ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Данная заявка испрашивает приоритет по предварительной заявке на выдачу патента США № 61/945,917, поданной 28 февраля 2014 года, и заявке на выдачу патента США № 14/561,215, поданной 4 декабря 2014 года, содержимое которых включено в материалы настоящей заявки посредством ссылки. Данная заявка связана с патентом США № 8,950,662, выданным 10 февраля 2015 года, и с предварительными заявками на выдачу патента США № 61/605,369, поданной 1 марта 2012; № 61/676,113, поданной 26 июля 2012; и № 61/717,711, поданной 24 октября 2012. Содержимое каждого из этих документов включено в материалы настоящей заявки посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее раскрытие в целом относится к технологии машинного зрения и, более конкретно, к способам и системе для проверки подлинности напечатанного предмета.
УРОВЕНЬ ТЕХНИКИ
[0003] Некоторые современные способы для проверки подлинности напечатанного предмета обычно основаны на открытых или скрытых метках, преднамеренно нанесенных на предмет, обычно посредством печати. Другие способы опираются на естественные изменения в подложке материала (ориентации волокон в бумаге, например), который должен использоваться в качестве уникального идентификатора. В существующей технологии имеются значительные недостатки. Они включают в себя необходимость преднамеренно добавлять открытые или скрытые метки на предмет вдобавок к любым меткам, уже присутствующим на предмете для других целей. В случае способа изменения подложки, необходима специализированная система, которая воспринимает изменения. Кроме того, для подложек, которые не вносят легко идентифицируемый уникальный признак, (некоторых пластиковых пленок, например) этот способ не может быть использован. Эти недостатки существенно снижают полезность этих способов в технических областях, рассматриваемых в материалах настоящей заявки.
ЧЕРТЕЖИ
[0004] В то время как прилагаемая формула изобретения подробно излагает признаки настоящих методик, эти методики, вместе со своими целями и преимуществами, проще всего понять из дальнейшего подробного описания, взятого в соединении с прилагаемыми чертежами, на которых:
[0005] Фиг. 1 - иллюстрация примера напечатанной метки, используемой посредством способов согласно варианту осуществления.
[0006] Фиг. 2 - иллюстрация метки по фиг. 1 с признаками границ метки, извлеченными для ясности.
[0007] Фиг. 3 - иллюстрация второго примера той же самой метки, что и на фиг. 1, которая может представлять поддельную версию метки по фиг. 1.
[0008] Фиг. 4 - иллюстрация метки по фиг. 3 с признаками границ метки, извлеченными для ясности.
[0009] Фиг. 5 - пример двумерной матрицы данных, напечатанной посредством процесса термопереноса, иллюстрирующий некоторые признаки, которые могут использоваться в настоящих способах.
[0010] Фиг. 6 - иллюстрация, сравнивающая признаки верхних левых секций по фиг. 2 и фиг. 4.
[0011] Фиг. 7 - пример фотокопии матрицы данных, схожей с таковой по фиг. 5.
[0012] Фиг. 8 - схема компьютерной системы.
[0013] Фиг. 9 - структурная схема компьютерной системы, работоспособной для выполнения процесса согласно варианту осуществления.
[0014] Фиг. 10 - блок-схема последовательности операций варианта осуществления способа записи новой метки.
[0015] Фиг. 11 - диаграмма взвешивания признаков характеристик.
[0016] Фиг. 12 - блок-схема последовательности операций варианта осуществления способа оценивания метки.
[0017] Фиг. 13 - сравнительный гарфик величин артефактов.
[0018] Фиг. 14 - часть фиг. 13, в более крупном масштабе, чем на фиг. 13.
[0019] Фиг. 15 - одномерный штриховой код, иллюстрирующий некоторые признаки, которые могут использоваться в варианте осуществления.
[0020] Фиг. 16 - график полиномиальной аппроксимации автокорреляционных рядов для подлинного предмета с подлинным «проверяемым» символом.
[0021] Фиг. 17 - график степенных рядов для подлинных данных по фиг. 16.
[0022] Фиг. 18 - график, схожий с фиг. 17, для «проверяемых» данных по фиг. 16.
[0023] Фиг. 19 - график, схожий с фиг. 17, для поддельного «проверяемого» символа.
[0024] Фиг. 20 - график, схожий с фиг. 17, для поддельных данных, используемых на фиг. 19.
[0025] Фиг. 21 - график моментов инерции для измерения контраста.
ОПИСАНИЕ
[0026] Настоящее раскрытие относится к использованию изменений, которые ранее рассматривались, как слишком маленькие, чтобы быть надежными для проверки подлинности, чтобы детектировать определенные категории механических копий подлинных предметов.
[0027] Аспекты настоящего раскрытия находятся в технической области борьбы с подделками и присвоения серийных номеров предметам для целей безопасности цепочки поставок на основе отслеживания и контроля.
[0028] В одном из вариантов осуществления, например, оригинальный предмет, напечатанный, используя процесс термопереноса или струйной печати, содержит в высокой степени однородные, сплошные, черные или другие напечатанные области. Процессы электростатической печати обычно производят напечатанные области, в которых черные области являются более серыми при низком разрешении и пятнистыми при высоком разрешении. Различие является очень незначительным, но, посредством методик, раскрытых в данной спецификации, различие может быть детектировано с достаточным уровнем достоверности, в достаточной доле случаев, чтобы являться полезными при разграничении напечатанного с помощью термопереноса оригинала и фотокопии этого оригинала.
[0029] Один из раскрытых вариантов осуществления предоставляет способ проверки подлинности напечатанного предмета, состоящий в том, что: проверяют непроверенный предмет на непроверенные артефакты, характерные для непроверенного предмета; извлекают информацию, связанную с непроверенными артефактами; извлекают сохраненные данные, содержащие информацию, связанную с оригинальными артефактами оригинального предмета, из устройства хранения; ранжируют непроверенную информацию согласно величине характеристики либо непроверенных артефактов, либо оригинальных артефактов; сравнивают ранжированную информацию, связанную с непроверенными артефактами, и информацию, связанную с оригинальными артефактами, соответственно, отранжированными отдельно для артефактов в первом диапазоне величин и артефактов во втором диапазоне величин, при этом второй диапазон включает в себя более мелкие артефакты, чем самые мелкие артефакты в первом диапазоне; и когда разница между информацией, связанной с непроверенными артефактами, и информацией, связанной с оригинальными артефактами, выше для второго диапазона, чем для первого, более чем на пороговое значение, идентифицируют непроверенный предмет, как копию.
[0030] В настоящей заявке термин «напечатанный» должен пониматься в широком смысле, как включающий в себя любой процесс, формирующий символ, который мог бы быть разумно имитирован посредством процесса формирования изображения. Раскрытые способы главным образом (хотя и не исключительно) связаны с детектированием фотокопий, поэтому термин «напечатанный предмет» включает в себя что угодно, что может быть подвергнуто фотокопированию. Это включает в себя не только процессы нанесения картины чернилами, пигментом, красителем или тому подобным одного цвета (не обязательно черного или черноватого) на подложку второго цвета (не обязательно белого или беловатого), но также аблятивные процессы, в которых изначально присутствует поверхностный слой или покрытие второго цвета, и его часть удаляется для формирования картины. Ссылки на «принтер», соответственно, должны пониматься в широком смысле.
[0031] Как более подробно пояснено ниже, «более мелкие артефакты, чем самые мелкие артефакты в первом диапазоне» могут включать в себя, или состоять из местоположений, в которых вообще нет артефактов, или нет артефактов, детектируемых из статистического шума системы детектирования, или детектируется только шум.
[0032] Разница может являться средней или агрегированной разницей в величинах или отношением величин артефактов, или статистической мерой изменения в величинах артефактов.
[0033] Вариант осуществления дополнительно состоит в том, что, перед сравнением, по отдельности: сравнивают информацию, связанную с непроверенными артефактами, и информацию, связанную с оригинальными артефактами, для артефактов, имеющих величину в первом диапазоне; оценивают статистическую вероятность того, что информация непроверенных артефактов соответствует информации оригинальных артефактов; в случае если статистическая вероятность превышает первое пороговое значение, определяют, что непроверенный предмет является проверенным оригинальным предметом; в случае если статистическая вероятность меньше второго порогового значения, которое ниже первого порогового значения, определяют, что непроверенный предмет не является оригинальным предметом; и выполняют этап сравнения по отдельности только в том случае, если статистическая вероятность находится между первым и вторым пороговыми значениями.
[0034] Первый диапазон может включать в себя предопределенное количество артефактов, имеющих самые высокие величины, и/или второй диапазон может включать в себя предопределенное количество артефактов, имеющих самые низкие величины или самые низкие величины выше порогового значения детектирования. Первый и второй диапазоны могут перекрываться.
[0035] Вариант осуществления дополнительно содержит расчет автокорреляционных рядов ранжированной информации непроверенных артефактов для каждого из первого и второго диапазонов, где сравнение содержит отдельное сравнение непроверенного и оригинального автокорреляционных рядов для каждого из первого и второго диапазонов. Сохраненные данные могут содержать данные, представляющие автокорреляционные ряды ранжированных артефактов оригинального предмета для каждого из первого и второго диапазонов, или автокорреляционные ряды для артефактов оригинального предмета могут генерироваться только в момент сравнения.
[0036] По меньшей мере некоторые из артефактов могут являться артефактами символа, который кодирует данные и поддерживает детектирование ошибок, и извлечение информации, представляющей непроверенные артефакты, может включать в себя определение состояния ошибки символа, содержащего непроверенные артефакты. Состояние ошибки может обозначать, что часть символа повреждена, и в этом случае сравнение может содержать уменьшение значимости артефактов в поврежденной части символа.
[0037] В целом «уменьшение значимости» артефакта включает в себя придание этому артефакту более низкого статистического ранга, чем другим сравнимым артефактам, размещение этого артефакта в отдельном классе артефактов, которые не могут быть точно оценены и/или ранжированы, отношение к этому артефакту, как к местоположению без детектированного артефакта этой категории, и полное игнорирование этого артефакта. Разные подходы из упомянутых подходов могут применяться в разных точках даже в пределах одного варианта осуществления.
[0038] Сравнение может включать в себя поправку на свойства по меньшей мере одного из: устройства, которое создало оригинальные артефакты, устройства, используемого при проверке оригинального предмета на информацию, представляющую оригинальные артефакты, и устройства, используемого при проверке непроверенного предмета на информацию, представляющую непроверенные артефакты.
[0039] Артефакты могут относиться к отдельным категориям. Определение того, соответствует ли информация непроверенных артефактов информации оригинальных артефактов, может содержать сравнение непроверенных артефактов и оригинальных артефактов в каждой категории и объединение результатов сравнений. Поправка может содержать взвешивание объединения согласно известной тенденции устройства, которое создало оригинальные артефакты, производить артефакты в разных категориях с разными частотами или разными значениями характеристики.
[0040] Вариант осуществления дополнительно состоит в том, что: проверяют оригинальный напечатанный предмет на артефакты, характерные для предмета; извлекают информацию, связанную с артефактами; ранжируют информацию согласно характеристике артефактов; и сохраняют данные, представляющие ранжированную информацию, в виде упомянутых сохраненных данных на энергонезависимом машиночитаемом устройстве хранения отдельно от оригинального предмета.
[0041] По меньшей мере некоторые из артефактов могут являться артефактами, которые не могут быть произведены управляемым образом при производстве оригинального предмета.
[0042] Оригинальный предмет может содержать метку, которая содержит идентификатор и по меньшей мере один артефакт, при этом идентификатор связан с оригинальным предметом, и по меньшей мере один артефакт не изменяет связь. В этом случае, сохранение может содержать сохранение информации таким образом, чтобы ее можно было по меньшей мере частично локализовать, используя идентификатор.
[0043] Вариант осуществления предоставляет систему для проверки подлинности предмета посредством вышеупомянутого способа, содержащую проверочное сканирующее устройство, работоспособное для проверки непроверенного предмета и излечения информации, представляющей непроверенные артефакты непроверенного предмета, и процессор, работоспособный для извлечения из устройства хранения сохраненных данных, содержащих информацию, представляющую ранжированные оригинальные артефакты оригинального предмета, сравнения информации непроверенных и оригинальных артефактов, и производства вывода в зависимости от результатов сравнения.
[0044] Вариант осуществления предоставляет систему для проверки подлинности предмета посредством вышеупомянутого способа, содержащую сканирующее устройство оригинального предмета, работоспособное для проверки предмета и извлечения информации, представляющей непроверенные артефакты предмета, кодирующее устройство, работоспособное для ранжирования информации согласно характеристике артефактов, и кодирования извлеченной информации в машиночитаемые данные, и машиночитаемое устройство хранения, работоспособное для хранения данных.
[0045] Система может дополнительно содержать устройство производства оригинального предмета, работоспособное для производства оригинального предмета, при этом артефакты являются признаками предмета, которые формируются при производстве предмета посредством устройства производства оригинального предмета, и по меньшей мере некоторые из артефактов не могут быть произведены управляемым образом посредством устройства производства оригинального предмета.
[0046] Система может дополнительно содержать по меньшей мере один оригинальный предмет, для которого ранжированные данные артефактов хранятся на машиночитаемом устройстве хранения.
[0047] Вариант осуществления предоставляет энергонезависимое машиночитаемое устройство хранения, которое хранит машиночитаемые команды, которые, при выполнении на подходящем вычислительном процессоре, проверяют подлинность предмета согласно одному из вышеупомянутых способов.
[0048] Вариант осуществления предоставляет способ проверки подлинности напечатанного предмета, состоящий в том, что: формируют изображение напечатанных областей непроверенного напечатанного предмета; извлекают информацию, связанную с пространственным контрастом напечатанных областей; извлекают из устройства хранения сохраненные данные, содержащие информацию, связанную с пространственным контрастом соответствующих напечатанных областей оригинального предмета; сравнивают информацию, связанную с пространственным контрастом соответствующих напечатанных областей непроверенного напечатанного предмета и оригинального напечатанного предмета; и, когда разница в информации, связанной с пространственным контрастом соответствующих напечатанных областей непроверенного напечатанного предмета и оригинального напечатанного предмета, превосходит пороговое значение, идентифицируют непроверенный предмет, как копию.
[0049] Информация, связанная с пространственным контрастом напечатанных областей, может являться моментом инерции матрицы совпадений уровня серого.
[0050] Соответствующая информация с множества меток или других напечатанных предметов может сохраняться в одном устройстве хранения, например, в форме базы данных, и, используя идентификатор из одной из упомянутых меток, можно извлекать соответствующую информацию из определенного количества меток, меньшего, чем упомянутое множество меток, и содержащего упомянутую одну метку. В примере идентификатор может идентифицировать группу или категорию предметов. В этом случае, идентификатор можно использовать, чтобы извлекать из базы данных только сохраненную информацию, относящуюся к предметам в этой группе категорий, снижая сложность дальнейшего поиска для идентификации информации одного предмета. В другом примере, меньшее количество меток может являться только одной меткой. Например, идентификатор может являться уникальным идентификатором (UID), который явным образом идентифицирует только один предмет, и информация может сохраняться таким образом, чтобы ее можно было извлечь, используя UID.
[0051] Сохраненная информация может включать в себя информацию, указывающую на тип принтера, используемого при создании оригинальных артефактов. Сохраненная информация может включать в себя информацию, указывающую на разрешение устройства, используемого при проверке оригинального предмета.
[0052] Если артефакты относятся к разным категориям, определение того, соответствует ли информация непроверенных артефактов информации оригинальных артефактов, может содержать сравнение детектированных артефактов в каждой категории и объединение результатов сравнений, а поправка может содержать взвешивание объединения согласно известной тенденции устройства, которое создало оригинальные артефакты, производить артефакты в разных категориях с разными частотами или разными величинами.
[0053] Извлечение информации может дополнительно содержать определение типа принтера, используемого для производства артефактов, где артефакты относятся к множеству отдельных категорий. В этом случае, кодирование ранжированной информации оригинальных артефактов и сохранение могут содержать по меньшей мере одно из ранжирования разных категорий артефактов согласно типу принтера и сохранения данных, указывающих на тип принтера, в виде части сохраненных данных. Эта информация может быть полезной, так как разные типы принтеров могут производить разные категории артефактов с разными диапазонами величин, более или менее часто, или с другими изменениями, которые могут влиять на то, как можно оценивать разные категории артефактов, или какие веса им придавать.
[0054] Другая информация, относящаяся к оригинальному предмету, может быть включена в сохраненные данные вдобавок к информации, представляющей оригинальные артефакты. Другая информация об оригинальном предмете может включать в себя серийный номер, характерный для оригинального предмета. В этом случае, такая другая информация может быть восстановлена из извлеченных сохраненных данных вдобавок к информации, представляющей оригинальные артефакты.
[0055] Если по меньшей мере некоторые из артефактов являются артефактами символа, который кодирует данные, и закодированные данные включают в себя уникальный идентификатор (UID) для отдельного экземпляра символа или другие идентифицирующие данные, сохраненные данные могут храниться таким образом, чтобы их можно было извлечь, используя UID или другие идентифицирующие данные. Если другие идентифицирующие данные лишь частично идентифицируют символ, например, идентифицируют категорию или группу предметов, меньшую, чем все предметы, для которых данные хранятся в базе данных, данные могут храниться таким образом, чтобы сохраненные данные для категории или группы можно было извлечь с помощью идентификатора, который можно получить из других идентифицирующих данных. Затем, сохраненные данные о требуемом отдельном оригинальном предмете могут быть извлечены посредством дальнейшего поиска в пределах извлеченной группы.
[0056] Если кодирование ранжированной информации оригинальных артефактов содержит расчет автокорреляционных рядов ранжированной информации оригинальных артефактов, кодирование может дополнительно содержать представление или аппроксимацию автокорреляционных рядов полиномом фиксированного порядка. Аппроксимация может выполняться с использованием полинома предопределенного порядка, и коэффициенты могут быть аппроксимированы с предопределенной точностью.
[0057] Если кодирование ранжированной информации оригинальных артефактов содержит расчет автокорреляционных рядов ранжированной информации оригинальных артефактов, сравнение может содержать расчет автокорреляционных рядов информации непроверенных артефактов и сравнение двух автокорреляционных рядов. Сравнение может дополнительно, или в качестве альтернативы, содержать сравнение степенных рядов дискретного преобразования Фурье (ДПФ) двух автокорреляционных рядов, и, затем, может содержать сравнение по меньшей мере одной из функций эксцесса и смещения распределения степенных рядов ДПФ.
[0058] Проверочное сканирующее устройство может быть соединено с устройством точки продаж. Проверочное сканирующее устройство может быть воплощено в виде сотового телефона.
[0059] Во многих вариантах осуществления, предпочтительно, чтобы артефакты являлись признаками, которые не влияют на, или по меньшей мере не ухудшают функционирование или коммерческую ценность метки, предмета или объекта, на котором они появляются.
[0060] Лучшее понимание разных признаков и преимуществ настоящих способов и устройств может быть получено посредством ссылки на дальнейшее подробное описание иллюстративных вариантов осуществления и прилагаемые чертежи. Несмотря на то, что эти чертежи изображают варианты осуществления рассматриваемых способов и устройств, они не должны восприниматься, как исключающие альтернативные или эквивалентные варианты осуществления, очевидные рядовым специалистам в данной области техники.
[0061] В варианте осуществления способ работает с метками, которые наносятся на предметы. Эти метки могут быть предназначены для цели уникальной идентификации предмета, как в случае с серийным номером, например, или они могут являться метками, предназначенными для других целей, таких как нанесение бренда, ярлыка или украшения. Эти метки могут быть напечатаны, вытравлены, отлиты, сформованы, перенесены или нанесены иным образом на предмет, используя разные процессы. Метки получают таким образом, чтобы они могли быть обработаны в электронной форме. Способы электронного получения изображения являются разнообразными, и могут включать в себя, но не в качестве ограничения, камеры машинного зрения, устройства считывания штрихового кода, устройства линейного сканирования, планшетные сканеры, ручные портативные устройства получения изображений или многие другие средства.
[0062] Теперь, со ссылкой на чертежи, на фиг. 1 показан пример напечатанной метки, в целом обозначенной номером ссылки 20, к которой могут быть применены настоящие способы. В данном примере, напечатанная метка является двумерным штриховым кодом. Этот штриховой код является носителем данных информации, где информация закодирована в виде рисунка из светлых областей 22 и темных областей 24 на метке. Идеальный пример двумерного штрихового кода состоял бы из прямоугольной решетки, при этом каждая ячейка или «модуль» 22, 24 в решетке являлся бы либо черным, либо белым, представляя бит данных.
[0063] Фиг. 2 предоставляет улучшенный вид некоторых из изменений, присутствующих на метке, показанной на фиг. 1. Фиг. 2 показывает только границы 26 между светлыми и темными областями метки, показанной на фиг. 1. Признаки, такие как линейность границ, разрывы областей и форма элемента в пределах метки, показанной на фиг. 1, являются легко различимыми. Множество неровностей вдоль границ напечатанных элементов метки четко видны. Отметим, что эта иллюстрация предоставлена для ясности и не обязательно является этапом обработки согласно настоящим способам. В некоторых из вариантов осуществления, приведенных в материалах настоящей заявки, такое извлечение границ является полезным и, следовательно, используется. В некоторых из вариантов осуществления извлекаются элементы, отличные от границ.
[0064] Фиг. 3 показывает пример второй напечатанной метки, в целом обозначенной номером ссылки 30, которая может представлять подделку метки 20, показанной на фиг. 1, или может представлять второй уникальный экземпляр метки для целей идентификации. Вторая напечатанная метка 30 также является двумерным штриховым кодом. Этот второй штриховой код 30, при считывании с помощью устройства считывания двумерного штрихового кода, представляет точно такую же декодированную информацию, как и метка 20 по фиг. 1. Когда метка 30 по фиг. 3 получена, настоящий вариант осуществления вновь распознает значимые признаки и собирает их в качестве данных «подписи», которые уникальным образом идентифицируют метку. Как и в случае по фиг. 1, эти данные подписи извлекаются из физических и оптических характеристик геометрии и внешнего вида метки, и, вдобавок, могут включать в себя данные, закодированные в метке, если метка является содержащим данные символом, таким как двумерный штриховой код. Свойства метки, оцененные для создания данных подписи, являются такими же, как и свойства, используемые при оценивании первого экземпляра метки, с тем чтобы две подписи являлись напрямую сравнимыми.
[0065] Фиг. 4 предоставляет улучшенный вид некоторых из изменений, присутствующих на метке 30, показанной на фиг. 3. Фиг. 4 показывает только границы 32 метки, показанной на фиг. 3, схожим образом с фиг. 2. Соответствующие признаки и изменения, такие как линейность границ, разрывы областей и форма элемента в пределах метки, показанной на фиг. 3, являются легко различимыми. Примеры некоторых из признаков, которые могут использоваться, более подробно показаны на фиг. 5, которая более подробно обсуждается ниже.
[0066] Фиг. 6 показывает близкое сравнение признаков верхнего левого угла по фиг. 2 и фиг. 4. Как лучше всего видно на фиг. 6, две напечатанные метки 20, 30 по фиг. 1 и 3, даже несмотря на то, что они идентичны в отношении своих открыто закодированных данных, содержат множество различий в более мелком масштабе, что является результатом дефектов в процессе печати, используемом для нанесения меток. Эти различия являются долговечными, обычно почти такими же долговечными, как и сама метка, и являются уникальными для практических целей, особенно если объединяется большое количество различий, которые можно обнаружить, между символами по фиг. 1 и фиг. 3. Дополнительно, эти различия сложно или почти невозможно подделать, так как оригинальный символ пришлось бы отобразить и перепечатать с разрешением, намного более высоким, чем оригинальная печать, в то же время не вводя новых различимых несовершенств печати. В то время как здесь показана только секция верхнего левого угла меток, различимые признаки между двумя метками, показанными на фиг. 1 и 3, присутствуют по всей поверхности меток и могут использоваться настоящим вариантом осуществления.
[0067] Фиг. 5 - пример двумерного штрихового кода, напечатанного с использованием термотрансферного принтера. Как видно на фиг. 5, термотрансферный принтер производит изображение со сплошными твердыми областями. Аблятивные процессы, в которых подложка изначально содержит непрерывное черное покрытие, части которого удаляются для производства белых областей на фиг. 5, также могут производить изображение со сплошными черными областями. Фиг. 7 - пример фотокопии двумерного штрихового кода, схожей по общей структуре со штриховым кодом по фиг. 5. Как видно на фиг. 7, электростатический процесс, используемый фотокопировальными устройствами, обычно производит пятнистый или крапчатый эффект, так что многие ячейки штрихового кода, которые могли бы быть восприняты, как сплошные твердые области на фиг. 5, воспринимаются на фиг. 7, скорее как серые, чем черные, и/или как черные с белыми пустотами. Важность этого различия более подробно описана ниже.
[0068] Со ссылкой на фиг. 8, один из вариантов осуществления вычислительной системы, в целом обозначенной номером ссылки 50, содержит, среди прочего оборудования, процессор или ЦП 52, устройства 54, 56 ввода и вывода, включающие в себя устройство 58 получения изображения, оперативное запоминающее устройство (ОЗУ, RAM) 60, постоянное запоминающее устройство (ПЗУ, ROM) 62 и магнитные диски или другие долговременные запоминающие устройства 64 для программ и данных. Вычислительная система 50 может включать в себя принтер 65 для формирования меток 20, или принтер 65 может являться отдельным устройством. Вычислительная система 50 может соединяться через интерфейс 66 с внешней сетью 68 или другой средой связи, и через сеть 68 с сервером 70 с долговременным запоминающим устройством 72. Хотя это и не показано для простоты, несколько схожих вычислительных систем 20 могут быть соединены с сервером 70 по сети 68.
[0069] Со ссылкой на фиг. 9, в одном из вариантов осуществления вычислительной системы, устройство получения изображения передает данные изображения на процессор 74 извлечения подписи и кодирования, который может являться программным обеспечением, выполняемом на главном ЦП 52 компьютерной системы 50, или может являться сопроцессором специального назначения. Процессор 74 извлечения подписи и кодирования передает данные подписи в хранилище 76 данных подписи метки с доступом через сеть, которое может являться долговременным запоминающим устройством 72 или сервером 70. Поисковая машина 78 подписи метки с доступом через сеть, которая может являться программным обеспечением, выполняемым на главном ЦП 52 компьютерной системы 50, или может являться сопроцессором специального назначения, принимает данные подписи с процессора 74 извлечения подписи и кодирования и/или хранилища 76 данных подписи. Процессор 80 сравнения подписей обычно сравнивает подпись, извлеченную процессором 74 извлечения подписи и кодирования из недавно отсканированной метки 30, с подписью, ранее сохраненной в хранилище 76 данных подписи и связанной с подлинной меткой 20. Как символически показано посредством разделения между верхней частью фиг. 9, относящейся к сбору и хранению подписи подлинной метки, и нижней частью фиг. 9, относящейся к сбору, сравнению и проверке подлинности подписи проверяемой метки, вычислительная система 50, которая сканирует проверяемую метку 30, может отличаться от вычислительной системы 50, которая отсканировала оригинальную метку 20. Если они различны, тогда, как правило, либо они делят доступ к хранилищу 76 данных подписи, либо копия сохраненных данных подписи передается от хранилища 76 системы 50 сбора подлинной метки в систему 50 оценивания проверяемой метки.
[0070] Более подробно, и со ссылкой на фиг. 10, в одном из вариантов осуществления способа согласно изобретению, на этапе 102, метка, которая в данном примере проиллюстрирована в виде двумерного штрихового кода, подобно метке, показанной на фиг. 1, наносится на объект или на ярлык, который в последствии будет нанесен на объект, посредством принтера 65. Как уже объяснялось, принтер, наносящий двумерный штриховой код, обычно вносит существенное количество артефактов, которые являются слишком маленькими, чтобы влиять на считываемость открытых данных, закодированных штриховым кодом, и являются слишком маленькими, чтобы их внешний вид мог контролироваться в процессе печати, но являются видимыми (возможно лишь при увеличении) и долговечными. Если конкретный принтер обычно не производит множество артефактов, некоторые принтеры можно вынудить включать в свой вывод случайные или псевдослучайные изменения.
[0071] На этапе 104, метку получают посредством подходящего устройства 58 получения изображения или другого устройства сбора данных. Устройство получения изображения может иметь любую подходящую форму, включая традиционные устройства или устройства, которые будут разработаны позднее. Единственное реальное ограничение в данном варианте осуществления состоит в том, что устройство получения изображения собирает данные о внешнем виде метки на уровне детализации, существенно более мелком, чем управляемый вывод устройства, которое нанесло метку. В примере, показанном на фиг. 1-4, деталь является формой границ между светлыми и темными областями, с разрешением, существенно более мелким, чем размер модулей напечатанного двумерного штрихового кода. Другие примеры подходящих признаков описаны ниже. Если метку используют в качестве меры против подделок, она является самой сильной, если устройство формирования изображения собирает данные на уровне детализации, существенно более мелком, чем управляемый вывод устройства, которое, вероятно, использовалось для нанесения или создания поддельной метки. Тем не менее, это не является обязательным, если возможно поддерживать в секрете тот факт, что конкретные детали в конкретной метке используются для этой цели.
[0072] На этапе 106, уникальный идентификационный номер (UID), включенный в открытые данные метки 20, декодируется. Если принтер 65 находится в той же вычислительной системе 50, что и устройство 58 получения изображения, UID может передаваться от одного другому, избегая необходимости декодировать UID из изображения, полученного посредством устройства 58 получения изображения. Если метка 20 не включает в себя UID, на этом этапе обычно требуется некоторая другая информация, уникальным образом идентифицирующая конкретный экземпляр метки 20.
[0073] На этапах 110 и 112, изображение метки 20 анализируется процессором 74 извлечения подписи и кодирования, чтобы выделить существенные признаки. Затем, на этапе 120, данные, относящиеся к этим признакам, будут сохранены в хранилище 76 данных подписи в виде данных «подписи», которые уникальным образом идентифицируют метку 20. Эти данные подписи извлекаются из физических и оптических характеристик геометрии и внешнего вида метки, и, вдобавок, могут включать в себя данные, закодированные в метке, если метка является содержащим данные символом, таким как двумерный штриховой код. Свойства метки, оцениваемые для создания данных подписи, могут включать в себя, но не в качестве ограничения, форму признака, контрастность признака, линейность границ, разрывы областей, наружные метки, дефекты печати, цвет, пигментация, изменения контрастности, соотношение сторон признака, местоположение и размер признака.
[0074] Если часть метки не содержит значимых признаков, данные для этой части метки также могут сохраняться в форме информации о том, что конкретная часть метки не содержит значимых признаков. В случае двумерного штрихового кода или схожего символа, который обычно разделен на отчетливые ячейки или модули, может сохраняться список черных модулей без существенных признаков. Для этой цели, термин «без существенных признаков» может включать в себя ячейки без детектируемых признаков, или ячейки с детектируемыми признаками, которые являются настолько маленькими, что они благоразумно рассматриваются, как чистый случайный шум, или оба этих типа ячеек.
[0075] В частности, как пояснено ниже, процесс детектирования фотокопии согласно настоящему описанию обычно является наиболее эффективным, когда его обеспечивают подачей модулей, про которые известно, что в оригинальной метке они являются сплошными черными, без белых пустот и очень темной серости.
[0076] Теперь также со ссылкой на фиг. 5, в дальнейшем примере, в качестве примерных переменных признаков используются отклонение в средней пигментации модуля или интенсивности 92 нанесения метки, смещение 94 положения модуля относительно оптимально подогнанной решетки, присутствие или местоположение наружных меток или пустот 96 в символе и форма (линейность) длинных непрерывных границ 98 в символе. Они выступают в качестве первичных метрик, формирующих уникальную подпись символа. Иллюстрации некоторых из этих признаков показаны на фиг. 5.
[0077] В случае если метка является содержащим данные символом, таким как двумерный штриховой код, настоящий вариант осуществления может с пользой использовать дополнительную информацию, представленную символом и закодированную в нем. Закодированная информация, например, уникальный или не уникальный серийный номер, может сама включаться в виде части данных подписи, или может использоваться для индексирования данных подписи для более простого поиска.
[0078] Дополнительно, в случае двумерного штрихового кода или другого носителя данных, для которого может быть установлена мера качества, на этапе 108, информация, представляющая качество символа, может опционально извлекаться и включаться в виде части данных подписи.
[0079] Информация о качестве может использоваться для детектирования изменений в метке 20, которые могли бы вызвать ложное определение метки, как поддельной, так как эти изменения могут менять данные подписи метки. Некоторыми из мер качества, которые могут использоваться, являются, но не в качестве ограничения, неиспользуемая коррекция ошибок или повреждение фиксированного образа, как определено в спецификации ISO 15415 «Процессы матричного ранжирования данных» или другом сравнимом стандарте. Эти меры позволяют детектировать области, которые повлияли бы на данные подписи, которые были изменены посредством повреждения метки, и, таким образом, исключить их из рассмотрения при сравнении данных подписи метки с сохраненными данными подписи подлинной метки.
[0080] Взвешивание метрик подписи
[0081] В данном примере, простота, с которой может быть извлечена каждая из четырех метрик, проиллюстрированных на фиг. 5, зависит от разрешения получения изображения, и метрики могут упорядочиваться в порядке разрешения, требуемого для извлечения полезных данных, относящихся к каждой из четырех метрик, как показано на фиг. 11. В порядке от самого низкого к самому высокому разрешению, это пигментация модуля, смещение положения модуля, местоположение пустоты/метки и проекция формы границы. Тем не менее, как будет более подробно пояснено ниже, некоторые метрики полезнее других для детектирования фотокопии, и, следовательно, на этом этапе могут использоваться разные веса.
[0082] Увеличение точности и разрешения изображения обеспечивает более точный анализ, использующий анализ более высокой точности. Например, на изображении с низким разрешением, возможно только средняя пигментация 92 модуля и смещение 94 положения модуля могут быть извлечены со значительной достоверностью, поэтому этим результатам придают большие веса при определении совпадения подписи проверяемого символа с сохраненными подлинными данными. С изображением высокого разрешения, обработка может быть продолжена до метрики 98 точной проекции границ и использования ее в качестве фактора с самым высоким весом при определении совпадения подписи. Если имеются расхождения среди других (имеющих меньший вес) мер в ожидаемой подписи, они могут быть вызваны повреждением символа или артефактами устройства получения изображения. Тем не менее, повреждение или изменение символа 20 или артефакты устройства формирования изображения вряд ли могут изменить поддельный код 30 так, чтобы он случайно с высокой точностью совпал с метрикой 98 подписи проекции границ подлинного предмета 20. Таким образом, проекция границ, если она высоко коррелированна и проявляет адекватную величину в динамическом диапазоне, может заменять метрики более низкого разрешения при поддержке высокой степени достоверности совпадения.
[0083] Дополнительно, в варианте осуществления, использующем код двумерной матрицы данных в качестве примера, информация о коррекции ошибок, предоставляемая стандартными алгоритмами декодирования этой символики, используется, чтобы дополнительно подходящим образом взвешивать данные метрики подписи. Если область данных в символе искажена посредством повреждения метки, и эта область производит расхождение с сохраненными данными подписи, в то время как другие неискаженные области хорошо согласованы, вес искаженной области будет уменьшен. Этот механизм предотвращает внесение детектируемыми искажениями символа ложноотрицательного результата в сравнение метрики проверяемого символа с данными подписи подлинного символа. Спецификация ISO 16022 «Символ матрицы данных» описывает пример того, как коды коррекции ошибок (ECC) могут быть распределены в двумерной матрице данных, и как могут быть идентифицированы искаженные и неискаженные области в матрице данных.
[0084] Фильтрация по величине
[0085] Как будет более подробно пояснено ниже, в настоящем варианте осуществления выбираются два разных диапазона величин. Первый диапазон может состоять из предопределенного количества присутствующих артефактов с самой высокой величиной. Второй диапазон может состоять из предопределенного количества артефактов с самой низкой величиной, которые могут быть надежно детектированы, или из предопределенного количества артефактов в диапазоне, следующем сразу за первым диапазоном, или в диапазоне, более низком, чем первый диапазон, но пересекающимся с ним. Второй диапазон может состоять, полностью или частично, из местоположений, в которых отсутствуют детектируемые артефакты, являющиеся достаточно большими, чтобы быть надежно отличимыми от случайного шума. Значимые признаки выбираются и оцениваются, чтобы населить оба диапазона.
[0086] На этапах 114 и 116, проверяемые признаки подписи для первого диапазона оцениваются, чтобы убедиться, что они обладают достаточной величиной, чтобы выступать в качестве части каждой метрики подписи. Этот этап обеспечивает, чтобы признаки, формирующие каждую метрику подписи, обладали реальным «сигналом» для кодирования в виде отличительной характеристики метки. Неспособность применить пороговые минимумы к проверяемым составляющим подписи может допустить подпись, которая может быть легко отнесена к шуму во время любых последующих попыток проверить метку по сравнению с подлинной сохраненной подписью, производя процесс проверки подлинности, очень восприимчивый к ограничениям качества и точности устройств, используемых для сбора данных метки для анализа подписи. Посредством обеспечения того, чтобы метрики подписи формировались исключительно из признаков, удовлетворяющих этим пороговым минимумам величины, может быть обеспечена или существенно улучшена способность выполнять успешную проверку подлинности подписей метки с помощью широкого диапазона устройств получения изображения (сотовые телефоны, оборудованные камерой, камеры машинного зрения, устройства получения изображения низкого качества или низкого разрешения, и т. д.) и в широком диапазоне внешних условий (переменное, слабое или неоднородное освещение, и т. д.).
[0087] В варианте осуществления, использующем код двумерной матрицы данных, в качестве примера, на этапах 110, 112 и 114, проверяемые признаки для четырех метрик 92, 94, 96, 98 извлекаются и сортируются по величине. Как описано ранее, метку 20 получают таким образом, чтобы признаки могли быть обработаны в электронной форме, как правило, в виде цветного или полутонового изображения. В качестве предварительного этапа, двумерная матрица данных сначала анализируется как целое, и определяется «оптимально подогнанная» решетка, определяющая «идеальные» положения границ между ячейками матрицы. Проверяемые признаки затем выбираются посредством нахождения признаков, сильнее всего отклоняющихся от «нормального» или «оптимального» состояния атрибута(-ов) меток для конкретной анализируемой метрики. Рассматривая пример кода двумерной матрицы данных, показанный на фиг. 5, некоторыми подходящими атрибутами являются:
[0088] 1. Модули 92, чей средний цвет, пигментация или интенсивность метки находятся ближе всего к глобальному среднему пороговому значению, отделяющему темные модули от светлых модулей, как определено алгоритмами чтения матрицы данных, то есть, «самые светлые» темные модули от «самых темных» светлых модулей. В фотокопии, как проиллюстрировано на фиг. 5 и 7, на низких разрешениях существенная доля темных модулей может представлять более светлый средний цвет, чем в оригинальной метке.
[0089] 2. Модули 94, которые отмечены в положении, которое сильнее всего отклоняется от идеализированного местоположения, определенного оптимально подогнанной решеткой, примененной ко всему символу 20. Существует два способа идентификации этих модулей: (a) извлекать положения границ модуля проверяемой метки и сравнивать эти положения границ с их ожидаемыми положениями, определенными идеализированной оптимально подогнанной решеткой для всего символа 20; (b) извлекать гистограмму граничной области между двумя соседними модулями противоположной полярности (светлый/темный или темный/светлый), с областью образца, перекрывающей одинаковую долю каждого модуля относительно оптимально подогнанной решетки, и оценивать отклонение гистограммы от двухрежимного распределения 50/50.
[0090] 3. Наружные метки или пустоты 96 в модулях символа, будь они светлыми или темными, определяются, как модули, обладающие широким диапазоном яркости или плотности пигмента; то есть, модули, обладающие уровнями пигментации с обеих сторон от глобального среднего порогового значения, отделяющего темные модули от светлых модулей, при этом наилучшими проверяемыми подписями являются те, гистограммы двухрежимной яркости которых имеют наибольшее расстояние между самыми наружными доминирующими режимами. В фотокопии, как проиллюстрировано на фиг. 5 и 7, на низких разрешениях, существенная доля темных модулей может представлять белые пустоты, которые не присутствуют в оригинальной метке.
[0091] 4. Форма длинных непрерывных границ 98 в символе, измеряющая либо их непрерывность/линейность, либо степень разрывности/нелинейности. Одним из способов извлечения этих данных является проекция значения яркости шириной в пиксель, с длиной проекции, составляющей один модуль, смещенная от оптимально подогнанной решетки на полмодуля, идущая перпендикулярно линии решетки, окружающей эту границу в оптимально подогнанной решетке для символа. Фотокопирование обычно воздействует на метрику формы границы схожим образом с подделкой. Тем не менее, величина изменения в метрике формы границы от фотокопирования обычно не является достаточной для надежного детектирования. В экспериментах, всего лишь около 50% фотокопий отклонялись, как очевидно поддельные, из-за изменений в метрике формы границы.
[0092] 5. Момент инерции (MI) матрицы совпадений уровня серого (GLCM) модулей 92. Эта мера очень чувствительна к пятнистости модуля, что очень полезно для детектирования фотокопий.
[0093] Двумерная матрица данных является хорошим примером, так как она состоит из черных и белых квадратных ячеек, на которых легко видны вышеупомянутые признаки. Тем не менее, такие же принципы, конечно, могут быть применены к другим формам видимой метки с кодированием данных или без кодирования данных.
[0094] Как только проверяемые признаки, удовлетворяющие вышеописанным критериям, идентифицированы, на этапе 114, проверяемые признаки сортируются в списке по порядку величины. Затем, чтобы определить первый диапазон, на этапе 116, проверяемые признаки могут подвергаться фильтрации ограничения величины посредством нахождения первого признака в каждом списке, который не удовлетворяет установленной минимальной величине, чтобы быть квалифицированным, как вносящий вклад в эту метрику. Пороговое значение может быть установлено на любой удобный уровень, достаточно низкий, чтобы включать разумное количество признаков, которые непросто воспроизвести, и достаточно высокий, чтобы исключить признаки, являющиеся недостаточно долговечными, или находящиеся рядом с минимальным уровнем шума устройства 58 получения изображения.
[0095] Нижнее пороговое значение для второго диапазона может быть установлено, чтобы включать признаки, расположенные слишком близко к пороговому значению шума, чтобы являться по отдельности удовлетворительными для первого диапазона, но все еще могут выполнять значимый анализ на статистическом уровне. В данном варианте осуществления, затем, конец низкой величины отсортированного списка отсекается от пороговой точки, и оставшиеся признаки (с самой высокой величиной) сохраняются, вместе со своими местоположениями на метке, в качестве данных подписи для этой метрики. Предпочтительно, все признаки выше порогового значения отсечения сохраняются, и это неявным образом включает в подпись информацию о том, что в других местах метки нет признаков подписи выше порогового значения фильтра по величине. Если первый и второй диапазоны являются смежными или перекрываются, они могут сохраняться в виде одного списка. Это предотвращает дублирование признаков в перекрывающейся области.
[0096] В варианте осуществления полный набор проверяемых признаков используется, например, если метка является двумерным штриховым кодом, и метрика является серостью номинально черного модуля, могут использоваться все номинально черные модули штрихового кода. В этом случае, первый диапазон может состоять из предопределенного количества самых светлых черных модулей, а второй диапазон может состоять из предопределенного количества самых темных черных модулей. Нельзя гарантировать, что любой из черных модулей является идеально черным, но эксперименты показывают, что для термотрансферного принтера в хорошем состоянии было бы исключительно не произвести достаточное количество достаточно черных модулей для целей настоящего процесса.
[0097] Некоторые метрики могут иметь маленькую ценность для детектирования фотокопий, например, как проиллюстрировано на фиг. 7, пятнистость намного менее выражена в номинально белых модулях, чем в номинально черных модулях. Второй диапазон данных для этих метрик может, таким образом, не использоваться. Тем не менее, может быть предпочтительно сохранять полный набор данных для всех метрик, как в интересах простоты, так и для того, чтобы позволить этим данным быть подвергнутыми повторному анализу, если аналитические алгоритмы будут впоследствии улучшены.
[0098] Так как заранее известно, что разные технологии маркировочных устройств представляют признаки подписи более высокой или более низкой степени в разных атрибутах для использования при формировании данных подписи метки, тип маркировочного устройства может использоваться, чтобы предварительно взвешивать метрики в так называемом профиле взвешивания. Например, если подлинные метки создаются, используя термотрансферный принтер, известно, что проекции границ, параллельные направлению материала подложки движения, вряд ли несут величину подписи, достаточную для кодирования в качестве части подлинных данных подписи. Тем не менее, фотокопия подлинной метки вероятнее всего проявит артефакты фотокопии вдоль этих проекций границ, и отсутствие артефактов в подлинной метке может сделать артефакты фотокопии более заметными и более легкодоступными. Это знание о различных поведениях маркировочных устройств может использоваться во время сбора оригинальных подлинных данных подписи. Если это применяется, все метрики, используемые при создании подписи подлинной метки, взвешиваются в соответствии с известными поведениями этого конкретного типа маркировочного устройства, и соответствующее усиливающее/ослабляющее отображение метрик становится профилем взвешивания метрик. На этапе 118, этот профиль взвешивания метрик, основанный на типе маркировочного устройства, используемого для создания оригинальной метки, сохраняется в виде части данных подписи.
[0099] На этапе 120 метрики подписи сохраняются в виде сортированных списков признаков, в порядке уменьшения величины. В нижнем конце списка, порядок может быть очень произвольным, так как главным образом это будет шум. Тем не менее в данном варианте осуществления порядок необходим, так как он будет использоваться на последующем этапе для сопоставления проверяемых признаков с оригинальными признаками. Элемент списка для каждого признака включает в себя информацию, локализующую положение в метке, из которого был извлечен этот признак.
[0100] В данном варианте осуществления запись для каждого символа индексируется по содержимому с уникальным идентификатором (как правило серийному номеру), включенному в открыто закодированные данные в символе. Запись может храниться на сервере или устройстве хранения данных с доступом через сеть, или может храниться локально там, где она необходима. Копии могут быть распределены в локальном хранилище во многих местоположениях.
[0101] Метрики подписи низкой амплитуды
[0102] Если экземпляр символа 20, или идентифицируемая область в символе не содержит ни одного признака подписи, удовлетворяющего минимальной величине для первого диапазона для одной или более из метрик подписи, в варианте осуществления, сам этот факт сохраняется в виде части данных подписи, тем самым используя отсутствие значимого изменения признака в качестве части уникальной идентификационной информации для этого символа. В данном случае, символ, подвергаемый проверке подлинности по этим данным, считается подлинным, только если он также обладает нулевыми признаками подписи, удовлетворяющими минимальной величине для рассматриваемой метрики(-к), или по меньшей мере намного менее существенными признаками, чтобы пройти статистический тест. В данных случаях, вес для этой конкретной метрики уменьшается, так как область без отличительных характеристик менее устойчива к идентификации признака, чем область с существенными отличительными характеристиками. Символ или область без существенного признака подписи наиболее полезна негативно. Отсутствие значащих признаков как в подлинной метке 20, так и в проверяемой метке 30, является лишь слабым свидетельством того, что проверяемая метка является подлинной. Присутствие значащего признака в проверяемой метке 30, когда подлинная метка 20 не содержит соответствующего значащего признака, является более сильным свидетельством того, что проверяемая метка является поддельной.
[0103] Исключение делается для признаков ощутимой величины подписи, которые могут быть приписаны повреждению символа в проверяем символе 30, обнаруженному с помощью вышеупомянутого использования информации о коррекции ошибок символов из декодирующих алгоритмов этой конкретной символики, в случае чего он подвергается принципам взвешивания метрик подписи точности полученного изображения, как описано ранее.
[0104] В экстремальном случае, когда как подлинная метка 20, так и проверяемая метка 30 содержат только данные ниже порогового значения (как в двух «идеальных» символах), они являлись бы неразличимыми посредством процесса согласно настоящему примеру, так как процесс опирается на определенное измеримое изменение либо в подлинной, либо в поддельной метке, выступающее в качестве пути детектирования. На практике это не является проблемой, так как ни один из сценариев использования, существующих в настоящее время, (обычно, онлайн, высокоскоростная печать) не производит идеальные символы. В частности, фотокопия «идеального» символа обычно дает в результате символ, который кажется идеальным относительно артефактов первого диапазона, но отображает артефакты фотокопии низкой величины во втором диапазоне.
[0105] Анализ
[0106] Со ссылкой на фиг. 12, в варианте осуществления метрики подписи сохраняются в виде сортированного списка, в порядке уменьшения величины, и включают в себя информацию, локализующую их положение в метке, из которой они были извлечены. В варианте осуществления, использующем код двумерной матрицы данных, в качестве примера, процесс, посредством которого оценивается проверяемая метка или символ, чтобы определить ее подлинность, состоит в следующем:
[0107] На этапе 152, изображение проверяемой метки 30 получают посредством устройства 58 получения изображения.
[0108] На этапе 154, открытые данные в проверяемой метке 30 декодируются, и его содержимое уникального идентификатора (UID) извлекается.
[0109] На этапе 156, UID используется, чтобы найти данные метрики подписи, изначально сохраненные для оригинального символа 20, содержащего этот UID. Сохраненные данные могут извлекаться из локального хранилища 64 или могут извлекаться из сервера или устройства 72 хранения данных с доступом через сеть. В случае если проверяемая метка 30 не содержит UID, может быть получена другая идентификационная информация, относящаяся к проверяемой метке 30. В качестве альтернативы, можно осуществлять поиск всей базы данных подписей подлинных меток на хранилище 64 или 72 после этапа 164 ниже, чтобы попробовать найти подлинную подпись, которая соответствует подписи проверяемой метки.
[0110] На этапе 158, в случае двумерного штрихового кода или другого носителя данных, для которого может быть установлена мера качества, измерения качества для проверяемой метки 30 могут быть получены, как они были получены на этапе 108 для подлинной метки 20. Измерения качества могут использоваться на последующих этапах анализа, чтобы уменьшить вес, приписанный метке, или части метки, которая, по-видимому, была повреждена с момента нанесения. Также, если измерения качества оригинального символа 20 были сохранены в виде части подлинных данных подписи, сохраненные измерения качества могут быть проверены на данных подписи, извлеченных из подлинной метки 30.
[0111] На этапе 160, значимые признаки подписи извлекаются из изображения подлинной метки 30, которая была получена на этапе 152. Вся проверяемая метка 30 (за исключением тех секций, которые были исключены, как поврежденные, посредством коррекции ошибок) проверяется на наличие значимых признаков. Вдобавок, информация, определяющая местоположения в пределах символа, из которых были извлечены данные подписи оригинального, подлинного символа, используется, чтобы определить, откуда извлекать данные подписи проверяемого символа. Это гарантирует, что признак, присутствующий в метке 20, но отсутствующий в метке 30, будет отмечен. Извлеченные признаки относятся как к первому, так и ко второму диапазонам.
[0112] На этапе 162, признаки подписи кодируются для анализа.
[0113] На этапе 164, данные подписи для по меньшей мере одного первого диапазона (высокой величины), извлеченные из проверяемого символа 30, сортируются в том же порядке, что и в оригинальном списке оригинального символа 20. Для первого диапазона, оригинальные и проверяемые артефакты могут быть отсортированы независимо в порядке величины. Для второго диапазона, в данном варианте осуществления, оригинальные и проверяемые артефакты сортируются в одинаковом порядке посредством ссылки на сохраненные данные о местоположении для оригинальных артефактов. Это позволяет каждому модулю проверяемой метки подвергаться сравнению с модулем в таком же местоположении оригинальной метки.
[0114] На этапе 166, проверяемые данные подписи для первого диапазона сравниваются с сохраненными оригинальными данными подписи для первого диапазона. Данные подвергаются статистической операции, показывающей числовую корреляцию между двумя наборами данных. Каждая метрика подвергается индивидуальному числовому анализу, производящему меру, отражающую индивидуальную достоверность того, что проверяемый символ является подлинным предметом, для этой метрики. Если метрика не содержит данных UID, и никакие альтернативные идентификационные данные не доступны, может возникнуть необходимость осуществить поиск по базе данных схожих меток, используя процедуры, обсуждаемые со ссылкой на фиг. 16 ниже. Например, в случае фиг. 1 и 3, может быть необходимо осуществить поиск по всем подлинным меткам 20, которые имеют такую же открытую картину черных и белых модулей. Цель поиска состоит в том, чтобы идентифицировать, или не смочь идентифицировать, одну подлинную метку 20, которая уникальным образом схожа с проверяемой меткой 30.
[0115] На этапе 186, на котором профиль взвешивания метрик был сохранен в виде части подлинных данных подписи, эта информация используется, чтобы усилить и/или ослабить метрики, как подходящие для типа маркировочного устройства, используемого для создания оригинальных подлинных меток.
[0116] На этапе 172, посредством исключения, ожидается, что все местоположения внутри метки, не представленные в отсортированном списке местоположений признаков, удовлетворяющих минимальному пороговому значению величины для первого диапазона, лишены значимых признаков подписи при анализе подлинной метки. Это условие оценивается посредством проверки величины признака подписи во всех местоположениях в проверяемой метке, в которых ожидаются признаки ниже порогового значения, и коррекции результатов для соответствующей метки в направлении отрицательных, когда обнаруживаются признаки, превышающие минимальное пороговое значение. Если значимые признаки обнаруживаются в области, определенной, как поврежденная, при оценивании на коррекцию ошибок символа или другие атрибуты качества, коррекция уменьшается или не выполняется вообще, в зависимости от местоположения повреждения относительно точки извлечения признака и от природы конкретной вовлеченной метрики. Например, если расхождение в данных подписи относительно оригинальной метки 20 извлекается из модуля проверяемой метки 30, который находится рядом с поврежденным модулем(-ями), но не в том же местоположении, негативная корректировка метрики из-за этого признака может быть уменьшена на величину, которая отражает уменьшенную достоверность в метрике подписи, так как бывший модуль, находящийся рядом с известной поврежденной областью, мог получить повреждение, которое влияет на метрику, но падает ниже детектируемого порогового значения качества механизма оценки ECC символики. Если расхождение извлекается напрямую из поврежденного модуля, или если метрика относится к одному из типов, который перекрывает несколько модулей, и перекрывание включает в себя поврежденный модуль, то коррекция вообще не будет применена.
[0117] Затем, на этапе 174, эти индивидуальные уровни достоверности используются, чтобы определить общую достоверность проверяемого символа 30, как подлинного (или поддельного), с индивидуальными уровнями достоверности, взвешенными надлежащим образом, как описано выше, используя точность изображения, разрешение и информацию о повреждении символа.
[0118] На этапе 176, определяют, является ли результат достаточно определенным, чтобы быть приемлемым. Если сравнение данных подписи дает неопределенный результат (например, индивидуальные метрики, содержащие противоречивые индикаторы, не разрешимые с помощью использования механизма взвешивания данных), пользователя, предоставившего символ для подтверждения подлинности, просят повторно предоставить другое изображение символа для обработки, и процесс возвращается к этапу 152.
[0119] По практическим причинам, количество разрешенных повторных попыток ограничено. На этапе 178, определяется, был ли превышен предел повторных попыток. Если это так, возвращение к повторному сканированию предотвращается.
[0120] Если результат этапа 176 неопределенный, тогда, на этапе 180, данные во втором диапазоне (низкой величины) как для оригинальной метки, так и для проверяемой метки, могут быть извлечены и подвергнуты сравнению посредством процесса, схожего с этапами со 166 по 178. В качестве альтернативы, этап 180 также может быть выполнен для меток, которые были идентифицированы на этапе 176, как подлинные. В качестве альтернативы, сравнение для второго диапазона может выполняться на этапах со 166 по 178 параллельно со сравнением для первого диапазона. Это может экономить время, хотя, если в большой доле случаев результат второго диапазона не нужен, это может быть менее эффективно. Тем не менее, в то время как сравнение для первого диапазона главным образом направлено на совпадение отдельных артефактов, сравнение для второго диапазона является статистическим, и главным образом направлено на измерение степени однородности артефактов.
[0121] На этапе 182, представляется отчет о результатах, и процесс заканчивается.
[0122] Со ссылкой на фиг. 13, показан график величины группы артефактов. Артефакты сортируются вдоль оси X в порядке уменьшения величины, вверх по оси Y, в оригинальной подписи подлинного предмета, сохраненной на этапе 120, и извлекаются на этапе 156. Для точности сравнения второго диапазона, одинаковые местоположения на метке используются на этапе 110 и этапе 160, даже если некоторые из этих местоположений, по-видимому, не показывают значащих артефактов ни на одном этапе. Также наносятся соответствующие величины, которые могли быть получены на этапе 152, для подлинной метки и для метки фотокопии. Как видно на фиг. 13, даже подлинная метка, отсканированная на этапе 152, показывает существенное случайное отклонение от оригинальных сохраненных данных из-за ухудшения метки с течением времени, и из-за использования на этапе 152 сканирующего устройства более низкого качества, чем на этапе 104, например, камеры на смартфоне. Тем не менее, метка фотокопии показывает намного более сильное случайное отклонение в направлении правой стороны фиг. 13, где метка, изначально отсканированная на этапе 104, содержит артефакты низкой величины. Таким образом, посредством сравнения отклонений в величине в двух диапазонах, один - слева на фиг. 13, и один - справа на фиг. 13, фотокопия может быть распознана с удивительно высокой степенью точности и достоверности, даже без попыток получить доступ к абсолютным значениям величин артефактов.
[0123] Может использоваться любая удобная статистическая мера неоднородности, такая как стандартное отклонение или сумма ошибок. Первый и второй диапазоны могут быть выбраны эмпирически для конкретной подлинной метки и конкретных метрик артефактов. Для меток, схожих с используемой для генерации набора данных, показанных на фиг. 13, удовлетворительные результаты были получены, используя точки данных от 1 до 100 для первого диапазона, и от 61 до 160 для второго диапазона. Набор из 160 точек данных представил все номинально черные модули в матрице данных, используемой для эксперимента. Тем не менее, как видно на фиг. 13, разница между проверочными сканированиями для подлинной и подвергнутой фотокопированию проверяемой метки является самой сильной для точек данных приблизительно от 110 до 160, которые более подробно показаны на фиг. 14.
[0124] Таким образом, если однородность артефактов в проверяемой метке во втором диапазоне ниже, чем однородность артефактов в оригинальной метке во втором диапазоне, и разница не пропорциональна соответствующей разнице для первого диапазона, это может показывать, что проверяемая метка является фотокопией. Результат этого теста может использоваться для корректировки результата этапа 178. Так как доступен этот дополнительный тест, некоторые результаты, которые в противном случае могли бы быть классифицированы, как подлинные или поддельные, но находятся радом с пограничной линией, могут рассматриваться, как неопределенные, на этапе 178, и могут повторно рассматриваться ввиду теста фотокопии на этапе 180. Результат, указывающий, что проверяемая метка не является фотокопией, обычно не является убедительным, так как существует много других способов копирования метки. Тем не менее, результат, указывающий, что проверяемая метка является фотокопией, может оправдать понижение оценки проверяемой метки с «подлинной» до «неопределенной», особенно если оценка «подлинная» была пограничной, или с «промежуточной» до «поддельной».
[0125] Как только анализ завершается успешно, отчет о результатах сравнительного анализа представляется на этапе 182. Отчет может являться успехом/неуспехом, или может обозначать уровень достоверности результата. Эти результаты могут отображаться локально или передаваться на подключенную к сети компьютерную систему или другое устройство для дальнейшего действия. Если результат все еще является неопределенным, когда достигнут предел повторных попыток, способ также переходит на этап 182, на котором может быть представлен отчет о самом неопределенном результате.
[0126] По сохранении данных подписи, извлеченных из метки 20, показанной на фиг. 1, настоящий способ может распознавать ту же самую метку, как подлинную, когда ее представляют в качестве проверяемой метки 30, на основании того факта, что, когда ее анализируют посредством того же процесса, определяется, что она обладает такими же данными подписи, по меньшей мере на желательном уровне статистической достоверности. Подобным образом, настоящий способ может идентифицировать поддельную копию 30 метки 20, показанной на фиг. 1, или отделять другой уникальный экземпляр 30 метки посредством распознавания того, что данные подписи, например, извлеченные из экземпляра метки на фиг. 3, не соответствуют данным, сохраненным изначально, когда подлинная метка, показанная на фиг. 1, была подвергнута изначальной обработке.
[0127] Взамен или в дополнение к использованию результата детектирования фотокопии на этапе 180, чтобы помочь определению того, является ли проверяемая метка 30 подлинной, результат может использоваться для целей диагностики или исследования. Например, может быть полезно узнать, что производитель подделок постоянно производит фотокопии подлинных меток 20, а идентификация объема и географического распространения деятельности производителя подделок может помочь его идентифицировать. Так как фотокопировальные аппараты не идентичны, в некоторых случаях характеристики артефактов в подвергнутых фотокопированию метках могут являться достаточно отличительными, чтобы идентифицировать разных производителей подделок.
[0128] Измерения локальных точек отсчета для данных метрики для устойчивости к внешним условиям
[0129] Чтобы сделать еще более надежным извлечение точных данных подписи, всякий раз, когда это возможно, способы согласно настоящему изобретению используют локальные точки отсчета внутри анализируемого символа для формирования данных подписи. Это обеспечивает более высокую устойчивость к таким вещам, как вышеупомянутая деформация подложки, неоднородное освещение проверяемого символа при получении для обработки, неидеальная или имеющая низкое качество оптика в устройстве получения изображения, или многие другие внешние условия или систематические изменения. Для варианта осуществления локальными точками отсчета метрик являются:
[0130] 1. Средний цвет модуля, пигментация или интенсивность метки отсчитываются от ближайшего соседа(-ей) в противоположном состоянии модуля (темный от светлого или светлый от темного). Если ячейка идентифицируется, как значимый признак 92 с отклоняющейся средней плотностью пигментации, ячейки, для которых она является ближайшим соседом, могут нуждаться в переоценке, уменьшая значимость идентифицированной отклоняющейся ячейки в качестве точки отсчета.
[0131] 2. Смещение положения решетки модуля отсчитывается от оптимально подогнанной решетки всего символа, и по существу имеет естественную адаптивную точку отсчета.
[0132] 3. Анализ внешних меток или пустот в модулях символа использует локальные точки отсчета цвета, пигментации или интенсивности меток модуля, то есть, гистограмма яркости изображения внутри самого анализируемого модуля предоставляет опорные значения для используемых способов.
[0133] 4. Способы проецирования, используемые для извлечения форм длинных непрерывных границ в символе, являются дифференциальными по своей природе и обладают естественной устойчивостью к обычным оказывающим воздействие переменным.
[0134] Теперь со ссылкой на фиг. 15, альтернативный вариант осуществления схож с процессом, описанным со ссылкой на фиг. 5, но может использовать типы меток, отличные от двумерного символа. Например, символ может являться одномерным линейным штриховым кодом, логотипом компании, и т. д. Фиг. 15 показывает некоторые признаки одномерного линейного штрихового кода 200, которые могут использоваться в качестве метрик подписи. Они включают в себя: изменения в ширине и/или расстоянии между штрихами 202; изменения в среднем цвете, пигментации или интенсивности 204; пустоты в черных штрихах 206 (или черные точки в белых полосах); или неровности в форме границ штрихов 208. Если сплошные черные области требуются для детектирования фотокопии, они могут быть взяты из частей более широких черных полос, которые не содержат артефактов с 204 по 206.
[0135] Анализ посредством автокорреляционного способа
[0136] В вариантах осуществления, описанных выше, сырой список данных для каждой метрики сначала сопоставляется по индексу массива и подвергается нормализованному вычислению корреляции с извлеченным набором метрик схожего порядка из проверяемого символа. Эти результаты вычисления корреляции используются, чтобы прийти к решению о совпадении/не совпадении (подлинный или поддельный). Чтобы сделать это, хранение подписи обязательно включает в себя порядок сортировки оригинальных модулей подлинного символа, а также сами тренированные значения метрик, завершенные для каждой метрики. Вдобавок к исчерпывающей необходимости в хранении, сырые данные не «нормализованы», так как каждая метрика имеет свою собственную шкалу, иногда неограниченную, что усложняет выбор битовой глубины хранения. Типичная реализация вышеописанных вариантов осуществления имеет размер сохраненной подписи, составляющий приблизительно 2 килобайта.
[0137] Теперь со ссылкой на фиг. с 16 по 20, альтернативный вариант осуществления способов постобработки, хранения и сравнения применяется после того, как оригинальные метрики артефактов были извлечены и сделаны доступными в виде связанного с массивом индексов списком (с которым можно связаться посредством положения модуля в символе). На основании автокорреляции, применение этого нового способа постобработки может по меньшей мере в некоторых обстоятельствах обеспечивать несколько существенных преимуществ по сравнению с подписями согласно предыдущим вариантам осуществления. В публикации заявки на выдачу патента США 2013/0228619 объясняется, что посредством генерирования на этапе 120 автокорреляционной функции и сохранения только автокорреляционных данных может быть достигнуто существенное уменьшение размера пакета данных. В описываемых сейчас способах, это уменьшение не обязательно может быть достигнуто, так как местоположение и порядок сортировки сохраняются по меньшей мере для второго диапазона элементов данных. Тем не менее, автокорреляция все еще обеспечивает устойчивый и эффективный способ сравнения оригинального и проверяемого наборов данных.
[0138] В то время как в вариантах осуществления, описанных выше, анализ конкретного набора данных метрик принимает форму сравнения отсортированных сырых метрик, извлеченных из проверяемого символа, с сырыми метриками схожего порядка, извлеченными из подлинного символа, автокорреляционный способ сравнивает автокорреляционные ряды отсортированных данных метрик проверяемого символа с автокорреляционными рядами (сохраненных) отсортированных данных подлинного символа - в сущности, теперь автокорреляции подвергаются вычислению корреляции. Автокорреляционные ряды генерируются отдельно для первого и второго диапазонов, и результаты вычисления корреляции двух пар автокорреляций сравниваются.
[0139] Для данных первого диапазона, обоснованная автокорреляция может быть возможна лишь посредством сортировки каждого из оригинального и проверяемого наборов данных по отдельности в порядке уменьшения величины артефактов. Это возможно, поскольку подлинная проверяемая метка будет содержать артефакты, очень схожие с таковыми у оригинальной метки. Тем не менее, для второго диапазона, корреляция между оригинальными и подлинными проверяемыми данными обычно является очень низкой. Изначальный порядок сортировки, таким образом, сохраняется на этапе 120, и тот же самый порядок используется для сортировки проверяемых данных на этапе 164, по меньшей мере для данных второго диапазона. Обычно, наиболее эффективным является также использование сохраненного порядка сортировки также и для данных первого диапазона.
[0140] Для ясности, широко известная статистическая операция
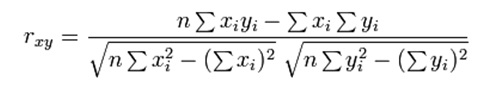
является общим нормализованным уравнением корреляции, где: r является результатом вычисления корреляции, n является длиной списка данных метрики, а x и у являются подлинным и проверяемым наборами данных.
[0141] Когда операция реализуется в виде автокорреляции, оба набора данных x и y совпадают.
[0142] Чтобы произвести автокорреляционные ряды, корреляция вычисляется много раз, каждый раз смещая ряд x на дополнительное положение индекса относительно ряда y (помня, что y является копией x). По мере продвижения смещения, набор данных «закручивается» назад в начало, так как последний индекс в ряду данных x превышается из-за смещения индекса x; это часто наиболее практично выполняется посредством удвоения данных y и «скользящего перемещения» данных x от смещения 0 до смещения n, чтобы генерировать автокорреляционные ряды.
[0143] При реализации автокорреляционного подхода, нет необходимости включать сами значения данных подписи в виде части финальных данных. При автокорреляции, ряд данных просто подвергается вычислению корреляции с самим собой. Поэтому, если раньше для проверки подлинности необходимо было передавать на устройство проверки подлинности как порядок извлечения (сортировки), так и значения подлинных данных подписи, теперь необходимо лишь предоставить порядок сортировки/извлечения для операции автокорреляционных рядов. Тем не менее, так как порядок сортировки и данные о величине сохраняются по меньшей мере для конца низкой величины диапазона, было обнаружено, что в некоторых вариантах осуществления наиболее компактным является сохранение реальных значений данных подписи и генерирование оригинальной автокорреляционной кривой, только когда она нужна, на этапе 166.
[0144] В варианте осуществления вычисляется rxy, где каждый член xi является артефактом, представленным своей величиной и местоположением, а каждый член yi=x(i+j), где j является смещением двух наборов данных, для j от 0 до (n-1). Так как xi сортируются по величине, а величина является самыми значимыми разрядами xi, имеется очень сильная корреляция при j=0 или около него, которая быстро падает при приближении к j=n/2. Так как y является копией x, j и n-j являются взаимозаменяемыми. Следовательно, автокорреляционные ряды всегда формируют U-образную кривую, показанную на фиг. 16, которая обязательно является симметричной относительно j=0 и j=n/2. Таким образом, фактически необходимо вычислять только одну половину кривой, хотя на фиг. 16 для ясности показана вся кривая от j=0 до j=n.
[0145] В варианте осуществления сырые данные метрик извлекаются из проверяемого символа и сортируются в том же самом порядке, что и оригинальные данные метрик, которые могут быть обозначены, как часть оригинальных данных подписи, если это не является предопределенным.
[0146] Проверяемые данные метрик подвергаются вычислению автокорреляции для каждого из первого и второго диапазонов. Затем, результирующие проверяемые автокорреляционные ряды могут подвергаться вычислению корреляции с оригинальными автокорреляционными кривыми для этой метрики, или, в качестве альтернативы, две пары кривых могут подвергаться сравнению посредством вычисления ошибки подбора кривой между кривыми каждой пары. Эта корреляция проиллюстрирована графически на фиг. 17 и 20. Эта конечная оценка корреляции затем становится отдельной оценкой «соответствия» для этой конкретной метрики. По завершении для всех метрик, оценки «соответствия» используются для принятия решения подлинный/поддельный для проверяемого символа.
[0147] Дополнительно, автокорреляционные кривые могут дополнительно использоваться посредством применения анализа степенных рядов к данным с помощью дискретного преобразования Фурье (ДПФ). Для ясности, широко известная операция
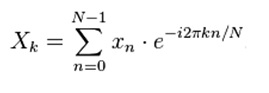
является дискретным преобразованием Фурье, где: Xk -это k-ый частотный компонент, N - это длина списка данных метрики, а x - это набор данных метрики.
[0148] Затем рассчитывается степенной ряд данных ДПФ. Каждый частотный компонент, представленный комплексным числом в ряду ДПФ, анализируется по величине, с отбрасыванием фазового компонента. Результирующие данные описывают распределение спектральной энергии данных метрики, от низкой до высокой частоты, и они становятся основой для дальнейшего анализа. Примеры этих степенных рядов показаны графически на фиг. 17, 18 и 20.
[0149] Используется две частотные техники анализа: эксцесс и мера распределения энергии вокруг средней частоты общего спектра, указываемая ссылкой, как смещение распределения. Эксцесс является обычной статистической операцией, используемой для измерения «островершинности» распределения, которая полезна здесь для оповещении о наличии плотно сгруппированных частот с ограниченным распространением диапазона в данных степенного ряда. Настоящий пример использует модифицированную функцию эксцесса, определенную
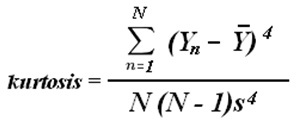
где: QUOTE  - это среднее значение данных величины степенного ряда, s - это стандартное отклонение величин, а N - это количество анализируемых дискретных спектральных частот.
- это среднее значение данных величины степенного ряда, s - это стандартное отклонение величин, а N - это количество анализируемых дискретных спектральных частот.
[0150] Смещение распределения рассчитывается как
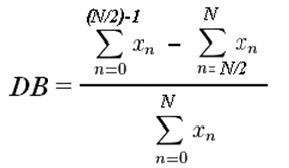
где N - это количество анализируемых дискретных спектральных частот.
[0151] Гладкая полиномиальная кривая подписей метрик подлинного символа (возникающая из сортировки по величине) производит узнаваемые характеристики в спектральной подписи при анализе в частотной области. Проверяемый символ, когда метрики данных извлекаются в том же самом порядке, как предписано подлинными данными подписи, будет представлять схожее спектральное распределение энергии, если символ является подлинным; то есть, если подлинный порядок сортировки «согласуется» с величинами метрик проверяемого символа. Расхождение в отсортированных величинах, или другие наложенные сигналы (такие как артефакты фотокопирования) обычно проявляются в виде высокочастотных компонентов, которые в ином случае отсутствуют в спектре подлинного символа, таким образом, обеспечивая дополнительную меру подлинности символа. Тем не менее, без дополнительного анализа, описанного в настоящей спецификации, высокочастотный компонент в проверяемых данных первого диапазона не является достаточно отличительным, чтобы быть надежным индикатором фотокопии. Это относится к вероятности того, что поддельные автокорреляционные ряды все еще могли бы удовлетворять минимальному пороговому значению статистического соответствия подлинного символа. Это является маловероятной возможностью, но предположительно может случиться при использовании нормализованной корреляции, если общий диапазон данных является большим по сравнению с величиной ошибок между отдельными точками данных, и естественный порядок сортировки доминантных величин метрики выглядит близким к порядку для подлинного символа. Характеристики распределения степенного ряда ДПФ такого сигнала покажут плохое качество соответствия по высоким частотам, присутствующим в ошибках соответствия небольшой амплитуды проверяемых рядов. Такое состояние могло бы указывать на фотокопию подлинного символа. В специальных терминах, здесь в спектре подлинного символа ожидается высокий эксцесс и высокий коэффициент распределения.
[0152] Вместе с оценкой соответствия автокорреляции, эта информация о распределении степенного ряда используется в качестве меры «достоверности» при проверке подлинности проверяемого символа.
[0153] Фиг. 16 показывает сравнение автокорреляционных рядов для одной метрики между подлинным предметом (полиномиальной аппроксимацией) и проверяемым символом (в данном случае подлинным). Отметим близкое соответствие, здесь, корреляция между двумя автокорреляционными рядами превышает 93%.
[0154] Фиг. 17 - степенной ряд из оригинальных подлинных автокорреляционных данных, используемых для фиг. 16. Очевидно, что в спектре доминируют низкие частоты.
[0155] Фиг. 18 - это степенной ряд, схожий с фиг. 17, из изображения, полученного с помощью сотового телефона, подлинного предмета по фиг. 17. Присутствует определенный шум изображения, но общий степенной спектр близко соответствует подлинному спектру, с таким же доминированием низкочастотных компонентов.
[0156] Фиг. 19 показывает сравнение автокорреляционных рядов для одной метрики между полиномиальной аппроксимацией подлинного предмета и проверяемым символом (в данном случае поддельным). Имеется существенное расхождение, и проверяемая автокорреляция является намного более зубчатой, чем на фиг. 16. Числовая корреляция между двумя рядами низкая (<5%), и зубчатая форма данных также очевидна при анализе ДПФ (ниже).
[00100] Фиг. 20 показывает степенной ряд из изображения, полученного с помощью сотового телефона, поддельного символа графика 4. Отметим, что низкочастотные компоненты уменьшились, с общей спектральной энергией, которая теперь распределена таким образом, что включает в себя существенные участки из более высокого диапазона частот.
[0157] Оценивание значения вероятности фотокопии
[0158] Если взвешенная агрегированная оценка для всех доступных метрик вычисляется для результатов, таких как показанные на фиг. 13 и 14, подлинная проверяемая метка обычно будет иметь существенно более высокое соответствие с оригинальной меткой, чем подвергнутая фотокопии проверяемая метка. Разница между двумя проверяемыми метками небольшая, и при простом сравнении между проверяемой меткой и оригинальными данными не всегда просто отличить фотокопию от подлинной проверяемой метки. Тем не менее, как видно даже при простой проверке фиг. 13, различия лучше проявляются в данных низкого значения, которые показаны в увеличенном виде на фиг. 14. Таким образом, посредством оценивания соответствия между данными оригинальной метки и данными проверяемой метки отдельно для диапазонов высокой и низкой величины и посредством сравнения двух оценок, может быть сделано намного более уверенное различение между оригинальной и подвергнутой фотокопированию проверяемыми метками.
[0159] В примере сравнение может быть выражено посредством P=ABS((r1 - r2)/(r1+2)), где: P - это оценка вероятности фотокопии; r1 - это агрегированная оценка соответствия между подлинными и проверяемыми подписями для первого диапазона (левая сторона на фиг. 13); r2 - это агрегированная оценка соответствия между подлинными и проверяемыми подписями для второго диапазона (правая сторона на фиг. 13).
[0160] В тесте, используя 135 экземпляров меток и их фотокопий, используя 100 наиболее выраженных артефактов (соответствующих артефактам с 1 по 100 по фиг. 13) для r1 и 100 наименее выраженных артефактов (соответствующих артефактам с 61 по 160 по фиг. 13) для r2, и используя полиномиальную аппроксимацию автокорреляционного значения, описанного выше для оценивания, только 9 подлинных проверяемых меток имели значение P выше чем 0.2, и только одна имела значение P выше чем 0.4. Только 9 подвергнутых фотокопированию меток имели значение P ниже чем 0.2, и только 21 имели значение P ниже чем 0.4. Посредством выбора подходящего порогового значения для P (приблизительно 0.2 на этих данных), фотокопии были идентифицированы с точностью выше 85%.
[0161] Статистическая изменчивость данных ниже порогового значения
[0162] Детектирование фотокопий может быть дополнительно улучшено посредством рассмотрения того, как распределение, диапазон и стандартное отклонение данных «ниже порогового значения» проверяемой метки соответствуют оригинальным значениям ниже порогового значения. Для данной цели, данные «ниже порогового значения» являются данными для модулей, которые в оригинальном снимке данных не проявили никаких артефактов, достаточно больших для надежного отделения от случайного шума. Несмотря на то, что точные значения данных обычно не являются полезными при прямом применении автокорреляции или другого анализа к области слабых сигналов (из-за того, что «шум», вносимый при получении проверяемого изображения, легко перекрывает любые «реальные» значения извлеченных данных метрики), артефакты фотокопии меняют этот шум измеримым образом. Базовая линия шума данных ниже порогового значения может, таким образом, быть охарактеризована в получаемых проверяемых изображениях, и если эта базовая линия превышается в одном или более измерениях (суммы ошибок, стандартного отклонения, и т. д.), это может быть воспринято, как указание на то, что другой процесс добавил изменчивости к тому, что должно являться меньшим диапазоном данных с более низкой амплитудой.
[0163] Используя только тест ниже порогового значения согласно US 2013/0228619, который просто показывает, что детектируемый артефакт не появлялся в ранее свободном от артефактов модуле, фотокопия подлинной метки обычно не является очевидной. Фотокопия действительно влияет на метрики метки, но обычно делает это посредством наложения изменения (визуального шума, изменения однородности, и т. д.) на каждый модуль внутри символа. Таким образом, при оценивании с помощью автокорреляции отсортированного списка, фотокопия выглядит подлинной - влияние сводится к «смещению DC» автокорреляционной кривой, или к добавлению константы, которая оказывает минимальное воздействие при расчете ошибки подбора кривой. Тем не менее, при рассмотрении области ниже порогового значения с точки зрения того, насколько однородным является набор данных ниже порогового значения по сравнению с таковым подлинного предмета (диапазон, стандартное отклонение, и т. д.), видно, что по существу создается новая метрика, характеризующая эту однородность. Оказывается, при фотокопировании, области с высокой однородностью становятся менее однородными хаотичным образом; то есть, данные ниже порогового значения, имеющие относительно низкую изменчивость в метке подлинного предмета, обычно являются более изменчивым набором значений в фотокопии, но в то же время в целом сохраняя величину ниже предела порогового значения.
[0164] Когда области ниже порогового значения для подлинной и подвергнутой фотокопированию проверяемых меток наносятся на график относительно оригинальных данных подписи для одинаковой метки, как проиллюстрировано посредством фиг. 14, видно, что значения, содержащие данные ниже порогового значения для фотокопий являются намного более изменчивыми, чем для данных подлинного предмета.
[0165] Несколько числовых способов могут использоваться для детектирования фотокопий с помощью использования данных в этой области. Первый способ является подходом суммы ошибок. Здесь, рассчитывается текущая сумма различий между данными ниже порогового значения подписи оригинальной метки и данными ниже порогового значения проверяемой метки. Как видно на фиг. 14, она явно больше в фотокопиях, чем в подлинных проверяемых метках. При кумулятивном нанесении на график текущей суммы относительно числа модулей, кривые для данных подписи фотокопии отклоняются от оригинальных данных подписи быстрее, чем кривые для данных подписи подлинной проверяемой метки. Таким образом, очень просто применить предел скорости роста к этому значению суммы ошибок и использовать его, чтобы обозначать присутствие схожего с фотокопией сигнала в областях ниже порогового значения проверяемых данных метрик подписи. Другие статистические способы также могут применяться к этой области данных.
[0166] Проверка моментов инерции матрицы совпадений уровня серого (GLCM)
[0167] В альтернативном варианте осуществления анализ текстуры используется для оценки однородных областей на изменения, созданные в процессе фотокопирования. Инерция (статистическая мера контраста) в признаках символа сравнивается с такой же инерцией, записанной во время извлечения метрик подписей оригинальной подлинной метки. Увеличение в статистике инерции GLCM обозначает, что проверяемая метка может являться фотокопированной репродукцией подлинной метки. В некоторых случаях, например, когда символ напечатан на пятнистой подложке, которая может давать ложную базовую линию, отношение инерции для целевого темного модуля к инерции для смежного светлого модуля может давать более точный результат, чем простая мера инерции для темного модуля. Выбранными признаками символа являются модули, которые являются сплошными черными в оригинальной метке. Обычно, они идентифицируются, как модули в нижней части отсортированного по величине списка черных модулей с белыми пустотами или черных модулей, которые являются более светлыми, чем номинальный черный цвет. Высокое значение инерции обозначает модуль, который содержит черную и белую пятнистость в масштабе пикселей, используемых для генерирования GLCM. Если оригинальный модуль имел низкую инерцию, а проверяемый модуль имеет намного более высокую инерцию, это обозначает увеличение пятнистости, что является серьезным основанием подозревать, что проверяемая метка является фотокопией. Для простого сравнения, сумма значений инерции может быть рассчитана для всех анализируемых ячеек в оригинальной и проверяемой метках. Если сумма для проверяемой метки превышает сумму для оригинальной метки более чем на установленное пороговое значение, это может быть рассмотрено, как указание на фотокопию.
[0168] Результаты теста моментов инерции (MI) были измерены для нескольких тестовых наборов двумерной матрицы данных. В качестве эксперимента, этот способ был протестирован, используя тот же набор данных, что и для других способов, поэтому пиксели, используемые для расчета GLCM, имели тот же размер, что и самые мальнькие признаки, детектируемые в других метриках, обычно по меньшей мере 500 пикселей на модуль стандартной двумерной матрицы данных. При получении оригинальной подписи подлинного предмета для этой метрики, MI оценивались для каждого модуля внутри метки, затем сортировались, чтобы придать наибольший вес самым однородным местоположениям (самым низким значениям MI). При оценивании проверяемой метки, значения MI извлекались, используя оргинальный подлинный порядок сортировки, и результирующие данные анализировались. Фиг. 21 - пример графика значений MI для оригинальных подлинных данных, и для подлинной проверяемой метки и фотокопии подлинной метки.
[0169] Из фиг. 21 очевидно, что фотокопии обычно проявляют повышенные значения MI по сравнению со значениями MI, найденными в тех же областях в подлинных метках. Таким образом, очень просто установить тест для этого состояния. Области под каждой из линий графика могут быть проинтегрированы, чтобы установить меру аггрегированного MI или площадь MI (AMI) по оцениваемым областям в метке. Затем определяется разница dAMI между оригинальным подлинным измерением площади MI и проверяемым измерением площади MI (dAMIgn для тестов подлинной проверяемой метки и dAMIpc для фотокопий).
[0170] Резюмируя результаты тестов для фиг. 21 и двух схожих примеров, видно, что:
[0171] Видно, что результат dAMI обычно выше в фотокопиях подлинных меток, чем в самих подлинных метках. Здесь может применяться простой тест порогового значения, чтобы указывать на присутствие возможных артефактов фотокопии в проверяемой метке. Этот тест на артефакты фотокопии может объединяться с любым из тестов для подлинной метки, описанных выше или в более ранней заявке US 2013/0228619 данного заявителя.
[0172] Преимущества некоторых или всех из раскрытых вариантов осуществления могут включать в себя, без ограничения, возможность уникальным образом идентифицировать предмет посредством использования метки, которая была размещена на предмете для другой цели, без необходимости специально вносить открытые или скрытые элементы для целей защиты от подделок. Другое преимущество состоит в том, что такую идентификацию может быть очень сложно подделать. Дополнительные преимущества включают в себя возможность встроить функции настоящего изобретения в существующие технологии, обычно используемые для считывания символов штрихового кода, такие как камеры машинного зрения, устройства считывания штрихового кода и потребительские «смартфоны», оборудованные камерами, не изменяя основного поведения, конструкции или удобства использования устройств. Другое преимущество, в случае двумерного штрихового кода, например, состоит в возможности использовать данные подписи в качестве средства предоставления избыточного носителя данных для цели идентификации предмета.
[0173] В случае, когда повреждение проверяемой метки делает ее лишь частично читаемой, или делает невозможным считывание и/или декодирование содержащего данные символа или тому подобного, неповрежденных идентифицирующих признаков всего лишь части метки может быть достаточно для идентификации метки. Как только проверяемая метка идентифицируется таким образом, как подлинная, подпись подлинной метки может быть извлечена из хранилища, и любая информация, которая была встроена в подпись, например, серийный номер отмеченного предмета, может быть восстановлена из извлеченной подписи вместо прямого извлечения из поврежденной метки. Таким образом, данные подписи, либо в комбинации с частично восстановленной закодированной информацией символа, либо отдельно, могут использоваться, чтобы уникальным образом идентифицировать предмет. Это имеет много преимуществ, в частности, в рассмотрении того, как содержащая данные метка может быть повреждена во время перемещения отмеченного предмета в цепочке поставок производителя. Эту проблему в прошлом обычно решали посредством обеспечения того, чтобы носитель данных создавался с очень высоким качеством или «степенью» в месте нанесения метки. Цель состояла в том, чтобы произвести метку такого высокого качества, что она все еще будет полностью читаема даже после того, как она подвергнется сущесвенному ухудшению из-за физического повреждения в цепочке поставок. Это накладывает лишнюю нагрузку на стоимость и объем производства для производителя предмета, так как он стремится гаранитровать, чтобы только метки самого высокого качестваа попадали в его цепочку поставок. Настоящий вариант осуществления имеет преимущество, состоящее в устранении необходимости производства меток наивысшего качества, в то же время все еще обеспечивая способ идентификации нечитаемых меток, которые не могут быть декодированы обычным способом из-за повреждения символа.
[0174] В то время как предшествующее письменное описание позволяет рядовому специалисту в данной области техники производить и использовать то, что в настоящее время считается наилучшим вариантом его осуществления, рядовые специалисты в данной области техники также поймут и оценят существование изменений, комбинаций и эквивалентов конкретного варианта осуществления, способа и примеров, приведенных в материалах настоящей заявки. Изобретение, таким образом, не ограничено вышеописанными вариантами осуществления, способами и примерами, но распространяется на все варианты осуществления и способы в пределах объема и духа раскрытия.
[0175] Например, пример признаков двумерного штрихового кода описан со ссылкой на фиг. 5. Пример признаков одномерного штрихового кода описан со ссылкой на фиг. 15. Как упоминалось выше, другие символы, такие как логотип компании, могут использоваться в качестве целевого символа. Признаки и конкретные изменения в этих признаках, которые используются в качестве метрик подписи, являются почти безграничными, и рядовой специалист в данной области техники, с пониманием настоящей спецификации, может выбрать подходящий или доступный символ и выбрать подходящие метрики и признаки, чтобы осуществить настоящие способы. В некоторых вариантах осуществления нет необходимости наносить метку с целью извлечения данных подписи согласно настоящим способам. Вместо этого могла бы использоваться метка, которая уже была создана, при условии, что она содержит подходящие признаки артефактов.
[0176] Если оригинальная метка наносится на оригинальный предмет, и/или оригинальный предмет наносится на оригинальный объект, метка или предмет могут содержать информацию о предмете или объекте. В этом случае, вышеописанные способы и системы могут включать в себя проверку информации о предмете или объекте, которая включена в метку или предмет, даже когда лежащий в основе предмет или объект не замещают физически и не изменяют. Например, если объект отмечен сроком годности, может быть желательно отклонить объект с измененным сроком годности, как «не подлинный», даже если сам объект является оригинальным. Варианты осуществления настоящих систем и способов будут производить этот результат, если артефакты, используемые для проверки, обнаруживаются в сроке годности, например, в виде дефектов печати. Другая информация, такая как номера лотов и другие данные отслеживания продукта, может проверяться схожим образом.
[0177] Варианты осуществления были описаны главным образом в терминах получения всего двумерного штрихового кода для данных подписи. Тем не менее, метка может быть разделена на более мелкие зоны. Если оригинальная метка является достаточно большой и содержит достаточно артефактов, которые являются потенциальными данными подписи, только одна зона или только часть всех зон могут быть получены и обработаны. Если получают и обрабатывают более одной зоны, данные подписи из разных зон могут записываться по отдельности. Это является особенно полезным, если метка является символом, кодирующим данные с помощью коррекции ошибок, и коррекция ошибок относится к зонам, более мелким, чем весь символ. Нарпимер, если коррекция ошибок указывает, что часть проверяемого символа повреждена, данные подписи из поврежденной части могут не учитываться.
[00101] Для простоты, были описаны конкретные варианты осуществления, в которых артефакты являются дефектами в печати напечатанной метки, нанесенной либо напрямую на предмет, который должен быть проверен, либо на ярлык, нанесенный на объект, который должен быть проверен. Тем не менее, как уже упоминалось, может использоваться любой признак, который является достаточно различимым и долговечным, и который достаточно сложно скопировать.
[0178] Некоторые из вариантов осущетслвения были описаны, как использующие базу данных подписей для подлинных предметов, в которой осуществляется поиск данных подписи, которые по меньшей мере частично соответствуют данным подписи, извлеченным из проверяемой метки. Тем не менее, если проверяемый предмет идентифицируется, как специальный подлинный предмет, каким-либо другим образом, поиск может не потребоваться, и данные подписи, извлекаемые из проверяемой метки, могут сравниваться напрямую с сохраненными данными подписи для специального подлинного предмета.
[0179] Соответственно, ссылка должна быть сделана скорее на прилагаемую формулу изобретения, чем на вышеприведенную спецификацию, в качестве обозначения объема изобретения.
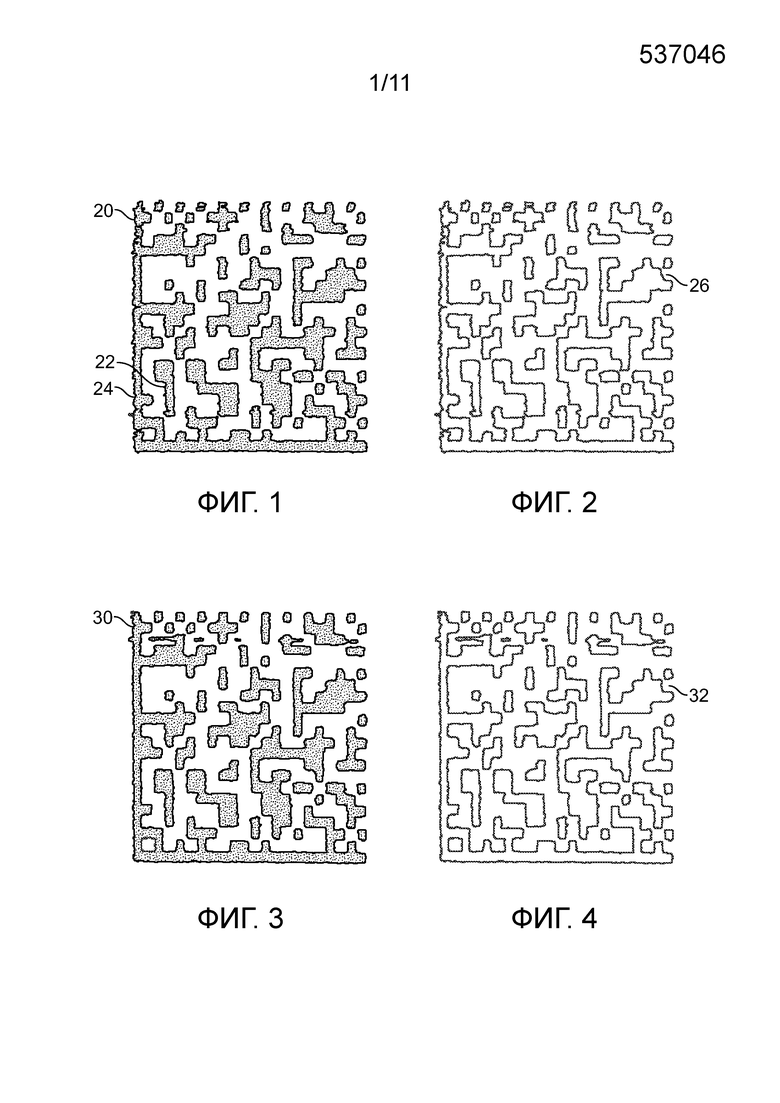
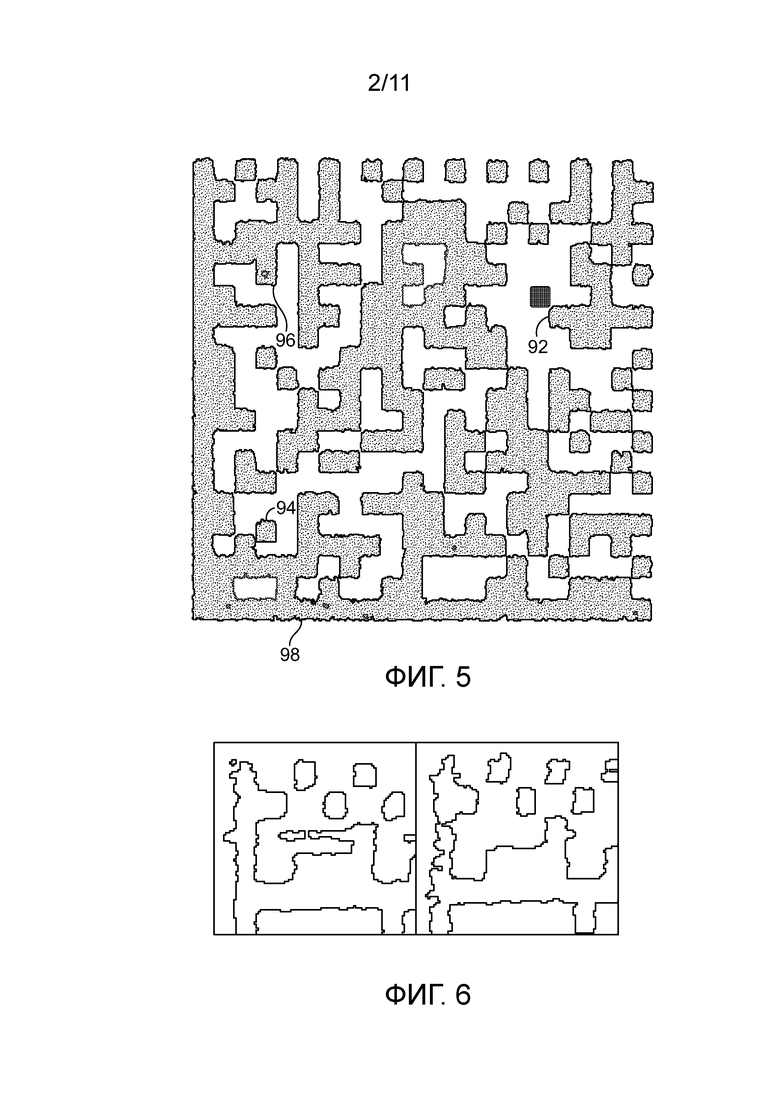
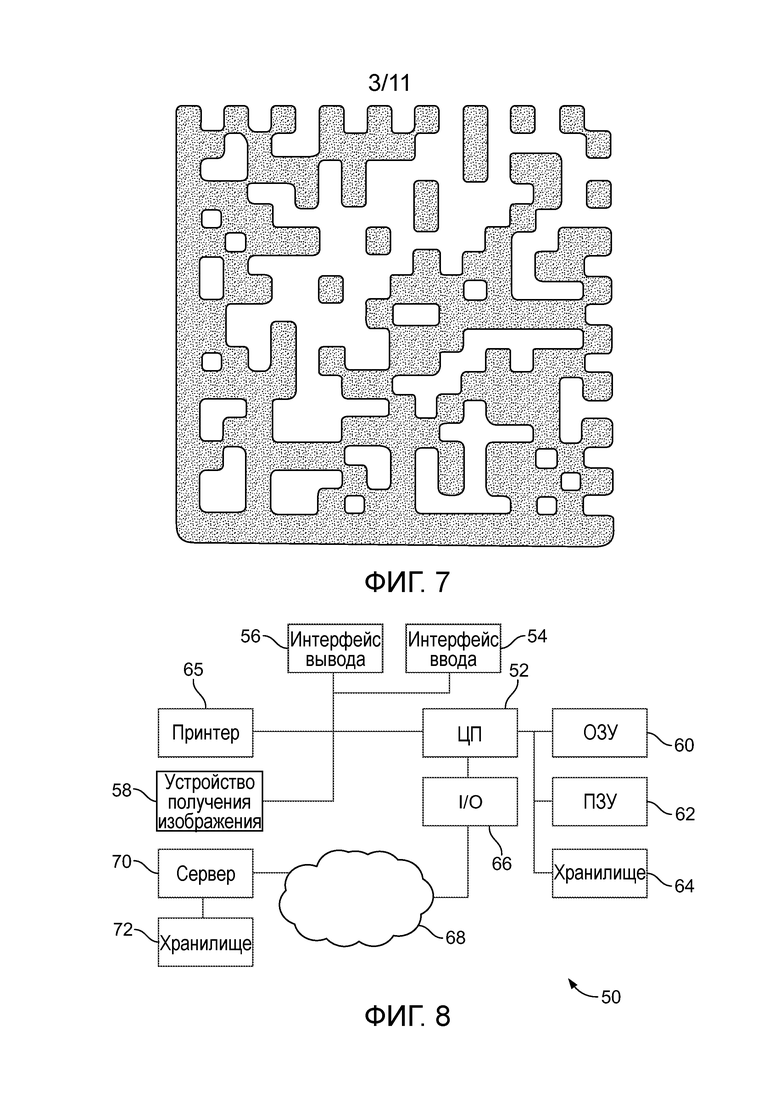
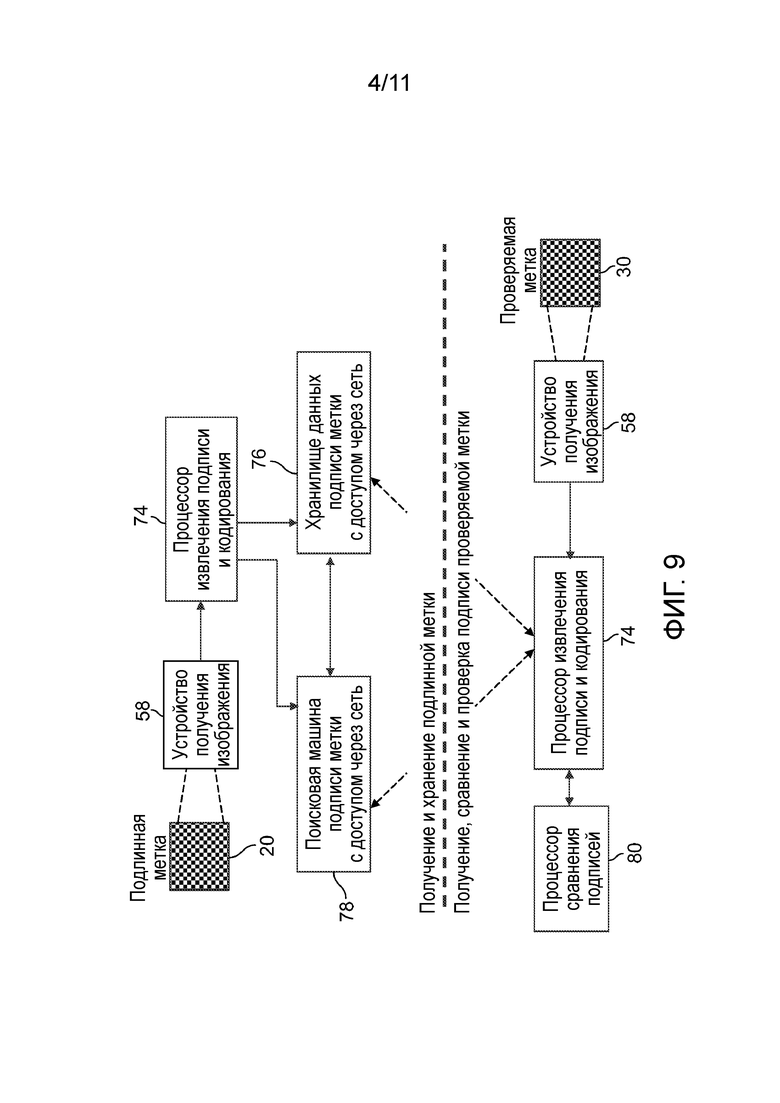
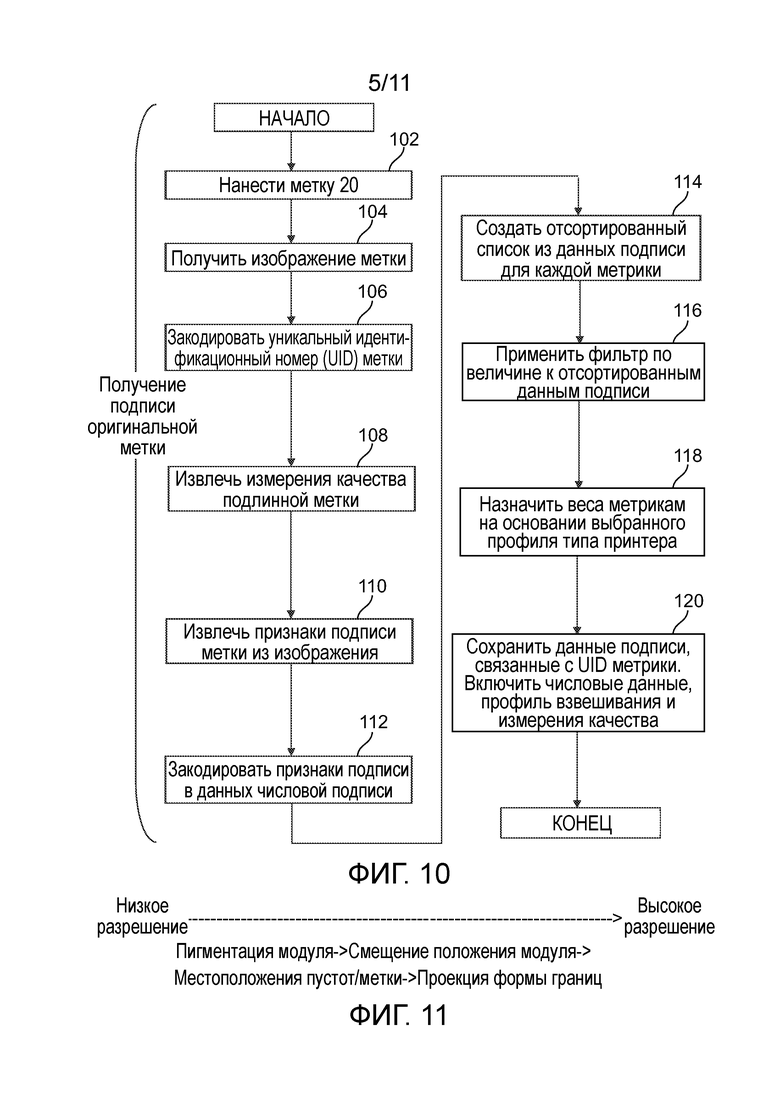
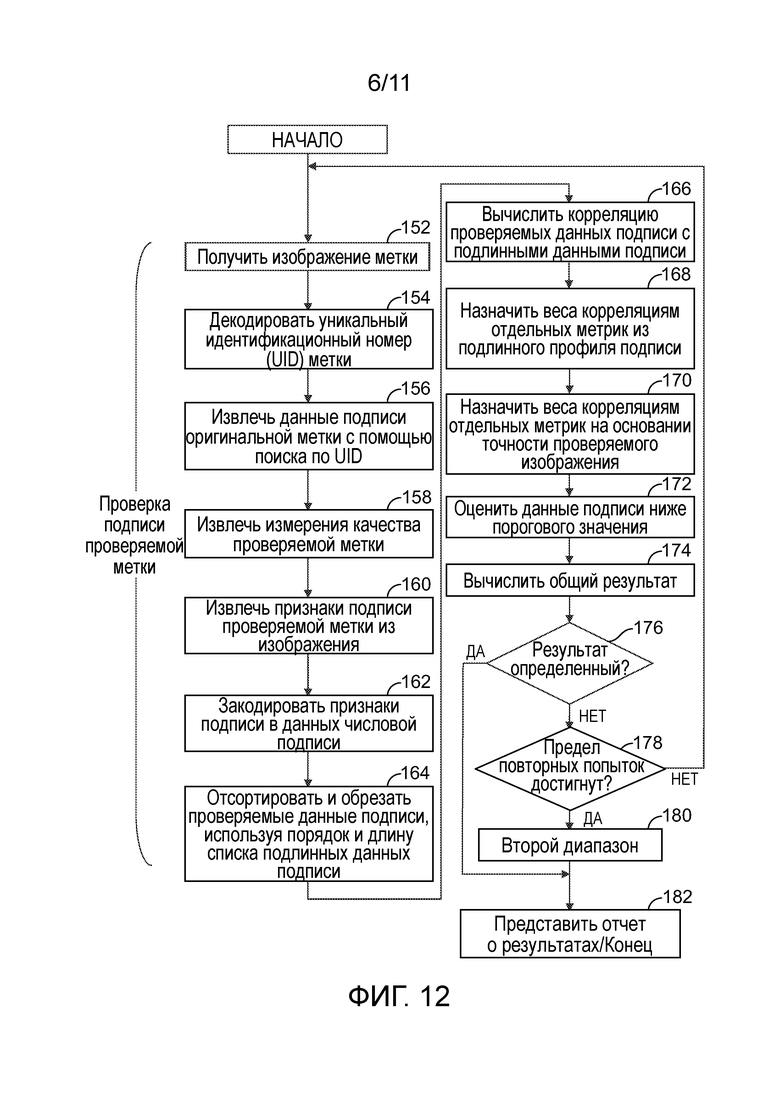
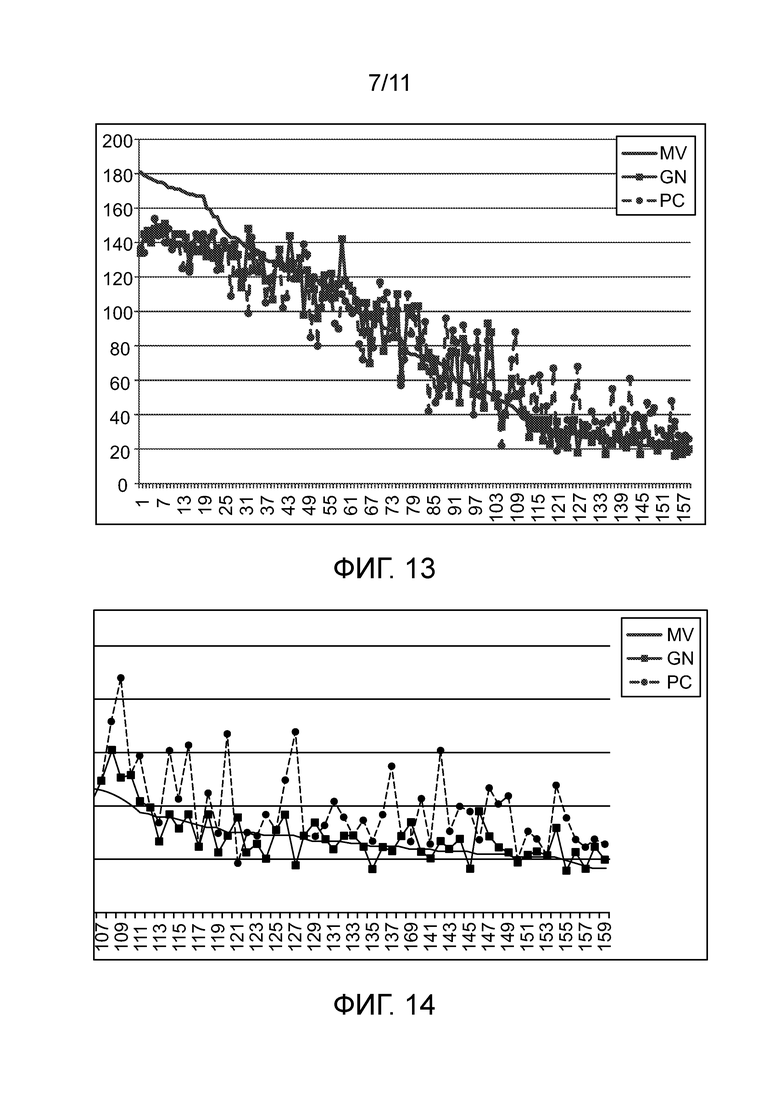
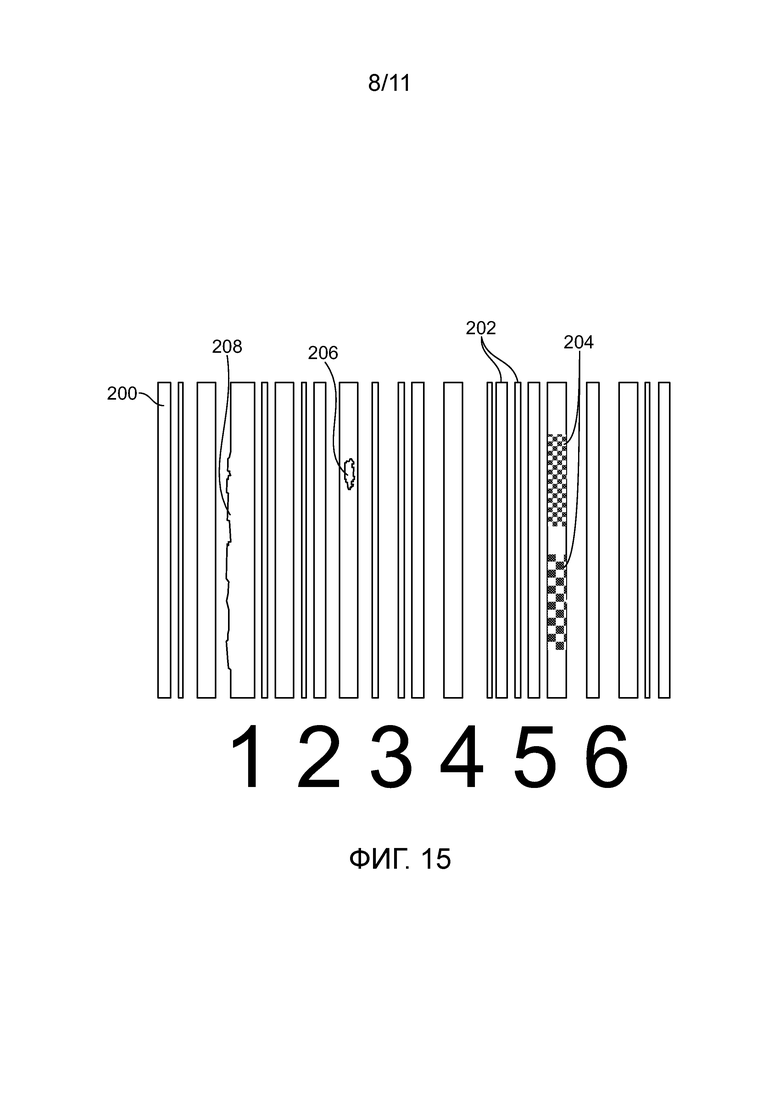
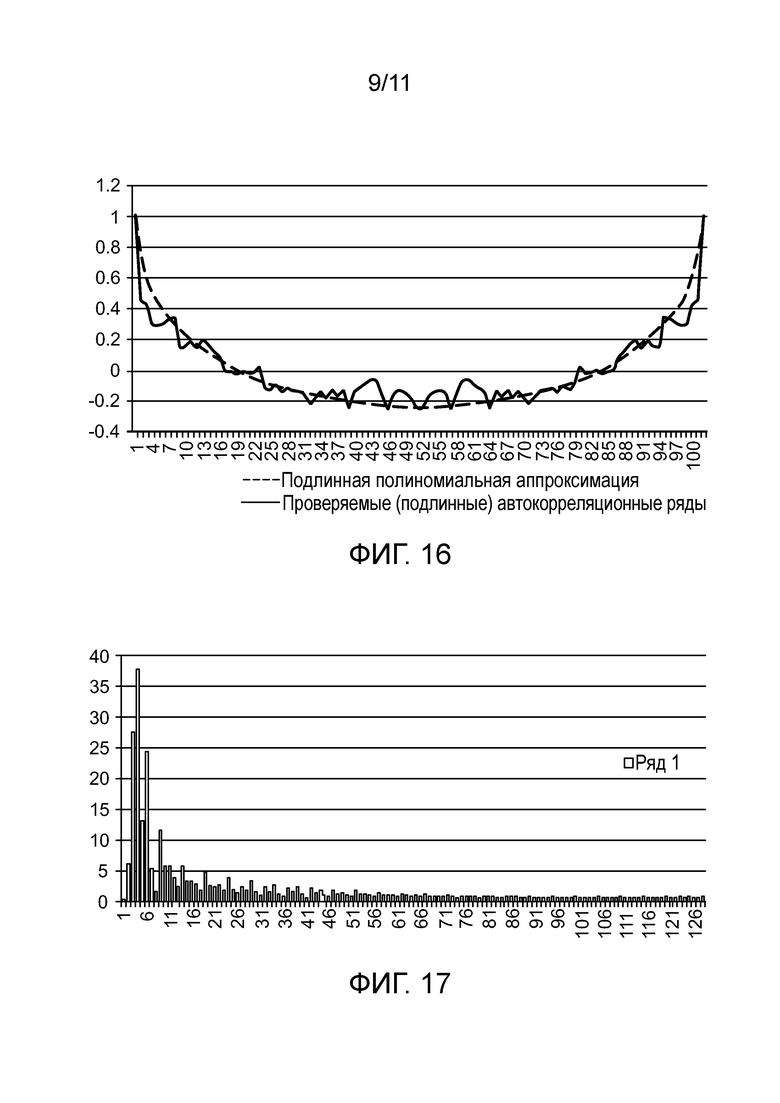
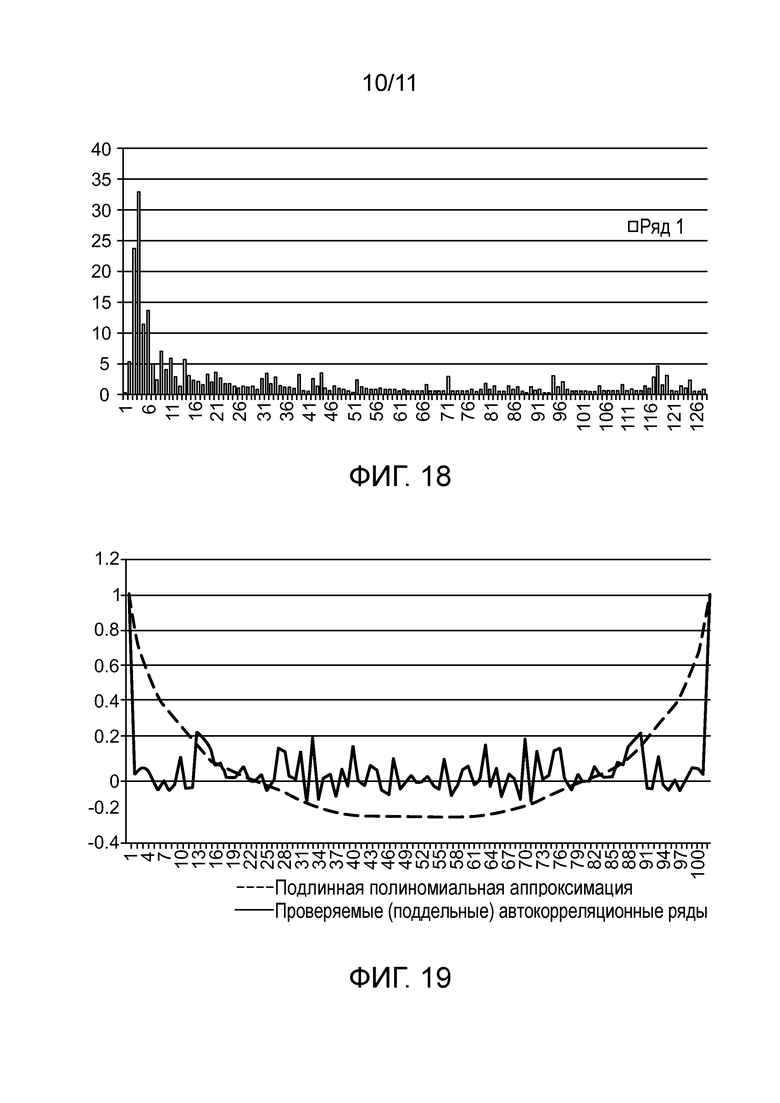
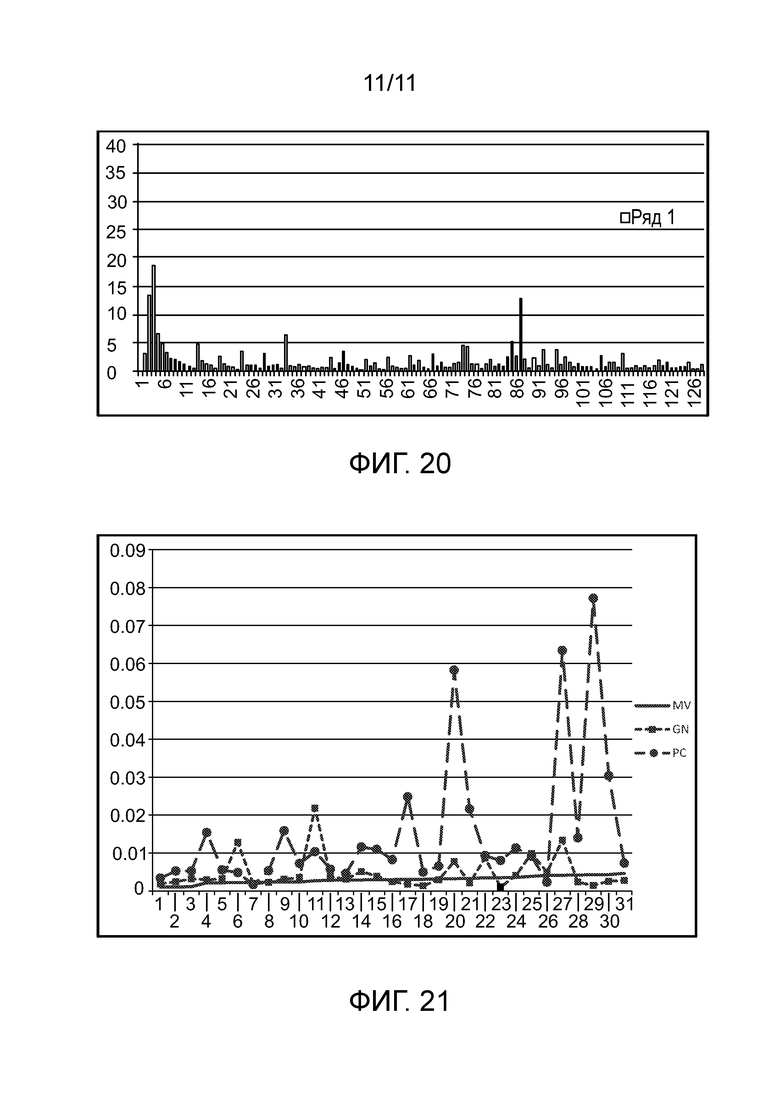
Изобретение относится к средствам проверки подлинности напечатанного предмета. Технический результат заключается в повышении надежности проверки. В способе получают изображение непроверенного напечатанного предмета, включающее в себя артефакты. По меньшей мере некоторые из артефактов не могут быть произведены управляемым образом при производстве непроверенного напечатанного предмета, извлекают информацию, связанную с артефактами непроверенного напечатанного предмета, ранжируют информацию, связанную с артефактами непроверенного напечатанного предмета, извлекают из устройства хранения ранжированную информацию, связанную с артефактами оригинального напечатанного предмета. В каждом из первого и второго диапазонов величин сравнивают ранжированную информацию, связанную с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета. 3 н. и 17 з.п. ф-лы, 21 ил.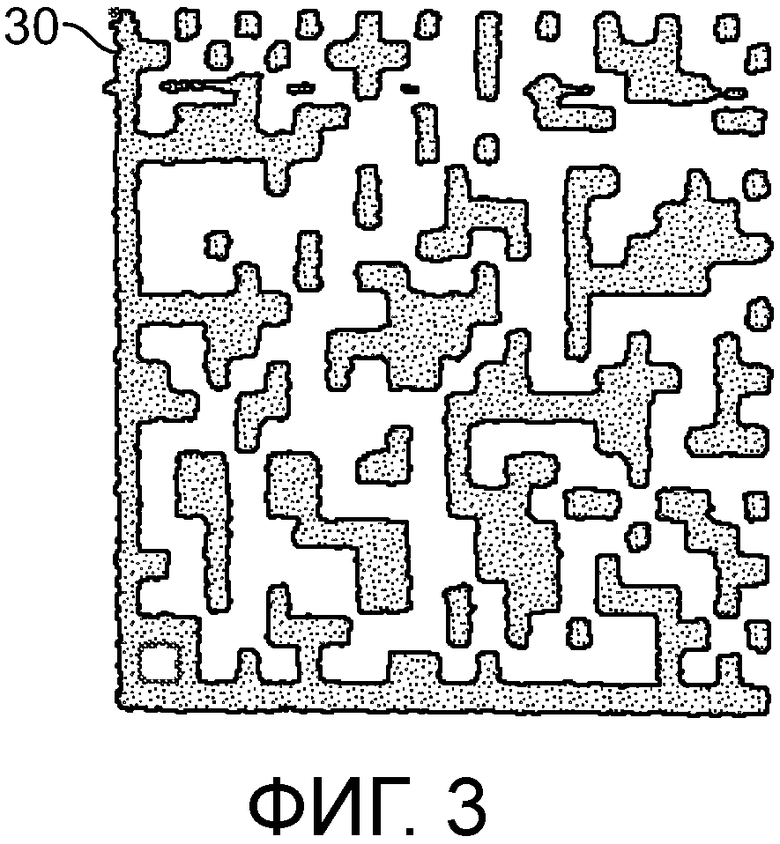
1. Способ проверки подлинности непроверенного напечатанного предмета, способ содержит этапы, на которых:
на устройстве получения изображения получают изображение непроверенного напечатанного предмета,
при этом непроверенный напечатанный предмет включает в себя артефакты и по меньшей мере некоторые из артефактов не могут быть произведены управляемым образом при производстве непроверенного напечатанного предмета;
на процессоре:
извлекают информацию, связанную с артефактами непроверенного напечатанного предмета;
ранжируют информацию, связанную с артефактами непроверенного напечатанного предмета;
извлекают сохраненную ранжированную информацию, связанную с артефактами оригинального напечатанного предмета, из устройства хранения;
в первом диапазоне величин, сравнивают ранжированную информацию, связанную с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета;
во втором диапазоне величин сравнивают ранжированную информацию, связанную с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета;
при этом второй диапазон включает в себя более мелкие артефакты, чем самые мелкие артефакты в первом диапазоне; и
когда разница между ранжированной информацией, связанной с артефактами непроверенного напечатанного предмета, и ранжированной информацией, связанной с артефактами оригинального напечатанного предмета, выше для второго диапазона, чем для первого, более чем на пороговое значение, идентифицируют непроверенный напечатанный предмет как копию.
2. Способ по п. 1, в котором разница является средней или агрегированной разницей в величинах, или отношением величин артефактов, или статистической мерой изменения в величинах артефактов.
3. Способ по п. 1, дополнительно содержащий этапы, на которых:
в первом диапазоне величин оценивают статистическую вероятность того, что информация, связанная с артефактами непроверенного напечатанного предмета, соответствует информации, связанной с артефактами оригинального напечатанного предмета;
в случае если статистическая вероятность превышает первое пороговое значение, определяют, что непроверенный напечатанный предмет является оригинальным напечатанным предметом;
в случае если статистическая вероятность меньше второго порогового значения, которое ниже первого порогового значения, определяют, что непроверенный напечатанный предмет не является оригинальным напечатанным предметом; и
выполняют этапы сравнения только в том случае, если статистическая вероятность находится между первым и вторым пороговыми значениями.
4. Способ по п. 1, в котором первый диапазон включает в себя предопределенное количество артефактов, имеющих самые высокие величины.
5. Способ по п. 1, в котором упомянутый второй диапазон включает в себя предопределенное количество артефактов, имеющих величины, расположенные ближе всех к самой низкой записанной величине.
6. Способ по п. 1, в котором первый и второй диапазоны перекрываются.
7. Способ по п. 1, дополнительно содержащий расчет автокорреляционных рядов ранжированной информации, связанной с артефактами непроверенного напечатанного предмета для каждого из первого и второго диапазонов.
8. Способ по п. 1,
в котором по меньшей мере некоторые из артефактов непроверенного напечатанного предмета являются артефактами символа, который кодирует данные и поддерживает детектирование ошибок,
в котором извлечение информации, представляющей артефакты непроверенного напечатанного предмета, включает в себя определение состояния ошибки символа, содержащего артефакты непроверенного напечатанного предмета, и
когда состояние ошибки обозначает, что часть символа повреждена, уменьшают значимость артефактов в поврежденной части символа.
9. Способ по п. 1, в котором каждый из этапов сравнения включает в себя ввод поправки на свойства по меньшей мере одного из: устройства, которое создало оригинальные артефакты, устройства, используемого при проверке оригинального напечатанного предмета на информацию, представляющую артефакты, и устройства, используемого при проверке непроверенного напечатанного предмета на информацию, представляющую артефакты.
10. Способ по п. 9, в котором:
артефакты непроверенного напечатанного предмета и оригинального напечатанного предмета относятся к отдельным категориям;
сравнение в первом диапазоне величин ранжированной информации, связанной с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета, содержит выполнение сравнения в каждой категории и объединение результатов сравнений;
сравнение во втором диапазоне величин ранжированной информации, связанной с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета, содержит выполнение сравнения в каждой категории и объединение результатов сравнений; и
поправка содержит взвешивание объединения согласно известной тенденции устройства, которое создало оригинальный напечатанный предмет, производить артефакты в разных категориях с разными частотами или разными значениями характеристики.
11. Способ по п. 1, дополнительно содержащий этапы, на которых:
проверяют оригинальный напечатанный предмет на артефакты, характерные для оригинального напечатанного предмета;
извлекают информацию, связанную с артефактами;
ранжируют информацию согласно характеристике артефактов; и
сохраняют данные, представляющие ранжированную информацию, в виде упомянутой ранжированной информации на энергонезависимом машиночитаемом устройстве хранения отдельно от оригинального напечатанного предмета.
12. Способ по п. 11, в котором:
оригинальный напечатанный предмет содержит метку, которая содержит идентификатор и по меньшей мере один из артефактов, при этом идентификатор связан с оригинальным напечатанным предметом и по меньшей мере один артефакт не изменяет связь; и
сохранение содержит сохранение информации таким образом, чтобы ее можно было по меньшей мере частично локализовать, используя идентификатор.
13. Система для проверки подлинности непроверенного напечатанного предмета, содержащая:
устройство получения изображения, которое получает изображение непроверенного напечатанного предмета,
при этом непроверенный напечатанный предмет включает в себя артефакты и по меньшей мере некоторые из артефактов не могут быть произведены управляемым образом при производстве непроверенного напечатанного предмета;
процессор, который выполняет этапы, состоящие в том, что:
извлекают информацию, связанную с артефактами непроверенного напечатанного предмета;
ранжируют информацию, связанную с артефактами непроверенного напечатанного предмета;
извлекают сохраненную ранжированную информацию, связанную с артефактами оригинального напечатанного предмета, из устройства хранения;
в первом диапазоне величин сравнивают ранжированную информацию, связанную с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета;
во втором диапазоне величин сравнивают ранжированную информацию, связанную с артефактами непроверенного напечатанного предмета, с ранжированной информацией, связанной с артефактами оригинального напечатанного предмета;
при этом второй диапазон включает в себя более мелкие артефакты, чем самые мелкие артефакты в первом диапазоне; и
когда разница между ранжированной информацией, связанной с артефактами непроверенного напечатанного предмета, и ранжированной информацией, связанной с артефактами оригинального предмета, выше для второго диапазона, чем для первого, более чем на пороговое значение, идентифицируют непроверенный напечатанный предмет как копию.
14. Система по п. 13, в которой непроверенный напечатанный предмет содержит множество областей и ранжированная информация, связанная с артефактами непроверенного предмета, содержит информацию, связанную с пространственным контрастом по меньшей мере некоторых из множества напечатанных областей.
15. Способ по п. 14, в котором информация, связанная с пространственным контрастом по меньшей мере некоторых из напечатанных областей, является моментом инерции матрицы совпадений уровня серого.
16. Система для проверки подлинности напечатанного предмета, содержащая:
устройство получения изображения, которое получает изображение напечатанного предмета; и
один или более процессоров, которые выполняют действия, состоящие в том, что:
получают изображение от устройства получения изображения;
анализируют изображение, чтобы идентифицировать дефекты в напечатанном предмете,
при этом дефекты связаны с метриками множества величин;
извлекают подпись подлинной метки из базы данных подписей подлинных меток,
при этом подпись подлинной метки основана на дефектах оригинального напечатанного предмета,
при этом подпись подлинной метки содержит данные множества величин;
в первом диапазоне величин идентифицированных дефектов и подписи подлинной метки сравнивают идентифицированные дефекты с подписью подлинной метки;
во втором диапазоне величин идентифицированных дефектов и подписи подлинной метки сравнивают идентифицированные дефекты с подписью подлинной метки;
при этом второй диапазон величин включает в себя более мелкие артефакты, чем самые мелкие артефакты в первом диапазоне; и
когда разница между идентифицированными дефектами и подписями подлинных меток выше для второго диапазона, чем для первого, более чем на пороговое значение, идентифицируют непроверенный напечатанный предмет как копию.
17. Система по п. 16, в которой напечатанная метка включает в себя закодированную информацию, относящуюся к произведенному предмету.
18. Система по п. 16, в которой напечатанная метка является логотипом.
19. Система по п. 17, в которой
закодированная информация включает в себя уникальный идентификатор и
один или более процессоров извлекают подпись подлинной метки из базы данных, используя уникальный идентификатор.
20. Система по п. 16, в которой устройство получения изображения содержит устройство считывания штрихового кода.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ ИЗГОТОВЛЕНИЯ ЗАЩИТНОГО ПРИЗНАКА НА ПЛОСКОЙ ОСНОВЕ | 2009 |
|
RU2507076C2 |
| СПОСОБ И СИСТЕМА ДЛЯ КОНТРОЛИРУЕМОГО ПРОИЗВОДСТВА ЗАЩИЩЕННЫХ ДОКУМЕНТОВ, В ОСОБЕННОСТИ БАНКНОТ | 2008 |
|
RU2461883C2 |

