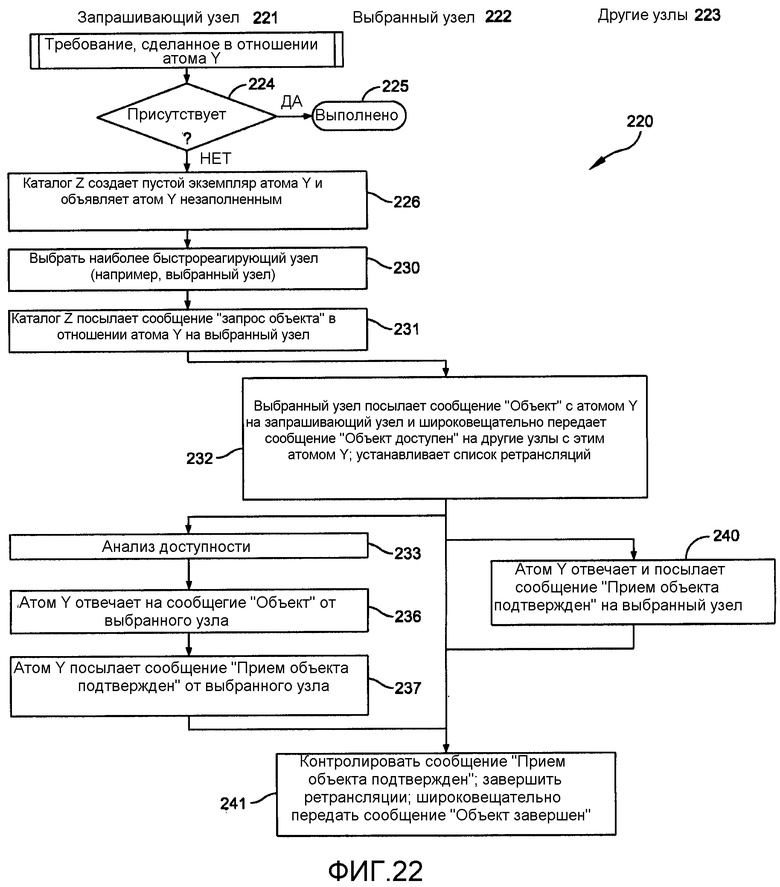
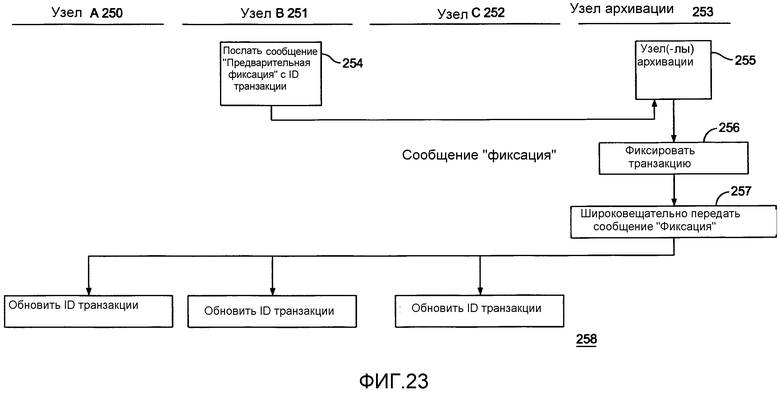
Изобретение относится к системам управления базой данных. Технический результат заключается в повышении отказоустойчивости системы. Объекты-атомы генерируют атомы, причем каждый атом содержит заданный фрагмент данных или метаданных, посредством чего набор всех экземпляров атомов совместно определяет все метаданные и данные в базе данных. Запрашивают от выбранного узла копии атома, который релевантен запросу, но не присутствует в этом узле, в ответ на системную команду от интерфейса. Реплицируют запрашиваемый атом для переноса на запрашивающий узел, посредством чего только атомы, требуемые для завершения запроса, должны располагаться в любом узле транзакции в любой заданный момент времени в ответ на запрос атома от другого узла. Реплицируют атом для переноса на каждый другой узел в системе, в котором этот атом является постоянно хранимым, в ответ на изменение в атоме на этом узле. 3 н. и 42 з.п. ф-лы, 24 ил.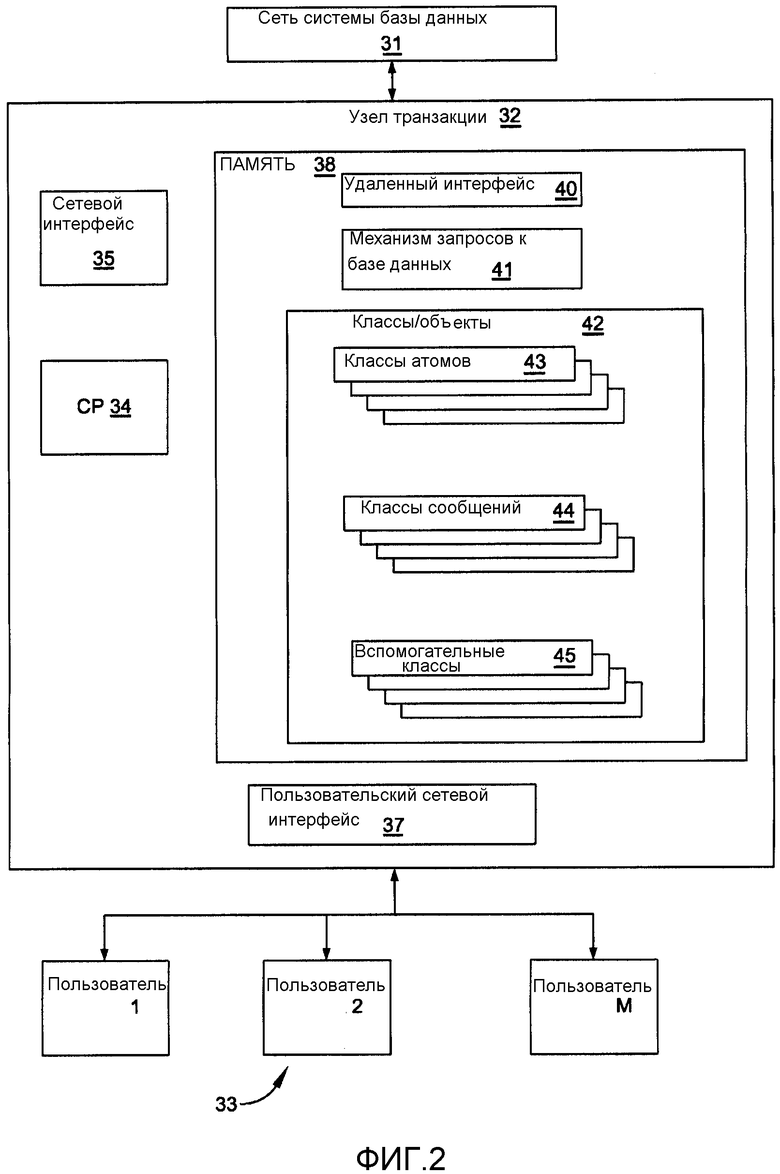
1. Система управления базой данных, которая обеспечивает пользователям возможность взаимодействовать с базой данных, содержащей данные и метаданные, причем упомянутая система содержит:
А) множество узлов, причем каждый узел содержит:
i) интерфейс между командами высокоуровневого ввода и вывода на пользовательском уровне и командами ввода и вывода на системном уровне, которые управляют последовательностью операций для взаимодействия с базой данных, при этом в ответ на некоторые команды системного уровня атомы генерируются как экземпляры объектов-атомов, определяемых классами атомов, причем каждый атом содержит заданный фрагмент данных или метаданных, посредством чего набор всех экземпляров атомов совместно определяет все метаданные и данные в базе данных,
ii) средство управления связью для установления канала связи с каждым другим узлом в системе,
iii) метод, реагирующий на системную команду от интерфейса для запрашивания от выбранного узла копии атома, который релевантен запросу, но не присутствует в этом узле,
iv) метод, реагирующий на запрос атома от другого узла для репликации запрашиваемого атома для переноса на запрашивающий узел, посредством чего только атомы, требуемые для завершения запроса, должны располагаться в любом узле транзакции в любой заданный момент времени, и
v) метод, реагирующий на изменение в атоме на этом узле для репликации этого атома для переноса на каждый другой узел в системе, в котором этот атом является постоянно хранимым,
B) средство, подсоединенное к упомянутому множеству узлов, для обеспечения каналов связи между всеми узлами, и
C) средство, подсоединенное к упомянутому средству связи, для обеспечения долговременного хранилища для информации в атоме, посредством чего коллекция атомов в долговременном хранилище совместно содержит все данные и метаданные в базе данных.
2. Система управления базой данных по п. 1, в которой из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают все атомы, которые являются постоянно хранимыми на этом узле, и местоположение каждого узла, который имеет копию каждого из этих постоянно хранимых атомов.
3. Система управления базой данных по п. 2, в которой одним из атомов каталога является атом главного каталога, который реплицируется в каждом узле, подсоединенном к системе, при этом другим из атомов является одиночный атом диспетчера транзакций для базы данных для отслеживания хода транзакций, инициированных интерфейсом, и при этом главный каталог идентифицирует местоположение атома диспетчера транзакций.
4. Система управления базой данных по п. 3, в которой база данных на пользовательском уровне содержит именованные таблицы с записями и полями и работает в соответствии с по меньшей мере одной именованной схемой, и из других из объектов-атомов создаются:
i) атом таблицы для каждой таблицы, которая содержит список полей,
ii) атом схемы устанавливает соответствие между схемой и именованными таблицами, соответствующими этой схеме, и
iii) атом базы данных, который устанавливает соответствие между базой данных и именованной схемой.
5. Система управления базой данных по п. 4, в которой таблицы базы данных на пользовательском уровне содержат идентифицированные записи, содержащие поля и данные, при этом из других объектов-атомов создаются атомы данных, которые содержат заранее заданное количество записей данных и атом состояний записи, который управляет версиями записи, и при этом упомянутый атом состояний записи включает в себя массив, который идентифицирует управляемые атомы данных, назначенные этому атому состояний записи, идентификатор каждой версии записи и для каждой версии записи информацию об этой версии и местоположении атома данных, содержащего эту версию.
6. Система управления базой данных по п. 5, в которой каждый атом данных дополнительно включает в себя адрес и длину каждой записи в атоме данных и записей данных.
7. Система управления базой данных по п. 4, в которой таблицы базы данных на пользовательском уровне содержат идентифицированные блобы, при этом из других объектов-атомов создаются атомы блоба, которые содержат блоб и атом состояний записи блоба, который включает в себя список всех ассоциированных атомов блоба и местоположение блоба в атоме блоба.
8. Система управления базой данных по п. 7, в которой каждый атом блоба включает в себя адрес и длину каждого блоба и блоб.
9. Система управления базой данных по п. 1, в которой каждый узел дополнительно содержит:
i) средство обмена сообщениями для генерирования и приема предопределенных сообщений в ответ на команды системного уровня, и
ii) средство для выбора одного из каналов связи для передачи сообщения.
10. Система управления базой данных по п. 9, в которой каждый узел содержит средство для асинхронного тестирования эффективности каждого канала связи.
11. Система управления базой данных по п. 10, в которой упомянутое средство тестирования включает в себя средство для генерирования сообщения тестового опроса и приема сообщения подтверждения приема тестового опроса для определения времени тестового опроса для каждого канала связи.
12. Система управления базой данных по п. 9, в которой упомянутое средство обмена сообщениями включает в себя средство для сериализации атома в сообщение и десериализации сообщения в атом, при этом каждое сообщение асинхронно посылается по выбранному каналу связи.
13. Система управления базой данных по п. 12, в которой сообщения посылаются согласно протоколу с управлением, которое сохраняет последовательности сообщений.
14. Система управления базой данных по п. 1, в которой отдельные узлы могут быть активными и подсоединенными к системе и могут быть отсоединенными от системы, и один из атомов является атомом главного каталога, который идентифицирует каждый активный узел в системе и который реплицируется в каждом узле, подсоединенном к системе, причем система содержит средства, позволяющие узлу присоединяться к системе, включающие в себя:
i) средство для установления соединения между присоединяющимся узлом и выбранным одним из активных узлов,
ii) средство в присоединяющемся узле для запрашивания выбранного узла на предмет подсоединения,
iii) средство в выбранном узле для обновления своего атома главного каталога для указания присоединяющегося узла в качестве активного узла,
iv) средство в выбранном узле для переноса на присоединяющийся узел сообщения, включающего в себя идентификатор выбранного узла, и для широковещательной передачи сообщения, указывающего доступность присоединяющегося узла, всем другим узлам в системе и долговременному хранилищу,
v) средство в упомянутом присоединяющемся узле для ответа на сообщение посредством запрашивания копии атома главного каталога с выбранного узла, и
vi) средство в выбранном узле для переноса своего обновленного атома главного каталога на присоединяющийся узел.
15. Система управления базой данных по п. 14, в которой упомянутый присоединяющийся узел включает в себя средство, реагирующее на прием обновленного атома главного каталога для запрашивания копий дополнительных атомов в ответ на запросы от интерфейса.
16. Система управления базой данных по п. 14, в которой выбранный узел выполняет широковещательную передачу доступности обновленного главного каталога всем другим узлам и долговременному хранилищу, и каждый другой узел и долговременное хранилище включают в себя средство для подтверждения приема им обновленного главного каталога выбранному узлу.
17. Система управления базой данных по п. 1, в которой интерфейс в одном из узлов выполняет запрос, который требует создания нового атома, при этом из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают атомы, которые являются постоянно хранимыми на этом узле, причем упомянутый один из упомянутых узлов дополнительно содержит:
i) средство в упомянутом атоме каталога, которое отслеживает новый атом, реагирующий на запрос интерфейса, чтобы вызывать создание атомом каталога этого нового атома без содержимого и объявлять новый атом в качестве председателя для этого атома,
ii) средство в атоме каталога, которое назначает идентификатор объекта новому атому,
iii) средство в атоме каталога для установления статуса для нового атома, который указывает, что нет избыточной копии нового атома и что новый атом недоступен для других узлов,
iv) средство в атоме каталога для широковещательной передачи всем другим соответствующим атомам каталога в системе существования нового атома,
v) средство для заполнения нового атома и выполнения нового атома доступным в системе.
18. Система управления базой данных по п. 17, в которой долговременное хранилище включает в себя средство, реагирующее на сохранение нового атома для посылки сообщения узлу, причем новый атом обновляет свой статус для указания существования избыточной копии.
19. Система управления базой данных по п. 1, в которой интерфейс в одном из узлов выполняет запрос атома, который существует только в других узлах, при этом из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают атомы, которые являются постоянно хранимыми на этом узле и других узлах, причем упомянутая система включает в себя:
i) средство в запрашивающем атоме каталога, реагирующее на запрос интерфейса, который отслеживает запрашиваемый атом в качестве реакции на запрос интерфейса, для создания этого пустого атома,
ii) средство в запрашивающем атоме каталога для установления выбора наиболее быстрореагирующего узла и запроса копии атома от наиболее быстрореагирующего узла,
iii) средство в выбранном узле для посылки копии запрашиваемого атома в сообщении объекта на запрашивающий узел и для широковещательной передачи доступности атома другим узлам, в которых атом,
iv) средство для оценки достоверности принятого сообщения объекта для заполнения пустого атома и для направления сообщения подтверждения приема объекта на выбранный узел.
20. Система управления базой данных по п. 19, в которой упомянутый выбранный узел генерирует список ретрансляций всех узлов, содержащих запрашиваемый атом, на которые выбранный узел будет направлять сообщения с других, относящихся к этому атому, на запрашивающий узел.
21. Система управления базой данных по п. 20, в которой один из других узлов, которые принимают широковещательное сообщение доступности объекта, включает в себя средство для посылки сообщения подтверждения приема объекта на выбранный узел, причем упомянутый выбранный узел включает в себя средство для обновления списка ретрансляций в ответ на прием каждого сообщения подтверждения приема объекта от другого узла для завершения ретрансляции любых последующих сообщений на запрашивающий узел.
22. Система управления базой данных по п. 1, приспособленная для обработки транзакций для гарантирования непротиворечивости базы данных, при этом система включает в себя первый узел, включающий в себя атом, подвергаемый фиксации, причем по меньшей мере один другой узел включает в себя копию этого атома, и копия этого атома включена в долговременное хранилище, причем упомянутая система включает в себя:
i) средство в первом узле для генерирования сообщения предварительной фиксации с идентификатором транзакции для пересылки в долговременное хранилище,
ii) средство, ассоциированное с долговременным хранилищем, реагирующее на сообщение предварительной фиксации, для фиксации транзакции и после этого - широковещательной передачи сообщения фиксации с идентификатором транзакции на все узлы,
iii) средство в первом и по меньшей мере одном другом узле, реагирующее на прием сообщения фиксации, для обновления идентифицированной транзакции.
23. Система управления базой данных, которая обеспечивает пользователям возможность взаимодействовать с базой данных, содержащей данные и метаданные, причем упомянутая система содержит:
A) по меньшей мере один узел транзакции, который предоставляет пользователям доступ к базе данных, и по меньшей мере один узел архивации, который поддерживает архив всей базы данных, причем каждый узел транзакции включает в себя подсистему запросов к базе данных, которая обеспечивает интерфейс между командами запроса высокоуровневого ввода и вывода на пользовательском уровне и командами ввода и вывода на системном уровне, которые управляют последовательностью операций для взаимодействия с базой данных, при этом в ответ на некоторые команды системного уровня атомы генерируются как экземпляры объектов-атомов, определяемых классами атомов, причем каждый атом содержит заданный фрагмент данных или метаданных, посредством чего набор всех экземпляров атомов совместно определяет все метаданные и данные в базе данных,
B) сеть системы базы данных, соединяющую между собой все узлы,
C) средство управления связью в каждом из узлов для установления канала связи с каждым другим узлом в системе,
D) метод в каждом узле транзакции, реагирующий на системную команду от подсистемы запросов к базе данных, для запрашивания копии атома, который релевантен команде запроса, но не присутствует в этом узле,
E) метод в каждом узле, реагирующий на запрос атома от другого узла, для репликации запрашиваемого атома для переноса на запрашивающий узел, посредством чего только атомы, необходимые для завершения команды запроса, должны располагаться в любом узле транзакции в любой заданный момент времени, и
F) метод в каждом узле транзакции, реагирующий на изменение в атоме на этом узле, для репликации этого изменения на каждый другой узел в системе, который содержит копию этого атома.
24. Система управления базой данных по п. 23, в которой из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают все атомы, которые являются постоянно хранимыми на этом узле, и местоположение каждого узла, который имеет копию каждого из постоянно хранимых атомов.
25. Система управления базой данных по п. 24, в которой один из атомов каталога является атомом главного каталога, который реплицируется в каждом узле, подсоединенном к системе, при этом другим из атомов является единичный атом диспетчера транзакций для базы данных для отслеживания хода транзакций, инициированных интерфейсом, причем главный каталог идентифицирует местоположение атома диспетчера транзакций.
26. Система управления базой данных по п. 25, в которой база данных на пользовательском уровне содержит именованные таблицы с записями и полями и работает в соответствии с по меньшей мере одной именованной схемой, и из других из объектов-атомов создаются:
i) атом таблицы для каждой таблицы, которая содержит список полей,
ii) атом схемы, который устанавливает соответствие между схемой и именованными таблицами, соответствующими этой схеме, и
iii) атом базы данных, который устанавливает соответствие между базой данных и именованной схемой.
27. Система управления базой данных по п. 26, в которой таблицы базы данных на пользовательском уровне содержат идентифицированные записи, содержащие поля и данные, причем из других объектов-атомов создаются атомы данных, которые содержат предопределенное количество записей данных, и атом состояний записи, который управляет версиями записи, при этом упомянутый атом состояний записи включает в себя массив, который идентифицирует управляемые атомы данных, назначенные этому атому состояний записи, идентификатор каждой версии записи и для каждой версии записи информацию об этой версии и местоположение атома данных, содержащего эту версию.
28. Система управления базой данных по п. 27, в которой каждый атом данных дополнительно включает в себя адрес и длину каждой записи в атоме данных и записей данных.
29. Система управления базой данных по п. 26, в которой таблицы базы данных на пользовательском уровне содержат идентифицированные блобы, при этом из других объектов-атомов создаются атомы блоба, которые содержат блоб и атом состояний записи блоба, который включает в себя список всех ассоциированных атомов блоба и местоположение блоба в атоме блоба.
30. Система управления базой данных по п. 29, в которой каждый атом блоба включает в себя адрес и длину каждого блоба и блоб.
31. Система управления базой данных по п. 23, в которой каждый узел дополнительно содержит:
i) средство обмена сообщениями для генерирования и приема предопределенных сообщений в ответ на команды системного уровня, и
ii) средство для выбора одного из каналов связи для передачи сообщения.
32. Система управления базой данных по п. 31, в которой каждый узел содержит средство для асинхронного тестирования эффективности каждого канала связи.
33. Система управления базой данных по п. 32, в которой упомянутое средство тестирования включает в себя средство для генерирования сообщения тестового опроса и приема сообщения подтверждения приема тестового опроса для определения времени тестового опроса для каждого канала связи.
34. Система управления базой данных по п. 31, в которой упомянутое средство обмена сообщениями включает в себя средство для сериализации атома в сообщение и десериализации сообщения в атом, при этом каждое сообщение асинхронно посылается по выбранному каналу связи.
35. Система управления базой данных по п. 34, в которой сообщения посылаются в соответствии с протоколом с управлением, которое сохраняет последовательности сообщений.
36. Система управления базой данных по п. 23, в которой отдельные узлы могут быть активными и подсоединенными к системе и могут быть отсоединенными от системы, и один из атомов является атомом главного каталога, который идентифицирует каждый активный узел в системе и который реплицируется в каждом узле, подсоединенном к системе, причем система содержит средства, позволяющие узлу присоединиться к системе, включающие в себя:
i) средство для установления соединения между присоединяющимся узлом транзакции и выбранным одним из активных узлов,
ii) средство в присоединяющемся узле транзакции для запрашивания выбранного узла на предмет подсоединения к системе,
iii) средство в выбранном узле для обновления его атома главного каталога для указания присоединяющегося узла транзакции в качестве активного узла,
iv) средство в выбранном узле для переноса сообщения на присоединяющийся узел транзакции, включающего в себя идентификатор выбранного узла, и для широковещательной передачи сообщения, указывающего доступность присоединяющегося узла транзакции, всем другим узлам в системе,
v) средство в упомянутом присоединяющемся узле транзакции для ответа на сообщение посредством запрашивания копии атома главного каталога у выбранного узла, и
vi) средство в выбранном узле для пересылки его обновленного атома главного каталога на присоединяющийся узел транзакции.
37. Система управления базой данных по п. 36, в которой упомянутый присоединяющийся узел транзакции включает в себя средство, реагирующее на прием обновленного атома главного каталога для запрашивания копий дополнительных атомов в ответ на системные команды от ее подсистемы запросов к базе данных.
38. Система управления базой данных по п. 36, в которой выбранный узел выполняет широковещательную передачу доступности обновленного главного каталога на все другие узлы, и каждый другой узел включает в себя средство для подтверждения им приема обновленного главного каталога на выбранный узел.
39. Система управления базой данных по п. 23, в которой подсистема запросов к базе данных в одном из узлов транзакции выполняет запрос, который требует создания нового атома, при этом из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают атомы, которые являются постоянно хранимыми на этом узле, причем упомянутый узел транзакции дополнительно содержит:
i) средство в упомянутом атоме каталога для отслеживания нового атома, реагирующего на запрос подсистемы запросов к базе данных, вызывающее создание атомом каталога этого нового атома без содержимого и объявляющее новый атом в качестве председателя для этого атома,
ii) средство в атоме каталога для назначения идентификатора объекта новому атому,
iii) средство в атоме каталога для установления статуса для нового атома, который указывает, что нет избыточной копии нового атома и что новый атом недоступен для других узлов,
iv) средство в атоме каталога для широковещательной передачи, на все другие соответствующие атомы каталога в системе, существования нового атома,
v) средство для заполнения нового атома и для выполнения нового атома доступным для других узлов в системе.
40. Система управления базой данных по п. 39, дополнительно включающая в себя средство в каждом узле архивации, реагирующее на сохранение нового атома, для посылки сообщения на новый атом, обновляющего его статус для указания существования избыточной копии.
41. Система управления базой данных по п. 23, в которой подсистема запросов к базе данных в одном узле транзакции запрашивает атом, который существует только в других узлах, причем из некоторых из объектов-атомов создаются атомы каталога, которые отслеживают атомы, которые являются постоянно хранимыми на этом узле и на других узлах, причем упомянутая система включает в себя:
i) средство, реагирующее на запрос в запрашивающем атоме каталога, которое будет отслеживать запрашиваемый атом для создания этого пустого атома,
ii) средство в запрашивающем атоме каталога для установления выбора наиболее быстрореагирующего узла и запрашивания копии атома от наиболее быстрореагирующего узла,
iii) средство в выбранном узле для посылки копии запрашиваемого атома в сообщении объекта на запрашивающий узел и для широковещательной передачи доступности атома другим узлам, в которых атом постоянно находится,
iv) средство для оценки достоверности принятого сообщения объекта, для заполнения пустого атома и для направления сообщения подтверждения приема объекта на выбранный узел.
42. Система управления базой данных по п. 41, в которой упомянутый выбранный узел генерирует список ретрансляций всех узлов, содержащих запрашиваемый атом, на который выбранный узел будет направлять сообщения другого, относящегося к этому атома, на запрашивающий узел.
43. Система управления базой данных по п. 42, в которой каждый из других узлов, которые принимают широковещательное сообщение доступности объекта, включает в себя средство для посылки сообщения подтверждения приема объекта на выбранный узел, причем упомянутый выбранный узел включает в себя средство для обновления списка ретрансляций в ответ на прием каждого сообщения подтверждения приема объекта от другого узла для завершения ретрансляции любых последующих сообщений на запрашивающий узел.
44. Система управления базой данных по п. 23, приспособленная для гарантирования непротиворечивости базы данных во время обработки транзакций, при этом система включает в себя первый узел, приводящий к фиксации атома, и по меньшей мере один другой узел, включающий в себя узел архивации, который включает в себя копию этого атома, причем упомянутая система включает в себя:
i) средство в первом узле для генерирования сообщения предварительной фиксации с идентификатором транзакции для переноса на узел архивации,
ii) средство, ассоциированное с узлом архивации, реагирующее на сообщение предварительной фиксации, для фиксации транзакции и затем - широковещательной передачи сообщения фиксации с идентификатором транзакции на все узлы, и
iii) средство в первом и по меньшей мере одном другом узле, реагирующее на прием сообщения фиксации для обновления идентифицированной транзакции.
45. Система управления базой данных для логической базы данных, содержащей записи данных, организованные в таблицы, к которым должен осуществляться доступ с многочисленных узлов транзакции, которые обрабатывают транзакции, связанные с логической базой данных, причем упомянутая система содержит:
A) средство для синтаксического разбора базы данных на фрагменты, при этом каждый фрагмент хранит часть метаданных и/или данных, относящихся к логической базе данных, для переноса в системе управления базой данных в качестве сериализованных сообщений и для сохранения в качестве десериализованного сообщения,
B) по меньшей мере один узел архивации, который хранит все фрагменты в десериализованном виде в долгосрочном хранилище, таким образом составляя единое хранилище для всей базы данных, при этом каждый узел транзакции содержит:
i) средство для ответа на запросы от пользователей посредством установления последовательности низкоуровневых команд для идентификации фрагментов, которые релевантны запросу,
ii) средство для ответа на низкоуровневые команды посредством получения только тех копий существующих фрагментов, которые релевантны запросу, обрабатываемому в нем, при том что заданный фрагмент может существовать на некотором другом узле или только на узле архивации, и
iii) средство для репликации любого измененного фрагмента на упомянутый по меньшей мере один узел архивации и каждый узел транзакции, в котором постоянно хранится копия этого фрагмента, посредством чего изменения выполняются в отношении фрагментов в других узлах на равноправной основе и посредством чего любой узел транзакции содержит только те фрагменты, которые относятся к запросам, выполняемым пользователями, осуществляющими доступ к базе данных посредством этого узла транзакции.
| MAZIN YOUSIF, Shared-storage clusters, Cluster Computing 2 (1999), c | |||
| Трансляция, предназначенная для телефонирования быстропеременными токами | 1921 |
|
SU249A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 7401094 B1, 15.07.2008 | |||
| US 7293039 B1, 06.11.2007 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СИСТЕМА ВЗАИМОДЕЙСТВИЯ БАЗ ДАННЫХ АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ УПРАВЛЕНИЯ | 2006 |
|
RU2324974C1 |

