Изобретение относится к способу классификации образца в одном из, по меньшей мере, двух классов на основании спектральных данных. Например, спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, частотный спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI. Спектры, полученные с использованием одного из этих методов, можно связывать с компонентами образца, т.е. с молекулами, присутствующими в образце.
Однако, независимо от технологии, используемой для получения спектров, происходят изменения между спектрами образцов, принадлежащими одному и тому же классу. Эти изменения можно объяснить стохастическими эффектами. Эти стохастические эффекты могут быть связаны с технологией измерения или с исследуемым образцом, или и с тем, и с другим.
Поэтому традиционные способы анализа спектральных данных требуют получения классифицируемых спектров из образцов, имеющих большое количество частиц, например молекул. Из-за необходимости большого количества частиц, признаки в спектрах, обусловленные стохастическими процессами, будут подавляться по сравнению с признаками, обусловленными стабильными процессами. Однако это делает традиционные способы непригодными для анализа образцов с малым количеством частиц. Когда стохастические эффекты по большей части обусловлены самой технологией измерения, традиционные способы требуют, чтобы классифицируемые спектры являлись так называемыми суммарными спектрами, также известными как совокупные спектры, полученными суммированием большого количества спектров одного и того же образца. При таком подходе, стохастические процессы, обусловленные технологией измерения, будут подавляться в суммарном спектре. Однако это делает традиционные способы непригодными для классификации образцов, когда не удается получить суммарные спектры.
Вышеозначенные проблемы будут проиллюстрированы на примере случая получения спектральных данных с использованием масс-спектрометрии (MS).
Традиционные масс-спектры и, в частности, времяпролетные (TOF) массовые спектры демонстрируют большие ионные интенсивности при массах, которые соответствуют массе часто встречающихся ионов в ионном факеле, образующемся при ионизации. В общем случае, эти часто встречающиеся ионы являются следствием часто встречающихся молекул, присутствующих в аналите.
Однако ввиду большой изменчивости ионизационной способности молекул, наличие часто встречающихся молекул не будет автоматически приводить к созданию большой ионной интенсивности.
Кроме того, эффективность ионизации зависит от многих факторов, которые могут сильно изменяться от одного события ионизации к другому. Примерами являются количество присутствующего аналита, отношение матрицы и аналита, кристаллическая структура матрицы и интенсивность лазерного пучка в положении матричного кристалла и аналита. Таким образом, ионная интенсивность, создаваемая событиями одинарной ионизации, будет значительно изменяться.
Кроме того, в ходе ионизации рассматриваемые молекулы могут распадаться на меньшие фрагменты, некоторые молекулы могут приобретать двойной или тройной заряд, молекулы могут образовывать кластеры в факеле и т.д. Следовательно, помимо высоких ионных интенсивностей возникающих при массах, которые соответствуют массам молекул аналита, спектр события одинарной ионизации будет демонстрировать пики в положении, не коррелирующем с массой молекул аналита. Однако, поскольку процесс распада, зарядки и кластеризации является весьма стохастическим по своей природе, позиция некоррелирующих пиков сильно изменяться от одного события ионизации к другому.
Для создания надежных и стабильных спектров, в традиционных способах классификации для MALDI MS, большое количество событий одинарной ионизации, зарегистрированных в разных положениях на пятне пластины-мишени, суммируется.
Таким образом, ионная интенсивность, обусловленная стохастическими процессами в ходе ионизации, будет подавляться по сравнению с ионной интенсивностью, обусловленной стабильными процессами. Стабильные процессы будут генерировать в суммированных спектрах узкие области высокой интенсивности (пики), тогда как процессы более стохастического характера будут генерировать в суммированных спектрах широкий отклик низкой интенсивности (базовую линию).
Пики, возникающие в суммированном спектре, могут быть связаны с легко (эффективно) ионизуемыми, часто встречающимися молекулами в аналите. В общем случае, эти пики используются для классификации спектров и, таким образом, рассматриваются как характерные особенности спектров.
Поскольку результирующий спектр происходит из большого количества событий одинарной ионизации, зарегистрированных в разных положениях на пятне пластины-мишени, эти традиционные спектры MALDI являются суммой спектров многих частиц образца. Например, в случае, когда образец содержит микроорганизмы, традиционные способы опираются на спектры, полученные из многих микроорганизмов.
Аналогичные проблемы возникают при применении традиционных способов к одночастичным спектрам, например, спектрам одиночных частиц аэрозоля. В традиционных способах, для генерации надежных и стабильных спектров, большое количество спектров одиночных частиц аэрозоля, полученных из микроорганизмов, которые происходят из единичного изолята, объединяются в суммарный спектр. Этот суммарный спектр характеризуется конечным количеством отдельных спектральных признаков (пиков), наложенных на гладкую базовую линию.
Отдельные одночастичные спектры, образующие накопленный спектр, характеризуются большим количеством пиков и отсутствием базовой линии. Некоторые пики возникают в положениях, которые совпадают с положением пиков в накопленном спектре, а другие пики возникают в положениях, которые не совпадают с ним. Кроме того, создается впечатление, что одночастичные спектры демонстрируют большое изменение от импульса к импульсу.
Фиг. 1 демонстрирует пример спектра (P), накопленного из большого количества одночастичных спектров, полученных из образцов, происходящих из единичного изолята, совместно с несколькими типичными примерами (Q, R, S, T) базисных одночастичных спектров.
В силу большого изменения от импульса к импульсу и ограниченной корреляции между положениями пиков одночастичного спектра и положениями пиков накопленного спектра, не существует никакого детерминистического соотношения между амплитудой спектра в определенном положении (массы по заряду) и наличием ионообразующего вещества с соответствующей массой.
Вышеприведенный пример демонстрирует проблемы традиционных способов анализа спектральных данных. Эти способы не позволяют работать непосредственно с одночастичными спектрами, поскольку они не учитывают изменения от импульса к импульсу. Кроме того, они не позволяют учитывать изменения, связанные с технологией измерения, например, вышеописанные изменения вследствие ионизации в MALDI MS.
Задачей изобретения является обеспечение усовершенствованного способа классификации образца в одном из, по меньшей мере, двух классов на основании спектральных данных, который является эффективным и надежным, когда спектры, принадлежащие одному и тому же классу, демонстрируют изменения.
Эта задача решается посредством способа классификации образца в одном из, по меньшей мере, двух классов на основании спектральных данных согласно изобретению, причем способ содержит этапы, на которых:
a) получают, по меньшей мере, два множества первых спектров для использования в качестве эталонных спектров, причем каждое множество содержит спектры эталонных образцов, принадлежащие одному и тому же классу;
b) определяют, для каждого из эталонных спектров, значение одной и той же, по меньшей мере, одной величины, связанной со спектральным признаком;
c) связывают вероятность с разными значениями величины на основании определенных значений;
d) получают спектр из образца и определяют значение одной и той же, по меньшей мере, одной величины этого спектра; и
e) вычисляют, на основании вероятностей и значения величины для полученного спектра для каждого из упомянутых, по меньшей мере, двух классов, вероятность того, что образец принадлежит этому классу.
Этапы a)-c) описывают создание эталонной библиотеки. Этапы d) и e) описывают сравнение образца с этой эталонной библиотекой.
На этапе b) значение одной и той же, по меньшей мере, одной величины определяется для каждого из эталонных спектров. Например, математическая операция осуществляется на спектральных данных для получения этого значения. Другими словами, этап b) описывает получение показателя (значения) путем применения заранее определенной функции или операции на каждом из эталонных спектров.
Результат этапа b) состоит в том, что с каждым из эталонных спектров связано, по меньшей мере, одно значение, причем каждое значение соответствующий заранее определенной величине, т.е. заранее определенной операции на спектре. Затем, для каждого множества эталонных спектров, вероятность связывается с разными значениями, по меньшей мере, одной величины на основании значений, определенных для спектров в этом множестве. Это можно рассматривать как построение функции плотности вероятности (PDF). Например, PDF является дискретной функцией плотности вероятности, которую можно представить, например, в виде массива или гистограммы.
Конечный результат этапов a)-c) состоит в том, что с каждым множеством эталонных спектров связывается, для каждой из, по меньшей мере, одной величины, PDF значения соответствующей величины. Например, в случае MS спектральных данных, одной из выбранных величин является интенсивность спектра, также известная как амплитуда спектра, при M/Z=1000 дальтонов. В этом примере, для каждого множества эталонных спектров создается PDF для интенсивности при M/Z=1000 дальтонов. Заметим, что PDF, в общем случае, будут сильно отличаться для разных множеств эталонных спектров, поскольку они соответствуют разным классам.
На этапе d) получается спектр образца, и также для этого спектра определяется значение, по меньшей мере, одной величины. На основании ранее построенных PDF на этапе e) вычисляется вероятность того, что образец принадлежит каждому из эталонных классов.
Поскольку способ согласно изобретению использует PDF значения (показателя) величины (связанной с заранее определенной операцией/функцией) для каждого класса, способ учитывает изменения в спектрах одного и того же класса. В частности, заметим, что как наличие, так и отсутствие признака, представленное значением, по меньшей мере, одной величины, учитывается в способе согласно настоящему изобретению.
Дополнительное преимущество способа согласно изобретению состоит в том, что конечным результатом на этапе e) является вероятность. Поскольку вероятность является нормализованной величиной, т.е. вероятность принимает значение между 0 и 1, вероятность того, что спектр образца принадлежит первому эталонному классу, можно сравнивать с вероятностью того, что спектр принадлежит второму классу. В этом состоит преимущество перед традиционными способами, в которых вычисляется показатель, который не является нормализованным.
Кроме того, изобретение позволяет задавать критерий принятия или отказа от классификации. В общем случае, спектр назначается классу, для которого вероятность того, что спектр образца принадлежит этому классу, максимальна. Однако эта вероятность может быть сравнительно низкой, например 0.2. Изобретение позволяет задавать порог, представляющий минимальное значение для приемлемой классификации. Спектры образцов, для которых максимальная вероятность для всех классов ниже порога, не классифицируются, т.е. они заносятся в класс "неизвестный". Такая процедура невозможна при использовании ненормализованного показателя, как в традиционных способах, поскольку порог в этом случае будет произвольным.
В предпочтительном варианте осуществления способа согласно изобретению спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, частотный спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI, предпочтительно, времяпролетный масс-спектр MALDI.
Как указано выше, в частности, в масс-спектре MALDI и времяпролетных масс-спектрах MALDI, изменение между спектрами, принадлежащими одному и тому же классу частиц значительно. Поэтому способ согласно изобретению особенно преимущественен для этих технологий измерения.
В предпочтительном варианте осуществления настоящего изобретения эталонные спектры и спектр, полученный из образца, являются спектрами одиночных частиц.
Это представляет предельный случай малого количества частиц. Как упомянуто выше, способ согласно изобретению способен учитывать изменение в спектрах, принадлежащих одному и тому же классу, которые, в частности, будут присутствовать в спектрах одиночных частиц.
Как упомянуто выше, способ согласно изобретению можно применять как для одиночных частиц, так и для двух или более частиц и даже для многих частиц.
Предпочтительно, способ содержит получение одночастичных спектров из образца с использованием MALDI MS, предпочтительно, MALDI TOF-MS. Это позволяет анализировать смеси частиц. Вместо анализа спектра, полученного из многих частиц смеси, т.е. составного спектра, получаются спектры для одиночных частиц смеси, и отдельные частицы классифицируются на основании одночастичных спектров.
Например, массовые спектры MALDI, в частности, времяпролетные масс-спектры MALDI, получаются из одиночных частиц путем разделения образца на капли, содержащие максимум одну частицу. Из этих капель формируются аэрозоли, которые затем ионизируются и анализируются с использованием MALDI MS. Рассмотрим документ WO 2010/021548, который включен посредством ссылки в полном объеме, где описаны система и способ генерации капель, содержащих, самое большее, одну клетку, для последующего анализа посредством MALDI MS. С использованием такого устройства, получаются спектры отдельных клеток смесей. Эти спектры можно классифицировать с использованием способа согласно изобретению, для получения классификации компонентов образца.
В предпочтительном варианте осуществления образец является биологическим образцом.
Биологический образец содержит молекулы организмов, например микроорганизмов, или молекулы, вырабатываемые такими организмами, например белки. В частности, эталонные спектры и спектр, полученный из образца, являются спектрами одиночных частиц биологического образца. Изменение спектров биологических образцов, принадлежащих одному и тому же классу, особенно выражено, что делает способ изобретения особо преимущественным для биологических образцов. Эти изменения происходят, например, из жизненного цикла организмов и различий между индивидами организмов одного и того же класса, например вида.
В дополнительно предпочтительном варианте осуществления согласно изобретению биологический образец содержит микроорганизмы, и классификация содержит классификацию микроорганизмов.
Предпочтительно, эталонные спектры и спектр, полученный из образца, являются спектрами одиночных микроорганизмов. Это позволяет анализировать смеси микроорганизмов. Например, смесь микроорганизмов разводится и затем разделяется на капли, содержащие самое большее, одну частицу, и затем спектры получаются из капель с использованием MALDI MS, например, описанной выше.
В предпочтительном варианте осуществления согласно изобретению, по меньшей мере, одна величина выбирается на основании характерного спектрального признака эталонного класса.
Например, PDF получаются на этапах a)-c) для классов A, B и C для значения величины, которая относится к характерному спектральному признаку класса A. Например, спектр класса A демонстрирует пик в положении X, что является характерным спектральным признаком. Соответственно, интенсивность спектра в положении X выбирается в качестве значения (показателя). Эта интенсивность в положении X вычисляется для всех класса A, класса B и класса C. Поскольку пик в положении X характерен для класса A, PDF, полученная для класса A, будет показывать высокую вероятность для высоких интенсивностей в X. В общем случае, класс B и класс C будут показывать более низкие вероятности для высоких интенсивностей в положении X. Таким образом, путем выбора характерный спектральный признак определенного класса в качестве одной из, по меньшей мере, одной величины, способ способен определять, принадлежит ли спектр этому классу, на основании наличия или отсутствия характерного спектрального признака.
Предпочтительно, более чем одна величина выбирается на основании, предпочтительно, более чем одного характерного спектрального признака, предпочтительно, более чем одного эталонного класса. Например, для классов A, B и C вычисляются показатели I1 и I2, которые относятся к двум разным спектральным признакам эталонного класса A. В другом примере вычисляются показатели I1, I2 и I3, где I1 относится к спектральному признаку класса A, I2 относится к спектральному признаку класса B, и I3 относится к спектральному признаку класса C.
Предпочтительно, характерный спектральный признак определяется на основании совокупного спектра эталонного класса. Совокупный спектр эталонного класса можно получить, например, суммированием спектров отдельных эталонных образцов, принадлежащих одному и тому же классу. Как упомянуто выше, эти совокупные спектры будут демонстрировать признаки, характерные для данного класса, хотя они могут не присутствовать в каждом отдельно взятом спектре класса. Заметим, что величину можно определять с использованием множеств эталонных спектров, как описано на этапе a), суммируя эталонные спектры каждого множества и определяя характерные спектральные признаки суммарных спектров.
Предпочтительно, характерные спектральные признаки содержат пик в совокупном спектре эталонного класса. Например, алгоритм нахождения пика применяется к суммарному спектру для нахождения положений характерных пиков. В этом случае выбранные величины являются интенсивностями в этих положениях пиков или с заранее определенным интервалом, содержащим эти положения.
В предпочтительном варианте осуществления изобретения способ содержит вычисление, для спектра образца, для которого получено значение Ii, связанного со спектральным признаком, величины Qi, причем вероятность P(Aj|Ii) того, что образец принадлежит эталонному классу Aj при условии значения Ii, определяется согласно:
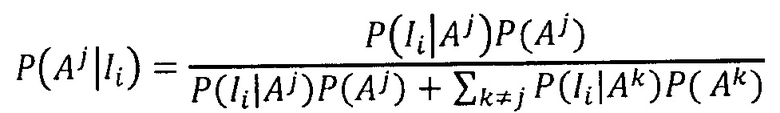
где P(Ii|Aj) - вероятность, связанная со значением Ii для эталонного класса Aj, и P(Ii|Ak) при k≠j - вероятность, связанная со значением Ii для, по меньшей мере, одного эталонного класса, отличного от эталонного класса Aj.
Признаки Qi, предпочтительно, связаны с характерными признаками конкретного класса. Например, величины Q1, Q2 связаны с признаком класса A1, и величины Q3, Q4 и Q5 связаны с признаком класса A2.
Заметим, что в случае, когда величина Qi связана с конкретным классом Aj, эту величину также можно использовать для получения вероятности для другого класса Ak≠j. Согласно вышеприведенному примеру, значение I2 величины Q2 является мерой для характерного признака класса A1, однако, его можно использовать для вычисления P(A2|I1), т.е. вероятности того, что спектр принадлежит классу A2 при условии измерения I1.
Когда классы сильно отличаются друг от друга, это будет приводить к очень низкой вероятности. Однако такое вычисление может становиться более важным для классов с более схожими признаками.
На этапе c) способа, PDF вычисляется для значения Ii для каждого эталонного класса Aj. С использованием этой PDF вычисляется вероятность значения, полученного для образца, P(Ii|Aj). Эта вероятность представляет вероятность того, что образец даст измеренное значение Ii, если образец принадлежит эталонному классу Aj. Согласно теореме Байеса, это может коррелировать с вероятностью того, что, при условии измерения значения Ii, образец принадлежит классу Aj.
Как указано в формуле, это вычисление также требует суммирования P(Ii|Ak)P(Ak) по всем остальным эталонным классам. Опять же, значение P(Ii|Ak) для каждого k получается с использованием PDF, полученных на этапе c) способа.
Предпочтительно исходить из того, что вероятности P(Aj) равны для всех j (в том числе j=k). Можно видеть, что члены P(Aj) и P(Ak) выбывают из уравнения. Этот подход оправдан, если предположить, что вероятность того, что спектр образца принадлежит эталонному классу, одинакова для каждого эталонного класса библиотеки. Этот подход особенно полезен в отсутствие первоначальной информации о содержании образца. Если же имеется первоначальная информация, на основании которой, априорная вероятность того, что образец принадлежит определенному классу выше или ниже, чем для других классов, можно использовать разные значения P(Aj) согласно изобретению.
В предпочтительном варианте осуществления согласно изобретению этап b) содержит определение, для каждого из эталонных спектров, значения одних и тех же, по меньшей мере, двух величин, связанных со спектральным признаком, и этап e) содержит объединение вероятностей, полученный для всех величины, в полную вероятность того, что образец принадлежит соответствующему классу.
Если только одна величина используется в классификации спектров с использованием вышеописанного способа изобретения, для каждого эталонного класса будет получена единственная вероятность, соответствующая этой одной величине. Если же для спектров определяется более чем одна величина, т.е., по меньшей мере, два разные величины, то для каждого эталонного спектра получается несколько вероятностей, соответствующих каждой величине. Согласно этому варианту осуществления изобретения эти вероятности объединяются в полную вероятность, например, посредством логической операции ИЛИ и/или И. это переводится в суммирование и сложение отдельных вероятностей для отдельных величин.
Это можно представить как функцию F (P(Aj|I1), P(Aj|I2), …, P(Aj|In)) для каждого из эталонных классов Aj.
Для функций F можно определить две предельные формы:
- все n признаков, присутствующих в классе Aj
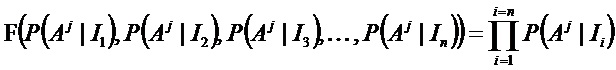
- любой из n признаков, присутствующих в классе Aj
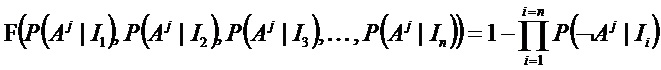
где
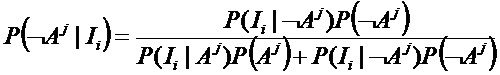
Помимо двух вышеупомянутых предельных форм, можно использовать любые другие способы классификации со многими переменными (самообучающиеся), например, анализ главных компонентов или машину опорных векторов.
Заметим, что выражение для 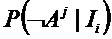
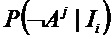
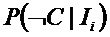
В предпочтительном варианте осуществления согласно настоящему изобретению значение относится к интенсивности при, по меньшей мере, одном заранее определенном спектральном значении или в заранее определенном диапазоне спектральных значений.
Например, значение является скаляром, который равен интенсивности при заранее определенном спектральном значении, т.е. амплитуде в данном положении вдоль оси x спектра. В другом примере, значение равно сумме интенсивностей заранее определенного диапазона спектральных значений.
Например, в массовом спектре, величина представляет собой интенсивность пика при заранее определенном отношении массы к заряду или в заранее определенном диапазоне отношений массы к заряду.
Предпочтительно, заранее определенное спектральное значение или заранее определенный спектральный диапазон выбирается на основании характерного спектрального признака эталонного класса. Например, спектральное значение или диапазон спектральных значений выбирается в качестве значения или диапазона, в котором суммарный спектр эталонного класса демонстрирует пик в спектре.
В предпочтительном варианте осуществления полученное значение нормализуется.
Нормализация корректирует изменение интенсивности разных спектров, например, вследствие изменения полного выхода ионов в масс-спектрах. Такое изменение может происходить, например, вследствие стохастических эффектов или вследствие дрейфа измерительной системы. Кроме того, при использовании двух или более измерительных систем для получения спектральных данных для способа, предполагаются различия в интенсивностях для спектров, полученных разными системами.
Поэтому нормализация приводит к более надежному алгоритму. Например, значение нормализуется делением его на сумму интенсивностей по всему или части спектра. Затем нормализованные спектры используются для получения PDF согласно этапу c) способа. Кроме того, значение, полученное из спектра образца, нормализуется для сравнения с PDF каждого эталонного класса для соответствующей величины.
В дополнительно предпочтительном варианте осуществления значение определяется путем умножения соответствующего спектра по заранее определенному диапазону спектральных значений на весовую функцию.
Например, если спектр представлен в виде вектора, т.е. массив заранее определенного количества скаляров, представляющих амплитуду спектра, весовая функция принимает форму весового вектора. Умножение весовой функции на спектр в этом случае соответствует вычислению скалярного произведения весового вектора и спектрального вектора.
На практике, некоторые области спектров более соответствуют данной величине, чем другие. Это можно учитывать путем умножения на весовую функцию. Например, весь спектр умножается на весовую функцию. Однако в большинстве случаев, выбирается только определенная область спектра, представляющая интерес, и умножается на весовую функцию. Заметим, что это эквивалентно умножению всего спектра на весовую функцию, где весовая функция имеет значение 0 вне области, представляющей интерес.
Предпочтительно, способ содержит нормализацию значения и умножение на весовую функцию. Заметим, что эти этапы можно объединить, выбрав надлежащую весовую функцию.
В дополнительно предпочтительном варианте осуществления весовая функция базируется на совокупном спектре спектров одного и того же класса.
Как описано выше, весовая функция присваивает больший вес важным частям спектра. Какие части спектра фактически являются важными частями, может базироваться на совокупном спектре соответствующий класс. Например, алгоритм нахождения пика применяется к совокупному спектру для нахождения положения пика в суммарном спектре, и весовая функция выбирается так, чтобы присваивать больший вес интенсивностями в положении и/или в окрестности пика относительно других частей спектров. Например, в совокупном спектре обнаружен пик, и ширина пика определена. Затем весовая функция выбирается как копия спектра, причем значение весовой функции вне ширины пика задается равным нулю. В необязательном порядке, весовая функция также корректируется по базовой линии совокупного спектра. Предпочтительно, весовая функция нормализуется таким образом, чтобы сумма ее значений была равна 1, или площадь под кривой спектра была равна 1.
В принципе, весовая функция вышеприведенного примера будет присваивать наибольший вес на максимуме пика и меньший вес на интенсивностях на удалении от пика.
В дополнительно предпочтительном варианте осуществления согласно изобретению, значение представляет собой отношение интенсивностей при, по меньшей мере, двух заранее определенных спектральных значениях или в, по меньшей мере, двух заранее определенных спектральных диапазонах.
Это имеет преимущество в том, что значение чувствительно к корреляции между определенными областями спектра.
В альтернативном варианте осуществления значение относится к положению пика в заранее определенном диапазоне спектральных значений.
Как упомянуто выше, значение может быть скалярным значением. Однако в предпочтительном варианте осуществления согласно изобретению значение является вектором. В этом случае вероятность, связанная с вектором, будет функцией плотности вероятности многих переменных P(I1, I2,..|Aj). Например, элементы вектора связаны с разными величинами, т.е. значения связаны с разными спектральными признаками. В предельном случае вычисляется только один вектор, причем элементы вектора соответствуют всем выбранным спектральным признакам. В этом случае объединение вероятностей разных величин с использованием логических операций И и/или ИЛИ, например, объединение этих вероятностей с использованием функции F(…), как описано выше, не требуется.
В предпочтительном варианте осуществления согласно настоящему изобретению этапы d) и e) осуществляются для первого множества эталонных классов и затем для второго множества эталонных классов, причем второе множество выбирается на основании классификации образца в одном из эталонных классов первого множества.
Таким образом, задается иерархия эталонных библиотек. Сначала образец классифицируется в главном классе (первом множестве эталонных классов) и затем классифицируется в подклассе главного эталонного класса (втором множестве эталонных классов). Это требует меньшей вычислительной мощности, чем классификация с использованием эталонной библиотеки, содержащей все классы самого низкого уровня. Поэтому способ согласно изобретению эффективен.
Кроме того, для каждого этапа классификации, образец сравнивается с эталонной библиотекой, содержащей относительно немного эталонных классов. Это позволяет выбирать множества эталонных классов таким образом, чтобы эталонные классы каждого множества не сильно перекрывались, и качество классификации возрастало.
Предпочтительно, первое множество и второе множество выбираются на основании иерархии биологической классификации.
Например, когда образец содержит биологический образец, для классификации образца можно использовать иерархию биологической классификации. Например, выбор множеств классификации базируется на отряде, семействе, роде, виде или штамме микроорганизма.
В предпочтительном варианте осуществления, этап d) содержит получение, по меньшей мере, двух спектров из образца и определение значения одной и той же, по меньшей мере, одной величины этих, по меньшей мере, двух спектров и этап e) содержит объединение спектров образцов, отнесенных к одному и тому же классу, в совокупный спектр и сравнение этого совокупного спектра с совокупным эталонным спектром, полученным путем объединения эталонных спектров соответствующего класса.
Этот этап обеспечивает необязательную окончательную проверку классификации. Из образца получаются множественные спектры. Эти спектры образцов классифицируются вышеописанным образом. Затем спектры, отнесенные к одному классу, объединяются, например, суммируются, для получения совокупного спектра образца. Этот совокупный спектр образца сравнивается с совокупным спектром эталонных спектров соответствующего класса.
Заметим, что образец может содержать смесь компонентов, например, смесь разных молекул или микроорганизмов. Поэтому спектры такой смеси можно относить к разным классам. В этом случае спектры объединяются по классам.
Например, образец содержит частицы A и B. Из образца получается 100 одночастичных спектров. С использованием способа изобретения, 89 спектров классифицируются как принадлежащие классу A и 11 классифицируются как принадлежащие классу B. Затем совокупный спектр образца для класса A получается путем объединения соответствующих 89 спектров образцов. Также, для класса B совокупный спектр образца получается с использованием соответствующих 11 спектров. Затем совокупные спектры образцов для класса A и класса B сравниваются с совокупными эталонными спектрами для класса A и класса B. Это обеспечивает окончательную проверку.
Предпочтительно, сравнение совокупного спектра образца и совокупного эталонного спектра присваивает больший вес величинам, отличным от, по меньшей мере, одной величины этапа b). Другими словами, окончательная проверка присваивает больший вес спектральным признакам, которые не использовались для классификации спектров образцов. Предпочтительно, рассматриваются только эти признаки, т.е. в сравнении не используется, по меньшей мере, одна величина этапа b).
Это гарантирует, что окончательная проверка по большей части или полностью не зависит от этапов классификации.
Предпочтительно, способ осуществляется с использованием первого множества эталонных классов и затем с использованием второго множества эталонных классов, причем второе множество выбирается на основании сравнения между совокупным спектром образца и совокупным эталонным спектром.
Задается процедура иерархической классификации. Сначала образец классифицируется с использованием первой библиотеки эталонных классов. Классификация проверяется с использованием совокупного спектра образца и совокупного эталонного спектра. Если это сравнение приводит к заключению, что образец можно дополнительно классифицировать по подклассам, образец затем сравнивается со второй библиотекой.
Например, сравнение выявляет, что в совокупном спектре образца присутствуют дополнительные пики по сравнению с совокупным эталонным спектром. Это указывает, что образец может содержать смесь частиц, например, молекул или микроорганизмов, которые принадлежат разным классам. Поэтому образец затем сравнивается со вторым множеством эталонных классов.
Изобретение дополнительно относится к способу создания базы данных для использования в классификации образца в одном из, по меньшей мере, двух классов на основании спектральных данных, содержащему этапы, на которых:
a) получают, по меньшей мере, два множества первых спектров для использования в качестве эталонных спектров, причем каждое множество содержит спектры эталонных образцов, принадлежащие одному и тому же классу;
b) определяют, для каждого из эталонных спектров, значение одной и той же, по меньшей мере, одной величины, связанной со спектральным признаком; и
c) связывают вероятность с разными значениями величины на основании определенных значений.
Кроме того, изобретение относится к способу классификации образца в одном из, по меньшей мере, двух классов на основании спектральных данных с использованием базы данных, полученной вышеописанным способом, причем способ содержит этапы, на которых:
d) получают спектр из образца и определяют значение одной и той же, по меньшей мере, одной величины этого спектра; и
e) вычисляют, на основании вероятностей, полученных из базы данных и значения величины для полученного спектра для каждого из упомянутых, по меньшей мере, двух классов, вероятность того, что образец принадлежит этому классу.
Изобретение дополнительно относится к компьютерной программе, которая, при выполнении на компьютере, выполняет этапы одного из вышеописанных способов, и к носителю данных, содержащему такую компьютерную программу.
Кроме того, изобретение относится к системе для классификации образца на основании спектральных данных, содержащей:
- средство для получения спектра из образца;
- средство анализа для осуществления способа согласно изобретению вышеописанным образом.
Те же преимущества и эффекты, которые описаны для способа классификации образца на основании спектральных данных, применяются к способу создания базы данных, способу использования базы данных, компьютерной программе, носителю данных и системе согласно изобретению. В частности, признаки, описанные в связи со способом классификации образца на основании спектральных данных, можно объединить со способом создания базы данных, способом использования базы данных, компьютерной программой, носителем данных и системой согласно изобретению.
В предпочтительном варианте осуществления системы согласно изобретению система содержит средство для получения одночастичного спектра из образца. Например, система содержит средство для создания капель образца, таким образом, что капли содержит самое большее, одну частицу, и средство для получения спектра предназначено для получения спектра из отдельных капель.
Дополнительные преимущества, признаки и детали изобретения поясняются на основе предпочтительных вариантов его осуществления, рассмотренных со ссылкой на прилагаемые чертежи, в которых:
- фиг. 1 демонстрирует спектр (P), накопленный из большого количества одночастичных спектров, полученных из образцов, происходящих из единичного изолята, и несколько типичных примеров (Q, R, S, T) базисных одночастичных спектров;
- фиг. 2 демонстрирует схему системы согласно изобретению, включающей в себя подсистемы;
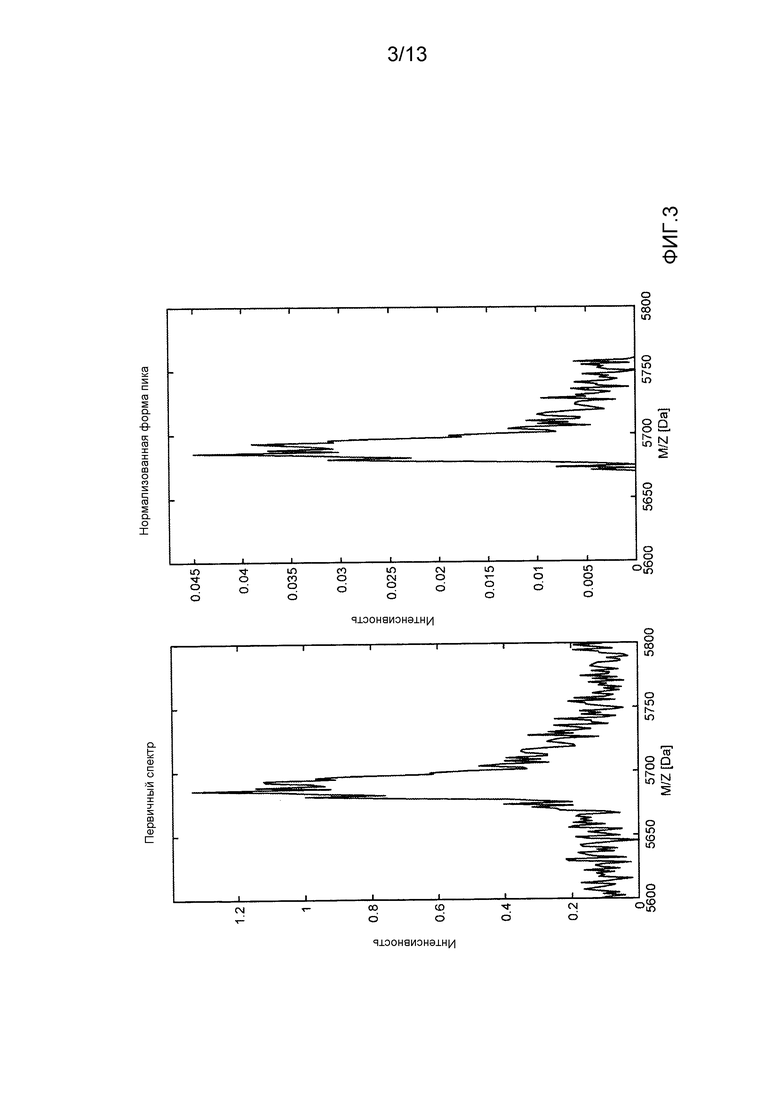
- фиг. 3 графически иллюстрирует пример формы пика, для первичного спектра (левый график) и нормализованную и скорректированную по базовой линии форму пика (правый график);
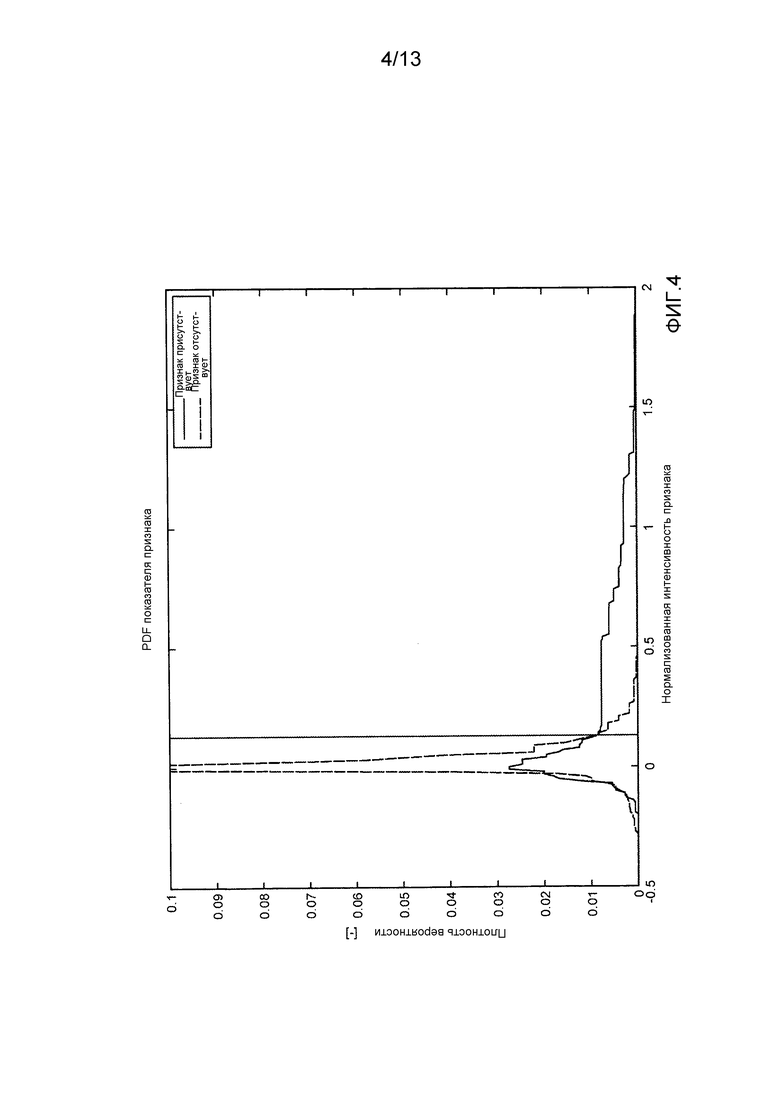
- фиг. 4 демонстрирует пример PDF показателя для спектрального признака для совокупности частиц (вида A), которая содержит вещество, обеспечивающее признак (P(I|A)), и совокупности (вида B), которая не содержит это вещество (P(I|¬A)), соответственно;
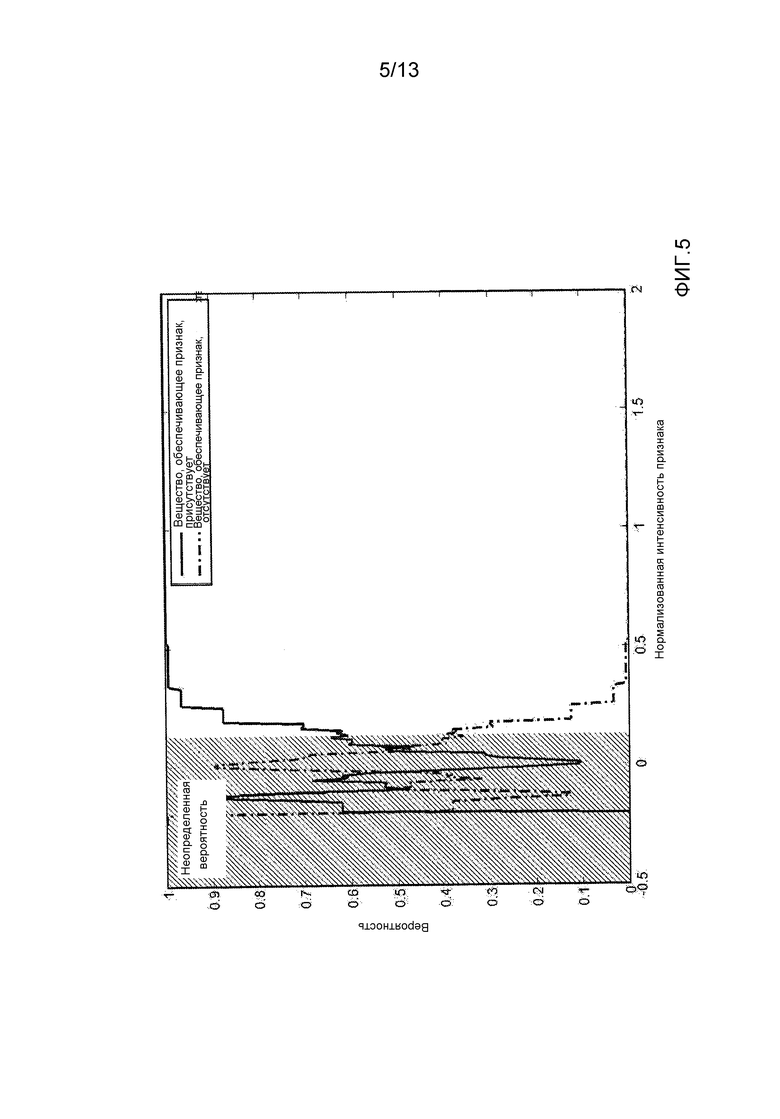
- фиг. 5 демонстрирует вероятность присутствия/отсутствия вещества, обеспечивающего признак, как функцию интенсивности признака спектра события одинарной ионизации, на основании функции плотности вероятности, представленной на фиг. 4;
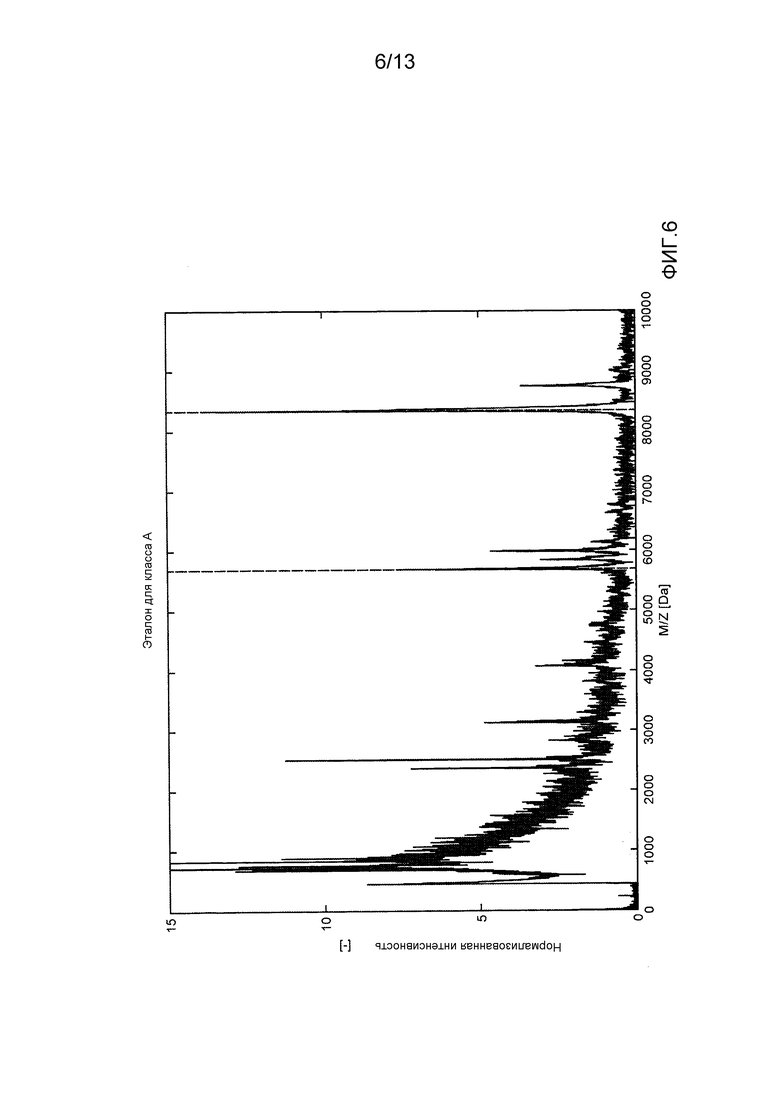
- фиг. 6 демонстрирует эталон для вида A, содержащего частицы, собранный накоплением одночастичных спектров, используемых для оценивания PDF пиков при M/Z=5689 и M/Z=8339, указанных вертикальными линиями;
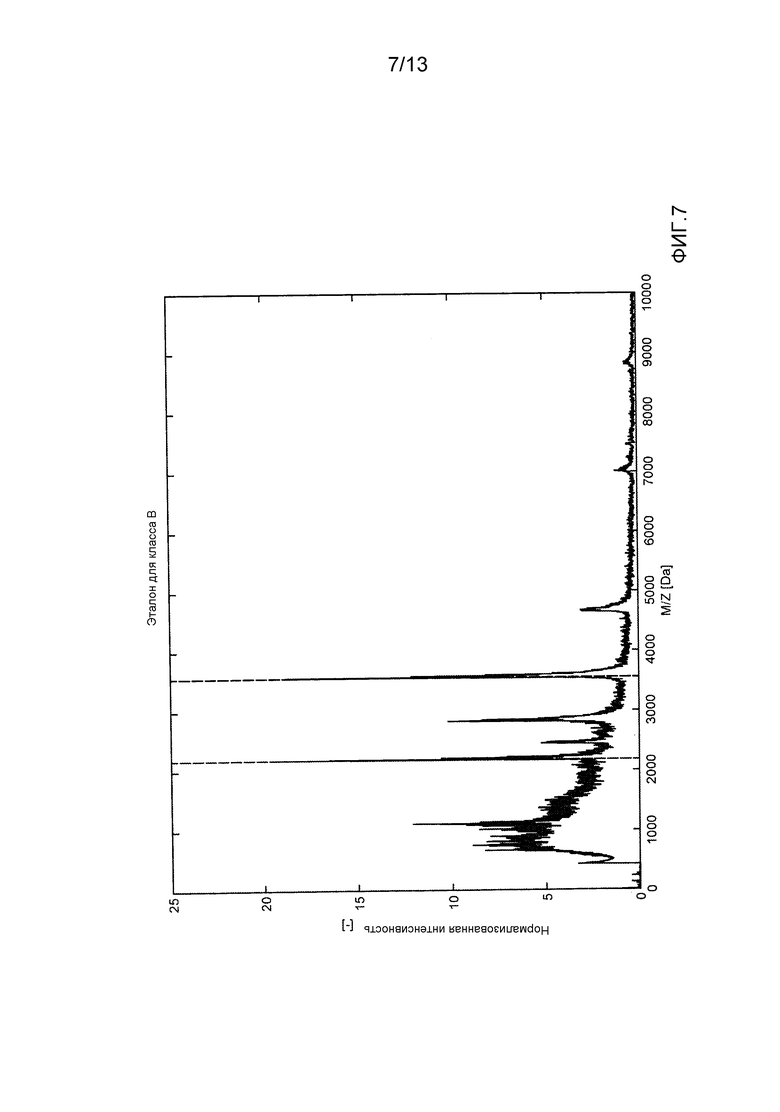
- фиг. 7 демонстрирует эталон для вида B, содержащего частицы, собранный накоплением одночастичных спектров, используемых для оценивания PDF пиков при M/Z=2187 и M/Z=3558, указанных вертикальными линиями;
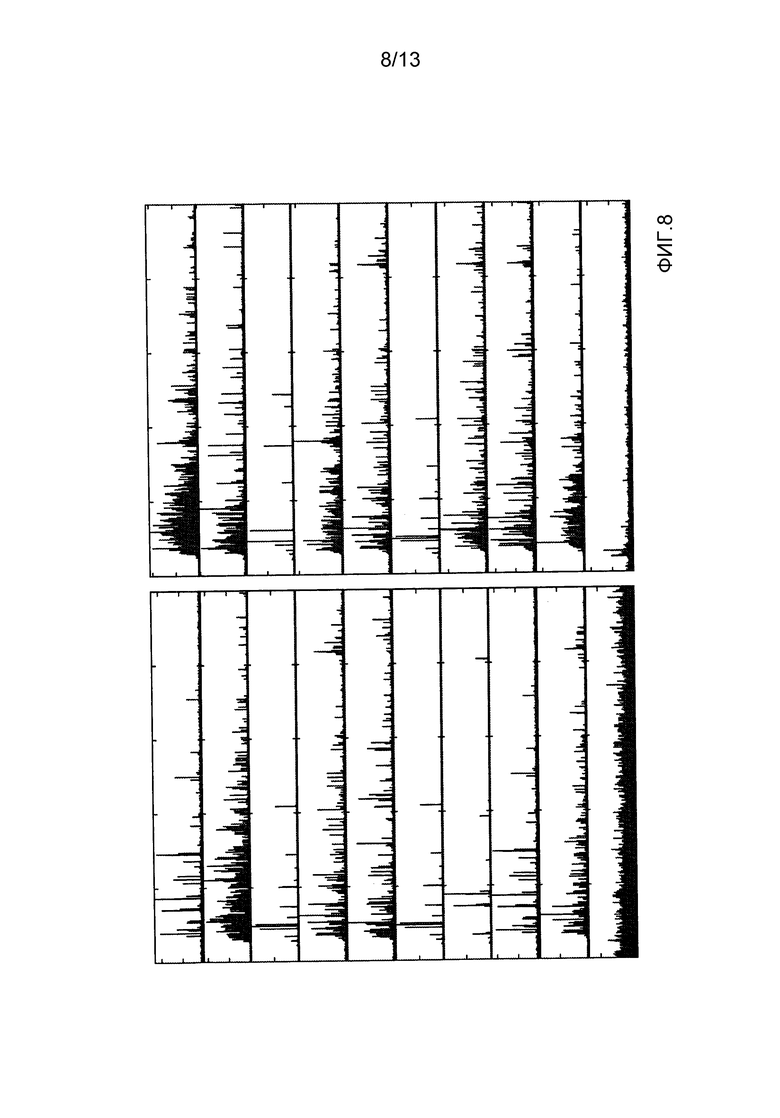
- фиг. 8 демонстрирует последовательность спектров событий одинарной ионизации, зарегистрированных из образца, содержащего смесь двух организмов (вида A и вида B);
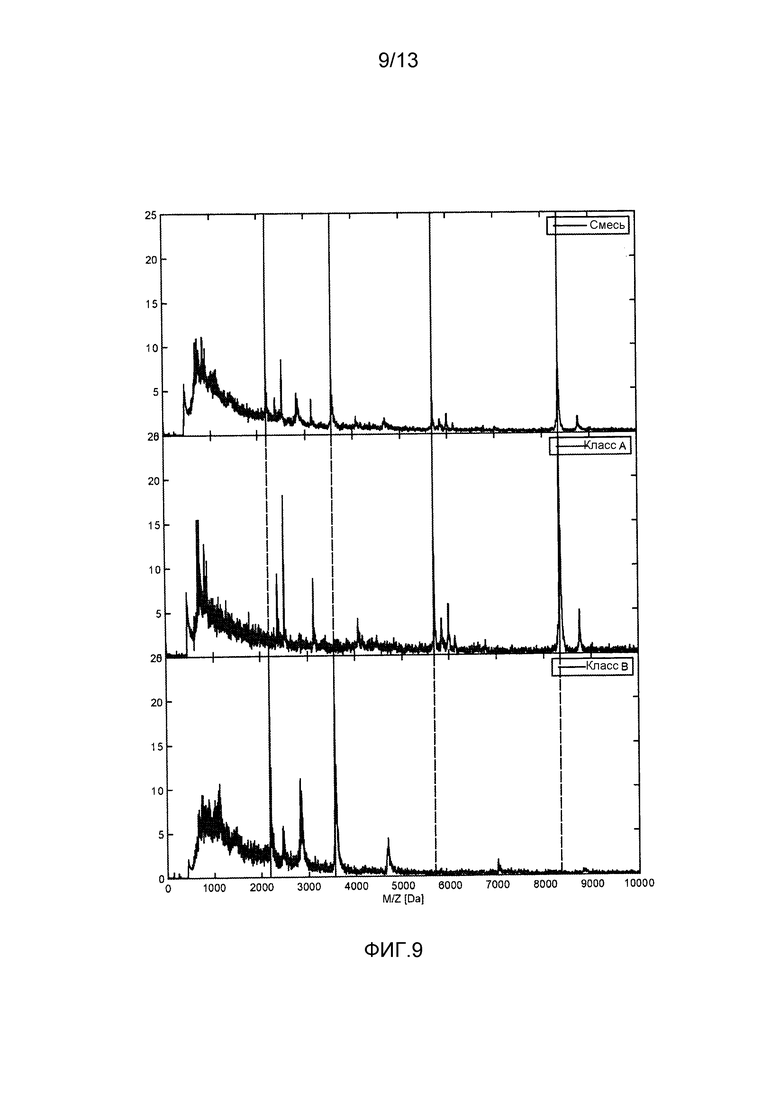
- фиг. 9 демонстрирует накопленный спектр смеси одночастичных спектров (вверху), одночастичные спектры, назначенные классу вида A (посередине) и одночастичные спектры, назначенные классу вида B (внизу);
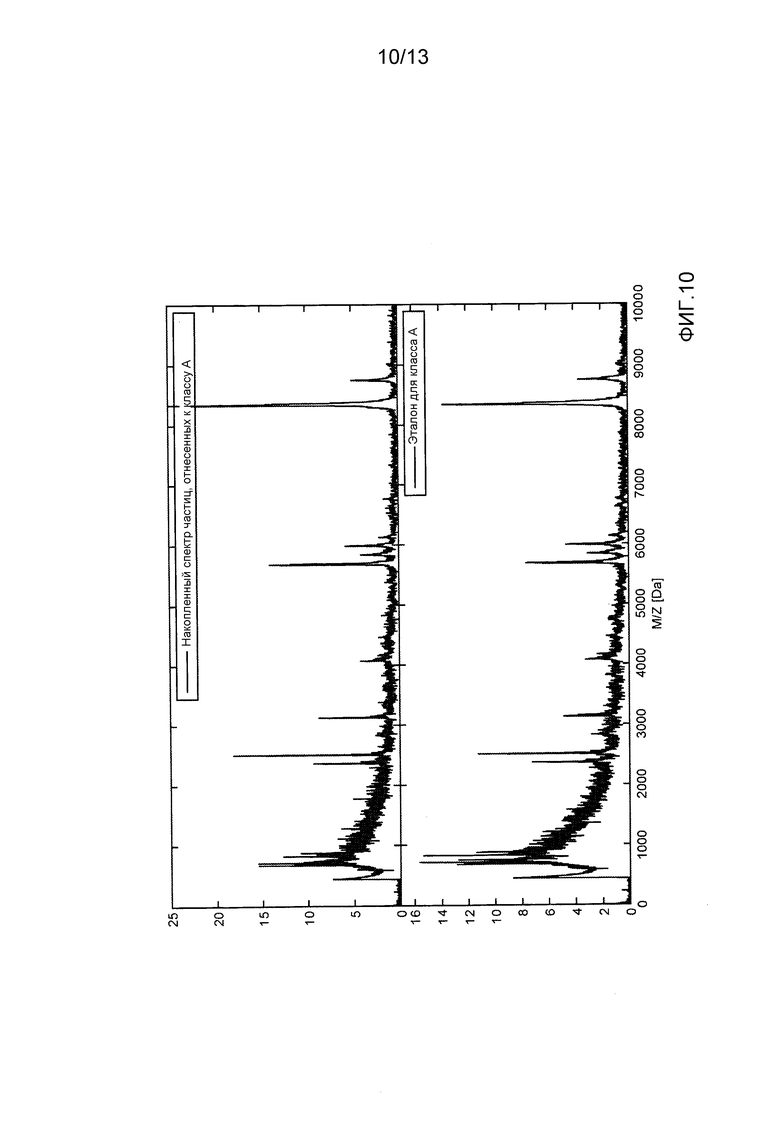
- фиг. 10 демонстрирует сравнение между накопленным спектром частиц, назначенным классу вида A, и накопленными спектрами частиц, которые происходят из изолята вида A;
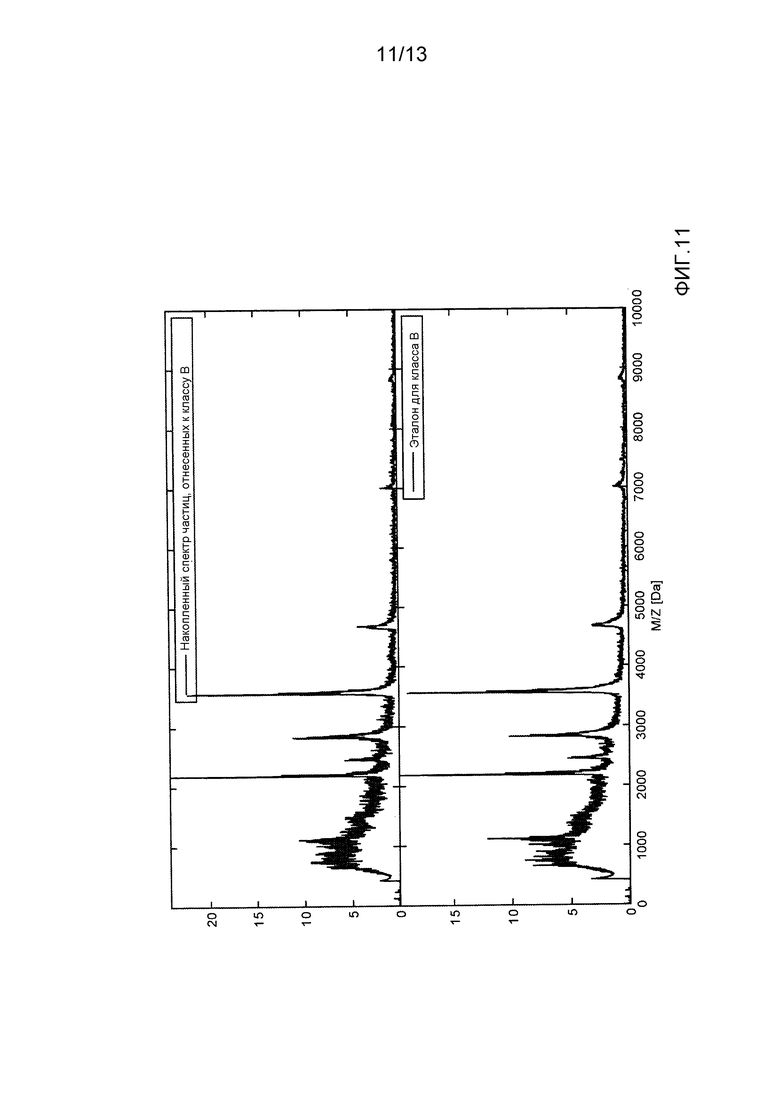
- фиг. 11 демонстрирует сравнение между накопленным спектром частиц, назначенным классу вида B, и накопленными спектрами частиц, которые происходят из изолята вида B;
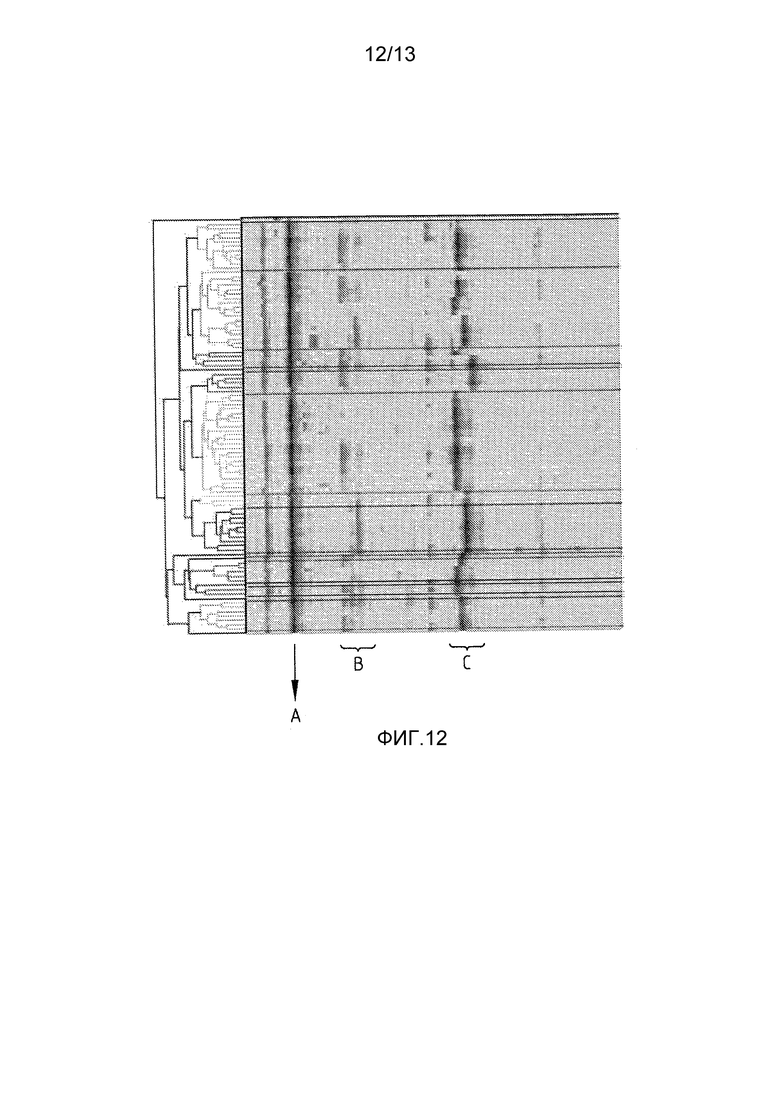
- фиг. 12 демонстрирует пример кластерограммы совокупности 95 штаммов золотистого стафилококка на основании массовых спектров MALDI, зарегистрированных из этих штаммов;
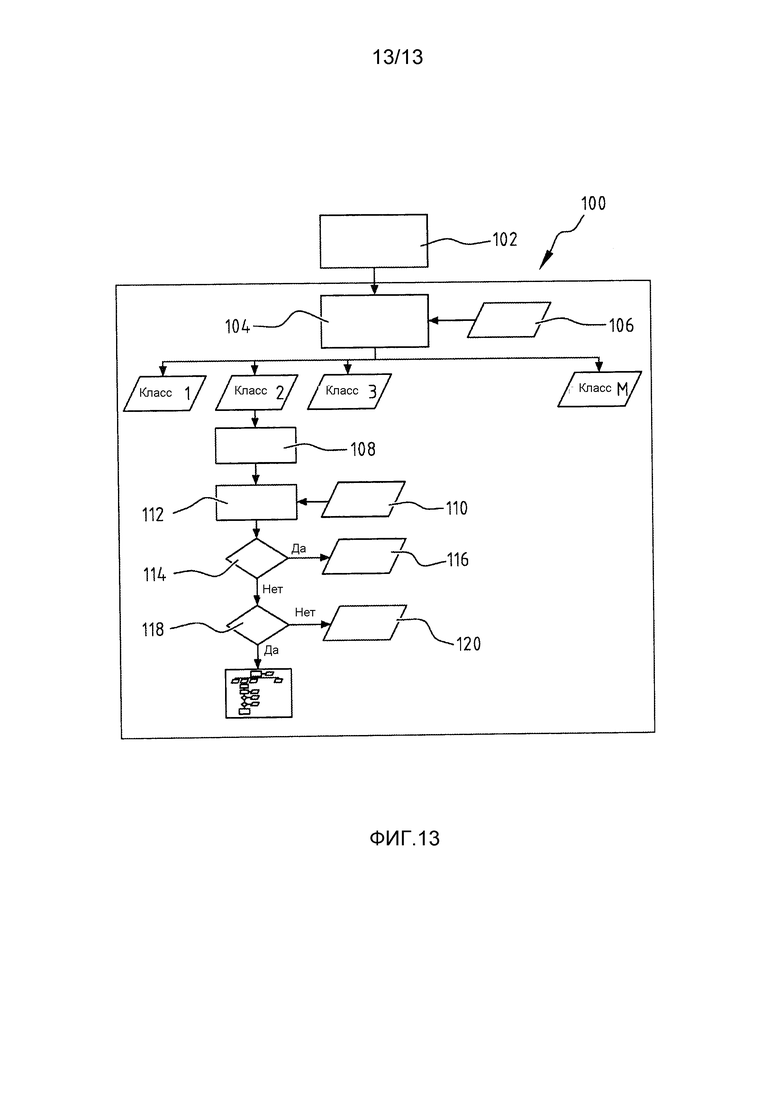
- фиг. 13 демонстрирует схему иерархической классификации согласно изобретению.
В иллюстративном варианте осуществления, система 2 (фиг. 2) согласно изобретению выполнена с возможностью создания спектров из аэрозолей для обнаружения биологического материала, например бактерий, в воздухе с использованием MALDI TOF MS. Различие между этой системой и классическим прибором MALDI состоит в том, что на входе располагается аэрозольный пучковый генератор 4, 12, 14, и приготовлением образца, где матрица добавляется последовательно. Она построена таким образом, что отдельные присутствующие в воздухе частицы поступают в систему в аэрозольном пучке 6. Это дает возможность анализировать отдельные частицы, например, бактерии, вирусы или другой биологический материал определенного размера в смеси аэрозоля. Например, возможны системы медицинского применения. Подсистема 8 системного контроллера используется для задания, контроля, измерения, регистрации и мониторинга параметров из подсистем.
Для приготовления аэрозолей образца система 2 дополнительно содержит блок 10 приготовление образца, в том числе, для разведения образца, первый каскад 12, аэродинамические линзы 14 и компоновку форсунок и сепараторов 4.
Лазерная подсистема 16 содержит ионизационный лазер 18 и ионизационную оптику 20, управляемую триггерной электроникой 22. Триггерная электроника 22 подключена к системному контроллеру 8 и к детектору 24 на основе фотоумножителя, который снабжен фотоумножительной оптикой 26. Кроме того, в подсистеме 16 обеспечены лазер 28 обнаружения и оптика 30 обнаружения.
Масс-спектрометрическая подсистема 32 содержит источник 34 ионов, то есть место, где аэрозоли ионизируются с использованием лазерного пучка из лазера 18. Масс-спектрометрическая подсистема 32 дополнительно содержит ионный дефлектор 36 и MS-детектор 38. Источник 34 ионов, ионный дефлектор 36 и MS-детектор 38 содержатся в трубке 40 получателя и пролета. В этой трубке поддерживается вакуум посредством манометров 42, компоновки турбомолекулярных насосов 44, 46 и форвакуумного насоса 48. Источник 34 ионов и ионный дефлектор 36 подключены к блоку 50 управления источника ионов, который подключен к триггерной электронике 22 и подсистема 52 обработки сигнала и управления данными.
Подсистема 52 содержит аналого-цифровой преобразователь 54, подключенный к MS-детектору 38. Через управление данными модуль 56 аналого-цифровой преобразователь 54 подключен к системному контроллеру 8. Системный контроллер 8 подключен к анализатору 58.
Система 2 дополнительно содержит блок 60 питания. Хотя на фигуре не показано никаких соединения, блок обеспечивает питание для разных компонентов. Кроме того, для системы 2 корпуса обеспечены системная стойка 62 и воздушное/водяное охлаждение 64.
С использованием аэрозолированных бактерий и частиц белка, подтверждение принципа было реализовано в системе 2. В этом иллюстративном варианте осуществления этапы способа согласно изобретению осуществляются с использованием анализатора 58.
УСТАНОВЛЕНИЕ НАЛИЧИЕ ВЕЩЕСТВ В ОДИНОЧНЫХ ЧАСТИЦАХ
В силу весьма стохастического характера спектров событий одинарной ионизации в MS, интенсивность I одночастичного спектра в положении, которое соответствует массе молекулы аналита, можно рассматривать только как меру вероятности, P(A|I), что эта молекула аналита, A, присутствует в частице.
Количественное представление этой вероятности опирается на теорему Байеса и функцию плотности вероятности, P(I|A), которая указывает вероятность интенсивности I признака, при наличии молекулы аналита A:
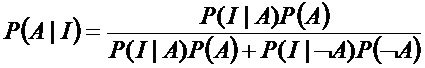
где - P(A) - доля частиц, которые содержат вещество A;
- P(I|¬A) - функция плотности вероятности для интенсивности I для частиц, которые не содержат вещество A; и
- P(¬A) - доля частиц которые не содержат вещество A.
Следовательно, при условии, что функции P(I|A) и P(I|¬A) известны, вероятность присутствия вещества A в частице, можно получить из измеренной интенсивности спектрального признака, обусловленного наличием вещества A.
Поэтому опорная информация, необходимая для классификации одночастичных спектров, должна содержать PDF для всех предполагаемых признаков.
УСТАНОВЛЕНИЕ ПРОИСХОЖДЕНИЯ ОДНОКЛЕТОЧНОГО ОРГАНИЗМА НА ОСНОВАНИИ ЕГО ОДНОЧАСТИЧНОГО МАССОВОГО СПЕКТРА
Микроорганизмы, например бактерии, характеризуются наличием многих веществ, которые обеспечивают признаки, различимые посредством MALDI-MS. В зависимости от организма (бактерия, вирус и т.д.) и состояния организма (растительный клетка, спора), это количество может изменяться от всего лишь 5 до целых 50 или даже более.
Некоторые из этих признаков характеризуют род, которому принадлежит данный организм, некоторые из них - вид и некоторые из них - штамм.
Для каждого признака Qi, функция плотности вероятности P(Ii|Aj) задается как представление вероятности измерения интенсивности Ii для признака Qi спектра образца, содержащего вещество Aj.
Кроме того, pdf P(Ii|¬Aj) задается как представление вероятности измерения значения Ii для признака Qi, когда образец не содержит вещество Aj.
Эти две pdf объединяются с P(Aj) и P(¬Aj) в соответствии с теоремой Байеса для получения вероятности P(Aj|Ii) присутствия вещества, обеспечивающего признак Aj, при условии измеренной интенсивности Ii признака.
Заметим, что в этом примере, рассматривается ‘вещество Aj’ вместо ‘класса Aj’, как описано выше. Фактически, этот пример представляет предельный случай, когда класс Aj содержит единичное вещество. Например, вещество содержит конкретный белок.
Для оценивания вероятности того, что спектр MALDI-MS одноклеточного организма происходит из организма, принадлежащего роду, виду или штамму, вероятности для отдельных признаков нужно объединять в вероятность того, что комбинация признаков, которые характеризуют род, вид или штамм, присутствует в спектре, с использованием функции F(P(Aj|I1), P(Aj|I2), P(Aj|I3),…, P(Aj|In) ):
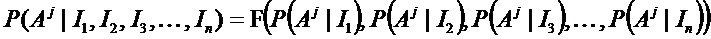
Кроме того, вероятности для каждого вещества Aj, в необязательном порядке, можно объединять. Например, вероятности для каждого белка из множества белков объединяются для получения полной вероятности для данного микроорганизм.
Однако не все признаки, которые могут быть установлены в спектре, накопленном из большого количества спектров одиночных клеток, обязаны присутствовать в каждом спектре одиночной клетки, см. фиг. 1.
Например, на разных фазах их жизненного цикла (непосредственно перед делением, непосредственно после деления и т.д.), клетка может экспрессировать разные белки. Следовательно, хотя накопленный спектр демонстрирует все ионизуемые белки, вырабатываемые организмами на всех фазах их жизненного цикла, спектр отдельного организма может демонстрировать только те экспрессируемые белки, которые вырабатываются на конкретной фазе конкретной анализируемой клетки.
Строго говоря, знание зависимости экспрессии белка от фазы жизненного цикла, позволяет задать функцию F(…). К сожалению, в общем случае, эта информация недоступна.
Однако, как указано выше, помимо различий, обусловленных различиями в фазе жизненного цикла, существует гораздо больше причин для изменчивости между спектрами одиночных клеток. Следовательно, даже при наличии вышеуказанной информации, функция F(…) на ее основе, будет, в лучшем случае, оценкой.
Если не пользоваться возможностями, предоставляемыми информацией о соотношении между фазой жизненного цикла и экспрессией белка одноклеточного организма, можно определить две предельные формы функции F(…):
- все присутствующие признаки
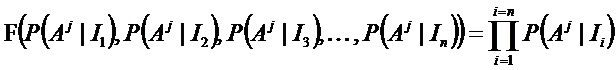
- любой присутствующий признак
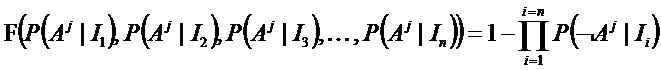
где
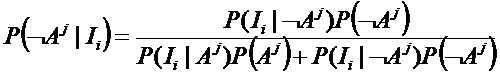
ОПРЕДЕЛЕНИЕ ФУНКЦИЙ ПЛОТНОСТИ ВЕРОЯТНОСТИ P(I|A) И P(I|¬A)
ВВЕДЕНИЕ
PDF для P(I|Aj) и P(I|¬Aj) можно аппроксимировать, оценивая достаточно большого множества эталонных частиц, которые, соответственно, содержат вещество Aj и не содержат вещество Aj.
Для определения P(Ii|Aj) для всех признаков Qi, нужно использовать множество одночастичных спектров частиц, в отношении которых известно, что они содержат вещество Aj, которое генерирует признак Qi.
Признаки Qi характеризуются значением математического ожидания интенсивности, при массах, связанных с этим признаком, которые больше значения математического ожидания в соседних областях массы. Таким образом, при суммировании большого количества одночастичных спектров, накопленный спектр будет демонстрировать пик (или комбинацию пиков в случае полимера).
PDF для признака, характеризуемого пиком в накопленном спектре, можно просто оценить, регистрируя амплитуду при соответствующей массе для каждого одночастичного спектра, распределяя эти амплитуды по дискретным контейнерам амплитуды и деля показатель в каждой ячейке на суммарное количество зарегистрированных одночастичных спектров.
При достаточно большом количестве одночастичных спектров и достаточно тонком распределении по ячейкам, получается адекватная оценка функции плотности вероятности.
ВЫДЕЛЕНИЕ ПРИЗНАКОВ
Для любого реального масс-спектрометра пики в накопленном спектре будут иметь конечную ширину. Следовательно, при регистрации одночастичной амплитуды для каждого признака, нужно допускать конечную ширину интервала массы, где может возникать признак.
При этом форма пика в накопленном спектре используется для учета влияния конечной ширины пика. С этой целью, форма накопленного спектра в интервале масс, где может возникнуть пик, копируется, корректируется по амплитуде базовой линии на краю интервала и нормализуется таким образом, что 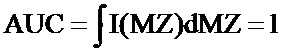
Таким образом, функция формы признака Sfeature можно задавать таким образом, что:
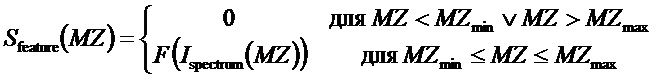
где F(Ispectrum(MZ)) задана таким образом, что:
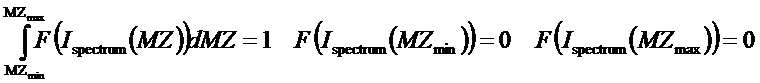
Наконец, показатель IS интенсивности для одночастичного спектра можно задавать как интеграл произведения функции форма и одночастичного спектра ионной интенсивности по всему диапазону массы масс-спектрометра:
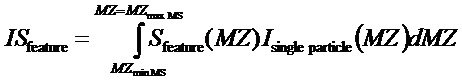
Поскольку ионная интенсивность регистрируется с конечной частотой дискретизации, вышеозначенный интеграл заменяется дискретной суммой:
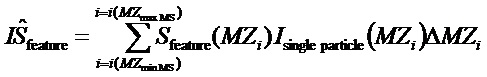
Таким образом, показатель интенсивности можно представить внутренним произведением двух векторов:

где
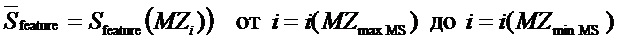
это вектор выбора признака, и
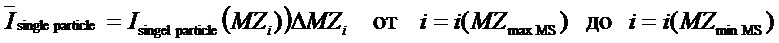
вектор одночастичного спектра энергии.
ОЦЕНИВАНИЕ P(I|A)
В общем случае, спектры MALDI микроорганизмов характеризуются ограниченным количеством пиков, обычно от 10 до 50 в области массы от 2000 Да до 20000 Да. Эти пики указывают наличие таких веществ, как белки, пептиды и т.д.
Некоторые из этих веществ характерны для больших групп организмов (родов), некоторые из них характерны для малых групп (видов), и некоторые из них, возможно, даже для одиночного организма (штамма).
При наличии эталонной колонии бактерий, с достаточно характерными картинами пиков, можно построить библиотеку функций плотности вероятности. Эта библиотека позволит классифицировать неизвестную частицу, содержащую одиночную бактерию, в отношении вероятности присутствия характерных веществ в частице.
Полная совокупность признаков, подлежащая представлению в эталонной библиотеке, является объединением всех признаков для всех организмов:
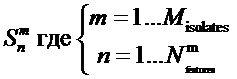
(заметим, что количество признаков на изолят, зависит от данного организма)
Когда полная совокупность признаков преобразуется во множество векторов Snm выбора признака, эти векторы могут преобразовываться в матрицу выбора признака,
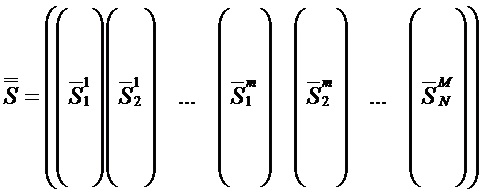
с числом столбцов NS, равным суммарному количеству признаков, присутствующему совокупность признаков, и числом строк MMZ, равным количеству временных (массовых) выборок в одночастичных массовых спектрах.
Умножение вектора одночастичного спектра энергии на эту матрицу выбора признака дает вектор IS показателя интенсивности, который задает показатель интенсивности для всех признаков:
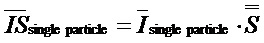
Как указано выше, обрабатывая достаточно большое множество одночастичных спектров, обусловленных микроорганизмами, происходящими из единичного изолята, можно для строить функции плотности вероятности. Используя вышеупомянутую матрицу выбора признака, функции плотности вероятности Pm1…NS, связанные с конкретным изолятом m, можно определить за один проход.
Оценивание P(I|¬A)
Функции плотности вероятности для признаков, которые связаны с веществом, присутствующим в рассматриваемом организме, будут значительно отличаться от тех, которые не относятся к веществу, присутствующему в организме. В порядке примера, фиг. 4 демонстрирует пример из PDF признака для совокупности частиц, содержащих вещество, обеспечивающее признак, и совокупности частиц, которые не содержат это вещество.
Фиг. 4 показывает, что амплитуда PDF для совокупности, которая содержит вещество, превышает амплитуду PDF для совокупности, которая не содержит это вещество, для интенсивностей признака выше приблизительно 0.08 и наоборот.
В этом простом примере с только двумя возможными типами частиц, один из которых содержит вещество A1, которое обеспечивает признак Q1, и другой содержит вещество A2, PDF для совокупности, которая не содержит A1, т.е. ¬A1, равна PDF частиц, которые содержат A2:
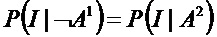
Как указано выше, зная функцию плотности вероятности P(I|A) и P(I|¬A), можно определить вероятность того, что отдельная частица содержит вещество, обеспечивающее признак.
Для вычисления вероятности присутствия вещества A, помимо PDF, нужно обеспечивать вероятность обнаружения наличия A, P(A). В этом простом примере, где рассматривается только два типа частиц, частицы, которые содержат A, и частицы, которые не содержат A. Поэтому вероятность обнаружения наличия A предполагается равной P(A)=P(¬A)=0,5.
СЛОЖНЫЕ СОВОКУПНОСТИ ЧАСТИЦ
Если рассматривается более сложные совокупности частиц, с n возможными типами частиц, где тип частицы l содержит вещество Aj, произведение P(I|¬Aj)P(¬Aj) равно:
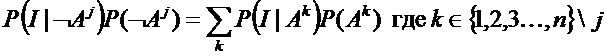
Таким образом, как и в случае двойной смеси, в сложных смесях, вероятность P(Aj) обнаружения наличия равна P(Ai)=1/n.
АНАЛИЗ ДВОЙНОЙ СМЕСИ
На основании PDF признаков, представленных на фиг. 4, и теоремы Байеса, можно получить вероятность присутствия (или отсутствия) вещества, обеспечивающего признак A, как функцию интенсивности признака (одночастичного спектра). Фиг. 5 демонстрирует эту вероятность.
Согласно этой фигуре, в случае превышения критической интенсивности (указанной тонкой вертикальной линией на фиг. 5, равной приблизительно 0,08), вероятность присутствия вещества, обеспечивающего признак, определенно больше, чем вероятность того, что это вещество отсутствует.
Таким образом, в случае превышения этой интенсивности, этот признак является надежной мерой наличия этого вещества.
В случае более низкой интенсивности, соотношение между вероятностью и интенсивностью признака неоднозначно. Это не позволяет принять решение в отношении наличия вещества, обеспечивающего признак, и P(A|I) следует пометить как неопределенную.
Для иллюстрации функциональных возможностей вышеописанной методологии, можно компилировать (двойную) смесь ранее зарегистрированных одночастичных спектров. Для выявления этой смеси, для частиц обоих типов, необходимо задать признаки и оценить соответствующие PDF.
На фиг. 6 и 7 показаны накопленные спектры частиц, используемые для оценивания этих PDF признаков. В этом случае, для частиц обоих типов в качестве признаков было выбрано два строго очерченных пика (указанные вертикальными линиями на фиг. 6 и фиг. 7).
Фиг. 8 демонстрирует последовательность одночастичных спектров, случайно выбранных из двух партий ранее зарегистрированных одночастичных спектров (заметим, что для смеси, используются другие партии, чем для оценивания PDF). Опять же, фиг. 8 демонстрирует крайнюю изменчивость в одночастичных спектрах и очевидную недостаточность корреляции одночастичных спектров с эталонными спектрами.
В этом примере одночастичные спектры классифицируются согласно следующим правилам:
- вероятность того, что одночастичный спектр происходит из одного из эталонных изолятов, Ptotal, получается из двух вероятностей единичного признака для каждого из двух изолятов согласно правилу ‘любой присутствующий признак’, как описано выше.
- только когда интенсивность I признака, превышает критическую интенсивность для однозначной вероятности признака (см. фиг. 5), для этого признака выделяется вероятность признака, в противном случае вероятность признака указывается как “неопределенная”.
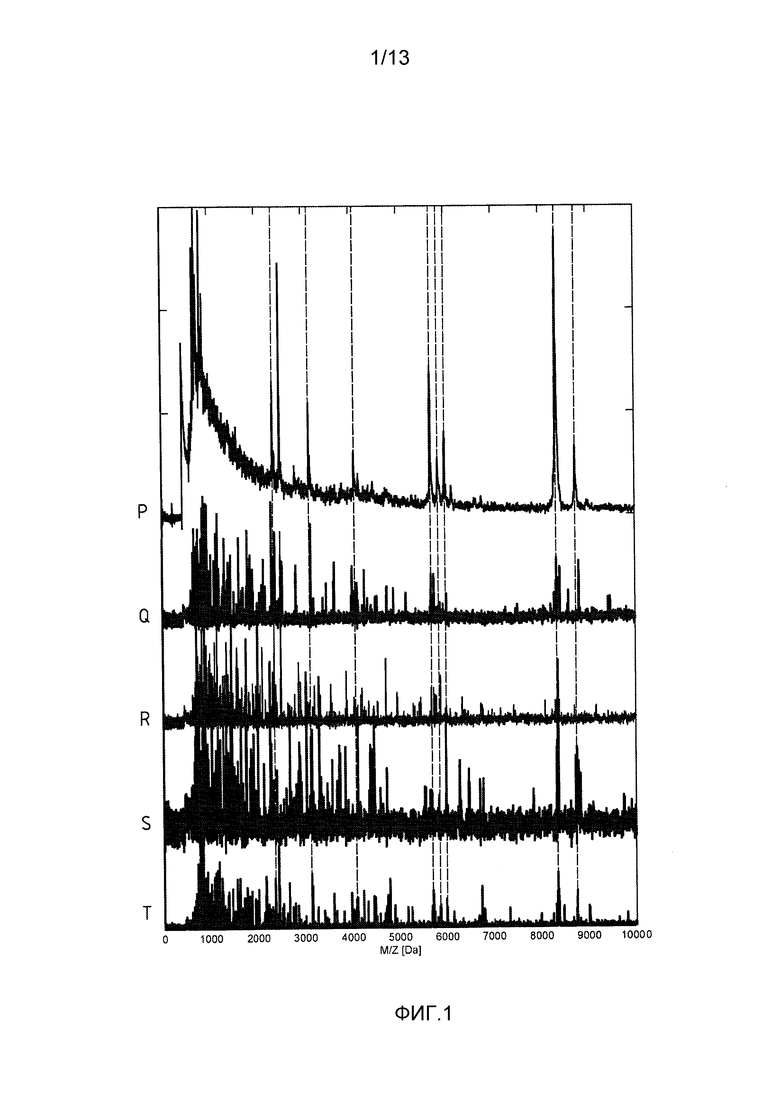
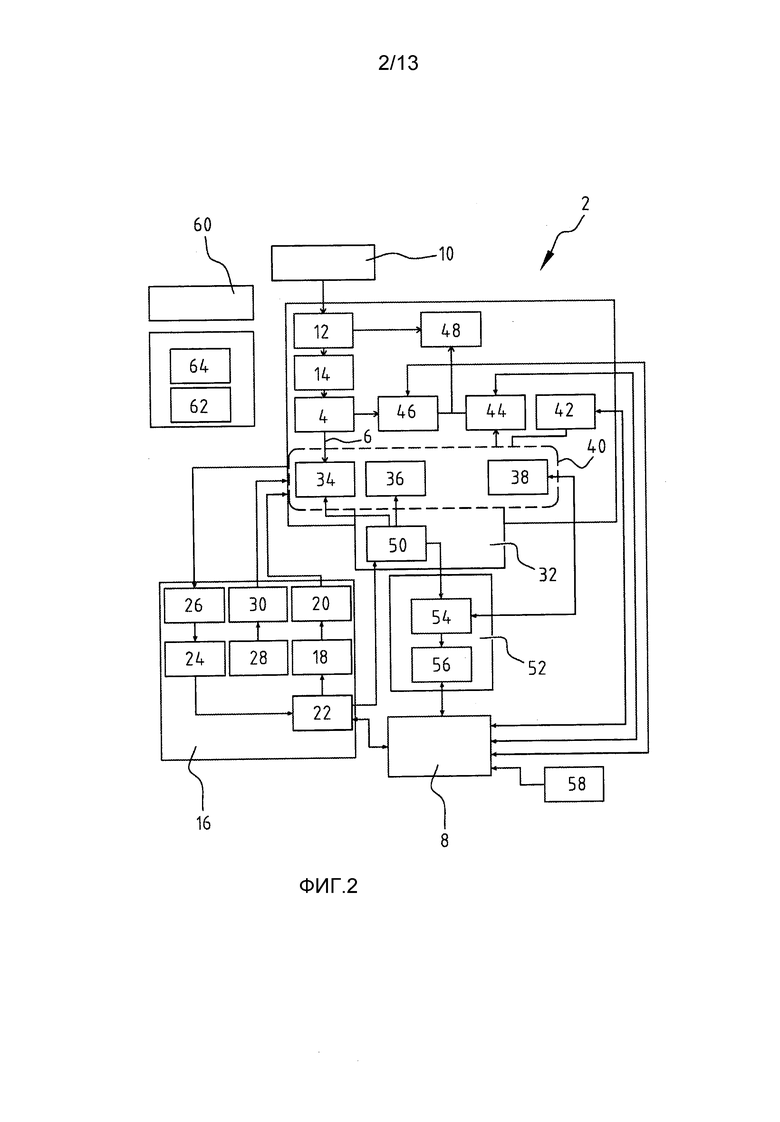
Спектры назначаются классу (изоляту) 1, когда
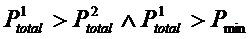
и классу 2, коггда
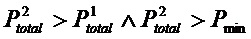
где Pmin - пороговая вероятность, которая должна быть превышена для классификации спектра. В этом примере используется пороговая вероятность Pmin=0,9.
Те спектры, которые не превышают пороговую вероятность, например, по той причине, что обе вероятности признака помечены как неопределенные, зачисляются в класс “неизвестный”.
Когда спектры, зачисляемые в один из классов, накапливаются, создается впечатление, что результирующие спектры для двух классов значительно отличаются друг от друга и от накопленного спектра смеси, см. фиг. 9.
Из фиг. 9 следует, что в положениях пиков (указанных вертикальными линиями), пики сохраняются только для спектра, соответствующего эталонному изоляту. Это указывает, что алгоритм классификации эффективен в том смысле, что позволяет выбирать те спектры, которые участвуют в признаке, и позволяет игнорировать спектры, которые не участвуют.
Таким образом, алгоритм позволяет выбирать одночастичные спектры, которые участвуют в признаке, и накопленные спектры, которые обусловлены выбором на основании признаков, которые принадлежат разным эталонам, значительно отличаются друг от друга. Однако, в некоторых конкретных случаях, не удается окончательно подтвердить, что два класса, формируемые согласно алгоритму, действительно соответствуют эталонам.
Поэтому, для окончательной проверки, можно проводить сравнение между спектром образца и эталонным спектром на основании информации, отличной от той, которая используется для классификации.
ПОДТВЕРЖДЕНИЕ РЕЗУЛЬТАТА КЛАССИФИКАЦИИ
Для подтверждения, что одночастичные спектры, отнесенные к разным классам, действительно соответствуют эталонным спектрам, накопленные одночастичные спектры для каждого класса можно сравнивать с эталонными спектрами.
На Фиг. 10 и фиг. 11 показано это сравнение для двух классов частиц. Эти фигуры демонстрируют, что помимо пиков используемых для выбора, также другие пики, присутствующие в спектрах, которые собраны из классифицированных частиц, соответствуют пикам в эталонных спектрах.
Кроме того, спектры, накопленные из классифицированных частиц, не содержат пики, отсутствующие в эталонных спектрах.
Оба свойства отчетливо указывают, что спектры, собранные из классифицированных спектров, действительно соответствуют эталонным спектрам. Следовательно, частицы, порождающие классифицированные спектры, действительно содержат клетки (их фрагменты), которые соответствуют клеткам, содержащимся в изоляте, используемом для эталонных спектров.
ПРОЦЕДУРА ИЕРАРХИЧЕСКОЙ КЛАССИФИКАЦИИ
В общем случае, накопленные спектры бактерий содержат где-то от 10 до 40 различимых пиков. Потенциально все положения пиков (в отношении их массы) можно использовать как признак для одночастичной классификации.
Необходимое условие пригодности пика состоит в том, что функция плотности вероятности для интенсивности одночастичного пика достаточно отличается от функции плотности вероятности для других изолятов в эталонной библиотеке при той же массе.
Удобной мерой различия/равенства двух распределений является статистика Колмогорова-Смирнова. Статистика Колмогорова-Смирнова количественно выражает расстояние между двумя эмпирическими функциями совокупного распределения двух образцов. Если эта статистика достаточно велика, две базисных функции плотности вероятности можно считать различимыми.
В силу конечного разрешения масс-спектрометра, чем больше наполнена эталонная библиотека, тем больше вероятность того, что пики разных изолятов (частично) перекрываются. Очевидно, перекрытие пиков разных изолятов делает их менее пригодными для классификации.
Следовательно, в зависимости от содержимого библиотеки эталонной библиотеки, только часть пиков, присутствующих в спектрах, можно эффективно использовать для одночастичной классификации.
Количество различимых классов определяется количеством используемых пиков. Количество различимых классов составляет порядка 2N, где N - количество неперекрывающихся пиков, присутствующих в эталонной библиотеке.
Первоначально, когда нужно рассматривать всевозможные организмы, эталонная библиотека будет очень наполненной. Следовательно, количество неперекрывающихся пиков будет невелико, и количество различимых классов будет невелико. Следовательно, при анализе образца, содержащего организмы смешанного происхождения, опасность того, что единичный класс содержит более чем один вид, относительно высока.
Однако, когда одночастичные спектры сохраняются по отдельности, их можно вторично классифицировать.
Поскольку теперь необходимо учитывать только эталоны, которые принадлежат классу, к которому отнесены эти спектры, можно построить эталонную библиотеку для данного класса, которая наполнена значительно меньше, чем первоначальная эталонная библиотека.
Поскольку эталонная библиотека для данного класса менее наполнена, вероятность перекрытия пиков снижается. Следовательно, некоторые пики, не пригодные в первоначальной библиотеке, будут пригодны в библиотеке для данного класса. Следовательно, смесь, содержащая образец, можно дополнительно различать.
Таким образом, рекурсивно классифицируя смесь и переопределяя эталонную библиотеку, образец, содержащий организмы смешанного происхождения, можно различать с большой степенью специфичности.
Существует связь между наличием пиков и таксономией. Выбор пиков можно осуществлять на основании микробиологии, путем использования пиков, специфичных для отряда, семейства, рода, вида или штамма микроорганизма. Таким образом, реализуется схема иерархической классификации.
На фиг. 12 показан пример кластерограммы для схемы иерархической классификации. В кластерограмме изображены пики в массовых спектрах разных штаммов золотистого стафилококка. Ось x представляет m/z. Разные штаммы отложены по оси y. Черные области соответствуют пикам в спектре соответствующих штаммов.
Кластерограмма показывает, что все штаммы содержат пики A для конкретного вида. Однако их можно различать с использованием пиков конкретного штамма в областях B и C.
В иллюстративном варианте осуществления, схема 100 иерархической классификации (фиг. 13) согласно изобретению принимает в качестве входных данных одночастичные спектры, полученные на этапе 102. Затем одночастичные спектры классифицируются на этапе 104 с использованием первого эталонного множества PDF 106. На основании этой классификации, спектры образцов причисляются к классу 1, классу 2, …, классу M.
Для каждой группы спектров образцов производится сравнение между спектрами в группе и эталонными спектрами соответствующего класса. Это проиллюстрировано для класса 2. На первом этапе 108 спектры образцов накапливаются, т.е. создается совокупный спектр образца. На этапе 110 вычисляется совокупный эталонный спектр. Совокупный спектр образца и совокупный эталонный спектр сравниваются на этапе 112 посредством согласования рисунка.
На этапе 114 вычисляется совпадение между совокупными спектрами. Если совпадение выше минимального порога, классификация считается правильной, и алгоритм возвращает эту классификацию на этапе 116. Если совпадение ниже порога, т.е. неприемлемо, алгоритм проверяет на этапе 118, является ли совокупный спектр образца смешанным спектром. Например, если в совокупном спектре образца присутствуют дополнительные пики, которые отсутствуют в совокупном эталонном спектре, совокупный спектр образца считается смешанным спектром.
Когда спектр не является смешанным спектром, алгоритм возвращает эту информацию и вычисляет таксономическое расстояние спектра до ближайшего родственного организма на этапе 120. Другими словами, организм исключается из классов библиотеки 106. Однако, на следующем этапе, спектры можно сравнивать с другой библиотекой.
Если на этапе 118 определено, что спектр является смешанным спектром, алгоритм возвращается к этапу 104, где используется другая библиотека. Эта новая библиотека содержит подклассы класса смешанного спектра, в данном случае, подклассы класса 2.
Другими словами, если наблюдается смешанный спектр, алгоритм углубляется в иерархию, переходя к подклассам соответствующего класса. Когда совпадение найдено на этапе 114, эта процедура останавливается. Если совпадения не найдено, и ни одного смешанного спектра не наблюдается, организм исключается из первоначальных классов 106.
Ниже приведен псевдокод для этапов способа согласно алгоритму.
ГЕНЕРАЦИЯ И ВЫБОР ФУНКЦИЙ ПЛОТНОСТИ ВЕРОЯТНОСТИ
%ГЕНЕРАЦИЯ ВЕКТОРОВ ВЫБОРА ПРИЗНАКА%
Цикл по изолятам
Цикл по файлам одночастичных спектров
Считывать одночастичный спектр как массив интенсивностей
Вычислить полный отсчет ионов
Нормализовать спектр по полному отсчету ионов
Прибавить нормализованный спектр к суммарному спектру
Конец цикла
Отобразить суммированный спектр
Пометить спектральные признаки (вручную или автоматически)
Сохранить идентификацию признака/изолята
Цикл по признакам
Выделить функции формы признака
Сохранить функцию формы признака как вектор выбора признака
Конец цикла
Конец цикла
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%ГЕНЕРАЦИЯ ФУНКЦИЙ ПЛОТНОСТИ ВЕРОЯТНОСТИ ПРИЗНАКА%
Цикл по изолятам
Цикл по одночастичным файлам
Считывать одночастичный спектр как массив интенсивностей
Выделить интенсивности признаков для всех признаков, принадлежащих всем изолятам
Сохранить интенсивность признака для всех признаков в соответствующих массивах интенсивностей признаков
Конец цикла
Цикл по признакам
Распределить элементы массивов интенсивностей признаков по надлежащим образом разнесенным контейнерам
Возвратить количество элементов на контейнер в частотном массиве интенсивностей признака
Разделить частотный массив интенсивностей признака на количество обработанных одночастичных спектров
Конец цикла
Конец цикла
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%ВЫБОР ФУНКЦИЙ ПЛОТНОСТИ ВЕРОЯТНОСТИ ПРИЗНАКА%
Цикл по функциям плотности вероятности признака
Генерировать функция плотности совокупной вероятности
Конец цикла
Цикл по изолятам
Выбрать признаки ‘природный’ для изолята согласно таблице идентификации признака/изолята
Цикл по ‘природным’ признакам
Цикл по ‘другим’ признакам
Определить и сохранить статистику Колмогорова-Смирнова для каждой комбинации природных признаков и других признаков
Конец цикла
Определить наименьшую статистику Колмогорова-Смирнова для каждого ‘природного’ признака и сохранить как minKS
Конец цикла
Выбрать N (количество, указанное пользователем, но, по меньшей мере, один) признаков с наибольшим minKS
Сохранить выбор признака для каждого изолята
Конец цикла
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%АНАЛИЗ СМЕСИ
%ОДНОЧАСТИЧНАЯ КЛАССИФИКАЦИЯ%
Ждущий цикл
Считывать одночастичный массовый спектр
Нормализовать одночастичный массовый спектр
Определить интенсивность (выбранных) признаков
Цикл по (выбранным) признаам
Цикл по изолятам
Определить P(I|Amn)P(A) и вклад в P(I|¬An)P(¬A)
Конец цикла
Определить P(Amn|I)
Конец цикла
Цикл по изолятам
С использованием списка ‘природных’ признаков, определить Ptotal для каждого изолята
Конец цикла
Отнести спектр к одному из классов, которые соответствуют эталонам, или к классу "неизвестный"
Конец цикла
Цикл по классам
Если количество спектров больше минимального количества
Суммировать все спектры, отнесенные к классу
Сгладить накопленный спектр
Повторно дискретизировать сглаженный спектр
Вычесть базовую линию из повторно дискретизированного спектра
Выделить пики
Классифицировать список пик по подклассам (например, видам) которые принадлежат рассматриваемому классу (например, роду)
Если классификация успешна
Сообщить идентификатор
Иначе
Проверить, может ли присутствовать в классе смесь видов
Если смесь присутствует
Генерировать новое множество признаков для дополнительного различения смеси
Произвести новую одночастичную классификацию для частиц, причисленных к рассматриваемой группе
Иначе
Определить таксономическое расстояние между накопленным спектром и эталонными спектрами
Конец
Конец
Конец
Конец цикла
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Таким образом, изобретение описано посредством предпочтительных вариантов осуществления. Однако следует понимать, что это раскрытие является исключительно иллюстративным. Представлены различные детали, касающиеся структуры и функции, но следует понимать, что вносимые изменения, полностью охватываемые общим смыслом терминов, в которых выражена нижеследующая формула изобретения, должны отвечать принципу настоящего изобретения. Описание и чертежи следует использовать для интерпретации формулы изобретения. Формулу изобретения следует использовать в том смысле, что заявленный объем защиты следует понимать как заданный строгим, буквальным смыслом выражений, используемых в формуле изобретения, причем описание и чертежи используются только с целью устранения неопределенности, найденной в формуле изобретения. С целью определения объема защиты, заявленного формулой изобретения, следует принимать во внимание любой элемент, который эквивалентен указанному в ней элементу.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИДЕНТИФИКАЦИИ И ПРОГНОЗИРОВАНИЯ Р-АЛКИЛЬНЫХ РАДИКАЛОВ ГОМОЛОГОВ О-АЛКИЛАЛКИЛФТОРФОСФОНАТОВ | 2018 |
|
RU2695039C1 |
| Способ оценки параметров профиля поверхности на основе вероятностно-статистической классификации спектра профилограммы | 2019 |
|
RU2708500C1 |
| Способ оперативной идентификации морских целей по их информационным полям на базе нейро-нечетких моделей | 2021 |
|
RU2763125C1 |
| Способ и система для анализа спектральных данных | 2017 |
|
RU2764200C2 |
| КЛАССИФИКАЦИЯ ДАННЫХ ВЫБОРОК | 2009 |
|
RU2517286C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ АЛКИЛЬНЫХ РАДИКАЛОВ СОЕДИНЕНИЙ ГОМОЛОГИЧЕСКОГО РЯДА О-АЛКИЛАЛКИЛФТОРФОСФОНАТОВ | 2016 |
|
RU2662047C2 |
| СПОСОБ И СИСТЕМА ДЛЯ НЕРАЗРУШАЮЩЕГО IN OVO ОПРЕДЕЛЕНИЯ ПОЛА ПТИЦЫ | 2017 |
|
RU2756447C2 |
| СПОСОБ И УСТРОЙСТВО ЧАСТОТНОГО АНАЛИЗА ДАННЫХ | 2009 |
|
RU2503938C2 |
| Способ идентификации растительных объектов по космическим снимкам дистанционного зондирования | 2018 |
|
RU2693880C1 |
| СПОСОБЫ И БАЗЫ ДАННЫХ ДЛЯ ИДЕНТИФИКАЦИИ НУКЛИДОВ | 2010 |
|
RU2539779C1 |
Изобретение относится к аналитическим измерениям. Способ классификации образца в одном из классов осуществляется на основании спектральных данных, причем спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI. Способ содержит этапы, на которых: a) получают по меньшей мере два множества первых спектров для использования в качестве эталонных спектров, причем каждое множество содержит спектры эталонных образцов, принадлежащие одному и тому же классу; b) определяют, для каждого из эталонных спектров, значение одной и той же по меньшей мере одной величины, связанной со спектральным признаком посредством применения предварительно определенной функции или операции к каждому эталонному спектру; c) для каждого набора эталонных спектров строят функцию плотности вероятности (PDF) значения упомянутой по меньше мере одной величины посредством связывания вероятности с разными значениями величины на основании значений, определенных на этапе b); d) получают спектр из образца и определяют значение одной и той же величины этого спектра; e) вычисляют, на основании множества PDF, определенных на этапе с) и значения величины для полученного спектра для каждого из упомянутых классов, вероятность того, что образец принадлежит этому классу, причем эталонные спектры и спектр, полученный из образца, являются спектрами одиночных частиц. Технический результат заключается в обеспечении возможности повышения эффективности и надежности классификации образца. 5 н. и 15 з.п. ф-лы, 13 ил.
1. Способ классификации образца в одном из по меньшей мере двух классов на основании спектральных данных, причем спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI, причем способ содержит этапы, на которых:
a) получают по меньшей мере два множества первых спектров для использования в качестве эталонных спектров, причем каждое множество содержит спектры эталонных образцов, принадлежащие одному и тому же классу;
b) определяют, для каждого из эталонных спектров, значение одной и той же по меньшей мере одной величины, связанной со спектральным признаком посредством применения предварительно определенной функции или операции к каждому эталонному спектру;
c) для каждого набора эталонных спектров строят функцию плотности вероятности (PDF) значения упомянутой по меньше мере одной величины посредством связывания вероятности с разными значениями величины на основании значений, определенных на этапе b);
d) получают спектр из образца и определяют значение одной и той же по меньшей мере одной величины этого спектра; и
e) вычисляют, на основании множества PDF, определенных на этапе с) и значения величины для полученного спектра для каждого из упомянутых по меньшей мере двух классов, вероятность того, что образец принадлежит этому классу,
причем эталонные спектры и спектр, полученный из образца, являются спектрами одиночных частиц.
2. Способ по п. 1, в котором образец является биологическим образцом.
3. Способ по п. 2, в котором биологический образец содержит микроорганизмы, и классификация содержит классификацию микроорганизмов.
4. Способ по п. 1, в котором по меньшей мере одна величина выбирается на основании характерного спектрального признака эталонного класса.
5. Способ по п. 1, содержащий вычисление, для спектра образца, для которого получено значение Ii, связанного со спектральным признаком, величины Qi, причем вероятность P(Aj|Ii) того, что образец принадлежит эталонному классу Aj при заданном значении Ii, определяется согласно:
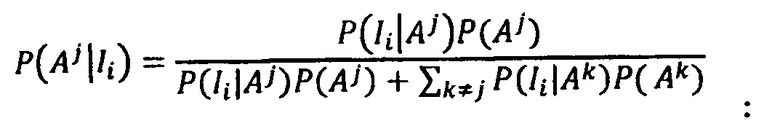
где P(Ii|Aj) - вероятность, связанная со значением Ii для эталонного класса Aj, и P(Ii|Ak) при k≠j - вероятность, связанная со значением Ii для по меньшей мере одного эталонного класса, отличного от эталонного класса Aj.
6. Способ по п. 1, в котором этап b) содержит определение для каждого из эталонных спектров значения одних и тех же по меньшей мере двух величин, связанных со спектральным признаком, и этап е) содержит объединение вероятностей, полученных для всех величин, в полную вероятность того, что образец принадлежит соответствующему классу.
7. Способ по п. 1, в котором значение относится к интенсивности при по меньшей мере одном заранее определенном спектральном значении или в заранее определенном диапазоне спектральных значений.
8. Способ по п. 1, в котором значение нормализуется.
9. Способ по п. 1, в котором значение определяется путем умножения интенсивностей соответствующего спектра по заранее определенному диапазону спектральных значений на весовую функцию.
10. Способ по п. 9, в котором весовая функция базируется на совокупном спектре спектров одного и того же класса.
11. Способ по п. 1, в котором значение относится к отношению между интенсивностями при заранее определенных спектральных значениях или в заранее определенных спектральных диапазонах.
12. Способ по п. 1, в котором значение относится к положению пика в заранее определенном диапазоне спектральных значений.
13. Способ по п. 1, в котором значение является вектором.
14. Способ по п. 1, в котором этапы d) и е) осуществляются для первого множества эталонных классов и затем для второго множества эталонных классов, причем второе множество выбирается на основании классификации образца в одном из эталонных классов первого множества.
15. Способ по п. 3 или 14, в котором первое множество и второе множество выбираются на основании иерархии биологической классификации.
16. Способ по п. 1, в котором этап d) содержит получение по меньшей мере двух спектров из образца и определение значения одной и той же по меньшей мере одной величины этих по меньшей мере двух спектров и этап е) содержит объединение спектров образцов, отнесенных к одному и тому же классу, в совокупный спектр и сравнение этого совокупного спектра с совокупным эталонным спектром, полученным путем объединения эталонных спектров соответствующего класса.
17. Способ создания базы данных для использования в классификации образца в одном из по меньшей мере двух классов на основании спектральных данных, причем спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI, причем способ содержит этапы, на которых:
a) получают по меньшей мере два множества первых спектров для использования в качестве эталонных спектров, причем каждое множество содержит спектры эталонных образцов, принадлежащие одному и тому же классу;
b) определяют, для каждого из эталонных спектров, значение одной и той же по меньшей мере одной величины, связанной со спектральным признаком посредством применения предварительно определенной функции или операции к каждому эталонному спектру; и
c) для каждого набора эталонных спектров строят функцию плотности вероятности (PDF) значения упомянутой по меньше мере одной величины посредством связывания вероятности с разными значениями величины на основании определенных значений, причем эталонные спектры являются спектрами одиночных частиц.
18. Способ классификации образца в одном из по меньшей мере двух классов на основании спектральных данных с использованием базы данных, полученной способом по п. 17, причем спектральные данные содержат спектр комбинационного рассеяния, ближний инфракрасный спектр, ИК-Фурье спектр, масс-спектр MALDI или времяпролетный масс-спектр MALDI, причем способ содержит этапы, на которых:
d) получают одночастичный спектр из образца и определяют значение одной и той же по меньшей мере одной величины этого спектра; и
e) вычисляют, на основании множества PDF, полученных из базы данных и значения величины для полученного спектра для каждого из упомянутых по меньшей мере двух классов, вероятность того, что образец принадлежит этому классу.
19. Носитель данных, содержащий исполняемые компьютером команды, которые при исполнении предписывают компьютеру выполнять этапы способа по пп. 1-16.
20. Система для классификации образца на основании спектральных данных, содержащая:
- средство для получения одночастичного спектра из образца;
- средство анализа для осуществления способа по любому из пп. 1-16.
| US 2007184455 A1, 09.08.2007 | |||
| WO 03031954 A1, 17.04.2003 | |||
| US 20090012723 A1, 08.01.2009 | |||
| EA 200700576 A1, 26.10.2007.. |

