Уровень техники
Представленное изобретение в основном относится к прогнозируемым торговым системам, и более конкретно, к способам и системам для приближенного сравнения строк в базе данных с добавляемой записью в базу данных, находящуюся в сети обслуживания банковских карт.
Исторически, использование "платежных" карт для транзакций потребительских платежей был» самым распространенным и основанным на связи между выдающими кредиты локальными банками и различными локальными продавцами. Отрасль платежных карт с тех пор развилась до формирования ассоциаций банков кредиторов (например, MasterCard) и включает сторонние компаний обработки транзакций (например, " Merchant Acquirers"), чтобы позволить владельцам кредитных карточек широко использовать платежные карточки в любых торговых учреждениях, независимо от банковских отношений продавца с банком, выпустившим карту.
Например, фигура 1 представленной заявки показывает примерную многостороннюю систему индустрии платежной карты для проведения транзакции оплаты картой. Как показано, у продавца и выпускающего карту не обязательно должна быть непосредственная связь. Все же, сегодня существуют различные сценарии в отрасли оплаты картой, где у выпускающего карты есть специальная или специализированная связь с определенным продавцом, или группой продавцов.
Более 25 миллионов торговых точек принимают к оплате карты. Одна из ассоциаций содержит информацию о названии и адресе для тысяч продавцов и торговых точек в том, что упоминается здесь как хранилище данных. На уровне местонахождении торговых точек, в этом хранилище данных имеются миллионы записей. Многие из записей местонахождений, как известно, копируются из-за изменений названия и/или информации об адресах в данных транзакций. Например, один тот же адрес улицы может быть записан разными способами, все из которых допустимы (например, (e.g., 400 South Fourth Street, 400 S. Fourth St., 400 South 4th Street и т.д.). Названия могут иногда также представляться многими способами, каждый из которых допустим. Текущая технология баз данных очень ограничена в возможности идентифицировать записи с подобными значениями полей, такими как название и адрес. Таким образом, много близких копий названий торговых точек и местоположений вводятся в хранилище данных.
В обычный операционный день для ассоциации поступает приблизительно 15 ООО местоположений кандидата (например, новые местоположения торговых точек), которые должны быть проверены на соответствие приблизительно пяти миллионам записей -местоположений, находящимся уже в хранилище данных. Проверка соответствия служит, по меньшей мере, двум целям. Первая, местоположения с аналогичными названиями и/или адресами могут быть идентифицированы как один объект, а не несколько. Дополнительно, если названия или адреса слишком отличаются, ассоциация может решить, что объект переместился, или что один объект прекратил операции и был заменен другим объектом.
С проблемой соответствия названия и местоположения также встречаются в некоторых других контекстах, в случае предоставления третьей стороной хранилища данных с файлами транзакции, поддерживаемого ассоциацией и соответственно списков торговых точек и адресов (местоположения), для улучшения и/или проверки хранилища данных. В другом примере, третей стороны может быть получен список всех местоположений для крупного национального ретейлера, или могут быть получены списки названий и адресов филиалов. Команда, занимающаяся поддержанием хранилища данных, занимается задачей соответствия полученного списка, известным местоположениям для ретейлера или цепочки.
Один из способов проверить соответствие между существующими местоположениями и новыми местоположениями является строковый алгоритм соответствия. Поэтому, любые решения, которые могут быть использованы для сравнения строк, могут быть масштабируемыми в пределах системы платформы базы данных (хранилища данных). Действительно существуют решения определения приблизительного строкового соответствия. Однако, у этих решений обычно есть один или более недостатков, включающих непомерную стоимость решения, специфику сферы деятельности или инструментов, или решение является внешним по отношению к системе базы данных (хранилищу данных).
Поэтому, существует прежде не решаемая задача разработки способа, который позволил бы команде хранилища данных выполнять проверку названия и адреса на соответствие записям о торговых точках масштабируемым способом в пределах системы базы данных. Достигаемым результатом является компактное и точное хранилище данных, способное к поддержке других зависимых приложений, например, использующих исторические данные транзакций для предсказания будущих транзакций финансовых карт и определения, есть ли корреляция этих данных.
Сущность изобретения
В одном аспекте, представлен компьютерно-основаный способ сравнения символьных строк, символьной строки кандидата с множеством записей символьных строк, сохраненных в базе данных. Способ включает a), идентификацию набора ссылочных символьных строк в базе данных, ссылочные символьные строки идентифицируются с использованием оптимизированного поиска набора разнородных символьных строк, b) генерирование представления n-граммы одной из ссылочных символьных строк в наборе ссылочных символьных строк, c) генерирование представления n-граммы символьной строки кандидата, d) определение подобия между представлениями n-грамм, e) повторение шагов b) и d) для оставшихся ссылочных символьных строк в наборе идентифицированных ссылочных символьных строк, и f) индексация символьной строки кандидата в базе данных, основанная на определении релевантности между представлением n-граммы символьной строки кандидата и ссылочными символьными строками в идентифицированном наборе.
В другом аспекте, представлен компьютер, обеспечивающий посредством программирования использование оптимизированного поиска, чтобы идентифицировать набор разнородных ссылочных символьных строк в базе данных, генерирование представление n-граммы для символьной строки кандидата, генерирование представления n-граммы для каждой из разнородных ссылочных символьных строк в наборе, определение подобия между представлением n-граммы символьной строки кандидата и каждым представлением n-граммы набора разнородных ссылочных символьных строк, и индексирование символьной строки кандидата в базе данных, основанное на общих чертах, определенных в представлениях n-граммы.
В еще одном аспекте, обеспечивается компьютерно-основаный способ для приблизительного сравнения символьной строки кандидата с набором ссылочных символьных строк в базе данных. Способ включает индивидуальное сравнение представления n-граммы символьной строки кандидата с представлениями n-граммы каждой ссылочной символьной строки в наборе ссылочных символьных строк, и генерирование двоичного индексного значения, связанного с символьной строкой кандидата, двоичное индексное значение указывает на подобие между символьной строкой кандидата и каждой из ссылочных символьных строк.
Краткое описание чертежей
Фигура 1 - принципиальная схема, иллюстрирующая примерную многостороннюю систему индустрии платежной карты для проведения транзакции оплаты картой.
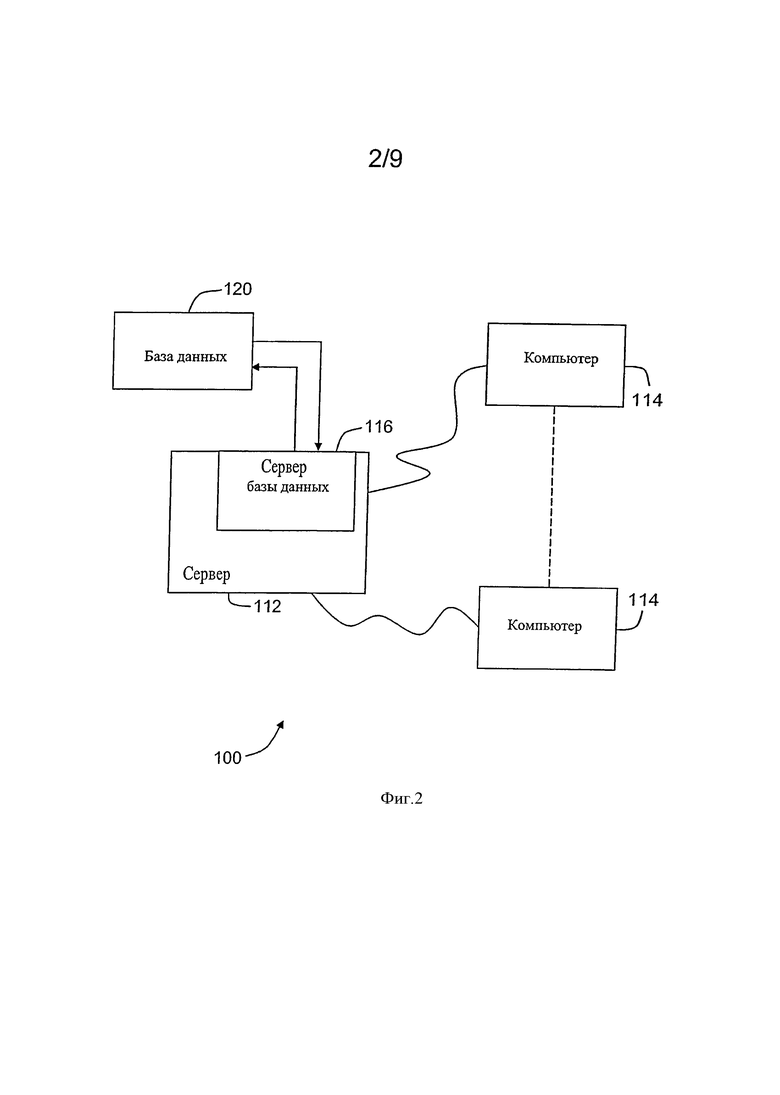
Фигура 2 - упрощенная блок-схема примерного варианта осуществления архитектуры сервера системы в соответствии с одним из вариантов осуществления представленного изобретения.
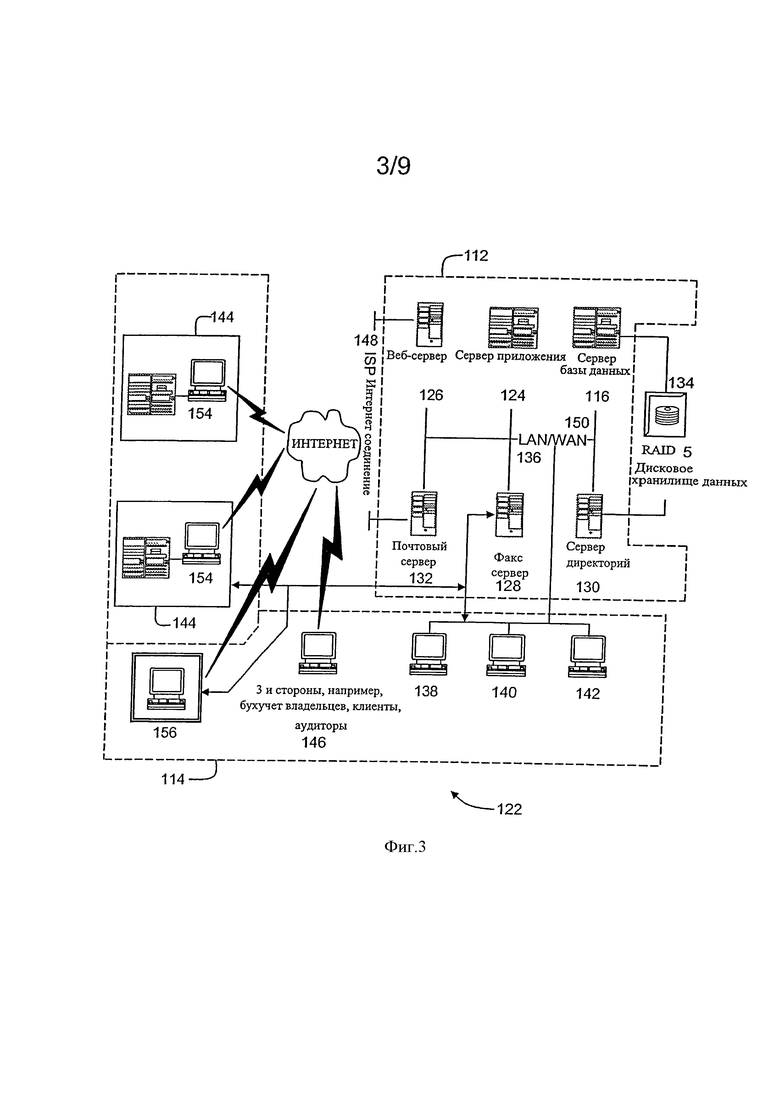
Фигура 3 - расширенная блок-схема примерного варианта осуществления архитектуры сервера системы в соответствии с одним из вариантов осуществления представленного изобретения.
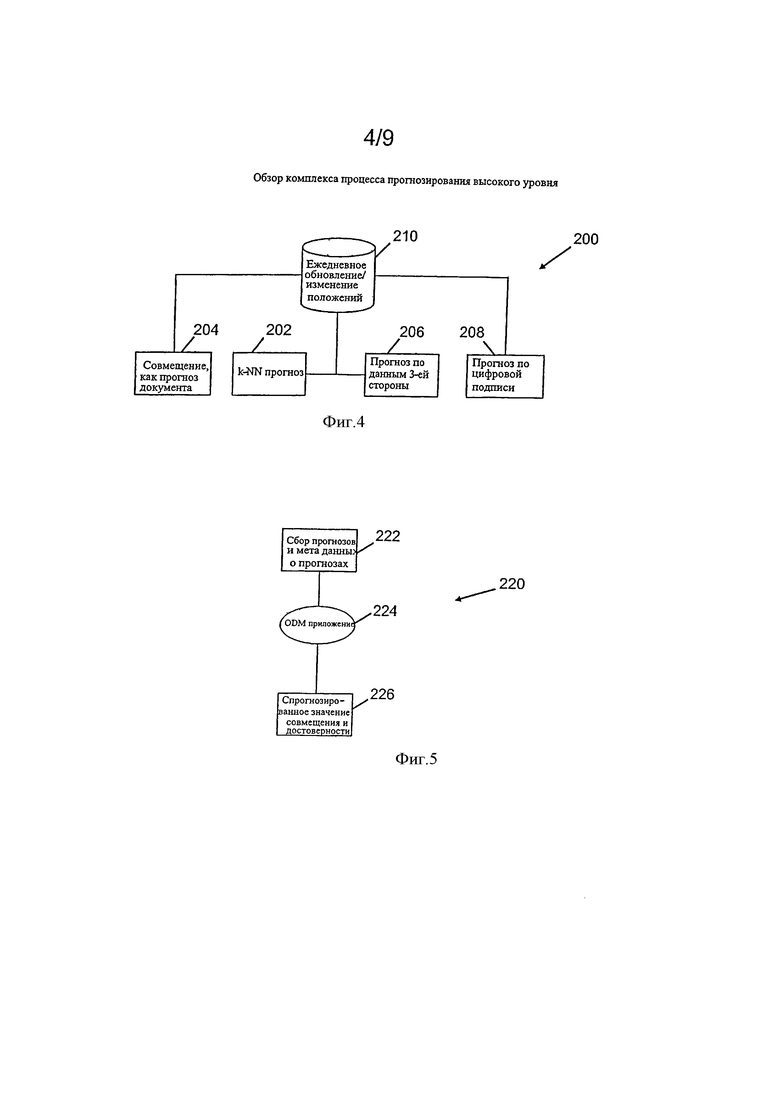
Фигура 4 - блок-схема, иллюстрирующая высокоуровневые компоненты объединенной совокупности торговой системы прогноза.
Фигура 5 - блок-схема, иллюстрирующая работу механизма ведущего подсчет, связанного с объединенной совокупности торговой системы прогноза.
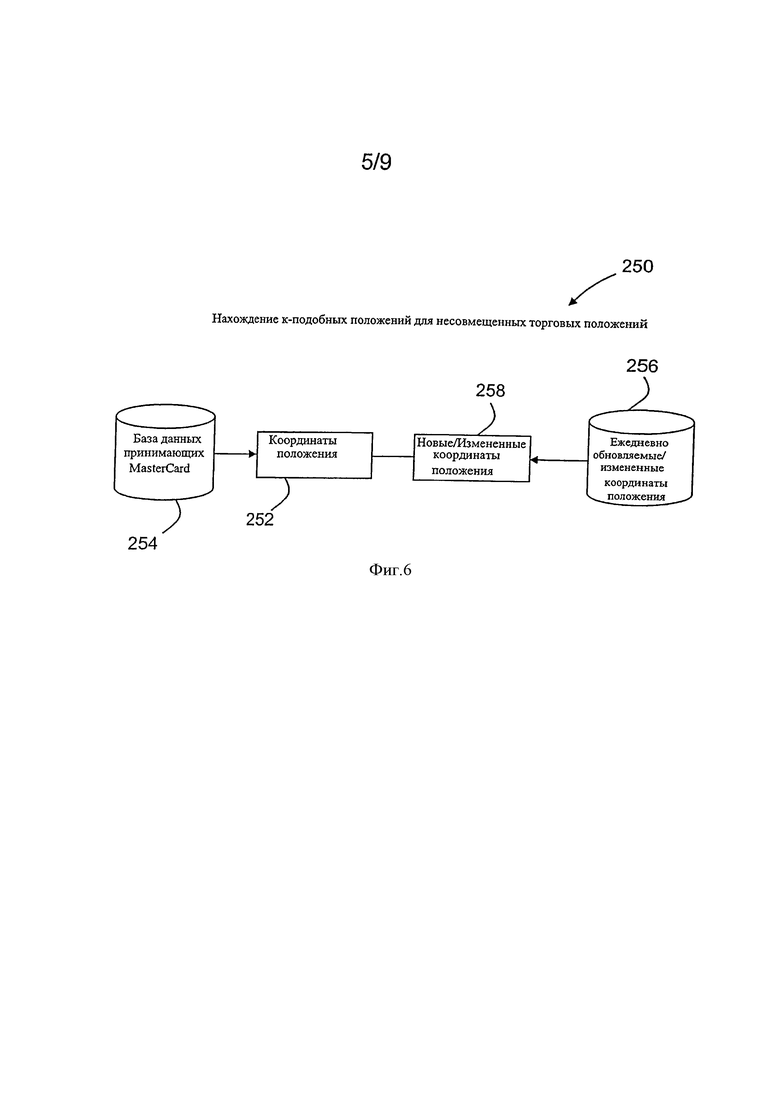
Фигура 6 - блок-схема 250, иллюстрирующая данные, которые вводятся в алгоритм, который классифицирует местоположения торговых точек.
Фигура 7 - блок-схема, описывающая алгоритм, который классифицирует местоположения торговых точек.
Фигура 8 - схема, иллюстрирующая, как торговые точки собираются и размещаются в виде документов в системе классификации.
Фигура 9 - блок-схема, иллюстрирующая определение набора ссылочных символьных строк, или основных компонентов, в базе данных.
Фигура 10 - блок-схема, иллюстрирующая использование набора ссылочных строк, чтобы определить метрику подобия для символьной строки кандидата.
Подробное описание изобретения.
Варианты осуществления, описанные здесь, касаются эффективного способа для получения приблизительного соответствия строки (например, символьной строки) в базе данных, без необходимости вычислять метрику подобия по всей базе данных. Посредством приблизительного строкового сравнения, например, полученных данных местоположения, которые несколько отличаются по содержанию, может быть определено соответствие в местоположении. Эта эффективность достигается генерированием двоичного индекса, получением относительной позиции (степени соответствия) каждой строки относительно набора ссылочных строк, охватывающих пространство строк для соответствующего поля. В то время как способ описан в контексте названий и местоположений торговых точек, связанных с работой системы финансовых транзакций карт, важно отметить, что способ приблизительного строкового сравнения применим к более общим задачам, таким как информационный поиск, с заменой сравнения символьных строк информации о названии и адресе торговых точек. Один из примеров - использование способа для сравнения документов в компьютерной системе.
Технический эффект систем и процессов, описанных здесь, включает, по меньшей мере, один из (a) способ для выполнения приблизительного сравнения названия и адреса, чтобы сравнивать торговые записи масштабируемым способом в системе баз данных (b) учет для определения метрики подобия символьной строки кандидата относительно каждого множества ссылочных символьных строк; (c) генерирование двоичного индекса, который отражает относительную позицию символьной строки каждого кандидата в наборе ссылочных символьных строк, который охватывает пространство строк в базе данных для соответствующих полей; и (d), получение приблизительного сравнения строки совпадений между символьной строкой кандидата и базой данных, которая содержит множество записей символьных строк, без необходимости вычислять метрику подобия для всей базы данных записей.
В одном варианте осуществления обеспечивается компьютерная программа, программа воплощается на компьютерно-читаемом носителе и использует Структурированный Язык Запросов (SQL) с клиентским пользовательским внешним интерфейсом для администрирования и веб-интерфейсом для стандартного ввода данных и отчетов пользователем. В примерном варианте осуществления система представляет собой сеть, включая и осуществляемую на предприятиях сеть интранет. В еще одном варианте осуществления к системе полностью получают доступ пользователи, имеющие санкционированный доступ, вне брандмауэра предприятия, через Интернет. В дополнительном примерном варианте осуществления система выполняется в среде Windows® (Windows - зарегистрированная торговая марка Microsoft Corporation, Redmond, Washington). Приложение гибко и разрабатывается для работы во всевозможных средах, без ущерба основной функциональности.
Системы и процессы не ограничиваются определенными вариантами осуществлениями, описанными здесь. Кроме того, компоненты каждой системы и каждого процесса могут быть осуществлены независимо и отдельно от других компонентов и процессов, описанных здесь. Каждый компонент и процесс также может использоваться в комбинации с другими комплектами элементов и процессами.
В качестве уровня техники фигура 1 представляет принципиальную схему 20, иллюстрирующую примерную многостороннюю систему индустрии платежной карты для проведения обычных транзакции оплаты картой, в которых история транзакции используются, по меньшей мере, частично с объединенной совокупностью прогноза торговой системы. Как представлено здесь, совокупный продавец обращается к группирующимся на высоком уровне торговым точкам. Более конкретно, различные отдельные торговые точки ретейлера группируются вместе (например, соединены друг с другом в базе данных) для формирования совокупного продавца. Одна торговая точка представляет собой компонент совокупного продавца. Как правило, совокупный продавец используется, при обращении к цепочке магазинов, и местоположения сгруппированы вместе, как далее описано здесь, основываясь на многих значениях полей, сохраненных в базе данных транзакции.
Данное изобретение относится к системам платежных карт, такой как система платежей по кредитной карте, использующая MasterCard® обмен информацией. MasterCard® обмен информации является собственным коммуникационным стандартом, провозглашенным MasterCard International Incorporated® для обмена данными финансовых операций между финансовыми учреждениями, которые являются элементами MasterCard International Incorporated ®, (MasterCard зарегистрированная торговая марка MasterCard International Incorporated, расположенной в Purchase, New York).
В обычной карточной платежной системе финансовое учреждение обращалось к "выпускающему" платежную карту, такую как кредитную карту, потребителю, который предоставлял платежную карту в качестве средства оплаты за покупку продавцу. Для приема оплаты с платежной карты обычно торговец должен создавать учетную запись в финансовом учреждении, которое является частью финансовой платежной системы. Это финансовое учреждение обычно называют "инвестиционным банком" или "банком получения" или "банком получателя". Когда потребитель 22 производит оплату за покупку посредством платежной карты (также известной как карта финансовой операции), торговец 24 запрашивает авторизацию в инвестиционном банке 26 суммы покупки. Запрос может быть выполнен по телефону, но, обычно, выполняется с помощью терминала продаж, который считывает информацию об учетной записи потребителя с магнитной дорожки на платежной карте и связывается, электронным путем с компьютерами обработки транзакций инвестиционного банка. Альтернативно, инвестиционный банк может разрешить третьей стороне выполнять обработку транзакций от своего лица. В этом случае кассовый терминал будет сконфигурирован так, чтобы связываться с третьей стороной. Такую третью сторону обычно называют "торговым процессором" или "процессором получения".
Используя обмен 28, компьютеры инвестиционного банка или торгового процессора связываются с компьютерами банка, выпустившего карту 30, чтобы определить, является ли учетная запись потребителя в положительном положении и покрывается ли покупка доступным кредитным лимитом потребителя. Основываясь на этих определениях, просьба на авторизацию будет отклонена или принята. Если запрос принимается, код авторизации посылается торговцу.
Когда запрос на авторизацию принимается, доступный кредитный лимит учетной записи 32 потребителя уменьшается. Обычно, запрос средств не сразу отправляется на учетную запись потребителя, потому что ассоциации банковских карт, такие как MasterCard International Incorporated®, провозгласили правила, которые не позволяют торговцу запрашивать средства или "получать", транзакцию, пока товары или услуги не предоставляются. Когда торговец поставляет или предоставляет товары или службы, торговец получает транзакцию, например, процедура получения соответствующих данных на терминале продажи. Если потребитель отменяет транзакцию прежде, чем она будет получена, генерируется "пустая операция". Если потребитель возвращает товары после того, как транзакция была получена, то "кредит" генерируется.
После того, как осуществляется транзакция, транзакция урегулируется между торговцем, инвестиционным банком, и выпускающим карту. Урегулирование относится к передаче финансовых данных или фондов, связанных с транзакцией, между учетной записью продавца, инвестиционным банком, и выпускающим карту. Обычно, транзакции проходят и накапливаются в "пакет", которые урегулируются как группа. Данные, которые связанны с такими транзакциями, как описано далее, используются в области предсказания будущих действий покупателя.
Карты финансовых транзакций или платежные карты могут относиться к кредитным картам, дебетовым картам, и картам с предоплатой. Все эти карты могут использоваться в качестве способа оплаты за выполнение транзакции. Как описано здесь, термины "финансовая операция карты" или "платежная карта" включают карты, такие как кредитные карты, дебетовые карты, и карты с предоплатой, но также включают любые другие устройства, которые могут содержать платежную информацию об учетной записи, такую как мобильные телефоны, персональные цифровые секретари (PDA), и брелки.
Фигура 2 - упрощенная блок-схема примерной системы 100 в соответствии с одним из вариантов осуществления представленного изобретения. В одном варианте осуществления система 100 является системой платежной карты, используемой для реализации, например, связи между выпускающим карты и продавцом, и в то же время обработки данных, связанных с историей транзакций. В другом варианте осуществления система 100 является системой платежной карты, которая может быть использована владельцами банковского счета для того, чтобы ввести коды обработки, которые будут применены к актам платежа.
Более конкретно, в варианте осуществления, в качестве примера, система 100 включает систему сервера 112, и множество клиентских подсистем, также называемых клиентскими системами 114, соединенных с системой сервера 112. В одном варианте осуществления клиентские системы 1 14 являются компьютерами, включающими веб-браузер, так, что система сервера 112 доступна для клиентских систем 114 при использовании Интернета. Клиентские системы 114 присоединяются к Интернету через различные интерфейсы, включающие сети, такие как локальная сеть (LAN) или глобальная сеть (WAN), соединения удаленного доступа, кабельные модемы и специальные высокоскоростные линии ISDN. Клиентские системы 114 могут быть любым устройством, способным к соединению к Интернету, включая сетевой телефон, персональный цифровой секретарь (PDA), или другое сетевое соединяемое оборудование. Сервер базы данных 116 соединяется с базой данных 120, содержащей информацию о множестве тем, как описано ниже более подробно. В одном варианте осуществления централизованная база данных 120 записана в системе сервера 112 и к ней может быть получен доступ потенциальными пользователями в одной из клиентских систем 114, посредством регистрации на системе сервера 112 через одну из клиентских систем 114. В альтернативном варианте осуществления база данных 120 сохранена удаленно от системы сервера 112 и может быть не централизована.
Так же как описано ниже, база данных 120 хранит данные транзакции, сгенерированные как часть деятельности по продаже, проводимой по банковской сети, включающей данные, касающиеся продавцов, владельцев банковского счета или клиентов, и покупок. База данных 120 дополнительно включает данные, касающиеся программ поощрений и специальных предложений, включая обработку кодов и деловых правил, связанных с различными программами поощрений и специальными предложениями.
Фигура 3 - расширенная блок-схема примерного варианта осуществления архитектуры сервера системы 122 в соответствии с одним из вариантов осуществления представленного изобретения. Компоненты системы 122, идентичные компонентам системы 100 (показанной на фигуре 2), обозначены на фигуре 3, с использованием тех же ссылочные цифр как использовались на фигуре 2. Система 122 включает систему сервера 112 и клиентские системы 114. Система сервера 112 дополнительно включает сервер базы данных 116, сервер приложений 124, веб-сервер 126, факс сервер 128, сервер каталогов 130, и почтовый сервер 132. Дисковый накопитель 134 связывается с сервером базы данных 116 и сервером каталогов 130. Серверы 116, 124, 126, 128, 130, и 132 связываются в локальной сети (LAN) 136. Кроме того, системная рабочая станция администратора 138, пользовательская рабочая станция 140, и рабочая станция супервизора 142 присоединяются к LAN 136. Альтернативно, рабочие станции 138, 140, и 142 связываются с LAN 136, при использовании соединения Интернет или присоединяются через Интранет.
Каждая рабочая станция, 138, 140, и 142 является персональным компьютером, имеющим веб-браузер. Хотя функции, выполняемые на рабочих станциях, обычно, иллюстрируются как выполняемые на соответствующих рабочих станциях 138, 140, и 142, такие функции могут быть выполнены в одном из многих персональных компьютеров, связанных с LAN 136. Рабочие станции 138, 140, и 142 иллюстрируются как связываемые с отдельными функциями только, чтобы облегчить понимание различных типов функций, которые могут быть выполнены пользователями, имеющими доступ к LAN 136.
Система сервера 112 конфигурируется так, чтобы быть коммуникативно объединенной с различными пользователями, включая сотрудников 144 и третьи стороны, например, владельцы банковского счета, клиенты, аудиторы, и т.д., 146, используя Интернет-соединения ISP 148. Система взаимодействия, в примерном варианте осуществления, иллюстрируется как выполняемая, с использованием Интернет, однако, любая другая глобальная сеть (WAN), тип передачи может быть использован в других вариантах осуществления, то есть, системы и процессы не ограничиваются тем осуществлением, в котором используется Интернет. Кроме того, в предпочтительном варианте, локальная сеть 136 может быть использована вместо WAN 150.
В примерном варианте осуществления любой авторизованный пользователь, имеющий рабочую станцию 154, может получить доступ к системе 122. По меньшей мере, одна из клиентских систем включает рабочую станцию менеджера 156, расположенную в удаленном местоположении. Рабочие станции 154 и 156 являются персональными компьютерами, имеющими веб-браузер. Кроме того, рабочие станции 154 и 156 конфигурируются, чтобы связываться с системой сервера 112. Кроме того, факс - сервер 128 связывается с удаленно расположенными клиентскими системами, включая клиентскую систему 156, используя телефонные линии. Факс - сервер 128 также конфигурируется, чтобы связываться с другими клиентскими системами 138, 140, и 142.
Фигура 4 - блок-схема 200, иллюстрирующая высокоуровневые функциональные компоненты объединенной совокупности прогнозируемой торговой системы, где каждый компонент обеспечивает прогноз, касающийся операций сети операций финансовой карты. Затем прогнозы соединяются в единый прогноз, как описано далее. Это соединение прогнозов иногда упоминается как совмещенный прогноз. Один пример, относящийся к варианту осуществления, описанному здесь, включает комплексные прогнозы, которые касаются полученных торговых данных местоположения. Как представлено на фигуре 4, все алгоритмы прогноза более полно описываются здесь.
Первый компонент - алгоритм прогноза подобного местоположения 202 (иногда называемый k-подобный алгоритм прогноза местоположения), который конфигурируется, чтобы получить "к" торговых местоположений, которые являются самыми подобными данному торговому местоположению. Алгоритм прогноза 202 далее функционирует для классификации группы подобных торговых местоположений как режим группировки полученного числа "к" наиболее подобных местоположений.
Совмещение Местоположений, как алгоритм Прогноза Документов 204 используется, чтобы вычислить релевантности для каждого значения поля и значения поля относительно каждого совмещения местоположений (высокоуровневая группировка данных) в пространстве известных значений, результаты сохраняются как документ. Самые релевантные значения этих документов используются, чтобы генерировать прогноз.
Сторонний алгоритм Прогноза Данных 206, включает систему сравнения местоположения, используется, если прогноз ассоциируется с определенным сторонним брендом. По меньшей мере, один ввод алгоритма 206 включает записи транзакции, полученные от третьей стороны, которые используются в генерировании прогноза. В одном варианте осуществления генерирование прогноза выполняется после того, как выполнено сравнение местоположения с данными стороннего источника данных. Числовой алгоритм Прогноза Подписи 208, вариант осуществления которого базируется в значительной степени на Законе Бенфорда, и дополнительно основан на наблюдаемой тенденции для продавцов, принадлежащих одной группе, отличаться от распределения, определяемого Законом Бенфорда, включенного в систему 200 относительно последовательным способом. Прогноз, следующий из алгоритма 208, становится группой местоположений, у которых самое подобное числовое распределение по сравнению с каждым торговым местоположением.
Статистическая модель верхнего уровня и механизма подсчета 210, в одном варианте осуществления, реализована в Oracle, использует прогнозы алгоритмов 202, 204, 206, и 208, для определения состава группы среди данных, которые недавно получены и/или сохранены в базе данных. Пример данных - данные о местоположения торговых точек. По меньшей мере, в одном варианте осуществления, и как далее описано, данные о местоположения торговых точек в базе данных описываются с точки зрения местоположения и расстояния, например, несколько торговых местоположений, которые находятся на данном расстояния от данного местоположения. По меньшей мере, в одном аспекте, местоположение и расстояние являются не обязательно географическими, а скорее основаны на подобии, вычисленном с использованием торговых данных, хранившихся в базе данных. В определенных вариантах осуществления местоположение и расстояние основаны на подобии как измеряемом перекрестном атрибуте, имеющего вес, частоту термина/инверсия частоты документа (TF/IDF), вычисление значений полей и маркировка полей значений в базе данных.
Фигура 5 - блок-схема 220, иллюстрирующая работу механизма подсчета 210. Главным образом, механизм подсчета 210 использующий 222 прогнозы местоположений торговых точек алгоритмов 202, 204, 206, и 208, наряду с метаданными, относящимися к прогнозированию в интеллектуальном анализе данных Oracle (ODM) приложение 224, для описания обстоятельств, относящихся к каждому отдельному прогнозу, затем производит 226 заключительный прогноз - скомпонованный из отдельных прогнозов. Этот заключительный прогноз может относиться к торговому местоположению. Приложение также производит подсчет доверия, связанный с компоновкой прогнозов, касающихся множества алгоритмов 202, 204, 206, и 208.
Каждый из этих четырех алгоритмов 202, 204, 206, и 208 теперь будет описан в дополнительных деталях.
К-Подобных Местоположений (алгоритм 202)
Фигура 6 - блок-схема 250, иллюстрирующая данные, которые вводятся в алгоритм 202, который классифицирует торговые местоположения, основываясь на подобии, например, подобии местоположения. Набор местоположений на уровне полей, или координат местоположений 252, которые, как известно, значимы в контексте цепочки получения или участия в наборе (например, группе), идентифицируется в базе данных учреждений 254, которые принимают карту финансовых операций. Дополнительно, данные ежедневно новой/измененной базы данных местоположений 256 наряду с ассоциацией их новым/измененным координатам местоположений 258, обеспечивают для ниже описанного алгоритма классификации местоположения торговых точек.
Фигура 7 - блок-схема 280, описывает один из алгоритмов (алгоритм 202 показанный на фигуре 4), который используется для классификации местоположения торговых точек в составе группы. Алгоритм 202 использует, по меньшей мере, данные, описанные относительно блок-схемы 250 фигуры 6. Определенно, торговые данные местоположений в базе данных ищутся 282 для нахождения нескольких (к) местоположений, которые в пределах данного расстояния от данного местоположения. Дополнительно, для местоположения на данном расстоянии ищется подобие, чтобы определить 284 любые новые и/или измененные местоположения. Значение режима определяется 286, классификацией торговых местоположений, которые фигурируют среди (к) местоположений в пределах определенного пространства функции (область, от которой данные транзакции вводятся в алгоритм 202). Наиболее часто фигурируемое значение, которое следует из классификации (к) записей местоположения, имеет самый высокий весовой коэффициент и выступает как значение режима, определенное как описано ниже. Это значение режима возвращается 288 как прогноз от алгоритма 202.
Как описано далее, поля (координаты местоположения 252 и 258) маркируются, и инверсная частота документа вычисляется для всех маркируемых значений полей, охватывающих пространство функции. В одном варианте осуществления, для каждого местоположения, разреженная матрица метрик весовых коэффициентов вычисляется для каждого значения поля и каждого маркируемого значения поля как частота/инверсии термина в текстовом документе. Значение прогноза вычисляется, присоединением данного поля местоположения к любому полю местоположения, основываясь на одно или больше типе поля и значении поля.
Разреженная матрица включает, местоположения, типы полей и веса для значений термина, и маркера термина и генерируется как описано в абзацах ниже.
Матрица создается такой, что содержит обратную частоту документа всех значений полей и маркируемых значений полей, и в одном варианте осуществления имеет девять размерностей. В определенном варианте осуществления эти девять размерностей включают торговый код категории, ассоциацию карты Международного банка (ICA) код, бизнес регион, торговое название, торговый номер телефона, торговый идентификатор получателя, идентификатор уровня продавца, торговое официальное название, и идентификатор федерального налога. Эти размерности включаются во все торговые записи местоположения. Инверсная частота документа - логарифм (в одной определенной реализации в основе 2) частного числа записей, разделенных на число записей, содержащих определенное значение. Один пример показан в Таблице 1. В одном варианте осуществления это частное вычисляется отдельно для каждой из этих девяти размерностей. Число записей вычисляется как число торговых местоположений. Число записей, содержащих определенный термин, вычисляется, считая число торговых местоположений, которые содержат каждый термин в каждом типе поля.
Для каждого местоположения перекрестный атрибут нормализует частоту термина - дважды инверсный вес частоты документа вычисляется для значений и маркировок значений, всех девять размерностей как иллюстрировано в Таблице 2, где эти девять размерностей снова включают торговый код категории, код ICA, бизнес регион, торговое название, торговый номер телефона, получение торгового идентификатора, уровня торгового идентификатора, торговое официальное название, и идентификатор федерального налога.
федерального
налога
Прогноз состава группы и доверие для данного местоположения вычисляются, присоединяя предсказанное местоположение ко всем другим местоположениям по типу поля и значению поля, тогда суммируя результат частоты термина, двойной/инверсной частоты документа весового коэффициента для сравнения общих типов полей и значений полей. Результаты местоположения тогда сортируются в порядке убывания получающегося результата, и среди сумм происходит группировка, например, тринадцать местоположений с самым высоким результатом даются как прогноз. Результат доверия этого прогноза представляется числом местоположений среди лучших тринадцати местоположений, которые содержатся одной группой (ожидаемое значение), отдельных весовых коэффициентов для к местоположений, которые принадлежат предсказанной группе, и колебанию среди весовых компонентов.
Совмещение Местоположений как Прогноз Документов (алгоритм 204)
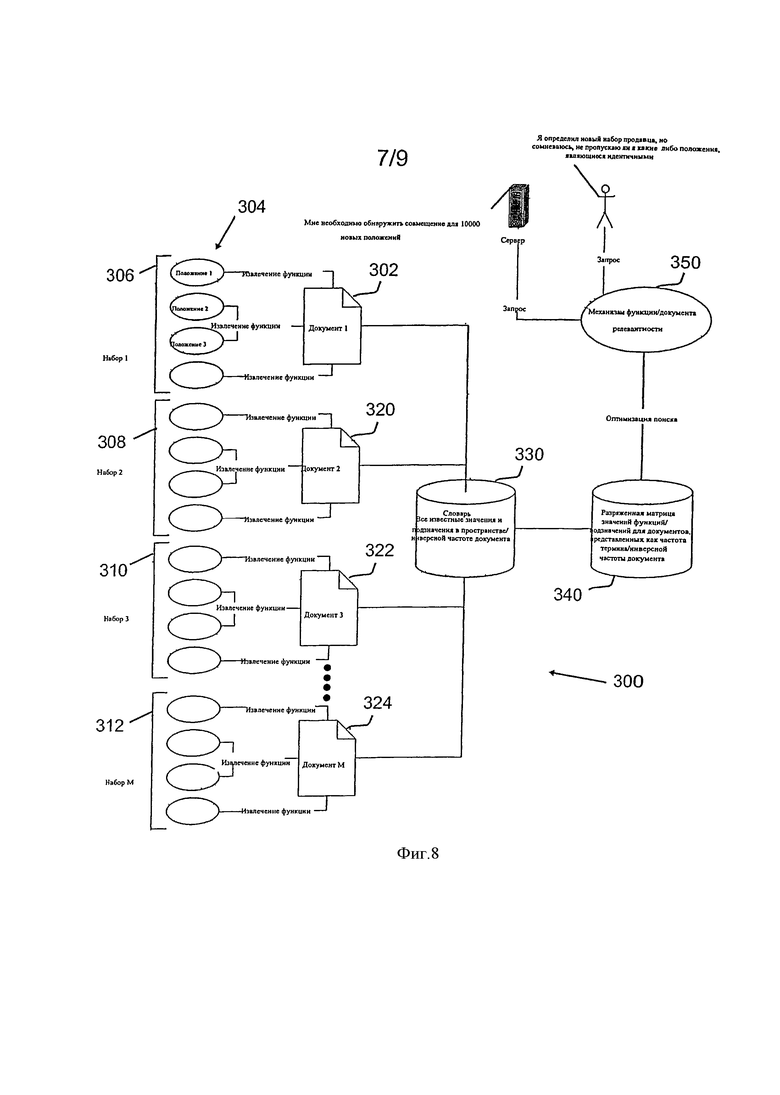
Фигура 8 - схема 300, иллюстрирующая местоположения, совмещенные в наборы документов как системы классификации. Алгоритм 204 (показанный на фигуре 4), который генерирует документы совмещенный местоположений, похож на алгоритмы релевантности документов, обычно используемые механизмами поиска в Интернете. Определенно, релевантность данного торгового местоположения к каждому компоненту совмещения, или набора, торговых местоположений вычисляется как описано ниже.
Для генерирования документа 302 релевантных признаков, например, адрес улицы, извлекаются из базы данных данные, касающиеся множества местоположений 304, и группируются в наборы, например, набор 306. В целях иллюстрации схема 300 включает четыре набора местоположений, 306, 308, 310, и 312. Набор 312, маркируется как Набор М, указывая, что в определенной реализации число наборов может быть больше или меньше четырех проиллюстрированных. Аналогично число местоположений в пределах набора может измениться от одного до "N".
Сгенерированные документы 302, 320, 322, и 324, каждый из которых включает извлеченные релевантные признаки, собираются в словаре 330. Используя словарь 330, формируется разреженная матрица 340, посредством чего вычисляется релевантность каждого значения поля и маркируемого значения поля, используя извлеченные признаки, для каждой совмещенной торговой группы, основанной на, по меньшей мере, одного из, частоте термина и обратной частоте документа.
В разреженной матрице 340, матрица уровней весовых коэффициентов местоположения соединяется с матрицей весовых коэффициентов торговых групп, основанной на типе поля и значении поля. Сумма этих весовых коэффициентов используется, в одном варианте осуществления, как механизм релевантности 350, чтобы определить релевантность каждого местоположения в каждой торговой группе. Торговая группа с самой высокой уместностью возвращается как ожидаемое значение, описанное выше. Более конкретно генерирование разреженной матрицы групп, типов полей, и весовых коэффициентов для правил термина и маркеров термина описано в следующих абзацах.
Во-первых, создается матрица, содержащая инверсную частоту документа всех значений полей и маркируемых значений полей, охватывающих эти девять размерностей, перечисленных выше, конкретно, торговый код категории, код ICA, бизнес регион, торговое название, торговый номер телефона, торговый идентификатор получателя, идентификатор уровня продавца, торговое официальное название, и идентификатор федерального налога, через все торговые записи местоположения.
Относительно совмещения местоположений как алгоритма прогноза документов, и как показано в Таблице 3, инверсная частота документа - логарифм (база 2 в одном определенном варианте осуществления) частного: число записей, разделенных на число записей, содержащих определенное значение. В одном варианте осуществления инверсная частота документа вычисляется отдельно для каждой из девяти размерностей. Число записей вычисляется как число торговых местоположений. Число записей, содержащих определенный термин, вычисляется, считая число торговых местоположений, которые содержат каждый термин в каждом поле каждого типа.
Для каждой группы перекрестный атрибут нормализованной частоты термина - дважды инверсной частоты документа, вычисляется для значений и маркированных значений, охватывая девять размерностей торгового кода категории, кода ICA, бизнес региона, названия торговой точки, номера телефона торговой точки, идентификатор получателя торговой точки, идентификатор уровня торговой точки, официальное название торговой точки, и идентификатор федерального налога, как показано в Таблице 4, и всех торговых точек, принадлежащих каждой группе.
Один прогноз состава группы вычисляется для данного местоположения, присоединением к строкам матрицы (k)-подобная местоположений, которая описана выше, к матрице групп по типу поля и значении поля, затем суммируя результаты весовых коэффициентов частоты термина-двойная инверсная частота документа для общих типов полей и значений полей. Предсказанные группы и оценка доверия - группа с самой высокой оценкой подобия (данной суммой весовых коэффициентов * весовые коэффициенты значений сравниваемых полей и маркируемых значений). Оценка доверия для прогноза - получающееся значение.
Прогноз данных третей стороны и сравнение местоположения (алгоритм 206)
Третий компонент совокупного прогноза - алгоритм 206 (показанный на фигуре 4), который использует данные, обеспеченные третьей стороной, которые были сравнены базой данных финансовых операций торгового местоположения. В одном варианте осуществления сторонним записям присваивается цепочечный идентификатор, который связан, например, с поставщиком. Эти цепочечные идентификаторы связаны с группами торговых местоположений, связанных с брендом карты финансовых операций (например, выпускающим карты). Прогноз, поэтому является просто группировкой торговых данных, соответствующих цепочке, с которой была соединена сторонняя запись. Это соединение сопровождает сравнение местоположения, как описано в следующем абзаце.
Набор данных торговых местоположений извлекается из стороннего источника данных, причем местоположения были присвоены (поставщиком) к цепочке. Каждой цепочке в пространстве сторонних местоположений продавца присваивается соотнесение к соответствующей группе. Механизм приблизительного сравнения торговых местоположений используется, чтобы присоединить к набору сторонних записей местоположения продавца к набору торговых записей местоположения, сохраненных у выпускающего карты. Предсказанная группа для данного местоположения вычисляется, тогда, как группа, соответствующая цепочке, соответствующей сторонней записи местоположений, которая была сравнена с записью местоположения продавца. Оценка доверия - сравнительная оценка доверия, присвоенная механизмом приблизительного сравнения торгового местоположения.
Числовой Прогноз Подписи (алгоритм 208)
В одном варианте осуществления алгоритма числовой подписи продавца 208 (показанного на фигуре 4) используется наблюдение за распределением цифр в первой позиции суммы транзакции и объема транзакций за день. В основном, распределение имеет тенденцию быть специфическим, когда различные торговые данные совмещены. Кроме того, распределение имеет тенденцию не входить в противоречие с распределением, предложенным Законом Бенфорда в натуральных данных. На практике цепочка ресторанов быстрого обслуживания может показывать тенденцию иметь определенную неоднократно появляющуюся цифру, как первую цифра количества транзакции. Такая тенденция может быть использована, по меньшей мере частично, чтобы идентифицировать, например, местоположение франшизополучателя цепочки ресторана быстрого обслуживания в определенном местоположении или адресе.
Одним примером прогноза, использующего такой алгоритм, является случайная выборка десяти процентов торговых местоположений каждого совокупного продавца (группировка торговых данных). Распределение чисел 1-9, находящихся в первой позиции количества транзакции и объема транзакции, вычисляется и суммируется относительно совокупного продавца. Вычисляется угловое расстояние между распределением и распределением, идентифицированным Законом Бенфорда.
Распределение чисел 1-9, находящихся в первой позиции количества транзакции и объема транзакции, тогда вычисляется для данного торгового местоположения. Вычисляется угловое расстояние между распределением и распределением, идентифицированным Законом Бенфорда. Совокупного торговца с угловым расстоянием, самым близким к угловому расстоянию торгового местоположения, определяют как предсказанного совокупного торговца для данного местоположения.
Более конкретно, и для каждой группы распределение частоты возникновения каждого числа (то есть, 1, 2, 3, 4, 5, 6, 7, 8, 9) охватывающих все местоположения в пределах группы среди количества транзакции, количество транзакции и среднее количество транзакции вычисляется и представляется как процент от целого. Упомянутое распределение сохраняется в таблице, представление которой показано в Таблице 5.
Как только вычислены распределения для каждой группы, определяется числовая подпись для каждой группы, вычисляя скалярное произведение вектора распределения группы и вектора распределения, предложенного Законом Бенфорда. Скалярное произведение (угол расхождения) делится на сумму квадратов вектора распределения для каждой группы. Распределение, идентифицированное в законе Бенфорда, вычисляется и сохраняется в таблице, представление которой иллюстрируется Таблицей 6.
Для каждого местоположения, распределение частоты возникновения каждого числа (1, 2, 3, 4, 5, 6, 7, 8, 9), показывающего количество транзакции, сумму транзакций и среднее количество транзакции, наблюдается во время интервала за один месяц для данного местоположения, вычисляется и представляется как процент от целого. Затем эти распределения сохраняются в таблице, представление которой иллюстрирует Таблица 7.
Как только вычисляются распределения для каждого местоположения, числовая подпись для каждого местоположения определяется, вычислением скалярного произведения вектора распределения местоположения и вектора распределения, предложенного Законом Бенфорда. Это скалярное произведение (угол расхождения) разделенный на сумму квадратов вектора распределения для каждого местоположения, и распределения, идентифицированного в законе Бенфорда, вычисляется и сохраняется в таблицу, представление которой иллюстрируется Таблицей 8.
Предсказанный состав группы для данного местоположения тогда вычисляется, находя группу с числовой подписью, самой близкой к числовой подписи данного местоположения, с оценкой доверия, вычисленной как расстояние между этими двумя подписями.
Статистическая Модель и Оценка
Как было описано выше относительно фигуры 5, каждое ожидаемое значение из четырех прогнозирующих алгоритмов (202, 204, 206, и 208), наряду с большим набором метаданных, описывающих обстоятельства каждого прогноза, собирается 222 и вводится в приложение Oracle Интеллектуальный Анализ Oracle (ODM) 224. Приложение 224 ODM 224 использует, в одном из вариантов осуществления, статистическую модель (дерево решений), созданную, используя маркированные формирующие данные, чтобы присвоить оценку доверия каждому ожидаемому значению. Ожидаемое значение с самой высокой оценкой доверия, тогда определяется как окончательное предсказанное совокупное значение для каждого торгового местоположения.
Приблизительное Строковое Сравнение
Как описано выше, один компонент совокупного прогноза - алгоритм, который использует данные местоположения, которые были сравнены, например, с местоположением продавца в базе данных финансовых транзакций карты. Некоторые данные могут быть обеспечены сторонними источниками. Варианты осуществления, описанные ниже, относятся к способам и системам получения приблизительной строки (например, символьной строки), сравненной с данными базы данных. В вариантах осуществления, сравнение строки используется, чтобы определить, например, представлена ли, строка, представляющая местоположение, в базе данных другой строкой. Такой алгоритм подходит различным вариантам осуществления из-за изменений, которые происходят в записях транзакций, тем более, что записи касаются торгового названия и местоположения.
Система приблизительного сравнения строк базы данных, действует, чтобы присоединить один набор записей к другому набору записей, когда нет общего ключа присоединения, такого как точное соответствие, или общих значений полей, которые присутствуют в данных. Предполагается, что есть некоторое подобие в наборах записей.
Как правило, когда два набора данных присоединяются в базе данных, они совместно используют идентичные значения в одном или более полях. Когда идентичные значения полей не используются совместно двумя источниками данных (наборы записей) из-за различий в данных, традиционный подход к присоединению наборов данных от соответствующих источников данных реализует функцию, которая принимает два значения, затеи вычисляет и возвращает их подобие. Чтобы использовать этот тип функции как, основной для присоединения наборов данных требуется много итераций, количественно равных числу записей в каждом наборе данных, который присоединяется.
Как пример, если есть 10 ООО записей в наборе данных A и 500 ООО записей в наборе данных В, функция вычисления подобия должна быть вызвана пять миллиардов раз, чтобы присоединить набор данных А к набору данных В. Кроме того, не могут быть использованы индексы, основанные на индексах и функциях оптимизатором базы данных, при вызове такой функции. Этот тип набора данных очень неэффективен и обрабатывается слишком интенсивно для использования при присоединении наборов данных, имеющих нетривиальные объемы данных.
Был разработан способ сравнения строк, который реализуется в различных вариантах осуществления, используя один или более следующих компонентов. Специально, набор ссылочных строк используется вместе с критерием, который получается, используя основной компонентный факторного анализа (PCFA). PCFA стремится идентифицировать набор очень несходных представленных строк в пространстве известных значений, которые будут использоваться в качестве ссылочных строк.
Другой компонент - вычисление n-грамм частоты подобия, реализуемое на чистом ASCII структурированном языке запроса (SQL), чтобы максимизировать производительность в системе управления реляционной базой данных (RDBMS). Дополнительно, процесс реализуется в RDBMS, используя вычисление n-грамм частоты подобия, чтобы сформировать двоичный ключ, как описано ниже, который указывает на подобие данной записи с каждой из ссылочных строк, идентифицированных в PCFA.
В одном варианте осуществления набор управляемых данными стандартизованных функций реализуется в RDBMS, как таблица, содержащая инверсную частоту документа (TDF) всех n-грамм, и вычисление SQL перекрестного атрибута весовых коэффициентов частоты термина/инверсной частоты документа (TF/IDF).
Один из вариантов осуществления способа строкового сравнения включает параметризованный аналитический запрос SQL, который присоединяется к записям, которые совместно используют то же двоичное значение ключа, после чего сортирует их релевантность, суммируя значения весовых коэффициентов TFADF всех сравниваемых n-грамм. i-й бит в двоичном ключе устанавливается в логическую 1, если соответствие записи i-й ссылочной строке выше определенного порога.
Процесс реализуется в RDBMS для присвоения оценки доверия каждому соответствию, получаемому из присоединения, в то время как включается модель данных RDBMS для хранения данных, включенных в присоединение наборов данных.
Одна простая версия проблемы присоединения набора данных - соответствие одного названия (или адреса) большому набору названий (или адресов), содержащихся в базе данных, такой как таблица Oracle. Пример этого n-грамм соответствия иллюстрируется Таблицей 9.
Элемент, необходимый для решения присоединения набора данных, является метрикой измерения любого подобия между строками, n-грамма - просто уникальная строка n символов, и n-грамм сравнение - является процессом определения соответствие между n-граммами. Для случая, где n равен двум, адрес кандидата в Таблице 1 состоит из следующих 2 граммов: "10", "00", "01", "14", "4<space>", "<space>S", "S<space>","<space>C", "Cl", "la"…, "Rd".
Таблица 10 - суммарный алгоритм сравнения n-грамм, который включает определение вектора частоты n-грамма для строки кандидата (например, массив Кандидата), определение вектора частоты n-граммы для каждой записи в базе данных соответствия кандидата (например, Candidate_Match_Array), измерение степени подобия между Candidate_Array и Candidate_Match_Array, и сохранение тех соответствий кандидата, которые превышают указанный порог. Например, "JoJo's Diner", становится
Таблицы 11, 12, и 13 являются примерами n-грамм Сравнения Метрик. "Скалярное внутреннее произведение" - скалярное произведение массива, "Величины" - корень квадратный суммы квадратов, "Косинус (угла)" - скалярное произведение, деленное на скалярное произведение Величин, и угол - инверсный Косинус скалярного произведения, деленного на скалярное произведение Величин.
Ссылочные строки
Вышеупомянутые таблицы и описание иллюстрируют возможность представить строки количественно, и измерить подобие между ними. В этой точке индекс для каждой записи в базе данных может быть создан, основываясь на ее относительной позиции в малом наборе ссылочных строк.
При выборе ссылочных строк, относительная позиция новой записи к каждой из ссылочных строк может быть вычислена. Дополнительно, у каждой записи в базе данных есть своя собственная предварительно вычисленная позиция относительно ссылочных строк. Поэтому, приблизительные соответствия могут быть найдены, получением записей, индексированных в близости, без необходимости вычисления полной метрики подобия между новой записью и всех записей базы данных. Одна цель выбора ссылочных строк состоит в том, чтобы выбрать записи, которые являются несходными, таким образом, давая лучшую перспективу. Один подход к выбору ссылочных строк обрисовывается в общих чертах в следующих абзацах.
Ссылочные строки идентифицируются, взятием выборки строк из индексируемой базы данных. Генерируются n-грамм представления для каждой строки в выборке, создавая вектор частот, где; i-й компонент вектора содержит число встреч n-граммы в этой строке. Генерируется матрица подобия, измеряя подобие между каждой парой выбранных строк, используя косинусную метрику подобия.
Одним способом нахождения несходных компонентов в наборе подобных данных является основной компонентный анализ. Основной компонентный анализ проводится на матрице подобия, и сохраняется первый k основной компонент. Выбранная строка с максимальной нагрузкой на каждом компоненте сохраняется, формируя набор ссылочных строк.
Двоичный Индекс и Информационный поиск
Для группировки подобных строк вместе, чтобы индекс мог быть создан для обеспечения быстрого извлечение кандидата во время приблизительного сравнения строк, каждой потенциальной записи кандидата и каждой записи сравнения, по сравнению с каждой из ссылочных строк, используется SQL вычисление n-грамм частоты подобия.
Если вычисление подобия приводит к значению выше, чем предопределенный порог, позиции двоичного ключа, соответствующего ссылочной строке, присваивается значение 1. Если значение ниже порога, соответствующей позиции двоичного ключа присваивается 0.
Вычисление Подобия N-ГРАММЫ
Запрос SQL был разработан для формирования двумерного вектора, содержащего частоту возникновения всего представленного уникального N-ГРАММа в двух данных строках. Затем запрос делит каждую получившеюся сумму частоты на квадрат величины вектора частоты каждой размерности для получения нормализованной метрики подобия.
Такое вычисление представляется следующим примером, в котором строкой сравнения А является "MASTERCARD", и строкой сравнения В - "MASTERCHARGE". Следующая таблица, Таблица 14, является двумерным вектором, содержащим частоты возникновения каждого уникального «-грамма в пределах двух строк сравнения:
Величина строки А вычисляется как квадратный корень суммы квадратов для каждого значения частоты в распределении А, определенно, величина строки А, 3.0. Величина строки В вычисляется как квадратный корень суммы квадратов каждого значения частоты в размерности В, определенно, величина В 3.3166247903554. Скалярное произведение вектора вычисляется, и для этого примера скалярное произведение 7.0 (число записей таблицы, где и А и В имеют значение 1). Подобие вычисляется как скалярное произведение / (Величина А × Величина В), или 0.703526470681448 для иллюстративного примера.
Формирование значения двоичного ключа
Если вычисление подобия приводит к значению выше, чем предопределенный порог, позиции двоичного ключа, соответствующего ссылочной строке, присваивается значение 1. Если значение ниже порога, соответствующей позиции ключа присваивается 0. В одном варианте осуществления процесс для определения позиции двоичного ключа реализуется, использованием комбинации SQL и PL/SQL. Реализация алгоритма минимизирует число необходимых вычислений сравнений строк при использовании аналитического структурированного языка запроса, чтобы автоматически присвоить данной строке двоичное значение ключа, если двоичное значение ключа было вычислено для точно того же значения в более ранней итерации алгоритма. Эта оптимизация выполняется в SQL. Уникальный идентификатор и каждое двоичное значение ключа сохранены в организованной таблице разделенного индекса (IOT) в RDBMS. Каждый уникальный набор данных сохранен в единственном разделе, и никакие два набора данных не используют совместно тот же раздел. Чтобы максимизировать производительность, нагрузка каждого набора данных в таблице выполняется, используя создание таблицы в качестве выбора (CTAS) и изменения раздела. Данные в каждом разделе хранятся в порядке двоичных значений ключа, чтобы максимизировать производительность присоединения.
Стандартизация данных
Чтобы улучшить точность сравнений подобия и распределение двоичных значений ключа, в одном из вариантов осуществления данные стандартизируются для известных сокращений и синонимов. Чтобы выполнить такую стандартизацию данных, таблица составляется так, что содержит все известные сокращения и синонимы для различных типов полей, наряду с их соответствующим стандартными представлениями. Тогда алгоритм работает для маркировки каждого элемента данных и отображения любого известного сокращения или синонима к их стандартным формам.
Таблица IDF
Для более высокой производительности при вычислении весовых коэффициентов TF/IDF для всех n-грамм, существующих в полях, включенных в соединение приблизительного сравнения, создается таблица, содержащая инверсную частоту документа всех двух символов «-грамм в записи кандидата. Формирование всех n-грамм пространства выполняется через PL/SQL, в то время как вычисление IDF делается в SQL ASCII. Таблица IDF хранит значение IDF для каждого возможного n-грамм для каждой категории данных. Таблица - индекс, организованный согласно категориям данных и n-граммам для максимизации производительности присоединения.
Перекрестный Атрибут весовых коэффициентов TF/IDF
Чтобы присвоить весовой коэффициент, или значение, к каждым двум символам n-грамм, существующих в данной записи для каждого поля, включенного в соединение по приблизительному сравнению, перекрестный атрибут весового коэффициента частоты термина/инверсной частоты документа TF/IDF, значение вычисляется для каждого значения n-грамма. Вычисляются n-грамм терминов и их частоты возникновения в каждой данной записи и поле, используя конвейерную табличную функцию, которая берет REF_CURSOR как вход. Это вычисление немного отличается от традиционных вычислений весовых коэффициентов TF/IDF тем, что после вычисления TF/IDF для каждого n-грамма в каждом поле, корректируется весовой коэффициент для всех n-грамм в каждом поле, увеличивая или уменьшая согласно значению суммы весовых коэффициентов n-граммов, в других полях той же самой записи. Этот способ приводит к динамической корректировке уровня записи относительного весовых коэффициентов соответствия n-граммы согласно общему значению значений в каждом поле.
Как упомянуто выше, уникальные идентификаторы для каждой записи в данном наборе данных, наряду с их n-граммами терминов и вычисленными значениями весовых коэффициентов сохраняются в разделенной. Индексно Организованной Таблице (IOT), чтобы максимизировать производительность присоединения. Таблица организуется согласно уникальному идентификатору, категории данных, и значению n-грамма термина. Каждый уникальный набор данных сохранен в отдельном разделе в таблице. Каждый раздел загружается, используя составление таблицы в качестве выбора и изменения раздела, чтобы максимизировать производительность загрузки.
Запрос соединения
Однажды вычисленные двоичные ключи и перекрестные атрибуты TF/IDF загружаются в RDBMS, аналитический запрос соединения используется, чтобы получить все записи сравнения кандидата и сортировать их согласно их релевантности или качеству сравнения по сравнению с записью сравнения. Это выполняется, сначала объединяя записи со сравнением значений двоичного ключа, затем присоединением n-грамм значений для получившейся записи кандидата и вычисления суммы результатов их весовых коэффициентов.
Присвоение оценки доверия
Результаты запроса соединения отправляются через функцию, реализованную в RDBMS, которая выполняет очень низкоуровневое сравнение каждой входящей записи и записи кандидата, затем присваивает оценку доверия, используя статистическую модель для использования в приложении анализа данных Oracle, описанную выше.
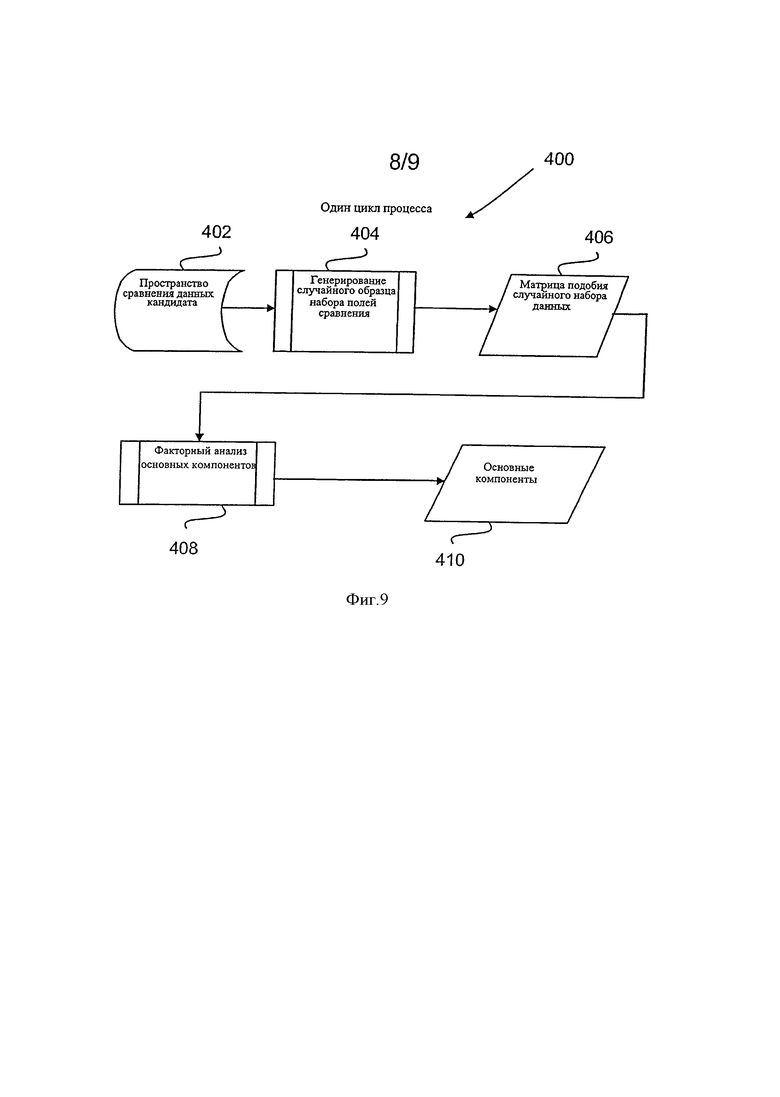
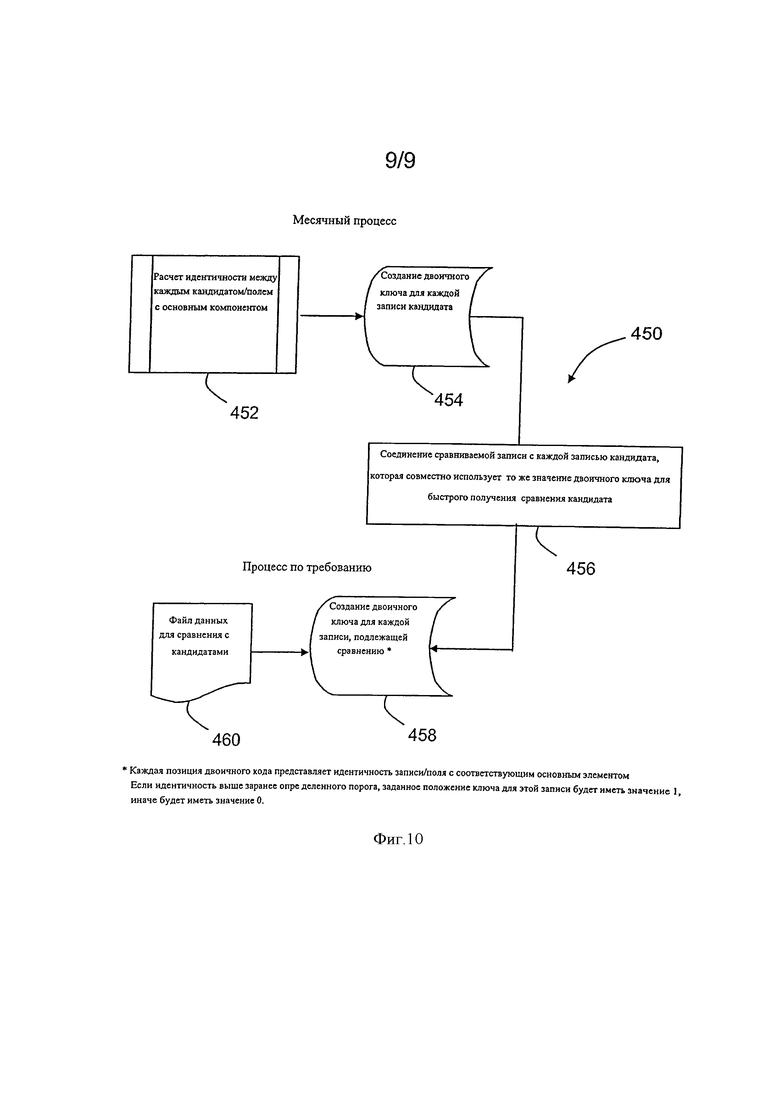
Вышеупомянутые описанные процессы, связанные с приблизительным сравнением строки, дополнительно иллюстрируются рисунками 9 и 10, которые являются блок-схемами 400 и 450, соответственно иллюстрирующими определение набора ссылочных символьных строк, и иллюстрирующими использование набора ссылочных строк для определения метрики подобия символьной строки кандидата. Выбранные строки с максимальной нагрузкой на каждом компоненте сохраняются для формирования набора ссылочных строк. Эти выбранные строки представляют основной компонент в целях корреляции. Метрика подобия основана на многих соответствиях л-грамм при сравнении символьной строки кандидата и отдельных символьных строк в выбранном наборе ссылочных символьных строк.
Обращаясь к фигуре 9, база данных включает пространство данных сравнения потенциального кандидата 402, которое иногда упоминается как база данных символьных строк (например, названия и/или данных местоположения для продавцов). Как описано, случайная выборка полей сравнения или записей базы данных, генерируется 404, основанная на, например, оптимизированном поиске набора разнородных символьных строк. Вычисляется матрица подобия 406, и основной компонентный фактор анализа
предназначается 408, с получением основных компонентов 410, каждый из которых обращается к соответствующей ссылочной символьной строке. Этот набор ссылочных символьных строк используется для сравнения с символьными строками кандидатов, потому что набор был специально сгенерирован, чтобы включать несходные данные.
Обращаясь к фигуре 10, после получения символьной строки кандидата, вычисляется подобие 452 между каждой символьной строкой кандидата и ссылочной строкой, связанной с каждым основным компонентом. Как описано здесь, такое сравнение может быть основано на алгоритме соответствия «-граммы, так, что создается двоичный ключ 454, показывающий подобие символьной строки кандидата к каждой ссылочной строке и соответствующему основному компоненту. Для быстрого и эффективного приблизительного сравнения символьной строки записи (ссылочные символьные строки) присоединяются 456 к символьным строкам кандидата, основываясь на сравнении их соответствующих двоичных ключей записей. Такой процесс позволяет пользователю быстро получать соответствия высокой вероятности между ссылочными символьными строками (которые могут включать торговое название и/или данные местоположения) к символьной строке кандидата, которая может представлять торговое название и/или данные местоположения. Создавая 458 двоичный ключ для каждой записи базы данных, которая будет сравниваться, может быть сгенерирован 460 файл соответствия ссылочных символьных строк к символьным строкам кандидата.
В то время как изобретение было описано с точки зрения различных определенных вариантов осуществления, специалисту в данной области техники понятно, что изобретение может быть осуществлено с изменениями в пределах сущности и контекста формулы.


Изобретение относится к способам и системам для приближенного сравнения строк в базе данных с добавляемой записью в базу данных, находящуюся в сети обслуживания банковских карт. Техническим результатом является повышение скорости и эффективности получения приблизительного соответствия символьной строки в базе данных, без необходимости вычислять метрику подобия по всей базе данных. В способе сравнения символьных строк для сравнения символьной строки кандидата с множеством записей символьных строк, сохраненных в базе данных, выделяют символьную строку во множестве записей символьных строк для создания набора ссылочных символьных строк посредством факторного анализа основных компонент (PCFA). Генерируют для каждой символьной строки во множестве записей и для символьной строки кандидата двоичный индексный ключ, содержащий несколько бит двоичной информации. Каждый бит показывает степень подобия символьной строки набору ссылочных символьных строк. Определяют набор записей символьных строк, который включает двоичный индексный ключ, точно совпадающий с двоичным индексным ключом символьной строки кандидата. Индексируют запись символьной строки кандидата в базе данных, основанную на совпадении. 2 н. и 16 з.п. ф-лы, 10 ил., 14 табл.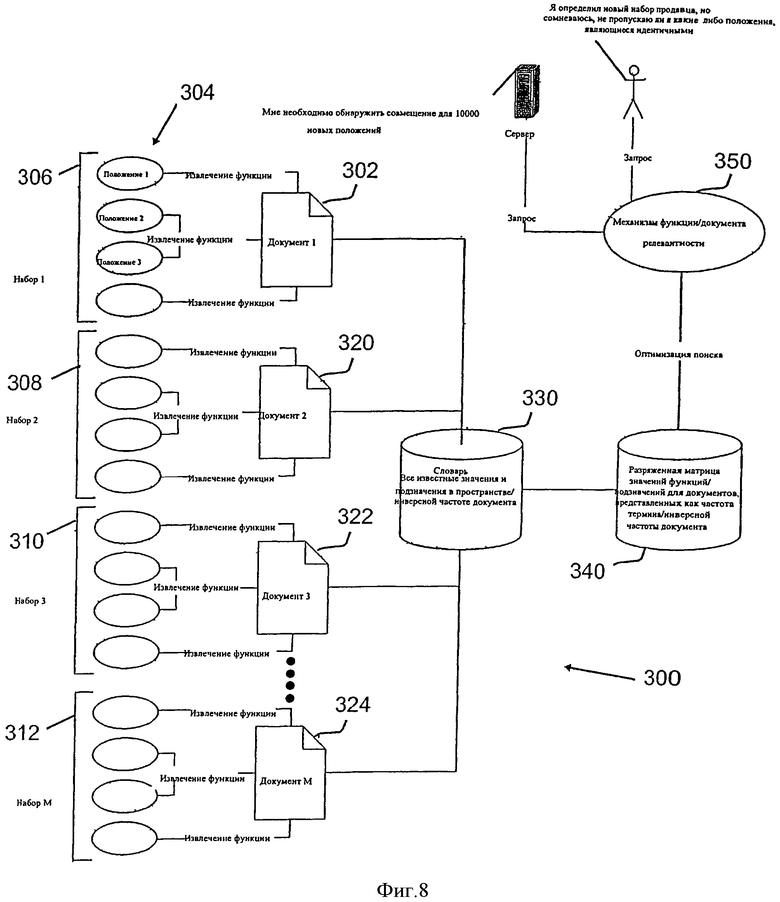
1. Компьютерный способ сравнения символьных строк для сравнения символьной строки кандидата с множеством записей символьных строк, сохраненных в базе данных, причем упомянутый способ включает:
выделение одной или более символьных строк во множестве записей символьных строк для создания набора ссылочных символьных строк посредством факторного анализа основных компонент (PCFA) для идентификации разнородных ссылочных символьных строк во множестве записей символьных строк;
генерацию двоичного индексного ключа для каждой из символьных строк в наборе символьных строк, причем двоичный индексный ключ содержит несколько бит двоичной информации и каждый бит показывает степень подобия символьной строки набору ссылочных символьных строк;
генерацию двоичного индексного ключа для символьной строки кандидата;
определение набора записей символьных строк, сохраненных в базе данных, который включает двоичный индексный ключ, точно совпадающий с двоичным индексным ключом символьной строки кандидата;
создание определенного набора записей символьных строк, сохраненных в базе данных, который включает двоичный индексный ключ, точно совпадающий с двоичным индексным ключом символьной строки кандидата, определяющим местонахождение каждой записи символьной строки, чья выделенная символьная строка совпадает с соответствующей символьной строкой записи строки кандидата; и
индексацию записи символьной строки кандидата в базе данных, основанную на этом совпадении.
2. Способ по п. 1, отличающийся тем, что генерация двоичного индексного ключа для каждой из символьных строк в наборе символьных строк содержит сравнение n-граммного представления одной из выделенных символьных строк в наборе символьных строк с n-граммным представлением каждой строки из набора разнородных ссылочных символьных строк, в которой i-й бит двоичного индексного ключа представляет степень сходства строки кандидата с i-й ссылочной символьной строкой.
3. Способ по п. 2, отличающийся тем, что i-й бит в двоичном индексном ключе установлен в логическую 1, если степень сходства этой записи с i-й ссылочной строкой выше предопределенного порога.
4. Способ по п. 2, отличающийся тем, что база данных управляется системой управления реляционными базами данных (СУРБД), и генерация двоичного индексного ключа содержит создание двоичного индексного ключа посредством процесса, выполняемого в СУРБД, чтобы использовать расчет метрики подобия по частоте встречаемости n-грамм, показывающей степень подобия данной записи с каждой из ссылочных строк, идентифицированных посредством PCFA.
5. Способ по п. 1, дополнительно включающий:
вычисление двумерного вектора, содержащего частоту вхождения всех уникальных n-грамм в символьную строку кандидата и частоту вхождения всех уникальных n-грамм в ссылочную символьную строку;
вычисление метрики подобия для символьной строки кандидата, относительно ссылочной символьной строки, основанного на двумерном векторе;
определение величины вектора, ассоциированного с символьной строкой кандидата, как величины А;
определение величины вектора, ассоциированного со ссылочной символьной строкой, как величины В;
вычисление скалярного произведения между этими двумя векторами; и
вычисление метрики подобия согласно (скалярное произведение / (Величина А × Величина В)).
6. Способ по п. 5, отличающийся тем, что вычисление метрики подобия для символьной строки кандидата включает сравнение значений двумерного вектора, проведенного посредством вычисления с использованием языка структурированных запросов.
7. Способ по п. 5, отличающийся тем, что вычисление метрики подобия включает проведение расчета метрики подобия по частоте встречаемости n-грамм на языке структурированных запросов ASCII.
8. Способ по п. 5, дополнительно включающий вычисление метрики подобия по частоте встречаемости n-грамм для создания двоичного индексного ключа, который показывает подобие между символьной строкой кандидата и каждой из идентифицированных ссылочных символьных строк.
9. Способ по п. 1, дополнительно включающий идентификацию разнородных ссылочных символьных строк во множестве записей символьных строк, сохраненных в базе данных, с использованием оптимизированного поиска для генерации набора разнородных ссылочных символьных строк.
10. Способ по п. 1, отличающийся тем, что индексирование символьной строки кандидата в базе данных включает:
реализацию вычисления метрики подобия по частоте встречаемости n-грамм;
использование вычисления для создания двоичных ключей, которые указывают на подобие между записью, связанной с символьной строкой кандидата, и записью, связанной с каждой из идентифицированных ссылочных символьных строк;
присоединение записей, которые совместно используют то же значение двоичного ключа; и
сортировку присоединенных записей по релевантности суммированием всех подходящих n-грамм, взвешенных по частоте.
11. Способ по п. 1, отличающийся тем, что индексация символьной строки кандидата включает генерирование матрицы метрик подобия символьной строки кандидата с набором ссылочных символьных строк.
12. Способ по п. 1, отличающийся тем, что индексация символьной строки кандидата включает:
присвоение двоичному индексному ключу, соответствующему ссылочной символьной строке, значения 1, если метрика подобия выше предопределенного порога; и
присвоение двоичному индексному ключу, соответствующему ссылочной символьной строке, значения 0, если метрика подобия ниже предопределенного порога.
13. Система с компьютерной базой данных, предназначенная для сопоставления символьной строки кандидата с множеством записей символьных строк, сохраненных в базе данных, управляемой системой управления реляционными базами данных (СУРБД), при этом система содержит:
память, содержащую:
первую структуру данных, содержащую символьные строки идентификационных данных для множества получателей платежа;
вторую структуру данных, содержащую двоичный индексный ключ, представляющий метрику подобия выделенных символьных строк набору предопределенных разнородных ссылочных строк;
процессор, запрограммированный на:
выделение одной или более символьных строк в первой структуре данных для создания набора предопределенных разнородных ссылочных строк;
генерацию двоичного индексного ключа для каждой из выделенных символьных строк, причем двоичный индексный ключ содержит множество бит двоичной информации, где каждый бит показывает степень сходства символьной строки с набором ссылочных символьных строк, и созданный двоичный индексный ключ использует процесс, встроенный в СУРБД, чтобы использовать его для вычисления метрики подобия по частоте встречаемости n-грамм, которая показывает степень сходства данной записи с каждой из ссылочных строк, идентифицированных посредством факторного анализа основных компонент (PCFA);
генерацию двоичного индексного ключа для символьной строки кандидата;
определение набора записей символьных строк, сохраненных в первой структуре данных, которая связана с двоичным индексным ключом, точно соответствующим двоичному индексному ключу символьной строки кандидата;
создание определенного набора записей символьных строк, сохраненных в первой структуре данных, которая включает двоичный индексный ключ, точно соответствующий двойному индексному ключу символьной строки кандидата, определяющему местонахождение каждой записи символьной строки, чья выделенная символьная строка совпадает с соответствующей символьной строкой записи строки кандидата; и
индексирование записи символьной строки кандидата в базе данных на основе сходства.
14. Система по п. 13, отличающаяся тем, что указанный процессор дополнительно запрограммирован на идентификацию набора разнородных символьных строк во множестве записей символьных строк, сохраненных в базе данных, посредством метода главных компонент факторного анализа для идентификации набора разнородных записей символьных строк.
15. Система по п. 13, отличающаяся тем, что указанный процессор дополнительно запрограммирован на сравнение n-граммного представления одной из выделенных строк в наборе выделенных строк с n-граммным представлением каждой строки из набора разнородных ссылочных символьных строк, причем i-й бит двоичного индексного ключа представляет степень подобия строки кандидата и с i-й ссылочной символьной строкой.
16. Система по п. 15, отличающаяся тем, что i-й бит в двоичном индексном ключе установлен в логическую 1, если степень подобия этой записи с i-й ссылочной строкой выше предопределенного порога.
17. Система по п. 13, отличающаяся тем, что указанный процессор дополнительно запрограммирован на идентификацию набора разнородных символьных строк во множестве записей символьных строк, сохраненных в базе данных, посредством оптимизированного поиска, чтобы создать набор разнородных ссылочных символьных строк.
18. Система по п. 13, отличающаяся тем, что вычисление метрики подобия включает проведение расчета метрики подобия по частоте встречаемости n-грамм на языке структурированных запросов ASCII.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6944344 B2, 13.09.2005 | |||
| US 6502064 B1, 31.12.2002 | |||
| US 5992737 A, 30.11.1999 | |||
| СПОСОБ ПРОГНОЗИРОВАНИЯ ПОГОДЫ | 1997 |
|
RU2163026C2 |

