Область техники
Предлагаемое изобретение относится к кодеру аудиосигнала, формирующему кодированное представление аудиоконтента на базе входного представления аудиоконтента.
Предлагаемое изобретение относится к декодеру аудиосигнала, формирующему декодированное представление аудиоконтента на базе кодированного представления аудиоконтента.
Предлагаемое изобретение относится к способу формирования кодированного представления аудиоконтента на базе входного представления аудиоконтента.
Предлагаемое изобретение относится к способу формирования декодированного представления аудиоконтента на базе кодированного представления аудиоконтента.
Реализация заявляемого изобретения относится к компьютерным программам осуществления названных способов.
Реализация заявляемого изобретения относится к новой гибридной схеме кодирования речи и звука с малой задержкой.
Предшествующий уровень техники
Обзорно рассмотрим предпосылки к созданию изобретения, чтобы отчетливо выделить его новизну и преимущества.
Последние десять лет активные усилия направлены на реализацию возможностей хранения и передачи в цифровом формате звуковых данных при оптимизации использования вычислительного ресурса. Одним из важных достижений на этом пути стало оформление Международного стандарта ISO/IEC 14496-3. Часть 3 Стандарта посвящена кодированию и декодированию звукоданных, а в подразделе 4 части 3 изложены основы кодирования обычного звука. В части 3, подразделе 4 Стандарта ISO/IEC 14496 сформулирована концепция кодирования и декодирования общезвуковых данных. Кроме прочего, внесены предложения по совершенствованию качества и/или снижению скорости передачи данных (битрейта).
Наряду с этим были разработаны аудиокодеры и аудиодекодеры, предназначенные специально для речи. Подобного рода целевые речевые аудиокодеры описаны, в частности, в спецификациях "Партнерского проекта третьего поколения" (Third Generation Partnership Project) "3GPP TS 26.090", 3GPP TS 26.190" и "3GPP TS 26.290".
Выявлено, что в ряде прикладных программ необходимо, чтобы задержка при кодировании и декодировании была небольшой. В частности, короткая задержка желательна в мультимедийных приложениях в реальном времени, так как значительная задержка в таких случаях вызывает у пользователя отрицательные ощущения.
Между тем, было установлено, что сбалансированное соотношение между качеством и скоростью передачи данных требует время от времени переключения между разными режимами кодирования в зависимости от аудиоконтента. На практике замечено, что изменения аудиоконтента требуют изменения режимов кодирования, например, переключения между режимом линейного предсказания с кодовым возбуждением из трансформанты и режимом линейного предсказания с кодовым возбуждением (например, режимом области линейного предсказания с кодовым алгебраическим возбуждением), или между режимом частотной области и режимом области линейного предсказания с кодовым возбуждением. Это происходит в силу того, что некоторый аудиоконтент (или некоторые составляющие непрерывного потока звуковых данных) кодируется с высокой эффективностью в одном режиме, в то время как другой аудиоконтент (или другие составляющие этого же непрерывного потока звуковых данных) более эффективно кодируется в другом режиме.
В контексте сложившейся ситуации было сделано заключение о целесообразности коммутации между разными режимами, которая не требует большого избыточного битрейта значительных уступок по качеству (например, „щелчков" при переключении). Кроме того, к основной цели уменьшения задержки при кодировании и декодировании добавилась задача переключение между режимами.
Таким образом, целью изобретения является концепция мультирежимного аудиокодирования, обеспечивающего сбалансированное соотношение между эффективной скоростью передачи данных, качеством звука и задержкой при коммутация между различными режимами кодирования.
Краткое описание изобретения
Предлагаемое изобретение является основой для создания кодера аудиосигнала (аудиокодера) для формирования кодированного представления звуковых данных (аудиоконтента) на базе входящего (вводимого) представления звукового материала (аудиоконтента). Кодер аудиосигнала включает в свою схему тракт области трансформанты (области спектральных преобразований), предназначенный для выведения ряда спектральных коэффициентов и параметров формирования искажения (ограничения шума) (например, информации о коэффициентах масштабирования или информации о параметрах области линейного предсказания) на базе представления во временной области части входящего потока звукоданных, подлежащей кодированию в режиме трансформанты, таким образом, что спектральные коэффициенты (коэффициенты трансформанты) описывают спектр ограниченной по шуму версии аудиоконтента (например, пересчитанный с использованием масштабного коэффициента или преобразованный с формированием искажения в области линейного предсказания). В схему тракта области трансформанты включен преобразователь из временной области в частотную область (время-частотный преобразователь), предназначенный для оконного взвешивания временного представления аудиоконтента или его предварительно обработанной версии и формирования оконно-взвешенного представления аудиоконтента с дальнейшим применением время-частотного преобразования для выведения из оконно-взвешенного временного представления аудиоконтента ряда спектральных коэффициентов. Кроме этого, кодер аудиосигнала включает в свою схему тракт области линейного предсказания с кодовым возбуждением (кратко - тракт ACELP), предназначенный для формирования данных кодового возбуждения (например, возбуждения алгебраическими кодами) и данных области линейного предсказания на базе части аудиоконтента, подлежащего кодированию в режиме области линейного предсказания с кодовым возбуждением (кратко - режим CELP) (в частности, в режиме области линейного предсказания с алгебраическим кодовым возбуждением). Преобразователь из временной области в частотную область предназначен для применения расчетного асимметричного окна анализа для взвешивания текущего фрагмента аудиоконтента, подлежащего кодированию в режиме трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме трансформанты, в обоих случаях, если за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме трансформанты, и если за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP. Кодер аудиосигнала выполнен с возможностью избирательного формирования информации по устранению эффекта наложения спектров (данных антиалиасинга) в том случае, когда за текущим фрагментом аудиоконтента (закодированным в режиме трансформанты) следует порция звукоданных, подлежащая кодированию в режиме CELP.
Реализация заявляемого изобретения в этой части основывается на заключении, что надлежащий баланс между эффективностью кодирования (например, в пересчете на средний битрейт), акустическим качеством и задержкой при кодирования может быть достигнут посредством коммутации режимов трансформанты и CELP, когда оконное взвешивание фрагмента звуковых данных, подлежащих кодированию в режиме трансформанты, не зависит от режима кодирования следующего фрагмента звукоданных, и когда благодаря выборочной подготовке антиалиасинговой информации возможно ослабление или устранение артефактов алиасинга, результирующих из применения весового алгоритма, не рассчитанного на переход к фрагменту аудиоконтента, закодированному в режиме CELP. Таким образом, избирательная подготовка антиалиасинговой информации позволяет взвешивать элементы звуковых данных (например, фреймы или подфреймы), закодированные в режиме трансформанты, с использованием окон, обеспечивающих перекрывание по времени (или даже перекрывание, компенсирующее алиасинг) очередных фрагментов аудиоконтента. В силу этого достигается надлежащая эффективность кодирования последовательных фрагментов аудиоконтента, закодированных в режиме трансформанты, поскольку использование окон с временным наложением последовательных фрагментов аудиоконтента обеспечивает особенно эффективное сложение наложением на стороне декодера. Более того, задержка сохраняется на низком уровне благодаря использованию того же самого окна для взвешивания фрагмента аудиоконтента, кодируемого в режиме трансформанты, и идущего за фрагментом аудиоконтента, закодированным в режиме трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP. Другими словами, нет необходимости знать, в каком режиме закодирован последующий элемент звуковых данных, чтобы выбрать оконную функцию для взвешивания текущего фрагмента аудиоконтента. Таким образом, задержка при кодировании остается небольшой, поскольку текущий фрагмент аудиоконтента может быть взвешен до того, как определен режим кодирования следующей составляющей аудиоконтента. Тем не менее, артефакты, которые могут проявиться при использовании оконной функции, которая не полностью удовлетворяет условиям перехода от фрагмента аудиоконтента, закодированного в области трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP, могут быть устранены на стороне декодера благодаря использованию антиалиасинговой информации.
Из этого следует, что надлежащая общая эффективность кодирования достигается даже при потребности в некоторой дополнительной антиалиасинговой информации при переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP. Акустическое качество сохраняется на высоком уровне благодаря формированию антиалиасинговой информации, при этом задержки остаются небольшими благодаря подбору оконной функции независимо от режима, в котором закодирована очередная порция звуковых данных.
Исходя из сказанного, аудиокодер сочетает в себе надлежащую эффективность использования вычислительного ресурса при низкой задержке кодирования с сохранением подобающего качества звука.
Время-частотный преобразователь в предпочтительном техническом исполнении характеризуется применением одного и того же окна для взвешивания текущего фрагмента аудиоконтента, подлежащего кодированию в режиме трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме трансформанты, в обоих случаях - как при смене текущего фрагмента аудиоконтента фрагментом аудиоконтента, кодируемьм в режиме трансформанты, так и при смене текущего фрагмента аудиоконтента фрагментом аудиоконтента, кодируемьм в режиме CELP.
В предпочтительном варианте реализации подобранное асимметричное окно состоит из левой половины окна и правой половины окна. Левая половина окна включает в себя левосторонний скос перехода, где значения оконной функции равномерно возрастают от нуля до центрального значения окна (значения в середине окна), и область всплеска, в которой величины оконной функции превышают значение центра окна, и в которую входит максимальное значение окна. Правая половина окна включает в себя правосторонний скат перехода, где значения оконной функции равномерно убывают от срединного оконного значения до нуля, и правостороннюю нулевую область. Применяя такое асимметричное окно, задержку кодирования можно сохранять на заметно низком уровне. Более того, выделяя левую половину окна за счет участка всплеска, на сравнительно небольшом уровне можно удерживать артефакты алиасинга на переходе к фрагменту аудиоконтента, закодированному в режиме CELP. Следовательно, антиалиасинговую информацию можно закодировать при эффективном битрейте.
Левая половина окна предпочтительно содержит не более 1% нулевых значений окна, а правосторонняя нулевая область имеет длину не менее 20% от оконных значений правой половины окна. Было определено, что подобная оконная функция хорошо соответствует применению в аудиокодере для коммутации между режимом трансформанты и режимом CELP.
Правая половина выбранного асимметричного аналитического окна
преимущественно содержит значения, меньшие, чем центральное значение окна, и не содержит область всплеска. Установлено, что такая форма окна обеспечивает относительно небольшое наличие артефактов алиасинга на переходе к фрагменту аудиоконтента, закодированному в режиме CELP.
Ненулевая область заданного асимметричного окна анализа в соответствии с предпочтительным техническим решением, по меньшей мере, на 10% короче длины фрейма. Следовательно, задержка остается небольшой.
Аудиокодер в предпочтительном варианте схемотехнически решен так, что последовательные фрагменты аудиоконтента, подлежащие кодированию в режиме трансформанты, содержат временное наложение, как минимум, порядка 40%. В таком случае предпочтительная компоновка кодера аудиосигнала подразумевает также, что текущий фрагмент аудиоконтента, кодируемый в режиме трансформанты, и последующий фрагмент аудиоконтента, подлежащий кодированию в линейно-предиктивном режиме с кодовым возбуждением, имеют перекрывание по времени. Аудиокодер выполнен с возможностью селективно формировать антиалиасинговую информацию, содержащую команду на нейтрализацию алиасинга, по которой на стороне аудиодекодера должны быть устранены артефакты алиасинга при переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP. Значительное взаимное перекрывание последовательных фрагментов (например, фреймов или субфреймов) аудиоконтента, подлежащих кодированию в режиме трансформанты, обеспечивает возможность преобразования с наложением, такого как модифицированное дискретное косинусное преобразование, для трансформации из временной области в частотную область, при котором алиасинг во временной области будет редуцирован или даже полностью купирован за счет наличия перекрытия между следующими друг за другом фреймами, закодированными в режиме трансформанты. Тем не менее, при переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP, также образуется определенное временное наложение, которое, однако, не способствует полной компенсации алиасинга (или даже совершенно не способствует компенсации алиасинга). Временное наложение используют во избежание чрезмерного видоизменения фреймов при фрагментировании на переходах между фрагментами аудиоконтента, закодированными, в разных режимах. Между тем, для того, чтобы ослабить или нейтрализовать артефакты наложения спектров (алиасинга), возникающие при перекрывании на переходе между фрагментами аудиоконтента, закодированными в разных режимах, дозируется антиалиасинговая информация. Более того, алиасинг
удерживается в сравнительно небольших пределах благодаря асимметрии расчетного окна анализа, при этом информация по устранению алиасинга кодируется в эффективном режиме.
Кодер аудиосигнала согласно изобретению предпочтительно выполнен с возможностью выбора весового окна для текущего фрагмента звуковых данных (который преимущественно кодируют в режиме трансформанты) независимо от режима кодирования следующего фрагмента звукоданных, который имеет временное наложение с текущим фрагментом звукоданных таким образом, что оконное представление текущего фрагмента звуковых данных (который преимущественно кодируется в режиме трансформанты) перекрывается с очередным фрагментом звукоданных, даже если очередной фрагмент звукоданных кодируется в режиме CELP. Аудиокодер выполнен с возможностью отклика на распознавание очередного фрагмента аудиоконтента, подлежащего кодированию в режиме CELP, в виде антиалиасинговой информации, содержащей компоненты сигнала антиалиасинга, введенные в представление следующего фрагмента аудиоконтента в режиме трансформанты. Соответственно, устранение алиасинга, получаемое (альтернативно, то есть при наличии последующих фрагментов аудиоконтента, закодированных в режиме трансформанты) путем сложения наложением представлений во временной области двух фрагментов аудиоконтента, закодированных в режиме трансформанты, достигают за счет антиалиасинговой информации при переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP. В силу этого при использовании целевой (специальной) антиалиасинговой информации оконное взвешивание фрагмента аудиоконтента, предшествующего переключению режимов, можно оставить без изменения, что позволяет уменьшить задержку.
Время-частотный преобразователь в предпочтительной аппаратной версии рассчитывает и применяет асимметричное окно для взвешивания текущего фрагмента аудиоконтента, кодируемого в режиме трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме CELP, таким образом, что фрагменты аудиоконтента, подлежащие кодированию в режиме трансформанты, взвешивают с использованием одного и того же расчетного асимметричного окна анализа, независимо от режима кодирования предыдущего фрагмента аудиоконтента и независимо от режима кодирования последующего фрагмента аудиоконтента. Кроме того, оконное взвешивание выполняется так, что оконное представление текущего фрагмента аудиоконтента, кодируемого в режиме трансформанты, перекрывает по времени предыдущий фрагмент аудиоконтента, закодированный в режиме CELP. Из этого может быть выведена упрощенная схема весового алгоритма, согласно которому фрагменты аудиоконтента, закодированные в режиме трансформанты, постоянно (допустим, в продолжение некоторого отрывка фонограммы) кодируются с использованием одного и того же заданного асимметричного окна анализа. Благодаря этому отпадает необходимость сигнализировать тип используемого аналитического окна, что повышает эффективность битрейта. Более того, в умеренных пределах сохраняется сложность конструкции кодера (и декодера). Согласно полученным результатам, как рассматривалось выше, асимметричное окно анализа хорошо отвечает требованиям переходов от режима трансформанты к режиму CELP и, наоборот, от режима CELP к режиму трансформанты.
Аудиокодер согласно изобретению выполнен с возможностью избирательного формирования антиалиасинговой информации в случаях, когда текущий фрагмент звуковых данных следует за сегментом аудиоконтента, закодированным в режиме CELP. Опыт показывает, что дозирование антиалиасинговой информации в отношении таких переходов также целесообразно и позволяет добиваться хорошего качества звука.
Время-частотный преобразователь в предпочтительной схемотехнической версии задействует целевое асимметричное окно анализа перехода, отличное от расчетного асимметричного окна анализа, для оконного взвешивания текущего фрагмента аудиоконтента, подлежащего кодированию в области трансформанты и идущего следом за фрагментом аудиоконтента, закодированным в режиме CELP. Было выявлено, что применение целевой оконной функции после перехода помогает сократить избыточность битрейта при переходе. Еще было определено, что использование специального асимметричного анализирующего окна перехода после перехода не ведет к существенной дополнительной задержке, потому что решение о применении специального асимметричного окна анализа перехода может быть принято на основе информации, которая уже доступна в момент принятия решения. В силу этого объем антиалиасинговой информации может быть сокращен, а в некоторых случаях необходимость в какой-либо антиалиасинговой информации может быть исключена вообще.
Тракт области линейного предсказания с кодовым возбуждением (тракт CELP) в предпочтительной схемотехнической версии представляет собой тракт области линейного предсказания с алгебраическим кодовым возбуждением (тракт ACELP), формирующий на выходе информацию о алгебраическом кодовом возбуждении и информацию о параметрах области линейного предсказания, на основе фрагмента звуковых данных, подлежащего кодированию в режиме области линейного предсказания с алгебраическим кодовым возбуждением (в режиме ACELP) (используемом как режим области линейного предсказания с кодовым возбуждением). Использование тракта области линейных предикторов, возбуждаемых алгебраическими кодами, для выполнения функций тракта области возбуждаемого кодами линейного предсказания во многих случаях дает особенно эффективный результат при кодировании.
Предлагаемое изобретение служит основой для осуществления декодера, предназначенного для формирования декодированного представления звуковых данных на базе кодированного представления звуковых данных. Декодер аудиосигнала (аудиодекодер) включает в свой состав тракт области трансформанты, формирующий представление во временной области фрагмента аудиоконтента, закодированного в режиме трансформанты, исходя из набора спектральных коэффициентов и информации о формировании искажения. В тракт области трансформанты входит частотно-временной преобразователь, трансформирующий данные из частотной области во временную область и выполняющий оконное взвешивание с выведением оконно-взвешенного представления аудиоконтента во временной области на основе набора спектральных коэффициентов или их предварительно обработанной интерпретации. Далее, в состав аудиодекодера входит тракт области линейного предсказания с кодовым возбуждением, формирующий представление во временной области фрагмента аудиоконтента, закодированного в режиме области линейного предсказания с кодовым возбуждением на основе информации о кодовом возбуждении и информации о параметрах области линейного предсказания. Частотно-временной преобразователь характеризуется возможностью применения заданного асимметричного окна синтеза для оконного взвешивания текущего фрагмента аудиоконтента, закодированного в режиме трансформанты и следующего непосредственно за фрагментом аудиоконтента, закодированным в режиме трансформанты, для обоих случаев, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме CELP. Аудиодекодер предусматривает возможность избирательной инициации сигнала антиалиасинга, исходя из антиалиасинговой информации, когда текущий фрагмент аудиоконтента сменяется фрагментом аудиоконтента, закодированным в режиме CELP.
Данный декодер аудиосигнала базируется на заключении о возможности достижения сбалансированного соотношения между эффективностью кодирования, акустическим качеством и задержкой при кодировании при использовании одного и того же заданного асимметричного окна синтеза для оконного взвешивания фрагмента аудиоконтента, закодированного в режиме трансформанты, независимо от того, в каком режиме закодирован очередной фрагмент аудиоконтента - области трансформанты или области CELP. Благодаря применению асимметричного окна синтеза могут быть улучшены характеристики низкой продолжительности задержки аудиодекодера. Высокая эффективность кодирования может поддерживаться за счет перекрывания между окнами, налагаемыми на следующие друг за другом фрагменты аудиоконтента, закодированные в режиме трансформанты. Тем не менее, артефакты наложения спектров (алиасинга), проявляющиеся при перекрывании на переходах между фрагментами аудиоконтента, закодированными в разных режимах, нейтрализуют сигналом антиалиасинга, который селективно инициируется при переходе от фрагмента (например, фрейма или подфрейма) аудиоконтента, закодированного в режиме трансформанты, к фрагменту аудиоконтента, закодированному в режиме CELP. В дополнение следует подчеркнуть, что описываемый здесь аудиодекодер имеет те же преимущества, что и представленный выше кодер, при том что оба эти устройства полностью совместимы.
Частотно-временной преобразователь характеризуется тем, что задействует одну и ту же оконную функцию для взвешивания текущего фрагмента звуковых данных, закодированного в режиме трансформанты и следующего непосредственно за фрагментом звукоданных, закодированным в режиме трансформанты, в обоих случаях, когда за текущим фрагментом звукоданных следует фрагмент звукоданных, закодированный в режиме трансформанты, и когда за текущим фрагментом звуковых данных следует фрагмент звукоданных, закодированный в режиме CELP.
В предпочтительном варианте реализации заданное асимметричное окно состоит из левой половины окна и правой половины окна. Левая половина окна включает в себя левостороннюю нулевую область и левосторонний скос перехода, где значения оконной функции равномерно возрастают от нуля центрального значения окна. Правая половина окна включает в себя область всплеска, в которой величины оконной функции превышают значение центра окна, и в которую входит максимальное значение окна. Правая половина окна включает в себя правосторонний скат перехода, где значения оконной функции равномерно убывают от срединного оконного значения до ноля. Было установлено, что такой выбор задаваемого асимметричного окна синтеза дает в результате особенно низкую задержку, в силу того, что наличие левосторонней нулевой области позволяет реконструировать аудиосигнал (предыдущего фрагмента аудиоконтента) вплоть до (правостороннего) конца указанной нулевой области, независимо от аудиосигнала временной области текущего фрагмента звукоданных. Благодаря этому акустический материал может быть воспроизведен со сравнительно короткой задержкой.
Левостороння нулевая область предпочтительно имеет длину не менее 20% от значений оконной функции левой половины окна, а правая половина окна содержит не более 1% от нулевых значений окна. Было подтверждено, что подобная асимметричная оконная функция полностью соответствует требованиям малой задержки, и что такое заданное асимметричное окно синтеза полностью совместимо с описанным выше предпочтительным задаваемым асимметричным окном анализа.
Левая половина заданного асимметричного окна преимущественно содержит значения, меньшие, чем центральное значение окна и не содержит область всплеска. В комбинации с рассмотренной выше асимметричной аналитической оконной функцией это обеспечивает качественную реконструкцию акустического материала с небольшой задержкой. В дополнение к этому такое окно имеет хорошую частотную характеристику.
Ненулевая область расчетного асимметричного окна синтеза преимущественно короче длины фрейма, как минимум, на 10%.
Аудиодекодер в предпочтительной конфигурации предусматривает временное перекрывание следующих друг за другом фрагментов аудиоконтента, закодированных в режиме трансформанты, не менее, чем на 40%,. Кроме того, конфигурация аудиодекодера предусматривает временное наложение между текущим фрагментом аудиоконтента, закодированным в режиме трансформанты, и следующим фрагментом аудиоконтента, закодированным в режиме CELP. Конфигурация аудиодекодера выстроена с возможностью избирательно инициировать на основе антиалиасинговой информации сигнал нейтрализации алиасинга, ослабляющий или подавляющий артефакты наложения спектров при переходе от текущего фрагмента аудиоконтента (закодированного в режиме трансформанты) к последующему фрагменту аудиоконтента, закодированному в режиме CELP. Существенный „нахлест" между последовательными фрагментами аудиоконтента, закодированными в режиме трансформанты, обеспечивает плавность переходов и устранение артефактов алиасинга, результирующих из преобразования с наложением (например, обратного модифицированного дискретного косинусного преобразования). Таким образом, значительное перекрывание способствует повышению эффективности кодирования и сглаживанию переходов между последовательными фрагментами (например, фреймами или подфреймами) звуковых данных, закодированными в режиме трансформанты. Во избежание разнородности разбиения на фреймы и для обеспечения приложения заданного асимметричного окна синтеза независимо от режима кодирования очередной порции звукоданных применено временное наложение между текущим фрагментом аудиоконтента, закодированным в режиме трансформанты, и последующим фрагментом аудиоконтента, закодированным в режиме CELP. Вместе с тем, артефакты, возникающие на таких переходах, нейтрализуют сигналом антиалиасинга. В силу этого, сохранение короткой задержки при кодировании и поддержание высокой средней эффективности кодирования помогают добиваться на переходах надлежащего качества звука.
Аудиодекодер в предпочтительной схемотехнической версии предусматривает подбор оконной функции для взвешивания текущего фрагмента аудиоконтента независимо от режима кодирования следующего фрагмента аудиоконтента, который накладывается по времени на текущий фрагмент аудиоконтента таким образом, что оконное представление текущего фрагмента аудиоконтента перекрывается следующим фрагментом аудиоконтента, даже если следующий фрагмент аудиоконтента закодирован в режиме CELP. В дополнение к этому аудиодекодер предусматривает отклик на распознавание кодировки CELP в очередном фрагменте аудиоконтента в виде сигнала антиалиасинга, ослабляющего или устраняющего артефакты алиасинга на переходе от текущего фрагмента аудиоконтента, закодированного в режиме трансформанты, к очередному (последовательному) фрагменту аудиоконтента, закодированному в режиме CELP. Следовательно, артефакты алиасинга, которые могли бы быть нейтрализованы представлением во временной области следующего аудиофрейма, закодированного в трансформанте, если бы за текущим фрагментом аудиоконтента следовал фрагмент аудиоконтента, закодированный в режиме трансформанты, в описываемой ситуации, когда за текущим фрагментом аудиоконтента в действительности следует фрагмент аудиоконтента, закодированный в режиме CELP, устраняют с использованием сигнала антиалиасинга. Этот механизм помогает избежать деградацию качества перехода даже в случае, когда следующий фрагмент аудиоконтента закодирован в режиме CELP.
Преобразователь из частотной области во временную область в предпочтительном исполнении предусматривает возможность приложения заданного асимметричного окна синтеза для взвешивания текущего фрагмента аудиоконтента, закодированного в режиме трансформанты и сменяющего фрагмент аудиоконтента, закодированный в режиме CELP, таким образом, что фрагменты аудиоконтента, закодированные в режиме трансформанты, взвешиваются одним и тем же заданным асимметричным окном синтеза независимо от режима кодирования предшествующего фрагмента аудиоконтента и независимо от режима кодирования последующего фрагмента аудиоконтента. Расчетное асимметричное окно синтеза задают таким образом, что оконно-взвешенное представление во временной области текущего фрагмента аудиоконтента, закодированного в режиме трансформанты, перекрывает по времени представление во временной области предшествующего фрагмента аудиоконтента, закодированного в режиме CELP. Таким образом, одно и то же заданное асимметричное окно синтеза применяют к фрагментам аудиоконтента, закодированным в режиме трансформанты, независимо от режимов кодирования смежных - предыдущих и последующих - фрагментов аудиоконтента. Благодаря этому обеспечивается простота схемотехнической реализации декодера аудиосигнала. Кроме этого, отпадает необходимость подачи сигнала идентификации типа окна синтеза, что снижает требования к скорости обработки данных.
Аудиодекодер преимущественно выполнен с возможностью избирательной инициации сигнала компенсации алиасинга на основе антиалиасинговой информации в случае, если текущий фрагмент аудиоконтента следует за фрагментом аудиоконтента, закодированным в режиме CELP. Установлено, что противоалиасинговые действия на основе антиалиасинговой информации иногда необходимы также при переходе от фрагмента аудиоконтента, закодированного в режиме CELP, к фрагменту аудиоконтента, закодированному в режиме трансформанты. На практике определено, что эта концепция обеспечивает баланс между эффективностью битрейта и величиной задержки.
Частотно-временной преобразователь в предпочтительной схемотехнической версии задействует целевое (специальное) асимметричное окно синтеза перехода, отличное от заданного асимметричного окна синтеза, для оконного взвешивания текущего фрагмента аудиоконтента, подлежащего кодированию в области трансформанты и сменяющего фрагмент аудиоконтента, закодированный в режиме CELP. Определено, что при осуществлении этой концепции возможно предупреждение артефактов алиасинга. Кроме того, было подтверждено, что применение специальной оконной функции после перехода не влияет отрицательно на низкую длительность задержки в силу того, что информация, требуемая для подбора такой целевой оконной функции, уже доступна в момент приложения целевого окна синтеза.
В предпочтительном схемотехническом варианте тракт области линейного предсказания с кодовым возбуждением (тракт CELP) представляет собой тракт области линейного предсказания с алгебраическим кодовым возбуждением (тракт ACELP), формирующий временное представление аудиоконтента, закодированного в режиме области линейного предсказания с алгебраическим кодовым возбуждением (в режиме ACELP) (используемый в качестве режима области линейного предсказания с кодовым возбуждением), на основе информация об алгебраических кодах возбуждения и информации о параметрах области линейного предсказания. Использование тракта области линейных предикторов, возбуждаемых алгебраическими кодами, для выполнения функций тракта области возбуждаемого кодами линейного предсказания во многих случаях дает особенно эффективный результат при кодировании.
Предлагаемое изобретение осуществляется также в виде способа формирования кодированного представления звуковых данных на основе входного представления массива акустических данных и способа формирования декодированного представления аудиоконтента на основе кодированного представления звуковых данных. Еще одной формой реализации заявляемого изобретения является компьютерная программа осуществления, по меньшей мере, одного из названных способов.
Обозначенные способы и компьютерная программа основаны на тех же представленных выше аспектах концепции, на которых построены описанные ранее аудиокодер и аудиодекодер, и могут быть дополнены за счет любого из существенных признаков и функциональных возможностей, относящихся к кодеру и декодеру аудиосигнала.
Краткое описание фигур
Конструктивные решения в соответствии с настоящим изобретением будут рассмотрены в дальнейшем со ссылкой на прилагаемые фигуры, где на фиг.1 представлена принципиальная блочная схема реализации кодера аудиосигнала в соответствии с настоящим изобретением; на фиг.2A-2C представлены принципиальные блочные схемы вариантов тракта области трансформанты в составе аудиокодера на фиг.1;
на фиг.3 представлена принципиальная блочная схема реализации декодера аудиосигнала в соответствии с данным изобретением; на фиг.4A-4C представлены принципиальные блочные схемы вариантов тракта области трансформанты в составе аудиодекодера на фиг.3; на фиг.5 дано сравнение окна анализа G.718 (сплошная линия), используемого в вариантах реализации изобретения, с синусным окном (пунктир); на фиг.6 дано сравнение окна синтеза G.718 (сплошная линия), используемого в вариантах реализации изобретения, с синусным окном (пунктир); на фиг.7 графически представлена последовательность синусных окон; на фиг.8 графически представлена последовательность окон анализа G.718; на фиг.9 графически представлена последовательность окон синтеза G.718; на фиг.10 графически представлена последовательность синусных окон (сплошная линия) и ACELP (квадратно-пунктирная линия); на фиг.11 графически представлен первый вариант гибридного кодирования речи и звука (USAC) с короткой задержкой, куда входят последовательность окон анализа G.718 (сплошная линия), ACELP (квадратно-пунктирная линия) и прямой антиалиасинг (FAC) (пунктир); на фиг.12 графически представлена последовательность синтеза, соответствующего первому варианту гибридного кодирования речи и звука с малой задержкой на фиг.11; на фиг.13 графически представлен второй вариант гибридного кодирования речи и звука (USAC) с короткой задержкой с использованием последовательности окон анализа G.718 (сплошная линия), ACELP (квадратно-пунктирная линия) и прямого антиалиасинга (FAC) (пунктир); на фиг.14 графически представлена последовательность синтеза, соответствующего второму варианту гибридного кодирования речи и звука с малой задержкой на фиг.13; на фиг.15 графически представлен переход от режима „передовой технологии аудиокодирования" (ААС) к режиму „адаптивного многоскоростного широкополосного-плюс кодирования" (AMR-WB+); на фиг.16 графически представлен переход от режима „адаптивного многоскоростного широкополосного-плюс кодирования" (AMR-WB+) к режиму „передовой технологии аудиокодирования" (ААС); на фиг.17 графически представлено аналитическое окно модифицированного дискретного косинусного преобразования с короткой задержкой (LD-MDCT) в формате „передовой технологии аудиокодирования с особо малой задержкой" (AAC-ELD); на фиг.18 графически представлено окно синтеза модифицированного дискретного косинусного преобразования с короткой задержкой (LD-MDCT) в формате „передовой технологии аудиокодирования с особо малой задержкой" (AAC-ELD); на фиг.19 графически представлен пример последовательности окон при коммутации между режимом AAC-ELD и кодеком временной области; на фиг.20 графически представлен пример последовательности окон анализа при коммутации между режимом AAC-ELD и кодеком временной области; на фиг.21A графически представлено окно анализа для перехода от кодека временной области к формату AAC-ELD; на фиг.21B графически сопоставлены окно анализа для перехода от кодека временной области к режиму AAC-ELD (сплошная) и стандартное окно анализа AAC-ELD (пунктир); на фиг.22 графически представлен пример последовательности окон синтеза при коммутации между режимом AAC-ELD и кодеком временной области; на фиг.23A графически представлено окно синтеза для перехода от режима AAC-ELD к кодеку временной области; на фиг.23B графически сопоставлены окно синтеза для перехода от режима AAC-ELD к кодеку временной области и стандартное окно синтеза в режиме AAC-ELD; на фиг.24 графически представлен выбор окон перехода для коммутации оконной последовательности между режимом AAC-ELD и кодеком временной области; на фиг.25 графически представлены примеры альтернативного оконного взвешивания сигнала временной области и альтернативного разбиения на фреймы; и на фиг.26 графически представлены варианты введения сигналов TDA (наложения во временной области) в кодек временной области и достижения посредством этого критической дискретизации.
Подробное техническое описание
Далее следует обсуждение нескольких вариантов осуществления заявляемого изобретения.
Сначала необходимо уточнить, что в описываемых в дальнейшем конструктивных решениях тракт области линейного предсказания с алгебраическим кодовым возбуждением (тракт ACELP) будет взят на вооружение как вариант тракта области линейного предсказания с кодовым возбуждением (тракт CELP), и что режим области линейного предсказания с алгебраическим кодовьм возбуждением (режим ACELP) будет рассматриваться как пример режима области линейного предсказания с кодовым возбуждением (режима CELP). Информация о возбуждении алгебраическими кодами будет принята в качестве примера информации о кодовом возбуждении.
При этом, вместо рассматриваемого здесь варианта тракта ACELP могут быть введены другие типы трактов области линейного предсказания с кодовым возбуждением. Вместо тракта ACELP может быть использована любая другая версия тракта области линейного предсказания с кодовым возбуждением, в том числе тракт RCELP, тракт LD-CELP или тракт VSELP.
В качестве обобщения следует заметить, что для реализации тракта области линейного предсказания с кодовым возбуждением могут быть привлечены различные подходы, общим для которых являются использование модели источника-фильтра для воспроизведения речи на основе линейного предсказания как на стороне кодера, так и на стороне декодера, прямое - без преобразования в частотную область - формирование информации о кодовом возбуждении на стороне кодера кодированием сигнала возбуждения (называемого также стимулирующим сигналом /задающим сигналом), который предназначен для возбуждения (стимуляции) модели линейного предсказания (например, фильтра синтеза линейного предсказания) при реконструкции аудиоконтента, кодируемого в режиме CELP, и прямое - без преобразования из частотной области во временную область - извлечение сигнала возбуждения из информации о кодовом возбуждении на стороне аудиодекодера при реконструкции сигнала возбуждения (называемого также стимулирующим сигналом), который возбуждает (стимулирует) модель линейного предсказания (например, фильтра синтеза линейного предсказания) при реконструкции аудиоконтента, закодированного в режиме CELP.
Другими словами, тракты CELP аудиокодера и аудиодекодера, как правило, характеризуются использованием модели (или фильтра) области линейного предсказания (преимущественно для моделирования речевого тракта) с кодированием и декодированием во временной области сигнала возбуждения (или стимулирующего сигнала, или остаточного сигнала). При упомянутом выше кодировании или декодировании во временной области сигнал возбуждения (или стимулирующий сигнал или остаточный /разностный сигнал) кодируют или декодируют напрямую (без предварительного время-частотного или частотно-временного преобразования сигнала возбуждения), используя соответствующие кодовые слова. Для кодирования и декодирования возбуждающего сигнала используют различные типы кодовых слов. Например, коды Хаффмана (или схему кодирования Хаффмана, или схему декодирования Хаффмана) используют для кодирования или декодирования отсчетов сигнала возбуждения (таким образом, что коды Хаффмана составляют информацию о кодовом возбуждении). Однако, для кодирования и декодирования возбуждающего сигнала применяют и другие адаптивные и/или фиксированные кодовые книги, а при необходимости - в комбинации с векторным квантованием или векторным кодированием/декодированием (когда кодовые слова формируют данные кодового возбуждения). Кроме того, наряду с различными типами кодовых словарей в некоторых версиях реализации для кодирования и декодирования сигнала возбуждения задействуют алгебраические кодовые таблицы (ACELP).
Исходя из сказанного, для тракта CELP применимы разнообразные алгоритмы „прямого" кодирования сигнала возбуждения. Таким образом, алгоритм ACELP как схема кодирования и декодирования рассматривается здесь лишь как одна из большого выбора возможностей осуществления тракта CELP.
1. Реализация кодера звукового сигнала в контексте фиг.1
Далее, со ссылкой на фиг.1 рассмотрим кодер аудиосигнала (аудиокодер) 100, конструктивно решенный на основе представленного изобретения. Аудиокодер 100 принимает входное представление 110 аудиоконтента и на его базе генерирует кодированное представление 112 аудиоконтента. Аудиокодер 100 включает в свою компоновку тракт области трансформанты (тракт области спектральных преобразований) 120, предназначенный для приема на входе представления во временной области 122 фрагмента (например, фрейма или субфрейма) звуковых данных, подлежащего кодированию в режиме трансформанты, и для расчета на его базе набора спектральных коэффициентов 124 (возможно, в кодированном виде) и выведения информации о формировании искажения (ограничении шума) 126. Тракт трансформанты 120 рассчитывает спектральные коэффициенты 124 таким образом, что они описывают спектр фрагмента звукоданных в версии с ограниченным (сформированным) шумом.
Кроме того, аудиокодер 100 включает в свою компоновку тракт области линейного предсказания с алгебраическим кодовым возбуждением (сокращенно - тракт ACELP) 140, предназначенный для приема на входе представления во временной области 142 фрагмента аудиоконтента, подлежащего кодированию в режиме ACELP, и для получения на его основе информации о алгебраическом кодовом возбуждении 144 и информации о параметрах области линейного предсказания 146. Наряду с этим в компоновку аудиокодера 100 включен контур подготовки антиалиасинговой информации 160, предназначенный для формирования инструкций по устранению эффекта наложения спектров (алиасинга) 164.
Тракт области трансформанты включает в свой состав преобразователь из временной области в частотную область (время-частотный преобразователь) 130, введенный в схему для выполнения оконного взвешивания представленного во временной области потока аудиоданных 122 (или, точнее, представления во временной области фрагмента аудиоконтента, подлежащего кодированию в режиме трансформанты), или его предварительно обработанной версии, для формирования оконного представления аудиоконтента (или, точнее, взвешенного варианта фрагмента аудиоконтента, подлежащего кодированию в режиме трансформанты), и для выполнения время-частотного преобразования оконного представления (во временной области) аудиоданных с выведением набора спектральных коэффициентов 124. Время-частотный преобразователь 130 предназначен для приложения расчетного асимметричного окна анализа для взвешивания текущего фрагмента аудиоконтента, подлежащего кодированию в режиме трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме трансформанты, в обоих случаях, если за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме трансформанты, и если за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме ACELP.
Аудиокодер, или, точнее, контур формирования антиалиасинговой информации 160, выполнен с возможностью избирательной подготовки инструкций по устранению эффекта наложения спектров, когда за текущим фрагментом аудиоконтента (если он закодирован в режиме трансформанты) следует порция звукоданных, подлежащая кодированию в режиме ACELP. Если же за текущим фрагментом звукоданных (закодированным в режиме трансформанты) следует фрагмент звукоданных, подлежащий кодированию в режиме трансформанты, необходимость в антиалиасинговой информации может не возникнуть.
Следовательно, одно и то же заданное асимметричное окно анализа используют для оконного взвешивания фрагмента аудиоданных, кодируемого в режиме трансформанты, независимо от того, в каком режиме будет закодирован очередной фрагмент аудиоданных - в трансформанте или в ACELP. Предварительно задаваемое асимметричное окно анализа обычно предусматривает наложение последовательных сегментов (например, фреймов или подфреймов) потока звукоданных, что, как правило, обеспечивает надлежащую эффективность кодирования и сложения наложением в аудиодекодере и в силу этого предупреждает возникновение паразитных артефактов. Однако, как правило, нейтрализация артефактов алиасинга возможна также на стороне кодера путем сложения наложением, если два последовательных (и частично перекрывающихся) фрагмента аудиоконтента подлежат кодированию в режиме трансформанты. Наоборот, использование заданного асимметричного окна анализа даже на переходе между фрагментом аудиоконтента, закодированным в режиме трансформанты, и следующим за ним фрагментом аудиоконтента, кодируемым в режиме ACELP, вызывает затруднения, заключающиеся в том, что компенсация алиасинга наложением и сложением, которая действенна для переходов между последовательными фрагментами аудиоданных, закодированными в режиме трансформанты, теряет свою эффективность, поскольку, как правило, в режиме ACELP кодируют только крайне ограниченные по времени блоки отсчетов без перекрывания (и, в частности, без разбиения на окна с нарастанием или с затуханием). Между тем, было установлено, что одно и то же асимметричное аналитическое окно, которое используется на переходах между последовательными фрагментами аудиоконтента, закодированными в режиме трансформанты, могут быть применено и на переходе между фрагментом аудиоконтента, закодированным в режиме трансформанты, и следующим за ним фрагментом аудиоконтента, закодированным в режиме ACELP, если для такого перехода дозировано задействовать антиалиасинговую информацию.
Благодаря этому время-частотный преобразователь 130 не должен распознавать режим кодирования очередной порции звукоданных для выбора окна анализа аудиоконтента в текущий интервал времени. Как результат, задержка может быть сохранена на весьма незначительном уровне при продолжении применения асимметричных окон анализа с достаточным перекрыванием, обеспечивающим эффективное сложение наложением на стороне декодера. В дополнение к этому обеспечивается возможность переключения с режима трансформанты на режим ACELP без существенных потерь в качестве звука, поскольку на таких переходах формируется антиалиасинговая информация 164, сигнализирующая, что заданное асимметричное окно анализа не полностью адаптировано для этого перехода.
На очереди более глубокая детализация кодера аудиосигнала 100.
1.1. Детализация тракта области трансформанты
1.1.1. Тракт области трансформанты на фиг.2A
Фиг.2A отображает принципиальную блочную схему тракта области
трансформанты 200, подобного тракту области трансформанты 120, который может рассматриваться как тракт частотной области.
Тракт области трансформанты 200 характеризуется тем, что принимает представление во временной области 210 аудиофрейма, подлежащего кодированию в режиме частотной области, при этом режим частотной области является вариантом режима трансформанты. На базе представления во временной области 210 тракт области трансформанты 200 формирует кодированный набор спектральных коэффициентов 214 и кодированные масштабные коэффициенты 216. В тракт области трансформанты 200 произвольно введен контур предварительной обработки 220 представления во временной области 210 для получения на выходе предобработанной (прошедшей препроцессинг) версии 220а представления во временной области 210. Наряду с этим тракт области трансформанты 200 рассчитан на выполнение оконного взвешивания 221 путем применения заданного асимметричного окна анализа (как описано выше) к представлению во временной области 210 или к его предобработанной версии 220а с формированием оконно-взвешенного представления во временной области 221 а фрагмента аудиоконтента, подлежащего кодированию в режиме частотной области. Кроме того, тракт области трансформанты 200 выполняет преобразование из временной области в частотную область 222, при котором представление в частотной области 222а генерируют на основе оконно-взвешенного представления во временной области 221 фрагмента аудиоконтента, подлежащего кодированию в режиме частотной области. Далее, тракт области трансформанты 200 предусматривает спектральную обработку 223, при которой выполняют формирование спектра посредством коэффициентов частотной области или спектральных коэффициентов, составляющих представление в частотной области 222а. Таким образом получают спектрально масштабированное частотное представление 223а, например, в виде набора коэффициентов частотной области (трансформанты) или спектральных коэффициентов. Спектрально масштабированное (т.е. рассчитанное по форме спектра) частотное представление 223а квантуют и кодируют 224 с выведением кодированного набора спектральных коэффициентов 240.
Тракт области трансформанты 200 также включает в свои функции психоакустический анализ 225 аудиоконтента, например, с выявлением частотных и временных маскирующих эффектов и дифференциацией элементов звуковых данных (допустим, спектральных коэффициентов) по уровню разрешающей способности для кодирования. Следовательно, благодаря психоакустическому анализу 225 можно, например, вывести масштабные коэффициенты (масштабные множители) 225а, описывающие, в частности, релевантность слухового восприятия множества частотных полос масштабных множителей. Например, (относительно) высокие коэффициенты масштабирования могут быть соотнесены с полосами частот масштабных множителей (относительно) высокой психоакустической релевантности, в то время как (относительно) низкие коэффициенты масштабирования могут быть соотнесены с полосами частот масштабных множителей (относительно) низкой психоакустической релевантности.
При спектральной обработке 223 спектральные коэффициенты 222а взвешивают с учетом масштабных множителей 225а. Например, спектральные коэффициенты 222а различных полос масштабных множителей взвешивают с учетом масштабных множителей 225а соответствующих названных полос масштабных множителей. Соответственно, спектральные коэффициенты одной полосы масштабного множителя с высокой психоакустической релевантностью при взвешивании оценивают выше, чем спектральные коэффициенты полос масштабных множителей с более низкой психоакустической релевантностью в частотном представлении со сформированным спектром 223а. Таким образом, к спектральным коэффициентам полос масштабных множителей с более высокой психоакустической релевантностью на стадии квантования/кодирования 224 эффективнее применять более глубокое квантование (с большей степенью разрешения), поскольку они имеют более высокий вес после спектральной обработки 223. Спектральные коэффициенты 222а полос масштабных множителей с более низкой психоакустической релевантностью на стадии квантования/кодирования 224 эффективнее квантовать с меньшей разрешающей способностью в силу их меньшего веса после спектральной обработки 223.
В результате на выходе тракт частотной области 200 генерирует кодированный набор спектральных коэффициентов 214 и кодированную информацию о масштабных коэффициентах 216, которая представляет собой кодированное представление масштабных множителей 225а. Кодированная информация о масштабных коэффициентах 216 по сути составляет данные по формированию искажения (ограничению шума), поскольку описывает масштабирование спектральных коэффициентов 222а в процессе спектральной обработки 223, что точно отображает распределение шума квантования по различным полосам масштабных множителей.
Более подробную информацию можно найти в литературе по так называемому „усовершенствованному кодированию звука" („advanced audio coding" / AAC), затрагивающей кодирование в режиме частотной области аудиофрейма, представленного во временной области.
Кроме того, следует указать на то, что тракт области трансформанты 200, как правило, обрабатывает аудиофреймы с наложением (перекрыванием) по времени.
Преимущественно преобразование из временной области в частотную область 222 включает в себя выполнение преобразования с наложением, такое как модифицированное дискретное косинусное преобразование (МДКП). Отсюда следует, что только примерно N/2 спектральных коэффициентов 222а входит в аудиофрейм, вмещающий N временных отсчетов. В силу этого кодированный набор из N/2 спектральных коэффициентов 214 не достаточен для точной (или приблизительно точной) реконструкции фрейма из N временных отсчетов. Правильнее сказать, что наложение двух последовательных фреймов необходимо для точной (или, по меньшей мере, приблизительно точной) реконструкции представления аудиоконтента во временной области. Другими словами, на стороне декодера, как правило, требуются кодированные наборы спектральных коэффициентов 214 двух последовательных аудиофреймов для компенсации алиасинга (эффекта наложения спектров) в секторе временного наложения двух последовательных фреймов, закодированных в режиме частотной области.
Ниже будет более подробно рассмотрен способ устранения алиасинга на участке перехода от фрейма, закодированного в режиме частотной области, к фрейму, закодированному в режиме ACELP.
1.1.2. Тракт области трансформанты на фиг.2B
Фиг.2B отображает принципиальную блочную схему тракта области трансформанты 230, который может быть введен вместо тракта области трансформанты 120.
Тракт области трансформанты 230, который можно рассматривать как тракт области линейного предсказания с возбуждением, закодированным в трансформанте, принимает на входе представление во временной области 240 аудиофрейма, подлежащего кодированию в режиме области линейного предсказания с возбуждением, закодированным в трансформанте (далее также сокращенно - режим TCX-LPD), где режим TCX-LPD - пример режима трансформанты. Тракт области трансформанты 230 генерирует на выходе кодированный набор спектральных коэффициентов 244 и закодированные параметры области линейного предсказания 246, которые можно рассматривать как информацию о формировании искажения (ограничении шума). Тракт области трансформанты 230 может в качестве опции выполнять предварительную обработку (препроцессинг) 250 с формированием предварительно обработанного варианта 250а представления во временной области 240. Тракт области трансформанты также включает в себя вычислитель параметров области линейного предсказания 251, предназначенный для выведения параметров фильтра области линейного предсказания 251 а из представления во временной области 240. Вычислитель параметров области линейного предсказания 251 предусматривает, например, выполнение корреляционного анализа представления во временной области 240 с выведением параметров фильтра области линейного предсказания. В частности, вычисление параметров области линейного предсказания 251 может осуществляться согласно описанию в документах „3GPP TS 26.090", „3GPP TS 26.190" и „3GPP TS 26.290" из „Проекта партнерства третьего поколения" (3GPP).
Тракт области трансформанты 230 также включает в себя функцию фильтрования на основе кодирования с линейным предсказанием (LPC) 262, при котором представление во временной области 240 или его предобработанная версия 250а проходит фильтрацию с использованием фильтра, задаваемого по параметрами фильтра области линейного предсказания 251а. Таким образом, фильтрованием 262 на основе параметров области линейного предсказания 251а получают отфильтрованный сигнал временной области 262а. После фильтрации сигнал временной области 262а проходит оконное взвешивание 263 с выводом оконно-взвешенного сигнала временной области 263а. Взвешенный сигнал временной области 263а преобразуют в частотное представление путем преобразования из временной области в частотную область 264 с получением набора спектральных коэффициентов 264а. Затем, набор спектральных коэффициентов 264а квантуют и кодируют 265 с получением на выходе кодированного набора спектральных коэффициентов 244.
Тракт области трансформанты 230, кроме того, включает в себя функцию квантования и кодирования 266 параметров области линейного предсказания 251а, генерируя на выходе кодированные параметры области линейного предсказания 246.
Говоря о функциях тракта области трансформанты 230, следует указать, что вычислением параметров области линейного предсказания 251 формируют информацию о фильтре области линейного предсказания 251а, который применяют при фильтровании 262. Прошедший фильтрацию сигнал временной области 262а представляет собой рассчитанный по форме спектра вариант представления во временной области 240 или его предобработанную версию 250а. Оценивая в целом, можно сказать, что фильтрованием 262 выполняется формирование искажения, при котором элементы представления во временной области 240, более важные для ясности восприятия звукового сигнала, представленного во временной области 240, имеют больший вес, чем элементы представления во временной области 240, менее важные для разборчивости звукоданных, представленных во временной области 240. Следовательно, спектральные коэффициенты 264а компонент спектра представления во временной области 240, более значимые для восприятия аудиоконтента, выделены относительно спектральных коэффициентов 264а компонент спектра, менее значимых для восприятия аудиоконтента.
Отсюда следует, что спектральные коэффициенты, относящиеся к более значимьм компонентам спектра временного представления аудиосигнала 240, эффективнее квантовать с большей глубиной квантования, чем спектральные коэффициенты менее существенных компонент спектра. Тем самым, шум квантования на стадии квантования/кодирования 250 формируется так, что более важные (для восприятия аудиоконтента) спектральные компоненты слабее подвергаются воздействию шумов квантования, чем менее важные (для восприятия аудиоконтента) спектральные компоненты.
Таким образом, кодированные параметры области линейного предсказания 246 можно рассматривать как информацию о формировании искажения, которая описывает в закодированной форме процедуру фильтрования 262 при формировании шума квантования.
В дополнение к этому рекомендуется для время-частотного преобразования 264 применять метод перекрывания. В частности, для время-частотного преобразования 264 может использоваться модифицированное дискретное косинусное преобразование (МДКП). Отсюда следует, что количество кодированных спектральных коэффициентов 244 на выходе тракта области трансформанты меньше количества временных отсчетов аудиофрейма. Допустим, для аудиофрейма, состоящего из N временных отсчетов может быть сгенерирован кодированный набор из N/2 спектральных коэффициентов 244. Следовательно, точное (или приблизительно точное) воссоздание N временных отсчетов звукового фрейма не возможно на базе кодированного набора из N/2 спектральных коэффициентов 244, относящихся к данному фрейму. Скорее, наложение и сложение реконструируемых временных представлений двух последовательных звуковых фреймов требуется для нейтрализации алиасинга во временной области, возникающего из-за того, что меньшее число, например, N/2, спектральных коэффициентов соотносится с аудиофреймом, содержащим N временных отсчетов. Таким образом, как правило, на стороне декодера требуется перекрывание - двух последовательных аудиофреймов в их представлении во временной области, закодированных в режиме TCX-LPD, чтобы нейтрализовать артефакты алиасинга на участке временного наложения между упомянутыми двумя последовательными фреймами.
Однако, механизмы устранения алиасинга на переходе между аудиофреймом, закодированным в режиме TCX-LPD, и следующим за ним аудиофреймом, закодированным в режиме ACELP, будут описаны ниже.
1.1.3. Тракт области трансформанты на фиг.2C
Фиг.2C отображает принципиальную блочную схему тракта области трансформанты 260, который в некоторых конструктивных решениях может быть введен вместо тракта области трансформанты 120 и который можно рассматривать как тракт области линейного предсказания с возбуждением, закодированным в трансформанте.
Тракт области трансформанты 260 принимает на входе представление во временной области аудиофрейма, подлежащего кодированию в режиме TCX-LPD, и на его основе генерирует кодированный набор спектральных коэффициентов 274 и закодированные параметры области линейного предсказания 276, которые можно рассматривать как информацию о формировании искажения. Тракт области трансформанты 260 может включать в себя в качестве опции препроцессинг 280, который может быть идентичным предварительной обработке 250 и генерировать предобработанную версию представления во временной области 270. Тракт области трансформанты 260 также включает в себя функцию вычисления параметров области линейного предсказания 281, которая может быть идентична вычислению параметров области линейного предсказания 251 и с помощью которой рассчитывают параметры фильтра области линейного предсказания 281а. Тракт области трансформанты 260, кроме того, выполнен с возможностью преобразования из области линейного предсказания в спектральную область 282, которое заключается в приеме параметров фильтра области линейного предсказания 281а и генерации на их основе представления в спектральной области 282а параметров фильтра области линейного предсказания. Тракт области трансформанты 260 также выполняет оконное взвешивание 283 путем ввода представления аудиофрейма во временной области 270 или его предобработанной интерпретации 280а и вывода оконно-взвешенного сигнала временной области 283а для преобразования из временной области в частотную область 284. Время-частотное преобразование 284 дает набор спектральных коэффициентов 284а. Набор спектральных коэффициентов 284 проходит спектральную обработку 285. При этом, например, каждый из спектральных коэффициентов 284а масштабируется по соответствующему значению спектрального представления 282а параметра фильтра области линейного предсказания. Таким образом, на выходе получают ряд масштабированных (т.е. рассчитанных по форме спектра) спектральных коэффициентов 285а. Набор масштабированных спектральных коэффициентов 285а квантуют и кодируют 286 с выведением кодированного набора спектральных коэффициентов 274. При этом, спектральным коэффициентам 284а, которым соответствует относительно большое значение спектрального представления 282а, при спектральной обработке 285 присваивается сравнительно высокий вес, в то, время как спектральным коэффициентам 284а, которым соответствует относительно маленькое значение спектрального представления 282а, при спектральной обработке 285 присваивается сравнительно низкий вес. Таким образом, в процессе выведения спектральных коэффициентов 285а спектральным коэффициентам 284а присваиваются различные веса с учетом значений спектрального представления 282а.
Тракт области трансформанты 260 формирует спектр аналогично тракту области трансформанты 230, несмотря на то, что формирование спектра выполняется спектральным процессором 285, а не банком фильтров 262.
Здесь также параметры фильтра области линейного предсказания 281 а квантуют и кодируют 288, получая на выходе кодированные параметры области линейного предсказания 276. Кодированные параметры области линейного предсказания 276 описывают в кодированной форме процедуру формирования искажения, которая осуществляется при спектральной обработке 285.
Вновь необходимо указать на то, время-частотное преобразование 284 предпочтительно выполняют, используя преобразование с перекрытием, когда кодированный набор спектральных коэффициентов 274 содержит меньшее число, например, N/2, спектральных коэффициентов относительно числа, например, N, временных отсчетов аудиофрейма. Из этого следует, что полноценное (или приближенное к полноценному) восстановление аудиофрейма, закодированного в режиме TCX-LPD, невозможно на базе одного кодированного набора спектральных коэффициентов 274. Рекомендуется, чтобы на стороне декодера аудиосигнала выполнялось сложение наложением временных представлений двух последовательных аудиофреймов, закодированных в режиме TCX-LPD, для нейтрализации артефактов алиасинга.
При этом, концепция компенсации артефактов алиасинга на переходе от аудиофрейма, закодированного в режиме TCX-LPD к аудиофрейму, закодированному в режиме ACELP, будет представлена далее.
1.2. Детализация тракта области линейного предсказания с алгебраическим кодовым возбуждением
Рассмотрим подробнее тракт области линейного предсказания с алгебраическим кодовым возбуждением 140.
Тракт ACELP 140 выполнен с возможностью вычисления параметров области линейного предсказания 150, которое может быть идентичным вычислению параметров области линейного предсказания 251 и в некоторых случаях вычислению параметров области линейного предсказания 281. Тракт ACELP 140 также выполнен с возможностью вычисления возбуждения ACELP 152 с выведением информации о возбуждении ACELP 152 на основе представления во временной области 142 фрагмента аудиоданных, подлежащего кодированию в режиме ACELP, и на основе параметров области линейного предсказания 150а (которые могут быть параметрами фильтра области линейного предсказания), полученных в результате вычисления параметров области линейного предсказания 150. Тракт ACELP 140 также выполнен с возможностью кодирования 154 данных возбуждения ACELP 152 с формированием информации о алгебраическом кодовом возбуждении 144. Кроме того, тракт ACELP 140 предусматривает квантование и кодирование 156 информации о параметрах области линейного предсказания 150а с выведением кодированной информации о параметрах области линейного предсказания 146. Следует отметить, что тракт ACELP может выполнять операции, подобные или даже аналогичные операциям кодирования ACELP, описанным, например, в документах „3GPP TS 26.090", „3GPP TS 26.190" и „3GPP TS 26.290" „Партнерского проекта третьего поколения" (Third Generation Partnership Project). Тем не менее, технические решения по формированию информации об алгебраическом кодовом возбуждении 144 и информации о параметрах области линейного предсказания 146 на базе представления во временной области 142 могут основываться и на других концепциях.
1.3. Детализация контура формирования антиалиасинговой информации
Рассмотрим некоторые детали контура подготовки антиалиасинговой информации 160, формирующего информацию по устранению алиасинга 164.
Следует обратить внимание на то, что преимущественно антиалиасинговая информация избирательно формируется для перехода от фрагмента аудиоконтента, закодированного в режиме трансформанты (например, в режиме частотной области или в режиме TCX-LPD), к следующему фрагменту аудиоконтента, закодированному в режиме ACELP, в то время как на переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к последующему фрагменту аудиоконтента, также закодированному в режиме трансформанты, антиалиасинговая информация не требуется. Антиалиасинговая информация 164 может, например, содержать в закодированном виде сигнал, направленный на нейтрализацию артефактов алиасинга, возникающих в представлении во временной области фрагмента звуковых данных, сгенерированного при одиночном декодировании (без сложения наложением с представлением во временной области последующего фрагмента аудиоконтента, закодированного в режиме трансформанты) фрагмента аудиоконтента, сформированного на базе набора спектральных коэффициентов 124 и данных о формировании искажения 126.
Как пояснялось выше, представление во временной области, полученное декодированием одиночного аудиофрейма на базе набора спектральных коэффициентов 124 и на базе данных о формировании искажения 126, содержит алиасинг во временной области, что вызвано применением перекрывания при преобразовании из временной области в частотную область, а также в преобразователе из частотной области во временную область аудиодекодера.
Контур формирования антиалиасинговой информации 160 характеризуется, например, возможностью вычисления результатов синтеза 170, где результирующий синтезированный сигнал 170а описывает результат синтеза, который будет также получен в декодере аудиосигнала после обособленного декодирования текущего фрагмента аудиоконтента на базе набора спектральных коэффициентов 124 и информации о формировании искажения 126. Результирующий сигнал синтеза 170а может быть введен в вычислитель ошибки 172, в который также может поступать входное представление 110 звуковых данных. Вычислитель ошибки 172 может сравнивать результирующий сигнал синтеза 170а с входным представлением 110 звукоданных и генерировать сигнал ошибки 172а. Сигнал ошибки 172а описывает разницу между результатом синтеза, полученным аудиодекодером, и входным представлением 110 звукоданных. Поскольку основной взнос в сигнал ошибки 172, как правило, определяется алиасингом во временной области, сигнал ошибки 172 хорошо подходит для нейтрализации алиасинга на стороне декодера. Контур формирования антиалиасинговой информации 160 также имеет в своем составе кодер ошибки 174, в котором сигнал ошибки 172а кодируется в виде информации по устранению алиасинга 164. При этом кодирование сигнала ошибки 172а факультативно может быть адаптировано к ожидаемьм характеристикам сигнала ошибки 172а с выведением антиалиасинговой информации 164, которая описывала бы сигнал ошибки 172а эффективно по битрейту. Благодаря этому антиалиасинговая информация 164 обеспечивает возможность реконструкции на стороне декодера сигнала компенсации алиасинга, предназначенного для ослабления или даже устранения артефактов алиасинга при переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к следующему фрагменту аудиоконтента, закодированному в режиме ACELP.
Для кодирования ошибки 174 применяют различные алгоритмы. Например, к сигналу ошибки 172а может быть применено кодирование в частотной области (которое включает в себя преобразование из временной области в частотную, выведение спектральных величин, квантование и кодирование этих спектральных величин). Используют также различные приемы формирования (ограничения) шума квантования.
Кроме того, разнообразные методы аудиокодирования могут быть задействованы для кодирования сигнала ошибки 172а.
Более того, при расчете ошибки 172 можно учитывать дополнительные сигналы устранения ошибки, которые могут быть сгенерированы в аудиодекодере.
2. Декодер аудиосигнала на фиг.3
На очереди рассмотрение декодера аудиосигнала, предназначенного для приема кодированного представления аудиоконтента 112 от кодера аудиосигнала 100 и декодирования принятого кодированного представления аудиоконтента. Фиг.3 отображает принципиальную блочную схему реализации такого аудиодекодера 300 в соответствии с настоящим изобретением.
Аудиодекодер 300 принимает кодированное представление 310 аудиоконтента и на его основе формирует декодированное представление 312 этого аудиоконтента.
Аудиодекодер 300 имеет в своем составе тракт области трансформанты 320, предназначенный для приема набора спектральных коэффициентов 322 и информации о формирования искажения 324. Тракт области трансформанты 320 на базе набора спектральных коэффициентов 322 и информации о формирования искажения 324 выводит представление во временной области 326 фрагмента аудиоконтента, закодированного в режиме трансформанты (например, в режиме частотной области или в режиме области линейного предсказания с возбуждением, закодированным в трансформанте). Аудиодекодер 300 также имеет в своем составе тракт области линейного предсказания с алгебраическим кодовым возбужден (тракт ACELP) 340. Тракт ACELP 340 предназначен для приема информации о алгебраических кодах возбуждения 342 и информацию о параметрах области линейного предсказания 344. Тракт ACELP 340 формирует представление во временной области 346 фрагмента аудиоконтента, закодированного в области линейного предсказания с возбуждением алгебраическими кодами на базе информации о алгебраических кодах возбуждения 342 и информации о параметрах области линейного предсказания 344.
Далее, аудиодекодер 300 имеет в своем составе активатор („провайдер") антиалиасингового сигнала 360, который принимает антиалиасинговую информацию 362 и на ее основе генерирует сигнал компенсации алиасинга 364.
Аудиодекодер 300, кроме того, имеет в своем составе, например, комбинатор 380, выполняющий сведение представления во временной области 326 фрагмента аудиоконтента, закодированного в режиме трансформанты, и представления во временной области 346 фрагмента аудиоконтента, закодированного в режиме ACELP, с выводом декодированного представления 312 звуковых данных.
Тракт области трансформанты 320 включает в себя преобразователь из частотной области во временную область (частотно-временной преобразователь) 330, который выполняет частотно-временное преобразование 332 и оконное взвешивание 334 с выведением из набора спектральных коэффициентов 322 или их предобработанного варианта оконно-взвешенного представления аудиоконтента во временнбй области. Частотно-временной преобразователь 330 выполнен с возможностью приложения заданного асимметричного окна синтеза для оконного взвешивания текущего фрагмента аудиоконтента, закодированного в режиме трансформанты, и следующего за фрагментом аудиоконтента, закодированным в режиме трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме ACELP.
Аудио декодер (или, точнее, активатор антиалиасингового сигнала 360) выполнен с возможностью избирательной инициации антиалиасингового сигнала 364 (сигнала компенсации наложения спектров), исходя из антиалиасинговой информации 362, когда текущий фрагмент аудиоконтента (который закодирован в режиме трансформанты) сменяется фрагментом аудиоконтента, закодированным в режиме ACELP.
Аудио декодер 300 предусматривает формирование декодированного представления 312 звуковых данных, фрагменты которых закодированы в разных режимах, в частности, в режиме трансформанты и в режиме ACELP. Фрагмент (например, фрейм или субфрейм) аудиоконтента, закодированный в режиме трансформанты, тракт области трансформанты 320 представляет во временной области 326. Однако, представление во временной области 326 фрейма аудиоконтента, закодированного в режиме трансформанты, может содержать алиасинг во временной области, так как в частотно-временном преобразователе 330 для формирования представления во временной области 326, как правило, используют обратное преобразование с перекрыванием. При обратном преобразовании с перекрыванием, например, при обратном модифицированном дискретном косинусном преобразовании (ОМДКП), набор спектральных коэффициентов 322 может быть перенесен на временные, отсчеты фрейма, где количество временных отсчетов фрейма может превышать количество спектральных коэффициентов 322, соотнесенных с данным фреймом. Предположим, с аудиофреймом могут быть соотнесены N/2 спектральных коэффициентов, а в тракте области трансформанты 320 этот же фрейм может быть разбит на N временных отсчетов. Следовательно, путем сложения наложением (например, в комбинаторе 380) (сдвинутых во времени) представлений во временной области, полученных для двух последовательных фреймов, закодированных в режиме трансформанты, обеспечивается существенная компенсация алиасинга во временном представлении.
Между тем, нейтрализация алиасинга представляет большую сложность при переходе от сегмента аудиоданных (например, фрейма или субфрейма), закодированного в режиме трансформанты, к следующему за ним сегменту аудиоданных, закодированному в режиме ACELP. Преимущественно при этом представление во временной области фрейма или подфрейма, закодированного в режиме трансформанты, расширяют во времени до интервала (обычно, в форме блока), в котором (ненулевые) временные отсчеты заполняют данными тракта ACELP. Далее, фрагмент аудиоконтента, закодированный в режиме трансформанты и предшествующий фрагменту аудиоконтента, закодированному в режиме ACELP, обычно содержит некоторую степень временного алиасинга, который, однако, не может быть устранен за счет временных отсчетов, сгенерированных трактом ACELP для фрагмента аудиоконтента, закодированного в режиме ACELP (в то время как алиасинг во временной области должен в значительной степени быть компенсирован за счет представления во временной области, сгенерированного ветвью области трансформанты, если следующий фрагмент аудиоконтента был закодирован в режиме трансформанты).
Между тем, алиасинг на переходе от фрагмента аудиоконтента, закодированного в режиме трансформанты, к последующему фрагменту аудиоконтента, закодированному в режиме ACELP, ослабляется или даже нейтрализуется антиалиасинговым сигналом 364, сгенерированным активатором антиалиасингового сигнала 360. Для этого активатор антиалиасингового сигнала 360 оценивает информацию по устранению алиасинга и, исходя из нее, генерирует сигнал удаления алиасинга во временной области. Антиалиасинговый сигнал 364 добавляется, например, к правой половине (или к более короткой правой части) представления во временной области, например, N временных отсчетов сгенерированных для фрагмента аудиоконтента, закодированного в режиме трансформанты трактом области трансформанты, чтобы в результате редуцировать или даже купировать временной алиасинг. Антиалиасинговый сигнал 364 может быть добавлен как к отрезку времени, в котором (ненулевое) представление во временной области 346 фрагмента аудиоконтента, закодированного в режиме ACELP, не перекрывает представление во временной области аудиоконтента, закодированного в режиме трансформанты, так и к отрезку времени, в котором (ненулевое) представление во временной области фрагмента аудиоконтента, закодированного в режиме ACELP, перекрывает представление во временной области предыдущего фрагмента аудиоконтента, закодированного в режиме трансформанты. Благодаря этому достигается плавный переход (без артефактов в виде „щелчка") между фрагментом представления во временной области, закодированным в режиме трансформанты, и следующим за ним фрагментом аудиоконтента, закодированным в режиме ACELP, Использование антиалиасингового сигнала позволяет ослабить или даже нейтрализовать артефакты алиасинга.
Таким образом, декодер аудиосигнала 300 характеризуется возможностью эффективной обработки последовательности фрагментов (например, фреймов) звуковых данных, закодированных в режиме трансформанты. В таком случае алиасинг во временной области устраняется сложением и наложением представлений во временной области (например, N временных отсчетов) последовательного ряда (перекрывающихся по времени) фреймов, закодированных в режиме трансформанты. Благодаря этому плавность переходов достигается без какого-либо дополнительного перекрывания. Так, путем оценивания N/2 спектральных коэффициентов аудиофрейма и применения 50%-ного временного перекрывания фреймов может быть достигнута критическая (адаптивная) дискретизация. Для такой последовательности аудиофреймов, закодированных в режиме трансформанты, возможна очень высокая эффективность кодирования с одновременным предотвращением блокирующих артефактов.
Кроме того, при использовании одно и того же заданного асимметричного окна синтеза независимо от того, следует ли за текущим фрагментом аудиоконтента, закодированным в режиме трансформанты, фрагмент аудиоконтента, закодированный в режиме трансформанты, или фрагмент аудиоконтента, закодированный в режиме ACELP, задержку можно сохранять достаточно непродолжительной.
Более того, благодаря инициации антиалиасингового сигнала, генерируемого на основе антиалиасинговой информации, возможно поддержание высокого качества звука на переходах между фрагментом аудиоконтента, закодированным в режиме трансформанты, и следующим за ним фрагментом аудиоконтента, закодированным в режиме ACELP, даже без применения специально рассчитываемого окна синтеза.
В силу сказанного, декодер аудиосигнала 300 обеспечивает приемлемый компромисс между эффективностью кодирования, задержкой при кодировании и акустическим качеством.
2.1. Детализация тракта области трансформанты [аудиодекодера]
Далее, на примерах аппаратных версий более детально будет рассмотрен тракт области трансформанты 320.
2.1.1. Тракт области трансформанты на фиг.4A
Фиг.4A отображает принципиальную блочную схему тракта области трансформанты 400, который может быть заменен трактом области трансформанты 320 в некоторых реализациях заявляемого изобретения и который рассматривается как тракт частотной области.
Тракт области трансформанты 400 предназначен для приема кодированного набора спектральных коэффициентов 412 и кодированной информации о масштабных множителях (коэффициентах) 414. Тракт области трансформанты 400 предназначен для формирования на выходе представления во временной области 416 фрагмента аудиоконтента, закодированного в режиме частотной области.
Тракт области трансформанты 400 выполняет декодирование и обратное квантование 420, заключающееся в приеме кодированного набора спектральных коэффициентов 412 и формировании на его основе декодированного и обратно квантованного набора спектральных коэффициентов 420а. Тракт области трансформанты 400 также выполняет декодирование и обратное квантование 421, заключающееся в приеме кодированной информации о коэффициентах масштабирования 414 и компоновке на ее основе декодированной и обратно квантованной информации о коэффициентах масштабирования 421а.
Тракт области трансформанты 400, кроме того, выполняет спектральную обработку 422, которая может включать в себя, например, масштабирование декодированных и обратно квантованных спектральных коэффициентов 420а в соответствии с частотными полосами масштабных множителей. В результате формируется масштабированный (т.е. рассчитанный по форме спектра) набор спектральных коэффициентов 422а. В процессе спектральной обработки 422 (сравнительно) небольшой коэффициент масштабирования может быть применен к полосам масштабных множителей, имеющим сравнительно высокую психоакустическую релевантность, в то время как (сравнительно) большой коэффициент масштабирования применяют к спектральным коэффициентам полос масштабных множителей, имеющим относительно низкую психоакустическую релевантность. В силу этого для спектральных коэффициентов полос масштабных множителей, имеющих относительно высокую психоакустическую релевантность, эффективный шум квантования меньше по сравнению с эффективным шумом квантования для спектральных коэффициентов полос масштабных множителей, имеющих относительно низкую психоакустическую релевантность. В процессе спектральной обработке спектральные коэффициенты 420а могут быть умножены на соответствующие масштабные множители с получением масштабированных спектральных коэффициентов 422а.
Тракт области трансформанты 400 предусматривает также преобразование из частотной области во временную область (частотно-временное преобразование) 423, при котором на базе принятых масштабированных спектральных коэффициентов 422а генерируется сигнал временной области 423а. Например, частотно-временное преобразование может представлять собой обратное преобразование с перекрыванием, такое как обратное модифицированное дискретное косинусное преобразование. Таким образом, в результате частотно-временного преобразования 423 может быть сформировано, например, представление во временной области 423а N временных отсчетов на базе N/2 масштабированных (со сформированным спектром) спектральных коэффициентов 422а. Тракт области трансформанты 400 также может выполнять оконное взвешивание 424 сигнала временной области 423а. В частности, как говорилось ранее и как более подробно будет рассмотрено позже, к сигналу временной области 423а может быть приложено заданное асимметричное окно синтеза с получением производного оконно-взвешенного сигнала временной области 424а. В качестве опции к оконно-взвешенному сигналу временной области 424а может быть применен постпроцессинг 425с формированием представления во временной области 426 фрагмента аудиоконтента, закодированного в режиме частотной области.
Таким образом, тракт области трансформанты 400, который можно рассматривать как тракт частотной области, предназначен для формирования представления во временной области 416 фрагмента аудиоконтента, закодированного в режиме частотной области, с формированием шума квантования по масштабным коэффициентам, которое используется на этапе спектральной обработки 422. Представление во временной области N временных отсчетов формируется преимущественно за счет ряда из N/2 спектральных коэффициентов, при этом представление во временной области 416 содержит алиасинг вследствие того, что количество временных отсчетов представления во временной области 416 (для данного фрейма) превышает (например, с коэффициентом 2, или иным коэффициентом) количество спектральных коэффициентов в кодированном наборе 412 (для данного фрейма).
Тем не менее, как обсуждалось выше, алиасинг во временной области снижают или устраняют операцией сложения наложением последовательных фрагментов аудиоконтента, закодированных в частотной области, или добавлением антиалиасингового сигнала 364 в случае перехода между фрагментом аудиоконтента, закодированным в режиме частотной области, и фрагментом аудиоконтента, закодированном в режиме ACELP.
2.1.2. Тракт области трансформанты на фиг.4B
Фиг.4B отображает принципиальную блочную схему тракта области линейного предсказания с возбуждением, закодированным в трансформанте (TCX-LPD) 430, который является трактом области трансформанты и который может быть введен вместо тракта области трансформанты 320.
Тракт TCX-LPD 430 принимает кодированный набор спектральных коэффициентов 442 и закодированные параметры области линейного предсказания 444, которые можно рассматривать как информацию о формировании искажения. Тракт TCX-LPD 430 предназначен для формирования представления во временной области 446 фрагмента аудиоконтента, закодированного в режиме TCX-LPD, на базе кодированного набора спектральных коэффициентов 442 и закодированных параметров области линейного предсказания 444.
Тракт TCX-LPD 430 выполняет функции декодирования и обратного квантования 450 кодированного набора спектральных коэффициентов 442 с получением в результате декодированного и обратно квантованного набора спектральных коэффициентов 450а. Далее, декодированные и обратно квантованные спектральные коэффициенты 450а проходят процедуру преобразования из частотной области во временную область 451с формированием сигнала временной области 451а. Частотно-временное преобразование 451 может представлять собой обратное преобразование с перекрытием декодированных и обратно квантованных спектральных коэффициентов 450а с получением результирующего сигнала временной области 451а. В частности, для формирования из декодированных и обратно квантованных спектральных коэффициентов 450а сигнала временной области 451а может быть применено обратное модифицированное дискретное косинусное преобразование. Количество (например, N) временных отсчетов представления во временной области 451а может быть больше, чем количество (например, N/2) спектральных коэффициентов 450а на входе частотно-временного преобразования, если преобразование выполняется с перекрыванием, когда, например, N, временных отсчетов сигнала временной области 451а может быть введено на покрытие N/2 спектральных коэффициентов 450а.
Тракт TCX-LPD 430 также выполняет функцию оконного взвешивания 452 с использованием оконной функции синтеза сигнала временной области 451 а и с получением на выходе оконно-взвешенного сигнала временной области 452а. В частности, при оконном взвешивании 452 для формирования оконно-взвешенного сигнала временной области 452а как взвешенного варианта сигнала временной области 451а может быть применено заданное асимметричное окно синтеза. Тракт TCX-LPD 430, кроме того, выполняет функцию декодирования и обратного квантования 453 закодированных параметров области линейного предсказания 444 с извлечением декодированной информации о параметрах области линейного предсказания 453а. Декодированная информация о параметрах области линейного предсказания может содержать (или описывать), в том числе, коэффициенты пропускания фильтра линейного предсказания. Декодирование коэффициентов фильтрации (коэффициентов пропускания фильтра) могут осуществляться, в частности, согласно спецификациям „Партнерского проекта третьего поколения" (Third Generation Partnership Project) "3GPP TS 26.090", "3GPP TS 26.190" и "3GPP TS 26.290". Соответственно, коэффициенты фильтрации 453а могут быть использованы при фильтровании оконно-взвешенного сигнала временной области 452а на основе линейно-предиктивного кодирования 454. Формулируя иначе, коэффициенты пропускания фильтра (например, фильтра конечной импульсной характеристики), который применен для формирования отфильтрованного сигнала временной области 454а на основе оконно-взвешенного сигнала временной области 452а, могут быть приведены в соответствие с декодированной информацией о параметрах области линейного предсказания 453а, описывающей указанные коэффициенты фильтрации. Таким образом, оконно-взвешенный сигнал временной области 452а может служить стимулом синтеза сигнала на базе кодирования с линейным предсказанием 454 с настройкой по коэффициентам фильтрации 453а.
В качестве опции может быть введен постпроцессинг 455 для оформления представления во временной области 446 фрагмента аудиоконтента, закодированного в режиме TCX-LPD на основе прошедшего фильтрацию сигнала временной области 454а.
Итак, исходя из сказанного, фильтрование 454, описываемое закодированными параметрами области линейного предсказания 444, применяют для формирования представления во временной области 446 фрагмента аудиоконтента, закодированного в режиме TCX-LPD, на базе стимулирующего фильтр сигнала 452а, описываемого кодированным набором спектральных коэффициентов 442. Следовательно, хорошая эффективность кодирования достигается в отношении таких сигналов, которые легко предсказуемы, то есть хорошо адаптированы к фильтру линейного предсказания. Задающее воздействие для таких сигналов может быть эффективно закодировано с помощью набора спектральных коэффициентов 442, в то время как другие корреляционные характеристики сигнала могут быть учтены при фильтровании 454, исходя из коэффициентов пропускания фильтра линейного предсказания 453а.
Тем не менее, следует учитывать, что при частотно-временном преобразовании в представление во временной области 446 за счет операции перекрывания 451 вносится временной алиасинг. Алиасинг во временной области может быть устранен наложением со сложением (сдвинутых во времени) представлений во временной области 446 последовательных фрагментов аудиоконтента, закодированных в режиме TCX-LPD. Временной алиасинг может быть также уменьшен или устранен посредством антиалиасингового сигнала 364 при переходе между фрагментами аудиоконтента, закодированными в разных режимах.
2.1.3. Тракт области трансформанты на фиг.4C
Фиг.4C отображает принципиальную блочную схему тракта области трансформанты 460, который в некоторых реализациях заявляемого изобретения может быть введен вместо тракта области трансформанты 320.
Тракт области трансформанты 460 представляет собой тракт области линейного предсказания с возбуждением, закодированным в трансформанте (тракт TCX-LPD), использующий формирование искажения в частотной области. Тракт TCX-LPD 460 принимает кодированный набор спектральных коэффициентов 472 и закодированные параметры области линейного предсказания 474, которые можно рассматривать как информацию о формировании искажения. Тракт TCX-LPD 460 предназначен для формирования представления во временной области 476 фрагмента аудиоконтента, закодированного в режиме TCX-LPD, на базе кодированного набора спектральных коэффициентов 472 и на базе закодированных параметров области линейного предсказания 472.
Тракт TCX-LPD 460 выполняет декодирование/обратное квантование 480, при котором на основе принятого кодированного набора спектральных коэффициентов 472 генерирует декодированные и обратно-квантованные спектральные коэффициенты 480а. Тракт TCX-LPD 460 выполняет также декодирование и обратное квантование 481, при котором на основе принятых кодированных параметров области линейного предсказания 472 генерирует декодированные и обратно-квантованные параметры области линейного предсказания 481 а, в частности, коэффициенты пропускания фильтра линейно-предиктивного кодирования (LPC-фильтра). Тракт TCX-LPD 460, наряду с этим, выполняет преобразование из области линейного предсказания в спектральную область (трансформанту) 482, в результате которого на основе принятых декодированных и обратно-квантованных параметров области линейного предсказания 481 формирует спектральное представление 482а параметров области линейного предсказания 481а.
Например, спектральное представление 482а может быть спектральным представлением характеристик фильтра, описанных параметрами области линейного предсказания 481а. Далее, тракт TCX-LPD 460 выполняет спектральную обработку 483, в процессе которой масштабирует спектральные коэффициенты 480а, исходя из спектрального представления 482а параметров области линейного предсказания 481, генерируя в результате набор масштабированных спектральных коэффициентов 483а. Предположим, каждый из спектральных коэффициентов 480а умножается на масштабный коэффициент (множитель), заданный в соответствии с или в зависимости от одного или более спектральных коэффициентов спектрального представления 482а. Благодаря этому вес спектральных коэффициентов 480а эффективно определяется спектральной характеристикой фильтра линейно-предиктивного кодирования, который описывается параметрами области линейного предсказания 472. Скажем, спектральные коэффициенты 480а частот, входящих в достаточно широкий диапазон частотных характеристик фильтра линейного предсказания, при спектральной обработке 483 можно масштабировать с небольшим масштабным коэффициентом, в силу чего связанный с этими спектральными коэффициентами 480а шум квантования будет снижен. Напротив, спектральные коэффициенты 480а частот, входящих в сравнительно узкий диапазон частотных характеристик линейно-предиктивного фильтра, описанного кодированными параметрами области линейного предсказания 472, при спектральной обработке 483 можно масштабировать с относительно высоким масштабным коэффициентом, в силу чего эффективный шум квантования таких спектральных коэффициентов 480а будет некоторьм образом повышен. Таким образом, спектральная обработка 483 эффективно содействует формированию шума квантования в соответствии с закодированными параметрами области линейного предсказания 472.
Масштабированные спектральные коэффициенты 483а далее проходят преобразование из частотной области во временную область 484 для формирования сигнала временной области 484а. Такое частотно-временное преобразование 484 может включать в себя, допустим, преобразование с перекрытием, например, обратное модифицированное дискретное косинусное преобразование. Соответственно, результатом такого частотно-временного преобразования на базе масштабированных (т.е. рассчитанных по форме спектра) спектральных коэффициентов 483а должно стать представление во временной области 484а. Следует учитывать, что количество временных отсчетов представления во временной области 484а может превышать количество масштабированных спектральных коэффициентов 483а, задействуемых в частотно-временном преобразовании. Следовательно, сигнал временной области 484а включает в себя компоненты временного алиасинга, нейтрализуемые наложением со сложением представлений во временной области 476 последовательных фрагментов (например, фреймов или подфреймов) аудиоконтента, закодированных в режиме TCX-LPD, или добавлением антиалиасингового сигнала 364 в случае перехода между фрагментами аудиоконтента, закодированными в разных режимах.
Тракт TCX-LPD 460, наряду с названным, выполняет оконное взвешивание 485 сигнала временной области 484а, генерируя оконно-взвешенный сигнал временной области 485а. Как будет рассмотрено далее, в некоторых схемотехнических версиях представленного изобретения при оконном взвешивании 485 может быть применено предварительно рассчитанное (заданное) асимметричное окно синтеза.
По усмотрению пользователя для формирования из оконно-взвешенного сигнала временной области 485а представления во временной области 476 в схему может быть введен постпроцессинг 486.
Итак, тракт TCX-LPD 460 характеризуется возможностью выполнения основной функции - спектральной обработки 483, в процессе которой по декодированным и обратно-квантованным спектральным коэффициентам 480а формируют искажение (ограничение шума), которое корректируют в зависимости от параметров области линейного предсказания. Затем, на базе масштабированных, ограниченных по шуму (со сформированным искажением) спектральных коэффициентов 483а после частотно-временного преобразования 484 и оконного взвешивания 485, выполняемых преимущественно с использованием перекрывания, которое вносит определенную степень алиасинга, формируют оконно-взвешенный сигнал во временной области 485а.
2.2. Детализация тракта ACELP
Дальше, более подробно будет рассмотрен тракт ACELP 340.
Важно, что тракт ACELP 340 выполняет функции, обратные функциям тракта ACELP 140. Тракт ACELP 340 выполняет декодирование 350 данных алгебраического кодового возбуждения 342. В процессе декодирования 350 извлекают декодированную информацию о алгебраических кодах возбуждения 350а, которая затем передается для вычисления сигнала возбуждения и последующей обработки (постпроцессинга) 351, после которых формируется сигнал возбуждения ACELP 351 а. Тракт ACELP выполняет также декодирование 352 параметров области линейного предсказания. В процессе декодирования 352 из принятой информации о параметрах области линейного предсказания 344 выводят параметры области линейного предсказания 352а, в том числе, коэффициенты пропускания фильтра линейного предсказания (фильтра LPC). Тракт ACELP осуществляет также синтезирующее фильтрование 353 сигнала возбуждения 351a, исходя из параметров области линейного предсказания 352а. Синтезированный сигнал временной области 353а как результат синтезирующего фильтрования 353 факультативно может пройти постпроцессинг 354 с формированием представления во временной области 346 фрагмента аудиоконтента, закодированного в режиме ACELP.
Тракт ACELP предназначен для формирования представления во временной области ограниченного во времени фрагмента аудиоконтента, закодированного в режиме ACELP. Например, представление во временной области 346 может самостоятельно отображать фрагмент аудиоданных в виде сигнала во временной области. Другими словами, представление во временной области 346 может не содержать алиасинг во временной области и может быть ограничено блочным окном. Следовательно, представление во временной области 346 может быть достаточным для реконструкции аудиосигнала четко разграниченного временного блока (с блочной формой окна), хотя необходимо предусматривать возможность возникновения блокирующих артефактов на границах такого блока.
Далее обсудим детали.
2.3. Детализация активатора антиалиасингового сигнала
Рассмотрим активатор антиалиасингового сигнала 360 подробнее. Активатор („провайдер") антиалиасингового сигнала 360 принимает информацию по устранению алиасинга (антиалиасинговую информацию) 362 и декодирует 370 ее, извлекая декодированную антиалиасинговую информацию 370а. На основе декодированной антиалиасинговой информации 370а активатор антиалиасингового сигнала 360 реконструирует 372 антиалиасинговый сигнал 364.
Как пояснялось ранее, информация по нейтрализации алиасинга 362 может быть закодирована в различных формах. Например, антиалиасинговая информация 362 может быть закодирована в частотной области или в линейно-предиктивной области. Следовательно, для восстановлении 372 сигнала, компенсирующего алиасинг, применяют разные алгоритмы формирования шума квантования. В некоторых случаях для реконструкции антиалиасингового сигнала 364 могут быть применены масштабные множители (коэффициенты), относящиеся к фрагменту аудиоконтента, закодированному в режиме частотной области. В других случаях для восстановлении 372 сигнала компенсации алиасинга 364 могут быть задействованы параметры области линейного предсказания (например, коэффициенты пропускания линейно-предиктивного фильтра). Вместо этого, или вместе с этим, в закодированные данные по нейтрализации алиасинга 362 может быть включена информация о формировании искажения, например, в дополнение к представлению в частотной области. Более того, при реконструкции 372 антиалиасингового сигнала 364 в качестве опции может быть использована дополнительная информация из тракта области трансформанты 320 или из тракта ACELP 340. Наряду с этим для реконструкции 372 антиалиасингового сигнала может быть задействовано оконное взвешивание, что подробнее описано ниже.
Исходя из сказанного, существуют различные алгоритмы декодирования сигнала, применимые для формирования антиалиасинговых сигналов 364 на базе антиалиасинговой информации 362 в зависимости от формата антиалиасинговой информации 362.
3. Алгоритмы оконного взвешивания и антиалиасинга
На очереди более детальное рассмотрение алгоритма оконного взвешивания и устранения алиасинга для применения в аудиокодере 100 и аудиодекодере 300.
Далее предлагается описание статуса оконных последовательностей в гибридном кодировании речи и звука (USAC) с малой задержкой.
В современных разработках по реализации гибридного кодирования речи и звука с малой задержкой (USAC) не применяют окно малой задержки формата „усовершенствованного метода аудиокодирования с особо малой задержкой" (AAC-ELD), в котором использовано расширенное перекрывание прошедшего интервала времени. Вместо этого используют синусное окно или окно малой задержки, идентичное или подобное окну, включенному в стандарт ITU-T G.718 (например, в время-частотном преобразователе 130 и/или в частотно-временном преобразователе 330). Такое окно G.718 имеет несимметричную конфигурацию, аналогичную окну AAC-ELD, рассчитанную на сокращение задержки, однако оно обеспечивает лишь двукратное перекрывание (перекрывание 2х), то есть - такое же, как у стандартного синусного окна. Представленные далее фигуры (в частности, фиг.5-9) иллюстрируют различия между синусным окном и окном G.718.
Уточним, что на приведенных фигурах длина фрейма составляет 400 отсчетов, что позволяет лучше встраивать оконные функции в координатную сетку графиков. Тем не менее, на практике длина фрейма предпочтительно составляет 512 отсчетов.
3.1. Сравнение синусного окна с окном анализа G.718 (фиг.5-9)
На фиг.5 дано сопоставление синусного окна (обозначенного пунктиром) с аналитическим окном G.718 (обозначенного сплошной). На фиг.5 дан график значений синусной взвешивающей оконной функции (синусного окна) и аналитической оконной функции (окна анализа) G.718, где абсцисса 510 отображает время в пересчете на временные отсчеты с индексами между 0 и 400, и где ордината 512 отображает значения оконной функции (окна) (которые могут быть, например, нормализованными величинами).
Очевидно, что окно анализа G.718 на фиг.5, обозначенное сплошной линией 520, асимметрично. Видно, что левая половина окна (временные отсчеты от 0 до 199) состоит из наклонной восходящего фронта 522 перехода, где значения оконной функции монотонно возрастают от 0 до центрального значения окна 1, и участка всплеска 524 (выброса на фронте импульса), где значения оконной функции превышают центральное значение окна 1. Отрезок всплеска 524 включает в себя максимум 524а окна. Окно анализа G.718 520 также имеет центральное (срединное) значение 1 в центральной точке 526. Окно анализа G.718 520 имеет также правую половину (временные отсчеты с 201 по 400). Правая половина окна состоит из правосторонней наклонной нисходящего фронта 520а перехода, где значения оконной функции монотонно убывают от значения центра окна 1 до 0. Помимо этого, правая половина окна включает в себя правостороннюю нулевую область 530. Здесь следует отметить, что аналитическое окно G.718 520 может быть применено в время-частотном преобразователе 130 для взвешивания фрагмента (например, фрейма или субфрейма) с длиной фрейма 400 отсчетов, где последними 50 отсчетами фрейма можно пренебречь благодаря наличию правосторонней нулевой области 530 окна анализа G.718. Следовательно, преобразование из временной области в частотную область может быть начато прежде, чем все 400 отсчетов фрейма станут доступными. Достаточно, чтобы были доступны 350 отсчетов анализируемого в данный момент фрейма, чтобы начать время-частотное преобразование.
Кроме того, асимметричная форма окна 520, которое включает в себя участок всплеска 524 (только) в левой половине, специально предназначена для реконструкции сигнала с короткой задержкой в технологической цепочке аудиокодера/аудиодекодера.
Итак, на фиг.5 дано сравнение синусного окна (пунктир) и аналитического окна G.718 (сплошная линия), где 50 отсчетов в правой части окна G.718 520 дают в результате сокращение задержки в кодере на 50 отсчетов (по сравнению с кодером, использующим синусное окно).
На фиг.6 дано сопоставление синусного окна (пунктирная линия) с синтезирующим окном G.718 (сплошная линия). Абсцисса 610 отображает время с шагом, равным временным отсчетам с индексами от 0 до 400. Ордината 612 отображает (нормализованные) значения оконной функции.
Видно, что окно синтеза G.718 620, используемое для оконного взвешивания в преобразователе из частотной области во временную область 330, состоит из левой половины окна и правой половины окна. Левая половина окна (отсчеты с 0 по 199) включает в себя левостороннюю нулевую область 622 и левый скос перехода 624, где значения оконной функции монотонно возрастают от нуля (отсчет 50) до центрального значения окна, например, 1. Окно синтеза G.718 620 содержит также центральное значение окна 1 (отсчет 200). Правая часть окна (отсчеты 201-400) включает в себя участок всплеска 628, содержащий максимум 628а. Кроме того, правая половина окна (отсчеты 201-400) включает в себя правосторонний скос перехода 630, где значения оконной функции монотонно убывают от значения центра окна (1) до нуля.
Окно синтеза G.718 620 может быть применено в тракте области трансформанты 320 для взвешивания 400 отсчетов аудиофрейма, закодированного в режиме трансформанты. 50 отсчетов в левой части окна G.718 (левостороння нулевая область 622) дают в результате сокращение задержки еще на 50 отсчетов в декодере (например, по сравнению с окном, включающим в себя ненулевое временное расширение из 400 отсчетов). Сокращение задержки происходит за счет того, что выход звуковых данных предшествующего аудиофрейма может продолжаться вплоть до 50-го отсчета текущего фрейма аудиоконтента прежде, чем начнется формирование представления во временной области текущего фрагмента звукоданных. В силу этого (ненулевая) область перекрывания между предыдущим аудиофреймом (или аудиосубфреймом) и текущим аудиофреймом (или аудиосубфреймом) сокращается на длину левосторонней нулевой области 622, в результате чего при формировании декодированного представления аудиосигнала задержка уменьшается. Однако, последующие фреймы могут быть сдвинуты на 50% (например, на 200 отсчетов). Более подробные пояснения приведены дальше.
Из вышесказанного следует, что на фиг.6 дано сравнение синусного окна (пунктир) и окна синтеза G.718 (сплошная линия). 50 отсчетов в левой части окна G.718 дают в результате сокращение задержки еще на 50 отсчетов в декодере. Синтезирующее окно G.718 620 может быть применено, например, в частотно-временном преобразователе 330, при оконном взвешивании 424, при оконном взвешивании 452 или при оконном взвешивании 485.
На фиг.7 дано графическое представление последовательности синусных окон. Абсцисса 710 отображает время в пересчете на значения аудиоотсчетов, а ордината 712 отображает унифицированные значения окна. Как можно видеть, первое синусное окно 720 совпадает с первым аудиофреймом 722, имеющем длину фрейма, допустим, 400 отсчетов (индексы отсчетов от 0 до 399). Второе синусное окно 730 совпадает со вторым аудиофреймом 732 длиной 400 аудиоотсчетов (индексы отсчетов от 200 до 599). Заметно, что второй аудиофрейм 732 смещен относительно первого аудиофрейма 722 на 200 отсчетов. Более того, первый аудиофрейм 722 и второй аудиофрейм 732 включают в себя перекрывание по времени, в частности, 200 аудиоотсчетов (индексы отсчетов - между 200 и 399). Другими словами, первый аудиофрейм 722 и второй аудиофрейм 732 содержат примерно 50-процентное перекрывание по времени (с допустимым отклонением, например, +/-1 отсчет).
На фиг.8 дано графическое представление последовательности окон анализа G.718. Абсцисса 810 отображает время в пересчете на аудиоотсчеты временной области, а ордината 812 отображает нормализованные значения оконной функции. Первое окно анализа G.718 820 соответствует первому аудиофрейму 822, который охватывает отсчеты от 0 до 399. Второе окно анализа G.718 830 соответствует второму аудиофрейму 832, который охватывает отсчеты от 200 до 599. Как видно на графике, первое и второе аналитические окна G.718 820, 830 содержат перекрывание по времени (если учитывать только ненулевые значения оконной функции), например, в 150 отсчетов (+/-1 отсчет). При этом следует обратить внимание на то, что первое окно анализа G.718 820 соответствует первому фрейму 822, который включает в себя отсчеты 0 и 399. Однако, первое аналитическое окно G.718 820 включает в себя правостороннюю нулевую область (правостороннюю нулевую область 530), например, в 50 отсчетов, таким образом, что перекрывание (взятое для ненулевых значений окна) окон анализа 820, 830 сужено до 150 значений отсчетов (+/-1 отсчет). Как видно на фиг.8, перекрывание по времени есть между двумя смежными аудиофреймами 822, 832 (всего 200 значений отсчетов +/-1 отсчет), а также перекрывание по времени (всего 150 отсчетов +/-1 отсчет) есть между ненулевыми сегментами двух (и не более, чем двух) окон 820, 830.
Следует указать на то, что последовательность аналитических окон G.718, показанная на фиг.8, может быть использована частотно-временным преобразователем 130 и трактами области трансформанты 200, 230, 260.
На фиг.9 дано графическое представление последовательности окон синтеза G.718. Абсцисса 910 отображает время в пересчете на аудиоотсчеты временной области, а ордината 912 отображает нормализованные значения окон синтеза.
Последовательность синтезирующих окон G.718 на фиг.9 включает в себя первое и второе окна синтеза G.718 920, 930. Первое окно синтеза G.718 920 соответствует первому фрейму 922 (аудиоотсчеты с 0 по 399), где левосторонняя нулевая область окна синтеза G.718 920 (соответствующая левосторонней нулевой области 622) включает в себя множество, например, из 50 отсчетов в начале первого фрейма 922. Соответственно, ненулевая область первого окна синтеза G.718 распространяется на отсчеты, начиная приблизительно с 50, до 399. Второе окно синтеза G.718 930 соотносится со вторым аудиофреймом 932, который длится от аудиоотсчета 200 до аудиоотсчета 599. На графике видно, что левосторонняя нулевая область второго окна синтеза G.718 930 лежит между отсчетами 200 и 249 и, соответственно, покрывает множество, например, из 50 отсчетов в начале второго аудиофрейма 932. Ненулевая область второго окна синтеза G.718 930 пролегает от отсчета 250 до отсчета 599. Можно видеть, что область перекрытия включает в себя отсчеты от 250 до 399 между ненулевыми областями первого 920 и второго 930 окон синтеза G.718. Как видно на фиг.9, последующие синтезирующие окна G.718 далее равномерно распределены.
3.2. Чередование синусных окон и ACELP
На фиг.10 дано графическое представление последовательности синусных окон (сплошная линия) и линейного предсказания управляемого алгебраическим кодом ACELP (линия с квадратами). Можно видеть, что первый фрейм области трансформанты 1012 лежит между отсчетами 0 и 399, второй аудиофрейм области трансформанты. 1022 лежит между отсчетами 200 и 599, первый аудиофрейм ACELP 1032 длится от отсчета 400 до 799 с ненулевыми значениями между отсчетами 500 и 700, второй аудиофрейм ACELP 1042 длится от отсчета 600 до 999 с ненулевыми значениями между отсчетами 700 и 900, третий аудиофрейм области трансформанты 1052 занимает отсчеты с 800 до 1199, и четвертый аудиофрейм области трансформанты 1062 включает в себя отсчеты с 1000 по 1399. Наблюдается перекрывание по времени между вторьм аудиофреймом области преобразования 1022 и ненулевой областью первого аудиофрейма ACELP 1032 (между отсчетами 500 и 600). Аналогичное перекрывание можно видеть между ненулевой областью второго аудиофрейма ACELP 1042 и третьим аудиофреймом области трансформанты 1052 (между отсчетами 800 и 900).
Сигнал прямого (упреждающего) антиалиасинга 1070 (обозначенный пунктиром и акронимом FAC) генерируется при переходе от второго аудиофрейма области трансформанты 1022 к первому аудиофрейму ACELP 1032, а также при переходе от второго аудиофрейма ACELP 1042 к третьему аудиофрейму трансформанты 1052.
На фиг.10 видно, что такие переходы обеспечивают полную реконструкцию (или, по меньшей мере, приближенную к полной реконструкцию) за счет упреждающей нейтрализации наложения спектров (РАС) 1070, 1072, обозначенной пунктиром. Обратим внимание на то, что геометрия окна прямого антиалиасинга 1070, 1072 дана лишь иллюстративно и не отражает реальные значения. Для симметричных окон (таких, как синусные окна) такой механизм подобен, или даже аналогичен, алгоритму, который используется также при гибридном кодировании речи и звука в формате MPEG (USAC).
3.3. Оконное взвешивание переходов между режимами - вариант первый
Далее, со ссылкой на фиг.11 и 12 рассмотрим первый вариант перехода между аудиофреймами, закодированными в режиме трансформанты, и аудиофреймами, закодированными в режиме ACELP.
На фиг.11 дано графическое представление первого варианта весового оконного алгоритма гибридного кодирования речи и звука (USAC) с малой задержкой. На фиг.11 графически отображена последовательность окна анализа G.718 (сплошная линия), окна ACELP (линия с квадратами) и окна прямого антиалиасинга (пунктир).
На фиг.11 абсцисса 1110 отображает время в пересчете на (временные) аудиоотсчеты, а ордината 1112 отображает нормализованные значения оконной функции. Первый аудиофрейм 1122, закодированный в режиме трансформанты, содержит отсчеты от 0 до 399. Второй аудиофрейм 1132 закодирован в режиме трансформанты и содержит отсчеты от 200 до 599. Третий аудиофрейм 1142, закодированный в режиме ACELP, включает в себя аудиоотсчеты 400-799. Четвертый аудиофрейм 1152 также закодирован в режиме ACELP и включает в себя отсчеты 600-999. Пятый аудиофрейм 1162, который длится от аудиоотсчета 800 до аудиоотсчета 1199, закодирован в режиме трансформанты. Шестой аудиофрейм 1172 также закодирован в режиме трансформанты и содержит аудиоотсчеты 1000-1399.
На графике видно, что отсчеты первого аудиофрейма 1122 взвешены с использованием окна анализа G.718 1120, которое может быть идентичным, например, окну анализа G.718 520 на фиг.5. Аналогично этому на фиг.11 (временные) отсчеты второго аудиофрейма 1132 взвешены с использованием окна анализа G.718 1130, которое включает в себя ненулевую область перекрытия с окном анализа G.718 1120 в интервале между отсчетами 200 и 350. Блок отсчетов с 500 по 700, входящих в аудиофрейм 1142, закодирован в режиме ACELP. Однако, аудиоотсчеты с индексами в интервале между 400 и 500, а также - между 700 и 800 находятся вне параметров ACELP (информации о алгебраических кодах возбуждения и параметрах области линейного предсказания), относящихся к третьему аудиофрейму 1142. Следовательно, информация ACELP (данные возбуждения алгебраическими кодами 144 и параметры линейных предикторов 146), относящаяся к третьему аудиофрейму 1142, позволяет восстановить только аудиоотсчеты с индексами между 500 и 700. Аналогично информация о блоке аудиоотсчетов с индексами между 700 и 900, закодированная в ACELP, связана с четвертым аудиофреймом 1152. Иначе говоря, в аудиофреймах 1142,1152, закодированных в режиме ACELP, относящимися к области ACELP можно считать только ограниченные во времени блоки аудиоотсчетов в центре каждого из соответствующих аудиофреймов 1142, 1152. И наоборот, расширенную левостороннюю нулевую область (допустим, порядка 100 отсчетов) и расширенную правостороннюю нулевую область (примерно 100 отсчетов) рассматривают как не относящиеся к аудиофрейму, закодированному в режиме ACELP. Из этого следует, что кодирование аудиофрейма в режиме ACELP затрагивает приблизительно 200 ненулевых временных отсчетов (в частности, отсчеты 500-700 для третьего фрейма 1142 и отсчеты 700-900 для четвертого фрейма 1152). В противоположность этому, большее число ненулевых аудиоотсчетов в аудиофрейме кодируется в режиме трансформанты. Например, аудиофрейм, закодированный в режиме трансформанты, содержит приблизительно 350 кодированных аудиоотсчетов (скажем, аудиоотсчеты от 0 до 349 для первого аудиофрейма 1122 и аудиоотсчеты от 200 до 549 для второго аудиофрейма 1132). Кроме того, окно анализа G.718 1160 использовано для взвешивания временных отсчетов при кодировании в области трансформанты пятого аудиофрейма 1162. Окно анализа G.718 1170 применено также для взвешивания временных отсчетов при кодировании в области трансформанты шестого аудиофрейма 1172.
Можно наблюдать, что правосторонний скос перехода (ненулевой области) аналитического окна G.718 1130 - перекрывает во времени блок 1140 (ненулевых) аудиоотсчетов, закодированных в третьем аудиофрейме 1142. При этом вследствие того, что правосторонний скос перехода окна G.718 1130 не перекрывает левосторонний скос перехода следующего аналитического окна G.718, должны возникнуть элементы алиасинга во временной области. Однако, такие элементы временного алиасинга определяют взвешиванием с помощью окна прямого антиалиасинга (окно FAC 1136) и кодируют в виде антиалиасинговой информации 164. Интерпретируя сказанное, эффект спектрального наложения (алиасинг), проявляющийся во временной области при переходе от аудиофрейма, закодированного в режиме трансформанты, к следующему за ним аудиофрейму, закодированному в режиме ACELP, обозначают, используя окно FAC 1136, и кодируют, формируя информацию 164 по нейтрализации такого эффекта наложения спектров. Окно FAC 1136 может быть применено при вычислении ошибки 172 или при кодировании ошибки 174 в аудиокодере 100. Таким образом, антиалиасинговая информация 164 может представлять в кодированном виде эффект наложения спектров (алиасинг), который проявляется при переходе от второго аудиофрейма 1132 к третьему аудиофрейму 1142, при этом окно 1136 упреждающей нейтрализации наложения спектров (FAC) может быть использовано для взвешивания алиасинга (например, для оценивания алиасинга, сгенерированного в кодере аудиосигнала).
Аналогичным образом алиасинг может возникнуть при переходе от четвертого аудиофрейма 1152, закодированного в режиме ACELP, к пятому аудиофрейму 1162, закодированному в режиме трансформанты. Алиасинг на этом переходе, вызванный тем, что левая часть перехода окна анализа G.718 1160 перекрывает не правосторонний скос перехода предыдущего окна анализа G.718, а блок аудиоотсчетов во временной области, закодированных в режиме ACELP, распознают (например, используя вычисление результата синтеза 170 и вычисление ошибки 172) и кодируют, например, используя кодирование ошибки 174, формируя антиалиасинговую информацию 164. При кодировании 174 сигнала алиасинга может быть использовано окно прямого антиалиасинга 1156.
Таким образом, антиалиасинговая информация избирательно предоставляется при переходе от второго фрейма 1132 к третьему фрейму 1142, а также при переходе от четвертого фрейма 1152 к пятому фрейму 1162.
Итак, фиг.11 иллюстрирует первый вариант гибридного кодирования речи и звука с малой задержкой. На фиг.11 показана последовательность окон анализа G.718 (сплошная линия), ACELP (линия с квадратами) и РАС (пунктир). Было установлено, что комбинирование асимметричных окон, таких, как окно G.718, с FAC способствует значительной оптимизации процесса по сравнению с общепринятыми подходами. В частности, достигается надлежащий баланс между задержкой при кодировании, качеством звука и эффективностью кодирования.
На фиг.12 дано графическое представление последовательности синтеза, соответствующего алгоритму анализа, проиллюстрированному на фиг.11. Другими словами, на фиг.12 графически представлен процесс фрагментирования на фреймы и оконного взвешивания, который может быть применен в декодере аудиосигнала 300 согласно фиг.3.
Абсцисса 1210 отображает время в пересчете на (временные) аудиоотсчеты, а ордината 1212 отображает нормализованные значения оконной функции. Первый аудиофрейм 1222, закодированный в режиме трансформанты, включает в себя аудиоотсчеты от 0 до 399, второй аудиофрейм 1232, закодированный в режиме трансформанты, содержит в себе аудиоотсчеты 200-599, третий аудиофрейм 1242, который закодирован в режиме ACELP, состоит из аудиоотсчетов с 400 по 799, четвертый аудиофрейм 1252, также закодированный в режиме ACELP, включает в себя аудиоотсчеты 600-999, пятый аудиофрейм 1262 опять закодирован в режиме трансформанты и длится от аудиоотсчета 800 до 1199, и шестой аудиофрейм 1272, также закодированный в режиме трансформанты, содержит аудиоотсчеты с 1000 по 1399. Аудиоотсчеты первого аудиофрейма 1222, полученные частотно-временным преобразованием 423, 451, 484, взвешивают с использованием первого синтезирующего окна G.718 1220, которое может быть идентичным окну синтеза G.718 620 на фиг.6. Аналогично аудиоотсчеты второго аудиофрейм 1232 взвешивают с использованием синтезирующего окна G.718 1230. Следовательно, в первый аудиофрейм 1222 входят аудиоотсчеты с индексами между 0 и 399, или, точнее, ненулевые аудиоотсчеты с индексами между 50 и 399 (то есть - отсчеты, полученные из набора спектральных коэффициентов 322, относящихся к первому аудиофрейму 1222, и из информации о формировании искажения 324, относящейся к первому аудиофрейму 1222). Точно так же аудиоотсчеты с индексами между 200 и 599 входят во второй аудиофрейм 1232 (где ненулевые аудиоотсчеты имеют значения между 250 и 599). Следовательно, образуется перекрывание по времени между (ненулевыми) аудиоотсчетами первого аудиофрейма 1222 и (ненулевыми) аудиоотсчетами второго аудиофрейма 1232. Аудиоотсчеты первого аудиофрейма 1222 суммируют наложением с аудиоотсчетами второго аудиофрейма 1232, компенсируя таким образом алиасинг.При этом аудиоотсчеты с индексами между 200 и 599, относящиеся ко второму аудиофрейму 1232, взвешивают с использованием второго окна синтеза G.718 1230. В третий аудиофрейм 1242, закодированный в режиме ACELP, (ненулевые) аудиоотсчеты временной области входят только в пределах ограниченного блока 1240, что характерно для кодирования в режиме ACELP. Однако, временные отсчеты второго аудиофрейма 1232, взвешенные правосторонним скосом перехода синтезирующего окна G.718 1230, заходят во временной интервал блока 1240, в котором (ненулевые) временные отсчеты сгенерированы трактом ACELP 340. Однако, временных отсчетов, поступивших из тракта ACELP 340, не достаточно для нейтрализации алиасинга в правой половине окна синтеза G.718 1230. На помощь приходит антиалиасинговый сигнал, компенсирующий алиасинг на переходе от второго фрейма 1232, закодированного в режиме трансформанты, к третьему аудиофрейму 1242, закодированному в режиме ACELP (то есть - в пределах участка перекрывания между вторым аудиофреймом 1232 и третьим аудиофреймом 1242, расположенного между отсчетами 400 и 599, или, по меньшей мере, в пределах некоторой части этого участка). Сигнал компенсации алиасинга (антиалиасинговый сигнал) инициируется на основе антиалиасинговой информации 362, которая извлекается из потока двоичных данных (битстрима), представляющего закодированные звуковых данные (аудиоконтент). Антиалиасинговую информацию декодируют (шаг 370), и на базе декодированной антиалиасинговой информации реконструируют антиалиасинговый сигнал (шаг 372). При реконструкции антиалиасингового сигнала 364 используют окно прямого (упреждающего) антиалиасинга 1236. Таким образом, на переходе между вторым аудиофреймом 1232, закодированным в режиме трансформанты, и третьим аудиофреймом 1242, закодированным в режиме ACELP, антиалиасинговый сигнал ослабляет или даже устраняет алиасинг, который при нормальных условиях (при отсутствии перехода) компенсируется (оконно-взвешенными) временными отсчетами следующего аудиофрейма, закодированного в области трансформанты.
Четвертый аудиофрейм 1252 закодирован в режиме ACELP. Соответственно, блок 1250 временных отсчетов относится к четвертому аудиофрейму 1252. При этом ненулевые аудиоотсчеты, сгенерированные трактом ACELP 340, применимы только для центрального фрагмента четвертого аудиофрейма 1252. Однако, расширенная левостороння нулевая область (аудиоотсчеты 600-700) и расширенная правосторонняя нулевая область (аудиоотсчеты 900-1000) сформированы трактом ACELP для дополнения четвертого аудиофрейма 1152.
Представление во временной области, сформированное для пятого аудиофрейма 1262, взвешено с использованием синтезирующего окна G.718 1260. Левосторонняя ненулевая область (наклонная фронта перехода) окна синтеза G.718 1260 перекрывает отрезок времени, в котором содержатся ненулевые аудиоотсчеты, сгенерированные трактом ACELP 340 для четвертого аудиофрейма 1252. В результате аудиоотсчеты, выведенные трактом ACELP 340 для четвертого аудиофрейма 1252, складываются наложением с аудиоотсчетами, выведенными трактом области трансформанты для пятого аудиофрейма 1262.
В дополнение к этому при переходе от четвертого аудиофрейма 1252 к пятому аудиофрейму 1262 (в частности, в процессе формирования перекрывания по времени между четвертым аудиофреймом 1252 и пятым аудиофреймом 1262) активатор антиалиасингового сигнала 360, исходя из антиалиасинговой информации 362, инициирует антиалиасинговый сигнал 364. При реконструкции антиалиасингового сигнала может быть применено антиалиасинговое окно 1256. Следовательно, антиалиасинговый сигнал 364 хорошо настраивается на нейтрализацию алиасинга при выполнении сложения наложением временных отсчетов четвертого аудиофрейма 1252 и пятого аудиофрейма 1262.
3.4. Оконное взвешивание переходов между режимами - вариант второй
Дальше рассмотрим модифицированный оконно-весовой алгоритм для переходов между аудиофреймами, закодированными в разных режимах.
Уточним, что оконно-весовой алгоритм в соответствии с фиг.13 и 14 тождественен схеме оконного взвешивания фиг.11 и 12 в части применения к переходу от режима трансформанты к режиму ACELP. В то же время весовой алгоритм в соответствии с фиг.13 и 14 отличается от схемы оконного взвешивания фиг.11 и 12 в части перехода от режима ACELP к режиму трансформанты.
На фиг.13 дано графическое представление второго варианта гибридного кодирования речи и звука с короткой задержкой. Фиг.13 отображает график последовательности окон анализа G.718 (сплошная линия), ACELP (линия с квадратами) и прямого антиалиасинга (пунктир).
Упреждающую нейтрализацию наложения спектров (прямой антиалиасинг) используют только для перехода от кодера области трансформанты к ACELP. Для перехода от ACELP к кодеру области трансформанты применяют окно прямоугольной формы для левой стороны окна перехода к режиму кодирования в трансформанте.
На фиг.13 абсцисса 1310 отображает время в пересчете на аудиоотсчеты временной области, а ордината 1312 отображает нормализованные значения оконной функции. Первый аудиофрейм 1322 закодирован в режиме трансформанты, второй аудиофрейм 1332 закодирован в режиме трансформанты, третий аудиофрейм 1342 закодирован в режиме ACELP, четвертый аудиофрейм 1352 закодирован в режиме ACELP, пятый аудиофрейм 1362 закодирован в режиме трансформанты, и шестой аудиофрейм 1372 также закодирован в режиме трансформанты.
Следует указать на то, что кодирование первого фрейма 1322, второго фрейма 1332 и третьего фрейма 1342 идентично кодированию первого фрейма 1122, второго фрейма 1132 и третьего фрейма 1142 в описании фиг.11. При этом обратим внимание на то, что аудиоотсчеты центрального сегмента 1350 четвертого аудиофрейма 1352 закодированы с использованием только тракта ACELP 140, что отражено на фиг.13. Если перефразировать сказанное, отсчеты во временной области, имеющие индексы между 700 и 900, рассматриваются как источник информации ACELP 144, 146 для четвертого аудиофрейма 1352. Для получения информации касательно области трансформанты 124, 126, относящейся к пятому аудиофрейму 1362, в время-частотном преобразователе 130 задействуют целевое аналитическое окно перехода 1360 (например, для оконного взвешивания 221, 263, 283). Соответственно, временные отсчеты, закодированные трактом ACELP 140 при кодировании четвертого аудиофрейма 1352 (предшествующего переходу от режима кодирования ACELP к режиму кодирования трансформанты), не учитывают при кодировании пятого аудиофрейма 1362 с использованием тракта трансформанты 120.
Специализированное окно анализа перехода 1360 включает в себя левосторонний скос восходящего фронта перехода (который в разных схемотехнических версиях может быть скачкообразным или резким увеличением), постоянную (ненулевую) область окна и правосторонний скат перехода. При этом целевое анализирующее окно перехода 1360 не содержит участок всплеска. Скорее, значения целевого окна анализа перехода 1360 ограничены центральным значением одного из окон анализа G.718. Также следует отметить, что правая половина окна или правосторонний граничный скат специального окна анализа перехода 1360 могут быть конгруэнтными правой половине окна или правостороннему скату перехода другого окна анализа G.718.
Шестой аудиофрейм 1372, который сменяет пятый аудиофрейм 1362, взвешивают окном анализа G.718 1370, идентичным анализирующим окнам G.718 1320, 1330, используемым для взвешивания первого 1322 и второго 1332 аудиофреймов. В частности, левосторонний нарастающий фронт перехода анализирующего окна G.718 1370 перекрывает по времени правосторонний граничный скат специального окна анализа перехода 1360.
Из сказанного следует, что целевое окно перехода 1360 применяют для оконного взвешивания аудиофрейма, закодированного в области трансформанты, следующего непосредственно за аудиофреймом, закодированным в области ACELP. В этом случае аудиоотсчеты предшествующего фрейма 1352, закодированного в области ACELP (в частности, аудиоотсчеты с индексами между 700 и 900), при кодировании следующего фрейма 1362 в области трансформанты не принимаются во внимание благодаря конфигурации специального анализирующего окна перехода 1360. Целевое окно анализа перехода 1360 включает в себя нулевую область для аудиоотсчетов, закодированных в режиме ACELP (в частности, для аудиоотсчетов блока ACELP 1350).
Соответственно, эффект наложения частот (алиасинг) при переходе от режима ACELP к режиму трансформанты отсутствует. Но, при этом должно быть применен определенный тип целевой оконной функции, в частности, целевое анализирующее окно перехода 1360.
Теперь, обращаясь к фиг.14, рассмотрим алгоритм декодирования, соответствующий алгоритму кодирования, описанному в контексте фиг.13.
На фиг.14 дано графическое представление последовательности синтеза, соответствующей анализу, проиллюстрированному на фиг.13. Другими словами, фиг.14 отображает график последовательности окон синтеза, которые могут быть использованы в декодере аудиосигнала 300 на фиг.3. Абсцисса 1410 отображает время в пересчете на аудиоотсчеты, а ордината 1412 отображает нормализованные значения оконной функции.
Первый аудиофрейм 1422, закодированный в режиме трансформанты, подлежит декодированию с использованием окна синтеза G.718 1420, второй аудиофрейм 1432, закодированный в режиме трансформанты, также подлежит декодированию с помощью окна синтеза G.718 1430, третий аудиофрейм 1442 закодирован в режиме ACELP и декодируется с образованием блока ACELP 1440, четвертый аудиофрейм 1452 также закодирован в режиме ACELP и декодируется с образованием блока ACELP 1450, пятый аудиофрейм 1462 закодирован в режиме трансформанты и подлежит декодированию с применением специализированного окна синтеза перехода 1460, и шестой аудиофрейм 1472, закодированный в режиме трансформанты, декодируется с использованием окна синтеза G.718 1470.
Уточним, что декодирование первого аудиофрейма 1422, второго аудиофрейма 1432 и третьего аудиофрейма 1442 идентично декодированию аудиофреймов 1222, 1232, 1242, описанному в контексте фиг.12. Однако, при переходе от четвертого аудиофрейма 1452, закодированного в режиме ACELP, к пятому аудиофрейму 1462, закодированному в режиме трансформанты, использован другой способ декодирования.
От синтезирующего окна G.718 1260 специальное синтезирующее окно перехода 1460 отличается тем, что конфигурация его левой половины задается таким образом, что оно включает в себя нулевые значения для (ненулевых) аудиоотсчетов, сгенерированных трактом ACELP 340. Говоря иначе, специальное синтезирующее окно перехода 1460 содержит нулевые значения, соответствующие нулевьм дискретам времени, генерируемым трактом области трансформанты 320 только для замещения их нулевыми отсчетами во временной области, генерируемыми трактом ACELP (т.е. - для блока 1450). Благодаря этому избегают перекрывания между (ненулевыми) отсчетами во временной области, сгенерированными трактом ACELP для аудиофрейма 1452 (блок ненулевых временных дискретов 1450), и отсчетами во временной области, сгенерированными трактом области трансформанты 320 для аудиофрейма 1462.
Наряду с этим следует обратить внимание на то, что кроме левосторонней нулевой области (отсчеты 800-899) специальное окно синтеза перехода 1460 включает в себя левостороннюю постоянную область (отсчеты 900-999), в которой оконная взвешивающая функция принимает центральное значение окна (например, один). Таким образом предупреждают или, по меньшей мере, ослабляют артефакты алиасинга в левой части специализированного окна синтеза перехода 260. Правая половина целевого синтезирующего окна перехода 1460 преимущественно тождественна правой половине синтезирующего окна G.718.
Итак, специальное (целевое) синтезирующее окно перехода 260 применяют для оконного взвешивания 424, 452, 485 при формировании представления во временной области 326 фрагмента (фрейма) аудиоконтента, закодированного трактом области трансформанты 320 в режиме трансформанты, за которым следует аудиофрейм, закодированный в режиме ACELP. Целевое окно синтеза перехода 1460 включает в себя левостороннюю нулевую область, которая может составлять, например, 50% от левой половины окна (отсчеты 800-899), и. левостороннюю постоянную область, которая может занимать остальные 50% (+/-1 отсчет) левой половины целевого окна синтеза перехода 1460 (отсчеты 900 - 999). Правая половина целевого синтезирующего окна перехода 1460 может быть конгруэнтной правой половине окна синтеза G.718 и может включать в себя участок всплеска и правосторонний скос перехода. Благодаря этому достигается безалиасинговый переход между фреймом 1452, закодированным в режиме ACELP, и фреймом 1462, закодированным в режиме трансформанты.
В итоге, на фиг.13 проиллюстрирован второй вариант гибридного кодирования речи и звука с короткой задержкой. Фиг.13 отображает график последовательности окон анализа G.718 (сплошная линия), ACELP (линия с квадратами) и прямого антиалиасинга (пунктир). Прямой (упреждающий) антиалиасинг применяют только при переходах от сигнала кодера области трансформанты (тракта области трансформанты) к сигналу ACELP (тракта ACELP). При переходе из ACELP в трансформанту применяют окно (1360) прямоугольной (или ступенчатой) конфигурации в левой части (в частности, в области отсчетов 800-999).
Фиг.14 отображает график последовательности синтеза, соответствующего последовательности анализа на фиг.13.
3.5. Обсуждение вариантов переходов
В настоящее время в разработках систем гибридного кодирования речи и звука с короткой задержкой учитываются оба варианта построения переходов (в соответствии с фиг.11 и 12 и в соответствии с фиг.13 и 14). Первый вариант (в соответствии с фиг.11 и 12) имеет то преимущество, что одна и та же оконная взвешивающая функция с хорошей частотной характеристикой применима для всех блоков с кодированием в трансформанте. Недостатком этого варианта является необходимость кодирования дополнительной информации для области FAC (в частности, данных прямого антиалиасинга).
Второй вариант отличает то преимущество, что дополнительные данные не требуются для прямого антиалиасинга (FAC) на переходе от ACELP к области трансформанты. Это преимущество особенно ценно, когда требуется постоянная скорость обмена данными. Однако, недостатком этого варианта является то, что частотная характеристика оконной взвешивающей функции перехода (1360 или 1460) хуже, чем у обычного окна (1320, 1330, 1370; 1420, 1430, 1470).
3.6. Оконное взвешивание переходов между режимами - вариант третий
Дальше рассмотрим еще один вариант. Третий вариант заключается в использовании прямоугольного окна также для перехода кодера области трансформанты к ACELP. Однако, при третьем варианте вносится дополнительная задержка, вызванная необходимостью принятия решения о выборе между кодером области трансформанты и ACELP. Следовательно, этот вариант не является оптимальным для гибридного кодирования речи и звука с малой задержкой. Тем не менее, третий вариант может быть задействован в версиях реализации, где задержки не является приоритетной задачей.
4. Альтернативные конструктивные решения
4.1. Обзор
Рассмотрим еще одну, новую, схему гибридного кодирования речи и звука (USAC) с короткой задержкой. Например, она может базироваться на коммутации между кодеком „усовершенствованного аудиокодирования с особо малой задержкой" AAC-ELD в частотной области и „адаптивным многоскоростным широкополосным" кодеком AMR-WB или „адаптивным многоскоростным широкополосным - плюс" кодеком AMR-WB+во временной области. Такая система (наравне с заявляемым изобретением) обладает преимуществом адаптивной к контенту коммутации между аудиокодеком и кодеком речи, сохраняя при этом задержку на уровне, достаточно низком для интегрирования со средствами коммуникации. Банк фильтров с малой задержкой (LD-MDCT / МДКП с малой задержкой), используемый в AAC-ELD, в рассматриваемой схеме задействован с применением корректировки окнами переходов, что обеспечивает переход наплывом (затухание/нарастание) от и к кодеку во временной области без внесения дополнительной задержки в отличие от AAC-ELD.
Обратим внимание на то, что подход, представленный далее, может быть применен в аудиокодере 100 на фиг.1 и/или в аудиодекодере 300 на фиг.3.
4.2. Пример из существующей практики 1: гибридное кодирование речи и звука (USAC)
Так называемый кодек USAC основан на коммутации между режимами музыки и речи. В музыкальном режиме USAC используется кодек на базе МДКП, аналогичный усовершенствованному методу кодирования звука ААС. В речевом режиме кодека USAC используется режим области линейного предсказания LPD, аналогичный адаптивному многоскоростному широкополосному-плюс кодеку AMR-WB+. Особое внимание уделяется плавному и эффективному переходу между этими двумя режимами, что будет рассмотрено ниже.
Представим алгоритм перехода от ААС к AMR-WB+. Согласно этому алгоритму последний фрейм перед переключением на AMR-WB+взвешивают с помощью окна, однотипного „стартовому" окну в ААС, но без временного алиасинга в правой части. Предусмотрена область перехода из 64 отсчетов, в которой отсчеты, закодированные в ААС, переходят наплывом в отсчеты, закодированные в AMR-WB+. Это проиллюстрировано на фиг.15. На фиг.15 дано графическое представление окна, используемого при переходе от ААС к AMR-WB+в гибридном кодировании речи и звука. Абсцисса 1510 отображает шкалу времени, а ордината 1512 - шкалу значений оконной функции. Для детализации обратимся к фиг.15.
Ниже кратко рассмотрим переход от AMR-WB+к ААС.При обратном переключении на усовершенствованный метод кодирования звука (ААС) первый фрейм ААС взвешивают окном, идентичным „стоповому" окну ААС. За счет этого в диапазон перехода наплывом вносится алиасинг во временной области, который устраняют направленным введением соответствующего отрицательного временного алиасинга в закодированный во временной области сигнал AMR-WB+. Это проиллюстрировано на фиг.16, где дано графическое представление алгоритма перехода от AMR-WB+ к ААС. Абсцисса 1610 отображает временную шкалу аудиоотсчетов, а ордината 1612 отображает шкалу значений оконной взвешивающей функции. Для более глубокой детализации обратимся к фиг.16.
4.3. Пример из существующей практики 2: усовершенствованное аудиокодирование с особо малой задержкой (AAC-ELD) формата MPEG-4
Так называемый кодек „с усовершенствованным кодированием звука с особо малой задержкой" (сокращенно - AAC-ELD) базируется на специфической разновидности модифицированного дискретного косинусного преобразования (МДКП) с короткой задержкой, иначе - LD-MDCT / МДКП с малой задержкой. В МДКП с малой задержкой (LD-MDCT) перекрывание расширено до коэффициента четыре вместо коэффициента два для МДКП. Это достигается без дополнительной задержки, поскольку перекрывание вводят несимметрично с использованием только отсчетов прошедшего интервала времени. С другой стороны, упреждение сокращается на несколько нулевых значений в правой части окна анализа. Окна анализа и синтеза отображены на фиг.17 и 18, где на фиг.17 дано графическое представление окна анализа LD-MDCT в формате ААС, и где на фиг.18 дано графическое представление окна синтеза LD-MDCT в AAC-ELD. На фиг.17 абсцисса 1710 отображает время, выраженное в аудиоотсчетах, а ордината 1712 отображает шкалу значений оконной функции. Линия 1720 описывает значения оконной взвешивающей функции анализа. На фиг.18 абсцисса 1810 отображает время, выраженное в аудиоотсчетах, ордината 1812 отображает значения оконной функции, а линия 1820 описывает значения оконной функции синтеза.
Для кодирования в формате AAC-ELD используют только это окно и не используют никакое переключение с изменением конфигурации окна или длины блока, которое могло бы внести задержку. Это одно окно (например, окно анализа 1720 на фиг.17 для аудиокодера и окно синтеза 1820 на фиг.18 для аудиодекодера) обслуживает любой типа аудиосигнала, как стационарного, так и нестационарного.
4.4. Обсуждение примеров существующей практики
Обсудим кратко примеры существующего уровня техники, приведенные в подразделах 4.2 и 4.3.
Кодек USAC предусматривает коммутирование между кодеками общего звука и речи, которое, однако, вносит задержку. Поскольку для перехода в речевой режим необходимо окно перехода, требуется упреждение для определения наличия в очередном фрейме сигнала, подобного речевому. При наличии такового текущий фрейм должен быть взвешен оконной функцией перехода. Отсюда следует, что данный подход не целесообразен для системы кодирования с малой задержкой, интегрируемой в коммуникационные приложения.
Небольшая задержка кодека AAC-ELD позволяет использовать его в средствах связи, однако, что касается кодирования голосовых сигналов на низких битрейтах, рабочие параметры этого кодека уступают эффективности специализированных речевых кодеков (например, AMR-WB), которые также характеризуются малой задержкой.
В данной ситуации было признано, что для наибольшей эффективности кодирования как музыкальных, так и речевых сигналов, желательно ввести коммутацию между AAC-ELD и голосовым кодеком. При этом рассчитано, что такая коммутация идеально не должна вносить в систему дополнительную задержку.
Было определено, что при использовании LD-MDCT в рамках формата AAC-ELD прямое переключение на речевой кодек невозможно. Кроме того, было установлено, что вероятное решение задачи кодирования всего кластера временной области, содержащего окна LD-MDCT речевого сегмента, приведет к огромному переизбытку протокольных данных (оверхеду) вследствие четырехкратного (4х) перекрывания при МДКП с малой задержкой. Для замещения одного фрейма отсчетов, закодированных в частотной области (допустим, 512 частотных значений), потребуется кодирование 4×512 отсчетов во временной области.
При сложившемся положении возникает потребность в концепции оптимизации соотношения между эффективностью кодирования, задержкой и акустическим качеством.
4.5. Алгоритм оконного взвешивания по фиг.19-23b
Рассмотрим далее подход к эффективной коммутации без задержки между ААС-ELD и кодеком временной области согласно заявленному изобретению.
В данном разделе предложен подход, где использован МДКП с малой задержкой (LD-MDCT) в формате AAC-ELD (например, в время-частотном преобразователе 130 или в частотно-временном преобразователе 330) с корректировкой посредством окон перехода, обеспечивающих эффективную коммутацию кодека временной области без внесения дополнительной задержки.
На фиг.19 приведен пример последовательности окон. Фиг.19 иллюстрирует последовательность окон при переключении между AAC-ELD и кодеком временным области. На фиг.19 абсцисса 1910 отображает шкалу времени, выраженную в аудиоотсчетах, а ордината 1912 отображает шкалу значений оконной функции. Для детализации построения кривых графиков обратимся к легенде фиг.19.
Так, на фиг.19 показаны окна анализа LD-MDCT 1920а-1920е, окна синтеза LD-MDCT 1930а-1930е, взвешивание 1940 сигнала, закодированного во временной области, и взвешивание 1950а, 1950b алиасинга во временной области сигнала временной области.
Дальше подробнее разберем процедуру анализирующего оконного взвешивания. На фиг.20 представлена последовательность окон анализа (та же, что на фиг.19) без окон синтеза. Абсцисса 2010 отображает шкалу времени, выраженную в аудиоотсчетах, а ордината 2012 отображает шкалу значений оконной взвешивающей функции. Другими словами, на фиг.20 проиллюстрирован пример последовательности анализирующих окон для переключения между AAC-ELD и кодеком временной области. Для детализации кривых графиков обратимся к легенде фиг.20.
На фиг.20 показаны окна анализа LD-MDCT (МДКП с малой задержкой) 2020а-2020е, взвешивание 2040 закодированного во временной области сигнала и взвешивание 2050а, 2050b алиасинга во временной области сигнала временной области.
На фиг.20 можно видеть, что последовательность состоит из обычных окон LD-MDCT 2020а, 2020b (как на фиг.17) до тех пор, пока в действие не вступает кодек временной области. Для перехода от AAC-ELD к кодеку временной области не требуется специальное переходное окно. В силу этого для принятия решения о переключении на кодек временной области упреждение не требуется, а следовательно нет и дополнительной задержки.
При переходе от кодека временной области к AAC-ELD применяют окно 2020 с специальной переходной формы, отличающееся от обычных окон AAC-ELD 2020a, 2020b, 2020d, 2020e, но только в левой его части, которая перекрывает сигнал, закодированный во временной области (взвешивающее окно 2040 для сигнала, закодированного во временной области). Это переходное окно 2020 с показано на фиг.21 а и сопоставлено с обычным окном анализа AAC-ELD на фиг.21b.
На фиг.21 а графически представлено окно анализа 2020 с перехода от кодека временной области к AAC-ELD. Абсцисса 2110 отображает шкалу времени в аудиоотсчетах, а ордината 2112 отображает шкалу значений оконной функции.
Кривая 2120 описывает значения оконной функции анализа 2020 с в зависимости от положения отсчета внутри окна.
На фиг.21B графически сопоставлены окно анализа 2020 с, 2120 перехода от кодека временной области к AAC-ELD (сплошная линия) и нормированное окно анализа AAC-ELD 2020a, 2020b, 2020d, 2020e, 2170 (пунктирная линия). Абсцисса 2160 отображает время в пересчете на аудиоотсчеты, а ордината 2162 отображает (нормализованные) значения окна.
Обратим внимание на то, что в последовательности аналитических окон на фиг.20 все окна анализа, следующие за окном перехода 2020 с, не используют входные отсчеты, расположенные слева от ненулевой области переходного окна 2020 с.Несмотря на то, что эти оконные коэффициенты (или значения оконной взвешивающей функции) отражены на графике фиг.20, в действительности их не используют в обработке входного сигнала. Так происходит благодаря обнулению входного буфера при анализирующем оконном взвешивании слева от ненулевой области окна перехода 2020 с.
Дальше следует детализация алгоритма оконно-весового синтеза. Синтезирующее оконное взвешивание может быть применено в аудиодекодере, описанном ранее. На фиг.22 графически представлена соответствующая последовательность окон синтеза. Эта последовательность выглядит подобной инвертированной во времени последовательности оконного взвешивания анализа, однако в силу особенностей вносимой задержки она требует отдельного рассмотрения.
Другими словами, на фиг.22 графически отображен пример последовательности окон синтеза переходов между AAC-ELD и кодеком временной области. Для детализации построения графиков обратимся к легенде фиг.22.
На фиг.22 абсцисса 2210 отображает время в пересчете на аудиоотсчеты, а ордината 2212 отображает значения оконной функции. На фиг.22 представлены окна синтеза LD-MDCT (МДКП с малой задержкой) 2220а-2220е, оконное взвешивание 2240 закодированного во временной области сигнала и взвешивание 2250а, 2250b алиасинга во временной области сигнала временной области.
Перед переключением с AAC-ELD на кодек временной области применено окно перехода 2220 с, показанное на графике фиг.23A. Тем не менее, это переходное окно 2220 с не вносит в декодер никакую дополнительную задержку, поскольку левая часть этого окна, предназначенная для выполнения сложения наложением и, следовательно, для оптимальной реконструкции выходного сигнала обратного LD-MDCT во временной области, тождественна левой части нормированного синтезирующего окна AAC-ELD (в частности, окон синтеза 2220а, 2220b, 2220d, 2220е), что видно на фиг.23B. Следует указать на то, что, как и в последовательности окон анализа, участки окон синтеза 2220а, 2220b, предшествующих окну перехода 2220е, расположенные справа от ненулевой области окна перехода 2220е, в реальности не задействованы в формировании выходного сигнала. На практике это достигается обнулением выходного сигнала этих окон в правой части относительно ненулевой области переходного окна 2220е.
Для обратного переключая с кодека временной области на AAC-ELD специальные окна не требуются. Использование обычного окна синтеза AAC-ELD 2220е может быть возобновлено с самого начала закодированной в AAC-ELD составляющей сигнала.
На фиг.23A графически представлено окно синтеза 2220е, 2320 для перехода от AAC-ELD к кодеку временной области. На фиг.23A абсцисса 2310 отображает шкалу времени в аудиоотсчетах, а ордината 2312 отображает шкалу значений окна. Кривая 2320 описывает значения окна синтеза 2220е как функцию от идеального положения отсчетов.
На фиг.23B графически сопоставлены окно синтеза 2220е перехода от AAC-ELD к кодеку временной области (сплошная линия) и нормированное окно синтеза AAC-ELD 2020а, 2020b, 2020d, 2020e, 2370 (пунктирная линия). Абсцисса 2360 отображает время в пересчете на аудиоотсчеты, а ордината 2362 отображает (нормализованные) значения оконной функции}.
Далее следует описание взвешивания сигнала, закодированного во временной области.
Несмотря на то, что взвешивание закодированного во временной области сигнала отображено как на фиг.20 (последовательность анализирующих окон), так и на фиг.22 (последовательность синтезирующих окон), оно применяется только один раз, преимущественно после кодирования и декодирования во временной области, то есть - в декодере 300. Кроме того, оно также может быть применено в кодере, то есть - перед кодированием во временной области, или в кодере и в декодере таким образом, что конечный результат взвешивания соответствует весовой функции, задействованной на фиг.19, 20 и 22.
На указанных фигурах видно, что полный диапазон отсчетов временной области, охватываемый весовой функцией (сплошная линия с точками 1940, 2040, 2240) несколько превышает длину двух фреймов входных отсчетов. Если быть точнее, в приведенном примере требуются 2*N+0,5*N отсчетов, закодированных во временной области, чтобы заполнить промежуток, созданный двумя фреймами (с N новых входных отсчетов на фрейм), не закодированными кодеком в формате LD-MDCT. Если, предположим, N=512, то 2*512+256 отсчетов временной области должны быть закодированы во временной области вместо 2*512 спектральных величин. Таким образом, при переключении на кодек временной области и обратно будет введен оверхед, объемом всего в половину фрейма.
На очереди более подробное рассмотрение алиасинга во временной области. При переходах к кодеку временной области и обратно - к кодеку трансформанты во временную область целевым образом вводят алиасинг для нейтрализации алиасинга во временной области, вносимого соседними фреймами, закодированными в LD-MDCT. Кроме прочего, алиасинг во временной области может быть внесен активатором антиалиасингового сигнала 360. Пунктирные линии с точками 1950а, 1950b, 2050a, 2050b, 2250a, 2250b отображают весовую функцию для этой операции. Закодированный во временной области сигнал умножают на эту весовую функцию, и затем складывают с, или, соответственно, вычитают из оконно-взвешенного сигнала временной области в обратном временном представлении.
4. 6. Алгоритм оконного взвешивания в соответствии с фиг.24
Ниже рассмотрим альтернативное построение длин переходов. При более близком рассмотрении последовательностей анализа на фиг.20 и синтеза на фиг.22 можно заметить, что окна переходов не являются полными временными инверсиями друг друга. Переходные окна анализа и синтеза не служат друг другу точным зеркальным отражением. Синтезирующее окно перехода (фиг.23A) имеет более короткую ненулевую область, чем анализирующее окно перехода (фиг.21A). И при анализе, и при синтезе такая длина задается независимо как в более короткую, так и в более длинную сторону. Однако, выбор длины (как показано на фиг.20 и 22) имеет под собой определенные обоснования. Чтобы уточнить эти обоснования, рассмотрим далее оба варианта выбора на примере диаграммы фиг.24.
На фиг.24 графически представлены варианты выбора окон перехода при коммутации оконной последовательности между AAC-ELD и кодеком временной области. На фиг.24 абсцисса 2410 отображает время в пересчете на аудиоотсчеты, а ордината 2412 отображает значения оконной функции. На фиг.24 представлены окна анализа МДКП с малой задержкой (LD-MDCT) 2420а к 2420е, окна синтеза МДКП с малой задержкой 2430а к 2430е, оконное взвешивание 2440 сигналов, закодированных во временной области, и взвешивание 2450а к 2450b алиасинга во временной области сигнала временной области. Детализация построения графиков с различными типами линий дана в легенде фиг.24.
На альтернативных графиках фиг.24 видно, что весовые функции для алиасинга во временной области при переходах от AAC-ELD к кодеку временной области расширены влево. Это означает необходимость введения дополнительной составляющей сигнала временной области, причем, для целевого алиасинга во временной области (или для устранения алиасинга во временной области), а не для формирования реального перехода наплывом. Это считается неэффективным и излишним. Следовательно, для перехода от AAC-ELD к кодеку временной области предпочтителен выбор более короткого синтезирующего окна перехода и, соответственно, более короткий участок алиасинга во временной области (как показано на фиг.19).
С другой стороны, при переходе от кодека временной области к AAC-ELD более короткое окно анализа перехода на фиг.24 (по сравнению с фиг.19) в результате формирует для этого окна худшую частотную характеристику. Кроме того, более длинный участок алиасинга во временной области на фиг.19 на этом переходе не требует никаких дополнительных отсчетов, закодированных кодеком временной области, поскольку эти отсчеты в любом случае доступны в кодекс временной области. Из этого следует, что для перехода от кодека временной области к AAC-ELD выбор более длинного окна перехода и, соответственно, более длинного участка алиасинга во временной области (как на фиг.19) является предпочтительным.
Тем не менее, в некоторых вариантах реализации кодера 100 и декодера 300 применима схема оконного взвешивания в соответствии с фиг.24 даже при том, что схема оконного взвешивания согласно фиг.19 является более выигрышной для аудиокодера 100 или аудиодекодера 300.
4.7. Алгоритм оконного взвешивания в соответствии с фиг.25
Рассмотрим альтернативную схему оконного взвешивания сигнала временной области и альтернативный способ разбиения на фреймы.
До сих пор в данном описании сигнал временной области подвергался оконному взвешиванию только один раз, после кодирования и декодирования во временной области. Эта процедура оконного взвешивания может быть разделена на два этапа: перед кодированием во временной области и после декодирования во временной области. Это проиллюстрировано на фиг.25, на примере перехода от AAC-ELD к кодеку временной области.
На фиг.25 графически представлены альтернативные способы оконного взвешивания сигнала временной области и фрагментирования на фреймы. Абсцисса 2510 отображает время в пересчете на аудиоотсчеты, а ордината 2512 отображает (нормализованные) значения оконной функции. На фиг.25 представлены окна анализа LD-MDCT 2520а-2520е, окна синтеза LD-MDCT 2530a-2530d, окно анализа 2542 для взвешивания перед кодеком временной области, окно синтеза 2552 для свертывания/развертывания алиасинга во временной области (TDA) и взвешивания после кодека временной области, окно анализа 2562 для первого МДКП после кодека временной области и окно синтеза 2572 для первого МДКП после кодека временной области.
На фиг.25 также представлен альтернативный способ разбиения на фреймы для кодека временной области. В кодеке временной области все фреймы могут быть одной длины, поскольку отсутствует необходимость компенсации пропущенных отсчетов благодаря некритической дискретизации на переходе. Однако, в последующем кодеку МДКП может потребоваться такая компенсация за счет первого после кодека временной области фрейма МДКП, который содержит больше спектральных величин, чем другие фреймы МДКП (линии 2562 и 2572).
В целом, вариант на фиг.25 делает кодек очень похожим на кодек гибридного кодирования речи и звука (кодек USAC), но с гораздо меньшей задержкой.
Дальнейшая небольшая модификация этого варианта реализации приведет к перемещению оконно-взвешенного перехода из кодека временной области в AAC-ELD (линии 2542, 2552, 2562, 2572) посредством прямоугольного перехода, как это осуществляется в AMR-WB+при переходе из ACELP в ТСХ. В кодеке, использующем AMR-WB+в качестве „кодека временной области", это может также означать, что после фрейма ACELP нет прямого перехода от ACELP к AAC-ELD, но между ними всегда есть фрейм ТСХ. За счет этого нейтрализуется потенциальная дополнительная задержка, вносимая этим специфическим переходом, и вся система в целом имеет столь же малую задержку как AAC-ELD. Дополнительно это делает коммутацию более гибкой, так как оперативное обратное переключение на AAC-ELD в случае речеподобных сигналов более эффективно, чем переключение с AAC-ELD на ACELP, поскольку ACELP и ТСХ имеют общую фильтрацию LPC.
4.8. Алгоритм оконного взвешивания в соответствии с фиг.26
Далее, рассмотрим механизм ввода в кодек временной области сигналов TDA и получения критической дискретизации.
На фиг.26 представлен еще один альтернативный вариант реализации. Формулируя точнее, на фиг.26 продемонстрирован способ введения в кодек временной области сигналов алиасинга во временной области (TDA) и достижения посредством этого критической (адаптивной) дискретизации. На фиг.26 абсцисса 2610 отображает шкалу времени в аудиоотсчетах, а ордината 2612 отображает шкалу (нормализованных) значений оконной взвешивающей функции. На фиг.26 представлены окна анализа LD-MDCT 2620а - 2б20е, окна синтеза LD-MDCT 2630a - 2630е, окно анализа 2642а для взвешивания и свертывания TDA перед кодеком временной области и окно синтеза 2652а для развертывания и взвешивания TDA после кодека временной области. Детализация кривых диаграммы дана в легенде фиг.26.
В этом варианте входной сигнал для кодека временной области обрабатывают с задействованием того же механизма оконного взвешивания и TDA, что и LD-MDCT, a сигнал алиасинга во временной области вводят в кодек временной области. После декодирования TDA, развертывание и оконное взвешивание применяют к выходному сигналу кодека временной области.
Преимущество этого варианта реализации состоит в том, что на переходах достигается критическая дискретизация. Недостаток состоит в том, что во временной области кодируется сигнал TDA вместо сигнала временной области. После развертывания декодированного сигнала TDA ошибки кодирования зеркально отражаются и в силу этого могут вызывать артефакты предэха.
4.9. Другие альтернативные решения
Перейдем к обсуждению некоторых альтернативных подходов, способных усовершенствовать процессы кодирования и декодирования.
В рамках разработок кодека USAC, ведущихся в настоящее время в стандарте MPEG, большие усилия направлены на унификацию форматов ААС и ТСХ. Такая унификация базируется на методах прямого антиалиасинга (FAC) и формирования искажения в частотной области (FDNS). Этот инструментарий может быть использован также в контексте коммутирования между AAC-ELD и AMR-WB+в качестве кодека с сохранением малой задержки AAC-ELD.
Некоторые детали данной концепции обсуждались в контексте фиг.1-14. Дальше кратко коснемся возможного применения так называемого „лифтинга" в некоторых конструктивных решениях. МДКП с малой задержкой / LD-MDCT в формате AAC-ELD также может осуществляться с использованием эффективной схемы лифтинга. Для описываемых здесь переходных окон лифтинг также может быть применен с формированием окон перехода путем простого исключения некоторых коэффициентов лифтинга.
5. Возможные модификации
Все рассмотренные выше конструктивные решения допускают внесение в них ряда модификаций. К ним относится изменение длины окна в зависимости от конкретных требований. Масштабирование окон также может быть видоизменено. Безусловно, допускается изменение масштабирования между окнами в тракте области трансформанты и при оконном взвешивании в тракте ACELP. Кроме того, могут быть введены некоторые шаги по выполнению операций предварительной обработки (препроцессинга) и/или последующей обработки (постпроцессинга) на входе блоков обработки, описанных выше, а также - между блоками обработки, описанными выше, без изменения основной концепции изобретения. Естественно, допускаются и другие виды модификаций.
6. Альтернативные конструктивные решения
Несмотря на то, что здесь в основном рассматривается оборудование с точки зрения его технического устройства, понятно, что аспекты материальной части тесно связаны с описанием соответствующих способов ее применения, и какое-либо изделие или блок соответствуют особенностям метода или технологической операции. Аналогично, рассматриваемые технологии и рабочие операции непосредственно связаны с соответствующим машинным оборудованием и его элементной базой. Некоторые или все шаги предлагаемого способа могут быть выполнены с использованием аппаратных средств, таких, например, как микропроцессор, программируемый компьютер или электронная схема. В некоторых случаях осуществления одна или больше ответственных операций, составляющих данный способ, могут быть выполнены таким устройством.
Относящийся к изобретению кодированный аудиосигнал может быть сохранен в цифровой запоминающей среде или может быть транслирован в среде передачи информации, такой как беспроводная передающая среда или проводная передающая среда, например, Интернет.
В зависимости от конечного назначения и особенностей практического применения изобретение может быть реализовано в аппаратных или программных средствах. В реализации могу быть применены такие цифровые носители информации, как гибкий диск, DVD, „Блю-рей", CD, ПЗУ, ППЗУ, программируемое ПЗУ, СППЗУ или ФЛЭШ-память, содержащие электронно-считываемые управляющие сигналы, которые взаимодействуют (или совместимы) с программируемой компьютерной системой таким образом, что предлагаемый способ может быть осуществлен. Следовательно, цифровая среда хранения данных может быть читаемой компьютером.
Некоторые варианты конструкции согласно данному изобретению имеют в своем составе носитель информации, содержащий электронно считываемые сигналы управления, совместимый с программируемой компьютерной системой и способный участвовать в реализации одного из описанных здесь способов.
В целом данное изобретение может быть реализовано как компьютерный программный продукт с кодом программы, обеспечивающим осуществление одного из предлагаемых способов при условии, что компьютерный программный продукт используется с применением компьютера. Код программы может, например, храниться на машиночитаемом носителе.
Различные варианты реализации включают в себя компьютерную программу, хранящуюся на машиночитаемом носителе, для осуществления одного из описанных здесь способов
Таким образом, формулируя иначе, относящийся к изобретению способ осуществляется с помощью компьютерной программы, имеющей код программы, обеспечивающий реализацию одного из описанных здесь способов, если компьютерную программу выполняют с использованием компьютера.
Далее, следовательно, техническое исполнение изобретенного способа включает в себя носитель данных (либо цифровой накопитель информации, либо читаемую компьютером среду), содержащий записанную на нем компьютерную программу, предназначенную для осуществления одного из способов, описанных здесь. Носитель данных, цифровая среда хранения или средства записи информации, как правило, представляют собой материальные предметы и/или не подлежат передаче средствами связи.
Отсюда следует, что реализация изобретения подразумевает наличие потока данных или последовательности сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов могут быть рассчитаны на передачу через средства связи, например, Интернет.
Кроме того, реализация включает в себя аппаратные средства, например, компьютер или программируемое логическое устройство, предназначенные или приспособленные для осуществления одного из описанных здесь способов.
Далее, для технического исполнения требуется компьютер с установленной на нем компьютерной программой для осуществления одного из описанных здесь способов.
Аппаратная версия заявляемого изобретения может быть дополнена средством или системой передачи (например, электронной или оптической) компьютерной программы осуществления одного из представленных здесь способов на удаленное принимающее устройство. Принимающее устройство может представлять собой, например, компьютер, мобильное устройство, ЗУ и т.п. Устройство или система, например, могут включать в себя файловый сервер для передачи компьютерной программы на принимающее устройство.
Некоторые версии конструкции для реализации одной или всех функциональных возможностей описанных здесь способов могут потребовать применение программируемого логического устройства (например, полевой программируемой матрицы логических элементов). В зависимости от назначения версии базовый матричный кристалл может сочетаться с микропроцессором для осуществления одного из описанных здесь способов. Как правило, описываемые способы могут быть реализованы с использованием любого аппаратного средства.
Описанные выше конструктивные решения являются лишь иллюстрациями основных принципов настоящего изобретения. Подразумевается, что для специалистов в данной области возможность внесения изменений и усовершенствований в компоновку и элементы описанной конструкции очевидна. В силу этого, представленные здесь описания и пояснения вариантов реализации изобретения ограничиваются только рамками патентных требований, а не конкретными деталями
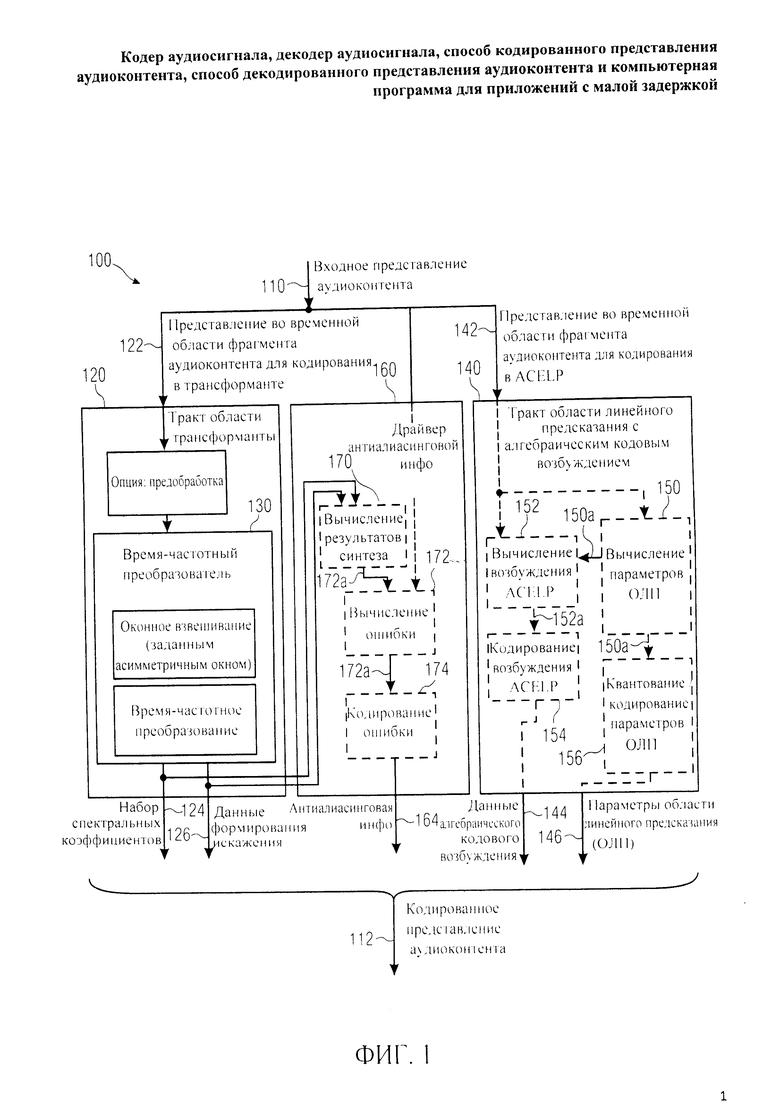
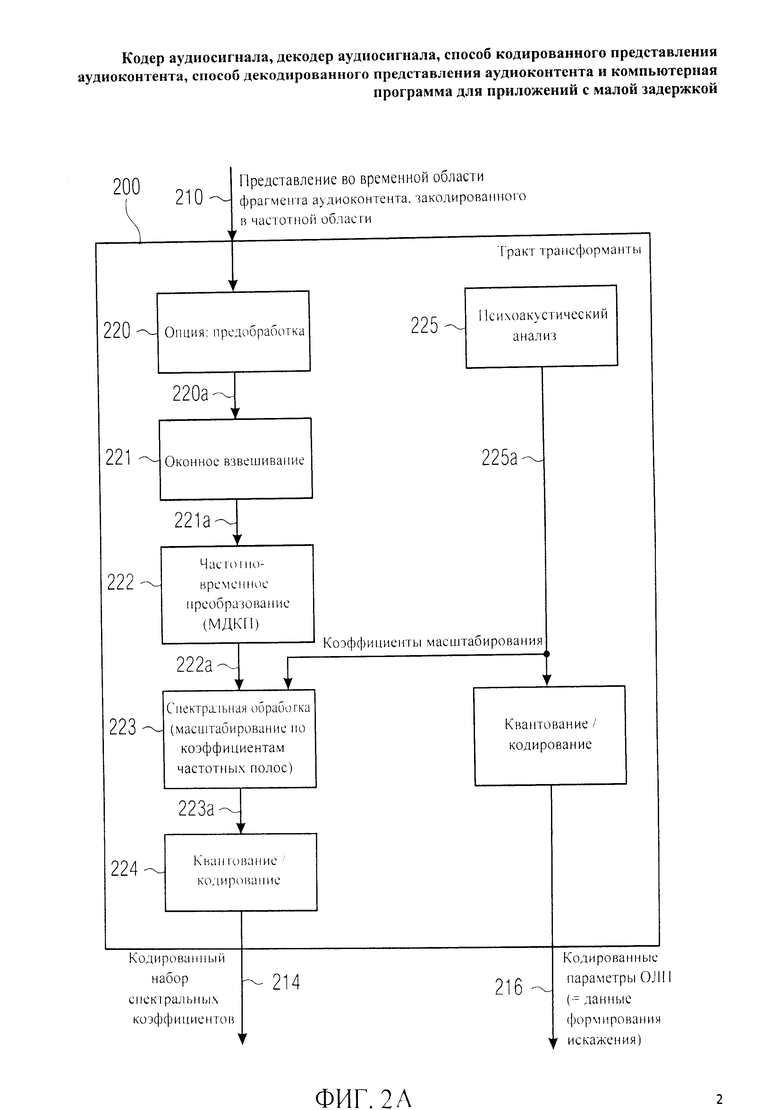
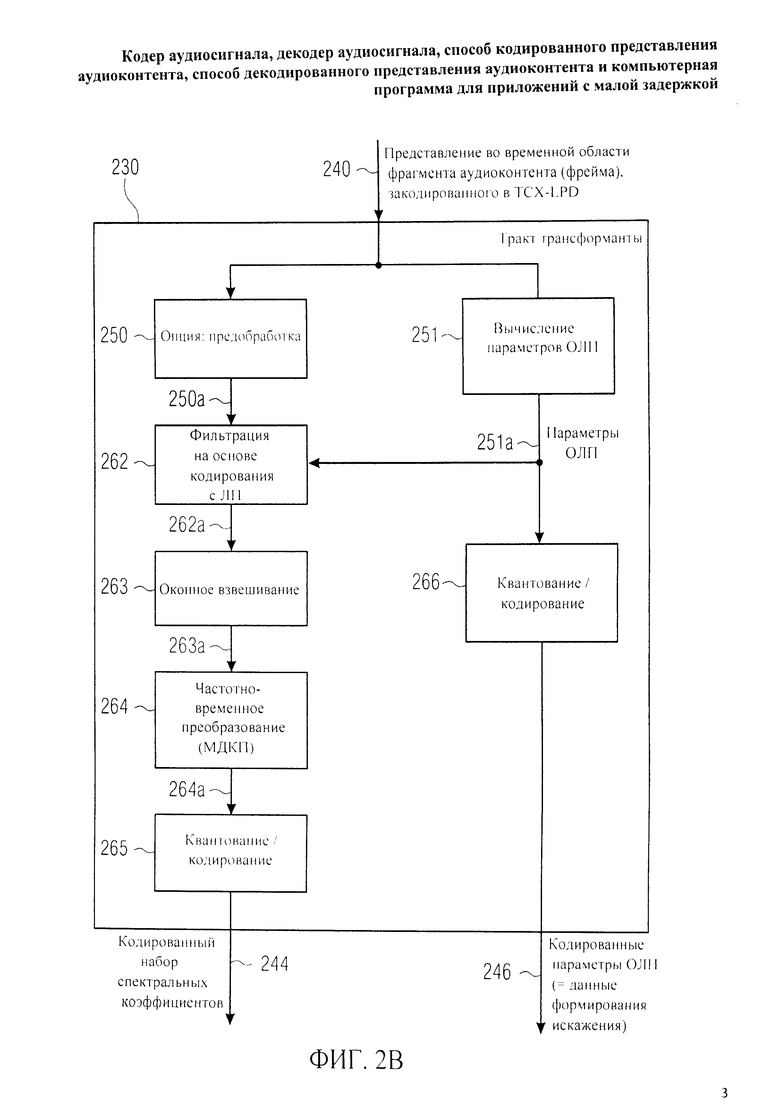
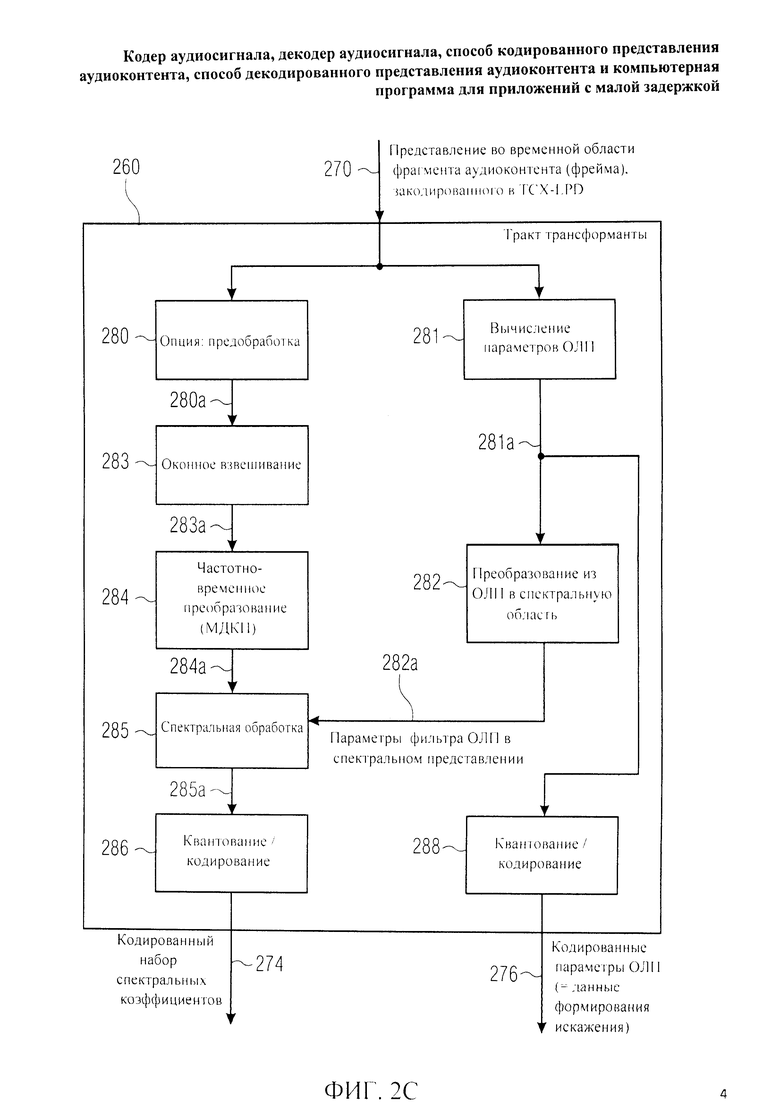
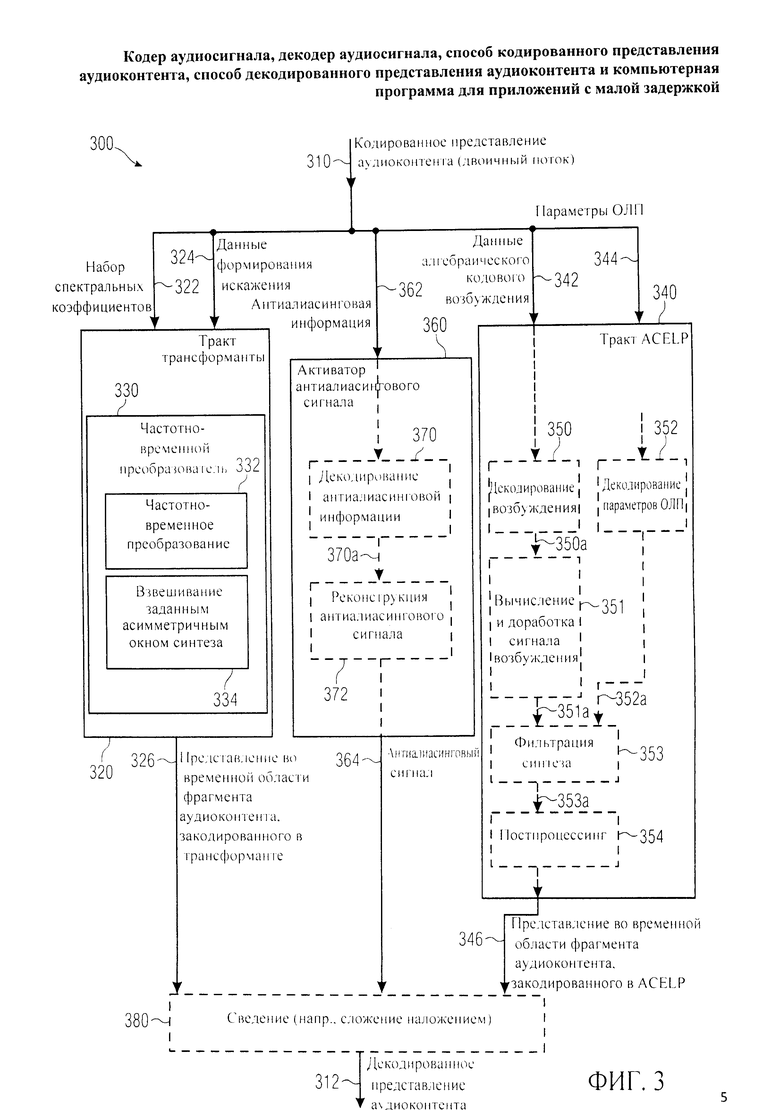
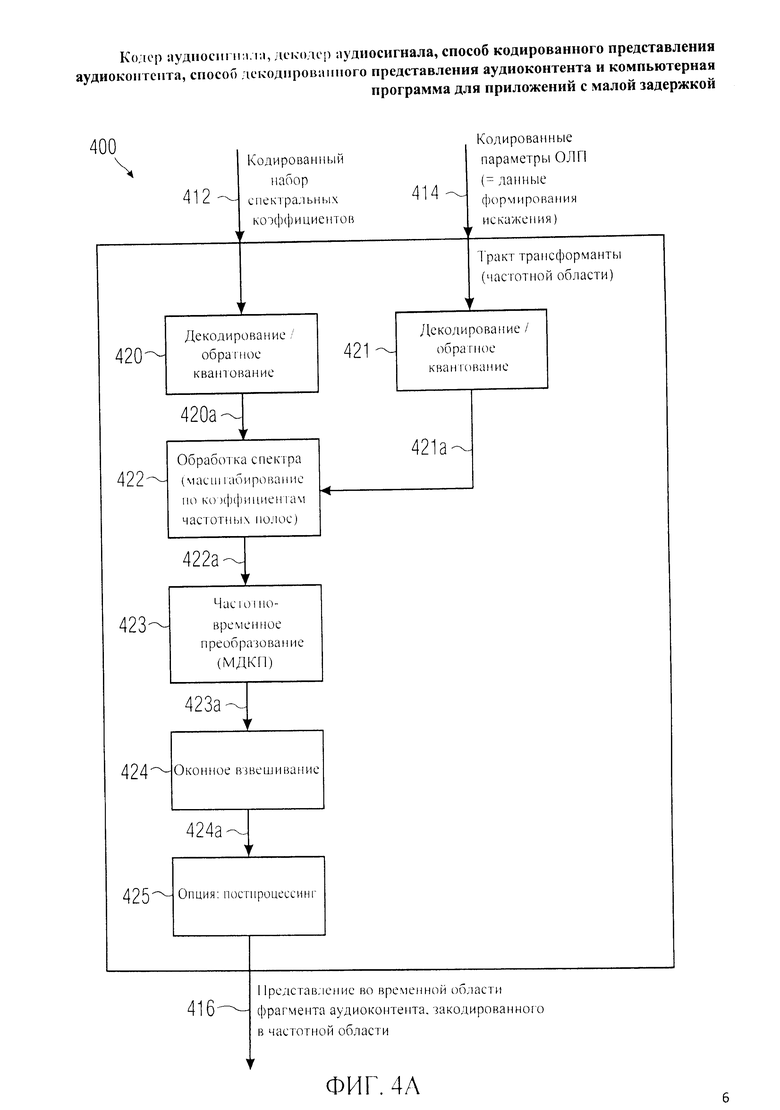
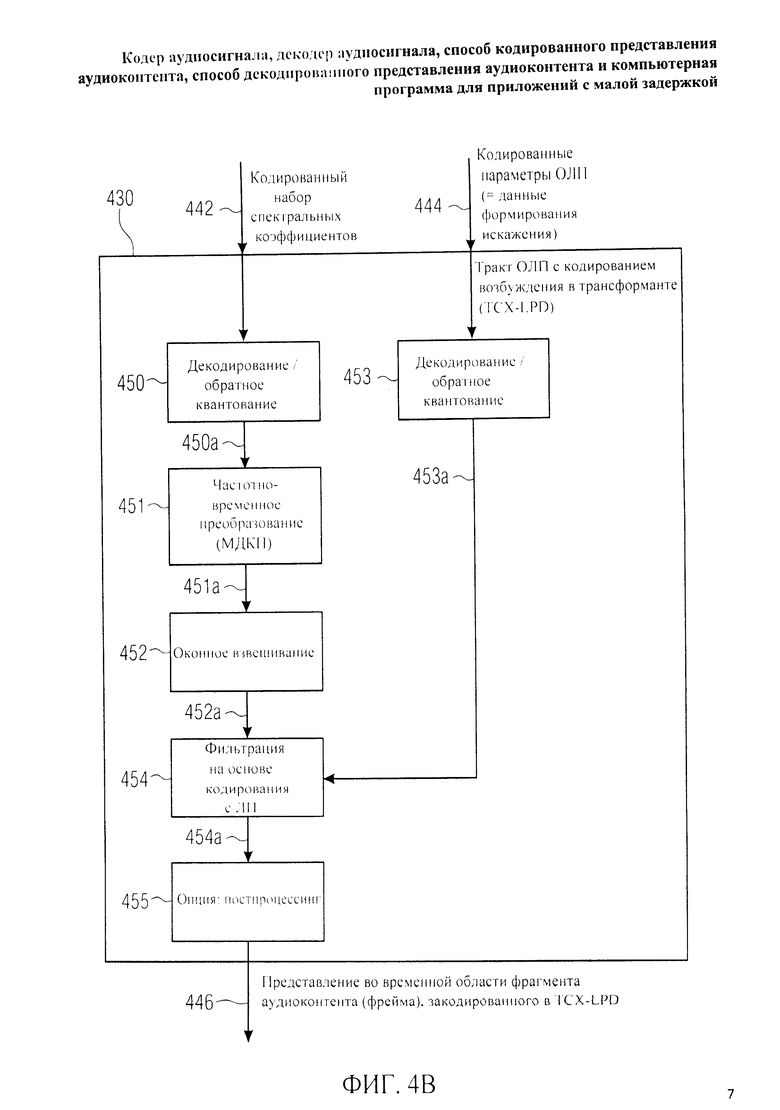
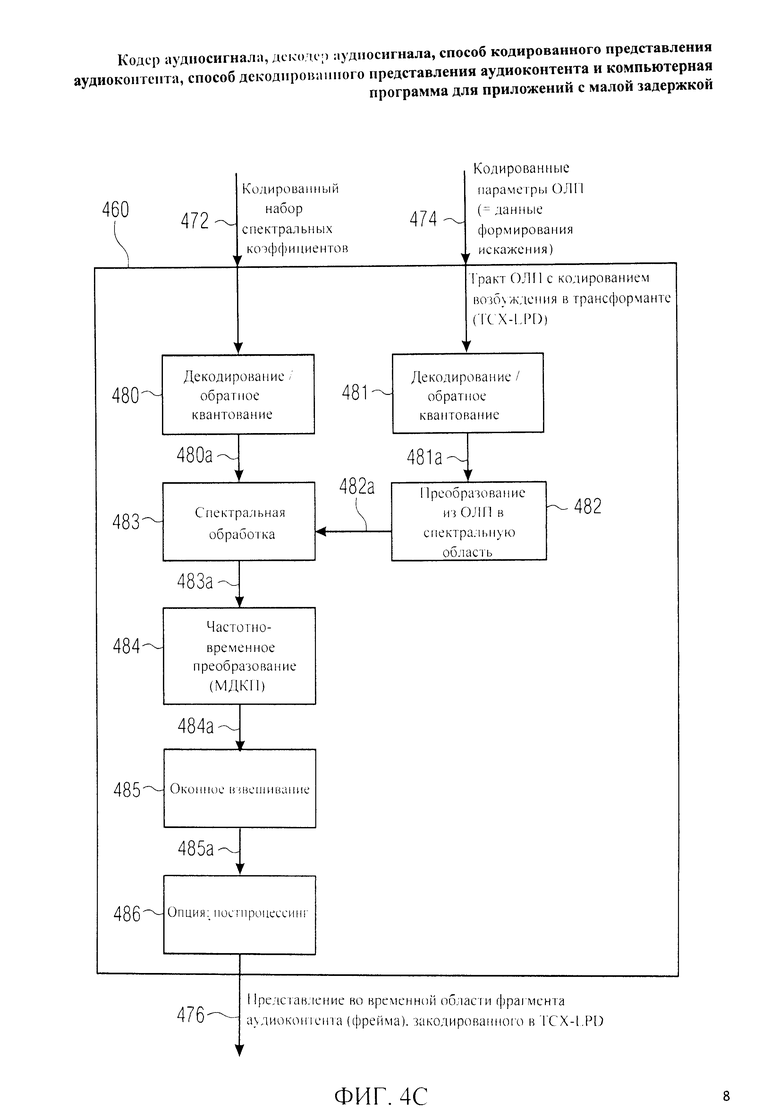

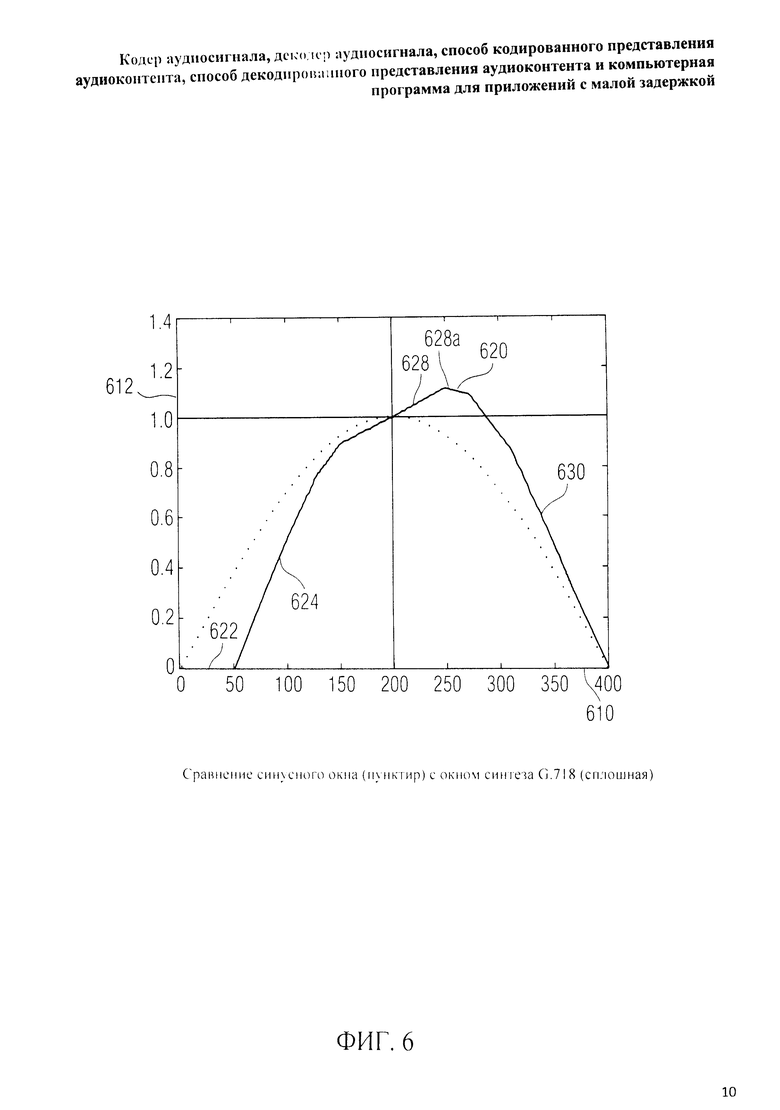
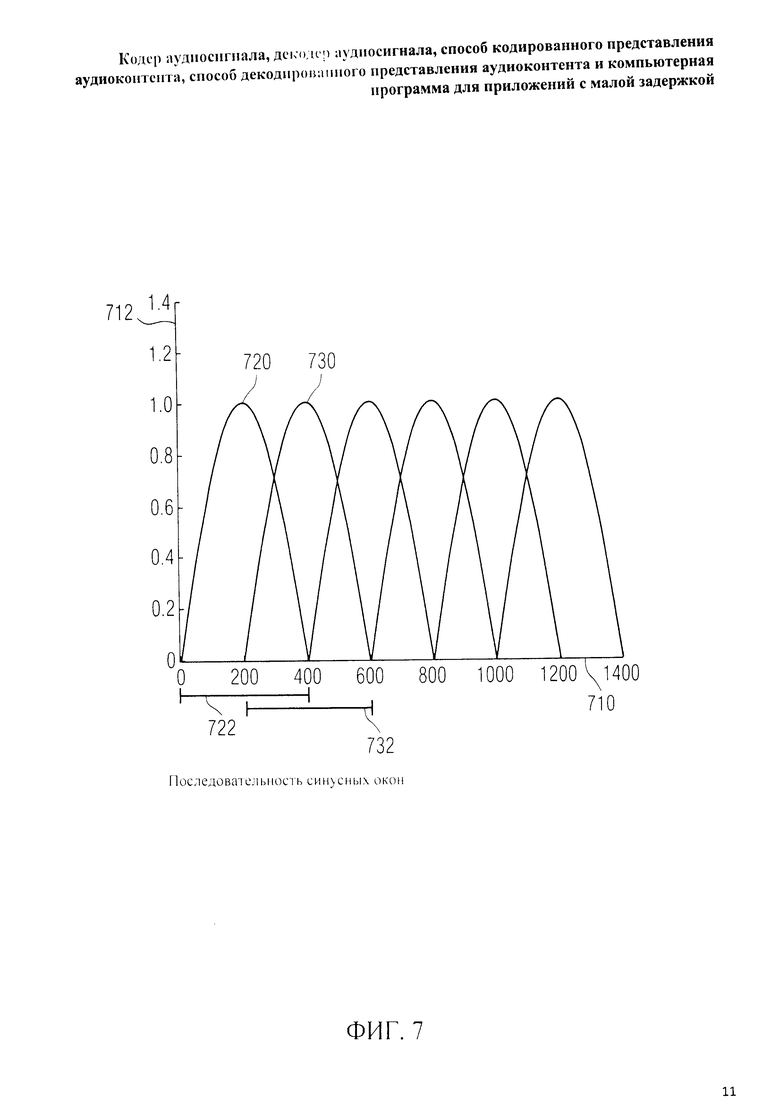
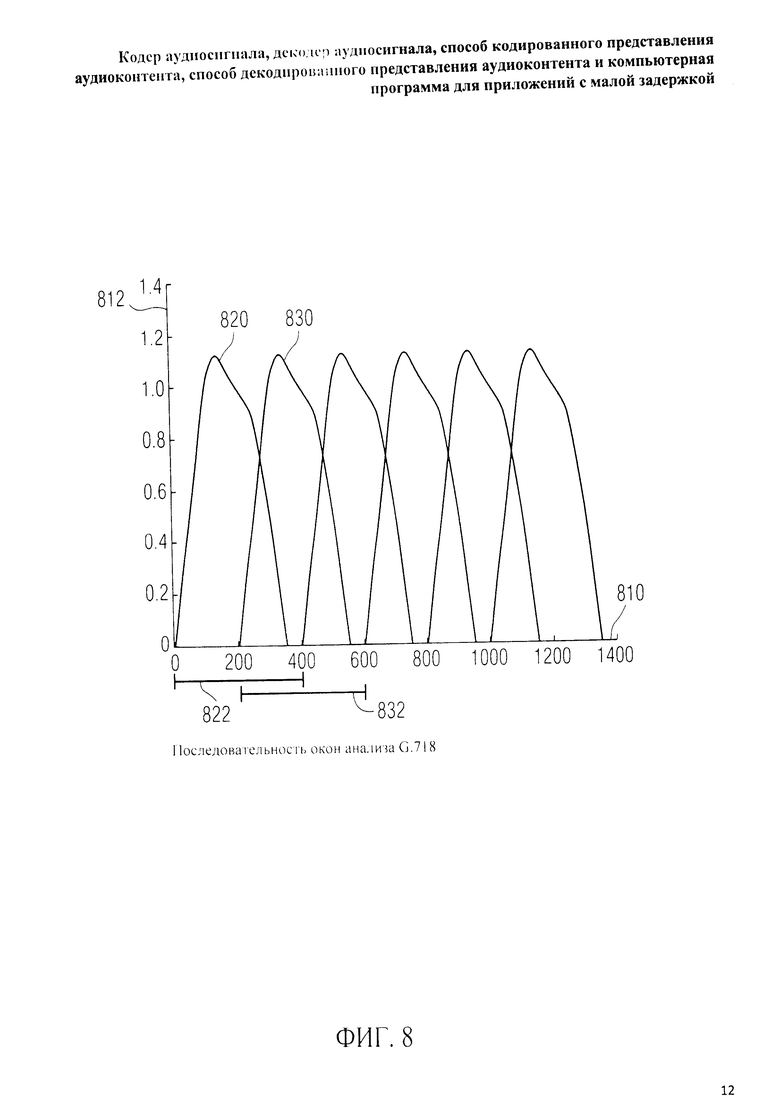
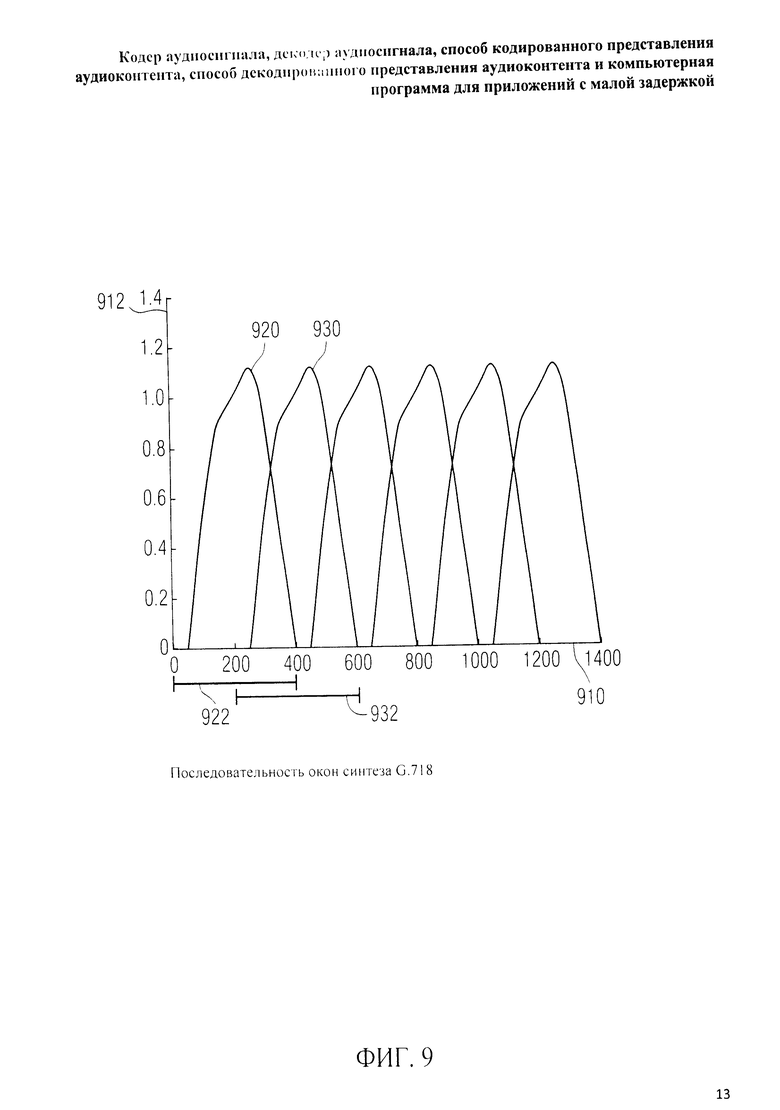
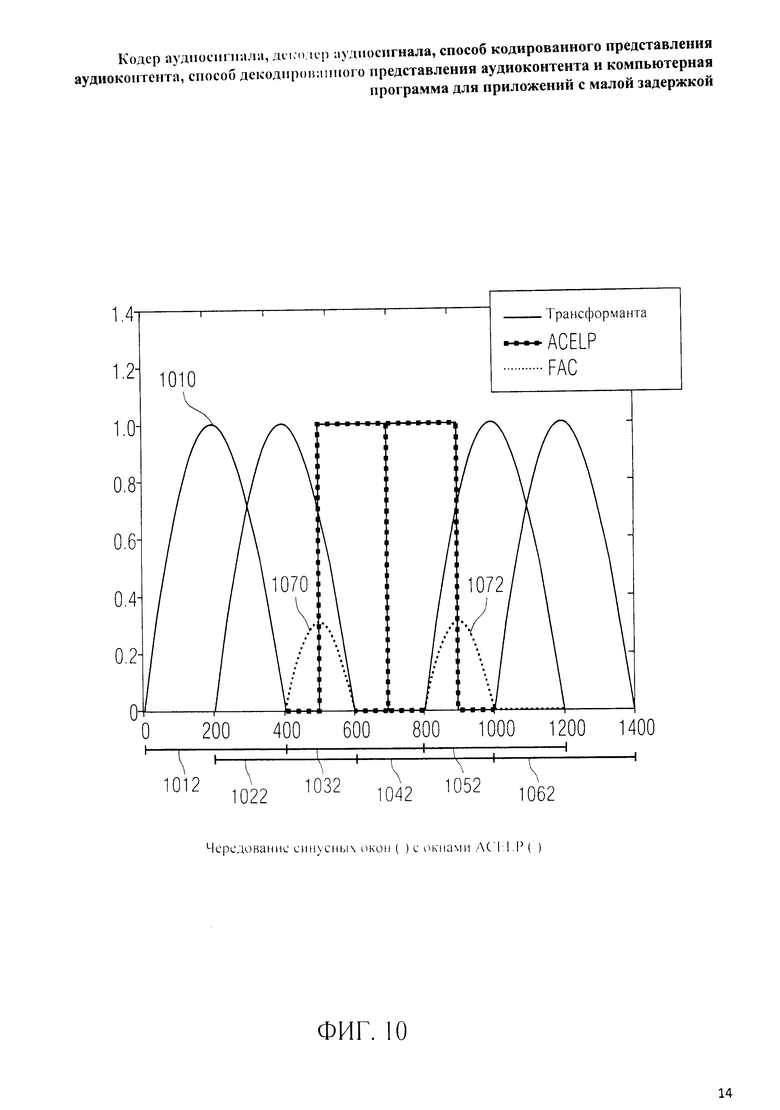
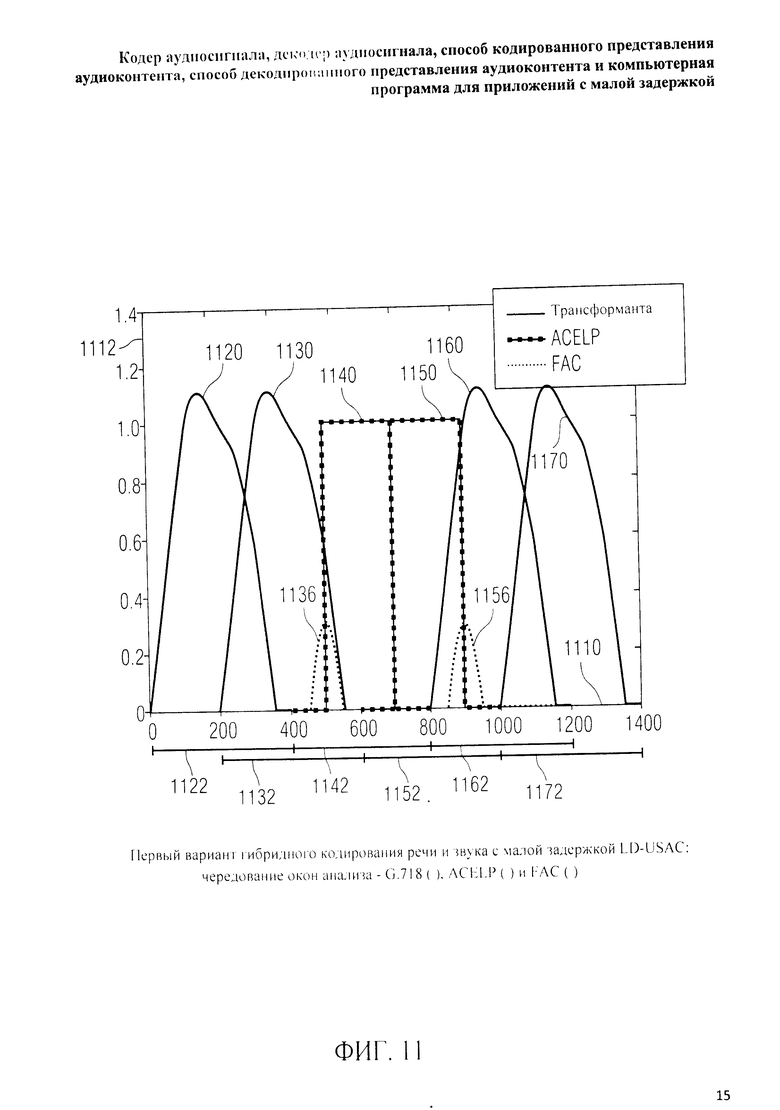
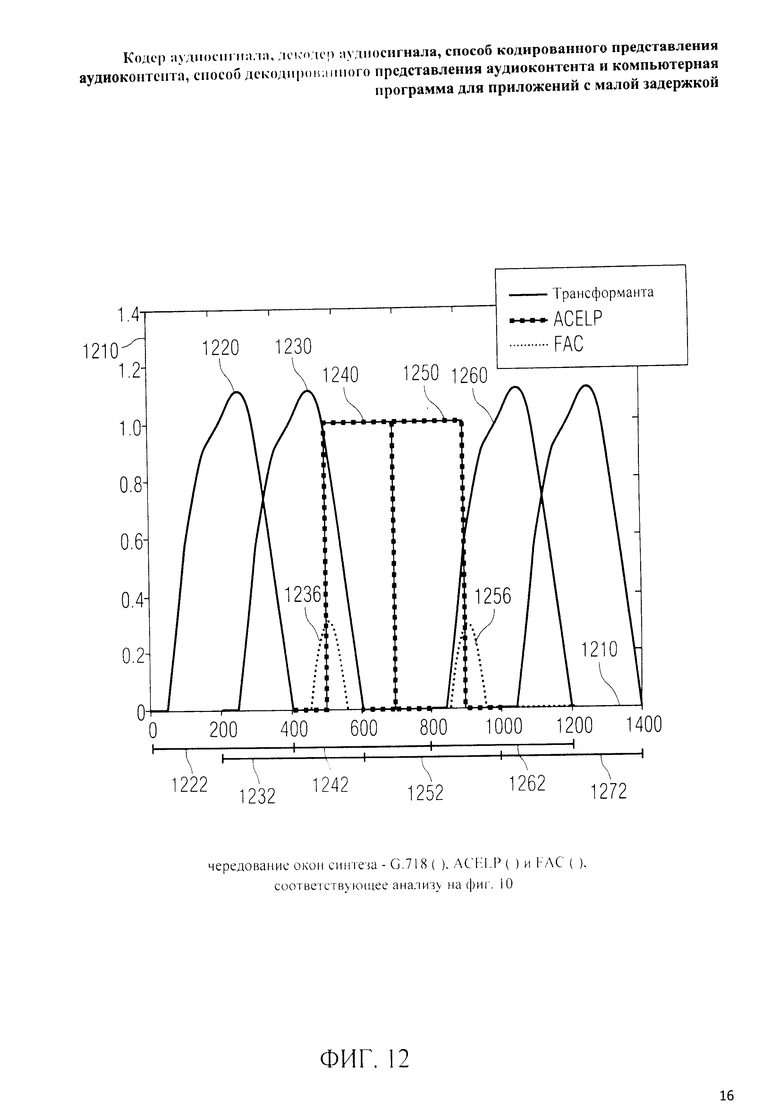
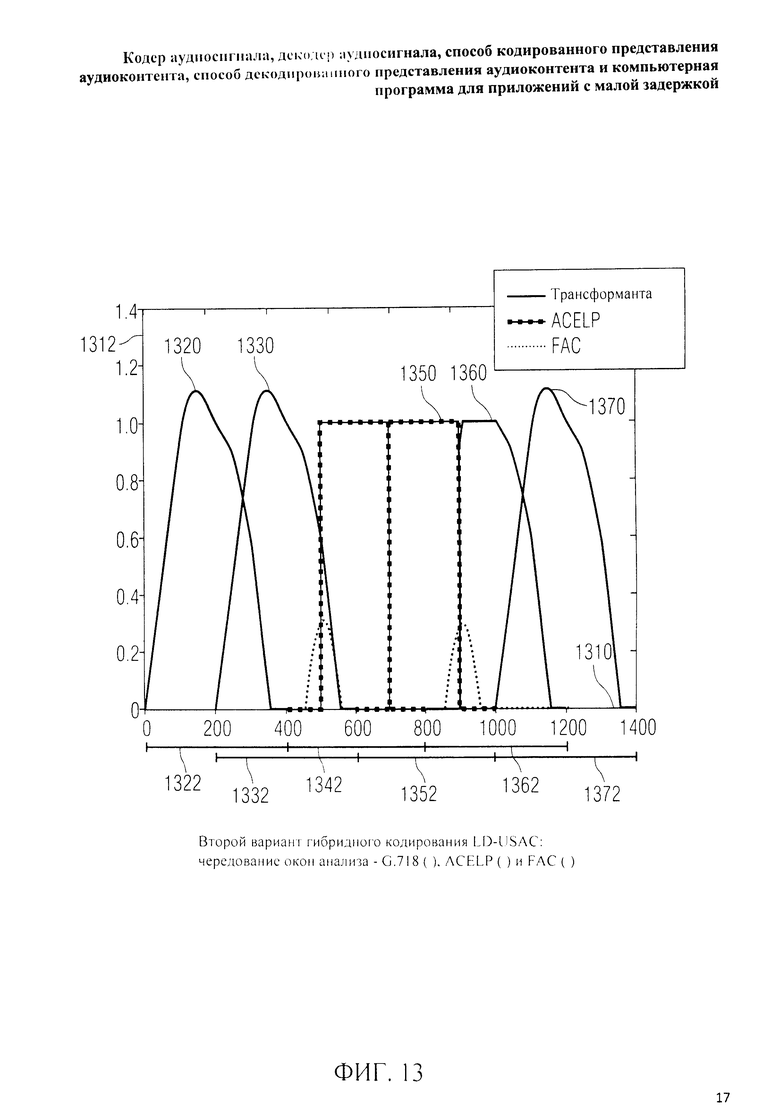
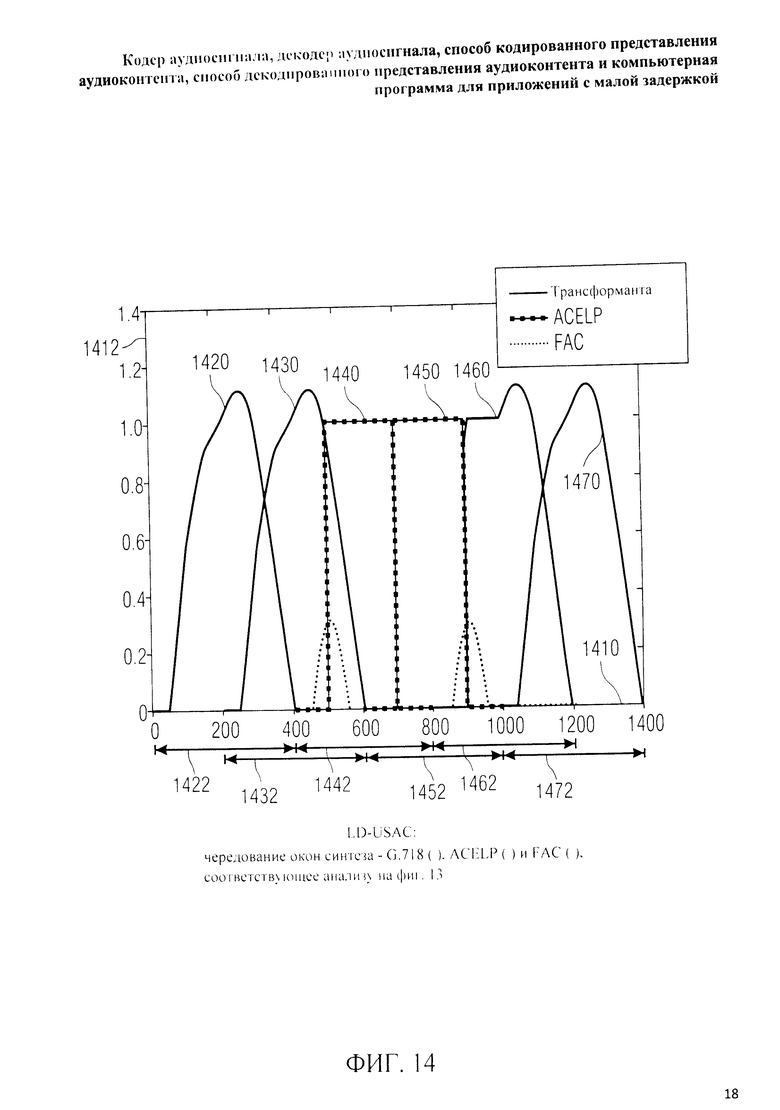
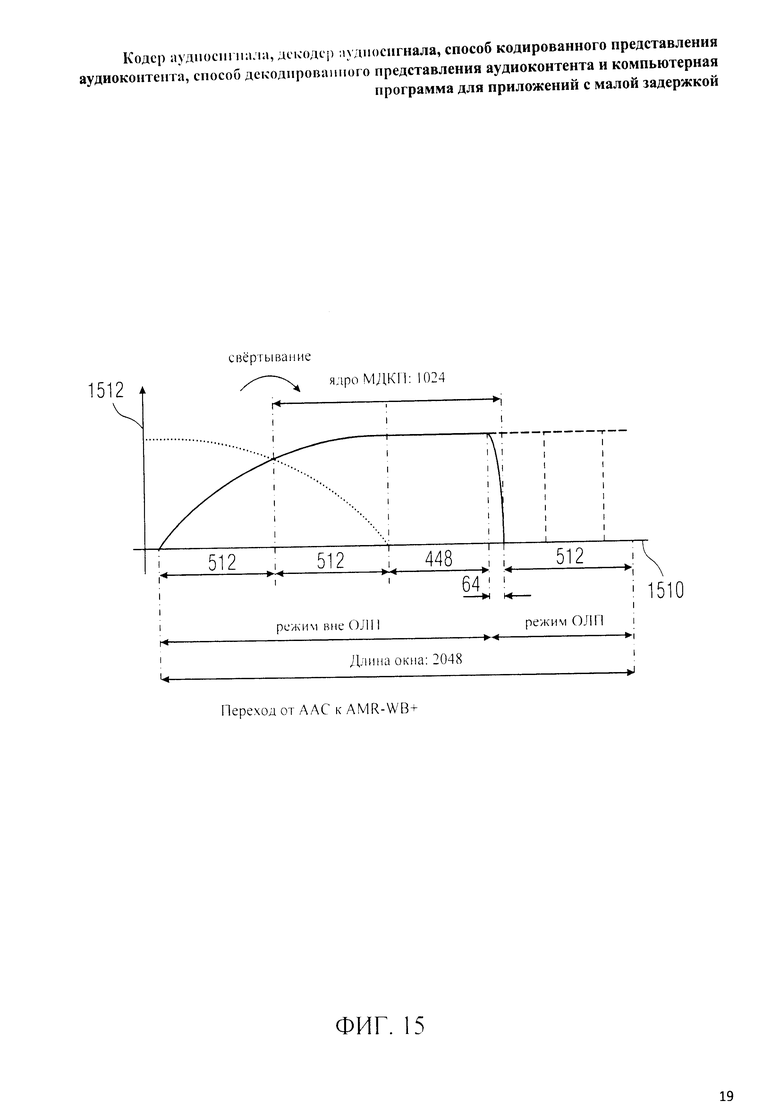
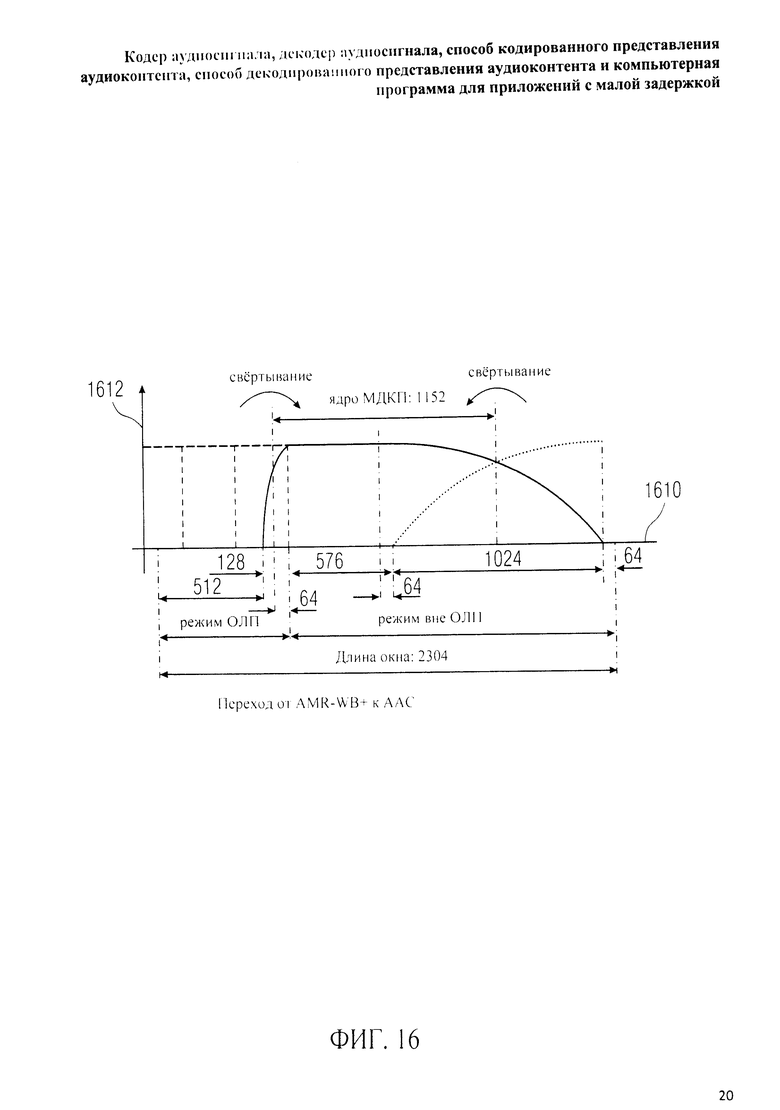
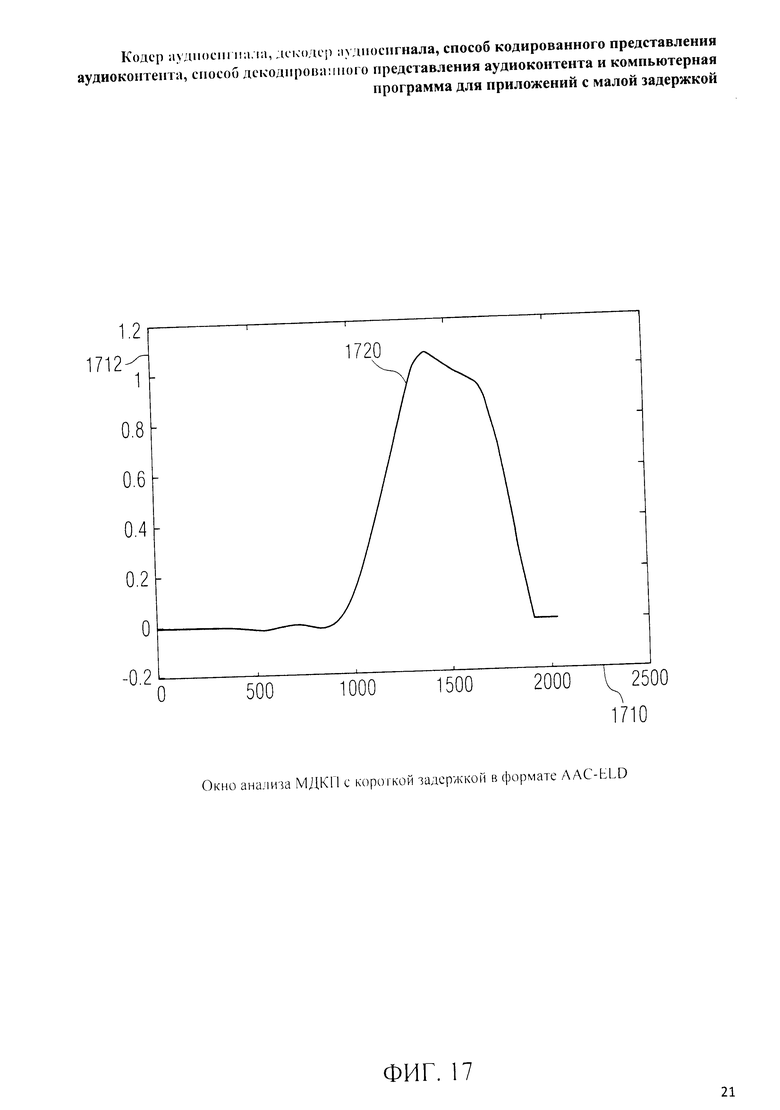

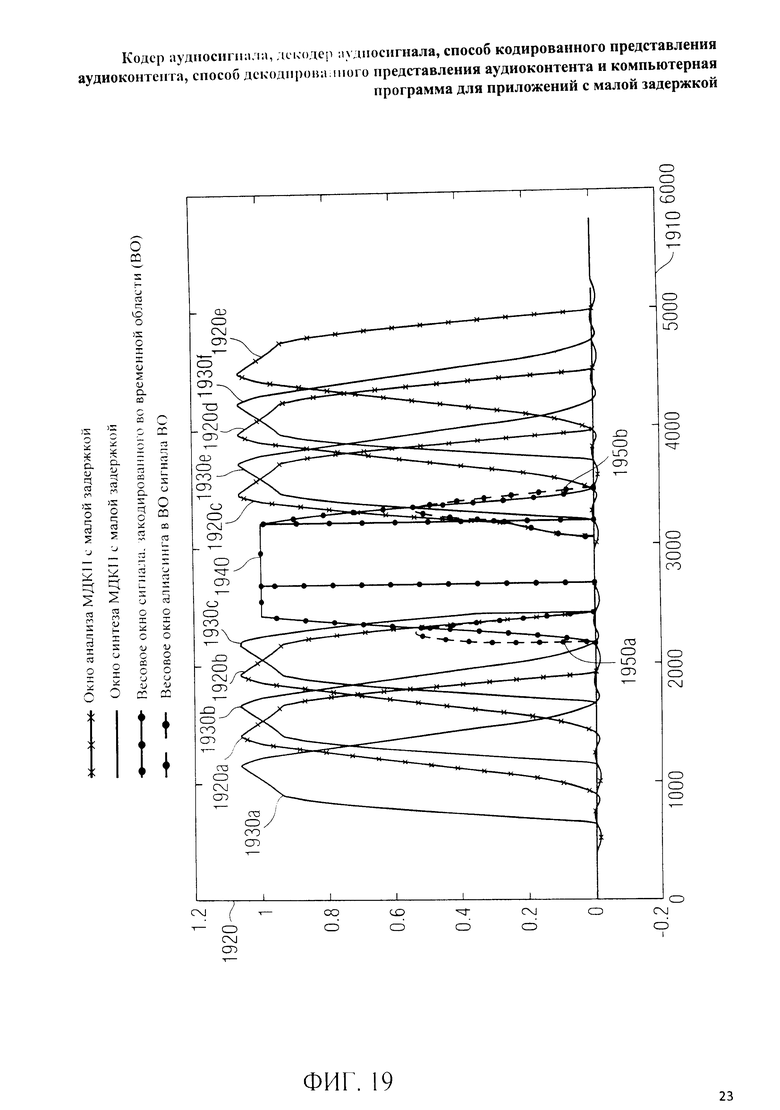

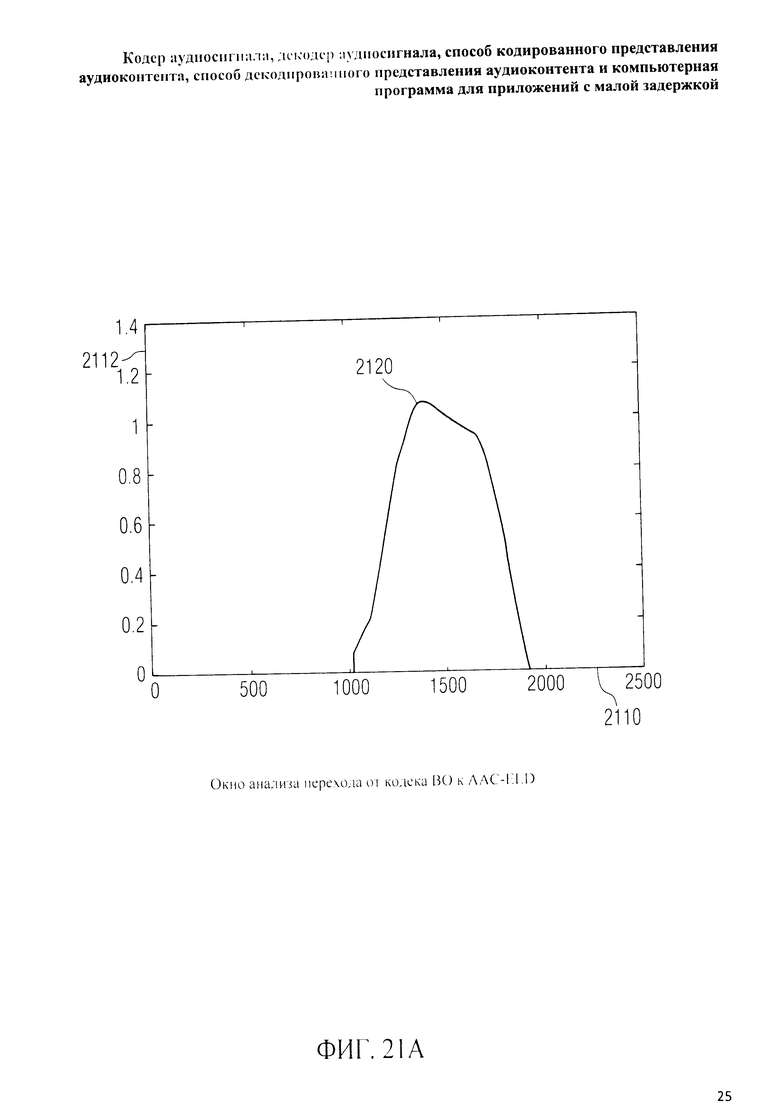
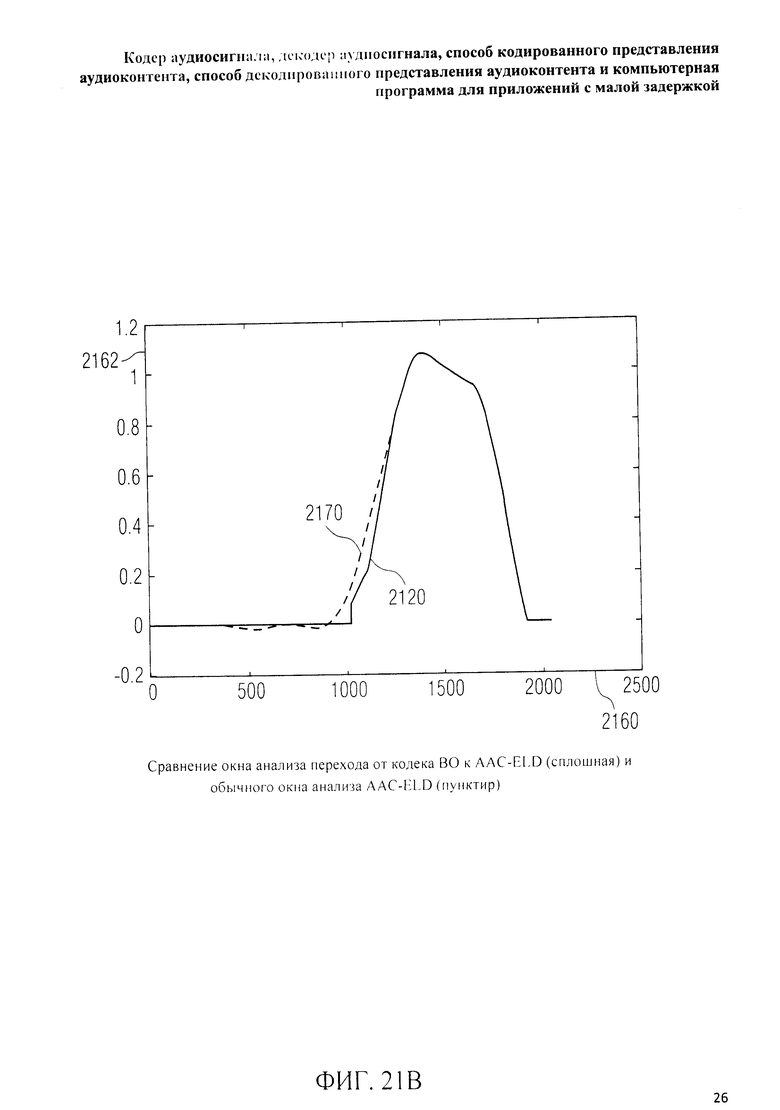
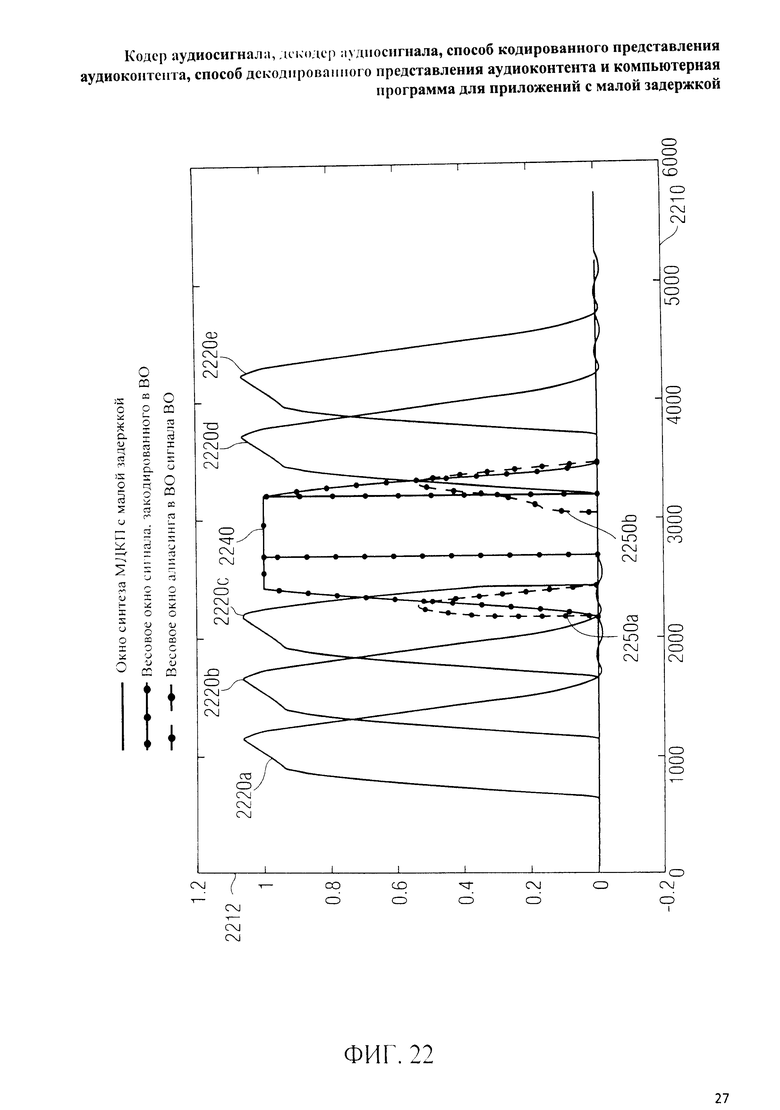
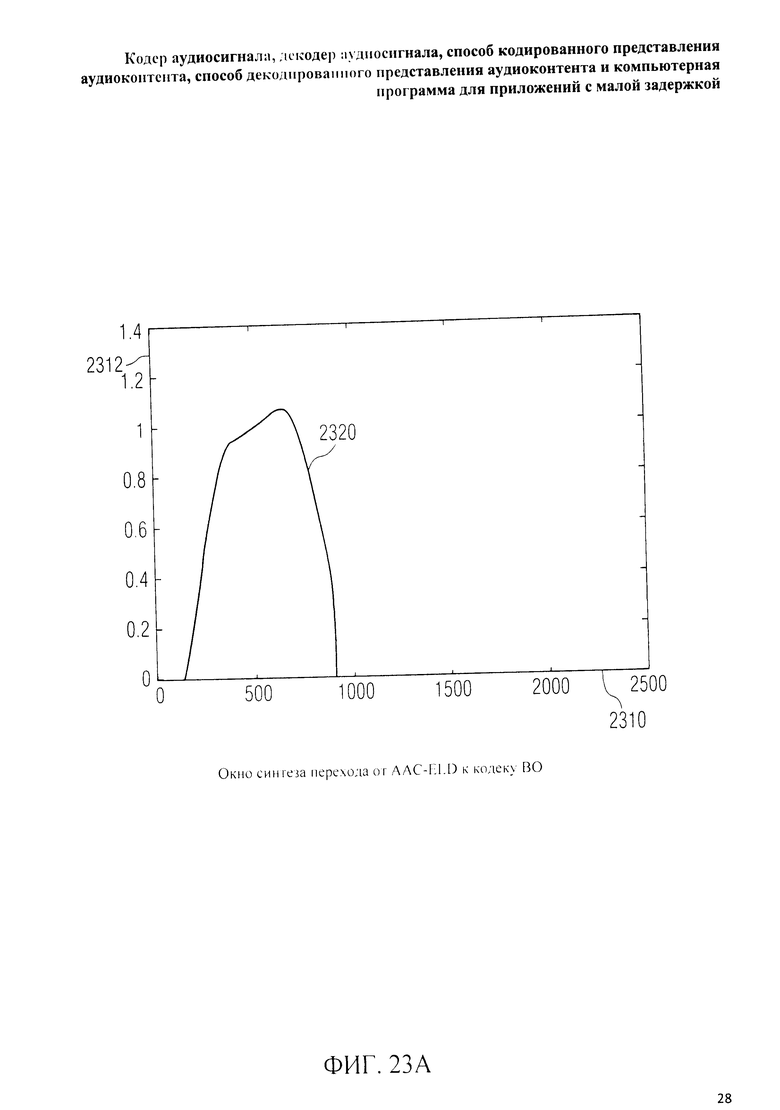
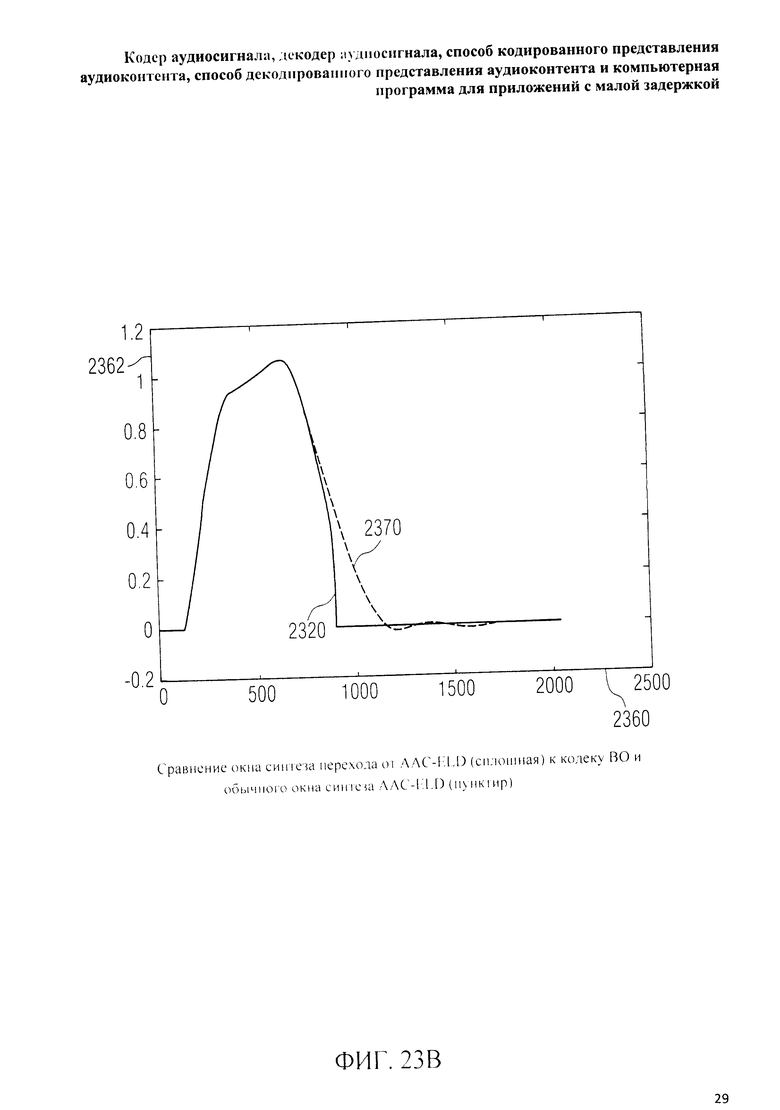
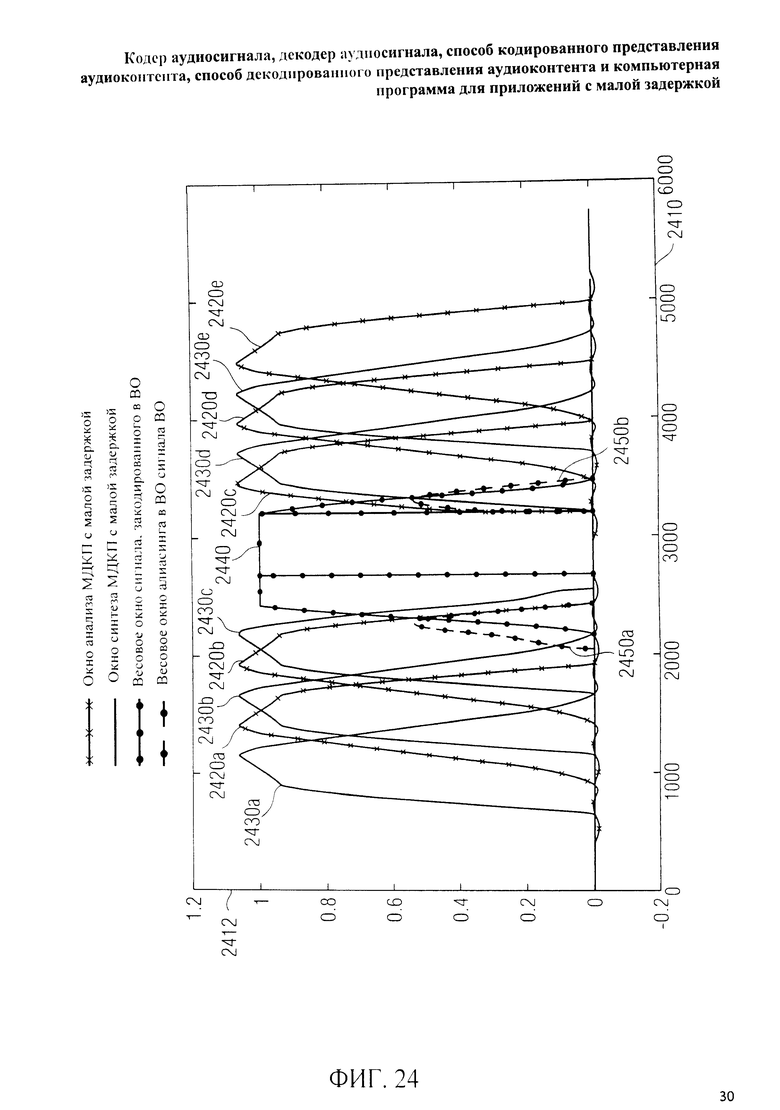
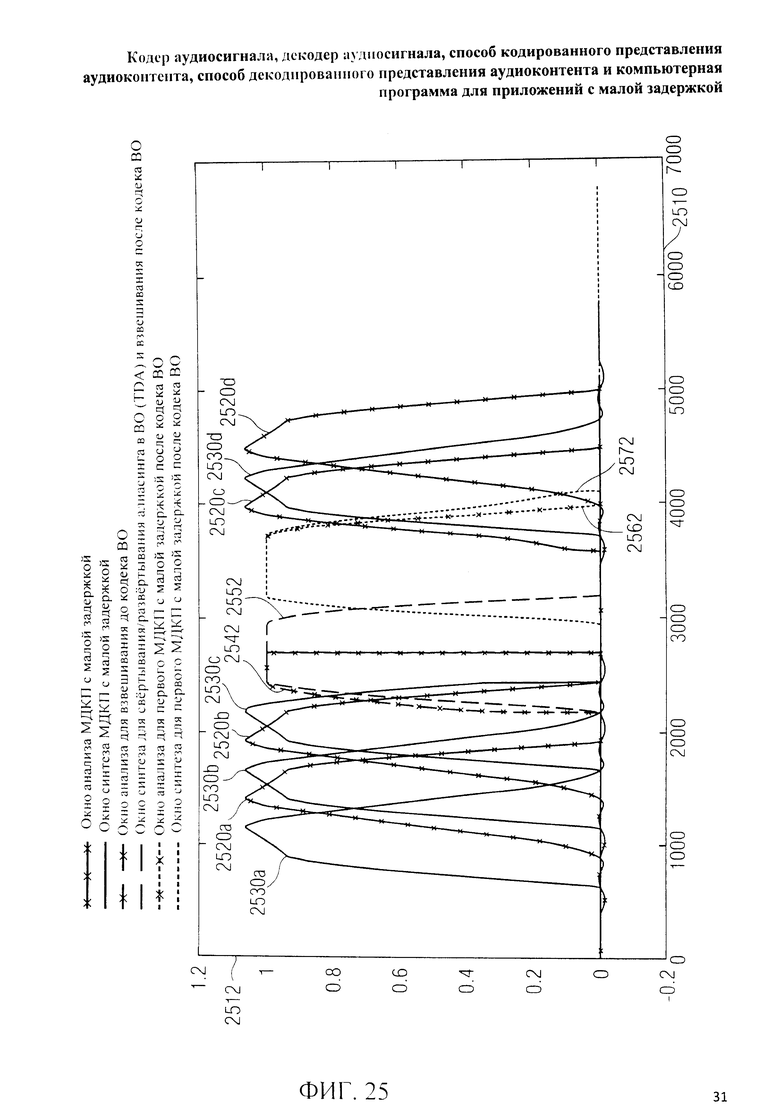
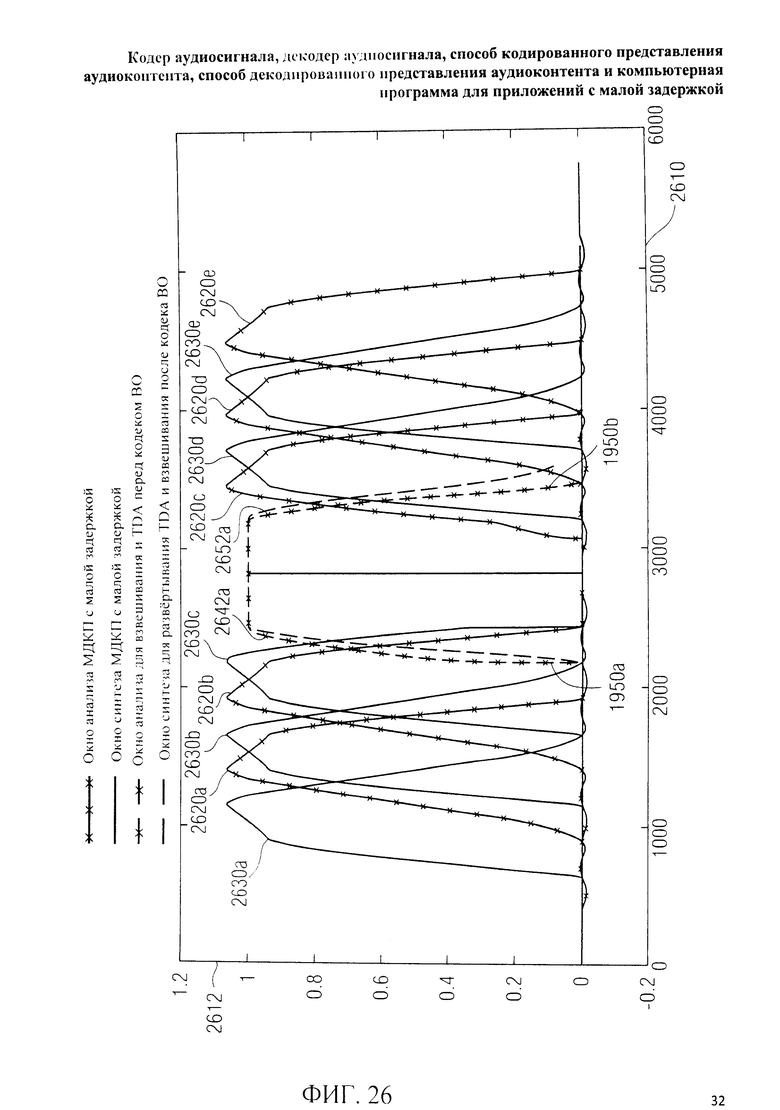
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности кодирования последовательных фрагментов аудиоконтента. Кодер аудиосигнала содержит тракт области трансформанты для выведения набора спектральных коэффициентов и информации о формировании искажения на основе представления во временной области фрагмента аудиоконтента, кодируемого в трансформанте. Тракт области трансформанты содержит время-частотный преобразователь, выполняющий оконное взвешивание представления аудиоконтента во временной области и выводящий набор спектральных коэффициентов с помощью время-частотного преобразования оконно-взвешенного временного представления аудиоконтента. Кодер аудиосигнала содержит тракт области линейного предсказания с кодовым возбуждением (CELP), который извлекает информацию о кодовом возбуждении и параметрах области линейного предсказания из фрагмента аудиоконтента, закодированного в режиме CELP. Кодер аудиосигнала предусматривает возможность избирательного формирования антиалиасинговой информации, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, кодируемый в режиме CELP. 6 н. и 22 з.п. ф-лы, 32 ил.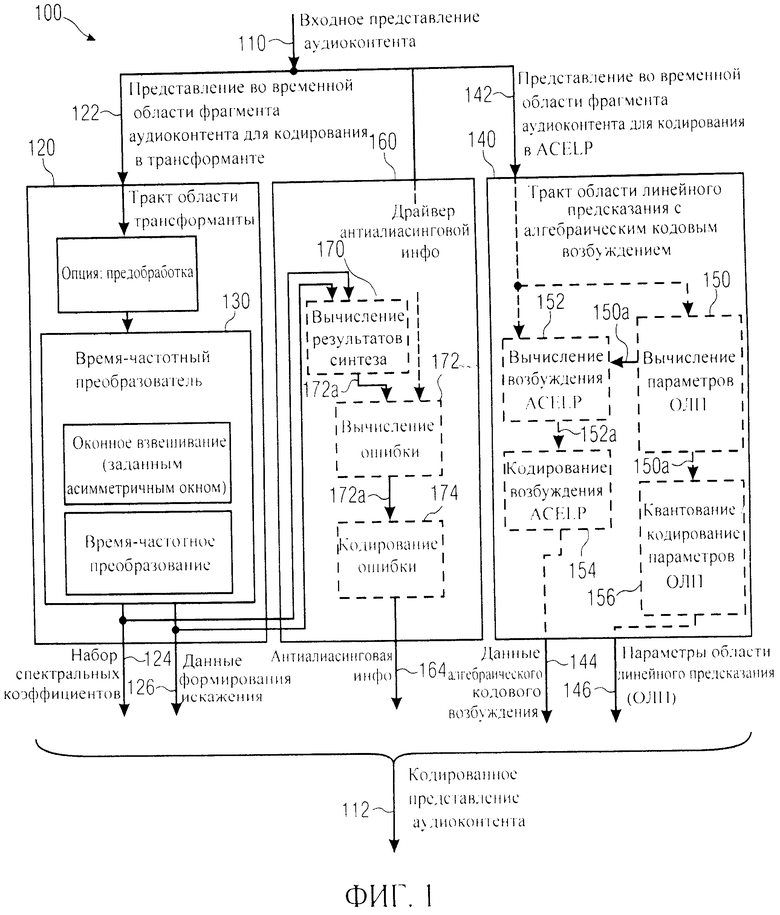
1. Кодер аудиосигнала (100), предназначенный для формирования кодированного представления (112) звуковых данных на основе входного представления (110) аудиоконтента, включающий тракт области трансформанты (120), реализованный для выведения набора спектральных коэффициентов (124) и информации о формировании искажения (126) на основе представления во временной области (122) фрагмента аудиоконтента, подлежащего кодированию в режиме области трансформанты, в результате чего спектральные коэффициенты (124) описывают спектр ограниченной по шуму версии (223а; 262а; 285а) аудиоконтента; при этом тракт области трансформанты (120; 200; 230; 260) включает в себя время-частотный преобразователь (130; 222; 264; 284), выполняющий оконное взвешивание представления аудиоконтента во временной области (220а; 280а) или его предобработанной версии (262а) с выведением оконно-взвешенного представления (221а; 263а; 283а) аудиоконтента и рассчитывающий при время-частотном преобразовании из оконно-взвешенного представления аудиоконтента во временной области набор спектральных коэффициентов (222а; 264а; 284а); и тракт области линейного предсказания с кодовым возбуждением (тракт CELP) (140), реализованный для формирования данных кодового возбуждения (144) и параметров области линейного предсказания (146) на базе фрагмента аудиоконтента, подлежащего кодированию в режиме области линейного предсказания с кодовым возбуждением (в режиме CELP); где время-частотный преобразователь (130; 221, 222; 263, 264; 283, 284) предусматривает применение заданного асимметричного окна анализа (520; 1130; 1330) для оконного взвешивания текущего фрагмента (1132; 1332) аудиоконтента, подлежащего кодированию в режиме области трансформанты и следующего за фрагментом (1122; 1322) аудиоконтента, закодированным в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент (1142; 1342) аудиоконтента, подлежащий кодированию в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP; одновременно, аудиокодер выполнен с возможностью избирательного формирования антиалиасинговой информации (164), содержащей компоненты антиалиасингового сигнала, которые будут введены в представление последующего фрагмента (1142; 1342) аудиоконтента в области трансформанты, когда за текущим фрагментом (1132; 1332) аудиоконтента следует фрагмент (1142; 1342) аудиоконтента, подлежащий кодированию в режиме CELP.
2. Кодер аудиосигнала (100) по п.1, в котором время-частотный преобразователь (130; 222; 264; 284) использует одно и то же окно (520, 1130, 1330) для взвешивания текущего фрагмента (1132; 1332) аудиоконтента, подлежащего кодированию в режиме области трансформанты и следующего за фрагментом (1122; 1322) аудиоконтента, закодированным в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент (1142; 1342) аудиоконтента, подлежащий кодированию в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP.
3. Кодер аудиосигнала (100) по п.1, использующий заданное асимметричное окно анализа (520, 1130, 1330), которое состоит из левой половины окна и правой половины окна, из которых левая половина окна содержит левосторонний скос фронта перехода (522), где значения оконной взвешивающей функции монотонно возрастают от нуля до центрального значения окна, и содержит участок всплеска (524), где значения оконной функции превышают центральное значение окна и где оконная функция достигает своего максимального значения (524а); и из которых правая половина окна содержит правосторонний скат перехода (528), где значения оконной взвешивающей функции монотонно убывают от центрального значения окна до нуля, и содержит правостороннюю нулевую область (530).
4. Кодер аудиосигнала (100) по п.3, задействующий окно, у которого левая половина содержит не более одного процента нулевых значений оконной функции и у которого правосторонняя нулевая область (530) содержит по меньшей мере 20% значений правой половины окна.
5. Кодер аудиосигнала (100) по п.3, использующий заданное асимметричное окно анализа (520), правая половина которого содержит значения, меньшие, чем центральное значение окна, и не содержит участок всплеска.
6. Кодер аудиосигнала (100) по п.1, использующий заданное асимметричное окно анализа (520), ненулевая область которого короче по меньшей мере на 10%, чем длина фрейма.
7. Кодер аудиосигнала (100) по п.1, предусматривающий по меньшей мере 40-процентное временное перекрывание при кодировании последовательных фрагментов (1122, 1132, 1162, 1172; 1322, 1332, 1362, 1372) аудиоконтента в режиме трансформанты; и предусматривающий временное перекрывание при кодировании текущего фрагмента (1132; 1332) аудиоконтента в режиме области трансформанты и кодировании последующего фрагмента (1142; 1342) аудиоконтента в режиме области линейного предсказания с кодовым возбуждением; и выполненный с возможностью избирательной подготовки антиалиасинговой информации (164) для инициации на стороне аудиодекодера (300) антиалиасингового сигнала (364), устраняющего артефакты алиасинга при переходе от фрагмента (1232) аудиоконтента, закодированного в режиме трансформанты, к фрагменту (1242) аудиоконтента, закодированному в режиме CELP.
8. Кодер аудиосигнала (100) по п.1, предусматривающий возможность выбора окна (1130; 1330) для взвешивания текущего фрагмента (1132; 1332) аудиоконтента, независимо от режима кодирования последующего фрагмента (1142; 1342) аудиоконтента, который перекрывает по времени текущий фрагмент аудиоконтента таким образом, что оконно-взвешенное представление (221а; 263а; 283а) текущего фрагмента аудиоконтента взаимно перекрывается с последующим фрагментом (1142; 1342) аудиоконтента, даже если последующий фрагмент аудиоконтента кодируется в режиме CELP; и предусматривающий в качестве отклика на распознавание ожидаемого кодирования последующего фрагмента (1142; 1342) аудиоконтента в режиме CELP формирование антиалиасинговой информации (164), содержащей компоненты антиалиасингового сигнала, которые вводятся в представление последующего фрагмента (1142; 1342) аудиоконтента в режиме области трансформанты.
9. Кодер аудиосигнала (100) по п.1, в котором время-частотный преобразователь (130; 221, 222; 263, 264; 283, 284) использует заданное асимметричное окно анализа (520; 1160) для взвешивания текущего фрагмента (1162) аудиоконтента, подлежащего кодированию в режиме трансформанты и следующего за фрагментом (1152) аудиоконтента, закодированным в режиме CELP, таким образом, что оконно-взвешенное представление (221а; 263а; 283а) текущего фрагмента (1162) аудиоконтента, подлежащего кодированию в режиме области трансформанты, перекрывает по времени предшествующий фрагмент (1152) аудиоконтента, закодированный в режиме CELP, и таким образом, что фрагменты (1122, 1132, 1162, 1172) аудиоконтента, подлежащие кодированию в режиме трансформанты, взвешиваются с использованием одного и того же заданного асимметричного окна анализа (530, 1120, 1130, 1160, 1170) независимо от режима кодирования предшествующего фрагмента аудиоконтента и независимо от режима кодирования последующего фрагмента аудиоконтента.
10. Кодер аудиосигнала (100) по п.9, выполненный с возможностью избирательного формирования антиалиасинговой информации (164), когда текущий фрагмент (1162) аудиоконтента следует за фрагментом (1152) аудиоконтента, закодированным в режиме CELP.
11. Кодер аудиосигнала (100) по п.1, в котором время-частотный преобразователь (130; 221, 222; 263, 264; 283, 284) выполнен с возможностью применения целевого асимметричного окна анализа перехода (1360), отличного от заданного асимметричного окна анализа (520; 1320, 1330, 1370), для оконного взвешивания текущего фрагмента (1362) аудиоконтента, подлежащего кодированию в режиме трансформанты и следующего за фрагментом (1352) аудиоконтента, закодированным в режиме CELP.
12. Кодер аудиосигнала по п.1, в котором тракт области линейного предсказания с кодовым возбуждением (тракт CELP) (140), представляющий собой тракт области линейного предсказания с алгебраическим кодовым возбуждением, формирует информацию о алгебраическом кодовом возбуждении (144) и информацию о параметрах области линейного предсказания (146) на базе фрагмента аудиоконтента, подлежащего кодированию в режиме области линейного предсказания с алгебраическим кодовым возбуждением (режим CELP).
13. Декодер аудиосигнала (300), предназначенный для формирования декодированного представления (312) аудиоконтента на основе кодированного представления (310) аудиоконтента, включающий тракт области трансформанты (320; 400; 430; 460), реализованный для формирования представления во временной области (326; 416; 446; 476) фрагмента (1222, 1232, 1262, 1272; 1422, 1432, 1462, 1472) аудиоконтента, закодированного в режиме области трансформанты на основе набора спектральных коэффициентов (322; 412, 442, 472) и информации о формировании искажения (324; 414; 444; 474); при этом тракт области трансформанты включает частотно-временной преобразователь (330; 423, 424; 451, 452; 484, 485), выполняющий преобразование из частотной области во временную (423; 451; 484) и оконное взвешивание (424; 452; 485) с выведением оконно-взвешенного представления аудиоконтента во временной области (424а; 452а; 485а) из набора спектральных коэффициентов или из его предобработанной версии; тракт области линейного предсказания с кодовым возбуждением (340), реализованный для формирования представления во временной области (346) аудиоконтента, закодированного в режиме области линейного предсказания с кодовым возбуждением (в режиме CELP) на базе информации о кодовом возбуждении (342) и информации о параметрах области линейного предсказания (344); и где частотно-временной преобразователь предусматривает применение заданного асимметричного окна синтеза (620; 1230; 1430) для оконного взвешивания текущего фрагмента (1232; 1432) аудиоконтента, закодированного в режиме области трансформанты и следующего за фрагментом (1222; 1422) аудиоконтента, закодированного в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент (1242; 1442) аудиоконтента, закодированный в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме CELP; одновременно, аудиодекодер (300) выполнен с возможностью избирательной инициации антиалиасингового сигнала (364) исходя из антиалиасинговой информации (362), включенной в представление аудиоконтента, содержащей компоненты антиалиасингового сигнала, введенные в представление последующего фрагмента (1142; 1342) аудиоконтента в области трансформанты, когда за текущим фрагментом аудиоконтента, закодированным в режиме области трансформанты, следует фрагмент аудиоконтента, закодированный в режиме CELP.
14. Декодер аудиосигнала (300) по п.13, в составе которого частотно-временной преобразователь (330; 423, 424; 451, 452; 484, 485) использует одно и то же окно (620; 1230; 1430) для взвешивания текущего фрагмента (1232; 1432) аудиоконтента, закодированного в режиме области трансформанты и следующего за фрагментом (1222; 1422) аудиоконтента, закодированным в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом (1232; 1432) аудиоконтента следует фрагмент (1242; 1442) аудиоконтента, закодированный в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме CELP.
15. Декодер аудиосигнала (300) по п.13, использующий заданное асимметричное окно синтеза (620; 1230; 1430), которое состоит из левой половины окна и правой половины окна, из которых левая половина окна содержит левостороннюю нулевую область (622) и левосторонний скос фронта перехода (624), где значения оконной функции монотонно возрастают от нуля до центрального значения окна; и из которых правая половина окна содержит участок всплеска (628), где значения оконной функции превышают центральное значение окна и где оконная функция достигает своего максимального значения (628а), и содержит правосторонний скат перехода (630), где значения оконной функции монотонно убывают от центрального значения окна до ноля.
16. Декодер аудиосигнала (300) по п.15, задействующий окно, у которого левостороння нулевая область (622) содержит по меньшей мере 20% значений левой половины окна, и у которого правая половина окна содержит не более одного процента нулевых значений оконной функции.
17. Декодер аудиосигнала (300) по п.15, использующий заданное асимметричное окно синтеза (620; 1220, 1230, 1260; 1420, 1430, 1470), левая сторона которого содержит значения, меньшие, чем центральное значение окна, и не содержит участок всплеска.
18. Декодер аудиосигнала по п.13, использующий заданное асимметричное окно синтеза (620; 1220, 1230, 1260; 1420, 1430, 1470), ненулевая область которого короче по меньшей мере на 10%, чем длина фрейма.
19. Декодер аудиосигнала (300) по п.13, предусматривающий по меньшей мере 40 процентное временное перекрывание последовательных фрагментов (1222, 1232, 1262, 1272; 1422, 1432, 1462, 1472) аудиоконтента, закодированных в режиме области трансформанты; и предусматривающий временное перекрывание текущего фрагмента (1232; 1432) аудиоконтента, закодированного в режиме области трансформанты, и следующего за ним фрагмента (1242; 1442) аудиоконтента, закодированного в режиме области линейного предсказания с кодовым возбуждением; и выполненный с возможностью избирательный инициации на основе антиалиасинговой информации (362) антиалиасингового сигнала (364), ослабляющего или нейтрализующего артефакты алиасинга при переходе от текущего фрагмента аудиоконтента, закодированного в режиме области трансформанты, к следующему фрагменту аудиоконтента, закодированному в режиме CELP.
20. Декодер аудиосигнала (300) по п.13, предусматривающий возможность выбора окна (1230; 1430) для взвешивания текущего фрагмента (1232; 1432) аудиоконтента, независимо от режима кодирования последующего фрагмента (1242; 1442) аудиоконтента, который перекрывает по времени текущий фрагмент (1232; 1432) аудиоконтента таким образом, что оконно-взвешенное представление (424а; 452а; 485а) текущего фрагмента аудиоконтента обоюдно перекрывается по времени с последующим фрагментом аудиоконтента, даже если последующий фрагмент аудиоконтента закодирована в режиме CELP; и предусматривающий в качестве отклика на распознавание кодирования последующего фрагмента аудиоконтента в режиме CELP инициацию антиалиасингового сигнала (364), ослабляющего или устраняющего артефакты алиасинга при переходе от текущего фрагмента (1232; 1432) аудиоконтента, закодированного в режиме области трансформанты, к следующему за ним фрагменту (1242; 1442) аудиоконтента, закодированному в режиме CELP.
21. Декодер аудиосигнала (300) по п.13, в составе которого частотно-временной преобразователь (330; 423, 424; 451, 452; 484, 485) использует заданное асимметричное окно синтеза (620; 1230; 1430) для оконного взвешивания текущего фрагмента (1262; 1462) аудиоконтента, закодированного в режиме области трансформанты и следующего за фрагментом (1252; 1452) аудиоконтента, закодированным в режиме CELP, таким образом, что фрагменты (1222; 1232; 1262; 1272) аудиоконтента, закодированные в режиме области трансформанты, взвешиваются с использованием одного и того же заданного асимметричного окна синтеза (620; 1220, 1230, 1260, 1270) независимо от режима кодирования предшествующего фрагмента аудиоконтента и независимо от режима кодирования последующего фрагмента аудиоконтента, и таким образом, что оконно-взвешенное представление во временной области (424а; 452а; 485а) текущего фрагмента аудиоконтента, закодированного в режиме области трансформанты, перекрывает по времени предыдущий фрагмент (1252; 1452) аудиоконтента, закодированный в режиме CELP.
22. Декодер аудиосигнала (300) по п.21, выполненный с возможностью избирательной активации антиалиасингового сигнала (364) исходя из антиалиасинговой информации (362), когда текущий фрагмент (1262) аудиоконтента следует за фрагментом (1252) аудиоконтента, закодированным в режиме CELP.
23. Декодер аудиосигнала (300) по п.13, в составе которого частотно-временной преобразователь (330; 423, 424; 451, 452; 484, 485) выполнен с возможностью применения целевого асимметричного окна синтеза перехода (1460), отличного от заданного асимметричного окна синтеза (620; 1230; 1430), для оконного взвешивания текущего фрагмента (1462) аудиоконтента, закодированного в режиме области трансформанты и следующего за фрагментом (1452) аудиоконтента, закодированным в режиме CELP.
24. Декодер аудиосигнала по п.13, в составе которого тракт области линейного предсказания с кодовым возбуждением (340), представляющий собой тракт области линейного предсказания с алгебраическим кодовым возбуждением, формирует представление во временной области (346) аудиоконтента, закодированного в режиме области линейного предсказания с алгебраическим кодовым возбуждением на основе информации о алгебраическом кодовом возбуждении (342) и информации о параметрах области линейного предсказания (344).
25. Способ формирования кодированного представления аудиоконтента на основе представления входного массива акустических данных, включающий в себя: выведение набора спектральных коэффициентов и информации о формировании искажения на основе представления во временной области фрагмента аудиоконтента, подлежащего кодированию в режиме области трансформанты, таким образом, что спектральные коэффициенты описывают спектр ограниченной по шуму версии аудиоконтента; при этом представление аудиоконтента во временной области, подлежащее кодированию в режиме области трансформанты, или его предобработанную версию, взвешивают, и оконно-взвешенное временное представление аудиоконтента преобразуют из временной области в частотную область, выводя набор спектральных коэффициентов; подготовку информации о кодовом возбуждении и данных области линейного предсказания на базе фрагмента аудиоконтента, подлежащего кодированию в режиме области линейного предсказания с кодовым возбуждением (режим CELP); при этом с помощью заданного асимметричного окна анализа выполняют оконное взвешивание текущего фрагмента аудиоконтента, подлежащего кодированию в режиме области трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP; и при этом антиалиасинговая информация, которая содержит компоненты антиалиасингового сигнала, введенные в представление последующего фрагмента (1142; 1342) аудиоконтента в области трансформанты, формируется избирательно, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, подлежащий кодированию в режиме CELP.
26. Способ формирования декодированного представления аудиоконтента на основе кодированного представления аудиоконтента, включающий в себя: формирование представления во временной области фрагмента аудиоконтента, закодированного в режиме области трансформанты на базе набора спектральных коэффициентов и информации о формировании искажения, при этом для формирования оконно-взвешенного представления аудиоконтента во временной области на основе набора спектральных коэффициентов или их предобработанной версии выполняют частотно-временное преобразование и оконное взвешивание; и формирование временного представления аудиоконтента, закодированного в режиме области линейного предсказания с кодовым возбуждением на основе информации о кодовом возбуждении и информации о параметрах области линейного предсказания; при этом с помощью заданного асимметричного окна синтеза выполняют оконное взвешивание текущего фрагмента аудиоконтента, закодированного в режиме области трансформанты и следующего за фрагментом аудиоконтента, закодированным в режиме области трансформанты, в обоих случаях, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме области трансформанты, и когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме CELP; и при этом на основе антиалиасинговой информации, включенной в представление аудиоконтента, содержащей компоненты антиалиасингового сигнала, введенные в представление последующего фрагмента (1142; 1342) аудиоконтента в области трансформанты, избирательно инициируется антиалиасинговый сигнал, когда за текущим фрагментом аудиоконтента следует фрагмент аудиоконтента, закодированный в режиме CELP.
27. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 25 при условии выполнения этой компьютерной программы с использованием компьютерной техники.
28. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 26 при условии выполнения этой компьютерной программы с использованием компьютерной техники.
| Устройство для заточки сверл | 1985 |
|
SU1278184A1 |
| US 7490036 B2, 10.02.2009 | |||
| US 7386445 B2, 10.06.2008 | |||
| US 7020605 B2, 28.03.2006 | |||
| УСОВЕРШЕНСТВОВАНИЕ ИСХОДНОГО КОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ДУБЛИРОВАНИЯ СПЕКТРАЛЬНОЙ ПОЛОСЫ | 1998 |
|
RU2256293C2 |

