Перекрестная ссылка на родственные заявки
Данная заявка претендует на приоритет следующих приоритетных заявок: предварительная заявка США 62/754758 (ссылка: D18053USP1), поданная 2 ноября 2018 г., европейская заявка 18204046.9 (ссылка: D18053EP), поданная 2 ноября 2018 г., и предварительная заявка США 62/793073 (ссылка: D18053USP2), поданная 16 января 2019 г., которые посредством ссылки включены в настоящее описание.
Область техники, к которой относится изобретение
Настоящее изобретение относится к области кодирования звука, а более конкретно к звуковому декодеру, имеющему по меньшей мере два режима декодирования, и сопутствующим способам декодирования и декодирующему программному обеспечению для такого звукового декодера. Настоящее изобретение также относится к соответствующему звуковому кодеру и сопутствующим способам кодирования и кодирующему программному обеспечению для такого звукового кодера.
Предпосылки изобретения
Звуковая сцена в целом может содержать звуковые объекты. Звуковой объект представляет собой звуковой сигнал, обладающий связанным с ним пространственным положением. Если пространственное положение звукового объекта может изменяться с течением времени, звуковой объект обычно называют динамическим звуковым объектом. Если положение является статическим, звуковой объект обычно называют статическим звуковым объектом или объектом тракта. Объект тракта обычно представляет собой звуковой сигнал, непосредственно соответствующий каналу многоканальной конфигурации динамиков, такой как классическая конфигурация стереозвука с левым и правым динамиком или так называемая конфигурация динамиков 5.1 с тремя передними динамиками, двумя окружающими динамиками и динамиком низкочастотных эффектов и т.д. Тракт может содержать от одного до нескольких объектов тракта. Таким образом, именно набор объектов тракта может соответствовать многоканальной конфигурации динамиков.
Так как количество звуковых объектов, как правило, может быть очень большим, например, порядка десятков или сотен звуковых объектов, существует потребность в способах кодирования, позволяющих эффективно сжимать звуковые объекты на стороне кодера, например, для передачи в виде битового потока (потока данных и т.д.), особенно когда целью являются низкие битовые скорости для передачи. В этом случае кластеры динамических звуковых объектов, в определенных режимах декодирования в звуковом декодере, могут быть параметрически восстановлены обратно в отдельные звуковые объекты для рендеринга в группу выходных звуковых сигналов в зависимости от конфигурации выходного устройства (например, динамиков, наушников и т.д.), используемого для проигрывания звукового сигнала. Однако в некоторых случаях декодер вынужден работать в базовом режиме, что означает, что параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов является невозможным, например, из-за ограничений вычислительной мощности декодера или по другим причинам. Это может привести к проблеме, особенно если пользователь, который слушает выходной звук, ожидает звук с эффектом присутствия (например, 3D звук).
Таким образом, в этом контексте существует необходимость в улучшениях.
Краткое описание изобретения
Учитывая вышесказанное, целью настоящего изобретения, таким образом, является устранение или уменьшение по меньшей мере некоторых из вышеописанных проблем. В частности, цель настоящего изобретения заключается в предоставлении выходного звука, предпочтительно с эффектом присутствия, из принятых динамических звуковых объектов в декодере в базовом режиме декодирования. Кроме этого, цель настоящего изобретения заключается в предоставлении кодера для кодирования звукового битового потока из группы динамических звуковых объектов таким образом, который позволяет декодировать звуковой битовый поток в выходной звук, предпочтительно с эффектом присутствия, согласно вышеописанному. Дополнительные и/или альтернативные цели настоящего изобретения будут очевидны для читателя этого описания.
Согласно первому аспекту изобретения предоставлен звуковой декодер, содержащий один или более буферов для сохранения принятого звукового битового потока и контроллер, соединенный с одним или более буферами.
Контроллер приспособлен для работы в режиме декодирования, выбранном из множества разных режимов декодирования, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает полное декодирование одного или более кодированных динамических звуковых объектов в битовом потоке в восстановленные отдельные звуковые объекты.
Когда выбранный режим декодирования представляет собой второй режим декодирования, контроллер приспособлен для осуществления доступа к принятому звуковому битовому потоку, для определения того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов, и в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, для преобразования по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков.
Путем включения этапа преобразования по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов можно получить выходной звук с эффектом присутствия из битового потока с низкой битовой скоростью, например, ограниченного таким образом, чтобы содержать не более 10 звуковых объектов (динамических и статических) или не более 7, 5 и т.д. звуковых объектов, даже в декодере, работающем в режиме декодирования низкой сложности (базовое декодирование), где параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов является невозможным (полное декодирование является невозможным).
В контексте настоящего технического описания под термином «выходной звук с эффектом присутствия» необходимо понимать конфигурацию выходных каналов, содержащую каналы для верхних динамиков.
Под термином «конфигурация динамиков с эффектом присутствия» следует понимать подобное значение, т.е. конфигурацию динамиков, содержащую верхние динамики.
Кроме этого, в настоящем варианте осуществления предоставлен гибкий способ декодирования, поскольку не все принятые динамические звуковые объекты обязательно преобразованы в группу статических звуковых объектов, соответствующих предопределенной конфигурации динамиков. Например, это позволяет включать дополнительные диалоговые объекты в звуковой битовый поток, которые служат для другой цели, например, для диалогов или соответствующего им звука.
Кроме этого, настоящий вариант осуществления обеспечивает гибкий процесс предоставления и последующего рендеринга группы статических звуковых объектов, которая будет подробнее описана ниже, например, чтобы достичь меньшей сложности вычисления или позволить повторно использовать существующий код/функции программного обеспечения, использованные для реализации декодера.
В общем, настоящий вариант осуществления обеспечивает гибкость на стороне декодера в сценарии с низкой битовой скоростью и низкой сложностью.
Этап определения контроллером того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, может быть реализован разными способами. Согласно некоторым вариантам осуществления это определяют на основании битового потока, например, метаданных, таких как целочисленные значения или значения флагов и т.д. В других вариантах осуществления это можно определить с помощью анализа звукового объекта или метаданных, связанных с объектом.
Контроллер может выбирать режим декодирования разными способами. Например, выбор может быть осуществлен с помощью параметра битового потока, и/или учитывая выходную конфигурацию подвергнутых рендерингу выходных звуковых сигналов, и/или путем проверки количества динамических звуковых объектов (подвергнутых понижающему микшированию звуковых объектов, кластеров и т.д.) в звуковом битовом потоке, и/или на основании пользовательского параметра и т.д.
Следует отметить, что решение преобразовать по меньшей мере один из одного или более динамических звуковых объектов в группу статических звуковых объектов может быть принято, используя больше информации, чем простое определение того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов. Согласно некоторым вариантам осуществления контроллер также основывает такое решение на дополнительных данных, таких как параметры битового потока.
В качестве примера, если определено, что принятый звуковой битовый поток не содержит динамических звуковых объектов, или иным образом определено, что преобразование динамических звуковых объектов, описанных выше, не стоит выполнять, контроллер может принять решение выполнить рендеринг принятых статических звуковых объектов (объектов тракта) непосредственно в группу выходных каналов звука, например, используя принятые коэффициенты рендеринга (например, коэффициенты понижающего микширования), применимые к конфигурации выходных каналов звука. В этом режиме работы контроллера рендеринг любых принятых динамических звуковых объектов традиционно выполняют в выходные каналы звука.
Согласно некоторым вариантам осуществления, когда выбранный режим декодирования представляет собой второй режим декодирования, контроллер дополнительно приспособлен для рендеринга группы статических звуковых объектов в группу выходных каналов звука. Рендеринг любых других статических звуковых объектов, принятых в звуковом битовом потоке (таком как LFE), также выполняют в группу выходных каналов звука, преимущественно на том же этапе рендеринга.
Согласно некоторым вариантам осуществления конфигурация группы выходных каналов звука отличается от предопределенной конфигурации динамиков, используемой для преобразования динамических звуковых объектов в группу статических звуковых объектов, как описано выше. Поскольку предопределенная конфигурация динамиков не ограничена конфигурацией выходных каналов звука, достигается повышенная гибкость.
Согласно некоторым вариантам осуществления звуковой битовый поток содержит первую группу коэффициентов понижающего микширования, при этом контроллер приспособлен для использования первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука. В случае дополнительных принятых статических звуковых объектов в битовом потоке, коэффициенты понижающего микширования будут применены как к группе статических звуковых объектов, так и к дополнительным статическим звуковым объектам.
В некоторых вариантах осуществления контроллер может использовать принятую первую группу коэффициентов понижающего микширования как есть для рендеринга группы статических звуковых объектов в группу выходных каналов звука. Однако в других вариантах осуществления первую группу коэффициентов понижающего микширования сначала необходимо обработать на основании конкретного типа операции понижающего микширования на стороне кодера, результатом которой стали один или более динамических звуковых объектов, принятых в битовом потоке.
В некоторых вариантах осуществления контроллер дополнительно приспособлен для приема информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов на стороне кодера. Информация может быть принята в битовом потоке или может быть предопределена в декодере. В этом случае контроллер может быть приспособлен для соответствующей модификации первой группы коэффициентов понижающего микширования при использовании первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука. Следовательно, ослабление, содержащееся в коэффициентах понижающего микширования, но уже примененное на стороне кодера, не применяется дважды, что приводит к улучшенному впечатлению от прослушивания.
В некоторых вариантах осуществления контроллер дополнительно приспособлен для приема информации, относящейся к операции понижающего микширования, выполняемой на стороне кодера, при этом информация обозначает исходную конфигурацию каналов звукового сигнала, при этом операция понижающего микширования приводит к понижающему микшированию звукового сигнала в один или более динамических звуковых объектов. В этом случае контроллер может быть приспособлен для выбора подгруппы первой группы коэффициентов понижающего микширования на основании информации, относящейся к информации о понижающем микшировании, при этом использование первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука включает использование подгруппы первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука. Это может привести к более гибкому способу декодирования, который справляется со всеми типами операций понижающего микширования, выполняемых на стороне кодера и результатом которых является один или более принятых динамических звуковых объектов.
Согласно некоторым вариантам осуществления контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в комбинированном вычислении, используя одну матрицу. Преимущественным образом это может уменьшить сложность вычисления рендеринга звуковых объектов в принятом звуковом битовом потоке.
Согласно некоторым вариантам осуществления контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в отдельных вычислениях, используя соответственные матрицы. В этом варианте осуществления рендеринг одного или более динамических звуковых объектов предварительно выполняют в группу статических звуковых объектов, т.е. обозначают промежуточное представление на тракте одного или более динамических звуковых объектов. Преимущественным образом это позволяет повторно использовать существующий код/функцию программного обеспечения, использованные для реализации декодера, который выполнен с возможностью рендеринга представления на тракте звуковой сцены в группу выходных каналов звука. Кроме того, этот вариант осуществления уменьшает дополнительную сложность реализации изобретения, описанного в настоящем документе, в декодере.
Согласно некоторым вариантам осуществления принятый звуковой битовый поток содержит метаданные, идентифицирующие по меньшей мере один из одного или более динамических звуковых объектов. Это обеспечивает увеличенную гибкость способа декодирования, поскольку не все из одного или более принятых динамических звуковых объектов нужно преобразовывать в группу статических звуковых объектов, и контроллер может легко определить, используя указанные метаданные, какие из одного или более принятых динамических объектов необходимо преобразовать, а какие необходимо перенаправить непосредственно в рендеринг группы выходных каналов звука.
Согласно некоторым вариантам осуществления метаданные указывают на то, что N из одного или более динамических звуковых объектов предназначены для преобразования в группу статических звуковых объектов, при этом в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов N из одного или более динамических звуковых объектов, выбранных из предопределенной области или предопределенных областей в принятом звуковом битовом потоке. Например, N динамических звуковых объектов могут представлять собой первые N принятых динамических звуковых объектов или последние N принятых динамических звуковых объектов. Следовательно, в некоторых вариантах осуществления в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов первых N из одного или более динамических звуковых объектов в принятом звуковом битовом потоке. Это позволяет использовать меньше метаданных для идентификации по меньшей мере одного из одного или более динамических звуковых объектов, например, целочисленное значение.
Согласно некоторым вариантам осуществления один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат больше чем N динамических звуковых объектов. Как было упомянуто выше, например, для звука, содержащего диалоги на разных языках, может быть преимущественно предоставить динамический звуковой объект для каждого из поддерживаемых языков.
Согласно некоторым вариантам осуществления один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат N динамических звуковых объектов и K дополнительных динамических звуковых объектов, при этом контроллер приспособлен для рендеринга группы статических звуковых объектов и K дополнительных звуковых объектов в группу выходных каналов звука. Соответственно, например, рендеринг выбранного языка (т.е. соответствующего динамического звукового объекта) согласно вышеописанному примеру может быть выполнен, таким образом, вместе с группой статических звуковых объектов в группу выходных звуковых сигналов.
Согласно некоторым вариантам осуществления группа статических звуковых объектов состоит из M статических звуковых объектов, и M > N > 0. Преимущественно можно сохранить битовую скорость, поскольку количество динамических звуковых объектов, подлежащих преобразованию, можно уменьшить. В качестве альтернативы, количество (K) дополнительных динамических звуковых объектов в звуковом битовом потоке можно увеличить.
Согласно некоторым вариантам осуществления принятый звуковой битовый поток дополнительно содержит один или более дополнительных статических звуковых объектов. Дополнительные статические объекты могут содержать LFE или другие объекты тракта или промежуточного пространственного формата (ISF).
Согласно некоторым вариантам осуществления группа выходных каналов звука представляет собой одно из следующего: выходные каналы стереозвука; выходные каналы окружающего звука 5.1, выходные каналы звука с эффектом присутствия 5.1.2; или выходные каналы звука с эффектом присутствия 5.1.4.
Согласно некоторым вариантам осуществления предопределенная конфигурация динамиков представляет собой конфигурацию динамиков 5.0.2. В этом варианте осуществления N может быть равно 5.
Согласно второму аспекту изобретения по меньшей мере некоторых из вышеуказанных целей достигают с помощью способа, выполняемого в декодере, включающего следующие этапы:
- прием звукового битового потока и сохранение принятого звукового битового потока в одном или более буферах;
- выбор режима декодирования из множества разных режимов декодирования, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов;
- обеспечение работы контроллера, соединенного с одним или более буферами, в выбранном режиме декодирования;
- когда выбранный режим декодирования представляет собой второй режим декодирования, способ дополнительно включает следующие этапы:
• осуществление контроллером доступа к принятому звуковому битовому потоку;
• определение контроллером того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и
• в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразование контроллером по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков.
Согласно третьему аспекту изобретения по меньшей мере некоторых из вышеуказанных целей достигают с помощью компьютерного программного продукта, содержащего машиночитаемый носитель с командами машинного кода, приспособленными для выполнения способа согласно второму аспекту при исполнении устройством, имеющим возможность обработки.
Второй и третий аспекты могут в целом иметь такие же признаки и преимущества, что и первый аспект.
Согласно четвертому аспекту изобретения по меньшей мере некоторых из вышеуказанных целей достигают с помощью звукового кодера, содержащего:
приемный компонент, приспособленный для приема группы звуковых объектов;
компонент понижающего микширования, приспособленный для понижающего микширования группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков;
компонент, предоставляющий коэффициенты понижающего микширования, приспособленный для определения первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков, в группу выходных каналов звука на стороне декодера;
мультиплексор битового потока, приспособленный для мультиплексирования по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
Согласно некоторым вариантам осуществления компонент понижающего микширования дополнительно приспособлен для предоставления метаданных, идентифицирующих по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов, в мультиплексор битового потока, при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования метаданных в звуковой битовый поток.
Согласно некоторым вариантам осуществления кодер дополнительно выполнен с возможностью определения информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов, когда выполняется понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к ослаблению, в звуковой битовый поток.
Согласно некоторым вариантам осуществления мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к конфигурации каналов звуковых объектов, принятых приемным компонентом.
Согласно пятому аспекту изобретения по меньшей мере некоторых из вышеуказанных целей достигают с помощью способа, выполняемого в кодере, включающего следующие этапы:
- прием группы звуковых объектов;
- понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков;
- определение первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков, в группу выходных каналов звука на стороне декодера; и
- мультиплексирование по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
Согласно шестому аспекту изобретения по меньшей мере некоторых из вышеуказанных целей достигают с помощью компьютерного программного продукта, содержащего машиночитаемый носитель с командами машинного кода, приспособленными для выполнения способа согласно пятому аспекту при исполнении устройством, имеющим возможность обработки.
Пятый и шестой аспекты могут в целом иметь такие же признаки и преимущества, что и четвертый аспект. Кроме этого, четвертый, пятый и шестой аспекты могут в целом иметь соответствующие признаки (но на стороне кодера), как и первый, второй и третий аспекты. Например, кодер может быть выполнен таким образом, чтобы включать статические звуковые объекты (такие как LFE) в звуковой битовый поток.
Также следует отметить, что настоящее изобретение относится ко всем возможным комбинациям признаков, если явным образом не заявлено иное.
Краткое описание графических материалов
Вышеизложенную цель, а также другие цели, признаки и преимущества настоящего изобретения можно лучше понять из следующих наглядного и неограничивающего подробного описания предпочтительных вариантов осуществления настоящего изобретения со ссылкой на сопроводительные графические материалы, где для подобных элементов используются подобные номера ссылок, на которых:
на фиг. 1 показан звуковой декодер согласно некоторым вариантам осуществления;
на фиг. 2 показана операция декодирования согласно первому варианту осуществления;
на фиг. 3 показана операция декодирования согласно второму варианту осуществления;
на фиг. 4 показана операция декодирования согласно третьему варианту осуществления;
на фиг. 5 показана операция кодирования согласно некоторым вариантам осуществления;
на фиг. 6 показан в качестве примера блок звукового декодера для создания матрицы усиления, используемой для рендеринга группы выходных каналов звука.
Подробное описание вариантов осуществления
Настоящее изобретение будет более подробно описано ниже со ссылкой на сопроводительные графические материалы, на которых показаны варианты осуществления изобретения. Системы и устройства, раскрытые в настоящем документе, будут описаны во время работы.
Формат звука Dolby AC-4 (как опубликовано в документе ETSI TS 103 190-2 V1.2.1 (2018-02)) будет использован ниже в качестве контекста для иллюстрации примера настоящего изобретения. Однако следует отметить, что объем изобретения не ограничен AC-4, и разные варианты осуществления, описанные в настоящем документе, могут быть использованы для любого подходящего формата звука.
Из-за вычислительных ограничений в некоторых звуковых декодерах параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов является невозможным. Кроме этого, ограничения целевой битовой скорости для звукового битового потока могут устанавливать ограничение содержимого звукового битового потока, например, ограничивая количество передаваемых звуковых объектов/каналов звука до 10. Дальнейшее ограничение может происходить из используемого стандарта кодирования, например, ограничивающего использование определенных инструментов кодирования в некоторых конкретных случаях. Например, декодер AC-4 имеет разные уровни конфигурации, при этом декодер третьего уровня ограничивает использование инструментов кодирования, таких как A-JCC (усовершенствованное совместное кодирование каналов) и A-CPL (усовершенствованная связь), которые в ином случае могут преимущественно использоваться для достижения звука с эффектом присутствия в некоторых обстоятельствах. Такие обстоятельства могут включать режим кодирования основного канала, но при этом декодер не имеет инструментов кодирования, чтобы декодировать такое содержимое (например, использование A-JCC не разрешено). В этом случае настоящее изобретение может быть использовано для «имитации» эффекта присутствия, основанного на каналах, как описано ниже. Дальнейшие возможные ограничения содержат возможность включения как содержимого, основанного на каналах, так и динамических/статических звуковых объектов (дискретных звуковых объектов) в одном битовом потоке, что может быть запрещено в некоторых обстоятельствах.
В этом документе термин «кластеры» относится к звуковым объектам, подвергнутым понижающему микшированию в кодере, как будет описано далее со ссылкой на фиг. 5. В неограничивающем примере 10 отдельных динамических объектов могут быть введены в кодер. В некоторых случаях, как описано выше, невозможно независимо кодировать все 10 динамических звуковых объектов. Например, целевая битовая скорость является таковой, что позволяет кодировать только 5 динамических звуковых объектов. В этом случае необходимо уменьшить общее количество динамических звуковых объектов. Возможным решением является объединение 10 динамических звуковых объектов в меньшее количество, в этом примере - 5, динамических звуковых объектов. Эти 5 динамических звуковых объектов, полученных объединением (понижающим микшированием) 10 динамических звуковых объектов, являются подвергнутыми понижающему микшированию динамическими звуковыми объектами, которые в настоящей заявке обозначены термином «кластеры».
Настоящее изобретение направлено на устранение некоторых из вышеописанных ограничений и предоставление преимущественных впечатлений от прослушивания слушателю выходного звука с низкой битовой скоростью и сложностью декодера.
На фиг. 1 в качестве примера показан звуковой декодер 100. Звуковой декодер содержит один или более буферов 102 для сохранения принятого звукового битового потока 110. В некоторых вариантах осуществления принятый звуковой битовый поток содержит вложенный поток A-JOC (усовершенствованное совместное кодирование объектов), например, представляющий музыку и эффекты (M&E) или сочетание M&E и диалогов (D) (т.е. полный MAIN (CM)).
Усовершенствованное совместное кодирование объектов (A-JOC) является инструментом параметрического кодирования для эффективного кодирования группы объектов. A-JOC основано на параметрической модели содержимого, основанного на объектах. Этот инструмент кодирования может определять зависимости среди звуковых объектов и использовать основанную на восприятии параметрическую модель для достижения высокой эффективности кодирования.
Звуковой декодер 100 дополнительно содержит контроллер 104, соединенный с одним или более буферами 102. Таким образом, контроллер 104 может извлекать по меньшей мере части 112 звукового битового потока 110 из буфера (буферов) 102 для декодирования кодированного звукового битового потока в группу выходных каналов 118 звука. Затем группа выходных каналов 118 звука может быть использована для проигрывания с помощью группы динамиков 120.
Как описано выше, звуковой декодер 100 или контроллер 104 могут работать в разных режимах декодирования. Далее это будет проиллюстрировано на примере двух режимов декодирования. Однако могут быть использованы дополнительные режимы декодирования.
В первом режиме декодирования (режим полного декодирования, режим сложного декодирования и т.д.) возможно параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов. В контексте AC-4 первый режим декодирования может называться полным декодированием с A-JOC. В вышеописанном неограничивающем примере с 10 отдельными динамическими объектами и 5 кластерами (динамическими подвергнутыми понижающему микшированию звуковыми объектами) режим полного декодирования позволяет восстановить 10 исходных отдельных динамических объектов (или их приближенное представление) из 5 кластеров.
Во втором режиме декодирования (базовое декодирование, декодирование низкой сложности и т.д.) такое восстановление не выполняется из-за ограничений в декодере 100. В контексте AC-4 второй режим декодирования может называться базовым декодированием с A-JOC. В вышеописанном неограничивающем примере с 10 отдельными динамическими объектами и 5 кластерами (динамическими подвергнутыми понижающему микшированию звуковыми объектами) режим базового декодирования не способен восстановить 10 исходных отдельных динамических объектов (или их приближенное представление) из 5 кластеров.
Таким образом, контроллер приспособлен для выбора режима декодирования, а именно первого или второго режима декодирования. Такое решение может быть принято на основании внутренних параметров 116 декодера 100, например, сохраненных в запоминающем устройстве 106 декодера. В качестве альтернативы или дополнения решение также может быть принято на основании ввода 114, осуществленного, например, пользователем. В качестве альтернативы или дополнения решение также может быть принято на основании содержимого звукового битового потока 110. Например, если принятый звуковой битовый поток содержит больше предельного количества динамических подвергнутых понижающему микшированию звуковых объектов (например, больше 6, или больше 10, или любое другое подходящее количество в зависимости от контекста), контроллер может выбрать второй режим декодирования. Звуковой битовый поток 110 в некоторых вариантах осуществления может содержать значение флага, указывающее контроллеру, какой режим декодирования выбрать.
Например, в контексте AC-4, согласно одному варианту осуществления, выбор первого режима декодирования может представлять собой одно или несколько из следующего:
• уровень представления равен 2 или ниже (параметр битового потока);
• выходная ступень настроена для выхода в формате 5.1.2 (пользовательский параметр);
• вложенный поток A-JOC содержит не более 5 подвергнутых понижающему микшированию объектов (кластеров) (параметр битового потока);
• приложение не вынуждает использовать базовое декодирование посредством API (пользовательский параметр).
Второй режим декодирования (базовое декодирование) далее будет проиллюстрирован на примерах в сочетании с фиг. 2-4.
На фиг. 2 показан первый вариант 109a осуществления второго режима 109 декодирования, который будет описан в сочетании с фиг. 1.
Контроллер 104 приспособлен для определения того, содержит ли принятый звуковой битовый поток 110 один или более динамических звуковых объектов (все из которых в этом варианте осуществления преобразованы в группу статических звуковых объектов), и для принятия решения, как декодировать принятый звуковой битовый поток, на основании этого. Согласно некоторым вариантам осуществления контроллер также основывает такое решение на дополнительных данных, таких как параметры битового потока. Например, в AC-4 контроллер может определить, что необходимо декодировать принятый звуковой битовый поток, как описано на фиг. 2, согласно значению одного или обоих из следующих параметров битового потока, т.е. если одно из следующего верно:
1) «num_bed_obj_ajoc» больше нуля (например, от 1 до 7); или
2) «num_bed_obj_ajoc» отсутствует в битовом потоке, и «n_fullband_dmx_signals» меньше 6.
В случае если контроллер 104 определяет, что необходимо учесть один или более динамических звуковых объектов 210, и необязательно также учитывая другие данные, как описано выше, контроллер приспособлен для преобразования по меньшей мере одного 210 из одного или более динамических звуковых объектов в группу статических звуковых объектов. На фиг. 2 все принятые динамические звуковые объекты преобразованы в группу статических звуковых объектов 222, причем группа статических звуковых объектов 222 соответствует предопределенной конфигурации динамиков. Преобразование выполняют согласно нижеприведенному. Звуковой битовый поток 110 содержит N динамических звуковых объектов 210. Звуковой битовый поток дополнительно содержит N элементов метаданных 212 соответствующих объектов (метаданных звуковых объектов, OAMD). Каждый элемент OAMD 212 определяет свойства каждого из N динамических звуковых объектов 210, например, усиление и положение. N элементов OAMD 212 используются для вычисления 206 матрицы 218 усиления, которая используется для предварительного рендеринга 202 N динамических звуковых объектов 210 в группу статических звуковых объектов 222. Размер группы статических звуковых объектов равен M. N динамических звуковых объектов 210, таким образом, трансформируются (преобразуются) в тракт 222, например, тракт формата 5.0.2 (M = 7). В равной степени возможны другие конфигурации, такие как 7.0.2 (M = 9). Конфигурация тракта (например, 5.0.2) предопределена в декодере 100, который использует эту информацию для вычисления 206 матрицы 218 усиления. Другими словами, группа статических звуковых объектов 222 соответствует предопределенной конфигурации динамиков. Таким образом, матрица 218 усиления в этом случае имеет размер MXN.
Согласно некоторым вариантам осуществления M > N > 0.
Преимущество фактического рендеринга N динамических звуковых объектов 210 в тракте 222 заключается в том, что остальные операции декодера 100 (т.е. создание группы выходных звуковых сигналов 118) могут быть выполнены путем повторного использования существующего кода/функций программного обеспечения, используемых для реализации декодера, который выполнен с возможностью рендеринга тракта 222 (и необязательно дополнительных динамических звуковых объектов, как описано на фиг. 3) в группу выходных звуковых сигналов 118.
Декодер создает группу дополнительных OAMD 214. Эти OAMD 214 определяют положения и усиления для тракта 222, рендеринг которого выполнен промежуточным образом. Таким образом, OAMD 214 не преобразовываются в битовый поток, но вместо этого локально «генерируются» в декодере для описания конфигурации (обычно 5.0.2) каналов, генерируемой на выходе предварительного рендеринга 202. Например, если промежуточный тракт 222 имеет конфигурацию 5.0.2, OAMD 214 определяют положения (L, R, C, Ls, Rs, Ltm, Rtm) и усиления для тракта 222 формата 5.0.2. Если используется другая конфигурация промежуточного тракта, например, 3.0.0, положения будут представлять собой L, R, C. Количество OAMD 214 в этом варианте осуществления, таким образом, соответствует количеству статических звуковых объектов 222, например, 7 в случае тракта 222 формата 5.0.2. В некоторых вариантах осуществления усиление в каждом из элементов OAMD 214 является единичным усилением (1). Таким образом, OAMD 214 содержат свойства для группы статических звуковых объектов 222, например, усиление и положение для каждого статического звукового объекта 222. Другими словами, OAMD 214 указывают на предопределенную конфигурацию тракта 222.
Звуковой битовый поток 110 дополнительно содержит коэффициенты 216 понижающего микширования. В зависимости от конфигурации группы выходных каналов 118, контроллер выбирает соответствующие коэффициенты 216 понижающего микширования для использования при вычислении второй матрицы 220 усиления. В качестве примера, группа выходных каналов звука представляет собой одно из следующего: выходные каналы стереозвука; выходные каналы окружающего звука 5.1; выходные каналы звука с эффектом присутствия 5.1.2 (конфигурация выходного звука с эффектом присутствия); выходные каналы звука с эффектом присутствия 5.1.4 (конфигурация выходного звука с эффектом присутствия); выходные каналы окружающего звука 7.1; или выходные каналы окружающего звука 9.1. Таким образом, полученная в результате матрица усиления имеет размер Ch (количество выходных каналов) X M. Выбранные коэффициенты понижающего микширования могут использоваться как есть при вычислении второй матрицы 220 усиления. Однако, как будет описано ниже в сочетании с фиг. 6, выбранные коэффициенты понижающего микширования могут нуждаться в модификации для компенсации ослабления, выполняемого на стороне кодера, когда выполняется понижающее микширование исходного звукового сигнала с целью получения N динамических звуковых объектов 210. Кроме этого, в некоторых вариантах осуществления процесс выбора коэффициентов понижающего микширования из принятых коэффициентов 216 понижающего микширования, которые будут использованы для вычисления второй матрицы 220 усиления, также может быть основан на операции понижающего микширования, выполняемой на стороне кодера, в дополнение к конфигурации группы выходных каналов 118. Это также будет описано дополнительно ниже в сочетании с фиг. 6.
Вторая матрица усиления используется на ступени 204 рендеринга декодера 100 для рендеринга группы статических звуковых объектов 222 в группу выходных каналов 118 звука.
Следует отметить, что LFE не показан на фиг. 2. В этом контексте LFE должен быть передан непосредственно на завершающую ступень 204 рендеринга для включения в группу выходных каналов 118 звука (или микширования с ее получением).
На фиг. 3 изображен второй вариант осуществления 109b второго режима 109 декодирования. Подобно варианту осуществления, изображенному на фиг. 2, в этом варианте осуществления изображена низкоскоростная передача (звуковой битовый поток с низкой битовой скоростью), декодированная в режиме базового декодирования. Разница на фиг. 3 заключается в том, что принятый звуковой битовый поток 110 несет дополнительные звуковые объекты 302 в дополнение к N динамических звуковых объектов 210, которые преобразованы в статические звуковые объекты 222. Такие дополнительные звуковые объекты могут содержать дискретные и совместные (A-JOC) динамические звуковые объекты и/или статические звуковые объекты (объекты тракта) или ISF. Например, дополнительные звуковые объекты 302 могут содержать:
• LFE (от нуля до нескольких);
• другие объекты тракта;
• другие динамические объекты;
• ISF.
Соответственно, в некоторых вариантах осуществления количество динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, превышает N динамических звуковых объектов 210. Например, динамические звуковые объекты, содержащиеся в принятом звуковом битовом потоке, содержат N динамических звуковых объектов и K дополнительных динамических звуковых объектов. Согласно некоторым вариантам осуществления принятый звуковой битовый поток содержит M&E + D. В этом случае, если необходимо добавить отдельный диалог при рендеринге группы выходных каналов 118, это может привести к проблеме в случае использования низкой скорости, где только 10 звуковых объектов могут быть включены в принятый звуковой битовый поток 110. В случае если группа выходных каналов 118 имеет конфигурацию 5.1.2, и были использованы объекты тракта (т.е. известное решение), будет необходимо передать 8 объектов тракта. Это оставит только два возможных звуковых объекта, представляющих диалог, что может быть слишком мало, например, если нужно поддерживать пять разных диалоговых объектов. Используя здесь настоящее изобретение, в этом случае можно получить на выходе звук с эффектом присутствия, например, путем передачи четырех (N) динамических звуковых объектов для M&E, которые преобразованы 202 в группу статических звуковых объектов 222, одного дополнительного статического объекта 302 для LFE и пяти (K) дополнительных динамических объектов для диалога.
В варианте осуществления по фиг. 3 предварительный рендеринг N динамических звуковых объектов 210 выполняют в M статических звуковых объектов 222, как описано выше в сочетании с фиг. 2.
Для рендеринга 204 используется группа OAMD 214. В этом примере принятый звуковой битовый поток содержит 6 элементов OAMD 214, по одному для каждого дополнительного звукового объекта 302. Таким образом, эти 6 OAMD включены в звуковой битовый поток на стороне кодера с целью использования в декодере 100 для процесса декодирования, описанного в настоящем документе. Кроме этого, как описано выше в сочетании с фиг. 2, декодер создает группу дополнительных OAMD 214, которая определяет положения и усиления для тракта 222, рендеринг которого выполнен промежуточным образом. В общем, в этом примере существует 13 элементов OAMD 214. OAMD 214 содержат свойства для группы статических звуковых объектов 222, например, усиление (т.е. единичное усиление) и положение для каждого статического звукового объекта 222, а также свойства для дополнительных звуковых объектов 302, например, усиление и положение для каждого дополнительного звукового объекта 302.
Звуковой битовый поток 110 дополнительно содержит коэффициенты 216 понижающего микширования, используемые для рендеринга группы выходных каналов 118 подобно тому, как было описано выше в сочетании с фиг. 2 и будет описано ниже в сочетании с фиг. 6.
Вторая матрица 220 усиления используется на ступени 204 рендеринга декодера 100 для рендеринга группы статических звуковых объектов 222 и группы дополнительных звуковых объектов 302 (которые могут содержать динамические звуковые объекты, и/или статические звуковые объекты, и/или объекты ISF, как указано выше) в группу выходных каналов 118 звука.
В случае, описанном на фиг. 3, контроллер должен знать, какие принятые динамические звуковые объекты необходимо преобразовать в группу статических звуковых объектов 222, а какие необходимо передать непосредственно на заключительную ступень 204 рендеринга. Это можно выполнить несколькими разными способами. Например, каждый принятый звуковой объект может содержать значение флага, информирующее контроллер о том, необходимо ли преобразовывать звуковой объект (выполнять его предварительный рендеринг). В другом примере принятый звуковой битовый поток содержит метаданные, идентифицирующие динамический звуковой объект (динамические звуковые объекты), который (которые) необходимо преобразовать. Следует отметить, что в контексте AC-4 только в случае, если любые дополнительные динамические объекты являются частью того же вложенного потока A-JOC, что и N динамических звуковых объектов, необходимо выявить подгруппу, предварительный рендеринг 202 которой будет выполнен, например, используя значение флага или метаданные, как описано выше.
В одном варианте осуществления метаданные указывают на то, что N из одного или более динамических звуковых объектов должны быть преобразованы в группу статических звуковых объектов, благодаря чему контроллер знает, что эти N динамических звуковых объектов необходимо выбрать из предопределенной области или предопределенных областей в принятом звуковом битовом потоке. Динамические звуковые объекты 210, которые необходимо преобразовать, например, могут представлять собой первые или последние N звуковых объектов в звуковом битовом потоке 110. Количество звуковых объектов, которые необходимо преобразовать, может быть указано значением флага Num_bed_obj_ajoc (также может иметь вид num_obj_with_bed_render_info) и/или n_fullband_dmx_signals в стандарте AC-4 (как опубликовано в документе ETSI TS 103 190-2 V1.2.1 (2018-02)). В других стандартах могут использоваться другие названия значений флагов. Также следует отметить, что значения флагов могут быть переименованы в новых версиях стандарта AC-4, упомянутого выше. Согласно некоторым вариантам осуществления, если num_bed_obj_ajoc больше нуля, это означает, что num_bed_obj_ajoc динамических объектов преобразованы в группу статических звуковых объектов. Согласно некоторым вариантам осуществления, если num_bed_obj_ajoc отсутствует, и n_fullband_dmx_signals меньше шести, это означает, что все динамические объекты преобразованы в группу статических звуковых объектов.
В некоторых вариантах осуществления динамические звуковые объекты принимают перед любыми статическими звуковыми объектами в принятом битовом потоке 110. В других вариантах осуществления LFE принимают первым в битовом потоке 110 перед динамическими звуковыми объектами и любыми дополнительными статическими звуковыми объектами.
На фиг. 4 в качестве примера изображен третий вариант осуществления 109c второго режима 109 декодирования. Сдвоенные ступени 202, 204 рендеринга в вариантах осуществления по фиг. 2-3 в некоторых случаях могут считаться неэффективными из-за сложности вычисления. Следовательно, в некоторых вариантах осуществления две матрицы 218, 220 усиления объединены 402 в одну матрицу 404 перед рендерингом 204 звуковых объектов 210, 302 принятого звукового битового потока 110 в группу выходных каналов 118. В этом варианте осуществления используется одна ступень 204 рендеринга. Схема, изображенная на фиг. 4, применима как к случаю, описанному на фиг. 2, где в принятый звуковой битовый поток 110 включены только те динамические объекты 210, которые преобразованы в группу статических звуковых объектов 222, так и к случаю, описанному на фиг. 3, где принятый звуковой битовый поток 110 кроме этого содержит дополнительные звуковые объекты 302. В случае фиг. 3 следует отметить, что в матрицу 218 необходимо добавить дополнительные столбцы и/или строки, обрабатывающие «прохождение» дополнительных объектов 302, в случае если нужно использовать матричное умножение согласно фиг. 4.
На фиг. 5 в качестве примера изображен кодер 500 для кодирования звукового битового потока 110, предназначенного для декодирования согласно любому вышеописанному варианту осуществления. В общих чертах, кодер 500 содержит компоненты, соответствующие содержимому звукового битового потока 110, для получения такого битового потока 110, как понятно читателю данного описания. Обычно кодер 500 содержит приемный компонент (не изображен), приспособленный для приема группы звуковых объектов (динамических и/или статических). Кодер 500 дополнительно содержит компонент 502 понижающего микширования, приспособленный для понижающего микширования группы звуковых объектов 508 в один или более подвергнутых понижающему микшированию динамических звуковых объектов 510, при этом по меньшей мере один подвергнутый понижающему микшированию звуковой объект 510 из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков. Компонент 502 понижающего микширования может ослаблять некоторые из звуковых объектов, как будет описано ниже в сочетании с фиг. 6. В этом случае выполненное ослабление необходимо компенсировать на стороне декодера. Следовательно, информация о выполненном ослаблении и/или конфигурации звуковых объектов 508 в некоторых вариантах осуществления включена в битовый поток 110. В других вариантах осуществления в конфигурацию декодера предварительно включена вся эта информация/некоторая ее часть, и, следовательно, такую информацию можно исключить из битового потока 110. Другими словами, в некоторых вариантах осуществления мультиплексор 506 битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к конфигурации каналов звуковых объектов 508, принятых приемным компонентом, в звуковой битовый поток. Исходная конфигурация каналов (формат исходного звукового сигнала) может представлять собой любую подходящую конфигурацию, такую как 7.1.4, 5.1.4 и т.д. В некоторых вариантах осуществления кодер (например, компонент 502 понижающего микширования) дополнительно выполнен с возможностью определения информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов 510, когда выполняется понижающее микширование группы звуковых объектов 508 в один или более подвергнутых понижающему микшированию динамических звуковых объектов 510. Эту информацию (не изображена на фиг. 5) затем передают в мультиплексор 506 битового потока, приспособленный для мультиплексирования информации, относящейся к ослаблению, в звуковой битовый поток 110.
Кодер 500 дополнительно содержит компонент 504, предоставляющий коэффициенты понижающего микширования, приспособленный для определения первой группы коэффициентов 516 понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков, в группу выходных каналов звука на стороне декодера. Как описано ниже в сочетании с фиг. 6, в зависимости, например, от операции понижающего микширования, выполняемой компонентом понижающего микширования (ослабление и/или тип выполненного понижающего микширования, из какой конфигурации в какую конфигурацию), декодеру может понадобиться осуществить дополнительный процесс выбора и/или регулировки в первой группе коэффициентов 516 понижающего микширования перед фактическим использованием итоговых коэффициентов понижающего микширования для рендеринга.
Кодер дополнительно содержит мультиплексор 506 битового потока, приспособленный для мультиплексирования по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта 510 и первой группы коэффициентов 516 понижающего микширования в звуковой битовый поток 110.
В некоторых вариантах осуществления компонент 502 понижающего микширования также предоставляет метаданные 514, идентифицирующие по меньшей мере один подвергнутый понижающему микшированию звуковой объект 510 из одного или более подвергнутых понижающему микшированию динамических звуковых объектов для мультиплексора 506 битового потока. В этом случае, мультиплексор 506 битового потока дополнительно приспособлен для мультиплексирования метаданных 514 в звуковой битовый поток 110.
В некоторых вариантах осуществления компонент 502 понижающего микширования принимает целевую битовую скорость 509 для определения особенностей операции понижающего микширования, например, сколько подвергнутых понижающему микшированию звуковых объектов необходимо вычислить из группы динамических звуковых объектов 508. Другими словами, целевая битовая скорость может определить параметр кластеризации для операции понижающего микширования.
Следует понимать, что, в случае если один или более подвергнутых понижающему микшированию динамических звуковых объектов 510 содержат больше, чем динамический звуковой объект, предназначенный для преобразования в группу статических звуковых объектов на стороне декодера, также необходимо вычислить коэффициенты понижающего микширования для них. Кроме этого, статические звуковые объекты (например, LFE и т.д.) также могут быть переданы мультиплексором 506 битового потока для включения в звуковой битовый поток 110, вместе с соответствующими коэффициентами понижающего микширования. Более того, каждый звуковой объект, включенный в звуковой битовый поток 110, будет иметь соответствующие OAMD, например, OAMD 512, соответствующие всем динамическим звуковым объектам 510, предназначенным для преобразования в группу статических звуковых объектов на стороне декодера, которые будут мультиплексированы в звуковой битовый поток 110.
На фиг. 6 в качестве примера показаны дополнительные подробности способа определения второй матрицы 220 усиления по фиг. 2-4 с помощью блока 208 вычисления матрицы усиления. Как описано выше, блок 208 вычисления матрицы усиления принимает коэффициенты 216 понижающего микширования из битового потока. В этом варианте осуществления блок 208 вычисления матрицы усиления также принимает данные 612, относящиеся к типу понижающего микширования звукового сигнала, который был выполнен на стороне кодера. Таким образом, данные 612 содержат информацию, относящуюся к операции понижающего микширования, выполняемой на стороне кодера, причем результатом операции понижающего микширования являются N динамических звуковых объектов 210. Данные 612 могут определять/указывать исходную конфигурацию каналов звукового сигнала, подвергаемого понижающему микшированию в N динамических звуковых объектов 210. На основании принятых данных 612 и принятых коэффициентов 216 понижающего микширования блок 606 выбора и модификации коэффициентов понижающего микширования (DC) определяет коэффициенты 608 понижающего микширования, которые будут впоследствии использованы в блоке 610 вычисления матрицы усиления для образования второй матрицы 220 усиления, используя OAMD 214, как описано выше, а также конфигурацию выходных каналов 118, например, 5.1. Блок 610 вычисления матрицы усиления, таким образом, выбирает из коэффициентов 608 понижающего микширования те коэффициенты, которые подходят для запрошенной конфигурации выходных каналов 118, и определяет вторую матрицу 220 усиления для использования в этой конкретной схеме для рендеринга звука. В некоторых вариантах осуществления блок 606 выбора и модификации DC может непосредственно выбирать группу коэффициентов 608 понижающего микширования из принятых коэффициентов 216 понижающего микширования. В других вариантах осуществления блоку 606 выбора и модификации DC может понадобиться сначала выбрать коэффициенты понижающего микширования, а затем модифицировать их с целью получения коэффициентов 608 понижающего микширования, которые будут использованы в блоке 610 вычисления матрицы усиления для вычисления второй матрицы 220 усиления.
Функциональность блока 606 выбора и модификации DC далее будет проиллюстрирована на примерах конкретных схем кодированного и декодированного звука.
В некотором варианте осуществления кодер применяет ослабление в некоторых/к некоторым из переданных звуковых объектов 210. Такое ослабление является результатом процесса понижающего микширования исходного звукового сигнала в подвергнутый понижающему микшированию звуковой сигнал в кодере. Например, если формат исходного звукового сигнала представляет собой 7.1.4 (L, R, C, LFE, Ls, Rs, Lb, Rb, Tfl, Tfr, Tbl, Tbr), который подвергают понижающему микшированию в формат 5.1.2 (Ld, Rd, Cd, LFE, Lsd, Rsd, Tld, Trd) в кодере, сигнал Lsd определяют в кодере как:
-N дБ (Ls + Lb),
и сигнал Tld определяют в кодере как:
-M дБ (Tfl + Tbl).
Обычно N = M = 3, но могут быть применены другие уровни ослабления.
Таким образом, в этой схеме ослабление величиной 3 дБ уже применено в Lsd и Tld. В этих примерах описаны только каналы с левой стороны, в то время как каналы с правой стороны обрабатываются соответствующим образом.
Следует отметить, что результат понижающего микширования (например, звук с конфигурацией каналов 5.1.2) дополнительно уменьшается в кодере, например, до пяти динамических звуковых объектов (210 на фиг. 2 и 3), чтобы еще больше уменьшить битовую скорость.
В этом случае соответствующими коэффициентами 216 понижающего микширования, передаваемыми в битовом потоке, являются:
• gain_tfb_to_tm: усиления верхнего переднего и/или верхнего заднего каналов в верхний средний канал;
• gain_t2a, gain_t2b: усиления верхних передних каналов в соответственные верхние и окружающие каналы;
• обычно/по умолчанию: gain_t2a преобразуется в -Inf дБ, gain_t2b преобразуется в -3 дБ, что означает понижающее микширование в окружающие каналы с -3 дБ;
• gain_t2d, gain_t2e: усиления для верхних задних каналов либо в передние, либо в окружающие каналы;
• обычно/по умолчанию: gain_t2d преобразуется в -Inf дБ, gain_t2e преобразуется в -3 дБ, что означает понижающее микширование в окружающие каналы с -3 дБ;
• gain_b4_to_b2: задние и окружающие каналы в окружающие каналы;
• обычно/по умолчанию: преобразуется в -3 дБ.
Однако если вышеуказанные коэффициенты понижающего микширования непосредственно применяются в случае, когда форматом звука выходных каналов 118 является 5.1, это приведет к тому, что верхние каналы Tfl и Tbl ослабляются с величиной 6 дБ в окружающем выходном сигнале, т.е. M равняется 3 дБ, которые уже применены в кодере, и 3 дБ коэффициента понижающего микширования gain_t2b, принятого в битовом потоке. То же самое относится к нижним каналам Ls и Lb, которые также будут ослаблены с величиной 6 дБ в окружающем выходном сигнале, т.е. N равняется 3 дБ, которые уже применены в кодере, и 3 дБ коэффициента понижающего микширования gain_b4_to_b2, принятого в битовом потоке. В этом случае для компенсации ослабления, уже выполненного на стороне кодера, блок 606 выбора и модификации DC приспособлен для определения коэффициентов 608 понижающего микширования, так что рендеринг выходных каналов будет выполнен следующим образом:
Lout = Ld + (+M дБ + gain_t2a) Tld = L + gain_t2a (Tfl + Tbl); и
Lsout = (+N дБ + gain_b4_to_b2) Lsd + (+M дБ + gain_t2b) Tld = gain_b4_to_b2 (Ls + Lb) + gain_t2b (Tfl + Tbl).
В этом варианте осуществления декодер выбирает gain_t2a, gain_t2b, которые являются усилениями для верхнего переднего канала в соответственные передние и окружающие каналы. Таким образом, они могут быть предпочтительнее, чем gain_t2d, gain_t2e, которые являются усилениями для верхних задних каналов. Также следует отметить, что вышеуказанные уравнения предназначены для выражения идеи компенсации ослабления, выполненного кодером, в декодере, и что в действительности будут разработаны уравнения для достижения этого с целью гарантирования того, что, например, обеспечивается правильная обработка преобразования из усилений/ослаблений в логарифмической области дБ в линейные усиления.
Для достижения вышеуказанной цели декодер должен знать об ослаблении, выполненном кодером. В некоторых вариантах осуществления значения N (дБ) и M (дБ) указаны в битовом потоке в качестве дополнительных метаданных 602. Дополнительные метаданные 602, таким образом, определяют информацию, относящуюся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов на стороне кодера. В других вариантах осуществления в конфигурацию декодера (в запоминающее устройство 604) предварительно заложено ослабление 603, примененное в кодере. Например, декодер может знать, что ослабление величиной 3 дБ всегда выполняется в случае понижающего микширования 7.1.4 (или 5.1.4) в 5.1.2 в кодере. В вариантах осуществления декодер принимает информацию 602, 603, относящуюся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов на стороне кодера. Эта информация 602, 603 в сочетании с принятыми данными 612, указывающими на тип понижающего микширования, примененного в кодере, может быть использована для выбора и/или регулировки коэффициентов 216 понижающего микширования в блоке 606 выбора и модификации DC. Выбранные и/или отрегулированные коэффициенты 608, как упоминалось выше, будут использованы блоком 610 вычисления матрицы усиления в сочетании с OAMD 214 и конфигурацией выходного звукового сигнала 118 для образования второй матрицы 220 усиления.
В другой иллюстративной схеме исходный звуковой сигнал в кодере имеет формат 5.1.2 с верхними передними каналами (L, R, C, LFE, Ls, Rs, Tfl, Tfr), который подвергнут понижающему микшированию в формат 5.1.2 с верхними средними каналами вместо (Ld, Rd, Cd, LFE, Lsd, Rsd, Tld, Trd). В этом варианте осуществления в кодере не выполняется ослабление. Однако в этом случае блоку 606 выбора и модификации DC необходимо знать исходную конфигурацию сигнала на стороне кодера, чтобы выбрать подходящие коэффициенты понижающего микширования для выходного сигнала 118 в формате 5.1. В этом случае соответствующими коэффициентами 216 понижающего микширования, переданными в битовом потоке, являются: gain_t2a, gain_t2b, которые представляют собой усиления для верхних передних каналов в соответственные передние и окружающие каналы. В этом случае блок 606 выбора и модификации DC приспособлен для определения коэффициентов 608 понижающего микширования, так что выходные каналы 118 будут преобразованы как:
Lout = Ld + gain_t2a (Tld) = L + gain_t2a (Tfl); и
Lsout = Lsd + gain_t2b (Tld) = Ls + gain_t2b (Tfl).
Дополнительные варианты осуществления настоящего изобретения будут очевидны для специалиста в данной области техники после изучения описания, приведенного выше. Несмотря на то что настоящее описание и графические материалы раскрывают варианты осуществления и примеры, раскрытие не ограничивается данными конкретными примерами. Возможны многочисленные модификации и изменения в пределах объема настоящего изобретения, определенного сопутствующей формулой изобретения. Любые ссылочные позиции, встречающиеся в пунктах формулы изобретения, не должны рассматриваться как ограничивающие их объем.
Кроме того, после изучения графических материалов, описания и прилагаемой формулы изобретения специалисту могут быть понятны изменения раскрытых вариантов осуществления, и они могут быть использованы им при практической реализации изобретения. В формуле изобретения слово «содержащий» не исключает другие элементы или этапы, и единственное число не исключает множественное. Сам факт того, что некоторые признаки упоминаются во взаимно отличных зависимых пунктах формулы изобретения, не говорит о том, что не может быть использована с выгодой комбинация этих признаков.
Системы и способы, раскрытые выше, могут быть осуществлены в виде программного обеспечения, программно-аппаратного обеспечения, аппаратного обеспечения или их комбинации. При осуществлении в виде аппаратного обеспечения разделение задач между функциональными узлами, о которых говорилось в вышеприведенном описании, не обязательно соответствует разделению на физические узлы; наоборот, один физический компонент может выполнять несколько функций, и одно задание может быть выполнено несколькими физическими компонентами во взаимодействии. Некоторые компоненты или все компоненты могут быть осуществлены в виде программного обеспечения, исполняемого процессором цифровых сигналов или микропроцессором, или быть осуществлены в виде аппаратного обеспечения или в виде зависимой от приложения интегральной микросхемы. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители информации (или постоянные носители) и средства связи (или временные носители). Как хорошо известно специалисту в данной области техники, термин «компьютерные носители информации» содержит как энергозависимые, так и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители информации содержат, но не ограничиваются этим, RAM, ROM, EEPROM, флеш-память или другую технологию памяти, компакт-диски, универсальные цифровые диски (DVD) или другие оптические диски для хранения информации, магнитные кассеты, магнитную ленту, магнитный диск для хранения информации, или другие магнитные устройства для хранения информации, или любой другой носитель, который может быть использован для хранения желаемой информации и который может быть доступным с помощью компьютера. Как также хорошо известно специалисту в данной области техники, средства связи, как правило, содержат машиночитаемые команды, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна или другой механизм передачи, и содержат любые средства доставки информации.
Различные аспекты настоящего изобретения можно понять из следующих пронумерованных примерных вариантов осуществления (EEE).
EEE1. Звуковой декодер, содержащий:
один или более буферов для сохранения принятого звукового битового потока; и
контроллер, соединенный с одним или более буферами и приспособленный для:
работы в режиме декодирования, выбранном из множества разных режимов декодирования, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов; и,
когда выбранный режим декодирования представляет собой второй режим декодирования:
осуществления доступа к принятому звуковому битовому потоку;
определения того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и
в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразования по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков.
EEE2. Звуковой декодер согласно EEE1, при этом контроллер дополнительно приспособлен для рендеринга группы статических звуковых объектов в группу выходных каналов звука, когда выбранный режим декодирования представляет собой второй режим декодирования.
EEE3. Звуковой декодер согласно EEE2, при этом звуковой битовый поток содержит первую группу коэффициентов понижающего микширования, при этом контроллер приспособлен для использования первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
EEE4. Звуковой декодер согласно EEE3, при этом контроллер дополнительно приспособлен для приема информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов на стороне кодера, при этом контроллер приспособлен для соответствующей модификации первой группы коэффициентов понижающего микширования при использовании первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
EEE5. Звуковой декодер согласно EEE3 или EEE4, при этом контроллер дополнительно приспособлен для приема информации, относящейся к операции понижающего микширования, выполняемой на стороне кодера, при этом информация обозначает исходную конфигурацию каналов звукового сигнала, при этом операция понижающего микширования приводит к понижающему микшированию звукового сигнала в один или более динамических звуковых объектов, при этом контроллер приспособлен для выбора подгруппы первой группы коэффициентов понижающего микширования на основании информации, относящейся к информации о понижающем микшировании, при этом использование первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука включает использование подгруппы первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
EEE6. Звуковой декодер согласно любому из EEE2-EEE5, при этом контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в комбинированном вычислении, используя одну матрицу.
EEE7. Звуковой декодер согласно любому из EEE2-EEE5, при этом контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в отдельных вычислениях, используя соответственные матрицы.
EEE8. Звуковой декодер согласно любому из предыдущих EEE, при этом принятый звуковой битовый поток содержит метаданные, идентифицирующие по меньшей мере один из одного или более динамических звуковых объектов.
EEE9. Звуковой декодер согласно EEE8, при этом метаданные указывают на то, что N из одного или более динамических звуковых объектов должны быть преобразованы в группу статических звуковых объектов,
при этом в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов N из одного или более динамических звуковых объектов, выбранных из предопределенной области или предопределенных областей в принятом звуковом битовом потоке.
EEE10. Звуковой декодер согласно EEE9, при этом один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат больше чем N динамических звуковых объектов.
EEE11. Звуковой декодер согласно EEE10, при этом один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат N динамических звуковых объектов и K дополнительных динамических звуковых объектов, при этом контроллер приспособлен для рендеринга группы статических звуковых объектов и K дополнительных звуковых объектов в группу выходных каналов звука.
EEE12. Звуковой декодер согласно любому из EEE9-EEE11, при этом в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов первых N из одного или более динамических звуковых объектов в принятом звуковом битовом потоке.
EEE13. Звуковой декодер согласно любому из EEE9-EEE12, при этом группа статических звуковых объектов состоит из M статических звуковых объектов, и M > N > 0.
EEE14. Звуковой декодер согласно любому из предыдущих EEE, при этом принятый звуковой битовый поток дополнительно содержит один или более дополнительных статических звуковых объектов.
EEE15. Звуковой декодер согласно EEE2 или любому из предыдущих EEE, в той части, которая зависима от EEE2, при этом группа выходных каналов звука представляет собой одно из следующего: выходные каналы стереозвука; выходные каналы окружающего звука 5.1; выходные каналы звука с эффектом присутствия 5.1.2; или выходные каналы звука с эффектом присутствия 5.1.4.
EEE16. Звуковой декодер согласно любому из предыдущих EEE, при этом предопределенная конфигурация динамиков представляет собой конфигурацию динамиков 5.0.2.
EEE17. Способ, выполняемый в декодере, включающий следующие этапы:
прием звукового битового потока и сохранение принятого звукового битового потока в одном или более буферах;
выбор режима декодирования из множества разных режимов декодирования, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает параметрическое восстановление отдельных динамических звуковых объектов из кластеров динамических звуковых объектов;
обеспечение работы контроллера, соединенного с одним или более буферами, в выбранном режиме декодирования;
когда выбранный режим декодирования представляет собой второй режим декодирования, способ дополнительно включает следующие этапы:
осуществление контроллером доступа к принятому звуковому битовому потоку;
определение контроллером того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и
в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразование контроллером по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков.
EEE18. Звуковой кодер, содержащий:
приемный компонент, приспособленный для приема группы звуковых объектов;
компонент понижающего микширования, приспособленный для понижающего микширования группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков;
компонент, предоставляющий коэффициенты понижающего микширования, приспособленный для определения первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков, в группу выходных каналов звука на стороне декодера;
мультиплексор битового потока, приспособленный для мультиплексирования по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
EEE19. Кодер согласно EEE18, при этом компонент понижающего микширования дополнительно приспособлен для предоставления метаданных, идентифицирующих по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов, в мультиплексор битового потока,
при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования метаданных в звуковой битовый поток.
EEE20. Кодер согласно любому из EEE18-EEE19, при этом кодер дополнительно выполнен с возможностью определения информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов, когда выполняется понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов,
при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к ослаблению, в звуковой битовый поток.
EEE21. Кодер согласно любому из EEE18-EEE20, при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к конфигурации каналов звуковых объектов, принятых приемным компонентом, в звуковой битовый поток.
EEE22. Способ, выполняемый в кодере, включающий следующие этапы:
прием группы звуковых объектов;
понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков;
определение первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков, в группу выходных каналов звука на стороне декодера; и
мультиплексирование по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
EEE23. Компьютерный программный продукт, содержащий машиночитаемый носитель информации с командами, приспособленными для выполнения способа согласно любому из EEE17 или EEE22 при исполнении устройством, имеющим возможность обработки.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНЦЕПЦИЯ ДЛЯ ОБЪЕДИНЕННОГО СЖАТИЯ ДИНАМИЧЕСКОГО ДИАПАЗОНА И УПРАВЛЯЕМОГО ПРЕДОТВРАЩЕНИЯ ОТСЕЧЕНИЯ ДЛЯ АУДИОУСТРОЙСТВ | 2014 |
|
RU2659490C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКОВОГО ПРЕДСТАВЛЕНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ ЗАКОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ТРАНСПОРТНЫХ МЕТАДАННЫХ И СООТВЕТСТВУЮЩИЕ КОМПЬЮТЕРНЫЕ ПРОГРАММЫ | 2020 |
|
RU2792050C2 |
| СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ И КОДИРОВАНИЯ МАТРИЦЫ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ, СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА, КОДЕР И ДЕКОДЕР ДЛЯ МАТРИЦЫ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ, АУДИОКОДЕР И АУДИОДЕКОДЕР | 2014 |
|
RU2648588C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ПОВТОРНОГО ОТОБРАЖЕНИЯ ОТНОСЯЩИХСЯ К ЭКРАНУ ЗВУКОВЫХ ОБЪЕКТОВ | 2015 |
|
RU2683380C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН | 2014 |
|
RU2608847C1 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ ВЫХОДНЫХ ЗВУКОВЫХ СИГНАЛОВ ПОСРЕДСТВОМ ИСПОЛЬЗОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ МЕТАДАННЫХ | 2009 |
|
RU2604342C2 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ ВЫХОДНЫХ ЗВУКОВЫХ СИГНАЛОВ ПОСРЕДСТВОМ ИСПОЛЬЗОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ МЕТАДАННЫХ | 2009 |
|
RU2510906C2 |
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН, СОДЕРЖАЩИХ ЗВУКОВЫЕ ОБЪЕКТЫ | 2014 |
|
RU2745832C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИОСИГНАЛОВ | 2013 |
|
RU2643644C2 |
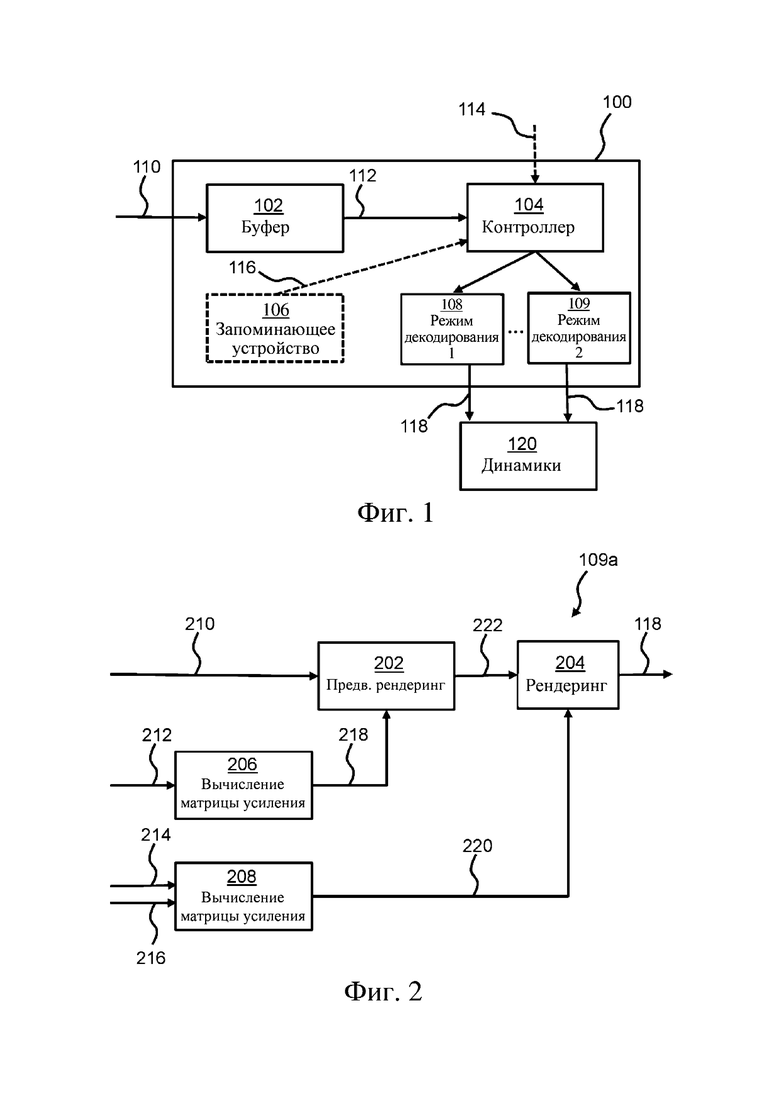
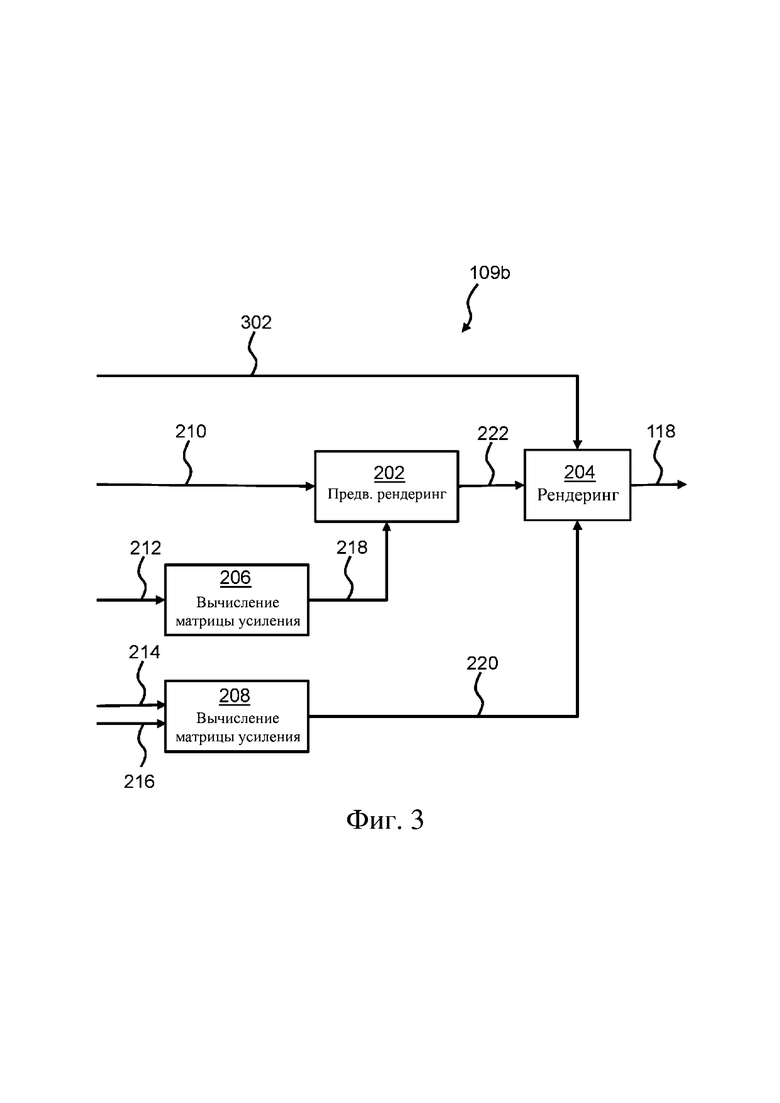
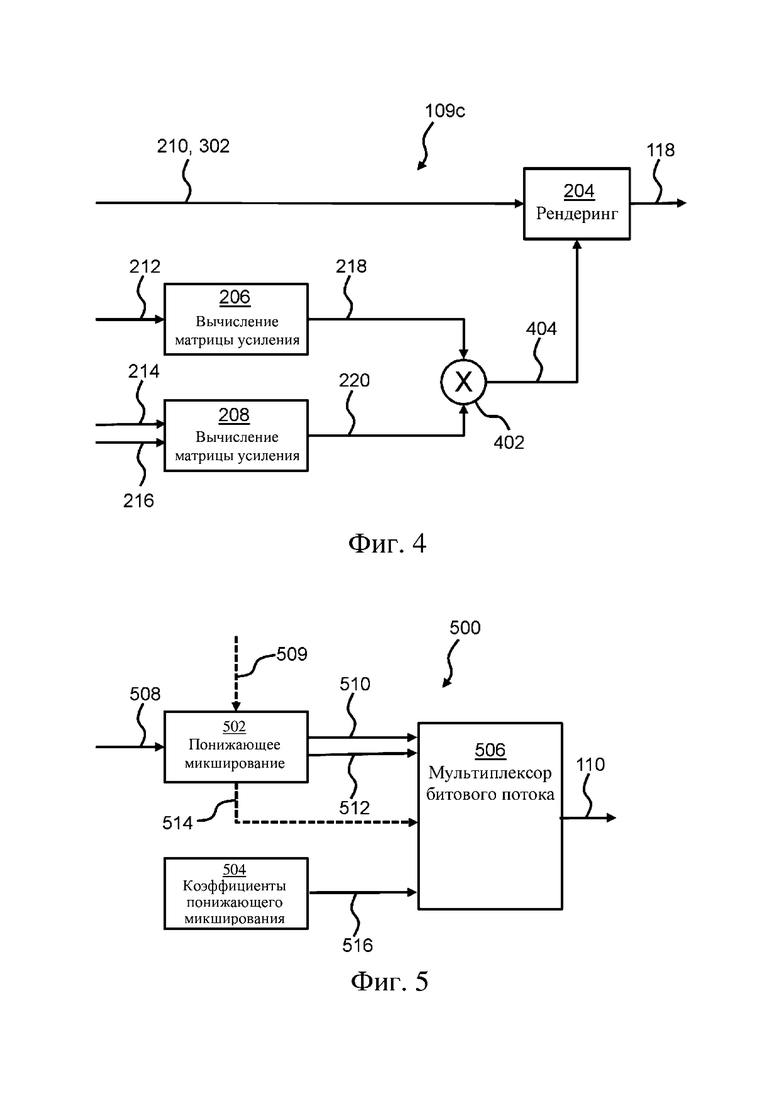
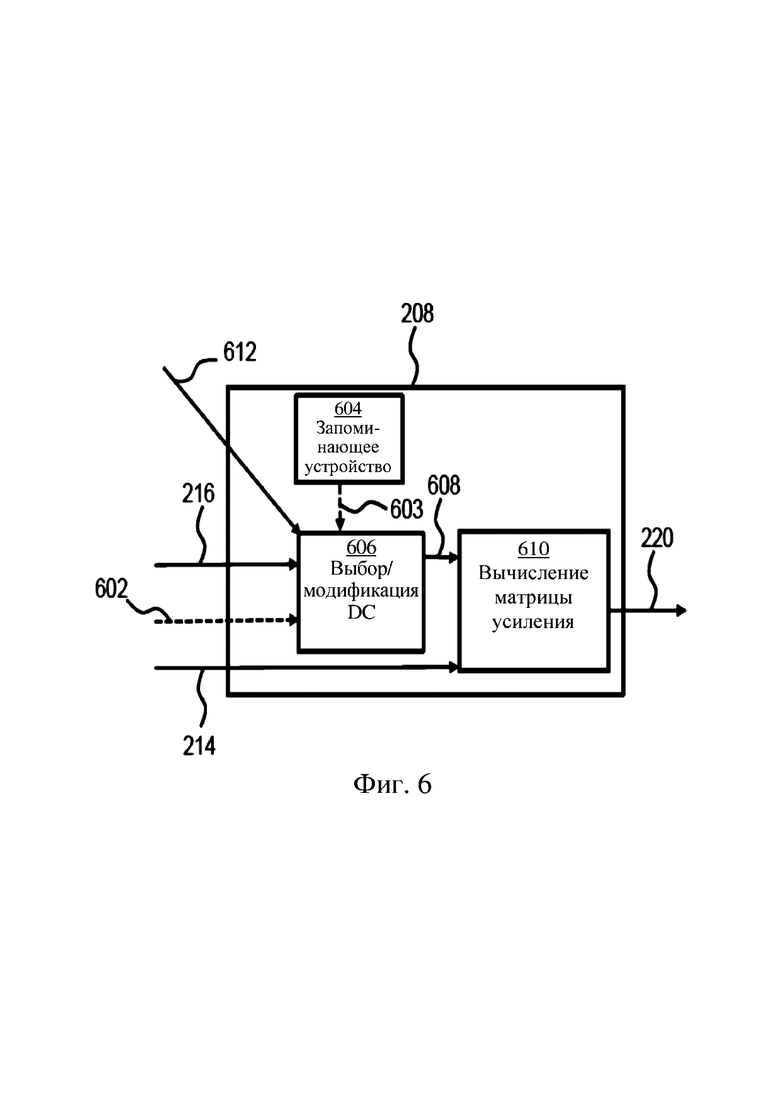
Изобретение относится к области аудиообработки. Технический результат заключается в обеспечении возможности предоставлении выходного звука с эффектом присутствия из принятых динамических звуковых объектов. Технический результат достигается за счет осуществления доступа к принятому звуковому битовому потоку; определения того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразования по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков с эффектом присутствия. 6 н. и 18 з.п. ф-лы, 6 ил.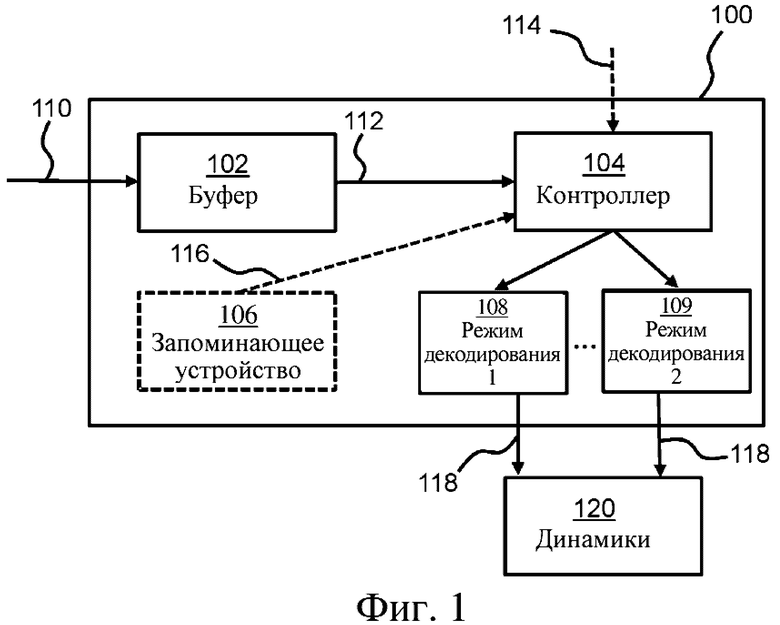
1. Звуковой декодер, содержащий:
один или более буферов для сохранения принятого звукового битового потока; и
контроллер, соединенный с одним или более буферами и приспособленный для:
работы в режиме декодирования, выбранном из множества разных режимов декодирования, для декодирования принятого звукового битового потока в один или более динамических или статических звуковых объектов, причем динамический или статический звуковой объект содержит звуковой сигнал, связанный либо с изменяющимся во времени, либо со статическим пространственным положением, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает полное декодирование одного или более кодированных динамических звуковых объектов в битовом потоке в восстановленные отдельные звуковые объекты; и
когда выбранный режим декодирования представляет собой второй режим декодирования:
осуществления доступа к принятому звуковому битовому потоку;
определения того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и
в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразования по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков с эффектом присутствия.
2. Звуковой декодер по п. 1, отличающийся тем, что контроллер дополнительно приспособлен для рендеринга группы статических звуковых объектов в группу выходных каналов звука, когда выбранный режим декодирования представляет собой второй режим декодирования.
3. Звуковой декодер по п. 2, отличающийся тем, что звуковой битовый поток содержит первую группу коэффициентов понижающего микширования, при этом контроллер приспособлен для использования первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
4. Звуковой декодер по п. 3, отличающийся тем, что контроллер дополнительно приспособлен для приема информации, относящейся к ослаблению, применяемому в по меньшей мере одном из одного или более динамических звуковых объектов на стороне кодера, при этом контроллер приспособлен для соответствующей модификации первой группы коэффициентов понижающего микширования при использовании первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
5. Звуковой декодер по п. 3 или 4, отличающийся тем, что контроллер дополнительно приспособлен для приема информации, относящейся к операции понижающего микширования, выполняемой на стороне кодера, при этом информация обозначает исходную конфигурацию каналов звукового сигнала, при этом операция понижающего микширования приводит к понижающему микшированию звукового сигнала в один или более динамических звуковых объектов, при этом контроллер приспособлен для выбора подгруппы первой группы коэффициентов понижающего микширования на основании информации, относящейся к информации о понижающем микшировании, при этом использование первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука включает использование подгруппы первой группы коэффициентов понижающего микширования для рендеринга группы статических звуковых объектов в группу выходных каналов звука.
6. Звуковой декодер по любому из пп. 2-5, отличающийся тем, что контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в комбинированном вычислении, используя одну матрицу.
7. Звуковой декодер по любому из пп. 2-5, отличающийся тем, что контроллер приспособлен для выполнения преобразования по меньшей мере одного из одного или более динамических звуковых объектов и рендеринга группы статических звуковых объектов в отдельных вычислениях, используя соответственные матрицы.
8. Звуковой декодер по любому из предыдущих пунктов, отличающийся тем, что принятый звуковой битовый поток содержит метаданные, идентифицирующие по меньшей мере один из одного или более динамических звуковых объектов.
9. Звуковой декодер по п. 8, отличающийся тем, что метаданные указывают на то, что N из одного или более динамических звуковых объектов должны быть преобразованы в группу статических звуковых объектов,
при этом в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов N из одного или более динамических звуковых объектов, выбранных из предопределенной области или предопределенных областей в принятом звуковом битовом потоке.
10. Звуковой декодер по п. 9, отличающийся тем, что один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат больше чем N динамических звуковых объектов.
11. Звуковой декодер по п. 10, отличающийся тем, что один или более динамических звуковых объектов, содержащихся в принятом звуковом битовом потоке, содержат N динамических звуковых объектов и K дополнительных динамических звуковых объектов, при этом контроллер приспособлен для рендеринга группы статических звуковых объектов и K дополнительных звуковых объектов в группу выходных каналов звука.
12. Звуковой декодер по любому из пп. 9-11, отличающийся тем, что в ответ на метаданные контроллер приспособлен для преобразования в группу статических звуковых объектов первых N из одного или более динамических звуковых объектов в принятом звуковом битовом потоке.
13. Звуковой декодер по любому из пп. 9-12, отличающийся тем, что группа статических звуковых объектов состоит из M статических звуковых объектов, и M > N > 0.
14. Звуковой декодер по любому из предыдущих пунктов, отличающийся тем, что принятый звуковой битовый поток дополнительно содержит один или более дополнительных статических звуковых объектов.
15. Звуковой декодер по любому из пп. 2-7, отличающийся тем, что группа выходных каналов звука представляет собой одно из следующего: выходные каналы стереозвука; выходные каналы окружающего звука 5.1; выходные каналы звука с эффектом присутствия 5.1.2; или выходные каналы звука с эффектом присутствия 5.1.4.
16. Звуковой декодер по любому из предыдущих пунктов, отличающийся тем, что предопределенная конфигурация динамиков с эффектом присутствия представляет собой конфигурацию динамиков 5.0.2.
17. Способ звукового декодирования, выполняемый звуковым декодером, включающий следующие этапы:
прием звукового битового потока и сохранение принятого звукового битового потока в одном или более буферах;
выбор режима декодирования из множества разных режимов декодирования для декодирования принятого звукового битового потока в один или более динамических или статических звуковых объектов, причем динамический или статический звуковой объект содержит звуковой сигнал, связанный либо с изменяющимся во времени, либо со статическим пространственным положением, причем множество разных режимов декодирования содержит первый режим декодирования и второй режим декодирования, при этом только первый режим декодирования из первого и второго режимов декодирования обеспечивает полное декодирование одного или более кодированных динамических звуковых объектов в битовом потоке в восстановленные отдельные звуковые объекты;
обеспечение работы контроллера, соединенного с одним или более буферами, в выбранном режиме декодирования;
когда выбранный режим декодирования представляет собой второй режим декодирования, способ дополнительно включает следующие этапы:
осуществление контроллером доступа к принятому звуковому битовому потоку;
определение контроллером того, содержит ли принятый звуковой битовый поток один или более динамических звуковых объектов; и
в ответ по меньшей мере на определение того, что принятый звуковой битовый поток содержит один или более динамических звуковых объектов, преобразование контроллером по меньшей мере одного из одного или более динамических звуковых объектов в группу статических звуковых объектов, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков с эффектом присутствия.
18. Звуковой кодер, содержащий:
приемный компонент, приспособленный для приема группы звуковых объектов;
компонент понижающего микширования, приспособленный для понижающего микширования группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем статические звуковые объекты содержат звуковой сигнал, связанный со статическими пространственными положениями, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков с эффектом присутствия;
компонент, предоставляющий коэффициенты понижающего микширования, приспособленный для определения первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков с эффектом присутствия, в группу выходных каналов звука на стороне декодера;
мультиплексор битового потока, приспособленный для мультиплексирования по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
19. Кодер по п. 18, отличающийся тем, что компонент понижающего микширования дополнительно приспособлен для предоставления метаданных, идентифицирующих по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов, в мультиплексор битового потока,
при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования метаданных в звуковой битовый поток.
20. Кодер по любому из п. 18 или 19, отличающийся тем, что кодер дополнительно выполнен с возможностью определения информации, относящейся к ослаблению, применяемому по меньшей мере в одном из одного или более динамических звуковых объектов, когда выполняется понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов,
при этом мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к ослаблению, в звуковой битовый поток.
21. Кодер по любому из пп. 18-20, отличающийся тем, что мультиплексор битового потока дополнительно приспособлен для мультиплексирования информации, относящейся к конфигурации каналов звуковых объектов, принятых приемным компонентом, в звуковой битовый поток.
22. Способ звукового кодирования, выполняемый звуковым кодером, включающий следующие этапы:
прием группы звуковых объектов;
понижающее микширование группы звуковых объектов в один или более подвергнутых понижающему микшированию динамических звуковых объектов, при этом по меньшей мере один из одного или более подвергнутых понижающему микшированию динамических звуковых объектов предназначен в по меньшей мере одном из множества режимов декодирования на стороне декодера для преобразования в группу статических звуковых объектов, причем статические звуковые объекты содержат звуковые сигналы, связанные со статическими пространственными положениями, причем группа статических звуковых объектов соответствует предопределенной конфигурации динамиков с эффектом присутствия;
определение первой группы коэффициентов понижающего микширования для использования с целью рендеринга группы статических звуковых объектов, соответствующих предопределенной конфигурации динамиков с эффектом присутствия, в группу выходных каналов звука на стороне декодера; и
мультиплексирование по меньшей мере одного подвергнутого понижающему микшированию динамического звукового объекта и первой группы коэффициентов понижающего микширования в звуковой битовый поток.
23. Машиночитаемый носитель информации с командами, приспособленными для выполнения способа по п. 17 при исполнении устройством, имеющим возможность обработки.
24. Машиночитаемый носитель информации с командами, приспособленными для выполнения способа по п. 22 при исполнении устройством, имеющим возможность обработки.
| Токарный резец | 1924 |
|
SU2016A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| КОДЕР, ДЕКОДЕР И СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 2015 |
|
RU2662407C2 |
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН, СОДЕРЖАЩИХ ЗВУКОВЫЕ ОБЪЕКТЫ | 2014 |
|
RU2630754C2 |

