ОБЛАСТЬ ТЕХНИКИ
[1] Настоящая технология относится к алгоритмам машинного обучения и, конкретнее, к способам и системам ранжирования множества документов.
УРОВЕНЬ ТЕХНИКИ
[2] Развитие вычислительной техники в купе с увеличением числа соответствующих мобильных электронных устройств, повышают интерес к развитию решений задач автоматизации, прогнозирования результатов, классификации информации и обучения на основе опыта, что относится к области машинного обучения. Машинное обучение, связанное со сбором данных (датамайнинг), вычислительной статистикой и оптимизацией, охватывает процесс обучения и создания алгоритмов, которые могут обучаться и делать прогнозы на основе данных.
[3] Область машинного обучения динамично развивается в последнее десятилетие, что приводит к появлению таких технологий как машины без водителя, распознавание голоса, распознавание изображений, персонализация, расшифровка человеческого генома. Дополнительно, машинное обучение расширяет различные способы получения информации, например, поиск документов, совместная фильтрация, анализ чувств и так далее.
[4] Алгоритмы машинного обучения (MLA) могут в общем случае быть разделены на такие большие категории как обучение с учителем, обучение без учителя и обучение с подкреплением. Обучение с учителем включает в себя алгоритм машинного обучения с помощью обучающих данных, состоящих из вводов и выводов, размеченных асессорами, задача которых состоит в том, чтобы обучить алгоритм машинного обучения таким образом, чтобы алгоритм выучил общее правило для установления соответствия между вводом и выводом. Обучение без учителя включает в себя алгоритм машинного обучения с неразмеченными данными, и целью алгоритма машинного обучения является поиск структуры или неявного паттерна в данных. Обучение с подкреплением включает в себя алгоритм развития в динамической среде без алгоритма с размеченными данными или исправлений.
[5] Поисковые системы широко используются для поиска и получения информации, что позволяет идентифицировать и ранжировать документы в ответ на пользовательские запросы, а также предоставлять их пользователям. Обучение ранжированию (LTR) является применением машинного обучения при создании моделей ранжирования для извлечения информации и является распространенным инструментом поисковых систем для ранжирования документов в ответ на поисковые запросы. В общем случае, система может содержать коллекцию документов, в которой модель ранжирования может ранжировать документы в ответ на запрос и далее выдавать наиболее релевантные документы. Модель ранжирования может быть заранее обучена на обучающих документах. Как было упомянуто ранее, большой объем документов, который доступен в Интернете и продолжает расти, не только сложно размечать, это также требует больших вычислительных мощностей и материальных вложений, поскольку это часто осуществляется людьми-асессорами. Кроме того, метки, назначенные людьми-асессорами данному документу, могут быть ошибочными.
[6] Американская патентная заявка №8,935,258, выданная 13 января 2015 года автору Свору и др., описывает идентификацию образцов элементов данных, обладающих максимальной вероятностью ошибочной разметки при предыдущем решении, и выбор этих элементов данных для повторного решения. В одном аспекте, значения лямба-градиента суммируются для пар образцов элементов данных для вычисления значений повторной оценки для этих образцов элементов данных. Значений повторной оценки указывают на относительную вероятность неверной отметки. После повторной оценки выбранных образцов элементов данных, становится доступен новый обучающий набор, и может быть обучен новый элемент ранжирования.
[7] Дополнительно, в некоторых вариантах осуществления, модели ранжирования, используемые поисковыми системами, оценивают релевантность документов на основе предыдущих взаимодействий пользователя или фидбэке, связанном с документами. Следовательно, разреженность данных, связанных с предыдущими взаимодействиями пользователя или фидбэком, ограничивает размер коллекции или разнообразие обучающих данных, используемых во время обучения конкретных моделей ранжирования и, в свою очередь, может ограничивать возможности поисковых систем для эффективного ранжирования некоторых документов в соответствии с их релевантностью пользовательскому запросу.
[8] Американская патентная заявка No. 2012/0109860 А1 авторства Ксу и др. описывает, что обучающие данные используются алгоритмом обучения ранжированию для формулирования алгоритмов ранжирования. Обучающие данные могут быть изначально предоставлены оценивающими людьми, и далее смоделированы с учетом данных о кликах для определения вероятных ошибок ранжирования. Вероятные ошибки ранжирования предоставляются оценивающим людям, которые могут уточнить обучающие данные с учетом этой информации.
[9] По нижеследующим причинам, существует необходимость в способах и системах для идентификации потенциально ошибочно ранжированных документов с помощью алгоритма машинного обучения.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[10] Варианты осуществления настоящей технологии были разработаны на основе предположений разработчиков о том, что, несмотря на различные разработанные способы машинного обучения для ранжирования информации, часто сложно определить ошибки в ранжировании. Варианты осуществления настоящего технического решения были разработаны с учетом определения разработчиками по меньшей мере одного технического недостатка, связанного с известным уровнем техники. Следовательно, изобретатели разработали способ и системы выбора потенциально ошибочно ранжированных документов с помощью алгоритма машинного обучения.
[11] Первым объектом настоящей технологии является способ ранжирования множества документов на странице результатов поиска (SERP) в ответ на запрос, связанный с пользователем поисковой системы. Способ выполняется на сервере, выполняющем поисковую систему. Способ включает в себя вычисление, алгоритмом машинного обучения (MLA) ранжирования, исполняемым сервером, оценки ранжирования для каждого документа из множества документов. Данная оценка ранжирования указывает на расчетную релевантность соответствующего документа для запроса и оригинальный ранг соответствующего документа на SERP. Способ также включает в себя вычисление, сервером, оценки классовой связи для каждого документа из множества документов. Данная оценка классовой связи является вероятностью связи соответствующего документа с соответствующим заранее определенным классом документов, который был определен оператором. Данная оценка классовой связи используется при увеличении уровня изменений оригинального ранга соответствующего документа. Способ также включает в себя вычисление сервером измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи. Данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа для запроса. Способ также включат в себя инициирование сервером отображения SERP с документами из множества документов, которые были ранжированы на основе соответствующей измененной оценки ранжирования.
[12] В некоторых вариантах осуществления технологии, множество документов включает в себя по меньшей один документ, связанный с ограниченным предыдущим пользовательским фидбэком, и измененная оценка ранжирования по меньшей мере одного документа является одной из самых высоких или самых низких для соответствующей оценки ранжирования.
[13] В некоторых вариантах осуществления технологии, способ далее включает в себя сбор сервером пользовательского фидбэка, связанного по меньшей мере с одним документом, когда пользователь взаимодействует по меньшей мере с одним документом, ранжированным на основе соответствующей измененной оценки ранжирования на SERP.
[14] В некоторых вариантах осуществления технологии, способ также включает в себя хранение сервером пользовательского фидбэка, связанного по меньшей мере с одним документом в хранилище.
[15] В некоторых вариантах осуществления технологии, ранжирование алгоритма машинного обучения было обучено на основе, по меньшей мере набора обучающих документов, соответственно связанных с предыдущим пользовательским фидбэком для каждого обучающего документа из набора обучающих документов, и соответственно связанной оценки человека-асессора для каждого обучающего документа из набора обучающих документов. Таким образом, способ далее включает в себя переобучение, сервером, MLA ранжирования на основе расширенного набора обучающих документов и соответственно связанного предыдущего пользовательского фидбэка для каждого обучающего документа из расширенного набора обучающих документов. Расширенный набор обучающих документов включает в себя обучающие документы из набора обучающих документов и по меньшей мере один документ.
[16] В некоторых вариантах осуществления технологии, измененная оценка ранжирования используется для инициирования изменений оригинального ранга по меньшей мере одного документа.
[17] В некоторых вариантах осуществления технологии, изменение оригинального ранга по меньшей мере одного документа используется при увеличении вероятности пользовательского взаимодействия по меньшей мере с одним документом в сравнении с оригинальным рангом.
[18] В некоторых вариантах осуществления технологии, этап вычисления оценки классовой связи для каждого документа выполняется с помощью MLA прогнозирования, который реализован сервером. MLA прогнозирования отличается от MLA ранжирования. MLA прогнозирования был обучен на основе второго набора обучающих документов и соответствующего размеченного людьми-асессорами класса каждого обучающего документа из второго набора обучающих документов. Каждый соответствующий размеченный людьми-асессорами класс является одним из множества размеченных людьми-асессорами классов.
[19] В некоторых вариантах осуществления технологии, для данного документа из множества документов, MLA прогнозирования выдает вероятность того, что данный документ будет связан с заранее определенным классом документов. Заранее определенный класс является одним из множества размеченных людьми-асессорами классов.
[20] В некоторых вариантах осуществления технологии, набор обучающих документов и второй набор обучающих документов содержат по меньшей мере один идентичный обучающий документ.
[21] В некоторых вариантах осуществления технологии, данный документ, обладающий высокой вероятностью разметки в заранее определенный класс, скорее всего будет связан с высоким уровнем изменений оригинального ранга данного документа, чем другой документ, обладающий низкой вероятностью связи с заранее определенным классом.
[22] В некоторых вариантах осуществления технологии, способ далее включает в себя вычисление сервером параметра модуляции для каждого документа из множества документов, данный параметр модуляции используется при контроле уровня изменений оригинального ранга соответствующего документа. Таким образом, этап вычисления сервером измененной оценки ранжирования для каждого документа из множества документов основан на соответствующей оценке ранжирования, соответствующей оценке классовой связи и соответствующем параметре модуляции.
[23] В некоторых вариантах осуществления технологии, этап вычисления сервером измененной оценки ранжирования для каждого документа из множества документов включает в себя применение формулы:
ARSd=RSd+Wd*CAVd
[24] Вторым объектом настоящей технологии является сервер ранжирования множества документов на странице результатов поиска (SERP) в ответ на запрос, связанный с пользователем поисковой системы. Сервер реализует поисковую систему и выполнен с возможностью осуществлять вычисление, с помощью алгоритма машинного обучения (MLA) ранжирования, исполняемого сервером, оценки ранжирования для каждого документа из множества документов. Данная оценка ранжирования указывается на расчетную релевантность соответствующего документа для запроса и оригинальный ранг соответствующего документа на SERP. Сервер также выполнен с возможностью осуществлять вычисление оценки классовой связи для каждого документа из множества документов. Данная оценка классовой связи является вероятностью связи соответствующего документа с соответствующим заранее определенным классом документов, который был определен оператором. Также, данная оценка классовой связи используется при увеличении уровня изменений оригинального ранга соответствующего документа. Сервер также выполнен с возможностью осуществлять вычисление измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи. Данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа для запроса. Сервер также выполнен с возможностью осуществлять инициирование отображения SERP с документами из множества документов, которые были ранжированы на основе соответствующей измененной оценки ранжирования.
[25] В некоторых вариантах осуществления технологии, множество документов включает в себя по меньшей один документ, связанный с ограниченным предыдущим пользовательским фидбэком и измененная оценка ранжирования по меньшей мере одного документа является одной из самых высоких или самых низких для соответствующей оценки ранжирования.
[26] В некоторых вариантах осуществления технологии, сервер далее выполнен с возможностью осуществлять сбор пользовательского фидбэка, связанного по меньшей мере с одним документом, когда пользователь взаимодействует по меньшей мере с одним документом, ранжированным на основе соответствующей измененной оценки ранжирования на SERP.
[27] В некоторых вариантах осуществления технологии, сервер также выполнен с возможностью сохранять пользовательский фидбэк, связанный по меньшей мере с одним документом в хранилище.
[28] В некоторых вариантах осуществления технологии, ранжирование алгоритма машинного обучение было обучено на основе, по меньшей мере набора обучающих документов, соответственно связанных с предыдущим пользовательским фидбэком для каждого обучающего документа из набора обучающих документов, и соответственно связанной оценки человека-асессора для каждого обучающего документа из набора обучающих документов. Сервер также выполнен с возможностью осуществлять переобучение MLA ранжирования на основе расширенного набора обучающих документов и соответственно связанного предыдущего пользовательского фидбэка для каждого обучающего документа из расширенного набора обучающих документов. Расширенный набор обучающих документов включает в себя обучающие документы из набора обучающих документов и по меньшей мере один документ.
[29] В некоторых вариантах осуществления технологии, измененная оценка ранжирования используется для инициирования изменений оригинального ранга по меньшей мере одного документа.
[30] В некоторых вариантах осуществления технологии, изменение оригинального ранга по меньшей мере одного документа используется при увеличении вероятности пользовательского взаимодействия по меньшей мере с одним документом в сравнении с оригинальным рангом.
[31] В некоторых вариантах осуществления технологии, сервер выполнен с возможностью вычисления оценки классовой связи для каждого документа с помощью MLA прогнозирования, который реализован сервером. MLA прогнозирования отличается от MLA ранжирования. MLA прогнозирования был обучен на основе второго набора обучающих документов и соответствующего размеченного людьми-асессорами класса каждого обучающего документа из второго набора обучающих документов, каждый соответствующий размеченный людьми-асессорами класс является одним из множества размеченных людьми-асессорами классов.
[32] В некоторых вариантах осуществления технологии, для данного документа из множества документов, MLA прогнозирования выдает вероятность того, что данный документ будет связан с заранее определенным классом документов. Заранее определенный класс является одним из множества размеченных людьми-асессорами классов.
[33] В некоторых вариантах осуществления технологии, набор обучающих документов и второй набор обучающих документов содержат по меньшей мере один идентичный обучающий документ.
[34] В некоторых вариантах осуществления технологии, данный документ, обладающий высокой вероятностью разметки в заранее определенный класс, скорее всего будет связан с высоким уровнем изменений оригинального ранга данного документа, чем другой документ, обладающий низкой вероятностью связи с заранее определенным классом.
[35] В некоторых вариантах осуществления технологии, сервер также выполнен с возможностью осуществлять вычисление параметра модуляции для каждого документа из множества документов. Данный параметр модуляции используется для контроля уровня изменений оригинального ранга соответствующего документа. Также, сервер выполнен с возможностью осуществлять вычисление измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования, соответствующей оценки классовой связи и соответствующего параметра модуляции.
[36] В некоторых вариантах осуществления технологии, сервер также выполнен с возможностью осуществлять вычисление измененной оценки ранжирования для каждого документа из множества документов включает в себя применение формулы:
ARSd=RSd+Wd*CAVd
[37] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один компьютер или одну компьютерную систему, однако ни одно, ни другое не является обязательным в отношении предлагаемой технологии. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[38] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. В контексте настоящего описания, термин "электронное устройство" указывает на то, что устройство может функционировать как сервер для других электронным устройств и электронных устройство, хотя это не является необходимым для настоящей технологии. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Важно иметь в виду, что в контексте настоящего описания факт того, что устройство функционирует как электронное устройство не означает того, что оно не может функционировать как сервер для других электронных устройств. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[39] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. В контексте настоящего описания в общем случае «клиентское устройство» связано с пользователем клиентского устройства. Таким образом, некоторые (неограничивающие) варианты осуществления клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и так далее), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, функционирующее как клиентское устройство в настоящем контексте может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[40] В контексте настоящего описания «информация» включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[41] В контексте настоящего описания «программный компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[42] В контексте настоящего описания «носитель компьютерной информации» (также упоминаемый как носитель информации) подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. Множество компонентов может быть объединено в носитель компьютерной информации, включая два или более мультимедийных компонента одного типа и/или два или более компонента разных типов.
[43] В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[44] В контексте настоящего описания слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первая база данных" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или компонентами аппаратного обеспечения, а в других случаях они могут являться разными компонентами программного и/или аппаратного обеспечения.
[45] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[46] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[47] Эти и другие аспекты, свойства и преимущества настоящей технологии будут лучше понятны с учетом следующего описания, прилагаемой формулы изобретения и чертежей, где:
[48] На Фиг. 1 представлена система ранжирования множества документов в соответствии с некоторыми вариантами осуществления настоящей технологии.
[49] На Фиг. 2 схематически представлена обучающая фаза приложения ранжирования, выполняемого системой, показанной на Фиг. 1.
[50] На Фиг. 3 представлен обучающий объект, используемый во время процедуры обучения MLA ранжирования приложения ранжирования.
[51] На Фиг. 4 представлен обучающий объект, используемый во время процедуры обучения MLA прогнозирования приложения ранжирования.
[52] На Фиг. 5 схематически представлена фаза работы приложения ранжирования, выполняемого системой, показанной на Фиг. 1.
[53] На Фиг. 6 представлен список ранжированных документов, которые были ранжированы на основе соответствующих оценок ранжирования в контексте первого сценария и в соответствии с некоторыми вариантами осуществления настоящей технологии.
[54] На Фиг. 7 представлен процесс вычисления измененных оценок ранжирования для множества документов в контексте второго сценария и в соответствии с некоторыми вариантами осуществления настоящей технологии.
[55] На Фиг. 8 представлен первый измененный список ранжированных документов, которые были ранжированы на основе соответствующих измененных оценок ранжирования, показанных на Фиг. 7.
[56] На Фиг. 9 представлена схема сравнения между оригинальным рангом документов в списке ранжированных документов, показанном на Фиг. 6, и измененными рангами документов в первом измененном списке ранжированных документов, показанном на Фиг. 8.
[57] На Фиг. 10 представлен процесс вычисления измененных оценок ранжирования для множества документов в контексте третьего сценария и в соответствии с некоторыми вариантами осуществления настоящей технологии.
[58] На Фиг. 11 представлен второй измененный список ранжированных документов, которые были ранжированы на основе соответствующих измененных оценок ранжирования, показанных на Фиг. 10.
[59] На Фиг. 12 представлена схема сравнения между оригинальным рангом документов в списке ранжированных документов, показанном на Фиг. 6, измененными рангами документов в первом измененном списке ранжированных документов, показанном на Фиг. 8, и измененными рангами документов во втором измененном списке ранжированных документов, показанном на Фиг. 11.
[60] На Фиг. 13 схематически представлена блок-схема способа ранжирования множества документов в соответствии с некоторыми вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[61] На Фиг. 1 представлена система 100, реализованная в соответствии с вариантами осуществления настоящей технологии. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[62] Система 100 включает в себя сеть 102 передачи данных, которая обеспечивает связь между различными компонентами системы 100, которые с ней коммуникативно связаны. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 102 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящего технического решения, сеть 102 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п. Сеть 102 передачи данных может поддерживать обмен сообщениями и данными в открытом формате или в зашифрованном виде, с использованием известных стандартов шифрования.
[63] Система 100 включает в себя пользовательское устройство 104, соединенное с сетью 102 передачи данных. Следует отметить, что объем настоящей технологии не ограничен системой 100, включающей в себя одно пользовательское устройство, например, пользовательское устройство 104, и в общем случае можно утверждать, что множество пользовательских устройств, обладающих любым числом пользовательских устройств, может быть коммуникационно соединено с сетью 102 передачи данных.
[64] Пользовательское устройство 104 связано с пользователем (не изображен). Следует отметить, что тот факт, что пользовательское устройство 104 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного. Варианты пользовательского устройства 104 конкретно не ограничены, но в качестве примера пользовательского устройства 104 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). На Фиг. 1, тем не менее, пользовательское устройство 104 реализовано как смартфон.
[65] К сети 102 передачи данных также присоединены сервер 130 обучения и сервер 132 ранжирования. Несмотря на то, что в представленном варианте осуществления технологии сервер 130 обучающий и сервер 132 ранжирования представлены как отдельные элементы, их функциональность может быть выполнена одним сервером.
[66] В примере варианта осуществления настоящей технологии, обучающий сервер 130 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что обучающий сервер 130 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, обучающий сервер 130 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих его объем, функциональность обучающего сервера 130 может быть разделена и может выполняться с помощью нескольких серверов.
[67] В примере варианта осуществления настоящей технологии, сервер 132 ранжирования может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 132 ранжирования может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, обучающий 132 ранжирования является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 132 ранжирования может быть разделена и может выполняться с помощью нескольких серверов.
[68] Несмотря на то, что сервер 130 обучения и сервер 132 ранжирования поискового ранжирования были в целях иллюстрации описаны как работающие на одном аппаратном обеспечении, это не является обязательным.
[69] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования находится под контролем и/или управлением поисковой системы, например, поисковой системы YANDEX™ компании ООО «Яндекс», расположенной по адресу: 119021, Москва, ул. Льва Толстого, дом 16. Тем не менее, сервер 132 ранжирования может быть реализован иначе (например, через локальный поисковик и так далее). Сервер 132 ранжирования выполнен с возможностью поддерживать поисковую базу 134 данных, которая содержит указание на различные ресурсы, доступные через сеть 102 передачи данных.
[70] Процесс заполнения и поддержания поисковой базы 134 данных в общем случае известен как «сбор информации», когда приложение 140 поискового робота, которое выполняется сервером 132 ранжирования, выполнено с возможностью «посещать» различные веб-сайты и веб-страницы, доступные через сеть 102 передачи данных и индексировать их содержимое (например, связывать данный веб-ресурс с одним или несколькими ключевыми словами). В некоторых вариантах осуществления настоящей технологии, приложение 140 поискового робота поддерживает поисковую базу 134 данных как «инвертированный индекс». Следовательно, приложение 140 поискового робота сервера 132 ранжирования выполнено с возможностью сохранять информацию о проиндексированных веб-ресурсах в поисковой базе 134 данных.
[71] Сервер 132 ранжирования выполнен с возможностью получать уточнения поиска от пользователя или какими-либо другими способами для того, чтобы начать извлекать ресурсы, связанные с уточнениями поиска. Уточнения поиска могут представлять собой запрос, в котором использовано одно или несколько ключевых слов для поиска ресурсов.
[72] Например, когда сервер 132 ранжирования получает поисковый запрос от пользователя (например, "Best travelling destinations in South America" («лучшие места для путешествия в Южной Америке»)), сервер 132 ранжирования выполнен с возможностью реализовать приложение 160 ранжирования. В общем случае, данное приложение ранжирования выполнено с возможностью извлекать и ранжировать поисковые результаты, которые могут быть созданы с помощью любой поисковой системы или алгоритма извлечения ресурсов.
[73] Приложение 160 ранжирования выполнено с возможностью получать доступ к поисковой базе 134 данных для получения указания на множество ресурсов, которые потенциально релевантны введенному пользователем поисковому запросу. В данном примере, приложение 160 ранжирования дополнительно выполнено с возможностью ранжировать таким образом полученные потенциальные релевантные ресурсы, чтобы они могли быть представлены в ранжированном порядке на странице результатов поиска (SERP) данному пользователю, причем на странице результатов поиска наиболее релевантные ранжированные ресурсы расположены в верхней части списка. В ответ на отображение на SERP, данный пользователь может "взаимодействовать" с некоторыми ресурсами на SERP. Что предоставляет пользовательский фидбэк одному или нескольким ресурсам, с которыми взаимодействует пользователь. Эти пользовательские взаимодействия могут быть записаны, собраны и сохранены в связи с соответствующими ресурсами в поисковой базе 134 данных.
[74] Для ранжирования таким образом извлеченных потенциально релевантных ресурсов на SERP, приложение 160 ранжирования может быть выполнено с возможностью выполнить алгоритм ранжирования. В некоторых вариантах осуществления настоящей технологии, алгоритм ранжирования представляет собой алгоритм машинного обучения (MLA). В некоторых вариантах осуществления настоящей технологии, приложение 160 ранжирования может реализовать алгоритм на основе нейронной сети, алгоритм на основе деревьев принятия решений, MLA на основе обучения ассоциативным правилам, MLA на основе глубинного обучения, индуктивно логически запрограммированный MLA, MLA на основе метода опорных векторов, MLA на основе кластеризации, Байесову сеть, MLA на основе обучения с подкреплением, MLA на основе репрезентативного обучения, MLA на основе метрик и схожести, MLA на основе разреженного словаря, MLA на основе генетического алгоритма и так далее. Приложение 160 ранжирования может использовать MLA на основе обучения с учителем и/или MLA на основе частичного обучения с учителем, не выходя за границы настоящей технологии.
[75] В некоторых вариантах осуществления настоящей технологии, как показано на Фиг. 1, приложение 160 ранжирования может использовать по меньшей мере MLA 162 ранжирования для ранжирования потенциально релевантных ресурсов на SERP.
[76] В других вариантах осуществления настоящей технологии, как будет описано далее, приложение 160 ранжирования может использовать больше одного алгоритма ранжирования для ранжирования потенциально релевантных ресурсов на SERP. Например, приложение 160 ранжирование может использовать MLA 162 ранжирования и MLA 164 прогнозирования для ранжирования потенциально релевантных ресурсов на SERP. Соответствующие функции MLA 162 ранжирования и MLA 164 прогнозирования далее будут описаны более подробно.
[77] Следует отметить, что, несмотря на то что для простоты следующее описание дано в контексте извлечения и ранжирования документов с помощью поисковой системы, описанные здесь способы и методики могут применяться к онлайн ресурсам в общем случае и к другим типам операций извлечения и ранжирования, например, фильтрация информации, смысловой анализ, выбор онлайн содержимого, выбор целевого содержимого, системы рекомендаций и так далее - не выходя за границы объема настоящей технологии.
[78] В общем случае, приложение 160 ранжирования может быть использовано в двух фазах. Первая из двух фаз - фаза обучения. Во время фазы обучения, приложение 160 ранжирования "обучается" для вывода формулы MLA ранжирования для MLA 162 ранжирования. Также во время фазы обучения, как будет более подробно описано далее, приложение 160 ранжирования "обучается" для вывода формулы MLA прогнозирования для MLA 164 прогнозирования.
[79] Вторая из двух фаз - фаза использования, в которой приложение 160 ранжирования используется для ранжирования документов.
[80] В дополнительных вариантах осуществления технологии, приложение 160 ранжирования может быть "переобучено", далее в фазе использования, для вывода новой формулы MLA ранжирования или для настройки формулы MLA ранжирования для MLA 162 ранжирования. В самом деле, как будет более подробно описано далее, MLA 162 ранжирования может быть "переобучен" на основе расширенных данных обучения, которые выводятся при реализации некоторых вариантов осуществления настоящей технологии.
[81] На Фиг. 2, фаза обучения приложения 160 ранжирования схематически представлена с помощью процесса 200 обучения "необученного" MLA 162 ранжирования и с помощью процесса 250 обучения "необученного" MLA 164 прогнозирования. Процессы 200 и 250 обучения могут выполняться, например, сервером 130 обучения. С этой целью, "необученный" MLA 162 ранжирования и "необученный" MLA 164 прогнозирования могут быть предоставлены серверу 130 обучения сервером 132 ранжирования. Например, сервер 132 ранжирования может предоставить информацию, связанную с "необученным" MLA 162 ранжирования и "необученным" MLA 164 прогнозирования, серверу 130 обучения в пакете данных MLA (не показано), который может быть передан через сеть 102 передачи данных.
[82] Процесс 200 обучения "необученного" MLA 162 ранжирования будет описан далее.
[83] Как часть процесса 200 обучения, "необученный" MLA 162 ранжирования поддерживается набором обучающих объектов 202, набор обучающих объектов 202 включает в себя множество обучающих объектов - а именно, первый обучающий объект 204, второй обучающий объект 206, третий обучающий объект 208, а также другие обучающие объекты, потенциально присутствующие в наборе обучающих объектов 202. Следует отметить, что набор обучающих объектов 202 не ограничивается первым обучающим объектом 204, вторым обучающим объектом 206 и третьим обучающим объектов 208, изображенными на Фиг. 2. И, таким образом, набор обучающих объектов 202 может включать в себя ряд дополнительных обучающих объектов (например, сотни, тысячи, или сотни тысяч обучающих объектов, аналогичных изображенным первому обучающему объекту 204, второму обучающему объекту 206 и третьему обучающему объекту 208).
[84] На Фиг. 3 схематически изображен данный обучающий объект из набора обучающих объектов 202 (в данном случае, первый обучающий объект 204). Аналогично примеру первого обучающего объекта, каждый обучающий объект 204, 206, 208 в наборе обучающих объектов 202 включает в себя пару «запрос - документ» (которая включает в себя указание на обучающий запрос 302 и связанный обучающий документ 304, потенциально отвечающий на поисковый запрос 302, расчетный класс 306 и момент 308 сбора предыдущего пользовательского фидбэка в ответ на то, что предыдущий пользовательский фидбэк связан с обучающим документом 304.
[85] Следует отметить, тем не менее, что по меньшей мере в некоторых вариантах осуществления настоящей технологии, "необученный" MLA 162 ранжирования мог первоначально использоваться в фазе предварительного обучения. Во время фазы предварительного обучения, данная предварительная формула ранжирования может быть выведена для использования "необученного" MLA 162 ранжирования. Данная предварительная формула ранжирования может быть выведена на основе пар запрос-документ и соответствующих размеченных классов, которые используются как данные предварительного обучения. Другими словами, для использования "необученного" MLA 162 ранжирования сервером 132 ранжирования и для дальнейшего обучения его с помощью процесса 200 обучения, данная предварительная формула ранжирования может быть выведена на основе данных предварительного обучения, включающих в себя пары запрос-документ и соответствующие размеченные классы.
[86] В общем случае, размеченный класс 306 указывает на то, насколько соответствует или насколько полезен обучающий документ 304 обучающему запросу 302 (качество или польза обучающего документа 304 для данного пользователя, производящего поисковый запрос, который идентичен или похож на обучающий запрос 302). Размеченный класс 306 был назначен обучающему документу 304 человеком-асессором. В некоторых вариантах осуществления технологии, человек-асессор может выбирать данный класс из множества размеченных людьми-асессорами классов документов, и назначать его как размеченный класс 306 обучающему документу 304. В зависимости от конкретных вариантов осуществления технологии, данному человеку-асессору предоставляется одна из различных назначающих класс инструкций (т.е. одно из различных множеств размеченных людьми-асессорами классов), например, без установления ограничений:
- шкала от «1» до «5 »,
- шкала от «1» до «2»,
- шкала от «1» до «10»,
- шкала «хорошо» и «плохо»,
- шкала «низкая польза», «средняя польза» и «высокая польза»,
- шкала «Идеально-Отлично-Хорошо-Нормально-Плохо»,
- и так далее.
[87] В некоторых вариантах осуществления настоящего технического решения обучающий сервер 130 может хранить указание на данный обучающий объект 204, 206, 208 и соответствующий размеченный класс 306 в базе данных 136 обучающих объектов, соединенной с обучающим сервером 130 или иным способом доступной для обучающего сервера 130. Для целей иллюстрации предположим, что размеченный класс 306 указывает на то, какой оценкой пользы обладает обучающий документ 304 в контексте обучающего запроса 302 - "Плохо", "Нормально", "Хорошо", "Отлично" или "Идеально". Тем не менее, следует отметить, что другие множества размеченных людьми-асессорами классов документов могут быть предоставлены людям-асессорам как часть инструкций по назначению классов для назначения одного из множества размеченных людьми-асессорами классов каждой паре запрос-документ.
[88] В общем случае, момент 308 сбора предыдущего пользовательского фидбэка указывает на предыдущие пользовательские взаимодействия с обучающим документом 304, после проведения поисковых запросов, которые идентичны или аналогичны обучающему запросу 302. Например, момент 308 сбора предыдущего пользовательского фидбэка может содержать предыдущие данные о кликах, связанные с обучающим документом 304, и при этом предыдущие данные о кликах собирались от пользователей, которые "взаимодействовали" с обучающим документом 304 после ввода поисковых запросов, которые аналогичны или идентичны обучающему запросу 302. Таким образом, предыдущий пользовательский фидбэк может включать в себя информацию, связанную с:
- количеством кликов или выборов обучающего документа 304,
- количеством времени, которое пользователи провели за просмотром обучающего документа 304,
- числом кликов, выполняемых пользователями во время просмотра обучающего документа 304, и
- числом ссылок, на которые кликали и которые были выбраны пользователями в обучающем документе 304.
[89] Следует отметить, что данные о кликах могут содержать информацию, относящуюся к дополнительным метрикам, например, о количестве или частоте пользовательских взаимодействий отличных от тех, которые были упомянуты ранее. Следует отметить, что момент 308 сбора предыдущего пользовательского фидбэка может указывать на другие предыдущие пользовательские взаимодействия, которые отличаются от предыдущих данных о кликах, не выходя за границы настоящей технологии.
[90] В некоторых вариантах осуществления настоящей технологии, набор обучающих объектов 202 может быть получен или предоставляться обучающей базой 136 данных, которая представлена на Фиг. 1. Обучающая база 136 данных может сохранять информацию, связанную с набором обучающих объектов 202. Например, обучающая база 136 данных может содержать большое число пар запрос-документ. Обучающая база 136 данных также может хранить информацию, связанную с соответствующим размеченным классом, который связан с каждой парой запрос-документ, которая там хранится. Кроме того, обучающая база 136 данных может сохранять моменты сбора предыдущего пользовательского фидбэка, связанные с каждой соответствующей парой запрос-документ. Тем не менее, следует отметить, что обучающая база 136 данных может хранить дополнительную информацию для целей обучения приложения 160 ранжирования.
[91] Следовательно, при проведении обучающего процесса 200, сервер 130 обучения может быть выполнен с возможностью запрашивать набор обучающих объектов 202 из обучающей базы 136 данных. В ответ на это, обучающая база 136 данных может быть выполнена с возможностью создавать обучающий пакет данных (не показано), содержащий информацию, связанную с набором обучающих объектов 202. В некоторых вариантах осуществления настоящей технологии, каждый из набора обучающих объектов 202 может случайно выбираться из пула обучающих документов (не показано). В других вариантах осуществления настоящей технологии, каждый из набора обучающих объектов 202 может быть алгоритмически выбран из пула обучающих документов для предоставления большего разнообразия обучающих объектов для процесса 200 обучения. В еще одном варианте осуществления технологии, каждый из набора обучающих объектов 202 может быть выбран из пула обучающих документов на основе конкретного критерия, определенного оператором приложения 160 ранжирования, или на основе конкретной задачи ранжирования или приложения MLA 162 ранжирования.
[92] В некоторых вариантах осуществления настоящей технологии, обучающий объект 204, 206, 208 может также быть связан с соответствующим вектором 310 характеристик. Вектор 310 характеристик может быть создан обучающим сервером 130 в течение фазы обучения приложения 160 ранжирования. Вектор 310 характеристик представляет одну или несколько характеристик связанного обучающих объектов 204, 206, 208. Использование вектора 308 характеристик объекта будет описано далее более подробно.
[93] Возвращаясь к описанию Фиг. 2, как часть процесса 200 обучения, "необученный" MLA 162 ранжирования может анализировать набор обучающих объектов 202 для выведения формулы 210 MLA ранжирования, которая в некотором смысле основана на скрытых отношениях между различными компонентами каждого обучающего объекта, например, между соответствующими обучающими запроса, соответствующими обучающими документами, соответствующими размеченными классами и соответствующими моментами сбора предыдущего пользовательского фидбэка.
[94] В некоторых вариантах осуществления настоящей технологии, "необученный" MLA 162 ранжирования обучен с помощью процесса 200 обучения для вычисления данной оценки ранжирования для данного документа на основе данной пары запрос-документ и соответствующего момента сбора предыдущего пользовательского фидбэка, связанного с документов данной пары запрос-документ. Другими словами, когда MLA 162 ранжирования был обучен в процессе 200 обучения, в MLA 162 ранжирования может быть введена пара запрос-документ и соответствующий момент сбора предыдущего пользовательского фидбэка. В ответ на это, MLA 162 ранжирования выполнен с возможностью выводить (т.е. вычислять) данную оценку ранжирования для данного документа данной пары запрос-документ.
[95] В общем случае, данная оценка ранжирования указывает на расчетную релевантность данного документа для данного запроса. Другими словами, что данная оценка ранжирования предоставляет для данной пары запрос-документ, данная оценка ранжирования указывает на расчетную релевантность документа из данной пары запрос-документ для запроса из данной пары запрос-документ.
[96] В некоторых вариантах осуществления настоящей технологии, MLA 162 ранжирования выполнен с возможностью вычислять данную оценку ранжирования на основе соответствующего вектора характеристик объекта, связанного с данной парой запрос-документ. Данный вектор характеристик может содержать информацию, связанную с соответствующим запросом, соответствующим документом, соответствующим моментом сбора предыдущего пользовательского фидбэка и дополнительными характеристиками документа.
[97] В некоторых вариантах осуществления настоящей технологии, после завершения процесса 200 обучения "необученного" MLA 162 ранжирования, формула 210 MLA ранжирования может быть передана или иным образом предоставлена сервером 130 обучения серверу 132 ранжирования через сеть 102 передачи данных. Например, сервер 130 обучения может передавать ("пушить") информацию, связанную с формулой 210 MLA ранжирования серверу 132 ранжирования без запроса на это со стороны сервера 132 ранжирования. В другом примере, сервер 132 ранжирования может требовать ("пуллить") или иным образом запрашивать информацию, связанную с формулой 210 MLA ранжирования от сервера 130 обучения. С этой целью, сервер 130 обучения может быть выполнен с возможностью создавать пакет данных пост-обучения (не показано), содержащий информацию, связанную с формулой 210 MLA ранжирования, и передавать его серверу 132 ранжирования. После получения пакета данных пост-обучения, MLA 162 ранжирования может быть выполнен с возможностью выполнять формулу 210 MLA ранжирования.
[98] Со ссылками на Фиг. 1-5, после завершения процесса 200 обучения, пользователь пользовательского устройства 104 может вводить запрос 504 в поисковую системы сервера 132 ранжирования. С этой целью, пользователь может открывать браузерное приложение (не показано), исполняемое на пользовательском устройстве, и вводить запрос 504 через устройство пользовательского интерфейса, реализуемое пользовательским устройством 104, например, клавиатуру. Альтернативно, пользователь может продиктовать одно или несколько слов, и пользовательское устройство 104 может выполнить алгоритм распознавания речи для определения запроса 504 на основе одного или несколько слов. Далее, пользовательское устройство может быть выполнено с возможностью создавать пакет 190 данных запроса, который содержит информацию, связанную с запросом 504, для которого пользователь желает получить поисковые результаты от сервера 132 ранжирования. Пользовательское устройство 104 может передавать пакет 190 данных запроса серверу 132 ранжирования через сеть 102 передачи данных.
[99] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может быть выполнен с возможностью получать доступ к поисковой базе 132 данных для извлечения множества документов 510, которые потенциально релевантны запросу 504. Сервер 132 ранжирования может далее переходить к ранжированию всех документов из множества документов 510. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью получать доступ к поисковой базе 134 данных для извлечения соответствующего момента сбора предыдущего пользовательского фидбэка, связанного с каждым документом из множества документов 510. Как показано на Фиг. 5, сервер 132 ранжирования может быть выполнен с возможностью извлекать набор моментов 520 сбора предыдущего пользовательского фидбэка, например, если таковые доступны.
[100] Для целей иллюстрации, множество документов 510 содержит документы 511, 512, 513, 514, 515, 516 и 517 и набор моментов 520 сбора предыдущего пользовательского фидбэка содержит соответственно связанные моменты 521, 522, 523, 524, 525, 526 и 527 моменты предыдущего пользовательского фидбэка. Тем не менее, как подразумевается в некоторых вариантах осуществления настоящей технологии, по меньшей мере один документ из множества документов 510 может быть связан с ограниченным предыдущим пользовательским фидбэком. Другими словами, по меньшей мере один документ не подвергался "взаимодействию" или не был достаточно "изучен" пользователями поисковой системы. Например, по меньшей мере один документ является документом 515, и ограниченный предыдущий пользовательский фидбэк представлен моментом 525 сбора предыдущего пользовательского фидбэка, связанной с документом 515.
[101] Для ранжирования документов из множества документов 510, сервер 132 ранжирования может вводить в MLA 162 ранжирования информацию 502 о запросах-документах, которая содержит запрос 504 и множество документов 510, и набор моментов 520 сбора предыдущего пользовательского фидбэка. В информации 502 о запросах-документах, каждая пара запрос-документ содержит запрос 504 и соответствующий документ из множества документов 510. Другими словами, в этом примере, сервер 132 ранжирования может быть выполнен с возможностью вводить семь пар запрос-документ с соответствующим моментом сбора предыдущего пользовательского фидбэка, если таковые доступны. Каждая пара запрос-документ с соответствующим пользовательским фидбэком, введенная в MLA 162 ранжирования во время фазы использования, будет упомянута как "введенный набор ранжирования".
[102] В некоторых вариантах осуществления настоящей технологии, MLA 162 ранжирования может быть выполнен с возможностью выводить (т.е. вычислять) данную оценку ранжирования для каждого введенного набора ранжирования, который был введен сервером 132 ранжирования. Исключительно для целей иллюстрации, MLA 162 ранжирования может быть выполнен с возможностью вычислять:
- Первую оценку 531 ранжирования для первого введенного набора ранжирования, который содержит запрос 504, документ 511 и момент 521 сбора предыдущего пользовательского фидбэка;
- Вторую оценку 532 ранжирования для второго введенного набора ранжирования, который содержит запрос 504, документ 512 и момент 522 сбора предыдущего пользовательского фидбэка;
- Третью оценку 533 ранжирования для третьего введенного набора ранжирования, который содержит запрос 504, документ 513 и момент 523 сбора предыдущего пользовательского фидбэка;
- Четвертую оценку 534 ранжирования для четвертого введенного набора ранжирования, который содержит запрос 504, документ 514 и момент 524 сбора предыдущего пользовательского фидбэка;
- Пятую оценку 535 ранжирования для пятого введенного набора ранжирования, который содержит запрос 504, документ 515 (т.е. по меньшей мере один документ, связанный с ограниченным предыдущим пользовательским фидбэком) и момент 525 сбора предыдущего пользовательского фидбэка (т.е. ограниченный предыдущий пользовательский фидбэк);
- Шестую оценку 536 ранжирования для шестого введенного набора ранжирования, который содержит запрос 504, документ 516 и момент 526 сбора предыдущего пользовательского фидбэка; и
- Седьмую оценку 537 ранжирования для седьмого введенного набора ранжирования, который содержит запрос 504, документ 517 и момент 527 сбора предыдущего пользовательского фидбэка.
[103] Каждая данная оценка ранжирования из множества оценок ранжирования 530 указывает на расчетную релевантность соответствующего документа для запроса 504. В зависимости от конкретных вариантов осуществления технологии, каждая из множества оценок 530 ранжирования может находиться в диапазоне от "0" до "1", от "0" до "100" или в другом подходящем диапазоне для ранжирования соответствующего документа. Следует отметить, что диапазон возможных значений данной оценки ранжирования не является ограничивающей характеристикой настоящей технологии.
[104] Предположим, что оценки ранжирования из множества оценок ранжирования 530 вычисляются путем ранжирования MLA 162 в диапазоне от "0" до "10". В одном примере, MLA 162 ранжирования может вычислять, что:
- Первая оценка 531 ранжирования составляет 6,0/10;
- Вторая оценка 532 ранжирования составляет 9,0/10;
- Третья оценка 533 ранжирования составляет 8,0/10;
- Четвертая оценка 534 ранжирования составляет 7,3/10;
- Пятая оценка 535 ранжирования составляет 6,6/10;
- Шестая оценка 536 ранжирования составляет 5,4/10; и
- Седьмая оценка 537 ранжирования составляет 7,2/10.
[105] Для простоты понимания, поскольку оценка 532 ранжирования является наиболее высокой оценкой ранжирования из множества оценок 530 ранжирования, документ 512 рассчитан как наиболее релевантный документ из множества документов 510 для запроса 504. Поскольку оценка 536 ранжирования является наиболее низкой оценкой ранжирования из множества оценок 530 ранжирования, документ 516 рассчитан как наименее релевантный документ из множества документов 510 для запроса 504.
[106] Приложение 160 ранжирования может быть выполнено с возможностью выполнять ранжирование всех документов из множества документов 510 на основе их соответствующих оценок ранжирования из множества оценок 530 ранжирования. Приложение 160 ранжирования может выполнять ранжирование всех документов из множества документов 510 в убывающем порядке соответствующих оценок 530 ранжирования. Со ссылкой на Фиг. 6, все оценки ранжирования из множества оценок 530 ранжирования ранжируются приложением 160 ранжирования в список ранжированных оценок 602 ранжирования. В результате, все документы из множества документов 510 могут быть ранжированы в соответствии с соответствующим рангом соответствующей оценки ранжирования в списке ранжированных оценок 602 ранжирования.
[107] Таким образом, все документы из множества документов 510 могут быть ранжированы приложением 160 ранжирования в список ранжированных документов 600. Для простоты понимания, после ранжирования всех документов из множества документов 510 в убывающем порядке соответствующих оценок 530 ранжирования:
- Документ 512 ранжирован первым в списке ранжированных документов 600;
- Документ 513 ранжирован вторым в списке ранжированных документов 600;
- Документ 514 ранжирован третьим в списке ранжированных документов 600;
- Документ 517 ранжирован четвертым в списке ранжированных документов 600;
- Документ 515 ранжирован пятым в списке ранжированных документов 600;
- Документ 511 ранжирован шестым в списке ранжированных документов 600; и
- Документ 516 ранжирован седьмым в списке ранжированных документов 600.
[108] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может предоставлять пользовательскому устройству 104 список ранжированных документов 600. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью создавать пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную со списком ранжированных документов 600, и всю информацию, необходимую для отображения SERP со множеством документов 510, который был ранжирован в соответствии со списком ранжированных документов 600.
[109] Не ограничиваясь какой-либо конкретной теорией, по меньшей мере некоторые варианты осуществления настоящей технологии основаны на предположении о том, что некоторые документы во множестве документов 510 могут быть связаны с ограниченным предыдущим пользовательским фидбэком, и что желателен дополнительный пользовательский фидбэк для этих документов. Тем не менее, некоторые из этих документов могут быть ранжированы слишком низко в списке ранжированных документов 600 (благодаря, по меньшей мере частично, ограниченному предыдущему пользовательскому фидбэку), что снижает вероятность взаимодействия пользователя с этими документами и создания дополнительного пользовательского фидбэка, связанного с ним.
[110] Дополнительно или по меньшей мере некоторые варианты осуществления настоящей технического решения могут быть основаны на предположении о том, что MLA 162 ранжирования необходимо переобучить, и, следовательно, для его переобучения может потребоваться пул обучающих документов.
[111] Следовательно, в некоторых вариантах осуществления настоящей технологии, вместо предоставления SERP со множеством документов 510, ранжированных в соответствии со списком ранжированных документов 600, пользовательскому устройству 104, сервер 132 ранжирования может быть выполнен с возможностью изменять по меньшей некоторые оценки ранжирования из множества оценок 530 ранжирования. С этой целью, сервер 132 ранжирования может реализовать MLA 162 прогнозирования.
[112] До описания некоторых возможных вариантов осуществления технологии и различных функций MLA 164 прогнозирования, процесс 250 обучения "необученного" MLA 164 прогнозирования будет описан далее.
[113] Как было упомянуто ранее, в некоторых вариантах осуществления настоящей технологии, со ссылкой на Фиг. 2, фаза обучения приложения 160 ранжирования может включать в себя процесс 250 обучения. Во время процесса 250 обучения "необученного" MLA 164 прогнозирования, "необученному" MLA прогнозирования представляется второй обучающий набор данных 212, причем второй обучающий набор данных 212 включает в себя множество обучающих объектов - а именно, четвертый обучающий объект 214, пятый обучающий объект 216, шестой обучающий объект 218, а также другие обучающие объекты, потенциально присутствующие во втором обучающем наборе данных 212. Следует иметь в виду, что второй набор обучающих объектов 212 никак конкретно не ограничен и может включать в себя ряд дополнительных обучающих объектов (например, сотни, тысячи, или сотни тысяч обучающих объектов, аналогичных изображенным четвертому обучающему объекту 214, пятому обучающему объекту 216 и шестому обучающему объекту 218).
[114] Второй набор обучающих объектов 212 может сохраняться в обучающей базе 136 данных. При проведении обучающего процесса 250, сервер 130 обучения может быть выполнен с возможностью запрашивать второй набор обучающих объектов 212 из обучающей базы 136 данных. В ответ на это, обучающая база 136 данных может быть выполнена с возможностью создавать другой обучающий пакет данных (не показано), содержащий информацию, связанную со вторым набором обучающих объектов 212. В некоторых вариантах осуществления настоящей технологии, каждый из второго набора обучающих объектов 212 может случайно выбираться из пула обучающих документов. В других вариантах осуществления настоящей технологии, каждый из набора обучающих объектов 202 может быть алгоритмически выбран из пула обучающих документов для предоставления большего разнообразия обучающих объектов во время процесса 250 обучения. В еще одном варианте осуществления технологии, каждый из набора обучающих объектов 202 может быть выбран из пула обучающих документов на основе конкретного критерия, определенного оператором, или на основе конкретной задачи ранжирования или приложения MLA 164 прогнозирования. В дополнительных вариантах осуществления технологии, по меньшей мере некоторые объекты из набора обучающих объектов 202 и второго набора объектов 212 могут быть связаны с идентичными парами запрос-документ.
[115] На Фиг. 4 схематически изображен данный обучающий объект из второго набора обучающих объектов 212 (в данном случае, четвертый обучающий объект 214), используя пример четвертого обучающего объекта 214, каждый обучающий объект 214, 216, 218 во втором наборе обучающих объектов 212 включает в себя соответствующую пару запрос-документ (которая включает в себя указание на четвертый обучающий запрос 402 и связанный четвертый обучающий документ 404, который потенциально соответствует обучающему запросу 402) и соответствующий назначенный класс 406.
[116] В общем случае, четвертый обучающий объект 214 может быть реализован аналогично первому обучающему объекту 204, который используется для обучения "необученного" MLA 162 ранжирования. Например, четвертый обучающий объект 214 может также быть связан с соответствующим вектором 410 характеристик. Тем не менее, в отличие от обучающих объектов в наборе обучающих объектов 202, соответствующий момент сбора пользовательского фидбэка связан с каждой парой запрос-документ во втором наборе обучающих объектов 212, может быть опущен.
[117] Возвращаясь к описанию Фиг. 2, как часть процесса 250 обучения, "необученный" MLA 164 прогнозирования, который выполняется приложением 160 ранжирования, может анализировать второй набор обучающих объектов 212 для выведения формулы 220 MLA прогнозирования, которая в некотором смысле основана на скрытых отношениях между различными компонентами каждого обучающего объекта во втором наборе обучающих документов 212, например, между соответствующими обучающими запросами, соответствующими обучающими документами и соответствующими размеченными классами.
[118] В некоторых вариантах осуществления настоящей технологии, "необученный" MLA 164 прогнозирования обучен с помощью процесса 250 обучения для вычисления данной оценки классовой связи на основе данной пары запрос-документ. Другими словами, когда "необученный" MLA 164 прогнозирования был обучен в процессе 250 обучения, в MLA 164 прогнозирования может быть введена пара запрос-документ. В ответ на это, MLA 164 прогнозирования выполнен с возможностью выводить (т.е. вычислять) данную оценку классовой связи для данного документа данной пары запрос-документ.
[119] В общем случае, данная оценка классовой связи является вероятностью связи соответствующего документа с данным заранее определенным классом документов. Заранее определенный класс документов определен оператором приложения 160 ранжирования путем выбора одного из множества размеченных человеком-асессором классов. Другими словами, оператор может выбирать один из множества размеченных людьми-асессорами классов, которые были использованы как инструкции для разметки классов для людей-асессоров во время разметки классов обучающих документов. После того как оператор выбрал один из множества размеченных людьми-асессорами, классов, данная оценка классовой связи будет являться вероятностью связи соответствующего документа с таким образом связанным классом.
[120] Например, когда множество из размеченных людьми-асессорами классов включает в себя классы документов "Плохо", "Нормально", "Хорошо", "Отлично" и "Идеально", оператор приложения 160 ранжирования может выполнять "необученный" MLA 164 прогнозирования для выведения (т.е. вычисления) вероятности связи данного документа с одним из классов "Плохо", "Нормально", "Хорошо", "Отлично" и "Идеально". Таким образом, оператор может выполнять "необученный" MLA 164 прогнозирования для "изучения" прогнозирования вероятности, с которой данный документ из данной пары запрос-документ, будет связан, например, с классом "Хорошо". В другом примере, оператор может выполнять "необученный" MLA 164 прогнозирования для "изучения" прогнозирования вероятности, с которой данный документ будет связан, например, с классом "Идеально".
[121] В зависимости от конкретных вариантов осуществления технологии, данная оценка классовой связи может находиться в диапазоне от "0" до "1" или от "0" до "100". Следует отметить, что другие диапазоны оценок классовой связи могут быть использованы в зависимости от конкретных вариантов осуществления технологии, не выходя за рамки ее объема.
[122] В итоге, фаза обучения приложения 160 ранжирования включает в себя процесс 200 обучения и процесс 250 обучения, оба представлены на Фиг. 2. Во время процесса 200 обучения, "необученный" MLA 162 ранжирования обучен на основе набора обучающих объектов 202 для выведения формулы 210 MLA 210 ранжирования. Каждый обучающий объект в наборе обучающих документов 202 может включать в себя соответствующий запрос, соответствующий документ, соответствующий назначенный класс и соответствующий момент сбора предыдущего пользовательского фидбэка. Во время процесса 250 обучения, "необученный" MLA 164 прогнозирования обучен на основе второго набора обучающих объектов 212 для выведения формулы 220 MLA 210 прогнозирования. Каждый обучающий объект во втором наборе обучающих документов 212 может включать в себя соответствующий запрос, соответствующий документ и соответствующий назначенный класс. В некоторых вариантах осуществления настоящей технологии, по меньшей мере один обучающий объект из набора обучающих объектов 202, может быть связан с идентичной парой запрос-документ, в отличие от другого обучающего объекта из второго набора обучающих документов 212.
[123] Фаза использования приложения 160 ранжирования будет описана далее со ссылкой на Фи. 5-12.
[124] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может быть выполнен с возможностью предоставлять пользователю пользовательского устройства 104 данный измененный список ранжированных документов из множества документов 510. То, как именно сервер 132 ранжирования предоставляет данный измененный список ранжированных документов пользователю, будет описано далее с помощью нескольких неограничивающих примеров. Конкретнее, для целей иллюстрации вышеупомянутого, будет описано два сценария того, как сервер 132 ранжирования может ранжировать и предоставлять документы из множества документов 510 пользователю пользовательского устройства 104 во время фазы использования приложения 160 ранжирования.
[125] Сценарий 1. Ранжирование на основе оценок ранжирования и оценок классовой связи
[126] В этом сценарии, сервер 132 ранжирования может вводить в MLA 164 прогнозирования информацию 502 о запросах-документах, содержащую запрос 504 и множество документов 510, как показано на Фиг. 5.ю Как было упомянуто ранее, в информации 502 о запросах-документах, каждая пара запрос-документ содержит запрос 504 и соответствующий документ из множества документов 510. В этом примере, сервер 132 ранжирования может быть выполнен с возможностью вводить семь пар запрос-документ. Каждая пара запрос-документ, введенная в MLA 164 прогнозирования во время фазы использования, будет упомянута как "введенный набор прогнозирования".
[127] MLA 164 прогнозирования может быть выполнен с возможностью выводить (т.е. вычислять) данную оценку классовой связи для каждого введенного набора прогнозирования, который был введен сервером 132 ранжирования. В одном примере, MLA 164 прогнозирования может вычислять:
- Первую оценку 541 классовой связи для первого введенного набора прогнозирования, которая включает запрос 504 и документ 511;
- Вторую оценку 542 классовой связи для второго введенного набора прогнозирования, которая включает запрос 504 и документ 512;
- Третью оценку 543 классовой связи для третьего введенного набора прогнозирования, которая включает запрос 504 и документ 513;
- Четвертую оценку 544 классовой связи для четвертого введенного набора прогнозирования, которая включает запрос 504 и документ 514;
- Пятую оценку 545 классовой связи для пятого введенного набора прогнозирования, которая включает запрос 504 и документ 515 (т.е. по меньшей мере один документ, связанный с ограниченным предыдущим пользовательским фидбэком);
- Шестую оценку 546 классовой связи для шестого введенного набора прогнозирования, которая включает запрос 504 и документ 516; и
- Седьмую оценку 547 классовой связи для седьмого введенного набора прогнозирования, которая включает запрос 504 и документ 517.
[128] Как будет описано далее, каждая оценка классовой связи может позволить изменить соответствующую оценку ранжирования соответствующего документ из множества документов 510.
[129] Как было упомянуто ранее, каждая оценка классовой связи является вероятностью связи (т.е. принадлежности) данного документа с конкретным (заранее определенным) классом из множества размеченных людьми-асессорами классов. В зависимости от конкретных вариантов осуществления технологии, каждая из множества оценок 540 классовой связи может находиться в диапазоне от "0" до "1", от "0" до "100" или в другом подходящем диапазоне. Следует отметить, что диапазон всех возможных значений оценок классовой связи не является ограничивающей характеристикой настоящей технологии.
[130] Предположим, что множество размеченных людьми-асессорами классов, которое было использовано как инструкции по разметке классов, содержит следующие классы документов: "Плохо", "Нормально", "Хорошо", "Отлично" и "Идеально". Также предположим, что оператор приложения 160 ранжирования определил, что заранее определенный класс - "Хорошо" из множества размеченных людьми-асессорами классов. Это означает, что MLA 164 прогнозирования может быть обучен и выполнен с возможностью вычислять соответствующую оценку классовой связи для каждого из документов из множества документов 510, причем соответствующая оценка классовой связи является вероятностью связи соответствующего документа из множества документов 510 с классом документов "Хорошо". Например, как показано на Фиг. 7, MLA 164 прогнозирования может вычислять, что:
- Первая оценка классовой связи 541 составляет 0,1/1;
- Вторая оценка классовой связи 542 составляет 0,1/1;
- Третья оценка классовой связи 543 составляет 0,2/1;
- Четвертая оценка классовой связи 544 составляет 0,1/1;
- Пятая оценка классовой связи 545 составляет 0,9/1;
- Шестая оценка классовой связи 546 составляет 0,8/1; и
- Седьмая оценка классовой связи 547 составляет 0,1/1;
[131] Исключительно для целей иллюстрации, поскольку оценки 541, 542, 543, 544 и 547 классовой связи являются низкими, документы 511, 512, 513, 514 и 517 вряд ли будут связаны с классом документов "Хорошо". Поскольку пятая оценка 545 классовой связи является высокой, это означает, что документ 515 вероятно будет связана с классом документов "Хорошо". Поскольку шестая оценка 546 классовой связи больше, чем оценки 541, 542, 543, 544 и 547 классовой связи, документ 516 более вероятно будет связан с классом документов "Хорошо", чем документы 511, 512, 513, 514 и 517. Также, поскольку шестая оценка 546 классовой связи больше, чем пятая оценка 545 классовой связи, документ 516 более вероятно будет связан с классом документов "Хорошо", чем документ 515.
[132] В некоторых вариантах осуществления настоящей технологии, подразумевается, что приложение 160 ранжирования может быть выполнено с возможностью вычислять соответствующую измененную оценку ранжирования для каждой пары запрос-документ в информации 502 о запросах-документах. Соответствующая измененная оценка может быть вычислена на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи. В общем случае, данная измененная оценка ранжирования может указывать на измененную релевантность соответствующего документа из множества документов 510 для запроса 504. Другими словами, расчетная релевантность данного документа (т.е. соответствующая оценка ранжирования) может быть изменена на основе вероятности связи этого документа с заранее определенным классом документов.
[133] В некоторых вариантах осуществления настоящей технологии, данная измененная оценка ранжирования для соответствующего документа может быть вычислена приложением 160 ранжирования в виде суммы соответствующей оценки ранжирования, вычисленной MLA 162 ранжирования, и соответствующей оценки классовой связи, вычисленной MLA 164 прогнозирования, как показано на Фиг. 7. Например, приложение 160 ранжирования может вычислять, что:
- Первая измененная оценка 711 ранжирования составляет 6,1/10;
- Вторая измененная оценка 712 ранжирования составляет 9,1/10;
- Третья измененная оценка 713 ранжирования составляет 8,2/10;
- Четвертая измененная оценка 714 ранжирования составляет 7,4/10;
- Пятая измененная оценка 715 ранжирования составляет 7,5/10;
- Шестая измененная оценка 716 ранжирования составляет 6,2/10; и
- Седьмая измененная оценка 717 ранжирования составляет 7,3/10.
[134] Другими словами, приложение 160 ранжирования может быть выполнено с возможностью вычислять множество измененных оценок 710 ранжирования на основе множества оценок 530 ранжирования и множество оценок 540 классовой связи. Множество измененных оценок 710 ранжирования представляет собой соответствующую измененную оценку ранжирования для каждого документа из множества документов 510.
[135] В некоторых вариантах осуществления настоящей технологии, приложение 160 ранжирования может быть выполнено с возможностью выполнять ранжирование всех документов из множества документов 510 на основе их соответствующих измененных оценок ранжирования из множества измененных оценок 710 ранжирования. Приложение 160 ранжирования может выполнять ранжирование всех документов из множества документов 510 в убывающем порядке соответствующих измененных оценок ранжирования.
[136] Co ссылкой на Фиг. 8, все измененные оценки ранжирования из множества измененных оценок 710 ранжирования ранжируются приложением 160 ранжирования в первый список измененных ранжированных оценок 802 ранжирования. В результате, все документы из множества документов 510 могут быть ранжированы в соответствии с соответствующим рангом соответствующей измененной оценки ранжирования в первом списке ранжированных измененных оценок 802 ранжирования.
[137] Таким образом, все документы из множества документов 510 могут быть ранжированы приложением 160 ранжирования в первый измененный список ранжированных документов 800. Для простоты понимания, после ранжирования документов из множества документов 510 в убывающем порядке соответствующих измененных оценок 530 ранжирования из первого измененного списка измененных оценок 802 ранжирования:
- Документ 512 ранжирован первым в первом измененном списке ранжированных документов 800;
- Документ 513 ранжирован вторым в первом измененном списке ранжированных документов 800;
- Документ 515 ранжирован третьим в первом измененном списке ранжированных документов 800;
- Документ 514 ранжирован четвертым в первом измененном списке ранжированных документов 800;
- Документ 517 ранжирован пятым в первом измененном списке ранжированных документов 800;
- Документ 516 ранжирован шестым в первом измененном списке ранжированных документов 800; и
- Документ 511 ранжирован седьмым в первом измененном списке ранжированных документов 800.
[138] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может предоставлять пользовательскому устройству 104 первый измененный список ранжированных документов 800. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью создавать пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную с первым измененным списком ранжированных документов (в отличие от списка ранжированных документов 600) и всю информацию, необходимую для отображения SERP со множеством документов 510, который был ранжирован в соответствии с первым измененным списком ранжированных документов 800.
[139] На Фиг. 9 представлено сравнение между оригинальными рангами каждого из множества документов 510 (т.е. в соответствии со списком ранжированных документов 600) и измененными рангами каждого из множества документов 510 (т.е. в соответствии с первым измененным списком ранжированных документов 800). Следует отметить, что оригинальные ранги по меньшей мере некоторых документов изменились.
[140] Кроме того, документы 512 и 513 ранжированы как первый и второй, соответственно, в обоих списках ранжированных документов 600 и первом измененном списке ранжированных документов 800. Это означает, что они являются наиболее релевантными документами в соответствии с обоими списками: списком ранжированных документов 600 и первым измененным списком ранжированных документов 800. Другими словами, ранжированный сервер 132 может изменять оригинальные ранги некоторых документов на основе их оценок классовой связи без необходимости изменять оригинальные ранги большинства релевантных документов. Например, в качестве одного аспекта настоящей технологии, может быть желательно, чтобы оператор приложения ранжирования хотел "перемешать" ранги некоторых документов без негативного эффекта на степень удовлетворенности пользователя, которому предоставляется SERP.
[141] Также документ 515 ранжирован пятым в списке ранжированных документов 600 и ранжирован третьим в первом измененном списке ранжированных документов 800. Следовательно, уровень изменений оригинального ранга документа 515 равен "2", что является абсолютной разницей между оригинальным и измененным рангом документа 515. Это означает, то измененная оценка 715 ранжирования используется для инициирования изменений оригинального ранга документа 515. Например, для настоящей технологии может быть желательно, чтобы оператор приложения 160 ранжирования хотел собрать новый пользовательский фидбэк, связанный с документом 515, например, поскольку документ 515 теперь ранжирован выше, чем был изначально.
[142] Кроме того, документ 516 ранжирован седьмым в списке ранжированных документов 600 и ранжирован шестым в первом измененном списке ранжированных документов 800. Следовательно, уровень изменений оригинального ранга документа 516 равен "1", что является абсолютно разницей между оригинальным и измененным рангом документа 516.
[143] Другими словами, данный уровень изменений оригинального ранга данного документа представляет собой абсолютную разницу между оригинальным рангом данного документа (т.е. в списке ранжированных документов 600) и измененным рангом данного документа (т.е. в первом измененном списке ранжированных документом 800).
[144] В некоторых вариантах осуществления настоящей технологии, подразумевается, что данная оценка классовой связи вычисляется MLA 164 прогнозирования для изменения оригинального ранга соответствующего документа. Другими словами, данная оценка классовой связи может использоваться при увеличении уровня изменений оригинального ранга соответствующего документа.
[145] В некоторых вариантах осуществления настоящей технологии, любая из оценок классовой связи (например, оценки 541-547 классовой связи), которые были связаны с документами соответственно, может быть определена на основе пользовательского фидбэка (пользовательского выбора соответствующего документа, пользовательской жалобы на качество документа). Дополнительно, оценка классовой связи может быть определена на основе мета-признаков документа соответственно: типа документа (видеофрагмента, изображения, песни), метатегов документа и т.д.
[146] С учетом того, что оценки 545 и 546 классовой связи, которые связаны с документами 515 и 516 соответственно, сравнительно выше при сравнении с оценками классовой связи документов 511, 512, 513, 514 и 517, можно сказать, что уровень изменений оригинальных рангов документов 515 и 516 вырос, по меньшей мере частично, благодаря тому, что оценки 545 и 546 классовой связи соответственно выше, чем оценки 541, 542, 543, 544 и 547 классовой связи.
[147] Тем не менее, следует иметь в виду, что несмотря на то, что данная оценка классовой связи может быть выше для данного документа, уровень изменений оригинального ранга по-прежнему зависит от измененных оценок ранжирования других документов из множества документов 510. Тем не менее, чем выше оценка классовой связи для данного документа, тем вероятнее то, что уровень изменений оригинального ранга данного документа будет выше. Это означает, что, в общем случае, документы, связанные с высокими оценками классовой связи, более вероятно будут обладать высокими уровнями изменений их оригинальных рангов в сравнении с документами, связанными с низкими оценками классовой связи. Другими словами, подразумевается, что документы, которые обладают высокой вероятностью связи с заранее определенным классом документов, более вероятно будут обладать (более) высокими уровнями изменений их оригинальных рангов в сравнении с документами, которые обладают низкой вероятностью связи с заранее определенным классом документов.
[148] В некоторых вариантах осуществления настоящей технологии, подразумевается, что измененные ранги документов на отображаемой SERP, которые более вероятно будут частью заранее определенного класса документов, могут увеличивать число различных взаимодействий пользователей с этими документами без отрицательного эффекта на степень удовлетворенности пользователя отображаемой SERP. В самом деле, как показано на Фиг. 9. оригинальный ранг документа 515 (который связан с ограниченным предыдущим пользовательским фидбэком) был изменен, несмотря на то, что оригинальные ранги большинства релевантных документов 512 и 513 остаются без изменений.
Сценарий 2. Ранжирование на основе оценок ранжирования и оценок весовых коэффициентов классовой связи
[149] В других вариантах осуществления настоящей технологии, данная измененная оценка ранжирования для соответствующего документа может быть вычислена приложением 160 ранжирования в виде взвешенной суммы соответствующей оценки ранжирования, вычисленной MLA 162 ранжирования, и соответствующей оценки классовой связи, вычисленной MLA 164 прогнозирования. Другими словами, приложение 160 ранжирования может быть выполнено с возможностью вычислять каждую измененную оценку ранжирования на основе следующего уравнения:

Где:
ARSd - измененная оценка ранжирования, связанная с данным документом d из множества документов 510,
RSd - оценка ранжирования, связанная с данным документом d и вычисленная MLA 162 ранжирования,
CAVd - оценка классовой связи, связанная с данным документом d и вычисленная MLA 164 прогнозирования; и
Wd - весовой параметр, вычисленный приложением 160 ранжирования для данного документа d.
[150] В некоторых вариантах осуществления настоящей технологии, весовой параметр Wd может быть реализован для "нормализации" оценок классовой связи в отношении оценок ранжирования. Этот эффект нормализации весового фактора Wd может относиться к константе к нормализации, на основе которой вычисляется весовой фактор Wd.
[151] Эффект нормализации может быть необходим, если диапазон оценок классовой связи и оценки ранжирования считаются оператором "несовпадающими". Например, если диапазон оценок ранжирования находится между "0" и "10", и диапазон оценок классовой связи находится между "0" и "100", эти диапазоны могут считаться несовпадающими, поскольку данная оценка классовой связи будет весомее, чем соответствующая оценка ранжирования во время вычисления соответствующей измененной оценки ранжирования. Следовательно, в этом примере, константа к нормализации, которая основана на весовом факторе Wd, может составлять "0,01", например, для "нормализации" диапазона оценок классовой связи. Следует отметить, что в зависимости от конкретного варианта осуществления, константа к нормализации может быть выбрана эмпирически или может быть выбрана другим образом, подходящим для оператора приложения 160 ранжирования.
[152] В других вариантах осуществления технологии, весовой параметр Wd может использоваться при контроле уровня изменений оригинального ранга данного документа. Этот эффект контроля весового фактора Wd может относиться к параметру mp модуляции, на основе которого вычисляется весовой фактор Wd. Параметр mp модуляции может быть случайной величиной между -1 и 1. В некоторых вариантах осуществления технологии, параметр mp модуляции может быть выбран между -1 и 1 для каждого документа из множества документов 510.
[153] В некоторых вариантах осуществления настоящей технологии, этот эффект контроля может быть необходим, если оператор желает не только потенциально увеличить оригинальные ранги данных документов на основе их соответствующих оценок классовой связи, но также быть способным потенциально снизить оригинальные ранги документов на основе их соответствующих оценок классовой связи. В самом деле, параметр mp модуляции данного документа может быть положительным или отрицательным. В результате, если соответствующая оценка классовой связи умножается на параметр mp модуляции, соответствующая измененная оценка ранжирования данного документа будет уступать оценке ранжирования данного документа. Следовательно, измененный ранг данного документа более вероятно снизится в сравнении с оригинальным рангом данного документа.
[154] В других вариантах осуществления настоящей технологии, этот эффект контроля может также требоваться, если оператор желает снизить влияние оценок классовой связи на соответствующие уровни изменений оригинальных рангов. Как было упомянуто ранее, данная оценка классовой связи используется при увеличении соответствующего уровня изменений оригинального ранга соответствующего документа. В самом деле, данная оценка классовой связи добавляется к оценке ранжирования, которая может приводить к изменению оригинального ранга соответствующего документа. Чем выше данная оценка классовой связи, тем более вероятно, что соответствующий уровень изменения оригинального ранга будет увеличиваться. Тем не менее, поскольку в данном сценарии данная оценка классовой связи является взвешенной (т.е. умноженной) данным параметром mp модуляции, который находится между -1 и 1, данная оценка ранжирования будет одинаково или меньше изменена в сравнении с вариантом, когда данная оценка классовой связи не является взвешенной. Следовательно, уровень изменений оригинального ранга соответствующего документа более вероятно будет снижен, когда оценка классовой связи является взвешенной данным параметром mp модуляции в сравнении с вариантом, когда данная оценка классовой связи не является взвешенной.
[155] На Фиг. 10 представлен пример использования уравнения (1) приложением 160 ранжирования для вычисления множества измененных оценок 1010 ранжирования. Предположим, что MLA 162 ранжирования вычисляет множество оценок 540 ранжирования и MLA 164 прогнозирования вычисляет множество оценок 540 классовой связи. Тем не менее, в отличие от процедур вычисления в сценариях 1 и 2, множество измененных оценок 1010 ранжирования вычисляется на основе множества оценок 530 ранжирования, множества оценок 540 классовой связи и множества весовых параметров 1020.
[156] Для целей упрощения предположим, что диапазоны оценок классовой связи и оценок ранжирования были выбраны подходящим образом и, следовательно, константа к нормализации может быть равна "1". В результате, поскольку соответствующий весовой параметр Wd является результатом соответствующей константы k нормализации и соответствующего параметра mp модуляции, предположим, для простоты понимания, что множество весовых параметров 1020 является множеством параметров 1020 модуляции.
[157] Как было упомянуто ранее, каждый из множества параметров 1020 модуляции может быть выбран между -1 и 1 для каждого документа из множества документов 510. В одном примере, приложение 160 ранжирования может вычислять, что:
- Первый параметр 1021 модуляции составляет 0,5;
- Второй параметр 1022 модуляции составляет -0,75;
- Третий параметр 1023 модуляции составляет 0,9;
- Четвертый параметр 1024 модуляции составляет -0,75;
- Пятый параметр 1025 модуляции составляет 0,9;
- Шестой параметр 1026 модуляции составляет 0,5; и
- Седьмой параметр 1027 модуляции составляет 0,5.
[158] Для упрощения описания, поскольку параметры 1021, 1023, 1025, 1026 и 1027 модуляции из множества параметров 1020 модуляции являются положительными, их соответствующие измененные оценки 1011, 1013, 1015, 1016 и 1017 ранжирования из множества измененных оценок 1010 ранжирования превышают их соответствующие оценки 531, 533, 535, 536 и 537 ранжирования. В другом примере, поскольку параметры 1022 и 1024 модуляции из множества параметров 1020 модуляции являются отрицательными, их соответствующие измененные оценки 1012 и 1014 ранжирования из множества измененных оценок 1010 ранжирования превышают их соответствующие оценки 532 и 534 ранжирования.
[159] Следовательно, подразумевается, что в некоторых вариантах осуществления технологии, данный параметр модуляции используется для того, чтобы соответствующая измененная оценка ранжирования была выше или ниже, чем соответствующая оценка ранжирования в зависимости от знака данного параметра модуляции. Другими словами, данный параметр модуляции может способствовать не только увеличению, но и уменьшению соответствующей оценки ранжирования.
[160] В некоторых вариантах осуществления настоящей технологии, приложение 160 ранжирования может быть выполнено с возможностью выполнять ранжирование всех документов из множества документов 510 на основе их соответствующих измененных оценок ранжирования из множества измененных оценок 1010 ранжирования. Приложение 160 ранжирования может выполнять ранжирование документов из множества документов 510 в убывающем порядке соответствующих оценок 530 ранжирования.
[161] Со ссылкой на Фиг. 11, все измененные оценки ранжирования из множества измененных оценок 1010 ранжирования ранжируются приложением 160 ранжирования во второй список измененных ранжированных оценок 1102 ранжирования. В результате, все документы из множества документов 510 могут быть ранжированы в соответствии с соответствующим рангом соответствующей измененной оценки ранжирования во втором списке ранжированных измененных оценок 1102 ранжирования.
[162] Таким образом, все документы из множества документов 510 могут быть ранжированы приложением 160 ранжирования во второй измененный список ранжированных документов 1100. Для простоты понимания, после ранжирования документов из множества документов 510 в убывающем порядке соответствующих измененных оценок 530 ранжирования из второго измененного списка измененных оценок 1102 ранжирования:
- Документ 512 ранжирован первым во втором измененном списке ранжированных документов 1100;
- Документ 513 ранжирован вторым во втором измененном списке ранжированных документов 1100;
- Документ 515 ранжирован третьим во втором измененном списке ранжированных документов 1100;
- Документ 517 ранжирован четвертым во втором измененном списке ранжированных документов 1100;
- Документ 514 ранжирован пятым во втором измененном списке ранжированных документов 1100;
- Документ 511 ранжирован шестым во втором измененном списке ранжированных документов 1100; и
- Документ 516 ранжирован седьмым во втором измененном списке ранжированных документов 1100.
[163] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может предоставлять пользовательскому устройству 104 второй измененный список ранжированных документов 1100. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью создавать пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную со вторым измененным списком ранжированных документов 1100 (в отличие от списка ранжированных документов 600 или первого измененного списка ранжированных документов 800) и всю информацию, необходимую для отображения SERP со множеством документов 510, которые были ранжированы в соответствии со вторым измененным списком ранжированных документов 1100.
[164] На Фиг. 12 представлено сравнение между оригинальными рангами из множества документов 510 в соответствии со списком ранжированных документов 600, измененными рангами из множества документов 510 в соответствии с первым измененным списком ранжированных документов 800 и измененными рангами из множества документов 510 в соответствии со вторым измененным списком ранжированных документов 1100. Следует отметить, что оригинальные ранги по меньшей мере некоторых документов были изменены.
[165] Конкретнее, документы 512 и 513 ранжированы как первый и второй, соответственно, в списке ранжированных документов 600, первом измененном списке ранжированных документов 800 и втором измененном списке ранжированных документов 1100. Это означает, что документы 512 и 513 ранжированы как наиболее релевантные документы из множества документов 510 в соответствии со списком ранжированных документов 600, первым измененном списком ранжированных документов 800 и вторым измененном списком ранжированных документов 1100. В результате, некоторые варианты осуществления настоящей технологии позволяют изменять оригинальные ранги некоторых документов без изменения оригинальных рангов наиболее релевантных документов для запроса 504.
[166] Также, документ 515 ранжирован выше в первом и втором измененных списках ранжированных документов 800 и 1100 в сравнении со списком ранжированных документов 600. Уровень изменений оригинального ранга документа 515 может быть по меньшей мере частично инициирован соответствующей оценкой 545 классовой связи. В самом деле, поскольку вероятность связи документа 515 с классом документов "Хорошо" высока, уровень изменений оригинального ранга документа 515 также высок; в этом случае, уровень изменений оригинального ранга документа 515 является наиболее высоким уровнем изменений среди всех документов из множества документов 510.
[167] Далее, документ 516 связан с уровнем изменений оригинального ранга " 1" в первом измененном списке ранжированных документов 800. Тем не менее, документ 516 связан с уровнем изменений оригинального ранга "0" во втором измененном списке ранжированных документов 1100. Это снижение уровня изменений оригинального ранга документа 516 с "1" на "0" между первым измененным списком ранжированных документов 800 и вторым измененным списком ранжированных документов 1100, по меньшей мере частично связано с шестым параметром 1026 модуляции, который используется при контроле уровня изменений оригинального ранга документа 516.
[168] После предоставления пакета 195 данных SERP пользовательскому устройству 104, фаза использования приложения 160 ранжирования может считаться завершенной.
[169] Как было упомянуто ранее со ссылкой на Фиг. 5, документ 515 связан с моментом 525 сбора предыдущего пользовательского фидбэка, который считается ограниченным предыдущим пользовательским фидбэком. Это означает, что пользователи поисковой системы ранее не "взаимодействовали" с документом 515 или не достаточно его "просматривали". Подразумевается, что в некоторых вариантах осуществления настоящей технологии, желателен новый пользовательский фидбэк для документа 515.
[170] Как показано на Фиг. 12, измененный ранг документа 515 в первом и втором измененных списках ранжированных документов 800 и 1100 выше, чем оригинальный ранг документа 515 в списке ранжированных документов 600. Следовательно, для увеличения вероятности пользовательского взаимодействия с документом 515, сервер 132 ранжирования может предоставлять пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную с любым из первого и второго измененных списков ранжированных документов 800 и 1100 и всю информацию, которая необходима для инициирования отображения SERP со множеством документов 510, которые были ранжированы в соответствии с любым из первого и второго измененных списков ранжированных документов 800 и 1100.
[171] В результате предоставления множества документов 510, ранжированных в соответствии с любым из первого и второго измененных списков ранжированных документов 800 и 1100, пользовательское устройство 104 может отображать пользователю SERP с документом 515, который ранжирован третьим на SERP в отличие от отображения пользователю SERP с документом 515, который был ранжирован пятым на SERP.
[172] В самом деле, поскольку документ 515 ранжирован выше в любом из первого и второго измененных списков ранжированных документов 800 и 1100, чем в списке ранжированных документов 600, вероятность пользовательского взаимодействия с документом 515 может увеличиться (когда пользователю предоставлен любой из первого и второго измененных списков ранжированных документов 800 и 110 в сравнении с предоставлением списка ранжированных документов 600), поскольку пользователь с большей вероятностью выберет документ 515, когда он ранжирован третьим, чем когда он ранжирован пятым. Подразумевается, что изменение оригинального ранга документа 515 может быть использовано при увеличении вероятности пользовательского взаимодействия с документом 515.
[173] Пользователь пользовательского устройства 104 может взаимодействовать с документом 515 на SERP. В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может быть выполнен с возможностью собирать новый пользовательский фидбэк, который предоставляется пользователем пользовательского устройства 104, связанного с документом 515, ранжированным в соответствии с измененной оценкой 715 ранжирования (т.е. в соответствии с первым измененным списком ранжированных документов 800) или измененной оценкой 1015 ранжирования (т.е. в соответствии со вторым измененным списком ранжированных документов 1100). Следовательно, можно сказать, что документ 515 может быть связан с расширенным предыдущим пользовательским фидбэком, который включает в себя момент 525 сбора предыдущего пользовательского фидбэка (т.е. ограниченный предыдущий пользовательский фидбэк) и новый пользовательский фидбэк, собранный после взаимодействия пользователя с документом 515, который был ранжирован третьим на SERP.
[174] В дополнительных вариантах осуществления технологии, сервер 132 ранжирования может быть выполнен с возможностью осуществлять сохранение нового пользовательского фидбэка, связанного с документом 515, в поисковой базе 134 данных и/или в базе 136 данных обучения. Альтернативно, сервер 132 ранжирования может обновлять момент 525 сбора предыдущего пользовательского фидбэка путем связывания и сохранения нового пользовательского фидбэка с предыдущим пользовательским фидбэком 525. Другими словами, сервер 132 ранжирования может сохранять расширенный пользовательский фидбэк в связи с документом 515.
[175] В другом варианте осуществления технологии, поскольку документ 515 теперь связан с расширенным пользовательским фидбэком, в отличие от связи с моментом 525 сбора предыдущего пользовательского фидбэка (т.е. ограниченным предыдущим пользовательским фидбэком), документ 515 может быть использован во время "переобучения" MLA 162 ранжирования. В самом деле, сервер 132 ранжирования может быть выполнен с возможностью запрашивать человека-асессора назначить размеченный класс документу 515 из множества размеченных людьми-асессорами классов и сохранять таким образом назначенный размеченный класс в связи с документом 515. Альтернативно, данный размеченный класс мог быть уже назначен человеком-асессором и ранее сохранен в связи с документом 515.
[176] Следовательно, может быть создан новый обучающий объект, который содержит запрос 504, документ 515, расширенный пользовательский фидбэк (т.е. момент 525 сбора предыдущего пользовательского фидбэка и новый пользовательский фидбэк) и таким образом назначенный размеченный класс. В результате, MLA 162 ранжирования может быть "переобучен" на основе расширенного набора обучающих объектов, которые включают в себя набор обучающих объектов 202 и новый обучающий объект, связанный с документом 515.
[177] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может быть выполнен с возможностью выполнять способ 1300, блок-схема которого схематически представлена на Фиг. 13. Различные этапы способа 1300 будут описаны далее более подробно.
ЭТАП 1302: Вычисление оценки ранжирования для каждого документа из множества документов
[178] Способ 1300 начинается с того, что сервер 132 ранжирования вычисляет соответствующую измененную оценку ранжирования для каждого документа из множества документов 510. На Фиг. 5, множество документов 510 содержит документы 511, 512, 513, 514, 515, 516 и 517.
[179] Для вычисления соответствующей оценки ранжирования для каждого из множества документов 510, сервер 132 ранжирования может вводить в MLA 162 ранжирования информацию 502 о запросах-документах, которая содержит запрос 504 и множество документов 510, и набор моментов 520 сбора предыдущего пользовательского фидбэка, который содержит соответствующие моменты 521, 522, 523, 524, 525, 526 и 527 сбора предыдущего пользовательского фидбэка.
[180] В результате, MLA 162 ранжирования может вычислять множество оценок 530 ранжирования, которое содержит соответствующую оценку ранжирования для каждого из множества документов 510.
Данная оценка ранжирования может указывать на расчетную релевантность соответствующего документа для запроса 504.
[181] В некоторых вариантах осуществления настоящей технологии, соответствующая оценка ранжирования может указывать на оригинальный ранг соответствующего документа в списке ранжированных документов 600, как показано на Фиг. 6. Список ранжированных документов 600 содержит все документы из множества документов 510, которые ранжированы в порядке убывания их соответствующих оценок ранжирования из множества оценок 530 ранжирования.
ЭТАП 1304: Вычисление оценки классовой связи для каждого документа из множества документов.
[182] Способ 1300 продолжается на этапе 1304, где сервер 132 ранжирования вычисляет соответствующую оценку классовой связи для каждого документа из множества документов 510. Со ссылкой на Фиг. 5, для вычисления соответствующей оценки классовой связи для каждого из множества документов 510, сервер 132 ранжирования может вводить в MLA 164 прогнозирования информацию 502 о запросах-документах, которая содержит запрос 504 и множество документов 510.
[183] В результате, MLA 164 прогнозирования может вычислять множество оценок 540 классовой связи, которое содержит соответствующую оценку классовой связи для каждого из множества документов 510.
[184] В некоторых вариантах осуществления настоящей технологии, данная оценка классовой связи может являться вероятностью связи соответствующего документа с соответствующим заранее определенным классом документов, который был определен оператором приложения 160 ранжирования. Оператор может определять заранее определенный класс документов из множества размеченных людьми-асессорами классов документов.
[185] Например, когда множество из размеченных людьми-асессорами классов включает в себя классы документов "Плохо", "Нормально", "Хорошо", "Отлично" и "Идеально", оператор приложения 160 ранжирования может выполнять MLA 164 прогнозирования для выведения вероятности связи данного документа с одним из классов "Плохо", "Нормально", "Хорошо", "Отлично" и "Идеально". Таким образом, оператор может выполнять MLA 164 прогнозирования для "изучения" прогнозирования вероятности, с которой данный документ будет связан, например, с классом "Хорошо". В другом примере, оператор может выполнять MLA 164 прогнозирования для "изучения" прогнозирования вероятности, с которой данный документ будет связан, например, с классом "Идеально".
[186] В других вариантах осуществления настоящей технологии, данная оценка классовой связи используется при увеличении уровня изменений оригинального ранга соответствующего документа.
ЭТАП 1306: Вычисление измененной оценки ранжирования для каждого документа из множества документов
[187] Способ 1300 продолжается на этапе 1306, где сервер 132 ранжирования вычисляет измененную оценку ранжирования для каждого документа из множества документов 510 на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи.
[188] В некоторых вариантах осуществления настоящей технологии и со ссылкой на Фиг. 7, представлено множество измененных оценок 710 ранжирования, которое включает в себя соответствующую измененную оценку ранжирования для каждого из множества документов 510. Можно сказать, что в некоторых вариантов осуществления настоящей технологии, данная измененная оценка ранжирования может быть вычислена в виде суммы соответствующей оценки ранжирования и соответствующей оценки классовой связи для каждого из множества документов 510.
[189] Все документы из множества документов 510 могут быть ранжированы в соответствии с соответствующей измененной оценкой ранжирования из множества измененных оценок 710 ранжирования. В результате, сервер 132 ранжирования может создавать первый измененный список ранжированных документов 800, как показано на Фиг. 8. Данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа для запроса.
[190] В некоторых вариантах осуществления настоящей технологии, чем выше оценка классовой связи для данного документа, тем вероятнее то, что уровень изменений оригинального ранга данного документа будет выше. Это означает, что, в общем случае, документы, связанные с высокими оценками классовой связи, более вероятно будут обладать высокими уровнями изменений их оригинальных рангов в сравнении с документами, связанными с низкими оценками классовой связи. Другими словами, подразумевается, что документы, которые обладают высокой вероятностью связи с заранее определенным классом документов, более вероятно будут обладать высокими уровнями изменений их оригинальных рангов в сравнении с документами, которые обладают низкой вероятностью связи с заранее определенным классом документов.
[191] Можно сказать, что уровень изменений оригинального ранга документа 515 (т.е. в списке ранжированных документов 600) увеличился, по меньшей мере частично, благодаря тому факту, что оценка 545 классовой связи, которая связана с документом 515, является высокой.
[192] В других вариантах осуществления настоящей технологии, данная измененная оценка ранжирования может быть вычислена в виде взвешенной суммы соответствующей оценки ранжирования и соответствующей оценки классовой связи для каждого из множества документов 510. В самом деле, данная измененная оценка ранжирования для соответствующего документа может быть вычислена в соответствии с уравнением 1.
[193] Когда измененные оценки ранжирования из множества измененных оценок ранжирования 1010 (см. Фиг. 10) вычислена как взвешенные сумма соответствующих оценок ранжирования и соответствующих оценок классовой связи, соответствующие весовые параметры могут "нормализовать" диапазоны оценок ранжирования и оценок классовой связи, если оператор приложения 160 ранжирования считает их "несовпадающими". Этот эффект нормализации может относиться к константе к нормализации, на основе которой вычисляется весовой параметр. Дополнительно, соответствующие весовые параметры могут контролировать уровни изменений оригинальных рангов соответствующих документов. В самом деле, этот эффект контроля может позволить как увеличить соответствующую измененную оценку ранжирования в сравнении с соответствующей оценкой ранжирования, так и уменьшить ее. Этот эффект контроля может также снизить влияние соответствующей оценки классовой связи на соответствующий уровень изменений оригинального ранга соответствующей документа.
[194] На Фиг. 10 представлены измененные оценки ранжирования из множества измененных оценок 1010 ранжирования вычислено как взвешенные суммы соответствующих оценок ранжирования и соответствующих оценок классовой связи. На Фиг. И представлен второй измененный список ранжированных документов 1100, которые были ранжированы на основе соответствующих измененных оценок ранжирования, показанных на Фиг. 10.
ЭТАП 1308: Инициирование отображения SERP с документами, которые ранжированы на основе измененных оценок ранжирования
[195] Способ 1300 завершается на этапе 1308, где сервер 132 ранжирования инициирует отображение SERP с документами из множества документов 510, которые были ранжированы на основе соответствующих измененных оценок ранжирования.
[196] В некоторых вариантах осуществления настоящей технологии, сервер 132 ранжирования может предоставлять пользовательскому устройству 104 первый измененный список ранжированных документов 800. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью создавать пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную с первым измененным списком ранжированных документов 800, и всю информацию, необходимую для инициирования отображения SERP со множеством документов 510, который был ранжирован в соответствии с первым измененным списком ранжированных документов 800.
[197] В других вариантах осуществления настоящей технологии, сервер 132 ранжирования может предоставлять пользовательскому устройству 104 список ранжированных документов 1100. С этой целью, сервер 132 ранжирования может быть выполнен с возможностью создавать пакет 195 данных SERP, как показано на Фиг. 1, который содержит информацию, связанную со вторым списком ранжированных документов 1100, и всю информацию, необходимую для отображения SERP со множеством документов 510, которые были ранжирован в соответствии со вторым измененным списком ранжированных документов 1100.
[198] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
[199] Варианты осуществления настоящей технологии могут быть кратко изложены в пронумерованных пунктах.
[200] ПУНКТ 1. Способ (1300) ранжирования множества документов (510) на странице результатов поиска (SERP) в ответ на запрос (504), связанный с пользователем поисковой системы, способ (1300) используется на сервере (132), который выполняет поисковую систему, способ (1300) включает в себя:
- вычисление (1302), путем ранжирования алгоритма (162) машинного обучения, выполняемого сервером (132), оценки ранжирования для каждого документа из множества документов (510), данная оценка ранжирования указывает на расчетную релевантность соответствующего документа запросу (504) и оригинальный ранг соответствующего документа на SERP;
- вычисление (1304) сервером (132) оценки классовой связи для каждого документа из множества документов (510), данная оценка классовой связи является вероятностью связи соответствующего документа с заранее определенным классом документов, которые были определены оператором, данная оценка классовой связи используется при увеличении степени изменения оригинального ранга соответствующего документа;
- вычисление (1306) сервером (132) измененной оценки ранжирования для каждого документа из множества документов (510) на основе соответствующей оценки ранжирования, и соответствующей оценки классовой связи, данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа запросу (504); и
- инициирование (1308) сервером (132) отображения SERP с документами из множества документов (510), которые были ранжированы на основе соответствующей измененной оценки ранжирования.
[201] ПУНКТ 2. Способ (1300) по п. 1, в котором множество документов (510) включает в себя по меньшей один документ (515), связанный с ограниченным предыдущим пользовательским фидбэком (525) и в котором измененная оценка (715, 105) ранжирования по меньшей мере одного документа (515) является одной из самых высоких или самых низких для соответствующей оценки (535) ранжирования.
[202] ПУНКТ 3. Способ (1300) по п. 2, в котором способ (1300) далее включает в себя сбор сервером (132) пользовательского фидбэка, связанного по меньшей мере с одним документом (515), когда пользователь взаимодействует по меньшей мере с одним документом (515), ранжированным на основе соответствующей измененной оценки (715, 1015) ранжирования на SERP.
[203] ПУНКТ 4. Способ (1300) по п. 3, в котором способ (1300) также включает в себя хранение сервером (132) пользовательского фидбэка, связанного по меньшей мере с одним документом (515) в хранилище (134).
[204] ПУНКТ 5. Способ (1300) по п. 4, в котором ранжирование алгоритма (162) машинного обучение было обучено на основе, по меньшей мере набора обучающих документов, соответственно связанных с предыдущим пользовательским фидбэком для каждого обучающего документа из набора обучающих документов, и соответственно связанной оценки человека-асессора для каждого обучающего документа из набора обучающих документов, способ (1300) далее включает в себя:
- переобучение сервером (132) MLA ранжирования (162) на основе расширенного набора обучающих документов и соответственно связанного предыдущего пользовательского фидбэка для каждого обучающего документа из расширенного набора обучающих документов, расширенный набор обучающих документов включает в себя обучающие документы из набора обучающих документов и по меньшей мере один документ (515).
[205] ПУНКТ 6. Способ (1300) по п. 4, в котором измененная оценка (712, 1015) ранжирования используется для инициирования изменений оригинального ранга по меньшей мере одного документа (515).
[206] ПУНКТ 7. Способ (1300) по п. 6, в котором изменение оригинального ранга по меньшей мере одного документа (515) используется при увеличении вероятности пользовательского взаимодействия по меньшей мере с одним документом (515) в сравнении с оригинальным рангом.
[207] ПУНКТ 8. Способ (1300) по п. 1, в котором вычисление (1304) оценки классовой связи для каждого документа выполняется алгоритмом (164) машинного обучения прогнозирования, который реализован сервером (132), алгоритм (164) машинного обучения прогнозирования был обучен на основе второго набора обучающих документов и соответствующего размеченного людьми-асессорами класса каждого обучающего документа из второго набора документов, каждый соответствующий размеченный людьми-асессорами класс является одним из множества размеченных людьми-асессорами классов.
[208] ПУНКТ 9. Способ (1300) по п. 8, в котором для данного документа из множества документов (510), MLA (164) выдает вероятность того, что данный документ будет связан с заранее определенным классом документов, заранее определенный класс является одним из множества размеченных людьми-асессорами классов.
[209] ПУНКТ 10. Способ (1300) по п. 9, в котором набор обучающих документов и второй набор обучающих документов содержат по меньшей мере один идентичный обучающий документ.
[210] ПУНКТ 11. Способ (1300) по п. 1, в котором данный документ, обладающий высокой вероятностью разметки в заранее определенный класс, скорее всего будет связан с высоким уровнем изменений оригинального ранга данного документа, чем другой документ, обладающий низкой вероятностью связи с заранее определенным классом.
[211] ПУНКТ 12. Способ (1300) по п. 1, в котором способ (1300) дополнительно включает в себя:
- вычисление сервером (132) параметра модуляции для каждого документа из множества документов (510), данный параметр модуляции используется при контроле уровня изменений оригинального ранга соответствующего документа;
и в котором вычисление (1306) сервером (132) измененной оценки ранжирования для каждого документа из множества документов (510) основано на соответствующей оценке ранжирования, соответствующей оценки классовой связи и соответствующем параметре модуляции.
[212] ПУНКТ 13. Способ (1300) по п. 12, в котором вычисление (1306) сервером (132) измененной оценки ранжирования для каждого документа из множества документов (510) включает в себя применение формулы:
ARSd=RSd+Wd*CAVd
[213] ПУНКТ 14. Сервер (132) ранжирования множества документов (510) на странице результатов поиска (SERP) в ответ на запрос (504), связанный с пользователем поисковой системы, сервер (132) исполняет поисковую систему, сервер (132) выполнен с возможностью выполнять способ (1300) по любому из пп. 1-13.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТА РЕКОМЕНДУЕМОГО СОДЕРЖИМОГО ПОЛЬЗОВАТЕЛЮ | 2017 |
|
RU2699574C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Способ и система определения положений элементов в ранжировании содержимого системой ранжирования | 2021 |
|
RU2831411C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |



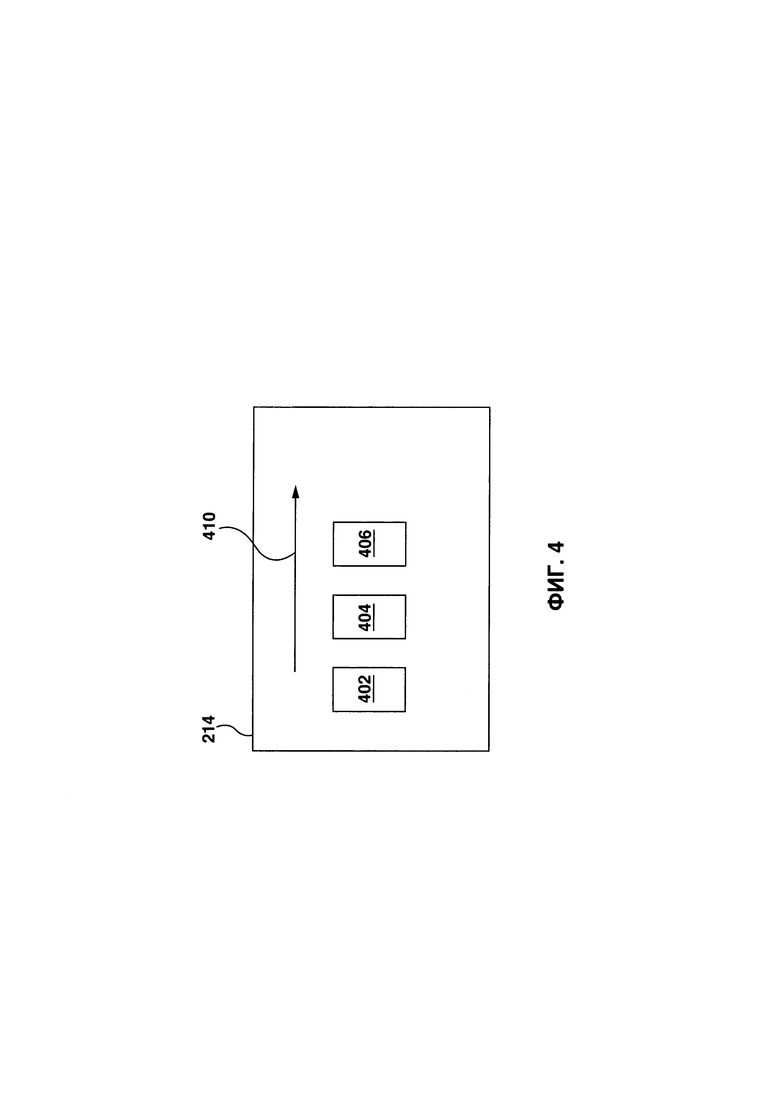


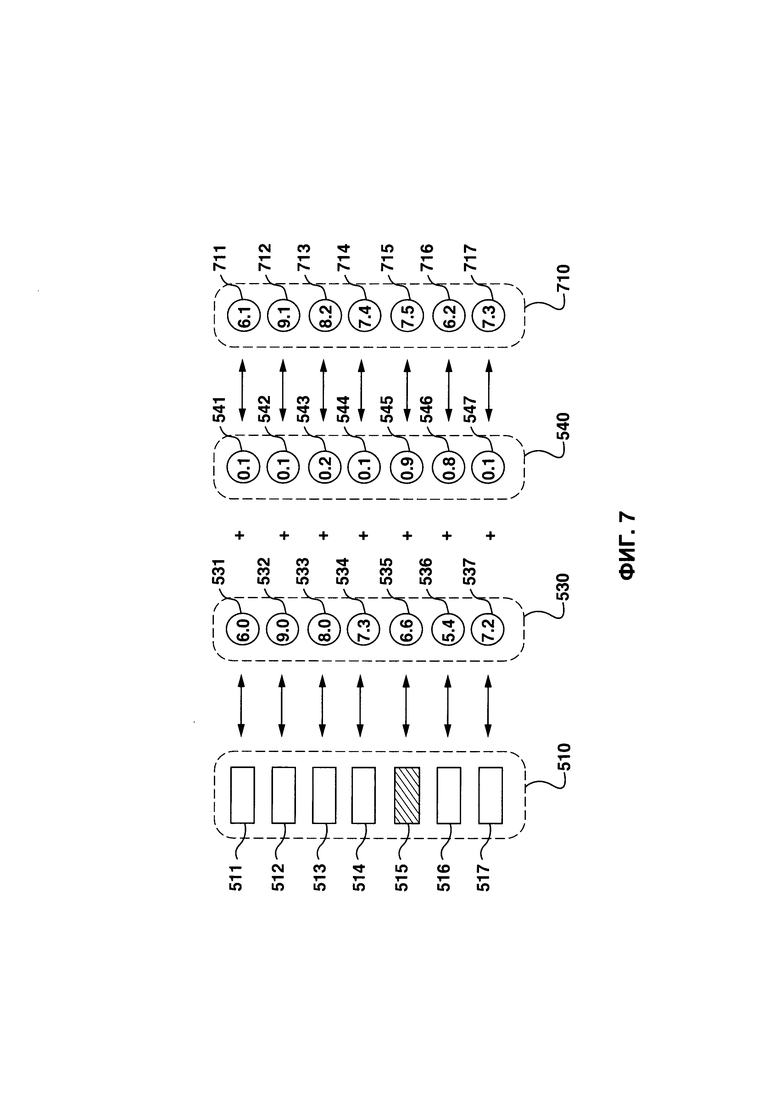






Изобретение относится к способу и серверу ранжирования множества документов на странице результатов поиска (SERP). Технический результат заключается в повышении эффективности ранжировании найденных документов. В способе выполняют вычисление, с использованием алгоритма машинного обучения (MLA), оценки ранжирования для каждого документа из множества документов, указывающей на расчетную релевантность соответствующего документа запросу и оригинальный ранг соответствующего документа на SERP, вычисление оценки классовой связи для каждого документа из множества документов, являющейся вероятностью связи соответствующего документа с заранее определенным классом документов и используемой при увеличении уровня изменения оригинального ранга соответствующего документа, представляющего собой разницу между оригинальным и измененным рангом документа, вычисление измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи, указывающей на измененную релевантность соответствующего документа запросу, и инициирование отображения SERP с документами, которые были ранжированы на основе соответствующей измененной оценки ранжирования. 2 н. и 18 з.п. ф-лы, 13 ил.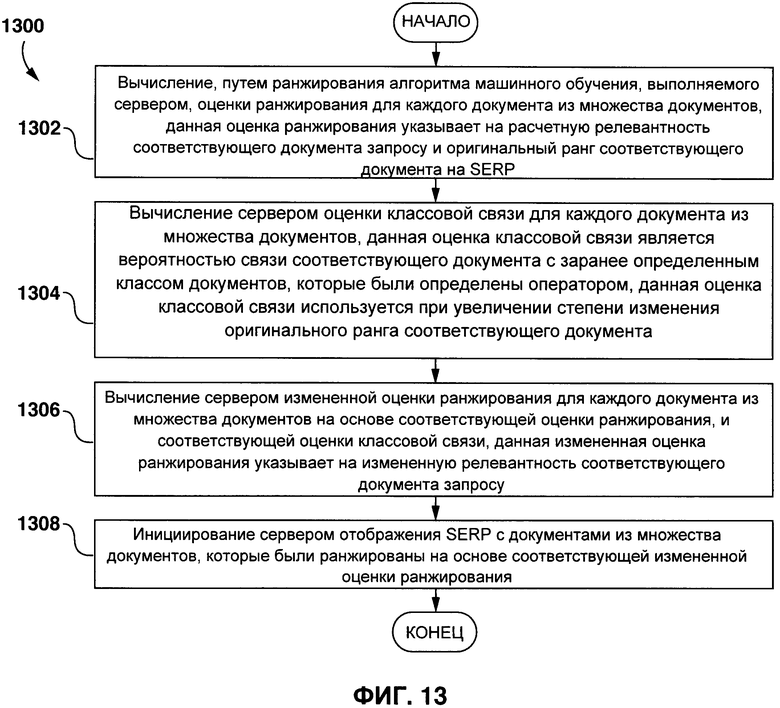
1. Способ ранжирования множества документов на странице результатов поиска (SERP) в ответ на запрос, связанный с пользователем поисковой системы, способ используется на сервере, который выполняет поисковую систему, способ включает в себя:
вычисление, с использованием алгоритма машинного обучения (MLA), выполняемого сервером, оценки ранжирования для каждого документа из множества документов, данная оценка ранжирования указывает на расчетную релевантность соответствующего документа запросу и оригинальный ранг соответствующего документа на SERP;
вычисление сервером оценки классовой связи для каждого документа из множества документов, данная оценка классовой связи является вероятностью связи соответствующего документа с заранее определенным классом документов, которые были определены оператором, данная оценка классовой связи используется при увеличении уровня изменения оригинального ранга соответствующего документа, представляющего собой разницу между оригинальным и измененным рангом документа;
вычисление сервером измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи, данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа запросу, и
инициирование сервером отображения SERP с документами из множества документов, которые были ранжированы на основе соответствующей измененной оценки ранжирования.
2. Способ по п. 1, в котором множество документов включает в себя по меньшей один документ, связанный с ограниченным предыдущим пользовательским фидбэком, и в котором измененная оценка ранжирования по меньшей мере одного документа является одной из самых высоких или самых низких для соответствующей оценки ранжирования.
3. Способ по п. 2, в котором способ далее включает в себя сбор сервером пользовательского фидбэка, связанного по меньшей мере с одним документом, когда пользователь взаимодействует по меньшей мере с одним документом, ранжированным на основе соответствующей измененной оценки ранжирования на SERP.
4. Способ по п. 3, в котором способ также включает в себя хранение сервером пользовательского фидбэка, связанного по меньшей мере с одним документом в хранилище.
5. Способ по п. 4, в котором ранжирование алгоритма машинного обучения было обучено на основе по меньшей мере набора обучающих документов, соответственно связанных с предыдущим пользовательским фидбэком для каждого обучающего документа из набора обучающих документов, и соответственно связанной оценки человека-асессора для каждого обучающего документа из набора обучающих документов, способ далее включает в себя
переобучение сервером MLA ранжирования на основе расширенного набора обучающих документов и соответственно связанного предыдущего пользовательского фидбэка для каждого обучающего документа из расширенного набора обучающих документов, расширенный набор обучающих документов включает в себя обучающие документы из набора обучающих документов и по меньшей мере один документ.
6. Способ по п. 4, в котором измененная оценка ранжирования используется для инициирования изменений оригинального ранга по меньшей мере одного документа.
7. Способ по п. 6, в котором изменение оригинального ранга по меньшей мере одного документа используется при увеличении вероятности пользовательского взаимодействия по меньшей мере с одним документом в сравнении с оригинальным рангом.
8. Способ по п. 1, в котором вычисление оценки классовой связи для каждого документа выполняется алгоритмом машинного обучения прогнозирования, который реализован сервером, алгоритм машинного обучения прогнозирования был обучен на основе второго набора обучающих документов и соответствующего размеченного людьми-асессорами класса каждого обучающего документа из второго набора документов, каждый соответствующий размеченный людьми-асессорами класс является одним из множества размеченных людьми-асессорами классов.
9. Способ по п. 8, в котором для данного документа из множества документов MLA выдает вероятность того, что данный документ будет связан с заранее определенным классом документов, заранее определенный класс является одним из множества размеченных людьми-асессорами классов.
10. Способ по п. 9, в котором набор обучающих документов и второй набор обучающих документов содержат по меньшей мере один идентичный обучающий документ.
11. Способ по п. 1, в котором данный документ, обладающий высокой вероятностью разметки в заранее определенный класс, скорее всего будет связан с более высоким уровнем изменений оригинального ранга данного документа, чем другой документ, обладающий низкой вероятностью связи с заранее определенным классом.
12. Способ по п. 1, дополнительно включающий в себя
вычисление сервером параметра модуляции для каждого документа из множества документов, данный параметр модуляции используется при контроле уровня изменений оригинального ранга соответствующего документа,
и в котором вычисление сервером измененной оценки ранжирования для каждого документа из множества документов основано на соответствующей оценке ранжирования, соответствующей оценке классовой связи и соответствующем параметре модуляции.
13. Способ по п. 12, в котором вычисление сервером измененной оценки ранжирования для каждого документа из множества документов включает в себя применение формулы
ARSd=RSd+Wd*CAVd.
14. Сервер ранжирования множества документов на странице результатов поиска (SERP) в ответ на запрос, связанный с пользователем поисковой системы, сервер выполняет поисковую систему, сервер выполнен с возможностью осуществлять:
вычисление, путем выполнения алгоритма машинного обучения (MLA) ранжирования, оценки ранжирования для каждого документа из множества документов, данная оценка ранжирования указывает на расчетную релевантность соответствующего документа запросу и оригинальный ранг соответствующего документа на SERP;
вычисление оценки классовой связи для каждого документа из множества документов, данная оценка классовой связи является вероятностью связи соответствующего документа с заранее определенным классом документов, которые были определены оператором, данная оценка классовой связи используется при увеличении уровня изменения оригинального ранга соответствующего документа, представляющего собой разницу между оригинальным и измененным рангом документа;
вычисление измененной оценки ранжирования для каждого документа из множества документов на основе соответствующей оценки ранжирования и соответствующей оценки классовой связи, данная измененная оценка ранжирования указывает на измененную релевантность соответствующего документа запросу, и
инициирование отображения SERP с документами из множества документов, которые были ранжированы на основе соответствующей измененной оценки ранжирования.
15. Сервер по п. 14, в котором множество документов включает в себя по меньшей один документ, связанный с ограниченным предыдущим пользовательским фидбэком, и в котором измененная оценка ранжирования по меньшей мере одного документа является одной из самых высоких или самых низких для соответствующей оценки ранжирования.
16. Сервер по п. 15, в котором сервер далее выполнен с возможностью осуществлять сбор пользовательского фидбэка, связанного по меньшей мере с одним документом, когда пользователь взаимодействует по меньшей мере с одним документом, ранжированным на основе соответствующей измененной оценки ранжирования на SERP.
17. Сервер по п. 16, в котором сервер также выполнен с возможностью сохранять пользовательский фидбэк, связанный по меньшей мере с одним документом в хранилище.
18. Сервер по п. 17, в котором ранжирование алгоритма машинного обучения было обучено на основе по меньшей мере набора обучающих документов, соответственно связанных с предыдущим пользовательским фидбэком для каждого обучающего документа из набора обучающих документов, и соответственно связанной оценки человека-асессора для каждого обучающего документа из набора обучающих документов, сервер далее выполнен с возможностью осуществлять
переобучение MLA ранжирования на основе расширенного набора обучающих документов и соответственно связанного предыдущего пользовательского фидбэка для каждого обучающего документа из расширенного набора обучающих документов, расширенный набор обучающих документов включает в себя обучающие документы из набора обучающих документов и по меньшей мере один документ.
19. Сервер по п. 17, в котором измененная оценка ранжирования используется для инициирования изменений оригинального ранга по меньшей мере одного документа.
20. Сервер по п. 19, в котором изменение оригинального ранга по меньшей мере одного документа используется при увеличении вероятности пользовательского взаимодействия по меньшей мере с одним документом в сравнении с оригинальным рангом.
| US 8935258 B2, 13.01.2015 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| РАНЖИРАТОР РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2608886C2 |

