Область техники, к которой относится изобретение
[01] Настоящее техническое решение относится к системам и способам управления данными, связанными с иерархической структурой данных. Конкретнее, предлагаемые системы и способы нацелены на сохранение, извлечение и/или обновление данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных.
Уровень техники
[02] С появлением компьютерных систем стали развиваться технологии, отражающие желание пользователя разделить информацию на категории в соответствии с иерархической организацией. Категории, на которые обычно подразделяется информация, могут обладать некоторой иерархией, которая определяет их иерархическую организацию.
[03] Например, компьютерные файловые системы обычно реализованы с помощью иерархических принципов организации. Обычная компьютерная файловая система обладает каталогами, которые организованы иерархически, и файлами, которые хранятся в каталогах. В идеале иерархические связи между каталогами отражают некоторую интуитивную связь между значениями, которые были присвоены каталогам. Аналогично, может быть желательно, чтобы каждый документ был сохранен в каталоге на основе некоторой интуитивной связи между содержимым документа и значением, которое присвоено каталогу, в котором хранится документ.
[04] Пример обычной файловой системы 300 представлен на Фиг. 3. Представленная файловая система 300 включает в себя корневой каталог 302, озаглавленный "/". Корневой каталог 302 определяет начало пути к каталогу или к документу, который хранится в каталоге. Корневой каталог 302 находится в дочерне-родительской связи с папкой 304, озаглавленной "папка А" (англ. "folder А") и папкой 310, озаглавленной "папка D" (англ. "folder D"). Папка 304 находится в дочерне-родительской связи с папкой 306, озаглавленной "папка В" (англ. "folder В"), и в дочерне-родительской связи с файлом 308, озаглавленном "файл С" (англ. "file С"). Папка 310 находится в дочерне-родительской связи с файлом 312, озаглавленном "файл Е" (англ. "file Е"). В примере, показанном на Фиг. 3, папки 304, 306 и 310 являются файлами каталога (также упоминаются как "файлы папки"), а файлы 308 и 312 являются файлами документов.
[05] Когда электронная информация организована иерархически, каждый элемент (например, файл каталога или файл документа) может быть идентифицирован с помощью пути к элементу в иерархии. В рамках иерархической файловой системы, путь к элементу начинается с корневого каталога (например, корневого каталога 302) и проходит по нисходящей в иерархии каталогов до того каталога, в котором содержится интересующий элемент. Например, путь к файлу 308 состоит из папок 302, 304 - в этом же порядке.
[06] Иерархические системы хранения позволяют различным элементам обладать одинаковыми именами. Например, файлы 308 и 312 на Фиг. 3 могут обладать одним и тем же именем. Соответственно, для того, чтобы однозначно идентифицировать данный документ, одного имени документа будет недостаточно. Идентификация и определение местоположения конкретного элемента информации, который хранится в системе иерархического хранения, могут осуществляться, например, при помощи "имени пути". Имя пути создается на основе последовательности имен, которые упоминаются как элементы пути. В контексте файловых систем, каждое имя в последовательности имен представляет собой "имя файла". Термин "имя файла" относится как к именам каталогов, так и к именам документов, поскольку и каталоги и документы считаются "файлами". В рамках файловой системы, последовательность имен файлов в данном имени пути начинается с имени корневого каталога, включает в себя имена всех каталогов пути от корневого каталога до интересующего элемента. Обычно, список каталогов, которые необходимо пройти, перечисляется в имени пути последовательно, с помощью разделяющего знака препинания (например, "/", "\" или ","). Таким образом, имя пути для файла 308 может представлять собой "/folder A/file С", а имя пути для файла 312 может представлять собой "/folder D/file Е".
[07] Связь между папками и содержащимся в них содержимым может варьироваться в различных типах иерархически организованных систем. Например, файловые системы Microsoft Windows™ и DOS требуют, чтобы каждый файл обладал только одним родителем, что позволяет формировать древовидную модель. В качестве второго примера, файловые системы UNIX могут позволить файлами обладать несколькими родителями, что позволяет формировать графовую модель.
[08] В отличие от иерархических подходов к организации электронной информации, база данных (например, реляционная база данных) сохраняет информацию в таблицах, которые состоят из строк и столбцов. Каждая строка может представлять собой конкретную запись и может быть идентифицирована с помощью уникального ID. Каждый столбец может представлять собой признак или поле записи. Данные далее могут быть получены из базы данных путем ввода запросов в сервер базы данных, который ею управляет.
[09] И иерархические файловые системы и реляционные базы данных обладают своими достоинствами и недостатками.
[10] Иерархически организованная система хранения может быть простой, интуитивной, простой в реализации и может обладать стандартной моделью, которая используется большинством программных приложений. К сожалению, простота иерархической организации не подходит для сложных операций извлечения данных. Например, содержимое каждого каталога может быть необходимо проверить для получения всех документов, которые были созданы в конкретный день, которые обладают конкретными именем файла. Поскольку может быть необходимо проверить все каталоги, иерархическая организация может не обеспечивать достаточно быстрой скорости извлечения.
[11] Реляционная база данных может хорошо подходить для хранения больших объемов информации и для получения доступа к данным в более свободной форме по сравнению с иерархически организованными системами, данные, которые соответствуют даже сложному поисковому критерию, могут быть легко и эффективно извлечены из системы реляционной базы данных. Тем не менее, процесс формулирования и ввода запросов в сервер базы данных может быть менее интуитивным, чем простые переходы по иерархии каталогов.
[12] Чтобы снизить ограничения в работе иерархических файловых систем и реляционных баз данных, были совершены попытки разработать реляционно организованные системы, которые позволяют эмулировать иерархически организованную систему. Этот тип эмуляции может быть особенно желателен в тех случаях, когда необходимы возможности хранения и гибкости, которые присущи реляционной системе, но одновременно желательны интуитивность и широкая распространенность, которые присущи иерархической системе.
[13] В качестве первого примера попытки снизить ограничения, которые были описаны выше, реляционные базы данных, совместимые с языком структурированных запросов (SQL), могут быть основаны на параметре CONNECT BY что позволяет пользователю вводить запросы, которые будут обращаться к базе данных, основанной на иерархической организации. Параметр CONNECT BY может быть использован для уточнения одного или нескольких условий, которые определяют иерархическую связь, на которой основана иерархическая организация. Тем не менее, использование параметров CONNECT BY для формулирования запросов может иметь некоторые недостатки, включая, например: (i) вычислительные ресурсы, которые необходимы серверу базы данных для обработки таких запросов; и (ii) сложность добавления параметров CONNECT BY в запросы, которые обычно и так достаточно сложно сформулировать.
[14] В качестве второго примера, в патенте США №US 7366708, опубл. 29.04.2008 описан способ и систему хранения иерархических данных в реляционной базе данных. В представленном подходе, информация обо всех дочерних элементах данного элемента сохраняется в записи этого элемента. Дополнительно, независимые ID основаны на уникальных идентификаторах родительских и дочерних элементов. Несмотря на то, что этот подход обеспечивает быструю идентификацию всех дочерних элементов данного элемента, тем не менее, могут присутствовать некоторые недостатки, например, в случае перемещения элементов из одного узла иерархической организации в другой узел иерархической организации.
[15] Дополнительно к вышеописанным первому и второму примеру, были разработаны другие подходы к хранению иерархических данных. Подобные другие подходы могут быть разделены на так называемый "иерархический тип" и "ID тип".
[16] При подходах иерархического типа, каждый элемент иерархической структуры обладает своим ID, который никогда не меняется, и ссылкой на родительский элемент. При подходах иерархического типа, операции над элементами иерархической структуры обладают вычислительной сложностью О(М), где М - уровень конкретного элемента в иерархической структуре, на котором могут проводиться одна или более операций. В результате, сложность операции зависит от глубины иерархической структуры, что приводит к тому, что операции могут быть потенциально затратными с точки зрения вычислительных мощностей, например, в случае перемещения элементов из одного узла иерархической организации в другой.
[17] При подходах ID типа, каждый элемент иерархической структуры обладает ID, который зависит от пути в иерархической структуре (например, от коревого узла структуры до элемента), и ссылкой на родительский элемент. При подходах ID типа, операции над элементами иерархической структуры обладают вычислительной сложностью O(1), но это приводит к ограниченности и/или сложности перемещения элементов в рамках иерархической структуры, поскольку все ID дочерних элементов того элемента, который перемещается, будут модифицированы. В результате, для больших и сложных иерархических структур подобные операции могут привести к серьезным затратам с точки зрения вычислительных мощностей.
Раскрытие изобретения
[18] Варианты осуществления настоящего технического решения были разработаны с учетом изобретательского понимания по меньшей мере одной проблемы, связанной с известным уровнем техники.
[19] Как было представлено ранее, несмотря на то, что были разработаны многие способы и системы хранения иерархических данных в базе данных, тем не менее, могут быть желательны дальнейшие улучшения, в частности - улучшения, нацеленные на эффективное управление перемещением элементов в рамках иерархической структуры, которая хранится в базе данных, например, реляционной базе данных. Подобные улучшения могут быть особенно желательны, когда количество данных достигает конкретного размера и/или когда сложность иерархической структуры достигает конкретного уровня. Подобные улучшения могут быть также желательны для увеличения скорости обработки данных, которые хранятся в базе данных и/или для уменьшения вычислительной мощности, которая требуется для обработки данных, которые хранятся в базе данных.
[20] Настоящее техническое решение было создано автором(ами) на основе их наблюдения о том, что хранение данных, связанных с иерархической структурой, в базе данных может основываться на иерархической таблице и файловой таблице, которые хранят определенные поля данных. В результате, при определенных обстоятельствах, изменения в организации иерархической структуры (например, позиция файла каталога, которая была модифицирован в иерархической структуре) могут отражаться в базе данных путем обновления иерархической таблицы, иногда независимо от обновления файловой таблицы. При определенных обстоятельствах, поскольку данные, связанные с иерархической структурой, хранятся в базе данных в первом наборе полей данных в иерархической таблице и во втором наборе полей данных в файловой таблице, не будет необходимости обновлять записи из файловой таблицы, которые соответствуют дочерним элементам, и которые зависят от перемещаемого файла каталога. Подобный подход может снизить вычислительную сложность и/или количество времени, которое необходимо для завершения обновления в базе данных, в которой расположена иерархическая таблица и/или файловая таблица, поскольку необходимо обновлять только иерархическую таблицу. Другие преимущества также будут очевидны специалистам в данной области техники, которые ознакомились с описанием настоящего технического решения.
[21] Первым объектом настоящего технического решения является исполняемый на компьютере способ хранения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
получение доступа к данным с постоянного машиночитаемого носителя;
по меньшей мере для одного из элементов пути, связанного с данными, сохранение в иерархической таблице, которая доступна на постоянном машиночитаемом носителе, иерархического идентификатора, связанного с отрезком пути, который ведет по меньшей мере к одному элементу пути в иерархической структуре данных; независимого идентификатора иерархической таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути в иерархической таблице, и идентификатора родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит по меньшей мере один элемент пути; и
по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, независимого идентификатора файловой таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути и файл в файловой таблице; и идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит по меньшей мере один элемент пути и файл.
[22] В некоторых вариантах осуществления настоящего технического решения, иерархический идентификатор создается путем применения хэш-функции к отрезку пути.
[23] В некоторых дополнительных вариантах осуществления настоящего технического решения, отрезок пути является полным путем между корнем иерархической структуры данных и узлом, который определен по меньшей мере одним из элементов пути.
[24] В некоторых вариантах осуществления настоящего технического решения, способ дополнительно включает в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, независимого идентификатора независимой родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависит по меньшей мере один из элементов пути или файл.
[25] В некоторых дополнительных вариантах осуществления настоящего технического решения, способ дополнительно включает в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, текстового потока, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом.
[26] В некоторых вариантах осуществления настоящего технического решения, идентификатор родительского элемента в файловой таблице создается на основе независимого идентификатора файловой таблицы, который связан с родительским элементом пути; и имени, которое связано по меньшей мере с одним из элементов пути и файлом.
[27] В некоторых дополнительных вариантах осуществления настоящего технического решения по меньшей мере один из элементов пути представляет собой файл каталога.
[28] В некоторых вариантах осуществления настоящего технического решения, файл определяет лист в иерархической структуре и файл каталога определяет узел в иерархической структуре.
[29] В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица и файловая таблица реализованы с помощью реляционной базы данных.
[30] Другим объектом настоящего технического решения является исполняемый на компьютере способ извлечения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
получение доступа к иерархической таблице и файловой таблице с постоянного машиночитаемого носителя;
создание иерархического идентификатора на основе пути;
идентификация в иерархической таблице по меньшей мере одной записи, которая соответствует иерархическому идентификатору; и
идентификация в файловой таблице по меньшей мере одной записи, которая обладает идентификатором родительского элемента в файловой таблице, соответствующим идентификатору родительского элемента в иерархической таблице, который связан по меньшей мере с одной записью, соответствующей иерархическому идентификатору.
[31] В некоторых вариантах осуществления настоящего технического решения, создание иерархического идентификатора включает в себя применение хэш-функции к пути.
[32] В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица структурирована следующим образом:
иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице; и
идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[33] В некоторых вариантах осуществления настоящего технического решения, файловая таблица структурирована следующим образом:
независимый идентификатор файловой таблицы уникальным образом идентифицирует один из элементов пути и файл в файловой таблице; и
идентификатор родительского элемента в файловой таблице связан с независимым идентификатором файловой таблицы, который связан с родительским элементом пути, от которого зависит один из элементов пути и файл.
[34] Другим объектом настоящего технического решения является исполняемый на компьютере способ обновления данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
определение модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации;
получение доступа на постоянном машиночитаемом носителе к иерархической таблице, которая содержит данные, относящиеся к пути, данные независимы от файловой таблицы, которая содержит данные, относящиеся к файлу;
создание первого иерархического идентификатора на основе последовательности элементов пути до модификации;
создание второго иерархического идентификатора на основе последовательности элементов пути после модификации;
идентификация в иерархической таблице по меньшей мере одной записи, которая соответствует первому иерархическому идентификатору; и
замена в иерархической таблице по меньшей мере одной записи на второй иерархический идентификатор.
[35] В некоторых вариантах осуществления настоящего технического решения обновление данных, связанных с путем и файлом выполняется без модификации содержимого файловой таблицы.
[36] В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица структурирована следующим образом:
иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице; и
идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[37] Другим объектом настоящего технического решения является постоянный машиночитаемый носитель, хранящий программные инструкции для сохранения данных, связанных с путем и файлом и/или для извлечения данных, связанных с путем и файлом и/или для обновления данных, связанных с путем и файлом, программные инструкции выполняются процессором компьютерной системы для осуществления одного или нескольких упомянутых выше способов.
[38] Другим объектом настоящего технического решения является компьютерная система, например, без установления ограничений, электронное устройство, которое включает в себя по меньшей мере один процессор и память, хранящую машиночитаемые инструкции для сохранения данных, связанных с путем и файлом и/или для извлечения данных, связанных с путем и файлом и/или для обновления данных, связанных с путем и файлом, программные инструкции выполняются одним или несколькими процессорами компьютерной системы для осуществления одного или нескольких упомянутых выше способов.
[39] В контексте настоящего описания, если четко не указано иное, "электронное устройство", "сервер", "удаленный сервер" и "компьютерная система" подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и так далее), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[40] В контексте настоящего описания, если четко не указано иное, "машиночитаемый носитель" и "память" подразумевает под собой носитель абсолютно любого типа и характера, не ограничивающие примеры включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[41] В контексте настоящего описания, если четко не указано иное, "указание" информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, признак файла может включать в себя сам файл (т.е. его содержимое), или же он может являться уникальным дескриптором файла, идентифицирующим файл по отношению к конкретной файловой системе, или каким-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передачи ключа базы данных - необходимо и достаточно для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[42] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер " не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[43] Каждый вариант осуществления настоящего технического решения включает по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые объекты настоящего технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять другим целям, отдельно не указанным здесь.
[44] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[45] Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[46] на Фиг. 1 схематично показана компьютерная система, которая подходит для реализации настоящего технического решения и/или которая используется в сочетании с вариантами осуществления настоящего технического решения;
[47] на Фиг. 2 показана схема базы данных, которая расположена на сервере базы данных в соответствии с вариантом осуществления настоящего технического решения;
[48] на Фиг. 3 показана схема обычной файловой системы;
[49] на Фиг. 4 показана схема иерархической таблицы и файловой таблицы в соответствии с вариантом осуществления настоящего технического решения;
[50] на Фиг. 5 показана блок-схема, отображающая первый исполняемый на компьютере способ, являющийся вариантом осуществления настоящего технического решения;
[51] на Фиг. 6 показана блок-схема, отображающая второй исполняемый на компьютере способ, являющийся вариантом осуществления настоящего технического решения; и
[52] на Фиг. 7 показана блок-схема, отображающая третий исполняемый на компьютере способ, являющийся вариантом осуществления настоящего технического решения.
[53] Также следует отметить, что чертежи выполнены не в масштабе, если специально не указано иное.
Осуществление изобретения
[54] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящего технического решения, а не для установления границ его объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящего технического решения и находятся в границах его объема.
[55] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящего технического решения. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[56] Некоторые полезные примеры модификаций настоящего технического решения также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающего списка. Кроме того, те случаи, где не были представлены примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящего технического решения.
[57] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящего технического решения, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящего технического решения. Аналогично, любые блок-схемы, диаграммы переходного состояния, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор или нет.
[58] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящего технического решения процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина "процессор" или "контроллер" не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[59] Программные модули или простые модули, представляющие собой программное обеспечение, которое может быть использовано здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[60] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления настоящего технического решения.
[61] На Фиг. 1 схематично показана компьютерной система 100, которая подходит для некоторых вариантов осуществления настоящего технического решения, компьютерная система 100 включает в себя различные аппаратные компоненты, включая один или несколько одно- или многоядерных процессоров, которые представлены процессором 110, графический процессор (GPU) 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 монитора, и интерфейс 150 ввода/вывода.
[62] Связь между различными компонентами компьютерной системы 100 может осуществляться с помощью одной или несколько внутренних и/или внешних шин 160 (например, шины PCI, универсальной последовательной шины, высокоскоростной шины IEEE 1394, шины SCSI, шины Serial ATA и так далее), с которыми электронно соединены различные аппаратные компоненты. Интерфейс 140 монитора может быть соединен с монитором 142 (например, через HDMI-кабель 144), видимый пользователю 170, интерфейс 150 ввода/вывода может быть соединен с сенсорным экраном (не показан), клавиатурой 151 (например, через USB-кабель 153) и мышью 152 (например, через USB-кабель 154), как клавиатура 151, так и мышь 152 используются пользователем 170.
[63] В соответствии с вариантами осуществления настоящего технического решения твердотельный накопитель 120 хранит программные команды, подходящие для загрузки в ОЗУ 130, и использующиеся процессором 110 и/или графическим процессором GPU 111. Например, программные инструкции могут представлять собой часть библиотеки или приложения.
[64] На Фиг. 2 представлена компьютерная система 200, содержащая сервер 202 базы данных и базу 204 данных. Сервер 202 базы данных может быть реализован как обычный компьютерный сервер или, альтернативно, как компьютерный сервер, предназначенный для управления базой данных. В примере варианта осуществления настоящего технического решения, сервер 202 базы данных может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 202 базы данных может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем ее объем, сервер 202 базы данных является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность сервера 202 базы данных может быть разделена, и может выполняться с помощью нескольких серверов.
[65] Варианты осуществления сервера 202 базы данных широко известны среди специалистов в данной области техники. Тем не менее, коротко говоря, сервер 202 базы данных содержит интерфейс связи (не показан), настроенный и выполненный с возможностью связываться с различными элементами (не показаны) через сеть передачи данных (не показана). Сервер 202 базы данных дополнительно включает в себя одно или несколько из следующего: компьютерный процессор (не показан), функционально соединенный с интерфейсом связи и настроенный и выполненный с возможностью выполнять различные процессы, описанные здесь. В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных может включать в себя по меньшей мере некоторые компоненты компьютерной системы 100, представленной на Фиг. 1.
[66] Основной задачей сервера 202 базы данных является предоставление услуг базы данных другим компьютерным программам и/или вычислительным устройствам, например, вычислительным устройствам, которые взаимодействуют с сервером 202 базы данных через сеть. В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных размещает систему управления базой данных, что обеспечивает функциональности и позволяет проводить операции в базе 204 данных. В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных может быть выполнен с возможностью взаимодействовать с другими компьютерными программами и/или вычислительными устройствами в соответствии с моделью клиент-сервер для обеспечения доступа к базе 204 данных. В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных может размещать систему управления базой данных (DBMS). В некоторых вариантах осуществления настоящего технического решения сервер 202 базы данных может размещать внешний модуль, который получает запрос на доступ к базе 204 данных от электронного устройства и/или возвращать результаты электронному устройству. Сервер 202 базы данных также может размещать внутренний модуль, который управляет данными из базы 204, позволяя получить доступ к существующим данным, модифицировать существующие данные и/или дополнительные данные. Внутренний модуль также может быть выполнен с возможностью работать в соответствии с одним или несколькими языками запроса (например, SQL) и обрабатывать один или несколько запросов и выполнять соответствующие операции в базе 204 данных для хранения и/или обновления данных базы 204 данных. В некоторых вариантах осуществления настоящего технического решения, внешний модуль и/или внутренний модуль, по одиночке или в комбинации могут выполнять инструкции для реализации настоящего технического решения и, конкретнее, сохранять и/или извлекать и/или обновлять иерархические данные в базе 204 данных. Несмотря на то, что внешний модуль и внутренний модуль могут выполнять инструкции для реализации настоящего технического решения, такая конфигурация не является ограничивающей, и возможны и другие варианты того, как будет реализовано настоящее техническое решение, и как именно будет происходить управление сохранением и/или извлечением и/или обновлением иерархических данных в базе 204 данных - не выходя за пределы настоящего технического решения. Дополнительные подробности, касающиеся того, как сохраняются и/или извлекаются и/или обновляются иерархические данные в базе 204 данных, представлены ниже в описании Фиг. 3-7.
[67] В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных может представлять собой частный сервер, например, сервер Oracle™, DB2™, Informix™ и/или Microsoft™ SQL Server. В некоторых вариантах осуществления настоящего технического решения, сервер 202 базы данных может быть публичным сервером базы данных, например, без установления ограничений, сервером Универсальной общественной лицензии GNU, Ingres и/или MySQL. Этот вариант не является ограничивающим, и другие возможные варианты осуществления настоящего технического решения, не выходящие за его границы, будут ясны специалистам в данной области техники.
[68] В некоторых вариантах осуществления настоящего технического решения, база 204 данных находится на сервере 202 базы данных. В некоторых вариантах осуществления настоящего технического решения, база 204 данных размещается на другом сервере, и при этом удаленно контролируется сервером 202 базы данных. В некоторых вариантах осуществления настоящего технического решения, база 204 данных может быть распределена между несколькими серверами и/или несколькими серверами баз данных (например, первая таблица базы 204 данных может размещаться на первом сервере базы данных, а вторая таблица базы 204 данных может размещаться на втором сервере базы данных). В некоторых вариантах осуществления настоящего технического решения, база 204 данных выполнена таким образом, что представляет собой реляционную базу данных, включающую в себя таблицу данных, которая организована в соответствии с реляционной моделью. Несмотря на то, что на Фиг. 2 представлена реляционная база данных, этот вариант осуществления не должен считаться ограничивающим. В некоторых вариантах осуществления настоящего технического решения, база 204 данных выполнена как объектная база данных или как объектно-реляционная база данных. В некоторых вариантах осуществления настоящего технического решения, база 204 данных выполнена как пост-реляционная база данных. Другие возможные варианты предусмотрены и будут ясны специалистам в данной области техники.
[69] Грубо говоря, база 204 данных представляет собой организованный набор данных. В некоторых вариантах осуществления настоящего технического решения, база 204 данных включает в себя набор данных в соответствии с моделью данных, например, набор таблиц данных, каждый из которого включает в себя одну или несколько строк и один или несколько столбцов данных, например, как набор таблиц данных, который представлен на Фиг. 4. Другие варианты того, как может быть структурирована база 204 данных, также возможны и будут понятны специалистам в данной области техники. База 204 данных может быть структурирована таким образом, чтобы сохранять несколько типов данных. Например, без установления ограничений, база данных 204 может содержать административную информацию, финансовую информацию, техническую информацию, информацию о файловой системе. База 204 данных может также быть использована для хранения файлов документов и/или файлов папки в соответствии с иерархической файловой системой, например, файлы документов и файлы папок, представленные на Фиг. 3. То, что может содержать база 204 данных и/или формат данных, которые могут в ней содержаться, никак не ограничены. Соответственно, и этот пример не является ограничивающим, и многие другие возможные варианты будут ясны специалистам в данной области техники. В некоторых вариантах осуществления настоящего технического решения база 204 данных может содержать сами данные (например, содержимое файла) и/или метаданные, связанные с данными (например, имя файла). В некоторых вариантах осуществления настоящего технического решения, база 204 данных может опираться на постоянную и/или оперативную память (например, твердотельный накопитель 120 или ОЗУ 130) для постоянного или временного сохранения данных, которые содержатся в базе 204 данных.
[70] Далее, на Фиг. 4 представлена схема иерархической таблицы 404 и файловой таблицы 402 в соответствии с вариантом осуществления настоящего технического решения. В одном варианте осуществления настоящего технического решения, иерархическая таблица 404 и файловая таблица 402 хранятся в базе 204 данных. В других вариантах осуществления настоящего технического решения, иерархическая таблица 404 и файловая таблица 402 хранятся в разных базах данных. В примере, показанном на Фиг. 4, иерархическая таблица 404 и файловая таблица 402 хранят данные и информацию, относящуюся к данным, которые описаны в таблице "Сохраняемые данные" 406. Таблица 406 уточняет данные, которые создают файловую систему 300, представленную на Фиг. 3. В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица 404 и файловая таблица 402 могут размещать и "реконструировать" иерархические связи между файлами каталогов и/или файлами документов, как показано на Фиг. 3. В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица 404 может позволить сохранять для каждого элемента информацию, относящуюся к связи между элементом и другим(и) элементом(ами), а файловая таблица 402 позволяет сохранять для каждого элемента информацию, которая относится к самому элементу независимо от его связи с другим(и) элементом(ами). В результате, в некоторых вариантах осуществления настоящего технического решения, иерархическая таблица 404 может содержать иерархическую структуру, а файловая таблица 402 может содержать структуру данных.
[71] В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица 404 может содержать только элементы, которые обладают родительско-дочерней связью с другим элементом или элементами. Например, иерархическая таблица 404 может содержать только элементы, связанные с одним или несколькими дочерними элементами. В таких вариантах осуществления настоящего технического решения, элементы могут также упоминаться как "узлы" древовидной структуры. В некоторых вариантах осуществления настоящего технического решения, путь определяет связь между файлом (т.е. файлом каталога или файлом документа) и иерархической структурой данных. Путь может включать в себя последовательность элементов пути, каждый из которых определяет узел в иерархической структуре данных. Например, папка 304 является элементом пути, который определен связкой из корневого каталога 302, папкой 304 и папкой 306. Одновременно обращаясь к Фиг. 3 и Фиг. 4, иерархическая таблица 404 содержит только записи о корневом каталоге 302 (т.е. "/"), папке А 304 (англ. "folder А"), папке В 306 (англ. "folder В") и папке D 310 (англ. "folder D").
[72] В некоторых вариантах осуществления настоящего технического решения иерархическая таблица 404 может включать в себя для каждого элемента множество информационных компонентов. В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302) может быть элементом пути (т.е., элементом, который обладает по меньшей мере одним дочерним элементом в иерархической структуре данных, например, файлом каталога), который связан с (i) иерархическим идентификатором, который связан с отрезком пути к элементу пути в иерархической структуре данных. Иерархический идентификатор может зависеть от пути к элементу, который определяется как отрезок к элементу пути. Словосочетание "отрезок пути" используется в описании для упрощения различий между частичным путем, связанным с элементом, который обладает одним или несколькими дочерними элементами, и путем, связанным с элементом, который определяет лист иерархической структуры данных. Тем не менее, следует отметить, что словосочетание "отрезок пути" не является ограничивающим, и что словосочетание "отрезок пути" может быть заменено на слово "путь", не выходя за границы настоящего технического решения. В качестве примера, папка 306 может обладать иерархическим идентификатором, который связан с отрезком пути «/папка А/» (англ. "/folder А/"), который определяет путь от корневой папки 302 к папке 306. В некоторых вариантах осуществления настоящего технического решения, отрезок пути может быть определен как начинающийся с корневой папки. В некоторых других вариантах осуществления настоящего технического решения, отрезок пути может быть определен как начинающийся с не-корневой папки. Дополнительно, в некоторых вариантах осуществления настоящего технического решения, иерархический идентификатор может быть создан путем применения хэш-функции к отрезку пути (или пути), связанному с элементом пути. Хэш-функция может представлять собой любую хэш-функцию, что должно быть понятно специалисту в данной области техники. В примере, показанном на Фиг. 4, иерархический идентификатор упоминается как "hid". Например, значение hid, связанное с корневой папкой 302 равно "0", значение hid, связанное с папкой 304 - "11аа", значение hid, связанное с папкой 306 - "22bb", значение hid, связанное с папкой 310 - "44dd".
[73] В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302) может также быть связан с (ii) независимым идентификатором иерархической таблицы, который уникальным образом идентифицирует элемент пути в иерархической таблице 404. В некоторых вариантах осуществления настоящего технического решения, значение, которое представляет независимый идентификатор иерархической таблицы, может быть целым числом, но могут быть применены и многие другие варианты, не выходя за пределы настоящего технического решения. В примере, показанном на Фиг. 4, независимый идентификатор иерархической таблицы упоминается как "id". Например, значение id, связанное с корневой папкой 302 равно "0", значение id, связанное с папкой 304 - "1", значение id, связанное с папкой 306 - "2", значение id, связанное с папкой 310 - "4".
[74] В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302) может также быть связан с (iii) идентификатором родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит элемент. В некоторых вариантах осуществления настоящего технического решения, значение, которое представляет родительский иерархический идентификатор, может быть связано с соответствующим иерархическим идентификатором соответствующего родительского элемента (например, соответствующим хэш-значением), но могут быть применены и многие другие варианты, не выходя за пределы настоящего технического решения. В некоторых вариантах осуществления настоящего технического решения, идентификатор родительского элемента в иерархической таблице может быть ссыпкой на родительский элемент пути. В примере, показанном на Фиг. 4, идентификатор родительского элемента в иерархической таблице упоминается как родитель (англ. "parent"). Например, значение parent, связанное с корневой папкой 302 равно "NULL", значение parent, связанное с папкой 304 - "0", значение parent, связанное с папкой 306 -"11аа", значение parent, связанное с папкой 310 - "0".
[75] В некоторых вариантах осуществления настоящего технического решения, файловая таблица 402 может содержать только элементы, которые обладают родительско-дочерней или дочерне-родительской связью с другим элементом или элементами. В качестве примера, файловая таблица 402 может содержать элементы, которые обладают родительско-дочерней связью (т.е. элемент, связанный с дочерним элементом) и/или элементы, которые обладают дочерне-родительской связью (т.е. элемент, связанный с родительским элементом). В таких вариантах осуществления настоящего технического решения, элементы могут упоминаться как "узел" (т.е. элемент, связанный только с дочерним элементом) или "лист" (т.е. элемент, связанный с только с родительским элементом) древовидной структуры. Например, файловая таблица 402 может содержать элементы, которые представляют путь элемента (например, файла каталога) и/или элементы, которые представляют файл (например, файл каталога или файл документа). Одновременно обращаясь к Фиг. 3 и Фиг. 4, файловая таблица 402 содержит записи для корневого каталога 302 (т.е. "/"), папки А 304 (англ. "folder А"), папки В 306 (англ. "folder В"), папки D 310 (англ. "folder D") и также для файла С 308 (англ. "file С") и файла Е 312 (англ. "file Е").
[76] В некоторых вариантах осуществления настоящего технического решения файловая таблица 402 может включать в себя, для каждого элемента множество информационных компонентов. В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302, файл 308) может быть элементом пути (т.е. элементом, который обладает по меньшей мере одним дочерним элементом в иерархической структуре данных, например, файлом каталога) или файлом (т.е. элементом, который обладает по меньшей мере одним дочерним элементом в иерархической структуре данных или элементом, который не является родительским по отношению к другому элементу, например, файлу документа). Каждый элемент может быть связан с (i) независимым идентификатором файловой таблицы, который уникально идентифицирует элемент пути или файл в файловой таблице 402. В некоторых вариантах осуществления настоящего технического решения, значение, которое представляет независимый идентификатор файловой таблицы, может быть целым числом, но могут быть применены и многие другие варианты, не выходя за пределы настоящего технического решения. В некоторых вариантах осуществления настоящего технического решения, независимый идентификатор файловой таблицы, относящийся к файловой таблице 402, может быть идентичен соответствующему независимому идентификатору иерархической таблицы, относящемуся к иерархической таблице 404. В примере, показанном на Фиг. 4, независимый идентификатор файловой таблицы упоминается как "id". Например, значение id, связанное с корневой папкой 302 равно "0", значение id, связанное с папкой 304 - "1", значение id, связанное с папкой 306 - "2", значение id, связанное с папкой 308 - "3", значение id, связанное с папкой 310 - "4", а значение id, связанное с файлом 312 - "5".
[77] В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302 или файл 308) может также быть связан с (ii) идентификатором родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящимся к родительскому элементу пути, от которого зависит элемент. В некоторых вариантах осуществления настоящего технического решения, значение, которое представляет идентификатор родительского элемента в файловой таблице, может быть значением, связанным с соответствующим независимым идентификатором файловой таблицы, но могут быть применены и многие другие варианты, не выходя за пределы настоящего технического решения и которые будут ясны специалистам в данной области техники. В некоторых вариантах осуществления настоящего технического решения, идентификатор родительского элемента в файловой таблице может быть ссылкой на родительский элемент пути. В примере, показанном на Фиг. 4, идентификатор родительского элемента в файловой таблице упоминается как «родитель» (англ. "parent"). Например, значение parent, связанное с корневой папкой 302 равно "NULL", значение parent, связанное с папкой 304 - "0", значение parent, связанное с папкой 306 - "1", значение parent, связанное с файлом 308 - "1", значение parent, связанное с папкой 310 - "0", а значение parent, связанное с файлом 312 - "4".
[78] В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302 или файл 308) может также быть связан с (iii) независимым идентификатором родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависят элементы пути или файла. В некоторых вариантах осуществления настоящего технического решения, независимый идентификатор родительского элемента в файловой таблице также может быть связан с именем, которое связано с независимым идентификатором файловой таблицы, который связан с родительским элементом пути, от которого зависят элементы пути или файла. Дополнительно, в некоторых вариантах осуществления настоящего технического решения, независимый идентификатор родительского элемента в файловой таблице может быть создан путем применения хэш-функции к независимому идентификатору файловой таблицы, который связан с родительским элементом пути, от которого зависят элементы пути, и/или к имени, которое связано с родительским элементом пути, от которого зависят элементы пути или файл. Хэш-функция может представлять собой любую хэш-функцию, что должно быть понятно специалисту в данной области техники. В примере, показанном на Фиг. 4, независимый идентификатор родительского элемента в файловой таблице упоминается как "pid". Например, значение pid, связанное с корневой папкой 302 равно "0", значение pid, связанное с папкой 304 - "хх", значение pid, связанное с папкой 306 - "xl", значение pid, связанное с файлом 308 - "xy", значение pid, связанное с папкой 310 - "xz", а значение pid, связанное с файлом 312 - "zy".
[79] В некоторых вариантах осуществления настоящего технического решения, каждый элемент (например, корневой каталог 302 или файл 308) может также быть связан с (iv) текстовым потоком, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом. В примере, показанном на Фиг. 4, текстовый поток упоминается как имя (англ. "name"). Например, текстовый поток, связанный с корневой папкой 302 представляет собой "/", текстовый поток, связанный с папкой А 304 - "folder А", текстовый поток, связанный с папкой В 306 - "folder В", текстовый поток, связанный с файлом С 308 - "file С", текстовый поток, связанный с папкой D 310 - "folder D", текстовый поток, связанный с файлом Е 312 - "file Е".
[80] С учетом структуры данных, представленной в вышепредставленных параграфах, способ извлечения данных, которые хранятся в иерархической таблице 404 и файловой таблице 402, может выполняться, опираясь на путь (или отрезок пути). Например, извлечение файла С 308 (англ. "file С") может выполняться путем создания иерархического идентификатора на основе пути, связанного с файлом 308. В этом конкретном примере, иерархический идентификатор может быть создан на основе пути "/folder А/". В некоторых вариантах осуществления настоящего технического решения, иерархический идентификатор может быть создан путем применения хэш-функции к пути. В этом примере, иерархический идентификатор, основанный на хэшированием пути, представляет собой "11аа". Далее идентифицируется иерархический идентификатор иерархической таблицы 404, соответствующий "11аа". В этом примере, извлекается запись, соответствующая папке А (англ. "folder А"). Далее, соответствующий независимый идентификатор иерархической таблицы, относящийся к иерархической таблице 404 (т.е. "1"), берется в расчет для определения в файловой таблице 402 одной или нескольких записей, которые обладают идентификатором родительского элемента в файловой таблице, связанным с записью, которая соответствует иерархическому идентификатору. В данном примере способ может идентифицировать папку 306 или файл 308 как обладающие идентификатором родительского элемента в иерархической таблице, который обладает значением "1". Далее, файл 308 может быть определен, например, путем поиска просмотра поискового потока, соответствующего файлу С ("file С").
[81] Далее, с учетом структуры данных, представленной в последующих параграфах, способ модифицкации иерархической структуры после перемещения файла каталога может выполняться только путем обновления иерархической таблицы 404 без необходимости обновлять файловую таблицу 402. В некоторых вариантах осуществления настоящего технического решения, подобное перемещение может отражаться в иерархической таблице 404 путем обновления соответствующего иерархического идентификатора и/или соответствующего идентификатора родительского элемента в иерархической таблице. В некоторых вариантах осуществления настоящего технического решения, с учетом представленной в последующих параграфах структуры данных, записи в файловой таблице 402, которые соответствуют дочерним элементам, зависящим от файла каталога, который будет перемещен, не нуждаются в обновлении, что снижает вычислительную мощность и/или количество времени, которое необходимо для выполнения подобного обновления в базе данных, которая размещает иерархическую таблицу 404 и/или файловую таблицу 402.
[82] Со ссылками на Фиг. 1 - Фиг. 4, были описаны некоторые не ограничивающие примеры систем и компьютерных способов, используемые в связи с проблемой обработки документа в распределенной архитектуре, и далее следует описание общего решения этой проблемы со ссылкой на Фиг. 5-7.
[83] Конкретнее, на Фиг. 5 представлена блок-схема, отображающая первый исполняемый на компьютере способ 500, являющийся вариантом осуществления настоящего технического решения. Исполняемый на компьютере способ, представленный на Фиг. 5, включает в себя выполняемый на компьютере способ, реализуемый процессором сервера 202 базы данных, способ включает в себя серию этапов, выполняемых сервером 202 базы данных.
[84] Исполняемый на компьютере способ, представленный на Фиг. 5, может быть осуществлен, например, в случае сервера 202 базы данных, процессором 110, выполняющими программные инструкции, загруженные в ОЗУ 130 с твердотельного накопителя 120 сервера 202 базы данных.
[85] Способ 500 позволяет осуществлять хранение данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных. Способ 500 начинается на этапе 502 путем получения доступа к данным на постоянном машиночитаемом носителе. Далее, на этапе 504, по меньшей мере для одного из элементов пути, связанного с данными, способ 500 осуществляет сохранение в иерархической таблице, которая доступна на постоянном машиночитаемом носителе, (i) иерархического идентификатора, связанного с отрезком пути, который ведет по меньшей мере к одному элементу пути в иерархической структуре данных; (ii) независимого идентификатора иерархической таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути в иерархической таблице, и (iii) идентификатора родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит по меньшей мере один элемент пути.
[86] На этапе 506, по меньшей мере для одного из элементов пути и файла, связанного с данными, способ 500 осуществляет сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, (i) независимого идентификатора файловой таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути и файл в файловой таблице; (ii) идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит по меньшей мере один элемент пути и файл.
[87] В некоторых вариантах осуществления настоящего технического решения, иерархический идентификатор создается путем применения хэш-функции к отрезку пути. В некоторых других вариантах осуществления настоящего технического решения, отрезок пути является полным путем между корнем иерархической структуры данных и узлом, который определен по меньшей мере одним из элементов пути.
[88] В некоторых вариантах осуществления настоящего технического решения, способ дополнительно включает в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, (iii) независимого идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависит по меньшей мере один элемент пути и файл.
[89] Способ 500 также может дополнительно включать в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, (iv) текстового потока, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом.
[90] В некоторых вариантах осуществления настоящего технического решения, идентификатор родительского элемента в файловой таблице создается на основе (i) независимого идентификатора файловой таблицы, который связан с родительским элементом пути и (ii) имени, которое связано по меньшей мере с одним из элементов пути и файлом. В некоторых дополнительных вариантах осуществления настоящего технического решения, по меньшей мере один из элементов пути представляет собой файл каталога. В некоторых вариантах осуществления настоящего технического решения, файл определяет лист в иерархической структуре и файл каталога определяет узел в иерархической структуре. В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица и файловая таблица реализованы с помощью реляционной базы данных.
[91] На Фиг. 6 представлена блок-схема, отображающая второй исполняемый на компьютере способ 600, являющийся вариантом осуществления настоящего технического решения. Исполняемый на компьютере способ, представленный на Фиг. 6, включает в себя выполняемый на компьютере способ, реализуемый процессором сервера 202 базы данных, способ включает в себя серию этапов, выполняемых сервером 202 базы данных.
[92] Что касается исполняемого на компьютере способа, представленного на Фиг. 5, исполняемый на компьютере способ, представленный на Фиг. 6, может быть осуществлен, например, в случае сервера 202 базы данных, процессором 110, выполняющими программные инструкции, загруженные в ОЗУ 130 с твердотельного накопителя 120 сервера 202 базы данных.
[93] Способ 600 позволяет осуществлять извлечение данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных. Способ 600 начинается на этапе 602 путем получения доступа к иерархической таблице и файловой таблице с постоянного машиночитаемого носителя. Далее, на этапе 604 способ 600 создает иерархический идентификатор на основе пути. На этапе 606, способ 600 переходит к идентификации в иерархической таблице по меньшей мере одной записи, которая соответствует иерархическому идентификатору. Далее, на этапе 608 способ 600 переходит к идентификации в файловой таблице по меньшей мере одной записи, которая обладает идентификатором родительского элемента в файловой таблице, соответствующим идентификатору родительского элемента в иерархической таблице, который связан по меньшей мере с одной записью, соответствующей иерархическому идентификатору.
[94] В некоторых вариантах осуществления настоящего технического решения, создание иерархического идентификатора включает в себя применение хэш-функции к пути. Также, в некоторых вариантах осуществления настоящего технического решения, иерархическая таблица структурирована следующим образом: (i) иерархический идентификатор, связанный с отрезком пути, который ведет к одному элементу пути в иерархической структуре данных; (ii) независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице, и (iii) идентификатор родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[95] В некоторых вариантах осуществления настоящего технического решения, файловая таблица структурирована следующим образом: (i) независимый идентификатор файловой таблицы идентифицирует один из элементов пути и файл в файловой таблице; и (ii) идентификатор родительского элемента в файловой таблице связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит один из элементов и файл.
[96] На Фиг. 7 представлена блок-схема, отображающая третий исполняемый на компьютере способ 700, являющийся вариантом осуществления настоящего технического решения. Исполняемый на компьютере способ, представленный на Фиг. 7, включает в себя выполняемый на компьютере способ, реализуемый процессором сервера 202 базы данных, способ включает в себя серию этапов, выполняемых сервером 202 базы данных.
[97] Что касается исполняемых на компьютере способов, представленных на Фиг. 5 и Фиг. 6, исполняемый на компьютере способ, представленный на Фиг. 7, может быть осуществлен, например, в случае сервера 202 базы данных, процессором 110, выполняющими программные инструкции, загруженные в ОЗУ 130 с твердотельного накопителя 120 сервера 202 базы данных.
[98] Способ 700 позволяет осуществлять обновление данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных. Способ 700 начинается на этапе 702 при определении модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации. Далее на этапе 704, осуществляется получение доступа на постоянном машиночитаемом носителе к иерархической таблице, которая содержит данные, относящиеся к пути, данные независимы от файловой таблицы, которая содержит данные, относящиеся к файлу.
[99] На этапе 706 способ 700 создает первый иерархический идентификатор на основе последовательности элементов пути до модификации. Способ 700 далее продолжается на этапе 708 при создании второго иерархического идентификатора на основе последовательности элементов пути после модификации. На этапе 710, способ 700 переходит к идентификации в иерархической таблице по меньшей мере одной записи, которая соответствует первому иерархическому идентификатору. На этапе 712, способ 700 осуществляет замену в иерархической таблице по меньшей мере одной записи на второй иерархический идентификатор.
[100] В некоторых вариантах осуществления настоящего технического решения обновление данных, связанных с путем и файлом выполняется без модификации содержимого файловой таблицы. В некоторых вариантах осуществления настоящего технического решения, иерархическая таблица структурирована следующим образом: (i) иерархический идентификатор, связанный с отрезком пути, который ведет к одному элементу пути в иерархической структуре данных; (ii) независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице, и (iii) идентификатор родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[101] С учетом вышеописанных вариантов осуществления настоящего технического решения, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящего технического решения. Соответственно, порядок и группировка этапов не является ограничением для настоящего технического решения.
[102] Таким образом, способы и системы, реализованные в соответствии с некоторыми неограничивающими вариантами осуществления настоящего технического решения, могут быть представлены следующим образом в пронумерованных пунктах.
[103] [Пункт 1] Исполняемый на компьютере способ хранения данных, связанных с путем и файлом (500), путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором (110) и включает в себя:
получение доступа к данным с постоянного машиночитаемого носителя (120, 130);
по меньшей мере для одного из элементов пути, связанного с данными, сохранение в иерархической таблице (404), которая доступна на постоянном машиночитаемом носителе (120, 130), (i) иерархического идентификатора, связанного с отрезком пути, который ведет по меньшей мере к одному элементу пути в иерархической структуре данных; (ii) независимого идентификатора иерархической таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути в иерархической таблице (404), и (iii) идентификатора родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит по меньшей мере один элемент пути; и
по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице (402), которая доступна на постоянном машиночитаемом носителе (120, 130), (i) независимого идентификатора файловой таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути и файл в файловой таблице (402); и (ii) идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит по меньшей мере один элемент пути и файл.
[104] [Пункт 2] Способ по п. 1, в котором иерархический идентификатор создается путем применения хэш-функции к отрезку пути.
[105] [Пункт 3] Способ по п. 1, в котором отрезок пути является полным путем между корнем иерархической структуры данных и узлом, который определен по меньшей мере одним из элементов пути.
[106] [Пункт 4] Способ по п. 1, который дополнительно включает в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице (402), которая доступна на постоянном машиночитаемом носителе (110, 130), (iii) независимого идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависит по меньшей мере один элемент пути и файл.
[107] [Пункт 5] Способ по п. 4, который дополнительно включает в себя, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице (402), которая доступна на постоянном машиночитаемом носителе (120, 130), (iv) текстового потока, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом.
[108] [Пункт 6] Способ по п. 4, в котором идентификатор родительского элемента в файловой таблице создается на основе (i) независимого идентификатора файловой таблицы, который связан с родительским элементом пути и (ii) имени, которое связано по меньшей мере с одним из элементов пути и файлом.
[109] [Пункт 7] Способ по п. 1, в котором по меньшей мере один из элементов пути представляет собой файл каталога.
[110] [Пункт 8] Способ по п. 7, в котором файл определяет лист в иерархической структуре и файл каталога определяет узел в иерархической структуре.
[111] [Пункт 9] Способ по п. 1, в котором иерархическая таблица (404) и файловая таблица (402) реализованы с помощью реляционной базы данных.
[112] [Пункт 10] Исполняемый на компьютере способ извлечения данных, связанных с путем и файлом (600), путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором (110) и включает в себя:
получение доступа к иерархической таблице (404) и файловой таблице (402) с постоянного машиночитаемого носителя (110, 130);
создание иерархического идентификатора на основе пути;
идентификация в иерархической таблице (404) по меньшей мере одной записи, которая соответствует иерархическому идентификатору; и
идентификация в файловой таблице (402) по меньшей мере одной записи, которая обладает идентификатором родительского элемента в файловой таблице, соответствующим идентификатору родительского элемента в иерархической таблице, который связан по меньшей мере с одной записью, соответствующей иерархическому идентификатору.
[113] [Пункт 11] Способ по п. 10, в котором создание иерархического идентификатора включает в себя применение хэш-функции к пути.
[114] [Пункт 12] Способ по п. 10, в котором иерархическая таблица (404) структурирована следующим образом:
(i) иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
(ii) независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице (404); и
(iii) идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[115] [Пункт 13] Способ по п. 10, в котором файловая таблица (402) структурирована следующим образом:
(i) независимый идентификатор файловой таблицы уникальным образом идентифицирует один из элементов пути и файл в файловой таблице (402); и
(ii) идентификатор родительского элемента в файловой таблице связан с независимым идентификатором файловой таблицы, который связан с родительским элементом пути, от которого зависит один из элементов пути и файл.
[116] [Пункт 14] Исполняемый на компьютере способ обновления данных, связанных с путем и файлом (700), путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором (110) и включает в себя:
определение модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации;
получение доступа на постоянном машиночитаемом носителе (110, 130) к иерархической таблице (404), которая содержит данные, относящиеся к пути, данные независимы от файловой таблицы, которая содержит данные, относящиеся к файлу;
создание первого иерархического идентификатора на основе последовательности элементов пути до модификации;
создание второго иерархического идентификатора на основе последовательности элементов пути после модификации;
идентификация в иерархической таблице (404) по меньшей мере одной записи, которая соответствует первому иерархическому идентификатору; и
замена в иерархической таблице (404) по меньшей мере одной записи на второй иерархический идентификатор.
[117] [Пункт 15] Способ по п. 14, в котором обновление данных, связанных с путем и файлом выполняется без модификации содержимого файловой таблицы (402).
[118] [Пункт 16] Способ по п. 14, в котором иерархическая таблица (404) структурирована следующим образом:
(i) иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
(ii) независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице (404); и
(iii) идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
[119] [Пункт 17] Исполняемая на компьютере система, выполненная с возможностью выполнять способ по любому из пп. 1-16.
[120] [Пункт 18] Постоянный машиночитаемый носитель, включающий в себя машиночитаемые инструкции, которые инициируют систему исполнять способ в соответствии с любым из пп. 1-17.
[121] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящего технического решения.
[122] Некоторые из этих этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[123] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| СПОСОБ УПРАВЛЕНИЯ СИНХРОНИЗАЦИЕЙ ФАЙЛОВ (ВАРИАНТЫ), ЭЛЕКТРОННОЕ УСТРОЙСТВО (ВАРИАНТЫ) И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ | 2014 |
|
RU2643429C2 |
| МЕХАНИЗМЫ ОБНАРУЖИВАЕМОСТИ И ПЕРЕЧИСЛЕНИЯ В ИЕРАРХИЧЕСКИ ЗАЩИЩЕННОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2408070C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ АППАРАТНОЙ/ПРОГРАММНОЙ ИНТЕРФЕЙСНОЙ СИСТЕМОЙ | 2004 |
|
RU2377646C2 |
| АРЕНДА КАТАЛОГА | 2011 |
|
RU2596986C2 |
| СИСТЕМА И СПОСОБЫ ОБЕСПЕЧЕНИЯ УЛУЧШЕННОЙ МОДЕЛИ БЕЗОПАСНОСТИ | 2004 |
|
RU2564850C2 |
| СИСТЕМЫ И СПОСОБЫ РАСШИРЕНИЙ И НАСЛЕДОВАНИЯ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО-ПРОГРАММНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2412475C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ДАННЫХ | 2014 |
|
RU2646349C2 |
| УВЕДОМЛЕНИЯ ОБ ИЗМЕНЕНИИ ДАННЫХ | 2006 |
|
RU2421803C2 |
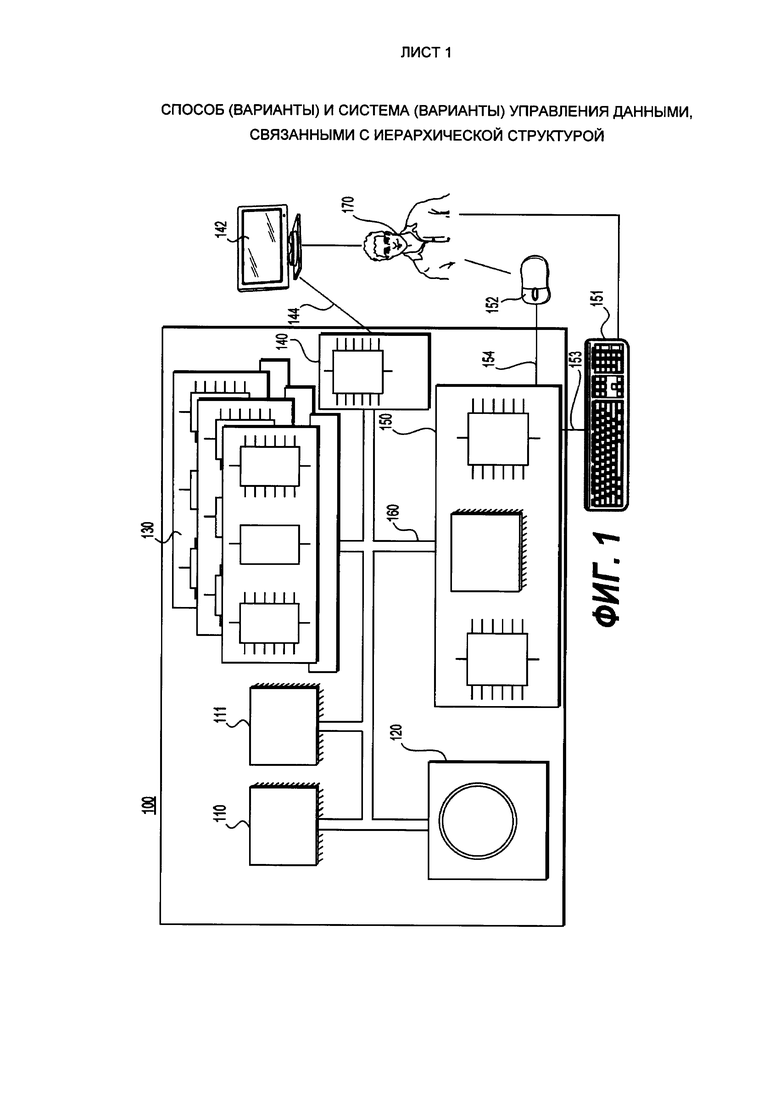
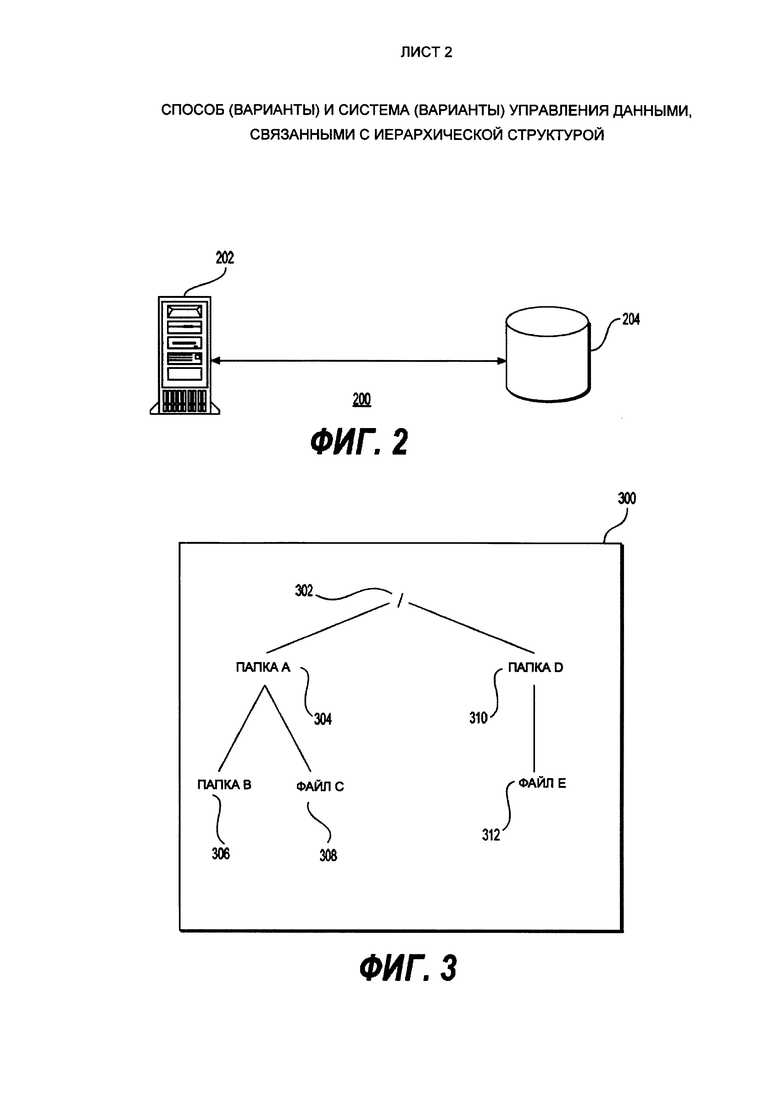
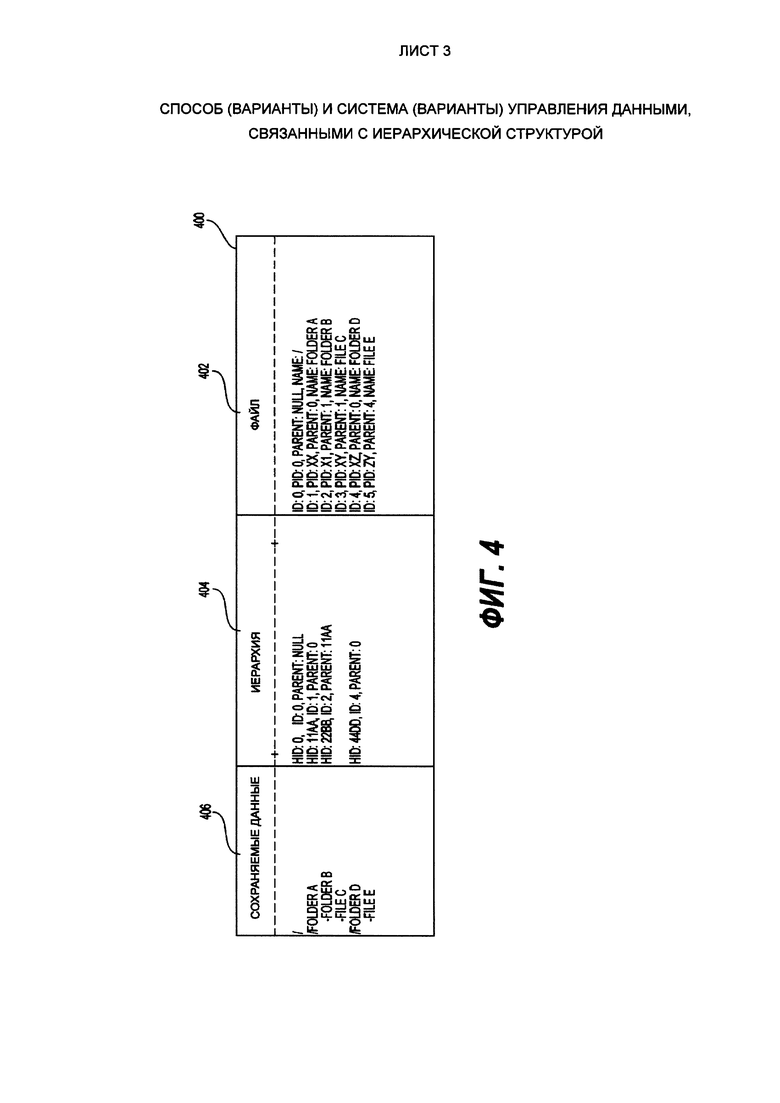
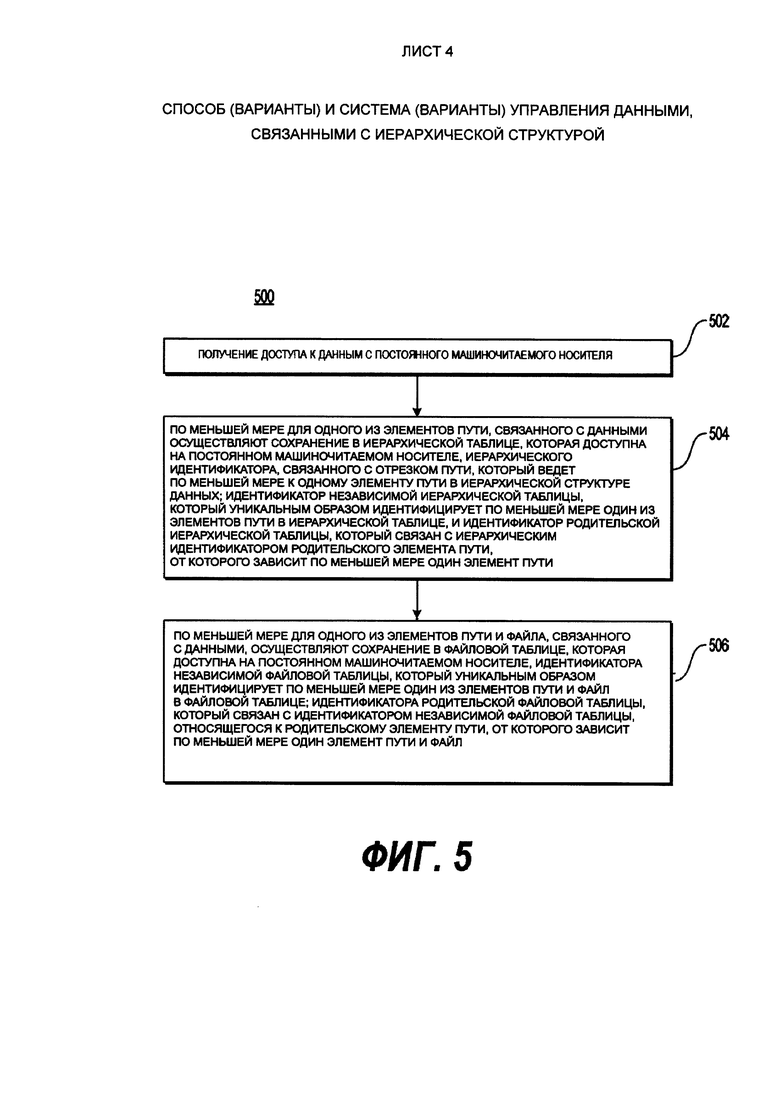
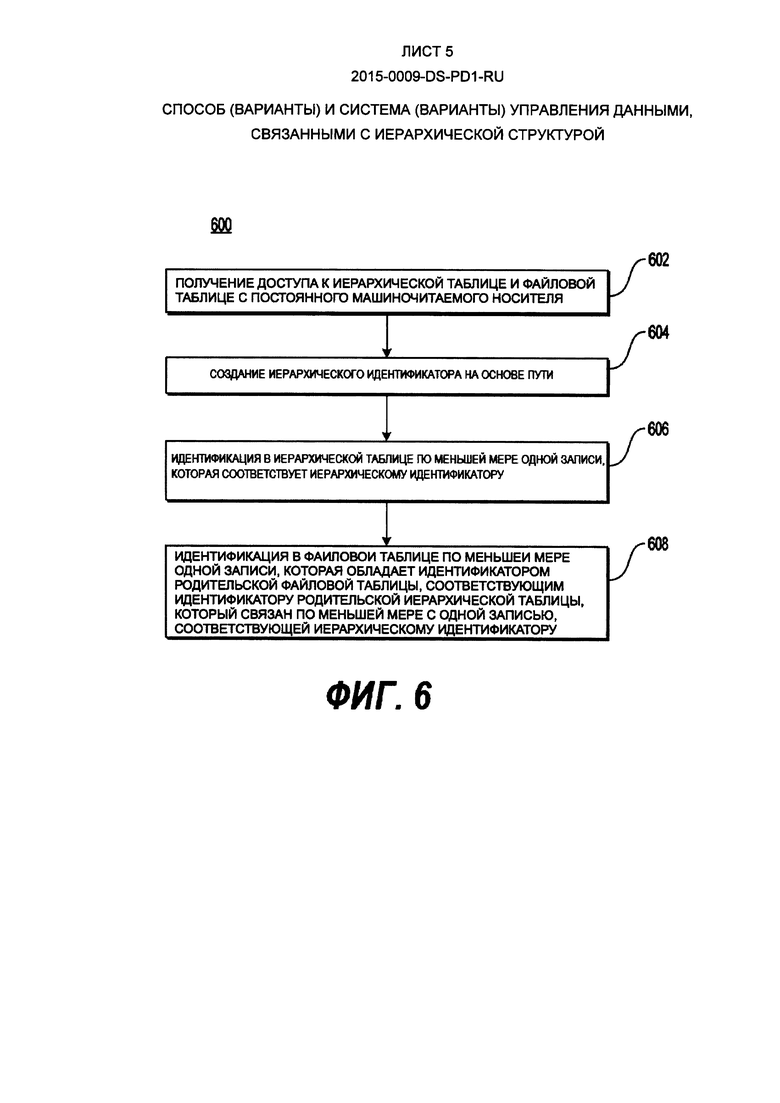
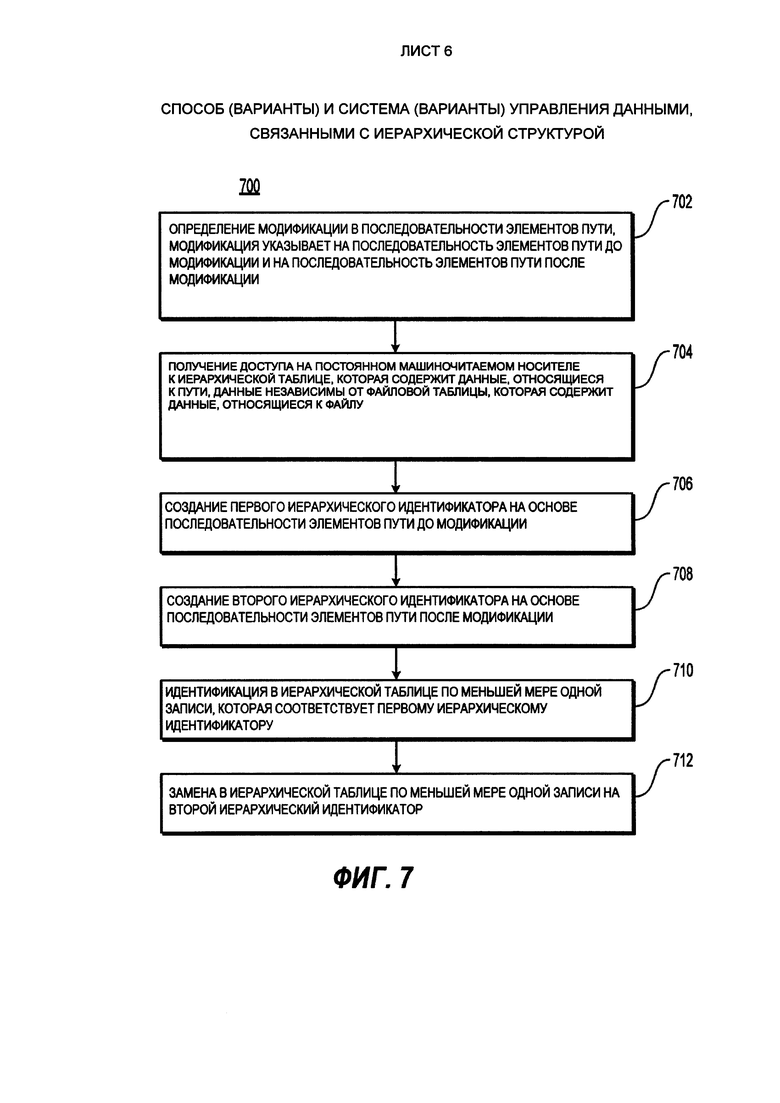
Изобретение относится к способам и системам хранения, извлечения и обновления данных, связанных с путем и файлом. Технический результат заключается в повышении эффективности обработки данных. В способе обновления данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных и включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя определение модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации, получение доступа на постоянном машиночитаемом носителе к иерархической таблице, содержащей данные, относящиеся к пути, данные независимы от файловой таблицы, содержащей данные, относящиеся к файлу, создание первого иерархического идентификатора на основе последовательности элементов пути до модификации, создание второго иерархического идентификатора на основе последовательности элементов пути после модификации, идентификацию в иерархической таблице записи, которая соответствует первому иерархическому идентификатору и замену в иерархической таблице записи на второй иерархический идентификатор. 6 н. и 15 з.п. ф-лы, 7 ил.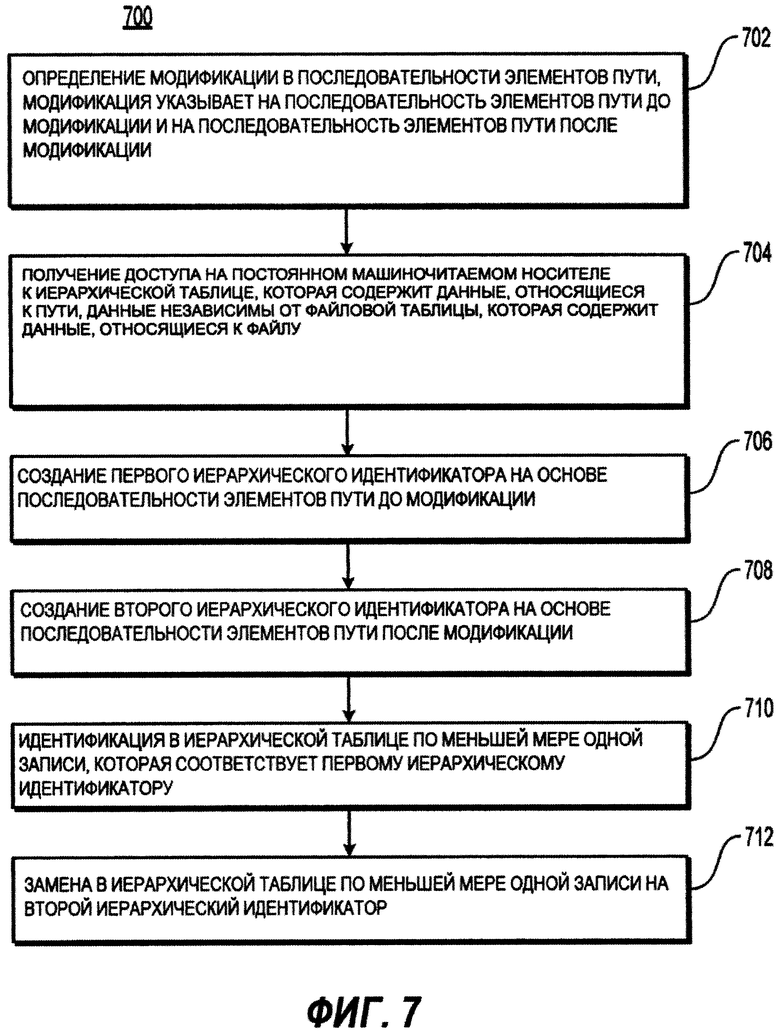
1. Исполняемый на компьютере способ хранения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
получение доступа к данным с постоянного машиночитаемого носителя;
по меньшей мере для одного из элементов пути, связанного с данными, сохранение в иерархической таблице, которая доступна на постоянном машиночитаемом носителе: иерархического идентификатора, связанного с отрезком пути, который ведет по меньшей мере к одному элементу пути в иерархической структуре данных; независимого идентификатора иерархической таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути в иерархической таблице, и идентификатора родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит по меньшей мере один элемент пути; и
по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе: независимого идентификатора файловой таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути и файл в файловой таблице, и идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит по меньшей мере один элемент пути и файл.
2. Способ по п. 1, в котором иерархический идентификатор создают путем применения хэш-функции к отрезку пути.
3. Способ по п. 1, в котором отрезок пути является полным путем между корнем иерархической структуры данных и узлом, который определен по меньшей мере одним из элементов пути.
4. Способ по п. 1, в котором дополнительно выполняют, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, независимого идентификатора родительского элемента файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависит по меньшей мере один элемент пути и файл.
5. Способ по п. 1, в котором по меньшей мере один из элементов пути представляет собой файл каталога.
6. Способ по п. 1, в котором иерархическая таблица и файловая таблица реализованы с помощью реляционной базы данных.
7. Способ по п. 4, в котором дополнительно выполняют, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, текстового потока, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом.
8. Способ по п. 4, в котором идентификатор родительского элемента в файловой таблице создают на основе независимого идентификатора файловой таблицы, который связан с родительским элементом пути и имени, которое связано по меньшей мере с одним из элементов пути и файлом.
9. Способ по п. 5, в котором файл определяет лист в иерархической структуре и файл каталога определяет узел в иерархической структуре.
10. Исполняемый на компьютере способ извлечения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
получение доступа к иерархической таблице и файловой таблице с постоянного машиночитаемого носителя;
создание иерархического идентификатора на основе пути;
идентификацию в иерархической таблице по меньшей мере одной записи, которая соответствует иерархическому идентификатору; и
идентификацию в файловой таблице по меньшей мере одной записи, которая обладает идентификатором родительского элемента в файловой таблице, соответствующим идентификатору родительского элемента в иерархической таблице, который связан по меньшей мере с одной записью, соответствующей иерархическому идентификатору.
11. Способ по п. 10, в котором при создании иерархического идентификатора выполняют применение хэш-функции к пути.
12. Способ по п. 10, в котором иерархическую таблицу структурируют следующим образом:
иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице; и
идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
13. Способ по п. 10, в котором файловую таблицу структурируют следующим образом:
независимый идентификатор файловой таблицы уникальным образом идентифицирует один из элементов пути и файл в файловой таблице; и
идентификатор родительского элемента в файловой таблице связан с независимым идентификатором файловой таблицы, который связан с родительским элементом пути, от которого зависит один из элементов пути и файл.
14. Исполняемый на компьютере способ обновления данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути
определяет узел в иерархической структуре данных, способ выполняется процессором и включает в себя:
определение модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации;
получение доступа на постоянном машиночитаемом носителе к иерархической таблице, которая содержит данные, относящиеся к пути, данные независимы от файловой таблицы, которая содержит данные, относящиеся к файлу;
создание первого иерархического идентификатора на основе последовательности элементов пути до модификации;
создание второго иерархического идентификатора на основе последовательности элементов пути после модификации;
идентификацию в иерархической таблице по меньшей мере одной записи, которая соответствует первому иерархическому идентификатору; и
замену в иерархической таблице по меньшей мере одной записи на второй иерархический идентификатор.
15. Способ по п. 14, в котором обновление данных, связанных с путем и файлом, выполняют без модификации содержимого файловой таблицы.
16. Способ по п. 14, в котором иерархическую таблицу структурируют следующим образом:
иерархический идентификатор связан с отрезком пути к одному из элементов пути в иерархической структуре данных;
независимый идентификатор иерархической таблицы уникальным образом идентифицирует один из элементов пути в иерархической таблице; и
идентификатор родительского элемента в иерархической таблице связан с иерархическим идентификатором родительского элемента пути, от которого зависит один из элементов пути.
17. Исполняемая на компьютере система хранения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, система включает в себя:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
получение доступа к данным с постоянного машиночитаемого носителя;
по меньшей мере для одного из элементов пути, связанного с данными, сохранение в иерархической таблице, которая доступна на постоянном машиночитаемом носителе: иерархического идентификатора, связанного с отрезком пути, который ведет по меньшей мере к одному элементу пути в иерархической структуре данных; независимого идентификатора иерархической таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути в иерархической таблице, и идентификатора родительского элемента в иерархической таблице, который связан с иерархическим идентификатором родительского элемента пути, от которого зависит по меньшей мере один элемент пути; и
по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, независимого идентификатора файловой таблицы, который уникальным образом идентифицирует по меньшей мере один из элементов пути и файл в файловой таблице, и идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, относящегося к родительскому элементу пути, от которого зависит по меньшей мере один элемент пути и файл.
18. Система по п. 17, в которой процессор дополнительно выполнен с возможностью осуществлять по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, независимого идентификатора родительского элемента в файловой таблице, который связан с независимым идентификатором файловой таблицы, связанным с родительским элементом пути, от которого зависит по меньшей мере один элемент пути и файл.
19. Система по п. 18, в которой процессор дополнительно выполнен с возможностью осуществлять, по меньшей мере для одного из элементов пути и файла, связанного с данными, сохранение в файловой таблице, которая доступна на постоянном машиночитаемом носителе, текстового потока, который определяет имя, связанное по меньшей мере с одним из элементов пути и файлом.
20. Исполняемая на компьютере система извлечения данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, система включает в себя:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
получение доступа к иерархической таблице и файловой таблице с постоянного машиночитаемого носителя;
создание иерархического идентификатора на основе пути;
идентификацию в иерархической таблице по меньшей мере одной записи, которая соответствует иерархическому идентификатору; и
идентификацию в файловой таблице по меньшей мере одной записи, которая обладает идентификатором родительского элемента в файловой таблице, соответствующим идентификатору родительского элемента в иерархической таблице, который связан по меньшей мере с одной записью, соответствующей иерархическому идентификатору.
21. Исполняемая на компьютере система обновления данных, связанных с путем и файлом, путь определяет связь между файлом и иерархической структурой данных, путь включает в себя последовательность элементов пути, и каждый из элементов пути определяет узел в иерархической структуре данных, система включает в себя:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
определение модификации в последовательности элементов пути, модификация указывает на последовательность элементов пути до модификации и на последовательность элементов пути после модификации;
получение доступа на постоянном машиночитаемом носителе к иерархической таблице, которая содержит данные, относящиеся к пути, данные независимы от файловой таблицы, которая содержит данные, относящиеся к файлу;
создание первого иерархического идентификатора на основе последовательности элементов пути до модификации;
создание второго иерархического идентификатора на основе последовательности элементов пути после модификации;
идентификацию в иерархической таблице по меньшей мере одной записи, которая соответствует первому иерархическому идентификатору; и
замену в иерархической таблице по меньшей мере одной записи на второй иерархический идентификатор.
| US 6965903 B1, 15.11.2005 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Itzik Ben-Gan et al, "Advanced Transact-SQL for SQL Server 2000", Apress, 2000 год, 586 страниц, доступно по URL: http://www.sqlbooks.ru/books/AdvT-Sql.zip | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 20090307241 A1, 10.12.2009 | |||
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |

