ОБЛАСТЬ ТЕХНИКИ
Настоящая заявка относится к автоматической обработке изображений отсканированных документов и других изображений, содержащих текст, и, в частности, к способам и системам эффективного преобразования изображений символов, полученных из отсканированных документов, в кодовые комбинации соответствующих символов с использованием дерева решений, которое включает классификаторы, каждый из которых распознает символ, соответствующий символу изображения.
УРОВЕНЬ ТЕХНИКИ
Печатные, машинописные и рукописные документы на протяжении долгого времени используются для записи и хранения информации. Несмотря на современные тенденции отказа от бумажного делопроизводства, печатные документы продолжают широко использоваться в коммерческих организациях, учреждениях и домах. С развитием современных компьютерных систем создание, хранение, поиск и передача электронных документов превратились, наряду с непрекращающимся применением печатных документов, в чрезвычайно эффективный и экономически выгодный альтернативный способ записи и хранения информации. Из-за подавляющего преимущества в эффективности и экономической выгоде, обеспечиваемого современными средствами хранения и передачи электронных документов, печатные документы легко преобразуются в электронные с помощью различных способов и систем, включающих преобразование печатных документов в цифровые изображения отсканированных документов с использованием электронных оптико-механических сканирующих устройств, цифровых камер, а также других устройств и систем, и последующую автоматическую обработку изображений отсканированных документов для получения электронных документов, закодированных в соответствии с одним или более различными стандартами кодирования электронных документов. Например, в настоящее время можно использовать настольный сканер и современные программы оптического распознавания символов (OCR), позволяющие с помощью персонального компьютера преобразовывать печатный документ в соответствующий электронный документ, который можно просматривать и редактировать с помощью текстового редактора.
Хотя современные системы OCR развились до такой степени, что позволяют автоматически преобразовывать в электронные документы сложные печатные документы, включающие в себя изображения, рамки, линии границ и другие нетекстовые элементы, а также текстовые символы множества распространенных алфавитных языков, остается нерешенной проблема преобразования печатных документов, содержащих китайские и японские иероглифы или корейские морфо-слоговые блоки.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящий документ относится к способам и системам распознавания символов, соответствующих изображениям символов, полученных из изображения отсканированного документа или другого изображения, содержащего текст, включая символы, соответствующие китайским или японским иероглифам или корейским морфо-слоговым блокам, а также символам других языков, в которых применяется большое количество знаков для записи и печати. В одном варианте реализации изобретения способы и системы, раскрытые в настоящем документе, направлены на создание и хранение дерева решений, узлы которого включают классификаторы, каждый из которых распознает символ, соответствующий изображения символа. Ввод символа изображения в дерево решений и обработка изображения символов в одном или более узлах дерева решений возвращает символ, соответствующий изображению символа.
Технический результат от внедрения изобретения состоит в оптическом распознавании символов на изображении документа, напечатанного на языке, в котором применяется большое количество знаков для записи и печати.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг. 1А-В показан печатный документ.
На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в электронные, которые можно хранить на запоминающих устройствах и/или в электронной памяти.
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2
На Фиг. 4 представлена общая архитектурная схема разных типов компьютеров и других устройств, управляемых процессором.
На Фиг. 5 показано цифровое представление отсканированного документа.
На Фиг. 6 показан гипотетический набор символов.
На Фиг. 7А-В показаны различные аспекты наборов символов для естественных языков.
На Фиг. 8А-В показаны параметры и значения параметров, вычисленных для изображений символов.
На Фиг. 9 показана таблица значений параметров, рассчитанных для всех символов из набора, изображенного в качестве примера на Фиг. 6.
На Фиг. 10 показан трехмерный график для символов из набора, изображенного в качестве примера на Фиг. 6, на котором каждое из измерений представляет значения одного из трех разных параметров.
На Фиг. 11А-В показаны символы, содержащиеся в каждом из кластеров, представленных точками трехмерного пространства, изображенного на Фиг. 10.
На Фиг. 12А показан отдельный параметр, который можно использовать в комбинации с тремя параметрами, соответствующими каждому из измерений трехмерного пространства параметров, изображенного на Фиг. 10, для полного распознавания каждого из символов в кластере 8.
На Фиг. 12В показано значение дополнительного параметра для каждого символа из кластера 8, которое следует рассматривать со ссылкой на Фиг. 12А.
На Фиг. 13А показан дополнительный параметр, используемый для определения характеристик изображений символов.
На Фиг. 13В показан полный набор значений параметров для гипотетического набора символов, показанного на Фиг. 6.
На Фиг. 14А-17С показано построение четырех деревьев принятия решений из четырех подмножеств гипотетического набора символов, показанного на Фиг. 6.
На Фиг. 18А-В показана классификация изображений символов с помощью леса решений.
На Фиг. 19-23В приведен ряд иерархически связанных структур данных, используемых описываемой системой OCR с целью выявления и вывода кода символа для входного изображения символа.
На Фиг. 24А-В показан проход узла промежуточного уровня дерева решений и конечный узел дерева решений.
На Фиг. 25А-В показано определение веса по структуре данных эталона и логика OCR для входного изображения символа.
На Фиг. 26А-В показано вычисление веса и принятие решения классификатором для входного изображения символа.
На Фиг. 27А-Е показано создание и обучение дерева решений OCR.
На Фиг. 28 показана ступенчатая конструкция и одновременное обучение дерева решений OCR в одном варианте реализации системы OCR.
На Фиг. 29 показана альтернативная логика принятия решений классификатором.
На Фиг. 30A-G приведены блок-схемы, которые иллюстрируют обработку документов в соответствии с описываемой системой OCR.
На Фиг. 31A-D показаны блок-схемы, иллюстрирующие построение и одновременное обучение в дереве решений OCR.
ПОДРОБНОЕ ОПИСАНИЕ
Настоящий документ относится к способам и системам распознавания символов, соответствующих изображениям символов, полученных из изображения отсканированного документа. В одном варианте реализации способы и системы, которые рассматриваются в настоящем документе, используются для создания и хранения дерева решений, узлы которого содержат классификаторы, каждый из которых распознает конкретный символ. Ввод символа изображения в дерево решений и обработка изображения символов в одном или более узлах дерева решений возвращает символ, соответствующий изображению символа. Приведенное ниже обсуждение включает в себя три подраздела: (1) обзор отсканированных образов изображений документов и электронных документов; (2) описание примеров методов и систем OCR; и (3) обсуждение распознавания изображений символов на основе дерева решений, на которые нацелена эта заявка на изобретение и формула изобретения.
Изображения отсканированных документов и электронные документы
На Фиг. 1А-В показан печатный документ. На Фиг. 1А показан исходный документ с текстом на японском языке. Печатный документ (100) включает в себя фотографию (102) и пять разных содержащих текст областей (104-108), включающих в себя японские иероглифы. Этот документ будет использоваться в качестве примера при рассмотрении способа и систем определения смысла, к которым относится настоящая заявка. Текст на японском языке может писаться слева направо, построчно, как пишется текст на английском языке, но альтернативно может использоваться способ написания сверху вниз в вертикальных столбцах. Например, область (107) явно содержит вертикально написанный текст, в то время как текстовый блок (108) содержит текст, написанный горизонтально На Фиг. 1В печатный документ, изображенный на Фиг. 1А, показан переведенным на русский язык.
Печатные документы могут быть преобразованы в цифровые изображения отсканированных документов с помощью различных средств, включающих электронные оптико-механические сканирующие устройства и цифровые камеры. На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в электронные, которые можно хранить на запоминающих устройствах и/или в электронной памяти. Настольное сканирующее устройство (202) включает в себя прозрачное стекло (204), на которое лицевой стороной вниз помещается документ (206). Запуск сканирования приводит к получению оцифрованного изображения отсканированного документа, которое можно передать на персональный компьютер (ПК) (208) для хранения на запоминающем устройстве. Программа, предназначенная для отображения отсканированного документа, может вывести оцифрованное изображение отсканированного документа на экран (210) устройства отображения ПК (212).
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2 Оптические компоненты этого CCD-сканера расположены под прозрачным стеклом (204). Фронтально перемещаемый источник яркого света (302) освещает часть сканируемого документа (304), свет от которой отражается вниз. Этот свет отражается от фронтально перемещаемого зеркала (306) на неподвижное зеркало (308), которое отражает излучаемый свет на массив CCD-элементов (310), формирующих электрические сигналы пропорционально интенсивности света, поступающего на каждый из них. Цветные сканеры могут включать в себя три отдельные строки или массива CCD-элементов с красным, зеленым и синим фильтрами. Фронтально перемещаемые источник яркого света и зеркало двигаются вместе вдоль документа для получения изображения сканируемого документа. Другой тип сканера, использующего контактный датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми цветными светодиодами (LED), при этом отраженный свет светодиодов улавливается массивом фотодиодов, который перемещается вместе с цветными светодиодами.
На Фиг. 4 представлена общая архитектурная схема разных типов компьютеров и других устройств, управляемых процессором. Архитектурная схема высокого уровня позволяет описать современную компьютерную систему (например, ПК, изображенный на Фиг. 2), в которой программы отображения отсканированного документа и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи в электронную память и выполнения одним или более процессорами, что позволяет преобразовать компьютерную систему в специализированную систему оптического распознавания символов. Компьютерная система содержит один или множество центральных процессоров (ЦП) (402-405), один или более модулей электронной памяти (408), соединенных с ЦП при помощи шины подсистемы ЦП/память (410) или множества шин, первый мост (412), который соединяет шину подсистемы ЦП/память (410) с дополнительными шинами (414) и (416) или другими средствами высокоскоростного взаимодействия, включающими в себя множество высокоскоростных последовательных линий. Эти шины или последовательные линии, в свою очередь, соединяют ЦП и память со специализированными процессорами, такими как графический процессор (418), а также с одним или более дополнительными мостами (420), взаимодействующими с высокоскоростными последовательными линиями или с множеством контроллеров (422-427), например с контроллером (427), которые предоставляют доступ к различным типам запоминающих устройств (428), электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
На Фиг. 5 показано цифровое представление отсканированного документа. На Фиг. 5 небольшой круглый фрагмент изображения (502) печатного документа (504), используемого в качестве примера, показан в увеличенном виде (506). Соответствующий фрагмент оцифрованного изображения отсканированного документа (508) также представлен на Фиг. 5. Оцифрованный отсканированный документ включает в себя данные, которые представляют собой двухмерный массив значений пикселей. В представлении (508) каждая ячейка сетки под символами (например, ячейка (509)) представляет собой квадратную матрицу пикселей. Небольшой фрагмент (510) сетки показан с еще большим увеличением (512 на Фиг. 5), при котором отдельные пиксели представлены в виде элементов матрицы (например, элемента матрицы (514)). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения света заданной яркости. В файле оцифрованного отсканированного документа каждый пиксель представлен фиксированным числом битов, при этом кодирование пикселей осуществляется последовательно. Заголовок файла содержит информацию о типе кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодирования пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Для представления оцифрованного отсканированного документа в виде монохромных изображений с оттенками серого обычно используют 8-разрядное или 16-разрядное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в зависимости от стандарта кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-разрядных значения, закодированных с помощью 24-разрядного значения. Таким образом, оцифрованное отсканированное изображение, по существу, представляет собой документ в той же степени, в какой цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении закодированных пикселей, например информация, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ. Фрагменты изображения, соответствующие изображениям символов, могут обрабатываться для получения битов изображения символа, в котором биты со значением «1» соответствуют изображению символа, а биты со значением «0» соответствуют фону. Растровое отображение удобно для представления как полученных изображений символов, так и эталонов, используемых системой OCR для распознавания конкретных символов.
В отличие от этого обычный электронный документ, созданный с помощью текстового редактора, содержит различные типы команд рисования линий, ссылки на представления изображений, таких как оцифрованные фотографии, а также текстовые символы, закодированные в цифровом виде. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII (американский стандартный код обмена информацией) и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие неалфавитные текстовые языки. Большая часть вычислительной работы, которую выполняет программа OCR, связана с распознаванием изображений текстовых символов, полученных из оцифрованного изображения отсканированного документа, и с преобразованием изображений символов в соответствующие кодовые комбинации стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения растровых изображений текстовых символов. Кроме того, текстовые символы стандарта Юникод можно редактировать, используя различные шрифты, а также обрабатывать всеми доступными в текстовых редакторах способами, в то время как оцифрованные изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
На начальном этапе преобразования изображения отсканированного документа в электронный документ печатный документ (например, документ (100), показанный на Фиг. 1) анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие области. Дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу, и шесть конечных узлов, каждый из которых соответствует одной определенной области. Области можно определить, применяя к изображению разные методы, среди которых различные типы статистического анализа распределения пикселей или значений пикселей. Например, в цветном документе фотографию можно выделить по большему изменению цвета в области фотографии, а также по более частым изменениям значений яркости пикселей по сравнению с областями, содержащими текст.
Как только начальный анализ выявит различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR для выявления и преобразования текстовых символов в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать содержащие текст области, определяется начальная ориентация содержащей текст области, благодаря чему в подпрограммах OCR эффективно используются различные способы сопоставления с эталоном для определения текстовых символов. Следует отметить, что изображения в документах могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в позиционировании документа на сканере или другом устройстве, формирующем изображение, из-за нестандартной ориентации содержащих текст областей или по другим причинам. Области, содержащие текст, затем делят на фрагменты изображений, содержащие отдельные знаки или символы, после чего эти фрагменты целиком масштабируются и ориентируются, а изображения символов центрируются внутри этих фрагментов для облегчения последующего автоматического распознавания символов, соответствующих изображениям символов.
Пример способов и систем OCR
Для перехода к конкретному обсуждению различных методов оптического распознавания символов в качестве примера будет использоваться набор символов для некоторого гипотетического языка. На Фиг. 6 показан гипотетический набор символов. На Фиг. 6 показаны 48 различных символов, расположенных в 48 прямоугольных областях, таких как прямоугольная область (602). В правом верхнем углу каждой прямоугольной области указан числовой индекс или код символа, вписанный в круг; например, индекс или код «1» (604), соответствует первому символу (606), показанному в прямоугольной области (602). Данный пример выбран для демонстрации работы как существующих в настоящее время способов и систем OCR, так и новых способов и систем, описанных в настоящем документе. Фактически для письменных иероглифических языков, включая китайский и японский языки, для печати и письма могут использоваться десятки тысяч различных символов.
На Фиг. 7А-В показаны различные аспекты наборов символов для естественных языков. На Фиг. 7А в столбце показаны различные формы изображения восьмого символа из набора, показанного на Фиг. 6. В столбце (704) для восьмого символа (702) из набора символов, показанного на рисунке 6, представлены разные формы написания, встречающиеся в разных стилях текста. Во многих естественных языках могут использоваться различные стили текста, а также различные варианты написания каждого символа.
На Фиг. 7В показаны разные подходы к распознаванию символов естественного языка На Фиг. 7В конкретный символ естественного языка представлен узлом (710) на схеме (712). Конкретный символ может иметь множество различных общих письменных или печатных форм. В целях оптического распознавания символов каждая из этих общих форм представляется в виде отдельной графемы. В некоторых случаях определенный символ может содержать две или более графем. Например, китайские иероглифы могут содержать комбинацию из двух или более графем, каждая из которых присутствует в других иероглифах. Корейский язык, на самом деле, основан на алфавите, при этом в нем используются корейские морфо-слоговые блоки, содержащие ряд буквенных символов в различных позициях. Таким образом, корейский морфо-слоговой блок может представлять собой символ более высокого уровня, состоящий из множества компонентов графем. Для символа (710), показанного на Фиг. 7В, существуют шесть различных графем (714-719). Кроме того, есть одна или более различных печатных или письменных форм начертания графем, каждая из которых представлена соответствующим эталоном. На Фиг. 7В каждая из графем (714) и (716) имеет два возможных варианта начертания, представленных эталонами (720)-(721) и (723)-(724) соответственно. Каждая из графем (715) и (717) - (719) связана с одним эталоном (722) и (725)-(727) соответственно. Например, восьмой символ из набора, показанного в качестве примера на Фиг. 6, может быть связан с тремя графемами, первая из которых соответствует начертаниям (702), (724), (725) и (726), вторая - (728) и (730), а третья - (732). В этом примере к первой графеме относятся начертания, в которых используются прямые горизонтальные элементы, ко второй графеме относятся начертания, в которых используются горизонтальные элементы и короткие вертикальные элементы с правой стороны, а к третьей графеме относятся начертания, включающие в себя изогнутые (а не прямые) элементы. В альтернативном варианте осуществления все начертания восьмого символа (702), (728), (724), (732), (725), (726) и (730) можно представить в виде эталонов, связанных с единственной графемой для восьмого символа. В определенной степени выбор графем осуществляется произвольно. В некоторых типах иероглифических языков много тысяч разных графем. Эталоны можно рассматривать в качестве альтернативного представления или изображения символа, при этом они могут быть представлены в виде набора пар «параметр - значение параметра», как описано ниже.
Хотя отношение между символами, графемами и эталонами показано на Фиг. 7В как строго иерархическое, при котором каждая графема связана с одним конкретным родительским символом, фактические отношения не могут быть так просто структурированы. На Фиг. 7С показан несколько более сложный набор отношений, когда два символа (730) и (732) являются родителями двух разных графем (734) и (736). В качестве примера можно привести следующие символы английского языка: строчная буква «o», прописная буква «О», цифра «0» и символ градусов «°», которые могут быть связаны с кольцеобразной графемой. Отношения могут быть альтернативно представлены в виде графов или сетей. В некоторых случаях графемы (в отличие от символов или в дополнение к ним) могут отображаться на самых высоких уровнях в рамках выбранного представления отношений. В сущности, идентификация символов, графем, выбор эталонов для конкретного языка, а также определение отношений между ними осуществляются в большой степени произвольно.
На Фиг. 8А-В показаны параметры и значения параметров, рассчитанные для изображений символов. Следует заметить, что словосочетание «изображение символа» может описывать печатный, рукописный или отображаемый на экране символ или графему. В следующем примере параметры и значения параметров рассматриваются применительно к изображениям символов, но в фактическом контексте реального языка параметры и значения параметров часто применяются для характеристики и представления изображений графем. На Фиг. 8А показано изображение прямоугольного символа (802), полученное из содержащего текст изображения, которое соответствует 22-му символу из набора, показанного в качестве примера на Фиг. 6. На Фиг. 8В показано изображение прямоугольного символа (804), полученное из содержащего текст изображения, которое соответствует 48-му символу из набора, показанного в качестве примера на Фиг. 6. При печати и письме на гипотетическом языке, соответствующем набору символов, приведенному в качестве примера, символы размещаются в середине прямоугольных областей. Если это не так, системы OCR выполнят стадию начальной обработки изображений, изменив ориентацию, масштаб и положение полученных изображений символов относительно фоновой области для нормализации полученных изображений символов для дальнейших стадий обработки.
На Фиг. 8А показаны три разных параметра, которые могут использоваться системой OCR для характеристики символов. Следует заметить, что область изображения символа, или окно символа, характеризуется вертикальным размером окна символа (806), обозначаемым сокращенно «vw», и горизонтальным размером окна символа (808), обозначаемым сокращенно «hw». Первым параметром является самый длинный в изображении символа непрерывный горизонтальный отрезок линии, обозначаемый «h» (810). Это самая длинная последовательность смежных темных пикселей на фоне по существу белых пикселей в окне символа. Вторым параметром является самый длинный в изображении символа непрерывный вертикальный отрезок линии (812) (v). Третий параметр представляет собой отношение пикселей изображения символа к общему числу пикселей в окне символа, выраженное в процентах; в данном примере это процент черных пикселей в по существу белом окне символа (b). Во всех трех случаях значения параметров могут быть непосредственно рассчитаны сразу после того, как будет создано растровое отображение окна символа. На Фиг. 8В показаны два дополнительных параметра. Первым параметром является число внутренних горизонтальных белых полос в изображении символа; изображение символа, показанного на Фиг. 8В, имеет одну внутреннюю горизонтальную белую полосу (816). Вторым параметром является число внутренних вертикальных белых полос в изображении символа. В 48-м символе из набора, представленном изображением в окне символа (804) на Фиг. 8В, имеется одна внутренняя вертикальная белая полоса (818). Число горизонтальных белых полос обозначается как «hs», а число внутренних вертикальных белых полос - «vs».
На Фиг. 9 показана таблица значений параметров, рассчитанных для всех символов из набора, изображенного в качестве примера на Фиг. 6. В каждой строке таблицы (902), показанной на Фиг. 9, представлены значения параметров, рассчитанные для конкретного символа. Следующие параметры включают в себя: (1) отношение самого длинного непрерывного горизонтального отрезка линии к окну символа, 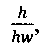 (904); (2) отношение самого длинного непрерывного вертикального отрезка линии к вертикальному размеру окна символа,
(904); (2) отношение самого длинного непрерывного вертикального отрезка линии к вертикальному размеру окна символа, 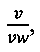 (906); (3) выраженная в процентах общая площадь, соответствующая изображению символа или черной области, b, (908); (4) количество внутренних вертикальных полос, vs, (910); (5) количество внутренних горизонтальных полос, hs, (912); (6) общее количество внутренних вертикальных и горизонтальных полос, vs+hs, (914); и (7) отношение самого длинного непрерывного вертикального отрезка к самому длинному непрерывному горизонтальному отрезку,
(906); (3) выраженная в процентах общая площадь, соответствующая изображению символа или черной области, b, (908); (4) количество внутренних вертикальных полос, vs, (910); (5) количество внутренних горизонтальных полос, hs, (912); (6) общее количество внутренних вертикальных и горизонтальных полос, vs+hs, (914); и (7) отношение самого длинного непрерывного вертикального отрезка к самому длинному непрерывному горизонтальному отрезку, 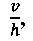 (916). Как и следовало ожидать, в первой строке (920) таблицы (902), представленной на рисунке 9, первый символ набора ((606) на Фиг. 6) представляет собой вертикальную черту, и численное значение параметра
(916). Как и следовало ожидать, в первой строке (920) таблицы (902), представленной на рисунке 9, первый символ набора ((606) на Фиг. 6) представляет собой вертикальную черту, и численное значение параметра 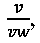 равное 0,6, значительно больше численного значения параметра
равное 0,6, значительно больше численного значения параметра 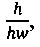 равного 0,2. Символ (606) занимает всего 12 процентов всего окна символа (602). У символа (606) нет ни внутренних горизонтальных, ни внутренних вертикальных белых полос, поэтому значения параметров vs, hs и vs+hs равны 0. Соотношение
равного 0,2. Символ (606) занимает всего 12 процентов всего окна символа (602). У символа (606) нет ни внутренних горизонтальных, ни внутренних вертикальных белых полос, поэтому значения параметров vs, hs и vs+hs равны 0. Соотношение 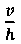 равно 3. Поскольку используемые в качестве примера символы имеют относительно простую блочную структуру, то значения каждого из параметров в таблице (902) отличаются незначительно.
равно 3. Поскольку используемые в качестве примера символы имеют относительно простую блочную структуру, то значения каждого из параметров в таблице (902) отличаются незначительно.
Несмотря на то что значения каждого из параметров, рассмотренных выше в отношении Фиг. 9, имеют относительно небольшие отличия для используемых в качестве примера 48 символов, всего трех параметров достаточно для разделения всех этих символов на 18 частей, или кластеров. На Фиг. 10 показан трехмерный график для символов из набора, изображенного в качестве примера на Фиг. 6, на котором каждое из измерений представляет значения одного из трех разных параметров. На Фиг. 10 первая горизонтальная ось (1002) представляет параметр 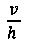 ((916) на Фиг. 9), вторая горизонтальная ось (1004) представляет параметр vs+hs ((914) на Фиг. 9), а третья вертикальная ось (1006) представляет параметр b ((908) на Фиг. 9). На графике есть 18 различных точек (таких как нанесенная точка (1008)), каждая из которых показана в виде небольшого черного диска с вертикальной проекцией на горизонтальную плоскость, проходящую через оси (1002) и (1004); эта проекция представлена в виде вертикальной пунктирной линии, такой как вертикальная пунктирная линия (1010), соединяющая точку (1008) с ее проекцией на горизонтальную плоскость (1012). Код или номер последовательности символов, которые соответствуют определенной точке на графике, перечислены в скобках справа от соответствующей точки. Например, символы 14, 20 и 37 (1014) соответствуют одной точке (1016) с координатами (1, 0, 0,32) относительно осей (1002), (1004) и (1006). Каждая точка связана с номером части или кластера, который указан в небольшом прямоугольнике слева от точки. Например, точка 1016 связана с кластером с номером «14» (1018). На Фиг. 11А-В показаны символы, содержащиеся в каждом из кластеров, представленных точками трехмерного пространства, изображенного на Фиг. 10. Рассмотрев символы, входящие в состав этих кластеров или частей, можно легко заметить, что три параметра, используемые для распределения символов в трехмерном пространстве, показанном на Фиг. 10, эффективно разбивают 48 символов, используемых в качестве примера, на связанные наборы символов.
((916) на Фиг. 9), вторая горизонтальная ось (1004) представляет параметр vs+hs ((914) на Фиг. 9), а третья вертикальная ось (1006) представляет параметр b ((908) на Фиг. 9). На графике есть 18 различных точек (таких как нанесенная точка (1008)), каждая из которых показана в виде небольшого черного диска с вертикальной проекцией на горизонтальную плоскость, проходящую через оси (1002) и (1004); эта проекция представлена в виде вертикальной пунктирной линии, такой как вертикальная пунктирная линия (1010), соединяющая точку (1008) с ее проекцией на горизонтальную плоскость (1012). Код или номер последовательности символов, которые соответствуют определенной точке на графике, перечислены в скобках справа от соответствующей точки. Например, символы 14, 20 и 37 (1014) соответствуют одной точке (1016) с координатами (1, 0, 0,32) относительно осей (1002), (1004) и (1006). Каждая точка связана с номером части или кластера, который указан в небольшом прямоугольнике слева от точки. Например, точка 1016 связана с кластером с номером «14» (1018). На Фиг. 11А-В показаны символы, содержащиеся в каждом из кластеров, представленных точками трехмерного пространства, изображенного на Фиг. 10. Рассмотрев символы, входящие в состав этих кластеров или частей, можно легко заметить, что три параметра, используемые для распределения символов в трехмерном пространстве, показанном на Фиг. 10, эффективно разбивают 48 символов, используемых в качестве примера, на связанные наборы символов.
Можно использовать дополнительные параметры для однозначного распознавания каждого символа в каждом кластере или части. Рассмотрим, например, кластер 8 (1102), показанный на Фиг. 11А. Этот кластер символов включает в себя четыре угловых (L-образных) символа, отличающихся углом поворота и имеющих коды 26, 32, 38 и 44, а также Т-образный символ с кодом 43 и крестообразный символ с кодом 45. На Фиг. 12А показан отдельный параметр, который можно использовать в комбинации с тремя параметрами, соответствующими каждому из измерений трехмерного пространства параметров, изображенного на Фиг. 10, для полного распознавания каждого из символов в кластере 8. В дальнейшем этот параметр называется р. Как показано на Фиг. 12А, окно символа (1202) делится на четыре квадранта Q1 (1204), Q2 (1205), Q3 (1206) и Q4 (1207). После этого в каждом квадранте вычисляется площадь, занимаемая изображением символа, которая указывается рядом с квадрантом Например, в квадранте Q1 (1204) часть изображения символа занимает 13,5 единиц площади (1210). Затем вычисленные значения единиц площади каждого квадранта присваиваются переменным Q1, Q2, Q3 и Q4. Следовательно, в примере, представленном на Фиг. 12А, переменной Q1 присвоено значение 13,5, переменной Q2 присвоено значение 0, переменной Q3 присвоено значение 18, а переменной Q4 присвоено значение 13,5. Затем согласно небольшому фрагменту псевдокода (1212), представленному на Фиг. 12А под окном символа, рассчитывается значение нового параметра р. Например, если все четыре переменные Q1, Q2, Q3 и Q4 имеют одинаковые значения, то параметру p будет присвоено значение 0 (1214), что указывает на равенство четырех квадрантов в окне символа относительно количества единиц площади, занимаемой изображением символа. На Фиг. 12В показано значение дополнительного параметра для каждого символа из кластера 8, которое следует рассматривать со ссылкой на Фиг. 12А. Как можно увидеть из значений параметров, связанных с символами на Фиг. 12В, новый параметр, описанный выше касательно Фиг. 12А, имеет разное значение для каждого из шести символов в кластере 8. Другими словами, можно использовать комбинацию трех параметров, используемых для создания трехмерного графика, показанного на Фиг. 10, и дополнительного параметра, рассмотренного выше на Фиг. 12А, для однозначной идентификации всех символов в кластере 8.
На Фиг. 13А показан дополнительный параметр, используемый для определения характеристики изображений символов. Ниже дополнительный параметр называется, параметром «самый длинный отрезок». Этот параметр показывает направление самого длинного отрезка в изображении символа. Если самым длинным отрезком является вертикальное ребро (1302), параметр самого длинного отрезка имеет значение «0» (1304). Если самым длинным отрезком символа является горизонталь (1306), параметр самого длинного отрезка имеет числовое значение «1» (1308). Если самым длинным отрезком символа является диагональ (1310), параметр самого длинного отрезка имеет числовое значение «2» (1312). Наконец, если такой отрезок отсутствует, как в случае символа, показанного в ячейке (1314) на Фиг. 13А, параметр самого длинного отрезка имеет числовое значение «3» (1316).
На Фиг. 13В показан полный набор значений параметров для гипотетического набора символов, показанного на Фиг. 6. Таблица, показанная на Фиг. 13В, идентична таблице (902), ранее изображенной на Фиг. 9, за исключением двух последних колонок (1320) и (1322), которые включают значения параметра р, описанные выше со ссылкой на Фиг. 12А, и параметра самого длинного отрезка, обсуждавшегося выше со ссылкой на Фиг. 13А.
На Фиг. 14А-17С показано построение четырех деревьев решений из четырех подмножеств гипотетического набора символов, показанного на Фиг. 6. На Фиг. 14А показаны 36 символов, выбранных из 48 символов гипотетического набора символов, показанного на Фиг. 6. Это первое подмножество символов затем используется для построения дерева решений, которое может использоваться для классификации входного символа, как наилучшего соответствия конкретному символу в подмножестве символов, показанном на Фиг. 14А. На Фиг. 14В показана таблица значений параметров для 36 символов в подмножестве символов, показанном на Фиг. 14А. Эти значения параметров используются для построения дерева решений. На Фиг. 14С показано дерево решений, построенное для подмножества символов, показанного на Фиг. 14А на основе значений параметров для символов, показанных на Фиг. 14В. Следует отметить, что значение параметра, показанное на Фиг. 14В является подмножеством полной таблицы значений параметров, показанной на Фиг. 13В.
Существует много различных типов деревьев принятия решений. Деревья принятия решений, созданные в примере, показанном на Фиг. 14А-17С, являются бинарными деревьями решений. Каждый узел дерева решений, такой как узел (1402) на Фиг. 14С, представляет собой решение или проверку, которые позволяют выбирать, на какой из двух узлов нижнего уровня (1404) и (1406), следует перейти при обходе дерева решений на основе набора значения параметров, вычисленных для изображения символа. Дерево принятия решений создается с помощью подмножества символов, показанного на Фиг. 14А, а также значения параметра, показанного на Фиг. 14В. В качестве первого шага при построении дерева принятия решений рассматриваются различные значения параметров для каждого из девяти параметров, рассчитанных для каждого изображения символа в подмножестве символ-изображение, с целью определения конкретного параметра, который наиболее равномерно делит подмножество изображений символов на две части, а также для определения его порогового числового значения. В случае подмножества символов, показанного на Фиг. 14А, параметр 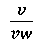 является подходящим параметром для первого испытания, представленного узлом (1402) - корневым узлом дерева принятия решений. Используя пороговое числовое значение 0,33, испытание на то, что числовое значение для конкретного изображения символа из подмножества изображений символов меньше или равно пороговому значению 0,33, делит 36 изображений символов в подмножестве символов на первую часть с 18 символами (1408) и вторую часть с 18 символами (1410). На каждом этапе построения дерева решения ищется испытание на основе параметра, которое наиболее равномерно делит множество входных символов узла входа на две выходные части. Этот процесс осуществляется рекурсивно по узлам и по уровням, для построения всего дерева решений (1400). Корневой узел (1402) представляет собой первый уровень дерева принятия решений. Второй уровень дерева решений включает в себя узлы (1404) и (1406). Оба этих узла включают испытание на основе параметра p, описанного со ссылкой на Фиг. 12А. В случае узла (1404) пороговое значение для испытания равно 11, а в случае узла (1406), пороговое значение равно 4. Конечные узлы дерева обведены кружками, например, конечный узел (1412) на Фиг. 14С. Конечные узлы представляют отдельные символы из подмножества символов, используемых для построения дерева решений. Имеется 36 конечных узлов, соответствующих 36 символам в подмножестве символов, показанном на Фиг. 14А.
является подходящим параметром для первого испытания, представленного узлом (1402) - корневым узлом дерева принятия решений. Используя пороговое числовое значение 0,33, испытание на то, что числовое значение для конкретного изображения символа из подмножества изображений символов меньше или равно пороговому значению 0,33, делит 36 изображений символов в подмножестве символов на первую часть с 18 символами (1408) и вторую часть с 18 символами (1410). На каждом этапе построения дерева решения ищется испытание на основе параметра, которое наиболее равномерно делит множество входных символов узла входа на две выходные части. Этот процесс осуществляется рекурсивно по узлам и по уровням, для построения всего дерева решений (1400). Корневой узел (1402) представляет собой первый уровень дерева принятия решений. Второй уровень дерева решений включает в себя узлы (1404) и (1406). Оба этих узла включают испытание на основе параметра p, описанного со ссылкой на Фиг. 12А. В случае узла (1404) пороговое значение для испытания равно 11, а в случае узла (1406), пороговое значение равно 4. Конечные узлы дерева обведены кружками, например, конечный узел (1412) на Фиг. 14С. Конечные узлы представляют отдельные символы из подмножества символов, используемых для построения дерева решений. Имеется 36 конечных узлов, соответствующих 36 символам в подмножестве символов, показанном на Фиг. 14А.
Опять же, существует много различных типов деревьев решений и методов построения таких деревьев. В данном примере каждый узел включает простое испытание, которое сравнивает значение параметра с пороговым значением. В других типах деревьев решений испытания могут быть более сложными и могут включать несколько параметров. В определенных видах деревьев решений параметры, используемые для испытаний, выбирают из случайных подмножеств параметра с целью введения случайности по отношению к серии деревьев принятия решений, созданных для характеристики определенного набора символов или других объектов. Выбор параметров и пороговых значений может использоваться для минимизации или максимизации некоторой целевой функции, в том числе целевых функций, основанных на информационно-теоретических понятиях энтропии и прироста информации. Как дополнительно обсуждается ниже, несколько деревьев решений, построенных для конкретного набора изображений символов или других объектов, с другим подмножеством объектов, используемым для построения каждого из множества деревьев решений, могут совместно образовать лес решений, что часто обеспечивает более надежную и точную классификацию. По темам деревьев решений, лесов решений и случайных лесов решений было выполнено значительное количество исследований и разработок, в результате которых были получены подробные характеристики и разработаны концепции деревьев решений и лесов решений, а также их применения в конкретных типах предметных областей. Поскольку в настоящем примере используются простые бинарные деревья решений, в соответствии с настоящим документом для обработки изображений символов в системах OCR может использоваться любое дерево решений из широкого спектра различных типов деревьев решений и любой лес решений из широкого спектра различных типов лесов решений.
На Фиг. 14С дерево решений (1400) имеет пять полных уровней узлов (1414)-(1418). Большинство узлов шестого уровня (1420) являются конечными узлами, однако в некоторых случаях на шестом уровне имеются дополнительные внутренние узлы решения (1422)-(1425), которые создают пары конечных узлов на седьмом уровне. Как дополнительно описано ниже, можно классифицировать произвольное изображение символа как соответствующее одному из 36 символов в наборе символов, показанном на Фиг. 14А, путем расчета значений числового параметра для изображения символа, а затем обходя дерево от корневого узла к конечному узлу, используя эти значения параметров и испытания, включенные в каждом узле. На Фиг. 15А-С показано построение второго дерева решений (1500) из второго набора из 36 символов, показанного на Фиг. 15А, выбранного из 48 символов гипотетического набора символов, показанного на Фиг. 6. Аналогичным образом на Фиг. 16А-С показано построение третьего дерева решений (1600) из третьего подмножества символов, выбранных из 48 символов гипотетического набора символов, показанного на Фиг. 6. Наконец, на Фиг. 17А-С показано построение четвертого дерева решений (1700) из четвертого подмножества символов, выбранных из набора 48 гипотетических символов, показанных на Фиг. 6. В этом примере каждое из четырех деревьев принятия решений (1400), (1500), (1600), (1700) строится из другого подмножества 36 символов, выбранных из 48 символов гипотетического набора символов, показанных на Фиг. 6. Однако это несколько искусственный пример. В общем случае, когда из обучающей выборки строится лес деревьев решений, для построения каждого дерева решений каждый раз случайным образом с заменой выбирается некоторая относительно большая доля объектов в обучающей выборке. В том случае, когда для построения каждого дерева случайным образом выбираются 90% из объектов, то можно ожидать, что среднее перекрытие обучающих объектов, использующихся для построения любой конкретной пары деревьев, будет превышать 90%, поскольку случайный выбор объектов каждый раз производится из всей совокупности объектов. Тем не менее, этот пример дает простую иллюстрацию построения и использования леса решений.
На Фиг. 18А-В показана классификация изображений символов с помощью леса решений. На Фиг. 18А показаны три изображения символов (1802), (1804) и (1806) вместе с числовыми значениями, рассчитанными для этих изображений символов для девяти рассмотренных выше параметров (1808), (1810) и (1812), соответственно. Символ изображения (1802) - это точное совпадение изображения символа для символа 22 набора гипотетических символов, изображенных на Фиг. 6. Таким образом, параметры (1808), вычисленные для этого изображения символа, идентичны параметрам, показанным в строке (1319) на Фиг. 13В. Изображение символа (1804) аналогично изображению символа (1802), но относительные ширины сегментов были уменьшены, получая несколько более тонкий символ. Изображение символа (1806) представляет собой более тонкий горизонтальный отрезок с двумя обращенными внутрь удлинениями на вершинах вертикальных элементов символа. Значения параметров (1810), вычисленные для изображения символа (1804), и значения параметров (1812), вычисленные для изображения символа (1806), не соответствуют ни одному из значений параметров, показанных на Фиг. 13В, поскольку изображения символов (1804) и (1806) не соответствует ни одному из изображений для символов гипотетического набора символов, показанного на Фиг. 6.
На Фиг. 18В показано использование небольшого леса решений, включающего деревья решений (1400), (1500), (1600) и (1700), изображенных на Фиг. 14С, 15С, 16С, и 17С, соответственно. Каждая строка текста справа от изображений символов на Фиг. 18В представляет собой обход одного из четырех деревьев принятия решений. Например, строка текста (1820) на Фиг. 18В представляет обход дерева принятия решений (1400) на Фиг. 14С, именуемого «дерево 1», используя параметры (1808), вычисленные для изображения символа (1802). Первый или корневой узел ((1402) на Фиг. 14С) дерева решений (1400) выполняет проверку: 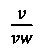 ≤0,33. Расчетное значение
≤0,33. Расчетное значение 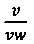 для изображения символа (1802) показано на Фиг. 18А, как 0,6. Значение 0,6 превышает 0,33, поэтому испытание, выполненное в узле (1402), приводит переходу к узлу (1406) вправо, как показано буквой «R» (1822) и текстовой строкой (1820). Узел (1406) выполняет проверку: p≤4. Расчетное значение параметра р для изображения символа (1802) показано на Фиг. 18А как 1. Таким образом, в случае узла (1406), проверка завершается успешно и таким образом выбирается левая стрелка вниз (1430), представленная буквой «L» (1824) на Фиг. 18В. Узел (1432) выполняет проверку b≤0,2. Значение параметра b для изображения символа (1802) на Фиг. 18А, равно 0,28. Таким образом, проверка в узле (1432) заканчивается неудачей, и в качестве следующего дополнительного поперечного перехода выбирается правая стрелка вниз (1434), которая обозначается буквой "R" (1826) на Фиг. 18В. Узел (1436) выполняет проверку: p<1. Значение параметра р для изображения символа (1802) на Фиг. 18А равно 1. Проверка в узле (1436) оканчивается неудачей, и в качестве следующего дополнительного пути перехода выбирается правая стрелка вниз (1438), обозначенная буквой «R» (1828) на Фиг. 18В. Узел (1440) содержит проверку: р<4. Поскольку значение параметра р для изображения символа (1802) составляет 1, эта проверка завершается успешно, и поэтому левая направленная вниз стрелка (1442) выбирается в качестве следующего частичного перехода, который обозначен буквой «L» (1830) на Фиг. 18В. Это приводит к конечному узлу (1444), который представляет собой символ с кодом символа 22. Текстовые строки (1832)-(1834) представляют переходы со второго по четвертое дерево решений, (1500), (1600) и (1700), которые дают коды символов 37, 22 и 22. Наиболее часто получаемый код символа в обходах по четырем деревьям - это код символа 22 ((1836) на Фиг. 18В), который является результатом применения параметров (1808) к лесу решений, включающему деревья решений (1400), (1500), (1600) и (1700). Отметим, что поднабор символов, используемых для построения второго дерева принятия решений, которое выбрало код символа 37, не включает символ 22. Поэтому неудивительно, что код символа, который формируется переходом по этому дереву, не является кодом символа 22. Применение параметров (1810) изображения символа (1804) к лесу решений дает неоднозначный результат: либо код символа 45, либо код символа 22 (1838). Применение рассчитанных параметров (1812) для изображения символа (1806) приводит к выбору кода символа 22 (1840).
для изображения символа (1802) показано на Фиг. 18А, как 0,6. Значение 0,6 превышает 0,33, поэтому испытание, выполненное в узле (1402), приводит переходу к узлу (1406) вправо, как показано буквой «R» (1822) и текстовой строкой (1820). Узел (1406) выполняет проверку: p≤4. Расчетное значение параметра р для изображения символа (1802) показано на Фиг. 18А как 1. Таким образом, в случае узла (1406), проверка завершается успешно и таким образом выбирается левая стрелка вниз (1430), представленная буквой «L» (1824) на Фиг. 18В. Узел (1432) выполняет проверку b≤0,2. Значение параметра b для изображения символа (1802) на Фиг. 18А, равно 0,28. Таким образом, проверка в узле (1432) заканчивается неудачей, и в качестве следующего дополнительного поперечного перехода выбирается правая стрелка вниз (1434), которая обозначается буквой "R" (1826) на Фиг. 18В. Узел (1436) выполняет проверку: p<1. Значение параметра р для изображения символа (1802) на Фиг. 18А равно 1. Проверка в узле (1436) оканчивается неудачей, и в качестве следующего дополнительного пути перехода выбирается правая стрелка вниз (1438), обозначенная буквой «R» (1828) на Фиг. 18В. Узел (1440) содержит проверку: р<4. Поскольку значение параметра р для изображения символа (1802) составляет 1, эта проверка завершается успешно, и поэтому левая направленная вниз стрелка (1442) выбирается в качестве следующего частичного перехода, который обозначен буквой «L» (1830) на Фиг. 18В. Это приводит к конечному узлу (1444), который представляет собой символ с кодом символа 22. Текстовые строки (1832)-(1834) представляют переходы со второго по четвертое дерево решений, (1500), (1600) и (1700), которые дают коды символов 37, 22 и 22. Наиболее часто получаемый код символа в обходах по четырем деревьям - это код символа 22 ((1836) на Фиг. 18В), который является результатом применения параметров (1808) к лесу решений, включающему деревья решений (1400), (1500), (1600) и (1700). Отметим, что поднабор символов, используемых для построения второго дерева принятия решений, которое выбрало код символа 37, не включает символ 22. Поэтому неудивительно, что код символа, который формируется переходом по этому дереву, не является кодом символа 22. Применение параметров (1810) изображения символа (1804) к лесу решений дает неоднозначный результат: либо код символа 45, либо код символа 22 (1838). Применение рассчитанных параметров (1812) для изображения символа (1806) приводит к выбору кода символа 22 (1840).
В рассматриваемом простом примере все три вариации U-образного символа 22 (1802), (1804) и (1806), были охарактеризованы как символы, имеющие код символа 22, или код символа 22 или 45, согласно лесу решений, содержащему деревья решений (1400), (1500), (1600) и (1700). Тем не менее, изображения U-образных символов, которые больше отклоняются от традиционного изображения символа, показанного на Фиг. 6, для кода символа 22, скорее всего будут давать более различающиеся результаты. Лес из четырех деревьев решений в этом примере не очень надежен по многим причинам. Одна из причин этого заключается в том, что большинство решений в четырех деревьях решений содержат проверки, которые включают лишь небольшую часть от общего числа параметров. Таким образом, деревья решений в основном полагаются на немногие из девяти параметров. Кроме того, числовые значения параметров не обязательно упорядочены по отношению к подобию в изображении символов, формирующих числовые значения. Например, числовые значения параметра р, обсуждаемые со ссылкой на Фиг. 12А, не имеют численного представления степени сходства между символами, имеющими различные числовые значения этого параметра. Другая проблема заключается в том, что каждое дерево решений было построено с использованием всего 75% от общего числа символов, причем эти 75% символов не были выбраны случайным образом. Следовательно, существует значительно меньшее перекрытие в наборах символов, используемых для построения дерева, чем обычно используется для получения надежного леса решений. Наконец, практический лес решений, скорее всего, включает большее количество деревьев решений, построенных на основе подмножеств гораздо большего набора лучше распределенных параметров.
Распознавание изображений символов на основе дерева решений
В этом документе раскрывается система оптического распознавания символов («OCR») на основе дерева решений, которая определяет код символа, соответствующий каждому изображению символа, извлеченному из изображения документа. Коды символов используются для создания электронного документа, соответствующего изображению документа. Чтобы создать электронный документ, система OCR анализирует изображение документа на иерархических уровнях, форматирует изображение документа, чтобы повторить форматирование изображения документа и заменяет не символьные признаки изображения документа аналогичными кодировками электронного документа. Изображения символов в изображении документа заменяются в электронном документе кодами символов, такими как кодировки Unicode. В этом документе рассматривается процесс принятия решений на основе дерева, осуществляемый системой OCR, в результате которого выводится код символа для каждого исходного изображения символа.
На Фиг. 19-23В приведен ряд иерархически связанных структур данных, используемых в соответствии с описанными в настоящем документе системами OCR с целью выявления и вывода кода символа для исходного изображения символа. Структуры данных, показанные на Фиг. 19-23В, в сочетании с многочисленными подпрограммами OCR, содержащими машинные команды, которые хранятся в электронной памяти и исполняются одним или более процессорами, управляют системой OCR для осуществления процесса распознавания изображений символов, в результате которого выдается код символа для каждого исходного изображения символа. В приведенном ниже обсуждении некоторые из структур данных рассматриваются как структуры, включающие компонентные функции, общие в объектно-ориентированном программировании, которые осуществляют методы OCR, используя информацию, содержащуюся в структурах данных и, в случае классификаторов, как структуры, возвращающие решения. Знакомые с компьютерной наукой специалисты понимают, что, с другой стороны, структурами данных могут манипулировать отдельные подпрограммы, которые выполняют методы OCR и которые принимают решения для системы OCR на основании информации, содержащейся в структурах данных. Более того, можно использовать много различных альтернативных кодировок структур данных, включая структуры данных, которые содержат значения и подструктуры, а не ссылки на значения и подструктуры, структуры данных, которые содержат ссылки на значения и подструктуры, а не сами значения и подструктуры, и структуры данных, содержащие дополнительную и/или другую информацию. Последующее обсуждение и формула изобретения предназначены для описания нового полезного вычислительного подхода к распознаванию символов изображения, включенного в системы OCR, который может быть реализован различными способами.
На Фиг. 19 показан набор с числовыми индексами функций признаков и соответствующими значениями кэша, дающие основные численные значения или значения параметров, которые управляют процессом распознавания изображения символа. Функции признаков и соответствующие значения кэша показаны в содержащей две колонки таблице (1902) на Фиг. 19. Первая колонка содержит функции признаков или ссылки на функции признаков (1904), а вторая колонка (1906) содержит кэшированные значения, полученные соответствующей функцией признака. Каждая пара «функция признака/ значение кэша» численно проиндексирована по численным индексам, приведенным в левой колонке (1908). Функции признаков описаны выше со ссылкой на Фиг. 8А-В, 9, 10, 12А, 13А-В и другие фигуры. Функции признаков рассчитывают значения основных параметров и характеристик изображения символа, например, самую длинную горизонтальную линию на изображении символа, отношение количества черных пикселей к количеству белых пикселей в изображении символа и другие подобные параметры и характеристики. В описываемой системе OCR каждая функция признака возвращает вещественное значение в диапазоне [0, 1]. Разумеется, можно использовать и другие области значений функций признаков.
Набор функций признаков, содержащийся в двухколоночной таблице, используются для расчета значений признаков вводимого символа изображения. Индекс признака (1910) используется для выбора той или иной функции признака (1912). Затем исходное изображение символа (1914) поступает на вход функции признака (1912), выбранной индексом признака (1910) для получения соответствующего значения признака (1916). При первом доступе к функции признака для любого конкретного исходного изображения символа сохраняется значение признака, как показано стрелкой (1918), в записи кэша (1920), соответствующей функции признака (1912). После этого вместо того чтобы вызвать функцию признака с целью возврата значения функции, для повышения эффективности вычислений может быть немедленно возвращено кэшированное значение признака.
На Фиг. 20А-В показан индексированный набор структур данных эталонов. На Фиг. 20А показано табличное представление структуры данных эталона. Структура данных эталона (2002) содержит цифровую индикацию количества индексов признаков, содержащихся в структуре данных эталона (2004), значение кэша (2006), колонку индексов признаков (2008), и вторую колонку, содержащую соответствующие ожидаемые значения признаков (2010). Колонки функций признаков и соответствующие ожидаемые значения могут альтернативно считаться набором или списком кортежей, причем каждый кортеж содержит индекс признаков и соответствующее ожидаемое значение. Значение кэша (2006) может быть установлено, когда структура данных эталона сначала применяется к изображению символа, а затем используется в качестве веса изображения символа в процессе обработки изображения символа.
Структура данных эталона содержит коллекцию индексов признаков, индексирующих набор функций признаков, которые используются совместно для определения основных частей изображения символа. Как обсуждается далее ниже, структура данных эталона используется системой OCR для расчета веса из исходного изображения символа, отражающего вероятность того, что основной компонент изображения символа, распознанного структурой данных эталона, присутствует в исходном изображении символа. Вес вычисляется как сумма разностей абсолютных значений признаков, полученных индексированными функциями признаков, и соответствующих ожидаемых значений. В описываемом варианте реализации чем меньше вес, тем выше вероятность того, что компонент изображения символа, распознанный структурой данных эталона, присутствует в исходном изображении символа. В текущем варианте реализации рассчитанные веса представляют собой вещественные числа в диапазоне [0, 1]. Разумеется, что при расчетах вещественные числа представлены значениями с плавающей точкой. Как показано на Фиг. 20В, описываемая система OCR использует большой набор структур данных эталонов, представленный массивом записанных в виде строки векторов как структур данных эталонов (2012), которые численно проиндексированы по индексу эталона (2014).
На Фиг. 21 показана структура данных классификатора. Структура данных классификатора (2102) используется для идентификации конкретного класса или группы изображений символов, которые соответствуют коду символа. Другими словами, например, большое количество различных визуализаций конкретного символа естественного языка, например, буквы «А» в русском языке, будет представлять класс изображений символов, каждый член которого соответствует символу, характеризуемому кодом символа для буквы «А». Структура данных классификатора (2102) содержит указание на количество структур данных эталона, используемых структурой данных классификатора (2104), код символа (2106) в классе изображений символов, распознанных структурой данных классификатора, содержащей двухстрочную таблицу (2108) индексов структуры данных эталона и соответствующих ожидаемых значений, четыре пороговых значения (2110)-(2113) и функцию классификатора (2116), которая использует данные, содержащиеся в структуре данных классификатора для классификации исходного изображения символа. Содержащая две строки таблица (2108) индексов структур данных эталона и соответствующих ожидаемых значений может альтернативно рассматриваться как набор или список кортежей, причем каждый кортеж содержит индекс структуры данных эталона и соответствующее ожидаемое значение.
Функция классификатора (2116) получает исходный символ изображения s (2118) и дает в качестве выхода решение (2120). В описываемом варианте реализации обобщенный классификатор дает одно из пяти решений: (1) «левый» - индикация того, что исходное изображение символа не соответствуют классу изображений символов, распознаваемых этим классификатором, но может быть распознано другими классификаторами, к которым может быть совершен переход в результате навигации по левому ребру, исходящему из этого классификатора; (2) «левый серый» - индикация того, что этот классификатор не распознает это изображение символа как принадлежащее к классу символов изображений, распознаваемых этим классификатором, но указывающая, что соответствующий классификатор для изображения символа может быть обнаружен путем навигации по левому ребру или линии связи, исходящей из этого классификатора, а также указывает на значительный уровень неопределенности в отношении того, следует ли использовать левую линию связи или правую линию связи для нахождения соответствующего классификатора; (3) «правый серый» - индикация, похожая на решение «левый серый», которая указывает на то, что изображение символа не распознано этим классификатором, но что оно может быть распознано классификатором, на который можно перейти по правой линии связи или ребру, исходящему из этого классификатора, а также указывает на значительный уровень неопределенности в отношении того, следует ли использовать левую линию связи или правую линию связи для нахождения соответствующего классификатора; (4) «правый» - индикация того, что соответствующий классификатор исходного изображения символа может быть найден путем перехода по правому ребру или линии связи, исходящей из этого классификатора; и (5) «найдено» - индикация того, что исходное для классификатора изображение символа принадлежит к классу изображений символов, распознаваемых этим классификатором. Как описано более подробно ниже, классификаторы могут давать все пять типов решений, или альтернативно при вызове при построении дерева решений могут дать решения «влево», «вправо», «влево и вправо» и «найдено», причем решение «влево и вправо» показывает, что символ должен быть пропущен через узел, содержащий классификаторы как по левым, так и по правым линиям связи. Аналогичным образом в процессе распознавания символов изображения классификатор корневого узла или промежуточного узла может давать только решения «влево», «вправо» и «найдено», в то время как классификатор конечного узла может производить либо решение «найдено» либо иное решение, а также вычислять вес. В некоторых вариантах реализации, опять же, классификаторы не производят пронумерованные решения, а вместо этого с помощью подпрограмм OCR формируются эквивалентные решения на основании веса, рассчитанного с использованием данных, содержащихся в классификаторе, или данных, на которые ссылается классификатор.
На Фиг. 22 показана взаимосвязь между изображениями символов, признаками и значениями признаков, эталонами и весами, получаемыми эталонами и классификаторами. На Фиг. 22 в середине рисунка показано конкретное изображение символа (2202), соответствующее иероглифу мандаринского диалекта китайского языка. Несколько функций и соответствующих значений признаков показаны в первой части рисунка (2204), обведенной пунктирной линией. Приведенные значения признаков включают отношение числа черных пикселей в символе к площади изображения символа (2206), отношение площади пробелов или фоновых пикселей к общей площади изображения символа (2208), самой длинной горизонтальной линии в изображении символа (2210), самой длинной вертикальной линии в изображении символа (2212), отношение числа черных пикселей в левой части изображения к числу черных пикселей в правой части изображения (2214), и отношение количества черных пикселей в верхней части изображения символа к числу черных пикселей в нижней части изображения символа (2216). Это всего лишь несколько примеров из множества различных функций признаков и соответствующих значений признаков. Значения признаков - это вещественные числа в диапазоне [0, 1], связанные с некоторыми исходными параметрами и характеристиками изображения символов, которые в общем случае не отражают независимо отсутствие или наличие компонентов изображения символа. Эталоны и соответствующие значения эталонов, примеры которых показаны во второй области, охватываемой штриховой линией (2220) на Фиг. 22, напротив, дают веса - действительные числа в диапазоне [0, 1], отражающие отсутствие или наличие конкретных компонент изображения символа. Например, эталоны в соответствующих значениях эталона используются для выявления наклонной похожей на плюс структуры (2222), наличия трех параллельных горизонтальных элементов (2224), наличия в центре компактного элемента (2226), наличия в нижней центральной части изображение похожего на крюк элемента (2228), наличия в центре горизонтального похожего на крюк элемента (2230), наличия горизонтально ориентированного сжатого похожего на J элемента (2232), и наличия компактного элемента над горизонтальным элементом в верхней средней части изображения символа (2234). Классификатор (2236) связан с классом изображений символов, соответствующих конкретному символу или символу из набора символов естественного языка. Например, классификатор (2236) распознает класс изображений символов, включающий изображение символа (2202). Таким образом, признаки и соответствующие значения признака представляет собой низший уровень в иерархии инструментов распознавания символов, эталоны и соответствующие значения эталонов представляют собой промежуточный уровень иерархии инструментов распознавания символов, а классификаторы представляют собой инструменты распознавания символов самого верхнего уровня иерархии.
На Фиг. 23А-В показано дерево решений, которое содержит структуры классификатора данных в узлах дерева решений. Как показано на Фиг. 23А, дерево решений (2302) содержит корневой узел (2304) на уровне корня «0» (2306), два узла промежуточного уровня (2308) и (2310) на первом уровне дерева (2312), четыре узла промежуточного уровня (2314)-(2317) на втором уровне (2318) в дереве решений, многочисленные дополнительные уровни промежуточных узлов (2320) и набор конечных узлов, в том числе конечных узлов (2322)-(2327). Это бинарное дерево решений, в котором корневой узел и узлы промежуточного уровня имеют по два дочерних узла. Количество узлов на уровне «L» равно 2L, а число узлов в дереве с самым высоким уровнем узла L равно 2(L+1)-1. Каждый из корневых узлов и узлов среднего уровня содержит отдельный классификатор, изображенный на Фиг. 23А небольшим прямоугольником (2328), помеченным буквой «С». Каждый конечный узел содержит несколько классификаторов, таких как классификаторы (2330)-(2337) в конечном узле (2322). Число узлов, уровней и классификаторов в конечных узлах варьируется в зависимости от конкретного естественного языка, к которому относится дерево решений. В некоторых случаях дерево решений может содержать 20 или более уровней. Как обсуждается более подробно ниже, каждый корневой узел и каждый узел промежуточных уровней связан с другим классификатором, но конечные узлы могут содержать классификаторы, которые также могут иметь место в узле промежуточного уровня или в других конечных узлах.
На Фиг. 23В показан обход дерева решений. Исходное изображение символа (2340) является первыми исходными данными для классификатора (2328) корневого узла (2304). Если классификатор возвращает решение «найдено», то обход прекращается, и дерево решений возвращает код символа, связанный с классификатором (2328) и соответствующий исходному изображению символа. В примере, показанном на Фиг. 23В, классификатор (2328) вместо этого возвращает решение «левый», в результате чего происходит переход вниз к промежуточному узлу (2308). Если изображение символа вводится в классификатор (2342), содержащийся в промежуточном уровне (2308), в примере, показанном на Фиг. 23В, то классификатор возвращает решение «правый». Если бы классификатор возвратил решение «найдено», то дерево решений возвратило бы код символа, связанный с классификатором (2342), и дальнейший обход был бы прекращен. Однако в данном примере производится переход в узел (2315). Исходное изображение символа поступает в классификатор (2344), содержащийся в узле (2315). В этом примере классификатор возвращает решение «левый». Этот процесс продолжается до тех пор, пока классификаторы в обходимых узлах не возвратят решение «найдено». Если при обходе достигается конечный узел, например, конечный узел (2325) в примере, показанном на Фиг 23В, то выполняется обход классификаторов внутри конечного узла. Опять же, если какой-либо из этих классификаторов вернет решение «найдено», то обход прекращается, и дерево решений возвращает код символа, связанный с этим классификатором. В противном случае, если все классификаторы в конечном узле были пройдены, то классификатор, который возвращает самый малый вес для исходного символа, выбирается в качестве классификатора, соответствующего изображению символа и возвращается код символа, связанный с этим классификатором.
На Фиг. 24А-В показан проход узла промежуточного уровня дерева решений и конечных узлов дерева решений. На Фиг. 24А показан узел дерева решений промежуточного уровня, содержащий один классификатор (2404). Если этот узел будет достигнут во время обхода дерева решений, то рассматриваемое в данный момент изображение символа (2406) подается на вход классификатора (2404). Этот классификатор выдает решение d. Если полученное решение d - это «левый» или «левый серый», что определено на этапе обработки условия (2408), то обход дерева решений продолжается по левой линии связи (2410), выходящей из узла промежуточного уровня (2402). Напротив, если решение d - это «правый» или «правый серый», что определяется на этапе обработки условия (2412), то обход дерева решений продолжается по правой линии связи (2414), выходящей из узла промежуточного уровня (2402). Если же решение d равно «найдено», в результате чего дерево решений возвращает (2418) код символа (2416), содержащийся в классификаторе (2404), как код символа, соответствующий исходному изображению символа.
На Фиг. 24В показан обход классификатора в конечном узле дерева решений. Когда изображение символа (2420) поступает в следующий классификатор (2422) в конечном узле, этот классификатор выдает решение d и расчетный вес (2424). Если решение d равно «найдено», что определяется на этапе обработки условия (2426), код символа (2428), содержащийся в классификаторе, возвращается в качестве кода символа, соответствующего исходному изображению символа. В противном случае обход классификатора внутри конечного узла продолжается в следующем классификаторе (2430).
На Фиг. 25А-В показано определение веса по структуре данных эталона и логика OCR для исходного изображения символа. Исходное изображение символа (2502) поступает в первую функцию признака (2504), выбранную из множества функций признака ((1904) на Фиг. 19) индексом первого признака (2506) в структуре данных эталона. Ожидаемое значение (2508), соответствующее первому показателю признака (2506), вычитается из значения признака (2510), полученного с помощью функции признака (2504), а абсолютное значение результата берется в качестве значения локальной переменной diff (2512). Затем значение diff масштабируется в строках псевдокода (2514) так, чтобы значение diff находилось в диапазоне [0, 1]. Затем значение diff добавляется к локальной переменной sum (2516). Как показано на Фиг. 25В, этот процесс продолжается с каждым дополнительным индексом признака в структуре данных эталона, как показано изогнутыми стрелками (2520)-(2524). Наконец, последний индекс признака (2526) и соответствующее ожидаемое значение (2528) используются для вычисления окончательного значения diff (2530), которое масштабируется и затем добавляется к локальной переменной sum (2516). Содержание этой переменной затем делится на n (2531), число индексов признака в структуре данных эталона, чтобы получить вес эталона Wp (2532), соответствующий исходному изображению символа. В описываемом варианте реализации вес, полученный структурой данных эталона, является вещественным числом в диапазоне [0, 1].
На Фиг. 26А-В показано вычисление веса и принятие решения классификатором для исходного изображения символа. Как показано на Фиг. 26а, первая пара «ожидаемое значение»/«индекс эталона» (2602) в классификаторе используется для вычисления первого веса эталона (2603) для изображения символа Wp. Индекс эталона (2604) используется для выбора конкретной ссылки (2606) из индекса эталона (2608), показанного как (2014) на Фиг. 20В, и ссылка используется для доступа к соответствующей структуре данных эталона (2610). Исходное изображение символа (2612) поступает на вход в структуру данных эталона (2610) для получения веса эталона Wp (2603) с помощью процесса, описанного выше со ссылкой на Фиг. 25А-В. Затем значение diff вычисляется как абсолютное значение разности между весом эталона Wp и ожидаемым значением (2616) в первой паре «ожидаемое значение» - «индекс эталона» (2602). Значение diff масштабируется псевдокодом (2618), так что значение diff гарантированно будет вещественным числом в диапазоне [0,1]. Затем значение diff добавляют к локальной переменной sum (2620). Как показано на Фиг. 26В, процесс, описанный на Фиг. 26А, повторяется для каждой последующей пары «ожидаемое значение»/«индекс эталона» в виде изогнутых стрелок (2622) на Фиг. 26В, для получения последовательных значений diff, которые добавляются к локальной переменной sum (2620). Наконец, последняя пара «ожидаемое значение»/«индекс эталона» (2624) используется в процессе описанного выше со ссылкой на Фиг. 26А для получения окончательного значения diff value (2626), которое добавляется к локальной переменной sum (2620). Далее, вес классификатора W (162%) получается путем деления значения локальной переменной sum на число эталонов num_patterns, содержащихся в этом классификаторе. Затем вес классификатора W вводится на этапе проверки условия (2630). Если W меньше нижнего порога, то решение «найдено» вместе с кодом символа, содержащимся в классификаторе, возвращаются в результате (2632). В противном случае, как это определено на этапе проверки условия (2634), если W меньше, чем левый серый порог, возвращается решение «налево» (2636). В противном случае, если W меньше, чем порог «правый/левый», который определен на этапе (2638), то возвращается решение «левый серый» (2640). В противном случае, если W меньше, чем порог «правый серый», что определяется на этапе (2642), то на этапе (2644) возвращается решение «правый серый». В противном случае, на шаге (2646) возвращается решение «правый».
На Фиг. 27А-Е показано создание и обучение дерева решений OCR. Как показано на Фиг. 27А, создание и обучение дерева решений основано на базе данных изображений символов (2702) и списке классификаторов для естественного языка, на который ориентировано дерево решений (2704), причем классификаторы отсортированы в порядке убывания частоты появления соответствующих кодов символов для классификаторов в естественном языке. Список классификаторов (2704) называется «не назначенными классификаторами», потому что по мере того как классификаторы связываются с узлами дерева решений во время создания и обучения дерева решений OCR, они удаляются из этого списка. База данных изображений символов может содержать миллионы изображений символов, выбранных из широкого спектра различных типов документов на естественном языке, для которого предназначено дерево решений. База данных изображений символов обычно содержит сбалансированную репрезентативную подборку изображений символов для каждого класса изображений символа, в которой класс изображений символов соответствует конкретному коду символа или символа естественного языка, для которого предназначено дерево решений. Каждая запись в базе данных изображений символов содержит изображение символов и соответствующий код символа. Эти пары «изображение символа/код символа» постоянно проходят через возникающее дерево решений, как описано ниже. В ходе последующего обсуждения, когда изображения символов передаются по создаваемому дереву изображений символа, в процессе создания деревьев, изображение символа обрабатывается классификаторами, в то время как код символа остается связанным с изображением символа, пока либо не прекратится обход дерева либо изображение символа и соответствующий код символа не будут введены в одну из трех различных баз данных пар «символ изображения» - «код символа».
Процесс создания дерева решений и обучения описан по отношению к обобщенному корневому узлу или узлу промежуточного уровня (2706). Этот процесс повторяется для всех узлов промежуточного уровня, а также для корневого узла во время построения дерева решений. На первом этапе, показанном на Фиг. 27В, первый классификатор (2708) в отсортированном списке классификаторов (2704) выбирается для включения в узел (2706). Далее, как показано на Фиг. 27С, каждое изображение символа в базе данных изображений символов вводится (2710) последовательно в текущее дерево решений. Эти изображения символа, которые завершают ввод в рассматриваемый в настоящий момент узел (2706), затем обрабатываются текущим выбранным классификатором (2708) и направляются в базу данных «найдено» (2712), в базу данных «левый» (2714) или в базу данных «правый» (2716) в зависимости от окончательного решения, принятого текущим классификатором (2708). Опять же, как уже отмечалось выше, каждый символ изображения связывается с соответствующим кодом символа в этих трех базах данных. Затем содержание баз данных «найдено», «левый» и «правый» используется для получения метрики для первого классификатора m (2718), который, как показано на Фиг. 27D, связан с первым классификатором (2708). Далее из отсортированного списка классификаторов (2704) выбирается второй классификатор (2720) для включения в рассматриваемый в настоящий момент узел (2706). Затем, как показано на Фиг. 27Е, изображения символов в базе данных изображений символов снова вводятся в дерево решений (2722), и те изображения символов, которые оканчиваются при проходе рассматриваемого в настоящее время узла (2706), направляются на повторную инициализацию баз данных «найдено», «левый» и «правый» (2724), (2725) и (2726). Метрика (2728) рассчитывается из содержимого этих трех баз данных, она связана со вторым классификатором (2720). Этот процесс продолжается до тех пор, пока все пока еще не назначенные классификаторы не будут связаны с метриками. Классификатор с наибольшей метрикой отбирается для включения в рассматриваемый в настоящий момент узел. Затем этот классификатор удаляется из отсортированного списка не назначенных классификаторов, и процесс осуществляется снова для следующего узла дерева решений.
На Фиг. 28 показана ступенчатая конструкция и одновременное обучение дерева решений OCR в одном варианте реализации системы OCR. На Фиг. 28 пунктирные прямоугольники, например, пунктирный прямоугольник (2802), указывают на только что созданный корневой узел или узел промежуточного уровня, для которого еще не назначен классификатор, а образованные сплошными линиями прямоугольники, такие как образованный сплошными линиями прямоугольник (2804), указывают корневой узел или узел промежуточного уровня, которым был назначен классификатор. На первом этапе создается начальный корневой узел (2802). Затем в процессе назначения классификатора, который обсуждался выше со ссылкой на Фиг. 27А-Е, показанного на Фиг. 28 горизонтальной стрелкой (2806), этот классификатор назначается корневому узлу. Затем создается новый левый дочерний узел (2808) для корневого узла. Процесс назначения классификатора на Фиг. 27А-Е снова применяется для назначения классификатора левому дочернему узлу (2808), а для корневого узла создается новый правый узел (2810). Чередование этапов назначения классификатора и создания узла приводит к построению структурно полного дерева решений (2812). Структурно полное дерево решений (2812) содержит конечные узлы, такие как конечный узел (2814), которым классификаторы до сих пор не назначены. На заключительном этапе построения и обучения дерева решений классификаторы назначаются каждому конечному узлу для получения окончательного полного дерева решений (2816). В окончательном, полном дереве решений (2816) каждый конечный узел, например, конечный узел (2818), содержит несколько классификаторов.
Логика возврата решений, включающая дополнительные этапы (2630), (2632), (2634), (2636), (2638), (2640), (2642), (2644) и (2646), которая показана в нижней части Фиг. 26В, может быть изменена для адаптации классификаторов к определенным ролям и рабочим состояниям. Например, во время построения дерева, когда база данных изображений символов передается через дерево в ходе процесса назначения классификаторов, описанного выше со ссылкой на Фиг. 27А-Е, классификатор возвращает только четыре различных решения: (1) «найдено»; (2) «левый»; (3) «правый» и (4) «правый и левый», », это указывает, что изображение символа должно быть выведено правой и левой линиями связи, исходящими от узла, через который передаются изображения символов. Таким образом, при создании деревьев решения и одновременном обучении, используется логика, которая немного отличается от логики принятия решений, применяемой корневыми узлами и узлами промежуточного уровня. На Фиг. 29 показана альтернативная логика принятия решений классификатором. Если рассчитанный классификатором вес W, меньше нижнего порогового значения, определенного на этапе (2902), то на этапе (2904) возвращается решение «найдено». В противном случае, если W меньше порога «левый серый», определенного на этапе (2906), то на этапе (2908) возвращается значение «левый». В противном случае, если W меньше порога «правый серый», определенного на этапе (2910), то на этапе (2912) возвращается значение «левый и правый». В противном случае на этапе (2914) возвращается значение «правый». Напротив, при нормальной работе распознавания OCR дерева решений логика классификатора изменена и возвращает только три решения: «найдено», «левый» и «правый». Значение «найдено» определяется, если W меньше нижнего порога, значение «левый» возвращается, если W меньше порога «левый/правый», в ином случае возвращается значение «правый». На самом деле логика, показанная на Фиг. 26В, является наиболее общей логикой, и ее можно использовать для любых целей при условии, что логика распознавания правильно использует решения для различных типов навигации при различных рабочих состояниях конкретного классификатора.
На Фиг. 30A-G приведены блок-схемы, которые иллюстрируют обработку документов описываемой системой OCR. На этапе (3002) на Фиг. 30А система OCR получает документ и инициализирует электронный документ, содержащий кодировку принятого изображения документа, полученного с помощью процесса OCR. Части процесса OCR, непосредственно не связанные с присвоением кодов символов изображениям символа, не обсуждаются со ссылкой на Фиг 30A-G. В общем случае обработка OCR содержит много иерархических уровней процессов, направленных на распознание областей, форматирование и неязыковые признаки документа и предоставление соответствующих кодировок этих областей, форматирование и не содержащие символы части изображения документа в электронном документе. Некоторые из этих процессов могут выполняться на этапе (3002) до распознавания изображения символа. В ходе общего процесса OCR он выявляет изображения отдельных символов в документе на этапе (3004), как описано выше. В цикле for на этапах (3006)-(3009) обрабатывается каждое выявленное изображение символа в полученном изображении документа. Каждое выявленное изображение символа преобразуется в код символа после вызова подпрограммы на этапе (3007), а затем код символа включается в электронный документ на этапе (3008). После обработки выявленных символов изображения, на этапе (3010) выполняется обработка документа. Выполнение обработки документов может включать дополнительные этапы обработки OCR, связанные с распознаванием и кодированием не содержащих символы участков изображения документа.
На Фиг. 30В показана блок-схема для подпрограммы «преобразовать изображение символа в код символа», вызываемая на этапе (3007) на Фиг. 30А. На этапе (3011) эта процедура получает изображение символа и очищает все значения кэша в наборе функций признаков (колонка (1906) на Фиг. 19) и в структурах данных эталона ((2006) на Фиг. 20а). Затем на этапе (3012) эта подпрограмма вызывает рекурсивную подпрограмму «обхода дерева» и передает этой подпрограмме принятое изображение символа и заранее подготовленную ссылку на корневой узел дерева решений методами, изложенными выше со ссылкой на Фиг. 27А-Е и Фиг. 28, которые более подробно описаны ниже. Рекурсивная подпрограмма «обхода дерева» возвращает код символа для принятого символа изображения. Этот код символа возвращается из подпрограммы «преобразования изображения символа в код символа» на этапе (3013).
На Фиг. 30С показана блок-схема операций для рекурсивной подпрограммы «обхода дерева», вызываемой на этапе (3012) на Фиг. ЗОВ. На этапе (3016) подпрограмма «обхода дерева» получает изображение символа и указатель на узел. На этапе (3018) рекурсивная подпрограмма «обход дерева» определяет, ссылается ли указатель узла на конечный узел дерева решений (лист дерева решений). Если это так, то подпрограмма «обхода дерева» вызывает процедуру «проход листа» на этапе (3019) и на этапе (3020) возвращает код символа, полученный в подпрограмме «проход листа». В противном случае на этапе (3022) полученное изображение символа подается на вход классификатора узла, на который ссылается полученный указатель узла, представленный на Фиг. 30С вызовом процедуры «неконечный классификатор». Если классификатор возвращает решение «найдено», определенное на этапе (3024), связанный с классификатором код символа возвращается подпрограммой «обхода дерева» на этапе (3026). В противном случае, если возвращаемое классификатором решение - это «левый», то в том случае, если логика классификатора возвращает три решения «найдено», «левый» и «правый», или если классификатор возвращает решение «левый» или решение «серый влево» в случае логики решения, показанной на Фиг. 26В, подпрограмма «обхода дерева» рекурсивно вызывает себя в левом дочернем элементе узла, на который ссылается полученный указатель на узел на этапе (3030). В противном случае процедура обхода дерева вызывает себя в правом дочернем элементе узла, на который ссылается полученной указатель узла на этапе (3031).
На Фиг. 30D показана блок-схема для подпрограммы «обхода листьев», вызываемой на этапе (3019) на Фиг. 30С. На этапе (3032) подпрограмма «обход листа» получает изображение символа и указатель на конечный узел, который требуется пройти. На этапе (3033) процедура «обход листа» устанавливает локальную переменную minW равной 1,1, a cptr - равной NULL. Затем в цикле for на шагах (3034)-(3040), подпрограмма «обход листа» проходит последовательность классификаторов внутри конечного узла. Для каждого классификатора на этапе (3035) подпрограмма «обход листа» представляет изображение символа, в форме вызова подпрограммы «классификатор листа». Когда классификатор листа возвращает решение «найдено», определенное на этапе (3036), подпрограмма «обход листа» возвращает код символа, связанный с рассматриваемым в настоящий момент классификатором на этапе (3037). В противном случае, если вес, рассчитанный рассматриваемым классификатором, меньше локальной переменной minW, определенной на этапе (3038), то переменная minW устанавливается равной весу, возвращаемому рассматриваемым в настоящий момент классификатором, а переменная cptr устанавливается равной адресу рассматриваемого в настоящий момент классификатора на этапе (3039). В случае завершения цикла for код символа, содержащий классификатор, на который ссылается локальная переменная cptr, возвращается подпрограммой «обход листа» на этапе (3042).
На Фиг. 30Е с помощью блок-схемы показана подпрограмма «неконечный классификатор», вызываемый на этапе (3022) на Фиг. 30С. На этапе (3044) подпрограмма «неконечный классификатор» получает изображение символа и устанавливает локальную переменную W равной 0. В цикле for на этапах (3045)-(3049) каждый индекс эталона из связанных с данным классификатором индексов эталона используется для доступа к соответствующей структуре данных эталона и вычисления веса эталона с помощью этой структуры данных эталона. Этот процесс представлен вызовом процедуры «обработать изображение символа с помощью эталона» на этапе (3046). На этапе (3047), как описано выше со ссылкой на Фиг. 26А, вычисляется и затем масштабируется абсолютное значение разности между весом, возвращаемым структурой данных эталона Wp, и ожидаемым значением веса, содержащимся в части кортежа, соответствующей ожидаемому значению, при этом кортеж содержит индекс эталона, который ссылается на структуру данных эталона. Локальная переменная W увеличивается на этапе (3048) на найденную разность после масштабирования. После того, как все эталоны вычислили веса эталонов для изображения символа, и эти веса были добавлены к локальной переменной W, локальная переменная W на этапе (3050) делится на количество эталонов, связанных с классификатором, для получения веса, представляющего вероятность распознания классификатором изображения символа. Если этот вес меньше нижнего порога, определенного на этапе (3051), то на этапе (3052) возвращается решение «найдено» и связанный с классификатором код символа. В противном случае, если W меньше связанного с классификатором порога правый/левый, определенного на этапе (3053), то на этапе (3054) возвращается решение «левый». В противном случае на этапе (3055) возвращается решение «правый».
На Фиг. 30F показана блок-схема для подпрограммы «конечный классификатор», вызываемой на этапе (3035) на Фиг. 30D. Начальные этапы подпрограммы конечного классификатора идентичны начальным этапам (3044)-(3050) подпрограммы «неконечного классификатора», рассмотренной выше со ссылкой на Фиг. 30Е. На этапе (3056) конечный классификатор определяет, меньше ли расчетный вес W нижнего порога. В этом случае подпрограмма «конечный классификатор» возвращает расчетный вес W и решение «найдено» на этапе (3057). В противном случае подпрограмма «конечный классификатор» возвращает расчетный вес W и решение, отличное от «найдено», на этапе (3058).
На Фиг. 30G показана блок-схема для подпрограммы «обработать изображение символа с помощью эталона», вызываемой на этапе (3046) на Фиг. 30Е и аналогичном этапе на Фиг. 30F. На этапе (3060) процедура «обработать изображение символа с помощью эталона» получает изображение символа и индекс эталона. На этапе (3061) процедура «обработать изображение символа с помощью эталона» использует индекс эталона для ссылки на структуру данных эталона в наборе структур данных эталона ((2012) на Фиг. 20В), используемом системой OCR. Если имеется действующая запись в кэше структуры данных эталонов, как определено на этапе (3062), то запись в кэше возвращается на этапе (3063). В противном случае на этапе (3064) локальной переменной Wp присваивается значение 0. Затем в цикле for на этапах (3065)-(3075) каждый индекс признака в структуре данных эталона (колонка (2008) на Фиг. 20А) используется для индексации записи признака (например, записи признака (1912) и (1920) на Фиг. 19) в наборе функций признаков ((1902) на Фиг. 19), используемых системой OCR на этапе (3066). Если запись признака имеет действительный элемент кэша, как определено на этапе (3067), то абсолютное значение разности в записи кэша и ожидаемого значения признака (ожидаемого значения в колонке (2010) на Фиг. 20А, связанного с рассматриваемым в настоящее время индексом признака в колонке (2008) на Фиг. 20А). В противном случае на этапе (3069) функция признака в записи признака вызывается с изображением символа в качестве аргумента для получения возвращаемого значения res и записи кэша, связанной с набором записей признака, которым задается значение, хранящееся в параметре res. Затем на этапе (3070) локальная переменная diff устанавливается равной абсолютной величине разности между res и ожидаемым значением признака в колонке (2010) на Фиг. 20А, связанным с индексом признака для функции признака в колонке (2008) на Фиг. 20А. Если ожидаемое значение меньше 1 за вычетом ожидаемого значения, как определено на этапе (3071), то значение diff масштабируется путем деления diff на 1 минус ожидаемое значение (на этапе (3072)). В противном случае значение diff масштабируется путем деления diff на ожидаемое значение на этапе (3073). На этапе (3074) локальная переменная Wp увеличивается на diff. Если имеются другие индексы признаков, которые необходимо рассмотреть, что определено на этапе (3075), то управление возвращается на этап (3066). В противном случае Wp делится на количество признаков n в структуре данных шаблона на шаге (3076), а запись в кэше для структуры данных эталона на этапе (3077) устанавливается равной Wp. Значение Wp возвращается на этапе (3078).
На Фиг. 31A-D показаны блок-схемы, иллюстрирующие построение и одновременное обучение в дереве решений OCR. На этапе (3102) на Фиг. 31А подпрограмма «создать дерево решений» получает базу данных изображений символов ((2702) на Фиг. 27а) и упорядоченный набор классификаторов ((2704) на Фиг. 27А). На этапе (3104) создается корневой узел для дерева решений. На этапе (3106) подпрограмма «выбрать классификатор для узла» вызывается с использованием корневого узла в качестве аргумента. Подпрограмма «выбрать классификатор для узла» осуществляет процесс, описанный выше со ссылкой на Фиг 27А-Е. На этапе (3108) подпрограмма «создать дерево решений» создает левый и правый дочерние узлы для корневого узла. На этапе (3109) подпрограмма «создать дерево решений» вызывает подпрограмму «продолжить создание» со ссылкой на левый дочерний узел в качестве аргумента. На этапе (3110) подпрограмма «создать дерево решений» вызывает подпрограмму «продолжить создание» со ссылкой на правый дочерний узел корневого узла в качестве аргумента. На этапе (3112) ссылка на корневой узел возвращается в качестве выходного значения для функции «создать дерево решений».
На Фиг. 31В показана блок-схема для рекурсивной подпрограммы «продолжить создание», вызываемой на этапах (3109) и (3110) на Фиг. 31А. На этапе (3116) подпрограмма «продолжить создание» получает указатель на корень поддерева. На этапе (3118) подпрограмма «продолжить создание» вызывает подпрограмму «выбор классификатора для узла», предоставляя ссылку на корень поддерева в качестве аргумента. Эта подпрограмма осуществляет процесс, описанный выше со ссылкой на Фиг. 27А-Е. На этапе (3120) подпрограмма «продолжить создание» определяет количество изображений символов, которые прошли через корневой узел, на который ссылается полученный указатель, используя базы данных «найдено», «левый» и «правый», которые собирают изображения символов, проходящие через этот узел, как описано выше со ссылкой на Фиг. 27А-Е. Если количество изображений символов, который прошли через корневой узел, меньше значения порога, определенного на этапе (3122), то на этапе (3124) процедура «продолжить создание» создает левый и правый конечные узлы для корневого узла поддерева, на который ссылается полученный указатель. На этапе (3126) процедура «продолжить создание» определяет правый/левый порог для поддерева корневого узла, чтобы направить примерно равное количество изображений символов в каждый из конечных узлов, созданных на этапе (3124). Порог «правый/левый» предназначен не только для направления примерно равного количества изображений символов к каждому конечному узлу, порог левый/правый также предназначен для обеспечения того, чтобы, когда это возможно, все изображения символов, проходящие через корневой узел поддерева, и принадлежащие к определенному классу символов, направлялись на левый или на правый конечный узел. Класс символов относится к набору изображений символов, каждый из которых соответствует одному символу и соответствующему коду символа в естественном языке. Например, колонка (704) на Фиг. 7А содержит различные формы восьмого символа в наборе символов, показанном на Фиг. 6. Этот набор различных форм восьмого символа представляет собой класс символов для восьмого символа. Класс символа в большой базе данных изображений символов может иметь сотни, тысячи или более изображений символов, которые отражают различные многочисленные формы символа и возможные визуализации конкретного символа в различных типах печатного и отображаемого текста. Таким образом, если для направления всех изображений символов, принадлежащих большему числу классов символов влево или вправо, можно внести небольшие изменения порога левый/правый, то эти изменения производятся до тех пор, пока общее количество изображений символов, направляемых в левый и правый конечные узлы, остается относительно сбалансированным. Затем в цикле for на этапах (3128)-(3131) для каждого из двух оконечных узлов, созданных на этапе (3124), в изображениях символа, направленных в оконечный узел определяется классификатор для каждого класса изображения символа, а на этапе (3130) эти классификаторы добавляются к конечным узлам в порядке убывания частоты встречаемости соответствующего класса символа в текстах на естественном языке. Если количество изображений символов, прошедших через корневой узел поддерева в процессе классификации/выбора на этапе (3118), не меньше порогового значения, определенного на этапе (3122), то на этапе (3134), для корневого узла поддерева создаются правый и левый дочерние узлы, а в шагах (3135) и (3136) рекурсивно вызывается подпрограмма «продолжить создание» для левого и правого узлов, соответственно.
На Фиг. 31С показана блок-схема операций для подпрограммы «Выбор классификатора для узла», вызываемой на этапе (3106) на Фиг. 31А и на этапе (3118) на Фиг. 31В. На этапе (3140) процедура «выбрать классификатор для узла» получает указатель или ссылку на узел. В цикле for на этапах (3142)-(3146) рассматривается каждый еще не выбранный или не назначенный классификатор. На этапе (3143) рассматриваемый в настоящее время классификатор вставляется в узел в качестве единственного классификатора внутри узла. На этапе (3144) вызывается подпрограмма для запуска базы данных изображений символов в дереве для создания баз данных «левый», «правый» и «найдено», содержащих символы изображения, которые проходят через узел, на который ссылается принятый указатель узла. На этапе (3145) рассчитывается метрика для классификатора на основе баз данных «найдено», «левый» и «правый», заполненных изображениями символа, которые прошли через этот узел во время прохождения базы данных изображений символов через дерево решений на этапе (3144). После оценки всех назначенных классификаторов на этапе (3148) классификатор с наилучшей метрикой выбирается из узла и удаляется из набора невыбранных классификаторов.
На Фиг. 31D показана блок-схема для подпрограммы, вызываемой на этапе (3144) на Фиг. 31С. На этапе (3150) определяется путь, ведущий от корневого узла к целевому узлу, для которого с помощью подпрограммы, показанной на Фиг. 31С, выбирается классификатор. В цикле for на этапах (3152)-(3167) каждый символ в базе данных изображений символов проходит по определенному пути в дереве решений. На этапе (3153), «найдено», кэши очищаются, и исходное изображение символа поступает в корневой узел дерева решений. В цикле while на этапах (3154)-(3156) выходное изображение символа из предыдущего узла поступает в следующий узел на пути, ведущем к целевому узлу. Разумеется, если изображение символа выводится узлом на пути к узлу, не лежащему на пути, то обработка для рассматриваемого изображения символа завершается и управление переходит к этапу (3158). Если символ выводится из более высокого уровня узла в целевой узел, как определено на этапе (3157), то на этапе (3159) изображение символа проходит через целевой узел, что подразумевает ввод сигнала в классификатор в целевом узле и получение решения от классификатора. Если классификатор указывает, что символ должен быть выведен в левый и в правый узлы, как определено на этапе (3160), то символ добавляется и к базе данных «правый» и к базе данных «левый» на этапе (3161). В противном случае, если классификатор показывает, что символ должен выводиться в правый узел, что определяется на этапе (3162), то на этапе (3163) это изображение символа добавляется к правой базе данных. Если классификатор показывает, что изображение символа выводится в левый дочерний узел, что определяется на этапе (3164), то на этапе (3165) это изображение символа добавляется к левой базе данных. Если классификатор указывает, что изображение символа не выводится в какой-либо дочерний узел, что определяется на этапе (3164), то на этапе (3166) это изображение символа добавляется к базе данных «найдено».
Метрика, рассчитываемая на этапе (3145) на Фиг. 31С, может рассчитываться разными способами. Эта метрика должна достигать максимального значения для наиболее подходящего классификатора из пока еще не присвоенных классификаторов для присвоения узла. Обычно наиболее подходящий классификатор - это классификатор, который направляет все изображения символов, соответствующих каждому классу символов, в базы данных «левый», «правый» или «найдено». Кроме того, подходящий классификатор - это такой классификатор, который направляет большинство изображений символов в базу данных «найдено». В одном варианте реализации изобретения подходящий классификатор - это такой классификатор, который чаще направляет все символы изображения, соответствующие каждому классу символов, только в одном направлении. В другом варианте реализации изобретения количество изображений символов, направленных влево и вправо, должно быть примерно одинаковым для наиболее подходящего классификатора. Несмотря на то, что баланс количеств изображений символов, направленных в левый и правый дочерний узлы может, в некоторых случаях казаться противоречащей варианту, при котором все символы изображений каждого класса символов направляются только в одном направлении, оптимальный классификатор может создавать сбалансированное распределение изображений символов вправо и влево, а также направлять изображения символов, соответствующих конкретному классу символов, только в одном направлении. Приведенный ниже пример рассчитанной метрики содержит взвешенные вклады или условия для всех упомянутых выше целей: максимизация количества изображений символов, направленных в базу данных «найдено», балансировка количества изображений символов, направленных в левый и правый дочерние узлы, и направление изображений символов каждого класса символов только одному дочернему узлу:
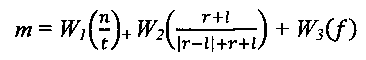
где W1, W2 и W3 - постоянные веса;
n = число классов символов, не распределенных между линиями связи направо и налево;
t = общее количество классов символов, проходящих через узел;
r = число классов символов, которые выведены по ссылке вправо;
l = число классов символов, которые выведены по ссылке влево; и
f = количество изображений символов, выявленных как найденные узлом.
Разумеется, возможно использование других типов метрик, для которых рассчитывается больше или меньше членов и промежуточных расчетных значений и которые не включают веса или включают меньше или больше весов. Вычисленное значение метрики может быть дополнительно нормализовано для соответствия определенному диапазону значений, например, [0, 1]. Для других типов метрик, можно использовать нелинейную функцию для вычисления значения метрики. В целом метрика обеспечивает значение, отражающее одну или несколько целей, что позволяет выбрать наилучший классификатор из числа еще невыбранных классификаторов для каждого узла в процессе построения дерева решений.
Хотя настоящее изобретение описывается на примере конкретных вариантов осуществления, предполагается, что оно не будет ограничено только этими вариантами осуществления. Специалистам в данной области будут очевидны возможные модификации сущности настоящего изобретения. Например, порядок построения узлов в дереве решений OCR может изменяться в зависимости от различных вариантов реализации. Можно использовать различные типы метрик для выбора классификаторов для корневого узла и узлов промежуточных уровней. Пороговые значения, включенные в классификаторы и использующиеся для прекращения создания промежуточных узлов и созданий вместо них оконечных узлов, могут иметь различные значения для различных целевых естественных языков и различных вариантов реализации. Значения используемых в классификаторах порогов также могут варьироваться в различных вариантах реализации. Система OCR, содержащая выявление кодов символов для изображения символов на основе дерева решений OCR, может быть реализована по-разному путем изменения любого из многих параметров проектирования и реализации, включая выбор аппаратных систем, операционных систем, языков программирования, модульной организации, структур данных, управляющих структур и других подобных параметров разработки и осуществления.
Следует понимать, что представленное выше описание раскрытых вариантов осуществления предоставлено для того, чтобы дать возможность любому специалисту в данной области повторить или применить настоящее описание. Специалистам в данной области будут очевидны возможные модификации представленных вариантов осуществления, при этом общие принципы, представленные здесь, могут применяться к другим вариантам осуществления без отступления от сущности или объема описания. Таким образом, настоящее описание не ограничено представленными здесь вариантами осуществления, оно соответствует широкому кругу задач, связанных с принципами и новыми отличительными признаками, раскрытыми в настоящем документе.
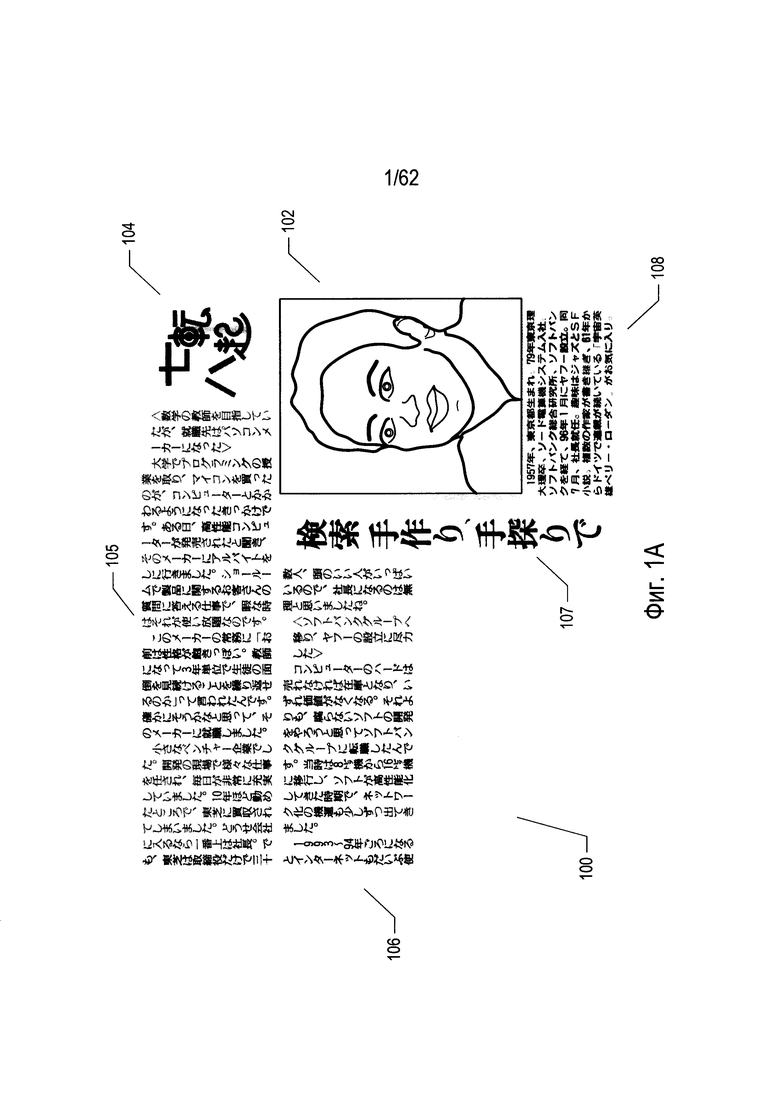

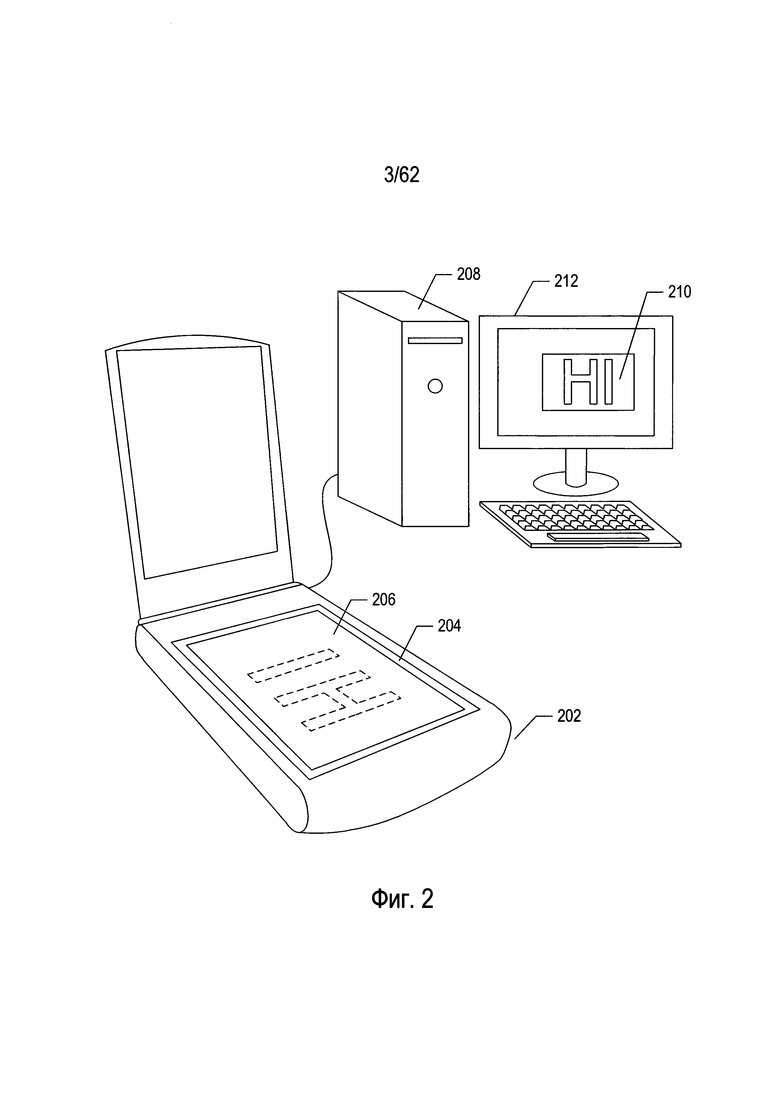
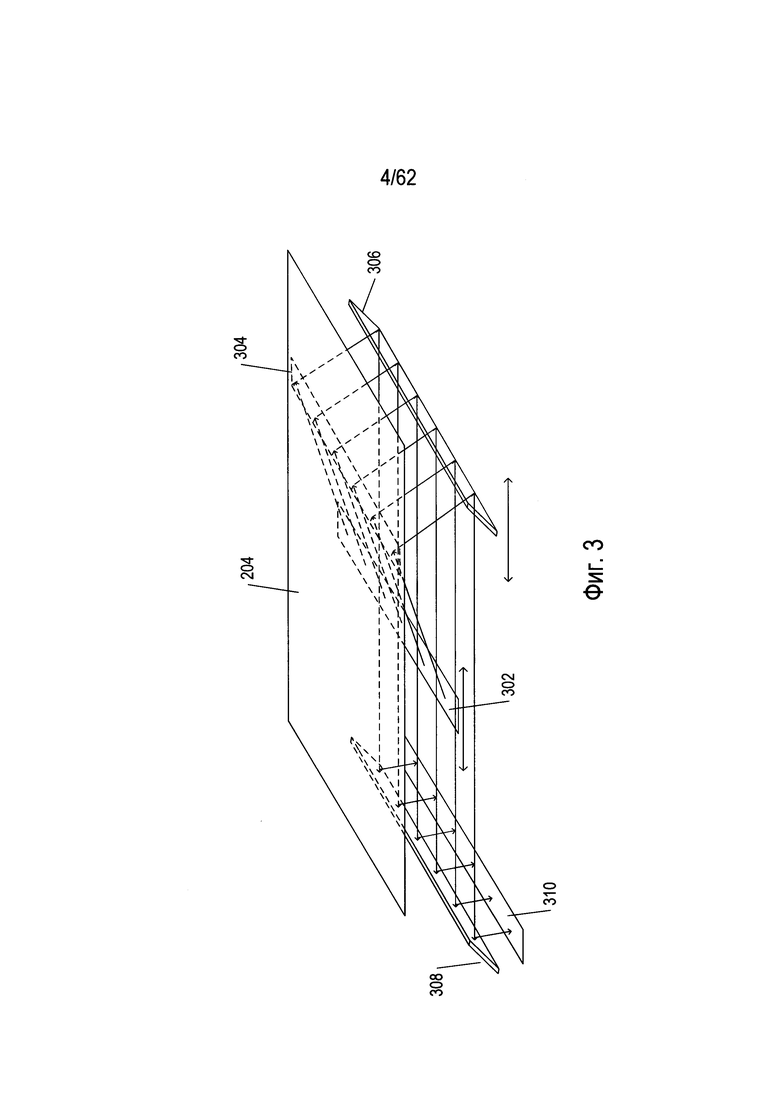
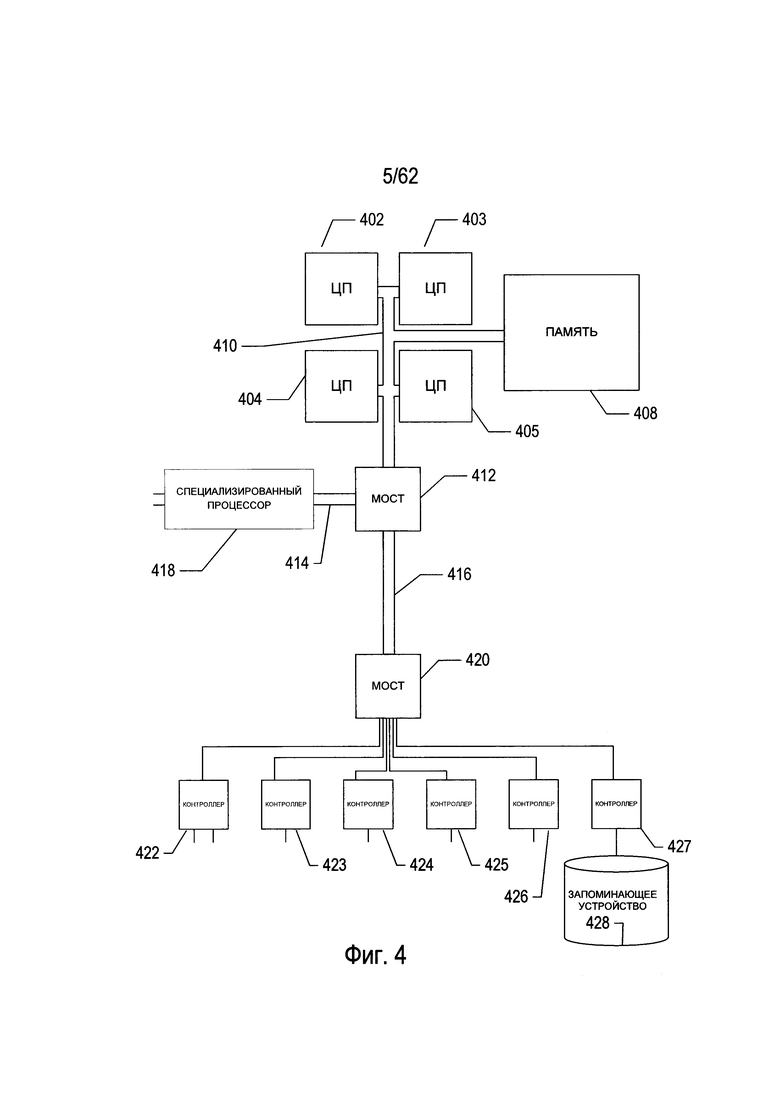
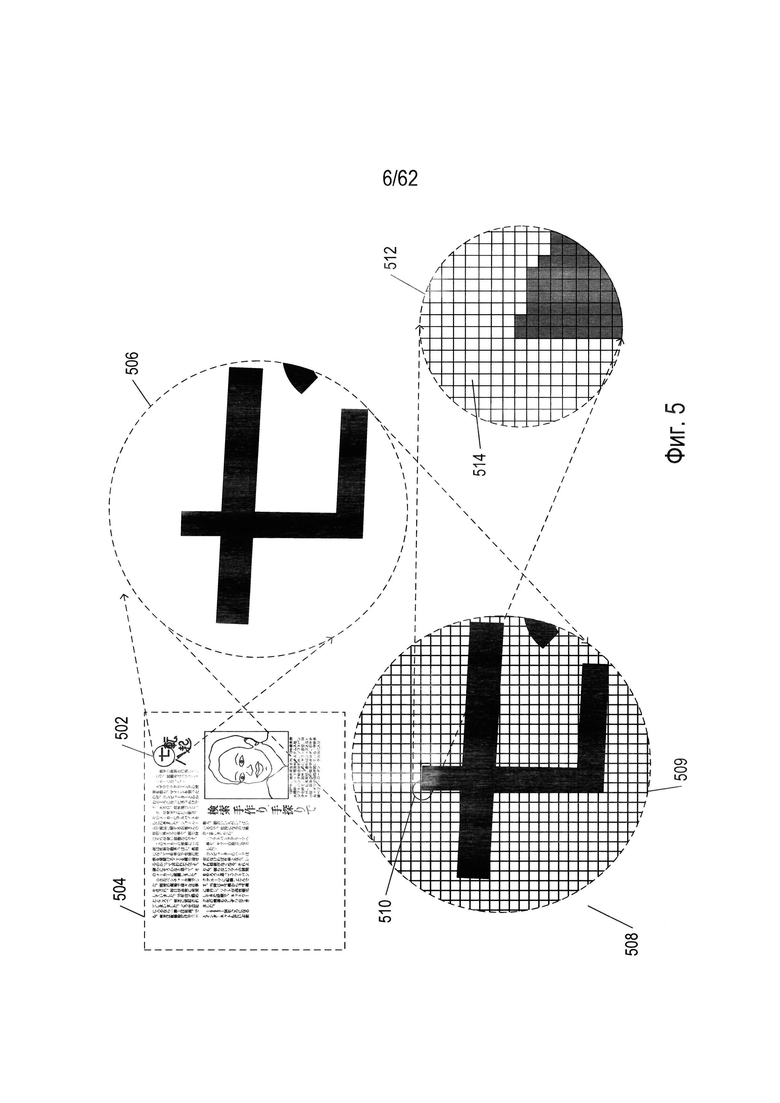
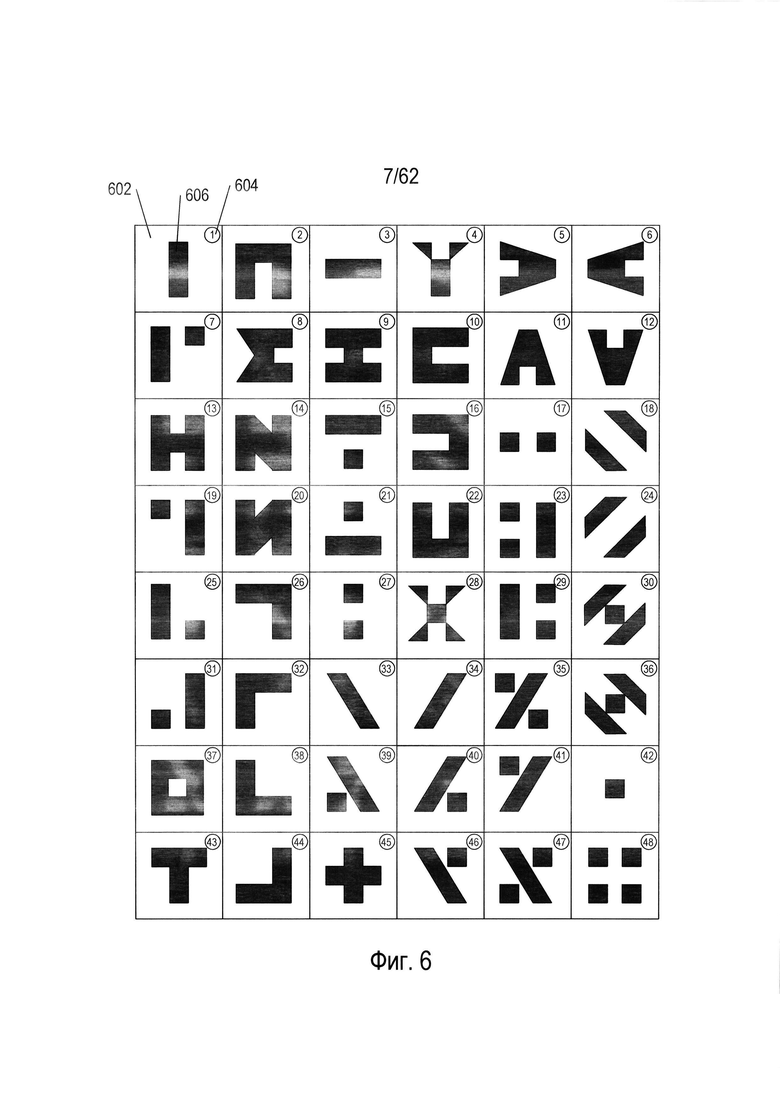
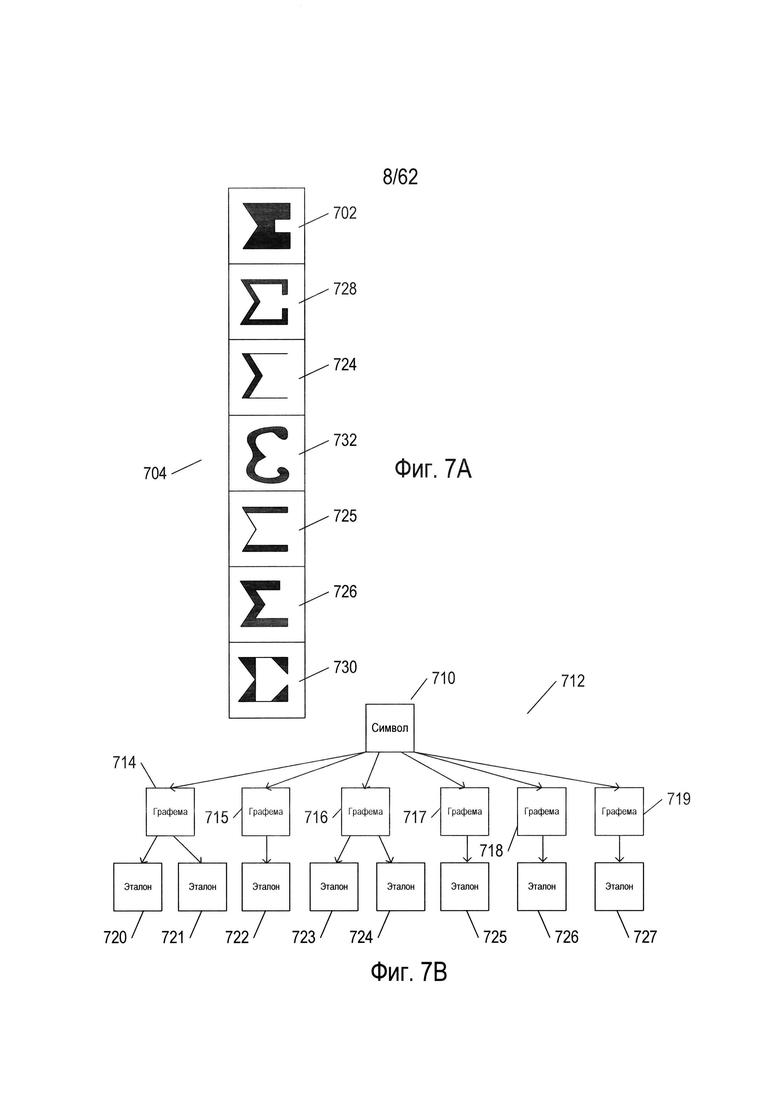
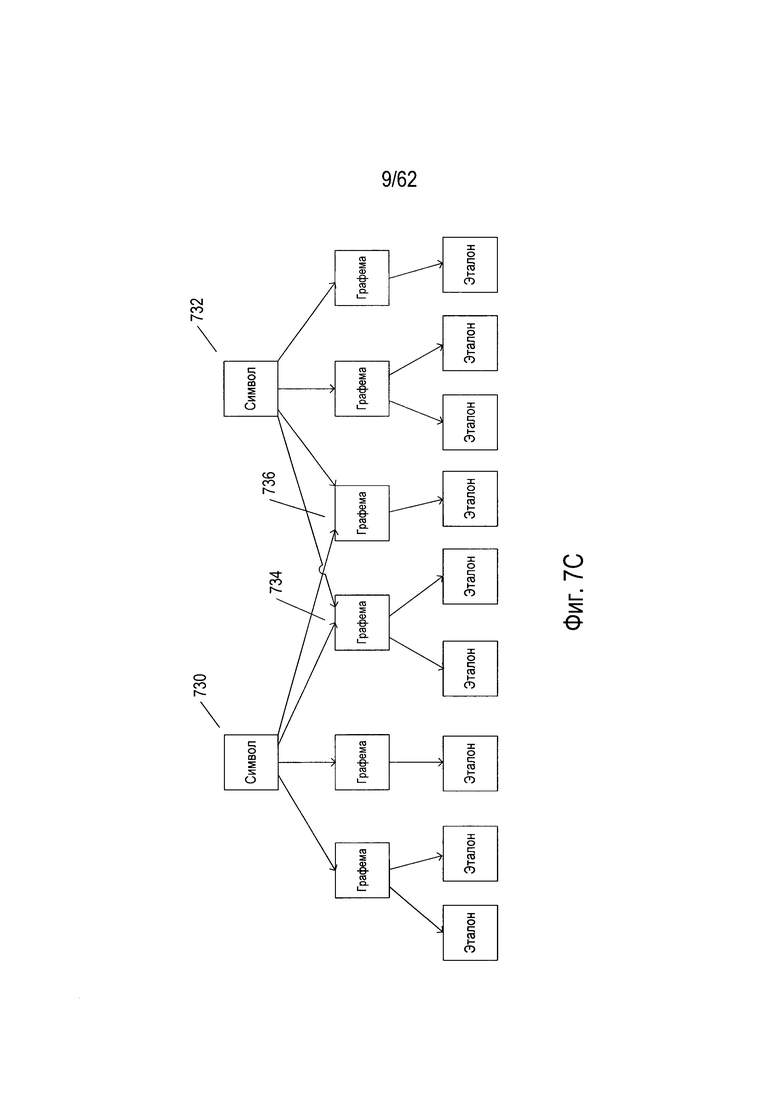
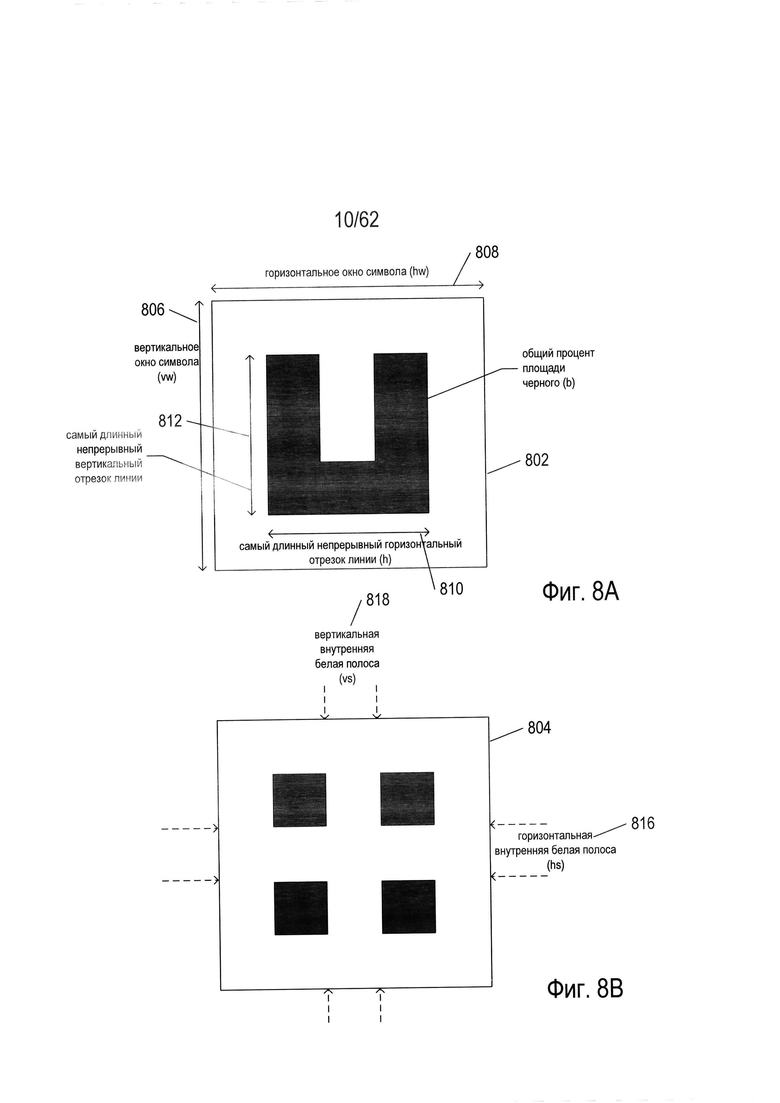

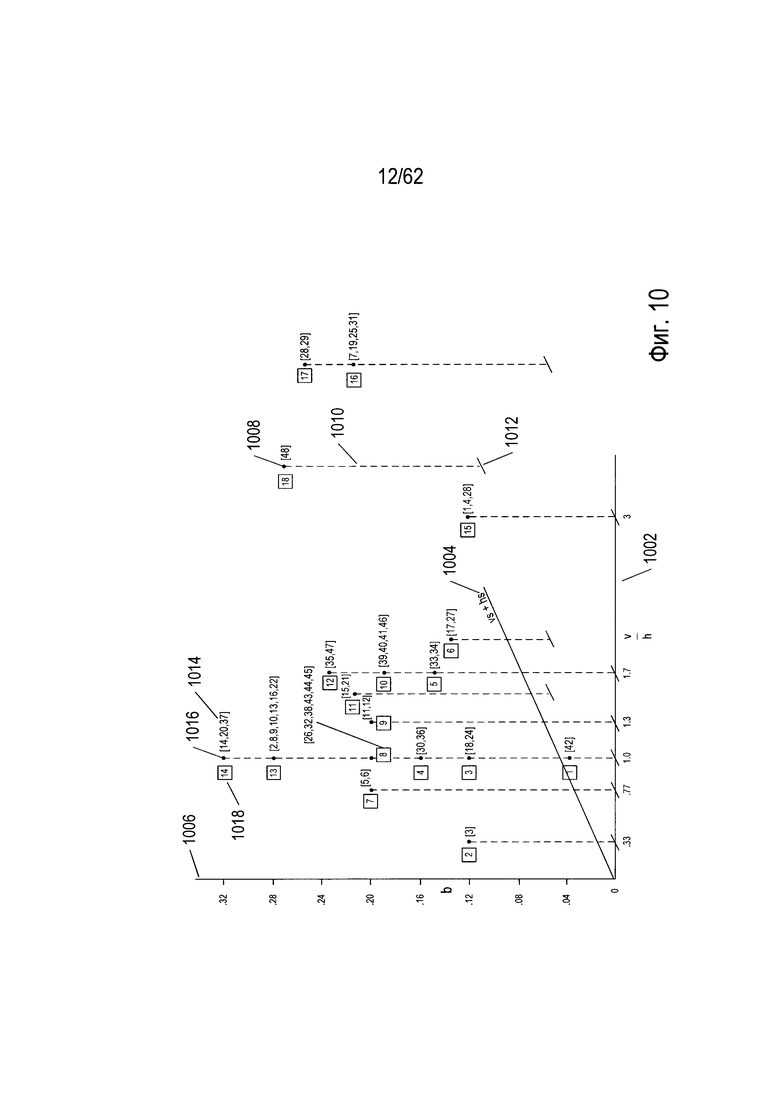
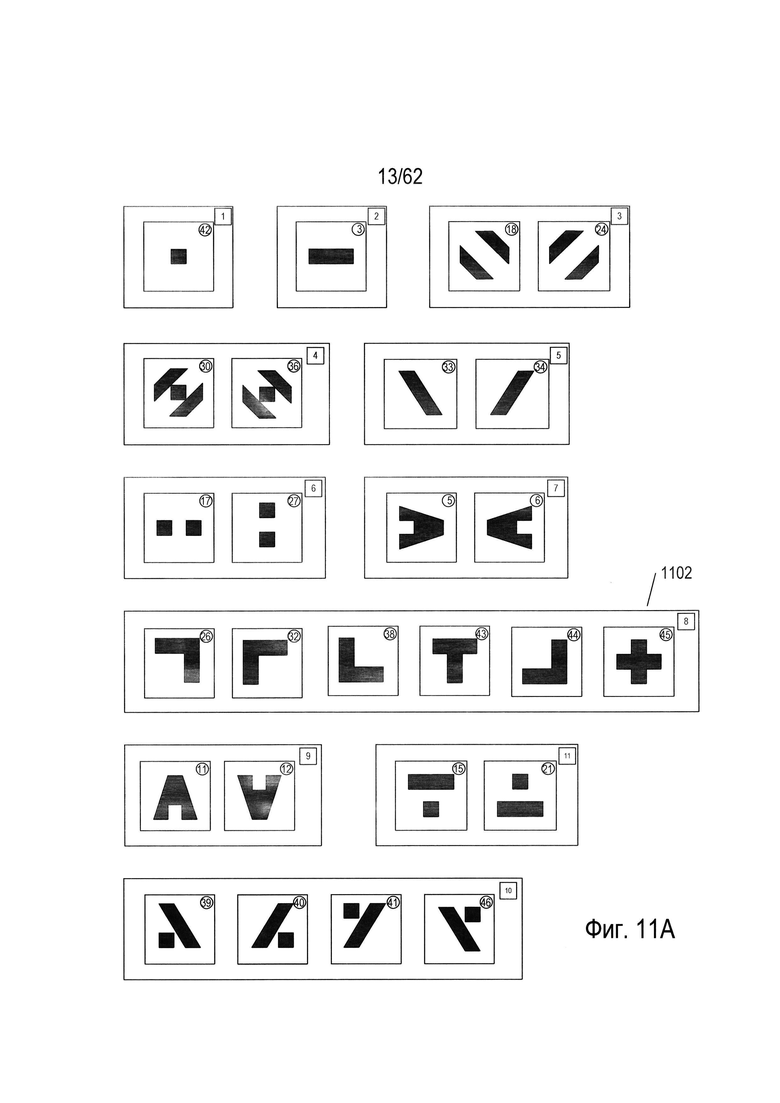
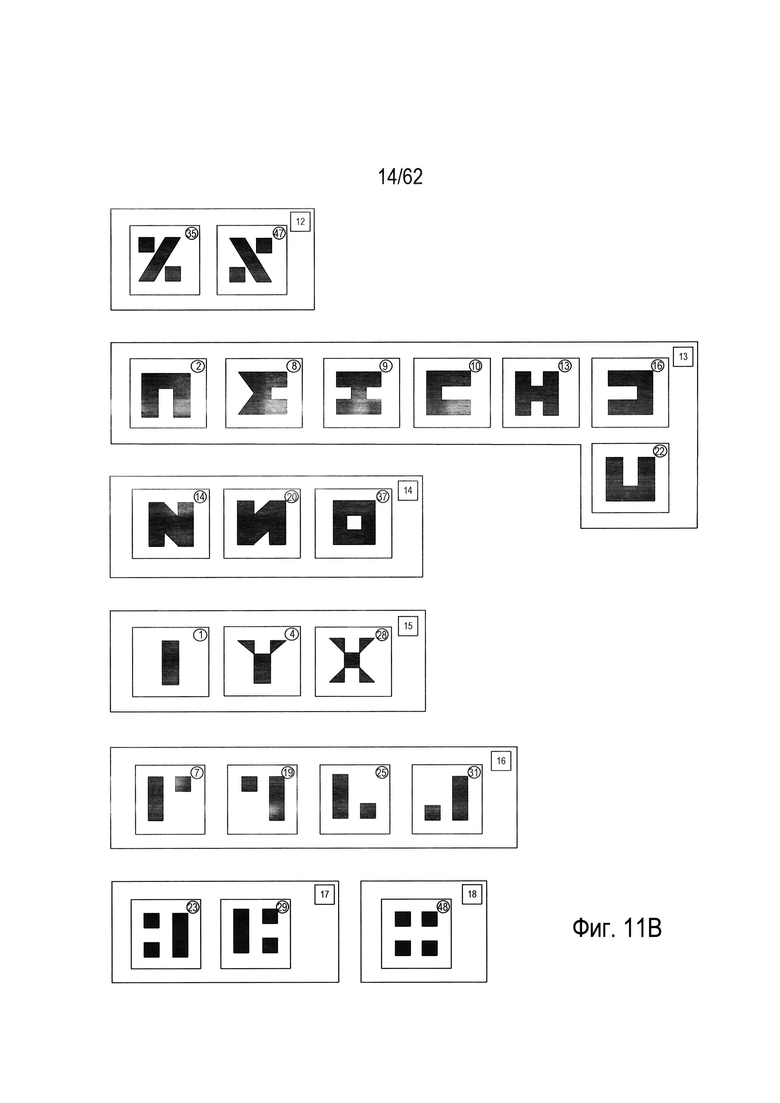
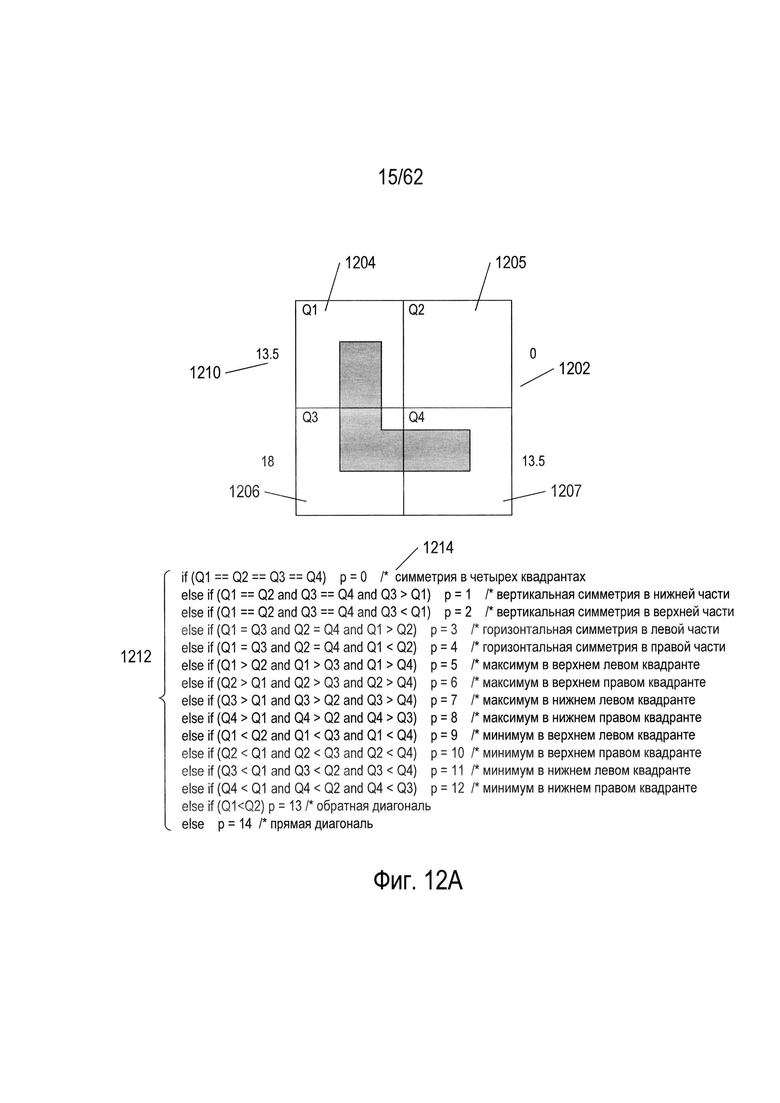
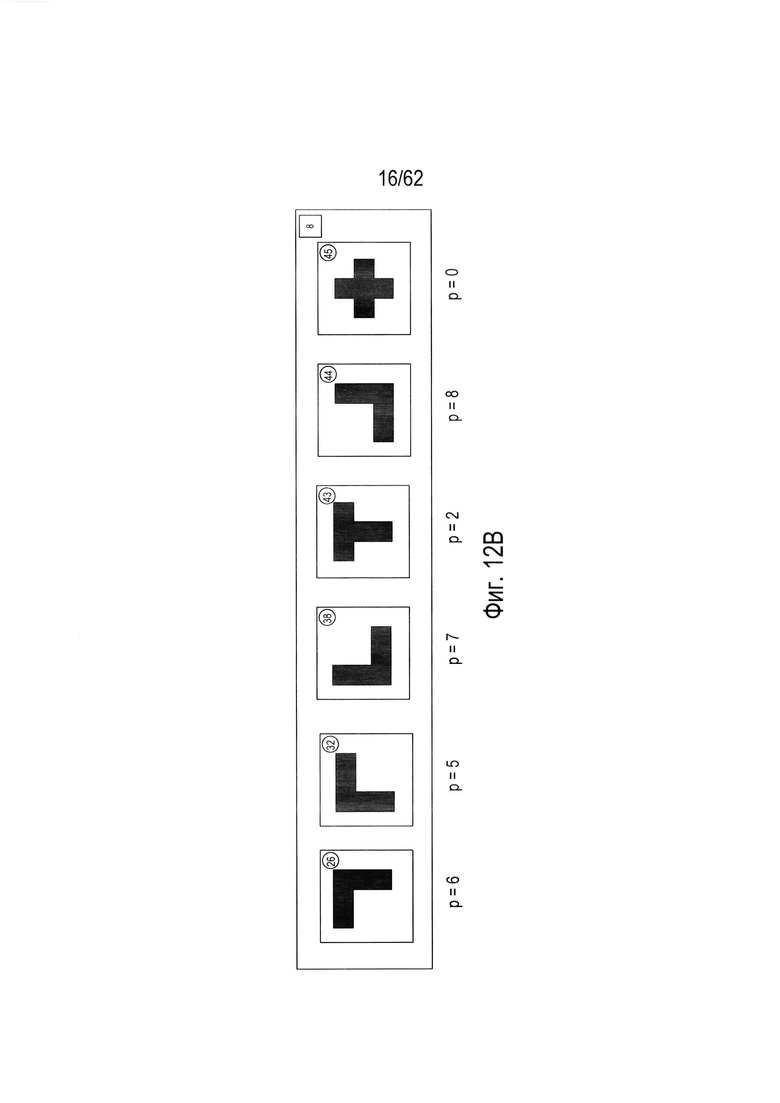
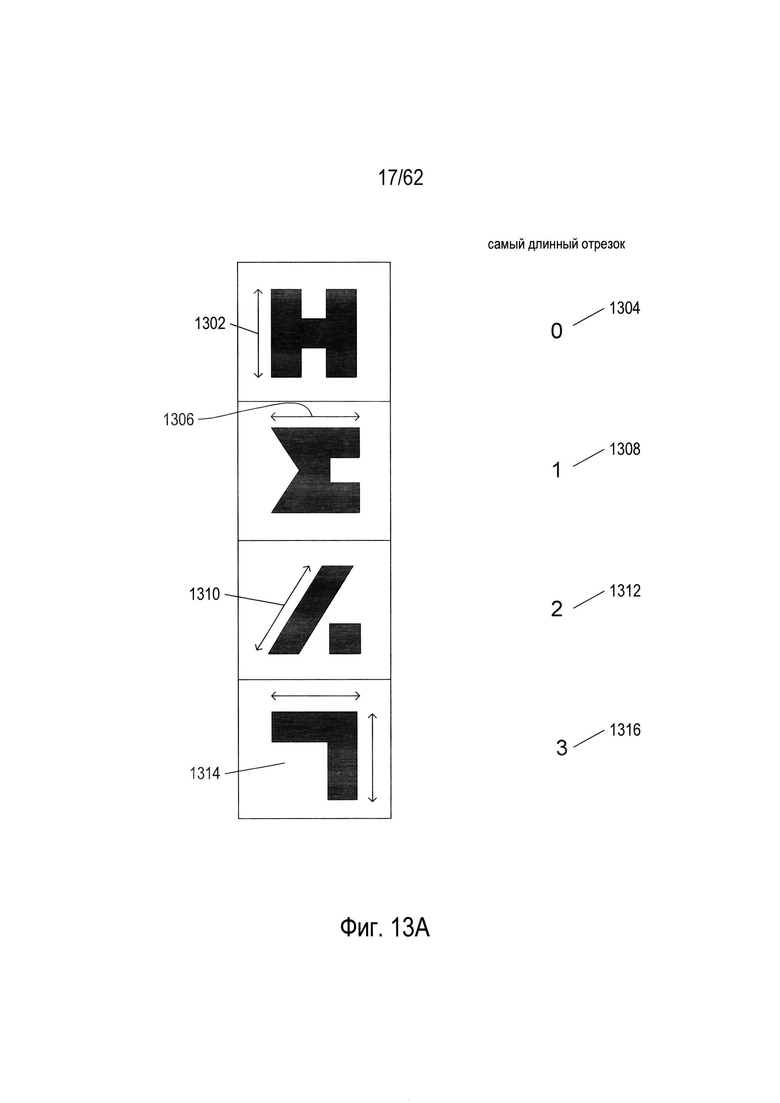

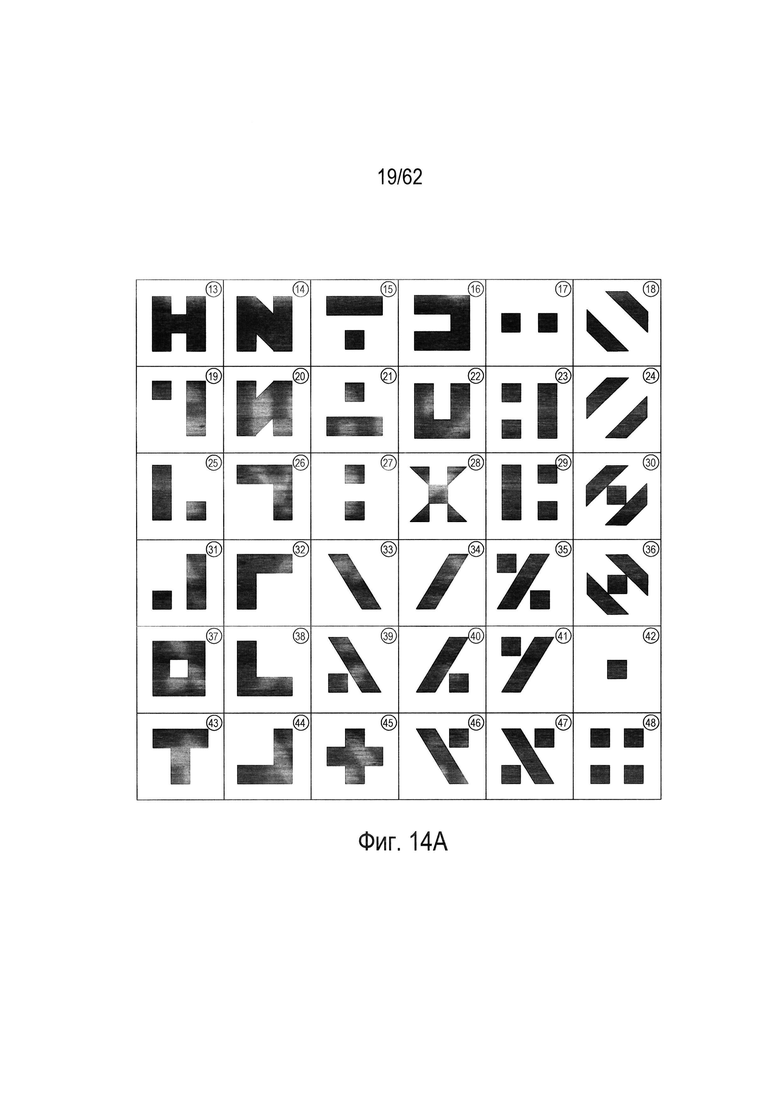
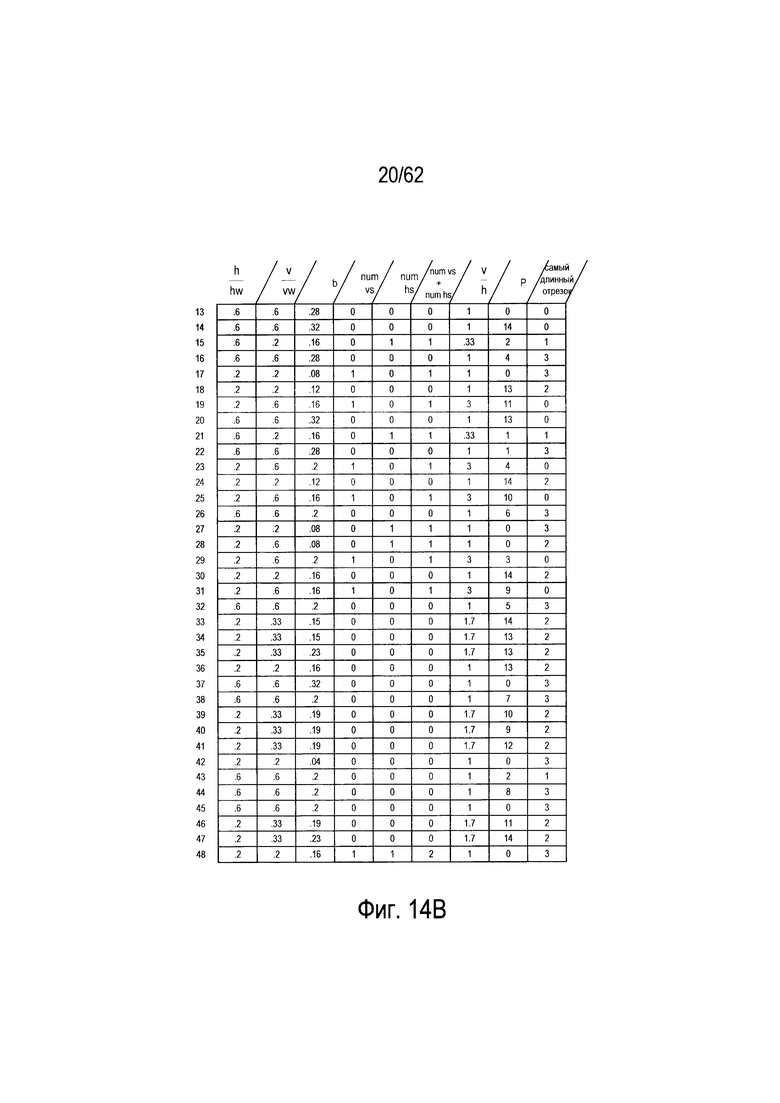
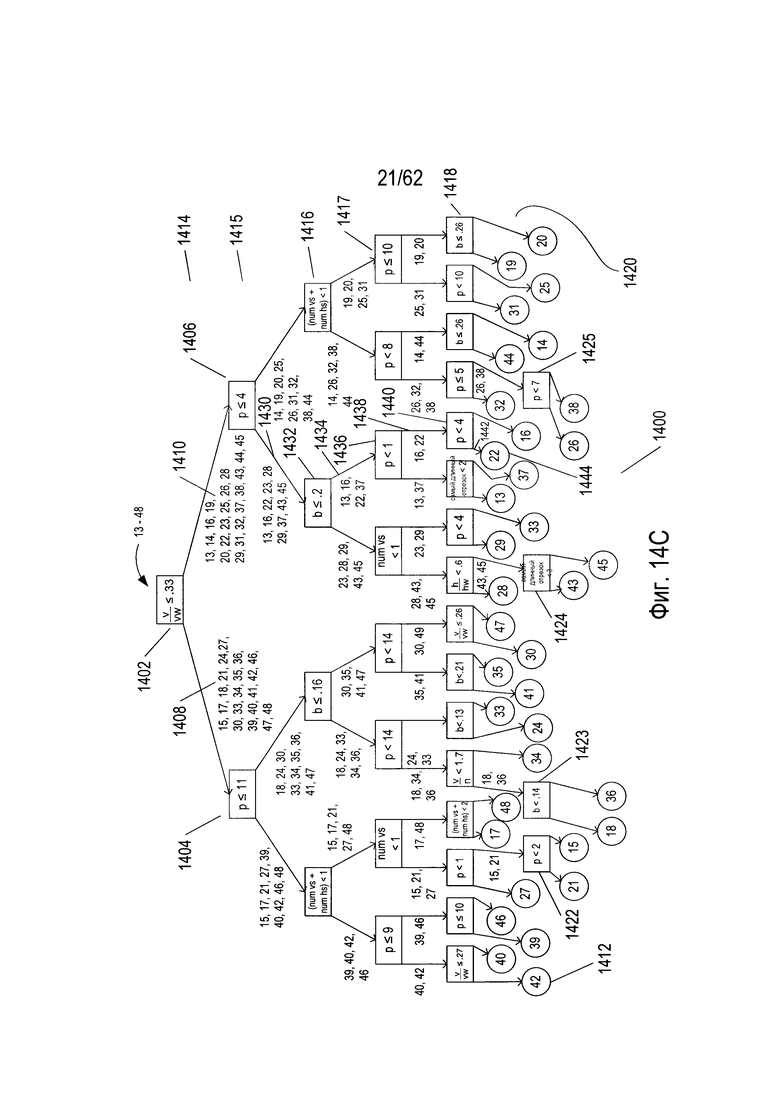
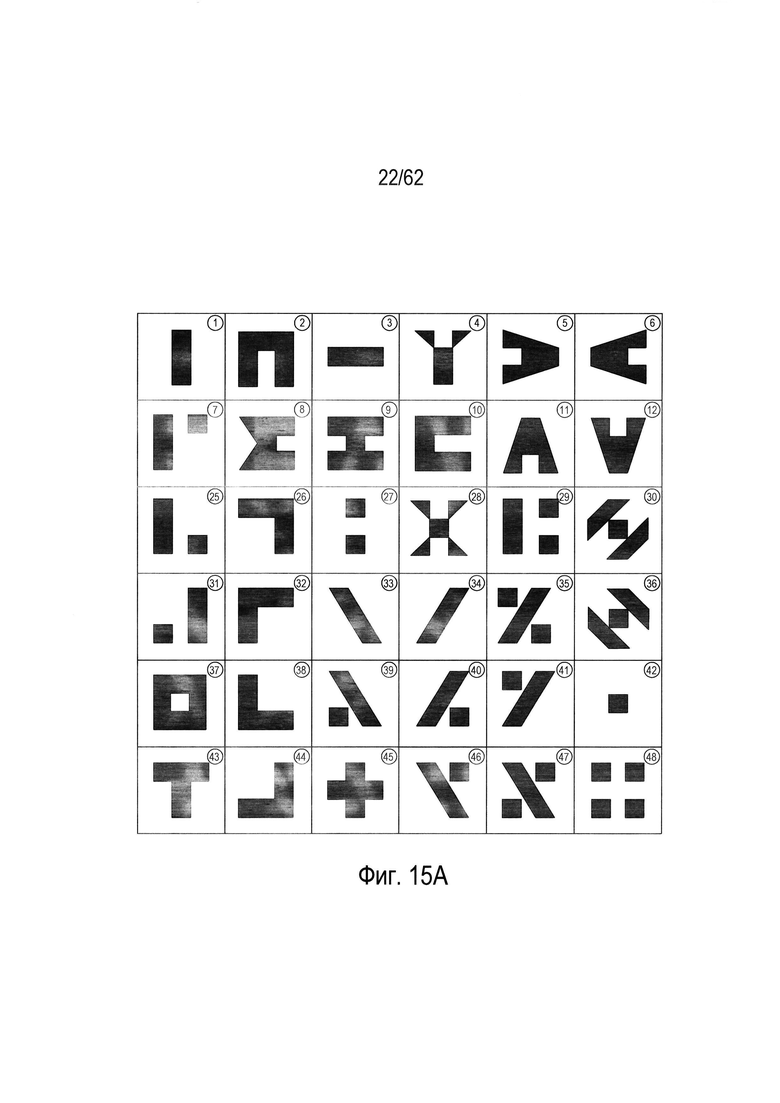

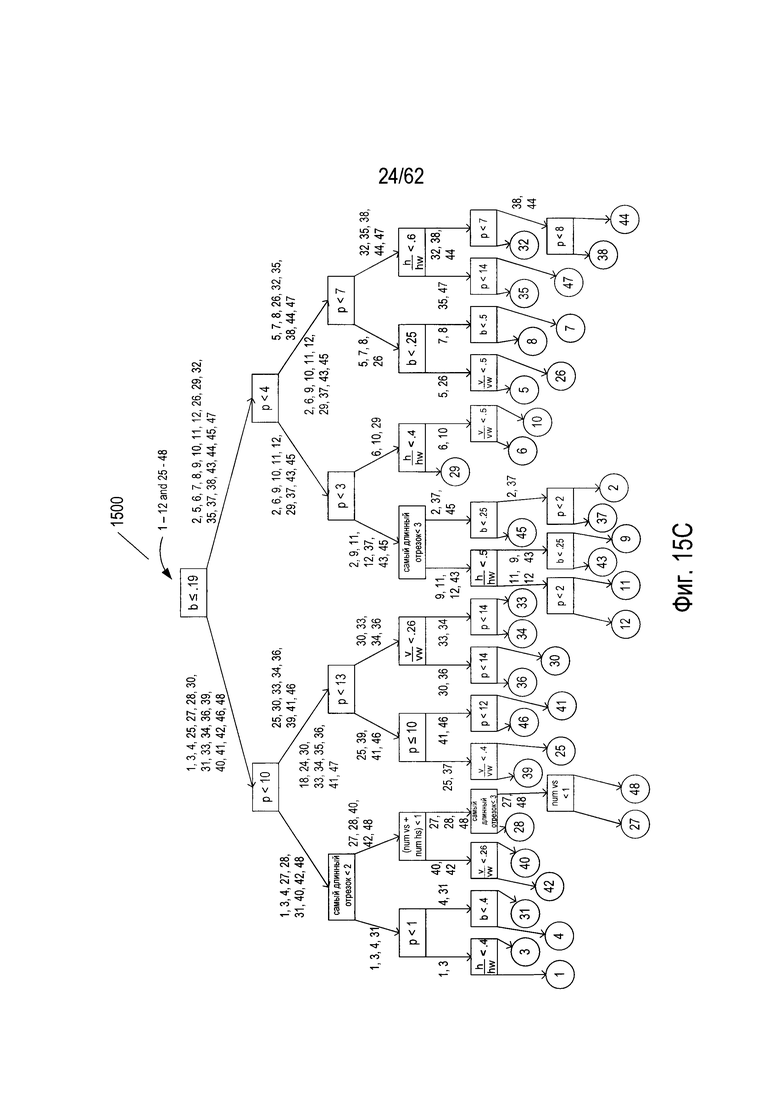
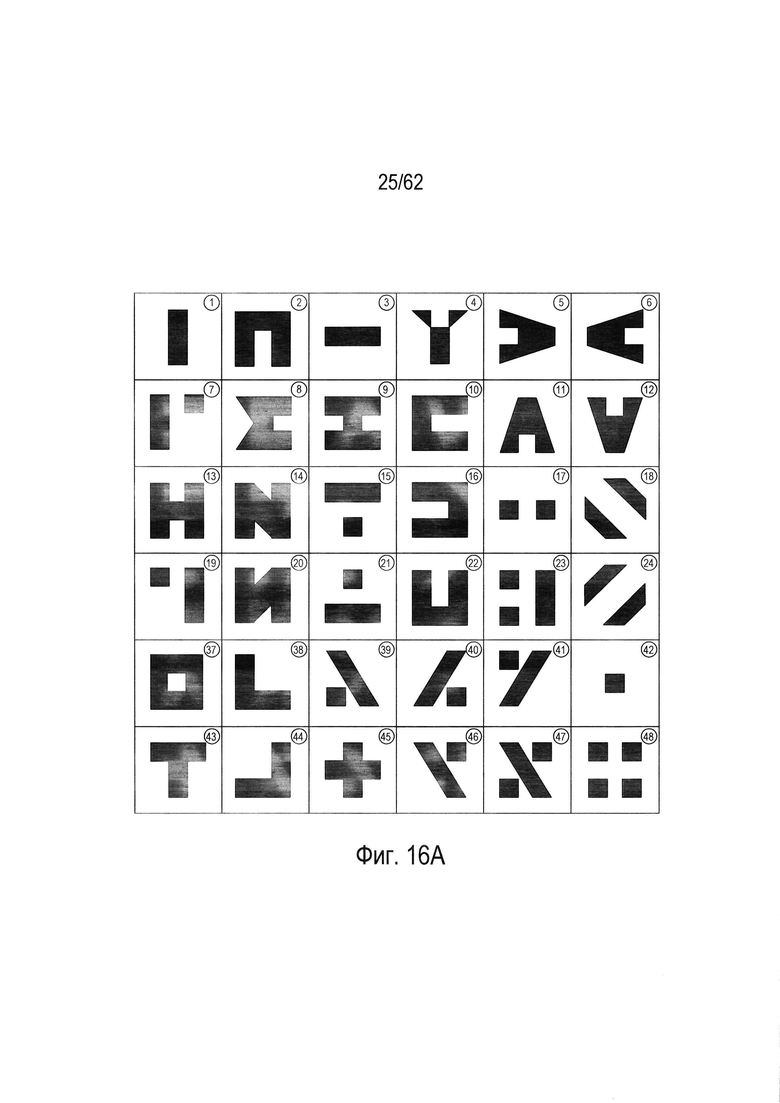

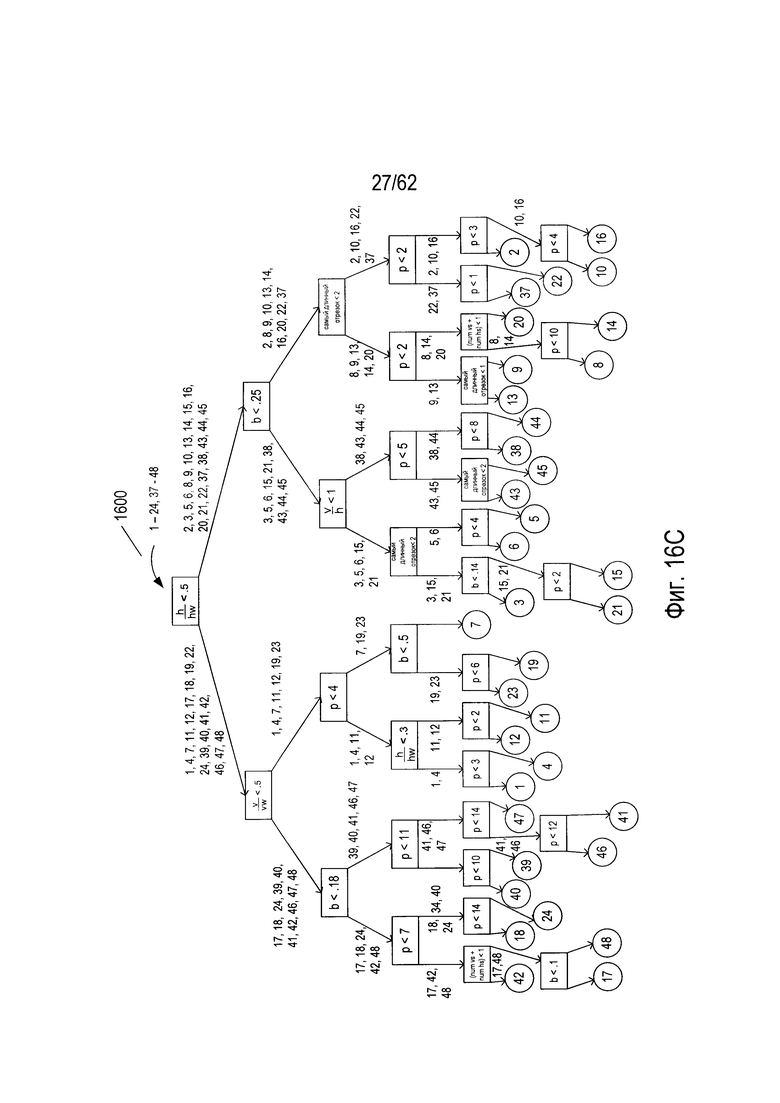
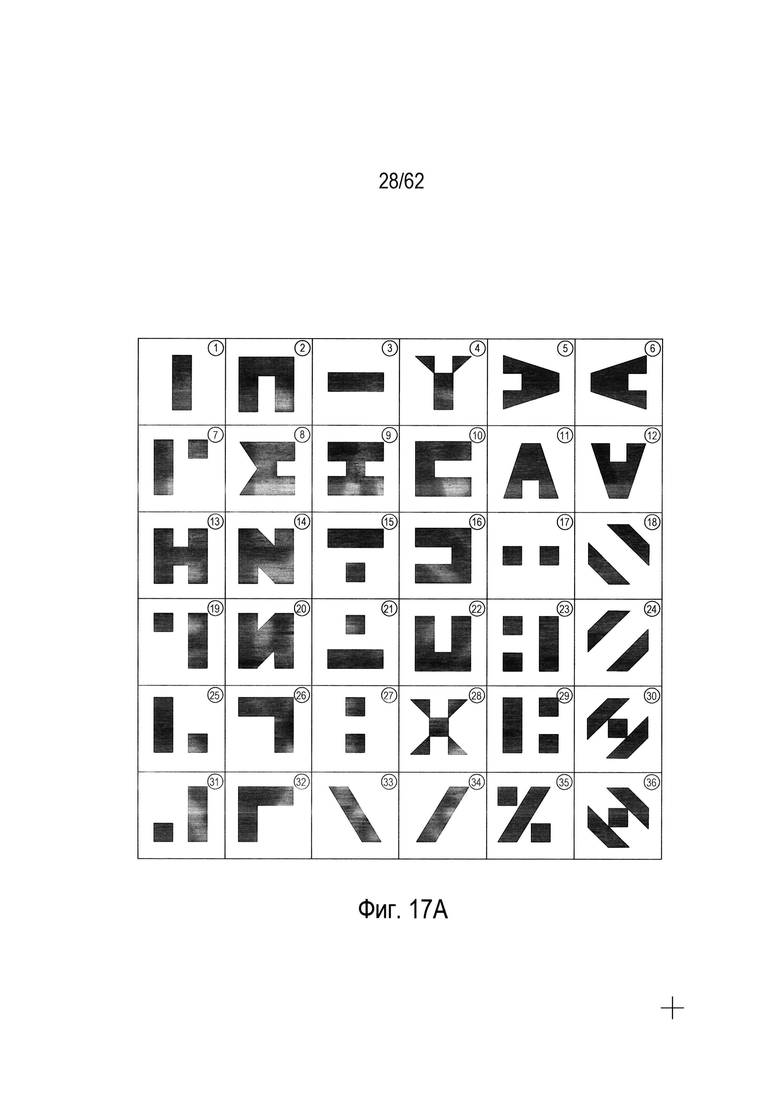
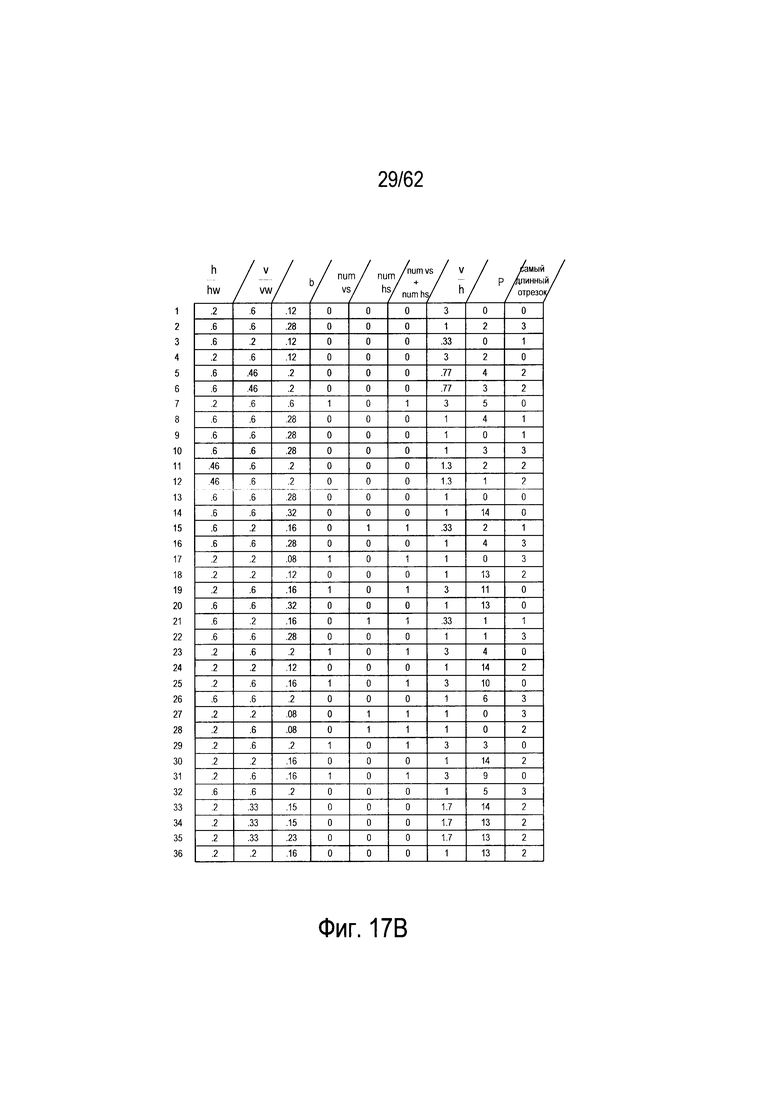
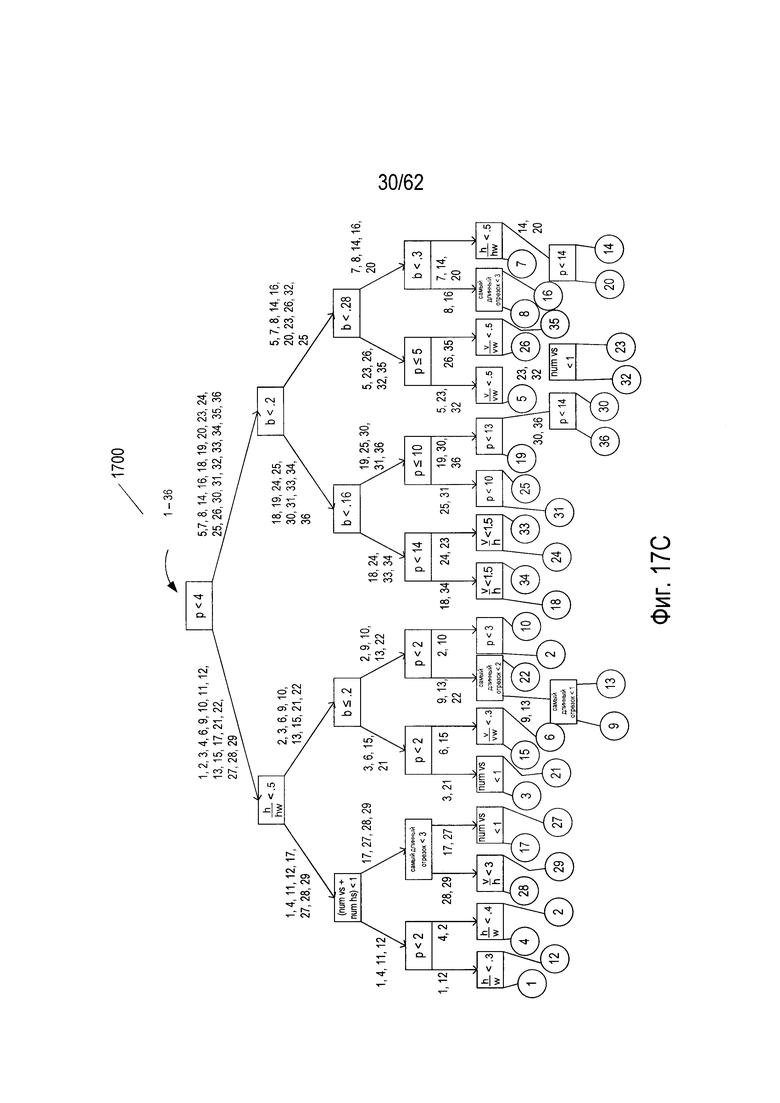
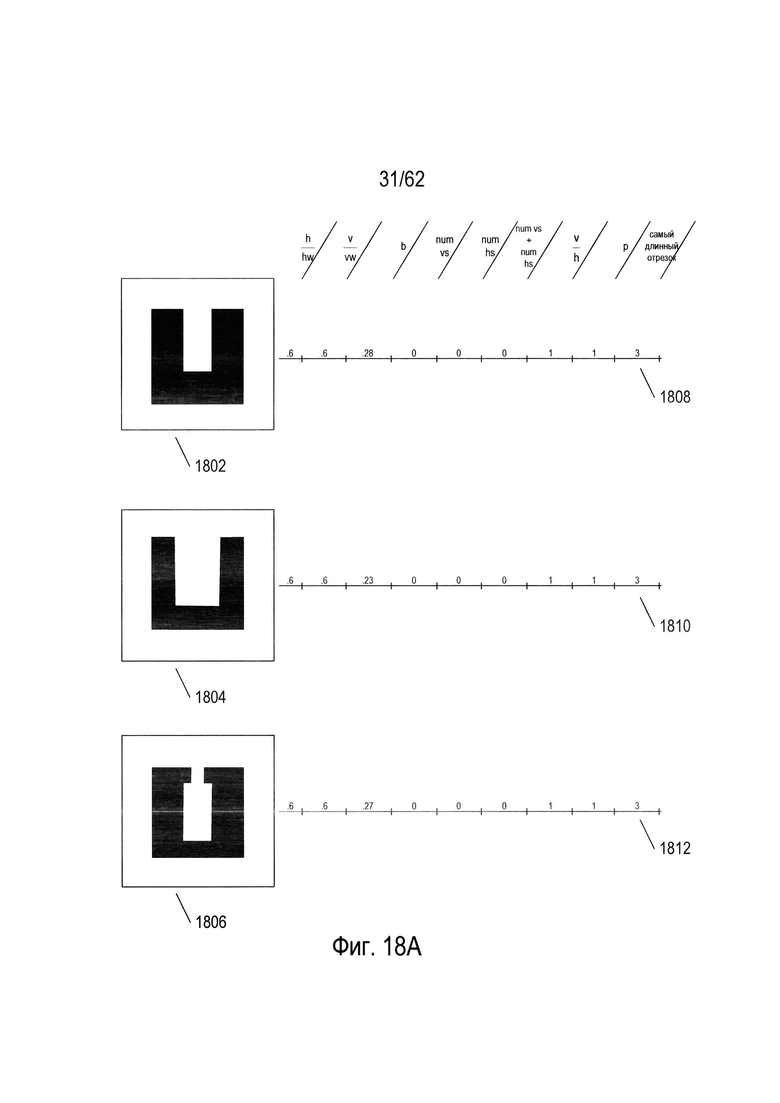
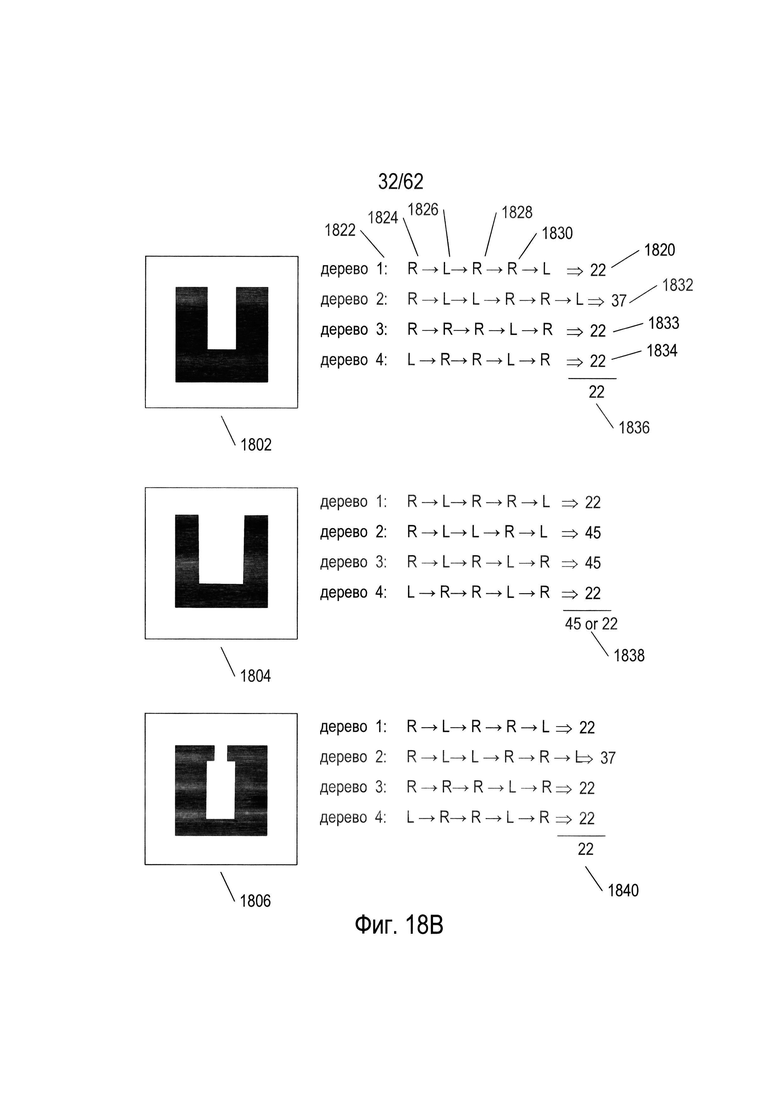
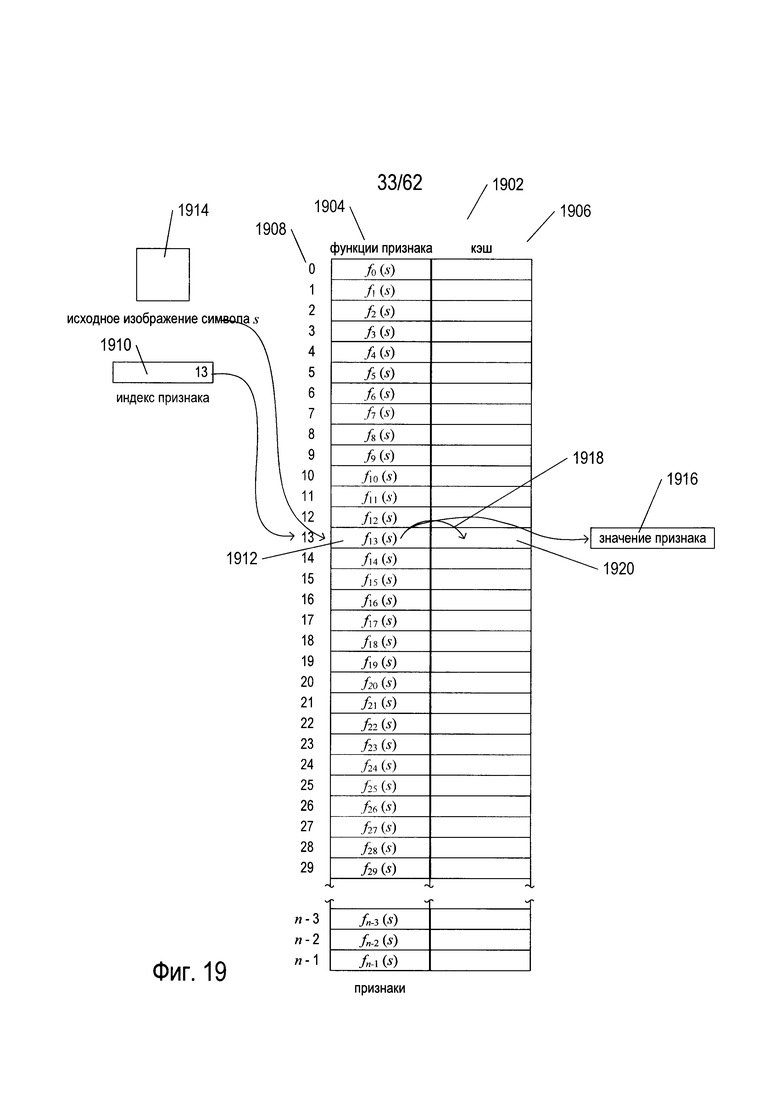
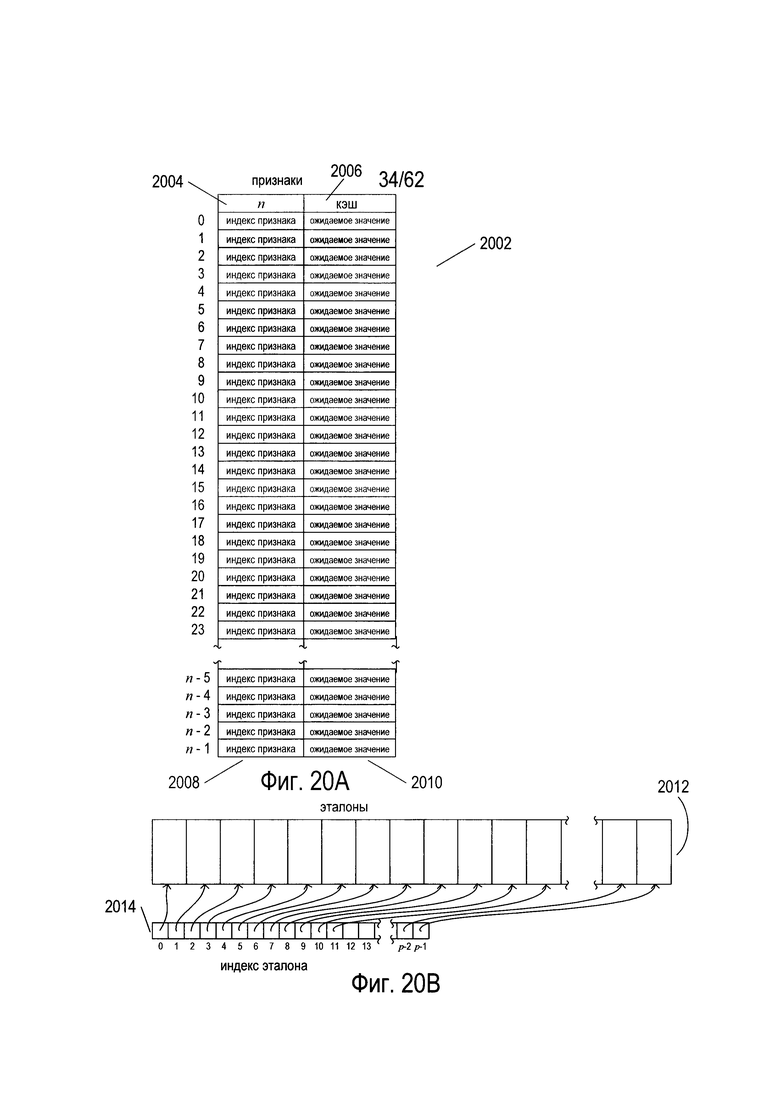
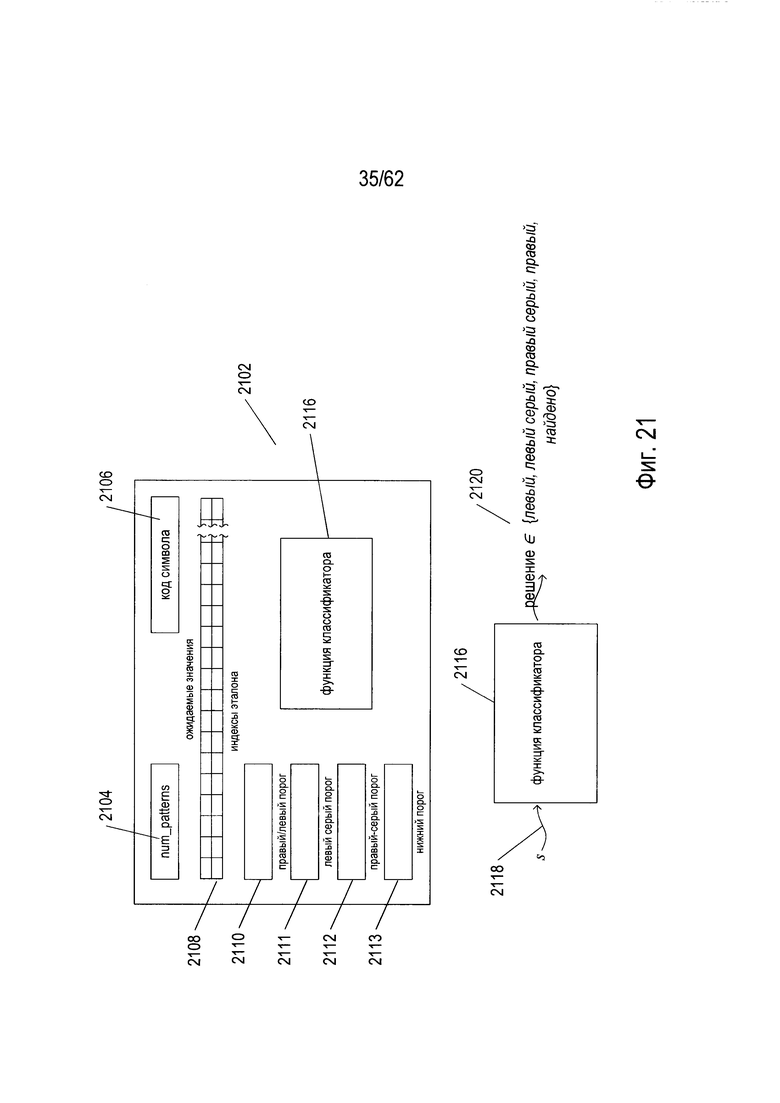
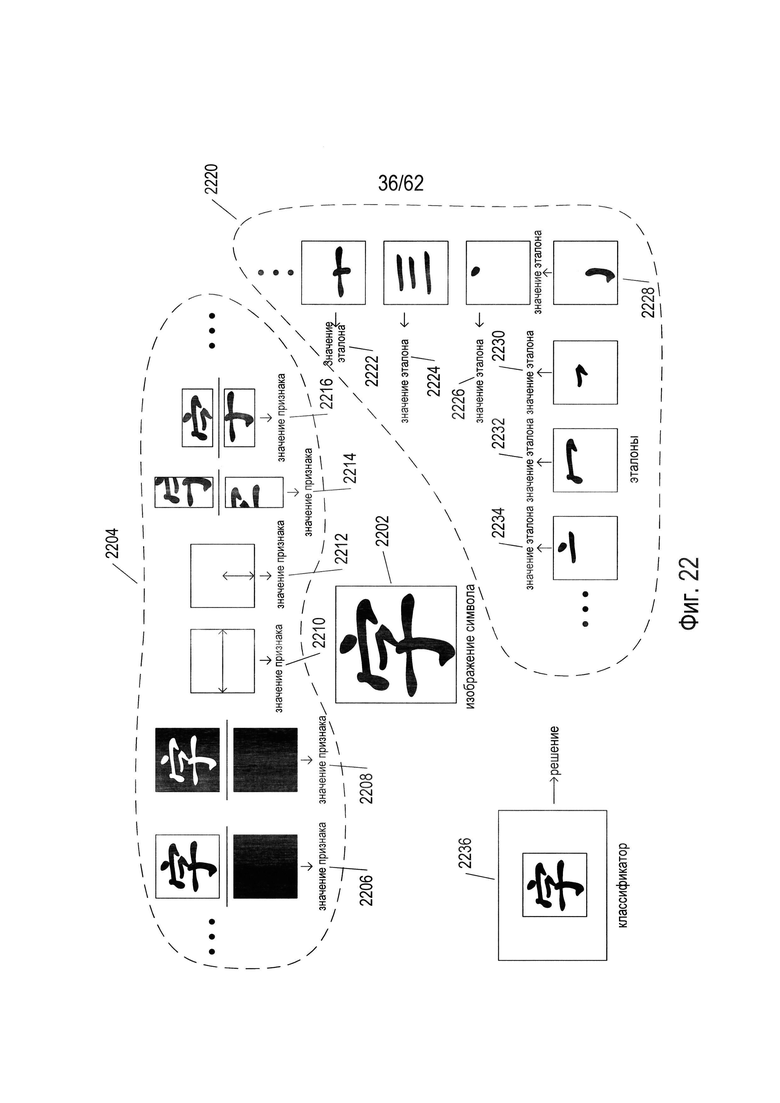

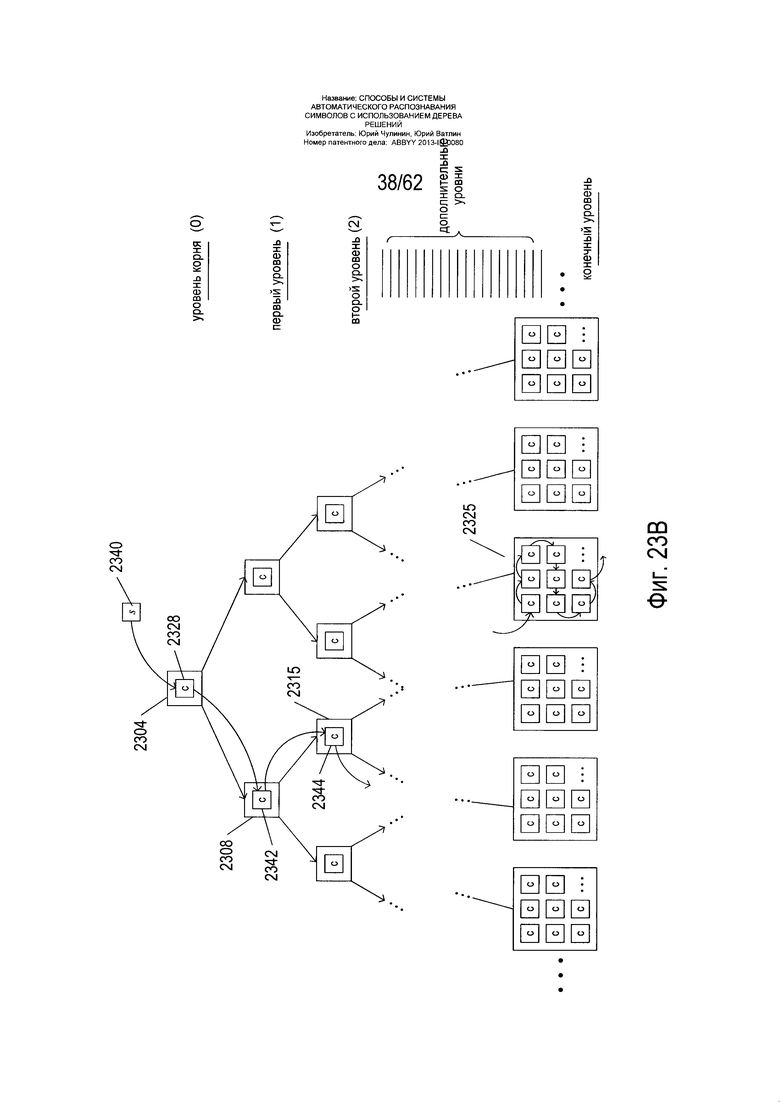
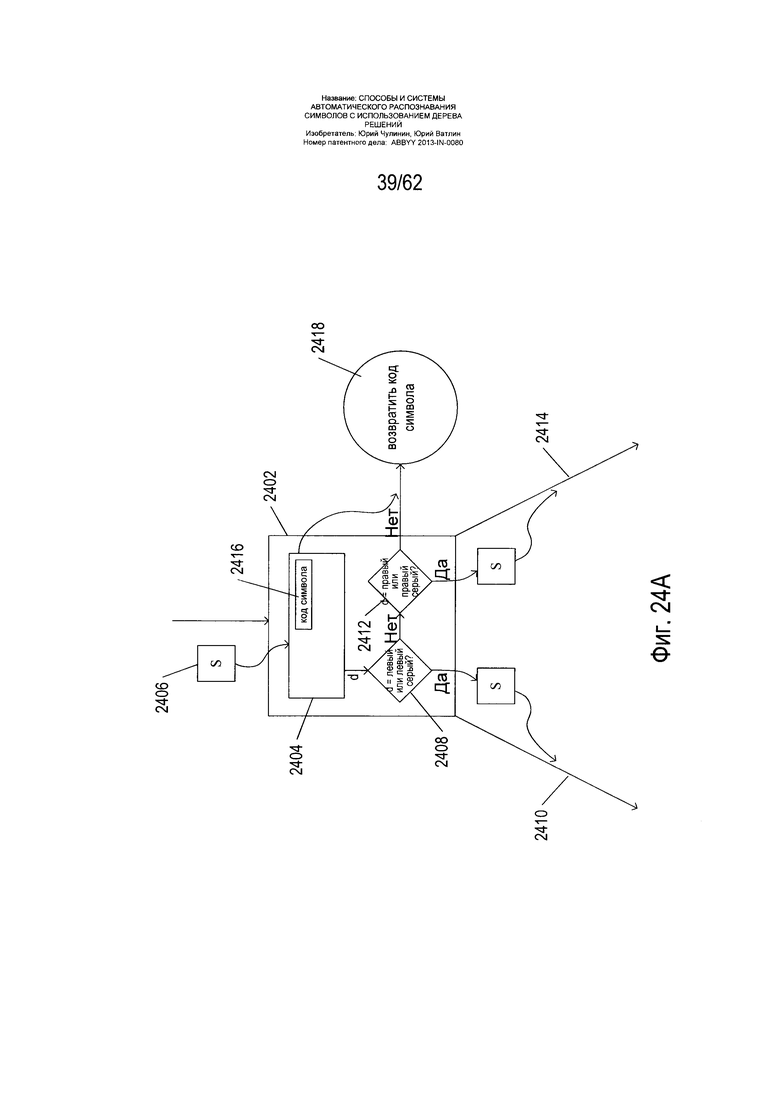
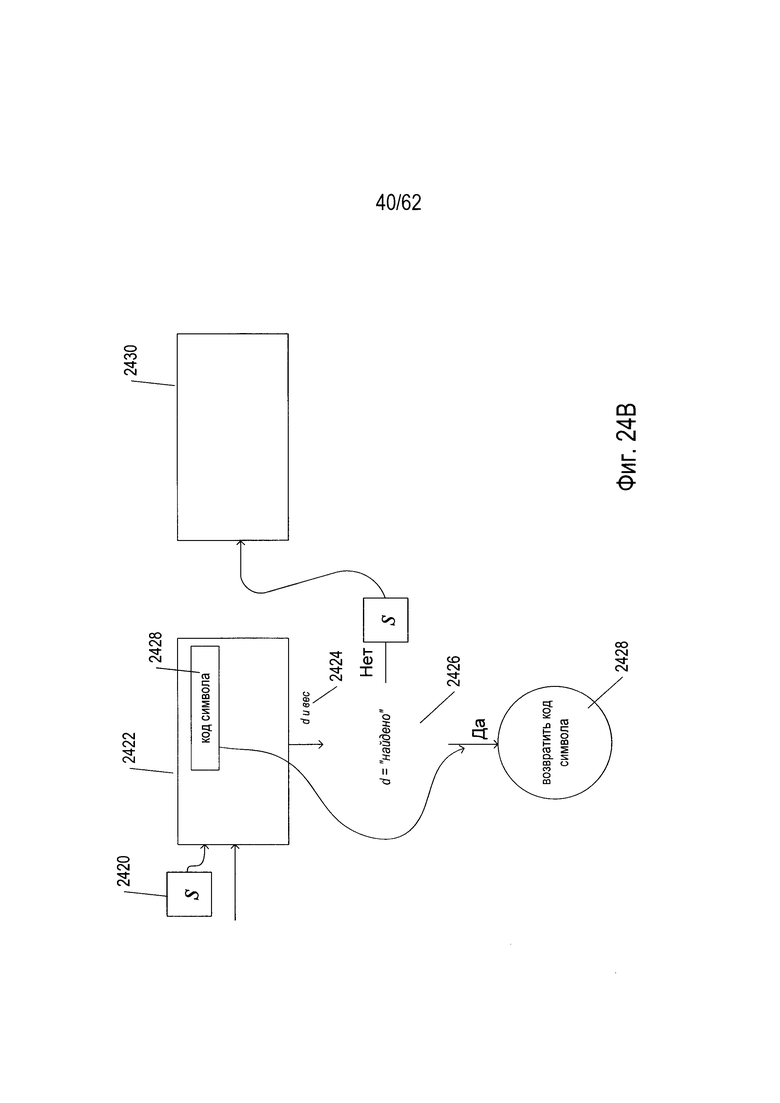
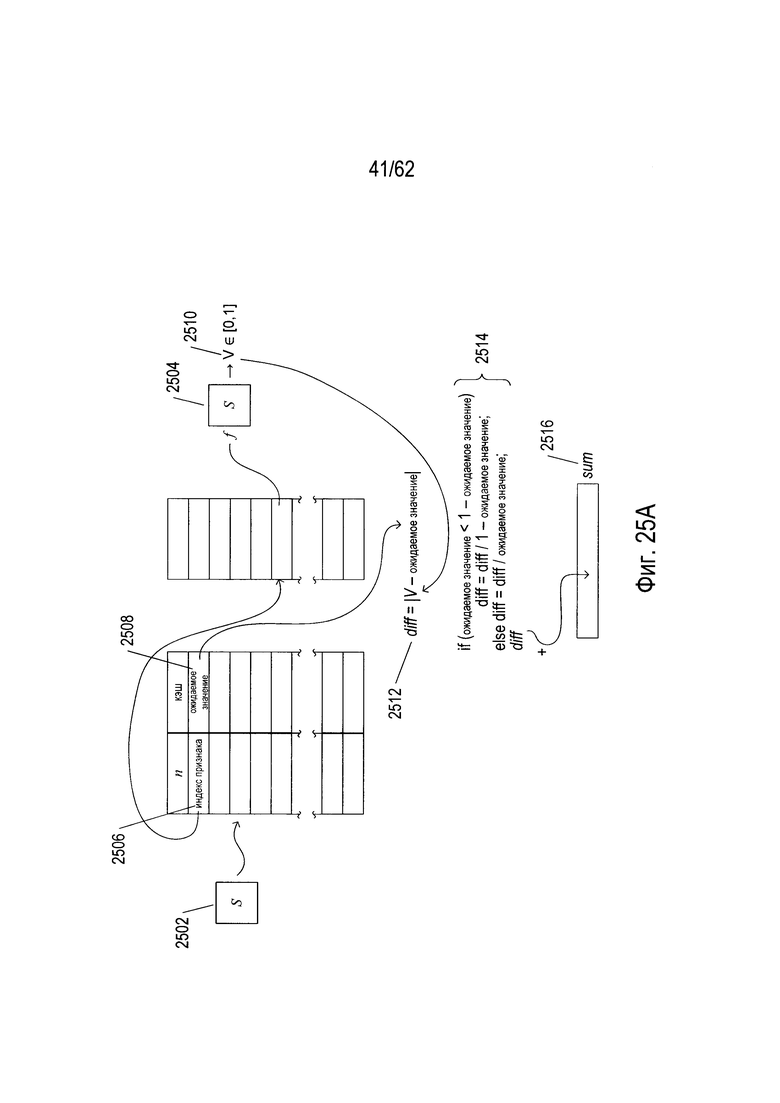
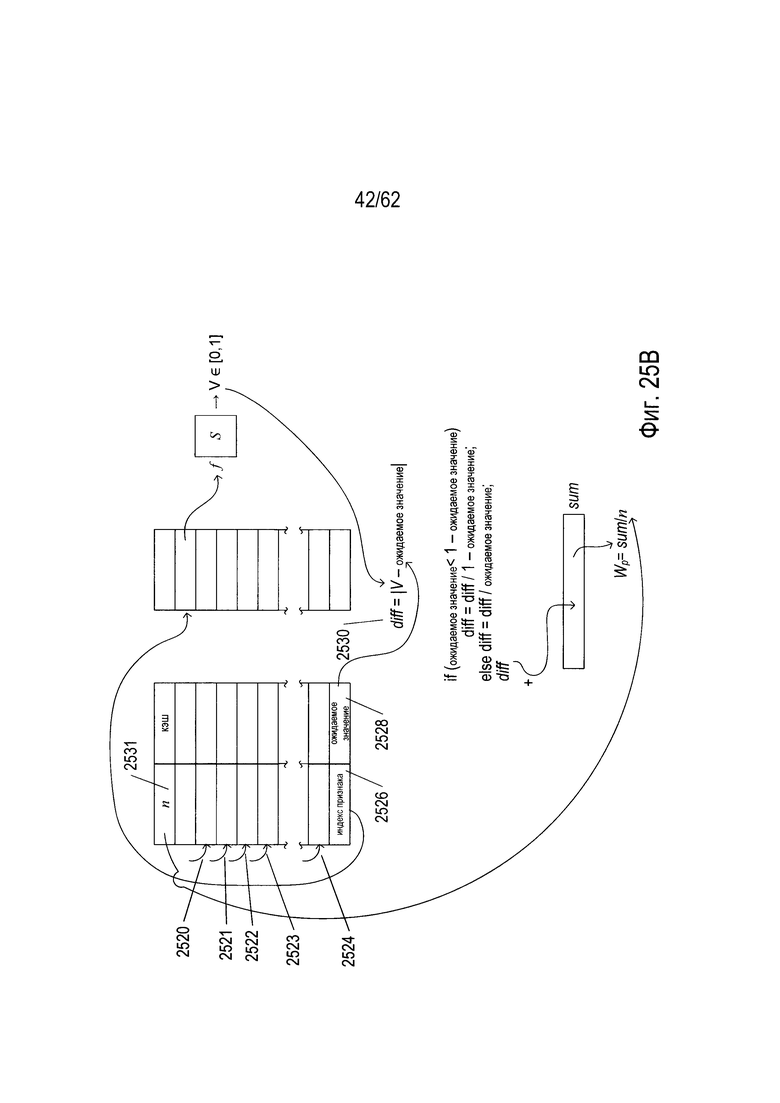
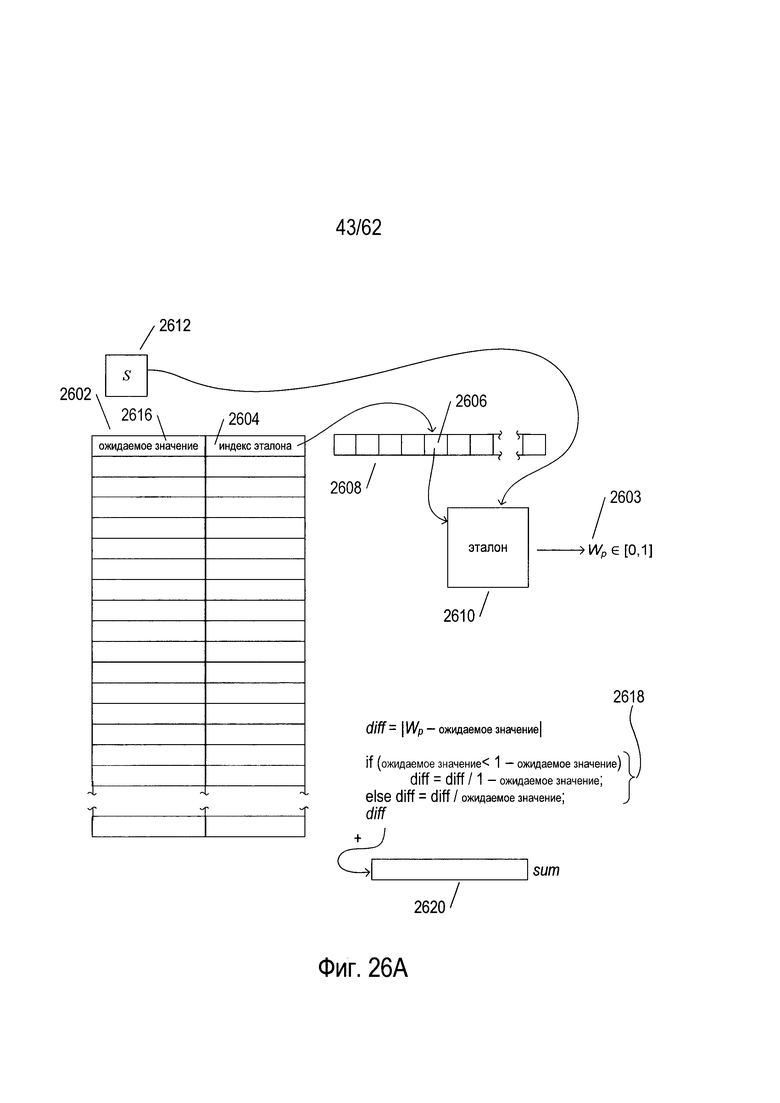
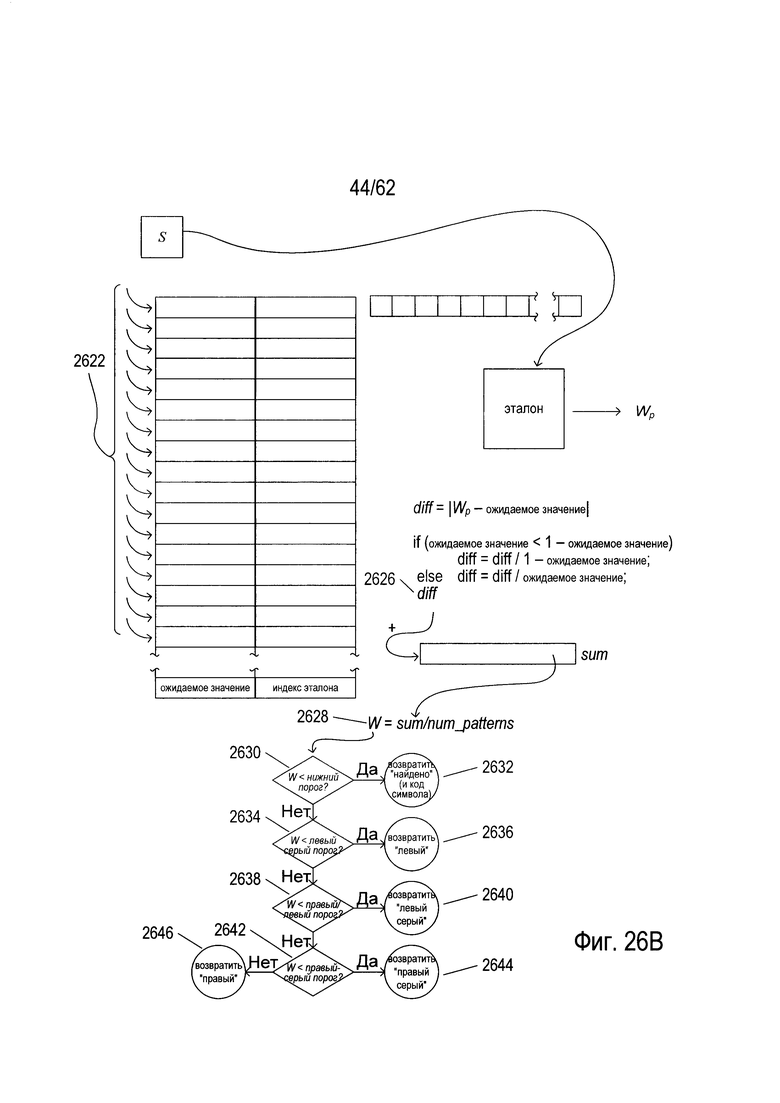
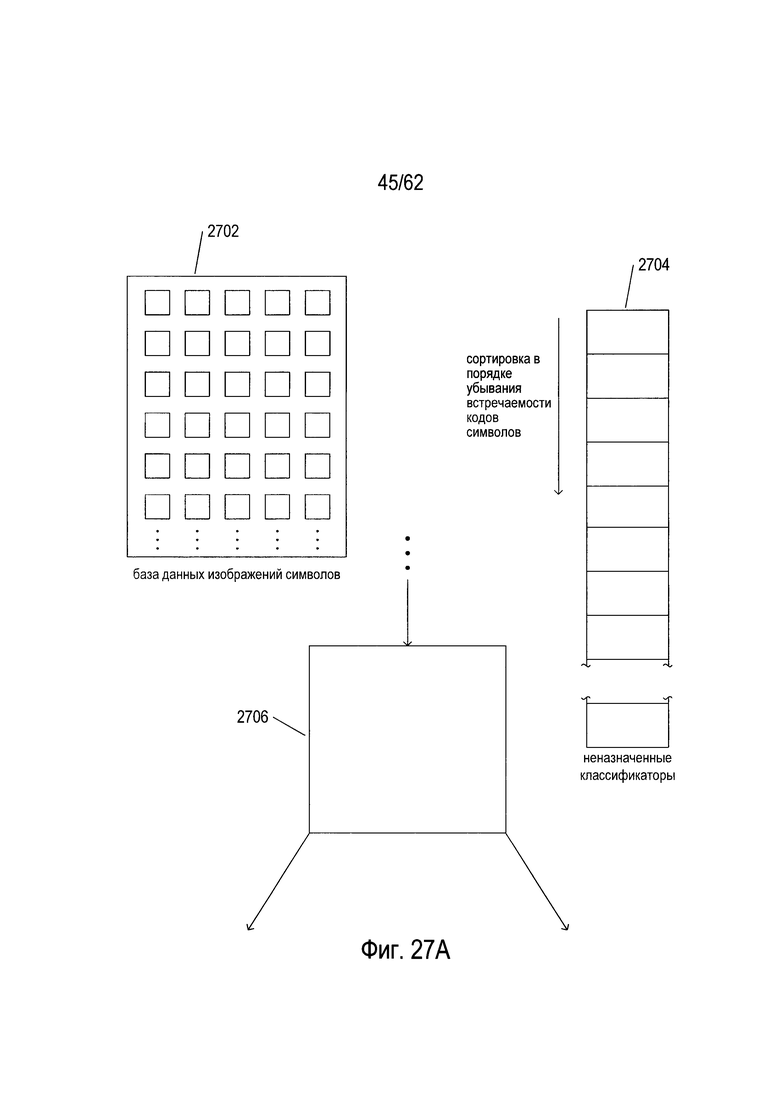
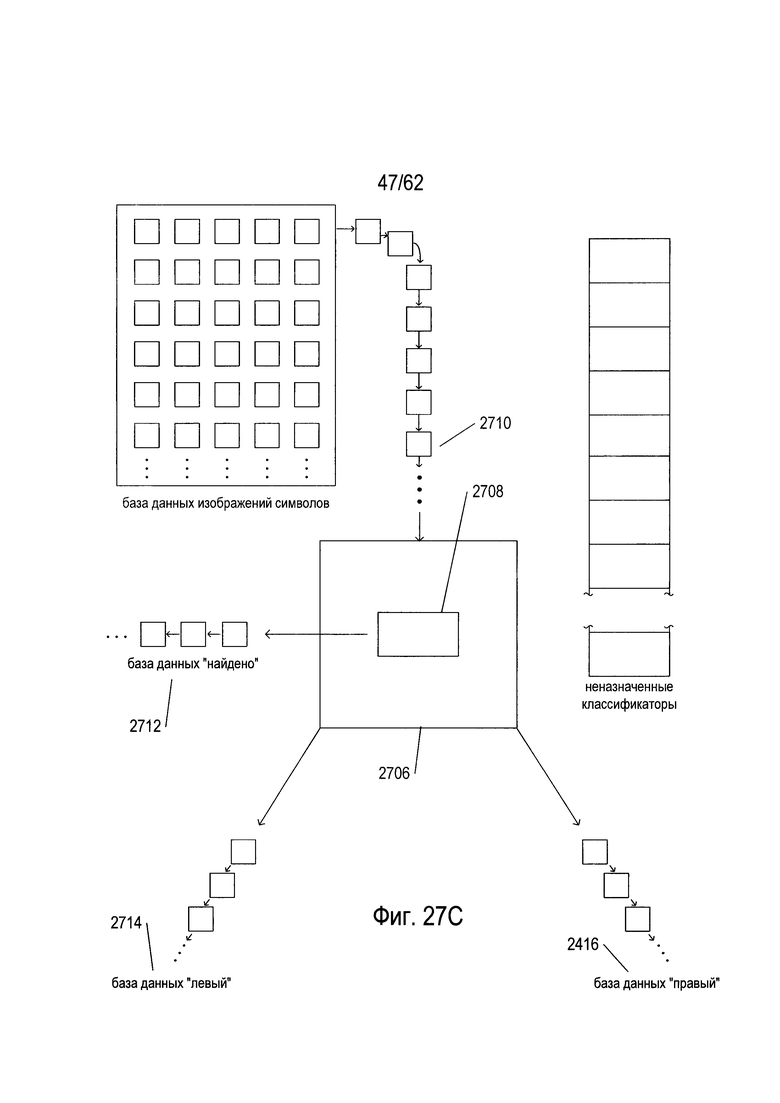
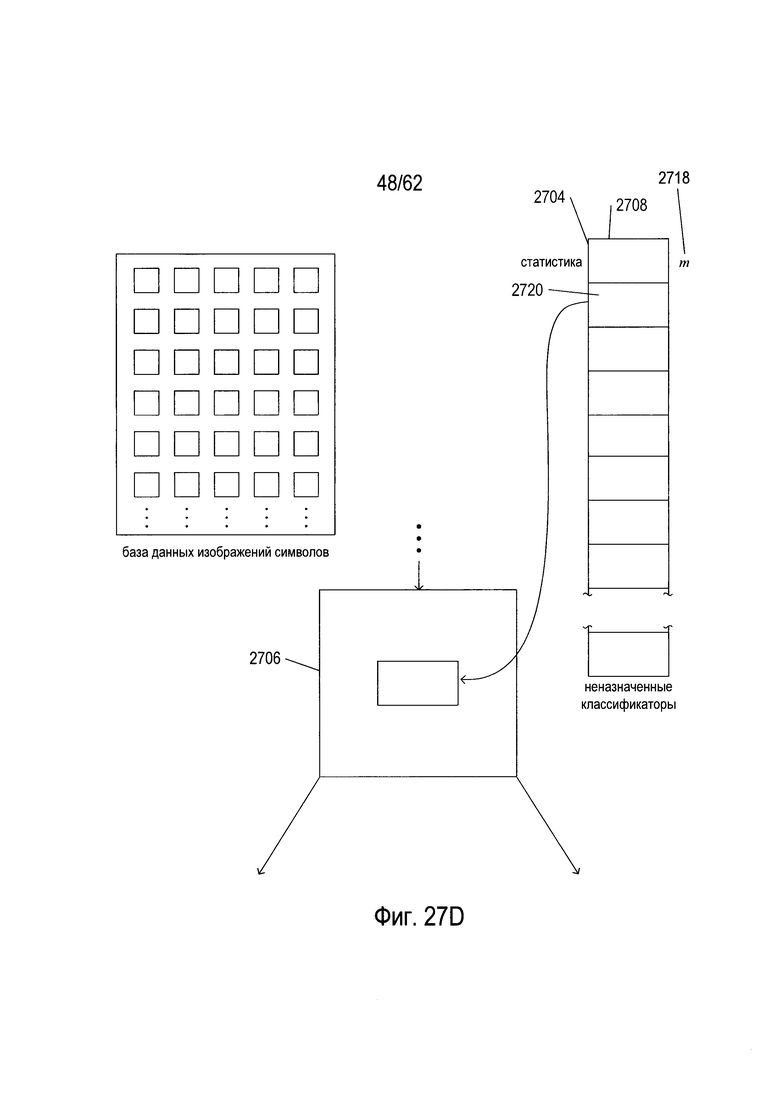
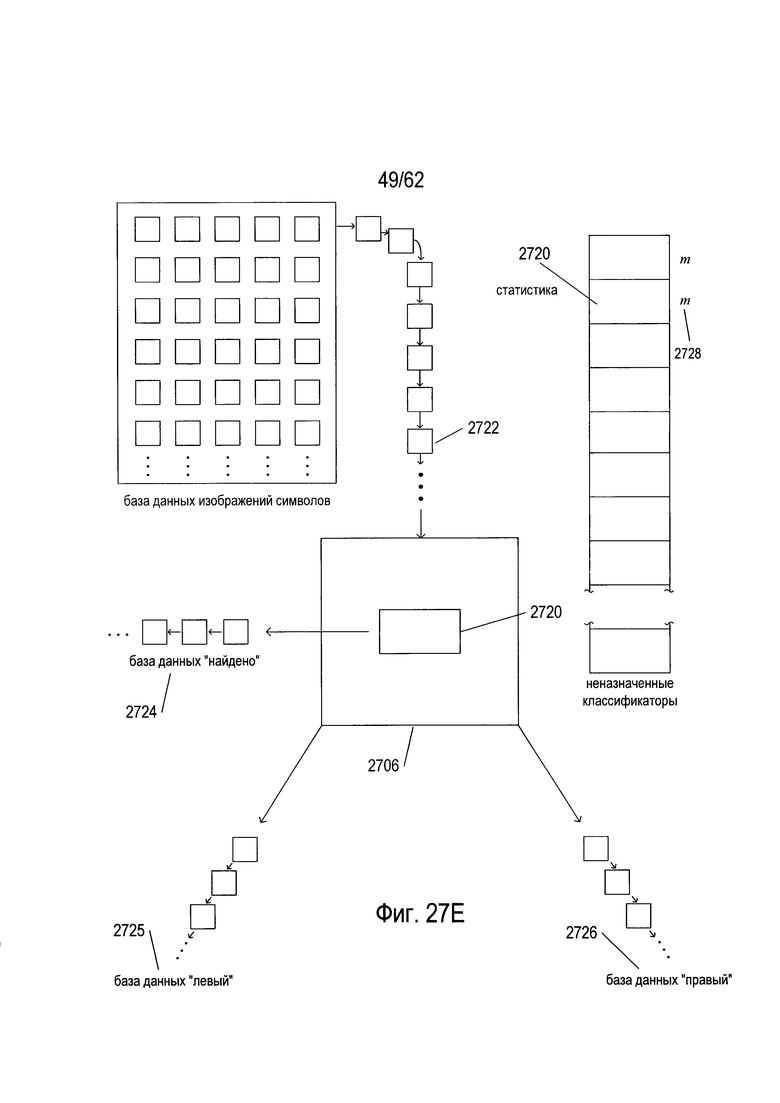
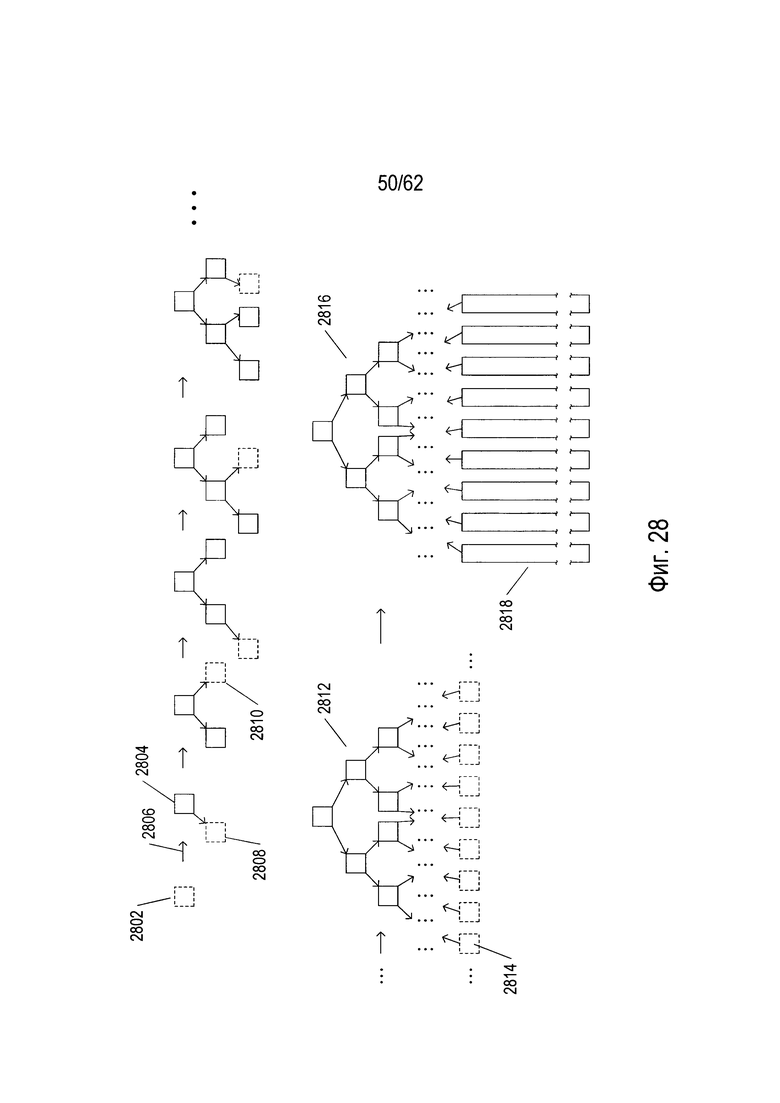

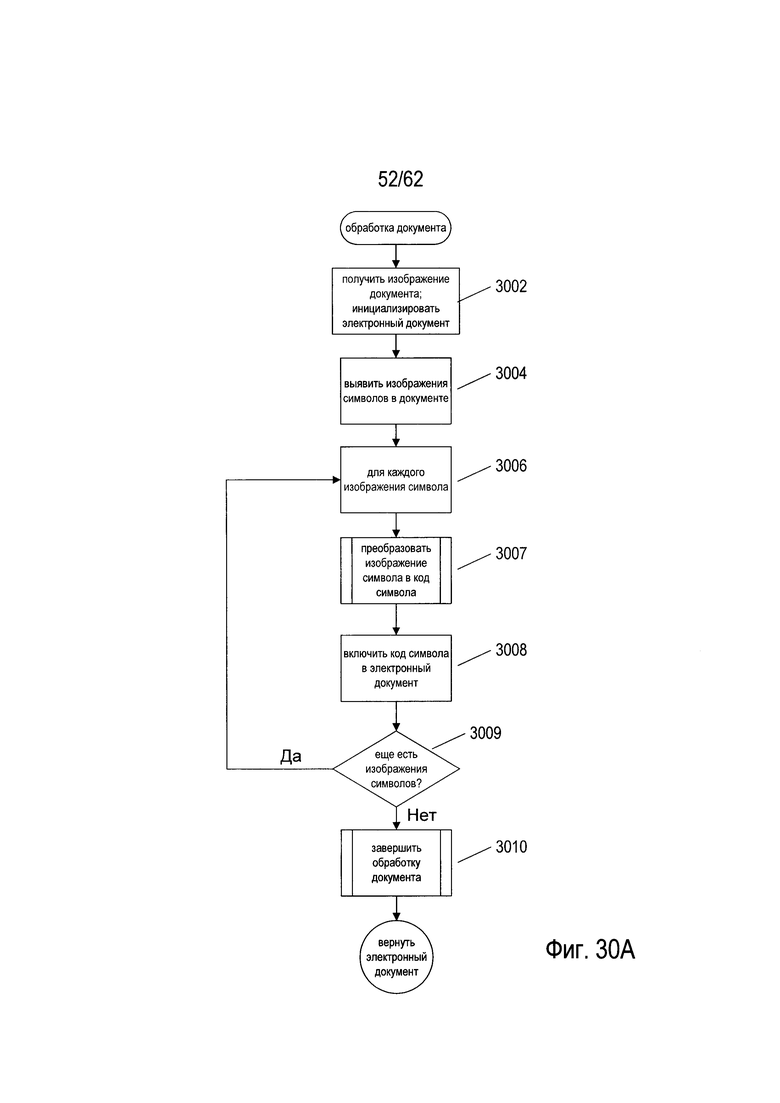
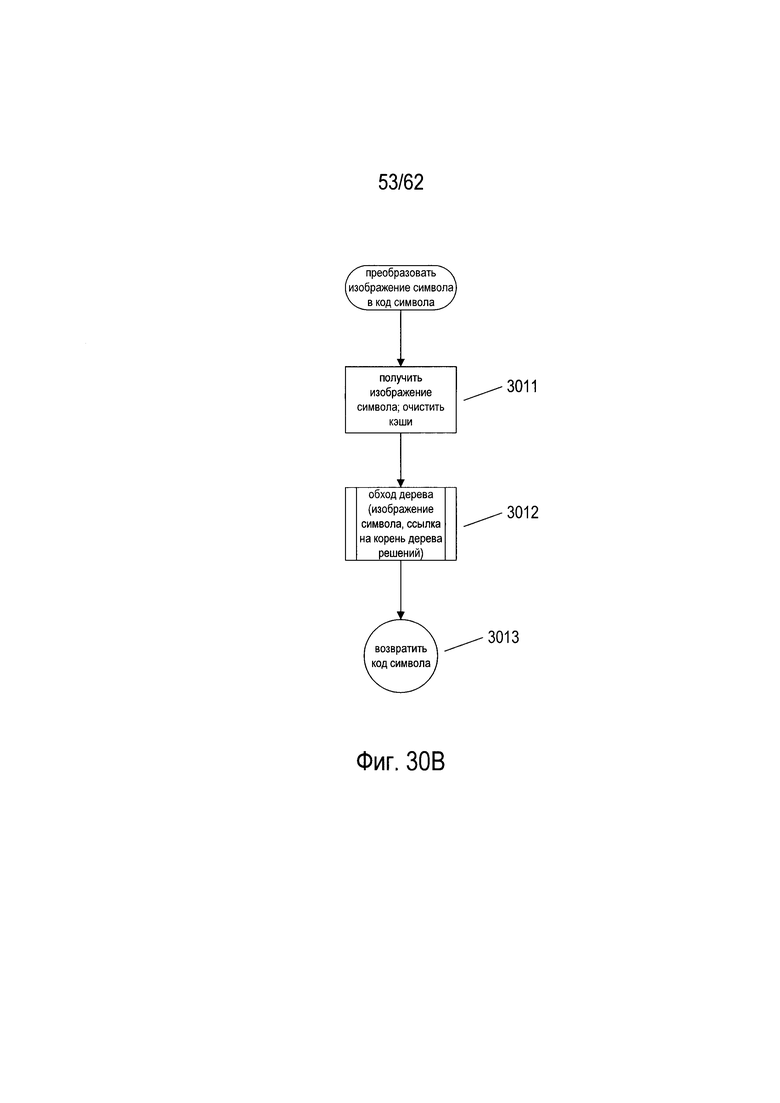
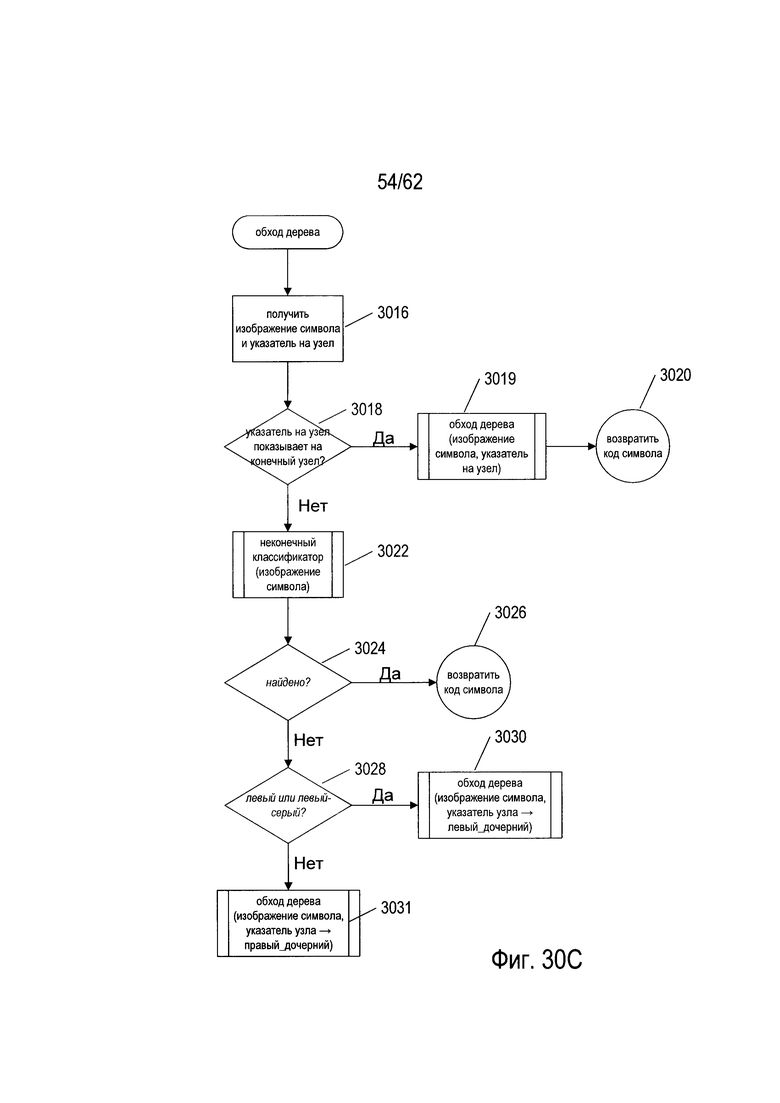
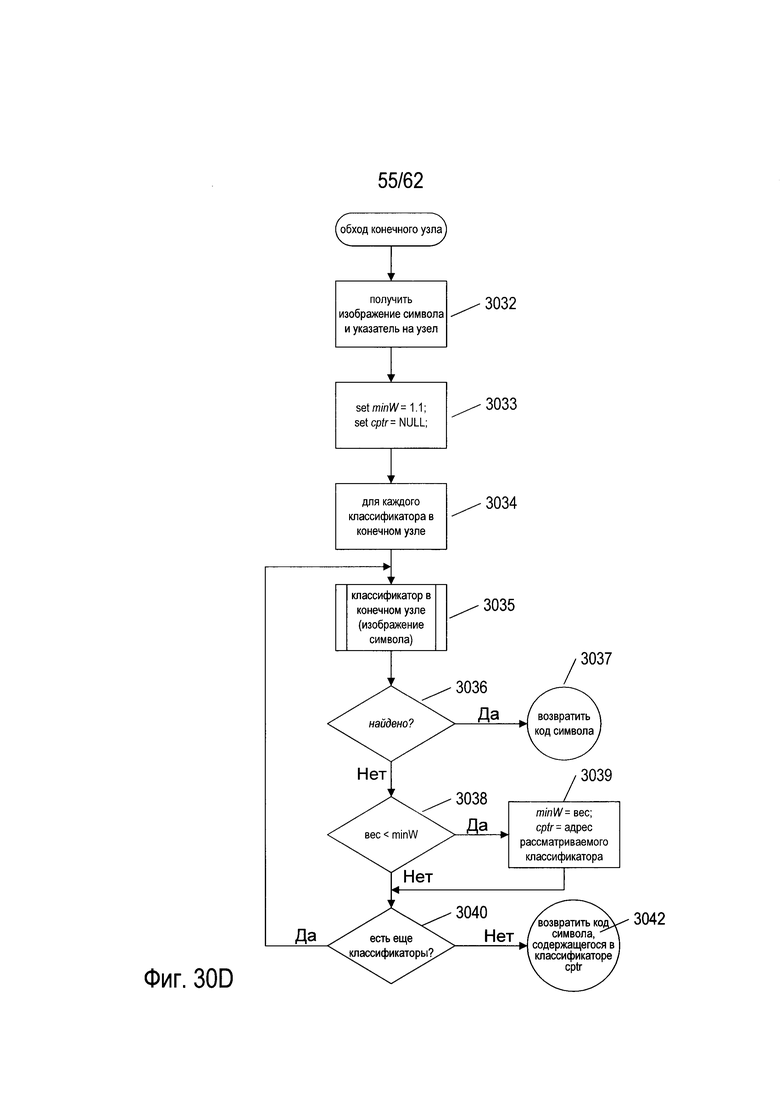
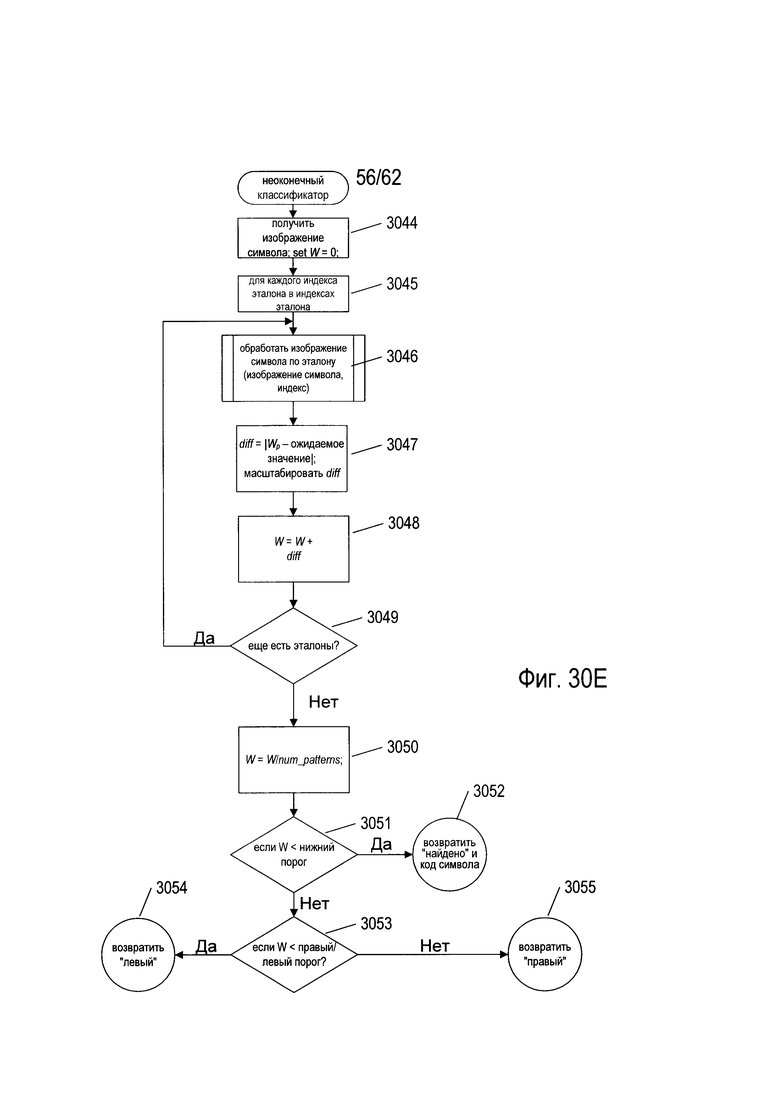
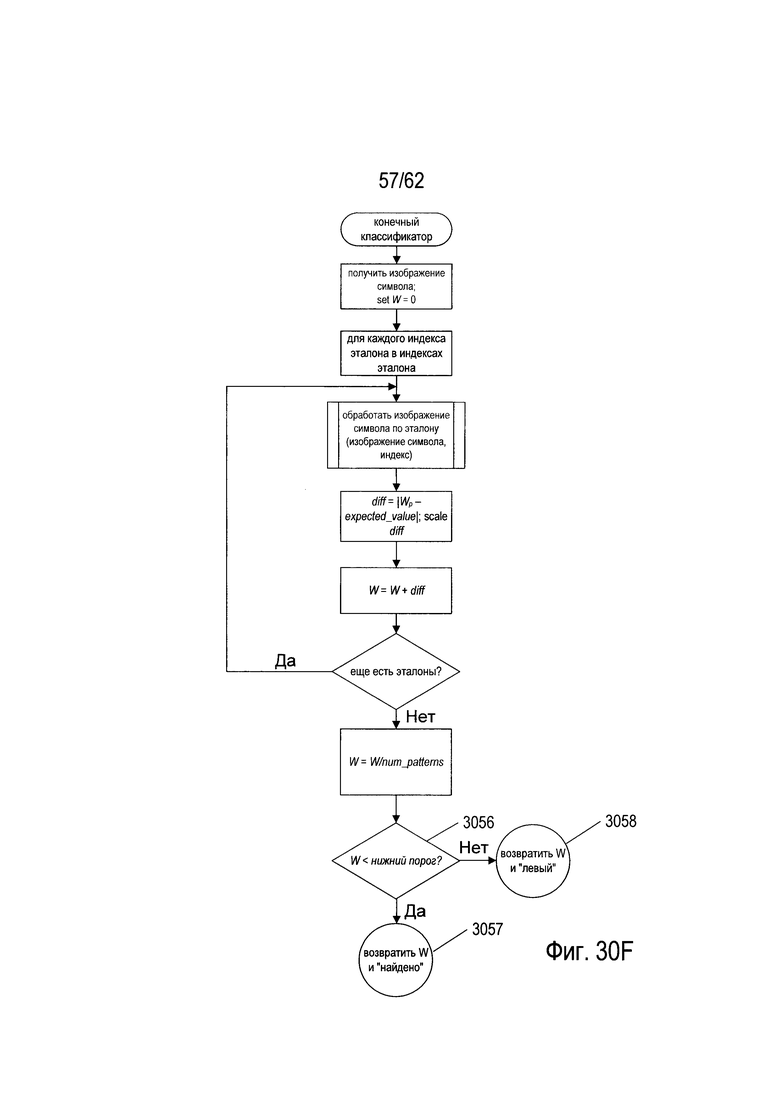
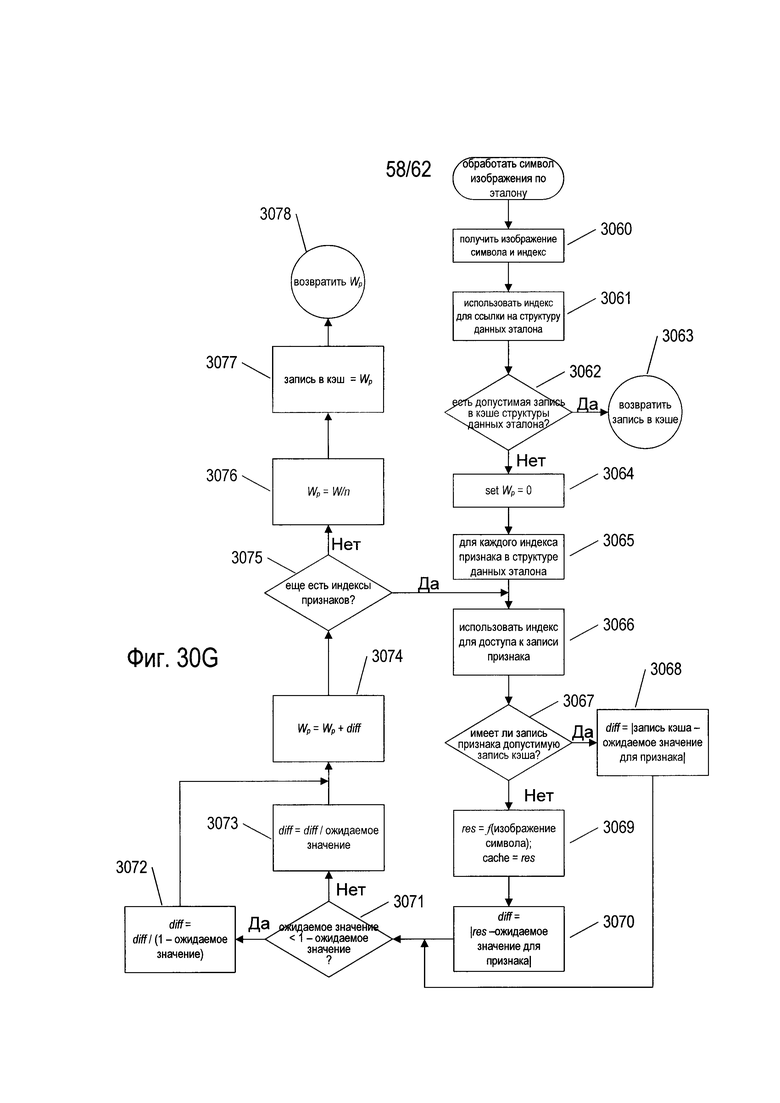
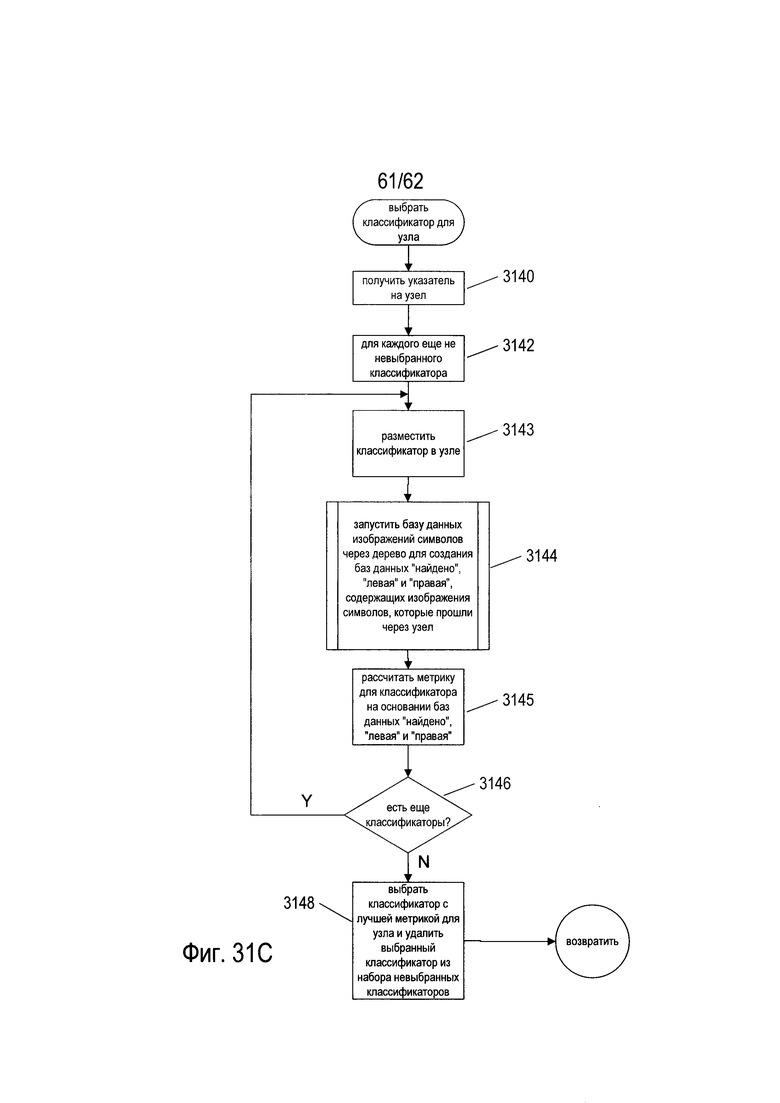
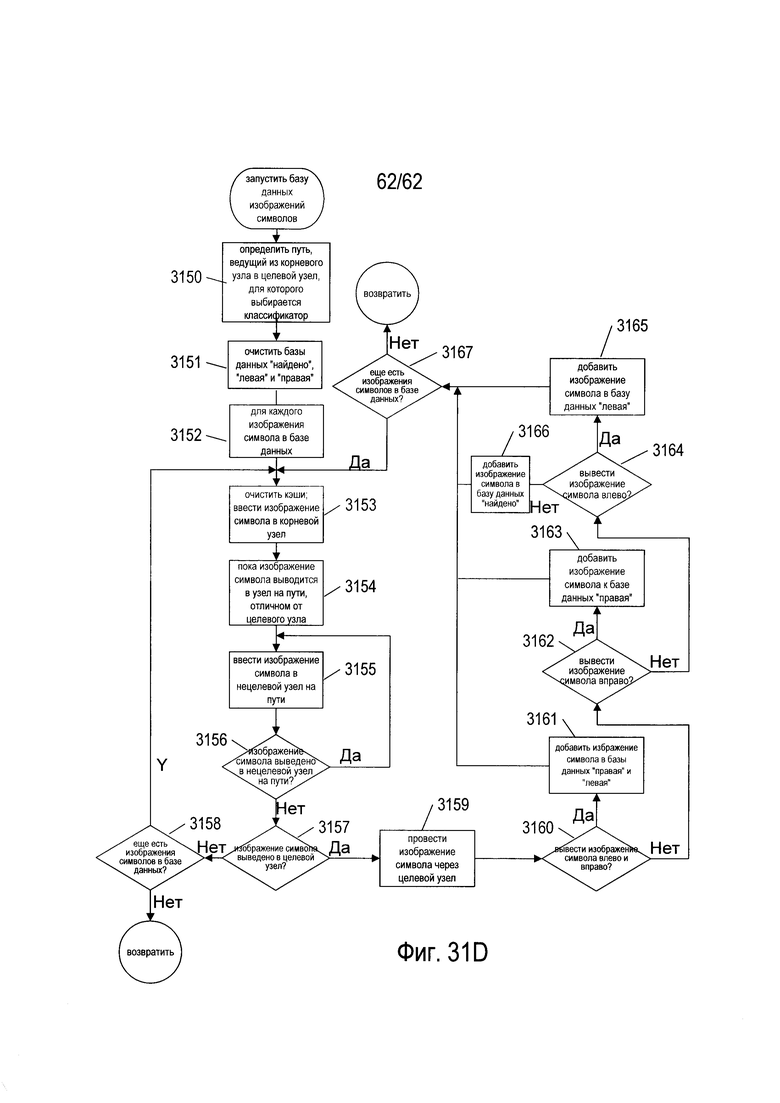
Группа изобретений относится к технологиям распознавания символов, соответствующих изображениям символов, полученных из изображения отсканированного документа или другого изображения, содержащего текст. Техническим результатом является обеспечение оптического распознавания символов на изображении документа. Предложена система оптического распознавания символов. Система содержит один или более процессоров, один или более модулей памяти, одно или более запоминающих устройств. Команды машинного кода, хранящиеся в запоминающих устройствах, при выполнении процессором управляют системой оптического распознавания символов для обработки содержащего текст отсканированного изображения документа за счет идентификации изображений символов в отсканированном изображении документа. Причем, для каждого выявленного изображения символа, начиная с корневого узла дерева решений, хранящегося в системе оптического распознавания символов, осуществляют рекурсивный обход дерева решений. В каждом узле один или несколько классификаторов выполняют распознавание изображения символа до тех пор, пока для данного изображения символа не будет получено решение «найдено». 3 н. и 20 з.п. ф-лы, 64 ил.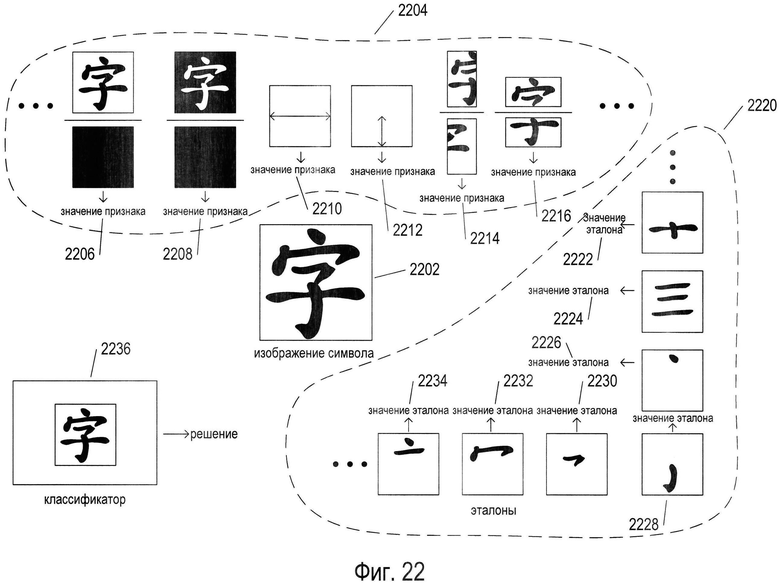
1. Система оптического распознавания символов, содержащая:
один или более процессоров;
один или более модулей памяти;
одно или более запоминающих устройств; и
команды в машинном коде, хранящиеся в одном или более из одного или более запоминающих устройств, при выполнении одним или более из одного или более процессоров управляют системой оптического распознавания символов для обработки содержащего текст отсканированного изображения документа за счет:
идентификации изображений символов в отсканированном изображении документа;
для каждого выявленного изображения символа,
начиная с корневого узла дерева решений, хранящегося в системе оптического распознавания символов, рекурсивного обхода дерева решений, причем в каждом узле один или несколько классификаторов выполняют распознавание изображения символа до тех пор, пока для данного изображения символа не будет получено решение «найдено»; и
представления изображение символа с помощью кода символа, связанного с классификатором, и
подготовки обработанного документа, содержащего коды символов, которые представляют собой изображения символов в изображении отсканированного документа и хранение обработанного документа в одном или более из одного или более накопителей данных и устройствах памяти.
2. Система оптического распознавания символов по п. 1, отличающаяся тем, что дерево решений содержит:
корневой узел, который содержит классификатор;
несколько узлов промежуточного уровня, каждый из которых содержит классификатор; и
несколько конечных узлов, каждый из которых содержит несколько классификаторов.
3. Система оптического распознавания символов по п. 2, отличающаяся тем, что строящееся дерево решений в каждом корневом узле и узле промежуточного уровня, каждый из которых связан с двумя или более дочерними узлами, содержит классификатор, выбранный из еще не выбранных классификаторов на основании расчетного показателя, отражающего одну или более целей, которые содержат:
при обходе дерева решений распознание максимального количества изображений символов;
при обходе дерева решений направление максимально возможного количества нераспознанных изображений символов, которые соответствуют одному классу символов, в один дочерний узел; и
во время обхода дерева решений, передача аналогичного количества нераспознанных изображений символов в каждый дочерний узел.
4. Система оптического распознавания символов по п. 2, отличающаяся тем, что каждый корневой узел и промежуточный узел дерева решений имеет левую линию связи с первым дочерним узлом более низкого уровня и правую линию связи со вторым дочерним узлом более низкого уровня.
5. Система оптического распознавания символов по п. 2, отличающаяся тем, что каждый классификатор, содержащийся в узле дерева решений, содержит:
количество кортежей, причем каждый кортеж содержит ссылку на структуру данных эталона и ожидаемое значение;
указание количества кортежей, содержащихся в классификаторе;
код символа или ссылку на код символа, для символа, распознанного классификатором; и
несколько значений порогов.
6. Система оптического распознавания символов по п. 5, отличающаяся тем, что каждый классификатор в корневом узле или в узле промежуточного уровня получает в качестве входных данных изображение символа и возвращает в качестве выходных данных решение.
7. Система оптического распознавания символов по п. 6, отличающаяся тем, что каждый классификатор в корневом узле или в узле промежуточного уровня после получения введенного изображения символов:
вычисляет значение веса из весов, полученных структурой данных эталона, на которую ссылается каждый кортеж, и ожидаемого значения, содержащегося в каждом кортеже; и
определяет решение о выходе на основе одного или более из нескольких пороговых значений и расчетного значения веса.
8. Система оптического распознавания символов по п. 7, отличающаяся тем, что значение веса рассчитывается:
для каждого кортежа
путем вычитания значения веса, полученного структурой данных эталона, на которую имеется ссылка, содержащаяся в кортеже, и ожидаемого значения, содержащегося в кортеже для получения разности,
путем вычисления абсолютного значения разности,
путем масштабирования вычисленного абсолютного значения и
путем добавления масштабированного расчетного абсолютного значения к кэшу; и
путем деления значения в кэше на количество кортежей, содержащихся в классификаторе.
9. Система оптического распознавания символов по п. 7, отличающаяся тем, что решение, возвращаемое каждым классификатором корневого узла и узла промежуточного уровня, в который во время обхода дерева решений поступает изображение символа с целью распознавания символа, выбирается из решений:
«найдено», возвращаемого классификатором, если расчетный вес меньше низкого порога;
«левый», возвращаемого классификатором, если расчетный вес меньше левого/правого порога и больше или равен низкому порогу; и
«правый», возвращаемого классификатором, если расчетный вес больше левого/правого порога.
10. Система оптического распознавания символов по п. 7, отличающаяся тем, что решение, возвращаемое каждым классификатором корневого узла и узла промежуточного уровня, для которого во время построения и одновременного обучения дерева решений вводится изображение символа с целью распознавания символа, выбирается из решений:
«найдено», возвращаемого классификатором, если расчетный вес меньше низкого порога;
«левый», возвращаемого классификатором, если расчетный вес меньше «левого серого» порога и больше или равен нижнему порогу;
«левый и правый», возвращаемого классификатором, если расчетный вес меньше правого серого порога и больше или равен левому серому порогу; и
«правый», возвращаемого классификатором, если расчетный вес больше или равен правому серому порогу.
11. Система оптического распознавания символов по п. 5, отличающаяся тем, что каждый классификатор в конечном узле в качестве входных данных принимает изображение символа и возвращает в качестве выхода решение и вес.
12. Система оптического распознавания символов по п. 11, отличающаяся тем, что каждый классификатор в конечном узле после получения введенного изображения символа:
рассчитывает значение веса из весов, полученных структурой данных эталона, на которую ссылается кортеж, и ожидаемого значения, содержащегося в каждом кортеже;
выводит расчетное значение веса и решение «найдено», если расчетный вес меньше нижнего порога; и
в противном случае выводит расчетный вес и решение, отличное от решения «найдено».
13. Система оптического распознавания символов по п. 5, отличающаяся тем, что каждая структура данных эталона, содержащаяся в каждом классификаторе, включает:
количество кортежей, причем каждый кортеж содержит ссылку на функцию признака и ожидаемое значение; и
указание на количества кортежей, содержащихся в структуре данных эталона.
14. Система оптического распознавания символов по п. 13, отличающаяся тем, что структура данных эталона получает вес для изображения символа:
для каждого кортежа
путем вычитания значения веса, полученного функцией признака, на которую имеется ссылка, содержащаяся в кортеже, обрабатывающей изображение символа из ожидаемого значения, содержащегося в кортеже для получения разности,
путем вычисления абсолютного значения разности,
путем масштабирования вычисленного абсолютного значения и
путем добавления масштабированного расчетного абсолютного значения к кэшу; и
путем деления значения в кэше на количество кортежей, содержащихся в структуре данных эталона.
15. Система оптического распознавания символов по п. 1, отличающаяся тем, что, начиная с корневого узла дерева решений, хранящегося в системе оптического распознавания символов, обход дерева решений, до тех пор, пока классификатор в узле дерева решений не распознает изображение символа, дополнительно включает:
рекурсивный обход, начиная с корневого узла дерева решений, который считается рассматриваемым в настоящее время узлом,
ввод изображения символа в классификатор рассматриваемого в настоящий момент узла;
если классификатор возвращает решение «найдено», возвращение кода символа, содержащегося в классификаторе или на который классификатор ссылается, в качестве кода символа, соответствующего изображению символа;
если классификатор возвращает решение «левый», и левый дочерний узел рассматриваемого узла является узлом промежуточного уровня, принятие левого дочернего узла рассматриваемого узла в качестве следующего рассматриваемого узла для следующей рекурсии;
если классификатор возвращает решение «правый», а правый дочерний узел рассматриваемого узла является узлом промежуточного уровня, принятие правого дочернего узла рассматриваемого узла в качестве следующего рассматриваемого узла для следующей рекурсии; и
если классификатор возвращает решение «левый» или решение «правый», а дочерними узлами рассматриваемого являются конечные узлы, выполнение обхода классификаторов в пределах указанного оконечного узла для определения кода символа, соответствующего изображению символа.
16. Система оптического распознавания символов по п. 15, отличающаяся тем, что обход классификаторов в пределах указанного конечного узла для определения кода символа, соответствующего изображению символа, дополнительно включает:
ввод изображения символа для каждого последующего классификатора в конечном узле, пока либо классификатор не вернет решение «найдено», и в этом случае код символа, содержащийся в классификаторе или на который ссылается классификатор, идентифицируется как код символа, соответствующий изображению символа, либо до тех пор, пока не останется классификаторов, в которые можно вводить код символа, в этом случае код символа, содержащийся в классификаторе или на который ссылается классификатор, который возвратил самое малое значение веса, идентифицируется как код символа, соответствующий изображению символа.
17. Способ, встроенный в систему оптического распознавания символов, использующую один или более процессоров, один или более устройств памяти, один из более накопителей данных, и дерево решений, хранящееся в одном или более из одного или более устройств памяти и одном из более накопителей данных, причем этот способ реализован с помощью машинных команд, хранящихся в одном или более из одного или более накопителей данных, которые при их выполнении одним или более из одного или более процессоров, управляют системой оптического распознавания символов для идентификации кода символа, соответствующего символу изображения, отличающийся тем, что способ содержит:
рекурсивный обход дерева решений, в каждом узле которого один или несколько классификаторов выполняют распознавание изображения символа, начиная с корневого узла дерева решений, до тех пор, пока для данного изображения символа не будет получено решение «найдено»; и
хранение ассоциации изображения символа с кодом символа, которая представляет изображение символа, распознанного классификатором в одном или более из одного или более устройств памяти и одном или более накопителе данных.
18. Способ по п. 17,
отличающийся тем, что дерево решений содержит
корневой узел и несколько узлов промежуточного уровня, каждый из которых содержит классификатор, и каждый такой узел содержит правую линию связи с правым дочерним узлом и левую линию связи с левым дочерним узлом, а также несколько конечных узлов, каждый из которых содержит несколько классификаторов; и
отличающийся тем, что каждый классификатор ссылается на несколько структур данных эталона и для каждой структуры данных эталона содержит ожидаемое значение, при этом каждая структура данных эталона, на которую имеются ссылки из классификатора, ссылается на несколько функций признаков и содержит ожидаемое значение для каждой функции признака, на которую имеется ссылка.
19. Способ по п. 18, отличающийся тем, что классификатор в корневом узле или в узле промежуточного уровня в дополнение к ссылке на структуры данных эталона и соответствующим ожидаемым значениям содержит:
указание на количество структур данных эталона, на которые ссылается этот классификатор;
код символа или ссылку на код символа, для символа, распознанного классификатором; и
несколько пороговых значений.
20. Способ по п. 19, отличающийся тем, что каждый классификатор в корневом узле или в узле промежуточного уровня принимает в качестве входных данных изображение символа и возвращает в качестве выходных данные решение следующим образом:
для каждой структуры данных эталона, на которую имеется ссылка:
путем вычитания веса, полученного с помощью структуры данных эталона для изображения символа, и ожидаемого значения, соответствующего ссылочной структуре данных эталона для получения разности;
путем вычисления абсолютного значения разности,
путем масштабирования вычисленного абсолютного значения и
путем добавления масштабированного расчетного абсолютного значения к накопителю; и
путем деления значения в кэше на количество структур данных эталона, на которые ссылается классификатор для получения расчетного веса;
если расчетный вес меньше нижнего порога, то возвращается решение «найдено»;
если расчетный вес меньше левого/правого порога и больше или равен нижнему порогу, то возвращается решение «левый»; и
если расчетный вес больше, чем левый/правый порог, то возвращается решение «правый».
21. Способ по п. 18, отличающийся тем, что каждый классификатор в конечном узле принимает в качестве входных данных изображение символа и возвращает в качестве выходных данных решение и вес следующим образом:
для каждой структуры данных эталона, на которую имеется ссылка:
путем вычитания веса, полученного структурой данных эталона для изображения символа, и ожидаемого значения, соответствующего структуре данных эталона, на которую имеется ссылка, для получения разности,
путем вычисления абсолютного значения разности,
путем масштабирования вычисленного абсолютного значения и
путем добавления масштабированного расчетного абсолютного значения к накопителю; и
путем деления значения в кэше на количество структур данных эталона, на которые ссылается классификатор для получения расчетного веса;
если расчетный вес меньше нижнего порога, то возвращается решение «найдено» и расчетный вес; и
если расчетный вес больше или равен нижнему порогу, то возвращается решение, отличное от «найдено» и расчетный вес.
22. Способ по п. 17, отличающийся тем, что, начиная с корневого узла дерева решений, выполняется рекурсивный обход дерева решений до тех пор, пока классификатор в узле дерева решения не распознает изображение символа, дополнительно включающий:
рекурсивный обход, начиная с корневого узла дерева решения, как рассматриваемого узла,
ввод изображения символа в классификатор рассматриваемого узла;
если классификатор возвращает решение «найдено», возврат кода символа, содержащегося в классификаторе или на который классификатор ссылается в качестве кода символа, соответствующего изображению символа;
если классификатор возвращает решение «левый», а левый дочерний узел рассматриваемого узла является узлом промежуточного уровня, принятие левого дочернего узла рассматриваемого узла в качестве следующего рассматриваемого узла для следующей рекурсии;
если классификатор возвращает решение «правый», а правый дочерний узел рассматриваемого узла является узлом промежуточного уровня, принятие правого дочернего узла рассматриваемого узла в качестве следующего рассматриваемого узла для следующей рекурсии; и
если классификатор возвращает решение «левый» или решение «правый», а дочерними узлами рассматриваемого являются конечные узлы, выполнение обхода классификаторов в пределах указанного конечного узла, в зависимости от принятого решения, для определения кода символа, соответствующего изображению символа.
ввод изображения символов в каждый последующий классификатор внутри указанного оконечного узла до тех пор, пока классификатор не возвратит решение «найдено», и в этом случае код символа, содержащийся в классификаторе или на который ссылается классификатор, идентифицируется как код символа, соответствующий изображению символа, или до тех пор, пока больше не будет классификаторов, в которые можно ввести код символа, и в этом случае код символа, содержащийся в классификаторе или на который ссылается классификатор, который возвратил наименьшее значение веса, считается кодом символа, соответствующим изображению символа.
23. Машиночитаемый носитель данных, содержащий исполняемые процессором команды, реализующие способ, встроенный в систему оптического распознавания символов, имеющую один или более процессоров, одно или более устройств памяти, один из нескольких накопителей данных, а также дерево решений, которое хранится в одном или более из одного или более устройств памяти и одном или более накопителей данных, причем этот способ реализуется с помощью компьютерных команд, хранящихся в одном или более из одного или более накопителей данных, которые при их выполнении одним или более из одного или более процессоров управляют системой оптического распознавания символов для определения кода символа, соответствующего изображению символа, причем этот способ содержит следующее:
рекурсивный обход дерева решений, в каждом узле которого один или несколько классификаторов выполняют распознавание изображения символа, начиная с корневого узла дерева решений, до тех пор, пока для данного изображения символа не будет получено решение «найдено»; и
хранение ассоциации изображения символа с кодом символа, которая представляет изображение символа, распознанного классификатором в одном или более из одного или более устройств памяти и одном или более накопителе данных.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| RU 2009139274 A, 27.04.2011. | |||

