Перекрестная ссылка на родственные заявки
Настоящая заявка заявляет приоритет даты подачи предварительной заявки на патент США № 61/827246, поданной 24 мая 2013 г., предварительной заявки на патент США № 61/893770, поданной 21 октября 2013 г., и предварительной заявки на патент США № 61/973,625, поданной 1 апреля 2014 г., каждая из которых ссылкой полностью включается в данное описание.
Область техники
Раскрытие данного описания в целом относится к кодированию звуковой сцены, содержащей звуковые объекты. В частности, оно относится к кодеру, декодеру и связанным с ними способам кодирования и декодирования звуковых объектов.
Предпосылки создания изобретения
Звуковая сцена в целом может содержать звуковые объекты и звуковые каналы. Звуковой объект представляет собой звуковой сигнал, обладающий связанным с ним пространственным положением, которое может изменяться во времени. Звуковой канал представляет собой звуковой сигнал, напрямую соответствующий каналу многоканальной конфигурации громкоговорителей, такой как так называемая конфигурация громкоговорителей 5.1 с тремя передними громкоговорителями, двумя окружающими громкоговорителями и громкоговорителем низкочастотных эффектов.
Так как количество звуковых объектов, как правило, может быть очень большим, например, порядка сотен звуковых объектов, существует потребность в способах кодирования, позволяющих эффективно восстанавливать звуковые объекты на стороне декодера. Были предложения комбинировать звуковые объекты в многоканальное понижающее микширование (т. е. в множество звуковых каналов, соответствующее каналам определенной многоканальной конфигурации громкоговорителей, такой как конфигурация 5.1) на стороне кодера и параметрически восстанавливать звуковые объекты из многоканального понижающего микширования на стороне декодера.
Одним из преимуществ такого подхода является то, что унаследованный декодер, не поддерживающий восстановление звуковых объектов, может использовать многоканальное понижающее микширование непосредственно для воспроизведения на многоканальной конфигурации громкоговорителей. Например, понижающее микширование 5.1 можно воспроизводить непосредственно на громкоговорителях конфигурации 5.1.
Однако одним из недостатков данного подхода является то, что многоканальное понижающее микширование может не позволять достаточно хорошо восстанавливать звуковые объекты на стороне декодера. Например, рассмотрим два звуковых объекта, имеющих такое же горизонтальное положение, как и левый передний громкоговоритель конфигурации 5.1, но разное вертикальное положение. Эти звуковые объекты, как правило, скомбинированы в одном и том же канале понижающего микширования 5.1. Это может составить затруднительную ситуацию при восстановлении звукового объекта на стороне декодера, когда необходимо восстанавливать приближения двух звуковых объектов для одного и того же канала понижающего микширования — процесс, не способный обеспечить совершенное восстановление и иногда даже приводящий к слышимым артефактам.
Поэтому существует потребность в способах кодирования/декодирования, обеспечивающих эффективное и усовершенствованное восстановление звуковых объектов.
В ходе восстановления звуковых объектов, например, исходя из понижающего микширования, часто используют дополнительную информацию, или метаданные. Форма и контекст такой дополнительной информации могут, например, оказывать влияние на точность воспроизведения восстановленных звуковых объектов и/или на вычислительную сложность выполнения восстановления. Поэтому было бы желательно создать способы кодирования/декодирования с новым и альтернативным форматом дополнительной информации, позволяющим повысить точность воспроизведения восстановленных звуковых объектов и/или позволяющим снизить вычислительную сложность восстановления.
Краткое описание графических материалов
Далее приводится описание примерных вариантов осуществления со ссылками на прилагаемые графические материалы, на которых:
фиг. 1 - схематическая иллюстрация кодера согласно примерным вариантам осуществления;
фиг. 2 - схематическая иллюстрация декодера, поддерживающего восстановление звуковых объектов, согласно примерным вариантам осуществления;
фиг. 3 - схематическая иллюстрация декодера с низкой сложностью, не поддерживающего восстановление звуковых объектов, согласно примерным вариантам осуществления;
фиг. 4 - схематическая иллюстрация кодера, содержащего последовательно расположенный компонент кластеризации для упрощения звуковой сцены, согласно примерным вариантам осуществления;
фиг. 5 - схематическая иллюстрация кодера, содержащего компонент кластеризации, расположенный параллельно для упрощения звуковой сцены, согласно примерным вариантам осуществления;
на фиг. 6 проиллюстрирован типичный известный процесс вычисления матрицы представления для набора экземпляров метаданных;
на фиг. 7 проиллюстрировано получение кривой коэффициента, используемой при представлении звуковых сигналов;
на фиг. 8 проиллюстрирован способ интерполяции экземпляров метаданных согласно одному из примерных вариантов осуществления;
на фиг. 9 и 10 проиллюстрированы примеры введения добавочных экземпляров метаданных согласно примерным вариантам осуществления; и
на фиг. 11 проиллюстрирован способ интерполяции с применением схемы выборки и хранения с фильтром пропускания нижних частот согласно одному из примерных вариантов осуществления.
Все фигуры являются схематическими и, как правило, показывают лишь те части, которые необходимы для разъяснения изобретения; другие части могут быть опущены или просто подразумеваться. Если не указано иного, подобные части на разных фигурах обозначены подобными ссылочными позициями.
Подробное описание
Ввиду вышесказанного целью является, таким образом, создание кодера, декодера и связанных с ними способов, делающих возможным эффективное и усовершенствованное восстановление звуковых объектов, и/или позволяющих повысить точность воспроизведения восстановленных звуковых объектов, и/или позволяющих снизить вычислительную сложность восстановления.
I. Обзор - Кодер
Согласно первой особенности, предлагается способ кодирования, кодер и компьютерный программный продукт для кодирования звуковых объектов.
Согласно примерным вариантам осуществления, предлагается способ кодирования звуковых объектов в поток данных, включающий:
прием N звуковых объектов, где N>1;
вычисление М сигналов понижающего микширования, где M≤N, путем формирования комбинаций N звуковых объектов в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей;
вычисление дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
включение М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер.
В приведенной выше схеме М сигналов понижающего микширования, таким образом, формируют из N звуковых объектов независимо от какой-либо конфигурации громкоговорителей. Это предполагает, что М сигналов понижающего микширования не ограничены звуковыми сигналами, пригодными для воспроизведения каналов из конфигурации громкоговорителей с М каналов. Вместо этого, М сигналов понижающего микширования можно более свободно выбирать в соответствии с некоторым критерием так, чтобы они, например, адаптировались к динамике N звуковых объектов и совершенствовали восстановление этих звуковых объектов на стороне декодера.
Возвращаясь к примеру с двумя звуковыми объектами, имеющими такое же горизонтальное положение, как и левый передний громкоговоритель конфигурации 5.1, но разное вертикальное положение, предлагаемый способ позволяет поместить первый звуковой объект в первый сигнал понижающего микширования, а второй звуковой объект — во второй сигнал понижающего микширования. Это делает возможным совершенное восстановление звуковых объектов в декодере. В целом, такое совершенное восстановление возможно до тех пор, пока количество активных звуковых объектов не превышает количество сигналов понижающего микширования. Если количество активных звуковых объектов выше, то предлагаемый способ позволяет выбрать звуковые объекты, которые необходимо смешать в один и тот же сигнал понижающего микширования так, чтобы возможные ошибки приближения, возникающие в восстановленном звуковом объекте в декодере, не оказывали или оказывали наименьшее возможное воспринимаемое воздействие на восстанавливаемую звуковую сцену.
Второе преимущество того, что М сигналов понижающего микширования являются адаптивными, является способность содержать определенные звуковые объекты строго отдельно от других звуковых объектов. Например, может быть преимущественным содержание какого-либо диалогового объекта отдельно от фоновых объектов с тем, чтобы обеспечить то, что диалог будет представлен точно в выражении пространственных признаков и будет допускать такую обработку объекта в декодере, как усиление диалога или увеличение громкости диалога, с целью повышения разборчивости. В других применениях (например, в караоке) может быть преимущественным обеспечение возможности полного приглушения одного или нескольких объектов, что также требует, чтобы такие объекты не были смешаны с другими объектами. Традиционные способы, использующие многоканальное понижающее микширование, соответствующее конкретной конфигурации громкоговорителей, не позволяют полностью заглушать звуковые объекты, присутствующие в микшировании с другими звуковыми объектами.
Термин "сигнал понижающего микширования" отражает то, что сигнал понижающего микширования представляет собой микширование, т. е. комбинацию, других сигналов. Термин "понижающее" указывает на то, что количество М сигналов понижающего микширования, как правило, меньше количества N звуковых объектов.
Согласно примерным вариантам осуществления, способ также может включать связывание каждого сигнала понижающего микширования с пространственным положением и включение пространственных положений сигналов понижающего микширования в поток данных как метаданных для сигналов понижающего микширования. Это является преимущественным в том, что позволяет использовать декодирование с низкой сложностью в случае унаследованной системы воспроизведения. Точнее, метаданные, связанные с сигналами понижающего микширования, можно использовать на стороне декодера для представления этих сигналов понижающего микширования в каналы унаследованной системы воспроизведения.
Согласно примерным вариантам осуществления, N звуковых объектов связаны с метаданными, содержащими пространственные положения N звуковых объектов, а пространственные положения, связанные с сигналами понижающего микширования, вычисляют на основе пространственных положений N звуковых объектов. Таким образом, сигналы понижающего микширования можно интерпретировать как звуковые объекты, имеющие пространственное положение, зависящее от пространственных положений N звуковых объектов.
Кроме того, пространственные положения N звуковых объектов и пространственные положения, связанные с М сигналов понижающего микширования, могут быть переменными по времени, т. е. они могут изменяться между временными кадрами звуковых данных. Иными словами, сигналы понижающего микширования можно интерпретировать как динамические звуковые объекты, имеющие связанное положение, изменяющееся между временными кадрами. Это представляет отличие от систем, известных из уровня техники, где сигналы понижающего микширования соответствуют фиксированным пространственным положениям громкоговорителей.
Как правило, дополнительная информация также является переменной по времени, посредством чего параметры управляют временным изменением восстановления звуковых объектов.
Для вычисления сигналов понижающего микширования кодер может применять различные критерии. Согласно примерным вариантам осуществления, в которых N звуковых объектов связаны с метаданными, содержащими пространственные положения N звуковых объектов, критерий вычисления М сигналов понижающего микширования может основываться на пространственной близости N звуковых объектов. Например, в один и тот же сигнал понижающего микширования можно скомбинировать звуковые объекты, близкие друг к другу.
Согласно примерным вариантам осуществления, в которых метаданные, связанные с N звуковых объектов, также содержат значения значимости, указывающие значимость N звуковых объектов относительно друга друга, критерий вычисления М сигналов понижающего микширования также может основываться на значениях значимости N звуковых объектов. Например, наиболее значимый (значимые) из N звуковых объектов может отображаться непосредственно в сигнал понижающего микширования, тогда как остальные звуковые объекты комбинируют для формирования остальных сигналов понижающего микширования.
В частности, согласно примерным вариантам осуществления, этап вычисления М сигналов понижающего микширования включает первую процедуру кластеризации, включающую связывание N звуковых объектов с М кластеров на основе пространственной близости и значений значимости, если необходимо, N звуковых объектов и вычисление сигнала понижающего микширования для каждого кластера путем формирования комбинации звуковых объектов, связанных с этим кластером. В некоторых случаях звуковой объект может образовывать часть самое большее одного кластера. В других случаях звуковой объект может образовывать часть нескольких кластеров. Таким образом, из звуковых объектов формируют различные группы, т. е. кластеры. В свою очередь, каждый кластер представлен сигналом понижающего микширования, который можно рассматривать как звуковой объект. Кластерный подход позволяет связывать каждый сигнал понижающего микширования с пространственным положением, вычисленным на основе пространственных положений звуковых объектов, связанных с кластером, соответствующим сигналу понижающего микширования. Поэтому в такой интерпретации первая процедура кластеризации гибким образом уменьшает размерность массива N звуковых объектов до М звуковых объектов.
Пространственное положение, связанное с каждым сигналом понижающего микширования, можно вычислить, например, как центроид или взвешенный центроид пространственных положений звуковых объектов, связанных с кластером, соответствующим сигналу понижающего микширования. Весовые коэффициенты могут быть основаны, например, на значениях значимости звуковых объектов.
Согласно примерным вариантам осуществления, N звуковых объектов связывают с М кластеров путем применения алгоритма обучения методом К-средних, содержащего пространственные положения N звуковых объектов в качестве ввода.
Так как звуковая сцена может содержать огромное количество звуковых объектов, в способе также можно предпринимать дальнейшие меры по уменьшению размерности массива звуковой сцены, посредством чего снижая вычислительную сложность на стороне декодера при восстановлении звуковых объектов. В частности, способ также может включать вторую процедуру кластеризации с целью уменьшения первого множества звуковых объектов до второго множества звуковых объектов.
Согласно одному из вариантов осуществления, вторую процедуру кластеризации выполняют перед вычислением М сигналов понижающего микширования. В этом варианте осуществления первое множество звуковых объектов, таким образом, соответствует первоначальным звуковым объектам звуковой сцены, а второе, уменьшенное, множество звуковых объектов соответствует N звуковых объектов, на основе которых вычисляют М сигналов понижающего микширования. Кроме того, в таком варианте осуществления набор звуковых объектов (подлежащих восстановлению в декодере), сформированный на основе N звуковых объектов, соответствует, т. е. равен, N звуковых объектов.
Согласно другому варианту осуществления, вторую процедуру кластеризации выполняют параллельно с вычислением М сигналов понижающего микширования. В таком варианте осуществления N звуковых объектов, на основе которых вычисляют М сигналов понижающего микширования, а также первое множество звуковых объектов, являющееся вводом во вторую процедуру кластеризации, соответствуют первоначальным звуковым объектам звуковой сцены. Кроме того, в таком варианте осуществления второму множеству звуковых объектов соответствует набор звуковых объектов (подлежащих восстановлению в декодере), сформированный на основе N звуковых объектов. При таком подходе М сигналов понижающего микширования, таким образом, вычисляют на основе первоначальных звуковых объектов звуковой сцены, а не на основе уменьшенного количества звуковых объектов.
Согласно примерным вариантам осуществления, вторая процедура кластеризации включает:
прием первого множества звуковых объектов и связанных с ними пространственных положений;
связывание первого множества звуковых объектов с по меньшей мере одним кластером на основе пространственной близости первого множества звуковых объектов;
генерирование второго множества звуковых объектов путем представления каждого из по меньшей мере одного кластера посредством звукового объекта, представляющего собой комбинацию звуковых объектов, связанных с кластером;
вычисление метаданных, содержащих пространственные положения для второго множества звуковых объектов, при этом пространственное положение каждого звукового объекта из второго множества звуковых объектов вычисляют на основе пространственных положений звуковых объектов, связанных с соответствующим кластером; и
включение метаданных для второго множества звуковых объектов в поток данных.
Иными словами, во второй процедуре кластеризации используют пространственную избыточность, присутствующую в звуковой сцене, такую как объекты, обладающие равными или очень похожими положениями. В дополнение, при генерировании второго множества звуковых объектов можно учитывать значения значимости звуковых объектов.
Как упоминалось выше, звуковая сцена также может содержать звуковые каналы. Такие звуковые каналы можно рассматривать как звуковой объект, связанный с постоянным положением, то есть с положением громкоговорителя, соответствующего звуковому каналу. Более подробно, вторая процедура кластеризации также может включать:
прием по меньшей мере одного звукового канала;
преобразование каждого из по меньшей мере одного звукового канала в звуковой объект, обладающий постоянным пространственным положением, соответствующим положению громкоговорителя этого звукового канала; и
включение преобразованного по меньшей мере одного звукового канала в первое множество звуковых объектов.
Таким образом, способ позволяет кодировать звуковую сцену, содержащую звуковые каналы, а также звуковые объекты.
Согласно примерным вариантам осуществления, предлагается компьютерный программный продукт, содержащий машиночитаемый носитель с командами для выполнения способа декодирования согласно примерным вариантам осуществления.
Согласно примерным вариантам осуществления, предлагается кодер для кодирования звуковых объектов в поток данных, содержащий:
компонент приема, выполненный с возможностью приема N звуковых объектов, где N>1;
компонент понижающего микширования, выполненный с возможностью вычисления М сигналов понижающего микширования, где M≤N, путем формирования комбинаций N звуковых объектов в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей;
компонент анализа, выполненный с возможностью вычисления дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент уплотнения, выполненный с возможностью включения М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер.
II. Обзор — Декодер
Согласно второй особенности, предлагается способ декодирования, декодер и компьютерный программный продукт для декодирования многоканального звукового содержимого.
Вторая особенность может в целом обладать такими же характерными признаками и преимуществами, как и первая особенность.
Согласно примерным вариантам осуществления, предлагается способ декодирования в декодере потока данных, содержащего кодированные звуковые объекты, включающий:
прием потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, вычисленные в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей, где M≤N, и дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
восстановление набора звуковых объектов, сформированного на основе N звуковых объектов, исходя из М сигналов понижающего микширования и дополнительной информации.
Согласно примерным вариантам осуществления, поток данных также содержит метаданные для М сигналов понижающего микширования, содержащие пространственные положения, связанные с М сигналов понижающего микширования, при этом способ также включает:
выполнение этапа восстановления набора звуковых объектов, сформированного на основе N звуковых объектов, исходя из М сигналов понижающего микширования и дополнительной информации, при условии, что декодер выполнен с возможностью поддержки восстановления звуковых объектов; и
применение метаданных для М сигналов понижающего микширования для представления М сигналов понижающего микширования в выходные каналы системы воспроизведения, при условии, что декодер не выполнен с возможностью поддержки восстановления звуковых объектов.
Согласно примерным вариантам осуществления, пространственные положения, связанные с М сигналов понижающего микширования, являются переменными по времени.
Согласно примерным вариантам осуществления, дополнительная информация является переменной по времени.
Согласно примерным вариантам осуществления, поток данных также содержит метаданные для набора звуковых объектов, сформированного на основе N звуковых объектов, в том числе пространственные положения набора звуковых объектов, сформированного на основе N звуковых объектов, при этом способ также включает:
применение метаданных для набора звуковых объектов, сформированного на основе N звуковых объектов, для представления восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, в выходные каналы системы воспроизведения.
Согласно примерным вариантам осуществления, набор звуковых объектов, сформированный на основе N звуковых объектов, равен N звуковых объектов.
Согласно примерным вариантам осуществления, набор звуковых объектов, сформированный на основе N звуковых объектов, содержит множество звуковых объектов, которые представляют собой комбинации N звуковых объектов, и количество которых меньше N.
Согласно примерным вариантам осуществления, предлагается компьютерный программный продукт, содержащий машиночитаемый носитель с командами для выполнения способа декодирования согласно примерным вариантам осуществления.
Согласно примерным вариантам осуществления, предлагается декодер для декодирования потока данных, содержащего кодированные звуковые объекты, содержащий:
компонент приема, выполненный с возможностью приема потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, вычисленные в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей, где M≤N, и дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент восстановления, выполненный с возможностью восстановления набора звуковых объектов, сформированного на основе N звуковых объектов, исходя из М сигналов понижающего микширования и дополнительной информации.
III. Обзор — Формат для дополнительной информации и метаданных
Согласно третьей особенности, предусмотрен способ кодирования, кодер и компьютерный программный продукт для кодирования звуковых объектов.
Способы, кодеры и компьютерные программные продукты согласно третьей особенности могут в целом обладать характерными признаками и преимуществами, общими со способами, кодерами и компьютерными программными продуктами согласно первой особенности.
Согласно примерным вариантам осуществления, предлагается способ кодирования звуковых объектов в поток данных. Этот способ включает:
прием N звуковых объектов, где N>1;
вычисление М сигналов понижающего микширования, где M≤N, путем формирования комбинаций N звуковых объектов;
вычисление изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
включение М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер.
В настоящих примерных вариантах осуществления способ также включает включение в поток данных:
множества экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления набора звуковых объектов, сформированного на основе N звуковых объектов; и
данных перехода для каждого экземпляра дополнительной информации, содержащих две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информацией, и момент времени для завершения перехода.
В этом примерном варианте осуществления дополнительная информация является изменяющейся во времени, например переменной по времени, допускающей изменение параметров, управляющих восстановлением звуковых объектов, относительно времени, что отражается присутствием экземпляров дополнительной информации. Используя формат дополнительной информации, содержащий данные перехода, которые определяют моменты времени для начала и момент времени для завершения переходов от текущих установок восстановления к соответствующим требуемым установкам восстановления, экземпляры дополнительной информации делаются более независимыми друг от друга в том смысле, что интерполяцию можно выполнять на основе текущей установки восстановления и единственной требуемой установки восстановления, определяемой единственным экземпляром дополнительной информации, т. е. в отсутствие знания о каких-либо других экземплярах дополнительной информации. Предусматриваемый формат дополнительной информации, таким образом, содействует вычислению/введению добавочных экземпляров дополнительной информации между существующими экземплярами дополнительной информации. В частности, предусматриваемый формат дополнительной информации допускает вычисление/введение добавочных экземпляров дополнительной информации без воздействия на качество воспроизведения. В данном раскрытии процесс вычисления/введения новых экземпляров дополнительной информации между существующими экземплярами дополнительной информации именуется "передискретизацией" дополнительной информации. Передискретизация дополнительной информации часто требуется в ходе определенных задач обработки звуковых данных. Например, при редактировании звукового содержимого, например посредством вырезки/слияния/микширования, такие редакции могут происходить между экземплярами дополнительной информации. В этом случае может потребоваться передискретизация дополнительной информации. Другим таким случаем является случай, когда звуковые сигналы и связанную с ними дополнительную информацию кодируют звуковым кодеком на основе кадров. В этом случае желательно иметь, по меньшей мере, один экземпляр дополнительной информации для каждого кадра звукового кодека, предпочтительно с временной отметкой в начале такого кадра кодека, для повышения устойчивости к ошибкам потерь кадров при передаче. Например, звуковые сигналы/объекты могут составлять часть аудиовизуального сигнала, или мультимедийного сигнала, содержащего видеосодержимое. В таких применениях может быть желательно модифицировать частоту кадров звукового содержимого для согласования с частотой кадров видеосодержимого, в силу чего может быть необходима соответствующая передискретизация дополнительной информации.
Поток данных, в который заключают сигнал понижающего микширования и дополнительную информацию, может представлять собой, например, битовый поток, в частности сохраняемый или передаваемый битовый поток.
Следует понимать, что вычисление М сигналов понижающего микширования путем формирования комбинаций N звуковых объектов означает, что каждый из М сигналов понижающего микширования получают путем формирования комбинации, например линейной комбинации, звукового содержимого одного или нескольких из N звуковых объектов. Иными словами, каждый из N звуковых объектов необязательно вносит вклад в каждый из М сигналов понижающего микширования.
Термин "сигнал понижающего микширования" отражает то, что сигнал понижающего микширования представляет собой микширование, т. е. комбинацию, других сигналов. Сигнал понижающего микширования может, например, представлять собой аддитивное микширование других сигналов. Термин "понижающее" указывает на то, что количество М сигналов понижающего микширования, как правило, меньше количества N звуковых объектов.
Сигналы понижающего микширования можно вычислять, например, формируя комбинации N звуковых сигналов в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей, согласно любому из примерных вариантов осуществления в рамках первой особенности. В качестве альтернативы, сигналы понижающего микширования можно вычислять, например, формируя комбинации N звуковых сигналов так, чтобы сигналы понижающего микширования были пригодны для воспроизведения в каналах конфигурации громкоговорителей с М каналов, что в данном описании именуется "обратно совместимым понижающим микшированием".
Под данными перехода, содержащими две независимо присваиваемые части, подразумевается то, что две части являются присваиваемыми взаимонезависимо, то есть могут быть присвоены независимо одна от другой. Однако следует понимать, что части данных перехода могут, например, совпадать с частями данных перехода для дополнительной информации, или метаданных, других типов.
В этом примерном варианте осуществления две независимо присваиваемые части данных перехода в комбинации определяют момент времени для начала перехода и момент времени для завершения перехода, т. е. эти два момента времени можно получить, исходя их двух независимо присваиваемых частей данных перехода.
Согласно одному из примерных вариантов осуществления, способ может также включать процедуру кластеризации с целью уменьшения первого множества звуковых объектов до второго множества звуковых объектов, при этом N звуковых объектов составляют либо первое множество звуковых объектов, либо второе множество звуковых объектов, и при этом набор звуковых объектов, сформированный на основе N звуковых объектов, совпадает со вторым множеством звуковых объектов. В этом примерном варианте осуществления процедура кластеризации может включать:
вычисление изменяющихся во времени метаданных кластеров, содержащих пространственные положения для второго множества звуковых объектов; и
дальнейшее включение в поток данных для передачи в декодер:
множества экземпляров метаданных кластеров, определяющих соответствующие требуемые установки представления для представления второго набора звуковых объектов; и
данных перехода для каждого экземпляра метаданных кластеров, содержащих две независимо присваиваемые части, в комбинации определяющие момент времени для начала перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров, и момент времени для завершения перехода к требуемой установке представления, определяемой экземпляром метаданных кластеров.
Так как звуковая сцена может содержать огромное количество звуковых объектов, в способе согласно этому примерному варианту осуществления предпринимают дальнейшие меры для уменьшения размерности массива звуковой сцены путем уменьшения первого множества звуковых объектов до второго множества звуковых объектов. В этом примерном варианте осуществления набор звуковых объектов, сформированный на основе N звуковых объектов и подлежащий восстановлению на стороне декодера на основе сигналов понижающего микширования и дополнительной информации, совпадает со вторым множеством звуковых объектов, соответствующим упрощению и/или представлению с пониженной размерностью массива звуковой сцены, представляемой первым множеством звуковых сигналов, а вычислительная сложность восстановления на стороне декодера снижается.
Включение метаданных кластеров в поток данных делает возможным представление второго набора звуковых сигналов на стороне декодера, например, после того, как второй набор звуковых сигналов был восстановлен на основе сигналов понижающего микширования и дополнительной информации.
Аналогично дополнительной информации метаданные кластеров в этом примерном варианте осуществления являются изменяющимися во времени, например переменными по времени, делая возможным изменение относительно времени параметров, управляющих представлением второго множества звуковых объектов. Формат для метаданных понижающего микширования может быть аналогичен формату дополнительной информации и может обладать такими же или соответствующими преимуществами. В частности, форма метаданных кластеров, предусматриваемая в этом примерном варианте осуществления, способствует передискретизации метаданных кластеров. Передискретизацию метаданных кластеров можно, например, использовать для создания общих моментов времени для начала и завершения соответствующих переходов, связанных с метаданными кластеров и дополнительной информацией, и/или для коррекции метаданных кластеров относительно частоты кадров связанных с ними звуковых сигналов.
Согласно одному из примерных вариантов осуществления, процедура кластеризации может также включать:
прием первого множества звуковых объектов и связанных с ними пространственных положений;
связывание первого множества звуковых объектов с по меньшей мере одним кластером на основе пространственной близости первого множества звуковых объектов;
генерирование второго множества звуковых объектов путем представления каждого из по меньшей мере одного кластера посредством звукового объекта, представляющего собой комбинацию звуковых объектов, связанных с кластером; и
вычисление пространственного положения каждого звукового объекта из второго множества звуковых объектов на основе пространственных положений звуковых объектов, связанных с соответствующим кластером, т. е. с кластером, представляющим звуковой объект.
Иными словами, в процедуре кластеризации используется присутствующую в звуковой сцене пространственную избыточность, такую как объекты, имеющие равные или очень похожие местоположения. В дополнение, при генерировании второго множества звуковых объектов можно учитывать значения значимости звуковых объектов, как описывается в отношении примерных вариантов осуществления в рамках первой особенности.
Связывание первого множества звуковых объектов с по меньшей мере одним кластером включает связывание каждого звукового объекта из первого множества звуковых объектов с одним или несколькими из по меньшей мере одного кластера. В некоторых случаях звуковой объект может образовывать часть самое большее одного кластера, тогда как в других случаях звуковой объект может образовывать часть нескольких кластеров. Иными словами, в некоторых случаях, как часть процедуры кластеризации, звуковой объект может быть разделен между несколькими кластерами.
Пространственная близость первого множества звуковых объектов может относиться к расстояниям между соответствующими звуковыми объектами в первом множестве звуковых объектов и/или к их относительным положениям. Например, с одним и тем же кластером могут быть связаны звуковые объекты, близкие друг к другу.
Под звуковым объектом, представляющим собой комбинацию звуковых объектов, связанных с кластером, подразумевается то, что звуковое содержимое/сигнал, связанные с звуковым объектом, могли быть сформированы как комбинация звукового содержимого/сигналов, связанных с соответствующими звуковыми объектами, связанными с кластером.
Согласно одному из примерных вариантов осуществления, соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных кластеров, могут совпадать с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации.
При использовании одинаковых моментов времени для начала и завершения переходов, связанных с дополнительной информацией и метаданными кластеров, облегчается совместная обработка дополнительной информации и метаданных кластеров, такая как совместная передискретизация.
Более того, применение общих моментов времени для начала и для завершения переходов, связанных с дополнительной информацией и метаданными кластеров, способствует совместному восстановлению и представлению на стороне декодера. Например, если выполнять восстановление и представление на стороне декодера как совместную операцию, то можно определить совместные установки для восстановления и представления для каждого экземпляра дополнительной информации и экземпляра метаданных, и/или можно использовать интерполяцию между совместными установками для восстановления и представления вместо выполнения интерполяции отдельно для соответствующих установок. Такая совместная интерполяция может уменьшить вычислительную сложность на стороне декодера, так как необходимо интерполировать меньше коэффициентов/параметров.
Согласно одному из примерных вариантов осуществления, процедуру кластеризации можно выполнять перед вычислением М сигналов понижающего микширования. В этом примерном варианте осуществления первое множество звуковых объектов соответствует первоначальным звуковым объектам звуковой сцены, а N звуковых объектов, на основе которых вычисляют М сигналов понижающего микширования, составляет второе, уменьшенное, множество звуковых объектов. Таким образом, в этом примерном варианте осуществления набор звуковых объектов (подлежащий восстановлению на стороне декодера), сформированный на основе N звуковых объектов, совпадает с N звуковых объектов.
В качестве альтернативы, процедуру кластеризации можно выполнять параллельно с вычислением М сигналов понижающего микширования. Согласно настоящей альтернативе, N звуковых объектов, на основе которых вычисляют М сигналов понижающего микширования, составляют первое множество звуковых объектов, соответствующих первоначальным звуковым объектам звуковой сцены. При таком подходе М сигналов понижающего микширования, таким образом, вычисляют на основе первоначальных звуковых объектов звуковой сцены, а не на основе уменьшенного количества звуковых объектов.
Согласно одному из примерных вариантов осуществления, способ также может включать:
связывание каждого сигнала понижающего микширования с изменяющимся во времени пространственным положением для представления сигналов понижающего микширования; и
дальнейшее включение в поток данных метаданных понижающего микширования, содержащих пространственные положения сигналов понижающего микширования,
при этом способ также включает включение в поток данных:
множества экземпляров метаданных понижающего микширования, определяющих соответствующие требуемые установки представления понижающего микширования для представления сигналов понижающего микширования; и
данных перехода для каждого экземпляра метаданных понижающего микширования, содержащих две независимо присваиваемые части, в комбинации определяющие момент времени для начала перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования, и момент времени для завершения перехода к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования.
Включение метаданных понижающего микширования в поток данных является преимущественным в том, что это делает возможным применение декодирования с низкой сложностью в случае унаследованного оборудования для воспроизведения. Точнее, метаданные понижающего микширования можно использовать на стороне декодера для представления сигналов понижающего микширования в каналы унаследованной системы воспроизведения, т. е. без восстановления множества звуковых объектов, сформированного на основе N объектов, что в вычислительном смысле, как правило, является более сложной операцией.
Согласно этому примерному варианту осуществления, пространственные положения, связанные с М сигналов понижающего микширования, могут изменяться во времени, т. е. быть переменными по времени, и сигналы понижающего микширования можно интерпретировать как динамические звуковые объекты, обладающие связанным с ними положением, которое может изменяться между временными кадрами, или экземплярами метаданных понижающего микширования. Это представляет отличие от систем, известных из уровня техники, где сигналы понижающего микширования соответствуют фиксированным пространственным положениям громкоговорителей. Следует напомнить, что в системе декодирования с более развитыми возможностями тот же поток данных можно воспроизводить с ориентацией на объект.
В некоторых примерных вариантах осуществления N звуковых объектов могут быть связаны с метаданными, содержащими пространственные положения N звуковых объектов, а пространственные положения, связанные с сигналами понижающего микширования, можно вычислить, например, на основе пространственных положений N звуковых объектов. Таким образом, сигналы понижающего микширования можно интерпретировать как звуковые объекты, имеющие пространственные положения, зависящие от пространственных положений N звуковых объектов.
Согласно одному из примерных вариантов осуществления, соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных понижающего микширования, могут совпадать с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации. Применение одинаковых моментов времени для начала и для завершения переходов, связанных с дополнительной информацией и метаданными понижающего микширования, способствует совместной обработке, например передискретизации, дополнительной информации и метаданных понижающего микширования.
Согласно одному из примерных вариантов осуществления, соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных понижающего микширования, могут совпадать с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров метаданных кластеров. Применение одинаковых моментов времени для начала и окончания переходов, связанных с метаданными кластеров и метаданными понижающего микширования, способствует совместной обработке, например передискретизации, метаданных кластеров и метаданных понижающего микширования.
Согласно примерным вариантам осуществления изобретения, предлагается кодер для кодирования N звуковых объектов в виде потока данных, где N>1. Этот кодер содержит:
компонент понижающего микширования, выполненный с возможностью вычисления М сигналов понижающего микширования, где M≤N, путем формирования комбинаций N звуковых объектов;
компонент анализа, выполненный с возможностью вычисления изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент уплотнения, выполненный с возможностью включения М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер,
при этом компонент уплотнения также выполнен с возможностью включения в поток данных для передачи в декодер:
множества экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления набора звуковых объектов, сформированного на основе N звуковых объектов; и
данных перехода для каждого экземпляра дополнительной информации, содержащих две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информацией, и момент времени для завершения перехода.
Согласно четвертой особенности, предлагается способ декодирования, декодер и компьютерный программный продукт для декодирования многоканального звукового содержимого.
Способы, декодеры и компьютерные программные продукты согласно четвертой особенности предназначены для совместного применения со способами, кодерами и компьютерными программными продуктами согласно третьей особенности и могут обладать соответствующими характерными признаками и преимуществами.
Способы, декодеры и компьютерные программные продукты согласно четвертой особенности могут в целом обладать характерными признаками и преимуществами, общими со способами, декодерами и компьютерными программными продуктами согласно второй особенности.
Согласно примерным вариантам осуществления, предлагается способ восстановления звуковых объектов на основе потока данных. Этот способ включает:
прием потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, где N>1 и M≤N, и изменяющуюся во времени дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
восстановление на основе М сигналов понижающего микширования и дополнительной информации набора звуковых объектов, сформированного на основе N звуковых объектов;
при этом поток данных содержит множество экземпляров дополнительной информации, при этом поток данных также содержит, для каждого экземпляра дополнительной информации данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода, и при этом восстановление набора звуковых объектов, сформированного на основе N звуковых объектов, включает:
выполнение восстановления в соответствии с текущей установкой восстановления;
начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации, перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации; и
завершение перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации.
Как описывалось выше, применение формата дополнительной информации, включающего данные перехода, определяющие моменты времени для начала и моменты времени для завершения переходов от текущих установок восстановления к соответствующим требуемым установкам восстановления, например, способствует передискретизации дополнительной информации.
Поток данных может быть принят, например, в форме битового потока, например, сгенерированного на стороне кодера.
Восстановление, на основе М сигналов понижающего микширования и дополнительной информации, набора звуковых объектов, сформированного на основе N звуковых объектов, может включать, например, формирование по меньшей мере одной линейной комбинации сигналов понижающего микширования с применением коэффициентов, определяемых на основе дополнительной информации. Восстановление, на основе М сигналов понижающего микширования и дополнительной информации, набора звуковых объектов, сформированного на основе N звуковых объектов, может, например, включать формирование линейных комбинаций сигналов понижающего микширования и, при необходимости, одного или нескольких добавочных (например, декоррелированных) сигналов, полученных исходя из сигналов понижающего микширования, с применением коэффициентов, определяемых на основе дополнительной информации.
Согласно одному из примерных вариантов осуществления, поток данных также может содержать изменяющиеся во времени метаданные кластеров для набора звуковых объектов, сформированного на основе N звуковых объектов, при этом метаданные кластеров содержат пространственные положения для набора звуковых объектов, сформированного на основе N звуковых объектов. Поток данных может содержать множество экземпляров метаданных кластеров, и поток данных также может содержать, для каждого экземпляра метаданных кластеров данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров, и момент времени для завершения перехода к требуемой установке представления, определяемой экземпляром метаданных кластеров. Способ также может включать:
применение метаданных кластеров для представления восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, в выходные каналы с предварительно определенной конфигурацией каналов, при этом представление включает:
выполнение представления в соответствии с текущей установкой представления;
начало, в момент времени, определяемый данными перехода для экземпляра метаданных кластеров, перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров; и
завершение перехода к требуемой установке представления в момент времени, определяемый данными перехода для экземпляра метаданных кластеров.
Предварительно определенная конфигурация каналов может, например, соответствовать конфигурации выходных каналов, совместимой с конкретной системой воспроизведения, т. е. пригодной для воспроизведения на конкретной системе воспроизведения.
Представление восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, в выходные каналы с предварительно определенной конфигурацией каналов может включать, например, отображение, в компоненте представления, восстановленного набора звуковых сигналов, сформированного на основе N звуковых объектов, в выходные каналы (с предварительно определенной конфигурацией каналов) компонента представления под управлением метаданных кластеров.
Представление восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, в выходные каналы с предварительно определенной конфигурацией каналов может включать, например, формирование линейных комбинаций восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, с применением коэффициентов, определенных на основе метаданных кластеров.
Согласно одному из примерных вариантов осуществления, соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных кластеров, могут совпадать с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации.
Согласно одному из примерных вариантов осуществления, способ может также включать:
Выполнение, по меньшей мере, части восстановления и по меньшей мере части представления как комбинированной операции, соответствующей первой матрице, сформированной как матричное произведение матрицы восстановления и матрицы представления, связанных соответственно с текущей установкой восстановления и текущей установкой представления;
начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации и экземпляра метаданных кластеров, комбинированного перехода от текущих установок восстановления и представления к требуемым установкам восстановления и представления, определяемым соответственно экземпляром дополнительной информации и экземпляром метаданных кластеров; и
завершение комбинированного перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации и экземпляра метаданных кластеров, при этом комбинированный переход включает интерполяцию между матричными элементами первой матрицы и матричными элементами второй матрицы, сформированными как матричное произведение матрицы восстановления и матрицы представления, связанными соответственно с требуемой установкой восстановления и требуемой установкой представления.
При выполнении вместо раздельных переходов установок восстановления и установок представления комбинированного перехода в вышеописанном смысле необходимо интерполировать меньше параметров/коэффициентов, что позволяет снизить вычислительную сложность.
Следует понимать, что такая матрица, как матрица восстановления или матрица представления, на которую делается ссылка в этом примерном варианте осуществления изобретения, может состоять, например, из одной строки или одного столбца и, таким образом, соответствовать вектору.
Восстановление звуковых объектов, исходя из сигналов понижающего микширования, часто выполняют, используя различные матрицы восстановления в разных полосах частот, тогда как представление часто выполняют, используя для всех частот одну и ту же матрицу представления. В таких случаях матрица, соответствующая комбинированной операции восстановления и представления, например первая и вторая матрицы, на которые делается ссылка в этом примерном варианте осуществления изобретения, как правило, может зависеть от частоты, т. е. для разных полос частот, как правило, могут использоваться разные значения для матричных элементов.
Согласно одному из примерных вариантов осуществления, набор звуковых объектов, сформированный на основе N звуковых объектов, может совпадать с N звуковых объектов, т. е. способ может включать восстановление N звуковых объектов на основе М сигналов понижающего микширования и дополнительной информации.
В качестве альтернативы, набор звуковых объектов, сформированный на основе N звуковых объектов, может содержать множество звуковых объектов, которые представляют собой комбинации N звуковых объектов, и количество которых меньше N, т. е. способ может включать восстановление этих комбинаций N звуковых объектов на основе М сигналов понижающего микширования и дополнительной информации.
Согласно одному из примерных вариантов осуществления, поток данных может также содержать метаданные понижающего микширования для М сигналов понижающего микширования, содержащие изменяющиеся во времени пространственные положения, связанные с М сигналов понижающего микширования. Поток данных может содержать множество экземпляров метаданных понижающего микширования, а также поток данных может также содержать для каждого экземпляра метаданных понижающего микширования данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования, и момент времени для завершения перехода к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования. Способ может также включать:
выполнение этапа восстановления на основе М сигналов понижающего микширования и дополнительной информации, при этом набор звуковых объектов сформирован на основе N звуковых объектов, при условии, что декодер является функциональным (или выполненным с возможностью) для поддержки восстановления звуковых объектов; и
вывод метаданных понижающего микширования и М сигналов понижающего микширования для представления М сигналов понижающего микширования, при условии, что декодер не является функциональным (или выполненным с возможностью) для поддержки восстановления звуковых объектов.
В случае, если декодер является функциональным для поддержки восстановления звуковых объектов и поток данных также содержит метаданные кластеров, связанные с набором звуковых объектов, сформированным на основе N звуковых объектов, декодер может, например, выводить восстановленный набор звуковых объектов и метаданные кластеров для представления восстановленного набора звуковых объектов.
В случае, если декодер не является функциональным для поддержки восстановления звуковых объектов, он может, например, отбрасывать дополнительную информацию и, если необходимо, метаданные кластеров и представлять в качестве вывода метаданные понижающего микширования и М сигналов понижающего микширования. Тогда вывод может быть использован компонентом представления для представления М сигналов понижающего микширования в выходные каналы компонента представления.
При необходимости способ может также включать представление М сигналов понижающего микширования в выходные каналы с предварительно определенной выходной конфигурацией, например в выходные каналы компонента представления или в выходные каналы декодера (в случае, если декодер обладает возможностями представления), на основе метаданных понижающего микширования.
Согласно примерным вариантам осуществления, предлагается декодер для восстановления звуковых объектов на основе потока данных. Декодер содержит:
компонент приема, выполненный с возможностью приема потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, где N>1 и M≤N, и изменяющуюся во времени дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент восстановления, выполненный с возможностью восстановления, на основе М сигналов понижающего микширования и дополнительной информации, набора звуковых объектов, сформированного на основе N звуковых объектов;
при этом указанный поток данных содержит множество связанных экземпляров дополнительной информации, и при этом поток данных также содержит, для каждого экземпляра дополнительной информации данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода. Компонент восстановления сконфигурирован для восстановления набора звуковых объектов, сформированного на основе N звуковых объектов, посредством, по меньшей мере:
выполнения восстановления в соответствии с текущей установкой восстановления;
начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации, перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации; и
завершение перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации.
Согласно одному из примерных вариантов осуществления, способ в рамках третьей или четвертой особенности может также включать генерирование одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, как и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними. Также предусматриваются примерные варианты осуществления, в которых аналогичным образом генерируют добавочные экземпляры метаданных кластеров и/или метаданных понижающего микширования.
Как описывалось выше, передискретизация дополнительной информации путем генерирования большего количества экземпляров дополнительной информации может являться преимущественной в нескольких ситуациях, как, например, когда звуковые сигналы/объекты и связанную с ними дополнительную информацию кодируют с применением звукового кодека на основе кадров, так как тогда требуется иметь в наличии, по меньшей мере, один экземпляр дополнительной информации для каждого кадра звукового кодека. На стороне кодера экземпляры дополнительной информации, создаваемые посредством компонента анализа, могут, например, быть распределены во времени таким образом, что они не согласуются с частотой кадров сигналов понижающего микширования, создаваемых посредством компонента понижающего микширования, и поэтому дополнительную информацию можно преимущественно подвергать передискретизации путем введения новых экземпляров дополнительной информации так, чтобы на каждый кадр сигналов понижающего микширования приходился, по меньшей мере, один экземпляр дополнительной информации. Аналогично, на стороне декодера принимаемые экземпляры дополнительной информации могут, например, быть распределены во времени таким образом, что они не согласуются с частотой кадров принимаемых сигналов понижающего микширования, и поэтому дополнительную информацию преимущественно можно подвергнуть передискретизации путем введения новых экземпляров дополнительной информации так, чтобы на каждый кадр сигналов понижающего микширования приходился, по меньшей мере, один экземпляр дополнительной информации.
Добавочный экземпляр дополнительной информации можно генерировать, например, для выбранного момента времени путем: копирования экземпляра дополнительной информации, следующего непосредственно за добавочным экземпляром дополнительной информации, и определения данных перехода для добавочного экземпляра дополнительной информации на основе выбранного момента времени и моментов времени, определяемых данными перехода для следующего экземпляра дополнительной информации.
Согласно пятой особенности, предлагается способ, устройство и компьютерный программный продукт для перекодировки дополнительной информации, закодированной в потоке данных вместе с М звуковых сигналов.
Способы, устройства и компьютерные программные продукты согласно пятой особенности предназначены для совместного применения со способами, кодерами, декодером и компьютерными программными продуктами согласно третьей и четвертой особенностям и могут обладать соответствующими характерными признаками и преимуществами.
Согласно примерным вариантам осуществления, предлагается способ перекодировки дополнительной информации, закодированной в потоке данных вместе с М звуковых сигналов. Этот способ включает:
прием потока данных;
извлечение из потока данных М звуковых сигналов и связанной с ними изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов из М звуковых сигналов, где M≥1, и при этом извлекаемая дополнительная информация содержит:
множество экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления звуковых объектов; и
данные перехода для каждого экземпляра дополнительной информации, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода;
генерирование одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними; и
включение М звуковых сигналов и дополнительной информации в поток данных.
В этом примерном варианте осуществления один или несколько добавочных экземпляров дополнительной информации можно генерировать после того, как дополнительная информация была извлечена из принятого потока данных, а сгенерированные один или несколько добавочных экземпляров дополнительной информации можно затем включать в поток данных вместе с М звуковых сигналов и другими экземплярами дополнительной информации.
Как описывалось выше в отношении третьей особенности, передискретизация дополнительной информации путем генерирования большего количества экземпляров дополнительной информации может являться преимущественной в нескольких ситуациях, как, например, тогда, когда звуковые сигналы/объекты и связанная с ними дополнительная информация закодированы с применением звукового кодека на основе кадров, так как тогда требуется иметь в наличии, по меньшей мере, один экземпляр дополнительной информации на каждый кадр звукового кодека.
Также предусматриваются варианты осуществления, в которых поток данных также содержит метаданные кластеров и/или метаданные понижающего микширования, как описывается в отношении третьей и четвертой особенностей, и при этом способ также включает генерирование добавочных экземпляров метаданных понижающего микширования и/или экземпляров метаданных кластеров аналогично тому, как генерируют добавочные экземпляры дополнительной информации.
Согласно одному из примерных вариантов осуществления, М звуковых сигналов может быть закодировано в принимаемом потоке данных в соответствии с первой частотой кадров, и способ может также включать:
обработку М звуковых сигналов с целью изменения частоты кадров, в соответствии с которой закодировано М сигналов понижающего микширования, до второй частоты кадров, отличающейся от первой частоты кадров; и
передискретизацию дополнительной информации с целью согласования и/или совмещения со второй частотой кадров, по меньшей мере, посредством генерирования одного или нескольких добавочных экземпляров дополнительной информации.
Как описывалось выше в отношении третьей особенности, в нескольких ситуациях может являться преимущественной обработка звуковых сигналов с тем, чтобы изменить частоту кадров, используемую для их кодирования, например, так, чтобы модифицированная частота кадров согласовывалась с частотой кадров видеосодержимого аудиовизуального сигнала, к которому принадлежат звуковые сигналы. Присутствие данных перехода для каждого экземпляра дополнительной информации способствует передискретизации дополнительной информации, как описано выше в отношении третьей особенности. Дополнительную информацию можно подвергнуть передискретизации для согласования с новой частотой кадров, например, путем генерирования добавочных экземпляров дополнительной информации так, чтобы на каждый кадр обработанных звуковых сигналов приходился, по меньшей мере, один экземпляр дополнительной информации.
Согласно примерным вариантам осуществления, предлагается устройство для перекодировки дополнительной информации, закодированной в потоке данных вместе с М звуковых сигналов. Устройство содержит:
компонент приема, выполненный с возможностью приема потока данных и извлечения из потока данных М звуковых сигналов и связанной с ними изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов из М звуковых сигналов, где M≥1, и при этом извлекаемая дополнительная информация содержит:
множество экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления звуковых объектов; и
данные перехода для каждого экземпляра дополнительной информации, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода.
Устройство также содержит:
компонент передискретизации, выполненный с возможностью генерирования одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними; и
компонент уплотнения, выполненный с возможностью включения М звуковых сигналов и дополнительной информации в поток данных.
Согласно одному из примерных вариантов осуществления, способ в рамках третьей, четвертой или пятой особенностей также может включать: расчет разности между первой требуемой установкой восстановления, определяемой первым экземпляром дополнительной информации, и одной или несколькими требуемыми установками восстановления, определяемыми одним или несколькими экземплярами дополнительной информации, непосредственно следующими за первым экземпляром дополнительной информации; и удаление одного или нескольких экземпляров дополнительной информации в ответ на то, что рассчитанная разность ниже предварительно определенного порога. Также предусматриваются примерные варианты осуществления, в которых аналогичным образом удаляют экземпляры метаданных кластеров и/или экземпляры метаданных понижающего микширования.
Удаляя экземпляры дополнительной информации согласно этому примерному варианту осуществления, можно избежать необязательных расчетов на основе этих экземпляров дополнительной информации, например, в ходе восстановления на стороне декодера. Устанавливая предварительно определенный порог на соответственном (например, достаточно низком) уровне, можно удалять экземпляры дополнительной информации, тогда как качество и/или точность воспроизведения восстанавливаемых звуковых сигналов, по меньшей мере, приблизительно сохраняются.
Разность между требуемыми установками восстановления можно рассчитать, например, на основе разностей между соответствующими значениями для набора коэффициентов, используемого как часть восстановления.
Согласно примерным вариантам осуществления в рамках третьей, четвертой или пятой особенностей, две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации могут представлять собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
Иными словами, моменты времени для начала и для окончания перехода можно определить в данных перехода либо посредством двух временных отметок, указывающих соответствующие моменты времени, либо комбинации одной из временных отметок и параметра продолжительности интерполяции, указывающего продолжительность перехода.
Соответствующие временные отметки могут, например, указывать соответствующие моменты времени посредством отсылки к временной развертке, используемой для представления М сигналов понижающего микширования и/или N звуковых объектов.
Согласно примерным вариантам осуществления в рамках третьей, четвертой или пятой особенностей, две независимо присваиваемые части данных перехода для каждого экземпляра метаданных кластеров могут представлять собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления.
Согласно примерным вариантам осуществления в рамках третьей, четвертой или пятой особенностей, две независимо присваиваемые части данных перехода для каждого экземпляра метаданных понижающего микширования могут представлять собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования.
Согласно примерным вариантам осуществления, предлагается компьютерный программный продукт, содержащий машиночитаемый носитель с командами для выполнения любого способа из способов в рамках третьей, четвертой или пятой особенностей.
IV. Примерные варианты осуществления
На фиг. 1 проиллюстрирован кодер 100 для кодирования звуковых объектов 120 в поток 140 данных согласно одному из примерных вариантов осуществления. Кодер 100 содержит компонент приема (не показан), компонент 102 понижающего микширования, компонент 104 кодера, компонент 106 анализа и компонент 108 уплотнения. Ниже описывается работа кодера 100 для кодирования одного временного кадра звуковых данных. Однако следует понимать, что описываемый ниже способ повторяется на основе временных кадров. То же самое применимо и к описанию фиг. 2-5.
Компонент приема принимает множество звуковых объектов (N звуковых объектов) 120 и метаданные 122, связанные со звуковыми объектами 120. Термин "звуковой объект" в рамках данного описания относится к звуковому сигналу, обладающему связанным с ним пространственным положением, которое, как правило, является переменным по времени (между временными кадрами), т. е. пространственное положение является динамическим. Метаданные 122, связанные со звуковыми объектами 120, как правило, содержат информацию, описывающую то, каким образом следует представлять звуковые объекты 120 с целью воспроизведения на стороне декодера. В частности, метаданные 122, связанные со звуковыми объектами 120, содержат информацию о пространственном положении звуковых объектов 120 в трехмерном пространстве звуковой сцены. Пространственные положения можно представить в декартовых координатах или посредством таких направляющих углов, как азимут и возвышение, при необходимости дополняемых расстоянием. Метаданные 122, связанные со звуковыми объектами 120, также могут содержать размер объекта, громкость объекта, значимость объекта, тип содержимого объекта, специальные команды представления, такие как применение усиления диалога или исключение некоторых громкоговорителей из представления (так называемые маски зон), и/или другие свойства объекта.
Как будет описываться со ссылкой на фиг. 4, звуковые объекты 120 могут соответствовать упрощенному представлению звуковой сцены.
N звуковых объектов 120 представляют вводят в компонент 102 понижающего микширования. Компонент 102 понижающего микширования вычисляет некоторое количество М сигналов 124 понижающего микширования путем формирования комбинаций, как правило, линейных комбинаций, N звуковых объектов 120. В большинстве случаев количество сигналов 124 понижающего микширования меньше количества звуковых объектов 120, т. е. M<N, так что уменьшается объем данных, включаемых в поток 140 данных. Однако в тех применениях, где целевая битовая скорость передачи данных потока 140 данных является высокой, количество сигналов 124 понижающего микширования может быть равно количеству объектов 120, т. е. M=N.
Компонент 102 понижающего микширования также может вычислять один или несколько вспомогательных звуковых сигналов 127, обозначаемых здесь как L вспомогательных звуковых сигналов 127. Роль вспомогательных звуковых сигналов 127 заключается в совершенствовании восстановления N звуковых объектов 120 на стороне декодера. Вспомогательные звуковые сигналы 127 могут соответствовать одному или нескольким из N звуковых объектов 120 либо непосредственно, либо как их комбинация. Например, вспомогательные звуковые сигналы 127 могут соответствовать особо значимым объектам из N звуковых объектов 120, таким как звуковой объект 120, соответствующий диалогу. Значимость можно отразить или получить исходя из метаданных 122, связанных с N звуковых объектов 120.
М сигналов 124 понижающего микширования и L вспомогательных сигналов 127, если они присутствуют, могут впоследствии кодироваться компонентом 104 кодера, обозначаемым здесь как базовый кодер, с целью генерирования М кодированных сигналов 126 понижающего микширования и L кодированных вспомогательных сигналов 129. Компонент 104 кодера может представлять собой перцепционный звуковой кодек, известный в данной области техники. Примеры известных перцепционных звуковых кодеков включают Dolby Digital и MPEG AAC.
В некоторых вариантах осуществления компонент 102 понижающего микширования также может связывать М сигналов 124 понижающего микширования с метаданными 125. В частности, компонент 102 понижающего микширования может связывать каждый сигнал 124 понижающего микширования с пространственным положением и включать пространственное положение в метаданные 125. Аналогично метаданным 122, связанным со звуковыми объектами 120, метаданные 125, связанные с сигналами 124 понижающего микширования, также могут содержать параметры, относящиеся к размеру, громкости, значимости и/или другим свойствам.
В частности, пространственные положения, связанные с сигналами 124 понижающего микширования, можно вычислить на основе пространственных положений N звуковых объектов 120. Так как пространственные положения N звуковых объектов 120 могут быть динамическими, то есть переменными по времени, также могут быть динамическими и пространственные положения, связанные с М сигналов 124 понижающего микширования. Иными словами, М сигналов 124 понижающего микширования можно самих по себе интерпретировать как звуковые объекты.
Компонент 106 анализа вычисляет дополнительную информацию 128, содержащую параметры, позволяющие восстанавливать N звуковых объектов 120 (или пригодное для восприятия приближение N звуковых объектов) исходя из М сигналов 124 понижающего микширования и L вспомогательных сигналов 129, если они присутствуют. Дополнительная информация 128 также может быть изменяющейся во времени. Например, компонент 106 анализа может вычислять дополнительную информацию 128 путем анализа М сигналов 124 понижающего микширования, L вспомогательных сигналов 127, если они присутствуют, и N звуковых объектов 120 в соответствии с любой известной методикой параметрического кодирования. В качестве альтернативы, компонент 106 анализа может вычислять дополнительную информацию 128, анализируя N звуковых объектов, и информацию о том, каким образом М сигналов понижающего микширования было создано из N звуковых объектов, например, создавая (переменную по времени) матрицу понижающего микширования. В этом случае М сигналов 124 понижающего микширования в качестве ввода в компонент 106 анализа строго не требуется.
М кодированных сигналов 126 понижающего микширования, L кодированных вспомогательных сигналов 129, дополнительная информация 128, метаданные 122, связанные с N звуковых объектов, и метаданные 125, связанные с сигналами понижающего микширования, затем вводят в компонент 108 уплотнения, включающий свои входные данные в единый поток 140 данных с применением методик уплотнения. Поток 140 данных, таким образом, может содержать четыре типа данных:
М сигналов 126 понижающего микширования (и при необходимости L вспомогательных сигналов 129);
метаданные 125, связанные с М сигналов понижающего микширования;
дополнительную информацию 128 для восстановления N звуковых объектов из М сигналов понижающего микширования; и
метаданные 122, связанные с N звуковых объектов.
Как упоминалось выше, некоторые системы для кодирования звуковых объектов, известные из уровня техники, требуют того, чтобы М сигналов понижающего микширования были выбраны так, чтобы они были пригодны для воспроизведения на каналах конфигурации громкоговорителей с М каналов, что в данном описании именуется "обратно совместимым понижающим микшированием". Такое требование из известного уровня техники ограничивает вычисление сигналов понижающего микширования в том, что звуковые объекты можно комбинировать только предварительно определенным образом. Соответственно, согласно известному уровню техники, сигналы понижающего микширования не выбирают с точки зрения оптимизации восстановления звуковых объектов на стороне декодера.
В противоположность системам из известного уровня техники, компонент 102 понижающего микширования вычисляет М сигналов 124 понижающего микширования адаптивным к сигналам образом в отношении N звуковых объектов. В частности, компонент 102 понижающего микширования может вычислять для каждого временного кадра М сигналов 124 понижающего микширования как комбинацию звуковых объектов 120, в данный момент оптимизирующую некоторый критерий. Критерий, как правило, определяют так, чтобы он не зависел от какой-либо конфигурации громкоговорителей, такой как 5.1 или другая конфигурация громкоговорителей. Это предполагает то, что М сигналов 124 понижающего микширования, или по меньшей мере один из них, не ограничено звуковыми сигналами, пригодными для воспроизведения на каналах конфигурации громкоговорителей с М каналов. Соответственно, компонент 102 понижающего микширования может адаптировать М сигналов 124 понижающего микширования к временному изменению N звуковых объектов 120 (в том числе к временному изменению метаданных 122, содержащих пространственные положения N звуковых объектов), например, с целью совершенствования восстановления звуковых объектов 120 на стороне декодера.
Для вычисления М сигналов понижающего микширования компонент 102 понижающего микширования может применять различные критерии. Согласно одному из примеров, М сигналов понижающего микширования можно вычислить так, чтобы было оптимизировано восстановление N звуковых объектов на основе М сигналов понижающего микширования. Например, компонент 102 понижающего микширования может минимизировать ошибку восстановления, сформированную из N звуковых объектов и восстановления N звуковых объектов на основе М сигналов 124 понижающего микширования.
Согласно другому примеру, критерий основан на пространственных положениях, в частности на пространственной близости, N звуковых объектов 120. Как обсуждалось выше, N звуковых объектов 120 имеют связанные с ними метаданные 122, содержащие пространственные положения N звуковых объектов 120. На основе метаданных 122 можно получить пространственную близость N звуковых объектов 120.
Более подробно, компонент 102 понижающего микширования может применять с целью определения М сигналов 124 понижающего микширования первую процедуру кластеризации. Первая процедура кластеризации может включать связывание N звуковых объектов 120 с М кластеров на основе пространственной близости. В ходе связывания звуковых объектов 120 с М кластеров также могут учитываться другие свойства N звуковых объектов 120, представляемые связанными метаданными 122, содержащими размер объекта, громкость объекта, значимость объекта.
Согласно одному из примеров, для связывания N звуковых объектов 120 с М кластеров на основе пространственной близости можно использовать хорошо известный алгоритм обучения методом К-средних с метаданными 122 (пространственными положениями) N звуковых объектов в качестве ввода. Другие свойства N звуковых объектов 120 можно использовать в алгоритме обучения методом К-средних в качестве весовых коэффициентов.
Согласно другому примеру, первая процедура кластеризации может основываться на процедуре выбора, использующей в качестве критерия выбора значимость звуковых объектов, задаваемую метаданными 122. Более подробно, компонент 102 понижающего микширования может пропускать наиболее значимые звуковые объекты 120 так, чтобы один или несколько из М сигналов понижающего микширования соответствовали одному или нескольким из N звуковых объектов 120. Остальные, менее значимые, звуковые объекты могут быть связаны с кластерами на основе пространственной близости, как обсуждалось выше.
Другие примеры кластеризации звуковых объектов приведены в предварительной заявке на патент США № 61/865072 или в последующих заявках, заявляющих приоритет этой заявки.
Согласно еще одному примеру, первая процедура кластеризации может связывать звуковой объект 120 с более чем одним из М кластеров. Например, звуковой объект 120 может быть распределен по М кластеров, при этом распределение зависит, например, от пространственного положения звукового объекта 120, а также, при необходимости, от других свойств звукового объекта, в том числе от размера объекта, громкости объекта, значимости объекта и т. д. Это распределение может быть отражено в процентных долях так, что звуковой объект распределен, например, по трем кластерам в соответствии с процентными долями 20%, 30%, 50%.
Как только N звуковых объектов 120 будут связаны с М кластеров, компонент 102 понижающего микширования вычисляет сигнал 124 понижающего микширования для каждого кластера путем формирования комбинации, как правило, линейной комбинации, звуковых объектов 120, связанных с кластером. Как правило, в качестве весовых коэффициентов при формировании комбинации компонент 102 понижающего микширования может использовать параметры, содержащиеся в метаданных 122, связанных со звуковыми объектами 120. Например, звуковые объекты 120, являющиеся связанными с кластером, можно взвешивать в соответствии с размером объекта, громкостью объекта, значимостью объекта, положением объекта, расстоянием от объекта относительно пространственного положения, связанного с кластером (см. подробности ниже), и т. д. В случае, если звуковые объекты 120 распределены по М кластеров, в качестве весовых коэффициентов при формировании комбинации можно использовать процентные доли, отражающие распределение.
Первая процедура кластеризации является преимущественной в том, что она позволяет легко связывать каждый из М сигналов 124 понижающего микширования с пространственным положением. Например, компонент 120 понижающего микширования может вычислять пространственное положение сигнала 124 понижающего микширования, соответствующего кластеру, на основе пространственных положений звуковых объектов 120, связанных с кластером. С этой целью можно использовать центроид, или взвешенный центроид, пространственных положений звуковых объектов, связанных с кластером. В случае взвешенного центроида при формировании комбинации звуковых объектов 120, связанных с кластером, можно использовать одинаковые весовые коэффициенты.
На фиг. 2 проиллюстрирован декодер 200, соответствующий кодеру 100 по фиг. 1. Декодер 200 относится к типу, поддерживающему восстановление звуковых объектов. Декодер 200 содержит компонент 208 приема, компонент 204 декодера и компонент 206 восстановления. Декодер 200 также может содержать компонент 210 представления. В качестве альтернативы, декодер 200 может быть связан с компонентом 210 представления, образующим часть системы воспроизведения.
Компонент 208 приема сконфигурирован для приема потока 240 данных из кодера 100. Компонент 208 приема содержит компонент разуплотнения, выполненный с возможностью разуплотнения принятого потока 240 данных на его составляющие, в данном случае — на М кодированных сигналов 226 понижающего микширования, при необходимости L кодированных вспомогательных сигналов 229, дополнительную информацию 228 для восстановления N звуковых объектов исходя из М сигналов понижающего микширования и L вспомогательных сигналов и метаданные 222, связанные с N звуковых объектов.
Компонент 204 декодера обрабатывает М кодированных сигналов 226 понижающего микширования для генерирования М сигналов 224 понижающего микширования и при необходимости L вспомогательных сигналов 227. Как дополнительно обсуждалось выше, М сигналов 224 понижающего микширования было адаптивно сформировано на стороне кодера из N звуковых объектов, т. е. путем формирования комбинаций N звуковых объектов в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей.
Компонент 206 восстановления объектов затем восстанавливает N звуковых объектов 220 (или пригодное для восприятия приближение этих звуковых объектов) на основе М сигналов 224 понижающего микширования и при необходимости L вспомогательных сигналов 227, руководствуясь дополнительной информацией 228, полученной на стороне кодера. Компонент 206 восстановления объектов может применять для такого параметрического восстановления звуковых объектов любую известную методику.
Восстановленные N звуковых объектов 220 затем обрабатывают посредством компонента 210 представления с применением метаданных 222, связанных со звуковыми объектами 222, и знания о конфигурации каналов системы воспроизведения с целью генерирования многоканального выходного сигнала 230, пригодного для воспроизведения. К типичным конфигурациям для воспроизведения громкоговорителями относятся 22.2 и 11.1. Воспроизведение на системах громкоговорителей звуковой панели или в наушниках (бинауральное представление) также возможно со специальными компонентами представления, предназначенными для таких систем воспроизведения.
На фиг. 3 проиллюстрирован декодер 300 с низкой сложностью, соответствующий кодеру 100 по фиг. 1. Декодер 300 не поддерживает восстановление звуковых объектов. Декодер 300 содержит компонент 308 приема и компонент 304 декодирования. Декодер 300 также может содержать компонент 310 представления. В качестве альтернативы, декодер связан с компонентом 310 представления, образующим часть системы воспроизведения.
Как обсуждалось выше, системы, известные из уровня техники, использующие обратно совместимое понижающее микширование (такое как понижающее микширование 5.1), т. е. понижающее микширование, содержащее М сигналов понижающего микширования, пригодных для непосредственного воспроизведения на системе воспроизведения с М каналов, легко делают возможным декодирование с низкой сложностью для унаследованных систем воспроизведения (например, тех, которые поддерживают только многоканальную установку с громкоговорителями5.1). Такие системы, известные из уровня техники, как правило, декодируют сами обратно совместимые сигналы понижающего микширования и отбрасывают такие добавочные части потока данных, как дополнительная информация (ср. с позицией 228 по фиг. 2) и метаданные, связанные со звуковыми объектами (ср. с позицией 222 по фиг. 2). Однако когда сигналы понижающего микширования сформированы адаптивно, как описывается выше, то сигналы понижающего микширования обычно не годятся для непосредственного воспроизведения на унаследованной системе.
Декодер 300 представляет собой один из примеров декодера, позволяющего с низкой сложностью декодировать М сигналов понижающего микширования, адаптивно сформированных для воспроизведения на унаследованной системе воспроизведения, поддерживающей только конкретную конфигурацию воспроизведения.
Компонент 308 приема принимает битовый поток 340 из такого кодера, как кодер 100 по фиг. 1. Компонент 308 приема разуплотняет битовый поток 340 на составляющие. В данном случае, компонент 308 приема будет поддерживать только М кодированных сигналов 326 понижающего микширования и метаданные 325, связанные с М сигналов понижающего микширования. Другие компоненты потока 340 данных, такие как L вспомогательных сигналов (ср. с позицией 229 по фиг. 2), метаданные, связанные с N звуковых объектов (ср. с позицией 222 по фиг. 2), и дополнительная информация (ср. с позицией 228 по фиг. 2), отбрасываются.
Компонент 304 декодирования декодирует М кодированных сигналов 326 понижающего микширования для генерирования М сигналов 324 понижающего микширования. Затем М сигналов понижающего микширования вместе с метаданными понижающего микширования вводят в компонент 310 представления, представляющий М сигналов понижающего микширования в многоканальный вывод 330, соответствующий унаследованному формату воспроизведения (как правило, содержащему М каналов). Так как метаданные 325 понижающего микширования содержат пространственные положения М сигналов 324 понижающего микширования, компонент 310 представления, как правило, может быть аналогичен компоненту 210 представления по фиг. 2 с тем лишь отличием, что теперь компонент 310 представления принимает в качестве ввода М сигналов 324 понижающего микширования и метаданные 325, связанные с М сигналов 324 понижающего микширования, вместо звуковых объектов 220 и связанных с ними метаданных 222.
Как упоминалось выше в связи с фиг. 1, N звуковых объектов 120 могут соответствовать упрощенному представлению звуковой сцены.
В целом, звуковая сцена может содержать звуковые объекты и звуковые каналы. Под звуковым каналом здесь подразумевается звуковой сигнал, соответствующий каналу из многоканальной конфигурации громкоговорителей. Примеры такой многоканальной конфигурации громкоговорителей включают конфигурацию 22.2, конфигурацию 11.1 и т. д. Звуковой канал можно интерпретировать как неподвижный звуковой объект, имеющий пространственное положение, соответствующее положению громкоговорителя канала.
В некоторых случаях количество звуковых объектов и звуковых каналов в звуковой сцене может быть огромным, например, более 100 звуковых объектов и 124 звуковых канала. Если все эти звуковые объекты/каналы подлежат восстановлению на стороне декодера, то требуется большая вычислительная мощность. Кроме того, если в качестве ввода представлено большое количество объектов, то результирующая скорость передачи данных, связанная с метаданными объектов и дополнительной информацией, как правило, будет очень высокой. По этой причине является преимущественным упрощение звуковой сцены с целью сокращения количества звуковых объектов, подлежащих восстановлению на стороне декодера. С этой целью кодер может содержать компонент кластеризации, уменьшающий количество звуковых объектов в звуковой сцене на основе второй процедуры кластеризации. Вторая процедура кластеризации нацелена на применение пространственной избыточности, присутствующей в звуковой сцене, такой как звуковые объекты, имеющие равные или очень похожие положения. Кроме того, можно учитывать значимость звуковых объектов для восприятия. В целом, такой компонент кластеризации может быть расположен последовательно или параллельно с компонентом 102 понижающего микширования по фиг. 1. Последовательное расположение будет описано со ссылкой на фиг. 4, а параллельное расположение будет описано со ссылкой на фиг. 5.
На фиг. 4 проиллюстрирован кодер 400. Кроме компонентов, описанных со ссылкой на фиг. 1, кодер 400 содержит компонент 409 кластеризации. Компонент 409 кластеризации расположен последовательно с компонентом 102 понижающего микширования, и это означает, что вывод компонента 409 кластеризации является вводом в компонент 102 понижающего микширования.
Компонент 409 кластеризации принимает в качестве ввода звуковые объекты 421а и/или звуковые каналы 421b вместе со связанными метаданными 423, содержащими пространственные положения звуковых объектов 421а. Компонент 409 кластеризации преобразовывает звуковые каналы 421b в неподвижные звуковые объекты путем связывания каждого звукового канала 421b с пространственным положением громкоговорителя, соответствующим звуковому каналу 421b. Звуковые объекты 421а и неподвижные звуковые объекты, сформированные из звуковых каналов 421b, можно рассматривать как первое множество звуковых объектов 421.
Компонент 409 кластеризации обычно уменьшает первое множество звуковых объектов 421 до второго множества звуковых объектов, здесь соответствующего N звуковых объектов 120 по фиг. 1. С этой целью компонент 409 кластеризации может применять вторую процедуру кластеризации.
Вторая процедура кластеризации в целом аналогична первой процедуре кластеризации, описанной выше в отношении компонента 102 понижающего микширования. Поэтому описание первой процедуры кластеризации также применимо ко второй процедуре кластеризации.
В частности, вторая процедура кластеризации включает связывание первого множества звуковых объектов 121 с по меньшей мере одним кластером, здесь с N кластеров, на основе пространственной близости первого множества звуковых объектов 121. Как также описывается выше, связывание с кластерами также может быть основано на других свойствах звуковых объектов, представляемых метаданными 423. Тогда каждый кластер представляют как объект, представляющий собой (линейную) комбинацию звуковых объектов, связанных с этим кластером. В проиллюстрированном примере имеется N кластеров, и, таким образом, генерируется N звуковых объектов 120. Компонент 409 кластеризации также вычисляет метаданные 122 для сгенерированных таким образом N звуковых объектов 120. Метаданные 122 содержат пространственные положения N звуковых объектов 120. Пространственное положение каждого из N звуковых объектов 120 можно вычислить на основе пространственных положений звуковых объектов, связанных с соответствующим кластером. Например, пространственное положение можно вычислить как центроид, или взвешенный центроид, пространственных положений звуковых объектов, связанных с кластером, что также разъясняется выше со ссылкой на фиг. 1.
N звуковых объектов 120, сгенерированных компонентом 409 кластеризации, затем вводят в компонент 120 понижающего микширования, что также описывается со ссылкой на фиг. 1.
На фиг. 5 проиллюстрирован кодер 500. Кроме компонентов, описанных со ссылкой на фиг. 1, кодер 500 содержит компонент 509 кластеризации. Компонент 509 кластеризации расположен параллельно с компонентом 102 понижающего микширования, и это означает, что компонент 102 понижающего микширования и компонент 509 кластеризации имеют одинаковый ввод.
Ввод содержит первое множество звуковых объектов, соответствующих N звуковых объектов 120 по фиг. 1, вместе со связанными метаданными 122, содержащими пространственные положения первого множества звуковых объектов. Первое множество звуковых объектов 120 может, аналогично первому множеству звуковых объектов 121 по фиг. 4, содержать звуковые объекты и звуковые каналы, преобразованные в неподвижные звуковые объекты. В отличие от последовательного расположения по фиг. 4, где компонент 102 понижающего микширования работает на уменьшенном количестве звуковых объектов, соответствующем упрощенной версии звуковой сцены, компонент 102 понижающего микширования по фиг. 5 работает на полном звуковом содержимом звуковой сцены с целью генерирования М сигналов 124 понижающего микширования.
Компонент 509 кластеризации по своим функциональным возможностям аналогичен компоненту 409 кластеризации, описанному со ссылкой на фиг. 4. В частности, компонент 509 кластеризации уменьшает первое множество звуковых объектов 120 до второго множества звуковых объектов 521, иллюстрируемого здесь посредством К звуковых объектов, где, как правило, M<K<N (для приложений с высокой битовой скоростью передачи данных M≤K≤N), путем применения вышеописанной второй процедуры кластеризации. Второе множество звуковых объектов 521, таким образом, представляет собой набор звуковых объектов, сформированный на основе N звуковых объектов 126. Более того, компонент 509 кластеризации вычисляет для второго множества звуковых объектов 521 (К звуковых объектов) метаданные 522, содержащие пространственные положения второго множества звуковых объектов 521. Метаданные 522 включаются в поток 540 данных компонентом 108 разуплотнения. Компонент 106 анализа вычисляет дополнительную информацию 528, позволяющую восстанавливать второе множество звуковых объектов 521, т. е. набор звуковых объектов, сформированный на основе N звуковых объектов (здесь — К звуковых объектов), исходя из М сигналов 124 понижающего микширования. Дополнительная информация 528 включается компонентом 108 уплотнения в поток 540 данных. Как также разъясняется выше, компонент 106 анализа может, например, получать дополнительную информацию 528 путем анализа второго множества звуковых объектов 521 и М сигналов 124 понижающего микширования.
Поток 540 данных, генерируемый кодером 500, обычно можно декодировать декодером 200 по фиг. 2 или декодером 300 по фиг. 3. Однако восстановленные звуковые объекты 220 по фиг. 2 (обозначенные как N звуковых объектов) теперь соответствуют второму множеству звуковых объектов 521 (обозначенных как К звуковых объектов) по фиг. 5, а метаданные 222, связанные со звуковыми объектами (обозначенные как метаданные для N звуковых объектов), теперь соответствуют метаданным 522 второго множества звуковых объектов (обозначенным как метаданные для К звуковых объектов) по фиг. 5.
В системах звукового кодирования/декодирования на основе объектов дополнительная информация или метаданные, связанные с объектами, как правило, обновляются во времени относительно нечасто (редко) с целью ограничения связанной с этим скорости передачи данных. Как правило, интервалы обновления для положений объектов могут находиться в интервале от 10 до 500 миллисекунд в зависимости от скорости объекта, требуемой точности определения положения, доступной полосы пропускания для хранения и передачи метаданных и т. д. Столь редкие, или даже нерегулярные, обновления метаданных требуют интерполяции метаданных и/или матриц представления (т. е. матриц, используемых при представлении) для дискретных значений звуковых данных между двумя последовательными экземплярами метаданных. В отсутствие интерполяции последовательные ступенчатые изменения в матрице представления могут вызывать нежелательные артефакты переключения, щелкающие звуки, шумы застежки-молнии или другие нежелательные артефакты в результате размывания спектра, вносимого ступенчатыми обновлениями матрицы.
На фиг. 6 проиллюстрирован типичный известный процесс вычисления матриц представления для представления звуковых сигналов или звуковых объектов на основе набора экземпляров метаданных. Как показано на фиг. 6, набор экземпляров (m1—m4) 610 метаданных соответствует набору моментов времени (t1—t4), указанных посредством их положений на оси 620 времени. Впоследствии каждый экземпляр метаданных преобразовывают в соответствующую матрицу 630 (c1—c4) представления, или установку представления, достоверную на тот же момент времени, что и указанный экземпляр метаданных. Таким образом, как показано, экземпляр m1 метаданных создает матрицу с1 представления в момент времени t1, экземпляр m2 метаданных создает матрицу с2 представления в момент времени t2 и т. д. Для простоты на фиг. 6 показана только одна матрица представления для каждого экземпляра m1—m4 метаданных. В системах, применяемых на практике, однако, матрица с1 представления может содержать набор коэффициентов матрицы представления, или коэффициентов c_(1,i,j) усиления, подлежащих применению к соответствующим звуковым сигналам x_i (t) с целью создания выходных сигналов y_j (t):
y_j (t)=∑_i▒ [(x_i (t) c_(1,i,j) )].
Матрицы 630 представления обычно содержат коэффициенты, представляющие значения усиления в разные моменты времени. Экземпляры метаданных определяют на определенные моменты времени, а для дискретных значений звуковых данных между моментами времени метаданных матрицу представления интерполируют, что указано штриховой линией 640, соединяющей матрицы 630 представления. Такую интерполяцию можно выполнить линейно, однако можно использовать и другие способы интерполяции (такие как интерполяция с ограниченной полосой, синусная/косинусная интерполяция и т. д.). Промежуток времени между экземплярами метаданных (и соответствующими матрицами представления) называется "продолжительностью интерполяции", и такие промежутки могут быть равномерными, или они могут отличаться, например, более длительная продолжительность интерполяции между моментами времени t3 и t4 в сравнении с продолжительностью интерполяции между моментами времени t2 и t3.
Во многих случаях, вычисление коэффициентов матрицы представления исходя из экземпляров метаданных, является хорошо определенным, однако обратный процесс вычисления экземпляров метаданных при заданной (интерполированной) матрице представления часто является затруднительным или даже невозможным. В этом отношении процесс генерирования матрицы представления исходя из метаданных, иногда можно рассматривать как криптографическую одностороннюю функцию. Процесс вычисления новых экземпляров метаданных между существующими экземплярами метаданных именуется "передискретизацией" метаданных. Передискретизация метаданных часто требуется в ходе определенных задач обработки звуковых данных. Например, при редактировании звукового содержимого посредством вырезки/слияния/смешивания и т. д. такие редакции могут происходить между экземплярами метаданных. В этом случае требуется передискретизация метаданных. Другой такой случай имеет место тогда, когда звук и связанные с ним метаданные кодируют звуковым кодеком на основе кадров. В этом случае требуется наличие по меньшей мере одного экземпляра метаданных для каждого кадра звукового кодека, предпочтительно с временной меткой в начале этого кадра кодека, для того чтобы повышать устойчивость к ошибкам потерь кадров в ходе передачи. Более того, интерполяция метаданных также неэффективна для метаданных некоторых типов, таких как метаданные с двоичными значениями, где стандартные методики приводили бы к неверному значению приблизительно в каждом втором случае. Например, если для исключения некоторых объектов из представления в некоторые моменты времени используют такие двоичные флаги, как маски исключения зон, то оценить достоверный набор метаданных, исходя из коэффициентов матрицы представления или из соседних экземпляров метаданных, практически невозможно. Это показано на фиг. 6 как неудачная попытка экстраполяции, или получения, экземпляра m3a метаданных исходя из коэффициентов матрицы представления в продолжительности интерполяции между моментами времени t3 и t4. Как показано на фиг. 6, экземпляры mx метаданных точно определяются лишь в дискретные моменты времени tx, в свою очередь, вырабатывая связанный набор матричных коэффициентов cx. Между этими дискретными моментами времени tx наборы матричных коэффициентов нужно интерполировать на основе прошлых или будущих экземпляров метаданных. Однако, как описывалось выше, современные схемы интерполяции метаданных страдают от потери качества пространственного звука по причине неизбежных неточностей в процессах интерполяции метаданных. Альтернативные схемы интерполяции согласно примерным вариантам осуществления будут описаны ниже со ссылкой на фиг. 7—11.
В примерных вариантах осуществления, описываемых со ссылкой на фиг. 1—5, метаданные 122, 222, связанные с N звуковых объектов 120, 220, и метаданные 522, связанные с К объектов 522, по меньшей мере в некоторых примерных вариантах осуществления происходят из компонентов 409 и 509 кластеризации и могут называться метаданными кластеров. Кроме того, метаданные 125, 325, связанные с сигналами 124, 324 понижающего микширования, могут называться метаданными понижающего микширования.
Как описано со ссылкой на фиг. 1, 4 и 5, компонент 102 понижающего микширования может вычислять М сигналов 124 понижающего микширования путем формирования комбинаций N звуковых объектов 120 адаптивным к сигналу образом, т. е. в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей. Такое действие компонента 102 понижающего микширования представляет собой характерную особенность примерных вариантов осуществления в рамках первой особенности. Согласно примерным вариантам осуществления в рамках других особенностей, компонент 102 понижающего микширования может, например, вычислять М сигналов 124 понижающего микширования путем формирования комбинаций N звуковых объектов 120 адаптивным к сигналу образом или, в качестве альтернативы, так, чтобы М сигналов понижающего микширования были пригодны для воспроизведения на каналах конфигурации громкоговорителей с М каналов, т. е. как обратно совместимое понижающее микширование.
В одном из примерных вариантов осуществления кодер 400, описанный со ссылкой на фиг. 4, использует формат метаданных и дополнительной информации, особенно подходящий для передискретизации, т. е. для генерирования добавочных экземпляров метаданных и дополнительной информации. В этом примерном варианте осуществления компонент 106 анализа вычисляет дополнительную информацию 128 в форме, включающей множество экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления N звуковых объектов 120, и для каждого экземпляра дополнительной информации данные перехода, включая две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода. В этом примерном варианте осуществления две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой: временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления. Интервал, в течение которого должен происходить переход, в этом примерном варианте осуществления однозначно определяется временем, в которое переход должен начаться, и продолжительностью интервала перехода. Данная конкретная форма дополнительной информации 128 будет описана ниже со ссылкой на фиг. 7—11. Следует понимать, что имеется несколько других способов однозначного определения этого интервала перехода. Например, для однозначного определения этого интервала в данных перехода можно использовать опорную точку в форме начальной, конечной или средней точки интервала, сопровождаемой продолжительностью интервала. В качестве альтернативы, для однозначного определения интервала можно использовать начальную и конечную точки интервала.
В этом примерном варианте осуществления компонент 409 кластеризации уменьшает первое множество звуковых объектов 421 до второго множества звуковых объектов, здесь соответствующего N звуковых объектов 120 по фиг. 1. Компонент 409 кластеризации вычисляет метаданные 122 кластеров для сгенерированных N звуковых объектов 120, что позволяет представлять N звуковых объектов 122 в компоненте 210 представления на стороне декодера. Компонент 409 кластеризации представляет метаданные 122 кластеров в форме, которая включает множество экземпляров метаданных кластеров, определяющих соответствующие требуемые установки представления для представления N звуковых объектов 120, и для каждого экземпляра метаданных кластеров данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров, и момент времени для завершения перехода к требуемой установке представления. В этом примерном варианте осуществления две независимо присваиваемые части данных перехода для каждого экземпляра метаданных кластеров представляют собой: временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления. Данная конкретная форма метаданных 122 кластеров будет описана ниже со ссылкой на фиг. 7–11.
В этом примерном варианте осуществления компонент 102 понижающего микширования связывает каждый сигнал 124 понижающего микширования с пространственным положением и включает пространственное положение в метаданные 125 понижающего микширования, позволяющие представлять М сигналов понижающего микширования в компоненте 310 представления на стороне декодера. Компонент 102 понижающего микширования предоставляет метаданные 125 понижающего микширования в форме, которая включает множество экземпляров метаданных понижающего микширования, определяющих соответствующие требуемые установки представления понижающего микширования для представления сигналов понижающего микширования, и, для каждого экземпляра метаданных понижающего микширования данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования, и момент времени для завершения перехода к требуемой установке представления понижающего микширования. В этом примерном варианте осуществления две независимо присваиваемые части данных перехода для каждого экземпляра метаданных понижающего микширования представляют собой: временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования.
В этом примерном варианте осуществления для дополнительной информации 128, метаданных 122 кластеров и метаданных 125 понижающего микширования используют один и тот же формат. Это формат ниже будет описан со ссылкой на фиг. 7—11 в выражении метаданных для представления звуковых сигналов. Однако следует понимать, что в нижеследующих примерах, описываемых со ссылкой на фиг. 7—11, такие термины или выражения, как "метаданные для представления звуковых сигналов", можно с таким же успехом заменить такими соответствующими терминами или выражениями, как "дополнительная информация для восстановления звуковых объектов", "метаданные кластеров для представления звуковых объектов" или "метаданные понижающего микширования для представления сигналов понижающего микширования".
На фиг. 7 проиллюстрировано получение, на основе метаданных, кривых коэффициентов, используемых при представлении звуковых сигналов согласно одному из примерных вариантов осуществления. Как показано на фиг. 7, набор экземпляров mx метаданных, сгенерированных в разные моменты времени tx, например, связанные с однозначными временными отметками, преобразуют посредством преобразователя 710 в соответствующие наборы значений cx матричных коэффициентов. Эти наборы коэффициентов представляют значения усиления, также именуемые коэффициентами усиления, подлежащие применению для представления звуковых сигналов в различные громкоговорители и ВЧ/СЧ-громкоговорители в системе воспроизведения, представлению в которой подлежит звуковое содержимое. Интерполятор 720 затем интерполирует коэффициенты cx усиления, вырабатывая кривую коэффициента между отдельными моментами времени tx. В одном из вариантов осуществления временные отметки tx, связанные с каждым экземпляром mx метаданных, могут соответствовать случайным моментам времени, синхронным моментам времени, генерируемым хронирующей схемой, событиям времени, относящимся к звуковому содержимому, таким как границы кадра, или каким-либо другим соответственным событиям с учетом времени. Следует отметить, что, как описывалось выше, описание, представляемое со ссылкой на фиг. 7, аналогично применимо к дополнительной информации для восстановления звуковых объектов.
На фиг. 8 проиллюстрирован формат метаданных согласно одному из вариантов осуществления (и, как описывалось выше, нижеследующее описание аналогично применимо к соответствующему формату дополнительной информации), направленному на, по меньшей мере, некоторые трудности интерполяции, связанные с вышеописанными современными способами, путем определения временной отметки как начального времени перехода или интерполяции и дополнения каждого экземпляра метаданных параметром продолжительности интерполяции, представляющим продолжительность перехода, или продолжительность интерполяции (также именуемую "величиной изменения"). Как показано на фиг. 8, набор экземпляров m2—m4 (810) метаданных определяет набор матриц c2—c4 (830) представления. Каждый экземпляр метаданных генерируется в конкретный момент времени tx, и каждый экземпляр метаданных определяется относительно его временной отметки: m2 относительно t2, m3 относительно t3 и т. д. Связанные матрицы 830 представления генерируются после выполнения переходов в течение соответствующих продолжительностей d2, d3, d4 (830) интерполяции исходя из связанной с ними временной отметки (t1—t4) каждого из экземпляров 810 метаданных. Параметр продолжительности интерполяции, указывающий продолжительность интерполяции (или величину изменения), включается в каждый экземпляр метаданных, т. е. экземпляр m2 метаданных содержит d2, m3 содержит d3 и т. д. Схематически это можно представить следующим образом: mx = (метаданные (tx), dx) ◊ cx. Таким образом, метаданные по существу, представляют схему того, как двигаться от текущей установки представления (например, текущей матрицы представления, являющейся результатом предыдущих метаданных) к новой установке представления (например, к новой матрице представления, являющейся результатом текущих метаданных). Подразумевается, что каждый экземпляр метаданных вступает в силу в определенный момент времени в будущем относительно момента, в который экземпляр метаданных был принят, а кривая коэффициента получается исходя из предыдущего состояния коэффициента. Так, на фиг. 8 m2 генерирует c2 после продолжительности d2, m3 генерирует c3 после продолжительности d3, и m4 генерирует c4 после продолжительности d4. В этой схеме интерполяции нет необходимости в знании предыдущих метаданных — требуется только предыдущая матрица представления или состояние представления. Используемая интерполяция может являться линейной или нелинейной в зависимости от ограничений и конфигураций системы.
Как показано на фиг. 9, формат метаданных по фиг. 8 допускает передискретизацию метаданных без потерь данных. На фиг. 9 проиллюстрирован первый пример обработки метаданных без потерь данных согласно одному из примерных вариантов осуществления (и, как описывается выше, нижеследующее описание аналогично применимо к соответствующему формату дополнительной информации). На фиг. 9 показаны экземпляры m2—m4 метаданных, относящиеся к будущим матрицам c2—c4 представления и содержащие продолжительности d2—d4 интерполяции соответственно. Временные отметки экземпляров m2—m4 метаданных имеют вид t2—t4. В примере по фиг. 9 в момент времени t4a добавляется экземпляр m4a метаданных. Такие метаданные могут быть добавлены по нескольким причинам, например, для повышения устойчивости системы к ошибкам или для синхронизации экземпляров метаданных с началом/концом звукового кадра. Например, время t4a может представлять время, в которое звуковой кодек, используемый для кодирования звукового содержимого, связанного с метаданными, начинает новый кадр. Для работы без потерь данных значения метаданных m4a идентичны таковым для m4 (т. е. оба они описывают целевую матрицу с4 представления), но время d4a для достижения этого момента было уменьшено на d4–d4a. Иными словами, экземпляр m4a метаданных идентичен таковому для предыдущего экземпляра m4 метаданных, и поэтому кривая интерполяции между c3 и c4 не меняется. Однако новая продолжительность d4a интерполяции является более краткой, чем первоначальная продолжительность d4. Это эффективно повышает скорость передачи данных для экземпляров метаданных, что может быть преимущественным в некоторых обстоятельствах, таких как исправление ошибок.
Второй пример интерполяции метаданных без потерь данных показан на фиг. 10 (и, как описывалось выше, нижеследующее описание аналогично применимо к соответствующему формату дополнительной информации). В этом примере целью является включение нового набора метаданных m3a между двумя экземплярами m3 и m4 метаданных. На фиг. 10 проиллюстрирован случай, когда матрица представления остается неизменной в течение некоторого периода времени. Поэтому в данной ситуации значения нового набора метаданных m3a идентичны таковым для предыдущих метаданных m3 за исключением продолжительности d3a интерполяции. Значение продолжительности d3a интерполяции следует приравнять значению, соответствующему t4–t3a, т. е. разности между моментом времени t4, связанным со следующим экземпляром m4 метаданных, и моментом времени t3a, связанным с новым набором метаданных m3a. Случай, проиллюстрированный на фиг. 10, возникает, например, тогда, когда звуковой объект является неподвижным, и инструментальное средство разработки останавливает отправку новых метаданных для объекта по причине его неподвижной сущности. В таком случае может быть желательно вставить новые экземпляры m3a метаданных, например, для синхронизации метаданных с кадрами кодека.
В примерах, проиллюстрированных на фиг. 8-10, интерполяцию от текущей к требуемой матрице представления, или состоянию представления, выполняли посредством линейной интерполяции. В других примерных вариантах осуществления также можно использовать другие схемы интерполяции. Одна из таких альтернативных схем интерполяции использует схему выборки и хранения в комбинации с последующим фильтром пропускания нижних частот. На фиг. 11 проиллюстрирована схема интерполяции, использующая схему выборки и хранения с фильтром пропускания нижних частот согласно одному из примерных вариантов осуществления (и, как описывается выше, нижеследующее описание аналогично применимо к соответствующему формату дополнительной информации). Как показано на фиг. 11, экземпляры m2—m4 метаданных преобразовывают в коэффициенты с2 и с3 матрицы представления с выборкой и хранением. Это процесс выборки и хранения вызывает мгновенный скачок состояний коэффициентов в требуемое состояние, что, как показано, в результате приводит к ступенчатой кривой 1110. Эта кривая 1110 впоследствии подвергается фильтрации с пропусканием нижних частот с целью получения гладкой, интерполированной кривой 1120. Параметры интерполирующего фильтра (например, частота среза или постоянная времени) можно сигнализировать как часть метаданных в дополнение к временным отметкам и параметрам продолжительности интерполяции. Следует понимать, что в зависимости от требований системы и характерных особенностей звукового сигнала можно использовать разные параметры.
В одном из примерных вариантов осуществления продолжительность интерполяции, или величина изменения, может иметь любое практически применимое значение, в том числе значение, по существу близкое к нулю. Такая небольшая продолжительность интерполяции особенно полезна в таких случаях, как инициализация с целью обеспечения возможности задания матрицы представления непосредственно в первом дискретном значении файла, или допущение редакций, сращивания или сцепления потоков. Для разрушающих редакций такого типа обладание возможностью мгновенного изменения матрицы представления может быть полезно для сохранения пространственных свойств содержимого после редактирования.
В одном из примерных вариантов осуществления схема интерполяции, описываемая в данном описании, является совместимой с удалением экземпляров метаданных (и, аналогично, как описывается выше, с удалением экземпляров дополнительной информации), таким как в схеме прореживания, уменьшающей битовую скорость передачи метаданных. Удаление экземпляров метаданных позволяет системе производить передискретизацию с частотой кадров ниже исходной частоты кадров. В этом случае экземпляры метаданных и связанные с ними данные продолжительности интерполяции, представляемые кодером, можно удалять на основе определенных характерных особенностей. Например, компонент анализа в кодере может анализировать звуковой сигнал с целью определения того, имеется ли период значительного статического равновесия сигнала, и, в таком случае, удалять некоторые экземпляры метаданных, уже сгенерированные для уменьшения требований полосы пропускания при передаче данных на сторону декодера. Удаление экземпляров метаданных можно, в качестве альтернативы или в дополнение, выполнять в компоненте, отдельном от кодера, таком как декодер или преобразователь кода. Преобразователь кода может удалять экземпляры метаданных, которые были сгенерированы или добавлены кодером, и его можно использовать в преобразователе скорости передачи данных, который подвергает звуковой сигнал передискретизации от первой частоты ко второй частоте, где вторая частота может быть и может не быть целочисленно кратной первой частоте. В качестве альтернативы, для анализа звукового сигнала с целью определения того, какие экземпляры метаданных следует удалить, кодер, декодер или преобразователь кода может анализировать метаданные. Например, со ссылкой на фиг. 10, можно рассчитать разность между первой требуемой установкой c3 восстановления (или матрицей восстановления), определяемой первым экземпляром m3 метаданных, и требуемыми установками c3a и c4 восстановления (или матрицами восстановления), определяемыми экземплярами m3a и m4 метаданных, непосредственно следующими за первым экземпляром m3 метаданных. Разность можно рассчитать, например, путем использования матричной нормы для соответствующих матриц представления. Если разность находится ниже предварительно определенного порога, например, соответствующего допустимому искажению восстанавливаемых звуковых сигналов, экземпляры m3a и m4 метаданных, следующие за первым экземпляром m2 метаданных, можно удалить. В примере, проиллюстрированном на фиг. 10, экземпляр m3a метаданных, следующий непосредственно за первым экземпляром m3 метаданных, определяет такие же установки c3=c3a представления, как и первый экземпляр m3 метаданных, и поэтому будет удален, тогда как следующая установка m4 метаданных определяет отличающуюся установку c4 представления, и ее можно, в зависимости от используемого порога, сохранить в качестве метаданных.
В декодере 200, описанном со ссылкой на фиг. 2, компонент 206 восстановления объектов может использовать интерполяцию как часть восстановления N звуковых объектов 220 на основе М сигналов 224 понижающего микширования и дополнительной информации 228. По аналогии со схемой интерполяции, описанной со ссылкой на фиг. 7—11, восстановление N звуковых объектов 220 может, например, включать: выполнение восстановления в соответствии с текущей установкой восстановления; начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации, перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации; и завершение перехода к требуемой установке восстановления в момент времени, определяемый данными перехода для экземпляра дополнительной информации.
Аналогично, компонент 210 представления может использовать интерполяцию как часть представления восстановленных N звуковых объектов 220 с целью генерирования многоканального выходного сигнала 230, пригодного для воспроизведения. По аналогии со схемой интерполяции, описанной со ссылкой на фиг. 7—11, представление может включать: выполнение представления в соответствии с текущей установкой восстановления; начало, в момент времени, определяемый данными перехода для экземпляра метаданных кластеров, перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров; и завершение перехода к требуемой установке представления в момент времени, определяемый данными перехода для экземпляра метаданных кластеров.
В некоторых примерных вариантах осуществления секция 206 восстановления объектов и компонент 210 представления могут представлять собой отдельные модули и/или могут соответствовать операциям, выполняемым как отдельные процессы. В других примерных вариантах осуществления секция 206 восстановления объектов и компонент 210 представления могут быть воплощены как единый модуль или процесс, в котором восстановление и представление выполняются как комбинированная операция. В таких примерных вариантах осуществления матрицы, используемые для восстановления и представления, можно скомбинировать в единую матрицу, которую можно интерполировать, вместо выполнения интерполяции на матрице представления и матрице восстановления по отдельности.
В декодере 300 с низкой сложностью, описанном со ссылкой на фиг. 3, компонент 310 представления может выполнять интерполяцию как часть представления М сигналов 324 понижающего микширования в многоканальный вывод 330. По аналогии со схемой интерполяции, описанной со ссылкой на фиг. 7—11, представление может включать: выполнение представления в соответствии с текущей установкой представления понижающего микширования; начало, в момент времени, определяемый данными перехода для экземпляра метаданных понижающего микширования, перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования; и завершение перехода к требуемой установке представления понижающего микширования в момент времени, определяемый данными перехода для экземпляра метаданных понижающего микширования. Как описывалось ранее, компонент 310 представления может быть заключен в декодере 300 или может представлять собой отдельное устройство/модуль. В примерных вариантах осуществления, где компонент 310 представления является отдельным от декодера 300, декодер может выводить метаданные 325 понижающего микширования и М сигналов 324 понижающего микширования для представления М сигналов понижающего микширования в компоненте 310 представления.
Эквиваленты, расширения, альтернативы и прочее
Другие варианты осуществления настоящего раскрытия станут очевидны специалисту в данной области техники после изучения приведенного выше описания. Несмотря на то, что настоящее описание и графические материалы раскрывают варианты осуществления и примеры, раскрытие этими конкретными примерами не ограничивается. Возможны многочисленные модификации и изменения без отклонения от объема настоящего изобретения, определенного прилагаемой формулой изобретения. Любые ссылочные позиции, встречающиеся в формуле изобретения, не должны рассматриваться как ограничивающие ее объем.
Кроме того, после изучения графических материалов, раскрытия и прилагаемой формулы изобретения специалисту могут быть понятными изменения раскрытых вариантов осуществления, и они могут использоваться им при практической реализации раскрытия. В формуле изобретения слово "содержащий" не исключает другие элементы или этапы, и единственное число не исключает множественное. Сам факт, что некоторые признаки упоминаются во взаимно отличных зависимых пунктах формулы изобретения, не говорит о том, что не может быть использована с выгодой комбинация этих признаков.
Системы и способы, раскрытые выше, могут быть осуществлены в виде программного обеспечения, программно-аппаратного обеспечения, аппаратных средств или их сочетания. При осуществлении в виде аппаратных средств разделение задач между функциональными узлами, о которых говорилось в вышеприведенном описании, не обязательно соответствует разделению на физические модули; наоборот, один физический компонент может выполнять несколько функций, и одно задание может выполняться несколькими физическими компонентами совместно. Некоторые компоненты или все компоненты могут быть осуществлены в виде программного обеспечения, выполняемого процессором цифровых сигналов или микропроцессором, или могут быть осуществлены в виде аппаратных средств или в виде зависимой от приложения интегральной микросхемы. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители информации (или постоянные носители) и средства коммуникации (или временные носители). Как хорошо известно специалисту в области техники, термин "компьютерные носители информации" включает энергозависимые и энергонезависимые, сменные и несменные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. К компьютерным носителям информации без ограничения относятся ОЗУ, ПЗУ, ЭСППЗУ, флеш-память или другая технология памяти, компакт-диски постоянной памяти, компакт-диски формата DVD (DVD-диски) или другие накопители на оптических дисках; магнитные кассеты, магнитная лента, накопители на магнитных дисках или другие магнитные устройства для хранения информации; или любой другой носитель, который может быть использован для хранения требуемой информации и который может быть доступным с помощью компьютера. Кроме того, специалисту хорошо известно, что в средствах коммуникации, как правило, выполняются машиночитаемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как несущая волна или другой механизм переноса, и содержаться любые средства для доставки информации.
Все фигуры являются схематическими и, как правило, показывают лишь те части, которые необходимы для разъяснения раскрытие, тогда как другие части могут быть опущены или просто подразумеваться. Если не указано иное, подобные части на разных фигурах обозначены подобными ссылочными позициями.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН, СОДЕРЖАЩИХ ЗВУКОВЫЕ ОБЪЕКТЫ | 2014 |
|
RU2630754C2 |
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН, СОДЕРЖАЩИХ ЗВУКОВЫЕ ОБЪЕКТЫ | 2021 |
|
RU2831398C2 |
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН, СОДЕРЖАЩИХ ЗВУКОВЫЕ ОБЪЕКТЫ | 2014 |
|
RU2745832C2 |
| КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН | 2014 |
|
RU2608847C1 |
| ОБРАБОТКА ПРОСТРАНСТВЕННО ДИФФУЗНЫХ ИЛИ БОЛЬШИХ ЗВУКОВЫХ ОБЪЕКТОВ | 2020 |
|
RU2803638C2 |
| ОБРАБОТКА ПРОСТРАНСТВЕННО-ДИФФУЗНЫХ ИЛИ БОЛЬШИХ ЗВУКОВЫХ ОБЪЕКТОВ | 2014 |
|
RU2716037C2 |
| ОБРАБОТКА ПРОСТРАНСТВЕННО ДИФФУЗНЫХ ИЛИ БОЛЬШИХ ЗВУКОВЫХ ОБЪЕКТОВ | 2014 |
|
RU2646344C2 |
| ЗВУКОВОЙ КОДЕР И ЗВУКОВОЙ ДЕКОДЕР | 2019 |
|
RU2795865C2 |
| СТРУКТУРА ДЕКОРРЕЛЯТОРА ДЛЯ ПАРАМЕТРИЧЕСКОГО ВОССТАНОВЛЕНИЯ ЗВУКОВЫХ СИГНАЛОВ | 2014 |
|
RU2641463C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКОВОГО ПРЕДСТАВЛЕНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ ЗАКОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ТРАНСПОРТНЫХ МЕТАДАННЫХ И СООТВЕТСТВУЮЩИЕ КОМПЬЮТЕРНЫЕ ПРОГРАММЫ | 2020 |
|
RU2792050C2 |
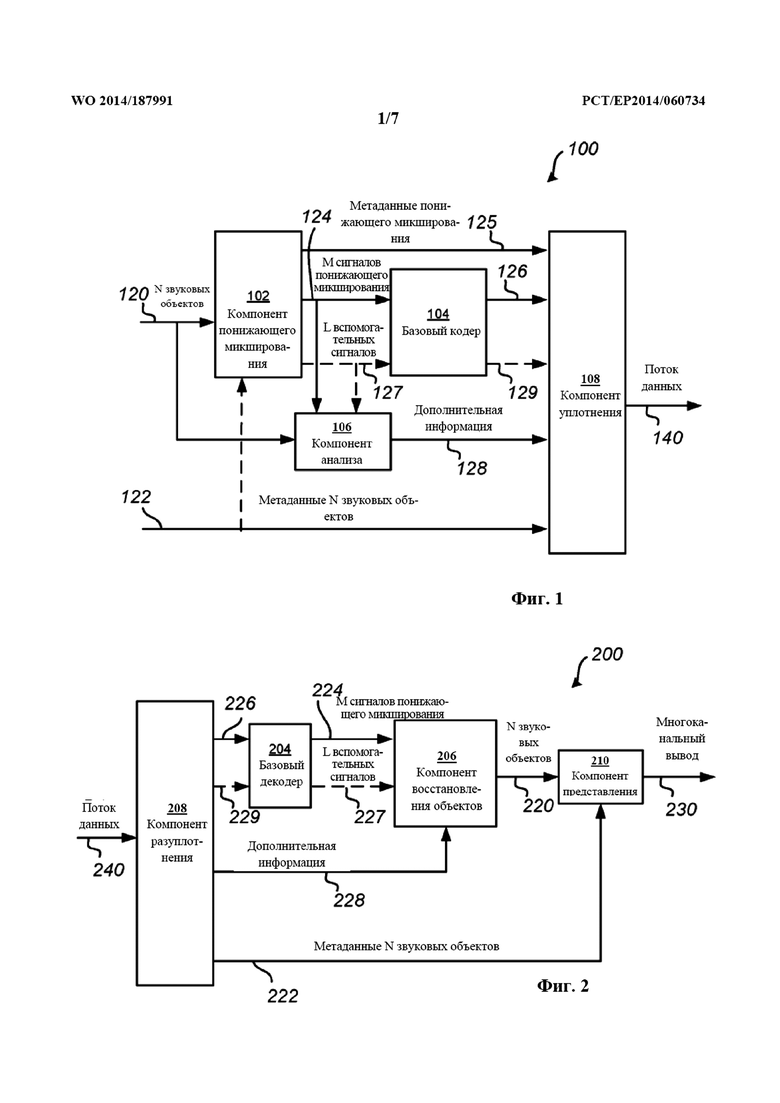
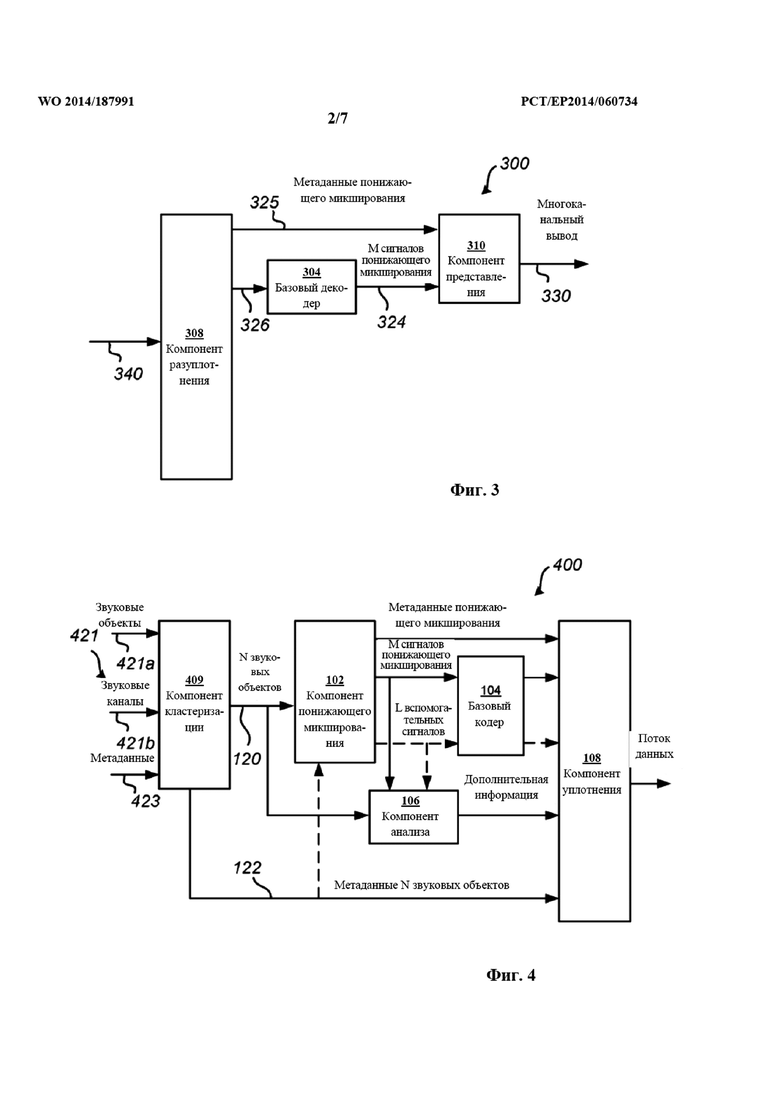
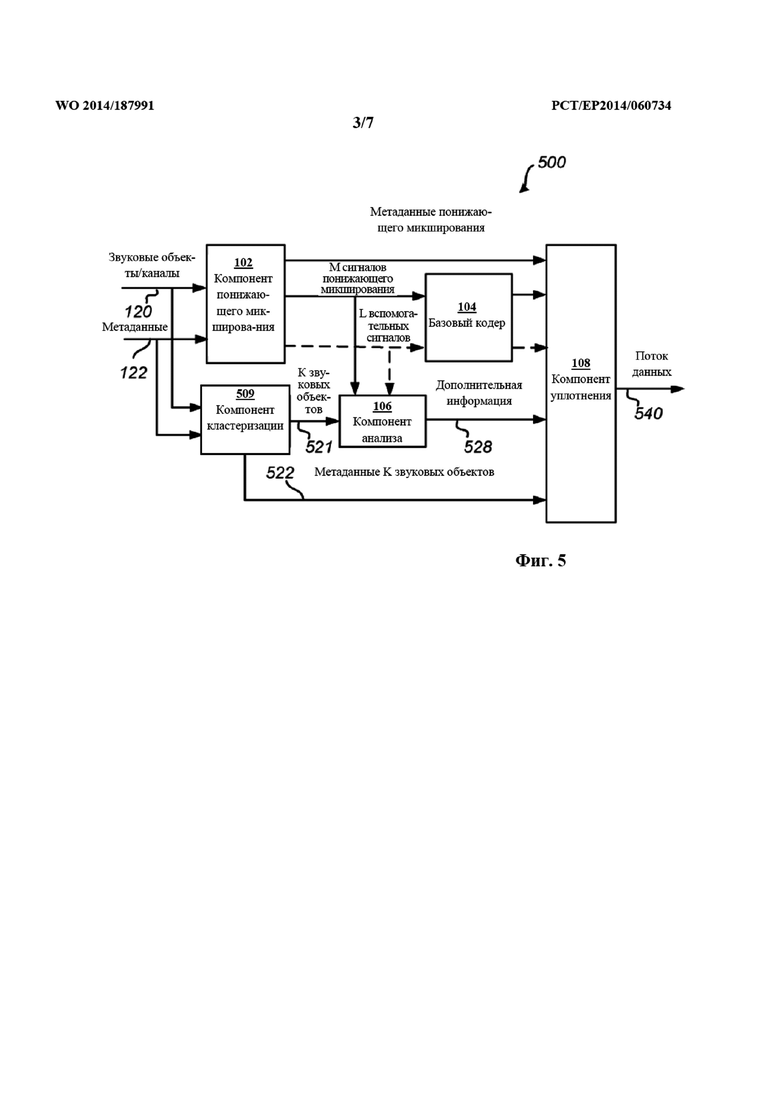
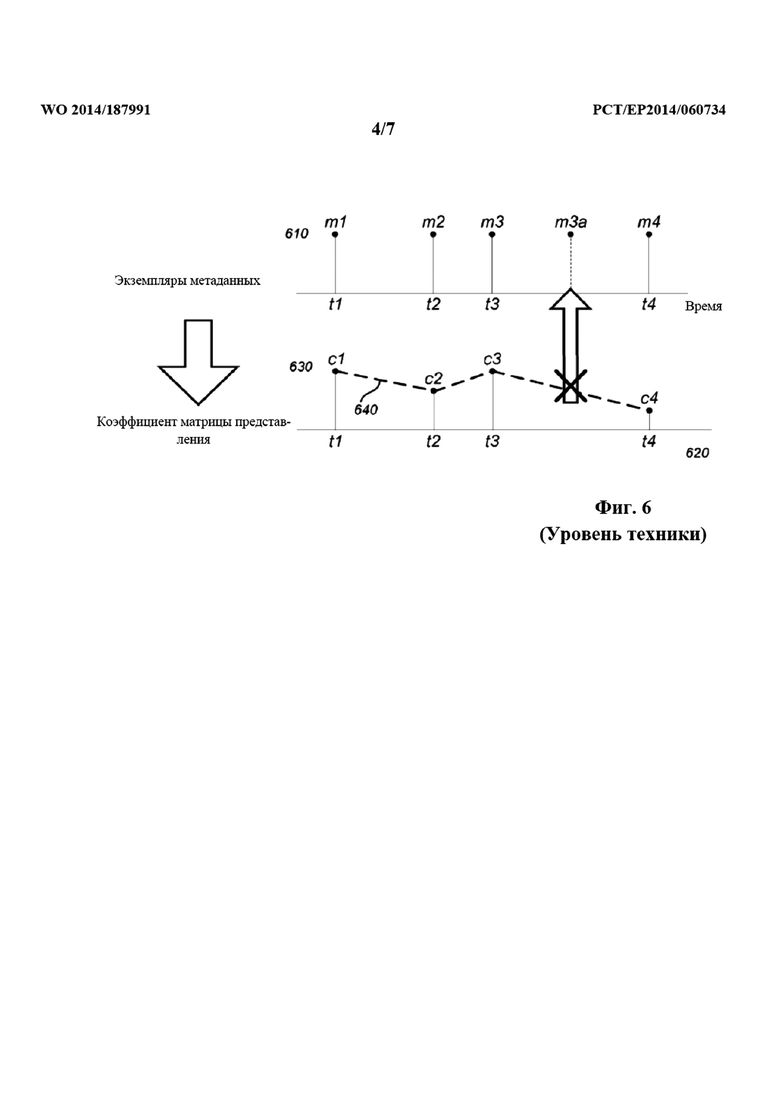
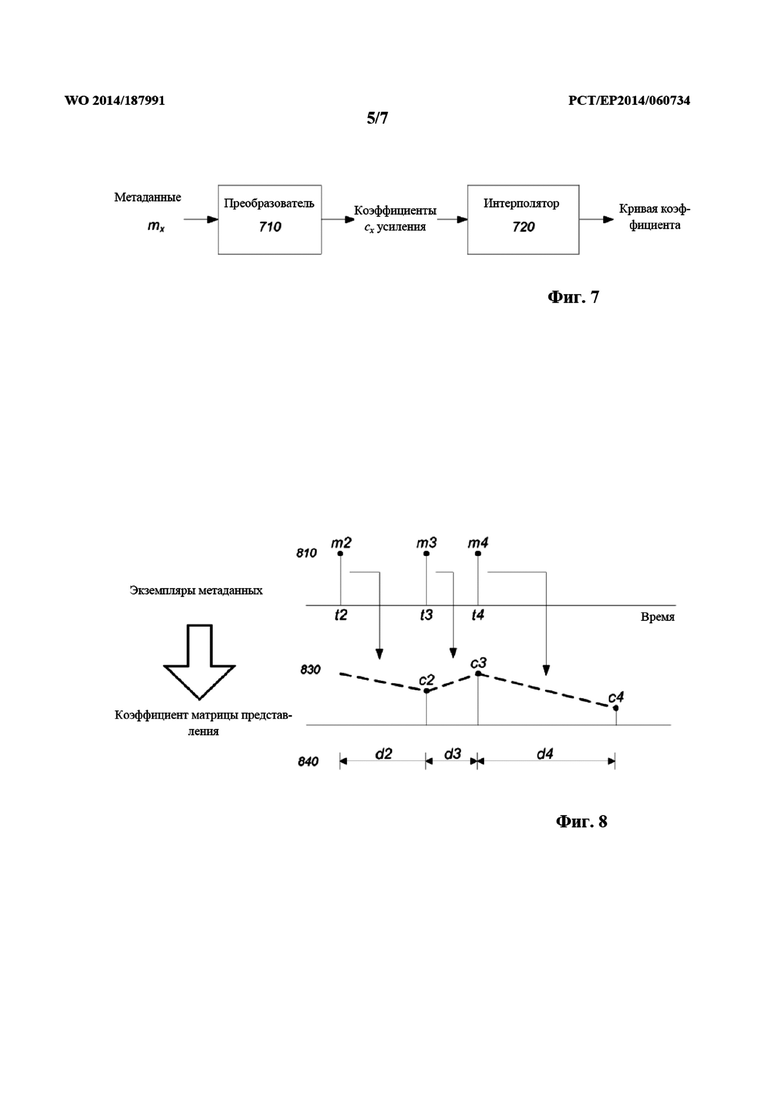
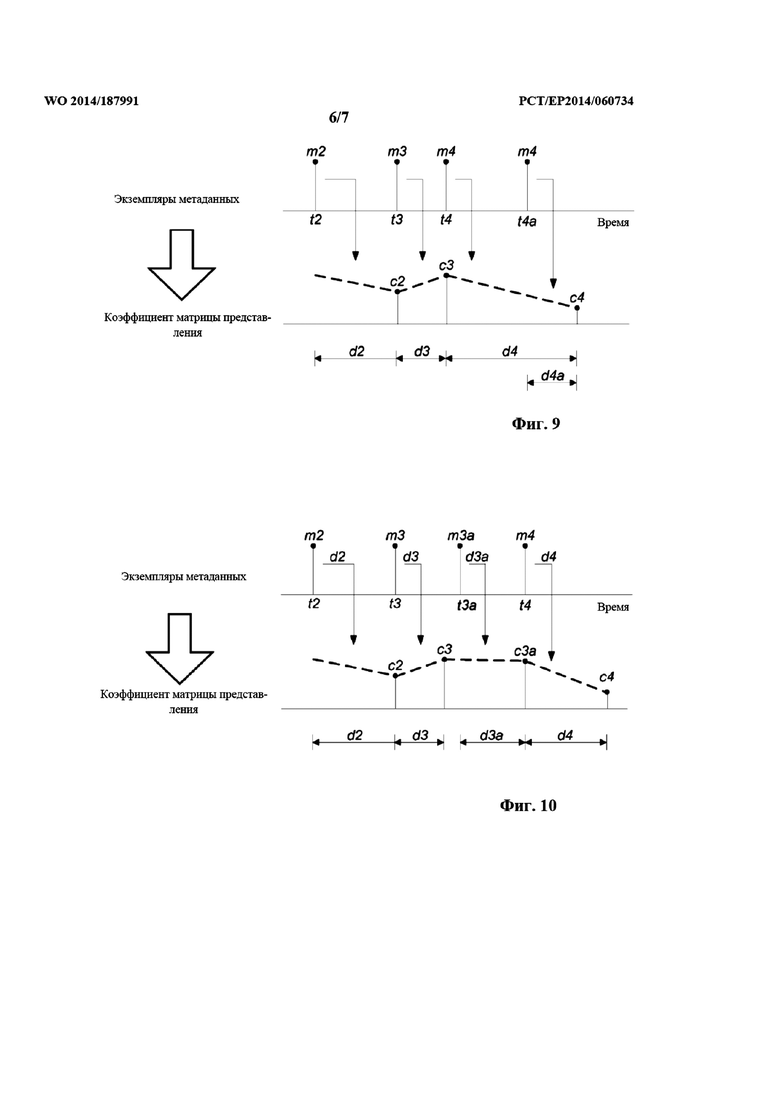
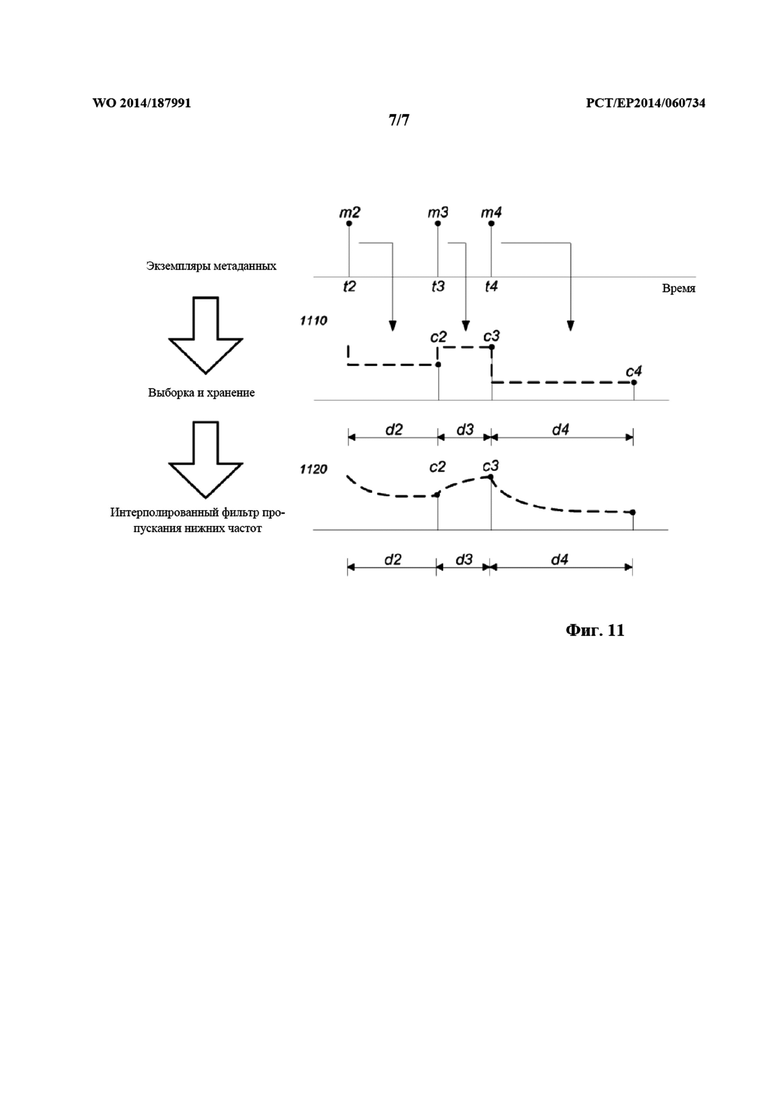
Изобретение относится к средствам для кодирования и декодирования звука. Технический результат заключается в повышении эффективности кодирования и декодирования звуковых объектов. Способов кодирования включает, среди прочего, вычисление М сигналов понижающего микширования путем формирования комбинаций N звуковых объектов, где M≤N, и вычисление параметров, позволяющих восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования. Вычисление М сигналов понижающего микширования осуществляют в соответствии с критерием, не зависящим от какой-либо конфигурации громкоговорителей. 7 н. и 29 з.п. ф-лы, 11 ил.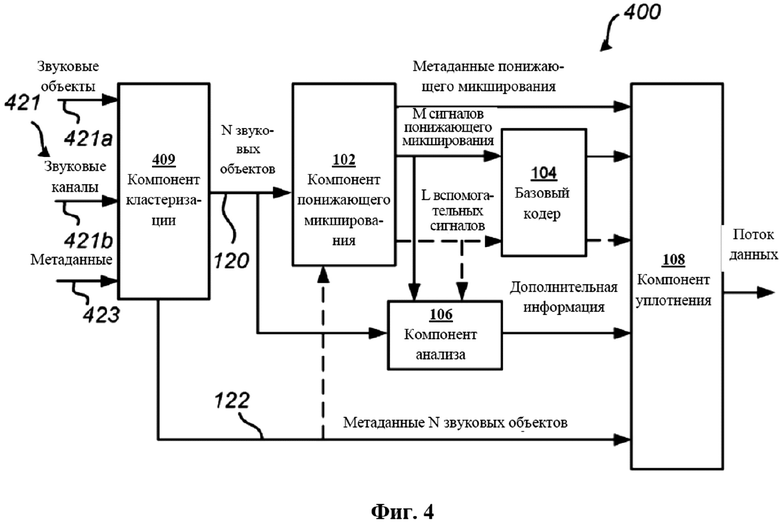
1. Способ кодирования звуковых объектов в виде потока данных, включающий:
прием N звуковых объектов, где N>1;
вычисление М сигналов понижающего микширования, где M≤N, путем формирования комбинаций,
N звуковых объектов;
вычисление изменяющейся во времени дополнительной информации, содержащей параметры, которые позволяют восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
включение М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер;
при этом способ также включает включение в поток данных:
множества экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления набора звуковых объектов, сформированного на основе N звуковых объектов; и
данных перехода для каждого экземпляра дополнительной информации, содержащих две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода.
2. Способ по п. 1, дополнительно включающий процедуру кластеризации для уменьшения первого множества звуковых объектов до второго множества звуковых объектов; при этом N звуковых объектов составляет, либо первое множество звуковых объектов, либо второе множество звуковых объектов; при этом указанный набор звуковых объектов, сформированный на основе N звуковых объектов, совпадает со вторым множеством звуковых объектов; и при этом процедура кластеризации включает:
вычисление изменяющихся во времени метаданных кластеров, содержащих пространственные положения для второго множества звуковых объектов; и
дополнительное включение в поток данных:
множества экземпляров метаданных кластеров, определяющих соответствующие требуемые установки представления для представления второго набора звуковых объектов; и
данных перехода для каждого экземпляра метаданных кластеров, содержащих две независимо присваиваемые части, в комбинации определяющие момент времени для начала перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров, и момент времени для завершения перехода к требуемой установке представления, определяемой экземпляром метаданных кластеров.
3. Способ по п. 2, в котором процедура кластеризации дополнительно включает:
прием первого множества звуковых объектов и связанных с ними пространственных положений;
связывание первого множества звуковых объектов по меньшей мере с одним кластером на основе пространственной близости первого множества звуковых объектов;
генерирование второго множества звуковых объектов путем представления каждого из по меньшей мере одного кластера посредством звукового объекта, представляющего собой комбинацию звуковых объектов, связанных с кластером; и
вычисление пространственного положения каждого звукового объекта из второго множества звуковых объектов на основе пространственных положений звуковых объектов, связанных с кластером, который звуковой объект представляет.
4. Способ по п. 2 или 3, в котором соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных кластеров, совпадают с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации.
5. Способ по п. 2 или 3, в котором N звуковых объектов составляет второе множество звуковых объектов.
6. Способ по п. 2 или 3, в котором N звуковых объектов составляет первое множество звуковых объектов.
7. Способ по п. 1, дополнительно включающий:
связывание каждого сигнала понижающего микширования с изменяющимся во времени пространственным положением для представления сигналов понижающего микширования; и
дальнейшее включение в поток данных метаданных понижающего микширования, содержащих пространственные положения сигналов понижающего микширования;
при этом способ также включает включение в поток данных:
множества экземпляров метаданных понижающего микширования, определяющих соответствующие требуемые установки представления понижающего микширования для представления сигналов понижающего микширования; и
данных перехода для каждого экземпляра метаданных понижающего микширования, содержащих две независимо присваиваемые части, в комбинации определяющие момент времени для начала перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования, и момент времени для завершения перехода к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования.
8. Способ по п. 7, в котором соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных понижающего микширования, совпадают с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации.
9. Способ по п. 1, дополнительно включающий:
генерирование одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними.
10. Способ по п. 1, дополнительно включающий:
расчет разности между первой требуемой установкой восстановления, определяемой первым экземпляром дополнительной информации, и одной или несколькими требуемыми установками восстановления, определяемыми одним или несколькими экземплярами дополнительной информации, непосредственно следующими за первым экземпляром дополнительной информации; и
удаление указанного одного или нескольких экземпляров дополнительной информации в ответ на то, что рассчитанная разность ниже предварительно определенного порога.
11. Способ по п. 1, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
12. Способ по п. 2, в котором две независимо присваиваемые части данных перехода для каждого экземпляра метаданных кластеров представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления.
13. Способ по п. 7, в котором две независимо присваиваемые части данных перехода для каждого экземпляра метаданных понижающего микширования представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования.
14. Кодер для кодирования N звуковых объектов в виде потока данных, где N>1, содержащий:
компонент понижающего микширования, сконфигурированный для вычисления М сигналов понижающего микширования, где M≤N, путем формирования комбинаций N звуковых объектов;
компонент анализа, сконфигурированный для вычисления изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент уплотнения, сконфигурированный для включения М сигналов понижающего микширования и дополнительной информации в поток данных для передачи в декодер;
при этом компонент уплотнения дополнительно выполнен с возможностью включения в поток данных:
множества экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления указанного набора звуковых объектов, сформированного на основе N звуковых объектов; и
данных перехода для каждого экземпляра дополнительной информации, содержащих две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода.
15. Кодер по п. 14, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
16. Способ восстановления звуковых объектов на основе потока данных, включающий:
прием потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, где N>1 и M≤N, и изменяющуюся во времени дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и восстановление на основе M сигналов понижающего микширования и дополнительной информации указанного набора звуковых объектов, сформированного на основе N звуковых объектов;
при этом поток данных содержит множество экземпляров дополнительной информации; при этом поток данных дополнительно содержит, для каждого экземпляра дополнительной информации данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода; и при этом восстановление указанного набора звуковых объектов, сформированного на основе N звуковых объектов, включает:
выполнение восстановления в соответствии с текущей установкой восстановления;
начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации, перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации; и
завершение перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации.
17. Способ по п. 16, в котором поток данных дополнительно содержит изменяющиеся во времени метаданные кластеров для указанного набора звуковых объектов, сформированного на основании N звуковых объектов, при этом метаданные кластеров содержат пространственные положения для указанного набора звуковых объектов, сформированного на основании N звуковых объектов; при этом поток данных содержит множество экземпляров метаданных кластеров; при этом поток данных дополнительно содержит, для каждого экземпляра метаданных кластеров данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром метаданных кластеров, и момент времени для завершения перехода к требуемой установке восстановления, определяемой экземпляром метаданных кластеров; и при этом способ дополнительно включает:
применение метаданных кластеров для представления восстановленного набора звуковых объектов, сформированного на основе N звуковых объектов, в выходные каналы с предварительно определенной конфигурацией каналов, при этом представление включает:
выполнение представления в соответствии с текущей установкой представления;
начало, в момент времени, определяемый данными перехода для экземпляра метаданных кластеров, перехода от текущей установки представления к требуемой установке представления, определяемой экземпляром метаданных кластеров; и
завершение перехода к требуемой установке представления в момент времени, определяемый данными перехода для экземпляра метаданных кластеров.
18. Способ по п. 17, в котором соответствующие моменты времени, определяемые данными перехода для соответствующих экземпляров метаданных кластеров, совпадают с соответствующими моментами времени, определяемыми данными перехода для соответствующих экземпляров дополнительной информации.
19. Способ по п. 18, дополнительно включающий:
выполнение по меньшей мере части восстановления и представления в виде комбинированной операции, соответствующей первой матрице, сформированной в виде матричного произведения матрицы восстановления и матрицы представления, связанных соответственно с текущей установкой восстановления и текущей установкой представления;
начало, в момент времени, определяемый данными перехода для экземпляра дополнительной информации и экземпляра метаданных кластеров, комбинированного перехода от текущих установок восстановления и представления к требуемым установкам восстановления и представления, определяемым соответственно экземпляром дополнительной информации и экземпляром метаданных кластеров; и
завершение комбинированного перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации и экземпляра метаданных кластеров, при этом комбинированный переход включает интерполяцию между матричными элементами первой матрицы и матричными элементами второй матрицы, сформированной как матричное произведение матрицы восстановления и матрицы представления, связанных соответственно с требуемой установкой восстановления и требуемой установкой представления.
20. Способ по любому из пп. 16-19, в котором указанный набор звуковых объектов, сформированный на основании N звуковых объектов, совпадает с N звуковых объектов.
21. Способ по любому из пп. 16-19, в котором указанный набор звуковых объектов, сформированный на основании N звуковых объектов, содержит множество звуковых объектов, которые представляют собой комбинации N звуковых объектов и количество которых меньше N.
22. Способ по п. 16, выполняемый в декодере, в котором поток данных дополнительно содержит метаданные понижающего микширования для M сигналов понижающего микширования, содержащие изменяющиеся во времени пространственные положения, связанные с M сигналов понижающего микширования; при этом поток данных содержит множество экземпляров метаданных понижающего микширования; при этом поток данных дополнительно содержит для каждого экземпляра метаданных понижающего микширования данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки представления понижающего микширования к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования, и момент времени для завершения перехода к требуемой установке представления понижающего микширования, определяемой экземпляром метаданных понижающего микширования; и при этом способ дополнительно включает:
выполнение этапа восстановления на основе М сигналов понижающего микширования и дополнительной информации, при этом указанный набор звуковых объектов сформирован на основе N звуковых объектов, при условии, что декодер является выполненным с возможностью поддержки восстановления звуковых объектов; и
вывод метаданных понижающего микширования и М сигналов понижающего микширования для представления М сигналов понижающего микширования, при условии, что декодер не является выполненным с возможностью поддержки восстановления звуковых объектов.
23. Способ по п. 16, дополнительно включающий:
генерирование одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними.
24. Способ по п. 16, дополнительно включающий:
расчет разности между первой требуемой установкой восстановления, определяемой первым экземпляром дополнительной информации, и одной или несколькими требуемыми установками восстановления, определяемыми одним или несколькими экземплярами дополнительной информации, непосредственно следующими за первым экземпляром дополнительной информации; и
удаление указанного одного или нескольких экземпляров дополнительной информации в ответ на то, что рассчитанная разность ниже предварительно определенного порога.
25. Способ по п. 22, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
26. Способ по п. 23, в котором две независимо присваиваемые части данных перехода для каждого экземпляра метаданных кластеров представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления от момента времени для начала перехода к требуемой установке представления.
27. Способ по п. 22, в котором две независимо присваиваемые части данных перехода для каждого экземпляра метаданных понижающего микширования представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования;
временную отметку, указывающую момент времени для начала перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке представления понижающего микширования, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки представления понижающего микширования от момента времени для начала перехода к требуемой установке представления понижающего микширования.
28. Декодер для восстановления звуковых объектов на основе потока данных, содержащий:
компонент приема, выполненный с возможностью приема потока данных, содержащего М сигналов понижающего микширования, представляющих собой комбинации N звуковых объектов, где N>1 и M≤N, и изменяющуюся во времени дополнительную информацию, содержащую параметры, позволяющие восстанавливать набор звуковых объектов, сформированный на основе N звуковых объектов, исходя из М сигналов понижающего микширования; и
компонент восстановления, выполненный с возможностью восстановления, на основе М сигналов понижающего микширования и дополнительной информации, набора звуковых объектов, сформированного на основе N звуковых объектов;
при этом поток данных содержит множество экземпляров дополнительной информации; при этом поток данных дополнительно содержит, для каждого экземпляра дополнительной информации данные перехода, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода; и при этом компонент восстановления выполнен с возможностью восстановления указанного набора звуковых объектов, сформированного на основе N звуковых объектов посредством, по меньшей мере:
выполнения восстановления в соответствии с текущей установкой восстановления;
начала, в момент времени, определяемый данными перехода для экземпляра дополнительной информации, перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации; и
завершения перехода в момент времени, определяемый данными перехода для экземпляра дополнительной информации.
29. Декодер по п. 28, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
30. Способ перекодировки дополнительной информации, закодированной вместе с M звуковых сигналов в потоке данных, включающий:
прием потока данных;
извлечение из потока данных М звуковых сигналов и связанной с ними изменяющейся во времени дополнительной информации, содержащей параметры, позволяющие восстанавливать набор звуковых объектов из М звуковых сигналов, где M>1, и при этом извлекаемая дополнительная информация содержит:
множество экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления звуковых объектов; и
данные перехода для каждого экземпляра дополнительной информации, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода;
генерирование одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними; и
включение М звуковых сигналов и дополнительной информации в поток данных.
31. Способ по п. 30, в котором M звуковых сигналов кодируют в принятом потоке данных в соответствии с первой частотой кадров; при этом способ дополнительно включает:
обработку М звуковых сигналов для изменения частоты кадров, в соответствии с которой закодировано М сигналов понижающего микширования, до второй частоты кадров, отличающейся от первой частоты кадров; и
передискретизацию дополнительной информации для согласования со второй частотой кадров, по меньшей мере, посредством генерирования одного или нескольких добавочных экземпляров дополнительной информации.
32. Способ по п. 30, дополнительно включающий:
расчет разности между первой требуемой установкой восстановления, определяемой первым экземпляром дополнительной информации, и одной или несколькими требуемыми установками восстановления, определяемыми одним или несколькими экземплярами дополнительной информации, непосредственно следующими за первым экземпляром дополнительной информации; и
удаление указанного одного или нескольких экземпляров дополнительной информации в ответ на то, что рассчитанная разность ниже предварительно определенного порога.
33. Способ по п. 30, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
34. Устройство для перекодировки дополнительной информации, закодированной вместе с M звуковых сигналов в потоке данных, содержащее:
компонент приема, выполненный с возможностью приема потока данных и извлечения из потока данных М звуковых сигналов и связанной с ними изменяющейся во времени дополнительной информации, содержащей параметры, которые позволяют восстанавливать набор звуковых объектов из М звуковых сигналов, где M>1, и при этом извлекаемая дополнительная информация содержит:
множество экземпляров дополнительной информации, определяющих соответствующие требуемые установки восстановления для восстановления звуковых объектов; и
данные перехода для каждого экземпляра дополнительной информации, содержащие две независимо присваиваемые части, которые в комбинации определяют момент времени для начала перехода от текущей установки восстановления к требуемой установке восстановления, определяемой экземпляром дополнительной информации, и момент времени для завершения перехода;
компонент передискретизации, выполненный с возможностью генерирования одного или нескольких добавочных экземпляров дополнительной информации, определяющих по существу такую же установку восстановления, что и экземпляр дополнительной информации, непосредственно предшествующий одному или нескольким добавочным экземплярам дополнительной информации или непосредственно следующий за ними; и
компонент уплотнения, выполненный с возможностью включения М звуковых сигналов и дополнительной информации в поток данных.
35. Устройство по п. 34, в котором две независимо присваиваемые части данных перехода для каждого экземпляра дополнительной информации представляют собой:
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления;
временную отметку, указывающую момент времени для начала перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления; или
временную отметку, указывающую момент времени для завершения перехода к требуемой установке восстановления, и параметр продолжительности интерполяции, указывающий продолжительность для достижения требуемой установки восстановления от момента времени для начала перехода к требуемой установке восстановления.
36. Машиночитаемый носитель, содержащий компьютерный программный продукт, на котором сохранены команды для выполнения способа по любому из пп. 16-27.
| КОМПОЗИЦИЯ ДЛЯ ПРОФИЛАКТИКИ И ЛЕЧЕНИЯ БОЛЕЗНЕЙ, ВЫЗЫВАЕМЫХ ДЕФИЦИТОМ КАЛЬЦИЯ (ВАРИАНТЫ) | 2004 |
|
RU2273492C1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| АУДИОКОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2008 |
|
RU2452043C2 |

