УРОВЕНЬ ТЕХНИКИ
[0001] Работа с изображениями документов, содержащих изображения текста, часто представляет собой нелегкую задачу для пользователя, поскольку формат документа не дает пользователю прямого доступа к визуально представленному тексту (поскольку текст хранится в виде изображения). Таким образом, пользователь не может работать с текстовым содержимым документа такого типа без предварительного распознавания визуально представленного текста с помощью технологий OCR (оптического распознавания символов). Например, в документе, представляющем собой только изображение, сложно выполнить поиск текста и многие другие операции с текстом (такие как выделение текста, копирование характеристик текста, редактирование текста и т.д.).
[0002] Формат PDF (англ. Portable Document Format) является одним из наиболее широко используемых типов форматов электронных файлов для хранения документов. Этот формат получил широкое распространение благодаря своей универсальности, файлы в этом формате отображаются одинаково на всех компьютерах, на которых установлено какое-либо приложение для чтения файлов в формате PDF. Для этого в файле в формате PDF содержится подробная информация о конфигурации текста, таблице кодов символов и графике документа. Различают PDF-файлы двух типов. Первый тип PDF - это Searchable PDF (формат PDF с возможностью поиска текста), он содержит текстовый слой и изображения. Текстовым слоем обычно называют область PDF-файла, содержащую полностью или частично текст, включенный в этот документ. В документе, имеющем формат Searchable PDF, возможен поиск, выделение, копирование и редактирование текста, а также копирование изображений. Вторым типом PDF является Image-only PDF. PDF-файл этого типа содержит только изображение и не содержит текстового слоя. Поэтому в документах Image-only PDF визуально представленный текст на изображении невозможно сразу отредактировать или выделить, поиск текста по нему также невозможен без предварительной обработки или преобразования файла.
[0003] Кроме Image-only PDF, другим широко распространенным форматом, представляющим собой только изображение, является TIFF (англ. Tagged Image File Format). Формат TIFF особенно часто используют для хранения растровых графических изображений. Как известно, растровое изображение представляет собой (обычно прямоугольную) сетку из пикселей (цветных точек), которую можно отобразить на экране электронного устройства или напечатать на бумаге. Можно привести и другие примеры типов документов, которые включают только изображения. Например, снимок цифровой фотокамеры может храниться в формате JPEG, PNG, BMP, RAW и др.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] В настоящем изобретении раскрываются способы, системы и машиночитаемые носители для интеллектуальной обработки электронного документа. Один из вариантов осуществления относится к способу, включающему получение процессором электронного документа, где этот электронный документ содержит изображение с визуально представленным текстом, причем этот электронный документ не содержит текстовые данные, соответствующие визуально представленному на изображении тексту. Этот способ далее включает автоматическое распознавание в фоновом режиме изображения, содержащего визуально представленный текст, отличающееся тем, что внешний вид электронного документа для пользователя остается неизменным. Этот способ далее включает формирование текстового слоя, включающего распознанные данные, где эти распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст. Этот способ далее включает вставку текстового слоя под изображение, содержащего визуально представленный текст, так что текстовый слой остается скрытым от пользователя при отображении электронного документа, где скрытый текстовый слой настраивается так, чтобы пользователь имел возможность производить операцию над текстом, соответствующим распознанным данным. Этот способ далее включает сохранение на запоминающем устройстве результата операции пользователя в виде части изображения электронного документа. Созданный текстовый слой может не сохраняться по умолчанию (т.е. тип документа может не изменяться).
[0005] Другой вариант осуществления относится к системе, включающей процессор. Этот процессор настроен на получение электронного документа, где этот электронный документ содержит изображение с визуально представленным текстом, причем в этом электронном документе отсутствуют текстовые данные, соответствующие визуально представленному тексту на изображении. Этот процессор далее настроен на автоматическое распознавание изображения, содержащего визуально представленный текст, отличающееся тем, что автоматическое распознавание производится в фоновом режиме так, что внешний вид электронного документа для пользователя остается неизменным. Этот процессор далее настроен на формирование текстового слоя, содержащего распознанные данные, отличающееся тем, что эти распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст. Этот процессор далее настроен на вставку текстового слоя под изображение, содержащего визуально представленный текст, так что текстовый слой остается скрытым от пользователя при отображении этого электронного документа, где скрытый текстовый слой настраивается так, чтобы пользователь имел возможность производить операцию над текстом, соответствующим распознанным данным. Этот процессор далее настроен на сохранение результата операции пользователя на запоминающем устройстве в виде части изображения электронного документа. Созданный текстовый слой может не сохраняться по умолчанию (т.е. тип документа может не изменяться).
[0006] Другой вариант осуществления относится к энергонезависимому машиночитаемому носителю, в котором хранятся команды, которые включают команды для получения электронного документа, где этот электронный документ включает изображение с визуально представленным текстом, при этом в этом электронном документе отсутствуют текстовые данные, соответствующие визуально представленному тексту на изображении. Эти команды далее содержат команды для автоматического распознавания изображения, содержащего визуально представленный текст, отличающиеся тем, что распознавание производится в фоновом режиме так, что внешний вид электронного документа для пользователя остается неизменным. Эти команды далее содержат команды для создания текстового слоя, включающего распознанные данные, отличающиеся тем, что распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст. Эти команды далее содержат команды для вставки текстового слоя под изображение, содержащее визуально представленный текст, таким образом, что текстовый слой остается скрытым от пользователя при отображении электронного документа, отличающиеся тем, что скрытый текстовый слой настраивается так, чтобы пользователь имел возможность производить операцию над текстом, соответствующим распознанным данным. Эти команды далее содержат команды для сохранения результата операции пользователя на запоминающем устройстве в виде части изображения электронного документа. Созданный текстовый слой может не сохраняться по умолчанию (т.е. тип документа может не изменяться).
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Вышеуказанные и другие особенности настоящего изобретения станут более очевидными из последующего описания и прилагаемой формулы изобретения, рассматриваемых совместно с прилагаемыми чертежами. Представленные иллюстрации показывают лишь несколько вариантов осуществления в соответствии с раскрытием изобретения и, следовательно, не должны рассматриваться как ограничивающие его область. Изобретение будет раскрыто с дополнительной конкретизацией и подробностями посредством прилагаемых чертежей.
[0008] На Фиг. 1А приведен пример PDF-документа с возможностью поиска (Searchable PDF).
[0009] На Фиг. 1Б приведен пример PDF-документа, представляющего собой только изображение (Image-only PDF).
[0010] На Фиг. 2 приведена блок-схема способа обработки документа, представляющего собой только изображение, в соответствии с одним из вариантов осуществления изобретения.
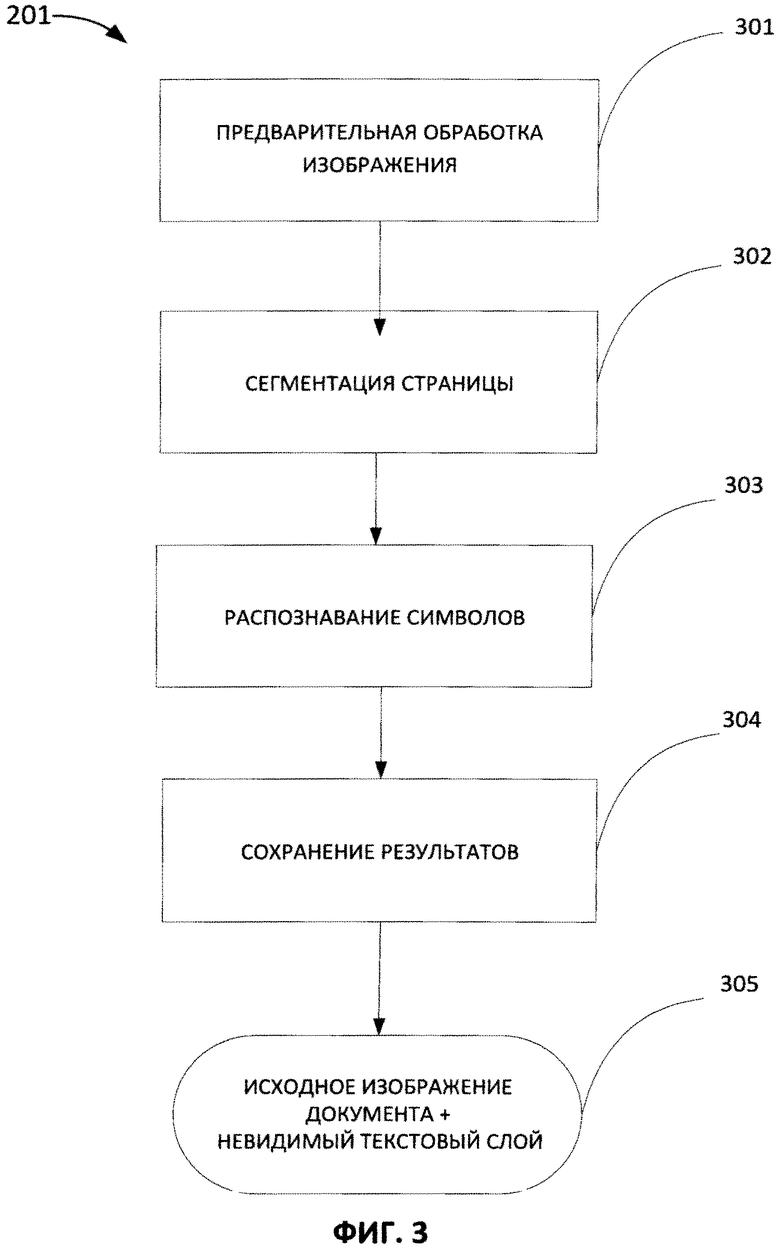
[0011] На Фиг. 3 приведена блок-схема процесса распознавания в соответствии с одним из вариантов осуществления изобретения.
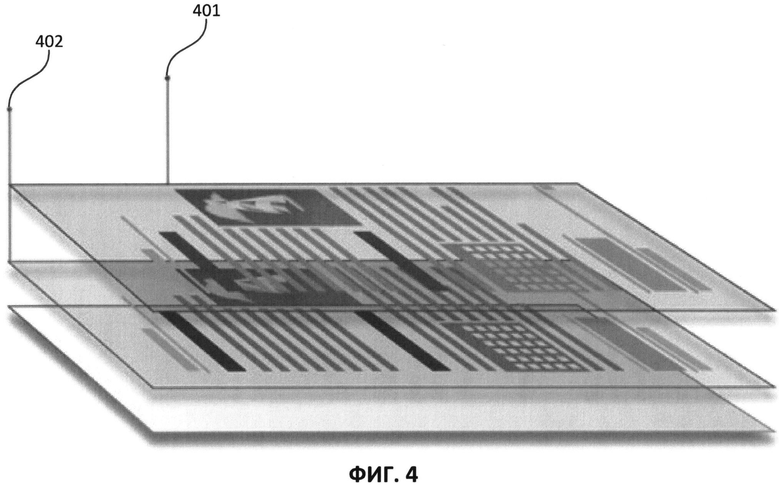
[0012] На Фиг. 4 приведен пример структуры документа, представляющего собой только изображения, созданного в соответствии с одним из вариантов осуществления изобретения.
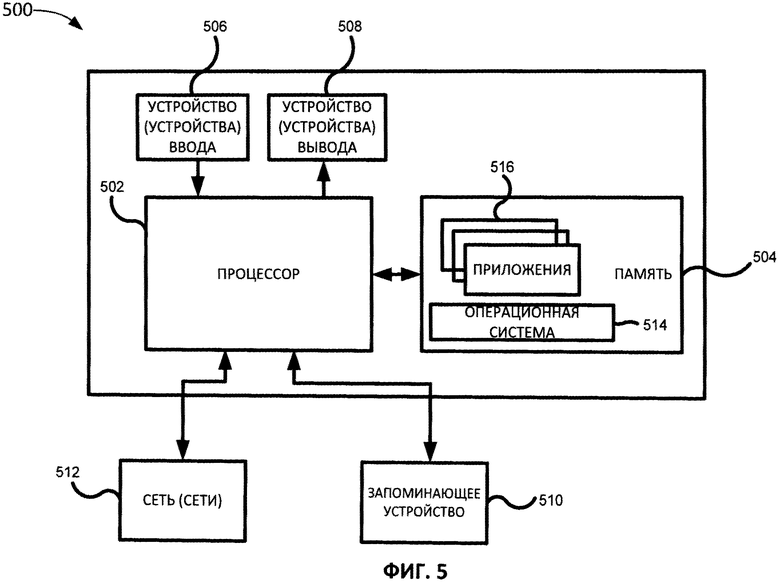
[0013] На Фиг. 5 приведен пример вычислительного средства, которое может использоваться для применения способов и методов, описанных в настоящем документе.
[0014] Нижеследующее подробное описание содержит ссылки на прилагаемые иллюстрации. На чертежах одинаковые символы обычно используются для идентификации одинаковых компонентов, если по смыслу не требуется указать иное. Варианты реализации, представленные в подробном описании, чертежах и формуле изобретения, служат лишь для иллюстрации изобретения, но не для ограничения области его применения. В рамках представленной в настоящей заявке сущности изобретения можно создать иные варианты реализации, а также модифицировать уже описанные. Важно отметить, что компоненты раскрываемого изобретения, описанного и проиллюстрированного в настоящей заявке, можно сочетать, взаимно заменять и применять множеством различных способов, при этом все они являются равнозначными и относятся к области раскрываемого изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0015] Документы, называемые в настоящем документе "Image-only", могут содержать другую информацию (например, данные заголовка, метаданные, данные структуры файла, данные разметки и т.п.). Термином «Image-only документ» обозначается документ, содержащий изображение, на котором визуально представлен текст, но не содержащий текстовые данные, относящиеся к этому визуальному представлению (т.е. текст, который можно выделить как текст, отредактировать как текст или по которому можно осуществить поиск). Иными словами, в документе, представляющем собой только изображение, для визуально представленного текста отсутствуют текстовые данные в кодировке ASCII, UTF-8 или любой иной кодировке. Таким образом, Image-only документ может содержать представление текста только в форме изображения, причем текст хранится в формате изображения (например, как часть изображения или как текстовая графика и т.д.). В документах, представляющих собой только изображение, не поддерживается возможность поиска, выделения и копирования текста. Эту проблему можно проиллюстрировать на примере двух документов, показанных на Фиг. 1А (Searchable PDF, т.е. PDF с возможностью поиска текста) и Фиг. 1Б (Image-only PDF, т.е. PDF, представляющий собой только изображение).
[0016] На Фиг. 1А показан снимок экрана PDF-файла с возможностью поиска текста (100а). Как отмечалось выше, особенностью данного формата является то, что документ такого типа содержит текстовый слой, благодаря которому возможен поиск, выделение, копирование и редактирование текста. На Фиг. 1А показано, что текст документа может быть выделен (101). Например, в тексте (101) можно выделить отдельную строку, слово или его часть одним из хорошо известных способов (например, с помощью мыши). На Фиг. 1Б показан снимок экрана с Image-only PDF (1006), в котором текст представлен в виде изображения (102). Как уже отмечалось выше, особенностью данного формата является то, что документ такого типа содержит данные изображения, где текст визуально представлен и по этой причине не является легкодоступным. Таким образом, поиск, выделение, копирование и редактирование текста невозможны без дополнительной обработки (например, с помощью оптического распознавания символов). На Фиг. 1Б показано, что текст, содержащийся на изображении (102), невозможно отделить, когда он является частью изображения (102) без дополнительной обработки. Соответственно, трудно осуществлять другие дополнительные операции над текстом и картинками (103) документа, поскольку и текст, и картинки (103) являются частями одного файла, представляющего собой только изображение (102).
[0017] Настоящее раскрытие изобретения дает пользователю возможность работать с текстом и картинками документа, представляющего собой только изображение, так, как если бы было осуществлено распознавание данного документа по инициативе пользователя. В этом документе явное распознавание означает такой процесс распознавания, который запускается по явной команде пользователя при соответствующих настройках приложения. При этом в документ добавляется текстовый слой с распознанным текстом так, чтобы пользователь мог осуществлять текстовый поиск и выполнять другие операции над текстом (например, выделение, копирование и пр.) непосредственно в документе, представляющем собой только изображение. Раскрытые в настоящем документе способы, системы и машиночитаемые носители позволяют пользователю работать с распознанным текстом (и другими объектами) в документе, представляющем собой только изображение, без предварительного явного применения процесса распознавания к документу, представляющему собой только изображение. Такая возможность особенно полезна в том случае, когда пользователь не подозревает о существовании различных типов документов и, следовательно, о наличии или отсутствии возможности работы с содержимым этих документов.
[0018] В одном варианте осуществления процесс распознавания запускается в фоновом режиме в тот момент, когда документ, представляющий собой только изображение, открывается. В настоящем документе фоновое (или неявное) распознавание означает процесс распознавания, который запускается без явной команды пользователя. Все раскрываемые в настоящем документе процессы могут осуществляться как в виде отдельного приложения, так и внутри другого приложения (например, с помощью установки подключаемого модуля для этого приложения и т.д.). В результате процесса фонового распознавания создается текстовое представление документа, с помощью которого можно осуществлять поиск и некоторые другие операции над текстом непосредственно в документе, представляющем собой только изображение. После выполнения пользователем необходимой операции над распознанным объектом, возможно сохранение документа и запись результатов операций пользователя. Текстовые данные, созданные во время фонового автоматического процесса распознавания, не сохраняются в долгосрочной памяти, и тип исходного документа не изменяется. Исключением является случай, когда текстовый слой создается с помощью явной команды пользователя (например, команды "Распознать"). Пользователь может изменить заданные по умолчанию настройки (например, с помощью пользовательского интерфейса), чтобы также сохранять полученный распознанный текст (это может привести к тому, что изменится формат документа на тот, который будет поддерживать поиск по тексту).
[0019] На Фиг. 2 представлена блок-схема способа интеллектуальной обработки электронного документа согласно одному из вариантов осуществления изобретения. В альтернативных вариантах осуществления количество действий может быть меньше, могут быть добавлены дополнительные действия и/или могут выполняться другие действия. Кроме того, использование блок-схемы не накладывает ограничения на порядок выполнения действий. На вход система получает документ, представляющий собой только изображение (200). Например, это может быть документ в формате Image-only PDF, TIFF, JPEG, PNG, BMP, GIF, RAW и т.д. Необходимо отметить, что содержание настоящего раскрытия изобретения не ограничивается перечнем конкретных типов файлов документов, представляющих собой только изображения. После ввода документа, представляющего собой только изображения, в систему, этот документ распознается в фоновом режиме (201). Системы оптического распознавания символов используются для преобразования бумажных документов или изображений (например, документов в формате PDF) в машиночитаемые, редактируемые электронные файлы, в которых возможен текстовый поиск. Программное обеспечение для оптического распознавания символов преобразует документ, представляющий собой только изображение, в текстовый документ. Это программное обеспечение может содержать алгоритмы распознавания символов, букв, знаков препинания, цифр и т.д., а также способно сохранять распознанные элементы в машиночитаемом и редактируемом формате (например, в формате закодированного текста). В основном варианте осуществления изобретения процесс распознавания запускается в тот момент, когда пользователь открывает документ для просмотра. В этом случае процесс распознавания запускается автоматически, т.е. без активного нажатия пользователем на кнопку «Распознать» (или аналогичную кнопку) или вызова команды, явно запускающей процесс распознавания. С точки зрения пользователя процесс распознавания выполняется в фоновом режиме (т.е. на заднем плане, без активного участия пользователя). В результате работы процесса распознавания создается по меньшей мере один невидимый (скрытый) текстовый слой, содержащий весь текст, извлеченный из изображения документа. В других вариантах осуществления изобретения процесс распознавания может по крайней мере частично запускаться по выбору пользователя. Например, система может формировать команду "копировать" в ответ на выбор пользователем фрагмента визуально представленного текста или другой части этого документа. После этого выбранная область может ограничить процесс распознавания определенной частью документа, таким образом, выделенная область распознается моментально. При этом результаты распознавания (например, текст или отдельные иллюстрации) быстро становятся доступными пользователю. Например, результат распознавания выбранной области может быть скопирован в буфер обмена и затем может быть извлечен из буфера обмена. Таким образом, этот вариант осуществления изобретения позволяет производить распознавание в фоновом режиме, как обсуждалось выше, но при этом приоритет распознавания различных фрагментов документа задает пользователь. Более подробно процесс распознавания (201) будет описан ниже и проиллюстрирован на Фиг. 3.
[0020] После распознания документа, представляющего собой только изображение, пользователь может работать с любым содержимым этого документа (202). Например, пользователь может провести полнотекстовый поиск (поиск слова по всему тексту документа). Работа с содержимым документа становится возможной благодаря тому, что создается информация о распознанных символах (например, координаты символов и типы символов) на основе исходного изображения документа. Например, поиск может запускаться автоматически при вводе символов в строку поиска, если такая строка имеется в интерфейсе пользователя. Поскольку распознавание документа происходит автоматически в фоновом режиме, что уже обсуждалось выше, поиск может быть запущен одновременно с процессом распознавания. Например, начиная с момента, когда пользователь закончил ввод слова (или символа) для поиска в строке поиска, процессы распознавания и поиска могут выполняться параллельно. После завершения процесса распознавания (201) и создания невидимого текстового слоя результаты поиска могут отображаться в пользовательском интерфейсе. В одном из вариантов осуществления точные совпадения, найденные при поиске, можно показать пользователю одним из известных способов (например, подсвечивая текст, удовлетворяющий условию поиска, или выделяя границы текста, совпавшего с поисковым запросом и т.д.).
[0021] Помимо выполнения поиска, пользователь может выполнять другие действия или операции с распознанным текстом. Например, текст можно выделять и копировать. В качестве другого примера, текст можно помечать (например, выделять цветом или иным способом отображать его границу). В качестве другого примера, возможно выделение в виде подчеркивания, перечеркивания или другим способом. В качестве другого примера, к тексту можно добавлять комментарии. В одном из вариантов осуществления система после окончания процесса распознавания текста может автоматически распознавать и делать активными гиперссылки, адреса электронной почты и прочие ссылки.
[0022] Помимо операций над текстом, описанный в этом документе способ позволяет работать с картинками, которые были распознаны в документе, представляющем собой только изображение. Например, можно копировать, комментировать, редактировать и т.д. любые картинки в документе.
[0023] Отметим, что описанные здесь пользовательские операции приведены в качестве иллюстрации и что они не ограничивают область применения настоящего изобретения. Эти операции могут производиться с любым распознанным содержимым документа, представляющего собой только изображение, распознанное в фоновом режиме, в котором невидимый текстовый слой был создан в соответствии с раскрытием данного изобретения.
[0024] После того как пользователь выполнил все необходимые операции над документом (с использованием полученного невидимого текстового слоя, содержащего распознанные символы), результаты таких операций могут быть сохранены, например, в памяти или на жестком диске (203). В одном из вариантов осуществления по умолчанию сохраняются только результаты операций, а невидимый текстовый слой, созданный в процессе распознавания (201), удаляется при закрытии (или сохранении) этого документа. При этом получается Image-only документ, который содержит правки пользователя (которые хранятся в формате изображения отдельно либо как часть изображений image-only документа (204)). Исключение представляет случай, когда текстовый слой был создан с помощью явной команды пользователя (например, с помощью команды "Распознать"). В другом варианте осуществления пользователь может изменить настройки по умолчанию (например, используя интерфейс пользователя), причем пользователь может явно определить сохранение невидимого текстового слоя. В этом варианте осуществления файл может быть сохранен в формате с возможностью поиска текста по сравнению с image-only документом.
[0025] На Фиг. 3 представлена блок-схема процесса распознавания, создающего невидимый текстовый слой (например, с помощью обсуждавшегося выше процесса распознавания (201)) для одного из вариантов осуществления. В ходе процесса (201) документ, представляющий собой только изображение, анализируется и преобразуется, в него добавляются текстовые данные для визуально представленного текста. Процесс распознавания включает в себя несколько шагов. В альтернативных вариантах осуществления количество действий может быть меньше, могут быть добавлены дополнительные действия и/или могут выполняться другие действия. Кроме того, использование блок-схемы не накладывает ограничения на порядок выполнения действий. Изображение документа, представляющего собой только изображение, (например, страница или часть страницы) подвергается предобработке (301) с целью получения изображения с наиболее высоким качеством для распознавания. Например, на вход системы распознавания может быть подано растровое изображение документа (200). Улучшение качества изображения с помощью предобработки позволяет избежать неточностей и проблем распознавания. Например, если изображение с визуально представленным текстом зашумлено (например, текст располагается поверх фонового изображения), является нерезким (например, изображение смазано или расфокусировано), имеет низкую контрастность или другие проблемы, то это усложнит задачу распознавания. Поэтому предобработка изображения (301) направлена на улучшение качества изображения перед дальнейшей обработкой изображения с помощью алгоритмов распознавания.
[0026] Предварительная обработка изображения может включать в себя несколько способов. В одном из вариантов осуществления производится коррекция отклонений в изображении (например, выравнивание линий в изображении). В другом варианте осуществления система может автоматически определять ориентацию каждой страницы документа и при необходимости корректировать ее (например, поворачивает страницу на 90, 180, 270 градусов или на произвольный угол для получения правильной ориентации страницы). В другом варианте осуществления система фильтрует изображение от шумов. В другом варианте осуществления система может повышать или корректировать разрешение и контрастность изображения. В другом варианте осуществления система может обработать изображение и преобразовать его в другой формат, оптимальный для распознавания. Например, в ходе предварительной обработки можно обнаружить дефекты в виде смаза или расфокусировки текста и устранить их с помощью метода, описанного в U.S. Patent Application No. 13/305 768 с названием "Detecting and Correcting Blur and Defocusing" (Обнаружение и корректировка смаза и расфокусировки).
[0027] Страница предобработанного изображения документа (или предобработанное изображение документа целиком) может быть сегментировано (302) путем выявления и анализа структурных единиц в image-only документе. При анализе структурных единиц документа обычно выделяют несколько иерархически организованных логических уровней, основанных на структурных единицах. В одном из вариантов осуществления объектом наивысшего уровня обрабатываемого документа (т.е., корневым узлом) может быть страница, содержащая элементы более низкого иерархического уровня - фрагмент текста, картинку, таблицу и так далее. Например, фрагмент текста может состоять из абзацев, абзацы - из строк, строки - из слов, а слово, в свою очередь, может состоять из отдельных букв (символов). Символы, слова или структуры, образованные из знаков (например, предложения, параграфы и т.п.), могут быть распознаны программным обеспечением оптического распознавания символов (OCR).
[0028] Image-only документ можно распознать с помощью любого метода оптического распознавания символов. В одном из вариантов осуществления процесс распознавания (303) включает выдвижение и проверку гипотез. На основе общих характеристик изображения (таких как символы, слова и т.д) выдвигается некоторое количество гипотез о том, что может быть на изображении. Затем эти гипотезы проверяются используя различные критерии. Если какой-то признак в изображении отсутствует, то проверка соответствующей гипотезы сразу прекращается, что позволяет ограничить перебор вариантов на ранних стадиях. В одном из вариантов осуществления процесс распознавания одновременно с выдвижением гипотез об отдельных символах выдвигает гипотезы о целых словах. При этом результаты оптического распознавания отдельных символов можно использовать для выдвижения гипотез и для оценки слов, сформированных этими символами. Для дополнительной проверки правильности гипотез о целых словах может использоваться словарь.
[0029] Затем результаты распознавания сохраняются (304). С помощью информации, полученной при анализе структуры документа на шаге (302), осуществляется синтез электронного документа, т.е. строки и абзацы объединяются в соответствии с исходным документом. В одном из вариантов осуществления фоновое распознавание может отличаться от описанного выше процесса. Например, в процессе фоновой обработки каждая страница многостраничного документа может обрабатываться как отдельный документ. Это позволяет уменьшить время обработки, поскольку время не будет тратиться на анализ подробной структуры всего документа (например, анализ иерархии заголовков и подзаголовков различных уровней во всем документе) на шагах 302 и 304, поскольку каждая страница документа обрабатывается как отдельный документ. Процесс фонового распознавания разных страниц может производиться независимо или одновременно с пользовательскими операциями над содержимым страницы, на которой в настоящее время работает пользователь. Кроме того, процесс фонового распознавания может начинаться со страницы, на которой работает пользователь, а затем распространяться независимо или одновременно на другие страницы этого документа.
[0030] В результате процесса распознавания страница преобразуется из набора графических образов в текстовые символы, получена информация о расположении (координатах) текста и картинок на исходном изображении и т.д. Полученные на выходе данные сохраняются в невидимом для пользователя (т.е. скрытом) текстовом слое, в результате получают используемое для распознавания исходное изображение и невидимый (скрытый) текстовый слой (305).
[0031] На Фиг. 4 показан пример структуры документа, представляющего собой только изображение с невидимым (скрытым) текстовым слоем согласно одному из вариантов осуществления. В таком документе сохраняется исходное изображение страницы (401), а текстовый слой, содержащий распознанный текст, помещается под изображение (402) и остается скрытым от пользователя.
[0032] На Фиг. 5 представлено аппаратное оборудование 500, которое можно использовать для реализации методов, описанных в настоящем документе. Как показано на фиг.5, аппаратное оборудование 500, как правило, включает по меньшей мере один процессор 502, соединенный с памятью 504, имеющий экран дисплея как устройство вывода 508 и устройство ввода 506. 506. Процессор 502 может представлять собой любое имеющееся на рынке ЦПУ. Процессор 502 может представлять собой один или более процессоров, которые могут использоваться в виде процессора общего назначения, специализированной интегральной схемы (ASIC), одной или нескольких программируемых вентильных матриц (FPGA), цифрового сигнального процессора (DSP), группы обрабатывающих компонентов или иных подходящих электронных компонентов для обработки данных. Память 504 может представлять собой оперативное запоминающее устройство (ОЗУ), содержащее главное устройство хранения аппаратного оборудования 500, а также любые дополнительные уровни памяти, например кэш-память, энергонезависимую память или резервные запоминающие устройства (например, программируемую или флэш-память), ПЗУ и т.п. Кроме того, память 504 может включать в себя запоминающие устройства, физически расположенные в другом месте аппаратного оборудования 500, например, какая-либо кэш-память в процессоре 502, а также любые запоминающие устройства, используемые в качестве виртуальной памяти, например съемные запоминающие устройства 510. В памяти 504 могут храниться (отдельно или во взаимодействии с запоминающим устройством 510) компоненты базы данных, компоненты объектного кода, компоненты сценария или иные типы структур данных для поддержки различных действий и информационных структур, описанных в настоящем документе. Память 504 или запоминающее устройство 510 могут передавать компьютерный код или команды в процессор 502 для выполнения процессов, описанных в настоящем документе
[0033] Аппаратное оборудование 500 также, как правило, имеет ряд входов и выходов для обмена информацией с внешними устройствами. Для работы с пользователем аппаратное оборудование 500, как правило, содержит одно или более устройств пользовательского ввода 506 (например, клавиатуру, мышь, устройство, формирующее изображения, сканер и т.п.) и одно или более устройств вывода 508 (например, жидкокристаллический дисплей (ЖКД), устройство воспроизведения звука (динамик)). В качестве дополнительного устройства хранения аппаратное оборудование 500 также может включать в себя одно или более съемных запоминающих устройств 510, например, среди прочих, накопитель на гибких магнитных или иных съемных дисках, накопитель на жестком диске, запоминающее устройство с прямым доступом (DASD), оптический привод (например, привод компакт-дисков (CD), компакт-дисков в формате DVD и т.п.) и/или ленточный накопитель. Более того, аппаратное оборудование 500 может включать в себя интерфейс для взаимодействия с одной или более сетями 512 (например, среди прочих, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернетом) для осуществления обмена информацией с другими компьютерами, подключенными к сетям. Следует принимать во внимание, что аппаратное оборудование 500, как правило, включает в себя подходящие аналоговые и/или цифровые интерфейсы между процессором 502 и каждым из компонентов 504, 506, 508 и 512, что хорошо известно специалистам в данной области.
[0034] Вычислительное средство 500 может работать под управлением операционной системы 514, на нем можно запускать различные программные приложения 516, включая компоненты, программы, объекты, модули и т.д. для осуществления описанных выше процессов. В частности, в числе прикладных компьютерных программ может использоваться приложение для оптического распознавания символов, приложение для создания невидимого текстового слоя, приложение для отображения или редактирования документов, приложение-словарь, а также другие установленные приложения для распознавания текста в документе, представляющем собой только изображение, и его преобразования с целью выполнения пользователем поиска и других операций (например, редактирования, выделения, копирования, и пр.) над распознанным текстом и иллюстрациями непосредственно в документе, представляющем собой только изображение. Все описанные выше приложения могут быть частью единого приложения или являться отдельными приложениями, подключаемыми модулями и т.д. Приложения (516) также могут запускаться на одном или нескольких процессорах другого компьютера, соединенного с аппаратным обеспечением 500 через сеть 512, например, в среде распределенных вычислений, причем вычисления, необходимые для реализации функций компьютерной программы, могут быть распределены по нескольким компьютерам в сети.
[0035] В общем случае, процедуры, выполняемые для реализации вариантов осуществления, могут быть реализованы частью операционной системы или специальным приложением, компонентой, программой, объектом, модулем или последовательностью команд, которые обобщенно можно назвать «компьютерными программами». Компьютерные программы, как правило, содержат один или более наборов команд в разное время в разных устройствах памяти и хранения в компьютере, которые, при их считывании и исполнении одним или более процессорами компьютера, приводят к выполнению компьютером операций, необходимых для исполнения элементов описанных вариантов осуществления. Следует указать, что различные варианты осуществления были описаны в контексте полностью функционирующих компьютеров и компьютерных систем. Специалистам в данной области техники будет понятно, что различные варианты осуществления могут распространяться в виде программного продукта в различных формах, при этом возможности и назначение всех таких вариантов будут одинаковы вне зависимости от применяемого конкретного типа машиночитаемых носителей, используемых для распространения программного продукта. Примерами машиночитаемых носителей являются съемные записывающие носители, такие как энергозависимые и энергонезависимые запоминающие устройства, дискеты и другие съемные диски, жесткие диски, оптические диски (например, постоянные запоминающие устройства на основе компакт-диска (CD-ROM), универсальные цифровые диски (DVD), флэш-память и т.д.) и другие. Программное обеспечение также может распространяться через Интернет.
[0036] В приведенном выше описании множество конкретных деталей приводят в разъяснительных целях. Однако специалисту в данной области очевидно, что эти конкретные детали являются только примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание затруднения процесса объяснения.
[0037] Упоминание в данном описании терминов «один вариант осуществления» или «вариант осуществления» означает, что конкретный элемент, структуру или характеристику, описанную вместе с вариантом осуществления, включают по меньшей мере в один вариант осуществления. Фраза «в одном варианте осуществления», встречающаяся в различных местах описания, не обязательно обозначает один и тот же вариант осуществления или же отдельные или альтернативные варианты осуществления, взаимоисключающие другие варианты осуществления. Более того, описываются особенности, которые могут проявлять некоторые варианты осуществления, но не проявлять другие варианты осуществления. Аналогично, описываются различные требования, которые могут относиться к одним вариантам осуществления и не относиться к другим вариантам осуществления.
[0038] Хотя некоторые примеры осуществления описаны и представлены на прилагаемых рисунках, следует понимать, что такие варианты осуществления являются лишь иллюстративными, но не ограничивающими, и что эти варианты осуществления не ограничены конкретными показанными и описанными схемами и комбинациями, поскольку обычному специалисту в данной области после изучения описания будут очевидны и различные другие модификации. В такой области технологий, как данная, где рост происходит быстро и дальнейшие достижения предвидеть непросто, описанные варианты осуществления можно легко подвергать модификациям по расположению и деталям, чему будут способствовать технологические достижения, и это не будет отклонением от принципов настоящего описания.
| название | год | авторы | номер документа |
|---|---|---|---|
| Сохранение контента в конвертированных документах | 2014 |
|
RU2648636C2 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| РЕДАКТИРОВАНИЕ СОДЕРЖИМОГО ЭЛЕКТРОННОГО ДОКУМЕНТА | 2014 |
|
RU2656581C2 |
| РЕДАКТИРОВАНИЕ ТЕКСТА НА ИЗОБРАЖЕНИИ ДОКУМЕНТА | 2016 |
|
RU2642409C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕОБХОДИМОСТИ ОБУЧЕНИЯ ЭТАЛОНА ПРИ ВЕРИФИКАЦИИ РАСПОЗНАННОГО ТЕКСТА | 2014 |
|
RU2641225C2 |
| ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2016 |
|
RU2634194C1 |
| СПОСОБ УПРАВЛЕНИЯ ДАННЫМИ В СФОРМИРОВАННОМ КОМПЬЮТЕРНОМ ДОКУМЕНТЕ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ С ЗАПИСАННОЙ НА НЕМ ПРОГРАММОЙ | 2007 |
|
RU2379748C2 |
| ОБРАБОТКА ДОКУМЕНТА С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ ПОТОКОВ ОБРАБОТКИ | 2014 |
|
RU2579899C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| ВСПЛЫВАЮЩАЯ ПАНЕЛЬ ВЕРИФИКАЦИИ | 2014 |
|
RU2665274C2 |


Изобретение относится к способу, системе и машиночитаемому носителю для обработки электронного документа. Техническим результатом является обеспечение возможности пользователю работать с распознанным текстом в документе, представляющим собой только изображение, без предварительного явного применения процесса распознавания текста к документу. Способ обработки электронного документа включает получение процессором электронного документа, включающего изображение, содержащее визуально представленный текст, в котором отсутствуют текстовые данные, соответствующие визуально представленному тексту этого изображения; автоматическое распознавание изображения, которое содержит визуально представленный текст, в фоновом режиме так, что внешний вид этого электронного документа для пользователя остается неизменным; создание текстового слоя, включающего распознанные данные; добавление текстового слоя под изображение, которое содержит визуально представленный текст, таким образом, что он скрыт от пользователя при отображении электронного документа, где скрытый текстовый слой настроен так, что он предоставляет пользователю возможность производить операции над текстом, который соответствует распознанным данным, и сохранение результатов операций пользователя на запоминающем устройстве в виде части электронного документа. 3 н. и 17 з.п. ф-лы, 6 ил.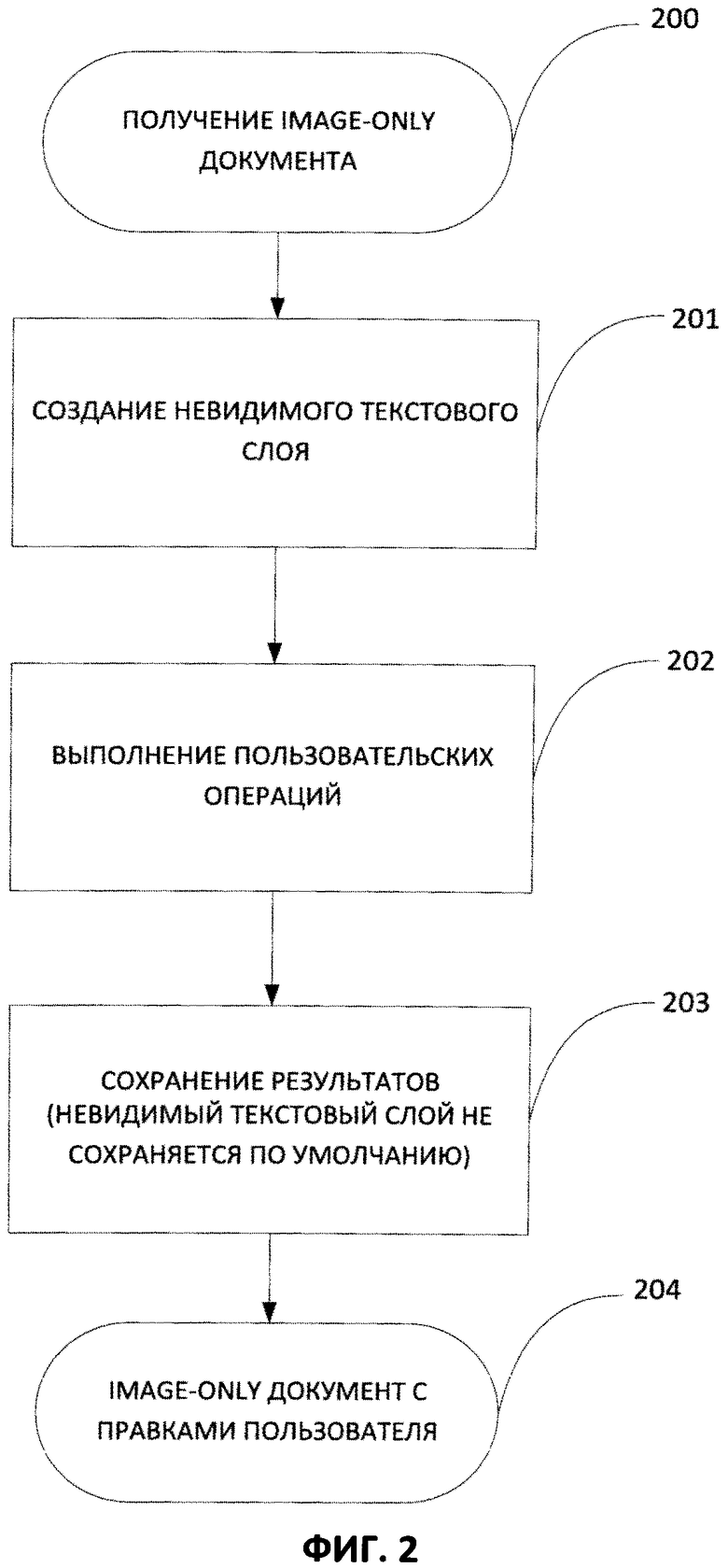
1. Способ обработки электронного документа, включающий
получение процессором электронного документа, где этот электронный документ включает изображение, которое содержит визуально представленный текст, в котором отсутствуют текстовые данные, соответствующие визуально представленному тексту этого изображения;
автоматическое распознавание изображения, которое содержит визуально представленный текст, где автоматическое распознавание осуществляется в фоновом режиме так, что внешний вид этого электронного документа для пользователя остается неизменным;
создание текстового слоя, включающего распознанные данные, где распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст;
добавление текстового слоя под изображение, которое содержит визуально представленный текст, таким образом, что он скрыт от пользователя при отображении электронного документа, где скрытый текстовый слой настроен так, что он предоставляет пользователю возможность производить операции над текстом, который соответствует распознанным данным, и
сохранение результатов операций пользователя на запоминающем устройстве в виде части электронного документа.
2. Способ обработки электронного документа по п. 1, отличающийся тем, что текст, соответствующий распознаваемым данным, представляет собой текстовые данные, полученные в результате автоматического распознавания.
3. Способ обработки электронного документа по п. 1, отличающийся тем, что электронный документ включает по меньшей мере один файл в формате image-only PDF, TIFF, JPEG, PNG, BMP, GIF или RAW.
4. Способ обработки электронного документа по п. 1, отличающийся тем, что пользовательская операция включает по меньшей мере одну из следующих операций: поиск по тексту, соответствующему распознанным данным, выделение текста, соответствующего распознанным данным, копирование текста, соответствующего распознанным данным, и добавление пометок в текст, соответствующий распознанным данным.
5. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом включает использование оптического распознавания символов визуально представленного текста.
6. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом также включает предобработку изображения с целью повышения точности распознавания.
7. Способ обработки электронного документа по п. 6, отличающийся тем, что предобработка изображения включает по меньшей мере одно из следующих действий: исправление перекосов на изображении, исправление ориентации изображения, фильтрацию изображения, изменение резкости изображения, изменение контрастности изображения и корректировку смаза изображения.
8. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом дополнительно включает выдвижение и проверку гипотезы о символе.
9. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом дополнительно включает:
выявление и анализ структурных единиц электронного документа и
иерархическую организацию структурных единиц на основании типа каждой структурной единицы.
10. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом запускается без команды пользователя.
11. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения с визуально представленным текстом инициализируется, когда документ открывается пользователем.
12. Способ обработки электронного документа по п. 1, отличающийся тем, что автоматическое распознавание в фоновом режиме изображения, содержащего визуально представленные текст, производится независимо и одновременно с пользовательскими операциями над содержимым страницы, на которой в настоящее время работает пользователь.
13. Система обработки электронного документа, включающая:
один или несколько электронных процессоров, настроенных на
получение электронного документа, где этот электронный документ включает изображение, которое содержит визуально представленный текст, в котором отсутствуют текстовые данные, соответствующие визуально представленному тексту этого изображения;
автоматическое распознавание изображения, которое содержит визуально представленный текст, где автоматическое распознавание осуществляется в фоновом режиме так, что внешний вид этого электронного документа для пользователя остается неизменным;
создание текстового слоя, включающего распознанные данные, где распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст;
добавление текстового слоя под изображение, которое содержит визуально представленный текст, таким образом, чтобы он скрыт от пользователя при отображении электронного документа, и где скрытый текстовый слой настроен так, что он предоставляет пользователю возможность производить операции над текстом, который соответствует распознанным данным: и
сохранение результатов операций пользователя на запоминающем устройстве в виде части электронного документа.
14. Система обработки электронного документа по п. 13, отличающаяся тем, что электронный документ включает по меньшей мере один файл в формате image-only PDF, TIFF, JPEG, PNG, BMP, GIF или RAW.
15. Система обработки электронного документа по п. 13, отличающаяся тем, что пользовательская операция включает по меньшей мере одно из следующего: поиск по тексту, соответствующего распознанным данным, выделение текста, соответствующего распознанным данным, копирование текста, соответствующего распознанным данным, и добавление пометок в текст, соответствующий распознанным данным.
16. Система обработки электронного документа по п. 13, отличающаяся тем, что автоматическое распознавание в фоновом режиме изображения, содержащего визуально представленный текст, включает использование оптического распознавания символов визуально представленного текста.
17. Система обработки электронного документа по п. 13, отличающаяся тем, что автоматическое распознавание в фоновом режиме изображения, содержащего визуально представленный текст, дополнительно включает:
выявление и анализ структурных единиц электронного документа и
иерархическую организацию структурных единиц на основании типа каждой структурной единицы.
18. Система обработки электронного документа по п. 13, отличающаяся тем, что автоматическое распознавание в фоновом режиме изображения, содержащего визуально представленный текст, инициализируется, когда документ открывается пользователем.
19. Энергонезависимый машиночитаемый носитель, содержащий команды, которые включают:
команды для получения электронного документа, где этот электронный документ включает изображение, которое содержит визуально представленный текст, в котором отсутствуют текстовые данные, соответствующие визуально представленному тексту этого изображении;
команды для автоматического распознавания изображения, которое содержит визуально представленный текст, где автоматическое распознавание производится в фоновом режиме так, что внешний вид этого электронного документа для пользователя остается неизменным;
команды для создания текстового слоя, включающего распознанные данные, где распознанные данные получены в результате автоматического распознавания изображения, содержащего визуально представленный текст;
команды для добавления текстового слоя под изображение, которое содержит визуально представленный текст, таким образом, что он скрыт от пользователя при отображении этого электронного документа, где скрытый текстовый слой настроен так, что он предоставляет возможность пользователю производить операции над текстом, который соответствует распознанным данным; и
команды для сохранения результатов операций пользователя на запоминающем устройстве в виде части электронного документа.
20. Энергонезависимый машиночитаемый носитель по п. 19, отличающийся тем, что электронный документ включает по меньшей мере один файл в формате image-only PDF, TIFF, JPEG, PNG, BMP, GIF или RAW.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ВЕКТОРНО-РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2005 |
|
RU2309456C2 |
| RU 2006141518 A, 10.06.2008. | |||

