ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[1]. Настоящее техническое решение относится к способу обработки поискового запроса и серверу поисковой системы.
УРОВЕНЬ ТЕХНИКИ
[2]. Обычные поисковые системы, относящиеся к известному уровню техники, выполнены с возможностью получать поисковый запрос от вычислительного устройства пользователя и применять модель ранжирования, которая агрегирует свойства, полученные до предоставления обратной связи, которые описывают содержимое вебстраниц, и свойства, полученные из истории, на основе данных о поведении пользователя, которые хранятся в журналах запросов, чтобы определить одну или несколько веб-страниц, которые будут представлены в ответ на поисковый запрос в форме страницы результатов поиска (SERP).
[3]. Это приводит к последующему итерационному процессу взаимодействия с пользователями, которые повторно вводят конкретный запрос (даже если разные пользователи). На первом этапе, когда запрос является относительно новым для системы, поисковая система ранжирует веб-ресурсы по оценке с помощью информации о них, полученной до предоставления обратной связи. Далее, на втором этапе, система корректирует это ранжирование с помощью собранных явных данных обратной связи. В момент этой фазы стабилизации, оценки наиболее высоко ранжированных веб-ресурсов, которые получают отрицательную обратную связь от пользователей, опускаются ниже, и эти веб-ресурсы меняются с другими веб-ресурсами, которые получают высокие оценки обратной связи от пользователей. После того, как алгоритм ранжирования находит достаточное количество веб-ресурсов, которые получают в основном положительные отзывы от пользователей, ранжирование далее не изменяется по двум причинам: во-первых, алгоритм ранжирования продолжает получать только избыточные подтверждения наибольшей релевантности верхних веб-ресурсов, и, во-вторых, ни один из веб-ресурсов, в котором отсутствуют свойства, полученные из истории, не обладает оценкой выше, чем те веб-ресурсы, у которых они есть.
[4]. С учетом всего вышеописанного, информация, полученная до предоставления обратной связи, не может полностью отобразить все аспекты веб-ресурсов, которые потенциально могут влиять на степень удовлетворенности пользователя. Следовательно, несмотря на то, что некоторые веб-ресурсы, которые не обладают данными об обратной связи от пользователей, могут быть более релевантными, чем те, которые были ранжированы выше, эти веб-ресурсы почти не отображаются пользователю, который выполняет поиск.
[5]. Таким образом, неточность отображения результатов поиска может повысить необходимость проведения повторного поиска для пользователя, в результате чего будет увеличиваться расход энергии и расход трафика.
[6]. Патентная заявка US 2011/0196733 (Ли и др., 11 августа 2011 г.) описывает систему, которая разделяет ранжированную группу онлайн сообщений на первый список, второй список и набор продвижения. Каждое сообщение в первом списке обладает оценкой производительности, которая выше, чем каждая из оценок производительности сообщений во втором списке и наборе продвижения. Система перемещает сообщение из набора продвижения в третий список как функцию доверительного значения, и перемещает сообщение из одного из третьего или второго списка в первый список на основе исхода экспериментального события. Система передает верхние сообщения в первом списке через сеть для отображения на компьютере получателя (абстрактном).
[7]. Патентная заявка US 2014/0280548 (Ланглуа и др., 18 сентября 2014 г.) описывает способ и систему для изучения списка интересов пользователя вне границ текущих известных интересов пользователя путем определения метрик расстояния в пространстве интересов. Новый способ, система и системная цель для изучения элементов интереса, которые близки к текущему набору интересов пользователя, что значительно улучшает шанс того, что один из элементов изучения понравится пользователю.
[8]. Патентная заявка WO 2013189261 (Иоаннидис и др., 27 декабря 2013 г.) описывает способ выбора, который максимизирует ожидаемый выигрыш при сборе выигрыша в контексте многорукого бандита от случайно выбранных элементов в базе данных элементов, где элементы соответствуют рукам многорукого бандита. Изначально, элемент выбирается случайным образом и передается пользовательскому устройству, которое генерирует выигрыш. Элементы и поступающие награды записываются. Далее, пользовательским устройством создается контекст, который инициирует систему обучения и выбора вычислять оценку для каждой руки в конкретном контексте, и оценка вычисляется с использованием записанных элементов и полученных выигрышей. С помощью оценки, элемент из базы данных выбирается и передается пользовательскому устройству. Выбранный элемент выбирается для максимизации вероятности выигрыша от пользовательского устройства.
[9]. Патент US 7707131 (Чикеринг и др., 5 октября 2016 г.) описывает системы и способ для онлайн обучения с подкреплением. Конкретнее, предлагается способ выполнения поиска баланса между экспериментированием и эксплуатированием. Несмотря на то, что способ является эвристическим, он может быть применен, в соответствии с установленными принципами, в момент одновременного изучения параметров и/или структуры модели (например, Байесовкой сетевой модели).
[10]. Патентная заявка US 2011/0264639 (Сливкинс и др., 27 октября 2011 г.) описывает селектор документов, который выбирает и ранжирует документы, которые релевантны запросу. Селектор документов выполняет один алгоритм многорукого бандита для выбора документа для каждого раздела страницы результатов в соответствии с одной или несколькими стратегиями. Документы выбираются в порядке, который определяется страницей результатов, и документы, которые были выбраны для предыдущих разделов, используются для направления выбора документа в текущем разделе. Если документ в разделе выбирается последовательно, стратегия, которая используется для выбора документа, получает положительную обратную связь. Когда неопределенность в оценке полезности стратегии ниже, чем вариация между документами, связанными со стратегией, стратегия разделяется на несколько под-стратегий. Селектор документов способен «концентрироваться» на эффективных стратегиях и предоставлять более релевантные результаты поиска.
[11]. Патентная заявка US 2012/0016642 (Ли и др., 19 января 2012 г.) описывает способы и устройства для выполнения исполнимых на компьютере персонализированных рекомендаций. Может быть получена пользовательская информация, касающаяся множества свойств множества пользователей. Дополнительно, может быть получена информация об элементе, касающаяся множества свойств множества элементов. Множество наборов коэффициентов линейной модели может быть получено на основе, по меньшей мере частично, информации пользователя и/или информации элементов, таким образом, что каждый из множества наборов коэффициентов соответствует различным элементам из множества элементов, причем каждый из множества наоборот коэффициентов включает в себя множество коэффициентов, каждое из множества коэффициентов соответствует одному из множества свойств. Дополнительно, по меньшей мере один из множества коэффициентов может быть общим среди множества наборов коэффициентов для множества коэффициентов. Каждая из множества оценок для пользователя может быть вычислена с помощью линейной модели на основе, по меньшей мере частично, соответствующего набора из множества наборов коэффициентов, связанного с соответствующим элементом из множества элементов, причем каждая из множества оценок указывает на уровень интереса к соответствующему элементу среди множества элементов. Может быть установлено множество доверительных интервалов, каждый из множества доверительных интервалов указывает на диапазон, представляющий доверительный уровень в соответствующей оценке из множества оценок, связанных с соответствующим элементом из множества элементов. Один из множества элементов, для которых сумма соответствующей оценки из множества оценок и соответствующего интервала из множества доверительных интервалов является наивысшей, может быть рекомендован.
[12]. Патент US 8001001 (Брэйдиидр., 16 августа 2011 г.) описывает улучшенную систему и способ для использования отбора проб с целью обнаружения расположений вебстраниц в онлайн публикации содержимого. Движок многорукого бандита может предоставляться для отбора проб элементов содержимого путем обнаружения расположений веб-страниц различного качества для элементов содержимого и оптимизации выигрыша в целях максимальной прибыли. Поставщики могут предоставлять элементы содержимого, которые будут опубликованы, и выводить оценки по клику. Благодаря процессу оценки, отношение количества щелчков мышью к количеству показов для элементов содержимого и значения элементов содержимого может быть извлечено путем отбора проб. По мере продолжения процесса изучения оценки, настоящее техническое решение может сильнее приближаться к отношению количества щелчков мышью к количеству показов для элементов содержимого для того чтобы обнаружить расположения веб-страниц для элементов содержимого, которые могут оптимизировать макет содержимого путем максимизации дохода. Настоящее техническое решение может вычислять отношение количества щелчков мышью к количеству показов для новых элементов содержимого и поддерживать множество расположений веб-страниц различного качества.
[13]. Патент US 8923621 (Слэни и др., 30 декабря 2014 г.) описывает программное обеспечение для инициализированного эксперимента-эксплуатации, которое создает множество распределений вероятности. Каждое из этих распределений вероятности создается путем ввода численного описания одного или нескольких свойств, связанных с изображением, в регрессионную модель, которая выводит распределение вероятности для измерения привлекательности изображения. Каждое из изображений концептуально связано с другими изображениями. Программное обеспечение использует множество распределений вероятности для инициализации модели многорукого бандита, которая выводит схему выдачи для каждого из изображений. Далее программное обеспечение выдает множество изображений на веб-странице, которая отображает результаты поиска, на основе, по меньшей мере частично, схемы подачи.
[14]. Патентная заявка US 2009/0043597 (Агарвал и др., 12 февраля 2009 г.) описывает улучшенную систему и способ сопоставления объектов с помощью кластерно-зависимого многорукого бандита. Сопоставление может выполняться с помощью многорукого бандита, руки которого могут быть зависимыми. В данном варианте осуществления технического решения, может быть получен набор объектов разделяется на сегменты во множество кластеров зависимых объектов, и далее двухэтапная политика может применяться к многорукому бандиту с помощью, сначала, просмотра кластеров рук с целью выбора кластера и, далее, с помощью выбора конкретной руки внутри выбранного кластера. Многорукий бандит может использовать зависимости между руками для эффективной поддержки эксперимента с большим числом рук. Различные варианты осуществления технического решения могут включать в себя варианты политики для дисконтированных выигрышей и для недисконтированных выигрышей. В этих политиках каждый кластер может рассматриваться по отдельности в момент обработки и, следовательно, может значительно уменьшать размер большого пространства состояний для поиска решения.
[15]. Патентная заявка US 2010/0250523 (Джин и др., 30 сентября 2010 г.) описывает улучшенную систему и способ изучения модели ранжирования, которая оптимизирует метрики оценки ранжирования для ранжирования результатов поиска по поисковому запросу. Оптимизированная модель ранжирования нормализованного дисконтированного совокупного выигрыша (NDCG), которая оптимизирует приближение средней метрики оценки ранжирования NDCG, может быть создана с помощью обучающих данных с помощью итерационного способа форсирования для извлечения более точно ранжированного списка результатов поиска по запросу. Комбинация слабых классификаторов ранжирования может быть итерационно определена, что позволит оптимизировать приближение средней метрики оценки ранжирования NDCG для обучающих данных путем обучения слабого классификатора ранжирования на каждой итерации для каждого документа в обучающих данных с вычисленным весовым коэффициентом, и назначить метку класса, и затем обновить оптимизированную модель ранжирования NDCG путем добавления слабого классификатора ранжирования с комбинированным весовым коэффициентом к оптимизированной модели NDCG.
[16]. Патент US 8473486 (Хи и др., 25 января 2013 г.) описывает контролируемый способ, который использует актуальность суждений для обучения парсера зависимости таким образом, чтобы он аппроксиматично оптимизировал NDCG при извлечении информации. Взвешенное дерево дистанции изменения между синтаксическим деревом для запроса и синтаксическим деревом для документа добавляется к функции ранжирования, причем весовые коэффициенты дистанции изменения являются параметрами для парсера. Использование параметров в функции ранжирования позволяет аппроксимировать оптимизацию параметров парсера для NDCG путем добавления некоторых ограничений к целевой функции.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[17]. Задачей предлагаемого технического решения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[18]. Настоящее описание основано на предположении разработчиков о том, что используемые в настоящем уровне техники взаимодействия система-пользователь могут не позволить найти характеристики, основанные на пользовательском взаимодействии, которые необходимы для адекватного ранжирования веб-ресурсов, в которых недостаточно свойств, полученных из истории, поскольку эти низкоранговые веб-ресурсы с меньшей вероятностью будут помещены на страницу результатов поиска и, следовательно, обладают более низким потенциалом получения обратной связи на основе пользовательского взаимодействия. Следовательно, возможно использовать другие механизмы для помещения более низкоранговых веб-ресурсов на более высокие позиции для привлечения к ним пользовательских отзывов. Таким образом, поставщик поисковой системы может потенциально ухудшить выполнение запроса на короткий период времени, принимая на себя риск при показывании некоторых менее релевантных веб-ресурсов на верхних позициях, но при этом улучшить его в долговременной перспективе, предоставляя шанс получить обратную связь от пользователей (и, следовательно, улучшить их оценку) для потенциально более релевантных веб-ресурсов.
[19]. Разработчиками разработаны варианты осуществления технического решения для принятого «Алгоритма Бандита». В общем случае, в соответствии с алгоритмом бандита, существует две различных стратегии ранжирования: стратегия эксплуатации, нацеленная на каждом шагу на максимизирование выполнения ранжирования в отношении конкретного запроса, и стратегия экспериментирования, которая позволяет собирать больше обратной связи от пользователей на более низкоранговых веб-ресурсах, пусть и с ухудшением выполнения ранжирования в отношении некоторых запросов. Поэтому особенно важно достичь оптимального баланса между двумя этими стратегиями, который бы максимизировал совокупное качество серии последовательных запросов. В данном техническом решении эта проблема также называется проблемой онлайн-обучения ранжированию с балансом между экспериментированием и эксплуатированием (OLREE). Что является частным случаем задачи поиска баланса между экспериментированием и эксплуатированием, которая сформулирована в отношении стохастической задачи многорукого бандита (SMAB).
[20]. Одним объектом настоящего технического решения является способ обработки поискового запроса, способ выполняется сервером поисковой системы, который соединен с базой данных просмотренных поисковым роботом ресурсов и с сетью передачи. Способ включает в себя получение сервером поисковой системы поискового запроса от электронного устройства, связанного с пользователем; выбор алгоритмом ранжирования сервера поисковой системы по меньшей мере одного релевантного веб-ресурса для поискового запроса, причем по меньшей мере один релевантный веб-ресурс обладает по меньшей мере одним свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса для включения его на страницу результатов поиска (SERP); получение из базы данных просмотренных поисковым роботом ресурсов множества веб-ресурсов кандидатов, каждый из множества веб-ресурсов кандидатов не обладает свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования; применение первого машинно-обученного алгоритма для определения, для каждого из веб-ресурсов во множестве веб-ресурсов кандидатов, параметра предсказанной релевантности, параметр предсказанной релевантности основан, по меньшей мере частично, на соответствующих присущих веб-ресурсу данных, параметр предсказанной релевантности указывает на предсказанную релевантность соответствующего веб-ресурса для поискового запроса; применение второго машинно-обученного алгоритма для определения для каждого из множества веб-ресурсов кандидатов оценки эксперимента на основе, по меньшей мере частично, соответствующего параметра предсказанной релевантности, и ввод определенной оценки эксперимента множества веб-ресурсов кандидатов в алгоритм ранжирования на основе «многорукого бандита» для: ранжирования множества веб-ресурсов кандидатов; выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP; создание SERP для отображения результатов поиска в порядке убывания релевантности, создание включает в себя добавление к высокоранжированным позициям на SERP: подмножества высокоранжированных веб-ресурсов из множества веб-ресурсов кандидатов; по меньшей мере одного веб-ресурса, релевантного для поискового запроса; получение данных о пользовательском взаимодействии, которые указывают на пользовательское взаимодействие с отображаемым веб-ресурсом на SERP, отображаемый веб-ресурс представляет собой один из по меньшей мере одного веб-ресурса из подмножества высокоранжированных веб-ресурсов из множества веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса; и сохранение указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов из множества веб-ресурсов кандидатов.
[21]. В некоторых вариантах осуществления способа первый машинно-обученный алгоритм включает в себя: третий машинно-обученный алгоритм и четвертый машинно-обученный алгоритм; третий машинно-обученный алгоритм для определения вероятности выигрыша; четвертый машинно-обученный алгоритм для доверительного параметра выигрыша, причем вероятность выигрыша и доверительный параметр определяют параметр предсказанной релевантности.
[22]. В некоторых вариантах осуществления способа третий машинно-обученный алгоритм представляет собой алгоритм градиентного бустинга деревьев решений.
[23]. В некоторых вариантах осуществления способа третий машинно-обученный алгоритм выполнен с возможностью анализировать присущие веб-ресурсу данные для извлечения присущих веб-ресурсу свойств и использовать присущие веб-ресурсу кандидату свойства как вводные свойства.
[24]. В некоторых вариантах осуществления способа четвертый машинно-обученный алгоритм выполнен с возможностью получать, по меньшей мере, результаты предсказаний третьего машинно-обученного алгоритма в виде вводных свойств для предсказания абсолютной ошибки третьего машинно-обученного алгоритма.
[25]. В некоторых вариантах осуществления способа вероятность выигрыша преобразуется в среднюю вероятность выигрыша.
[26]. В некоторых вариантах осуществления способа преобразование осуществляется с помощью изотонической регрессии с разрывом связей.
[27]. В некоторых вариантах осуществления способа второй машинно-обученный алгоритм выполнен с возможностью получать в виде вводных свойств, по меньшей мере: среднюю вероятность выигрыша и доверительный параметр вероятности выигрыша.
[28]. В некоторых вариантах осуществления способа конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов, не обладающий свойствами, полученными из истории, которые могут быть использованы алгоритмом ранжирования по умолчанию, включает в себя минимальный набор свойств, полученных из истории, который не достаточен для использования алгоритмом ранжирования, и определение параметра предсказанной релевантности для конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов включает в себя определение второй вероятности выигрыша, которая основывается по меньшей мере на одном из числа предыдущих отображений конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов на предыдущей странице результатов поиска (SERP), числа кликов на конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов на предыдущей SERP, и параметра апостериорной плотности распределения вероятностей.
[29]. В некоторых вариантах осуществления способа данные, которые указывают на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
[30]. В некоторых вариантах осуществления способа сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя анализ данных о взаимодействии с помощью модели зависимых кликов (DCM), если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая совпадает или превышает позицию выбранного отображаемого веб-ресурса.
[31]. В некоторых вариантах осуществления способа сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя использование алгоритма максимизации на основе эксперимента (ЕМ), или Байесовского вывода, если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая ниже позиции выбранного отображаемого веб-ресурса.
[32]. Другим объектом настоящего технического решения является сервер поисковой системы, соединенный с базой данных просмотренных поисковым роботом веб-ресурсов и сетью передачи данных. Сервер поисковой системы включает в себя интерфейс связи, выполненный с возможностью устанавливать соединение между сервером поисковой системы и сетью передачи данных; по меньшей мере один компьютерный процессор, функционально соединенный с интерфейсом связи, который выполнен с возможностью осуществлять: получение, сервером поисковой системы, поискового запроса от электронного устройства, связанного с пользователем; выбор алгоритмом ранжирования сервера поисковой системы по меньшей мере одного релевантного веб-ресурса для поискового запроса, причем по меньшей мере один релевантный веб-ресурс обладает по меньшей мере одним свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса для включения его на страницу результатов поиска (SERP); получение из базы данных просмотренных поисковым роботом ресурсов множества веб-ресурсов кандидатов, каждый из множества веб-ресурсов кандидатов не обладает свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования; применение первого машинно-обученного алгоритма для определения для каждого из веб-ресурсов кандидатов во множестве веб-ресурсов кандидатов параметра предсказанной релевантности, причем параметр предсказанной релевантности основан, по меньшей мере частично, на соответствующих присущих веб-ресурсу данных, параметр предсказанной релевантности указывает на предсказанную релевантность соответствующего веб-ресурса для поискового запроса; применение второго машинно-обученного алгоритма для определения для каждого из множества веб-ресурсов кандидатов оценки эксперимента на основе, по меньшей мере частично, соответствующего параметра предсказанной релевантности, и ввод определенной оценки эксперимента множества веб-ресурсов кандидатов в алгоритм ранжирования на основе «многорукого бандита» для: ранжирования множества веб-ресурсов кандидатов; выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP; создание SERP для отображения результатов поиска в порядке убывания релевантности, создание включает в себя добавление к высокоранжированным позициям на SERP: подмножества высокоранжированных веб-ресурсов кандидатов; по меньшей мере одного веб-ресурса, релевантного для поискового запроса; получение данных о пользовательском взаимодействии, которые указывают на пользовательское взаимодействие с отображаемым веб-ресурсом на SERP, отображаемый веб-ресурс представляет собой один из по меньшей мере одного веб-ресурса из подмножества высокоранжированных веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса; и сохранение указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов кандидатов.
[33]. В некоторых вариантах осуществления сервера первый машинно-обученный алгоритм включает в себя: третий машинно-обученный алгоритм и четвертый машинно-обученный алгоритм: третий машинно-обученный алгоритм для определения вероятности выигрыша; четвертый машинно-обученный алгоритм - доверительный параметр выигрыша, где вероятность выигрыша и доверительный параметр определяют параметр предсказанной релевантности.
[34]. В некоторых вариантах осуществления сервера третий машинно-обученный алгоритм представляет собой алгоритм градиентного бустинга деревьев решений.
[35]. В некоторых вариантах осуществления сервера третий машинно-обученный алгоритм выполнен с возможностью анализировать присущие веб-ресурсу данные для извлечения присущих веб-ресурсу свойств и использовать присущие веб-ресурсу кандидату свойства как вводные свойства.
[36]. В некоторых вариантах осуществления сервера четвертый машинно-обученный алгоритм выполнен с возможностью получать, по меньшей мере, результаты предсказаний третьего машинно-обученного алгоритма в виде вводных свойств для предсказания абсолютной ошибки третьего машинно-обученного алгоритма.
[37]. В некоторых вариантах осуществления сервера процессор дополнительно выполнен с возможностью осуществлять преобразование вероятности выигрыша в среднюю вероятность выигрыша.
[38]. В некоторых вариантах осуществления сервера преобразование осуществляется с помощью изотонической регрессии с разрывом связей.
[39]. В некоторых вариантах осуществления сервера второй машинно-обученный алгоритм выполнен с возможностью получать в качестве вводных свойств, по меньшей мере: среднюю вероятность выигрыша; и доверительный параметр вероятности выигрыша.
[40]. В некоторых вариантах осуществления сервера конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов, не обладающий свойствами, полученными из истории, которые могут быть использованы алгоритмом ранжирования по умолчанию, включает в себя минимальный набор свойств, полученных из истории, который не достаточен для использования алгоритмом ранжирования, причем определение параметра предсказанной релевантности для конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов включает в себя определение второй вероятности выигрыша, которая основывается по меньшей мере на одном из числа предыдущих отображений конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов на предыдущей странице результатов поиска (SERP), числа кликов на конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов на предыдущей SERP, и параметра последующей плотности распределения вероятностей.
[41]. В некоторых вариантах осуществления сервера данные, которые указывают на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
[42]. В некоторых вариантах осуществления сервера сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя анализ данных о взаимодействии с помощью модели зависимых кликов (DCM), если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая совпадает или превышает позицию выбранного отображаемого веб-ресурса.
[43]. В некоторых вариантах осуществления сервера сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя использование алгоритма максимизации на основе эксперимента (ЕМ), или Байесовского вывода, если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая ниже позиции выбранного отображаемого веб-ресурса.
[44]. В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данного технического решения. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[45]. В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной передачи данных между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер " не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[46]. В контексте настоящего описания, если конкретно не указано иное, термин «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов. Технический результат заключается в снижении необходимости проведения повторного поиска для пользователя, в результате чего будет снижаться расход энергии и трафика.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[47]. Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[48]. На Фиг. 1 представлено схематическое изображение системы, соответствующей неограничивающим вариантам осуществления настоящего технического решения.
[49]. На Фиг. 2 представлено схематичное изображение архитектуры сервера поисковой системы, выполненной в соответствии с некоторыми неограничивающими вариантами осуществления настоящего технического решения.
[50]. На Фиг. 3 представлено схематическое изображение архитектуры модуля экспериментального ранжирования сервиса поисковой системы, показанной на Фиг. 1, модуль экспериментального ранжирования реализован в соответствии с некоторым неограничивающим вариантом осуществления настоящего технического решения.
[51]. На Фиг. 4 представлено схематическое изображение примера поисковых логов, соответствующих некоторому неограничивающему варианту осуществления настоящего технического решения, поисковые логи доступны серверу поисковой системы или формируют часть сервера поисковой системы, который показан на Фиг. 2.
[52]. На Фиг. 5 представлена блок-схема примерного способа обработки поискового запроса.
[53]. В конце настоящего описания предусмотрено приложение. Приложение включает в себя копию опубликованной статьи, озаглавленной «Сбор дополнительных параметров обратной связи в отношении поисковых результатов с помощью алгоритма многорукого бандита в контексте ранжирования» (обозначена как 34055-529 Приложение А), и копию опубликованной статьи «Улучшение качества поиска с помощью алгоритма бандита» (обозначена как 34055-529 Приложение В). Эти статьи предоставляют дополнительную информацию об известном уровне техники, описание вариантов осуществления настоящего технического решения, а также примеры. Эти статьи представляют собой часть приложения в виде файлов. Эти статьи включены здесь в полном объеме посредством ссылки для всех юрисдикции, допускающих включение в описание сведений посредством ссылки.
ОСУЩЕСТВЛЕНИЕ
[54]. На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящего технического решения. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[55]. Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[56]. В контексте настоящего описания, если конкретно не указано иное, «электронное устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[57]. Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104. В общем случае, задачей поискового приложения 104 является предоставление пользователю возможности выполнять веб-поиск. С этой целью, поисковое приложение 104 включает в себя интерфейс запроса 106 и интерфейс результатов поиска 108.
[58]. Реализация поискового приложения 104 никак конкретно не ограничена. Один из примеров поискового приложения 104 может быть реализован в вызове пользователем веб-сайта, соответствующего поисковой системе, для получения доступа к поисковому приложению 104. Например, поисковое приложение может быть вызвано путем ввода URL, связанного с поисковой системой Yandex, доступной по адресу www.yandex.ru. Важно иметь в виду, что поисковое приложение 104 может быть вызвано с помощью любой другой коммерчески доступной или собственной поисковой системы.
[59]. В общем случае, поисковое приложение 104 выполнено с возможностью получать от пользователя запрос, например, «поисковую строку», и предоставлять поисковые результаты, которые отвечают на запрос. Коротко говоря, запрос передается серверу 114 поисковой системы (описан ниже) по сети 110 передачи данных (описан ниже), и сервер 114 поисковой системы передает запрос или инициирует передачу запроса.
[60]. Электронное устройство 102 соединено с сетью 110 передачи данных через линию 112 передачи данных. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящего технического решения сеть связи 110 может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[61]. Реализация линии связи 112 не ограничена и будет зависеть от того, какое электронное устройство 102 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящего технического решения, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 112 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных сети 3G, линия передачи данных сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi, Bluetooth и т.п.).
[62]. Важно иметь в виду, что варианты осуществления электронного устройства 102, линии 112 передачи данных и сети 110 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут легко оценить другие конкретные подробности различных вариантов осуществления электронных устройств 102. Таким образом, представленные здесь примеры не ограничивают объем настоящего технического решения.
[63]. С сетью 110 передачи данных соединен сервер 114 поисковой системы. Сервер 114 поисковой системы может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения сервер 114 поисковой системы может представлять собой сервер Dell PowerEdge, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 114 поисковой системы может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 114 поисковой системы является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 114 хостинга содержимого может быть разделена, и может выполняться с помощью нескольких серверов.
[64]. В общем случае, сервер 114 поисковой системы находится под контролем и/или управлением поставщика поисковой системы (не показан), такого, например, как оператор поисковой системы Yandex. Таким образом, сервер 114 поисковой системы может быть выполнен с возможностью выполнять один или несколько поисков в ответ на «поисковую строку», введенную пользователем в интерфейс 106 запроса. Сервер 114 поисковой системы также выполнен с возможностью передавать электронному устройству 102 набор результатов поиска, который будет отображаться пользователю через интерфейс 108 результатов поиска.
[65]. Сервер 114 поисковой системы также выполнен с возможностью выполнять функцию поискового робота и, с этой целью, включает в себя приложение 120 поискового робота. В общем случае, приложение 120 поискового робота выполнено с возможностью получать доступ к серверам веб-ресурсов (описано ниже) для идентификации и получения веб-ресурсов 136, которые расположены на них. Достаточно сказать, что указание на просмотренные поисковым роботом веб-ресурсы индексируется и сохраняется в базе 116 данных поискового робота. Несмотря на то, что база 116 данных просмотренных поисковым роботом веб-ресурсов представлена как отдельная от сервера 114 поисковой системы и соединенная с ним с помощью соответствующей линии (не пронумерована), она может быть реализована как часть сервера 114 поисковой системы. В общем случае, база 116 данных просмотренных поисковым роботом веб-ресурсов также содержит записи для каждого просмотренного объекта, причем запись может включать в себя данные, такие как дата последнего просмотра или получения доступа, которые могут быть использованы приложением 120 поискового робота для поддержания базы 116 данных просмотренных поисковым роботом веб-ресурсов в актуальном состоянии, и в дальнейшем для избавления от дубликатов.
[66]. Сервер 114 поисковой системы также соединен с поисковыми логами 130 через линию (не пронумерована). Коротко говоря, поисковые логи 130 выполнены с возможностью сохранять свойства, полученные из истории, с конкретным веб-ресурсом, связанные со множеством пользовательских сетевых взаимодействий с помощью поискового приложения 104. Для целей этого настоящего технического решения, «свойства, полученные из истории» относятся к «поисковой строке», которую вводит один или несколько пользователей в поисковое приложение 104, а также к данным поисковых действий (например, таких как, без установления ограничений, данные о кликабельности, позиции вое-ресурсов, по которым был произведен клик) пользователей, которые хранятся в поисковых логах 130. Несмотря на то, что поисковые логи 130 представлены как отдельные от сервера 114 поисковой системы элементы, возможно, что поисковые логи 130 реализованы как часть сервера 114 поисковой системы.
[67]. Для того, чтобы выполнять поиск с помощью поискового приложения 104, сервер 114 поисковой системы выполнен с возможностью выполнять веб-поиски. Функциональность сервера 114 поисковой системы общеизвестна, но, излагая коротко, сервер 114 поисковой системы выполнен с возможностью осуществлять: (i) получение поискового запроса от электронного устройства 102 через поисковое приложение 104; (ii) обработку поискового запроса (нормализация поискового запроса, и т.д.); (iii) выполнение поиска для веб-ресурсов, которые соответствуют поисковому запросу, путем получения доступа к базе 116 данных просмотренных поисковым роботом веб-ресурсов, которая содержит индекс просмотренных поисковым роботом веб-ресурсов (описано ниже) и (iv) выводить список результатов поиска (не пронумерован) электронному устройству 102 для поискового приложения 104 с целью вывода страницы результатов поиска (SERP), содержащей ссылку на веб-ресурсы, которые соответствуют поисковому запросу.
[68]. То, как именно реализован выводимый список, никак не ограничено. В общем случае, результаты поиска, которые включены в список, упорядочены на основании ранжирования релевантности. Таким образом, в некоторых вариантах осуществления настоящего технического решения, сервер 114 поисковой системы включает в себя алгоритм 118 ранжирования для анализа множества критериев с целью определения того, какой из просмотренных поисковым роботом веб-ресурсов является более релевантным, чем другие. Например, без установления ограничений, алгоритм 118 ранжирования ранжирует просмотренные поисковым роботом веб-ресурсы на основе свойства, полученного из истории, которое хранится в поисковых логах 130, и присущих веб-ресурсу данных 132 (описано ниже).
[69]. Другими словами, список результатов поиска, который отображается на SERP, отображается в порядке, основывающемся на релевантности. Веб-ресурсы, которые определены с помощью алгоритма 118 ранжирования как обладающие высокой релевантностью, будут расположены на достаточно высоких позициях на SERP, например, на первой позиции первой страницы SERP. Альтернативно, веб-ресурсы, которые определены с помощью алгоритма 118 ранжирования как обладающие меньшей релевантностью, будут расположены на достаточно низких позициях на SERP, например, на последней странице SERP.
[70]. Для целей иллюстрации, в системе 100 предусмотрены первый сервер 122 веб-ресурса и второй сервер 124 веб-ресурса. В некоторых вариантах осуществления настоящего технического решения первый сервер 122 веб-ресурса и второй сервер 1244 веб-ресурса соединены с сетью 110 передачи данных через соответствующую линию (не показано). Каждый из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса может быть реализован тем же способом, что и сервер 114 поисковой системы.
[71]. Излишне говорить, что каждый из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. Дополнительно, данный из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса может быть реализован отлично от другого.
[72]. Также, в представленном неограничивающем варианте осуществления настоящего технического решения каждый из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность каждого из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса может быть разделена и может выполняться с помощью нескольких серверов.
[73]. Каждый из первого сервера 122 веб-ресурса и второго сервера 124 веб-ресурса выполнен с возможностью размещать веб-ресурсы 136, доступные электронному устройству 102 через сеть передачи данных. В общем случае, соответствующие веб-ресурсы 136 могут быть доступны для электронного устройства 102 путем ввода URL в браузерное приложение (не показано) электронного устройства 102 или выполнения веб-поиска с помощью сервера 114 поисковой системы.
[74]. В представленном варианте осуществления технического решения первый сервер 122 веб-ресурса размещает набор старых веб-ресурсов 127, который содержит по меньшей мере один старый веб-ресурс 126. Второй сервер 124 веб-ресурса размещает набор веб-ресурсов 129 кандидатов, который содержит по меньшей мере один веб-ресурс 128 кандидат. Важно иметь в виду, что представленный вариант осуществления технического решения является только примерным и не обозначает, что первый сервер 122 веб-ресурса предназначен только для размещения набора старых веб-ресурсов 127 и, альтернативно, что второй сервер 124 веб-ресурса предназначен только для размещения набора веб-ресурсов 129 кандидатов. Естественно, первый сервер 122 веб-ресурса может размещать оба набора старых веб-ресурсов 127 и веб-ресурсов 129 кандидатов, или только набор веб-ресурсов 129 кандидатов, и то же относится наоборот ко второму серверу 124 веб-ресурса.
[75]. Для целей настоящего технического решения «старый веб-ресурс» обозначает веб-ресурс, который был ранее просмотрен приложением 120 поискового робота и который содержит достаточное количество свойств, полученных из истории, в поисковых логах 130, что позволяет отобразить его на регулярной основе на высокой позиции на SERP в ответ на конкретный запрос с помощью алгоритма 118 ранжирования. Другими словами, старый веб-ресурс 126 был ранее просмотрен поисковым роботом и был отображен по меньшей мере один раз (но, вероятнее, несколько раз) на SERP в результате выполнения конкретной «поисковой строки», для которой в поисковых логах 130 хранятся свойства, полученные из истории, например, данные, указывающие на пользовательское взаимодействие. С другой стороны, термин «веб-ресурс кандидат» обозначает веб-ресурс, который был недавно просмотрен приложением 120 поискового робота, но не содержит никаких (или недостаточное количество) свойств, полученных из истории, в поисковых логах 130, чтобы быть отображенным на высокой позиции на SERP в ответ на конкретный запрос с помощью алгоритма 118 ранжирования. Другими словами, веб-ресурс кандидат 128 был просмотрен поисковым роботом, но не был отображен на SERP в результате выполнения конкретной «поисковой строки», и, следовательно, не содержит данных, указывающих на пользовательское взаимодействие, хранящихся в поисковых логах 130. Альтернативно, веб-ресурс 128 кандидат был просмотрен поисковым роботом, но был показан на SERP достаточно малое количество раз, которое не является достаточным для предоставления указания на пользовательское взаимодействие, которое было бы достаточным для алгоритма ранжирования 118 для адекватного ранжирования веб-ресурса 128 кандидата на высокую позицию на SERP.
[76]. Как уже было вкратце упомянуто, каждый из веб-ресурсов 136, которые расположены на первом сервере 122 веб-ресурса и втором сервере 124 веб-ресурса, включает в себя уникальные присущие веб-ресурсу данные 132. Присущие веб-ресурсу данные 132 относятся к присущим свойствам данного веб-ресурса. Например, без установления ограничения, присущие веб-ресурсу свойства могут включать в себя метаданные, числа и связи с гиперссылками, встроенными объектами, текстами и так далее.
[77]. В некоторых вариантах осуществления настоящего технического решения, в дополнение к алгоритму 118 ранжирования, сервер 114 поисковой системы также включает в себя модуль 134 экспериментального ранжирования. В некоторых вариантах осуществления настоящего технического решения модуль 134 экспериментального ранжирования выполнен с возможностью выбирать заранее определенное число потенциально релевантных веб-ресурсов 128 кандидатов для включения на высокую позицию на SERP в ответ на конкретный запрос от электронного устройства 102.
[78]. Модуль 134 ранжирования выполнено с возможностью осуществлять: (i) предварительный выбор заранее определенного числа веб-ресурсов кандидатов из набора веб-ресурсов 129 кандидатов для включения на высокую позицию на SERP в отношении конкретного запроса; и (ii) сбор данных, указывающих на пользовательское взаимодействие с отображенными веб-ресурсами кандидатами, для сохранения в поисковых логах 130 в виде свойств, полученных из истории, для последующего поискового запроса. В общем случае, при выборе веб-ресурсов кандидатов из набора веб-ресурсов 129 кандидатов, модуль 134 экспериментального ранжирования выполнен с возможностью максимизировать число веб-ресурсов кандидатов, которые модуль 134 экспериментального ранжирования «заставляет» включить в SERP для сбора информации о пользовательском взаимодействии, одновременно минимизируя потенциальное влияние на пользовательский опыт при взаимодействии с SERP в случае, если один или несколько веб-ресурсов 128 кандидатов не удовлетворяют необходимому уровню релевантности для поискового запроса.
[79]. На Фиг. 2 представлена схема, показывающая архитектуру 200, которая иллюстрирует процесс ранжирования веб-ресурсов 136, которые содержат алгоритм ранжирования 118 и модуль 134 экспериментального ранжирования, базу 116 данных просмотренных поисковым роботом веб-ресурсов и поисковые логи 130 в соответствии с некоторыми вариантами осуществления технического решения.
[80]. Как было упомянуто ранее, сервер 114 поисковой системы может быть выполнен с возможностью выполнять один или несколько поисков в ответ на «поисковую строку», введенную пользователем в интерфейс 106 запроса. Например, на Фиг. 2 сервер 114 поисковой системы получает, через сеть 110 передачи данных, пакет 202 данных, который содержит поисковый запрос.
[81]. В ответ на получение пакета 202 данных сервер 114 поисковой системы обрабатывает пакет 202 данных и получает от базы 116 данных просмотренных поисковым роботом веб-ресурсов пакет 204 данных, который содержит список множества веб-ресурсов 136, которые считаются релевантными для поискового запроса. В некоторых неограничивающих вариантах осуществления настоящего технического решения пакет 204 данных включает в себя данные, которые указывают на набор старых веб-ресурсов 127, и набор веб-ресурсов 129 кандидатов.
[82]. При получении пакета 204 данных сервер 114 поисковой системы инициирует алгоритм 118 ранжирования, который ранжирует список веб-ресурсов 136. Способ, в соответствии с которым выполняется ранжирование, был упомянут ранее, и, следовательно, достаточно сказать, что алгоритм 118 ранжирования ранжирует веб-ресурсы на основе по меньшей мере свойств, полученных из истории, веб-ресурсов 136. Таким образом, в некоторых вариантах осуществления настоящего технического решения алгоритм 118 ранжирования получает от поисковых логов 130 пакет 206 данных, содержащий данные, которые указывают на свойства, полученные из истории, для каждого из старых веб-ресурсов 126 и веб-ресурсов 128 кандидатов. В представленном варианте осуществления технического решения алгоритм 118 ранжирования выбирает подмножество ранжированных веб-ресурсов 208, которое содержит по меньшей мере один (если не все) старый(е) веб-ресурс(ы) 126.
[83]. Также в сервере 114 поисковой системы содержится модуль 134 экспериментального ранжирования. В некоторых вариантах осуществления настоящего технического решения модуль 134 экспериментального ранжирования выполнен с возможностью идентифицировать набор веб-ресурсов 129 кандидатов путем анализа пакета 204 данных и пакета 206 данных. Конкретнее, модуль 134 экспериментального ранжирования выполнен с возможностью получать набор веб-ресурсов 129 кандидатов, для которых нет никаких (или достаточного числа) свойств, полученных из истории, что приводит к ранжированию их на более низкой позиции с помощью алгоритма 118 ранжирования. После получения модуль 134 экспериментального ранжирования применяет набор правил для ранжирования веб-ресурсов 129 кандидатов для включения на высокие позиции на SERP.
[84]. Для описания набора правил, на Фиг. 3 представлена схема, демонстрирующая архитектуру 300, которая иллюстрирует пример набора правил, применяемых к модулю 134 экспериментального ранжирования. В соответствии с некоторыми вариантами осуществления настоящего технического решения набор веб-ресурсов 129 кандидатов ранжируется на основе оценки 318 эксперимента.
[85]. Определение оценки эксперимента
[86]. В некоторых вариантах осуществления технического решения, для каждого поискового запроса, который получен через пакет 202 данных, модуль 134 экспериментального ранжирования сохраняет информацию о каждом веб-ресурсе 128 кандидате, который включает в себя (i) вероятность выигрыша 314 и (ii) достоверность 316 в вероятности выигрыша 314. Для целей настоящего технического решения термин «вероятность выигрыша» относится к вероятности того, что данный веб-ресурс 128 кандидат удовлетворяет поисковому запросу (полученному через пакет 202 данных). В некоторых вариантах осуществления настоящего технического решения модуль 134 экспериментального ранжирования вычисляет оценку 318 эксперимента следующим образом:

Где St(d) является оценкой 318 эксперимента для данного веб-ресурса 128 кандидата, Ft(d) является параметром 312 предсказанной релевантности и SB,t является либо случайной, либо детерминированной функцией в зависимости от конкретного алгоритма бандита (описано ниже). Для целей настоящего технического решения термин «параметр предсказанной релевантности» относится к предсказанной релевантности веб-ресурса 128 кандидата для поискового запроса (полученного через пакет 202 данных) и основывается, частично, на вероятности выигрыша 314 и достоверности 316. Способ определения оценки 318 эксперимента никак конкретно не ограничен, и в некоторых вариантах осуществления настоящего технического решения предоставляются два типа алгоритма бандита.
[87]. Первоначально, в соответствии с алгоритмом UCB-1, оценка 318 эксперимента для каждого веб-ресурса 128 кандидата для конкретного этапа вычисляется следующим образом:
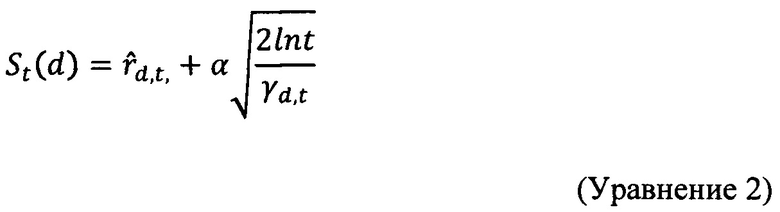
где точечная оценка вероятности выигрыша 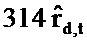
[88]. Таким образом, параметр 312 предсказанной релевантности (Ft(d) состоит из двух компонентов ϒd,t и Wd,t.
[89]. С другой стороны, Байесовский подход к алгоритму бандита полагается на функцию апостериорной плотности распределения вероятностей pd,t(r), r∈[0,1], вероятности выигрыша 314, где параметр 312 предсказанной релевантности совпадает с {pd,t(r)}r∈[0, 1].
[90]. Альтернативно, в некоторых вариантах осуществления настоящего технического решения алгоритм UCB-1 модифицируется, и точечная вероятность выигрыша 314 модифицируется в соответствии со следующим правилом: 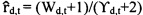 .
.
[91]. В дополнительном варианте осуществления технического решения, Байесовский подход к алгоритму бандита модифицируется и оценка 318 эксперимента вычисляется следующим образом:

[92]. Естественно, если веб-ресурс 128 кандидат не содержит никаких свойств, полученных из истории, модуль 134 экспериментального ранжирования должен сначала предсказать вероятность выигрыша 314 и достоверность 316, чтобы получить «первоначальный» параметр 312 предсказанной релевантности. Тем не менее, следует иметь в виду, и как будет более подробно описано далее, варианты осуществления настоящего технического решения не ограничиваются теми веб-ресурсами 128 кандидатами, которые не обладают никакими свойствами, полученными из истории. Следует иметь в виду, что варианты осуществления настоящего технического решения могут применяться к данному веб-ресурсу 128 кандидату, который обладает ограниченным числом свойств, полученных из истории, которое не является достаточным для использования алгоритмом 118 ранжирования для их адекватного ранжирования.
[93]. Определение параметра релевантности
[94]. В некоторых вариантах осуществления настоящего технического решения модуль экспериментального ранжирования включает в себя первый машинно-обученный алгоритм 301, который включает в себя машинно-обученный алгоритм 302 предсказания среднего значения (MVPML) и машинно-обученный алгоритм 304 предсказания среднего абсолютного отклонения (MADPML). Кроме того, модуль 134 экспериментального ранжирования также включает в себя второй машинно-обученный алгоритм, конкретнее - алгоритм 306 бандита и алгоритм 308 ранжирования на основе многорукого бандита (BBRA).
[95]. В некоторых вариантах осуществления настоящего технического решения, где данный веб-ресурс 128 кандидат не обладает никакими свойствами, полученными из истории, первый машинно-обученный алгоритм 301 получает пакет 310 данных, который включает в себя присущие веб-ресурсу данные 132 для данного веб-ресурса 128 кандидата. В некоторых вариантах осуществления настоящего технического решения первый машинно-обученный алгоритм 301 выполнен с возможностью определять параметр 312 предсказанной релевантности для данного веб-ресурса 128 кандидата на основе полученного пакета 310 данных.
[96]. Способ, в соответствии с которым определяется параметр 312 предсказанной релевантности, никак конкретно не ограничен. В некоторых вариантах осуществления настоящего технического решения, параметр 312 предсказанной релевантности определяется с помощью алгоритмов MVPML 302 и MADPML 304.
[97]. В некоторых вариантах осуществления настоящего технического решения параметр 312 предсказанной релевантности включает в себя две переменные, конкретнее - вероятность выигрыша 314 веб-ресурса 128 кандидата, и достоверность 316 вероятности выигрыша 314. Способ, в соответствии с которым определяется вероятность выигрыша 314, никак конкретно не ограничена и может быть определена с помощью алгоритма MVPML 302. Аналогичным образом, способ, в соответствии с которым определяется достоверность 316, никак конкретно не ограничен и может быть определен с помощью алгоритма MADPML 304.
[98]. В некоторых вариантах осуществления настоящего технического решения алгоритм MVPML 302 является алгоритмом на основе градиентного бустинга деревьев решений, который выполнен с возможностью анализировать пакет 310 данных для предсказания вероятности выигрыша 314. В некоторых вариантах осуществления настоящего технического решения алгоритм MVPML 302 обучен с помощью векторов из множества свойств ранжирования алгоритма 118 ранжирования. Количество свойств ранжирования из множества свойств ранжирования никак конкретно не ограничивается, и может находиться в диапазоне от по меньшей мере двух до нескольких сотен или даже нескольких тысяч свойств ранжирования. Таким образом, вероятность выигрыша 314 определяется путем извлечения присущих веб-ресурсу данных 132, которые включают в себя присущие веб-ресурсу свойства, и использования присущих веб-ресурсу данных 132 как вводных свойств.
[99]. В дополнительном варианте осуществления технического решения предсказания алгоритма MADPML 304 используются для обучения алгоритма MVMPL 302. Конкретнее, достоверность 316 определяется с помощью алгоритма MADPML 304, который вычисляет абсолютную ошибку предсказания результатов алгоритма MVMPL 302. В некоторых вариантах осуществления настоящего технического решения вероятность выигрыша 314 (определяется с помощью алгоритма MVPML 302) корректируется до средней вероятности выигрыша (не показано). В некоторых вариантах осуществления настоящего технического решения средняя вероятность выигрыша приводит к тому же ранжированию, что и в том случае, если бы веб-ресурс 138 кандидат был ранжирован алгоритмом 118 ранжирования. В некоторых вариантах осуществления настоящего технического решения средняя вероятность выигрыша определяется с помощью изотонической регрессии с разрывом связей. Таким образом, на основе вероятности выигрыша 314 (или средней вероятности выигрыша) и достоверности 316, первый машинно-обученный алгоритм предсказывает параметр 312 предсказанной релевантности.
[100]. Определение оценки эксперимента
[101]. С помощью полученного параметра 312 предсказанной релевантности алгоритм 306 бандита выполняется с возможностью вычислять оценку 318 эксперимент (см. Уравнение 1).
[102]. При получении оценки 318 эксперимента для набора веб-ресурсов 129 кандидатов. Алгоритм BBRA 308 выполнен с возможностью ранжировать набор веб-ресурсов 129 кандидатов. В некоторых вариантах осуществления настоящего технического решения алгоритм BBRA 308 может быть сформулирован в соответствии с алгоритмом 1:

[103]. Таким образом, в некоторых вариантах осуществления настоящего технического решения на основе оценки 318 эксперимента каждый из веб-ресурсов 128 кандидатов ранжируется.
[104]. В дополнительном варианте осуществления технического решения алгоритм BBRA 308 дополнительно выполнен с возможностью применять заранее определенный параметр включения для выбора подмножества высокоранжированных веб-ресурсов 320 кандидатов. Например, алгоритм BBRA 308 может выбирать, без установления ограничений, только 10 верхних высокоранжированных веб-ресурсов 320 кандидатов.
[105]. Возвращаясь к Фиг. 2, модуль 134 экспериментального ранжирования выполнен с возможностью передавать алгоритму 118 ранжирования пакет 210 данных. Пакет 210 данных включает в себя данные, указывающие на подмножество высокоранжированных веб-ресурсов 320 кандидатов.
[106]. В ответ на получение пакета 210 данных алгоритм 118 ранжирования передает электронному устройству 102 пакет 212 данных. Пакет 212 данных включает в себя данные, указывающие на список поисковых результатов, который включает в себя как подмножество высокоранжированных веб-ресурсов 320 кандидатов, так и подмножество высокоранжированных веб-ресурсов 208. В некоторых вариантах осуществления настоящего технического решения пакет 210 данных также включает в себя информацию о ранжировании результатов поиска для отображения на электронном устройстве 102. Например, пакет данных может содержать инструкции для интерфейса 108 результатов поиска, чтобы расположить подмножество высокоранжированных веб-ресурсов 320 кандидатов на более высокой позиции, чем подмножество высокоранжированных веб-ресурсов 208 на SERP, в порядке убывания. Альтернативно, пакет данных может указывает на расположение высокоранжированных веб-ресурсов 320 кандидатов вместе с подмножеством высокоранжированных веб-ресурсов 208 на высокой позиции на SERP.
[107]. На Фиг. 4 представлено схематичное изображение архитектуры 400, демонстрирующее пример поисковых логов 130, выполненный в соответствии с вариантом осуществления технического решения.
[108]. С учетом того, что электронное устройство 102 отображало ранжированный список результатов поиска, полученный с помощью пакета 21 данных, и что пользователь взаимодействовал с SERP, пакет 402 данных передается от электронного устройства серверу 114 поисковой системы через сеть 110 передачи данных.
[109]. В некоторых вариантах осуществления технического решения пакет 402 данных включает в себя данные, указывающие на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, отображенный веб-ресурс представляет собой один из по меньшей мере одного из подмножества высокоранжированных веб-ресурсов 320 кандидатов и подмножества высокоранжированных веб-ресурсов 208 кандидатов. В некоторых вариантах осуществления технического решения данные, которые указывают на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса пользователю.
[110]. Обновление параметра релевантности
[111]. В некоторых вариантах осуществления настоящего технического решения параметр 312 предсказанной релевантности (т.е. Ft(d)) данного отображаемого веб-ресурса 128 кандидата обновляется. Конкретнее, любой из алгоритмов бандита с параметром 312 предсказанной релевантности, который может быть вычислен на основе {Wa,b ϒa,b{pa,t(r)}r∈[0, 1]}, может быть обновлен с помощью модели зависимых кликов (DCM). В общем случае, DCM основывается на каскадной гипотезе и экспериментальной гипотезе. С учетом ранжирования в ответ на ввод запроса t, позиция веб-ресурса i обозначается с помощью di(t) и представлена в виде двух бинарных переменных  и
и 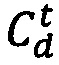 , которые указывают на изучение отрывка веб-ресурса
, которые указывают на изучение отрывка веб-ресурса  и нажатие на веб-ресурс
и нажатие на веб-ресурс 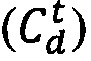 . Таким образом, веб-ресурс 128 кандидат, который отображается на SERP, который расположен над или на самой нижней кликовой позиции, считается изученным (и считается, что на него было произведено нажатие, если он находится на самой низшей кликовой позиции).
. Таким образом, веб-ресурс 128 кандидат, который отображается на SERP, который расположен над или на самой нижней кликовой позиции, считается изученным (и считается, что на него было произведено нажатие, если он находится на самой низшей кликовой позиции).
[112]. В некоторых вариантах осуществления настоящего технического решения оценка 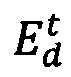 для веб-ресурса 128 кандидата, который расположен под самой низкой кликовой позицией, может быть проигнорирована при обновлении параметра 312 предсказанной релевантности. Альтернативно, в некоторых вариантах осуществления технического решения, это может быть определено путем оценки последующей вероятности, которая участвовала в эксперименте. Например, при алгоритме UCB-1 и модифицированном алгоритме UCB-1, оценка
для веб-ресурса 128 кандидата, который расположен под самой низкой кликовой позицией, может быть проигнорирована при обновлении параметра 312 предсказанной релевантности. Альтернативно, в некоторых вариантах осуществления технического решения, это может быть определено путем оценки последующей вероятности, которая участвовала в эксперименте. Например, при алгоритме UCB-1 и модифицированном алгоритме UCB-1, оценка 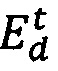 вычисляется с помощью алгоритма максимизации на основе эксперимента. Альтернативно, при Байесовском алгоритме бандита и модифицированном Байесовском алгоритме бандита, оценка
вычисляется с помощью алгоритма максимизации на основе эксперимента. Альтернативно, при Байесовском алгоритме бандита и модифицированном Байесовском алгоритме бандита, оценка 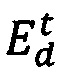 вычисляется, например, на основе Байесовского вывода.
вычисляется, например, на основе Байесовского вывода.
[113]. Несмотря на получение первых свойств, полученных из истории, в большинстве случаев, этого недостаточно для алгоритма 118 ранжирования, чтобы ранжировать веб-ресурс 128 кандидат на высокую позицию на SERP для последующего поискового запроса. Таким образом, в некоторых вариантах осуществления настоящего технического решения модуль 134 экспериментального ранжирования может определять последующий параметр предсказанной релевантности (не показан) для веб-ресурса 128 кандидата, который обладает ограниченным числом свойств, полученных из истории, в ответ на последующий поисковый запрос. В некоторых вариантах осуществления технического решения параметр предсказанной релевантности включает в себя вторую вероятность выигрыша (не показано), определенную первым машинно-обученным алгоритмом 301, вторая вероятность выигрыша основана по меньшей мере на одном из (i) числе предыдущих показов веб-ресурса 128 кандидата на предыдущих SERP (т.е. ϒd,t), (ii) числе кликов на веб-ресурс 128 кандидат на предыдущих SERP (т.е. Wd,t) и, (iii) параметре апостериорной плотности распределения вероятности веб-ресурса кандидата (т.е. pd,t,(r), r∈[0,1]). В дополнительном варианте осуществления технического решения на основе последующего параметра предсказанной релевантности алгоритм 306 бандита определяет последующую оценку эксперимента (не показано). Последующая оценка эксперимента далее ранжируется с помощью BBRA 308
[114]. На Фиг. 5 представлена блок-схема способа 500, реализованного сервером 114 поисковой системы в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[115]. Этап 502: Получение сервером поисковой системы, поискового запроса от электронного устройства, связанного с пользователем.
[116]. На этапе 502 сервер 114 поисковой системы получает поисковый запрос (через пакет 202 данных) от электронного устройства 102, связанного с пользователем.
[117]. Этап 504: Выбор алгоритмом ранжирования сервера поисковой системы, по меньшей мере одного релевантного веб-ресурса для поискового запроса, причем по меньшей мере один релевантный веб-ресурс обладает по меньшей мере одним свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса для включения его на страницу результатов поиска (SERP).
[118]. На этапе 504 алгоритм 108 ранжирования сервера 114 поисковой системы выбирает подмножество релевантных высокоранжированных веб-ресурсов 208 для включения на SERP. Выбор выполняется, по меньшей мере частично, на основе свойств, полученных из истории, которые содержатся в поисковых логах 103.
[119]. Этап 506: Получение из базы данных просмотренных поисковым роботом ресурсов множества веб-ресурсов кандидатов, каждый из множества веб-ресурсов кандидатов не обладает свойством, полученным заранее из истории, которое может быть использовано алгоритмом ранжирования.
[120]. На этапе 506 сервер 114 поисковой системы получает из базы 116 данных просмотренных поисковым роботом веб-ресурсов набор веб-ресурсов 129 кандидатов. Как было указано выше, поисковые логи 130 не содержат каких-либо, или достаточное количество, свойств, полученных из истории, для веб-ресурсов 128 кандидатов, чтобы отобразить на высокой позиции на SERP с помощью алгоритма 118 ранжирования.
[121]. Этап 508: Применение первого машинно-обученного алгоритма для определения, для каждого из веб-ресурсов во множестве веб-ресурсов кандидатов, параметра предсказанной релевантности, параметр предсказанной релевантности основан, по меньшей мере частично, на соответствующих присущих веб-ресурсу данных, параметр предсказанной релевантности указывает на предсказанную релевантность соответствующего веб-ресурса для поискового запроса.
[122]. На этапе 508 сервер 114 поисковой системы применяет первый машинно-обученный алгоритм 301 к каждому подмножеству веб-ресурсов 129 кандидатов для получения соответствующего параметра 312 предсказанной релевантности, параметр 312 предсказанной релевантности определяется на основе, по меньшей мере, присущих веб-ресурсу данных 132.
[123]. В некоторых вариантах осуществления настоящего технического решения параметр предсказанной релевантности содержит две переменных, а именно - вероятность выигрыша 314 и достоверность 316, которые определены с помощью алгоритмов MVPML 302 и MADPML 304 соответственно.
[124]. Этап 510: Применение второго машинно-обученного алгоритма для определения, для каждого из множества веб-ресурсов кандидатов, оценки эксперимента на основе, по меньшей мере частично, соответствующего параметра предсказанной релевантности, и ввод определенной оценки эксперимента множества веб-ресурсов кандидатов в алгоритм ранжирования на основе «многорукого бандита» для: (i) ранжирования множества веб-ресурсов кандидатов; (ii) выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP.
[125]. На этапе 510 на основе предсказанного параметра 312 вероятности алгоритм 306 бандита определяет оценку 318 эксперимента для соответствующего подмножества веб-ресурсов 129 кандидатов. Оценка 318 эксперимента далее вводится в алгоритм BBRA 308 для ранжирования. В некоторых вариантах осуществления настоящего технического решения алгоритм BBRA 308 применяет заранее определенный параметр включения, указывающий на допустимое число веб-ресурсов кандидатов, которые будут добавлены на SERP.
[126]. Этап 512: Создание SERP для отображения результатов поиска в порядке убывания релевантности, создание включает в себя добавление к высокоранжированным позициям на SERP: (i) подмножества высокоранжированных веб-ресурсов кандидатов; (ii) по меньшей мере одного веб-ресурса, релевантного для поискового запроса.
[127]. На этапе 512 сервер 114 поисковой системы создает SERP в ответ на поисковый запрос, полученный через пакет 202 данных интерфейсом 108 результатов поиска.
[128]. Созданная SERP содержит на высокой позиции подмножество высокоранжированных веб-ресурсов 320 кандидатов, определенных модулем 134 экспериментального ранжирования, и высокоранжированные веб-ресурсы 208, определенные алгоритмом 118 ранжирования.
[129]. Этап 514: Получение данных о пользовательском взаимодействии, которые указывают на пользовательское взаимодействие с отображаемым веб-ресурсом на SERP, отображаемый веб-ресурс представляет собой один из по меньшей мере одного веб-ресурса из подмножества высокоранжированных веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса.
[130]. На этапе 514 сервер 114 поисковой системы получает пакет 402 данных, который включает в себя данные, указывающие на пользовательское взаимодействие с одним из отображенных веб-ресурсов на SERP, отображенный веб-ресурс включает в себя по меньшей мере одно из подмножества высокоранжированных веб-ресурсов 320 кандидатов и высокоранжированные веб-ресурсы 208 кандидатов.
[131]. Этап 516: Сохранение указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов кандидатов.
[132]. На этапе 516 указание на данные о пользовательском взаимодействии, которое связано с любым из веб-ресурсов, которые включают в себя подмножество высокоранжированных веб-ресурсов 320 кандидатов, хранится в поисковых логах 130.
[133]. В некоторых вариантах осуществления настоящего технического решения указание на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов используется алгоритмом 118 ранжирования для подмножества поисковых запросов как свойства, полученные из истории, набора веб-ресурсов 129 кандидатов.
[134]. В некоторых вариантах осуществления настоящего технического решения данные, которые указывают на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
[135]. В дополнительных вариантах осуществления технического решения сохранение дополнительно включает в себя анализ данных о пользовательском взаимодействии с помощью модели зависимого клика (DCM), если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая совпадает или превышает позицию выбранного отображаемого веб-ресурса.
[136]. Альтернативно, если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая находится ниже по сравнению с выбранным отображаемым веб-ресурсом, сохранение дополнительно включает в себя анализ данных о пользовательском взаимодействии с помощью алгоритма максимизации на основе эксперимента или Байесовского вывода.
[137]. В результате в ответ на поисковый запрос сервер 114 поисковой системы может совмещать подмножество высокоранжированных веб-ресурсов 320 кандидатов и по меньшей мере один релевантный веб-ресурс 208 на высокой позиции на SERP. Таким образом, поставщик поисковой системы может потенциально ухудшить выполнение запроса на короткий период времени, принимая на себя риск при показывании некоторых менее релевантных веб-ресурсов на верхних позициях, но при этом улучшить его в долговременной перспективе, предоставляя шанс получить обратную связь пользователей (и, следовательно, улучшить их оценку) для потенциально более релевантных веб-ресурсов.
[138]. Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
[139]. Таким образом, с некоторой точки зрения, варианты осуществления настоящего технического решения, описанные выше, можно изложить следующим образом в виде пронумерованных пунктов.
[140]. ПУНКТ 1. Способ (500) обработки поискового запроса, способ выполняется на сервере (114) поисковой системы, сервер (114) поисковой системы связан с базой (116) данных просмотренных поисковым роботом веб-ресурсов и сетью (110) передачи данных, способ (500) включает в себя:
a) получение (502) сервером (114) поисковой системы, поискового запроса от электронного устройства (102), связанного с пользователем;
b) выбор (504) алгоритмом (118) ранжирования сервера (114) поисковой системы, по меньшей мере одного релевантного веб-ресурса (208) для поискового запроса, причем по меньшей мере один релевантный веб-ресурс (208) обладает по меньшей мере одним свойством, полученным заранее из истории, которое может быть использовано алгоритмом (118) ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса (208) для включения его на страницу результатов поиска (SERP);
c) получение (506) из базы (116) данных просмотренных поисковым роботом ресурсов множества веб-ресурсов (129) кандидатов, каждый (128) из множества веб-ресурсов (129) кандидатов не обладает свойством, полученным заранее из истории, которое может быть использовано алгоритмом (118) ранжирования;
d) применение (508) первого машинно-обученного алгоритма (301) для определения, для каждого (128) из веб-ресурсов во множестве веб-ресурсов (129) кандидатов, параметра (312) предсказанной релевантности, параметр (312) предсказанной релевантности основан, по меньшей мере частично, на соответствующих присущих веб-ресурсу данных (132), параметр (312) предсказанной релевантности указывает на предсказанную релевантность соответствующего веб-ресурса для поискового запроса;
e) применение (510) второго машинно-обученного алгоритма (306) для определения, для каждого из множества веб-ресурсов (128) кандидатов, оценки (318) эксперимента на основе, по меньшей мере частично, соответствующего параметра (312) предсказанной релевантности, и ввод определенной оценки (318) эксперимента множества веб-ресурсов (129) кандидатов в алгоритм (308) ранжирования на основе «многорукого бандита» для:
i) ранжирования множества веб-ресурсов (129) кандидатов;
ii) выбора подмножества высокоранжированных веб-ресурсов (320) кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP;
f) создание (512) SERP для отображения результатов поиска в порядке убывания релевантности, создание включает в себя добавление к высокоранжированным позициям на SERP:
i) подмножества высокоранжированных веб-ресурсов (320) кандидатов;
ii) по меньшей мере один релевантный веб-ресурс (208) для поискового запроса;
g) получение (514) данных о пользовательском взаимодействии, которые указывают на пользовательское взаимодействие с отображаемым веб-ресурсом на SERP, отображаемый веб-ресурс представляет собой один из по меньшей мере одного веб-ресурса из подмножества высокоранжированных веб-ресурсов (320) кандидатов и по меньшей мере одного релевантного веб-ресурса. (208); и
h) сохранение (516) указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов (320) кандидатов.
[141]. ПУНКТ 2. Способ по п. 1, в котором первый машинно-обученный алгоритм (301) включает в себя: третий машинно-обученный алгоритм (302) и четвертый машинно-обученный алгоритм (304):
i) третий машинно-обученный алгоритм (302) для определения вероятности выигрыша (314);
j) четвертый машинно-обученный алгоритм (304) - доверительный параметр выигрыша (314),
где вероятность выигрыша (314) и доверительный параметр (316) определяют параметр (312) предсказанной релевантности.
[142]. ПУНКТ 3. Способ по п. 2, в котором третий машинно-обученный алгоритм (302) использует модель градиентного бустинга деревьев решений.
[143]. ПУНКТ 4. Способ по п. 3, в котором третий машинно-обученный алгоритм (302) выполнен с возможностью анализировать присущие веб-ресурсу данные (132) для извлечения присущих веб-ресурсу свойств и использовать присущие веб-ресурсу (128) кандидату свойства как вводные свойства.
[144]. ПУНКТ 5. Способ по п. 2, в котором четвертый машинно-обученный алгоритм (304) выполнен с возможностью получать, по меньшей мере, результаты предсказаний третьего машинно-обученного алгоритма (302) в виде вводных свойств для предсказания абсолютной ошибки третьего машинно-обученного алгоритма.
[145]. ПУНКТ 6. Способ по п. 2, дополнительно включающий в себя преобразование вероятности выигрыша (314) в среднюю вероятность выигрыша.
[146]. ПУНКТ 7. Способ по п. 6, в котором преобразование осуществляется с помощью изотонической регрессии с разрывом связей.
[147]. ПУНКТ 8. Способ по п. 6, в котором второй машинно-обученный алгоритм (306) выполнен с возможностью получать в качестве вводных свойств, по меньшей мере:
k) среднюю вероятность выигрыша; и
l) доверительный параметр (316) вероятности выигрыша (314).
[148]. ПУНКТ 9. Способ по п. 1, в котором конкретный веб-ресурс кандидат из набора веб-ресурсов (129) кандидатов, не обладающий свойствами, полученными из истории, которые могут быть использованы алгоритмом (118) ранжирования, включает в себя минимальный набор свойств, полученных из истории, который не достаточен для использования алгоритмом ранжирования, и определение параметра 312 предсказанной релевантности для конкретного веб-ресурса кандидата из набора веб-ресурсов (129) кандидатов включает в себя определение второй вероятности выигрыша, которая основывается, по меньшей мере на одном из (i) числе предыдущих отображений конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов на предыдущей странице результатов поиска (SERP), (ii) числе кликов на конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов на предыдущей SERP, и (iii) параметре апостериорной плотности распределения вероятностей.
[149]. ПУНКТ 10. Способ по п. 1, в котором данные, которые указывают на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
[150]. ПУНКТ 11. Способ по п. 1, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов (320) кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя анализ данных о взаимодействии с помощью модели зависимых кликов (DCM), если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая совпадает или превышает позицию выбранного отображаемого веб-ресурса.
[151]. ПУНКТ 12. Способ по п. 1, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов (320) кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя использование алгоритма максимизации на основе эксперимента (ЕМ), или Байесовского вывода, если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая ниже позиции выбранного отображаемого веб-ресурса.
[152]. ПУНКТ 13. Сервер (114) поисковой системы выполнен с возможностью выполнять способ по любому из пп. 1-12.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| Способ и система для рекомендации свежих саджестов поисковых запросов в поисковой системе | 2018 |
|
RU2692045C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОТПРАВКИ ТАРГЕТИРОВАННОГО СООБЩЕНИЯ ЭЛЕКТРОННОМУ УСТРОЙСТВУ ПОЛЬЗОВАТЕЛЯ | 2019 |
|
RU2805513C1 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |
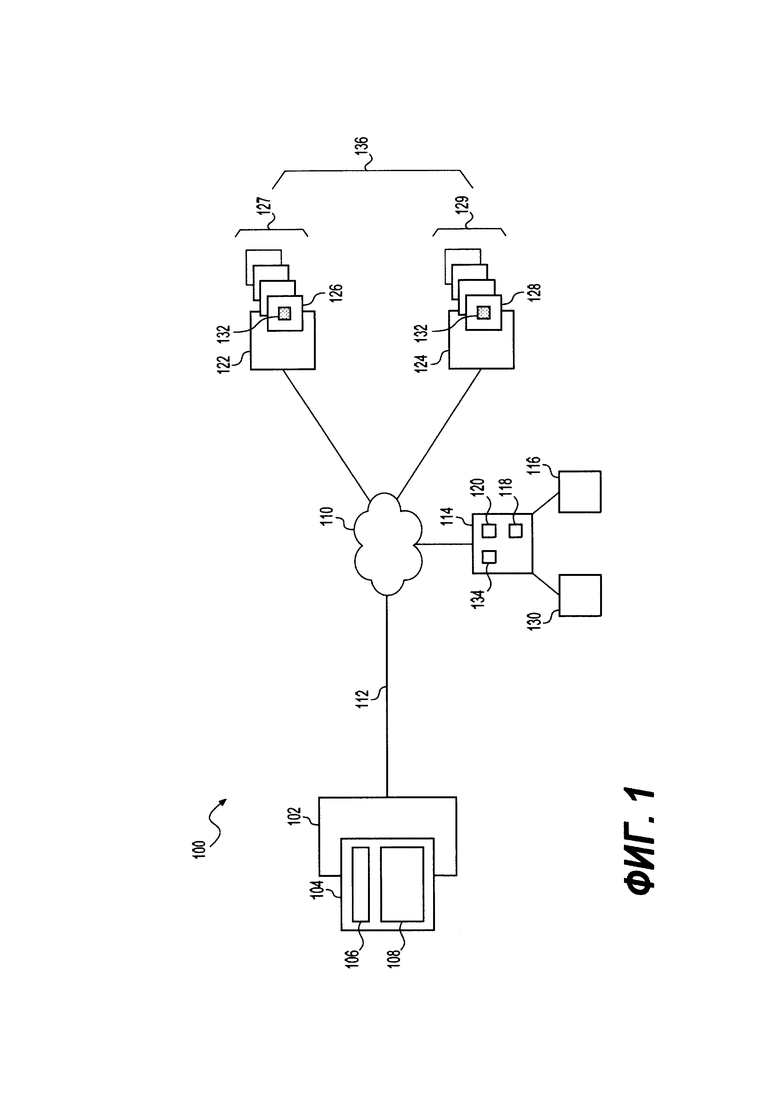
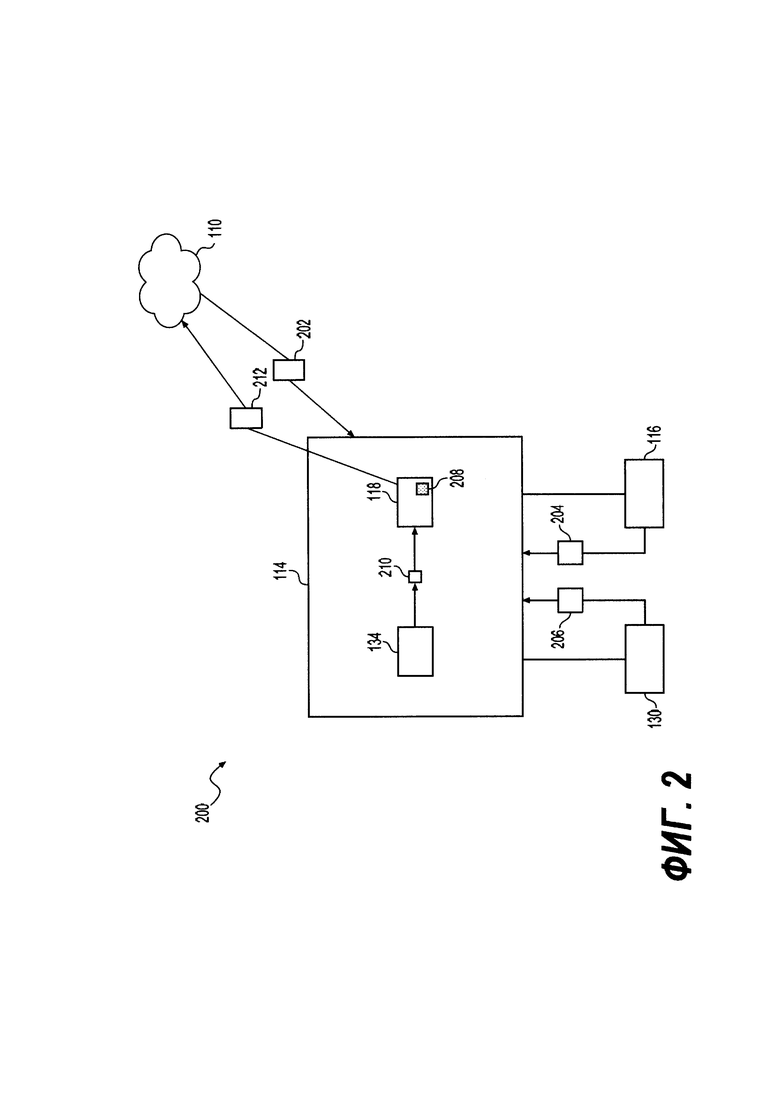
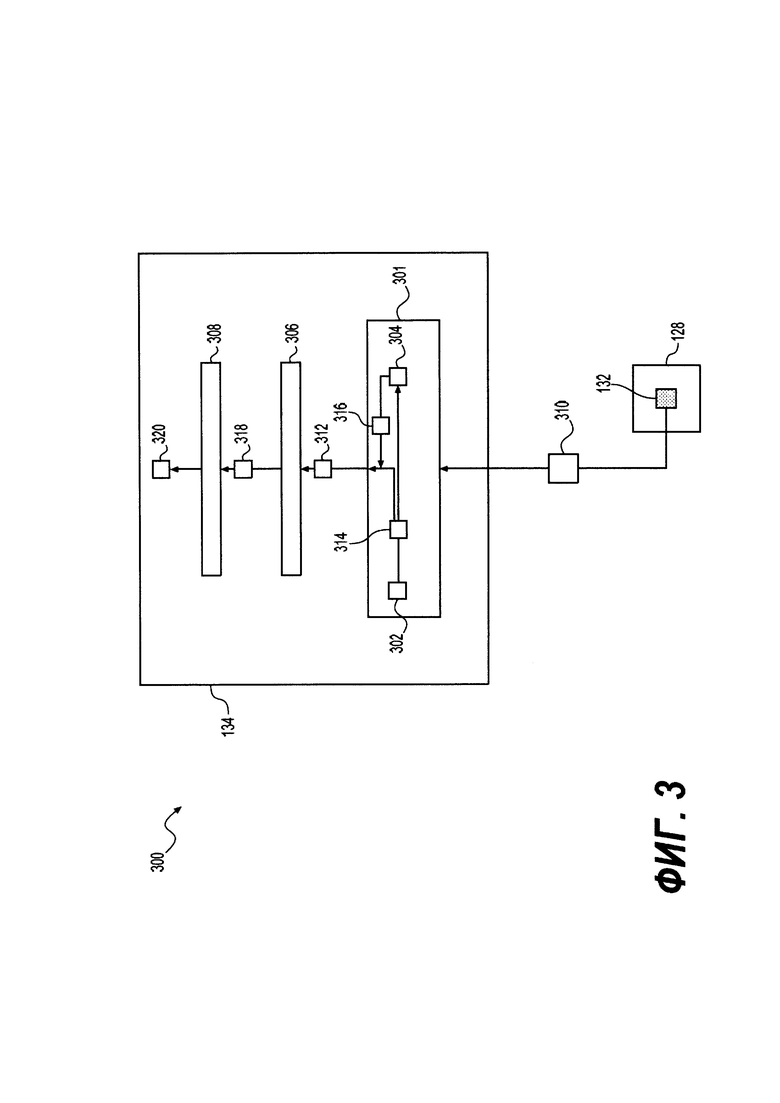
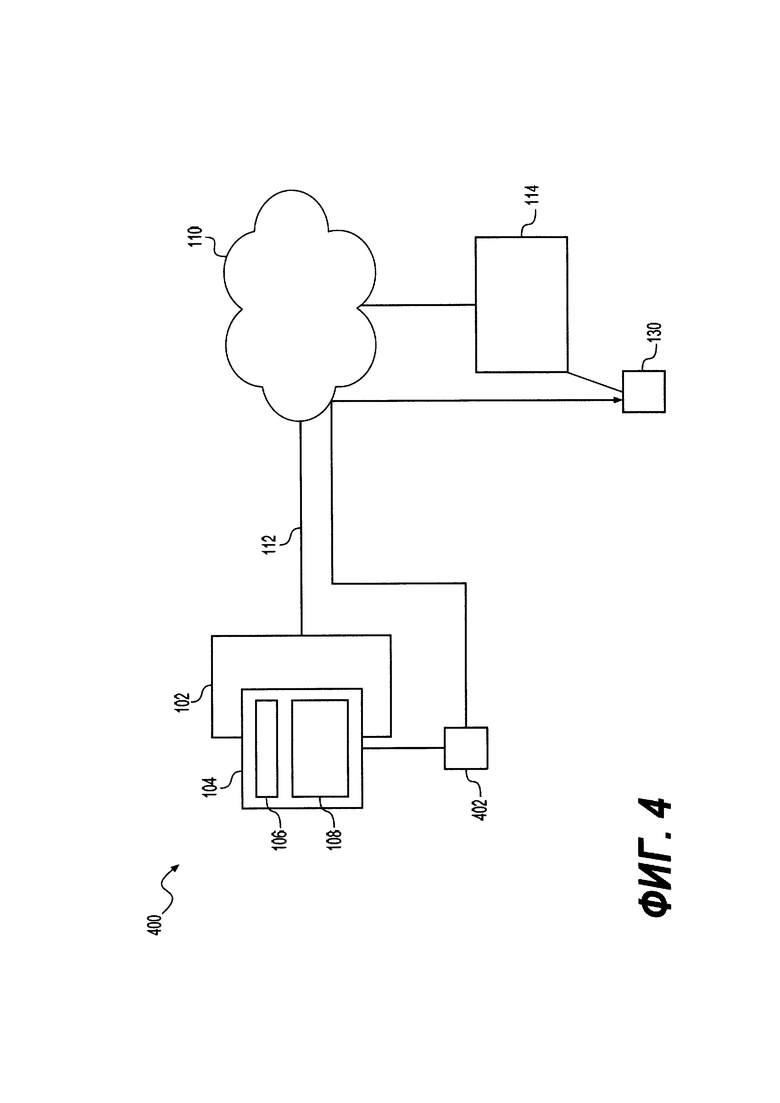

Изобретение относится к области компьютерной техники. Технический результат заключается в повышении качества обработки поискового запроса. Технический результат достигается за счет выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в страницу результатов поиска (SERP), создание сервером SERP для отображения результатов поиска в порядке убывания релевантности, включающее в себя добавление к высокоранжированным позициям на SERP: подмножества высокоранжированных веб-ресурсов кандидатов, по меньшей мере один релевантный веб-ресурс для поискового запроса, получение сервером данных о пользовательском взаимодействии, указывающих на взаимодействие с отображаемым веб-ресурсом, представляющим собой по меньшей мере один веб-ресурс из подмножества высокоранжированных веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса на SERP, сохранение сервером указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов кандидатов. 2 н. и 22 з.п. ф-лы, 5 ил.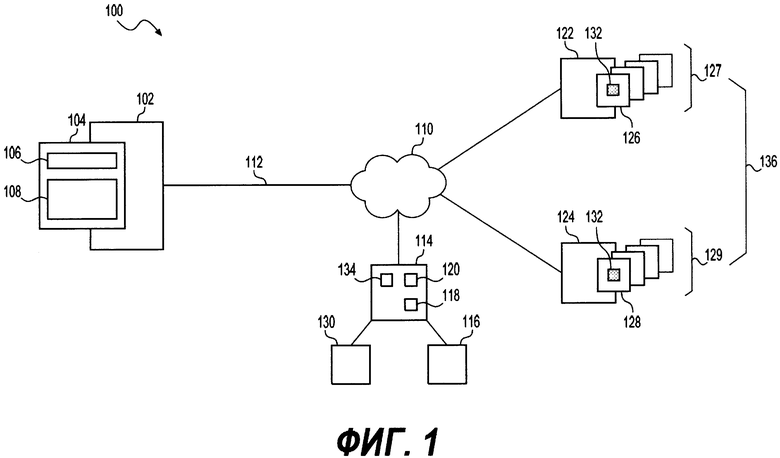
1. Способ обработки поискового запроса, выполняемый на сервере поисковой системы, связанном с базой данных просмотренных поисковым роботом веб-ресурсов и сетью передачи данных, включающий:
получение сервером поисковой системы поискового запроса от электронного устройства, связанного с пользователем;
выбор для поискового запроса сервером поисковой системы, исполняющим алгоритм ранжирования, по меньшей мере одного релевантного веб-ресурса, обладающего по меньшей мере одним свойством, использующимся алгоритмом ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса для включения его на страницу результатов поиска (SERP);
получение из базы данных просмотренных поисковым роботом веб-ресурсов множества веб-ресурсов кандидатов, не обладающих свойством, использующимся алгоритмом ранжирования;
применение сервером для каждого из веб-ресурсов кандидатов первого машинно-обученного алгоритма для определения параметра предсказанной релевантности, основанного по меньшей мере частично на соответствующих присущих веб-ресурсу данных и указывающего на предсказанную релевантность соответствующего веб-ресурса для поискового запроса;
применение сервером для каждого из веб-ресурсов кандидатов второго машинно-обученного алгоритма для определения оценки эксперимента, заключающегося по меньшей мере частично в вычислении функции и соответствующего параметра предсказанной релевантности;
ввод сервером определенной оценки эксперимента множества веб-ресурсов кандидатов в алгоритм ранжирования для:
ранжирования множества веб-ресурсов кандидатов;
выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения, указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP;
создание сервером SERP для отображения результатов поиска в порядке убывания релевантности, включающее в себя добавление к высокоранжированным позициям на SERP:
подмножества высокоранжированных веб-ресурсов кандидатов;
по меньшей мере один релевантный веб-ресурс для поискового запроса;
получение сервером данных о пользовательском взаимодействии, указывающих на взаимодействие с отображаемым веб-ресурсом, представляющим собой по меньшей мере один веб-ресурс из подмножества высокоранжированных веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса на SERP; и
сохранение сервером указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов кандидатов.
2. Способ по п. 1, в котором первый машинно-обученный алгоритм включает в себя: третий машинно-обученный алгоритм и четвертый машинно-обученный алгоритм, где
третий машинно-обученный алгоритм используется для определения вероятности выигрыша, относящейся к вероятности того, что данный веб-ресурс кандидат удовлетворяет поисковому запросу;
четвертый машинно-обученный алгоритм, использующийся для определения доверительного параметра выигрыша, где вероятность выигрыша и доверительный параметр определяют параметр предсказанной релевантности.
3. Способ по п. 2, в котором сервер применяет третий машинно-обученный алгоритм, использующий модель градиентного бустинга деревьев решений.
4. Способ по п. 3, в котором сервер применяет третий машинно-обученный алгоритм, выполненный с возможностью анализировать присущие веб-ресурсу данные для извлечения присущих веб-ресурсу свойств и использовать присущие веб-ресурсу кандидату свойства как вводные свойства третьего машинно-обученного алгоритма.
5. Способ по п. 2, в котором четвертый машинно-обученный алгоритм выполнен с возможностью получать по меньшей мере результаты предсказаний третьего машинно-обученного алгоритма в виде вводных свойств для предсказания абсолютной ошибки третьего машинно-обученного алгоритма.
6. Способ по п. 2, дополнительно включающий в себя преобразование вероятности выигрыша в среднюю вероятность выигрыша.
7. Способ по п. 6, в котором преобразование осуществляется с помощью изотонической регрессии с разрывом связей.
8. Способ по п. 6, в котором второй машинно-обученный алгоритм выполнен с возможностью получать в качестве вводных свойств, по меньшей мере:
среднюю вероятность выигрыша; и
доверительный параметр вероятности выигрыша.
9. Способ по п. 1, в котором конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов, не обладающий свойствами, которые используются алгоритмом ранжирования по умолчанию, включает в себя набор свойств, недостаточный для использования алгоритмом ранжирования, где определение параметра предсказанной релевантности для конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов, включающее в себя определение второй вероятности выигрыша, относящейся к вероятности того, что данный веб-ресурс кандидат удовлетворяет поисковому запросу, и основанной по меньшей мере на одном из числа предыдущих отображений конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов на предыдущей странице результатов поиска (SERP), числа кликов на конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов на предыдущей SERP, и параметра апостериорной плотности распределения вероятностей.
10. Способ по п. 1, в котором данные, указывающие на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
11. Способ по п. 1, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя анализ данных о взаимодействии с помощью модели зависимых кликов (DCM) при расположении данного веб-ресурса кандидата на ранжированной позиции на SERP, совпадающей или превышающей позицию выбранного отображаемого веб-ресурса.
12. Способ по п. 1, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножеством высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя использование алгоритма максимизации на основе эксперимента (ЕМ), или Байесовского вывода при расположении данного веб-ресурса кандидата на ранжированной позиции на SERP ниже позиции выбранного отображаемого веб-ресурса.
13. Сервер поисковой системы, соединенный с базой данных просмотренных поисковым роботом ресурсов и сетью передачи данных, включающий:
интерфейс связи, выполненный с возможностью устанавливать соединение с сервером поисковой системы через сеть передачи данных;
по меньшей мере один компьютерный процессор, функционально соединенный с интерфейсом связи, выполненный с возможностью осуществлять:
получение сервером поисковой системы поискового запроса от электронного устройства, связанного с пользователем;
выбор для поискового запроса сервером поисковой системы, исполняющим алгоритм ранжирования, по меньшей мере одного релевантного веб-ресурса, обладающего по меньшей мере одним свойством, использующимся алгоритмом ранжирования для ранжирования по меньшей мере одного релевантного веб-ресурса для включения его на страницу результатов поиска (SERP);
получение из базы данных просмотренных поисковым роботом веб-ресурсов множества веб-ресурсов кандидатов, не обладающих свойством, использующимся алгоритмом ранжирования;
применение сервером для каждого из веб-ресурсов кандидатов первого машинно-обученного алгоритма для определения параметра предсказанной релевантности, основанного, по меньшей мере частично, на соответствующих присущих веб-ресурсу данных и указывающего на предсказанную релевантность соответствующего веб-ресурса для поискового запроса;
применение сервером для каждого из веб-ресурсов кандидатов второго машинно-обученного алгоритма для определения оценки эксперимента, заключающегося по меньшей мере частично в вычислении функции и соответствующего параметра предсказанной релевантности;
ввод сервером определенной оценки эксперимента множества веб-ресурсов кандидатов в алгоритм ранжирования для:
ранжирования множества веб-ресурсов кандидатов;
выбора подмножества высокоранжированных веб-ресурсов кандидатов путем применения заранее определенного параметра включения,
указывающего на допустимое число веб-ресурсов кандидатов из множества веб-ресурсов кандидатов, которые будут включены в SERP;
создание сервером SERP для отображения результатов поиска в порядке убывания релевантности, включающее в себя добавление к высокоранжированным позициям на SERP:
подмножества высокоранжированных веб-ресурсов кандидатов;
по меньшей мере один релевантный веб-ресурс для поискового запроса;
получение сервером данных о пользовательском взаимодействии, указывающих на взаимодействие с отображаемым веб-ресурсом, представляющим собой по меньшей мере один веб-ресурс из подмножества высокоранжированных веб-ресурсов кандидатов и по меньшей мере одного релевантного веб-ресурса на SERP; и
сохранение сервером указания на данные о пользовательских взаимодействиях в связи с подмножеством высокоранжированных веб-ресурсов кандидатов.
14. Сервер поисковой системы по п. 13, в котором первый машинно-обученный алгоритм включает в себя третий машинно-обученный алгоритм и четвертый машинно-обученный алгоритм, где
третий машинно-обученный алгоритм используется для определения вероятности выигрыша, относящейся к вероятности того, что данный веб-ресурс кандидат удовлетворяет поисковому запросу;
четвертый машинно-обученный алгоритм, использующийся для определения доверительного параметра выигрыша,
где вероятность выигрыша и доверительный параметр определяют параметр предсказанной релевантности.
15. Сервер поисковой системы по п. 14, который применяет третий машинно-обученный алгоритм использует модель градиентного бустинга деревьев решений.
16. Сервер поисковой системы по п. 15, который применяет третий машинно-обученный алгоритм, выполненный с возможностью анализировать присущие веб-ресурсу данные для извлечения присущих веб-ресурсу свойств и использовать присущие веб-ресурсу кандидату свойства как вводные свойства третьего машинно-обученного алгоритма.
17. Сервер поисковой системы по п. 14, который применяет четвертый машинно-обученный алгоритм, выполненный с возможностью получать по меньшей мере результаты предсказаний третьего машинно-обученного алгоритма в виде вводных свойств для предсказания абсолютной ошибки третьего машинно-обученного алгоритма.
18. Сервер поисковой системы по п. 14, в котором процессор дополнительно выполнен с возможностью осуществлять преобразование вероятности выигрыша в среднюю вероятность выигрыша.
19. Сервер поисковой системы по п. 18, в котором преобразование осуществляется с помощью изотонической регрессии с разрывом связей.
20. Сервер поисковой системы по п. 18, в котором второй машинно-обученный алгоритм выполнен с возможностью получать в качестве вводных свойств по меньшей мере:
среднюю вероятность выигрыша; и
доверительный параметр вероятности выигрыша.
21. Сервер поисковой системы по п. 13, в котором конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов, не обладающий свойствами, которые используются алгоритмом ранжирования по умолчанию, включает в себя набор свойств, недостаточный для использования алгоритмом ранжирования, и определение параметра предсказанной релевантности для конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов, включающее в себя определение второй вероятности выигрыша, относящейся к вероятности того, что данный веб-ресурс кандидат удовлетворяет поисковому запросу, и основанной по меньшей мере на одном из числа предыдущих отображений конкретного веб-ресурса кандидата из набора веб-ресурсов кандидатов на предыдущей странице результатов поиска (SERP), числа кликов на конкретный веб-ресурс кандидат из набора веб-ресурсов кандидатов на предыдущей SERP, и параметра апостериорной плотности распределения вероятностей.
22. Сервер поисковой системы по п. 13, в котором данные, указывающие на пользовательское взаимодействие с отображенным веб-ресурсом на SERP, включают в себя местоположение выбранного отображаемого веб-ресурса.
23. Сервер поисковой системы по п. 13, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножества высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя анализ данных о взаимодействии с помощью модели зависимых кликов (DCM), если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, совпадающей или превышающей позицию выбранного отображаемого веб-ресурса.
24. Сервер поисковой системы по п. 13, в котором сохранение указания на данные о пользовательском взаимодействии в связи с подмножества высокоранжированных веб-ресурсов кандидатов включает в себя сохранение указания на данные о пользовательском взаимодействии с данным веб-ресурсом кандидатом, причем сохранение дополнительно включает в себя использование алгоритма максимизации на основе эксперимента (ЕМ), или Байесовского вывода, если данный веб-ресурс кандидат расположен на ранжированной позиции на SERP, которая ниже позиции выбранного отображаемого веб-ресурса.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| ПОИСК ПРОИЗВОЛЬНОГО ТЕКСТА И ПОИСК ПО АТРИБУТАМ В ДАННЫХ ЭЛЕКТРОННОГО РУКОВОДСТВА ПО ПРОГРАММАМ | 2004 |
|
RU2365984C2 |

