ОБЛАСТЬ ТЕХНИКИ
Настоящая заявка относится к автоматической обработке изображений отсканированных документов и других изображений, содержащих текст, и, в частности, к способам и системам определения ориентации для области или блока содержащего текст изображения.
УРОВЕНЬ ТЕХНИКИ
Уже на протяжении долгого времени для записи и хранения информации используются печатные, машинописные и рукописные документы. Несмотря на современные тенденции отказа от бумажного делопроизводства, печатные документы продолжают широко использоваться в коммерческих организациях, учреждениях и домашних обстановках. С развитием современных компьютерных систем создание, хранение, поиск и передача электронных документов превратились, наряду с непрекращающимся применением печатных документов, в чрезвычайно эффективный и экономически выгодный альтернативный способ записи и хранения информации. Из-за подавляющего преимущества в эффективности и экономической выгоде, обеспечиваемого современными средствами хранения и передачи электронных документов, печатные документы легко преобразуются в электронные с помощью различных способов и систем, включающих преобразование печатных документов в цифровые изображения отсканированных документов с использованием электронных оптико-механических сканирующих устройств, цифровых камер, а также других устройств и систем, и последующую автоматическую обработку изображений отсканированных документов для получения электронных документов, закодированных в соответствии с одним или более различными стандартами кодирования электронных документов. Например, в настоящее время можно использовать настольный сканер и современные программы оптического распознавания символов (OCR), позволяющие с помощью персонального компьютера преобразовывать печатный документ в соответствующий электронный документ, который можно просматривать и редактировать с помощью текстового редактора.
Хотя современные программы OCR развились до такой степени, что позволяют автоматически преобразовывать в электронные документы сложные печатные документы, включающие в себя изображения, рамки, линии границ и другие нетекстовые элементы, а также текстовые символы множества распространенных алфавитных языков, остается нерешенной проблема преобразования в соответствующие электронные документы печатных документов, содержащих текст на неалфавитных языках.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящая заявка относится к способам и системам автоматического определения ориентации областей изображений отсканированных документов. В одном из вариантов реализации рассматриваемые в настоящей заявке способ и система определения ориентации задействуют относительно небольшой набор символов ориентации, часто встречающихся в печатном тексте. В этом варианте реализации для, по меньшей мере, одного набора символов ориентации, каждая из двух или более различных ориентаций содержащих символ подобластей в содержащей символ области отсканированного изображения документа сравнивается с каждым символом ориентации из, по меньшей мере, одного набора символов ориентации, для того, чтобы определить ориентацию для каждой содержащей символ подобласти относительно исходного положения содержащей текст области. Выявленные для содержащих символы подобластей ориентации затем используются для определения ориентации содержащей текст области изображения отсканированного документа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг. 1А-В показан печатный документ.
На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в закодированные в цифровом виде электронные документы, которые можно хранить на запоминающих устройствах и (или) в электронной памяти.
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2.
На Фиг. 4 представлена общая архитектурная схема различных видов компьютеров и других устройств с процессорным управлением.
На Фиг. 5 показано цифровое представление отсканированного документа.
На Фиг. 6 показаны шесть областей изображения отсканированного документа, распознанного в ходе начальной стадии преобразования изображения отсканированного документа, на примере типового документа 100, показанного на Фиг. 1.
На Фиг. 7 показано вращение в горизонтальной плоскости.
На Фиг. 8-10 показан подход к определению исходной ориентации области, содержащей текст.
На Фиг. 11A-D показаны 16 различных возможных ориентаций для содержащей текст области.
На Фиг. 12 показана задача распознания символов текста для различных типов иероглифических языков или языков, в которых текст представлен не в виде простых строк символов алфавита.
На Фиг. 13 показаны симметрии вращения знаков или символов.
На Фиг. 14A-F показан описанный ранее подход к формированию возможной абсолютной ориентации содержащей текст области, а также несколько альтернативных способов определения ориентации текстовой области, рассматриваемых в настоящем документе.
На Фиг. 15 показан первый этап определения ориентации содержащей символ подобласти в соответствии со способами, описываемыми в настоящем документе.
На Фиг. 16А-Н показано использование областей символов в рамке для расчета вектора значений признаков для символа в рамке.
На Фиг. 17А-В показан пример трансформации значения признака.
На Фиг. 18 приведена таблица, показывающая небольшое количество примеров классов трансформации.
На Фиг. 19A-F представлены блок-схемы, показывающие в обобщенном виде способ ориентации содержащей текст области, который охватывает способы, рассмотренные на Фиг. 14Е и F.
На Фиг. 19G представлена блок-схема, показывающая способ вычисления балла для сопоставления признаков, рассчитанных для содержащей символ подобласти, и признаков, рассчитанных для каждой пары символ-ориентации/ориентации.
На Фиг. 19Н представлена блок-схема, показывающая способ вычисления ориентации для вычисления ориентации содержащей текст области.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
Настоящая заявка относится к способам и системам автоматического определения ориентации для содержащих текст областей отсканированных изображений документов за счет определения ориентации некоторого количества символов ориентации или знаков в содержащей текст области. В рамках нижеследующего обсуждения сначала описываются вопросы, связанные с изображениями отсканированных документов и электронными документами, а затем - способы определения общей ориентации содержащих текст областей изображений отсканированных документов. Далее рассматриваются задачи определения ориентации областей изображения, содержащих текстовые знаки языка, в особенности языка, текст в котором не записывается в виде строк последовательных символов алфавита. Наконец, рассматриваются символы ориентации или эталоны ориентации символов и приводится детальное описание способов и систем для использования эталонов ориентации символов с целью определения ориентации содержащей текст области отсканированного изображения документа.
На Фиг. 1А-В показан печатный документ. На Фиг. 1А показан исходный документ с текстом на японском языке. Печатный документ (100) включает в себя фотографию (102) и пять разных содержащих текст областей (104-108), включающих в себя японские иероглифы. Этот документ будет использоваться в качестве примера при рассмотрении способа и систем определения ориентации, к которым относится настоящая заявка. Текст на японском языке может писаться слева направо, построчно, как пишется текст на английском языке, но альтернативно может использоваться способ написания сверху вниз в вертикальных столбцах. Например, как видно, область (107) содержит вертикально написанный текст, в то время как фрагмент текста (108) содержит текст, написанный горизонтально. На Фиг. 1В показан перевод на русский язык печатного документа, изображенного на Фиг. 1А.
Печатные документы могут быть преобразованы в закодированные в цифровом виде изображения отсканированных документов различными средствами, в том числе с использованием электронных оптико-механических сканирующих устройств и цифровых камер. На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в закодированные в цифровом виде электронные документы, которые можно хранить на запоминающих устройствах и (или) в электронной памяти. Настольное сканирующее устройство (202) включает в себя прозрачное стекло (204), на которое лицевой стороной вниз помещается документ (206). Запуск сканирования приводит к получению закодированного в цифровом виде изображения отсканированного документа, которое можно передать на персональный компьютер (далее ПК) (208) для хранения на запоминающем устройстве. Программа отображения отсканированного документа может вывести закодированное в цифровом виде изображение отсканированного документа на экран (210) устройства отображения ПК (212).
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2. Оптические компоненты этого сканера с приборами с зарядовой связью (ПЗС) расположены под прозрачным стеклом (204). Фронтально перемещаемый источник яркого света (302) освещает часть сканируемого документа (304), свет от которой отражается вниз. Переизлученный и отраженный свет отражается от фронтально перемещаемого зеркала (306) на неподвижное зеркало (308), которое отражает излучаемый свет на массив элементов ПЗС (310), формирующих электрические сигналы пропорционально интенсивности света, падающего на каждый из них. Цветные сканеры могут включать в себя три отдельных ряда или набора элементов ПЗС с красным, зеленым и синим фильтрами. Фронтально перемещаемые источник яркого света и зеркало двигаются вместе вдоль документа, в результате чего получается изображение сканируемого документа. Другой тип сканера, использующего контактный датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми цветными светодиодами (LED), при этом отраженный свет светодиодов улавливается набором фотодиодов, который перемещается вместе с цветными светодиодами.
На Фиг. 4 представлена общая архитектурная схема различных видов компьютеров и других устройств с процессорным управлением. Современную компьютерную систему можно описать с помощью высокоуровневой архитектурной схемы, как, например, ПК на Фиг. 2, на которой программы преобразования изображений отсканированных документов и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи в электронную память и выполнения одним или несколькими процессорами. Компьютерная система содержит один или множество центральных процессоров (ЦП) (402-405), один или более модулей электронной памяти (408), соединенных с ЦП при помощи шины подсистемы ЦП/память (410) или множества шин, первый мост (412), который соединяет шину подсистемы ЦП/память (410) с дополнительными шинами (414) и (416) или другими средствами высокоскоростного взаимодействия, включающими в себя множество высокоскоростных последовательных линий. Данные шины или последовательные линии, в свою очередь, соединяют ЦП и запоминающее устройство со специализированными процессорами, такими как графический процессор (418), а также с одним или несколькими дополнительными мостами (420), межсоединенными с высокоскоростными последовательными линиями или с несколькими контроллерами (422-427), такими как контроллер (427), которые предоставляют доступ к различным видам устройств массовой памяти (428), электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
На Фиг. 5 показано цифровое представление отсканированного документа. На Фиг. 5 в увеличенном виде (506) показан небольшой круглый фрагмент изображения (502) типового печатного документа (504). На Фиг. 5 также представлен соответствующий фрагмент закодированного в цифровом виде изображения отсканированного документа (508). Закодированный в цифровом виде отсканированный документ включает в себя данные, которые представляют собой двухмерный массив кодировок значений пикселов. В представлении (508) каждая ячейка сетки под символами (например, ячейка (509)) представляет собой квадратную матрицу пикселов. Небольшой фрагмент (510) сетки показан с еще большим увеличением (512 на Фиг. 5), при котором отдельные пиксели представлены в виде элементов матрицы (например, элемента матрицы (514)). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения света заданной яркости. В файле оцифрованного отсканированного документа каждый пиксель представлен фиксированным числом битов, при этом кодирование пикселей осуществляется последовательно. Заголовок файла содержит информацию о типе кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодирования пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Для цифрового кодирования отсканированного изображения документа в виде монохромных изображений с оттенками серого обычно используют 8-битное или 16-битное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в зависимости от стандарта кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-битных значения, закодированных с помощью 24-битного значения. Таким образом, оцифрованное отсканированное изображение, по существу, представляет документ аналогично тому, как цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении закодированных пикселей, например информация, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ.
Напротив, обычный электронный документ, созданный с помощью текстового редактора, содержит различные виды команд рисования линий, ссылки на представления изображений, такие как закодированные в цифровом виде фотографии и закодированные в цифровом виде текстовые символы. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII (американский стандартный код обмена информацией) и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие неалфавитные текстовые языки. Большая часть вычислительной работы, которую выполняет программа OCR, связана с распознаванием изображений текстовых символов, полученных из оцифрованного изображения отсканированного документа, и с преобразованием изображений символов в соответствующие кодовые комбинации стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения растровых изображений текстовых символов. Более того, текстовые символы, закодированные по стандарту Юникод, можно редактировать, переформатировать в различные шрифты и обрабатывать множеством доступных в программах обработки текстов способов, в то время как закодированные в цифровом виде изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
На начальной стадии преобразования изображения отсканированного документа в электронный документ печатный документ (например, документ (100), показанный на Фиг. 1) анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие области. На Фиг. 6 показаны шесть различных областей типового документа (100), показанного на Фиг. 1, которые были распознаны на начальной стадии преобразования изображения отсканированного документа. В данном случае дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу в целом, и шесть тупиковых узлов, каждый из которых соответствует одной из идентифицированных областей (602-607). Области можно идентифицировать применяя целый ряд различных способов, в том числе различные виды статистического анализа распределения кодировок пикселей или значений пикселей по поверхности изображения. Например, в цветном документе фотографию можно выделить по большему изменению цвета в области фотографии, а также по более частым изменениям значений яркости пикселей по сравнению с областями, содержащими текст.
Как только в рамках начальной стадии анализа будут установлены различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR для выявления и преобразования текстовых символов в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать содержащие текст области, определяется исходная ориентация содержащей текст области, благодаря чему в подпрограммах OCR эффективно используются различные способы сопоставления с эталоном для определения текстовых символов. Следует отметить, что изображения в документах могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в позиционировании документа на сканере или другом устройстве, формирующем изображение, из-за нестандартной ориентации содержащих текст областей или по другим причинам. В случаях, когда подпрограммы OCR не могут воспринять стандартную ориентацию строк и столбцов текста, вычислительная задача сопоставления шаблонов символов с областями изображения отсканированного документа будет намного более сложной и ее выполнение будет намного менее эффективным, так как подпрограммы OCR будут, как правило, пытаться повернуть шаблон символа на угловые интервалы до 360° и при каждом повороте будут пытаться сопоставить данный шаблон символа с потенциальной содержащей текст областью изображения.
Следует пояснить, что исходная ориентация определяется поворотами содержащей текст области в горизонтальной плоскости. На Фиг. 7 показано вращение в горизонтальной плоскости. На Фиг. 7 квадратная область изображения отсканированного документа (702) располагается горизонтально с вертикальной осью вращения (704), проходящей по центру области. При вращении квадратной области по часовой стрелке на 90° получается ориентация (706), показанная на правой стороне Фиг. 7.
Как правило, сразу после выявления содержащей текст области изображение содержащей текст области преобразуется из изображения на основе пикселов в растр (данный процесс именуется «бинаризацией»), когда каждый пиксель представляется значением бита «0», что указывает на то, что данный пиксель не содержится во фрагменте текстового символа, или значением бита «1», что означает, что данный пиксель содержится в текстовом символе. Таким образом, например, в черно-белой содержащей текст области изображения отсканированного документа, в которой текст напечатан черным цветом на белом фоне, пиксели со значениями менее порогового значения, соответствующего темным областям данного изображения, переводятся в биты со значением «1», тогда как пиксели со значениями, равными или превышающими пороговое значение, соответствующее фону, переводятся в биты со значение «0». Преобразование в значения битов, естественно, имеет произвольный характер, и возможно обратное преобразование, при этом значение «1» означает фон, а значение «0» - символ. Для более эффективного хранения битовую карту можно сжать с помощью кодирования по длинам серий (RLE).
На Фиг. 8-10 показан подход к определению исходной ориентации области, содержащей текст. На Фиг. 8 показано формирование гистограммы, соответствующей одной ориентации содержащей текста области. На Фиг. 8 содержащая текст область (802) имеет вертикальную ориентацию. Содержащая текст область разделяется на столбцы, разграничиваемые вертикальными линиями, такими как вертикальная линия (804). В каждом столбце по дочитывается количество битов со значением «1» на битовой карте, соответствующей содержащей текст области, которое используется для формирования гистограммы (806), показанной над содержащей текст области. Столбцы в содержащей текст области, не содержащие фрагментов символов или, что то же самое, содержащие только биты со значением «0», не имеют соответствующих столбцов в гистограмме, тогда как столбцы, содержащие фрагменты символов, соотносятся с столбцам в гистограмме высотой, соответствующей пропорции битов в столбце со значением «1». В качестве альтернативы, высота столбцов гистограммы может масштабироваться с учетом абсолютного количества битов со значением «1» или представлять часть битов в столбце со значением «1» или часть количества битов со значением «1» в столбце в отношении общего количества битов со значением «1» в содержащей текст области.
На Фиг. 9 показаны гистограммы, сформированные для столбцов и строк надлежащим образом ориентированной содержащей текст области. На Фиг. 9 содержащая текст область (902) выравнивается по границам страницы, строкам текста, параллельного верхней и нижней части страницы, и столбцам текста, параллельного сторонам страницы. Способ формирования гистограмм, описанный выше со ссылкой на Фиг. 8, был применен ко всей содержащей текст области (902) для формирования гистограмм для вертикальных столбцов в содержащей текст области (904) и для горизонтальных строк в содержащей текст области (906). Следует отметить, что гистограммы показаны в виде слитных кривых, пики которых, такие как пик (908) в гистограмме (904) соответствуют центральным фрагментам столбцов и строк текста, таких как текстовый столбец (910), которому соответствует пик (908), а впадины, такие как впадина (912), соответствуют столбцам и строкам пробелов между столбцами и строками текста, таким как столбец пробела (914) между столбцами текста (916) и (918). Сетка стрелок (920) на Фиг. 9 указывает на направление вертикальных и горизонтальных разделов, используемых для формирования гистограммы столбцов (904) и гистограммы строк (906).
На Фиг. 10 показана та же содержащая текст область изображения, что показана на Фиг. 9, но с другой угловой ориентацией. В случае содержащей текст области с другой ориентацией (1002) применяется тот же способ, что был описан выше со ссылкой на Фиг. 9, когда гистограммы столбцов (1004) и гистограммы строк (1006) формируются с помощью разделов столбцов и строк в направлении вертикальных и горизонтальных стрелок (1008). В данном случае гистограммы обычно не имеют объектов и не имеют равноудаленных пиков и впадин, как на гистограммах, показанных на Фиг. 9. Причину этому можно легко понять, рассмотрев вертикальный столбец (1010), показанную на Фиг. 10 пунктирными линиями. Данный вертикальный столбец проходит через текстовые столбцы (1012-1015) и столбцы пробелов (1016-1020). Почти каждый вертикальный столбец и горизонтальная строка, кроме находящихся на крайних концах гистограмм, проходит как через текст, так и через пробел, в результате чего каждый из вертикальных столбцов и горизонтальных строк, как правило, содержит биты со значением «1» и биты со значением «0».
Таким образом, подпрограммы оптического распознавания символов (OCR) могут изначально определить ориентацию содержащей текст области путем поворота данной области в пределах 90° и вычисления гистограмм столбцов и строк на определенных угловых интервалах, в результате чего получается, как минимум, одна гребневидная гистограмма, а чаще всего две гребневидные гистограммы, как показано на Фиг. 9, с наилучшими соотношениями пик-впадина. Следует также отметить, что о пробелах между символами в строках и столбцах можно судить по пробелам (922) и (924) между пиками в гистограммах столбцов и строк.
Существует множество различных альтернативных способов определения исходной ориентации содержащей текст области. Описанный выше со ссылкой на Фиг. 8-10 способ приведен в качестве примера типовых подходов, которые можно реализовать. Во многих случаях расстояния между символами могут быть не такими повторяемыми, как показано на Фиг. 9-10, в результате чего для определения границ символов могут использоваться различные методики. При одном таком подходе вертикальные столбцы пробелов определяются для горизонтальной строки текстовых символов, а расстояния между такими столбцами показаны на гистограмме. Затем определяются границы символов в виде траектории обхода строки от одного столбца пробелов к другому по элементам, наиболее полно соответствующим ожидаемым разрывам между символами, расположенными между столбцами пробелов, на основе гистограммы.
После определения исходной ориентации все еще существует, по меньшей мере, 16 различных возможных ориентаций для содержащей текст области. На Фиг. 11A-D показаны 16 различных возможных ориентаций. На Фиг. 11A-D показаны 16 различных возможных ориентаций для примера содержащей текст области, используемой на Фиг. 9 и 10. В этих ориентациях принимается, что текстовые символы читаются слева направо в горизонтальных рядах, как показано стрелками 1104-1107. Если исходная ориентация содержащей текст области показана в левой части Фиг. 11А 1108, которой произвольно назначается значение вращения 0°, то содержащая текст область может быть повернута на 90° для создания второй ориентации 1110, на 180° для создания третьей ориентации 1112, и на 270° для создания четвертой ориентации 1114.
На Фиг. 11В показаны дополнительные четыре ориентации. В этом случае принимается, что текст читается вертикально вниз, как показано с помощью стрелок 1116-1119. Так же, как на Фиг. 11А, содержащая текст область может быть повернута на 0°, 90°, 180° и 270° для создания четырех дополнительных ориентаций. На Фиг. 11C-D показаны восемь дополнительных ориентаций, при этом предполагается, что при ориентации на Фиг. 11С текст читается справа налево по горизонтали, а на Фиг. 11D - вертикально сверху вниз.
На Фиг. 12 показана задача распознания символов текста для различных типов иероглифических языков или языков, в которых текст представлен не в виде простых строк символов алфавита. Если текст содержит символы иероглифических языков, подпрограмме OCR может быть необходимо выполнить сопоставление 40000 или более эталонов символов 1202 для каждого изображения символа в каждой возможной ориентации в содержащей текст области. Даже если при различных соображениях и исходных анализах количество возможных ориентаций может быть снижено с 16 возможных ориентаций, как показано на Фиг. 11A-D, до всего лишь четырех возможных ориентаций 1204-1207, вычислительная сложность задачи определения фактической ориентации остается высокой. Вычислительная сложность может быть выражена следующим образом:
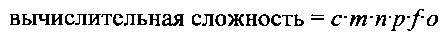
где с - вычислительная сложность для сопоставления отдельного эталона с изображением символа;
m - количество строк в исходной ориентации 0°;
n - количество столбцов в исходной ориентации 0°;
р - количество эталонов символов для заданного языка;
 - доля изображений символов в содержащей текст области, которые должны быть оценены для успешного определения ориентации содержащей текст области;
- доля изображений символов в содержащей текст области, которые должны быть оценены для успешного определения ориентации содержащей текст области;
о - количество возможных ориентаций.
Вычислительная сложность определяется переменной р, значение которой, как было сказано выше, может достигать 40000 и более для иероглифических языков. При одном из подходов программа OCR может выполнять попытку сопоставления каждой возможной ориентации с некоторой долей изображений символов и затем определять, какая из возможных ориентаций дает наибольшую долю совпадений с эталонами с высокой вероятностью. Учитывая большое количество эталонов символов и сложность задачи сопоставления с эталоном, вероятно, что для значительной доли изображений символов в содержащей текст области может потребоваться сопоставление с эталоном для обеспечения точного определения ориентации содержащей текст области.
Настоящая заявка относится к способам и системам определения ориентации содержащей текст области в изображении сканированного документа, которые связаны с гораздо меньшей вычислительной сложностью, чем описанный выше способ со ссылкой на Фиг. 12. Рассматриваемые в настоящей заявке способы и системы направлены на снижение вычислительной сложности задачи определения ориентации содержащей текст области путем снижения величины рис.
На Фиг. 13 показаны симметрии вращения знаков или символов. Далее рассматриваются симметрии относительно осей вращения. Существует неограниченный ряд различных возможных симметрий относительно осей вращения. Примером текстового символа с самой высокой степень симметрии относительно осей вращения является символ алфавита «о». Как показано в верхней строке 1302 на Фиг. 13, буква «о» имеет одинаковый вид независимо от того, на какой угол повернут этот символ вокруг центральной оси вращения, перпендикулярной плоскости символа. Тип оси вращения считается осью вращения с бесконечным количеством вариантов поворота. Символ «+» имеет четырехкратную симметрию вращения, как показано в строке 1304 на Фиг. 13. Внешний вид этого символа показан при вращении вокруг перпендикулярной оси вращения на 0° (1306 на Фиг. 13), 90° (1308 на Фиг. 13), 180° (1310 на Фиг. 13), и 270° (1312 на Фиг. 13). Вращение на другой градус, кроме 0°, 90°, 180° и 270° приведет к ориентации символа, при которой внешний вид символа будет отличаться от символа «+», в котором вертикальный элемент пересекается с горизонтальным. Символ «-» имеет двукратную симметрию вращения, как показано в строке 1316 на Фиг. 13. Символ может быть повернут на 180° вокруг центральной оси вращения, перпендикулярной плоскости символа, без изменения внешнего вида символа. В последней строке 1318 на Фиг. 13 показан японский символ с однократной симметрией вращения. Для этого символа отсутствует другая ориентация, кроме ориентации 0° 1320, при которой символ выглядит так же, как при ориентации 0°. Однократная симметрия вращения представляет собой минимальную степень симметрии вращения, которую может иметь символ. Символы с однократной симметрией вращения называются «асимметричными знаками» или «асимметричными символами». Асимметричные символы являются надежными кандидатами для эффективного определения ориентации содержащей текст области в соответствии со способами и системами, описываемыми в настоящей заявке. Следует отметить, что термин «символ« может относиться к букве алфавитного языка или к символу или знаку на таких языках, как мандаринский, которые основаны на большом наборе символов в виде изображений, а не элементов алфавита. Иными словами термин «символ» относится к элементу письменного или печатного языка, независимо от того, является этот язык алфавитным или нет.
На Фиг. 14A-F показан описанный ранее подход к формированию возможной абсолютной ориентации содержащей текст области, а также несколько альтернативных способов определения ориентации текстовой области, рассматриваемых в настоящем документе. На Фиг. 14А показана содержащая текст область с использованием преобразований иллюстрации, применяемых на многих из последующих фигур в настоящем документе. Содержащая текст область 1402 считается обработанной различными описанными выше способами для определения исходной ориентации содержащей текст области и для наложения сетки на содержащую текст область, которая отделяет каждую содержащую символ или знак подобласть или содержащее символ или знак под-изображение в содержащей текст области. Таким образом, каждая ячейка в сетчатом представлении содержащей текст области, например, ячейка 1403, представляет собой подобласть, которая содержит один символ или знак. Для простоты иллюстрации принимается, что на содержащую текст область может быть наложена ровная прямоугольная сетка для разграничения отдельных содержащих символы подобластей. Для случаев, когда содержащие символы подобласти расположены неравномерно и имеют неравномерный размер, может потребоваться использование неровной сетки.
Один из подходов к формированию вероятной абсолютной ориентации содержащей текст области, представленный на Фиг. 14В, подразумевает рассмотрение каждой содержащей символы подобласти по траектории обхода. На Фиг. 14В пунктирной изгибающейся стрелкой 1404 представлена траектория обхода, при этом каждая содержащая символы подобласть начинается с первой содержащей символ подобласти 1403 и заканчивается конечной содержащей символ подобластью 1405 на траектории обхода 1404. Конечно, существует множество различных траекторий обхода, которые можно использовать. Рассмотрение содержащей символ подобласти во время обхода подразумевает расчет значений признаков для образца из значений пикселей 0 и 1 в содержащей символ подобласти, и сравнение рассчитанных значений признаков с соответствующими рассчитанными значениями признаков для набора символов ориентации или знаков. Существует несколько различных возможных признаков, для которых могут быть рассчитаны значения. Например, один признак представляет соотношение пикселей со значением 1 к общему количеству пикселей в содержащей символ подобласти. Значение, формируемое вычитанием этого значения из 1, соответствует отношению пикселей со значением 0 к общему количеству пикселей в содержащей символ подобласти, что представляет собой другой, связанный признак. Еще одним признаком является центр масс для точечного изображения на основанного на весах 0 или 1 для пикселей в содержащей символы подобласти. Еще одним признаком является размер в пикселях самой крупной непрерывной области с пикселями, имеющими значение 1. Еще одним признаком является самая длинная строка или столбец из пикселей со значением 1 в содержащей символ подобласти. Существует множество различных признаков, для которых значения могут быть рассчитаны для заданной содержащей символ подобласти.
Как показано на Фиг. 14С, результатом рассмотрения содержащей символ подобласти при обходе, рассмотренном выше со ссылкой на Фиг. 14В, является выявление вероятной ориентации символа. Как описано выше, исходная ориентация содержащей текст подобласти дает 4-кратную неоднозначность ориентации символа относительно сетки, сформированной за счет исходной ориентации содержащей текст области. Символ может иметь следующую ориентацию: (1) вертикальную ориентацию, произвольно назначаемую ориентации 0°, которая представлена направленной вверх стрелкой 1406; (2) направленную вправо горизонтальную ориентацию, назначенную для ориентации 90°, как показано стрелкой 1407; (3) направленную вниз ориентацию, назначенную ориентации 180°, как представлено стрелкой 1408; или (4) горизонтальную направленную влево ориентацию, назначенную ориентации 270°, как представлено стрелкой 1409. Следует отметить, что в настоящем описании используется стандартное направление вращения по часовой стрелке. В примере на Фиг. 14А-С обход содержащих символы подобластей в содержащей текст области приводит к определению ориентаций символов, показанных стрелками 1402 на Фиг. 14С. Для символов без стрелки, например, для символа в содержащей символ подобласти 1410, определение вероятной ориентации невозможно. Затем, как показано в правой части 1412 Фиг. 14С, рассчитывается количество ориентаций, выявленных для каждой из четырех возможных описанных выше ориентаций, а также процент от общего количества выявленных ориентаций, представленных конкретной возможной ориентацией. Например, для содержащей текст области 1402 было выявлено 105 (1413 на Фиг. 14С) вертикальных ориентаций (1414 на Фиг. 14С), что соответствует 71% (1415 на Фиг. 14С) от количества содержащих символы подобластей, для которых были определены ориентации. Как показано небольшой выдержкой из блок-схемы 1416, когда процент общих выявленных ориентаций для одной из четырех возможных ориентаций выше порогового значения, как определено на этапе 1417, это направление считается ориентацией содержащей текст области. В ином случае может быть предпринят более тщательный альтернативный анализ, как показано на этапе 1418, для формирования вероятной абсолютной ориентации для содержащей текст области.
На Фиг. 14D более подробно показано определение ориентации конкретной содержащей символ подобласти. Для определения ориентации используется набор символов и (или) знаков. Каждый столбец двухмерной матрицы 1421, представляющий собой набор символов, соответствует отдельному символу или знаку языка, на котором напечатан документ, если язык был определен, или для двух или более языков, если язык не был определен. Таким образом, каждому столбцу присваивается индекс символа, как, например, индекс символа 1422 для столбца 1423. Каждая строка двухмерной матрицы 1421 соответствует одной из четырех возможных ориентаций символа. Таким образом, строки индексируются с помощью четырех индексов ориентации 1424. Например, символ «Б» 1422 в столбце 1423 имеет четыре различных ориентации в столбце 1426-1429, что соответствует индексам ориентации 1424. Для каждого признака в наборе признаков рассчитывается и сохраняется значение признака для каждой ориентации каждого символа, или, иными словами, для каждой ячейки в двухмерной матрице 1421. При рассмотрении конкретной содержащей символ подобласти 1430 в текстовой области, на траектории обхода, показанной на Фиг. 14В, рассчитываются значения признаков для каждого символа с соответствующей ориентацией в содержащей текст области с исходной ориентацией и сопоставляются со значениями для каждого символа/ориентации на пути обхода двухмерной матрицы 1421, который представлен изгибающейся пунктирной стрелкой 1431 на Фиг. 14D. При сопоставлении признаков, рассчитанных для каждой содержащей текст подобласти 1430, и признаков, рассчитанных для каждого символа/ориентации, формируется балл. В примере, представленном на Фиг. 14D, чем выше балл, тем в более полной мере рассчитанный для содержащей символ подобласти 1430 признак, соответствует признаку для конкретного символа/ориентации. При других способах сопоставления, включая описанные выше, более низкий балл, дает более полное совпадение. Таким образом, путь обхода, представленный пунктирной изгибающейся стрелкой 1431, формирует балл для каждой ячейки в двухмерной матрице 1421, как показано в нижней двухмерной матрице 1434 на Фиг. 14D. Иными словами, баллы, сформированные и сохраненные в матрице 1434, представляют результаты сопоставления рассматриваемой содержащей символ подобласти и каждой возможной ориентации каждого элемента набора символов ориентации и (или) знаков 1420. Матрица 1434, таким образом, представляет набор баллов, с помощью которых может быть предпринята попытка определения ориентации рассматриваемой содержащей символ подобласти. Каждая ячейка в матрице содержит балл, сформированный при сопоставлении набора признаков для рассматриваемой содержащей символ подобласти и набора признаков, рассчитанных для конкретной пары символ-ориентации/ориентация, где столбец, в котором находится ячейка, связан с конкретным символом, а строка связана с конкретной ориентацией. Затем баллы сортируются в порядке убывания для описываемой схемы сортировки, как показано в виде массива 1435 на Фиг. 14D. В конечном итоге принимается решение в соответствии с выдержкой из блок-схемы 1436 на Фиг. 14D. Если максимальный или высочайший балл превосходит первое пороговое значение, как определено на этапе 1437, и если разность между максимальным и предмаксимальным баллом превышает второе пороговое значение, как определено на этапе 1438, то на этапе 1439 возвращается ориентация символа, используемая для формирования высочайшего балла. В ином случае на этапе 1440 возвращается указание на то, что ориентация не могла быть определена.
Описанный выше способ со ссылкой на Фиг. 14A-D представляет описанный ранее способ для определения ориентации содержащих текст областей в документе. Эффективность способа зависит от количества и сущности символов, а также от конкретного набора признаков, задействованных для сопоставления содержащей текст подобласти с конкретным символом ориентации. В целом, при наличии надлежащим образом определенного набора признаков и символов ориентации и (или) знаков, этот способ обеспечивает достаточно надежное определение ориентации содержащей текст области. При этом в языках с большим количеством символов, например, в Мандаринском в памяти необходимо хранить очень большое количество рассчитанных значений признаков, включая набор значений признаков для каждой из четырех различных ориентаций каждого символа ориентации, чтобы обеспечить обход содержащей символ подобласти, представленный пунктирной изогнутой стрелкой 1431 на Фиг. 14D. Требования к памяти могут стать обременительными для определенных типов устройств с процессорным управлением, имеющих ограниченный объем памяти и (или) медленный доступ к памяти, включая определенные мобильные устройства.
На Фиг. 14E-F показаны два способа, рассматриваемые в настоящей заявке. Эти способы решают проблему с переполнением памяти при применении описанного ранее способа со ссылкой на Фиг. 14A-D. При новых способах для рассматриваемой содержащей символ подобласти рассчитывается набор значений признаков. Затем при многочисленных обходах символов для сравнения значений признаков, рассчитанных для рассматриваемой содержащей символ подобласти со значениями признаков, сохраненными для символов ориентации в массиве значений признаков символов ориентации, рассчитанные значения признаков для содержащей символ подобласти трансформируются между последовательными обходами для формирования соответствующих значений признаков для различных состояний вращения рассматриваемой содержащей символ подобласти. Обходы выполняются для меньшего набора ячеек с содержащими значения признаков символами в матрице сохраненных значений признаков символов ориентации. За счет трансформации рассчитанных значений признаков содержащей символ подобласти для выполнения сопоставления возможных вариантов поворота рассматриваемой содержащей символ подобласти с поднабором возможных символов ориентации, вместо хранения значений признаков для каждой возможной ориентации символов ориентации, для определения ориентации содержащей текст области задействуется значительно меньший объем памяти.
На Фиг. 14Е показан первый из двух способов, представляющих подход к ориентации, содержащей текст области, рассматриваемых в настоящем документе. При этом способе для каждого символа ориентации сохраняются только два набора значений признаков, как показано с помощью индексов ориентации 1442. Рассчитанные значения признаков для исходной ориентации, содержащей символ подобласти, применяются 1443 при первом обходе, представленном пунктирной изогнутой стрелкой 1444, ячеек с символами ориентации в меньшей двухмерной матрице 1446. После этого значения признаков для содержащей символ подобласти трансформируются для обеспечения соответствия значениям признаков, которые должны быть рассчитаны для содержащей символ подобласти после вращения содержащей символ подобласти на 180° 1448 и трансформированные значения признаков применяются во втором обходе меньшей двухмерной матрицы 1446, как показано пунктирной изогнутой стрелкой 1444. Двухмерная матрица 1446 в два раза меньше двухмерной матрицы 1421, представленной на Фиг. 14D, однако по ней выполняется два обхода вместо одного. Следует отметить, что каждая ячейка в двухмерной матрице 1446 относится к конкретному столбцу и конкретной строке. Столбец связан с конкретным символом ориентации, а строка связана с конкретной ориентацией символа ориентации. Значения признаков сохраняются в заданных ячейках в двухмерной матрице, в связи с чем они могут считаться репрезентативными или характеризующими для конкретной пары символ-ориентации/ориентация. Конечно, также можно рассчитать два набора значений признаков для содержащей символ подобласти и выполнить два сопоставления наборов значений признаков для содержащей символ подобласти со значениями признаков каждого символа ориентации за один обход. Эти два подхода являются эквивалентными. При первом способе для содержащей символ подобласти 1450 рассчитывается одинаковое количество баллов, как показано в двухмерной матрице 1452, которые рассчитываются указанным выше способом со ссылкой на Фиг. 14D. Для каждой возможной относительной ориентации содержащей символ подобласти также рассчитывается балл относительно каждого символа ориентации. При первом обходе относительные ориентации содержащей символ подобласти и каждый оцениваемый символ ориентации включают относительные ориентации 0° и 90°. При втором обходе оцениваемые относительные ориентации соответствуют 180° и 270°. Поскольку для каждой содержащей символ подобласти рассчитывается одинаковое количество баллов, как представлено в двухмерной матрице 1452 на Фиг. 14Е, выполняются этапы, аналогичные этапам, показанным в нижней части Фиг. 14D, для определения ориентации содержащей символ подобласти. Описанный выше со ссылкой на Фиг. 14Е способ, таким образом, использует в два раза меньше сохраненных значений признаков для каждого символа, по сравнению с описанным выше со ссылкой на Фиг. 14D способом.
На Фиг. 14F показан второй новый способ. При этом способе для каждого символа ориентации в массиве 1456 сохраняется только один набор значений признаков. Значения признаков для содержащей символ подобласти 1458 изначально рассчитываются и затем трансформируются три раза для обеспечения сравнения четырех различных возможных ориентаций 1460-1463 рассматриваемой содержащей символ подобласти в отношении каждого символа ориентации. Обход массива 1456 выполняется четыре раза - по одному разу для каждой относительной ориентации содержащей символ подобласти в отношении символов ориентации, для создания того же количества баллов 1466, что при использовании способов, описанных со ссылкой на Фиг. 14Е и 14D. Для каждой возможной относительной ориентации содержащей символ подобласти опять формируется балл в отношении каждого символа ориентации. Показанный на Фиг. 14Е способ задействует в четыре раза меньший объем памяти для хранения значений признаков символов ориентации, чем способ, описанный выше со ссылкой на Фиг. 14D. Этот процесс, опять же, аналогичен исходному расчету значений признаков для всех состояний поворота содержащей символ подобласти с последующим выполнением четырех сравнений в отношении каждого символа ориентации за один обход значений признаков, сохраненных для символов ориентации. В этом случае каждая ячейка в массиве 1456, опять же, может рассматриваться, как содержащая значения признаков для конкретного символа-ориентации/ ориентации, даже при том, что в этом случае существует только одна пара символ-ориентации/ ориентация для каждого символа ориентации.
Возвращаясь к Фиг. 14В и 14С, в определенных вариантах реализации способа определения ориентации содержащих текст областей, раскрываемого в настоящем документе, обход содержащих символы подобластей, представленный на Фиг. 14В, может рассматривать только наиболее перспективные содержащие символы подобласти -кандидаты на пути обхода, а не все содержащие символы подобласти. Наиболее перспективными содержащими символы подобластями-кандидатами являются те подобласти, которые содержат асимметричные области со значением пикселей 1, или асимметричные символы, которые за счет своей асимметрии создают четыре различных и легко различимых изображения в четырех различных состояниях поворота на 0°, 90°, 180° и 270°. В качестве примера, содержащая символ подобласть, в которой значительное большинство пикселей со значением 1 встречаются в одном из четырех квадрантов, полученных при вертикальном и горизонтальном делении содержащей текст подобласти, будет хорошим кандидатом для определения ориентации, поскольку внешний вид содержащей символ подобласти имеет очевидные отличия при каждом повороте на четыре разных угла. За счет выбора только наиболее перспективных содержащих символы подобластей, вычислительные расходы на определение ориентации содержащих символы подобластей, которая в результате не может быть определена, представлена пустыми ячейками в матрице 1402 на Фиг. 14С, могут быть опущены.
Подводя итог, относительно большой объем задействованной памяти при использовании способов со ссылкой на Фиг. 14A-D может быть значительно сокращен за счет расчета значений признаков для содержащей символ подобласти, сопоставления исходных рассчитанных значений признаков со значениями, сохраненными для символов ориентации с определенной ориентацией путем обхода небольшого набора сохраненных значений признаков для символов ориентации с последующей трансформацией исходно рассчитанных значений признаков для содержащей символ подобласти перед выполнением дополнительного обхода небольшого набора сохраненных значений признаков символов ориентации, вместо сохранения значений признаков для каждого возможного поворота каждого символа ориентации в соответствии с описанным способом со ссылкой на Фиг. 14A-D. Описанные выше со ссылкой на Фиг. 14E-F новые способы создают баллы для каждой из возможных относительных ориентаций содержащей символ подобласти и каждого символа ориентации, точно также, как в описанном выше со ссылкой на Фиг. 14A-D исходном способе, однако при объеме памяти для хранения признаков символов ориентации в два и четыре раза меньше, соответственно, чем при исходном способе.
Если бы новые способы использовались для выполнения первичного расчета значений признаков для каждого поворота содержащей символ подобласти, повышенные вычислительные расходы, связанные с этими способами, могут подняться выше приемлемого уровня. Поэтому новые способы зависят не только от использования трансформации значений признаков, рассчитанных для содержащих символы подобластей при сравнении содержащих символы подобластей с символами ориентации, но также от эффективных способов трансформации значений признаков для отражения различных состояний поворота содержащей символ подобласти.
На Фиг. 15 показан первый этап определения ориентации содержащей символ подобласти в соответствии со способами, описываемыми в настоящем документе. На Фиг. 15 показана содержащая символ подобласть 1502, в которой представлен пример ячейки из наложенной на содержащую текст область сетки, как, например, содержащая текст область 1402, показанная на Фиг. 14А. На начальном этапе 1503 оформления рамки рассчитывается прямоугольная рамка 1504 для содержащей символ подобласти, имеющая минимальный размер, но содержащая все из пикселей со значением 1 в пределах содержащей символ подобласти 1502. Для создания начальной рамки могут применяться различные типы обработки для снижения шума в содержащей символ подобласти 1502 с целью обеспечения того, что исходная рамка не имела больший, неоптимальный размер за счет наличия «шумных» пикселей со значением 1. Подавление шума может выполняться различными способами, включая удаление смежных областей пикселей со значением 1 или ниже порогового значения. Затем, как показано в выдержке из блок-схемы 1506 на Фиг. 15, символ в исходной рамке проходит дальнейшую обработку. Дальнейшая обработка применяется для обеспечения того, что символ в рамке не имел увеличенный размер по вертикали или в боковом направлении. Если на этапе 1508 выявлено, что отношение высоты исходной рамки символа к ее ширине составляет менее порогового значения 1/3, как показано в примере на Фиг. 15, высота увеличивается на этапе 1510, а на этапе 1512 символ получает рамку с новой высотой. В ином случае, если на этапе 1514 определено, что отношение высоты к ширине символа в исходной рамке составляет более 3, как в текущем примере, на этапе 1516 ширина увеличивается, а на этапе 1518 символ получает новую рамку с новой шириной для создания символа с новой рамкой 1520. Как описано ниже, корректировка высоты или ширины может быть ограничена высотой и шириной содержащей символ подобласти 1502, поскольку корректировка ширины или высоты с выходом получившего новую рамку символа 1520 за границы содержащей символ подобласти 1502 может непреднамеренно привести к нахлесту символа в новой рамке с подобластью прилегающего символа. Таким образом, на исходном этапе, показанном на Фиг. 15, создается рамка с разумной формой и минимальным размером, которая содержит символ в содержащей символ подобласти.
На Фиг. 16А-Н показано использование подобластей символа в рамке для расчета вектора значений признаков для символа в рамке. На Фиг. 16А показан пример символа в рамке 1602. В этом примере символ в рамке это символ R. Как показано на Фиг. 16В, для символа в рамке создаются четыре различных подобласти символа в рамке. Первая подобласть символа в рамке, показанная на Фиг. 16В небольшим прямоугольником 1604 в рамке 1606 символа в рамке 1602, строится путем создания высоты и ширины подобласти с известной долей высоты и ширины рамки, например 0,75, как показано на Фиг. 16В. Таким образом, высота рамки h показана вертикальной стрелкой 1607, а ширина рамки w показана горизонтальной стрелкой 1608, при этом высота подобласти, показанная вертикальной стрелкой 1609 имеет длину равную 0,75 от высоты рамки 1607, а ширина подобласти, представленная горизонтальной стрелкой 1610, имеет длину, равную 0,75 от ширины рамки 1608. Следует отметить, что первая подобласть 1604 занимает верхнюю левую часть символа в рамке 1606. На Фиг. 16В показаны дополнительные подобласти символа в рамке 1612-1614, имеющие тот же размер, но другое расположение - в нижнем правом, верхнем правом и нижнем левом углу символа в рамке соответственно. Таким образом, как показано на Фиг. 16В, четыре перекрывающиеся подобласти символа в рамке строятся для каждой содержащей символ области.
Четыре представленные выше подобласти символа в рамке со ссылкой на Фиг. 16В напрямую связаны друг с другом простыми операциями симметрии. На Фиг. 16С-Е представлены простые операции симметрии, с помощью которых из подобласти 1 создаются подобласти 3, 2 и 4. На Фиг. 16С показан поворот на 180° вокруг оси, представленной пунктирной линией 1620, лежащей в плоскости символа в рамке, при котором происходит преобразование подобласти символа в рамке типа 1 1622 в подобласть символа в рамке типа 3 1624. Координаты обобщенной точки 1626 в первой подобласти (х,y) после трансформации по симметрии становятся (w-x,y) 1627, где w-ширина символа в рамке. Такая же операция по трансформации координат может использоваться, если w' равно ширине подобласти для координат в отношении подобласти символа в рамке, а не самого символа в рамке. Как показано на Фиг. 16D, поворот на 180° или двойной поворот вокруг оси вращения 1628 перпендикулярно плоскости символа в рамке приводит к трансформации подобласти типа 1 в подобласть типа 2 1630. В этом случае трансформация координат изменяет координаты обобщенной точки 1632 с координатами (х,y) на координаты (w-x,h-y) 1633. Наконец, как показано на Фиг. 16Е, вращение символа в рамке вокруг горизонтальной оси 1636 приводит к преобразованию первой подобласти символа в рамке 1622 в подобласть типа 4 1638. В этом случае трансформация координат приводит к преобразованию координат (х,y) для обобщенной точки 1640 в координаты (х,h-y) 1642.
На Фиг. 16F-G представлены трансформации подобластей символа в рамке с помощью вращения символа в рамке. На Фиг. 16F, символ в рамке 1644 расположен вертикально, что произвольно принимается как соответствие положению 0°. Обобщенная точка 1646 в подобласти первого типа 1648 показана с обобщенными координатами (х,y). Ширина символа в рамке - w 1649, а высота символа в рамке - h 1650. Подобласть символа в рамке типа 1 (1648 на Фиг. 16F) и подобласть символа в рамке типа 2 (1652 на Фиг. 16F) показаны в пределах символа в рамке. Из этого иллюстративного примера очевидно, что подобласть символа в рамке типа 1 (1648 на Фиг. 16F) и подобласть символа в рамке типа 2 (1652 на Фиг. 16F) имеют значительное перекрытие во внутренней прямоугольной области 1654. На Фиг. 16F также показан символ в рамке, повернутый на 90°, 1656. Поворот на 90° приводит к появлению у символа в рамке новой ширины w' 1658, равной высоте h 1650 символа в рамке в положении 0°, 1644. Повернутый символ в рамке также имеет новую высоту h' 1659, равную ширине w символа в положении 0°, 1644. При повороте на 90° подобласть символа в рамке типа 1 (1648 на Фиг. 16F) преобразовалась в подобласть символа в рамке типа 3 (1660 на Фиг. 16F), а подобласть символа в рамке типа 2 (1652 на Фиг. 16F) преобразовалась в подобласть символа в рамке типа 4 (1661 на Фиг. 16F). Иными словами, как описано выше со ссылкой на Фиг. 16В, тип подобластей связан с их положением относительно размера и углов рамки. После поворота на 90° подобласть символа в рамке типа 1 (1648 на Фиг. 16F) теперь занимает верхнюю правую часть повернутого символа в рамке и становится подобластью символа в рамке типа 3 (1660 на Фиг. 16F). На Фиг. 16F также показана трансформация координат обобщенной точки. Таким образом, как показано в нижней части Фиг. 16F, подобласть символа в рамке типа 1 (1662 на Фиг. 16F) с обобщенной точкой, имеющей координаты (х,y) 1663 трансформируется в подобласть символа в рамке типа 3 (1664 на Фиг. 16F) с координатами (y,w-x) 1665, которые можно альтернативно выразить как (y,h'-x) 1666 с применением новой высоты h' повернутой рамки символа или как (х',y') 1667 в отношении повернутого символа в рамке. Последняя строка 1668 на Фиг. 16F указывает на то, что подобласть символа в рамке типа 2 преобразуется в подобласть символа в рамке типа 4 с поворотом на 90° рамки символа при такой же трансформации координат. На Фиг. 16G с помощью тех же иллюстративных понятий, которые использовались для Фиг. 16F, показаны трансформации подобластей символов в рамке 1670 и 1671 типа 3 и 4 для символа в рамке 1644 при положении 0° в подобласти символов в рамке типа 1 (1672 на Фиг. 16G) и типа 2 (1673 на Фиг. 16G) за счет поворота символа в рамке на 90°. Эти трансформации представлены в строках 1674-1675 в нижней части Фиг. 16G с использованием тех же понятий, которые использовались для выражения трансформаций на Фиг. 16F.
На Фиг. 16Н показаны трансформации подобласти для всех четырех ориентаций символа в рамке. На Фиг. 16Н, показаны четыре ориентации символа в рамке 1644 в каждом из четырех столбцов 1676-1679. К этим ориентациям относятся положения символа в рамке 0°, 90°, 180° и 270°, соответственно. На Фиг. 16Н под каждым символом в рамке показана вектороподобная карта 1680. Вектороподобные карты указывают на трансформации подобласти символа в рамке и определяют трансформации для каждого положения, как описано выше со ссылкой на Фиг. 16F-G. Первая вектороподобная карта 1680 указывает на то, что в положении 0° типы и координаты подобластей символа в рамке считаются не трансформированными. Элементы на всех вектороподобных картах упорядочены сверху вниз относительно типов подобластей символа в рамке 1, 2, 3 и 4 для символа в рамке в положении 0°. Иными словами элементы вектороподобной карты упорядочены или индексированы по признакам подобластей символа в рамке в положении 0°. Поворот на 90°, показанный в столбце 1677, включает вектороподобную карту 1682, которая показывает, как было описано выше со ссылкой на Фиг. 16F-G, что подобласть символа в рамке типа 1 преобразовалась в подобласть символа в рамке типа 3 (1684 на Фиг. 16Н), подобласть символа в рамке типа 2 преобразовалась в подобласть символа в рамке типа 4 (1685 на Фиг. 16Н); подобласть символа в рамке типа 3 преобразовалась в подобласть символа в рамке типа 2 (1686 на Фиг. 16Н), а подобласть символа в рамке типа 4 преобразовалась в подобласть символа в рамке типа 1 (1687 на Фиг. 16Н). Таким образом, вектороподобная карта 1682 показывает новые типы подобластей символа в рамке после поворота на 90° подобластей символа в рамке в положении 0°. Вектороподобные карты 1690 и 1692 показывают новые типа подобластей символа в рамке в положении 0° после поворота подобласти символа в рамке 1644 из положения 0° на 180° и 270° соответственно. Иными словами, порядок элементов в вектороподобных картах соответствует числовому порядку подобластей символа в рамке для символа в рамке в положении 0°, однако номера типов и координаты в элементе относятся к результату трансформации символа в рамке после поворота, с которым связана вектороподобная карта.
Описанные выше со ссылкой на Фиг. 16А-Н симметричные трансформации дают основания для трансформаций значений признаков с вычислительной эффективностью, которые дают основание для вычисления значений признаков для остальных трех положений символа в рамке без необходимости полного перерасчета значений признаков по значениям пикселей в символе в рамке и без необходимости расчета вращения самого символа в рамке. На Фиг. 17А-В показан пример трансформации значения признака. Пример признака - признак медианной точки (MP, median-point). Координата х медианной точки подобласти представляет собой точку, в которой имеется равное количество черных пикселей слева от точки и справа от точки. Координата y медианной точки представляет собой значение координаты y, количество черных пикселей или пикселей со значением 1 выше которого равно количеству пикселей со значением 1 ниже координаты y. Очевидно, что расчет признака медианной точки MP для подобласти символа в рамке подразумевает учет всех пикселей в подобласти символа в рамке, и, несмотря на математическую простоту, этот расчет является вычислительно нетривиальным. Как показано на Фиг. 17А, медианная точка для первой подобласти символа в рамке 1702 типа 1 имеет координаты (.33,.56) 1704. Медианная точка 1706 для подобласти символа в рамке типа 2 (1708 на Фиг. 17А) имеет координаты (.57,.63) 1710. Медианные точки 1712 и 1714 для подобластей символа в рамке типа 3 и 4 (1716 и 1718) имеют координаты (.52,.56) 1720 и (.19,.63) 1722, соответственно. Таким образом, как показано на Фиг. 17А, для каждой подобласти символа в рамке рассчитываются различные медианные точки с различными координатами для формирования четырех значений признаков для признака медианной точки символа в рамке. Как показано на Фиг. 17В, эти четыре значения признака расположены в виде вектора значений признака 1730 для положения 0° символа в рамке 1732. Теперь, основываясь на вектороподобных картах, описанных выше со ссылкой на Фиг. 16Н, можно напрямую рассчитать соответствующие векторы значений признаков 1734-1736 для положений 90°, 180° и 270°, 1738-1740 соответственно символа в рамке. Показанные на Фиг. 17А координаты медианных точек выражаются в терминах относительных координат по осям х и y подобластей символа в рамке от 0 до 1. Поэтому такая трансформация как w - х достигается за счет вычитания х из 1. В качестве одного примера, для расчета медианной точки подобласти символа в рамке типа 1 при повороте символа в рамке на 90°, 1738, выбирается четвертое значение признака в векторе значений признаков для положения 0°, как показано в записи 1687 на вектороподобной карте 1682 на Фиг. 16Н, а координаты в пределах выбранного четвертого значения признака трансформируются в соответствии с трансформацией, показанной в вектороподобной карте 1682 на Фиг. 16Н для определения значения медианной точки для подобласти символа в рамке типа 1 при повороте на 90° с координатами (.63,.81) 1742. Аналогичным образом, медианная точка по вектороподобной карте 1682 для подобласти символа в рамке типа 2 с поворотом на 90°, 1744, определяется по медианной точке подобласти символа в рамке типа в положении 0° с соответствующей трансформацией координат, как показано на вектороподобной карте 1682. Таким образом, три вектора значений признаков 1734-1736 получаются за счет изменения порядка значений признаков в векторе значений признака 1730 с последующим применением соответствующих трансформаций координат для значений с измененным порядком. Этот процесс, конечно же, гораздо легче с вычислительной точки зрения, чем повторный расчет значений медианной точки на основе значений пикселей в символьных рамках, повернутых расчетным путем.
Существует множество различных возможных признаков, которые могут быть рассчитаны для подобластей символа в рамке, и в целом относятся к одной разновидности различных классов трансформации. На Фиг. 18 приведена таблица, показывающая небольшое количество примеров классов трансформации. Классы трансформации представлены строками в таблице, а первые четыре столбца в таблице соответствуют поворотным положениям. Количество базовых ориентаций для класса трансформации показано в последнем столбце 1802. Первый класс трансформации 1804 соответствует признакам, имеющим инвариантное положение и ориентацию. Пример такого признака - процент пикселей со значением 1 в пределах подобласти. Процент при повороте подобласти не изменяется. Поэтому векторопободные карты для этого класса трансформации, такие как вектороподобная карта 1806, указывают на новые типы подобластей символа в рамке с поворотом на 0°, 90°, 180° и 270°. Для формирования всех четырех наборов значений признаков требуется только одна ориентация символа в рамке, в результате чего имеется только одна базовая ориентация. Второй пример класса трансформации 1819 включает признаки, которые рассчитываются различным образом для поворотных положений на 0° и 180° с одной стороны и на 90° и 270° с другой. Один из примеров - самый крупный вертикальный столбец пикселей со значением 1 в пределах подобласти. Значение этого признака одинаково для поворотных положений 0° и 180°, но является различным для положений 90° и 270°. Таким образом, имеется первый набор связанных вектороподобных карт 1812 и 1813 для поворотных положений 0° и 180° и второй набор вектороподобных карт 1814 и 1815 для положений 90° и 270°. Трансформации подобластей символа в рамке выполняются за счет изменения порядка значений признаков в векторе значений признаков, однако существуют различные базовые ориентации для двух различных наборов вектороподобных карт. Третий класс трансформации 1820 включает признаки, которые соответствуют точкам в расчетном положении в пределах подобласти. Признак медианной точки, описанный выше со ссылкой на Фиг. 17А-В, является примером признака, который попадает в этот класс трансформации. В этом случае вектороподобные карты содержат как указания на изменение порядка признака для подобластей символа в рамке, так и на трансформацию координат. Еще один пример класса трансформации 1822 - это признак, который рассчитывается по различному для поворотных положений 0° и 180° и для положений 90° и 270°, как в случае для описанного выше класса вертикальной/горизонтальной трансформации 1810. Однако в этом случае направление также имеет значение. Примером признака для этого класса трансформации может быть самый длинный вертикальный столбец из пикселей со значением 1, после которого идет столбец из пикселей со значением 0, направление признаков которого соответствует направлению от пикселей со значением 0 к пикселям со значением 1. Вектороподобные карты для этого класса трансформации аналогичны картам для класса вертикальной/горизонтальной трансформации 1810, за тем исключением, взаимозаменяются не только значения подобластей, но также и знаки значений признаков. Последний класс трансформации, показанный в таблице на Фиг. 18 1824, соответствует признаку, для которого отсутствует трансформация на основе симметрии. Для таких признаков значения должны быть пересчитаны из значений пикселей для каждой подобласти в каждом поворотном положении. Это показано на вектороподобных картах для данного класса трансформации в виде функциональной записи, где аргумент для функций - это подобласть символа в рамке. Очевидно, что для использования описанного выше способа со ссылкой на Фиг. Е признак должен относиться к классам трансформации, в которых имеется две основные ориентации, тогда как при использовании описанного выше способа со ссылкой на Фиг. 14F признак должен относиться к классам трансформации, имеющим единую базовую ориентацию. Ниже описан более общий способ для смешанных классов трансформации.
Хотя возможно, как описано ниже, возможно использование различных наборов символов ориентации, каждый из которых соответствует символам ориентации, связанным с различным числом базовых ориентаций, в альтернативных вариантах реализации также можно использовать только один набор значений признаков для каждого символа, как показано на Фиг. 14F. Если символы ориентации имеют две базовые ориентации, каждая пара символ-ориентации/ориентация может считаться отличным символом. В альтернативном варианте реализации, когда признаки для рассматриваемой содержащей символ подобласти трансформируются, значения признаков в наборе значений признаков, связанные с несколькими базовыми ориентациями, могут быть трансформированы соответствующим образом или пересчитаны из изображения символа. В альтернативном варианте реализации для определенных трансформаций содержащей символ подобласти на определенный угол поворота значения признаков, связанные с одной парой символ-ориентации/ориентация для каждого символа ориентации, имеющего две базовые ориентации и трансформированные значения признаков для содержащей символ подобласти, могут быть спроецированы для включения только значений признаков, которые могут быть практически трансформированы для конкретных поворотных положений. Иными словами, если большая часть признаков связана только с одной базовой ориентацией, в исключительных случаях некоторые признаки, связанные с двумя базовыми ориентациями, могут обрабатываться по разному, как особые случаи, для недопущения необходимости в избыточном хранении многочисленных наборов значений признаков для всех символов ориентации или для недопущения возникновения дополнительной сложности, связанной с описанным ниже способом.
На Фиг. 19A-F представлены блок-схемы, показывающие обобщенный способ определения ориентации содержащей текст области, который включает описанные выше способы со ссылкой на Фиг. 14Е и F. На Фиг. 19А представлена блок-схема высокого уровня для подпрограммы «ориентация области». На этапе 1902 подпрограмма получает содержащую текст область с уже разграниченными символами, например, содержащую текст область 1402 на Фиг. 14А. На этапе 1903 вектор счета ориентации с элементами, соответствующими четырем различным возможным поворотными положениями 0°, 90°, 180° и 270° устанавливается на ноль. Во вложенном цикле 1904-1909 каждая содержащая символ область в полученной содержащей текст области рассматривается при обходе, как описано выше со ссылкой на Фиг. 14В. Для каждой содержащей символ подобласти символ заключается в рамку через вызов функции рамки символа на этапе 1905, после чего определяется его ориентация вызовом функции ориентации 1906. После возврата функцией ориентации символа 1906 определенной ориентации значение в элементе вектора ориентации, соответствующее возвращенной ориентации увеличивается на этапе 1908. На этапе 1910 выполняется вызов функции расчета ориентации для определения ориентации, содержащей текст области, исходя из счетных значений, накопленных по вектору счета ориентации. Когда на этапе 1911 подпрограмма возвращается к ориентации, на этапе 1912 эта ориентация возвращается как ориентация содержащей текст области. В ином случае выполняется дополнительный этап анализа 1913, а результат этого анализа возвращается на этапе 1914. Могут выполняться много различных типов дополнительных анализов, включая рассмотрение пар соседних символов с учетом частоты наблюдаемых пар символов в естественном языке, с попыткой сопоставления слов с последовательностями символов и иные подобные анализы.
На Фиг. 19В показана блок-схема функции рамки символа, вызываемой на этапе (1905) на Фиг. 19А. На этапе 1916 принимается разграниченная содержащая символ область, имеющая высоту Н и ширину W. На этапе 1917, строится наиболее подходящий прямоугольник с высотой h и шириной w, как описано выше со ссылкой на Фиг. 15, и выполняется расчет соотношения 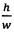 . Если рассчитанное соотношение превышает первый предел t1, в соответствии с определением на этапе 1918, ширина наиболее подходящего прямоугольника на этапе 1919 корректируется таким образом, чтобы она составляла не менее 1/t1 от ширины или равнялась ширине полученного разграниченного символа W, в зависимости от того, какое из этих значений меньше. В ином случае, когда соотношение меньше второго порога t2, как определено на этапе 1920, высота наиболее подходящего прямоугольника на этапе 1922 корректируется таким образом, чтобы она составляла не менее 1/t2 от ширины или равнялась высоте исходной полученной разграниченной содержащей символ области Н. Рамка, имеющая высоту h и ширину w, строится из наиболее подходящего прямоугольника и возвращается на этапе 1924, как было описано выше со ссылкой на Фиг. 15. В альтернативных вариантах реализации, если после выполнения шагов 1918-1922 наиболее подходящий прямоугольник все еще имеет слишком непропорциональны размер, могут быть предприняты дополнительные шаги, включающие изменение как высоты, так и ширины наиболее подходящего прямоугольника.
. Если рассчитанное соотношение превышает первый предел t1, в соответствии с определением на этапе 1918, ширина наиболее подходящего прямоугольника на этапе 1919 корректируется таким образом, чтобы она составляла не менее 1/t1 от ширины или равнялась ширине полученного разграниченного символа W, в зависимости от того, какое из этих значений меньше. В ином случае, когда соотношение меньше второго порога t2, как определено на этапе 1920, высота наиболее подходящего прямоугольника на этапе 1922 корректируется таким образом, чтобы она составляла не менее 1/t2 от ширины или равнялась высоте исходной полученной разграниченной содержащей символ области Н. Рамка, имеющая высоту h и ширину w, строится из наиболее подходящего прямоугольника и возвращается на этапе 1924, как было описано выше со ссылкой на Фиг. 15. В альтернативных вариантах реализации, если после выполнения шагов 1918-1922 наиболее подходящий прямоугольник все еще имеет слишком непропорциональны размер, могут быть предприняты дополнительные шаги, включающие изменение как высоты, так и ширины наиболее подходящего прямоугольника.
Как описано выше со ссылкой на Фиг. 14D-F, определение ориентации символа включает обход набора символов ориентации, сравнение значений признаков для рассматриваемого символа в рамке со значениями признаков для каждого символа ориентации с целью создания балла для каждой ориентации каждого символа ориентации. Затем выбирается лучший из баллов, и если выбранный балл удовлетворяет определенным условиям, ориентация символа ориентации, связанного с этим баллом, выбирается как ориентация символа в рамке. В рассмотренном ранее способе, как описано выше со ссылкой на Фиг. 14D, значения признаков для всех четырех возможных ориентаций символов ориентаций пересчитываются и сохраняются для обеспечения обхода посредством сохраненных значений признаков для сравнения символа в рамке с каждой возможной ориентацией каждого возможного символа ориентации. При этом, как описывалось выше со ссылкой на Фиг. 14E-F, в настоящей заявке рассматриваются эффективные с точки зрения памяти способы, при которых рассчитанные значения признаков для символов в рамках трансформируются для отображения поворотов символа в рамке с отдельным обходом каждой трансформации для снижения количества хранимых значений признаков символов ориентации. Описываемый способ является обобщенным способом, который включает аспекты описанных выше со ссылкой на Фиг. 14Е и F способов. В этом обобщенном способе признаки разделяются на набор признаков, для которого имеется единая базовая ориентация, как описано выше со ссылкой на Фиг. 18, и набор признаков, для которого имеются две базовых ориентации. Значения признаков для символов этих двух различных классов признаков хранятся в двух различных матрицах. Для обеспечения эффективности обход этих матриц выполняется отдельно, при этом для одной требуется четыре трансформации значений признаков символа в рамке, для которого необходимо определить ориентацию, а для другой требуется две трансформации значений признаков символа в рамке. Обобщенный способ фактически является даже еще более обобщенным в том смысле, что он может включать любые классы признаков с любым произвольным количеством базовых ориентаций.
На Фиг. 19С представлены хранимые значения признаков символов ориентации. В первой матрице значений признаков хранятся значения для признаков, связанных с базовой ориентацией, содержащей единую ориентацию, например, для признаков, описанных выше со ссылкой на Фиг. 14А, и для строк 1804 и 1820 в таблице, представленной на Фиг. 18. В этой матрице имеется одна строка, в связи с чем, по сути, она является массивом. Во второй матрице со значениями признаков 1927 содержатся две строки; эта матрица используется для признаков, в которых имеется две базовых ориентации, как описано выше со ссылкой на Фиг. 14Е, и строки 1810 и 1822 на Фиг. 18. Ссылки на две матрицы значений признаков содержатся в небольшом массиве ссылок 1928, записи в котором проиндексированы по количеству базовых ориентаций. Каждая ячейка в матрице значений признаков, например, ячейка 1929 в матрице значений признаков 1926, содержит вектор из векторов значений признаков. Эти векторы представляют собой векторы значений признаков для каждого из n1 признаков, относящихся к классу признаков, связанных с матрицей значений признаков. Как показано в дополнительном наборе 1930, в котором представлены детали для элемента 1931 в векторе из векторов значений признаков 1932, каждый элемент вектора из векторов значений признаков, например, элемент 1931, является сам по себе вектором 1932 с четырьмя значениями для конкретного признака, рассчитанного для четырех различных подобластей символа в конкретном поворотном положении, как описано выше со ссылкой на Фиг. 16А-17В. Столбцы двух матриц значений признаков 1926 и 1927 совмещены и имеют общую индексацию с применением идентификатора символа ориентации. В целом количество элементов n1 в векторе из векторов значений признаков в ячейке матрицы значений признаков 1926 отличается от количества элементов n2 в векторах из векторов значений признаков в ячейках матрицы значений признаков 1927. Опять же, количество элементов в векторе из векторов значений признаков равно количество признаков в классе признаков, соответствующем матрице значений признаков. Как можно увидеть по потенциальному множеству различных возможных значений признаков, хранимых в каждой ячейке матриц значений признаков, описываемые способы, которые значительно снижают количество строк в матрицах значений признаков, хранимых в памяти, как описано выше со ссылкой на Фиг. 14D-F, значительно сокращают затраты на память для определения ориентации содержащей текст области. Как показано на Фиг. 19В, баллы, созданные при обходах матриц значений признаков, хранятся в единой матрице баллов 1935, столбцы которой индексируются по идентификатору символов ориентации, а строки индексируются по поворотному положению, как описано выше со ссылкой на Фиг. 14D-F.
На Фиг. 19Е показана блок-схема для подпрограммы определения ориентации символов, вызываемой на этапе 1906 на Фиг. 19А. На этапе 1936 подпрограмма определения ориентации символов получает символ в рамке, для которого необходимо определить ориентацию или ссылку на символ в рамке и устанавливает на 0 значения для ячеек в матрице баллов, как описано выше со ссылкой на Фиг. 19D. Во вложенном цикле этапов 1937-1942 рассматривается каждый из различных классов признаков, дифференцируемых по количеству ориентаций в базовой ориентации. Для каждого класса признаков рассчитывается вектор из векторов значений признаков для полученного символа в рамке для первой базовой ориентации на этапе 1938. На этапе 1939 этот вектор из векторов значений признаков затем используется при обходе матрицы значений признаков или матрицы символов ориентации для определенного класса признаков, например, матрицы 1926 и 1927, описанные выше со ссылкой на Фиг. 19С. При наличии большего количества базовых ориентаций, как определено на этапе 1940, вектор из векторов значений признаков для символа в рамке на этапе 1942 трансформируется в соответствии с правилами трансформаций, как, например, описано выше со ссылкой на Фиг. 17А-18. После этого происходит возврат на этап 1939 для еще одного обхода матрицы символов ориентации для класса признаков. Этот этап трансформации аналогичен повороту символа в рамке, как описано выше со ссылкой на Фиг. 14E-F. Если, как определено на этапе 1940, базовых ориентаций больше нет, то при наличии дополнительных классов признаков, как определено на этапе 1941, выполняется возврат к этапу 1938. После обхода всех матриц значений признаков для всех необходимых поворотов символа в рамке, два наименьших балла s1 и s2 определяются в матрице баллов на этапе 1943. Если наименьший балл меньше первого порогового значения t3, как определено на этапе 1944, и если разность между следующим наименьшим баллом и наименьшим баллом превосходит второе пороговое значение t4, как определено на этапе 1945, ориентация, соответствующая наименьшему баллу s1 выбирается на этапе 1946 как ориентация для полученного символа в рамке, и эта ориентация возвращается на этапе 1947. Ориентация отображается в виде ориентации или индекса поворотного положения в строке, в которой балл присутствует в матрице баллов. При отрицательных результатах проверки на этапе 1944 и 1945, возвращается индикация отсутствия ориентации. Конечно же, могут иметься иные критерии, используемые для определения ориентации символа на основе баллов, хранимых в матрице символов, а также, как описано ниже, могут иметься способы определения балла, отличающиеся от способов, показанных в описываемом варианте реализации. В одном варианте реализации вместо обязательного отделения определяющего балла от следующего наиболее определяющего балл по разности пороговых значений, для определения ориентации может применяться более сложный критерий с применением наилучшего балла, связанного с этой ориентацией, отделяемого пороговым расстоянием от наилучшего балла, связанного с любой другой ориентацией.
На Фиг. 19F показана блок-схема для подпрограммы обхода матрицы символов на этапе 1939 на Фиг. 19Е. На этапе 1950 выбирается матрица значений признаков или матрица символов ориентации, соответствующая рассматриваемому количеству базовых ориентаций или итерация вложенного цикла этапов 1937-1942 на Фиг. 19Е. Затем во вложенном цикле на этапах 1952-1956 выполняется обход матрицы значений признаков. На этапе 1953, абсолютная ориентация символа, соответствующая рассматриваемому вектору из векторов значений признаков, или запись в матрице значений признаков определяется как произведение ориентации для рассматриваемой базовой ориентации для символа в рамке и ориентации, соответствующей рассматриваемому вектору из векторов значений признаков, как описано выше со ссылкой на Фиг. 14E-F. Например, если рассматриваемое поворотное положение символа в рамке соответствует 180°, а ориентация символа ориентации соответствует 90°, то абсолютная ориентация символа соответствует 270°. Далее, на этапе 1954 путем сравнения вектора из векторов значений признаков для символа в рамке и рассматриваемого вектора из векторов значений признаков символа ориентации при вызове функции расчета балла вычисляется балл. Далее на этапе 1955 расчетный балл добавляется к записи в матрице баллов, соответствующий абсолютной ориентации, определенной на этапе 1953, и к символу ориентации, соответствующему рассматриваемому вектору из векторов значений признаков. Если имеются еще векторы из векторов значений признаков, как определено на этапе 1956, выполняется возврат на этап 1953. В ином случае возвращается подпрограмма обхода матрицы символов ориентации.
На Фиг. 19G показана блок-схема для подпрограммы расчета балла, вызываемой на этапе 1954 на Фиг. 19F. На этапе 1958 подпрограмма расчета балла получает вектор из векторов значений признаков для символа в рамке, V1, и рассматриваемый вектор из векторов значений признаков для символа ориентации V2. На этапе 1959 локальной переменной балл присваивается значение 0. Во вложенном цикле этапов 1960-1966 рассматривается каждая соответствующая пара векторов из векторов значений признаков m1 и m2 в векторах V1 и V2. На этапе 1961 определяется вес w для рассматриваемого признака. Как описано выше, каждый элемент в векторе из векторов значений признаков соответствует признаку и, в определенных вариантах реализации, каждый признак связан с определенной весом. Во внутреннем вложенном цикле этапов 1962-1964 абсолютное значение разности между каждой парой значений признаков подобласти символа в рамке и значениями признаков символа ориентации в рассматриваемых векторах значений признаков рассчитывается и добавляется к баллу. На этапе 1965 балл умножается на вес w.
Подводя итог по Фиг. 19F и G, способ обобщенной ориентации содержащей текст области сравнивает каждый набор значений признаков, полученный для содержащей символ подобласти с каждым набором значений признаков в одном или более наборах значений признаков символов ориентации для формирования балла, который объединяется с баллом в полученном наборе баллов. Для каждой пары символ-ориентации/ориентация, для которой сохранен набор значений признаков, обобщенный способ определения ориентации содержащей текст области выполняет сравнение набора значений признаков для поворотного положения содержащей символ подобласти с набором значений признаков для пары символ-ориентации/ориентация с целью формирования балла, объединяет базовую ориентацию пары символ-ориентации/ориентация и поворотное положение для создания ориентации, определяет балл в наборе баллов, соответствующий символу ориентации и сформированной ориентации, и изменяет выявленный балл для получения нового значения за счет объединения текущего значения выявленного балла со сформированным баллом.
На Фиг. 19Н показана блок-схема для подпрограммы расчета ориентации на этапе 1910 на Фиг. 19А. На этапе 1970 определяется самое большое количество с и следующее по величине количество n в векторе счета ориентаций. На этапе 1971 определяется сумма счетов по вектору счета ориентации s. Если соотношение c/s превышает первый порог t5, как определено на этапе 1972, то на этапе 1974 возвращается указание на то, что ориентация не была рассчитана. Как вариант, если соотношение n/c меньше второго порогового значения t6, как определено на этапе 1973, то на этапе 1975 возвращается ориентация, соответствующая элементу со счетом с.
Хотя настоящее изобретение описывается на примере конкретных вариантов осуществления, предполагается, что оно не будет ограничено только этими вариантами осуществления. Специалистам в данной области будут очевидны возможные модификации сущности настоящего изобретения. Так, любой из ряда различных видов вариантов реализации раскрываемого способа определения ориентации области содержащего текст изображения на основе символов с маркерами ориентации может быть осуществлен путем изменения любого из множества различных параметров проектирования и реализации, включая язык программирования, операционную систему, структуры данных, управляющие структуры, модульную организацию и прочие подобные параметры разработки и реализации. Как описано выше, для определения ориентации символов в области, содержащего текст изображения, и для определения ориентаций этих символов может использоваться любой из широкого ряда способов и признаков. Для определения совпадения символа с ориентацией с символом из изображения и для определения возможности оценки содержащей текст области на основе счета ориентаций символов с маркером ориентации, выявленных в содержащей текст области, может использоваться ряд различных пороговых значений. Несмотря на то, что описанные и проиллюстрированные выше способ и подпрограмма определения ориентации определяют ориентацию содержащей текст области, описанный выше способ может применяться для различных типов и размеров областей, включая отдельные строки или столбцы текста, блоки текстовых символа, целые страницы текста и иные типы содержащих текст областей. В описанном выше способе предпринимается попытка сопоставления каждого текстового символа в содержащей текст области с каждой возможной ориентацией каждого символа, но в альтернативных способах и системах может потребоваться сопоставление только части текстовых символов в содержащей текст области с каждой возможной ориентацией каждого символа, при этом такая часть определяется вероятностью ориентации, которая определяется в каждом отдельном случае на основе части, превосходящей пороговое значение.
Следует понимать, что представленное выше описание раскрываемых вариантов реализации приведено для того, чтобы оно могло бы дать возможность любому специалисту в данной области техники воспроизвести или применить настоящее изобретение. Специалистам в данной области техники будут очевидны возможные модификации представленных вариантов реализации, при этом общие принципы, представленные здесь, без отступления от сущности и объема настоящего изобретения могут быть применены в рамках других вариантов реализации. Таким образом, подразумевается, что настоящее изобретение не ограничено представленными здесь вариантами реализации. Напротив, в его объем входят все возможные варианты реализации, согласующиеся с раскрываемыми в настоящем документе принципами и новыми отличительными признаками.


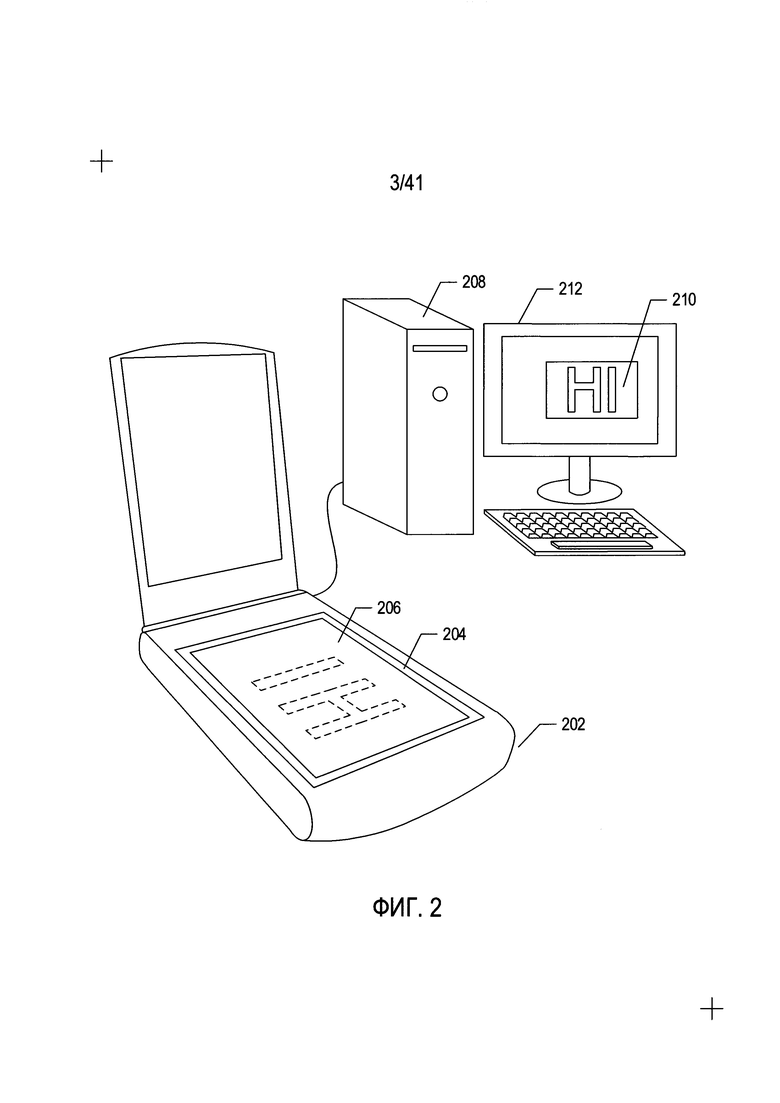
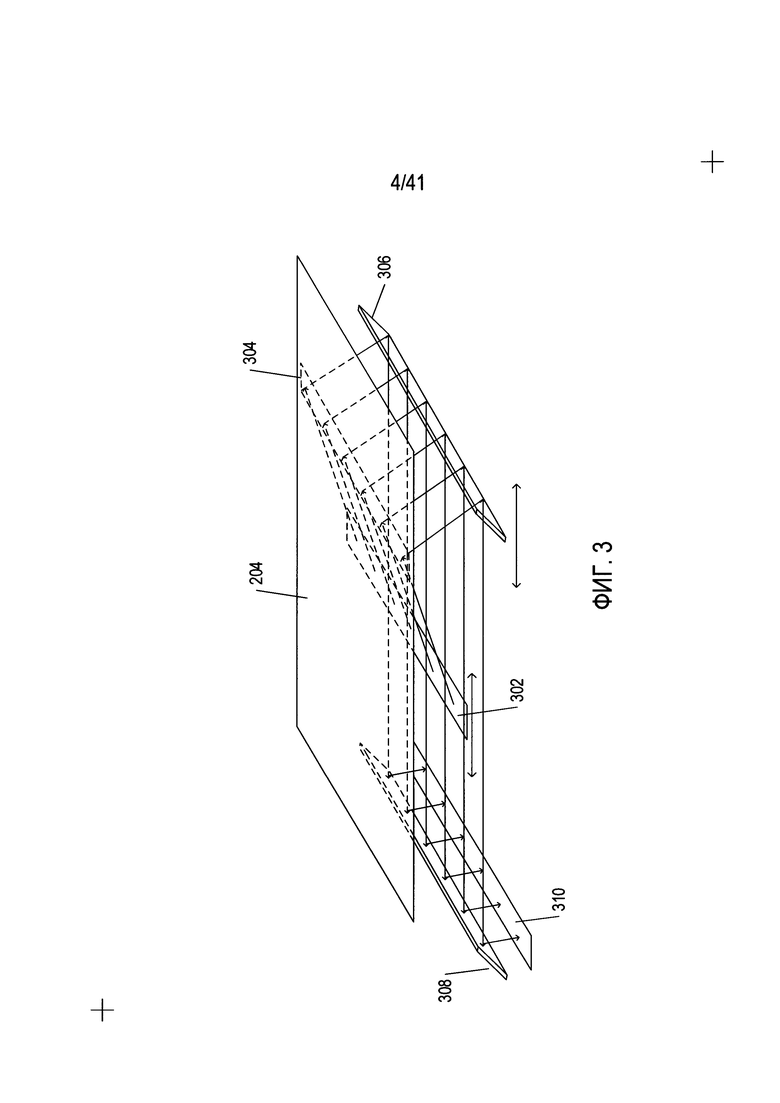
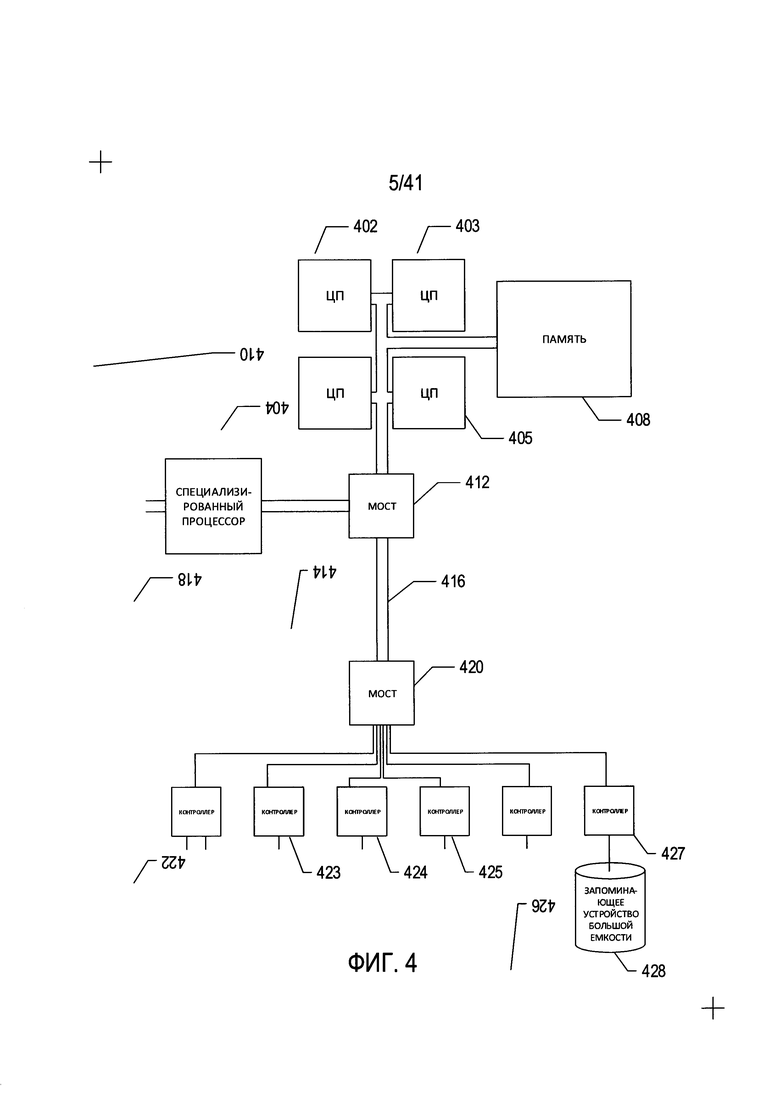

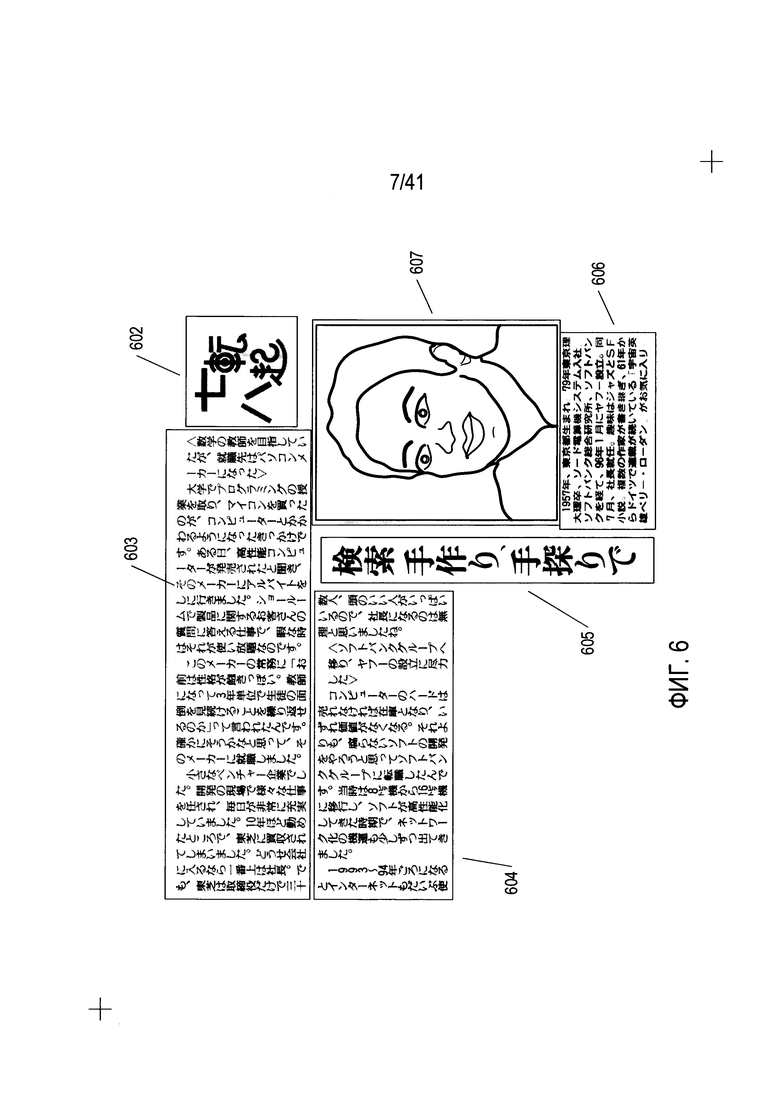
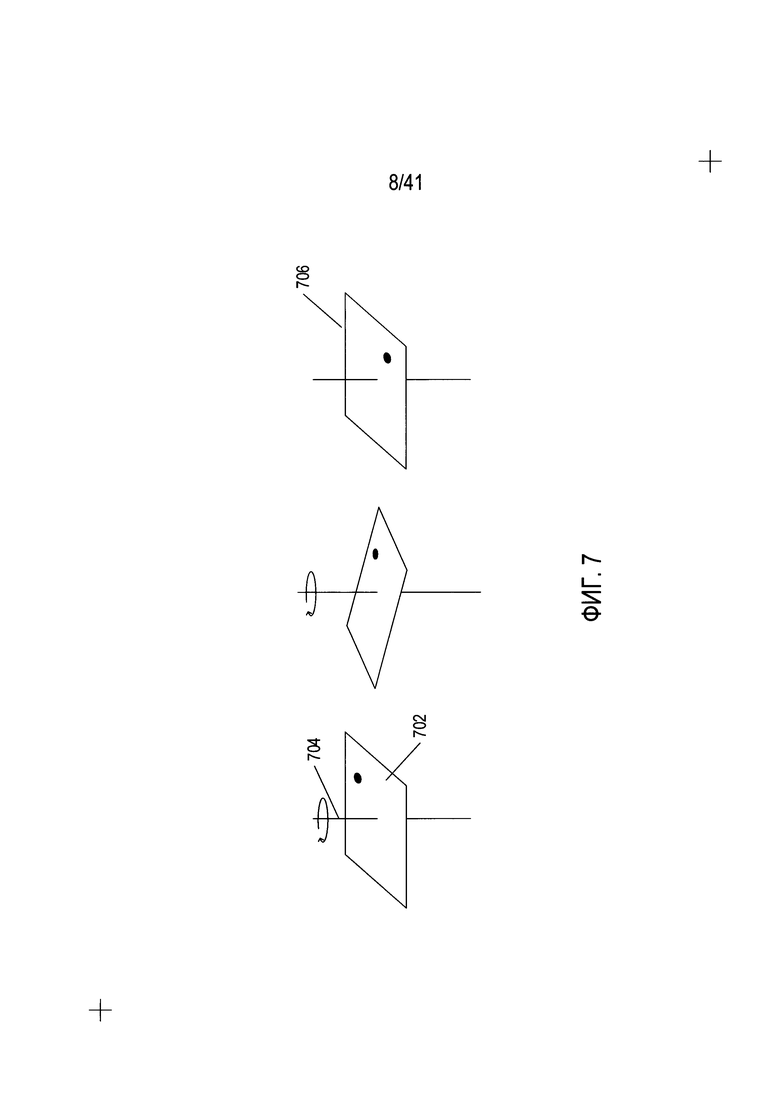


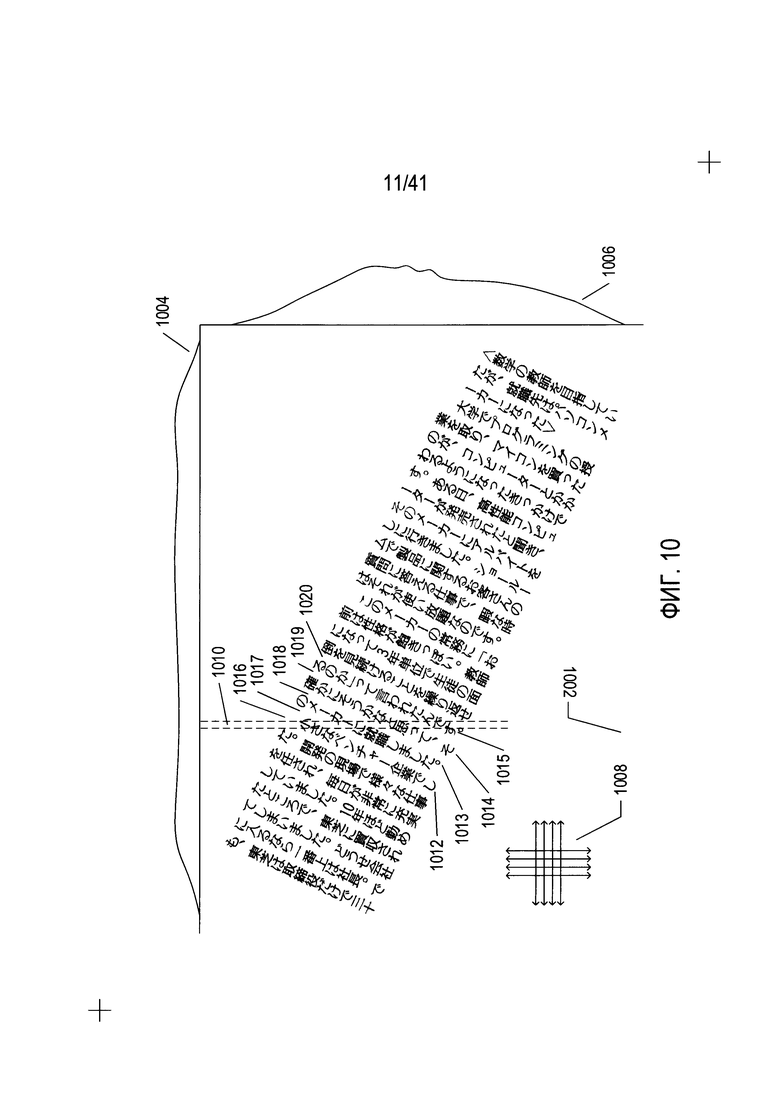


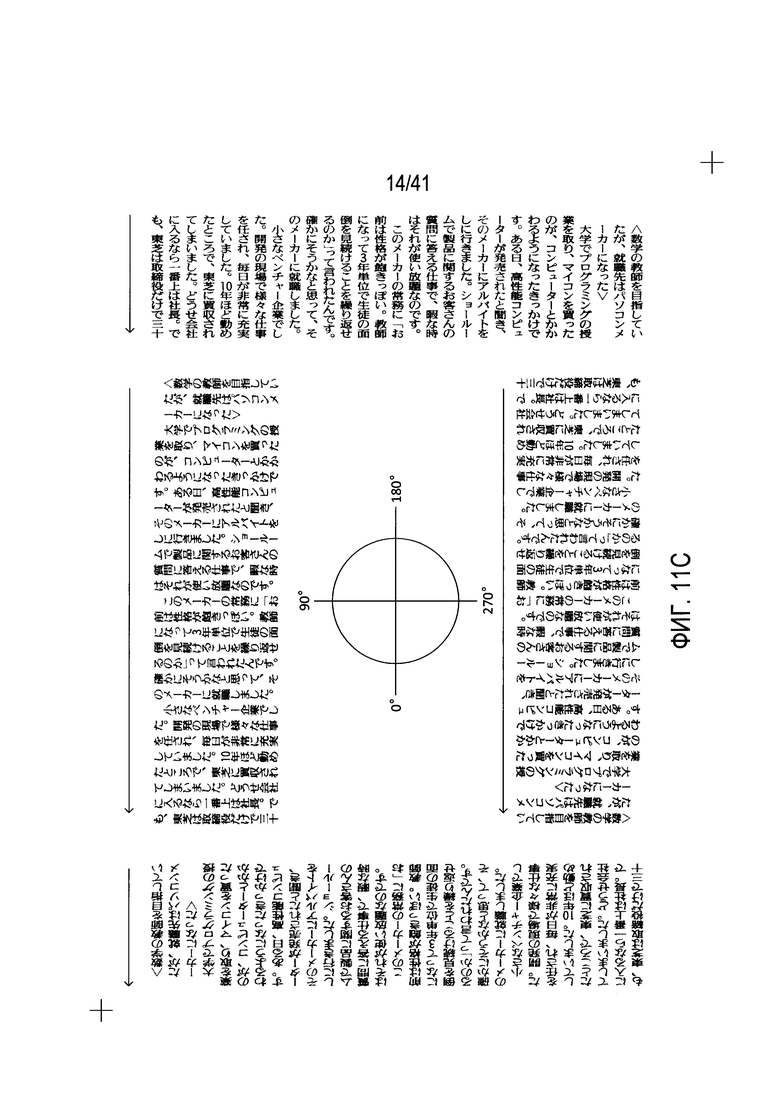
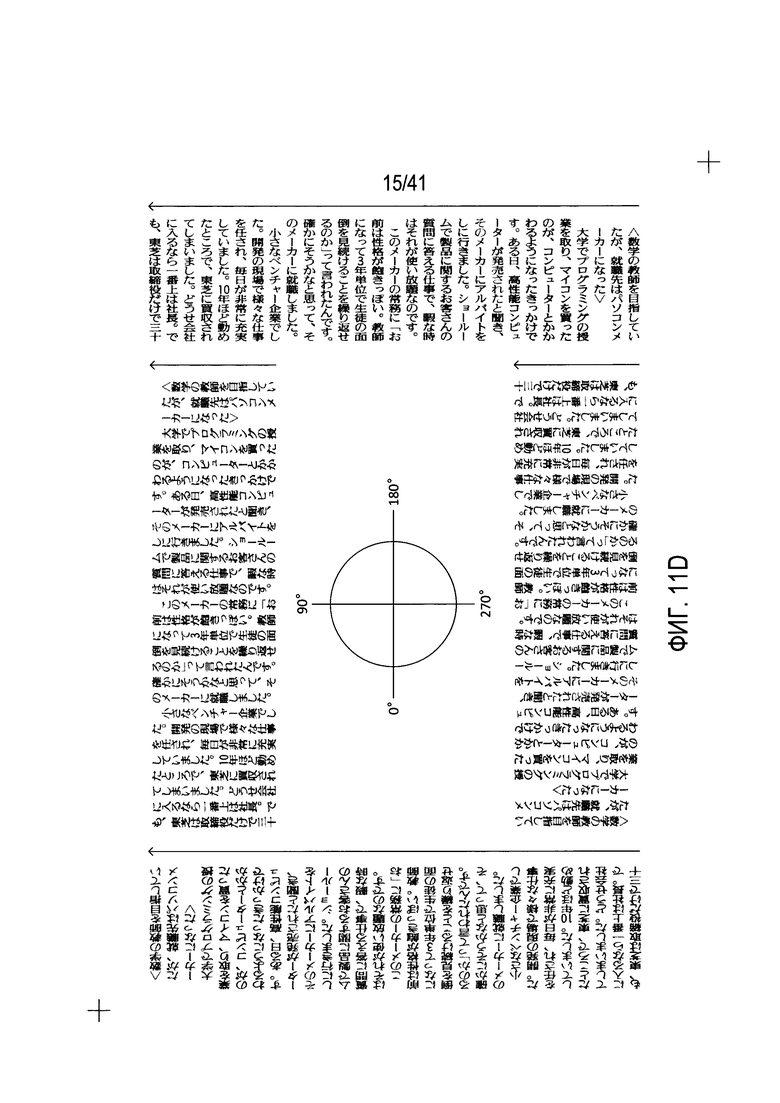
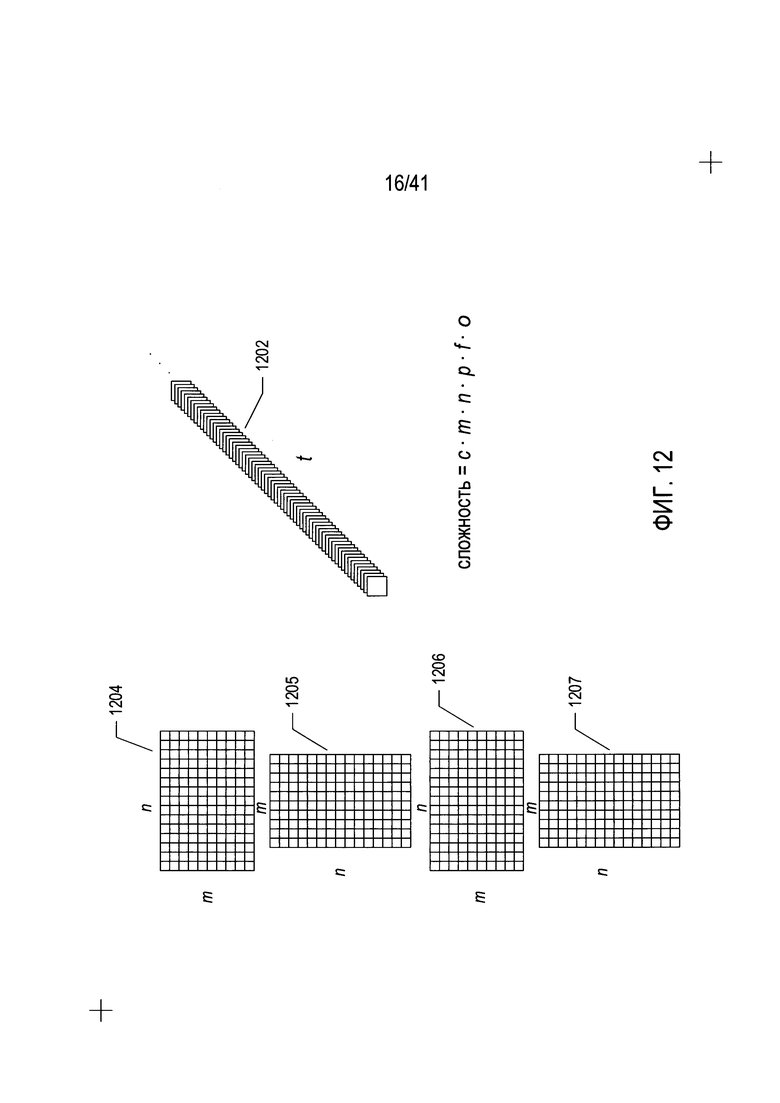
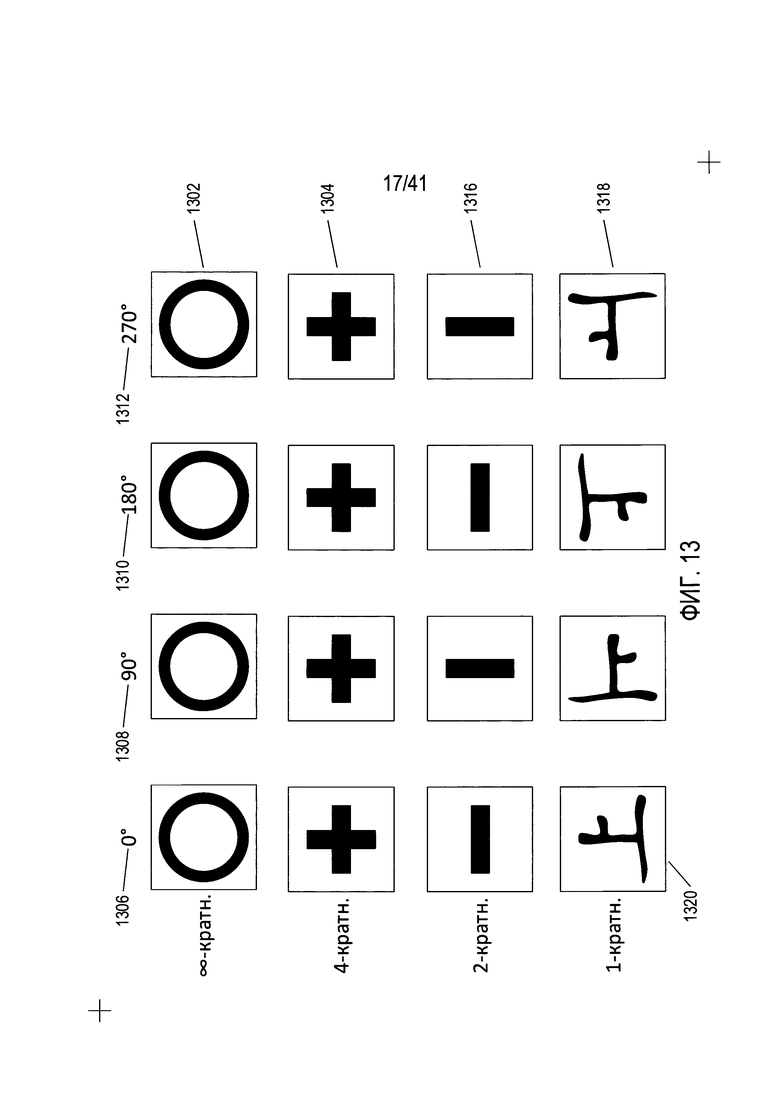
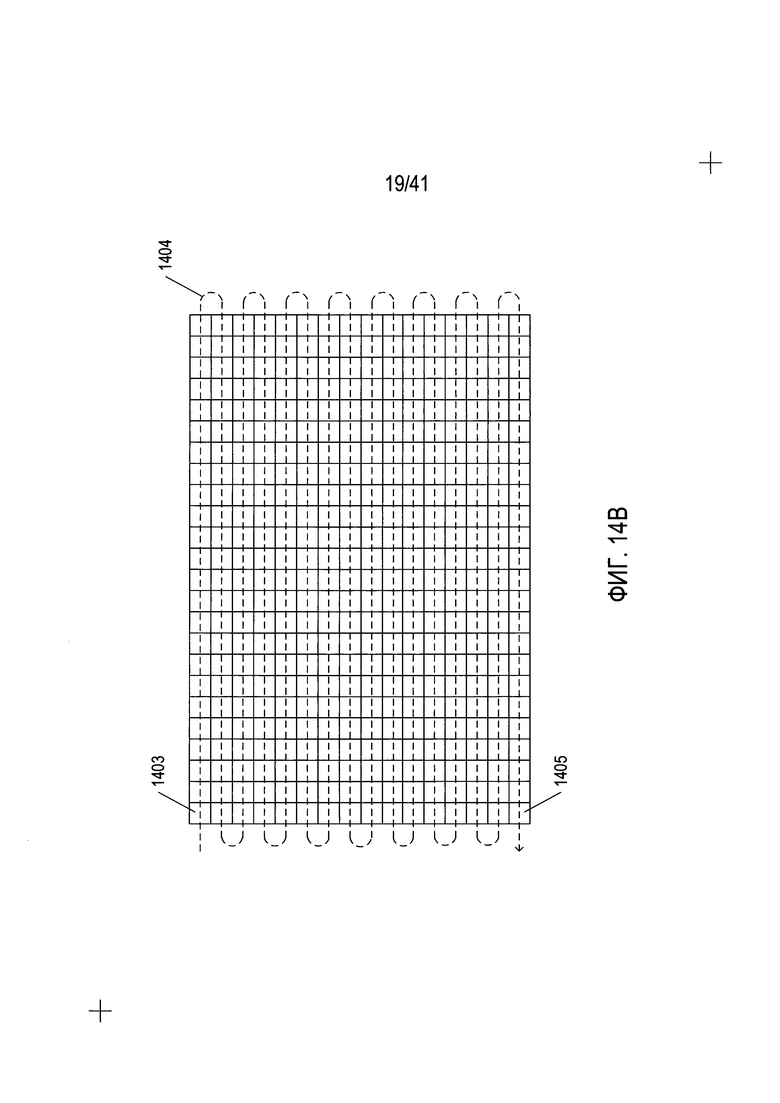

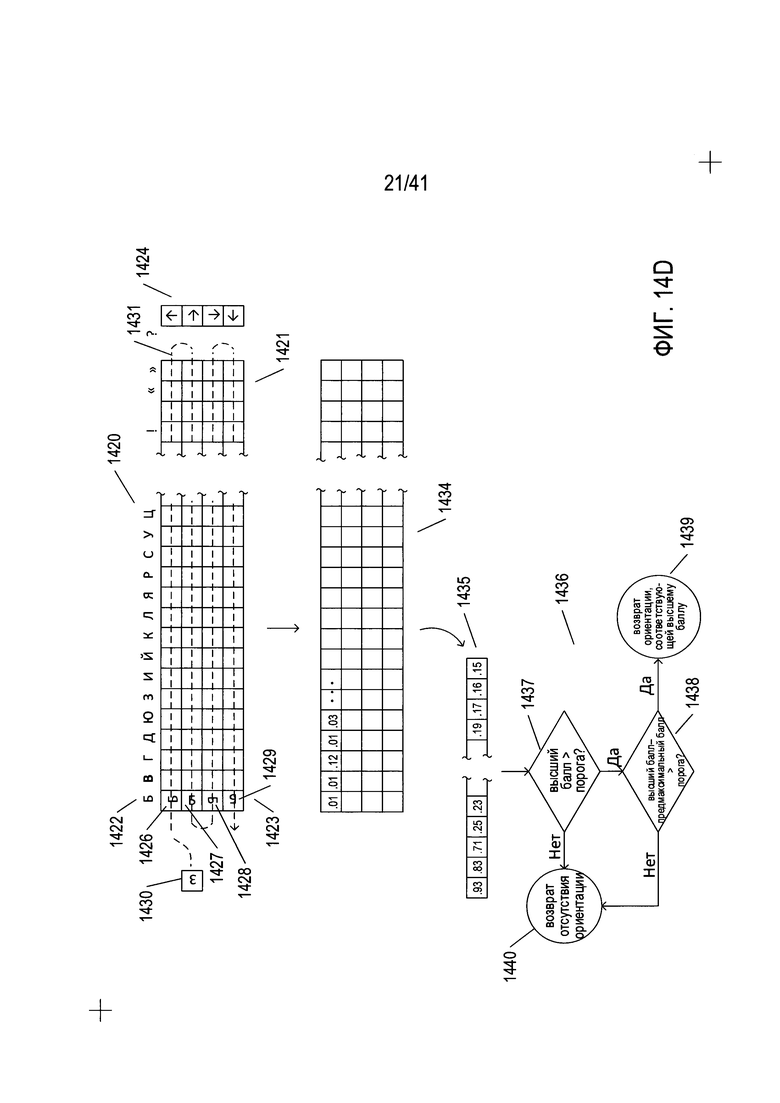

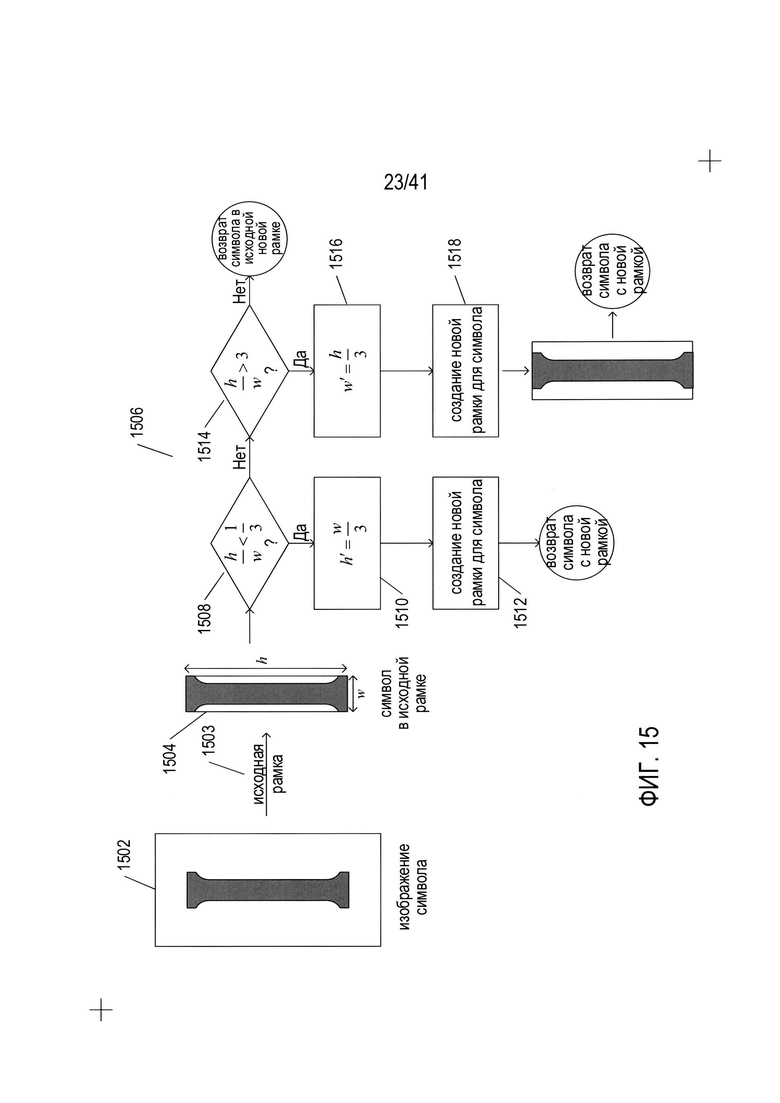
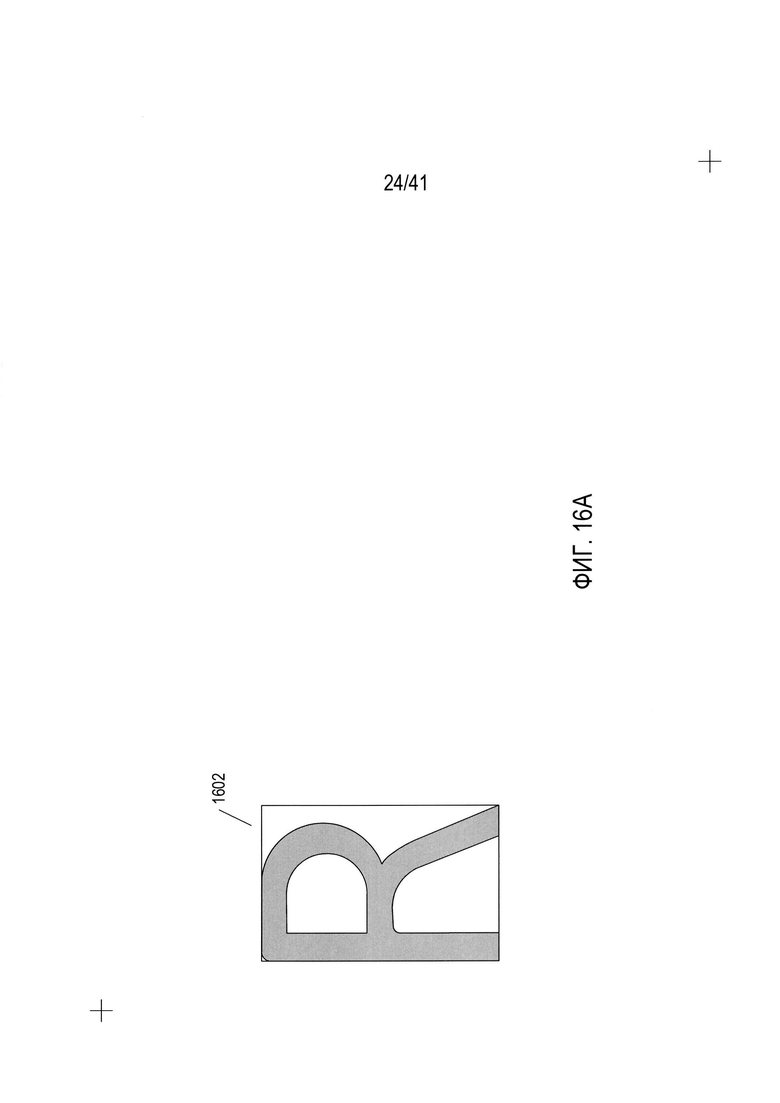

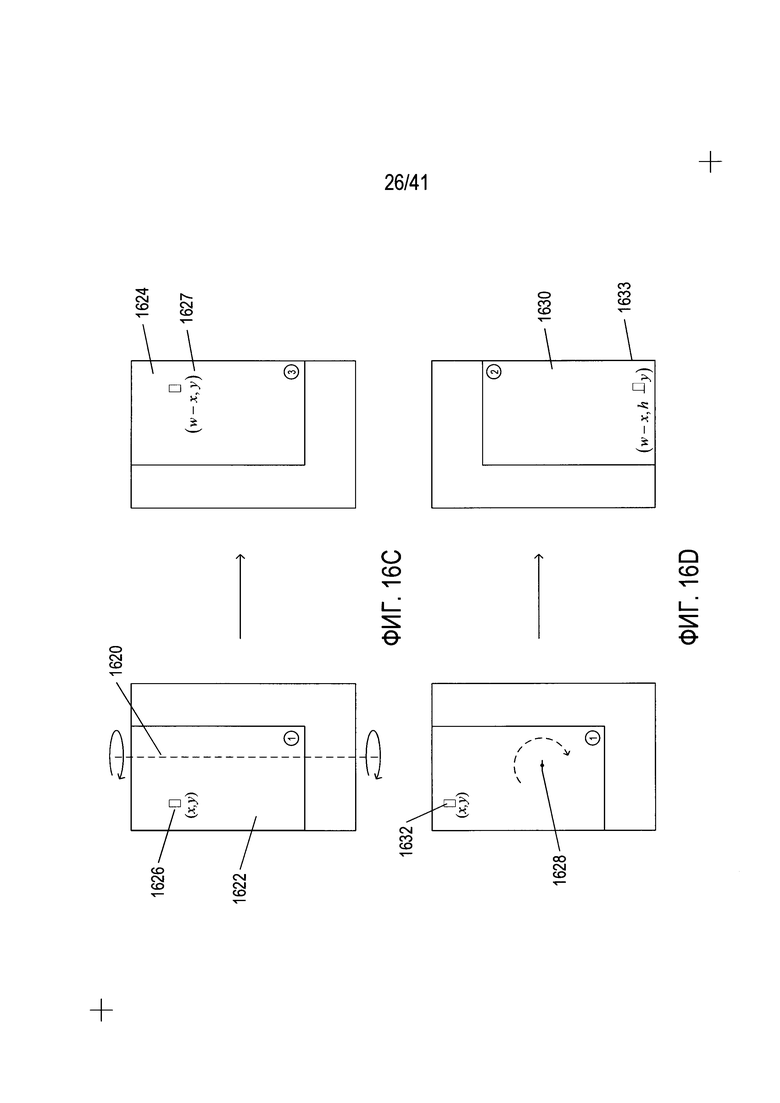

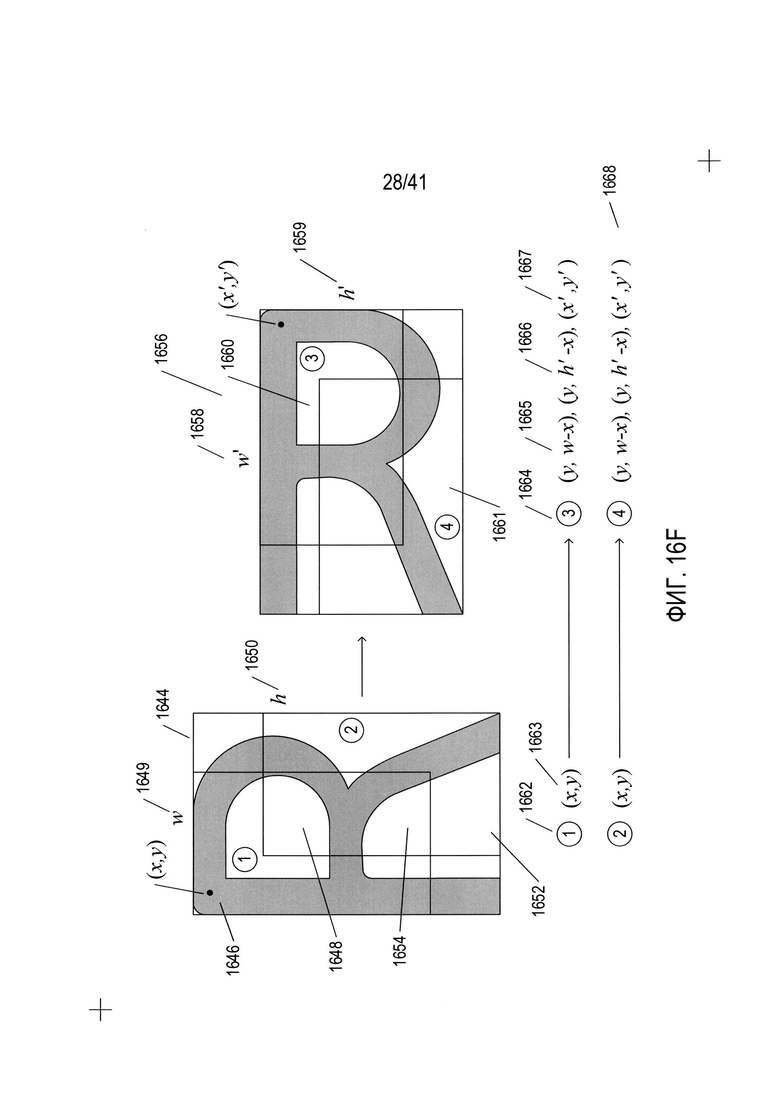


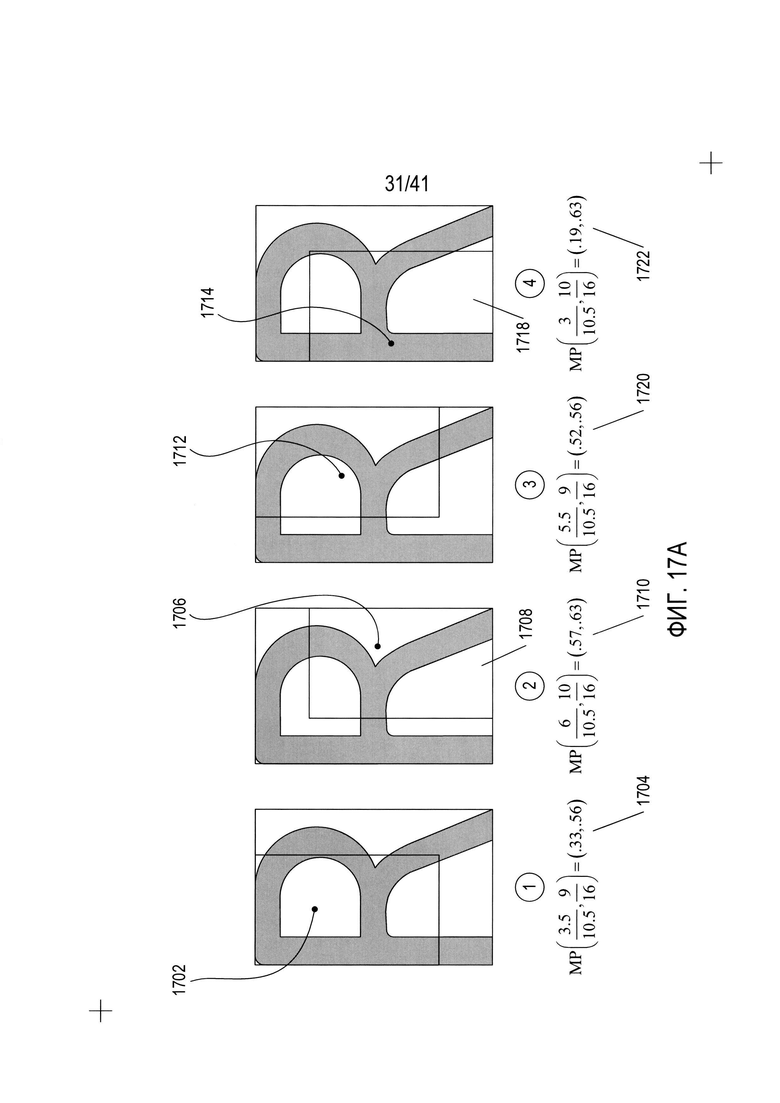

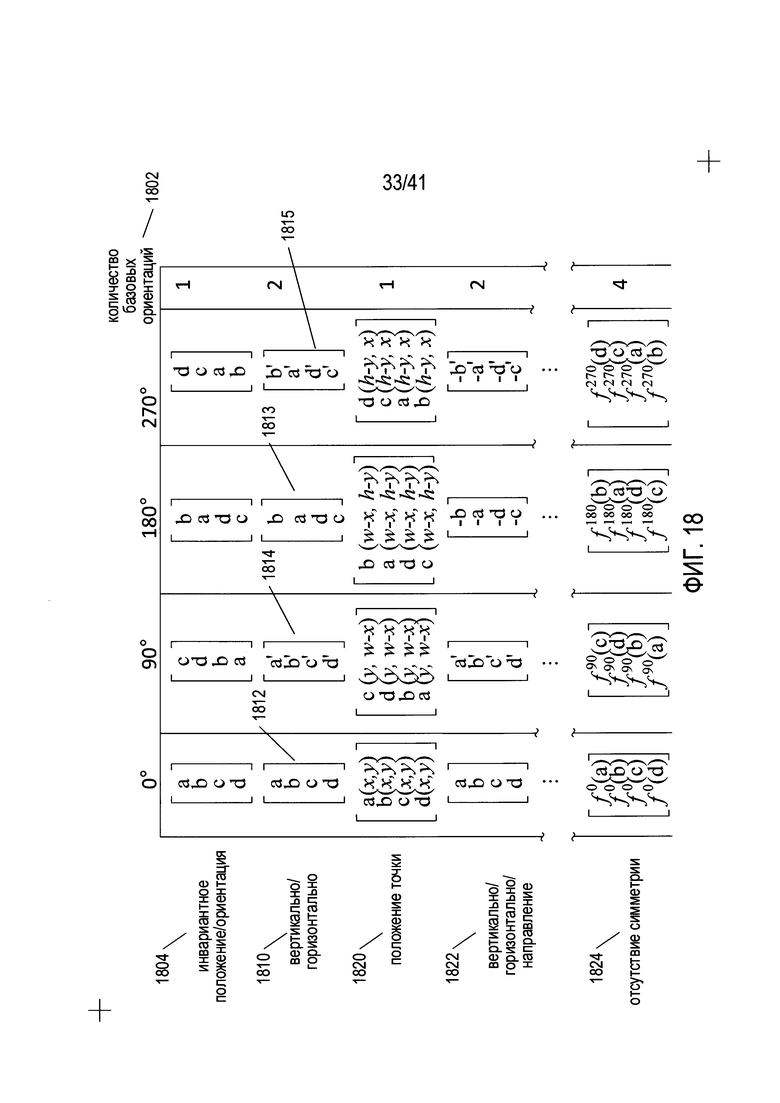

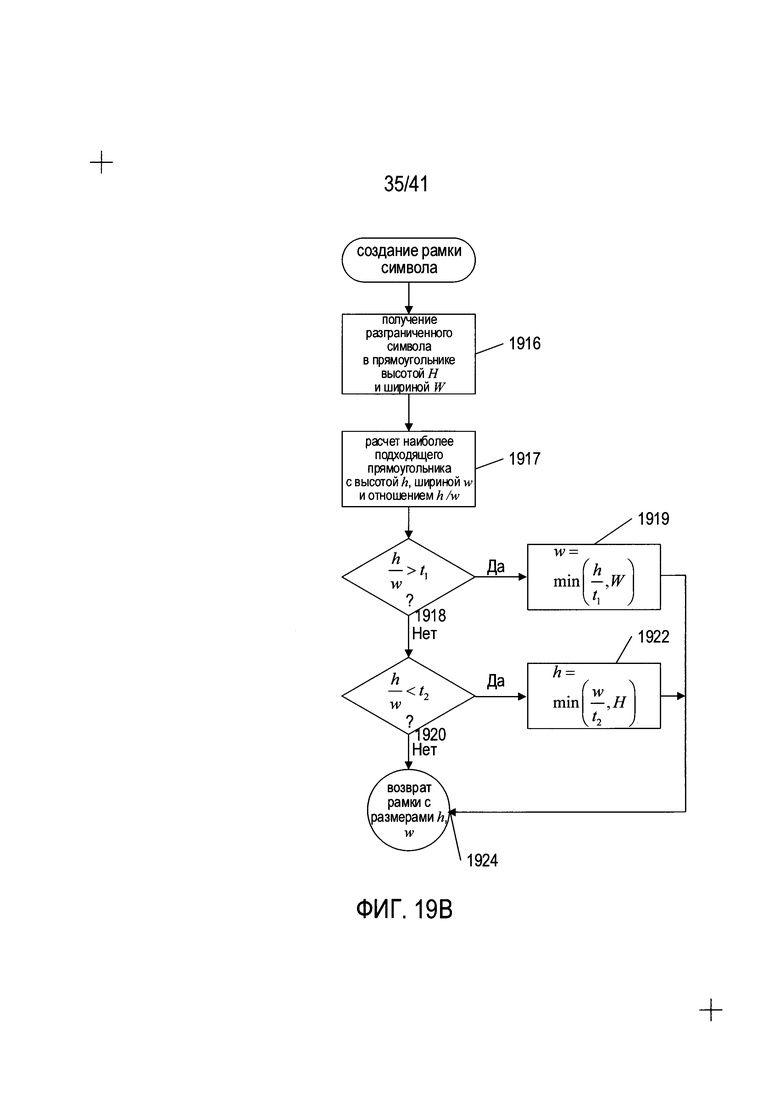
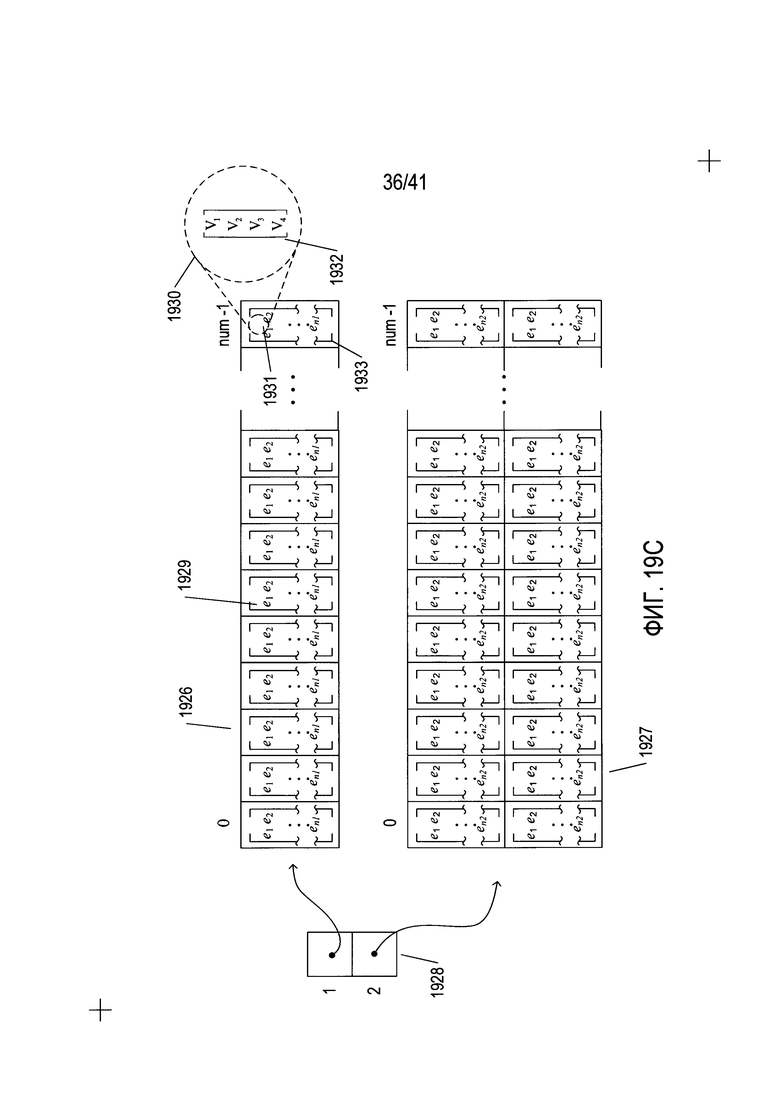


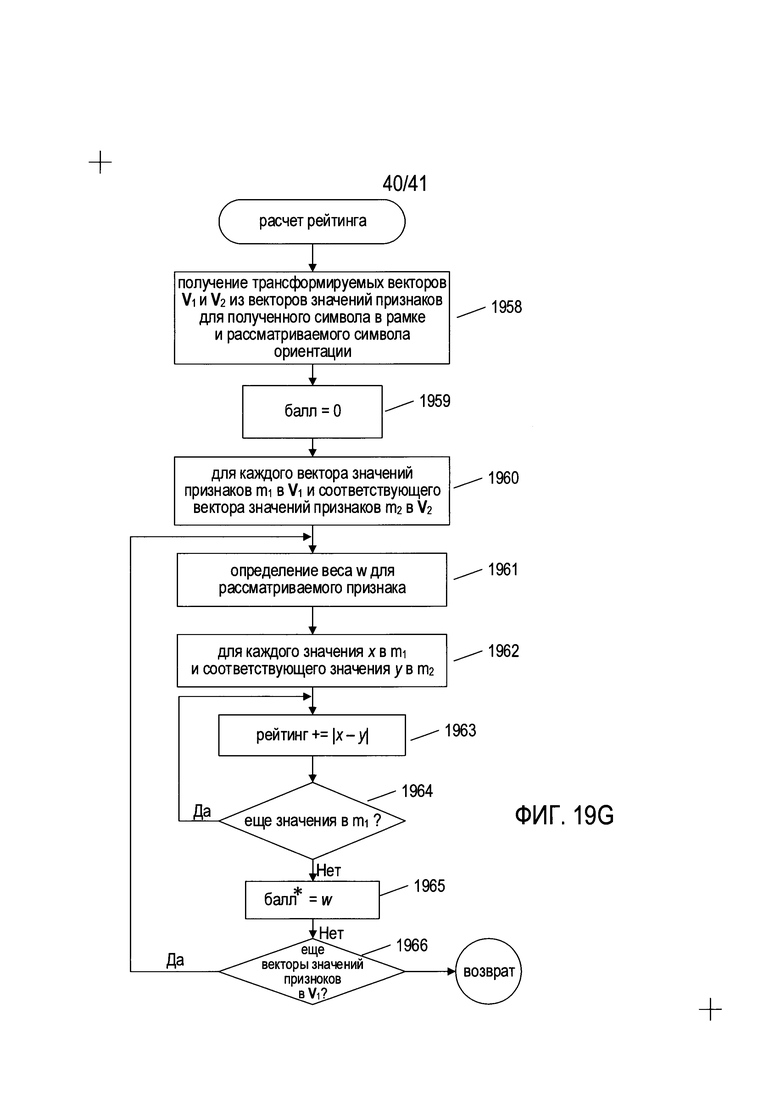
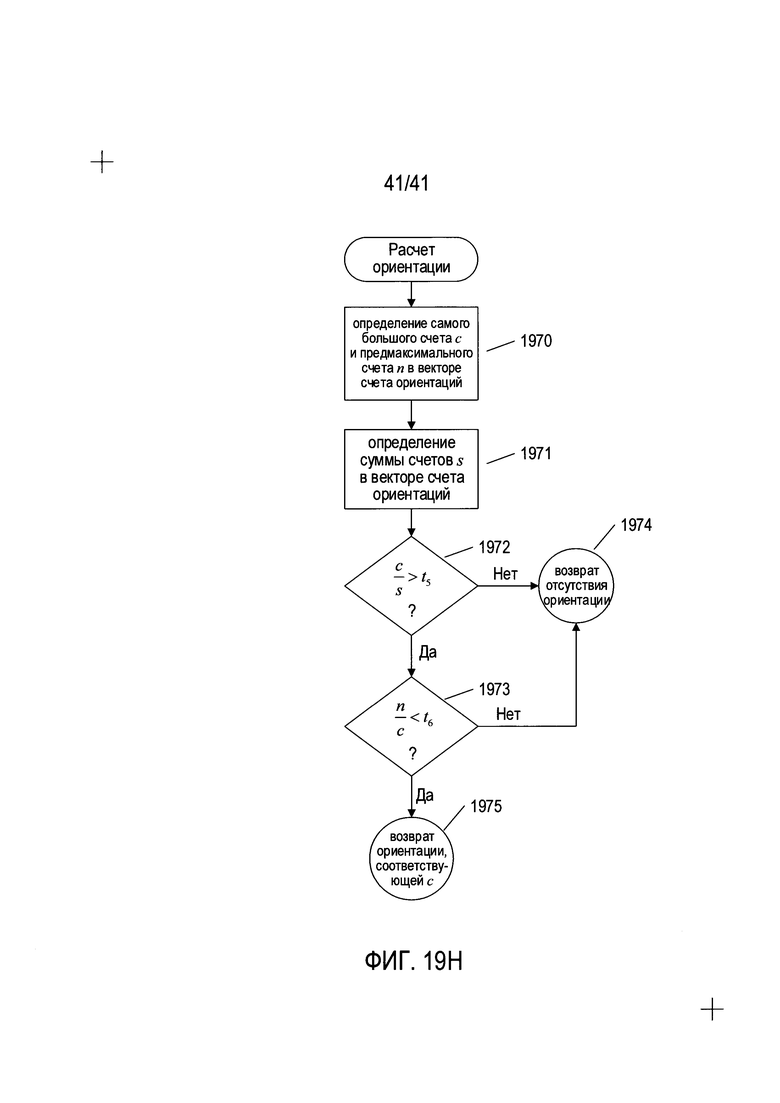
Изобретение относится к способам и системам автоматического определения ориентации областей изображений отсканированных документов. Технический результат – обеспечение возможности преобразования в соответствующие электронные документы печатных документов, содержащих текст на неалфавитных языках. В одном из вариантов реализации изобретения задействуют относительно небольшой набор символов ориентации, часто встречающихся в печатном тексте. При этом для, по меньшей мере, одного набора символов ориентации каждая из двух или более различных ориентаций содержащих символ подобластей в содержащей текст области отсканированного изображения документа сравнивается с каждым символом ориентации в, по меньшей мере, одном наборе символов ориентации, чтобы определить ориентацию для каждой из содержащих символы подобластей относительно исходной ориентации содержащей текст области. Выявленные для содержащих символы подобластей ориентации затем используются для определения ориентации содержащей текст области изображения отсканированного документа. 3 н. и 20 з.п. ф-лы, 43 ил.
1. Система обработки изображений, определяющая ориентацию содержащей текст области в изображении, включающая:
один или более процессоров;
один или более модулей памяти;
одно или более запоминающих устройств;
один или более наборов символов-ориентации, где каждый символ-ориентации связан с одним или более наборов значений признаков соответствующих одной или более ориентаций символа-ориентации, хранимых в одном или более из одного или более электронных запоминающих устройств;
компьютерные команды, хранимые в одном или более электронных запоминающих устройств, которые управляют системой обработки изображений для
получения изображения с содержащей текст областью,
для сохранения представления содержащей текст области в одном или более из одного или более электронных запоминающих устройств;
для выявления количества содержащих символы подобластей в пределах содержащей текст области, каждая из которых совпадает с одним из символов-ориентации в одной из ориентаций, за счет сравнения одного или более наборов значений признаков, рассчитанных для каждого из двух или более поворотных положений содержащей символ подобласти, с наборами значений признаков, хранимыми для каждого символа ориентации в одном или более наборах из наборов значений признаков символов-ориентации;
для определения ориентации содержащей текст области по количеству подобластей, содержащих символы, где каждая из подобластей соответствует одному из символов-ориентации в одной из ориентаций.
2. Система обработки изображений по п. 1, отличающаяся тем, что символ-ориентации является эталоном символа для определения ориентации содержащей текст области.
3. Система обработки изображений по п. 1, отличающаяся тем, что количество символов-ориентации составляет менее 10% от общего количества символов языка содержащей текст области.
4. Система обработки изображений по п. 1, отличающаяся тем, что количество символов-ориентации составляет менее 1% от общего количества символов языка содержащей текст области.
5. Система обработки изображений по п. 1, отличающаяся тем, что количество символов-ориентации составляет менее 0,1% от общего количества символов языка содержащей текст области.
6. Система обработки изображений по п. 1, отличающаяся тем, что:
каждый набор из наборов значений признаков символов-ориентации соответствует набору признаков, имеющих общее количество базовых ориентаций;
каждый набор из наборов значений признаков символов-ориентации включает значения признаков для каждого символа-ориентации в каждой базовой ориентации для набора из наборов значений признаков символов-ориентации;
каждый набор значений признаков включает набор значений признаков для каждого признака.
7. Система обработки изображений по п. 6, отличающаяся тем, что система обработки изображений определяет количество подобластей, содержащих символы, где каждая из подобластей соответствует одному из символов ориентации в одной из ориентаций за счет:
для каждой содержащей символ подобласти в пределах содержащей текст области,
инициализации набора баллов, содержащего балл для каждого символа-ориентации в одной из ориентаций,
для каждого поворотного положения содержащей символ подобласти в сочетании с базовой ориентацией символа-ориентации для определения ориентации символа-ориентации относительно содержащей текст области, для каждого набора признаков, имеющего общее количество базовых ориентаций,
расчет набора значений признаков,
сравнение каждого набора значений признаков, рассчитанных для содержащей символ подобласти, с каждым набором значений признаков из одного или более наборов значений признаков символа-ориентации для формирования балла, который объединяется с баллом в наборе баллов;
если балл в наборе баллов указывает на то, что соответствующий баллу символ-ориентации в одной из ориентаций совпадает с содержащей символ подобластью, выдается ориентация символа-ориентации в одной из ориентаций, связанная с баллом как ориентация содержащей символ подобласти.
8. Система обработки изображений по п. 7, отличающаяся тем, что сравнение каждого набора значений признаков, рассчитанных для содержащей символ подобласти, с каждым набором значений признаков из одного или более наборов значений признаков символа-ориентации для формирования балла, который объединяется с баллом в наборе баллов, дополнительно содержит:
для каждого набора признаков, имеющего общее количество базовых ориентаций,
для каждого используемого поворотного положения содержащей символ подобласти в сочетании с базовыми ориентациями, связанными с набором признаков,
для каждого символа-ориентации в одной из ориентаций, для которого в наборе из наборов значений признаков символа-ориентации сохраняется набор значений признаков, соответствующий набору признаков,
сравнение набора значений признаков для поворотного положения содержащей символ подобласти с набором значений признаков для символа-ориентации в одной из ориентаций для формирования балла;
объединение базовой ориентации символа-ориентации в одной из ориентаций и поворотного положения для формирования ориентации;
выявление балла в наборе баллов, соответствующего символу-ориентации и сформированной ориентации;
изменение выявленного балла для получения нового значения за счет объединения текущего значения выявленного балла со сформированным баллом.
9. Система обработки изображений по п. 8, отличающаяся тем, что сравнение набора значений признаков для поворотного положения содержащей символ подобласти с набором значений признаков символа-ориентации в одной из ориентаций для формирования балла дополнительно содержит:
инициализацию сравнительного значения;
для каждого набора значений признаков в наборе значений признаков для определенного поворотного положения содержащей символ подобласти сравнение набора значений признаков с соответствующим набором значений признаков в наборе значений признаков символа-ориентации в одной из ориентаций для формирования значения, которое объединяется с текущим сравнительным значением для формирования нового сравнительного значения.
10. Система обработки изображений по п. 7, отличающаяся тем, что балл в наборе баллов указывает на то, что соответствующий баллу символ-ориентации в одной из ориентаций соответствует содержащей символ подобласти, когда:
балл имеет крайнее значение для диапазона значений баллов в наборе баллов;
разность между значением балла и ближайшим значением любого другого балла больше порогового значения разности.
11. Система обработки изображений по п. 7, отличающаяся тем, что каждое значение признака в наборе значений признаков в пределах каждого набора значений признаков формируется функцией, которая рассчитывается по растровому изображению либо символа-ориентации, либо содержащей символ подобласти.
12. Система обработки изображений по п. 1, отличающаяся тем, что определение ориентации содержащей текст области по ориентациям количества содержащих символы подобластей, каждая из которых соответствует символу-ориентации в одной из ориентаций, дополнительно содержит:
выбор в качестве определенной ориентации той ориентации, которая связана с самым большим количеством содержащих символы подобластей.
13. Способ, выполняемый в системе обработки изображений с одним или более процессорами, одним или более электронными устройствами памяти, одним или более запоминающими устройствами, одним или более наборов символов-ориентации, где каждый символ-ориентации связан с одним или более наборов значений признаков, соответствующих одной или более ориентаций символа-ориентации, хранимых в одном или более электронных запоминающих устройствах, который определяет ориентацию содержащей текст области на изображении и содержит следующее:
получение изображения с содержащей текст области;
сохранение представления содержащей текст области в одном или более из одного или более электронных запоминающих устройств;
выявление количества содержащих символы подобластей в пределах содержащей текст области, каждая из которых совпадает с одним из символов-ориентации в одной из ориентаций, за счет сравнения одного или более наборов значений признаков, рассчитанных для каждого из двух или более поворотных положений содержащей символ подобласти, с наборами значений признаков, хранимыми для каждого символа-ориентации в одном или более наборах из наборов значений признаков символов-ориентации;
определение ориентации содержащей текст области по количеству подобластей, содержащих символы, где каждая из подобластей соответствует одному из символов-ориентации в одной из ориентаций.
14. Способ по п. 13 отличающийся тем, что символ-ориентации является эталоном символа для определения ориентации содержащей текст области.
15. Способ по п. 13, характеризующийся тем, что:
каждый набор из наборов значений признаков символов-ориентации соответствует набору признаков, имеющих общее количество базовых ориентаций;
каждый набор значений признаков символов-ориентации включает значения признаков для каждого символа-ориентации в каждой базовой ориентации для набора из наборов значений признаков символов-ориентации;
каждый набор значений признаков включает набор значений признаков для каждого признака.
16. Способ по п. 13, отличающийся тем, что определение количества содержащих символы подобластей в содержащей текст области, каждая из которых совпадает с одним из символов-ориентации в одной из ориентаций, дополнительно содержит:
для каждой содержащей символ подобласти в пределах содержащей текст области,
инициализацию набора баллов, содержащего балл для каждого символа-ориентации в одной из ориентаций,
для каждого поворотного положения содержащей символ подобласти в сочетании с базовой ориентацией символа-ориентации для определения ориентации символа-ориентации относительно содержащей текст области,
для каждого набора признаков, имеющего общее количество базовых ориентаций,
расчет набора значений признаков,
сравнение каждого набора значений признаков, рассчитанных для содержащей символ подобласти, с каждым набором значений признаков из одного или более наборов значений признаков символа-ориентации для формирования балла, который объединяется с баллом в наборе баллов;
если балл в наборе баллов указывает на то, что соответствующий баллу символ-ориентации в одной из ориентаций совпадает с содержащей символ подобластью, выдается ориентация символа-ориентации в одной из ориентаций, связанная с баллом как ориентация содержащей символ подобласти.
17. Способ по п. 16, отличающийся тем, что сравнение каждого набора значений признаков, рассчитанных для содержащей символ подобласти, с каждым набором значений признаков из одного или более наборов значений признаков символа-ориентации для формирования балла, который объединяется с баллом в наборе баллов, дополнительно содержит:
для каждого набора признаков, имеющего общее количество базовых ориентаций,
для каждого используемого поворотного положения содержащей символ подобласти в сочетании с базовыми ориентациями, связанными с набором признаков,
для каждого символа-ориентации, для которого в наборе из наборов значений признаков символа-ориентации сохраняется набор значений признаков, соответствующий набору признаков,
сравнение набора значений признаков для поворотного положения содержащей символ подобласти с набором значений признаков для символа-ориентации в одной из ориентаций с целью формирования балла;
объединение базовой ориентации символа-ориентации в одной из ориентаций и поворотного положения для формирования ориентации;
выявление балла в наборе баллов, соответствующего символу и сформированной ориентации;
изменение выявленного балла для получения нового значения за счет объединения текущего значения выявленного балла со сформированным баллом.
18. Способ по п. 16, отличающийся тем, что сравнение набора значений признаков для поворотного положения содержащей символ подобласти с набором значений признаков символа-ориентации с целью формирования балла дополнительно содержит:
инициализацию сравнительного значения;
для каждого набора значений признаков в наборе значений признаков для определенного поворотного положения содержащей символ подобласти сравнение набора значений признаков с соответствующим набором значений признаков в наборе значений признаков символа-ориентации для формирования значения, которое объединяется с текущим сравнительным значением для формирования нового сравнительного значения.
19. Способ по п. 16, отличающийся тем, что балл в наборе баллов указывает на то, что соответствующий баллу символ-ориентации в одной из ориентаций соответствует содержащей символ подобласти, когда:
балл имеет крайнее значение для диапазона значений баллов в наборе баллов;
разность между значением балла и ближайшим значением любого другого источника больше порогового значения разности.
20. Способ по п. 16, отличающийся тем, что каждое значение признака в наборе значений признаков в пределах каждого набора значений признаков формируется функцией, которая рассчитывается по растровому изображению либо символа-ориентации, либо содержащей символ подобласти.
21. Физическое запоминающее устройство, хранящее команды в машинном коде, которые, при извлечении из запоминающего устройства, хранящего один или более наборов символов-ориентации, где каждый символ-ориентации связан с одним или более наборов значений признаков соответствующих одной или более ориентаций символа-ориентации, и выполнении одним или более процессорами в системе обработки изображений с одним или более процессорами, одним или более электронными устройствами памяти, одним или более запоминающими устройствами, одним или более наборами значений признаков, хранящихся в одном или более электронных запоминающих устройствах, управляют системой обработки изображений для:
получения изображения с содержащей текст области;
сохранения представления содержащей текст области в одном или более из одного или более электронных запоминающих устройств;
выявления количества содержащих символы подобластей в пределах содержащей текст области, каждая из которых совпадает с одним из символов-ориентации, за счет сравнения одного или более наборов значений признаков, рассчитанных для каждого из двух или более поворотных положений содержащей символ подобласти, с наборами значений признаков, хранимыми для каждого символа-ориентации в одном или более наборах из наборов значений признаков символов-ориентации;
определения ориентации содержащей текст области по количеству подобластей, содержащих символы, где каждая из подобластей соответствует одному из символов-ориентации в одной из ориентаций.
22. Физическое запоминающее устройство по п. 21, отличающееся тем, что символ-ориентации является эталоном символа для определения ориентации содержащей текст области.
23. Физическое запоминающее устройство по п. 21, отличающееся тем, что:
каждый набор из наборов значений признаков-ориентации соответствует набору признаков, имеющих общее количество базовых ориентаций;
каждый набор значений признаков символов-ориентации включает значения признаков для каждого символа-ориентации в каждой базовой ориентации для набора из наборов значений признаков символов-ориентации;
каждый набор значений признаков включает набор значений признаков для каждого признака.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| МАШИННО-СЧИТЫВАЕМАЯ ЭТИКЕТКА И СПОСОБ ИДЕНТИФИКАЦИИ ПО МЕНЬШЕЙ МЕРЕ ОДНОГО ИЗДЕЛИЯ | 1992 |
|
RU2115167C1 |
| Приспособление для автоматизации процесса ионообменной очистки сахарных растворов | 1953 |
|
SU97199A1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ КОРРЕКТНОЙ ОРИЕНТАЦИИ ДОКУМЕНТОВ ПРИ АВТОМАТИЧЕСКОЙ ПЕЧАТИ | 2011 |
|
RU2469398C1 |

