ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[01] Настоящее изобретение относится к иерархическим структурам данных, и, конкретнее - к способу создания иерархической структуры данных.
УРОВЕНЬ ТЕХНИКИ
[02] Различные глобальные или локальные сети связи (Интернет, Всемирная Паутина, локальные сети и подобные им) предлагают пользователю большой объем информации. Информация включает в себя контекстные разделы, такие как, среди прочего, новости и текущие события, карты, информацию о компаниях, финансовую информацию и ресурсы, информацию о траффике, игры и информацию развлекательного характера. Пользователи используют множество клиентских устройств (настольный компьютер, портативный компьютер, ноутбук, смартфон, планшеты и подобные им) для получения доступа к богатому информационному контенту (например, изображениям, аудио- и видеофайлам, анимированным изображениям и прочему мультимедийному контенту подобных сетей).
[03] Одним из популярных сервисов является электронная доска объявлений. Такие доски могут содержать рекламные объявления о продаже автомобилей (новых и б/у), недвижимости (домов, квартир и т.д.) с различными признаками. Например, объявления об автомобилях могут содержать такие признаки как марка, модель, год выпуска и так далее. Объявления о недвижимости могут содержать такие признаки как год строительства, размер объекта или квартиры, количество комнат и так далее.
[04] Пользователи используют подобные доски объявлений для поиска рекламных объявлений, связанных с товарами или услугами, в которых они заинтересованы. Они могут искать рекламные объявления с помощью доступных инструментов: сортировки (по времени добавления, по цене и так далее), с помощью фильтров, которые позволяют им уточнять критерии поиска, и так далее. Фильтры являются полезными инструментам, особенно в тех случаях, когда доски объявлений содержат несколько рекламных объявлений, а пользователь знает параметры искомого объекта.
[05] Каждая категория объявлений на доске объявлений (например, автомобили, недвижимость и прочее) может содержать сотни и тысячи рекламных объявлений, хранящихся в соответствующем хранилище в форме необработанных данных или в форме иерархической структуры данных. Проще хранить информацию в форме необработанных данных, но организованные структуры данных часто обладают преимуществами, особенно на некотором этапе поиска данных, поскольку они предоставляют возможность быстрого поиска.
[06] Специалистам в данной области техники известны несколько подходов к переводу необработанных данных в форму упорядоченной структуры данных. Примерами подобных подходов могут быть: ряды, списки, деревья и графы. Каждая из этих (и других известных) структур обладает соответствующими преимуществам, а также соответствующими ограничениями.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[07] Одним из технических результатов настоящего решения является повышение скорости поиска данных.
[08] Первым объектом настоящего решения является выполняемый на компьютере способ создания иерархической структуры данных. Выполняемый на компьютере способ выполняется на сервере. Выполняемый на компьютере способ включает в себя: определение множества элементов данных для поиска, множество элементов данных обладает набором дескрипторов, и каждый дескриптор в наборе дескрипторов связан с типом данных, отличным от типов данных других дескрипторов в наборе дескрипторов; определение иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла; родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; соответствующий второй дескриптор относится к тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
[09] В некоторых вариантах осуществления способа родительский узел представляет собой первый родительский узел, и определение иерархической структуры данных дополнительно включает определение второго родительского узла для сохранения дескриптора из набора дескрипторов; дескриптор отличается от дескриптора первого родительского узла; оба дескриптора относятся к одному первому типу данных.
[10] В некоторых вариантах осуществления способа определение иерархической структуры данных дополнительно включает в себя определение третьего дочернего узла и четвертого дочернего узла, оба из которых зависят от второго родительского узла; каждый из третьего родительского узла и четвертого родительского узла предназначен для хранения соответствующего дескриптора других элементов данных; соответствующий другой дескриптора относится к тому же второму типу данных.
[11] В некоторых вариантах осуществления способа определение иерархической структуры данных дополнительно включает в себя определение третьего уровня, на котором размещен первый дочерний подузел и второй дочерний подузел, оба из которых зависят от первого дочернего узла; каждый из первого дочернего подузла и второго дочернего подузла предназначен для хранения соответствующего третьего дескриптора, который соответствует одному или несколькими элементам данных; соответствующий третий дескриптор относится к тому же третьему типу данных; третий тип данных отличается от первого и второго типа данных.
[12] В некоторых вариантах осуществления способа определение иерархической структуры данных выполняется в ответ на получение указания на элемент данных из множества элементов данных, причем элемент данных будет индексирован в иерархической структуре данных, элемент данных связан с набором дескрипторов, и набор дескрипторов обладает первым дескриптором и вторым дескриптором.
[13] В некоторых вариантах осуществления способа, в ответ на получение указания на элемент данных, связанный с первым дескриптором, который относится к первому типу данных, определение включает в себя идентификацию родительского узла на первом уровне иерархической структуры данных.
[14] В некоторых вариантах осуществления способа, в ответ на получение указания на элемент данных, связанный со вторым дескриптором, который относится ко второму типу данных, определение включает в себя идентификацию первого дочернего узла на втором уровне иерархической структуры данных.
[15] В некоторых вариантах осуществления способа, элемент данных представляет собой первый элемент данных, и в котором, в ответ на получение указания на второй элемент данных, связанный со вторым дескриптором, который относится ко второй типу данных, второй дескриптор отличается от второго дескриптора первого элемента данных, и определение включает в себя идентификацию второго дочернего узла на втором уровне иерархической структуры данных.
[16] В некоторых вариантах осуществления способа, родительский узел представляет собой первый родительский узел, и в котором, в ответ на получение указания на второй элемент данных, связанный с дескриптором; оба дескриптора относятся к одному типу данных, определение дополнительно включает в себя идентификацию второго родительского узла на первом уровне иерархической структуры данных.
[17] В некоторых вариантах способа, в ответ на получение указания на элемент данных, связанный с первым дескриптором, который относится к первому типу данных, вторым дескриптором, который относится ко второму типу данных, и третьим дескрипторов, который относится к третьему типу данных, определение включает идентификацию первого листового узла, соответствующего первому дочернему узлу; первый листовой узел предназначен для хранения третьего дескриптора.
[18] В некоторых вариантах осуществления способа элемент данных представляет собой первый элемент данных, и в котором, в ответ на получение указания на второй элемент данный, связанный с тем же первым дескриптором и тем же вторым дескриптором, что и первый элемент данных, но другой третий дескриптор того же третьего типа данных, определение дополнительно включает в себя связь второго элемента данных с первым листовым узлом.
[19] В некоторых вариантах осуществления способ включает обновление первого листового узла с помощью статистического снимка третьего дескриптора первого элемента данных, и отличающийся третий дескриптор второго элемента данных.
[20] В некоторых вариантах осуществления способа статистический снимок включает в себя (i) ряд элементов данных, связанных с первым листовым узлом, (ii) указание на минимальное значение одного из третьих дескрипторов первого элемента данных и второго элемента данных и (iii) указание на максимальное значение другого третьего дескриптора первого элемента данных и второго элемента данных.
[21] В некоторых вариантах осуществления способа, в ответ на получение указания на третий элемент данный, связанный с тем же первым дескриптором и тем же вторым дескриптором, что и первый и второй элементы данных, но другой третий дескриптор того же третьего типа данных, определение дополнительно включает в себя связь третьего элемента данных с первым листовым узлом.
[22] В некоторых вариантах способ включает в себя обновление статистического снимка с помощью информации, связанной с третьим элементом данных.
[23] В некоторых вариантах осуществления способа, обновление включает в себя: (i) обновление счетчика с помощью ряда элементов данных, (ii) определение того, необходимо ли обновить указание на минимальное значение и максимальное значение на основе третьего дескриптора третьего элемента данных.
[24] В некоторых вариантах осуществления способа, определение того, необходимо ли обновить указание на минимальное значение и максимальное значение, включает в себя проверку того, попадает ли значение третьего дескриптора в диапазон между минимальным и максимальным значениями.
[25] В некоторых вариантах осуществления способа, в ответ на то, что значение третьего дескриптора находится за пределами диапазона между минимальным и максимальным значениями, изменение соответствующего минимального или максимального значение на значение третьего дескриптора третьего элемента данных.
[26] В некоторых вариантах способа, элемент данных представляет собой первый элемент данных, и в ответ на получение указания на четвертый элемент данных, связанный с тем же первым дескриптором и вторым дескриптором, который относится к типу данных, но отличается от второго дескриптора первого элемента данных, и третьим дескриптором, который относится к тому же третьему типу данных, определение дополнительно включает в себя идентификацию второго листового узла, соответствующего второму дочернему узлу; второй листовой узел предназначен для хранения третьего дескриптора, соответствующего четвертому элементу данных.
[27] Другим объектом является способ поиска данных с помощью иерархической структуры данных. Способ включает получение поискового запроса, обладающего поисковым параметром; поисковый параметр связан с типом данных; обнаружение ветви в иерархической структуре данных; ветвь содержит по меньшей мере один узел, связанный с дескриптором, который относится к тому же типу данных; дескриптор совпадает с поисковым параметром; получение доступа к листовому узлу, обладающему по меньшей мере одним элементов данных, который соответствует по меньшей мере дескриптору; извлечение по меньшей мере одного элемента данных из листового узла.
[28] В некоторых вариантах способа, по меньшей мере один узел является родительским узлом, и в котором ветвь содержит дочерний узел, зависящий от родительского узла, причем дочерний узел соответствует второму дескриптору; и в котором поисковый запрос включает второй параметр, относящийся ко второму типу данных, отличному от первого типа данных; и в котором обнаружение выполняется в ответ на совпадение второго дескриптора со вторым поисковым параметром.
[29] В некоторых вариантах осуществления способа, дочерний узел является первым дочерним узлом, и в котором ветвь дополнительно содержит второй дочерний узел, зависящий от родительского узла, причем второй дочерний узел соответствует третьему дескриптору; и в котором поисковый запрос включает второй параметр, относящийся ко второму типу данных, отличному от первого типа данных; и в котором второй дескриптор совпадает со вторым поисковым параметром, а третий дескриптор не совпадает с поисковым параметром; и обнаружение включает обнаружение ветви, содержащей первый дочерний узел и не содержащей второй дочерний узел.
[30] В некоторых вариантах осуществления способа, поисковый параметр представляет собой первый поисковый параметр, относящийся к первому типу данных, и в котором в ответ на получение указания на поисковый запрос, который обладает первым параметром и вторым параметром, относящимися ко второму типу данных, отличных от первого типа данных, поиск включает в себя: (i) обнаружение второй ветви, содержащей первый родительский узел и второй дочерний узел, который зависит от первого родительского узла; первый родительский узел соответствует первому дескриптору, совпадающему с первым поисковым параметром; второй дочерний узел соответствует второму дескриптору, совпадающему со вторым поисковым параметром; (ii) получение доступа к первому листовому узлу, соответствующему первой ветви; (iii) извлечение по меньшей мере одного элемента данных из второго листового узла, элемент данных соответствует первому дескриптору и второму дескриптору, оба из которых реагируют на поисковый запрос.
[31] В некоторых вариантах осуществления способа, в ответ на получение указания на поисковый запрос, поиск включает в себя извлечение статистического снимка из первого листового узла, включая ряд элементов данных в первом листовом узле, минимальное значение и максимальное значение третьего дескриптора.
[32] В некоторых вариантах осуществления способа, в ответ на получение указания на поисковый запрос, поиск включает в себя извлечение статистического снимка из второго листового узла, включая ряд элементов данных во втором листовом узле, минимальное значение и максимальное значение третьего дескриптора.
[33] В некоторых вариантах осуществления способа, в ответ на получение указания на поисковый запрос, поиск дополнительно включает в себя извлечение статистического снимка из первого листового узла и второго листового узла, включая ряд элементов данных в первом листовом узле и втором листовом узле, минимальное значение и максимальное значение третьего дескриптора в первом листовом узле, минимальное значение и максимальное значение третьего дескриптора во втором узле.
[34] В некоторых вариантах осуществления способ включает общее число элементов данных в первом и втором листовом узлах, минимальное значение третьего дескриптора во всех элементах данных первого и второго листовых узлов, максимальное значение третьего дескриптора во всех элементах данных первого и второго листовых узлов.
[35] Другим объектом является сервер, выполненный с возможностью создавать иерархическую структуру данных. Сервер содержит постоянный носитель информации для хранения машиночитаемых инструкций, выполнение которых сервером позволяет ему осуществлять: определение множества элементов данных для поиска, множество элементов данных обладает набором дескрипторов, и каждый дескриптор в наборе дескрипторов связан с типом данных, отличным от типов данных других дескрипторов в наборе дескрипторов; определение иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла; родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; соответствующий второй дескриптор относится к тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
[36] Еще одним объектом является постоянный машиночитаемый носитель, содержащий инструкции (машиночитаемые коды), выполнение которых сервером позволяет ему осуществлять: определение множества элементов данных для поиска, множество элементов данных обладает набором дескрипторов, и каждый дескриптор в наборе дескрипторов связан с типом данных, отличным от типов данных других дескрипторов в наборе дескрипторов; определение иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла; родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; соответствующий второй дескриптор относится к тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[37] Для лучшего понимания настоящего решения, а также других его аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[38] На Фиг. 1 представлена принципиальная схема, изображающая структуру системы, которая выполнена в соответствии с вариантами осуществления, не ограничивающими объем притязаний.
[39] На Фиг. 2 представлено поисковое приложение, которое выполняется на электронном устройстве, показанном на Фиг. 1, электронное устройство выполнено в соответствии с вариантами осуществления.
[40] На Фиг. 3 представлена схема представления содержимого первого партнерского сообщения, которое передается между компонентами системы, показанной на Фиг. 1.
[41] На Фиг. 4 представлена принципиальная схема, изображающая структуру поисковой системы, которая относится к системе, показанной на Фиг. 1, и выполнена в соответствии с вариантами осуществления решения.
[42] На Фиг. 5 представлена принципиальная схема древовидной структуры данных, расположенной в поисковой системе, которая представлена на Фиг. 4, древовидная структура данных представлена на первом этапе заполнения, структура данных выполнена в соответствии с вариантами осуществления решения.
[43] На Фиг. 6 представлена принципиальная схема древовидной структуры данных, показанной на Фиг. 5, древовидная структура данных представлена на втором этапе заполнения.
[44] На Фиг. 7 представлена принципиальная схема древовидной структуры данных, показанной на Фиг. 5, древовидная структура данных представлена на третьем этапе заполнения.
[45] На Фиг. 8 представлена принципиальная схема древовидной структуры данных, показанной на Фиг. 5, древовидная структура данных представлена на четвертом этапе заполнения.
[46] На Фиг. 9 представлен пример последовательной структуры данных, являющейся примером физической структуры данных, которая может быть использована для реализации дерева данных, показанного на Фиг. 8.
[47] На Фиг. 10 представлена блок-схема способа, выполняемого в соответствии с вариантами осуществления.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[48] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления решения, не ограничивающими объем притязаний. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления. Таким образом, все последующее описание представлено только как описание иллюстративного примера решения. Это описание не предназначено для определения объема или установления границ решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления будут обладать гораздо большей сложностью.
[49] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[50] Варианты электронного устройства 102 конкретно не ограничены, но в качестве примера электронного устройства 102 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104.
[51] В общем случае, целью поискового приложения 104 является предоставление пользователю (не показан) возможности выполнять поиск. Таким образом, поисковое приложение включает в себя интерфейс запроса 105 и интерфейс результатов поиска 106. Основной задачей интерфейса 105 запроса является предоставление возможности пользователю (не показан) вводить свой запрос. Основной задачей интерфейса результатов поиска 106 является предоставление результатов поиска, отвечающих поисковому запросу, который был введен в интерфейс 105 запроса.
[52] Реализация поискового приложения 104 никак конкретно не ограничена. Один из примеров поискового приложения 104 может быть реализован с помощью вызова пользователем веб-сайта, соответствующего поисковой системе, для получения доступа к поисковому приложению 104. Поисковое приложение может быть вызвано путем ввода URL, связанного с поисковой системой Яндекс. Авто™ - www.auto.yandex.ru. Важно иметь в виду, что поисковое приложение 104 может быть вызвано с помощью другой коммерчески доступной или собственной поисковой системы.
[53] В других вариантах осуществления, поисковое приложение 104 может представлять собой браузерное приложение на портативном устройстве (например, беспроводном устройстве связи). Для тех случаев (но не только), когда электронное устройство 102 является портативным устройством, таким как, например, Samsung™ Galaxy™ SIII, электронное устройство может использовать приложение Яндекс браузер. Важно иметь в виду, что любое другое коммерчески доступное или собственное браузерное приложение может быть использовано для реализации вариантов осуществления.
[54] В представленных ниже примерах предполагается, что пользователь (не показан) использует вертикальную поисковую системы Яндекс. Авто для поиска выставленных на продажу автомобилей. Пользователь может ввести поисковый запрос "BMW Х5 2012" с помощью интерфейса 105 запроса. Пользователю предоставляется страница результатов поиска (SERP), снимок экрана с которой представлен на Фиг. 2 как снимок SERP 200. На снимке экрана, представленном на Фиг. 2, пользователю представлено несколько полей, хорошо известных в данной области техники. Среди этих полей есть такие как: вышеупомянутый интерфейс 105 запроса, вышеупомянутый интерфейс 106 результатов поиска, поле 107 заголовка, поле 108 рекламы и интерфейс 109 дескрипторов.
[55] Как было упомянуто, целью интерфейса 105 запроса является предоставление пользователю возможности вводить свой запрос или "поисковую строку" (в данном случае "BMWX5 2012"). Основной целью интерфейса 109 дескрипторов является ввод одного или нескольких дополнительных дескрипторов или параметров автомобилей, которые могут быть использованы как дополнительный поисковый критерий и/или фильтр для сужения результатов поиска, которые в другом случае будут соответствовать поисковому запросу, введенному в интерфейс 105 запроса.
[56] Альтернативно, интерфейс 109 дескрипторов может быть использован вместо интерфейса 105 запроса для ввода поисковых запросов пользователем. Альтернативно или дополнительно, один из интерфейса 105 запроса и интерфейса 109 дескрипторов может быть опущен. Основной задачей интерфейса 106 результатов поиска является предоставление результатов поиска, отвечающих поисковому запросу, который был введен в интерфейс 105 запроса.
[57] В качестве иллюстративного примера страница результатов поиска по запросу SERP 200 содержит поле 107 заголовка с коротким описанием BMW Х5 (т.е. объекта, который соответствует поисковому запросу, введенному в интерфейс 105 запроса). SERP 200 включает в себя поле 108 рекламы, которое содержит множество рекламных объявлений, соответствующих поисковому запросу (т.е. продажа 2012 BMW Х5).
[58] Пользователь может выбирать одно из рекламных объявлений из множества рекламных объявлений в поле 108 рекламы. После выбора пользователем конкретного одного из множества рекламных объявлений, пользователю будет отображаться полное описание конкретного выбранного автомобиля. Излишне говорить, что вышеупомянутое описание SERP 200 (его содержимое и форм-фактор) показано только в качестве примера. SERP 200 в соответствии с различными неограничивающими вариантами осуществления может принимать и другие формы, а информация, представленная на ней, ограничивается соответствием поисковому запросу, введенному в интерфейс 105 запроса и/или дескрипторами, выбранными в поле 109 дескрипторов.
[59] Возвращаясь к описанию Фиг. 1, электронное устройство 102 соединено с сетью 114 передачи данных через линию 112 связи. В некоторых вариантах осуществления, сеть 114 связи может представлять собой Интернет. В других вариантах осуществления, сеть 114 передачи данных может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[60] Реализация линии 112 передачи данных никак конкретно не ограничена, и будет зависеть от того, как именно реализовано электронное устройство. В качестве примера, но не ограничения, в данных вариантах осуществления когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия связи 102 представляет собой беспроводную сеть связи (например, среди прочего, линия связи сети 3G, линия связи сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 102 представляет собой портативный компьютер, линия связи может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
[61] Важно иметь в виду, что варианты осуществления воплощения электронного устройства 102, линии 112 связи и сети 114 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 102, линии связи 112 и сети связи 114. То есть, представленные здесь примеры не ограничивают объем решения.
[62] Также на Фиг. 1 представлен первый партнер 120, второй партнер 122 и третий партнер 124, все они соединены с сетью 114 передачи данных через соответствующую линию передачи данных (отдельно не пронумерована). Следует отметить, что число партнеров, потенциально присутствующих в системе 100, никак конкретно не ограничено. В вышеупомянутом примере предполагается, что каждый из партнеров - первый партнер 120, второй партнер 122 и третий партнер 124 - хочет загрузить соответствующие рекламные объявления, связанные с продажей б/у автомобилей, в хранилище 140 партнерских данных поисковой системы 130, поисковая система 130 также соединена с сетью 114 передачи данных.
[63] В некоторых вариантах осуществления, каждый из партнеров - первый партнер 120, второй партнер 122 и третий партнер 124 - выполнен с возможностью передачи хранилищу 140 партнерских данных соответствующего объявления, содержащего подробности рекламного объявления, причем соответствующее объявление представляет собой первое партнерское объявление 121, второе партнерское объявление 123 и третье партнерское объявление 125. В некоторых вариантах осуществления каждое партнерское объявление - первое партнерское объявление 121, второе 123 и третье партнерское объявление 125 - может быть реализовано на расширяемом языке разметки (XML). В других вариантах осуществления, каждое партнерское объявление - первое партнерское объявление 121, второе партнерское объявление 123 и третье партнерское объявление 125 - может быть реализовано в любом другом подходящем коммерчески доступном или собственном формате.
[64] Содержимое каждого партнерского объявления - первого партнерского объявления 121, второго партнерского объявления 123 и третьего партнерского объявления 125 - никак конкретно не ограничено и, естественно, будет зависеть от типа информации, содержащейся в хранилище 140 партнерских данных. Примеры содержимого первого партнерского объявления 121, второго партнерского объявления 123 и третьего партнерского объявления 125 предоставлены со ссылкой на Фиг. 3, на которой представлено содержимое первого партнерского объявления 121 (только в качестве иллюстрации). Следует отметить, что остальные - второе партнерское объявление 123 и третье партнерское объявление 125 - могут быть выполнены по существу аналогичным (но не обязательно идентичным) образом.
[65] Первое партнерское объявление 121 включает в себя индикатор 302 источника, который обычно указывает на имя источника, отправляющего первое партнерское объявление 121. В этом примере, индикатор 302 источника указывает на первого партнера 120, являющегося источником первого партнерского объявления 121. В некоторых вариантах осуществления, индикатор 302 источника может содержать уникальный идентификатор, связанный с источником партнерского объявления, название компании источника партнерского объявления или Единый Указатель Ресурсов (URL), связанный с расположением конкретного рекламного объявления на конкретном партнерском веб-сайте, с которым связано первое объявление 121.
[66] Первое партнерское объявление 121 дополнительно включает в себя первую рекламную часть 304, вторую рекламную часть 306, третью рекламную часть 308 и N-ную рекламную часть 310. Естественно, число рекламных частей 304, 306, 308, 310, содержащихся в первом партнерском объявлении 118, не ограничивается представленными здесь. Таким образом, можно предположить, что данное первое партнерское объявление 121 может включать в себя один экземпляр первой рекламной части 304 - посвященный, соответственно, только одному рекламному объявлению. С другой стороны, данное первое партнерское объявление 121 может включать в себя множество N рекламных частей 310, каждая из которых представляет соответствующее рекламное объявление. Поэтому можно говорить, что данное первое партнерское объявление 121 может представлять собой одно рекламное объявление или несколько рекламных объявлений.
[67] Содержимое каждой из рекламных частей - первой рекламной части 304, второй рекламной части 306, третьей рекламной части 308 и N-ной рекламной части 310 - будет зависеть, конечно, от природы рекламного объявления. Возвращаясь к используемому примеру, рекламное объявление о продаже б/у автомобилей, каждая из рекламных частей - первая рекламная часть 304, вторая рекламная часть 306, третья рекламная часть 308 и N-ная рекламная часть 310 - будет включать в себя некоторые или все следующие аспекты: (i) год выпуска автомобиля; (ii) марку автомобиля; (iii) модель автомобиля; (iv) цену; (v) изображение или изображения автомобиля; (vi) дополнительную информацию об автомобиле. Естественно, каждая или некоторые из рекламных частей - первой рекламной части 304, второй рекламной части 306, третьей рекламной части 308 и N-ной рекламной части 310 - будут обладать более или менее одинаковой или различной информацией.
[68] Следует отметить, что в рамках вариантов осуществления, представленных выше, первое партнерское объявление 121 связано с одним поставщиком объявлений (например, первым партнером 120). Естественно, возможно, что данное партнерское объявление 121, в других вариантах осуществления, фактически может быть связано с объявлениями от нескольких партнеров. Таким образом, возможно, что данное первое партнерское объявление 121 будет включать несколько индикаторов 302 источника. Например, каждый индикатор 302 источника может быть связан с соответствующей рекламной частью - первой рекламной частью 304, второй рекламной частью 306, третьей рекламной частью 308 и N-ной рекламной частью 310. Даже если первое партнерское объявление 121 связано с одним поставщиком объявлений, оно может содержать несколько индикаторов 302 источника, каждый индикатор 302 источника связан с соответствующей рекламной частью - первой рекламной частью 304, второй рекламной частью 306, третьей рекламной частью 308 и N-ной рекламной частью 310.
[69] Возвращаясь к описанию Фиг. 1, хранилище 140 партнерских объявлений представлено на Фиг. 1 в виде части поисковой системы 130, находящейся под контролем поисковой системы (поискового средства) 150. Объявления от партнеров (т.е. первое партнерское объявление 121, второе партнерское объявление 123 и третье партнерское объявление 125) передаются поисковой системе 130, которая сохраняет их в хранилище 140 партнерских данных. Следует отметить, что процесс получения объявлений от партнеров и сохранения их в хранилище 140 партнерских данных может быть организован различными способами.
[70] Несмотря на то, что в неограничивающем варианте осуществления, представленном на Фиг. 1, хранилище 140 партнерских данных представляет собой единый объект, в других вариантах осуществления, хранилище 140 партнерских данных может быть реализовано в распределенном виде. В качестве примера в других вариантах осуществления, хранилище 140 партнерских данных может быть выполнено в виде множества устройств для хранения данных (не показаны), каждое из множества устройств для хранения данных может быть связано, например, с конкретным партнером и соответствующими партнерскими объявлениями или подгруппой партнеров и соответствующей подгруппой партнерских объявлений.
[71] В некоторых вариантах осуществления хранилище 140 партнерских данных может быть реализовано в виде отдельного кластера серверов (не показаны), который сохраняет объявления в базе данных. Например, кластер может включать один или несколько серверов. База данных может быть реализована в виде единого устройства хранения или в распределенном виде. Серверы кластеры могут получать объявления от партнеров 120, 122, 124 через сеть 114 передачи данных или через поисковую систему 150, что будет описано ниже. В других вариантах осуществления хранилище 140 партнерских данных представляет собой распределенную базу данных, содержащую множество устройств хранения данных (не показаны), причем каждое из множества устройств хранения может быть связано, например, с конкретным партнером.
[72] Следует отметить, что термин «партнерский» в термине «хранилище партнерских данных» или «партнерское объявление» не подразумевает каких-либо особых отношений между источником данных в хранилище 140 партнерских данных и оператором, управляющим поисковой системой 150. В некоторых вариантах, хранилище 140 партнерских данных может хранить данные от нескольких источников, каждый из которых не имеет никаких особых отношений с оператором, управляющим поисковой системой 150. В этих примерах, каждый источник может загружать свои данные в хранилище 140 партнерских данных без вступления в какие-либо деловые отношения с оператором, управляющим поисковой системой 150.
[73] В других вариантах осуществления, хранилище 140 партнерских данных может хранить данные от нескольких источников, причем каждый источник (или, по меньшей мере, некоторые из источников) находится в соглашении с оператором, управляющим поисковой системой 150. То, как именно выглядит структура этого соглашения, никак конкретно не ограничено, и может включать в себя неоплачиваемую подписку на данные от источника, оплачиваемую подписку на данные от источника, подписку в обмен на предоставление рекламных баннеров или даже подписку «обратной оплаты», в рамках которой источник данных получает оплату за загрузку его данных на хранилище 140 партнерских данных.
[74] Кроме того, в некоторых вариантах осуществления, хранилище 140 партнерских данных может принадлежать и/или управляться и/или контролироваться тем же лицом, что и оператор, управляющий поисковой системой 150. В других вариантах осуществления, хранилище 140 партнерских данных может принадлежать и/или управляться и/или контролироваться лицом, отличным от того, которое контролирует оператора поисковой системы 150. В этих примерах, хранилище 140 партнерских данных может принадлежать и/или управляться и/или контролироваться одним из лиц, загружающих данные на поисковую систему 150 (которое будет выступать в качестве агрегатора объявлений от различных источников), либо же третьей стороной, которая будет выступать в качестве агрегатора данных от различных источников.
[75] Данные, размещенные в хранилище 140 партнерских данных могут принимать различные формы. Поэтому содержимое хранилища 140 партнерских данных или партнерские объявления, полученные из него (как будет описано ниже) не должны быть истолкованы как ограничение вариантов осуществления. В некоторых вариантах осуществления, данные, размещенные в хранилище 140 партнерских данных, могут представлять собой рекламные объявления о различных товарах или услугах. В качестве примера и только с иллюстративными целями различных вариантов осуществления, предполагается, что хранилище 140 партнерских данных содержит данные, представляющие собой рекламные объявления о продаже б/у автомобилей. Излишне говорить, что данные, хранящиеся в хранилище 140 партнерских данных, и соответствующие партнерские объявления могут включать в себя новостные ленты, новости фондовых бирж, RSS-каналы и т.п.
[76] Как было упомянуто выше, поисковая система 130 включает в себя вышеупомянутую поисковую систему 150. Важно иметь в виду, что для упрощения нижеследующего описания конфигурация поисковой системы 150 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации поисковой системы 150 и его компонентов, которые могли быть опущены в описании с целью упрощения.
[77] На Фиг. 4 представлена принципиальная схема поисковой системы 150, выполненной в соответствии с вариантами осуществления. Важно иметь в виду, что поисковая система 150 представляет собой описание иллюстративных вариантов осуществления. Таким образом, все последующее описание представлено только как описание иллюстративного примера.
[78] Поисковая система 150 может представлять собой сервер. Альтернативно, поисковая система 150 может быть выполнена в распределенном виде, в котором некоторые или все компоненты поисковой системы 150 могут быть распределены. Например, в варианте осуществления, поисковая система 150 обработки объявлений может представлять сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что поисковая система 150 может представлять собой другое подходящее аппаратное и/или прикладное, и/или системное программное обеспечение или их комбинацию.
[79] В некотором варианте осуществления структура поисковой системы состоит из двух кластеров - кластера 450 индексации и поискового кластера 460. Кластер 450 индексации включает в себя разделитель 451. В общем случае, разделитель 451 выполнен с возможностью содержать базу 453 данных обработанных партнерских объявлений (будет описано ниже), в котором находятся партнерские объявления, получать обновленные партнерские объявления, инициировать индексацию обновленных партнерских объявлений и так далее. С этой целью разделитель 451 имеет доступ к хранилищу 140 партнерских данных.
[80] Кластер 450 индексации включает в себя базу 453 данных обработанных партнерских объявлений. База 453 данных обработанных партнерских объявлений получает обработанные партнерские объявления от разделителя 451 и хранит их, как будет более подробно описано ниже. Кластер 450 индексации дополнительно включает индексатор 455. В общем случае, задачей индексатора 455 является создание индексов на основе обработанных партнерских объявлений, хранящихся в базе данных обработанных партнерских объявлений 453, и обновление индексов на основе обновлений объявлений, полученных от хранилища 140 партнерских данных.
[81] Даже если индексатор 450 изображен как одна физическая единица, в других вариантах осуществления, индексатор 450 может быть реализован в распределенном виде. В этих вариантах осуществления, когда индексатор 450 реализован в распределенном виде, передача информации между разделителем 451 и одним из множества индексаторов 455 может быть реализована путем распределения нагрузки. Другими словами, разделитель 451 может выбирать один из множества доступных индексаторов 455 на основе того, насколько загружен данный индексатор из множества индексаторов 455 по сравнению с другими из множества доступных индексаторов 455.
[82] Далее будет описана функция разделителя 451 в контексте того, как разделитель 451 обрабатывает новые партнерские объявления. Тем не менее, некоторые из описанных процессов, применяемых к новым партнерским объявлениям, могут быть с соответствующими изменениями применены к получению и обработке обновленных партнерских объявлений (будет описано ниже).
[83] Разделитель 451 получает объявление из хранилища 140 партнерских данных (объявление было загружено в хранилище 140 партнерских данных одним или несколькими партнерами - первым партнером 120, вторым партнером 122 или третьим партнером 124). Следует отметить, что в некоторых вариантах осуществления, новое (или обновленное) партнерское объявление, полученное из хранилища 140 партнерских данных может отражать информацию от одного из партнеров - первого партнера 120, второго партнера 122 и третьего партнера 124. В других вариантах осуществления, новое (или обновленное) партнерское объявление, полученное из хранилища 140 партнерских данных может отражать информацию от нескольких партнеров - первого партнера 120, второго партнера 122 и третьего партнера 124.
[84] В некоторых вариантах осуществления, разделитель 451 получает доступ к хранилищу 140 партнерских данных для получения объявления. Получение доступа может осуществляться на периодической или случайной основе, например, каждые 15 минут, каждый час, каждый день, каждую неделю, каждый понедельник, вторник, пятницу данной недели или в любой комбинации из вышеприведенных вариантов. Эти варианты осуществления можно рассматривать как «pull» технологию. В других вариантах осуществления, хранилище 140 партнерских данных может передавать объявление разделителю 451. Передача также может осуществляться на периодической или случайной основе, например, каждые 15 минут, каждый час, каждый день, каждую неделю, каждый понедельник, вторник, пятницу данной недели или в любой комбинации из вышеприведенных вариантов. Эти варианты осуществления можно рассматривать как «push» технологию. Естественно, комбинация обоих подходов также может быть использована.
[85] Как только разделитель 451 получает объявление, разделитель 451 разбирает полученное объявление на множество рекламных объявлений, потенциально содержащихся в нем. С учетом примера первого партнерского объявления 121, разделитель 451 извлекает индикатор 302 источника и разбирает первое партнерское объявление 121 на первое рекламное объявление, содержащее первую рекламную часть 304, второе рекламное объявление, содержащее вторую рекламную часть 306, третье рекламное объявление, содержащее вторую рекламную часть 308; и N-ное рекламное объявление, содержащее N-ную рекламную часть 310.
[86] Разделитель 451 затем выполняет функцию унификации каждого из сгенерированных подобным образом рекламных объявлений. Более конкретно, функцией разделителя 451 является проверка того, чтобы каждое из рекламных объявлений содержало ключевые поля, сформированные одним и тем же образом. Функция унификации может быть особенно полезной в том случае, если формат предоставления партнерских объявлений никак заранее не был определен. Естественно, в тех случаях, когда формат предоставления партнерских объявлений был заранее определен, функция унификации может не выполняться.
[87] Для целей данного примера, представленных ниже, ключевыми полями могут быть «марка», «модель» и «год», связанные с продажей б/у автомобилей. Естественно, в тех вариантах осуществления, где предметом рекламных объявлений является объект другого типа, ключевые поля будут выглядеть иначе. Также следует отметить, что число ключевых полей не ограничено. В общем случае, число и содержимое ключевых полей может быть выбрано таким образом, что ключевые поля идентифицируют предмет рекламного объявления, и позволяют их разделить, как будет описано ниже.
[88] В общем случае, целью индексатора 455 является индексация разделов для создания постоянного индекса, который может быть использован для поиска рекламных объявлений. В некоторых вариантах осуществления, индексатор 455 выполнен с возможностью индексацией разделов независимо друг от друга. В других вариантах осуществления, индексатор 455 выполнен с возможностью параллельной индексации разделов. В других вариантах осуществления, индексатор 455 выполнен с возможностью индексации по меньшей мере некоторых разделов параллельно и независимо друг от друга.
[89] Индексатор 455 может затем выполнять одну или несколько следующих операций. В некоторых вариантах осуществления, индексатор 455 подготавливает данные к индексации. Фактически индексатор 455 может выполнять одну или несколько следующих функций: (i) десериализацию; (ii) унификацию; (iii) проверку раздела на соответствие бизнес-логике; (iv) обработку изображений; (v) подсчет статической релевантности; (vi) кластеризацию рекламных объявлений; (vii) проверку объема кластера и (viii) сериализацию обработанных разделов.
[90] Далее некоторые из этих функций будут описаны более подробно.
[91] Индексатор 455 может выполнять процесс десериализации, сначала конвертируя полученные партнерские объявления из компактного формата, подходящего для передачи по сети, в формат более подходящий для использования, как будет более подробно описано ниже. В некоторых вариантах функция десериализации может быть выполнена разделителем 451 после получения партнерского объявления. Индексатор 455 может дополнительно отдельно выполнять функцию сериализации.
[92] Индексатор 455 может выполнять функцию унификации путем перевода ключевых полей каждого из партнерских полей в унифицированный формат. В рамках представленных вариантов осуществления индексатор 455 получает гарантии в том, что все поля - марка, модель, года - будут записаны в одном формате. С этой целью индексатор 455 может получить доступ к тезаурусу или другим базам данных синонимов. Те партнерские объявления, которые в виде части ключевых полей содержат слова, которые не могут быть унифицированы, могут быть просто проигнорированы индексатором 455. В некоторых вариантах осуществления, функция унификации может быть выполнена разделителем 451 после получения партнерского объявления. Индексатор 455 может отдельно выполнять функцию унификации.
[93] Индексатор 455 выполняет функцию проверки, точнее проверку раздела на соответствие бизнес-логике. В некоторых вариантах осуществления, индексатор 455 нацелен на определение того, не является ли какое-либо из рекламных объявлений, содержащихся в разделах несуществующим, мошенническим или по каким-либо иным причинам не должно быть отображено пользователям, выполняющим этот поиск.
[94] Индексатор 455 может выполнять подсчет статической релевантности с помощью определения того, насколько уместным является данное рекламное объявление в пределах партнерского объявления. Индексатор 455 может использовать многочисленные алгоритмы для определения статической релевантности в зависимости от конкретных деловых нужд. Например, индексатор 455 может определять, сколько раз данный источник партнерских объявлений являлся источником мошеннических или устаревших рекламных объявлений.
[95] Кроме того, индексатор 455 может выполнять кластеризацию данных. В некоторых вариантах осуществления, в качестве этапа выполнения функции кластеризации, индексатор 455 анализирует данные, чтобы проверить их на наличие дубликатов. В общем случае, дубликаты могут появляться в тех случаях, когда одно и то же рекламное объявление было передано дважды (или несколько раз), что может происходить время от времени, когда агрегатор повторно отправляет оригинал рекламного объявления от одного из партнеров - первого партнера 120, второго партнера 122 и третьего партнера 124. Естественно, дубликаты могут возникать и по другим причинам. Если какие-то дубликаты обнаруживаются на этапе выполнения функции кластеризации, индексатор 455 может инициировать удаление дубликатов из базы 453 данных обработанных партнерских объявлений.
[96] Индексатор 455 может выполнять проверку объема кластера, определяя, не превышает ли размер данного раздела средний размер предыдущих разделов. Наконец, индексатор 455 может осуществлять сериализацию обработанных разделов в формат, подходящий для хранения и/или передачи.
[97] Также на Фиг. 4 представлено устройство 457 вспомогательной информации. Устройство 457 вспомогательной информации отвечает за получение, хранение и управление дополнительной информацией, необходимой для управления процессами в поисковой системе 150. Примеры информации, которая может быть получена устройством 457 вспомогательной информации, сохранена на устройстве 457 и может управляться устройством 457 вспомогательной информации, включают в себя (среди прочего): каталоги различных автомобилей, словари для перевода и унификации названий, курсы валют, региональные ценовые схемы и т.п. Естественно, в других вариантах осуществления, когда партнерское объявление не связано с продажей б/у автомобилей, устройство 457 вспомогательной информации может быть выполнено с возможностью получения, хранения и управления информацией другого рода.
[98] После того, как индексатор 455 закончил обработку данных, хранящихся в постоянном хранилище 453, он передает их поисковому кластеру 460 и, точнее, устройству 461 приема индекса поискового кластера 460. Устройство 461 приема индексов отвечает за получение обработанных разделов от индексатора 455 и создание постоянных индексов для возможности проведения поиска. В некоторых вариантах осуществления, устройство 461 приема индексов сначала преобразует полученные разделы в формат поисковых индексов, который может представлять собой, например, формат библиотеки Lucent или любой другой коммерчески доступный или собственный формат.
[99] После преобразования устройство 461 приема индексов создает поисковые индексы для разделов в хранилище 463 индексов. Ненесущий ограничений пример индекса, содержащегося в хранилище 463 индексов, может выглядеть следующим образом:

[100] Устройство 465 управления деревом индексов получает доступ к поисковому индексу в хранилище 463 индексов при создании дерева индексов и сохранении его в хранилище 465 дерева индексов. Алгоритм этого процесса будет описан ниже. Поисковик 467 может запрашивать устройство 465 управления дерева индексов для получения данных из хранилища 465 дерева индексов при выполнении поисков по запросу от внешнего устройства 470.
[101] Поисковый индекс, хранящийся в хранилище 463 индексов, обрабатывается устройством 465 управления деревом индексов. Основной задачей этой обработки является оптимизация поисковых данных в индексе с помощью создания иерархической структуры данных из данных, хранящихся в индексе.
[102] В соответствии с Фиг. 4, устройство 465 управления деревом индексов получает данных из хранилища 463 индексов, создает дерево индексов и сохраняет его в хранилище 465 дерева индексов. Устройство 465 управления деревом индексов может запускать этот процесс периодически, например, каждый час. Периодичность может зависеть от различных факторов, таких как частота обновлений индекса в хранилище 465 дерева индексов, некоторых технических требований и других причин, которые понятны специалистам в данной области техники.
[103] Пример процесса создания индекса для рекламных объявлений автомобилей описан ниже. Каждое рекламное объявление, как показано выше, включает часть или все из следующего: (i) год выпуска автомобиля; (ii) марку автомобиля; (iii) модель автомобиля; (iv) цену; (v) изображение или изображения автомобиля; (vi) дополнительную информацию об автомобиле. Например, элемент данных "автомобиль" может обладать набором дескрипторов: "BMW", "Х5", "2012". Другой возможный набор дескрипторов: "Audi", "А6", "2007". В контексте описания "тип данных" это название сущности, описывающей категорию описания. Таким образом, элемент данных "автомобиль" может обладать дескрипторами таких типов данных как "марка автомобиля", "модель автомобиля", "год выпуска автомобиля".
[104] Также в контексте описания каждый дескриптор в рамках набора дескрипторов для одного элемента данных должен быть связан с конкретным типом данных, которых отличается от типов данных других дескрипторов в рамках этого набора дескрипторов.
[105] В некоторых неограничивающих вариантах осуществления самый простой пример дерева 900 данных представлен на Фиг. 5. В соответствии с вариантом осуществления дерево 900 данных обладает несколькими уровнями, в частности - первым уровнем 950, вторым уровнем 960, третьим уровнем 970 и четвертым уровнем 980. Следует отметить, конкретное число уровней определено числом типов данных.
[106] Процесс создания и построения дерева 900 данных будет описан далее. Каждый уровень дерева 900 данных (первый уровень 950, второй уровень 960, третий уровень 970 и четвертый уровень 980) выполнен с возможностью сохранять элемент типов данных, который отличается от типов данных, хранящихся на других уровнях (первом уровне 950, втором уровне 960, третьем уровне 970 и четвертом уровне 980).
[107] В представленном примере, где дерево данных 900 построено для элементов данных, описывающих автомобиль, который описан с помощью дескрипторов, относящихся к трем типам данных: "марка автомобиля", "модель автомобиля", "год выпуска автомобиля", дерево 900 данных требует трех уровней, связанных с этими типами данных, а также листовой уровень.
[108] Определение типа данных для каждого из уровней дерева 900 данных (первый уровень 950, второй уровень 960, третий уровень 970 и четвертый уровень 980) может выполняться устройством 465 управления деревом индексов либо случайным образом (т.е. в любом порядке марки, модели и года выпуска автомобиля), либо на основе заранее определенной процедуры.
[109] В рамках показанного варианта осуществления, устройство 465 управления деревом индексов обладает: первым уровнем 950 с типом данных "марка автомобиля", вторым уровнем 960 с типом данных "модель автомобиля" и третьим уровнем 970 с типом данных "год выпуска автомобиля". Устройство 465 управления деревом индексов дополнительно связано с четвертым уровнем 980, являющимся листовым узлом в конкретной ветви с статистической информацией.
[110] Следует отметить, что число уровней зависит от числа типов данных, которые далее будут использованы в качестве критерия поиска элементов данных. Все типы данных или только подмножество типов данных, связанных с элементами данных, которые будут сохранены в дереве 900 данных, могут быть выбраны для определения уровней дерева 900 данных (первого уровня 950, второго уровня 960, третьего уровня 970 и четвертого уровня 980).
[111] Например, возможно, что тип данных "год выпуска автомобиля" не будет использован, и число уровней в дереве 900 данных уменьшится до двух. Если по меньшей мере один из элементов данных обладает четвертым дескриптором с типом данных, отличным от типов данных других дескрипторов, к дереву 900 данных может быть добавлен четвертый уровень.
[112] Также следует отметить, что порядок уровней ("марка автомобиля" - "модель автомобиля" - "год выпуска автомобиля"), описанный в вышеупомянутом примере, не является строгим. Любой другой порядок, например, "марка автомобиля" - "год выпуска автомобиля" - "модель автомобиля" или "модель автомобиля" - "год выпуска автомобиля" - "марка автомобиля" или "год выпуска автомобиля" - "модель автомобиля" - "марка автомобиля" или какой-либо другой, может быть использован для определения уровней дерева 900 данных.
[113] Как было упомянуто выше, четвертый уровень 980 создан для листового элемента. В рамках варианта осуществления настоящей технологии, четвертый уровень 980 используется для хранения статистического снимка об элементах данных, хранящихся в конкретной ветви дерева 900 данных.
[114] В некоторых вариантах осуществления статистический снимок может включать в себя дескрипторы с типами данных, которые отличаются от типов данных предыдущих уровней, например, дескрипторы с типом данных "цена автомобиля", минимальные и максимальные значения этих дескрипторов, число элементов данных, содержащихся в данной ветви дерева 900 данных.
[115] В общем случае, статистический снимок может включать в себя различные типы информации, такие как различные дескрипторы, изображения, видеозаписи о соответствующих элементах данных и так далее. В различных неограничивающих вариантах листовой узел четвертого уровня 980 может хранить статистическую информацию. Альтернативно, узел четвертого уровня 980 может хранить указатель на место в устройстве хранения, где может храниться статистическая информация.
[116] На каждом уровне дерева 900 данных содержится по меньшей мере один узел, содержащий элементы того же типа данных, что и другие узлы на этом уровне. В качестве иллюстративного примера, если конкретный уровень из: первого уровня 950, второго уровня 960, третьего уровня 970 и четвертого уровня 980 - связан с типом данных "марка автомобиля", различные узлы на этом уровне могут содержать один из дескрипторов, например: "Audi", "BMW", "Toyota" и так далее.
[117] Узлы в дереве 900 данных могут быть одного из четырех типов: корневые, родительские, дочерние и листовые, которые хорошо известны из теории графов. Если две узла связаны друг с другом, то узел, расположенный на более высоком уровне считается родительским узлом или уровнем, а другой - дочерним узлом или уровнем. Основной целью корневого узла является обозначение базы дерева 900 данных.
[118] Корневой узел содержит по меньшей мере один дочерний узел и не зависит ни от одного родительского узла. С другой стороны, листовой узел связан с наиболее низким уровнем (т.е. четвертым уровнем 980). Листовой узел обладает родительским узлом, но у него отсутствуют дочерние узлы. В рамках вариантов осуществления, листовой узел содержит статистический снимок, связанный с элементами, которые содержатся в ветви, ведущей к листовому узлу (ветвь является набором узлом между корневым узлом и листовым узлом).
[119] Для целей иллюстрации процесса построения дерева 900 данных, будут использованы следующие наборы дескрипторов для элементов данных, которые будут храниться в дереве 900 данных:
[120] Элемент данных 1: "Audi" - "А4" - "2008" - "15000" - "черный"
[121] Элемент данных 2: "Audi" - "А4" - "2008" - "17000" - "синий"
[122] Элемент данных 3: "Audi" - "А6" - "2007" - "22000" - "красный"
[123] Элемент данных 4: "BMW" - "Х5" - "2007" - "25000" - "серый".
[124] В начале процедуры построения (которая может выполняться устройством 465 управления деревом индексов) дерева 900 данных оно не содержит никаких элементов. Первым этапом построения является добавление корня 901 к дереву 900 данных. Как упоминалось выше, корень 901 расположен на верхнем уровне дерева 900 данных, который не связан с каким-либо типом данных. Корень 901 также не связан ни с каким дескриптором.
[125] Далее первый элемент данных с набором дескрипторов "Audi" - "А4" - "2008" - "черный" - "15000" может сохраняться в дереве 900 данных. Результат этого процесса схематически представлен на Фиг. 5. Конкретнее, узел 910 создается на первом уровне 950 дерева 900 данных, который связан с типом данных "марка автомобиля". Дескриптор с типом данных "марка автомобиля" поступает от первого набора дескриптором и сохраняется в узле 910. В данном примере дескриптор "Audi" сохраняется в узле 910.
[126] Узел 911 создается на втором уровне 960 дерева 900 данных, узел 911 связан с типом данных "модель автомобиля". Следовательно, узел 911 связан с родительским узлом 910. Дескриптор с типом данных "модель автомобиля" поступает от первого набора дескрипторов и сохраняется в узле 911. В данном примере дескриптор "А4" сохраняется в узле 911.
[127] Узел 913 создается на третьем уровне 970 дерева 900 данных, узел 913 связан с типом данных "год выпуска автомобиля". Следовательно, узел 913 связан с родительским узлом 911. Дескриптор с типом данных "год выпуска автомобиля" поступает от первого набора дескрипторов и сохраняется в узле 913. В данном примере дескриптор "2008" сохраняется в узле 913.
[128] Следует отметить, что дерево 900 данных связано с тремя уровнями узлов и листовым узлом, связанным с ними. С других вариантах осуществления технологии, где дерево 900 данных связано с большим числом уровней, процесс создания узлов может быть продолжен до n-ного количества дополнительных уровней, потенциально присутствующих в дереве 900 данных. Например, четвертый уровень, связанный с типом данных "цвет автомобиля" может быть добавлен к дереву 900 данных. В этом случае узел "черный" (не представлен) из первого набора дескрипторов будет введен в четвертый уровень (не представлен, и он связан с родительским узлом 913.
[129] Когда все узлы на уровнях дерева 900 данных завершены, лист 915 добавляется на наиболее низкий уровень дерева 900 данных в виде дочернего по отношению к родительскому узлу 913. Лист 915 может быть рассмотрен как лист ветви, созданной от корневого узла 901, узла 910, узла 911 и узла 913.
[130] В соответствии с вариантами осуществления настоящей технологии, лист 915 выполнен с возможностью сохранять статистический снимок для элементов данных, связанный с набором дескрипторов "Audi", "А4", "2008" или, другими словами, хранящихся в ветви, которая соответствует листу 915. Снимок в листе 915 может включать в себя ряд элементов данных, цену автомобиля, указание на минимальное и максимальное значения дескрипторов, которые относятся к одинаковым типам данных. В некоторых вариантах осуществления лист 915 может хранить значения дескрипторов, которые не были добавлены в дерево 900 данных. Например, дескриптор "черный" из набора дескрипторов для первого элемента может быть сохранен в листе 915.
[131] В качестве примера предполагается, что лист 915 хранит три статистических параметра: минимальное и максимальное значения дескриптора "цена автомобиля" и число элементов данных, хранящихся в соответствующей ветви. Из вышеупомянутого описания очевидно, что на этом этапе минимальное и максимальное значения равны "15000", а число элементов данных равно "1".
[132] На Фиг. 5 первая ветвь (созданная от корневого узла 901, узла 910, узла 911, узла 913 и узла 915) была добавлена к дереву 900 данных в результате сохранения первого элемента данных.
[133] Следующим этапом является сохранение второго элемента данных, описанного набором дескрипторов "Audi" - "А4" - "2008" - "черный" - "17000", результат этого процесса представлен на Фиг. 6. Процедура сохранения дополнительных элементов данных (например, второго элемента данных) отличается от сохранения первого элемента, поскольку дерево 900 данных уже содержит некоторые узлы, связанные с дескрипторами из набора. Следовательно, до добавления дескриптора из набора, дочерние элементы по отношению к соответствующему родительскому будут проверены на предмет того, есть ли среди уже созданных узел с тем же дескриптором, который уже был добавлен.
[134] Если такой узел есть, к дереву 900 данных не будет добавлен новый узел. Если же такого ранее созданного узла нет, новый узел будет добавлен в виде дочернего по отношению к соответствующему родительскому узлу.
[135] В соответствии с примером второй элемент данных обладает дескриптором "Audi", относящимся к типу данных "марка автомобиля". Первый уровень 950 дерева 900 данных, связанный с этим типом данных, уже содержит узел 910, зарезервированный под "Audi, который является дочерним узлом корневого узла 901. Соответственно, на первый уровень 950 не будет добавлен новый узел, и процедура переходит ко второму уровню 960.
[136] Второй уровень 960 соответствует типу данных "модель автомобиля". Набор дескрипторов второго элемента содержит дескриптор "А4", относящийся к этому типу данных. Следовательно, процедура проверяет узлы второго уровня 960 на наличие узла с дескриптором "А4". Как видно, дескриптор "А4" был ранее добавлен в виде узла 911. Следовательно, процедура не добавляет никаких дополнительных узлов на второй уровень 960 и переходит к третьему уровню 970.
[137] Третий уровень 970 соответствует типу данных "год выпуска автомобиля" и набор данных второго элемента данных, который обладает дескриптором "2008", относящимся к этому типу данных. Следовательно, процедура проверяет узлы третьего уровня 970 на наличие узла с дескриптором "2008". Как видно, узел 913, связанный с дескриптором "2008", уже существует, и процедура не добавляет дополнительных узлов на третий уровень 970.
[138] Процедура далее обновляет лист 915 и, конкретнее, обновляет статистический снимок, содержащейся в нем. Первыми этапами является обновление счетчика в ряде элементов данных. Обновленный счетчик установлен на "2", и указание на счетчик добавлено к листу 915.
[139] Второй этап в обновлении статистического снимка - определение того, необходимо ли обновить минимальное или максимальное значения. Это определение выполняется на основе значений, которые хранятся в листе 915, и значений нового добавленного элемента. Конкретнее, минимальное и максимальное значения дескриптора поступают от листа 915, этот дескриптор относится к тому же типу данных, что и новый добавленный элемент. Как упоминалось ранее, в данном примере лист 915 содержит минимальное и максимальное значения только одного дескриптора в типе данных "цена автомобиля", и эти значения поступают от листа 915.
[140] Затем значение дескриптора сравнивается с максимальным и минимальным значениями. Если значение дескриптора не входит в диапазон от минимального до максимального значения, то по меньшей мере одно из минимального и максимального значений необходимо обновить. За минимальное значение принимается значение дескриптора, если значение дескриптора ниже минимального значения, хранящегося в листе 915. Если значение дескриптора выше максимального значения, хранящегося в листе 915, за максимальное значение принимается значение дескриптора.
[141] В описанном здесь примере значение дескриптора равно "17000", и оно устанавливается как новое максимальное значение дескриптора, связанного с типом данных "цена автомобиля" (поскольку оно превосходит ранее сохраненный максимум "15000"). Обновленный статистический снимок записан в листе 915.
[142] Далее будет описан процесс добавления третьего элемента данных, описанный набором дескрипторов "Audi" - "А6" - "2007" - "22000" - "черный". Результат обновления представлен со ссылкой на Фиг. 7. Как видно, часть дескрипторов из третьего элемента данных перекрывается набором дескрипторов элементов данных, хранящихся в дереве 900 данных, но только частично.
[143] Третий элемент данных обладает дескриптором "Audi", относящимся к типу данных "марка автомобиля". Процедура сначала проверяет узлы первого уровня 950 на наличие узла "Audi". Как видно, узел 910, связанный с "Audi" существует на первом уровне 950. Следовательно, процедура не добавляет никаких новых узлов на первый уровень 950.
[144] Второй уровень 960 соответствует типу данных "модель автомобиля". Дескриптор "А6", который относится к этому типу данных, поступает из набора дескрипторов. Далее процедура проверяет, содержит ли второй уровень 960 какие-либо узлы, которые связаны с дескриптором "А6". Как видно, дескриптор "А6" является новым, т.е. родительский узел 910 "Audi" не содержит дочернего узла, связанного с дескриптором "А6". Тогда создается узел 912, связанный с дескриптором "А6", на втором уровне 960 в виде дочернего узла для родительского узла 910 "Audi".
[145] Третий уровень 970 связан с типом данных "год выпуска автомобиля", а дескриптор "2007", который относится к тому же типу данных, поступает от набора дескрипторов из третьего элемента. Далее процедура проверяет дочерние узлы родительского узла 912 "А6" на наличие узла, связанного с дескриптором "2007". В общем случае, проверка в данном случае не является обязательной, поскольку родительский узел 912 "А6" только что был создан на втором уровне 960, и, соответственно, еще не содержит никаких дочерних узлов.
[146] Но в некоторых вариантах осуществления эта проверка, тем не менее, может выполняться. Например, построение дерева 900 данных может выполняться в нескольких параллельных процессах, и каждый из них может выполняться независимо от других. Таким образом, два или более параллельных процесса могут пытаться добавить узел (дочерний или родительский) одновременно. В таких условиях, проверка может помочь избежать нежелательного дублирования дочерних узлов.
[147] Таким образом, узел 914 для родительского узла 912 "А6" добавлен на третий уровень 970, как узел, связанный с дескриптором "2007".
[148] Поскольку пока еще нет листа, связанного с родительским узлом 914, лист 916 добавляется к родительскому узлу 914. Лист 916 выполнен с возможностью хранить статистический снимок, связанный с элементами данных, которые соответствуют набору дескрипторов: "Audi", "А6", "2007" или, другими словами, дескрипторам, хранящимся в ветви дерева 900 данных, созданной от корневого узла 901, узла 910, узла 911 и узла 914. Аналогично листу 915, снимок для листа 916 включает в себя ряд элементов данных, указание на минимальное и максимальное значения дескрипторов, которые относятся к одним типам данных.
[149] Лист 916 хранит те же три статистических параметра, что и лист 915% минимальное и максимальное значения дескриптора "цена автомобиля" и число элементов данных. В рамках представленного варианта осуществления технологии на этапе, представленной на Фиг. 7, минимальное и максимальное значения, которые будут сохранены во втором листе, равны "22000", а число элементов данных равно "1".
[150] Процесс сохранения четвертого элемента данных в ряде дескрипторов "BMW" - "Х5" - "2007" - "25000" - "серый" по существу аналогичен добавлению первого элемента данных, который был описан выше. Результат этого процесса схематически представлен на Фиг. 8.
[151] Процедура сначала проверяет первый уровень 950 (связанный с типом данных "марка автомобиля") дерева 900 данных для определения того, содержит ли оно узлы, связанные с дескриптором "BMW". Как видно на Фиг. 8, такого узла нет. Следовательно, процедура добавляет дочерний узел 920 к корню 901 на первом уровне 950 (связанному с типом данных "марка автомобиля"), дочерний узел 920 связан с дескриптором "BMW".
[152] Далее, после создания в процедуре нового узла на первом уровне 950, остальная часто процедуры может быть по существу аналогична описанной ранее по отношению к первому элементу данных (т.е. последовательное создание новых дочерних узлов). Тем не менее, в некоторых вариантах осуществления, поиск дочернего узла "Х5" родительского узла 920 "BMW" может выполняться для проверки того, существует ли узел "Х5". Результат поиска отрицателен, поскольку новый родительский узел 920 "BMW" был только что добавлен на первый уровень 950 и не имеет никаких дочерних узлов. Тем не менее, как упоминалось ранее, подобная проверка может выполняться в некоторых вариантах осуществления (с многопоточными процессами и т.п.).
[153] Следовательно, узел 921, связанный с дескриптором "Х5", добавляется на второй уровень 960. Тот же процесс повторяется для третьего уровня 970, и дочерний узел 923, связанный с дескриптором "2007", добавляется на третий уровень 970.
[154] Далее процедура создает лист 923 на четвертом уровне 980 дерева 900 данных в виде дочернего по отношению к родительскому узлу 925 "2007". В соответствии с вариантами осуществления, лист 925 выполнен с возможностью сохранять статистический снимок для элементов данных, связанный с набором дескрипторов "BMW", "Х5", "2007" или, другими словами, хранящихся в ветви, определенной корнем 901, узлом 920, узлом 921 и узлом 923.
[155] В качестве примера, лист 923 хранит три статистических параметра: минимальное и максимальное значения дескриптора "цена автомобиля" и число элементов данных. Очевидно, что на этом этапе минимальное и максимальное значения равны "25000", а число элементов данных рано "1".
[156] Несмотря на то, что вышеупомянутый процесс построения дерева 900 данных был описан с использованием трех элементов данных, на практике процедура может повторяться большое количество раз для наполнения дерева 900 данных.
[157] Описанное выше построение дерева 900 данных может выполняться после первичного запуска системы. Аналогичная процедура может выполняться в момент обновления дерева 900 данных. Обновление аналогично первому построению дерева 900 данных. Процесс обновления может быть запущен автоматически или вручную. Автоматическое обновление может быть инициировано, например, в ответ на получение указания нового элемента данных. Если, например, новый элемент данных поступает на устройство 461 приема индекса и сохраняется в хранилище 463 индексов, устройство 465 управления деревом индексом может инициировать выполнение процесса обновления. Альтернативно, процесс обновления может быть инициирован накоплением в хранилище 463 индексов заранее определенного числа новых или обновленных объявлений. Автоматический процесс может запускаться в соответствии с расписанием, хранящимся, например, в устройстве 465 управления деревом индексов.
[158] Описание процесса наполнения и обновления дерева 900 данных были описаны, теперь будет описан процесс поиска информации посредством дерева 900 данных.
[159] Этот процесс выполняется в ответ на получение поискового запроса. Как упоминалось ранее, поисковый запрос может быть инициирован пользователем электронного устройства 102 с помощью поискового приложения 104 и передан через сеть 113 передачи данных поисковой системе 130 (см. Фиг. 1).
[160] Поисковый запрос передается поисковику 467 для выполнения поиска в хранилище 465 дерева индексов. Далее будут описаны примеры процесса поиска.
[161] В качестве первого примера предполагается, что поисковик 467 получает поисковый запрос, и этот поисковый запрос поисковик 467 разбивает на ключевые слова "Audi" - "А6" - "2007". Ключевые слова могут быть получены из запроса различными способами, например, при разбиении и последовательном сравнении слов из запроса с заранее определенными шаблонами, описывающими "марку автомобиля", "модель автомобиля" и "год выпуска автомобиля" (важно отметить, что оригинальный поисковый запрос может содержать ряд незначимых параметров: "купить audi а6 новую или б/у", "б/у audi модель а6 купить у официального дилера" и так далее).
[162] Процедура поиска (которая может быть выполнена поисковиком 467) начинается на первом уровне 950, связанном с типом данных "марка автомобиля", и первый дескриптор, связанный с этим типом данных, поступает из множества дескрипторов "Audi" - "Аб" - "2007". В данном примере дескриптор данного типа - "Audi".
[163] Далее процедура поиска проверяет узлы первого уровня 950 на наличие узла, соответствующего дескриптору "Audi". С этой целью поступает первый дескриптор, связанный с первым узлом первого уровня 950, и он сравнивается с дескриптором "Audi". Если результат отрицателен, проверяется следующий узел первого уровня 950. Эта процедура выполняется до тех пор пока не будет найден дескриптор "Audi" или до тех пор пока все узлы первого уровня 950 не будут проверены (и совпадения не будут найдены).
[164] В представленном примере, узел 910 определен как связанный с дескриптором "Audi".
[165] Процедура поиска далее проверяет дочерние узлы узла 910, расположенный на втором уровне 960. Второй уровень 960 связан с типом данных "модель автомобиля", и второй дескриптор, соответствующий этому типу данных, поступает из разобранного на ключевые слова поискового запроса. В данном примере поступает дескриптор "А6". Далее, процедура поиска проверяет, содержится ли дескриптор "А6" в каком-либо дочернем узле второго уровня 960. Поиск по сути аналогичен поиску, описанному со ссылкой на первый уровень 950.
[166] В представленном примере, узел 912 определен как связанный с дескриптором "А6".
[167] Процедура поиска далее проверяет дочерние узлы узла 912, расположенный на третьем уровне 970. Третий уровень 970 связан с типом данных "год выпуска автомобиля", и второй дескриптор, соответствующий этому типу данных, поступает из разобранного на ключевые слова поискового запроса. В данном примере поступает дескриптор "2007". Далее, процедура поиска проверяет, содержится ли дескриптор "2007" в каком-либо дочернем узле третьего уровня 970. Поиск по сути аналогичен поиску, описанному со ссылкой на первый уровень 950 и на второй уровень 960.
[168] В представленном примере, узел 914 определен как связанный с дескриптором "2007".
[169] Как упоминалось ранее, лист в дереве 900 данных выполнен с возможностью сохранять статистический снимок, связанный с элементами данных, которые хранятся в ветви, которой принадлежит лист, в данном случае - в ветви, связанной с дескрипторами "Audi" - "А6" - "2007" (ветвь определяется корнем 901, узлом 910, узлом 912 и узлом 914).
[170] Поисковик 467 далее получает статистический снимок, который в данном случае содержит: (минимальная цена автомобиля)=(максимальная цена автомобиля)=22000 и (число автомобилей)=1. Информация из статистического снимка может быть использована для создания быстрого ответа или превью поискового запроса.
[171] Естественно, поисковый запрос может содержать другие параметры, которые могут учитываться при создании ответа на поисковый запрос. Например, пользователь может ввести запрос "Audi А6 2007 года с ценой не больше 20000" в интерфейс 105 запроса или с помощью графического элемента 210 интерфейса 109 дескрипторов (см. Фиг. 2) для выбора фильтра цены искомого автомобиля.
[172] В данном случае дополнительный дескриптор "цена автомобиля" может быть получен из запроса, и может учитываться при создании ответа на поисковый запрос. Возможны, конечно, несколько сценариев. Например, пользователь может ввести диапазон цен с помощью графического элемента (см. Фиг. 2), что будет означать, что поиск ограничен минимальным и максимальным значениями цены продажи. Если, с другой стороны, было введено только минимальное значение, поиск будет ограничен автомобилями с ценой выше той, которая указана в поисковом запросе. Если только максимальное значение было введено. Поиск будет ограничен автомобилями с ценой продажи ниже той, которая указана в поисковом запросе.
[173] В зависимости от того, как именно пользователь ограничивает диапазон цен для поиска в поисковом запросе, возможны несколько сценариев. Для целей иллюстрации далее представлено несколько примеров:
- (цена автомобиля в поисковом запросе)<(минимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой ниже цены, указанной в поисковом запросе, то нет найденных результатов.
- (цена автомобиля в поисковом запросе)>(максимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой выше цены, указанной в поисковом запросе, то нет найденных результатов.
- (цена автомобиля в поисковом запросе)<(минимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой выше цены, указанной в поисковом запросе, то результатом будут все автомобили, расположенные в соответствующей ветви.
- (цена автомобиля в поисковом запросе)>(максимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой ниже цены, указанной в поисковом запросе, то результатом будут все автомобили, расположенные в соответствующей ветви.
- (минимальная цена автомобиля)<(цена автомобиля в поисковом запросе)<(максимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой ниже цены, указанной в поисковом запросе, то результатом будут все автомобили, расположенные в соответствующей ветви с ценой между "минимальной ценой автомобиля" и "ценой автомобиля".
- (минимальная цена автомобиля)<(цена автомобиля в поисковом запросе)<(максимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой выше цены, указанной в поисковом запросе, то результатом будут все автомобили, расположенные в соответствующей ветви с ценой между "максимальной ценой автомобиля" и "ценой автомобиля".
- (минимальная цена автомобиля)<(цена автомобиля в поисковом запросе)<(максимальная цена автомобиля) и инструкция отобразить результаты поиска с ценой ниже цены, указанной в поисковом запросе, то результатом будут все автомобили, расположенные в соответствующей ветви с ценой между "минимальной ценой автомобиля" и "ценой автомобиля".
[174] Второй пример поиска элементов данных соответствует множеству дескрипторов "Audi" - "2008", извлеченных из другого поискового запроса.
[175] Процедура поиска начинается на первом уровне 950, связанном со вторым типом данных "марка автомобиля". В данном примере процедура поиска получает дескриптор этого типа из поискового запроса - "Audi". Далее процедура поиска проверяет узлы первого уровня 950 на наличие узла, соответствующего дескриптору "Audi". Процесс по сути аналогичен процессу, описанному со ссылкой на первый пример. Таким образом, узел 910 "Audi" был определен.
[176] Второй уровень 960 соответствует типу данных "модель автомобиля". Тем не менее, следует отметить, что поисковые термины, извлеченные из поискового запроса, не содержат дескриптор данного типа. Таким образом, процедура поиска извлекает все дочерние узлы родительского узла 910 "Audi". В данном примере есть два дочерних узла родительского узла 910 "Audi": узел 911 "А4" и узел 912 "А6".
[177] Третий уровень 970 связан с типом данных "год выпуска автомобиля", и третий дескриптор, соответствующий этому типу данных, поступает из разобранного на ключевые слова поискового запроса. В представленном примере дескриптором является "2008". Далее процедура поиска проверяет дочерние узлы родительского узла 911 "А4" и родительского узла 912 "А6". Эта процедура аналогична поиску для узла 914 "2007" из первого примера.
[178] Второй пример дочернего узла 913 "2008" существует только для родительского узла 911 "А4". Следовательно, процедура поиска извлекает лист 915, связанный с узлом 913. Конкретнее, процедура поиска извлекает статистический снимок, содержащийся в листе 915, включая (минимальная цена автомобиля)=15000, (максимальная цена автомобиля)=17000 и (число автомобилей)=2.
[179] Далее предлагается третий пример поиска элементов данных на основе поискового запроса, содержащего "Audi" - "А4" - "А6".
[180] Процесс поиска начинается на первом уровне 950 и процесс по существу аналогичен тем, которые описаны со ссылкой на два предыдущих примера. Таким образом, узел 910 был определен.
[181] Следует напомнить, что второй уровень 960 соответствует типу данных "модель автомобиля". Процедура поиска извлекает дескриптор, связанный с типом данных от разобранного на ключевые слова поискового запроса. В представленном примере есть два дескриптора следующих типов: "А4" и "А6", таким образом процедура поиска выполняет поиск всех дочерних узлов узла 910 для дескрипторов "А4" и "А6". Порядок поиска может отличаться: например, процедура поиска может сначала проводить поиск дескриптора "А4", а затем проводить поиск дескриптора "А6" или наоборот. Альтернативно, процедура поиска может выполнять поиски параллельно.
[182] Поскольку есть два дочерних узла: узел 911 "А4" и узел 912 "А6" - процедура поиска определяет их оба.
[183] Третий уровень 970 соответствует типу данных "год выпуска автомобиля". Важно отметить, что в примере, который здесь описан, в поисковом запросе не указаны никакие границы для дескриптора "год выпуска автомобиля". Следовательно, процедура поиска определяет все дочерние узлы узла 922 и узла 912 (т.е. узел 913 и узел 914 соответственно).
[184] На четвертом уровне 980 процедура поиска извлекает статистическую информацию от листов 915, 916, связанных с узлом 911 и узлом 912 соответственно. Процедура поиска далее объединяет статистическую информацию, содержащуюся в листах 915 и 916. Конкретнее, процедура поиска вычисляет новое минимальное значение и новое максимальное значение, а также обновляет ряд элементов данных. Следовательно, процедура поиска создает объединенную статистическую информацию - новое число элементов данных равно "3", минимальное и максимальные значения "цена автомобиля" равны 15000 и 22000 соответственно.
[185] Четвертый пример поиска элементов данных соответствует множеству, включающему в себя один дескриптор "2007".
[186] Процедура поиска начинается на первом уровне 950, связанном со вторым типом данных "марка автомобиля". В представленном примере нет дескриптора с подобным типом данных в поисковом запросе. Следовательно, процедура поиска определяет все узлы первого уровня 950.
[187] Второй уровень 960 соответствует типу данных "модель автомобиля". Аналогично идентификаторы первого уровня 950, поисковый запрос не содержит идентификатора второго уровня 960. Следовательно, процедура поиска определяет все узлы второго уровня 960.
[188] Третий уровень 970 соответствует типу данных "год выпуска автомобиля". Процедура поиска извлекает дескриптор, связанный с типом данных поискового запроса. В представленном примере процедура поиска определяет дескриптор "2007". Далее процедура поиска проверяет узлы третьего уровня 970 на наличие узла(ов), соответствующего(их) дескриптору "2007".
[189] В представленном примере есть два узла, связанные с дескриптором "2007" -узел 914 для родительского узла 912 "А6" во второй ветви, и узел 923 для родительского узла 921 "Х5" в третьей ветви. Следовательно, процедура поиска определяет листы 916 и 925. Далее, процедура поиска создает объединенную статистическую информацию, аналогичную тому, чтобы было описано выше.
[190] Описанная здесь структура данных может быть выполнена различными способами. При проектировании структуры данных важно учитывать некоторые требования. Одним из требования проектирования подобной структуры является предоставления возможности быстрого поиска. Другим требованием является компактность, поскольку в некоторых вариантах осуществления структура данных может быть передана для поиска различным внешним сервисам, для проведения локального поиска.
[191] Первое требование обычно удовлетворяется с помощью объектно-ориентированных моделей, например, на основе Java или Apache Lucene. В таких моделях каждый узел древовидной структуры 900 является объектом, который хранит дескриптор, ссылки на родительский узел и дочерние узлы, а также дополнительную информацию, например, заголовки, активные поля и так далее. Тем не менее, как правило, подобные модели не удовлетворяют требованию компактности. А с учетом того факта, что древовидная структура может быть достаточно большой, и может включать в себя более 10 миллионов объектов, важность этого требования возрастает.
[192] В некоторых вариантах осуществления, древовидная структура 900 может быть выполнена в виде последовательной записи клеток, содержащих дескрипторы и дополнительную структуру данных для навигации. Запись может выполняться устройством 465 управления деревом индексов. Начальные данные для создания последовательной записи клеток поступают от хранилища 463 индексов. Получение начальных данных и их обновление могут быть инициированы автоматически устройством 465 управления деревом индексов с указанной частотой, например, один раз в час. Фактически такая запись может представлять собой, например, файл или запись в базе данных. Следует отметить, что структура, особенности которой подробно описаны далее, является только одним возможным вариантом осуществления, и другие неограничивающие варианты осуществления также являются возможными.
[193] Со ссылкой на Фиг. 9, на которой представлен пример последовательной структуры данных, описан процесс заполнения последовательной структуры данных. Первая ячейка 1200 связана с корнем 901 и содержит ряд дочерних узлов. В примере корень 901 содержит два дочерних узла (хорошо видно на Фиг. 8), и устройство 465 управления деревом индексов заполняет первую ячейку 1200 значением "2".
[194] Устройство 465 управления деревом индексов далее заполняет вторую ячейку 1201 и третью ячейку 1202 соответствующими дескрипторами из дочерних узлов корня 901. В этом примере тип дескрипторов "марка автомобиля"; число записей (т.е. число дочерних узлов) равно двум, и две ячейки было создано, конкретнее - вторая ячейка 1201 и третья ячейка 1202, в которые добавлены соответственно дескрипторы «Audi» и «BMW». Естественно, порядок записей может быть произвольным (т.е. "Audi" до "BMW" или наоборот). Тем не менее, в представленном примере, вторая ячейка 1201 содержит дескриптор "Audi", а третья ячейка 1202 - "BMW".
[195] Следует отметить, что в некоторых вариантах осуществления строка дескрипторов "Audi" и "BMW" может быть представлена цифровым кодом. В этом сценарии каждая строка дескриптора может быть заранее связана с уникальным цифровым идентификатором. Это усложняет процесс формирования структуры, но, тем не менее, это может быть полезным для уменьшения времени поиска, как известно специалистам в данной области техники, обработка цифровых значений является более быстрой, чем обработка буквенных значений.
[196] Кроме того, использование цифрового идентификатора заданного размера может быть полезным для ускорения вычисления начальной позиции следующей ячейки из структуры в памяти, поскольку смещение от конца одной ячейки к началу другой равно числу байт, занятых идентификатором.
[197] Четвертая ячейка 1203 создана для сохранения номера ячейки, в которой записан номер ячейки, связанной с дочерними узлами родительского узла 910 "Audi". Как будет видно, ячейка является заполненной только в том случае, когда информация о дочерних узлах становится доступна и, таким образом, в момент времени, когда структура создается впервые, четвертая ячейка 1203 может не быть создана и/или заполнена. Пятая ячейка 1204 выполняет аналогичную функцию для дочернего узла "BMW".
[198] В некоторых вариантах осуществления вместо использования чисел, которые позволяют установить отношения между двумя ячейками из памяти, возможно использование ссылок, адресов и других известных приемов. Использование этих способов не ограничивает объем настоящего решения и хорошо известно специалистам в данной области техники. В рамках представленных здесь вариантов осуществления различные ячейки (например, четвертая ячейка 1203) сохраняют ссылки, указывающие на отношение между ячейками, связанными с узлами в дереве 900 данных. В представленном дереве 900 данных (например, на Фиг. 7) подобные отношения обозначены прямыми линиями между соответствующими узлами дерева 900 данных.
[199] В результате применения описанных действий в ячейках 1200-1204, появляются данные об узлах первого уровня, являющихся дочерними узлами корня 901: числа, дескрипторы и ссылки. Следующим этапом является запись данных, относящихся к дочерним узлам родительского узла 910.
[200] Узел 910 связан с дескриптором "Audi". В дереве 900 данных этот узел 910 обладает двумя дочерними узлами - это инициирует создание шестой ячейки 1205. В рамках представленного варианта осуществления, четвертая ячейка 1203 делает отсылку (с помощью ссылки или тому подобного) на шестую ячейку 1205, следовательно, после создания шестой ячейки 1205, это число добавляется к третьей ячейке 1203 (с помощью ссылки или т.п.); в данном случае число - "5".
[201] Следующие две ячейки, седьмая ячейка 1206 и восьмая ячейка 1207 созданы для хранения дескрипторов, связанных с дочерними узлами родительского узла 910 "Audi". В этом примере родительский узел 910 обладает двумя узлами - дочерним узлом 911 и дочерним узлом 912, и созданы две ячейки, в которых соответственно находятся дескрипторы "А4" и "А6".
[202] Девятая ячейка 1208 создана для хранения ссылки на ячейку с дескриптором ячейки, связанным с дочерним узлом родительского узла 911 "А4". На этом этапе такая ячейка еще не была создана, и ссылка на нее будет добавлена позже, после создания такой ячейки. Аналогичная ситуация возникает для десятой ячейки 1209, которая создана для хранения ссылки на ячейку с дескриптором дочернего узла, относящегося к родительскому узлу 912 "А6".
[203] Инициализация соответствующих ячеек с шестой по восьмую 1205-1207, которые созданы для сохранения данных, соответствующих узлам 911 "А4" и 912 "А6" из дерева 900 данных, которые являются дочерними узлами для родительского узла 910 "Audi", приостановлена, и будет завершена после инициализации девятой ячейки 1208 и десятой ячейки 1209. Устройство 465 управления деревом индексов далее начинает запись данных, которые относятся к дочерним узлам узла 911 "А4".
[204] Одиннадцатая ячейка 1210 создана для хранения числа дочерних элементов родительского узла 911 "А4". В этом примере родительский узел 911 обладает только одним дочерним узлом 913, поэтому значение "1" сохранено в одиннадцатой ячейке 1210. Ссылка на одиннадцатую ячейку 1210 включена в девятую ячейку 1208 - следовательно число "10" сохранено в девятой ячейке 1208. Дескриптор дочернего узла 913 "2008" сохранен в двенадцатой ячейке 1211. Тринадцатая ячейка 1212 создана с возможностью сохранять ссылку на список дочерних узлов родительского узла 913, и, поскольку ячейки для таких дочерних узлов еще не созданы, тринадцатая ячейка 1212 пока пуста.
[205] Родительский узел 911 "А4" не содержит каких-либо дополнительных дочерних узлов, и следующим этапом является определение списка дочерних узлов родительского узла 913 "2008" в дереве 900 данных. С этой целью значение сохранено в ячейке 1213. Значение является указание того, что следующая ячейка - пятнадцатая ячейка 1214 создана для сохранения статистического снимка.
[206] Следует отметить, что этот способ указания является лишь одним из многих способов. Заранее определенное цифровое, альфа-цифровое или буквенное значение, также как и другие хорошо известные приемы программирования, могут быть использованы для идентификации списка. Например, обозначение может осуществляться путем указания числа байт, занятых данными ячейки, со знаком минус. Как показано далее, пятнадцатая ячейка 1214 содержит статистический снимок, содержащий три значения: "15000", "17000" и "2". Результатом записи данных, разделенных в ячейке запятой, является формирование строки, содержащей 13 символов: "15000,17000,2". Соответственно, строка занимает объем, равный 13 байтам памяти, и значение "-13" записывается в пятнадцатой ячейке 1214. Число байт, указание на которое хранится в пятнадцатой ячейке 124, может быть далее использовано для перемещения от четырнадцатой ячейки 1213 к шестнадцатой ячейке 1215, поскольку оно представляет смещение в памяти между двумя ячейками.
[207] Далее, номер четырнадцатой ячейки 1213 хранится в тринадцатой ячейке 1212, а в пятнадцатой ячейке 1214 хранится статистический снимок. В данном примере статистический снимок включает в себя минимальное и максимальное значения дескриптора "цена автомобиля" и число элементов, соответствующих набору дескрипторов, связанных с узлами 910, 911 и 913. Пример вычисления этих значений был показан выше, они соответственно представляют собой "15000", "17000" и "2". Эти значения записаны в пятнадцатой ячейке 1214.
[208] Далее важно инициализировать шестнадцатую ячейку 1215, семнадцатую ячейку 1616 и восемнадцатую ячейку 1217 с данными о дочерних узлах родительского узла 912 "А6". В этом примере родительский узел 912 содержит только один дочерний узел, поэтому значение "1" сохранено в шестнадцатой ячейке 1215. После инициализации шестнадцатой ячейки 1215, которая содержит описание дочернего узла родительского узла 912 "А6", его номер может быть сохранен в десятой ячейке 1209; в этом примере число "15". Далее описание узла 914 сохраняется в семнадцатой ячейке 1216, в данном случае дескриптор - "2007". Восемнадцатая ячейка 1217 создана для определения отношений с дочерним узлом родительского узла 914.
[209] Дочерний узел родительского узла 914 является списком, и следующим шагом является создание девятнадцатой ячейки 1218 и заполнение ее значением "-1". Как указано выше, это значение используется как ссылка на список в структуре Фиг. 9. В других вариантах осуществления могут быть использованы другие способы обозначения списка. Ссылка на девятнадцатую ячейку 1218 сохранена в восемнадцатой ячейке 1217, которая заполнена значением "18".
[210] Двадцатая ячейка 1219 предназначена для хранения статистического снимка. Эта ячейка записывает минимальное максимальное значение дескриптора "цена автомобиля" и число элементов, связанных с набором дескрипторов узлов 910, 912, 914: «Audi» - «А6» - «2007». В соответствии с этим примером, эти значения равны "22000", "22000" и "1" соответственно.
[211] Результатом этих этапов является заполнение структуры данных, описывающей первую и вторую ветви дерева 900 данных (точнее, узлы 910-911-913-915 и узлы 910-912-914-917). Дальнейший процесс предназначен для записи данных, связанных с третьей ветвью, которая состоит из узлов 920-921-923-925. Этот процесс по существу аналогичен тому, который описан выше.
[212] Двадцать первая ячейка 1220 выполнена с возможностью хранить дочерние узлы родительского узла 920. В этом примере узел 920 обладает одним дочерним узлом, и поэтому значение "1" сохранено в двадцать первой ячейке 1220. После инициализации, в пятой ячейке 1204 появляется ссылка на эту ячейку - в представленном примере, пятая ячейка 1204 заполнена числом "20".
[213] Двадцать вторая ячейка 1221 выполнена с возможностью хранить дескриптор дочернего узла родительского узла 920; в данном примере значение - "Х5". Наконец, создается двадцать третья ячейка 1222, но она остается пустой, поскольку она должна содержать ссылку на начальную ячейку (которая будет создана далее) с данными о дочерних узлах родительского узла 921.
[214] Двадцать четвертая ячейка 1223 выполнена с возможностью хранить данные, связанные с дочерними узлами родительского узла 921. Как можно понять из дерева 900 данных, значение "1" хранится в двадцать четвертой ячейкой 1223. После инициализации ссылка на эту ссылку, которая является числом "23", сохраняется в двадцать третьей ячейкой 1222. Двадцать пятая 1224 создается для дескриптора "2007", а двадцать шестая ячейка 1225 создается для ссылки на ячейку с данными о дочерних узлах родительского узла 923. Двадцать шестая ячейка 1225 заполняется числом "26" из двадцать седьмой ячейки 1226, которая содержит идентификатор списка "-1".
[215] Двадцать восьмая ячейка 1227 выполнена с возможностью сохранять статистический снимок, связанный с набором дескрипторов узлов 920, 921, 923 - «BMW» - «Х5» - «2007». В соответствии с этим примером, статистический снимок включает в себя значения "25000", "25000" и "1", соответствующие минимальному и максимальному значениям дескриптора "цена автомобиля" и числу элементов.
[216] Процесс создания физической структуры данных, соответствующих дереву 900 данных, теперь завершен. Структура может быть сохранена в хранилище 465 дерева индексов и сохранена для поиска. Процесс нахождения с помощью таким образом заполненной структуры далее будет представлен с примерами.
[217] В первом примере используется запрос содержит дескрипторы "Audi" - "А6" - "2007". Поиск начинается в первой ячейке 1200 структуры, показанной на Фиг. 9. Извлекается значение первой ячейки 1200 - в данном случае это "2". Устройство 465 управления деревом индексов анализирует полученное значение и устанавливает, что две следующие ячейки содержат дескрипторы. В соответствии с вариантом осуществления, типы дескрипторов и их последовательность в структуре заранее определены, и в данном примере первый тип анализируемого дескриптора - "марка автомобиля". Сначала дескриптор этого типа извлекается из запроса, т.е. "Audi", и выполняется поиск по следующим двум ячейкам. Устройство 465 управления деревом индексов обнаруживает, что дескриптор из поискового запроса совпадает с дескриптором, хранящимся во второй ячейке 1201.
[218] После того как было найдено совпадение с дескриптором "Audi", устройство 465 управления деревом индексов обнаруживает ячейки, которые содержат дескрипторы следующего заранее определенного типа, т.е. "модель автомобиля". Устройство 465 управления деревом индексов обнаруживает, что четвертая ячейка 1203 и пятая ячейка 1204 хранят этот тип дескрипторов. На Фиг. 9 видно, что четвертая ячейка 1203 и пятая ячейка 1204 последовательно организованы в рамках структуры, показанной на Фиг. 9, аналогично второй ячейке 1201 и третьей ячейке 1202. Поэтому устройство 465 управления деревом индексов обнаруживает номер четвертой ячейки 1203 при получении номера, хранящегося во второй ячейке 1201 с дескриптором "Audi". Устройство 465 управления деревом индексов далее получается из четвертой ячейки 1203 ссылку "5", которая относится к шестой ячейке 1205, и запрашивает шестую ячейку 1205.
[219] Выполняется поиск следующего дескриптора заранее определенного типа, в этом случае это может быть дескриптор типа "модель автомобиля". Процедура аналогична описанной выше. Значение "2" извлекается из шестой ячейки 1205, оно сообщает устройству 465 управления деревом индексов, что дескрипторы содержатся в двух следующих ячейках - седьмой ячейке 1206 и восьмой ячейке 1207. Дескрипторы извлекаются из седьмой ячейки 1206 и восьмой ячейки 1207. Устройство 465 управления деревом индексов далее сравнивает извлеченные дескрипторы с дескриптором "А6", который был получен из поискового запроса. В данном примере дескриптор "А6" совпадает с дескриптором, хранящимся в восьмой ячейке 1207. Далее устройство 465 управления деревом индексов переходит к десятой ячейке 1209, из которой извлекается ссылка "15".
[220] Шестнадцатая ячейка 1215 (связанная с номером "15") содержит значение "1", означающее, что только одна следующая ячейка в структуре содержит дескриптор, т.е. семнадцатая ячейка 1216. Семнадцатая ячейка 1216 содержит дескриптор типа "год выпуска автомобиля". Дескриптор "2007" извлекается из семнадцатой ячейки 1216 и сравнивается с дескриптором того же типа из полученного запроса. Дескрипторы совпадают друг с другом, поэтому устройство 465 управления деревом индексов переходит к девятнадцатой ячейке 1218.
[221] Значение "-1", извлеченное из девятнадцатой ячейки 1218, означает, что следующая ячейка (т.е. двадцатая ячейка 1219) содержит статистический снимок. Поэтому устройство 465 управления деревом индексов переходит к двадцатой ячейке 1219 и извлекает оттуда минимальное и максимальное значения дескриптора "цена автомобиля" и число элементов, т.е. "22000", "22000" и "1" соответственно. Таким образом, извлекается статистика о запросе "Audi" - "А6" - "2007".
[222] В качестве другого примера предлагается запрос, содержащий единственный дескриптор "Audi". Этап поиска в структуре с дескриптором "Audi" аналогичен первому примеру, представленному выше. Данный вариант осуществления технологии предполагает последовательный переход по ячейкам 1200-1201-1203-1205. Дальнейшие этапы несколько отличаются, поскольку дескриптор типа "модель автомобиля" отсутствует в запросе. Поэтому все дескрипторы данного типа, относящиеся к дескриптору "Audi", будут проанализированы; это дескрипторы, содержащиеся к восьмой ячейке 1207 и девятой ячейке 1208.
[223] Девятая ячейка 1208 содержит дескриптор, связанный с "А6". Процедура получения статистического снимка аналогична описанной раннее и выполняется в результате перехода по цепи ячеек 1207-1209-1215-1216-1217-1218-1219. Следует отметить, что шестнадцатая ячейка 1215 содержит значение "1", поэтому единственный дескриптор типа "год выпуска автомобиля", хранящийся в семнадцатой ячейке 1216, будет проанализирован.
[224] В случае наличия других дескрипторов данного типа устройство 465 управления деревом индексов извлекало бы и их статистические снимки. В результате перехода из двадцатой ячейки 1219 извлекается статистический снимок, относящийся ко всем моделям "Audi А6", выпущенных в 2007, т.е. "22000", "22000" и "1".
[225] Десятая ячейка 1209 содержит дескриптор, связанный с "А4". В соответствии с той же логикой, что была показана ранее для перехода между ячейками в структуре, представленной на Фиг. 9, устройство 465 управления деревом индексов переходит по цепи ячеек 1206-1208-1210-1211-1212-1213-1214 для получения статистического снимка. В результате анализ будет получен статистический снимок из пятнадцатой ячейки 1214, содержащий "15000", "17000" и "2".
[226] Статистические снимки, полученные от двадцатой ячейки 1219 и пятнадцатой ячейки 1214 объединяются. Действие может быть выполнено, например, с помощью модуля устройства 465 управления деревом индексов. Объединение включает в себя вычисление минимального и максимального значений дескрипторов - в данном случае "цена автомобиля" - а также вычисление суммы числа элементов в этих ячейках.
[227] Очевидно, результатом объединения для данного запроса является минимальное значение "15000", максимальное значение "22000" и число элементов, равное "3".
[228] В качестве третьего примера используется запрос "Audi" - "2008", содержащий два дескриптора. Поиск начинается на первой ячейке 1200 и он не отличается от первого примера с дескриптором "Audi". Переход по цепи ячеек 1200-1201-1203-1205 выполняется в результате поиска данного дескриптора.
[229] Дескриптор типа "модель автомобиля" не присутствует в запросе, поэтому необходимо анализировать все дескрипторы, связанные с дескриптором "Audi", которые расположены в ячейках 1206-1207. Выполняется переход от седьмой ячейки 1206, содержащей дескриптор "А4", к девятой ячейке 1208, содержащей ссылку на одиннадцатую ячейку 1210.
[230] В одиннадцатой ячейке 1210 хранится значение "1", указывающее устройству 465 управления деревом индексов анализировать единственный дескриптор типа "год выпуска автомобиля" в следующей ячейке. Этот дескриптор поступает из двенадцатой ячейки 1211 и сравнивается с дескриптором "2008", извлеченным из поискового запроса. Поскольку дескрипторы совпадают, выполняется переход к следующей ячейке, конкретно - к тринадцатой ячейке 1212, содержащей ссылку на четырнадцатую ячейку 1213, и далее к пятнадцатой ячейке 1214, из которой извлекается статистический снимок.
[231] Далее, выполняется переход от восьмой ячейки 1207, содержащей дескриптор "А6", к десятой ячейке 1209, содержащей ссылку на шестнадцатую ячейку 1215. Значение "1" извлекается из шестнадцатой ячейки 1215, которое указывает устройству 465 управления деревом индексов, что только один дескриптор типа "год выпуска автомобиля" содержится в следующей ячейке. Дескриптор "2007" извлекается из семнадцатой ячейки 1216 и сравнивается с дескриптором "2008" из запроса. Поскольку дескрипторы не совпадают, процесс поиска статистического снимка элементов, удовлетворяющих набору дескрипторов «Audi» - «А6» - «2008», прерывается.
[232] Таким образом, результаты поиска для "Audi" - "2008" содержат значения "15000", "17000" и "2".
[233] Естественно, структура, показанная на Фиг. 9, позволяет обрабатывать и более сложные запросы, например, минимальная цена для всех автомобилей марок "Audi" и "BMW", выпущенных в 2007 году. Обработка такого запроса включает в себя получение статистического снимка из набора дескрипторов «Audi» - «BMW» - «2007».
[234] Сначала дескрипторы, которые сравниваются с дескрипторами запроса типа "марка автомобиля", извлекаются из второй ячейки 1201 и третьей ячейки 1202. Запрос содержит дескрипторы "Audi" и "BMW", оба они есть в структуре. Статистические снимки для элементов, содержащих дескрипторы «Audi» - «2007» поступают из двадцатой ячейки 1219 в результате последовательных переходов по цепи ячеек 1200-1201-1203-1205-1207-1209-1215-1216-1217-1218-1219. Статистические снимки для элементов, содержащих дескрипторы «BMW» - «2007» поступают из двадцать восьмой ячейки 1227 в результате последовательных переходов по цепи ячеек 1200-1202-1204-1220-1221 -1222-1223-1224-1225-1226-1227.
[235] Естественно, структура, представленная на Фиг. 9, требует обновления при появлении новой доступной информации (аналогично тому, что было описано выше). Например, добавление элемента с дескрипторами «Audi» - «А4» - «2008» - "18000" изменит максимальное значение цены на "18000", а число элементов на "3" в пятнадцатой ячейке 1214.
[236] Аналогичным образом, добавление элемента с дескрипторами «Audi» - «А4» - «2008» - "14000" изменит минимальное значение цены на "14000", а число элементов на "3" в пятнадцатой ячейке 1214.
[237] В случае добавления элементов, связанных с дескрипторами, которые не были ранее записаны в структуре, представленной на Фиг. 9, новые ячейки могут быть созданы в дополнение к существующим или же они могут перезаписывать существующие ячейки. Устройство 465 управления деревом индексов получает индекс из хранилища 463 индексов, и создает структуру, показанную на Фиг. 9, как было описано выше. Во время создания текущая структура, хранящаяся в хранилище 465 дерева индексов, используется для выполнения поиска. После окончания процесса создания, новая структура начинает использоваться для поиска, а старая удаляется.
[238] С учетом вышеупомянутой архитектуры, возможно выполнить исполняемый на компьютере способ создания иерархической структуры данных. На Фиг. 10 представлена блок-схема способа 2000, который выполняется в соответствии с не ограничивающими вариантами осуществления решения. Способ 2000 может быть выполнен с помощью устройства 465 управления деревом индексов (сервера).
[239] Этап 2002 - определение множества искомых элементов данных, множество элементов данных содержит набор дескрипторов, каждый из которых связан с типом данных, отличных от типов данных других дескрипторов в наборе дескрипторов
[240] Способ 2000 начинается на этапе 2002, на котором устройство 465 управления деревом индексов определяет множество искомых элементов данных, множество элементов данных содержит набор дескрипторов, каждый из которых связан с типом данных, отличных от типов данных других дескрипторов в наборе дескрипторов.
[241] Этап 2004 - определение иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла: родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; соответствующий второй дескриптор относится к тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
[242] Далее способ 2000 переходит к этапу 2004, на котором устройство 465 управления деревом индексов определяет иерархическую структуру данных, обладающую первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла: родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; соответствующий второй дескриптор относится к тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
[243] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления. Например, варианты осуществления могут быть выполнены с проявлением других технических результатов.
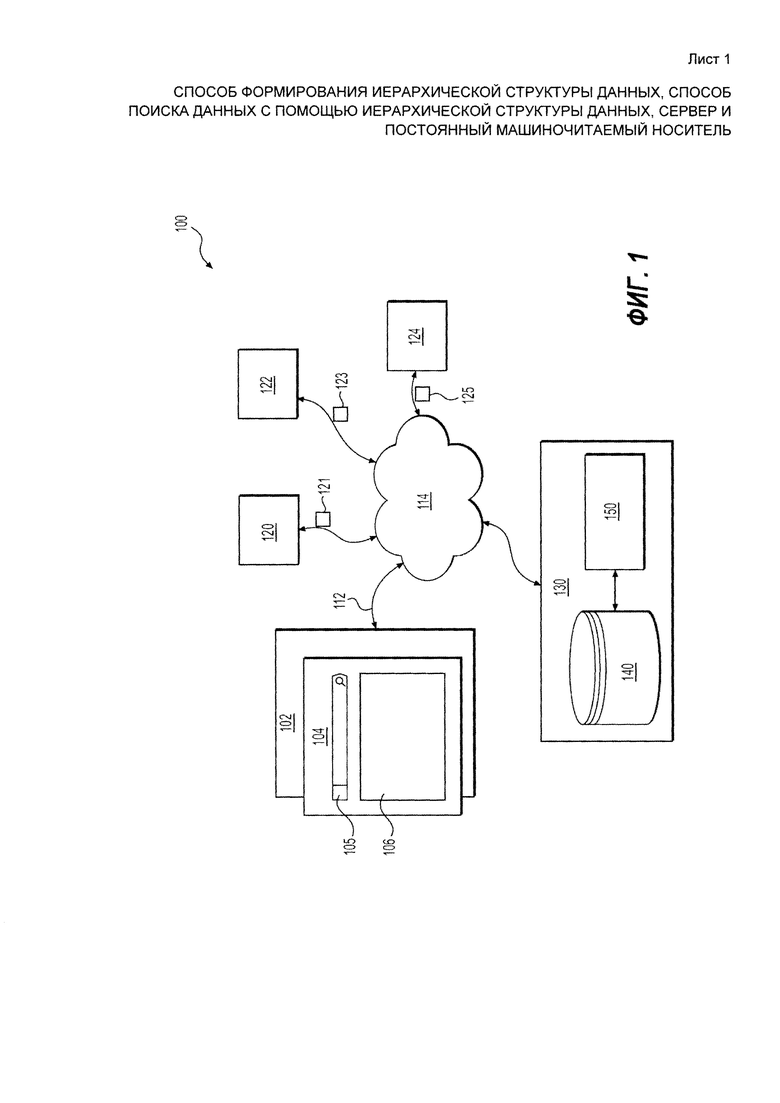
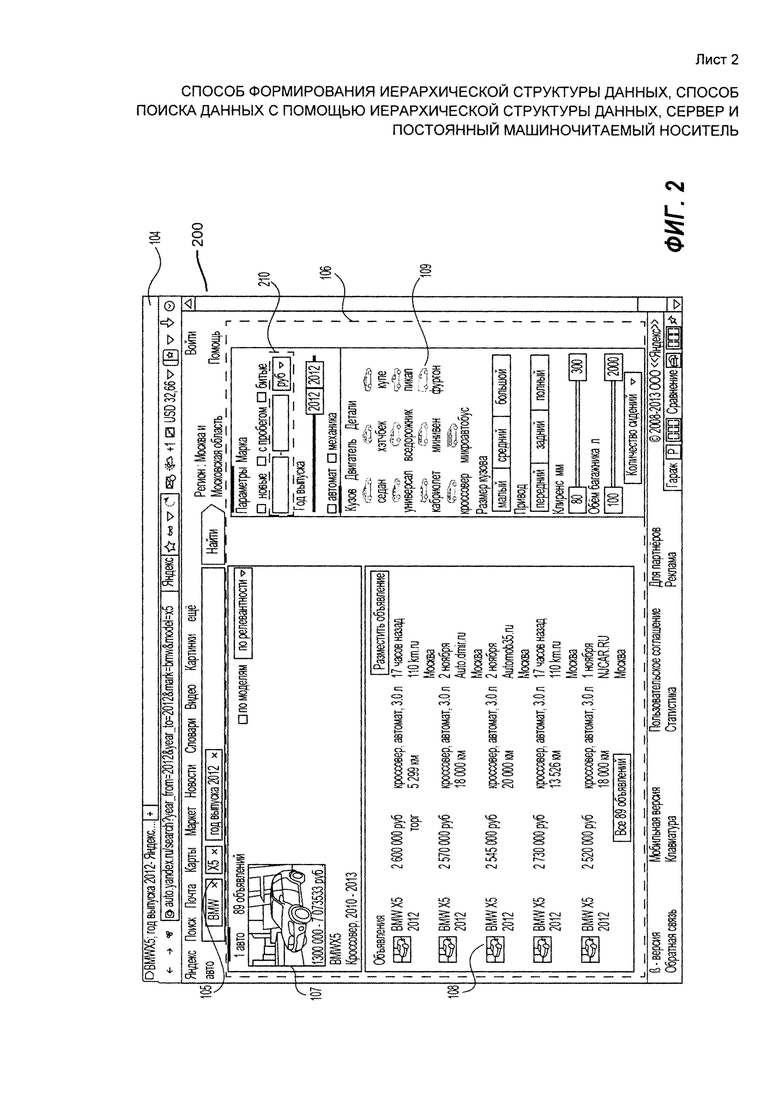

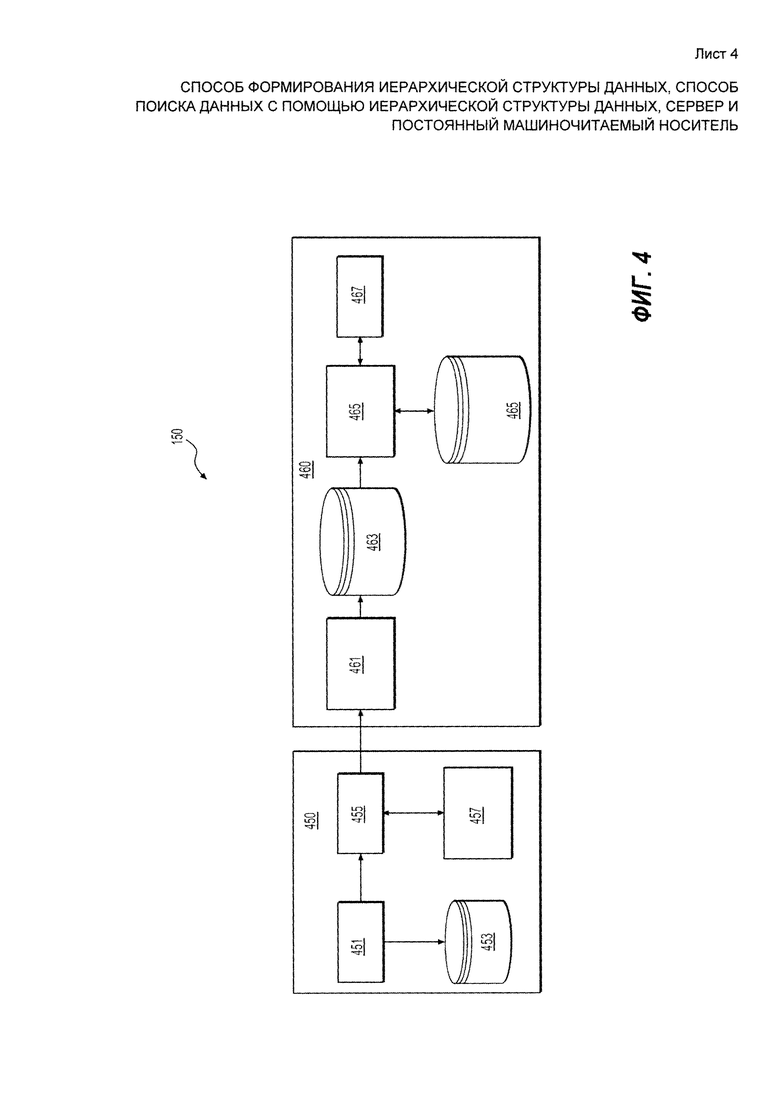
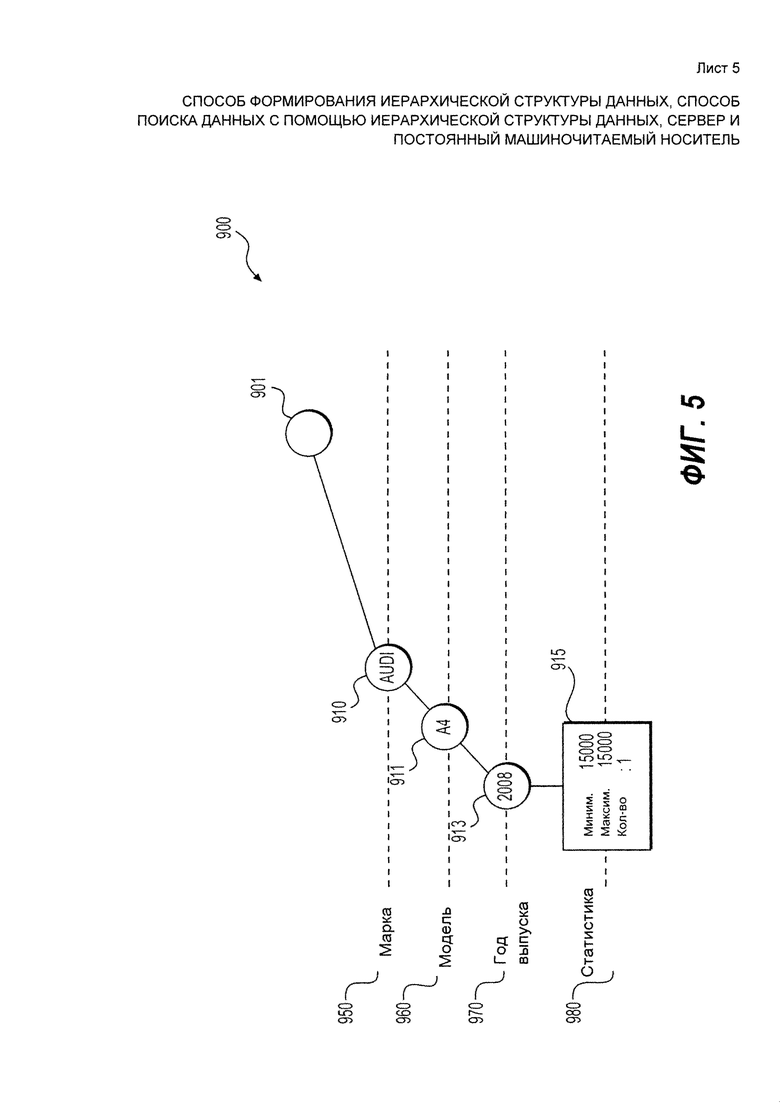
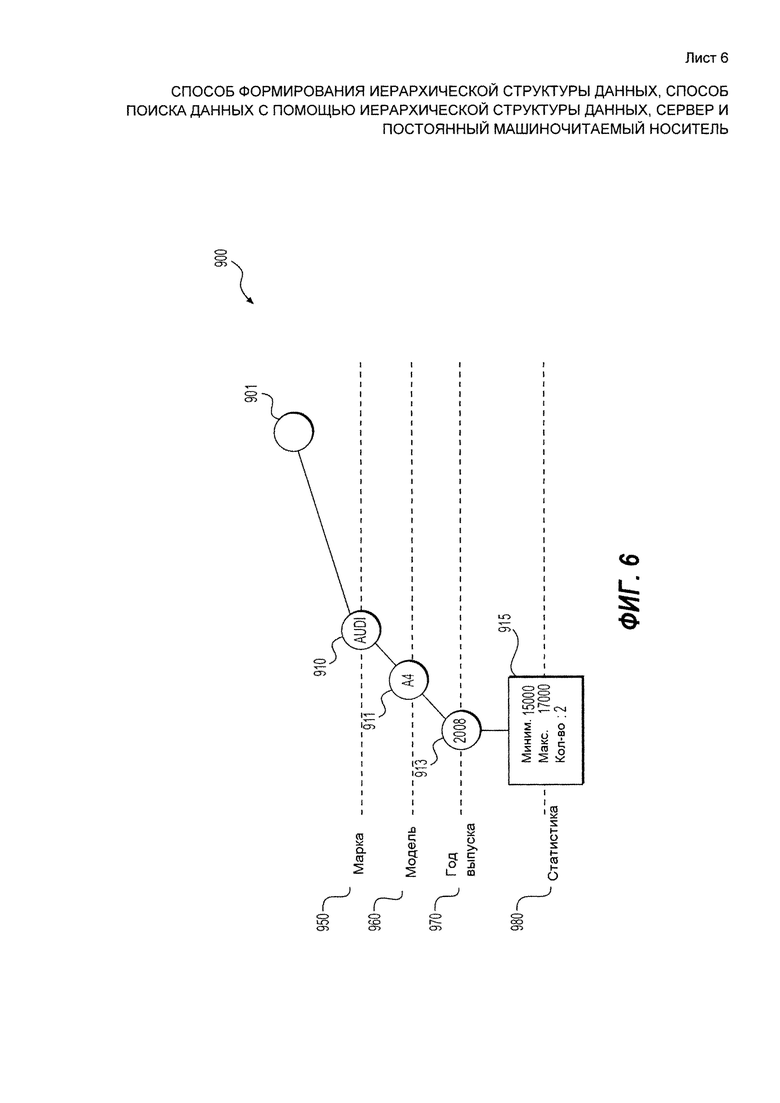
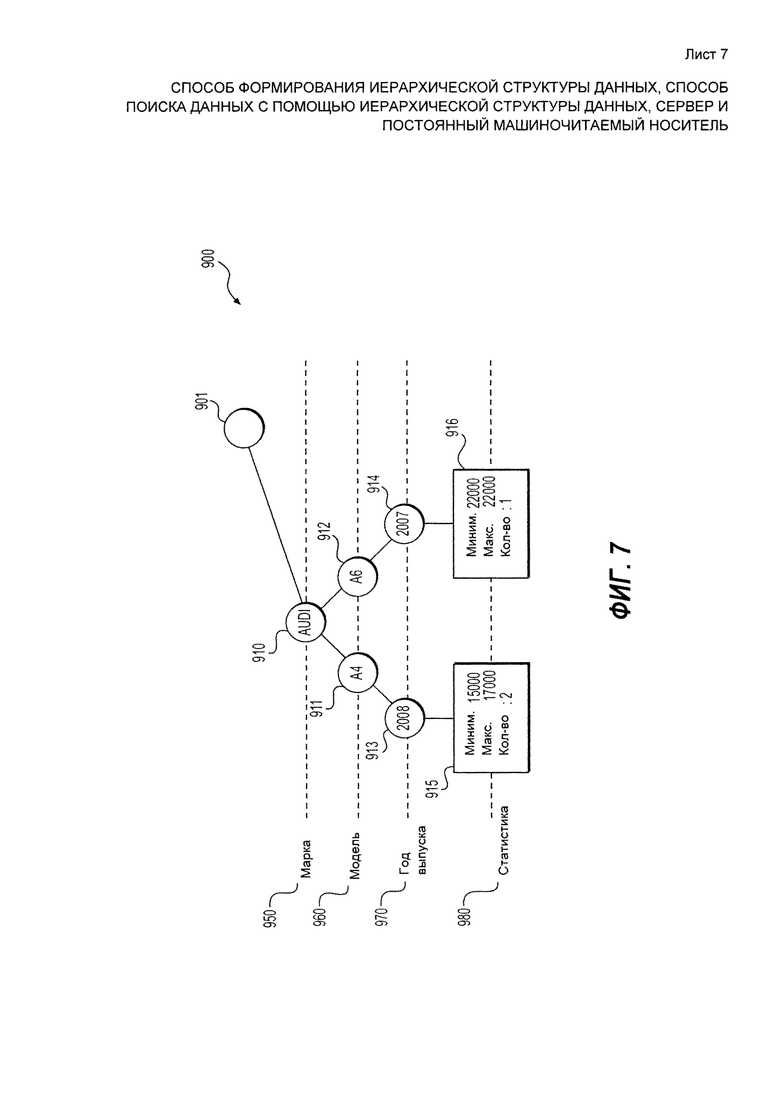
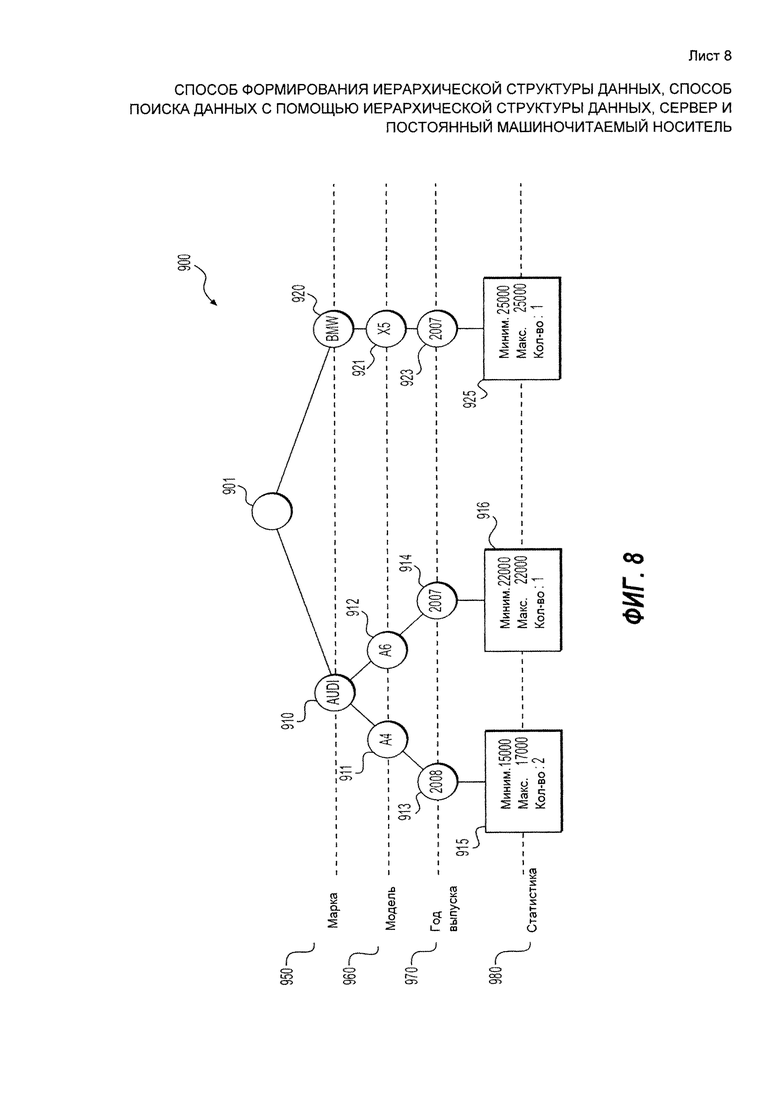
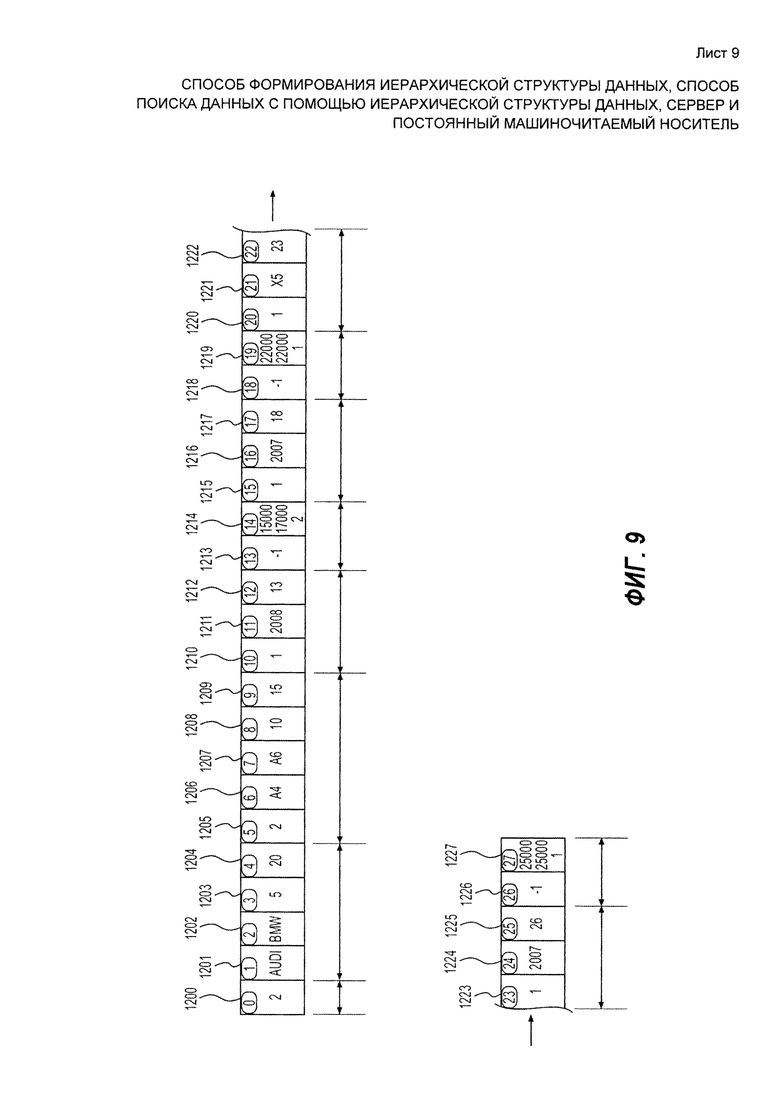
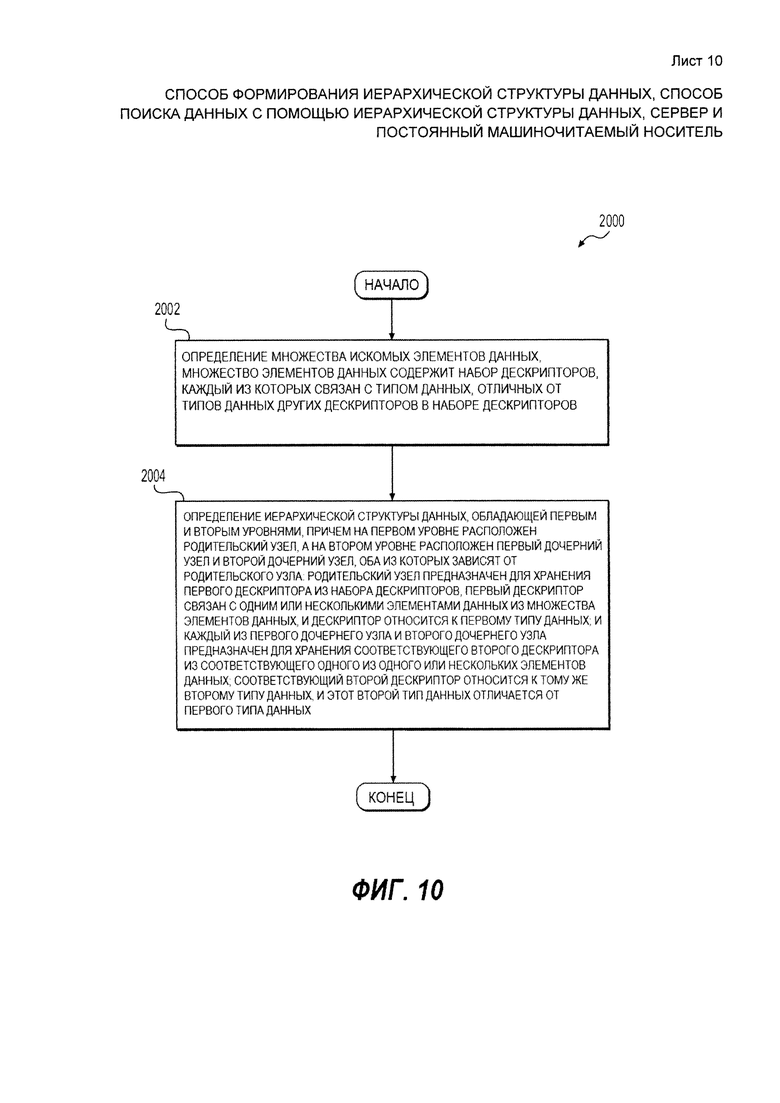
Изобретение относится к иерархическим структурам данных и конкретнее к способу создания иерархической структуры данных. Техническим результатом является повышение скорости поиска данных. В способе создания иерархической структуры данных определяют множество искомых элементов данных, содержащее набор дескрипторов, каждый из которых связан с типом данных, описывающим искомые элементы данных и отличным от типов данных других дескрипторов. Создают иерархическую структуру данных, обладающую первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположены первый и второй дочерние узлы, зависящие от родительского узла. При этом родительский узел предназначен для хранения первого дескриптора, связанного с элементами данных и относящегося к первому типу данных. Каждый из первого и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего элемента данных. Каждый соответствующий второй дескриптор относится к одному и тому же второму типу данных, который отличается от первого типа данных. 4 н. и 25 з.п. ф-лы, 10 ил.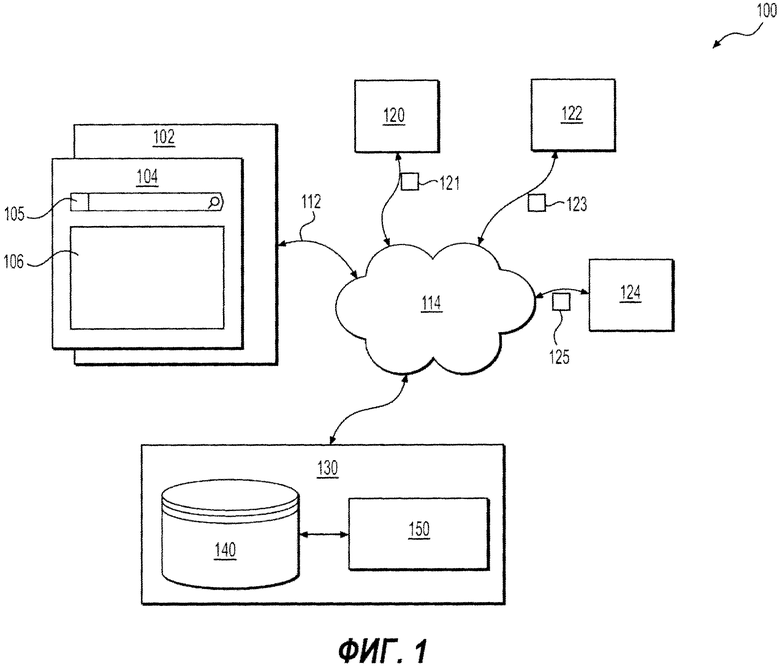
1. Способ формирования иерархической структуры данных, выполняемый на сервере и включающий:
определение множества искомых элементов данных, содержащего набор дескрипторов, каждый из которых связан с типом данных, описывающим искомые элементы данных и отличным от типов данных других дескрипторов в наборе дескрипторов;
создание иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, зависящие от родительского узла;
при этом родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и
каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; каждый соответствующий второй дескриптор относится к одному и тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
2. Способ по п. 1, в котором родительский узел представляет собой первый родительский узел, а при определение иерархической структуры данных включает определение второго родительского узла для сохранения дескриптора из набора дескрипторов; при этом дескриптор отличается от дескриптора первого родительского узла; и оба дескриптора относятся к одному и тому же первому типу данных.
3. Способ по п. 2, в котором определение иерархической структуры данных включает определение третьего дочернего узла и четвертого дочернего узла, оба из которых зависят от второго родительского узла; при этом каждый из третьего родительского узла и четвертого родительского узла предназначен для хранения соответствующего дескриптора других элементов данных; причем соответствующий другой дескриптор относится к тому же второму типу данных.
4. Способ по п. 1, в котором определение иерархической структуры данных включает определение третьего уровня, на котором размещен первый дочерний подузел и второй дочерний подузел, оба из которых зависят от первого дочернего узла; каждый из первого дочернего подузла и второго дочернего подузла предназначен для хранения соответствующего третьего дескриптора, который соответствует по меньшей мере одному элементу данных; соответствующий третий дескриптор относится к тому же третьему типу данных, отличному от первого и второго типа данных.
5. Способ по п. 1, в котором осуществляют определение иерархической структуры данных в ответ на получение указания на элемент данных из множества элементов данных, причем элемент данных индексируют в иерархической структуре данных, элемент данных связан с набором дескрипторов, а набор дескрипторов обладает первым дескриптором и вторым дескриптором.
6. Способ по п. 5, в котором, в ответ на получение указания на элемент данных, связанный с первым дескриптором, который относится к первому типу данных, определение включает идентификацию родительского узла на первом уровне иерархической структуры данных.
7. Способ по п. 6, в котором, в ответ на получение указания на элемент данных, связанный со вторым дескриптором, который относится ко второму типу данных, определение включает в себя идентификацию первого дочернего узла на втором уровне иерархической структуры данных.
8. Способ по п. 6, в котором элемент данных представляет собой первый элемент данных и в котором, в ответ на получение указания на второй элемент данных, связанный со вторым дескриптором, который относится ко второму типу данных, второй дескриптор второго элемента данных отличается от второго дескриптора первого элемента данных, а определение включает в себя идентификацию второго дочернего узла на втором уровне иерархической структуры данных.
9. Способ по п. 6, в котором родительский узел представляет собой первый родительский узел и в котором, в ответ на получение указания на второй элемент данных, связанный с дескриптором, оба дескриптора относятся к одному типу данных, определение включает в себя идентификацию второго родительского узла на первом уровне иерархической структуры данных.
10. Способ по п. 5, в котором, в ответ на получение указания на элемент данных, связанный с первым дескриптором, который относится к первому типу данных, и вторым дескриптором, который относится ко второму типу данных, и третьим дескрипторов, который относится к третьему типу данных, определение включает в себя идентификацию первого листового узла, соответствующего первому дочернему узлу; причем первый листовой узел предназначен для хранения третьего дескриптора.
11. Способ по п. 10, в котором элемент данных представляет собой первый элемент данных и в котором, в ответ на получение указания на второй элемент данный, связанный с тем же первым дескриптором и тем же вторым дескриптором, что и первый элемент данных, но другой третий дескриптор того же третьего типа данных, определение включает установление связи второго элемента данных с первым листовым узлом.
12. Способ по п. 11, в котором обновляют первый листовой узел с помощью статистического снимка третьего дескриптора первого элемента данных и отличающийся третий дескриптор второго элемента данных.
13. Способ по п. 12, в котором статистический снимок включает в себя (i) ряд элементов данных, связанных с первым листовым узлом, (ii) указание на минимальное значение одного из третьих дескрипторов первого элемента данных и второго элемента данных и (iii) указание на максимальное значение другого третьего дескриптора первого элемента данных и второго элемента данных.
14. Способ по п. 11, в котором, в ответ на получение указания на третий элемент данных, связанный с тем же первым дескриптором и тем же вторым дескриптором, что и первый, и второй элементы данных, но другой третий дескриптор того же третьего типа данных, определение включает в себя связь третьего элемента данных с первым листовым узлом.
15. Способ по п. 14, в котором обновляют статистический снимок с помощью информации, связанной с третьим элементом данных.
16. Способ по п. 15, в котором этап обновления включает в себя: (i) обновление счетчика с помощью ряда элементов данных, (ii) определение того, необходимо ли обновить указание на минимальное значение и максимальное значение на основе третьего дескриптора третьего элемента данных.
17. Способ по п. 16, в котором определяют необходимость обновления указания на минимальное значение и максимальное значение посредством проверки расположения значения третьего дескриптора в диапазоне между минимальным и максимальным значениями.
18. Способ по п. 17, в котором при определении нахождения третьего дескриптора за пределами диапазона между минимальным и максимальным значениями, изменяют соответствующее минимальное или максимальное значение на значение третьего дескриптора третьего элемента данных.
19. Способ по п. 10, в котором элемент данных представляет собой первый элемент данных, и в ответ на получение указания на четвертый элемент данных, связанный с тем же первым дескриптором и вторым дескриптором, который относится к тому же второму типу данных, но отличается от второго дескриптора первого элемента данных, и третьим дескриптором, который относится к тому же третьему типу данных, определение включает в себя идентификацию второго листового узла, соответствующего второму дочернему узлу; при этом второй листовой узел предназначен для хранения третьего дескриптора, соответствующего четвертому элементу данных.
20. Способ поиска данных с помощью иерархической структуры данных, определенной выполнением способа по любому из пп. 10-19, включающий:
получение поискового запроса, обладающего поисковым параметром, связанным с типом данных, описывающим искомые элементы данных; обнаружение в иерархической структуре данных ветви, содержащей по меньшей мере один узел, связанный с дескриптором, относящимся к тому же типу данных и совпадающим с поисковым параметром;
получение доступа к листовому узлу, обладающему по меньшей мере одним элементом данных, соответствующим по меньшей мере дескриптору; извлечение по меньшей мере одного элемента данных из листового узла.
21. Способ по п. 20, в котором по меньшей мере один узел является родительским узлом и в котором ветвь содержит дочерний узел, зависящий от родительского узла, причем дочерний узел соответствует второму дескриптору; и в котором поисковый запрос включает в себя второй параметр, относящийся ко второму типу данных, отличному от первого типа данных; и в котором обнаружение выполняется в ответ на совпадение второго дескриптора со вторым поисковым параметром.
22. Способ по п. 21, в котором дочерний узел является первым дочерним узлом, и в котором ветвь содержит второй дочерний узел, зависящий от родительского узла, причем второй дочерний узел соответствует третьему дескриптору; и в котором поисковый запрос включает в себя второй параметр, относящийся ко второму типу данных, отличному от первого типа данных; и в котором второй дескриптор совпадает со вторым поисковым параметром, а третий дескриптор не совпадает с поисковым параметром; и в котором обнаружение включает в себя обнаружение ветви, содержащей первый дочерний узел и не содержащей второй дочерний узел.
23. Способ по п. 20, в котором поисковый параметр представляет собой первый поисковый параметр, относящийся к первому типу данных, и в котором в ответ на получение указания на поисковый запрос, обладающий первым параметром и вторым параметром, относящимися ко второму типу данных, отличных от первого типа данных, поиск включает в себя:
(i) обнаружение второй ветви, содержащей первый родительский узел и второй дочерний узел, зависящий от первого родительского узла; причем первый родительский узел соответствует первому дескриптору, совпадающему с первым поисковым параметром; второй дочерний узел соответствует второму дескриптору, совпадающему со вторым поисковым параметром;
(ii) получение доступа к первому листовому узлу, соответствующему первой ветви;
(iii) извлечение по меньшей мере одного элемента данных из второго листового узла, соответствующего первому дескриптору и второму дескриптору, оба из которых соответствуют поисковому запросу.
24. Способ по п. 21, в котором, в ответ на получение указания на поисковый запрос, поиск включает в себя извлечение статистического снимка из первого листового узла с рядом элементов данных в первом листовом узле, минимальное значение и максимальное значение третьего дескриптора.
25. Способ по п. 22, в котором, в ответ на получение указания на поисковый запрос, поиск включает в себя извлечение статистического снимка из второго листового узла с рядом элементов данных во втором листовом узле, минимальное значение и максимальное значение третьего дескриптора.
26. Способ по п. 23, в котором, в ответ на получение указания на поисковый запрос, поиск включает в себя извлечение статистического снимка из первого листового узла и второго листового узла с рядами элементов данных в первом листовом узле и втором листовом узле, минимальное значение и максимальное значение третьего дескриптора в первом листовом узле, минимальное значение и максимальное значение третьего дескриптора во втором узле.
27. Способ по п. 26, в котором определяют общее число элементов данных в первом и втором листовом узлах, минимальное значение третьего дескриптора во всех элементах данных первого и второго листовых узлов, максимальное значение третьего дескриптора во всех элементах данных первого и второго листовых узлов.
28. Сервер, выполненный с возможностью создавать иерархическую структуру данных, содержащий постоянный носитель для хранения машиночитаемых кодов, выполнение которых позволяет осуществлять:
определение множества искомых элементов данных, множество элементов данных содержит набор дескрипторов, каждый из которых связан с типом данных, описывающим искомые элементы данных и отличным от типов данных других дескрипторов в наборе дескрипторов;
создание иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла;
родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и
каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; каждый соответствующий второй дескриптор относится к одному и тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
29. Постоянный машиночитаемый носитель, содержащий машиночитаемые коды, выполнение которых сервером позволяет ему осуществлять:
определение множества искомых элементов данных, множество элементов данных содержит набор дескрипторов, каждый из которых связан с типом данных, описывающим искомые элементы данных и отличным от типов данных других дескрипторов в наборе дескрипторов;
создание иерархической структуры данных, обладающей первым и вторым уровнями, причем на первом уровне расположен родительский узел, а на втором уровне расположен первый дочерний узел и второй дочерний узел, оба из которых зависят от родительского узла;
родительский узел предназначен для хранения первого дескриптора из набора дескрипторов, первый дескриптор связан с одним или несколькими элементами данных из множества элементов данных, и дескриптор относится к первому типу данных; и
каждый из первого дочернего узла и второго дочернего узла предназначен для хранения соответствующего второго дескриптора из соответствующего одного из одного или нескольких элементов данных; каждый соответствующий второй дескриптор относится к одному и тому же второму типу данных, и этот второй тип данных отличается от первого типа данных.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ ФОРМИРОВАНИЯ СТРУКТУРЫ АГРЕГИРОВАННЫХ ДАННЫХ И СПОСОБ ПОИСКА ДАННЫХ ПОСРЕДСТВОМ СТРУКТУРЫ АГРЕГИРОВАННЫХ ДАННЫХ В СИСТЕМЕ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ | 2010 |
|
RU2433467C1 |

