Многорежимный декодировщик аудиосигнала для получения декодированного представления аудиоконтента [содержания] из кодированного представления аудиоконтента, содержащего определитель спектральных значений, настроенный на получение набора декодированных спектральных коэффициентов для нескольких частей аудиоконтента. Декодировщик аудиосигнала также включает в себя спектральный процессор, предназначенный для формирования спектра из набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированной в режиме линейного предсказания, и выполнения процедуры формирования спектра из набора закодированных спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от параметров набора коэффициентов масштабирования для части аудиоконтента, закодированной в частотной области. Декодировщик аудиосигнала содержит преобразователь частотной области во временную область, настроенный на получение представления аудиоконтента во временной области на основе сформированного спектра в виде набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме линейного предсказания, а также получения представления аудиоконтента во временной области на основе сформированного спектра в виде набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в частотной области. Также описан кодировщик аудиосигнала.
Область техники
Воплощения в соответствии с настоящим изобретением относятся к многорежимным декодировщикам аудиосигнала для обеспечения декодированного представления аудиоконтента на основе закодированного представления аудиоконтента.
Дополнительные варианты в соответствии с изобретением относятся к способам обеспечения декодированного представления аудиоконтента на основе закодированного представления аудиоконтента.
Дальнейшие варианты в соответствии с изобретением связаны со способом создания закодированного представления аудиоконтента на основе входного представления аудиоконтента.
Дальнейшие варианты в соответствии с изобретением связаны с компьютерными программами, реализующими названные способы.
Предпосылки создания изобретения
Далее в целях облегчения понимания изобретения будут объяснены некоторые предпосылки создания изобретения и его преимущества.
В течение последнего десятилетия, большие усилия были направлены на создание возможностей для цифрового хранения и распространения аудиоконтента. Одним из важных достижений на этом пути является создание международного стандарта ISO/IEC 14496-3. Часть 3 данного стандарта связана с кодированием и декодированием аудиоконтента, а подраздел 4 части 3 связан с общим аудиокодированием. ISO/IEC 14496, часть 3, подраздел 4 определяет концепцию кодирования и декодирования обычного аудиоконтента. Кроме того, были предложены дальнейшие варианты для улучшения качества и/или уменьшения необходимой скорости передачи данных [битрейта].
Кроме того, было установлено, что аудиокодирование в частотной области не является оптимальным для аудиоконтента, содержащего речь. В последнее время был предложен единый аудио/речевой кодировщик, который эффективно сочетает в себе обе методики, а именно речевое и аудиокодирование (см., например, в работе [1].)
В таких аудиокодировщиках некоторые звуковые фреймы кодируются в частотной области, а другие аудиофреймы кодируются способом линейного предсказания.
Однако было установлено, что трудно осуществить переход между фреймами, закодированными в различных областях, без значительных потерь битрейта.
В связи с этим существует необходимость создания концепции для кодирования и декодирования аудиоконтента, включающего как речь, так и звуковые сигналы общего вида, которая позволила бы эффективно реализовать переходы между закодированными частями различных типов.
Сущность изобретения
Воплощение в соответствии с изобретением создает многорежимное декодирование аудиосигнала для формирования представления декодированного аудиоконтента на основе закодированного представления аудиоконтента. Декодировщик аудиосигнала включает в себя определитель спектральных значений, настроенный на получение набора декодированных спектральных коэффициентов для нескольких частей аудиоконтента. Многорежимный декодировщик аудиосигналов также имеет в своем составе спектральный процессор, настроенный на создание сформированного спектра в виде набора декодированных спектральных коэффициентов, или его предварительно обработанной версии, в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированной в способом линейного предсказания, и настроенный на создание сформированного спектра из набора декодированных спектральных коэффициентов, или их предварительно обработанных версий, вне зависимости от набора параметров коэффициента масштабирования для части аудиоконтента, закодированной в частотной области. Многорежимный декодировщик аудиосигналов также содержит преобразователь частотной области во временную область, настроенный на получение представления аудиоконтента во временной области на основе сформированного спектра в виде набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме линейного предсказания, а также на получение представления контента во временной области на основе сформированного спектра в виде набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в частотной области.
Многорежимный декодировщик аудиосигнала создан на идее от том, что могут быть получены эффективные переходы между частями аудиоконтента, закодированными в различных режимах формирования спектра в частотной области так, что спектр формируется в виде набора декодированных спектральных коэффициентов как для части аудиоконтента, закодированного в частотной области, так и для части аудиоконтента, закодированного в режиме линейного предсказания. При использовании такого подхода представление во временной области, полученное на основе сформированного спектра в виде набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной способом линейного предсказания 'в той же области' (например, выходные значения после преобразования из частотной области во временную область преобразуются в такой же тип), в то время как представление во временной области получается на основе сформированного спектра в виде набора декодированных спектральных коэффициентов, для части аудиоконтента, закодированной в частотной области. Таким образом, представление части аудиоконтента во временной области, закодированной в режиме линейного предсказания и части аудиоконтента, закодированной в частотной области, могут быть эффективно объединены и не будут иметь неприемлемых искажений. Например, характеристики отмены алиасинга [перекрытия] типичного преобразователя из частотной области во временную область могут быть использованы для преобразования сигналов из частотной области во временную область, которые находятся в одной и той же области (например, оба сигнала представляют собой аудиоконтенты из одной и той же области аудиоконтента). Таким образом, между частями аудиоконтента, закодированными в различных режимах, может быть получено хорошее качество переходов, не требующее значительного битрейта для осуществления таких переходов.
В предпочтительном варианте, многорежимный декодировщик аудиосигналов дополнительно содержит блок перекрытия, настроенный на перекрытие и сложение представления части аудиоконтента во временной области, закодированного в режиме линейного предсказания, с частью аудиоконтента, закодированного в частотной области. За счет перекрытия частей аудиоконтента, закодированных в различных областях, достигается преимущество, которое можно получить с помощью введения сформированного спектра в виде набора декодированных спектральных коэффициентов в преобразователь из частотной области во временную область, что может быть реализовано в обоих режимах многорежимного декодировщика аудиосигнала. При выполнении формирования спектра перед преобразованием из частотной области во временную область в обоих режимах многорежимного декодировщика аудиосигнала, представления частей аудиоконтента во временной области, закодированных в различных режимах, обычно имеют очень хорошие характеристики перекрытия и сложения, которые позволяют получить хорошее качество переходов, не требующее дополнительной информации.
В предпочтительном варианте, преобразователь из частотной области во временную область настроен на получение представления аудиоконтента во временной области для части аудиоконтента, закодированного в режиме линейного предсказания с использованием преобразования с перекрытием, и получения представления аудиоконтента во временной области для части аудиоконтента, закодированного в частотной области с использованием режима преобразования с перекрытием. Предпочтительно, чтобы в этом случае блок перекрытия был настроен на перекрытие во временной области представления последовательных частей аудиоконтента, закодированных в различных режимах. Таким образом, могут быть получены плавные переходы. В связи с тем, что для обоих режимов формирование спектра применяется в частотной области, представления во временной области, осуществленные преобразователем из частотной области во временную область, в обоих режимах совместимы и позволяют получить хорошее качество перехода. Использование преобразования с перекрытием позволяет получить улучшенный компромисс между качеством и эффективностью битрейта при переходах, потому что преобразования с перекрытием позволяют получить плавные переходы даже при наличии ошибок дискретизации, исключая при этом значительные затраты битрейта.
В предпочтительном варианте, преобразователь из частотной области во временную область настроен на применение преобразования с перекрытием для одного и того же типа преобразований с получением представления аудиоконтента во временной области для частей аудиоконтента, закодированных в различных режимах. В этом случае блок перекрытия настроен на перекрытие и сложение представлений во временной области последовательных частей аудиоконтента, закодированных в различных режимах, так что алиасинг во временной области, вызванный преобразованием с перекрытием уменьшается или устраняется при использовании перекрытия и сложения. Эта концепция основана на том, что для обоих режимов при преобразовании из частотной области во временную область выходные сигналы получаются в той же области (области аудиоконтента), и при применении как параметров коэффициентов масштабирования, так и параметров линейного предсказания в частотной области. Таким образом, может быть достигнуто исключение алиасинга, которое получается обычным образом при применении преобразований с перекрытием последовательных преобразований одного и того же типа и частично перекрывающимися частями представления аудиосигнала.
В предпочтительном варианте, блок перекрытия настроен на перекрытие и сложение первой части аудиоконтента, закодированной в первом режиме, как это обеспечивается при синтезе преобразования перекрытия, или амплитудно-масштабированной и спектрально неискаженной его версии, и представления во временной области последующей второй части аудиоконтента, закодированной во втором режиме, как это предусмотрено при синтезе преобразования перекрытия, или его амплитудно-масштабированной и спектрально неискаженной версии. При синтезе преобразования перекрытия (например, при фильтрации и т.п.) исключается любая обработка выходных сигналов, которая не являлась бы общей для различных режимов кодирования, использующихся для последовательных (частично перекрывающих друг друга) частей аудиоконтента, что можно осуществить с помощью характеристик отмены алиасинга при преобразовании с перекрытием.
В предпочтительном варианте, преобразователь из частотной области во временную область настроен на представление во временной области частей аудиоконтента, закодированных независимым образом так, что полученные представления во временной области являются такими областями, в которых используется линейная комбинация без применения операции фильтрации при формировании сигнала к одному или обоим представлениям, улучшенным во временной области. Иными словами, выходные сигналы при преобразовании частотной области во временную область являются представлениями во временной области самих аудиоконтентов для обоих режимов (при отсутствии сигналов возбуждения для операции фильтрации при преобразовании области возбуждения во временную область).
В предпочтительном варианте, преобразователь из частотной области во временную область настроен для выполнения модифицированного обратного дискретного косинусного преобразования и получения, в результате, представления во временной области аудиоконтента части аудиосигнала, как для части аудиоконтента, закодированного в режиме линейного предсказания, так и для части аудиоконтента, закодированного в режиме частотной области.
В предпочтительном варианте, многорежимный декодировщик аудиосигнала содержит определитель коэффициентов LPC-фильтра, настроенный на получение декодированных коэффициентов LPC-фильтра на основе представления закодированных коэффициентов LPC-фильтра для части аудиоконтента, закодированного в режиме линейного предсказания. В этом случае, многорежимный декодировщик аудиосигналов также включает в себя преобразователь коэффициентов фильтра, настроенный на преобразование декодированных коэффициентов LPC-фильтра в спектральное представление для получения значений коэффициентов усиления, связанных с различными частотами. Таким образом, коэффициенты LPC-фильтра могут использоваться в качестве параметров области линейного предсказания. Многорежимный декодировщик аудиосигналов также включает в себя определитель коэффициентов масштабирования, настроенный на получение декодированных значений коэффициентов масштабирования (которые используются в качестве параметров коэффициента масштабирования) на основе закодированного представления значений коэффициентов масштабирования части аудиоконтента, закодированной в частотной области. Спектральный процессор включает в себя преобразователь спектра, настроенный на суммирование набора декодированных спектральных коэффициентов, связанных с частью аудиоконтента, закодированного в режиме линейного предсказания, или его предварительно обработанной версии, со значениями коэффициента усиления в режиме линейного предсказания, для получения обработанной версии коэффициентов усиления (и, следовательно, сформированного спектра) спектральных коэффициентов (декодированных), в которой вклад декодированных спектральных коэффициентов, или их предварительно обработанных версий, масштабируется в зависимости от значений коэффициентов усиления. Кроме того, преобразователь спектра настроен на суммирование набора декодированных спектральных коэффициентов, связанных с частью аудиоконтента, закодированного в частотной области, или его предварительно обработанной версии, с декодированными значениями коэффициента масштабирования, для получения обработанной версии коэффициентов масштабирования (сформированного спектра) спектральных коэффициентов (декодированных), в которой вклад декодированных спектральных коэффициентов, или их предварительно обработанных версий, масштабируется в зависимости от значений коэффициентов масштабирования.
С использованием этого подхода, в обоих режимах многорежимного декодирования аудиосигнала может быть получено ограничение собственного шума при условии, что преобразователь из частотной области во временную область обеспечивает выходной сигнал с хорошими переходными характеристиками для переходов между частями аудиосигнала, закодированного в различных режимах.
В предпочтительном варианте, преобразователь коэффициентов настроен на преобразование декодированных коэффициентов LPC-фильтров, которые представляют собой импульсные отклики во временной области кодирующего фильтра с линейным предсказанием (LPC-фильтр), в спектральное представление нечетного дискретного преобразования Фурье. Фильтр преобразователя коэффициентов настроен на получение значения усиления в режиме линейного предсказания из спектрального представления декодированных коэффициентов LPC-фильтра так, что значения усиления зависят от магнитуды коэффициентов спектрального представления. Таким образом, при формировании спектра, которое выполняется в режиме линейного предсказания, также производится ограничение шума с помощью фильтр кодирования с линейным предсказанием. Таким образом, шум дискретизации в декодированном спектральном представлении (или его предварительно обработанной версии) изменяется таким образом, чтобы шум дискретизации был сравнительно небольшим для 'важных' частот, для которых имеется сравнительно большое спектральное представление декодированных коэффициентов LPC-фильтра.
В предпочтительном варианте, преобразователь коэффициентов фильтра и сумматор настроены таким образом, чтобы вклад этих декодированных спектральных коэффициентов, или их предварительно обработанных версий, чтобы усиленная версия данного спектрального коэффициента определялась значением усиления, связанного с данным декодированным спектральным коэффициентом, в режиме линейного предсказания.
В предпочтительном варианте, определитель спектральных значений настроен на использование деквантования [цифроаналогового преобразования] для дискретизированных декодированных спектральных значений и получения декодированных и деквантованных [аналоговых] спектральных коэффициентов. В этом случае преобразователь спектра настроен на выполнение ограничения шумов дискретизации с регулировкой эффективного шага дискретизации для данного декодированного спектрального коэффициента в зависимости от значения усиления в режиме линейного предсказания, связанного с данным декодированным спектральным коэффициентом. Соответственно, ограничение шума, которое проводится в спектральной области, адаптировано к характеристикам сигнала, представленного коэффициентами LPC- фильтра.
В предпочтительном варианте, многорежимный декодировщик аудиосигнала настроен на использование стартового фрейма на промежуточном этапе режима линейного предсказания при переходе от фрейма в частотной области к комбинированному фрейму режима линейного предсказания/режима линейного предсказания с возбуждением по алгебраической кодовой книге [CELP-модель]. В этом случае декодировщик аудиосигнала настроен на получение набора декодированных спектральных коэффициентов для стартового фрейма режима линейного предсказания. Кроме того, аудиодекодировщик настроен на формирование спектра из набора декодированных спектральных коэффициентов для стартового фрейма режима линейного предсказания, или его предварительно обработанной версии, в зависимости от набора параметров связанной с ним области линейного предсказания. Декодировщик аудиосигнала также настроен на получение представления во временной области для стартового фрейма режима линейного предсказания на основе сформированного спектра в виде набора декодированных спектральных коэффициентов. Аудиодекодировщик также настроен на применение стартового окна, имеющего сравнительно плавную огибающую левого фронта и сравнительно резкий спад огибающей правого фронта представления во временной области для стартового фрейма режима линейного предсказания. В этом случае создается переход между фреймом в режиме частотной области и комбинированным фреймом режима линейного предсказания/линейного предсказания с возбуждением по алгебраической кодовой книге, который имеет хорошие характеристики перекрытия и сложения с предыдущим фреймом в частотной области и который, в то же время, делает коэффициенты области линейного предсказания доступными для использования в последующим комбинированным фреймом режима линейного предсказания/линейного предсказания с возбуждением по алгебраической кодовой книге.
В предпочтительном варианте, многорежимный декодировщик аудиосигнала настроен на перекрытие правосторонней части представления во временной области для фрейма в режиме частотной области, предшествующего первому фрейму режима линейного предсказания, с левосторонней частью представления во временной области для стартового фрейма режима линейного предсказания, чтобы получить сокращение или отмену алиасинга во временной области. Этот вариант основан на идее получения хороших характеристик отмены алиасинга во временной области путем проведения формирования спектра в режиме линейного предсказания для стартового фрейма в частотной области, так как формирование спектра предыдущего фрейма в частотной области также осуществляется в частотной области.
В предпочтительном варианте, аудиодекодировщик сигнала настроен на использование параметров области линейного предсказания, связанных с первым фреймом режима линейного предсказания для инициализации декодировщика с возбуждением по алгебраической кодовой книге в режиме линейного предсказания и декодирования, по крайней мере части фрейма, в комбинированном режиме линейного предсказания/линейного предсказания с возбуждением по алгебраической кодовой книге. Таким образом, исключается необходимость передачи дополнительного набора параметров области линейного предсказания, которая существует в некоторых традиционных подходах. Точнее, первый фрейм режима линейного предсказания позволяет создать плавный переход от предыдущего фрейма в режиме частотной области, даже при сравнительно большой области перекрытия, а также позволяет инициализировать декодировщик в режиме линейного предсказания с возбуждением по алгебраической кодовой книге (ACELP). Таким образом, могут быть получены переходы с хорошим качеством звука и очень высокой степенью эффективности.
Другой вариант, согласно изобретению, представляет многорежимный кодировщик аудиосигнала для обеспечения закодированного представления аудиоконтента на основе представления входного аудиоконтента. Кодировщик содержит преобразователь из частотной области во временную область для обработки представления входного аудиоконтента и получения представления аудиоконтента в частотной области. Кодировщик дополнительно содержит спектральный процессор, настроенный на выполнение формирования спектра, или его предварительно обработанной версии, в виде набора спектральных коэффициентов в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированного в области линейного предсказания. Спектральный процессор также настроен на выполнение формирования спектра, или его предварительно обработанной версии, в виде набора спектральных коэффициентов в зависимости от набора параметров коэффициентов масштабирования для части аудиоконтента, которая кодируется в режиме частотной области.
Описанный выше многорежимный кодировщик аудиосигнала основан на идее о том, что можно получить эффективное аудиокодирование, которое позволяет выполнить простое аудиодекодирование с небольшими искажениями, если входное представление аудиоконтента преобразуется в частотную область (также называемой временно-частотной областью) как для части аудиоконтента, закодированной в режиме линейного предсказания, так и для и части аудиоконтента, закодированной в частотной области. Кроме того, было установлено, что ошибки дискретизации можно уменьшить при использовании формирования спектра (или его предварительно обработанной версии) в виде набора спектральных коэффициентов как для части аудиоконтента, закодированной в режиме линейного предсказания, так и для части аудиоконтента, закодированной в частотной области. Если для получения сформированного спектра в различных режимах (в частности, параметров области линейного предсказания в режиме линейного предсказания и параметров коэффициентов масштабирования в режиме частотной области) используются параметры различных типов, то в этом случае может быть одновременно применено как ограничение шума для характеристик обрабатываемой в данный момент части аудиоконтента, так и преобразование из временной области в частотную область к одним и тем же (участкам) аудиосигнала в различных режимах.
Следовательно, многорежимный кодировщик аудиосигнала способен обеспечить хорошую производительность при кодировании аудиосигналов, имеющих как аудиоучастки общего вида, так и аудиоучастки речевого типа путем избирательного применения формирования спектра соответствующего типа для набора спектральных коэффициентов. Другими словами, формирование спектра на основе набора параметров области линейного предсказания может быть применено к набору спектральных коэффициентов аудиофрейма, который имеет признаки речи, а формирование спектра на основе набора параметров коэффициентов масштабирования может быть применено к набору спектральных коэффициентов аудиофрейма, который был определен как аудио общего, а не речевого, типа.
Подводя итог, многорежимный кодировщик аудиосигнала позволяет кодировать аудиоконтент, имеющий изменяющиеся мгновенные характеристики (речевого типа для одних участков и общего типа для других участков), причем представление аудиоконтента во временной области преобразуется в частотную область таким же образом, как и участки аудиоконтента, закодированные в различных режимах. Различные характеристики для различных участков аудиоконтента подразумевают использование формирования спектра на основе различных параметров (параметров области линейного предсказания, либо параметров коэффициентов масштабирования) для получения спектрально сформированных спектральных коэффициентов или последовательной дискретизации.
В предпочтительном варианте преобразователь из временной области в частотную область настраивается на преобразование представления аудиоконтента участка аудиосигнала во временной области в представление аудиоконтента в частотной области как для участков аудиоконтента, закодированных в режиме линейного предсказания, так и для участков аудиоконтента, закодированных в частотной области. При выполнении преобразования из временной области в частотную область (например, при операциях преобразования, подобных операции преобразования MDCT или операции разделения по частоте с использованием набора фильтров) для одного и того же входного сигнала, как для режима частотной области, так и для режима линейного предсказания, эта операция может быть выполнена с особенно высокой эффективностью в блоке перекрытия и сложения декодировщика, что облегчает восстановление сигнала в декодировщике и избавляет от необходимости передачи дополнительных данных в случае, когда существует переход между различными режимами.
В предпочтительном варианте осуществление преобразования из временной области в частотную область настроено на применение анализа преобразований перекрытия для преобразований одинакового типа и получения представлений в частотной области для частей аудиоконтента, закодированных в различных режимах. Кроме того, использование преобразований перекрытия для преобразований одинакового типа позволяет просто восстановить аудиоконтент с отсутствием блочных искажений. В частности, можно использовать критическую выборку без значительных затрат.
В предпочтительном варианте, спектральный процессор настроен на выборочное применение сформированного спектра (или его предварительно обработанной версии) в виде набора спектральных коэффициентов, в зависимости от набора параметров области линейного предсказания, полученных с использованием соответствующего анализа участка аудиоконтента, закодированного в режиме линейного предсказания, или в зависимости от набора параметров коэффициентов масштабирования, полученных с помощью анализа психоакустической модели участка аудиоконтента, закодированного в частотной области. При таком подходе может быть достигнуто соответствующее ограничение шума как для участков аудиоконтента речевого типа, для которых корреляционный анализ позволяет получить значительное ограничение шума, так и для участков аудиоконтента общего типа, для которых значительное ограничение шума можно получить при анализе с использованием психоакустической модели.
В предпочтительном варианте, кодировщик аудиосигнала содержит селектор режима, настроенный на анализ аудиоконтента для определения, как следует кодировать участок аудиоконтента - в режиме линейного предсказания или в режиме частотной области. Таким образом, может быть выбрана соответствующая концепция ограничения шума, с исключением неэффективного в некоторых случаях режима преобразования из временной области в частотную область.
В предпочтительном варианте, многорежимный кодировщик аудиосигнала настроен на кодирование аудиофрейма, который находится между фреймом в частотной области и первым фреймом в комбинированных режимах линейного предсказания/линейного предсказания с возбуждением по алгебраической кодовой книге, в качестве стартового фрейма в режиме линейного предсказания. Для получения оконного представления во временной области многорежимный кодировщик аудиосигнала настроен на применение стартового окна, имеющего сравнительно пологий левосторонний склон и сравнительно резкий правосторонний склон в представлении во временной области для стартового фрейма в режиме линейного предсказания. Многорежимный кодировщик аудиосигнала также настроен на получение представления в частотной области на основе оконного представления во временной области для стартового фрейма в режиме линейного предсказания. Многорежимный кодировщик аудиосигнала также настроен на получение набора параметров области линейного предсказания для стартового фрейма в режиме линейного предсказания и использование, в зависимости от набора параметров области линейного предсказания, спектрально сформированного представления в частотной области для оконного представления во временной области стартового фрейма в режиме линейного предсказания, или его предварительно обработанной версии. Кодировщик аудиосигнала также настроен на кодирование набора параметров области линейного предсказания и формирование спектра с представлением в частотной области оконного представления во временной области для стартового фрейма в режиме линейного предсказания. Таким образом, получается закодированная информация о переходном аудиофрейме, которая может быть использована для восстановления аудиоконтента, причем закодированная информация о переходном аудиофрейме позволяет создать гладкий левосторонний переход и, в то же время, позволяет инициализировать в декодировщике режим ACELP декодирования последующего аудиофрейма. Затраты, вызванные переходом между различными режимами многорежимного кодировщика сигнала сведены к минимуму.
В предпочтительном варианте, многорежимный кодировщик аудиосигнала настроен на использование параметров области линейного предсказания, связанных с первым фреймом режима линейного предсказания, для инициализации режима линейного предсказания с возбуждением по алгебраической кодовой книге для кодирования, по крайней мере, части фрейма в комбинированном режиме линейного предсказания/линейного предсказания с возбуждением по алгебраической кодовой книге, следующего за стартовым фреймом режима линейного предсказания. Таким образом, параметры области линейного предсказания, полученные для режима линейного предсказания стартового фрейма, и закодированные в потоке битов, представляющих аудиоконтент, повторно используются для кодирования последующего аудиофрейма, в котором используется ACELP режим. Это повышает эффективность кодирования, а также позволяет эффективно декодировать без дополнительной информации по инициализации ACELP.
В предпочтительном варианте, многорежимный кодировщик аудиосигнала включает в себя определитель коэффициентов LPC-фильтра, настроенный на анализ части аудиоконтента, или его предварительно обработанной версии, которая будет кодироваться в режиме линейного предсказания, и определение коэффициентов LPC-фильтра, связанных с частью аудиоконтента, которая должна быть закодирована в режиме линейного предсказания. Многорежимный кодировщик аудиосигнала также содержит преобразователь коэффициентов фильтра, настроенный на преобразование декодированных коэффициентов LPC-фильтра в спектральное представление, с целью получения значений усиления в режиме линейного предсказания, связанных с различными частотами. Многорежимный кодировщик аудиосигнала также включает в себя определитель коэффициентов масштабирования, настроенный на анализ части аудиоконтента, или его предварительно обработанной версии, которая будет закодирована в частотной области, для определения коэффициентов масштабирования, связанных с частью аудиоконтента, которая будет закодирована в частотной области. Многорежимный кодировщик аудиосигнала также включает в себя суммирующее устройство, настроенное на суммирование в частотной области представления части аудиоконтента, или его обработанной версии, которая должна быть закодирована в режиме линейного предсказания, со значениями усиления в режиме линейного предсказания и получение значений усиления спектральных компонент (также называемых коэффициентами), причем вклад спектральных компонент (или спектральных коэффициентов) представления аудиоконтента в частотной области, взвешивается в зависимости от значений усиления в режиме линейного предсказания. Сумматор также настроен на суммирование представления части аудиоконтента в частотной области, или его обработанной версии, которая должна быть закодирована в частотной области, с масштабными коэффициентами для получения значений усиления спектральных составляющих, причем вклад спектральных компонент (или спектральных коэффициентов) представления аудиоконтента в частотной области взвешивается в зависимости от коэффициентов масштабирования.
В этом варианте коэффициенты усиления обработанных спектральных составляющих представляют собой набор спектральных коэффициентов (или спектральных составляющих) сформированного спектра.
Другой вариант, согласно изобретению создает способ для обеспечения декодированного представления аудиоконтента на основе его закодированного представления.
Еще один вариант, согласно изобретению создает способ получения закодированного представления аудиоконтента на основе представления входного аудиоконтента.
Еще один вариант, согласно изобретению, представляет собой компьютерную программу для выполнения одного или нескольких указанных способов.
Способы и компьютерная программа основаны на тех же результатах, что и представленная выше аппаратная часть.
Краткое описание рисунков
Далее будут описаны воплощения изобретения со ссылкой на приложенные чертежи, на которых:
на фиг.1 показана блок-схема кодировщика аудиосигнала, в соответствии с воплощением изобретения;
на фиг.2 показана блок-схема базового кодировщика аудиосигнала;
на фиг.3 показана блок-схема кодировщика аудиосигнала в соответствии с воплощением изобретения;
на фиг.4 показан результат интерполяции LPC коэффициентов для ТСХ окна;
на фиг.5 показан код компьютерной программы для получения значений усиления области линейного предсказания на основе декодированных коэффициентов LPC фильтра;
на фиг.6 показан код компьютерной программы для суммирования набора декодированных спектральных коэффициентов со значениями усиления режима линейного предсказания (или значениями усиления области линейного предсказания);
на фиг.7 показано схематическое представление различных фреймов и связанной с ними информации, также называемой 'LPC' - затратами, для переключения режимов кодировщика во временной области/частотной области (TD/FD);
на фиг.8 показано схематическое представление фреймов и связанных с ними параметров для переключения режимов кодировщика от частотной области к области линейного предсказания с помощью 'LPC2MDCT';
на фиг.9 показано схематическое представление кодировщика аудиосигнала с ограничением шума на основе LPC для ТСХ и кодировщика частотной области;
на фиг.10 показано унифицированное представление единого речевого и аудиокодирования (USAC) с помощью ТСХ MDCT, выполненного в области сигнала;
на фиг.11 показана блок-схема декодирования аудиосигнала, в соответствии с воплощением изобретения;
на фиг.12 показано представление единого USAC декодировщика с использованием ТСХ MDCT в области сигнала;
на фиг.13 показано схематическое изображение этапов обработки, которые могут осуществляться в аудиодекодировщиках сигнала в соответствии с фиг.7 и 12;
на фиг.14 показано схематическое представление обработки последовательных аудиофреймов в аудиодекодировщиках в соответствии с фиг.11 и 12;
на фиг.15 показана таблица, представляющая набор спектральных коэффициентов, в зависимости от переменной MOD [];
на фиг.16 показана таблица, представляющая последовательности окон и окна преобразования;
на фиг.17а показано схематическое представление переходов между аудиоокнами в воплощениях изобретения;
на фиг.17б показана таблица, представляющая переходы аудиоокон в воплощении в соответствии с изобретением, и
На фиг.18 показан поток обработки для получения значений усиления в области линейного предсказания g[k] в зависимости от закодированных коэффициентов LPC-фильтра.
Подробное описание воплощения
1. Кодировщик аудиосигнала в соответствии с фиг.1
Далее, в соответствии с вариантом осуществления изобретения, со ссылкой на фиг.1, будет рассмотрен кодировщик аудиосигнала, который показывает блок-схему такого многорежимного кодировщика аудиосигнала 100. Многорежимный кодировщик аудиосигнала 100 для краткости иногда будет называться аудиокодировщиком.
Кодировщик 100 настроен на получение входного представления 110 аудиоконтента, которое, как правило, представляет вход 100 в режиме временной области. Аудиокодировщик 100 обеспечивает получение закодированного представления аудиоконтента. Например, кодировщик 100 обеспечивает поток битов 112, который является закодированным аудиопредставлением. Кодировщик 100 содержит преобразователь из временной области в частотную область 120, который настроен на получение входного представления 110 аудиоконтента, или его предварительно обработанной версии 110'. Преобразователь из временной области в частотную область 120 обеспечивает, на основе входных представлений 110, 110', представление 122 аудиоконтента в частотной области. Представление в частотной области 122 может принимать вид последовательности наборов спектральных коэффициентов. Например, преобразователь из временной области в частотную область может быть оконным преобразователем из временной области в частотную область, который формирует первый набор спектральных коэффициентов на основе выборок во временной области стартового фрейма входного аудиоконтента, а также обеспечивает получение второго набора спектральных коэффициентов на основе выборок во временной области второго фрейма входного аудиоконтента. Например, первый фрейм входного аудиоконтента может перекрываться, примерно на 50%, со вторым фреймом входного аудиоконтента. Оконная операция во временной области может быть применена для получения первого набора спектральных коэффициентов первого аудиофрейма, также оконная операция может быть применена для получения второго набора спектральных коэффициентов второго аудиофрейма. Таким образом, преобразование из временной области в частотную область может быть настроено для выполнения преобразования перекрытия оконных частей (например, перекрытие фреймов) входной аудиоинформации.
Кодировщик 100 также включает в себя спектральный процессор 130, который настроен на получение представления 122 аудиоконтента в частотной области (или, дополнительно, после спектральной обработки его версии 122'), и создание, на этой основе, последовательности спектрально сформированного набора 132 спектральных коэффициентов. Спектральный процессор 130 может быть сконфигурирован для применения формирования спектра к набору 122 спектральных коэффициентов, или его предварительно обработанной версии 122', в зависимости от набора параметров 134 области линейного предсказания для части (например, фрейма) аудиоконтента, кодируемого в режиме линейного предсказания, для получения сформированного спектра в виде набора 132 спектральных коэффициентов. Спектральный процессор 130 может быть настроен на использование сформированного спектра в виде набора 122 спектральных коэффициентов, или их предварительно обработанных версий 122', в зависимости от набора параметров коэффициентов масштабирования 136 для части (например, фрейма) аудиоконтента, кодируемого в режиме частотной области для получения сформированного спектра в виде набора 132 спектральных коэффициентов для указанной части аудиоконтента, который будет закодирован в режиме частотной области. Спектральный процессор 130 может, например, включать формирователь параметров 138, который настроен на создание набора параметров области линейного предсказания 134 и набора параметров коэффициента масштабирования 136. Например, формирователь параметров 138 может сформировать набор параметров области линейного предсказания 134 помощью анализатора области линейного предсказания, а также обеспечить набор параметров коэффициента масштабирования 136 с помощью процессора психоакустической модели. Однако, также могут быть применены и другие возможности обеспечения параметров области линейного предсказания 134 или набора параметров коэффициента масштабирования 136.
Кодировщик 100 также включает в себя кодировщик дискретизации 140, который настроен на получение сформированного спектра в виде набора 132 спектральных коэффициентов (обеспечиваемого спектральным процессором 130) для каждой части (например, для каждого фрейма) аудиоконтента. Кроме того, кодировщик дискретизации 140 может получить, после обработки версии 132', сформированный спектр в виде набора 132 спектральных коэффициентов. Кодировщик дискретизации 140 сконфигурирован для получения закодированной версии 142 сформированного спектра в виде набора спектральных коэффициентов 132 (или, дополнительно, их предварительно обработанной версии). Кодировщик дискретизации 140, например, можно настроить на работу с закодированной версией 142 сформированного спектра в виде набора спектральных коэффициентов 132 для части аудиоконтента, кодируемой в режиме линейного предсказания, а также для создания закодированной версии 142 сформированного спектра в виде набора спектральных коэффициентов 132 для части аудиоконтента, кодируемой в режиме частотной области. Другими словами, один и тот же кодировщик дискретизации 140 может быть использован для кодирования сформированного спектра в виде набора спектральных коэффициентов независимо от того, что часть аудиоконтента должна быть закодирована в режиме линейного предсказания, а другая - в режиме частотной области.
Кроме того, кодировщик 100 может дополнительно содержать блок форматирования выходного потока битов 150, который настроен на формирование потока 112 на основе закодированной версии 142 сформированного спектра в виде набора спектральных коэффициентов. Тем не менее, на выходе блока форматирования выходного потока битов 150, в потоке битов 112 может также содержаться дополнительная закодированная информация, а также информация о конфигурации, управляющая информация и т.д. Например, дополнительный кодировщик 160 может получить закодированный набор 134 параметров области линейного предсказания и/или набор 136 параметров коэффициентов масштабирования и сформировать его закодированную версию в блоке форматирования выходного потока битов 150. Таким образом, закодированная версия набора 134 параметров области линейного предсказания может быть включена в поток битов 112 части аудиоконтента, которая кодируется в режиме линейного предсказания, а закодированная версия набора 136 параметров коэффициентов масштабирования может быть включена в поток битов 112 части аудиоконтента, которая будет закодирована в частотной области.
Кодировщик 100 дополнительно включает, при необходимости, контроллер режима 170, который предназначен для определения в каком режиме должна быть закодирована часть аудиоконтента (например, фрейм из аудиоконтента): в режиме линейного предсказания или в частотном режиме. Для решения этой задачи контроллер 170 может получать входное представление аудиоконтента 110, его предварительно обработанную версию 110', либо для представления в частотной области 122 контроллер режима 170 может использовать, например, алгоритм обнаружения речи для определения участков аудиоконтента речевого типа и формирует сигнал управления режимом 172, который обеспечивает выбор режима линейного предсказания для кодирования части аудиоконтента в случае обнаружения участка речевого типа. С другой стороны, если контроллер режима считает, что данный участок аудиоконтента не является речевым, контроллер режима 170 формирует такой сигнал управления режимом 172, чтобы он задавал для указанной части аудиоконтента частотный режим кодирования.
Далее более подробно будет обсуждаться общая функциональность кодировщика 100. Многорежимный кодировщик аудиосигнала 100 настроен на эффективное кодирование как частей аудиоконтента, которые являются речевыми, так и частей аудиоконтента, которые не являются речевыми. Для этого кодировщик 100 использует, по крайней мере, два режима, а именно: режим линейного предсказания и частотный режим. Для этого преобразователь из временной области в частотную область 120 кодировщика 110 настроен на преобразование одного и того же представления аудиоконтента во временной области (например, входного представления 110, или его предварительно обработанной версии 110') в частотную область, как для режима линейного предсказания, так и для режима частотной области. Разрешение по частоте представления в частотной области 122, однако, может быть различным для различных режимов работы. Представление в частотной области 122 непосредственно сразу не дискретизируется и не кодируется, сначала, перед выполнением дискретизации и кодированием, формируется спектр. Формирование спектра осуществляется таким образом, что эффект шума дискретизации, вносимый кодировщиком дискретизации 140, сохраняется достаточно малым для исключения чрезмерных искажений. В режиме линейного предсказания формирование спектра осуществляется в зависимости от набора 134 параметров области линейного предсказания, которые получаются на основе аудиоконтента. В этом случае формирование спектра может быть выполнено, например, таким образом, что спектральные коэффициенты выделяются (весовой коэффициент больше), если соответствующий спектральный коэффициент представления в частотной области параметров области линейного предсказания имеет сравнительно большое значение. Другими словами, спектральные коэффициенты представления в частотной области 122 взвешиваются в зависимости от соответствующих спектральных коэффициентов параметров области линейного предсказания в представлении спектральной области. Соответственно, спектральные коэффициенты представления в частотной области 122, для которых соответствующие спектральные коэффициенты параметров области линейного предсказания в представлении спектральной области принимают сравнительно большие значения, дискретизируются со сравнительно высоким разрешением за счет увеличения весовых коэффициентов в спектрально сформированном наборе 132 спектральных коэффициентов. Другими словами, часть аудиоконтента, для которой формирование спектра происходит в соответствии с параметрами области линейного предсказания 134 (например, в соответствии с представлением спектральной области параметров области линейного предсказания 134) дает хорошее ограничение шума вследствие того, что спектральные коэффициенты представления в частотной области 132, которые более чувствительны по отношению к шуму дискретизации, при формировании спектра масштабируются с большими весовыми коэффициентами, так, что для эффективный шум дискретизации, введенный кодировщиком дискретизации 140 существенно уменьшается.
С другой стороны, к частям аудиоконтента, закодированным в режиме частотной области, применяется другой способ формирования спектра. Для этого параметры коэффициентов масштабирования 136 определяются, например, с использованием процессора психоакустической модели. [Неспособность человека в определенных случаях различать тихие звуки в присутствии более громких, называемая эффектом маскировки, используется в алгоритмах сокращения психоакустической избыточности. Эффекты слухового маскирования зависят от спектральных и временных характеристик маскируемого и маскирующего сигналов и могут быть разделены на две основные группы: частотное (одновременное) маскирование и временное (неодновременное) маскирование]. Процессор психоакустической модели оценивает частотное маскирование и/или временное маскирование спектральных компонент представления в частотной области 122. Эта оценка частотного маскирования и временного маскирования используется для определения, какие спектральные компоненты (например, спектральные коэффициенты) в частотной области представления 122 должны быть закодированы с высокой точностью дискретизации, а какие спектральные компоненты (например, спектральные коэффициенты) представления в частотной области 122 могут быть закодированы с относительно низкой точностью дискретизации. Другими словами, процессор психоакустической модели может определить, например, психоакустическую значимость различных спектральных компонент и показать, что психоакустически менее важные компоненты спектра следует дискретизировать с низкой или даже очень низкой точностью дискретизации.
Таким образом, при формировании спектра (которое выполняется спектральным процессором 130) выполняется процедура взвешивания спектральных компонент (например, спектральных коэффициентов) представления в частотной области 122 (или его версии 122' после обработки), в соответствии с параметрами коэффициентов масштабирования 136, предоставляемых процессором психоакустической модели. При формировании спектра психоакустически важные компоненты спектра получают большой весовой коэффициент, так, что они эффективно дискретизируются с высокой точностью дискретизации кодировщиком дискретизации 140. Таким образом, коэффициенты масштабирования могут описывать психоакустическую значимость различных частот или частотных диапазонов.
В заключение, аудиокодировщик 100 позволяет производить переключение, по крайней мере, между двумя различными режимами, а именно режимом линейного предсказания и частотным режимом. Перекрывающиеся участки аудиоконтента могут быть закодированы в различных режимах. Для этого представления в частотной области различных (но, желательно перекрывающихся) участков одного и того же аудиосигнала используются при кодировании последующих (например, следующих сразу после данного участка) участков аудиоконтента в различных режимах. Из компонент спектральной области представления в частотной области 122 формируется спектр в зависимости от набора параметров области линейного предсказания для части аудиоконтента, которая будет закодирована в режиме частотной области, и в зависимости от параметров коэффициентов масштабирования формируется спектр для части аудиоконтента, которая будет закодирована в режиме частотной области. Различные концепции, которые используются для определения соответствующего способа формирования спектра, которые проводят к преобразованию от временной области к частотной области и дискретизации/кодированию, позволяют иметь хорошую эффективность кодирования и низкий уровень шумовых искажений при формировании аудиоконтентов различных типов (речевого и неречевого типа).
2. Аудиокодировщик в соответствии с фиг.3
Далее будет описан кодировщик 300 в соответствии с другим вариантом осуществления изобретения со ссылкой на фиг.3. На фиг.3 показана блок-схема такого кодировщика 300. Следует отметить, что кодировщик 300 является улучшенной версией базового аудиокодировщика 200, блок-схема которого показана на фиг.2.
2.1 Базовый аудиокодировщик сигнала, в соответствии с фиг.2.
Другими словами, для облегчения понимания работы кодировщика 300 в соответствии с фиг.3, сначала будет описан базовый единый кодировщик 200 для речевого и аудиокодирования (кодировщик USAC) со ссылкой на функциональную блок-схему USAC кодировщика, которая показана на фиг.2. Базовый аудиокодировщик 200 настроен на получение входного представления 210 аудиоконтента, которое, как правило, является представлением во временной области, и формирование на его основе закодированного представления 212 аудиоконтента. Например, кодировщик 200 может содержать переключатель или дистрибьютор 220, который настроен на формирование входного представления 210 аудиоконтента для кодировщика частотной области 230 и/или кодировщика области линейного предсказания 240. Кодировщик частотной области 230 настроен на получение входного представления 210' аудиоконтента и формирование на его основе закодированного спектрального представления 232 и закодированной информации коэффициента масштабирования 234. Кодировщик области линейного предсказания 240 настроен на получение входного представления 210' и представление на его основе закодированного возбуждения 242 и закодированной информации коэффициентов LPC фильтра 244. Кодировщик частотной области 230 включает в себя, например, преобразователь модифицированного дискретного косинус-преобразования из временной области в частотную область 230а, который обеспечивает спектральное представление аудиоконтента 230b. Кодировщик частотной области 230 также включает в себя психоакустический анализ 230 с, который настроен на анализ спектрального и временного маскирования аудиоконтента и получение коэффициентов масштабирования 230d и закодированной информации коэффициентов масштабирования 234. Кодировщик частотной области 230 также включает в себя блок масштабирования 230е, который настроен на масштабирование спектральных значений, выполняемое преобразователем из временной области в частотную область 230а в соответствии с коэффициентами масштабирования 230d, с получением масштабированного спектрального представления 230f аудиоконтента. Кодировщик частотной области 230 также включает в себя блок дискретизации 230g, настроенный на дискретизацию масштабированного спектрального представления 230f аудиоконтента, и кодировщик энтропии 230h, настроенный на кодировку энтропии дискретизированного масштабированного спектрального представления аудиоконтента, предоставляемого блоком дискретизации 230g. Кодировщик энтропии 230h, следовательно, обеспечивает закодированное спектральное представление 232.
Кодировщик области линейного предсказания 240 настроен на работу с закодированным возбуждением 242 и закодированной информацией коэффициентов LPC-фильтра 244 на основе входного аудиопредставления 210'. LPD кодировщик 240 включает анализ линейного предсказания 240а, который настроен на получение коэффициентов LPC-фильтра 240b и закодированной информации коэффициентов LPC-фильтра 244 на основе входного представления 210' аудиоконтента. LPD кодировщик 240 также включает в себя кодирование возбуждения, которое состоит из двух параллельных ветвей, а именно ветви ТСХ 250 и ветви ACELP 260. Ветви можно переключать (например, с помощью переключателя 270), либо обеспечить преобразование кодирования возбуждения 252 или возбуждение алгебраического кодирования 262. Ветвь ТСХ 250 включает в себя LPC-фильтр 250а, который настроен на получение как входного представления 210' аудиоконтента, так и коэффициентов LPC фильтра 240b, предоставляемых LP анализом 240а. LPC фильтр 250а формирует выходной сигнал фильтра 250b, который может использоваться в качестве возбуждающего для LPC-фильтра для получения выходного сигнала, который достаточно похож на входное представление 210' аудиоконтента. Ветвь ТСХ также включает в себя модифицированное дискретное косинус-преобразование (MDCT), настроенное на прием возбуждающего сигнала 250d и получение представления в частотной области 250d возбуждающего сигнала 250b. Ветвь ТСХ также включает в себя блок дискретизации 250е, настроенный на получение представления в частотной области 250b и создание его дискретизированной версии 250f. Ветвь ТСХ также включает в себя кодировщик энтропии 250, настроенный на получение дискретизированной версии 250f представления в частотной области 250d возбуждающего сигнала 250b и создание на его основе закодированного преобразования возбуждающего сигнала 252.
Ветвь ACELP 260 включает в себя LPC фильтр 2б0а, который настроен на получение коэффициентов LPC фильтра 240b, сформированных при LP анализе 240а, и также создание входного представления 210' аудиоконтента. LPC фильтр 2б0а настроен на создание возбуждающего сигнала 260b, который представляет собой, например, возбуждение, необходимое декодировщику от LPC фильтра для получения восстановленного сигнала, который достаточно похож на входное представление 210' аудиоконтента. ACELP ветвь 260 также включает в себя ACELP кодировщик 260 с, настроенный на кодирование возбуждающего сигнала 260b с помощью соответствующего алгоритма алгебраического кодирования.
Подводя итог вышесказанному, переключение аудиокодировщиков, таких как, например, аудиокодировщик в соответствии с рабочим проектом MPEG-D единого речевого и аудиокодирования (USAC), который описан в работе [1], и обработка смежных сегментов входного сигнала могут быть проведены различными кодировщиками. Например, при аудиокодировании в соответствии с рабочим проектом единого речевого и аудиокодирования (USAC WD), может проводиться переключение между кодированием в частотной области на основе так называемого улучшенного аудиокодирования (ААС), которое описано, например, в работе [2], и кодированием в области линейного предсказания (LPD), а именно ТСХ и ACELP, основанным на так называемой концепции AMR-WB, которая описана, например, в [3]. Кодировщик USAC показан на фиг.2.
Было установлено, что организация переходов между различными кодировщиками является важным и даже необходимым вопросом для возможности переключения между различными кодировщиками. Было также обнаружено, что, как правило, трудно добиться такого перехода за счет различных способов кодирования, совмещенных в структуре переключателя. Тем не менее, было установлено, что общие инструменты в составе различные кодировщиков могут облегчить переход. Принимая теперь во внимание аудиокодировщик 200 в соответствии с фиг.2, видно, что при использовании USAC кодировщик частотной области 230 вычисляет улучшенное дискретное косинусное преобразование (MDCT) области сигнала, в то время как ветвь возбуждения преобразования кодирования (ТСХ) вычисляет модифицированное дискретное косинусное преобразование (MDCT 250 с) в LPC остаточной области (с использованием LPC остаточного сигнала 250b). Кроме того, оба кодировщика (а именно, кодировщик частотной области 230 и ветвь ТСХ 250) в разных областях используют один и тот же тип набора фильтров. Таким образом, базовый аудиокодировщик 200 (который может быть аудиокодировщиком USAC) не может полностью использовать колоссальные возможности MDCT, особенно отмену алиасинга во временной области (TDAC) при переходе от одного кодировщика (например, от кодировщика в частотной области 230) к другому кодировщику (например, к ТСХ кодировщику 250).
Снова принимая во внимание базовый аудиокодировщик 200 в соответствии с фиг.2, можно заметить, что ветвь ТСХ 250 и ветвь ACELP 260 совместно используют инструмент кодирования с линейным предсказанием (LPC). Ключевым моментом для ACELP, как исходной модели кодировщика, является использование LPC для моделирования речевого голосового тракта. Для ТСХ, LPC используется для формирования шумов дискретизации при введении MDCT коэффициентов 250d. Делается это путем фильтрации (например, с использованием LPC фильтра 250а) входного сигнала 210' во временной области перед выполнением MDCT 250с. Кроме того, LPC используется в ТСХ при переходе к ACELP для получения возбуждающего сигнала, подаваемого в адаптивную кодовую книгу ACELP. Это позволяет дополнительно получить интерполированные наборы коэффициентов LPC для следующего фрейма ACELP.
2.2 Кодировщик аудиосигнала в соответствии с фиг.3
Далее будет описан кодировщик аудиосигнала 300 в соответствии с фиг.3. Для этого будут использоваться ссылки на базовый аудиокодировщик 200 в соответствии с фиг.2, так как кодировщик аудиосигнала 300 в соответствии с фиг.3 имеет некоторое сходство с базовым аудиокодировщиком 200 в соответствии с фиг.2.
Кодировщик аудиосигнала 300 настроен на формирование входного представления аудиоконтента 310, а также получение на его основе закодированного представления аудиоконтента 312. Кодировщик аудиосигнала 300 настроен на возможность переключения между режимом частотной области, в котором кодирование представления участков аудиоконтента обеспечивается кодировщиком частотной области 230, и режимом линейного предсказания, в котором закодированные представления участков аудиоконтента формируются кодировщиком области линейного предсказания 340. Участки аудиоконтента, закодированные в различных режимах, могут перекрываться в некоторых вариантах, а в других вариантах могут быть неперекрывающимися.
Кодировщик частотной области 330 получает входное представление 310' аудиоконтента для части аудиоконтента, которая будет закодирована в частотной области и формирует, на ее основе, закодированное спектральное представление 332. Кодировщик области линейного предсказания 340 получает входное представление 310' аудиоконтента для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, и обеспечивает, на его основе, закодированное возбуждение 342. При необходимости, для передачи входного представления 310 на кодировщик частотной области 330 и/или на кодировщик области линейного предсказания 340, может быть использован переключатель 320.
Кодировщик частотной области обеспечивает кодирование информации коэффициентов масштабирования 334. Кодировщик области линейного предсказания 340 обеспечивает закодированную информацию 344 коэффициентов LPC-фильтра.
Выходной мультиплексор 380 сконфигурирован для обеспечения, как закодированного представления 312 аудиоконтента, закодированного спектрального представления 332 и закодированной информации коэффициентов масштабирования 334 для части аудиоконтента, который будет кодироваться в частотной области, так и для обеспечения закодированного представления 312 аудиоконтента, закодированного возбуждения 342 и закодированной информации коэффициентов LPC-фильтра 344 для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания.
Кодировщик частотной области 330 включает в себя модифицированное дискретное косинусное преобразование 330а, которое получает представление во временной области 310' аудиоконтента и преобразовывает его в представление аудиоконтента во временной области 310', чтобы получить преобразованное MDCT представление 33 Ob в частотной области аудиоконтента. Кодировщик в частотной области 330 также включает в себя психоакустический анализ 330 с, который настроен на получение представления аудиоконтента во временной области 310' и получение, на его основе, коэффициентов масштабирования 330d и закодированной информации коэффициентов масштабирования 334. Кодировщик в частотной области 330 также включает в себя сумматор 330е, настроенный на применение коэффициентов масштабирования 330е для MDCT преобразования представления аудиоконтента 330d в частотной области в целях масштабирования различных спектральных коэффициентов MDCT преобразования для представления 330b аудиоконтента в частотной области с различными значениями коэффициентов масштабирования. Таким образом, получается сформированная версия 330f спектра при MDCT преобразовании для представления аудиоконтента 330d в частотной области, в котором формирование спектра осуществляется в зависимости от коэффициентов масштабирования 330d. Причем в областях спектра, в которых имеются сравнительно большие коэффициенты масштабирования 330е, дополнительно выделяются спектральные подобласти, в которых имеются сравнительно меньшие коэффициенты масштабирования 330е. Кодировщик частотной области 330 также включает в себя блок дискретизации, настроенный на получение масштабированной (спектрально сформированной) версии 330f при MDCT преобразовании представления в частотной области 330b аудиоконтента, и создание ее дискретизированной версии 330h. Кодировщик частотной области 330 также включает в себя кодировщик энтропии 330i, настроенный на получение дискретизированной версии 330h и создание на ее основе закодированного спектрального представления 332.
Блок дискретизации 330 и кодировщик энтропии 330i можно рассматривать как кодировщик дискретизации.
Кодировщик области линейного предсказания 340 включает в себя ветвь ТСХ 350 и ACELP ветвь 360. Кроме того, LPD кодировщик 340 включает в себя LP анализ 340а, который обычно используется в ветви ТСХ 350 и ветви ACFXP 360. LP анализ 340а позволяет получить коэффициенты LPC-фильтра 340b и закодированные коэффициенты информации LPC-фильтра 344.
Ветвь ТСХ 350 включает в себя преобразование MDCT 330а, которое настроено на получение, в качестве входного MDCT преобразования, представления во временной области 310'. Важно отметить, что MDCT 330а кодировщика в частотной области и MDCT 330а в ТСХ ветви 350 получат (разные) части одного и того же представления во временной области аудиоконтента, в качестве преобразованных входных сигналов.
Соответственно, если последовательные и дублирующие друг друга части (например, фреймы) аудиоконтента кодируются в различных режимах, MDCT 330а кодировщика частотной области 330 и MDCT 350а ветви ТСХ 350 могут получить представления во временной области, имеющие временные перекрытия, в качестве преобразованных входных сигналов. Другими словами, MDCT 330а кодировщика в частотной области 330 и MDCT 350а ветви ТСХ 350 получают преобразования входных сигналов, которые находятся 'в одной и той же области', т.е. они оба являются сигналами, представляющими аудиоконтент во временной области. В этом состоит отличие от кодировщика 200, в котором MDCT 230а кодировщика в частотной области 230 получает представление аудиоконтента во временной области, а MDCT 250 с ветви ТСХ 250 получает остаточное представление сигнала во временной области или возбуждающий сигнал 250b, а не представление во временной области самого аудиоконтента.
Ветвь ТСХ 350 дополнительно включает преобразователь коэффициентов фильтра 340b, который настроен на преобразование LPC коэффициентов фильтра 340b в спектральной области и получение значений усиления 350с. Преобразователь коэффициентов фильтра 340b также иногда называется 'преобразователь линейного предсказания в MDCT'. Ветвь ТСХ 350 также включает в себя сумматор 350d, который получает MDCT преобразованные представления аудиоконтента и значения усиления 350с и формирует, на их основе, спектрально сформированную версию 350е из преобразованного с помощью MDCT представления аудиоконтента. Для этого сумматор 350d взвешивает преобразованные с помощью MDCT спектральные коэффициенты представления аудиоконтента в зависимости от значений коэффициентов усиления 350с для получения спектрально сформированной версии 350е. Ветвь ТСХ 350 также включает в себя блок дискретизации 350f, который настроен на получение спектрально сформированной версии 350е MDCT преобразованного представления аудиоконтента и создания дискретизированной версии 350. Ветвь ТСХ 350 также включает в себя кодировщик энтропии 350h, который настроен на выполнение кодировки энтропии (например, арифметической кодировки) версии дискретизированного представления 350 в качестве закодированного возбуждения 342.
Ветвь ACELP включает фильтр на основе LPC 360а, который получает коэффициенты LPC фильтра 340b, сформированные при LP анализе 340а, и также получает представление во временной области 310' аудиоконтента. LPC фильтр 360а берет на себя такую же функциональность как LPC фильтр 260а и вырабатывает возбуждающий сигнал 360b, который эквивалентен сигналу возбуждения 260b. ACELP ветвь 360 также включает в себя ACELP кодировщик 360с, который эквивалентен ACELP кодировщику 260с. Кодировщик ACELP 360с формирует закодированное возбуждение 342 части аудиоконтента, которая будет закодирована с использованием режима ACELP (который является разновидностью режима линейного предсказания).
Что касается общей функциональности кодировщика 300, можно сказать, что часть аудиоконтента может быть закодирована либо в режиме частотной области, либо в режиме ТСХ (который является первой разновидностью режима линейного предсказания), либо в режиме ACELP (который является второй разновидностью режима линейного предсказания). Если часть аудиоконтента кодируется в режиме частотной области или в режиме ТСХ, часть аудиоконтента сначала преобразуются в частотную область с использованием MDCT 330а в кодировщике частотной области или с использованием MDCT 330а в ветви ТСХ. MDCT 330а, так же как и MDCT 350а, обрабатывает представление аудиоконтента во временной области, и, по крайней мере частично, работает даже с одинаковыми частями аудиоконтента, когда происходит переход между режимом частотной области и ТСХ режимом. В режиме частотной области, формирование спектра для представления в частотной области, осуществляемое MDCT преобразователем 330а, производится в зависимости от масштабного коэффициента, получаемого при психоакустическом анализе 330с, аналогичным образом в режиме ТСХ, формирование спектра для представления в частотной области осуществляется MDCT 330а в зависимости от коэффициентов LPC фильтра, полученных при LP анализе 340а. Дискретизация 330 может быть похожа, или даже идентична дискретизации 350f, a кодирование энтропии 330i может быть аналогично, или даже идентично, кодированию энтропии 35 Oh. Кроме того, MDCT преобразование 330а может быть аналогично, или даже идентично, MDCT преобразованию 330а. Таким образом, различные аспекты MDCT преобразования могут быть использованы для частотной области в кодировщиках 330 и ветви ТСХ 350.
Кроме того, можно заметить, что коэффициенты LPC фильтра 340b используются обеими ветвями: ТСХ 350 и ACELP 360. Это облегчает переходы между частями аудиоконтента, закодированными в режиме ТСХ и частями аудиоконтента, закодированными в режиме ACELP.
Подводя итог вышесказанному, отметим один из вариантов осуществления настоящего изобретения, состоящий в выполнении, в рамках единого речевого и аудиокодирования (USAC), MDCT 330а в ТСХ во временной области и использовании LPC-фильтрации в частотной области (сумматор 350d). LPC анализ (например, LP анализ 340а) осуществляется как и раньше (например, как в кодировщике аудиосигнала 200), а коэффициенты (например, коэффициенты 340b) по-прежнему передаются обычным образом (например, в виде закодированных коэффициентов LPC фильтра 344). Тем не менее, ограничение шума теперь происходит не при использовании фильтра во временной области, а при взвешивании в частотной области (которое выполняется, например, сумматором 350d). Ограничение шума в частотной области достигается путем преобразования LPC коэффициентов (например, коэффициентов LPC фильтра 340b) в область MDCT (которое может быть выполнено преобразователем коэффициентов фильтра 340b). Для получения дополнительной информации, можно сослаться на фиг.3, который показывает концепцию применения LPC ограничения шума для ТСХ в частотной области.
2.3 Подробности о расчете и применении LPC коэффициентов
Далее будет описан расчет и применение LPC коэффициентов. Во-первых, соответствующий набор LPC коэффициентов рассчитывается для текущего окна ТСХ, например, с использованием LPC анализа 340а. Окно ТСХ может быть оконным участком представления во временной области аудиоконтента, который должен быть закодирован в режиме ТСХ. Окна LPC анализа находятся на границах фреймов LPC кодировщика, как показано на фиг.4.
Как показано на фиг.4 фрейм ТСХ, т.е. аудиофрейм, будет закодирован в режиме ТСХ. Абсцисса 410 показывает время, а ордината 420 показывает значения магнитуды функции окна.
Интерполяция делается при расчете набора LPC коэффициентов 340b, соответствующего центру тяжести окна ТСХ. Интерполяция выполняется для иммитанса спектральных составляющих (ISF область), где LPC коэффициенты, как правило, дискретизируются и кодируются. Интерполированные коэффициенты помещаются в центр ТСХ окна с размером: sizeR+sizeM+sizeL.
Для получения дополнительной информации, можно обратиться к фиг.4, который показывает LPC интерполяцию коэффициентов ТСХ окна.
Интерполированные LPC коэффициенты, взвешенные как это выполняется в ТСХ (подробности см. в [3]), используются для создания соответствующего встроенного алгоритма ограничения шума с психоакустическим анализом. Полученные интерполированные и взвешенные LPC коэффициенты (также кратко обозначенные как lpc_coeffs), наконец, превращаются в MDCT коэффициенты масштабирования (также называемые значениями усиления в режиме линейного предсказания) с помощью способа, псевдокод которого показан на фиг.5 и 6.
На фиг.5 показан псевдокод программы функции 'LPC2MDCT' для получения MDCT коэффициентов масштабирования ('mdct_scaleFactors') с использованием входных LPC коэффициентов ('lpc_coeffs'). Как видно, функция 'LPC2MDCT' получает в качестве входных переменных LPC коэффициенты 'lpc_coeffs', значение порядка LPC 'lpc_prder' и значения размера окна 'sizeR', 'sizeM', 'sizeL'. На первом этапе, элементы массива 'InRealData[I]' заполняются модулированной версией LPC коэффициентов, как показано на рисунке цифрой 510. Видно, что для записей в массиве 'InRealData' и записей в массиве 'InlmagData' с номерами от 0 до lpc_order - 1 установлены значения, определяемые соответствующими LPC коэффициентами 'lpcCoeffs[i]', модулированными косинусами или синусами. Записи массива 'InRealData' и 'InlmagData' с индексами i>lpc_order устанавливаются в 0.
Таким образом, массивы 'InRealData' и 'InlmagData' описывают действительную и мнимую части отклика во временной области, описываемого LPC коэффициентами, модулированными в терминах комплексной модуляции
(cos(i·π/sizeN)-j·sin(i·π/sizeN)).
Затем применяется комплексное быстрое преобразование Фурье, при котором массивы 'InRealData[i]' и 'InlmagData[i]' описывают входной сигнал комплексного быстрого преобразования Фурье. Результат комплексного быстрого преобразования Фурье записывается в массивы 'OutRealData' и 'OutImagData'. Таким образом, массивы 'OutRealData' и 'OutImagData' описывают спектральные коэффициенты (с частотными индексами i), представляющими отклик LPC фильтра, описывающий коэффициенты фильтра во временной области.
Затем вычисляются так называемые коэффициенты масштабирования MDCT, которые имеют частотные индексы i, и которые обозначены 'mdct_scaleFactors[i]'. Коэффициент масштабирования MDCT 'mdct_scaleFactors[i]' рассчитывается как обратная величина от абсолютного значения соответствующего спектрального коэффициента (представляются записями в 'OutRealData[i]' и 'OutImagData[i]').
Следует отметить, что операция комплексной модуляции, показанная цифрой 510 и выполняющая комплексное быстрое преобразование Фурье, показанное цифрой 520, фактически является нечетным дискретным преобразованием Фурье (ODFT). Нечетное дискретное преобразование Фурье имеет следующую формулу:
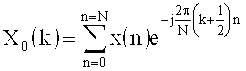
где N=sizeN, что в два раза больше MDCT.
В приведенной выше формуле, LPC коэффициенты lpc_coeffs[n] имеют смысл преобразования входной функции x(n). Выходная функция Х0 (k) представлена значениями 'OutRealData[k]' (действительная часть) и 'OutImagData[k]' (мнимая часть).
Функция 'complex_fft()' является быстрой реализацией обычного комплексного дискретного преобразования Фурье (DFT). Полученные MDCT коэффициенты масштабирования 'mdct_scaleFactors' являются положительными значениями, которые затем используются для масштабирования MDCT коэффициентов (полученных от MDCT 330а) входного сигнала. Масштабирование будет осуществляться в соответствии с псевдокодом, показанном на фиг.6.
2.4 Подробности, относящиеся к оконным операциям и перекрытию
Оконные операции и перекрытия между последовательными фреймами показаны на фиг.7 и 8.
На фиг.7 показана оконная операция, которая выполняется при включении кодировщика временной/частотной области, формирующего на выходе LPCO. На фиг.8 показана оконная операция, которая осуществляется при переключении от кодировщика частотной области к кодировщику во временной области, с использованием 'lpc2mdct' для перехода.
Принимая теперь во внимание ссылку на фиг.7, первый аудиофрейм 710 кодируется в режиме частотной области и обрабатывается в окне 712.
Второй аудиофрейм 716, который перекрывается с первым аудиофреймом 710 примерно на 50%, закодированный в режиме частотной области, обрабатывается в окне 718, которое обозначается как 'стартовое окно'. Стартовое окно имеет длинный левосторонний склон 718а и короткий правосторонний склон 718с.
Третий аудиофрейм 722, который кодируется в режиме линейного предсказания, обрабатывается в режиме линейного предсказания в окне 724, которое имеет переходной участок с коротким левосторонним склоном 724а, соответствующим правостороннему склону переходного участка 718 с, и переходной участок с коротким правосторонним склоном 724 с.Четвертый аудиофрейм 728, закодированный в режиме частотной области, обрабатывается в окне с использованием 'финишного окна' 730, имеющего переходной участок со сравнительно небольшим левосторонним склоном 730а и сравнительно длинным правосторонним склоном 730 с.
При переходе из режима частотной области к режиму линейного предсказания, т.е. таком как переход между вторым аудиофреймом 716 и третьим аудиофреймом 722, дополнительный набор LPC коэффициентов (также обозначаемый 'LPCO') традиционно используется для обеспечения надлежащего перехода к режиму кодирования в области линейного предсказания.
Тем не менее, воплощение в соответствии с изобретением создает кодировщик с новым типом стартового окна для перехода между режимами частотной области и линейного предсказания. Принимая теперь во внимание ссылку на фиг.8, понятно, что первый аудиофрейм 810 обрабатывается в окне с использованием так называемого 'длинного окна' 812 и кодируется в режиме частотной области. 'Длинное окно' 812 имеет переходной участок со сравнительно небольшим правосторонним склоном 812b. Второй аудиофрейм 816 обрабатывается в окне с использованием стартового окна 818 области линейного предсказания, которое имеет переходной участок со сравнительно небольшим левосторонним склоном 818а, соответствующим правостороннему склону переходного участка 812b в окне 812. Стартовое окно области линейного предсказания 818 также включает в себя сравнительно короткий правосторонний склон переходного участка 818b. Второй аудиофрейм 816 кодируется в режиме линейного предсказания. Соответственно, коэффициенты LPC фильтра определяются для второго аудиофрейма 816, и выборки во временной области второго аудиофрейма 816, также преобразуются в спектральное представление, использующее MDCT. Коэффициенты LPC фильтра, которые были определены для второго аудиофрейма 816, затем применяются в частотной области и используются для получения спектрально сформированных спектральных коэффициентов с помощью MDCT на основе представления аудиоконтента во временной области.
Третий аудиофрейм 822 обрабатывается в окне 824, который совпадает с окном 724, описанным выше. Третий аудиофрейм 822 кодируется в режиме линейного предсказания. Четвертый аудиофрейм 828 обрабатывается в окне 830, которое по существу идентично окну 730.
Концепция, описанная со ссылкой на фиг.8, имеет преимущество в том, что переход между аудиофреймом 810, который закодирован в режиме частотной области с использованием так называемого 'длинного окна', и третьим аудиофреймом 822, который закодирован в режиме линейного предсказания с помощью окна 824, осуществляется через промежуточный (частично перекрывающийся) второй аудиофрейм 816, который кодируется в режиме линейного предсказания с помощью окна 818. В качестве второго аудиофрейма, как правило, закодированного таким образом, чтобы формирование спектра осуществлялось в частотной области (например, с помощью преобразователя коэффициентов фильтра 340b), может быть получено хорошее перекрытие и суммирование между аудиофреймом 810, закодированным в режиме частотной области с использованием окна, имеющего сравнительно длинный правосторонний склон переходного участка 812b, и вторым аудиофреймом 816. Кроме того, вместо значений коэффициентов масштабирования во второй аудиофрейм 816 передаются закодированные коэффициенты LPC фильтра. Это отличает переход, показанный на фиг.8, от перехода, показанного на фиг.7, где дополнительные коэффициенты LPC (LPCO) передаются в дополнение к значениям коэффициентов масштабирования. Следовательно, переход между вторым аудиофреймом 816 и третьим аудиофреймом 822 может быть выполнен с хорошим качеством без передачи добавочных дополнительных данных, похожих, например, на коэффициенты LPCO, передаваемые в случае на фиг.7. Таким образом, информация, которая требуется для инициализации кодировщика области линейного предсказания, используемого в третьем аудиофрейме 822, доступна без передачи дополнительной информации.
Итак, в варианте, описанном со ссылкой на фиг.8, в стартовом окне 818 области линейного предсказания можно использовать LPC ограничение шума вместо обычных коэффициентов масштабирования (которые передаются, например, для аудиофрейма 716). Окно LPC анализа 818 соответствуют стартовому окну 718, при отсутствии необходимости отправления дополнительных настроек для LPC коэффициентов (как, например, в случае LPCO коэффициентов), как это показано на фиг.8. В этом случае адаптивная кодовая книга ACELP (которая может быть использована для кодирования, по крайней мере, части третьего аудиофрейма 822) может быть легко создана с расчетом в режиме LPC оставшегося декодированного стартового окна 818 кодировщика области линейного предсказания.
Подводя итог вышесказанному, на фиг.7 показана функция, включающая кодировщик временной/частотной области, который должен отправить на выход дополнительный набор LPC коэффициентов, называемых LPO. На фиг.8 показан переход от кодировщика частотной области к кодировщику области линейного предсказания с помощью так называемой 'LPC2MDCT'.
3. Кодировщик аудиосигнала в соответствии с фиг.9
Далее будет описан, со ссылкой на фиг.9, кодировщик аудиосигнала 900, который адаптирован к реализации концепции, описанной на фиг.8. Кодировщик аудиосигнала 900 в соответствии с фиг.9 очень похож на кодировщик аудиосигнала 300 в соответствии с фиг.3 в том, что идентичные средства и сигналы обозначены одинаковыми индексами. Обсуждение этих идентичных средств и сигналов будет опущено, а необходимые ссылки можно посмотреть в кодировщике аудиосигнала 300.
Тем не менее, кодировщик аудиосигнала 900 расширен по сравнению с кодировщиком аудиосигнала 300 в той части, что сумматор 330е в кодировщике частотной области 930 может избирательно применять коэффициенты масштабирования 340d или значения усиления области линейного предсказания 350 с для формирования спектра. Для этого используется переключатель 930j, который позволяет получать либо коэффициенты масштабирования 330d, либо значения усиления области линейного предсказания 350с для сумматора 330е при формировании спектра в виде спектральных коэффициентов 330b. Таким образом, кодировщик сигнала 900 позволяет использовать даже три режима работы, а именно:
1. Режим частотной области: представление аудиоконтента во временной области преобразуется в частотную область с использованием MDCT 330а и выполняется формирование спектра для представления аудиоконтента в частотной области 330b в зависимости от коэффициентов масштабирования 330d. Дискретизированные и закодированные версии 332 спектрально сформированного представления в частотной области 330f, и закодированная информация коэффициентов масштабирования 334 включаются в поток битов для аудиофрейма, кодируемого в режиме частотной области.
2. Режим линейного предсказания: в режиме линейного предсказания коэффициенты LPC фильтра 340b определяются для части контента, и выполняется либо преобразование кодирования возбуждения (первый суб-режим), либо выполняется ACELP кодирование возбуждения с использованием указанных коэффициентов LPC фильтра 340b, в зависимости от того, какое кодированное возбуждение имеет более эффективный битрейт, закодированное возбуждение 342 и закодированная информация коэффициентов LPC фильтра 344 включаются в поток битов для аудиофрейма, закодированного в режиме линейного прогнозирования.
3. Режим частотной области с коэффициентами LPC фильтра, полученными при формировании спектра: дополнительная возможность третьего режима состоит в том, что аудиоконтент может быть обработан в кодировщике частотной области 930. Однако, вместо коэффициентов масштабирования 330d, применяются значения усиления 350 с области линейного предсказания для формирования спектра в сумматоре 330е. Соответственно, дискретизированная с кодированной энтропией версия 332 спектрально сформированного представления в частотной области 330f аудиоконтента включается в поток битов, в котором представление в частотной области 330f в соответствии со значениями усиления 350с области линейного предсказания спектрально формируются в кодировщике области линейного предсказания 340. Кроме того, закодированная информация коэффициентов LPC фильтра 344 включается в поток битов такого аудиофрейма.
С использованием описанного выше третьего способа, можно осуществить переход, который был описан со ссылкой на фиг.8 для второго аудиофрейма 816. Здесь следует отметить, что кодирование аудиофрейма с использованием кодировщика частотной области 930 с формированием спектра в зависимости от значений усиления области линейного предсказания эквивалентно кодированию аудиофрейма 816с помощью кодировщика области линейного предсказания, если размерность MDCT, используемая в кодировщике частотной области 930 соответствует размерности MDCT, используемой в ветви ТСХ 350, а также если дискретизация 330g, используемая в кодировщике частотной области 930, соответствует дискретизации 350f, используемой в ветви ТСХ 350, а также если кодирование энтропии 330е, используемое в кодировщике частотной области соответствует кодированию энтропии 350h, используемому в ветви ТСХ. Другими словами, кодирование аудиофрейма 816 может быть сделано либо путем такой адаптации ветви ТСХ 350, чтобы MDCT 350 использовала характеристики MDCT 330а, и такой адаптации, чтобы дискретизация 350f использовала характеристики дискретизации 330е, и такой адаптации, чтобы кодирование энтропии 350h использовало характеристики кодирования энтропии 330i, либо путем применения значений усиления области линейного предсказания 350с в кодировщике частотной области 930. Оба решения эквивалентны и приводят к обработке стартового окна 816, как описано со ссылкой на фиг.8.
4. Декодировщик аудиосигнала в соответствии с фиг.10
Далее будет описана со ссылкой на фиг.10 единая концепция USAC (единого речевого и аудиокодирования) с использованием ТСХ MDCT в применении к области сигнала.
Следует отметить, что в некоторых вариантах в соответствии с изобретением ветвь ТСХ 350 и кодировщик частотной области 330, 930 содержат практически одни и те же средства кодирования (MDCT 330а, 330а, сумматор 330е, 350d; блок дискретизации 330, 350f, кодировщик энтропии 330i, 350h) и могут рассматриваться как один кодировщик, как это показано на фиг.10. Таким образом, варианты в соответствии с настоящим изобретением позволяют создать более унифицированную структуру переключения кодировщика USAC с использованием только двух типов кодировок (кодировщик в частотной области и кодировщик во временной области), которые могут быть разделены.
Обратившись теперь к ссылке на фиг.10, видно, что кодировщик аудиосигнала 1000 настроен на получение входного представления аудиоконтента 1010 и предоставление на его основе закодированного представления аудиоконтента 1012. Входное представление аудиоконтента 1010, которое, как правило, является представлением во временной области, используется в качестве входного для MDCT 1030А, если часть аудиоконтента должна быть закодирована в режиме частотной области или в суб-режиме ТСХ режима линейного предсказания. MDCT 1030А обеспечивает представление в частотной области 1030b представления во временной области 1010. Представление в частотной области 1030b является входным для сумматора 1030е, который суммирует представление в частотной области 1030b со значениями сформированного спектра 1040, для получения спектрально сформированной версии 103 Of представления в частотной области ЮЗОЬ. Представление сформированного спектра 1030i дискретизируется помощью блока дискретизации 1030g для получения его дискретизированной версии 1030п,идискретизированная версия 1030h направляется на кодировщик энтропии (например, арифметический кодировщик) 1030L Кодировщик энтропии 1030i обеспечивает дискретизацию и представление дискретизированной закодированной энтропии для представления сформированного спектра в частотной области 1030i, дискретизированное закодированное представление, которое обозначается 1032. MDCT 1030А, сумматор 1030е, блок дискретизации 1030g и кодировщик энтропии 1030i образуют общий путь обработки сигнала для режима частотной области и суб-режима ТСХ режима линейного предсказания.
Кодировщик аудиосигнала 1000 включает в себя путь ACELP обработки сигнала 1060, который также получает представление аудиоконтента во временной области 1010, и который формирует, на его основе, закодированное возбуждение 1062 с использованием информации 1040b коэффициентов LPC-фильтра. Путь ACELP обработки сигнала 1060, который можно рассматривать как дополнительный, включает в себя LPC фильтр 1060а, который получает представление 1010 аудиоконтента во временной области и формирует остаточный сигнал или сигнал возбуждения 1060b для ACELP кодировщика 1060 с.Кодировщик ACELP создает закодированное возбуждение 1062 на основе сигнала возбуждения или остаточного сигнала 1060b.
Кодировщик аудиосигнала 1000 также включает в себя общий анализатор сигналов 1070, который сконфигурирован для получения представления аудиоконтента 1010 во временной области и предоставления на его основе информации формирования спектра 1040а и информации коэффициентов. LPC фильтра 1040b, а также закодированную дополнительную информацию, необходимую для декодирования текущего аудиофрейма. Таким образом, общий анализатор сигналов 1070 формирует информацию формирования спектра 1040а с использованием психоакустического анализа 1070а, если текущий аудиофрейм кодируется в режиме частотной области, а также формирует закодированную информацию коэффициентов масштабирования, если текущий аудиофрейм кодируется в режиме частотной области. Информация коэффициентов масштабирования, которая используется для формирования спектра, обеспечивается при помощи психоакустического анализа 1070а, а закодированная информация коэффициентов масштабирования, в виде коэффициентов масштабирования 1070b, входит в поток битов 1012 аудиофрейма, закодированного в режиме частотной области.
Для аудиофрейма, закодированного в суб-режиме ТСХ режима линейного предсказания, общий анализатор сигналов 1070 создает информацию для формирования спектра (информацию сформированного спектра) 1040а с помощью анализа линейного предсказания 1070 с.Анализ линейного предсказания 1070 с формирует набор коэффициентов LPC фильтра, который преобразуется в спектральное представление линейного предсказания для MDCT блока 1070d. Таким образом, информация сформированного спектра 1040а получается из коэффициентов LPC фильтра при LP анализе 1070 с, как описано выше. Следовательно, для аудиофрейма, закодированного в суб-режиме возбуждения закодированного преобразования режима линейного предсказания, общий анализатор сигналов 1070 создает информацию формирования спектра 1040а на основе анализа линейного предсказания 1070 с (а не на основе психоакустического анализа 1070а), а также формирует закодированную информацию коэффициентов LPC фильтра, а не закодированную информацию коэффициентов масштабирования, для включения в поток битов 1012.
Кроме того, для аудиофрейма, кодирующегося в суб-режиме ACELP режима линейного предсказания, анализ линейного предсказания 1070 с в общем анализаторе сигналов 1070 позволяет передать информацию коэффициентов 1040b LPC фильтра на LPC-фильтр 1060а в ветви ACELP обработки сигналов 1060. В этом случае общий анализатор сигналов 1070 формирует закодированную информацию коэффициентов LPC-фильтра для включения в поток битов 1012.
Подводя итог вышесказанному, аналогичный путь обработки сигнала используется для частотного режима и суб-режима ТСХ режима линейного предсказания. Тем не менее, оконная операция применяется до этого или в комбинации с MDCT, а размерность MDCT 1030а может варьироваться в зависимости от режима кодирования. Тем не менее, режим частотной области и суб-режим ТСХ режима линейного предсказания отличаются тем, что закодированная информация коэффициентов масштабирования включается в поток битов в частотной области, в то время как закодированная информация коэффициентов LPC фильтра включается в поток битов в режиме линейного предсказания. В ACELP суб-режиме режима линейного предсказания, закодированное ACELP возбуждение и закодированная информация коэффициентов LPC фильтра включаются в поток битов.
5. Декодировщик аудиосигнала в соответствии с фиг.11
5,1. Обзорная информация по декодировщику
Далее будет описан декодировщик аудиосигнала, который способен декодировать закодированное представление аудиоконтента, созданное кодировщиком аудиосигнала, описанным выше.
Декодировщик аудиосигналов 1100 в соответствии с фиг.11 настроен на получение закодированного представления 1110 аудиоконтента и обеспечивает формирование, на его основе, декодированного представления 1112 аудиоконтента. Кодировщик аудиосигнала 1110 включает в себя дополнительный блок деформатирования выходного потока битов 1120, который настроен на прием битов, составляющих представление закодированного аудиоконтента 1110 и извлечение закодированного представления аудиоконтента из указанного потока битов, в результате чего происходит извлечение закодированного представления 1110' аудиоконтента.
Дополнительный блок деформатирования выходного потока битов 1120 может извлечь из потока битов закодированную информацию коэффициентов масштабирования, закодированную информацию коэффициентов LPC- фильтра и, в результате, получить дополнительную информацию управления или дополнительную информацию об усилении сигнала.
Декодировщик аудиосигналов 1100 также включает в себя определитель спектральных значений 1130, настроенный на получение нескольких наборов 1132 декодированных спектральных коэффициентов для нескольких частей (например, дублирующихся или неперекрывающихся аудиофреймов) аудиоконтента. Наборы декодированных спектральных коэффициентов могут быть дополнительно предварительно обработаны с помощью препроцессора 1140, при этом создается предварительно обработанный набор 1132' декодированных спектральных коэффициентов.
Декодировщик аудиосигналов 1100 также включает в себя спектральный процессор 1150, настроенный на применение операции формирования спектра к набору 1132 декодированных спектральных коэффициентов, или их предварительно обработанных версий 1132', в зависимости от набора 1152 параметров области линейного предсказания для части аудиоконтента (например, аудиофрейма), закодированной в режиме линейного предсказания, и применение операции формирования спектра к набору 1132 декодированных спектральных коэффициентов, или их предварительно обработанных версий 1132', в зависимости от набора 1154 параметров коэффициентов масштабирования для части аудиоконтента (например, аудиофрейма), закодированной в режиме частотной области. Соответственно, спектральный процессор 1150 получает спектрально сформированный набор 1158 декодированных спектральных коэффициентов.
Декодировщик аудиосигналов 1100 также содержит преобразователь из частотной области во временную область 1160, который настроен на получение спектрально сформированного набора 1158 декодированных спектральных коэффициентов и получения представления во временной области 1162 аудиоконтента на основе спектрально сформированного набора 1158 декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме линейного предсказания. Преобразователь из частотной области во временную область 1160 также настраивается на получение представления во временной области 1162 аудиоконтента на основе соответствующего спектрально сформированного набора 1158 декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме частотной области.
Декодировщик аудиосигналов 1100 также включает в себя дополнительный процессор во временной области 1170, который дополнительно выполняет последующую (пост-) обработку во временной области для представления 1162 аудиоконтента во временной области, и получения представления декодированного аудиоконтента 1112. Тем не менее, при отсутствии пост-процессора во временной области 1170, декодированное представление 1112 аудиоконтента может быть эквивалентно представлению 1162 аудиоконтента во временной области, предоставляемому преобразователем из частотной области во временную область 1160.
5,2 Дополнительные детали
Далее будет представлена более подробная информация об декодировщике 1100, в которой подробно будут рассмотрены дополнительные улучшения при декодировании аудиосигнала.
Следует отметить, что декодировщик аудиосигналов 1100 является многорежимным декодировщиком аудиосигнала, который способен обрабатывать закодированные представления сигнала, причем последовательные части (например, дублирующие или неперекрывающиеся аудиофреймы) аудиоконтента кодируется с использованием различных режимов. Далее аудиофреймы будут рассматриваться в качестве простых примеров участков аудиоконтента. Так как аудиоконтент подразделяются на аудиофреймы, особенно важно иметь плавные переходы между декодированными представлениями последовательных (частично перекрывающихся или не перекрывающихся) аудиофреймов, закодированных в одинаковых режимах, а также между последовательными (перекрывающимися или неперекрывающимися) аудиофреймами, закодированными в различных режимах. Предпочтительно, чтобы декодировщик аудиосигналов 1100 обрабатывал такие представления аудиосигнала, в которых последовательные аудиофреймы накладываются друг на друга примерно на 50%, несмотря на то, что перекрытие может быть значительно меньше, в отдельных случаях и/или для некоторых переходов.
По этой причине, декодировщик аудиосигналов 1100 включает в себя блок перекрытия, настроенный на перекрытие и суммирование представлений во временной области последовательных аудиофреймов, закодированных в различных режимах. Блок перекрытия может, например, быть частью преобразователя из частотной области во временную область 1160, или может быть расположен на выходе преобразователя из частотной области во временную область 1160. Для того чтобы получить высокую эффективность и хорошее качество при перекрытии последовательных аудиофреймов, преобразователь из частотной области во временную область настроен на получение представления аудиофрейма во временной области, закодированного в режиме линейного предсказания (например, для суб-режима преобразования кодирования возбуждения) с помощью преобразования перекрытия, а также получение представления аудиофрейма во временной области, закодированного в режиме частотной области с использованием преобразования перекрытия. В этом случае блок перекрытия настроен на перекрытие во временной области представлений последовательных аудиофреймов, закодированных в различных режимах. С помощью такого синтеза преобразования перекрытия для переходов из частотной области к временной области, которые предпочтительно могут иметь одинаковый тип преобразований аудиофреймов, закодированных в различных режимах, можно использовать критическую выборку [в соответствии с теоремой Найквиста], при этом будут сведены к минимуму затраты, вызванные операцией перекрытия и сложения. В этом случае также происходит отмена алиасинга во временной области между перекрывающимися во временной области частями представлений последовательных аудиофреймов. Следует отметить, что возможность получения отмены алиасинга во временной области при переходе между последовательными аудиофреймами, закодированными в различных режимах, вызвана тем, что преобразование из частотной области во временную область применяется к одной и той же области в различных режимах, так, что выходной сигнал после синтеза преобразования перекрытия, использующийся для формирования спектра первого аудиофрейма, закодированного в первом режиме, в виде набора декодированных спектральных коэффициентов, может непосредственно суммироваться (например, суммироваться без операции промежуточной фильтрации) с выходом преобразования перекрытия, выполняемого при формировании спектра последующего аудиофрейма, закодированного во втором режиме, в виде набора декодированных спектральных коэффициентов. Таким образом, выполняется линейная комбинация выхода преобразования перекрытия, выполняемого для аудиофрейма, закодированного в первом режиме, и выхода преобразования перекрытия для аудиофрейма, закодированного во втором режиме. Естественно, что соответствующие оконные операции перекрытия могут быть выполнены как часть процесса преобразования перекрытия или последующего процесса преобразования перекрытия.
Соответственно, отмена алиасинга во временной области получается с помощью простого перекрытия и сложения между представлениями последовательных аудиофреймов во временной области, закодированными в различных режимах.
Другими словами, важно, что преобразователь из частотной области во временную область 1160 создает выходные сигналы во временной области, которые находятся в одной и той же области для обоих режимов. Тот факт, что выходные сигналы, преобразованные из частотной области во временную область (например, при преобразовании перекрытия в сочетании с соответствующей оконной операцией перехода), находятся в одной и той же области для обоих режимов означает, что выходные сигналы при преобразовании из частотной области во временную область могут линейно комбинироваться даже при переходе между различными режимами. Например, оба выходных сигнала при преобразовании из частотной области во временную область являются представлениями аудиоконтента во временной области, описывающими изменения сигнала громкоговорителя во времени. Другими словами, представления 1162 аудиоконтента во временной области для последовательных аудиофреймов могут быть обработаны обычным образом для получения сигналов громкоговорителя.
Кроме того, следует отметить, что спектральный процессор 1150 может включать в себя формирователь параметров 1156, который настроен на предоставление набора 1152 параметров области линейного предсказания и получение параметров коэффициентов масштабирования 1154 на основе информации, извлеченной из битового потока 1110, например, закодированной информации коэффициентов масштабирования и закодированной информации параметров LPC фильтра. Формирователь параметров 1156 может, например, содержать определитель коэффициентов LPC фильтра, настроенный на получение декодированных коэффициентов LPC фильтра на основе закодированного представления коэффициентов LPC фильтра для части аудиоконтента, закодированной в режиме линейного предсказания. Кроме того, формирователь параметров 1156 может включать в себя преобразователь коэффициентов фильтра, настроенный на преобразование декодированных коэффициентов LPC фильтра в спектральное представление с целью получения значений усиления в режиме линейного предсказания, связанных с различными частотами. Значения усиления в режиме линейного предсказания (иногда обозначаемые g[k]) могут представлять собой набор 1152 параметров области линейного предсказания.
Формирователь параметров 1156 может дополнительно содержать определитель коэффициентов масштабирования, настроенный на получение декодированных значений коэффициентов масштабирования на основе закодированного представления значений коэффициентов масштабирования аудиофрейма, закодированного в режиме частотной области. Декодированные значения коэффициентов масштабирования могут использоваться в качестве набора 1154 параметров коэффициентов масштабирования.
Таким образом, формирование спектра, которое можно рассматривать как изменение спектра, настроенное на выполнение суммирования набора декодированных спектральных коэффициентов 1132, связанных с аудиофреймом, закодированным в режиме линейного предсказания, или его предварительно обработанной версии 1132', со значениями усиления в режиме линейного предсказания (составляющих набор параметров области линейного предсказания 1152), для получения обработанных значений усиления (т.е. сформированного спектра) версии 1158 декодированных спектральных коэффициентов 1132, причем вклад декодированных спектральных коэффициентов 1132, или их предварительно обработанных версий 1132', масштабируется в зависимости от значений усиления в режиме линейного предсказания. Кроме того, преобразователь спектра может быть настроен на суммирование набора 1132 декодированных спектральных коэффициентов, связанных с аудиофреймом, закодированным в режиме частотной области, или его предварительно обработанной версии 1132', со значениями коэффициента масштабирования (которые составляют набор 1154 параметров коэффициентов масштабирования) для получения обработанных коэффициентов масштабирования (например, спектрально сформированной) версии 1158 декодированных спектральных коэффициентов 1132, причем вклад декодированных спектральных коэффициентов 1132, или их предварительно обработанной версии 1132', масштабируется в зависимости от значений коэффициентов масштабирования (набора 1154 параметров коэффициентов масштабирования). Таким образом, первый тип формирования спектра, а именно формирование спектра в зависимости от набора 1152 параметров области линейного предсказания, осуществляется в режиме линейного предсказания, а второй тип формирования спектра, а именно формирование спектра в зависимости от набора 1154 параметров коэффициентов масштабирования, производится в режиме частотной области. Таким образом, вредное воздействие шумов дискретизации представления во временной области 1162 остается небольшим как для речевых фреймов, таких как аудиофреймы (для которых формирование спектра предпочтительно проводить в зависимости от набора 1152 параметров области линейного предсказания), так и для аудиофреймов общего вида, например, неречевого типа, таких как аудиофреймы, для которых формирование спектра предпочтительно проводить в зависимости от набора 1154 параметров коэффициентов масштабирования. Однако, выполняя ограничение шума при помощи формирования спектра как для речевых, так и неречевых аудиофреймов, т.е. как для аудиофреймов, закодированных в режиме линейного предсказания и аудиофреймов, закодированных в режиме частотной области, многорежимный аудиодекодировщик 1100 включает в себя структуры небольшой сложности, обеспечивающие в то же время устранение алиасинга путем перекрытия и сложения представлений аудиофреймов во временной области 1162, закодированных в различных режимах.
Другие подробности будут описаны ниже.
6. Декодировщик аудиосигнала в соответствии с фиг.12
На фиг.12 показана блок-схема декодирования аудиосигнала 1200, в соответствии с другим вариантом изобретения. На фиг.12 показано представление декодировщика единого речевого и аудиокодирования (USAC) с преобразованием возбуждения модифицированного дискретного косинус-преобразования (TCX-MDCT) в области сигнала.
Декодировщик аудиосигналов 1200 в соответствии с фиг.12 содержит поток битов демультиплексора 1210, который может принимать функцию блока деформатирования выходного потока битов 1120. Поток битов демультиплексора 1210 извлекается из потока битов, представляющих аудиоконтент закодированного представления аудиоконтента, который может содержать закодированные спектральные значения и дополнительную информацию (например, информацию закодированных коэффициентов масштабирования и закодированную информацию параметров LPC фильтра).
Декодировщик аудиосигналов 1200 также включает в себя переключатели 1216, 1218, которые предназначены для распределения компонентов закодированных представлений аудиоконтентов, сформированных в потоке битов демультиплексора для различных компонентов обрабатываемых блоков сигналов аудиодекодировщика 1200. Например, декодировщик аудиосигналов 1200 включает в себя комбинированную ветвь 1230 с режимом частотной области/суб-режимом ТСХ, которая получает от переключателя 1216 закодированные представления 1228 в частотной области и формирует, на его основе, представление 1232 аудиоконтента во временной области декодировщика аудиосигналов 1200, включающего также ACELP декодировщик 1240, который настроен на получение от переключателя 1216 информации закодированнного возбуждения ACELP 1238 и получение на этой основе представления 1242 аудиоконтента во временной области.
Декодировщик аудиосигналов 1200 также включает в себя формирователь параметров 1260, который настроен на получение от переключателя 1218 информации закодированных коэффициентов масштабирования 1254 для аудиофрейма, кодирующегося в режиме частотной области и закодированной информации коэффициентов LPC-фильтра 1256 для аудиофрейма, закодированного в режиме линейного предсказания, который включает в себя суб-режим ТСХ и суб-режим ACELP. Формирователь параметров 1260 также настроен на получение управляющей информации 1258 от переключателя 1218. Формирователь параметров 1260 настроен на получение информации формирования спектра 1262 для комбинированной ветви 1230 с режимом частотной области/суб-режимом ТСХ. Кроме того, формирователь параметров 1260 настроен на передачу информации коэффициентов 1264 LPC фильтра на ACELP декодировщик 1240.
Комбинированная ветвь 1230 с режимом частотной области/суб-режимом ТСХ может содержать декодировщик энтропии 1230а, который получает закодированную информацию частотной области 1228 и формирует, на ее основе, декодированную информацию частотной области 1230b, которая подается в блок деквантования [цифроаналоговое преобразование] 1230с. Блок деквантования 1230с обеспечивает получение, на основе декодированной информации в частотной области 1230b, декодированной и деквантованной 1230d информации в частотной области, например, в виде набора декодированных спектральных коэффициентов. Сумматор 1230е настроен на суммирование декодированной и деквантованной 1230d информации в частотной области с информацией формирования спектра 1262 для получения информации формирования спектра в частотной области 1230f. Обратное модифицированное дискретное косинусное преобразование 1230g получает информацию формирования спектра в частотной области 1230f и создает, на ее основе, представление аудиоконтента во временной области 1232.
Декодировщик энтропии 1230а, блок деквантования 1230с и обратное модифицированное дискретное косинусное преобразование 1230g могут получать некоторую дополнительную контрольную информацию, которая может вводиться или извлекаться из потока битов формирователем параметров 1260.
Формирователь параметров 1260 включает в себя декодировщик коэффициентов масштабирования 1260а, который получает закодированную информацию коэффициентов масштабирования 1254 и формирует декодированную информацию коэффициентов масштабирования 1260b. Формирователь параметров 1260 также включает в себя декодировщик 1260с LPC коэффициентов, который настроен на прием закодированной информации коэффициентов LPC фильтра 1256 и создание на ее основе декодированной информации коэффициентов LPC фильтра 1260d для преобразователя коэффициентов 1260е фильтра. Кроме того, декодировщик 1260 с LPC коэффициентов предоставляет информацию коэффициентов LPC-фильтра 1264 для ACELP декодировщика 1240. Преобразователь коэффициентов фильтра 1260е настроен на преобразование LPC коэффициентов фильтра 1260d в частотную область (также называемую спектральной областью) с последующим формированием значений усиления в режиме линейного предсказания 1260Гдля коэффициентов LPC фильтра 1260d. Кроме того, формирователь параметров 1260 настроен на выборочное получение, например, с помощью переключателя 1260g, декодированных коэффициентов масштабирования 1260b или значений усиления в режиме линейного предсказания 1260f в качестве информации для формирования спектра 1262.
Следует отметить, что кодировщик аудиосигнала 1200 в соответствии с фиг.12 может быть дополнен рядом дополнительных этапов предварительной обработки и постобработки. Этапы предварительной обработки и пост-обработки могут быть различными для различных режимов.
Некоторые подробности будут описаны далее.
7. Поток сигналов в соответствии с фиг.13
Далее будет описан возможный поток сигналов со ссылкой на фиг.13. Поток сигналов 1300 в соответствии с фиг.13 может возникать в декодировщике аудиосигналов 1200 в соответствии с фиг.12.
Следует отметить, что прохождение сигнала 1300 на фиг.13 для простоты описывает работу только в режиме частотной области и суб-режиме ТСХ режима линейного предсказания. Однако декодирование в суб-режиме ACELP режима линейного предсказания может быть сделано способом, описанным со ссылкой на фиг.12.
Общая ветвь 1230 режима частотной области/суб-режима ТСХ получает закодированную информацию частотной области 1228. Закодированная информация частотной области 1228 может включать в себя так называемые арифметически закодированные спектральные данные 'ac_spectral_data', которые извлекаются из потока битов канала частотной области ('fd_channel_stream') в режиме частотной области. Закодированная информация частотной области 1228 может включать в себя так называемое ТСХ кодирование ('tcx_coding')>, которое может быть извлечено из потока битов канала частотной области ('Ipd_channel_stream') в суб-режиме ТСХ. Декодирование энтропии 1330а может осуществляться декодировщиком энтропии 1230а. Например, декодирование энтропии 1330а может быть выполнено с использованием арифметического декодировщика. Соответственно, дискретизированные спектральные коэффициенты 'x_ac_quant' получены для закодированных аудиофреймов в частотной области, а дискретизированные спектральные коэффициенты 'x_tex_quant' режима ТСХ получены для аудиофреймов, закодированных в режиме ТСХ. Дискретизированные спектральные коэффициенты режима частотной области и спектральные коэффициенты режима ТСХ могут быть целыми числами в некоторых воплощениях изобретения. Декодирование энтропии позволяет, например, совместно декодировать закодированные группы спектральных коэффициентов контекстно-зависимым способом. Кроме того, число битов, необходимых для кодирования определенного спектрального коэффициента, может варьироваться в зависимости от магнитуды спектральных коэффициентов, например, что большее число бит в закодированном слове необходимо для кодирования спектральных коэффициентов, имеющих сравнительно большую магнитуду.
Затем будет выполняется, например, с помощью блока деквантования 1230 с, деквантование 1330 с дискретизированных спектральных коэффициентов в режиме частотной области и дискретизированных спектральных коэффициентов в режиме ТСХ. Деквантование может быть описано следующей формулой:
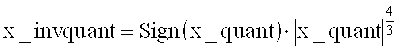
Соответственно, деквантованные спектральные коэффициенты ('x_ac_invquant') в частотном режиме могут быть получены для аудиофреймов, закодированных в режиме частотной области, и деквантованные спектральные коэффициенты ('x_tcx_invquant') могут быть получены в режиме ТСХ для аудиофреймов, закодированных в суб-режиме ТСХ.
7.1 Обработка аудиофреймов, закодированных в частотной области Далее будут обобщены вопросы обработки в режиме частотной области. В режиме частотной области, заполнение шумом 1340 дополнительно применяется в частотном режиме к деквантованным спектральным коэффициентам для получения версии с заполнением шумом 1342 деквантованных спектральных коэффициентов 1330d ('x_acjnvquant') в частотном режиме. Затем может быть выполнено масштабирование, обозначенное цифрой 1344, версии с заполнением шумом 1342 деквантованных спектральных коэффициентов в частотном режиме. При масштабировании параметры коэффициентов масштабирования (также называемые для краткости коэффициентами масштабирования или sf[g] [sfb]) применяются для масштабирования деквантованных спектральных коэффициентов ('x_ac_invquant') в частотном режиме 1342. Например, различные коэффициенты масштабирования могут быть связаны с спектральными коэффициентами различных частотных диапазонов (диапазонов частот или диапазонов коэффициентов масштабирования). Соответственно, деквантованные спектральные коэффициенты 1342 могут умножаться на соответствующие коэффициенты масштабирования для получения масштабированных спектральных коэффициентов 1346. Масштабирование 1344 предпочтительно выполнять, как описано в международном стандарте ISO/IEC 14496-3, подраздел 4, подпункты 4.6.2 и 4.6.3. Масштабирование 1344 может, например, выполняться с помощью сумматора 1230е. Таким образом, в режиме частотной области получается масштабированная (и, следовательно, спектрально сформированная) версия спектральных коэффициентов 1346 'x-escal', что может быть эквивалентно представлению в частотной области 1230f. Впоследствии комбинация mid/side обработки 1348 и процедуры ограничения шума во времени 1350 может быть выполнена на основе масштабированной версии 1346 спектральных коэффициентов в режиме частотной области для получения постобработанной версии 1352 масштабированных спектральных коэффициентов в режиме частотной области 1346. Дополнительная mid/side обработка 1348 может выполняться, например, как описано в ISO/IEC 14496-3: 2005, информационные технологии кодирования аудио- и видеообъектов - часть 3: Аудио, подраздел 4, подпункт 4,6.8.1. Дополнительное ограничение шума во времени может быть выполнено, как описано в ISO / IEC 14496-3: 2005, информационные технологии кодирования аудио- и видео-объектов - часть 3: Аудио, подраздел 4, подпункт 4.6.9.
Затем улучшенное обратное дискретное косинусное преобразование 1354 может быть применено к масштабированной версии 1346 спектральных коэффициентов в режиме частотной области или их обработанной версии 1352. Следовательно, получается представление во временной области 1356 аудиоконтента текущего обрабатываемого аудиофрейма. Представление во временной области 1356 также обозначается xi, n. В качестве упрощающего предположения, можно предположить, что есть только одно представление xi, n для аудиофрейма во временной области. Тем не менее, в некоторых случаях, в которых несколько окон (например, так называемые 'короткие окна') связаны с одним аудиофреймом, аудиофрейма может иметь множество представлений во временной области xi, n.
Затем оконная операция 1358 применяется к представлению во временной области 1356, чтобы получить оконное представление во временной области 1360, которое также обозначается zi, n. Таким образом, в упрощенном варианте, в котором есть одно окно для аудиофрейма, одно оконное представление во временной области 1360 получается для аудиофрейма, закодированного в режиме частотной области. 7.2. Обработка аудиофрейма, закодированного в режиме ТСХ Далее будет описана обработка фреймов, закодированных полностью или частично в режиме ТСХ. Что касается этого вопроса, следует отметить, что аудиофрейм может быть разделен на несколько, например, четыре суб-фрейма, которые могут быть закодированы в различных суб-режимах в режиме линейном предсказания. Например, суб-фреймы аудиофрейма выборочно могут быть закодированы в суб-режиме ТСХ режима линейного предсказания или в суб-режиме ACELP режима линейного предсказания. Соответственно, каждый из суб-фреймов может быть закодирован таким образом, что будет достигнута оптимальная эффективность кодирования или оптимальный компромисс между качеством звука и битрейтом. Например, с использованием массива под названием 'mod []' в поток битов для аудиофрейма, закодированного в режиме линейного предсказания, могут быть включены соответствующие сигналы, указывающие какой из суб-фреймов указанного аудиофрейма закодирован в суб-режиме ТСХ, а какие закодированы в суб-режиме ACELP. Тем не менее, следует отметить, что представленную концепцию наиболее просто понять, если предположить, что весь фрейм кодируется в режиме ТСХ. В остальных случаях, в которых аудиофреймы включают в себя два подфрейма, ТСХ следует рассматривать как дополнительное расширение указанной концепции.
Если предположить, что весь фрейм кодируется в режиме ТСХ, то можно заметить, что заполнение шумом 1370 применяется к деквантованным спектральным коэффициентам режима ТСХ 1330d, который также обозначается как 'quant[]' Таким образом, получается заполнение шумом набора спектральных коэффициентов 1372 в режиме ТСХ, которые также обозначаются как 'r[i]'. Кроме того, вновь сформированный спектр 1374 применяется к заполненному шумом набору спектральных коэффициентов 1372 режима ТСХ, для получения вновь сформированного набора 1376 спектральных коэффициентов режима ТСХ, который также обозначается как 'r[i]'. Затем применяется формирование спектра 1378, причем формирование спектра осуществляется в зависимости от значений усиления области линейного предсказания, которые получаются из закодированных LPC коэффициентов, описывающих отклик фильтра кодирования с линейным предсказанием (LPC). Формирование спектра 1378, например, может быть выполнено с использованием сумматора 1230а. Таким образом, получается восстановленный набор 1380 спектральных коэффициентов режима ТСХ, также обозначаемый 'rr[i]'. Далее применяется обратная операция MDCT 1382 с использованием восстановленного набора 1380 спектральных коэффициентов режима ТСХ для получения представления 1384 фрейма во временной области (или, дополнительно, подфрейма), закодированного в режиме ТСХ. Затем выполняется новое масштабирование 1386 для представления 1384 фрейма (или подфрейма) во временной области, закодированного в режиме ТСХ, для получения представления 1388, заново масштабированного во временной области, для фрейма (или подфрейма), закодированного в режиме ТСХ, в котором заново масштабированное во временной области представление также обозначено 'xw[i]'. Следует отметить, что масштабирование 1386, как правило, выполняется с равномерным масштабом для значений во всех временных областях для фреймов, закодированных в режиме ТСХ, или подфреймов, закодированных в режиме ТСХ. Таким образом, масштабирование 1386, как правило, не вызывает собственных частотных искажений, потому что оно не является избирательным по частоте.
После масштабирования 1386, применяется оконная операция 1390 для заново масштабированного представления во временной области 1388 фреймов (или подфреймов), закодированных в режиме ТСХ. Таким образом, получаются выборки 1392 оконной операции во временной области (также обозначаемые zi, n, которые представляют собой аудиоконтент фрейма (или подфрейма), закодированного в режиме ТСХ.
7.3. Процедура перекрытия и сложения
Представления во временной области 1360, 1392 из последовательности фреймов суммируются с помощью процедуры 1394 перекрытия и сложения. При процедуре перекрытия и сложения, выборки во временной области правосторонняя (более поздняя во времени) часть первого аудиофрейма накладывается и суммируется с выборкой во временной области левосторонней (более ранней во времени) частью последующего второго аудиофрейма. Это процедура перекрытия и сложения 1394 осуществляется как для последовательных аудиофреймов, закодированных в одном и том же режиме, так и для последовательных аудиофреймов, закодированных в различных режимах. Исключение алиасинга во временной области осуществляется с помощью процедуры перекрытия и сложения 1394, даже если кодируются последовательные аудиофреймы в различных режимах (например, в режиме частотной области и в режиме ТСХ) в связи с особенностями структуры аудиодекодировщика, которая позволяет избежать эффекта искажения между выходом обратной процедуры MDCT 1954 и процедурой перекрытия и сложения 1394, а также между выходами обратной процедуры MDCT 1382 и процедуры перекрытия и сложения 1394. Другими словами, отсутствуют дополнительные этапы обработки между обратными процедурами MDCT 1354,1382 и процедурой перекрытия и сложения 1394, за исключением оконных операций 1358,1390 и масштабирования 1386 (и, дополнительно, спектрально не искажающего суммирования при предварительной фильтрации и обработке).
8. Детальное описание MDCT на основе ТСХ
8.1. Описание MDCT на основе инструментов ТСХ
Когда основным режимом является режим линейного предсказания (который задается с помощью приравнивания к единице переменной 'core_mode' потока битов), и когда для одного или более из трех режимов ТСХ (например, на выходе первого режима ТСХ формируется участок ТСХ из 512 выборок, в том числе 256 выборок перекрытия, на выходе второго режима ТСХ создается 768 выборок во временной области, в том числе 256 выборок перекрытия, а на выходе третьего режима ТСХ формируется 1280 выборок ТСХ, в том числе 256 выборок перекрытия) выбирается кодирование в 'области линейного предсказания', т.е. если один из четырех элементов массива 'mod[x]' больше нуля (в котором четыре элемента массива mod[0], mod[1], mod[2], mod[3] получены из потока битов переменных и указывают на суб-режимы LPC для четырех суб-фреймов текущего фрейма, т.е. указывают, кодируется ли подфрейм в суб-режиме ACELP режима линейного предсказания или в суб-режиме ТСХ режима линейного предсказания, а также указывают какая используется кодировка: является ли ТСХ кодирование сравнительно длинным, средней длины или коротким), используется MDCT, основанное на инструментах ТСХ. Другими словами, инструмент ТСХ используется в случае, если один из суб-фреймов текущего аудиофрейма кодируется в суб-режиме ТСХ режима линейного предсказания. MDCT на основе ТСХ получает дискретизированные спектральные коэффициенты от арифметического декодировщика (которые могут быть получены в реализации декодировщика энтропии 1230а или при декодировании энтропии 1330а). Дискретизированные коэффициенты (или их деквантованные версии 1230b), прежде всего, характеризуются комфортным уровнем шума (который может быть создан при операции заполнения шумом 1370). LPC, основанный на ограничении шума в частотной области, применяется затем к полученным спектральным коэффициентам (например, с использованием сумматора 1230е или операции формирования спектра 1378) (или его спектрально сформированной версии), и для получения синтезированного сигнала во временной области выполняется обратное преобразование MDCT (которое может быть реализовано с помощью MDCT 1230g или обратной операции MDCT 1382).
8.2. MDCT на основе определений ТСХ
Далее будут приведены некоторые определения.
'lg' обозначает число дискретизированных спектральных коэффициентов на выходе арифметического декодировщика (например, для аудиофрейма, закодированного в режиме линейного предсказания).
Переменная потока битов 'noise_factor' обозначает уровень шума индекса дискретизации.
Переменная 'noise_factor' обозначает уровень шума, вводимого в реконструированный [восстановленный] спектр.
Переменная 'noise []' обозначает вектор генерируемого шума.
Переменная потока битов 'global_gain' обозначает усиление индекса дискретизации при повторном масштабировании.
Переменная 'g' обозначает усиление при повторном масштабировании.
Переменная 'rms' обозначает среднеквадратичное отклонение синтезированного сигнала во временной области 'x []'.
Переменная 'x []' обозначает синтезированный сигнал во временной области.
8.3. Процесс декодирования
MDCT, основанный на ТСХ, запрашивает от арифметического декодировщика 1230а набор дискретизированных спектральных коэффициентов, lg, которые определяются значениями mod[] (т.е. значениями переменной mod[]). Это значение (т.е. значение переменной mod[]) определяет также длину и форму окна, которое будет применяться в обратной процедуре MDCT 1230g (или обратной процедуре MDCT 1382 и соответствующей оконной операции 1390). Окно состоит из трех частей, левой стороны перекрытия из L выборок (также называемая левосторонним склоном переходного участка), средней части из М выборок и правой части перекрытия (также называемой правосторонним склоном переходного участка) из R выборок. Для получения окна MDCT длиной 2*lg, ZL нули добавляются с левой стороны и ZR нули добавляются с правой стороны.
В случае перехода или при 'short_window' соответствующая область перекрытия L или R, возможно, должна быть сокращена до 128 (выборок) для адаптации к возможно более коротким склонам окна 'short_window'. Следовательно, М область и соответствующие обе нулевые области ZL и ZR, возможно, должны быть расширены на 64 выборки.
Другими словами, как правило, имеет место перекрытие из 256 выборок = L=R. Оно уменьшается до 128 в случае перехода от режима FD к режиму LPD.
Схема на фиг.15 показывает набор спектральных коэффициентов как функцию от mod[], а также количество выборок во временной области для левой нулевой области ZL, левой L области перекрытия, средней М части, правой области перекрытия R и правой нулевой области ZR.
Окно MDCT задается следующим образом:
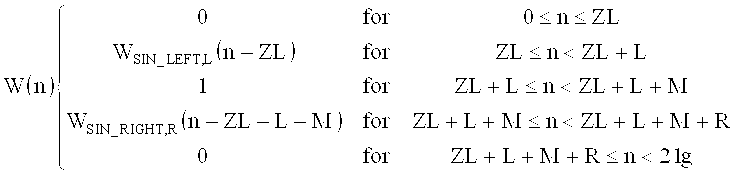
Определения для WSIN_LEFT, L и WSIN_RIOHT,R будут приведены ниже.
Окно MDCT W (n) применяется в оконной операции 1390, которая может рассматриваться как часть обратной оконной операции MDCT (например, обратной операции MDCT 1230g).
Дискретизированные спектральные коэффициенты, обозначенные также как 'quant []', которые получаются в арифметическом декодировщике 1230а (или, альтернативно, при обратной дискретизации в блоке деквантования 1230 с), формируют комфортный уровень шума. Уровень введенного шума определяется декодированной переменной потока битов 'noise factor' следующим образом:
noisejevel=0.0625*(8-noise_factor)
Затем вычисляется вектор шума, также обозначенный 'noise[]', с помощью случайной функции, обозначенной 'randomsign()', принимающей значения -1 или 1. Справедливо соотношение:
noise[i]=random_sign()*noise_level;
Векторы 'quant[]' и 'noise[i]' суммируются в реконструированном векторе спектральных коэффициентов, также обозначенном 'r[]', таким образом, что 8 последовательных нулей в 'quant[]' заменяются компонентами 'noise[]' Замененные 8 ненулевых значений определяются в соответствии со следующей формулой:
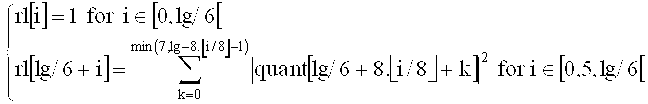
Восстановленный спектр получается следующим образом:
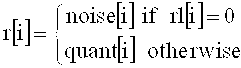
Описанное выше наполнение шумом может быть выполнено как пост-обработка между декодированием энтропии, выполненным декодировщиком энтропии 1230а и суммированием, выполненным сумматором 1230е.
Новая операция формирования спектра применяется к реконструированному спектру (например, восстановленному спектру 1376, r[i]) в соответствии со следующими этапами:
1. вычисляется энергия Em 8-мерного блока с индексом m для каждого 8-мерного блока в первой четверти спектра
2. вычисляется коэффициент Rm=sqrt(Em/EI), где I является индексом блока с максимальным значением из всех Em
3. если Rm<0.1, то набор Rm=0.1
4. если Rm<Rm-1, то набор Rm=Rm-1.
Каждый 8-мерный блок, относящиеся к первой четверти спектра, умножается на коэффициент Rm.
Операция формирования спектра будет производиться при пост-обработке, находящейся на пути сигнала между декодировщиком энтропии 1230а и сумматором 1230е. Операция формирования спектра может, например, создать вновь сформированный спектр 1374.
Перед применением обратной операции MDCT, создаются два дискретизированных LPC фильтра, соответствующие краям блока MDCT (т.е. левой и правой точкам свертки), вычисляются их взвешенные версии, и вычисляются соответствующие уничтожаемые спектры (64 точки, независимо от длины преобразования).
Иными словами, для первого промежутка времени получается первый набор коэффициентов LPC фильтра, а для второго промежутка определяется второй набор LPC коэффициентов фильтра. Наборы LPC коэффициентов фильтра предпочтительно получать на основе закодированного представления указанных коэффициентов LPC фильтра, которые входят в поток битов. Первый промежуток времени желательно задавать сразу после или перед началом текущего кодируемого ТСХ фрейма (или суб-фрейма), а второй промежуток времени, предпочтительно задавать во время или после окончания закодированного ТСХ фрейма или под- фрейма. Таким образом, эффективный набор коэффициентов LPC фильтра определяется при формировании средневзвешенных коэффициентов первого набора LPC фильтра и коэффициентов второго набора LPC фильтра.
Взвешенные LPC спектры рассчитываются на основе применения нечетного дискретного преобразования Фурье (ODFT) к коэффициентам LPC фильтров. Комплексная модуляция применяется к коэффициентам LPC (фильтра) при вычислении нечетного дискретного преобразования Фурье (ODFT), так что ODFT частотные элементы дискретизации должны (желательно полностью) соответствовать MDCT частотным элементам дискретизации. Например, взвешенный LPC синтезированный спектр данного LPC фильтра A(z) вычисляется следующим образом:
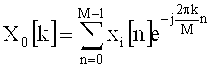
где
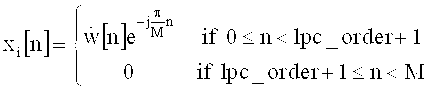
где w[n], n=0…lpc_order+1, являются коэффициентами LPC фильтра, взвешенными по формуле:
W(z)=A(z/γ1), где γ1=0.92.
Другими словами, отклик фильтра LPC во временной области, представленный значениями w[n], с п от 0 до lpc_prder-1, превращается в спектральную область, для получения спектральных коэффициентов Xo[k]. Отклик фильтра LPC во временной области w[n] может быть получен из коэффициентов временной области от a1 до a16, описывающих фильтр кодировки с линейным предсказанием.
Коэффициент усиления g[k] может быть вычислен из спектрального представления Xo[k] коэффициентов LPC (например, от a1 до a16) по следующей формуле:

где М=64 число диапазонов, в которых применяются рассчитанные коэффициенты усиления.
Впоследствии, восстановленный спектр 123 Of, 1380, rr[i] получается в зависимости от расчетного коэффициента усиления g[k] (также называемого значением усиления в режиме линейного предсказания). Например, значение усиления g[k] может быть связано со спектральным коэффициентом 1230d, 1376, r[i]. Кроме того, множество значений усиления может быть связано со спектральным коэффициентом 1230d, 1376, r[i]. Весовой коэффициент a[i] может быть получен из одного или нескольких значений усиления g[k], или весовой коэффициент a[i], в некоторых вариантах, может быть даже идентичен значению усиления g[k]. Следовательно, весовой коэффициент a[i], может быть умножен на соответствующие спектральные значения r[i], чтобы определить вклад спектрального коэффициента r[i] в спектрально сформированный спектральный коэффициент rr[i].
Например, следующее уравнение может содержать:
n-[i]=g[k]-r[i].
Тем не менее, другие соотношения также могут быть использованы.
В приведенном выше примере, переменная k равна i/(lg/64) с учетом того факта, что LPC спектры были уничтожены. Восстановленный спектр гг[] поступает на обратное преобразование MDCT 1230g, 1382. При выполнении обратного преобразования MDCT, которое будут подробно описано ниже, восстановленные значения спектра rr[i] служат в качестве значений частота-время Xi,k, или в качестве частотно-временных значений spec[i][k]. Следующие отношения могут использоваться:
Xi,k=rr[k], или spec[i][k]=rr[k].
Следует отметить здесь, что в приведенных выше рассуждениях по обработке спектра в ветви ТСХ, переменная i является частотным индексом. В противоположность этому, при описании MDCT набора фильтров и блока переключения, переменная i является индексом окна. Специалистам в данной области будет легко понять из контекста, является ли переменная i частотным индексом или индексом окна.
Кроме того, следует отметить, что индекс окна может быть эквивалентен индексу фрейма, если аудиофрейм содержит только одно окно. В случае, если фрейм состоит из нескольких окон, для фрейма может быть несколько значений индекса окна.
Выходной сигнал x[] без оконной обработки будет перемасштабирован с помощью коэффициента усиления g, полученного при обратной дискретизации декодированных глобальных индексов усиления ('global_gain'):
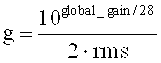
Где rms вычисляется следующим образом:
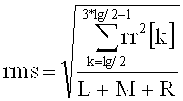
Вновь масштабированный синтезированный во временной области сигнал будет равен: xw[n]=x[n]-g После нового масштабирования применяются оконная операция и операция перекрытия и сложения. Оконную операцию можно выполнить с помощью окна W(n), как описано выше, и с учетом оконных параметров, показанных на фиг.15. Таким образом, получается оконное представление сигнала во временной области zi,n:
zi,n=xw[n]·W(n).
В дальнейшем будет описана концепция, которая полезна, если имеются и ТСХ закодированные фреймы (или аудиоподфреймы) и ACELP закодированные аудиофреймы (или аудиоподфреймы). Кроме того, следует отметить, что коэффициенты LPC фильтра, которые передаются при кодировке ТСХ фреймов или подфреймов, будут использоваться в некоторых вариантах для инициализации ACELP декодирования.
Отметим также, что длина ТСХ синтеза задается длиной ТСХ фрейма (без перекрытия): 256, 512 или 1024 выборок для mod[] 1,2 и 3 соответственно.
В дальнейшем изложении приняты следующие обозначения: x[] обозначает выход обратного модифицированного дискретного косинусного преобразования, z[] - декодированный в оконной операции сигнал во временной области и out [] - синтезированный сигнал во временной области.
Выход обратного модифицированного дискретного косинусного преобразования затем масштабируется и обрабатывается в окне следующим образом:
z[n]=x[n]·w[w]·g; ∀ 0≤n<N
N соответствует размеру MDCT окна, то есть N=2lg.
Когда предыдущий использованный режим кодирования был либо режимом FD, либо режимом MDCT на основе ТСХ, применяется обычное перекрытие и сложение между текущим декодированным оконным сигналом zi,n и предыдущим декодированным оконным сигналом zi-1,n, где индекс i отсчитывает количество уже декодированных MDCT окон. Результат синтеза во временной области out получается по следующим формулам.
В случае, если zi-1,n приходит из режима FD:
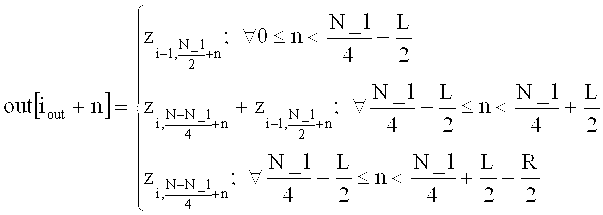
N_l является размером окна для последовательностей, приходящих из режима FD. Индексы i_out выходного буфера увеличиваются на количество записанных выборок
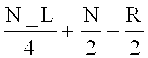
В случае, если zi-1,n приходит из режима MDCT на основе ТСХ:
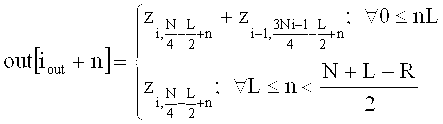
где Ni-1 является размером предыдущего окна MDCT. Индексы i_out выходного буфера out увеличивается на количество (N+L-R)/2 записанных выборок.
В дальнейшем будут описаны некоторые возможности для уменьшения искажений при переходе из фрейма или подфрейма, закодированного в режиме ACELP, к фрейму или подфрейму, закодированному в режиме MDCT на основе ТСХ. Тем не менее, следует отметить, что могут быть использованы и другие подходы.
Далее будет кратко описано первое применение изобретения. При поступлении из ACELP, конкретное окно может использоваться для следующего ТСХ путем уменьшения R до 0, а затем область перекрытия между двумя последовательными фреймами устраняется.
Далее будет кратко описан второй подход (как это описано в USAC WD5 и ранее). При поступлении из ACELP, следующее окно ТСХ увеличивается за счет увеличения М (средней длины) на 128 выборок. В декодировщике правая часть окна, то есть первые R ненулевых декодированных выборок просто отбрасываются и заменяются декодированными выборками ACELP.
Восстановленный синтез out[iout+n] затем фильтруется через корректирующий фильтр (1-0.68z-1). Полученный скорректированный синтез затем фильтруется с помощью фильтра анализа A(z) для получения сигнала возбуждения. Рассчитанное обновление возбуждения ACELP по адаптивной кодовой книге позволяет переключиться от ТСХ на ACELP в следующем фрейме. Коэффициенты фильтра анализа интерполируются на основе подфреймов.
9. Подробности о наборе фильтров и блоке переключения
Далее будут описаны более подробно детали, касающиеся обратного модифицированного дискретного косинусного преобразования и блока переключения, то есть перекрытие и сложение осуществляется между последовательными фреймами и подфреймами. Следует отметить, что обратное модифицированное дискретное косинусное преобразование, описанное далее, можно применять как для аудиофреймов, закодированных в частотной области, так и для аудиофреймов или аудиоподфреймов, закодированных в режиме ТСХ. В то время как окна (W(n)) для использования в режиме ТСХ были описаны выше, далее будут обсуждаться окна, используемые для частотного режима: следует отметить, что выбор соответствующих окон, в частности, при переходе от фрейма, закодированного в частотном режиме, к последующему фрейму, закодированному в режиме ТСХ, или, наоборот, позволяет исключить алиасинг во временной области, так, что в выходном битрейте могут быть получены переходы с низким или нулевым уровнем алиасинга.
9.1. Описание набора фильтров и блока переключения.
Представление сигнала по времени/частоте (например, представление по времени/частоте 1158,1230, 1352,1380) отображается во временной области путем подачи ее в модуль набора фильтров (например, модуль 1160, 1230g, 1354-1358-1394, 1382-1386-1390-1394). Этот модуль состоит из обратного модифицированного дискретного косинусного преобразования (IMDCT), а также окна и функции перекрытия и сложения. Для того, чтобы адаптировать разрешение по времени/частоте набора фильтров с характеристиками входного сигнала, также используется инструмент блока переключения. N представляет собой длину окна, где N является функцией переменной потока битов 'window_sequence'. Для каждого канала N/2 значений Xi,k по времени/частоте преобразовываются в N значений во временной области xi,n через IMDCT. После применения функции окна для каждого канала, в первой половине последовательности zi,n добавляется ко второй половине последовательности предыдущего оконного блока z(i-1),n для восстановления выходных выборок для каждого канала outi,n.
9.2. Набор фильтров и блок переключения - определения Далее будут даны некоторые определения переменных потока битов. Переменная потока битов 'window_sequence' состоит из двух бит, указывающих, какая последовательность окна (например, размер блока) используется. Переменная потока битов 'window_sequence' обычно используется для аудиофреймов, закодированных в частотной области.
Переменная потока битов 'window_shape' содержит один бит, показывающий, какая оконная функция выбрана.
В таблице на фиг.16 показаны одиннадцать последовательностей окна (также обозначенных как window_sequences) на основе семи окон преобразований. (ONLY_LONG_SEQUENCE,LONG_START_SEQUENCE,EIGHT_SHORT_SEQUENCE, LONG_STOP_SEQUENCE,STOP_START_SEQUENCE).
Используемая далее последовательность LPD_SEQUENCE относится ко всем разрешенным комбинациям режимов окно/кодирование внутри так называемого кодировщика области линейного предсказания. В контексте декодирования в частотной области закодированных фреймов важно знать только то, что следующий фрейм закодирован в режиме кодирования LP области, которая представлена последовательностью LPD_SEQUENCE. Тем не менее, точная структура в пределах LPD_SEQUENCE необходима в том случае, когда декодируется фрейм, закодированный в LP области.
Другими словами, аудиофрейм, закодированный в режиме линейного предсказания, может представлять собой один закодированный ТСХ фрейм, множество закодированных ТСХ подфреймов или комбинацию ТСХ закодированных под- фреймов и ACELP закодированных подфреймов.
9.3. Процесс декодирования в наборе фильтров и блоке переключения
9.3.1 IMDCT в наборе фильтров и блоке переключения
Аналитическое выражение IMDCT это:
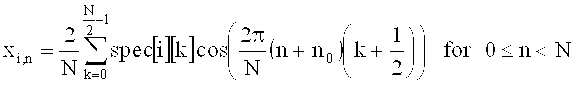
где:
n=индекс выборки
i=индекс окна
k=коэффициент спектрального индекса N=длина окна на основе значения window_sequences n0=(N/2+1)/2
Длина синтезированного окна N для обратного преобразования является функцией элемента синтаксиса "window_sequence" и алгоритмического контекста. Она определяется следующим образом;
Для окна длиной 2048:
Значок ( ) ячейке данной таблицы на фиг.17а и 17б показывает, что последовательность окна, показанная в данной строке, может сопровождаться последовательностью окна, показанной в соответствующем столбце.
) ячейке данной таблицы на фиг.17а и 17б показывает, что последовательность окна, показанная в данной строке, может сопровождаться последовательностью окна, показанной в соответствующем столбце.
Переходы между основными блоками первого варианта изобретения приведены на фиг.17а. Переходы между основными блоками в дополнительном варианте изобретения приведены в таблице на фиг.17в. Переходы между дополнительными блоками блок в варианте изобретения в соответствии с фиг.17б будут отдельно объяснены ниже.
9.3.2 Оконная операция и блок переключения для набора фильтров и блока переключения
Различные оконные преобразования используются в зависимости от переменных потока битов (или элементов) 'window_sequence' и элементов "window_shape'. Комбинация из половин окна описывается следующим образом и предлагает все возможные последовательности окна. Для 'window_shape'=1, коэффициенты окна задаются весовой функцией Кайзера - Бесселя (KBD) следующим выражениями:
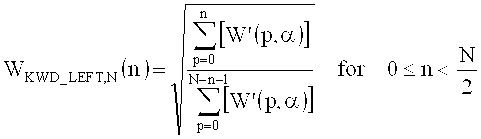
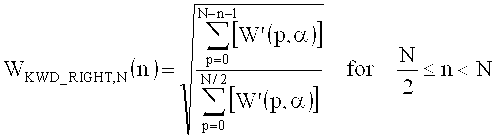
где:
W' ядро окна функции Кайзера - Бесселя, см. также [5], определяемое следующим образом:
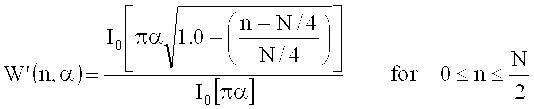

α = альфа-коэффициент ядра окна,
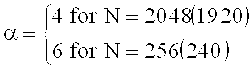
В противном случае, для 'window_shape'=0, синусное окно используется следующим образом;
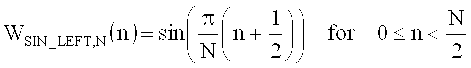
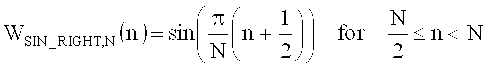
Длина окна N может быть 2048 (1920) или 256 (240) для KBD и синусного окна. Как получить возможные последовательности окон объясняется в частях а)-е)
настоящего подпункта.
Для всех видов оконных последовательностей переменная 'window_shape' в левой половине первого окна преобразования определяется формой окна предыдущего блока, которая описывается переменной 'window_shape_previous_block'. Следующая формула выражает этот факт:
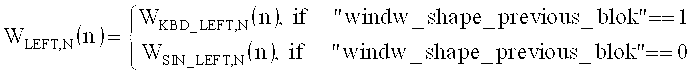
где:
'window_shape_previous_block' это переменная, которая равна переменной потока битов 'window_shape' предыдущего блока (i-1).
Когда декодируется первый ряд блока данных 'raw_data_block()', переменная 'window_shape' в левой и правой половинах окна одинаковы.
В случае, если предыдущий блок кодируется с использованием режима LPD, 'window_shape_previous_block' установлен в 0.
а) Последовательность ONLY_LONG_SEQUENCE:
Последовательность окна, обозначенная window_sequence=ONLY_LONG_SEQUENCE, равна одному окну типа 'LONG_WINDOW с общей длиной окна n_l, равной 2048(1920).
Для window_shape=1 окно для значения переменной „ONLY LONG_SEQUENCE' дается следующим выражением:
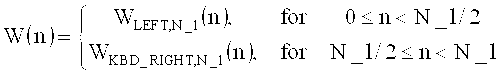
Если window_shape=0 окно для значения переменной 'ONLY_LONG_SEQUENCE' может быть описано следующим образом:
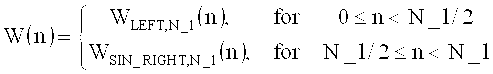
После оконной операции, значения во временной области (г;,п) могут быть выражены как:
zi,n=w(n)-xi,n;
b) Последовательность LONG_START_SEQUENCE:
Окно типа uLONG_START_SEQUENCE' может быть использовано для получения правильного перекрытия и сложения для блока перехода от окна типа 'ONLY_LONG_SEQUENCE' к любому блоку с небольшим перекрытием (короткий склон окна) левой половины окна (EIGHT_SHORT_SEQUENCE, LONG_STOP_SEQUENCE, STOP_START_SEQUENCE или LPD_SEQUENCE).
В случае, если последовательность окна не является окном типа 'LPDJSEQUENCE': длина окна N_l и N_s устанавливаются равными 2048 (1920) и 256 (240) соответственно.
В случае, если последовательность окна является окном типа 'LPD_SEQUENCE': длина окна N_l и N_s устанавливаются равными 2048 (1920) и 512 (480) соответственно.
Если window_shape=1, окно является окном типа 'LONG_START_SEQUENCE' и задается следующим образом:
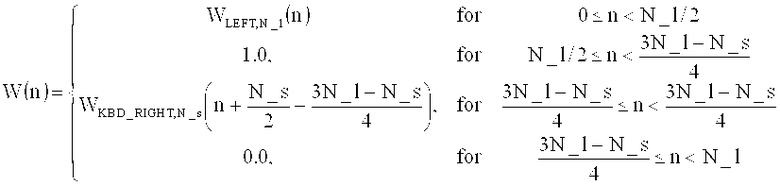
Если windowjshape=0, окно является окном типа 'LONG_START_SEQUENCE' и выглядит следующим образом:
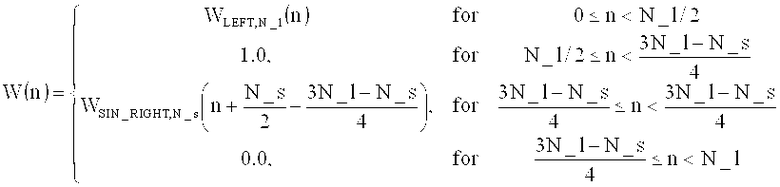
Значения окон во временной области могут быть рассчитаны по формуле, объясненной в а).
с) Последовательность EIGHT_SHORT
Последовательность окна window_sequence=EIGHT_SHORT состоит из восьми перекрывающихся и суммируемых последовательностей SHORT_WINDOW с длинами N_s, равными 256 (240) каждая.
Общая длина window_sequence с учетом ведущих значений и последующих нулей равна 2048 (1920). Каждый из восьми коротких оконных блоков, прежде всего, обрабатывается в отдельном окне. Короткий номер блока индексируется переменной j=0,…,M-1(M=N_l/N_s).
The windowjshape предыдущего блока влияет только на первый из восьми коротких блоков (W0(n)). Если window_shape=1, функции окна могут быть предоставлены следующим образом:

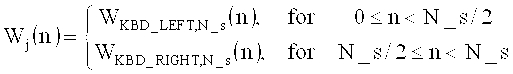
В противном случае, если window shape=0, функции окна могут быть описаны следующим образом:
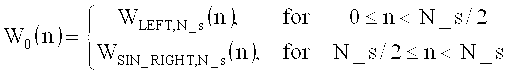
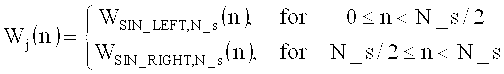
Перекрытие и суммирование выполняется между EIGHT_SHORT и window_sequence, в результате чего оконные значения во временной области zi,n описывается следующим образом:

d) Последовательность LONG_STOP_SEQUENCE
Эта последовательность window_sequence используется при переключении от последовательности окна 'EIGHT_SHORT_SEQUENCE' типа окна 'LPD_SEQUENCE' обратно к окну типа 'ONLY_LONG_SEQUENCE. В случае, если предыдущая последовательность окна является LPD_SEQUENCE: для длин окон N_l и N_sis устанавливаются значения 2048 (1920) и 256 (240) соответственно.
В случае, если предыдущая последовательность окна является LPD_SEQUENCE: для длин окон N_l и N_s устанавливаются значения 2048 (1920) и 512 (480) соответственно.
Если window_shape=1, окно для типа окна 'LONG_STOP_SEQUENCE'
определяется следующим образом:
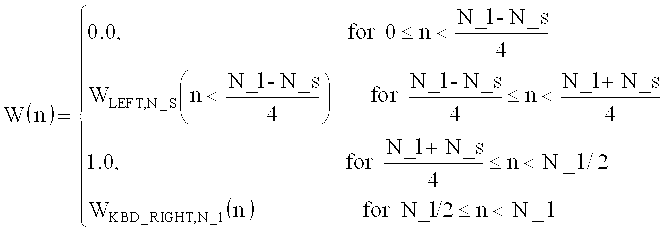
Если window_shape==0, окно LONG_START_SEQUENCE определяется:

Оконные значения во временной области могут быть рассчитаны по формуле а).
е) Последовательность STOP_START_SEQUENCE:
Тип окна 'STOP_START_SEQUENCE' может быть использован для получения правильного перекрытия и суммирования для блока перехода от любого блока с небольшим перекрытием окна (короткий склон окна) правой половины окна к любому блоку с небольшим перекрытием окна (короткий склон окна) левой половины окна и если требуется одно длинное преобразование для текущего фрейма.
В случае, если предыдущая последовательность окна была не LPD_SEQUENCE: для длин окон N_l и N_s устанавливаются значения 2048 (1920) и 256 (240) соответственно.
В случае, если предыдущая последовательность окна была LPD_SEQUENCE: для длин окон N_l и N_s устанавливаются значения 2048 (1920) и 512 (480) соответственно.
Если window_shape=1, оконная операция для типа окна 'STOP_START_SEQUENCE' дается следующим выражением:
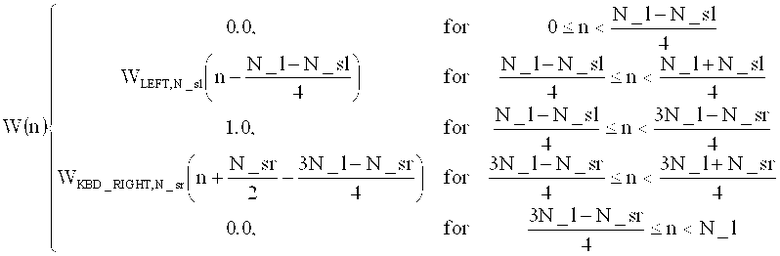
Если window_shape==0, оконная операция для типа окна 'STOP_START_SEQUENCE' задается аналогичным образом:
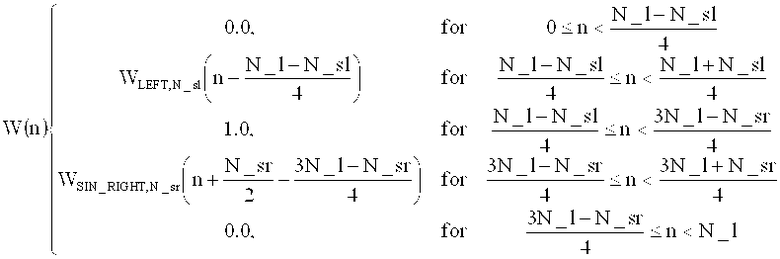
Оконные значения во временной области могут быть рассчитаны по формуле, описанной в а).
9.3.3 Перекрытие и сложение с предыдущей оконной последовательностью в наборе фильтров и блоке переключения
При перекрытии и суммировании в оконной последовательности EIGHT_SHORT первая (левая) часть каждой последовательности window sequence (или каждого фрейма или суб-фрейма) перекрывается и суммируется со второй (правой) частью предыдущей последовательности window sequence (или предыдущего фрейма или суб-фрейма), с получением значений в конечной временной области outin. Математическое выражение для этой операции может быть описано следующим образом.
В случаях ONLY_LONG_SEQUENCE, LONG_START_SEQUENCE, EIGHT_SHORT_SEQUENCE, LONG_STOP_SEQUENCE, STOP_START_SEQUENCE:
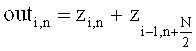
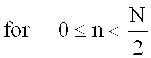
Приведенные выше уравнения для перекрытия и сложения между аудиофреймами, закодированными в режиме частотной области, могут также использоваться для перекрытия и сложения представлений во временной области аудиофреймов, закодированных в различных режимах.
Кроме того, перекрытие и сложение может быть определено следующим образом:
В случае ONLY_LONG_SEQUENCE, LONG_START_SEQUENCE,
EIGHT_SHORT_SEQUENCE,LONG_STOP_SEQUENCE,
STOP_START_SEQUENCE:
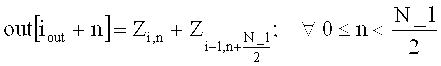
N_l является размером последовательности окна. Индексы i_out являются индексами выходного буфера out и увеличиваются на число N_L/2 записанных выборок.
В случае последовательности LPDJSEQUENCE:
Далее в будет описан первый подход, который может быть использован для снижения искажений. Приходя из ACELP, конкретное окно используется для следующего окна ТСХ путем уменьшения R до 0 с последующим устранением области перекрытия между двумя последовательными фреймами.
Далее будет описан второй подход, который может быть использован для уменьшения искажений (как это описано в USAC WD5 и предыдущих версиях). Приходя из ACELP, следующее окно ТСХ увеличивается за счет увеличения М (средней длины) на 128 выборок и также за счет увеличения числа MDCT коэффициентов, связанных с ТСХ окном. В декодировщике правая часть окна, то есть первые R ненулевых декодированных выборок просто отбрасываются и заменяются декодированными выборками ACELP. Другими словами, при использовании дополнительных коэффициентов MDCT (например, 1152 вместо 1024), искажения уменьшаются. Сформированные независимо предоставленные дополнительные коэффициенты MDCT (например, таким образом, что число коэффициентов MDCT больше половины числа выборок во временной области аудиофрейма), можно получить свободное от искажений представление во временной области, что исключает необходимость специального исключения алиасинга за счет некритических выборок спектра.
В противном случае, когда предыдущий декодированный оконный сигнал zi-1,n, полученный с помощью MDCT на основе ТСХ, для получения окончательного временного сигнала out применяется обычное перекрытие и суммирование. При использовании FD режима последовательностей окон LONG_START_SEQUENCE или EIGHT_SHORT_SEQUENCE, перекрытие и суммирование можно выразить следующей формулой:
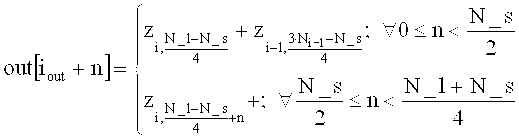
N,.i соответствует размеру 2lg предыдущего окна, применяемого в MDCT на основе ТСХ. Индексы i_out относятся к выходному буферу out и увеличиваются на количество (N_l+N_s)/4 записанных выборок. N_s/2 должно быть равно значению L предыдущего MDCT на основе ТСХ, определенному в таблице на фиг.15.
Для последовательности STOP_START_SEQUENCE перекрытие и суммирование между FD режимом и MDCT на основе ТСХ дается следующим выражением:
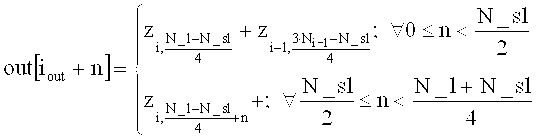
Ni-l соответствует размеру 2lg предыдущего окна, применяемого в MDCT на основе ТСХ. Индексы i_out относятся к выходному буферу out и увеличиваются на количество (N_l+N_s)/4 записанных выборок. N_sl/2 должно быть равно значению L предыдущего MDCT на основе ТСХ, определенному в таблице на фиг.15.
10. Подробная информация о вычислении w[n]
Для лучшего понимания далее будут описаны некоторые подробности, касающиеся вычислений значений усиления для области линейного предсказания g[k], Как правило, поток битов представляет закодированный аудиоконтент (закодированный в режиме линейного предсказания), включающий в себя закодированные коэффициенты LPC фильтра. Закодированные коэффициенты LPC фильтра могут быть описаны, например, соответствующими кодовыми словами и могут описывать фильтр линейного предсказания для восстановления аудиоконтента. Следует отметить, что число наборов коэффициентов LPC фильтра, переданных в LPC-закодированные фреймы, может меняться. Действительно, фактическое число наборов коэффициентов LPC фильтра, которые закодированы в потоке битов аудиофрейма, закодированного в режиме линейного предсказания, зависит от комбинации режимов ACELP-TCX аудиофрейма (который иногда также называется 'суперфрейм'). Эта комбинация режимов ACELP-TCX может быть определена с помощью потока переменных. Однако, естественно, существуют также случаи, в которых есть доступен только один режим ТСХ, также существуют случаи, в которых не доступен режим ACELP.
Поток битов, как правило, анализируется для получения показателей дискретизации, соответствующих каждому из наборов коэффициентов LPC фильтра, требующих комбинацию режимов ACELP-TCX.
На первом этапе обработки 1810, выполняется обратная дискретизация LPC фильтра. Следует отметить, что LPC фильтра (т.е. набор коэффициентов LPC фильтра, например, от а1 до a16) дискретизируется с использованием представления частот линий спектра (LSF) (которое является закодированным представлением коэффициентов LPC фильтра). На первом этапе обработки 1810 частоты спектральных линий (LSF) получаются из закодированных индексов в процессе деквантования.
Для этого на этапе первого приближения можно вычислить уточненное значение дополнительной векторной дискретизации алгебраического представления (AVQ). Частоты линий спектра (LSF) получаются в процессе деквантования [цифроаналоговом преобразовании] путем добавления результата аппроксимации на первом этапе и вклада невзвешенных AVQ. Наличие уточненного значения AVQ может зависеть от фактического режима дискретизации LPC фильтра.
Вектор деквантованных частот спектральных линий, который может быть получен из закодированного представления коэффициентов LPC фильтра, позднее преобразуется в вектор из двух параметров спектральных линий, которые затем интерполируются и превращаются снова в LPC параметры. Деквантование, выполненное на этапе обработки 1810, приводит к набору LPC параметров в области частот спектральных линий. Частоты спектральных линий преобразуются на этапе обработки 1820, в область косинусов, которая описывается парами спектральных линий. Таким образом, получаются пары спектральных линий q,. Для каждого фрейма или подфрейма, коэффициенты q, пар спектральных линий (или их интерполированных разновидностей) преобразуются в коэффициенты фильтра линейного предсказания да, которые используются для синтеза восстановленного сигнала в фрейме или под- фрейме. Переход в область линейного предсказания осуществляется следующим образом. Коэффициенты f1(i) и f2(i) может быть получены, например, с помощью следующего рекуррентного соотношения:
for i=1 to 8
f1(i)=-2q2i-1f1(i-1)+2f1(i-2)
for j=i-1 down to 1
f1(j)=f1(j)-2 q2i-1f1(i-1)+2f1(i-2)
end
end
с начальными значениями f1(0)=1 и f1(-1)=0. коэффициенты f2(i) вычисляются аналогично путем замены q2i-1 на q2i.
После того, коэффициенты f1(i) и f2(i) будут найдены, коэффициенты f1'(i) и f2'(i) вычисляются по формулам:

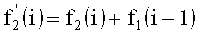
Наконец, LP коэффициенты вычисляются из f1'(i) и f2'(i) следующим образом:
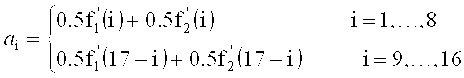
Подводя итог, LPC коэффициенты а, получаются пары коэффициентов q, спектральных линий с помощью этапов обработки 1830,1840, 1850, как описано выше.
Коэффициенты w[n], n=0…1pc_order-l, которые являются коэффициентами взвешивающего LPC фильтра, получены на этапе обработки 1860. При получении коэффициентов w[n] из коэффициентов a i, полагаем, что коэффициенты а, являются коэффициентами во временной области фильтра, имеющего характеристики фильтра A[z], также полагаем, что коэффициенты w[n] являются коэффициентами во временной области фильтра, имеющего отклик в частотной области W[z]. Кроме того, полагаем, что справедливо соотношение:
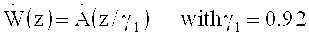
В связи с вышеизложенным, можно видеть, что коэффициенты w[n] могут быть легко получены из закодированных коэффициентов LPC фильтра, которые представлены, например, соответствующими индексами в потоке битов.
Следует также отметить, что xt[n], получаются на этапе обработки 1870, как было сказано выше. Кроме того, вычисление Xo[k] также было показано выше. Выше, на этапе 1890, обсуждалось и вычисление значений усиления g[k] области линейного предсказания.
11. Альтернативное решение для формирования спектра
Следует отметить, что описанная выше концепция формирования спектра, применяемая для аудиофреймов, закодированных в области линейного предсказания, основана на преобразовании LPC коэффициентов фильтра Wn[n] в спектральное представление Xo[k], из которого получаются значения усиления области линейного предсказания. Как уже говорилось выше, коэффициенты LPC фильтра w[n] преобразуются в представление в частотной области Xo[k] с использованием нечетного дискретного преобразования Фурье с 64 равноотстоящими по частоте элементами дискретизации. Однако, естественно считать, что нет необходимости в получении значений в частотной области Xo[k], которые расположены равномерно по частоте. Лучше сказать, что это можно рекомендовать при использовании значений в частотной области Xo[k], которые расположены неравномерно по частоте. Например, в частотной области значения Xo[k] могут быть расположены в логарифмическом масштабе по частоте или могут быть разнесены по частоте в соответствии с шкалой Bark. Такие нелинейные промежутки между значениями в частотной области Xo[k] и значениями коэффициента усиления g[k] в области линейного предсказания, могут привести к особенно хорошему компромиссу между впечатлением при прослушивании и вычислительной сложностью. Тем не менее, нет необходимости для использования такой концепции в случае нелинейных промежутков по частоте для значений коэффициента усиления в области линейного предсказания.
12. Расширенная концепция перехода
Далее будет описана улучшенная концепция перехода от аудиофрейма, закодированного в частотной области и аудиофреймом, закодированным в области линейного предсказания. Эта улучшенная концепция используется для стартового окна так называемого режима линейного предсказания, который будет показан ниже.
Принимая во внимание прежде всего фиг.17а и 176, следует отметить, что условно говоря, окна, имеющие сравнительно короткий правый склон перехода, применяются для выборок во временной области аудиофреймов, закодированных в режиме частотной области, когда производится переход к аудиофрейму, закодированному в режиме линейно- предсказания. Как видно из фиг.17а, окна типов 'LONG_START_SEQUENCE', EIGHT_SHORT_SEQUENCE', 'STOP_START_SEQUENCE' традиционно применяются к аудиофреймам, закодированным в области линейного предсказания. Таким образом, условно говоря, нет возможности непосредственного перехода от фреймов, закодированных в частотной области, в котором окно, имеющее сравнительно длинный правосторонний склон, применяется к аудио-фрейму, закодированному в режиме линейного предсказания. Это связано с тем, что условно говоря, существуют серьезные проблемы, связанные с алиасингом в большой временной области на участке аудиофрейма, закодированного в частотной области, для которого используется окно, имеющее сравнительно длинный правосторонний склон. Как видно из фиг.17а, обычно не представляется возможным осуществление перехода от аудиофрейма, для которого применяется тип окна 'only_long_sequence', или от аудиофрейма, для которого применяется тип окна 'long_stop_sequence', к последующему аудиофрейму, закодированному в режиме линейного предсказания.
Тем не менее, в некоторых вариантах в соответствии с изобретением, используется новый тип аудиофрейма, а именно: аудиофрейм, для которого стартовое окно связано с режимом линейного предсказания.
Новый тип аудиофрейма (также для краткости называемый стартовым фреймом режима линейного предсказания) кодируется в ТСХ суб-режиме режима области линейного предсказания. Стартовый фрейм режима линейного предсказания состоит из одного ТСХ фрейма (т.е. не подразделяется на подфреймы ТСХ). Следовательно, 1024 MDCT коэффициентов в закодированном виде включаются в поток битов, так же как и стартовый фрейм режима линейного предсказания. Другими словами, количество MDCT коэффициентов, связанных со стартовым фреймом линейного предсказания, совпадает с числом MDCT коэффициентов, относящихся к частотной области закодированного аудиофрейма, с которым связан тип окна 'only_long_sequence'. Кроме того, окно, связанное со стартовым фреймом режима линейного предсказания может быть окном типа 'LONG_START_SEQUENCE'. Таким образом, режим линейного предсказания связан с начальным типом 'long_start_sequence'. Тем не менее, стартовый фрейм режима линейного предсказания отличается от аудиофрейма, закодированного в частотной области, тем, что формирование спектра осуществляется в зависимости от значений усиления в области линейного предсказания, а не в зависимости от значений коэффициентов масштабирования. Таким образом, закодированные коэффициенты фильтра линейного предсказания включены в поток битов стартового фрейма режима линейного предсказания.
Так как обратное преобразование MDCT 1354,1382 применяется в той же области (как описано выше), как для аудиофрейма, закодированного в режиме частотной области, так и аудиофрейма, закодированного в режиме линейного предсказания, исключение алиасинга во временной области при операции перекрытия и суммирования с хорошими характеристиками отмены алиасинга во временной области может быть получено в промежутке от предыдущего аудиофрейма, закодированного в режиме частотной области и имеющего сравнительно длинный правосторонний склон перехода (например, 1024 выборок), и стартового фрейма в режиме линейного предсказания, имеющего сравнительно длинный левосторонний склон перехода (например, 1024 выборок), причем склон перехода соответствует времени исключения алиасинга. Таким образом, стартовый фрейм режима линейного предсказания кодируется в режиме линейного предсказания (т.е. выполняется кодирование с помощью коэффициентов фильтра линейного предсказания) и включает в себя значительно больший (например, по крайней мере, в 2 раза, или в 4 раза, или даже в 8 раз) левосторонний склон перехода, чем другие аудиофреймы, закодированные в режиме линейного предсказания, чтобы создать дополнительные возможности при переходе.
Как следствие, стартовый фрейм режима линейного предсказания может заменить аудиофрейм, закодированный в частотной области, имеющий тип окна 'long_sequence'. Режим линейного предсказания стартового фрейма имеет преимущество в том, что коэффициенты MDCT фильтра передаются в режиме линейного предсказания для стартового фрейма, который доступен для последующего аудиофрейма, закодированного в режиме линейного предсказания. Следовательно, нет необходимости включать дополнительную информацию коэффициентов LPC фильтра в поток битов, чтобы иметь информацию для инициализации при декодировании последующего аудиофрейма, закодированного в режиме линейного предсказания.
Фиг.14 иллюстрирует эту концепцию. На фиг.14 показано графическое представление последовательности из четырех аудиофреймов, 1410, 1412, 1414, 1416, которые имеют длину в 2048 аудиовыборок, и которые накладываются друг на друга примерно на 50%. Первый аудиофрейм 1410, закодированный в режиме частотной области, использует последовательность 'only_long_sequence' окна 1420, второй аудиофрейм 1412 кодируется в режиме линейного предсказания с помощью режима линейного предсказания стартового окна, которое использует последовательность 'long_start_sequence' окна, третий аудиофрейм 1414 кодируются в режиме линейного предсказания с использованием, например, окна W[n], как это определено выше для значения mod[x]=3, которое обозначено 1424. Следует отметить, что режим линейного предсказания стартового окна 1422 включает в себя левосторонний склон перехода длиной 1024 выборок и правосторонний склон перехода длиной 256 выборок.
Окно 1424 содержит левосторонний склон перехода длиной 256 выборок и правосторонний склон перехода длиной 256 выборок. Четвертый аудиофрейм 1416 кодируется в режиме частотной области с использованием последовательности 'long_stop_sequence' окна 1426, которое включает в себя левосторонний склон перехода длиной 256 выборок и правосторонний склон перехода длиной 1024 выборки.
Как видно на фиг.14, выборки во временной области для аудиофреймов получаются с помощью обратного модифицированного дискретного косинусного преобразования 1460, 1462, 1464, 1466. Для аудиофреймов 1410, 1416, закодированных в режиме частотной области, формирование спектра осуществляется в зависимости от значений коэффициентов масштабирования. Для аудиофреймов 1412, 1414, закодированных в режиме линейного предсказания, формирование спектра осуществляется в зависимости от значений усиления области линейного предсказания, которые получаются из коэффициентов фильтра линейного предсказания. В любом случае, спектральные значения обеспечивают декодирование (и, возможно, деквантование).
13. Заключение
Подводя итог, воплощения в соответствии с изобретением используют ограничение шума на основе LPC, применяемое в частотной области для переключения аудиокодировщика.
Воплощения в соответствии с изобретением применяют фильтр на основе LPC в частотной области для облегчения перехода между различными кодировщиками при переключении режимов аудиокодирования.
Некоторые варианты, решающие эти проблемы, осуществляют эффективные переходы между тремя режимами кодирования: кодированием в частотной области, ТСХ кодированием (преобразование кодирования возбуждения в области линейного предсказания) и ACELP кодированием (кодирования возбуждения с алгебраическим линейным предсказанием). Однако, в некоторых других вариантах, достаточно иметь только два указанных режима, например, кодирование в частотной области и режим ТСХ.
Воплощения в соответствии с изобретением позволяют решить также следующие альтернативные задачи:
- отсутствие критических переходов между кодировщиком в частотной области и кодировщиком в области линейного предсказания (см., например, в [4]);
- генерацию некритических выборок, имеющих компромисс между размером перекрытия и выходной информацией, в случае, когда выходная информация не в полной мере использует потенциал MDCT (отмену алиасинга во временной области TDAC).
- необходимость передачи дополнительного набора LPC коэффициентов при переходе от кодировщика в частотной области к кодировщику LPD.
- использование отмены алиасинга во временной области (TDAC) в различных областях (см., например, в [5]). LPC фильтрация осуществляется внутри MDCT между операциями сложения и DCT:
- в случаях, когда сигнал алиасинга во временной области не может использоваться для фильтрации и
- при необходимости передачи дополнительного набора LPC коэффициентов при переходе от кодировщика в частотной области к кодировщику LPD.
- вычисление коэффициентов LPC MDCT области не требует переключение кодировщика (Twin VQ) (см., например, в [6]);
- LPC используется только для получения огибающей спектра при выравнивания спектра. При этом LPC не используется ни для формирования шумов дискретизации, ни для облегчения перехода при переключении на другой режим аудиокодирования.
Воплощения в соответствии с настоящим изобретением позволяют выполнить кодировку в частотной области и MDCT кодировку LPC в той же области, с использованием LPC для формирования ошибки дискретизации в MDCT области. Это приводит к целому ряду преимуществ:
- LPC можно по-прежнему использовать для перехода на речевой кодировщик, аналогичный ACELP;
- возможна отмена алиасинга во временной области (TDAC) при переходе от/к кодировщика ТСХ от/к кодировщику в частотной области, при этом сохраняется критическая выборка;
- LPC по-прежнему используется в качестве ограничителя шума в среде ACELP, что позволяет максимально использовать одинаковые функции для ТСХ и ACELP (например, основанное на LPC взвешивание сегментов SNR в замкнутом процессе принятия решения).
Для дальнейших выводов важными аспектами являются:
1. переход между преобразованием кодирования возбуждения (ТСХ) и частотной областью (FD) значительно упрощается/унифицируется с применением кодирования линейного предсказания в частотной области;
2. поддерживается передача LPC коэффициентов в случае ТСХ, переходы между ТСХ и ACELP могут быть реализованы с такими же преимуществами, как и в других реализациях (при применении LPC фильтра во временной области).
Реализация альтернативных способов
Хотя некоторые аспекты были описаны применительно к аппаратной части, ясно, что эти аспекты также представляют собой описание соответствующих способов, в которых блок, устройство или особенность соответствуют этапу способа. Аналогично, аспекты, описанные применительно к способу, также могут быть представлены в виде описания соответствующего блока, элемента или функции с соответствующим аппаратным исполнением. Некоторые или все этапы способов могут быть выполнены (или использованы) в аппаратном устройстве таком, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах, один или несколько самых важных этапов способов могут быть выполнены таким аппаратным устройством.
Изобретенный способ кодирования аудиосигнала может быть сохранен на цифровом носителе или может быть передан по передающей среде, таких как беспроводная передающая среда или проводная передающая среда, например Интернет.
В зависимости от определенных требований реализации, воплощения изобретения может быть реализованы аппаратно или программно. Реализация может быть выполнена с использованием цифрового носителя, например дискеты, DVD, Blue-Ray, CD, ROM, FROM, EPROM, EEPROM или флэш-памяти, имеющими хранящиеся на них читаемые электронным способом управляющие сигналы, которые совместимы (или способны совмещаться) с программируемой системой компьютера, таким образом, что выполняется соответствующий способ. Таким образом, цифровой носитель может быть совместим с компьютером.
Некоторые воплощения настоящего изобретения имеют вид носителя информации с электронно-считываемыми управляющими сигналами, которые способны взаимодействовать с программной системой компьютера, например так, что выполняется один из описанных здесь способов.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы в виде программного продукта на компьютере, программный код позволяет оперативно выполнить один из способов при запуске его на компьютере. Программный код может быть сохранен, например, на машинно-читаемом носителе.
Другие варианты изобретения могут быть реализованы в компьютерной программе, хранящейся на машинно-читаемых носителях, для выполнения одного из описанных способов.
Иными словами, воплощением изобретения является компьютерная программа, с программным кодом для выполнения одного из описанных здесь способов при запуске программы на компьютере.
Еще один вариант изобретения, таким образом, представляет собой носитель информации (цифровой носитель, или машинно-читаемый носитель), включающей записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой носитель или записывающая среда, как правило, материальны и/или не является перемещаемыми.
Еще один вариант предлагаемого способа является, таким образом, потоком данных или последовательностью сигналов, представляющих собой компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, может быть сконфигурирована для передачи через порт передачи данных, например через Интернет.
Еще один вариант включает в себя средства обработки, например, компьютер или программируемое логическое устройство, настроенные или адаптированные для выполнения одного из способов, описанных в настоящем документе.
Еще один вариант включает в себя компьютер с установленной на нем компьютерной программой для выполнения одного из способов, описанных в настоящем документе.
Еще один вариант, согласно изобретению включает в себя устройство или систему, настроенную на передачу (например, электронным или оптическим способом) компьютерной программы для выполнения одного из описанных здесь способов. Приемник может быть, например, компьютером, мобильным устройством, запоминающим устройством и тому подобное. Устройство или система могут, например, включать файл-сервер для передачи компьютерных программ в приемник.
В некоторых вариантах, программируемое логическое устройство (например, программируемая логическая матрица) могут быть использованы для выполнения всех или некоторых из функциональных способов, описанных в настоящем документе. В некоторых вариантах программируемая вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Как правило, эти способы можно выполнять на любых аппаратных средствах.
Описанные выше варианты являются просто иллюстрациями принципов настоящего изобретения. Понятно, что улучшение и изменение описанного здесь оборудования и деталей, будут очевидны для других специалистов в данной области. Это изобретение, следовательно, может быть ограничено только приведенной ниже формулой изобретения, а не конкретными данными, представленными в виде описаний и объяснений вариантов изобретения.
Ссылки:
[1] 'Unified speech and audio coding scheme for high quality at low bitrates'. Max Neuendorfet al., in iEEE Int, Conf. Acoustics, Speech and Signal Processing, ICASSP, 2009
[2] Generic Coding of Moving Pictures and Associated Audio: Advanced Audio Coding. International Standard 13818-7, ISO/IEC JTC1/SC29/WG11 Moving Pictures Expert Group, 1997
[3] 'Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec', 3GPP TS 26.290 V6.3.0, 2005-06, Technical Specification
[4] 'Audio Encoder and Decoder for Encoding and Decoding Audio Samples', FH080703PUS, F49510, incorporated by reference,
[5] 'Apparatus and Method for Encoding/Decoding an Audio Signal Usign an Aliasing Switch Scheme', FH080715PUS, F49522, incorporated by reference
[6] 'High-quality audio-coding at less than 64 kbits/s 'by using transform-domain weighted interleave vector quantization (Twin VQ)', N.Iwakami and T.Moriya and S.Miki, ШЕЕ ICASSP, 1995
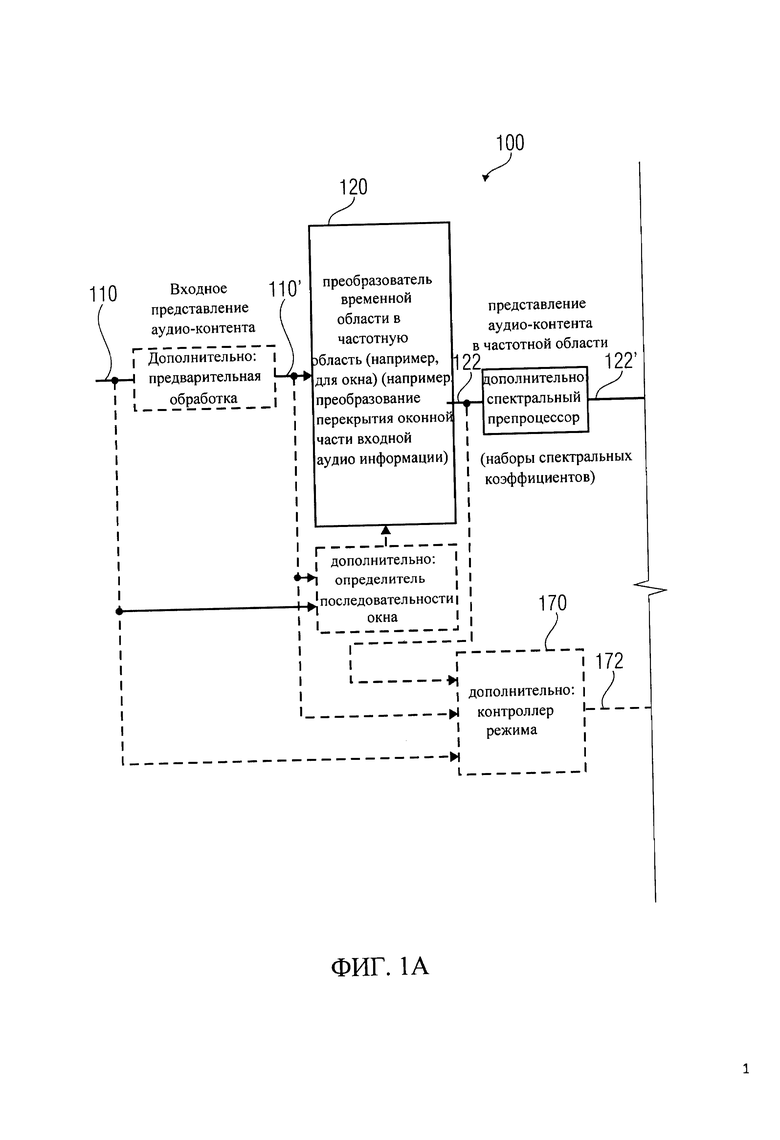
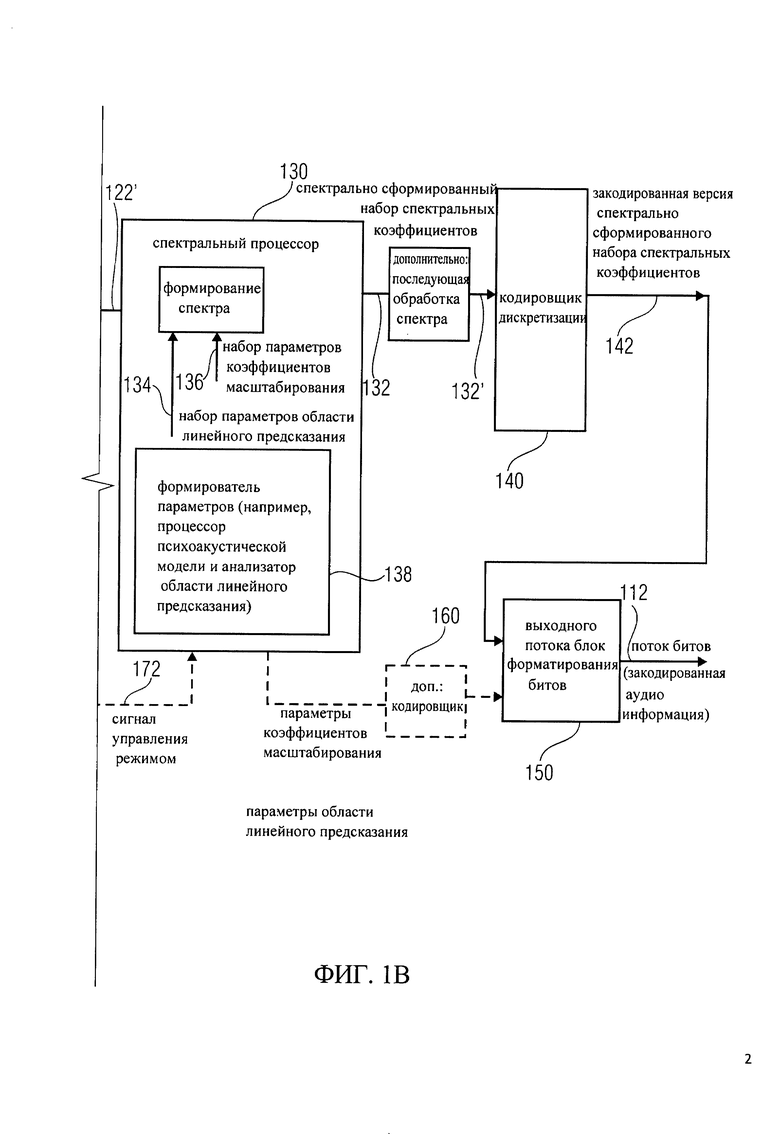
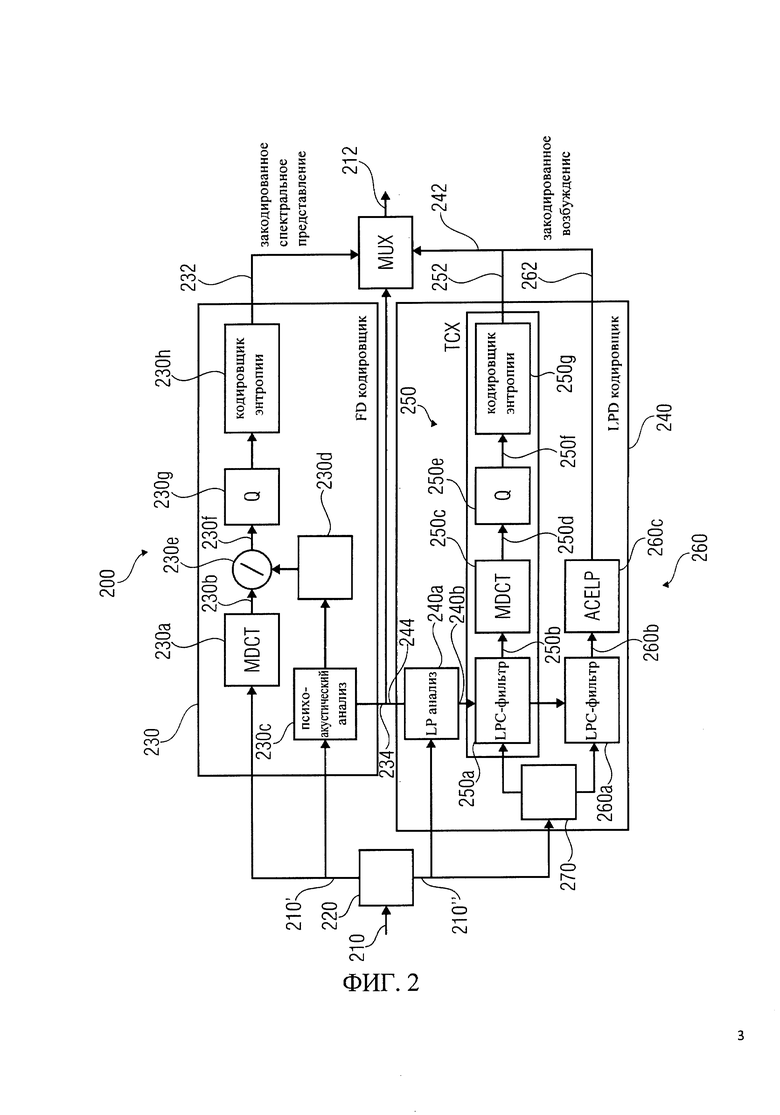
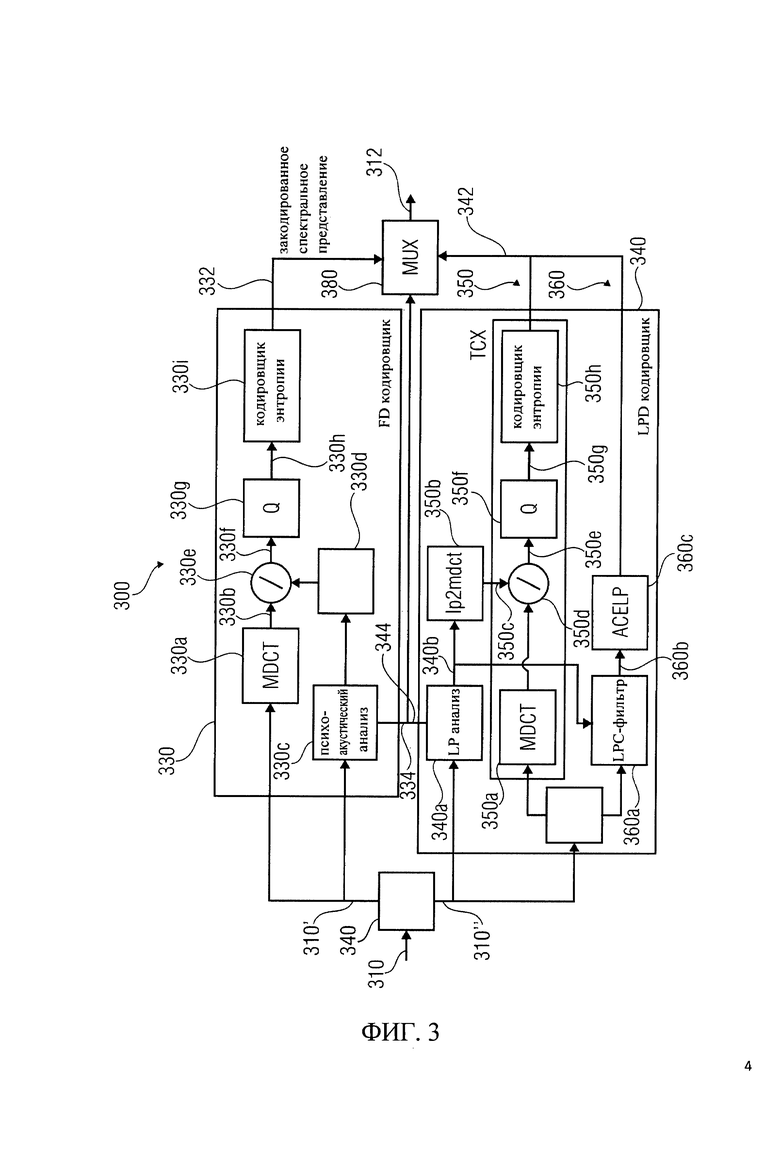
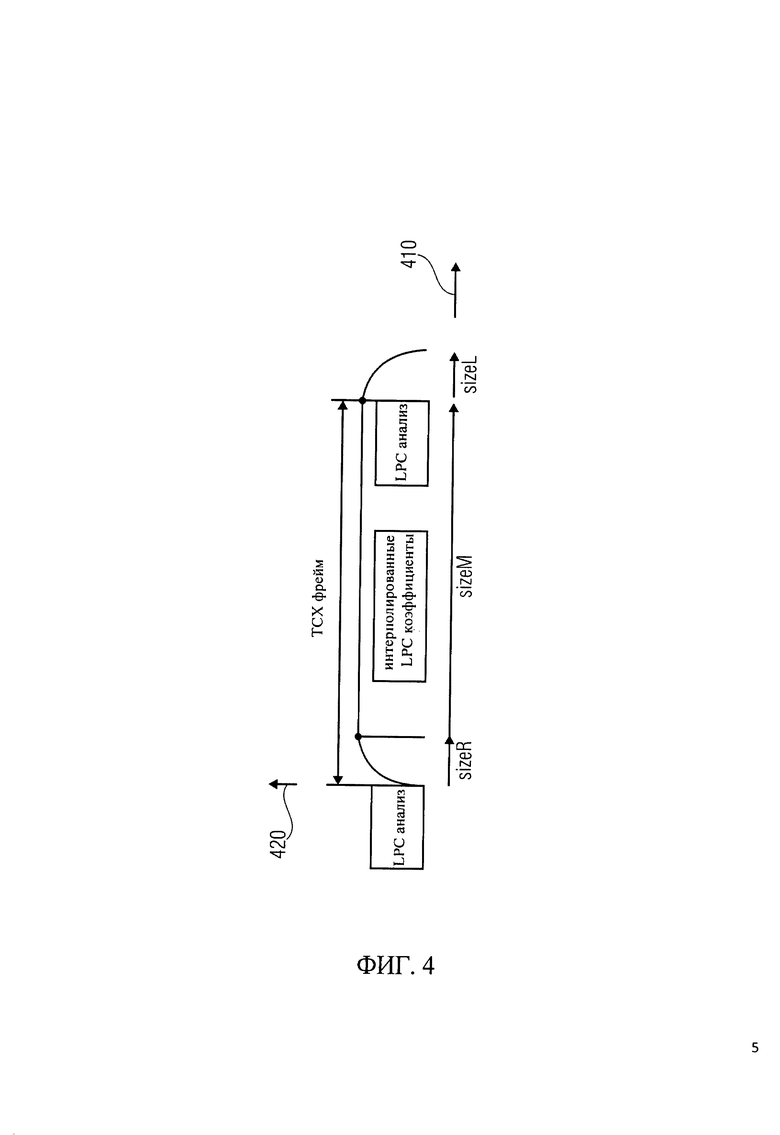

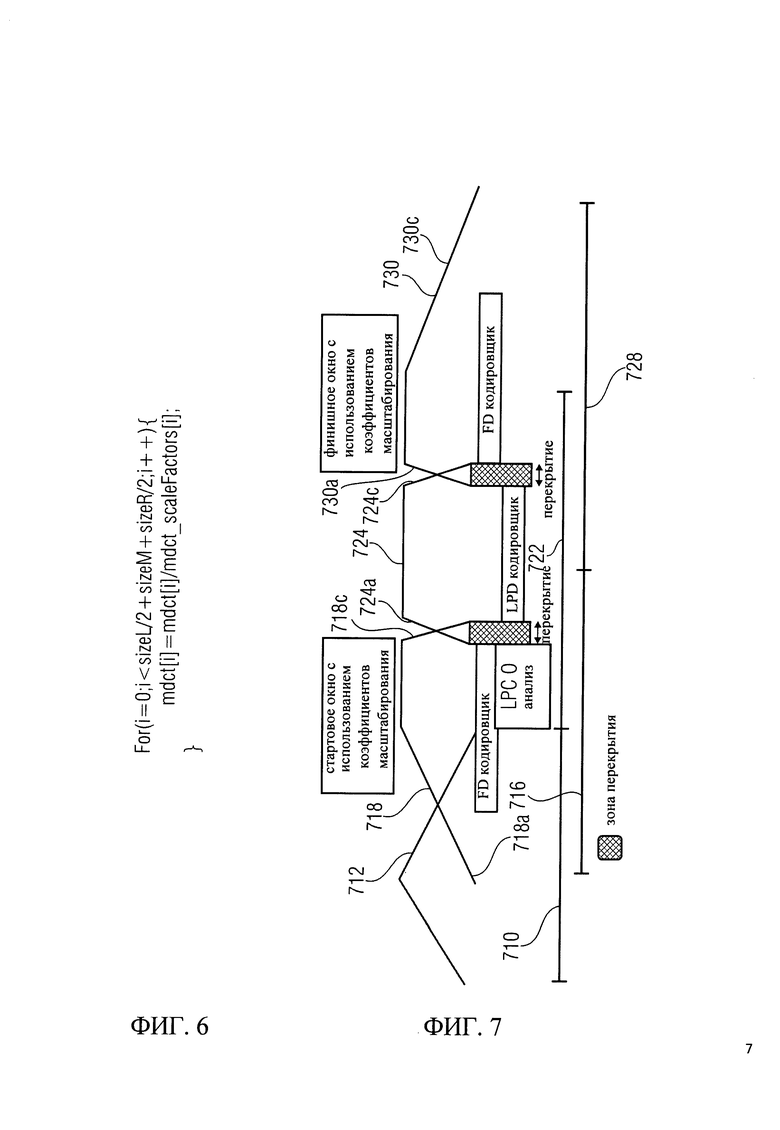
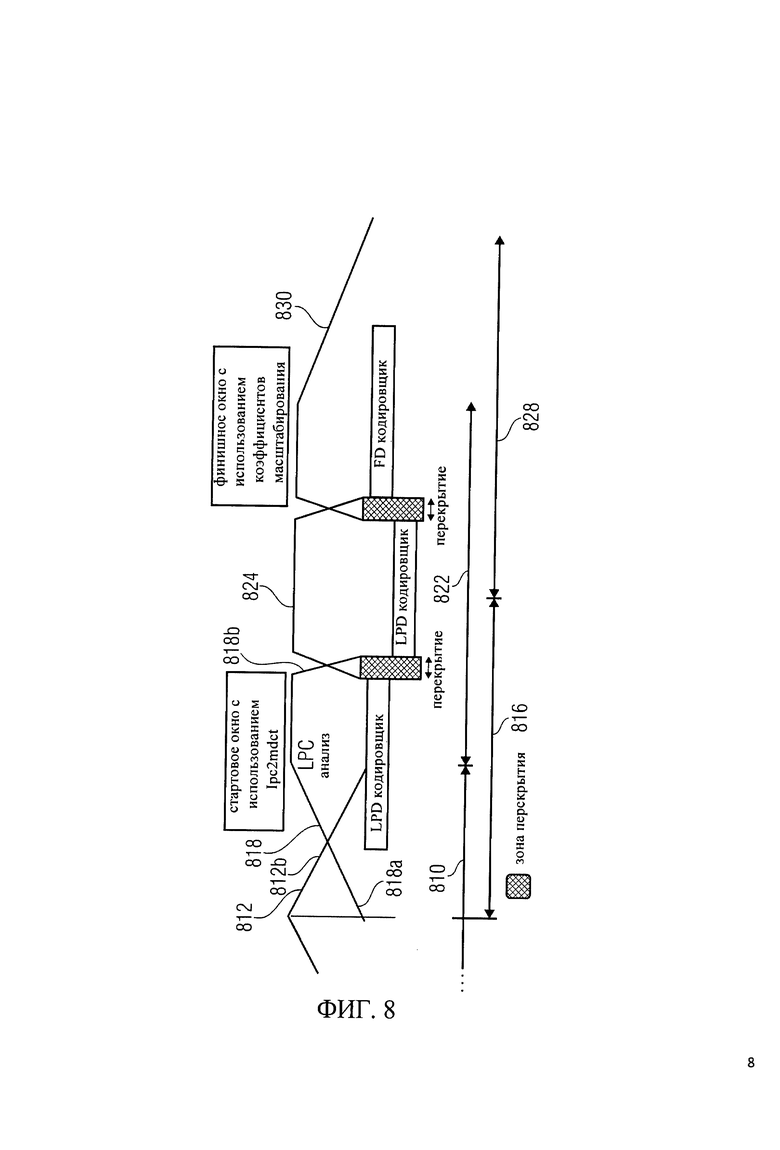
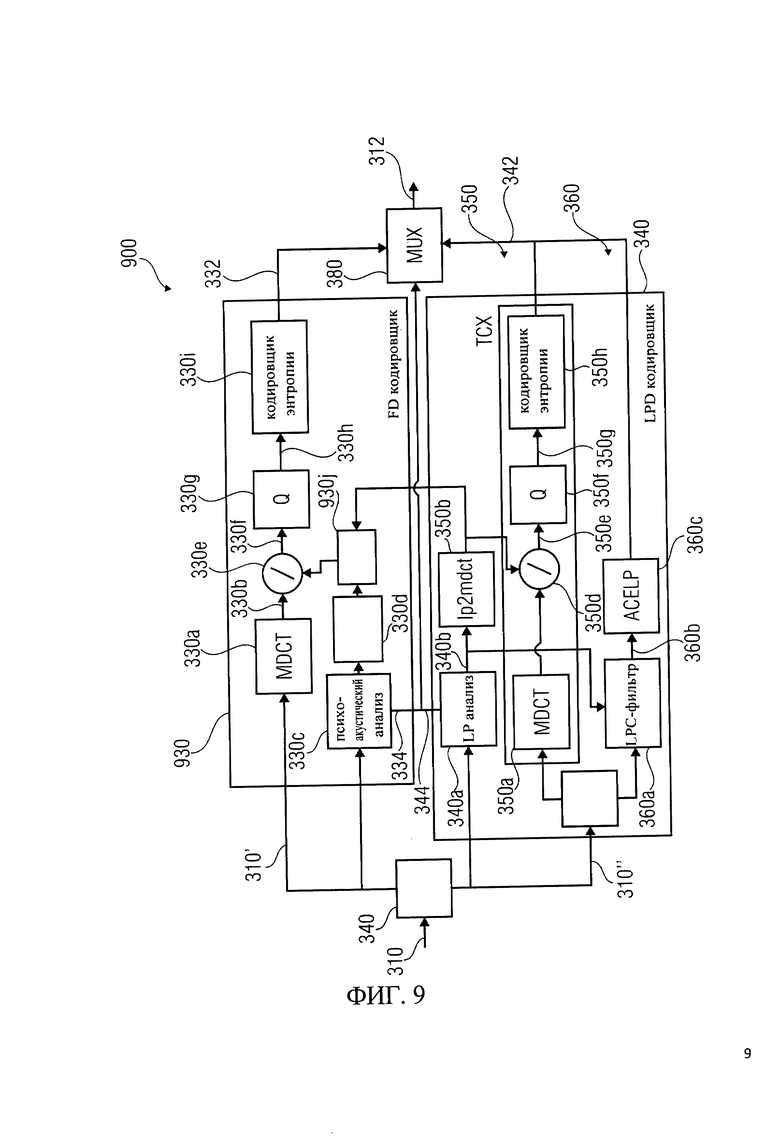
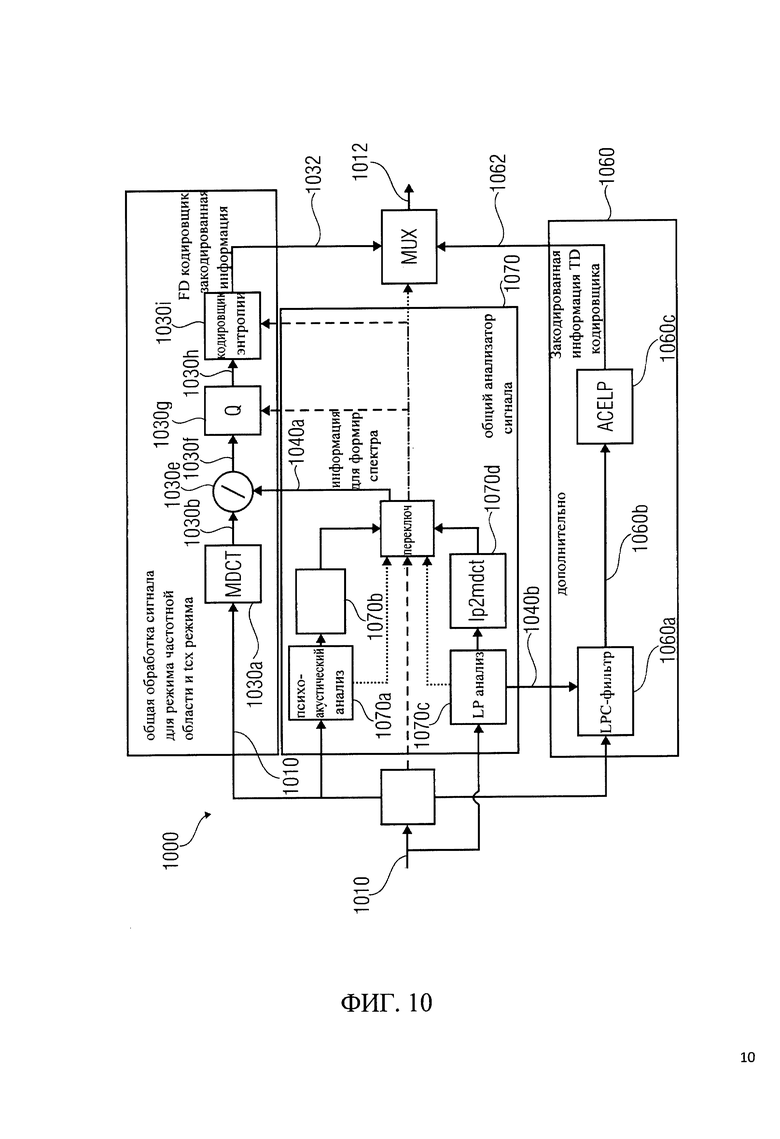
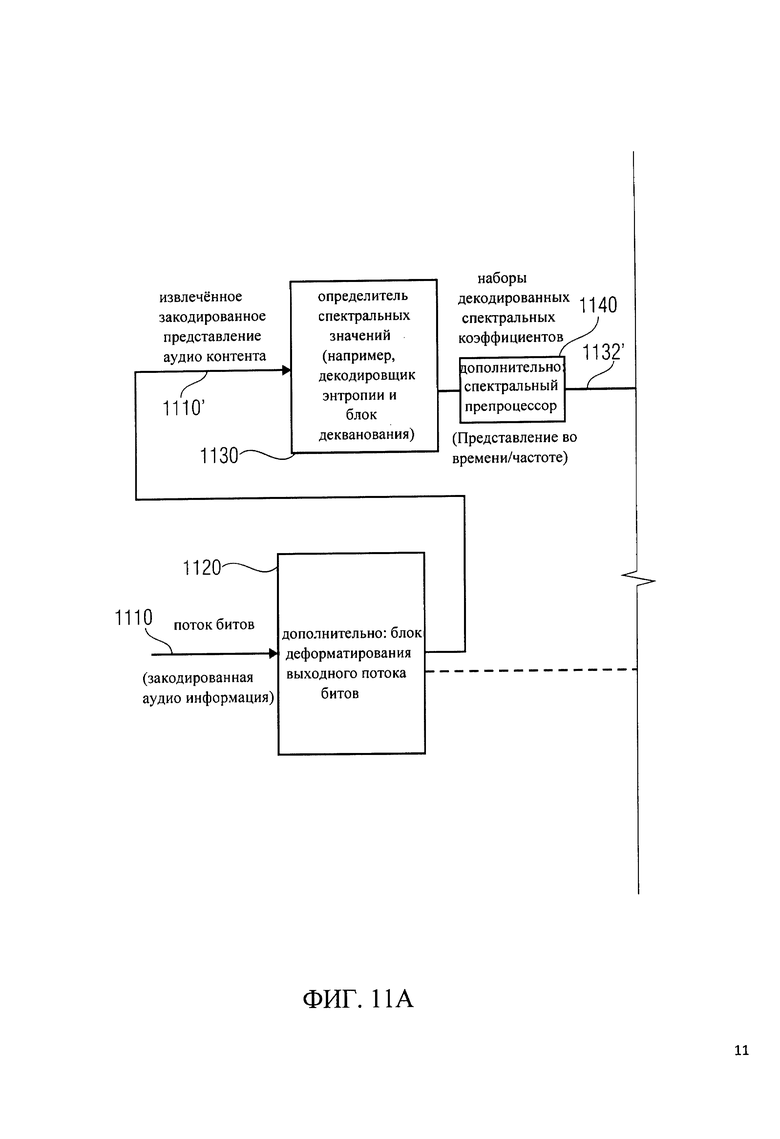
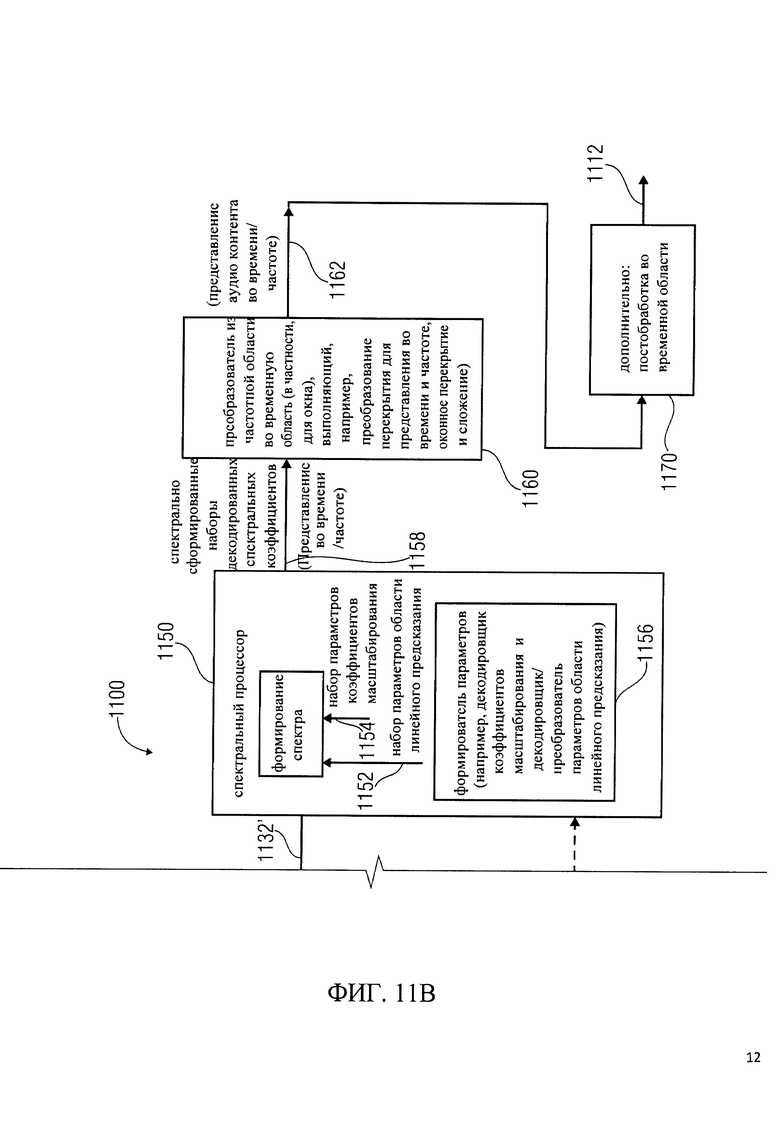
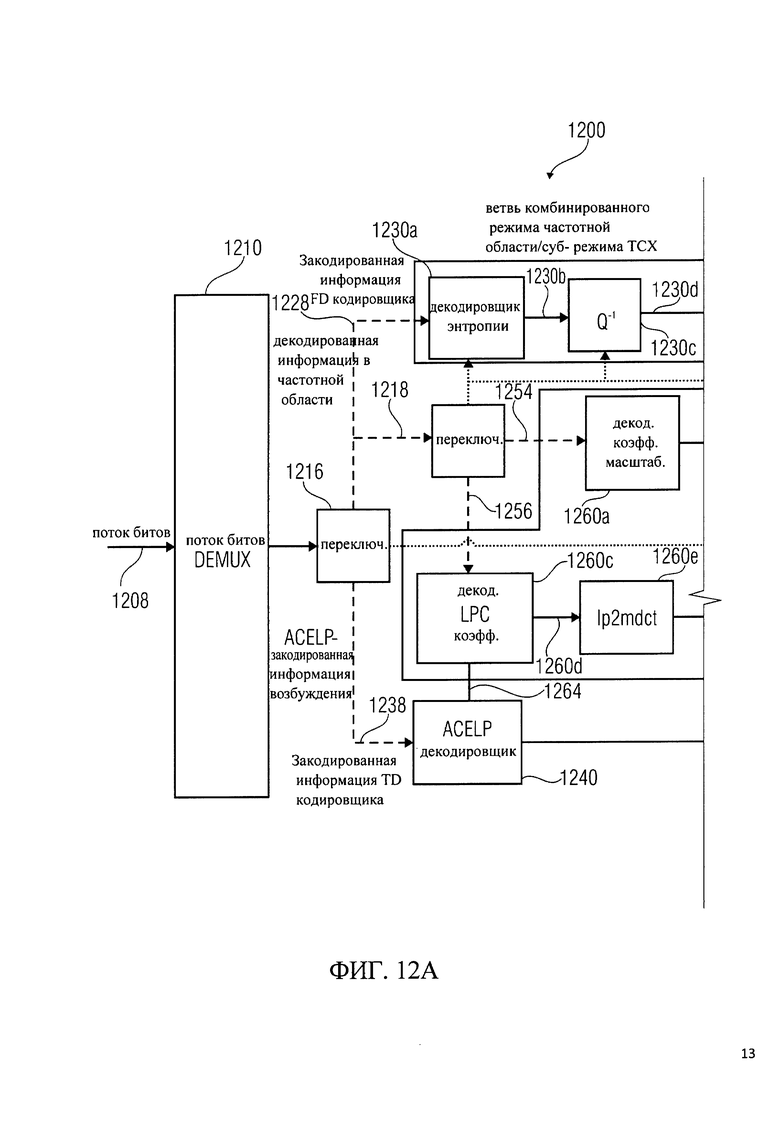
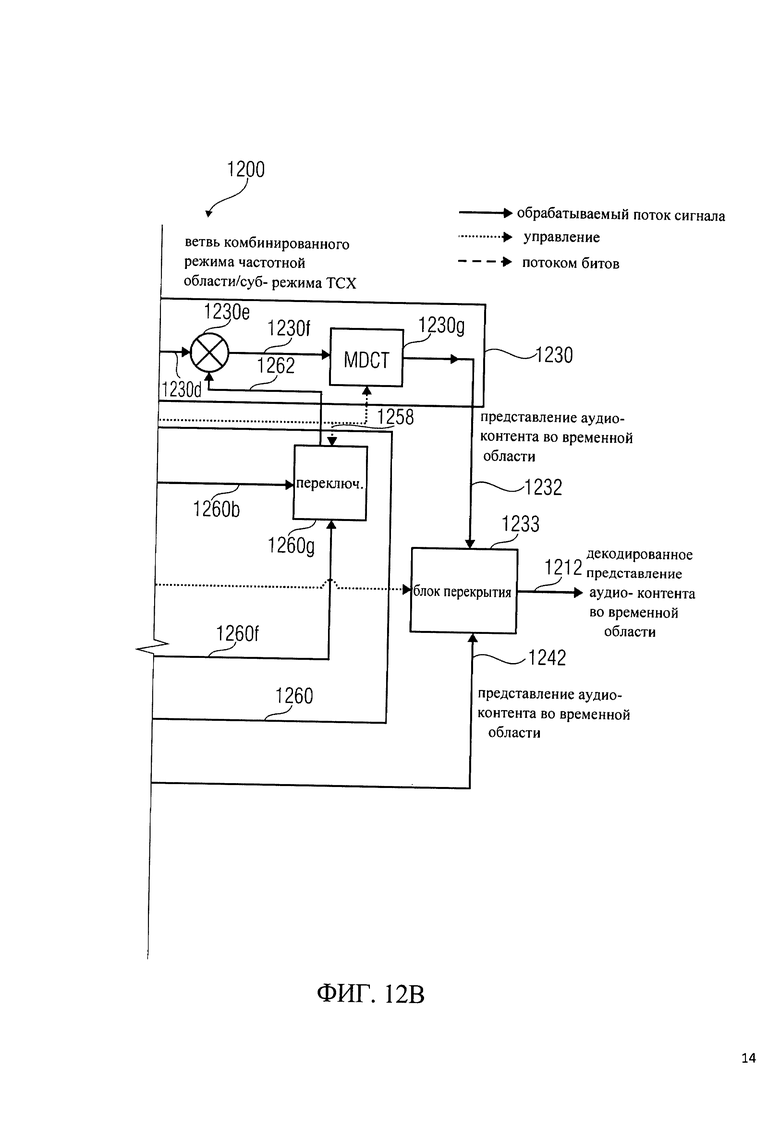
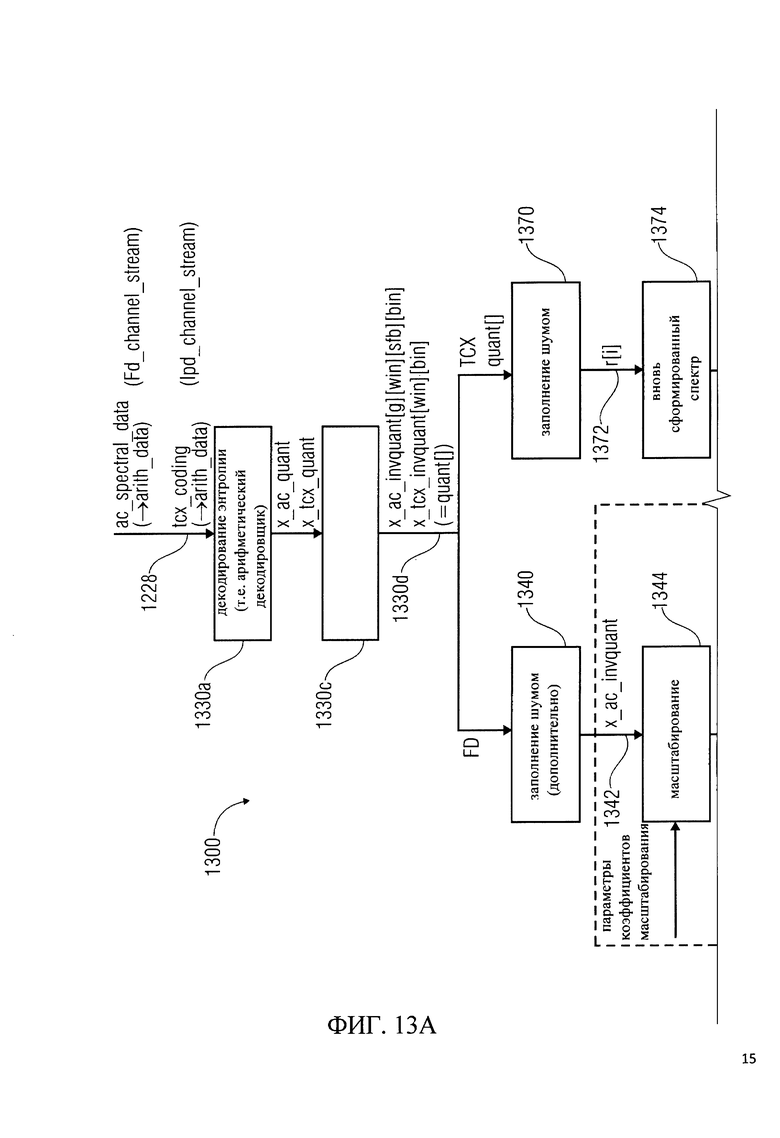
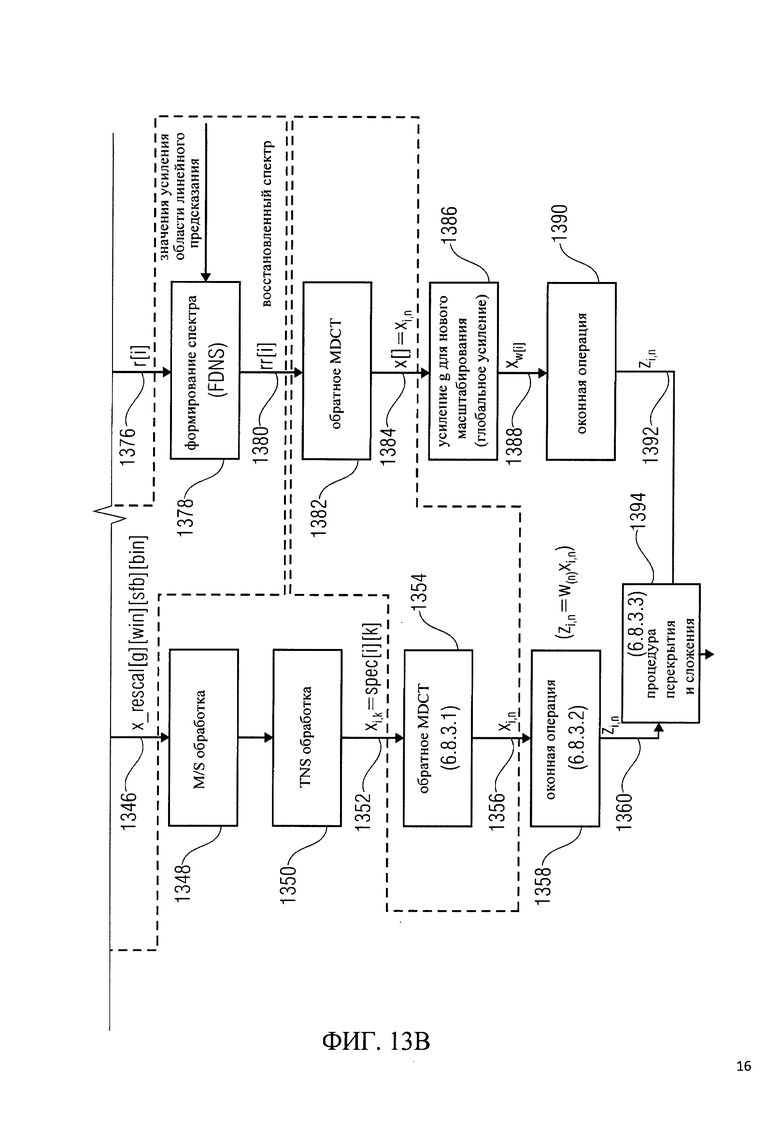
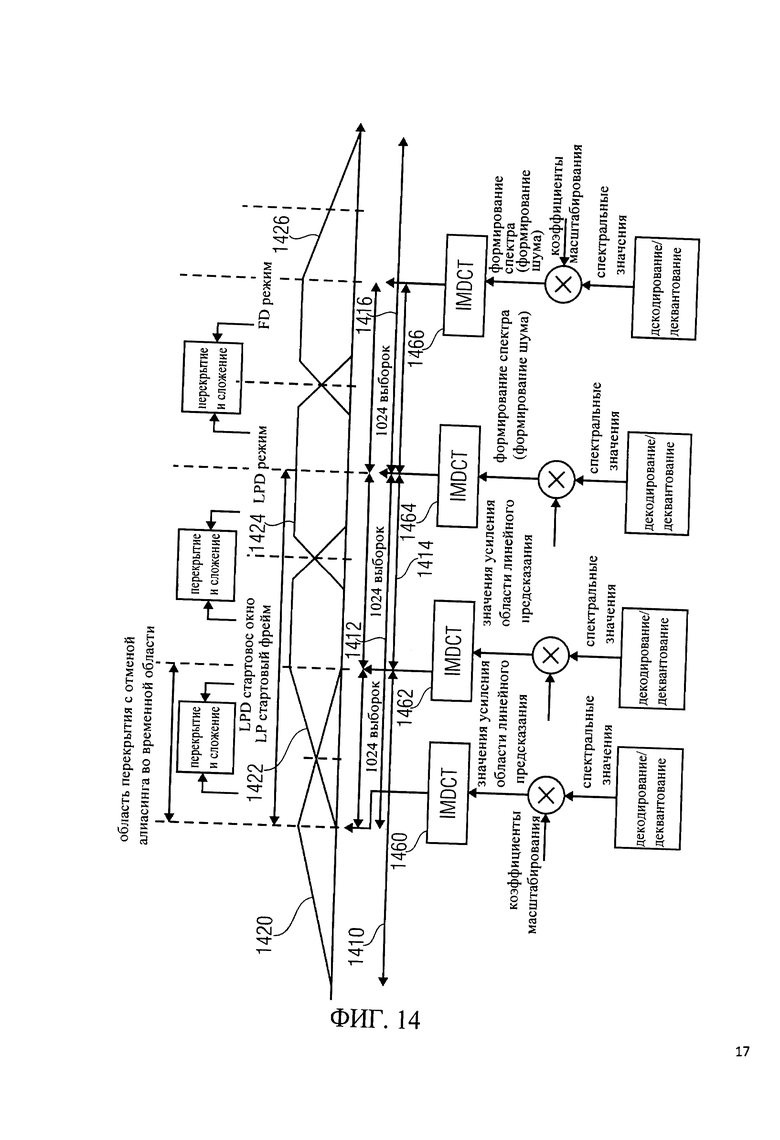

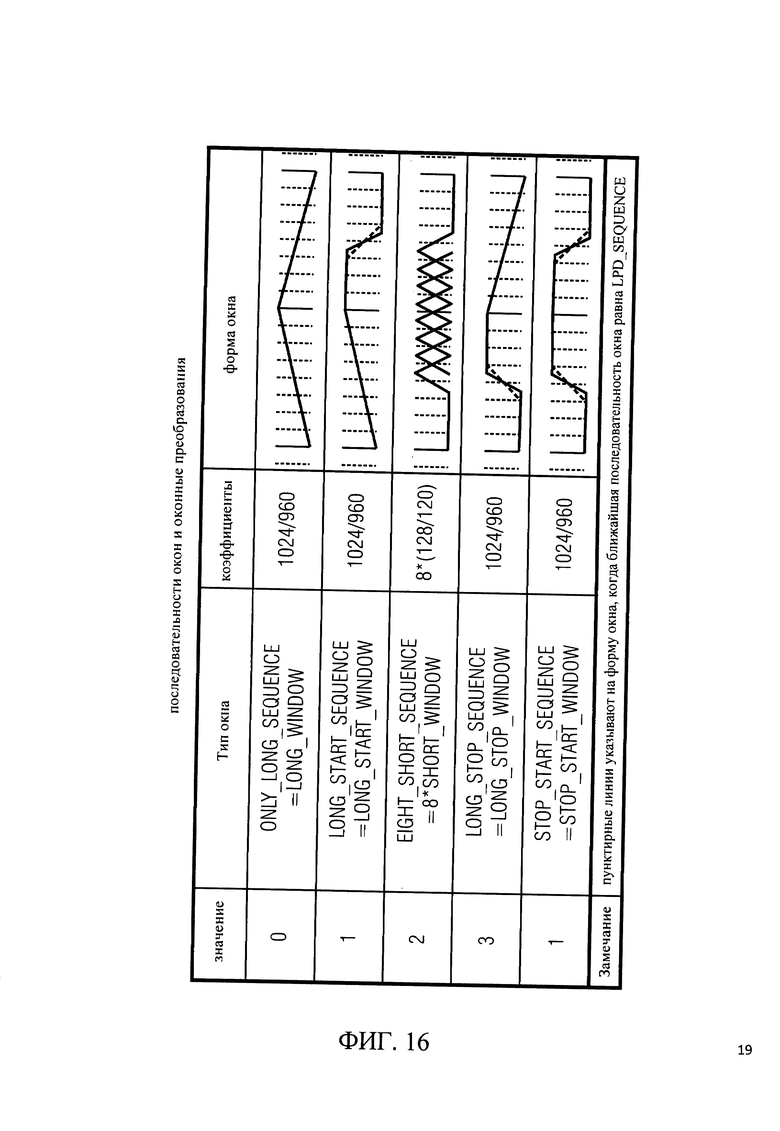

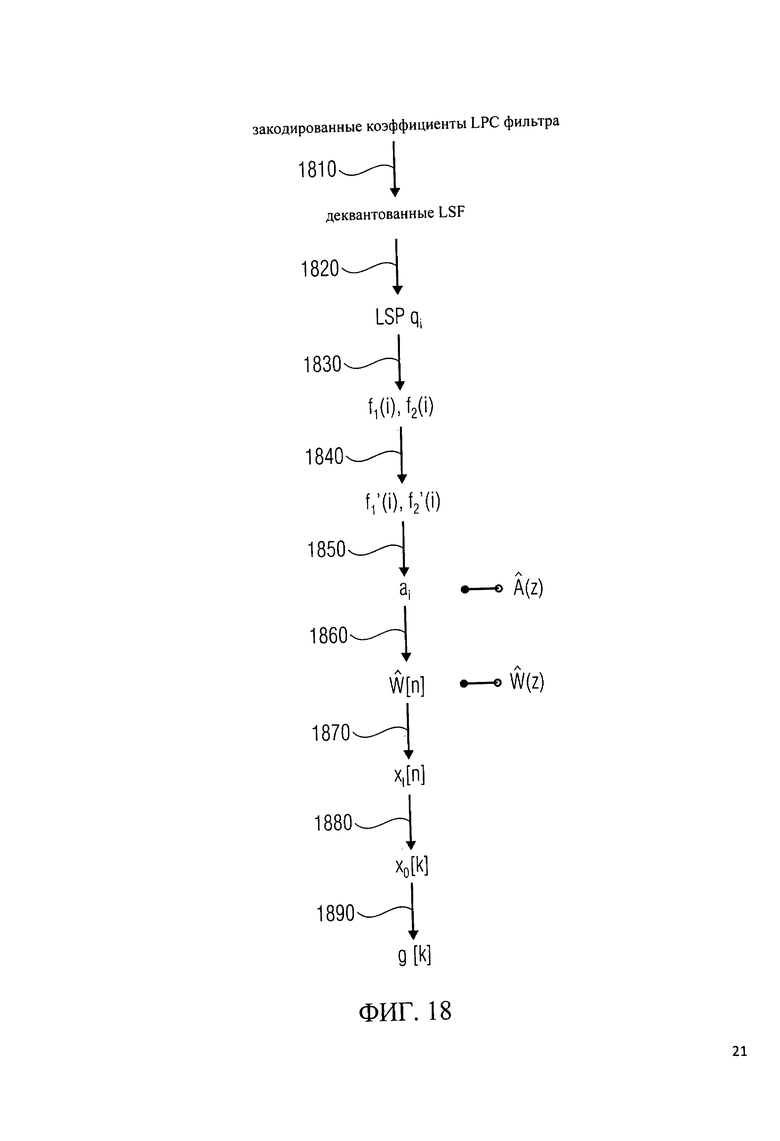
Изобретение относится к средствам кодирования и декодирования аудиосигнала. Технический результат заключается в повышении эффективности кодирования аудио, включающего речевые и неречевые части, за счет повышения эффективности кодирования переходов между данными частями. Декодировщик аудиосигнала включает в себя спектральный процессор, предназначенный для формирования спектра из набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированной в режиме линейного предсказания, и выполнения процедуры формирования спектра из набора закодированных спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от параметров набора коэффициентов масштабирования для части аудиоконтента, закодированной в частотной области. 6 н. и 21 з.п. ф-лы, 19 ил.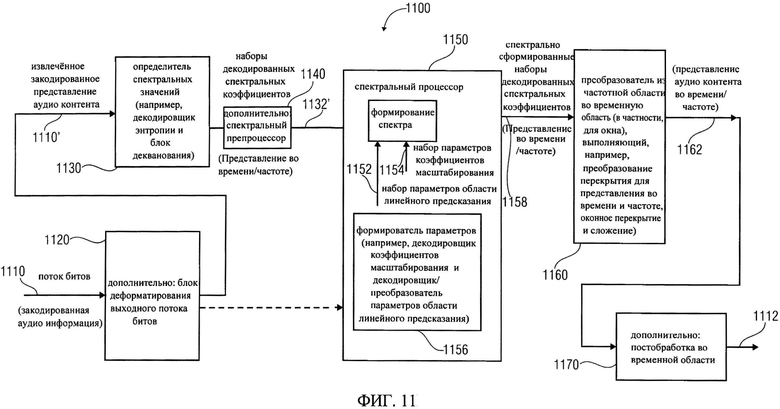
1. Многорежимный декодировщик аудиосигнала (1100, 1200) для получения декодированного представления аудиоконтента (1112, 1212) на основе закодированного представления аудиоконтента (1110, 1208), декодировщик аудиосигнала, включающий:
определитель спектральных значений (1130; 1230а, 1230с), настроенный на получение набора (1132, 1230d) декодированных спектральных коэффициентов (1132; 1230d, r[i]) для нескольких частей (1410, 1412, 1414, 1416) аудиоконтента;
спектральный процессор (1230е, 1378), настроенный на выполнение формирования спектра из набора декодированных спектральных коэффициентов (1132, 1230d, r[i]), или их предварительно обработанной версии (1132'), в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированной в режиме линейного предсказания, и выполнение формирования спектра из набора декодированных спектральных коэффициентов (1132, 1230d, r[i]), или их предварительно обработанной версии (1232'), в зависимости от набора параметров коэффициентов масштабирования (1152, 1260b) для части (1410, 1416) аудиоконтента, закодированной в режиме частотной области, и преобразователь из частотной области во временную область (1160, 1230g), настроенный на получение представления во временной области (1162, 1232, xi,n) аудиоконтента на основе спектрально-сформированного набора декодированных спектральных коэффициентов (1158, 1230f) для части аудиоконтента, закодированной в режиме линейного предсказания, а также для получения представления во временной области (1162, 1232) аудиоконтента на основе спектрально-сформированного набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме частотной области.
2. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что он дополнительно содержит блок перекрытия (1233), настроенный на перекрытие и суммирование представления части аудиоконтента во временной области, закодированного в режиме линейного предсказания, с частью аудиоконтента, закодированной в режиме частотной области.
3. Многорежимный декодировщик аудиосигнала по п.2, характеризующийся тем, что преобразователь из частотной области во временную область (1160, 1230g) настроен на получение представления аудиоконтента во временной области для части (1412, 1414) аудиоконтента, закодированной в режиме линейного предсказания с помощью преобразования перекрытия, а также получения представления аудиоконтента во временной области для части аудиоконтента (1410, 1416), закодированной в режиме частотной области с использованием преобразования перекрытия, причем блок перекрытия настроен на перекрытие представлений последовательных частей аудиоконтента, закодированных в различных режимах, во временной области.
4. Многорежимный декодировщик аудиосигнала по п.3, характеризующийся тем, что преобразователь из частотной области во временную область (1160; I230g) настроен на использование одного и того же типа преобразования, преобразования с перекрытием, для получения представлений аудиоконтента во временной области для частей аудиоконтента, закодированных в различных режимах, причем блок перекрытия настроен на перекрытие и суммирование во временной области представлений последовательных частей аудиоконтента, закодированных в различных режимах таким образом, что алиасинг во временной области, вызванный преобразованием с перекрытием, сокращается или исключается.
5. Многорежимный декодировщик аудиосигнала по п.4, характеризующийся тем, что блок перекрытия настроен на перекрытие и суммирование оконного представления во временной области для первой части (1414) аудиоконтента, закодированного в первом из режимов таким образом, как это предусмотрено в соответствующем преобразовании с перекрытием, или его амплитудно-масштабированной, но спектрально неискаженной, версии, и оконного представления во временной области второй последовательной части аудиоконтента (1416), закодированной во втором режиме, как это предусмотрено в соответствующем преобразовании с перекрытием, или его амплитудно-масштабированной, но спектрально неискаженной, версии.
6. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что преобразователь из частотной области во временную область (1160, 1230g) настроен на получение представления во временной области частей аудиоконтента (1410, 1412, 1414, 1416), закодированных в различных режимах, так что полученные представления во временной области находятся в той же области, в которой находится их линейная комбинация, без применения операции фильтрации сформированного сигнала, за исключением операций перехода к другим окнам, для одного или обоих сформированных представлений во временной области.
7. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что преобразователь из частотной области во временную область (1160, 1230g) настроен на выполнение обратного модифицированного дискретного косинусного преобразования и получение, в результате, обратного модифицированного дискретного косинусного преобразования временного представления аудиоконтента в области аудиосигнала как для части аудиоконтента, закодированной в режиме линейного предсказания, так и для части аудиоконтента, закодированной в режиме частотной области.
8. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что включает определитель коэффициентов фильтра при кодировании с линейным предсказанием, настроенный на получение декодированных коэффициентов фильтра при кодировании с линейным предсказанием (от α1 до α16) на основе закодированного представления коэффициентов фильтра при кодировании с линейным предсказанием для части аудиоконтента, закодированной в режиме линейного предсказания;
преобразователь коэффициентов фильтра (1260е) настроен на преобразование декодированных коэффициентов при кодировании с линейным предсказанием (1260d; от α1 до α16) в спектральное представление (1260f; Xo[k]), для получения в режиме линейного предсказания значений усиления (g[k]), связанных с различными частотами;
определитель коэффициентов масштабирования (1260а), настроенный на получение декодированных значений коэффициентов масштабирования (1260f) на основе закодированного представления (1254) значений коэффициентов масштабирования для части аудиоконтента, закодированной в режиме частотной области;
причем спектральный процессор (1150, 1230е) включает в себя преобразователь спектра, настроенный на суммирование набора (1132; 1230d; r[i]) декодированных спектральных коэффициентов, связанных с закодированной в режиме линейного предсказания частью аудиоконтента, или ее предварительно обработанной версии, со значениями усиления в режиме линейного предсказания (g[k]), для получения обработанной усиленной версии (1158; 1230f; rr[i]) декодированных спектральных коэффициентов, в которых вклад декодированных спектральных коэффициентов (1130; 1230d; r[i]), или их предварительно обработанных версий, масштабируются в зависимости от значений усиления в режиме линейного предсказания (g[k]), также [преобразователь спектра] настроен на суммирование наборов (1132; 1230d; x_ac_invquant) декодированных спектральных коэффициентов, связанных с закодированной в режиме частотной области частью аудиоконтента, или ее предварительно обработанной версией, со значениями коэффициента масштабирования (1260b) для получения обработанной версии коэффициентов масштабирования (x_rescal) декодированных спектральных коэффициентов (x_ac_invquant), в которых вклад декодированных спектральных коэффициентов, или их предварительно обработанных версий, масштабируются в зависимости от значений коэффициентов масштабирования.
9. Многорежимный декодировщик аудиосигнала по п.8, характеризующийся тем, что преобразователь коэффициентов фильтра (1260е) настроен на преобразование декодированных коэффициентов фильтра при кодировании с линейным предсказанием (1260d), в результате которого импульсный отклик во временной области (w[n]) в фильтре кодирования с линейным предсказанием преобразуется в спектральное представление (X0[k]) с использованием нечетного дискретного преобразования Фурье, причем преобразователь коэффициентов фильтра (1260е) настроен на получение значений усиления в режиме линейного предсказания (g[k]) из спектрального представления (XoM) декодированных коэффициентов фильтра (1260d; от α1 до α16) при кодировании с линейным предсказанием так, что значения усиления являются функцией магнитуд коэффициентов (Xo[k]) спектрального представления (Xo[k]).
10. Многорежимный декодировщик аудиосигнала по п.8, характеризующийся тем, что преобразователь коэффициентов фильтра (I260e) и сумматор (1230е) настроены таким образом, чтобы вклад данных декодированных спектральных коэффициентов (r[i]) или их предварительно обработанных версий, в обработанную усиленную версию (rr[i]) данного спектрального коэффициента определялся магнитудой значения усиления в режиме линейного предсказания (g[k]), связанной с данным декодированным спектральным коэффициентом (r[i]).
11. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что спектральный процессор (I230e) настроен таким образом, чтобы вклад данного декодированного спектрального коэффициента (r[i]), или его предварительно обработанной версии, в обработанную усиленную версию (rr[i]) данного спектрального коэффициента увеличивался с ростом магнитуды значения усиления в режиме линейного предсказания (g[k]), связанной с данным декодированным спектральным коэффициентом (r[i]), или [спектральный процессор настроен таким образом], чтобы вклад данного декодированного спектрального коэффициента (r[i]), или его предварительно обработанной версии, в обработанную усиленную версию (rr[i]) данного спектрального коэффициента уменьшался с увеличением магнитуды соответствующего спектрального коэффициента (Xo[k]) спектрального представления декодированных коэффициентов фильтра при кодировании с линейным предсказанием.
12. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что определитель спектральных значений (1130; 1230а, 1230е) настроен на применение деквантования к декодированным дискретизированным спектральным коэффициентам, для получения декодированных и деквантованных спектральных коэффициентов (1132; 1230d), и причем спектральный процессор (1230е) настроен на снижение шумов дискретизации путем подбора эффективного шага дискретизации в режиме линейного предсказания для данных декодированных спектральных коэффициентов (r[i]) в зависимости от магнитуды значений усиления (g[k]), связанной с данным декодированным спектральным коэффициентом (r[i]).
13. Многорежимный декодировщик аудиосигнала по п.1, характеризующийся тем, что декодировщик аудиосигнала настроен на использование промежуточного стартового фрейма в режиме линейного предсказания (1212) для перехода от фрейма в частотном режиме (1410) к комбинированному фрейму режима линейного предсказания/режима линейного предсказания с возбуждением по алгебраической кодовой книге, причем декодировщик аудиосигнала настроен на получение набора декодированных спектральных коэффициентов для стартового фрейма режима линейного предсказания, а также выполнение формирования спектра из набора декодированных спектральных коэффициентов в режиме линейного предсказания для стартового фрейма, или его предварительно обработанной версии, в зависимости от набора параметров области линейного предсказания, связанных с ним, и для получения представления во временной области стартового фрейма в режиме линейного предсказания на основе сформированного спектра в виде набора декодированных спектральных коэффициентов, а также для использования стартового окна, имеющего сравнительно длинный левосторонний склон огибающей перехода и сравнительно небольшой правосторонний склон огибающей перехода, для представления во временной области стартового фрейма в режиме линейного предсказания.
14. Многорежимный декодировщик аудиосигнала по п.13, характеризующийся тем, что декодировщик аудиосигнала настроен на перекрытие правосторонней части представления во временной области фрейма в частотной области (1410), предшествующего стартовому фрейму в режиме линейного предсказания (1412) с левосторонней частью представления во временной области стартового фрейма в режиме линейного предсказания для получения уменьшения или отмены алиасинга во временной области.
15. Многорежимный декодировщик аудиосигнала по п.13, характеризующийся тем, что декодировщик аудиосигнала настроен на использование параметров области линейного предсказания, связанных со стартовым фреймом в режиме линейного предсказания (1412), для инициализации режима линейного предсказания декодировщика с возбуждением по алгебраической кодовой книге и декодирования по крайней мере части комбинированного фрейма в режиме линейного предсказания/режиме линейного предсказания с возбуждением по алгебраической кодовой книге, следующего после стартового фрейма в режиме линейного предсказания.
16. Многорежимный кодировщик аудиосигнала (100, 300, 900, 1000) для формирования закодированного представления (112; 312; 1012) аудиоконтента на основе входного представления аудиоконтента (110, 310; 1010), кодировщик аудиосигнала, содержащий:
преобразователь частотной области во временную область (120, 330а, 330а, 1030А), настроенный на обработку входного представления аудиоконтента (110, 310; 1010), для получения представления аудиоконтента в частотной области (122; 330b; 1030b); где представления частотной области (122) состоят из последовательности наборов спектральных коэффициентов;
спектральный процессор (130, 330е, 350D, 1030е), настроенный на выполнение формирования спектра из набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров области линейных предсказания (134, 340b) для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, для получения спектрально-сформированного набора 132 спектральных коэффициентов и выполнение формирования спектра из набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров коэффициентов масштабирования (136) для части аудиоконтента, которая должна быть закодирована в режиме частотной области для получения спектрально-сформированного набора 132 спектральных коэффициентов,
а также кодировщик дискретизации (140, 330, 330i, 350f, 350h; 1030g, 1030i), настроенный на получение закодированной версии (142, 322, 342; 1032) спектрально-сформированного набора (132, 350е, 1030i) спектральных коэффициентов для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, а также [кодировщик дискретизации, настроенный] на получение закодированной версии (342, 322, 342; 1032) спектрально-сформированного набора (132, 330f, 1030i) спектральных коэффициентов для части аудиоконтента, которая должна быть закодирована в режиме частотной области.
17. Многорежимный кодировщик аудиосигнала по п.16, характеризующийся тем, что преобразователь частотной области во временную область (120, 330a, 350а; 1030а) настроен на преобразование представления во временной области (110, 310; 1010) аудиоконтента в области аудиосигнала в представление в частотной области (122; 330b, 1030b) аудиоконтента как для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, так и для части аудиоконтента, которая должна быть закодирована в режиме частотной области.
18. Многорежимный кодировщик аудиосигнала по п.16, характеризующийся тем, что преобразователь частотной области во временную область (120, 330а, 330а, 1030А) настроен выполнение преобразования с перекрытием для преобразований одного и того же типа и получение представления в частотной области для частей аудиоконтента, которые должны быть закодированы в различных режимах.
19. Многорежимный кодировщик аудиосигнала по п.16, характеризующийся тем, что спектральный процессор (130, 330е, 340b, 1030е) настроен на выполнение избирательного формирования спектра из набора (122, 330b, 1030b) спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора (134, 340b) параметров области линейного предсказания, полученных с помощью корреляционного анализа, части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, или в зависимости от набора (136, 330d, 1070b) параметров коэффициентов масштабирования, полученных с помощью анализа по психоакустической модели (330с, 1070а), части аудиоконтента, которая должна быть закодирована в режиме частотной области.
20. Многорежимный кодировщик аудиосигнала по п.19, характеризующийся тем, что кодировщик аудиосигнала содержит селектор режимов, настроенный на анализ аудиоконтента и принятие решения о кодировании части аудиоконтента в режиме линейного предсказания либо в режиме частотной области.
21. Многорежимный кодировщик аудиосигнала по п.16, характеризующийся тем, что многорежимный кодировщик аудиосигнала настроен на кодирование аудиофрейма, который находится между фреймом в режиме частотной области и комбинированным фреймом в режиме линейного предсказания/режиме линейного предсказания с возбуждением по алгебраической кодовой книге, в качестве стартового фрейма режима линейного предсказания, причем многорежимный кодировщик аудиосигнала настроен на использование стартового окна, имеющего сравнительно длинный левосторонний склон (огибающей) перехода и сравнительно короткий правосторонний склон перехода для представления стартового фрейма во временной области в режиме линейного предсказания, и получение оконного представления во временной области, а также формирование представления в частотной области оконного представления во временной области для стартового фрейма в режиме линейного предсказания, и получение набора параметров области линейного предсказания для стартового фрейма в режиме линейного предсказания, и выполнение формирования спектра в виде представления в частотной области на основе оконного представления во временной области стартового фрейма, или его предварительно обработанной версии, в режиме линейного предсказания в зависимости от набора параметров области линейного предсказания, а также для кодирования набора параметров области линейного предсказания и спектрально-сформированного представления в частотной области на основе оконного представления во временной области стартового фрейма в режиме линейного предсказания.
22. Многорежимный кодировщик аудиосигнала по п.21, характеризующийся тем, что многорежимный кодировщик аудиосигнала настроен на использование параметров области линейного предсказания, связанных со стартовым фреймом режима линейного предсказания, для инициализации режима кодировщика с линейным предсказанием с возбуждением по алгебраической кодовой книге для кодирования по крайней мере части комбинированного фрейма в режиме линейного предсказания/режиме линейного предсказания с возбуждением по алгебраической кодовой книге, следующего после стартового фрейма в режиме линейного предсказания.
23. Многорежимный кодировщик аудиосигнала по п.16, характеризующийся тем, что кодировщик аудиосигнала содержит
определитель коэффициентов фильтра при кодировании с линейным предсказанием (340а, 1070с), настроенный на анализ части аудиоконтента, или ее предварительно обработанной версии, которая должна быть закодирована в режиме линейного предсказания, для определения коэффициентов фильтра, связанных с частью аудиоконтента, которая должна быть закодирована в режиме линейного предсказания;
преобразователь коэффициентов фильтра (340b; 1070d), настроенный на преобразование коэффициентов фильтра при кодировании с линейным предсказанием в спектральное представление (Xo[k]), и получение значений усиления в режиме линейного предсказания (g[k], 350с), связанных с различными частотами;
определитель коэффициентов масштабирования (330с, 1070а), настроенный на анализ части аудиоконтента, или ее предварительно обработанной версии, которая должна быть закодирована в режиме частотной области, для определения коэффициентов масштабирования, связанных с частью аудиоконтента для кодирования в режиме частотной области;
блок сумматора (330е, 350d; 1030е), настроенный на суммирование представления в частотной области для части аудиоконтента, или ее предварительно обработанной версии, которая должна быть закодирована в режиме линейного предсказания, со значениями усиления (g[k]) в режиме линейного предсказания, для получения усиленных спектральных составляющих, причем вклады спектральных компонент в представление аудиоконтента в частотной области взвешиваются в зависимости от значений усиления в режиме линейного предсказания, и [для] суммирования представления в частотной области для части аудиоконтента, или ее предварительно обработанной версии, которая должна быть закодирована в режиме частотной области, с коэффициентами масштабирования, и [для] получения усиленных спектральных составляющих, в которых вклад спектральных компонент представления аудиоконтента в частотной области взвешивается в зависимости от коэффициентов масштабирования, причем усиленные спектральные составляющие формируют наборы спектральных коэффициентов.
24. Способ для получения представления декодированного аудиоконтента на основе закодированного представления аудиоконтента, способ включающий:
получение набора декодированных спектральных коэффициентов для нескольких частей аудиоконтента;
выполнение формирования спектра из набора декодированных спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров области линейного предсказания для части аудиоконтента, закодированной в режиме линейного предсказания, и выполнение формирования спектра из набора декодированных спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров коэффициентов масштабирования для части аудиоконтента, закодированной в режиме частотной области, и получение представления аудиоконтента во временной области на основе спектрально-сформированного набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме линейного предсказания, а также получение представления аудиоконтента во временной области на основе сформированного набора декодированных спектральных коэффициентов для части аудиоконтента, закодированной в режиме частотной области.
25. Способ получения закодированного представления аудиоконтента на основе входного представления аудиоконтента, включающий:
обработку входного представления аудиоконтента для получения представления аудиоконтента в частотной области; где представления частотной области (122) содержат последовательность набора спектральных коэффициентов;
выполнение формирования спектра из набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров области линейного предсказания для части аудиоконтента, которая должна быть закодирована в режиме линейного предсказания, для получения спектрально-сформированного набора (132) спектральных коэффициентов;
выполнение формирования спектра их набора спектральных коэффициентов, или их предварительно обработанных версий, в зависимости от набора параметров коэффициента масштабирования для части аудиоконтента, которая будет закодирована в режиме частотной области для получения спектрально-сформированного набора (132) спектральных коэффициентов;
формирование закодированного представления сформированного набора спектральных коэффициентов для части аудиоконтента, которая должна быть закодирована в режиме линейном предсказания, с использованием дискретизированного кодирования; и
получение закодированной версии сформированного набора спектральных коэффициентов для части аудиоконтента, которая должна быть закодирована в режиме частотной области, с использованием дискретизированного кодирования.
26. Машиночитаемый носитель данных с сохраненной на нем компьютерной программой для осуществления способа по п. 24, при запуске ее на компьютере.
27. Машиночитаемый носитель данных с сохраненной на нем компьютерной программой для осуществления способа по п. 25, при запуске ее на компьютере.
| Колосоуборка | 1923 |
|
SU2009A1 |
| МЕТАЛЛОПЛАКИРУЮЩИЙ СМАЗОЧНЫЙ СОСТАВ | 1992 |
|
RU2063417C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Устройство для измерения малых коэффициентов гармоник сигналов | 1990 |
|
SU1798724A1 |
| DE 102006022346 A1, 15.11.2007 | |||
| КОДИРОВАНИЕ ЗВУКА | 2005 |
|
RU2346339C2 |

