ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Область техники
[0001] Настоящее изобретение относится к области обработки изображений, а именно к способу обработки изображений документов с помощью технологий Оптического распознавания символов (OCR) без потери данных.
Уровень техники
[0002] Системы Оптического распознавания символов (OCR) имеют широкое применение. Основным фактором в системе OCR является точность распознавания отдельных символов, поскольку большинство ошибок возникает на этапе распознавания символов. Для обеспечения высокой точности распознавания при OCR необходимо свести к минимуму количество ошибок при распознавании отдельных символов.
[0003] В современном обществе все большую роль играет переносимость документа между платформами. Так, документы с изображениями можно преобразовать из конкретного формата файла в другой формат файла, например, когда документ экспортируется в формат файла с возможностью поиска для дальнейшего хранения, отправки по электронной почте или для совместного использования с контактами социальной сети с целью рецензирования и комментирования и т.д. Максимальная эффективность такой конвертации, как в OCR процессах, при минимальном числе ошибок и минимальной потере информации является существенным преимуществом.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0004] Распространение переносимости документов обуславливает постоянно растущую потребность в эффективном преобразовании документов, в особенности документов, содержащих изображения, из одного формата в другой при сохранении целостности документа и сведения к минимуму потерь связанной с документом информации в результате такой конвертации. Кроме того, существует постоянная потребность в улучшении возможностей поиска в таких документах и соответствующей информации для повышения производительности и иных улучшений, например, удобства использования.
[0005] В частности, для удовлетворения этих потребностей предусматриваются различные варианты реализации конвертации без потерь в документы типа PDF. В одном таком варианте реализации, приводимом только в качестве примера, изначально имеется документ типа PDF, возможно имеющий первый текстовый слой. Оценивается качество первого текстового слоя. Выясняется, что первого текстового слоя не существует, либо этот слой неприемлемого качества. Для формирования второго текстового слоя распознается текст документа. Создается второй текстовый слой для поиска или копирования.
[0006] В дополнение к изложенному выше варианту реализации приводятся и другие примеры систем и вариантов реализации раскрываемого изобретения в виде компьютерных программ, с указанием их преимуществ.
[0007] Выше изложено краткое описание понятий в упрощенной форме. Оно будет более подробно раскрыто в детальном описании изобретения. Это описание сущности изобретения не предназначено для определения основных или существенных характеристик заявленного предмета или для определения объема заявленного предмета. Заявленный предмет не ограничивается вариантами осуществления, которые решают указанные выше проблемы полностью или частично.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ.
[0008] Для облегчения понимания всех перечисленных выше преимуществ изобретения в подробном описании изобретения будут использоваться ссылки на конкретные варианты его реализации, проиллюстрированные на приложенных чертежах. Учитывая, что эти чертежи отображают варианты реализации изобретения, и поэтому не могут рассматриваться как ограничивающие его объем, изобретение будет описано и объяснено более конкретно и детально с использованием прилагаемых чертежей, на которых:
[0009] Фиг. 1А является первой иллюстрацией конвертации в формат PDF с возможностью поиска, при которой теряется различная информация; в частности, на Фиг. 1А приведен документ типа PDF Image до конвертации;
[0010] На Фиг. 1АА приведен тот же документ, что и на Фиг. 1А, но после конвертации, при которой теряется информация в виде аннотаций (например, вставки текста), содержащаяся в документе PDF Image, приведенном на Фиг. 1A;
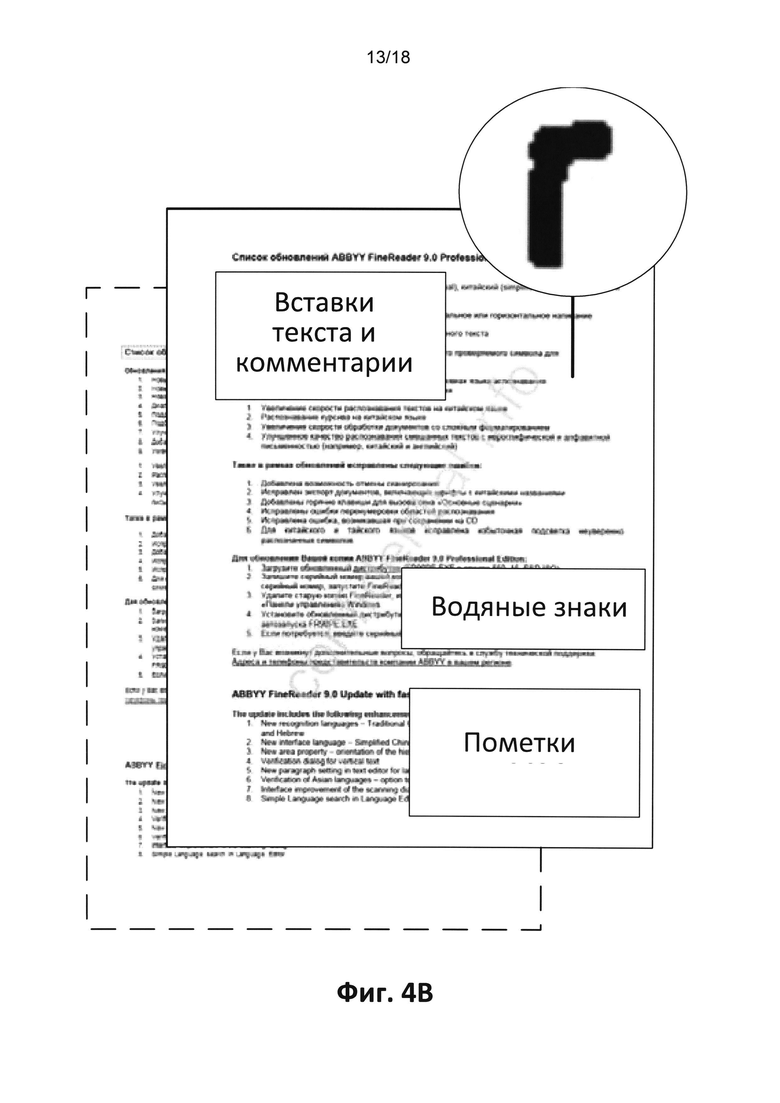
[0011] На Фиг. 1B приведен документ PDF Image + Text (PDF с возможностью поиска) содержащий аннотации, такие как вставки текста или комментарии, водяные знаки и пометки, до конвертации;
[0012] На Фиг. 1BB приведен тот же документ, что и на Фиг. 1B, но после конвертации, при которой теряется содержащаяся в документе информация в виде аннотаций;
[0013] На Фиг. 1С приведен документ PDF Normal, содержащий вставки текста или комментарии, изображения и пометки, до конвертации, при этом изображения представляют собой векторную графику;
[0014] На Фиг. 1СС приведен тот же документ что и на Фиг. 1С, но после конвертации, при которой теряется исходный текст, вставки текста или комментарии, и пометки, а изображения преобразованы в растровую графику;
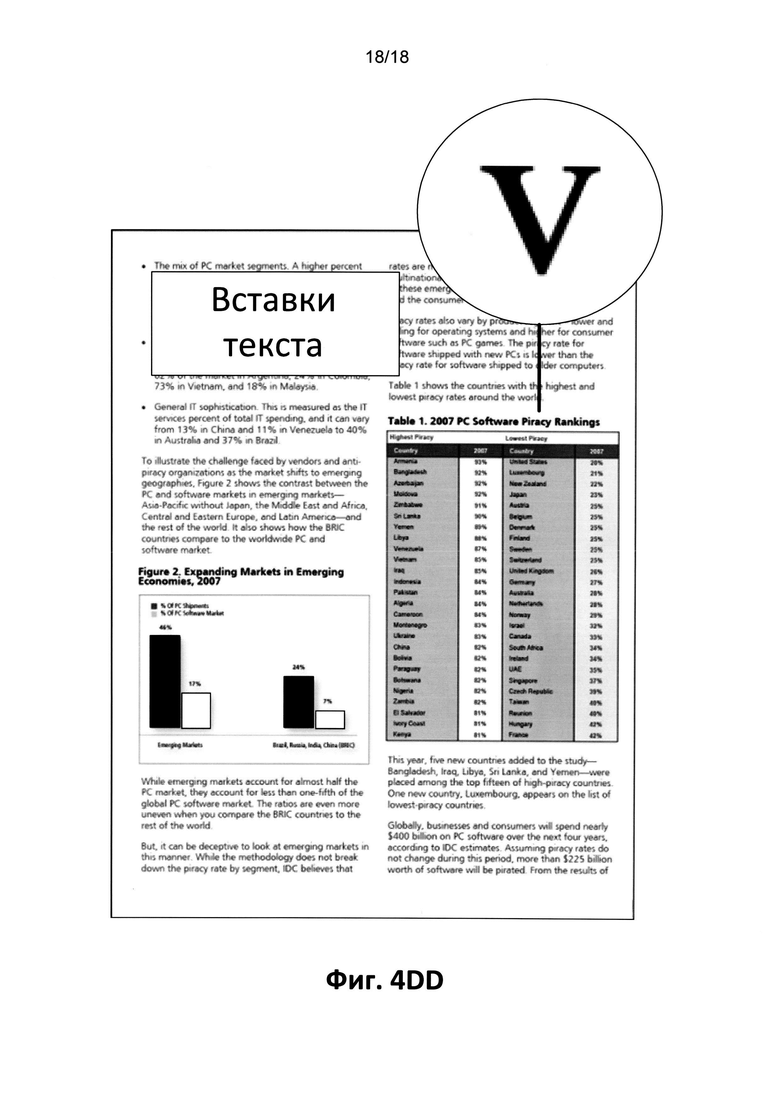
[0015] На Фиг. 1D приведен PDF-документ, в котором текст представлен в виде кривых, имеются вставки текста и векторные графические изображения, до конвертации;
[0016] На Фиг. 1DD приведен тот же документ, что и на Фиг. 1D, но после конвертации, при которой исходный текст был потерян, а векторные графические изображения были преобразованы в растровые графические изображения;
[0017] На Фиг. 2 приведена блок-схема иллюстративного метода эффективной конвертации документов без потерь в форму с возможностью поиска, в которой могут быть реализованы аспекты настоящего изобретения;
[0018] На Фиг. 3 приведена дополнительная блок-схема иллюстративного метода эффективной конвертации документов без потерь в форму с возможностью поиска, в которой также могут быть реализованы аспекты настоящего изобретения;
[0019] На Фиг. 4А приведена первая иллюстрация процесса конвертации в формат PDF с возможностью поиска в соответствии с одним из вариантов реализации настоящего изобретения, при которой в процессе конвертации сохраняется различная информация; в частности, на Фиг. 4А показан документа типа PDF Image до конвертации;
[0020] На Фиг. 4АА приведен тот же документ, что и на Фиг. 4А, но после конвертации, в процессе которой сохраняется информация в виде аннотации (в частности, вставки текста), содержащаяся в документе PDF Image, приведенном на Фиг. 1А;
[0021] На Фиг. 4B приведен документ PDF Image + Text (PDF с возможностью поиска) до конвертации, содержащий аннотации, такие как вставки текста или комментарии, водяные знаки и пометки, в дополнительном иллюстративном варианте реализации настоящего изобретения;
[0022] На Фиг. 4BB приведен тот же документ что и на Фиг. 4B, но после конвертации, также в соответствии с дополнительным вариантом реализации настоящего изобретения, при которой информация в виде аннотаций сохраняется;
[0023] На Фиг. 4С приведен документ PDF Normal, содержащий вставки текста или комментарии, изображения и пометки, до начала процесса конвертации в соответствии с третьим иллюстративным вариантом реализации настоящего изобретения, причем графическая информация содержится в документе в векторном виде;
[0024] На Фиг. 4СС приведен тот же документ, что и на Фиг. 4С, но после конвертации, также в соответствии с третьим вариантом реализации настоящего изобретения, при которой сохраняется исходный текст, вставки текста, комментарии и пометки, а графическая информация сохраняется в векторном виде;
[0025] На Фиг. 4D приведен PDF-документ с текстом, представленным в виде кривых, содержащий вставки текста, текст в векторной форме и векторные графические изображения до конвертации в соответствии с четвертым иллюстративным вариантом реализации изобретения;
[0026] На Фиг. 4DD приведен тот же документ, что и на Фиг. 4D, но после конвертации согласно четвертому варианту реализации изобретения, при которой сохраняется исходный текст и векторные графические изображения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0027] Как уже упоминалось, сохраняется потребность в эффективном механизме конвертации документов в необходимый для конкретной ситуации формат, например, для хранения с особыми свойствами. Выбранный формат с одной стороны должен обеспечивать автоматический поиск слова или словосочетания по тексту документа и высокое качество визуализации как графических, так и текстовых данных, с другой стороны файлы соответствующего формата должны иметь компактный размер. Предпринята попытка удовлетворить эти требования в одном из вариантов реализации изобретения использованием так называемого Portable Document Format (формата переносимых документов) или PDF.
[0028] PDF является популярным форматом для обмена документами. Однако далеко не все документы в формате PDF, полученные из разных источников (например, присланные коллегами, загруженные из интернета или полученные при сканировании), обладают свойствами удобными для хранения. Каждый PDF-файл уникален. Свойства файла и действия, которые можно с ним осуществлять, зависят от программы, в которой он был создан. Поэтому, например, в одних PDF-файлах можно легко осуществить поиск и скопировать текст, тогда как в других поиск и копирование недоступны для пользователя. Также встречается множество PDF-файлов, где поиск и копирование доступны, однако выполняются с ошибками. Например, слово не находится (не появляется в результатах поиска), хотя оно присутствует в документе. При копировании из PDF в какое-либо другое приложение вместо копируемых символов вставляется бессмысленный набор символов (абракадабра).
[0029] В качестве одного из основных способов борьбы с данной проблемой используется метод повторного распознавания документа, с помощью технологий оптического распознавания символов (OCR). Однако при распознавании некоторая содержащаяся в документе информация зачастую теряется. Например, пропадает исходный текст (исходный текст заменяется на распознанный); пропадают комментарии, закладки, выставленные предыдущим рецензентом; качественная векторная графика заменяется на растровую графику и т.д.
[0030] Векторная графика формируется из объектов - графических примитивов (точка, линия, окружность, прямоугольник и т.д.), которые хранятся в памяти компьютера в виде описывающих их математических формул. Например, графический примитив точка задается своими координатами (X, Y), линия - координатами начала (X1, Y1) и конца (Х2, Y2). Растровое изображение - это, наоборот, изображение, представляющее собой сетку пикселей или цветных точек (обычно прямоугольную) на экране электронного устройства, бумаге и других отображающих устройствах и материалах.
[0031] Достоинством векторной графики по сравнению с растровой графикой является то, что файлы, хранящие векторные графические изображения, имеют сравнительно небольшой объем, тогда как растровые изображения имеют потребность в больших объемах памяти. К тому же векторные графические изображения могут быть увеличены или уменьшены без потери качества, чего нельзя сказать о растровой графике.
[0032] В некоторых случаях потеря качества при конвертации документов из формата TIFF и PDF в формат PDF с возможностью осуществления поиска является критичной.
[0033] Кроме формата PDF для обмена документами часто используется формат TIFF. Документы в формате TIFF представляют собой растровое графическое изображение. Можно привести и другие примеры типов документов, которые содержат только изображения. Например, снимок цифровой фотокамеры может храниться в формате JPEG, PNG, BMP, RAW и др. В свою очередь, форматы файлов изображений имеют существенный недостаток, когда их используют для хранения, а именно, файлы таких форматов не обеспечивают возможность текстового поиска в документе без предварительного распознавания документа. Кроме того, для хранения файлов изображений требуется большой объем дискового пространства.
[0034] В одном из вариантов реализации изобретения механизмы настоящего изобретения описывают специальный режим конвертации (преобразования данных из одного формата в другой) разнотипных документов (например, в формате PDF, TIFF) в формат PDF, который обеспечивает возможность поиска без потери качества при более компактном размере файла.
[0035] Во многих документах в формате PDF и во всех документах в формате TIFF невозможно осуществить поиск/копирование без предварительного распознавания. Зачастую при распознавании документов теряется исходное качество документа.
[0036] На приведенных ниже рисунках Фиг. 1А-1DD проиллюстрированы примеры конвертации различных по типу PDF-документов в PDF с возможностью осуществления поиска, с использованием стандартного процесса распознавания В результате данной операции в документах типа PDF Image (только изображение) (1A) и PDF Image + Text (PDF с возможностью поиска) (1B) теряются все аннотации (1АА, 1BB).
[0037] Под аннотациями в данном контексте понимаются элементы, которые отображаются на странице документа, но при этом не являются частью самого содержимого документа: комментарии, пометки в тексте (подчеркивание, перечеркивание, выделение маркером) и т.д.
[0038] В документах типа PDF Normal (обычный PDF, получаемый при печати на виртуальный принтер из MS Word, Excel и т.д.) (1С) и PDF Vector (тип PDF файлов, где текст представлен в виде кривых) (1D) теряется исходный текст, все аннотации, а также векторная графика заменяется на растровую графику (1CC, 1DD). Замена исходного текста на распознанный нежелательна, т.к. может привести к ошибкам в тексте (например, в результате того, что какие-то символы могут быть распознаны некорректно), а также к потере визуального качества (например, в результате того, что произошла подмена шрифта в PDF из-за отсутствия первоначально использовавшегося шрифта на ПК пользователя).
[0039] Перейдем к этим иллюстрациям; на Фиг. 1А приведена первая иллюстрация процесса конвертации PDF, при которой в процессе конвертации теряется различная информация. В частности, на Фиг. 1А показан документ в формате PDF Image перед процессом конвертации. Для следующего шага на Фиг. 1АА приведен тот же документ, что и на Фиг. 1А, но после конвертации, при которой теряются аннотации (например, вставки текста), содержащиеся в документе PDF Image, приведенном на Фиг. 1А.
[0040] На следующем рисунке Фиг. 1B приведен документ PDF Image + Text (PDF с возможностью поиска) содержащий аннотации, такие как вставки текста или комментарии, водяные знаки и пометки, до конвертации. На следующем шаге на Фиг. 1BB приведен тот же документ, что и на Фиг. 1B, но после конвертации, при которой теряется информация в виде аннотации, содержащейся в документе, приведенном на Фиг. 1B.
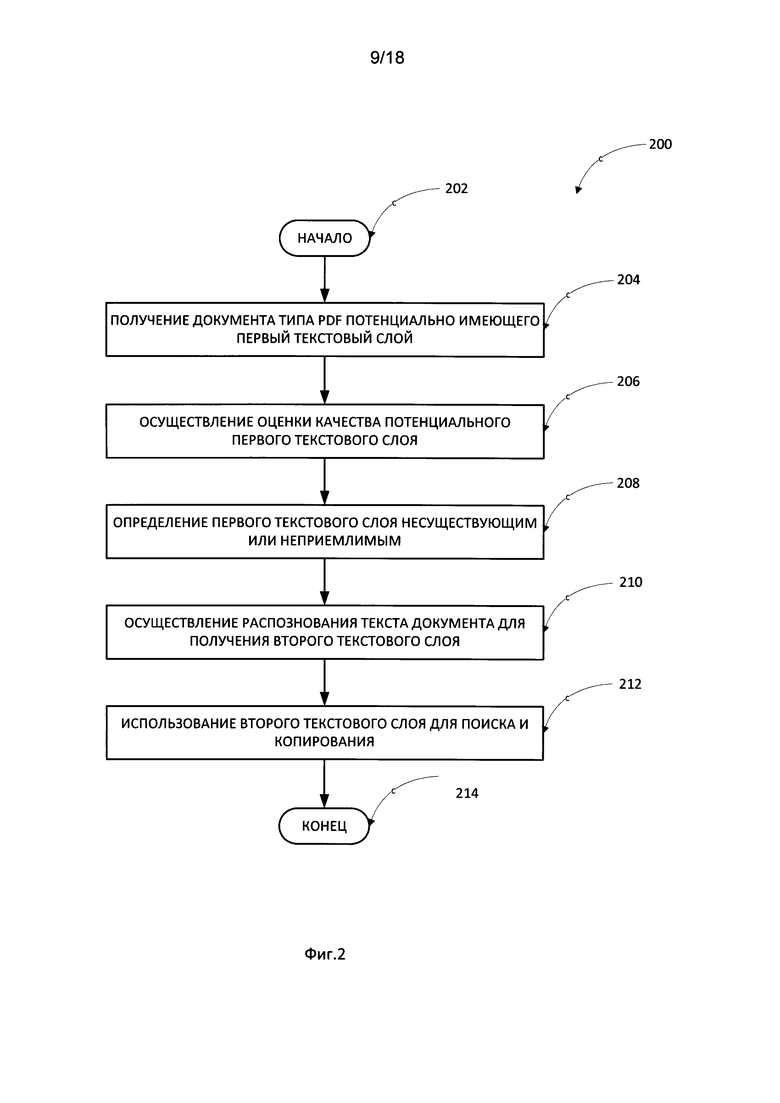
[0041] На Фиг. 1С приведен документ в формате PDF Normal, содержащий вставки текста или комментарии, изображения и пометки, до конвертации, причем графическая информация содержится в документе в векторном виде. На следующем шаге на Фиг. 1СС приведен тот же документ, но после конвертации, в ходе которой были потеряны вставки текста или комментарии и пометки, а информация изображения преобразуется в растровую графику более низкого качества.
[0042] Наконец, на Фиг. 1D приведен документ PDF с текстом, представленным в виде кривых, и содержащий вставки текста, текст в векторном виде и векторные графические изображения, до конвертации. На Фиг. 1DD приведен тот же документ, что и на Фиг. 1D, но после конвертации, в ходе которой исходный текст был потерян, вставки текста утрачены, а векторные графические изображения преобразованы в растровые графические изображения.
[0043] Для устранения описанных выше потерь и других ранее упомянутых проблем механизмы реализации настоящего изобретения в одном варианте описывают специальный режим конвертации документов в формат с возможностью поиска (например, в PDF с возможностью поиска), сохраняя при этом исходное качество документа. В данном случае в одном из вариантов реализации изобретения под исходным качеством документа понимается сохранение первоначального внешнего вида документа (графику) и всех данных, включая закладки, комментарии и т.д.
[0044] Для решения поставленной задачи предлагается метод, который составляет изобретение представленного описания. Например, пусть в качестве первого шага получен документ типа PDF. Далее документ конвертируется в формат, который предоставляет возможность осуществить поиск (например, PDF с возможностью поиска) с сохранением исходного качества, а именно исходных PDF-страниц (графики) и данных. В ходе конвертации может проверяться наличие текстового слоя в документе. В одном из вариантов реализации изобретения "текстовым слоем" принято называть область файла, содержащую (полностью или частично) находящийся в документе текст. Текстовый слой обеспечивает возможность поиска и копирования текста в документе.
[0045] В одном из вариантов реализации изобретения если исходный документ не содержит текстовый слой, то текстовый слой добавляется. Если исходный документ уже содержит текстовый слой (ниже называется "первый текстовый слой"), то проверяется качество этого текстового слоя. В случае плохого качества первый текстовый слой заменяется на новый более качественный второй текстовый слой. Под текстовым слоем плохого качества имеется в виду любой текстовый слой, который порождает ошибки при осуществлении поиска текста и копирования текста из документа в какой-либо текстовый редактор. При добавлении или замене текстового слоя сохраняется исходный вид документа, т.к. текстовый слой добавляется под изображение документа. Также сохраняются все закладки, комментарии и т.д. (если исходный PDF-документ их содержит). Кроме того, в описываемом режиме конвертации исходное изображение может быть сжато без потери качества по запросу пользователя. В результате, на выходе из режима конвертации обрабатываемый документ представляет собой документ с возможностью осуществления поиска, без потери визуального качества и данных исходного документа.
[0046] На Фиг. 2 представлена общая блок-схема способа (200) замены первого текстового слоя вторым текстовым слоем, если в первом текстовом слое обнаружены ошибки в соответствии с одним из вариантов реализации настоящего изобретения. Способ (200) начинается (шаг (202)) с момента получения документа типа PDF, возможно, имеющего первый текстовый слой (шаг (204)). Затем производится оценка качества первого текстового слоя (шаг (206)). В зависимости от оценки качества первый текстовый слой может быть определен как неприемлемый (шаг (208)). В последнем случае первый текстовый слой может блокироваться для функций поиска или копирования.
[0047] На следующем шаге для документа (как для изображения) выполняется процесс распознавания текста (например, OCR) для получения второго текстового слоя (шаг (210)). Полученный второй текстовый слой используется для поиска и копирования (шаг (212)). Затем способ (200) завершается (шаг (214)).
[0048] В частности, для PDF-файлов существует несколько основных типов PDF-документов. Первым типом является PDF (только изображение). Документы типа PDF (только изображения) содержат только изображение страницы и не содержат текстового слоя (Фиг. 1А). Данный тип обычно получается при сканировании или фотографировании документа и сохранении результатов в PDF формат. С такими PDF-файлами зачастую сложно работать, так как из-за отсутствия текстового слоя невозможно скопировать текст или выполнить поиск по содержимому документа.
[0049] Вторым типом PDF документов является PDF Normal (обычный PDF) (также True PDF, или Real PDF). Документы PDF Normal содержат только текстовый слой (Фиг. 1B). PDF-документ такого типа получается при конвертировании редактируемых файлов (MS Word, Excel, PowerPoint) в PDF-документ. Из файлов второго типа можно легко извлечь текст или изображение, а также быстро найти в них информацию с помощью поиска.
[0050] Третий тип - PDF с возможностью поиска (или PDF Image + Text). PDF с возможностью поиска является неким компромиссом между первым и вторым типами PDF, описанными выше. Документы в формате PDF с возможностью поиска получаются в результате распознавания документов PDF (только изображение) - то есть в результате обработки изображения программой с технологиями оптического распознавания (OCR). В таком документе сохраняется изображение страницы, распознанный текст помещается под изображение (Фиг. 1С). Таким образом, в документе такого типа возможно осуществлять поиск и копирование текста, при этом внешний вид PDF-документа неотличим от оригинала. Результаты поиска и копирования таких документов напрямую зависят от качества текстового слоя, который может отличаться от видимого изображения страницы.
[0051] И, наконец, четвертый тип - векторные PDF-файлы. Векторные PDF - это файлы, содержащие векторное изображение текста или файлы, где текст представлен в виде кривых (Фиг. 1D). Такие файлы встречаются достаточно редко и получаются при создании с помощью векторных графических редакторов с указанием специальных настроек. Из них невозможно скопировать текст или выполнить поиск по их содержимому.
[0052] В ходе конвертации документа последовательно выполняются несколько шагов. Эти шаги показаны на Фиг. 3 с последующим применением метода (350) в качестве иллюстративного варианта реализации эффективной конвертации документа без потерь, в котором реализованы аспекты настоящего изобретения. На вход системы попадает документ или фрагмент документа определенного типа, а именно либо только растровое изображение (например, TIFF или PDF Image) (300), либо растровое изображение с невидимым текстовым слоем (например, PDF Image + Text) (301), либо видимый текстовый слой (например, PDF Normal), либо векторное изображение, (например, Векторный PDF документ, где текст представлен в виде кривых) (303). Для обеспечения поиска документ дополняется качественным текстовым слоем. Для этого выполняется процесс распознавания документа (как изображения) с помощью технологий оптического распознавания символов (OCR) (304). Процесс распознавания выполняется независимо от того, содержит ли исходный документ текстовый слой или нет.
[0053] Системы оптического распознавания символов используются для конвертации бумажных документов или изображений, например документов в формате PDF, в машиночитаемые, редактируемые электронные файлы с возможностью осуществления поиска. Типичная система распознавания состоит из устройства, которое создает изображения документов и программного обеспечения, которое обрабатывает эти изображения. Как правило, это программное обеспечение включает программу распознавания, которая может распознавать символы, буквы, знаки, цифры и др. и сохранять их в машиноредактируемый формат - закодированный формат.
[0054] На выходе из системы распознавания страница преобразуется из набора графических образов в символы текста, появляется информация о расположении (о координатах) текста и картинок на исходном изображении и т.д. Данная информация может сохраняться в текстовом слое, связанным с этой страницей.
[0055] Если исходный документ или фрагмент документа не содержит текстовый слой (например, тип документов 300 и 303), то полученный в результате распознавания текстовый слой добавляется под исходное изображение (307 и 312). Этот дополнительный текстовый слой представляет собой слой, который впоследствии может использоваться для поиска и копирования. При этом внешний вид документа остается неизменным.
[0056] Если исходный документ или фрагмент документа представлен в формате PDF и уже содержит первый текстовый слой (тип документов 301 или 302), то этот первый текстовый слой проверяется на качественность (305, 306). Если исходный текстовый слой качественный, то при поиске в документе PDF формата и копировании текста из документа PDF формата не возникает ошибок. Если исходный текстовый слой некачественный, то поиск и копирование выполняются с ошибками. Например, при поиске слово может быть не найдено (не выводится в результатах поиска), хотя оно присутствует в тексте, а при копировании текста из PDF в какое-либо другое приложение вместо русских/латинских символов может вставляться бессмысленный набор символов (например, 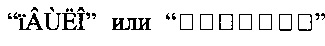 ). Ошибки могут быть связаны с некорректной кодировкой текста в PDF.
). Ошибки могут быть связаны с некорректной кодировкой текста в PDF.
[0057] В одной из реализаций изобретения, проверить первый текстовый слой на качество можно путем сравнения первого текстового слоя со вторым текстовым слоем, полученным в результате распознавания (304). Такое сравнение может быть осуществлено за счет наличия в текстовом слое информации о расположении отдельных символов и слов на исходном изображении. Таким образом, чтобы сравнить два текстовых представления одного и того же изображения документа, необходимо сравнить слова, расположенные на одном месте на исходной картинке (или имеющие одинаковые координаты). Если большинство слов совпадают, то исходный текстовый слой не содержит ошибок, т.е. качественный. Если большинство слов не совпадают, то исходный текстовый слой содержит ошибки, т.е. является некачественным. Если первый текстовый слой является недостаточно качественным, то можно создать второй текстовый слой, который будет использоваться для выполнения упомянутых раньше функций поиска текста и копирования.
[0058] Кроме этого способа существуют и другие варианты реализации изобретения для проверки текста на наличие ошибок. Например, исходный текст, извлеченный из документа PDF формата, можно проверить по словарям (выполнить словарную проверку). Если текст не содержит ошибок, то большинство слов в тексте являются словарными, т.е. содержатся в словаре.
[0059] В дополнительном варианте реализации изобретения ошибки в тексте также могут быть выявлены методом полиграмм. Согласно данному методу, например, все встречающиеся в тексте сочетания разделяются на двух - или трехбуквенные сочетания (биграммы и триграммы). Все полученные сочетания проверяются по таблице их допустимости в данном естественном языке. Например, триграмма «qqq» не может существовать ни в одном английском слове. Для русского языка можно аналогично сказать, что триграмма «ттт» не может встретиться ни в одном русском слове. Если в словоформе (слово в определенной грамматической форме) не содержится недопустимых полиграмм, то такая словоформа считается правильной, а иначе - сомнительной. Если текст не содержит ошибок, то он содержит много правильных полиграмм. Т.е. если относительно общего количества найденных в тексте триграмм количество нормальных триграмм больше некоторого порогового значения, то считается, что текст не содержит ошибок. С другой стороны, если количество нормальных триграмм меньше заданного порогового значения, то текст с ошибками.
[0060] Если исходный текстовый слой качественный, то он сохраняется (308, 310). Если текстовый слой некачественный, то он заменяется на новый, полученный в результате распознавания (снова шаг 304). При замене текстового слоя учитывается статус исходного текстового слоя. Например, этот статус может показывать, виден ли данный слой. Если исходный текстовый слой невидимый, он удаляется (309). Если видимый, то исходный текстовый слой сохраняется и делается недоступным для поиска и копирования. В этом случае под него подкладывается новый слой (311). Таким образом, внешний вид документа остается неизменным.
[0061] В одном варианте реализации для сохранения визуального качества исходное изображение электронного документа сохраняется после процесса конвертации.
[0062] При использовании механизмов иллюстративных вариантов реализации изобретения векторная графика остается нетронутой. Например, если исходный документ это векторный PDF формат, где текст представлен в виде кривых, в котором невозможен поиск и копирование текста, то при конвертации в searchable PDF в описываемом режиме текстовый слой будет добавлен под изображение текста. Таким образом, в документе появляется возможность поиска и копирования текста, при этом сохраняется красивый внешний вид документа.
[0063] Растровая графика может быть минимально изменена для того, чтобы улучшить качество распознавания текста и корректно совместить текстовый слой с изображением-оригиналом. Предобработка исходного растрового изображения включена в процесс распознавания документа (304). Для работы системы распознавания важно, чтобы поступающее на вход изображение было как можно более высокого качества. Если текст зашумлен (например, текст располагается на фоне), нерезкий (размыт, расфокусирован), имеет низкую контрастность и т.д., то это усложнит задачу распознавания. Поэтому может быть проведена его предварительная обработка, направленная на улучшение качества изображения. Предварительная обработка может включать в себя исправление перекосов строк (выпрямление строк), подбор ориентации страницы (система автоматически определяет ориентацию каждой страницы и при необходимости корректирует ее: поворачивает на 90, 180, 270 градусов), фильтрацию изображения от шумов, повышение резкости и контрастности изображения. Кроме того растровые изображения могут быть сжаты по запросу пользователя (307, 308, 309) с применением технологии сжатия смешанного растрового контента (Mixed Raster Content или MRC), которая позволяет получить меньшие размеры файлов без потери качества.
[0064] Кроме обеспечения поиска и сохранения визуального качества документа данный режим конвертации в PDF позволяет перенести из исходного PDF комментарии, пометки и другие аннотации, оставленные предыдущим рецензентом, а также метаданные (т.е. информацию относительно непосредственно самого документа, например, автор), совместимость с PDF/A форматом и.т.д.
[0065] PDF/A (разновидность PDF) - стандартизированный формат, предназначенный для длительного хранения документов в архиве. Формат PDF/A гарантирует, что сохраненный в этом формате документ может быть воспроизведен в первозданном виде спустя годы и десятилетия. Вся информация, необходимая для того, чтобы каждый раз отображать документ в неизменном виде, должна быть внедрена в файл. Сюда входит (не ограничиваясь только этим) все содержимое документа (текст, растровые изображения и векторная графика), шрифты и информация о цвете. Документы формата PDF/A не могут использовать информацию из внешних источников, к примеру, шрифтовые программы или гиперссылки.
[0066] На приведенных ниже рисунках Фиг. 4А-4DD проиллюстрированы примеры конвертации различных типов PDF документов в PDF с возможностью поиска, полученного используя различные аспекты иллюстративных вариантов реализации изобретения. На первом рисунке Фиг. 4А показан документ типа PDF (только изображение), в котором первоначально текстовый слой не был обнаружен. На следующем рисунке, Фиг. 4АА был добавлен текстовый слой, и, следовательно, как показано, аннотации в виде вставок текста сохраняются в процессе конвертации. Вставки текста играют важную роль в документах типа PDF Image, поскольку они представляют собой один из немногих инструментов для редактирования текста, который доступен в PDF Image.
[0067] Далее на Фиг. 4B показан документ PDF Image + Text (PDF с возможностью поиска). Существующий текстовый слой этого документа проверяется на качество, и, если это качество ниже предварительно определенного порога, то текстовый слой заменяется и/или восстанавливается более высококачественной версией. При этом комментарии, пометки, водяные знаки и другие элементы, которые присутствовали в предыдущем документе, показанном на Фиг. 4B, сохраняются на Фиг. 4BB, что также показано.
[0068] Обратимся теперь к Фиг. 4С, на котором показан пример документа типа PDF Normal, в котором опять имеется текстовый слой. Исследуется качество текстового слоя, и в случае необходимости он заменяется или восстанавливается, а вся векторная графика и прочие аннотации сохраняются, как показано далее, на Фиг. 4СС.
[0069] Наконец, на Фиг. 4D, показан дополнительный пример представления PDF-документа, в котором текст представлен в виде кривых. Первоначально текстовый слой отсутствует, и в результате процесса конвертации текстовый слой будет добавлен, благодаря чему становится возможным поиск по документу; при этом все аннотации сохраняются, как показано на следующем рисунке (Фиг. 4DD).
[0070] Таким образом, в результате показанных процессов конвертации в соответствии с аспектами настоящего изобретения документы получаются без потери качества изображения и сопутствующей текстовой и графической информации по сравнению с исходным документом, который подвергался преобразованию (Фиг. 3, шаг (313)).
[0071] Данное изобретение будет полезно всем учреждениям, имеющим крупный документооборот: юридическим фирмам, страховым компаниям, образовательным учреждениям, издательствам, крупным промышленным предприятиям, государственным организациям и т.д.
[0072] Специалистам в данной области ясно, что предметы раскрываемого изобретения могут использоваться в виде системы, способа или программного продукта для компьютера. Таким образом, аспекты данного изобретения могут иметь исключительно аппаратную реализацию, исключительно программную реализацию (включая встроенное программное обеспечение, резидентное программное обеспечение, микрокоманды и т.д.) либо вариант реализации, в котором сочетаются программные и аппаратные компоненты, что в целом может называться в этом документе «схемой», «модулем» или «системой». Кроме того, аспекты настоящего изобретения могут принимать форму компьютерного программного продукта, записанного на один машиночитаемый носитель или на несколько машиночитаемых носителей, содержащих машиночитаемый программный код.
[0073] Может использоваться любая комбинация одного машиночитаемого носителя или нескольких машиночитаемых носителей. Машиночитаемый носитель может представлять собой содержащую сигналы машиночитаемую среду или машиночитаемый носитель данных. Например, машиночитаемый носитель данных может, помимо прочего, представлять собой электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат или устройство, или любую подходящую комбинацию перечисленного выше. Более конкретные примеры машиночитаемых носителей включают следующее (неполный список): электрическое соединение, имеющее один провод или более, портативный компьютерный гибкий диск, жесткий диск, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), перезаписываемое программируемое постоянное запоминающее устройство (ППЗУ или флеш-память), оптическое волокно, портативный компакт-диск для однократной записи данных (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любую подходящую комбинацию перечисленного выше. В контексте этого документа машиночитаемый носитель данных может быть любым материальным носителем данных, который может содержать или хранить программу для использования выполняющей команды системой, аппаратом или устройством, либо при подключении к выполняющей команды системе, аппарату или устройству.
[0074] Записанный в машиночитаемом носителе программный код может передаваться с использованием любой подходящей среды, включая, помимо прочего, следующие среды: беспроводная среда, проводная среда, оптоволоконный кабель, радиочастотная среда и т.д., либо с помощью любой подходящей комбинации перечисленных выше сред. Компьютерный программный код для выполнения операций для предметов раскрываемого изобретения может быть написан в виде любой комбинации на одном или нескольких языках программирования, включая объектно-ориентированные языки программирования, такие как Java, Smalltalk, С++ и т.п., а также традиционные процедурные языки программирования, такие как язык программирования С или похожие языки программирования. Код программы может полностью выполняться на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть соединен с компьютером пользователя по сети любого типа, в том числе по локальной сети (LAN) или по глобальной сети (WAN), либо может быть организовано соединение с внешним компьютером (например, по сети Интернет с использованием поставщика услуг Интернета).
[0075] Аспекты настоящего изобретения были описаны выше со ссылкой на структурные схемы и/или блок-схемы способов, устройства (системы) и компьютерные программные продукты в соответствии с вариантами осуществления изобретения. Следует понимать, что каждый блок и комбинация блоков в структурных схемах и/или блок-схемах могут быть осуществлены с помощью команд компьютерной программы. Эти команды компьютерной программы могут быть переданы в процессор универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для получения машины таким образом, чтобы команды, которые выполняются с помощью процессора компьютера или другого программируемого устройства обработки данных, создали средства для реализации функций или действий, указанных в блоке или блоках структурной схемы и/или блок-схемы.
[0076] Эти команды компьютерной программы также могут храниться в машиночитаемом носителе, который может заставить компьютер, другое программируемое устройство обработки данных, или другие устройства работать определенным образом так, чтобы эти команды, хранящиеся в машиночитаемом носителе, производили изделие, в том числе команды, реализующие функцию или действие, предусмотренное в блоке или блоках структурной схемы и/или блок-схемы. Команды компьютерной программы также могут быть загружены в компьютер, в другое программируемое устройство обработки данных или в другие устройства, чтобы вызвать выполнение последовательностей рабочих шагов, которые должны выполняться в компьютере, другом программируемом устройстве или в других устройствах для выполнения реализованного в компьютере процесса таким образом, чтобы команды, которые выполняются в компьютере или в другом программируемом устройстве, предоставляли процессы для выполнения функции или действия, предусмотренного в блоке или блоках структурной схемы и/или блок-схемы.
[0077] Структурные схемы или блок-схемы на приведенных выше рисунках иллюстрируют архитектуру, функциональность и работу возможных вариантов реализации систем, способов и компьютерных программных продуктов в соответствии с различными вариантами реализации настоящего изобретения. В связи с этим каждый блок в структурной схеме или блок-схеме может представлять собой модуль, часть кода или сегмент, который содержит одну или несколько исполняемых команд для осуществления указанной логической функции (указанных логических функций). Следует также отметить, что в некоторых альтернативных реализациях отмеченные в блоке функции могут выполняться в порядке, отличном от того, который указан в иллюстрациях. Например, два блока, которые показаны как последовательные, фактически могут выполняться по существу одновременно, либо иногда блоки могут выполняться в обратном порядке, в зависимости от используемой функциональности. Кроме того, следует отметить, что каждый блок структурной схемы и/или блок-схемы и комбинации блоков в структурных схемах и/или блок-схемах могут быть реализованы с помощью специальных систем оборудования, которые выполняют заданные функции или действия, или с помощью комбинации специализированного оборудования и компьютерных команд.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНТЕЛЛЕКТУАЛЬНАЯ ОБРАБОТКА ЭЛЕКТРОННОГО ДОКУМЕНТА | 2013 |
|
RU2571379C2 |
| РЕДАКТИРОВАНИЕ СОДЕРЖИМОГО ЭЛЕКТРОННОГО ДОКУМЕНТА | 2014 |
|
RU2656581C2 |
| РЕДАКТИРОВАНИЕ ТЕКСТА НА ИЗОБРАЖЕНИИ ДОКУМЕНТА | 2016 |
|
RU2642409C1 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ВЕКТОРНО-РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2005 |
|
RU2309456C2 |
| ОБРАБОТКА ДОКУМЕНТА С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ ПОТОКОВ ОБРАБОТКИ | 2014 |
|
RU2579899C1 |
| СПОСОБ И СИСТЕМА ПОИСКА ГРАФИЧЕСКИХ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2807639C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| Способ управления печатью, устройство драйвера принтера и машиночитаемый носитель данных | 2021 |
|
RU2820425C1 |
| СОЦИАЛЬНАЯ ГЛАВНАЯ СТРАНИЦА | 2011 |
|
RU2604436C2 |















Изобретение относится к области обработки изображений. Технический результат заключается в обеспечении конвертации без потерь PDF документа в PDF документ с возможностью поиска. Технический результат достигается за счет получения PDF документа, имеющего первый текстовый слой для поиска и копирования, оценки качества первого текстового слоя, и если первый слой является некорректным, создания второго текстового слоя в PDF документе для поиска или копирования. 3 н. и 24 з.п. ф-лы, 18 ил.
1. Способ конвертации без потерь PDF документа в PDF документ с возможностью поиска с использованием процессорного устройства, включающий:
получение PDF документа, имеющего первый текстовый слой для поиска и копирования;
оценку качества первого текстового слоя; и
если первый слой является некорректным, создание второго текстового слоя в PDF документе для поиска или копирования.
2. Способ по п. 1, отличающийся тем, что второй текстовый слой создается за счет распознавания PDF документа.
3. Способ по п. 1, отличающийся тем, первый текстовый слой является некорректным, если он содержит ошибки, превышающие пороговое значение.
4. Способ по п. 1, отличающийся тем, что первый текстовый слой является видимым текстовым слоем, и дополнительно предусматривающий отключение возможности поиска или копирования видимого текстового слоя.
5. Способ по п. 1, отличающийся тем, что первый текстовый слой является невидимым слоем, и дополнительно предусматривающий удаление невидимого текстового слоя.
6. Способ по п. 1, отличающийся тем, что оценка качества первого текстового слоя включает сравнение первого текстового слоя со вторым текстовым слоем.
7. Способ по п. 6, отличающийся тем, что сравнение первого текстового слоя со вторым текстовым слоем содержит сравнение частей первого текстового слоя и второго текстового слоя, относящихся к одной и той же части изображения PDF документа.
8. Способ по п. 1, отличающийся тем, что оценка качества первого слоя текста включает сравнение первого текстового слоя по меньшей мере с одним словарем для выполнения операции проверки по словарю.
9. Способ по п. 1, отличающийся тем, что выполнение оценки качества первого текстового слоя дополнительно предусматривает использование метода полиграмм в первом текстовом слое:
разбиение каждого слова в первом текстовом слое на комбинации букв, причем комбинации букв представляют собой комбинации из двух букв и комбинации из трех букв; и
проверку комбинаций букв на основании таблицы приемлемости комбинаций букв в естественном языке.
10. Система для конвертации без потерь PDF документа в PDF документ с возможностью поиска, включающая в себя:
по меньшей мере одно процессорное устройство, причем по меньшей мере одно процессорное устройство:
получает PDF документ, содержащий первый текстовый слой для поиска и копирования;
оценивает качество первого текстового слоя; и
если первый текстовый слой является некорректным, создает второй текстовый слой в PDF документе для поиска или копирования.
11. Система по п. 10, отличающийся тем, что второй текстовый слой создается за счет распознавания PDF документа.
12. Система по п. 10, отличающийся тем, что первый текстовый слой является некорректным, если он содержит ошибки, превышающие пороговое значение.
13. Система по п. 10, отличающаяся тем, что первый текстовый слой представляет собой видимый текстовый слой и по меньшей мере одно процессорное устройство блокирует возможность поиска или копирования в видимом текстовом слое.
14. Система по п. 10, отличающаяся тем, что первый слой текста является невидимым слоем, дополнительно отличающаяся тем, что по меньшей мере одно процессорное устройство удаляет невидимый текстовый слой.
15. Система по п. 10, отличающаяся тем, что оценка качества первого текстового слоя включает сравнение первого текстового слоя со вторым текстовым слоем.
16. Система по п. 15, отличающаяся тем, что по меньшей мере одно процессорное устройство при сравнении первого текстового слоя со вторым текстовым слоем сравнивает части первого текстового слоя и второго слоя текста, относящиеся к одной и той же части изображения PDF документа.
17. Система по п. 10, отличающаяся тем, что по меньшей мере одно процессорное устройство при оценке качества первого текстового слоя сравнивает первый текстовый слой с по меньшей мере одним словарем при операции проверки по словарю.
18. Система по п. 10, отличающаяся тем, что по меньшей мере одно процессорное устройство в зависимости от оценки качества первого текстового слоя использует способ полиграмм для первого текстового слоя, выполняя:
разбиение каждого слова в первом текстовом слое на комбинации букв, причем комбинации букв представляют собой комбинации из двух букв и комбинации из трех букв; и
проверку комбинаций букв на основании таблицы приемлемости комбинаций букв в естественном языке.
19. Машиночитаемый носитель данных, содержащий компьютерные команды для конвертации без потерь PDF документа в PDF документ с возможностью поиска, которые вызывают выполнение процессорным устройством следующих действий:
получение PDF документа, который имеет первый текстовый слой для поиска и копирования;
оценку качества первого текстового слоя; и
если первый текстовый слой является некорректным, создание второго текстового слоя в PDF документе для поиска или копирования.
20. Машиночитаемый носитель данных по п. 19, отличающийся тем, что второй текстовый слой создается за счет распознавания PDF документа.
21. Машиночитаемый носитель данных по п. 19, отличающийся тем, что первый текстовый слой является некорректным, если он содержит ошибки, превышающие пороговое значение.
22. Машиночитаемый носитель данных по п. 19, отличающийся тем, что первый текстовый слой является видимым текстовым слоем; и включающий блокировку видимого текстового слоя для поиска или копирования.
23. Машиночитаемый носитель данных по п. 19, отличающийся тем, что первый текстовый слой является невидимым слоем, и дополнительно включающий удаление невидимого текстового слоя.
24. Машиночитаемый носитель данных по п. 19, отличающийся тем, что выполнение оценки качества первого текстового слоя содержит сравнение первого текстового слоя со вторым текстовым слоем.
25. Машиночитаемый носитель данных по п. 24, отличающийся тем, что сравнение первого текстового слоя со вторым текстовым слоем содержит сравнение части первого текстового слоя и второго текстового слоя, связанных с одной и той же частью изображения PDF документа.
26. Машиночитаемый носитель данных по п. 19, отличающийся тем, что оценка качества первого текстового слоя включает сравнение первого текстового слоя с по меньшей мере одним словарем для выполнения операции проверки по словарю.
27. Машиночитаемый носитель данных по п. 19, отличающийся тем, что при оценке качества первый текстовый слой дополнительно содержит использование метода полиграмм в первом текстовом слое:
разбиение каждого слова в первом текстовом слое на комбинации букв, причем комбинации букв представляют собой комбинации из двух букв и комбинации из трех букв; и
проверку комбинаций букв на основании таблицы приемлемости комбинаций букв в естественном языке.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ЦИФРОВОЙ ПОДПИСИ ПОСРЕДСТВОМ БАНКОМАТА | 2002 |
|
RU2258256C2 |

