УРОВЕНЬ ТЕХНИКИ
[0001] Изобретение относится к способам и системам для классификации электронных документов, в частности к системам и способам для фильтрации незапрашиваемых электронных сообщений (спама) и детекции поддельных сетевых документов.
[0002] Незапрашиваемые электронные сообщения, также известные как спам, составляют значительную часть коммуникационного трафика во всем мире, что оказывает влияние на службы обмена сообщениями посредством компьютеров и телефонов. Спам может принимать множество форм, от незапрашиваемых сообщений электронной почты до спамовых сообщений, замаскированных под комментарии пользователей на различных Интернет-сайтах, например на сайтах блогов и социальных сетей. Спам отнимает ценные аппаратные ресурсы и влияет на производительность, при этом он воспринимается многими пользователями коммуникационных услуг и/или Интернета как раздражающий и назойливый.
[0003] Интернет-мошенничество, в частности в виде фишинга и кражи идентификационных данных, представляет собой растущую угрозу для пользователей Интернета по всему миру. Конфиденциальная идентификационная информация, такая как имена пользователей, идентификаторы, пароли, записи социального обеспечения и медицинские записи, реквизиты банковских и кредитных карт, полученные обманным путем международными преступными сетями, работающими в Интернете, используются для вывода личных средств и/или продаются далее третьей стороне. Кроме прямого финансового ущерба для отдельных лиц, интернет-мошенничество также вызывает ряд нежелательных побочных эффектов, таких как увеличение расходов на обеспечение безопасности для компаний, более высокие розничные цены и банковские сборы, снижение стоимости акций, низкие заработные платы и снижение налоговых поступлений.
[0004] В примерной попытке фишинга, поддельный веб-сайт (который также называется клоном) может отображать себя в качестве подлинной веб-страницы, принадлежащей интернет-магазину или финансовому учреждению, и запрашивать у пользователя ввод некоторой личной информации, такой как имя пользователя или пароль, или финансовую информацию, например, номер кредитной карты, номер счета или защитный код. Как только информация будет введена ничего не подозревающим пользователем, ею завладеет поддельный веб-сайт. Кроме того, пользователя могут направить на другую веб-страницу, которая может установить вредоносное программное обеспечение на компьютере пользователя. Вредоносное программное обеспечение (например, вирусы, трояны) может продолжать похищать личную информацию путем записи клавиш, нажимаемых пользователем при посещении определенных веб-страниц, и может превратить компьютер пользователя в платформу для запуска других фишинговых или спамовых атак.
[0005] В случае спама электронной почты или мошенничества посредством электронной почты, программное обеспечение, выполняемое на компьютерной системе пользователя или провайдера услуг электронной почты, может использоваться для классификации сообщений электронной почты как спамовые/не спамовые (или как мошеннические/легитимные), и даже для различения между различными видами сообщений, например, между предложениями товаров, содержимым для взрослых и нигерийским мошенничеством. Спамовые/мошеннические сообщения могут затем направляться в специальные папки или удаляться. Сходным образом, программное обеспечение, выполняемое на компьютерных системах провайдера интернет-контента, может использоваться для перехвата спамовых/мошеннических сообщений, размещенных на веб-сайте, принадлежащем соответствующему провайдеру интернет-контента, а также для предотвращения отображения соответствующих сообщений или для отображения предупреждения пользователям веб-сайта о том, что соответствующие сообщения могут быть мошенническими или спамовыми.
[0006] Было предложено несколько подходов для идентификации спама и/или интернет-мошенничества, в том числе сравнение исходящего адреса сообщения со списками известных подозрительных или достоверных адресов (способы, которые соответственно называются занесением в черный или белый список), поиск определенных слов или образцов слов (например, рефинансирование, Viagra®, акции) и анализ заголовков сообщений. Иногда используются способы выделения сигнатур и/или сравнения сигнатур в сочетании с автоматизированными способами классификации данных (например, байесовская фильтрация, нейронные сети).
[0007] Некоторые предложенные способы используют хеширование для получения компактных представлений электронных текстовых сообщений. Такие представления обеспечивают эффективное сравнение между сообщениями с целью детекции спама или мошенничества.
[0008] Спамеры и интернет-мошенники пытаются обойти детекцию посредством использования различных способов запутывания, таких как неправильное написание некоторых слов, вложение спамового и/или мошеннического контента в более крупные блоки текста с маскированием под легитимные документы, и изменение формы и/или контента сообщений от одной волны распространения к другой. Способы борьбы со спамом и мошенничеством, использующие хеширование, как правило, уязвимы для такого запутывания, так как небольшие изменения в тексте могут привести к существенно различным хешам. Таким образом, для успешной детекции могут оказаться полезными способы и системы, которые могут распознавать полиморфный спам и мошенничество.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] Согласно одному аспекту клиентская компьютерная система содержит по меньшей мере один процессор, конфигурированный для определения сигнатуры текста целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, причем нижняя и верхняя границы предварительно определены. Определение сигнатуры текста содержит: отбор множества лексем текста целевого электронного документа и в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста. Определение сигнатуры текста дополнительно содержит: определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определен в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста и каждый фрагмент сигнатуры содержит последовательность символов, длина которой выбрана равной размеру фрагмента сигнатуры; и конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста.
[0010] Согласно другому аспекту серверная компьютерная система содержит по меньшей мере один процессор, конфигурированный для выполнения транзакций с множеством клиентских систем, причем транзакция содержит: получение сигнатуры текста из клиентской системы множества клиентских систем, при этом сигнатура текста определена для целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, причем нижняя и верхняя границы предварительно определены; и отправку в клиентскую систему целевой метки, указывающей на категорию документов, к которой принадлежит целевой электронный документ. Определение сигнатуры текста содержит: отбор множества лексем текста целевого электронного документа и в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста. Определение сигнатуры текста дополнительно содержит: определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определен в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста и каждый фрагмент сигнатуры содержит последовательность символов, длина которой выбрана равной размеру фрагмента сигнатуры; и конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста. Определение целевой метки содержит: извлечение эталонной сигнатуры из базы данных эталонных сигнатур, причем эталонная сигнатура определена для эталонного электронного документа, принадлежащего к указанной категории, и эталонная сигнатура отобрана в соответствии с длиной эталонной сигнатуры так, чтобы длина эталонной сигнатуры была между верхней и нижней границами; и определение, принадлежит ли целевой электронный документ к указанной категории в соответствии с результатом сравнения сигнатуры текста с эталонной сигнатурой.
[0011] Согласно другому аспекту способ содержит использование по меньшей мере одного процессора клиентской компьютерной системы для определения сигнатуры текста целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, причем верхнюю и нижнюю границы определяют предварительно. Определение сигнатуры текста содержит: отбор множества лексем текста целевого электронного документа и в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста. Определение сигнатуры текста дополнительно содержит: определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определяют в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста и каждый фрагмент сигнатуры содержит последовательность символов, длину которой выбирают равной размеру фрагмента сигнатуры; и конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста.
[0012] Согласно другому аспекту способ содержит использование по меньшей мере одного процессора серверной компьютерной системы, конфигурированного для выполнения транзакций с множеством клиентских систем, чтобы: получать сигнатуру текста из клиентской системы множества клиентских систем, причем сигнатуру текста определяют для целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, при этом нижнюю и верхнюю границы определяют предварительно; и отправлять в клиентскую систему целевую метку, определенную для целевого электронного документа, причем целевая метка указывает на категорию документов, к которой принадлежит целевой электронный документ. Определение сигнатуры текста содержит: отбор множества лексем текста целевого электронного документа и в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста. Определение сигнатуры текста дополнительно содержит: определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определяют в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста и каждый фрагмент сигнатуры содержит последовательность символов, длину которой выбирают равной размеру фрагмента сигнатуры; и конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста. Определение целевой метки содержит: извлечение эталонной сигнатуры из базы данных эталонных сигнатур, при этом эталонную сигнатуру определяют для эталонного электронного документа, принадлежащего к указанной категории, и эталонную сигнатуру отбирают в соответствии с длиной эталонной сигнатуры так, чтобы длина эталонной сигнатуры была между верхней и нижней границами; и определение, принадлежит ли целевой электронный документ к указанной категории в соответствии с результатом сравнения сигнатуры текста с эталонной сигнатурой.
Технический результат, достигаемый заявленными техническими решениями, заключается в увеличении скорости вычислений и уменьшении требуемого объема памяти при определении сигнатуры текста электронного документа без снижения точности сравнения электронных документов по их сигнатурам.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0013] Вышеизложенные аспекты и преимущества настоящего изобретения будут более понятными при чтении нижеследующего подробного описания со ссылками на чертежи, на которых:
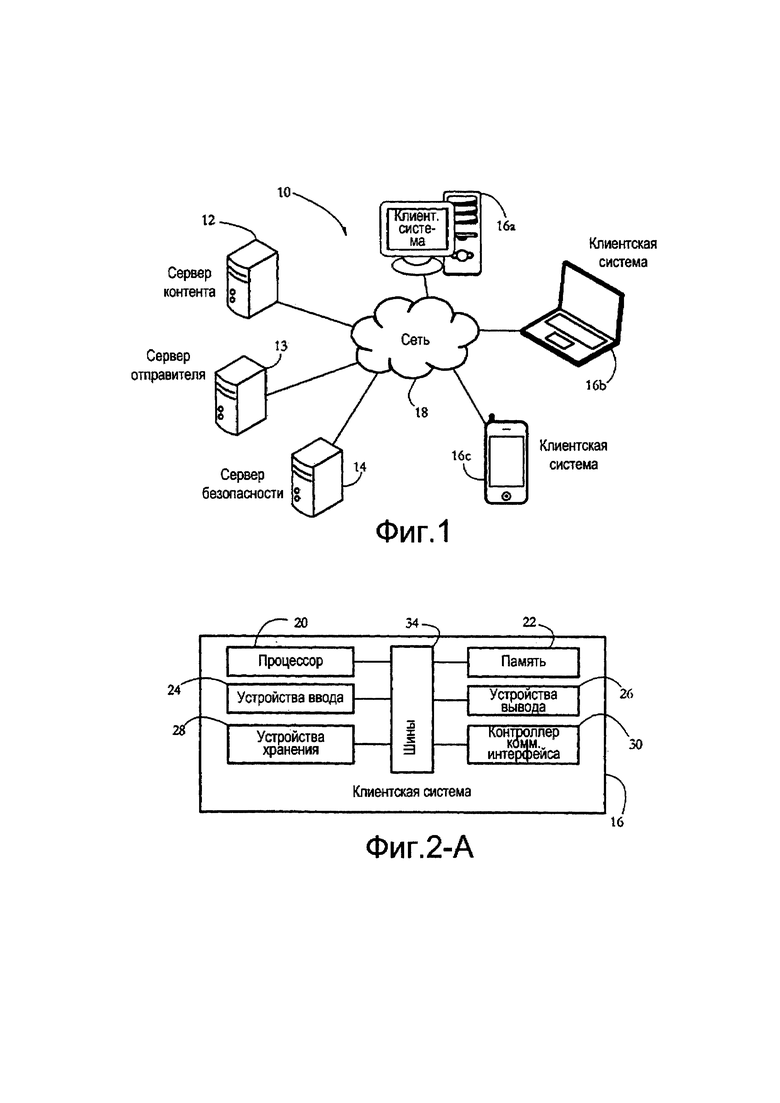
[0014] Фиг. 1 показывает примерную систему антиспама/антимошенничества, содержащую сервер безопасности, защищающий множество клиентских систем, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
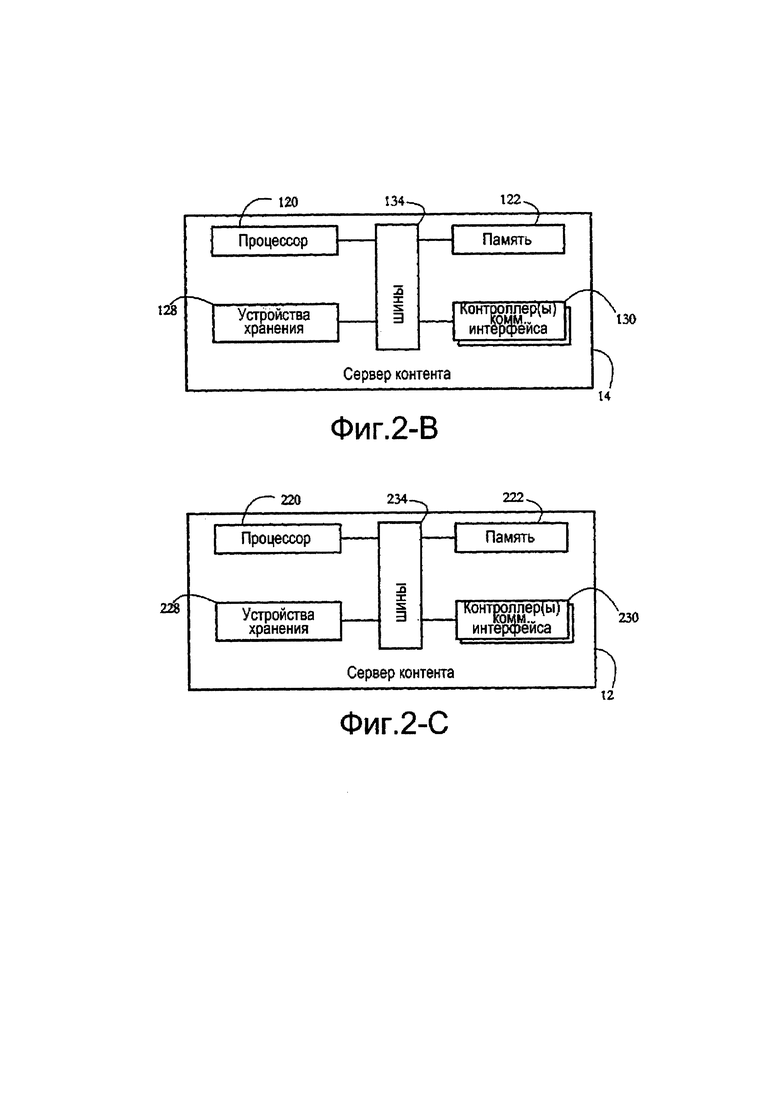
[0015] Фиг. 2-А показывает примерную конфигурацию аппаратного оборудования клиентской компьютерной системы в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0016] Фиг. 2-В показывает примерную конфигурацию аппаратного оборудования компьютерной системы сервера безопасности в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0017] Фиг. 2-С показывает примерную конфигурацию аппаратного оборудования компьютерной системы контент-сервера в соответствии с некоторыми вариантами осуществления настоящего изобретения.
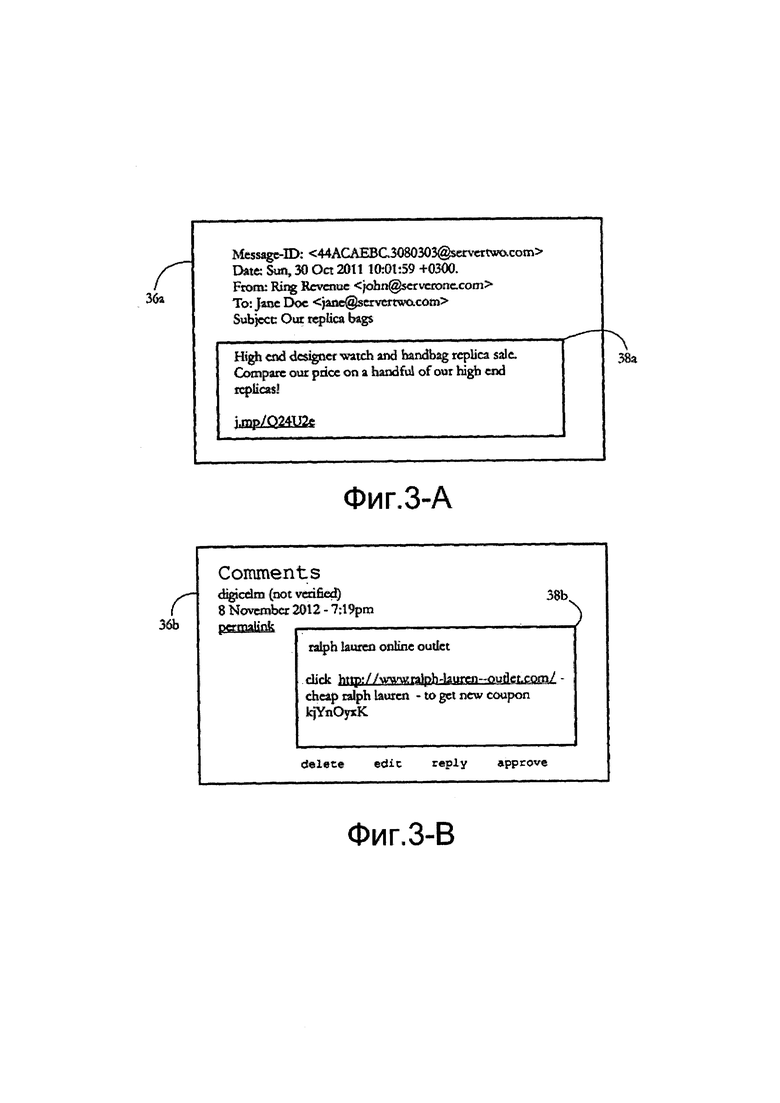
[0018] Фиг. 3-А показывает примерное спамовое сообщение электронной почты, включающее в себя блок текста, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0019] Фиг. 3-В показывает примерный спамовый комментарий блога, включающий в себя блок текста, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0020] Фиг. 3-С иллюстрирует примерную мошенническую веб-страницу, содержащую множество блоков текста, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
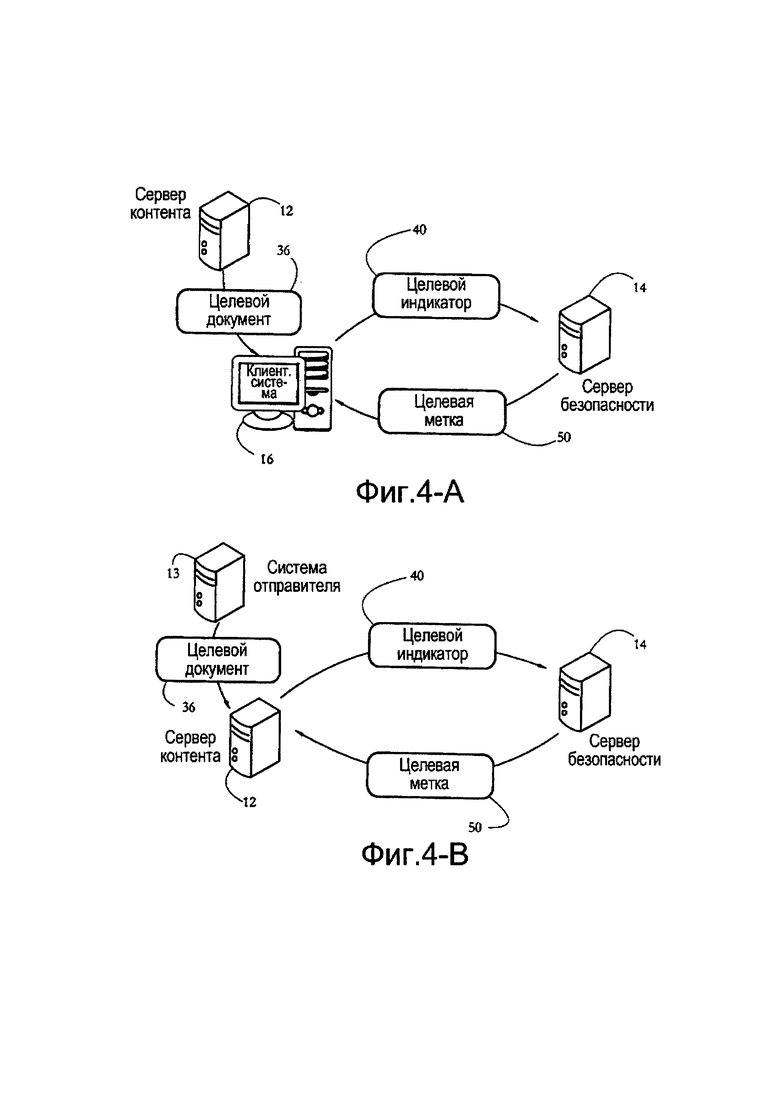
[0021] Фиг. 4-А иллюстрирует примерную транзакцию детекции спама/мошенничества между клиентским компьютером и сервером безопасности в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0022] Фиг. 4-В иллюстрирует примерную транзакцию детекции спама/мошенничества между контент-сервером и сервером безопасности в соответствии с некоторыми вариантами осуществления настоящего изобретения.
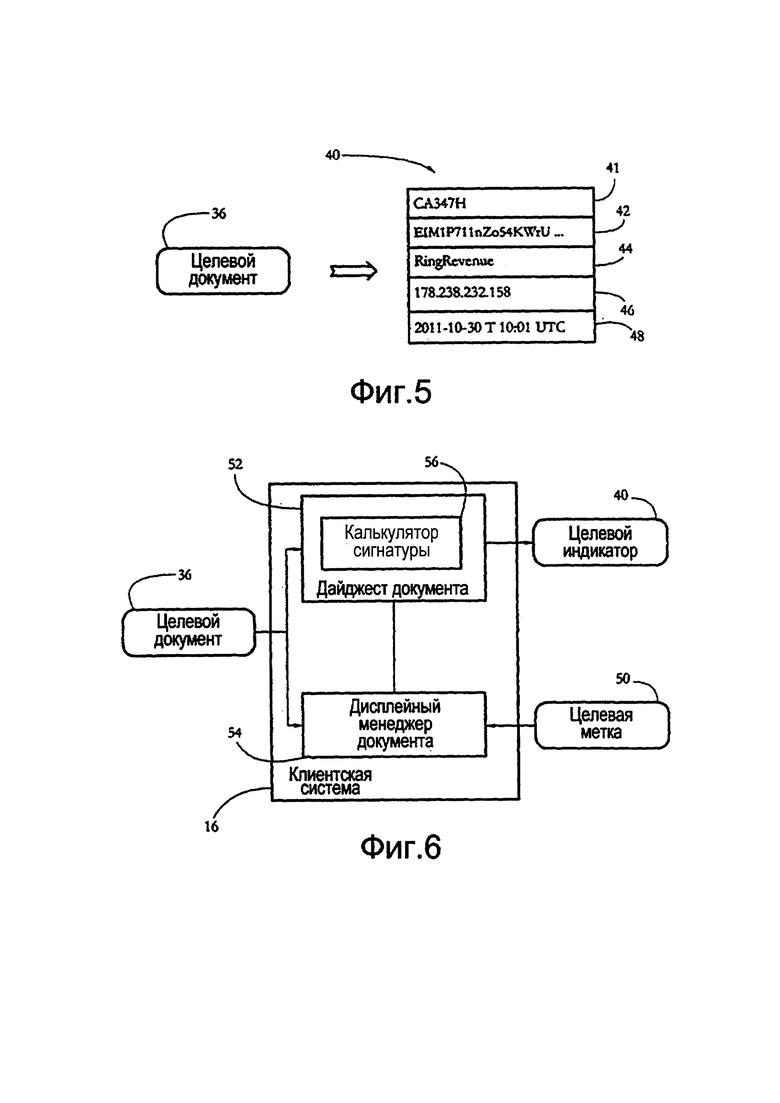
[0023] Фиг. 5 показывает примерный целевой индикатор целевого электронного документа, причем индикатор содержит сигнатуру текста и другие данные идентификации спама/мошенничества, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0024] Фиг. 6 показывает схематический вид примерного набора приложений, выполняемых на клиентской системе, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
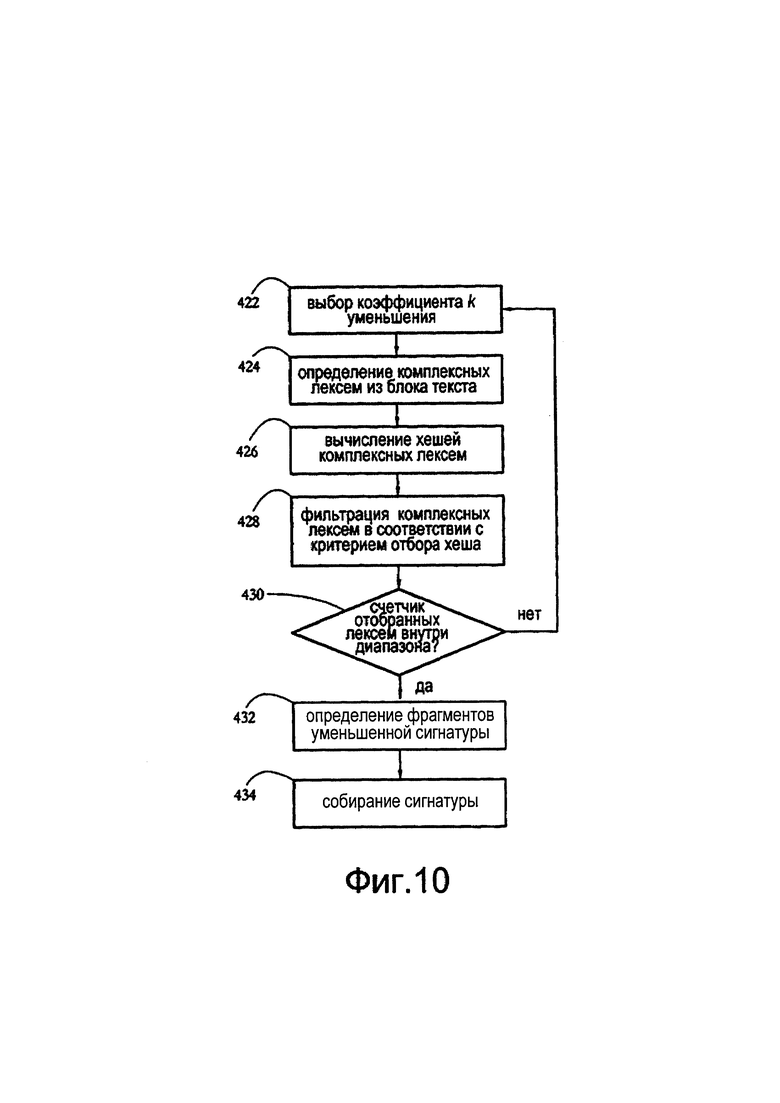
[0025] Фиг. 7 иллюстрирует примерную последовательность этапов, выполняемых калькулятором сигнатуры с фиг. 6, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
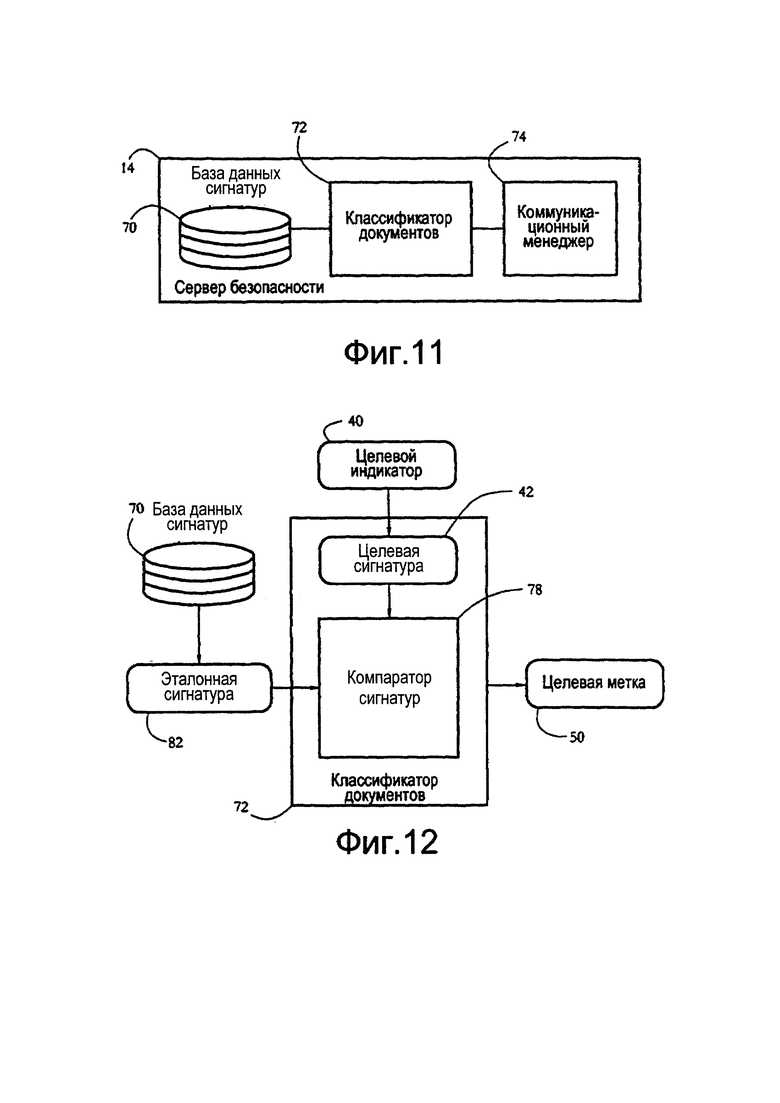
[0026] Фиг. 8 показывает примерное определение сигнатуры текста целевого блока текста в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0027] Фиг. 9 показывает множество сигнатур, определенных для целевого блока текста при различных коэффициентах увеличения и уменьшения, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0028] Фиг. 10 иллюстрирует примерную последовательность этапов, выполняемых калькулятором сигнатуры для определения сигнатуры уменьшения в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0029] Фиг. 11 показывает примерные приложения, выполняемые на сервере безопасности, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
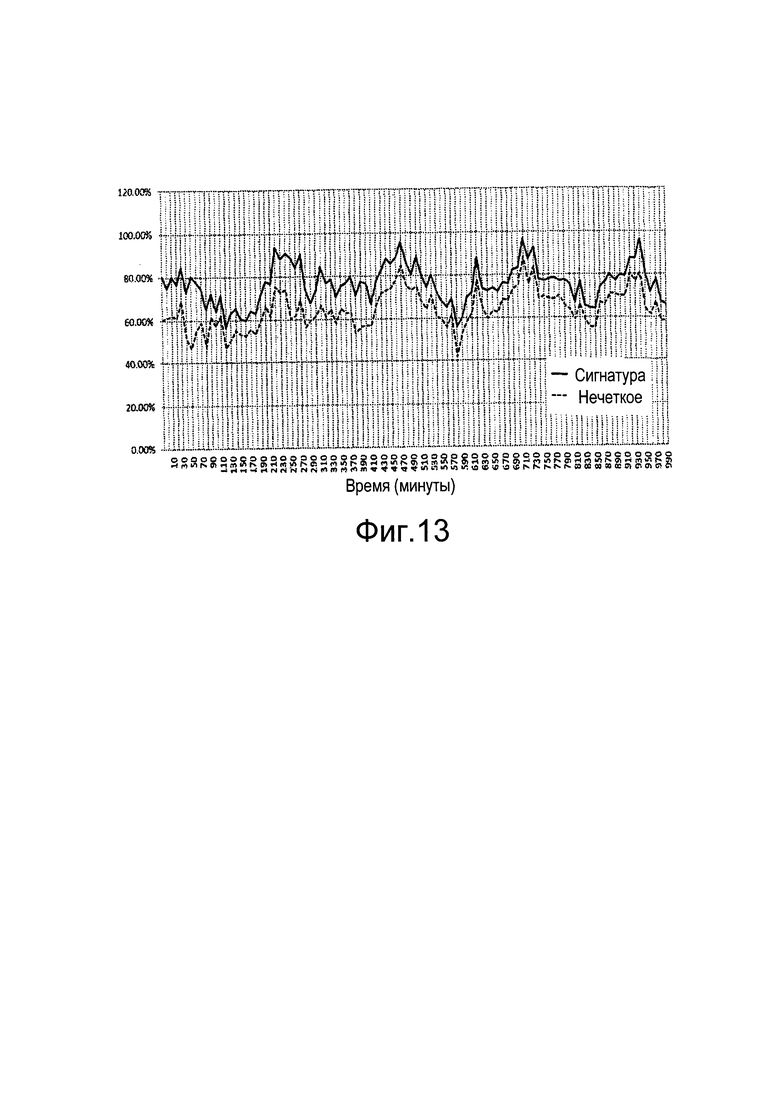
[0030] Фиг. 12 показывает схематический вид примерного классификатора документов, который выполняется на сервере безопасности, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0031] Фиг. 13 показывает вероятность детекции спама, полученную в компьютерном эксперименте, включающем в себя анализ потока фактических спамовых сообщений, причем анализ был проведен в соответствии с некоторыми вариантами осуществления настоящего изобретения; указанная вероятность детекции сравнивается с вероятностью детекции, полученной при помощи стандартных способов.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0032] В нижеследующем описании предполагается, что все перечисленные соединения между конструкциями могут быть непосредственными рабочими соединениями или опосредованными рабочими соединениями через промежуточные конструкции. Набор элементов включает в себя один или более элементов. Любое упоминание элемента подразумевает указание на по меньшей мере один элемент. Множество элементов включает в себя по меньшей мере два элемента. Если иное не требуется, любые описанные этапы способа не обязательно должны выполняться в определенном показанном порядке. Первый элемент (например, данные), полученный из второго элемента, включает в себя первый элемент, эквивалентный второму элементу, а также первый элемент, сгенерированный посредством обработки второго элемента и, опционально, других данных. Осуществление определения или принятие решения согласно параметру включает в себя осуществление определения или принятие решения согласно этому параметру и, опционально, согласно другим данным. Если не указано иное, индикатор некоторой величины/данных может представлять собой сами величины/данные или индикатор, отличный от самих величины/данных. Если не указано иное, хеш представляет собой вывод хеш-функции. Если не указано иное, хеш-функция представляет собой математическое преобразование, отображающее последовательность знаков (например, символов, битов) в счетчик или в битовую строку. Машиночитаемые носители включают в себя долговременные носители, такие как магнитные, оптические и полупроводниковые носители данных (например, жесткие диски, оптические диски, флэш-память, динамическая операционная память (DRAM)), а также коммуникационные линии, такие как проводящие кабели и волоконно-оптические коммуникации. Согласно некоторым вариантам осуществления настоящее изобретение обеспечивает, в частности, компьютерные системы, содержащие аппаратное обеспечение (например, один или несколько процессоров), программированное для выполнения описанных здесь способов, а также машиночитаемые носители, кодирующие инструкции для выполнения описанных здесь способов.
[0033] Нижеследующее описание иллюстрирует варианты осуществления изобретения в качестве примера и не обязательно в качестве ограничения.
[0034] Фиг. 1 показывает примерную систему 10 антиспама/антимошенничества в соответствии с некоторыми вариантами осуществления настоящего изобретения. Система 10 включает в себя контент-сервер 12, систему-отправитель 13, сервер 14 безопасности и множество клиентских систем 16а-с, которые все соединены коммуникационной сетью 18. Сеть 18 может быть глобальной сетью, такой как Интернет, в то время как части сети 18 могут также включать в себя локальную сеть (LAN).
[0035] В некоторых вариантах осуществления контент-сервер 12 конфигурирован для получения внесенного пользователем контента (например, статьи, записи в блогах, загрузки мультимедиа, комментарии и т.д.) от множества пользователей, а также для организации, форматирования, и распространения такого контента третьей стороне, такой как клиентские системы 16а-с. Примерный вариант осуществления контент-сервера 12 представляет собой сервер электронной почты, обеспечивающий доставку электронных сообщений на клиентские системы 16а-с. Другой вариант осуществления контент-сервера 12 представляет собой компьютерную систему, обеспечивающую хостинг блога или сайта социальной сети. В некоторых вариантах осуществления внесенный пользователем контент циркулирует по сети 18 в виде электронных документов, которые также называются целевыми документами в нижеследующем описании. Электронные документы включают в себя, среди прочего, веб-страницы (например, документы языка разметки гипертекста (HTML)) и электронные сообщения, такие как электронная почта и сообщения службы коротких сообщений (SMS). Часть внесенных пользователем данных, полученных на сервере 12, может содержать незапрашиваемые и/или мошеннические сообщения и документы.
[0036] В некоторых вариантах осуществления система-отправитель 13 содержит компьютерную систему, рассылающую незапрашиваемые сообщения, такие как спамовые сообщения электронной почты, в клиентские системы 16а-с. Такие сообщения могут быть получены на сервере 12, а затем отправлены в клиентские системы 16а-с. В качестве альтернативы сообщения, полученные на сервере 12, могут быть доступными (например, через веб-интерфейс) для извлечения клиентскими системами 16а-с. В других вариантах осуществления система-отправитель 13 может отправлять незапрашиваемые сообщения, такие как спамовые комментарии блогов или спам, размещенный на сайте социальной сети, в контент-сервер 12. Клиентские системы 16а-с могут затем получать эти сообщения через протокол, такой как протокол передачи гипертекста (HTTP).
[0037] Сервер 14 безопасности может содержать одну или несколько компьютерных систем, выполняющих классификацию электронных документов, как показано детально ниже. Выполнение этой классификации может включать в себя идентификацию незапрашиваемых сообщений (спама) и/или мошеннических электронных документов, таких как фишинговые сообщения и веб-страницы. В некоторых вариантах осуществления выполнение классификации включает в себя совместную транзакцию детекции спама/мошенничества, осуществляемую между сервером 14 безопасности и контент-сервером 12 и/или между сервером 14 безопасности и клиентскими системами 16а-b.
[0038] Клиентские системы 16а-с могут включать в себя компьютеры конечных пользователей, каждый из которых имеет процессор, память и запоминающее устройство и работает под управлением операционной системы, такой как Windows®, MacOS® или Linux. Некоторые компьютерные клиентские системы 16а-с могут представлять собой мобильные вычислительные и/или телекоммуникационные устройства, такие как планшетные персональные компьютеры (PC), мобильные телефоны, карманные персональные компьютеры (PDA), и бытовые приборы, такие как, среди прочего, телевизоры или музыкальные проигрыватели. В некоторых вариантах осуществления клиентские системы 16а-с могут представлять отдельных потребителей или несколько клиентских систем могут принадлежать одному и тому же потребителю. Клиентские системы 16а-с могут иметь доступ к электронным документам, например, к сообщениям электронной почты, либо путем получения этих документов из системы-отправителя 13 и сохранения их в локальном почтовом ящике, либо путем извлечения этих документов через сеть 18, например с веб-сайта, обслуживаемого контент-сервером 12.
[0039] Фиг. 2-А показывает примерную конфигурацию аппаратного обеспечения клиентской системы 16, такой как системы 16а-с с фиг. 1. Фиг. 2-А показывает компьютерную систему для иллюстративных целей; при этом конфигурация аппаратного обеспечения других устройств, таких как мобильные телефоны, может отличаться. В некоторых вариантах осуществления клиентская система 16 содержит процессор 20, блок 22 памяти, набор устройств 24 ввода, набор устройств 26 вывода, набор устройств 28 хранения и контроллер 30 коммуникационного интерфейса, которые все соединены множеством шин 34.
[0040] В некоторых вариантах осуществления процессор 20 содержит физическое устройство (например, многоядерную интегральную схему), конфигурированное для выполнения вычислительных и/или логических операций с набором сигналов и/или данных. В некоторых вариантах осуществления такие логические операции поступают в процессор 20 в виде последовательности инструкций процессора (например, машинный код или программное обеспечение другого типа). Блок 22 памяти может включать в себя энергозависимые машиночитаемые носители (например, оперативное запоминающее устройство (RAM)), хранящие данные/сигналы, доступные или генерируемые процессором 20 в течение выполнения инструкций. Устройства 24 ввода могут включать в себя, среди прочего, компьютерные клавиатуры, мыши и микрофоны, содержащие соответствующие интерфейсы и/или адаптеры аппаратного обеспечения, позволяющие пользователю вводить данные и/или инструкции в систему 16. Устройства 26 вывода могут включать в себя устройства отображения, такие как, среди прочего, мониторы и динамики, а также интерфейсы/адаптеры аппаратного обеспечения, такие как графические карты, позволяющие системе 16 передавать данные пользователю. В некоторых вариантах осуществления устройства 24 ввода и устройства 26 вывода могут имеют общую часть аппаратного обеспечения, как и в случае устройств с сенсорным экраном. Устройства 28 хранения включают в себя машиночитаемые носители, позволяющие долговременной памяти читать и записывать программные инструкции и/или данные. Примерные устройства 28 хранения включают в себя магнитные и оптические диски и устройства флэш-памяти, а также съемные носители, такие как компакт-диски (CD) и/или цифровые универсальные диски (DVD) и приводные устройства. Контроллер 30 коммуникационного интерфейса позволяет системе 16 соединяться с сетью 18 и/или с другими устройствами/компьютерными системами. Шины 34 вместе представляют собой множество системных, периферийных и микросхемных шин, и/или все другие схемы, обеспечивающие возможность внутренней коммуникации устройств 20-30 клиентской системы 16. Например, шины 34 могут включать в себя, среди прочего, северный мост, соединяющий процессор 20 с памятью 22, и/или южный мост, соединяющий процессор 20 с устройствами 24-30.
[0041] Фиг. 2-В показывает примерную конфигурацию аппаратного обеспечения сервера 14 безопасности в соответствии с некоторыми вариантами осуществления настоящего изобретения. Сервер 14 безопасности включает в себя процессор 120 и блок 122 памяти и может дополнительно содержать набор устройств 128 хранения и по меньшей мере один контроллер 130 коммуникационного интерфейса, которые все внутренне соединены при помощи набора шин 134. В некоторых вариантах осуществления работа процессора 120, памяти 122 и устройств 128 хранения могут быть соответственно сходны с работой элементов 20, 22 и 28, как описано выше со ссылками на фиг. 2-А. Блок 122 памяти хранит данные/сигналы, доступные или генерируемые процессором 120 в течение выполнения инструкций. Контроллер(ы) 130 позволяет(ют) серверу 14 безопасности соединяться с сетью 18 для передачи и/или получения данных в/от других систем, соединенных с сетью 18.
[0042] Фиг. 2-С показывает примерную конфигурацию аппаратного оборудования контент-сервера 12 в соответствии с некоторыми вариантами осуществления настоящего изобретения. Контент-сервер 12 включает в себя процессор 220 и блок 222 памяти и может дополнительно содержать набор устройств 228 хранения и, по меньшей мере, один контроллер 230 коммуникационного интерфейса, которые все внутренне соединены при помощи набора шин 234. В некоторых вариантах осуществления работа процессора 220, памяти 222 и устройств 228 хранения может быть, соответственно, аналогична работе элементов 20, 22 и 28, как описано выше. Блок 222 памяти хранит данные/сигналы, доступные или генерируемые процессором 220 в ходе выполнения инструкций. В некоторых вариантах осуществления контроллер(ы) 230 интерфейса позволяет(ют) контент-серверу 12 соединяться с сетью 18 и передавать и/или получать данные в другие системы и/или от других систем, которые соединены с сетью 18.
[0043] Фиг. 3-А показывает примерный целевой документ 36а, содержащий спам, в соответствии с некоторыми вариантами осуществления настоящего изобретения. Целевой документ 36а может содержать заголовок и полезную информацию, при этом заголовок содержит данные маршрута сообщения, например, индикатор отправителя и/или индикатор получателя, и/или другие данные, такие как временная метка, и индикатор типа контента, например, типа Многоцелевых Расширений Электронной Почты Интернета (MIME). Полезная информация может включать в себя данные, отображаемые в виде текста и/или изображений пользователю. Программное обеспечение, выполняемое на контент-сервере 12 и/или клиентских системах 16а-с, может обрабатывать полезную информацию для получения целевого блока 38а текста целевого документа 36а. В некоторых вариантах осуществления целевой блок 38а текста содержит последовательность знаков и/или символов, предназначенных для интерпретации в качестве текста. Блок 38а текста может включать в себя специальные символы, такие как знаки препинания, а также последовательности символов, представляющих, среди прочего, сетевые адреса, унифицированные указатели ресурсов (URL), адреса электронной почты, псевдонимы и псевдоимена. Целевой блок 38а текста может быть непосредственно встроен в целевой документ 36а, например, в качестве обычной части текста многоцелевого расширения функций электронной почты (MIME), или может содержать результат обработки набора компьютерных команд, встроенных в документ 36а. Например, целевой блок 38а текста может включать в себя результат обработки набора инструкций языка разметки гипертекста (HTML) или результат выполнения набора инструкций сценариев со стороны клиента или со стороны сервера (например, PHP, Javascript), встроенных в целевой документ 36а. В другом варианте осуществления целевой блок 38а текста может быть встроен в изображение, как в случае графического спама.
[0044] Фиг. 3-В показывает другой примерный целевой документ 36b, включающий в себя комментарий, размещенный на веб-странице, такой как блог, интернет-страница новостей или страница социальной сети. В некоторых вариантах осуществления документ 36b включает в себя содержимое набора полей данных, например, полей формы, встроенной в документе HTML. Заполнение такие полей формы может быть выполнено дистанционно, например, человеком-оператором и/или автоматически при помощи части программного обеспечения, выполняемого в системе 13 отправителя. В некоторых вариантах осуществления дисплей документа 36b содержит блок 38b текста, содержащий последовательность символов и/или знаков, предназначенных для интерпретации в качестве текста пользователем, имеющим доступ к соответствующему сайту. Блок 38b текста может включать в себя, среди прочего, гиперссылки, специальные символы, значки настроения и изображения.
[0045] На фиг. 3-С показан другой примерный целевой документ 36с, содержащий фишинговую веб-страницу. Документ 36с может быть доставлен в виде набора инструкций сценариев HTML и/или инструкций сценариев со стороны сервера или со стороны клиента, которые при выполнении определяют средство просмотра документов (например, веб-браузер), чтобы получить набор изображений и/или набор блоков текста. Два таких примерных блоков 38c-d текста показаны на фиг. 3-С. Блоки 36с-d текста могут включать в себя гиперссылки и адреса электронной почты.
[0046] Фиг. 4-А показывает примерную транзакцию детекции спама/мошенничества между примерной клиентской системой 16, такой как клиентские системы 16а-с на фиг. 1, и сервером 14 безопасности в соответствии с некоторыми вариантами осуществления настоящего изобретения. Показанный на фиг. 4-А обмен происходит, например, в варианте осуществления системы 10, конфигурированной для детекции спама электронной почты. После получения целевого документа 36, например, сообщения электронной почты, из контент-сервера 12 клиентская система 16 может определить целевой индикатор 40 целевого документа 36 и может отправить целевой индикатор 40 в сервер 14 безопасности. Целевой индикатор 40 содержит данные, позволяющие серверу 14 безопасности выполнять классификацию целевого документа 36, чтобы определить, например, является ли документ 36 спамом или нет. В ответ на получение целевого индикатора 40 сервер 14 безопасности может отправить целевую метку 50, указывающую на то, является ли документ 36 спамом или нет, в соответствующую клиентскую систему 16.
[0047] Еще один вариант осуществления транзакции детекции спама показан на фиг. 4-В и происходит между контент-сервером 12 и сервером 14 безопасности. Такие обмены могут происходить, например, с целью детекции незапрашиваемых сообщений, размещенных в блогах и/или на сайтах социальных сетей, или для детекции фишинговых веб-страниц. Контент-сервер 12, обеспечивающий хостинг и/или отображение соответствующего веб-сайта, может получать целевой документ 36 (например, комментарий в блоге). Контент-сервер 12 может обрабатывать соответствующую коммуникацию для получения целевого индикатора 40 соответствующего документа и может отправлять целевой индикатор в сервер 14 безопасности. В свою очередь сервер 14 может определять целевую метку 50, указывающую на то, является ли соответствующий документ спамом или мошенническим, и отправлять метку 50 в контент-сервер 12.
[0048] Фиг. 5 показывает примерный целевой индикатор 40, определенный для примерного целевого документа 36, такого как сообщение 36а электронной почты на фиг. 3-А. В некоторых вариантах осуществления целевой индикатор 40 представляет собой структуру данных, включающую в себя идентификатор 41 сообщения (например, индекс хеша), однозначно связанный с целевым документом 36, и сигнатуру 42 текста, определенную для блока текста документа 36, такого как блок 38а текста на фиг. 3-А. Целевой индикатор 40 может дополнительно включать в себя индикатор 44 отправителя, указывающий на отправителя документа 36, индикатор 46 маршрута, указывающий на сетевой адрес (например, IP-адрес), откуда происходит документ 36, и отметку 48 времени, указывающую на момент времени, когда документ 36 был отправлен и/или получен. В некоторых вариантах осуществления целевой индикатор 40 может содержать, среди прочего, другие признаки документа 36, указывающие на спам и/или указывающие на мошенничество, такие как флажок, указывающий на то, включает ли документ 36 изображения, флажок, указывающий на то, включает ли документ 36 гиперссылки, и индикатор макета документа, определенный для документа 36.
[0049] На фиг. 6 показан примерный набор компонентов, выполняемых на клиентской системе 16, в соответствии с некоторыми вариантами осуществления настоящего изобретения. Показанная на фиг. 6 конфигурация подходит, например, для детекции спамовых сообщений электронной почты, полученных в клиентской системе 16. Система 16 содержит дайджест 52 документа и дисплейный менеджер 54 документа, соединенный с дайджестом 52 документа. Дайджест 52 документа может дополнительно содержать калькулятор 56 сигнатуры. В некоторых вариантах осуществления дайджест 52 документа получает целевой документ 36 (например, сообщение электронной почты) и обрабатывает документ 36 для получения целевого индикатора 40. Обработка документа 36 может включать в себя, среди прочего, синтаксический разбор документа 36 для идентификации различных полей и/или типов данных и для различения данных заголовка от данных полезной информации. Когда документ 36 представляет собой сообщение электронной почты, примерный синтаксический разбор может производить, среди прочего, отдельные объекты данных для отправителя, IP-адрес, тему, метку времени и контенты соответствующего сообщения. Когда контенты документа 36 включают в себя данные множества типов MIME, синтаксический разбор может производить отдельный объект данных для каждого типа MIME, например, среди прочего, обычный текст, HTML и изображения. Дайджест 52 документа может затем формулировать целевой индикатор 40, например, путем заполнения соответствующих полей целевого индикатора 40, таких как, среди прочего, отправитель, адрес маршрута и метка времени. Программный компонент клиентской системы 16 может затем передать целевой индикатор 40 в сервер 14 безопасности для анализа.
[0050] В некоторых вариантах осуществления дисплейный менеджер 54 документа получает целевой документ 36, переводит его в визуальную форму и отображает его на устройстве вывода клиентской системы 16. Некоторые варианты осуществления дисплейного менеджера 54 могут также позволять пользователю клиентской системы 16 взаимодействовать с отображаемым контентом. Дисплейный менеджер 54 может быть интегрирован с готовым программным обеспечением отображения документа, таким как, среди прочего, веб-браузеры, приложениями для чтения электронной почты, приложениями для чтения электронных книг и медиа-плеерами. Такая интеграция может быть достигнута, например, в форме программных плагинов. Дисплейный менеджер 54 может быть конфигурирован для назначения целевого документа 36 (например, входящей электронной почты) классу документов, такому как спам, легитимный и/или различным другим классам и подклассам документов. Такая классификация может быть определена в соответствии с целевой меткой 50, полученной от сервера 14 безопасности. Дисплейный менеджер 54 может быть дополнительно конфигурирован для группирования спамовых/мошеннических сообщений в отдельные папки и/или только для отображения легитимных сообщений пользователю. Менеджер 54 также может маркировать документ 36 в соответствии с этой классификацией. Например, дисплейный менеджер 54 документа может отображать спамовые/мошеннические сообщения особым цветом или отображать флажок, указывающий на классификацию соответствующего сообщения (например, спам, фишинг, и т.д.), рядом с каждым спамовым/мошенническим сообщением. Аналогично, когда документ 36 представляет собой мошенническую веб-страницу, дисплейный менеджер 54 может блокировать доступ пользователя к соответствующей странице и/или отображать предупреждение пользователю.
[0051] В одном варианте осуществления, конфигурированном для детекции спама/мошенничества, размещенных в качестве комментариев в блогах и на сайтах социальных сетей, дайджест 52 документа и дисплейный менеджер 54 могут выполняться на контент-сервере 12 вместо клиентских систем 16а-с, как показано на фиг. 6. Такое программное обеспечение может быть реализовано на контент-сервере 12 в виде сценариев со стороны сервера, которые могут быть дополнительно втсроены, например, в качестве плагинов, в большие пакеты сценариев, например в качестве плагинов антиспама/антимошенничества для платформ публикации в Интернете Wordpress® или Drupal®. При определении того, что целевой документ 36 является спамом или мошенническим, дисплейный менеджер 54 может быть конфигурирован для блокирования соответствующего сообщения, предотвращая его отображение на соответствующем веб-сайте.
[0052] Калькулятор 56 сигнатуры (фиг. 6) конфигурирован для определения сигнатуры текста целевого документа 36, который представляет собой часть целевого индикатора 40 (например, элемент 42 на фиг. 5). В некоторых вариантах осуществления сигнатура, определенная для целевого электронного документа, содержит последовательность символов, причем длина последовательности ограничена между заданной верхней границей и заданной нижней границей (например, от 129 до 256 символов, включительно). Наличие таких сигнатур в пределах заданного диапазона длины может быть желательным, что позволяет эффективно сравнивать с коллекцией эталонных сигнатур, чтобы идентифицировать блоки текстов, содержащие спам и/или мошенничество, как показано более подробно ниже. В некоторых вариантах осуществления символы, образующие сигнатуру, могут включать в себя, среди прочего, буквенно-цифровые символы, специальные символы и знаки (например, *, /, $ и т.д.). Другие примерные символы, используемые для формирования сигнатур текста, включают в себя цифры или другие символы, используемые в представлении чисел в различных кодировках, таких как, среди прочего, двоичная, шестнадцатеричная и Base64.
[0053] Фиг. 7 иллюстрирует примерную последовательность этапов, выполняемых калькулятором 56 сигнатуры для определения сигнатуры. На этапе 402 калькулятор сигнатуры может выбрать целевой блок текста целевого документа 36 для вычисления сигнатуры. В некоторых вариантах осуществления целевой блок текста может содержать по существу весь контент текста целевого документа 36, например, часть MIME простого текста документа 36. В некоторых вариантах осуществления целевой блок текста может содержать один абзац части текста документа 36. В варианте осуществления, конфигурированном для фильтрования сетевого спама, целевой блок текста может состоять из контентов комментария в блоге или сообщения другого вида (например, сообщение на стене Facebook®, записи в Twitter® и т.д.), которые были отправлены пользователем и предназначены для размещения на соответствующем сайте. В некоторых вариантах осуществления целевой блок текста содержит контенты секции документа HTML, например, секцию, обозначенную тегами DIV или SPAN.
[0054] На этапе 404 калькулятор 56 сигнатуры может разделять целевой блок текста на лексемы текста. На фиг. 8 показана примерная сегментация блока 38 текста на множество лексем текста 60а-с. В некоторых вариантах осуществления лексемы текста представляют собой последовательности знаков/символов, отделенные от других лексем текста любым набором знаков/символов разделителя. Примерные разделители для сценариев на западных языках включают в себя, среди прочего, пробел, разрыв строки, табуляцию, '/г', '\0', точку, запятую, двоеточие, точку с запятой, круглые скобки и/или прямые скобки, обратные и/или прямые слеши, двойные слеши, математические символы, такие как '+', '-', '*' '^', знаки препинания, такие как '!' и '?', а также специальные символы, такие как '$' и '|'. Примерные лексемы на фиг. 8 представляют собой отдельные слова; другие примеры лексем текста могут включать в себя, среди прочего, последовательности нескольких слов, адреса электронной почты и URL-адреса. Чтобы идентифицировать отдельные лексемы блока 38 текста, калькулятор сигнатуры может использовать любой алгоритм токенизации строк, известный в данной области техники. Некоторые варианты осуществления калькулятора 56 сигнатуры могут рассматривать определенные лексемы, например общие слова, такие как "а" и "the" на английском языке, которые непригодны для вычисления сигнатуры. В некоторых вариантах осуществления лексемы, превышающие предварительно определенную максимальную длину, дополнительно разделяются на более короткие лексемы.
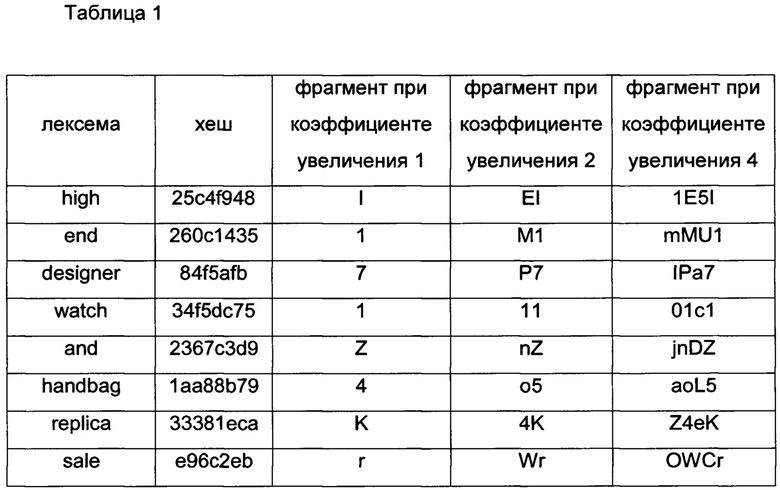
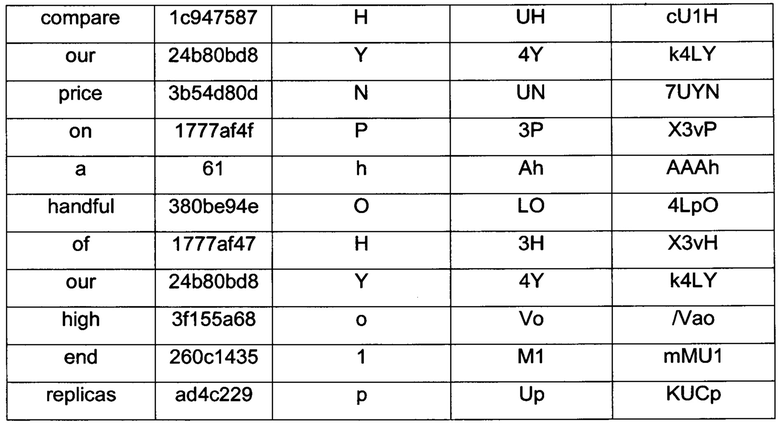
[0055] В некоторых вариантах осуществления длина сигнатур текста, определенных калькулятором 56, ограничена в пределах заданного диапазона (например, от 129 до 256 символов, включительно), независимо от длины или счетчика лексем соответствующего целевого блока текста. Чтобы вычислить такую сигнатуру, на этапе 406 калькулятор 56 сигнатуры может сначала определять счетчик лексем текста целевого блока текста и сравнивать указанный счетчик с предварительно определенным верхним порогом, определенным в соответствии с верхней границей длины сигнатур. Когда счетчик лексем превышает верхний порог (например, 256), на этапе 408 калькулятор 56 может определять увеличенную сигнатуру, как показано детально ниже.
[0056] Когда счетчик лексем меньше верхнего порога, на этапе 410 калькулятор сигнатуры может вычислять хеш каждой лексемы текста. На фиг. 8 показаны примерные хеши 62а-с, определенные соответственно для лексем 60а-с текста. Хеши 62а-с показаны в шестнадцатеричной системе счисления. В некоторых вариантах осуществления такие хеши являются результатом применения хеш-функции к каждой лексеме 60а-с. Многие такие хеш-функции и алгоритмы известны в данной области техники. Наивные алгоритмы хеширования являются быстрыми, однако они, как правило, производят большое количество коллизий (ситуаций, в которых различные лексемы имеют одинаковые хеши). Считается, что более сложные хеши, такие как вычисляемые при помощи алгоритма представления сообщения в кратной форме, сходного с MD5, являются без коллизий, однако они приводят к значительным вычислительным расходам. Некоторые варианты осуществления настоящего изобретения вычисляют хеши 62а-с с использованием хеш-алгоритмов, обеспечивающих компромисс между скоростью вычислений и предотвращением коллизий. Пример такого алгоритма приписывается Robert Sedgewick и он известен в данной области техники как RSHash. Псевдокод RSHash показан ниже:

где а и b обозначают целые числа, например, а=63689 и b=378551.
[0057] Размер (количество битов) хешей 62а-с может влиять на вероятность коллизии и, следовательно, вероятность детекции спама. В целом использование небольшого хеша увеличивает вероятность коллизий. Большие хеши в целом менее уязвимы к коллизиям, но являются более затратными с точки зрения скорости вычислений и памяти. Некоторые варианты осуществления калькулятора 56 сигнатуры вычисляют элементы 62а-с как 30-битные хеши.
[0058] Калькулятор 56 сигнатуры может теперь определять фактическую сигнатуру текста целевого блока текста. Фиг. 8 иллюстрирует примерную сигнатуру 42, определенную для целевого блока 38 текста. Сигнатура 42 текста содержит последовательность символов, определенных в соответствии с хешами 62а-с, определенными на этапе 410. В некоторых вариантах осуществления для каждой лексемы 60а-с калькулятор 56 сигнатуры определяет фрагмент сигнатуры, показанный как элементы 64а-с на фиг. 8. В некоторых вариантах осуществления такие фрагменты затем конкатенируются для получения сигнатуры 42.
[0059] Каждый фрагмент 64а-с сигнатуры может содержать последовательность символов, определенную в соответствии с хешем 62а-с соответствующей лексемы 60а-с. В некоторых вариантах осуществления все фрагменты 64а-с сигнатуры имеют одинаковую длину: в примере на фиг. 8 каждый фрагмент 64а-с состоит из двух символов. Указанная длина фрагментов сигнатуры определяется таким образом, что соответствующая сигнатура имеет длину в пределах требуемого диапазона, например, от 129 до 256 символов. В некоторых вариантах осуществления длину фрагментов сигнатуры называют коэффициентом k увеличения. Например, фрагменты длиной 1 являются фрагментами без увеличения (коэффициент увеличения 1), производящими сигнатуры без увеличения; фрагменты длиной 2 являются фрагментами с двукратным увеличением (коэффициент увеличения 2), производящими сигнатуры с двукратным увеличением, и так далее. На фиг. 9 показано множество сигнатур 42а-с текста, определенных для блока 38 текста при различных коэффициентах k увеличения.
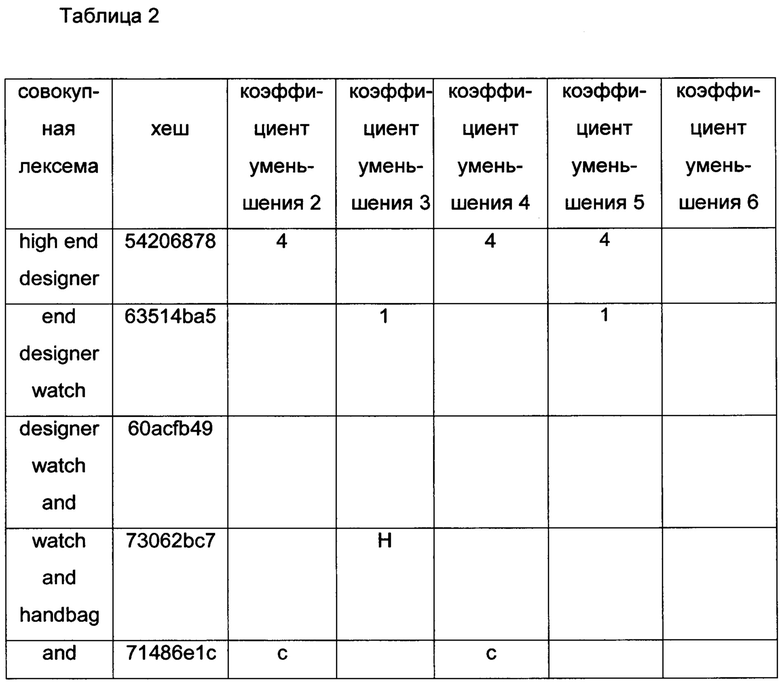
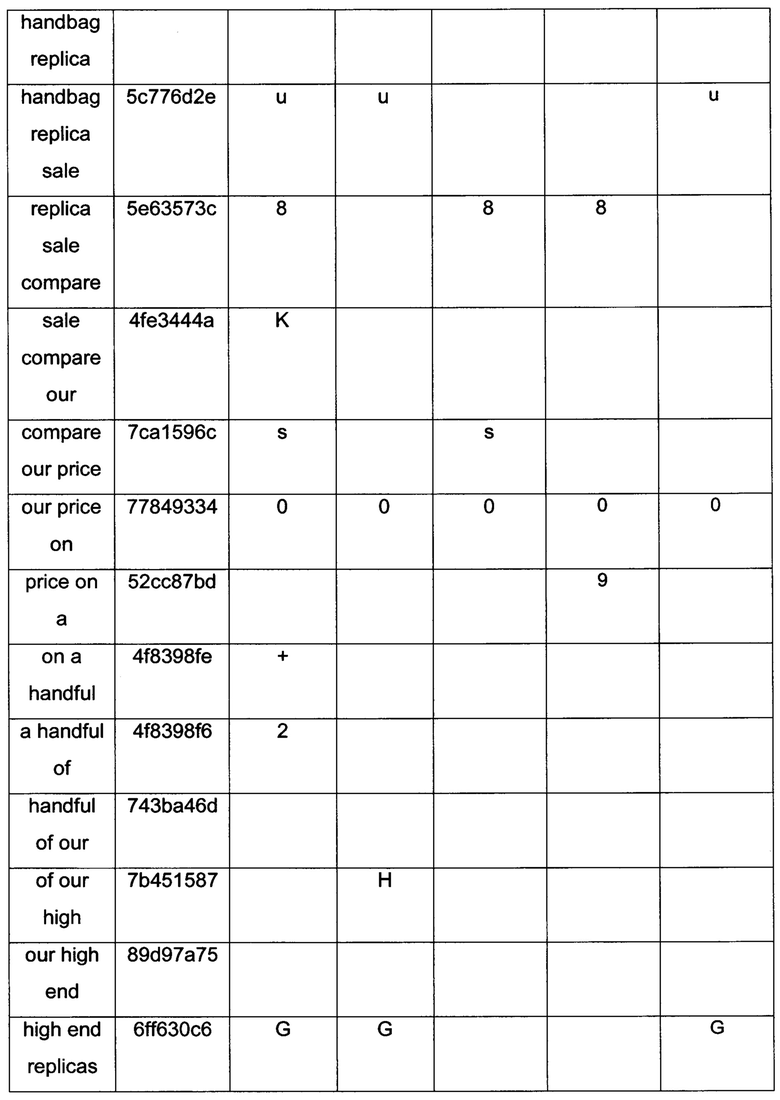
[0060] На этапе 412 (фиг. 7) калькулятор 56 сигнатуры определяет значение коэффициента k увеличения, который производит длину сигнатур в пределах требуемого, предварительно заданного диапазона. Например, когда счетчик лексем больше нижнего порога, определенного в соответствии с нижней границей требуемых длин сигнатур, калькулятор сигнатуры может принять решение вычислить сигнатуру без увеличения (k=1), так как сигнатура без увеличения уже находится в пределах требуемого диапазона длин. Когда блок 38 текста имеет слишком мало лексем, калькулятор сигнатуры может, например, вычислять сигнатуру с двух- или трехкратным увеличением.
[0061] Далее, на этапе 414 калькулятор 56 сигнатуры вычисляет фрагмент сигнатуры для каждой лексемы согласно соответствующему хешу указанной лексемы. Чтобы определить фрагменты 64а-с, калькулятор 56 сигнатуры может использовать любую схему кодирования, известную в данной области техники, такую как двоичное представление или представление Base64 хешей 62а-с. Такие схемы кодирования устанавливают взаимно однозначное преобразование между счетчиком и последовательностью символов из предварительного определенного алфавита. Например, при использовании представления Base64, каждая группа из шести последовательных битов хеша может быть преобразована в символ.
[0062] В некоторых вариантах осуществления множество фрагментов сигнатуры может быть определено для каждого хеша путем изменения количества символов, используемых для представления соответствующего хеша. Для получения фрагмента длиной 1 (например, коэффициент увеличения 1), некоторые варианты осуществления используют только шесть наименьших значащих битов соответствующего хеша. Фрагмент длиной 2 (например, коэффициент увеличения 2) может быть получен с использованием дополнительных шести битов соответствующего хеша и так далее. В представлении Base64 30-битовый хеш может, таким образом, произвести фрагменты сигнатуры длиной до 5 символов, что соответствует коэффициентам увеличения 5. Таблица 1 показывает примерные фрагменты сигнатуры, вычисленные при различных коэффициентах увеличения из примерного блока 38 текста на фиг.9.
[0063] На этапе 416 (фиг. 7), калькулятор 56 сигнатуры собирает сигнатуры 42 текста, например, путем конкатенации фрагментов, вычисленных на этапе 414.
[0064] Возвращаясь к этапу 406, когда было найдено, что счетчик лексем больше верхнего порога, калькулятор 56 сигнатуры определяет уменьшенную сигнатуру соответствующего блока текста. В некоторых вариантах осуществления уменьшение включает в себя вычисление сигнатуры 42 только из подгруппы лексем блока 38 текста. Отбор подгруппы может включать в себя обрезание множества лексем текста, определенных на этапе 404 в соответствии с критерием отбора хеша. Примерная последовательность этапов, выполняющих это вычисление, показана на фиг. 10. Этап 422 выбирает коэффициент уменьшения для вычисления сигнатур. В некоторых вариантах осуществления коэффициент уменьшения, обозначенный как k, указывает на то, что в среднем только 1/k лексем блока 38 текста используются для вычисления сигнатур. Таким образом, калькулятор 56 сигнатуры может выбирать коэффициент уменьшения в соответствии со счетчиком лексем, определенным на этапе 406 (фиг. 7). В некоторых вариантах осуществления начальный отбор коэффициента уменьшения может не произвести сигнатуру в пределах требуемого диапазона длин (см. ниже); в таких случаях этапы 422-430 могут выполняться в цикле, способом проб и ошибок, пока не будет сгенерирована сигнатура соответствующей длины. Например, калькулятор 56 сигнатуры может первоначально выбрать коэффициент уменьшения k=2; когда это значение не в состоянии произвести достаточно короткую сигнатуру, калькулятор 56 может выбрать k=3 и т.д.
[0065] Далее, калькулятор сигнатуры может отобрать лексемы в соответствии с критерием отбора хеша. При уменьшении калькулятор 56 сигнатуры может использовать лексемы, уже определенные на этапе 404 (фиг. 7), или может вычислять новые лексемы из блока 38 текста. В примере, показанном на фиг. 10, на этапе 424 калькулятор 56 сигнатуры определяет набор комплексных лексем блока 38 текста. В некоторых вариантах осуществления комплексные лексемы, показанные как элемент 60d на фиг. 9, определяются путем конкатенации отдельных последовательных лексем. Количество лексем, используемых для формирования комплексных лексем, может варьироваться в зависимости от коэффициента уменьшения.
[0066] На этапе 426 вычисляется хеш для каждой комплексной лексемы, например, с использованием способов, описанных выше. На этапе 428 калькулятор 56 отбирает подгруппу комплексных лексем в соответствии с критерием отбора хеша. В некоторых вариантах осуществления, для коэффициента k уменьшения, этот критерий отбора требует, чтобы все хеши, определенные для членов отобранной подгруппы, были равны по модулю к. Например, чтобы определить сигнатуру с двукратным уменьшением, калькулятор 56 может рассматривать только комплексные лексемы, хеши которых равны по модулю 2 (то есть, только нечетные хеши или только четные хеши). В некоторых вариантах осуществления критерий отбора хеша включает в себя отбор только тех лексем, хеши которых делятся на коэффициент k уменьшения.
[0067] На этапе 430 калькулятор 56 сигнатуры может проверить, находится ли счетчик лексем, отобранных на этапе 428, в пределах требуемого диапазона длин сигнатур. Если нет, калькулятор 56 может вернуться к этапу 422 и перезапуститься с другим коэффициентом k уменьшения. Когда счетчик отобранных лексем находится в пределах диапазона, на этапе 432 калькулятор 56 определяет фрагмент сигнатуры в соответствии с каждым хешем отобранной лексемы. На этапе 434 такие фрагменты собираются для получения сигнатуры 42. Фиг. 9 иллюстрирует ряд сигнатур 42d-h с уменьшением, которые определены для блока 38 текста. В таблице 2 приведены примерные фрагменты сигнатуры, которые определены для того же блока 38 текста на фиг. 9, при различных коэффициентах уменьшения.
[0068] На фиг. 11 показаны примерные компоненты, выполняемые на сервере безопасности (см. также фиг. 1), в соответствии с некоторыми вариантами осуществления настоящего изобретения. Сервер 14 безопасности содержит классификатор 72 документов, соединенный с коммуникационным менеджером 74 и с базой 70 данных сигнатур. Коммуникационный менеджер 74 управляет транзакциями детекции спама/мошенничества при помощи клиентских систем 16а-с, как показано выше в связи с фиг. 4-А-В. В некоторых вариантах осуществления классификатор 72 документов конфигурирован для получения целевого индикатора 40 при помощи коммуникационного менеджера 74 и для определения целевой метки 50, указывающей на классификацию целевого документа 36.
[0069] В некоторых вариантах осуществления классификация целевого документа 36 включает в себя назначение документа 36 категории документов в соответствии со сравнением между сигнатурой текста, определенной для документа 36, и набором эталонных сигнатур, причем каждая сигнатура указывает на категорию документов. Например, классификация документа 36 может включать в себя определение, является ли документ 36 спамовым и/или мошенническим, и определение того, что документ 36 принадлежит субкатегории спама/мошенничества, таких как товарные предложения, фишинг или нигерийское мошенничество. Для классификации документа 36 классификатор 72 документа может использовать любой способ, известный в данной области техники, в сочетании со сравнением сигнатур. Такие способы включают в себя, среди прочего, внесение в черный список и в белый список и алгоритмы сопоставления с образцом. Например, классификатор 72 документов может вычислять множество отдельных показателей, причем каждый показатель указывает на членство документа 36 в категории конкретных документов (например, спам), при этом каждый показатель определяется посредством способа отличающихся классификаций (например, сравнение сигнатур, внесение в черный список и т.д.). Классификатор 72 может затем определять классификацию документа 36 в соответствии с составным показателем, определенным как комбинация отдельных показателей.
[0070] Классификатор 72 документов может дополнительно содержать компаратор 78 сигнатур, как показано на фиг. 12, конфигурированный для классификации целевого документа 36 путем сравнения сигнатуры целевого документа с набором эталонных сигнатур, хранящихся в базе 70 данных. В некоторых вариантах осуществления база 70 данных сигнатур содержит хранилище сигнатур текста, определенных для набора эталонных документов, таких как, среди прочего, сообщения электронной почты, веб-страницы и комментарии веб-сайтов. База 70 данных может содержать сигнатуры спама/мошенничества, а также легитимных документов. Для каждой эталонной сигнатуры база 70 данных может хранить индикатор ассоциации между соответствующей сигнатурой и категорией документов (например, спам).
[0071] В некоторых вариантах осуществления все сигнатуры подгруппы эталонных сигнатур в базе 70 данных имеют длины в пределах заданного диапазона, например, от 129 до 256 символов. Кроме того, указанный диапазон совпадает с диапазоном длин целевых сигнатур, определенных для целевых документов калькулятором 56 сигнатуры (фиг. 6). Такая конфигурация, в которой все эталонные сигнатуры имеют приблизительно одинаковый размер и в которой эталонные сигнатуры имеют длину, приблизительно равную длине целевых сигнатур, может облегчить сравнение между целевыми и эталонными сигнатурами с целью классификации документов.
[0072] Для каждой эталонной сигнатуры некоторые варианты осуществления базы 70 данных могут хранить индикатор длины блока текста, для которого была определена соответствующая сигнатура. Примеры таких индикаторов включают в себя, среди прочего, длину строки соответствующего блока текста, длину фрагмента, используемого в определении соответствующей сигнатуры, и коэффициент увеличения/уменьшения. Хранение индикатора длины блока текста с каждой сигнатурой может облегчить сравнение документов путем обеспечения возможности выборочного извлечения компаратором 78 эталонных сигнатур, которые представляют блоки текста, сходные по длине блоку текста, генерирующему целевую сигнатуру 42.
[0073] Для классификации целевого документа 36 классификатор 72 может получать целевой индикатор 40, извлекать целевую сигнатуру 42 из индикатора 40 и направлять сигнатуру 42 в компаратор 78 сигнатур. Компаратор 78 может взаимодействовать с базой 70 данных, чтобы избирательно извлекать эталонную сигнатуру 82 для сравнения с целевой сигнатурой 42. В некоторых вариантах осуществления компаратор 78 сигнатур может предпочтительно извлекать эталонные сигнатуры, вычисленные для блоков текста с длиной, сходной с длиной целевого блока текста.
[0074] Классификатор 72 документов дополнительно определяет классификацию целевого документа 42 в соответствии со сравнением между целевой сигнатурой 42 и эталонной сигнатурой, выбранной из базы 70 данных. В некоторых вариантах осуществления сравнение включает в себя вычисление показателя сходства, который указывает на степень сходства сигнатур 42 и 82. Такой показатель сходства может быть определен, например, как:

где ƒT и ƒR соответственно обозначают целевую и эталонную сигнатуры d(ƒT, ƒR) обозначает расстояние редактирования, например, расстояние Левенштейна между этими двумя сигнатурами и |ƒT| и |ƒR| соответственно обозначают длину целевой и эталонной сигнатур.
Показатель S может принимать любое значение между 0 и 1, при этом значения, близкие к 1, указывают на высокую степень сходства между двумя сигнатурами. В примерном варианте осуществления говорят, что целевая сигнатура 42 соответствует эталонной сигнатуре 82, когда показатель S превышает заданный порог Т, например 0,9. Когда целевая сигнатура 42 соответствует по меньшей мере одной эталонной сигнатуре из базы 70 данных, классификатор 72 документов может классифицировать целевой документ в соответствии с индикатором категории документов соответствующей эталонной сигнатуры и может формулировать целевую метку 50, чтобы отразить эту классификацию. Например, когда целевая сигнатура 42 соответствует эталонной сигнатуре, определенной для спамового сообщения, целевой документ 36 может быть классифицирован как спам, при этом целевая метка 50 может указывать на классификацию спама.
[0075] Вышеописанные примерные системы и способы обеспечивают возможность детекции незапрашиваемой коммуникации (спама) в электронных системах обмена сообщениями, таких как электронная почта и веб-сайты с участием пользователей, а также детекции мошеннических электронных документов, таких как фишинговые веб-сайты. В некоторых вариантах осуществления сигнатура текста вычисляется для каждого целевого документа, при этом сигнатура содержит последовательность символов, определенных в соответствии с множеством лексем текста соответствующего документа. Сигнатура затем сравнивается с эталонными сигнатурами, определенными для коллекции документов, в том числе спамовых/мошеннических и легитимных документов. Когда целевая сигнатура соответствует эталонной сигнатуре, определенной для спамового/мошеннического сообщения, целевая коммуникация может быть помечена как спам/мошенничество.
[0076] Когда целевая коммуникация положительно идентифицирована как спам/мошенничество, компоненты системы антиспама/антимошенничества могут модифицировать отображение соответствующего документа. Например, некоторые варианты осуществления могут блокировать отображение соответствующего документа (например, не позволять отображение спамовых комментариев на веб-сайте), могут отображать соответствующий документ в отдельном месте (например, в папке спамовой электронной почты в отдельном окне браузера) и/или могут отображать предупреждение.
[0077] В некоторых вариантах осуществления лексемы текста включают в себя отдельные слова или последовательности слов целевого документа, а также адреса электронной почты и/или сетевые адреса, такие как унифицированные указатели ресурсов (URL), включенные в часть текста целевого документа. Некоторые варианты осуществления настоящего изобретения идентифицируют множество таких лексем текста в конечном документе. Хеш вычисляется для каждой лексемы, при этом фрагмент сигнатуры определяется в соответствии с соответствующим хешем. В некоторых вариантах осуществления фрагменты сигнатуры затем собираются посредством, например, конкатенации для получения сигнатуры текста соответствующего документа.
[0078] Некоторые электронные документы, такие как сообщения электронной почты, могут сильно варьироваться по длине. В некоторых стандартных системах антиспама/антимошенничества длина сигнатуры, определенного для таких документов, варьируется соответствующим образом. В отличие от этого, в некоторых вариантах осуществления настоящего изобретения длина сигнатуры текста ограничена в пределах предварительно определенного диапазона длин, например, от 129 до 256 символов, независимо от длины целевого блока текста или документа. Нахождение всех сигнатур текста в предварительно определенных пределах длины может существенно повысить эффективность сравнения между сообщениями.
[0079] Для определения сигнатур в предварительно определенном диапазоне длин некоторые варианты осуществления настоящего изобретения используют способы увеличения и уменьшения. Когда блок текста является относительно коротким, увеличение достигается путем регулировки длины фрагментов сигнатуры для получения сигнатуры необходимой длины. В примерном варианте осуществления каждые 6 бит 30-битового хеша могут быть преобразованы в символ (например, с использованием представления Base64), так что соответствующий хеш может генерировать фрагмент сигнатуры от 1 до 5 символов.
[0080] Для относительно длинных блоков текста некоторые варианты осуществления настоящего изобретения обеспечивают достижение уменьшения путем вычисления сигнатуры из подгруппы лексем, причем подгруппа выбирается в соответствии с критерием отбора хеша. Примерный критерий отбора хеша включает в себя отбор только лексем, хеши которых делятся на целое k, например, 2, 3 или 6. Для данного примера такой отбор приводит в результате к вычислению сигнатуры от приблизительно 1/2, 1/3 или 1/6 доступных лексем, соответственно. В некоторых вариантах осуществления уменьшение может дополнительно содержать применении этого отбора лексем для множества комплексных лексем, причем каждая комплексная лексема содержит конкатенацию нескольких лексем, таких как последовательность слов соответствующего электронного документа.
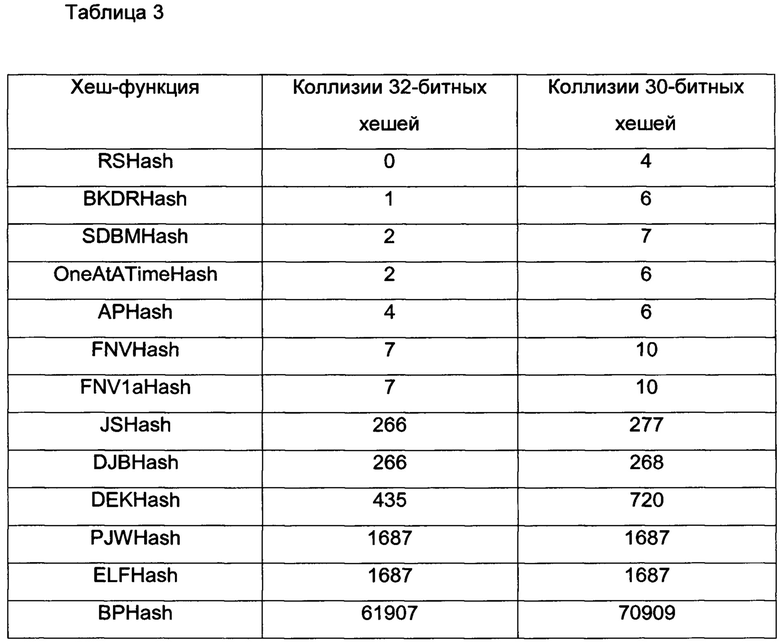
[0081] При определении фрагментов сигнатуры могут использоваться различные хеш-функции. В компьютерном эксперименте различные хеш-функции, известные в данной области техники, применялись к набору из 122000 слов, извлеченных из сообщений электронной почты на различных языках, с целью определения количества коллизий хешей (отличные слова, производящие одинаковые хеши), которые могут генерироваться каждой хеш-функцийе в фактическом спаме. Результаты, приведенные в таблице 3, показывают, что хеш-функция, известная в данной области техники как RSHash, производит наименьшее количество коллизий всех тестируемых хеш-функций.
[0082] В другом компьютерном эксперименте набор сообщений электронной почты, состоящих из общего количества электронной почты, полученной в течение одной недели на корпоративном сервере, и включающих в себя как спам, так и легитимные сообщения, анализировался с использованием некоторых вариантов осуществления настоящего изобретения. Чтобы определить сигнатуры текста длиной от 129 до 256 символов, 20,8% сообщений не требуют уменьшения/увеличения, 18,5% требуют 2-х кратного уменьшения, 8.1% требуют 3-х кратного уменьшения и 8,7% требуют 6-и кратного уменьшения. Из этого же набора сообщений 14,8% требуют 2-х кратного увеличения, 9,7% требуют 4-х кратного увеличения и 11,7% 8-и кратного увеличения. Приведенные выше результаты показывают, что длина сигнатур от 129 до 256 символов может быть оптимальной для детекции спама в электронной почте, так как вышеупомянутое разделение реального потока электронной почты на группы в соответствии с коэффициентом увеличения и/или уменьшения производит относительно равномерно населенные группы. Такая ситуация является предпочтительной для сравнения сигнатур, так как во всех группах может быть произведен поиск за приблизительно равное время.
[0083] В еще одном компьютерном эксперименте непрерывный поток спама, состоящий из приблизительно 865000 сообщений, собранных в течение 15 часов, был разделен на наборы сообщений, каждый из которых состоял из сообщений, полученных в течение отдельного 10-минутного интервала. Каждый набор сообщений был проанализирован с использованием классификатора документов, выполненного в соответствии с некоторыми вариантами осуществления настоящего изобретения (см., например, фиг. 11-12). Для каждого набора сообщений базы 70 данных сигнатур содержала сигнатуры, определенные для спамовых сообщений, принадлежащих к более ранним временным интервалам. Вероятность детекции спама, полученная при помощи уравнения [1] и пороговое значение Т=0,75 показаны на фиг. 13 (сплошная линия) в сравнении с вероятностью детекции спама, полученной с теми же наборами сообщений с использованием обычного способа детекции спама, известного в данной области техники как нечеткое хеширование (пунктирная линия).
[0084] Специалисту в данной области техники очевидно, что вышеупомянутые варианты осуществления могут быть изменены многими способами без отхода от объема настоящего изобретения. Соответственно, объем изобретения должен определяться прилагаемой формулой изобретения и ее законными эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ ОБНАРУЖЕНИЯ СПАМА С ПОМОЩЬЮ СИМВОЛЬНЫХ ГИСТОГРАММ | 2012 |
|
RU2601193C2 |
| СИСТЕМА И СПОСОБЫ ОБНАРУЖЕНИЯ СПАМА С ПОМОЩЬЮ ЧАСТОТНЫХ СПЕКТРОВ СТРОК СИМВОЛОВ | 2012 |
|
RU2601190C2 |
| СОХРАНЯЮЩАЯ КОНФИДЕНЦИАЛЬНОСТЬ СЛУЖБА ДОМЕННЫХ ИМЕН (DNS) | 2021 |
|
RU2837326C2 |
| СИСТЕМА И СПОСОБЫ ДЛЯ ОБНАРУЖЕНИЯ СЕТЕВОГО МОШЕННИЧЕСТВА | 2017 |
|
RU2744671C2 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| СИСТЕМЫ И СПОСОБЫ ДИНАМИЧЕСКОГО АГРЕГИРОВАНИЯ ПОКАЗАТЕЛЕЙ ДЛЯ ОБНАРУЖЕНИЯ СЕТЕВОГО МОШЕННИЧЕСТВА | 2012 |
|
RU2607229C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ СПИСКА ЭЛЕКТРОННЫХ СООБЩЕНИЙ | 2014 |
|
RU2595496C2 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕЗНАЧАЩИХ ЛЕКСИЧЕСКИХ ЕДИНИЦ В ТЕКСТОВОМ СООБЩЕНИИ И КОМПЬЮТЕР | 2014 |
|
RU2580424C1 |
| СПОСОБ И СИСТЕМА ПЕРЕФОРМАТИРОВАНИЯ ЭЛЕКТРОННОГО СООБЩЕНИЯ НА ОСНОВЕ ЕГО КАТЕГОРИИ | 2014 |
|
RU2595618C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФОРМАТИРОВАНИЯ ЭЛЕКТРОННОГО СООБЩЕНИЯ НА ОСНОВЕ ЕГО КАТЕГОРИИ | 2014 |
|
RU2595619C2 |


Изобретение относится к классификации электронных документов для фильтрации незапрашиваемых электронных сообщений (спама) и детекции поддельных сетевых документов. Техническим результатом является увеличение скорости вычислений и уменьшение требуемого объема памяти при определении сигнатуры текста без снижения точности сравнения документов по их сигнатурам. Для определения сигнатуры текста целевого документа, ограниченной предварительно определенными нижней и верхней границами, отбирают множество лексем текста путем отбора предварительного множества лексем текста, определения счетчика предварительного множества лексем и, когда предварительное множество лексем превышает заданный порог, обрезания этого множества для формирования отобранного множества лексем так, чтобы отобранное множество не превышало порога. Определяют размер фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества. Определяют множество фрагментов сигнатуры в соответствии с хешем отдельной лексемы отобранного множества, причем каждый фрагмент содержит последовательность символов, длина которой выбрана равной размеру фрагмента. Выполняют конкатенацию множества фрагментов для формирования сигнатуры текста. 4 н. и 18 з.п. ф-лы, 18 ил., 3 табл.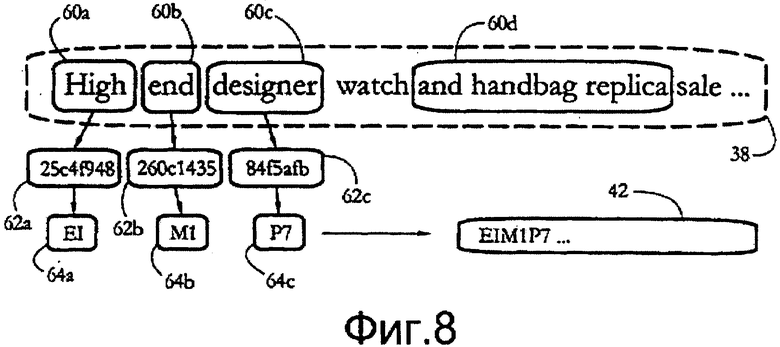
1. Клиентская компьютерная система, содержащая по меньшей мере один процессор, конфигурированный для определения сигнатуры текста целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, причем нижняя и верхняя границы предварительно определены, при этом определение сигнатуры текста содержит:
отбор множества лексем текста целевого электронного документа, при этом отбор множества лексем текста содержит:
отбор предварительного множества лексем текста целевого электронного документа;
определение счетчика предварительного множества лексем текста; и
в ответ, когда счетчик предварительного множества лексем текста превышает заданный порог, обрезание предварительного множества лексем текста для формирования отобранного множества лексем текста так, чтобы счетчик отобранного множества лексем не превышал заданного порога;
в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста;
определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определен в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста, и каждый фрагмент сигнатуры содержит последовательность символов, длина которой выбрана равной размеру фрагмента сигнатуры; и
конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста.
2. Клиентская компьютерная система по п. 1, в которой указанный по меньшей мере один процессор дополнительно конфигурирован для:
отправки сигнатуры текста в серверную компьютерную систему; и
получения от серверной компьютерной системы целевой метки, определенной для целевого электронного документа, причем целевая метка указывает на категорию документов, к которой принадлежит целевой электронный документ, при этом определение целевой метки включает в себя:
извлечение эталонной сигнатуры из базы данных эталонных сигнатур, причем эталонная сигнатура определена для эталонного электронного документа, принадлежащего к указанной категории, и эталонная сигнатура отобрана в соответствии с длиной эталонной сигнатуры так, чтобы длина эталонной сигнатуры была между верхней и нижней границами; и
определение, принадлежит ли целевой электронный документ к указанной категории в соответствии с результатом сравнения сигнатуры текста с эталонной сигнатурой.
3. Клиентская компьютерная система по п. 2, в которой указанная категория документов является категорией спама.
4. Клиентская компьютерная система по п. 2, в которой указанная категория документов является категорией мошеннических документов.
5. Клиентская компьютерная система по п. 1, в которой определение сигнатуры текста дополнительно содержит определение каждого символа последовательности символов в соответствии с отдельной группой битов хеша отдельной лексемы текста.
6. Клиентская компьютерная система по п. 1, в которой обрезание предварительного множества лексем текста содержит отбор целевой лексемы текста предварительного множества лексем текста в отобранное множество лексем текста в соответствии с хешем целевой лексемы текста.
7. Клиентская компьютерная система по п. 1, в которой обрезание предварительного множества лексем текста дополнительно содержит:
определение, делится ли хеш целевой лексемы текста на коэффициент уменьшения; и
в ответ, когда целевая лексема текста делится на коэффициент уменьшения, отбор целевой лексемы текста в отобранное множество лексем текста.
8. Клиентская компьютерная система по п. 1, в которой отбор множества лексем текста дополнительно содержит, когда счетчик предварительного множества лексем текста превышает заданный порог:
определение множества комплексных лексем текста, причем каждая комплексная лексема текста множества комплексных лексем текста содержит конкатенацию набора лексем текста предварительного множества лексем текста; и
отбор комплексной лексемы множества комплексных лексем в отобранное множество лексем текста в соответствии с хешем комплексной лексемы текста.
9. Клиентская компьютерная система по п. 1, в которой целевой электронный документ выбран из группы, включающей в себя сообщение электронной почты и документ языка разметки гипертекста (HTML).
10. Клиентская компьютерная система по п. 1, в которой отдельная лексема текста содержит элемент, отобранный из группы, включающей в себя слово, адрес электронной почты и унифицированный указатель ресурса (URL) целевой электронной коммуникации.
11. Серверная компьютерная система, содержащая по меньшей мере один процессор, конфигурированный для выполнения транзакций с множеством клиентских систем, причем транзакция содержит:
получение сигнатуры текста из клиентской системы множества клиентских систем, при этом сигнатура текста определена для целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, причем нижняя и верхняя границы предварительно определены; и
отправку в клиентскую систему целевой метки, указывающей на категорию документов, к которой принадлежит целевой электронный документ,
при этом определение сигнатуры текста содержит:
отбор множества лексем текста целевого электронного документа, причем отбор множества лексем текста содержит:
отбор предварительного множества лексем текста целевого электронного документа;
определение счетчика предварительного множества лексем текста; и
в ответ, когда счетчик предварительного множества лексем текста превышает заданный порог, обрезание предварительного множества лексем текста для формирования отобранного множества лексем текста так, чтобы счетчик отобранного множества лексем не превышал заданный порог,
в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста;
определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определен в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста, и каждый фрагмент сигнатуры содержит последовательность символов, длина которой выбрана равной размеру фрагмента сигнатуры; и
конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста,
при этом определение целевой метки содержит:
извлечение эталонной сигнатуры из базы данных эталонных сигнатур, причем эталонная сигнатура определена для эталонного электронного документа, принадлежащего к указанной категории, и эталонная сигнатура отобрана в соответствии с длиной эталонной сигнатуры так, чтобы длина эталонной сигнатуры была между верхней и нижней границами; и
определение, принадлежит ли целевой электронный документ к указанной категории в соответствии с результатом сравнения сигнатуры текста с эталонной сигнатурой.
12. Серверная компьютерная система по п. 11, в которой указанная категория документов является категорией спама.
13. Серверная компьютерная система по п. 11, в которой указанная категория документов является категорией мошеннических документов.
14. Серверная компьютерная система по п. 11, в которой определение сигнатуры текста дополнительно содержит определение каждого символа последовательности символов в соответствии с отдельной группой битов хеша отдельной лексемы текста.
15. Серверная компьютерная система по п. 11, в которой обрезание предварительного множества лексем текста содержит отбор целевой лексемы текста предварительного множества лексем текста в отобранное множество лексем текста в соответствии с хешем целевой лексемы текста.
16. Серверная компьютерная система по п. 15, в которой обрезание предварительного множества лексем текста дополнительно содержит:
определение, делится ли хеш целевой лексемы текста на коэффициент уменьшения; и
в ответ, когда целевая лексема текста делится на коэффициент уменьшения, отбор целевой лексемы текста в отобранное множество лексем текста.
17. Серверная компьютерная система по п. 11, в которой отбор множества лексем текста дополнительно содержит, когда счетчик предварительного множества лексем текста превышает заданный порог:
определение множества комплексных лексем текста, причем каждая комплексная лексема текста множества комплексных лексем текста содержит конкатенацию набора лексем текста предварительного множества лексем текста; и
отбор комплексной лексемы множества комплексных лексем в отобранное множество лексем текста в соответствии с хешем комплексной лексемы текста.
18. Серверная компьютерная система по п. 11, в которой целевой электронный документ выбран из группы, включающей в себя сообщение электронной почты и документ языка разметки гипертекста (HTML).
19. Серверная компьютерная система по п. 11, в которой отдельная лексема текста содержит элемент, выбранный из группы, включающей в себя слово, адрес электронной почты и унифицированный указатель ресурса (URL) целевой электронной коммуникации.
20. Способ определения сигнатуры текста целевого электронного документа с использованием по меньшей мере одного процессора клиентской компьютерной системы, в котором длина сигнатуры текста ограничена между нижней границей и верхней границей, причем верхнюю и нижнюю границы определяют предварительно, при этом определение сигнатуры текста содержит:
отбор множества лексем текста целевого электронного документа,
причем отбор множества лексем текста содержит:
отбор предварительного множества лексем текста целевого электронного документа;
определение счетчика предварительного множества лексем текста; и
в ответ, когда счетчик предварительного множества лексем текста превышает заданный порог, обрезание предварительного множества лексем текста для формирования отобранного множества лексем текста так, чтобы счетчик отобранного множества лексем не превышал заданный порог,
в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста;
определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определяют в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста, и каждый фрагмент сигнатуры содержит последовательность символов, длину которой выбирают равной размеру фрагмента сигнатуры; и
конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста.
21. Способ по п. 20, дополнительно содержащий использование указанного по меньшей мере одного процессора для определения категории документов, к которой принадлежит целевой электронный документ, в соответствии с сигнатурой текста.
22. Способ выполнения транзакций с множеством клиентских систем с использованием конфигурированного для этого по меньшей мере одного процессора серверной компьютерной системы, содержащий:
получение сигнатуры текста из клиентской системы множества клиентских систем, причем сигнатуру текста определяют для целевого электронного документа так, чтобы длина сигнатуры текста была ограничена между нижней границей и верхней границей, при этом нижнюю и верхнюю границы определяют предварительно; и
отправление в клиентскую систему целевой метки, определенной для целевого электронного документа, причем целевая метка указывает на категорию документов, к которой принадлежит целевой электронный документ,
при этом определение сигнатуры текста содержит:
отбор множества лексем текста целевого электронного документа,
причем отбор множества лексем текста содержит:
отбор предварительного множества лексем текста целевого электронного документа;
определение счетчика предварительного множества лексем текста; и
в ответ, когда счетчик предварительного множества лексем текста превышает заданный порог, обрезание предварительного множества лексем текста для формирования отобранного множества лексем текста так, чтобы счетчик отобранного множества лексем не превышал заданный порог,
в ответ на отбор множества лексем текста, определение размера фрагмента сигнатуры в соответствии с верхней и нижней границами и в соответствии со счетчиком отобранного множества лексем текста;
определение множества фрагментов сигнатуры, причем каждый фрагмент сигнатуры множества фрагментов сигнатуры определяют в соответствии с хешем отдельной лексемы текста отобранного множества лексем текста, и каждый фрагмент сигнатуры содержит последовательность символов, длину которой выбирают равной размеру фрагмента сигнатуры; и
конкатенацию множества фрагментов сигнатуры для формирования сигнатуры текста,
причем определение целевой метки содержит:
извлечение эталонной сигнатуры из базы данных эталонных сигнатур, при этом эталонную сигнатуру определяют для эталонного электронного документа, принадлежащего к указанной категории, и эталонную сигнатуру выбирают в соответствии с длиной эталонной сигнатуры так, чтобы длина эталонной сигнатуры была между верхней и нижней границами; и
определение, принадлежит ли целевой электронный документ к указанной категории в соответствии с результатом сравнения сигнатуры текста с эталонной сигнатурой.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7730316 B1, 01.06.2010 | |||
| Передвижная обжигательная камера для обжига кирпича | 1949 |
|
SU85247A1 |

