ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Варианты осуществления согласно изобретению создают аудиодекодеры для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации.
Некоторые варианты осуществления согласно изобретению создают способы для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации.
Некоторые варианты осуществления согласно изобретению создают компьютерные программы для осуществления одного из упомянутых способов.
Некоторые варианты осуществления согласно изобретению относятся к маскированию во временной области для кодека области преобразования.
УРОВЕНЬ ТЕХНИКИ
В последние годы наблюдается увеличение потребности в цифровой передаче и хранении аудиоконтента. Однако аудиоконтент часто передается по ненадежным каналам, что создает опасность того, что блоки данных (например, пакеты), содержащие один или более кадров аудио (например, в форме кодированного представления, например, кодированного представления частотной области или кодированного представления временной области) теряются. В ряде случаев, можно запрашивать повторение (повторную отправку) потерянных кадров аудио (или блоков данных, например, пакетов, содержащих один или более потерянных кадров аудио). Однако это обычно вносит существенную задержку, и поэтому требует обширной буферизации кадров аудио. В других случаях, вряд ли возможно запрашивать повторение потерянных кадров аудио.
Для получения хорошего, или, по меньшей мере, приемлемого, качества аудиосигнала при условии, что кадры аудио теряются без обеспечения обширной буферизации (которая потребляет большой объем памяти и также существенно снижает возможности аудиокодирования в реальном времени) желательно иметь принципы обработки потери одного или более кадров аудио. В частности, желательно иметь принципы, которые способствуют хорошее качество аудиосигнала, или, по меньшей мере, приемлемое качество аудиосигнала, даже в случае, когда кадры аудио теряются.
В прошлом разработаны некоторые принципы маскирования ошибки, которые можно применять в разных принципах аудиокодирования.
В дальнейшем будет описан традиционный принцип аудиокодирования.
В стандарте 3gpp TS 26.290, объяснено декодирование возбуждение, кодированное преобразованием (декодирование TCX) с маскированием ошибки. В дальнейшем, будут обеспечены некоторые объяснения, которые основаны на разделе ʺдекодирование и синтез сигнала в режиме TCXʺ в ссылке [1].
Декодер TCX согласно международному стандарту 3gpp TS 26.290 показан на фиг. 7 и 8, где фиг. 7 и 8 демонстрируют блок-схемы декодера TCX. Однако фиг. 7 демонстрирует эти функциональные блоки, которые имеют отношение к декодированию TCX в нормальном режиме работы или к случаю частичной потере пакетов. Напротив, фиг. 8 демонстрирует соответствующую обработку декодирования TCX в случае маскирования удаления пакета TCX-256.
Иначе говоря, фиг. 7 и 8 демонстрируют блок-схему декодера TCX, включающую в себя следующие случаи:
случай 1 (фиг. 8): маскирование удаления пакета в TCX-256, когда длина кадра TCX равна 256 выборок, и соответствующий пакет теряется, т.е. BFI_TCX=(1); и
случай 2 (фиг. 7): нормальное декодирование TCX, возможно, с частичными потерями пакетов.
В дальнейшем, будут обеспечены некоторые объяснения, касающиеся фиг. 7 и 8.
Как упомянуто, фиг. 7 демонстрирует блок-схему декодера TCX, осуществляющего декодирование TCX в нормальном режиме работы или в случае частичной потери пакетов. Декодер 700 TCX согласно фиг. 7 принимает параметры 710, относящиеся к TCX, и обеспечивает, на их основании, декодированную аудиоинформацию 712, 714.
Аудиодекодер 700 содержит демультиплексор ʺDEMUX TCX 720ʺ, который выполнен с возможностью приема параметров 710, относящихся к TCX, и информации ʺBFI_TCXʺ. Демультиплексор 720 разделяет параметры 710, относящиеся к TCX, и обеспечивает кодированную информацию 722 возбуждения, кодированную информацию 724 шумозаполнения и кодированную информацию 726 глобального коэффициента усиления. Аудиодекодер 700 содержит декодер 730 возбуждения, который выполнен с возможностью приема кодированной информации 722 возбуждения, кодированной информации 724 шумозаполнения и кодированной информации 726 глобального коэффициента усиления, а также некоторой дополнительной информации (например, флага битовой скорости ʺbit_rate_flagʺ, информации ʺBFI_TCXʺ и информации длины кадра TCX. Декодер 730 возбуждения обеспечивает, на ее основании, сигнал 728 возбуждения во временной области (также обозначенный ʺxʺ). Декодер 730 возбуждения содержит процессор 732 информации возбуждения, который демультиплексирует кодированную информацию 722 возбуждения и декодирует параметры алгебраического векторного квантования. Процессор 732 информации возбуждения обеспечивает промежуточный сигнал 734 возбуждения, который обычно представлен в частотной области, и который обозначен Y. Кодер 730 возбуждения также содержит инжектор 736 шума, который выполнен с возможностью инжекции шума в неквантованных поддиапазонах, для вывода шумозаполненного сигнала 738 возбуждения из промежуточного сигнала 734 возбуждения. Шумозаполненный сигнал 738 возбуждения обычно находится в частотной области и обозначен Z. Инжектор 736 шума принимает информацию 742 интенсивности шума от декодера 740 уровня шумозаполнения. Декодер возбуждения также содержит адаптивную низкочастотную коррекцию 744 предыскажений, которая выполнена с возможностью осуществления операции низкочастотной коррекции предыскажений на основании шумозаполненного сигнала 738 возбуждения, для получения, таким образом, обработанного сигнала 746 возбуждения, который все еще находится в частотной области, и который обозначен X'. Декодер 730 возбуждения также содержит преобразователь 748 из частотной области во временную область, который выполнен с возможностью приема обработанного сигнала 746 возбуждения и обеспечения, на его основании, сигнала 750 возбуждения во временной области, который связан с определенным временным участком, представленным набором параметров возбуждения в частотной области (например, обработанного сигнала 746 возбуждения). Декодер 730 возбуждения также содержит блок 752 масштабирования, который выполнен с возможностью масштабирования сигнала 750 возбуждения во временной области для получения, таким образом, масштабированного сигнала 754 возбуждения во временной области. Блок 752 масштабирования принимает информацию 756 глобального коэффициента усиления от декодера 758 глобального коэффициента усиления, в котором, в ответ, декодер 758 глобального коэффициента усиления принимает кодированную информацию 726 глобального коэффициента усиления. Декодер 730 возбуждения также содержит синтез 760 с перекрытием и добавлением, который принимает масштабированные сигналы 754 возбуждения во временной области, связанные с множеством временных участков. Синтез 760 с перекрытием и добавлением осуществляет операцию перекрытия и добавления (которая может включать в себя операцию взвешивания с помощью финитной функции) на основании масштабированных сигналов 754 возбуждения во временной области, для получения объединенного во времени сигнала 728 возбуждения во временной области на протяжении более длинного периода времени (более длинного, чем периоды времени, в течение которых обеспечиваются отдельные сигналы 750, 754 возбуждения во временной области).
Аудиодекодер 700 также содержит синтез 770 LPC, который принимает сигнал 728 возбуждения во временной области, обеспеченный синтезом 760 с перекрытием и добавлением, и один или более коэффициентов LPC, задающих функцию синтезирующего фильтра 772 LPC. Синтез 770 LPC может, например, содержать первый фильтр 774, который может, например, синтетически фильтровать сигнал 728 возбуждения во временной области, для получения, таким образом, декодированного аудиосигнала 712. Опционально, синтез 770 LPC также может содержать второй синтезирующий фильтр 772, который выполнен с возможностью синтетически фильтровать выходной сигнал первого фильтра 774 с использованием другой функции синтезирующего фильтра, для получения, таким образом, декодированного аудиосигнала 714.
В дальнейшем, декодирование TCX будет описано в случае маскирования удаления пакета TCX-256. Фиг. 8 демонстрирует блок-схему декодера TCX в этом случае.
Маскирование 800 удаления пакета принимает информацию 810 основного тона, которая также обозначена ʺpitch_tcxʺ и получена из предыдущего декодированного кадра TCX. Например, информацию 810 основного тона можно получать с использованием блока 747 оценивания преобладающего основного тона из обработанного сигнала 746 возбуждения на декодере 730 возбуждения (в ходе ʺнормальногоʺ декодирования). Кроме того, маскирование 800 удаления пакета принимает параметры 812 LPC, которые могут представлять функцию синтезирующего фильтра LPC. Параметры 812 LPC могут, например, быть идентичны параметрам 772 LPC. Соответственно, маскирование 800 удаления пакета может быть выполнено с возможностью обеспечения, на основании информации 810 основного тона и параметров 812 LPC, сигнала 814 с маскированием ошибки, который можно рассматривать как аудиоинформацию с маскированием ошибки. Маскирование 800 удаления пакета содержит буфер 820 возбуждения, который может, например, буферизовать предыдущее возбуждение. Буфер 820 возбуждения может, например, использовать адаптивную кодовую книгу ACELP и может обеспечивать сигнал 822 возбуждения. Маскирование 800 удаления пакета может дополнительно содержать первый фильтр 824, функцию фильтра которого можно задать, как показано на фиг. 8. Таким образом, первый фильтр 824 может фильтровать сигнал 822 возбуждения на основании параметров 812 LPC, для получения фильтрованной версии 826 сигнала 822 возбуждения. Маскирование удаления пакета также содержит ограничитель 828 амплитуды, который может ограничивать амплитуду фильтрованного сигнала 826 возбуждения на основании целевой информации или информации уровня rmswsyn. Кроме того, маскирование 800 удаления пакета может содержать второй фильтр 832, который может быть выполнен с возможностью приема ограниченного по амплитуде фильтрованного сигнала возбуждения 830 от ограничителя 822 амплитуды и обеспечения, на его основании, сигнала 814 с маскированием ошибки. Функция фильтра второго фильтра 832 может быть, например, задана, как показано на фиг. 8.
В дальнейшем будут описаны некоторые детали, касающиеся декодирования и маскирования ошибки.
В случае 1 (маскирование удаления пакета в TCX-256), информация для декодирования кадра TCX в 256 выборок недоступна. Синтез TCX находится посредством обработки прошлого возбуждения с задержкой на T, где T=pitch_tcx это отставание основного тона, оцененное в ранее декодированном кадре TCX, нелинейным фильтром, примерно эквивалентным 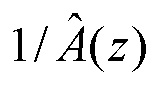 . Нелинейный фильтр используется вместо
. Нелинейный фильтр используется вместо 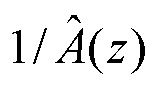 во избежание щелчков в синтезе. Этот фильтр разлагается на 3 этапа:
во избежание щелчков в синтезе. Этот фильтр разлагается на 3 этапа:
этап 1: фильтрация посредством
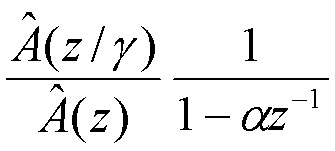
для отображения возбуждения с задержкой на T в целевую область TCX;
этап 2: применение ограничителя (величина ограничена±rmswsyn)
этап 3: фильтрация посредством
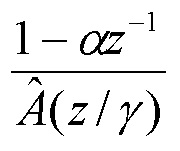
для нахождения синтеза. Заметим, что в этом случае буфер OVLP_TCX задается равным нулю.
Декодирование параметров алгебраического VQ
В случае 2, декодирование TCX предусматривает декодирование параметров алгебраического VQ, описывающих каждый квантованный блок 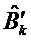 масштабированного спектра X', где X' описан на этапе 2 раздела 5.3.5.7 3gpp TS 26.290. Напомним, что X' имеет размер N, где N=288, 576 и 1152 для TCX-256, 512 и 1024 соответственно, и что каждый блок B'k имеет размер 8. Количество K блоков B'k, таким образом, равно 36, 72 и 144 для TCX-256, 512 и 1024 соответственно. Параметры алгебраического VQ для каждого блока B'k описаны на этапе 5 раздела 5.3.5.7. Для каждого блока B'k кодер отправляет три набора двоичных индексов:
масштабированного спектра X', где X' описан на этапе 2 раздела 5.3.5.7 3gpp TS 26.290. Напомним, что X' имеет размер N, где N=288, 576 и 1152 для TCX-256, 512 и 1024 соответственно, и что каждый блок B'k имеет размер 8. Количество K блоков B'k, таким образом, равно 36, 72 и 144 для TCX-256, 512 и 1024 соответственно. Параметры алгебраического VQ для каждого блока B'k описаны на этапе 5 раздела 5.3.5.7. Для каждого блока B'k кодер отправляет три набора двоичных индексов:
a) индекс кодовой книги nk, передаваемый в унарном коде, описанном на этапе 5 раздела 5.3.5.7;
b) ранг Ik выбранного узла c решетки в так называемой базовой кодовой книге, который указывает, какую перестановку применять к конкретному лидеру (см. этап 5 раздела 5.3.5.7) для получения узла c решетки;
c) и, если квантованный блок (узел решетки) отсутствует в базовой кодовой книге, 8 индексов вектора k индекса удлинения Вороного, вычисленного на подэтапе V1 этапа 5 в разделе; из индексов удлинения Вороного, вектор z удлинения можно вычислять, как в ссылке [1] 3gpp TS 26.290. Количество битов в каждой составляющей вектора k индекса определяется порядком r удлинения, который можно получить из значения унарного кода индекса nk. Масштабный коэффициент M удлинения Вороного определяется как M=2r.
Затем, из масштабного коэффициента M, вектор z удлинения Вороного (узел решетки в RE8) и узел решетки c в базовой кодовой книге (также узел решетки в RE8), каждый квантованный масштабированный блок можно вычислить, как
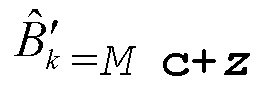
В отсутствие удлинения Вороного (т.е. nk < 5, M=1 и z=0), базовой кодовой книгой является любая кодовая книга Q0, Q2, Q3 или Q4 из ссылки [1] 3gpp TS 26.290. Тогда для передачи вектора k биты не требуется. В противном случае, когда удлинение Вороного используется, поскольку достаточно велик, в качестве базовой кодовой книги используется только Q3 или Q4 из ссылки [1]. Выбор Q3 или Q4 является неявным в значении nk индекса кодовой книги, описанном на этапе 5 раздела 5.3.5.7.
Оценивание значения преобладающего основного тона
Оценивание преобладающего основного тона осуществляется таким образом, чтобы следующий кадр, подлежащий декодированию, можно было правильно экстраполировать, если он соответствует TCX-256, и если соответствующий пакет потерян. Это оценивание основано на предположении о том, что пик максимальной величины в спектре цели TCX соответствует преобладающему основному тону. Поиск максимума M ограничен частотой ниже Fs/64 кГц
M=maxi=1..N/32(X'2i)2+(X'2i+1)2
и также находится минимальный индекс 1≤imax≤N/32, при котором (X'2i)2+(X'2i+1)2=M. Затем преобладающий основной тон оценивается по количеству выборок как Test=N/imax (это значение может не быть целочисленным). Напомним, что преобладающий основной тон вычисляется для маскирования удаления пакета в TCX-256. Во избежание проблем буферизации (ограничения буфера возбуждения 256 выборками), если Test>256 выборок, pitch_tcx задается равным 256; в противном случае, если Test≤256, множественные периоды основного тона 256 выборках устраняются путем задания pitch_tcx в виде
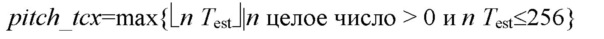
где  обозначает округление до ближайшего целого числа в направлении к -∞.
обозначает округление до ближайшего целого числа в направлении к -∞.
В дальнейшем будут кратко рассмотрены некоторые дополнительные традиционные принципы.
В ISO_IEC_DIS_23003-3 (ссылка [3]), декодирование TCX с использованием MDCT объяснено в контексте унифицированного речевого и аудиокодека.
В AAC, отвечающем уровню техники (согласно, например, ссылке [4]), описан только режим интерполяции. Согласно ссылке [4], декодер ядра AAC включает в себя функцию маскирования, которая увеличивает задержку декодера на один кадр.
В европейском патенте EP 1207519 B1 (ссылка [5]), он описан для обеспечения речевого декодера и способа компенсации ошибок, способного достигать дополнительного улучшения декодированной речи в кадре, в котором обнаружена ошибка. Согласно патенту, параметр кодирования речи включает в себя информацию режима, которая выражает особенности каждого короткого сегмента (кадра) речи. Речевой кодер адаптивно вычисляет параметры отставания и параметры коэффициента усиления, используемые для декодирования речи, согласно информации режима. Кроме того, речевой декодер адаптивно регулирует отношение адаптивного коэффициента усиления возбуждения и фиксированного коэффициента усиления коэффициент усиления возбуждения согласно информации режима. Кроме того, принцип согласно патенту содержит адаптивную регулировку адаптивных параметров коэффициента усиления возбуждения и фиксированных параметров коэффициента усиления возбуждения используемый для декодирования речи согласно значениям декодированных параметров коэффициента усиления в блоке нормального декодирования, в котором не обнаружено ошибок, сразу после блока декодирования, в отношении кодированных данных которого установлено, что они содержат ошибку.
В соответствии с уровнем техники, существует потребность в дополнительном улучшении маскирования ошибки, которое обеспечивает улучшенное слуховое восприятие.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Вариант осуществления согласно изобретению создает аудиодекодер для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Аудиодекодер содержит маскирование ошибки, выполненное с возможностью обеспечения аудиоинформации с маскированием ошибки для маскировки потери кадра аудио (или потери более одного кадра), следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области.
Этот вариант осуществления согласно изобретению основан на том факте, что улучшенное маскирование ошибки можно получить путем обеспечения аудиоинформации с маскированием ошибки на основании сигнала возбуждения во временной области, даже если кадр аудио, предшествующий потерянному кадру аудио, кодируется в представлении частотной области. Другими словами, было установлено, что качество маскирования ошибки обычно повышается, если маскирование ошибки осуществляется на основании сигнала возбуждения во временной области, по сравнению с маскированием ошибки, осуществляемым в частотной области, таким образом, что целесообразно переключаться на маскирование ошибки во временной области с использованием сигнала возбуждения во временной области, даже если аудиоконтент, предшествующий потерянному кадру аудио, кодируется в частотной области (т.е. в представлении частотной области). Это, например, справедливо для монофонического сигнала и, по большей части, для речи.
Соответственно, настоящее изобретение позволяет получать хорошее маскирование ошибки, даже если кадр аудио, предшествующий потерянному кадру аудио, кодируется в частотной области (т.е. в представлении частотной области).
В предпочтительном варианте осуществления, представление частотной области содержит кодированное представление множества спектральных значений и кодированное представление множества масштабных коэффициентов для масштабирования спектральных значений, или аудиодекодер выполнен с возможностью вывода множества масштабных коэффициентов для масштабирования спектральных значений из кодированного представления параметров LPC. Это можно делать с использованием FDNS (формирования шума в частотной области). Однако было установлено, что целесообразно выводить сигнал возбуждения во временной области (который может служить возбуждением для синтеза LPC (синтеза методом кодирования с линейным предсказанием)), даже если кадр аудио, предшествующий потерянному кадру аудио, первоначально закодирован в представлении частотной области, содержащем существенно другую информацию (а именно, кодированное представление множества спектральных значений в кодированном представлении множества масштабных коэффициентов для масштабирования спектральных значений). Например, в случае TCX мы отправляем (с кодера на декодер) не масштабные коэффициенты, а LPC и затем на декодере мы преобразуем LPC в представление масштабных коэффициентов для бинов MDCT. Иначе говоря, в случае TCX мы отправляем коэффициент LPC и затем на декодере мы преобразуем эти коэффициенты LPC в представление масштабных коэффициентов для TCX в USAC или в AMR-WB+ вовсе не существует масштабных коэффициентов.
В предпочтительном варианте осуществления, аудиодекодер содержит ядро декодера частотной области, выполненное с возможностью применения масштабирования на основе масштабных коэффициентов к множеству спектральных значений, выведенных из представления частотной области. В этом случае, маскирование ошибки выполнено с возможностью обеспечения аудиоинформации с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, содержащем множество кодированных масштабных коэффициентов, с использованием сигнала возбуждения во временной области, выведенного из представления частотной области. Этот вариант осуществления согласно изобретению основан на том факте, что вывод сигнала возбуждения во временной области из вышеупомянутого представления частотной области обычно обеспечивает лучший результат маскирования ошибки по сравнению с маскированием ошибки, осуществляемым непосредственно в частотной области. Например, сигнал возбуждения создается на основе синтеза предыдущего кадра, поэтому в действительности не имеет значения, является ли предыдущий кадр кадром частотной области (MDCT, FFT…) или кадром временной области. Однако конкретные преимущества можно наблюдать, если предыдущий кадр был кадром частотной области. Кроме того, следует отметить, что особенно хорошие результаты достигаются, например, для монофонического сигнала, например речи. В порядке другого примера, масштабные коэффициенты можно передавать как коэффициенты LPC, например, с использованием полиномиального представления, которое затем преобразуется в масштабные коэффициенты на стороне декодера.
В предпочтительном варианте осуществления, аудиодекодер содержит ядро декодера частотной области, выполненное с возможностью вывода представления аудиосигнала во временной области из представления частотной области без использования сигнала возбуждения во временной области в качестве промежуточной величины для кадра аудио, кодированного в представлении частотной области. Другими словами, было установлено, что использование сигнала возбуждения во временной области для маскирования ошибки имеет преимущество, даже если кадр аудио, предшествующий потерянному кадру аудио, кодируется в ʺистинномʺ частотном режиме, который не использует никакой сигнал возбуждения во временной области в качестве промежуточной величины (и который, следовательно, не основан на синтезе LPC).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения сигнала возбуждения во временной области на основании кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио. В этом случае, маскирование ошибки выполнено с возможностью обеспечения аудиоинформации с маскированием ошибки для маскировки потерянного кадра аудио с использованием упомянутого сигнала возбуждения во временной области. Другими словами, было установлено, что сигнал возбуждения во временной области, который используется для маскирования ошибки, следует выводить из кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, поскольку этот сигнал возбуждения во временной области, выведенный из кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, обеспечивает хорошее представление аудиоконтента кадра аудио, предшествующего потерянному кадру аудио, таким образом, что маскирование ошибки может осуществляться с умеренными затратами и хорошей точностью.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью осуществления анализа LPC (анализа методом кодирования с линейным предсказанием) на основании кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, для получения набора параметров кодирования с линейным предсказанием и сигнала возбуждения во временной области, представляющего аудиоконтент кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио. Было установлено, что целесообразны затраты для осуществления анализа LPC, для вывода параметров кодирования с линейным предсказанием и сигнала возбуждения во временной области, даже если кадр аудио, предшествующий потерянному кадру аудио, кодируется в представлении частотной области (которое не содержит никаких параметров кодирования с линейным предсказанием и никакого представления сигнала возбуждения во временной области), поскольку аудиоинформацию с маскированием ошибки хорошего качества можно получить для многих входных аудиосигналов на основании упомянутого сигнала возбуждения во временной области. Альтернативно, маскирование ошибки может быть выполнено с возможностью осуществления анализа LPC на основании кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, для получения сигнала возбуждения во временной области, представляющего аудиоконтент кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио. В качестве дополнительной альтернативы, аудиодекодер может быть выполнен с возможностью получения набора параметров кодирования с линейным предсказанием с использованием оценивания параметра кодирования с линейным предсказанием, или аудиодекодер может быть выполнен с возможностью получения набора параметров кодирования с линейным предсказанием на основании набора масштабных коэффициентов с использованием преобразования. Иначе говоря, параметры LPC можно получать с использованием оценивания параметров LPC. Это можно делать либо посредством взвешивания с помощью финитной функции/автокорреляции/алгоритма Левинсона-Дарбина на основании кадра аудио, кодированного в представлении частотной области, либо посредством преобразования из предыдущего масштабного коэффициента непосредственно в и представление LPC.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона (или отставания), описывающей основной тон кадра аудио, кодированного в частотной области предшествующий потерянному кадру аудио, и обеспечения аудиоинформации с маскированием ошибки в зависимости от информации основного тона. С учетом информации основного тона, можно добиться, чтобы аудиоинформация с маскированием ошибки (которая обычно является аудиосигналом с маскированием ошибки, охватывающим временную длительность, по меньшей мере, одного потерянного кадра аудио) была хорошо адаптирована к фактическому аудиоконтенту.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона на основании сигнала возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио. Было установлено, что вывод информации основного тона из сигнала возбуждения во временной области способствует высокой точности. Кроме того, было установлено, что преимущественно, если информация основного тона хорошо адаптирована к сигналу возбуждения во временной области, поскольку информация основного тона используется для модификации сигнала возбуждения во временной области. Выводя информацию основного тона из сигнала возбуждения во временной области, можно добиться такого близкого соотношения.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью оценивания кросс-корреляции сигнала возбуждения во временной области, для определения грубой информации основного тона. Кроме того, маскирование ошибки может быть выполнено с возможностью уточнения грубой информации основного тона с использованием поиска по замкнутому циклу вокруг основного тона, определенного грубой информацией основного тона. Соответственно, высокоточной информации основного тона можно добиться с умеренными вычислительными затратами.
В предпочтительном варианте осуществления, аудиодекодер с маскированием ошибки может быть выполнен с возможностью получения информации основного тона на основании вспомогательной информации кодированной аудиоинформации.
В предпочтительном варианте осуществления, маскирование ошибки может быть выполнено с возможностью получения информации основного тона на основании информации основного тона, доступной для ранее декодированного кадра аудио.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона на основании поиска основного тона, осуществляемого по сигналу временной области или по остаточному сигналу.
Иначе говоря, основной тон может передаваться как вспомогательная информация или может также поступать из предыдущего кадра, например, при наличии LTP. Информация основного тона также может передаваться в битовом потоке при наличии на кодере. Опционально, поиск основного тона можно производить непосредственно по сигналу временной области или по остатку, причем обычно лучшие результаты выдаются по остатку (сигнал возбуждения во временной области).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью копирования цикла основного тона сигнала возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, один раз или несколько раз, для получения сигнала возбуждения для синтеза аудиосигнала с маскированием ошибки. Копированием сигнала возбуждения во временной области один раз или несколько раз, можно добиться, чтобы детерминированная (т.е., по существу, периодическая) составляющая аудиоинформации с маскированием ошибки получалась с хорошей точностью и была хорошим продолжением детерминированной (например, по существу, периодической) составляющей аудиоконтента кадра аудио, предшествующего потерянному кадру аудио.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью фильтрации низких частот цикла основного тона сигнала возбуждения во временной области, выведенного из представления частотной области кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, с использованием фильтра, зависящего от частоты дискретизации, полоса пропускания которого зависит от частоты дискретизации кадра аудио, кодированного в представлении частотной области. Соответственно, сигнал возбуждения во временной области может быть адаптирован к доступной полосе пропускания аудиосигнала, что приводит к хорошему слуховому восприятию аудиоинформации с маскированием ошибки. Например, пропускание низких частот предпочтительно только на первом потерянном кадре, и предпочтительно, пропускание низких частот также возможно, только если сигнал не является на 100% стабильным. Однако следует отметить, что низкочастотная фильтрация является необязательной, и может осуществляться только на первом цикле основного тона. Например, фильтр может зависеть от частоты дискретизации, в результате чего частота среза не будет зависеть от полосы пропускания.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью предсказания основного тона на конце потерянного кадра для адаптации сигнала возбуждения во временной области или одной или более его копий, к предсказанному основному тону. Соответственно, можно рассматривать ожидаемые изменения основного тона на протяжении потерянного кадра аудио. Это позволяет избегать артефактов при переходе между аудиоинформацией с маскированием ошибки и аудиоинформацией правильно декодированного кадра, следующего за одним или более потерянными кадрами аудио (или, по меньшей мере, ослаблять их, поскольку только предсказанный основной тон не является действительным). Например, адаптация идет от последнего хорошего основного тона к предсказанному. Это осуществляется путем ресинхронизации импульсов [7].
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью объединения экстраполированного сигнала возбуждения во временной области и шумового сигнала, для получения входного сигнала для синтеза LPC. В этом случае, маскирование ошибки выполнено с возможностью осуществления синтеза LPC, причем синтез LPC выполнен с возможностью фильтрации входного сигнала синтеза LPC в зависимости от параметров кодирования с линейным предсказанием, для получения аудиоинформации с маскированием ошибки. Соответственно, можно рассматривать как детерминированную (например, приблизительно периодическую) составляющую аудиоконтента, так и шумоподобную составляющую аудиоконтента. Соответственно, получается, что аудиоинформация с маскированием ошибки содержит ʺестественноеʺ слуховое восприятие.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью вычисления коэффициента усиления экстраполированного сигнала возбуждения во временной области, который используется для получения входного сигнала для синтеза LPC, с использованием корреляции во временной области, которая осуществляется на основании представления временной области кадра аудио, кодированного в частотной области предшествующий потерянному кадру аудио, причем интервал корреляции устанавливается в зависимости от информации основного тона, полученной на основании сигнала возбуждения во временной области. Другими словами, интенсивность периодической составляющей определяется в кадре аудио, предшествующем потерянному кадру аудио, и эта определенная интенсивность периодической составляющей используется для получения аудиоинформации с маскированием ошибки. Однако было установлено, что вышеупомянутое вычисление интенсивности периодической составляющей обеспечивает особенно хорошие результаты, поскольку рассматривается фактический аудиосигнал временной области кадра аудио, предшествующего потерянному кадру аудио. Альтернативно, для получения информации основного тона можно использовать корреляцию в области возбуждения или непосредственно во временной области. Однако существуют также различные возможности, зависящие от того, какой вариант осуществления используется. Согласно варианту осуществления, информацией основного тона может быть только основной тон, полученный из ltp последнего кадра или основной тон, который передается как вспомогательная информация или вычисляется.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью фильтрации высоких частот шумового сигнала который объединяется с экстраполированным сигналом возбуждения во временной области. Было установлено, что высокочастотная фильтрация шумового сигнала (который обычно поступает в синтез LPC) приводит к естественному слуховому восприятию. Например, характеристика пропускания высоких частот может изменяться с величиной потери кадра, после определенной величины потери кадра может больше не существовать высокочастотного пропускания. Характеристика пропускания высоких частот также может зависеть от частоты дискретизации, на которой работает декодер. Например, высокочастотное пропускание зависит от частоты дискретизации, и характеристика фильтр может изменяться во времени (по мере потери последовательных кадров). Характеристика пропускания высоких частот также может, опционально, изменяться по мере потери последовательных кадров таким образом, что после определенной величины потери кадра больше не существует фильтрации, чтобы получить только полнодиапазонный сформированный шум для получения хорошего комфортного шума, близкого к фоновому шуму.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью выборочного изменения спектральной формы шумового сигнала (562) с использованием фильтра коррекции предыскажений, причем шумовой сигнал объединяется с экстраполированным сигналом возбуждения во временной области, если кадр аудио, кодированный в представлении частотной области, предшествующего потерянному кадру аудио является вокализованным кадром аудио или содержит начало звука (onset). Было установлено, что, согласно такому принципу, можно улучшить слуховое восприятие аудиоинформации с маскированием ошибки. Например, в ряде случаев лучше снижать коэффициенты усиления и форму и некотором месте лучше повышать их.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью вычисления коэффициента усиления шумового сигнала в зависимости от корреляции во временной области, которая осуществляется на основании представления временной области кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио. Было установлено, что такое определение коэффициента усиления шумового сигнала обеспечивает особенно точные результаты, поскольку можно рассматривать фактический аудиосигнал временной области, связанный с кадром аудио, предшествующим потерянному кадру аудио. С использованием этого принципа, можно иметь возможность получения энергии замаскированного кадра вблизи энергии предыдущего хорошего кадра. Например, коэффициент усиления для шумового сигнала можно генерировать путем измерения энергии результата: возбуждение входного сигнала - возбуждение на основе сгенерированного основного тона.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью модификации сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации с маскированием ошибки. Было установлено, что модификация сигнала возбуждения во временной области позволяет адаптировать сигнал возбуждения во временной области к желаемому временному развитию. Например, модификация сигнала возбуждения во временной области допускает ʺзатуханиеʺ детерминированной (например, по существу, периодической) составляющей аудиоконтента в аудиоинформации с маскированием ошибки. Кроме того, модификация сигнала возбуждения во временной области также позволяет адаптировать сигнал возбуждения во временной области к (оцененному или ожидаемому) изменению основного тона. Это позволяет регулировать характеристики аудиоинформации с маскированием ошибки во времени.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью использования одной или более модифицированных копий сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения информации маскирования ошибки. Модифицированные копии сигнала возбуждения во временной области можно получить с умеренными затратами, и модификация может осуществляться с использованием простого алгоритма. Таким образом, желаемые характеристики аудиоинформации с маскированием ошибки можно добиться с умеренными затратами.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью модификации сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для уменьшения, таким образом, периодической составляющей аудиоинформации с маскированием ошибки во времени. Соответственно, можно полагать, что корреляция между аудиоконтентом кадра аудио, предшествующего потерянному кадру аудио, и аудиоконтентом одного или более потерянных кадров аудио снижается во времени. Также можно избежать неестественного слухового восприятия, вызванного длительным сохранением периодической составляющей аудиоинформации с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для модификации, таким образом, сигнала возбуждения во временной области. Было установлено, что операцию масштабирование можно осуществлять с малыми затратами, причем масштабированный сигнал возбуждения во временной области обычно обеспечивает хорошую аудиоинформацию с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий. Соответственно, можно добиться затухания периодической составляющей в аудиоинформации с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от одного или более параметров одного или более кадров аудио, предшествующих потерянному кадру аудио, и/или в зависимости от количества последовательных потерянных кадров аудио. Соответственно, можно регулировать скорость, с которой детерминированная (например, по меньшей мере, приблизительно периодическая) составляющая затухает в аудиоинформации с маскированием ошибки. Скорость затухания может быть адаптирована к конкретным характеристикам аудиоконтента, что обычно можно видеть из одного или более параметров одного или более кадров аудио, предшествующих потерянному кадру аудио. Альтернативно или дополнительно, количество последовательных потерянных кадров аудио можно рассматривать при определении скорости, используемой для ослабления детерминированной (например, по меньшей мере, приблизительно периодическая) составляющей аудиоинформации с маскированием ошибки, что помогает адаптировать маскирование ошибки к конкретной ситуации. Например, коэффициент усиления тональной части и коэффициент усиления шумовой части можно уменьшать по отдельности. Коэффициент усиления для тональной части может сходиться к нулю после определенной величины потери кадра, тогда как коэффициент усиления шума может сходиться к коэффициенту усиления, определенному для достижения определенного комфортного шума.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от длины периода основного тона сигнала возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих меньшую длину периода основного тона, по сравнению с сигналами, имеющими бóльшую длину периода основного тона. Соответственно, можно избежать слишком частого повторения сигналов, имеющих меньшую длину периода основного тона, с высокой интенсивностью, поскольку это обычно приводит к неестественному слуховому восприятию. Таким образом, можно улучшить общее качество аудиоинформации с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от результата анализа основного тона или предсказания основного тона, таким образом, что детерминированная составляющая сигнала возбуждения во временной области, поступающего в синтез LPC, затухает быстрее для сигналов, имеющих большее изменение основного тона за единицу времени по сравнению с сигналами, имеющими меньшее изменение основного тона за единицу времени, и/или таким образом, что детерминированная составляющая сигнала возбуждения во временной области, поступающего в синтез LPC, затухает быстрее для сигналов, основной тон которых не удается предсказать, по сравнению с сигналами, основной тон которых удается предсказать. Соответственно, затухание можно ускорить для сигналов, где присутствует большая неопределенность основного тона по сравнению с сигналами, для которых неопределенность основного тона меньше. Однако, благодаря более быстрому затуханию детерминированной составляющей для сигналов, которые содержат сравнительно большую неопределенность основного тона, слышимых артефактов можно избежать или, по меньшей мере, существенно ослабить их.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью масштабирования по времени сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от предсказания основного тона в течение времени одного или более потерянных кадров аудио. Соответственно, сигнал возбуждения во временной области может быть адаптирован к изменяющемуся основному тону, таким образом, что аудиоинформация с маскированием ошибки содержит более естественное слуховое восприятие.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью обеспечения аудиоинформации с маскированием ошибки в течение времени, превышающего временную длительность одного или более потерянных кадров аудио. Соответственно, можно осуществлять операцию перекрытия и добавления на основании аудиоинформации с маскированием ошибки, что помогает ослабить артефакты блочности.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью осуществления перекрытия и добавления аудиоинформации с маскированием ошибки и представления временной области одного или более правильно принятых кадров аудио, следующих за одним или более потерянными кадрами аудио. Таким образом, можно избежать артефактов блочности (или, по меньшей мере, ослабить их).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью вывода аудиоинформации с маскированием ошибки на основании, по меньшей мере, трех частично перекрывающихся кадров или окон, предшествующих потерянному кадру аудио или потерянному окну. Соответственно, аудиоинформацию с маскированием ошибки можно получить с хорошей точностью даже для режимов кодирования, в которых более двух кадров (или окон) перекрываются (причем такое перекрытие может способствовать уменьшению задержки).
Другой вариант осуществления согласно изобретению создает способ обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Способ содержит обеспечение аудиоинформации с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области. Этот способ основан на тех же соображениях, что и вышеупомянутый аудиодекодер.
Еще один вариант осуществления согласно изобретению создает компьютерную программу для осуществления упомянутого способа, когда компьютерная программа выполняется на компьютере.
Другой вариант осуществления согласно изобретению создает аудиодекодер для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Аудиодекодер содержит маскирование ошибки, выполненное с возможностью обеспечения аудиоинформации с маскированием ошибки для маскировки потери кадра аудио. Маскирование ошибки выполнено с возможностью модификации сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации с маскированием ошибки.
Этот вариант осуществления согласно изобретению основан на идее о том, что маскирование ошибки с хорошим качеством аудиосигнала можно получить на основании сигнала возбуждения во временной области, причем модификация сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, позволяет адаптировать аудиоинформацию с маскированием ошибки к ожидаемым (или предсказанным) изменениям аудиоконтента на протяжении потерянного кадра. Соответственно, можно избежать артефактов и, в частности, неестественного слухового восприятия, вызванного неизменным использованием сигнала возбуждения во временной области. Следовательно, достигается улучшенное обеспечение аудиоинформации с маскированием ошибки, что позволяет маскировать потерянные кадры аудио с улучшенными результатами.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью использования одной или более модифицированных копий сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения информации маскирования ошибки. С использованием одна или более модифицированных копий сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, хорошего качества аудиоинформации с маскированием ошибки можно добиться с малыми вычислительными затратами.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью модификации сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для уменьшения, таким образом, периодической составляющей аудиоинформации с маскированием ошибки во времени. Благодаря уменьшению периодической составляющей аудиоинформации с маскированием ошибки во времени, можно избежать неестественно длительного сохранения детерминированного (например, приблизительно периодического) звука, что помогает добиться естественного звучания аудиоинформации с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для модификации, таким образом, сигнала возбуждения во временной области. Масштабирование сигнала возбуждения во временной области позволяет особенно эффективно изменять аудиоинформацию с маскированием ошибки во времени.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий. Было установлено, что постепенное уменьшение коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, позволяет получать сигнала возбуждения во временной области для обеспечения аудиоинформации с маскированием ошибки, таким образом, что детерминированные составляющие (например, по меньшей мере, приблизительно, периодические составляющие) затухают. Например, может существовать не только один коэффициент усиления. Например, может существовать один коэффициент усиления для тональной части (также именуемой приблизительно периодической частью), и один коэффициент усиления для шумовой части. Оба возбуждения (или составляющие возбуждения) могут затухать по отдельности с разными коэффициентами скорости и затем два результирующих возбуждения (или составляющих возбуждения) могут объединяться до подачи на LPC для синтеза. В случае, когда отсутствует какая-либо оценка фонового шума, коэффициент затухания для шумовой и тональной части может быть аналогичным, и тогда можно применять одно-единственное затухание к результатам двух возбуждений, умноженным на их собственные коэффициенты усиления и объединенным друг с другом.
Таким образом, можно избежать, чтобы аудиоинформация с маскированием ошибки содержала расширенную во времени детерминированную (например, по меньшей мере, приблизительно периодическую) аудиосоставляющая, что обычно обеспечивает неестественное слуховое восприятие.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от одного или более параметров одного или более кадров аудио, предшествующих потерянному кадру аудио, и/или в зависимости от количества последовательных потерянных кадров аудио. Таким образом, скорость затухания детерминированной (например, по меньшей мере, приблизительно периодической) составляющей в аудиоинформации с маскированием ошибки можно адаптировать к конкретной ситуации с умеренными вычислительными затратами. Поскольку сигнал возбуждения во временной области, используемый для обеспечения аудиоинформации с маскированием ошибки обычно является масштабированной версией (масштабированной с использованием вышеупомянутого коэффициента усиления) сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, изменение упомянутого коэффициента усиления (используемого для вывода сигнала возбуждения во временной области для обеспечения аудиоинформации с маскированием ошибки) дает простой, но эффективный способ адаптации аудиоинформации с маскированием ошибки к конкретным потребностям. Однако скоростью затухания также можно управлять с очень малыми затратами.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от длины периода основного тона сигнала возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих меньшую длину периода основного тона, по сравнению с сигналами, имеющими бóльшую длину периода основного тона. Соответственно, затухание осуществляется быстрее для сигналов, имеющих меньшую длину периода основного тона, что позволяет избежать копирования периода основного тона слишком много раз (что обычно приводят к неестественному слуховому восприятию).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала возбуждения во временной области, полученного для одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от результата анализа основного тона или предсказания основного тона, таким образом, что детерминированная составляющая сигнала возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих большее изменение основного тона за единицу времени по сравнению с сигналами, имеющими меньшее изменение основного тона за единицу времени, и/или таким образом, что детерминированная составляющая сигнала возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, основной тон которых не удается предсказать, по сравнению с сигналами, основной тон которых удается предсказать. Соответственно, детерминированная (например, по меньшей мере, приблизительно периодическая) составляющая затухает быстрее для сигналов с большей неопределенностью основного тона (где большее изменение основного тона за единицу времени, или даже неудача предсказания основного тона, указывает сравнительно большую неопределенность основного тона). Таким образом, можно избежать артефактов, возникающих вследствие обеспечения сильно детерминированной аудиоинформации с маскированием ошибки в ситуации неопределенного фактического основного тона.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью масштабирования по времени сигнала возбуждения во временной области, полученного для (или на основании) одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от предсказания основного тона в течение времени одного или более потерянных кадров аудио. Соответственно, сигнал возбуждения во временной области, который используется для обеспечения аудиоинформации с маскированием ошибки, модифицируется (по сравнению с сигналом возбуждения во временной области, полученным для (или на основании) одного или более кадров аудио, предшествующих потерянному кадру аудио, таким образом, что основной тон сигнала возбуждения во временной области отвечает требованиям периода времени потерянного кадра аудио. Следовательно, можно улучшить слуховое восприятие, которого можно добиться посредством аудиоинформации с маскированием ошибки.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения сигнала возбуждения во временной области, который использовался для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио, и для модификации упомянутого сигнала возбуждения во временной области, который использовался для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения модифицированного сигнала возбуждения во временной области. В этом случае, маскирование во временной области выполнен с возможностью обеспечения аудиоинформации с маскированием ошибки на основании модифицированного аудиосигнала временной области. Соответственно, можно повторно использовать сигнал возбуждения во временной области, который уже был использован для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио. Таким образом, вычислительные затраты могут оставаться очень малым, если сигнал возбуждения во временной области уже получен для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона, которая использовалась для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио. В этом случае, маскирование ошибки также выполнено с возможностью обеспечения аудиоинформации с маскированием ошибки в зависимости от упомянутой информации основного тона. Соответственно, можно повторно использовать ранее использованную информацию основного тона, что позволяет избежать вычислительных затрат для нового вычисления информации основного тона. Таким образом, маскирование ошибки особенно вычислительно эффективно. Например, в случае ACELP получается по 4 отставания и коэффициентов усиления основного тона на кадр. Можно использовать последние два кадра, чтобы иметь возможность предсказания основного тона в конце кадра, который нужно маскировать.
Сравним с вышеописанным кодеком частотной области, где выводятся только один или два основных тона на кадр (можно иметь более двух, но это дает значительное усложнение без особого выигрыша в качестве). В случае переключающегося кодека, который проходит, например, ACELP - FD - потеря, получается гораздо лучшую точность основного тона, поскольку основной тон передаются в битовом потоке и основаны на исходном входном сигнале (а не на декодированном, как на декодере). В случае высокой битовой скорости, например, также можно отправлять одну информация отставания и коэффициента усиления основного тона, или информацию LTP, для каждого кадра, кодированного в частотной области.
В предпочтительном варианте осуществления, аудиодекодер с маскированием ошибки может быть выполнен с возможностью получения информации основного тона на основании вспомогательной информации кодированной аудиоинформации.
В предпочтительном варианте осуществления, маскирование ошибки может быть выполнено с возможностью получения информации основного тона на основании информации основного тона, доступной для ранее декодированного кадра аудио.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона на основании поиска основного тона, осуществляемого по сигналу временной области или по остаточному сигналу.
Иначе говоря, основной тон может передаваться как вспомогательная информация или может также поступать из предыдущего кадра, например, при наличии LTP. Информация основного тона также может передаваться в битовом потоке при наличии на кодере. Опционально, поиск основного тона можно производить непосредственно по сигналу временной области или по остатку, причем обычно лучшие результаты выдаются по остатку (сигнал возбуждения во временной области).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения набора коэффициентов линейного предсказания, которые использовались для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио. В этом случае, маскирование ошибки выполнено с возможностью обеспечения аудиоинформации с маскированием ошибки в зависимости от упомянутого набора коэффициентов линейного предсказания. Таким образом, эффективность маскирования ошибки увеличивается за счет повторного использования ранее сгенерированной (или ранее декодированной) информации, например, ранее использованного набора коэффициентов линейного предсказания. Это позволяет избежать чрезмерно высокой вычислительной сложности.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью экстраполяции нового набора коэффициентов линейного предсказания на основании набора коэффициентов линейного предсказания, которые использовались для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио. В этом случае, маскирование ошибки выполнено с возможностью использования нового набора коэффициентов линейного предсказания для обеспечения информации маскирования ошибки. Выводя новый набор коэффициентов линейного предсказания, используемый для обеспечения аудиоинформации с маскированием ошибки, из набора ранее использованных коэффициентов линейного предсказания с использованием экстраполяции, можно избежать полного повторного вычисления коэффициентов линейного предсказания, что помогает сохранять вычислительные затраты довольно малыми. Кроме того, осуществляя экстраполяцию на основании ранее использованного набора коэффициентов линейного предсказания, можно гарантировать, что новый набор коэффициентов линейного предсказания, по меньшей мере, аналогичен ранее использованному набору коэффициентов линейного предсказания, что помогает избежать нарушений непрерывности при обеспечении информации маскирования ошибки. Например, после определенной величины потери кадра целесообразно оценивать форму LPC фонового шума. Скорость этого схождения, может, например, зависеть от характеристики сигнала.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации об интенсивности детерминированной составляющей сигнала в одном или более кадрах аудио, предшествующих потерянному кадру аудио. В этом случае, маскирование ошибки выполнено с возможностью сравнения информации об интенсивности детерминированной составляющей сигнала в одном или более кадрах аудио, предшествующих потерянному кадру аудио, с пороговым значением, для принятия решения, вводить ли детерминированную составляющую сигнала возбуждения во временной области в синтез LPC (синтез на основе коэффициентов линейного предсказания), или вводить ли только шумовую составляющую сигнала возбуждения во временной области в синтез LPC. Соответственно, можно исключить обеспечение детерминированной (например, по меньшей мере, приблизительно периодической) составляющей аудиоинформации с маскированием ошибки в случае, когда существует лишь малый вклад детерминированного сигнала в один или более кадров, предшествующих потерянному кадру аудио. Было установлено, что это помогает получить хорошее слуховое восприятие.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона, описывающей основной тон кадра аудио, предшествующего потерянному кадру аудио, и обеспечения аудиоинформации с маскированием ошибки в зависимости от информации основного тона. Соответственно, можно адаптировать основной тон информации маскирования ошибки к основному тону кадра аудио, предшествующего потерянному кадру аудио. Соответственно, можно избежать нарушений непрерывности и добиться естественного слухового восприятия.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона на основании сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио. Было установлено, что информация основного тона, полученная на основании сигнала возбуждения во временной области, особенно достоверна и также очень хорошо адаптирована к обработке сигнала возбуждения во временной области.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью оценивания кросс-корреляции сигнала возбуждения во временной области (или, альтернативно, аудиосигнала временной области), для определения грубой информации основного тона, и для уточнения грубой информации основного тона с использованием поиска по замкнутому циклу вокруг основного тона, определенного (или описанного) грубой информацией основного тона. Было установлено, что этот принцип позволяет получать очень точную информацию основного тона с умеренными вычислительными затратами. Другими словами, в некотором кодеке поиск основного тона осуществляется непосредственно по сигналу временной области, тогда как в каком-либо другом поиск основного тона осуществляется по сигналу возбуждения во временной области.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона для обеспечения аудиоинформации с маскированием ошибки на основании ранее вычисленной информации основного тона, которая использовалась для декодирования одного или более кадров аудио, предшествующих потерянному кадру аудио, и на основании оценивания кросс-корреляции сигнала возбуждения во временной области, который модифицируется для получения модифицированного сигнала возбуждения во временной области для обеспечения аудиоинформации с маскированием ошибки. Было установлено, что учет ранее вычисленной информации основного тона и информации основного тона, полученной на основании сигнала возбуждения во временной области (с использованием кросс-корреляции) повышает достоверность информации основного тона и, следовательно, помогает избежать артефактов и/или нарушений непрерывности.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью выбора пика кросс-корреляции, из множества пиков кросс-корреляции, в качестве пика, представляющего основной тон, в зависимости от ранее вычисленной информации основного тона, таким образом, что выбирается пик, который представляет основной тон, ближайший к основному тону, представленному ранее вычисленной информацией основного тона. Соответственно, можно преодолеть возможную неопределенность кросс-корреляции, которая может, например, приводить к множественным пикам. Таким образом, ранее вычисленная информация основного тона используется для выбора ʺправильногоʺ пика кросс-корреляции, что помогает существенно повысить достоверность. С другой стороны, фактический сигнал возбуждения во временной области рассматривается в основном для определения основного тона, что обеспечивает хорошую точность (которая существенно выше точности, которую можно получить на основании только ранее вычисленной информации основного тона).
В предпочтительном варианте осуществления, аудиодекодер с маскированием ошибки может быть выполнен с возможностью получения информации основного тона на основании вспомогательной информации кодированной аудиоинформации.
В предпочтительном варианте осуществления, маскирование ошибки может быть выполнено с возможностью получения информации основного тона на основании информации основного тона, доступной для ранее декодированного кадра аудио.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью получения информации основного тона на основании поиска основного тона, осуществляемого по сигналу временной области или по остаточному сигналу.
Иначе говоря, основной тон может передаваться как вспомогательная информация или может также поступать из предыдущего кадра, например, при наличии LTP. Информация основного тона также может передаваться в битовом потоке при наличии на кодере. Опционально, поиск основного тона можно производить непосредственно по сигналу временной области или по остатку, причем обычно лучшие результаты выдаются по остатку (сигнал возбуждения во временной области).
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью копирования цикла основного тона сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио, один раз или несколько раз, для получения сигнала возбуждения (или, по меньшей мере, его детерминированной составляющей) для синтеза аудиоинформации с маскированием ошибки. Благодаря копированию цикла основного тона сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио, один раз или несколько раз, и благодаря модификации упомянутых одной или более копий с использованием сравнительно простого алгоритма модификации, сигнал возбуждения (или, по меньшей мере, его детерминированная составляющая) для синтеза аудиоинформации с маскированием ошибки можно получить с малыми вычислительными затратами. Однако повторное использование сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио (благодаря копированию упомянутого сигнала возбуждения во временной области), позволяет избежать слышимых нарушений непрерывности.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью фильтрации низких частот цикла основного тона сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио, с использованием фильтра, зависящего от частоты дискретизации, полоса пропускания которого зависит от частоты дискретизации кадра аудио, кодированного в представлении частотной области. Соответственно, сигнал возбуждения во временной области адаптируется к полосе пропускания сигнала аудиодекодера, что приводит к хорошему воспроизведению аудиоконтента. За деталями и необязательными улучшениями обратимся, например, к вышеприведенным объяснениям.
Например, пропускание низких частот предпочтительно только на первом потерянном кадре, и предпочтительно, пропускание низких частот также возможно, только если сигнал не является невокализованным. Однако следует отметить, что низкочастотная фильтрация является необязательной. Кроме того, фильтр может зависеть от частоты дискретизации, в результате чего частота среза не будет зависеть от полосы пропускания.
В предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью предсказания основного тона на конце потерянного кадра. В этом случае, маскирование ошибки выполнено с возможностью адаптации сигнала возбуждения во временной области или одной или более его копий, к предсказанному основному тону. Благодаря модификации сигнала возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, который фактически используется для обеспечения аудиоинформации с маскированием ошибки модифицируется в отношении сигнала возбуждения во временной области, связанного с кадром аудио, предшествующим потерянному кадру аудио, можно рассматривать ожидаемые (или предсказанные) изменения основного тона на протяжении потерянного кадра аудио, таким образом, что аудиоинформация с маскированием ошибки хорошо адаптирована к фактическому развитию (или, по меньшей мере, к ожидаемому или предсказанному развитию) аудиоконтента. Например, адаптация идет от последнего хорошего основного тона к предсказанному. Это осуществляется путем ресинхронизации импульсов [7].
в предпочтительном варианте осуществления, маскирование ошибки выполнено с возможностью объединения экстраполированного сигнала возбуждения во временной области и шумового сигнала, для получения входного сигнала для синтеза LPC. В этом случае, маскирование ошибки выполнено с возможностью осуществления синтеза LPC, причем синтез LPC выполнен с возможностью фильтрации входного сигнала синтеза LPC в зависимости от параметров кодирования с линейным предсказанием, для получения аудиоинформации с маскированием ошибки. Путем объединения экстраполированного сигнала возбуждения во временной области (который обычно является модифицированной версией сигнала возбуждения во временной области, выведенного для одного или более кадров аудио, предшествующих потерянному кадру аудио) и шумового сигнала, детерминированные (например, приблизительно периодические) составляющие и шумовые составляющие аудиоконтента можно рассматривать в маскировании ошибки. Таким образом, можно добиться, чтобы аудиоинформация с маскированием ошибки обеспечивала слуховое восприятие, аналогичное слуховому восприятию, обеспеченному кадрами, предшествующими потерянному кадру.
Также, путем объединения сигнала возбуждения во временной области и шумового сигнала, для получения входного сигнала для синтеза LPC (который можно рассматривать как объединенный сигнал возбуждения во временной области), можно изменять процент детерминированной составляющей входного аудиосигнала для синтеза LPC при поддержании энергии (входного сигнала синтеза LPC, или даже выходного сигнала синтеза LPC). Следовательно, можно изменять характеристики аудиоинформации с маскированием ошибки (например, характеристики тональности) без существенного изменения энергии или громкости аудиосигнала с маскированием ошибки, что позволяет модифицировать сигнал возбуждения во временной области, не вызывая неприемлемые слышимые искажения.
Вариант осуществления согласно изобретению создает способ обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Способ содержит обеспечение аудиоинформации с маскированием ошибки для маскировки потери кадра аудио. Обеспечение аудиоинформации с маскированием ошибки содержит модификацию сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации с маскированием ошибки.
Этот способ основан на тех же соображениях, что и вышеописанный аудиодекодер.
Дополнительный вариант осуществления согласно изобретению создает компьютерную программу для осуществления упомянутого способа, когда компьютерная программа выполняется на компьютере.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления настоящего изобретения описаны ниже со ссылкой на прилагаемые чертежи, в которых:
фиг. 1 демонстрирует блок-схему аудиодекодера, согласно варианту осуществления изобретения;
фиг. 2 демонстрирует блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения;
фиг. 3 демонстрирует блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения;
фиг. 4 демонстрирует блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения;
фиг. 5 демонстрирует блок-схему маскирования во временной области для преобразовательного кодера;
фиг. 6 демонстрирует блок-схему маскирования во временной области для переключающегося кодека;
фиг. 7 демонстрирует блок-схему декодера TCX, осуществляющего декодирование TCX в нормальном режиме работы или в случае частичной потери пакетов;
фиг. 8 демонстрирует блок-схему декодера TCX, осуществляющего декодирование TCX в случае маскирования удаления пакета TCX-256;
фиг. 9 демонстрирует блок-схему операций способа обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, согласно варианту осуществления настоящего изобретения; и
фиг. 10 демонстрирует блок-схему операций способа обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, согласно другому варианту осуществления настоящего изобретения;
фиг. 11 демонстрирует блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
1. Аудиодекодер согласно фиг. 1
Фиг. 1 демонстрирует блок-схему аудиодекодера 100, согласно варианту осуществления настоящего изобретения. Аудиодекодер 100 принимает кодированную аудиоинформацию 110, которая может, например, содержать кадр аудио, кодированный в представлении частотной области. Кодированная аудиоинформация может, например, приниматься по ненадежному каналу, в результате чего время от времени происходит потерю кадра. Аудиодекодер 100 дополнительно обеспечивает, на основании кодированной аудиоинформации 110, декодированную аудиоинформацию 112.
Аудиодекодер 100 может содержать декодирование/обработку 120, которая обеспечивает декодированную аудиоинформацию на основании кодированной аудиоинформации в отсутствие потери кадра.
Аудиодекодер 100 дополнительно содержит маскирование 130 ошибки, которое обеспечивает аудиоинформацию с маскированием ошибки. Маскирование 130 ошибки выполнено с возможностью обеспечения аудиоинформации 132 с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области.
Другими словами, декодирование/обработка 120 может обеспечивать декодированную аудиоинформацию 122 для кадров аудио, которые кодируются в форме представления частотной области, т.е. в форме кодированного представления, кодированные значения которого описывают интенсивности в разных частотных бинах. Иначе говоря, декодирование/обработка 120 может, например, содержать аудиодекодер частотной области, который выводит набор спектральных значений из кодированной аудиоинформации 110 и осуществляет преобразование из частотной области во временную область для вывода, таким образом, представления временной области, которое образует декодированную аудиоинформацию 122 или образует основание для обеспечения декодированной аудиоинформации 122 в случае наличия дополнительной постобработки.
Однако маскирование 130 ошибки не осуществляет маскирование ошибки в частотной области, но зато использует сигнал возбуждения во временной области, который может, например, служить для возбуждения синтезирующего фильтра, например, синтезирующего фильтра LPC, который обеспечивает представление временной области аудиосигнала (например, аудиоинформации с маскированием ошибки) на основании сигнала возбуждения во временной области и также на основании коэффициентов фильтрации LPC (коэффициентов фильтрации кодирования с линейным предсказанием).
Соответственно, маскирование 130 ошибки обеспечивает аудиоинформацию 132 с маскированием ошибки, которая может быть, например, аудиосигналом временной области, для потерянных кадров аудио, где сигнал возбуждения во временной области, используемый маскированием 130 ошибки, может базироваться на, или выводиться из, одного или более предыдущих, правильно принятых кадров аудио (предшествующих потерянному кадру аудио), которые кодируются в форме представления частотной области. В итоге аудиодекодер 100 может осуществлять маскирование ошибки (т.е. обеспечивать аудиоинформацию 132 с маскированием ошибки), что препятствует снижению качества аудиосигнала вследствие потери кадра аудио на основании кодированной аудиоинформации, в которой, по меньшей мере, некоторые кадры аудио кодируются в представлении частотной области. Было установлено, что осуществление маскирования ошибки с использованием сигнала возбуждения во временной области, даже если кадр, следующий за правильно принятым кадром аудио, кодированным в представлении частотной области, потерян, способствует повышению качества аудиосигнала по сравнению с маскированием ошибки, которое осуществляется в частотной области (например, с использованием представления частотной области кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио). Это обусловлено тем, что плавного перехода между декодированной аудиоинформацией, связанной с правильно принятым кадром аудио, предшествующим потерянному кадру аудио, и аудиоинформацией с маскированием ошибки, связанной с потерянным кадром аудио, можно добиться с использованием сигнала возбуждения во временной области, поскольку синтез сигнала, который обычно осуществляется на основании сигнала возбуждения во временной области, помогает избежать нарушений непрерывности. Таким образом, можно добиться хорошего (или, по меньшей мере, приемлемого) слухового восприятия с использованием аудиодекодера 100, даже если за правильно принятым кадром аудио, кодированным в представлении частотной области, следует потерянный кадр аудио. Например, подход временной области приносит улучшение на монофоническом сигнале, например речи, поскольку он ближе к тому, что осуществляется в случае маскирования речевого кодека. Использование LPC помогает избежать нарушений непрерывности и улучшает формирование кадров.
Кроме того, следует отметить, что аудиодекодер 100 может быть дополнен любой из особенностей и функциональных возможностей, описанных в дальнейшем, по отдельности или совместно.
2. Аудиодекодер согласно фиг. 2
Фиг. 2 демонстрирует блок-схему аудиодекодера 200 согласно варианту осуществления настоящего изобретения. Аудиодекодер 200 выполнен с возможностью приема кодированной аудиоинформации 210 и обеспечения, на ее основании, декодированной аудиоинформации 220. Кодированная аудиоинформация 210 может, например, принимать форму последовательности кадров аудио, кодированных в представлении временной области, кодированных в представлении частотной области или кодированных как в представлении временной области, так и в представлении частотной области. Иначе говоря, все кадры кодированной аудиоинформации 210 можно кодировать в представлении частотной области, или все кадры кодированной аудиоинформации 210 можно кодировать в представлении временной области (например, в форме кодированного сигнала возбуждения во временной области и параметров синтеза кодированного сигнала, например, параметров LPC). Альтернативно, некоторые кадры кодированной аудиоинформации можно кодировать в представлении частотной области, и какие-либо другие кадры кодированной аудиоинформации можно кодировать в представлении временной области, например, если аудиодекодер 200 является переключающимся аудиодекодером, который может переключаться между разными режимами декодирования. Декодированная аудиоинформация 220 может быть, например, представлением временной области одного или более аудиоканалов.
Аудиодекодер 200 обычно содержит декодирование/обработку 220, который может, например, обеспечивать декодированную аудиоинформацию 232 для кадров аудио, которые правильно приняты. Другими словами, декодирование/обработка 230 может осуществлять декодирование в частотной области (например, декодирование типа AAC и т.п.) на основании одного или более кодированных кадров аудио, кодированных в представлении частотной области. Альтернативно или дополнительно, декодирование/обработка 230 может быть выполнена с возможностью осуществления декодирования во временной области (или декодирования в области линейного предсказания) на основании одного или более кодированных кадров аудио, кодированных в представлении временной области (или, другими словами, в представлении области линейного предсказания), например, декодирования с линейным предсказанием, возбуждаемого TCX (TCX = возбуждение, кодированное преобразованием) или декодирования ACELP (методом линейного предсказания с возбуждением алгебраическим кодом). Опционально, декодирование/обработка 230 может быть выполнена с возможностью переключения между разными режимами декодирования.
Аудиодекодер 200 дополнительно содержит маскирование 240 ошибки, которое выполнено с возможностью обеспечения аудиоинформации 242 с маскированием ошибки для одного или более потерянных кадров аудио. Маскирование 240 ошибки выполнено с возможностью обеспечения аудиоинформации 242 с маскированием ошибки для маскировки потери кадра аудио (или даже потери множественных кадров аудио). Маскирование 240 ошибки выполнено с возможностью модификации сигнала возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации 242 с маскированием ошибки. Иначе говоря, маскирование 240 ошибки может получать (или выводить) сигнал возбуждения во временной области для (или на основании) одного или более кодированных кадров аудио, предшествующих потерянному кадру аудио, и может модифицировать упомянутый сигнал возбуждения во временной области, который получен для (или на основании) одного или более правильно принятых кадров аудио, предшествующих потерянному кадру аудио, для получения, таким образом (путем модификации), сигнала возбуждения во временной области, который используется для обеспечения аудиоинформации 242 с маскированием ошибки. Другими словами, модифицированный сигнал возбуждения во временной области можно использовать в качестве входного сигнала (или в качестве составляющей входного сигнала) для синтеза (например, синтеза LPC) аудиоинформации с маскированием ошибки, связанной с потерянным кадром аудио (или даже с множественными потерянными кадрами аудио). Путем обеспечения аудиоинформации 242 с маскированием ошибки на основании сигнала возбуждения во временной области, полученного на основании одного или более правильно принятых кадров аудио, предшествующих потерянному кадру аудио, можно избежать слышимых нарушений непрерывности. С другой стороны, благодаря модификации сигнала возбуждения во временной области, выведенного для (или из) одного или более кадров аудио, предшествующих потерянному кадру аудио, и путем обеспечения аудиоинформации с маскированием ошибки на основании модифицированного сигнала возбуждения во временной области, можно рассматривать изменяющиеся характеристики аудиоконтента (например, изменение основного тона), и можно также избегать неестественного слухового восприятия (например, благодаря ʺзатуханиюʺ детерминированной (например, по меньшей мере, приблизительно периодической) составляющей сигнала). Таким образом, можно добиться, чтобы аудиоинформация 242 с маскированием ошибки содержала некоторое подобие с декодированной аудиоинформацией 232, полученной на основании правильно декодированных кадров аудио, предшествующих потерянному кадру аудио, и также можно добиться, чтобы аудиоинформация 242 с маскированием ошибки содержала несколько отличающийся аудиоконтент по сравнению с декодированной аудиоинформацией 232, связанной с кадром аудио, предшествующим потерянному кадру аудио, путем некоторой модификации сигнала возбуждения во временной области. Модификация сигнала возбуждения во временной области, используемого для обеспечения аудиоинформации с маскированием ошибки (связанной с потерянным кадром аудио) может, например, содержать масштабирование по амплитуде или масштабирование по времени. Однако возможны другие типы модификации (или даже комбинация масштабирования по амплитуде и масштабирования по времени), причем, предпочтительно, определенная степень соотношения между сигналом возбуждения во временной области, полученным (в качестве входной информации) маскированием ошибки, и модифицированным сигналом возбуждения во временной области, должна сохраняться.
В итоге, аудиодекодер 200 позволяет обеспечивать аудиоинформацию 242 с маскированием ошибки, таким образом, что аудиоинформация с маскированием ошибки обеспечивает хорошее слуховое восприятие даже в случае, когда один или более кадров аудио теряются. Маскирование ошибки осуществляется на основании сигнала возбуждения во временной области, причем изменение характеристик сигнала аудиоконтента на протяжении потерянного кадра аудио рассматривается благодаря модификации сигнала возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио.
Кроме того, следует отметить, что аудиодекодер 200 может быть дополнен любой из описанных здесь особенностей и функциональных возможностей, по отдельности или совместно.
3. Аудиодекодер согласно фиг. 3
Фиг. 3 демонстрирует блок-схему аудиодекодера 300, согласно другому варианту осуществления настоящего изобретения.
Аудиодекодер 300 выполнен с возможностью приема кодированной аудиоинформации 310 и обеспечения, на ее основании, декодированной аудиоинформации 312. Аудиодекодер 300 содержит анализатор 320 битового потока, который также может быть обозначен как ʺблок деформатирования битового потокаʺ или ʺблок разложения битового потокаʺ. Анализатор 320 битового потока принимает кодированную аудиоинформацию 310 и обеспечивает, на ее основании, представление 322 частотной области и, возможно, дополнительную информацию 324 управления. Представление 322 частотной области может, например, содержать кодированные спектральные значения 326, кодированные масштабные коэффициенты 328 и, опционально, дополнительную вспомогательную информацию 330, которая может, например, управлять конкретными этапами обработки, например, шумозаполнением, промежуточной обработкой или постобработкой. Аудиодекодер 300 также содержит декодирование 340 спектральных значений, которое выполнено с возможностью приема кодированных спектральных значений 326, и обеспечения, на его основании, набора декодированных спектральных значений 342. Аудиодекодер 300 также может содержать декодирование 350 масштабных коэффициентов, которое может быть выполнено с возможностью приема кодированных масштабных коэффициентов 328 и обеспечения, на его основании, набора декодированных масштабных коэффициентов 352.
Альтернативно декодированию масштабных коэффициентов, можно использовать преобразование 354 LPC в масштабный коэффициент, например, в случае, когда кодированная аудиоинформация содержит кодированную информацию LPC, вместо информации масштабных коэффициентов. Однако в некоторых режимах кодирования (например, в режиме декодирования TCX аудиодекодера USAC или в аудиодекодере EVS) набор коэффициентов LPC можно использовать для вывода набора масштабных коэффициентов на стороне аудиодекодера. Этой функциональной возможности можно добиться посредством преобразования 354 LPC в масштабный коэффициент.
Аудиодекодер 300 также может содержать блок 360 масштабирования, который может быть выполнен с возможностью применения набора масштабных коэффициентов 352 к набору спектральных значений 342, для получения, таким образом, набора масштабированных декодированных спектральных значений 362. Например, первую полосу частот, содержащую множественные декодированные спектральные значения 342, можно масштабировать с использованием первого масштабного коэффициента, и вторую полосу частот, содержащую множественные декодированные спектральные значения 342, можно масштабировать с использованием второго масштабного коэффициента. Соответственно, получается набор масштабированных декодированных спектральных значений 362. Аудиодекодер 300 может дополнительно содержать необязательную обработку 366, которая может применять некоторую обработку к масштабированным декодированным спектральным значениям 362. Например, необязательная обработка 366 может содержать шумозаполнение или какие-либо другие операции.
Аудиодекодер 300 также содержит преобразование 370 из частотной области во временную область, который выполнен с возможностью приема масштабированных декодированных спектральных значений 362 или их обработанной версии 368, и обеспечения представления 372 временной области, связанного с набором масштабированных декодированных спектральных значений 362. Например, преобразование 370 из частотной области во временную область может обеспечивать представление 372 временной области, которое связано с кадром или подкадром аудиоконтента. Например, преобразование из частотной области во временную область может принимать набор коэффициентов MDCT (которые можно рассматривать как масштабированные декодированные спектральные значения) и обеспечивать, на его основании, блок выборок временной области, которые могут формировать представление 372 временной области.
Аудиодекодер 300 может, опционально, содержать постобработку 376, которая может принимать представление 372 временной области и несколько модифицировать представление 372 временной области, для получения, таким образом, постобработанной версии 378 представления 372 временной области.
Аудиодекодер 300 также содержит маскирование 380 ошибки которое может, например, принимать представление 372 временной области от преобразования 370 из частотной области во временную область, и которое может, например, обеспечивать аудиоинформацию 382 с маскированием ошибки для одного или более потерянных кадров аудио. Другими словами, в случае потери кадра аудио, из-за чего, например, кодированные спектральные значения 326 недоступны для упомянутого кадра аудио (или подкадра аудио), маскирование 380 ошибки может обеспечивать аудиоинформацию с маскированием ошибки на основании представления 372 временной области, связанного с одним или более кадрами аудио, предшествующими потерянному кадру аудио. Обычно аудиоинформация с маскированием ошибки являются представлением временной области аудиоконтента.
Следует отметить, что маскирование 380 ошибки может, например, осуществлять функции вышеописанного маскирования 130 ошибки. Маскирование 380 ошибки может также, например, содержать функциональную возможность маскирования 500 ошибки, описанного со ссылкой на фиг. 5. Однако, вообще говоря, маскирование 380 ошибки может содержать любую из особенностей и функциональных возможностей, описанных здесь в отношении маскирования ошибки.
В отношении маскирования ошибки, следует отметить, что маскирование ошибки не происходит одновременно с декодированием кадра. Например, если кадр n является хорошим, осуществляется нормальное декодирование, и в конце сохраняется некоторая переменная, которая помогает в случае необходимости маскирования следующего кадра, то если n+1 теряется, вызывается функция маскирования, дающая переменную, происходящую из предыдущего хорошего кадра. Также обновляются некоторые переменные для помощи при следующей потере кадра или при восстановлении к следующему хорошему кадру.
Аудиодекодер 300 также содержит объединение 390 сигналов, которое выполнено с возможностью приема представления 372 временной области (или постобработанного представления 378 временной области в случае наличия постобработки 376). Кроме того, объединение 390 сигналов может принимать аудиоинформацию 382 с маскированием ошибки, которая также обычно является представлением временной области аудиосигнала с маскированием ошибки, обеспеченного для потерянного кадра аудио. Объединение 390 сигналов может, например, объединять представления временной области, связанные с последующими кадрами аудио. В случае наличия последующих правильно декодированных кадров аудио, объединение 390 сигналов может объединять (например, путем перекрытия и добавления) представления временной области, связанные с этими последующими правильно декодированными кадрами аудио. Однако в случае потери кадра аудио, объединение 390 сигналов может объединять (например, путем перекрытия и добавления) представление временной области, связанное с правильно декодированным кадром аудио, предшествующим потерянному кадру аудио, и аудиоинформацию с маскированием ошибки, связанную с потерянным кадром аудио, для обеспечения, таким образом, плавного перехода между правильно принятым кадром аудио и потерянным кадром аудио. Аналогично, объединение 390 сигналов может быть выполнено с возможностью объединения (например, перекрытия и добавления) аудиоинформации с маскированием ошибки, связанной с потерянным кадром аудио, и представления временной области, связанного с другим правильно декодированным кадром аудио, следующим за потерянным кадром аудио (или другой аудиоинформации с маскированием ошибки, связанной с другим потерянным кадром аудио в случае потери множественных последовательных кадров аудио).
Соответственно, объединение 390 сигналов может обеспечивать декодированную аудиоинформацию 312, таким образом, что представление 372 временной области или ее постобработанная версия 378, обеспечивается для правильно декодированных кадров аудио, и таким образом, что аудиоинформация 382 с маскированием ошибки обеспечивается для потерянных кадров аудио, причем операция перекрытия и добавления обычно осуществляется между аудиоинформацией (независимо от того, обеспечивается ли она преобразованием 370 из частотной области во временную область или маскированием 380 ошибки) последующих кадров аудио. Поскольку некоторые кодеки имеют некоторое наложение спектров на части перекрытия и добавления, которую необходимо маскировать, опционально, можно создавать некоторое искусственное наложение спектров на половине кадра, созданного для осуществления перекрытия и добавления.
Следует отметить, что функциональная возможность аудиодекодера 300 аналогична функциональной возможности аудиодекодера 100 согласно фиг. 1, причем дополнительные детали показаны на фиг. 3. Кроме того, следует отметить, что аудиодекодер 300 согласно фиг. 3 может быть дополнен любой из описанных здесь особенностей и функциональных возможностей. В частности, маскирование 380 ошибки может быть дополнено любой из описанных здесь особенностей и функциональных возможностей, в отношении маскирования ошибки.
4. Аудиодекодер 400 согласно фиг. 4
Фиг. 4 демонстрирует аудиодекодер 400 согласно другому варианту осуществления настоящего изобретения. Аудиодекодер 400 выполнен с возможностью приема кодированной аудиоинформации и обеспечения, на ее основании, декодированной аудиоинформации 412. Аудиодекодер 400 может, например, быть выполнен с возможностью приема кодированной аудиоинформации 410, причем разные кадры аудио кодируются с использованием разных режимов кодирования. Например, аудиодекодер 400 можно рассматривать как многорежимный аудиодекодер или ʺпереключающийсяʺ аудиодекодер. Например, некоторые кадры аудио можно кодировать с использованием представления частотной области, причем кодированная аудиоинформация содержит кодированное представление спектральных значений (например, значений FFT или значений MDCT) и масштабные коэффициенты, представляющие масштабирование разных полос частот. Кроме того, кодированная аудиоинформация 410 также может содержать ʺпредставление временной областиʺ кадров аудио, или ʺпредставление области кодирования с линейным предсказаниемʺ множественных кадров аудио. ʺПредставление области кодирования с линейным предсказаниемʺ (также кратко именуемое ʺпредставлением LPCʺ) может, например, содержать кодированное представление сигнала возбуждения, и кодированное представление параметров LPC (параметры кодирования с линейным предсказанием), причем параметры кодирования с линейным предсказанием описывают, например, синтезирующий фильтр кодирования с линейным предсказанием, который используется для реконструкции аудиосигнала на основании сигнала возбуждения во временной области.
В дальнейшем будут описаны некоторые детали аудиодекодера 400.
Аудиодекодер 400 содержит анализатор 420 битового потока, который может, например, анализировать кодированную аудиоинформацию 410 и извлекать, из кодированной аудиоинформации 410, представление 422 частотной области, содержащее, например, кодированные спектральные значения, кодированные масштабные коэффициенты и, опционально, дополнительную вспомогательную информацию. Анализатор 420 битового потока также может быть выполнен с возможностью извлечения представления 424 области кодирования с линейным предсказанием, которое может, например, содержать кодированное возбуждение 426 и кодированные коэффициенты 428 линейного предсказания (которые также могут рассматриваться как кодированные параметры линейного предсказания). Кроме того, анализатор битового потока может, опционально, извлекать дополнительную вспомогательную информацию, которую можно использовать для управления дополнительными этапами обработки, из кодированной аудиоинформации.
Аудиодекодер 400 содержит тракт 430 декодирования в частотной области, который может быть, например, по существу идентичен тракту декодирования аудиодекодера 300 согласно фиг. 3. Другими словами, тракт 430 декодирования в частотной области может содержать декодирование 340 спектральных значений, декодирование 350 масштабных коэффициентов, блок 360 масштабирования, необязательную обработку 366, преобразование 370 из частотной области во временную область, необязательную постобработку 376 и маскирование 380 ошибки как описано выше со ссылкой на фиг. 3.
Аудиодекодер 400 также может содержать тракт 440 декодирования в области линейного предсказания (который также может рассматриваться как тракт декодирования во временной области, поскольку синтез LPC осуществляется во временной области). Тракт декодирования в области линейного предсказания содержит декодирование 450 возбуждения, которое принимает кодированное возбуждение 426, обеспеченное анализатором 420 битового потока, и обеспечивает, на его основании, декодированное возбуждение 452 (которое может принимать форму декодированного сигнала возбуждения во временной области). Например, декодирование 450 возбуждения может принимать кодированную информацию возбуждения, кодированного преобразованием, и может обеспечивать, на ее основании, декодированный сигнал возбуждения во временной области. Таким образом, декодирование 450 возбуждения может, например, осуществлять функцию, которая осуществляется декодером 730 возбуждения, описанным со ссылкой на фиг. 7. Однако, альтернативно или дополнительно, декодирование 450 возбуждения может принимать кодированное возбуждение ACELP, и может обеспечивать декодированный сигнал 452 возбуждения во временной области на основании упомянутой кодированной информации возбуждения ACELP.
Следует отметить, что существуют разные возможности для декодирования возбуждения. Обратимся, например, к соответствующим стандартам и публикациям, задающим принципы кодирования CELP, принципы кодирования ACELP, модификации принципов кодирования CELP и принципов кодирования ACELP и принцип кодирования TCX.
Тракт 440 декодирования в области линейного предсказания опционально содержит обработку 454, в котором обработанный сигнал 456 возбуждения во временной области выводится из сигнала 452 возбуждения во временной области.
Тракт 440 декодирования в области линейного предсказания также содержит декодирование 460 коэффициентов линейного предсказания, которое выполнено с возможностью приема кодированных коэффициентов линейного предсказания и обеспечения, на их основании, декодированных коэффициентов 462 линейного предсказания. Декодирование 460 коэффициентов линейного предсказания может использовать разные представления коэффициента линейного предсказания в качестве входной информации 428 и может обеспечивать разные представления декодированных коэффициентов линейного предсказания в качестве выходной информации 462. Детали можно найти в разных стандартных документах, где описано кодирование и/или декодирование коэффициентов линейного предсказания.
Тракт 440 декодирования в области линейного предсказания опционально содержит обработку 464, которая может обрабатывать декодированные коэффициенты линейного предсказания и обеспечивать их обработанную версию 466.
Тракт 440 декодирования в области линейного предсказания также содержит синтез 470 LPC (синтез кодированием с линейным предсказанием), который выполнен с возможностью приема декодированного возбуждения 452 или его обработанной версии 456, и декодированных коэффициентов 462 линейного предсказания или их обработанной версии 466, и обеспечения декодированного аудиосигнала 472 временной области. Например, синтез 470 LPC может быть выполнен с возможностью применения фильтрации, которая задается декодированными коэффициентами 462 линейного предсказания (или их обработанной версией 466) к декодированному сигналу 452 возбуждения во временной области или его обработанной версии, таким образом, что декодированный аудиосигнал 472 временной области получается фильтрацией (синтетической фильтрацией) сигнала 452 возбуждения во временной области (или 456). Тракт 440 декодирования в области линейного предсказания может, опционально, содержать постобработку 474, которую можно использовать для уточнения или регулировки характеристик декодированного аудиосигнала 472 временной области.
Тракт 440 декодирования в области линейного предсказания также содержит маскирование 480 ошибки, которое выполнено с возможностью приема декодированных коэффициентов 462 линейного предсказания (или их обработанной версии 466) и декодированного сигнала 452 возбуждения во временной области (или его обработанной версии 456). Маскирование 480 ошибки может, опционально, принимать дополнительную информацию, например, информацию основного тона. Следовательно, маскирование 480 ошибки может обеспечивать аудиоинформацию с маскированием ошибки, которая может принимать форму аудиосигнала временной области, в случае потери кадра (или подкадра) кодированной аудиоинформации 410. Таким образом, маскирование 480 ошибки может обеспечивать аудиоинформацию 482 с маскированием ошибки таким образом, что характеристики аудиоинформации 482 с маскированием ошибки, по существу, адаптированы к характеристикам последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио. Следует отметить, что маскирование 480 ошибки может содержать любую из особенностей и функциональных возможностей, описанных в отношении маскирования 240 ошибки. Кроме того, следует отметить, что маскирование 480 ошибки также может содержать любую из особенностей и функциональных возможностей, описанных в отношении маскирования во временной области, показанного на фиг. 6.
Аудиодекодер 400 также содержит объединитель сигналов (или объединение 490 сигналов), который выполнен с возможностью приема декодированного аудиосигнала 372 временной области (или его постобработанной версии 378), аудиоинформации 382 с маскированием ошибки, обеспеченной маскированием 380 ошибки, декодированного аудиосигнала 472 временной области (или его постобработанной версии 476) и аудиоинформации 482 с маскированием ошибки, обеспеченной маскированием 480 ошибки. Объединитель 490 сигналов может быть выполнен с возможностью объединения упомянутых сигналов 372 (или 378), 382, 472 (или 476) и 482 для получения, таким образом, декодированной аудиоинформации 412. В частности, операция перекрытия и добавления может применяться объединителем 490 сигналов. Соответственно, объединитель 490 сигналов может обеспечивать плавные переходы между последующими кадрами аудио, для которых аудиосигнал временной области обеспечивается разными объектами (например, разными трактами 430, 440 декодирования). Однако объединитель 490 сигналов также может обеспечивать плавные переходы, если аудиосигнал временной области обеспечивается одним и тем же объектом (например, преобразованием 370 из частотной области во временную область или синтезом 470 LPC) для последующих кадров. Поскольку некоторые кодеки имеют некоторое наложение спектров на части перекрытия и добавления, которую необходимо маскировать, опционально, можно создавать некоторое искусственное наложение спектров на половине кадра, созданного для осуществления перекрытия и добавления. Другими словами, опционально, можно использовать искусственную компенсацию наложения спектров во временной области (TDAC).
Кроме того, объединитель 490 сигналов может обеспечивать плавные переходы к и от кадров, для которых обеспечена аудиоинформация с маскированием ошибки (которая также обычно является аудиосигналом временной области).
В итоге, аудиодекодер 400 позволяет декодировать кадры аудио, которые закодированы в частотной области, и кадры аудио, которые закодированы в области линейного предсказания. В частности, можно переключаться между использованием тракта декодирования в частотной области и использованием тракта декодирования в области линейного предсказания в зависимости от характеристик сигнала (например, с использованием информации сигнализации, обеспеченной аудиокодером). Различные типы маскирования ошибки можно использовать для обеспечения аудиоинформации с маскированием ошибки в случае потери кадра, в зависимости от того, был ли последний правильно декодированный кадр аудио закодирован в частотной области (или, эквивалентно, в представлении частотной области), или во временной области (или, эквивалентно, в представлении временной области, или, эквивалентно, в области линейного предсказания, или, эквивалентно, в представлении области линейного предсказания).
5. Маскирование во временной области согласно фиг. 5
Фиг. 5 демонстрирует блок-схему маскирования ошибки согласно варианту осуществления настоящего изобретения. Маскирование ошибки согласно фиг. 5 в целом обозначено 500.
Маскирование 500 ошибки выполнено с возможностью приема аудиосигнала 510 временной области и обеспечения, на его основании, аудиоинформации 512 с маскированием ошибки, которая может, например, принимать форму аудиосигнала временной области.
Следует отметить, что маскирование 500 ошибки может, например, замещать маскирование 130 ошибки, таким образом, что аудиоинформация 512 с маскированием ошибки может соответствовать аудиоинформации 132 с маскированием ошибки. Кроме того, следует отметить, что маскирование 500 ошибки может замещать маскирование 380 ошибки, таким образом, что аудиосигнал 510 временной области может соответствовать аудиосигналу 372 временной области (или аудиосигналу 378 временной области), и таким образом, что аудиоинформация 512 с маскированием ошибки может соответствовать аудиоинформации 382 с маскированием ошибки.
Маскирование 500 ошибки содержит коррекцию 520 предыскажений, которую можно рассматривать как необязательную. Коррекция предыскажений принимает аудиосигнал временной области и обеспечивает, на его основании, аудиосигнал 522 временной области с коррекцией предыскажений.
Маскирование 500 ошибки также содержит анализ 530 LPC, который выполнен с возможностью приема аудиосигнала 510 временной области или его версию 522 с коррекцией предыскажений, и получения информации 532 LPC, которая может содержать набор параметров 532 LPC. Например, информация LPC может содержать набор коэффициентов фильтрации LPC (или его представление) и сигнал возбуждения во временной области (который адаптирован для возбуждения синтезирующего фильтра LPC, сконфигурированного в соответствии с коэффициентами фильтрации LPC, для реконструкции, по меньшей мере, приблизительно, входного сигнал анализа LPC).
Маскирование 500 ошибки также содержит поиск основного тона 540, который выполнен с возможностью получения информации 542 основного тона, например, на основании ранее декодированного кадра аудио.
Маскирование 500 ошибки также содержит экстраполяцию 550, которая может быть выполнена с возможностью получения экстраполированного сигнала возбуждения во временной области на основании результата анализа LPC (например, на основании сигнала возбуждения во временной области, определенного посредством анализа LPC), и, возможно, на основании результата поиска основного тона.
Маскирование 500 ошибки также содержит генерацию 560 шума, которая обеспечивает шумовой сигнал 562. Маскирование 500 ошибки также содержит объединитель/микшер 570, который выполнен с возможностью приема экстраполированного сигнала 552 возбуждения во временной области и шумового сигнала 562, и обеспечения, на его основании, объединенного сигнала 572 возбуждения во временной области. Объединитель/микшер 570 может быть выполнен с возможностью объединения экстраполированного сигнала 552 возбуждения во временной области и шумового сигнала 562, причем микширование может осуществляться, таким образом, что относительный вклад экстраполированного сигнала 552 возбуждения во временной области (который определяет детерминированную составляющую входного сигнала синтеза LPC) снижается во времени, тогда как относительный вклад шумового сигнала 562 увеличивается во времени. Однако возможна также другая функциональная возможность объединителя/микшера. Также обратимся к нижеследующему описанию.
Маскирование 500 ошибки также содержит синтез 580 LPC, который принимает объединенный сигнал 572 возбуждения во временной области и который обеспечивает на его основании аудиосигнал 582 временной области. Например, синтез LPC также может принимать коэффициенты фильтрации LPC, описывающие формирующий фильтр LPC, который применяется к объединенному сигналу 572 возбуждения во временной области, для вывода аудиосигнала 582 временной области. Синтез 580 LPC может, например, использовать коэффициенты LPC, полученные на основании одного или более ранее декодированных кадров аудио (например, обеспеченных посредством анализа 530 LPC).
Маскирование 500 ошибки также содержит коррекцию 584 предыскажений, которую можно рассматривать как необязательную. Коррекция 584 предыскажений может обеспечивать аудиосигнал 586 временной области с маскированием ошибки с коррекцией предыскажений.
Маскирование 500 ошибки также содержит, опционально, перекрытие и добавление 590, которое осуществляет операцию перекрытия и добавления аудиосигналов временной области, связанные с последующими кадрами (или подкадрами). Однако следует отметить, что перекрытие и добавление 590 следует рассматривать как необязательное, поскольку маскирование ошибки также может использовать объединение сигналов, которое уже обеспечено в окружении аудиодекодера. Например, перекрытие и добавление 590 можно заменить объединением 390 сигналов в аудиодекодере 300 в некоторых вариантах осуществления.
В дальнейшем будут описаны некоторые дополнительные детали, касающиеся маскирования 500 ошибки.
Маскирование 500 ошибки согласно фиг. 5 охватывает контекст кодека области преобразования как AAC_LC или AAC_ELD. Иначе говоря, маскирование 500 ошибки хорошо адаптировано для использования в таком кодеке области преобразования (и, в частности, в таком аудиодекодере области преобразования). В случае чисто преобразовательного кодека (например, в отсутствие тракта декодирования в области линейного предсказания), выходной сигнал из последнего кадра используется как начальная точка. Например, аудиосигнал 372 временной области можно использовать как начальную точку для маскирования ошибки. Предпочтительно, сигнал возбуждения недоступен, а доступен только выходной сигнал временной области из (одно или более) предыдущих кадров (например, аудиосигнал 372 временной области).
В дальнейшем будут более подробно описаны подблоки и функциональные возможности маскирования 500 ошибки.
5.1. Анализ LPC
Согласно варианту осуществления, представленному на фиг. 5, маскирование полностью осуществляется в области возбуждения для получения более плавного перехода между последовательными кадрами. Поэтому необходимо сначала найти (или, в более общем случае, получить) правильный набор параметров LPC. Согласно варианту осуществления, представленному на фиг. 5, анализ 530 LPC осуществляется по прошлому сигналу 522 временной области с коррекцией предыскажений. Параметры LPC (или коэффициенты фильтрации LPC) используются для осуществления анализа LPC прошлого сигнала синтеза (например, на основании аудиосигнала 510 временной области или на основании аудиосигнала 522 временной области с коррекцией предыскажений) для получения сигнала возбуждения (например, сигнала возбуждения во временной области).
5.2. Поиск основного тона
Существуют разные подходы к получению основного тона, подлежащего использованию для построения нового сигнала (например, аудиоинформации с маскированием ошибки).
В контексте кодека, использующего фильтр LTP (фильтр долговременного предсказания), например AAC-LTP, если последний кадр был AAC с LTP, для генерации гармонической части используется это последнее принятое отставание основного тона LTP и соответствующий коэффициент усиления. В этом случае, коэффициент усиления используется для принятия решения, строить ли гармоническую часть в сигнале, или нет. Например, если коэффициент усиления LTP выше 0.6 (или любого другого заранее определенного значения), то информация LTP используется для построения гармонической части.
В отсутствие какой-либо информации основного тона, доступной из предыдущего кадра, существуют, например, два решения, которые будут описаны в дальнейшем.
Например, можно производить поиск основного тона на кодере и передавать в битовом потоке отставание основного тона и коэффициент усиления. Это аналогично LTP, но без применения какой-либо фильтрации (также без фильтрации LTP в чистом канале).
Альтернативно, поиск основного тона можно осуществлять на декодере. Поиск основного тона AMR-WB в случае TCX осуществляется в области FFT. В ELD, например, если используется область MDCT, то фазы пропадают. Поэтому поиск основного тона предпочтительно осуществлять непосредственно в области возбуждения. Это дает лучшие результаты, чем проведение поиска основного тона в области синтеза. Поиск основного тона в области возбуждения осуществляется сначала с разомкнутым циклом путем нормализованной кросс-корреляции. Затем, опционально, поиск основного тона уточняется путем осуществления поиска по замкнутому циклу вокруг основного тона разомкнутого цикла с определенной дельтой. Вследствие ограничений взвешивания ELD с помощью финитной функции, можно найти неправильный основной тон, таким образом, также нужно проверять, верен ли найденный основной тон, и отбрасывать его в противном случае.
В итоге, при обеспечении аудиоинформации с маскированием ошибки можно рассматривать основной тон последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио. В ряде случаев, существует информация основного тона, доступная из декодирования предыдущего кадра (т.е. последнего кадра, предшествующего потерянному кадру аудио). В этом случае, этот основной тон можно повторно использовать (возможно, с некоторой экстраполяцией и учетом изменения основного тона во времени). Также, опционально, можно повторно использовать основной тон более, чем одного кадра прошлого в попытке экстраполировать основной тон, необходимый в конце данного замаскированного кадра.
Также, при наличии доступной информации (например, обозначенной как коэффициент усиления долговременного предсказания), которая описывает интенсивность (или относительную интенсивность) детерминированной (например, по меньшей мере, приблизительно периодической) составляющей сигнала, это значение можно использовать для принятия решения, следует ли включать детерминированную (или гармоническую) составляющую в аудиоинформацию с маскированием ошибки. Другими словами, путем сравнения упомянутого значения (например, коэффициента усиления LTP) с заранее определенным пороговым значением, можно принимать решение, следует ли рассматривать сигнал возбуждения во временной области, выведенный из ранее декодированного кадра аудио для обеспечения аудиоинформации с маскированием ошибки, или нет.
В отсутствие информации основного тона, доступной из предыдущего кадра (или, точнее говоря, из декодирования предыдущего кадра), существуют различные возможности. Информацию основного тона можно передавать от аудиокодера на аудиодекодер, что упрощает аудиодекодер, но требует увеличения битовой скорости. Альтернативно, информацию основного тона можно определять в аудиодекодере, например, в области возбуждения, т.е. на основании сигнала возбуждения во временной области. Например, сигнал возбуждения во временной области, выведенный из предыдущего, правильно декодированного кадра аудио можно оценивать для идентификации информации основного тона, подлежащей использованию для обеспечения аудиоинформации с маскированием ошибки.
5.3. Экстраполяция возбуждения или создание гармонической части
Возбуждение (например, сигнал возбуждения во временной области), полученное из предыдущего кадра (либо только что вычисленное для потерянного кадра, либо сохраненное уже в предыдущем потерянном кадре в случае потери множественных кадров) используется для построения гармонической части (также обозначенной как детерминированная составляющая или приблизительно периодическая составляющая) в возбуждении (например, во входном сигнале синтеза LPC) благодаря копированию последнего цикла основного тона столько раз, сколько необходимо для получения полутора кадра. Для упрощения также можно создавать полтора кадра только для первого потерянного кадра и затем сдвигать обработку для следующего потерянного кадра на половину кадра и создавать по одному кадру. В этом случае всегда обеспечивается доступ к половине кадра перекрытия.
В случае первого потерянного кадра после хорошего кадра (т.е. правильно декодированного кадра), первый цикл основного тона (например, сигнала возбуждения во временной области, полученного на основании последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио) подвергается низкочастотной фильтрации фильтром, зависящим от частоты дискретизации (поскольку ELD охватывает действительно широкую комбинацию частот дискретизации - от ядра AAC-ELD к AAC-ELD с SBR или SBR двойной скорости AAC-ELD).
Основной тон в речевом сигнале почти всегда изменяется. Поэтому представленное выше маскирование имеет тенденцию создавать некоторые проблемы (или, по меньшей мере, искажения) при восстановлении, поскольку основной тон в конце замаскированного сигнала (т.е. в конце аудиоинформации с маскированием ошибки) часто не совпадает с основным тоном первого хорошего кадра. Поэтому, опционально, в некоторых вариантах осуществления предпринимается попытка предсказать основной тон в конце замаскированного кадра для согласования основного тона в начале кадра восстановления. Например, предсказывается основной тон в конце потерянного кадра (который рассматривается как замаскированный кадр), причем целью предсказания является установление основного тона в конце потерянного кадра (замаскированного кадра) близким к основному тону в начале первого правильно декодированного кадра, следующего за одним или более потерянными кадрами (причем первый правильно декодированный кадр также называется ʺкадром восстановленияʺ). Это можно осуществлять на протяжении потерянного кадра или на протяжении первого хорошего кадра (т.е. на протяжении первого правильно принятого кадра). Для получения еще лучших результатов, можно, опционально, повторно использовать некоторые традиционные инструменты и адаптировать их, например, предсказание основного тона и ресинхронизация импульсов. За подробностями можно обратиться, например, к ссылкам [6] и [7].
Если в кодеке частотной области используется долговременное предсказание (LTP), в качестве начальной информации об основном тоне можно использовать отставание. Однако, в некоторых вариантах осуществления, также желательно иметь повышенную дискретность, чтобы иметь возможность лучше отслеживать огибающую основного тона. Поэтому предпочтительно производить поиск основного тона в начале и в конце последнего хорошего (правильно декодированного) кадра. Для адаптации сигнала к движущемуся основному тону, желательно использовать ресинхронизацию импульсов, которая представлена в уровне техники.
5.4. Коэффициент усиления основного тона
В некоторых вариантах осуществления, предпочтительно применять коэффициент усиления на ранее полученном возбуждении для достижения желаемого уровня. ʺКоэффициент усиления основного тонаʺ (например, коэффициент усиления детерминированной составляющей сигнала возбуждения во временной области, т.е. коэффициент усиления, применяемый к сигналу возбуждения во временной области, выведенному из ранее декодированного кадра аудио, для получения входного сигнала синтеза LPC), можно получить, например, путем осуществления нормализованной корреляции во временной области в конце последнего хорошего (например, правильно декодированного) кадра. Длина корреляции может быть эквивалентна длине двух подкадров или может адаптивно изменяться. Задержка эквивалентна отставанию основного тона, используемому для создания гармонической части. Также, опционально, можно осуществлять вычисление коэффициента усиления только на первом потерянном кадре и затем применять затухание (уменьшенный коэффициент усиления) только для следующей потери последовательных кадров.
ʺКоэффициент усиления основного тонаʺ определяет величину создаваемой тональности (или величину детерминированных, по меньшей мере, приблизительно периодических составляющих сигнала). Однако желательно добавлять некоторый сформированный шум, чтобы не иметь только искусственный тон. В случае очень низкого коэффициента усиления основного тона, строится сигнал, который состоит только из сформированного шума.
В итоге, в ряде случаев сигнал возбуждения во временной области, полученный, например, на основании ранее декодированного кадра аудио, масштабируется в зависимости от коэффициента усиления (например, для получения входного сигнала для анализа LPC). Соответственно, поскольку сигнал возбуждения во временной области определяет детерминированную (по меньшей мере, приблизительно периодическую) составляющую сигнала, коэффициент усиления может определять относительную интенсивность упомянутых детерминированных (по меньшей мере, приблизительно периодических) составляющих сигнала в аудиоинформации с маскированием ошибки. Кроме того, аудиоинформация с маскированием ошибки может базироваться на шуме, также сформированном синтезом LPC, таким образом, что полная энергия аудиоинформации с маскированием ошибки адаптирована, по меньшей мере, до некоторой степени, к правильно декодированному кадру аудио, предшествующему потерянному кадру аудио, и, в идеале, также к правильно декодированному кадру аудио, следующему за одним или более потерянными кадрами аудио.
5.5. Создание шумовой части
ʺИнновацияʺ создается генератором белого шума. Этот шум, опционально, дополнительно подвергается высокочастотной фильтрации и, опционально, коррекции предыскажений для кадров вокализации и начала звука. Что касается пропускания низких частот гармонической части, этот фильтр (например, фильтр высоких частот) зависит от частоты дискретизации. Этот шум (который обеспечивается, например, генерацией 560 шума) формируется посредством LPC (например, синтезом 580 LPC) для получения максимально возможного приближения к фоновому шуму. Характеристика пропускания высоких частот также, опционально, изменяется по мере потери последовательных кадров таким образом, что сверх определенной величины потери кадра больше не производится фильтрации, чтобы получить только полнодиапазонный сформированный шум для получения комфортного шума, близкого к фоновому шуму.
Коэффициент усиления инновации (который может, например, определять коэффициент усиления шума 562 в комбинации/микшировании 570, т.е. коэффициент усиления, использующий шумовой сигнал 562, включен во входной сигнал 572 синтеза LPC), например, вычисляется путем удаления ранее вычисленного вклада основного тона (если он существует) (например, масштабированная версия, масштабированная с использованием ʺкоэффициента усиления основного тонаʺ, сигнала возбуждения во временной области, полученного на основании последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио) и осуществления корреляции в конце последнего хорошего кадра. Что касается коэффициента усиления основного тона, это можно осуществлять, опционально, только на первом потерянном кадре с последующим затуханием, но в этом случае затухание может либо доходить до 0, что приводит к полному заглушению, либо к оценке уровня шума, присутствующего в фоне. Длина корреляции, например, эквивалентна длине двух подкадров, и задержка эквивалентна отставанию основного тона, используемому для создания гармонической части.
Опционально, этот коэффициент усиления также умножается на (1-ʺкоэффициент усиления основного тонаʺ) для применения к шуму как можно большего коэффициента усиления для достижения дефицита энергии, если коэффициент усиления основного тона не равен единице. Опционально, этот коэффициент усиления также умножается на коэффициент шума. Этот коэффициент шума происходит, например, из предыдущего пригодного кадра (например, из последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио).
5.6. Затухание
Затухание, по большей части, используется для потери множественных кадров. Однако затухание также можно использовать в случае потери одного-единственного кадра аудио.
В случае потери множественных кадров, параметры LPC повторно не вычисляются. Либо последний вычисленный сохраняется, либо маскирование LPC осуществляется схождением к фоновой форме. В этом случае периодичность сигнала сходится к нулю. Например, сигнал 502 возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, все же использует коэффициент усиления, который постепенно уменьшается во времени, тогда как шумовой сигнал 562 остается постоянным или масштабируется с коэффициентом усиления, который постепенно увеличивается во времени, таким образом, что относительный вес сигнала 552 возбуждения во временной области уменьшается во времени по сравнению с относительным весом шумового сигнала 562. Следовательно, входной сигнал 572 синтеза 580 LPC становится все более и более ʺшумоподобнымʺ. Следовательно, ʺпериодичностьʺ (или, точнее говоря, детерминированная или, по меньшей мере, приблизительно периодическая составляющая выходного сигнала 582 синтеза 580 LPC) уменьшается во времени.
Скорость схождения, согласно которой периодичность сигнала 572 и/или периодичность сигнала 582, сходится к 0, зависит от параметров последнего правильно принятого (или правильно декодированного) кадра и/или количество последовательных удаленных кадров, и регулируется коэффициентом затухания, α. Коэффициент, α, дополнительно зависит от стабильности фильтра LP. Опционально, можно изменять коэффициент α пропорционально длине основного тона. Если основной тон (например, длина периода, связанная с основным тоном) действительно является длинным, α остается ʺнормальнымʺ, но если основной тон действительно является коротким, обычно требуется неоднократно копировать одну и ту же часть прошлого возбуждения. Это будет быстро звучать слишком искусственно, и поэтому предпочтительно быстрее ослаблять этот сигнал.
Дополнительно опционально, при наличии, можно учитывать выходное предсказание основного тона. Если предсказывается основной тон, это означает, что основной тон уже изменился в предыдущем кадре и поэтому, чем больше кадров теряется, тем дальше сигнал от оригинала. Поэтому, предпочтительно немного ускорять затухание тональной части в этом случае.
Если не удается предсказать основной тон ввиду слишком сильного изменения основного тона, это означает, что либо значения основного тона в действительности не являются достоверными, либо сигнал в действительности является непредсказуемым. Поэтому, опять же, предпочтительно более быстрое затухание (например, более быстрое затухание сигнала 552 возбуждения во временной области, полученного на основании одного или более правильно декодированных кадров аудио, предшествующих одному или более потерянным кадрам аудио).
5.7. Синтез LPC
Для возврата во временную область, предпочтительно осуществлять синтез 580 LPC на сумме двух возбуждений (тональной части и шумовой части) с последующей коррекцией предыскажений. Иначе говоря, предпочтительно осуществлять синтез 580 LPC на основании взвешенной комбинации сигнала 552 возбуждения во временной области, полученного на основании одного или более правильно декодированных кадров аудио, предшествующих потерянному кадру аудио (тональной части) и шумового сигнала 562 (шумовой части). Как упомянуто выше, сигнал 552 возбуждения во временной области можно модифицировать по сравнению с сигналом 532 возбуждения во временной области, полученным посредством анализа 530 LPC (помимо коэффициентов LPC, описывающих характеристику синтезирующего фильтра LPC, используемого для синтеза 580 LPC). Например, сигнал 552 возбуждения во временной области может быть масштабированной по времени копий сигнала 532 возбуждения во временной области, полученного посредством анализа 530 LPC, причем масштабирование по времени можно использовать для адаптации основного тона сигнала 552 возбуждения во временной области к желаемому основному тону.
5.8. Перекрытие и добавление
В случае чисто преобразовательного кодека, для получения наилучшего перекрытия и добавления, создается искусственный сигнал на половину кадра больше, чем замаскированный кадр, и на нем создается искусственное наложение спектров. Однако можно применять разные принципы перекрытия и добавления.
В контексте регулярного AAC или TCX, перекрытие и добавление применяется между дополнительным полукадром, происходящим из маскирования, и первой частью первого хорошего кадра (может быть половиной или менее для окон более низкой задержки в качестве AAC-LD).
В особом случае ELD (дополнительной низкой задержки), для первого потерянного кадра, предпочтительно выполнять анализ три раза для получения правильного вклада от последних трех окон и затем для первого кадра маскирования и для всех последующих анализ выполняется еще раз. Затем один синтез ELD осуществляется для возврата во временную область со всей правильной памяти для следующего кадра в области MDCT.
В итоге, входной сигнал 572 синтеза 580 LPC (и/или сигнал 552 возбуждения во временной области) может обеспечиваться в течение временной длительности, которая превышает длительность потерянного кадра аудио. Соответственно, выходной сигнал 582 синтеза 580 LPC также может обеспечиваться в течение периода времени, который длиннее потерянного кадра аудио. Соответственно, перекрытие и добавление может осуществляться между аудиоинформацией с маскированием ошибки (которая, следовательно, получена в течение более длительного периода времени, чем временное удлинение потерянного кадра аудио) и декодированной аудиоинформации, обеспеченной для правильно декодированного кадра аудио, следующего за одним или более потерянными кадрами аудио.
В итоге, маскирование 500 ошибки хорошо адаптировано к случаю, когда кадры аудио кодируются в частотной области. Хотя кадры аудио кодируются в частотной области, обеспечение аудиоинформации с маскированием ошибки осуществляется на основании сигнала возбуждения во временной области. Разные модификации применяются к сигналу возбуждения во временной области, полученному на основании одного или более правильно декодированных кадров аудио, предшествующих потерянному кадру аудио. Например, сигнал возбуждения во временной области, обеспеченный посредством анализа 530 LPC адаптируется к изменениям основного тона, например, с использованием масштабирования по времени. Кроме того, сигнал возбуждения во временной области, обеспеченный посредством анализа 530 LPC, также модифицируется путем масштабирования (применения коэффициента усиления), причем затухание детерминированной (или тональной или, по меньшей мере, приблизительно периодической) составляющей может осуществляться блоком масштабирования/микшером 570, таким образом, что входной сигнал 572 синтеза 580 LPC содержит как составляющую, которая выводится из сигнала возбуждения во временной области, полученного посредством анализа LPC, так и шумовую составляющую, которая основана на шумовом сигнале 562. Однако детерминированная составляющая входного сигнала 572 синтеза 580 LPC обычно является модифицированной (например, масштабированной по времени и/или масштабированной по амплитуде) в отношении сигнала возбуждения во временной области, обеспеченного посредством анализа 530 LPC.
Таким образом, сигнал возбуждения во временной области может быть адаптирован к потребностям, что позволяет избежать неестественного слухового восприятия.
6. Маскирование во временной области согласно фиг. 6
Фиг. 6 демонстрирует блок-схему маскирования во временной области, которое можно использовать для переключающегося кодека. Например, маскирование 600 во временной области согласно фиг. 6 может, например, замещать маскирование 240 ошибки или маскирование 480 ошибки.
Кроме того, следует отметить, что вариант осуществления согласно фиг. 6 охватывает контекст (можно использовать в контексте) переключающегося кодека с использованием объединения во временной и частотной области, например USAC (MPEG-D/MPEG-H) или EVS (3GPP). Другими словами, маскирование 600 во временной области можно использовать в аудиодекодерах, в которых происходит переключение между декодированием в частотной области и декодированием во временной области (или, эквивалентно, декодирование на основе коэффициентов линейного предсказания).
Однако следует отметить, что маскирование 600 ошибки согласно фиг. 6 также можно использовать в аудиодекодерах, которые осуществляют декодирование только во временной области (или эквивалентно, в области коэффициентов линейного предсказания).
В случае переключающегося кодека (и даже в случае кодека, осуществляющего декодирование только в области коэффициентов линейного предсказания) обычно уже имеется сигнал возбуждения (например, сигнал возбуждения во временной области), происходящий из предыдущего кадра (например, правильно декодированного кадра аудио, предшествующего потерянному кадру аудио). В противном случае (например, если сигнал возбуждения во временной области недоступен), можно поступать, как объяснено согласно варианту осуществления, представленному на фиг. 5, т.е. для осуществления анализа LPC. Если предыдущий кадр был подобен ACELP, также уже имеется информация основного тона подкадров в последнем кадре. Если последний кадр был TCX (возбуждение, кодированное преобразованием) с LTP (долговременное предсказание) также имеется информация отставания, происходящая из долговременного предсказания. И если последний кадр был в частотной области без долговременного предсказания (LTP), то поиск основного тона предпочтительно осуществлять непосредственно в области возбуждения (например, на основании сигнала возбуждения во временной области, обеспеченного анализом LPC).
Если декодер уже использует некоторые параметры LPC во временной области, они повторно используются и экстраполируются на новый набор параметров LPC. Экстраполяция параметров LPC основана на прошлом LPC, например, среднем трех последних кадров и (опционально) форме LPC, выведенной в ходе оценивания шума DTX, если в кодеке существует DTX (прерывистая передача).
Маскирование полностью осуществляется в области возбуждения для получения более плавного перехода между последовательными кадрами.
В дальнейшем будет более подробно описано маскирование 600 ошибки согласно фиг. 6.
Маскирование 600 ошибки принимает прошлое возбуждение 610 и прошлую информацию 640 основного тона. Кроме того, маскирование 600 ошибки обеспечивает аудиоинформацию 612 с маскированием ошибки.
Следует отметить, что прошлое возбуждение 610, принятое маскированием 600 ошибки, может, например, соответствовать выходному сигналу 532 анализа 530 LPC. Кроме того, прошлая информация 640 основного тона может, например, соответствовать выходной информации 542 поиска основного тона 540.
Маскирование 600 ошибки дополнительно содержит экстраполяцию 650, которая может соответствовать экстраполяции 550, рассмотренной выше.
Кроме того, маскирование ошибки содержит генератор 660 шума, который может соответствовать генератору 560 шума, рассмотренному выше.
Экстраполяция 650 обеспечивает экстраполированный сигнал 652 возбуждения во временной области, который может соответствовать экстраполированному сигналу 552 возбуждения во временной области. Генератор 660 шума обеспечивает шумовой сигнал 662, который соответствует шумовому сигналу 562.
Маскирование 600 ошибки также содержит объединитель/микшер 670, который принимает экстраполированный сигнал 652 возбуждения во временной области и шумовой сигнал 662 и обеспечивает, на его основании, входной сигнал 672 для синтеза 680 LPC, причем синтез 680 LPC может соответствовать синтезу 580 LPC, также в соответствии с вышеприведенными объяснениями. Синтез 680 LPC обеспечивает аудиосигнал 682 временной области, которая может соответствовать аудиосигналу 582 временной области. Маскирование ошибки также содержит (опционально) коррекцию 684 предыскажений, которая может соответствовать коррекции 584 предыскажений и которая обеспечивает аудиосигнал 686 временной области с маскированием ошибки с коррекцией предыскажений. Маскирование 600 ошибки опционально содержит перекрытие и добавление 690, которое может соответствовать перекрытию и добавлению 590. Однако вышеприведенные объяснения в отношении перекрытия и добавления 590 также применяются к перекрытию и добавлению 690. Другими словами, перекрытие и добавление 690 также можно заменить общим перекрытием и добавлением аудиодекодера, таким образом, что выходной сигнал 682 синтеза LPC или выходной сигнал 686 коррекции предыскажений можно рассматривать как аудиоинформацию с маскированием ошибки.
В итоге, маскирование 600 ошибки существенно отличается от маскирования 500 ошибки тем, что маскирование 600 ошибки непосредственно получает прошлую информацию 610 возбуждения и прошлую информацию 640 основного тона непосредственно из одного или более ранее декодированных кадров аудио без необходимости осуществлять анализ LPC и/или анализ основного тона. Однако следует отметить, что маскирование 600 ошибки может, опционально, содержать анализ LPC и/или анализ основного тона (поиск основного тона).
В дальнейшем будут более подробно описаны некоторые детали маскирования 600 ошибки. Однако следует отметить, что конкретные детали следует рассматривать как примеры, а не как существенные особенности.
6.1. Прошлый основной тон поиска основного тона
Существуют разные подходы к получению основного тона, подлежащего использованию для построения нового сигнала.
В контексте кодека с использованием фильтр LTP, например AAC-LTP, если последний кадр (предшествующий потерянному кадру) был AAC с LTP, имеется информация основного тона, происходящая из последнего отставания основного тона LTP и соответствующего коэффициента усиления. В этом случае используется коэффициент усиления для принятия решения, нужно ли строить гармоническую часть в сигнале, или нет. Например, если коэффициент усиления LTP выше 0,6, то используется информация LTP для построения гармонической части.
В отсутствие какой-либо информации основного тона, доступной из предыдущего кадра, существуют, например, два других решения.
Одно решение состоит в том, чтобы производить поиск основного тона на кодере и передавать в битовом потоке отставание основного тона и коэффициент усиления. Это аналогично долговременному предсказанию (LTP), но не применяется никакой фильтрации (также фильтрации LTP в чистом канале).
Другое решение состоит в осуществлении поиска основного тона на декодере. Поиск основного тона AMR-WB в случае TCX осуществляется в области FFT. Например, в TCX используется область MDCT, что приводит к потере фазы. Поэтому поиск основного тона осуществляется непосредственно в области возбуждения (например, на основании сигнала возбуждения во временной области, используемого в качестве входного сигнала синтеза LPC, или используемый для вывода входного сигнала для синтеза LPC) в предпочтительном варианте осуществления. Это обычно дает лучшие результаты, чем проведение поиска основного тона в области синтеза (например, на основании полностью декодированного аудиосигнала временной области).
Поиск основного тона в области возбуждения (например, на основании сигнала возбуждения во временной области) осуществляется сначала с разомкнутым циклом путем нормализованной кросс-корреляции. Затем, опционально, поиск основного тона можно уточнять путем осуществления поиска по замкнутому циклу вокруг основного тона разомкнутого цикла с определенной дельтой.
В предпочтительных реализациях, не просто рассматривается одно максимальное значение корреляции. При наличии информации основного тона из безошибочного предыдущего кадра, выбирается основной тон, который соответствует одному из пяти наивысших значений в области нормализованной кросс-корреляции, ближайшему к основному тону предыдущего кадра. Затем также осуществляется проверка того, что найденный максимум не является неправильным максимумом вследствие ограничения окна.
В итоге, существуют разные принципы для определения основного тона, в которых вычислительно эффективно рассматривать прошлый основной тон (т.е. основной тон, связанный с ранее декодированным кадром аудио). Альтернативно, информация основного тона может передаваться от аудиокодера на аудиодекодер. В порядке другой альтернативы, поиск основного тона может осуществляться на стороне аудиодекодера, причем определение основного тона предпочтительно осуществлять на основании сигнала возбуждения во временной области (т.е. в области возбуждения). Двухэтапный поиск основного тона, содержащий поиск по разомкнутому циклу и поиск по замкнутому циклу, может осуществляться для получения особенно достоверной и точной информации основного тона. Альтернативно или дополнительно, информация основного тона из ранее декодированного кадра аудио можно использовать, чтобы гарантировать, что поиск основного тона обеспечивает достоверный результат.
6.2. Экстраполяция возбуждения или создание гармонической части
Возбуждение (например, в форме сигнала возбуждения во временной области), полученное из предыдущего кадра (либо только что вычисленное для потерянного кадра, либо сохраненное уже в предыдущем потерянном кадре в случае потери множественных кадров), используется для построения гармонической части в возбуждении (например, экстраполированном сигнале 662 возбуждения во временной области) благодаря копированию последнего цикла основного тона (например, участка сигнала 610 возбуждения во временной области, временная длительность которого равна длительности периода основного тона) столько раз, сколько необходимо для получения, например, полутора (потерянного) кадра.
Для получения еще лучших результатов, опционально, можно повторно использовать некоторые инструменты, известные из уровня техники и адаптировать их. За подробностями можно обратиться, например, к ссылкам [6] и [7].
Было установлено, что основной тон в речевом сигнале почти всегда изменяется. Было установлено, что, поэтому представленное выше маскирование имеет тенденцию создавать некоторые проблемы при восстановлении, поскольку основной тон в конце замаскированного сигнала часто не совпадает с основным тоном первого хорошего кадра. Поэтому, опционально, предпринимается попытка предсказать основной тон в конце замаскированного кадра для согласования основного тона в начале кадра восстановления. Эта функциональная возможность осуществляется, например, посредством экстраполяции 650.
Если используется LTP в TCX, отставание можно использовать в качестве начальной информации об основном тоне. Однако желательно иметь повышенную дискретность, чтобы иметь возможность лучше отслеживать огибающую основного тона. Поэтому поиск основного тона, опционально, производится в начале и в конце последнего хорошего кадра. Для адаптации сигнала к движущемуся основному тону, можно использовать ресинхронизацию импульсов, которая представлена в уровне техники.
В итоге, экстраполяция (например, сигнала возбуждения во временной области, связанного с, или полученного на его основании, последним правильно декодированным кадром аудио, предшествующим потерянному кадру) может содержать копирование временного участка упомянутого сигнала возбуждения во временной области, связанного с предыдущим кадром аудио, причем скопированный временной участок можно модифицировать в зависимости от вычисления, или оценивания, (ожидаемого) изменения основного тона на протяжении потерянного кадра аудио. Доступны разные принципы для определения изменения основного тона.
6.3. Коэффициент усиления основного тона
Согласно варианту осуществления, представленному на фиг. 6, коэффициент усиления применяется на ранее полученном возбуждении для достижения желаемого уровня. Коэффициент усиления основного тона получается, например, путем осуществления нормализованной корреляции во временной области в конце последнего хорошего кадра. Например, длина корреляции может быть эквивалентна длине двух подкадров, и задержка может быть эквивалентна отставанию основного тона, используемому для создания гармонической части (например, для копирования сигнала возбуждения во временной области). Было установлено, что осуществление вычисления коэффициента усиления дает гораздо более достоверный коэффициент усиления во временной области, чем в области возбуждения. LPC изменяются в каждом кадре, и поэтому применение коэффициента усиления, вычисленного на предыдущем кадре, по сигналу возбуждения, который будет обрабатываться другим набором LPC, не даст ожидаемой энергии во временной области.
Коэффициент усиления основного тона определяет величину создаваемой тональности, но некоторый сформированный шум также будет добавляться для получения только искусственного тона. Если получается очень низкий коэффициент усиления основного тона, то можно построить сигнал, который состоит только из сформированного шума.
В итоге, коэффициент усиления, который применяется для масштабирования сигнала возбуждения во временной области, полученного на основании предыдущего кадра (или сигнала возбуждения во временной области, который получен для ранее декодированного кадра или связан с ранее декодированным кадром), регулируется для определения, таким образом, взвешивания тональной (или детерминированной или, по меньшей мере, приблизительно периодической) составляющей во входном сигнале синтеза 680 LPC, и, следовательно, в аудиоинформации с маскированием ошибки. Упомянутый коэффициент усиления можно определять на основании корреляции, который применяется к аудиосигналу временной области, полученному декодированием ранее декодированного кадра (причем упомянутый аудиосигнал временной области можно получать с использованием синтеза LPC, который осуществляется в ходе декодирования).
6.4. Создание шумовой части
Инновация создается генератором белого 660 шума. Этот шум дополнительно подвергается высокочастотной фильтрации и, опционально, коррекции предыскажений для кадров вокализации и начала звука. Высокочастотная фильтрация и коррекция предыскажений, которые могут выборочно осуществляться для кадров вокализации и начала звука, не показаны в явном виде на фиг. 6, но могут осуществляться, например, в генераторе 660 шума или в объединителе/микшере 670.
Шум формируется (например, после объединения с сигналом 652 возбуждения во временной области, полученным посредством экстраполяции 650) посредством LPC для максимально возможного приближения к фоновому шуму.
Например, коэффициент усиления инновации можно вычислять путем удаления ранее вычисленного вклада основного тона (если он существует) и осуществления корреляции в конце последнего хорошего кадра. Длина корреляции может быть эквивалентна длине двух подкадров, и задержка может быть эквивалентна отставанию основного тона, используемому для создания гармонической части.
Опционально, этот коэффициент усиления также можно умножать на (1 - коэффициент усиления основного тона) для применения к шуму как можно большего коэффициента усиления для достижения дефицита энергии, если коэффициент усиления основного тона не равен единице. Опционально, этот коэффициент усиления также умножается на коэффициент шума. Этот коэффициент шума может происходить из предыдущего пригодного кадра.
В итоге, шумовая составляющая аудиоинформации с маскированием ошибки получается формированием шума, обеспеченного генератором 660 шума с использованием синтеза 680 LPC (и, возможно, коррекции 684 предыскажений). Кроме того, можно применять дополнительную высокочастотную фильтрацию и/или коррекцию предыскажений. Вклад коэффициента усиления шума в входной сигнал 672 синтеза 680 LPC (также обозначенный ʺкоэффициент усиления инновацииʺ) можно вычислять на основании последнего правильно декодированного кадра аудио, предшествующего потерянному кадру аудио, причем детерминированную (или, по меньшей мере, приблизительно периодическую) составляющую можно удалять из кадра аудио, предшествующего потерянному кадру аудио, и затем корреляция может осуществляться для определения интенсивности (или коэффициента усиления) шумовой составляющей в декодированном сигнале временной области кадра аудио, предшествующего потерянному кадру аудио.
Опционально, к коэффициенту усиления шумовой составляющей можно применять некоторые дополнительные модификации.
6.5. Затухание
Затухание, по большей части, используется для потери множественных кадров. Однако затухание также можно использовать в случае потери одного-единственного кадра аудио.
В случае потери множественных кадров, параметры LPC повторно не вычисляются. Как объяснено выше, либо сохраняется последний вычисленный, либо осуществляется маскирование LPC.
Периодичность сигнала сходится к нулю. Скорость схождения зависит от параметров последнего правильно принятого (или правильно декодированного) кадра и количества последовательных удаленных (или потерянных) кадров, и регулируется коэффициентом затухания, α. Коэффициент, α, дополнительно зависит от стабильности фильтра LP. Опционально, коэффициент α может изменяться пропорционально длине основного тона. Например, если основной тон действительно является длинным, то α может оставаться нормальным, но если основной тон действительно является коротким, может быть желательно (или необходимо) неоднократно копировать одну и ту же часть прошлого возбуждения. Поскольку было установлено, что это будет быстро звучать слишком искусственно, поэтому сигнал затухает быстрее.
Кроме того, опционально, можно учитывать выходное предсказание основного тона. Если предсказывается основной тон, это означает, что основной тон уже изменился в предыдущем кадре и поэтому, чем больше кадров теряются, тем дальше сигнал от оригинала. Поэтому желательно немного ускорять затухание тональной части в этом случае.
Если не удается предсказать основной тон ввиду слишком сильного изменения основного тона, это означает либо значения основного тона в действительности не являются достоверными, либо сигнал в действительности является непредсказуемым. Поэтому, опять же, затухание должно осуществляться быстрее.
В итоге, вклад экстраполированного сигнала 652 возбуждения во временной области во входной сигнал 672 синтеза 680 LPC обычно уменьшается во времени. Этого можно добиться, например, путем уменьшения значения коэффициента усиления, который применяется к экстраполированному сигналу 652 возбуждения во временной области, во времени. Скорость, используемая для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала 552 возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио (или одной или более его копий) регулируется в зависимости от одного или более параметров одного или более кадров аудио (и/или в зависимости от количества последовательных потерянных кадров аудио). В частности, длина основного тона и/или скорость изменения основного тона во времени, и/или вопрос, успешно ли осуществляется предсказание основного тона, можно использовать для регулировки упомянутой скорости.
6.6. Синтез LPC
Для возврата во временную область, синтез 680 LPC осуществляется на сумме (или, в общем случае, взвешенной комбинации) двух возбуждений (тональной части 652 и шумовой части 662) с последующей коррекцией 684 предыскажений.
Другими словами, результат взвешенного (микшированного) объединения экстраполированного сигнала 652 возбуждения во временной области и шумового сигнала 662 образует объединенный сигнал возбуждения во временной области и поступает в синтез 680 LPC, который может, например, осуществлять синтезирующую фильтрацию на основании упомянутого объединенного сигнала возбуждения во временной области 672 в зависимости от коэффициентов LPC, описывающих синтезирующий фильтр.
6.7. Перекрытие и добавление
Поскольку в ходе маскирования неизвестно, какой будет режим следующего кадра (например, ACELP, TCX или FD), предпочтительно заранее подготавливать разные перекрытия. Для получения наилучшего перекрытия и добавления, если следующий кадр находится в области преобразования (TCX или FD) искусственный сигнал (например, аудиоинформацию с маскированием ошибки) можно, например, создавать на половину кадра больше, чем замаскированный (потерянный) кадр. Кроме того, на нем можно создавать искусственное наложение спектров (причем искусственное наложение спектров можно, например, адаптировать к перекрытию и добавлению MDCT).
Для получения хорошего перекрытия и добавления и отсутствия разрыва с будущим кадром во временной области (ACELP), делается то же, что и раньше, но без наложения спектров, чтобы иметь возможность для применения длинных окон перекрытия и добавления, или если необходимо использовать квадратное окно, отклик при отсутствии входного сигнала (ZIR) вычисляется в конце буфера синтеза.
В итоге, в переключающемся аудиодекодере (который может, например, переключаться между декодированием ACELP, декодированием TCX и декодированием в частотной области (декодированием FD)), перекрытие и добавление может осуществляться между аудиоинформацией с маскированием ошибки, которая обеспечивается в основном для потерянного кадра аудио, а также для определенного временного участка, следующего за потерянным кадром аудио, и декодированной аудиоинформацией, обеспеченной для первого правильно декодированного кадра аудио, после последовательности из одного или более потерянных кадров аудио. Для получения правильного перекрытия и добавления даже для режимов декодирования, которые способствуют наложению спектров во временной области при переходе между последующими кадрами аудио, может обеспечиваться информация подавления наложения спектров (например, обозначенная как искусственное наложение спектров). Соответственно, перекрытие и добавление между аудиоинформацией с маскированием ошибки и аудиоинформацией временной области, полученной на основании первого правильно декодированного кадра аудио, следующего за потерянным кадром аудио, приводит к подавлению наложения спектров.
Если первый правильно декодированный кадр аудио, следующий за последовательностью из одного или более потерянных кадров аудио, кодируется в режиме ACELP, можно вычислить конкретную информацию перекрытие, которая может базироваться на отклике при отсутствии входного сигнала (ZIR) фильтра LPC.
В итоге, маскирование 600 ошибки весьма пригодно для использования в переключающемся аудиокодеке. Однако маскирование 600 ошибки также можно использовать в аудиокодеке, который декодирует лишь аудиоконтент, кодированный в режиме TCX или в режиме ACELP.
6.8. Заключение
Следует отметить, что особенно хорошее маскирование ошибки достигается согласно вышеупомянутому принципу для экстраполяции сигнала возбуждения во временной области, для объединения результата экстраполяции с шумовым сигналом с использованием микширования (например, плавного микширования) и для осуществления синтеза LPC на основании результата плавного микширования.
7. Аудиодекодер согласно фиг. 11
Фиг. 11 демонстрирует блок-схему аудиодекодера 1100, согласно варианту осуществления настоящего изобретения.
Следует отметить, что аудиодекодер 1100 может быть частью переключающегося аудиодекодера. Например, аудиодекодер 1100 может заменять тракт 440 декодирования в области линейного предсказания в аудиодекодере 400.
Аудиодекодер 1100 выполнен с возможностью приема кодированной аудиоинформации 1110 и обеспечения, на ее основании, декодированной аудиоинформации 1112. Кодированная аудиоинформация 1110 может, например, соответствовать кодированной аудиоинформации 410, и декодированная аудиоинформация 1112 может, например, соответствовать декодированной аудиоинформации 412.
Аудиодекодер 1100 содержит анализатор 1120 битового потока, который выполнен с возможностью извлечения кодированного представления 1122 набора спектральных коэффициентов и кодированного представления коэффициентов 1124 кодирования с линейным предсказанием из кодированной аудиоинформации 1110. Однако анализатор 1120 битового потока может, опционально, извлекать дополнительную информацию из кодированной аудиоинформации 1110.
Аудиодекодер 1100 также содержит декодирование 1130 спектральных значений, которое выполнено с возможностью обеспечения набора декодированных спектральных значений 1132 на основании кодированных спектральных коэффициентов 1122. Для декодирования спектральных коэффициентов можно использовать любой известный принцип декодирования.
Аудиодекодер 1100 также содержит преобразование 1140 коэффициентов кодирования с линейным предсказанием в масштабные коэффициенты, которое выполнено с возможностью обеспечения набора масштабных коэффициентов 1142 на основании кодированного представления 1124 коэффициентов кодирования с линейным предсказанием. Например, преобразование 1140 коэффициентов кодирования с линейным предсказанием в масштабные коэффициенты может осуществлять функцию, описанную в стандарте USAC. Например, кодированное представление 1124 коэффициентов кодирования с линейным предсказанием может содержать полиномиальное представление, которое декодируется и преобразуется в набор масштабных коэффициентов преобразованием 1140 коэффициентов кодирования с линейным предсказанием в масштабные коэффициенты.
Аудиодекодер 1100 также содержит блок 1150 масштабирования, который выполнен с возможностью применения масштабных коэффициентов 1142 к декодированным спектральным значениям 1132, для получения, таким образом, масштабированных декодированных спектральных значений 1152. Кроме того, аудиодекодер 1100 содержит, опционально, обработку 1160, которая может, например, соответствовать вышеописанной обработке 366, причем обработанные масштабированные декодированные спектральные значения 1162 получаются посредством необязательной обработки 1160. Аудиодекодер 1100 также содержит преобразование 1170 из частотной области во временную область, которое выполнено с возможностью приема масштабированных декодированных спектральных значений 1152 (которые могут соответствовать масштабированным декодированным спектральным значениям 362), или обработанных масштабированных декодированных спектральных значений 1162 (которые могут соответствовать обработанным масштабированным декодированным спектральным значениям 368) и обеспечивать, на их основании, представление 1172 временной области, которое может соответствовать вышеописанному представлению 372 временной области. Аудиодекодер 1100 также содержит необязательную первую постобработку 1174 и необязательную вторую постобработку 1178, которая может, например, соответствовать, по меньшей мере, частично, вышеупомянутой необязательной постобработке 376. Соответственно, аудиодекодер 1110 получает (опционально) постобработанную версию 1179 представления 1172 аудиосигнала во временной области.
Аудиодекодер 1100 также содержит блок 1180 маскирования ошибки, который выполнен с возможностью приема представления 1172 аудиосигнала во временной области, или его постобработанной версии, и коэффициентов кодирования с линейным предсказанием (либо в кодированной форме, либо в декодированной форме) и обеспечения, на их основании, аудиоинформации 1182 с маскированием ошибки.
Блок 1180 маскирования ошибки выполнен с возможностью обеспечения аудиоинформации 1182 с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области, и поэтому аналогичен маскированию 380 ошибки и маскированию 480 ошибки, и также маскированию 500 ошибки и маскированию 600 ошибки.
Однако блок 1180 маскирования ошибки содержит анализ 1184 LPC, который, по существу, идентичен анализу 530 LPC. Однако анализ 1184 LPC может, опционально, использовать коэффициенты 1124 LPC для облегчения анализа (по сравнению с анализом 530 LPC). Анализ LPC 1134 обеспечивает сигнал 1186 возбуждения во временной области, который, по существу, идентичен сигналу 532 возбуждения во временной области (и также сигналу 610 возбуждения во временной области). Кроме того, блок 1180 маскирования ошибки содержит маскирование 1188 ошибки, который может, например, осуществлять функции блоков 540, 550, 560, 570, 580, 584 маскирования 500 ошибки, или может, например, осуществлять функции блоков 640, 650, 660, 670, 680, 684 маскирования 600 ошибки. Однако блок 1180 маскирования ошибки немного отличается от маскирования 500 ошибки и также от маскирования 600 ошибки. Например, блок 1180 маскирования ошибки (содержащий анализ 1184 LPC) отличается от маскирования 500 ошибки тем, что коэффициенты LPC (используемые для синтеза 580 LPC) не определяются посредством анализа 530 LPC, но (опционально) принимаются из битового потока. Кроме того, блок маскирования 1188 ошибки, содержащий анализ 1184 LPC, отличается от маскирования 600 ошибки тем, что ʺпрошлое возбуждениеʺ 610 получается посредством анализа 1184 LPC, вместо того, чтобы быть непосредственно доступным.
Аудиодекодер 1100 также содержит объединение 1190 сигналов, которое выполнено с возможностью приема представления 1172 аудиосигнала во временной области, или его постобработанной версии, и также аудиоинформации 1182 с маскированием ошибки (естественно, для последующих кадров аудио) и объединяет упомянутые сигналы, предпочтительно, с использованием операции перекрытия и добавления, для получения, таким образом, декодированной аудиоинформации 1112.
За дополнительными деталями следует обратиться к вышеприведенным объяснениям.
8. Способ согласно фиг. 9
Фиг. 9 демонстрирует блок-схему операций способа обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Способ 900 согласно фиг. 9 содержит обеспечение 910 аудиоинформации с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области. Способ 900 согласно фиг. 9 основан на тех же соображениях, что и аудиодекодер согласно фиг. 1. Кроме того, следует отметить, что способ 900 может быть дополнен любой из описанных здесь особенностей и функциональных возможностей, по отдельности или совместно.
9. Способ согласно фиг. 10
Фиг. 10 демонстрирует блок-схему операций способа обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации. Способ 1000 содержит обеспечение 1010 аудиоинформации с маскированием ошибки для маскировки потери кадра аудио, причем сигнал возбуждения во временной области, полученный для (или на основании) одного или более кадров аудио, предшествующих потерянному кадру аудио, модифицируется для получения аудиоинформации с маскированием ошибки.
Способ 1000 согласно фиг. 10 основан на тех же соображениях, что и вышеупомянутый аудиодекодер согласно фиг. 2.
Кроме того, следует отметить, что способ согласно фиг. 10 может быть дополнен любой из описанных здесь особенностей и функциональных возможностей, по отдельности или совместно.
10. Дополнительные замечания
В вышеописанных вариантах осуществления, потерю множественных кадров можно обрабатывать по-разному. Например, в случае потери двух или более кадров, периодическая часть сигнала возбуждения во временной области для второго потерянного кадра может быть выведена из (или равна) копии тональной части сигнала возбуждения во временной области, связанного с первым потерянным кадром. Альтернативно, сигнал возбуждения во временной области для второго потерянного кадра может основываться на анализе LPC сигнала синтеза предыдущего потерянного кадра. Например, в кодеке LPC может изменяться с каждым потерянным кадром, поэтому имеет смысл повторять анализ для каждого потерянного кадра.
11. Альтернативы реализации
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего оборудования. Некоторые или все из этапов способа могут выполняться аппаратным оборудованием (или с его использованием), например, микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления, некоторые один или более из наиболее важных этапов способа могут выполняться таким оборудованием.
В зависимости от определенных требований реализации, варианты осуществления изобретения можно реализовать аппаратными средствами или программными средствами. Реализация может осуществляться с использованием цифрового носителя данных, например, флоппи-диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, на котором хранятся электронно-читаемые сигналы управления, которые скооперированы (или способны кооперироваться) с программируемой компьютерной системой, благодаря чему, осуществляется соответствующий способ. Поэтому цифровой носитель данных может считываться компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-читаемые сигналы управления, которые способны кооперироваться с программируемой компьютерной системой, что позволяет осуществлять один из описанных здесь способов.
В общем случае, варианты осуществления настоящего изобретения можно реализовать как компьютерный программный продукт с программным кодом, причем программный код позволяет осуществлять один из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа, отвечающего изобретению, является, поэтому, компьютерной программой, имеющей программный код для осуществления одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Поэтому дополнительный вариант осуществления способов, отвечающих изобретению, является носителем данных (или цифровым носителем данных или компьютерно-читаемым носителем), на котором записана компьютерная программа для осуществления одного из описанных здесь способов. Носитель данных, цифровой носитель данных или носитель записи обычно являются вещественными и/или не промежуточным.
Поэтому дополнительный вариант осуществления способа, отвечающего изобретению, является потоком данных или последовательностью сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов может, например, быть выполнен(а) с возможностью переноса через соединение с передачей данных, например, через интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления согласно изобретению содержит оборудование или система, выполненное(ая) с возможностью переноса (например, электронно или оптически) компьютерной программы для осуществления одного из описанных здесь способов на приемник. Приемником может быть, например, компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система может, например, содержать файловый сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, вентильную матрицу, программируемую пользователем) можно использовать для осуществления некоторых или всех из функциональных возможностей описанных здесь способов. В некоторых вариантах осуществления, вентильная матрица, программируемая пользователем, может кооперироваться с микропроцессором для осуществления одного из описанных здесь способов. В общем случае, способы, предпочтительно, осуществляются любым аппаратным оборудованием.
Описанное здесь оборудование можно реализовать с использованием аппаратного оборудования или с использованием компьютера или с использованием комбинация аппаратного оборудования и компьютера.
Описанные здесь способы могут осуществляться с использованием аппаратного оборудования или с использованием компьютера или с использованием комбинации аппаратного оборудования и компьютера.
Вышеописанные варианты осуществления лишь иллюстрируют принципы настоящего изобретения. Следует понимать, что описанные здесь модификации и вариации конфигураций и деталей будут очевидны специалистам в данной области техники. Поэтому предполагается ограничение только объемом нижеследующей формулы изобретения, но не конкретными деталями, представленными здесь посредством описания и объяснения вариантов осуществления.
12. Заключение
В итоге, хотя некоторое маскирование для кодеков в области преобразования описано в условиях эксплуатации, варианты осуществления согласно изобретению превосходят традиционные кодеки (или декодеры). Варианты осуществления согласно изобретению используют смену области для маскирования (частотной области на временную или область возбуждения). Соответственно, варианты осуществления согласно изобретению создают высококачественное маскирование речи для декодеров в области преобразования.
Режим кодирования с преобразованием аналогичен режиму в USAC (согласно, например, ссылке [3]). Он использует модифицированное дискретное косинусное преобразование (MDCT) в качестве преобразования, и формирование спектрального шума достигается с применением спектральной огибающей, взвешенной LPC в частотной области (также известной как FDNS ʺформирование шума в частотной областиʺ). Иначе говоря, варианты осуществления согласно изобретению можно использовать в аудиодекодере, который использует принципы декодирования, описанные в стандарте USAC. Однако раскрытый здесь принцип маскирования ошибки также можно использовать в аудиодекодере типа ʺAACʺ или в любом кодеке (или декодере) семейства AAC.
Принцип согласно настоящему изобретению применяется к переключающемуся кодеку, например USAC, а также к кодеку чисто частотной области. В обоих случаях, маскирование осуществляется во временной области или в области возбуждения.
В дальнейшем, будут описаны некоторые преимущества и особенности маскирования во временной области (или маскирования в области возбуждения).
Традиционное маскирование TCX, как описано, например, со ссылкой на фиг. 7 и 8, также именуемое замещение шума, не очень пригодно для речеподобных сигналов или даже тональных сигналов. Варианты осуществления согласно изобретению создают новое маскирование для кодека области преобразования, который применяется во временной области (или области возбуждения декодера кодирования с линейным предсказанием). Оно аналогично маскированию типа ACELP и повышает качество маскирования. Было установлено, что информация основного тона имеет преимущество (или даже, в ряде случаев, необходима) для маскирования типа ACELP. Таким образом, варианты осуществления согласно настоящему изобретению выполнены с возможностью нахождения достоверных значений основного тона для предыдущего кадра, кодированного в частотной области.
Выше объяснены разные части и детали, например, на основании вариантов осуществления согласно фиг. 5 и 6.
В итоге, варианты осуществления согласно изобретению создают маскирование ошибки, которое превосходит традиционные решения.
БИБЛИОГРАФИЯ
[1] 3GPP, ʺAudio codec processing functions; Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec; Transcoding functions,ʺ 2009, 3GPP TS 26.290.
[2] ʺMDCT-BASED CODER FOR HIGHLY ADAPTIVE SPEECH AND AUDIO CODINGʺ; Guillaume Fuchs & al.; EUSIPCO 2009.
[3] ISO_IEC_DIS_23003-3_(E); Information technology - MPEG audio technologies - Part 3: Unified speech and audio coding.
[4] 3GPP, ʺGeneral Audio Codec audio processing functions; Enhanced aacPlus general audio codec; Additional decoder tools,ʺ 2009, 3GPP TS 26.402.
[5] ʺAudio decoder and coding error compensating methodʺ, 2000, EP 1207519 B1.
[6] ʺApparatus and method for improved concealment of the adaptive codebook in ACELP-like concealment employing improved pitch lag estimationʺ, 2014, PCT/EP2014/062589.
[7] ʺApparatus and method for improved concealment of the adaptive codebook in ACELP-like concealment employing improved pulse resynchronizationʺ, 2014, PCT/EP2014/062578.
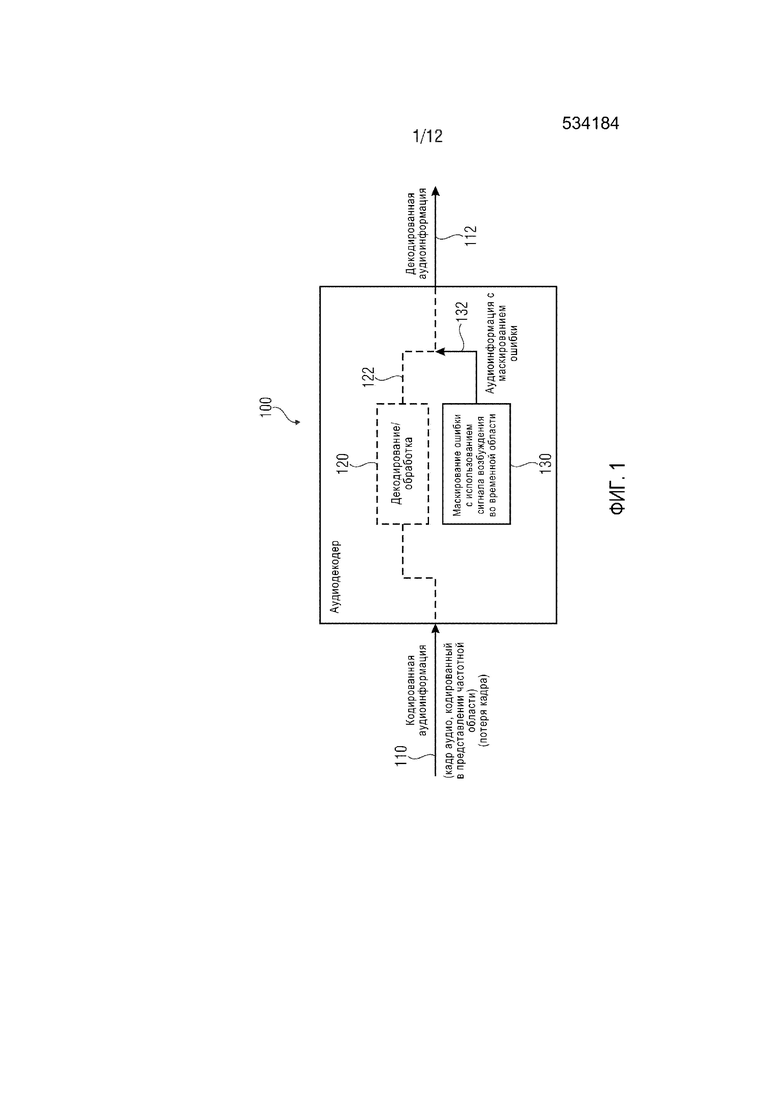
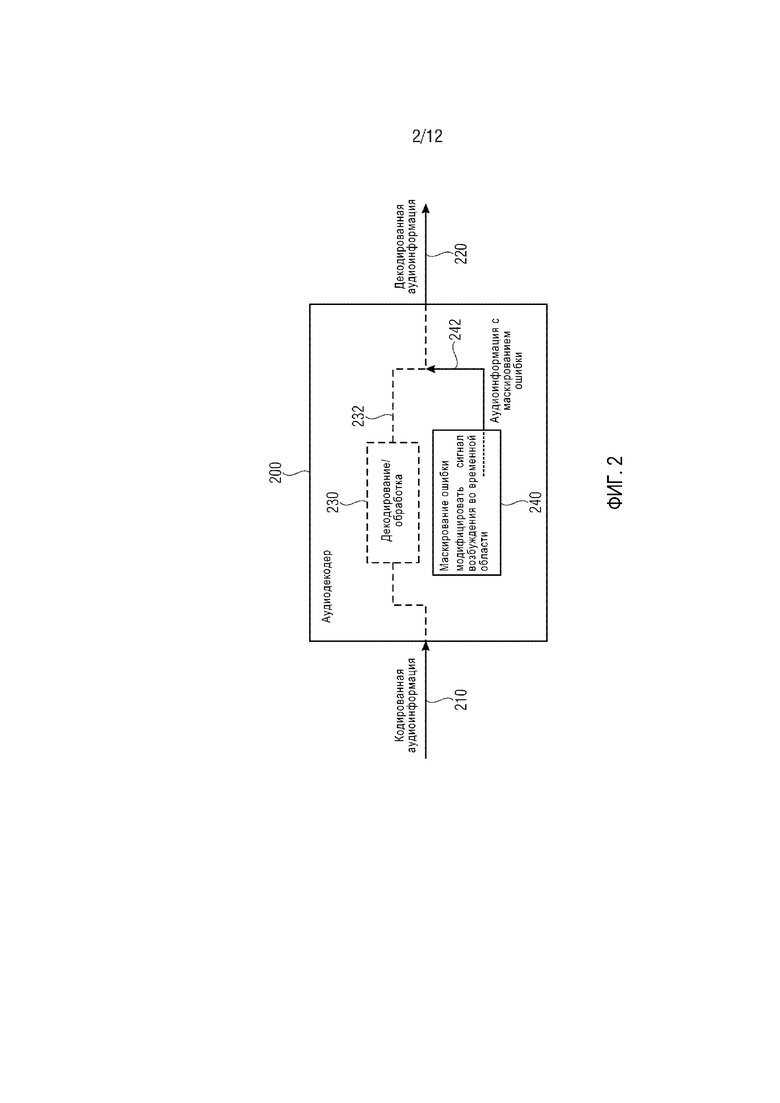
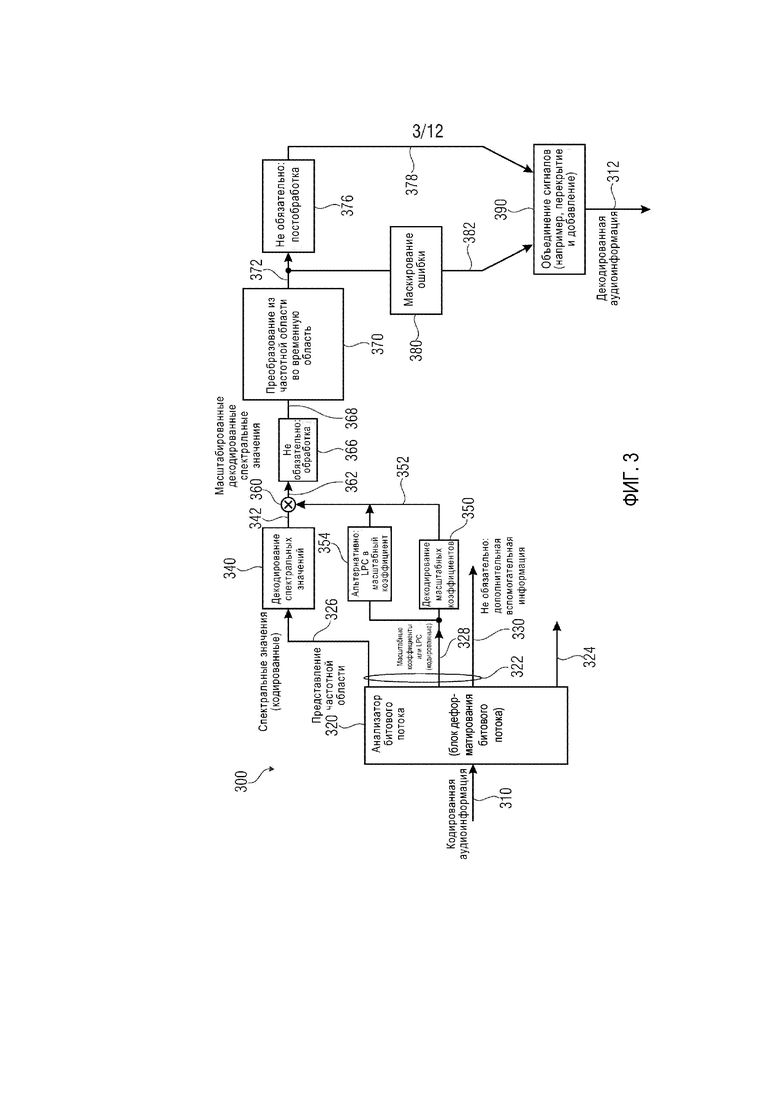
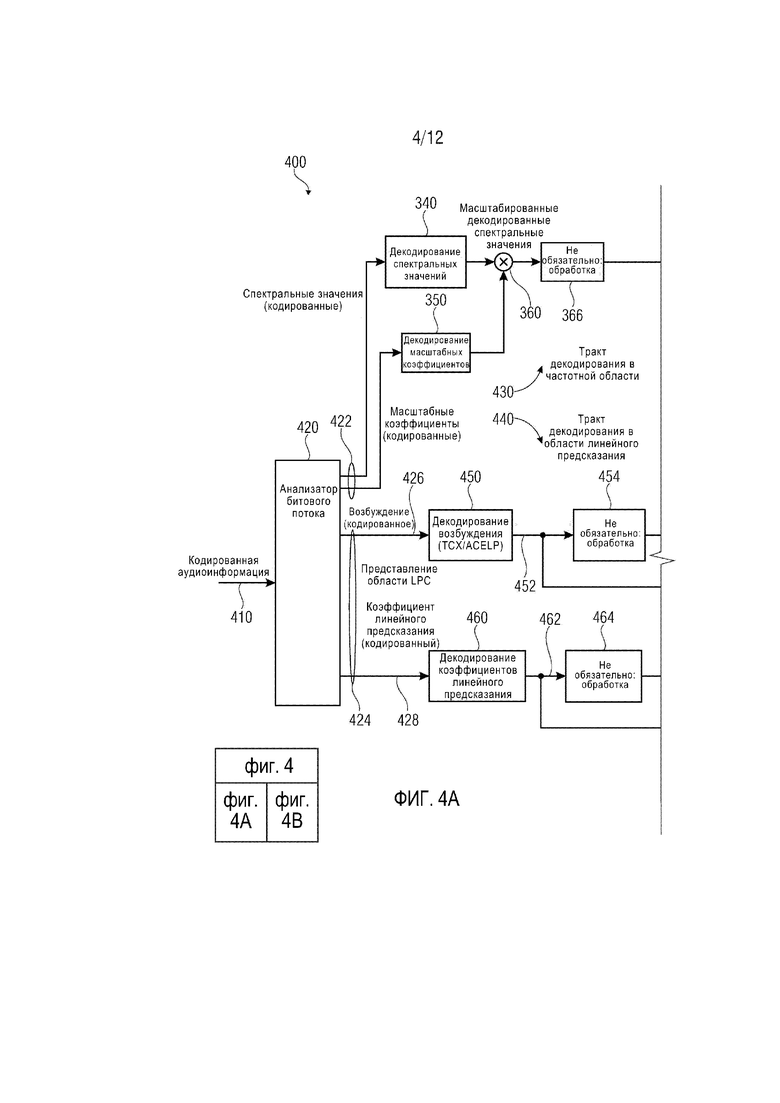
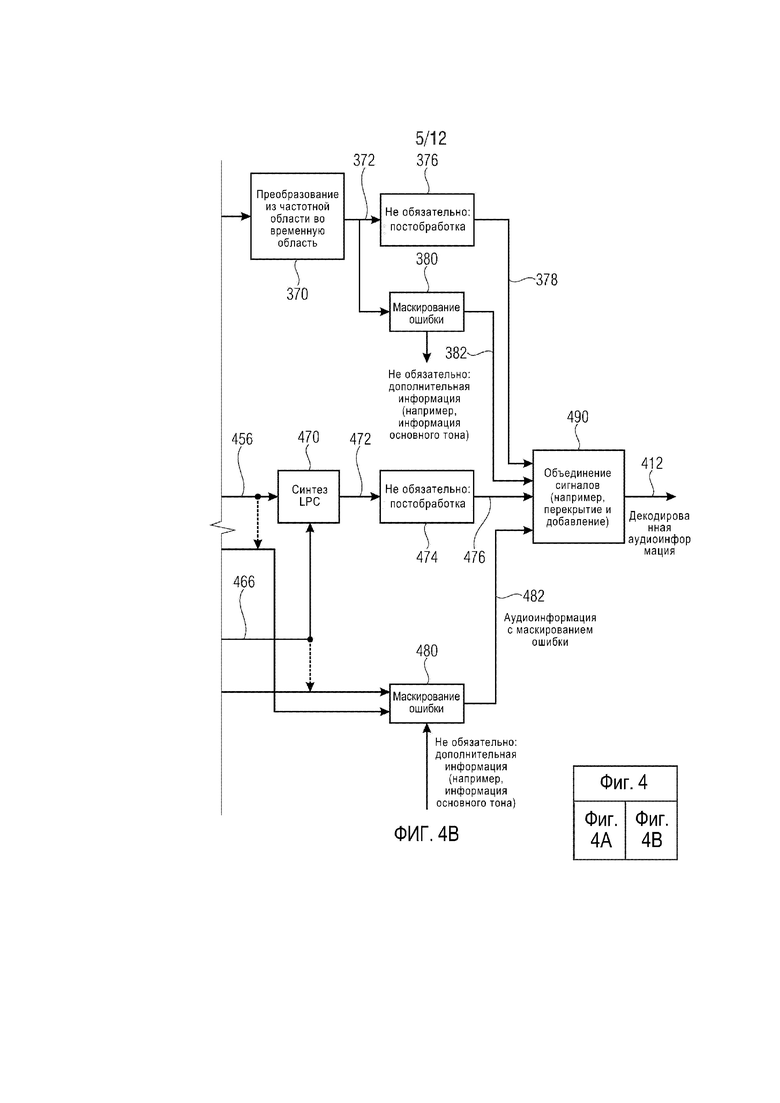
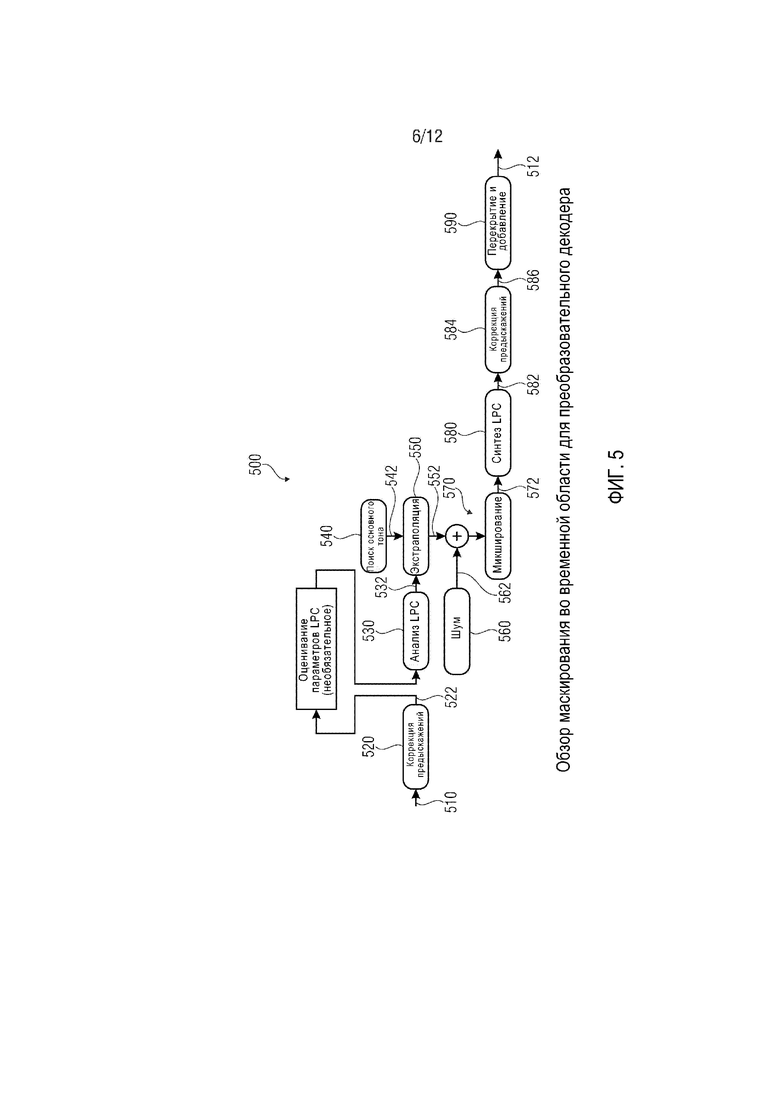
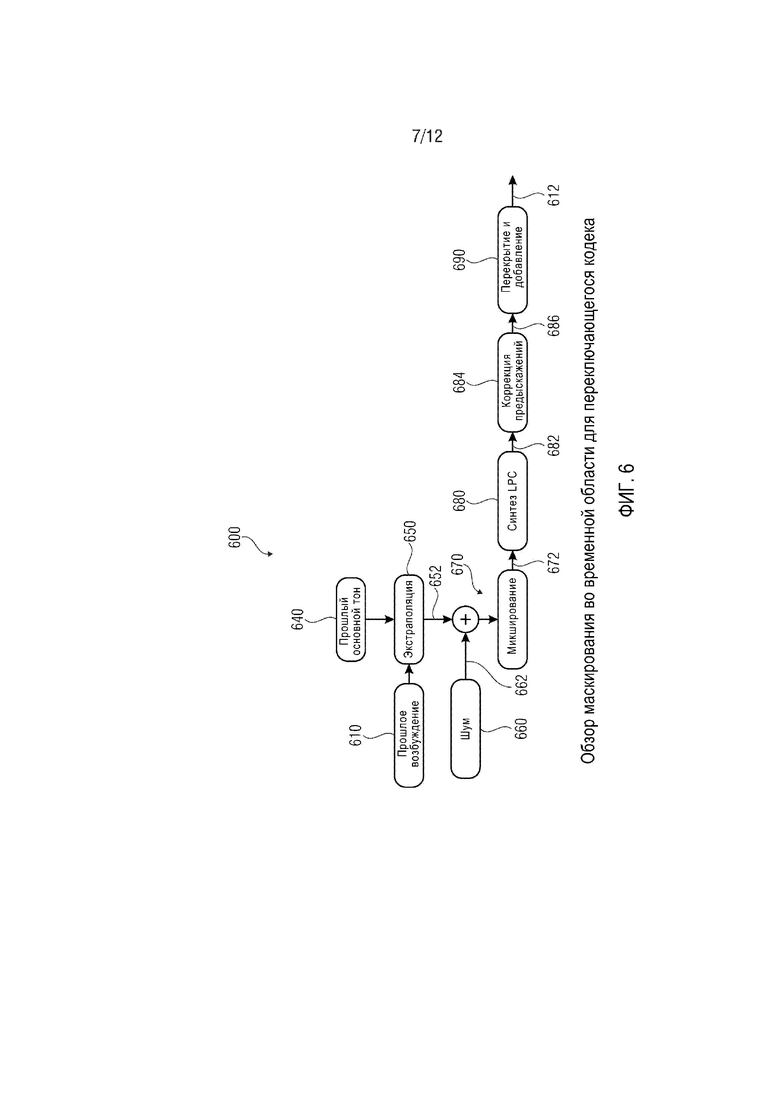
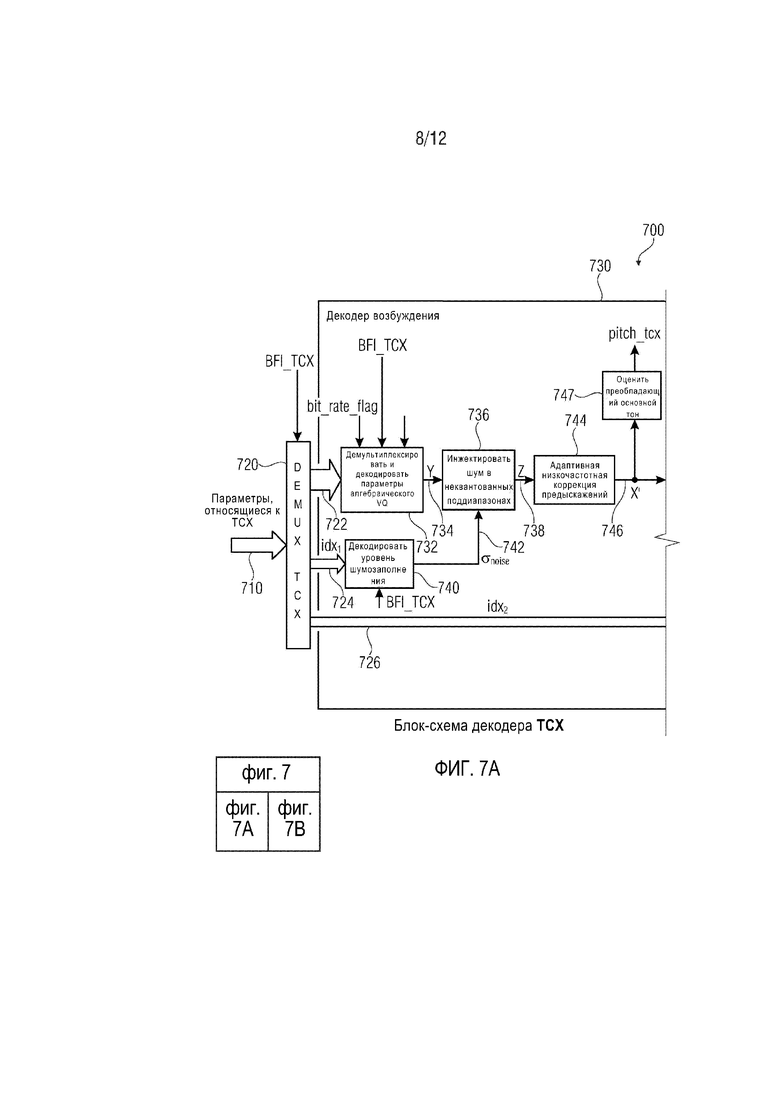
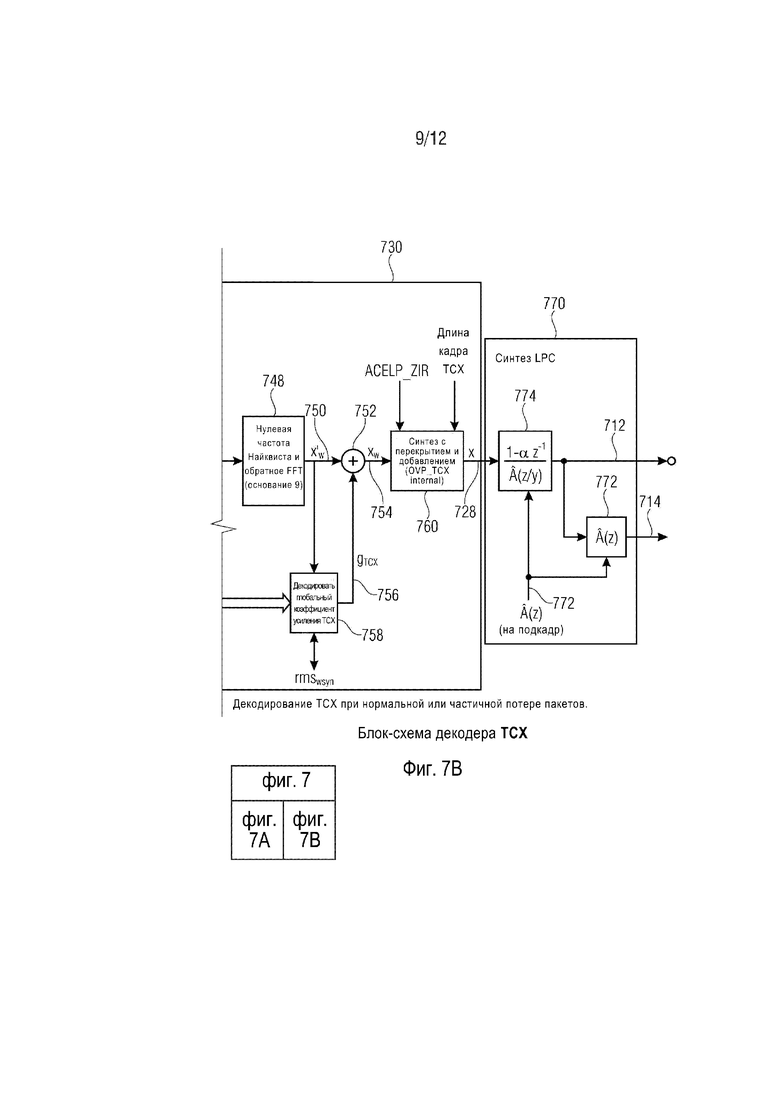
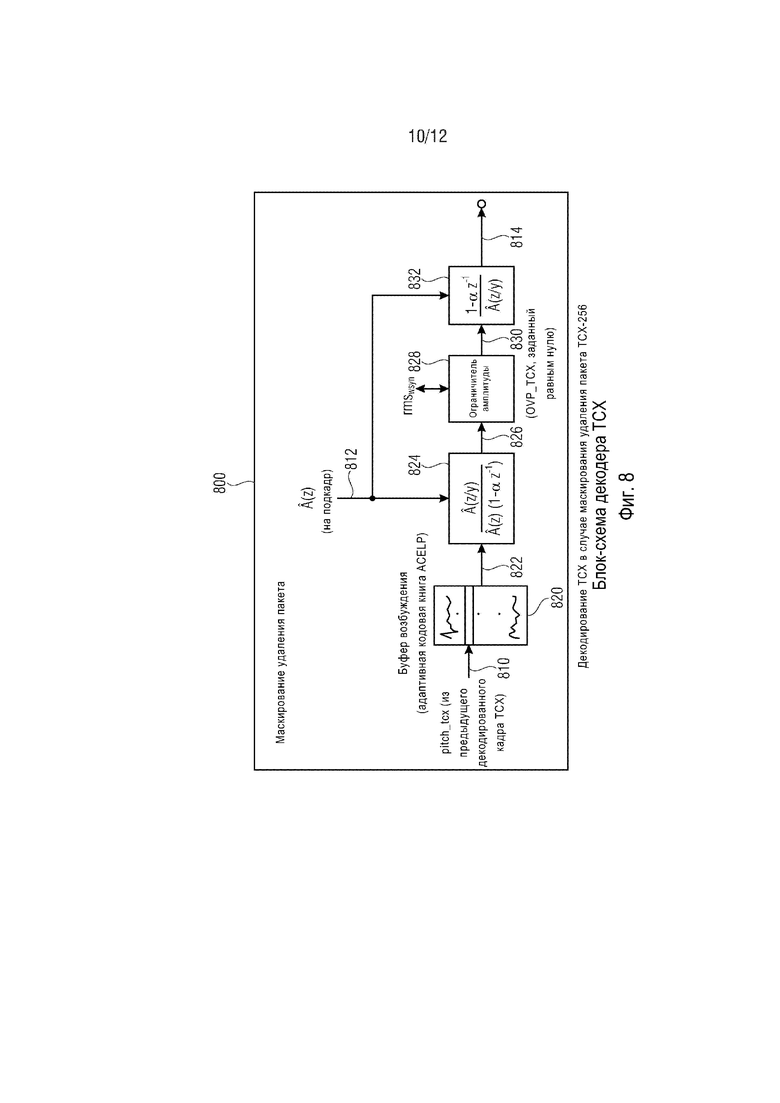
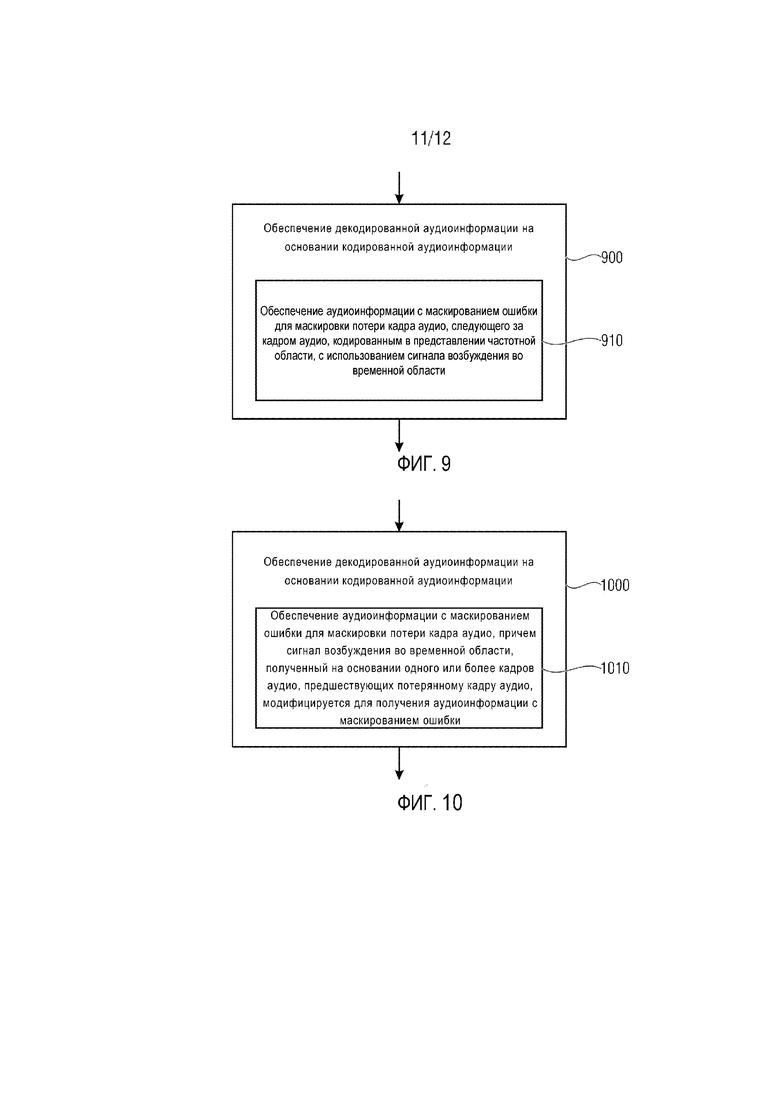
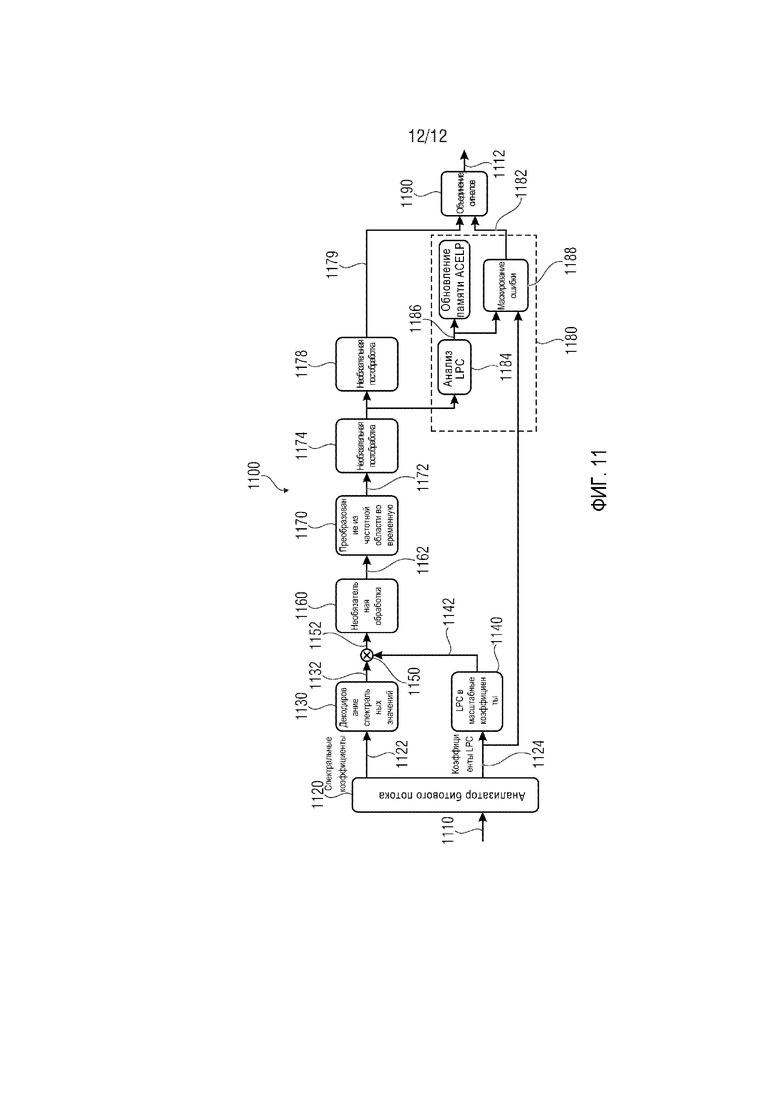
Изобретение относится к области декодирования аудиоинформации. Технический результат – обеспечение улучшенного маскирования ошибки аудиоинформации. Аудиодекодер для обеспечения декодированной аудиоинформации содержит: маскирование ошибки, для обеспечения аудиоинформации с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области; при этом маскирование ошибки выполнено с возможностью объединения экстраполированного сигнала возбуждения во временной области и шумового сигнала для получения входного сигнала для синтеза методом кодирования с линейным предсказанием (LPC), а также с возможностью осуществления синтеза LPC, выполненного с возможностью фильтрации входного сигнала синтеза LPC в зависимости от параметров кодирования с линейным предсказанием для получения аудиоинформации с маскированием ошибки; причем аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки. 15 н. и 29 з.п. ф-лы, 13 ил.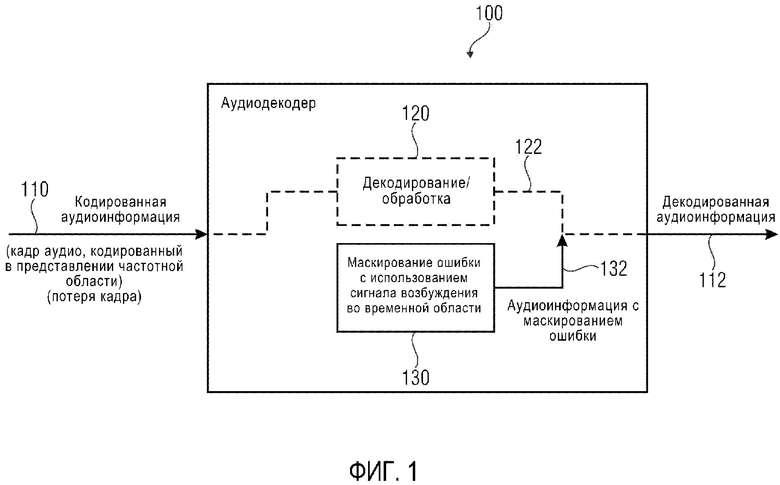
1. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью объединения экстраполированного сигнала (552) возбуждения во временной области и шумового сигнала (562) для получения входного сигнала (572) для синтеза (580) методом кодирования с линейным предсказанием (LPC), и
при этом маскирование ошибки выполнено с возможностью осуществления синтеза LPC,
при этом синтез LPC выполнен с возможностью фильтрации входного сигнала (572) синтеза LPC в зависимости от параметров кодирования с линейным предсказанием для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью фильтрации высоких частот шумового сигнала (562), который объединяется с экстраполированным сигналом (552) возбуждения во временной области,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
2. Аудиодекодер (100; 300) по п. 1, при этом аудиодекодер содержит ядро (120; 340, 350, 350, 366, 370) декодера частотной области, выполненное с возможностью вывода представления (122; 372) аудиосигнала во временной области из представления (322) частотной области без использования сигнала возбуждения во временной области в качестве промежуточной величины для кадра аудио, кодированного в представлении частотной области.
3. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью получения сигнала (532) возбуждения во временной области на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, и
при этом маскирование ошибки выполнено с возможностью обеспечения аудиоинформации (122; 382; 512) с маскированием ошибки для маскировки потерянного кадра аудио с использованием упомянутого сигнала возбуждения во временной области.
4. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью осуществления анализа (530) LPC на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, для получения набора параметров кодирования с линейным предсказанием и сигнала (532) возбуждения во временной области, представляющего аудиоконтент кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио; или
в котором маскирование (130; 380; 500) ошибки выполнено с возможностью осуществления анализа (530) LPC на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, для получения сигнала (532) возбуждения во временной области, представляющего аудиоконтент кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио; или
в котором аудиодекодер выполнен с возможностью получения набора параметров кодирования с линейным предсказанием с использованием оценивания параметра кодирования с линейным предсказанием; или
в котором аудиодекодер выполнен с возможностью получения набора параметров кодирования с линейным предсказанием на основании набора масштабных коэффициентов с использованием преобразования.
5. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью получения информации (542) основного тона, описывающей основной тон кадра аудио, кодированного в представлении частотной области, предшествующего потерянному кадру аудио, и обеспечения аудиоинформации (122; 382; 512) с маскированием ошибки в зависимости от информации основного тона.
6. Аудиодекодер (100; 300) по п. 5, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью получения информации (542) основного тона на основании сигнала (532) возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио.
7. Аудиодекодер (100; 300) по п. 6, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью оценивания кросс-корреляции сигнала (532) возбуждения во временной области или сигнала (522) временной области, для определения грубой информации основного тона, и
при этом маскирование ошибки выполнено с возможностью уточнения грубой информации основного тона с использованием поиска по замкнутому циклу вокруг основного тона, определенного грубой информацией основного тона.
8. Аудиодекодер по п. 1, в котором маскирование ошибки выполнено с возможностью получения информации основного тона на основании вспомогательной информации кодированной аудиоинформации.
9. Аудиодекодер по п. 1, в котором маскирование ошибки выполнено с возможностью получения информации основного тона на основании информации основного тона, доступной для ранее декодированного кадра аудио.
10. Аудиодекодер по п. 1, в котором маскирование ошибки выполнено с возможностью получения информации основного тона на основании поиска основного тона, осуществляемого по сигналу временной области или по остаточному сигналу.
11. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью копирования цикла основного тона сигнала (532) возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, один раз или несколько раз для получения сигнала (572) возбуждения для синтеза (580) аудиоинформации (132; 382; 512) с маскированием ошибки.
12. Аудиодекодер (100; 300) по п. 11, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью фильтрации низких частот цикла основного тона сигнала (532) возбуждения во временной области, выведенного из представления временной области кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, с использованием фильтра, зависящего от частоты дискретизации, полоса пропускания которого зависит от частоты дискретизации кадра аудио, кодированного в представлении частотной области.
13. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью предсказания основного тона в конце потерянного кадра, и
причем маскирование ошибки выполнено с возможностью адаптации сигнала (532) возбуждения во временной области или одной или более его копий к предсказанному основному тону, для получения входного сигнала (572) для синтеза (580) LPC.
14. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью объединения экстраполированного сигнала (552) возбуждения во временной области и шумового сигнала (562) для получения входного сигнала (572) для синтеза (580) LPC, и
при этом маскирование ошибки выполнено с возможностью осуществления синтеза LPC,
при этом синтез LPC выполнен с возможностью фильтрации входного сигнала (572) синтеза LPC в зависимости от параметров кодирования с линейным предсказанием для получения аудиоинформации (132; 382; 512) с маскированием ошибки.
15. Аудиодекодер (100; 300) по п. 14, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью вычисления коэффициента усиления экстраполированного сигнала (552) возбуждения во временной области, который используется для получения входного сигнала (572) для синтеза (580) LPC, с использованием корреляции во временной области, которая осуществляется на основании представления (122; 372; 378; 510) временной области кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, причем интервал корреляции устанавливается в зависимости от информации основного тона, полученной на основании сигнала (532) возбуждения во временной области, или с использованием корреляции в области возбуждения.
16. Аудиодекодер (100; 300) по п. 14, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью фильтрации высоких частот шумового сигнала (562), который объединяется с экстраполированным сигналом (552) возбуждения во временной области.
17. Аудиодекодер (100; 300) по п. 11, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью изменения спектральной формы шумового сигнала (562) с использованием фильтра коррекции предыскажений, причем шумовой сигнал объединяется с экстраполированным сигналом (552) возбуждения во временной области, если кадр аудио, кодированный в представлении (322) частотной области, предшествующий потерянному кадру аудио, является вокализованным кадром аудио или содержит начало звука.
18. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью вычисления коэффициента усиления шумового сигнала (562) в зависимости от корреляции во временной области, которая осуществляется на основании представления (122; 372; 378; 510) временной области кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио.
19. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации (132; 382; 512) с маскированием ошибки.
20. Аудиодекодер (100; 300) по п. 19, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью использования одной или более модифицированных копий сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения информации (132; 382; 512) маскирования ошибки.
21. Аудиодекодер (100; 300) по п. 19, в котором маскирование (132; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для уменьшения, таким образом, периодической составляющей аудиоинформации (132; 382; 512) с маскированием ошибки во времени.
22. Аудиодекодер (100; 300) по п. 19, в котором маскирование (132; 380; 500) ошибки выполнено с возможностью масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для модификации, таким образом, сигнала возбуждения во временной области.
23. Аудиодекодер (100; 300) по п. 21, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий.
24. Аудиодекодер (100; 300) по п. 21, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от одного или более параметров одного или более кадров аудио, предшествующих потерянному кадру аудио, и/или в зависимости от количества последовательных потерянных кадров аудио.
25. Аудиодекодер (100; 300) по п. 23, в котором маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от длины периода основного тона сигнала (532) возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих меньшую длину периода основного тона по сравнению с сигналами, имеющими бóльшую длину периода основного тона.
26. Аудиодекодер (100; 300) по п. 23, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от результата анализа (540) основного тона или предсказания основного тона,
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, имеющих большее изменение основного тона за единицу времени по сравнению с сигналами, имеющими меньшее изменение основного тона за единицу времени, и/или
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, основной тон которых не удается предсказать, по сравнению с сигналами, основной тон которых удается предсказать.
27. Аудиодекодер (100; 300) по п. 19, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью масштабирования по времени сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от предсказания (540) основного тона в течение времени одного или более потерянных кадров аудио.
28. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки в течение времени, превышающего временную длительность одного или более потерянных кадров аудио.
29. Аудиодекодер (100; 300) по п. 28, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью осуществления перекрытия и добавления (390; 590) аудиоинформации (132; 382; 512) с маскированием ошибки и представления (122; 372; 378; 512) временной области одного или более правильно принятых кадров аудио, следующих за одним или более потерянными кадрами аудио.
30. Аудиодекодер (100; 300) по п. 1, в котором маскирование (130; 380; 500) ошибки выполнено с возможностью вывода аудиоинформации (132; 382; 512) с маскированием ошибки на основании, по меньшей мере, трех частично перекрывающихся кадров или окон, предшествующих потерянному кадру аудио или потерянному окну.
31. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
причем аудиодекодер содержит ядро (120; 340, 350, 360, 366, 370) декодера частотной области, выполненное с возможностью применения масштабирования на основе масштабных коэффициентов (360) к множеству спектральных значений (342), выведенных из представления (322) частотной области, и
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, содержащего множество кодированных масштабных коэффициентов (328), с использованием сигнала (532) возбуждения во временной области, выведенного из представления частотной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью получения сигнала (532) возбуждения во временной области на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
32. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом представление частотной области содержит кодированное представление (326) множества спектральных значений и кодированное представление (328) множества масштабных коэффициентов для масштабирования спектральных значений, и при этом аудиодекодер выполнен с возможностью обеспечения множества декодированных масштабных коэффициентов (352, 354) для масштабирования спектральных значений на основании множества кодированных масштабных коэффициентов, или
при этом аудиодекодер выполнен с возможностью вывода множества масштабных коэффициентов для масштабирования спектральных значений из кодированного представления параметров LPC; и
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью получения сигнала (532) возбуждения во временной области на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
33. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью копирования цикла основного тона сигнала (532) возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, один раз или несколько раз для получения сигнала (572) возбуждения для синтеза (580) аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью фильтрации низких частот цикла основного тона сигнала (532) возбуждения во временной области, выведенного из представления временной области кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, с использованием фильтра, зависящего от частоты дискретизации, полоса пропускания которого зависит от частоты дискретизации кадра аудио, кодированного в представлении частотной области,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
34. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом маскирование (132; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для уменьшения, таким образом, периодической составляющей аудиоинформации (132; 382; 512) с маскированием ошибки во времени;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий;
при этом маскирование ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от длины периода основного тона сигнала (532) возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих меньшую длину периода основного тона по сравнению с сигналами, имеющими бóльшую длину периода основного тона,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
35. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью масштабирования по времени сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от предсказания (540) основного тона в течение времени одного или более потерянных кадров аудио,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
36. Аудиодекодер (100; 300) для обеспечения декодированной аудиоинформации (112; 312) на основании кодированной аудиоинформации (110; 310), причем аудиодекодер содержит:
маскирование (130; 380; 500) ошибки, выполненное с возможностью обеспечения аудиоинформации (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, с использованием сигнала (532) возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом маскирование (132; 380; 500) ошибки выполнено с возможностью модификации сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для уменьшения, таким образом, периодической составляющей аудиоинформации (132; 382; 512) с маскированием ошибки во времени, или
при этом маскирование (132; 380; 500) ошибки выполнено с возможностью масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, для модификации, таким образом, сигнала возбуждения во временной области;
при этом маскирование (130; 380; 500) ошибки выполнено с возможностью регулировки скорости, используемой для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, в зависимости от результата анализа (540) основного тона или предсказания основного тона,
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, имеющих большее изменение основного тона за единицу времени по сравнению с сигналами, имеющими меньшее изменение основного тона за единицу времени, и/или
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, основной тон которых не удается предсказать, по сравнению с сигналами, основной тон которых удается предсказать,
при этом аудиодекодер выполнен с возможностью обеспечения декодированной аудиоинформации с использованием аудиоинформации с маскированием ошибки.
37. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области;
причем способ содержит этап, на котором объединяют экстраполированный сигнал (552) возбуждения во временной области и шумовой сигнал (562) для получения входного сигнала (572) для синтеза (580) LPC, и
причем способ содержит этап, на котором осуществляют синтез LPC,
причем при синтезе LPC фильтруют входной сигнал (572) синтеза LPC в зависимости от параметров кодирования с линейным предсказанием для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
причем способ содержит этап, на котором осуществляют высокочастотную фильтрацию шумового сигнала (562), который объединяют с экстраполированным сигналом (552) возбуждения во временной области,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
38. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области; и
применяют масштабирование на основе масштабных коэффициентов (360) к множеству спектральных значений (342), выведенных из представления (322) частотной области;
причем аудиоинформацию (132; 382; 512) с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении (322) частотной области, содержащего множество кодированных масштабных коэффициентов (328), обеспечивают с использованием сигнала (532) возбуждения во временной области, выведенного из представления частотной области;
причем сигнал (532) возбуждения во временной области получают на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
39. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области;
при этом представление частотной области содержит кодированное представление (326) множества спектральных значений и кодированное представление (328) множества масштабных коэффициентов для масштабирования спектральных значений, и при этом множество декодированных масштабных коэффициентов (352; 354) для масштабирования спектральных значений обеспечивают на основании множества кодированных масштабных коэффициентов, или
при этом множество масштабных коэффициентов для масштабирования спектральных значений выводят из кодированного представления параметров LPC; и
при этом сигнал (532) возбуждения во временной области получают на основании кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
40. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области,
при этом цикл основного тона сигнала (532) возбуждения во временной области, выведенного из кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, копируют один раз или несколько раз для получения сигнала (572) возбуждения для синтеза (580) аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом цикл основного тона сигнала (532) возбуждения во временной области, выведенного из представления временной области кадра аудио, кодированного в представлении (322) частотной области, предшествующего потерянному кадру аудио, фильтруют по низкой частоте с использованием фильтра, зависящего от частоты дискретизации, полоса пропускания которого зависит от частоты дискретизации кадра аудио, кодированного в представлении частотной области,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
41. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области,
причем сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, модифицируют для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, модифицируют для уменьшения, таким образом, периодической составляющей аудиоинформации (132; 382; 512) с маскированием ошибки во времени;
при этом коэффициент усиления, применяемый для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, постепенно уменьшают;
при этом скорость, используемую для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, регулируют в зависимости от длины периода основного тона сигнала (532) возбуждения во временной области, таким образом, что сигнал возбуждения во временной области, поступающий в синтез LPC, затухает быстрее для сигналов, имеющих меньшую длину периода основного тона по сравнению с сигналами, имеющими бóльшую длину периода основного тона,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
42. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области;
причем сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, модифицируют для получения аудиоинформации (132; 382; 512) с маскированием ошибки;
при этом сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, масштабируют по времени в зависимости от предсказания (540) основного тона в течение времени одного или более потерянных кадров аудио,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
43. Способ (900) обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем способ содержит этап, на котором:
обеспечивают (910) аудиоинформацию с маскированием ошибки для маскировки потери кадра аудио, следующего за кадром аудио, кодированным в представлении частотной области, с использованием сигнала возбуждения во временной области;
причем способ содержит этап, на котором модифицируют сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, для получения аудиоинформации (132; 382; 512) с маскированием ошибки,
причем сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, модифицируют для уменьшения, таким образом, периодической составляющей аудиоинформации (132; 382; 512) с маскированием ошибки во времени, или
причем сигнал (532) возбуждения во временной области, полученный на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, масштабируют для модификации, таким образом, сигнала возбуждения во временной области;
причем скорость, используемая для постепенного снижения коэффициента усиления, применяемого для масштабирования сигнала (532) возбуждения во временной области, полученного на основании одного или более кадров аудио, предшествующих потерянному кадру аудио, или одной или более его копий, регулируют в зависимости от результата анализа (540) основного тона или предсказания основного тона,
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, имеющих большее изменение основного тона за единицу времени по сравнению с сигналами, имеющими меньшее изменение основного тона за единицу времени, и/или
таким образом, что детерминированная составляющая сигнала (572) возбуждения во временной области, поступающего в синтез (580) LPC, затухает быстрее для сигналов, основной тон которых не удается предсказать, по сравнению с сигналами, основной тон которых удается предсказать,
при этом способ содержит этап, на котором обеспечивают декодированную аудиоинформацию с использованием аудиоинформации с маскированием ошибки.
44. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по любому из пп. 37-43, когда компьютерная программа выполняется на компьютере.
| US 6757654 B1, 29.06.2004 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Вибрационный грохот | 1983 |
|
SU1207519A1 |
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |

