Область техники
Настоящее изобретение относится к системам и методам сравнения файлов и более конкретно к отнесению данного файла к определенной коллекции файлов в зависимости от степени схожести.
Уровень техники
Поиск объекта по некоторым признакам является важной проблемой в развитии современных информационных технологий. От выбора той или иной архитектуры системы поиска объектов зависит точность результатов, скорость обработки запросов, вид представляемых данных и область применения данной системы. Ключевыми особенностями каждой такой системы являются методы сравнения данных и способ хранения коллекций данных. Например, существуют методы сравнения по содержимому, атрибутам файлов, функционалу (для исполняемых файлов), бинарное сравнение и т.д., а данные можно хранить в реляционных, объектно-ориентированных базах данных и т.д.
Поиск файлов, содержащих текстовые поля, позволяет находить текстовые документы, скрипты, страницы интернет-сайтов и т.п. Подобные системы находят широкое применение в жизни и позволяют решать ряд проблем.
Иногда необходимо найти не только копии файла, а объекты, которые в определенной степени схожи с ним. Реализовать решение данной задачи можно, сравнивая строки файла.
Одной из областей применения такой системы является средство обнаружения вредоносных программ. Существуют методы детектирования неизвестных вредоносных программ методами сравнения строк в неизвестном файле с коллекцией известных файлов. Однако также существуют проблемы недостаточной точности таких решений, связанных с недостаточной широтой постановления задачи.
Данная проблема очень актуальна, потому что новых вредоносных программ появляется с каждым днем все больше, но подавляющее большинство новых вредоносных программ представляют собой небольшие модификации уже существующих. Чтобы защита от новых версий была более эффективна, необходимо развивать методы эвристического анализа. Именно к таким и относится метод сравнения файлов по строкам. Аналитики антивирусных лабораторий создают коллекции объектов: набор известных вредоносных программы и набор доверенных программ, не способных нанести вред (так называемый белый список, white list). Описываемый метод может рассчитать степень схожести файла с каждым объектом из коллекции и на основе результатов отнести его к вредоносным программам или к программам из доверенного списка.
Строки в значительной степени отражают реальный функционал файла. Таким образом, чтобы два файла были признаны похожими по функционалу, множества выделенных из них строк должны пересекаться в значительной степени.
На данный момент существуют различные методы построения коллекций файлов, а также методы сравнений файлов, которые описаны в различных патентах.
В патенте US 7447703 раскрывается идея создания коллекций информации, которые улучшают продуктивность работы сотрудников путем организации информации на компьютере.
В патенте US 6526574 раскрывается идея обновления файлов на компьютере путем создания файла-заплатки. Существующий оригинальный файл и исправленный файл являются исходными данными для программы построения файла-заплатки, которая находит разницу в файлах, и затем использует эти данные для создания файла-заплатки.
В заявке US 20070260651 A1 описывается технология сравнения одного неисполняемого файла с одним или несколькими файлами. Итогом сравнения является сообщение о том, что содержимое одного файла похоже на содержимое другого файла из коллекции больше, чем на остальные файлы коллекции.
В патенте US 6738515 описывается технология, позволяющая сравнивать каждый символ первой строки с каждым символом второй строки. Для вычисления оценки сравнения используется двумерная матрица.
В заявке US 20090158434 A1 описывается метод обнаружения вредоносных файлов, который составляет копию проверяемого файла, конвертирует ее в упрощенном виде и затем ищет сходство на вредоносный код у нормализованных данных.
До изобретения предлагаемого подхода использовались методы, основанные на бинарной похожести.
Файл, найденный таким методом похожести, перепроверяется методом сравнения по строкам, описанным в этой же заявке. Если файлы оказываются действительно похожими, и найденный файл - вредоносная программа, то накладывается детектирующая сигнатура.
Суть метода поиска схожести по строкам, описанного в представленной заявке - сразу же искать те файлы, которые заведомо окажутся похожими в момент перепроверки.
Еще одним преимуществом метода, представленного в текущей заявке, является то, что он позволяет найти все похожие файлы в коллекции, а не только самые похожие.
Кроме того, метод бинарной схожести имел ряд недостатков ввиду принципа его работы. Он был крайне неустойчив к изменениям в исходном файле, например к архивированию другим упаковщиком или распаковке файла другим способом (а именно к тому, что приводит к изменению структуры файла). В итоге похожий файл в коллекции уже не найдется.
Сущность изобретения
Настоящее изобретение предназначено для решения проблемы детектирования ранее неизвестных зловредных программ.
Техническим результатом настоящего изобретения является отнесение файла к коллекции объектов по результатам расчета степени схожести между ними. Описанный далее способ позволяет оптимизировать и тем самым ускорить процесс детектирования ранее неизвестных зловредных программ. Согласно способу отнесения файла к коллекции файлов, содержащему этапы, на которых: (а) получают файл, содержащий текстовые поля, который необходимо исследовать; (b) преобразуют полученный файл в объект данных, при этом удаляя строки-исключения из текстовых полей файлов; (с) преобразуют файлы из коллекции файлов в коллекцию объектов данных, при этом удаляя строки-исключения из текстовых полей файлов коллекции; (d) сравнивают объект данных со всеми объектами коллекций по строкам; (е) выявляют степень схожести объекта данных с объектами коллекций и (f) в зависимости от значения степени схожести и значений первого и второго порогов файл относят или добавляют в коллекции файлов или отправляют на дальнейший анализ.
В частном варианте реализации строки-исключения могут представлять собой строки упаковщиков, разархивирующие части самораспаковывающихся архивов, служебные части кода, которые добавляются компилятором, код популярных библиотек, имена импортируемых функций, другие строки, которые не отражают функционал данного файла.
Еще в одном частном варианте реализации полученный файл, представленный в запакованном виде, распаковывается перед преобразованием.
В другом частном варианте реализации преобразование файла состоит из извлечения из файла строк, удаления строк-исключений и создания массива данных, включающего в себя, по меньшей мере, идентификатор файла и результат расчета хэш-функции от извлеченных строк, выделенных из этого файла.
В другом частном варианте реализации массив данных преобразуют в другой массив данных, включающий в себя, по меньшей мере, результат расчета хэш-функции от извлеченной строки и идентификаторы файлов, в которых содержится эта строка.
В другом частном варианте реализации полученный файл относят к существующей коллекции, если степень схожести исследуемого файла с файлами данной коллекции превышает значение первого порога.
В другом частном варианте реализации полученный файл добавляют в существующую коллекцию, если степень схожести полученного файла с объектом данной коллекции превышает значение второго порога.
В другом частном варианте реализации значения первого и второго порогов рассчитываются по статистическим данным или устанавливаются экспертом исходя из полученного опыта.
В другом частном варианте реализации полученный файл отправляют на дальнейший анализ, в случае если не удалось отнести файл к какой-либо коллекции.
Система отнесения файла к коллекции файлов, содержит: (а) блок загрузки файла; (b) блок преобразования файлов, которыми являются файлы из базы данных коллекции файлов или файл из блока загрузки файла, в коллекцию объектов или объект данных соответственно путем извлечения из файлов строк, удаления из них строк-исключений из базы данных строк исключений, создания массива данных, содержащего, по меньшей мере, идентификатор файла и результаты расчета хэш-функции от извлеченных строк, содержащихся в этих файлах, преобразования этого массива в другой массив, включающий в себя, по меньшей мере, значение хэш-функции от строки и идентификаторы файлов, в которых содержится эта строка, и передачи результирующей коллекции объектов или объекта данных на вход компаратора; (с) базу данных коллекций файлов, связанную с блоком преобразования; (d) базу данных строк-исключений, связанную с блоком преобразования; (е) компаратор, который осуществляет сравнение объекта данных со всеми объектами коллекций, содержащимися в базе данных коллекций файлов, по строкам и (f) анализатор, который на основе результатов сравнения, выполняемых в компараторе, выявляет степень схожести объекта данных с объектами коллекций и на основе этих результатов относит или добавляет полученный файл к существующей коллекции файлов.
В частном варианте реализации база данных строк-исключений содержит, по меньшей мере, строки упаковщиков, разархивирующие части самораспаковывающихся архивов, служебные части кода, которые добавляются компилятором, код популярных библиотек, имена импортируемых функций, другие строки, которые не отражают функционал данного файла.
Еще в одном частном варианте реализации блок преобразования файла в объект данных распаковывает полученный файл, который представлен в запакованном виде.
В другом частном варианте реализации анализатор относит полученный файл к существующей коллекции, если степень схожести полученного файла с файлом данной коллекции превышает значение первого порога.
В другом частном варианте реализации анализатор добавляет полученный файл в существующую коллекцию, если степень схожести полученного файла с файлом данной коллекции превышает значение второго порога.
В другом частном варианте реализации значения первого и второго порогов рассчитываются по статистическим данным или устанавливаются экспертом исходя из полученного опыта.
В другом частном варианте реализации полученный файл отправляют на дальнейший анализ, в случае если не удалось отнести файл к какой-либо коллекции.
Машиночитаемый носитель для отнесения файла к коллекции файлов содержит компьютерную программу, которая при ее реализации на компьютере выполняет следующие этапы: (а) получают файл, содержащий текстовые поля, который необходимо исследовать; (b) преобразуют полученный файл в объект данных, при этом удаляя строки-исключения из текстовых полей файла; (с) преобразуют файлы из коллекции файлов в коллекцию объектов данных, при этом удаляя строки-исключения из текстовых полей файлов коллекции; (d) сравнивают объект данных со всеми объектами коллекций по строкам; (е) выявляют степень схожести объекта данных с объектами коллекций и (f) в зависимости от значения степени схожести и значений первого и второго порогов, файл относят или добавляют в коллекции файлов или отправляют на дальнейший анализ.
Краткое описание прилагаемых чертежей
Сопровождающие чертежи, которые включены для обеспечения дополнительного понимания изобретения и составляют часть этого описания, показывают варианты осуществления изобретения и совместно с описанием служат для объяснения принципов изобретения.
Фиг.1 показывает пример сравнения двух файлов по строкам.
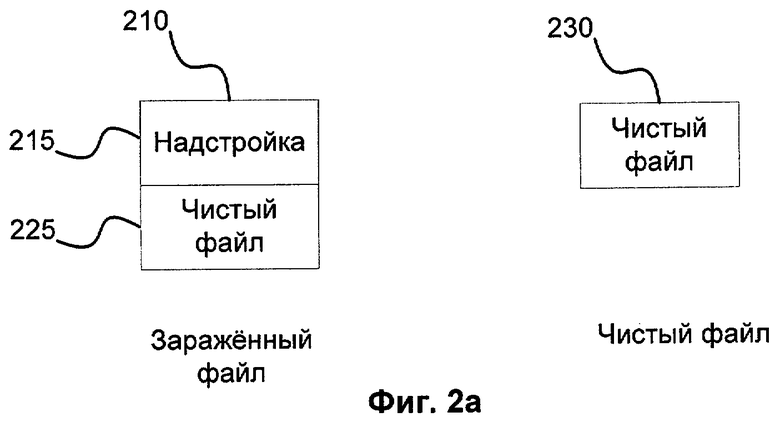
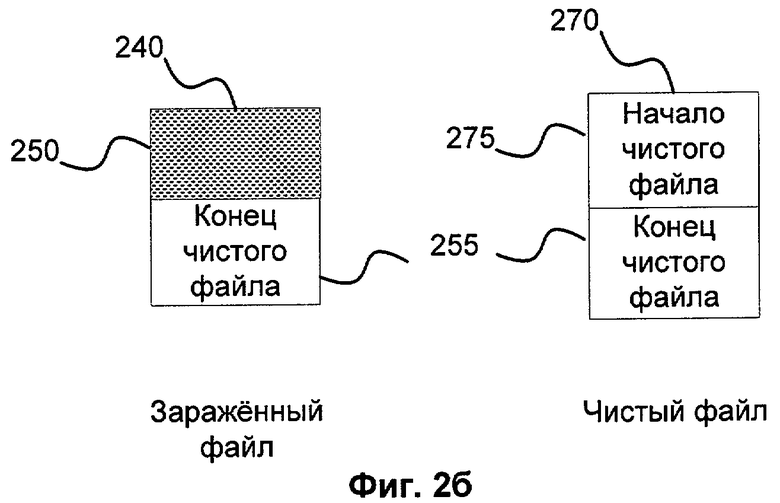
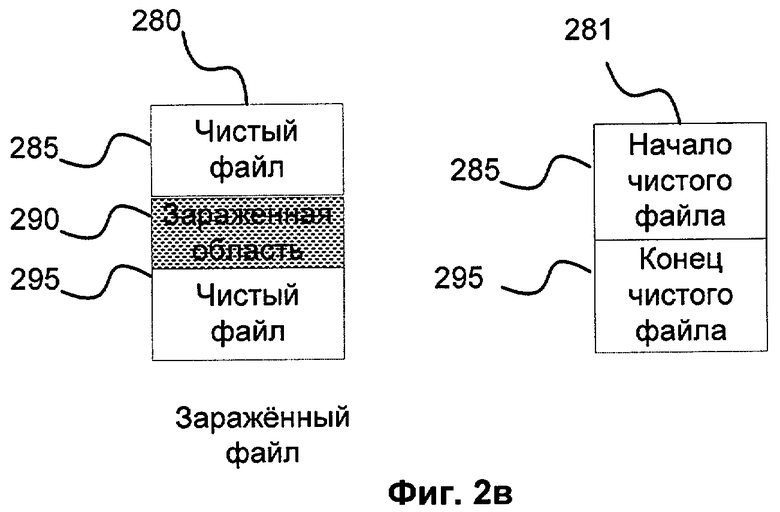
Фиг.2а, 2б и 2в показывают варианты заражения файлов зловредной программой, которая модифицирует чистые файлы путем копирования самой себя в одну из частей файла.
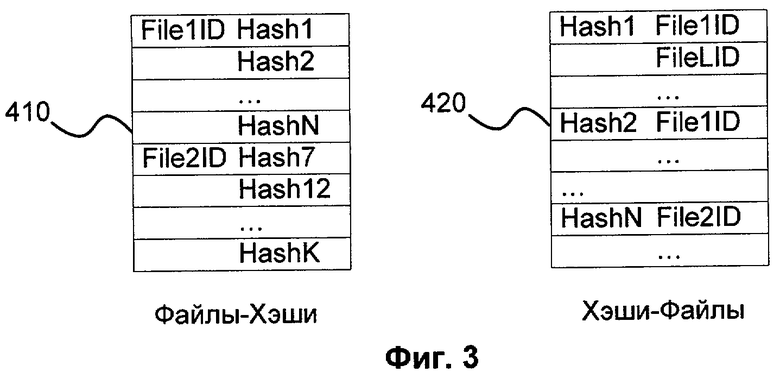
Фиг.3 показывает структуру объекта, в который преобразовали файл.
Фиг.4 показывает алгоритм предобработки коллекции перед процессом поиска.
Фиг.5 показывает алгоритм поиска файла в коллекции.
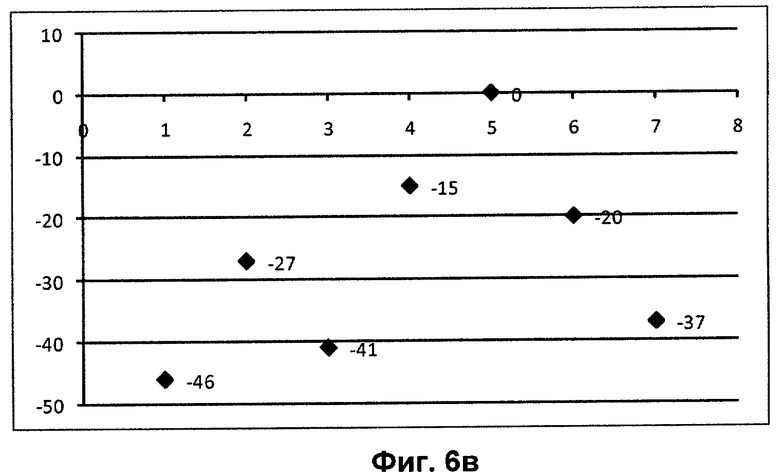
Фиг.6а, 6б, 6в показывают коллекцию файлов с проставленными значениями рейтинга, равными отрицательной сумме количества строк в файле коллекции и количества строк в подозреваемом файле.
Фиг.7 показывает систему, в которой может быть воплощено изобретение.
Подробное описание предпочтительных вариантов реализации
Строки в значительной степени отражают реальный функционал файла. Таким образом, чтобы два файла были признаны похожими по функционалу, множества выделенных из них строк должны пересекаться в значительной степени.
Предлагаемые методы описываются на примере использования в антивирусной индустрии. То есть схожесть исследуемого файла с известным вредоносным файлом позволяет говорить о том, что данный файл может при выполнении нанести ущерб. И наоборот, схожесть исследуемого файла с известным чистым файлом позволяет в некоторых случаях говорить о том, что данный файл, скорее всего, не представляет опасности. Сказать с уверенностью, что файл безвредный, - нельзя, так как вредоносный функционал может быть зашифрован, занимать малую часть чистого файла или не содержать строк, отражающих вредоносный функционал.
Методы так же можно использовать и в других областях, где необходимо производить сравнение объектов и/или поиск объектов на основе некоторых признаков объектов.
Исследуемый файл может быть получен по почте, загружен на сервер, передан на запоминающем устройстве и скопирован с него и т.д.
Коллекции файлов - это собранные, отсортированные по типу и сохраненные в базе данных файлы. Тип файлов может определяться функционалом, содержанием или другими характеристиками. Чем больше численность файлов в коллекции, тем точнее можно будет определить сходство файла с данной коллекцией. В антивирусной индустрии можно выделить две большие группы файлов: зловредные и чистые файлы. Зловредные в свою очередь можно разбить на типы программ различного действия и назначения: троянские программы, вирусы, черви и т.д. Таким образом, можно собрать коллекции копий файлов каждого типа и затем сравнивать интересующий нас файл с данными коллекциями, после чего с определенной точностью относить файл к типу и в некоторых случаях пополнять им коллекцию.
Изложим суть метода сравнения двух файлов по строкам. Принципы извлечения строк будут описаны ниже. Обозначим множество строк первого сравниваемого файла А, второго - В. Будем считать, что два файла похожи, если
Р(А∩В)>Р(АΔВ), где АΔВ - симметрическая разность множеств, А∩В - пересечение множеств, Р(Х) - мощность множества.
Иными словами, два файла похожи, если количество строк, присутствующих в обоих файлах, превышает количество строк, присутствующих только в одном из файлов.
Вводится понятие степень схожести - разность мощности симметрической разности множеств и мощности пересечения множеств. Нетрудно заметить, что два файла похожи, если степень схожести положительна. Отметим так же, что
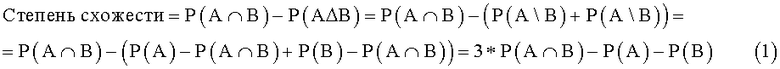
Последней формулой мы будем пользоваться для поиска наиболее похожих на исследуемый файл файлов по коллекции.
Поясним принципы сравнения двух файлов по строкам на примере, изображенном на фиг.1.
В среднем столбце 120 приведены строки, которые присутствуют в обоих файлах. В левом столбце 110 - строки, которые присутствуют только в первом, в правом 130 - только во втором. Степень схожести равна количеству строк в среднем столбце без количества строк в крайних. Файлы считаются похожими по строкам, так как 8-(1+2)=5>0.
Рассмотрим случаи, когда данный подход не позволяет дать точную оценку сходства двух файлов. Различающиеся по функционалу файлы признаются похожими.
Предположим, в коллекции вредоносных объектов есть зараженный вирусом файл notepad.exe 280, изображенный на фиг.2в. Заражение внесло незначительные изменения в файл 281 и в его функционал. Если на анализ впоследствии придет чистый файл notepad.exe, оригинальный компонент ОС Windows 281, то файлы будут признаны похожими, так как внесенное заражением 290 изменение добавило незначительное количество строк по сравнению с общим количеством строк чистого файла 285, 295. Чтобы избежать ложного срабатывания, инфицированные таким образом файлы не участвуют в поиске либо исключаются из результатов поиска.
Среди исполняемых файлов большая часть анализируемых являются РЕ-файлами (Portable Executable). Это - формат исполняемых файлов, используемый операционными системами Windows. РЕ-файлы имеют РЕ-заголовок, благодаря которому мы можем:
- найти начало РЕ-файла в потоке байт,
- определить длину РЕ-файла, используя информацию, записанную в РЕ-заголовке.
На фиг.2а рассмотрен другой тип заражения - паразитирование. Паразитический вирус поражает исполняемые файлы, не повреждая оригинальные данные повреждаемого файла. Создает модификацию 210 чистого файла 230 следующим образом. В начале файла 210 вредоносная часть, а затем уже оригинальный файл 225. Обычно файл 210 имеет имя и иконку, как и у чистого файла 230, а пользователь не видит разницы и запускает файл 210, думая, что это файл 230. Изначально запускается вредоносная часть 215 на фиг.2а. После исполнения вредоносного части 215 запускается чистый файл 225, который также нужен для общей маскировки файла под чистый 230. Предположим, чистая часть 225 существенно больше вредоносной части 215. Тогда при сравнении файлов будет замечено лишь незначительное отличие, что приведет к неправильной классификации файла 230 как вредоносного. Для обхода данной ситуации вводится понятие «pre-ехе сравнение». При нем внутри каждого из сравниваемых файлов ищется внутренний РЕ-файл. Файлы 210, 230, 215 имеют этот формат. В случае нахождения внутренних РЕ-файлов, сравниваемые файлы усекаются в месте нахождения. После этого усеченные файлы сравниваются описанным выше алгоритмом. Файлы признаются похожими, только если их сравнение целиком выявило похожесть, а так же сравнение усеченных файлов выявило похожесть. Заметим, что в результате pre-ехе сравнения будут сравниваться файлы 215 и 230. Они будут признаны различающимися, так как их функционал действительно различен.
На Фиг.2б изображена ситуация, когда у чистого файла 270 перезаписано начало на вредоносный код 250, который является загрузчиком. При получении аналогичного чистого файла выясняется, что они сильно похожи, т.к. вредоносная часть 250 сильно меньше оставшейся чистой части файла 255. И поэтому чистый файл 270 также будет принят за вредоносный. При запуске файла 240 не будет выполняться ожидаемых пользователем действий, т.к. часть оригинального файла перезаписана. Данная ситуация также может быть отловлена аналогично предыдущему примеру. С той лишь разницей, что усечение необходимо производить не в месте обнаружения внутреннего РЕ-файла, а в месте окончания начального РЕ-файла. В данном случае это будет конец файла 250.
Из вышеописанных примеров можно сделать вывод о необходимости выделять из содержимого файла его функционал, по возможности удаляя некоторые общеизвестные безопасные части кода, для чего требуется предобработка файлов.
Предобработка файлов необходима для извлечения значимой для метода информации из файлов. Из файла извлекаются строки:
- символы строк могут быть распечатаны (проверка может быть сделана с помощью функции языка С isprint()),
- строки должны быть длиннее 4 символов,
- строки оканчиваются на \0, \r, \n или концом файла,
- строки приводятся к нижнему регистру,
- извлекаются строки как под кодировкой Unicode, так и под другими кодировками,
- накладываются другие дополнительные ограничения,
- удаляются строки-исключения.
Оставшиеся строки отражают функционал файла. Для упрощения хранения и сравнения от строк вычисляется хеш-функция, например CRC32 или MD5. Согласно исследованиям эта процедура не влияет на качество поиска. В дальнейшем мы будем пользоваться терминами "хэши" и "строки" наравне.
Значительная часть файлов упакована. Это делается для сокрытия функционала файлов от наблюдателя, а также для уменьшения размера исполняемых файлов. Для качественного извлечения строк необходимо получить распакованную версию. Это можно сделать при помощи антивирусного ядра, а также при помощи снятия образа памяти процесса, использования эмуляции или стороннего распаковщика.
Не все строки из файлов отражают их функционал. В файлах, написанных, например, на языке Delphi, будет много строк, относящихся к работе компилятора Delphi, а не к функционалу файла. Это же касается всех других компиляторов, а также Easy-languages (языки программирования для платформ вроде TradeStation). Если файл был упакован упаковщиком или положен в архив, то строки из упаковщика или архиватора также не будут полезны при сравнении.
Если обнаруживается, что два файла, имеющих разный функционал, были упакованы одним упаковщиком, то поэтому они признаются похожими. В этом случае аналитик распознает причину. В данном случае это будет код упаковщика (общая часть файлов). Аналитик извлекает строки из этого кода и добавляет их в список исключений. Очевидно, различные версии одного и того же упаковщика обладают почти одинаковыми наборами строк.
На этапе предобработки выделенные строки, попадающие в список исключений, игнорируются и не участвуют в дальнейшей обработке.
Возможно автоматическое пополнение списка исключений. Возможен различный формат этого списка, например регулярные выражения.
В списки исключений попадают строки
- из упаковщиков,
- из разархивирующей части самораспаковывающихся архивов,
- из служебных частей кода, добавляемых компилятором в файлы,
- из популярных библиотек, используемых в различных файлах,
- имена импортируемых функций,
- другие строки, которые не отражают основной функционал данного файла.
На этапе предобработки коллекции файлов получается массив из структур данных: идентификатор файла и хэши извлеченных из него строк.
Данные, подготовленные на этапе предподготовки, которые можно условно назвать файлы-хэши, сортируются в структуру данных, называемую файлы-хэши. При этом для каждого уникального хэша находим все файлы, в которых встречается соответствующая строка. Это делается для ускорения процедуры поиска. Посчитаем так же количество строк в каждом из файлов и сохраним его в массиве для последующего использования. На фиг.3 изображена структура файлы-хэши 310. Из файла с идентификатором File1ID были выбраны строки с хешами Hash1, Hash2, …, HashN. Из файла с идентификатором File2ID были выбраны строки с хешами Hash7, Hash12, …, HashK. И так далее. Также на фиг.3 изображена структура хеши-файлы 320. Строку с хэшем Hash1 содержат файлы с идентификаторами File1ID, FileLID, …. Строку с хэшем Hash2 содержат файлы с идентификаторами File1ID, FileNID, … и т.д.
На Фиг.4 изображен алгоритм создания структур данных и поиска по ним. Открывается коллекция файлов для предобработки. Далее следует цикл, в котором получают файл для проверки 420, выделяют из него строки 425, проверяются критерии строк 430 и удаляются исключения 435. После того, как все файлы коллекции преобразовали, создается структура данных 440, представляющая собой массив из идентификаторов файла и значений хэш-функций от строк, содержащихся в данном файле. На основе этой структуры создается обратная ей, представляющая собой массив данных из значений хэш-функций от строк и идентификаторов файлов, содержащих данную строку 445. Представление информации в данном виде существенно ускоряет процесс поиска. Далее аналогичный процесс проходит с набором исследуемых файлов: получают исследуемый файл на обработку 460, выделяют из него строки 465, проверяются критерии строк 470 и удаляются исключения 475. Проводится поиск строк в массивах по равным значениям хэш-функций, из которых выявляются похожие файлы. После этого процесс завершается и готов к исследованию следующего файла. Далее описан более детальный процесс расчета рейтинга и определения файлов с наибольшей степенью схожести.
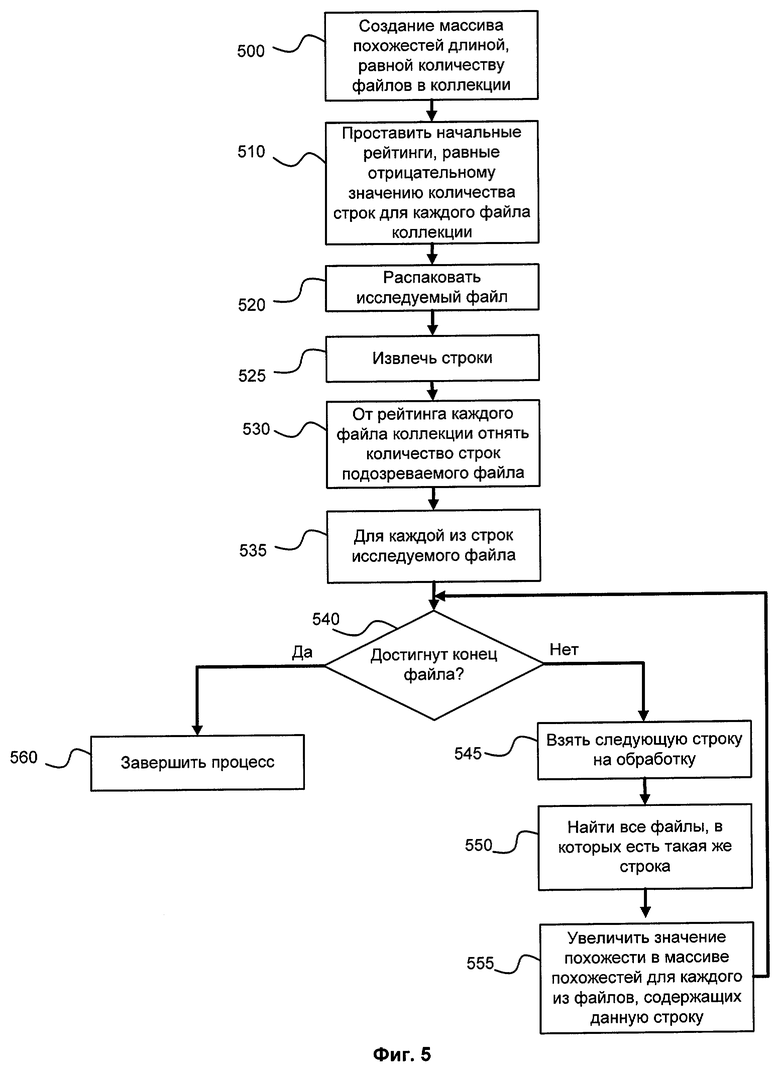
На фиг.5 изображен алгоритм поиска файла в коллекции. Определим массив, длина которого равна количеству файлов в коллекции. Элементами этого массива будет похожесть исследуемого файла на каждый из файлов коллекции. В процессе поиска будем заполнять этот массив значениями степени схожести на этапе 500. По окончании заполнения найдем максимальный элемент массива, соответствующий ему файл в коллекции будет наиболее похожим на исследуемый. Изложим более детально процесс заполнения этого массива.
В соответствии с выведенной формулой (1) похожесть двух файлов равна утроенному количеству строк, присутствующих в обоих файлах, вычесть количество строк в первом файле и количество строк во втором файле.
Преобразуется исследуемый файл в соответствии с изложенными выше принципами на этапах 320, 325. В результате получим множество строк исследуемого файла. Заполняется массив схожестей количеством строк в исследуемом файле со знаком «-» на этапе 310. Из каждого элемента массива вычитается количество строк в соответствующем файле коллекции на этапе 330. Эти значения были посчитаны на этапе построения базы для поиска.
Теперь, чтобы получить похожесть в соответствии с (1), к элементам осталось добавить утроенное количество пересекающихся строк исследуемого файла и соответствующего файла коллекции. Для этого для каждой строки исследуемого файла 335 определим по базе для поиска множество тех файлов, которые содержат эту строку 350. В массиве похожестей каждому из элементов, соответствующих этим файлам, добавим 3 на шаге 355. Перейдем к следующей строке исследуемого файла и повторим процедуру на шаге 340.
По окончании этого процесса мы получим массив, заполненный похожестями исследуемого файла на каждый из файлов в коллекции. Отметим особо, что этот процесс происходит очень быстро. Этапы 335 - 355 требует количества операций, равного сумме «популярностей» (частоты встречаемости) строк исследуемого файла. Скажем, если в исследуемом файле имеются три строки, которые встречаются соответственно в 1000, 10 и 100 файлах в коллекции соответственно, то количество операций на этапах 335-355 равно 1000+10+100=1110.
Получив в итоге общий массив похожестей, можно сделать вывод, что те файлы коллекции, у которых похожесть положительная, похожи на исследуемый файл. Для файлов с отрицательной похожестью считается, что файлы не похожи.
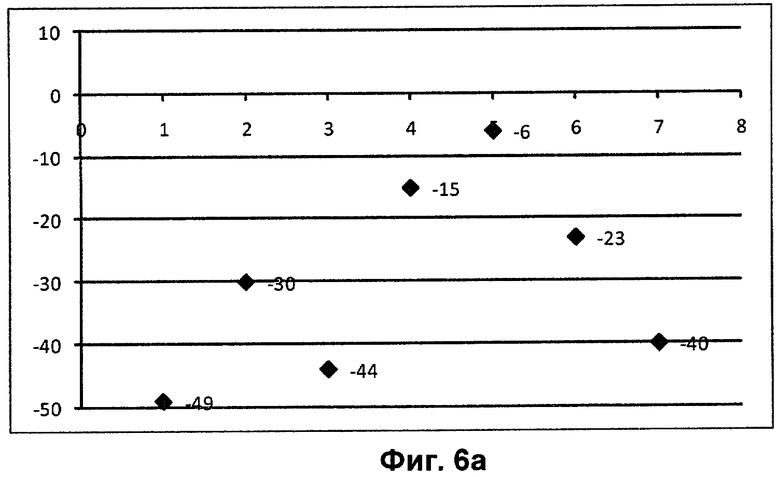
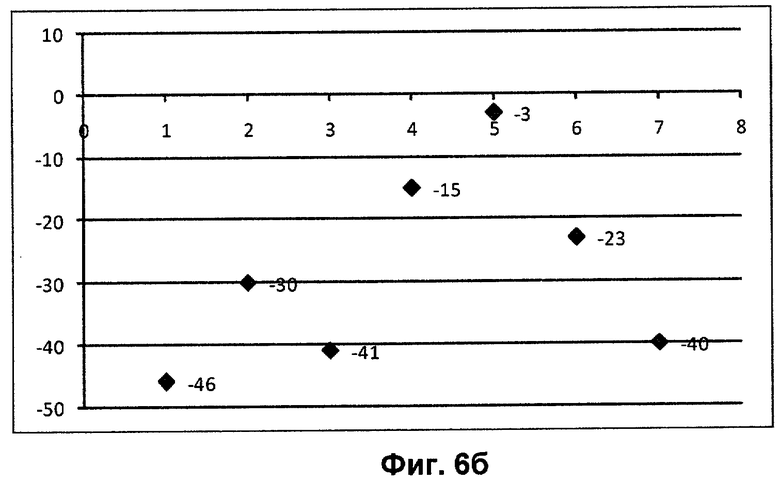
На фиг.6а изображена коллекция файлов с проставленными значениями рейтинга, равными отрицательной сумме количества строк в файле коллекции и количества строк в подозреваемом файле. Затем выполняется цикл для всех строк подозреваемого файла. На фиг.6б приводятся значения рейтингов для файлов, которые содержат первую строку подозреваемого файла. Такими файлами являются 1, 3, 5 элементы коллекции. На фиг.6в приводятся файлы, содержащие вторую строку подозреваемого файла - 2, 5, 6, 7 элементы коллекции.
Таким образом, в результате выявления сходства с файлом из коллекции файлов, можно сделать вывод, что данный файл обладает свойствами, характерными для данной коллекции.
Не всегда наличие общих строк, несущих функциональный смысл, определяет привязанность к той или иной коллекции. Поэтому необходимо определить некое пороговое значение степени схожести, преодолевая которую файлу можно приписать свойства схожей коллекции. Это значение будет первым порогом степени схожести.
Второй порог степени схожести определяет границу, за которой файлам приписываются свойства схожей коллекции и сохраняют в ней.
Значения данных порогов являются параметрами системы и могут быть изменены вручную или рассчитаны в зависимости от степени схожести файлов в коллекции между собой.
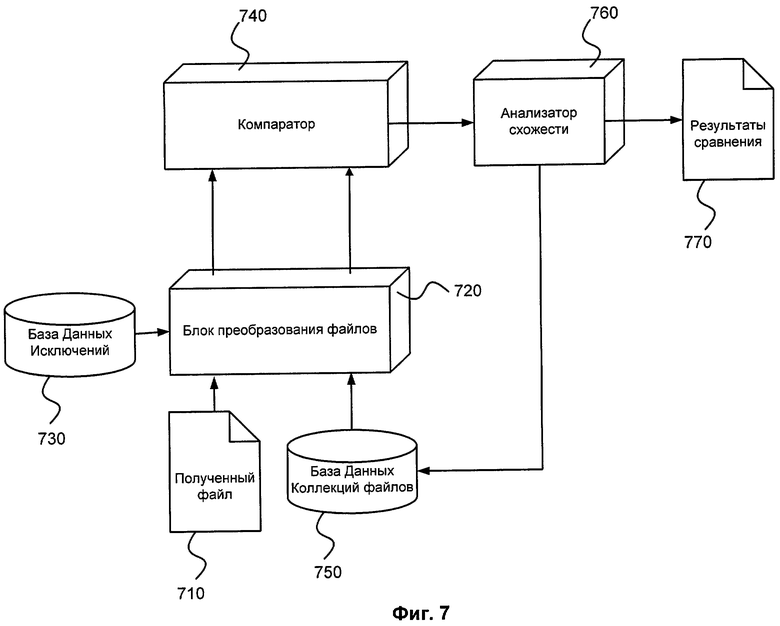
На фиг.7 изображена система, которая реализует описанный выше метод. Она состоит из баз данных, хранящих коллекции файлов 750 и исключения строк 730, блока преобразования файлов 720, компаратора 740, анализатора 760, полученного файла 710 и интерфейса с результатами 770.
Из полученного файла 710 выделяются строки, удаляются исключения и полученный результат сохраняется в виде массива данных как содержащий идентификатор файла и значения хэш-функции, рассчитанной от каждой строки, удовлетворяющей условиям. Эти операции осуществляются в блоке преобразования файлов 720, который проделывает цикл вышеописанных операций и для файлов из коллекции. Исключения строк хранятся отдельно в базе данных 730, которая может быть пополнена или отредактирована. На выходе получается два объекта: преобразованный файл и преобразованная коллекция файлов. Эти объекты попадают на вход компаратора 740, который для каждого файла ищет и рассчитывает количество совпадающих строк в исследуемом файле и каждом файле коллекции 750. Эти данные попадают в анализатор 760, в котором рассчитывается степень схожести и происходит сравнение с пороговыми значениями. Далее в зависимости от результата сравнения анализатор либо добавляет файл в коллекцию, либо делает вывод о сходстве файла с данной коллекцией, но не пополняет ее, либо отправляет файл на дальнейшее исследование. При этом результаты преобразования, сравнения и расчета человек может дополнительно наблюдать с помощью интерфейса 770.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объема настоящего изобретения, описанного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВАНИИ СХОДСТВА РЕСУРСОВ ИСПОЛНЯЕМЫХ ФАЙЛОВ | 2013 |
|
RU2541120C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| СИСТЕМА И СПОСОБ СРАВНЕНИЯ ФАЙЛОВ НА ОСНОВЕ ШАБЛОНОВ ФУНКЦИОНАЛЬНОСТИ | 2009 |
|
RU2427890C2 |
| Система и способ обнаружения вредоносных файлов с использованием элементов статического анализа | 2017 |
|
RU2654146C1 |
| Система и способ обнаружения вредоносных файлов на мобильных устройствах | 2015 |
|
RU2614557C2 |
| Система и способ блокировки выполнения сценариев | 2015 |
|
RU2606564C1 |
| Система и способ выбора средства обнаружения вредоносных файлов | 2019 |
|
RU2739830C1 |
| СПОСОБ И СИСТЕМА АНАЛИЗА РАБОТЫ ПРАВИЛ ОБНАРУЖЕНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2013 |
|
RU2568285C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ВРЕДОНОСНЫХ ФАЙЛОВ В НЕИЗОЛИРОВАННОЙ СРЕДЕ | 2020 |
|
RU2722692C1 |

Изобретение относится к системам и методам сравнения файлов и более конкретно к отнесению данного файла к определенной коллекции в зависимости от степени схожести. Технический результат заключается в ускорении процесса детектирования программ антивирусной индустрии. Рассчитывают результаты расчета степени схожести между ними, достигается за счет преобразования файлов в массивы данных, содержащих значения хэш-функций от текстовых строк файла, без учета присутствия строк-исключений, что позволяет сократить время на сравнение строк, не несущих функциональной нагрузки. Вычисляют степень схожести строк из полученного файла со строками из коллекции фалов. На основании уровня схожести судят о принадлежности файла к какой-либо из коллекций. 3 н. и 14 з.п ф-лы, 11 ил.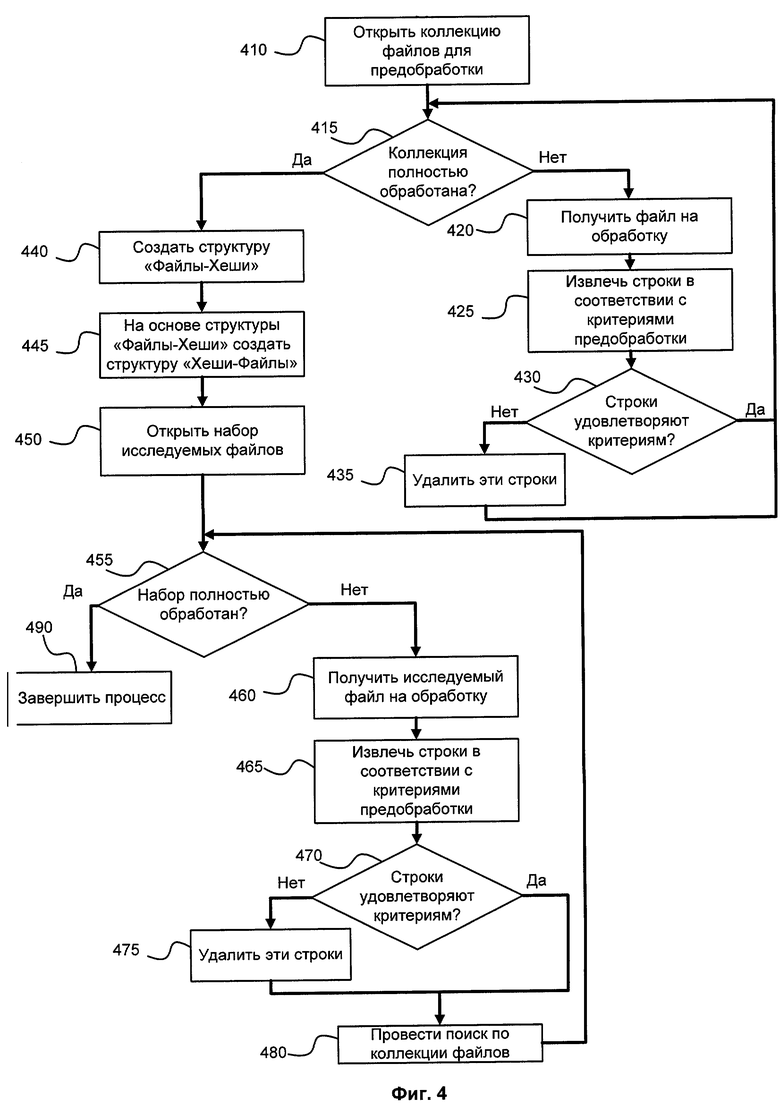
1. Способ отнесения файла к коллекции файлов, содержащий этапы, на которых
(а) получают файл, содержащий текстовые поля, который необходимо исследовать;
(б) преобразуют полученный файл в объект данных, при этом удаляя строки-исключения из текстовых полей файлов;
(в) преобразуют файлы из коллекции файлов в коллекцию объектов данных, при этом удаляя строки-исключения из текстовых полей файлов коллекции;
(г) сравнивают объект данных со всеми объектами коллекций по строкам;
(д) выявляют степень схожести объекта данных с объектами коллекций; и
(е) в зависимости от значения степени схожести и значений первого и второго порогов файл относят или добавляют в коллекции файлов или отправляют на дальнейший анализ.
2. Способ по п.1, в котором строки-исключения могут представлять собой строки упаковщиков, разархивирующие части самораспаковывающихся архивов, служебные части кода, которые добавляются компилятором, код популярных библиотек, имена импортируемых функций, другие строки, которые не отражают функционал данного файла.
3. Способ по п.1, в котором полученный файл, представленный в запакованном виде, распаковывается перед преобразованием.
4. Способ по п.1, в котором преобразование файла состоит из извлечения из файла строк, удаления строк-исключений и создания массива данных, включающего в себя, по меньшей мере, идентификатор файла и результат расчета хэш-функции от извлеченных строк, выделенных из этого файла.
5. Способ по п.4, в котором массив данных преобразуют в другой массив данных, включающий в себя, по меньшей мере, результат расчета хэш-функции от извлеченной строки и идентификаторы файлов, в которых содержится эта строка.
6. Способ по п.1, в котором полученный файл относят к существующей коллекции, если степень схожести исследуемого файла с файлами данной коллекции превышает значение первого порога.
7. Способ по п.1, в котором полученный файл добавляют в существующую коллекцию, если степень схожести полученного файла с объектом данной коллекции превышает значение второго порога.
8. Способ по п.6 или 7, в котором значения первого и второго порогов рассчитываются по статистическим данным или устанавливаются экспертом исходя из полученного опыта.
9. Способ по п.1, в котором полученный файл отправляют на дальнейший анализ, в случае если не удалось отнести файл к какой-либо коллекции.
10. Система отнесения файла к коллекции файлов, содержащая:
блок загрузки файла;
блок преобразования файлов, которыми являются файлы из базы данных коллекции файлов или файл из блока загрузки файла, в коллекцию объектов или объект данных соответственно, путем извлечения из файлов строк, удаления из них строк-исключений из базы данных строк-исключений, создания массива данных, содержащего, по меньшей мере, идентификатор файла и результаты расчета хэш-функции от извлеченных строк, содержащихся в этих файлах, преобразования этого массива в другой массив, включающий в себя, по меньшей мере, значение хэш-функции от строки и идентификаторы файлов, в которых содержится эта строка, и передачи результирующей коллекции объектов или объекта данных на вход компаратора;
базу данных коллекций файлов, связанную с блоком преобразования;
базу данных строк-исключений, связанную с блоком преобразования;
компаратор, который осуществляет сравнение объекта данных со всеми объектами коллекций, содержащимися в базе данных коллекций файлов, по строкам;
анализатор, который на основе результатов сравнения, выполняемых в компараторе, выявляет степень схожести объекта данных с объектами коллекций и на основе этих результатов относит или добавляет полученный файл к существующей коллекции файлов.
11. Система по п.10, в которой база данных строк-исключений содержит, по меньшей мере, строки упаковщиков, разархивирующие части самораспаковывающихся архивов, служебные части кода, которые добавляются компилятором, код популярных библиотек, имена импортируемых функций, другие строки, которые не отражают функционал данного файла.
12. Система по п.10, в которой блок преобразования файла в объект данных распаковывает полученный файл, который представлен в запакованном виде.
13. Система по п.10, в которой анализатор относит полученный файл к существующей коллекции, если степень схожести полученного файла с файлом данной коллекции превышает значение первого порога.
14. Система по п.10, в которой анализатор добавляет полученный файл в существующую коллекцию, если степень схожести полученного файла с файлом данной коллекции превышает значение второго порога.
15. Система по п.13 или 14, в которой значения первого и второго порогов рассчитываются по статистическим данным или устанавливаются экспертом исходя из полученного опыта.
16. Система по п.10, в которой полученный файл отправляют на дальнейший анализ, в случае если не удалось отнести файл к какой-либо коллекции.
17. Машиночитаемый носитель для отнесения файла к коллекции файлов, содержащий компьютерную программу, которая при ее реализации на компьютере выполняет следующие этапы:
(а) получают файл, содержащий текстовые поля, который необходимо исследовать;
(б) преобразуют полученный файл в объект данных, при этом удаляя строки-исключения из текстовых полей файла;
(в) преобразуют файлы из коллекции файлов в коллекцию объектов данных, при этом удаляя строки-исключения из текстовых полей файлов коллекции;
(г) сравнивают объект данных со всеми объектами коллекций по строкам;
(д) выявляют степень схожести объекта данных с объектами коллекций; и
(е) в зависимости от значения степени схожести и значений первого и второго порогов, файл относят или добавляют в коллекции файлов или отправляют на дальнейший анализ.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 6738515 B1, 08.05.2004 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| RU 2007140042 A, 10.05.2009. | |||

